

Consensus-based clustering and data aggregation in decentralized network of multi-agent systems
- Published
- Accepted
- Received
- Academic Editor
- Muhammad Aleem
- Subject Areas
- Agents and Multi-Agent Systems, Algorithms and Analysis of Algorithms, Distributed and Parallel Computing, Optimization Theory and Computation, Robotics
- Keywords
- Situational awareness, Clustering, Aggregation, Multi-agent systems, Optimization, Consensus, Distributed
- Copyright
- © 2023 Damanik et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2023. Consensus-based clustering and data aggregation in decentralized network of multi-agent systems. PeerJ Computer Science 9:e1445 https://doi.org/10.7717/peerj-cs.1445
Abstract
Multi-agent systems are promising for applications in various fields. However, they require optimization algorithms that can handle large number of agents and heterogeneously connected networks in clustered environments. Planning algorithms performed in the decentralized communication model and clustered environment require precise knowledge about cluster information by compensating noise from other clusters. This article proposes a decentralized data aggregation algorithm using consensus method to perform COUNT and SUM aggregation in a clustered environment. The proposed algorithm introduces a trust value to perform accurate aggregation on cluster level. The correction parameter is used to adjust the accuracy of the solution and the computation time. The proposed algorithm is evaluated in simulations with large and sparse networks and small bandwidth. The results show that the proposed algorithm can achieve convergence on the aggregated data with reasonable accuracy and convergence time. In the future, the proposed tools will be useful for developing a robust decentralized task assignment algorithm in a heterogeneous multi-agent multi-task environment.
Introduction
The field of multi-agent systems has gained increasing interest in recent years, particularly in the area of decentralized control (Xie & Liu, 2017). Although traditional centralized control systems are simple and robust (Oh, Park & Ahn, 2015), they have faced challenges in managing large numbers of agents and ensuring efficient performance (Ishaq et al., 2022). Thus, researchers have shifted their focus towards decentralized control methods which aim to distribute the computational and decision-making responsibilities among the agents in a local environment (Ponda et al., 2010). Applications of decentralized systems using multi-agent systems include air delivery systems (Oh et al., 2018; Damanik & Choi, 2021), search and rescue (Tomic et al., 2012), urban air mobility (Kim, Jeong & Choi, 2021), energy load management (Rasheed et al., 2019), surveillance (Samad, Bay & Godbole, 2007), and emergency relief systems (Bupe, Haddad & Rios-Gutierrez, 2015).
In addition to several advantages, decentralized control systems have one main challenge: communication between agents to perform coordination (Kwon & Hwang, 2020). Consensus (Choi, Brunet & How, 2009) may be one of the solutions to this. The sub-gradient method using consensus as proposed in Nedic & Ozdaglar (2009) is used to solve an optimization problem in a decentralized network of multi-agent systems. This algorithm implements the information evolution model proposed in Tsitsiklis (1984), which combines information from local neighbors using a weight rule. With this algorithm, the information from one agent is made available to every agent connected through communication links, either directly or indirectly, as illustrated in Fig. 1.
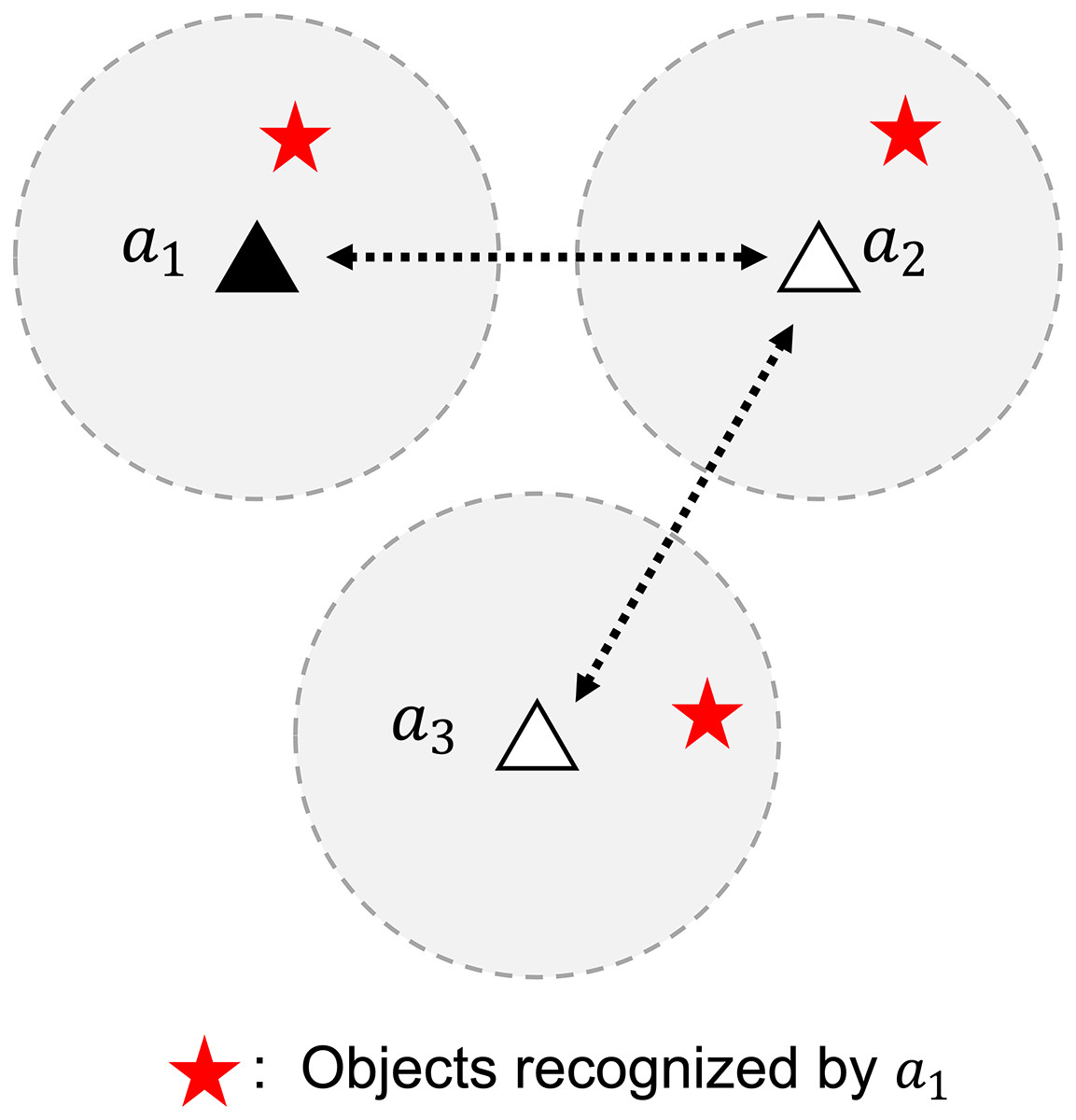
Figure 1: A problem of identifying objects in a decentralized network of multi-agent systems.
