
Adaptive resilient containment control using reinforcement learning for nonlinear stochastic multi-agent systems under sensor faults
- Published
- Accepted
- Received
- Academic Editor
- Ivan Miguel Pires
- Subject Areas
- Adaptive and Self-Organizing Systems, Agents and Multi-Agent Systems, Algorithms and Analysis of Algorithms
- Keywords
- Stochastic multi-agent systems (MASs), Sensor faults, neural network (NN), Reinforcement learning (RL)
- Copyright
- © 2024 Mo and Lyu
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Adaptive resilient containment control using reinforcement learning for nonlinear stochastic multi-agent systems under sensor faults. PeerJ Computer Science 10:e2126 https://doi.org/10.7717/peerj-cs.2126
Abstract
This article proposes an optimized backstepping control strategy designed for a category of nonlinear stochastic strict-feedback multi-agent systems (MASs) with sensor faults. The plan formulates optimized solutions for the respective subsystems by designing both virtual and actual controls, achieving overall optimization of the backstepping control. To address sensor faults, an adaptive neural network (NN) compensation control method is considered. The reinforcement learning (RL) framework based on neural network approximation is employed, deriving RL update rules from the negative gradient of a simple positive function correlated with the Hamilton-Jacobi-Bellman (HJB) equation. This significantly simplifies the RL algorithm while relaxing the constraints for known dynamics and persistent excitation. The theoretical analysis, based on stochastic Lyapunov theory, demonstrates the semi-global uniform ultimate boundedness (SGUUB) of all signals within the enclosed system, and illustrates the convergence of all follower outputs to the dynamic convex hull defined by the leaders. Ultimately, the proposed control strategy’s effectiveness is validated through numerical simulations.
Introduction
Multi-agent systems (MASs) have garnered considerable attention due to their ability to organize vast and intricate systems into smaller, intercommunicating, easily coordinated, and manageable subsystems. Currently, MASs find widespread applications in various domains such as aircraft formation, sensor networks, data fusion, parallel computing and cooperative control of multiple robots (Antonio et al., 2021; Tang et al., 2016; Liu et al., 2020; Zhao et al., 2023; De Sá & Neto, 2023). As a class of classical control problems from cooperative control, the containment control approach guarantees the convergence of all followers to a dynamic convex hull formed by multiple leaders. Numerous findings on containment control have been documented in the last decade (Li et al., 2022; Li, Pan & Ma, 2022; Li et al., 2023; Liang et al., 2021).
It is noteworthy that optimal control, formally introduced by Bellman (1957) and Pontryagin et al. (1962) half a century ago, has become the foundation and prevailing design paradigm of modern control systems. The key to solving the optimal control problem lies in solving the Hamilton–Jacobi–Bellman (HJB) equation. Theoretically, solving optimal control based on the HJB equation is nearly impossible using analytical methods due to its strong nonlinearity (Beard, Saridis & Wen, 1996). Fortunately, Werbos (Werbos, 1992) introduced the approximate technique referred to as Adaptive Dynamic Programming (ADP) or Reinforcement Learning (RL), providing an effective method for solving the HJB equation. To date, this technique has witnessed significant development and achievements, as seen in Wen, Xu & Li (2023), Chen, Dai & Dong (2022), Gao & Jiang (2018), Zargarzadeh, Dierks & Jagannathan (2012), Zargarzadeh, Dierks & Jagannathan (2012), Li, Sun & Tong (2019), Song & Dyke (2013), Hu & Zhu (2015), Rajagopal, Balakrishnan & Busemeyer (2017), Wen, Xu & Li (2023). In Wen, Xu & Li (2023), RL was combined with backstepping to design actual controls and virtual controls, optimizing the overall control of high-order systems. In Chen, Dai & Dong (2022), this technique was applied to underactuated surface vessels, ensuring optimal tracking performance for ship control. Gao & Jiang (2018) addressed the computation problem of adaptive nearly optimal trackers without prior knowledge of system dynamics. In Zargarzadeh, Dierks & Jagannathan (2012), investigated neural network-based adaptive optimal control for nonlinear continuous-time systems with known dynamics in strict-feedback form. Zargarzadeh, Dierks & Jagannathan (2015) extended their work to address nonlinear continuous-time systems characterized by uncertain dynamics in strict feedback form. They accomplished this by adapting the standard backstepping technique, as outlined in Zargarzadeh, Dierks & Jagannathan (2015), transforming the optimal tracking problem into an equivalent optimal control problem and generating adaptive control inputs. Li, Sun & Tong (2019) presented a data-driven robust approximate optimal tracking scheme for a subset of strict-feedback single-input, single-output nonlinear systems characterized by the presence of unknown non-affine nonlinear faults and unmeasured states. In addition to deterministic nonlinear systems, various optimal control methods have been explored for stochastic systems in the past decade. The numerical techniques, proposed by Song & Dyke (2013), aimed to reduce system responses under extreme loading conditions with stochastic excitations. Hu & Zhu (2015) introduced a stochastic optimization-based bounded control strategy for multi-degree-of-freedom strongly nonlinear systems. In Rajagopal, Balakrishnan & Busemeyer (2017), an offline ADP method based on neural networks was developed to address finite-time stochastic optimal control problems. Specifically, in Wen, Xu & Li (2023) applied the RL strategy with the actor-critic architecture to stochastic nonlinear strict-feedback systems. However, for more complex nonlinear stochastic MASs, the above methods have not been fully studied. The challenges lie in the stability analysis process where the quadratic form of the Lyapunov function is no longer applicable, necessitating a reproof of system stability. Furthermore, in contrast to the single-agent stochastic strict-feedback system discussed in Wen, Xu & Li (2023a), we consider complex multi-agent systems. Many practical multi-agent systems, especially in areas like intelligent transportation and smart grids, tackle complex large-scale problems that surpass the capabilities of individual nonlinear systems. Therefore, research on nonlinear multi-agent systems is more meaningful.
Furthermore, in real-world scenarios, MASs comprise numerous actuators and sensors. Faults of some actuators or sensors can lead to the deviation from global control objectives. Therefore, investigating fault-tolerant control for MASs can enhance their safety and reliability. For instance, Ding et al. (2018) applied a region-based segmentation analysis to overcome caused by multiple sensor faults in strict-feedback systems. Wang et al. (2018) introduced a fault model to achieve fault-tolerant consensus for a multi-vehicle wireless network system with different actuator faults. Cao et al. (2021) fully considered consensus problems in MASs with sensor faults, utilizing neural networks not only for identifying unknown nonlinearities but also for designing adaptive compensatory controllers. Although there have been studies related to sensor faults, the conclusions from the above research cannot be directly applied to randomly occurring systems with statistical characteristics.
Inspired by the discussions above, This paper presents an enhanced backstepping control method tailored for a class of nonlinear stochastic strict-feedback MASs experiencing sensor faults. The primary contributions are summarized as follows:
(1) In this article, the optimal backstepping (OB) control method is extended to the nonlinear stochastic MASs with multiple leaders, which is more general than the consensus control results of MASs and can solve the optimal containment control problem.
(2) Suppressing sensor faults is important to enhance the system’s safety and reliability. To tackle the challenge posed by sensor faults in stochastic MASs, consideration is given to an adaptive neural network (NN) compensation control method. This method is designed to alleviate the adverse effects of sensor faults on the MASs.
(3) The proposed adaptive control scheme successfully solves the problem of contained control with sensor faults, and the designed RL optimization method can optimize the control of unknown or uncertain stochastic dynamic systems.
Preliminariers and Problem Formulation
Graph theory
In the context of a group of N + M agents, the associated directed graph 𝔊 can be described by , where 𝔙 = 1, 2, …, N, …, N + M constitutes a set of nodes, and represents a set of edges. The adjacency matrix is , implies that nodes j and i can share information with one another. aij is defined as (1)
where the set of neighbors for a node i is denoted by . The Laplacian matrix is defined as (2)
where 𝔇 = {diagd1, …, dN} represents the degree matrix and di = ∑j∈𝔑iaij. In this paper, the focus is on N + M agents, comprising N followers and M leaders, within a directed graph topology. It is assumed that each follower has at least one neighbor. Consequently, one can observe (3)
where 𝕃1 ∈ ℝN×N, 𝕃2 ∈ ℝN×M.
