
Towards efficient verifiable multi-keyword search over encrypted data based on blockchain
- Published
- Accepted
- Received
- Academic Editor
- Huiyu Zhou
- Subject Areas
- Distributed and Parallel Computing, Security and Privacy
- Keywords
- Symmetric searchable encryption, Multi-keyword search, Result verification, Blockchain
- Copyright
- © 2022 Xu et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2022. Towards efficient verifiable multi-keyword search over encrypted data based on blockchain. PeerJ Computer Science 8:e930 https://doi.org/10.7717/peerj-cs.930
Abstract
Searchable symmetric encryption (SSE) provides an effective way to search encrypted data stored on untrusted servers. When the server is not trusted, it is indispensable to verify the results returned by it. However, the existing SSE schemes either lack fairness in the verification of search results, or do not support the verification of multiple keywords. To address this, we designed a multi-keyword verifiable searchable symmetric encryption scheme based on blockchain, which provides an efficient multi-keyword search and fair verification of search results. We utilized bitmap to build a search index in order to improve search efficiency, and used blockchain to ensure fair verification of search results. The bitmap and hash function are combined to realize lightweight multi-keyword search result verification, compared with the existing verification schemes using public key cryptography primitives, our scheme reduces the verification time and improves the verification efficiency. In addition, our scheme supports the dynamic update of files and realizes the forward security in update. Finally, formal security analysis proves that our scheme is secure against Chosen-Keyword Attacks (CKA), experimental analysis demonstrations that our scheme is efficient and viable in practice.
Introduction
With the development of artificial intelligence, the Internet of Things, the Internet of Vehicles and other emerging technologies, more and more enterprises and individuals outsource local data to the cloud, thereby reducing storage and management overhead. However, security and privacy concerns still hinder the deployment of the cloud storage system. Although data encryption can eradicate such concerns to some extent, it becomes difficult for users to search over the data.
Searchable symmetric encryption (SSE) provides an efficient mechanism to solve this, which enables users to search encrypted data efficiently without decryption. Since SSE was first proposed by Song, Wagner & Perrig (2000), how to perform efficient and versatile search on encrypted data has always been an important research direction. The existing SSE schemes mainly use linked lists and vectors to build indexes, the cloud server needs to traverse the whole list or vector to search for matching results during a query, which incurs high search overhead. In addition to efficient searching, dynamic updates are also very important in SSE. Zhang, Katz & Papamanthou (2016) has shown that adversaries can infer the critical information through the file injection attacks during the dynamic update of the SSE, while the forward-secure SSE can avoid this. Therefore, the forward security of the scheme must be fully considered when designing the SSE scheme.
Verifiability of the search results is another important research issue for SSE. Since the cloud server is untrusted, which may returns incorrect or incomplete results due to system failures or cost savings, so, it is necessary to verify the search results. In 2012, Chai & Gong (2012) proposed the concept of verifiable SSE (VSSE) and constructed a verifiable SSE scheme based on word tree. Following this work, a great many VSSE schemes are proposed Kurosawa & Ohtaki (2012), Sun et al. (2015), Zhu, Liu & Wang (2016), Liu et al. (2017), Zhang et al. (2019) and Chen et al., 2021). In these schemes, the verification is mainly performed by users, but the user may forge verification results to save costs, so the reliability of the verification cannot be guaranteed. To address this, some researchers (Cai et al., 2018; Hu et al., 2018; Li et al., 2019; Guo, Zhang & Jia, 2020) introduce blockchain into SSE to verify search results, which guarantees the fairness and reliability of the verification. Although blockchain achieves fair verification of search results, but the existing schemes are only for a single keyword, and there is little research on fair verification for multi-keywords.
In this paper, we introduce a verifiable multi-keyword SSE scheme based on blockchain, which can perform efficient multi-keyword search, ensures the fairness of verification, and supports the dynamic update of files. To our knowledge, this is the first scheme to verify the search results of multi-keywords fairly. In general, the contributions of this paper are summarized as follows:
-
Our scheme realizes efficient multi-keyword search and verification of search results, at the same time, our scheme supports dynamic update of files and achieves forward security.
-
Our scheme utilizes blockchain to verify the search results, ensuring the reliability and fairness of the verification results. Combining bitmap index and hash function, we realize lightweight multi-keyword verification to improve verification efficiency.
-
We formally prove that our scheme is adaptively secure against CKA, and we conduct a series of experiments to evaluate the performance of our scheme
Related Works
Searchable symmetric encryption
Since SSE was proposed, a number of works have been done to improve search efficiency, rich expression and advanced security. The first SSE scheme (Song, Wagner & Perrig, 2000) enables users to search keywords through full-text scanning, search time increases linearly with the size of files, which is impractical and inefficient. To improve efficient, Curtmola et al. (2006) proposed an inverted index SSE, which achieves sub-linear search time, and gives a definition of SSE security, but this scheme does not support dynamic operations. Wang et al. (2010) expanded the scheme of Curtmola et al. (2006) to support dynamic operations, and proved that the scheme was adaptively secure against chosen-keyword attacks (CKA2-secure). For the schemes that support dynamic operation, forward security is critically crucial. The research of Cash et al. (2013), Cash et al. (2015) and Zhang, Katz & Papamanthou (2016) indicated that in the SSE scheme without forward security, the adversary can recover most of the sensitive information in ciphertext at a small cost, their research shows the importance of forward security.
Multi-keyword search is a crucial means to improve search efficiency. In single-keyword search scheme (Song, Wagner & Perrig, 2000; Curtmola et al., 2006; Wang et al., 2010; Kamara, Papamanthou & Roeder, 2012), the server returns some irrelevant results, while the multi-keyword search (Cash et al., 2013; Lai et al., 2018; Xu et al., 2018; Wang et al., 2018; Liang et al., 2020; Hozhabr, Asghari & Javadi, 2021; Liang et al., 2021) gains higher search accuracy and more accurate results. To further improve search efficiency, Abdelraheem et al. (2016) proposed an SSE scheme on encrypted bitmap indexes to support multi-keyword search, but requires two rounds of interactions with the cloud server. Zuo et al. (2019) proposed a secure SSE scheme based on bitmap index which supports dynamic operations with forward and backward security, but this scheme lacks the verification of the results.
Verifiable searchable symmetric encryption
In SSE, it is necessary to verify the results since the server is untrusted. Chai & Gong (2012) proposed the concept of verifiable searchable symmetric encryption (VSSE) and constructed a VSSE scheme based on word tree. Along this direction, some other VSSE schemes (Kurosawa & Ohtaki, 2012; Zhu, Liu & Wang, 2016; Liu et al., 2017; Miao et al., 2019; Ge et al., 2019) are proposed. These schemes are the verification of single keyword search results, Azraoui et al. (2015) combined polynomial-based accumulators and Merkle trees to achieve conjunctive keyword verification. Wan & Deng (2016) used homomorphic MAC to verify the results of multi-keyword search. Li et al. (2021) utilized bitmap index to gain high efficiency of multi-keyword search, and verified the results by RSA accumulator. Ge et al. (2021) and Liu et al. (2021) proposed their verifiable schemes in the Internet of things. These schemes verify the results of multi-keyword search by public key cryptography primitives, which is computationally expensive and inefficient. What is more, these multi-keyword search verifiable schemes mainly focus on verifying the returned files are valid and whether the files really contains the query keywords, but they didn’t ensure all files containing the query keywords are returned.
Verifiable searchable symmetric encryption based on blockchain
In the existing SSE schemes, the verification of search results is performed by users. However, users may forge verification results for economic benefits, which damages the fairness of verification. To solve this, a flexible and feasible method is to adopt blockchain to verify search results, which uses the non-repudiable property of the blockchain to ensure the reliability and fairness of verification. Hu et al. (2018) built a distributed, verifiable and fair ciphertext retrieval scheme based on blockchain. Li et al. (2019) proposed a verifiable scheme combined blockchain and SSE, which can verify the results automatically and reduce the calculation of users. Guo, Zhang & Jia (2020) used the blockchain to realize the public authentication of search results, and ensures forward security of dynamic update. Although these schemes realize the fair verification of search results, but they are mainly for single keyword search, whereas there is little research on the fair verification of multi-keyword. Comparison results with existing schemes are shown in Table 1.
| Schemes | Single-keyword | Multi-keyword | Verification | Blockchain-based | Forward security |
|---|---|---|---|---|---|
| Kamara, Papamanthou & Roeder, 2012 | ✓ | × | × | × | × |
| Chai & Gong (2012) | ✓ | × | ✓ | × | × |
| Wang et al. (2018) | ✓ | ✓ | ✓ | × | × |
| Li et al. (2021) | ✓ | ✓ | ✓ | × | × |
| Hu et al., 2018 | ✓ | × | ✓ | ✓ | × |
| Guo, Zhang & Jia, 2020 | ✓ | × | ✓ | ✓ | ✓ |
| Our scheme | ✓ | ✓ | ✓ | ✓ | ✓ |
Preliminaries
Bitmap
To improve search efficiency, we use the bitmap (Spiegler & Maayan, 1985) to build inverted index. Bitmap uses a binary string to store a set of information, which can effectively save storage space, and it has been widely used in the field of ciphertext retrieval. In our scheme, each keyword wi corresponds to a bitmap, which contains ℓ bits, ℓ is the number of files in the system, if the i −th document contains wi the value of ℓ in position i is 1, otherwise 0. For example, there are four files (f1, f2, f3, f4) and two keywords (w1, w2), in Fig. 1, w1 is contained in f1 and f3, w2 is contained in f2 and f3, the bitmap of w1 and w2 are 1010 and 0110. If we want to search files that contains both (w1 and w2, we need to do AND operation on the two bitmaps, i.e., 1010∧0110 = 0010, that indicates that f3 contains both w1 and w2.
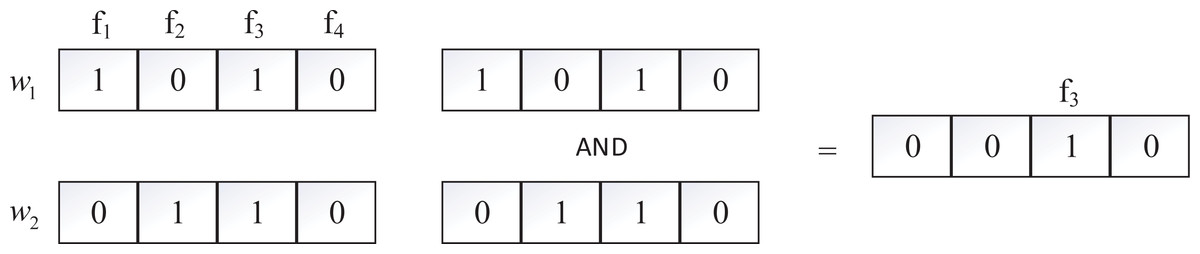
Figure 1: The example of bitmap.
{kind=link}
Blockchain
Blockchain is a distributed database, which is widely used in emerging cryptocurrencies to store transaction information such as bitcoin. The blockchain has the features of decentralization, transparency and unforgeability. There is no central server in the blockchain, all nodes participate in the operation and generate the calculation results, the information stored on the blockchain can be seen by all nodes in the network. All nodes of the blockchain share the same data record, under the action of the consensus mechanism, a single node cannot modify the data stored on the chain. The above characteristics of blockchain make it suitable to be a trusted third party for fair verification.
