
Electroencephalography (EEG) based epilepsy diagnosis via multiple feature space fusion using shared hidden space-driven multi-view learning
- Published
- Accepted
- Received
- Academic Editor
- Wenbing Zhao
- Subject Areas
- Bioinformatics, Artificial Intelligence, Data Mining and Machine Learning, Data Science, Databases
- Keywords
- Multi-view learning, EEG, Epilepsy, Shared hidden space
- Copyright
- © 2024 Hu et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. Electroencephalography (EEG) based epilepsy diagnosis via multiple feature space fusion using shared hidden space-driven multi-view learning. PeerJ Computer Science 10:e1874 https://doi.org/10.7717/peerj-cs.1874
Abstract
Epilepsy is a chronic, non-communicable disease caused by paroxysmal abnormal synchronized electrical activity of brain neurons, and is one of the most common neurological diseases worldwide. Electroencephalography (EEG) is currently a crucial tool for epilepsy diagnosis. With the development of artificial intelligence, multi-view learning-based EEG analysis has become an important method for automatic epilepsy recognition because EEG contains difficult types of features such as time-frequency features, frequency-domain features and time-domain features. However, current multi-view learning still faces some challenges, such as the difference between samples of the same class from different views is greater than the difference between samples of different classes from the same view. In view of this, in this study, we propose a shared hidden space-driven multi-view learning algorithm. The algorithm uses kernel density estimation to construct a shared hidden space and combines the shared hidden space with the original space to obtain an expanded space for multi-view learning. By constructing the expanded space and utilizing the information of both the shared hidden space and the original space for learning, the relevant information of samples within and across views can thereby be fully utilized. Experimental results on a dataset of epilepsy provided by the University of Bonn show that the proposed algorithm has promising performance, with an average classification accuracy value of 0.9787, which achieves at least 4% improvement compared to single-view methods.
Introduction
Epilepsy is a chronic, non-infectious but genetic disease that affects all ages and is caused by paroxysmal abnormal hypersynchrony of brain neurons. It is one of the most common neurological diseases globally. Due to the diversity and complexity of the clinical manifestation of epilepsy, it is often misdiagnosed or missed. Repetitive seizures can have a persistent negative impact on the patient’s mental and cognitive functions, even threatening their life. Therefore, the study of epilepsy diagnosis and treatment has important clinical significance. The brain electroencephalogram (EEG) is a microvolt-level electrical signal generated by synchronized neurons in the brain when electrodes are placed on the scalp at specific locations. As the most commonly used and cheapest non-invasive brain wave detection method, EEG has a history of over 70 years of research and is the most effective method for diagnosing epilepsy-related diseases, such as identifying seizures, predicting their occurrence, and localizing the affected areas. With the development of artificial intelligence, machine learning models are extensively used in automatic epilepsy recognition. Feature representation is a crucial step in machine learning. Research has indicated that EEG signals can be represented by both linear and non-linear features. Time-domain features are the fundamental features in EEG signal processing, primarily extracted by directly observing and calculating relevant characteristics from the raw signal. Their advantages lie in their simplicity of computation and ease of interpretation. However, the non-stationarity of EEG signals, individual differences, and external interferences can easily affect time-domain features. Frequency-domain features are based on the significant changes in energy in EEG during epileptic seizures, assuming that the background EEG is approximately stationary. Most frequency-domain features are derived from the study of signal power spectra, and various parameter estimation methods can be used for extracting spectral features. The accuracy of these parameters also affects the quality of frequency-domain features. If we consider the amount of information contained in the features, neither pure time-domain features nor frequency-domain features can comprehensively characterize an EEG signal. Additionally, EEG analysis based on the assumption of stationarity is not rigorous. Therefore, researchers have turned their attention to time-frequency analysis methods, such as time-frequency transformations, to re-represent non-stationary EEG signals and extract corresponding features. In addition to the aforementioned linear features, many studies also consider the brain as a nonlinear system and extract corresponding nonlinear features from descriptions of complexity, persistence, synchrony, and other changes in the system. These features are not affected by the non-stationarity of EEG signals and offer more flexibility in dealing with issues such as multi-channel correlation and channel loss. Based on the aforementioned linear or nonlinear feature representations, numerous scholars have constructed machine learning models for the automatic diagnosis of epilepsy. For example, the study conducted by Li, Chen & Zhang (2016) employed a dual-tree complex discrete wavelet transform to extract nonlinear features from individual components. The researchers utilized an ANOVA analysis to select relevant classification features, including the Hurst parameter and fuzzy entropy. For the classification task, a support vector machine (SVM) was employed. Reddy & Rao (2017) computed the central correlated entropy of wavelet components obtained from tunable Q-factor wavelet transform, and utilized models such as RF, LR, and multi-layer perceptron for epileptic signal recognition. Jaiswal & Banka (2017) proposed a feature extraction method called local gradient pattern transformation and applied classification methods such as k-nearest neighbors, SVM, and decision trees for epilepsy detection.
