
Enhanced architecture and implementation of spectrum shaping codes
- Published
- Accepted
- Received
- Academic Editor
- Sedat Akleylek
- Subject Areas
- Algorithms and Analysis of Algorithms, Computer Networks and Communications
- Keywords
- Spectrum shaping, K-constraint, Guided scrambling, Accumulated signal power, Spectrum null
- Copyright
- © 2024 Wang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Enhanced architecture and implementation of spectrum shaping codes. PeerJ Computer Science 10:e1883 https://doi.org/10.7717/peerj-cs.1883
Abstract
Spectral shaping codes are modulation codes widely used in communication and data storage systems. This research enhances the algorithms employed in constructing spectral shaping codes for hardware implementation. We present a parallel scrambling calculation with a time complexity of O(1). Second, in the minimum accumulated signal power (MASP) module, the sine-cosine accumulation needs to be determined by remainder with time complexity O(n2). We offer reduced MASP computations for short bit-width data, ROM storage, and addition pipelines. It can remove the remainder operation, reducing accumulated complexity to O(1). In addition, we present a search algorithm to generate segmented lines to replace the square operations in the MASP module. By employing the search algorithm and shift operations, we can reduce the complexity of the square from O(n2) to O(1). The implementation results reveal that the original and proposed MASPs yield nearly identical spectrum nulls. The encoder-decoder of the spectral shaping codes with proposed approaches consumes just 6% of the hardware resources when carried out with a Spartan6 XC6SLX25.
Introduction
Spectrum shaping codes are categorized as modulation codes, and they are applied initially to digital communications utilizing transformers to connect two lines. Transformers cannot transfer signals without significant distortion if the power spectral densities of signals include low frequency components. The shaping codes are designed to adjust source data to satisfy the features of the communication channel. These codes are also employed for digital recording systems to translate an arbitrary data sequence into a sequence with particular characteristics required by the systems (Immink & Cai, 2021). More recently, a novel concept of integrated microwave photonics spectral shaping is introduced to open avenues to advanced functionalities (Daulay et al., 2021).
Spectrum shaping technologies are utilized in a variety of fields. (1) In information processing and transmission fields, Chai et al. (2014) discuss the practical obstacles to implementing dynamic spectrum access (DSA) devices and offer solutions. In order to accommodate DSA in commercial off-the-shelf wireless devices, they also propose a general per-frame spectrum-shaping protocol. A simple spectrum shaping technique based on switching three loads has been presented for backscatter modulation-based Internet of Things (IoT) systems (Nagaraj, 2017). Danila (2021) describes theoretical research conducted in the terahertz G-band for a piezoelectrically-responsive ring-cone element metasurface composed of polyvinylidene fluoride (PVDF)/silicon and PVDF/silica glass. Utilizing the longitudinal piezoelectric effect of PVDF, this study examines the spectrum shaping ability of a polymer-based metasurface. Three distinct filter functions, such as Fano-like resonances, wavelength interleaving, and variable resonance mode splitting, are accomplished in Arianfard et al. (2021). The outcomes theoretically validate the proposed device as a compact photonic filter with many functions for adjustable spectral shaping. Dobre et al. (2021) developed spectrum-skirt-filled pulse-shaping filters corresponding to spectral mask response. The suggested system design achieves more excellent data rates in a dispersive microwave propagation environment than conventional transmission using Nyquist pulse shaping. Nasarre et al. (2021) present a novel concept of frequency-domain spectral shaping (FDSS) with spectral extension for the enhancement of the uplink (UL) coverage in 5G New Radio (NR), based on discrete Fourier transform spread orthogonal frequency-domain multiplexing. The results demonstrate that the spectrally-extended FDSS method is a highly effective solution for improving the 5G NR UL coverage. Furthermore, we can create dependable systems by integrating modern modulation techniques and rate-diverse error-correcting codes (Fang et al., 2023; Chen et al., 2023; Lin et al., 2023). (2) In information storage fields, spectrum shaping codes have spectrum nulls at specific frequencies (Pelusi et al., 2015). In addition, it is expected to enhance the performance of dedicated servo recording systems by using the shaping codes (Ng et al., 2015; Yuan et al., 2015), which is a promising technology for ultra-mobile hard disk drives. Shaping codes with spectrum nulls at non-zero frequencies effectively reduces interference between data signals and narrow band signals. In a dedicated servo recording system, there are two frequencies for servo signals, i.e., a frequency of f1 on even tracks and a frequency of f2 on odd tracks. In addition to avoiding interference between data and servo signals, it also permits filtering of low-frequency disc noise. Moreover, the applied recording systems require a run-length limit constraint (Tandon, Motani & Varshney, 2019), also known as the k-constraint. Kahlman & Immink (1995) concern the spectral shaping of both embedded pilot tones and spectral nulls in digital magnetic video tape recordings. The spectral notches are essential to prevent interference between the written data and the servo detecting mechanism. (3) In medical fields, Greffier et al. (2020) investigate the influence of tin filter-based spectral shaping computed tomography (CT) on image quality and radiation dose for use in ultralow-dose CT protocols. Tin filtering enhances the quality of the X-ray beam and the image quality characteristics of phantom images. Baldi et al. (2020) suggest a spectral shaping and third-generation dual-source multidetector CT scanner for evaluating osteolytic lesions caused by multiple myeloma. The outcome validates the benefits of whole-body low dose computed tomography for diagnosing patients with multiple myeloma. Agostini et al. (2021) investigate the function of third-generation iterative reconstruction (ADMIRE3) in a dual-source, high-pitch chest CT protocol with spectral shaping at 100 kVp coronavirus disease 2019 (COVID-19). The low-dose CT with spectral shaping and ADMIRE3 provides acceptable image quality for evaluating COVID-19 patients while significantly reducing radiation dose and motion anomalies. Hardening the X-ray beam, tin prefiltration is established for imaging high-contrast subjects in energy-integrating detector computed tomography (EID-CT) (Grunz et al., 2022). This study aims to examine the potential dose-saving effect of spectral shaping via tin prefiltration in photon-counting detector CT (PCD-CT) of the temporal bone. Seeking for matched image noise, high-voltage scan methods with tin prefiltration enables more significant dose savings in EID-CT. However, superior inherent denoising reduces the dose reduction potential of spectral shaping in PCD-CT.
