
Detecting hate speech in roman Urdu using a convolutional-BiLSTM-based deep hybrid neural network
- Published
- Accepted
- Received
- Academic Editor
- Siddhartha Bhattacharyya
- Subject Areas
- Data Mining and Machine Learning, Natural Language and Speech, Text Mining, Neural Networks
- Keywords
- Hybrid neural network, Roman Urdu, Deep learning, Short-term memory, Convolutional layers, Text data
- Copyright
- © 2025 Zohaib et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Detecting hate speech in roman Urdu using a convolutional-BiLSTM-based deep hybrid neural network. PeerJ Computer Science 11:e3342 https://doi.org/10.7717/peerj-cs.3342
Abstract
The detection of hate speech on social media has become a pressing challenge, particularly in multilingual and low-resource language settings such as Roman Urdu, where informal grammar, code-switching, and inconsistent orthography hinder accurate classification. Despite progress in hate speech detection for high-resource languages, limited research exists for Roman Urdu content. This study addresses this gap by proposing a computationally efficient deep learning framework based on a hybrid convolutional neural network and bidirectional long short-term memory (CNN-BiLSTM) architecture. The model leverages FastText pre-trained embeddings to capture subword-level semantics and combines convolutional layers for local feature extraction with BiLSTM for global context modeling. We evaluate our approach on a labeled Roman Urdu dataset and compare it with traditional machine learning models and deep learning baselines. Our proposed CNN-BiLSTM model achieves the highest performance with an accuracy of 80.67% and an F1-score of 81.47%, outperforming competitive baselines. These findings demonstrate the effectiveness and practicality of our lightweight architecture in detecting hate speech in Roman Urdu, offering a scalable solution for multilingual and resource-constrained environments.
Introduction
The number and popularity of social networking websites on the internet have significantly increased during the past ten years, resulting in an exponential hype in the number of users. These websites offer users the promising freedom to share their thoughts and engage with others from different backgrounds, leading to the formation of relationships and the exchange of ideas (Rizwan, Shakeel & Karim, 2020). Conversely, hostile, offensive, derogatory, or obscene language is utilized to disseminate, provoke, incite, or justify hate, violence, and prejudice between individuals based on their ethnicity, religion, gender, association with specific organizations, or opinions on particular events or topics, such as politics. Failure to address this type of content has been shown to cause violent acts and more serious confrontations. This renders it impractical to uphold civil rights, legal frameworks, and expression, all of which are essential for the establishment of a non-discriminatory open to democracy culture (Khan, Shahzad & Malik, 2021).
Most social media companies depend on information reporting and manual review by human personnel. However, this approach is limited by the speed of the reviewers, their understanding of emerging slang, jargon, and multilingual content, as well as their experience with such content (Mahmood et al., 2020). In addition to these challenges, it is worth noting that by the time the manual review process is carried out—a process that typically takes up to 24 h—the targeted harm may have already occurred. Furthermore, the subjective nature of determining what language is considered offensive and constitutes hate speech raises concerns about the potential for the manual procedure to be misused to silence minority groups and refrain from criticizing government actions, political opponents, and religious convictions. Hence, there is a need for the support the advancement of technologies capable of automatically recognizing inappropriate language and hate speech (Kovács, Alonso & Saini, 2021).
Recent incidents in Pakistan, including the execution of a student who was subjected to anti-religious propaganda on the internet, efforts to discredit prominent politicians and social media influencers, and the frequent targeting and abuse of women who express their opinions online, have prompted the government to enact legislation prohibiting hate speech on the internet. In response to attempts to target religious minorities and cause offense to their religious sentiments, the government has introduced the Nation Protection Act (Alkiviadou, 2019). These incidents vividly highlight the challenges Pakistan faces in combatting online hate speech and the need for automated methods are required to handle such kind of content. The English language has been the primary focus of hate speech and abusive language, despite Urdu being the country’s national language, while English is the official language (Mullah & Zainon, 2021). Individuals often use Latin scripts when writing in Urdu and frequently switch between the two languages during a conversation. This phenomenon involves the alternation of Urdu and English within the same language, phrase, sentence, or other linguistic unit (Noor et al., 2015). The term “Roman Urdu” refers to the distinctive and informal style of the Urdu language that incorporates characteristics such as colloquial jargon, non-standard grammar, divergent spellings, idiosyncratic abbreviations, and code-switching. As a result of these features, Roman Urdu is significantly more challenging to model than formal languages, which typically follow established grammatical rules and employ standardized terminology (Shakeel & Karim, 2020). It’s recognized that the content and characteristics of hate speech differ among different socioeconomic groups. Therefore, to enhance research in this area, there is a need for annotated corpus and models in multi languages to support the analysis of linguistic materials (Mandl et al., 2019).
Organizations such as Facebook and Twitter are believed to be Each year, they spend hundreds of millions of euros to counteract hate speech on their platforms. However, these companies continue to face criticism for not taking sufficient measures to deal with the problem (Al-Hassan & Al-Dossari, 2022). One reason for the continued criticism of organizations such as Twitter and Facebook regarding their attempts to oppose hate speech is the fact that traditional methods for detecting and removing inappropriate online content rely on manual analysis (Khan et al., 2025). This approach is known to be arduous, time-consuming, and ultimately unsustainable (Duwairi, Hayajneh & Quwaider, 2021). Research has been motivated by the vital requirement for automated and scalable hate speech recognition tools, which has led to the development of significant methods centered on machine learning (ML) and natural language processing (NLP) (Putri et al., 2020; Khan et al., 2022a). Due to the lack of comparative assessments and the use of distinct datasets by each study, it is not possible to evaluate the results of their considerable efforts.
The detection of hate speech in Roman Urdu poses unique challenges due to the language’s informal structure, heavy use of slang, inconsistent grammar, and frequent switching between English and Urdu (Ashiq et al., 2024; Khan et al., 2022b). These characteristics make it difficult for traditional models to effectively capture both the surface-level and contextual cues present in such texts. As a result, there is a pressing need for automated solutions that can interpret and learn from these noisy and unstructured language patterns.
To address this, we adopt a hybrid deep learning strategy that combines the strengths of convolutional neural network and bidirectional long short-term memory (BiLSTM) networks. CNNs are well-suited for extracting localized textual features such as offensive word combinations and repeated patterns, which are often indicative of hate speech. On the other hand, BiLSTM networks are capable of processing sequential dependencies in both directions, enabling the model to understand context and semantic flow across entire sentences. The integration of these two components allows the system to detect nuanced expressions of hate, even in code-mixed and grammatically irregular input. This architectural choice ensures a balance between effectiveness and computational efficiency, which is critical for real-time applications in resource-constrained environments.
This study presents a robust and computationally efficient deep learning framework for detecting hate speech in Roman Urdu, a domain that remains underrepresented in the current literature. The key contributions of our work are as follows.
We incorporate FastText pre-trained word embeddings, trained on large corpora, to enrich the semantic representation of Roman Urdu text. The model benefits from subword-level information, which is particularly effective for handling informal, morphologically complex, and non-standard language tokens.
We propose a hybrid architecture that integrates a CNN with a BiLSTM network, further enhanced with dual global pooling layers. This design enables the model to capture both localized lexical patterns and long-range contextual dependencies, striking a balance between accuracy and computational cost.
Extensive experiments are conducted using multiple classical machine learning baselines. Our results consistently demonstrate that the proposed model outperforms these baselines across all standard evaluation metrics, confirming its effectiveness for real-world applications in low-resource settings.
In contrast to many existing deep architectures that are computationally intensive, our model is lightweight and resource-efficient, making it well-suited for deployment in scenarios where processing power is constrained.
Moreover, while most hate speech detection research focuses on English or other high-resource languages, our work specifically addresses the linguistic and structural complexities of Roman Urdu, a code-mixed, colloquial form characterized by informal spelling, inconsistent grammar, and frequent switching between Urdu and English. This fills a critical gap in multilingual hate speech detection. The rest of this article is organized as follows: ‘Related Work’ reviews related work; ‘Proposed Methodology’ describes the proposed CNN-BiLSTM model; ‘Experimentation and Results Analysis’ outlines the datasets used; ‘Discussion’ details the experimental setup and results; and ‘Conclusion’ concludes the study.
Related work
The extensive lexical similarity between disrespectful language and slanderous remarks poses a significant challenge to the detection disrespectful language (Davidson et al., 2017). As a result, people have become accustomed to using insulting or vulgar language for leisure, humor, and sarcasm. Moreover, when a tweet is identified as hateful, research on anti-black racism indicates that 86 percent of respondents perceived the post as hostile, which often includes offensive language, making it challenging to distinguish between instances of disrespectful language and other forms of discourse (Wang et al., 2014). Previous research on hate speech recognition has established a set of criteria for identifying problematic tweets (Waseem & Hovy, 2016; Ashraf et al., 2022). Furthermore, research has indicated that the geographic distribution of website visitors does not influence the ability to identify objectionable posts. Another study has utilized statistical assessments to establish a connection between a user’s propensity to propagate offensive content, such as sexism and racism, and the corresponding labeled categories. The study found correlations of 0.71 and 0.76 for sexism and racism, respectively (Waseem, 2016).
In addition to unsupervised methods, several studies have investigated various approaches for hate speech detection., such as Nobata et al. (2016) and Malmasi & Zampieri (2017), Several studies have recommended the the utilization of supervised learning methods for detecting hatred. The first of These research used publicly available data sources. available sources, including financial and media comments from two distinct domains, which were utilized to create a corpus of hate speech. Additionally, the study examined various types of embeddically extracted features and syntactic characteristics. In comparison, in Malmasi & Zampieri (2017) a supervised classification approach was employed, utilizing word skip-grams and n-grams in their algorithms, resulting in an accuracy rate of 78 percent. The study employed three subcategories, including Hatred, Offense, and Normal, to classify the experimental dataset.
Recent research has demonstrated the performance of deep learning methods for identifying expressions of hatred. To categorize hate speech, deep learning approaches utilize deep artificial neural networks (DNNs), which utilize multiple stacked layers to learn implicit representations from input data. Various feature encodings, including many used by conventional approaches, may be employed to encode the input. However, these input features are not immediately utilized for classification. Instead, new abstract feature representations are added to the multi-layered structure for learning purposes. Consequently, deep learning systems prioritize the architecture of the network’s topology to automatically extract valuable properties from a fundamental input feature space. For instance, Badjatiya et al. (2017), the study utilized long short-term memory (LSTM), FastText, and CNN in their experimentation, and the research demonstrated that CNN outperformed LSTM with FastText Embedding. Additional research studies, such as Jha & Mamidi (2017), have utilized conventional supervised learning techniques, such as support vector machines (SVM), models that convert sequences to sequences and the most advanced FastText classifier, to annotate existing Twitter datasets for instances of sexism. A recently created dataset categorizes tweets into three groups: benevolent, hostile, and other. In another research on hateful speech identification, a group classifier was employed, wherein features were extracted via word frequency vectorization and subsequently fed to classifiers based on neural networks. The researchers claimed that their ensemble process is superior to current techniques for classifying short messages (Pitsilis, Ramampiaro & Langseth, 2018).
