
Privacy-preserving k-NN interpolation over two encrypted databases
- Published
- Accepted
- Received
- Academic Editor
- Shadi Aljawarneh
- Subject Areas
- Cryptography, Security and Privacy
- Keywords
- Big data, Cloud computing, Interpolation, k-nearest neighbour
- Copyright
- © 2022 Osmanoglu et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2022. Privacy-preserving k-NN interpolation over two encrypted databases. PeerJ Computer Science 8:e965 https://doi.org/10.7717/peerj-cs.965
Abstract
Cloud computing enables users to outsource their databases and the computing functionalities to a cloud service provider to avoid the cost of maintaining a private storage and computational requirements. It also provides universal access to data, applications, and services without location dependency. While cloud computing provides many benefits, it possesses a number of security and privacy concerns. Outsourcing data to a cloud service provider in encrypted form may help to overcome these concerns. However, dealing with the encrypted data makes it difficult for the cloud service providers to perform some operations over the data that will especially be required in query processing tasks. Among the techniques employed in query processing task, the k-nearest neighbor method draws attention due to its simplicity and efficiency, particularly on massive data sets. A number of k-nearest neighbor algorithms for query processing task on a single encrypted database have been proposed. However, the performance of k-nearest neighbor algorithms on a single database may create accuracy and reliability problems. It is a fact that collaboration among different cloud service providers yields more accurate and more reliable results in query processing. By considering this fact, we focus on the k-nearest neighbor (k-NN) problem over two encrypted databases. We introduce a secure two-party k-NN interpolation protocol that enables a query owner to extract the interpolation of the k-nearest neighbors of a query point from two different databases outsourced to two different cloud service providers. We also show that our protocol protects the confidentiality of the data and the query point, and hides data access patterns. Furthermore, we conducted a number of experiment to demonstrate the efficiency of our protocol. The results show that the running time of our protocol is linearly dependent on both the number of nearest neighbours and data size.
Introduction
Due to its low cost, scalability and reliability, cloud computing has increased its reputation in both the business and scientific communities. In addition to the benefits, it introduces new concerns that need to be addressed carefully (Krutz & Vines, 2010). One of the emerging issues in cloud computing is extracting knowledge from sensitive data while protecting the privacy of data owners, which is called privacy-preserving data mining (Agrawal & Srikant, 2000; Vaidya & Clifton, 2004). A privacy-preserving data mining method aims to provide data privacy using either data perturbation or cryptographic methods. Data perturbation-based models struggle with data quality issues, i.e. the valuable statistical information might be dissolved. This may yield less accurate and less reliable results. On the other hand, cryptographic-based models achieves the privacy of data owners through the encryption of data before outsourcing it to the cloud. However, this presents challenges of performing required operations over the encrypted data.
In addition to these facts, collaboration among different cloud service providers may also help them to create more accurate and reliable results in a privacy-preserving data mining method, i.e. more clouds can discover more knowledge than they can uncover on their own when they combine their data (Demir & Tugrul, 2018). There are some studies that propose privacy-preserving solutions for horizontally-partitioned databases to increase the total number of data samples with the goal of creating more accurate data mining models (Inan et al., 2007). In some cases, vertically-partitioned database solutions can be preferred to increase the number of attributes for the same instances (Skillicorn & McConnell, 2008). Institutions such as hospitals operating in different parts of a country may prefer the first choice. On the other hand, institutions such as banks and insurance companies may aggregate their data using the second choice.
In this study, we will examine the k-NN interpolation method that preserves the confidentiality of two different databases stored by two different cloud service providers. k-NN, categorized as a lazy learner, is a non-parametric method used for classification, clustering and interpolation which utilizes the idea that neighboring objects possess or display similar characteristics. Complex interpolation methods such as Kriging involve advanced operations and thus pose a great challenge to cloud computing. In addition, the high time requirements of such methods make them unsuitable in some scenarios such as healthcare applications. On the contrary, the simplicity and interpretability of the k-NN method make it an efficient tool for query processing tasks.
Our contribution
In this article, we introduce an efficient secure two-party k-NN (STPkNN) interpolation protocol that enables two different data owners to outsource their databases together with the query processing service to the cloud, and allows a query owner to extract the interpolation of the k-nearest neighbors of a query point from the encrypted databases. Our protocol preserves the confidentiality of data, assures the privacy of user’s query point, and hides data access patterns.
The STPkNN protocol can be considered as an extension of the protocol SkNNm proposed in Elmehdwi, Samanthula & Jiang (2014), that enables a query owner to retrieve the k-nearest neighbors of a query point from a single encrypted database, to two-cloud settings. Briefly, the SkNNm protocol calculates the k-nearest neighbors in an iterative way by performing the following steps k times: (i) it finds the minimum of the Euclidean distances between the data records and the query point, (ii) it calculates the one of the nearest neighbors that corresponds to the index of the minimum distance, and excludes the corresponding distance from the Euclidean distances. On the other hand, in two-cloud settings, the clouds have to share their local minimums of the Euclidean distances to decide on the global minimum that corresponds the index of the nearest neighbor of two databases at the moment, and remove that record from further iterations. However, it is not trivial to achieve this without revealing which data record corresponds to global minimum to any cloud.
To this aim, we first propose two new security primitives, the Secure Transformation (ST) protocol and the Secure Bit-AND-OR (SBAOR) protocol that enable the clouds to decide on the global minimum and exclude it from the further calculations without revealing data access pattern to any cloud. We show that both protocols protect the confidentiality of the input values which will be in encrypted form, i.e. no information about the input values is leaked to any party during the protocols, and the output is only revealed to one of the parties in the protocols. Briefly, the ST protocol allows the servers to securely transform the encryption of a record under a public key to an encryption of same record under another public key. On the other hand, for given the encryptions of two bit vectors x and y, the SBAOR protocol enables the servers to securely compute the negation of the logical disjunction of all bitwise multiplications xi · yi in encrypted form without revealing the bit vectors to any party.
By employing the ST and SBAOR protocols together with the other existing security protocols, we build our main protocol STPkNN that enables a query owner (QO) to extract the interpolation of the k-nearest neighbors of a query point chosen by QO from two different databases outsourced to two different cloud service providers. In the protocol, data owners encrypt their data before outsourcing them to the cloud service providers, and they do not participate in the STPkNN protocol. Thus, no information about the data is leaked to the cloud service providers during the protocol. Besides, our protocol guarantees that any record from both databases or any intermediate result generated in the protocol is not leaked to the cloud service providers. Also, it hides the data access pattern from both data owners and cloud service providers, i.e. the protocol does not reveal the information of which data records were used to produce the interpolation of k-nearest neighbors to any cloud service provider. On the other hand, the STPkNN protocol outputs the interpolation of k-nearest neighbors only to the query owner, and the query owner gets no information other than the interpolation.
We also conduct various experiments on two real-world datasets from the UCI machine learning repository, the cervical cancer (risk factors) dataset and the default of credit card clients dataset, to show the practicability of our protocol in real world scenarios. The experimental evaluation presents that our protocol scales well for the large datasets.
