
Multicriteria scheduling of two-subassembly products with batch availability and precedence constraints
- Published
- Accepted
- Received
- Academic Editor
- José Manuel Galán
- Subject Areas
- Agents and Multi-Agent Systems, Algorithms and Analysis of Algorithms, Optimization Theory and Computation, Theory and Formal Methods
- Keywords
- Multicriteria scheduling, Two-subassembly products, Precedence constraints, Maximum cost, Makespan
- Copyright
- © 2025 Wen and Li
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Multicriteria scheduling of two-subassembly products with batch availability and precedence constraints. PeerJ Computer Science 11:e3093 https://doi.org/10.7717/peerj-cs.3093
Abstract
This article studies the multicriteria problems of scheduling a set of n products on a fabrication facility, focusing on batch availability and precedence constraints. Each product is composed of two distinct subassemblies: a common subassembly, shared across all products, and a unique subassembly unique to each product. The common subassemblies are processed together in batches, with each batch requiring an initial setup, while unique subassemblies are handled individually. The availability of a common subassembly is contingent upon the completion of its entire batch (i.e., batch availability), whereas a unique subassembly becomes available immediately after its processing. The product completion time is determined by the availability of both subassemblies. Strict (weak) precedence means that if a product precedes another, then the latter can start only after the former is completed (the latter cannot start earlier than the former). We propose O(n4)-time algorithms to simultaneously optimize makespan and maximum cost, as well as to lexicographically optimize two maximum costs and makespan under strict or weak precedence constraints.
Introduction
Driven by the need to balance conflicting objectives, the field of multicriteria scheduling has garnered significant attention over the past few decades, see Hoogeveen, 2005, T’kindt & Billaut (2006). This article studies four specific multicriteria problems related to scheduling products with two subassemblies on a fabrication facility, subject to either strict or weak precedence constraints. The focus is on optimizing both makespan and maximum cost simultaneously, or alternatively, on the lexicographical optimization of two maximum costs along with makespan.
In formal terms, consider a set of products, denoted by , to be processed on a single fabrication facility. Each product, , consists of two parts: a common subassembly and a unique subassembly , with respective processing times and . For aerospace component production, strict precedence constraints might arise when assembling engines: a turbine blade subassembly ( ) must be fully completed before a combustion chamber subassembly ( ) can start, ensuring safety and structural integrity. The facility processes the common subassemblies in batches, where each batch incurs a setup time , while the unique subassemblies are processed individually. The setup time for each unique subassembly is incorporated into its total processing time, as it is unique to the product it belongs to. Consequently, it is assumed that unique subassemblies do not require setup times. The two subassemblies of a product may be processed in either order, but the facility can handle only one subassembly at a time, and no preemption is allowed during processing.
In this article, we adopt the assumption of batch availability for the common subassemblies, meaning that a common subassembly becomes available only after the entire batch to which it belongs has been fully processed (Santos & Magazine, 1985) (Alternatively, there is the item availability assumption, where a common subassembly becomes available immediately after its processing is finished). Conversely, unique subassemblies are considered available as soon as their individual processing is completed. A product is deemed complete only when both its common and unique subassemblies are fully processed and available. Moreover, each product, , is associated with two cost functions and , which represent the costs incurred based on the product’s completion time. It is assumed that these cost functions are regular, meaning and are non-decreasing with respect to the product completion times.
In practical terms, the cost functions and can be linked to real-world manufacturing metrics. often represents lateness penalties, such as contractual fines for delivering products after their due dates ( ). In just-in-time (JIT) production systems, this could model penalties for delaying shipments to assembly lines. may quantify resource utilization costs, such as idle machine fees or inventory holding charges for early-completed products. In aerospace manufacturing, this might reflect the cost of storing specialized components before final integration. These costs are “regular” because they increase with completion time, a common assumption in scheduling problems to align with real-world inefficiencies.
For a given schedule S, let represent the completion time of product in S. Define and as two costs associated with in the schedule. The values and correspond to the maximum costs under these criteria. Notably, two specific cases of maximum cost are the makespan, , and the maximum lateness, , where denotes the due date for product . The argument S can be omitted in the notation whenever the context is clear.
In addition, the problems under consideration have either strict or weak precedence constraints. A product may depend on a set of products that must be completed or started before it can start. Formally speaking, for the strict precedence relation , if ( precedes because of a higher priority), then can start only after is completed in any feasible schedule. Consequently, the common subassemblies of and must be in different batches. As for the weak precedence relation , if , then must start no later than in any feasible schedule. Therefore, the common subassemblies of and may be processed within the same batch.
The first two problems examined in this article focus on identifying Pareto optimal schedules that minimize both the makespan and the maximum cost simultaneously, while adhering to either strict or weak precedence constraints. Utilizing the notation conventions established in Hoogeveen (2005), T’kindt & Billaut (2006), Brucker (2007), these problems are represented as and , where “ ” and “ ” indicate strict and weak precedence constraints, respectively. The symbol “ ” refers to “two-subassembly products”, and “BA” denotes “batch availability”.
Let and represent the two performance criteria to be minimized. A schedule S is considered Pareto optimal or non-dominated if there exists no other feasible schedule S′ for which and where at least one of these inequalities is strict. When a schedule S meets these conditions, the resulting objective vector is termed a Pareto optimal point (Hoogeveen, 2005). This approach is referred to as Pareto optimization or simultaneous optimization.
The last two problems addressed in this article involve finding a lexicographically optimal schedule under strict or weak precedence constraints, where the criteria , , and are prioritized as primary, secondary, and tertiary objectives, respectively. These problems are represented as and . An optimal solution for is defined as the best possible schedule for within the subset of schedules that are already optimal for . This approach is known as lexicographical optimization or hierarchical optimization (Hoogeveen, 2005).
The structure of this article is as follows: “Literature Review” offers a review of relevant research in the field. “Algorithms for Pareto Scheduling Two-subassembly Products with Precedence Constraints” introduces -time algorithms for and . “The Experiments”, the experiment of the Algorithm Cmax-Fmax is given and compared with the algorithm of . “Algorithms for Lexicographical Scheduling Two-subassembly Products with Precedence Constraints” presents -time algorithms for and . In conclusion, “Conclusions” discusses potential directions for future research.
Literature review
For an in-depth exploration of multicriteria scheduling and batch scheduling, readers are encouraged to consult the surveys provided in Hoogeveen (2005), T’kindt & Billaut (2006), Herzel, Ruzika & Thielen (2021) and Potts & Kovalyov (2000), Allahverdi et al. (2008), respectively. In this article, we focus specifically on discussing results that are directly relevant to the scheduling of two-subassembly products within the context of batch availability.
Baker (1988) initially introduced the model of scheduling two-subassembly products with the goal of minimizing total completion time, denoted as . Operating under the agreeability assumption—where the processing time of a product’s common subassembly is shorter than another’s whenever the same relationship holds for their unique subassemblies—he devised an -time algorithm. Later, Coffman et al. (1990) enhanced this algorithm, reducing the runtime to . Subsequently, Gerodimos, Glass & Potts (2000) proposed an -time dynamic programming algorithm for . They also demonstrated that the problem of minimizing the total number of late products, denoted as , is NP-hard (here, if and otherwise). To address , they provided a pseudo-polynomial time dynamic programming solution. Furthermore, for the special case of where all common subassemblies share identical processing times, they developed an -time dynamic programming algorithm. Wagelmans & Gerodimos (2000) later refined the algorithm in Gerodimos, Glass & Potts (2000) for , reducing the runtime to . Yang (2004a) explored a different scenario where common subassemblies are divided into multiple families, each with setup times that are sequence-independent but not identical. He introduced a branch-and-bound algorithm aimed at minimizing total completion time. In a separate study, Yang (2004b) investigated the problem in the context of parallel machines, with the constraint that both subassemblies of a product must be processed on the same machine. He proposed two heuristic approaches to generate near-optimal schedules for minimizing total completion time. Li (2023) examined , a bicriteria scheduling problem for two-subassembly products on a single facility, focusing on minimizing both makespan and maximum lateness, and developed an -time algorithm with linear memory usage.