In addition to research on the English language, there has been additional research on identifying hate speech in Asian and European languages. Biradar, Saumya & Chauhan (2021) focused on code-mixed Hindi-English (Hinglish) content and used the multilingual bidirectional encoder representations from Transformers (mBERT) model for the detection of sentiment and hate speech. Their findings reinforce the importance of custom architectures for handling multilingual, informal social media content. For instance, Vigna et al. (2017), in the instance of the Italian language, collected a media group containing news articles on politicians, performers, groups, and celebrities was collected. The initial research aimed to distinguish between strong hatred, weak hatred, and no hatred. Compared to the initial round of trials, the categories of “strong hate” and Weak offensive were employed to create a binary categorization problem in the second set. SVM, a common supervised learning methodology, and LSTM, a deep learning method, were employed in experiments. SVM, a conventional method, outperformed deep learning approaches in both instances, with F1-scores of 0.75 and 0.851. The detection of hate speech in the German language has also been investigated (Eder, Krieg-Holz & Hahn, 2019). This study measures the relative offensiveness of lexical concepts using a vocabulary of 11,000 entries.
Apart from European languages, research has also been conducted to identify offensive language content on Arabic social networks (Mubarak, Darwish & Magdy, 2017). Another study (Ranasinghe & Zampieri, 2020) proposed multilingual offensive language identification with cross-lingual embeddings, which contributed valuable work in low-resource settings. Despite significant progress in detecting hate speech across languages such as Arabic and various European tongues, very limited research has focused on Roman Urdu, a code-mixed language characterized by non-standard orthography, inconsistent grammar, and high lexical variability (Khan et al., 2021). This linguistic complexity presents unique challenges for automated detection methods. To address this gap, our study constructs a dedicated Roman Urdu hate speech corpus and evaluates the performance of five traditional machine learning algorithms alongside five deep learning models. Unlike many existing approaches that require large-scale computational resources or are tailored for high-resource languages, we propose a lightweight hybrid CNN-BiLSTM architecture specifically designed for the noisy, low-resource environment of Roman Urdu social media content.
Proposed methodology
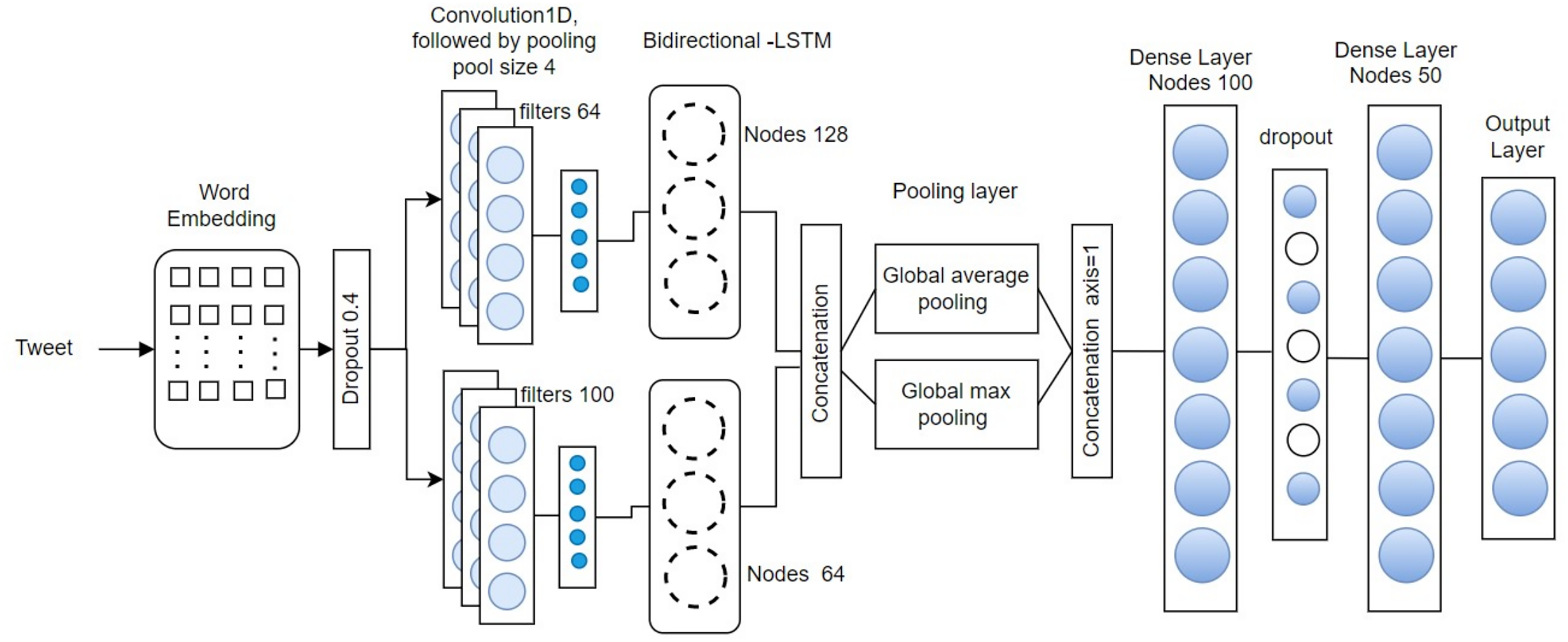
This section presents the proposed CNN-BiLSTM architecture, illustrated in Fig. 1. The architecture begins with an embedding layer that transforms each input text message, treated as a sequence of tokens, into a continuous vector space. This transformation is accomplished by mapping each word to a real-valued vector that captures its semantic representation across multiple dimensions.
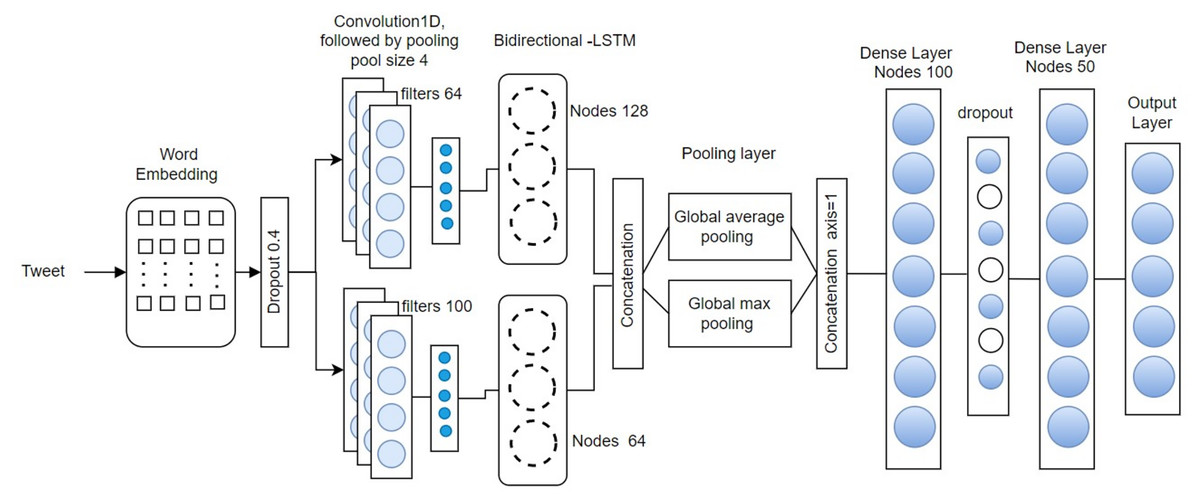
Figure 1: CNN-BiLSTM network architecture.
{kind=link}
For this study, we employed 300-dimensional word embeddings generated using a skip-gram model trained specifically on Roman Urdu text. These embeddings were used to initialize the weights of the embedding layer. To ensure uniform input length for model training, each tweet was standardized to a fixed length of 100 tokens—truncating longer messages and padding shorter ones with zero-valued vectors.
Proposed algorithm
The concatenated convolutional bidirectional long short-term memory network (CCBLSTM) used for hate speech detection is represented mathematically as follows:
-
Let be the input sequence of text data, where represents the word in the sequence,
-
Let E be the word embedding matrix, where Every word has been represented by a d-dimensional vector. Then, the embedding of the input sequence X is given by: , where .
-
Let be the weight matrix and be the bias vector of the convolutional layer. The output of the convolutional layer is given by: , where . Here, is the rectified linear unit activation function.
-
Let be the weight matrix and be the bias vector of the feedforward layer. The output of the feedforward layer is given by: , where .
-
Let be the weight matrix and be the bias vector of the softmax layer. The output of the softmax layer is given by: , where , for to . Here, is the number of output classes and is the exponential function.
-
Let be the hidden state of the bidirectional LSTM layer. The output of the bidirectional LSTM layer is given by: .
-
Let be the concatenated output of the convolutional layer and the bidirectional LSTM layer, where .
-
Let P be the dropout probability. The output of the dropout layer is given by: , where . Here, is a random binary vector with probability P of being and of being .
-
be the true labels for the input sequence X.
-
The loss function used for training the CCBLSTM model is the cross-entropy loss: , for to Here, is the predicted probability of the class.
The CCBLSTM model is trained to utilize a gradient descent optimization algorithm, such as Adam, to minimize the loss function and update the model parameters. The SoftMax function is utilize by the model to predict the probability of the output class for a new input sequence of text data. To prevent overfitting, After the embedding layer, a drop-out layer is applied, with a drop-out rate of 0.4. This has the effect of randomly dropping out a word in a sentence and ensuring that categorization does not rely on specific words.
Next, two 1D convolutional layers with 100, 64 filters each and a kernel size of 4 with padding set to “same” are applied to the drop-out layer’s output to make sure the length of the output matches the length of the input data. Activation is accomplished using the rectified linear unit (ReLU) function. A representation of the input feature space is generated, and this is further downsampled by a 1D maximum pooling layer with a pool size of four, resulting in an output of shape . There are 25 different dimensions, each of which has an “extractable feature”.
