
An improved similarity-based approach to predicting and mapping soil organic carbon and soil total nitrogen in a coastal region of northeastern China
- Published
- Accepted
- Received
- Academic Editor
- Tal Svoray
- Subject Areas
- Soil Science, Biogeochemistry, Spatial and Geographic Information Science
- Keywords
- Digital soil mapping, Environmental variables, Spatial variability, Uncertainty
- Copyright
- © 2020 Wang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2020. An improved similarity-based approach to predicting and mapping soil organic carbon and soil total nitrogen in a coastal region of northeastern China. PeerJ 8:e9126 https://doi.org/10.7717/peerj.9126
Abstract
Soil organic carbon (SOC) and soil total nitrogen (STN) are major soil indicators for soil quality and fertility. Accurate mapping SOC and STN in soils would help both managed and natural soils and ecosystem management. This study developed an improved similarity-based approach (ISA) to predicting and mapping topsoil (0–20 cm soil depth) SOC and STN in a coastal region of northeastern China. Six environmental variables including elevation, slope gradient, topographic wetness index, the mean annual temperature, the mean annual temperature, and normalized difference vegetation index were used as predictors. Soil survey data in 2012 was designed based on the clustering of the study area into six climatic vegetation landscape units. In each landscape unit, 20–25 sampling points were determined at different landform positions considering local climate, soil type, elevation and other environmental factors, and finally 126 sampling points were obtained. Soil sampling from the depth of 0–20 cm were used for model prediction and validation. The ISA model performance was compared with the geographically weighted regression (GWR), regression kriging (RK), boosted regression trees (BRT) considering mean absolute prediction error (MAE), root mean square error (RMSE), coefficient of determination (R2), and maximum relative difference (RD) indices. We found that the ISA method performed best with the highest R2 and lowest MAE, RMSE compared to GWR, RK, and BRT methods. The ISA method could explain 76% and 83% of the total SOC and STN variability, respectively, 12–40% higher than other models in the study area. Elevation had the largest influence on SOC and STN distribution. We conclude that the developed ISA model is robust and effective in mapping SOC and STN, particularly in the areas with complex vegetation-landscape when limited samples are available. The method needs to be tested for other regions in our future research.
Introduction
Soil organic carbon (SOC) and soil total nitrogen (STN) influence soil physical, chemical, biological properties and processes and determine soil quality that is related to food security by affecting agricultural productivity (Batjes, 1996; Wang, Zhang & Li, 2013; Elbasiouny et al., 2014). To a certain extent, SOC and STN affect the concentration of greenhouse gases in the atmosphere. The prediction of their sizes and changes has become a key climate change research area (Jobbagy & Jackson, 2000; Post & Kwon, 2000; Lal, 2004; Davidson & Janssens, 2006; Yang et al., 2015a; Yang et al., 2015b). Previous studies indicated that the spatially explicit information of SOC and STN plays an important role in quantifying global carbon and nitrogen cycles (Kieft et al., 1998; Yang et al., 2015a; Yang et al., 2015b; Wang et al., 2017).
Numerous studies have been conducted to understand the relationships between SOC and STN with environmental factors including topography, climate and biology (e.g., Yang et al., 2016a; Yang et al., 2016b). To map the spatial variations of SOC and STN based on field observations, Digital soil mapping (DSM) technologies have proven as a rapid and inexpensive approach over large areas using a limited amount of sample data (McBratney, Santos & Minasny, 2003; Yang et al., 2016a; Yang et al., 2016b; Scull et al., 2003; Taghizadeh-Mehrjardi et al., 2014). Commonly used DSM techniques include linear regression (Kunkel et al., 2011; Zhao et al., 2015), random forest (RF) (Grimm et al., 2008; Yang et al., 2016a; Yang et al., 2016b), regression kriging (RK) (Odeh, McBratney & Chittleborough, 1995; Zhao et al., 2015; Song et al., 2016), regression rules (Adhikari et al., 2014; Minasny & McBratney, 2008), boosted regression trees (BRT) (Yang et al., 2016a; Yang et al., 2016b; Wang et al., 2016), geographically weighted regression (GWR) (Kumar, Lal & Liu, 2012; Song et al., 2016; Clement et al., 2009), artificial neural networks (Burke et al., 1989; Were et al., 2015), similarity-based method (Zhu, 1997; Yang et al., 2015a; Yang et al., 2015b; Liu et al., 2016), and support vector machines (Kovačević, Bajat & Gajić, 2010; Stevens et al., 2010).