Method
System model
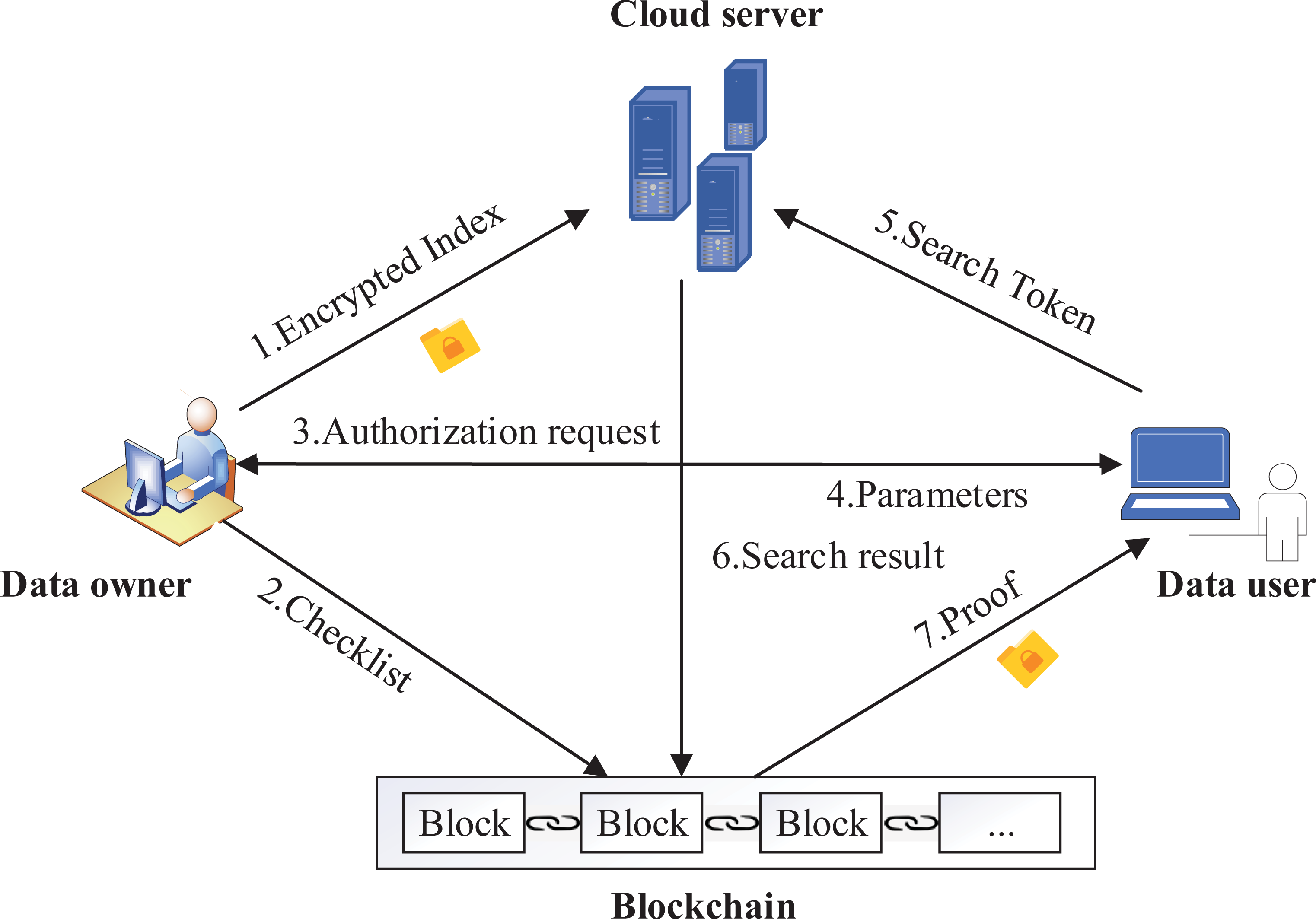
The system model of our scheme is shown in Fig. 2, there are four entities in the system: data owner, cloud server, data user, blockchain. For the files F in the system, data owner extracts all keywords and generates a keyword set W. Data owner encrypts files to a database T, builds an encrypted index and a checklist B, and T are sent to cloud server, and B are sent to blockchain. When a data user joins the system, it sends an authentication request to the data owner, obtains keys and system parameters. During a query, the data user generates search token TKi,Q according to the keywords to be queried with the help of keys and system parameters, and then sends it to cloud server and blockchain, respectively. Cloud server provides storage services for index and T. In addition, the cloud server performs ciphertext retrieval according to the search token TKi,Q, and sends the matched results to blockchain for verification.
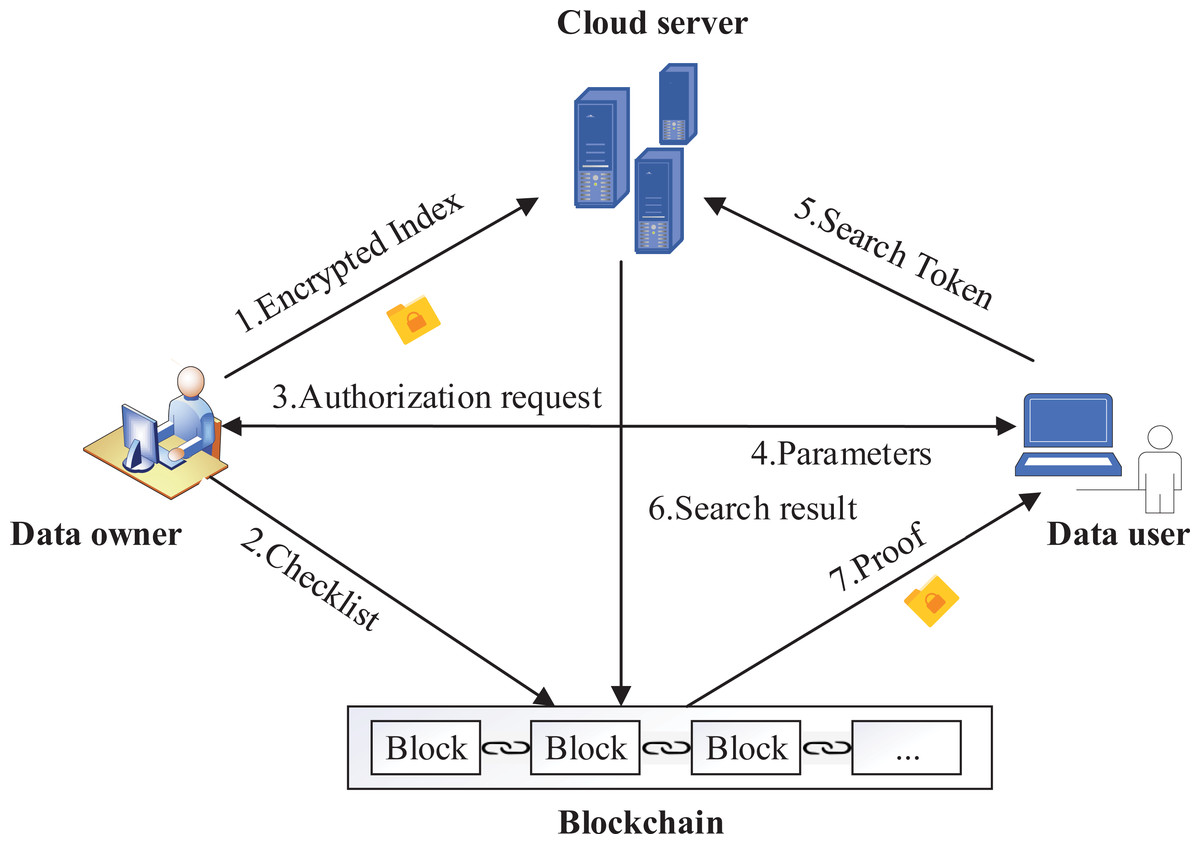
Figure 2: System model.
{kind=link}
To verify the search results of multiple keywords, the blockchain performs two steps: (1) benchmark. On receiving TKi,Q, the blockchain performs multi-keyword search on the index to get the identifiers ID of files that meets the query, then gets the corresponding hash values ℍ of files from the checklist B according ID, and computes the benchmark Acc using ℍ; (2) verification. After receiving the results returned by cloud server, the blockchain computes the hash values ℍ′ of results and computes the verification value Acc′, then the blockchain compares Acc and Acc′ to generate the proof. The proof and search results are sent to data user, the verification is completed.
Threat model
Like other verifiable SSE schemes (Soleimanian & Khazaei, 2019), we assume that the cloud server is malicious, which may return an incorrect or incomplete search result for selfish reasons, such as saving bandwidth or storage space. In addition, we assume that the data user is also untrusted, since it may forge the verification results for economic benefits. The data owner and blockchain are trusted, they execute the protocols in the system honestly.
Algorithm definitions
Our scheme includes eight polynomial time algorithms, ∏ = {KeyGen, Setup, ClientAuth, TokenGen, Search, Verify, UpdateToken, Update}, and the details are as follows:
-
K←KeyGen(1λ), takes system parameter λ as input, and outputs system keys K.
-
, takes system keys K, the keyword set W and the set of files F as input, outputs a database of encrypted files T, an encrypted index and a checklist B.
-
(K1, ∑)←ClientAuth(𝔸i), takes the attribute 𝔸i of user as input, outputs secret key K1 and the keyword status ∑ .
-
, takes secret key K1, a set of keywords to query , outputs the search token TKi,Q.
-
, takes search token TKi,Q, the encrypted database T, encrypted index and the checklist B as input, and outputs the search results R and the benchmark Acc.
-
(R, proof)←V erify(R, Acc), takes the search results R, and the benchmark Acc as input, outputs the verification proof proof and results R.
-
, takes the set of files to update , the set of keywords W′ and system keys K = {K1, K2, K3} as input, and outputs the update token (τs, τb).
-
, takes encrypted database T, encrypted index and the update token (τs, τb) as input, outputs the updated database T′, updated index and the updated checklist B′.
Security definitions
We prove the security of our scheme with the random oracle model, which can be executed by two probabilistic games and , and we have the following definitions:
Definition 1: CKA2-security, for the verifiable multi-keyword search scheme ∏ = {KeyGen, Setup, ClientAuth, TokenGen, Search, Verify, UpdateToken, Update}, let be the leakage function, is the adversary and is the simulator, there are two probabilistic experiments:
: The challenger runs KeyGen(1λ) to generate secret key K = {K1, K2, K3}, the adversary outputs F and W. The challenger triggers this experiment to run Setup(K, W, F), outputs the index , T and B, which are sent to generates a series of adaptive queries Q = {q1, q2, …, qt}, for each qi ∈ Q, the challenger generates search or update tokens, receives those tokens and generates a bit b as the output of this experiment.
: The adversary outputs F and W, the simulator generates the index , T and B through , receives them. generates a series of adaptive queries Q = {q1, q2, …, qt} , for each qi ∈ Q, the simulator generates search or update tokens with and , receives those tokens and generates a bit b as the output of this experiment. If for any probabilistic polynomial time (PPT) adversary , there exist an efficient simulator , which satisfies that:
we say ∏ is secure against CKA2, where negl is an negligible function and λ is the security parameter.
Construction
In this section, we present the construction of our scheme in detail. We take bitmap as index structure to achieve efficient search over encrypted data, and use blockchain to verify the search results. The bitmap is utilized to build the inverted index to achieve the optimal search time , where q is the keywords in search and |q| is the number of q.
In our scheme, the blockchain is used to fairly verify the search results. In Setup, the data owner calculates the hash value of files, generates a checklist B and saves it on the blockchain. During the verification, the blockchain smart contract computes the hash values of search results returned by the server and compares them with the existing results to obtain the verification results.
Specifically, in the single keyword setting, the blockchain stores the corresponding benchmark directly since the results corresponding to the keywords are determined. However, it’s impossible in multi-keyword search because the search results are variable, which can only store the verification value of each file. To ensure the credibility of the search results, the blockchain also needs to perform multi-keyword search to obtain the search results. Therefore, we save the index on the blockchain. During a query, the blockchain executes multi-keyword search to get the search results, and read the verification value hashi of each file in search results to generate the benchmark Acc, then the blockchain compares Acc with search results returned by cloud server to complete the verification.
Proposed construction
Our scheme contains eight algorithms ∏ = {KeyGen, Setup, ClientAuth, TokenGen, Search, Verify, UpdateToken, Update}, let F:{0, 1}∗ → {0, 1}m, H:{0, 1}∗ → {0, 1}n, be two Pseudo-Random Functions (PRFs), the constructions of our scheme are as follows.
K←KeyGen(1λ): This algorithm is executed by the data owner, given a security parameter λ ∈ ℕ, this algorithm generates the secret key K = {K1, K2, K3}, where K1, K2, K3←{0, 1}λ , K1, K2 are used to encrypt the bitmap index for each keyword wi ∈ W, K3 is used to encrypt files fi ∈ F and store the hash value of files.
: Given a set of files F, a set of keywords W and the secret keys K, this algorithm builds an encrypted index , a checklist B and a ciphertext database T, as is shown in Algorithm 1. For each file fi ∈ F, idi is the identifier of fi , the data owner encrypts fi by calculating ci←Enc(K3,fi), and computes the hash value using hashi←H(ci). Then data owner stores ci and hashi in T[li] and B[li], respectively.