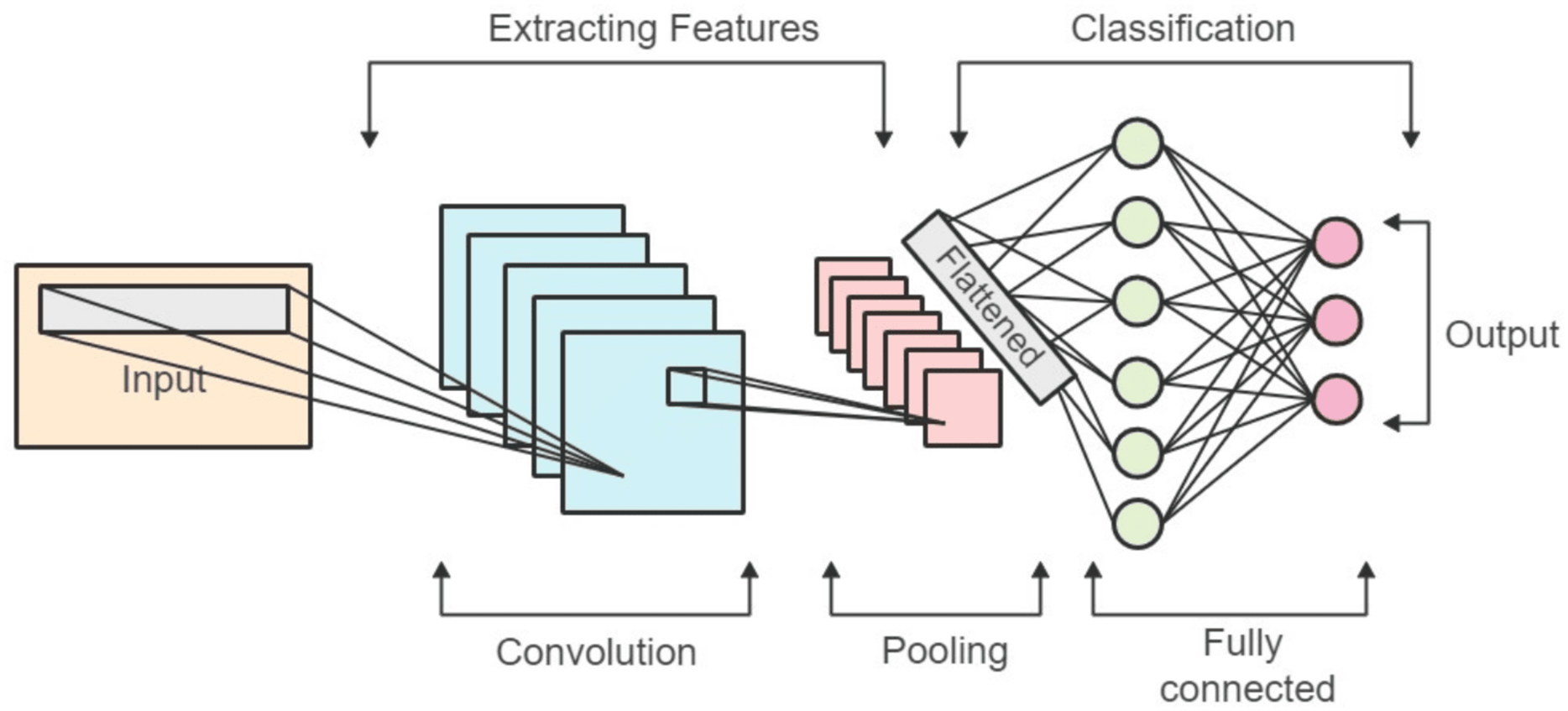
Convolutional neural networks (CNNs) are a type of deep neural network that is mostly applied to image-related applications. The block diagram of a convolutional network is depicted in Fig. 2. Among the various types of CNNs, one-dimensional CNNs are specialized for processing signal and time series data. In this research, we introduce a neural network constructed using the one-dimensional CNN architecture for the purpose of detecting hate speech. Within the hidden layers of the network, convolutions are executed, employing kernels as filters to retrieve characteristics from the input data. The convolutional layer typically entails the dot product operation applied to input vectors, and the ReLU (rectified linear unit) stands out as the most commonly employed activation function in this context.
(1)
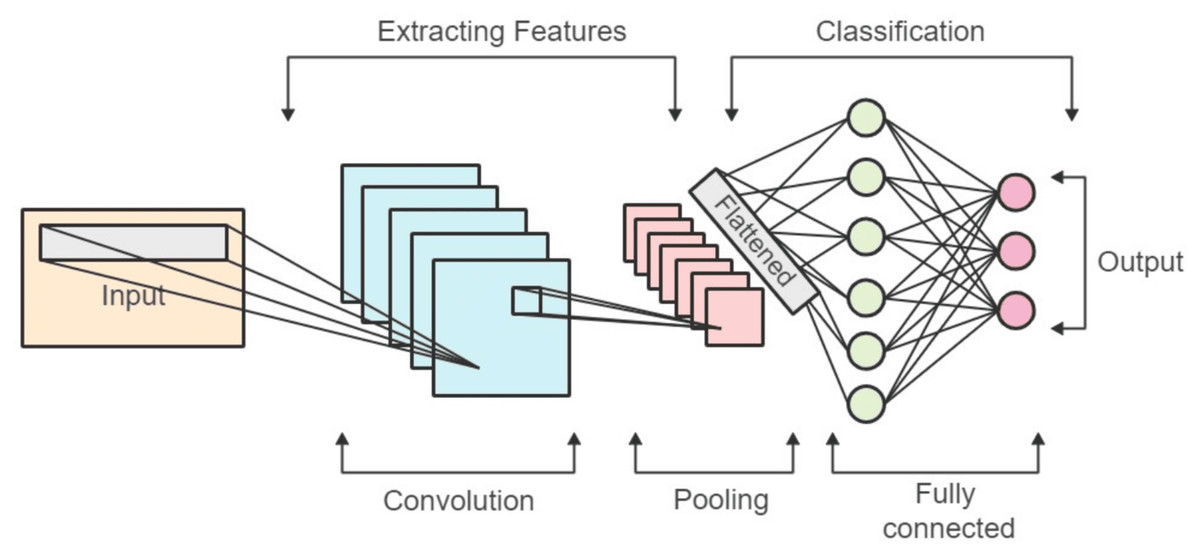
Figure 2: Block diagram of the convolutional network.
{kind=link}
To calculate the number of features in the output, the formula below is employed.
(2)
In the context provided, signifies the count of input features, represents the number of output features, stands for the convolution kernel size, denotes the padding size, and indicates the stride utilized in the convolution process.
The characteristics derived from the initial convolutional layer are subsequently propagated to LSTM in the BiLSTM layer, where they are treated as individual timesteps, resulting in the generation of 128 hidden units per timestep. The characteristics taken out of the secondary convolutional layer are subsequently channeled into the second BiLSTM layer for further processing.
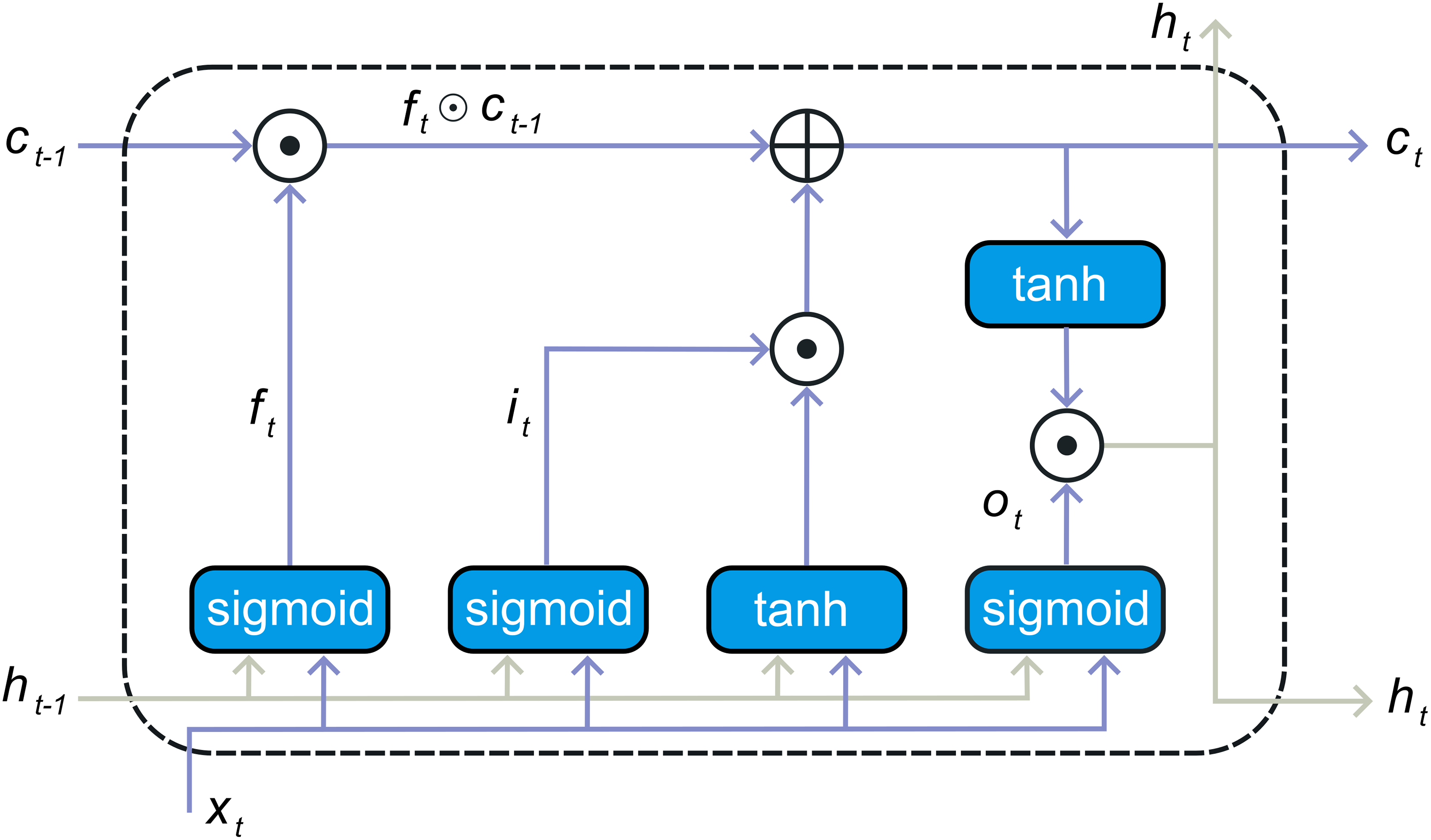
One type of specialized neural network is the recurrent neural network (RNN) model tailored for the examining of time series data. This model incorporates a feedback loop, enabling it to effectively utilize prior information. However, RNN encounters challenges related to memory limitations and information retention. It has trouble picking up long-term dependencies and is prone to the vanishing gradient issue. To overcome these issues, LSTM architecture was developed. LSTM created expressly to address RNN’s limitations in capturing enduring reliance and mitigating the vanishing gradient problem. The LSTM architecture employs memory cells to preserve historical data for extended periods, managing this information by using a gate approach. The LSTM unit has three types of gates that function: the gate for input ( ), the memory gap called forget-gate ( ), and the gate of outflow ( ), illustrated in Fig. 3. To control the state of the memory cells, each gate carries out sigmoid function and point-wise multiplication operations. The present input and the output of the preceding layer’s concealed state are passed into all three gates. Forget gate determines which information to retain or discard, utilizing the sigmoid function to transition information using the current input and the earlier stage of concealment , forget gate’s output ranges from zero to one: a value close to zero signifies that the values will be ignored, while a value close to one indicates that more learning will be retained. The following is the formula for calculating the forget gate:
(3) where, symbolizes the activation of the sigmoid, and and W represent the bias and weight of each gate unit, corresponding. The present input-data and the preceding hidden-state are fed into the sigmoid function. Through transformation into a scale ranging from zero to one, The input gate chooses which data should be reused. Here, zero signifies insignificance, while one signifies importance. The following is the expression for the input gate formulation as seen in Eq. (4) Khan et al. (2022a):
(4)
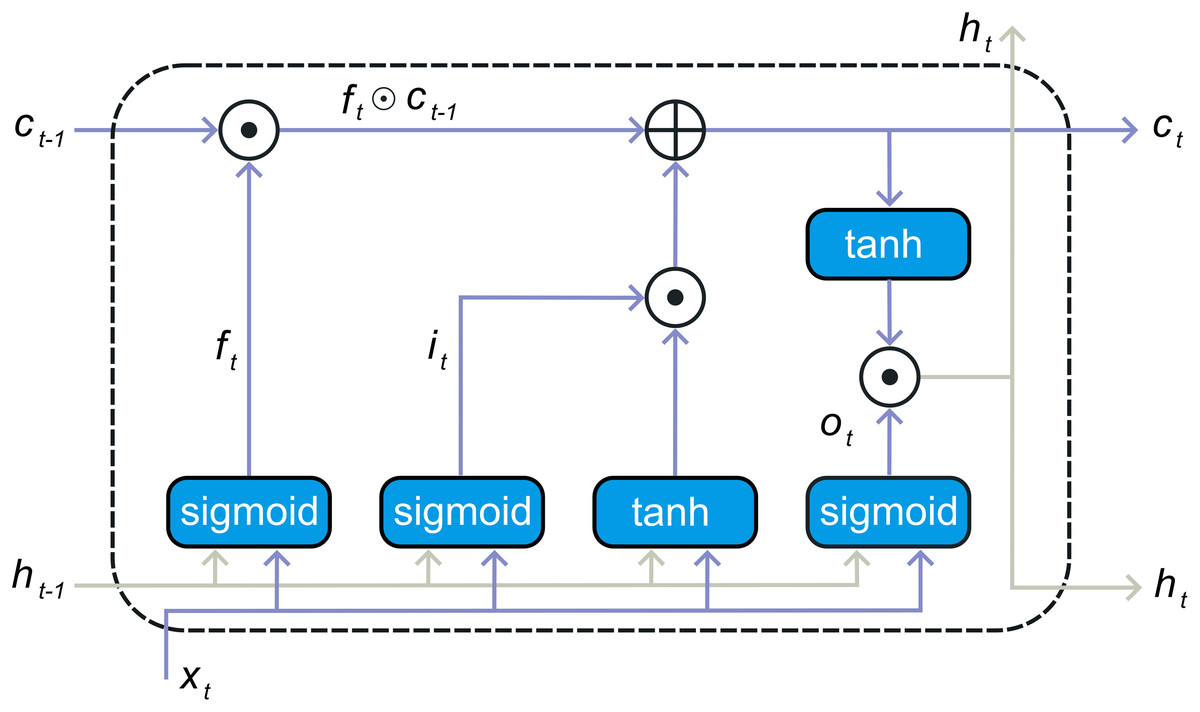
Figure 3: An illustrative block diagram of the LSTM network.
{kind=link}
Subsequently, the present-input and the hidden-state values are got through the operation. At this stage, the condition of the cell is computed, and the cell state is accordingly updated with the revised value. Refer to Eqs. (5) and (6) Zhu et al. (2020).
(5)
(6)
Here, denotes the activation function of hyperbolic tangent. The symbol represents the dot multiplication operator, and signifies the updated recall cell. The output gate selects the next concealed state when the operation comes to an end. The recently updated recall cell and a newly concealed state are subsequently forwarded to subsequent temporal intervals within the series as seen in Eqs. (7) and (8) Renna (2023).
(7)
(8)
A typical information is handled by LSTM solely from the preceding direction, relying solely on prior data. In contrary, The BiLSTM architecture consists of two LSTM layers: one in the backward direction and the other forward. The diagram representation of BiLSTM is illustrated in Fig. 1. The LSTM in front captures Previous information based on the input sequence, while the backward LSTM gathers upcoming data details, with the outputs from the merging of the two concealed layers. Consequently, the hidden-state of the BiLSTM at the present time encompasses both the upfront component and the in reverse component .
(9)
Here, represents the component-wise summation operation, utilized to combine the outputs from both the forward and backward elements. BiLSTM offers superior efficiency compared to traditional LSTM and RNN models due to its ability to leverage both preceding and subsequent information in the input sequence.
