
Gender differences and bias in open source: pull request acceptance of women versus men
- Published
- Accepted
- Received
- Academic Editor
- Arie van Deursen
- Subject Areas
- Human-Computer Interaction, Social Computing, Programming Languages, Software Engineering
- Keywords
- Gender, Bias, Open source, Software development, Software engineering
- Copyright
- © 2017 Terrell et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2017. Gender differences and bias in open source: pull request acceptance of women versus men. PeerJ Computer Science 3:e111 https://doi.org/10.7717/peerj-cs.111
Abstract
Biases against women in the workplace have been documented in a variety of studies. This paper presents a large scale study on gender bias, where we compare acceptance rates of contributions from men versus women in an open source software community. Surprisingly, our results show that women’s contributions tend to be accepted more often than men’s. However, for contributors who are outsiders to a project and their gender is identifiable, men’s acceptance rates are higher. Our results suggest that although women on GitHub may be more competent overall, bias against them exists nonetheless.
Introduction
In 2012, a software developer named Rachel Nabors wrote about her experiences trying to fix bugs in open source software (http://rachelnabors.com/2012/04/of-github-and-pull-requests-and-comics/). Nabors was surprised that all of her contributions were rejected by the project owners. A reader suggested that she was being discriminated against because of her gender.
Research suggests that, indeed, gender bias pervades open source. In Nafus’ interviews with women in open source, she found that “sexist behavior is…as constant as it is extreme” (Nafus, 2012). In Vasilescu and colleagues’ study of Stack Overflow, a question and answer community for programmers, they found “a relatively ‘unhealthy’ community where women disengage sooner, although their activity levels are comparable to men’s” (Vasilescu, Capiluppi & Serebrenik, 2014). These studies are especially troubling in light of recent research which suggests that diverse software development teams are more productive than homogeneous teams (Vasilescu et al., 2015). Nonetheless, in a 2013 survey of the more than 2000 open source developers who indicated a gender, only 11.2% were women (Arjona-Reina, Robles & Dueas, 2014).
This article presents an investigation of gender bias in open source by studying how software developers respond to pull requests, proposed changes to a software project’s code, documentation, or other resources. A successfully accepted, or ‘merged,’ example is shown in Fig. 1. We investigate whether pull requests are accepted at different rates for self-identified women compared to self-identified men. For brevity, we will call these developers ‘women’ and ‘men,’ respectively. Our methodology is to analyze historical GitHub data to evaluate whether pull requests from women are accepted less often. While other open source communities exist, we chose to study GitHub because it is the largest (Gousios et al., 2014), claiming to have over 12 million collaborators across 31 million software repositories (https://github.com/about/press).
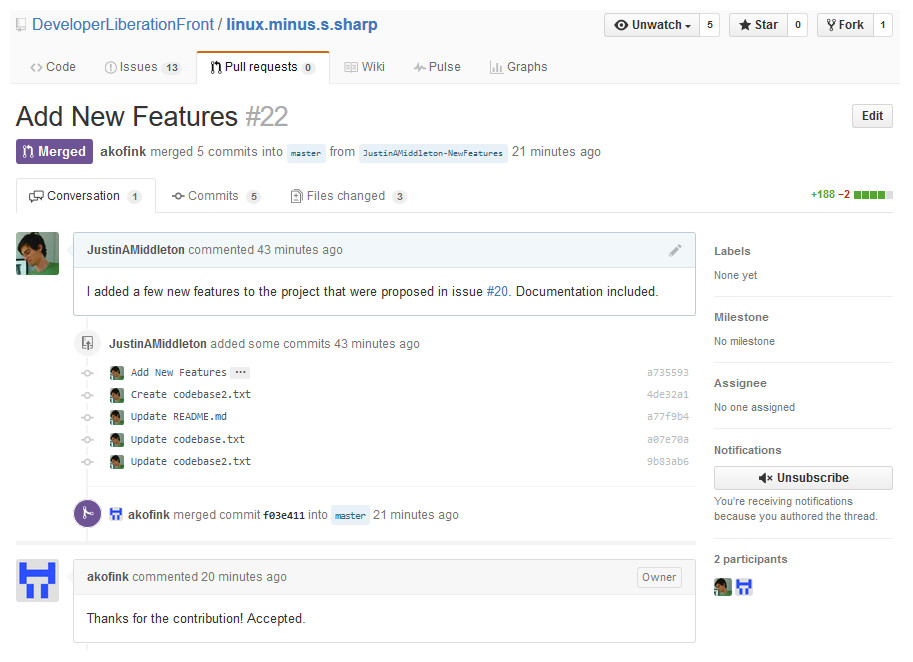
Figure 1: GitHub user ‘JustinAMiddleton’ makes a pull request; the repository owner ‘akofink’ accepts it by merging it.
The changes proposed by JustinAMiddleton are now incorporated into the project.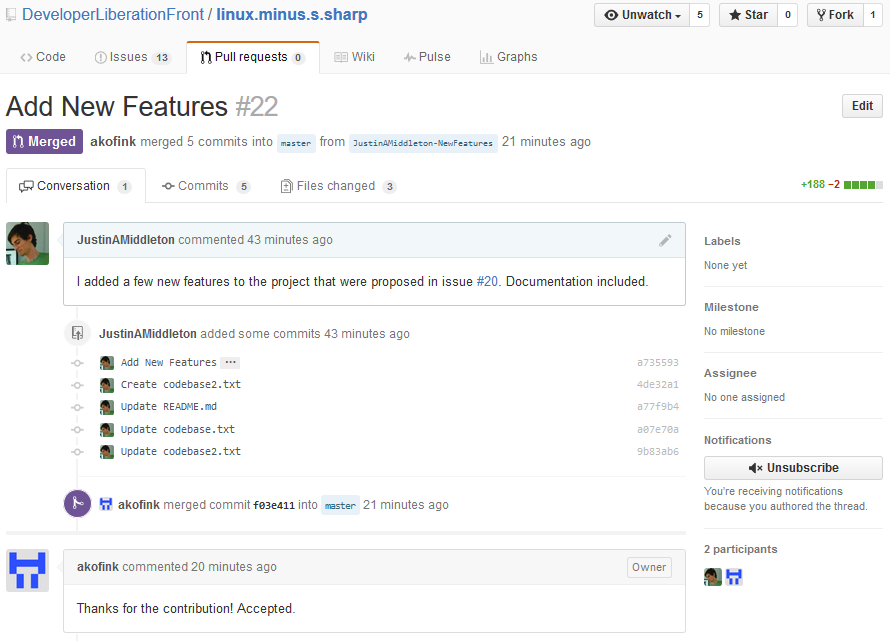{kind=link}
The main contribution of this paper is an examination of gender differences and bias in the open source software community, enabled by a novel gender linking technique that associates more than 1.4 million community members to self-reported genders. To our knowledge, this is the largest scale study of gender bias to date in open source communities.
Related Work
A substantial part of activity on GitHub is done in a professional context, so studies of gender bias in the workplace are relevant. Because we cannot summarize all such studies here, we instead turn to Davison and Burke’s meta-analysis of 53 papers, each studying between 43 and 523 participants, finding that male and female job applicants generally received lower ratings for opposite-sex-type jobs (e.g., nurse is a female sex-typed job, whereas carpenter is male sex-typed) (Davison & Burke, 2000).
The research described in Davison and Burke’s meta-analysis can be divided into experiments and field studies. Experiments attempt to isolate the effect of gender bias by controlling for extrinsic factors, such as level of education. For example, Knobloch-Westerwick, Glynn & Huge (2013) asked 243 scholars to read and evaluate research paper abstracts, then systematically varied the gender of each author; overall, scholars rated papers with male authors as having higher scientific quality. In contrast to experiments, field studies examine existing data to infer where gender bias may have occurred retrospectively. For example, Roth and colleagues’ meta-analysis of such studies, encompassing 45,733 participants, found that while women tend to receive better job performance ratings than men, women also tend to be passed up for promotion (Roth, Purvis & Bobko, 2012).
Experiments and retrospective field studies each have advantages. The advantage of experiments is that they can more confidently infer cause and effect by isolating gender as the predictor variable. The advantage of retrospective field studies is that they tend to have higher ecological validity because they are conducted in real-world situations. In this paper, we use a retrospective field study as a first step to quantify the effect of gender bias in open source.
Several other studies have investigated gender in the context of software development. Burnett and colleagues (2010) analyzed gender differences in 5 studies that surveyed or interviewed a total of 2,991 programmers; they found substantial differences in software feature usage, tinkering with and exploring features, and in self-efficacy. Arun & Arun (2002) surveyed 110 Indian software developers about their attitudes to understand gender roles and relations but did not investigate bias. Drawing on survey data, Graham and Smith demonstrated that women in computer and math occupations generally earn only about 88% of what men earn (Graham & Smith, 2005). Lagesen contrasts the cases of Western versus Malaysian enrollment in computer science classes, finding that differing rates of participation across genders results from opposing perspectives of whether computing is a “masculine” profession (Lagesen, 2008). The present paper builds on this prior work by looking at a larger population of developers in the context of open source communities.
Some research has focused on differences in gender contribution in other kinds of virtual collaborative environments, particularly Wikipedia. Antin and colleagues (2011). followed the activity of 437 contributors with self-identified genders on Wikipedia and found that, of the most active users, men made more frequent contributions while women made larger contributions.
There are two gender studies about open source software development specifically. The first study is Nafus’ anthropological mixed-methods study of open source contributors, which found that “men monopolize code authorship and simultaneously de-legitimize the kinds of social ties necessary to build mechanisms for women’s inclusion”, meaning values such as politeness are favored less by men (Nafus, 2012). The other is Vasilescu and colleagues’ (2015) study of 4,500 GitHub contributors, where they inferred the contributors’ gender based on their names and locations (and validated 816 of those genders through a survey); they found that gender diversity is a significant and positive predictor of productivity. Our work builds on this by investigating bias systematically and at a larger scale.
General Methodology
Our main research question was
To what extent does gender bias exist when pull requests are judged on GitHub?
We answer this question from the perspective of a retrospective cohort study, a study of the differences between two groups previously exposed to a common factor to determine its influence on an outcome (Doll, 2001). One example of a similar retrospective cohort study was Krumholz and colleagues’ (1992). review of 2,473 medical records to determine whether there exists gender bias in the treatment of men and women for heart attacks. Other examples include the analysis of 6,244 school discipline files to evaluate whether gender bias exists in the administration of corporal punishment (Gilbert, Williams & Lundberg, 1994) and the analysis of 1,851 research articles to evaluate whether gender bias exists in the peer reviewing process for the Journal of the American Medical Association (Shaw & Braden, 1990).
To answer the research question, we examined whether men and women are equally likely to have their pull requests accepted on GitHub, then investigated why differences might exist. While the data analysis techniques we used were specific to each approach, there were several commonalities in the data sets that we used, as we briefly explain below. For the sake of maximizing readability of this paper, we describe our methodology in detail in the ‘Material and Methods’ Appendix.
We started with a GHTorrent (Gousios, 2013) dataset that contained public data on pull requests from June 7, 2010 to April 1, 2015, as well as data about users and projects. We then augmented this GHTorrent data by mining GitHub’s webpages for information about each pull request status, description, and comments.
GitHub does not request information about users’ genders. While previous approaches have used gender inference (Vasilescu, Capiluppi & Serebrenik, 2014; Vasilescu et al., 2015), we took a different approach—linking GitHub accounts with social media profiles where the user has self-reported gender. Specifically, we extract users’ email addresses from GHTorrent, look up that email address on the Google+ social network, then, if that user has a profile, extract gender information from these users’ profiles. Out of 4,037,953GitHub user profiles with email addresses, we were able to identify 1,426,127 (35.3%) of them as men or women through their public Google+ profiles. We are the first to use this technique, to our knowledge.
We recognize that our gender linking approach raises privacy concerns, which we have taken several steps to address. First, this research has undergone human subjects IRB review, research that is based entirely on publicly available data. Second, we have informed Google about our approach in order to determine whether they believe our approach to linking email addresses to gender is a privacy violation of their users; they responded that it is consistent with Google’s terms of service (https://sites.google.com/site/bughunteruniversity/nonvuln/discover-your-name-based-on-e-mail-address). Third, to protect the identities of the people described in this study to the extent possible, we do not plan to release our data that links GitHub users to genders.
Results
We describe our results in this section; data is available in Supplemental Files.
Are women’s pull requests less likely to be accepted?
We hypothesized that pull requests made by women are less likely to be accepted than those made by men. Prior work on gender bias in hiring—that a job application with a woman’s name is evaluated less favorably than the same application with a man’s name (Moss-Racusin et al., 2012)—suggests that this hypothesis may be true.
To evaluate this hypothesis, we looked at the pull status of every pull request submitted by women compared to those submitted by men. We then calculate the merge rate and corresponding confidence interval, using the Clopper–Pearson exact method (Clopper & Pearson, 1934), and find the following:
| Gender | Open | Closed | Merged | Merge Rate | 95% Confidence interval |
| Women | 8,216 | 21,890 | 111,011 | 78.7% | [78.45%,78.88%] |
| Men | 150,248 | 591,785 | 2,181,517 | 74.6% | [74.57%,74.67%] |
The hypothesis is not only false, but it is in the opposite direction than expected; women tend to have their pull requests accepted at a higher rate than men! This difference is statistically significant (χ2(df = 1, n = 3, 064, 667) = 1, 170, p < .001). What could explain this unexpected result?