If all products consist solely of common subassemblies (i.e., all ), then the problem of scheduling two-subassembly products simplifies to the serial-batch scheduling problem. This problem can be modeled in two ways based on the batch capacity—the largest number of products that can be processed within a single batch. The first is the bounded model, where the batch capacity is limited, denoted as , and the second is the unbounded model, where the batch capacity is unlimited, denoted as .
Over the past two decades, serial-batch scheduling problems have received extensive attention and investigation (Baptiste, 2000; Cheng & Kovalyov, 2001; Yuan, Yang & Cheng, 2004; Ng, Cheng & Yuan, 2002; Webster & Baker, 1995; He, Lin & Yuan, 2008; He et al., 2013a, 2013b; He, Lin & Lin, 2015; Geng, Yuan & Yuan, 2018). Among the contributions, Baptiste (2000) introduced an -time algorithm for and , where products have varying release dates but identical processing times. In this context, “SUB” refers to the unbounded model of serial-batch scheduling, while “SBB” refers to the bounded model. Cheng & Kovalyov (2001) explored serial batch scheduling problems with the objective of minimizing various regular cost functions. For products with equal release dates, they developed dynamic programming algorithms aimed at minimizing several key criteria: maximum lateness, the number of late products, total tardiness, total weighted completion time, and total weighted tardiness, under the condition of equal due dates. These algorithms are polynomial when the number of distinct due dates or processing times is fixed. Additionally, they proposed more efficient algorithms for certain special cases and established the NP-hardness for several specific cases of the bounded model.
By suitably adjusting the release dates and due dates, problems (involving weak precedence constraints) and (where products have varying processing times but identical release dates) can be transformed in time into and (Yuan, Yang & Cheng, 2004; Ng, Cheng & Yuan, 2002). These transformed problems can then be solved in and time, respectively (Baptiste, 2000; Webster & Baker, 1995).
He, Lin & Yuan (2008) developed an -time algorithm for problem . This result was subsequently enhanced to an -time algorithm (He et al., 2013a), and further improved to an -time algorithm for problem (He et al., 2013b). He, Lin & Lin (2015) also proposed an -time algorithm for . Additionally, Geng, Yuan & Yuan (2018) introduced -time algorithms for both and . They also devised an -time algorithm for problem , and demonstrated that problems and are strongly NP-hard.
This article addresses multicriteria scheduling problems with theoretical significance: optimizing makespan and maximum cost under batch availability and precedence constraints. The polynomial-time complexity of our proposed algorithms is critical: it demonstrates it is computationally feasible to obtain optimal solutions for these problems, contrasting with NP-hard scheduling problems where only heuristic solutions exist.
To the best of our knowledge, problems , , and have not been studied in previous research. In this article, we present -time algorithms to solve each of these problems. Note that (Li, 2023) focused on a specific variant of the first problem, where products are not subject to precedence constraints, and the objective is to minimize maximum lateness rather than maximum cost.
While earlier studies focused on single-objective batch scheduling, recent research has shifted toward multicriteria optimization in dynamic manufacturing systems. Li (2024) proposed a hybrid heuristic for two-subassembly scheduling with energy consumption constraints, extending the batch availability model to sustainable manufacturing. Hidri & Tlija (2024) addressed sequence-dependent setup times in hybrid flow shops, a scenario analogous to our unique subassembly processing with individual setup costs. These advancements highlight the growing need to model real-world complexities like dynamic precedence rules and multi-echelon inventory constraints.
Additionally, Li (2024) examined the bounded model for scheduling two-subassembly products with equal processing times for all common subassemblies. Hidri & Tlija (2024) and Xu et al. (2024) introduces a heuristic algorithm to solve this complex problem. The flexible job shop scheduling problem (FJSP) is (Serna et al., 2021) combination problem. In this context, Li (2024) developed an -time algorithm for the simultaneous optimization of makespan and maximum lateness, along with an -time algorithm for the lexicographical optimization involving two maximum lateness objectives and makespan.
Algorithms for Pareto scheduling two-subassembly products with precedence constraints
In this section, we will present an -time algorithm designed to solve problem . Additionally, the final schedule produced by this algorithm is also optimal for the single criterion problem . Towards the end of this section, we will demonstrate how minor adjustments to the algorithm allow it to efficiently solve in time as well.
Precedence constraints on can be represented using a graph , where each vertex in V corresponds to a product in , and each edge in E represents a pair indicating that , i.e., must precede .
In the context of automotive component manufacturing, a workshop’s production scheduling problem for gearbox systems can be abstracted into the dual-component product scheduling model studied in this article. Specifically, each gearbox product consists of two types of subassemblies: one is a common subassembly shared by all models (e.g., the gearbox housing), which must be processed in batches with a 2-h mold setup time ( ) required before each batch production; the other is a customized unique subassembly (e.g., the gear set) for different vehicle models, which requires no additional preparation time and can be processed individually. During production, strict assembly sequence constraints exist between some models—for example, the basic-type gearbox must be completed before the high-performance type—corresponding to the strict precedence constraint ( ) in the model, meaning that the successor product can only start production after both the common and unique subassemblies of the predecessor product are completed. This scenario necessitates simultaneous optimization of two key objectives: minimizing makespan ( ) to enhance equipment utilization by reducing idle time of the CNC machining center, and minimizing maximum delay cost ( ) to avoid contractual penalty fees for late deliveries. This scenario necessitates simultaneous optimization of two key objectives: minimizing makespan ( ) to enhance equipment utilization by reducing idle time of the CNC machining center, and minimizing maximum delay cost ( ) to avoid contractual penalty fees for late deliveries.
The integration of these constraints and objectives is visualized in the following production scheduling flowchart (Fig. 1), which illustrates the batch processing of common subassemblies, individual machining of unique subassemblies, and the enforcement of strict precedence relationships within the dual-component scheduling framework.
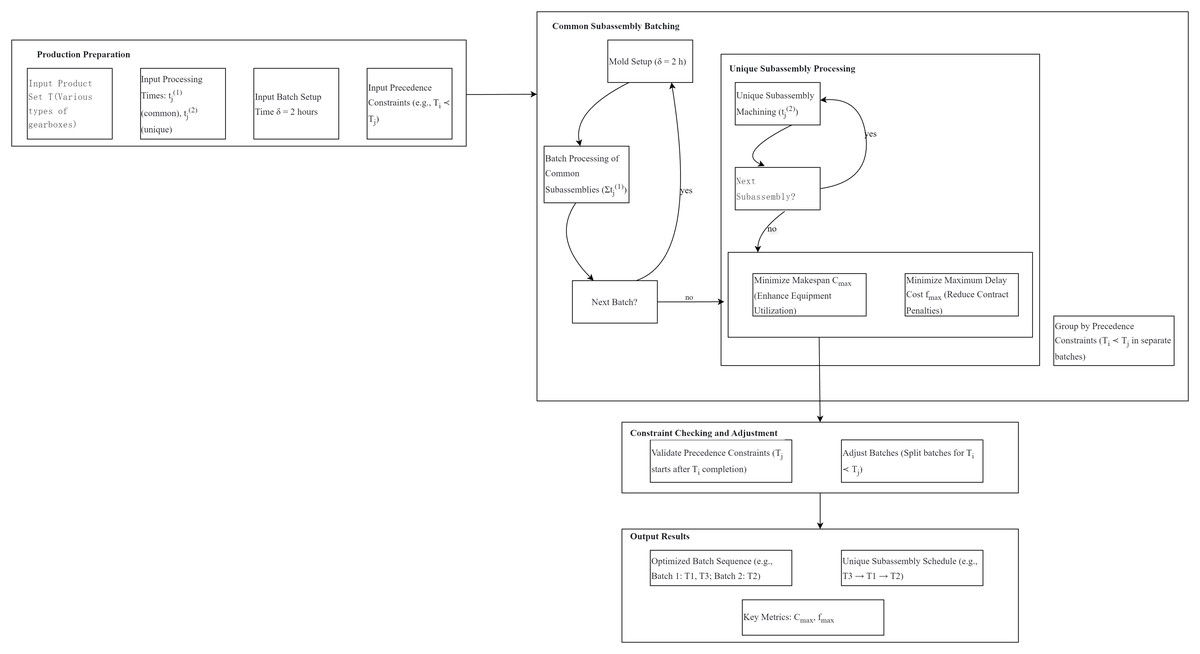
Figure 1: Production scheduling flowchart for automotive gearbox systems.