DSM conceptually applies the soil-landscape model of Jenny (1941) which describes the changes in soil properties as a function of factors related to climate, organism, topography, parent material and time. Therefore, the soil and its environment are specifically and spatially related. Topography plays an important role in the process of soil development and formation. Its impact on soil formation is mainly through the redistribution of water, nutrients, and energy, affecting microclimate and biomes, thus indirectly influencing the spatial distribution of SOC, and STN (Adhikari et al., 2018; Mondal et al., 2017; Garten Jr & Ashwood, 2002; Moore et al., 1993). In the central highlands of Ethiopia, Tesfaye et al. (2016) found topography as the main factor affecting the spatial variation of SOC and STN content in the region. Similarly, climatic influences on soil formation and development are mainly through temperature, and precipitation and their interactive effects. Jobbagy & Jackson (2000) applied three global-scale soil profile datasets to estimate the global SOC stocks in 3-m deep soil layer, and pointed out that temperature and precipitation were the main climatic factors affecting the changes in SOC stocks.
Hudson (1992) considered that soil-forming factors in a landscape interact with each other in a particular manner, indicating that the same soil-landscape presents with homogeneous soil types. According to this theory, the relationship between soil and soil-forming factors can be used to infer the spatial distribution of soil properties. Similarly, Zhu (1997) suggested that soil-forming factors indicate the spatial distribution of soil properties. Thus, similar soil-environmental conditions can be assumed to exhibit similar soil types and properties. Based on this hypothesis, the complex environment can be divided into several less heterogeneous landscape units with potentially similar soil-forming environment. Soil properties in these landscape units can be further represented by the characteristics of the sample points within the landscape. The similarity-based method (Zhu, 1997) has been applied and proven to be an efficient method in predictive soil mapping. It has been widely used in the prediction of soil properties and soil types (Liu et al., 2016; Liu, 2010; Zhu et al., 2010). Yang et al. (2015a); Yang et al. (2015b) used the similarity-based approach to map the spatial variation of soil salinity and obtained a higher prediction accuracy. A higher performance of similarity-based mapping approach was also confirmed by Shi et al. (2004), who generated a soil series map with 86% prediction accuracy. Liu (2010) indicated that the similarity-based approach exhibited notable predictive performance compared to a kriging interpolation method applied in Ili of Xinjiang, China. Similarly, Liu et al. (2016) integrated a similarity-based approach with depth functions to model the three-dimensional (3D) distribution of SOM and obtained a lower global mean error (0.06 g kg−1). Their findings showed that the similarity-based approach combined with other models can accurately predict soil properties.
The spatial distribution of SOC and STN in a landscape can be influenced by topography, organic matter input, temperature, humidity, vegetation, parent material and soil management (Sollins, Homann & Caldwell, 1996; Caminoserrano et al., 2014), and can be better estimated by dividing the landscape into sub-units. To achieve this, some previous studies used data segmentation techniques to establish the relationship between SOC and STN with specific environmental variables for smaller regions. For instance, Mulder, Lacoste & Richer-de Forges (2016) divided France into 10 soil-landscape types using a model-based clustering technology based on climate, vegetation, geology, and soil environmental variables and the regression models between SOC and environmental variables were established for each landscape. They found that the classification and prediction at each soil-landscape unit could better explain the SOC variations.
This study improved a similarity-based approach (ISA) to predict and map the spatial distribution of SOC and STN by applying soil property data and environmental variables. In the ISA model, the whole study area is clustered into several typical climatic-vegetation landscape units by using gaussian mixture model for model-based clustering (GMMC). The spatial prediction of SOC and STN was then carried out by using the similarity-based approach in this region. In the GMMC model, the expectation maximization algorithm is adopted to estimate the model parameters, whereas the Bayesian Information Criterion (BIC) is used to optimize the clustering results, the optimal model and the numbers of clusters are then selected. This study attempts to test the ISA model by comparing it with the commonly used DSM methods such as geographically weighted regression, regression kriging and boosted regression trees models. The proposed ISA model was tested to map SOC and STN in Montane ecosystems of Lushun City in the northeastern coastal areas of China. Our research objectives to: (1) developed a GMMC method to divide the study area into climate-vegetation landscape units; (2) model the effect of environmental variables on SOC and STN variation; and (3) map the SOC and STN distribution using ISA, GWR, RK, and BRT models and compared their performances.
