
Unravelling handwriting images: deep neural models for dyslexia, dysgraphia, and other learning disabilities detections and classifications: a literature review
- Published
- Accepted
- Received
- Academic Editor
- Consolato Sergi
- Subject Areas
- Artificial Intelligence, Computer Education, Computer Vision, Data Science, Visual Analytics
- Keywords
- Dyslexia, Dysgraphia, Feature extraction, Handwritten images, Learning disabilities, Deep learning
- Copyright
- © 2025 Al Abadleh et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Unravelling handwriting images: deep neural models for dyslexia, dysgraphia, and other learning disabilities detections and classifications: a literature review. PeerJ Computer Science 11:e3296 https://doi.org/10.7717/peerj-cs.3296
Abstract
Background
As a crucial cognitive and motor function, handwriting can reveal dyslexia, dysgraphia, and other neurodevelopmental conditions. With the emergence of AI, deep learning (DL) models can analyze handwriting patterns for early identification and categorization of these conditions with high level of accuracy.
Objective
This study presents a literature review by examining DL models in classifying learning disabilities using handwriting data. It identifies models’ shortcomings and suggests future research directions, improving model accuracy, fairness, and usability.
Methodology
By employing the standard literature guidelines, the authors identified 24 studies from a pool of 502 studies. They extracted dataset details, methodologies, and key findings from the studies.
Findings
The findings indicate the dominance of convolutional neural networks in improving learning disabilities classification through the extraction of fine-grained spatial handwritten patterns. Vision transformers (ViTs) show potential for long-range contextual feature extraction to enhance the model’s generalization capabilities. Despite these advances, dataset size, model generalizability, computational efficiency, interpretability, and real-world deployment continue to be significant challenges.
Conclusions
The review findings underscore the transformative potential of DL-based handwriting analysis in educational and clinical settings, providing early detection and intervention in learning disabilities.
Introduction
Learning disabilities are neurodevelopmental conditions, impairing the brain’s ability to process, store, and respond to information (Niazov, Hen & Ferrari, 2022; Yen, Wong & Chen, 2024). These disabilities, including dyslexia and dysgraphia, cause significant challenges to individuals, educational institutions, and healthcare professionals (Yen, Wong & Chen, 2024). Diagnostic and therapeutic approaches relied on standardized assessments, such as behavioral observations and manual analysis of written content (Schwartz & Kelly, 2021). Although these approaches deliver positive outcomes, they are time-consuming and lack an understanding of the complex patterns associated with these conditions (Georgiadou, Vlachou & Stavroussi, 2022). Dyslexia affects reading and language processing (Georgiadou, Vlachou & Stavroussi, 2022). Despite possessing normal intelligence and access to adequate educational opportunities, individuals with dyslexia face challenges in deciphering words, recognizing patterns, and interpreting written material (Parmenter, 2021). Phonological processing variations in the brain pose significant challenges to individuals in connecting sounds to letters and words (Parmenter, 2021). Consequently, the individuals struggle to remember and organize information. As reading and writing cognitive processes are closely related, dyslexia typically co-occurs with other learning disorders, resulting in inconsistent handwriting.
Dysgraphia is characterized by challenges in writing and fine motor skills (Thapliyal et al., 2022). It typically leads to poor handwriting, uneven letter formation, and difficulties with spelling and grammar. Motor dysgraphia is characterized by problems with fine motor skills and hand-eye coordination, whereas linguistic dysgraphia is characterized by difficulties in converting mental representations into written language (Thapliyal et al., 2022; Yen, Wong & Chen, 2024). Handwriting images may be used to study the writing speed, excessive erasures, and uneven pen pressure of individuals with dysgraphia (Faci et al., 2021; Shin et al., 2023; Mathew et al., 2024; Yen, Wong & Chen, 2024). Understanding the cognitive and physical difficulties associated with dysgraphia may be significantly aided by these visual indicators (Santhiya et al., 2023; Sharmila et al., 2023). Additionally, various learning disabilities may affect handwriting, overlapping with dyslexia and dysgraphia. Attention deficit hyperactivity disorder (ADHD) may cause individuals to have difficulties in maintaining attention and organization, resulting in inconsistent and impulsive writing patterns (Shin et al., 2023). Developmental coordination disorder (DCD) affects motor abilities, causing unsteady handwriting with inconsistent letter sizes (Yasunaga et al., 2024). Individuals with autism spectrum disorder (ASD) frequently exhibit repetitive or rigid writing patterns (Shin et al., 2023; Yasunaga et al., 2024). The coexistence of these conditions influences self-esteem, social relationships, and long-term career prospects. These conditions share common patterns, including irregular spacing, inconsistent pressure, and poor alignment, rendering handwriting images an effective source for learning disability detection (Shin et al., 2023).
The examination of pen strokes, letter construction, and spatial organization offers a unique opportunity to discover dyslexia (Faci et al., 2021; Mahto & Kumar, 2024). Researchers may utilize handwriting images to diagnose dyslexia in the early stages. Minor signs, such as uneven letter spacing, inconsistent scaling, or commonly misspelled words, can be used to distinguish between cognitively neutral and abnormal individuals (Mahto & Kumar, 2024). In recent years, the possibilities for studying and treating learning impairments have emerged with the development of machine learning (ML) models (Alone & Bamnote, 2023; Dinusha, Sreekumar & Lijiya, 2024; Zaibi & Bezine, 2024). Several factors contribute to the need for ML-based learning disability detection models. The primary factor is the increasing awareness of the limitations of conventional diagnostic procedures. These approaches are unable to deliver valuable outcomes. Deep learning (DL) models are advanced ML architectures, offering personalized and scalable solutions, recognizing patterns, and providing data-driven insights (Ahire et al., 2023). These models allow educators and therapists to focus on intervention by automating handwriting, speech, and other behavioral data processing. The proliferation of digital devices, including tablets, styluses, and smart pens, offers an opportunity to collect high-resolution data on handwriting dynamics, such as pen pressure, stroke direction, and writing frequency (Ahire et al., 2023).
Convolutional neural networks (CNNs) are a specialized class of DL models, learning spatial hierarchies of features from the images (Panjwani-Charania & Zhai, 2023). Vision transformers (ViTs) are a type of DL model, using transformers to capture the long-range spatial relationships (Panjwani-Charania & Zhai, 2023). Artificial intelligence (AI)-driven systems may be customized to individual features. For instance, a deep neural network can be trained to identify the unique handwriting patterns related to each subtype of dysgraphia in order to provide more targeted and individualized therapies. Due to a broad spectrum of learning disability symptoms and severity, this customization is essential (Vanitha & Kasthuri, 2021). The incorporation of deep learning models into educational and therapeutic environments may narrow the gap between research and practice. These models allow educators, parents, and clinicians to select intervention techniques with real-time feedback and actionable information (Santhiya et al., 2023). For instance, Predictive analytics may support clinicians in identifying individuals at risk of learning impairments in the initial stages. The existing reviews emphasize the accuracy and performance of DL models in controlled settings. The existing studies lack adequate solutions for key issues, such as data privacy, informed consent, and algorithmic bias, which are critical to the ethical development and deployment of AI-driven solutions (Nawer et al., 2023). Language, cultural, and socioeconomic position biases in DL-based learning disability detection remain unexplored. There is a lack of extensive information regarding the model’s generalizability, leaving educators and clinicians ill-equipped to assess the tools’ applicability to their requirements (Vanitha & Kasthuri, 2021; Ahire et al., 2023; Panjwani-Charania & Zhai, 2023; Dinusha, Sreekumar & Lijiya, 2024). Another significant limitation is the inability to consider the ethical and social consequences. The current reviews lack a critical evaluation of the methodological limitations (Ahire et al., 2023; Vanitha & Kasthuri, 2021; Panjwani-Charania & Zhai, 2023; Dinusha, Sreekumar & Lijiya, 2024). The shortcomings, including small sample sizes and insufficient validations, are not thoroughly analyzed. There is a demand for rigorous and transparent evaluation of the DL-based learning disabilities detection models. A holistic understanding of the challenges associated with developing DL model is crucial for building an explainable learning disability detection model. Moreover, the existing reviews either focused on a single disorder or evaluated algorithmic performance exclusively.