Reset and update gates are the only two gates in a Gated Recurrent Unit (GRU), whereas there are three in an LSTM (forget, input, and output gates). Consequently, BiLSTM is a complicated structure with more trainable parameters. In theory, this slows down training. After concatenating the outputs of each BiLSTM, A layer known as global max pooling, and a layer of the global average pooling “flatten” the output size generated by selecting the biggest and the mean figure for every timestep dimension to form a vector. This makes an obvious decision to represent a tweet using the qualities with the highest scores. A 0.4 dropout layer is then followed by a 100-node dense layer with full connectivity. Last but not least, this vector is used as input by a SoftMax layer to calculate the likelihood distribution across every potential class (n), in accordance with the databases. To train the model, we employ The cross-entropy loss function for categories and the Adam optimizer. Empirical evidence demonstrates that the first loss function is superior to others, including classification error and sum of the squared error. For classification tasks (McCaffrey & Colin, 2015) the benefits of two additional popular extensions of gradient descent with stochasticity to increase the basic stochastic gradient descent’s (SGD) effectiveness, utilized optimizer (AdaGrad and RMSProp).
Model parameters. All other parameters are taken from historical data, except batch, epochs, and learning rate, which are derived from experimentations. several the basis for our model’s parameters is earlier documented in experimental results, as previously said (more information adhere to). Perhaps Not the finest conditions for the best results,which are always reliant on dataset quality. Later on, we demonstrate, however, experimentally, that the model yields favorable outcomes with minimal data-driven parameter adjustment. Comparison with DNNs of a similar kind. Our network structure resembles that of those mentioned in Ordóñez & Roggen (2016), Djuric et al. (2015), Tsironi et al. (2017). Major variations encompass: (1) We employ a BiLSTM rather than a GRU for similar reasons as stated earlier; (2) Using a drop-out layer to make the learning process more consistent as well as a layer of global max pooling to extract information from the BiLSTM. since convolutional layers are used to get hierarchical image processing features. We don’t use such complicated models because we’ve shown that our CNN+BiLSTM works well for this task and may advantage of both the convolutional qualities and order information from data that BiLSTM gives us, which proves our hypothesis. For the same reason, we only use word embeddings to build our model, even though most people think character-level features are better. Later research shows that this structure is so good that it does a better job than DNN models that are based on character embeddings.
Experimentation and results analysis
In the process of developing and training the CNN-BiLSTM models, Keras, a popular deep learning framework, was utilized in conjunction with Tensorflow as the backend. The Scikit-learn package was used to analyze the data using random forests, naive Bayes, logistic regression, and SVM. Kaggle notebooks equipped with an NVIDIA GPU P100 and 16 GB of GPU internal memory were used for conducting experiments. Stratified five-fold cross-validation was employed to evaluate each model. This approach resulted in five stratified divisions for the corpus, each containing a nearly identical distribution of tweet classifications. One random partition was selected from each of the five folds as the testing set, while the remaining dataset served as the training corpus. The average recall, accuracy, precision, and F1 over all folds were computed for each model. As the dataset was imbalanced, accuracy was considered unreliable, and therefore F1 was chosen as the primary evaluation metric in this research. The formulae for these metrics are presented in the equations. Equation defines accuracy as the percentage of instances properly categorized relative to the total number of cases (Eq. (10)).
(10)
The symbols TP, TN, FP, and FN stand for tests that are positive, true negatives, and false negatives, respectively, and the number of correctly detected true negatives. Equation (11) measures the proportion of accurately detected positive instances to the total number of anticipated positive cases. Remember, as expressed in Eq. (12), quantifies the proportion of accurately classified positive cases.
(11)
(12)
The definition of F-measure is that it is meant to reflect the harmonic mean of recall and accuracy. Here is another common use of the phrase, as indicated by Eq. (13).
(13)
To ensure reproducibility, we report the key hyperparameters used in training our CNN-BiLSTM model. The maximum input sequence length was set to 150 tokens. The model was trained using the Adam optimizer with an initial learning rate of 0.02 and a learning rate decay factor of 0.2 applied after 5 epochs. A dropout rate of 0.4 was used to prevent overfitting. The model was trained for a maximum of 50 epochs with early stopping based on validation loss, using a patience value of 10. The batch size was set to 258, and L1 and L2 regularization were applied to the kernel weights.
Dataset description
The Roman Urdu language lacks sufficient linguistic resources, particularly for identifying hate speech. In the available literature, only a few corpora exist for Roman Urdu, which is a language with limited resources. There has been little effort made in this field for Roman Urdu, which poses challenges due to its informal nature, with frequent misspellings, elongated letters, and variations in spelling. Additionally, several terms are used interchangeably in both English and Urdu, further complicating the dataset acquisition process. As is well known, the scarcity of datasets is a significant challenge in this area of research. Many previous studies have utilized privately collected datasets to address various issues. To construct the largest dataset for offensive language, the author annotated tweets and made the dataset publicly available. The dataset was created by seeking for tweets that contained commonly appearing phrases, which were then evaluated manually for hate speech or specific entity identifiers.