Related works
Due to its usefulness in many application scenarios such as classification, similarity search, and collaborative filtering, the problem of computing the k-nearest neighbors of a query point has been gained a lot of attention in recent years. The early studies mostly focused on how to implement a secure k-NN method between data owner and clients without using cloud systems. Shaneck, Kim & Kumar (2009) proposed a privacy-preserving protocol that employs secure multiparty computation to compute k-NN in horizontally partitioned databases. Besides, they also showed how their protocol can be efficiently used in different application such as outlier detection, classification, and clustering problems. Moreover, Qi & Atallah (2008) proposed a provable secure protocol for the single-step k-NN search problem that enjoys linear computation and communication complexity. Vaidya & Clifton (2005) introduced a privacy-preserving algorithm that performs top-k queries in vertically partitioned data. Additionally, Kantarcoğlu & Clifton (2004) proposed a method that privately calculates the k-NN classification over horizontally partitioned data in the distributed database model. Note that all of the above methods require the data owners to perform the necessary calculations to generate the result, and to return it directly to the query users. However, in our model, the data is outsourced to the cloud in encrypted form instead of being kept by the data owners. All of the computation required to process k-NN queries are performed by the cloud.
The recent studies have mostly focused on solutions in cloud computing settings. Wong et al. (2009) proposed an asymmetric scalar-product-preserving encryption (ASPE) scheme that can be employed to construct a secure k-NN protocol. The protocol proposed in Wong et al. (2009) uses a distance comparison function instead of an exact distance calculation. However, the secret key in the protocol should be disclosed to the query users. Zhu, Huang & Takagi (2016) introduced a secure protocol that achieves k-NN query processing on encrypted data without totally revealing the data owner’s secret key to the query user. However, their scheme requires data owners to be involved in the encryption of query points. Hu et al. (2011) proposed a secure traversal framework that can used, together with privacy homomorphism, to achieve secure k-NN query processing protocol. Cheng et al. (2015) proposed a privacy-preserving protocol that employs an encrypted hierarchical index tree to perform k-NN queries over spatial data outsourced to cloud in encrypted form. All three protocols (Hu et al., 2011; Zhu, Huang & Takagi, 2016; Cheng et al., 2015) leak data access pattern to the cloud. On the other hand, Kesarwani et al. (2018) proposed a secure k-NN query processing protocol over encrypted data by utilizing a leveled fully homomorphic encryption scheme. Wu et al. (2019) introduced a privacy preserving k-NN classification scheme over the encrypted cloud database that is secure against known-plaintext attack. Besides, Lei et al. (2020) shed light on the connection between a secure k-NN query processing scheme and a secure range query scheme. Based on this connection, they utilize a secure range query scheme together with a data structure named as random Bloom filter to build a secure k-NN query processing scheme. All three protocols (Kesarwani et al., 2018; Wu et al., 2019; Lei et al., 2020) hide data access pattern as well as preserving the data privacy and query privacy. However, they require the decryption keys to be given the query users. However, in our model, the decryption keys are not shared with the query users.
On the other hand, Elmehdwi, Samanthula & Jiang (2014) tackled with the same problem using homomorphic encryption method. In addition to ensuring the confidentiality of data owners and clients, the protocol proposed in Elmehdwi, Samanthula & Jiang (2014) also achieves to hide data access patterns from the clouds. Moreover, Xu et al. (2017) proposed an efficient secure k-NN protocol which achieves sublinear computational complexity. Similar to Elmehdwi, Samanthula & Jiang (2014), their protocol also achieves hiding of data access patterns using garbled circuits to simulate Oblivious RAM. Furthermore, Guo & Sun (2020) adopted the data structure R-tree to build an efficient k-NN scheme that requires only two rounds of interactions between the client and cloud servers to generate the result. They also utilized the Merkle hash tree techniques to obtain a better k-NN scheme that is secure against even a malicious cloud servers. There are also some studies that engage in location-based query processing over encrypted geospatial data (Lei et al., 2019; Lian et al., 2020). Lian et al. (2020) proposed an efficient k-NN scheme by employing the Moore curves together with the AES encryption scheme, that ensures the spatial data and location privacy.
The aforementioned studies use k-NN methods for either classification or query search applications. Unlike previous solutions, Kalideen, Osmanoglu & Tugrul (2019) proposed an efficient solution for the problem of computing the interpolation of k-NN to a given point in cloud computing settings. However, their solution reveals the knowledge of which data records were used to produce the interpolation to the cloud servers, and leaking such information might not be desired in some application required the data security. Unlike the protocol presented in Kalideen, Osmanoglu & Tugrul (2019), our protocol assures the desired security features, i.e. it hides data access pattern.
Problem formulation
In this section, we will give more precise definition of the problem and its security requirements.
Secure two-party k-NN interpolation problem
In our system there are two data owners DO1 and DO2 holding two different spatial databases D1 and D2, respectively. Each database Du consists of n records such that each record is an m-dimensional spatial vector, i.e. where u = 1,2. There are also two cloud pairs (CSP1(u), CSP2(u)) so that each one is associated with a public key-secret key pair (pku, sku) of a public key encryption scheme that is semantically secure (Goldwasser & Micali, 1982). As the most of the studies in this field, we also consider each pair of cloud service providers (CSP1(u), CSP2(u)) as two non-colluding cloud servers, i.e. CSP1(u) stores the database and performs most of the homomorphic operations; on the other hand, CSP2(u) keeps the secret key and helps CSP1(u) to perform the complex operations over the ciphertexts.
In our problem, we assume that each data owner DOu initially encrypts his database Du as where consists of the attribute-wise encryptions for 1 ≤ i ≤ n and 1 ≤ j ≤ m. Each DOu then outsources together with the query processing service to CSP1(u). Note that the underlying public key encryption scheme should enable cloud servers to perform homomorphic operations over ciphertexts.
There is also an authorized query owner QO who wants to retrieve the interpolation of k-nearest neighbors of a query point Q from both databases D1 and D2 stored in CSP1(1) and CSP1(2), respectively. After QO requests the interpolation, the cloud service providers generate the result by performing required operations over the encrypted databases. This process should output the interpolation of k-nearest neighbors only to the query owner. The query owner should not learn any information other than the interpolation during this process. We denote such process as secure two-party k-nearest neighbors (STPkNN) protocol. We remark that STPkNN protocol should preserve the confidentiality of the records in the databases D1 and D2, and protect the privacy of the query point. Moreover, the protocol should hide data access patterns, i.e. it should not reveal the information of which data records were used to produce the interpolation of k-nearest neighbors to any data owner or any cloud service provider.
Example
In 2016, European Union adopted a new regulation on the protection of personal data, Regulation (EU) 2016/679 of the European Parliament and Of The Council (European-Parliament, 2016). The regulation states that ‘the protection of natural persons in relation to the processing of personal data is a fundamental right’. All of the personal health records that reveal information relating to the past, current or future physical or mental health status of the data subject are considered as personal sensitive data in the regulation. Therefore, the personal health records should be protected against unauthorized parties, i.e. only the one approved by the owner should be able to access to the data.
On the other hand, the processing of health data may be significant to advance research or healthcare practices. Consider a doctor who tries to determine whether a person has a particular hearth disease or not by analyzing the medical records of the person. In addition, the doctor may desire to compare the patient’s medical records with other patients’ presenting similar properties in order to improve diagnostic accuracy. In fact, this comparison enables the doctor to evaluate the validity of some tests, especially when the scores do not match the expected values. Consequently, the doctor can make an accurate diagnosis, if he is allowed to reach the data of other patients in the same region or across the country. Moreover, if the personal health records are stored in the cloud as encrypted in order not to violate the fundamental right of the owner of the records, it will be possible to perform reliable analysis on large datasets.