Materials & Methods
Study area
The study area (38.72°–38.97°N, 121.08°–121.47°E) covers approximately 512 km2 and is located in Lushun City, Liaoning Province in the northeast coast of China (Fig. 1). The area lies in the southwest corner of Liaodong Peninsula and faces towards the Yellow Sea on the east and Bohai Sea on the west. Therefore, this region presents typical continental and oceanic climate characteristics forming unique climate-vegetation landscapes including coastal plain, interior plain, medium-coverage grasslands, high-coverage grasslands, low-elevation forest, and low-mountain shrub. The area is dominated by mountain landscape, which accounts for 53.1% of the total area and is characterized by valleys and peaks, with an altitude ranging from 137 to 466 m above sea level. The mean annual temperature (MAT) in this region is nearly 10 °C, the maximum and minimum temperatures are 27.5 °C in September and 8.2 °C in January. The region experiences a total of 185 frost-free days with the mean annual precipitation (MAP) ranging from 585 mm to 720 mm, 65–75% of which falls between June and September. According to World Reference Base for Soil Resources (WRB), the dominant soil types are Cambisols and Fluvisols (Schad, Van Huyssteen & Micheli, 2014).
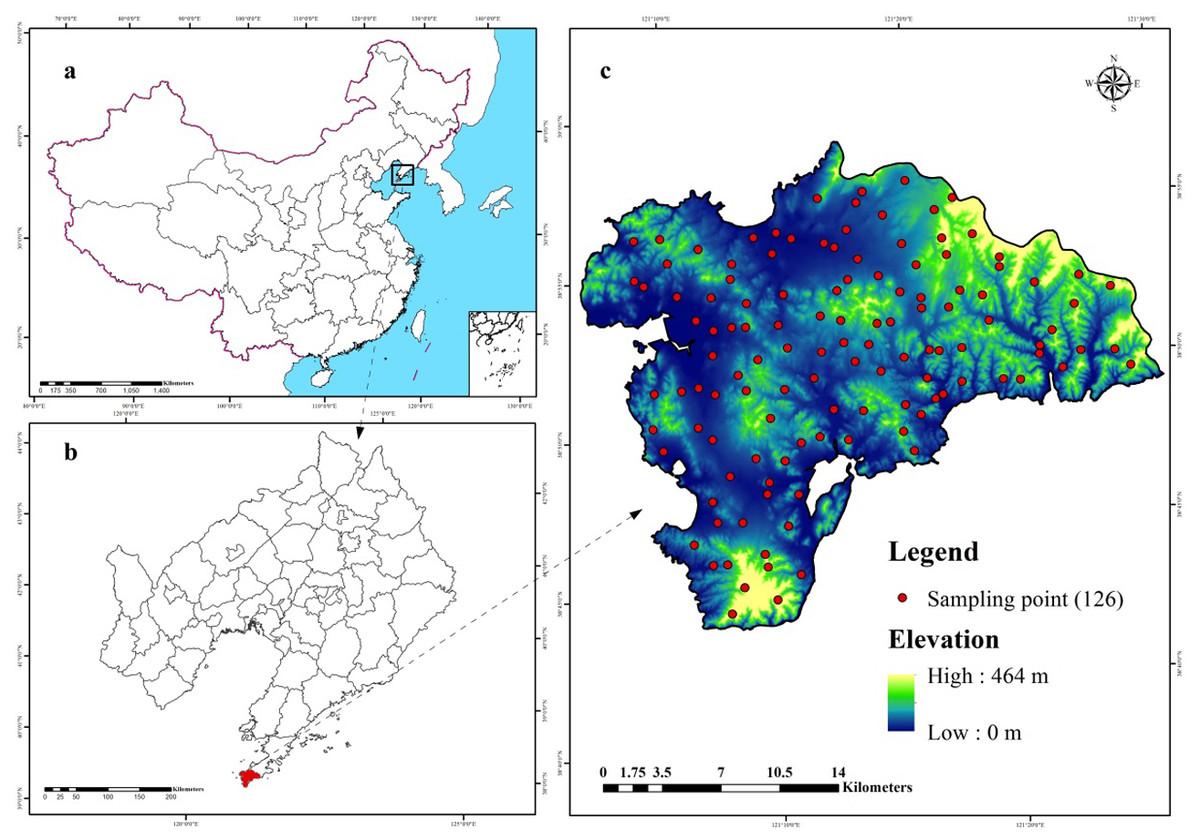
Figure 1: Location of the study area and 126 sampling sites (C) in Liaoning Province (B), China (A), which are shown superimposed on a 30-m resolution digital elevation model.