Roman Urdu Hate-Speech and Offensive Language Detection (RUHSOLD) database (Rizwan, Shakeel & Karim, 2020) undergoes meticulous annotation by three distinct annotators. To handle conflicts, a resolution is achieved through a majority vote among the annotators. If consensus cannot be reached or if there is inadequate information for labeling, the tweets in question are excluded and substituted with randomly selected tweets from the dataset. Two subtasks are defined as the standard for annotation. The first subtask involves binary labels for Hateful content and Normal content, representing offensive and inoffensive language respectively. This subtask is referred to as “coarse classification.” The second subtask involves characterizing hateful content with five specific descriptions, which are deemed most suitable for the demographics of Roman Urdu speakers based on relevant research. Table 1 presents the Twitter tags together with their respective counts.
| Label | Count |
|---|---|
| Sexism | 839 |
| Offensive | 2,402 |
| Religious hate | 782 |
| Profane | 640 |
| Normal | 5,349 |
| Total | 10,012 |
To highlight the linguistic challenges posed by Roman Urdu, Table 2 provides examples of hate speech instances in Roman Urdu along with their English translations. Roman Urdu exhibits characteristics such as inconsistent spelling, lack of grammatical standardization, and frequent use of colloquialisms, making automated processing particularly difficult. These examples also reflect the presence of offensive and religiously charged content, which further complicates classification.
| Roman Urdu text | English translation | Label |
|---|---|---|
| Tum kitni ghatiya aur beghairat aurat ho | You are such a vile and shameless woman | Offensive |
| Masjid ko ura do sab kafir hain | Blow up the mosque, all are infidels | Religious hate |
Pre-processing
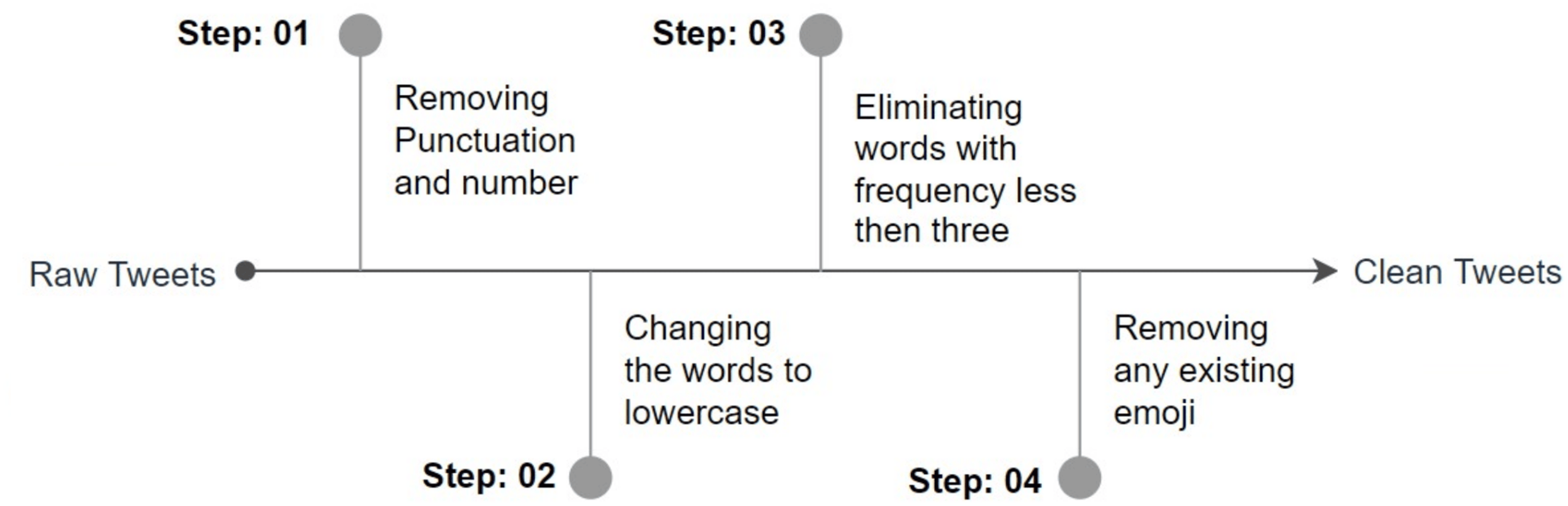
Pre-processing is a fundamental procedure that plays a crucial part in ensuring the accuracy of the classification results. Our pre-processing approach begins with standardizing the information included within each tweet. This involves several steps, including the removal of punctuation and numbers, conversion of words to lowercase, and reduction of word variations and accents. Sparse features that are not essential for learning are removed by eliminating tokens that occur in a document fewer than three times. We observed that this led to an improvement in classification accuracy. Additionally, we removed any existing emojis and encoded the class names using the Label Encoder. All of these tweets were cleaned up using pre-processing techniques, leaving only the natural language text for use in subsequent phases. Figure 4 below illustrates the steps involved in our pre-processing strategy.
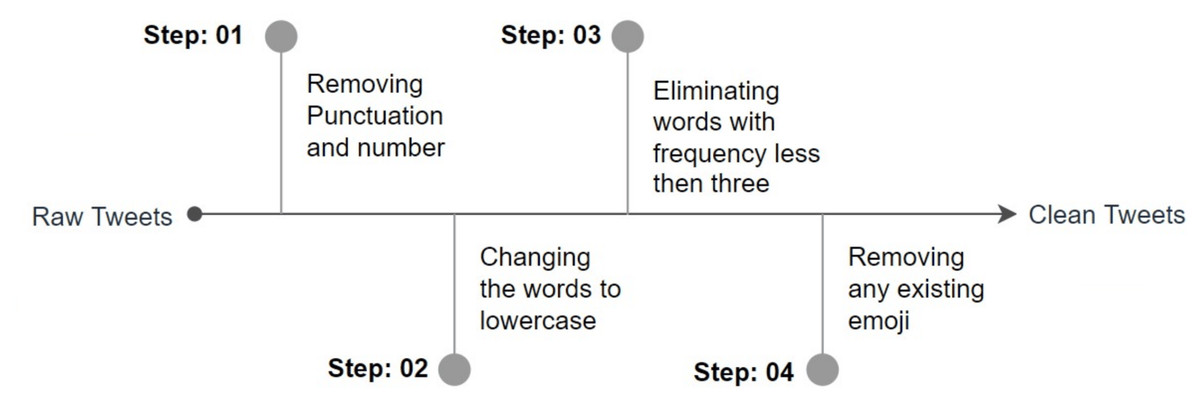
Figure 4: Steps pre-processing.
{kind=link}
Results
This section showcases the outcomes derived from the experiments conducted within this study, elucidating the efficacy of our proposed model. Concurrently, we analyze the implications of these findings within the broader scope of our research objectives. Our results unequivocally demonstrate the superiority of the CNN-BiLSTM model over the baseline model when evaluated against the five alternative models developed and tested. It is essential to note that multiple baseline models were established to facilitate comprehensive comparative analysis.
In the endeavor to identify instances of offensive conversation in Roman Urdu, we have engineered and trained five distinct machine learning models grounded in the encoded representations of the comments. Each of these models possesses its unique hyper-parameter space, encompassing the specific parameters tailored to each learning model. Following the allocation of a validation set from the training data in each of the five folds, rigorous manual scrutiny of the hyper-parameters for each model ensues. For instance, adjustments are made to parameters such as C and kernel in support vector machines, as well as the number of estimators, tree depth, and criteria for random forests. The outcomes derived from these five diverse machine learning models are illustrated in Fig. 5.
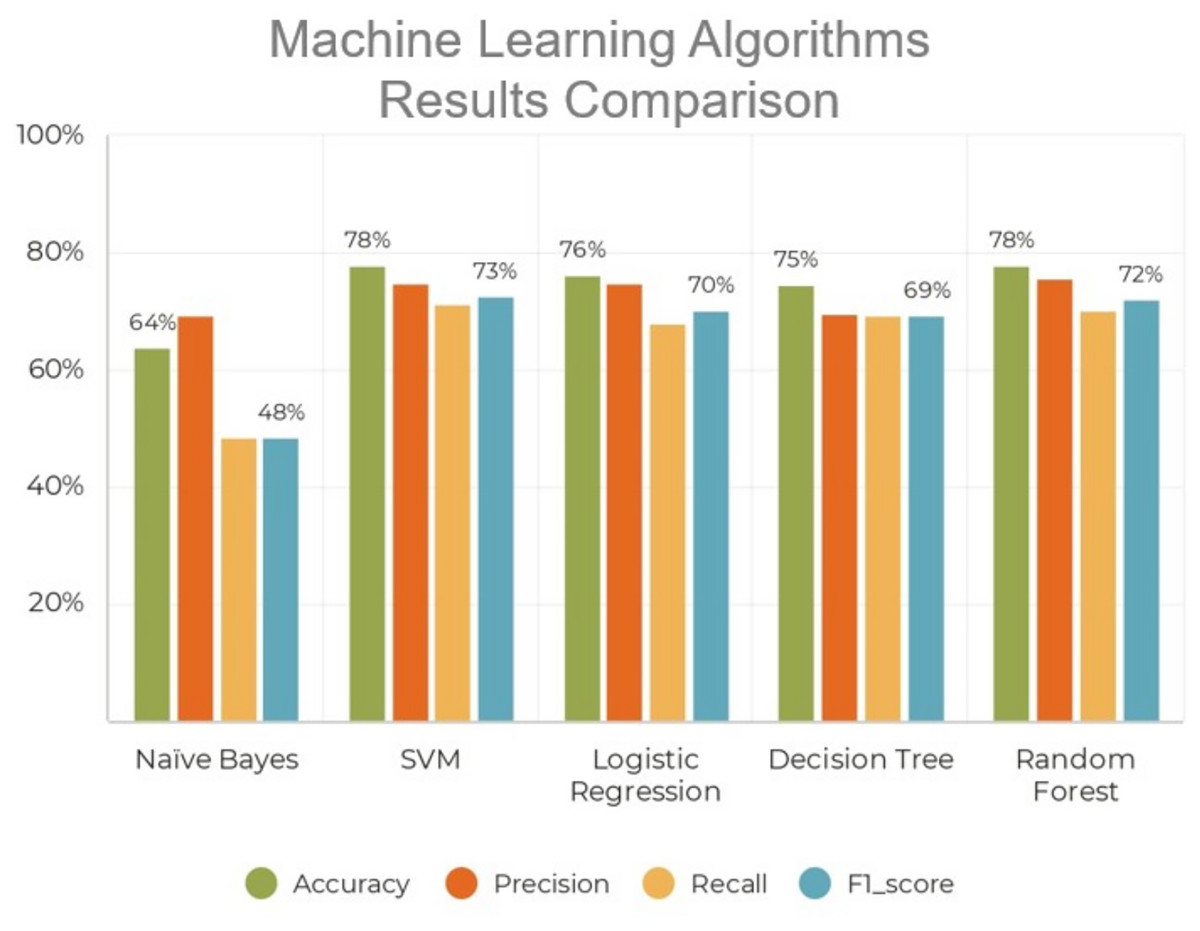
Figure 5: Performance analysis of traditional machine learning algorithms.
{kind=link}
To establish additional baseline models for deep learning, we implemented three models: CNN, BiLSTM, and bidirectional GRU (BiGRU). We then modified our CNN to construct the proposed model by removing the BiLSTM and replacing it with a BiGRU network. This made it possible for us to compare the two architectures and see how the changes affected a core CNN and GRU structure. Furthermore, the second model enabled us to determine whether GRU can extract relevant order information from short communications like tweets. These baseline models were applied to the RUSHOLD datasets, and the results were compared to those obtained by the proposed model, as seen in Fig. 6.