Based on the excellent performance of the research in Cai et al. (2017), this study presents the implementation of spectrum shaping codes deploying a field programmable gate array (FPGA). The shaping code architecture consists of scrambling and descrambling, k-constrained encoding and decoding (Immink, 2012), and a minimum accumulated signal power (MASP) module. We provide simplified approaches for these modules, which are suitable for hardware implementation. Scrambling is a highly effective technique (Park & Son, 2020; Xiao et al., 2020; Liu et al., 2021). In the proposed scrambling and descrambling, we use only XOR (exclusive or) logical operations and no other arithmetic operations. The algorithm for k-constrained encoding and decoding is then described. Furthermore, we propose improved calculations to reduce parameter storage and processing complexity in the MASP module.
The study is organized as follows. In ‘Shaping Code Algorithms’, we describe the overall architecture of the FPGA system implementation and present the algorithms of spectrum shaping codes. ‘The enhanced algorithms’ enhances the algorithms. ‘FPGA implementation of a spectrum shaping code’ demonstrates a specific hardware implementation of the shaping algorithms with reduced computations. The shaping code is synthesized, and the consumed resources are analyzed. ‘Discussion and conclusion’ gives the conclusion and discussion.
Shaping Code Algorithms
Figure 1 illustrates a block diagram of an encoder and a decoder for spectrum shaping codes. In the encoder, the first step is to generate 0 to 2p − 1 numbers in decimal form and convert them to binary vector A with the size of 2p × p, and p denotes the length of a scrambler. Then, we append A to the user data of length m bits, generating a vector B of size 2p × (m + p), that is, B = [B(0), B(1), …, B(2p − 1)]. Second, B is fed into a guided scrambler module and then is scrambled. Then, we can generate a vector C of size 2p × (m + p). Third, the scrambled vector C is encoded using a k-constrained encoder, yielding a vector D of size 2p × (m + p + 1). Finally, the accumulated signal power is calculated from D(0) to D(2p − 1), and the one with the least power vector T is chosen and sent. In the decoding process, the received signal R with a bit-width (m + p + 1) is fed into the k-constrained decoder, which produces the data Y with a bit-width (m + p). By descrambling Y, we can obtain the data Z with a bit-width (m + p). The original user data can be recovered by eliminating the redundant p bits.
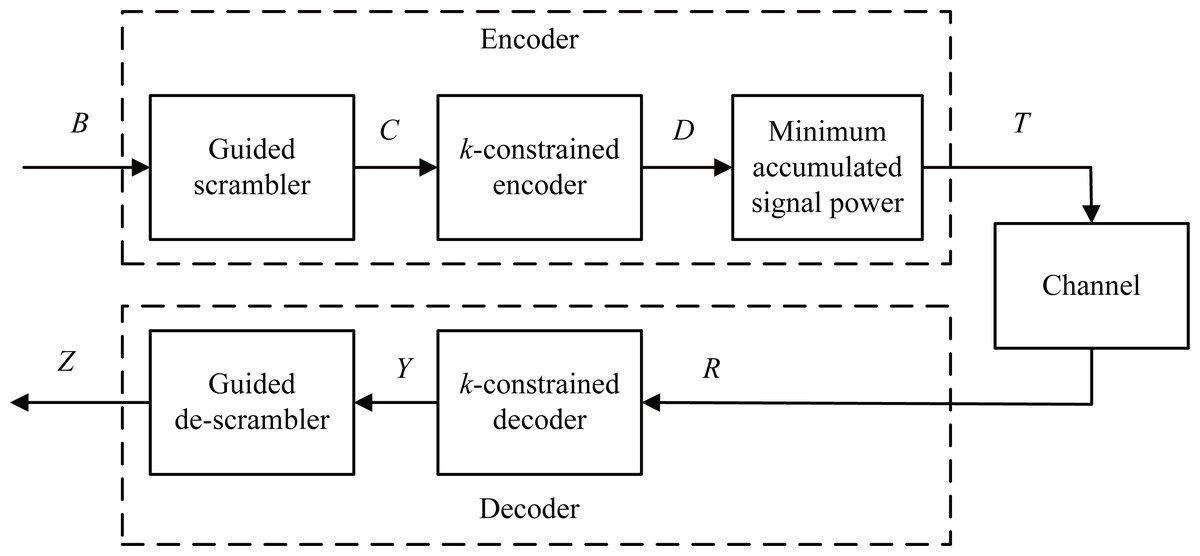
Figure 1: Schematic diagram of the spectrum shaping code with guided scrambling.
