
Confidence intervals for the common coefficient of variation of rainfall in Thailand
Author and article information
Abstract
The log-normal distribution is often used to analyze environmental data like daily rainfall amounts. The rainfall is of interest in Thailand because high variable climates can lead to periodic water stress and scarcity. The mean, standard deviation or coefficient of variation of the rainfall in the area is usually estimated. The climate moisture index is the ratio of plant water demand to precipitation. The climate moisture index should use the coefficient of variation instead of the standard deviation for comparison between areas with widely different means. The larger coefficient of variation indicates greater dispersion, whereas the lower coefficient of variation indicates the lower risk. The common coefficient of variation, is the weighted coefficients of variation based on k areas, presents the average daily rainfall. Therefore, the common coefficient of variation is used to describe overall water problems of k areas. In this paper, we propose four novel approaches for the confidence interval estimation of the common coefficient of variation of log-normal distributions based on the fiducial generalized confidence interval (FGCI), method of variance estimates recovery (MOVER), computational, and Bayesian approaches. A Monte Carlo simulation was used to evaluate the coverage probabilities and average lengths of the confidence intervals. In terms of coverage probability, the results show that the FGCI approach provided the best confidence interval estimates for most cases except for when the sample case was equal to six populations (k = 6) and the sample sizes were small (nI < 50), for which the MOVER confidence interval estimates were the best. The efficacies of the proposed approaches are illustrated with example using real-life daily rainfall datasets from regions of Thailand.
Cite this as
2020. Confidence intervals for the common coefficient of variation of rainfall in Thailand. PeerJ 8:e10004 https://doi.org/10.7717/peerj.10004Main article text
Introduction
Droughts and floods are regular natural disasters in Thailand. Droughts occur when the hot season begins after a year with unusually little rainfall. Moreover, floods happen nearly every year during the monsoon season. The monsoon seasons in the country are distinct by region. Thailand is divided into six geographical regions such as the north, the northeast, the west, the central, the east, and the south. Various regions are prone to seasonal flash-flooding. The floods often occur in the north, the northern east, and the south. Since rainfall varies greatly depending on region and season. Therefore, the common coefficient of variation is used to represent the rainfall dispersion in different regions.
The log-normal distribution, widely used to describe the distribution of right-skewed data, has been used to model various real-life applications (Jafari & Abdollahnezhad, 2015). For instance, in climate sciences and hydrology, the rainfall measurements are right-skewed (Thangjai, Niwitpong & Niwitpong, 2020a). The coefficient of variation of the log-normal distribution depends on the variance (σ2) only (Thangjai, Niwitpong & Niwitpong, 2016) whereas the coefficient of variation of normal distribution depends on the mean (µ) and σ2. Although the normal distribution is more well-known than the log-normal distribution in the natural and social sciences, the latter has been used in many applications. Examples of quantities which have approximate log-normal distributions include the particulate matter and rainfall frequency. Rumburg, Alldredge & Claiborn (2001) studied the statistical distributions of daily particulate matter data from Spokane, Washington from January 1995 to December 1997. They found that the PM2.5 data is best fit by a three parameter log-normal distribution. Thangjai, Niwitpong & Niwitpong (2020a) constructed the simultaneous confidence intervals for all differences of coefficients of variation of daily rainfall data on 17 July 2018 in different regions of Thailand. The daily rainfall data is log-normal distribution.
In statistics, the information in a sample X = (X1, X2, …, Xn) is used to make inferences about an unknown parameter θ. The inference methods are hypothesis testing, point estimation, and confidence interval estimation. The statistical hypothesis makes a statement about a population parameter. The hypothesis testing uses the sample from the population for deciding. Two complementary hypotheses in hypothesis testing are the null hypothesis and the alternative hypothesis. The point estimation uses the sample data to evaluate a single value. The point estimation is a guess of the single value as the value of the parameter. The value is called the point estimator. The point estimate is not absolutely accurate because the estimate is based on only the single random sample. For a contrasting point estimation method, the confidence interval estimation uses the sample data to calculate an interval of probable values. The confidence interval is called the confidence interval estimator. The confidence interval estimation is used rather than the point estimation because the confidence interval estimation has some guarantee of capturing the parameter. The goal of this paper is to examine the confidence interval for parameter of log-normal distribution. Confidence intervals associated with various functions of the log-normal distribution parameters have been reported by Land (1988), Zhou & Gao (1997), Zhou (1998), Joulious & Debarnot (2000), Taylor, Kupper & Muller (2002), Krishnamoorthy & Mathew (2003), Gupta & Li (2005), Hannig et al. (2006b), and Shen, Brown & Hui (2006). In these studies, confidence intervals were considered on linear functions of the mean and variance of the log-normal distribution. These results were later extended to stochastic processes such as homogeneous log-normal (Gutiérrez et al., 2007) and non-homogeneous log-normal (Gutiérrez et al., 2003).
The coefficient of variation is defined as the standard deviation divided by the mean (Kelley, 2007). It can be used to compare several populations that have different measurement units and is widely used to measure the precision and repeatability of data in many fields. In hematology and serology, the coefficient of variation has been used for the measurement of blood samples taken from different laboratories (Tsim et al., 1991) and as a measure of precision within and between laboratories (Tian, 2005). In finance, a test of the equality of the coefficients of variation for two stocks has been used to measure risk. In medicine, the coefficient of variation has been used to compare the variability in the ratio of total/high density lipoprotein cholesterol with the variability in vessel diameter change according to diet.
In climate sciences and hydrology, the coefficient of variation has been used to describe the rainfall and can be used to compare the rainfall variability in two or more different areas (Thangjai, Niwitpong & Niwitpong, 2020a). If the difference between the rainfall in a single area and the average rainfall over several areas is high, then the rainfall is high. In statistical analysis, combine the results of several independent studies is used in climate sciences and clinical trial. If it is assumed that the samples are collected from independent log-normal populations with a common coefficient of variation but possibly with different variances, then the confidence interval for the common coefficient of variation of several log-normal populations becomes the parameter of interest. Several researchers have focused on confidence interval estimation for the coefficient of variation of a log-normal distribution. For example, Niwitpong (2013) presented confidence intervals for the coefficient of variation of a log-normal distribution with a restricted parameter space. Ng (2014) proposed an approach to make inference on the common coefficient of variation of log-normal populations. Simultaneous confidence intervals for the differences in the coefficients of variation of log-normal distributions were proposed by Thangjai, Niwitpong & Niwitpong (2016) and Thangjai, Niwitpong & Niwitpong (2020a). Moreover, Nam & Kwon (2017) and Hasan & Krishnamoorthy (2017) studied the confidence intervals for the ratio of coefficients of variation of two log-normal distributions.