Open source effects
Perhaps our GitHub data are not representative of the open source community; while all projects we analyzed were public, not all of them are licensed as open source. Nonetheless, if we restrict our analysis to just projects that are explicitly licensed as open source, women continue to have a higher acceptance rate (χ2(df = 1, n = 1, 424, 127) = 347, p < .001):
| Gender | Open | Closed | Merged | Merge Rate | 95% Confidence Interval |
| Women | 1,573 | 7,669 | 32,944 | 78.1% | [77.69%,78.49%] |
| Men | 60,476 | 297,968 | 1,023,497 | 74.1% | [73.99%,74.14%] |
Insider effects
Perhaps women’s high acceptance rate is because they are already well known in the projects they make pull requests in. Pull requests can be made by anyone, including both insiders (explicitly authorized owners and collaborators) and outsiders (other GitHub users). If we exclude insiders from our analysis, the women’s acceptance rate (62.1% [61.65%,62.53%]) continues to be significantly higher than men’s (60.7% [60.65%,60.82%]) (χ2(df = 1, n = 1, 372, 834) = 35, p < .001).
Experience effects
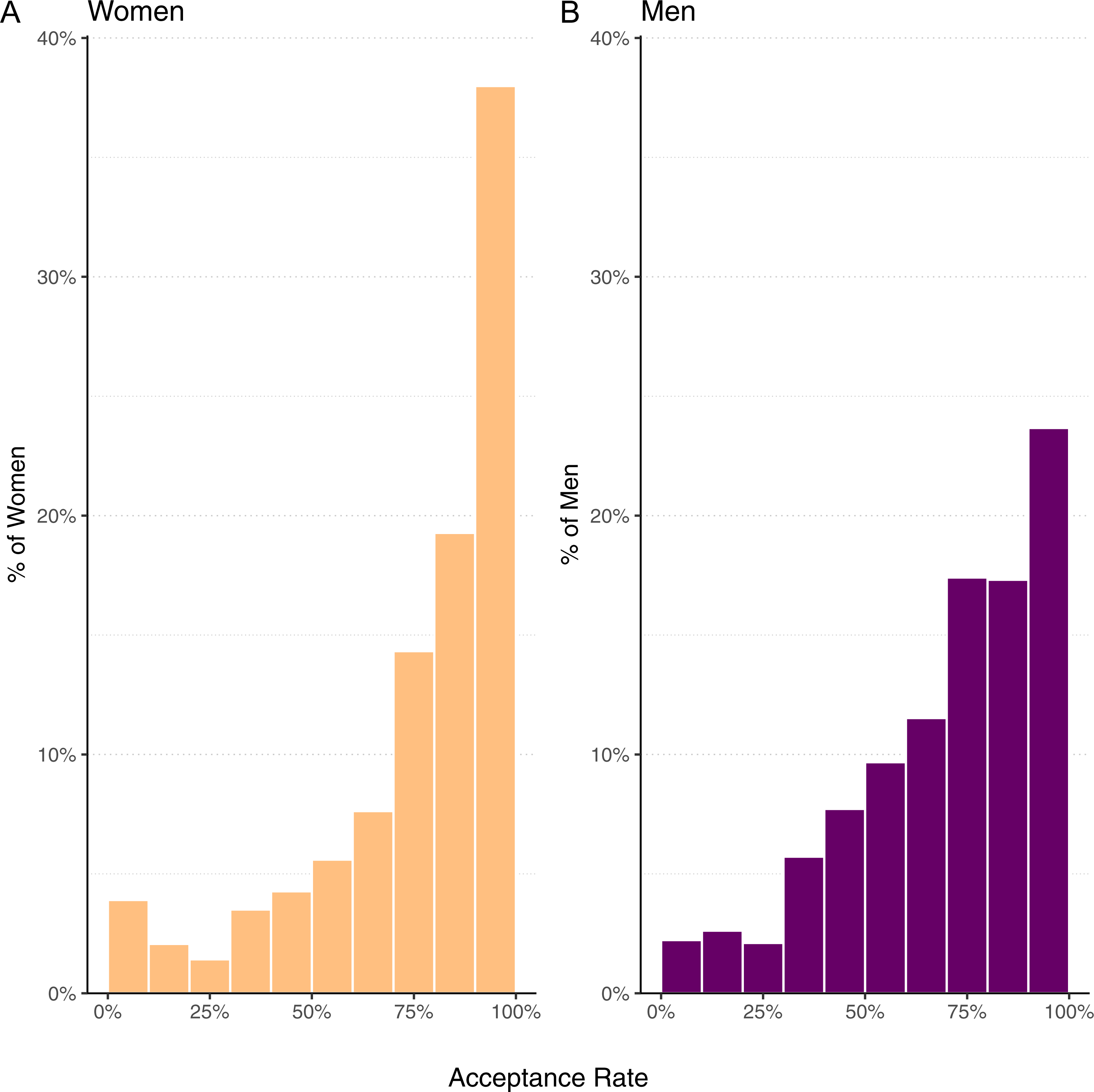
Perhaps only a few highly successful and prolific women, responsible for a substantial part of overall success, are skewing the results. To test this, we calculated the pull request acceptance rate for each woman and man with 5 or more pull requests, then found the average acceptance rate across those two groups. The results are displayed in Fig. 2. We notice that women tend to have a bimodal distribution, typically being either very successful (>90% acceptance rate) or unsuccessful (<10%). But these data tell the same story as the overall acceptance rate; women are more likely than men to have their pull requests accepted.
Why might women have a higher acceptance rate than men, given the gender bias documented in the literature? In the remainder of this section, we will explore this question by evaluating several hypotheses that might explain the result.
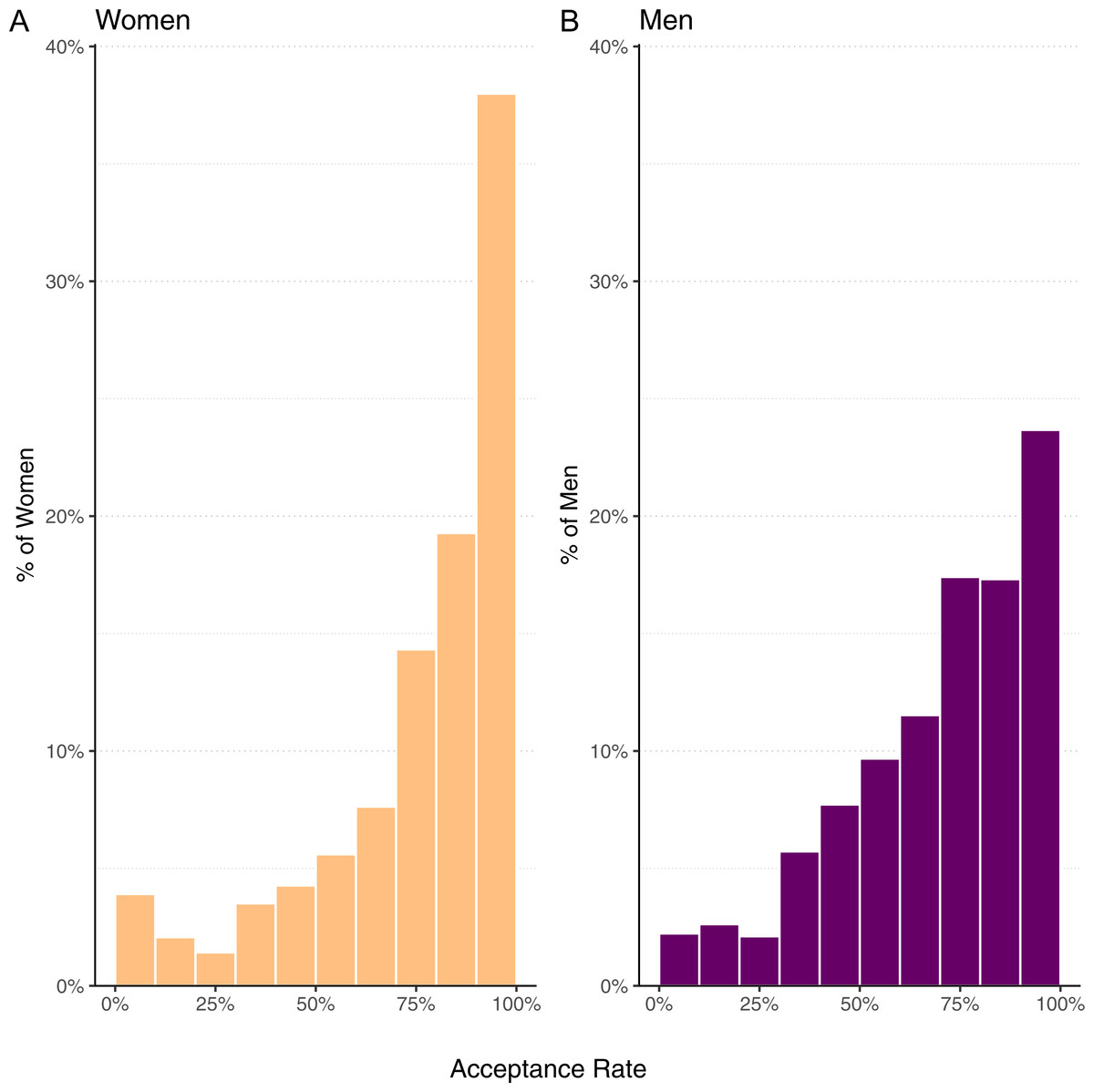
Figure 2: Histogram of mean acceptance rate per developer for women (mean 76.9%, median 84.9%) and men (mean 71.0%, median 76.0%).
{kind=link}
Do women’s pull request acceptance rates start low and increase over time?
One plausible explanation is that women’s first few pull requests get rejected at a disproportionate rate compared to men’s, so they feel dejected and do not make future pull requests. This explanation is supported by Reagle’s account of women’s participation in virtual collaborative environments, where an aggressive argument style is necessary to justify one’s own contributions, a style that many women may find to be not worthwhile (Reagle, 2012). Thus, the overall higher acceptance rate for women would be due to survivorship bias within GitHub; the women who remain and do the majority of pull requests would be better equipped to contribute, and defend their contributions, than men. Thus, we might expect that women have a lower acceptance rate than men for early pull requests but have an equivalent acceptance rate later.
To evaluate this hypothesis, we examine pull request acceptance rate over time, that is, the mean acceptance rate for developers on their first pull request, second pull request, and so on. Figure 3 displays the results. Orange points represent the mean acceptance rate for women, and purple points represent acceptance rates for men. Shaded regions indicate the pointwise 95% Clopper–Pearson confidence interval.
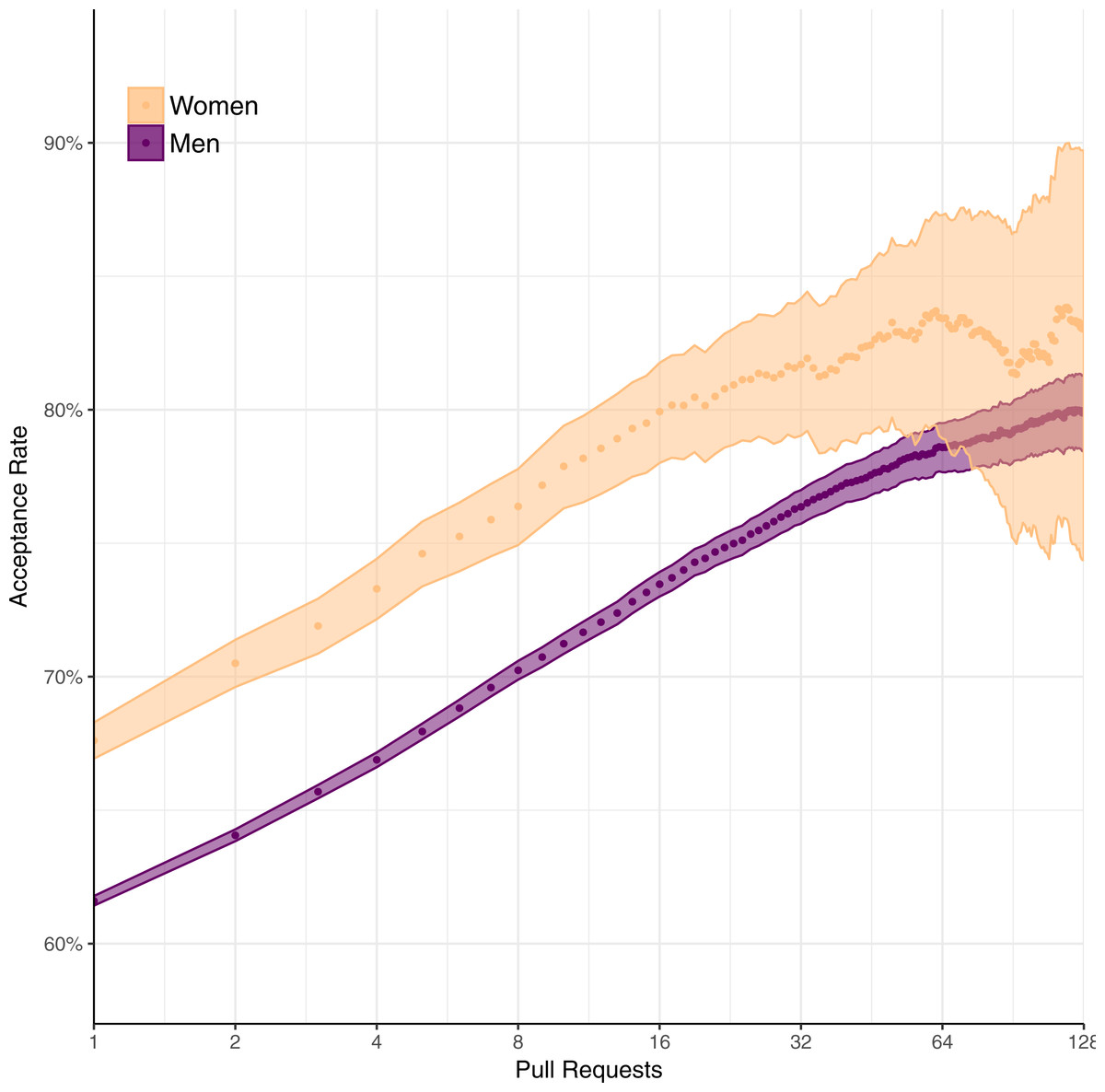
Figure 3: Pull request acceptance rate over time.
