
RT-Cabi: an Internet of Things based framework for anomaly behavior detection with data correction through edge collaboration and dynamic feature fusion
- Published
- Accepted
- Received
- Academic Editor
- Natalia Kryvinska
- Subject Areas
- Artificial Intelligence, Data Mining and Machine Learning, Data Science, Internet of Things
- Keywords
- IoT security, Anomaly behavior detection, Dynamic feature fusion, Data correction, Edge collaboration
- Copyright
- © 2024 Li and Chen
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. RT-Cabi: an Internet of Things based framework for anomaly behavior detection with data correction through edge collaboration and dynamic feature fusion. PeerJ Computer Science 10:e2306 https://doi.org/10.7717/peerj-cs.2306
Abstract
The rapid advancement of Internet of Things (IoT) technologies brings forth new security challenges, particularly in anomaly behavior detection in traffic flow. To address these challenges, this study introduces RT-Cabi (Real-Time Cyber-Intelligence Behavioral Anomaly Identifier), an innovative framework for IoT traffic anomaly detection that leverages edge computing to enhance the data processing and analysis capabilities, thereby improving the accuracy and efficiency of anomaly detection. RT-Cabi incorporates an adaptive edge collaboration mechanism, dynamic feature fusion and selection techniques, and optimized lightweight convolutional neural network (CNN) frameworks to address the limitations of traditional models in resource-constrained edge devices. Experiments conducted on two public datasets, Edge-IIoT and UNSW_NB15, demonstrate that RT-Cabi achieves a detection accuracy of 98.45% and 90.94%, respectively, significantly outperforming existing methods. These contributions not only validate the effectiveness of the RT-Cabi model in identifying anomalous behaviors in IoT traffic but also offer new perspectives and technological pathways for future research in IoT security.
Introduction
Background
The Internet of Things (IoT) is transforming the way we work and live. As the number of these devices increases rapidly, we are faced with unprecedented challenges in data processing and security. The vast amount of data generated by IoT devices requires not only real-time processing but also in-depth analysis to ensure the efficiency and security of the systems. The market value of IoT is expected to reach $534.3 billion by 2025, increasing the demand for real-time data monitoring. The projected number of IoT connections via LEO satellites is also on the rise—from six million in 2022 to 22 million by 2027, with an annual compound growth rate of 25%, highlighting the importance of real-time data processing (https://iot-analytics.com/number-connected-iot-devices/). The network security threats faced by IoT devices are significant, with data showing that on average, each device is attacked within five minutes of connecting to the internet, and routers suffer an average of 5,200 attacks per month, underscoring the urgency of strengthening security measures (https://dataprot.net/statistics/iot-statistics/). The global number of IoT devices is expected to grow by 16%, reaching 16.7 billion by 2025 (https://iot-analytics.com/number-connected-iot-devices/). This reflects the scale of cross-industry integration and the ensuing data management challenges, highlighting the need for efficient processing solutions to address this trend.
As IoT technology continues to be widely applied, the security challenges it presents, particularly in identifying anomalous traffic behaviors, are becoming increasingly important (Lee, Pak & Lee, 2020). The diversity of IoT devices and the complexity of the data they generate make the patterns of abnormal behavior more varied and complex. Existing detection methods often struggle with this high-dimensional, complex data, finding it difficult to adapt and learn in a constantly changing environment (Injadat et al., 2020; Di Mauro et al., 2021). (1) The process of data collection often comes with errors and inconsistencies, leading to frequent occurrences of data loss or missing fields, not only increasing the difficulty of anomaly detection but also making the effective correction and completion of data an urgent problem to solve. (2) Considering the limited resources of IoT devices, such as processing power, storage space, and power, there is an urgent need for an efficient and energy-saving algorithm to address these challenges.
Therefore, facing the challenges of diversity in IoT devices, incompleteness of data, and limitations of device resources, traditional anomaly detection algorithms often fall short. This study introduced the RT-Cabi framework, which utilizes an adaptive edge collaboration mechanism, dynamic feature fusion and selection technology, and an optimized lightweight convolutional neural network (CNN) model. This approach not only improves data communication between sensors for better accuracy and completeness but also significantly lowers resource requirements.
Literature review
Current research on anomaly detection in IoT edge computing environments
In the context of IoT edge computing, the identification of anomalous behaviors is crucial for ensuring network security and the stable operation of devices (Cui, Jiang & Xu, 2023). With the explosive increase in the number of IoT devices and the diversification of application scenarios, traditional methods of anomaly detection face new challenges, particularly in dealing with novel network attacks, encrypted traffic analysis, and device heterogeneity (Kamaraj, Dezfouli & Liu, 2019; Wijaya & Nakamura, 2023; Tong et al., 2023).
These challenges have prompted innovative solutions. Soukup, Čejka & Hynek (2019) introduced a method for detecting behavioral anomalies by analyzing encrypted IoT traffic at the network edge, combining two semi-supervised techniques aimed at improving the reliability of anomaly detection and effectively mitigating the limitations of single techniques. However, it also noted that processing encrypted traffic requires more complex data analysis methods. Kayan et al. (2021) developed AnoML-IoT, an end-to-end data science pipeline that supports various wireless communication protocols and can be deployed on edge, fog, and cloud platforms to address the challenges of IoT environment heterogeneity. Despite its promotion of anomaly detection mechanisms, its high requirements for multiple software tools and domain knowledge limit its widespread application. Li et al. (2022) proposed the ADRIoT framework, utilizing unsupervised learning with LSTM autoencoders and edge computing assistance, focusing on detecting network attacks in IoT infrastructures, especially unpredictable zero-day attacks. This method reduces reliance on labeled data and effectively improves the handling of new attack patterns, but it may limit the deployment and performance of detection modules on edge devices due to resource constraints.
The potential of dynamic feature fusion and selection techniques in optimizing edge computing
Dynamic feature fusion and selection techniques, key to solving high-dimensional data problems and enhancing the processing capabilities of edge computing, have garnered widespread attention in recent years. Their potential application in optimizing edge computing is based on the latest research developments.
Cai et al. (2018) discussed feature selection methods that provide an effective pathway for high-dimensional data analysis, reducing computation time and improving the accuracy of learning models. Specific applications may require tailored feature selection methods. Boulesnane & Meshoul (2018) proposed a hybrid model that combines an online feature selection process with dynamic optimization, enhancing the quality of the selected feature set. However, the dynamic adjustment of the algorithm in practical applications requires fine-tuning according to the characteristics of the data flow. On the other hand, Tubishat et al. (2020) introduced an improved Butterfly Optimization Algorithm (DBOA) with a mutation-based local search algorithm (LSAM), effectively avoiding local optima, significantly improving classification accuracy, and reducing the number of selected features, which may require additional computational resources. Wei et al. (2020) presented an improved feature selection algorithm (M-DFIFS) by combining classical filters and dynamic feature importance (DFI), significantly enhancing performance within an acceptable computation time, although the algorithm has high complexity and sensitivity to parameters.
Dynamic feature fusion and selection techniques show significant potential for application in optimizing edge computing. Through refined algorithm design and efficient feature processing strategies, they can significantly improve the efficiency and accuracy of data processing in IoT edge computing environments.
Research progress on adaptive collaborative frameworks and information sharing mechanisms
Research on adaptive collaborative frameworks and information sharing mechanisms is vital for enhancing system flexibility and efficiency. Wang, Zheghan & Wu (2023) proposed a content-aided IoT traffic anomaly detection approach that leverages both packet header and payload information to build machine learning models, achieving consistent detection results even under significant network condition changes. Chatterjee & Ahmed (2022) conducted a comprehensive survey on IoT anomaly detection methods and applications, highlighting current challenges such as data and concept drifts and data augmentation with a lack of ground truth data. Elsayed et al. (2023) empirically studied anomaly detection for IoT networks using unsupervised learning algorithms, showing high F1-scores and area under curve (AUC) values with the novelty approach. Eren, Okay & Ozdemir (2024) reviewed XAI-based anomaly detection methods for IoT, providing insights into the transparency and interpretability of anomaly detection models. Balega et al. (2024) optimized IoT anomaly detection using machine learning models like XGBoost, support vector machine (SVM), and deep convolutional neural network (DCNN) demonstrating the superior performance of XGBoost in both accuracy and computational efficiency.
The prospects of lightweight neural networks and multi-task learning in edge computing
The Edgent framework, proposed by Li et al. (2019), facilitates collaborative inference of deep neural networks in a device-edge collaborative manner, particularly emphasizing the importance of DNN partitioning and appropriate resizing. It effectively reduces computational latency and enhances edge intelligence, though its adaptability to actual network fluctuations still needs further verification. Moreover, Chen & Ran (2019) delve into the challenges and solutions of applying deep learning in edge computing applications, offering perspectives on accelerating deep learning inference and distributed training on edge devices, despite the complexity and resource consumption of deep learning models remaining significant challenges.
Addressing the resource allocation problem in IoT networks, Zhou et al. (2019) discuss edge intelligence, emphasizing the integration of edge computing and artificial intelligence technologies to fully exploit the potential of edge big data. Challenges include system performance, network technologies, and management. Liu, Yu & Gao (2020) explored computational task offloading mechanisms through a multi-agent reinforcement learning framework, improving energy efficiency and reducing channel estimation costs, though its performance in highly dynamic environments requires further research. Huang et al. (2022) introduced a lightweight collaborative deep neural network (LcDNN) that significantly reduces model size and lowers mobile energy consumption by executing binarized neural network (BNN) branches on the edge cloud, demonstrating potential applications in mobile Web applications, though its performance and adaptability in complex tasks and variable environments need further evaluation.