The aforementioned machine learning-based epilepsy diagnostic models utilize single EEG feature representation for epilepsy diagnosis, which have low model complexity and high interpretability. However, these models rely on expert knowledge, and deep features are not easily observed and extracted. As a result, the accuracy is limited. Multi-view learning (Zhao et al., 2017; Jiang et al., 2020; Zhang, Chung & Wang, 2018; Yan et al., 2021) improves the classification accuracy of models by utilizing the differences and similarities between multiple different views based on the principles of view consistency and complementarity. For example, Tian et al. (2019) utilized a convolutional neural network (CNN) model to extract deep features from EEG signals in the time domain, frequency domain, and time-frequency domain. These features were constructed as three views, and multi-view learning was conducted using a multi-view Takagi-Sugeno-Kang (TSK) fuzzy system, which improved the classification and detection performance compared to a single view. Yuan et al. (2018) implemented a multi-view epilepsy automatic diagnosis by utilizing channel characteristics and intra-channel time-frequency features of multi-channel EEG signals extracted using autoencoder (AE) through channel perception technology. Liu & Li (2019) utilized a user-sensitive model for channel selection and extracted time-frequency features from each sub-band of the selected channels, forming multi-view features. They extracted numerical and morphological features using a common spatial projection matrix and utilized a maximum average difference autoencoder to extract inter-channel time-frequency domain features, enabling automatic diagnosis of epilepsy with multiple views. These effective models based on collaborative regularization can construct a common feature space for multi-view learning. However, these models also have certain limitations. While these methods construct the density distributions of each view solely based on the corresponding observed data, they overlook the correlated information among all views. Additionally, they separate the original sample space from the common space obtained through mapping. This approach solely utilizes the common space for learning, neglecting the discriminative information present in the original space.
To overcome such shortcomings, in this study, a shared hidden feature space method is constructed by using kernel density estimation, and it is extended to an expanded space by combining it with the original space. Then, SVM is introduced and a multi-view SVM based on the shared hidden space is proposed to take a careful consideration of the differences and relationships between samples from different views. Through experimental verification on different multi-view data sets, the effectiveness of this method in addressing the challenges mentioned above has also been confirmed. The contributions of this study are mainly reflected in the following aspects:
(1) The kernel density estimation (KDE) technique is used to construct a new shared hidden space, and it is combined with the original space to construct an expanded space for multi-view learning, thus being able to effectively address the special issue mentioned above on multi-view learning.
(2) By constructing the expanded space and utilizing the information of both the shared hidden space and the original space for learning, thereby fully utilizing the relevant information of samples within and across views, we can effectively solve the problem that the difference between samples of the same class from different views is greater than the difference between samples of different classes from the same view.
(3) During the optimization phase, the proposed model is transformed into a classical Quadratic Programming (QP) problem, allowing for the utilization of pre-existing optimization methods that offer both high effectiveness and theoretical guarantees. This transformation enables the application of readily available optimization techniques, which have proven to be highly efficient in solving QP problems.
The following sections are organized as follows. In ‘Data’, we introduce the EEG data used in this study and the corresponding multiple feature space representation. In ‘Methodology’, we present the proposed model. In ‘Experimental studies’, experimental results are reported and in the last section, the whole study is summarized.
Data
The EEG data of epileptic patients used in this study was authorized and provided by the University of Bonn in Germany (Andrzejak et al., 2001), as shown in Table 1. The dataset included volunteers who could be divided into five groups, namely A, B, C, D, and E. Each group contained 100 single-channel EEG segments lasting 23.6 s, with a sampling rate of 173.6 Hz. The EEG signals of groups A and B were collected from healthy volunteers in a relaxed and conscious state, while the eyes of the volunteers were open during the data collection of group A and closed during the data collection of group B. The remaining three groups’ signals were collected from epileptic volunteers, with group C’s signals collected from the hippocampi of the two brain hemispheres, and group D’s signals collected from the epileptic foci. The signals of groups C and D were measured during periods without epileptic seizures, while group E collected signals during epileptic seizures. Figure 1 provides an example of EEG signals from five groups.