Data aggregation enables agent 1 to recognize objects beyond its sensor range.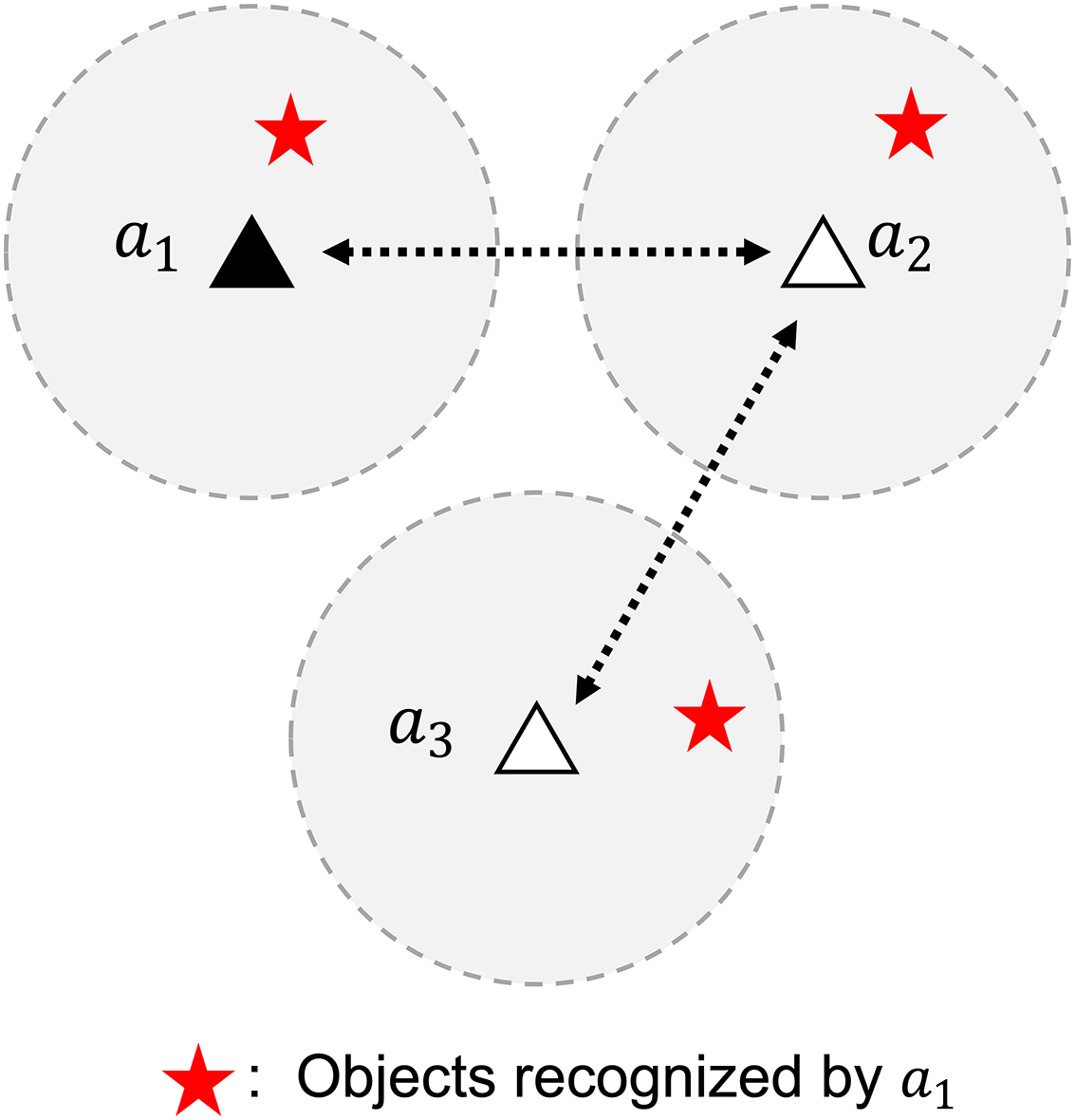{kind=link}
Based on the sub-gradient method, a decentralized clustering algorithm was proposed in Khawatmi, Zoubir & Sayed (2015), Khawatmi, Sayed & Zoubir (2017). This algorithm assumes that agents have no knowledge of the number of clusters and their respective information. Using a pairwise function, an agent determines the cluster in which it belongs and propagates its knowledge towards the consensus value of the cluster. This algorithm successfully performs clustering even in partially connected networks with few data exchanges and is comparable with centralized algorithms, including KMeans (MacQueen, 1967).
Decentralized local optimization, including decentralized multi-agent mission planning (Bertsekas, 1988; Choi, Brunet & How, 2009; Luo, Chakraborty & Sycara, 2014; Johnson, Choi & How, 2016) may require local knowledge to perform mission assignments in a decentralized network. However, highly complex tasks necessitating constraints, including coupled constraints as proposed in Whitten et al. (2011) and complex optimization objectives, including min-max tours as proposed in Prasad, Choi & Sundaram (2020) and Damanik & Choi (2021), require certain knowledge about the neighborhood which is difficult to acquire with conventional consensus in a partially connected network. To address this, data aggregation methods can be used.
The aim of data aggregation methods is to understand the data sensed by nodes and extract important information from it. Additionally, the system must be able to tackle various network restrictions. For example, in a partially connected network some data may be missing. The system must be capable of reconstructing the missing data using consensus between the agents. In a low energy network with limited bandwidth, data exchange must be executed efficiently to allow convergence to occur in a minimum number of inter-agent communications, without sacrificing the accuracy of the situational awareness. All of this must be possible without a substantial dependence on the central controller.
There are three types of data aggregation available: MIN/MAX aggregations, AVERAGE aggregations, and COUNT/SUM aggregations. MIN/MAX and AVERAGE aggregations are straightforward and various robust algorithms are available to execute these types of aggregation (Jesus, Baquero & Almeida, 2015; Fraser et al., 2012). Comparatively, COUNT/SUM aggregation is more challenging due to its sensitivity to duplicates, noise, and security attacks.
Several COUNT/SUM aggregation algorithms have been developed in order to solve the challenges posed, but each algorithm has its strengths and limitations. Token circulation, proposed in Dolev, Schiller & Welch (2006) and improved in Saha, Marshall & Reina (2019), is one approach for COUNT/SUM aggregation which implicates passing a token among the nodes and incrementing a counter every time the token is received. Probability density-based methods, such as probabilistic polling proposed in Friedman & Towsley (1999), Kalman-filter based polling in Alouf, Altman & Nain (2002), and maximum likelihood estimation in Baquero et al. (2012), require larger amounts of communication bandwidth to transmit probability density estimates between the nodes, limiting scalability.
Random walk-based algorithms, like Random-tour in Massoulié et al. (2006), Sample & Collide in Ganesh et al. (2007), and Capture-Recapture in Mane et al. (2005), have also been proposed for COUNT/SUM aggregation. These approaches involve nodes moving randomly through the network and incrementing a counter as they pass other nodes. However, these approaches are known to have low accuracy, particularly for larger numbers of nodes.
Recently, several gossip-based and consensus-based algorithms have been presented in order to overcome the limitations of previous methods. These approaches involve each node communicating with its neighbors, exchanging information and aggregating it over multiple rounds. Gossip-based algorithms such as Hop-sampling and interval density, proposed in Kostoulas et al. (2005) and Kostoulas et al. (2007) respectively, are examples of such algorithms. Consensus-based algorithms like Shames et al. (2012) and Lee et al. (2018) are other options. These algorithms do not require considerable bandwidth, produce accurate results, and converge in few iterations. However, no existing algorithm has been proposed for COUNT/SUM aggregation in a clustered network, which is common with large scale systems.
In order to tackle this limitation, this article presents a COUNT/SUM data aggregation in a clustered network of multi-agent systems. This algorithm takes into account the clustered network topology by using a notion of trust value, which reflects the trustworthiness of each node’s count value. The proposed algorithm requires relatively little communication and can achieve accurate results with few iterations, as proven through simulations and sensitivity analysis.
The rest of the article is organized as follows. ‘Proposed Algorithm’ proposes an algorithm that solves both clustering and data aggregation in a decentralized network. ‘Simulation’ details the simulation that was built and shows the simulation results. Finally, ‘Conclusion’ presents the concluding remarks.
Proposed algorithm
In this section, we will explore the consensus-based data aggregation technique for multi-agent systems working in a clustered network environment. The goal of the algorithm is to perform COUNT or SUM calculations of a global information with only the available local information. By leveraging consensus on the aggregation variable and two supporting variables with neighboring agents, we can perform counting or summing of a variable from all connected members in a cluster. Additionally, the algorithm can perform an accurate data aggregation even in heterogeneous networks, wherein agents can be connected with members belonging to different clusters. Despite the noise, the algorithm can selectively filter the data and achieve convergence to the cluster aggregate value quickly.
The algorithm relies on the consensus of three important variables:
The (approximate cluster) centroid vector ( ). The centroid vector is the prediction on the centroid of an agent’s cluster. During the consensus, an agent compares the predicted centroid of both itself and its neighbor to find out if they are in the same cluster.
The aggregation contribution vector ( ). The aggregation contribution variable is a measure of each agent’s contribution to the aggregation dynamics of the cluster, and it plays a critical role in determining the overall behavior of the system by ensuring that each agent’s contribution is properly accounted for.
The aggregate value ( ). On the other hand, the aggregate variable is the COUNT or SUM of the data being aggregated. This variable symbolizes the final result of the aggregation process, providing a comprehensive summary of the data collected and processed by the agents.
The multi-agent system is modeled as a graph , where V is the set of vertices or nodes representing agents, and E is the set of edges that signify the interactions between the agents. Each edge is a tuple , where and are nodes in V, indicating that agents represented by and are interacting. The graph can be weighted or unweighted, relying on whether or not the edges have a specific value or weight associated with them, which can represent the strength or significance of the interaction between the agents.
Each node in the environment belongs to a cluster from the cluster set in one-to-one relationships. Each cluster is identified with its centroid , with being the number of centroid’s dimensions. In this article, we assume that the network is heterogeneous, wherein there are edges between agents in different clusters. Let denote the set of ’s adjacent nodes, wherein node can belong to any cluster, it does not have to be in the same cluster with (Fig. 2).