{kind=link}
Simplified scrambling and unscrambling algorithms
In this study, the guided scrambler (GS) polynomial is (1) Where g0 is a constant bit of value 1, and gi is binary bit of 1 or 0, 0 < i < p. The is the bit set to be scrambled. The represents the scrambled bit set. The bi and ci are the binary bits, 0 ≤ i ≤ n − 2. Each value of is initialized to zero. The bits of can be generated by employing the encoding as (2)
As bi, ci, and gj are binary values of 1 or 0, 0 ≤ i ≤ n − 2, 0 ≤ j < p, and then the multiplication result of gi−k−1ci−k−1 is also binary. Moreover, logical XOR operation can replace the addition involved in Eq. (2). The XOR compares two bits and returns a bit 1 if the two bits are different, 0 if they are equal (Qiu et al., 2024). An XOR operation between a variable and 0 returns the variable itself. Let the operation ⊕ indicate bitwise XOR. Therefore, we can modify Eq. (2) as (3) Since Eq. (3) has a recursive structure, we perform a serial implementation, which takes n clock cycles to complete. Thus, the time complexity of GS encoding is O(n).
Next, we show the GS decoding process for restoring the original bit set from the encoded bit set . The GS encoding and decoding involve only XOR operations. In order to get bi from ci, we use Equation (2) or (3) and add bi⊕ci on the both hands side of Eqs. (2) or (3). Hence, we get the desired last Eq. (4) generating the values of bi. (4) By comparing Eqs. (2) with (4), we observe that we only need to change positions between ci and bi. Since the ci is the encoded bit and can be known, the GS decoding can be implemented in parallel.
The algorithm of k-constrained encoding and decoding
The k-constrained encoding algorithm is described as follows:
Step 1: Add a bit 1 to the scrambled bit set , and then generate , where e0 = 1 and (c0, c1, …, cn−2) = (e1, e2, …, en−1).
Step 2: The bit set e is splitted into L blocks of q bits, where L = 2q−1 and n = L∗q. The L blocks consist of L0 = (e0, e1, …, eq−1), L1 = (eq, eq+1, …, e2q−1), ⋯, Li = (ei∗q, ei∗q+1, …, e(i+1)∗q−1), ⋯, L2q−1−1 = (en−q, en−q+1, …, en−1), 0 ≤ i ≤ (2q−1 − 1).
Step 3: If (ei∗q, ei∗q+1, …, e(i+1)∗q−1) = [0]bin, then (ei∗q, ei∗q+1, …, e(i+1)∗q−1) = (eu∗q, eu∗q+1, …, e(u+1)∗q−1), where 0 ≤ u ≤ i ≤ (2q−1 − 1) and the []bin represents to take a binary number with q bits.
Step 4: (eu∗q, eu∗q+1, …, e(u+1)∗q−1) = [i]bin. Repeat steps 3 and 4 L − 1 times.
Step 5: If (ei∗q, ei∗q+1, …, e(i+1)∗q−1) = [2q − 1]bin and the first bit of (eu∗q, eu∗q+1, …, e(u+1)∗q−1) is 1, then (ei∗q, ei∗q+1, …, e(i+1)∗q−1) = [0]bin. Repeat step 5 L times.
The k-constrained decoding algorithm is presented as follows:
Step 1: If (ei∗q, ei∗q+1, …, e(i+1)∗q−1) = [0]bin, we can have (ei∗q, ei∗q+1, …, e(i+1)∗q−1) = [2q − 1]bin, 0 ≤ i ≤ (2q−1 − 1). Repeat step 1 L times.
Step 2: If the first bit of (ei∗q, ei∗q+1, …, e(i+1)∗q−1) is 0, we have z = [(ei∗q, ei∗q+1, …, e(i+1)∗q−1)]dec and (ez∗q, ez∗q+1, …, e(z+1)∗q−1) = [0]bin, where the []dec represents to take a decimal number. Repeat step 2 L times. Note that if the first bit e0 is 1, the step 2 is executed only once, and the decoded data is obtained by simply removing the first bit e0.
The algorithm of minimum accumulated signal power
As given in Cai et al. (2017), the MASP criterion is (5) Where , t is the number of spectrum nulls at frequencies f1, f2, ..., ft and n is the length of one codeword, l indicates the number of codewords that need to be computed. The w and w∗ express the current unencoded codeword and previous encoded codeword, respectively.
Let (6) where and are the sine-cosine accumulations of the l − 1 codewords and have been calculated. In Eq. (5), the left part is already obtained and can be directly added to the right part. By application of Euler’s formula, the unencoded codeword is computed by (7)
The enhanced algorithms
Parallel scrambling algorithms
The GS scrambler polynomial is employed as 1 + x2, where p, g0, and g1 are equivalent to the digits 2, 1, and 0, respectively. Based on the scrambling Eq. (2), the encoding is given by (8) where c0 and c1 are initially set to zero. We can see that this calculation is recursively executed in serial. In other words, one clock is taken to produce one ci. It takes n clocks to calculate all ci. Thus, the time complexity of the initial scrambling polynomial is O(n). To reduce this time consumption, we transform Eq. (8) as (9)
In this way, the calculation Eq. (9) is not recursive since the right side of Eq. (9), i.e., input data b and c0 and c1, are known in advance. Then, we can independently compute c3, c4, …, cn at one clock in parallel, with a time complexity of O(1). It means that the time complexity is reduced from O(n) in Eq. (8) to O(1).
The corresponding decoding is given by (10)
Recall that the encoding and decoding of scrambling only use XOR operations.
Improved MASP with remainder operation
Solving for sine and cosine is a critical step in Eq. (7), and we propose a minimum accumulated signal power with remainder (MASP-R), which is stated as follows.
Step 1: Convert the radian value 2πfsi to the degree value h1, (l − 1)n + 1 ≤ i ≤ ln.