| Group | #Volunteers | Collection information |
|---|---|---|
| A | 100 | This group was collected from a group of healthy volunteers who were instructed to keep their eyes open during the recording process. These volunteers did not have any known neurological or psychiatric disorders and were not experiencing any abnormal symptoms at the time of data collection. |
| B | 100 | This group was collected from a group of healthy volunteers under conditions where they kept their eyes closed. |
| C | 100 | This group was collected from the hippocampal formation of the contralateral hemisphere of the brain during seizure-free intervals. These samples were obtained when the patient was not experiencing any epileptic seizures. |
| D | 100 | This group was collected from the epileptogenic zone during periods of seizure freedom. This implies that the recordings were obtained when the patient was not experiencing seizures. |
| E | 100 | The group was collected during seizure activity phase offering a unique opportunity to study the dynamics and temporal dynamics of epileptic seizures, paving the way for the development of more accurate and reliable seizure detection and prediction algorithms. |
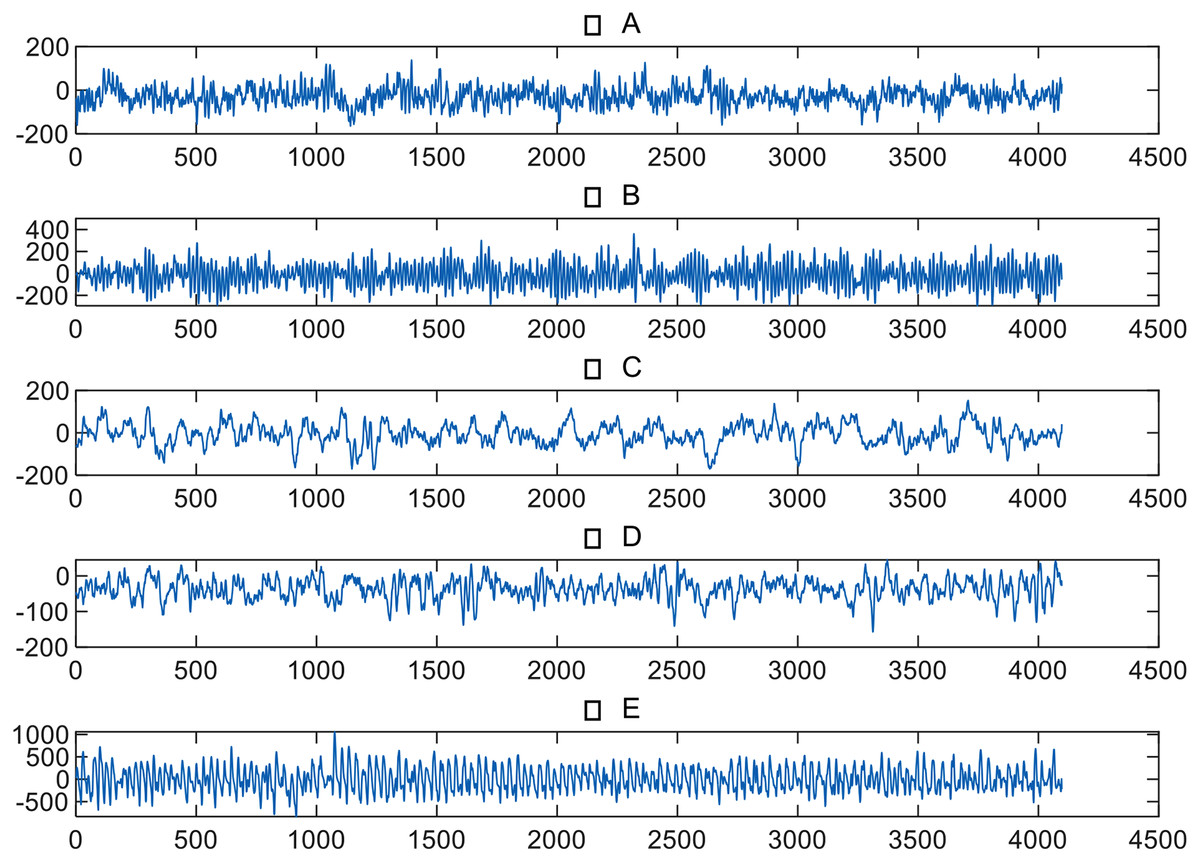
Figure 1: EEG signals from five groups.
{kind=link}
Frequency-domain representation extraction
Frequency-domain feature representation originates from the significant changes in energy in EEG during epileptic seizures. To extract frequency-domain representation from EEG signals, the Daubechies4 wavelet coefficients are utilized to decompose the original signals into a series of binary wavelets. The frequency band of each Daubechies4 wavelet coefficient is provided in Table 2. By applying these settings, the EEG signals are divided into six distinct frequency bands. An illustrative example of the decomposed signals from group E is depicted in Fig. 2.
| Coefficient | Frequency band |
|---|---|
| Daubechies4 (4, 0) | 0–2 Hz |
| Daubechies4 (4, 5) | 2–4 Hz |
| Daubechies4 (4, 4) | 4–8 Hz |
| Daubechies4 (4, 3) | 8–15 Hz |
| Daubechies4 (4, 2) | 16–30 Hz |
| Daubechies4 (4, 1) | 31–60 Hz |
Figure 2: Example of frequency-domain representation.
{kind=link}
Time-domain feature extraction
Time-domain features are the fundamental features in EEG signal processing, primarily extracted by directly observing and calculating relevant characteristics from the raw signal. Their advantages lie in their simplicity of computation and ease of interpretation for researchers. In this study, we employ kernel principal component analysis (KPCA) (Li et al., 2022b) on the raw EEG signals to enable complex nonlinear mapping. Previous research has shown that KPCA features offer discriminative patterns suitable for pattern recognition. An illustration depicting an example of KPCA features from group E can be observed in Fig. 3.