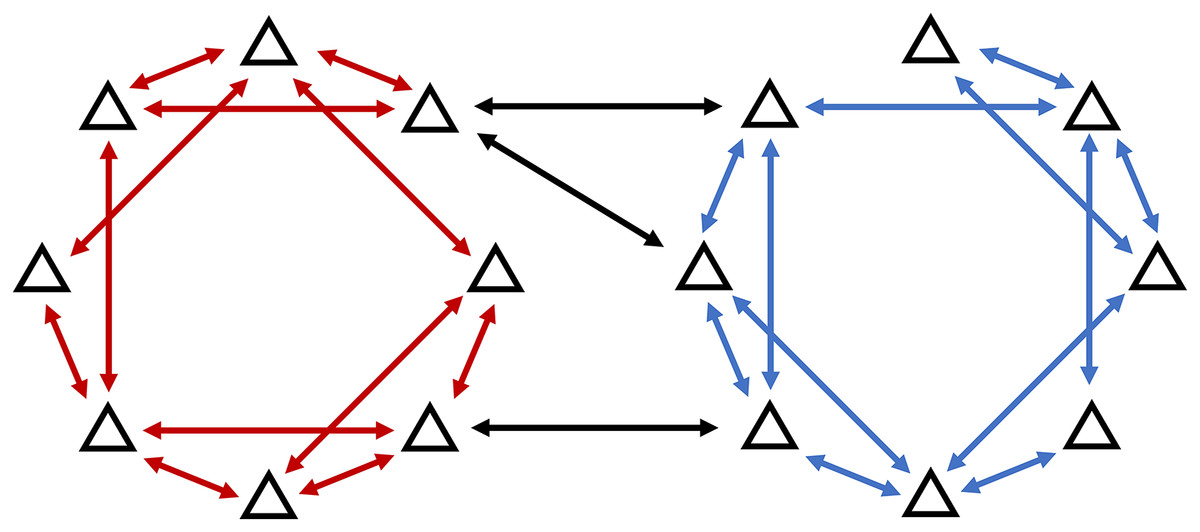
Figure 2: Heterogeneous network model allows for the communication between agents in different clusters.
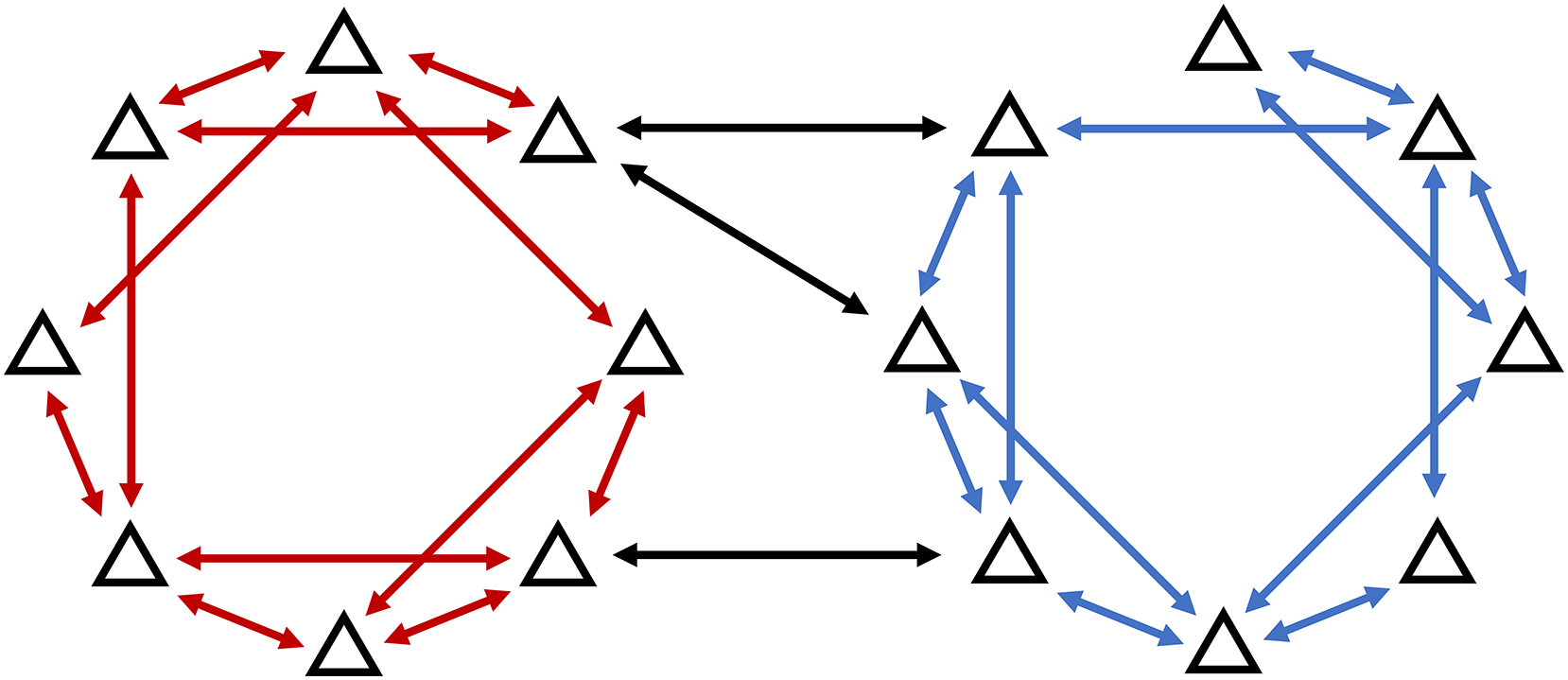{kind=link}
It is also assumed that there must be a set of edges that can connect every pair of agents in the cluster. This implies that communication between two agents in the same cluster is always possible, either directly or through several hops between agents in the cluster as illustrated in Fig. 3.
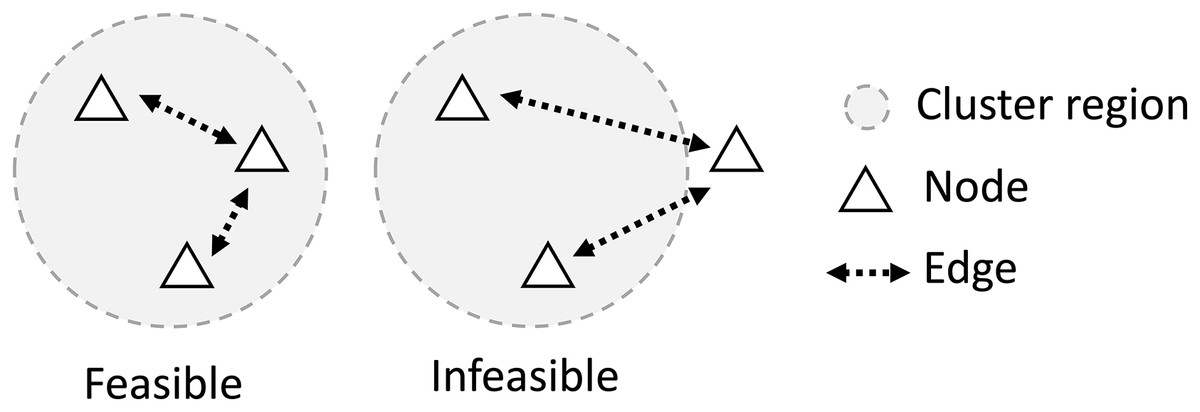
Figure 3: For a feasible network, all nodes in the cluster must be connected with at least one member of the same cluster, making the group of agents on the right unfeasible.
{kind=link}
In cooperative multi-agent systems, it is assumed that the system minimizes the total cost of the entire system, which is the sum of each agent’s cost. Specifically, this optimization problem can be expressed as where is the individual cost function of each agent.
In a decentralized network, the global knowledge of the environment’s state is not always available, thus agents must generate an estimate of the environment status, denoted as . Assuming that the agent updates its estimate in a discrete time domain, every time step an agent updates its estimate using the relation
(1) where is a weight vector used to calculate the average estimates from agent ’s neighbors. The weight vector must comply with the weight rules as follows
(2)
(3) where is any scalar between 0 and 1 ( ).
Consensus on centroid vector
In decentralized systems, agents do not know the exact values of cluster centroids and members of the clusters. Instead, they conduct consensus on an estimated centroid value and compare it with their neighbors to establish whether they belong to the same cluster. Let be agent ’s state used for the basis of clustering, and be the predicted centroid vector of its cluster . Then, we can define a variable called trust value, denoted as , that compares the predicted values of clusters of agents and . The trust value must satisfy the following equation.
(4)
The trust function can be employed to identify whether an agent is in the same cluster as agent or not. We can define a scalar as a boundary. Agents and are said to be within the same cluster if . We can utilize any convex function to define the trust function as long as it satisfies Eq. (4).
(5)
At the initial stage, each agent sets the centroid vector to its state . For each time iteration , every agent performs consensus on the centroid vector with their neighbors and updates the vector iteratively using the following equation.
(6)
Consensus on aggregation contribution vector
The data aggregation model proposed in this article is based on the network counting system proposed in Lee et al. (2018), using blended dynamics (Eq. (7)):
(7)
Using the steady-state theorem, it is easy to prove that . Developing the consensus model based on this dynamics leads to convergence to the number of members in a cluster. In this article, we extended this model in three ways:
In the original article, the counting mechanism requires a leader to generate dynamic feedback in order to reach convergence. In this article, we allow every member of the cluster to contribute a fraction of the dynamic feedback, thus removing the need for a cluster leader.
We extended the model to allow summing by introducing a state constant on the right-hand side of the dynamics in Eq. (7).
The original model assumes a homogeneous network, where no cluster notation is defined. In this article, we extended the blended model to work with heterogeneous networks with multiple clusters by implementing trust values into the consensus models.