Assumption 1: Each follower is connected to a minimum of one leader through a directed path, while leaders themselves lack neighboring nodes.
Lemma 1: According to Assumption 1, the matrix 𝕃1 issymmetric and positive definite, each element of is nonnegative scalar, and all row sums of equal to 1.
Assumption 2: (Yoo, 2013) The multiple leaders’ outputs yld, l ∈ (N + 1, …, N + M) and their derivatives are bounded.
Lemma 2: (Tong et al., 2011a) Existing continuously differentiable function V(t, x) ∈ ℝ+, it meets the conditions (4) (5)
where a > 0, c > 0 are constants, ν1(⋅ ), ν2(⋅ ) are K ∞ functions, the differential Eq. (9) has a singular, robust solution, and subsequent inequality is satisfied: (6)
Inequality Eq. (6) signifies that the solution x(t) showcases SGUUB when considering expectations.
Lemma 3: (Wang, Wang & Peng, 2015) Defining s∗1 = [s11,s21, …, sN1]T, yi = [y1, y2, …, yN]Twe have s∗1 = 𝔏1yi + 𝔏2yld. Then the following inequality holds: (7)
where is the minimum singular value of 𝕃1.
Lemma 4: (Young’s Inequality (Tong et al., 2011)): For all x, y ∈ ℝ+, the subsequent inequality is held: (8)
where p > 0, q < 0, 1/p + 1/q = 1.
Stochastic systems statement
Consider a group of nonlinear stochastic MASs described as follows: (9)
where m = 1 represents the state vector. ui ∈ ℝ denotes the control input, yi ∈ ℝ is the system output. h(xi1) = ki(t)xi1 + ρi(t) ,where ki(t) and ρi(t) denote the parameters of sensor faults. fim(⋅) ∈ ℝm and ψim(⋅) ∈ ℝm depict uncertain smooth functions. w ∈ ℝr denotes the independent r-dimensional standard Brownian motion.
Neural network approximation
It has been shown that a neural network (NN) can approximate any continuous function to a desired accuracy within a specified compact set Ωx ⊂ ℝn. The neural network approximation function can be represented as follows: (10)
where W ∈ ℝq×m is the weight matrix, q is the quantity of neurons, is the Gaussian basis function vector with represents the centers of receptive fields, and φi is the width of the Gaussian function.
To fulfill Eq. (10), there must exist an ideal weight W∗, and the function can be rewritten as (11)
where is the approximation error required to meet with δ being a positive constant.
The ideal weight matrix W∗ can be shown as (12)
The Eq. (12) implies that the NN approximation error in Eq. (11) represents the minimum achievable deviation between and .
Sensor faults
Within sensor fault model (Bounemeur, Chemachema & Essounbouli, 2018), the unspecified parameters adhere to and , where > 0 represents the minimum sensor effectiveness, , are the lower bound and the upper bound respectively. The parameters of the sensor fault models can be summarized as below:
-
If and ρi(t) is a constant, the sensor exhibits bias fault.
-
If , |ρi(t)| = ιt, 0 < ι ≪ 1, the sensor experiences a drift fault.
-
If , , this signifies that the sensor has incurred a loss of accuracy.
-
If , , this suggests that the sensor has undergone a loss of effectiveness.
Denote fsi = (ki(t) − 1)xi1 + ρi(t). Then yi can be reformulated as yi = xi1 + fsi. The derivative of yi can be rewritten as , where .
Operator 𝔏
For function V(t, x), calculate its differential operator 𝔏 as Mao, (2006) (13)
where Tr signifies the matrix trace.
Distributed Adaptive Optimal Containment Control
The backstepping technique is employed for controller design. Before we begin, to clearly demonstrate our ideas and process, let’s provide a brief overview using Fig. 1.
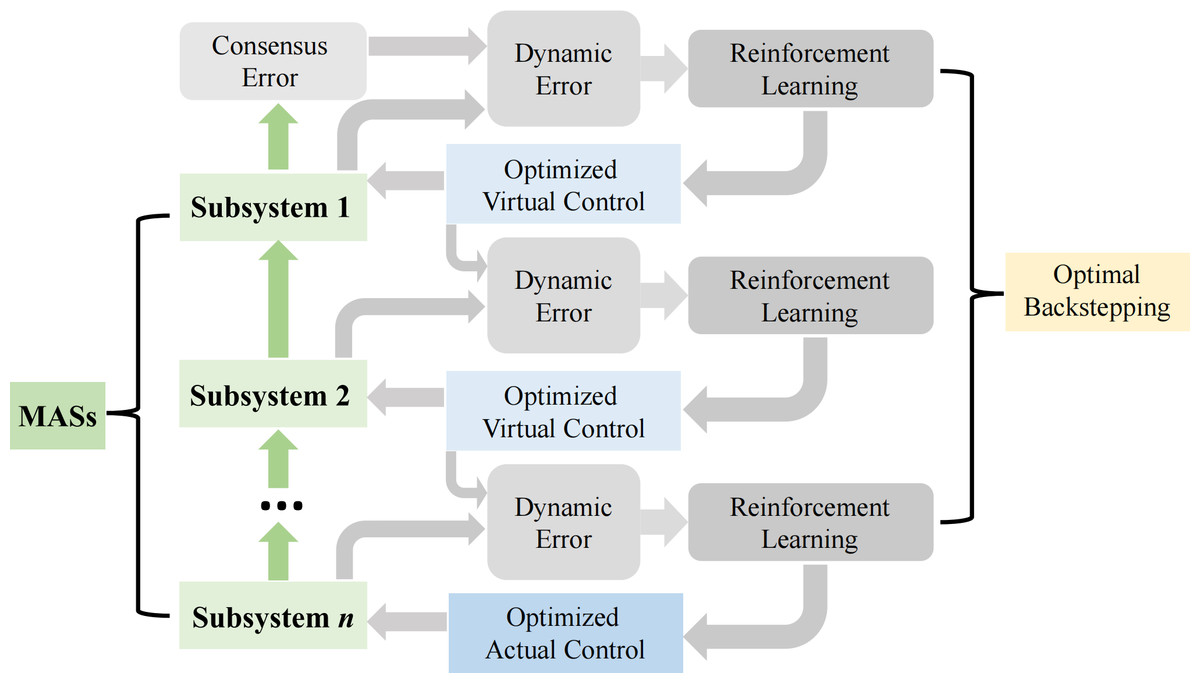
Figure 1: OB design in the i th agent, i = 1, …,n.
{kind=link}
Figure 1 illustrates the application process of RL in the design of optimized backstepping control. This process employs a Critic-Actor architecture to address the leader-following consensus control issue for nonlinear MASs. Within this method, the actor network is responsible for generating control actions, while the critic network evaluates the performance of the current control strategy. By iterating these two networks, the RL algorithm can learn an optimized control strategy that optimizes the control performance of the entire system.
Specifically, the optimal control problem is transformed into solving the HJB equation. However, due to the nonlinearity of the HJB equation, solving it directly is very challenging. To overcome this difficulty, a neural network-based RL method is proposed. This method derives the RL update rules from the negative gradient of a simple positive function, thereby avoiding the direct handling of multiple nonlinear terms in the HJB equation. This not only simplifies the algorithm but also relaxes the requirements for known system dynamics and persistent excitation.
During the RL learning process, the critic network first evaluates the performance of the current control strategy and provides it as feedback to the actor network. The actor network then adjusts its control actions based on this feedback, with the expectation of improving the system’s performance. In this way, the RL algorithm can continuously learn and optimize the control strategy through iteration until the optimal solution is found.
To start with, the i-th subsystem’s distributed containment error is defined as (14)
where αim−1 denotes the virtual controller. The OB control method is designed as follows.
Step 1: With Eq. (14) and Itô formula, the containment error can be calculated as follows: (15)
where:
Representing virtual control by αi1, the performance index function is formulated as (16)
where is the cost function.