This study presents a literature review of DL applications for detecting dyslexia, dysgraphia, ADHD, ASD, and related conditions using handwriting data. Unlike technical evaluations, it includes algorithmic bias and model generalizability across populations. In addition, this evaluation bridges the gap between clinical and technological viewpoints by identifying the models with the greatest quality of performance and their applicability in real-time educational and healthcare environments. In addition, the study suggests a future research roadmap that places an emphasis on explainable artificial intelligence (XAI), multimodal integration, and lightweight architectures ideal for deployment in low-resource settings. The contributions are as follows:
-
1.
Comprehensive synthesis of existing studies associated with DL-driven learning disabilities detection and classification.
By analyzing studies addressing disorders, such as dyslexia, dysgraphia, and related conditions, this review offers a comprehensive overview of the current state of the field. It highlights the significance of extracting subtle handwriting patterns associated with disorders. Additionally, it presents the strengths and limitations of the existing studies.
-
2.
Identification of research gaps and future directions.
This review emphasizes the importance of developing an interpretable model, offering insights into the underlying patterns of learning disabilities. It highlights the demand for developing models based on multi-modality data, including handwriting, speech, and eye-tracking data. It provides a roadmap for future research, presenting effective and practical solutions for diagnosing and managing learning disabilities. In this review, the authors underscore the significance of addressing ethical concerns, including data privacy, informed consent, and algorithmic bias. This review advocates for the development of inclusive models, emphasizing linguistic, cultural, and socioeconomic diversity. It recommends the use of advanced adaptive techniques, rendering services for different languages. Additionally, it provides guidelines for collecting and using sensitive data.
The remaining part of this study is structured as follows: ‘Survey Methodology’ offers survey methodology for thoroughly analyzing DL models’ performance in handwriting-based learning disability identification. To guarantee clarity and comparability across studies, this framework guides the selection, categorization, and synthesis of relevant literature. The synthesized findings across diverse learning disabilities are presented in ‘Handwriting-based Learning Disabilities Detection Models’. This section reveals the diagnostic potential of DL models. ‘Discussions’ presents the review implications and future research directions. It outlines the ethical framework, ensuring inclusivity, data privacy, and equitable AI applications. Finally, ‘Conclusions’ summarizes the review’s contributions and reinforces its role in guiding future research.
Survey methodology
In this section, we describe the selection criteria and thematic classification, exploring the application of DL models in detecting learning disabilities using handwriting analysis. We synthesize DL-driven studies on learning disability detection and classification aligning with Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (Sarkis-Onofre et al., 2021). This approach encompasses formulating research questions, establishing eligibility criteria, developing a search strategy, selecting studies, extracting data, assessing bias, and synthesizing results. A well-structured research questions are the foundations for the literature reviews. We employ the Population, Intervention, Comparison, and Outcome (PICO) framework to formulate the research questions in this study, ensuring specificity and relevance. The research questions are listed as follows:
Research question 1 (RQ1): How can DL models identify and classify learning disabilities, including dyslexia and dysgraphia, through handwriting?
Research question 2 (RQ2): What are the future avenues to improve the performance of the learning disability detection model? What ethical considerations need to be taken into account, and how can the model design be made more inclusive?
AI-based handwriting analysis, model efficacy, and limitations are considered during the research selection process. The extracted data highlights the features and shortcomings of DL models in addressing dyslexia, dysgraphia, and other learning disabilities. The authors conducted a comprehensive search of databases, including PubMed, IEEE Xplore, Scopus, and Web of Science, in order to retrieve peer-reviewed studies. By using Boolean operators and keyword combinations with key terms, including “deep learning” AND “handwriting analysis” AND “learning disabilities,” “CNNs OR RNN OR transformers” AND “dyslexia OR dysgraphia,” and “pen stroke analysis” AND “AI-based handwriting recognition”, the authors extracted the articles. The relevant literature was obtained using this comprehensive approach. The authors focused on empirical studies using performance indicators such as accuracy, precision, recall, and F1-measure. Non-deep learning, generic handwriting recognition (e.g., OCR), or non-peer-reviewed studies in grey literature or opinion articles were excluded. The inclusion and exclusion criteria are outlined in Table 1. These criteria facilitated the selection of relevant and high-quality studies.
| Criteria | Inclusion | Exclusion |
|---|---|---|
| Study focus | Studies based on the application of DL models | Studies unrelated to learning disabilities and handwriting images |
| Target disabilities | Dyslexia, dysgraphia, and other learning disabilities | Studies focusing on non-cognitive motor impairments |
| Publication type | Peer-reviewed journal articles and conference papers | Non-reviewed literature and unpublished research studies |
| Language | Studies published in English | Non-English and translated studies |
| Data characteristics | Studies using real-world datasets with sufficient details | Studies with insufficient dataset details |
Using eligibility criteria, two independent reviewers examined study titles and abstracts to exclude irrelevant articles. Subsequently, full-text review was conducted to guarantee that the articles aligned with inclusion criteria. Any discrepancies during the selection procedure were addressed through consultation with a third reviewer. To visualize the research selection process, a PRISMA flow diagram is used for recording the total number of studies identified, evaluated, and ultimately included.
In order to maintain uniformity between investigations, data was extracted using a predetermined extraction form. Key features, including study characteristics (authors, year, journal/conference), objective (deep learning and handwriting analysis study aims), methodology (type of DL model, dataset, preprocessing techniques, and evaluation metrics), findings (model accuracy, precision, recall, F1-score), challenges (data scarcity, computational costs, model interpretability), and proposed solutions, were extracted. To identify similarities and trends across the studies, the extracted data were combined.
To synthesize the data, the authors employed qualitative and quantitative methods. The results were classified into key themes through a qualitative thematic analysis. These themes include: (1) Methods for handwriting feature extraction (e.g., stroke pressure, letter spacing, and fluency); (2) DL model architectures (e.g., CNNs vs. recurrent neural networks (RNNs) vs. transformers); (3) challenges with AI-based diagnoses (e.g., data imbalance, model interpretability, bias in training datasets); and (4) clinical applications and implications (e.g., integration into healthcare and educational settings). The authors aggregated model accuracy, precision-recall values, and F1-scores across trials in a quantitative meta-analysis. The review approach, research selection criteria, and data extraction methods were recorded for transparency and reliability, reflecting the current landscape of DL-based handwriting classification in the context of learning disabilities. The following section presents the findings of this survey, establishing a foundation for understanding the significance of handwriting-based DL techniques in identifying learning disabilities.
