
The effect of node features on GCN-based brain network classification: an empirical study
- Published
- Accepted
- Received
- Academic Editor
- Feng Liu
- Subject Areas
- Cognitive Disorders, Computational Science, Data Mining and Machine Learning
- Keywords
- Graph convolutional network, Node features, Empirical study, Mild cognitive impairment, Autism spectrum disorder
- Copyright
- © 2023 Wang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. The effect of node features on GCN-based brain network classification: an empirical study. PeerJ 11:e14835 https://doi.org/10.7717/peerj.14835
Abstract
Brain functional network (BFN) analysis has become a popular technique for identifying neurological/mental diseases. Due to the fact that BFN is a graph, a graph convolutional network (GCN) can be naturally used in the classification of BFN. Different from traditional methods that directly use the adjacency matrices of BFNs to train a classifier, GCN requires an additional input-node features. To our best knowledge, however, there is no systematic study to analyze their influence on the performance of GCN-based brain disorder classification. Therefore, in this study, we conduct an empirical study on various node feature measures, including (1) original fMRI signals, (2) one-hot encoding, (3) node statistics, (4) node correlation, and (5) their combination. Experimental results on two benchmark databases show that different node feature inputs to GCN significantly affect the brain disease classification performance, and node correlation usually contributes higher accuracy compared to original signals and manually extracted statistical features.
Introduction
Resting-state functional magnetic resonance imaging (rs-fMRI) is an effective non-invasive technique for recording spontaneous neural activity in the brain when the subjects are awake and relaxed in the absence of task-specific stimuli. Based on rs-fMRI, the interaction between different regions of interest (ROIs) can be described by the brain functional network (BFN) (Van Den Heuvel & Pol, 2010) that has become an increasingly important tool to diagnose neurological or mental diseases, such as mild cognitive impairment (MCI) and autism spectrum disorder (ASD) (Lord et al., 2020).
In consideration of the fact that BFN is a graph, a graph convolutional network (GCN) can naturally be used to extract features from BFN for brain disease classification. For example, Parisot et al. (2018) combined imaging and non-imaging data for population brain analysis using GCN. Arya et al. (2020) used GCN to fuse structural and functional MRI for ASD classification. Additionally, many improved versions based on GCN were also developed from multi-layer (Yu et al., 2020; Song et al., 2022) and multi-view (Cao et al., 2021; Wen et al., 2022) methods to detect brain diseases. Unlike traditional classifiers that are trained directly by the adjacency matrices of BFNs, the GCN-based classification methods need the node feature matrix as an extra input. However, to the best of our knowledge, there is no systematic study to analyze the influence of different node features on the classification results.
In this article, we use/design four kinds of node feature matrices and evaluate their influence on GCN-based brain disorder classification. The first node feature is original signals (OS) directly extracted from the rs-fMRI. These signals are highly reproducible and provide data sets that can be easily compared across studies. The second node feature is one-hot encoding (OH) that can uniquely identify the location of each node. In addition, we compute several node statistics (NS), including local efficiency, node centrality, and local clustering coefficient, which are concatenated to generate the third type of node features. The fourth node feature is the correlation vector (CV) that reflects the relationship between the current ROI and other ROIs. For a more systematical evaluation, we also discuss the impact of different node feature combinations on the classification results.
Two classification tasks are conducted in this empirical study: (1) MCI identification (identifying subject with MCI from healthy controls) and (2) ASD identification (identifying subject with ASD from healthy controls). Experimental results suggest that different node feature inputs to GCN have significant effects on brain disease classification performance, and CV usually contributes more than other three features.
The rest of this article is organized as follows. In ‘Methods’, we introduce the relevant concepts and network architecture that will be used in this study. In ‘Materials’, we describe the data materials including data acquisition and data preprocessing. In ‘Experiments’, we report the experimental details and experimental setting. In ‘Results’ and ‘Discussion’, we report experimental results and discussion, respectively. Finally, we conclude this article in ‘Conclusions’.