First, to determine the fraction of contribution of each node on the blended dynamics, we introduce a contribution vector that satisfies
(8)
The vector is initially decided by each agent using Eq. (9) and then updated using the consensus rule based on the structure of the network. The idea is to generate a trust value that is proportional to the degree of the node. At the initial stage, each agent decides a vector such that
(9)
And then, at every time step, agents perform consensus with their neighbors using Eq. (10) below.
(10)
The consensus of the contribution vector might require a slightly higher bandwidth, as an entire vector must be exchanged between agents and their neighbors. However, by ensuring that the centroid vectors are converged, where the prediction distance between agents in a cluster is very small, the consensus on contribution vectors can reach convergence very quickly.
Consensus on the aggregation value
The consensus on the aggregation value is a critical aspect in many decentralized systems. The objective is to collect and sum the state variables of all agents in a cluster and arrive at a single value. The state variable of each agent to be aggregated is represented by , and the sum of all agents’ states in a cluster is represented by , as defined in Eq. (11):
(11)
Given as the contribution vector known by agent , the agent decides its ratio of contribution feedback to the aggregation dynamics (Eq. (7)) as . At every time step , the agents generate an addition to the consensus value.
To determine the contribution of each agent to the aggregation process, a contribution vector is used. This vector represents the ratio of contribution feedback from each agent to the aggregation dynamics. At every time step, each agent generates an addition to the consensus value by taking the ratio value of the agent as .
Each agent calculates the prediction value of as , which represents the approximate value of the sum of for all agents in the cluster . During the iteration process, agents exchange their prediction data using Eq. (12). This equation ensures that each agent has an updated and accurate prediction value of .
(12)
Equation (12) represents the aggregation of the prediction value of each agent during the iteration process. Here, is the prediction value of the sum of all agents’ states in the cluster at the -th time step. The equation computes the new prediction value based on the previous prediction values of the neighboring agents and the local state of the agent.
The term represents a weighted average of the prediction values of the neighboring agents and the current agent. The weight determines the influence of the prediction value of each neighboring agent on the new prediction value of the current agent.
The term represents the correction term that the agent applies to its previous prediction value based on its own local state . is the ratio of contribution feedback to the aggregation dynamics, and is a small positive constant that determines the magnitude of the correction term.
Equation (12) is calculated for every agent , where V is the set of all agents in the network. The iteration process continues until the prediction values of all agents converge to the same value, which represents the consensus on the sum of all agents’ states .
The complete algorithm is shown in Algorithm 1.
| Require: |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: while is not converged do |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: for do |
| Receive from j |
| 11: |
| 12: |
| 13: if is not converged then |
| 14: Receive from j |
| 15: |
| 16: |
| 17: end if |
| 18: Receive from j |
| 19: |
| 20: end for |