{kind=link}
Dataset
Field sample data
Almost 53% of the study area is under forests, and is densely covered with rivers and valleys where the river system is rather complicated in a rugged terrain. To represent the spatial characteristics of soil properties in such a complex landscape, we applied a stratified sampling scheme following two steps.
First, we used a GMCC method to divide the study area into several typical climatic-vegetation landscape units. The GMMC model is a hybrid model composed of the gaussian mixture model (GMM) and the expectation maximization (EM) algorithm (Dempster, Laird & Rubin, 1977). The GMM model is used to determine certain probability density functions (i.e., the probability of data points is partitioned into each category) (Banfield & Banfield, 1993) to achieve the division of datasets. The EM algorithm is adopted to estimate the model parameters, whereas the BIC is used to optimize the clustering results, and then the optimal model and the number of clusters are selected. The clustering model is established in the R version 3.2.2 (R Development Core Team, 2013) using the “mclust” package (Fraley & Raftery, 2002) for completion. Based on the pedogenetic information of the study area, environmental factors such as elevation, MAT, MAP, and normalized difference vegetation index (NDVI) were used as inputs (Zhu et al., 2008; Yang et al., 2013; Yang et al., 2016a; Yang et al., 2016b). The study area was divided into six climate-vegetation landscape units (Fig. 2). Within each climate-vegetation landscape, twenty to twenty-five sampling points were identified at different landform positions considering local climate, soil type, elevation and other environmental factors.
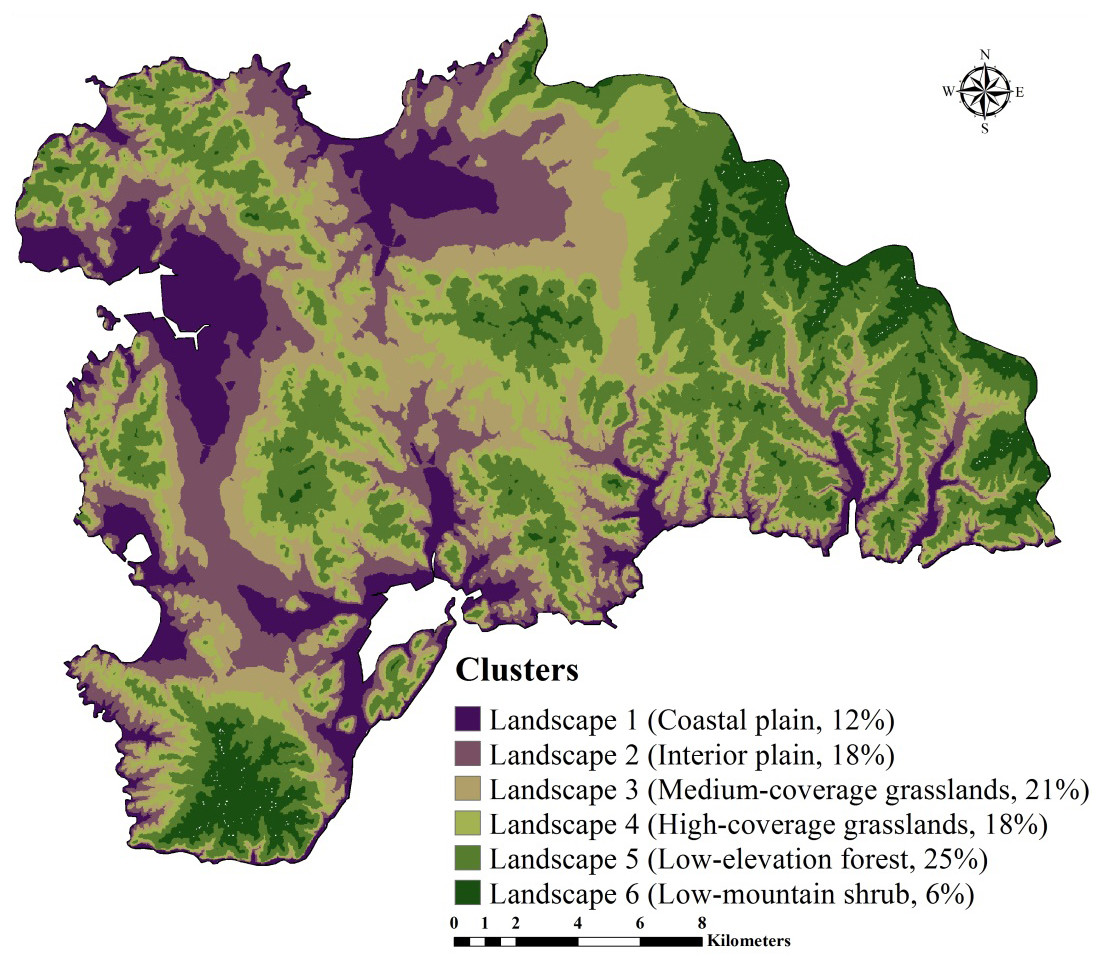
Figure 2: Climate-vegetation landscapes in the study area: Landscape 1, coastal plain; Landscape 2, interior plain; Landscape 3, medium-coverage grasslands; Landscape 4, high-coverage grasslands; Landscape 5, low-elevation forest; Landscape 6, low-mountain shrub.
{kind=link}
Although soil sampling in this study considered climate and vegetation properties of the landscape for clustering, it was further verified by the local soil experts to determine whether the units are typical and are representative of the study area. This data sampling was not based on probability sampling strategy, thus it might underestimate or overestimate the SOC and STN distribution in the region as reported in previous studies (Zhu, 1997; Yang et al., 2016a; Yang et al., 2016b; An et al., 2018). However, it was probably the best sampling option given that sampling was done in such a densely forested terrain and with limited resources. Overall flowchart of the proposed methodology is shown in Fig. 3.