Let us clarify it with an example. Consider the subset of heart disease data set from UCI Machine Learning Repository depicted in Table 1. There are 10 different instances shown in the table, and each instance is associated with five attributes: ID (patient’s identity), trestbps (resting blood pressure in mm Hg), chol (serum cholesterol in mg/dl), thalach (maximum heart rate achieved), and oldpeak (ST depression induced by exercise relative to rest). Assume the data owner, which can be viewed as hospital in this context, encrypts these attributes, and outsources the encrypted database Epk(D) together with the future query processing to the cloud. Also, assume there is a doctor who wants to determine whether a specific patient carries risk for a particular hearth disease. Let the medical record of the patient be . The doctor, that will be the query owner in our context, asks the interpolation of k-nearest neighbors of Q from the cloud by providing the encryption Epk(Q) to the cloud. Then, the cloud determines the interpolation of k-nearest neighbors by searching the encrypted database Epk(D). For simplicity, let k be 3 for this example. As we observe here, the instances having IDs 1, 7, and 9 will be the 3 nearest neighbors to Q. So, the cloud returns the interpolation to the doctor that will benefit from T to make an accurate diagnosis. Consequently, necessary analysis can be carried out without revealing any sensitive information about both his patient and the other patients.
| ID | trestbps | chol | thalach | oldpeak |
|---|---|---|---|---|
| 1 | 145 | 233 | 150 | 2.3 |
| 2 | 160 | 286 | 108 | 1.5 |
| 3 | 120 | 229 | 129 | 2.6 |
| 4 | 130 | 250 | 187 | 3.5 |
| 5 | 130 | 204 | 172 | 1.4 |
| 6 | 120 | 236 | 178 | 0.8 |
| 7 | 140 | 268 | 160 | 3.6 |
| 8 | 120 | 354 | 163 | 0.6 |
| 9 | 130 | 254 | 147 | 1.4 |
| 10 | 140 | 203 | 155 | 3.1 |
Effect of collaboration on interpolation accuracy
Aguilar et al. (2005) stated that if interpolation models are developed with an insufficient amount of data, they will be less accurate and reliable. Namely, the collaboration between participants affects the accuracy of interpolation models. We here conduct a series of experiments to assess the impact of collaboration between participants on the accuracy of prediction in the interpolation methods. In our experiments, we employ two publicly available datasets from U.S. National Geochemical Survey Database that present sodium (Na) content of the soil in two states: Colorado and Wisconsin. Summary statistics of both data sets are presented in Table 2.
| Colorado | Wisconsin | |
|---|---|---|
| Mean | 0.999 | 0.773 |
| Median | 0.912 | 0.771 |
| Minimum | 0.063 | 0.007 |
| Maximum | 3.230 | 2.043 |
| Standard Deviation | 0.460 | 0.299 |
| Skewness | 0.912 | −0.177 |
| Kurtosis | 4.034 | 3.131 |
There are various performance evaluation metrics for interpolation methods. We here employed Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE), which are often chosen as evaluation metrics for numerical prediction. The small values of both MAE and RMSE indicate that models will produce results that are more accurate. MAE and RMSE values are calculated as follows;
(1)
(2)
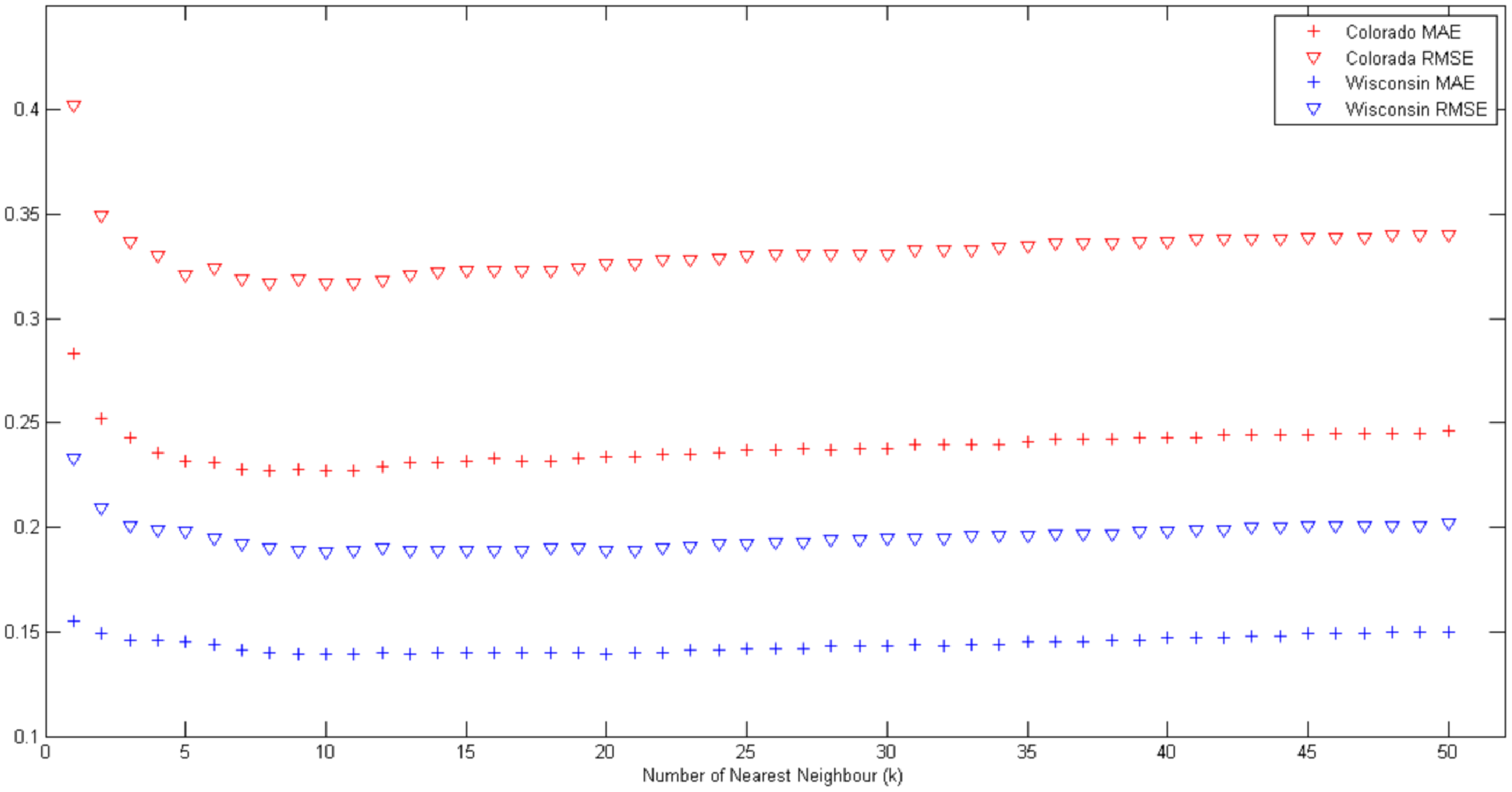
where n is the total number of data points in the dataset, p({xi, yi}) and z({xi, yi}) are predicted and actual values at location ({xi, yi}), respectively. The effects of varying k values on MAE and RMSE values are shown in Fig. 1.

Figure 1: Effects of varying k values on MAE and RMSE for Colorado and Wisconsin data sets.