| 21: if is not converged then |
| 22: |
| 23: |
| 24: else |
| 25: |
| 26: |
| 27: end if |
| 28: |
| 29: |
| 30: end while |
Simulation
The simulation environment was designed to emulate the proposed algorithm in a clustered network of multi-agent systems and to test the algorithms under various conditions. The results obtained from the simulations provide valuable insights into the efficiency and scalability of the algorithms and help to validate the theoretical findings presented in the article. This section will provide a detailed description of the simulation setup, the conditions tested, and the results obtained.
The simulation first generates sample data of 100 agents with locations in 2D domains using the make_blobs function from the sklearn.datasets module. A network with 100 agents is considered large and the algorithm can solve the data aggregation in a reasonable number of iterations. The sample data is sorted based on its cluster labels and stored in a state matrix X of size and a cluster label vector of size .
Next, a graph G is created with 100 nodes with X as the location of nodes (Fig. 4A). The edges in the graph are determined based on the distances between nodes. To generate strong connections within a cluster, the NearestNeighbors class from the sklearn.neighbors module is used to find the nearest neighbors for each node and we connect each agent with their 10 nearest neighbors. The graph is also augmented with random edges with a probability of 0.1% to increase its inter-cluster connectivity. The adjacency matrix of the graph is shown in Fig. 4B.
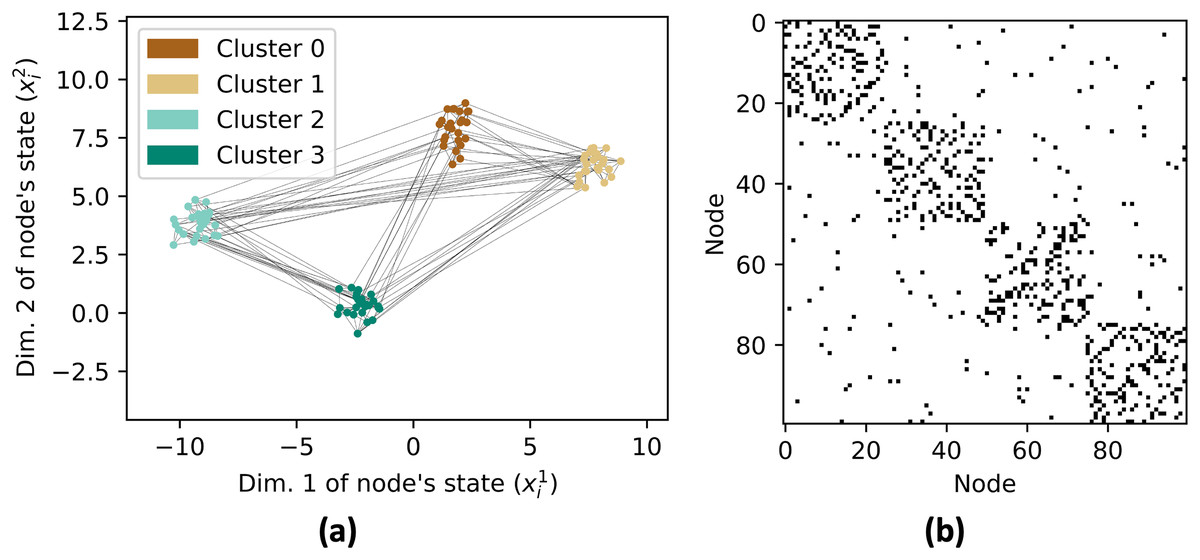
Figure 4: Network graph G consisting of 4 clusters with 25 nodes each.
Each node has edges with its nearest 10 neighbors and 10% probability with any random nodes as shown in (A). The resulting adjacency matrix is shown in (B).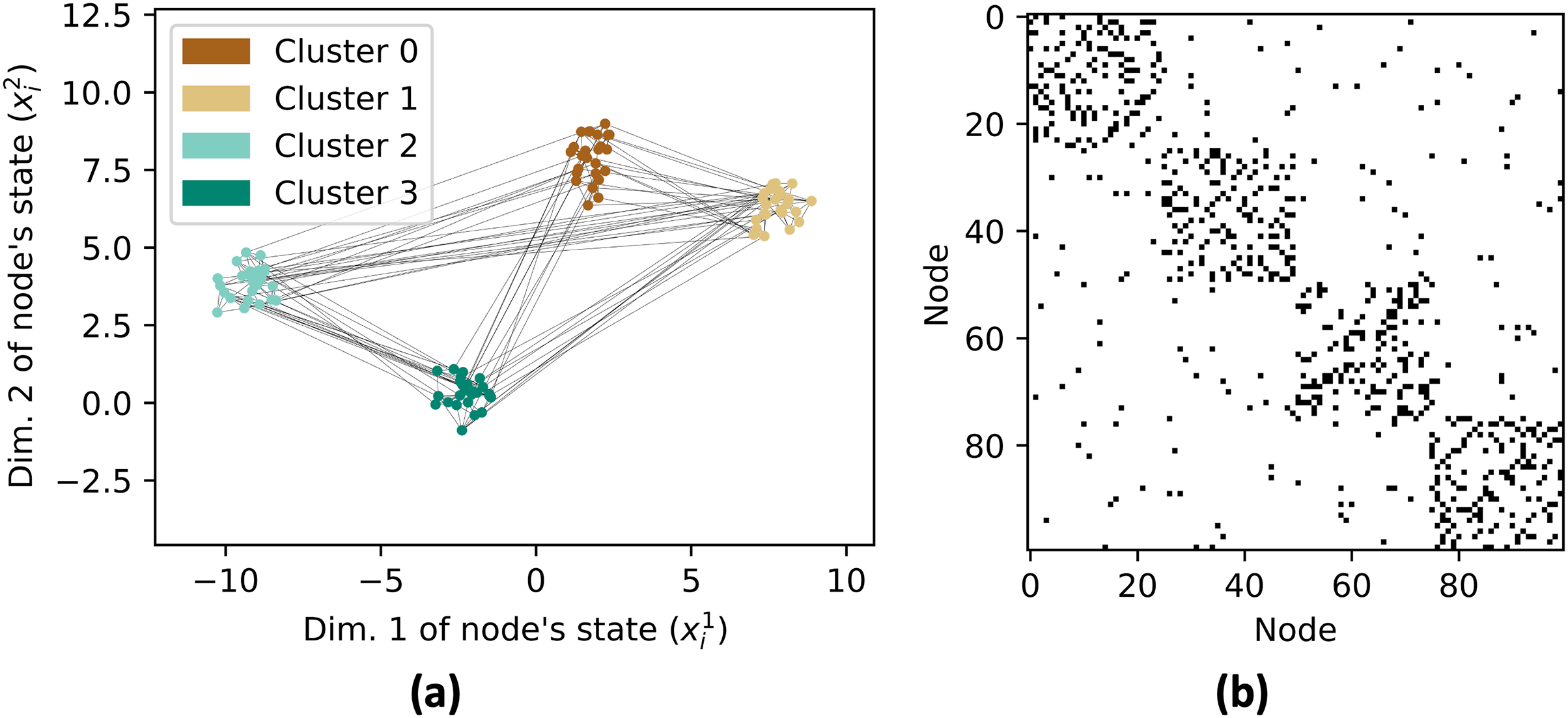{kind=link}
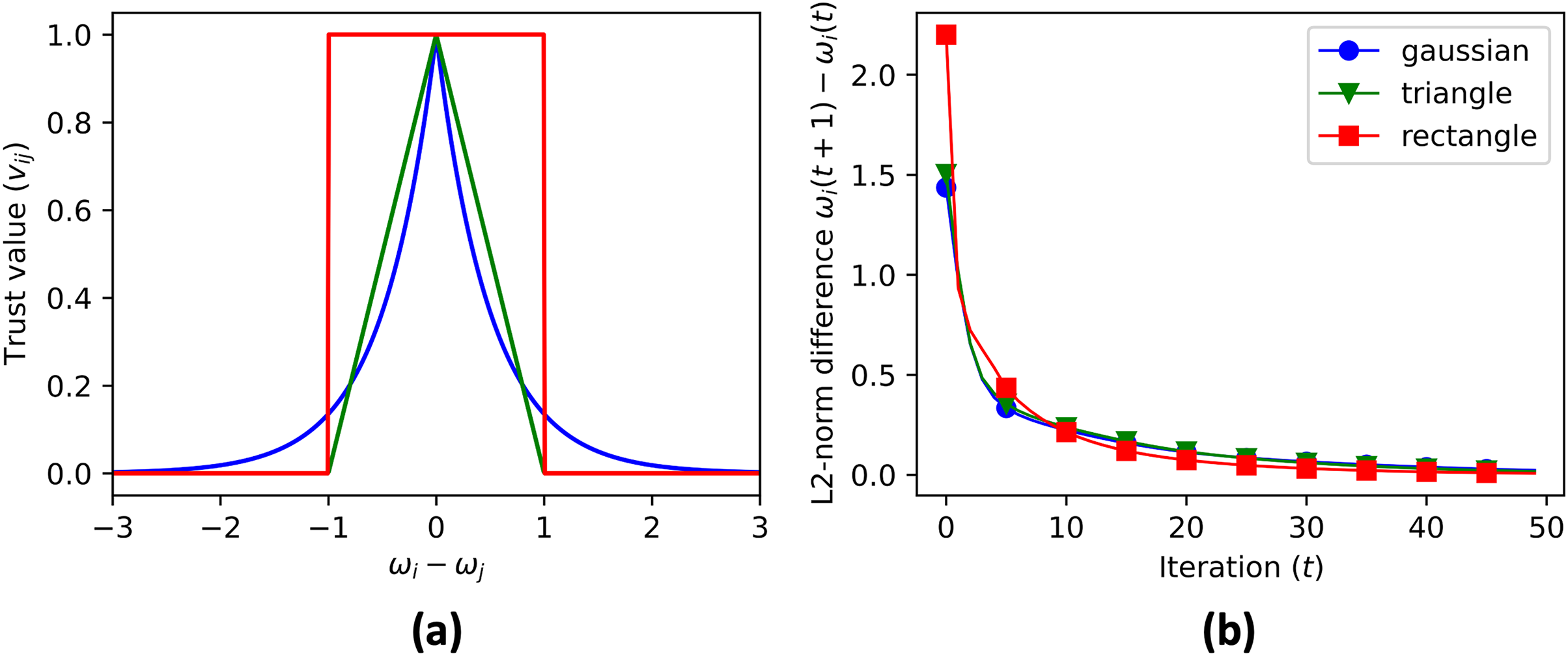
The code then initializes the cluster centroid prediction , contribution matrix , and aggregate matrix . These matrices are updated in each iteration of the data aggregation process using Eqs. (6), (10), and (12). The data to be aggregated is stored in a vector with initial value equal to ID of each node, . The real aggregate of the data is calculated and stored in a vector for error reference. The trust value is calculated using three different convex functions (Fig. 5A): Gaussian (Eq. (13)), triangular (Eq. (14)), and rectangular (Eq. (15)).
1. Gaussian function
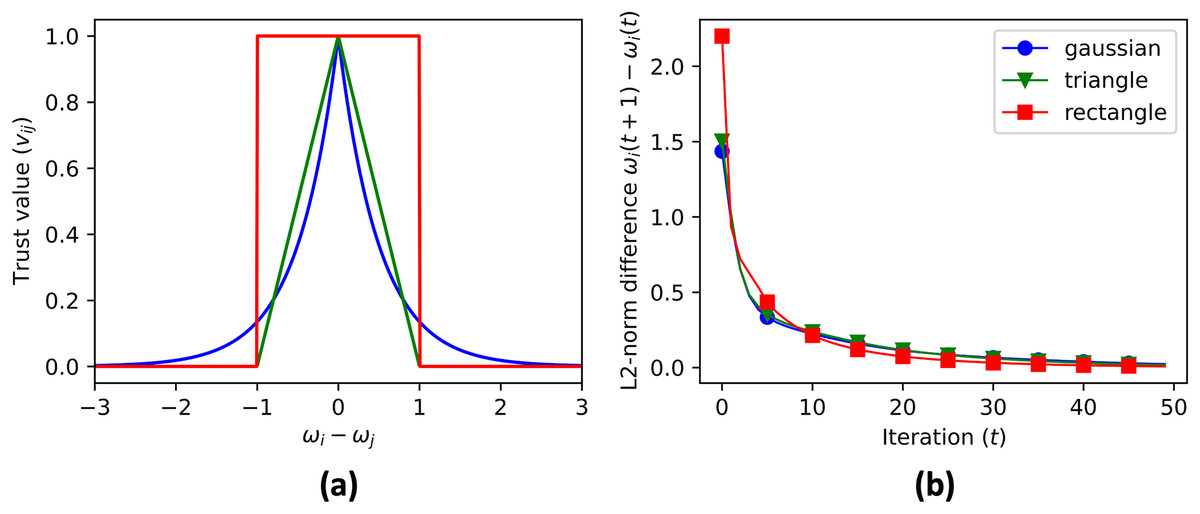
Figure 5: (A) The three convex functions used to generate trust value: gaussian (Eq. (13)), triangle (Eq. (14)), and rectangle (Eq. (14)) functions. The convergence rate of cluster centroid prediction is shown in (B).
{kind=link}
(13)
2. Triangular function
(14)
3. Rectangular function
(15)
The data aggregation process is repeated for a maximum number of iterations, specified by MAX_ITER. The code checks if the contribution vectors has converged by comparing the updated values with the previous values, and if the difference is within a given tolerance, the process terminates. After the convergence, the simulation skips the consensus on the contribution vector, and continues the consensus for the aggregate value until convergence. Figure 6 shows the cluster centroid predictions of all agents, over the course of the iterations. Figure 5B shows the convergence rate of the centroid cluster prediction using three different trust functions, and Fig. 7 shows the contribution vector of all agents at convergence.
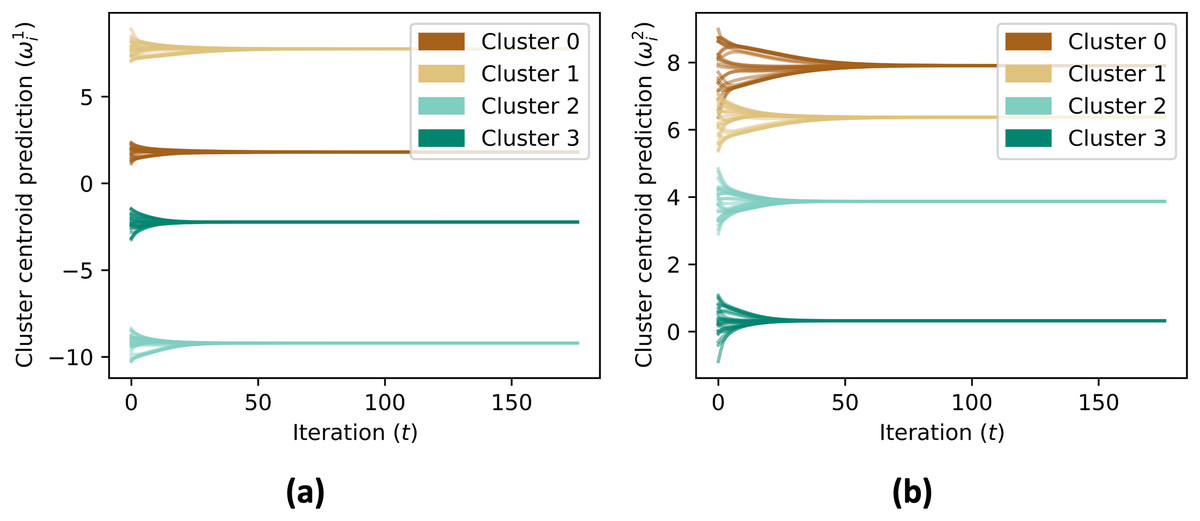
Figure 6: (A and B) The prediction of cluster centroid by all nodes.