{kind=link}
While developers making their initial pull requests do get rejected more often, women generally still maintain a higher rate of acceptance throughout. The acceptance rate of women tends to fluctuate at the right of the graph, because the acceptance rate is affected by only a few individuals. For instance, at 128 pull requests, only 103 women are represented. Intuitively, where the shaded region for women includes the corresponding data point for men, the reader can consider the data too sparse to conclude that a substantial difference exists between acceptance rates for women and men. Nonetheless, between 1 and 64 pull requests, women’s higher acceptance rate remains. Thus, the evidence casts doubt on our hypothesis.
Are women focusing their efforts on fewer projects?
One possible explanation for women’s higher acceptance rates is that they are focusing their efforts more than men; perhaps their success is explained by doing pull requests on few projects, whereas men tend to do pull requests on more projects. First, the data do suggest that women tend to contribute to fewer projects than men. While the median number of projects contributed to via pull request is 1 for both genders (that is, the 50th percentile of developers); at the 75th percentile it is 2 for women and 3 for men, and at the 90th percentile it is 4 for women and 7 for men.
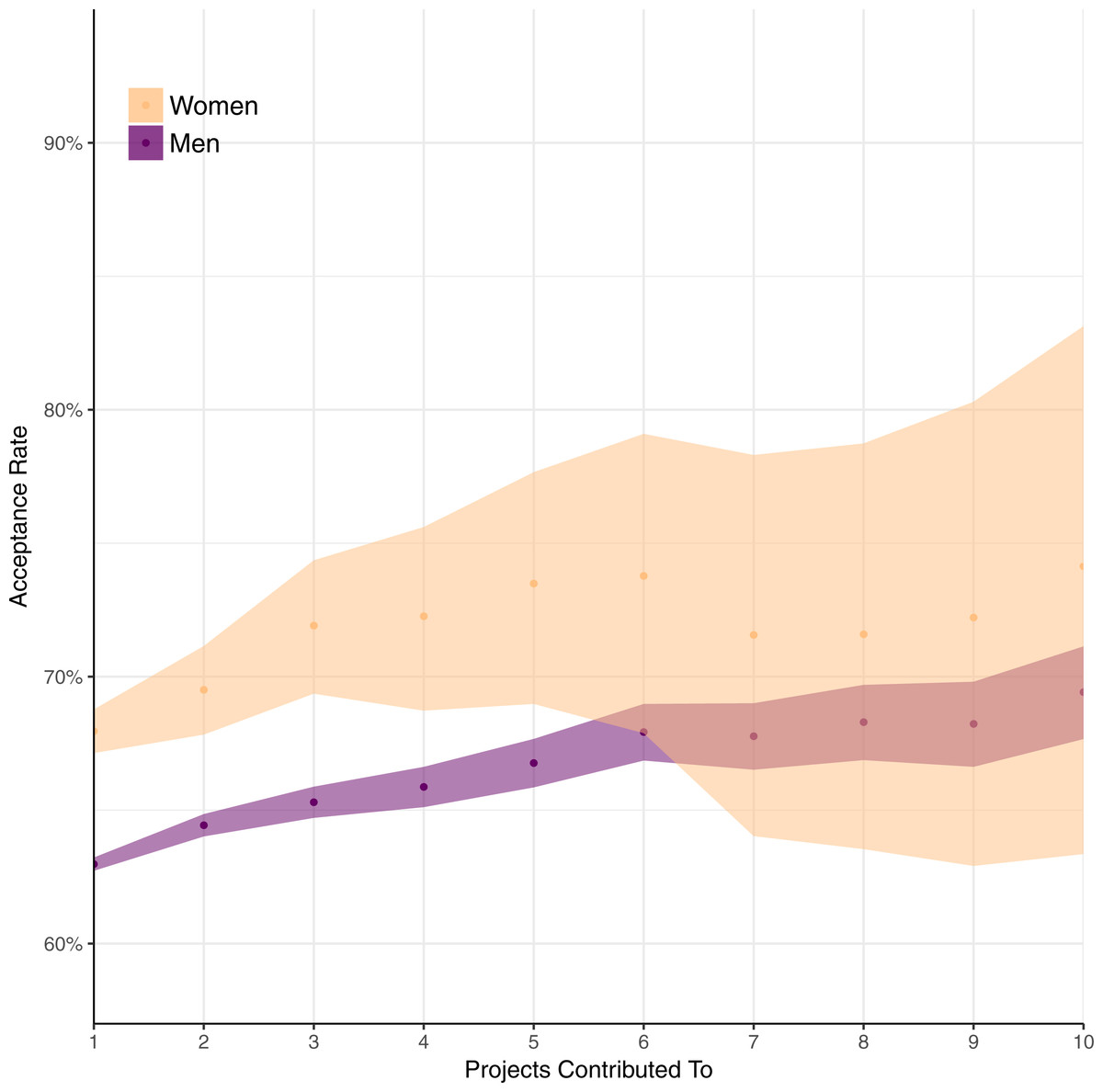
Figure 4: Pull request acceptance rate by number of projects contributed to.
{kind=link}
But the fact that women tend to contribute to fewer projects does not explain why women tend to have a higher acceptance rate. To see why, consider Fig. 4; on the y axis is mean acceptance rate by gender, and on the x axis is number of projects contributed to. When contributing to between 1 and 5 projects, women have a higher acceptance rate as they contribute to more projects. Beyond 5 projects, the 95% confidence interval indicates women’s data are too sparse to draw conclusions confidently.
Are women making pull requests that are more needed?
Another explanation for women’s pull request acceptance rate is that, perhaps, women disproportionately make contributions that projects need more specifically. What makes a contribution “needed” is difficult to assess from a third-party perspective. One way is to look at which pull requests link to issues in projects’ GitHub issue trackers. If a pull request references an issue, we consider it to serve a more specific and recognized need than an otherwise comparable one that does not. To support this argument with data, we randomly selected 30 pull request descriptions that referenced issues; in 28 cases, the reference was an attempt to fix all or part of an issue. Based on this high probability, we can assume that when someone references an issue in a pull request description, they usually intend to fix a specific problem in the project. Thus, if women more often submit pull requests that address an documented need and this is enough to improve acceptance rates, we would expect that these same requests are more often linked to issues.
We evaluate this hypothesis by parsing pull request descriptions and calculating the percentage of pulls that reference an issue. To eliminate projects that do not use issues or do not customarily link to them in pull requests, we analyze only pull requests in projects that have at least one linked pull request. Here are the results:
| Gender | Without reference | With reference | % | 95% Confidence Interval |
| Women | 33,697 | 4,748 | 12.4% | [12.02%,12.68%] |
| Men | 1,196,519 | 182,040 | 13.2% | [13.15%,13.26%] |
This data show a statistically significant difference (χ2(df = 1, n = 1, 417, 004) = 24, p < .001). Contrary to the hypothesis, women are slightly less likely to submit a pull request that mentions an issue, suggesting that women’s pull requests are less likely to fulfill an documented need. Note that this does not imply women’s pull requests are less valuable, but instead that the need they fulfill appears less likely to be recognized and documented before the pull request was created. Regardless, the result suggests that women’s increased success rate is not explained by making more specifically needed pull requests.
Are women making smaller changes?
Maybe women are disproportionately making small changes that are accepted at a higher rate because the changes are easier for project owners to evaluate. This is supported by prior work on pull requests suggesting that smaller changes tend to be accepted more than larger ones (Gousios, Pinzger & Deursen, 2014).
We evaluated the size of the contributions by analyzing lines of code, modified files, and number of commits included. The following table lists the median and mean lines of code added, removed, files changed, and commits across 3,062,677 pull requests:
| Lines added | Lines removed | Files changed | Commits | ||
| Women | Median | 29 | 5 | 2 | 1 |
| Mean | 1,591 | 597 | 29.2 | 5.2 | |
| Men | Median | 20 | 4 | 2 | 1 |
| Mean | 1,003 | 431 | 26.8 | 4.8 | |
| t-test | Statistic | 5.74 | 3.03 | 1.52 | 7.36 |
| df | 146,897 | 149,446 | 186,011 | 155,643 | |
| p | <.001 | 0.0024554 | 0.12727 | <.001 | |
| CI | [387.3,789.3] | [58.3,272] | [−0.7,5.4] | [0.3,0.5] |
The bottom of this chart includes Welch’s t-test statistics, comparing women’s and men’s metrics, including 95% confidence intervals for the mean difference. For three of four measures of size, women’s pull requests are significantly larger than men’s.
One threat to this analysis is that lines added or removed may exaggerate the size of a change whenever a refactoring is performed. For instance, if a developer moves a 1,000-line class from one folder to another, even though the change may be relatively benign, the change will show up as 1,000 lines added and 1,000 lines removed. Although this threat is difficult to mitigate definitively, we can begin to address it by calculating the net change for each pull request as the number of added lines minus the number of removed lines. Here is the result:
| Net lines changed | ||
| Women | Median | 11 |
| Mean | 995 | |
| Men | Median | 7 |
| Mean | 571 | |
| t-test | Statistic | 4.06 |
| df | 148,010 | |
| p | <.001 | |
| CI | [218.9,627.4] |
This difference is also statistically significant. So even in the face of refactoring, the conclusion holds: women make pull requests that add and remove more lines of code, and contain more commits. This is consistent with larger changes women make on Wikipedia (Antin et al., 2011).
Are women’s pull requests more successful when contributing code?
One potential explanation for why women get their pull requests accepted more often is that the kinds of changes they make are different. For instance, changes to HTML could be more likely to be accepted than changes to C code, and if women are more likely to change HTML, this may explain our results. Thus, if we look only at acceptance rates of pull requests that make changes to program code, women’s high acceptance rates might disappear. For this, we define program code as files that have an extension that corresponds to a Turing-complete programming language. We categorize pull requests as belonging to a single type of source code change when the majority of lines modified were to a corresponding file type. For example, if a pull request changes 10 lines in .js (javascript) files and 5 lines in .html files, we include that pull request and classify it as a .js change.
