
Efficient phrase search with reliable verification over encrypted cloud-IoT data
- Published
- Accepted
- Received
- Academic Editor
- Yue Zhang
- Subject Areas
- Algorithms and Analysis of Algorithms, Security and Privacy, Internet of Things, Blockchain
- Keywords
- Phrase search, Blockchain, Verification, Efficient
- Copyright
- © 2024 Xu et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Efficient phrase search with reliable verification over encrypted cloud-IoT data. PeerJ Computer Science 10:e2235 https://doi.org/10.7717/peerj-cs.2235
Abstract
Phrase search encryption enables users to retrieve encrypted data containing a sequence of consecutive keywords without decrypting, which plays an important role in cloud Internet of Things (IoT) systems. However, due to the sequential relationship between keywords in the phrase, phrase search and verification are more difficult than multi-keyword search. Furthermore, verification evidence is generated by the server in existing schemes, and cloud servers are generally considered untrustworthy, so the verification is unreliable. To address this, we propose an efficient phrase search scheme that supports reliable verification of search results, where blockchain is introduced to generate verification evidence and perform verification of the results. The immutable nature of blockchain guarantees the credibility of evidence and verification. During the verification, we use a multiset hash function to generate aggregated evidence, reducing storage and blockchain transaction costs. In addition, we design a novel composite index and discrimination algorithm based on homomorphic encryption, with which we can quickly identify phrases and improve search efficiency. Finally, we conducted security analysis and detailed experiments on our scheme, which proved that the scheme is secure and efficient.
Introduction
Currently, the Internet of Things (IoT) has developed rapidly and is widely used in agriculture, industry, medicine and other fields, helping to improve crop production, manufacturing efficiency, and protect patients’ health. Every day, hundreds of millions of IoT devices around the world generate massive amounts of data, which is stored on the local or cloud. Compared to local storage, cloud storage can not only reduce local storage and management costs, achieve efficient data processing and analysis, but also help to achieve data sharing between different users, so it has been widely researched and applied.
Although cloud storage brings many conveniences to users, it also poses security and privacy risks. Cloud servers are generally considered untrustworthy, the unauthorized inside user may attempt to access sensitive information (e.g., patient’s disease name, blood pressure, etc.), and some hackers may also illegally access data, which will lead to data destruction and privacy leaks. In this case, IoT devices generally encrypt data first, and then outsource the ciphertext to the cloud to protect the integrity and privacy of the data.
For data outsourced to the cloud, when users need to access it, they perform retrieval on ciphertext. To achieve keyword retrieval on encrypted data and maintain the balance between search efficiency and security, Song, Wagner & Perrig (2000) proposed the concept of searchable encryption (SE), according to the number of keywords queried, SE is divided into two categories: single keyword search and multi-keyword search. Phrase search is an important technology of searchable encryption, which can search for a series of conjunction keywords in sentences or documents (Tang et al., 2012; Anand et al., 2014). Designing an efficient phrase search solution is very challenging, existing single keyword (Curtmola et al., 2006; Stefanov, Papamanthou & Shi, 2014) or multi-keyword encryption search schemes (Cash et al., 2013; Poon & Miri, 2015) cannot be directly applied to phrase search because they cannot determine the location of keywords. For example, in the electronic medical system, certain diseases are expressed by phrases, such as “myocardial infarction”. When searching for this phrase with a multi-keyword encrypted search scheme, the cloud server may return search results that contain both “myocardium” and “infarction”, but they may not appear as a phrase. Obviously, the search results contain a lot of invalid files.
Another challenge for phrase search is the verification of search results. Since data is outsourced on the cloud, external or internal attacks on cloud server may compromise the integrity or confidentiality of the data. In addition, data may be lost or damaged during data transmission. Therefore, it is necessary to verify the results of phrase search.
Although there are some studies (Kissel & Wang, 2013; Ge et al., 2021) addressing the problem of phrase search result verification, unfortunately, these verification schemes lack reliability. The reason is that in the existing solution, the server calculates search results and uses methods such as RSA accumulators to generate verification evidence. These search results and verification evidence may be forged by the cloud server (for example, the server may store only a part of the file and search index for financial gain, in which case the search results and verification evidence are incomplete). In addition, data users may forge verification results for cost savings, which may also result in the unreliability of verification results. In recent studies, some researchers have adopted blockchain technology. These schemes guarantee the reliability of verification based on the immutable property of the blockchain and have obtained ideal experimental results. But, these schemes mainly focus on the encrypted search of single keyword and cannot be applied to phrase search.
To address these problems, we design a blockchain-based phrase search scheme supporting reliable verification over encrypted cloud-IoT data, our main contributions are as follows:
1) We propose an efficient phrase search scheme over encrypted cloud-IoT data. In our scheme, a composite index containing keyword position and a distance discrimination algorithm based on homomorphic encryption are proposed, which can not only reduce the complexity of phrase recognition, but also achieve efficient phrase search and result verification.
2) We propose a method that enables reliable verification of phrase search results. In our scheme, the verification evidence calculation and verification process of phrase search are both executed by the blockchain, breaking the pattern of the server generating both search results and verification evidence, so the reliability of phrase search is ensured. Furthermore, we use a multiset hash function to calculate cumulative evidence, which significantly reduces the overhead of the blockchain.
3) We conducted a security analysis of the scheme and conducted detailed experiments. The results demonstrate that our construction is secure and enjoys good search efficiency.
The article is structured as follows: “Related Work” introduces the current research progress related to phrase search and verification; “Problem Formulation” describes the system model, threat model, algorithm definitions, and security definitions; “Methods” provides a detailed description of the phrase search and verification algorithms used in our scheme; and finally, “Security Analysis” and “Results” respectively analyze the security and experimental results of the proposed solution.
Related work
Searchable symmetric encryption (SSE) was first proposed by Song, Wagner & Perrig (2000) in 2000, which provides users with a new way to perform retrieval on encrypted data. However, this scheme uses full-text matching, and the search time is linear. To improve the search efficiency, Anand et al. (2014) proposed an efficient searchable encryption scheme with the inverted index, achieving a subcaptionlinear search. Following this direction, a great many schemes have been proposed to support dynamic update (Kamara, Papamanthou & Roeder, 2012; Stefanov, Papamanthou & Shi, 2014; Liu et al., 2021), multi-client query (Sun, Zuo & Liu, 2022; Du et al., 2020) and privacy protection (Liu et al., 2014; Song et al., 2021). But these schemes are mainly focusing on a single keyword, and the cloud returns some irrelevant files. To further improve the search efficiency and accuracy, SSE schemes supporting multi-keyword search are proposed, such as boolean query (Cash et al., 2013) and conjunctive queries (Lai et al., 2018). Compared with single keyword query, multi-keyword search improves search accuracy and reduces the communication and storage overhead.
Phrase search is a special case of multi-keyword search, it requires a sequential relationship between multiple keywords. Anand et al. (2014) first defined the model of phrase search and its security definition, but it is impractical in real scenarios since the client and the server require two rounds of interaction to complete a phrase query. Poon & Miri (2015) proposed a low storage phrase search scheme using bloom filter and symmetric encryption, and further proposed a fast phrase search scheme based on n-gram filters in 2019 (Poon & Miri, 2019). Li et al. (2015) implemented phrase search based on relative position, and realizes lightweight transactions and storage during the retrieval process. Ge et al. (2021) proposed an intelligent fuzzy phrase search scheme over encrypted network data for IoT, which dentifies phrases through binary matrices and look-up tables, and uses a fuzzy keyword set to resolve spelling errors in phrase searches. Shen et al. (2019) proposed a phrase search scheme that protects user privacy, which uses homomorphic encryption and bilinear mapping to achieve phrase identification.
Verifiable search: As we all know, servers in SSE are not completely trusted and may return incorrect search results due to external or internal attacks, so verifiable search is necessary. The concept of verifiable searchable symmetric encryption (VSSE) was first proposed by Qi & Gong (2012) in 2012, since then, a series of VSSE schemes are proposed (Liu et al., 2016; Miao et al., 2021; Chen et al., 2021; Wu et al., 2023). Unfortunately, these schemes are valid for a single keyword but do not support multiple keywords. Wan & Deng (2018) used homomorphic MAC to design a scheme that can verify the search results of multiple keywords. Li et al. (2021) used RSA accumulators to verify multi-keyword search results and uses bitmaps to improve search efficiency. There are similar multi-keyword verifiable ciphertext retrieval schemes (Liu et al., 2021; Liang et al., 2020, 2021). Kissel & Wang (2013) utilized a validation tag to build a verifiable phrase search scheme over encrypted data, but they failed to verify the integrity of the file. For more complex phrase searches, Ge et al. (2021) used the MAC function and look-up tables to implement phrase search result verification. Although this construction can verify the phrase search, it adopts a two-phase query strategy, which means the user needs to interact with the server twice in a phrase search and generate a large number of trapdoors.
Verifiable search based on blockchain: In the above verifiable schemes, the server sends the search results and verification evidence to the user, and the user calculates the search results and compares them with the received evidence to complete the verification. But this approach has some disadvantages. First, the results and evidence are unreliable due to the server is untrusted. Second,this approach cannot solve the problem of fair verification between server and user. To address this problem, blockchain is introduced into verifiable search. Currently, some verifiable search solutions based on blockchain have been proposed (Hu et al., 2018; Li et al., 2019; Guo, Zhang & Jia, 2020), but these solutions mainly focus on single keyword search, while there are almost no reliable and fair verification solutions for multi-keyword search scenarios. The same is true for phrase searches, which are more complex than multi-keyword searches.
Problem formulation
In this section, we formally define the efficient and reliable phrase search scheme over encrypted cloud-IoT data. We present the system model, threat model and security definition. We denote a composite index as a secure index, a searched phrase as a query and an encrypted query as a trapdoor. The notations and symbols used in our system are shown in Table 1.
| Notation | Definition |
|---|---|
| The identifier of the file | |
| M | The number of files |
| N | The number of keywords |
| A bit-length of | |
| Number of elements in set | |
| Get the first |A| bits of | |
| Get the last bits of | |
| The query phrase | |
| R | A set of ciphertext satisfying phrase search |
| Verification result, : valid, : invalid | |
| || | Concatenation symbol, denotes the concatenation of message a and b. |
| Number of positions of keyword in file |
System model
Four entities are included in our system: IoT device, data user, cloud server, and blockchain. The system model is shown in Fig. 1. IoT device as the data owner collects data and stores them in the form of files . The IoT device extracts all the keywords in and adopts the bitmap to build composite index . The IoT device encrypts all the files in to ciphertexts by symmetric encryption, and calculates the hash value of each ciphertext in through , which will be added to the checklist L. At last, ( , ) and ( , L) are sent to the cloud server and the blockchain, respectively.
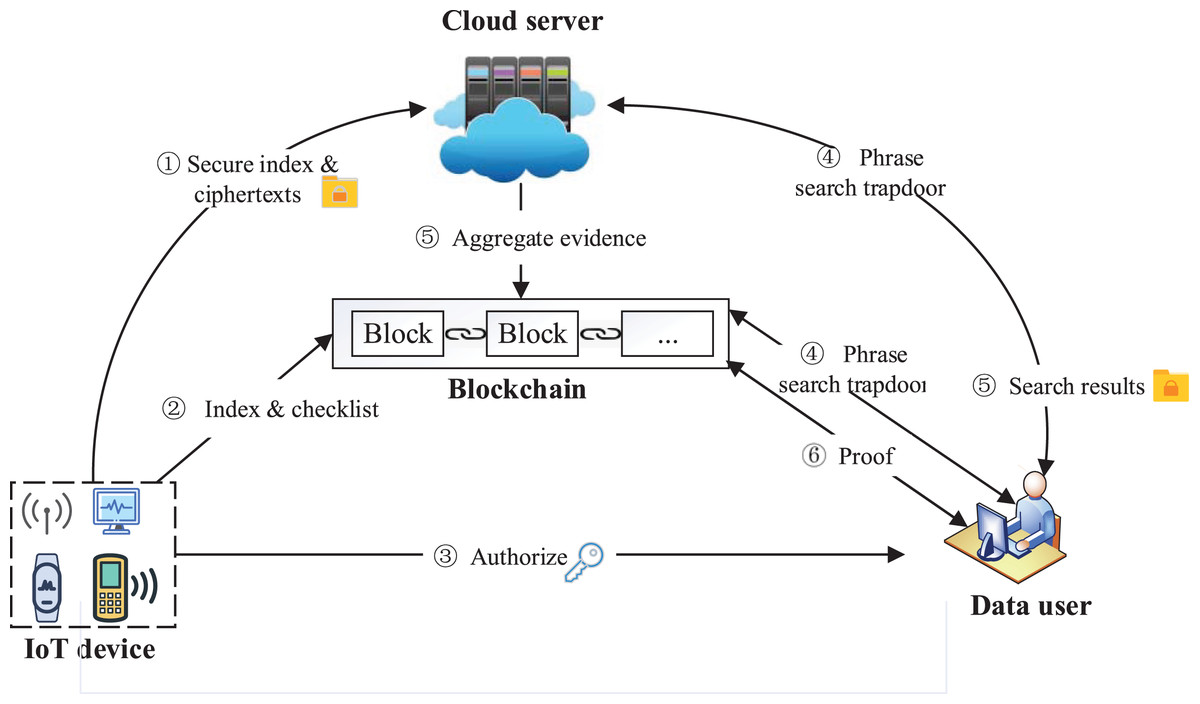
Figure 1: System model.