Intended audience
This review is intended for a multidisciplinary audience, including researchers, practitioners, and policymakers. Specifically, it targets the following groups:
AI and ML researchers: The included studies covers DL models for biomedical, behavioral, or educational data, supporting researchers to understand the current applications of CNNs and vision transformers. Additionally, it provides challenges associated with data imbalance, generalizability, and interpretability.
Clinician, special educators, and neurodevelopmental specialists: This review offers valuable insights into the early detection of learning disabilities, summarizing model capabilities, ethical considerations, and model implementation barriers. It outlines the diagnostic potential of AI-based tools in augmenting traditional assessments.
Policymakers: Using the study findings, policymakers can find guidance on ethical considerations, data privacy, and fairness issues related to the model deployment.
Handwriting-based learning disabilities detection models
This section synthesizes findings from selected studies, emphasizing the role of DL models in diagnosing and classifying learning disabilities. The findings are organized into three categories based on the specific conditions: dysgraphia, dyslexia, and other neurodevelopmental disorders. The methodological approaches, dataset characteristics, handwriting sample types, and performance metrics reported in the studies are presented in this section. This structured analysis lays the groundwork for broader insights into their effectiveness and potential for real-world deployment.
Figure 1 presents the extraction process based on the PRISMA standards. The identification phase involves a comprehensive search across multiple databases, including PubMed, Scopus, IEEE Xplore, and Web of Science, resulting in the identification of 502 studies.
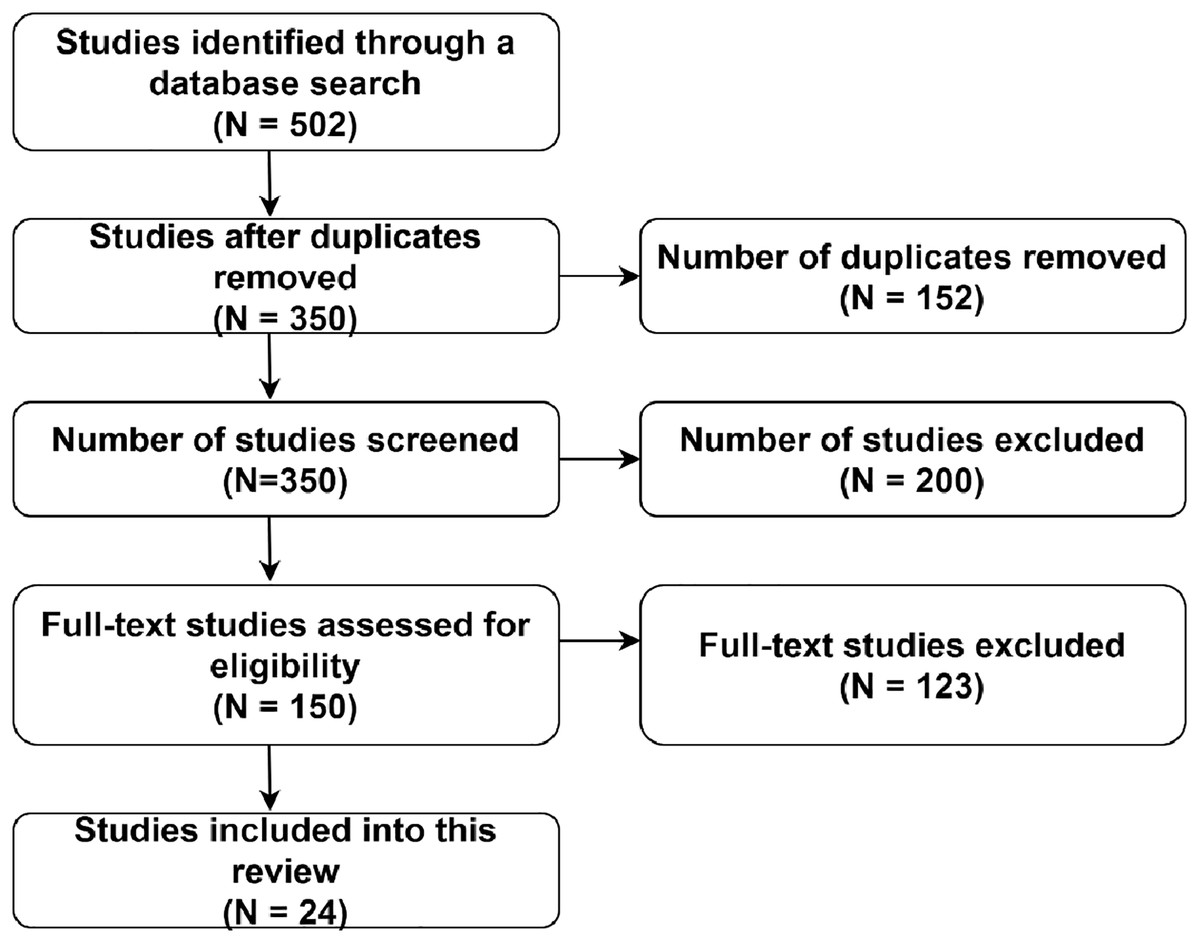
Figure 1: PRISMA flow diagram.
{kind=link}
Figure 2 presents the trends in the number of publications, focusing on the use of DL models in detecting learning disabilities, over the period from 2017 to 2024. It reveals significant insights into the evolution of the novel DL models. The period between 2017 and 2019 reflects the early stages of research based on DL models. During this phase, the research communities explore the foundational aspects of integrating AI with cognitive and motor impairments. The lack of large annotated datasets may have contributed to this slow progress. Between 2020 and 2022, the research outputs experienced a gradual rise. The introduction of accessible and cost-effective devices allowed researchers to collect high-quality handwriting datasets. In 2023, there is a significant surge in publications, reflecting a heightened interest among researchers in handwriting-based learning disability detection. The technological advancements in neural network architectures enabled the development of models to handle complex handwriting patterns with high accuracy. However, the year 2024 indicates a slight decline in research outputs. The slow pace of publications may reflect the prioritization of ethical considerations and inclusivity in model development, enhancing the quality of learning disability detection.