Figure 3: Flowchart of the methodology adopted in the study.
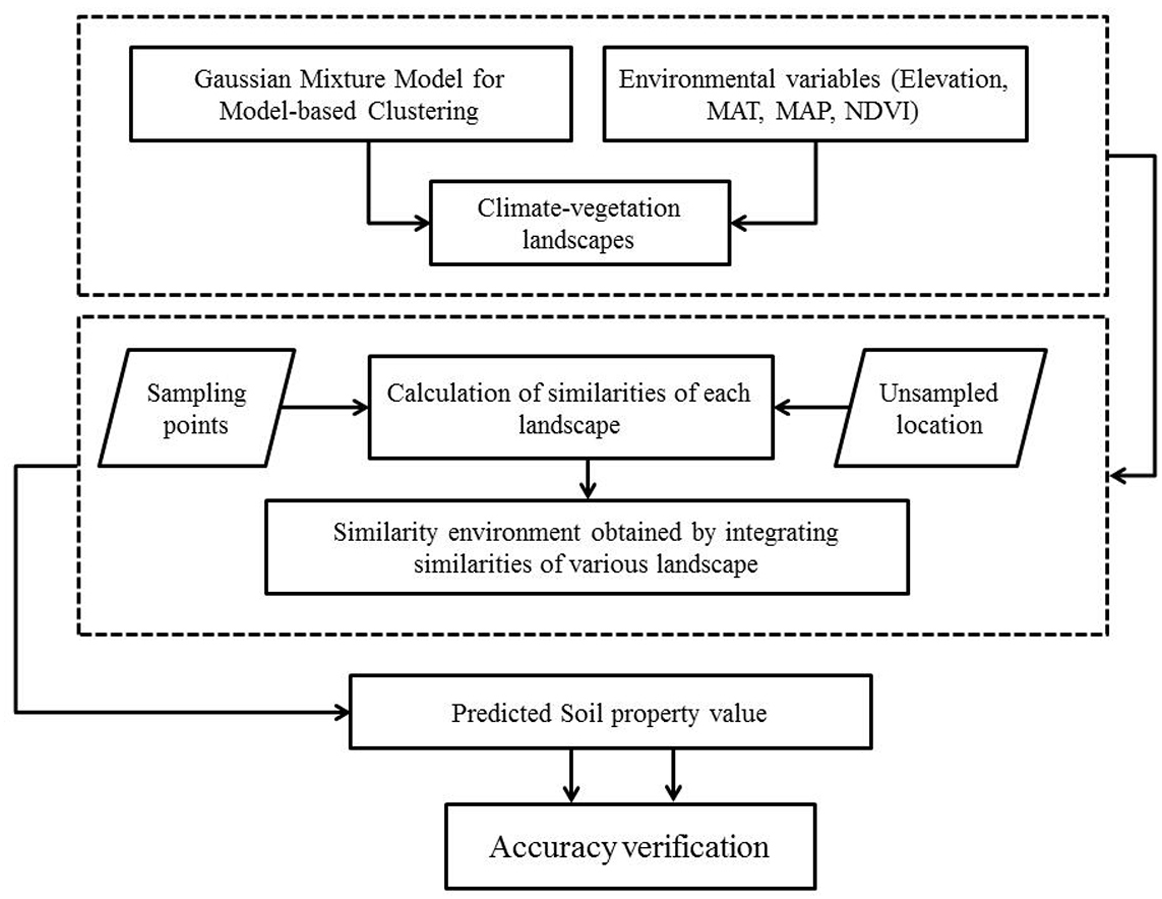{kind=link}
A total of 126 sample locations were established, and the geographic coordinates of each point was recorded by a handheld global positioning system (GPS) (Table S1). From each sample location, about 1 kg of topsoil (0–20 cm soil depth) sample was collected for laboratory analysis. In the Testing & Analysis Center of Shenyang agricultural University, Shenyang, Liaoning Provence, China, the litters were removed from samples. The samples were then air dried, grinded, and passed through a 2-mm sieve. SOC and STN contents were measured by a dry combustion method (Matejovic, 1993) using CN analyzer (Vario Max, Elementar Amerivas Ins., Germany). The soil depth considered in this study was limited to 0–20 cm because Wang et al. (2017) found that in Liaoning Province, 69% of SOC and STN were stored in the topsoil (0–30 cm). It has been further confirmed by Liu et al. (2012) who reported about 43% of the SOC stocks from the topsoil. In addition, 70% of all samples were randomly selected as training dataset (n = 88) and the rest 30% as independent verification dataset (n = 38).
Environmental variables
Two topographic variables including slope gradient and topographic wetness index (TWI) were used in addition to four other variables (elevation, MAP, MAT, and NDVI) for climate-vegetation landscape partition (Table 1), to predict the spatial distribution of SOC and STN content. The variables were collected from different sources and were converted to a raster grid of 30 m resolution. Measured data on SOC and STN, and all the predictors were brought into the geographic information system (GIS) in a common projection system (Krasovsky_1940_Albers) in ArcGIS 10.2 (ESRI Inc., USA) for further geospatial processing and analysis. Slope gradient and TWI were derived from a 30-m resolution digital elevation model (DEM) captured from Shuttle Radar Topography Mission (SRTM) (Farr & Kobrick, 2000; Conrad et al., 2015). MAT and MAP as two main climatic variables obtained from China Meteorological Data Service Center (http://data.cma.cn/en) as 30-year annual average (1980–2010). In addition, we selected NDVI to represent vegetation intensity, as determined by using two bands