Common problems in applied statistics are confidence interval estimation for the coefficient of variation and testing the equality of two or more coefficients of variation. Miller & Karson (1977) proposed a test for the equality of coefficients of variation in two normal populations. Gupta & Ma (1996) presented testing the equality of the coefficients of variation in k normal populations. Fung & Tsang (1998) compared parametric and nonparametric tests and Gokpinar & Gokpinar (2015) proposed a computational approach to test the equality of the coefficients of variation of k normal populations. Sangnawakij, Niwitpong & Niwitpong (2016) proposed two new confidence intervals for the ratio of the coefficients of variation of two-parameter exponential distributions. Sangnawakij & Niwitpong (2016) presented confidence interval estimation for the single coefficient of variation and the difference between two coefficients of variation in two-parameter exponential distributions.
Under many circumstances, confidence interval estimation or hypothesis testing for the common coefficient of variation based on several independent samples is of interest (Tian, 2005). Krishnamoorthy & Lu (2003) investigated procedures for confidence interval estimation and hypothesis testing of the common mean of several normal populations, while the problem of making inference from common populations with a common coefficient of variation of normal distributions was dealt with by Tian (2005). Tian & Wu (2007) proposed confidence interval estimation and hypothesis testing of the common mean of several log-normal populations using the generalized variable concept. Similarly, procedures for hypothesis testing and confidence interval estimation for the common mean of several inverse Gaussian populations were presented by Ye, Ma & Wang (2010). Moreover, Ng (2014) constructed a confidence interval for the common coefficient of variation from several independent log-normal samples based on the GCI approach, although there was no comparison with other approaches.
The concepts of the generalized pivotal quantity (GPQ) and the GCI first proposed by Weerahandi (1993) have been applied to solve many statistical problems. For example, Krishnamoorthy & Lu (2003) presented the generalized variable and GCI approaches for inference on the common mean of several normal populations. Tian (2005) studied inferences on the common coefficient of variation of several normal populations. Moreover, Tian & Wu (2007) proposed the generalized variable approach and the GCI approach for inferences on the common mean of several log-normal populations. Thangjai, Niwitpong & Niwitpong (2020b) developed confidence intervals for the common coefficient of variation of several normal populations using the GCI and adjusted GCI approaches. Hannig, Iyer & Patterson (2006a) suggested fiducial GPQ (FGPQ) as a subclass of GPQ, with the FGCI being constructed using the FGPQ under fairly general conditions. Furthermore, FGCIs have been constructed to solve many practical problems (Hannig et al., 2006b; Chang & Huang, 2009; Kharrati-Kopaei, Malekzadeh & Sadooghi-Alvandi, 2013; Thangjai, Niwitpong & Niwitpong, 2016). Although the FGCI approach is based on simulated data, one advantage is that it can be used to construct the confidence interval for complex parameters.
The method of variance estimates recovery (MOVER) approach was introduced by Zou & Donner (2008) and Zou, Taleban & Hao (2009). Several researchers have successfully used the MOVER approach to construct confidence intervals (Donner & Zou, 2012; Suwan & Niwitpong, 2013; Niwitpong & Wongkhao, 2016). The MOVER approach has the advantage of being easy to compute using the exact formula. However, the disadvantage of this approach is that one can construct it with or without the initial confidence interval for a single parameter of interest.
The computational approach proposed by Pal, Lim & Ling (2007) has been used by many researchers to test the equality of several populations (e.g., Jafari & Abdollahnezhad, 2015; Jafari & Kazemi, 2017; Gokpinar & Gokpinar, 2017). As an advantage, this approach does not require explicit knowledge of the sampling distribution of the test statistic. However, it is based on simulation and numerical computations using the maximum likelihood estimate only. The Bayesian approach uses Bayes’ theorem to compute and update probabilities after obtaining new data. Although it can be applied to estimate the confidence intervals for complex parameters, the disadvantages of applying it are that it requires prior information and is based on simulation.
Ng (2014) constructed the GCI of a log-normal distribution which used asymptotic variance and provided coverage probabilities close to the nominal confidence level of 0.95. The confidence interval constructed by transforming the log-normal coefficient of variation to the normal coefficient of variation. However, its use was only considered for homogeneous populations. Therefore, in this study, we extend the research of Ng (2014) to develop four novel approaches for confidence interval estimation for the common coefficient of variation of several log-normal populations based on the FGCI, MOVER, computational approach, and Bayesian approaches. Unlike Ng (2014), we compute the confidence intervals for the common coefficient of variation directly using the log-normal coefficient of variation that depends on σ2 only. Moreover, there is no previous literature on applying their methodology to PM2.5 concentration measurements. Therefore, to fill the gap, the novel approaches for the confidence interval estimation of the common coefficient of variation of log-normal distributions were proposed with considering the log-normality of PM2.5 concentration measurements.
Methods
Let us consider Y the log-normal distribution with parameters μY and σ2Y. It is well known that X = log(Y) follows a normal distribution with mean µand variance σ2, whereas the mean and variance of Y are given by (1)μY=exp(μ+(σ2∕2)) and (2)σ2Y=(exp(σ2)−1)⋅(exp(2μ+σ2)), respectively. From Eqs. (1) and (2), the coefficient of variation of Y is given by (3)θ=√exp(σ2)−1.
From Eq. (3), it is seen that the coefficient of variation of the log-normal distribution depends on parameter σ2 only, whereas the coefficient of variation of the normal distribution depends on µ and σ2. And the next result provides a useful approximation for the variance of an estimator of θ.
Let ˆθ=√exp(S2)−1 be an estimator of θ. Following the Niwitpong (2013) and Hasan & Krishnamoorthy (2017), the variance of ˆθ is (4)Var(ˆθ)≈σ4exp(2σ2)2(n−1)⋅(exp(σ2)−1).