In summary, the application prospects of lightweight neural networks and multi-task learning in edge computing are clear, providing strong technical support for real-time collaborative anomaly detection applications in IoT edge computing environments.
Our contributions
This study identifies gaps in data integrity, algorithm adaptability, and computational resource optimization, detailed in Table 1. We introduce a comprehensive solution, the RT-Cabi framework, shown in Fig. 1. Figure 1 illustrates the integration of various components, including negotiated filtering, distributed Kalman filtering, hard parameter sharing, multitasking attention mechanisms, and lightweight convolutional neural networks. These elements work together to enhance anomaly detection and collaborative detection algorithms for edge devices. The key contributions of our proposed framework are summarized as follows:
| Author | Application scenario | Research content | Possible shortcomings |
|---|---|---|---|
| Tubishat et al. (2020) | Feature selection | Proposed DBOA avoids local optima effectively through LSAM | Requires additional computational resources |
| Wei et al. (2020) | Feature selection | M-DFIFS proposed combining filters and DFI to enhance performance | Algorithm complexity is high and sensitive to parameters |
| Kayan et al. (2021) | IoT environments | Developed AnoML-IoT supports various wireless communication protocols, deployable on edge, fog, and cloud platforms | High demands for multiple software tools and domain knowledge limit its widespread application |
| Li et al. (2022) | IoT infrastructure | Unsupervised learning method using LSTM autoencoder, focused on network attack detection | May limit the deployment and performance of edge device resource modules |
| Wang et al. (2022) | IoT traffic anomaly detection | Proposed content-aided approach leveraging packet header and payload information | May require more computational resources for processing payload data |
| Chatterjee & Ahmed (2022) | IoT anomaly detection | Survey on IoT anomaly detection methods and applications | Lack of comprehensive methods for integrating various sensors and data augmentation |
| Elsayed et al. (2023) | IoT networks | Empirical study using unsupervised learning algorithms for anomaly detection | Performance may vary with different datasets and network conditions |
| Eren, Okay & Ozdemir (2024) | IoT anomaly detection | Survey on XAI-based anomaly detection methods for IoT | Interpretability may come at the cost of reduced model complexity |
| Balega et al. (2024) | IoT security | Optimized anomaly detection using machine learning models like XGBoost, SVM, and DCNN | The approach’s effectiveness may depend on the diversity of datasets and IoT environments |
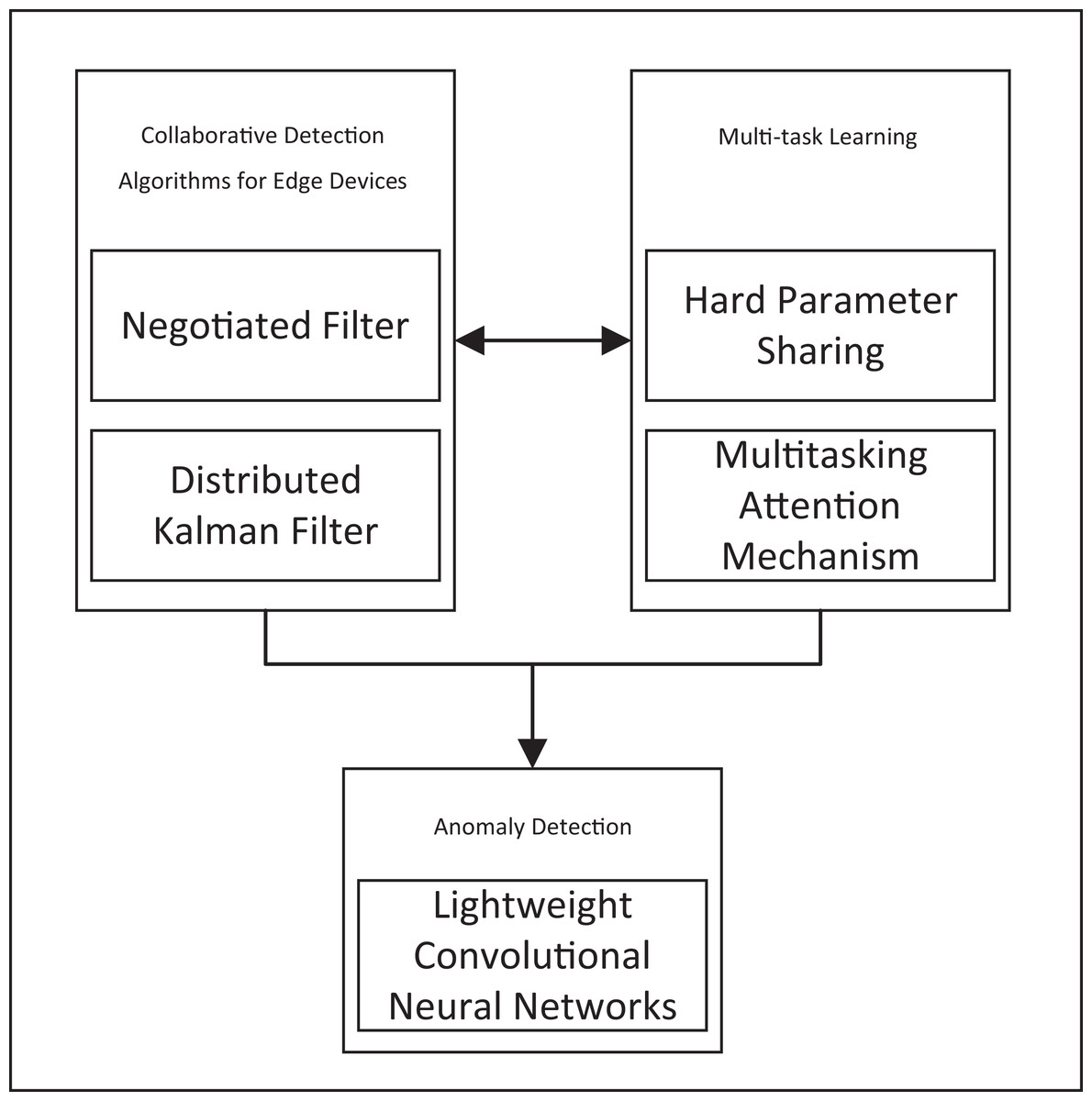
Figure 1: The RT-Cabi framework.
{kind=link}
-
Adaptive anomaly detection for IoT: We designed an edge collaborative framework based on adaptive parameter adjustment. This framework can capture environmental changes in real-time, dynamically adjust model parameters through weighted collaborative filtering and distributed Kalman filtering techniques. This approach ensures the model remains robust and responsive to new data patterns and anomalies.
Data anomaly correction and imputation strategy: We developed a dynamic feature fusion and selection mechanism combining hard parameter sharing and multi-task learning technologies. By introducing adaptive weight adjustment and an advanced multi-task dynamic attention mechanism, this strategy can effectively handle common feature missing issues in the IoT environment. This ensures data integrity and enhances the overall reliability of the system.
Mathematical collaborative optimization strategy: This study also proposes a set of mathematical collaborative optimization strategies, integrating methods from edge collaboration, feature fusion, and lightweight CNN optimization, forming a comprehensive model optimization scheme. This strategy reduces the computational demands and resource consumption in resource-constrained edge computing environments, making it practical for real-world IoT applications.
The rt-cabi framework
IoT anomaly detection model
Consider an IoT environment composed of N devices, denoted as . Each device can collect and process a local dataset , containing samples . These samples are independently and identically distributed (i.i.d.) drawn from the local distribution of device , with each sample including a training input and its corresponding label. Assume the data across devices is heterogeneous, i.e., the local distributions are non-i.i.d.
Each device trains a local model composed of parameters, represented by the vector , using its dataset. The training objective is to minimize the local objective function based on the loss metric , with device ’s local objective defined as:
(1)
Thus, the goal of device is to find the parameters that minimize Eq. (1):
(2)
The server aims to train a global model with parameters using the data available from the user side. The global learning objective is given by the following equation:
(3)
Therefore, the server seeks to solve the following minimization problem:
(4)
We introduce adaptive parameters , allowing the model to dynamically adjust according to changes in the environment, to enhance the accuracy and adaptability of anomaly detection in the IoT environment. The problem is transformed into a multi-objective optimization issue of simultaneously optimizing and to achieve optimal anomaly detection performance.
Motivation for adaptive edge collaboration framework: achieving efficient information sharing and task distribution
Existing edge computing frameworks often use centralized management or information exchange mechanisms based on simple protocols, which struggle in handling dynamically changing network environments and diverse device capabilities (Hu & Huang, 2022). This limitation leads to inefficient information sharing, inability to flexibly allocate tasks, and severely restricts the system’s response speed and adaptability to change (Wang et al., 2022; Patsias et al., 2023).
We propose an adaptive edge collaboration framework that integrates advanced algorithmic design, combining weighted collaborative filtering with distributed Kalman filtering. Its core innovation is the dynamic adjustment of task and resource allocation strategies in response to real-time network conditions and device capabilities, ensuring efficient resource use and quick task response under diverse conditions.
Mathematical model of the adaptive edge collaboration framework
We focus on how the adaptive edge collaboration framework enables effective information sharing and task allocation among multiple devices in an edge computing environment. The state at time is , following the dynamic model:
(5) where A is the state transition matrix, B is the control matrix, is the control input at time , and is the process noise, assumed , with Q as the covariance matrix of the process noise.
