
Predicting judging-perceiving of Myers-Briggs Type Indicator (MBTI) in online social forum
- Published
- Accepted
- Received
- Academic Editor
- Leonardo Gollo
- Subject Areas
- Psychiatry and Psychology, Data Mining and Machine Learning, Data Science
- Keywords
- Myers-Briggs Type Indicator, MBTI, Personality Computing, Judging-Perceiving, Light Gradient Boosting, Natural Language Processing
- Copyright
- © 2021 Choong and Varathan
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2021. Predicting judging-perceiving of Myers-Briggs Type Indicator (MBTI) in online social forum. PeerJ 9:e11382 https://doi.org/10.7717/peerj.11382
Abstract
The Myers-Briggs Type Indicator (MBTI) is a well-known personality test that assigns a personality type to a user by using four traits dichotomies. For many years, people have used MBTI as an instrument to develop self-awareness and to guide their personal decisions. Previous researches have good successes in predicting Extraversion-Introversion (E/I), Sensing-Intuition (S/N) and Thinking-Feeling (T/F) dichotomies from textual data but struggled to do so with Judging-Perceiving (J/P) dichotomy. J/P dichotomy in MBTI is a non-separable part of MBTI that have significant inference on human behavior, perception and decision towards their surroundings. It is an assessment on how someone interacts with the world when making decision. This research was set out to evaluate the performance of the individual features and classifiers for J/P dichotomy in personality computing. At the end, data leakage was found in dataset originating from the Personality Forum Café, which was used in recent researches. The results obtained from the previous research on this dataset were suggested to be overly optimistic. Using the same settings, this research managed to outperform previous researches. Five machine learning algorithms were compared, and LightGBM model was recommended for the task of predicting J/P dichotomy in MBTI personality computing.
Introduction
Two most prevailing personality models are the Big Five Inventory (BFI) and Myers-Briggs Type Indicator (MBTI). Unlike the BFI, which is a trait-based approach, the MBTI assessment is a type-based approach. MBTI assessment model is used in 115 countries with 29 languages available, and it is used by 88 of the Fortune 100 within the past five years (Kerwin, 2018). MBTI is a world-renowned assessment and practitioners have placed far more trust in it than did organization scholar (Lake et al., 2019).
Thanks to the widespread dissemination of free personality assessment models online, many people are sharing their personality on social media. Large scale self-reported personality assessment results had been made available conveniently through the means of datamining on social media platform. This is evident through Plank & Hovy (2015), where a corpus of 1.2 M tweets from 1,500 users that self-identified with an MBTI type were collected from Twitter within a week. Subsequently, a few more datasets on MBTI became available through social media platform, resonating the ease of data collection (Verhoeven, Plank & Daelemans, 2016; Celli & Lepri, 2018; Gjurković & Šnajder, 2018).
MBTI remains largely popular and outperform BFI in specific domains (Yoon & Lim, 2018; Yi, Lee & Jung, 2016). MBTI consists of four pairs of opposing dichotomies, namely: Extraversion-Introversion (E/I), Sensing-Intuition (S/N), Thinking-Feeling (T/F) and Judging-Perceiving (J/P). Accurate inference of users’ personality is substantial to the performance of downstream applications. One such application is personalized advertisement on social media. According to Shanahan, Tran & Taylor (2019), firm spending on social media marketing has more than quadrupled in the past decade; their result further suggests that social media personalization positively impacts consumer brand engagement and brand attachment. Self-reported personality assessments are not common across social media platform and represent a negligible population of the social media users. A more scalable and sustainable way to inference users’ personality is thru linguistic features from users’ interactions on social media.
In recent years, researches such as Li et al. (2018) have successes in prediction particularly E/I, S/N and T/F dichotomies with above 90% accuracy. However, most researches struggled with predicting J/P dichotomy from textual data. Judging-Perceiving (J/P) dichotomy in MBTI is a non-separable part of MBTI that dictates a person lifestyle preference which can have significant predictive power to infer human-behavior in real-world use cases. While the three dichotomies aside from J/P can be known for a person, a complete picture cannot be painted without knowing the J/P dichotomy of the person. The predicament on predicting this dichotomy more than the others had manifested itself consistently thru the poor prediction performance of previous researches data (Li et al., 2018; Lukito et al., 2016; Verhoeven, Plank & Daelemans, 2016; Plank & Hovy, 2015; Wang, 2015). The poor prediction performance on J/P dichotomy can affect one’s personal decision guided by the misrepresented dichotomy class. This can lead to distrust and stall development of MBTI in various real-world application. Since MBTI is not on a continuous scale, but of four opposing dichotomies, a wrong prediction would mean incorrectly predicting the opposing extreme of a type. This would give a conflicting effect. For instance, a wrong prediction in the J/P dichotomy could mean recommending a career which requires high order of structure like an engineer to a “Perceiving” type person who prefer more creativity and flexibility. Thus, it is crucial to be able to predict J/P dichotomy alike other three dichotomies with high confidence.
Researches till date on social media MBTI personality computing have focused on predicting the four personality pairs indifferently. Prediction on J/P dichotomy in past researches have been consistently underperforming the three other dichotomies. This is reflected in recent researches such as Lima & Castro (2019), Yamada, Sasano & Takeda (2019) and Keh & Cheng (2019), etc. A dedicated study on J/P dichotomy is key to tighten the performance gap among the four dichotomies in MBTI prediction. The J/P dichotomy is the crucial piece of puzzle to solve in MBTI prediction, by improving the prediction, a complete picture of the user’s MBTI personality can be inferred. Furthermore, J/P dichotomy alone is enough to infer insightful behaviors (Kostelic, 2019; Pelau, Serban & Chinie, 2018; Yoon & Lim, 2018; Wei et al., 2017).
The objectives of this research are focused on the prediction of the Judging/Perceiving dichotomy of MBTI. In order to do so, the research identified and selected a few linguistic features, subsequently run them through five classifiers, then finally recommend the best combination for this task. The rest of the paper is organized as follows: ‘Related Works’ presents the related works of the study followed by ‘Methodology’ on research methodology. ‘Results & Discussion’ catered for results and discussions. Finally, ‘Conclusion & Future Work’ concludes the research with the summary of the findings and future work.
Related Works
This section starts by providing a background of the four dichotomies in MBTI. An elaborative search and review of research pertaining to personality computing using online social forum dataset were conducted. As a result of that, personality computing for Judging/Perceiving dichotomy in MBTI were identified as the worst performing dichotomy and as the research gap of this research (Li et al., 2018; Lukito et al., 2016; Verhoeven, Plank & Daelemans, 2016; Plank & Hovy, 2015; Wang, 2015). The importance of Judging/Perceiving dichotomy was emphasized, and methodologies commonly used in this discipline were identified.
Myers-Briggs types indicator (MBTI)
The MBTI assessment is designed to identify personality preferences (Kerwin, 2018). MBTI find its relevance and effectiveness in the communication and development arena, where one deal with career planning, conflict management, organization team building, self-reflection, etc. (Moyle & Hackston, 2018). The author is aware of the criticism on MBTI in the past few decades, but it has little impact on MBTI’s popularity (Stein & Swan, 2019), and those criticism were well countered (Kerwin, 2018). In fact, recent study by Yoon & Lim (2018) demonstrated that MBTI preferences significantly affect impulsive and compulsive buying in online purchases, whereas BFI had no significant impact. In another study, Yi, Lee & Jung (2016) preferred MBTI over BFI in personality collaborative filtering recommendation system due to scalability problem associated with BFI when the number of users or items grows.
Myers-Briggs Type Indicator or MBTI is essentially a personality typology using four pairs of traits dichotomy to create 16 personality categories. The four pairs are: Extraversion-Introversion (E-I), Sensing-Intuition (S-N), Thinking-Feeling (T-F), and Judging-Perceiving (J-P). The result is a binary either-or representation from each of the four pairs, which are then combined to make a personality type. For instance, a person more dominant towards Extraversion, Sensing, Thinking and Judging will be of type ESTJ.
Significance of Judging-Perceiving dichotomy
Panait & Bucinschi (2018) and Farmer (2018) introduced J/P dichotomy as a representation of the way people function best while dealing with situation, projects and time management. According to Panait & Bucinschi (2018), a person who is a Judging type enjoys being task oriented while planning in advance, while a person who is a Perceiving type prefer to be spontaneous, going with the flow and adapting as event unfolds. J/P dichotomy being only one of the four dichotomies in MBTI, is insufficient to paint out a complete picture of a person’s personality, it is however important by itself to infer certain human behavior that ultimately shape the person status and lifestyle.