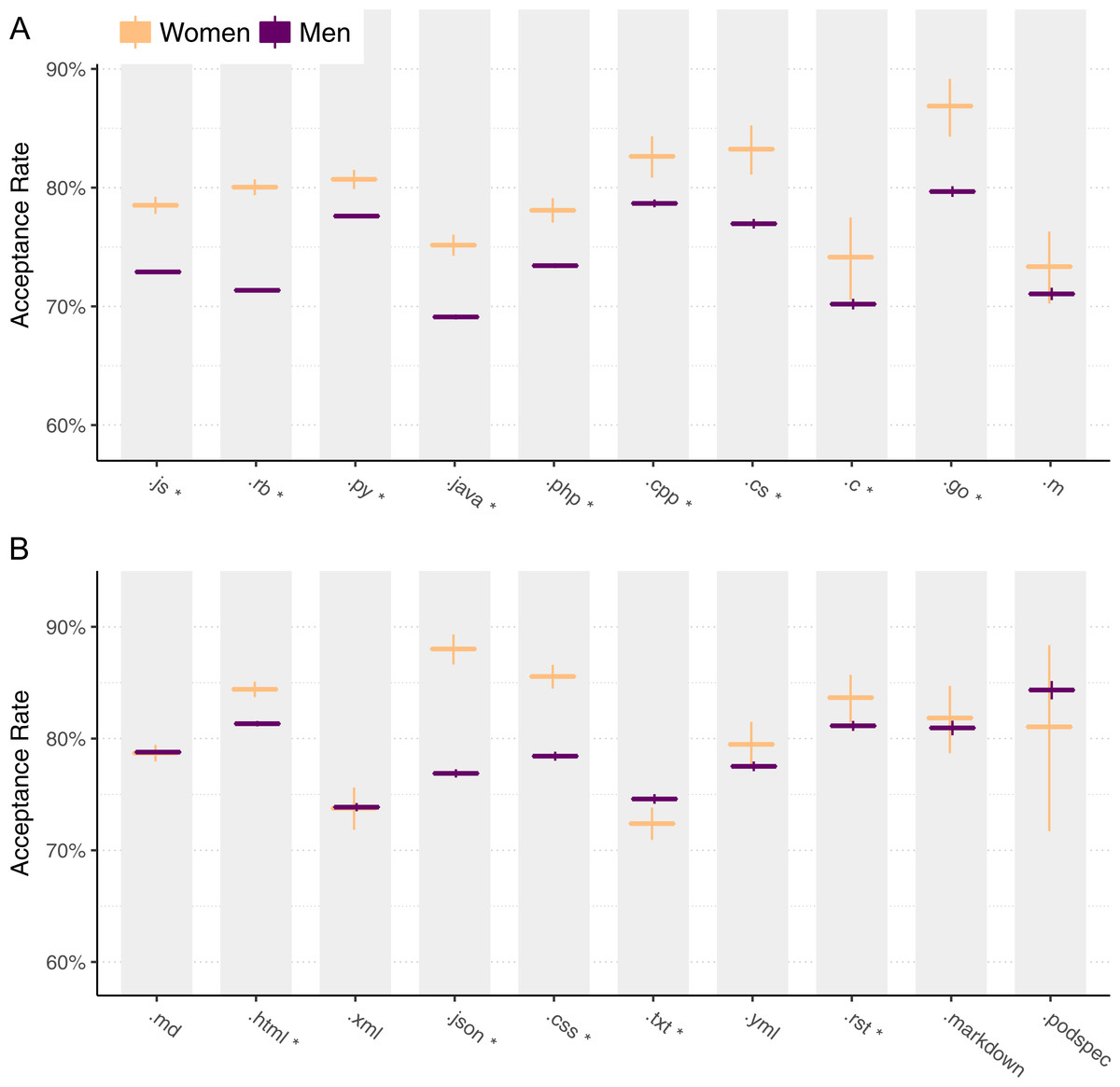
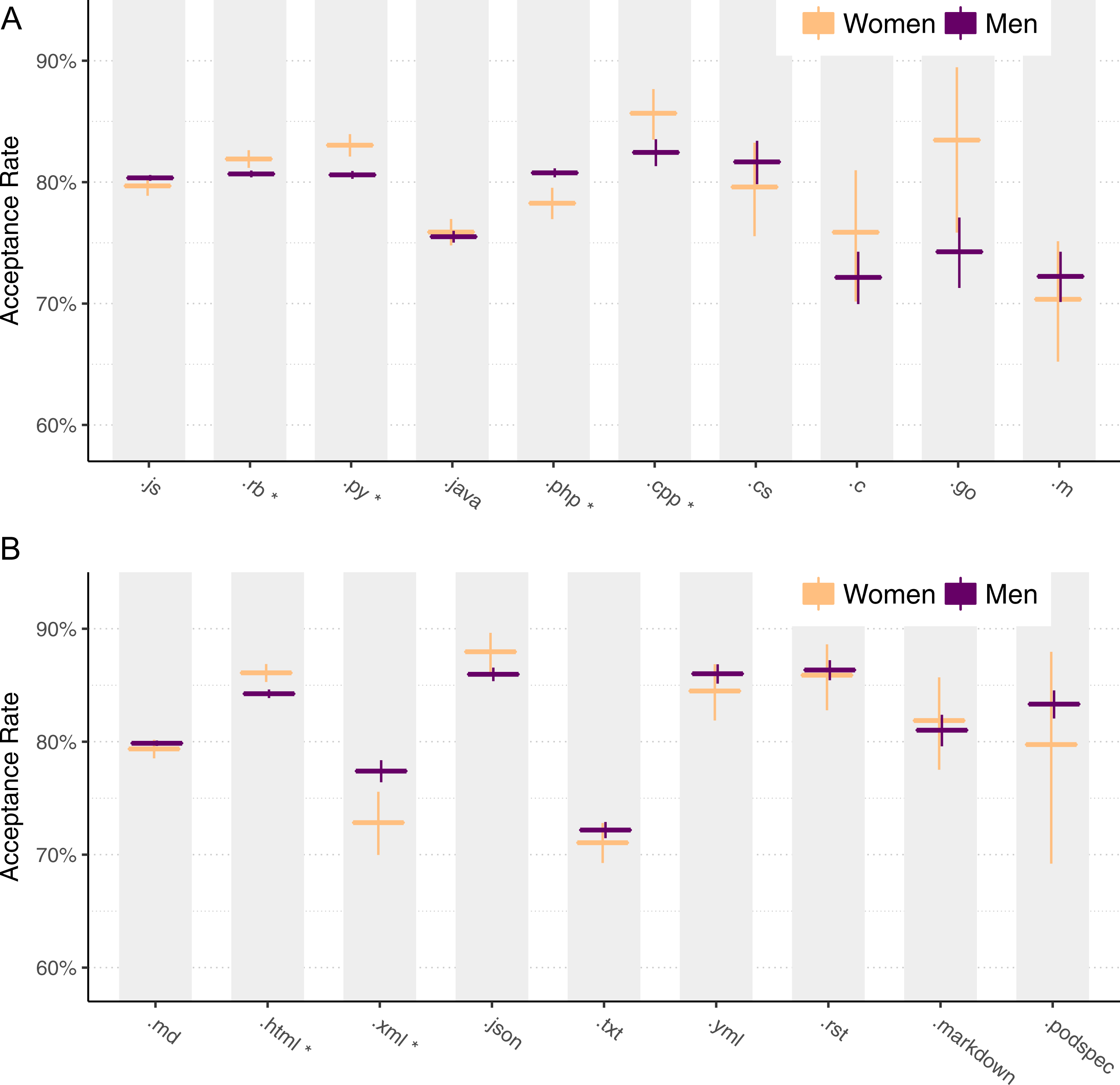
Figure 5: Pull request acceptance rate by file type, for programming languages (A) and non-programming languages (B).
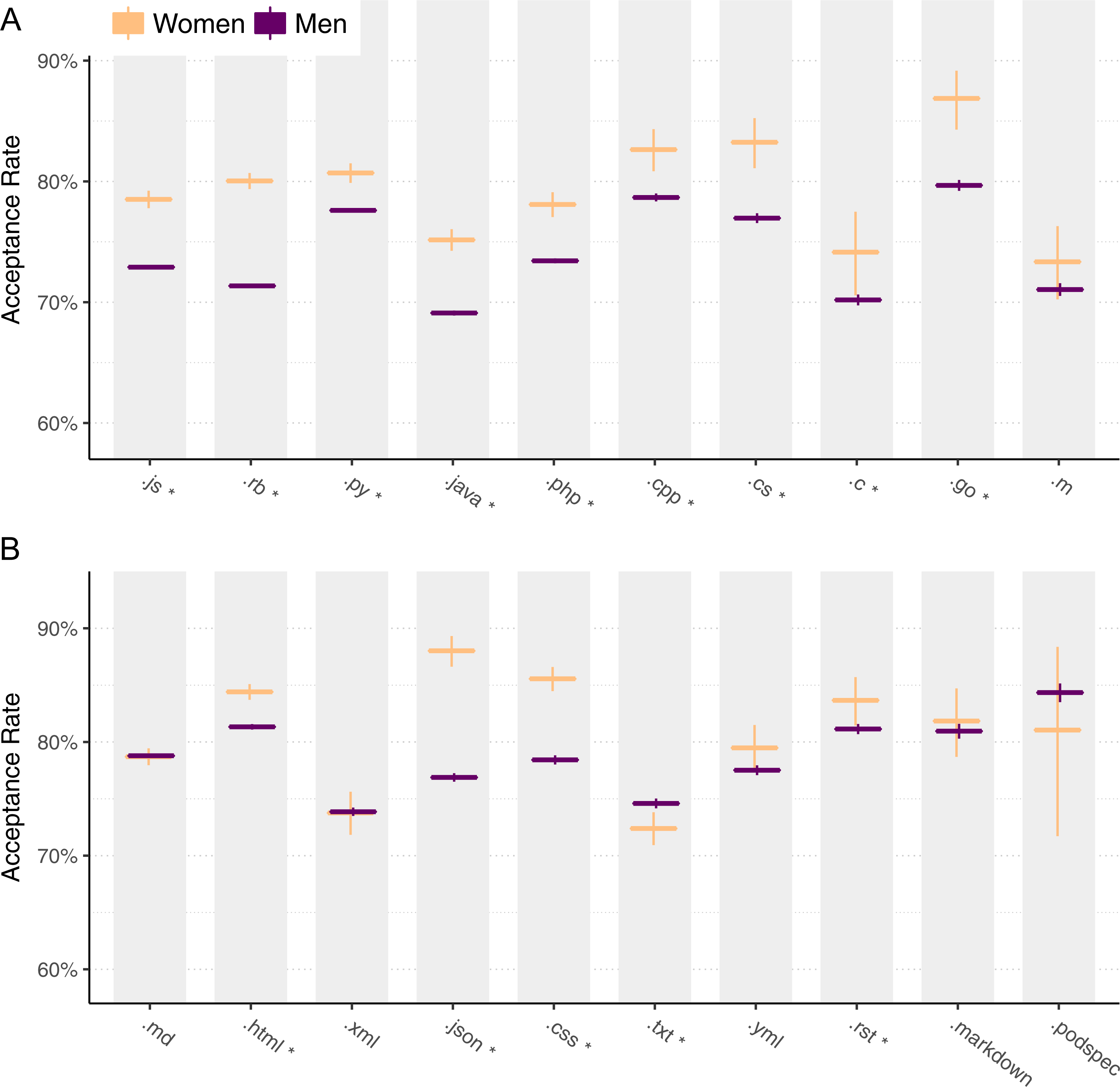{kind=link}
Figure 5 shows the results for the 10 most common programming language files (Fig. 5A) and the 10 most common non-programming language files (Fig. 5B). Each pair of bars summarizes pull requests classified as part of a programming language file extension, where the height of each bar represents the acceptance rate and each bar contains a 95% Clopper–Pearson confidence interval. An asterisk (*) next to a language indicates a statistically significant difference between men and women for that language using a chi-squared test, after a Benjamini–Hochberg correction (Benjamini & Hochberg, 1995) to control for false discovery.
Overall, we observe that women’s acceptance rates are higher than men’s for almost every programming language. The one exception is .m, which indicates Objective-C and Matlab, for which the difference is not statistically significant.
Is a woman’s pull request accepted more often because she appears to be a woman?
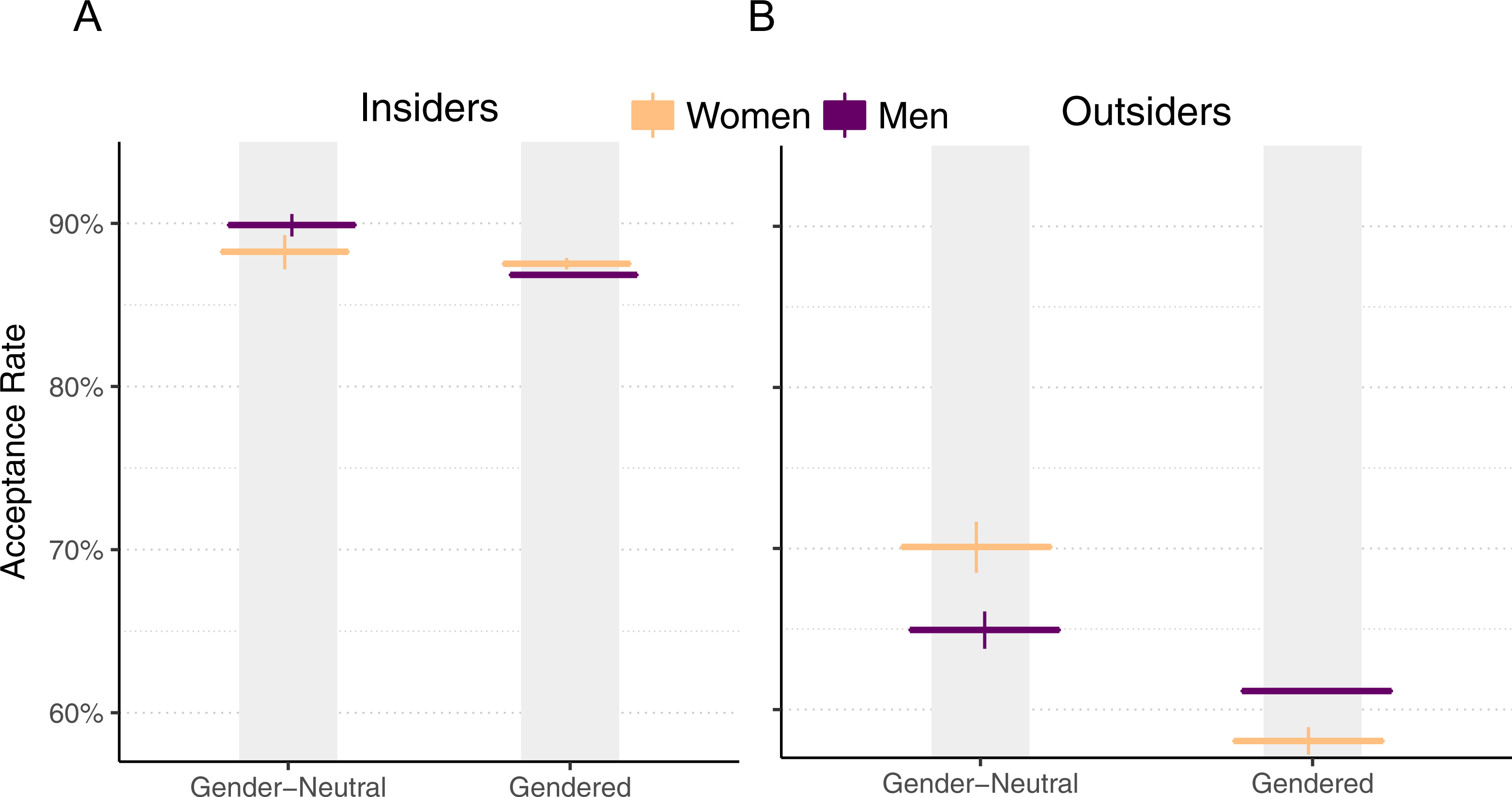
Another explanation as to why women’s pull requests are accepted at a higher rate would be what McLoughlin calls Type III bias: “the singling out of women by gender with the intention to help” (McLoughlin, 2005). In our context, project owners may be biased towards wanting to help women who submit pull requests, especially outsiders to the project. In contrast, male outsiders without this benefit may actually experience the opposite effect, as distrust and bias can be stronger in stranger-to-stranger interactions (Landy, 2008). Thus, we expect that women who can be perceived as women are more likely to have their pull requests accepted than women whose gender cannot be easily inferred, especially when compared to male outsiders.