The device observation at time , , is:
(6) where H is the observation matrix, and is the observation noise, assumed , with R as the covariance matrix of the observation noise. Estimation accuracy improves by merging information from different devices, described by the collaborative filtering algorithm:
(7) where is the Kalman gain of device at time , and N is the total number of devices. Information fusion among devices uses a weighted collaborative filtering algorithm to enhance overall state estimation accuracy:
(8) where and are the Kalman gains of device and external information source at time . Observations and come from device and external source . Matrices H and G represent internal and external observation models. R, S, Q, and P are covariance matrices of observation noise, external source noise, process noise, and estimation error. is device ’s state prediction based on prior information, used to generate the optimal estimate .
The distributed Kalman filtering algorithm lets each device update its state estimation based on local observations and neighbor information:
(9) where is the observation of device at time . Distributed Kalman filtering allows each device to use local observations and neighbor information to update its state estimate:
(10) where H is the observation model matrix, is the neighbor weight coefficient, and is the set of neighbor devices of device .
In each iteration, devices share state estimates and observation information through the network, adapting to network conditions and device capabilities. Considering the information exchange and dynamic adjustment of adaptive parameters, we define the following mathematical model:
(11) where represents advanced information fusion between device and its neighbor set . is an advanced information processing function dynamically adjusted based on device capabilities and network state. , , , and are dynamically adjusted weight coefficients. is a basic parameter set for adjusting the information processing, and is an additional parameter set for the interaction between device and its neighbor .
To adapt to changing network conditions and device capabilities, an adaptive parameter adjustment process updates the state estimate of device :
(12) where is the adaptive adjustment function, are dynamically adjusted parameters, is an adaptive learning rate, is the Hadamard product, is the gradient of the loss function with respect to the state estimate , and includes all related model parameters and network condition indicators.
Theorem 1 (Optimization of the adaptive edge collaboration framework) There exists an optimal parameter set , which can effectively coordinate the efficiency of information sharing and task allocation, while considering the timeliness of task execution:
(13)
Here, represents the efficiency of information sharing, denotes the responsiveness of task allocation, involves the complexity of task execution, and , , and are coefficients balancing the importance of these three aspects.
Corollary 1 (Parameter optimization strategy for the adaptive edge collaboration framework) In the adaptive edge collaboration framework, the key lies in the optimization of framework parameters to achieve the highest efficiency in information sharing and task allocation, while adapting to dynamic network conditions. We ensure that the framework parameters gradually converge to the optimal solution through the following strategy, to achieve the best system performance:
(14)
In this formula, represents the overall system performance loss, and are hyperparameters balancing different terms, is the weight of device , and respectively represent the predicted probability under parameters and the baseline probability, measures the difference between the prior and posterior distributions of parameters , reflecting the adaptability and generalization ability of the model. This optimization process not only enhances the framework’s performance but also ensures the gradual convergence of parameters, improving the overall system efficiency and adaptability.
The proof is presented in the appendix.
Motivation for feature data selection and optimization: achieving dynamic feature fusion and selection for feature data optimization
Existing feature selection and fusion techniques often fail to effectively address the challenges of dynamically changing data and complex inter-task relationships. These techniques, based primarily on a static data perspective, overlook the time-varying nature of IoT data streams and the complexity of interactions between devices, leading to limited model performance in a multi-task learning environment and difficulty in adapting to real-time application requirements (Tao et al., 2022; Wang et al., 2022; Patsias et al., 2023).
To address these issues, we designed an innovative mechanism for dynamic feature fusion and selection. The core innovation of this mechanism is its ability to dynamically adjust feature selection strategies based on real-time data streams and task requirements, achieving intelligent selection of the most representative and relevant features from large-scale, multi-source feature sets.
Mathematical principles of dynamic feature fusion and selection
To delve into the mathematical principles of dynamic feature fusion and selection, we propose a multi-task learning (MTL) model that combines hard parameter sharing and a multi-task attention mechanism. First, we define the overall objective function of multi-task learning, considering the relatedness between tasks and their uniqueness. The overall objective function combines the loss functions of all tasks as follows:
(15) where T is the total number of tasks; represents the weight of the th task; is the loss function of the th task; is the prediction function corresponding to the th task; X represents the input features; is the true label of the th task; represents the parameters shared across all tasks; is the task-specific parameters of the th task; is the weight of the regularization term; P is the number of shared parameters; is the weight for missing data imputation; N is the number of data points in the dataset; is a normalization factor; K is the number of historical data points considered at each time step; represents the variance of Gaussian noise; is a task-specific feature extraction function.
By considering the problem of multi-task learning (MTL) under a hard parameter sharing framework, we describe the structure and learning process of the model by introducing an equation for the parameter set of shared layers:
(16) where L represents the number of shared layers, is the weight matrix of the th layer, and indicates the tensor product operation, used to describe the complex interaction between parameters of different layers.
The overall objective function of multi-task learning is expressed as:
(17) where is the task-specific parameter set of the th task; and are the weight parameters of the regularization terms; represents the correlation adjustment parameter between tasks and ; and respectively indicate the Frobenius norm and norm.
To capture the dynamic relationships between tasks and optimize the process of multi-task learning, we introduce an adaptive weight adjustment mechanism based on task correlation:
(18) where is the learning rate, represents the iteration count, and indicates the adaptive importance weight of task at iteration .
To enhance the model’s capability in handling high-dimensional data and complex task relationships, we incorporate attention mechanisms from deep learning to dynamically focus on different tasks and features:
(19) where is a scaling factor to prevent the dot product from becoming too large in high-dimensional spaces.
Considering the complexity and diversity in a multi-task learning framework, we extend and deepen the original attention mechanism, introducing an advanced multi-task dynamic attention mechanism:
(20) where represents the dynamic attention weight vector for task , and are the task-specific attention mechanism’s weight matrix and bias vector, respectively. Vector is an enhanced output of the shared layer through a feature completion mechanism.
For the dynamic completion issue of features in a multi-task learning environment, a feature completion mechanism is proposed:
(21) where is the original output vector of the shared layer, represents a high-dimensional feature missing indicator vector, is element-wise multiplication, is a feature completion model based on the parameter set , and are the weight and bias in the completion model for handling non-missing features, is a nonlinear activation function.
A parameterized dynamic adjustment layer is introduced into the feature completion mechanism for dynamic adjustment of the enhanced feature representation after feature completion:
(22) where and are matrices learned during training, and represent the parameter sets of these two functions.
Following this, a multi-task attention mechanism allows each task to select and emphasize the most important features for feature fusion, also considering the completion of missing features:
(23) where is the feature representation of the task after attention weighting and feature complementation, and is a scaling factor. Task-specific parameters are used to further process the features selected and fused by the attention mechanism, adapting to environmental changes and missing features:
(24) where is the output of the task, is a non-linear transformation function for further processing the feature representation, and is a task-specific parameter set adaptively adjusted to adapt to changes in network conditions and computational capabilities:
(25) where represents a parameter adjustment operation, is a coefficient dynamically adjusted according to task ’s specific requirements at time , is a regularization coefficient, and represents a correlation adjustment parameter between task and task .
To improve the model’s performance and generalization ability in handling multiple tasks, an integrated loss function is introduced, aiming to minimize the total loss of all tasks. (26) where is the loss function of the task, , , , and are hyperparameters adjusting the importance of each loss component, is a regularization term, is an indicator vector for missing features of the task, is a feature complementation model, and are the parameters of the feature complementation model.
This addresses the feature complementation problem within the dynamic feature fusion and selection framework to enhance the robustness and accuracy of multi-task learning models in dealing with incomplete or noisy feature data.
Theorem 2 (Performance enhancement in MTL through dynamic feature processing) Through the dynamic feature fusion and selection strategy, the performance and generalization ability of multi-task learning models can be significantly enhanced. There exists an optimal set of parameters that optimizes model performance:
(27)
Here, is a composite loss function combining multi-task loss with feature processing loss, and are tuning coefficients, represents the dynamic weight at moment , and measures the model parameter’s generalization capability, proving the existence of the optimal solution.
Corollary 2 (Efficiency enhancement in MTL through dynamic feature processing) The dynamic feature fusion and selection mechanism significantly enhances the model’s performance in handling complex feature spaces, ensuring the optimization of overall learning efficiency and performance:
(28)
Here, combines all task losses , weights , and regularization term , indicating that the model, through dynamic feature processing strategies, gradually converges to the optimal parameter set that minimizes the overall objective function.
The proof process is presented in the appendix.
Motivation for computational resource constraints in the IoT: enhancing edge computing efficiency
Facing the issue of limited resources in edge devices within IoT applications, traditional computation-intensive models are often inapplicable due to their high computational power and storage space requirements. Existing strategies frequently overlook the resource constraints of edge computing, limiting the performance of edge devices (Xiong et al., 2020; Zikria et al., 2021; Mendez et al., 2022).
We propose an optimized lightweight CNN framework that reduces computational demand through efficient activation functions, network pruning, and model compression. Additionally, it features a dynamic resource allocation mechanism that smartly adjusts task distribution according to device capabilities and network status, enhancing efficiency while preserving accuracy.
Mathematical framework for optimizing lightweight convolutional neural networks
The optimization of lightweight CNNs for edge computing focuses on structural adjustments, efficient activation functions and pooling layers, network pruning, and dynamic feature processing to enhance efficiency, accuracy, and model simplification.