Most identified literatures on social media MBTI personality computing had shown a pattern that the Judging-Perceiving (J/P) dichotomy in MBTI is the hardest to predict. Li et al. (2018) suggested that difficulty in predicting J/P dichotomy could be because it involves looking at people’s actions and behaviours, not just words. Result from Lukito et al. (2016) demonstrated that prediction performance on J/P dichotomy does not correlate with number of tweets, and that is it difficult to learn from social media text information. Although Alsadhan & Skillicorn (2017) reported an optimistic accuracy and F1-measure above 80% for J/P dichotomy using an elaborated method, the same method of which source code is not available was attempted without reasonable success. Several other researches have acknowledged that the J/P dichotomy is difficult to be predicted, particularly with textual data (Li et al., 2018; Lukito et al., 2016; Verhoeven, Plank & Daelemans, 2016; Plank & Hovy, 2015; Wang, 2015). Thus, better features are needed for predicting the J/P dichotomy.
Since MBTI is not on a continuous scale, but of four opposing dichotomies, a wrong prediction would mean incorrectly predicting the opposing extreme of a type. This would give a conflicting effect. For instance, a wrong prediction in the J/P dichotomy could mean recommending a career which requires high order of structure like an engineer to a “Perceiving” type person who prefer more creativity and flexibility.
According to a survey conducted by Owens (2015), there is distinctive separations between Judging and Perceiving type participants in their average income and managerial responsibility. Kostelic (2019) studied 244 participants through an online questionnaire and found that J/P dichotomy is a significant variable contributing to one’s decision making and attitude towards solving problem independently or choosing an advisor for help in legal and financial situation. Pelau, Serban & Chinie (2018) acquired 207 valid questionnaires through survey carried out in an urban population, and they found that J/P dichotomy has a significant role on impulsive buying behavior. This result is supported by Yoon & Lim (2018) where the effect of BFI and MBTI on impulsive and compulsive online buying behavior were compared using 296 questionnaires obtained from online shopping mall users in Korea. Yoon & Li (2018) concluded that J/P dichotomy demonstrated a notable impact on both online impulsive and compulsive buying behavior, whereas BFI had no direct impact. In Wei et al. (2017), the authors classified 300 celebrities to their MBTI type and analyzed their respective clothing features from a collection of online images, where they confirmed that J/P dichotomy is significantly correlated to all three clothing features namely color, pattern and silhouette.
Above has demonstrated significance of J/P dichotomy and the impacts it could have on a person not limited to earning power, career responsibilities, inclination to seek help, spending behavior and fashion inclination. These attributes could potentially provide an additional dimension for use cases such as bank loan credibility evaluation, effective personalized advertisement targeting and appropriate career recommendation.
Feature extraction methods in MBTI prediction
This section describes common feature extraction methods used in MBTI prediction. According to Shah & Patel (2016), feature selection and feature extraction are two methods to solve complexity of machine learning model due to high dimensionality of feature space in text classification. N-gram features are extensively used in text classification. N-gram is a contiguous sequence of n characters or n words within a given n-window where unigram (1-gram) represents individual characters or words, bigram (2-gram) represents two characters or words next to each other, trigram (3-gram) represents three adjacent characters or words. Wang (2015) was able to show different personality behavior through use of bigram in which introvert tend to complain and refuse (“my god”, “holy shit”, “I don’t, I can’t”), while extroverts are more energetic (“so proud”, “can’t wait”, “so excited”).
The bag of words is a simple feature extraction method. The bag of words is essentially the occurrence of word within a defined vocabulary of words, represented thru binary encoding. Simply put, the bag of words checks for the presence of a word within a collection of vocabulary. This bag of words can be constrained to a specific dictionary like in Yamada, Sasano & Takeda (2019) where the author only used words in MeCab’s IPA dictionary. On the other hand, the use of bag of words can be extended with n-gram to include additional words in forms of bigram or trigram as was demonstrated in Wang (2015) and Cui & Qi (2017). In all three researches mentioned, the authors limited the size of the bag of words to n-most frequent words where n is the size defined by the author.
TF-IDF is composed of two parts namely, TF for term frequency and IDF for inverse document frequency. Term frequency measure how frequently a term occurs in a document, whereas inverse document frequency measure how important a term is. TF-IDF is used to evaluate how important a word is to a document. TF-IDF are usually used in combination to other feature extraction methods as a weight to the model. In Alsadhan & Skillicorn (2017), the authors used only term frequency feature alongside with their unique manipulation using digamma function and SVD, outperforming several researches on personality computing. In Gjurković & Šnajder (2018), the best model in the research uses TF-IDF weighted n-grams over logistic regression.
Part-of-speech tagging is a basic form of syntactic analysis where textual data is converted into a list of words, and the words are tagged with their corresponding part-of-speech tag such as whether the word is a noun, adjective, verb, etc. Wang (2015) suggested a correlation between common noun usage and personality where people who uses common noun more often tend to be in extroversion, intuition, thinking, or judging type.
A lexicon is the vocabulary of a language or subject, or simply dictionary words that are assigned to categories to treat them as a set of items with similar context. Individual words can have multiple meaning, thus can belong in multiple categories. A few popular lexical databases are LIWC (Pennebaker et al., 2015), MRC (Wilson, 1988), WordNet (Oram, 2001), Emolex (Mohammad & Turney, 2010). Li et al. (2018) mapped users’ posts into 126 subjectively defined “semantic categories” along with their weights of their categories, and this method was the most successful among other methods in the research for distinguishing all four pairs of dichotomies in MBTI. With the use of LIWC, Raje & Singh (2017) revealed that judging type personality are positively correlated to “work oriented” and “achievement focus” category, and negatively correlated to “leisure oriented”.
Word2Vec is a popular technique to learn word embeddings using shallow neural network that is developed by Mikolov et al. (2013). Word embeddings are vector representation of words where semantic and syntactic relationship between words can measured (Mikolov et al., 2013). Since word embeddings trained on larger datasets perform significantly better, several pretrained word embeddings emerged, for instance older ones like GloVe (Pennington, Socher & Manning, 2014) and more recent ones like ELMo (Peters et al., 2018). In Bharadwaj et al. (2018), the research uses ConceptNet, a pretrained word embeddings and found that it slightly boosted the MBTI prediction performance over original SVM model with TF-IDF+LIWC. Wang (2015) also trained a word2vec model based on an external twitter dataset, they found that the word vectors gave the best individual predictive performance among other features.
Doc2Vec, an extension of Word2Vec where documents are represented as vectors instead of words (Le & Mikolov, 2014). Yamada, Sasano & Takeda (2019) used Distributed Bag of Words (DBOW) model, a type of Doc2Vec but found it to be less effective than the regular Bag of Words model. This is because DBOW is the inferior version of Doc2Vec as compared to the Distributed Memory (DM) version, and usually these two versions are used together for consistency in performance (Le & Mikolov, 2014).
Topic Modeling aims to discover abstract “topics” that occur in a collection of documents. There are several approaches to doing so, the older method is Latent Semantic Analysis (LSA), which is a reduced representation of document based on word term frequency (Landauer, Foltz & Laham, 1998). That is followed by Latent Dirichlet Allocation (LDA) where each document can be described by a distribution of topics and each topic can be described by a distribution of words (Blei, Ng & Jordan, 2003). Gjurković & Šnajder (2018) derived topic distribution from user’s comments using LDA models but found that LDA gave a mediocre performance in MBTI prediction.
Classification methods used in MBTI prediction
MBTI personality computing is a classification task and thus this section discusses the classification models used in predicting MBTI. Allahyari et al. (2017) and Onan, Korukoğlu & Bulut (2016) identified five of the basic machine learning classifiers, namely: Naïve Bayes, Nearest Neighbour, Support Vector Machine, Logistic Regression, and Random Forest. Lima & Castro (2019) and Raje & Singh (2017) have demonstrated that basic classifier outperformed more advanced classifiers such as ensemble or neural network model in MBTI prediction. However, basic classifiers are suitable for text classification task.
Naïve Bayes classifier models the distribution of documents in each class using a probabilities model with assumption that the distribution of different terms is independent from each other. Naive Bayes classifier is computationally fast and work with limited memory. Multinomial Naïve Bayes model is commonly used for text classification task. However, Rennie et al. (2003) discourages the use of Multinomial Naïve Bayes model stating that it does not model text well. Instead they introduced Complement Naïve Bayes as a emulate a power law distribution that matches real term frequency distribution more closely. Celli & Lepri (2018) uses AutoWeka, a meta classifier that automatically find the best algorithm and setting for the task. AutoWeka had particularly chosen Naïve Bayes as the classifier of choice in prediction the Judging-Perceiving dichotomy.