Replace with (optimal virtual control) in Eq. (16), the function is obtained as (17)
According to the previous introduction, the function is given as follows: (18)
where Ω is a predefined compact set containing origin. By viewing xi2 as optimal control , the HJB equation linked with Eqs. (15) and (17) can be rewritten (19)
The optimal virtual controller can be derived by solving as (20)
To attain the tracking control, the term is partitioned as (21)
where γi1 > 0, βi1 > 0 are two designed constants, hi1(xi1, si1) = Fi1 + si1||Ψi1||4 and . Substituting Eqs. (21) into (20) yields (22)
Since two functions hi1(xi1, si1) and are uncertain yet continuous, they can be approximated by NN as (23) (24)
where ∈ℝp1 and ∈ℝq1 are the ideal NN weights, Shi1(xi1, si1) ∈ℝp1 and SJi1(xi1, si1) ∈ℝq1 are basis function vectors, and ɛhi1(xi1, si1) ∈ ℝ, ɛJi1(xi1, si1) ∈ ℝ denote approximation errors. Substitute Eqs. (23) and (24) into Eqs. (21) and (22), separately (25) (26)
where ɛi1 = 2ɛhi1 + ɛJi1. The optimal control Eq. (26) is unattainable due to the two ideal weights and are uncertain constant vectors.
To acquire an effective optimized virtual control, the implementation involves applying RL through the identifier-critic-actor architecture, utilizing the NNs. The uncertain function hi1(xi1, si1) of adaptive identifier is constructed in the following: (27)
where is the identifier output, and is the NN weight. The weight experiences updates based on the following law: (28)
where Γi1 is a positive-definite constant matrix, σi1 > 0 is constant. Designing the critic to evaluate the control performance aligns with Eq. (25) as (29)
where is the estimation of , is the NN weight of critic. The weight experiences updates based on the following law: (30)
where γci1 > 0 is constant. The formulation of the actor, responsible for executing the control action, corresponds to Eq. (25) as articulated below: (31)
where is the optimized virtual control, is the NN weight of actor. The weight experiences updates based on the following law: (32)
where γai1 > 0 is constant. These determined parameters, βi1, γi1, γci1, and γai1, are selected to satisfy (33)
According to Eqs. (19), (29) and (31), the HJB equation is calculated as (34)
Building upon the preceding analysis, the optimized control is foreseen as the sole solution to achieve Assuming the existence of and its unique solution, it is equivalent to the following equation: (35)
Define the positive function Pi1(t) as (36)
It is evident that Eq. (35) is the equivalent to . Given the fact that , the time derivative of along with Eqs. (29) and (31) is (37)
The inequality Eq. (37) suggests that the updating laws Eqs. (30) and (32) can ensure eventually. The key benefits of the RL design approach include: (1) comparatively, the optimized control algorithm demonstrates a substantially simpler structure than existing optimal methods, such as Vamvoudakis & Lewis (2010), Liu et al. (2013), Wen, Ge & Tu (2018). (2) this can alleviate the necessity for persistent excitation, a requirement prevalent in many optimal control methods. Replace xi2 with in the dynamic Eq. (14) to have (38)
The Lyapunov function candidate is designed as (39)
where , and represent corresponding errors. Compute the 𝔏 of Li1, along with Eqs. (28), (30), (32) and (39) to yield (40)
Design optimal virtual controller (41)
and then Eq. (31) becomes (42)
With Young’s inequality Eq. (8), there are following results: (43) (44) (45) (46)
Substituting inequalities Eqs. (43), (44), (45) and (46) into (42) has (47)
where hi1 = Fi1 + si1||Ψi1||4. Substituting Eqs. (24) into (47) results in the following inequality: (48)
From the facts , and the following equations can be derived: (49) (50) (51)
With Young’s inequality Eqs. (8) and limitation of (33), subsequent inequalities obtained: (52) (53)
Substituting Eqs. (49)–(53) into (48) yields (54)
where and |Bi1(t)| ≤ bi1, because all its terms are bounded, and will be handled in step 2′s hi2(xi2, si2).
Step m (2 ≤ m ≤ n − 1):Define the containment error as . According to Eq. (9), the error dynamic, along with Eq. (13), is (55)
where . Let αim denote virtual controller, the performance index function can be defined as (56)
where is the cost function. Denoted as the optimal virtual controller, substitute into Eq. (56), the function can be rewritten as (57)
Similar to Step 1, Eq. (57) manifests the subsequent characteristic (58)
By viewing xim+1(t) as optimal control , the HJB equation relate to Eqs. (55) and (57) is (59)
where (dw)/(dt) represents the white noise. Besides, is obtained by solving as (60)
To attain the containment control, the term is segmented as (61)
where γim > 0 and βim > 0 are two designed constants, , , and . By substituting Eqs. (61) into (60), optimal control transforms into (62)
Since two functions and are uncertain yet continuous, they can be approximated by NN as (63) (64)
where and are the ideal NN weights, Shim(xim, sim) ∈ℝpm, SJim(xim, sim) ∈ℝqm are basis vectors, ɛhim(xim, sim) ∈ ℝ, ɛJim(xim, sim) ∈ ℝ are bounded approximation errors. Substituting Eqs. (63) and (64) into Eqs. (61) and (62) has (65) (66)
where ɛim = 2ɛhim + ɛJim.The optimal control Eq. (66) is impractical due to the two ideal weights and are uncertain. To obtain a practical optimized control, RL is constructed based on Eqs. (65) and (66) as follows. The adaptive identifier is formulated as follows: (67)
where is the identifier output, is the NN weight. The weight experiences updates based on the following law: (68)
where Γim is a positive-definite constant matrix, σim > 0 is constant. The critic is designed in the following: (69)
where is the estimation of , is the NN weight of critic. The weight experiences updates based on the following law: (70)
where γcim > 0 is constant. The actor is designed as follows: (71)
where is the optimized virtual control, is the NN weight of actor. The weight experiences updates based on the following law: (72)
where γaim > 0 are constant. These designed parameters, βim, γim, γcim and γaim satisfy the following conditions:
(73)
Define containment error of the step m+1 as . Replace xim+1 with in the dynamic Eq. (55) to have (74)
Select the Lyapunov function candidate: (75)
where , and , and . Computing the infinitesimal generator 𝔏 of Lim, along with Eqs. (68), (70), (72) and (74) has (76)
Substituting the virtual control Eqs. (71) into (76) holds (77)
From the fact and previous results, following numerous operations resembling those in Eqs. (43)–(54) in Step 1, (87) can be expressed as (78)
where is the maximal eigenvalue of , is the minimal eigenvalue of .
And ,which satisfied |Bim| ≤ bim.Define , and then Eq. (78) can become the following one: (79)
Step n: The optimized control ui is obtained here. Based on Eq. (9), can be derived from Eq. (13) as follows: (80)
where .The performance index function related to Eq. (80) can be written as (81)
where is cost function. Denoted as optimal control, the function can be rewritten as (82)
The function Eq. (82) implies the following property: (83)
The HJB equation related to Eqs. (80) and (82) is (84)
Solving yields (85)
Split the term as (86)
where γin > 0 and βin > 0 are two designed constants, and hin = fin + sin||Ψin||4 ∈ ℝ, Substituting Eqs. (86) into (85) has (87)
Since the unknown functions and are continuous, which can be approximated by NN as (88) (89)
where ∈ℝpn, are the ideal NN weights, Shin(xin, sin) ∈ ℝpn and SJin(xin, sin) ∈ ℝqn are the basis function vectors, ɛhin(xin, sin) ∈ ℝ, ɛJin(xin, sin) ∈ ℝ are the bounded approximation errors. Substituting Eqs. (88) and (89) into Eqs. (86) and (87) yields (90) (91)
where ɛin = 2ɛhin + ɛJin.The adaptive identifier is formulated as (92)
where is the identifier output, is the NN weight of identifier.