(29) where L is the loss function, is the true label of the th sample, is the model’s prediction for the th sample, represents the model parameters, is the L1 regularization term, and are the regularization coefficient and the variance of the Gaussian distribution, respectively.
Next, ReLU is chosen as the efficient activation function:
(30) where is a positive coefficient less than 1, introduced to allow a negative slope. Max pooling layers are used to reduce the dimensionality of features:
(31) where is the th element within the pooling window, K is the size of the pooling window, and is a small positive coefficient.
Network pruning techniques are applied to reduce unnecessary parameters and feature maps:
(32)
(33) where is the pruning function, are the original model parameters, and is the pruning threshold.
Dynamic feature fusion aims to dynamically select and combine features based on input data:
(34) where is the th feature map, is the weight dynamically calculated based on input data, is a coefficient to adjust the influence of second-order interactions, represents the element-wise multiplication of feature maps and .
Finally, a feature selection mechanism is implemented through the following model:
(35) where S is the feature selection function, F′ is the set of fused features, I is the set of feature indices selected based on model performance, measures the mutual information between feature and target label , and is the threshold for feature selection.
RT-Cabi framework: mathematical co-optimization strategy under an integrated framework
The RT-Cabi combines adaptive collaboration, dynamic feature processing, and optimized lightweight CNNs, using mathematical optimization to achieve real-time monitoring and anomaly analysis of IoT devices, utilizing distributed Kalman filtering for state updates based on local data.
(36) where A and B respectively represent the state transition and control matrices, is the Kalman gain at time , is the observation, H is the observation matrix, and is the weight in the adjacency matrix.
The RT-Cabi framework optimizes feature usage through a dynamic feature fusion and selection mechanism. Let be the set of dynamic features extracted by device at time :
(37) where M is the number of feature maps, are data-driven fusion weights automatically adjusted, is a coefficient controlling second-order interactions, is the interaction strength between features and , and indicates element-wise multiplication.
To further enhance processing efficiency and alleviate network burden, RT-Cabi employs an optimized lightweight CNN structure, promoting parameter sparsity through regularization and applying network pruning techniques:
(38) where L is the loss function, and are regularization coefficients, represents the th element of the model parameters, is the variance of the Gaussian distribution for regularization, and is the set of all pruned parameters.
Within the RT-Cabi framework, these three components are coordinated through an integrated optimization process to form the following consolidated model:
(39) where represents the overall optimization objective, and are the efficacy functions for edge collaboration and feature fusion respectively, , , are weighting coefficients, and is the regularization coefficient for feature differentiation among adjacent devices, denotes the set of neighboring devices of device .
Theorem 3 (Optimization of lightweight CNN under the RT-Cabi framework) There exists an optimal set of parameters obtained by minimizing the following integrated optimization objective:
(40) where and respectively represent the efficacy functions for edge collaboration and feature fusion, is the optimization loss function for the lightweight CNN, , , are weighting coefficients, is the regularization coefficient for differentiating features among neighboring devices, and represents the set of neighboring devices of device . This optimization objective comprehensively considers the accuracy of state estimation, the efficiency of feature fusion, and the complexity of the CNN model.
Corollary 3 (Optimization of transfer learning and self-attention mechanism) In the transfer learning framework combined with LSTM and attention mechanism, there exists a set of parameters that achieves the best predictive performance by optimizing the following objective function:
(41) where and are hyperparameters, balancing the trade-off between self-attention efficacy and transfer learning generalization capability.
Algorithm pseudocode and complexity analysis
Algorithm 1, the Adaptive edge collaboration framework algorithm, primarily comprises two parts: the process of device state updating and information collection at each time step, and the process of information fusion across devices. Given the time steps as T, the total number of devices as N, and the average number of neighbors per device as M, the overall time complexity is . The complexity of state updating and information fusion operations for each device at each time step depends on the size of the state vector and neighbor information set, which are generally considered constant time operations, hence the overall time complexity remains unchanged. The space complexity is primarily determined by the storage of state, control inputs, observations, and neighbor information for each device, thus is , where , , , represent the dimensions of the state, control inputs, observations, and neighbor information respectively.
| Input: Set of devices , initial state of each device , control input , observation , set of neighboring devices , adaptive parameters |
| Output: State estimate for each device i |
| 1 Initialize the state and parameters for each device; |
| 2 for each time step do |
| 3 for each device do |
| 4 Update the state prediction according to the dynamic model, using Eq. (5); |
| 5 Collect the state and observation of neighboring devices, building the information set; |
| 6 for each neighbor do |
| 7 Integrate neighbor information and update the state estimate using Eqs. (7) and (8); |
| 8 Update the state estimate using the Kalman gain and control input according to Eqs. (9) or (10); |
| 9 Perform advanced information fusion using collected information and adaptive parameters with Eq. (11); |
| 10 Adjust adaptive parameters and update the state estimate with Eq. (12); |
| 11 if network conditions or device capabilities change then |
| 12 Dynamically adjust the adaptive parameters for each device; |
| 13 return ; |
For Algorithm 2, the time complexity depends on the number of training iterations R, the total number of tasks T, and the computation time for each task in feature completion, dynamic attention mechanism, feature fusion selection, and task-specific parameter adjustment. Assuming the complexity of each operation as , , , respectively, the total time complexity is . The space complexity primarily depends on the storage needs for model parameters, including shared parameters , task-specific parameters , and the storage of features, dynamic attention weights, and outputs, overall being .
| Input: Multi-task input data X, true label set , initialized parameters , learning rate η |
| Output: Predicted output for each task |
| 1 Initialize the task predicted output set ; |
| 2 for each training iteration do{ |
| 3 for each task do |
| //Feature completion |
| 4 Compute enhanced features , using Eq. (21); |
| //Apply dynamic attention mechanism |
| 5 Calculate dynamic attention weights Ai, using Eq. (20); |
| //Feature fusion and selection |
| 6 Calculate feature fusion output Fi, using Eq. (23); |
| //Adaptive adjustment of task-specific parameters |
| 7 Update , using Eq. (25); |
| //Task output computation |
| 8 Compute the output for each task Oi, using Eq. (24); |
| 9 Add Oi to the task predicted output set; |
| //Total loss calculation and parameter update |
| 10 Calculate total loss , using Eq. (26); |
| 11 Update parameters , etc. using gradient descent; |
| 12 if convergence then |
| //Check if the loss for all tasks has reached convergence criteria |
| 13 break; |
| 14 return ; |
Algorithm 3 is concerned with state estimation updates, feature extraction and fusion, feature selection, and optimization of lightweight CNN models among edge devices. Let the total number of edge devices be N, and the time complexities for state update, feature extraction and fusion, feature selection, and model optimization be , , , and , respectively. Then, the total time complexity is . The space complexity mainly includes the storage requirements for state estimation, feature sets, and model parameters, hence is , where represents the dimension of the state vector, represents the feature dimension, and represents the dimension of model parameters.
| Input: Observational data from edge devices X, true labels Y |
| Output: Predictions from the optimized lightweight CNN model |
| //State estimation and feature extraction of the adaptive edge collaboration framework |
| 1 for each edge device do |
| 2 Update the state estimate using Eq. (36); |
| 3 Extract features based on the state estimate and compute dynamic feature fusion referring to Eq. (37); |
| //Dynamic feature selection based on state estimation |
| 4 for each edge device do |
| 5 Calculate the feature selection weights and combine with Eq. (34) to select and fuse features F'; |
| 6 Apply the feature selection mechanism Eq. (35) to obtain the optimal feature subset S(F'); |
| //Optimize the lightweight CNN model |
| 7 Initialize the parameters of the lightweight CNN model θ; |
| 8 repeat |
| //Train the model using selected features |
| 9 Use S(F') as input, compute model predictions and the loss Lopt according to Eq. (29); |
| 10 Update the model parameters θ to minimize Lopt; |
| 11 until until θ converges; |
| //Collaborative optimization within the RT-Cabi framework |
| 12 for each edge device do |
| //Integrate optimization of state estimation, feature fusion, and CNN model |
| 13 Perform integrated optimization under the RT-Cabi framework using Eq. (39); |
| 14 Update , F', and θ according to the integrated model ; |
| 15 return Predictions using the RT-Cabi framework optimized lightweight CNN model; |
Experimental results
Dataset and experimental parameters introduction
In our study, we utilized two publicly available datasets: Edge-IIoT and UNSW_NB15, to evaluate the performance of our proposed model.
Edge-IIoT: The dataset is designed for the edge computing environment in Industrial Internet of Things (IIoT) (https://www.kaggle.com/datasets/mohamedamineferrag/edgeiiotset-cyber-security-dataset-of-iot-iiot), containing various normal and abnormal device behavior data, simulating network attacks such as DDoS and malware, suitable for edge computing security threat detection.
UNSW_NB15: The dataset, released by the University of New South Wales, Australia, is aimed at network intrusion detection research (https://www.kaggle.com/datasets/mrwellsdavid/unsw-nb15). It covers a diverse dataset of modern network attack characteristics, such as backdoors and DoS attacks, intended to support network security research, enhancing the generalization and robustness of intrusion detection systems.