Image credit: component source from https://www.iconfont.cn/.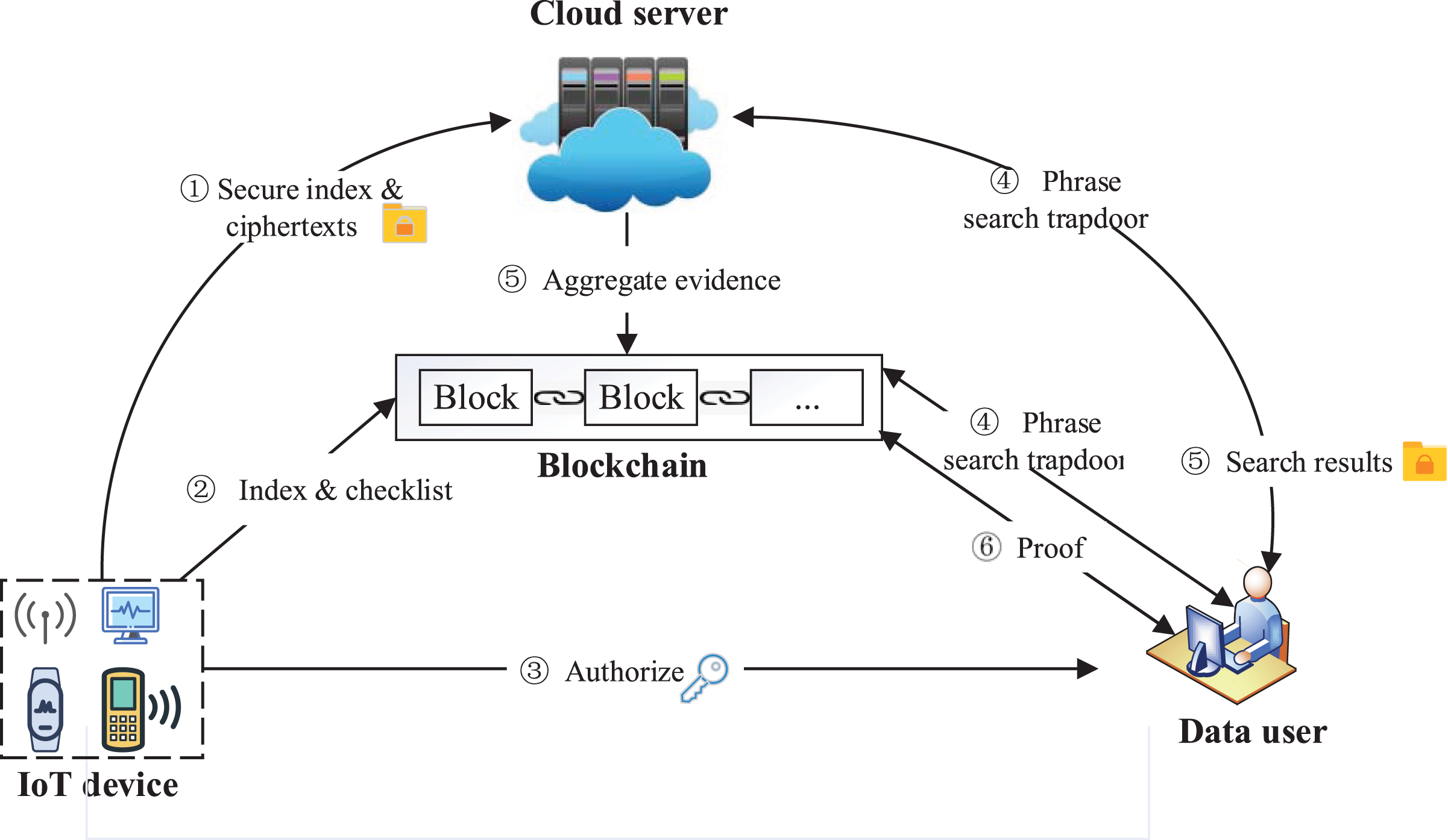{kind=link}
The data user obtains the system public parameters through the authorization of the IoT device, generates a search trapdoor through these public parameters and the phrases to be queried . The trapdoor will be sent to the server and blockchain for encrypted search and result verification, respectively. The data user receives the search results R and verification result from the blockchain, and accepts R if , otherwise rejects R.
The cloud server stores the index and ciphertexts sent by the IoT device, and performs a search over encrypted data using the trapdoor sent by the data user to generate the search result R and aggregate evidence . At last, the cloud server sends to the blockchain for verification, and sends R to the user.
The blockchain verifies aggregate evidence returned by the server and generates . To achieve reliable verification, the blockchain performs a phrase search in parallel with the cloud server to generate the verification standard value . The blockchain compares with the aggregated evidence returned by server, calculates the verification evidence , and sends it to the user. In particular, during the verification, multi-set hash functions are used to verify the aggregate hash results of the ciphertext, while the ciphertext is off-chain, thereby reducing blockchain storage and computing overhead.
Threat model
In our system, IoT devices and blockchains are completely trusted, IoT devices can collect data honestly, and generate secure indexes and checklists. The blockchain performs fair verification of search results, and the verification result is reliable and unforgeable.
Correspondingly, cloud servers and users are considered untrustworthy. The cloud server may only store part of the index and ciphertext for saving storage resources. At the same time, it may perform searches dishonestly in order to save computation costs. In addition, there may be other software/hardware malfunctions in the system. All the above reasons will make the file and the verification evidence returned by the server incomplete or incorrect. As for data users, it may falsify verification results for financial gain and is therefore not trustworthy.
Algorithm definitions
Our scheme consists of six polynomial algorithms :
1) , this algorithm inputs a secure parameter , and outputs the key set .
2) , this algorithm takes the set of files , the set of keywords , the key set K as input, and outputs the secure index , the encrypted database T, the checklist B.
3) , this algorithm takes a query phrase , a secret key and a public key as input, and outputs the search trapdoor .
4) , this algorithm takes the secure index , the encrypted database T and the search trapdoor as input, and outputs the aggregate evidence and search results R.
5) , this algorithm takes the secure index , aggregate evidence , the checklist B, the search trapdoor as input, and outputs the verification evidence .
6) , this algorithm takes the symmetric key and the encrypted file C as input, and outputs the plaintext F.
Leakage function
The goal of searchable encryption is to leak as little information as possible about the keywords and files during ciphertext retrieval. Similar to Wu et al. (2023), the leak function is defined as . According to the common definition, query history , which stores a series of query requests and corresponding database snapshots. The search pattern , which records each query request. The proof history . Then, we can define the leakage function , and .
Security definitions
Definition 1 (Verifiability). In an efficient and verifiable phrase search scheme, if the probability that the forged result generated by any probabilistic polynomial time (PPT) adversary passes the Verify algorithm is infinitesimal, the scheme satisfies verifiability.
Definition 2 (CKA2-security). For the verifiable phase search scheme ={ }, there is a leakage function , an adversary and an idealized simulator , as well as two games and , satisfying:
: The challenger generates system key and index ( , T, B) by executing algorithm and algorithm ,( , T, B) are transmitted to the adversary . proceeds to formulate a sequence of adaptive queries , with the challenger generating search tokens for each query, and receives the results of executing algorithms and . Finally, produces a bit as the output of this experiment.
: The simulator takes (F, W) generated by the adversary as input and outputs index ( , T, B) by executing algorithm . Then, for a series of adaptive queries generated by the adversary , generates search results by executing algorithms and , receives those results and produces a bit as the output of this experiment.
If there is a simulator such that for any PPT adversary :
then is –secure against adaptive chosen-keyword attack (CKA2), where is an negligible function and is the security parameter.
Preliminaries
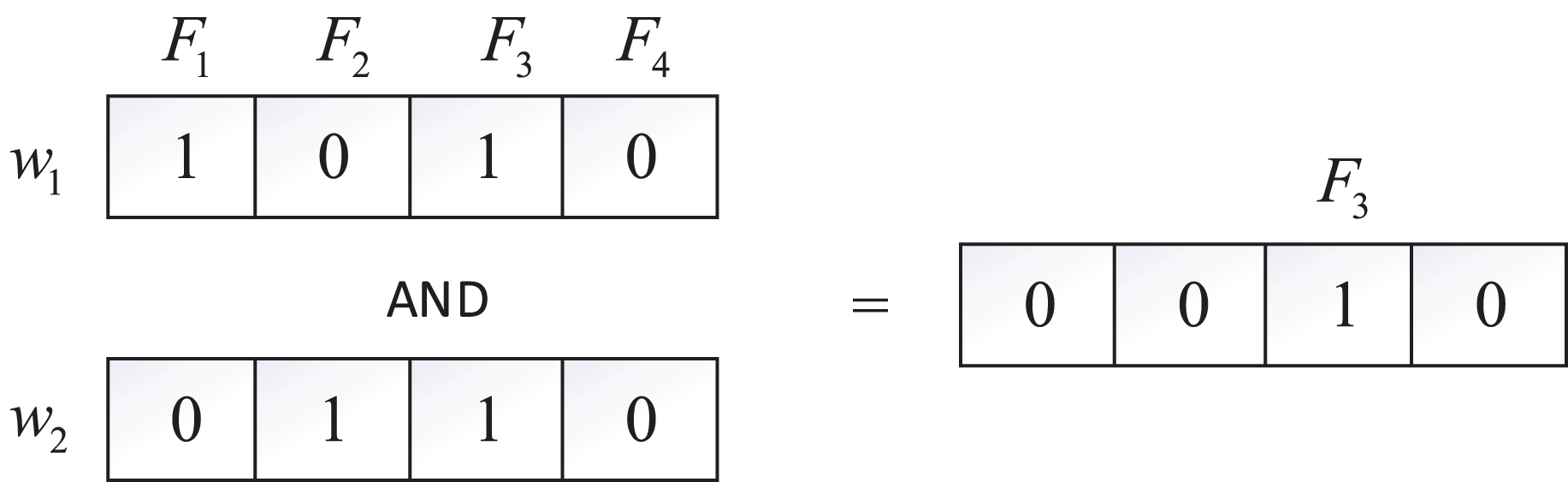
Bitmaps employ binary strings to represent information sets, commonly utilized for storing file identifiers in encrypted searches, thus efficiently reducing storage requirements. In our model, each keyword corresponds to a bitmap, and the bitmap is a string composed of a series of 0 or 1, each 0 or 1 denotes a file. If the document contains , the value of the string at position is set to 1, otherwise 0. For instance, with four files ( , , , ) and two keywords ( , ) in the system, depicted in Fig. 2, is found in and , while exists in and . The bitmaps for and are 1010 and 0110, respectively. To search for files containing both and , an “AND” operation on these two bitmaps is performed, yielding , indicating that contains both and .