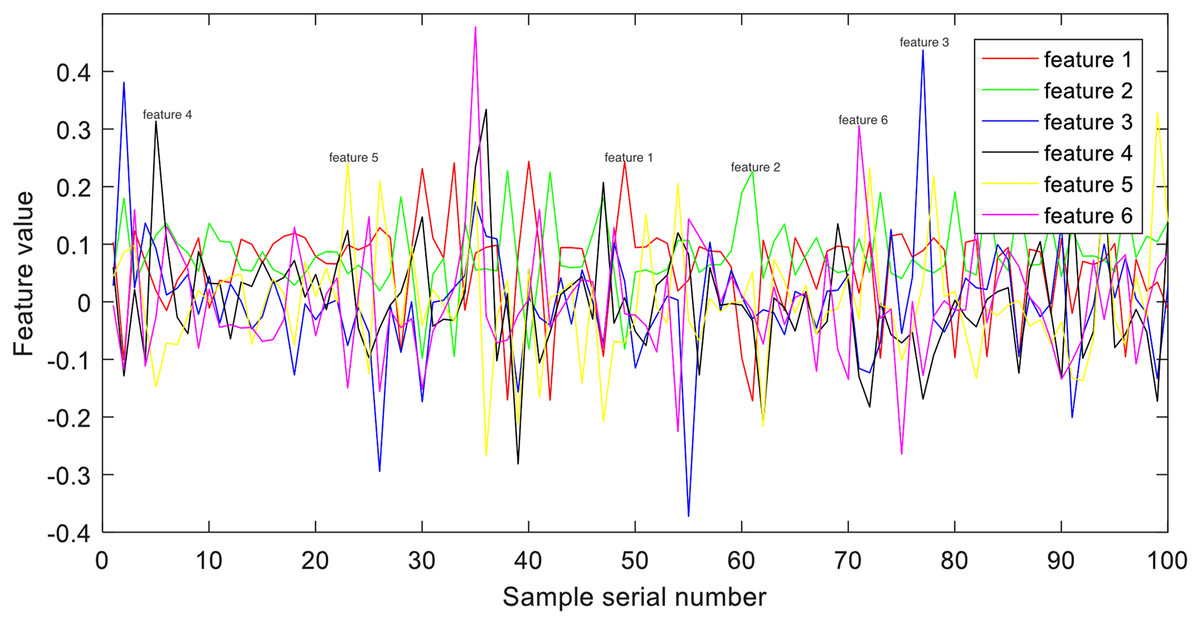
Figure 3: Example of time-domain representation.
{kind=link}
Time-frequency representation extraction
Pure time-domain or frequency-domain feature representations alone cannot comprehensively characterize an EEG signal, and EEG analysis based on the assumption of stationarity is not rigorous. Therefore, researchers have turned their attention to time-frequency analysis methods, such as time-frequency transformations, to re-represent non-stationary EEG signals and extract corresponding features. To capture time-frequency representation, researchers often employ the short-time Fourier transform (STFT) (Li et al., 2022a). STFT allows for the analysis of how the frequency content of a signal changes over time. It can be formulated as follows:
(1)
In the context of EEG signal analysis, Eq. (1) represents the transformation of continuous EEG signals, denoted as , into the time-frequency plane using the function and a limited width window centered around . This transformation, referred to as , provides a means to examine the time-varying nature of the EEG signals, revealing local spectrum discrepancies at different time points. To achieve this, the EEG signals undergo partitioning into several segments of local stationary signals using STFT. Through this process, the time-varying characteristics of the EEG signals are captured, highlighting variations in the spectrum. The extraction of six energy bands as features is accomplished using Eq. (1), which takes into account the observed discrepancies. A visualization of these six energy bands, exemplified by group E, is illustrated in Fig. 4.
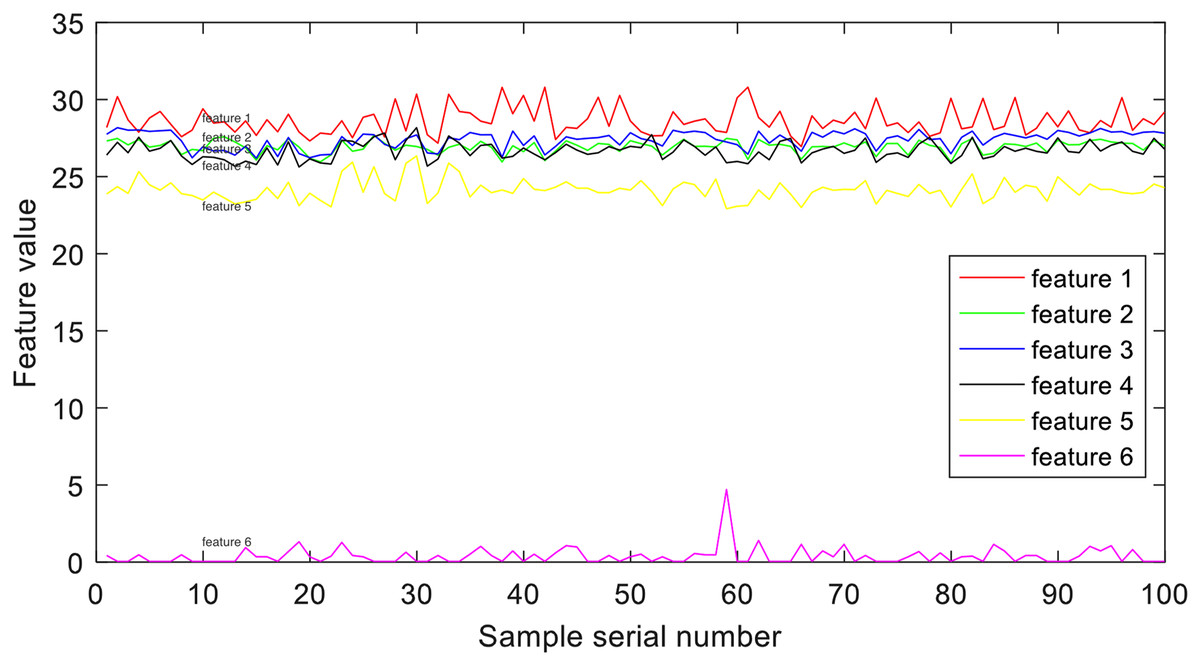
Figure 4: Example of time-frequency representation.