Our experimental parameters are set as shown in Table 2.
| Parameter name | Parameter value | Parameter name | Parameter value |
|---|---|---|---|
| Dataset | Edge-IIoT/UNSW_NB15 | Training rounds | 30 |
| Neurons per layer | 128/256/128 | Learning rate | 0.005 |
| Batch size | 128 | Iteration times | 20 |
| Optimizer | AdamW | Activation function | Leaky ReLU |
| Regularization | L2 | Regularization parameter | 0.001 |
| Early stopping criterion | No improvement in 10 rounds | Data augmentation | Adversarial training |
| Data preprocessing | Min-max normalization | Loss function | Cross-entropy + Dice loss |
| Evaluation metrics | Accuracy (ACC), F1 Score (F1) | Training/validation ratio | 70%/30% |
| Feature engineering | Dynamic feature selection and fusion | Data balancing | SMOTE + Tomek link |
| Computational resources | GPU Tesla V100 | Model saving | Best model |
| Self-attention mechanism parameters | Heads = 4, Dimension = 64 | Multi-task learning weights | Task 1 = 0.5, Task 2 = 0.5 |
| Kalman filter parameters | Q = 0.01, R = 0.01 | Convolutional layer configuration | 3 × 3 Convolution, Stride = 1 |
| Network pruning threshold | 0.15 | Pooling layer configuration | 2 × 2 Max Pooling, Stride = 2 |
| Adaptive parameter adjustment strategy | Online learning update | Feature fusion strategy | Weighted average + Quadratic term |
| Dynamic resource allocation | Yes | Lightweight model compression techniques | Quantization + Pruning |
| Edge collaboration update frequency | Every 2 rounds | Anomaly behavior detection threshold | Dynamically adjusted |
| Model initialization | Xavier initialization | Weight decay | 0.01 |
| Gradient clipping | 1.0 | Dropout rate | 0.5 |
| Learning rate decay | 0.9 per 10 rounds | Validation frequency | Every 5 rounds |
Experimental deployment data
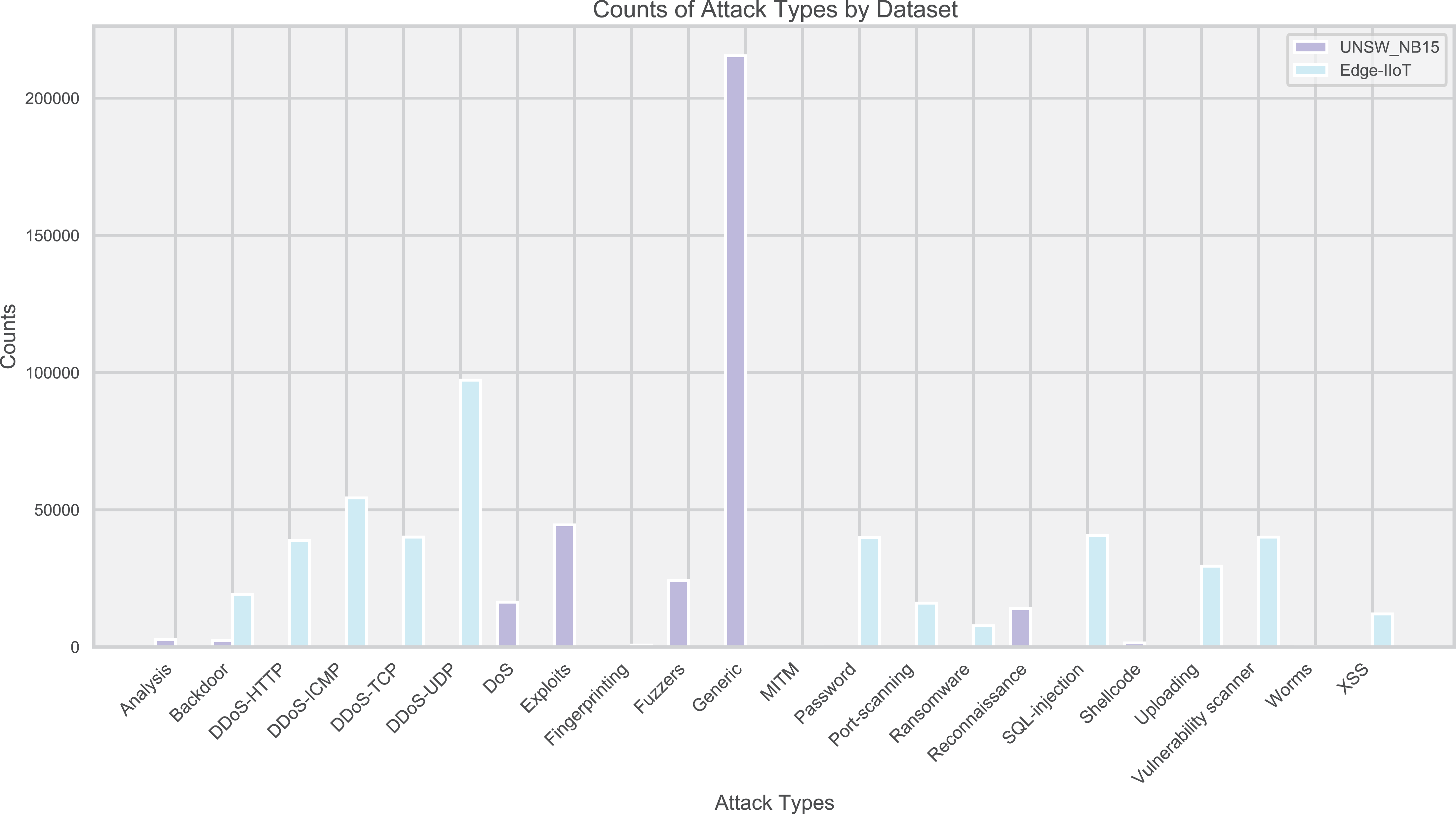
Edge-IIoT and UNSW_NB15 datasets were used to evaluate the IoT traffic anomaly detection model. These two datasets cover a variety of normal and abnormal traffic, reflecting the diversity of attack types. The distribution of attacks is intuitively displayed through bar charts (Fig. 2), guiding the model design and tuning.
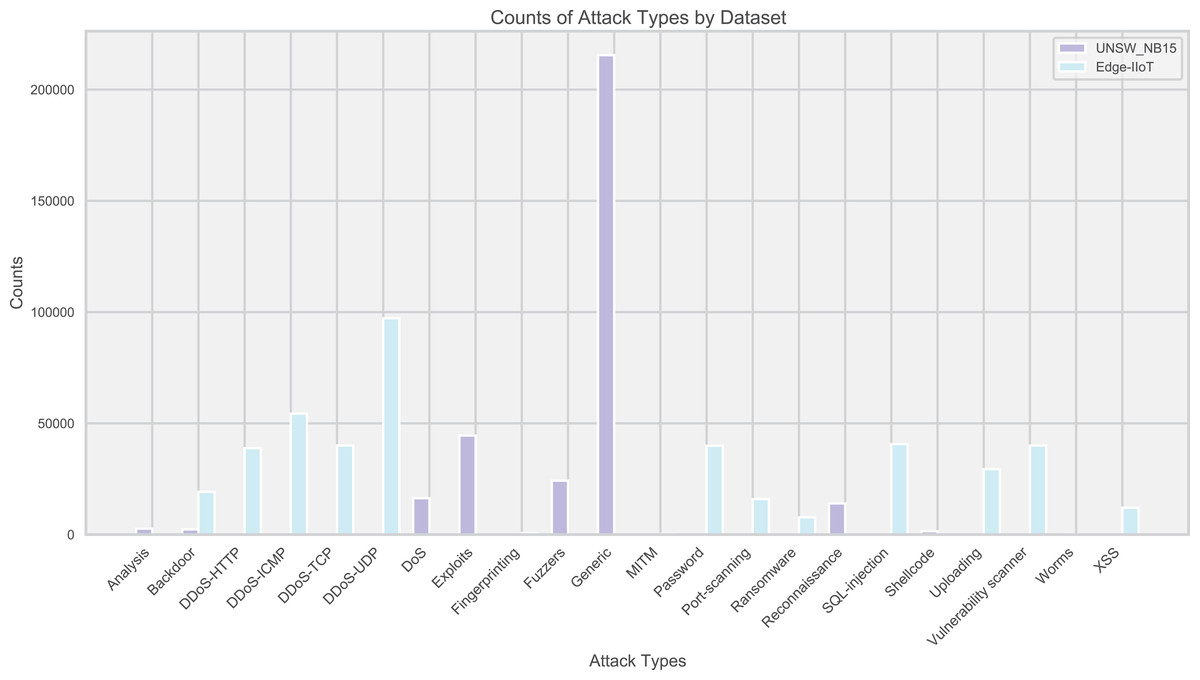
Figure 2: Distribution of attack types in the dataset.