We evaluate this hypothesis by comparing pull request acceptance rate of developers who have gender-neutral GitHub profiles and those who have gendered GitHub profiles. We define a gender-neutral profile as one where a gender cannot be readily inferred from their profile. Figure 1 gives an example of a gender-neutral GitHub user, “akofink”, who uses an identicon, an automatically generated graphic, and does not have a gendered name that is apparent from the login name. Likewise, we define a gendered profile as one where the gender can be readily inferred from the image or the name. Figure 1 also gives an example of a gendered profile; the profile of “JustinAMiddleton” is gendered because it uses a login name (Justin) commonly associated with men, and because the image depicts a person with masculine features (e.g., pronounced brow ridge (Brown & Perrett, 1993)). Clicking on a user’s name in pull requests reveals their profile, which may contain more information such as a user-selected display name (like “Justin Middleton”).
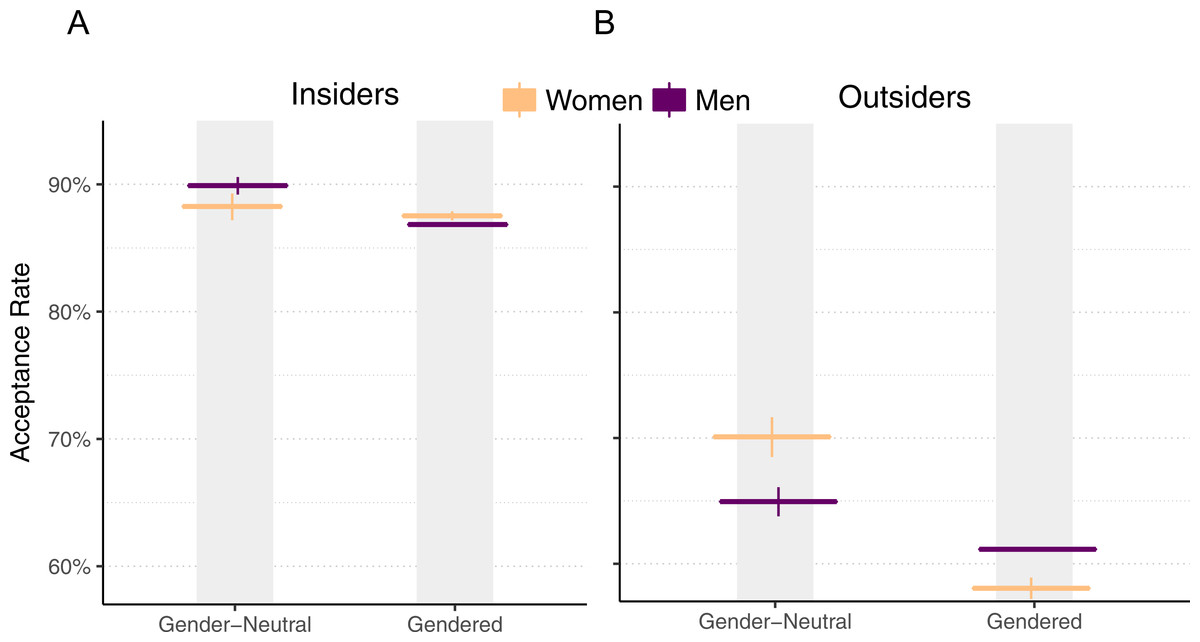
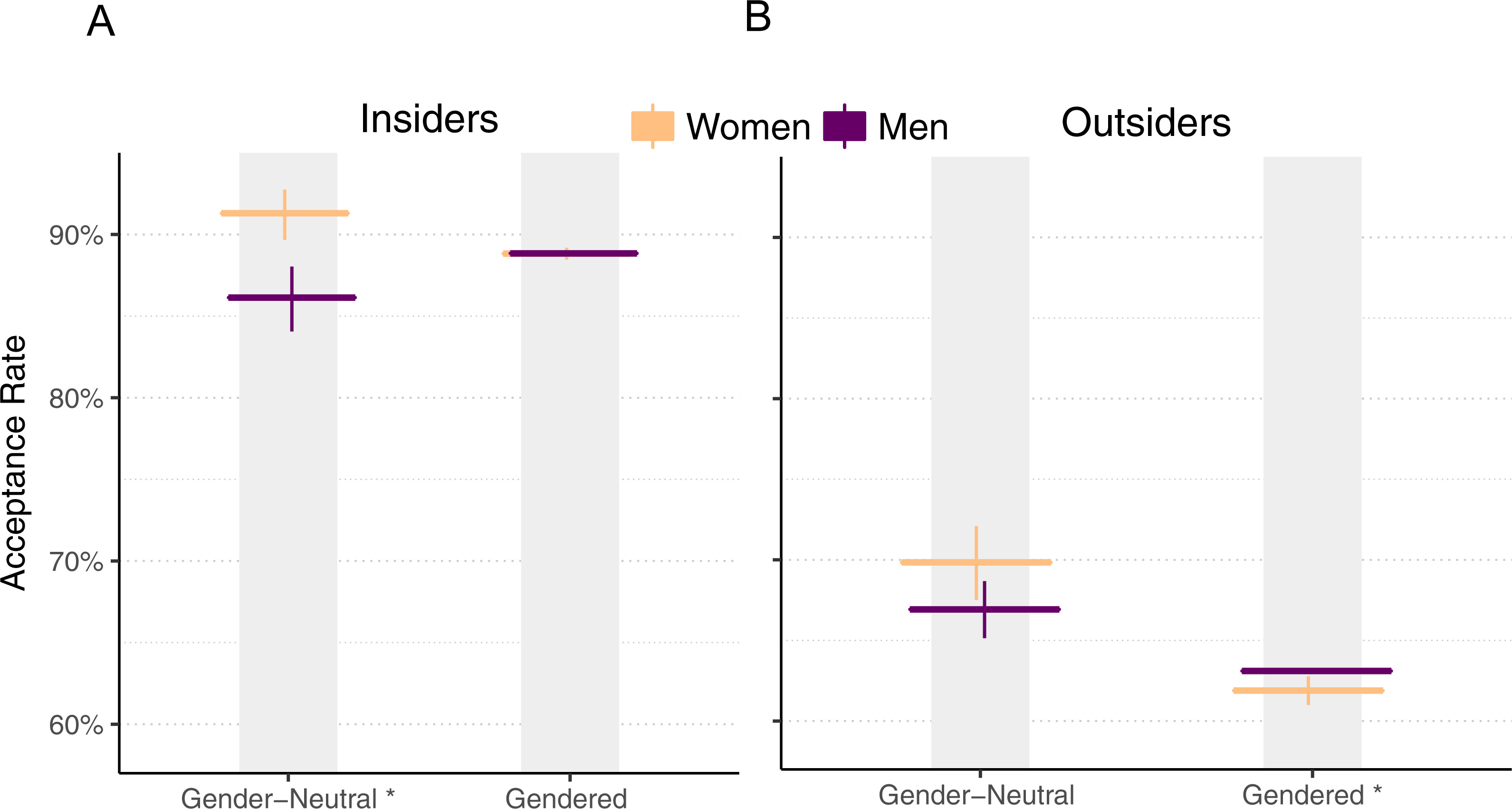
Figure 6: Pull request acceptance rate by gender and perceived gender, with 95% Clopper–Pearson confidence intervals, for insiders (A) and outsiders (B).
{kind=link}
Identifiable analysis
To obtain a sample of gendered and gender-neutral profiles, we used a combination of automated and manual techniques. For gendered profiles, we included GitHub users who used a profile image rather than an identicon and that Vasilescu and colleagues’ tool could confidently infer a gender from the user’s name (Vasilescu, Capiluppi & Serebrenik, 2014).For gender-neutral profiles, we included GitHub users that used an identicon, that the tool could not infer a gender for, and that a mixed-culture panel of judges could not guess the gender for.
While acceptance rate results so far have been robust to differences between insiders (people who are owners or collaborators of a project) versus outsiders (everyone else), for this analysis, there is a substantial difference between the two, so we treat each separately. Figure 6 shows the acceptance rates for men and women when their genders are identifiable versus when they are not, with pull requests submitted by insiders on the left and pull requests submitted by outsiders on the right.
Identifiable results
For insiders, we observe little evidence of bias when we compare women with gender-neutral profiles and women with gendered profiles, since both have similar acceptance rates. This can be explained by the fact that insiders likely know each other to some degree, since they are all authorized to make changes to the project, and thus may be aware of each others’ gender.
For outsiders, we see evidence for gender bias: women’s acceptance rates drop by 12.0% when their gender is identifiable, compared to when it is not (χ2(df = 1, n = 16, 258) = 158, p < .001). There is a smaller 3.8% drop for men (χ2(df = 1, n = 608,764) = 39, p < .001). Women have a higher acceptance rate of pull requests overall (as we reported earlier), but when they are outsiders and their gender is identifiable, they have a lower acceptance rate than men.
Are acceptance rates different if we control for covariates?
In analyses of pull request acceptance rates up until this point, covariates other than the variable of interest (gender) may also contribute to acceptance rates. We have previously shown an imbalance in covariate distributions for men and women (e.g., number of projects contributed to and number of changes made) and this imbalance may confound the observed gender differences. In this section, we re-analyze acceptance rates while controlling for these potentially confounding covariates using propensity score matching, a technique that supports causal inference by transforming a dataset from a non-randomized field study into a dataset that “looks closer to one that would result from a perfectly blocked (and possibly randomized) experiment” (Ho et al., 2011). That is, by making gender comparisons between subjects having the same propensity scores, we are able to remove the confounding effects, giving stronger evidence that any observed differences are primarily due to gender bias.
While full details of the matching procedure can be found in the Appendix, in short, propensity score matching works by matching data from one group to similar data in another group (in our case, men’s and women’s pull requests), then discards the data that do not match. This discarded data represent outliers, and thus the results from analyzing matched data may differ substantially from the results from analyzing the original data. The advantage of propensity score matching is that it controls for any differences we observed earlier that are caused by a measured covariate, rather than gender bias. One negative side effect of matching is that statistical power is reduced because the matched data are smaller than from the original dataset. We may also observe different results than in the larger analysis because we are excluding certain subjects from the population having atypical covariate value combinations that could influence the effects in the previous analyses.