{kind=link}
Methodology
In this section, we will design a shared hidden space-driven multi-view learning method to fuse time-frequency representation, frequency-domain representation and time-domain representation.
Construction of shared hidden feature space
Suppose that is an orthogonal matrix subject to , represents one kind of feature space, e.g., time-domain feature space, and represents another kind of feature space, then the hidden feature space of and can be generated by and , respectively, where represents the number of hidden features. To obtain a consistent hidden feature space between and , it is expected that the difference between them should be minimized as much as possible. Kernel density estimation (KDE), which is one of the non-parametric estimation methods in probability theory, is usually used to estimate the unknown probability density function (Wang, Wang & Chung, 2013). For a training set , its corresponding kernel density estimation function can be expressed as
(2) where is the kernel width, is the kernel function. If the Gaussian kernel function is adopted, then Eq. (2) can be updated as Therefore, the kernel density estimation of and can be expressed as follows when using the Gaussian kernel function, respectively,
(3)
(4)
In this study, the difference between and is measured by the mean square error, that is
(5)
By minimizing , the two-view data and can be made to have the maximum commonality in the shared hidden space, and thus the challenge of excessive variability between samples from different views can be addressed. In order to solve Eq. (6), we suppose that , then and can be updated as and . Therefore, Eq. (5) can be computed by . According to Wang, Wang & Chung (2013), Hansen, Jaumard & Xiong (1994), we have , Therefore, we have the following equations,
(6)
(7)
(8) where can be taken as another estimation of . Therefore, can be estimated by , and further . Similarly, can be estimated by . Thus, we finally have . Therefore, we have the following objective,
(9)
However, it is difficult to solve Eq. (9) directly. Thus, Taylor expansion can be used for getting an approximate solution. Hence, we have
(10)
Therefore, Eq. (9) can be further updated as
(11) in Eq. (11), implicit feature transformation matrix still cannot be solved directly, but can be solved by gradient descent method. Thus, Eq. (11) can be updated as
(12)
The partial derivative of w.r.t. is
(13)
Then the transformation matrix can be solved by gradient descent method, that is,
(14) where is the step size that can be solved by
(15)
According to the above analysis and derivation, the algorithm for solving implicit feature transformation matrix is described as follows.
Multi-view learning based on shared hidden feature space
After determining the shared hidden space between two views, the extended space can be generated by combining the original space and the shared hidden space. Then, a multi-view classifier based on SVM is designed for multi-view data classification in the extended space. In existing multi-view learning mechanisms, it is generally assumed that each view can provide a classifier containing specific information, and classifiers constructed from different view tend to be consistent. Additionally, since views can provide specific information to each other, the proposed model establishes the objective function by considering the mutual information between two views. In summary, the proposed model, based on SVM, restructures the slack variables on each view, and then narrows the gap between the two views by using the corresponding regularization term. The objective function of multi-view learning based on shared hidden feature space can be formulated as
(16) where , and are the regularization parameters. Observe that Eq. (16) consists of three parts: the first four terms reflect the outcome risk in the original feature space and the shared hidden space respectively; the second two terms represent the empirical risk; and the third term reflects the difference between the two views in the shared hidden space. The objective function in Eq. (16) strengthens the constraints based on the traditional SVM through the implicit mapping, so that the probability distributions of data from different views in the shared hidden space are as consistent as possible, which can well solve the problem described at the beginning of this study. In order to solve Eq. (16) efficiently, the relevant Lagrangian multipliers are introduced according to the Lagrangian optimization theory, hence Eq. (16) can be converted into the corresponding dual form as follows. The Lagrangian function corresponding to Eq. (16) is
(17) where , , , and are Lagrangian multipliers. By setting the partial derivatives of Lagrangian function with respect to , , , , , , , and to 0, we have
(18)
(19)
(20)
(21)
(22)
By submitting Eqs. (18–22) to Eq. (16), we have the dual problem of Eq. (24), which can be defined as
(23) where
(24)
(25)
(26)
(27)
(28)
(29) and is the kernel function. It is obvious that the optimization of Eq. (23) can be considered as a QP problem, which can be solved according to Deng et al. (2013). The decision function of the proposed model in this study is defined as
(30)
The algorithm of multi-view learning based on shared hidden feature space can be obtained, as shown in Algorithm 2. From Algorithm 2, we can find that the time complexity is mainly contributed by steps 1, 3 and 4. The time complexity of Algorithm 1 is The time complexity of step 3 is . The time complexity of step 4 is . Therefore, the time complexity of Algorithm 2 is
| Input: training samples of view-1: , training samples of view-2: , regularized parameters and |
| Output: , , , , and |
| Procedures: |
| 1. Use Algorithm 1 to obtain |
| 2. Use to obtain the shared hidden space |
| 3. Solve the according to Eq. (23) |
| 4. Solve the , , , , and by Eqs. (18)–(22) |
| 5. Construct the decision function based on , , , , and |
Experimental studies
Settings
To observe the merits of the proposed model, k-nearest neighbor (KNN) (Liu & Liu, 2016), support vector machine (SVM) (Liu & Liu, 2016), SVM2K (Farquhar et al., 2005), multi-view L2-SVM (MV-L2-SVM) (Huang, Chung & Wang, 2016), and alternative multi-view MED (AMVMED) (Chao & Sun, 2015) are introduced for comparison studies. Accuracy is used as the evaluation indicator in this study. SVM, SVM2K, MV-L2-SVM, and 2V-SVM-SH are all trained using a Gaussian kernel for experimentation. For all methods, ten-fold cross-validation (CV) is used to determine the optimal parameters. Table 3 provides the specific parameters and ranges used for each method. All experiments are conducted on a PC with a 16-core CPU with a clock speed of 3.40 GHz and 32 GB of memory. The programming environment was Matlab R2016a.