Methods
In this section, we introduce the relevant notation/concepts and architecture of the network used in this study.
Problem formulation
We represent each subject as a graph G = (V, E), where V = v1, v2, ⋯, vn denotes the node set, n is the number of nodes/ROIs, and E = e1, e2, ⋯, e|ɛ| stands for the edge set that is determined by the relationship between different nodes. Accordingly, the node feature matrix and graph adjacency matrix are denoted by X ∈ Rn×d and A ∈ 0, 1n×n, respectively, where xi ∈ Rd is the feature of node vi, d is the number of feature dimensions and Aij = 1if(vi, vj) ∈ E, 0 otherwise. We split subjects/graphs into training and test sets. Given an adjacency matrix A and a feature matrix X in the training sets, we learn a GCN-based classification model and predict the labels of subjects in the test set.
Network architecture
Our analysis is based on a spectral GCN with two convolution layers (Kipf & Welling, 2016), which has been empirically verified as an effective architecture for brain disorder identification in several recent works (Ying et al., 2018; Abu-El-Haija et al., 2020; Chu et al., 2022). Its mathematical model can be formulated as follows: (1) where , In is an identity matrix, and D is a diagonal matrix whose diagonal element Dii = ∑jAij represents the degree of the i-th node, W0 and W1are two layers of model parameters that need to be learned from data, and ReLU is a nonlinear activation function.
Suppose that F = fi(X, A) ∈ Rn×d′ is the learned representations of nodes, where fi isthe embedding of node vi, d′ is the dimension of the feature after embedding. We can further obtain a graph-level representation HG = r(F) ∈ Rd′ for G by aggregating the node-level embedding. The readout function r(⋅) is a concatenation of the maximum pooling and average pooling operation (Lee, Lee & Kang, 2019). It can be formulated as follows: (2) where ∥ denotes concatenation.
Materials
In this section, we describe the data preparation, including data acquisition and data preprocessing.
Data acquisition
In this article, two publicly available datasets are used to evaluate the effect of node feature on GCN-based method. One is from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset and the other is from the Autism Brain Imaging Data Exchange (ABIDE) dataset. The details of subjects involved in the two datasets are shown in Table 1, including distribution of ASD/MCI, gender (M/F), age and imaging parameters echo time (TE) and repetition time (TR). Specifically, the ADNI dataset consists of 137 subjects, including 69 HCs and 68 MCIs. The fMRI data were scanned by a 3.0-T Philips MRI scanner and the scanning parameters included TR = 3,000 ms, TE = 30 ms, flip angle = 80°, number of slices = 48, slice thickness = 3.3 mm, total volume = 140. For ABIDE dataset, 184 subjects are involved, including 79 ASDs and 105 HCs. All rs-fMRI data are obtained by 3.0-T Siemens Allegra scanner with the following imaging parameters: TR/TE = 2,000/15 ms, slices number = 33, voxel thickness = 4.0 mm, flip angle = 90°, and the scanning time is 6 min, resulting in 180 time points.
| Datasets | Class | Gender (M/F) | Age (Years) | TR/TE (ms) |
|---|---|---|---|---|
| ADNI | MCI | 39/29 | 76.50 ± 13.50 | 3000/30 |
| HC | 17/52 | 71.50 ± 14.50 | 3000/30 | |
| ABIDE | ASD | 68/11 | 18.58 ± 11.45 | 2000/15 |
| HC | 79/26 | 19.13 ± 11.85 | 2000/15 |
Notes:
- M/F
-
Male/Female
- TE/TR
-
Echo Time/Repetition Time
Data preprocessing
All the rs-fMRI data are preprocessed through DPARSF (Yan et al., 2016) and statistical parametric mapping (SPM12) based on the following standard pipeline: we discard the first five volumes of each functional time series and slice timing to allow signal stabilization. Then, the remaining nuisance signals, including ventricle and white matter signals, are regressed, and the Friston 24-parameter model is used to regress out the high-order effect of head motion. After that, the signals are spatially normalized to MNI space, and the fMRI data are spatially smoothed with the full-width-half-maximum of four mm. Finally, depending on the AAL atlas, the preprocessed rs-fMRI time series signals are partitioned into 116 ROIs and then averaged respectively to get a representative signal for each ROI.