Step 2: The h1 may be greater than 360 degrees, so we need to perform the remainder of the operation on h1. Furthermore, since sin(h1) = cos(h1 + 270°), we also need to calculate the remainder of h1 + 270° to 360°. Thus, the sine and cosine of 2πfsi can be given by (11)
Step 3: We construct a ROM and store the cosine values from 0 degrees to 359 degrees in the ROM. Determine the cosine values of hr1 and hr2 from the ROM.
Thus, given the cosine value in the first quadrant, we can determine the values in the other three quadrants. The ROM only needs to store 91 numbers from 0 to 90 degrees instead of 360 values, thus saving 3/4 of the storage space. When MASP solves for sine and cosine, it solves for cos(hr1) and cos(hr2). Next, we show an example of a modified cosine solution using hr1. (12)
Improved MASP with no remainder and square
Remove the remainder operation
Next, we propose an improved MASP algorithm with no remainder and square (MASP-NRS). According to the MASP formula Eq. (7), we compute a 360-degree remainder, obtain the related sine-cosine value, and perform an addition. A sine-cosine accumulation requires n clocks. The parallel execution for the accumulation is complex, and serial operation is employed instead. The time complexity of the remainder operation is O(n), while a sine-cosine accumulation requires n remainders. It leads to the time complexity of accumulation O(n2). To reduce this time complexity, we propose an algorithm to remove the remainder operation that includes the following methods.
Improvement 1: Reduce the number of codewords involved in accumulation. The and of the current l-th codeword need to be added to the and of the previous (l − 1) codewords. We have (13) The values of and increase as the number of codewords increases. After accumulating 64 codewords, we reset and to 0 to limit these values.
Improvement 2: Eliminate the remainder of the operation and use ROM storage instead. Let the shaping code utilize two dual servo frequencies, f1 and f2. A codeword w has n bits that is multiplied by four groups of sine-cosine cos(2πf1i), sin(2πf1i), cos(2πf2i), sin(2πf2i), and 0 ≤ i ≤ n − 1. Each sine-cosine group contains n data points. A total of 64×4×n sine-cosine values are stored.
Improvement 3: Adopt small bit-width. The initial sine-cosine values need to be transformed from decimals to integers to calculate on the FPGA. Multiply the initial sine-cosine values by 15 and round to the nearest integer number, which is approximately equivalent to moving the values left by four bits. As a result, including the sign bit, the bit width of four groups of sine-cosine values is 5, with a maximum value of 15.
Improvement 4: The parallel operation. Each item in codeword w has a value of either -1 or 1. The select operations can multiply w by sine and cosine. We can acquire n sine-cosine values from ROM at the same time and perform parallel selection operations to complete the sine-cosine accumulation in a single clock cycle. Thus, we eliminate the remainder operation, reducing the accumulation time complexity from O(n2) to O(1).
Remove the square operation
Equation (7) involves a square operation, which has a calculating cost of O(n2) and is challenging to compute. We provide a segmented line search algorithm with dynamic error. The search algorithm seeks segmented points, which are combined to produce a segmented curve. Applying the curve, we obtain an approximate estimation. The operation of this curve only involves deterministic shifts and additions/subtractions with a complexity of O(1). The complexity of the proposed search algorithm is two orders of magnitude lower than that of the square operation. The key features of the algorithm are the usage of dynamical error and the balanced coefficient of mean square error. The search algorithm is described in Algorithm 1 .
_____________________________________________________________________________
Algorithm 1 Segmented line search algorithm with dynamical error
Require: f(x): the square function; x: the independent variable;
Ensure: a set of segmented points;
1: x ∈ [x0, x1, ⋅⋅⋅, xn−1], k=1;
2: xb = x0, xv = x2, sp0 = x0;
3: for j = 2; j <= n − 1; j + + do
4: while xb < xi < xv do
5: compute ˆ f (xi) = f(xv)−f(xb)
xv−xb (xi − xb) + f(xb);
6: end while
7: compute error = v−1
∑
i=b+1 [ ˆ f (xi)−f(xi)]2
____________________________________
(v−b−1)e| ˆ f (xi)−f(xi)|α
β ;
8: if error ≥|f(xv) − f(xb)|μ then
9: spk = xv−1;
10: xb = xv;
11: xv = xv+2;
12: k = k + 1;
13: else
14: xb = xb;
15: xv = xj;
16: end if
17: end for
18: return sp = [sp0, sp1, sp2, ...];
_____________________________________________________________________________ We generally use expression Eq. (14) to calculate the mean square error. (14)
where represents the predicted value and f(xi) the actual value.
The large, varied item significantly influences the error expression Eq. (14), but the little various item has a minor impact. So, in Algorithm 1 , we propose a balanced-coefficient mean square error expression Eq. (15) to accurately describe the importance of each item. (15) where α and β are called fast and slow decay factors, respectively.
Multiple segmented line Eq. (16) can be generated when segmented points are provided. The product of x and k0, k1, …, can be replaced by shift operation on x. The complexity of calculating x2 is O(n2), whereas applying Eq. (16) and combining with the shift operation to compute the square of x decreases the complexity to O(1). As a result, we can rewrite Eq. (7) as Eq. (17). (16) (17)
The values of the cosine and sine functions range from −1 to 1 in Eq. (17). It can obtain large values of and , when the length n of a codeword is large and the binary bits wi are all positive 1. Note that we use the MASP algorithm only for comparison. Thus, we can simultaneously reduce the sum of the two trigonometric functions without affecting the comparison. Then, we can modify Eq. (17) as (18) Where num expresses an integer.