_______________________
Algorithm 1 Setup_____________________________________________________________________________
Require: K1,K2,K3,W,F
Ensure: TB,B,T
1: Data Owner DO:
2: TB ←{}, T ←{}, B ←{}
3: for fi ∈ F do
4: li ← H(idi||K3); ci ← Enc(K3,fi)
5: hashi ← H(ci); B[li] ← hashi; T[li] ← ci
6: end for
7: for wi ∈ W do
8: Generate a bitmap index Bwj for each wj
9: uwi ← F(K1,H(wi)); sti $
←{0,1}λ; twi ← H(uwi||sti)
10: vB ←Bwi ⊕ H(uwi||sti);TB[twi] ← vB;∑
[wi] = sti
11: end for
12: send (TB,B) to blockchain, send (T,TB) to cloud server_________________________ For each keyword wi ∈ W, data owner generates a bitmap , if idj contains keyword wi, then , where m = H(idj||K3), and the other positions of are all 0′s. The data owner encrypts through , and store in . At the end of the Setup, and are sent and stored on blockchain and cloud server, respectively.
(K1, ∑)←ClientAuth(𝔸i): It needs to register to the data owner when a new data user who wants to query files on the cloud server joins the system. The data user submits attribute 𝔸i to the data owner through this algorithm to obtain the keyword status ∑ and the key K1.
: It takes the key K1 and the set of keywords to query as input, output a search token TKi,Q, as is shown in Algorithm2. For each keyword , the data user computes the position lwi of wi in index as lwi←H(uwi||sti), where uwi←F(K1, H1(wi)), sti←∑[wi]. Data user sends TKi,Q to cloud server and blockchain, respectively.
: This algorithm takes search token TKi,Q, index and ciphertext database T as input, and outputs search results R. On receiving the search token, the cloud server and blockchain perform the same operations for multi-keyword search. They all parse out the position lwi of the keyword in the token TKi,Q, and get the bitmap through , . To achieve multi-keyword search, they compute , the cloud server gets files in T according to with regard to , and sends them to the blockchain to verify. Similarly, the blockchain gets hash values {hash1, hash2, …, hashs} of files in B according to , computes Acc = hash1⊕hash2⊕⋯⊕hashs as the benchmark for verification, and the details are shown in Algorithm 2.
_______________________________________________________________________________________________________
Algorithm 2 Search____________________________________________________________________________
Require: K1, ___W = {w1,w2,...,wt}, T, TB, B
Ensure: TKi,Q, R, Acc
1: Data user:
2: for wi ∈_W do
3: sti ←∑
[wi]; uwi ← F(K1,H(wi)); lwi ← H(uwi||sti)
4: end for
5: return TKi,Q ← (lw1,lw2,...,lwt)
6: Send TKi,Q to cloud server and blockchain
7: Server, Blockchain:
8: for lwi ∈ TKi,Q do
9: vB ← TB[lwi]; Bwi ← vB⊕ H(lwi)
10: end for
11: B = B1 ∧B2 ∧ ... ∧Bt
12: Server:
13: gets ciphertext R = {c1,c2,...,cs} form T
14: Blockchain:
15: gets checklist L = {hash1,hash2,...,hashs} from B with B
16: Acc = hash1 ⊕ hash2 ⊕⋅⋅⋅⊕ hashs_____________________________________________________ (R, proof)←V erify(R, Acc): This algorithm takes search results R and benchmark Acc as input, outputs search results R and proof, and the verify process is shown in Algorithm 3. To verify the integrity of files, the data owner calculates the hash value of each file through hashi←H(ci) in the Setup, and adds hashi to the checklist B, then B is sent to the blockchain. Through algorithm Search, the blockchain gets the search result of multiple keywords, obtains the hash value of each file in the result from B, and computes the benchmark Acc. To verify the search results, the blockchain calculates of R and compares it with Acc.
__________________________________________________________________________________________________________
Algorithm 3 Verify____________________________________________________________________________
Require: R,Acc
Ensure: proof, Result
1: Blockchain:
2: H__W ← ϕ
3: for ci ∈ R do
4: H__W ← H__W ⊕ H(ci)
5: end for
6: if H__W = Acc then
7: proof = true, Result ← R
8: else
9: proof = false, Result ← ϕ
10: end if
11: sends (proof, Result) to data user______________________________________________________ In Algorithm 3, for all ciphertexts ci ∈ R, blockchain computes , where H(ci) denotes the hash value of ci. Blockchain compares and Acc, if they are equal, the proof is true, otherwise false. At last, the search results R and proof are sent to data user. During the verification, Acc is calculated through the hash value stored on the blockchain, due to the unforgeability of blockchain, thus Acc is unforgeable. In addition, the verification is completed by the blockchain, so the proof is also unforgeable, which ensures the fairness of verification.
(τs, τb)←UpdateToken(F, W′, K): The data owner generates an update token through this algorithm, which takes files , a keyword set W′ and secret key K as input, and outputs update token(τs, τb). For files , the data owner encrypts and calculates the hash value of fk by ck←Enc(K3,fk) and hashk←H(ck), respectively. For keywords W′ = {w1,w2,…,ws} that contained in fk, the data owner generates a bitmap for each wj ∈ W′, and encrypts with , where lwj←H(uwj||st), uwj←F(K1, H(wj)), st←F(K2, st0).
: This algorithm takes encrypted database T, index , checklist B, update token (τs, τb) as input, and outputs updated database T′, updated index and updated checklist B′. The details are shown in Algorithm 4.
_______________________________________________________________________________________________________
Algorithm 4 Update__________________________________________________________________________
Require: __F, K = {K1,K2,K3}, W′, T,TB,B
Ensure: τs,τb,T′,TB′,B′
1: Data owner:
2: for fk ∈_F do
3: lk ← H(idk||K3), ck ← Enc(K3,fk), hashk ← H(ck)
4: fk, W′ = {w1,w2,...,ws}
5: for wj ∈ W′ do
6: generates a bitmap index Bwj for wj
7: if ∑
[wj] = ϕ then, then st0 $
←{0,1}λ
8: else
9: st0 ←∑
[wj], st ← F(K2,st0)
10: uwj ← F(K1,H(wj)), lwj ← H(uwj||st)
11: vBj ←Bwj ⊕ H(uwj||st), ∑
[wj] = st
12: end if
13: end for
14: return τs = {(lk,ck),(lwj,vBj)}, τb = {(lk,hashk),(lwj,vBj)}
15: end for
16: Server: T[lk] ← ck, TB[lwj] ← vBj, T′ ← T, TB′ ← T
B
17: Blockchain: B[lk] ← hashk, TB[lwj] ← vBj, B′ ← B, TB′ ← T
B________ Forward security
As described above, dynamic update is the foundation function of an SSE scheme, and forward security is an indispensable component of dynamic update. In Algorithm 4, when updating a file fi that contains keyword wj, the data owner retrieves the previous state st0 from the local state store ∑, and generates a new state st through st←F(K2, st0), where F is a pseudo random function and K2 is kept in local. To search a keyword wj, the data user retrieves the current state st0 from ∑, with st0 data user generates a token to be sent to the cloud server and blockchain. Without the key K2, the server cannot compute the current state st from a previous state st0, therefore it cannot get the current token from a previous, considering that the newly added file fi corresponds to the current token, that means the previous tokens cannot match fi, then forward security is achieved.
Security Analysis
In this section, we analysis the security of our scheme. For the scheme ∏ = KeyGen, Setup, ClientAuth, TokenGen, Search, Verify, UpdateToken, Update with the leakage function , we prove that our scheme is secure against CKA2 by proving that and are computationally indistinguishable.
Theorem 1. Our scheme ∏ is secure against CKA2, if the encryption algorithm is secure against chosen-plaintext attacks and the pseudo-random function F and H are secure pseudo-random.
Proof: We use a probabilistic polynomial time simulator to simulate indexes and a series of tokens. For a PPT adversary , we prove Theorem 1 by the computational indistinguishability between and . In , gets indexes ( and B), searches token TKi,Q and updates token (τs, τb) by running Setup, TokenGen and UpdateToken; in , gets indexes (, T′ and B′), searches token and updates token (τs′, τb′) by running , , . We prove that and are computational indistinguishable by proving that (, T, B, TKi,Q, τs, τb) and (, T′, B′, , τs′, τb′) are indistinguishable.
Simulating index. initializes three empty tables: T′, B′, , which are used to store file ciphertexts, verification values and bitmaps, respectively. randomly selects a string fi′ of length |fi|, and encrypts it through ci′←Enc(K3,fi′), where K3 is randomly sampled from maintains three mappings: H, U and L, H stores (idi||K3, ℓi′), U stores (H(wi), uwi′), and the mapping L stores (uwi′||sti,twi′). H, U and L are used and updated by the generation of search and update token. computes the hash value hashi′←H(ci′), ci′ is stored in T′[li′] and hashi′ is stored in selects a string of length , and stores it in .
T′, B′ and are simulated by through the leakage , the difference between (, T′, B′) and (, T, B) is the generation of (fi′, ci′, ). In ideal environment, (fi′, ci′, ) are randomly selected, since our encryption algorithm is secure against CKA2, F and H are secure pseudo-random functions, therefore , the probability that the adversary can distinguish between the real environment and the ideal environment is negligible.
Simulating search token. For the keyword wi to query, gets uwi′ from the mapping U through calculating H(wi), checks whether uwi′ is contained in U, if so returns the corresponding entity, otherwise randomly picks a uwi′ in {0, 1}ℓ and stores (H(wi), uwi′) in U. Similarly, the experiment gets lwi′ from L by L[uwi′||sti], the search token TKi,Q′ = lwi′. Under the assumption that F and H are secure pseudo-random functions, the adversary cannot distinguish TKi,Q and TKi,Q′ .
Simulating update token. For file fk to be added, first randomly selects a bit string ck′ of length |fk|, and encrypts it through computes the hash value hashk′←H(ck′), ck′ is stored in T′[lk′] and hashk′ is stored in B′[lk′], where lk′ is obtained from the mapping maintains a mapping E, which stores (st0, st), if there is no corresponding entity for st, it randomly picks a st in {0, 1}l, otherwise it returns the corresponding entity. gets uwi′ and lwi′ as in search token, selects a string of length , and stores it in . The update token (, ) and (, ) are indistinguishable for the adversary .
In such a way, (, T, B, TKi,Q, τs, τb) and (, T′, B′, TKi,Q′, τs′, τb′) are indistinguishable for , and it means for a PPT adversary , the probability of distinguishing between and is negligible, so we have:
Therefore, our scheme satisfies CKA2-security.
Performance Evaluation
In this section, we evaluate the performance of our scheme by constructing a series of experiments, and compared the experimental results with Li et al. (2021) and Guo, Zhang & Jia (2020). Since Guo, Zhang & Jia (2020) do not support multi-keyword search over encrypted data, we compared our scheme with (Li et al., 2021) which supports multi-keyword search. We also compared our scheme with (Guo, Zhang & Jia, 2020) in terms of dynamic operations.
We deploy our experiments on a local machine with an Intel Core i7-8550U CPU of 1.80 GHz, 8GB RAM. We use HMAC-SHA-256 for the pseudo-random functions, SHA-256 for the hash function. We use AES as the encryption algorithm to encrypt files. We implement the algorithms in data owner, data user and server using Python and construct the smart contract using Solidity, and the smart contract is tested in with the Ethereum blockchain using a local simulated network TestRPC.
For the dataset, we adopt a real-world dataset, Enron email dataset (WC., 2015), which contains more than 517 thousand documents. We utilize the Porter Stemmer to extract more than 1.67 million keywords and filter that meaningless keywords, such as of, the. At last, we build an inverted index with those keywords to improve the search efficiency of the experiment.
Evaluation of setup
In setup phase, data owner encrypts the files, calculates the initial verification values of ciphertexts, generates the bitmap indexes of keywords, stores them in T, B and , respectively.