Nearest Neighbour classifier is a proximity-based classifier which use distance-base measures to perform classification. k is referred as the number of neighbours to be considered., the most common class among k-Neighbours will be reported as the class label. Nearest Neighbour classifier is not particularly a popular classifier for text classification task. Only one research, Li et al. (2018) on MBTI prediction were found to be using this classifier without any comparison to other classifiers. The main goal of that research though is to compare and find the best distance computation methods for KNN in MBTI personality computing.
Support vector machine finds a “good” linear separator between various classes based on linear combinations of the documents features. Kernel techniques are used in SVM to transform linearly inseparable problems into higher dimensional space. Commonly used kernels are Radial Basis Function, Polynomial kernel and Gaussian function. It is important to note that while SVM run time is independent of the dimensionality of the input space, it scales with the number of data points with a time complexity of O(n3) (Abdiansah & Wardoyo, 2015). SVM classifier is a popular classifier for text classification tasks. Bharadwaj et al. (2018) compared SVM to Naïve Bayes and Neural Net classifiers in MBTI prediction and saw that SVM outperformed the other classifiers across three feature vector sets.
Logistic Regression takes the probability of some event’s happening and model it as a linear function of a set of predictor variables (Onan, Korukoğlu & Bulut, 2016). It only works with binary classes. Raje & Singh (2017) used Logistic Regression for the MBTI prediction task and found that the performance of the classifier slightly outperforms Artificial Neural Network (ANN) classifier. Gjurković & Šnajder (2018) compared three classifiers and saw that Logistic Regression outperforms SVM on MBTI prediction.
Random Forest is an ensemble of many randomized decision trees, where each decision trees gives a prediction to the task and the results are averaged or the major vote is selected to be the final prediction. Lima & Castro (2019) found that Random Forest consistently outperforms SVM and Naïve Bayes classifiers across multiple feature sets by a large degree in MBTI prediction.
Similar to Random Forest, Gradient Boosting Decision Tree (GBDT) is an ensemble model of decision trees but is trained in sequence for which each iteration GBDT learns the decision tree by fitting the negative gradients (Ke et al., 2017). A popular variant of GBDT is XGBoost, which has a track record of outperforming other ML models as observed on challenges hosted on a machine learning competition platform Kaggle (Chen & Guestrin, 2016). A more recent development is LightGBM, the authors Ke et al. (2017) demonstrated two features in LightGBM namely gradient-based one-side sampling and exclusive feature bundling that enabled LightGBM to significantly outperform XGBoost especially when training a model with sparse features. Although popular, none of the GBDT methods were found to be used in identified related work.
Table 1 shows a compilation of all identified related work along with their best classifier, features and performance metrics. Among all seventeen researches mentioned in Table 1, only nine were using overlapping datasets from three publicly available dataset. Two of these datasets were from Twitter and one was from Personality Café Forum. With the exception of Gjurković & Šnajder (2018), the rest of the researches uses private dataset and their method was not tested on publicly available dataset for comparison. This makes it difficult to tell how well their method fare among the other researches’ method.
| Research | Dataset | Best classification methods | Feature extraction methods |
Metric | E/I | S/N | T/F | J/P |
|---|---|---|---|---|---|---|---|---|
| Brinks & White (2012) | Naïve Bayes | TF, IDF | Accuracy | 63.90% | 74.60% | 60.80% | 58.50% | |
| Plank & Hovy (2015) | Twittera | Logistic Regression | n-grams, Metadata | Accuracy | 72.50% | 77.40% | 61.20% | 55.40% |
| Wang (2015) | Logistic Regression | POS, n-gram, word vector, BOW | AUC | 69.10% | 65.30% | 68.00% | 61.90% | |
| Lukito et al. (2016) | Naïve Bayes | n-gram | Accuracy | 80.00% | 60.00% | 60.00% | 60.00% | |
| Verhoeven, Plank & Daelemans (2016) | Twitterb | LinearSVC | n-gram | F-measure | 67.87% | 73.01% | 58.45% | 56.06% |
| Cui & Qi (2017) | Kagglec | LSTM | n-gram, BOW, POS, capital letter count | Accuracy | 89.51% | 89.85% | 69.10% | 67.65% |
| Raje & Singh (2017) | Logistic Regression | LIWC | Accuracy | 53.57% | 51.99% | 56.25% | 53.57% | |
| Alsadhan & Skillicorn (2017) | Twittera | SVD component distance threshold | TF | Accuracy | 90.00% | 92.00% | 80.00% | 83.00% |
| F-measure | 90.0% | 92.00% | 80.00% | 84.00% | ||||
| Twitterb | SVD component distance threshold | TF | Accuracy | 82.67% | 81.84% | 76.83% | 80.50% | |
| F-measure | 82.33% | 86.67% | 78.17% | 81.17% | ||||
| Bharadwaj et al. (2018) | Kagglec | SVM | BOW, TF-IDF, LIWC, EmoSenticNet, ConceptNet | Accuracy | 84.90% | 88.40% | 87.00% | 78.80% |
| Li et al. (2018) | Kagglec | K Nearest Neighbor | Word category, Nuance, TF, IDF,TF-IDF | Accuracy | 90.00% | 90.00% | 91.25% | 76.25% |
| Celli & Lepri (2018) | SVM | n-gram, LIWC, Metadata | Accuracy | 61.30% | 68.50% | 68.60% | 60.20% | |
| Keh & Cheng (2019) | Personality Cafe Forum | BERT | Pretrained BERT model | Accuracy | 75.83% | 74.41% | 75.75% | 71.90% |
| Gjurković & Šnajder (2018) | Redditd | Multilayer Perceptron | n-gram, TF-IDF, LIWC, MRC Metadata, temporal features | F-measure | 82.80% | 79.20% | 64.40% | 74.00% |
| Yamada, Sasano & Takeda (2019) | SVM | BOW, DBOW, Metadata | AUC | 73.18% | 69.89% | 70.96% | 62.10% | |
| Lima & Castro (2019) | Twittera | Random Forest | LIWC, oNLP | Accuracy | 82.05% | 88.38% | 80.57% | 78.26% |
| F-measure | 78.75% | 82.40% | 79.25% | 77.58% | ||||
| AUC | 86.94% | 87.16% | 87.94% | 88.02% | ||||
| Amirhosseini & Kazemian (2020) | Kagglec | XGBoost | TF-IDF | Accuracy | 78.17% | 86.06% | 71.78% | 65.70% |
| Mehta et al. (2020) | Kagglec | BERT + MLP | Pretrained BERT model,LIWC, SenticNet, NRC Emotion Lexicon, VAD Lexicon, Readability | Accuracy | 78.80% | 86.30% | 76.10% | 67.20% |
Notes:
As far as classification methods used, basic machine learning models were predominantly used in researches found. Only four out of seventeen researches utilized deep learning algorithm in their method. A few feature extraction methods were heavily used such as term frequency, n-gram and word categories like LIWC. Only two researches utilized word embeddings, and one used BERT sequence classification alone on raw sentences without any feature extraction.
Accuracy is the most used metric for these researches, however this is not the best metric to use for imbalance data. For example, in E/I dichotomy, if the distribution of class E is 80% and class I is 20%, predicting all samples as class E will yield 80% accuracy anyhow although class I is predicted wrongly 100% of the time. For dataset that are not openly available, there is no way to gauge the actual performance of the method in the research as the distribution of the classes is sometimes not specified.