The weight experiences updates based on the following law: (93)
where Γin is a positive-definite constant matrix, σin > 0 is constant. The critic is (94)
The weight experiences updates based on the following law: (95)
where γcin is a constant. The actor is (96)
The weight experiences updates based on the following law: (97)
These parameters are required to meet the following limitation: (98)
Select the Lyapunov function candidate for overall backstepping control as (99)
where , , . Compute 𝔏 of Lin, along with Eqs. (80), (93), (95) and (97), and then apply (96), resulting in the following: (100)
The following expression is derived from Eqs. (100): (101)
where is the maximal eigenvalue of , is the minimal eigenvalue of And ,which satisfied |Bin| ≤ bin.Let , and then Eq. (101) can become the following one (102)
Stability Analysis
Theorem 1: Consider MASs described by Eq. (13) and subjected to Assumptions 1-2, operating within a directed graph and employing the adaptive laws Eqs. (32), (72) and (97), together with the virtual controllers Eqs. (31) and (71), and the actual controller Eq. (96), the containment control protocol unequivocally guarantees the SGUUB of all signals within the closed-loop system. Furthermore, for a given ∀t > 0, tuning the design parameters leads the containment error to converge within an arbitrarily small neighborhood, as expressed: (103)
Proof: Consider the overall Lyapunov function L given by: (104)
Define and . Subsequently, Eq. (104) can be expressed as (105)
Based on Lemma 2, the following inequality is deduced from Eq. (105): (106) (107)
For s∗1 = [s11, s21, …, sN1]T, based on the definition of Lin and Eq. (99) (108)
where N denotes quantity of follower agents. With Eq. (99), for ∀ɛ > 0: (109)
Taking Eq. (109) and Lemma 3 into account to obtain (110)
The proof is completed and the RL control strategy process diagram is illustrated in Fig. 2.
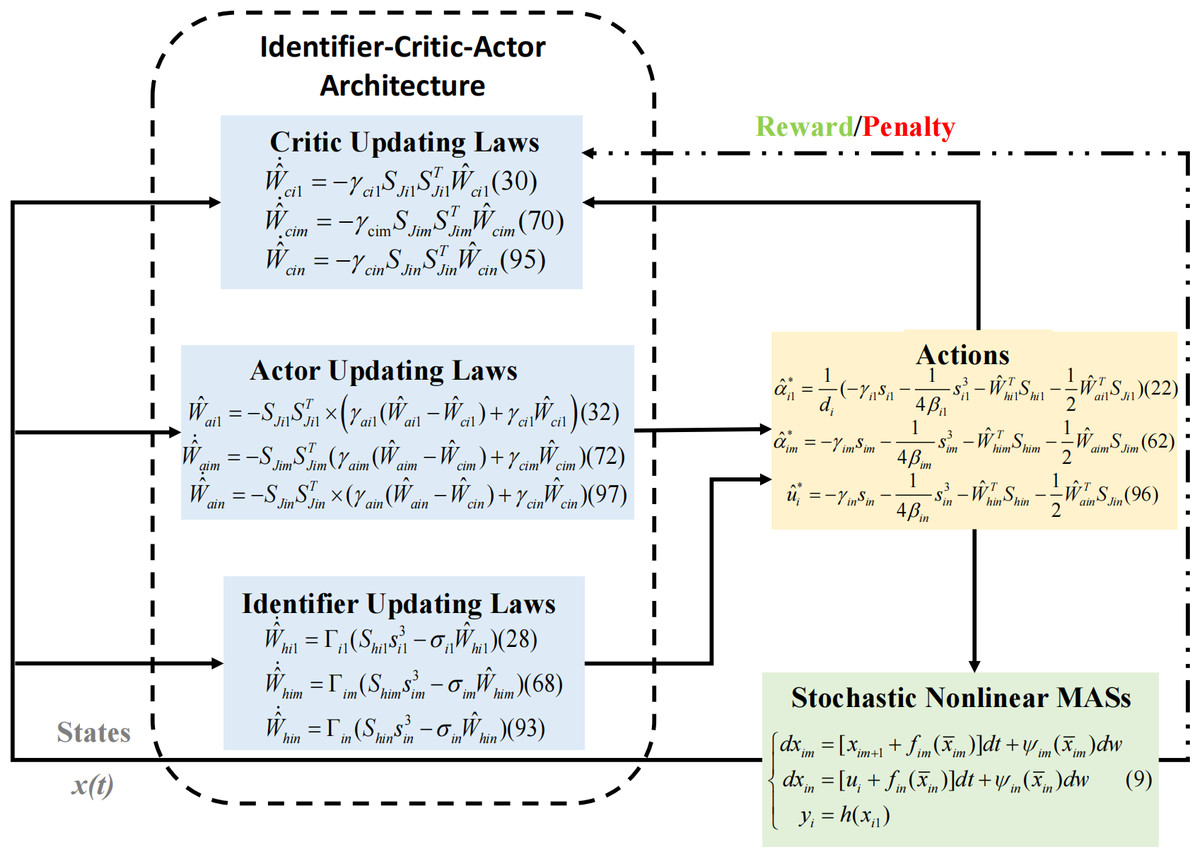
Figure 2: The RL control scheme.
{kind=link}
Simulation Example
In this section, the effectiveness of OB, RL and containment control is illustrated by a numerical example. For the nonlinear stochastic MASs consisting of 4 followers and 2 leaders, the following system dynamics are considered: (111)
where xi1, xi2 ∈ ℝ, u ∈ ℝ is the control input, , .The leaders are defined as: (112)
The communication graph that we used in the simulation is visualized in Fig. 3.
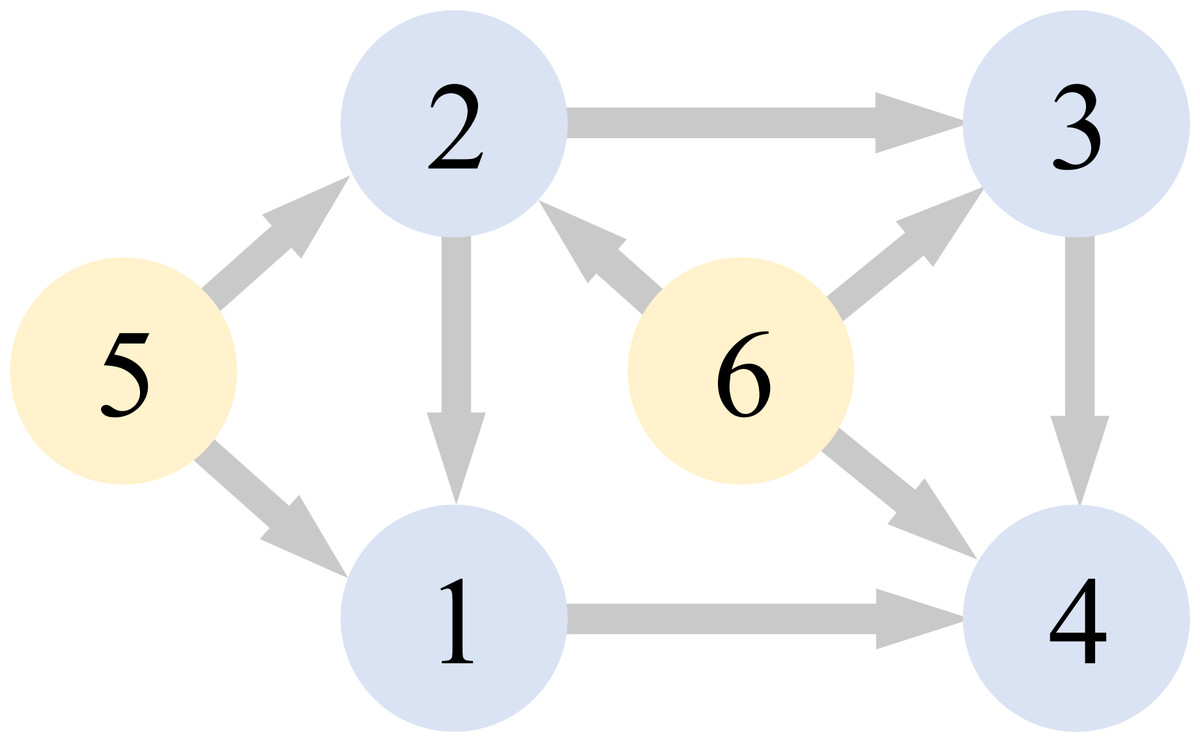
Figure 3: Communication graph.
{kind=link}
According to Fig. 3, the Laplacian matrix as: (113)
The NN update parameters are designed as: γai1 = 20, γai2 = 15, γci1 = 14, γci2 = 14, σi1 = 14. The design parameters for the optimized virtual control action corresponding to Eq. (41) are: γi1 = 12, βi1 = 5. The parameters of the optimized actual control action corresponding to Eq. (42) are set as γi2 = 5, βi2 = 2.