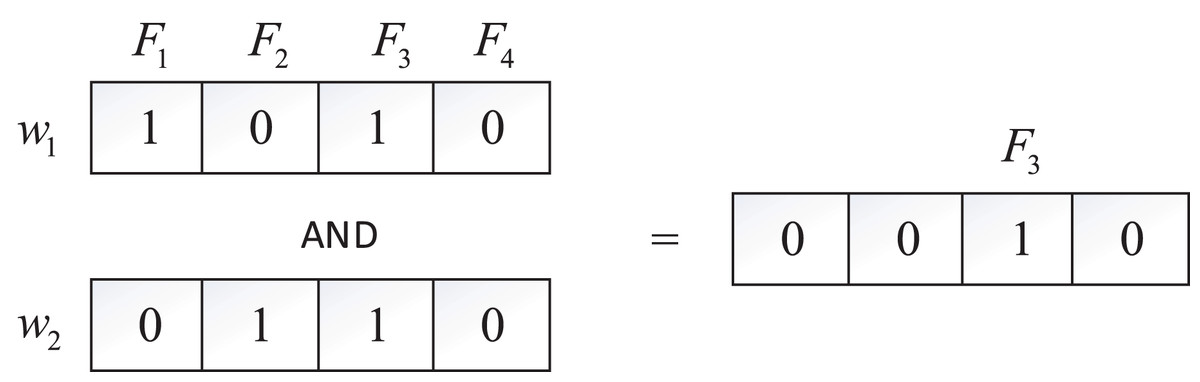
Figure 2: Bitmap.
{kind=link}
Homomorphic encryption represents an encryption technique capable of transforming a ciphertext into another without altering the decryption key. In this study, we employ the prevalent Paillier additive homomorphic encryption to compute the distance between keywords within phrases. In essence, its functionality can be outlined as follows:
1) Key Generation: Let and denote two large primes such that . Define and . Choose a random integer from satisfying , where and . Then, the public key and the private key are obtained.
2) Encryption: Given a message , it can be encrypted into its ciphertext as follows:
(1) where is randomly selected from .
3) Decryption: For the ciphertext , it can be decrypted into its plaintext as follows:
(2)
This algorithm exhibits additive homomorphism. Given two messages and along with their corresponding ciphertexts and , we can obtain the ciphertext of via , i.e., . This property can be leveraged to compute the distance between keywords in a phrase, aiding in determining their positional relationship.
Multiset Hash Function (Li et al., 2023): Multiset hash is a cryptographic tool that maps multiple sets of any finite size to a fixed hash length. Furthermore, multiset hash is also updateable: when the elements in the set change, the hash value only updates the current value without recalculating all.
Our scheme uses the most efficient multi-set hash function: MSet-XOR-Hash, containing three polynomial algorithms ( , , ). Given a multiset M, the MSet-XOR-Hash can be expressed as follows:
Methods
We present the construction of the efficient and reliable phrase search scheme over encrypted cloud-IoT data in this section.
Composite index containing files and locations
In phrase search, a phrase is composed of multiple keywords according to a certain positional relationship, which is also the difference between phrase search and multi-keyword search. To perform a phrase search, the cloud server not only needs to search for all keywords contained in the phrase, but also needs to determine whether the order between keywords is correct.
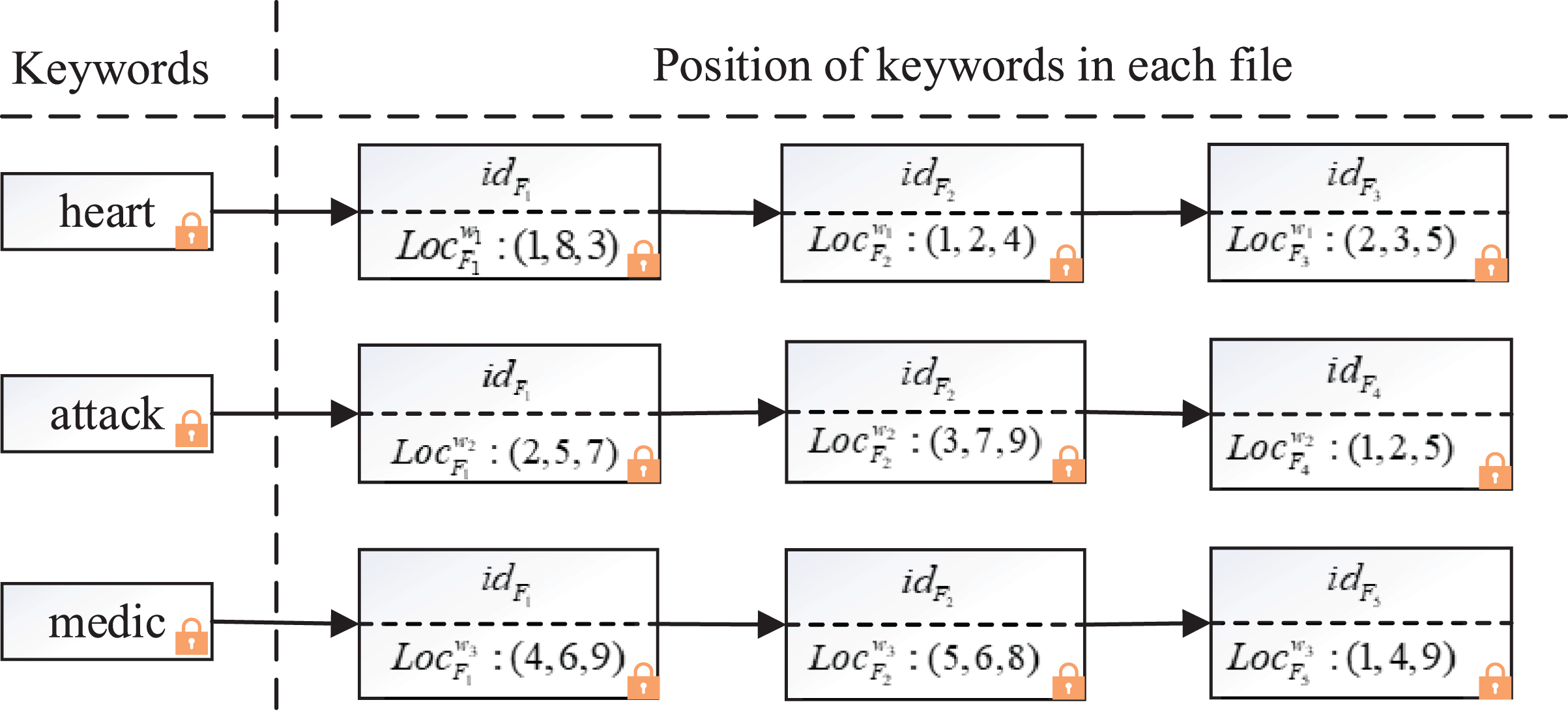
To identify the position relationship between keywords in phrases, we designed a composite index containing files and locations, the structure of the composite index is shown in Fig. 3.
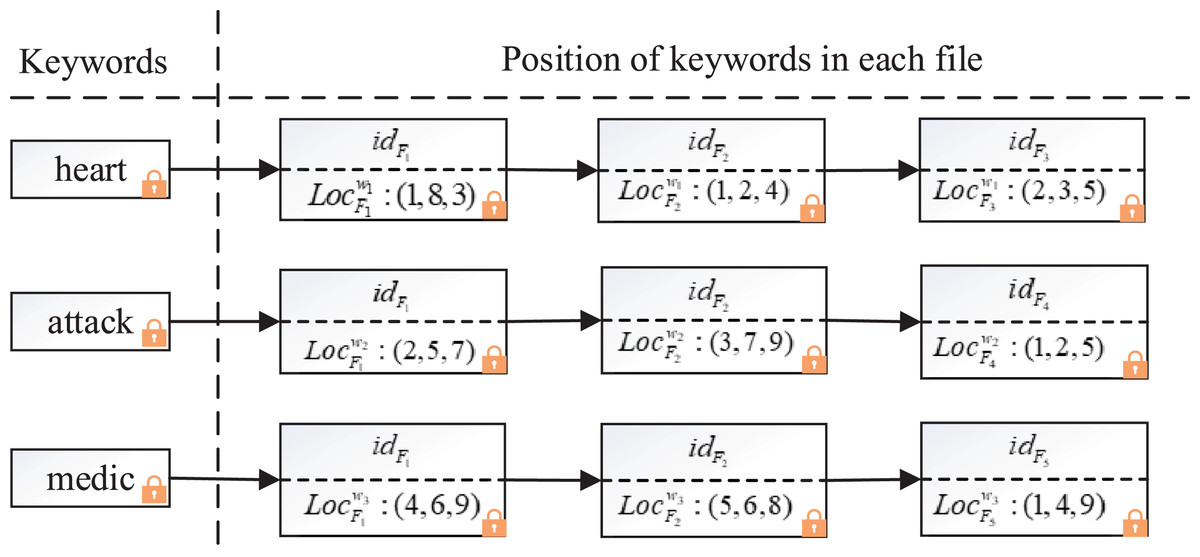
Figure 3: Example of the composite index structure.
{kind=link}
The composite index adopts inverted index structure to ensure high efficiency of search, but, it’s different from the general inverted index in that each keyword not only corresponds to the ID of a series of files, but also appends all the locations where the keyword appears in the file. For example, in Fig. 3, suppose there are three keywords (“ ”, “ ”, “ ”) and five corresponding files ( , , , , ), for simplicity, encryptions are not shown. The positions of keyword “ ” in files , , are (1, 8, 3), (1, 2, 4) and (2, 3, 5) respectively, the positions of keyword “ ” in files , , are (2, 5, 7), (3, 7, 9) and (1, 2, 5). When the cloud server searches the phrase “ ”, it finds that the location of keyword “ ” in is (1, 8, 3) through the composite index, then it finds the location of keyword “ ” in is (2, 5, 7). Using the encrypted distance discrimination algorithm, the cloud server computes the position of “ ” in file is 1 larger than that of “ ” by . Similarly, the cloud server computes that “ ” is after “ ” in through . After searching the location of all keywords in the composite index, the server calculates that and contain the phrase “heart attack”.
Encrypted distance discrimination algorithm-EDDA
The sequence of keywords in a phrase can be expressed by a sentinel and the distance between each remaining keyword and the sentinel. For example, in a phrase containing three keywords ( , , ), the position of , , are 1, 2, 3, we choose as the sentinel. The distance between and is 1, and the distance between and is 2. Suppose that positions of ( , , ) are ( , , ), if we can calculate and , we can recognize that ( , , ) is a phrase.
In our scheme, the positions of keywords stored in the composite index are encrypted, and the server should be able to recognize phrases without the decryption key. Therefore, we utilize the paillier homomorphic encryption to construct the distance discrimination algorithm to determine the location relationship between keywords,the details are as follows:
is the distance after paillier homomorphic encryption, and denotes the encrypted location of the keyword in file , the definition of is as follows:
(3)
E represents paillier homomorphic encryption function and represents hash function, is the original location of the keyword in file . In addition, keyword may appears in multiple locations in the same file, in this case, represents a series of positions.
In distance discrimination algorithm, is used to determine whether and belong to the same file, if so, . is used to calculate encrypted location of keyword , and is used to determine whether the keyword is located in the position after . When the user executes the phrase search request, he can designate the first word (i.e., ) in the phrase as the sentry, then calculate the distance between the remaining words and the sentry one by one, encrypt , and finally generate a search token and send it to the server for search.
Details of our construction
Like most searchable encryption schemes, we adopt an inverted index structure to construct the secure index. In the inverted index, we use a bitmap to store the identifier of the file. Let be secure pseudo-random functions (PRFs).
| Input: |
| Output: Flag |
| 1: |
| 2: |
| 3: if then |
| 4: |
| 5: |
| 6: if then |
| 7: |
| 8: end if |
| 9: end if |
| 10: return Flag |
. The IoT device uses the secret parameters to generate the key set , where , . is used to encrypt the identifier of files, is the secret key of symmetric encryption, is the key for PRF F, is the public key and the private key of paillier encryption.
. Given a set of files , a set of keywords , and the key set K, the IoT device generates the secure index , the encrypted database T, the checklist B, the details are shown in Algorithm 2.
| Input: |
| Output: |
| 1: for do |
| 2: |
| 3: |
| 4: end for |
| 5: for do |
| 6: for do |
| 7: |
| 8: Extract positions of keyword in file |
| 9: |
| 10: |
| 11: end for |
| 12: end for |
| 13: send to blockchain, send to cloud server |
For each file , IoT device encrypts it to the ciphertext with symmetric encryption . The ciphertext is stored in encrypted database T, and the hash value of is stored in checklist B for verification.