Methodology
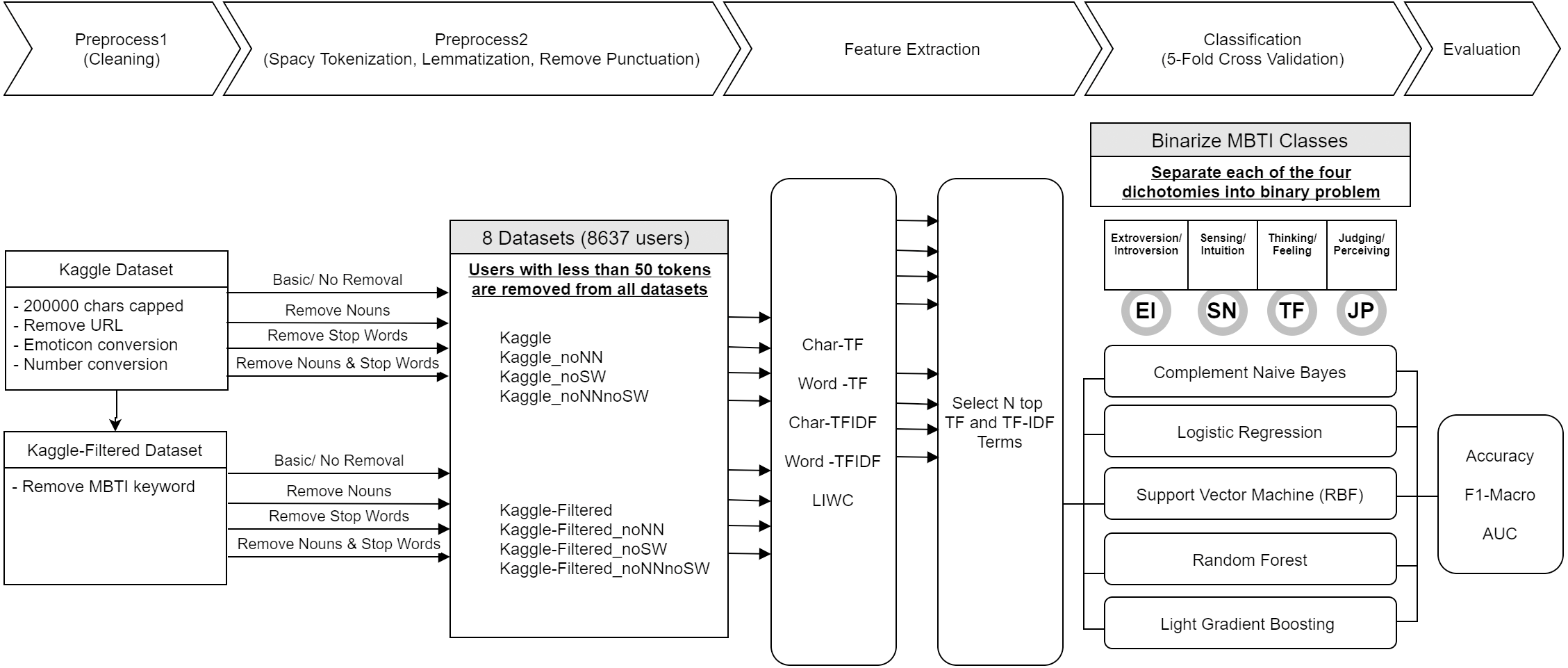
This research followed a customized framework for approaching MBTI’s Judging-Perceiving dichotomy classification on online social forum dataset as shown in Fig. 1. The preprocessing is in two stages, stage one deal with cleaning of the data such as removing duplication, standardizing the inputs, etc. Stage two performs the necessary tokenization along with lemmatization and punctuation removal. Additional preprocessing was performed such as stop word or noun removal to create a diverse dataset for comparison of the effect of these data processing methods. After preprocessing, features were extracted from datasets using several methods, which are discussed in detail in ‘Feature extractions and dimensionality reduction’. Subsequently under classification stage, the features and labels were fed into a machine-learning model for training and prediction. Finally, in evaluation, the metric results were evaluated.
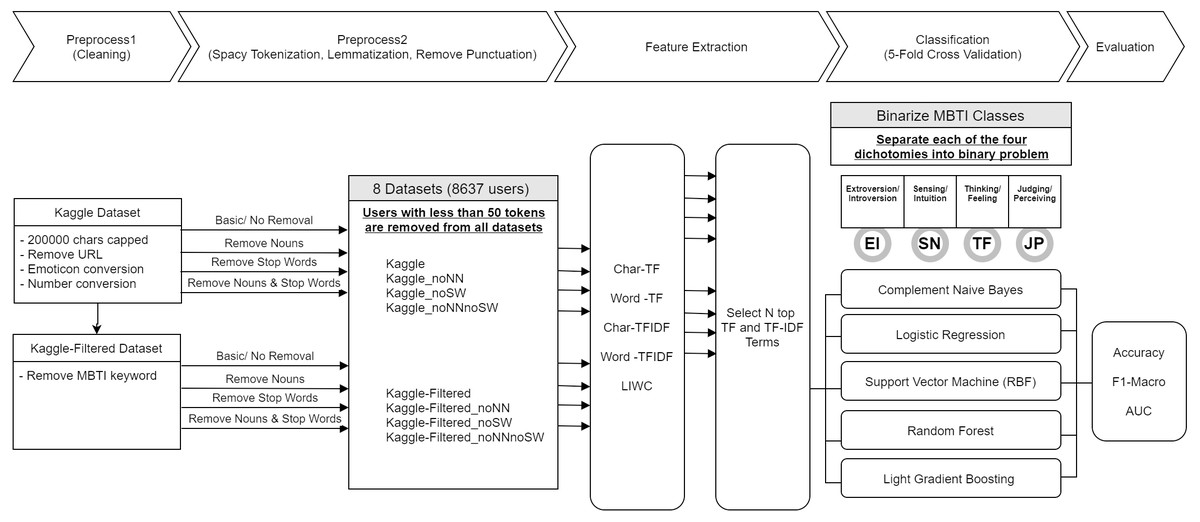
Figure 1: Research framework.
{kind=link}
Tools and resources
This research was conducted on Windows 10 using Python, a high-level scripting language in conjunction with Jupyter Notebook. Various open source Python libraries were used for this research, and they will be detailed in the following sections. Linguistic Inquiry and Word Count, LIWC 2015 by Pennebaker et al. (2015) is the only paid service subscribed in this research to replicate some of the work that had been done with the same dataset that this research was conducted on. For the purpose of reproducibility, all source codes were documented and made available on Github: https://github.com/EnJunChoong/MBTI_JP_Prediction.
Dataset
The dataset used in this research is referred as Kaggle dataset. The Kaggle dataset was crawled from Personality Cafe forum in 2017, it consists of the last 50 posts made by 8675 people, whom MBTI type were known from their discussion on this online social forum platform (Li et al., 2018). Using a simple white space tokenization, each person in the dataset has an average of 1226 words with standard deviation of 311 words. A further dive into the numbers found each post contains average of 26 words with a standard deviation of 13 words. Personality Cafe forum is a forum for conversation and discussion on personality. The Kaggle dataset is available on http://www.kaggle.com, which is a website dedicated to data science enthusiasts. The dataset only contained two columns, one is the user MBTI type, and another is their respective posts on Personality Cafe forum. Five researches on the same dataset were identified, namely Cui & Qi (2017), Bharadwaj et al. (2018), Li et al. (2018), Mehta et al. (2020) and Amirhosseini & Kazemian (2020). The justifications on the reasons of choosing this dataset are as follows:
-
Publicly available dataset of substantial size.
-
Dataset which is not based on microblogs (microblog data needs to be handled differently)
-
Cited at least twice to establish reference for comparison.