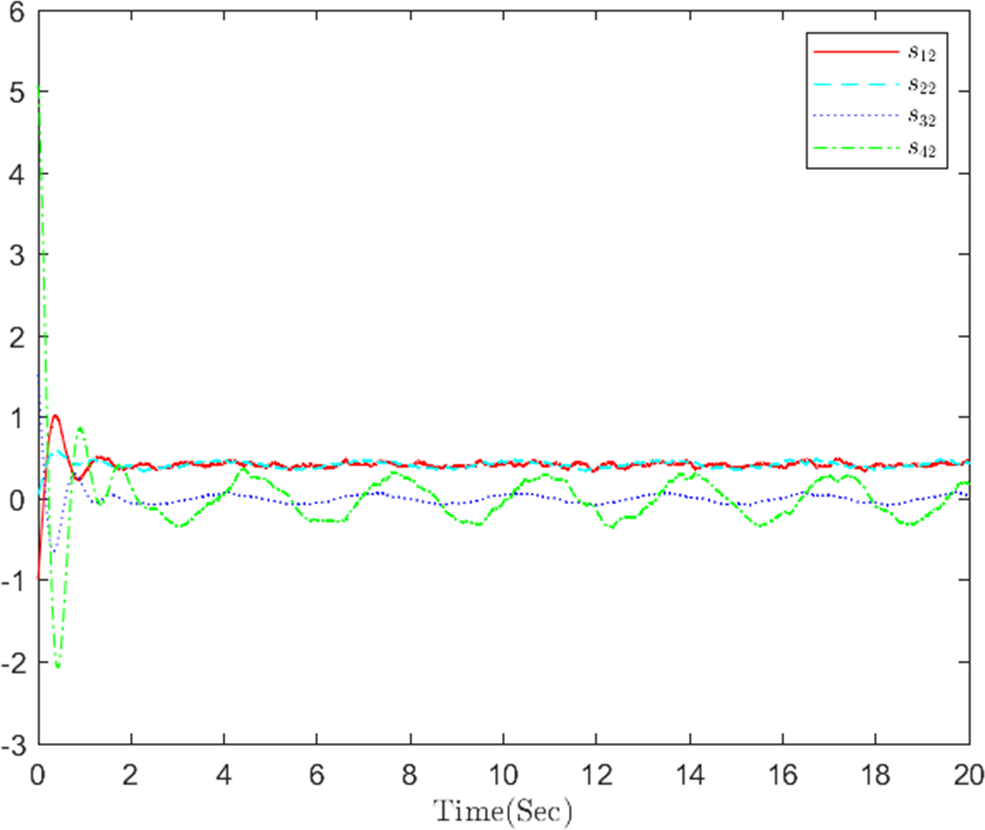
The simulation results, illustrating the application of the proposed OB method for stochastic nonlinear MASs, are presented in Figs. 4–12. Figure 4–6 depict the boundedness of the actor, identifier, and critic NN weights. The actor for performing the control action and the optimized control actor are illustrated in Figs. 7–8. Figure 9 displays the trajectories of leaders and followers, demonstrating the asymptotic convergence of all followers to the convex hull formed by the leaders. The distributed containment errors are shown in Figs. 10–11. The results verify that all closed-loop system signals are SGUUB. The simulation results demonstrate that the OB method used in MASs can achieve the desired control performance. Besides, Fig. 12 is the error curve without considering the adaptive compensation scheme in this paper. By comparing simulation results, it can be seen that through RL, adjusting the adaptive rate accelerates the convergence speed of the optimization algorithm, allowing sensor errors to converge more quickly.
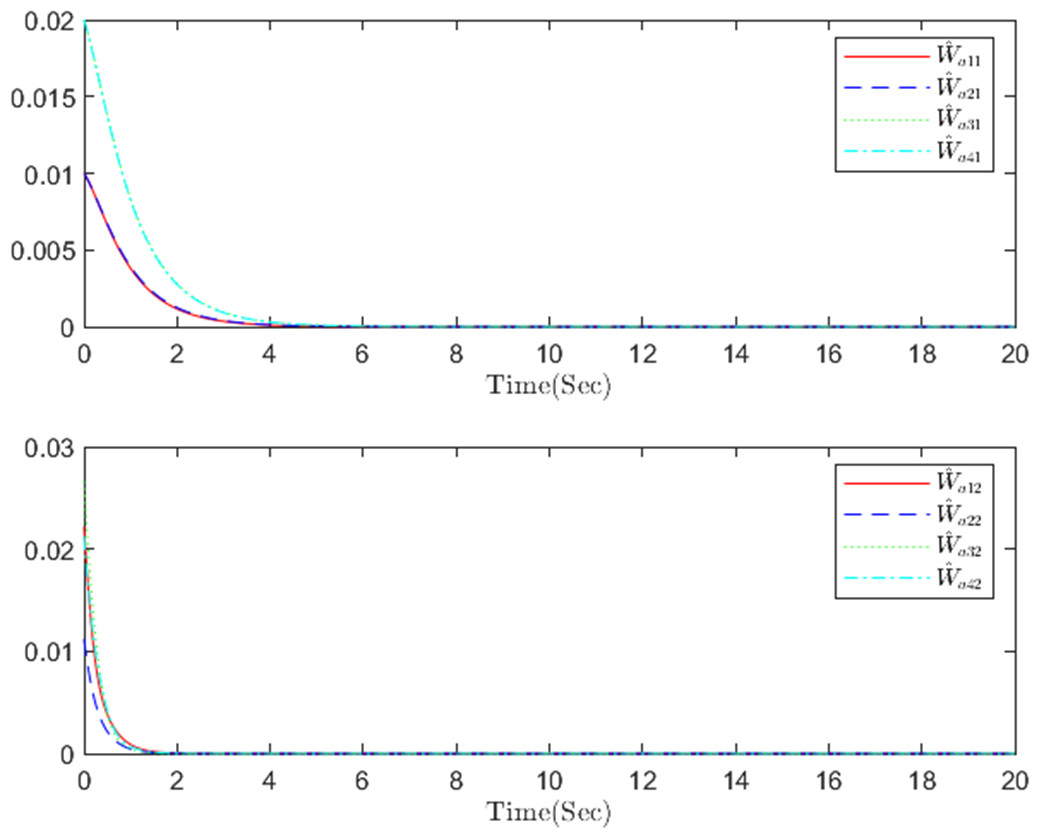
Figure 4: The actor NN weight a in step m.
{kind=link}
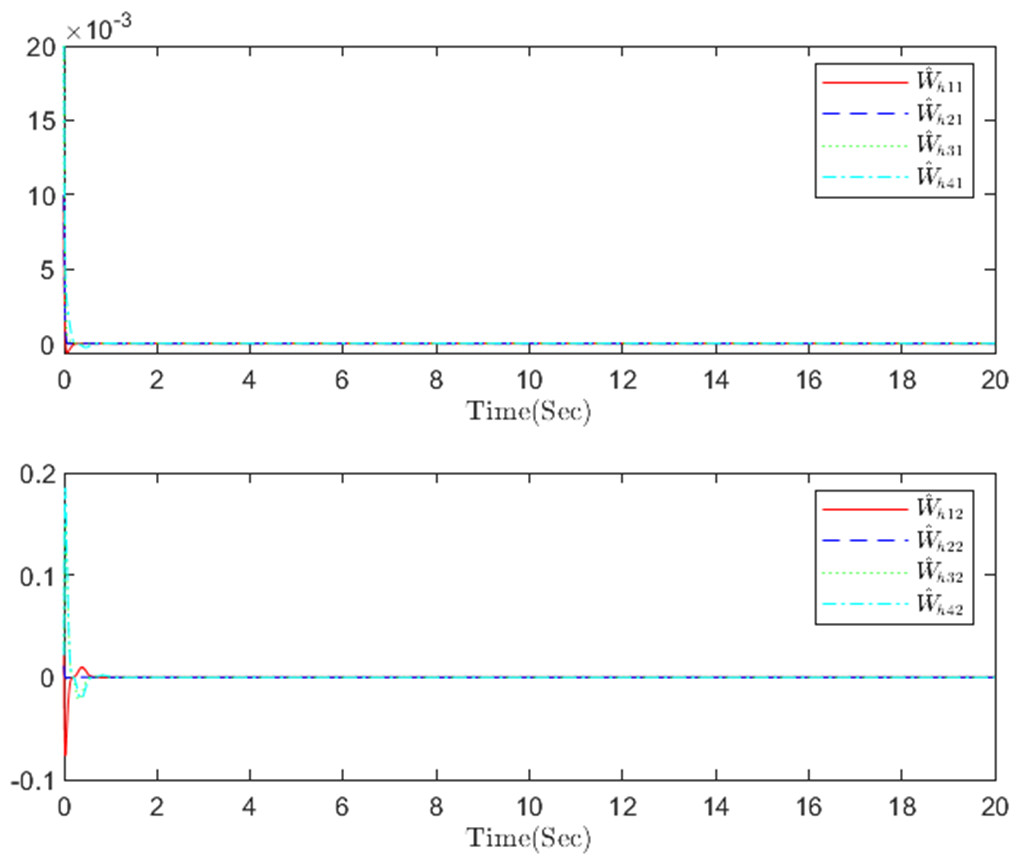
Figure 5: The identifier NN weight h in step m.