IoT device generates a bitmap for each keyword , is encrypted by and is stored in the secure index . Especially, in order to protect the privacy of files, IoT device uses to encrypt the of files, and then uses to generate . Since the stored on the server is encrypted, the server cannot obtain the real from , which ensures the privacy of the search pattern.
To identify phrases, the IoT device extracts positions of keyword in file , and encrypts them using :
. Authorized users get shared parameters from the IoT device. For the phrase to be queried, the trapdoor is generated as Algorithm 3.
| Input: The query phrase , the key set K |
| Output: The serach trapdoor |
| 1: Suppose that query phrase |
| 2: for do |
| 3: |
| 4: |
| 5: if then |
| 6: |
| 7: end if |
| 8: end for |
| 9: send to blockchain and cloud server |
Assume that the keywords in phrase are arranged in order. The data user calculates the distance between the keyword and the first keyword and encrypts it with . At last, and are added to the trapdoor and sent to the cloud server and the blockchain.
. As shown in Algorithm 4, the cloud server performs an encrypted search with the secure index , the encrypted database T and the trapdoor .
| Input: |
| Output: Search results R |
| 1: Parse |
| 2: for do |
| 3: |
| 4: end for |
| 5: |
| 6: Get from |
| 7: for do |
| 8: |
| 9: |
| 10: for do |
| 11: |
| 12: for do |
| 13: if then |
| 14: Set the position of flag to 1 |
| 15: break |
| 16: end if |
| 17: end for |
| 18: end for |
| 19: If all positions of flag are 1 |
| 20: get , |
| 21: end for |
| 22: Server sends { } to the blockchain for verification, and sends R to the data user |
After receiving the query request, the server parses the trapdoor . The server gets the bitmap of from the secure index through . To get the file that contains all the keywords in the phrase , the server performs the operation “AND” on the bitmap of all keywords as follows:
The file corresponding to the element with a value of “1” in contains all the keywords in the phrase. The server gets the set of identifiers of these files as according to .
Next, the server determines whether the sequence of the keywords in the file is consistent with the order of the keywords in the phrase, as described in line 7–line 20 in Algorithm 3. The server chooses a binary string of length , and set all values to “0”. The server gets all positions of the keyword in the file . For the position of the keyword in file , the server utilizes the distance discrimination algorithm EDDA to determine the distance between keyword and the first keyword in the phrase. Like
(4) where E represents the . If Formula (4) holds, the distance between keywords and is , which is the same as that in the phrase, the server sets the position of to “1”. If all positions of are “1”, then the file contains the phrase , and it is added to the search result R. Finally, the aggregation proof is sent to the blockchain for reliable verification, and the ciphertext collection of search results R is sent to the user.
. The blockchain utilizes for phrase searches to verify the aggregated evidence returned by the cloud server, as shown in Algorithm 5. To ensure the reliable verification of search results, the verification algorithm not only verifies the integrity of the files, but also verifies whether the server has returned all files that meet the search requirements.
| Input: , , ψ |
| Output: proof |
| 1: . |
| 2: Using search trapdoors to perform phrase searches same as line 1–line 6 of Algorithm 4. |
| 3: for do |
| 4: |
| 5: end for |
| 6: if then |
| 7: |
| 8: end if |
| 9: The blockchain sends proof to the data user. |
The blockchain performs the same operations as the server (line 1–line 6), retrieving the composite index stored on itself with the trapdoor , and calculates the search result . Due to the immutability of data on the blockchain, the composite index stored and search results calculated by the blockchain are reliable. Blockchain achieves reliable verification of phrase search results by comparing with the search result returned by the server.
For the file , the blockchain obtains the corresponding hash value by searching the checklist B and compresses it into the benchmark value . By comparing the aggregate evidence sent by the server with , the blockchain sets the value of as follows:
By comparing , the blockchain can determine: 1) whether the server has returned all files that meet the search requirements; 2) the content of the files has been modified.
Then the verification evidence are sent to the data user. The data user judges the received , and accepts the search result R if , otherwise rejects R. For the accepted search result R, the data user uses the symmetric key to decrypt the file in it, to get the plaintext of the file, and the phrase search process is completed.
Discussion
Ensuring the reliability of verification is an important target of our scheme. In the existing phrase search scheme, the secure index is stored on the server, and the verification evidence is generated by the server. Untrusted servers may only store partial indexes and ciphertexts, resulting in untrustworthy search results and verification evidence. Whereas in our scheme, blockchain uses search trapdoor to calculate verification evidence, the data stored on the blockchain is unforgeable, so the search results on the blockchain are reliable. At the same time, the verification of the results returned by the server is also performed by the blockchain, which prevents dishonest data users from falsifying the verification results and ensures the reliability of the verification results.
Security analysis
Theorem 1: The proposed efficient and reliable phrase search scheme satisfies verifiability.
Proof. Let be a PPT adversary who can produce a forgery , which can pass the verification algorithm . Assuming the correct search result is R, we will prove that there is no such adversary who can give a forgery satisfying .
Suppose the compressed hash values corresponding to R and are and , respectively, and we will discuss the following two cases:
Case 1: and . For each ciphertext in R, we have , similarly, we have for each ciphertext in . Since the data on the blockchain is unforgeable and , we have , which is contradictory to . Therefore this case does not hold.
Case 2: and . This implies that can discover a collision for H, which contradicts the collision resistance property of the hash function. Therefore, this case also does not hold.
In summary, the unforgeability of blockchain and the collision resistance of hash function ensures that any PPT adversary cannot forge search results. So, our scheme satisfies verifiability.
Theorem 2: If PRF F is pseudo-random, algorithm is secure against chosen plaintext attack (CPA-secure) and is secure against chosen ciphertext attack (CCA-secure), then our proposed scheme is ( )-secure against the adaptive chosen-keyword attack.
Proof. We establish the CKA2 security of our scheme by demonstrating the indistinguishability of and . The proof starts with and go through a series of indistinguishable games to achieve , thus proving that A and are indistinguishable.
Game : is the same with :
Game : We replace the output of the pseudorandom function F( and ) with a sequence of binary random numbers , the length of is equal to |F|, and store the binary sequence in buckets and . If the adversary can distinguish between F and the random number sequence, then they can distinguish between and . Then,
Game : In , the output of the hash function H( and ) is replaced by a series of randomly generated binary strings , . stores in buckets and . If the adversary can distinguish between H and , then they can distinguish between and . Then,
Game : In , the output of the multi-set hash function is computed based on , while in , the output of the multi-set hash function consists of a random binary string made up of a series of or . And, the binary string is recorded in a bucket . From the previous analysis, we can conclude that
: and are the same, except that introduces simulator , executes algorithm with the help of ( ) and the adversary can sniff the algorithm output. The algorithm details are shown in Algorithms 6–8. The adversary cannot distinguish between the output of the random oracle in this game and the actual data, hence
| Input: |
| Output: |
| 1: for do |
| 2: |
| 3: |
| 4: end for |
| 5: for do |
| 6: for do |
| 7: |
| 8: Extract positions of keyword in file |
| 9: |
| 10: |
| 11: end for |
| 12: end for |
| 13: send to blockchain, send to cloud server |
| Input: |
| Output: Search results R |
| 1: Parse as |
| 2: Parse |
| 3: for do |
| 4: |
| 5: end for |
| 6: |
| 7: Get from |
| 8: for do |
| 9: |
| 10: if then |
| 11: |
| 12: else |
| 13: |
| 14: end if |
| 15: |
| 16: for do |
| 17: |
| 18: for do |
| 19: if then |
| 20: Set the position of flag to 1 |
| 21: break |
| 22: end if |
| 23: end for |
| 24: end for |
| 25: If all positions of flag are 1 |
| 26: get , |
| 27: end for |
| 28: Server sends { } to the blockchain for verification, and sends R to the data user |
| Input: , , ψ |
| Output: proof |
| 1: Parse as |
| 2: . |
| 3: Using search trapdoors to perform phrase searches same as line 1–line 6 of Simulator 7. |
| 4: for do |
| 5: if then |
| 6: |
| 7: else |
| 8: |
| 9: end if |
| 10: |
| 11: end for |
| 12: if then |
| 13: |
| 14: end if |
| 15: The blockchain sends proof to the data user. |
From what we have discussed above, the adversary cannot distinguish the result in the experiment Real and the result in the experiment Ideal. That is:
Therefore, our proposed scheme satisfies CKA2 security.
Results
In order to objectively evaluate the performance of our scheme, we design a series of scientific experiments in this section. We conducted a comprehensive analysis of the experimental results and compared them with the existing phrase search scheme (Kissel & Wang, 2013) and scheme (Ge et al., 2021). Our experiments are deployed on a local laptop with a Linux operating system, Intel Core i7-8550 CPU, and 8 GB RAM. Experimental programs are developed using Python. As for the pseudo-random functions F and the hash function H in the algorithm, we use HMAC-SHA-256 and SHA-256 respectively to implement them. Additionally, we symmetrically encrypt files using AES-128, and the security parameter is set to 128 bits. To evaluate our scheme in practice, we employ the Enron email dataset (Cukierski, 2015), a real-world dataset comprising over 517 thousand documents. Using the Porter Stemmer, we extract more than 1.67 million keywords and eliminate irrelevant terms such as “of” and “the”.
Evaluation of IndexBuild
In this phase, the IoT device mainly completes the following work: (1) encrypt the files in the system into ciphertext; (2) generate the secure index for all the keywords; (3) calculate checklist of the ciphertext for verification.
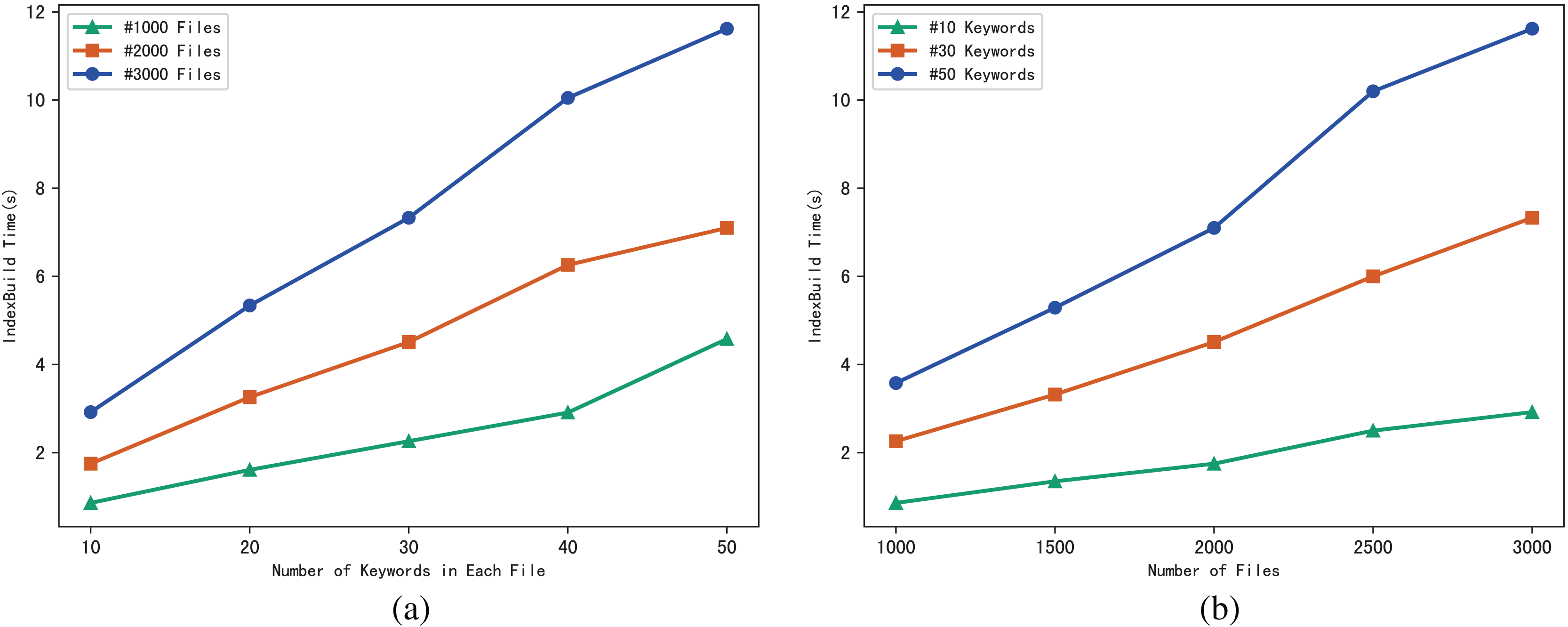
The performance of the scheme can be evaluated through the execution time of algorithm IndexBuild, and we evaluate the execution time of IndexBuild in different numbers of files and keywords respectively. Figure 4A shows the variation pattern between the execution time of IndexBuild and the number of keywords in a single file, while files changes from 1,000, 2,000 to 3,000; in contrast, Fig. 4B shows the variation between the execution time of IndexBuild and the number of files in the system, while keywords in a single file changes from 10, 30 to 50. Obviously, the execution time of algorithm IndexBuild is affected by both the number of files and keywords. The more files and keywords contained in each file, the more time it takes in IndexBuild.