| Method | Parameter settings |
|---|---|
| KNN | k ∈{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} |
| SVM | C ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, σ ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8} |
| SVM-2K | CA ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, CB ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, D ∈{2e−5, 2e−4, …, 2e0, 2e1, …, 2e4, 2e5},σ ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8} |
| MV-L2-SVM | CA ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, CB ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, σ ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8} |
| AMVMED | CA ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, CB∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, γ ∈{0.1, 0.2, …, 0.9} |
| Proposed model | CA ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, CB ∈ {2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, σ ∈{2e−8, 2e−7, …, 2e0, 2e1, …, 2e7, 2e8}, λ ∈{0.1, 0.2, …, 0.9, 1}; |
To construct a two-view learning scenario, based on “Data”, three feature extraction methods, namely wavelet packet decomposition (WPD), short-time Fourier transform (STFT) and kernel principal component analysis (KPCA) are adopted, to extract time-frequency features, frequency-domain features and time-domain features from the original EEG signals, as shown in Fig. 2. Finally, 12 datasets are constructed, as shown in Table 4.
| Datasets | Classification tasks | Views (view-A, view-B) | #Sample size |
|---|---|---|---|
| DS1 | AB vs CDE | WPD, STFT | 500 |
| DS2 | AB vs CDE | WPD, KPCA | 500 |
| DS3 | AB vs CDE | STFT, KPCA | 500 |
| DS4 | AB vs CD | WPD, STFT | 400 |
| DS5 | AB vs CD | WPD, KPCA | 400 |
| DS6 | AB vs CD | STFT, KPCA | 400 |
| DS7 | AB vs DE | WPD, STFT | 400 |
| DS8 | AB vs DE | WPD, KPCA | 400 |
| DS9 | AB vs DE | STFT, KPCA | 400 |
| DS10 | AB vs CE | WPD, STFT | 400 |
| DS11 | AB vs DE | WPD, KPCA | 400 |
| DS12 | AB vs CE | STFT, KPCA | 400 |
Experimental results and analysis
The experimental results are reported in Table 5. We can see from Table 5 that the proposed model wins the best performance on most datasets. Only on DS5, DS9, the proposed model performs worse than SVM-2K and MV-L2-SVM. The advantages of the proposed model indicate the promising ability of the shared hidden space. From the promising results, it can be found that by constructing the expanded space and utilizing the information of both the shared hidden space and the original space for learning, thereby fully utilizing the relevant information of samples within and across views, the proposed model effectively solves the problem that the difference between samples of the same class from different views is greater than the difference between samples of different classes from the same view. The experimental results also indicate the power of KDE which is used to construct the shared hidden space.
| Datasets | KNN_A (KNN on view-A) | KNN_B (KNN on view-B) | SVM_A (SVM on view-A) | SVM_B (SVM on view-B) | SVM-2K | MV-L2-SVM | AMVMED | Proposed model |
|---|---|---|---|---|---|---|---|---|
| DS1 | 0.9098 (0.0019) | 0.9176 (0.0045) | 0.9432 (0.0076) | 0.9521 (0.0087) | 0.9754 (0.0063) | 0.9543 (0.0065) | 0.9643 (0.0043) | 0.9876 (0.0023) |
| DS2 | 0.9213 (0.0032) | 0.9098 (0.0021) | 0.9583 (0.0065) | 0.9321 (0.0087) | 0.9654 (0.0063) | 0.9431 (0.0065) | 0.9546 (0.0043) | 0.9768 (0.0023) |