Experiments
Experimental details
As mentioned earlier, network architecture GCN with two convolution layers, due to its popularity and effectiveness, is used in our study. Furthermore, with the aim of conducting control experiments, we set the embedding dimension to 32, the number of epochs to 100, the learning rate to 0.001 and the weight decay to 1e−3. Four kinds of node features are involved to verify the classification performance as follows.
-
Original Signals (OS): OS capture the spontaneous fluctuations of brain activity associated with different ROIs, which is a manifestation of functional connectivity of the brain.
-
One-hot Encoding (OH): We associate each node with a one-hot indicator that uniquely identifies the spatial position of each ROI.
-
Node Statistics (NS): We design eight node statistics and concatenate them into a feature vector (Zhang et al., 2022). In particular, these statistics include three definitions of local clustering coefficients (Li, Shang & Yang, 2017), four centralities (Hamilton, 2020) (i.e., degree centrality, betweenness centrality, closeness centrality, and eigenvector centrality), as well as local efficiency.
-
Correlation vector (CV): CV reflect the relationship between the current ROIs and other ROIs. The most popular measure is Pearson’s correlation (PC) as follows:
where si ∈ Rm(i = 1, 2, ⋯, n) is the extracted rs-fMRI time series from the ith ROI, m is the number of time points, n is the number of ROIs, is the mean of si, and cij is the correlation coefficient between the i-th and j-th ROIs.
Experimental setting
In this study, we randomly select 80% of the subjects for training and the remaining 20% for testing. For all datasets, we report the mean of 100-run results to evaluate the performance of the involved methods. The performance metrics include
Accuracy = (TP + TN)/(TP + FP + TN + FN),
Sensitivity = TP/(TP + FN),
Specificity = TN/(TN + FP),
Precision = TP/(TP + FP),
F1 − score = 2 × TP/(2 × TP + FP + FN).
where TP, TN, FP, and FN indicate the true positive, true negative, false positive and false negative, respectively. Additionally, the area under curve (AUC) is adopted for measuring the classification performance.
Results
In Tables 2 and 3, we report the classification performance corresponding to four kinds of node features and their combinations based on PC adjacency matrix. From the above results, we have the following observations.
| Dataset | Features | Acc± std | Sen± std | Spe± std | Pre± std | F1 ± std | AUC ± std |
|---|---|---|---|---|---|---|---|
| ADNI | OS | 0.621 ± 0.009 | 0.570 ± 0.047 | 0.763 ± 0.022 | 0.721 ± 0.018 | 0.569 ± 0.005 | 0.637 ± 0.016 |
| OH | 0.553 ± 0.014 | 0.578 ± 0.011 | 0.515 ± 0.035 | 0.636 ± 0.016 | 0.606 ± 0.007 | 0.503 ± 0.002 | |
| NS | 0.605 ± 0.017 | 0.668 ± 0.099 | 0.538 ± 0.096 | 0.607 ± 0.022 | 0.631 ± 0.039 | 0.572 ± 0.085 | |