{kind=link}
Recall that Lawler’s algorithm (Lawler, 1973) solves (the problem of minimizing maximum cost under precedence constraints on a single facility) in time. The algorithm constructs the schedule in reverse order, relying on the following key insight: Let U be the set of unscheduled products and be the total processing time of all products in U. If a product has no successors in U and has the smallest -value—i.e., —then should be scheduled at the last position among all products in U to achieve an optimal schedule.
In the following algorithm (Algorithm 1: Algorithm Cmax-Fmax), we adapt the idea of Lawler’s algorithm to schedule the unique subassemblies of products in (where consists of unscheduled independent products, meaning there are no precedence constraints among them) within a designated time interval . For , we select a product such that and place it as the last product in U. The sequence represents the indices of the products in which are processed on the facility during the time interval . For simplicity, we will refer to this sequence as being scheduled in Lawler’s order.
| Step 1. Set , , and . Let the initial schedule be the natural feasible schedule described earlier. |
| Step 2. During the -th round: |
| Set . Adjust to construct the new schedule as follows: |
| Step 2.1. For , verify the precedence constraints and the inequality for each product in . The products in should be checked in reverse order. |
| Case (1). If a product is found such that at least one of its successors has already been moved into , and if , then set and proceed to Step 3. Otherwise ( ), remove from and insert it into , appending to the end of . Job will not be rechecked when next we are checking . |
| Case (2). If a product is found where the inequality is violated, and if or is the last product in , then set and proceed to Step 3. Otherwise, remove along with all the products in that are in but processed earlier than , and insert them into (following the optimality of Lawler’s order). Append these moved products to the end of . These products will not be rechecked when next we are checking . |
| Step 2.2. Update the modified schedule as follows: For , first process the common subassemblies of the products in as a batch. Then, process the unique subassemblies of the products in individually, following Lawler’s order. Update the cost for each product in the schedule according to Lemma 3. |
| Step 2.3. Repeat Steps 2.1 and 2.2 until all inequalities and precedence constraints in the modified schedule are satisfied. Once no violations remain, let be the final modified schedule. |
| Step 3. If , then set and return . Otherwise, if , then update . |
| Step 4. Set and go to Step 2. |
Let us briefly explain the meaning of , which will become clearer in Step 2.2 of Algorithm Cmax-Fmax. The algorithm essentially involves scheduling products in reverse order, moving backward along the time axis (from right to left). Suppose we begin scheduling certain unique subassemblies immediately after the completion of the -th batch of common subassemblies (counting from left to right). In this context, represents the exact beginning time of the first unique subassembly among those being scheduled.
We will utilize the following well-established method for multicriteria scheduling (Hoogeveen, 2005) to identify Pareto optimal schedules.
Lemma 1 (Hoogeveen, 2005). Let be the optimal value for the problem of minimizing under the constraint (where is a known upper bound on ), and let be the optimal value for the problem of minimizing under the constraint . Then, is identified as a Pareto optimal point for two criteria and .
The following lemma outlines the structure of the Pareto optimal schedules that we aim to identify. The proof is omitted here as it closely parallels the one presented in Gerodimos, Glass & Potts (2000).
Lemma 2. For every Pareto optimal point in , there is an associated schedule where the common subassembly of each product is placed in the batch that directly precedes its unique subassembly.
According to Lemma 2, a feasible schedule can be expressed as a sequence of product-subsequences , where comprises the products whose common subassemblies are processed in the -th batch. Particularly, we assume that only the last product-subsequences are nonempty. Hence, it is evident that the subsequences form a partition of and must adhere to the precedence constraints.
The sub-schedule for the products in can be represented as , where is a batch containing the common subassemblies of the products in , and is a unique-subsequence comprising the unique subassemblies of the products in arranged in Lawler’s order. Let and represent the processing times for the batch and the unique-subsequence of , respectively. The processing time of the entire product-subsequence is denoted by . Additionally, the processing time for any empty product-subsequence is considered to be zero. The setup time for batch is denoted by , which is if is nonempty, and 0 otherwise. The beginning time and completion time for are denoted by and , respectively. We have the relationship: . Therefore, we obtain:
Lemma 3. In a feasible schedule , the relationship is given by: , , .
A natural feasible schedule can be constructed, where includes all products (vertices) with an out-degree of zero in the graph , . The construction of from G requires time.
Let represent the set of all feasible schedules for . Our focus is on the subset of schedules in that possess the characteristics outlined in Lemmas 2 and 3. Define as the set of schedules in with a -value less than . Clearly, . Let represent the Pareto set, which includes all Pareto optimal points, with each point associated with a schedule.
We are ready to present the algorithm for solving , Algorithm Cmax-Fmax (Algorithm 1).
Step 1 of Algorithm Cmax-Fmax can be executed in time. Step 2 requires time for each pass. During each pass of Step 2.1, every product is checked exactly once, starting from the last product-subsequence and proceeding to the first. Multiple passes of Steps 2.1 and 2.2 may occur in a single round. Steps 3 and 4 can be completed in time per round.
In each pass, at least one product must be moved to the left. It is important to note that in Algorithm 1, products can only be moved leftward. Given that there are product-subsequences, each product can be moved to the left at most times. Consequently, the total number of passes is . Therefore, the overall running time of Algorithm Cmax-Fmax is .
Heuristic methods (e.g., Hidri & Tlija, 2024) are typically employed to handle complex dynamic constraints such as sequence-dependent setup times, but they come at the cost of optimality. The exact algorithm proposed above achieves a balance between computational efficiency and solution quality in polynomial time through rational design of batch structures (e.g., batch processing of common subassemblies and scheduling of unique subassemblies in Lawler’s order). Compared with heuristic methods, this algorithm provides theoretical optimality guarantees; compared with high-complexity exact methods (such as algorithms), its computational efficiency is significantly improved. Future research can further expand its applicability in industrial scenarios by integrating dynamic constraint management (e.g., real-time priority adjustment) and parallel computing technologies (e.g., GPU acceleration).
Lemma 4 Let be obtained at the -th round of Algorithm Cmax-Fmax, where . Let be any one in . Then, , .
Proof 1 The proof is conducted using induction on .
The base case is verified trivially. The initial schedule is the natural feasible schedule, which inherently satisfies the lemma. This is because each product in must have a successor in , and therefore, it cannot be included in in any schedule in , .
Assume that the lemma holds for and any schedule in . Now, consider and any schedule . Since , . By the inductive assumption, the lemma holds for and S. Therefore, for , we have . Equivalently, we have: for , .