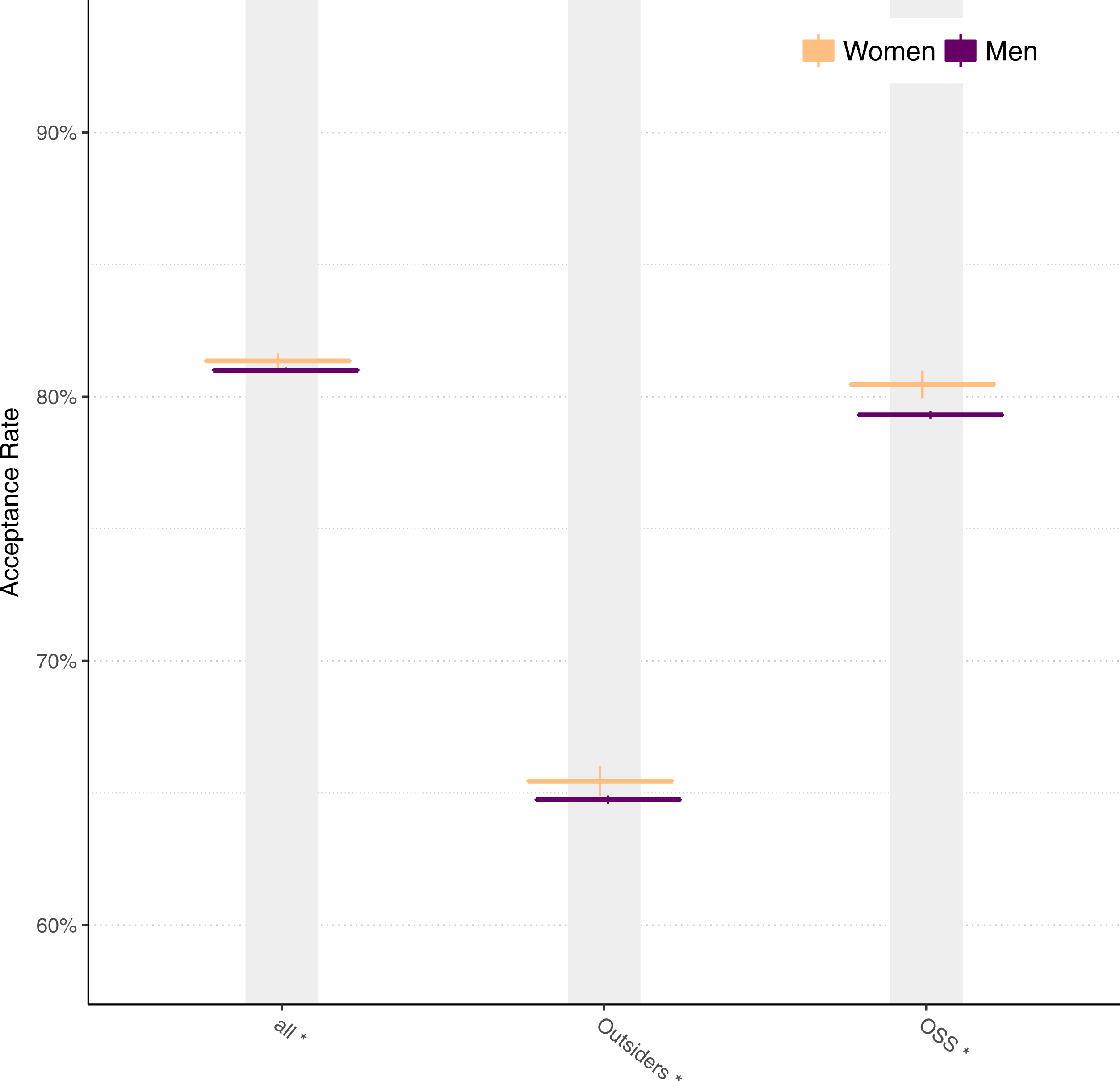
Figure 7 shows acceptance using matched data for all pull requests, for just pull requests from outsiders, and for just pull requests on projects that are open source (OSS) licenses. Asterisks (*) indicate that each difference is statistically significant using a chi-squared test, though the magnitude of the difference between men and women is smaller than for unmatched data.
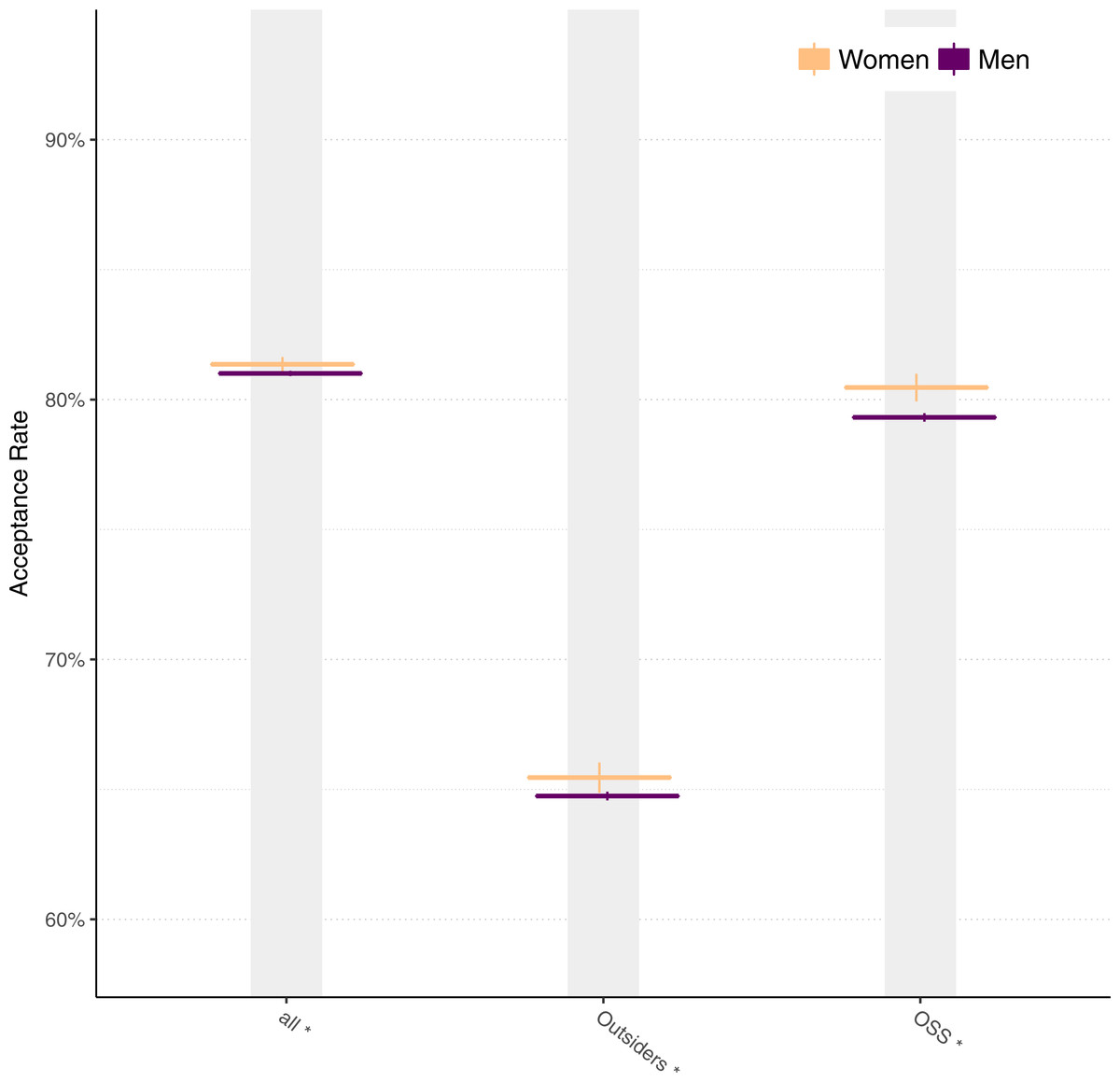
Figure 7: Acceptance rates for men and women for all data, outsiders, and open source projects using matched data.
{kind=link}
Figure 8 shows acceptance rates for matched data, analogous to Fig. 5. We calculate statistical significance with a chi-squared test, with a Benjamini–Hochberg correction (Benjamini & Hochberg, 1995). For programming languages, acceptance rates for three (Ruby, Python, and C + +) are significantly higher for women, and one (PHP) is significantly higher for men.
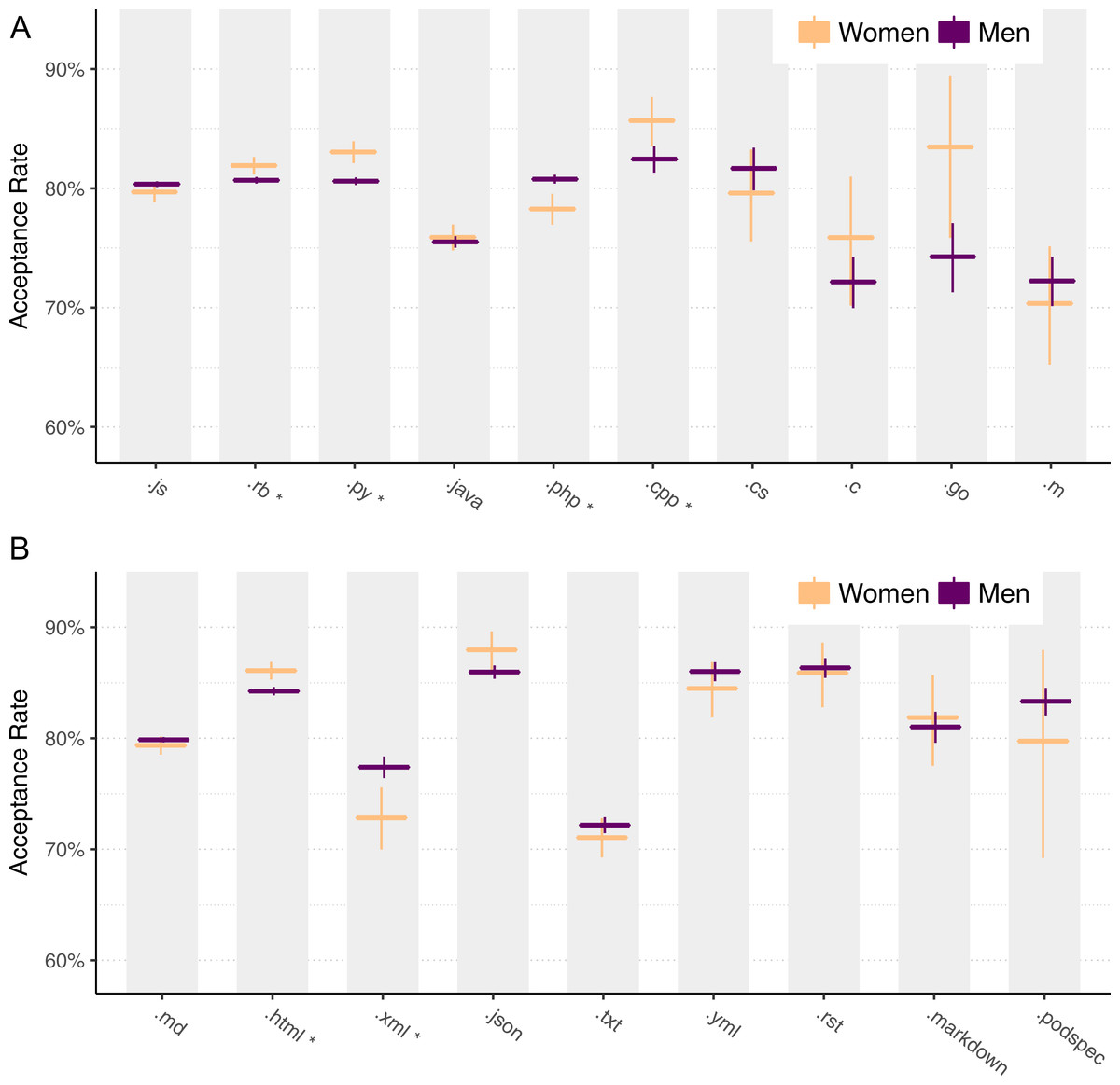
Figure 8: Acceptance rates for men and women using matched data by file type for programming languages (A) and non-programming languages (B).
{kind=link}
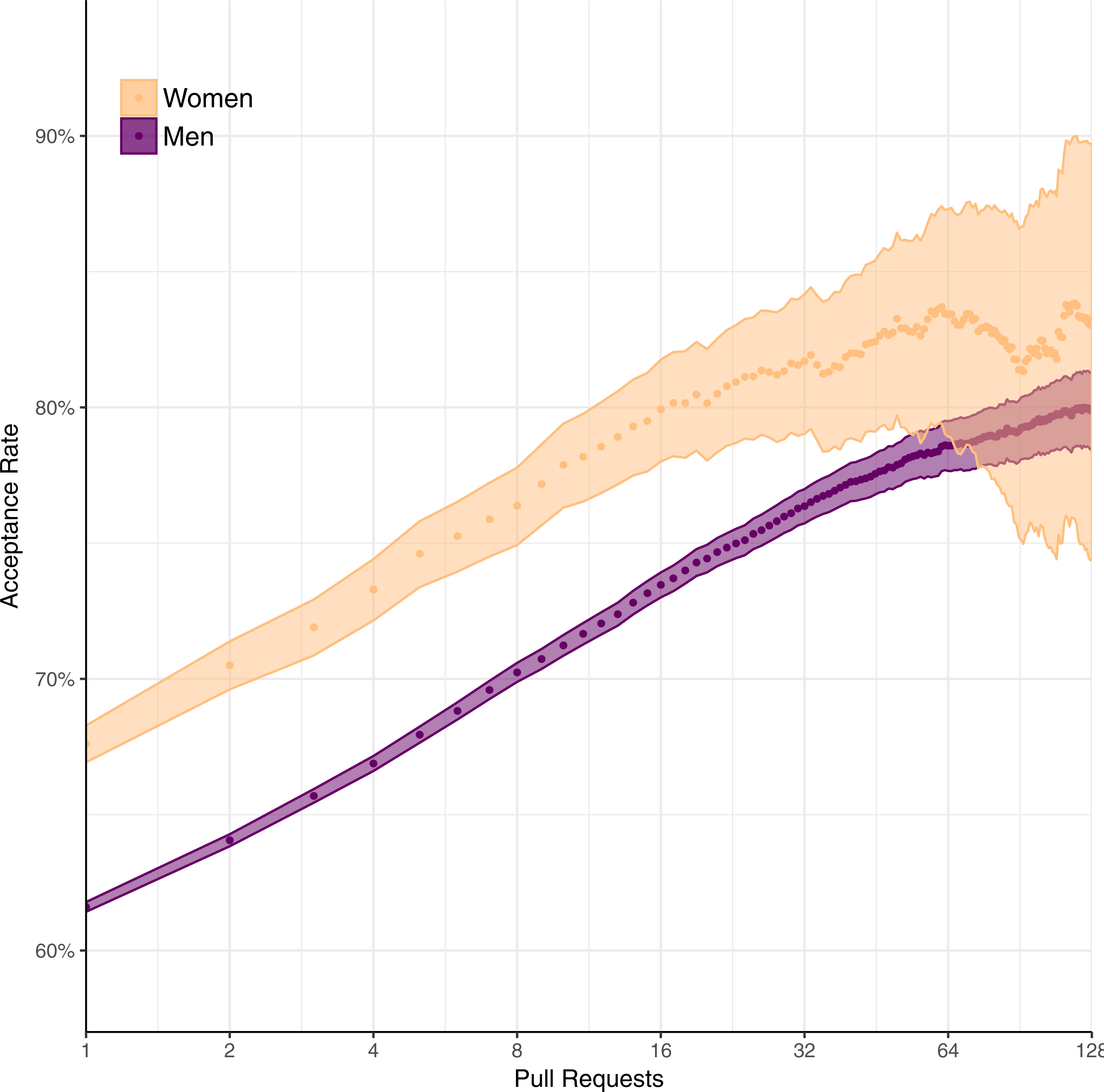
Figure 9 shows acceptance rates for matched data by pull request index, that is, for each user’s first pull request, second and third pull request, fourth through seventh pull request, and so on. We perform chi-squared tests and Benjamini–Hochberg corrections here as well. Compared to Fig. 3, most differences between genders diminish to the point of non-statistical significance.