{kind=link}
We assume that two data holders share all data points in the data set. Both data sets are randomly divided into two parts using sampling without replacement strategy, assuming each party has one of the pieces. In some situations, data holders may not have data in equal proportions. So, we have determined different sharing ratios considering the cases where there is no equal distribution. We specify the β value as the distribution ratio, which means that if one party holds β portion of the data, the other party will hold the remaining portion (1 − β). After several trials, the MAE and RMSE values obtained according to the various number of nearest neighbor counts are shown in the Tables 3 and 4, respectively.
| β | Wisconsin | Colorado | ||||||
|---|---|---|---|---|---|---|---|---|
| k | 25 | 50 | 75 | 100 | 25 | 50 | 75 | 100 |
| 1 | 0.183 | 0.169 | 0.163 | 0.155 | 0.319 | 0.298 | 0.290 | 0.283 |
| 5 | 0.156 | 0.147 | 0.146 | 0.145 | 0.258 | 0.241 | 0.235 | 0.232 |
| 10 | 0.158 | 0.145 | 0.143 | 0.139 | 0.258 | 0.242 | 0.234 | 0.227 |
| 15 | 0.161 | 0.147 | 0.142 | 0.140 | 0.259 | 0.245 | 0.236 | 0.232 |
| 30 | 0.167 | 0.154 | 0.149 | 0.143 | 0.269 | 0.252 | 0.244 | 0.238 |
| 50 | 0.181 | 0.161 | 0.154 | 0.150 | 0.286 | 0.262 | 0.252 | 0.246 |
| β | Wisconsin | Colorado | ||||||
|---|---|---|---|---|---|---|---|---|
| k | 25 | 50 | 75 | 100 | 25 | 50 | 75 | 100 |
| 1 | 0.254 | 0.243 | 0.241 | 0.233 | 0.443 | 0.421 | 0.408 | 0.402 |
| 5 | 0.208 | 0.199 | 0.199 | 0.198 | 0.361 | 0.334 | 0.327 | 0.321 |
| 10 | 0.212 | 0.196 | 0.193 | 0.188 | 0.358 | 0.337 | 0.325 | 0.317 |
| 15 | 0.215 | 0.198 | 0.193 | 0.189 | 0.358 | 0.341 | 0.329 | 0.323 |
| 30 | 0.224 | 0.206 | 0.200 | 0.195 | 0.368 | 0.348 | 0.338 | 0.331 |
| 50 | 0.238 | 0.214 | 0.207 | 0.202 | 0.385 | 0.360 | 0.347 | 0.340 |
As seen from the results, the smallest MAE and RMSE values are observed when the 10-nearest neighbors are used for all points in each data set. The smallest MAE and RMSE are underlined in the tables. As seen from the Table 3, if only half of the data is available for creating a prediction model, there will be a deterioration in MAE values of 4.31% for the Wisconsin data set and 6.60% for the Colorado data set. It is also possible to observe similar aspects in Table 4 for each split ratio. As observed from the results, the data holder who has less amount of data always produces less accurate predictions. On the contrary, if there is a sufficient amount of data, the predictions generated by the model are more accurate and reliable.
Premilinaries
In this section, we will present the notations and the definitions of some primitives that will be used in our proposed protocols.
Notation
We here give the notations used in this paper.
n, the number of records in each database
m, the number of the attributes in each record
, the domain size (in bits) of the squared Euclidean distance
DOu, the uth data owner
Du, the uth database
, the ith record of the database Du
QO, the query owner
Q, the query point
[x], the encryption of the individual bits of x
, the pth closest record to Q
(pku, sku), the public key-secret key pair assigned to the uth cloud pair
(CSP1(u), CSP2(u)), the uth cloud pair, i.e. the former holds the encryption of the database and the latter holds the corresponding secret key sku.
Homomorphic encryption
Homomorphic encryption is an encryption scheme that allows users to perform some mathematical operations on ciphertexts, such as addition and multiplication. This property enables to protect the confidentiality of the data, and makes the encryption scheme a very practical and useful tool in cloud computing, especially for the sensitive data. For that reason, homomorphic encryption schemes have been gaining a lot of attention in recent years. Within this direction, many homomorphic encryption schemes have been proposed (Goldwasser & Micali, 1982; Elgamal, 1984; Boneh, Goh & Nissim, 2005). In this study we use a well-known homomorphic encryption system, the Paillier scheme, to construct our protocols.
Let Epk(·) be the encryption function with the public key pk and Dsk(·) be the decryption function with the secret key sk. For any given two plaintexts a and b, the Paillier scheme satisfies the following properties:
Addition: Dsk(Epk(a + b)) = Dsk(Epk(a) * Epk(b) mod N2)
Multiplication: Dsk(Epk(a * b)) = Dsk(Epk(a)bmod N2)
Note that the Paillier encryption scheme is semantically secure (Paillier, 1999).
Basic security primitives
Here, we briefly explain a set of basic security protocols. In these protocols, it’s assumed that there exist two semi-honest parties P1 and P2 joining the protocols, and the Paillier’s secret key is known only to one of them. We will also introduce two new security primitives in “Construction” that will be employed together with the basic primitives given here as building blocks in forming our construction.
Secure multiplication (SM) protocol
Consider two parties P1 and P2 such that the former holds (Epk(x), Epk(y)) and the latter holds the secret key sk, where x and y are not known to both parties. The protocol outputs Epk(x * y) to P1. Note that the output Epk(x * y) is only known to P1, and no information about x and y is revealed to any party during the protocol.
Secure squared Euclidean distance (SSED) protocol
The protocol considers two parties P1 and P2 with the inputs (Epk(X), Epk(Y)) and the secret key sk, respectively, and outputs Epk(|X − Y|2) to P1, where X and Y are m dimensional vectors. In the protocol, the encryption of squared Euclidean distance Epk(|X − Y|2) is only known to P1.
Secure bit-decomposition (SBD) protocol
The protocol considers P1 with the input Epk(x) and P2 with the secret key sk, and outputs the encryptions of the bit-decomposition of x as , where . Note that the encryptions of bit-decomposition [x] is known to only P1.
Secure minimum (SMIN) protocol
In the protocol, P1 with the inputs ([x], [y]) and P2 with the secret key sk securely compute the encryption of individual bits of minimum between x and y as [min(x,y)]. Note that the output [min(x,y)] is only known to P1, and no information about x and y is revealed to any party during the protocol.
Secure minimum out of n numbers (SMINn) protocol
In the protocol, P1 with the inputs ([x1],…,[xn]) and P2 with the secret key sk securely compute [min(x1,…,xn)], where [min(x1,…,xn)] is the encryption of the individual bits of min(x1,…,xn). Note that the output [min(x1,…,xn)] is only known to P1, and no information about xi for any i is revealed to any party during the protocol.
Secure Bit-OR (SBOR) protocol
Consider two parties P1 and P2 such that the former holds (Epk(a), Epk(b)) and the latter holds the secret key sk, where a and b are two bits. The protocol outputs to P1. The output is only known to P1, and no information about a and b is revealed to any party during the protocol.
Since we don’t aim to study the existing protocols given above, we simply consider the most efficient implementation of them which were presented in Elmehdwi, Samanthula & Jiang (2014) and Samanthula, Hu & Jiang (2013). However, the implementation of the SMINn protocol given in Elmehdwi, Samanthula & Jiang (2014) fails for some inputs, i.e. it generates an incorrect output if the size of the input is given as n = 8k + 1 for some k ∈ Z. Let me illuminate it with an example: assume the protocol takes nine inputs ([x1],…,[x9]). At the last step, the protocol applies the SMIN protocol to the intermediate values [x′1] and [x′7]) (the encryptions of the local minimums), and outputs the encryption of 0 since [x′7] was set to the encryption of zero at some previous steps. Therefore, independent of the inputs, the protocol always outputs the encryption of zero as the final output when the size of the input is given as n = 8k + 1 for some k ∈ Z. Thus, we develop a new implementation of the SMINn protocol that simply works as follows:
The server P1 initially executes the SMIN protocol together with P2 on [x1] and [x2] to get [R1] = [min(x1,x2)] as the encryption of the individual bits of min(x1,x2),
it then iteratively runs the SMIN protocol together with P2 on [Ri−1] and [xi+1] to get [Ri] = [min(Ri−1,xi+1)] as the encryption of the individual bits of min(x1,x2,…,xi+1) for i = 2… (n − 1).