Consider the first (i.e., rightmost) inequality violation during the -th round. Let the first moved product be . Since the inequality does not hold and the unique subassemblies of the products in are scheduled in Lawler’s order, and all the products which are in but scheduled earlier than cannot stay in . Therefore, we move these products from into . By the inductive assumption, in S any of these products cannot stay in , otherwise the last one will complete no earlier than and thus incur an inequality violation.
After moving these products to the left in , we further adjust to obey the precedence constraints. Observing S accordingly, we can know that S coincides with the adjustment. Then we consider the next inequality violation, and so on. By repeating this argument, we ultimately demonstrate that the lemma holds for the -th round.
By applying the principle of induction, the proof is thereby completed.
We get:
Lemma 5 Let be obtained at the -th round of Algorithm Cmax-Fmax, where . Let be any one in . Then:
(1) , where and represent the number of nonempty product-subsequences in and S respectively;
(2) , ;
(3) , .
Lemma 6 Let be obtained at the -th round of Algorithm Cmax-Fmax, where . If , then . Otherwise, has minimum makespan in all schedules in .
Proof 2 In the implementation of Algorithm Cmax-Fmax, we will get when one of the following two cases occurs: Case (1). Find a product such that at least one of its successors has already been moved into and . Case (2). Find a product where is violated, and either or is the last product in . In Case (1), we know that cannot be scheduled without violating the precedence constraints in any feasible schedule. Therefore, we set indicating that . In Case (2), if , we know that no feasible schedule can arrange with a cost less than . If is the last product in , then there will be an empty product-subsequence between two nonempty product-subsequences. We do not need to consider such a case. Therefore, we also set indicating that .
Conversly, if , then by Lemma 5, has minimum makespan in all schedules in .
By integrating the results of Lemmas 1 and 6, we obtain the following result:
Theorem 1 Algorithm Cmax-Fmax solves problem in time. Moreover, the final schedule generated by the algorithm has the minimum makespan in all optimal schedules for .
To solve (the weak precedence constraints), we need to modify Step 1, Step 2.1 and Step 2.2 of Algorithm Cmax-Fmax slightly. In Step 1, we set the initial schedule , where the common subassemblies of the products in are first processed as a batch, followed by the unique subassemblies, which are processed individually according to Lawler’s order while adhering to the precedence constraints. That is, we use the actual Lawler’s algorithm (Lawler, 1973) to