In initial, the centroid is defined to each node’s state ( ). Using consensus rule on Eq. (6), the centroid prediction converged to mean value of each member’s state of the cluster.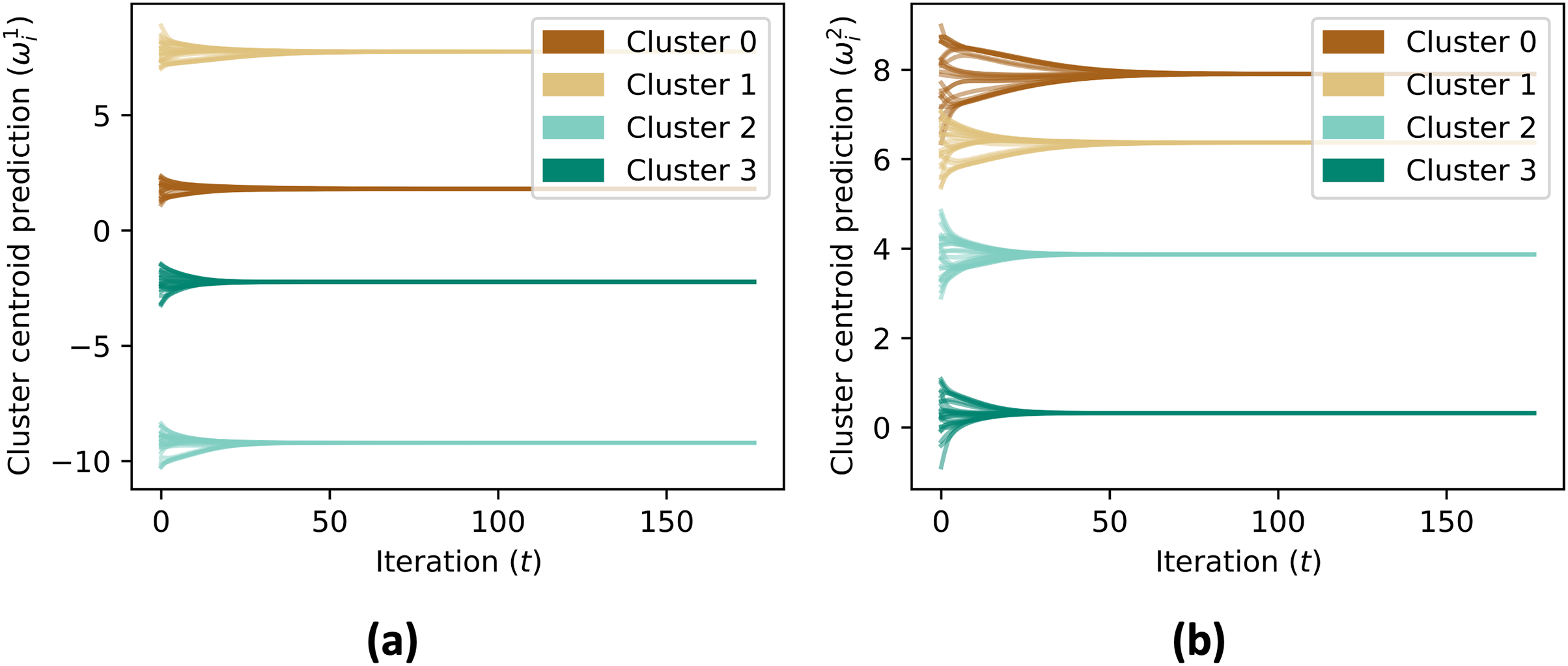{kind=link}
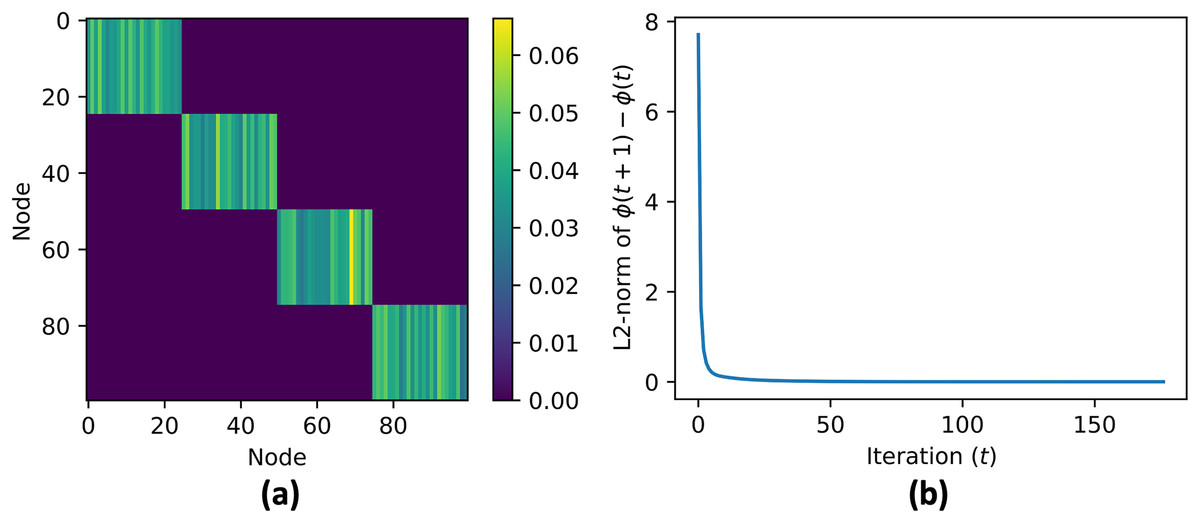
Figure 7: (A and B) Contribution vector value at convergence .
For every agents in the same cluster the contribution vector converge to the same value.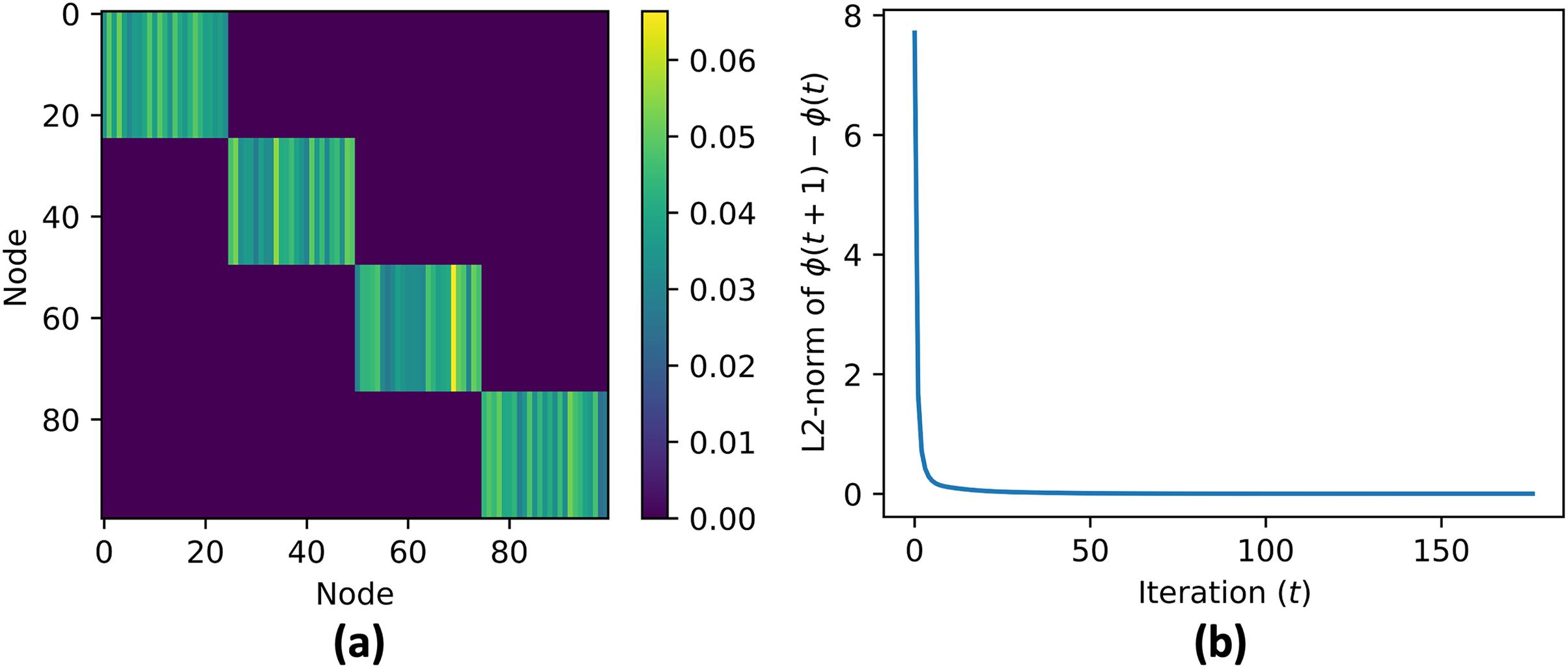{kind=link}
The simulation also calculates the mean squared error between the real aggregate value and the predicted aggregate value, which is a measure of the difference between the two. Figure 8B shows the mean squared error for each iteration.