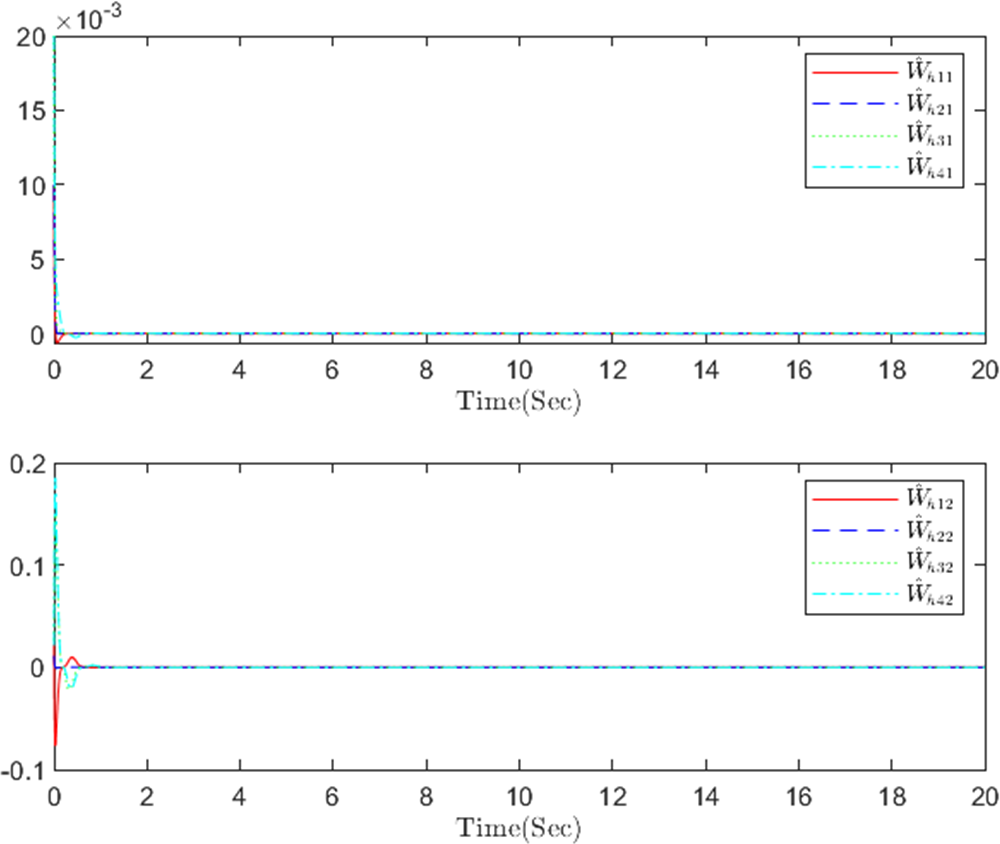{kind=link}
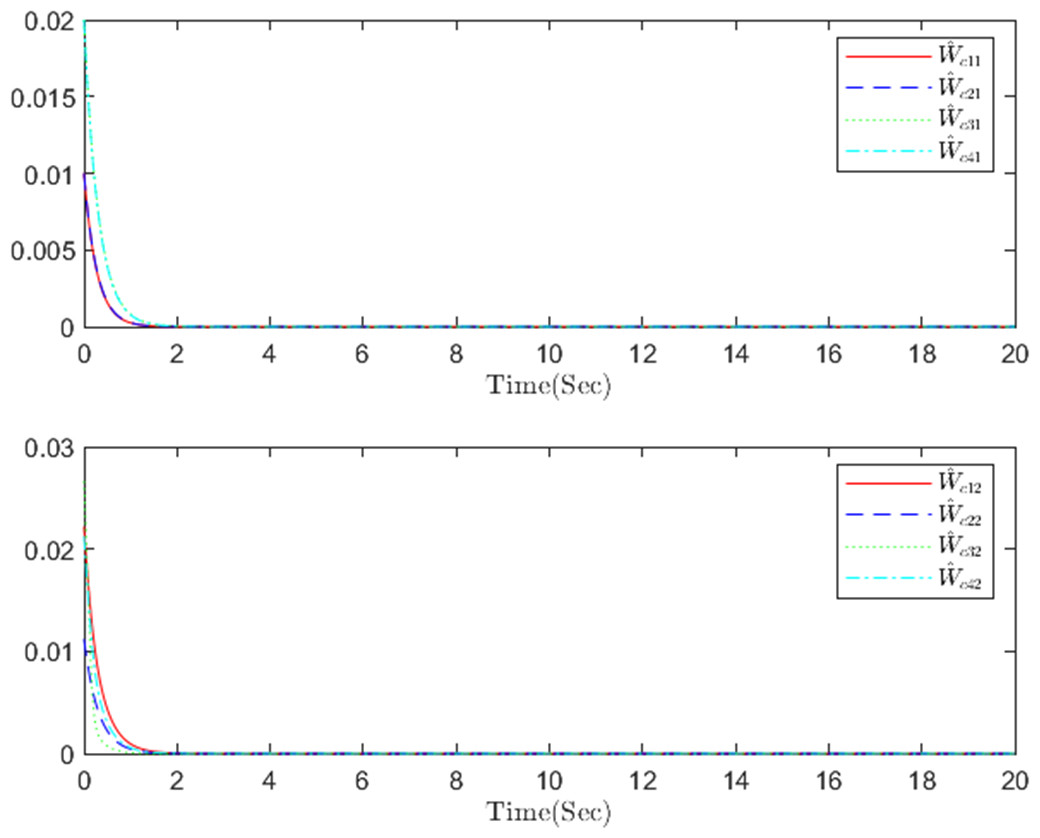
Figure 6: The critic NN weight c in step m.