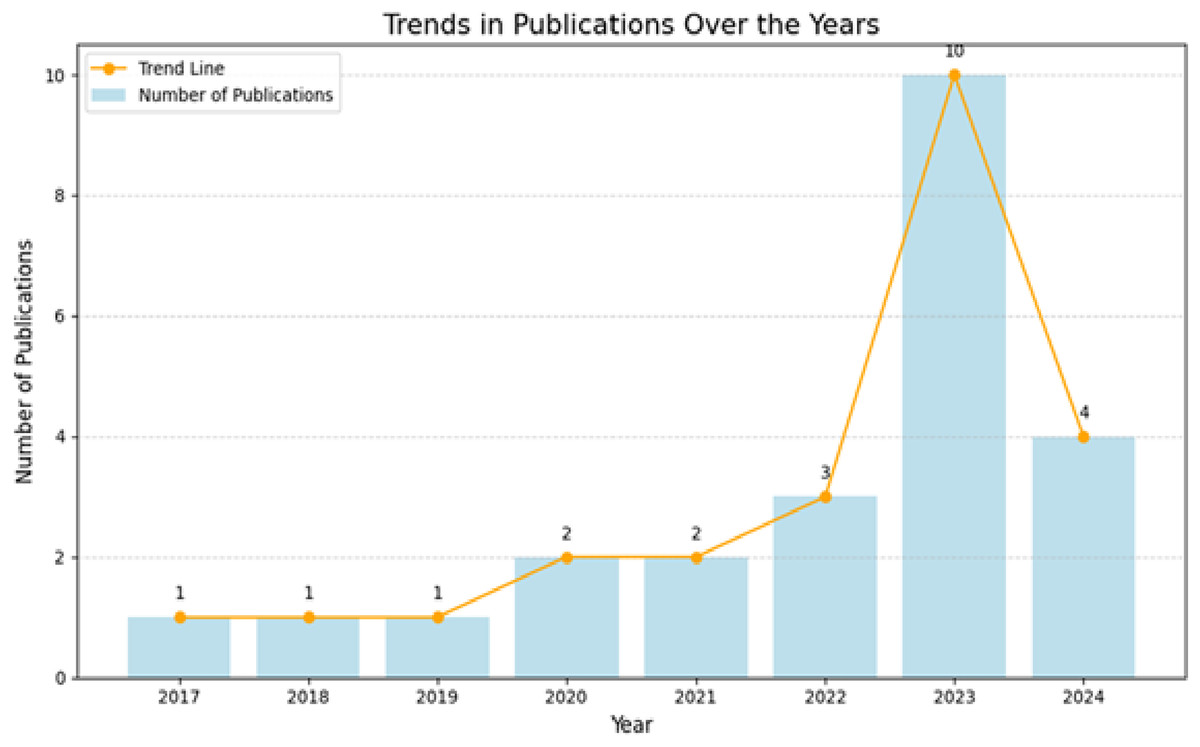
Figure 2: Publications per year.
{kind=link}
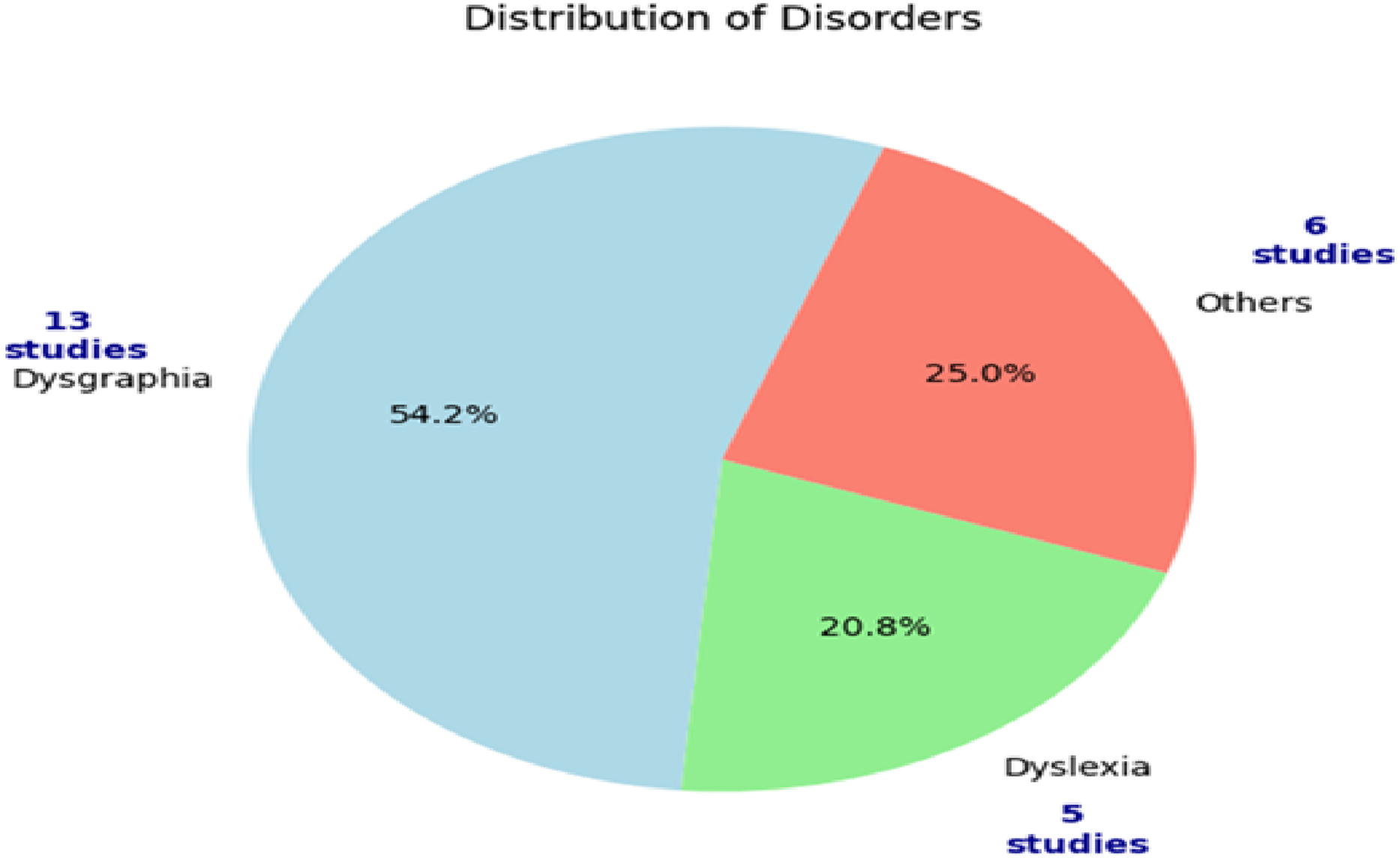
Figure 3 illustrates the distribution of the reviewed studies. It highlights that 54.2% of the studies focused on dysgraphia while dyslexia (20.8%) and other conditions accounted for 25.0%. The focus on dysgraphia indicates the importance of handwriting analysis as a diagnostic tool for this condition. The strong connection between this condition and handwriting motivated the researchers to build automated tools for the dysgraphia detection. Due to the reliance on other modalities, dyslexia detection based on handwriting is lesser than dysgraphia detection. The remaining studies emphasized other disabilities, including autism spectrum disorder (ASD) and attention deficit hyperactivity disorder (ADHD). These studies highlight the significance of handwriting analysis in uncovering neurological and developmental disorders.