Note that the final output of the iterative steps will be [Rn−1] = [min(x1,…,xn)], which is the encryption of the individual bits of min(x1,…,xn).
Construction
In this section, we first introduce two new security primitives: the Secure bit-AND-OR (SBAOR) protocol and Secure Transformation (ST) protocol. We then give the security analysis of this protocols. By utilizing SBAOR and ST protocols together with the basic security primitives given in “Premilinaries”, we construct our main protocol. Furthermore, we also give the security analysis of the main protocol and discuss the computation complexity at the end of this section.
Secure bit-AND-OR (SBAOR) protocol
The SBAOR protocol allows the servers to securely compute the negation of the logical disjunction of all bitwise multiplications xi · yi in encrypted form without revealing the bit vectors to any party. In the main protocol, it will help the servers to separate the index of the current closest record to the query point from all other records of both databases by assigning the encryption of 1 to that particular index and the encryption of 0 to all other indices. In this way, the servers will be able to calculate the current closest record, and remove the corresponding index from further calculations.
The protocol considers two parties P1 and P2 such that the former holds ([x], [y]) and the latter holds the secret key sk, where [x] and [y] are the encryption of individual bits of x and y. The protocol enables the parties P1 and P2 to securely compute the encryption where and . The output is only known to P1, and no information about x and y is revealed to any party during the protocol.
In the protocol, P1 and P2 first runs the SM protocol on the inputs Epk(xi) and Epk(yi) to calculate Epk(xi * yi) for where xi and yi are the i-th bits of x and y, respectively. Note that each Epk(xi * yi) is only revealed to P1. The server P1 then calculates as follows:
it initially executes the SBOR protocol together with P2 on Epk(x1 * y1) and Epk(x2 * y2) to get ,
it then iteratively runs the SBOR protocol together with P2 on Epk(Ri−1) and Epk(xi+1 * yi+1) to get .
Note that the final output of the iterative steps will be . Finally, P1 applies the equation to compute the final output.
| Input: ([x], [y]) from P1 and sk from P2 |
| Output: to P1 |
| 1. P1 and P2; |
| fori = 1 to do |
| ; |
| 2. P1 and P2; |
| ; |
| fori = 2 to − 1 do |
| ; |
| 3. P1; |
| ; |
Security Analysis of SBAOR: At the beginning of the protocol, the servers P1 and P2 execute the Secure Multiplication protocol. As emphasized in “Premilinaries”, the output of the protocol is only revealed to the server P1, and no information about the plaintexts xi and yi is revealed to any party during this protocol. Later, the servers run the Secure Bit-OR (SBOR) Protocol on the inputs Epk(Ri) and Epk(xi+1 * yi+1). The SBOR protocol outputs the new Epk(Ri+1) only to the server P1, and no information about the plaintexts is revealed to any party during the protocol. At the final, the server P1 only applies some homomorphic operations on the encryption computed at the previous step. Therefore, the SBAOR protocol protects the confidentiality of the data, i.e. no information about the contents of the encryptions is revealed to any party during the protocol.
Secure Transformation (ST) protocol
The ST Protocol enables the servers to transform the encryption of a record under a public key to the encryption of same record under another public key. In the main protocol, the servers employ ST Protocol to collect the encryptions of local minimums, that indicate the indexes of local closest records of both databases, under the same public key so that they can decide the minimum among them.
The protocol considers three parties with the input , with the secret key , and . The protocol simply aims to transform the encryption of a record t under the public key to the encryption of t under the public key . Note that no information about t is revealed to any party during the protocol and the output is only known to the party .
Briefly, first masks with the randomly chosen vector as , and sends μ to and to . After getting μ, first decrypts it as , then encrypts μ′ with the public key as , and finally sends the encryption to . After receiving the encryption, the party first removes the randomness r′ from the encryption and gets the encryption as . From the homomorphic property of the underlying encryption scheme, can easily be calculated as .
| Input: from P and from P |
| Output: to P |
| 1. P ; |
| ; ; |
| send μ to P and to P ; |
| 2. P ; |
| ; |
| send to P ; |
| 3. P ; |
| ; |
Security Analysis of ST: At the beginning of the protocol, the servers randomizes the encryption with before sending it to the server . So, the decryption computed by will be uniformly random in . Besides, P locally subtracts the encryption of the randomness r′ under the public key from the encryption sent by by performing some homomorphic operations. Thus, the protocol does not reveal any information about the record t to any party.
Main protocol