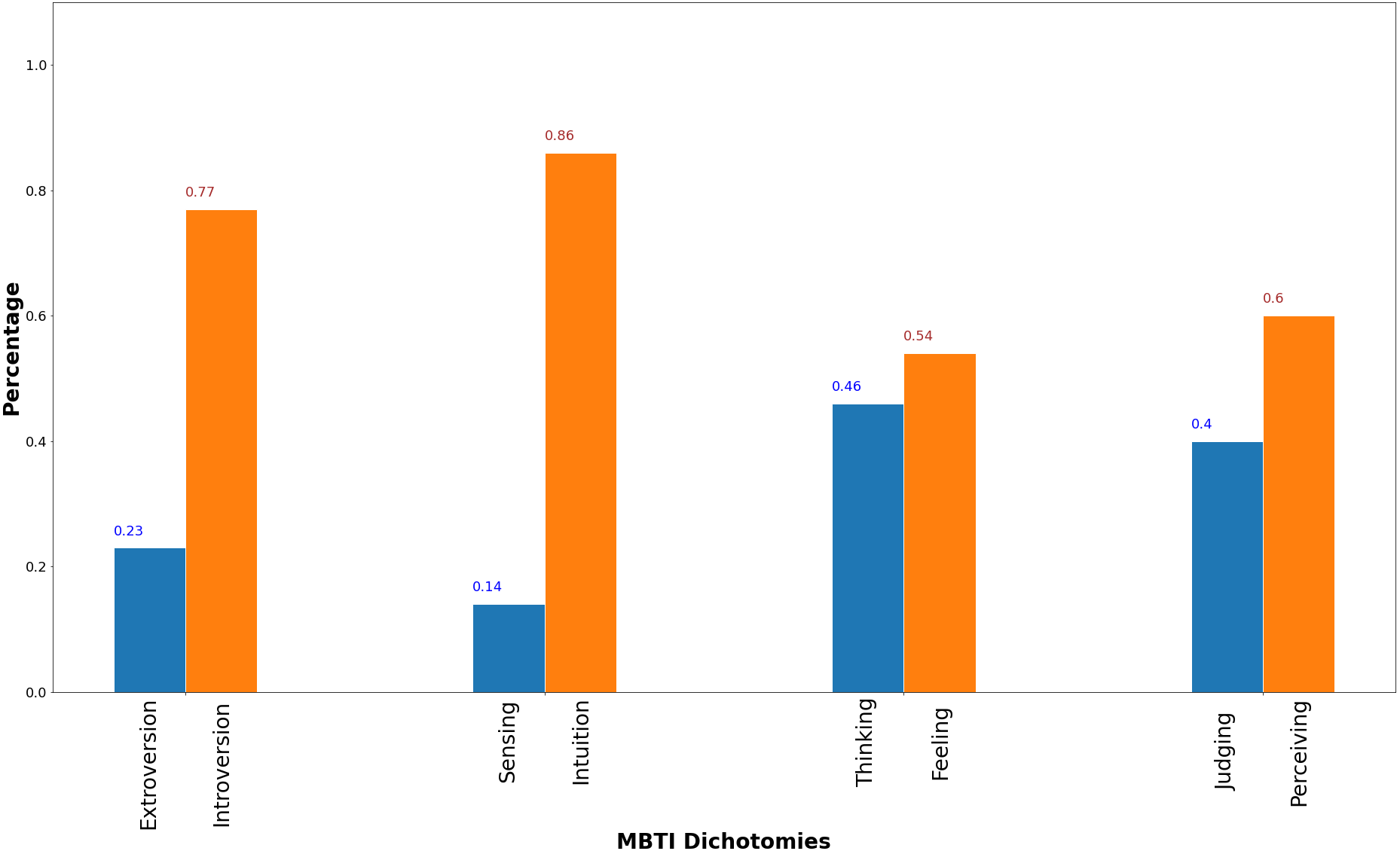
Figure 2 shows the dataset MBTI dichotomies distribution. The E/I is the most imbalance pair among the four followed by and S/I pair, then J/P pair and lastly T/F pair. At a 4:6 ratio for Judging to Perceiving, the J/P pair distribution is much more balanced than the distribution of E/I and S/I pairs. However, a more balanced dataset does not signify better prediction performance as shown in Table 1 where prediction performance on J/P pair is worse than E/I and T/F pairs for three related works that uses the same dataset denoted as Kaggle3.
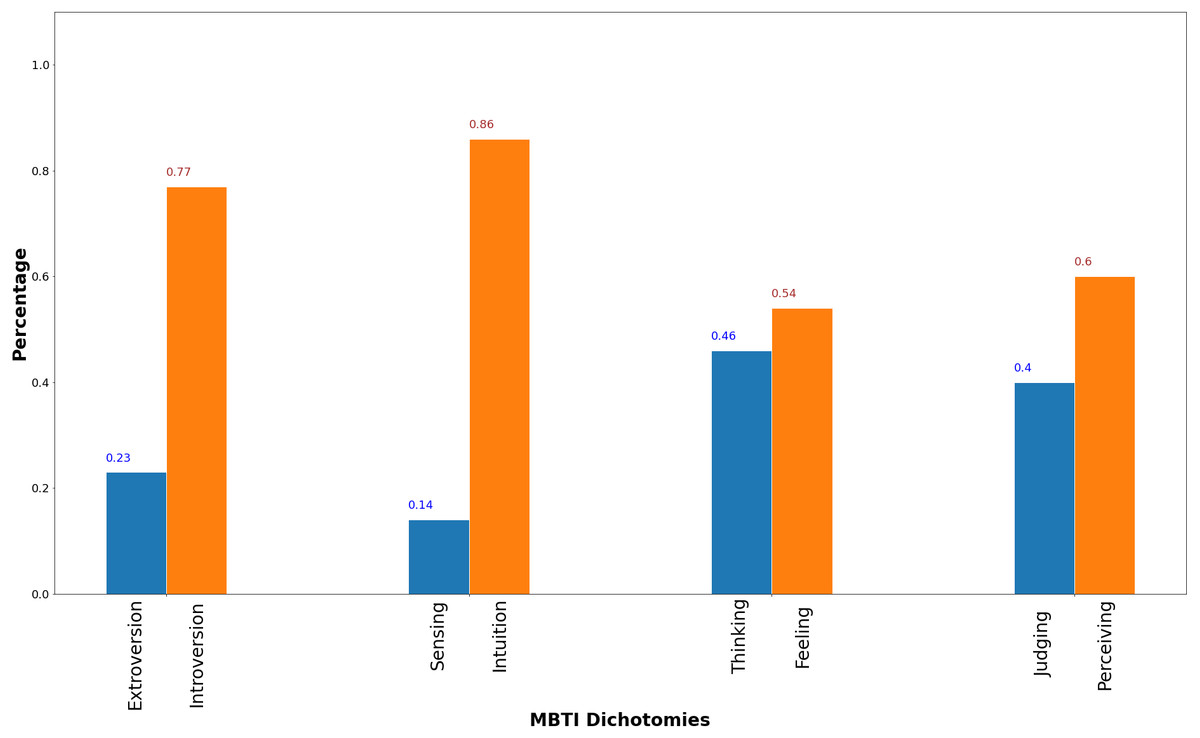
Figure 2: MBTI dichotomies dataset distribution.
{kind=link}
Data preprocessing
This research separated preprocessing into two parts. Part one dealt with data cleaning and wrangling, which is the removal of messy erroneous data. Then part two was the tokenization of the textual data, which is the transformation into structured machine comprehensible data. Figure 3 is an example of the transformation of the original data to the final tokens. It can be observed that URLs shaded in gray and MBTI keywords shaded in yellow were removed in first phase of preprocessing. And numbers shaded in green are replaced with an escape word. “NUMVAL”. Subsequently the data is tokenized, lemmatized and removed for punctuation. In this example, additional stop word and nouns were removed as well.

Figure 3: Preprocessing example.
{kind=link}
Data cleaning
For data cleaning, both datasets were capped at 200,000 characters per user. Regular expression was utilized to remove URLs, to convert emoticons into 4 categories (smileface, lolface, sadface and neutralface), and to convert any numeric digits into a category called numval. The Kaggle dataset is highly bias towards personality discussion, and very often the posts contain MBTI keywords. Cui & Qi (2017), Bharadwaj et al. (2018) and Li et al. (2018) did not mention removal of the MBTI keywords in their research on Kaggle dataset. On a similar dataset, Keh & Cheng (2019) scraped 68,000 posts from Personality Cafe Forum, and they explicitly removed the MBTI keyword. There is no absolute way to tell the effect of the MBTI keyword bias on the dataset. Thus, a new Kaggle-Filtered dataset was introduced where all 16 MBTI keywords were removed. The removal of MBTI keyword was done using regular expression.
Tokenization, lemmatization and punctuation removal
Tokenization was done with spaCy library using its’ pretrained medium size English model. The two datasets: Kaggle, Kaggle-Filtered were sent to spaCy for tokenization and lemmatization. Punctuation was removed by default for all dataset during this process. Common perception on stop words are that they are of little use and not informative (Wang, 2015). However, Plank & Hovy (2015) stated that stop word removal harms performance, and Alsadhan & Skillicorn (2017) argued that stop words are predictive of authorship and so of individual differences, the latter suggested that noun is to be removed instead. To investigate this problem, four versions for each of the dataset were introduced as follow:
-
No removal of noun or stop words
-
Removal of noun
-
Removal of stop words
-
Removal of noun and stop
In order to have enough representation of word tokens per user, users with less than 50-word tokens were identified and removed from the dataset group. Only Kaggle dataset were reduced from 8675 users to 8637 users. At this point, from the initial 2 datasets, additional datasets were generated to a total of 8 datasets at the end.
Feature extractions and dimensionality reduction
For each of the 8 datasets, the authors extracted a set of linguistic features from the users’ post or comments on the online social forum. A few popular feature extraction methods for social media MBTI prediction were identified, among them are TF-IDF, part of speech, word embeddings and word categories. Char-level TF-IDF, word-level TF-IDF, and LIWC were decided to be used as the research main feature extraction methods. The implementation of these features will be discussed in the following subsections.