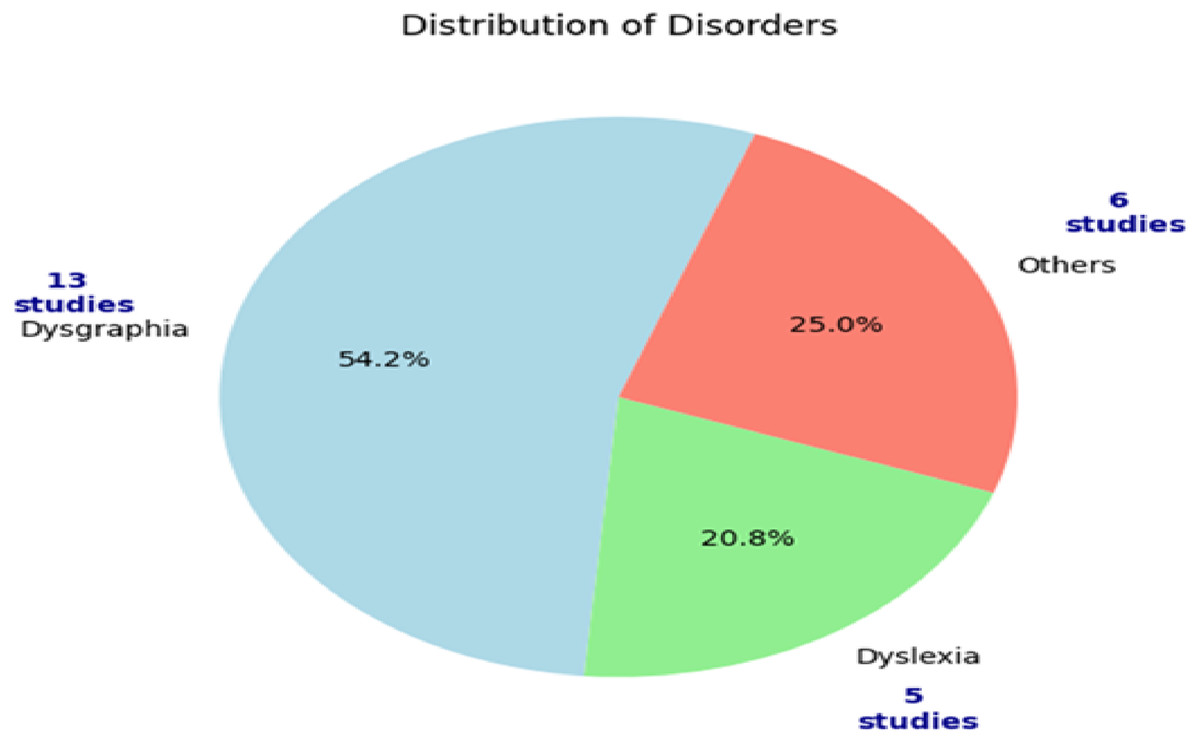
Figure 3: Classifications of included studies.
{kind=link}
Identification of learning disabilities using the key features
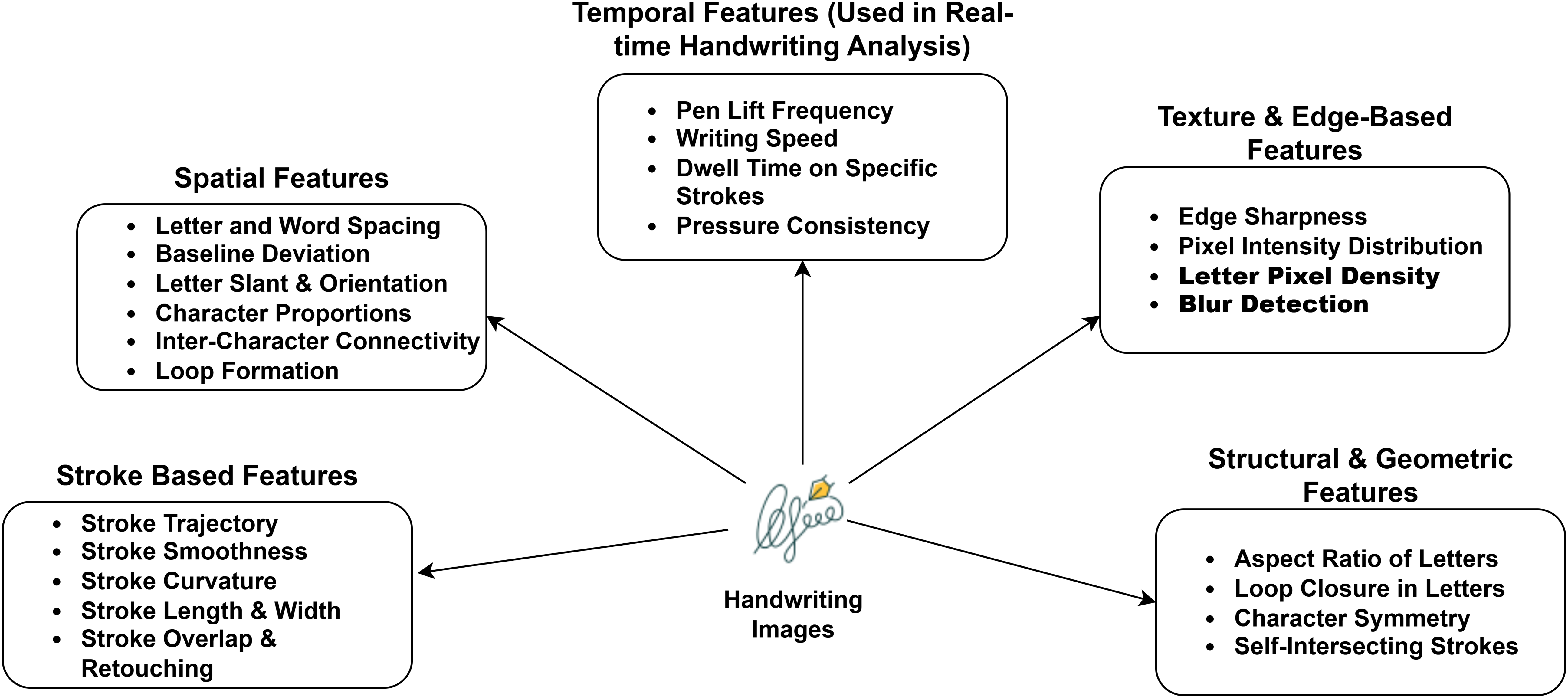
The review of 24 studies demonstrates the significance of handwriting images in diagnosing learning disabilities. These studies cover various conditions, including dysgraphia, dyslexia, and other learning disabilities. Handwriting requires fine motor skills, cognitive planning, and spatial awareness, offering a rich dataset to DL models. Through handwriting analysis, the studies uncover and categorize learning disabilities. With the use of multiple convolutional layers, CNNs capture intricate handwriting features. These models identify basic visual features such as edges and curves. Subsequently, the extracted features are refined in order to recognize higher-order structures, including letters, shapes, and stroke formations. Darker or thicker regions in the image typically indicate higher pressure while writing. However, features like pressure are deduced indirectly from pixel intensity and stroke width. Analyzing stroke continuity, curvature, and intersection points helps in approximating trajectory characteristics. Despite the lack of temporal data in images, CNNs use spatial clues to reconstruct probable sequences of strokes. Features such as uneven spacing, jagged contours, and abrupt directional shifts may be used to evaluate velocity and fluency, which are frequently disrupted in individuals with motor or cognitive impairments. To improve the extraction of inferred temporal relationships from image-based data, more complex systems integrate CNNs with sequence models such as long short-term memory (LSTMs) or ViTs, allowing the extraction of pseudo-kinematic features from handwriting samples for complex diagnostic categorization without real-time input. Figure 4 outlines the features, such as stroke-based, spatial, temporal, texture, edge, structural, and geometric, serving as critical indicators in evaluating handwriting irregularities associated with learning disabilities. However, these features are not universally applicable to all types of learning disabilities. Certain features are more indicative of specific conditions. Stroke-based and temporal features are relevant to dysgraphia and ADHD. For instance, children with dysgraphia and ADHD are frequently display inconsistent stroke length, frequent pauses, or unnatural pressure variation. Texture and edge features are associated with dyslexia detection, supporting to identify letter reversals, uneven spacing, and irregular shapes. Structural and geometric features, such as shape symmetry, letter height, and line alignment, are useful in identifying ASD.