{kind=link}
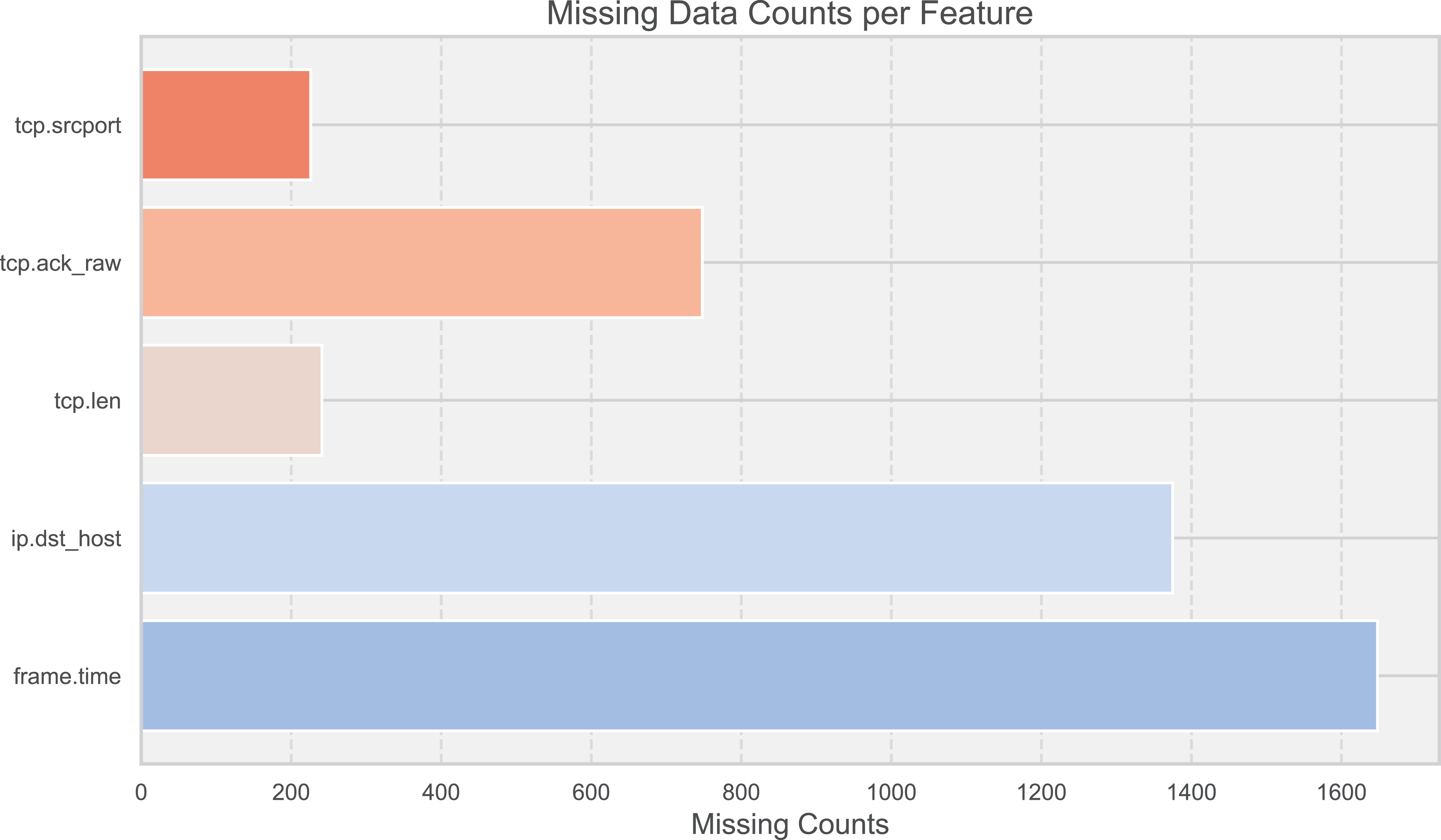
To enhance the robustness of the model, 10,000 records from each of the two datasets were randomly selected for testing. This sample size was chosen to ensure that the key characteristics of both datasets were adequately represented, providing a sufficient basis to validate the model’s performance. In the face of data missing and shifting (Fig. 3), corrections were made through a dynamic feature fusion strategy. Specifically, missing data were imputed using a combination of statistical methods and machine learning techniques, while shifting data distributions were adjusted using normalization techniques to ensure the accuracy of the results. The resource consumption of the RT-Cabi model is detailed in Table 3, covering time and space costs.To provide a comprehensive understanding of the training process, we conducted experiments over 20 training rounds. This number was chosen based on preliminary tests, which indicated that performance improvements plateaued after 20 rounds, making it an optimal choice for balancing training time and model efficiency.
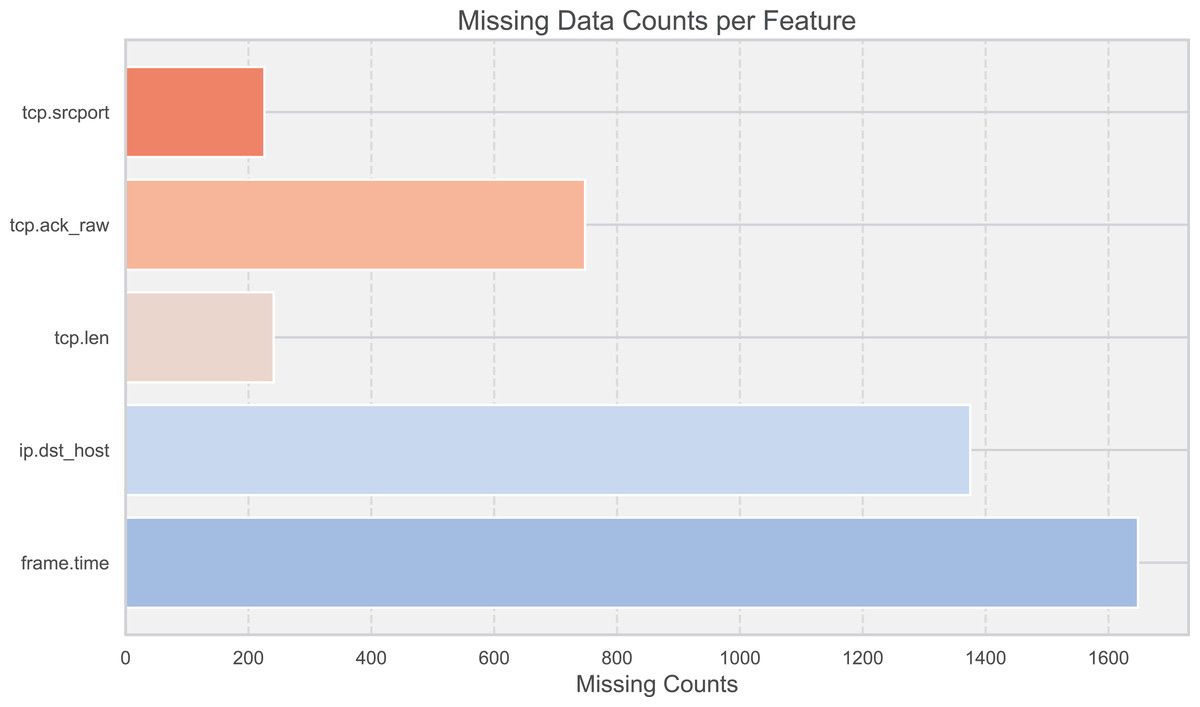
Figure 3: Missing data counts per feature.
{kind=link}
| Resource type | Description | Value |
|---|---|---|
| Time cost | Model deployment time | 2 h |
| Average inference time per sample | 10 ms | |
| Space cost | Model parameter size | 50 MB |
| Intermediate data storage space | 500 MB |
The RT-Cabi model was deployed and completed training within 2 h for 20,000 samples, indicating that the training process, from initializing the model to finishing the final epoch, was efficient and time-effective. This deployment was conducted on a machine equipped with an NVIDIA Tesla V100 GPU, 32 GB RAM, and an Intel Xeon CPU. The deployment time can vary depending on the number of epochs, batch size, and the specific hardware used. With an average inference time of 10 milliseconds per sample, this makes the model suitable for IoT applications that require rapid response. The space cost of the model includes 50 MB for parameter storage and approximately 500 MB for intermediate data storage, making the overall resource consumption reasonable for resource-constrained devices.
To address concerns about the time complexity of feature selection, our framework incorporates an efficient feature selection mechanism that balances flexibility and computational efficiency, ensuring that predictive tasks are not delayed significantly, even in the presence of potential attacks. This approach is particularly suitable for resource-constrained IoT devices such as smart sensors, wearable devices, and edge computing nodes, where computational power and memory are limited. By optimizing the feature selection process, we ensure that these devices can maintain high performance and quick response times, essential for real-time applications.