FPGA implementation of a spectrum shaping code
Here, we employ a specific shaping code as an example of FPGA implementation. Let the lengths of the shaping code and the original message be 80 and 77 bits. Then we get L = 16 and q = 80/L =5. The GS scrambler polynomial is 1 + x2, and the length of the scrambler is 2. Two bits are chosen from the binary set 00, 01, 10, 11 and appended to the original message. Next, the 79 bits need to be scrambled utilizing the parallel scrambling algorithms described in ‘Parallel scrambling algorithms’. After that, we add a bit 1 to the scrambled 79 bits to create 80 bits. The k-constrained and MASP algorithms are then executed.
The implementation of MASP-NRS
The implementation of removing reminder operation
Let the shaping code utilize two kinds of dual servo frequencies, f1 = 1/90 and f2 = 1/60. Each sine-cosine group contains 80 data points. We store 64 × 4× 80 groups of sine-cosine values, requiring a total of 64 × 4 × 80 × 5 = 12.5 KB.
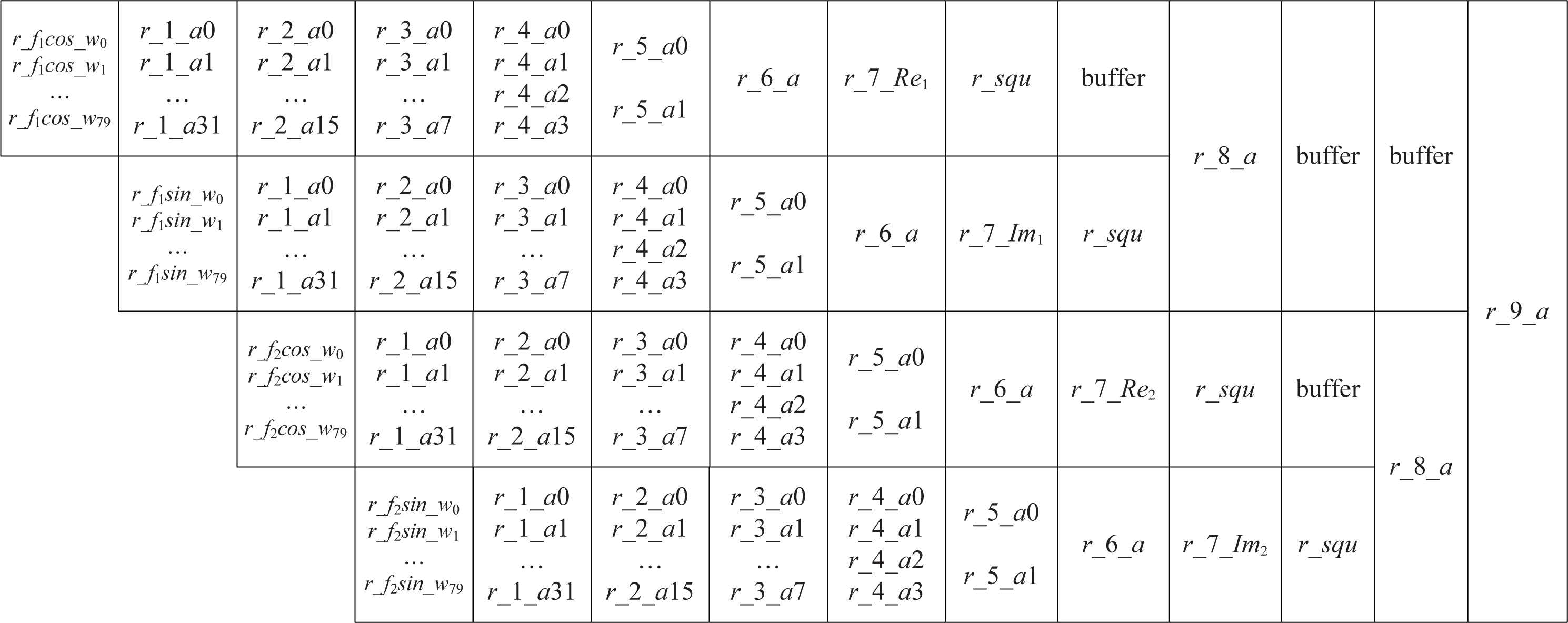
Next, using a pipelined operation, we implement the sine-cosine accumulation in Eq. (18). Figure 2 illustrates the pipeline structure.
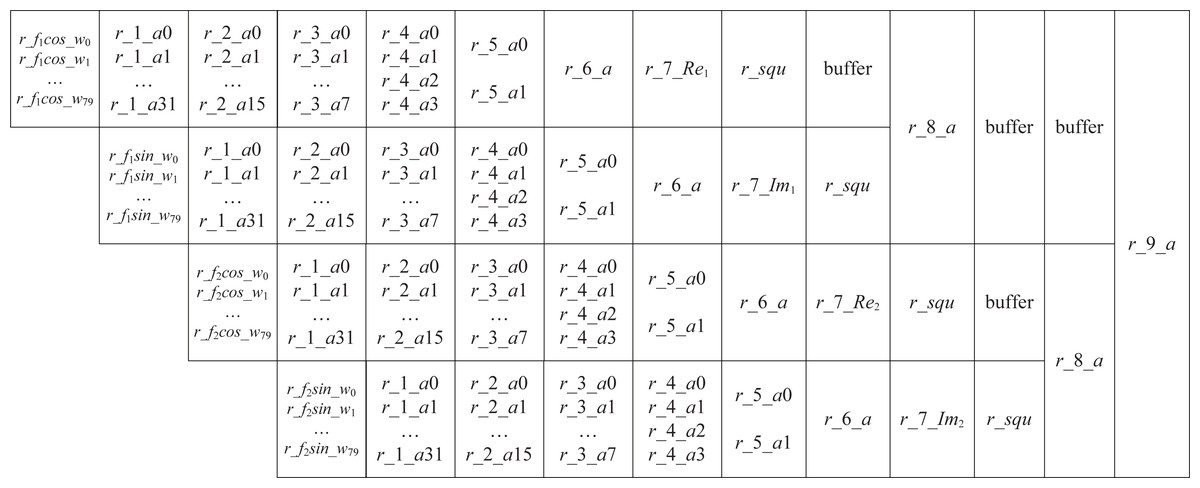
Figure 2: The pipeline of sine-cosine accumulation.