schedule the unique subassemblies of the products in in the time interval . In Step 2.1, since the common subassemblies of and its successors can be in the same batch, we do not need Case (1). We just need Case (2) to ensure that the predecessors of and obey the weak precedence constraints. In Step 2.2, the unique subassemblies of the products in must be processed individually, following Lawler’s order and complying with the precedence constraints.
Then we get:
Theorem 2 Modified Algorithm Cmax-Fmax solves problem in time. Moreover, the final schedule generated by the algorithm has the minimum makespan in all optimal schedules for .
The experiments
In this section, we present experimental results of our Algorithm Cmax-Fmax. Next, we will compare with algorithms for Pareto scheduling two-subassembly products without precedence constraints. The algorithm, implemented in PyCharm, was tested on randomly generated instances. We varied key factors. The number of jobs . The processing time for the common subassembly is uniformly distributed over the integer range [1, 5], and the processing time for the unique subassembly is uniformly distributed over the integer range [1, 10]. To implement the algorithm, 10 experiments were conducted for each order of magnitude of the job.
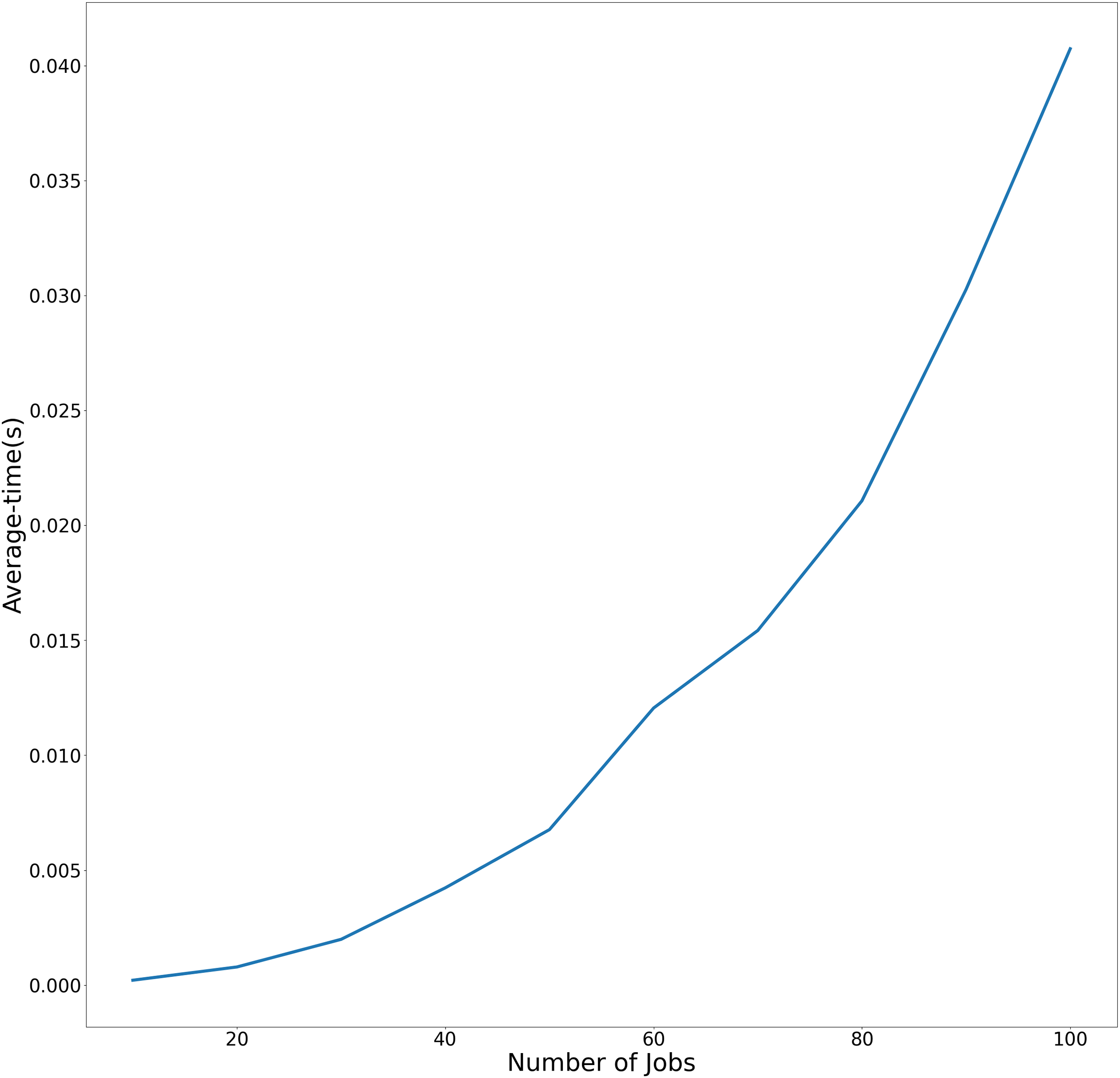
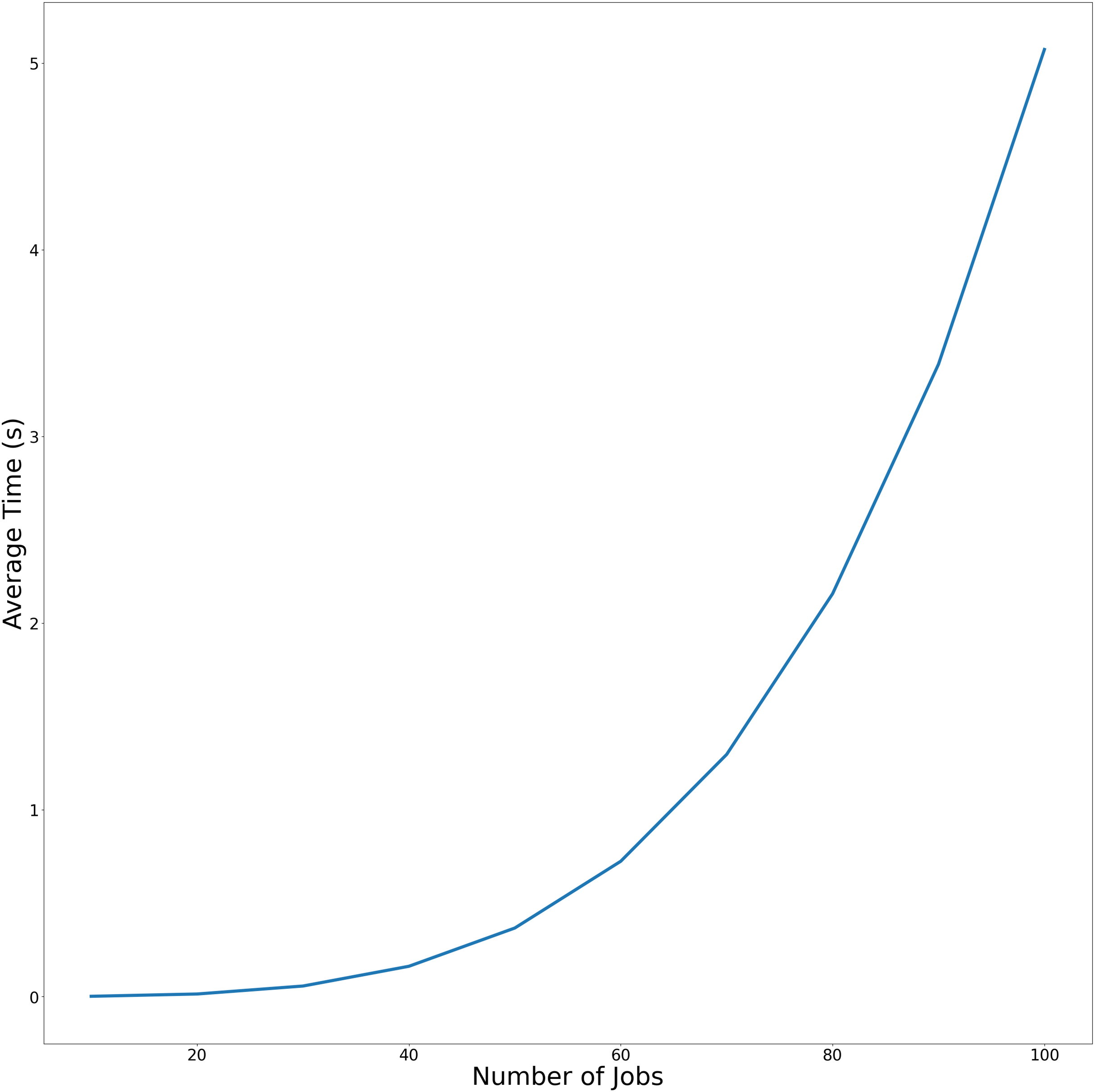
The average and maximum running times of Algorithm 1 in the article are shown in Table 1. In Table 2, we present the running times of the problem . To more effectively demonstrate the variation in average execution time relative to the number of jobs across both experimental conditions, the temporal performance trends are visualized in Figs. 2 and 3. using linear graphical representations.
| Number of jobs | Average-time (s) | Max-times (s) |
|---|---|---|
| 10 | 2.107859e−04 | 2.729893e−04 |
| 20 | 7.882357e−04 | 8.480549e−04 |
| 30 | 1.990342e−03 | 2.228498e−03 |
| 40 | 4.230165e−03 | 7.481098e−03 |
| 50 | 6.762409e−03 | 7.446527e−03 |
| 60 | 1.205318e−02 | 1.517057e−02 |
| 70 | 1.542490e−02 | 1.956534e−02 |
| 80 | 2.106686e−02 | 2.891660e−02 |
| 90 | 3.026404e−02 | 3.747702e−02 |
| 100 | 4.073451e−02 | 5.063152e−02 |
| Number of jobs | Average time (s) | Max time (s) |
|---|---|---|
| 10 | 1.636958E−03 | 2.530813E−03 |
| 20 | 1.394284E−02 | 1.494074E−02 |
| 30 | 5.668330E−02 | 5.867529E−02 |
| 40 | 1.624435E−01 | 1.744251E−01 |
| 50 | 3.673631E−01 | 3.688035E−01 |
| 60 | 7.248310E−01 | 7.265387E−01 |
| 70 | 1.296956E+00 | 1.299667E+00 |
| 80 | 2.157462E+00 | 2.162263E+00 |
| 90 | 3.386713E+00 | 3.426600E+00 |
| 100 | 5.072271E+00 | 5.111201E+00 |
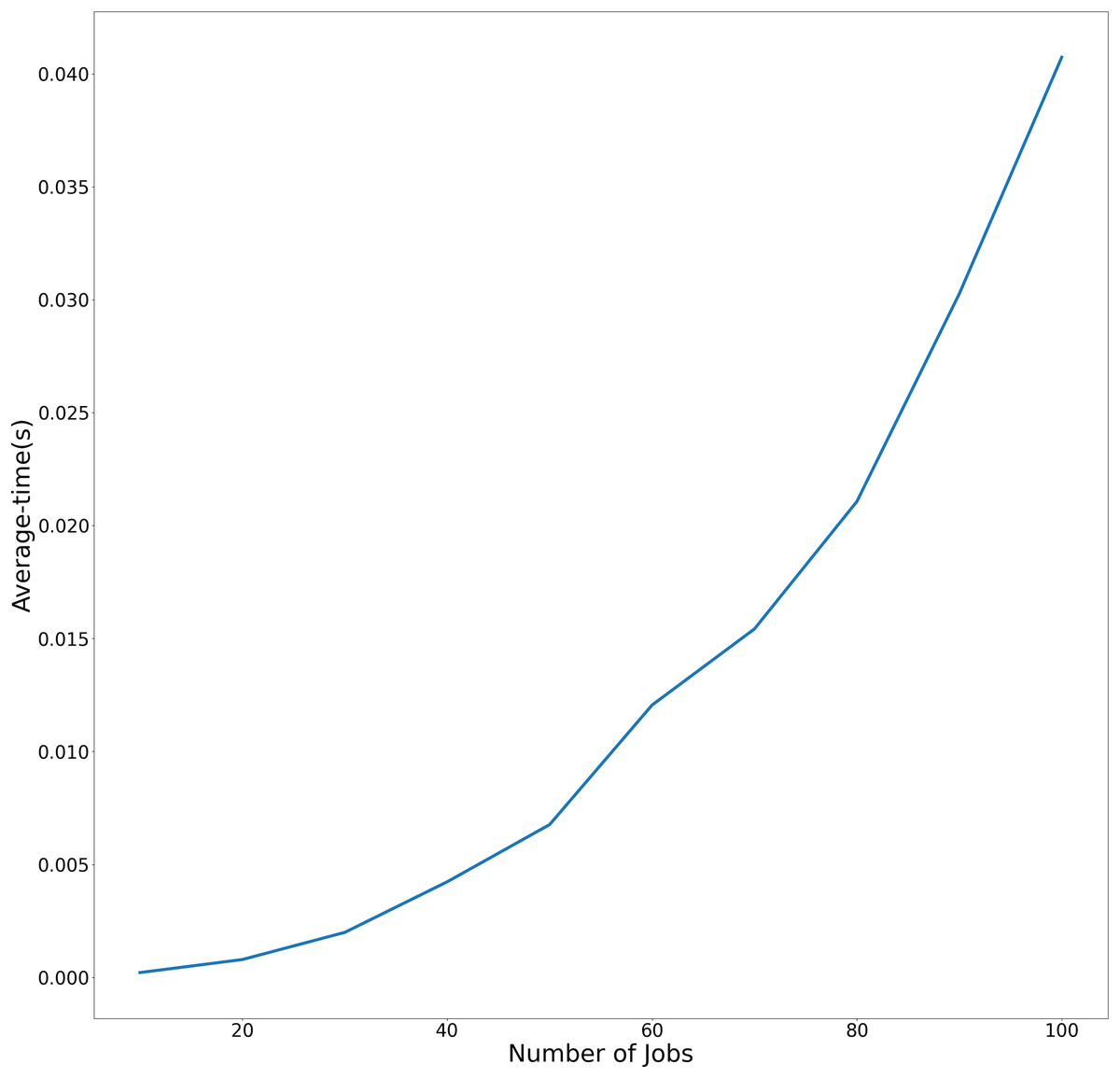
Figure 2: Average-time trend of Algorithm Cmax-Fmax with precedence constraints as the number of jobs increases.