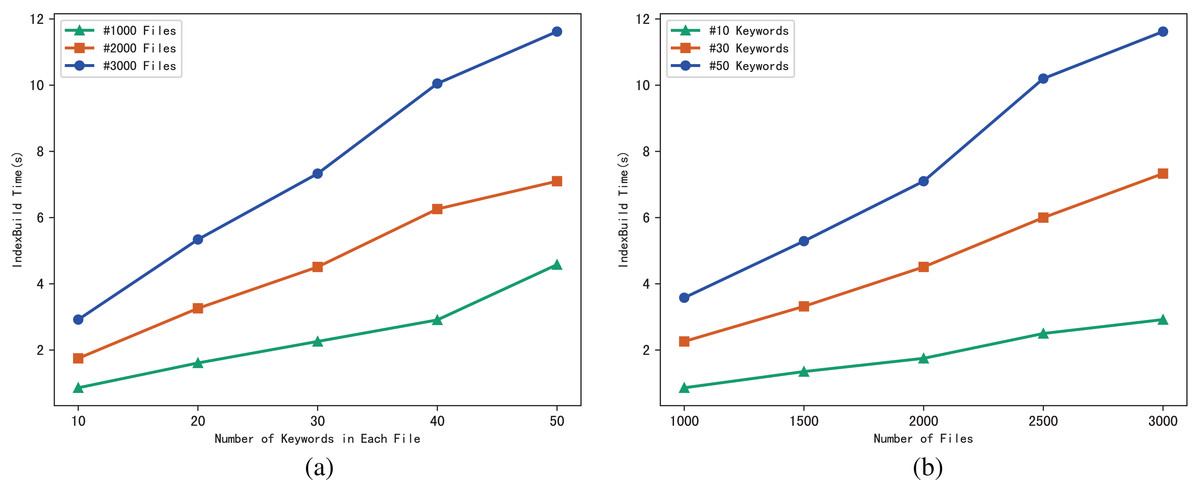
Figure 4: (A and B) Time of IndexBuild.
{kind=link}
Evaluation of TokenGen
Search trapdoors are generated by users, which contains the permutation value of each keyword in the query phrase and the encrypted distance for other keywords except the first one. Figure 5 shows the time it takes to calculate a search trapdoor for different sizes of search phrases, it’s clear that the time increases with the size of the query phrase. This is easy to understand, because the more keywords in the phrase, the more distances between keywords that need to be encrypted, resulting in more trapdoor calculation time.
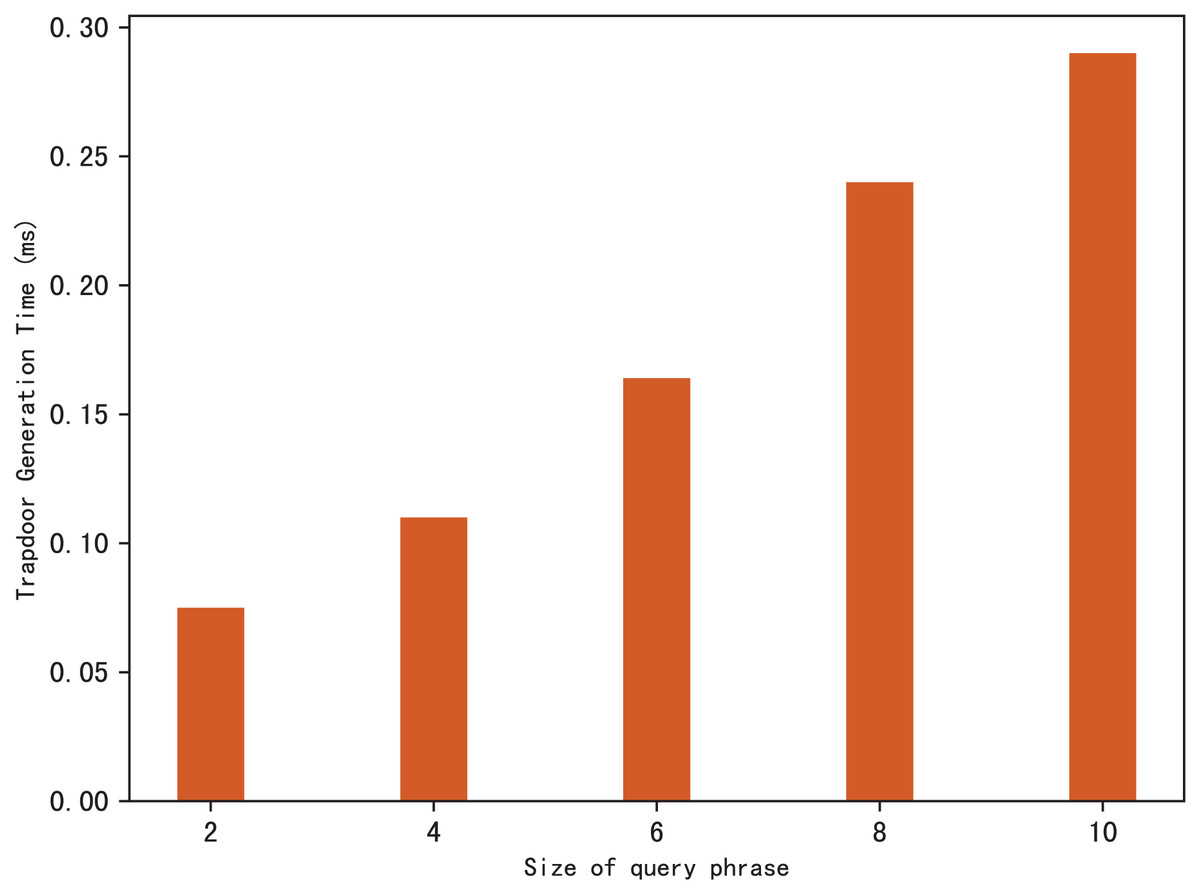
Figure 5: Time of trapdoor generation.
{kind=link}
Evaluation of search
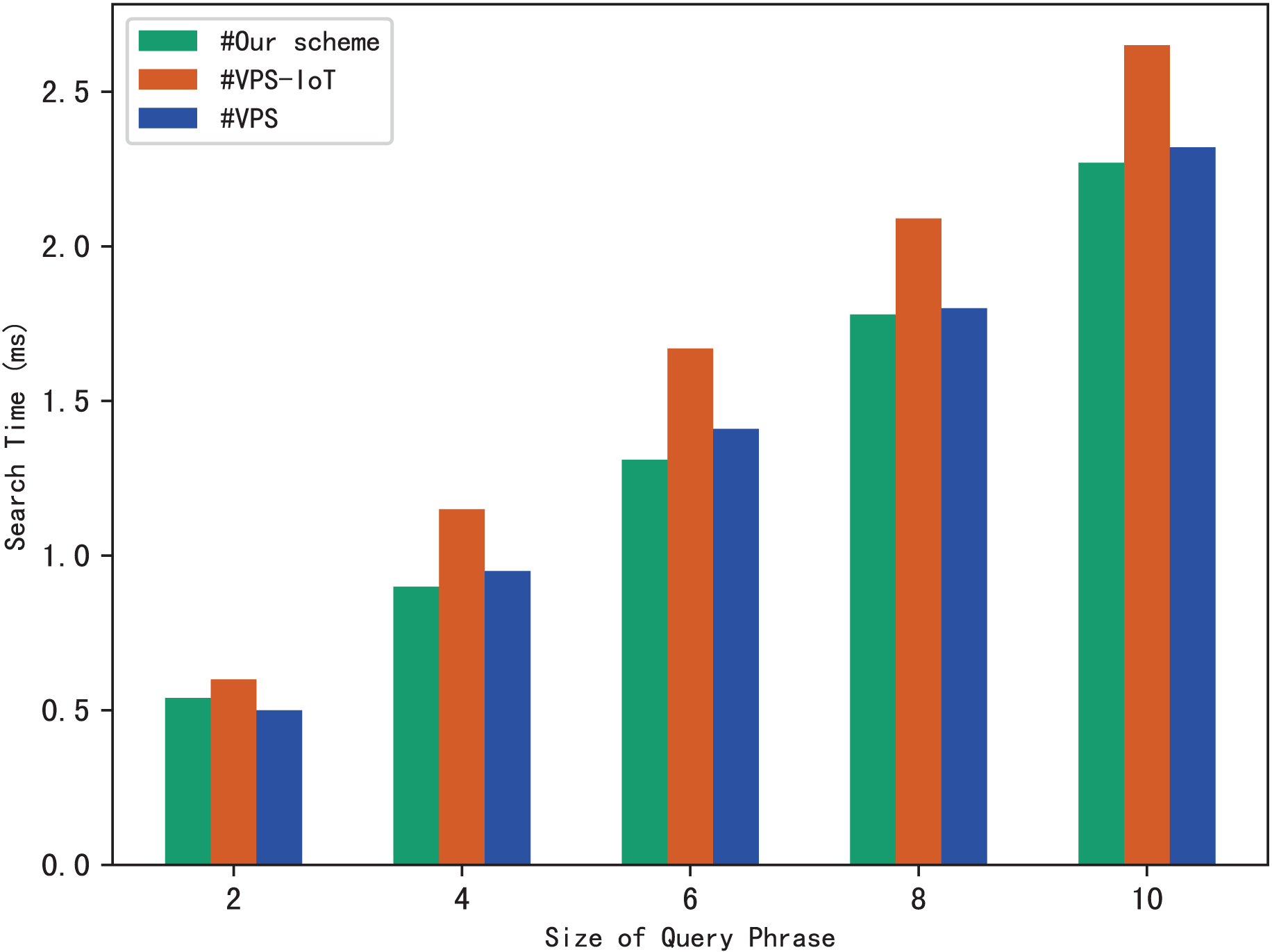
Similarly, we use execution time to evaluate the search efficiency of our scheme. Figure 6A shows how search time changes with query phrase size when the number of keywords contained in each file is 10, 30 and 50. Figure 6B shows how search time changes with query phrase size when the number of files is 1,000, 3,000 and 5,000.