An extra transformation step was done for the features before feeding them to the classification task. In Python, the authors selected scikit-learn’s preprocessing module called QuantileTransformer to transform all features into following a uniform distribution that range between 0 and 1. This method collapses any outlier to the range boundaries and is less sensitive to outlier than the common standard scaling or min-max scaling method.
Character-level TF and TF-IDF
The main purpose of TF and TF-IDF is to simply give a heavier weight to terms that have the highest likelihood to distinguish a document from the others. While word-level is a more common feature extraction method, Gjurković & Šnajder (2018) demonstrated that character-level TF has more relevant features than word TF, and that TF are generally better than TF-IDF in MBTI personality computing.
\CountVectorizer and TfidfVectorizer module of Sci-kit learn were used to perform the computation for character level TF and TF-IDF. The ngram parameter used were 2–3 ngram. However, it still takes whitespace as a gram if the adjacent character is at the edge of the word. For illustration:
| Sentence: | ‘I am a bear’ |
| Character ngram: | ‘I’, ‘a’, ‘am’, ‘a’, ‘b’, ‘be’,’bea’, ‘ea’, ‘ear’, ‘ar’, ‘r’ |
The authors capped the number of terms to 1500 and eliminate terms that have appearances less than 50 documents or more than 95% of the entire corpus.
Word-Level TF-IDF
Like the character-level TF and TF-IDF, similar logic was applied using the same TF and TF-IDF feature extraction method. This time however, word level instead of character level was used. The ngram parameter used will be from 1 to 3 since a word by itself could have much more importance as compared to a single alphabet in a big corpus. Here, the illustration is much simpler.
| Sentence: | ‘I am a bear’ |
| word ngram: | ‘I ‘, ‘am’, ‘a’, ’bear’, ‘I am’, ‘am a’, ‘a bear’, ‘I am a’, ‘am a bear’ |
The authors capped the number of terms to 1500 and eliminate terms that have appearances less than 50 documents or more than 95% of the entire corpus.
Classification and model validation
Logistic regression (LR), Complement Naïve Bayer (CNB), Support Vector Machine (SVM) and Random Forest (RF) were selected for their popularity and effectiveness in text classification problems (Gjurković & Šnajder, 2018; Rennie et al., 2003; Bharadwaj et al., 2018; Lima & Castro, 2019). LightGBM (LGB), a gradient boosting framework that uses tree-based learning algorithms was also added to the list of classifiers to provide an additional comparison. LightGBM was chosen instead of XGBoost due to the model effectiveness in dealing with sparse features as elaborated in ‘Data preprocessing’.
Like any classification task, the target variables and features need to be clearly defined. From the feature extraction step, following feature sets are obtained:
-
Character-level TF (1500 attributes)
-
Character-level TFIDF (1500 attributes)
-
Word-level TF (1500 attributes)
-
Word-level TFIDF (1500 attributes)
-
LIWC (78 attributes)
-
Combo (Combination of all features which comprise of Character-level TF, Character- level TFIDF, Word-level TF, Word-level TFIDF and LIWC) (6078)
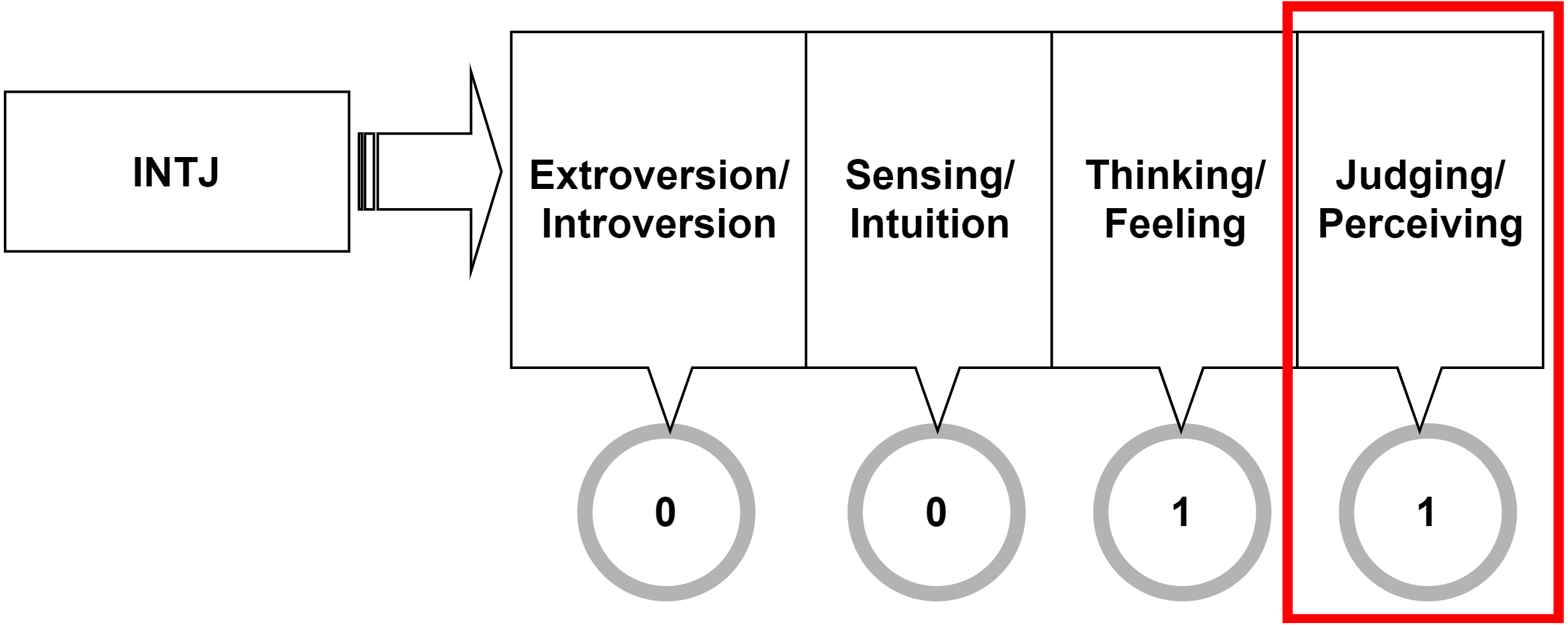
Since the research focus is on predicting MBTI’s judging and perceiving dichotomy, the problem must be binarized. For each user, their MBTI type is split into four dimensions accordingly to the four MBTI dichotomies. Figure 4 illustrates that the last column, bounded in the box is corresponding to Judging-Perceiving dichotomy, and this is the only column this research is interested in. In this research, judging/perceiving class is assigned the value of 1 in the label.
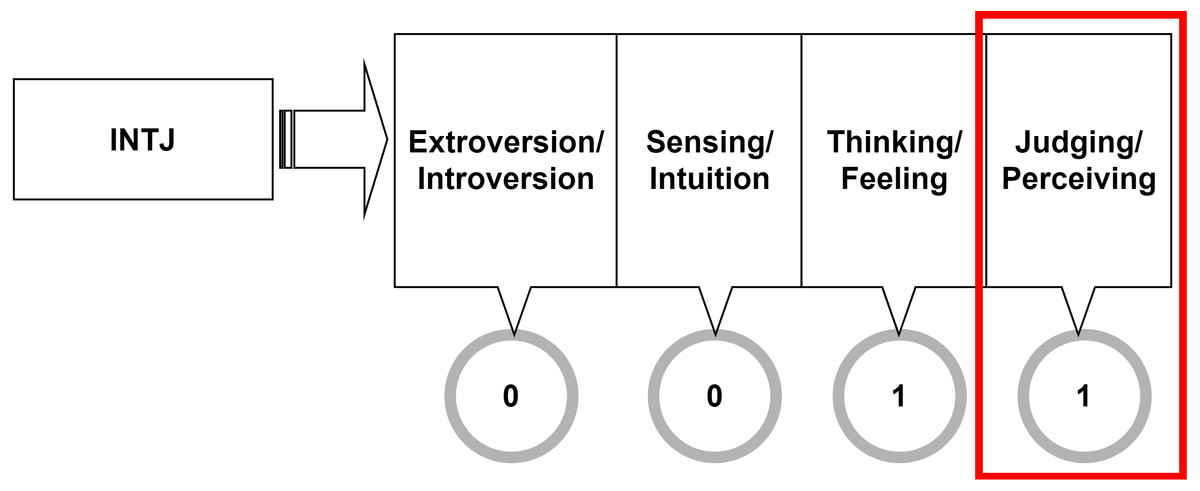
Figure 4: Target variable binarization.