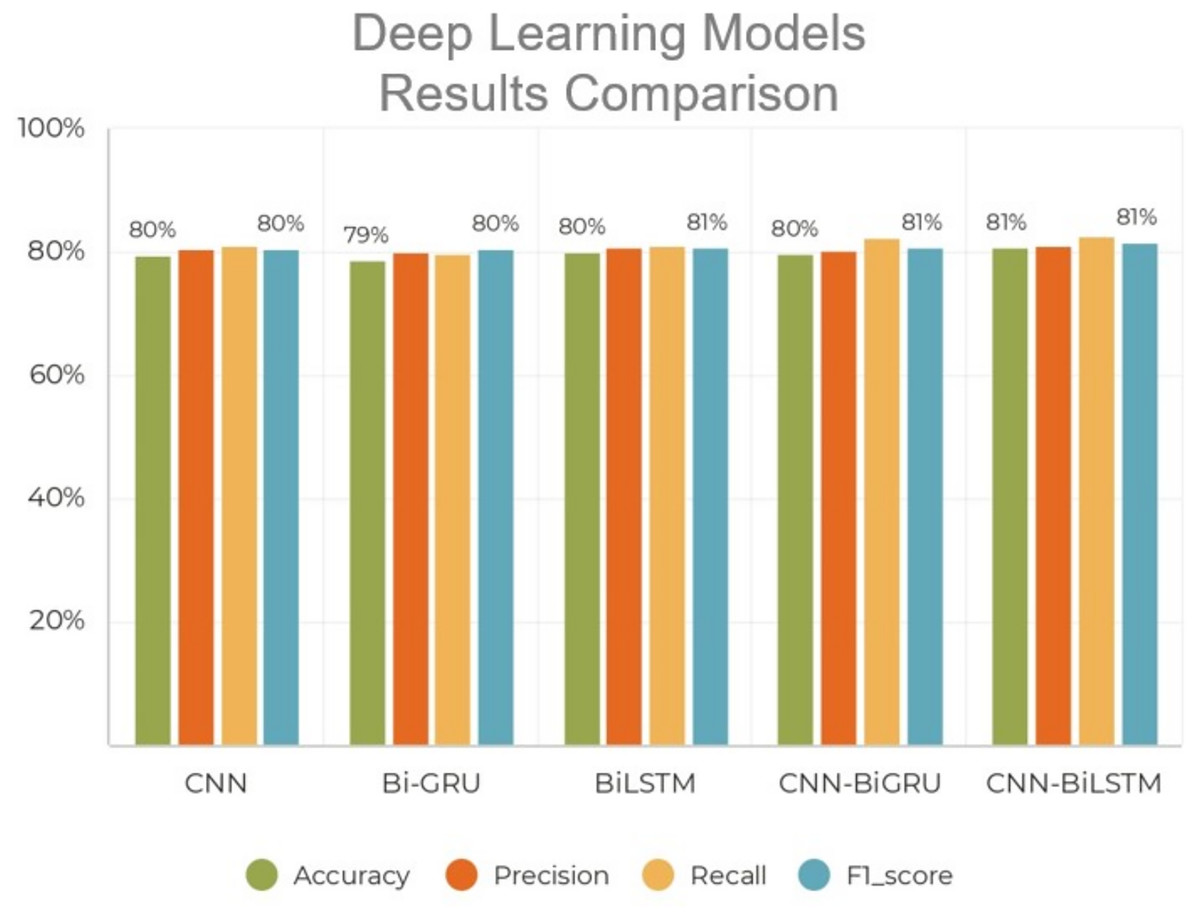
Figure 6: Performance comparison of advanced deep learning algorithms with proposed scheme.
{kind=link}
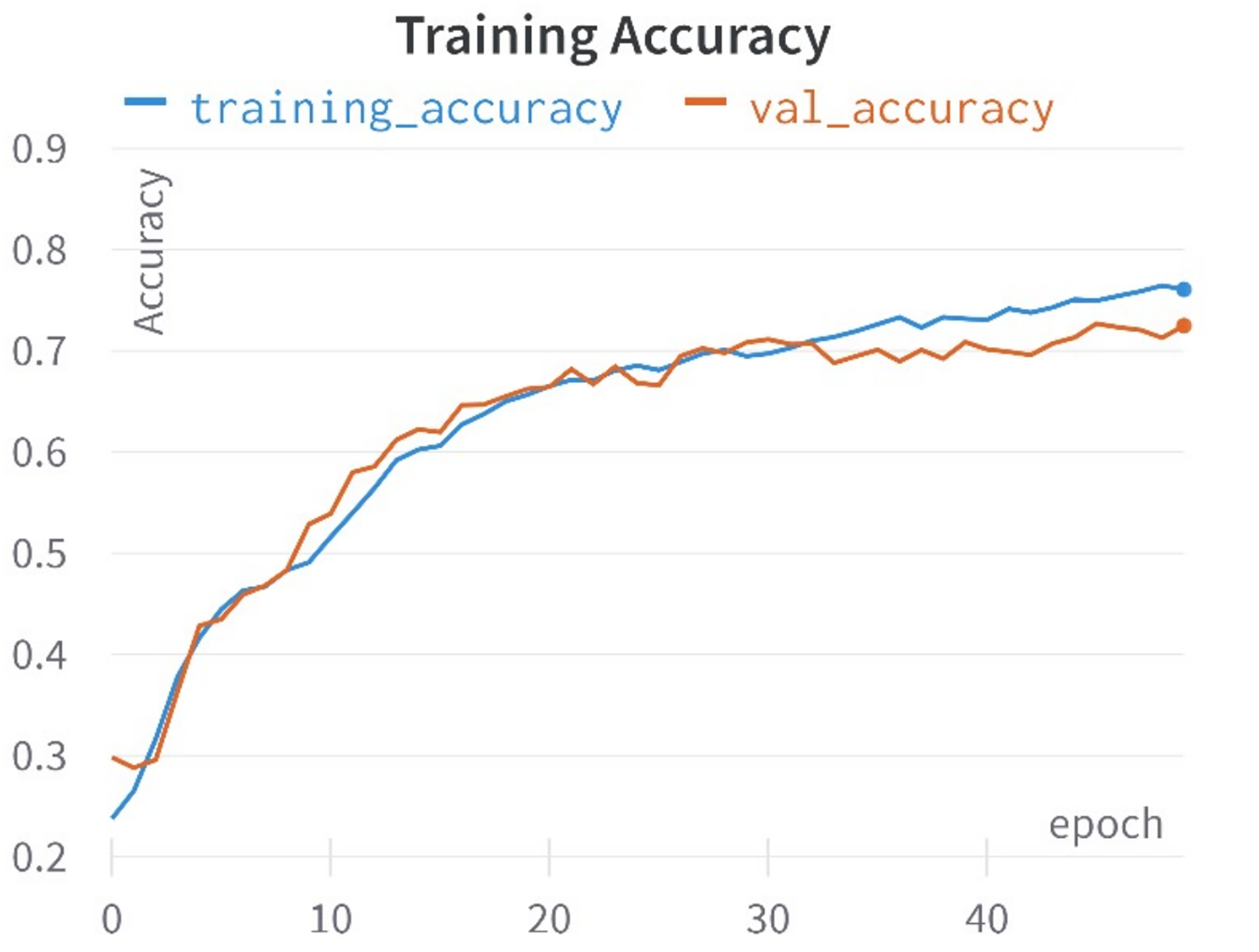
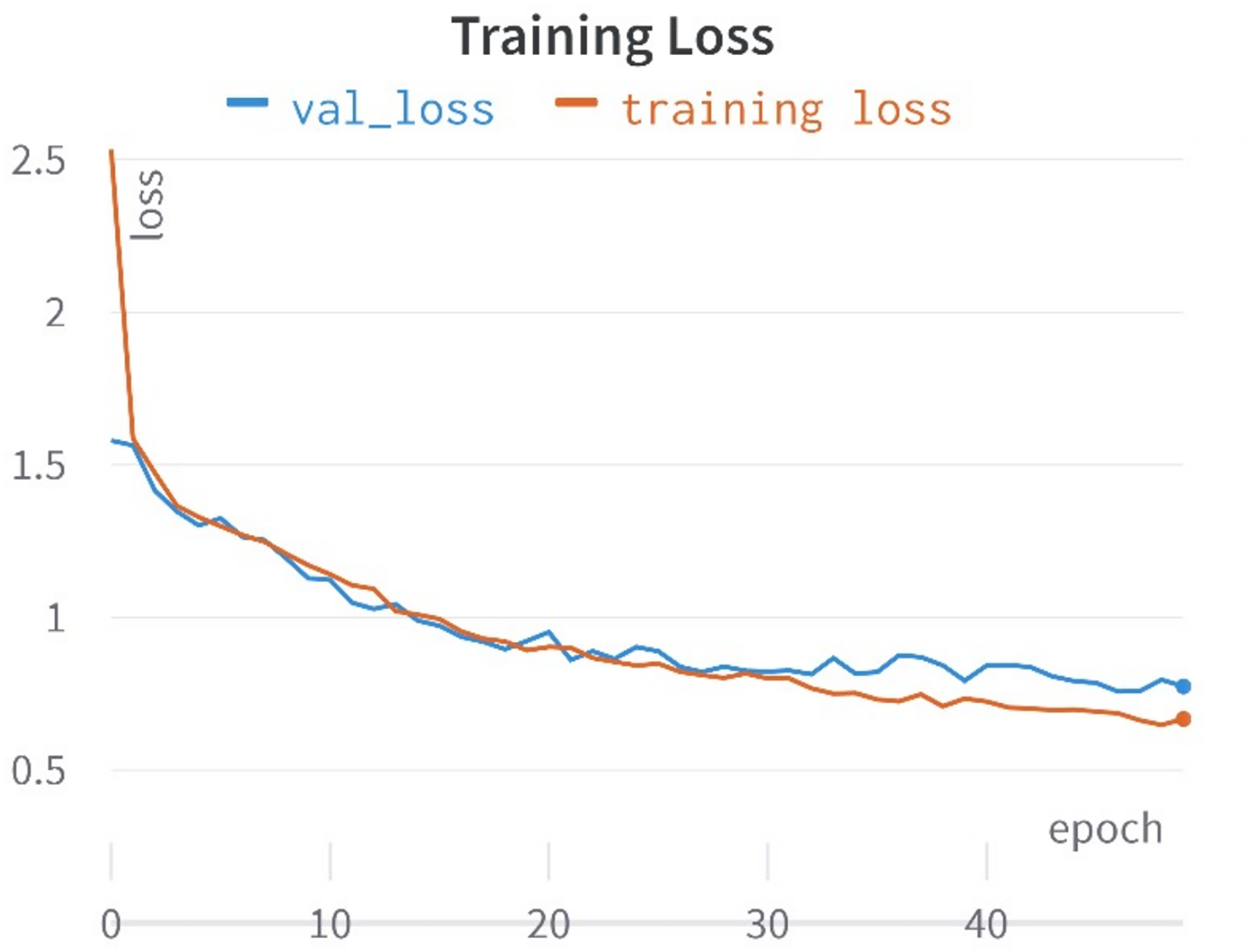
In this study, a comprehensive approach was taken, encompassing the training of 10 distinct learning models rooted in the encoded representations of tweets to identify hate speech in Roman Urdu. Each learning model possessed its distinctive hyper-parameter space, comprising unique parameters tailored to its specifications. To identify the optimal hyper-parameters for each model, a validation set was meticulously preserved from the training data in each of the five folds. These hyper-parameters underwent careful manual scrutiny and adjustment. For instance, parameters such as penalty, C, and solver for logistic regression, the number of estimators, tree depth, and criterion for random forests, as well as penalty, C, kernel, and gamma for support vector machines, Furthermore adjustments were made to: The parameters for deep models were adjusted, including batch size, learning rate decay, weight initialization, dropout rate, regularization, and early stopping. Hyper-parameter optimization was executed with the objective of maximizing the test set’s F1-score. To comprehensively evaluate the models across all folds, average accuracy,recall, precision, and F1-score was calculated for each model. Given the corpus is imbalanced structure, where accuracy might present a misleading picture, F1-score was employed as the primary evaluation metric, as highlighted in prior research (Khan, Shahzad & Malik, 2021). The accuracies and loss curves of the proposed CNN-BiLSTM model are visually shown in Figs. 7 and 8.