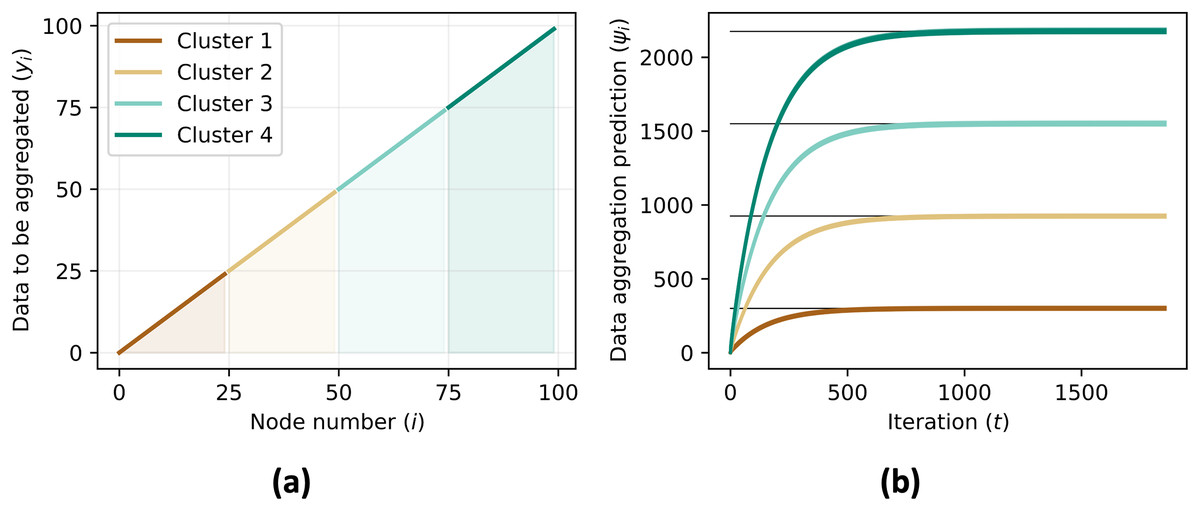
Figure 8: Data to be aggregated (A) for each nodes equals to the ID of each agents ( ) and the data aggregation (B) converges to the sum of data to be aggregated of all agents in the same cluster, .
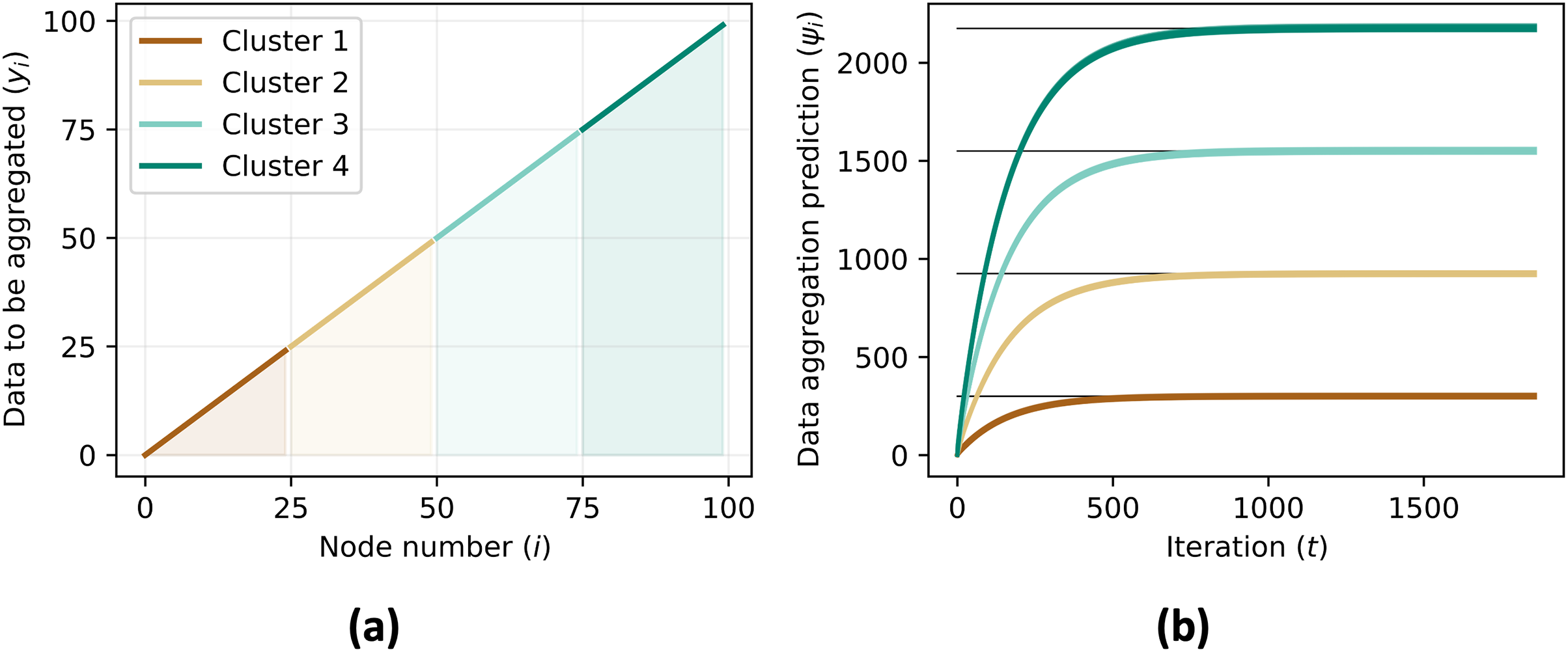{kind=link}
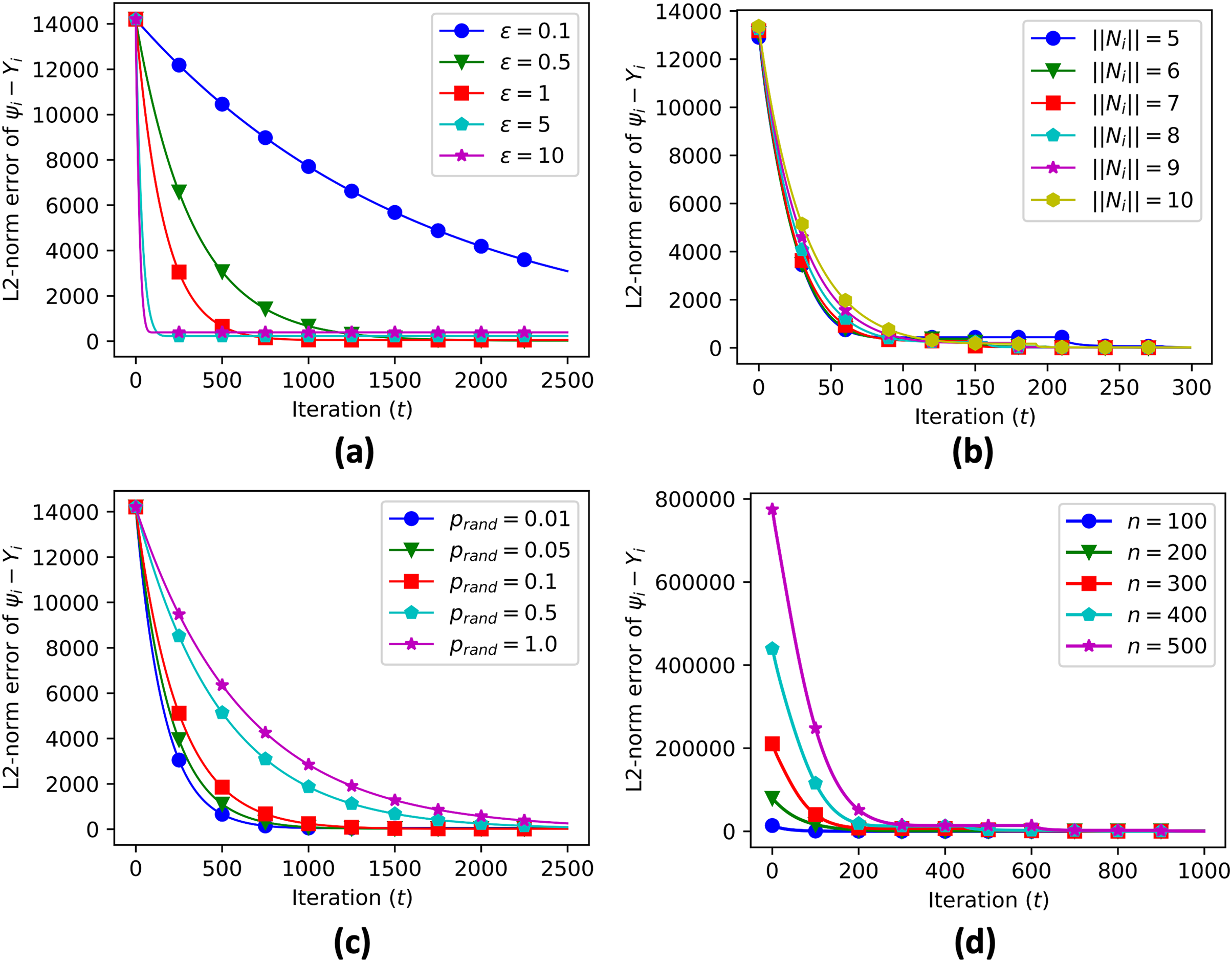
We also provide sensitivity analysis of our proposed algorithm. Sensitivity analysis is a crucial step in evaluating the performance of the proposed algorithms for decentralized data aggregation in clustered networks of multi-agent systems. In this study, sensitivity analysis was performed to investigate the effect of various parameters on the accuracy of data aggregation. The parameters considered in the sensitivity analysis include the value of epsilon (a threshold value used in the algorithm), the number of connected neighbors, the probability of random edge generation, and the number of sample nodes.