Suppose that random samples are taken from k log-normal distributions, Yi=(Yi1,Yi2,…,Yini)∼LN(μi,σ2i), where i = 1, 2, …, k. Let θi=√exp(σ2i)−1 be the coefficient of variation for i = 1, 2, …, k. Let Xi = (Xi1, Xi2, …, Xini) be a random variable of size ni from the normal distribution with μi and variance σ2i. Let ˆμi=ˉXi and ˆσ2i=S2i be estimators of μi and σ2i, respectively, where ˉXi and S2i denote the mean and variance of the log-transformed sample from a log-normal distribution. The mean and variance are given by (5)ˉXi=ni∑j=1Xijni and (6)S2i=ni∑j=1(Xij−ˉXi)2ni−1, where i = 1, 2, …, k and j = 1, 2, …, ni.
Let ˉxi and s2i be the observed values of ˉXi and S2i, respectively. The maximum likelihood estimator of the coefficient of variation θi, is also unbiased estimator, is given by (7)ˆθi=√exp(S2i)−1, where S2i is defined in Eq. (6).
Fiducial generalized confidence interval
The FGCI uses the FGPQs. The FGPQs are a subclass of the GPQs. The FGCI has correct frequentist coverage probability. For i = 1, 2, …, k, let ˉXi and S2i be the sample mean and the sample variance for log-transformed data and let ˉxi and s2i be the observed sample mean and the observed sample variance respectively. Let ˉX∗i and S2∗i be independent copies of ˉXi and S2i, respectively. Let ˉXi and ˉX∗i be independent and identically distributed with mean μi and variance σ2i∕ni. It is well known that (8)ˉXi∼N(μi,σ2ini)andˉX∗i∼N(μi,σ2ini).
Furthermore, let S2i and S2∗i be independent and identically distributed. Then (9)(ni−1)S2iσ2i∼χ2ni−1and(ni−1)S2∗iσ2i∼χ2ni−1, where χ2ni−1 is chi-squared distribution with ni − 1 degree of freedom.
According to Hannig, Iyer & Patterson (2006a) and Hannig et al. (2006b), the FGPQs of μi and σ2i are defined by (10)Rμi=ˉXi−SiS∗i(ˉX∗i−μi) and (11)Rσ2i=S2iS2∗iσ2i.
Therefore, the FGPQ for θi based on the FGPQ for σ2i is given by (12)Rθi=√exp(Rσ2i)−1.
The FGPQ of θi in Eq. (12) satisfies two conditions defined in Definition of Hannig, Iyer & Patterson (2006a) and Hannig et al. (2006b). The definition of Hannig, Iyer & Patterson (2006a) and Hannig et al. (2006b) has two conditions such as the distribution of the GPQ is free of all unknown parameters and the observed value of the GPQ is the parameter of interest. From Eq. (4), the variance of ˆθi is provided by (13)Var(ˆθi)≈σ4iexp(2σ2i)2(ni−1)⋅(exp(σ2i)−1).
The FGPQ of Var(ˆθi) is given by (14)RVar(ˆθi)=R2σ2iexp(2Rσ2i)2(ni−1)⋅(exp(Rσ2i)−1).
The FGPQ for the common coefficient of variation θ is a weighted average of the FGPQ Rθi based on k individual sample. Therefore, the FGPQ is given by (15)Rθ=k∑i=1RθiRVar(ˆθi)/k∑i=11RVar(ˆθi), where Rθi is defined in Eq. (12) and RVar(ˆθi) is defined in Eq. (14).
The FGPQ in Eq. (12) satisfies two conditions of the definition given above. The FGCI is constructed using the quantiles of FGPQ defined in Eq. (15). Therefore, the 100(1−α)% two-sided confidence interval for the common coefficient of variation θ based on the FGCI approach is (16)CIFGCI=[LFGCI,UFGCI]=[Rθ(α∕2),Rθ(1−α∕2)], where Rθ(α∕2) and Rθ(1−α∕2) denote the 100(α∕2)-th and 100(1−α∕2)-th percentiles of Rθ, respectively.
The following algorithm is used to construct the FGCI:
Algorithm 1
For a given ¯ xi and s2i, where i = 1,2,...,k
For g = 1 to m, where m is number of generalized computation
Generate X∗ and then compute ¯ x∗i and s2∗i
Generate χ2ni−1 from chi-squared distribution with ni − 1 degrees of
freedom
Compute Rσ2
i from Eq. (11)
Compute Rθi from Eq. (12)
Compute RV ar(ˆθ
i) from Eq. (14)
Compute Rθ from Eq. (15)
End g loop
Compute Rθ (α∕2) and Rθ (1 − α∕2) from Eq. (16) Method of variance estimates recovery confidence interval
Zou & Donner (2008) and Zou, Taleban & Hao (2009) proposed the MOVER approach to construct the confidence interval for the sum of two parameters. For i = 1, 2, let θ1 and θ2 be the parameters of interest. Let L and U be the lower limit and upper limit of the confidence interval for θ1 + θ2. Moreover, let ˆθ1 and ˆθ2 be the estimators of θ1 and θ2, respectively. The central limit theorem and the assumption of independence between the point estimates ˆθ1 and ˆθ2 are used. Therefore, the lower limit L is (17)L=ˆθ1+ˆθ2−zα∕2√̂Var(ˆθ1)+̂Var(ˆθ2), where zα∕2 is the 100(α∕2)-th percentile of the standard normal distribution.
Let li and ui be the lower limit and upper limit of the confidence interval for θi, where i = 1, 2. The lower limit L must be closer to l1 + l2 than to ˆθ1+ˆθ2. The variance estimate for ˆθi at θi = li is defined by (18)̂Var(ˆθli)=(ˆθi−li)2z2α∕2.
Substituting back into Eq. (17) as follows (19)L=ˆθ1+ˆθ2−√(ˆθ1−l1)2+(ˆθ2−l2)2.
Similarly, the variance estimate for ˆθi at θi = ui is defined by (20)̂Var(ˆθui)=(ui−ˆθi)2z2α∕2.
The upper limit U is (21)U=ˆθ1+ˆθ2+√(u1−ˆθ1)2+(u2−ˆθ2)2.
Therefore, the variance estimate for ˆθi at θi = li and θi = ui is defined by (22)̂Var(ˆθi)=12((ˆθi−li)2z2α∕2+(ui−ˆθi)2z2α∕2), where i = 1, 2.