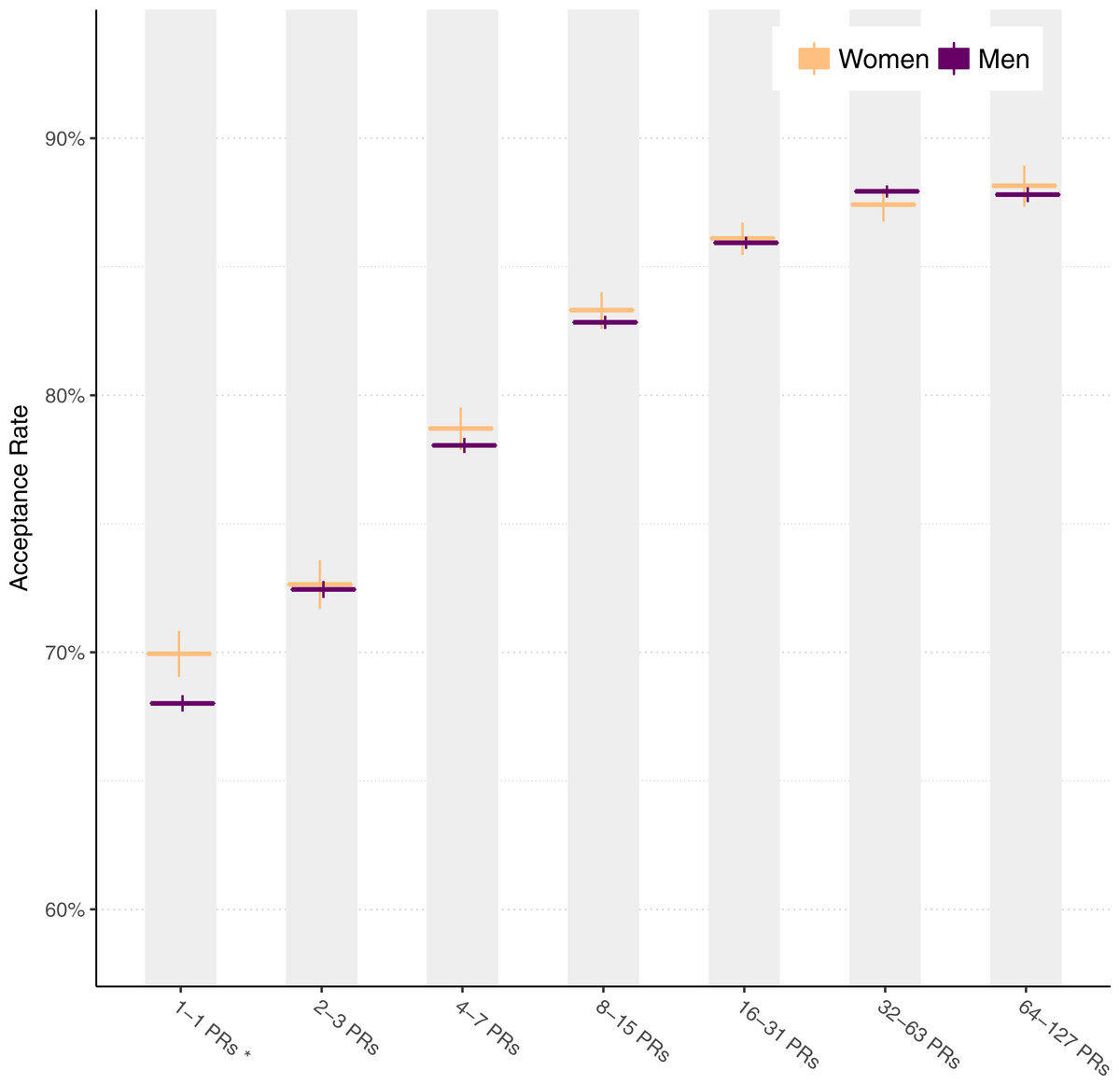
Figure 9: Pull request acceptance rate over time using matched data.
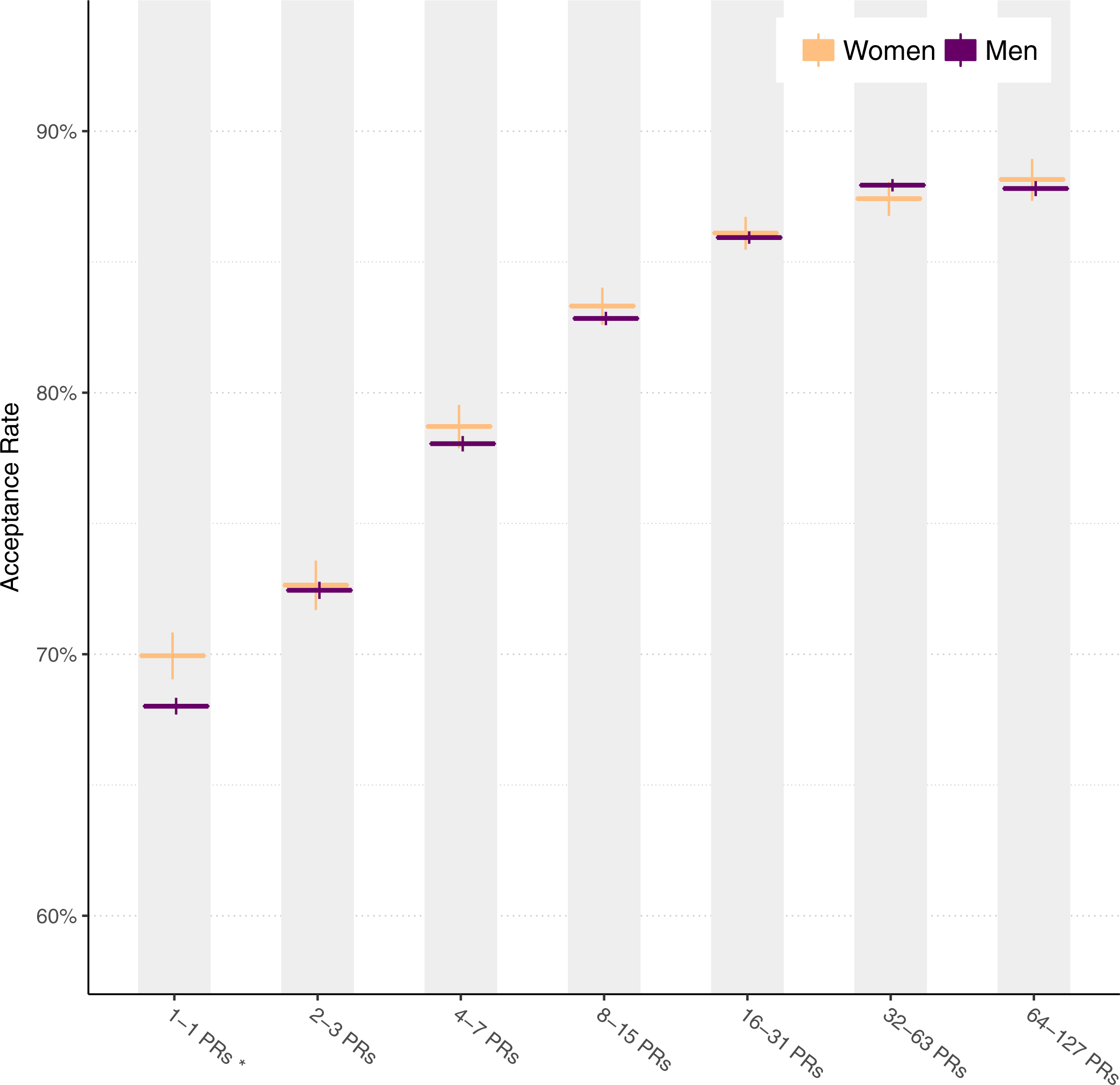{kind=link}
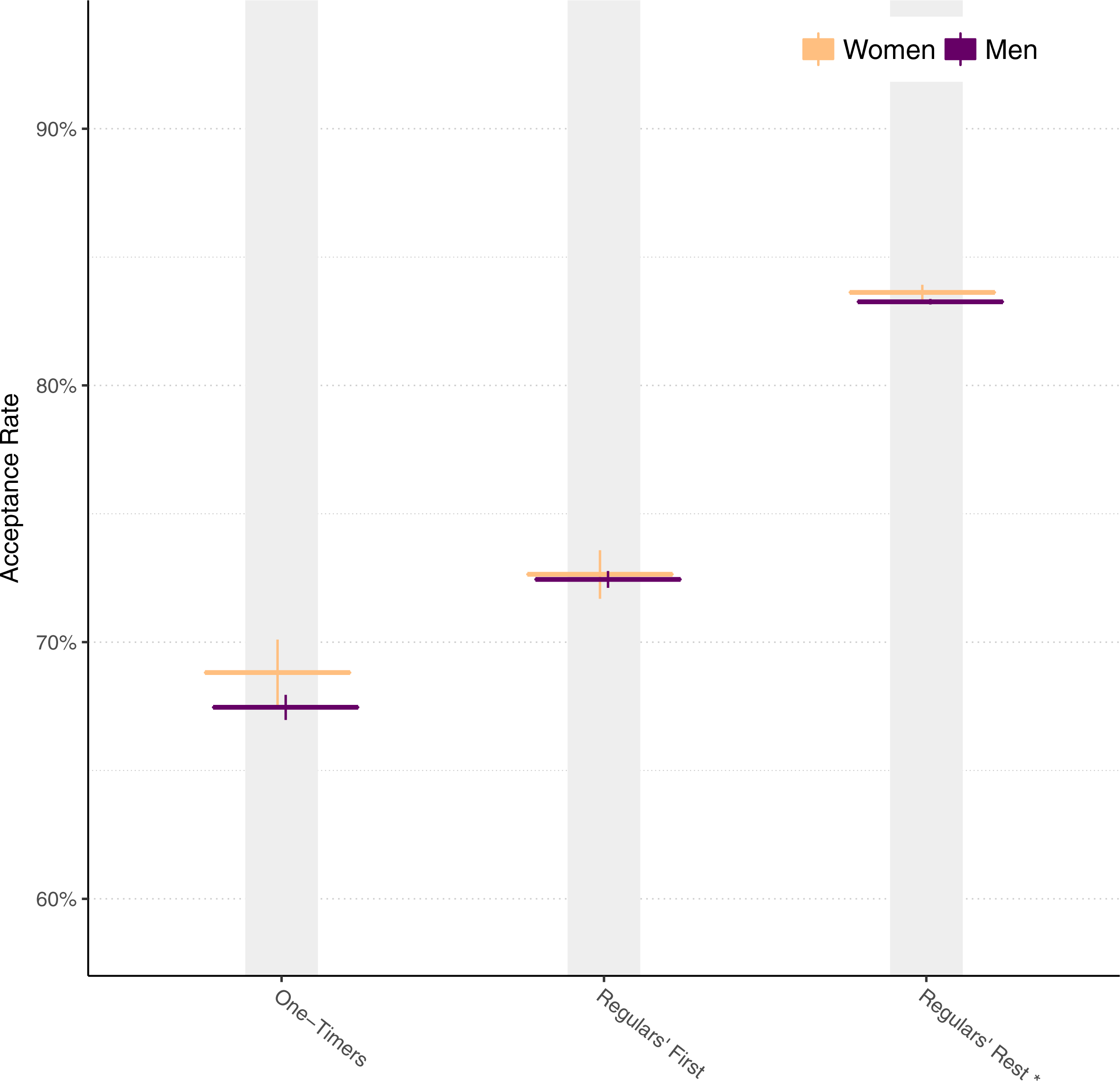
From Fig. 9, we might hypothesize that the overall difference in acceptance rates between genders is due to just the first pull request. To examine this, we separate the pull request acceptance rate into:
-
One-Timers: Pull requests from people who only ever submit one pull request.