{kind=link}
Once target variable and features sets were clearly defined, they are sent through a set of classifiers within a stratified 5-fold cross validation. While most researches use a simple 5-fold cross validation, this research use stratified 5-fold cross validation to maintain the distribution of classes among training and testing dataset.
Results & Discussion
Results
This section states the results obtained in this study. The prediction performance of the five proposed classifiers were evaluated based on the accuracy and F1-Macro score. Since accuracy metric is more sensitive to the distribution of the target variable, F1-Macro score is evaluated on top of accuracy since it is more important to capture the sensitivity and specificity performance of a classifier on an imbalance dataset.
The accuracy and F1-Macro score for the classifiers on Kaggle and Kaggle-Filtered dataset is tabulated in Table 2. According to Table 2, LightGBM classifier on average perform significantly better than the other classifiers on Kaggle dataset. However, in Kaggle-Filtered, LightGBM only slightly outperformed other classifiers.
| Dataset | Models | Accuracy (%) | F1-Macro (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CNB | LGB | LR | RF | SVM | CNB | LGB | LR | RF | SVM | ||
| kaggle | combo | 75.58 | 81.68 | 69.19 | 78.14 | 80.13 | 74.57 | 80.77 | 68.1 | 75.04 | 79.21 |
| char_tf | 67.23 | 81.66 | 73.16 | 76.30 | 75.20 | 66.52 | 80.76 | 72.31 | 72.16 | 74.44 | |
| char_tfidf | 67.13 | 81.22 | 73.60 | 76.14 | 75.58 | 66.44 | 80.29 | 72.76 | 71.89 | 74.86 | |
| word_tf | 68.94 | 80.17 | 69.70 | 71.18 | 73.35 | 68.16 | 79.2 | 68.83 | 63.78 | 72.33 | |
| word_tfidf | 68.80 | 79.90 | 69.85 | 70.75 | 73.35 | 68.04 | 78.94 | 68.99 | 63.17 | 72.37 | |
| LIWC | 56.65 | 57.4 | 58.16 | 60.69 | 57.84 | 55.98 | 56.23 | 57.45 | 46.74 | 57.18 | |
| CNB | LGB | LR | RF | SVM | CNB | LGB | LR | RF | SVM | ||
| kaggle-Filtered | combo | 61.22 | 66.26 | 59.28 | 62.01 | 64.04 | 60.27 | 63.83 | 58.04 | 45.84 | 62.84 |
| char_tf | 60.02 | 63.77 | 60.38 | 61.16 | 62.57 | 59.19 | 61.38 | 59.44 | 42.66 | 61.57 | |
| char_tfidf | 59.82 | 64.50 | 60.50 | 61.36 | 62.31 | 59.08 | 62.01 | 59.55 | 43.82 | 61.47 | |
| word_tf | 61.13 | 65.80 | 60.30 | 61.22 | 61.76 | 60.33 | 63.99 | 59.32 | 42.7 | 60.74 | |
| word_tfidf | 60.95 | 64.85 | 60.02 | 61.20 | 61.63 | 60.13 | 62.75 | 59.03 | 44.09 | 60.83 | |
| LIWC | 56.58 | 57.08 | 58.19 | 60.65 | 58.02 | 55.88 | 55.99 | 57.51 | 46.46 | 57.34 | |
Notes:
- bold values are highest value across classifiers.
- combo is the combination of char_tf, char_tfidf, word_tf, word_tfidf and LIWC.
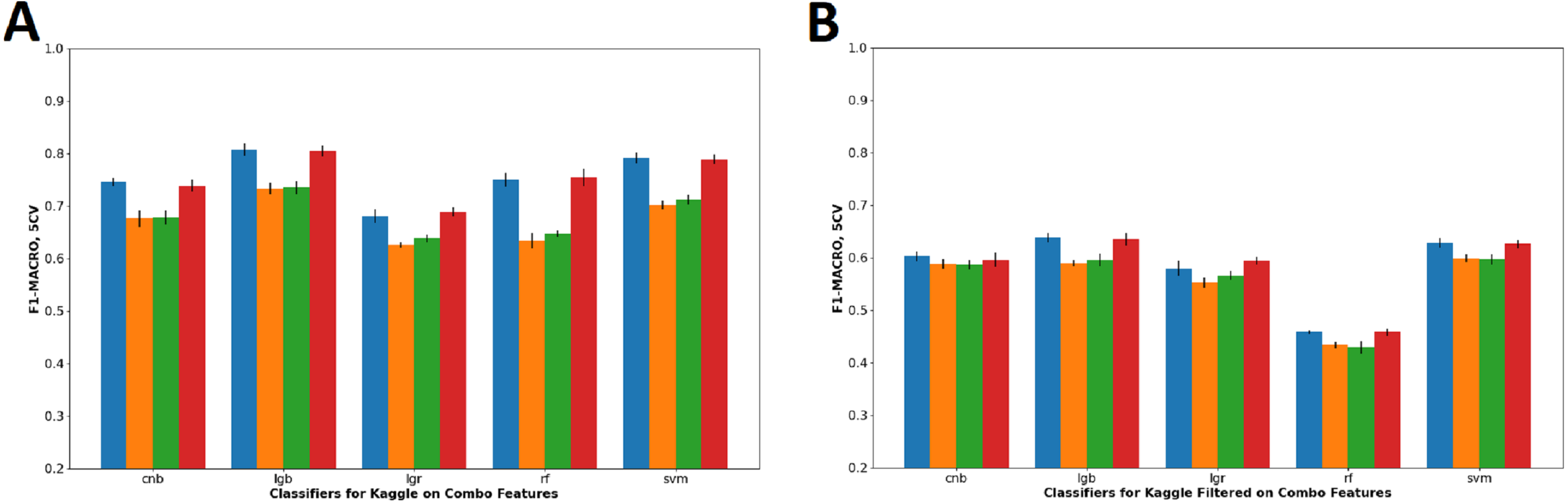
Table 3 shows the accuracy and F1-Macro score of classifiers on combo feature set. Combo feature set were chosen for comparison because combo feature set is inclusive of the other feature sets and thus can generalize the effect of the noun and stop words removal. Based on the result in Table 3 and corresponding visualization in Fig. 5, both depicts that the removal of noun words drastically reduces prediction performance of J/P dichotomy in Kaggle dataset, whereas slightly to no effect on Kaggle-Filtered dataset. The removal of stop words has negligible effect on the prediction performance in all datasets.
| Datasets | Accuracy on combo feature set (%) | F1-Macro on combo feature set (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| cnb | lgb | lgr | rf | svm | cnb | lgb | lgr | rf | svm | |
| Kaggle | 75.58 | 81.68 | 69.19 | 78.14 | 80.13 | 74.57 | 80.77 | 68.1 | 75.04 | 79.21 |
| Kaggle_noNN | 68.6 | 74.57 | 63.97 | 70.33 | 71.43 | 67.62 | 73.34 | 62.65 | 63.43 | 70.22 |
| Kaggle_noNNnoSW | 68.82 | 74.86 | 64.98 | 70.96 | 72.37 | 67.8 | 73.53 | 63.82 | 64.69 | 71.25 |
| Kaggle_noSW | 74.96 | 81.41 | 70.01 | 78.42 | 79.82 | 73.89 | 80.51 | 68.93 | 75.47 | 78.94 |
| Kaggle-Filtered | 61.22 | 66.26 | 59.28 | 62.01 | 64.04 | 60.27 | 63.83 | 58.04 | 45.84 | 62.84 |
| Kaggle-Filtered_noNN | 59.66 | 61.47 | 56.66 | 61.09 | 60.95 | 58.87 | 59.00 | 55.26 | 43.35 | 59.89 |
| Kaggle-Filtered_noNNnoSW | 59.59 | 61.83 | 57.99 | 60.81 | 60.61 | 58.69 | 59.59 | 56.67 | 42.98 | 59.67 |
| Kaggle-Filtered_noSW | 60.68 | 65.89 | 60.65 | 61.90 | 63.78 | 59.60 | 63.56 | 59.38 | 45.84 | 62.66 |
Notes:
- bold values are highest value across classifiers and datasets.
- noNN = Noun removed, noSW = Stop Words removed, noNNnoSW = Noun and Stopwords removed.
- combo is the combination of char_tf, char_tfidf, word_tf, word_tfidf and LIWC.