In this paper, the k parameters of interest are θ1, θ2, …, θk. The concepts of Zou & Donner (2008) and Zou, Taleban & Hao (2009) are motivated for constructing the confidence interval for θ1 + θ2 + … + θk are (23)L=ˆθ1+ˆθ2+…+ˆθk−√(ˆθ1−l1)2+(ˆθ2−l2)2+…+(ˆθk−lk)2 and (24)U=ˆθ1+ˆθ2+…+ˆθk+√(u1−ˆθ1)2+(u2−ˆθ2)2+…+(uk−ˆθk)2, where (l1, u1), (l2, u2), …, (lk, uk) contain the parameter values for θ1, θ2, …, θk, respectively.
According to Graybill & Deal (1959), the common coefficient of variation θ is weighted average of the coefficient of variation ˆθi based on k individual samples. Therefore, the common coefficient of variation is defined by (25)ˆθ=k∑i=1ˆθîVar(ˆθi)/k∑i=11̂Var(ˆθi), where ˆθi=√exp(S2i)−1 and ̂Var(ˆθi) is defined in Eq. (22).
Applying Krishnamoorthy & Oral (2017), the lower limit and upper limit of the confidence interval for the common coefficient of variation θ are defined by (26)LMOVER=ˆθ−√k∑i=1(ˆθi−li)2(̂Var(ˆθli))2/k∑i=11(̂Var(ˆθli))2 and (27)UMOVER=ˆθ+√k∑i=1(ui−ˆθi)2(̂Var(ˆθui))2/k∑i=11(̂Var(ˆθui))2, where ˆθ is defined in Eq. (25).
According to Niwitpong (2013), for i = 1, 2, …, k, the confidence interval for coefficient of variation of log-normal distribution based on the ith sample is given by (28)[li,ui]=[√exp((ni−1)S2iχ2(ni−1),(1−α∕2))−1,√exp((ni−1)S2iχ2(ni−1),(α∕2))−1], where χ2(ni−1),(1−α∕2) and χ2(ni−1),(α∕2) denote the 100(1−α∕2)-th and 100(α∕2)-th percentiles of the chi-squared distribution with ni − 1 degrees of freedom.
Therefore, the 100(1−α)% two-sided confidence interval for the common coefficient of variation θ based on MOVER approach is (29)CIMOVER=[LMOVER,UMOVER],
where LMOVER is defined in Eq. (26), UMOVER is defined in Eq. (27), and li and ui are defined in Eq. (28).
Computational confidence interval
Theorem 1: Let Yi=(Yi1,Yi2,…,Yini) be a log-normal population with parameters μi and σ2i, where i = 1, 2, …, k. For i = 1, 2, …, k and j = 1, 2, …, ni, let Xij=log(Yij) be the normal distribution with mean μi and variance σ2i. The maximum likelihood estimators of μi and θ given by Eq. (3) under θ1 = θ2 = … = θk = θ are given by (30)ˆμi=ˉXi and (31)k∑i=1niˆσ2ilog(θ2+1)−k∑i=1ni=0.
Proof: The log-likelihood function of normal distribution with parameters μi and θ is given by lnL=−12k∑i=1nilog(2πlog(θ2+1))−k∑i=1nilog(Yij)−k∑i=1ni∑j=1(log(Yij)−μi)22log(θ2+1).
Differentiating the lnL with respect to μi and θ, respectively, the maximum likelihood estimators of μi and θ are given by
k∑i=1niˆσ2ilog(θ2+1)−k∑i=1ni=0.
According to Pal, Lim & Ling (2007), the computational approach uses the maximum likelihood estimates (MLEs). The common coefficient of variation based on maximum likelihood estimator is defined by (32)ˆθML=k∑i=1ˆθîVar(ˆθi)/k∑i=11̂Var(ˆθi),
where ˆθi=√exp(S2i)−1 and ̂Var(ˆθi) is defined in Eq. (4) with σi replaced by si.
The computational approach is to obtain the restricted maximum likelihood estimates (RMLEs) of parameters. The maximum likelihood estimators of μi and θ under θ1 = θ2 = … = θk = θ provide the RMLEs of these parameters.
Then the RMLE of μi is defined by ˆμi(RML)=ˉXi. The RMLE of θ obtained iteratively from Eq. (31) by using bisection method. The θ converge to the RMLE denoted as ˆθRML.
Data replication from f(x|ˆμi(RML),ˆθRML) is used to construct the confidence interval based on computational approach. Let artificial sample Xi(RML)=(Xi1(RML),Xi2(RML),…,Xini(RML)) be the normal distribution with mean ˆμi(RML) and variance ˆσ2i(RML). Let ˉXi(RML) and S2i(RML) be the mean and variance of the log-transformed sample from a log-normal distribution for the ith artificial sample and let ˉxi(RML) and s2i(RML) be observed sample mean and observed sample variance, respectively.
Therefore, the common coefficient of variation based on k individual samples is defined by (33)ˆθRML=k∑i=1ˆθi(RML)̂Var(ˆθi(RML))/k∑i=11̂Var(ˆθi(RML)),
where ˆθi(RML)=√exp(S2i(RML))−1.
Therefore, the 100(1−α)% two-sided confidence interval for the common coefficient of variation θ based on computational approach is (34)CICA=[LCA,UCA]=[ˆθRML(α∕2),ˆθRML(1−α∕2)],
where ˆθRML(α∕2) and ˆθRML(1−α∕2) denote the (α∕2)-th and (1−α∕2)-th percentiles of ˆθRML, respectively.
The following algorithm is used to construct the computational confidence interval:
Algorithm 2
For a given ¯ xi, s2i, and θ, where i = 1,2,...,k
Compute ˆ μi(RML) and ˆ θRML from Eqs. (30)--31
For g = 1 to m
Generate xij(RML) from N (
ˆ μi(RML),∘
__________log (
ˆ θ2
RML + 1)
)
Compute ¯ xi(RML) and s2i(RML)
Compute ˆ θRML from Eq. (33)
End g loop
Compute ˆ θRML (α∕2) and ˆ θRML (1 − α∕2) from Eq. (34) Bayesian confidence interval
The FGCI approach, MOVER approach, and computational approach are the classical approach. The classical approach and the Bayesian approach are fundamentally different. In the classical approach, the parameter of interest θ is unknown, but it is fixed. In the Bayesian approach, the parameter is considered to be a quantity. The variation of the quantity is described by the prior distribution. Bayes (1763) introduced that Bayesian approach uses Bayes’ theorem to update probabilities. Bayes’ theorem describes the conditional probability of an event based on data. The data is prior information or beliefs about the event. The posterior distribution is combination of the likelihood function and the prior distribution. The Bayesian confidence interval is constructed based on the posterior distribution. The posterior distribution is a conditional distribution which is based on the observed values of the sample. The posterior distribution is used to make statements about the parameter. The parameter is considered a random quantity. The conditional posterior distribution for μi given σ2i and xi is the normal distribution with mean ˆμi and variance σ2i∕ni. The distribution is defined by (35)μi|σ2i,xi∼N(ˆμi,σ2i∕ni).