Experimental results
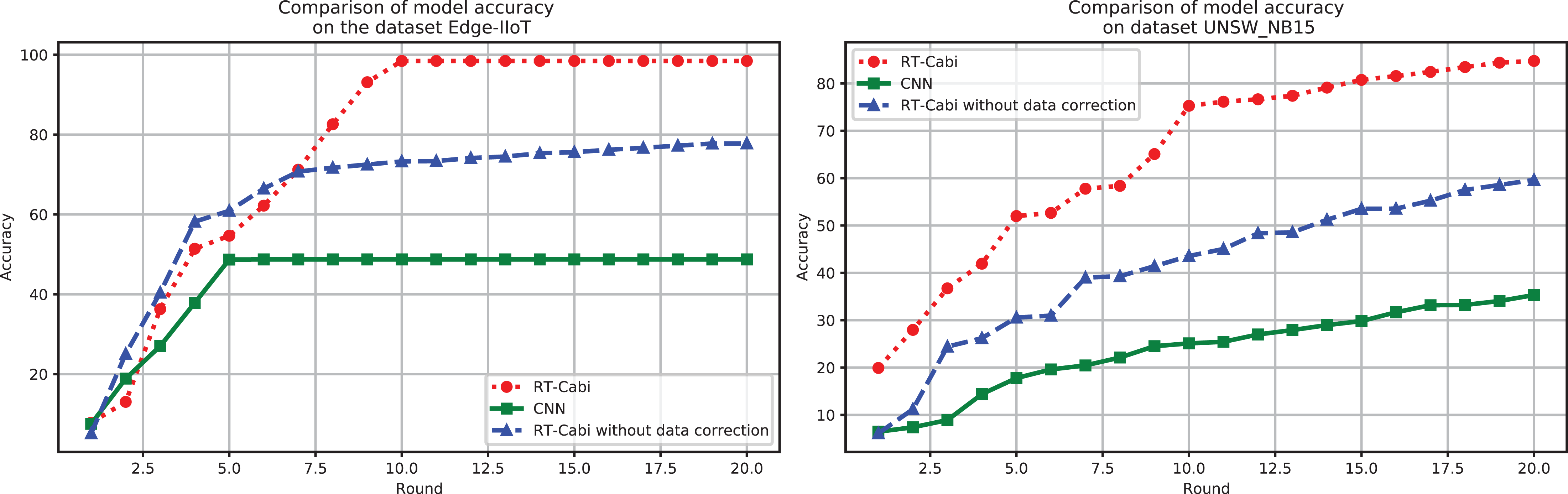
Figure 4 demonstrates the flexibility and superiority of the RT-Cabi model under various parameter settings and structures. In the Edge-IIoT dataset experiments, the model achieved a 97.15% accuracy rate after fine-tuning and feature engineering. Even without data correction, the accuracy rate was still 77.79%, showing strong robustness. In the UNSW_NB15 experiments, the accuracy rate increased from 75.59% to 84.75% after data correction, highlighting the importance of data preprocessing and the model’s adaptability to network security. In contrast, traditional CNNs, which serve as the baseline models in our study, showed significantly lower accuracy on both datasets than RT-Cabi, proving its advantages in processing IoT traffic. Traditional CNNs refer to standard convolutional neural networks without the optimizations and enhancements incorporated in RT-Cabi, such as dynamic feature fusion, adaptive parameter adjustment, and lightweight model compression.
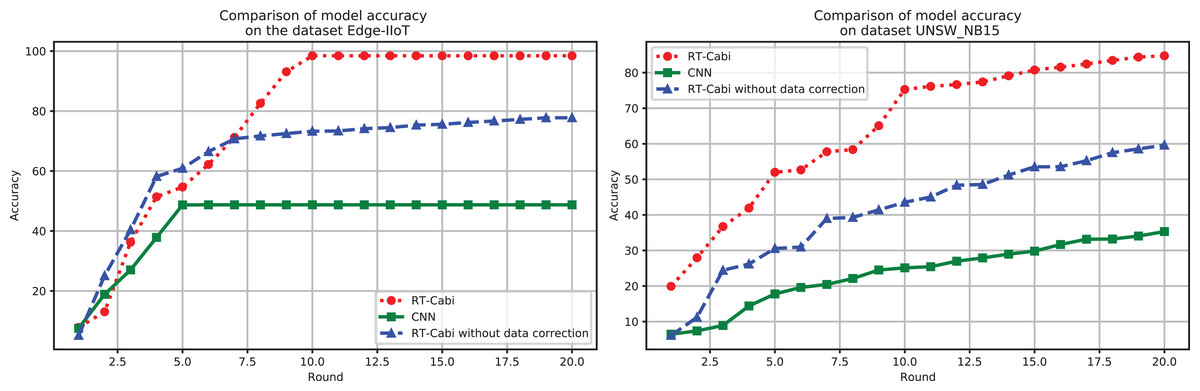
Figure 4: Model experiment accuracy performance comparison.
{kind=link}
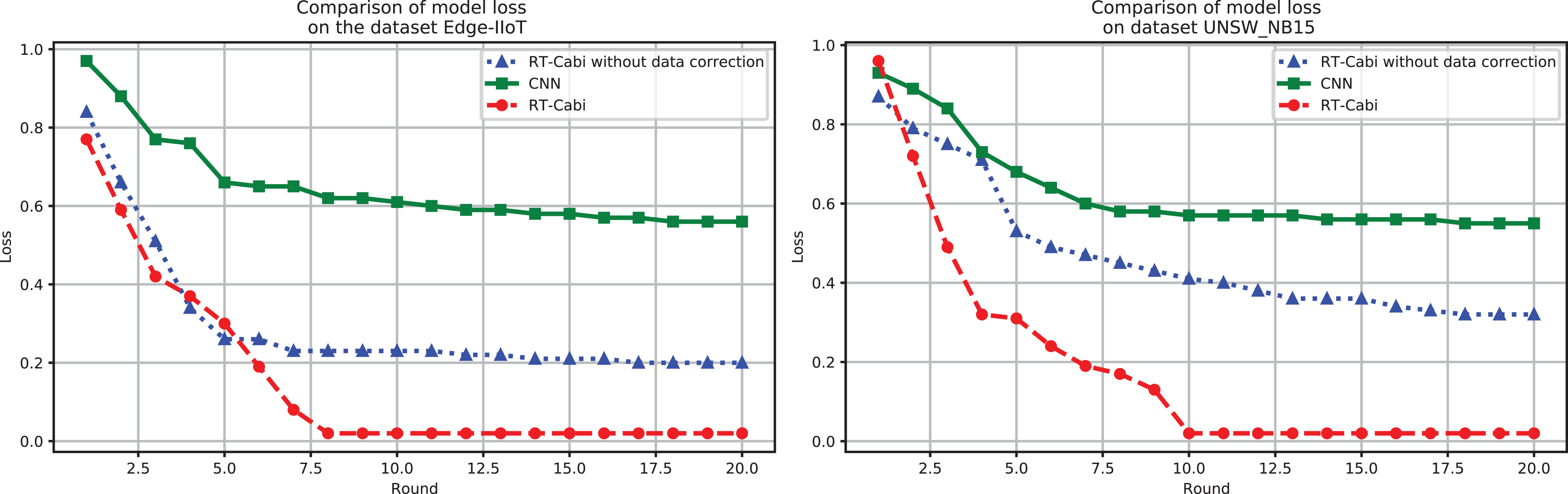
The performance of the RT-Cabi model is displayed through loss value analysis, as shown in Fig. 5. On the Edge-IIoT dataset, the loss value decreased from 1.03 to 0.006, showing its learning and optimization effects. Its performance on the UNSW_NB15 also demonstrated its generalization ability. These results not only confirm the efficiency and advanced nature of RT-Cabi in IoT anomaly detection but also provide guidance for future model design, helping to advance industrial IoT security research.
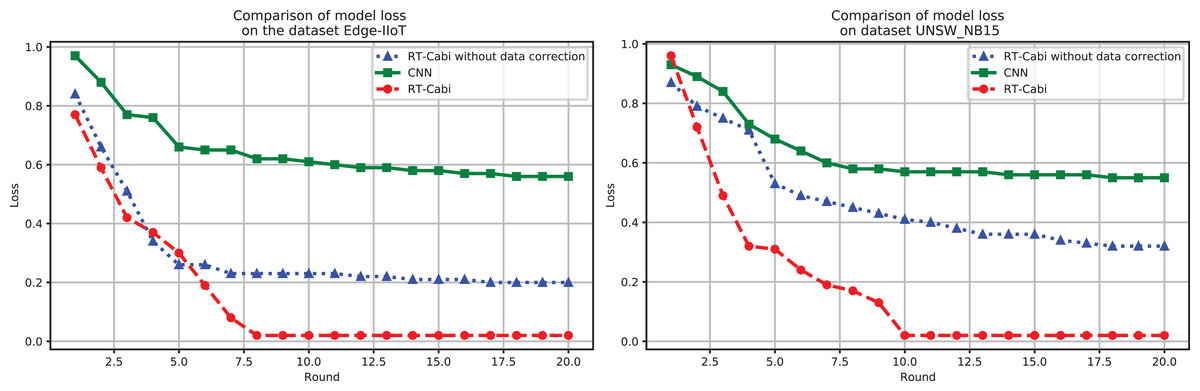
Figure 5: Model experiment loss performance comparison.
{kind=link}
Comparison with cutting-edge research
Table 4 summarizes the accuracy comparison between the RT-Cabi model and other significant models from the literature. The RT-Cabi model achieved accuracies of 97.15% and 84.75% on the Edge-IIoT and UNSW_NB15 datasets, respectively, outperforming existing research. Compared to Zhang et al. (2021) and Singh et al. (2021), it showed an improvement of 1.45% and nearly 2%, respectively, demonstrating its effectiveness and advantages in the field of IoT anomaly detection. This underscores the potential of RT-Cabi as an efficient solution.
| Method | Edge-IIoT dataset | UNSW_NB15 dataset |
|---|---|---|
| Ferrag et al. (2022) | 80.83 | _ |
| Wu et al. (2020) | _ | 73.93 |
| Tareq et al. (2022) | 94.94 | _ |
| Singh et al. (2021) | _ | 89.00 |
| Zhang et al. (2021) | 97.00 | _ |
| Meftah, Rachidi & Assem (2019) | _ | 84.24 |
| RT-Cabi | 97.15 | 84.75 |
Conclusion
This study introduces RT-Cabi, an innovative framework for anomaly detection in IoT traffic. RT-Cabi enhances the data processing and analysis capabilities of IoT devices through edge computing, effectively improving the accuracy and efficiency of anomaly detection. It adopts an adaptive edge collaboration mechanism, dynamic feature fusion selection technology, and optimized lightweight CNN framework, overcoming the limitations of traditional models on resource-constrained edge devices. Experiments on the Edge-IIoT and UNSW_NB15 public datasets show that RT-Cabi achieved detection accuracies of 98.45% and 90.94%, respectively, significantly outperforming existing methods. These achievements validate the effectiveness of RT-Cabi in identifying abnormal behaviors in IoT traffic and open new perspectives and technical paths for future research in the field of IoT security. Future work should address the scalability to larger datasets, real-time adaptability in dynamic environments, and integration with other IoT security technologies.