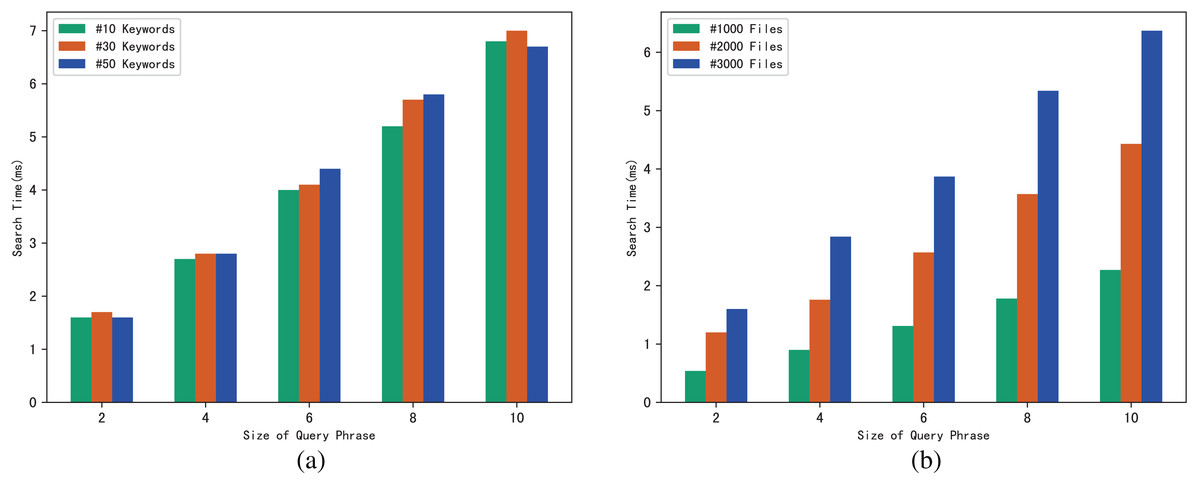
Figure 6: (A and B) Time of search.
{kind=link}
The results of Fig. 6 demonstrate that as the size of the query phrase grows or the number of documents grows, the search time will increase accordingly, which indicates that the more keywords in the phrase and the more files in the system, the more time it takes for the server to perform a phrase search. Furthermore, since we can use trapdoors to directly locate keywords in the inverted index, the search time is independent of the number of keywords contained in each file.
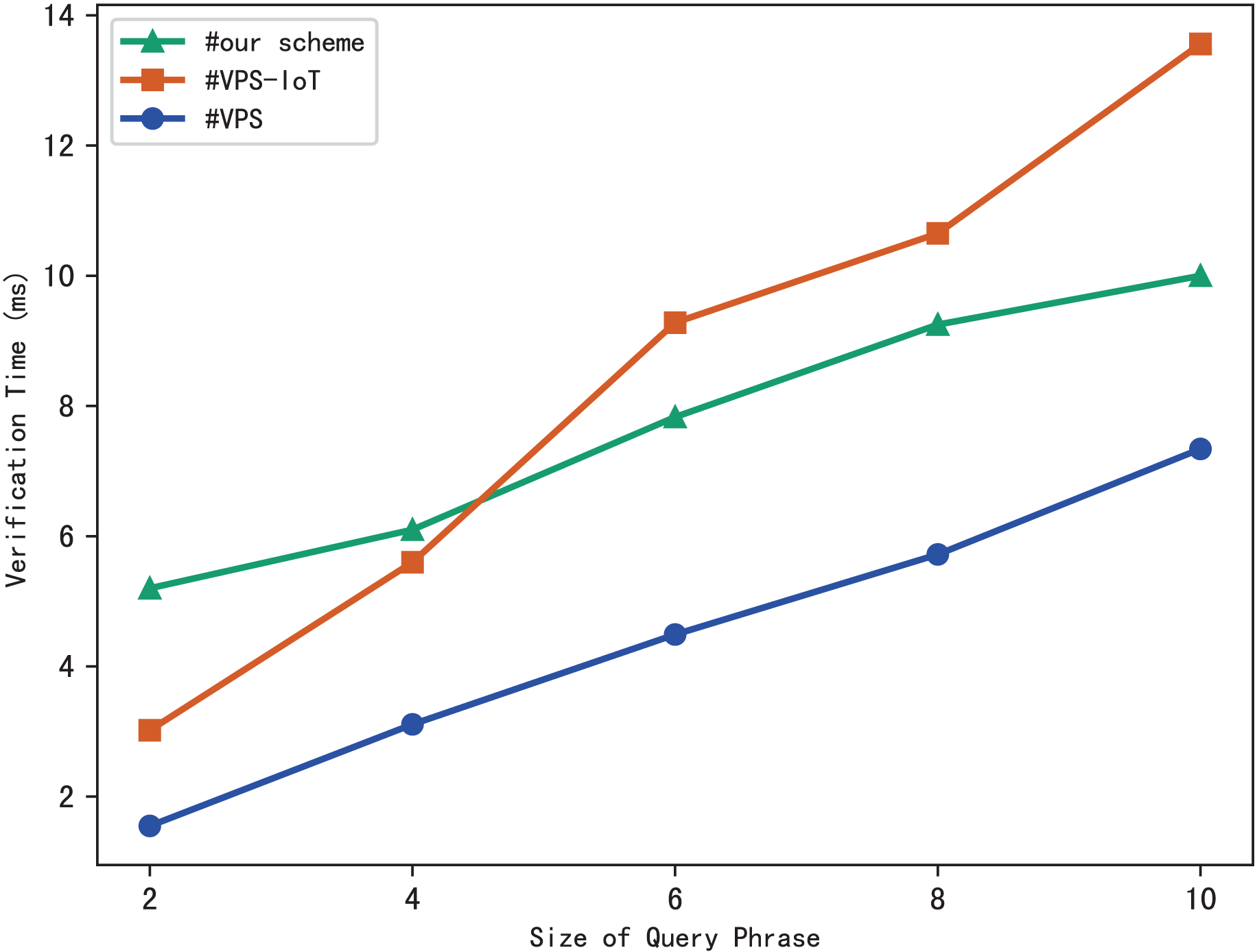
Evaluation of verification
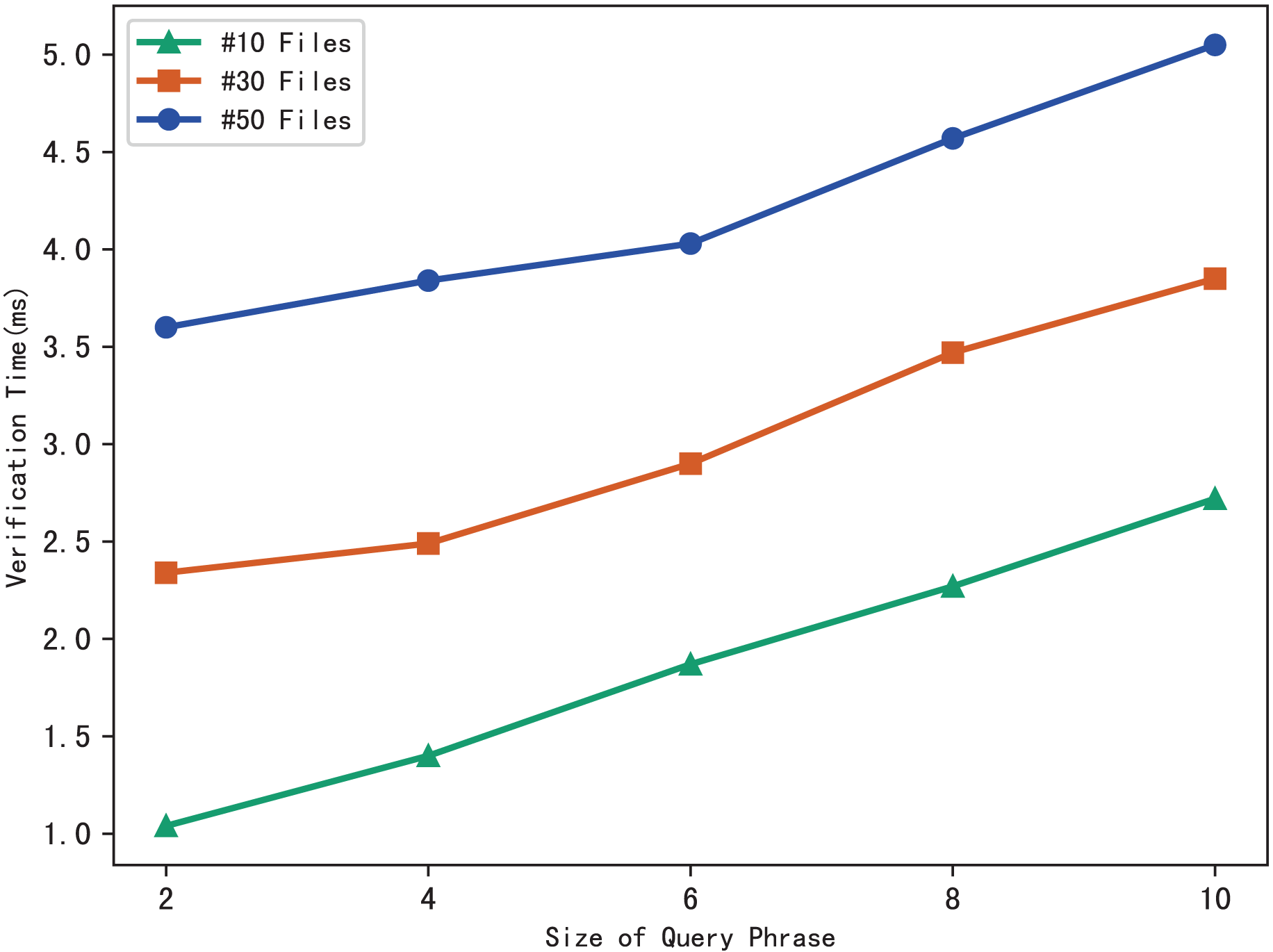
The blockchain first performs the similar operations as the server to search files that meet the search phrase, then gets the corresponding hash value through the checklist B, and finally calculates the benchmark based on the multi-set hash function. During the verification, the blockchain draws the verification conclusion by comparing with the search aggregation evidence returned by the server. Therefore, the verification time is related to the number of files that match the query phrase, and the experimental results are shown in Fig. 7. Clearly, the verification time grows sub-linearly with the number of files and the size of the phrase.
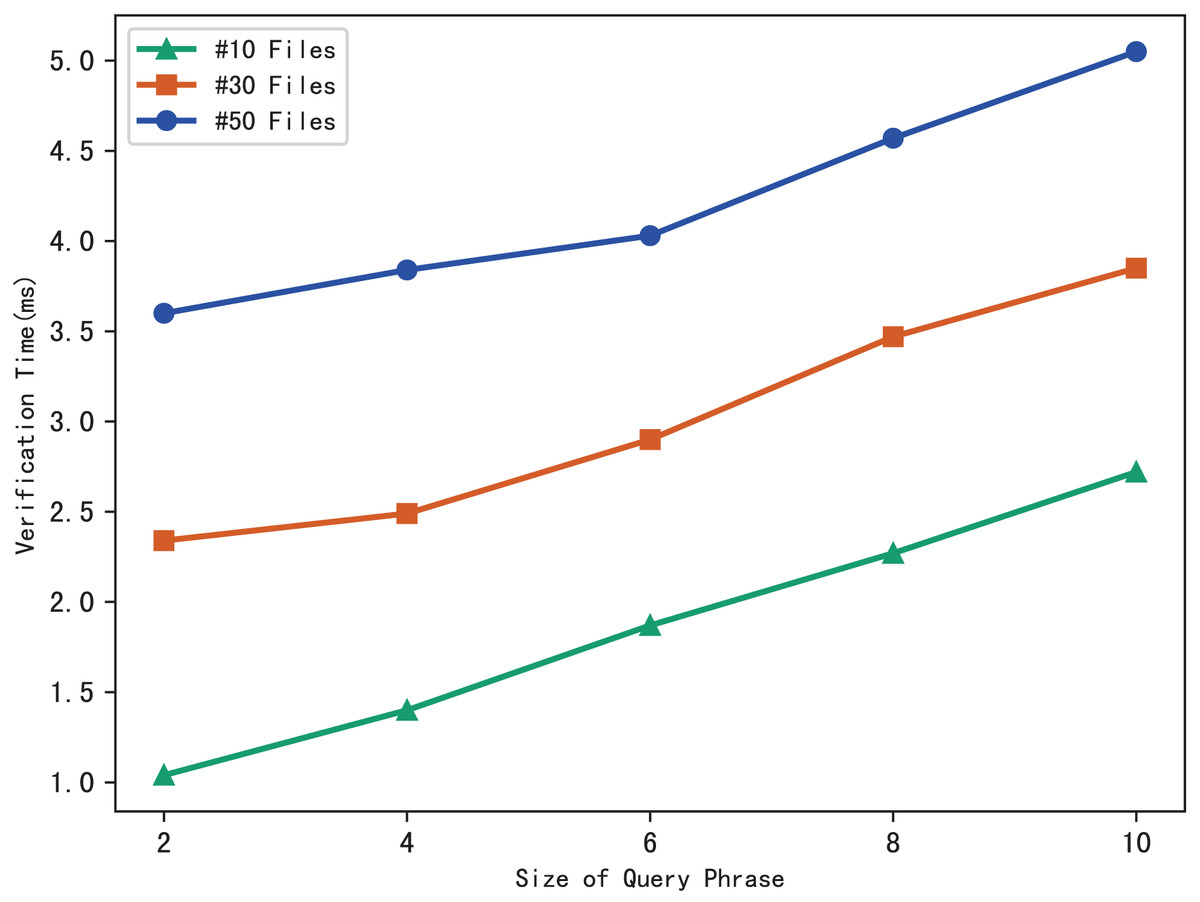
Figure 7: Time of verification.