The posterior distribution for σ2i is inverse gamma distribution. It is defined by (36)σ2i|xi∼IG((ni−1)∕2,(ni−1)s2i∕2).
The posterior distribution of coefficient of variation of log-normal distribution is (37)ˆθi=√exp(σ2i)−1, where σ2i is defined in Eq. (36).
The variance of ˆθi is (38)Var(ˆθi)≈σ4i(exp(2σ2i))2(ni−1)(exp(σ2i)−1), where σ2i is defined in Eq. (36).
The common coefficient of variation of log-normal distribution based on k individual samples which the parameter of interest defined by (39)ˆθBS=k∑i=1ˆθiVar(ˆθi)/k∑i=11Var(ˆθi),
where (ˆθi) is defined in Eq. (37) and Var(ˆθi) is defined in Eq. (38).
Gelman et al. (2013) introduced the highest posterior density interval to construct the Bayesian confidence interval. Therefore, the 100(1−α)% two-sided confidence interval for the common coefficient of variation θ based on Bayesian approach is (40)CIBS=[LBS,UBS], where LBS and UBS are the lower limit and the upper limit of the shortest 100(1−α)% highest posterior density interval of ˆθBS, respectively.
The following algorithm is used to construct the Bayesian confidence interval:
Algorithm 3
For a given ¯ xi and s2i, where i = 1,2,...,k
For g = 1 to m
Generate μi|σ2i,xi ∼ N(ˆμi,σ2i∕ni)
Generate σ2i|xi ∼ IG((ni − 1)∕2,(ni − 1)s2i∕2)
Compute θi from Eq. (37)
Compute V ar(ˆθi) from Eq. (38)
Compute θBS from Eq. (39)
End g loop
Compute LBS and UBS Results
A simulation study was performed to evaluate the coverage probabilities and average lengths of the FGCI (CIFGCI), MOVER (CIMOVER), computational (CICA), and Bayesian confidence intervals (CIBS). The confidence intervals were compared by measuring their coverage probabilities and average lengths and, in each case, the one with a coverage probability closest to the nominal confidence level (1 − α) and with the shortest average length was chosen as the most appropriate.
In this simulation study, the nominal confidence level was chosen as 0.95. The sample cases used were k = 3 and k = 6 with sample sizes n1, n2, …, nk, as in Tables 1 and 2. Following Tian & Wu (2007) and Ng (2014), the coefficient of variation of log-normal distribution, which equals √exp(σ2)−1, is chosen in the range from 0.05 - 2.00. Since the coefficient of variation of a log-normal distribution is independent of µ, the population means of the normal data within each sample were given the same value μ1 = μ2 = … = μk = μ = 1 to simplify matters, and the population standard deviations σ1, σ2, …, σk are as in Tables 1 and 2. For each parameter setting, 5,000 random samples were generated by applying Algorithm 4, and thus 1000Rθ, 1000ˆθRML, and 1000θBS were simulated by applying Algorithm 1, 2, and 3, respectively, for each of the random samples.
| (n1, n2, n3) | (σ1, σ2, σ3) | Coverage probability (Average length) | |||
|---|---|---|---|---|---|
| CIFGCI | CIMOVER | CICA | CIBS | ||
| (30,30,30) | (0.05,0.10,0.15) | 0.9514 | 0.9238 | 0.9188 | 0.9400 |
| (0.0317) | (0.0306) | (0.0305) | (0.0309) | ||
| (0.50,1.00,1.00) | 0.9496 | 0.9150 | 0.9246 ) | 0.9394 | |
| (0.3922) | (0.3672) | (0.3628 | (0.3781) | ||
| (50,50,50) | (0.05,0.10,0.15) | 0.9492 | 0.9234 | 0.9244 | 0.9408 |
| (0.0246) | (0.0230) | (0.0240) | (0.0241) | ||
| (0.50,1.00,1.00) | 0.9504 | 0.9054 | 0.9372 | 0.9442 | |
| (0.3060) | (0.2707) | (0.2909) | (0.2976) | ||
| (30,50,100) | (0.05,0.10,0.15) | 0.9530 | 0.9160 | 0.9200 | 0.9426 |
| (0.0331) | (0.0312) | (0.0329) | (0.0325) | ||
| (0.50,1.00,1.00) | 0.9498 | 0.8808 | 0.9186 | 0.9360 | |
| (0.4259) | (0.3831) | (0.4055) | (0.4147) | ||
| (50,100,200) | (0.05,0.10,0.15) | 0.9528 | 0.9222 | 0.9358 | 0.9430 |
| (0.0251) | (0.0234) | (0.0252) | (0.0247) | ||
| (0.50,1.00,1.00) | 0.9492 | 0.8722 | 0.9314 | 0.9410 | |
| (0.3357) | (0.2875) | (0.3272) | (0.3291) | ||
| (100,100,100) | (0.05,0.10,0.15) | 0.9502 | 0.9214 | 0.9388 | 0.9442 |
| (0.0174) | (0.0159) | (0.0172) | (0.0171) | ||
| (0.50,1.00,1.00) | 0.9478 | 0.8952 | 0.9398 | 0.9394 | |
| (0.2176) | (0.1852) | (0.2117) | (0.2129) | ||
| (200,200,200) | (0.05,0.10,0.15) | 0.9446 | 0.9178 | 0.9396 | 0.9404 |
| (0.0123) | (0.0111) | (0.0122) | (0.0121) | ||
| (0.50,1.00,1.00) | 0.9488 | 0.8944 | 0.9456 | 0.9434 | |
| (0.1542) | (0.1288) | (0.1520) | (0.1513) | ||
| (500,500,500) | (0.05,0.10,0.15) | 0.9482 | 0.9200 | 0.9444 | 0.9420 |
| (0.0078) | (0.0070) | (0.0078) | (0.0077) | ||
| (0.50,1.00,1.00) | 0.9480 | 0.8940 | 0.9470 | 0.9430 | |
| (0.0976) | (0.0807) | (0.0971) | (0.0961) | ||
| (1000,1000,1000) | (0.05,0.10,0.15) | 0.9428 | 0.9162 | 0.9446 | 0.9390 |
| (0.0055) | (0.0049) | (0.0055) | (0.0054) | ||
| (0.50,1.00,1.00) | 0.9574 | 0.9020 | 0.9552 | 0.9524 | |
| (0.0691) | (0.0569) | (0.0689) | (0.0681) | ||
| (n1, n2, n3, n4, n5, n6) | (σ1, σ2, σ3, σ4, σ5, σ6) | Coverage probability (Average length) | |||
|---|---|---|---|---|---|
| CIFGCI | CIMOVER | CICA | CIBS | ||
| (30,30,30,30,30,30) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9432 | 0.9818 | 0.8812 | 0.9328 |
| (0.0226) | (0.0298) | (0.0227) | (0.0222) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9218 | 0.9838 | 0.8418 | 0.8982 | |
| (0.2099) | (0.3278) | (0.2108) | (0.2054) | ||
| (30,50,100,30,50,100) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9400 | 0.9800 | 0.8928 | 0.9314 |