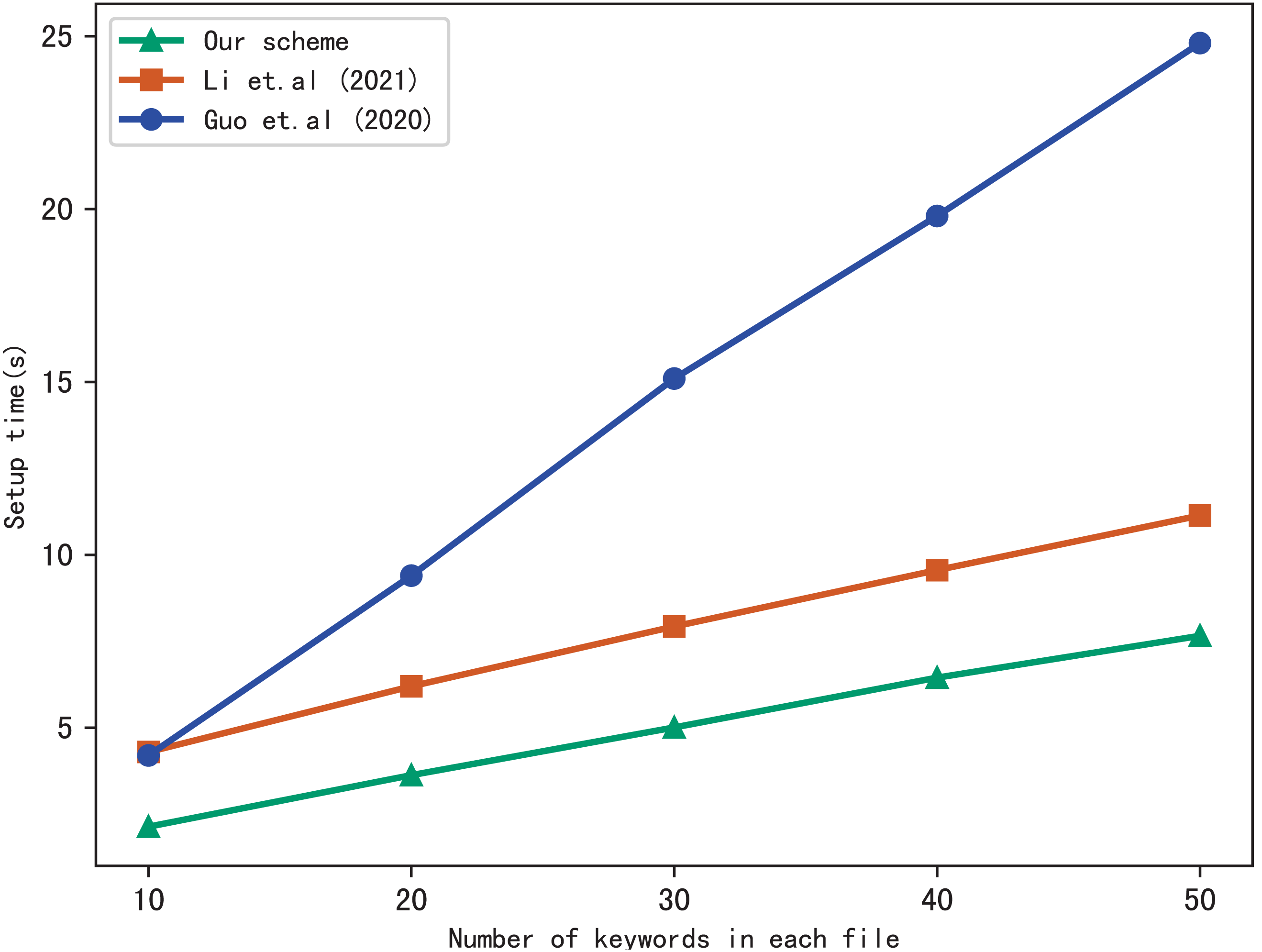
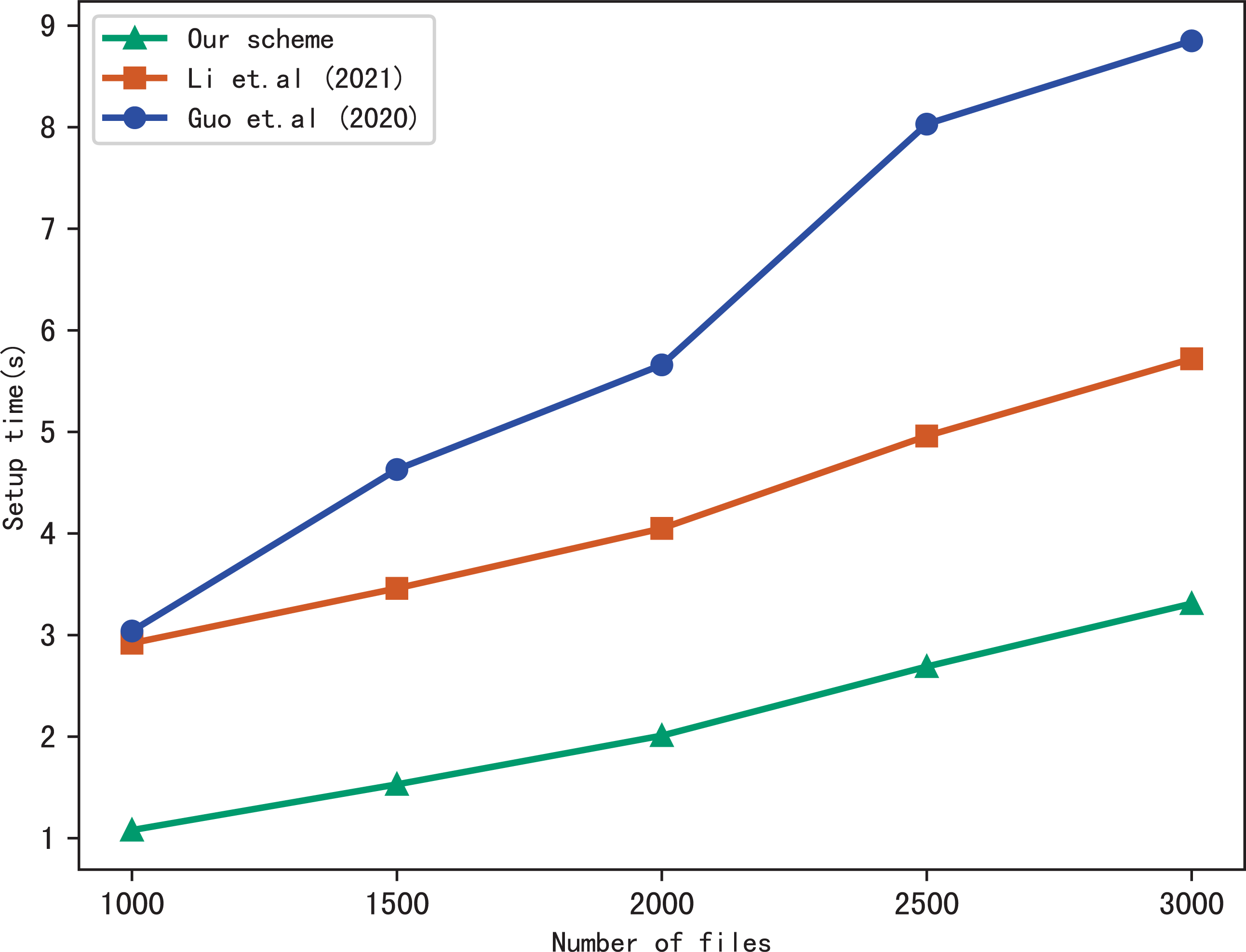
First, we compare the setup time of our scheme with Li et al. (2021) and Guo, Zhang & Jia (2020), the setup time is related to the number of files in the index and the number of keywords included in each file. Figure 3 shows the setup time with different number of keywords in each file while the number of files is fixed at 3137, Fig. 4 shows the setup time with different number of files when the number of keywords in each file is fixed at 20. Both figures show that the setup time is affected by the number of keywords in each file and the number of files, and the setup time increases linearly concerning the number of keywords and files.
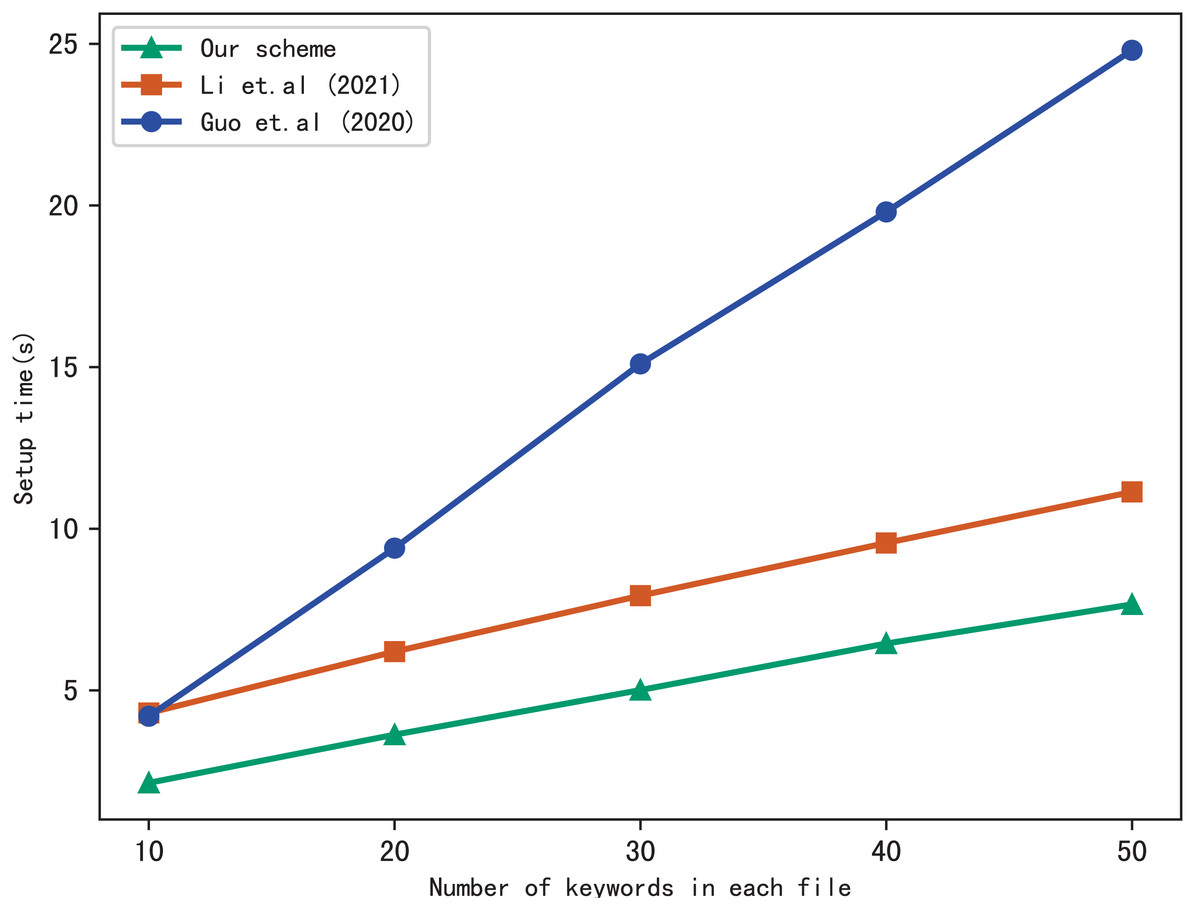
Figure 3: Performance of the setup, files = 3,137.
{kind=link}
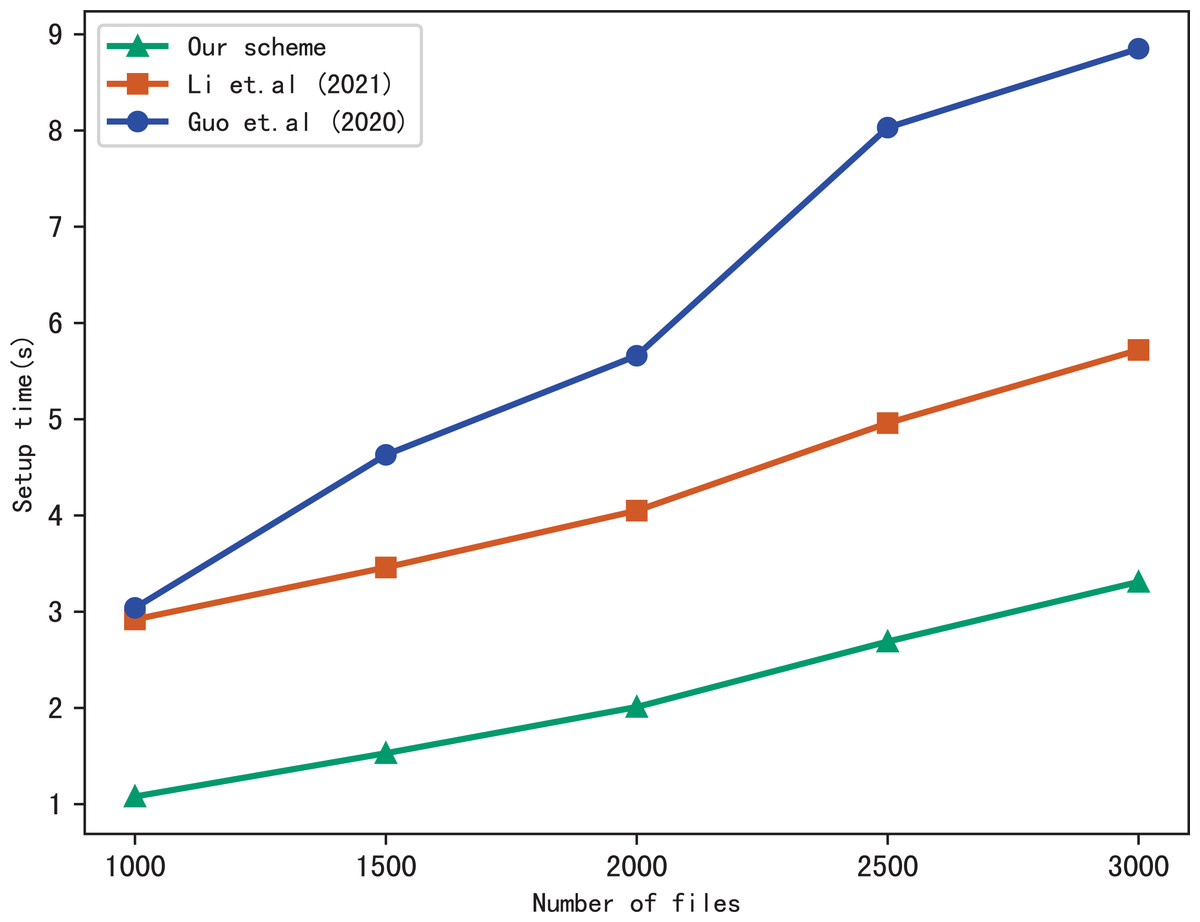
Figure 4: Performance of the setup, keywords = 20.