{kind=link}
The gas consumption during the verification process is shown in Fig. 8. During the verification process, the blockchain performs multiset hash calculations on the hash values in the checklist that meet that meet the requirements of the phrase search, so the gas consumption increases with the number of search results. When the number of resulting files is 5, the gas consumption is , and when the number of files is 25, the gas consumption is , gas consumption grows sublinearly.
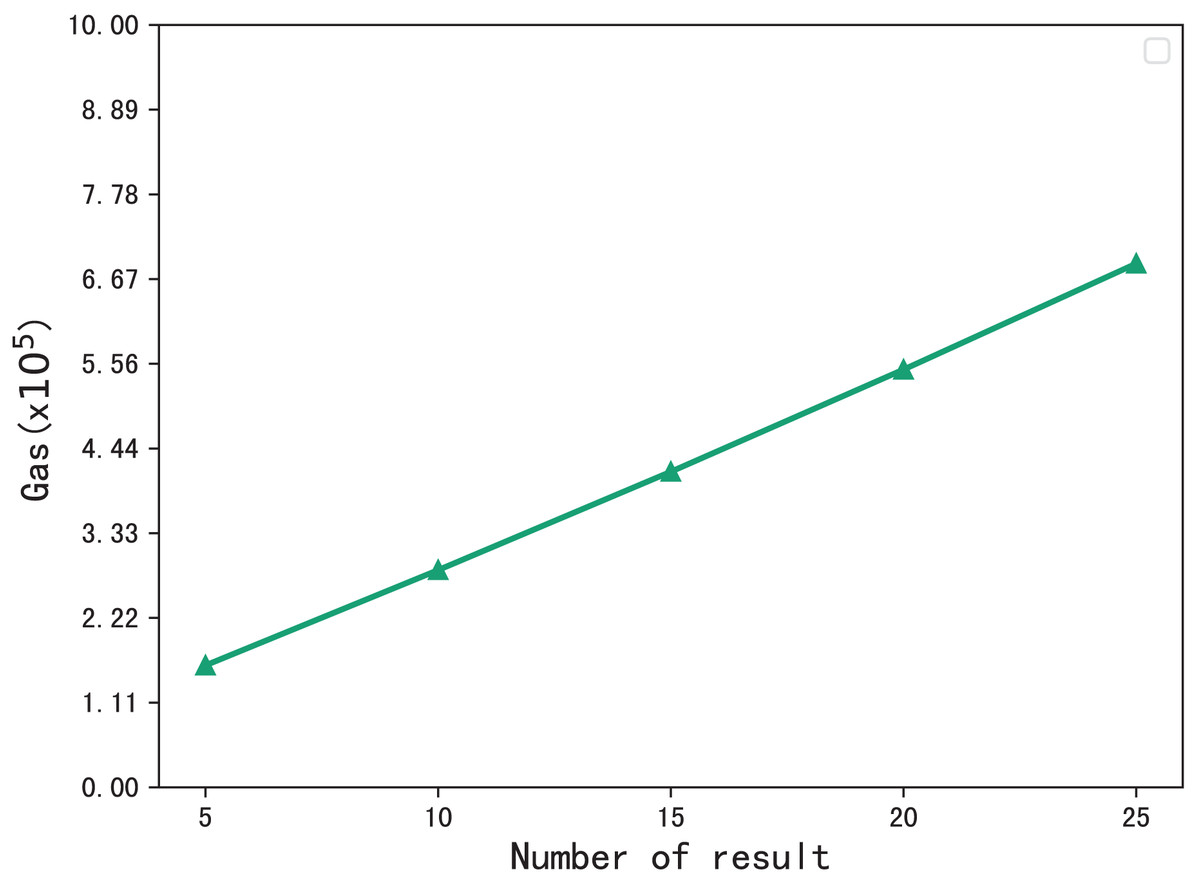
Figure 8: Gas consumption for verification.
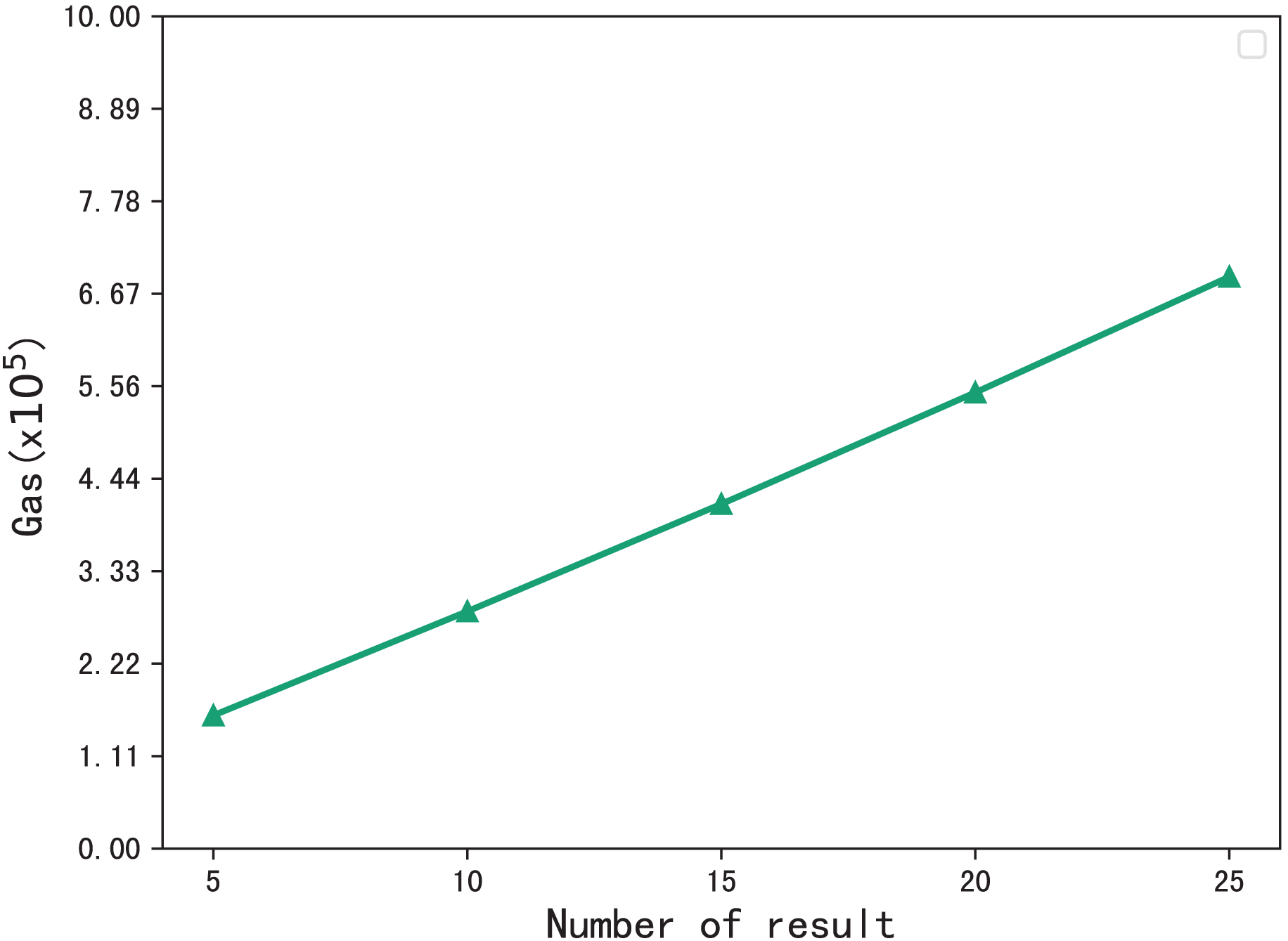{kind=link}
Comparison with existing schemes
We choose scheme (Kissel & Wang, 2013) and scheme (Ge et al., 2021) with similar functions to compare, and the results are shown Table 2, in which VPS and VPS-IoT denote scheme (Kissel & Wang, 2013) and scheme (Ge et al., 2021), respectively. Both VPS and VPS-IoT adopt a two-stage search strategy, so it takes two rounds of interaction between the user and the cloud server to complete a phrase search. Additionally, they calculate the verification evidence by the server. In this case, if the server is not trustworthy, the evidence may also be incorrect, which poses a huge threat to the reliability of verification.
| Scheme | Index building | Trapdoor generation | Query | Verification | Round |
|---|---|---|---|---|---|
| VPS | 2 | ||||
| VPS-IoT | 2 | ||||
| Our Scheme | 1 |
Note:
is the number of keywords contained in the file ; is a collection of different keywords in the file ; is the number of query keywords; is the number of files containing query keywords; is the size of the returned result file.
The experimental results are shown in Figs. 9–12. The results in Fig. 9 show that VPS takes the least time in building the index, while VPS-IoT takes the most. The reason lies in that VPS lacks verification of file integrity, so the calculation cost is low. Both our scheme and scheme VPS-IoT can verify the integrity of the file, but the structure of the lookup table in VPS-IoT is complex, requiring a large number of encryption and MAC operations on keyword positions, ciphertext, etc., so it needs more time than our scheme. Figure 10 represents that our scheme gains the highest efficiency in trapdoor generation. Both VPS and VPS-IoT adopt a two-phase query strategy, the data user generates two trapdoors for a query, while our scheme only needs to generate one trapdoor, obviously, our scheme is more efficient. Figure 11 shows the comparison of the query efficiency of the three schemes, the query is performed over 1,000 files and each file contains 20 keywords. The complexity of the three schemes is almost the same, the search time grows sub-linearly with the number of keywords in the phrase. As for verification efficiency, we deploy the three schemes on 50 files, and the experimental results are shown in Fig. 12. Scheme VPS-IoT performs best among the three schemes, but it cannot verify the integrity of the file. Our scheme takes less time than scheme VPS when the size of the query phrase becomes larger, which demonstrates the efficiency of our scheme. Furthermore, the verification is performed on the blockchain in our scheme, ensuring the reliability of verification.
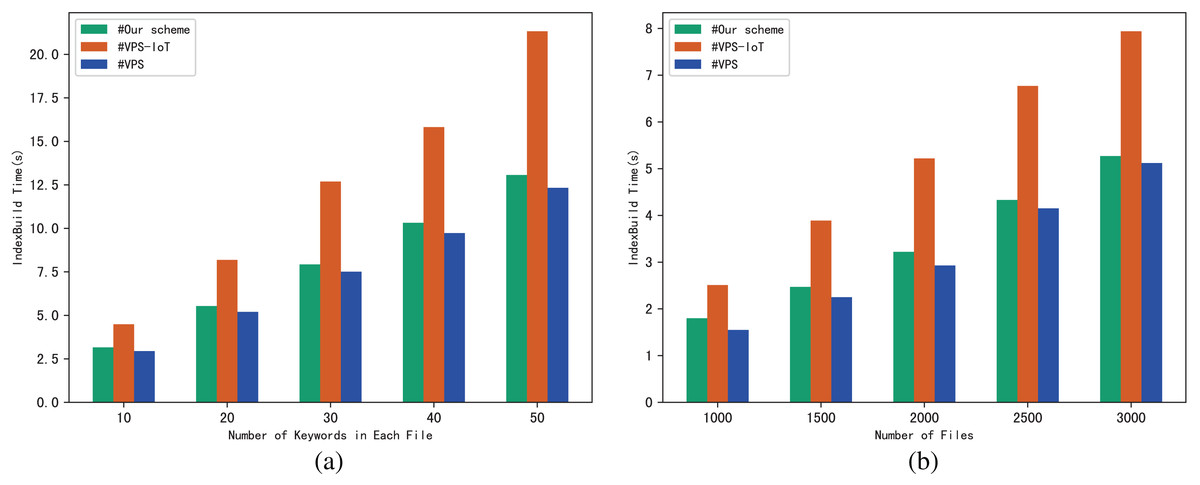
Figure 9: (A and B) IndexBuild.