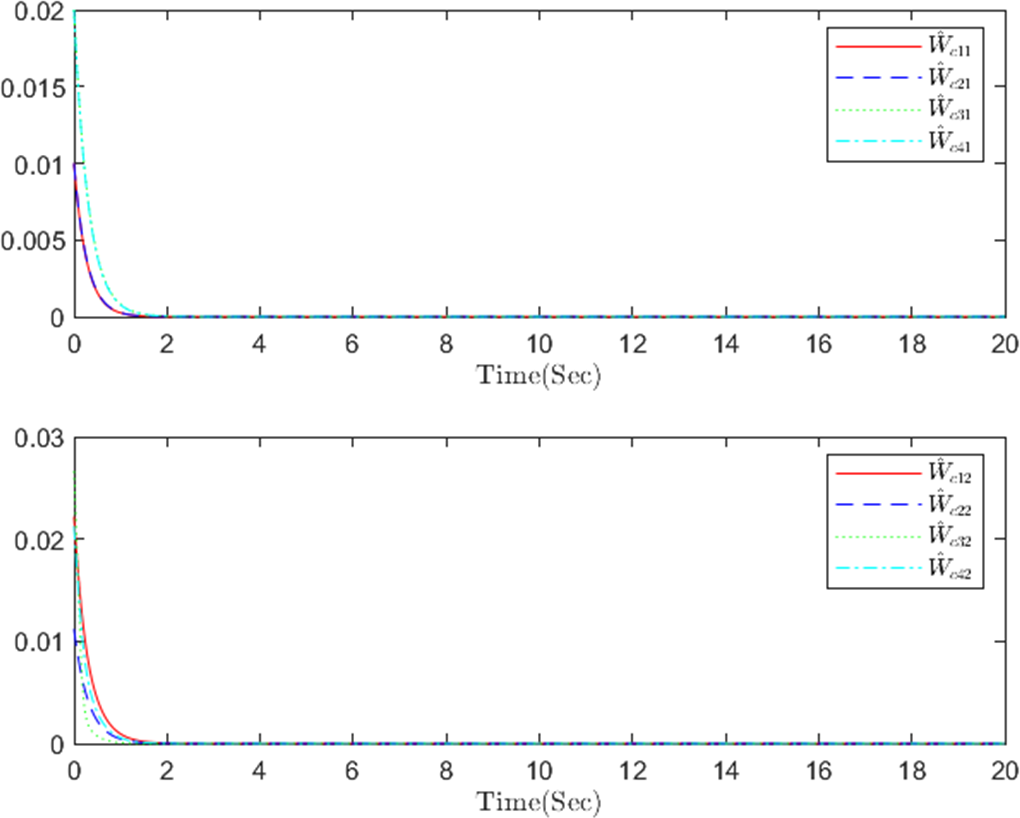{kind=link}
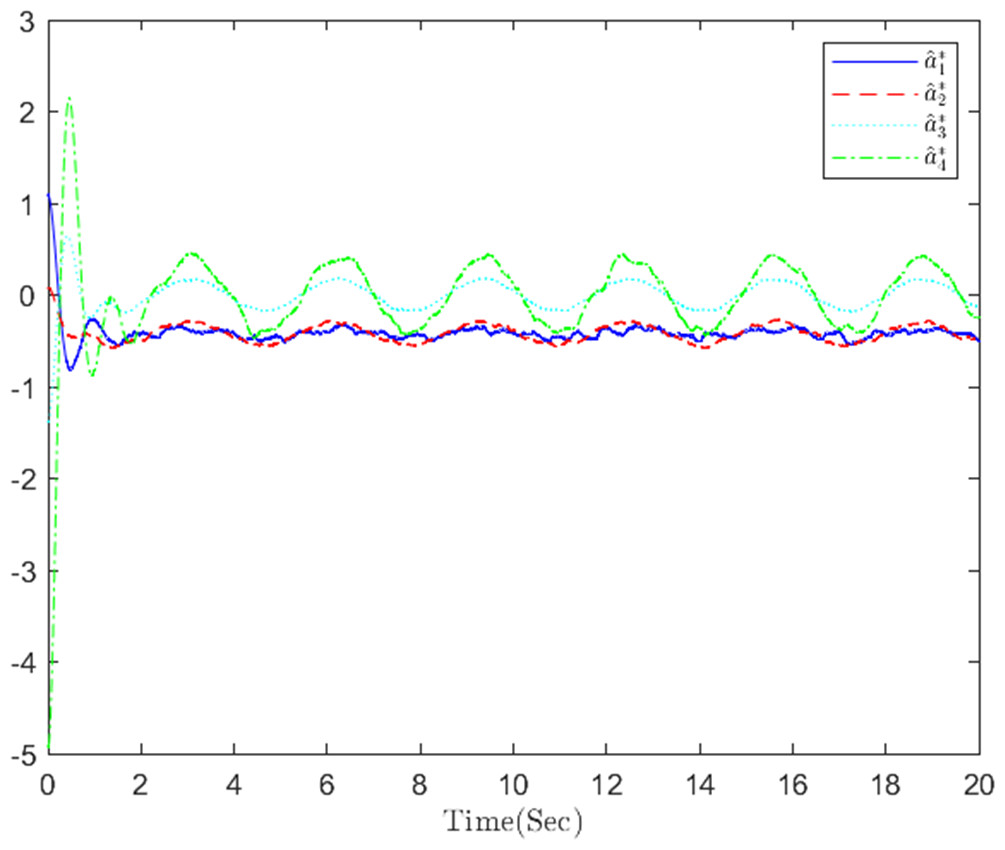
Figure 7: The optimized virtual control action in step 1.
{kind=link}
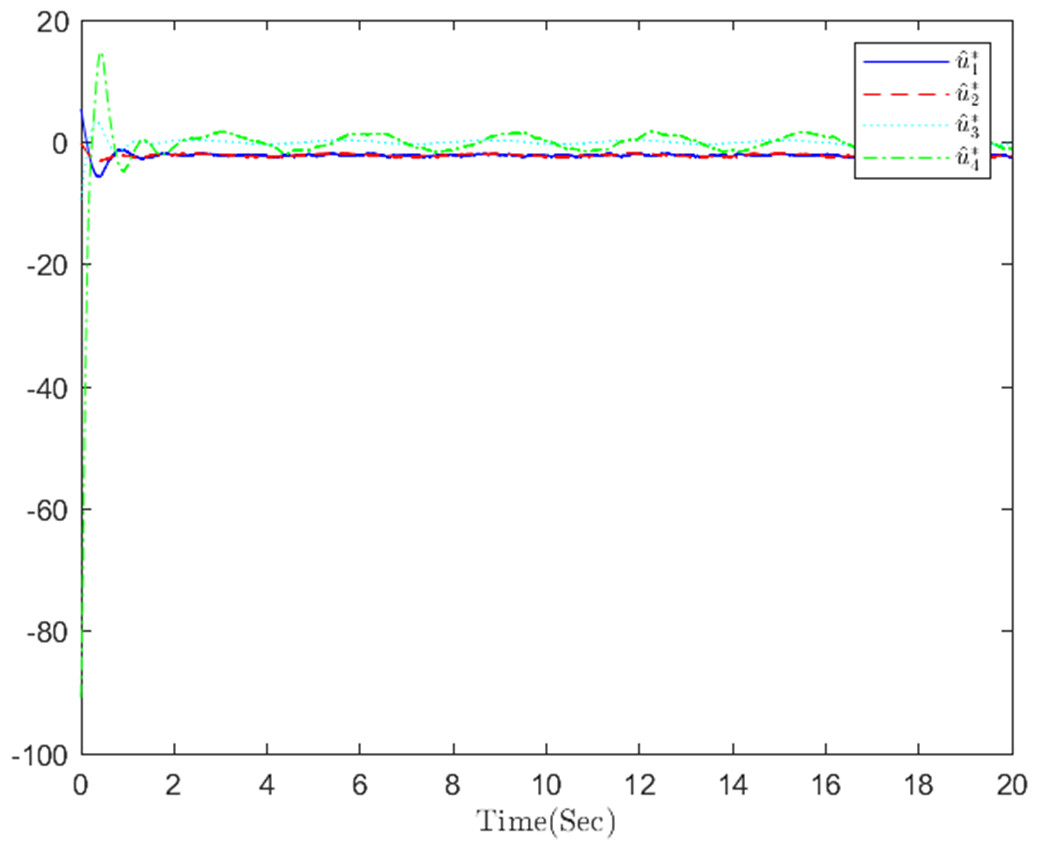
Figure 8: The optimized actual control action in step 2.
{kind=link}
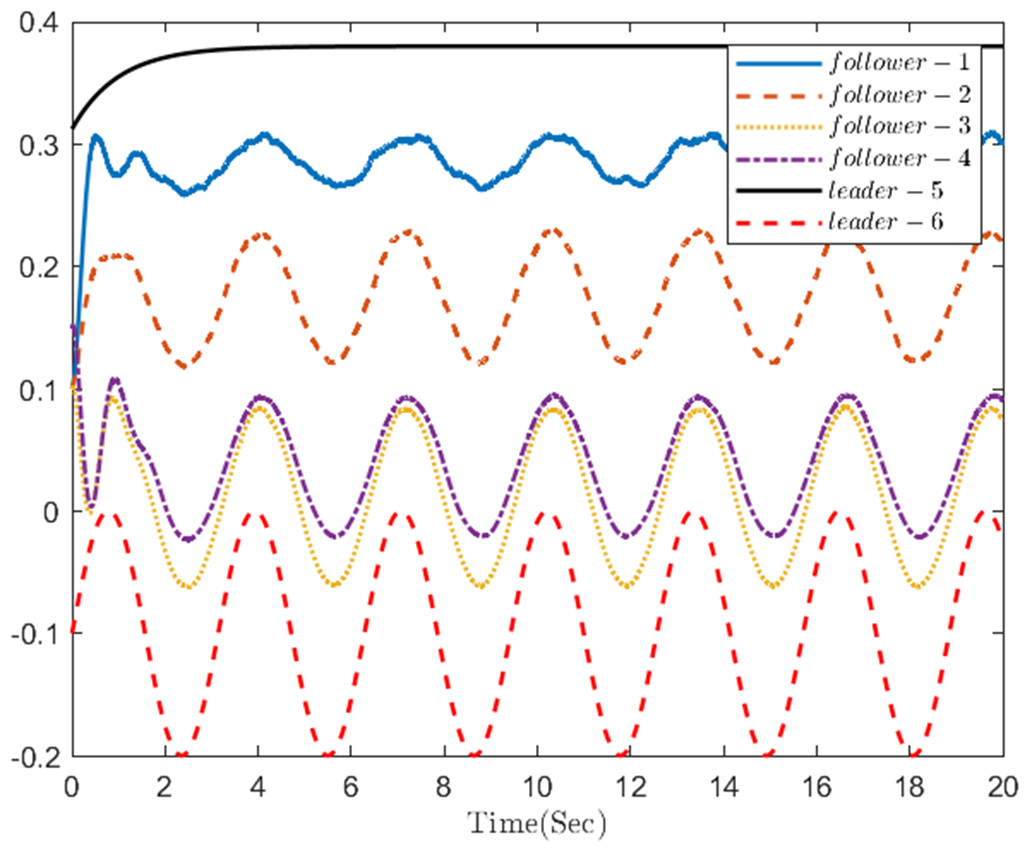
Figure 9: The trajectories of four followers and two leaders.