| CV | 0.767 ± 0.075 | 0.819 ± 0.086 | 0.736 ± 0.122 | 0.735 ± 0.133 | 0.766 ± 0.080 | 0.759 ± 0.073 | |
| OS + OH | 0.642 ± 0.031 | 0.833 ± 0.046 | 0.500 ± 0.030 | 0.555 ± 0.036 | 0.666 ± 0.024 | 0.687 ± 0.010 | |
| OH + NS | 0.636 ± 0.035 | 0.570 ± 0.004 | 0.793 ± 0.055 | 0.721 ± 0.026 | 0.569 ± 0.019 | 0.637 ± 0.027 | |
| OH + CV | 0.785 ± 0.028 | 0.857 ± 0.092 | 0.714 ± 0.064 | 0.750 ± 0.044 | 0.800 ± 0.027 | 0.885 ± 0.020 | |
| NS + CV | 0.721 ± 0.021 | 0.788 ± 0.049 | 0.420 ± 0.060 | 0.734 ± 0.015 | 0.803 ± 0.019 | 0.824 ± 0.015 | |
| OH + OS + NS | 0.642 ± 0.047 | 0.667 ± 0.110 | 0.545 ± 0.054 | 0.475 ± 0.078 | 0.545 ± 0.097 | 0.809 ± 0.095 | |
| OH + OS + CV | 0.585 ± 0.028 | 0.671 ± 0.065 | 0.500 ± 0.071 | 0.574 ± 0.026 | 0.617 ± 0.033 | 0.542 ± 0.013 | |
| OS + NS + CV | 0.657 ± 0.042 | 0.585 ± 0.171 | 0.728 ± 0.085 | 0.745 ± 0.015 | 0.573 ± 0.083 | 0.846 ± 0.020 | |
| OH + OS + NS + CV | 0.642 ± 0.028 | 0.600 ± 0.057 | 0.666 ± 0.010 | 0.500 ± 0.027 | 0.545 ± 0.040 | 0.682 ± 0.095 |
| Dataset | Features | Acc ± std | Sen ±std | Spe ± std | Pre ± std | F1 ± std | AUC ± std |
|---|---|---|---|---|---|---|---|
| ABIDE | OS | 0.584 ± 0.079 | 0.619 ± 0.110 | 0.551 ± 0.104 | 0.563 ± 0.101 | 0.589 ± 0.080 | 0.605 ± 0.072 |
| OH | 0.538 ± 0.022 | 0.731 ± 0.023 | 0.474 ± 0.026 | 0.574 ± 0.023 | 0.607 ± 0.114 | 0.510 ± 0.095 | |
| NS | 0.552 ± 0.014 | 0.661 ± 0.087 | 0.538 ± 0.035 | 0.573 ± 0.005 | 0.676 ± 0.040 | 0.536 ± 0.023 | |
| CV | 0.626 ± 0.055 | 0.662 ± 0.092 | 0.573 ± 0.107 | 0.642 ± 0.012 | 0.653 ± 0.060 | 0.677 ± 0.071 | |
| OS + OH | 0.705 ± 0.034 | 0.550 ± 0.100 | 0.718 ± 0.081 | 0.701 ± 0.075 | 0.606 ± 0.063 | 0.683 ± 0.010 | |
| OH + NS | 0.600 ± 0.057 | 0.712 ± 0.148 | 0.450 ± 0.130 | 0.632 ± 0.037 | 0.662 ± 0.085 | 0.589 ± 0.010 | |
| OH + CV | 0.626 ± 0.015 | 0.500 ± 0.000 | 0.707 ± 0.021 | 0.528 ± 0.014 | 0.560 ± 0.009 | 0.565 ± 0.013 | |
| NS + CV | 0.747 ± 0.031 | 0.757 ± 0.065 | 0.741 ± 0.069 | 0.636 ± 0.048 | 0.688 ± 0.028 | 0.850 ± 0.009 | |
| OH + OS + NS | 0.552 ± 0.026 | 0.532 ± 0.037 | 0.690 ± 0.044 | 0.561 ± 0.039 | 0.505 ± 0.035 | 0.568 ± 0.016 | |
| OH + OS + CV | 0.578 ± 0.019 | 0.525 ± 0.084 | 0.609 ± 0.101 | 0.500 ± 0.018 | 0.500 ± 0.036 | 0.514 ± 0.015 | |
| OS + NS + CV | 0.600 ± 0.025 | 0.750 ± 0.081 | 0.490 ± 0.044 | 0.518 ± 0.022 | 0.612 ± 0.015 | 0.727 ± 0.075 | |
| OH + OS + NS + CV | 0.684 ± 0.040 | 0.528 ± 0.110 | 0.733 ± 0.074 | 0.590 ± 0.065 | 0.593 ± 0.097 | 0.782 ± 0.015 |
First of all, for the single node feature, CV can generally result in a higher classification accuracy than the others, and the results are consistent on the two datasets and three differently estimated BFNs (adjacency matrices). This drives us to think that the relationship between ROIs may contain more comparable discriminative information for MCI and ASD identification.