A sensitivity analysis was conducted to evaluate the performance of the proposed algorithm. The parameters considered in the analysis were: (data aggregation step), the number of connected neighbors ( ), the number of sample nodes ( ), and the probability of random edge generation ( ). The results of the sensitivity analysis showed that the data aggregation error was sensitive to all of these parameters, as shown in Table 1. In particular, as the value of increased, the convergence time reduced significantly while increasing the convergence error (Fig. 9A). The sensitivity analysis also showed that various numbers of connected neighbors (Fig. 9B), probabilities of random edge generation (Fig. 9C), and number of sample nodes (Fig. 9D) still led to similar convergence values, demonstrating the robustness of the algorithm in heterogeneous networks.
| Convergence time | L2-Norm error | |||||
|---|---|---|---|---|---|---|
| (iteration) | (iteration) | |||||
| 0.1 | 5 | 100 | 0.01 | 159 | 26,236 | 5.325308 |
| 0.5 | 5 | 100 | 0.01 | 159 | 5,769 | 26.164664 |
| 1 | 5 | 100 | 0.01 | 159 | 2,994 | 51.233616 |
| 5 | 5 | 100 | 0.01 | 159 | 648 | 222.297639 |
| 10 | 5 | 100 | 0.01 | 159 | 343 | 389.116116 |
| 1 | 5 | 100 | 0.01 | 299 | 299 | 15.976597 |
| 1 | 6 | 100 | 0.01 | 299 | 299 | 3.558554 |
| 1 | 7 | 100 | 0.01 | 299 | 299 | 9.557468 |
| 1 | 8 | 100 | 0.01 | 299 | 299 | 11.039423 |
| 1 | 9 | 100 | 0.01 | 299 | 299 | 13.091504 |
| 1 | 10 | 100 | 0.01 | 299 | 299 | 16.758241 |
| 1 | 5 | 100 | 0.01 | 299 | 299 | 38.259445 |
| 1 | 5 | 200 | 0.01 | 299 | 299 | 729.815696 |
| 1 | 5 | 300 | 0.01 | 999 | 999 | 30.42748 |
| 1 | 5 | 400 | 0.01 | 999 | 999 | 236.236123 |
| 1 | 5 | 500 | 0.01 | 999 | 999 | 282.063527 |
| 1 | 5 | 100 | 0.01 | 159 | 2,994 | 51.233616 |
| 1 | 5 | 100 | 0.05 | 57 | 3,585 | 28.155643 |
| 1 | 5 | 100 | 0.1 | 31 | 4,447 | 19.498971 |
| 1 | 5 | 100 | 0.5 | 11 | 8,529 | 9.144341 |
| 1 | 5 | 100 | 1 | 6 | 9,999 | 6.898491 |
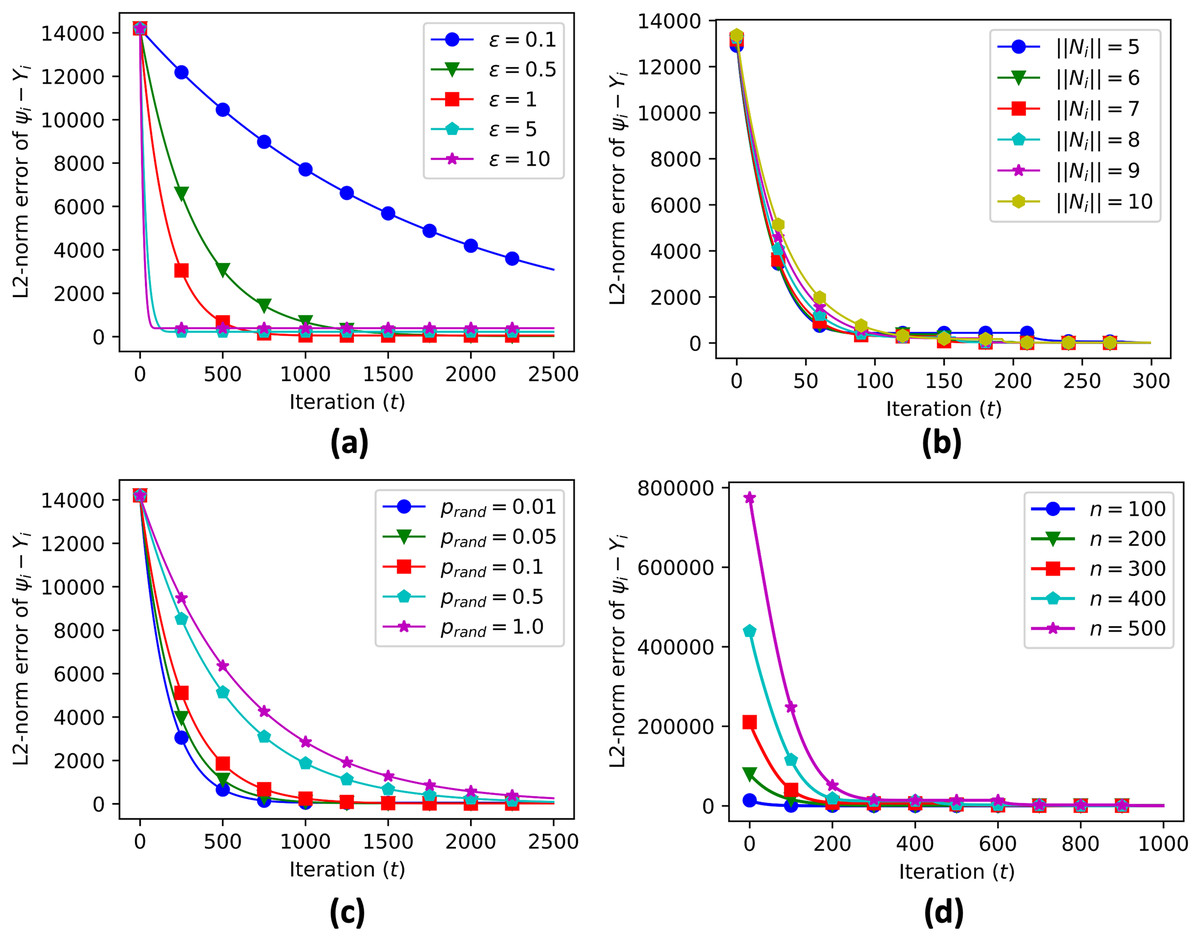
Figure 9: Sensitivity analysis of error propagation with various parameters, including data aggregation step size (A), number of connected neighbors (B), probability of random edge generation (C), and number of sample nodes (D).
{kind=link}
Concluding remarks
This article proposed an algorithm to perform data clustering and aggregation in a decentralized network of multi-agent systems, using consensus methods on three key variables: approximate cluster centroid vectors, aggregation contribution vectors, and aggregate values. The trust value used in the consensus rules enables data aggregation in a heterogeneously connected clustered network. Thus, data aggregation is performed in the cluster scale while still allowing inter-cluster communication.
The accuracy and convergence rate of the algorithm are dependent on the data aggregation step size constant . A bigger value of results in faster convergence time, but with higher aggregation errors, and vice versa. The main advantages of the proposed algorithm include the fact that it does not require many data transfers between its neighbors and that the data aggregation can reach convergence in a reasonable number of iterations, even in heterogeneous networks. These advantages allow both clustering and data aggregation in a decentralized network with limited bandwidth.
Future work includes extending the proposed algorithm to work in switching networks and improving the accuracy and convergence time by modifying the consensus rules for data aggregation. Furthermore, there are various applications which will benefit from this algorithm, such as decentralized task allocation algorithms and coordination algorithms in multi-agent systems.