| (0.0199) | (0.0247) | (0.0202) | (0.0196) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9350 | 0.9830 | 0.8992 | 0.9224 | |
| (0.1490) | (0.2033) | (0.1505) | (0.1461) | ||
| (50,50,50,50,50,50) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9392 | 0.9834 | 0.9060 | 0.9342 |
| (0.0175) | (0.0227) | (0.0175) | (0.0172) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9290 | 0.9890 | 0.8812 | 0.9182 | |
| (0.1628) | (0.2503) | (0.1638) | (0.1598) | ||
| (30,30,50,50,100,100) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9354 | 0.9808 | 0.8636 | 0.9218 |
| (0.0239) | (0.0305) | (0.0245) | (0.0235) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9218 | 0.9800 | 0.8596 | 0.9048 | |
| (0.2128) | (0.2931) | (0.2148) | (0.2086) | ||
| (50,50,100,100,200,200) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9432 | 0.9860 | 0.9028 | 0.9360 |
| (0.0180) | (0.0231) | (0.0184) | (0.0178) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9354 | 0.9822 | 0.9008 | 0.9218 | |
| (0.1598) | (0.2103) | (0.1611) | (0.1571) | ||
| (30,30,50,100,100,200) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9398 | 0.9800 | 0.8678 | 0.9312 |
| (0.0226) | (0.0283) | (0.0236) | (0.0223) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9284 | 0.9788 | 0.8618 | 0.9100 | |
| (0.2257) | (0.2980) | (0.2291) | (0.2216) | ||
| (100,100,100,100,100,100) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9480 | 0.9830 | 0.9282 | 0.9406 |
| (0.0123) | (0.0158) | (0.0124) | (0.0122) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9362 | 0.9952 | 0.9166 | 0.9256 | |
| (0.1149) | (0.1747) | (0.1154) | (0.1131) | ||
| (200,200,200,200,200,200) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9512 | 0.9872 | 0.9410 | 0.9428 |
| (0.0087) | (0.0111) | (0.0087) | (0.0086) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9418 | 0.9968 | 0.9322 | 0.9364 | |
| (0.0813) | (0.1231) | (0.0816) | (0.0801) | ||
| (500,500,500,500,500,500) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9510 | 0.9876 | 0.9440 | 0.9464 |
| (0.0055) | (0.0070) | (0.0055) | (0.0054) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9520 | 0.9960 | 0.9494 | 0.9494 | |
| (0.0514) | (0.0776) | (0.0514) | (0.0506) | ||
| (1000,1000,1000,1000,1000,1000) | (0.05,0.05,0.10,0.10,0.15,0.15) | 0.9520 | 0.9890 | 0.9496 | 0.9490 |
| (0.0039) | (0.0049) | (0.0039) | (0.0038) | ||
| (0.50,0.50,0.50,1.00,1.00,1.00) | 0.9520 | 0.9974 | 0.9488 | 0.9470 | |
| (0.0363) | (0.0548) | (0.0363) | (0.0358) | ||
The following algorithm is used to estimate the coverage probability and average length:
Algorithm 4
For a given (n1,n2,...,nk), (μ1,μ2,...,μk), (σ1,σ2,...,σk) and θ
For h = 1 to M
Generate xij from N(μi,σ2i), where i = 1,2,...,k and j = 1,2,...,ni
Calculate ¯ xi and s2i
Construct [LFGCI(h),UFGCI(h)]
Construct [LMOV ER(h),UMOV ER(h)]
Construct [LCA(h),UCA(h)]
Construct [LBS(h),UBS(h)]
Record whether or not all the values of θ fall in their correspond-
ing confidence intervals
Compute U(h) − L(h)
End h loop
Compute the coverage probability and the average length for each con-
fidence interval Tables 1 and 2 report the coverage probabilities and average lengths for k = 3 and k = 6, respectively. From Table 1, the simulation results indicate that for all sample sizes, the FGCI approach provided the best coverage probabilities whereas the MOVER confidence interval attained coverage probabilities under the nominal confidence level of 0.95. Furthermore, the coverage probabilities of the MOVER confidence interval decreased when the sample sizes increased. The computational confidence interval achieved coverage probabilities under the nominal confidence level of 0.95, which became closer to it as the sample sizes increased. The coverage probabilities of the Bayesian confidence interval performed well when the population standard deviations were (0.05,0.10,0.15) whereas they were less than the nominal confidence level of 0.95 when the population standard deviations were (0.50,1.00,1.00).
From Table 2, it can be seen that the coverage probabilities of the FGCI and the computational confidence interval were less than the nominal confidence level of 0.95 when the sample sizes were small. For large sample sizes, the coverage probabilities of the FGCI and the computational confidence interval were close to the nominal confidence level of 0.95, with those of the FGCIs being closer. The coverage probabilities of the MOVER confidence interval were greater than the nominal confidence level of 0.95 for small sample sizes and became close to 1.00 when the sample sizes increased, thereby showing conservative behavior when the sample case (k) was large and the sample sizes were large. Therefore, the MOVER approach can be considered as an alternative to estimate the confidence interval for the common coefficient of variation of log-normal distributions when the sample case (k = 6) is large and the sample sizes are small. The coverage probabilities of the Bayesian confidence interval were less than the nominal confidence level of 0.95 when the sample sizes were small and were close to the nominal confidence level of 0.95 when the sample sizes were large. The average lengths of the Bayesian confidence interval were shorter than those of the others.