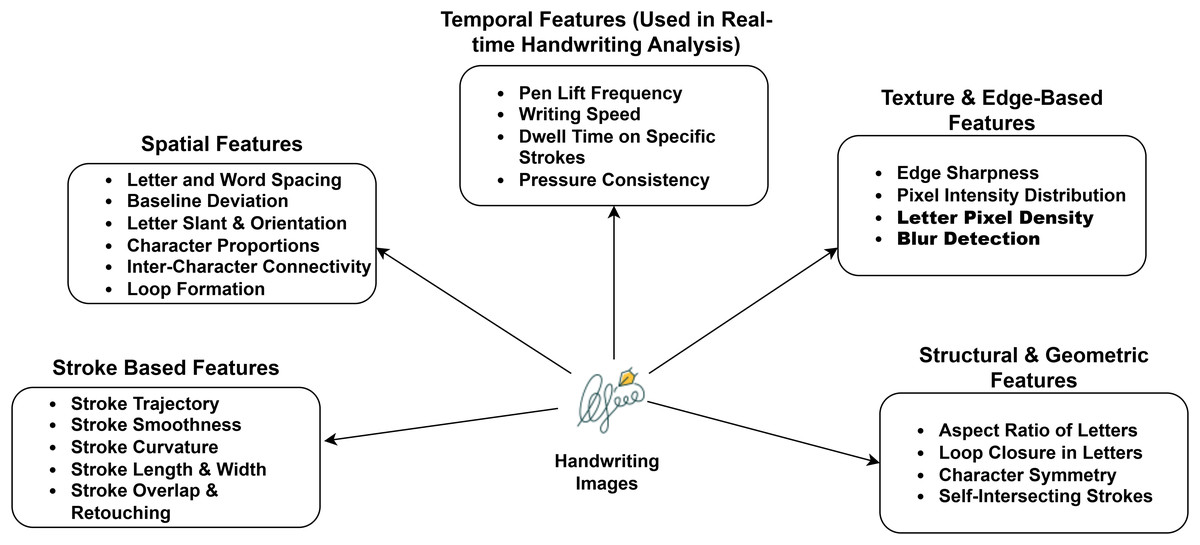
Figure 4: Key features.
{kind=link}
Dysgraphia detection
Table 2 presents the characteristics of DL-based dysgraphia detection models. It outlines various classification techniques, feature extraction approaches, and neural network architectures. The models rely on spatial, temporal, and kinematic handwriting features for differentiating typically normal individuals from individuals with dysgraphia. CNNs were typically used for extracting fine-grained spatial features. Drotár & Dobeš (2020) used sigma-lognormal models and CNNs to organize strokes into the kinematic components, revealing learning disability-related motor planning and execution deficits. Kedar (2021) used letter-spacing and writing fluency features to identify dysgraphia. Similarly, Gemelli et al. (2023) discussed the importance of stroke patterns and tremors in dysgraphia detection. Visual kinematics and feature fusion techniques were employed for improving the classification accuracy. Tablet-based models, including (Asselborn et al., 2018; Asselborn, Chapatte & Dillenbourg, 2020) are ideal for analyzing children’s handwriting, capturing dynamic features such as stroke pressure, writing fluency, and pen velocity. The lack of temporal resolution and dependence on spatial patterns reduce the performance of models based on scanned images. Feature-rich approaches, including (Kedar, 2021) and (Sharmila et al., 2023) report high accuracy due to use of the high-resolution images. However, these models encounter challenges in extracting crucial features related to the disorders. The majority of the models depend on private or language-specific datasets, limiting its generalizability. CNNs-based models offer promising outcomes in real-time settings. However, broader dataset diversity and lightweight deployment architectures are essential to enhance accessibility and inclusiveness.
| Authors | Dataset | Sample type | Data availability | Methodology | Key findings | Limitations |
|---|---|---|---|---|---|---|
| Rosenblum & Dror (2017) | Handwriting of 50 cognitively normal and 49 children with dysgraphia | Scanned | Private | Handwriting kinematic feature classification | Accuracy: 89.9% | Dataset homogeneity affects generalizability |
| Sensitivity: 90.0% | ||||||
| Specificity: 90.0% | ||||||
| Receiver operating | ||||||
| Characteristic: 0.91 | ||||||
| Asselborn et al. (2018) | Handwritings of 448 children | Digital tablet | Public | CNNs-based tablet model | Sensitivity: 96.6% | Reliance on Latin script |
| Specificity: 99.2% | ||||||
| F1-score: 97.98% and | ||||||
| False positive rate: 0.78 | ||||||
| Dankovičová, Hurtuk & Fecilak (2019) | Handwritings of 78 children | Scanned | Not specified | Random Forest classification model | Accuracy: 76.2 ± 3 | Limited linguistic representation |
| Sensitivity: 75.8 ± 5 | ||||||
| Specificity: 76.6 ± 9 | ||||||
| Drotár & Dobeš (2020) | Handwriting images of 120 Children | Scanned | Not specified | Sigma-lognormal model with machine learning classifiers | Accuracy: 79.5% | Language specific analysis and fixed writing tasks |
| Sensitivity: 79.7% | ||||||
| Specificity: 96.17 | ||||||
| Asselborn, Chapatte & Dillenbourg (2020) | Handwritings of 448 children | Tablet | Public | Utilized visual kinematic markers using CNNs | Sensitivity: 91.0% | Participants were native French students |
| Specificity: 90.0% | ||||||
| Kedar (2021) | Handwritings of 59 children | Digital stylus | Not specified | CNNs based classification using letter spacing and writing fluency | Accuracy: 92.59% | Lacks real-time corrective feedback for handwriting improvement |
| Precision: 92.85% | ||||||
| Recall: 92.85% | ||||||
| F1-score: 92.85 | ||||||
| Gouraguine, Qbadou & Mansouri (2022) | Handwritings of 110 children | Digital | Not specified | Robot aided data collection with DL-based classification | Accuracy: 75.0% | Moderate model accuracy |
| Recall: 75.0% | ||||||
| Precision: 66.0% | ||||||
| Specification: 75.0% | ||||||
| F1-score: 67.0% | ||||||
| Sharmila et al. (2023) | 810,000 isolated character images | Digital | Private | Ensemble learning approach | Accuracy: 98.22% | Fixed image resolution |
| Sensitivity: 95.84% | ||||||
| Specificity: 96.17% | ||||||
| Kunhoth et al. (2023) | 480 images | Scanned | Not specified | CNN based feature fusion | Accuracy: 97.3% | High computational resources |
| Lomurno et al. (2023) | Handwriting of 210 children (99 Female and 111 Male) | Digital tablet | Private | Accuracy: 84.62% | Integrated DL and Procrustes analysis | High false negatives rate |
| Precision: 100 | ||||||
| Recall: 6.25% | ||||||
| F1: 11.76% | ||||||
| Gemelli et al. (2023) | 475 handwriting lines of children and 106 handwriting pages of adults | Scanned | Private | DL classifier with pre-trained CNNs. | Precision: 0.819 ± 0.080 | Focus on single language, lacking diversity |
| Recall: 0.802 ± 0.063 | ||||||
| F1-score: 0.800 ± 0.061 | ||||||
| Bublin et al. (2023) | 12 Female and 10 Male | Digital | Private | SensoGrip-based DL analysis | Accuracy: 99.8% | Hardware dependent data collection and Small dataset |
| F1-score: 97.7% | ||||||
| Root mean square deviation: 0.68 | ||||||
| Ramlan et al. (2024) | 267,930 images | Digital | Not specified | Customized CNN architecture | Sequential Network (Accuracy: 86.0%) | Limited scope for multimodal integration |
| Directed acyclic graph network (Accuracy: 87.75%) |
Dyslexia detection
Table 3 highlights the performance of DL-based dyslexia detection models. The models were based on CNN, hybrid architectures, and deep feature extraction techniques. The studies showcase the effectiveness of the models in achieving classification accuracy greater than 99.0%. For instance, Alkhurayyif & Sait (2023) integrated CNN and gradient boosting algorithms to detect abnormal handwriting patterns. Similarly, Alqahtani, Alzahrani & Ramzan (2023), employed a DL model with feature engineering for analyzing images. They extracted features, including letter reversals, inconsistent spacing, and stroke fluidity variations, for the image classification. From a reproducibility standpoint, these approaches are commendable and essential for benchmarking and transparency in future research. Jasira, Laila & Jemsheer Ahmed (2023) explored CNN and long short-term memory (LSTM) models to identify temporal dependencies in handwriting sequences. However, the absence of data availability limits the performance of these models. The type of handwriting samples and data availability significantly influence the model’s interpretability and deployment readiness.