{kind=link}
Furthermore, Figs. 3 and 4 illustrate that our scheme is more efficient than Li et al. (2021) and Guo, Zhang & Jia (2020) under the same condition in setup time. Since Guo, Zhang & Jia (2020) utilizes the linked list instead of bitmap to build the index, it requires more time than the other schemes. Our scheme takes less time than Li et al. (2021), the reason is that Li et al. (2021) adopts RSA accumulator based on public key encryption to verify multi-keyword search results, in contrast, our scheme utilizes hash functions to verify search results, which reduces the computational overhead greatly.
Evaluation of search
For the performance of our scheme, we compare the search time of our scheme with Li et al. (2021). Moreover, to better evaluate the performance of the scheme in multi-keyword search, we perform two settings in a query: 5 keywords and 10 keywords, respectively. In figures, the suffix of the icon indicates the number of keywords in a query, i.e., our scheme_5 indicates the search time spent in our scheme during a query which contains five keywords: our scheme_10 indicates the search time spent in our scheme during a query which contains 10 keywords, similarly, Li et al. (2021)_5 and Li et al. (2021)_10 indicates the search time spent in Li et al. (2021) during a query which contains five keywords and 10 keywords, respectively.
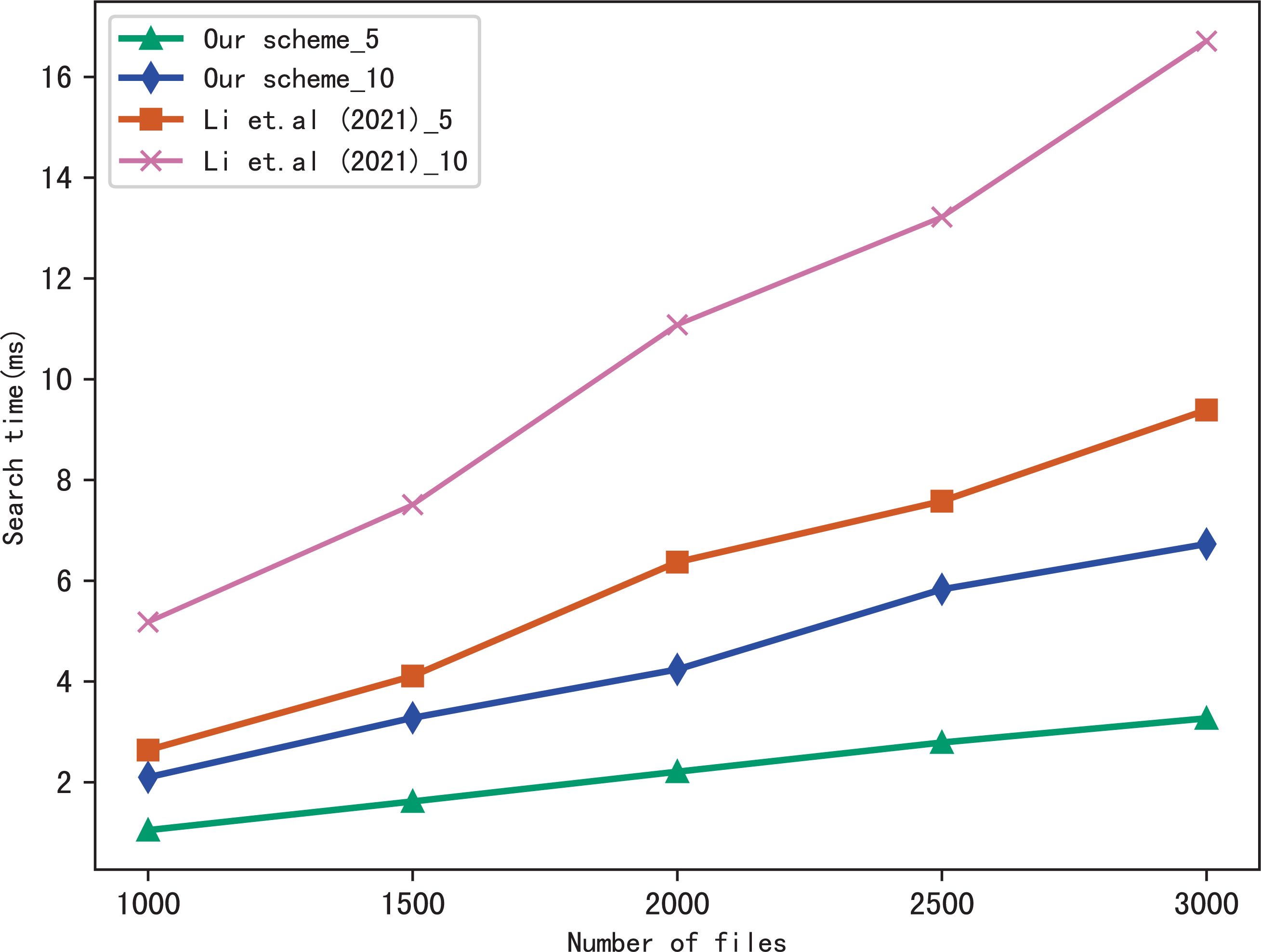
Figure 5 shows the search time with different number of keywords in each file when the number of files is fixed at 3,137, and Fig. 6 shows the search time with different number of files when the number of keywords in each file is fixed at 20. Both figures show that the search time is affected by the number of keywords in each file and the number of files, and the search time increases sub-linearly with the number of keywords and files.
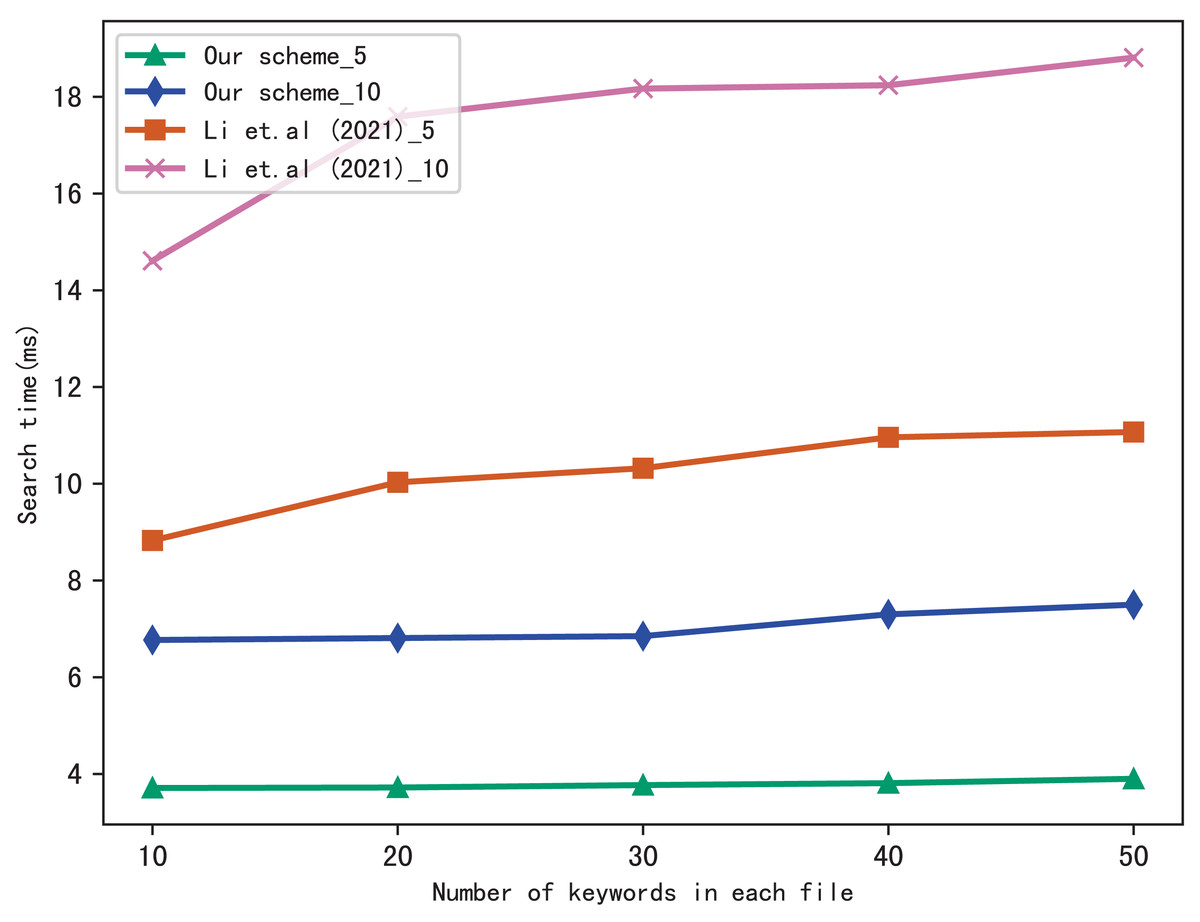
Figure 5: Performance of the search, files = 3,137.