As the sample case (k) increased, the coverage probabilities of the FGCI and the computational confidence interval tended to decrease because the common coefficient of variation θ is based on the variance of the coefficient of variation ˆθi for the k individual samples. Herein, we present only the results of μ = 1 because they tended toward the same direction regardless of the value of µ. In all cases, the coverage probabilities were affected by large σ values because the coefficient of variation of log-normal distributions θ=√exp(σ2)−1 depends on parameter σ only.
An empirical application
The rainfall has been the seasonal problem in Thailand. Rainy season in Thailand is between May and October. The daily rainfall appears on 17 June 2020. Real data example of rainfall data is used to illustrate the FGCI, MOVER, computational, and Bayesian approaches. All data were reported by the Thai Meteorological Department (https://www.tmd.go.th/climate/climate.php).
The rainfall data on 17 June 2020 in Northern, Northeastern, Central, Eastern, and Southern regions are reported in Dataset 1, and histogram and normal QQ-plots are presented in Figs. 1 and 2, respectively. The data sets consist of 30 measurements in Northern region, 31 measurements in Northeastern region, 21 measurements in Central region, 16 measurements in Eastern region, and 27 measurements in Southern region. The statistics is summarized in Table 3. The Shapiro–Wilk normality test is used to check the assumption that the log-data is normal distribution. The Shapiro–Wilk normality test with p-values 0.2176, 0.4981, 0.0009, 0.0128, and 0.2127 for Northern, Northeastern, Central, Eastern, and Southern regions, respectively. From p-values, the results show that the rainfall of the three regions follow log-normal distributions such as Northern, Northeastern, and Southern regions. The data of Northern, Northeastern, and Southern regions were used to construct the confidence interval for the common coefficient of variation based on the four approaches. The true common coefficient of variation was 1.2084. The point estimators of the common coefficient of variation based on the FGCI, MOVER, CA, and Bayesian approaches were 1.2776, 1.1486, 1.2273, and 1.2669. The FGCI, MOVER, computational, and Bayesian confidence intervals were [0.8380, 2.0301] with an interval length of 1.1921, [0.8460, 1.8481] with an interval length of 1.0021, [0.7745, 1.8663] with an interval length of 1.0918, and [0.7991, 1.7704] with an interval length of 0.9713, respectively. Hence, the length of the Bayesian confidence interval was shorter than those of the others, and so was more accurate.
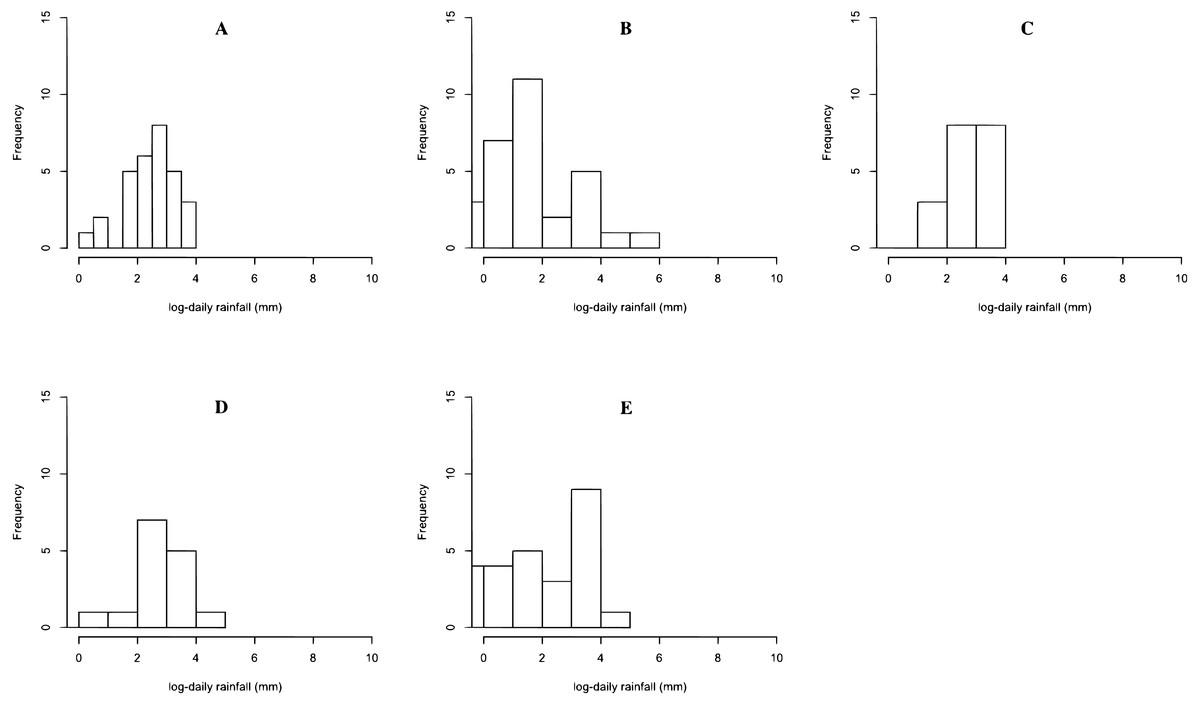
Figure 1: Histogram of rainfall data in (A) Northern (B) Northeastern (C) Central (D) Eastern (E) Southern regions.