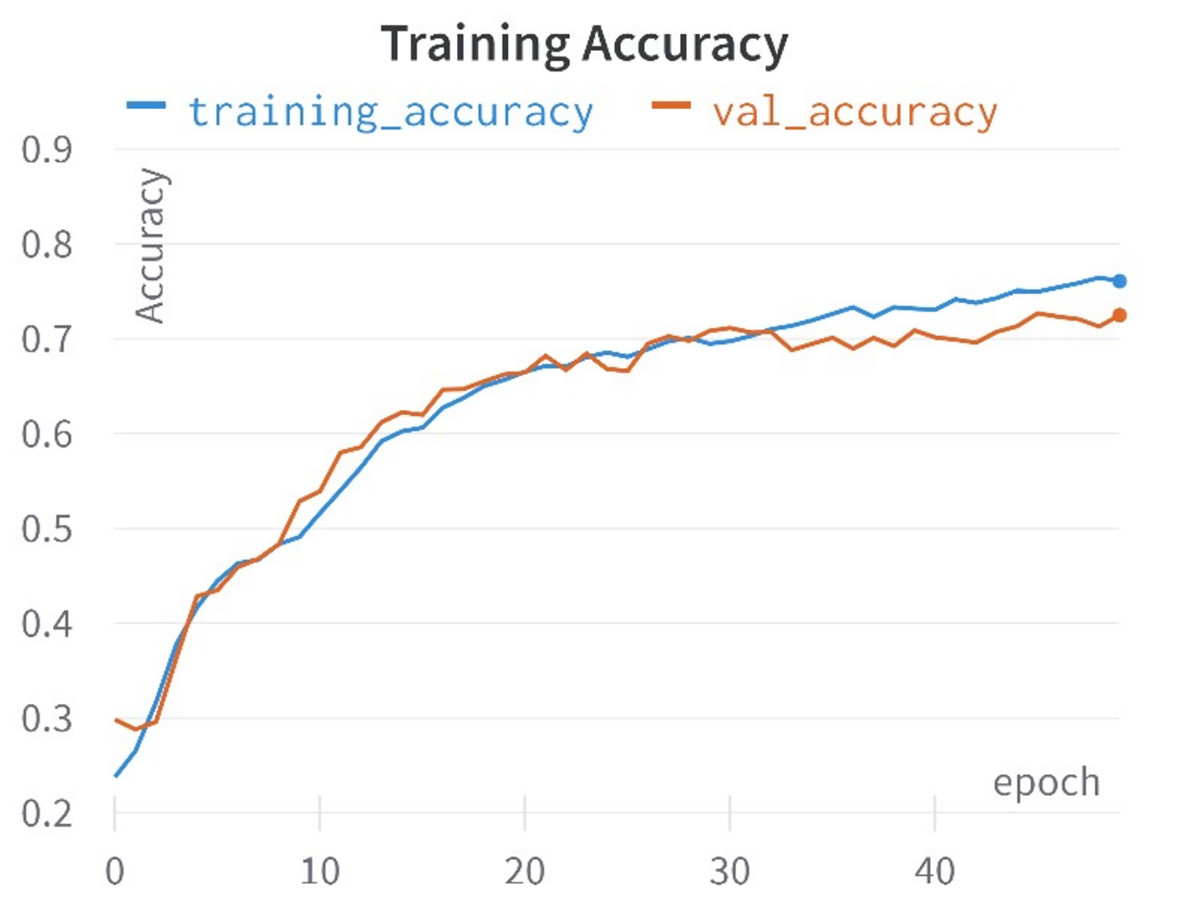
Figure 7: Training and validation accuracy curves.
{kind=link}
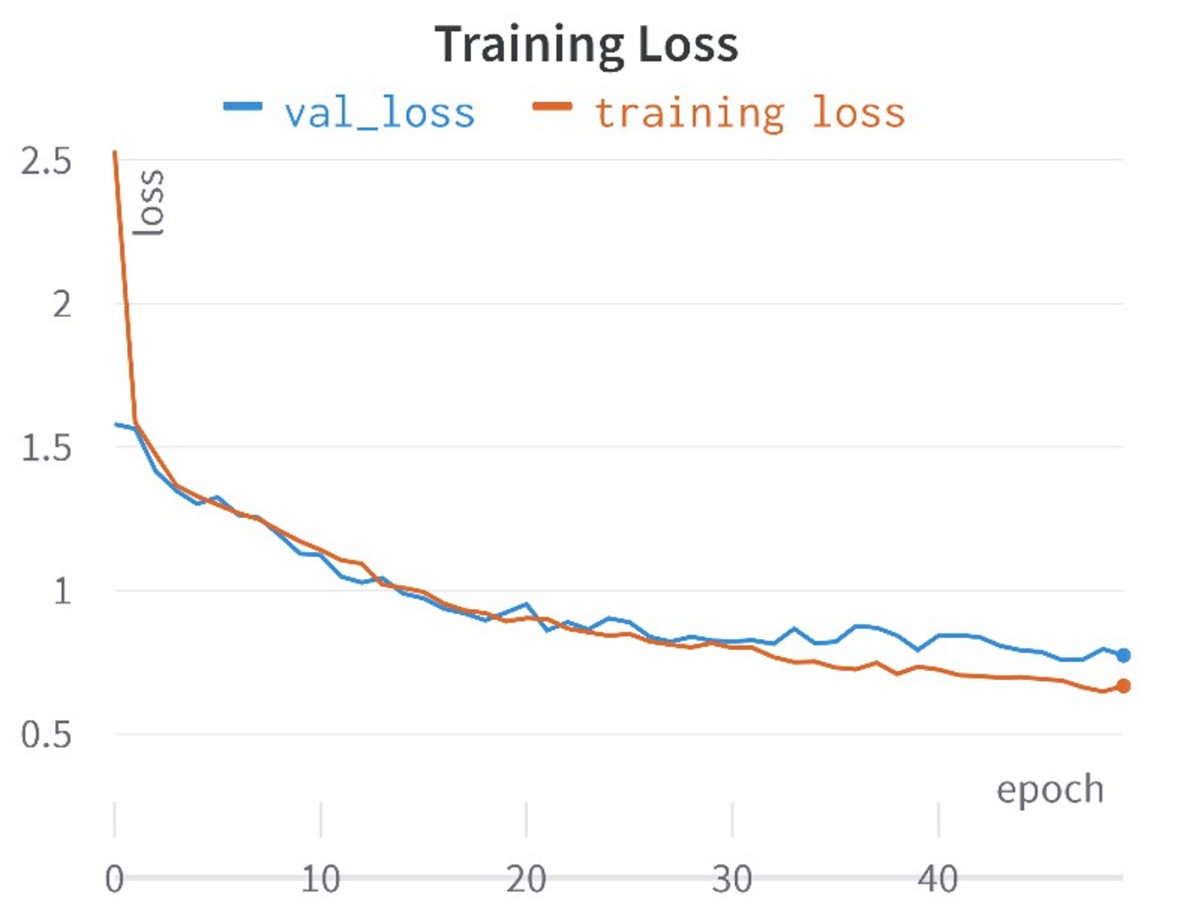
Figure 8: Training and validation lose curves.
{kind=link}
As shown in Table 3, deep learning models significantly outperform traditional machine learning approaches in detecting hate speech in Roman Urdu. The classical models, such as naïve Bayes, logistic regression, and decision tree, demonstrate notably lower F1-scores, primarily due to their limited ability to capture complex linguistic patterns, informal syntax, and code-switching behaviors common in Roman Urdu text. In contrast, deep learning architectures like CNN, BiLSTM, and BiGRU are capable of automatically learning hierarchical and sequential representations from raw text. The combination of convolutional layers (for capturing local patterns) and BiLSTM layers (for modeling long-range dependencies) in our proposed CNN-BiLSTM model further enhances performance, achieving the highest F1-score of 81.47%. This demonstrates the model’s robustness in handling noisy, informal language and its superiority in generalizing across complex data distributions. Additionally, the results highlight the importance of leveraging pre-trained embeddings and end-to-end learning in low-resource and code-mixed language scenarios like Roman Urdu.
| Model | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|
| Naïve Bayes | 62.06 | 43.33 | 28.80 | 26.30 |
| SVM | 75.84 | 72.14 | 61.23 | 65.35 |
| Logistic regression | 73.78 | 73.21 | 51.28 | 56.96 |
| Decision tree | 72.79 | 62.08 | 60.79 | 61.35 |
| Random forest | 75.02 | 73.14 | 57.16 | 62.35 |
| CNN | 79.56 | 80.47 | 80.92 | 80.45 |
| BiGRU | 78.67 | 80.03 | 89.57 | 80.47 |
| BiLSTM | 79.88 | 80.88 | 80.94 | 80.78 |
| CNN-BiGRU | 79.83 | 80.38 | 81.21 | 80.71 |
| BERT-CNN-gram (Rizwan, Shakeel & Karim, 2020) | 80.0 | 75.0 | 74.0 | 75.0 |
| CNN-BiLSTM | 80.67 | 81.03 | 82.57 | 81.47 |
To provide a more detailed analysis of the model’s classification performance, we include the confusion matrix of the proposed CNN-BiLSTM model as shown in Fig. 9. The matrix offers insights into how well the model distinguishes between hate and non-hate speech in Roman Urdu. It highlights the distribution of true positives, true negatives, false positives, and false negatives, allowing us to identify potential areas of misclassification. As observed, the model achieves strong performance in correctly identifying both classes, with a relatively low rate of false positives and false negatives, confirming its effectiveness in handling the nuanced and informal nature of Roman Urdu text.