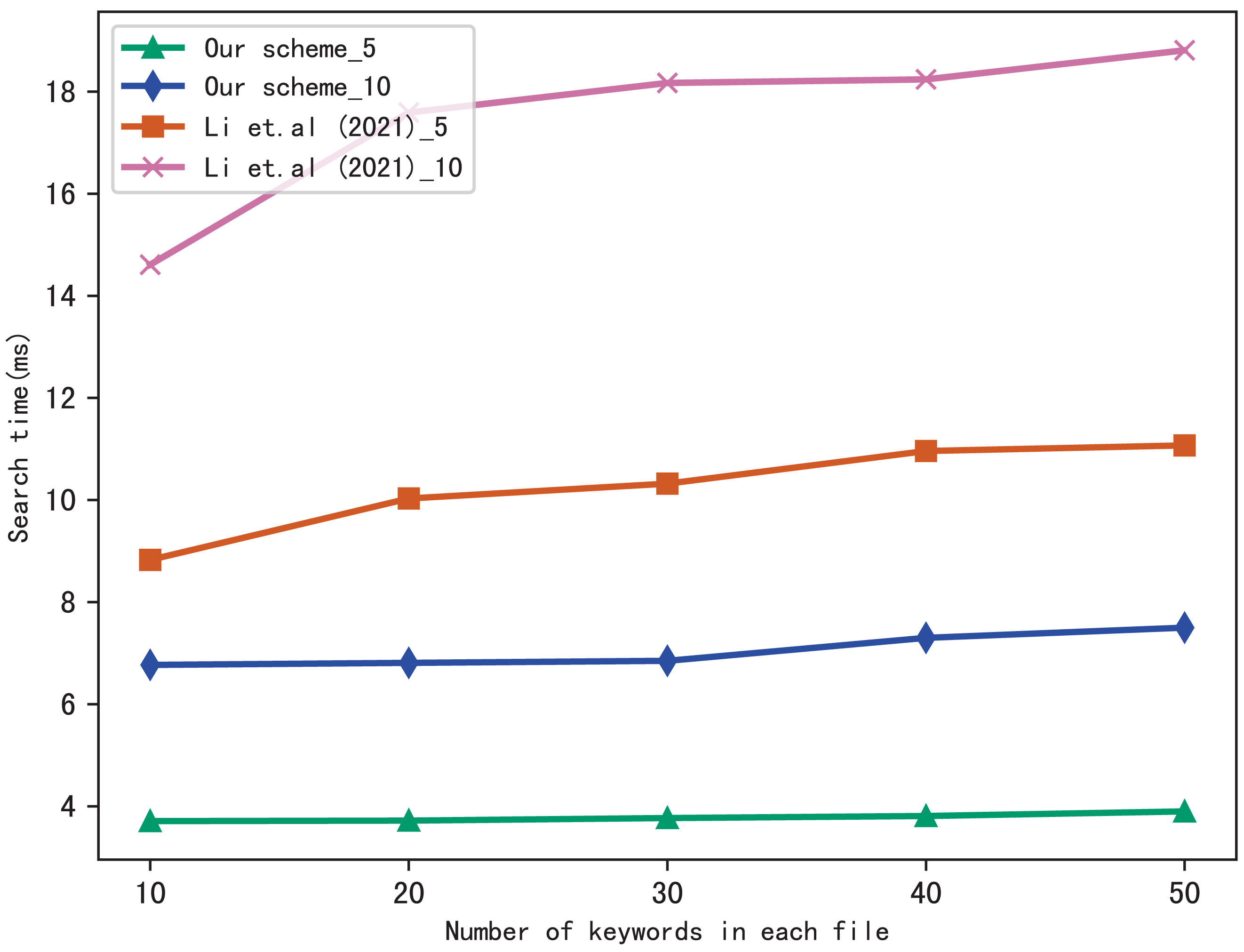{kind=link}
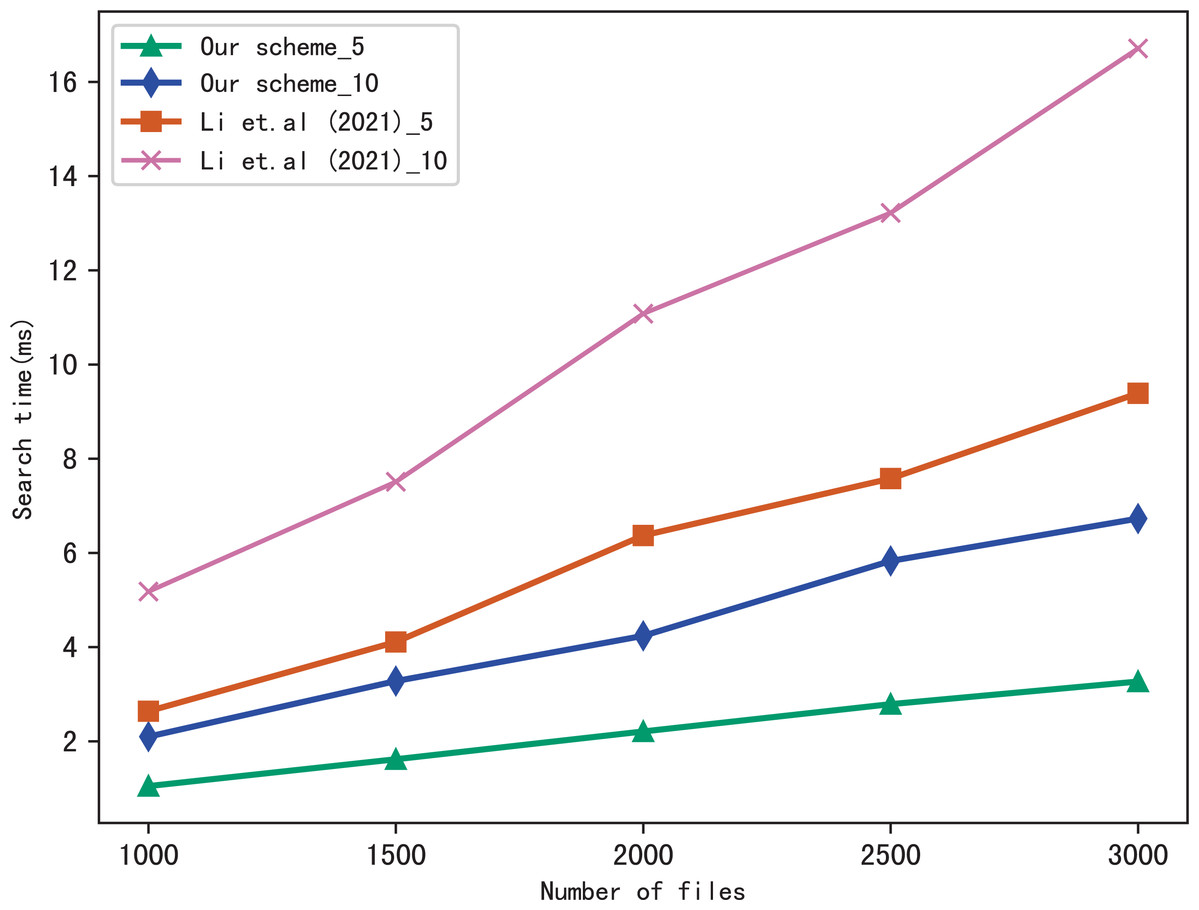
Figure 6: Performance of the search, keywords = 20.
{kind=link}
From Figs. 5 and 6, we can see that the more keywords included in a query, the more time it takes, this is because the more keywords, the search algorithm spends more time to calculate matched files. Another conclusion can be drawn that our scheme is more efficient than Li et al. (2021) in search, the reason is that the same as the setup algorithm, Li et al. (2021) takes more time to calculate the verification values.
Evaluation of verify
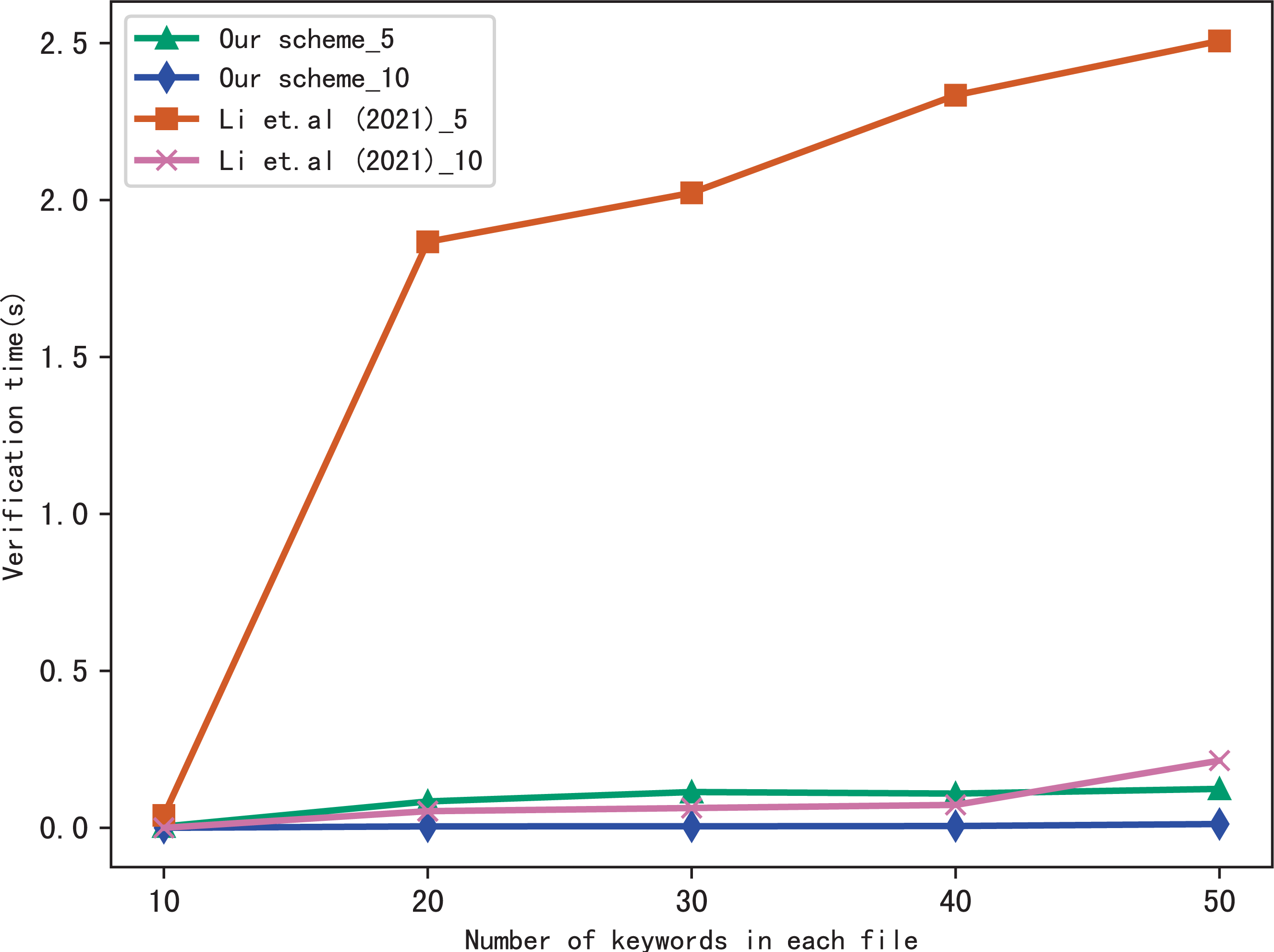
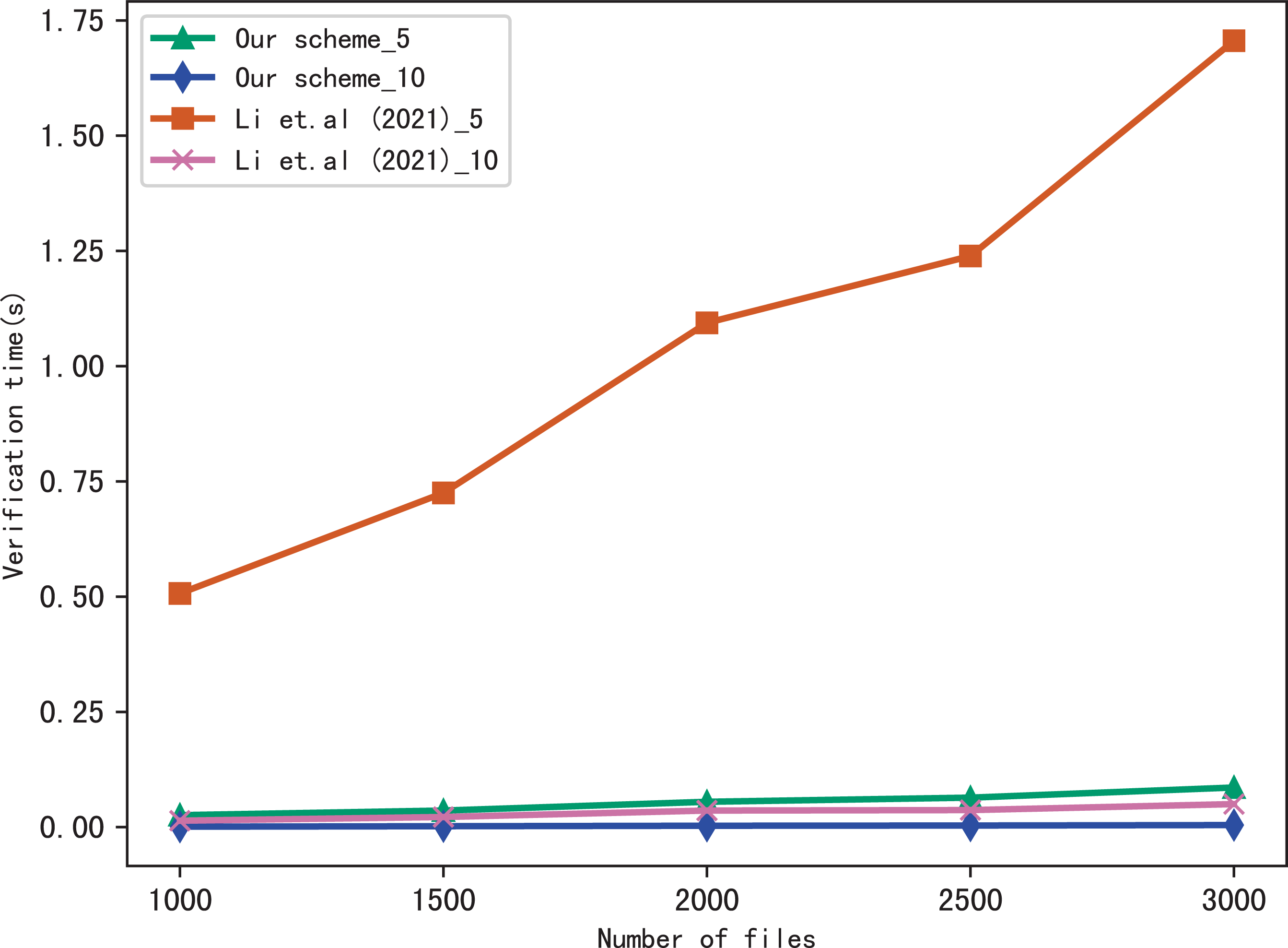
Here, we evaluate the performance of our scheme in verification, we verify the results of searching for 5 keywords and 10 keywords respectively, and compares the verification time with Li et al. (2021), the comparison results are shown in Figs. 7 and 8. Figure 7 shows the verification time with different number of keywords in each file when the number of files is fixed at 3,137, and Fig. 8 shows the verification time with different number of files when the number of keywords in each file is fixed at 20. From those two figures, we can see that the verification time is affected by the number of keywords in each file and the number of files, the verification time increases with the number of keyword and files.