{kind=link}
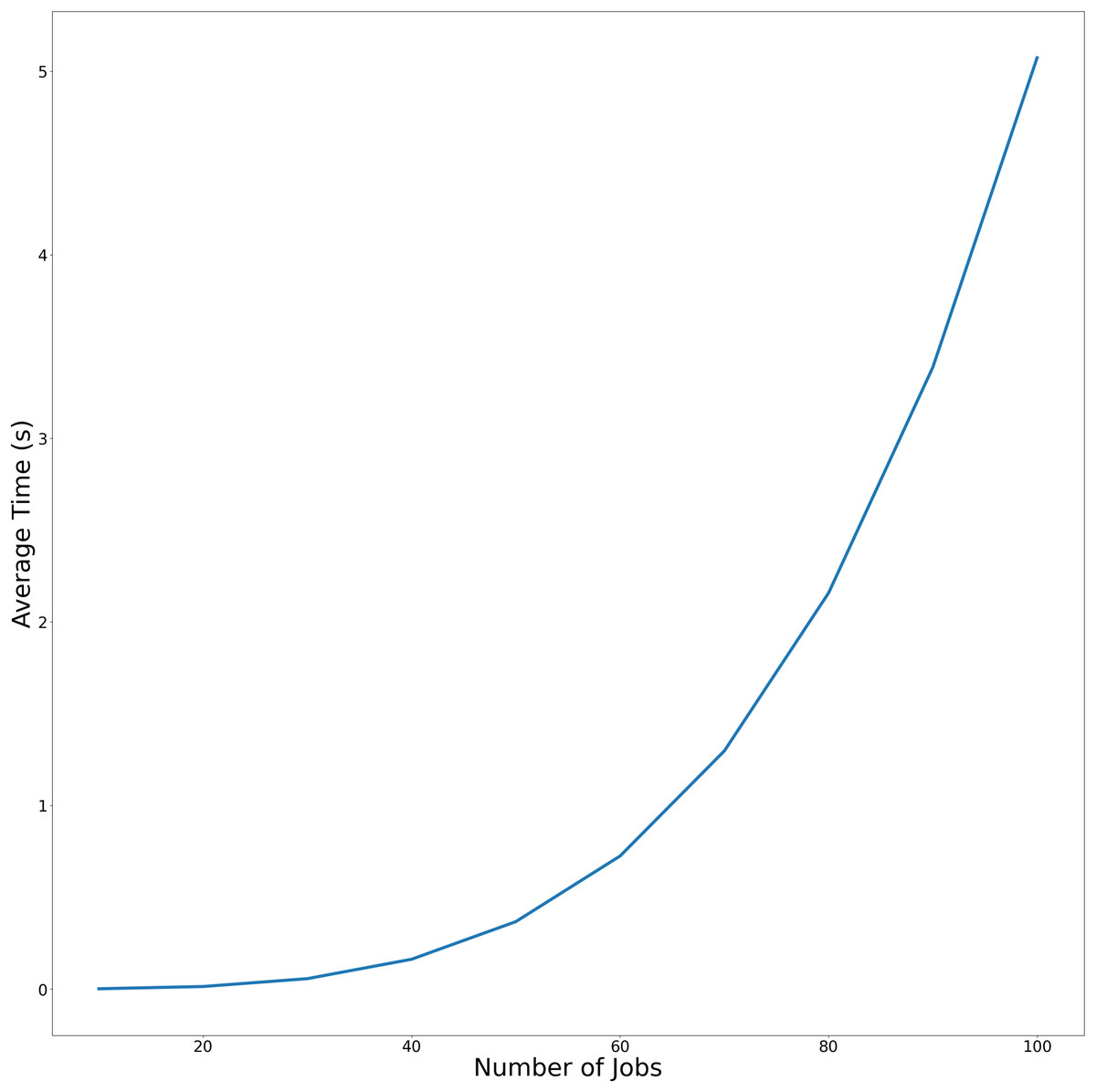
Figure 3: Average-time trend of Algorithm Cmax-Fmax without precedence constraints as the number of jobs increases.
{kind=link}
Figure 2 demonstrates Algorithm Cmax-Fmax performance With precedence constraints. This figure compares the average and maximum execution times of Algorithm Cmax-Fmax under precedence constraints. The x-axis represents the number of jobs (ranging from 10 to 100), while the y-axis shows the runtime in seconds. The linear trend demonstrates that the algorithm’s runtime scales polynomially with problem size, as expected from its theoretical complexity.
Figure 3 demonstrates Algorithm Cmax-Fmax performance without precedence constraints. Similar to Fig. 1, this figure plots the runtime of Algorithm 1 but excludes precedence constraints. The steeper slope of the curves indicates that Algorithm Cmax-Fmax with precendence constraints significantly reduce computational overhead.