| DS3 | 0.9223 (0.0034) | 0.9098 (0.0021) | 0.9345 (0.0022) | 0.9321 (0.0087) | 0.9654 (0.0023) | 0.9437 (0.0013) | 0.9554 (0.0063) | 0.9764 (0.0034) |
| DS4 | 0.9214 (0.0034) | 0.9097 (0.0011) | 0.9067 (0.0073) | 0.9164 (0.0027) | 0.9567 (0.0032) | 0.9511 (0.0023) | 0.9598 (0.0044) | 0.9690 (0.0036) |
| DS5 | 0.9214 (0.0034) | 0.9481 (0.0023) | 0.9875 (0.0046) | 0.9467 (0.0056) | 0.9892 (0.0017) | 0.9564 (0.0054) | 0.9578 (0.0023) | 0.9743 (0.0045) |
| DS6 | 0.9324 (0.0052) | 0.9481 (0.0023) | 0.9875 (0.0046) | 0.9467 (0.0056) | 0.9653 (0.0018) | 0.9511 (0.0034) | 0.9587 (0.0033) | 0.9811 (0.0056) |
| DS7 | 0.9331 (0.0026) | 0.9325 (0.0026) | 0.9481 (0.0017) | 0.9435 (0.0037) | 0.9563 (0.0032) | 0.9673 (0.0026) | 0.9543 (0.0046) | 0.9781 (0.0015) |
| DS8 | 0.9331 (0.0026) | 0.9221 (0.0025) | 0.9481 (0.0017) | 0.9387 (0.0026) | 0.9612 (0.0018) | 0.9671 (0.0056) | 0.9409 (0.0055) | 0.9812 (0.0035) |
| DS9 | 0.9631 (0.0015) | 0.9221 (0.0025) | 0.9511 (0.0090) | 0.9387 (0.0026) | 0.9654 (0.0143) | 0.9786 (0.0087) | 0.9765 (0.0049) | 0.9760 (0.0054) |
| DS10 | 0.9318 (0.0079) | 0.9543 (0.0056) | 0.9345 (0.0054) | 0.9245 (0.0064) | 0.9534 (0.0048) | 0.9501 (0.0047) | 0.9534 (0.0019) | 0.9756 (0.0087) |
| DS11 | 0.9134 (0.0078) | 0.9215 (0.0056) | 0.9381 (0.0054) | 0.9275 (0.0034) | 0.9452 (0.0036) | 0.9517 (0.0045) | 0.9732 (0.0017) | 0.9789 (0.0087) |
| DS12 | 0.9532 (0.0035) | 0.9378 (0.0043) | 0.9785 (0.0038) | 0.9634 (0.0014) | 0.9763 (0.0013) | 0.9587 (0.0054) | 0.9661 (0.0064) | 0.9898 (0.0034) |
| Average | 0.9311 | 0.9333 | 0.9472 | 0.9434 | 0.9646 | 0.9561 | 0.9596 | 0.9787 |
Note:
Bold entries indicate the best performance achieved by the corresponding method.
Statistical analysis
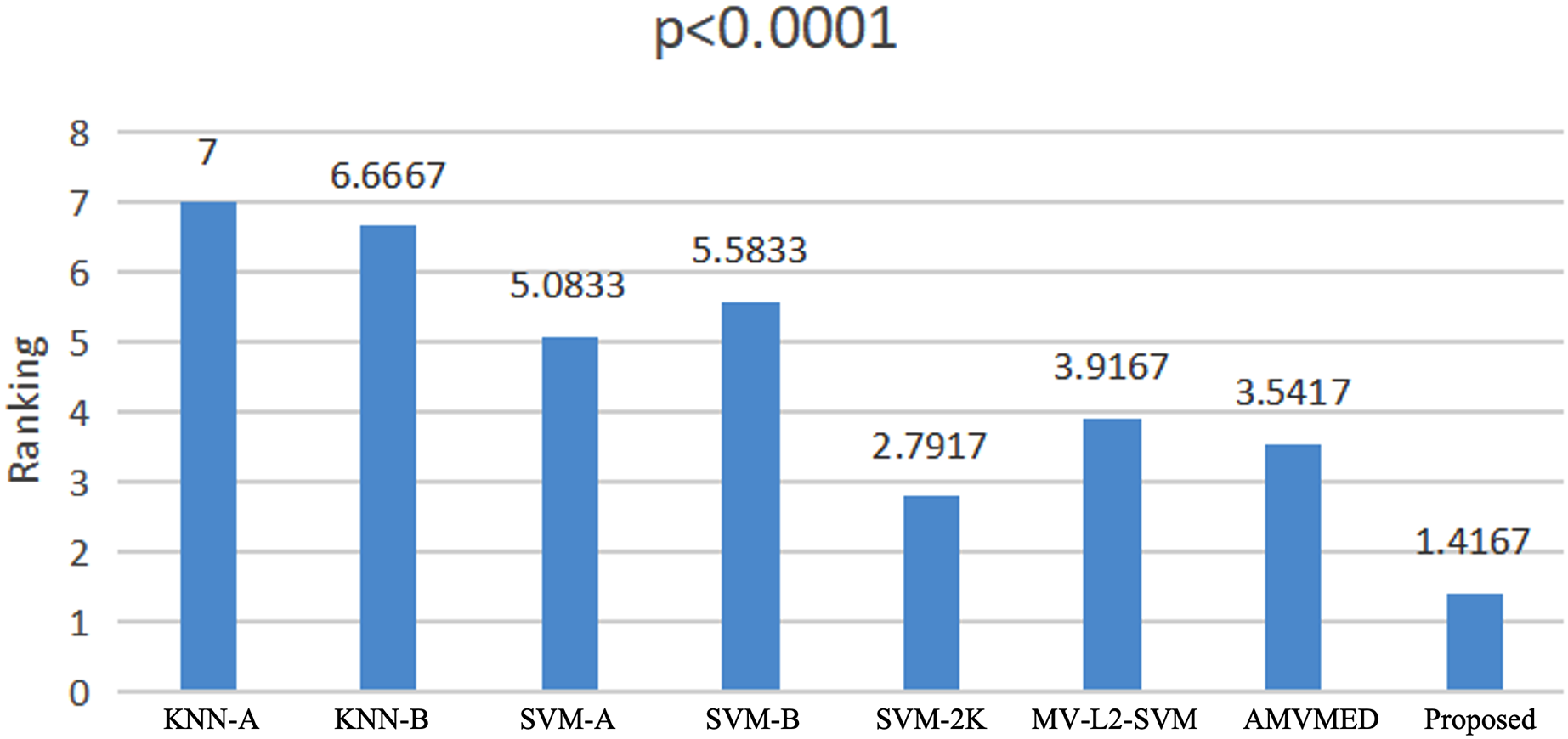
We use the Friedman test (Zimmerman & Zumbo, 1993; Sakamoto et al., 2015) to conduct a statistical analysis of the experimental results on all methods across all datasets. The Friedman test is a non-parametric testing method that can be used to analyze whether there are significant differences in performance among multiple methods on multiple datasets. The principle is to first obtain the average ranking of each method’s performance on all datasets, and then compare whether these rankings are the same. If they are the same, it indicates that all methods have the same performance, otherwise it suggests that there are significant differences in performance among all methods. If there are significant differences among all methods, we further use a Holm post-hoc hypothesis test to specifically analyze which methods and our proposed algorithm have significant differences. From Fig. 5, we see that 2V-SVM-SH wins the best ranking result. The p-values embedded in Fig. 5 computed by Friedman test hint that there are significant differences among different models. From Table 6, it can be seen that all hypothesis is rejected except the proposed model vs AMVMED and the proposed model vs SVM-2K. These results indicate that the proposed model performs significantly better than KNN-A, KNN-B, SVM-B, SVM-A and MV-L2-SVM. Although the hypothesis of the proposed model vs AMVMED and the proposed model vs SVM-2K is not reject, the low p-value of the proposed model vs AMVMED and the proposed model vs SVM-2K also indicates the reveal the competition of the proposed model.