| Authors | Dataset | Sample type | Data availability | Methodology | Key findings | Limitations |
|---|---|---|---|---|---|---|
| Sasidhar et al. (2022) | 78,275 Normal, 52,196 Reversal, and 8,029 Corrected samples | Digital | Not specified | Residual neural network | Accuracy: 90.0% | High computational demand |
| Precision: 97.6% | ||||||
| Recall: 97.6% | ||||||
| F1-score: 97.5% | ||||||
| Alkhurayyif & Sait (2023) | 208,372 images | Digital | Public | CNNs and gradient boosting algorithms | Accuracy: 99.2% | Absence of clinical validation |
| Precision: 96.8% | ||||||
| Recall: 97.3% | ||||||
| F1-score: 97.6% | ||||||
| Alqahtani, Alzahrani & Ramzan (2023) | 176,673 images | Digital | Public | Hybrid DL models with feature engineering | Accuracy: 99.33% | Limited dataset diversity and real-time testing |
| Precision: 99.13% | ||||||
| Recall: 99.4% | ||||||
| F1-score: 99.2% | ||||||
| Jasira, Laila & Jemsheer Ahmed (2023) | 86,115 images | Digital | Private | CNN-LSTM hybrid model | Accuracy: 98.2% | Lack of real-time handwriting tracking |
| Precision: 97.5% | ||||||
| Recall: 98.9% | ||||||
| F1-score: 98.2% | ||||||
| Aldehim et al. (2024) | 39,912 images of NIST special database 19 | Digital | Public | Customized CNN model | Accuracy: 96.4% | High computational costs |
| Precision: 95.0% | ||||||
| Recall: 96.0% | ||||||
| F1-score: 96.0% |
Other learning disabilities detection
Table 4 outlines the significance of DL models in detecting ADHD, ASD, and other cognitive impairments. These models utilize CNNs, ViTs, and multimodal approaches to extract features associated with neurodevelopmental disorders. Faci et al. (2021) used pen stroke kinematics to analyze handwriting patterns of ADHD individuals, achieving an accuracy of 90.78%. Vilasini et al. (2022) implemented a hybrid model through the integration of CNN and ViT models. They revealed the capabilities of ViTs in capturing long-range dependencies in handwriting images. Shin et al. (2023) developed a multi-feature ML model for classifying ADHD and ASD. Nawer et al. (2023) showed the effectiveness of multi-modal approaches by combining handwriting and electroencephalogram (EEG) signals, enhancing classification performance. The absence of open datasets, variability in sample types, and hardware dependencies present challenges in model deployment. For instance, Yen, Wong & Chen (2024) is tailored to Chinese character patterns, limiting its generalizability. The standardization of input formats and broader language presentation are crucial for developing effective diagnostic models to serve neuro-diverse populations.
| Authors | Type of learning disabilities | Dataset | Sample type | Data availability | Methodology | Key findings | Limitations |
|---|---|---|---|---|---|---|---|
| Faci et al. (2021) | ADHD | Handwriting of 12 children | Digital | Public | DL model based on pen stroke kinematics | Accuracy: 90.78% | Require optimization for real-world applications |
| Vilasini et al. (2022) | Cognitive disorders | 22,000 images | Digital | Not specified | CNN and ViT with hybrid feature extraction | CNN Accuracy: 79.47% | Lack of external validation |
| ViT Accuracy: 86.22% | |||||||
| Shin et al. (2023) | ADHD and ASD | Handwriting of 29 children | Digital | Private | Multi-feature ML model for ADHD and ASD | Accuracy: 93.1% | Bias in datasets towards specific languages |
| Precision: 95.0% | |||||||
| Recall: 90.48% | |||||||
| F1-score: 92.68% | |||||||
| ROC: 0.93 | |||||||
| Nawer et al. (2023) | ASD | Handwriting of 17 children | Digital | Not specified | SWIN transformer with EEG multi-modal fusion | Accuracy: 98.0% | Computationally expensive for deployment |
| F1-score: 98.0% | |||||||
| ROC: 0.98 | |||||||
| Cohen’s Kappa: 0.97 | |||||||
| Mathew et al. (2024) | ASD | 90 images | Scanned | Not specified | Customized CNN | Specificity: 99.2% | Requires specialized hardware |
| Sensitivity: 98.9% | |||||||
| Yen, Wong & Chen (2024) | ASD | Handwriting of 27 children | Scanned | Not specified | Fine-tuned CNN | F1-score: 93.6% | Rely on Chinese character patterns |
The following section builds on these insights to draw cross-condition comparisons. It proposes future directions for advancing the field of learning disability detection.
Discussions
Based on the comparative outcomes presented in the previous section, this section delves deeper into the implications of the selected studies. The study findings have significant implications for healthcare professionals, academics, and AI developers. The authors addressed RQ1 and RQ2 by providing strengths and limitations of existing models and future avenues for developing effective, inclusive AI-driven learning disabilities detection applications. Inconsistent letter sizes, slow writing rates, excessive pen pressure, and frequent corrections were the primary characteristics of dysgraphia handwriting. Likewise, dyslexic handwriting includes letter reversals, improper spacing, and unusual stroke sequences. The diagnostic accuracy has been greatly enhanced by the ability of DL algorithms to autonomously extract these micro-patterns. Several studies compared traditional diagnostic procedures, including neuropsychological evaluations and handwriting screening tests, with DL-based handwriting analysis. DL models provide standardized evaluations with consistent performance, whereas traditional approaches are typically affected by subjectivity and inter-rater variability. Based on the results, AI-based handwriting assessments are faster, objective, and scalable. However, these models lack the contextual knowledge and clinical experience of human investigators, affecting the reliability of their outcomes.
Quality and risk of bias in included studies
The existing DL models are effective in identifying handwriting-based learning disabilities. Focusing on handwriting-based models may introduce selection bias, neglecting potential studies associated with learning disabilities. Additionally, several limitations prevent its widespread application in clinical and educational contexts. The limitations include dataset problems, computational limits, model interpretability, and real-world validation. Addressing these limitations is crucial for developing a dependable AI-powered handwriting analysis tool for practical application.