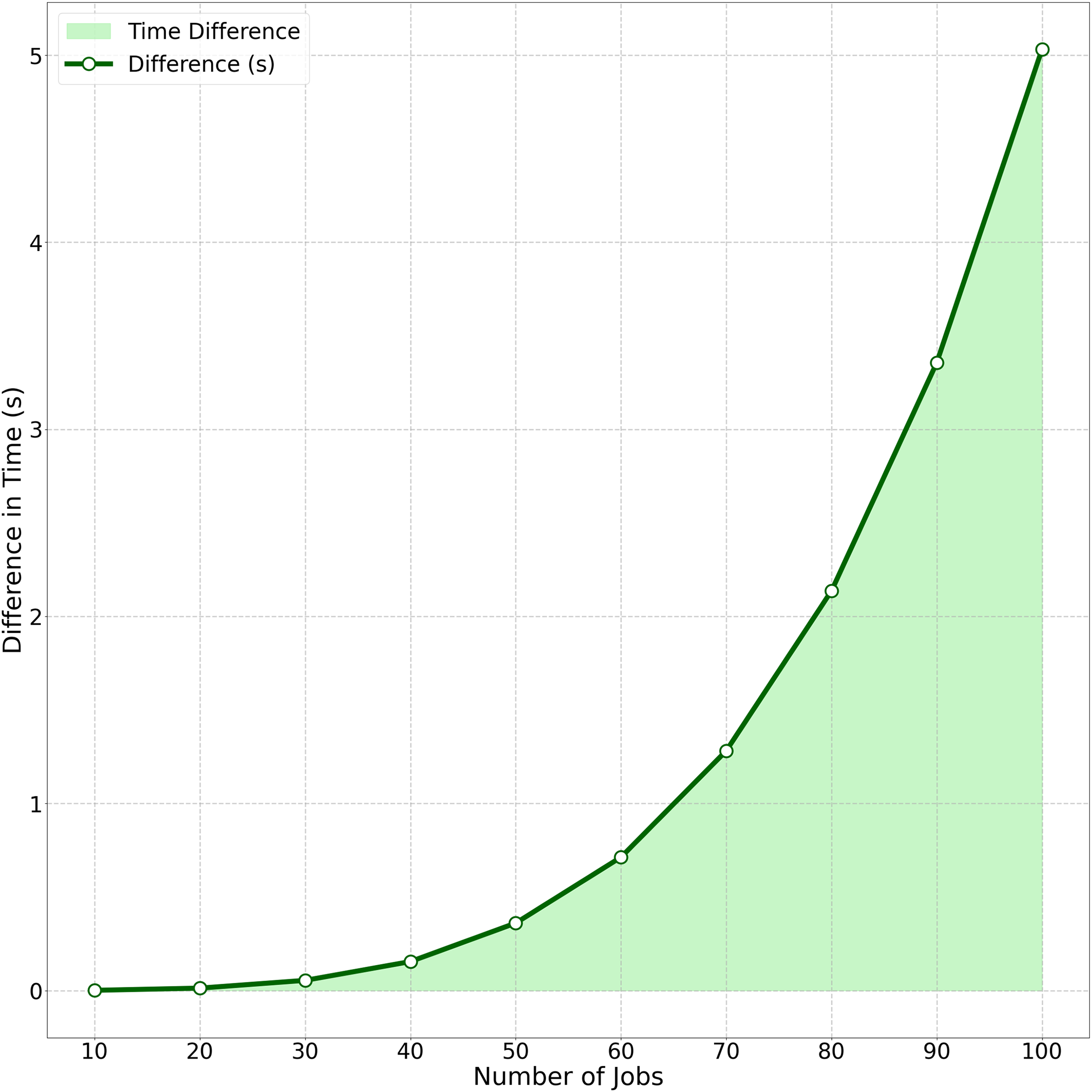
The computational efficiency comparison between Algorithm Cmax-Fmax (with precedence constraints) and Algorithm Cmax-Fmax (without precedence constraints) is quantified in Fig. 4. This area chart tracks the growing performance gap as job size ( ) increases from 10 to 100. Key observations include: At , the time difference is minimal (0.0014 s). The gap grows polynomially, reaching 5.03 s at . This visualization demonstrates how Algorithm 1’s strategic batch scheduling under precedence constraints consistently outperforms traditional approaches, particularly for where the difference becomes operationally significant in real-world scheduling scenarios.
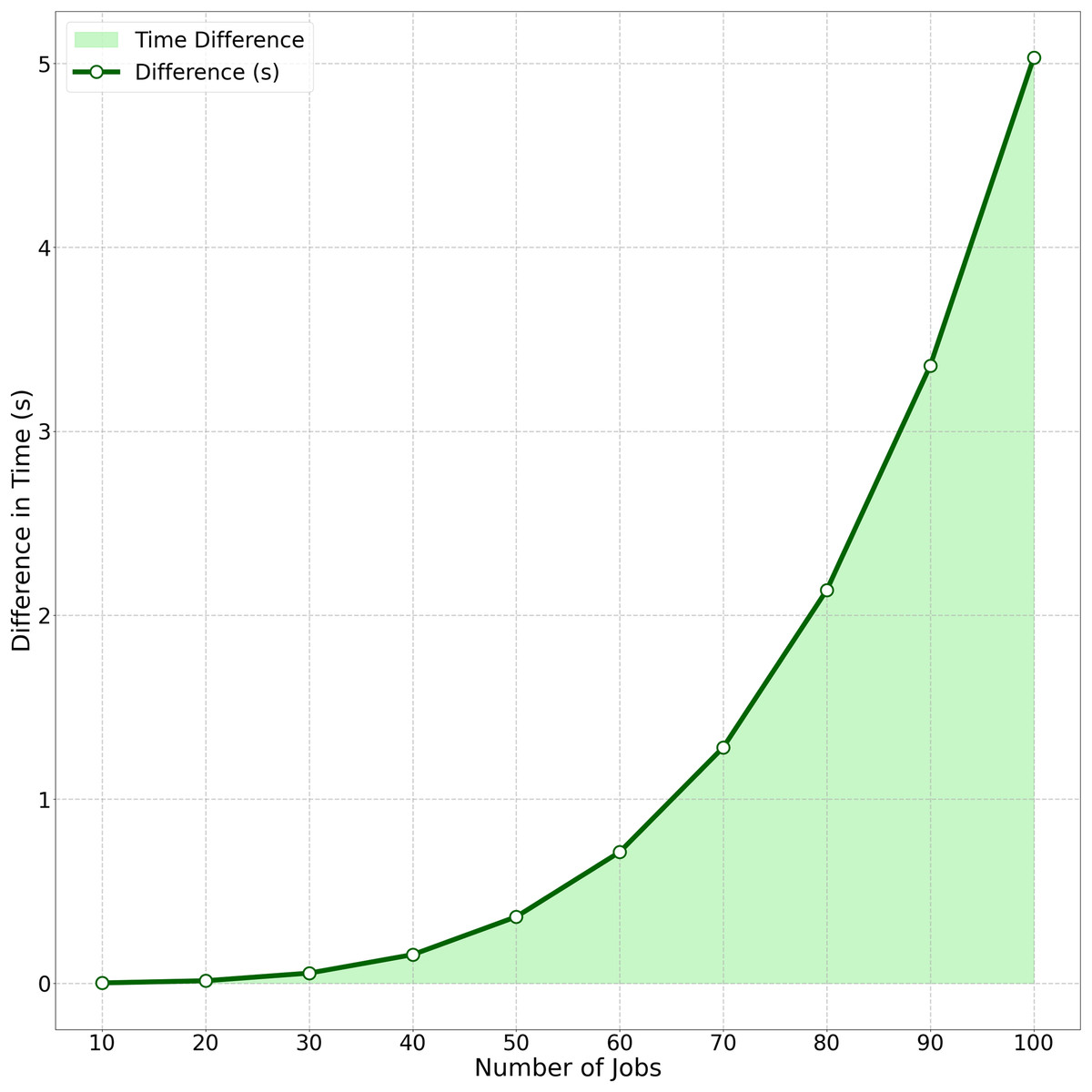
Figure 4: Average time difference between algorithm Cmax-Fmax (With precedence constraints) and algorithm Cmax-Fmax (Without precedence constraints).
{kind=link}
The significance of algorithm running time extends beyond mere efficiency; it also serves as a quantitative indicator of theoretical solvability, thereby determining whether the model can transition from a theoretical framework to practical implementation.
For real-world instances ( ), ensures solvability within seconds. Compared to others, slower algorithms (e.g., for bounded batch scheduling He, Lin & Lin (2015)) become infeasible.
Algorithms for lexicographical scheduling two-subassembly products with precedence constraints
Existing exact methods mostly focus on bi-objective optimization, while this article first achieves three-objective lexicographical optimization ( ), which is closer to the multi-dimensional optimization needs in practical manufacturing (such as considering delay penalties, resource costs, and makespan simultaneously).
In this section, we focus on presenting an -time algorithm designed to solve problem . Towards the end of this section, we will demonstrate how slight modifications to the algorithm enable it to also solve problem in time.
Let represent the final schedule produced by Algorithm Cmax-Fmax. According to Theorem 1, achieves the minimum makespan in all optimal schedules for problem .