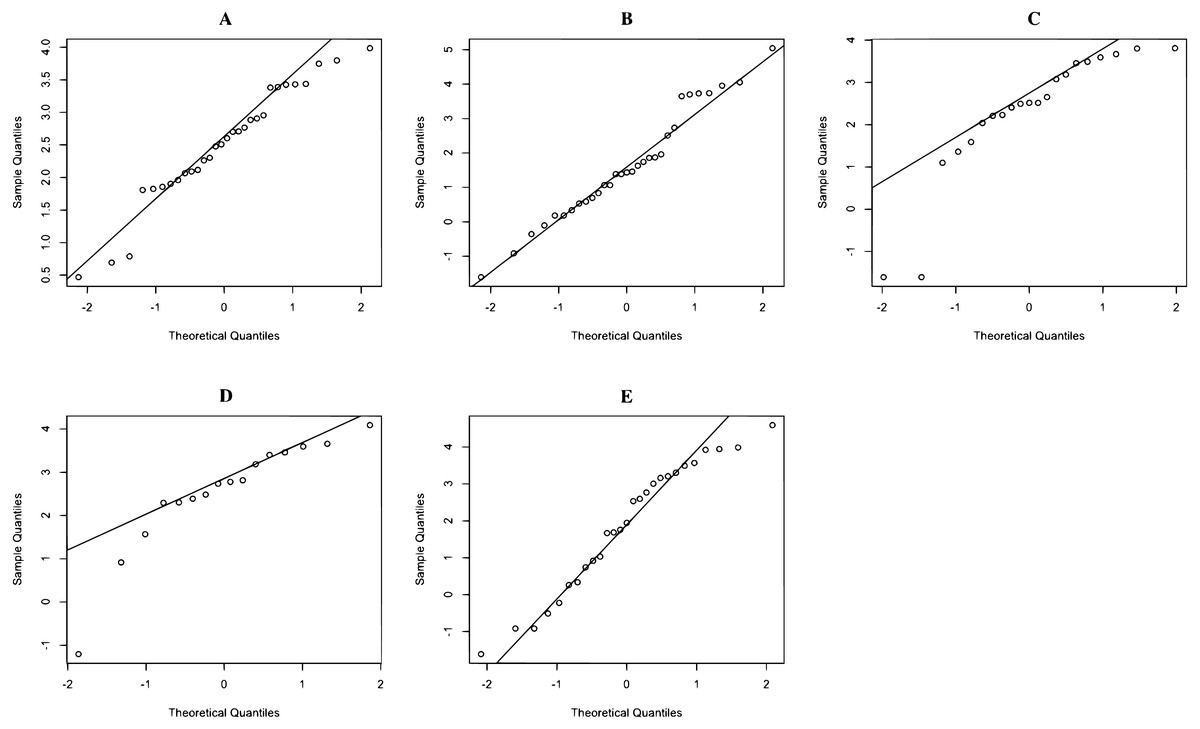
Figure 2: QQ-plot of log- rainfall data in (A) Northern (B) Northeastern (C) Central (D) Eastern (E) Southern regions
Discussion
As a limitation of this study, the coefficient of variation of log-normal distribution can be computed directly from log-normal data and the data transformed using the log function. The coefficients of variation based directly on log-normal data make it easy to construct the confidence interval for the common coefficient of variation of log-normal distributions because the coefficient of variation of a log-normal distribution is based on σ2 only. However, for a greater number of samples, i.e., n = 500 and a large σ2, i.e., σ2 = 10, the coverage probabilities of all of the proposed confidence intervals cannot be computed (the simulation results are not reported here). The coefficients of variation based on transformed data using the log function make it more difficult to estimate the confidence interval for the common coefficient of variation of log-normal distributions because the coefficient of variation of a normal distribution is based on both µ and σ2.
The MOVER approach makes it possible to compute the confidence interval online because this approach requires a simple formula to construct the confidence interval. Since the FGCI, computational, and Bayesian approaches are based on simulation techniques, it is not possible to compute the confidence intervals for them online.
As a final note, the results of the computational approach did not perform well for the confidence interval estimation for the common coefficient of variation of log-normal distributions. However, Thangjai, Niwitpong & Niwitpong (2020b) reported that it performs well for constructing the confidence interval for the common coefficient of variation of normal distributions when the sample case is large.
| Statistics | Northern region | Northeastern region | Central region | Eastern region | Southern region |
|---|---|---|---|---|---|
| n | 30 | 31 | 21 | 16 | 27 |
| ˉy | 17.1200 | 16.8677 | 17.9333 | 19.9688 | 18.3852 |
| sY | 13.5250 | 30.9424 | 14.7627 | 15.8678 | 23.2974 |
| ˉx | 2.5082 | 1.6238 | 2.2851 | 2.5292 | 1.8608 |
| sX | 0.8945 | 1.6007 | 1.5163 | 1.2827 | 1.7549 |
| ˆθ | 1.1072 | 3.4592 | 2.9942 | 2.0450 | 4.5550 |
Conclusions
The results in Tables 1 and 2 indicate that the FGCI approach provided much better confidence interval estimates than the other approaches in terms of coverage probability for almost all sample cases (k) and sample sizes (n), except that the MOVER approach provided the best confidence interval estimates when the sample case was equal to six populations (k = 6) and the sample sizes were small (ni < 50). Moreover, the FGCI approach was the best for constructing the confidence interval for all sample sizes (n) when the sample case is small (k = 3), for which the coverage probability of the FGCI approach was stable around the nominal confidence level of 0.95. For large sample cases (k = 6), the FGCI approach performed well for confidence interval estimation when the sample sizes were large. Furthermore, the FGPQ for the FGCI approach is not dependent on the population variances (σi). The results are similar to those of Hannig et al. (2006b), Chang & Huang (2009), Kharrati-Kopaei, Malekzadeh & Sadooghi-Alvandi (2013), and Thangjai, Niwitpong & Niwitpong (2016). Note that the GCIs based on Ng (2014) had coverage probabilities close to 1.00 when the sample size was small and close to the nominal confidence level of 0.95 when the sample size was large. Therefore, the GCIs based on Ng (2014) are rather conservative for small sample sizes.
Supplemental Information
R code for running coverage probability and average length width of all confidence intervals
Rainfall data of Northern, Northeastern, Central, Eastern, and Southern regions (mm)
Additional Information and Declarations
Competing Interests
The authors declare there are no competing interests.
Author Contributions
Warisa Thangjai conceived and designed the experiments, performed the experiments, analyzed the data, prepared figures and/or tables, authored or reviewed drafts of the paper, and approved the final draft.
Sa-Aat Niwitpong conceived and designed the experiments, prepared figures and/or tables, authored or reviewed drafts of the paper, and approved the final draft.
Suparat Niwitpong performed the experiments, analyzed the data, prepared figures and/or tables, authored or reviewed drafts of the paper, and approved the final draft.
Data Availability
The following information was supplied regarding data availability:
Raw data and code are available in the Supplemental Files.
Funding
This research was funded by King Mongkut’s University of Technology North Bangkok (Grant No. KMUTNB-62-KNOW-19). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.

{kind=link}
{kind=link}