In this section, we will give the construction of our main protocol that enables a query owner to extract the interpolation of k-nearest neighbors for a query point of his choice as shown in Fig. 2. As we stated in the “Introduction”, our construction can be viewed as an extension of the protocol presented in Elmehdwi, Samanthula & Jiang (2014) that proposes an efficient solution of the k-nearest neighbor query problem over encrypted database outsourced to a single cloud.
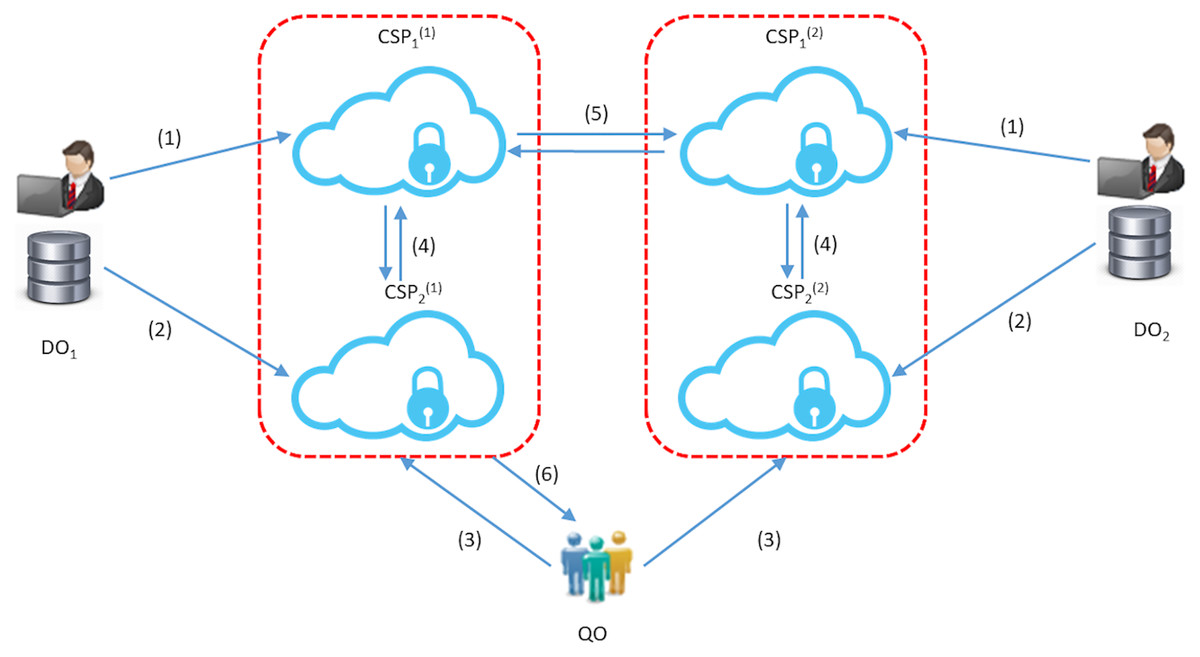
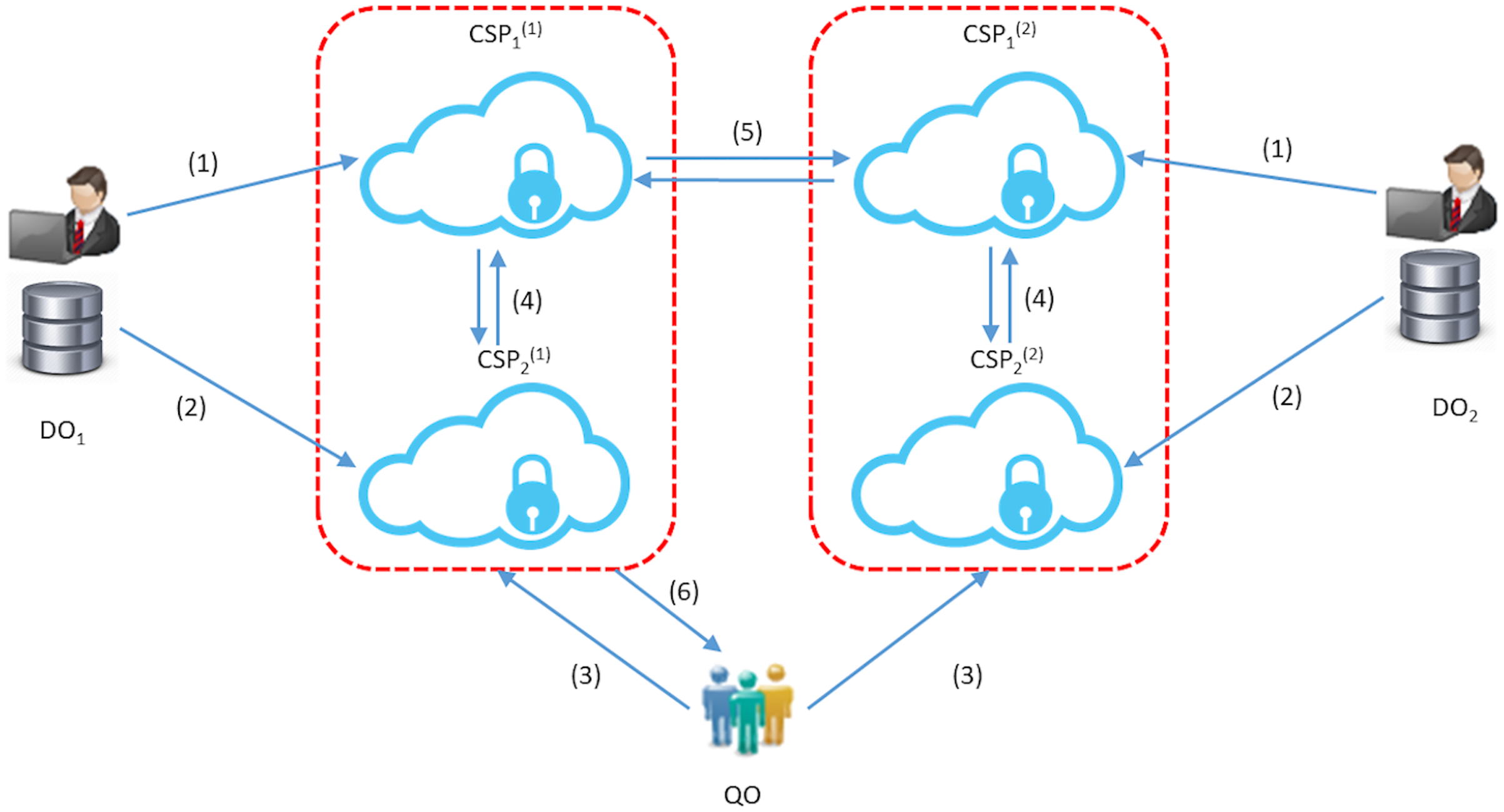
Figure 2: The STPkNN protocol: for u = 1, 2; (1) each DOu uploads its data to the server CSP1(u); (2) each DOu gives its secret key to CSP2(u); (3) QO sends its query point Q in encrypted form to the servers CSP1(u); (4) CSP1(u) and CSP2(u) find the local nearest neighbours; (5) CSP1(1) and CSP1(2) decide on the global nearest neighbour among the local nearest neighbors (4 and 5 are repeated k times in the protocol); (6) the final prediction value is forwarded to QO.
{kind=link}
We assume that each data owner DOu has a database Du that consists of n records where each is m-dimensional vector that lies in . We also assume that there exist two non-colluding semi-honest cloud service providers, and for each database Du where is given the encryption of the database Du and is given the corresponding secret key sku.
Initially, each DOu encrypts his database Du as where 1≤ i ≤ n and 1≤ j ≤ m. Each DOu then outsources the encryptions of the database, together with the future query service to the clouds, i.e. DOu gives to and his secret key sku to . When the query owner (QO) wants to retrieve the interpolation of the k-nearest neighbors for a query point Q, he produces two encryptions of his query point Q as and using the public keys of the data owners DO1 and DO2, respectively; and gives each encryption to the corresponding cloud service provider .
After receiving the encryption , each runs the SSED protocol together with the corresponding server on the input where for 1 ≤ i ≤ n, and obtains the encryption of the squared Euclidean distance between Q and as where . From the SSED protocol, is revealed only to .
Opposite to the protocol proposed in Kalideen, Osmanoglu & Tugrul (2019), instead of sending the encryptions to the server where 1 ≤ i ≤ n, that reveals the information of which indexes being used to compute the interpolation to , each securely runs the SBD protocol with the server on the inputs to compute , the encryptions of the individual bits of . Note that is only revealed to .
After this stage, the servers produce the interpolation of the k-nearest neighbours of the query point Q in an iterative way. In each iteration:
Each pair of servers and securely calculate the encryptions of the individual bits of the minimum value among by running the protocol SMINn. Note that is only revealed to .
Each then locally calculates the encryption of emin from as
At this stage of the protocol, the servers and have and as the encryption of the minimum distances. Now, the servers apply the following steps to decide the minimum among and :
– the servers with the input , with the secret key sk2, and securely runs the ST protocol to compute the encryption of under the public key pk1. Note that is only known to .
– the server now executes the SBD protocol with the server on the inputs and to compute and where . From the SBD protocol, and are only revealed to .
– then runs the SMIN protocol with on the inputs and , and gets .
– after getting [emin], locally calculates the encryption of emin as
– the servers with the input , with the secret key sk1, and securely runs the ST protocol to compute the encryption of emin under the public key pk2. Note that is only known to .
After identifying the minimum emin among and , each locally computes the encryption of difference for each i as .
Each then randomizes as where is a random number in ZN. It is a fact that only one is the encryption of zero among all 2n encryptions and all others are the encryptions of some random numbers where i = 1 … n and u = 1, 2.
Each securely runs the SBD protocol with the server on the inputs to compute , the encryptions of the individual bits of . Note that is only revealed to .
After getting the encryptions , each runs the SBAOR protocol with the server on and [1] for each i where , and gets . Note that one of the encryptions among all is and the remaining encryptions are where i ∈ [n] and u = 1,2. Furthermore, if , then is the closest record to Q from both databases.
securely runs the SM protocol with on the inputs and to compute , for 1 ≤ i ≤ n and 1 ≤ j ≤ m. Then, each can now calculate the encryption of its candidate for the first closest record as where . As we stated before, since only one of the encryptions among all is and the remaining are , one of the encryptions will be the encryption of zero and the other one will be the encryption of nonzero number that will be the first closest record.
with the input , with the secret key sk2, and securely runs the ST protocol to compute the encryption of under the public key pk1. Note that is only known to .
now can calculate the encryption of the first closest record as . From the homomorphic property of the underlying encryption scheme, , and since one of them is zero, will be the encryption of the first closest record from both databases.