Let denote the set of feasible schedules for whose -values are equal to . It is important to note that Lemma 2 (with “Pareto optimal” replaced by “lexicographically optimal”) and Lemma 3 still apply to . Therefore, our focus is on the schedules in that exhibit the properties described in Lemmas 2 and 3. Let represent the set of schedules in whose -values are less than Y. Consequently, we have .
We are ready to present the algorithm for solving , Algorithm Fmax-Gmax-Cmax (Algorithm 2).
| Step 1. Set and . Let the initial schedule , where is the last schedule generated by Algorithm Cmax-Fmax. The products in are stored in a cyclic queue, . |
| Step 2. During the -th round: |
| Set . Adjust to construct the new schedule as follows: |
| Step 2.1. For , for each product in , check both the precedence constraints and the two inequalities and . The products in are checked in reverse order, starting from the end of the queue. |
| Case (1). If a product is found where at least one of its successors has already been moved into , and if , then set and proceed to Step 3. Otherwise ( ), remove from and insert it into , appending it to the end of . Job will not be rechecked when next we are checking . |
| Case (2). If a product is found where either or is violated, let denote the set of products that are in but processed earlier than in . Let represent the set of suitable earlier products of . That is, We then distinguish between two different subcases: |
| Subcase (2.1). . |
| Pick a product in and let it be scheduled immediately after in the same product-subsequence. Thus, this product is completed exactly at . |
| Subcase (2.2). . |
| If or is the last scheduled product in , then set and proceed to Step 3. Otherwise, (DEQUEUE) remove along with all the products in , and (ENQUEUE) insert these products into . These products will not be rechecked when next we are checking . |
| Step 2.2. Update the modified schedule as follows: For , first process the common subassemblies of the products in as a batch. Then, process the unique subassemblies of the products in individually in the sorted order (which may differ from Lawler’s order). Update the two maximum costs for each product in the schedule according to Lemma 3. |
| Step 2.3. Repeat Steps 2.1 and 2.2 until all inequalities and precedence constraints in the modified schedule are satisfied. Once no violations remain, let be the final modified schedule. |
| Step 3. If , then set and go to Step 2. Otherwise, return . |
For further details on the cyclic queue data structure and its basic operations, DEQUEUE and ENQUEUE, the reader may refer to Cormen et al. (2022).
Similar to the time complexity analysis of Algorithm Cmax-Fmax, it can be demonstrated that the running time of Algorithm Fmax-Gmax-Cmax is .
We get:
Lemma 7 Let be obtained at the -th round of Algorithm Fmax-Gmax-Cmax, where . Let be any one in . Then, , .
Lemma 8 Let be obtained at the -th round of Algorithm Fmax-Gmax-Cmax, where . Let be any one in . Then:
(1) , where and represent the number of nonempty product-subsequences in and S respectively;
(2) , ;
(3) , .
Lemma 9 Let be obtained at the -th round of Algorithm Fmax-Gmax-Cmax, where . If , then . Otherwise, has minimum makespan in all schedules in .
Theorem 3 Algorithm Fmax-Gmax-Cmax solves in time.
To solve , we need to modify Step 1 and Step 2.1 of Algorithm Fmax-Gmax-Cmax slightly. In Step 1, we set the initial schedule , where is the last schedule generated by modified Algorithm Cmax-Fmax. In Step 2.1, since the common subassemblies of and its successors can be in the same batch, we do not need Case (1). We just need Case (2) to ensure that the predecessors of and obey the weak precedence constraints.
Then we get:
Theorem 4 Modified Algorithm Fmax-Gmax-Cmax solves in time.
For Algorithm Fmax-Gmax-Cmax, we perform the same experiment as in “The Experiments”. The running time of problem is shown in Table 3.
| Number of jobs | Average time (s) | Max time (s) |
|---|---|---|
| 10 | 5.454063E−04 | 2.706051E−03 |
| 20 | 1.091480E−03 | 2.664328E−03 |
| 30 | 2.777719E−03 | 9.774208E−03 |
| 40 | 1.028388E−02 | 5.631423E−02 |
| 50 | 9.011396E−03 | 5.189085E−02 |
| 60 | 1.748489E−02 | 7.746744E−02 |
| 70 | 1.449437E−02 | 4.745579E−02 |
| 80 | 1.357992E−02 | 2.614021E−02 |
| 90 | 3.757528E−02 | 1.367950E−01 |
| 100 | 2.615252E−02 | 8.715153E−02 |
Table 4 systematically compares two scheduling algorithms, Algorithm Cmax-Fmax and Algorithm Fmax-Gmax-Cmax, thereby highlighting their distinct optimization paradigms, theoretical underpinnings, and outputs.
| Aspect | Algorithm Cmax-Fmax | Algorithm Fmax-Gmax-Cmax |
|---|---|---|
| Objective | Bicriteria Pareto optimization: |
Lexicographic tri-criteria optimization: |
| Theoretical basis | Lemma 2 (Batch adjacency property) | Theorem 4 (Lexicographic optimality) |
| Output | Pareto frontier | Optimal schedule |
Algorithm Cmax-Fmax targets bicriteria Pareto optimization (minimizing and simultaneously) and leverages Lemma 2 to simplify batch sequencing, yielding a Pareto frontier of non-dominated solutions. In contrast, Algorithm Fmax-Gmax-Cmax enforces lexicographic tri-criteria priority ( ) grounded in Theorem 4, producing a optimal schedule . These design choices reflect trade-offs between exploring solution diversity (Cmax-Fmax) and enforcing strict priority (Fmax-Gmax-Cmax), enabling application-specific deployment.
Conclusions
In this article, we explored four multicriteria scheduling problems involving two-subassembly products with precedence constraints on a fabrication facility, assuming batch availability of the common subassemblies. We introduced an -time algorithm for the simultaneous optimization of makespan and maximum cost under both strict and weak precedence constraints. Additionally, we proposed an -time algorithm for the lexicographical optimization of two maximum costs and makespan, also under strict or weak precedence constraints. Future research could focus on developing algorithms with improved time complexity for these scheduling problems. A particularly intriguing direction would be to explore Pareto optimization for a general min-max objective function, in conjunction with a general min-max or min-sum objective function.
This study provides a foundational framework for multicriteria scheduling of two-subassembly products, but several promising avenues for extension exist, particularly those that balance theoretical rigor with industrial applicability:
(1) Parallelization for industrial-scale instances. Given the time complexity of the proposed algorithms, developing GPU-accelerated or distributed (MapReduce) implementations represents a high-impact direction. Such optimizations would bridge the gap to real-world manufacturing scenarios with large product portfolios (e.g., automotive subassembly lines), where real-time scheduling is critical.
(2) Dynamic precedence constraint management. Extending the model to handle real-time updated precedence graphs (e.g., in flexible manufacturing systems) is vital for Industry 4.0 applications. Xu et al. (2024) proposed an incremental scheduling algorithm with complexity per update, which could be integrated with our Pareto optimization framework to accommodate dynamic priority changes (e.g., rush orders or machine failures). This enhancement would improve adaptability in volatile production environments.
(3) Energy-aware multicriteria optimization. Incorporating energy consumption as a tertiary objective aligns with sustainability trends in manufacturing. Recent work by Hidri & Tlija (2024) shows that dual-objective algorithms can be extended to three criteria with only polynomial complexity growth. For example, minimizing energy use during batch setup ( ) or unique subassembly processing ( ) could be integrated into the lexicographical optimization framework, balancing makespan, cost, and environmental impact.
These directions are based on the theoretical foundation of this research and also address the unmet demands in industrial scheduling, ensuring the continuous relevance in both academic research and practical applications.