Appendix: mathematical theorems and corollary proofs
Theorem 1 (Optimization of the adaptive edge collaboration framework) There exists an optimal parameter set , which can effectively coordinate the efficiency of information sharing and task allocation while considering the timeliness of task execution:
(42)
where denotes the efficiency of information sharing, represents the responsiveness of task allocation, involves the complexity of task execution, and , , and are coefficients to balance the importance of these three aspects.
Proof 1 This theorem demonstrates the existence of a set of parameters , which can effectively balance the aforementioned system performance indicators, defining the system’s overall performance loss function :
(43)
We need to prove the existence of that minimizes . Using the method of Lagrange multipliers, we introduce a Lagrange multiplier , and construct the Lagrangian function to address the constraints in this optimization problem:
(44)
To find , we derive with respect to and respectively, and set the derivatives equal to zero:
(45)
By solving these equations, we obtain an optimized set of parameters that satisfy the minimization condition of the overall performance loss function . Further, we use the KKT (Karush-Kuhn-Tucker) conditions, which are necessary for solving constrained optimization problems, to ensure that the found is a global optimum:
(46)
At , not only is the overall performance loss function minimized, but also an optimal balance is achieved among all system performance indicators.
Corollary 1 (Parameter optimization strategy for the adaptive edge collaboration framework) In the adaptive edge collaboration framework, the key lies in optimizing the framework parameters to achieve the highest efficiency of information sharing and task allocation, while adapting to dynamic network conditions. Through the following strategy, we ensure that the framework parameters gradually converge to the optimal solution , achieving optimal system performance:
(47)
where represents the overall system performance loss, and are hyperparameters to balance different terms, is the weight of device , and respectively represent the predictive probability with parameters and the baseline probability, measures the divergence between the prior and posterior distribution of parameters , reflecting the model’s adaptability and generalization capability. This optimization process not only enhances the framework’s performance but also ensures gradual convergence of parameters, improving the overall system’s efficiency and adaptability.
Proof 2 Let be any initial set of parameters. We first prove that by adjusting , the system performance loss can be reduced. Considering the system performance is directly related to the parameters, we have:
(48)
representing the rate of change of system performance loss with a small change in .
By considering constraints on information sharing efficiency and task allocation responsiveness, we use the method of Lagrange multipliers to construct the following optimization problem:
(49)
where is the Lagrange multiplier, C is a predetermined performance target. By setting , we obtain a set of equations, indicating the existence of a set of parameters that minimizes system performance loss while satisfying constraints on information sharing efficiency and task allocation responsiveness.
By solving this set of equations:
(50)
We can find a set of parameters that minimize the system performance loss while satisfying the given constraint C. This proves that by meticulously adjusting the framework parameters, the overall system performance can be optimized while maintaining key performance indicators.
Theorem 2 (Performance Optimization through Dynamic Feature Processing in Multi-Task Learning) Significant improvements in performance and generalization capability of multi-task learning models can be achieved through dynamic feature fusion and selection strategies. There exists an optimal set of parameters , which optimizes the model performance:
(51)
Here, is a composite loss function combining multi-task loss and feature processing loss, and are tuning coefficients, represents the dynamic weight at time , and measures the model parameters’ generalization capability, proving the existence of an optimal solution.
Proof 3 By appropriately adjusting these parameters, we can effectively reduce the model’s prediction error , with respect to the sensitivity of parameters and :
(52)
We consider constraints on attention mechanisms and transfer learning efficiency, and construct an optimization problem using the method of Lagrange multipliers:
(53)
where is a Lagrange multiplier, C represents a performance target.
By solving for the extremum of this Lagrangian function, we obtain the optimal parameters and :
(54)
This set of equations indicates that there exists a set of parameters and , which under the given constraint C, can minimize the prediction error.
Further, we consider dynamically adjusting the self-attention weights to enhance model performance:
(55)
where is the learning rate, represents the self-attention weight at time step .
Considering the Kullback-Leibler divergence between the prior and posterior distributions of the transfer learning parameters , we quantify the model’s generalization capability:
(56)
where is a predefined threshold to ensure the model has good generalization capability.
We have shown that by appropriately adjusting the model parameters and , under constraints on attention mechanisms and transfer learning efficiency, the prediction error can be effectively reduced, thereby optimizing the model’s predictive performance while maintaining key performance indicators.
Corollary 2 (Efficiency Enhancement in Dynamic Feature Processing for Multi-Task Learning) Dynamic feature fusion and selection mechanisms significantly enhance the model’s performance in handling complex feature spaces, ensuring the optimization of overall learning efficiency and performance:
(57)
Here, integrates all task losses , weights , and regularization term , indicating that the model gradually converges to the optimal parameter set through a dynamic feature processing strategy, minimizing the overall objective function.
Proof 4 Our goal is to find an optimal set of parameters that minimizes the overall loss function , which combines the losses of all tasks, the correlation loss between tasks, and regularization terms:
(58)
where represents the loss function of the task, is the task weight, represents the parameters shared between tasks, and measures the correlation between tasks and .
Dynamic feature fusion and selection are optimized through the introduction of an additional loss term , considering the dynamics of feature selection and the effect of feature completion:
(59) where is a tuning coefficient, and represents the dynamic importance weight of the feature in the task.
The adjustment of task weights is based on the dynamic performance changes of tasks, updated through the following formula:
(60) where is the learning rate.
Shared parameters and task-specific parameters are updated through gradient descent to minimize the overall loss function:
(61)
Considering the convexity of and the boundedness of the parameter space, we can ensure that the parameters obtained by the iterative update strategy are globally optimal:
(62) proving the existence of a set of parameters , which can effectively balance the loss functions in multi-task learning with the support of a dynamic feature processing strategy, achieving model performance optimization.
Theorem 3 (Optimization of lightweight CNN under the RT-Cabi framework) There exists an optimal set of parameters obtained by minimizing the following integrated optimization objective:
(63)
where and respectively represent the efficacy functions of edge collaboration and feature fusion, is the optimization loss function of the lightweight CNN, , , are weight coefficients, is the regularization coefficient for neighboring device feature differentiation, and represents the set of neighboring devices for device . This optimization objective comprehensively considers the accuracy of state estimation, the efficiency of feature fusion, and the complexity of the CNN model.
Proof 5 By adjusting parameters within the RT-Cabi framework to optimize the performance of the lightweight CNN, we define the overall optimization objective , combining various aspects of performance enhancement for lightweight CNNs in edge computing:
(64)
where represents the loss function based on model parameters , represents the regularization term after dynamic feature fusion and selection, measures the feature differences between neighboring devices, and , , are weight parameters, adjusting the impact of different components.
Dynamic feature fusion can be expressed as:
(65)
where are dynamically computed weights, is a coefficient adjusting the second-order interaction items, and represents element-wise multiplication, optimizing the efficiency of feature fusion.
The structure optimization of the lightweight CNN takes the following form:
(66)
where and are regularization coefficients, is the variance of the Gaussian distribution, and represents the set of pruned parameters, aiming to promote parameter sparsity through regularization terms and apply network pruning techniques to streamline the model.
Finally, by minimizing the feature differences between neighboring devices, we promote model collaboration and consistency:
(67)
where is the regularization coefficient, and represents the set of neighboring devices for device . This term ensures the model’s collaborative working capability in the IoT device network, enhancing its generalization ability.
In the RT-Cabi framework, through precise adjustment of model parameters, we can effectively enhance the performance of the lightweight CNN in the edge computing environment, achieving efficient monitoring of IoT device behaviors and accurate analysis of abnormal behaviors.
Corollary 3 (Optimizing transfer learning and self-attention mechanisms) In the transfer learning framework combined with LSTM and attention mechanisms, there exists a parameter combination , which achieves optimal predictive performance by optimizing the following objective function:
(68)
where and are hyperparameters, adjusting the balance between self-attention efficacy and transfer learning generalization ability.
Proof 6 We revisit the model’s composite loss function , which integrates the contributions of prediction error, model complexity, and the effects of transfer learning:
(69)
where L is the loss function, and are regularization parameters, and is the variance.
We define two key metrics, self-attention efficacy and transfer learning generalization capability , to quantify the impacts of self-attention mechanisms and transfer learning parameters on model performance:
(70)
(71)
where represents the average value of the self-attention weights.
To optimize model performance, we set the objective function to minimize the composite loss while maximizing self-attention efficacy and maintaining the generalization capability of transfer learning parameters:
(72)
and are parameters adjusting the efficacy of self-attention and the generalization capability of transfer learning.
By adjusting the self-attention weights and transfer learning parameters , we further refine the model to strengthen its ability to process time-series data while maintaining adaptability to new datasets:
(73)
(74)
We proved that there exists a set of optimized parameters and , which can effectively balance between enhancing the ability to capture key time-series features and maintaining the model’s generalization ability on new datasets, achieving optimal predictive performance.