-
Regulars’ First: First pull requests from people who go on to submit other pull requests.
-
Regulars’ Rest: All other (second and beyond) pull requests.
Figure 10 shows the results. Overall, women maintain a significantly higher acceptance rate beyond the first pull request, disconfirming the hypothesis.
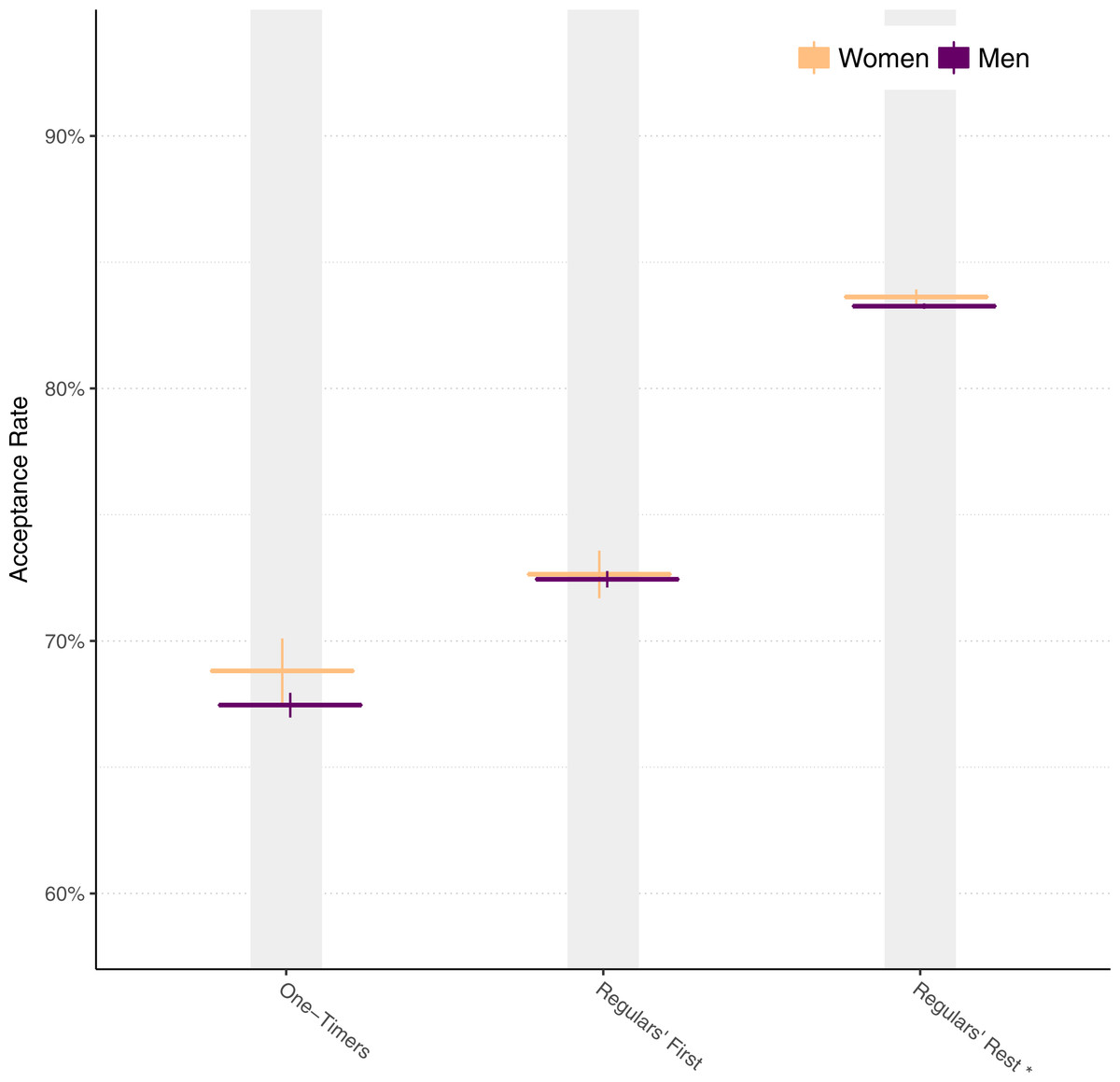
Figure 10: Acceptance rates for men and women broken down by category.
{kind=link}
We next investigate acceptance rate by gender and perceived gender using matched data. Here we match slightly differently, matching on identifiability (gendered, unknown, or neutral) rather than use of an identicon. Unfortunately, matching on identifiability (and the same covariates described in this section) reduces the sample size of gender neutral pulls by an order of magnitude, substantially reducing statistical power.1
Consequently, here we relax the matching criteria by broadening the equivalence classes for numeric variables. Figure 11 plots the result.
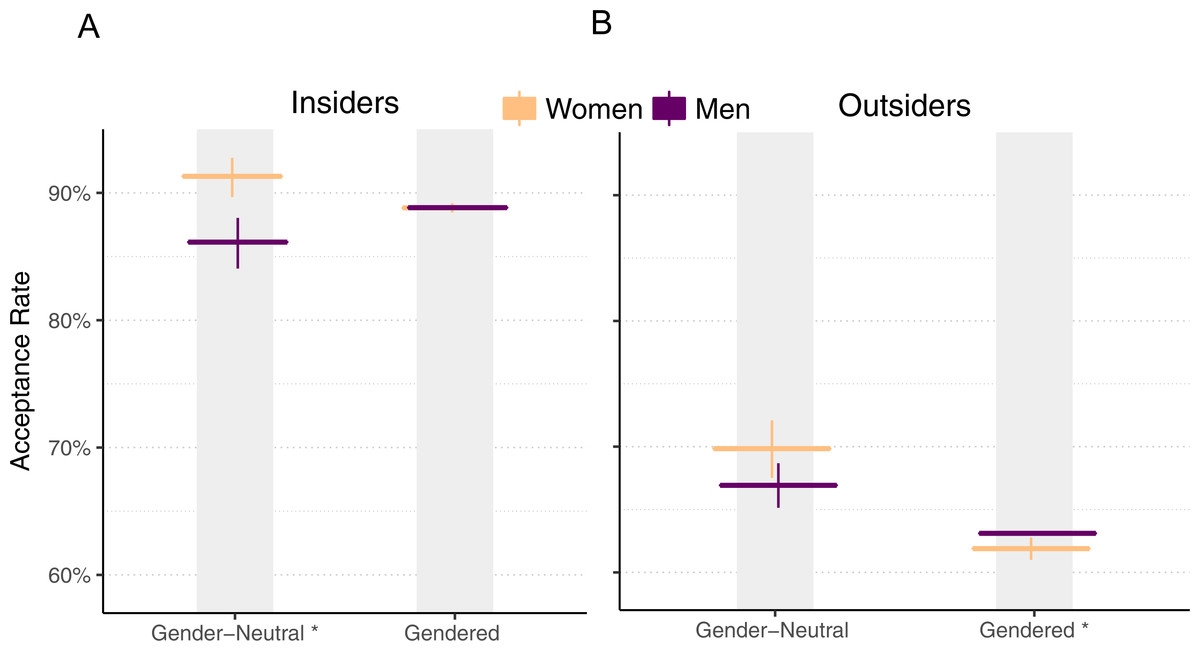
Figure 11: Pull request acceptance rate by gender and perceived gender, using matched data.
{kind=link}
For outsiders, while men and women perform similarly when their genders are neutral, when their genders are apparent, men’s acceptance rate is 1.2% higher than women’s (χ2(df = 1, n = 419,411) = 7, p < .01).
How has this matched analysis of the data changed our findings? Our observation about overall acceptance rates being higher for women remains, although the difference is smaller. Our observation about womens’ acceptance rates being higher than mens’ for all programming languages is now mixed; instead, women’s acceptance rate is significantly higher for three languages, but significantly lower for one language. Our observation that womens’ acceptance rates continue to outpace mens’ becomes less clear. Finally, for outsiders, although gender-neutral women’s acceptance rates no longer outpace men’s to a statistically significant extent, men’s pull requests continue to be accepted more often than women’s when the contributor’s gender is apparent.
Discussion
Why do differences exist in acceptance rates?
To summarize this paper’s observations:
-
Women are more likely to have pull requests accepted than men.
-
Women continue to have high acceptance rates as they do pull requests on more projects.
-
Women’s pull requests are less likely to serve an documented project need.
-
Women’s changes are larger.
-
Women’s acceptance rates are higher for some programming languages.
-
Men outsiders’ acceptance rates are higher when they are identifiable as men.
We next consider several alternative theories that may explain these observations as a whole.
Given observations 1–5, one theory is that a bias against men exists, that is, a form of reverse discrimination. However, this theory runs counter to prior work (e.g., Nafus, 2012), as well as observations 6.
Another theory is that women are taking fewer risks than men. This theory is consistent with Byrnes’ meta-analysis of risk-taking studies, which generally find women are more risk-averse than men (Byrnes, Miller & Schafer, 1999). However, this theory is not consistent with observation 4, because women tend to change more lines of code, and changing more lines of code correlates with an increased risk of introducing bugs (Mockus & Weiss, 2000).
Another theory is that women in open source are, on average, more competent than men. In Lemkau’s review of the psychology and sociology literature, she found that women in male-dominated occupations tend to be highly competent (Lemkau, 1979). This theory is consistent with observations 1–5. To be consistent with observations 6, we need to explain why women’s pull request acceptance rate drops when their gender is apparent. An addition to this theory that explains observation 6, and the anecdote described in the introduction, is that discrimination against women does exist in open source.
Assuming this final theory is the best one, why might it be that women are more competent, on average? One explanation is survivorship bias: as women continue their formal and informal education in computer science, the less competent ones may change fields or otherwise drop out. Then, only more competent women remain by the time they begin to contribute to open source. In contrast, less competent men may continue. While women do switch away from STEM majors at a higher rate than men, they also have a lower drop out rate then men (Chen, 2013), so the difference between attrition rates of women and men in college appears small. Another explanation is self-selection bias: the average woman in open source may be better prepared than the average man, which is supported by the finding that women in open source are more likely to hold Master’s and PhD degrees (Arjona-Reina, Robles & Dueas, 2014). Yet another explanation is that women are held to higher performance standards than men, an explanation supported by Gorman & Kmec (2007) analysis of the general workforce, as well as Heilman and colleagues’ (2004) controlled experiments.
Are the differences meaningful?
We have demonstrated statistically significant differences between men’s and women’s pull request acceptance rates, such as that, overall, women’s acceptance rates are 4.1% higher than men’s. We caution the reader from interpreting too much from statistical significance; for big data studies such as this one, even small differences can be statistically significant. Instead, we encourage the reader to examine the size of the observed effects. We next examine effect size from two different perspectives.
Using our own data, let us compare acceptance rate to two other factors that correlate with pull request acceptance rates. First, the slope of the lines in Fig. 3, indicate that, generally, as developers become more experienced, their acceptance rates increases fairly steadily. For instance, as experience doubles from 16 to 32 pull requests for men, pull acceptance rate increases by 2.9%. Second, the larger a pull request is, the less likely it is to be accepted (Gousios, Pinzger & Deursen, 2014). In our pull request data, for example, increasing the number of files changed from 10 to 20 decreases the acceptance rate by 2.0%.
Using others’ data, let us compare our effect size to effect sizes reported in other studies of gender bias. Davison and Burke’s meta-analysis of sex discrimination found an average Pearson correlation of r = .07, a standardized effect size that represents the linear dependence between gender and job selection (Davison & Burke, 2000). In comparison, our 4.1% overall acceptance rate difference is equivalent to r = .02.2 Thus, the effect we have uncovered is only about a quarter of the effect in typical studies of gender bias.
Conclusion
In closing, as anecdotes about gender bias persist, it is imperative that we use big data to better understand the interaction between genders. While our big data study does not prove that differences between gendered interactions are caused by bias among individuals, combined with qualitative data about bias in open source (Nafus, 2012), the results are troubling.
Our results show that women’s pull requests tend to be accepted more often than men’s, yet women’s acceptance rates are higher only when they are not identifiable as women. In the context of existing theories of gender in the workplace, plausible explanations include the presence of gender bias in open source, survivorship and self-selection bias, and women being held to higher performance standards.
While bias can be mitigated—such as through “bias busting” workshops (http://www.forbes.com/sites/ellenhuet/2015/11/02/rise-of-the-bias-busters-how-unconscious-bias-became-silicon-valleys-newest-target), open source codes of conduct (http://contributor-covenant.org) and blinded interviewing (https://interviewing.io)— the results of this paper do not suggest which, if any, of these measures should be adopted. More simply, we hope that our results will help the community to acknowledge that biases are widespread, to reevaluate the claim that open source is a pure meritocracy, and to recognize that bias makes a practical impact on the practice of software development.