{kind=link}
Step 1: In Fig. 2, we use r_fkcos_wi and r_fksin_wi to denote the product of wi with cos(2πfki) and sin(2πfki), k = 1, 2, and 0 ≤ i ≤ 79. According to the value of wi, we use selectors to determine the 80 values of r_f1cos_wi, 0 ≤ i ≤ 79.
Step 2: Accumulate r_f1cos_wi. If 80 data points are added two by two, the four-stage accumulation will need 40, 20, 10, and 5 addition operations, respectively. Thus, five operands are remaining after the four-stage addition. However, adding these five operands two by two is inconvenient. We construct a segmented accumulation equation because the r_f1cos_wi has a small five-bit width Eq. (19). Applying the equation, the first stage accumulation of 80 data requires only 32 addition operations. (19)
Step 3: In Fig. 2, the variables r_1_a0, …, r_1_a31, r_2_a0, …, r_2_a15, r_3_a0, …, r_3_a7, r_4_a0, …, r_4_a3, r_5_a0, …, r_5_a1, r_6_a, comprise a six-step sine-cosine cumulative pipeline. A two-by-two addition is then performed, i.e., (20) The cumulative result r_6_a = r_5_a0 + r_5_a1. Each r_6_a of the current codeword needs to be added to the accumulated values of the previous codewords (denoted by Re1, Im1, Re2 and Im2) to yield r_7_Re1, r_7_Im1, r_7_Re2 and r_7_Im2.
Step 4: Following accumulation, an operation instead of the square is performed, which is introduced in the next section. The accumulation of an encoded codeword is completed after 14 cycles. At the 5th clock, calculate the next encoded codeword. In Fig. 2, the buffer indicates a cache of one clock.
The implementation of removing square operation
For Eq. (18), a symbol contains 80 bits. Due to the k-constrained algorithm, there will not be five consecutive 1’s and five consecutive 0’s, and a symbol contains no more than 80*80% 1’s. In addition, the sine-cosine values are represented by integers in the range of 0 to 15. In extreme cases, 80*80% 1’s are required to multiply with these sine-cosine values. The sine-cosine values involved in the multiplication are considered as the mean value, 7.5, and then the multiplication result is 80*80% *7.5. The result of the current symbol needs to be added to that of the previous symbol, so the accumulated result can be 80*80% *7.5*2 = 960. To simplify calculating the square of large number, the num in Eq. (18) is set to 16. Thus, 80*80% *7.5*2/16 = 960/16 = 60. The division by 16 yields the same result as a 4-bit right shift. In order to prevent some accumulated results divided by 16 from exceeding 60, we add an overflow control. If any results are greater than 60, the results are set to 60.
In Algorithm 1 , the slow decay and fast decay factors are set to 1/2 and 4, and the µis 0.06, and then we get the segmented line equation
(21)
where the values of sp0, sp1, sp2, ..., sp12 are 0, 2, 4, 7, 11, 15, 20, 26, 32, 38, 45, 53, 60. We can explore other appropriate values in conjunction with optimization algorithms such as particle swarms (Chen et al., 2022). By replacing the multiplication in Eq. (21) with a shift operation, Eq. (21) become (22) where the < < indicates that the variable x is left-shifted.