The majority of studies use small or demographic-specific datasets. For instance, many dyslexia and dysgraphia detection models were trained on Latin script datasets, restricting their applicability to Arabic, Chinese, or other languages. Variations in handwriting style due to aging are frequently underestimated. Each age group has various handwriting traits. However, most datasets are biased toward children, making it hard for models to generalize to real-world applications. The accuracy of AI models across diverse populations is affected by the underrepresentation of gender-based variances, handedness (left vs. right-handed writers), and cultural writing variants in existing datasets. CNN, ViT, and hybrid architecture deep learning models demand substantial computational resources. The high resource requirements of the existing models make them unsuitable for use on mobile devices, tablets, or school-based computers. For instance, studies, including (Kunhoth et al., 2023) and (Nawer et al., 2023) employed customized CNNs architectures and Transformers. These models demand the use of graphical processing units or cloud-based infrastructure, which can be costly and impractical for schools, educators, and healthcare professionals who may not have access to high-performance computer resources. Moreover, due to deep learning inference, real-time handwriting analysis is challenging.
Insufficient interpretability in DL models for handwriting-based impairment diagnosis is another limitation. The reviewed studies are not transparent, offering predictions using complicated hierarchical feature extraction without explaining their association with disabilities. Lack of explainability in AI-driven exams leads to a trust gap for educators, healthcare professionals, and parents. Most models were trained on standardized writing tasks such as copying sentences or writing words. The controlled tasks contribute to model benchmarking. However, they fail to reflect natural and spontaneous handwriting. Similarly, the intricacy of handwriting differs across different writing media. For instance, Sharmila et al. (2023) and Bublin et al. (2023) concentrated on digital handwriting, which may not describe real-world note-taking. Currently, there is no universal benchmark for assessing the performance of DL-based handwriting analysis models for learning impairment diagnosis. It is challenging to determine which model is the best for real-world applications. For instance, some studies apply accuracy, precision, and recall, while others employ F1-scores or ROC. The most effective methodology for detecting learning disabilities cannot be reliably determined in the absence of a standardized screening framework. Additionally, the existing studies face challenges in maintaining data privacy, reducing algorithmic bias, ensuring fairness, accessibility, and ethnic diversity.
Ethical considerations
Data governance and model performance across varied contexts are required to improve the ethical and practical impact of DL-based learning disability detection models, demanding ethical data collection, model interpretation, fairness, and generalizability. Integrating industry standards in various domains is essential for fostering credibility, fairness, and practicality in practical contexts.
It is typical for handwriting data to include sensitive information, especially when it is collected from children in educational or therapeutic settings. Informed consent involves informing participants or their legal guardians about the study’s objective, how the data will be used, and any risks or advantages. Language on consent forms should be easy to understand and use, and participants should be able to withdraw their consent at any time without negative consequences.
To safeguard the identity of participants, anonymizing and minimizing data is essential. This involves removing names, identities, and information that could identify individuals. Encrypting digital samples and storing them on secure servers with strong access rules may prevent unauthorized usage. Researchers should strive for data sharing agreements that enable others to utilize information while preserving ethical standards, facilitating replication and benchmarking across studies.
Additionally, it is essential to ensure that the data gathering process is inclusive. Preventing cultural or linguistic bias requires handwriting samples to represent a diverse variety of languages, scripts, socioeconomic origins, and learning qualities, enhancing the model’s generalizability.
Future avenues
To maximize the use of the DL-based learning disability detection in real-time applications, future research should focus on enhancing dataset diversity, integrating multi-modal learning, improving model interpretability, and developing adaptive AI-driven interventions. Developing large-scale diverse handwriting datasets, capturing a wider range of writing styles, linguistic variations, age groups, and diverse populations, can improve the efficiency of the existing models. The inclusion of handwriting samples from left- and right-handed individuals can reveal differences in writing orientation. Additionally, there is a demand for a centralized dataset covering dyslexia, dysgraphia, ADHD, and ASD, allowing researchers to compare models effectively.
To minimize the high computational power, lightweight architectures can be used. Techniques, including pruning, quantization, and knowledge distillation, enable handwriting analyzing tools to operate on tablets, smartphones, and low-cost computing devices. By leveraging efficient neural networks, reliance on cloud-based AI models can be reduced. The development of green AI solutions with lower energy footprints can facilitate the integration of handwriting analysis into sustainable learning environments.
Future research should focus on integrating multiple modalities to improve classification accuracy. The use of multi-modalities can provide deeper insights into cognitive and motor impairments. Nawer et al. (2023) revealed the significance of electroencephalogram (EEG) signals in detecting learning disabilities. Similarly, combining handwriting images and real-time eye tracking can enhance the classification performance. AI-assisted educational tools can facilitate real-time feedback to students, enhancing early diagnosis and personalized interventions.
SHapley Additive exPlanations (SHAP) interprets the predictions made by AI models, quantifying the importance of a specific feature in the predicting learning disability. Gradient-weighted class activation mapping (Grad-CAM) generates heatmaps indicating the areas of an input image that were influential in the model’s decision-making process. These techniques can provide visual explanations of handwriting features, leading to the development of explainable AI. By adding confidence levels to predictions, educators can use the AI-driven learning disabilities detection tools. Future AI handwriting tools can leverage edge AI techniques, reducing data exposure risks and enhancing user control over personal information. Data encryption, anonymization, and secure storage protocols can be applied to ensure compliance with privacy laws and maintain user trust. In addition, researchers can explore alternative data collection methods, such as synthetic handwriting generation, mimicking diverse handwriting variations.
While this review provided deeper insights into diverse learning disabilities and their AI-driven diagnosis and management, it has certain limitations. The review relies on peer-reviewed manuscripts, leading to limited insights into real-world implementations. The dependence on English studies may result in the exclusion of significant research conducted in non-English-speaking regions. Incorporating multi-lingual research and industry applications can present a broader perspective on AI-driven handwriting analysis. The heterogeneity of methodologies and evaluation metrics may cause challenges in comparing the performance of the models. Focusing on a universal evaluation protocol can facilitate objective model comparisons.
Conclusions
This review highlights the significant role of DL in handwriting analysis for early and accurate diagnosis of learning disabilities. Through a systematic analysis, the authors identified 24 peer-reviewed studies, classifying dyslexia, dysgraphia, and other neurodevelopmental disorders. The key contributions of this review are the synthesis of diverse research methodologies, showcasing the efficacy of AI-powered handwriting analysis. It highlighted the importance of multi-modal approaches, enhancing handwriting analysis through the integration of eye-tracking, EEG signals, and other modalities. AI-driven procedures are more efficient and objective than conventional methods. However, dataset diversity, model interpretability, and ethical issues should be addressed. Future research should focus on developing scalable, explainable, and ethical AI models to improve learning and clinical decision-making in individuals with dyslexia, dysgraphia, and associated disorders. The incorporation of explainable AI frameworks is an additional significant research avenue. These frameworks allow models to offer visual explanations and feature attribution maps, enabling educators, clinicians, and parents to comprehend the reasons behind the classification of handwriting samples. While this review covered diverse studies, relevant research published in non-peer-reviewed journals or industry reports may offer substantial insights into learning disabilities. Broadening the range of included studies can provide a holistic perspective on AI applications in handwriting assessment.