Moreover, the OH gives the worst result among the four single features in most cases, especially on the ADNI dataset, which illustrates that only the spatial position of the ROIs is not enough to capture effective information for disease classification. Interestingly, however, the combination of OH and CV usually gets the best results. A possible reason is that spatial position encoded by OH can provide complementary information to CV for more discriminative feature representation/learning. For example, in Tables 2 and 3, we note that such a combination achieve the best classification accuracy (78.5% on ANDI dataset and 74.7% on ABIDE dataset, respectively).
Finally, different feature matrices do have a significant impact on the classification performance. It can also be seen that the designed single features usually cannot achieve the best accuracy. In contrast, when we incrementally concatenate these node features, the accuracy is generally improved. However, concatenating all features cannot achieve the best accuracy, indicating that simply increasing the feature dimension does not guarantee a good classification effect. In practice, the medical data are generally limited, and more features means more parameters, especially for GCN-based deep methods, which may lead to the overfitting problem. In fact, even if the data amount is sufficient, more features do not necessarily work well, since some redundant features can easily degrade the performance (Guyon & Elisseeff, 2003).
Discussion
In general, different BFN estimation methods have a significant influence on the classification performance (Sun et al., 2021; Jiang et al., 2022). Therefore, we discuss the effect of node features based on BFNs estimated by different methods, including PC, sparse representation (SR) (Qiao et al., 2018), and low-rank representation (LR) (Qiao, Chen & Tan, 2010). The visualizations of three BFNs are shown in Fig. 1.
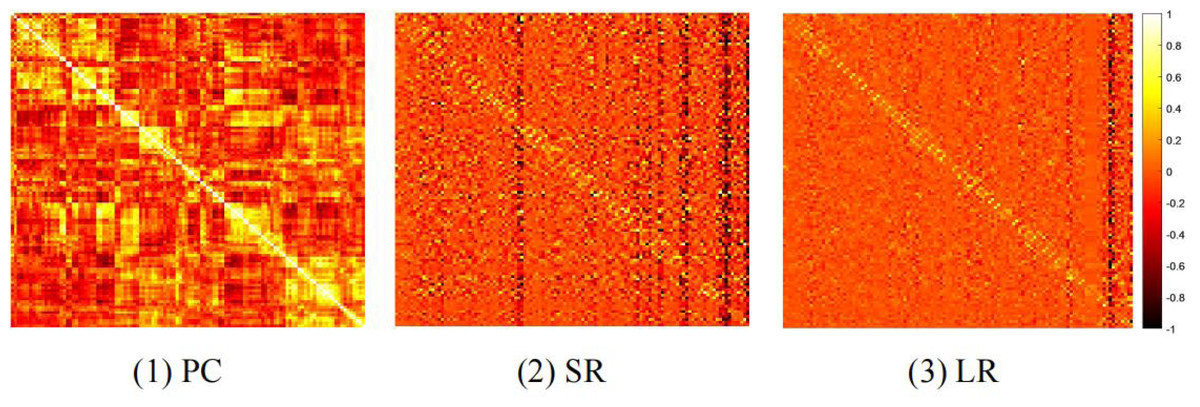
Figure 1: The heat map of adjacency matrices estimated by PC, SR and LR.