of Landsat 5, namely, band 3 and band 4 (Eq. (1)), and were downloaded from the United States Geological Survey (USGS). The imagery covers from July to September of 2012 with <10% cloud cover. Image processing included geometric correction, registration, image mosaic and clipping, cloud removal, and shadow processing and was performed in ENVI 4.7 software (Huang et al., 2007). (1)
| Property | Description | Units | Minimum | Mean | Maximum | SD | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| SOC | Level of organic carbon content in soil | g kg−1 | 8.50 | 12.95 | 22.02 | 3.78 | 1.07 | 0.06 |
| STN | Sum of various forms of nitrogen in soil | g kg−1 | 0.57 | 0.85 | 1.49 | 0.23 | 0.81 | −0.31 |
| NDVI | The difference between near infrared and red band reflectance is divided by the sum of their | index | 0.15 | 0.40 | 0.56 | 0.08 | −0.25 | 0.15 |
| MAT | Mean annual temperature from 1980 to 2010 | Celsius degree | 9.5 | 10.39 | 10.91 | 0.26 | −1.29 | 1.80 |
| MAP | Mean annual precipitation from 1980 to 2010 | mm | 605.8 | 609.2 | 622.6 | 3.97 | 1.54 | 1.95 |
| Elevation | Absolute vertical distance to geoid | m | 1 | 66.53 | 309 | 61.48 | 1.67 | 2.87 |
| Slope gradient | Maximum rate of change between cells and neighbors | degree | 0 | 9.46 | 41.90 | 9.78 | 1.33 | 1.29 |
| TWI | Calculates slope and specific catchment area based topographic wetness index | index | 2.33 | 5.04 | 10.13 | 1.87 | 0.89 | 0.52 |
Notes:
- SOC
-
soil organic carbon
- STN
-
soil total nitrogen
- TWI
-
topographic wetness index
- MAP
-
mean annual precipitation
- MAT
-
mean annual temperature
- NDVI
-
Normalized Difference Vegetation Index
- SD
-
Standard deviation
Model development
Improved similarity-based approach and its prediction consistency
An improved similarity-based approach was used to estimate the soil properties of unsampled location by acquiring the environmental similarity with sampling points. Specifically, this method was developed following three key steps:
Step 1 was to calculated the environmental similarity in each climate-vegetation landscape; (2)
In this equation, D is Euclidean distance; Si and Ui are sampled point S and unsampled point U, respectively, and the variable values in dimension i space. Suppose there are m sampling points and n unsampled points, then a set of Euclidean distance (DE) matrix can be obtained as: (3)