{kind=link}
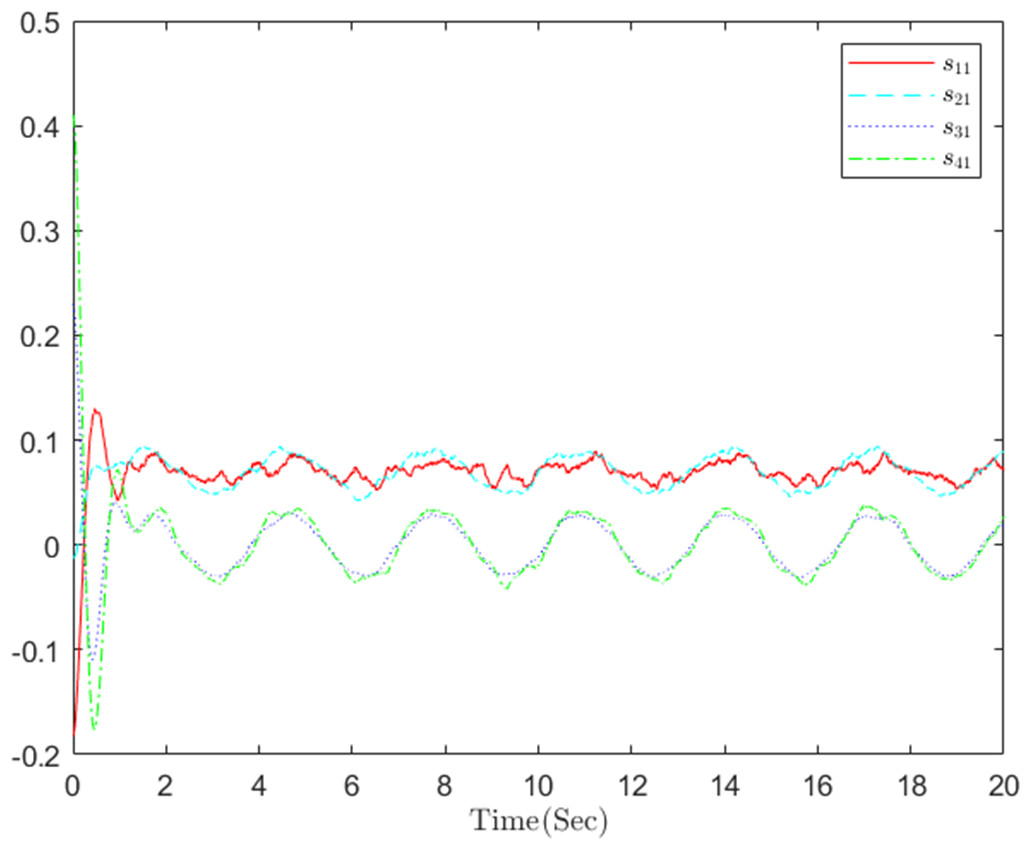
Figure 10: The distributed containment errors s in step 1.
{kind=link}
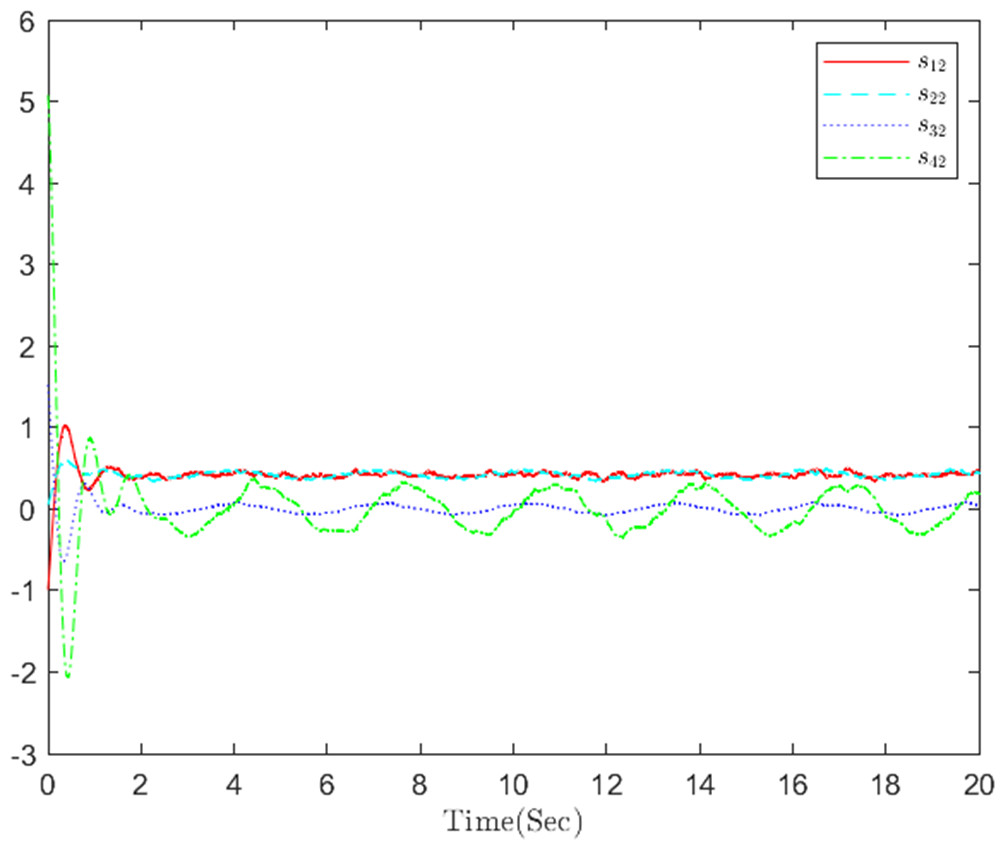
Figure 11: The distributed containment errors s in step 2.
{kind=link}
Figure 12: The distributed containment errors q in step 2.
{kind=link}
Conclusion
This article introduces an optimized backstepping control based on RL, which has been developed and applied to a class of nonlinear stochastic strict-feedback MASs experiencing sensor faults. Crafting virtual and actual controls as optimized solutions for their respective subsystems, an overall optimization of the backstepping control has been achieved. To address sensor faults, an adaptive neural network compensation control method has been constructed. Utilizing the RL framework based on neural network approximation, the rules for updating RL have been deduced from the negative gradient of a basic positive function linked to the HJB equation. In comparison with existing methods, not only did this approach significantly simplify the RL algorithm, but it also relaxed the requirements for known dynamics and persistent excitation. Additionally, the proposed control scheme has that the outputs of all followers converge to the dynamic convex hull formed by the leaders.
Supplemental Information
Simulation Code
The reinforcement learning (RL) framework based on neural network approximation is employed, deriving RL update rules from the negative gradient of a simple positive function correlated with the Hamilton–Jacobi-Bellman (HJB) equation. This significantly simplifies the RL algorithm while relaxing the constraints for known dynamics and persistent excitation.