{kind=link}
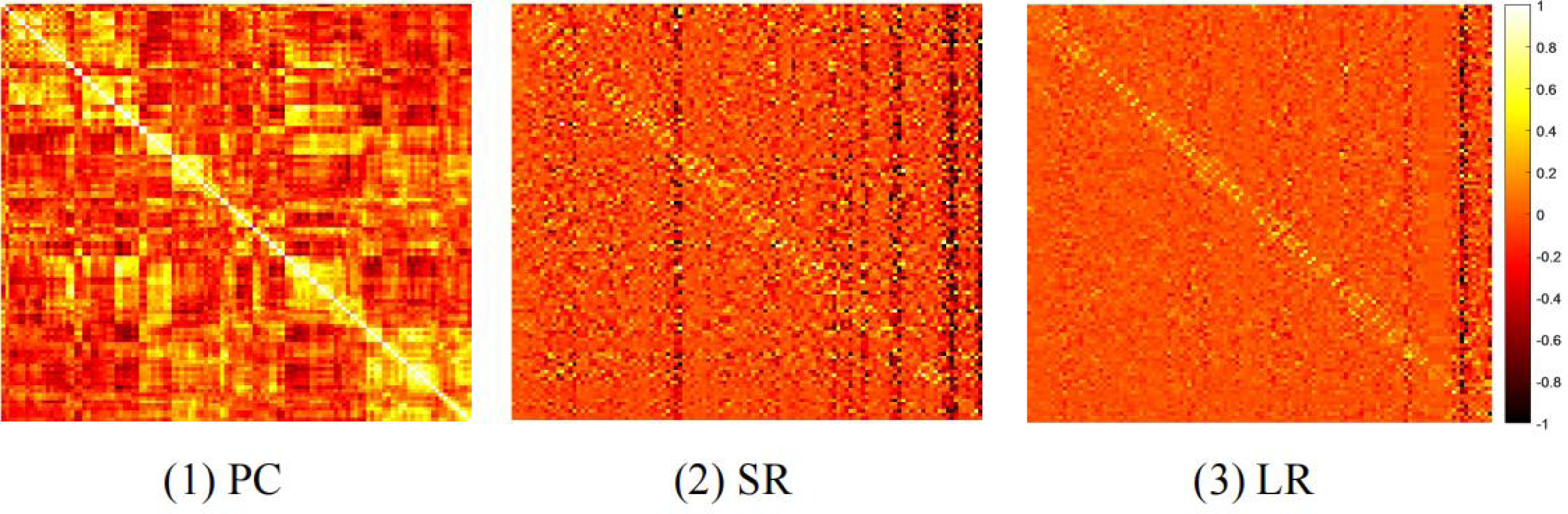
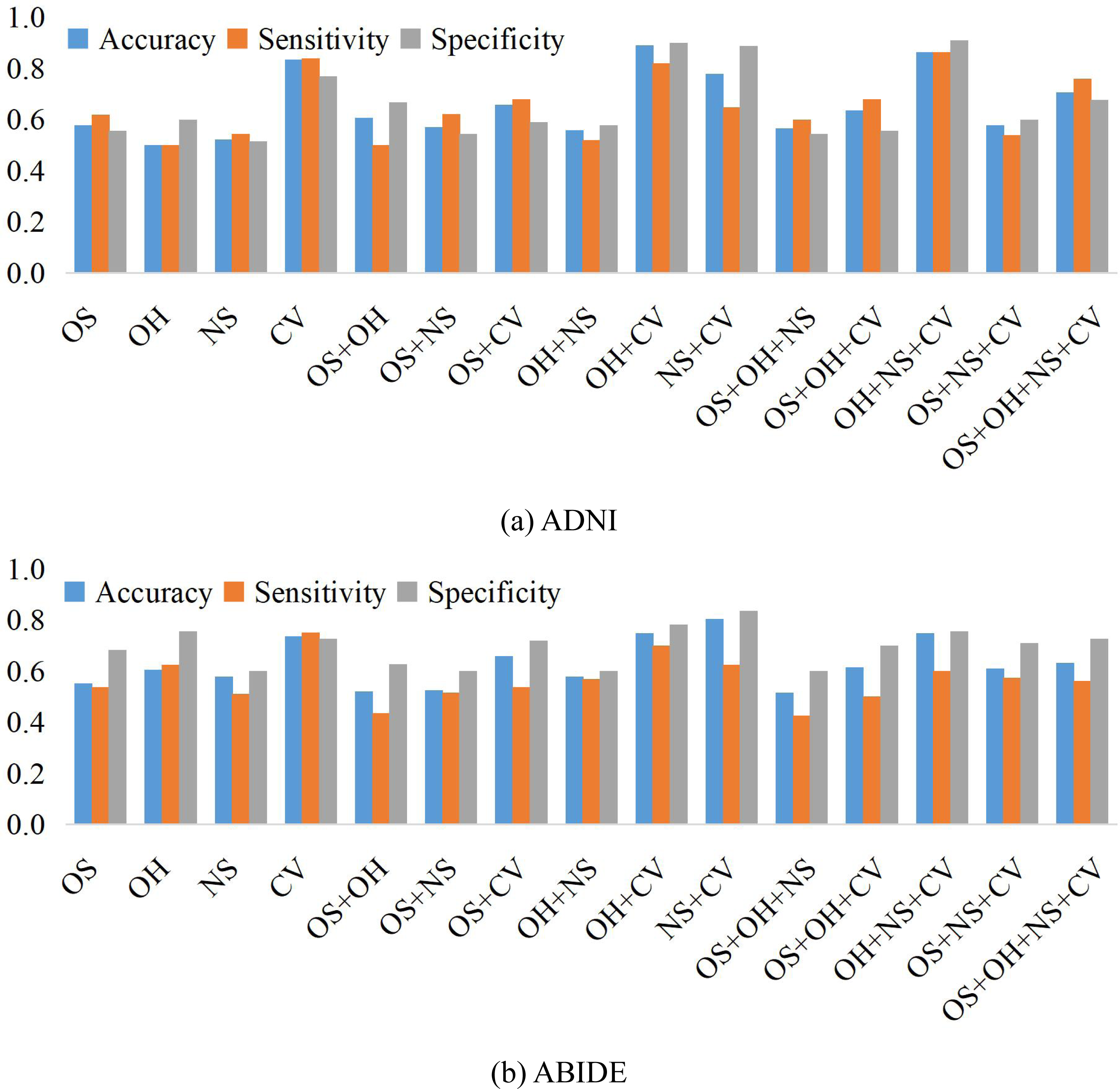
We compare the classification results on different datasets under three adjacency matrices. We show the impact of different node features based on SR and LR adjacency matrices in Figs. 2 and 3, respectively. The results show that on ADNI dataset LR-based adjacency matrix generally leads to a good performance, while on ABIDE dataset SR-based adjacency matrix works better. This suggests that appropriate sparsity is beneficial for brain disease diagnosis compared to the fully connected matrix estimated by PC. This is consistent with many existing studies (Dadi et al., 2019; Pervaiz et al., 2020).

Figure 2: The classification performance corresponding to four node features and their combinations on (A) ADNI and (B) ABIDE datasets, respectively, where the BFNs are estimated by SR.
{kind=link}

Figure 3: The classification performance corresponding to four node features and their combination on (A) ADNI and (B) ABIDE datasets, respectively, where the BFNs are estimated by LR.
{kind=link}
In this article, we mainly consider the commonly used features or design features based on classical node statistics. In fact, however, a graph generally contains complicated structures such as different motifs. Therefore, in theory, we can design various node statistics as the candidate of the node features in GCN. In addition, the brain network is generally expressed by a signed graph, and thus different possible triad configurations may be captured as the node features according to the structural balance theory (Newman, 2018). In the future, we will try more node features from different views or levels to improve the performance of brain disease classification.
Conclusions
In this article, we use/design four kinds of node feature matrices based on rs-fMRI data to empirically evaluate their influence on the GCN-based brain disorder classification tasks. In addition, we conduct control experiments of the feature matrix under three adjacency matrices that correspond to different BFN estimation methods. Experimental results demonstrate that different node features have significant effects on the classification performance. In general, CV, reflecting the relationship between ROIs, or features containing CV tends to result in higher classification performance. Additionally, we also note that combined features usually achieve higher accuracy than single features.