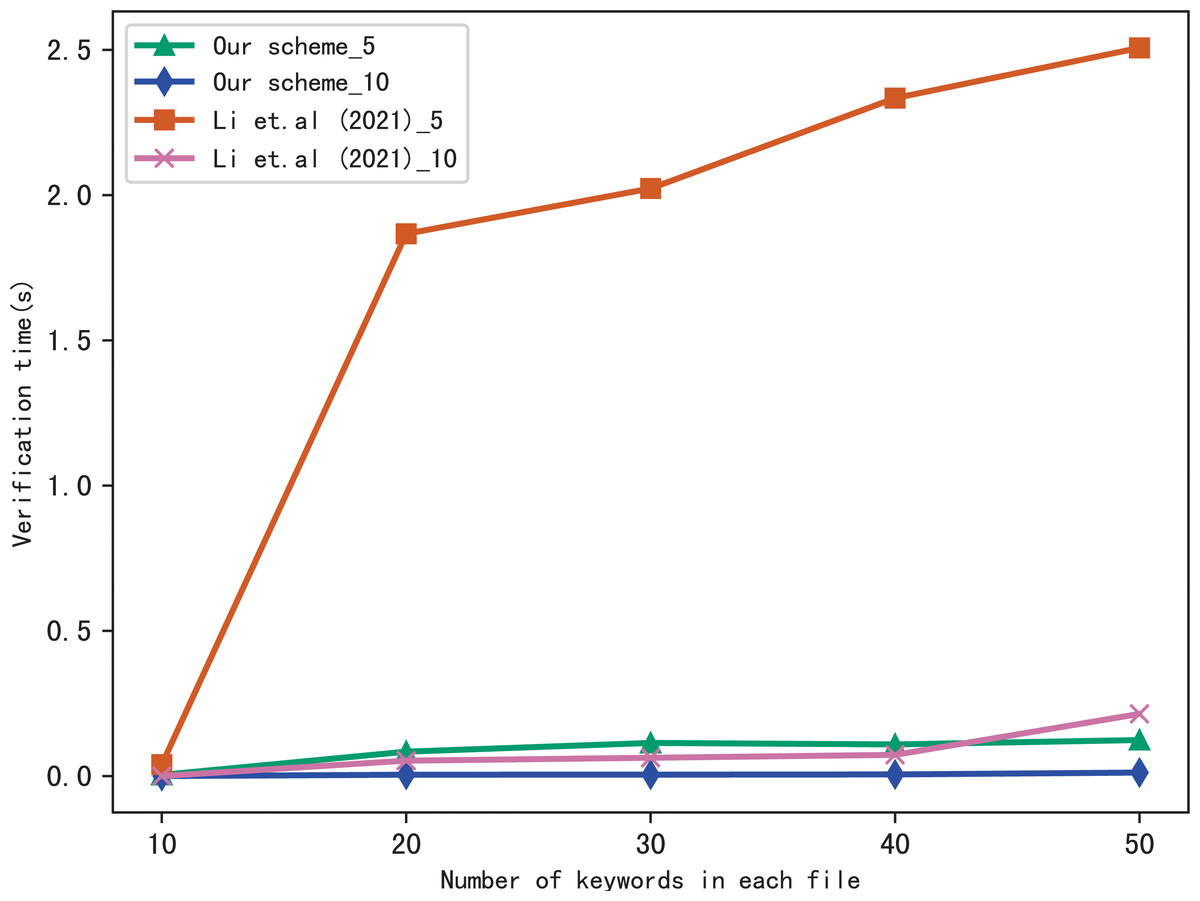
Figure 7: Performance of the verification, files = 3,137.
{kind=link}
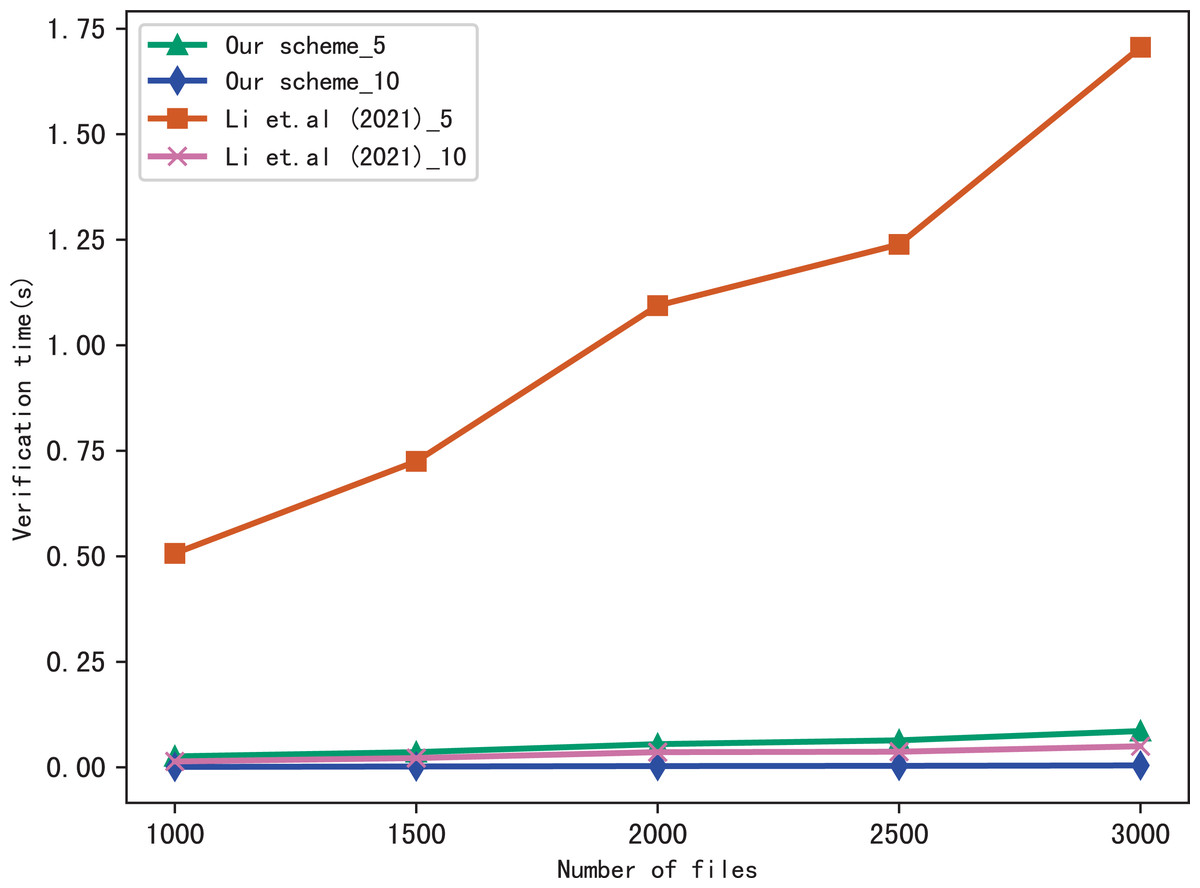
Figure 8: Performance of the verification, keywords = 20.
{kind=link}
Both figures shows that our scheme gains a higher verification efficiency than Li et al. (2021), the reason is that Li et al. (2021) takes additional time to compute , where ui = F(Kfi||ri), Kfi = G(K3, fi). In addition, the initial verification values in Li et al. (2021) are stored in untrusted server and the verification is performed by the data user, both the server and the user may forge the verification results, while in our scheme, the values are stored in blockchain and the verification is performed by blockchain, cannot be tampered with, hence, our scheme is more fair and secure in verification.
Dynamic update is the important function in SSE, so we evaluate the performance of our scheme in dynamic update by adding a file containing multiple keywords. Figures 9 and 10 show the performance of our scheme, Li et al. (2021) and Guo, Zhang & Jia (2020) in update time, _5 and _10 indicate that the update document contains 5 keywords and 10 keywords, respectively. We observe that the update time increases with the number of files, since the more files, the longer of the bitmap corresponding to a keyword, then the update algorithm performs more operations when calculating . Moreover, the update time is related to the number of keywords contained in the update file, since the more keywords the file contains, the more indexes to update.
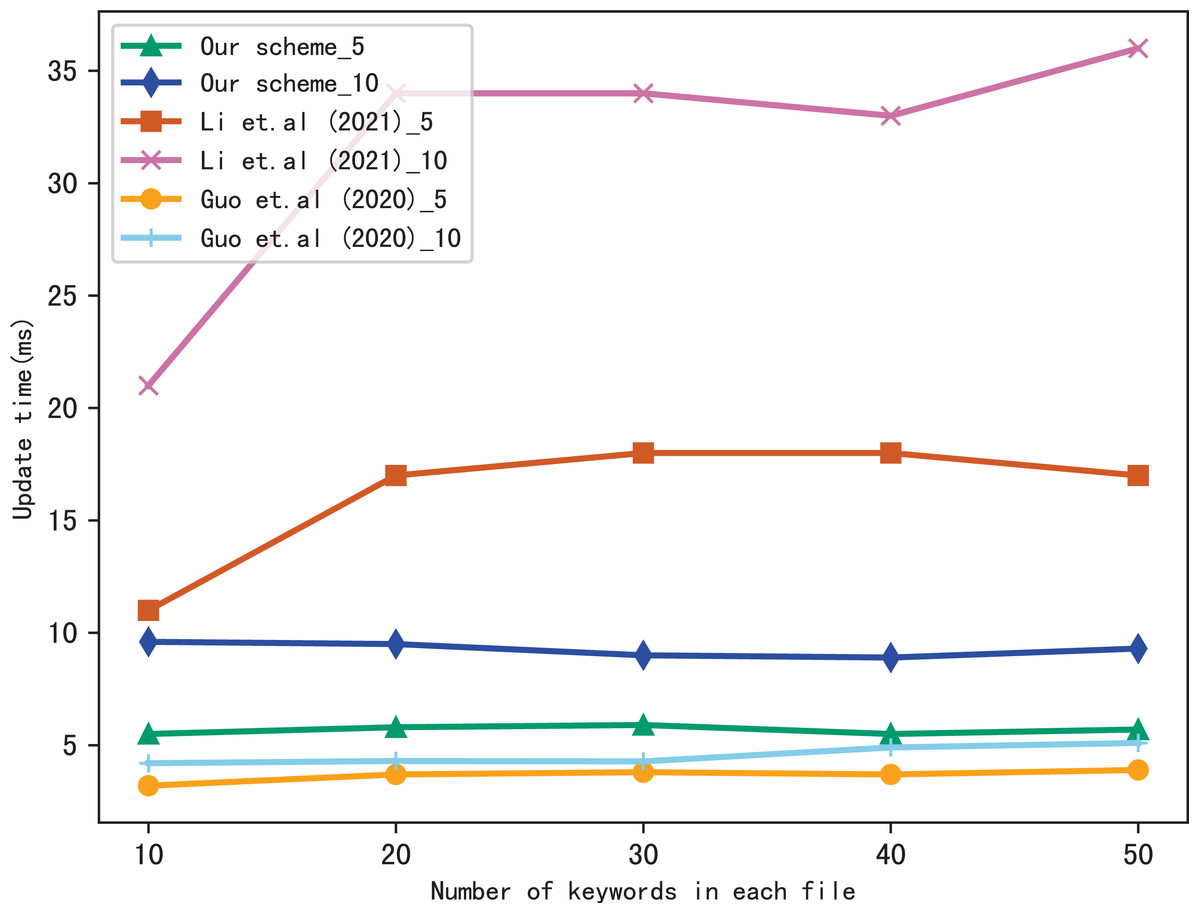
Figure 9: Performance of the update, files = 3,137.