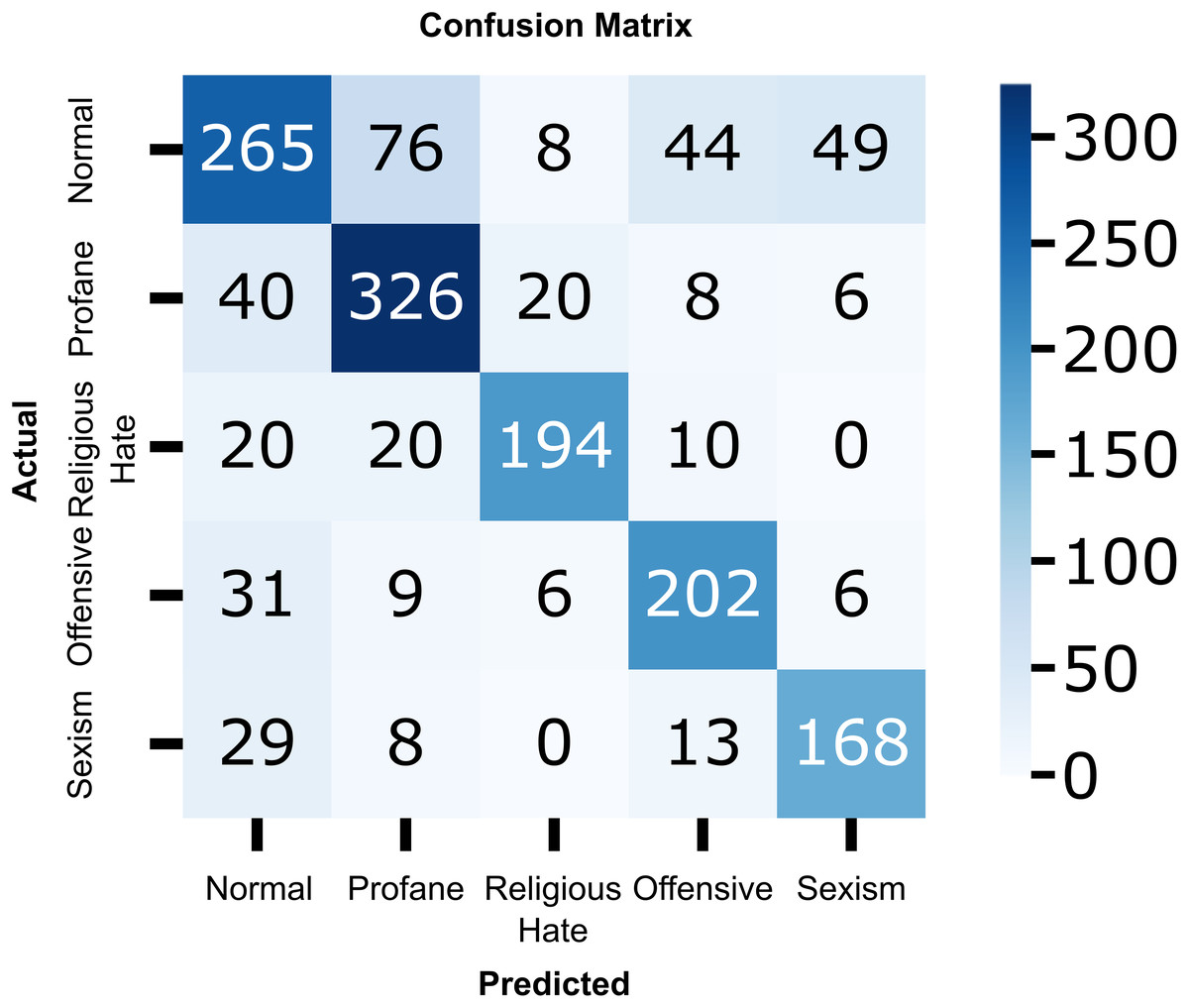
Figure 9: Confusion matrix of the proposed CNN-BiLSTM model.
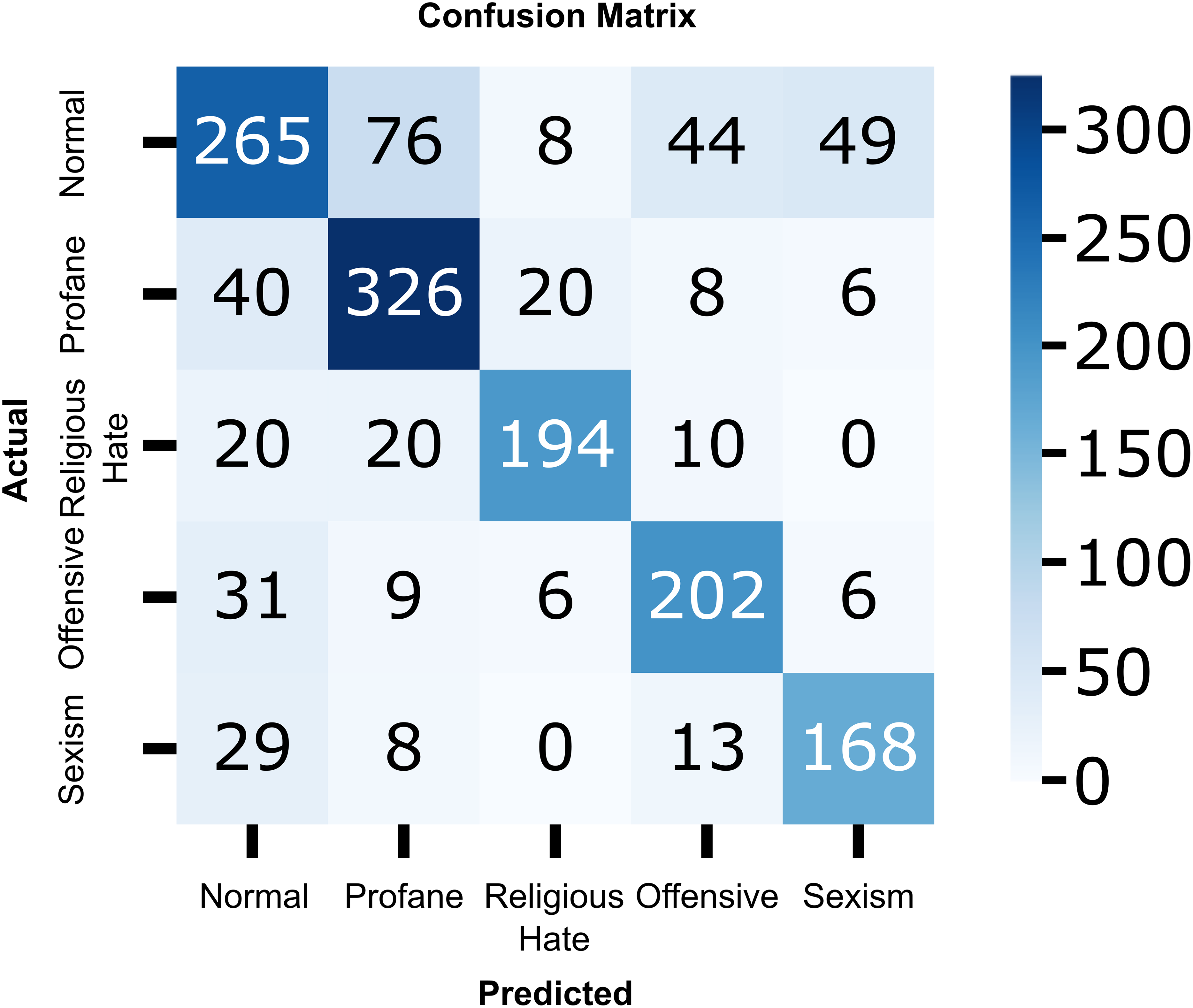{kind=link}
Computational efficiency: To ensure real-world feasibility, we prioritized a lightweight architecture in the model design. All experiments were executed on a single NVIDIA P100 GPU with 16 GB VRAM, using Kaggle notebooks. The proposed CNN-BiLSTM model required approximately 3 min and 17 s for training and 0.425 s for testing. These results underscore the model’s efficiency and potential for real-time deployment in environments with limited computational resources.
Discussion
Our comprehensive evaluation demonstrates that the proposed CNN-BiLSTM architecture exhibits superior performance compared to conventional machine learning algorithms and competing deep learning frameworks. The hybrid model leverages the complementary strengths of CNN and BiLSTM networks, enabling simultaneous extraction of fine-grained semantic patterns and comprehensive modeling of extended contextual dependencies inherent in Roman Urdu text. This dual-stage feature extraction methodology proves particularly efficacious for processing low-resource, code-mixed languages that exhibit substantial linguistic variability and spelling irregularities.
A distinguishing characteristic of the CNN-BiLSTM framework is its demonstrated resilience to noisy, informal Roman Urdu inputs that commonly manifest inconsistent spelling conventions, frequent code-switching phenomena, and colloquial linguistic expressions. The convolutional layers systematically identify salient local linguistic features, while the BiLSTM component effectively integrates these features within broader contextual frameworks, thereby facilitating robust generalization across diverse linguistic phenomena. Furthermore, the initialization with pre-trained Roman Urdu word embeddings substantially enriches semantic representations, effectively mitigating the adverse effects of data sparsity while enhancing overall classification performance. Empirical results across multiple hate speech detection experiments consistently demonstrate that the hybrid CNN-BiLSTM approach achieves superior F1-scores relative to baseline models, including standalone CNN and BiLSTM implementations.
Despite these strengths, certain limitations must be acknowledged. The training process for the CNN-BiLSTM model requires substantial computational resources, which may constrain its practical deployment in resource-limited environments. Additionally, while the proposed approach demonstrates effective generalization on the RUHSOLD dataset, its transferability and adaptability to other low-resource linguistic contexts require systematic.
Conclusion
The proliferation of hate speech on social media platforms has raised serious societal concerns, necessitating the development of automated and scalable detection techniques. In this study, we presented a deep learning-based approach, specifically a hybrid CNN-BiLSTM architecture, for the identification of hate speech in Roman Urdu, a linguistically complex and underrepresented language. The proposed model effectively combines convolutional layers to extract local textual patterns and BiLSTM layers to capture long-range dependencies, resulting in improved classification performance. We evaluated our method on a Roman Urdu dataset and demonstrated that it consistently outperforms several traditional machine learning classifiers and baseline deep learning models in terms of accuracy, precision, recall, and F1-score. Our results highlight the model’s capability to handle non-standard spellings (e.g., “Khoobsurat,” “Khobsorat,” “kubsoret”) and informal expressions typical in Roman Urdu content. Additionally, we investigated the impact of word embedding choices on model performance and discussed user-centered factors such as posting frequency and social engagement. This work establishes a foundation for future research in hate speech detection in low-resource, code-mixed languages. In the future, we aim to extend this study by incorporating multimodal features and evaluating the model across additional datasets to further assess its robustness and generalizability.