As the final step of the first iteration, the first closest records dmin1 should be excluded from the further iterations. To this aim, each securely executes the SBOR protocol with on the inputs and where 1 ≤ i ≤ n and . As the output of the protocol, gets the encryptions of renewed distances as . Observe that if for a particular j, the corresponding distance will take the maximum value, i.e. . On the other hand, if , the SBOR protocol will have no effect on .
Because our protocol outputs the interpolation of the k-nearest neighbors of the query point Q, the server does not need to keep all the nearest records separately. Instead, it gradually builds the interpolation, i.e. after each iteration, adds the current closest record to the previous sum as , and gets the current sum .
After k iterations, will have the sum as the encryption of the sum of the k-nearest neighbors of the query point Q. then computes the randomization of the encryptions as where rj are random numbers in ZN and 1 ≤ j ≤ m. then sends γj to and rj to the query owner. Upon receiving γj, decrypts them as and sends the decryptions to the query owner. The query owner QO then computes the sum of k-nearest record as where 1 ≤ j ≤ m. As the final step, QO computes the interpolation of k-nearest neighbors of Q as .
Security analysis
In this section, we will give the security analysis of the protocol shown in Algorithm 3. As we emphasized above, the data owners encrypt their data before outsourcing them to the cloud. Since they use the Paillier encryption scheme which is semantically secure, the data is not leaked to any cloud service provider. On the other hand, at the first step of Algorithm 3, the query point Q is encrypted before given to the corresponding cloud service providers. Similarly, since the underlying encryption scheme (the Paillier cryptosystem) is semantically secure, the query point Q is not revealed to any data owner or any cloud service provider.
| Input: from ; sku from ; Q from QO |
| Output:T, the interpolation of k-nearest neighbors of Q |
| 1. QO; |
| a) compute |
| b) send each to the corresponding server ; |
| 2. and ; |
| fori = 1 to ndo |
| ; |
| 3. forp = 1 to kdo |
| a) and ; |
| – ; |
| – computes ; |
| b) , , , and ; |
| – , , and execute ; |
| – and compute ; |
| – and compute ; |
| – computes ; |
| – , , and execute ; |
| c) and ; |
| fori = 1 to ndo |
| ; |
| , where ; |
| ; |
| ; |
| d) and ; |
| fori = 1 to n and j = 1 to mdo |
| ; |
| e) , , and ; |
| – ; |
| f) ; |
| – ; |
| – ; |
| g) and ; |
| fori = 1 to n and h = 1 to do |
| 4. ; |
| forj = 1 to mdo |
| – , where rj ∈RZN; |
| – sends γj to CSP and rj to QO |
| 5. ; |
| forj = 1 to mdo |
| – ; |
| – sends to QO |
| 6. QO; |
| a) forj = 1 to mdo |
| b) computes the interpolation as ; |
At the second step of Algorithm 3, the servers and execute the protocols SSED and SBD. As stated in Elmehdwi, Samanthula & Jiang (2014), the outputs of the protocols will be in the encrypted format, and will only be revealed to the servers . Besides, no information about the plaintexts is revealed to any party during these protocols. At the step 3(a) of each iteration in Algorithm 3, the output of the protocol SMINn is only revealed to the servers . Besides, the SMINn protocol guarantees that the servers involved in the protocol do not know which records from both databases correspond to the current minimum distances. Similarly, the output of the SMIN protocol executed at the step 3(b) of Algorithm 3 is only revealed to the server . Also, the protocol does not reveal which record corresponds to the current global minimum.
The servers also run the ST protocol at the steps 3(b) and 3(e) of Algorithm 3 to transform the encryption of the current minimum distance under the public key to the encryption under the public key . As we explained at the beginning of this section, the ST protocol protects the content of the encryption from all parties involved in the protocol. Furthermore, at the step 3(c), each server runs the SBAOR protocol with that outputs either the encryption of 1 just for the index corresponding to the current global minimum or the encryption of 0 for all the other indexes. Note that the SBAOR protocol uses the protocols SM and SBD as sub procedures, and it does not leak the index that corresponds to the current global minimum. Thus, data access patterns are protected from all the involved servers through the protocol, i.e. the servers do not know which data records used in producing the interpolation of k-nearest neighbors.
In conclusion, the STPkNN protocol preserves the confidentiality of the data, secures the privacy of user’s query point, and hides data access patterns.
Complexity analysis
In this section, we will discuss the computation complexity of our protocol. The servers perform n instantiations of SSED and SBD protocols at the second step of the protocol. Since the computation complexity of the SSED protocol proposed in Elmehdwi, Samanthula & Jiang (2014) is bounded by O(m) multiplications and O(m) exponentiations, and the computation complexity of the SBD protocol proposed in Samanthula, Hu & Jiang (2013) is bounded by multiplications and exponentiations, the computation complexity of this step is bounded by multiplications and exponentiations.
On the other hand, at the third step of our protocol, the servers perform the following operations O(k) times: a single instantiation of SMINn protocol, a single instantiation of SMIN, 2 instantiations of ST protocol, n instantiations of SBD and SBAOR protocols, n · m instantiations of SM protocol, and instantiations of SBOR protocol. The computation complexity of the SMINn protocol presented in this paper is bounded by multiplications and exponentiations and the computation complexity of the SMIN protocol presented in Elmehdwi, Samanthula & Jiang (2014) is bounded by multiplications and exponentiations. Besides, the ST protocol proposed in this paper, the SM protocol presented in Elmehdwi, Samanthula & Jiang (2014), and the SBOR protocol presented in Elmehdwi, Samanthula & Jiang (2014) only contain a constant number of multiplications and a constant number of exponentiations. Also, as we emphasized above, the computation complexity of the SBD protocol is bounded by multiplications and exponentiations (Samanthula, Hu & Jiang, 2013). Moreover, since the SBAOR protocol proposed in this paper deploys instantiations of SM protocol and instantiations of SBOR protocols as sub procedures, the computation complexity of the SBAOR protocol bounded by by multiplications and exponentiations. Thus, the computation complexity of the third step is bounded by multiplications and exponentiations at total.
In addition, the servers perform only O(m) operations at the remaining steps of the protocol. Thus, the total computation complexity of our protocol is bounded by multiplications and exponentiations.
Performance evaluation
In this section, we evaluated the performance of the proposed protocol STPkNN by carrying out a number of experiments under different parameter settings. We deployed Paillier cryptosystem (Paillier, 1999) for the encryption, and implemented the proposed protocols in Java. All the experiments were performed on a virtual Linux machine with an IntelR XeonR Two-CoreTM CPU 2.20 GHz processor and 4 GB RAM running Ubuntu 16.04 LTS. For the experiments, we utilized two real data sets from UCI machine learning repository (Dua & Graff, 2017); Heart Disease that consists of 600 data records such that each one contains 14 attributes concerning heart disease diagnosis, and Bank Marketing that contains 800 data records such that each one includes 15 attributes that helps to predict whether a new client will pay a term deposit. We first processed these data sets so that they contain only non-negative integer values. We then split each data set into two equal parts so that each one will be operated by a single cloud pair. Note that, for all the measurements, the experiment was repeated for multiple query points and the average time taken to execute a query was reflected to the table.