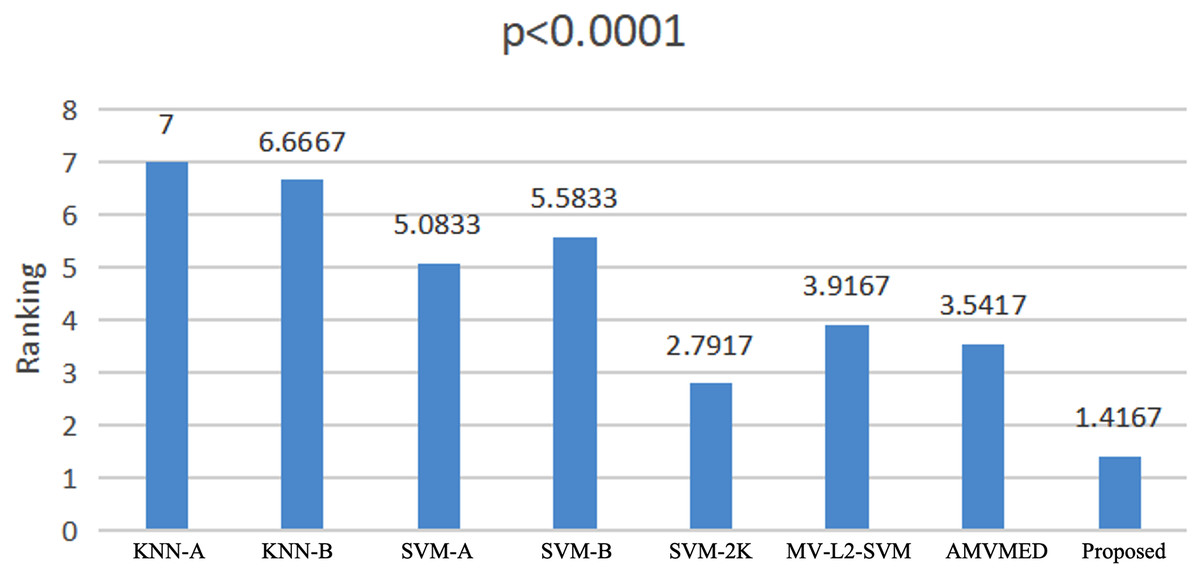
Figure 5: Friedman rankings of all models.
{kind=link}
| Algorithm | Hypothesis | ||||
|---|---|---|---|---|---|
| 7 | KNN-A | 5.583333 | 0 | 0.007143 | Rejected |
| 6 | KNN-B | 5.25 | 0 | 0.008333 | Rejected |
| 5 | SVM-B | 4.166667 | 0.000031 | 0.01 | Rejected |
| 4 | SVM-A | 3.666667 | 0.000246 | 0.0125 | Rejected |
| 3 | MV-L2-SVM | 2.5 | 0.012419 | 0.016667 | Rejected |
| 2 | AMVMED | 2.125 | 0.033587 | 0.025 | Not rejected |
| 1 | SVM-2K | 1.375 | 0.169131 | 0.05 | Not rejected |
Conclusions
In this study, a multi-view support vector machine based on a shared hidden space is constructed using kernel density estimation. The method is designed to address the problem of decreased recognition performance due to the difference in sample characteristics between different view models in multi-view learning. The method involves incorporating SVM into the shared hidden space, resulting in an effective solution to the problem of solving the classic QP problem. Experimental results on EEG-based epilepsy diagnosis demonstrate that our proposed method is better able to extract complementary information between different view models than other methods.
In practical applications, annotating training samples is often a time-consuming task. Therefore, in subsequent research, we intend to extend the multi-view algorithm proposed in this article to transfer learning scenarios, aiming to reduce the reliance on labeled samples.