As shown in Fig. 3, we compare the segmented line function with the square function f(x). It is seen that the two curves exhibit a high degree of concordance, suggesting a strong resemblance between them. Using Eq. (23), the correlation coefficient rela between the estimated and actual square values equals 1. (23) where E[f(xi)] denotes the expected actual value and denotes the expected estimated value. (24)
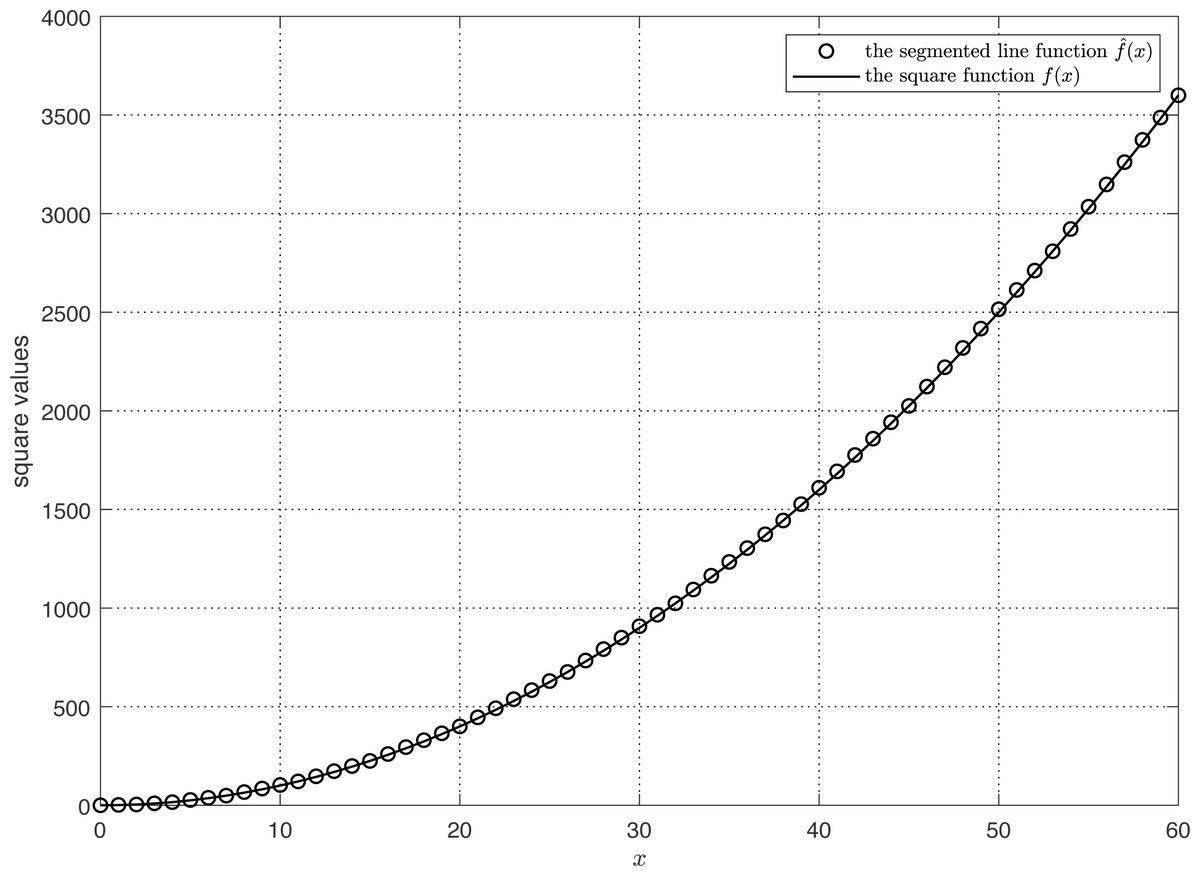
Figure 3: The comparison of segmented line prediction and actual square.
{kind=link}
Then, we define a variable td according to Eq. (24), consult the t-distribution table, and obtain a p-value of 0 that is less than the significance level (p = 0.05). As a result, the correlation coefficient rela is regarded as significant. The and f(x) are completely correlated. (25)
Next, we examine the R2 relationship between and f(x) as stated in Eq. (25). The calculated value of R2 is zero, demonstrating that the variance of the difference between and f(x) is 0% of the variance of f(x). The variance of the difference between and f(x) is extremely small, indicating that and f(x) are quite close in value.
Implementation result
We use a Spartan6 XC6SLX25 to implement the FPGA. Table 1 illustrates the resources consumed by spectrum shaping encoder based on MASP-R and MASP-NRS. These two MASPs employ the same decoding technique, and the hardware resources of decoder are detailed in Table 2. We can see that the encoder consumes more resources than the decoder, since the former one implements the MASP-R/MASP-NRS algorithms. The encoder consumes more 1,500 slice registers than the decoder. Also, it consumes twice as many LUT slices as decoder, due to MASP-R/MASP-NRS needs combinatorial logics such as addition. In particular, the encoder with MASP-R employs two DSPs to calculate the remainder and square operation as in Eq. (7), whereas the encoder with MASP-NRS needs no DSP. Since MASP-NRS eliminates the remainder operation, the corresponding encoder occupies some Block RAMs. Based on the Spartan6 XC6SLX25 implementation, the encoder and decoder with MASP-NRS can operate at frequencies of 121.560 MHz and 164.401 MHz, respectively.
| Logic utilization | Method | Used | Available | Utilization |
|---|---|---|---|---|
| Slice registers | MASP-R | 2,966 | 30,064 | 9% |
| MASP-NRS | 1,965 | 30,064 | 6% | |
| Slice LUTs | MASP-R | 5,250 | 15,032 | 34% |
| MASP-NRS | 4,273 | 15,032 | 28% | |
| Block RAM/FIFO | MASP-R | 0 | 52 | 0% |
| MASP-NRS | 24 | 52 | 46% | |
| BUFG/BUFGCTRLs | MASP-R | 1 | 16 | 6% |
| MASP-NRS | 1 | 16 | 6% | |
| DSP48E1s | MASP-R | 2 | 38 | 5% |
| MASP-NRS | 0 | 38 | 0% |
| Logic utilization | Used | Available | Utilization |
|---|---|---|---|
| Slice registers | 864 | 30,064 | 2% |
| Slice LUTs | 1,686 | 15,032 | 11% |
| Block RAM/FIFO | 0 | 52 | 0% |
| BUFG/BUFGCTRLs | 1 | 16 | 6% |
| DSP48E1s | 0 | 38 | 0% |
Figure 4 demonstrates the power spectrum densities for the same spectrum code. The dashed curve corresponds to the result of the initial MASP which is depicted in Eq. (7), while the solid curve represents the result of the MASP-NRS. Both curves use a code length of 80 bits, and the encoding and decoding methods are similar, except for the difference in the accumulated signal power method and scrambling. In Fig. 4, we can see that the MASP can generate spectrum nulls of −22.8 dB at frequency 1/90 and −20.0 dB at frequency 1/60. The improved algorithm MASP-NRS obtains spectrum nulls of −22.5 dB and −19.4 dB at frequencies 1/90 and 1/60, respectively. The spectrum nulls of MASP-NRS are 98.7% and 97.0% of those of the MASP, with losses of 1.3% and 3% due to truncation operations in MASP-NRS.