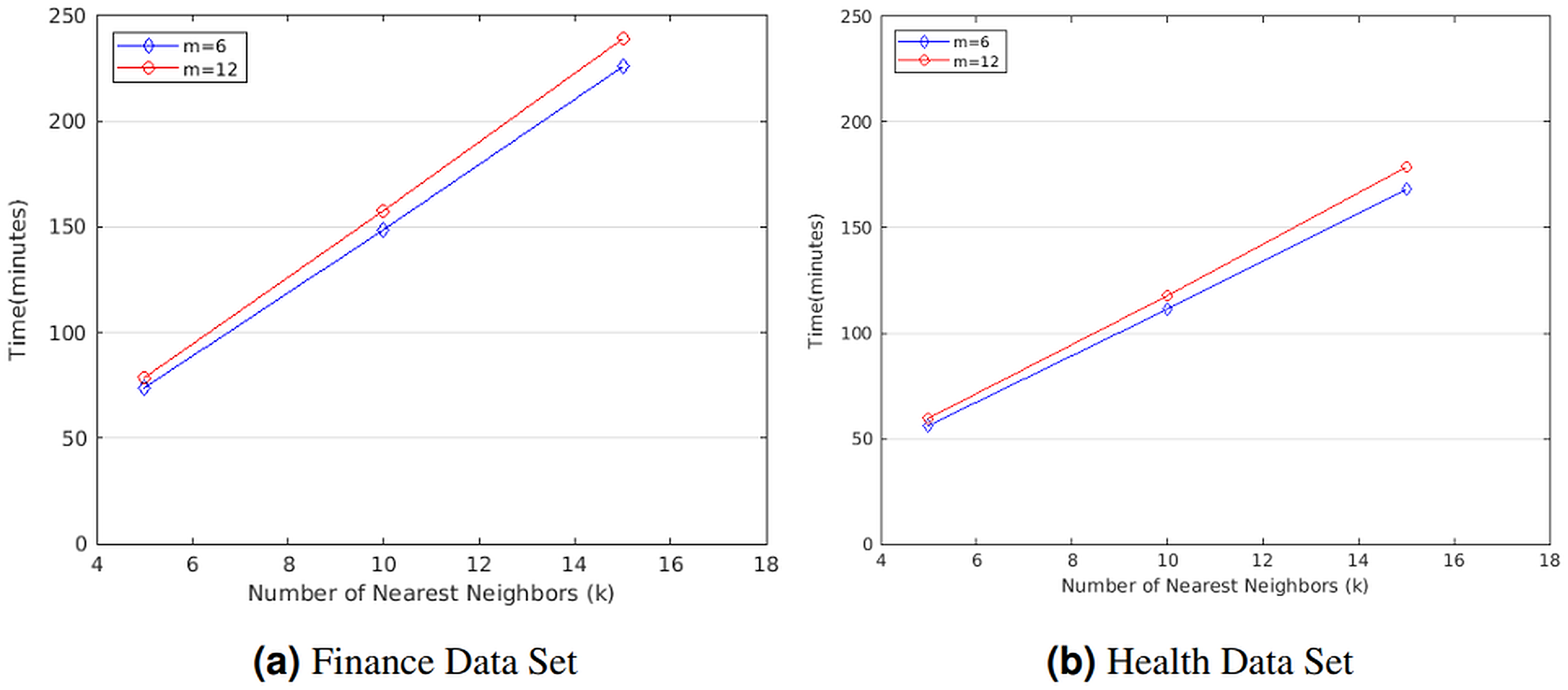
We first evaluated the computation cost of STPkNN on finance data set in minutes for varying the number of nearest neighbors (k) and the number of attributes (m). As shown in Fig. 3A, if we fix the number of attributes as m = 6, the running time of our protocol varies from 74.08 to 226.16 min for finance data set when k is changed from 5 to 15. Besides, for m = 12, the running time of our protocol varies from 78.85 to 239.21 min when k is changed from 5 to 15. So the running time of our protocol grows linear with k. Also, we observe that the computation cost of our protocol increases by nearly a factor of 1.06 when m is doubled.
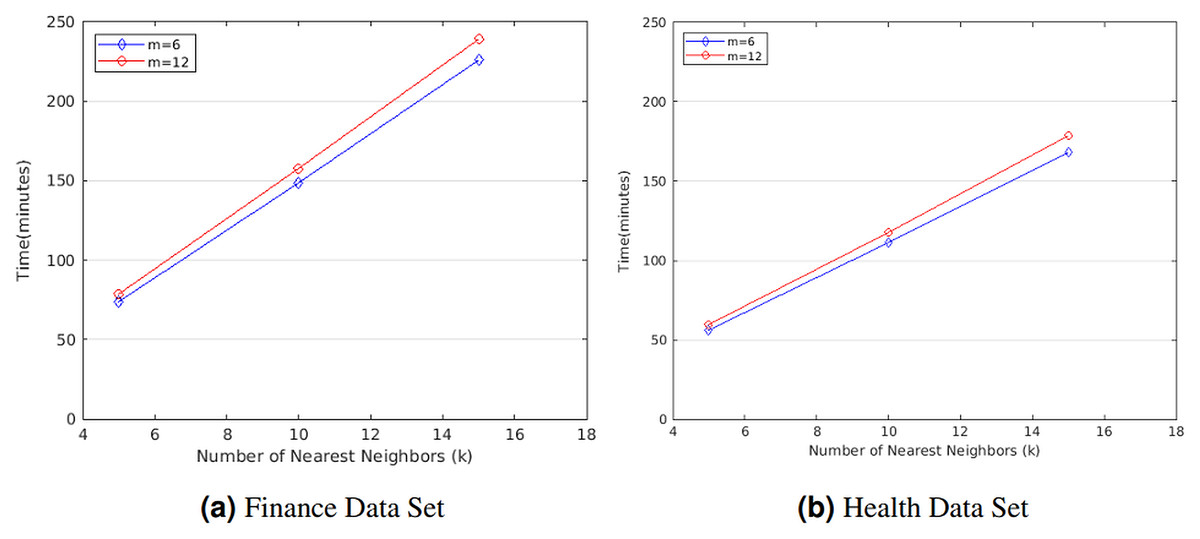
Figure 3: Running time of STPkNN for varying k values on the (A) finance and the (B) health data set.
{kind=link}
Similarly, we also evaluated the computation cost of STPkNN on heart disease data set in minutes for varying the number of nearest neighbors (k) and the number of attributes (m). As shown in Fig. 3B, if we set the number of attributes as m = 6, the running time of our protocol varies from 55.89 to 168.26 min when k is changed from 5 to 15. Besides, for m = 12, the running time of our protocol varies from 59.56 to 178.63 min when k is changed from 5 to 15. Thus, it is easy to observe that our protocol scales linearly with k. On the other hand, the running time of our protocol increases by almost a factor of 1.34 when the number of data records (n) is changed from 300 to 400. Thus, the running time of our protocol grows linear with n.
Conclusions
In this study, we proposed a secure k-NN method that produces an interpolation of k-nearest neighbors to a query point over encrypted databases. We here claimed that instead of using one, employing two different databases in the protocol will yield more accurate and reliable interpolation value. We validated this claim by conducting experiments on publicly available real data sets. We also showed that our protocol preserves the confidentiality of data, assures the privacy of user’s query point, and hides data access patterns. We finally analyzed the performance of the proposed protocol through a number of experiments under different parameter settings. As a future study, we will examine and expand our work to apply other interpolation methods on encrypted data in distributed architecture. We will extend our protocol, that considers two encrypted databases stored in two different clouds, to multi-cloud settings.