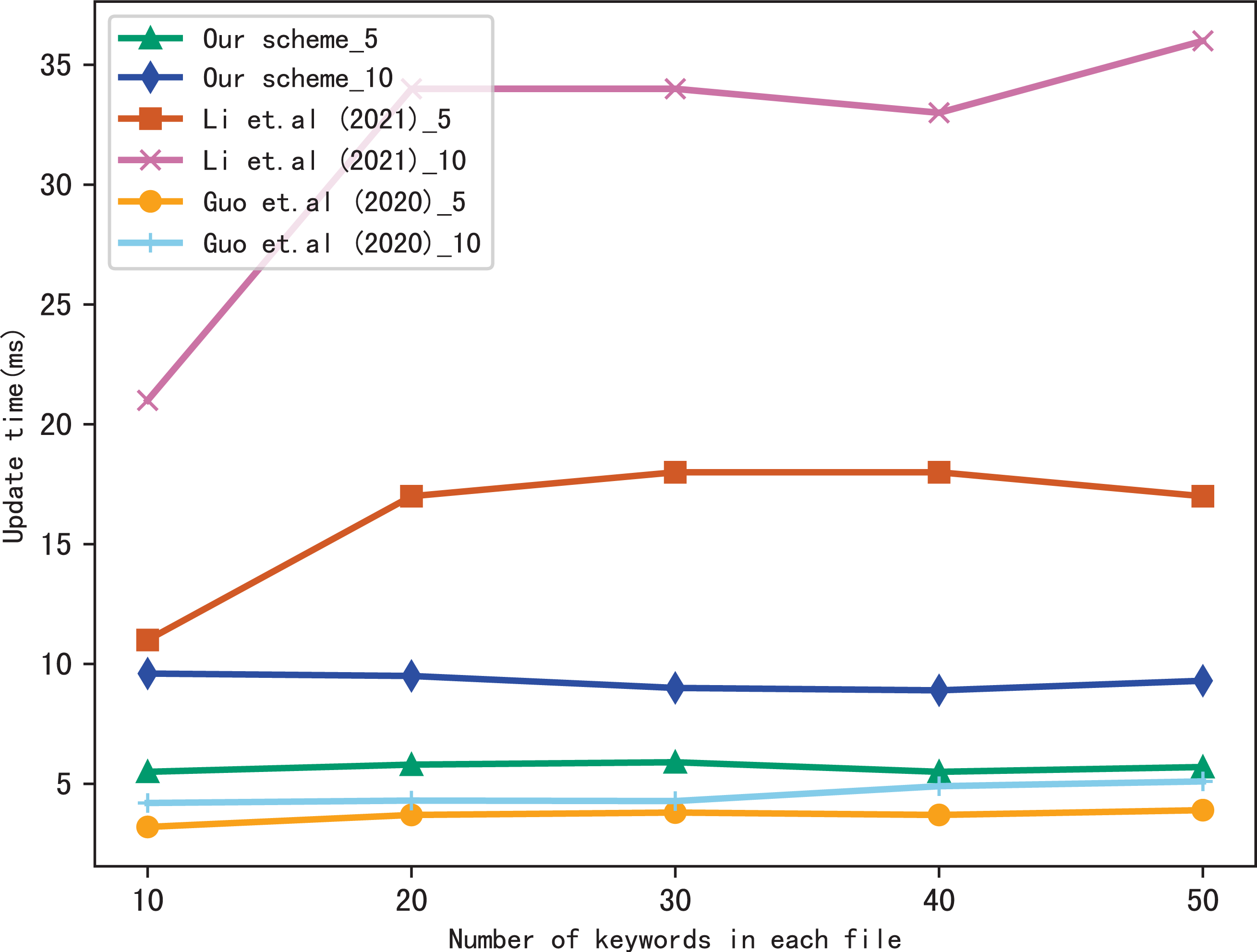{kind=link}
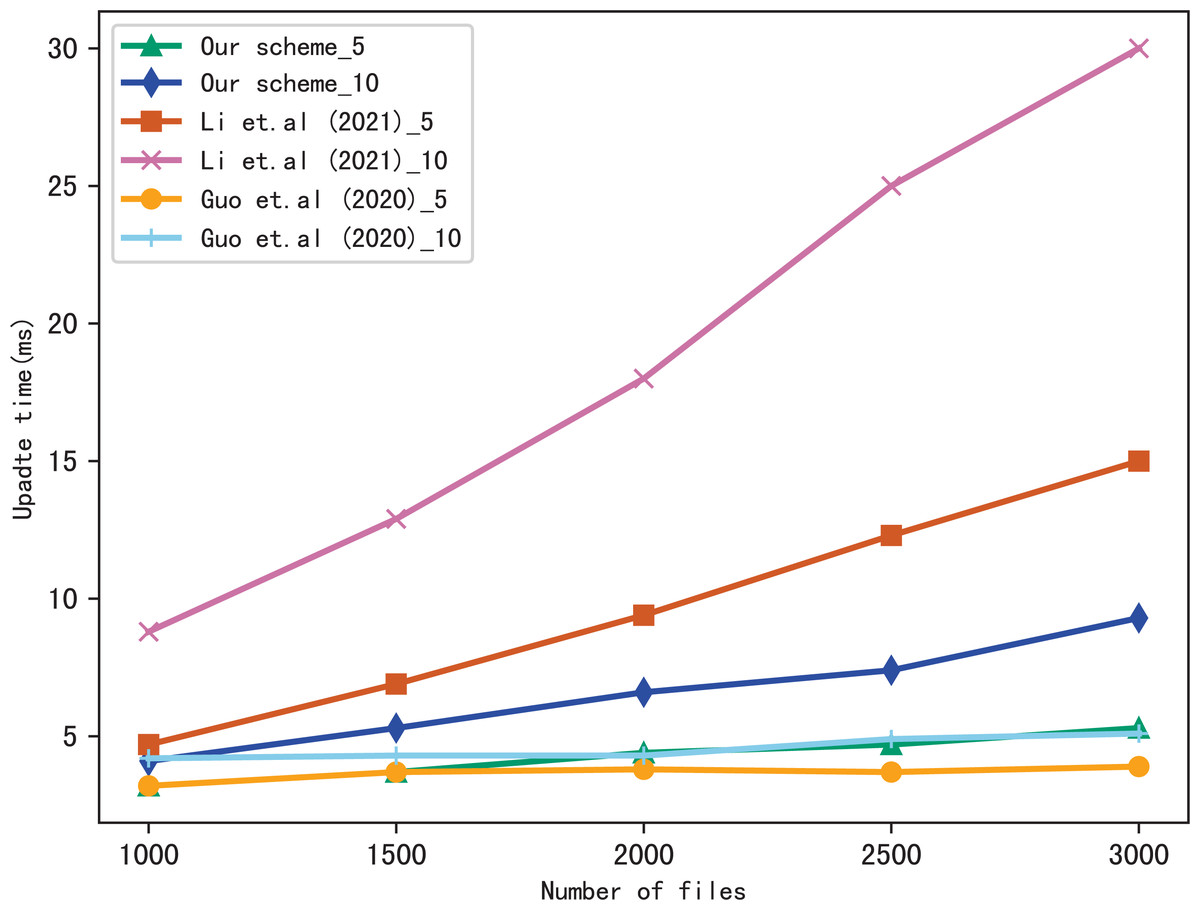
Figure 10: Performance of the update, keywords = 20.
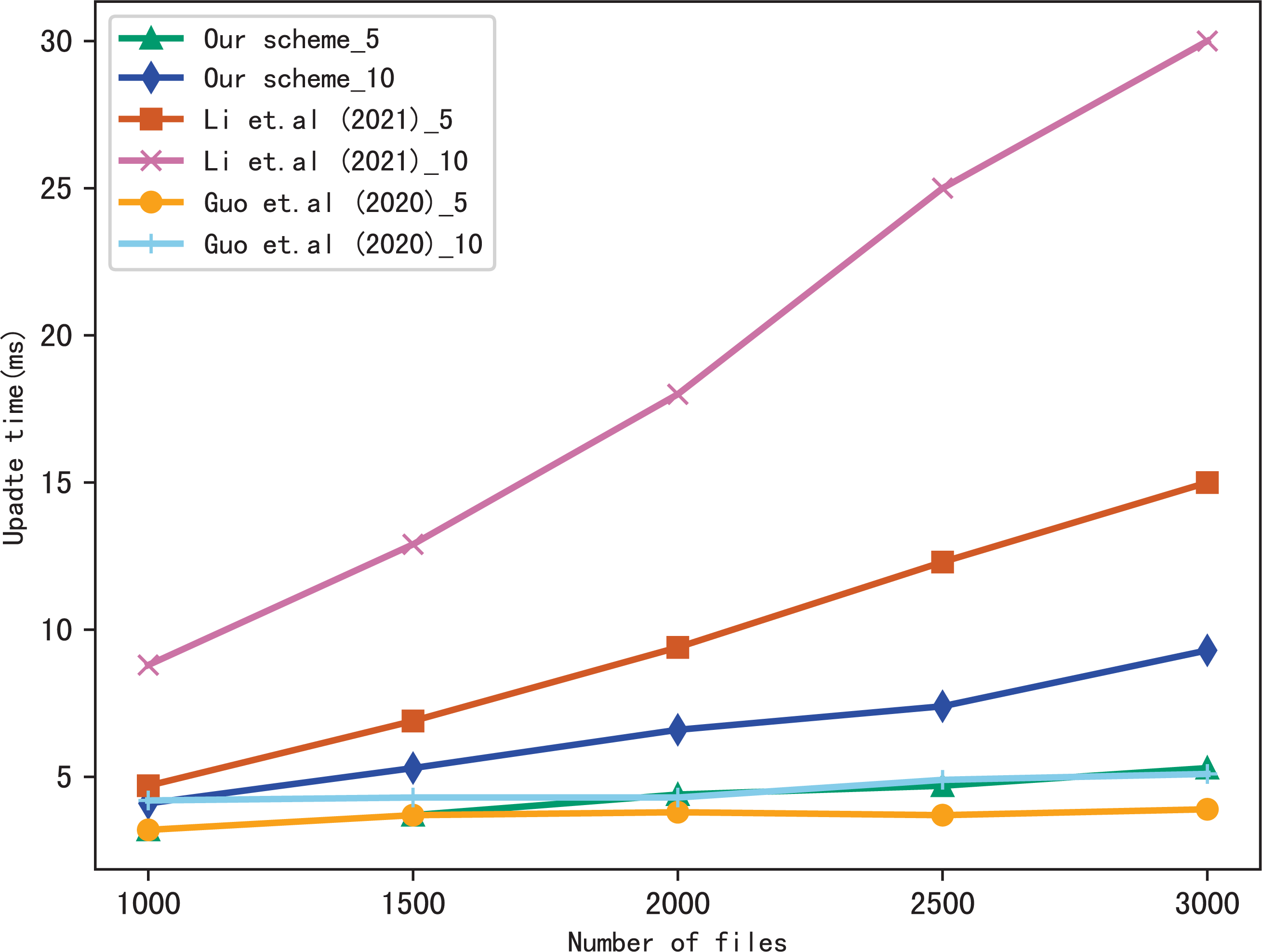{kind=link}
Conclusions
In this paper, we present an efficient verifiable multi-keyword search SSE scheme based on blockchain, which accomplishes efficient multi-keyword search and verification. In our scheme, the yardstick of the file is stored on the blockchain, and the verification of the search results is also completed by the blockchain, thus the fairness and reliability of the verification can be ensured. In addition, our solution supports the dynamic update of files and guarantees forward security during the update. Formal security analysis and experimental results show that our scheme is CKA2-security and efficient. Our scheme can be widely used in cloud storage systems such as data outsourcing, cloud-based IoT (Ge et al., 2021), medical cloud data (Li et al., 2017), etc., helping to achieve efficient multi-keyword searches, and ensuring the integrity and credibility of search results.