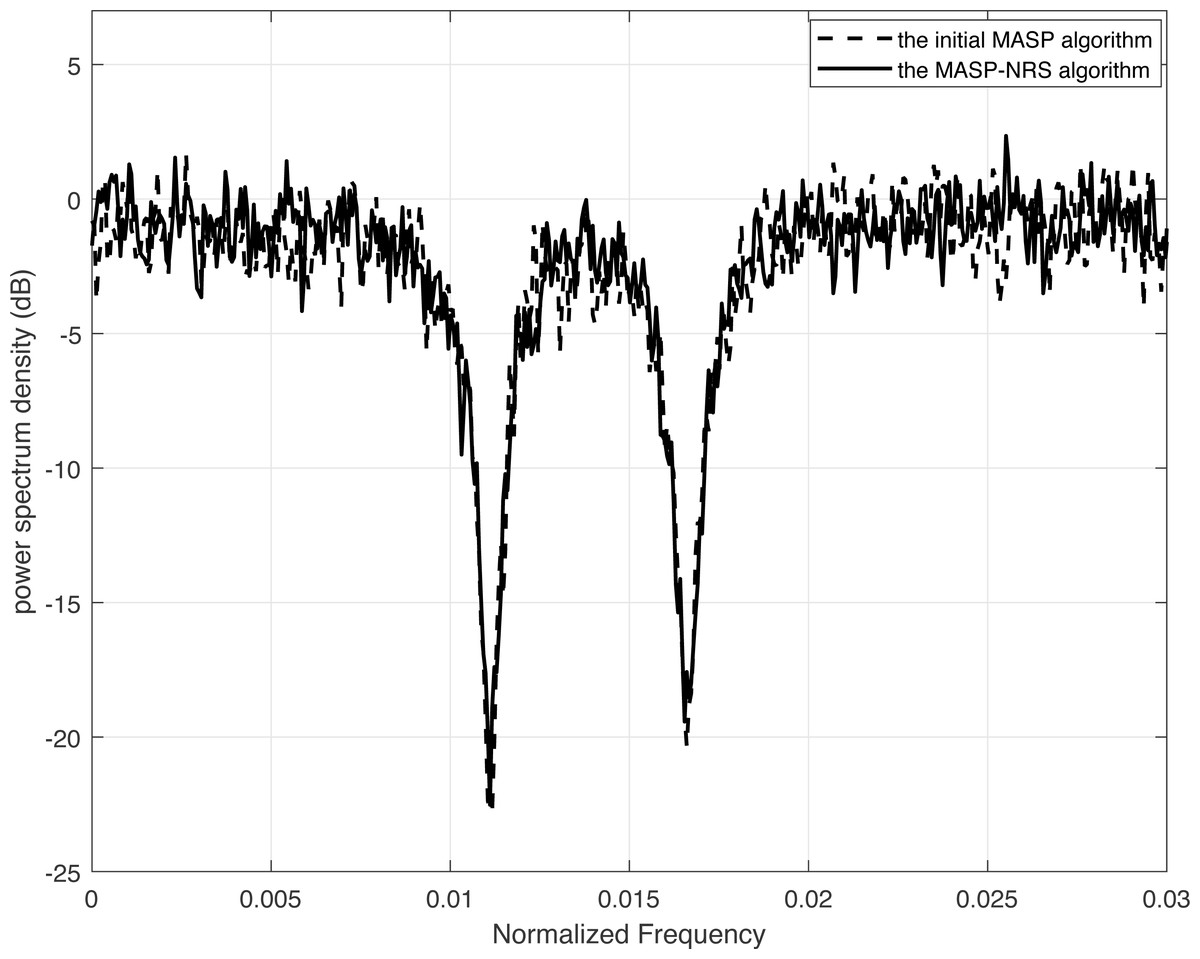
Figure 4: Comparison of the power spectrum density of MASP and MASP-NRS.
{kind=link}
Discussion and conclusion
In this research, we enhance the encoder–decoder algorithms for spectrum shaping codes in order to facilitate hardware implementation. We improve the scrambling algorithm and provide a mathematical description of the k-constrained algorithm. Concerning both descrambling and scrambling, we employ parallel operations that can be executed within a single schedule. We propose an enhanced MASP-R algorithm to compute remainder operations for sine-cosine accumulation; however, its execution in parallel is challenging due to its significant time complexity. Thus, we further present a MASP-NRS algorithm that quantizes sine-cosine values with short bit-width and stores them in ROM, eliminating the remainder operation. In particular, the MASP-NRS allows parallel operations for the sine-cosine accumulation within a single clock. It is capable of resolving the parallelization issue that plagued the initial MASP. Furthermore, we put forward a search algorithm that utilizes two approaches: dynamical error and balanced-coefficient mean square error. The search algorithm generates a curve similar to the square function f(x). By employing correlation and R2 analysis, it is possible to ascertain that f(x) and are almost equivalent. The complexity is reduced by two orders of magnitude through substituting the square operation in MASP with . Finally, the encoder–decoder of shaping codes is executed utilizing the Spartan6 XC6SLX25. The synthesis results show that the decoder is simpler than the encoder since it does not have to calculate the accumulated signal power. Furthermore, we demonstrate that the performance of initial MASP and MASP-NRS is nearly identical, yielding spectrum nulls of approximately −22.8 dB, which confirms the accuracy of the proposed algorithm.