{kind=link}
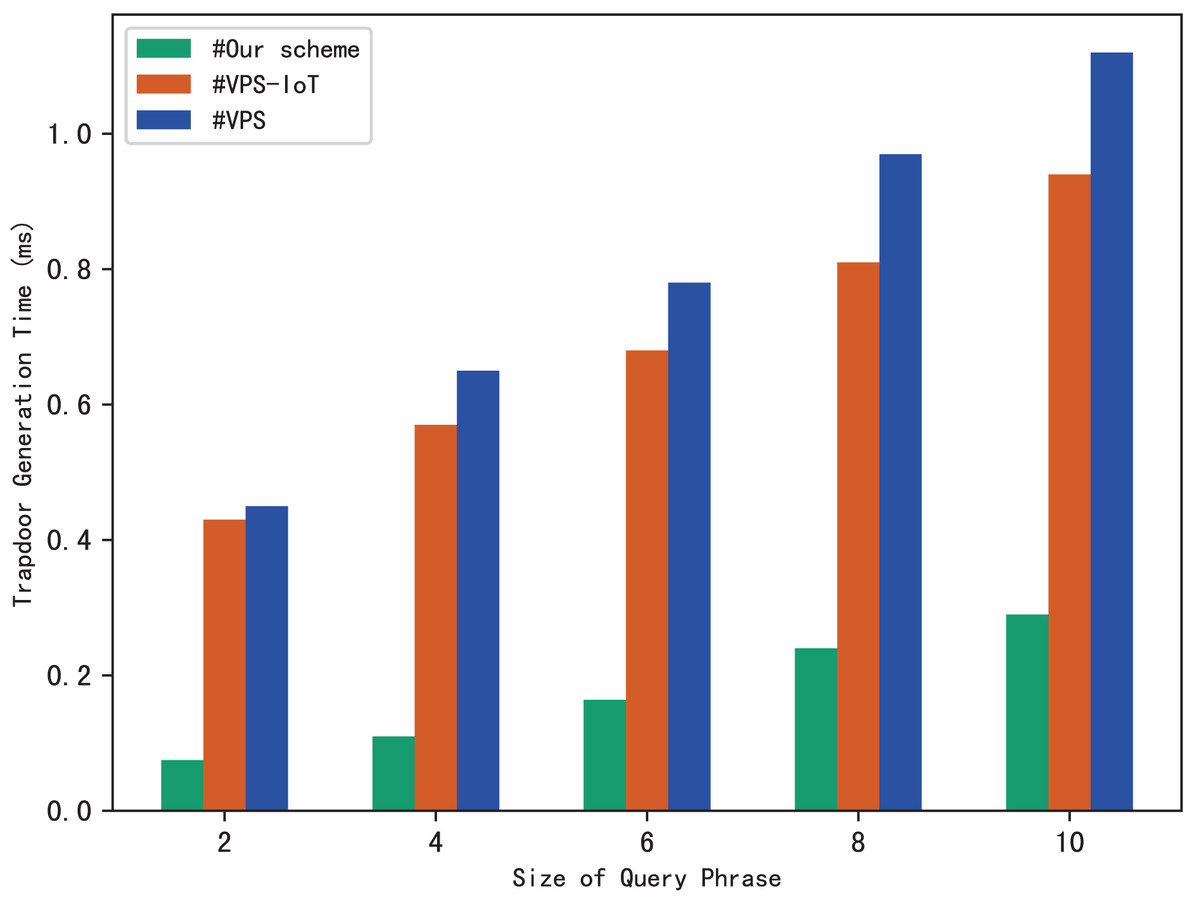
Figure 10: Trapdoor generation.
{kind=link}
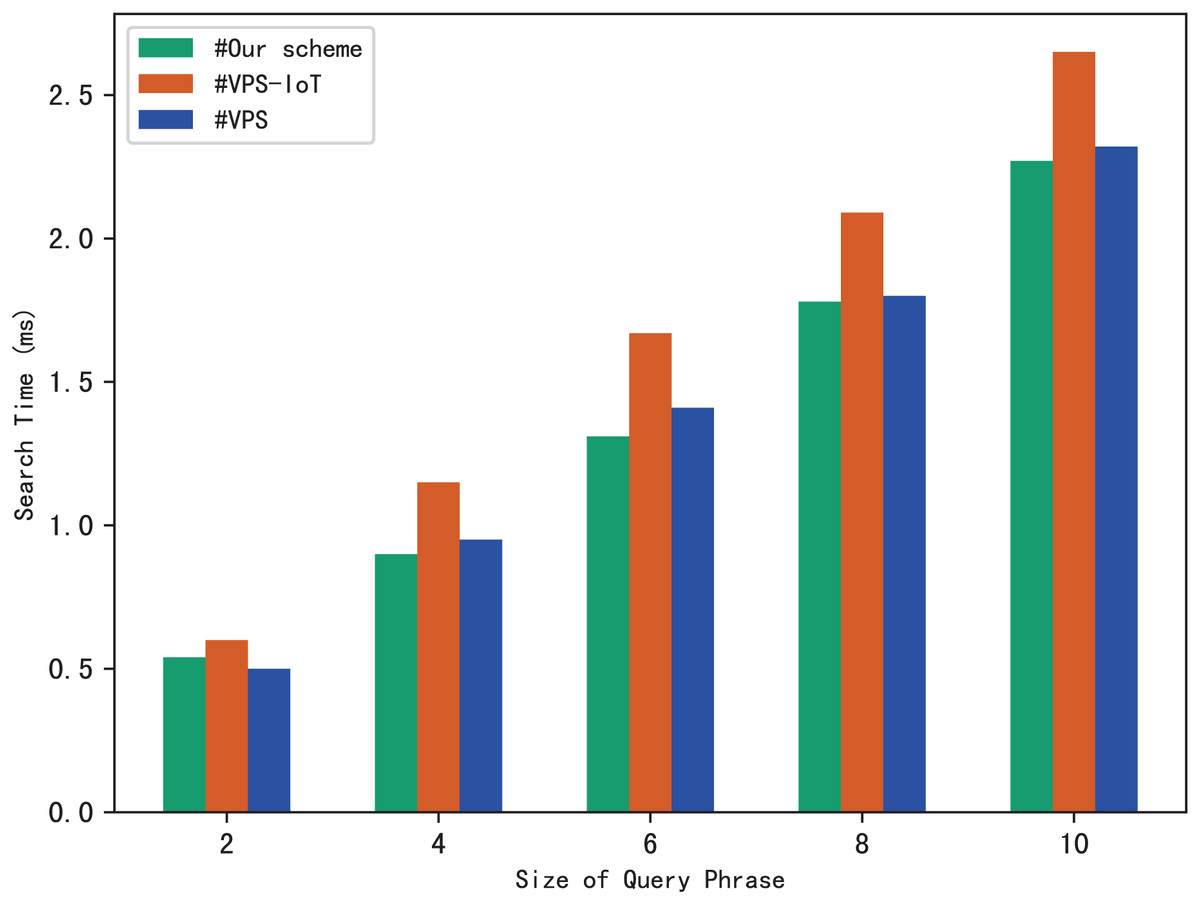
Figure 11: Phrase search.
{kind=link}
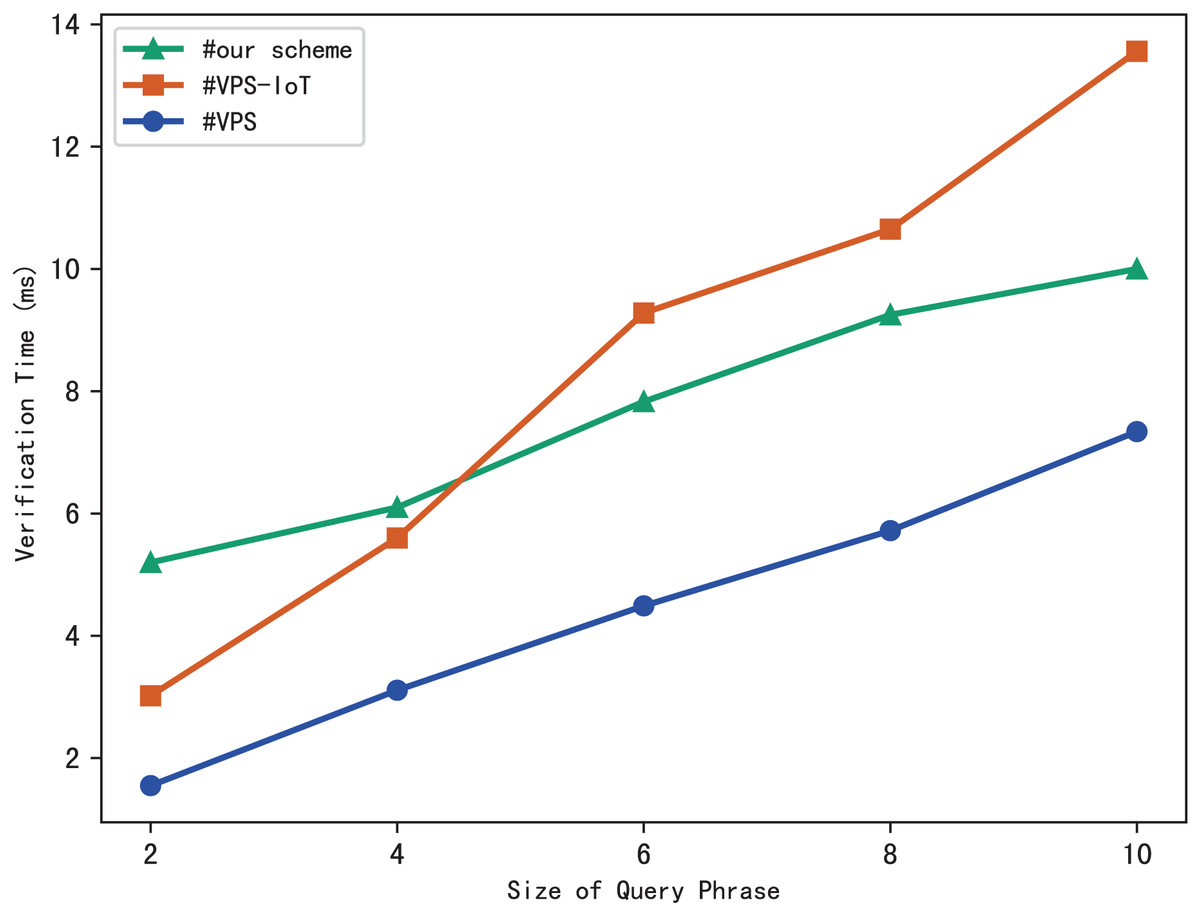
Figure 12: Verification.
{kind=link}
From what we have discussed above, our scheme has obvious advantages in index construction, trapdoor generation, and result verification compared with existing schemes, and the search efficiency is comparable to existing schemes. Furthermore, our scheme enables reliable and complete verification of search results with the help of blockchain, preventing the server from generating unreliable verification evidence due to only storing partial indexes and ciphertexts. At the same time, our scheme can prevent the unfair verification problem caused by malicious users forging verification results.
Discussion
In this article, we presented a efficient phrase search scheme with reliable verification over encrypted cloud-IoT data, which tackled the challenges of efficient phrase identification and reliable result verification. The scheme introduces the blockchain to the verification which ensures the reliability of the verification evidence and verification process. During the verification process, we use a multiset hash function to aggregate the on-chain evidence into a hash value, which significantly reduces the blockchain transaction cost. In addition, the scheme designs a novel compound Index and distance discrimination algorithm that can quickly determine the order of keywords and achieve efficient identification of phrases, which reduces the computational and communication overhead.
Supplemental Information
The experimental code for this scheme.
This code includes algorithms such as index construction, trapdoor generation, search, and result validation.