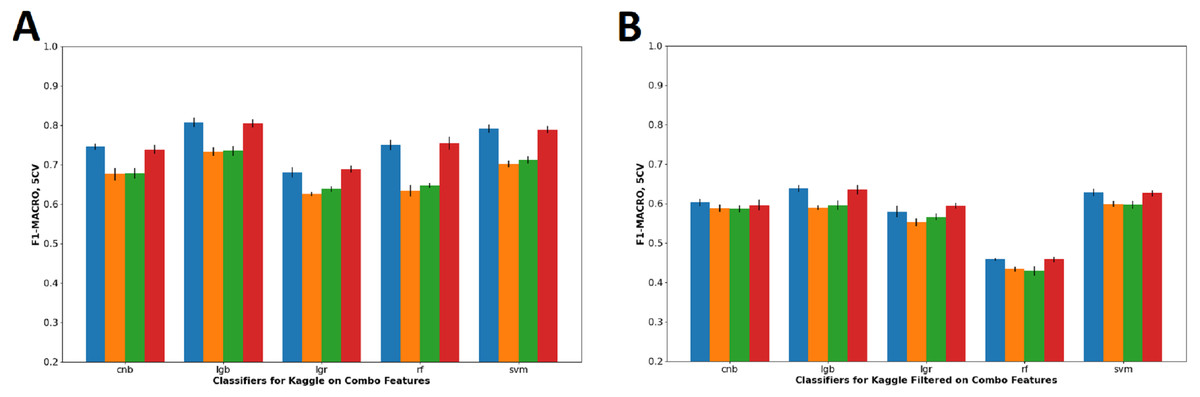
Figure 5: Visualization of combo features F1-Macro score on all dataset configuration.
{kind=link}
The combination of LightGBM and Combo Feature on Kaggle dataset produces the highest F1-Macro score of 80.77%. Table 4 tabulates the confusion matrix, recall, precision and f1-measure from the results of the 5-folds cross-validations. Visibly, the recall, precision and f1-measure for predicting Perceiving class is above 8–10% higher than predicting Judging class. This suggest that people with Perceiving traits have more prominent linguistic marker than people with Judging trait when it comes to communicating on social media.
| Confusion matrix | Performance metric score (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 5-folds cross validation | Predicted class | Accuracy | Recall | Precision | F1-Measure | AUROC | |||
| Judging | Perceiving | ||||||||
| Fold-1 | Actual Class | Judging | 522 | 162 | 82.41 | 76.32 | 78.61 | 77.45 | 89.03 |
| Perceiving | 142 | 902 | 86.4 | 84.77 | 85.58 | ||||
| Fold-2 | Judging | 531 | 153 | 82.23 | 77.63 | 77.52 | 77.57 | 90.32 | |
| Perceiving | 154 | 890 | 85.25 | 85.33 | 85.29 | ||||
| Fold-3 | Judging | 503 | 180 | 79.97 | 73.65 | 75.19 | 74.41 | 86.99 | |
| Perceiving | 166 | 878 | 84.1 | 82.99 | 83.54 | ||||
| Fold-4 | Judging | 513 | 170 | 81.24 | 75.11 | 76.91 | 76.00 | 88.60 | |
| Perceiving | 154 | 890 | 85.25 | 83.96 | 84.60 | ||||
| Fold-5 | Judging | 518 | 165 | 82.57 | 75.84 | 79.20 | 77.48 | 89.37 | |
| Perceiving | 136 | 908 | 86.97 | 84.62 | 85.78 | ||||
| Average/ Macro-Average | 81.68 | 80.65 | 80.91 | 80.77 | 88.86 | ||||
| Standard Deviation | 1.09 | 1.13 | 1.17 | 1.14 | 1.22 | ||||
| Methods | Dataset | Performance metric score ± Standard deviation (%) | Best configuration | ||
|---|---|---|---|---|---|
| Accuracy | F1-Macro | AUROC | |||
| Cui & Qi (2017) | Kaggle | 62.65% | NA | NA | NA |
| Bharadwaj et al. (2018) | Kaggle | 78.80% | NA | NA | NA |
| Li et al. (2018) | Kaggle | 76.25% | NA | NA | NA |
| Amirhosseini & Kazemian (2020) | Kaggle | 65.70% | NA | NA | NA |
| Mehta et al. (2020) | Kaggle | 67.20% | NA | NA | NA |
| Light GBM (This research) | Kaggle | 81.68±1.09% | 80.77± 1.14% | 88.86± 1.22% | Combo |
The results for all experimental configurations are tabulated in Appendix A: Tables A1 and A2 detail the 5-fold cross validation results average; whereas Tables A3 and A4 detail the results standard deviation for Kaggle and Kaggle-Filtered dataset respectively.
Benchmarking with previous researches
Compiling all results from this research, and the result from relevant research using the same dataset, Table 5 shows a comparison of this research with those of the past. Without addressing the data leakage in Kaggle dataset, Light GBM model with character-level TF managed to outperform J/P prediction performance of past researches on the same dataset. However, that cannot be reproduced with Kaggle-Filtered dataset with MBTI keyword removed. Four researches, Cui & Qi (2017), Bharadwaj et al. (2018), Li et al. (2018) and Mehta et al. (2020) did not mention explicitly about removal of MBTI keyword in their preprocessing step. Only Amirhosseini & Kazemian (2020) mentioned removal of MBTI keywords in their preprocessing steps.
Referring to Table 1 in the related works section, best performing algorithm from Cui & Qi (2017), Bharadwaj et al. (2018), Li et al. (2018), Mehta et al. (2020) and Amirhosseini & Kazemian (2020) are long short-term memory (LSTM), support vector machine (SVM), k nearest neighbor (KNN), BERT + MLP and XGBoost. LightGBM used in this research achieved 81.68% accuracy with a standard deviation of 1.09%, and had outperformed the accuracy of all previous work on this dataset as indicated in Table 5.
It is not surprising the LightGBM came up above SVM and KNN since most competition on Kaggle were won using gradient boosting algorithm such as LightGBM and XGboost. Unexpectedly, LSTM, a deep learning algorithm was the lowest among all. There is no concrete explanation to this, but it is worth nothing that Cui & Qi (2017) had remediated the data so that no one class out of the 16 MBTI type will be twice as large as the other. Thus, the final distribution of the classes is different, and the distribution were not mentioned in the research. Additionally, Cui & Qi (2017) were training the LSTM for a multi class problem to output 16 MBTI types, thus the model is not learning predominantly for judging/perceiving dichotomy. All being said, comparison of the results using accuracy as the metric on Cui & Qi (2017) is not valid.
Conclusion & Future Work
This research had demonstrated that there is negligible difference in social media MBTI Judging-Perceiving prediction performance between character-level TF, TF-IDF and word-level TF, TF-IDF. LIWC is consistently behind by a small margin in prediction. Word-level features are recommended over character-level feature for the better interpretability and marginally higher predictive power.
Five classifiers were compared in the task of MBTI Judging-Perceiving prediction. While both SVM and LightGBM are clearly superior as compared to other three classifiers, the prediction performance of LightGBM and SVM are rather similar. This research recommended LightGBM in the end for a better robustness in achieving convergence as SVM failed to do so in one of the datasets.
On the final objective, this research evaluated the J/P dichotomy prediction performance of all eight datasets. The highest F1-Macro score across the two groups for Kaggle and Kaggle-Filtered datasets are 81% and 65%, respectively. The importance of proper preprocessing is illustrated by showing the contrast in prediction performance between Kaggle, a dataset with data leakage and Kaggle-Filtered, a dataset without data leakage. . This suggest that J/P dichotomy prediction might rely heavily on the linguistic semantic rather than statistical approach on the terms like TF and TF-IDF. A semantic-based approach would be necessary for tackling the prediction of MBTI J/P dichotomy.
Past researchers raised a valid point that the posts drawn from Personality Cafe could lead to many inherent data biases since users and posts are only sampled from one forum with discussion revolving a focused topic. This cannot be generalized to users on another forum as the topic diversity is too narrow. Although some researchers have provided a social media MBTI corpus from reddit with a great topic diversity, it does not shy away from the fact that the classes of the users represented on the corpus are largely imbalance and is nowhere near the realistic distribution. Yet, another problem with the current available large corpuses is that the MBTI label from these corpuses are from self-administered MBTI assessment. There is no information on which version of MBTI assessment was used thus producing inconsistent data. Coming up with a validated corpus with a better representation of the MBTI distribution remains to be the number 1 task to be pursued.