Euclidean distance only measures the degree of distance between two points. In order to obtain the similarity between two points, it must be converted into the corresponding similarity (Danielsson, 1980). We first applied Eq. (4) to obtain standard range of Euclidean distance (DEscale) [0,1], and then applied Eq. (5) to convert it into similarity (SE) with range [0, 1].
(4) (5)
So, the similarity matrix (SE) between the unsampled locations and the sampling points was obtained using Eq. (6): (6)
Step 2 was to predict soil properties for the landscape unit according to its environmental similarity.
In each landscape, the soil property value of the unsampled locations was predicted by using the environmental similarity where elevation, MAT, MAP, NDVI, TWI, and slope gradient were used as predictors. The definite equation as follows: (7) where Vb is the predicted value of soil property at location b and Va is the soil property value at sampled location a; Sab is the environmental similarity between location b and sampled location a; m is the number of sampling points.
Step 3 was to calculate the prediction consistency using Eq. (8): (8) where Consistencym is the prediction consistency at point m, and the lower the value, the better the prediction consistency of the model; Snm is the environmental similarity between point n and sampled location m.
According to Eq. (8), the maximum value can be used to obtain the best representation of the similarity of the environment between unsampled locations and sampling points (i.e., most similar). With a low similarity, the sampling points cannot represent the unsampled locations (Liu, 2010) and the soil property values inferred from the sampling points will show a high degree of speculative consistency.
Geographically weighted regression
Geographically weighted regression was first introduced into the study of geography by Brunsdon, Fotheringham & Chariton (1998). It embeds the spatial structure of the data into a regression model making the regression parameters become a function of the geographical location of the observation points. GWR is a non-parametric technique based on local weighted regression developed for curve fitting and smoothing applications in statistics (Kumar, Lal & Liu, 2012). In this technique, local regression parameters are estimated using a subset of data close to the estimated points of models in variable spaces. The innovation of GWR is to use a subset of data in geographic space near the calibration location of the model. In our GWR model, six environmental variables were used to predict the spatial distribution of SOC and STN.
Regression kriging
Regression kriging is a spatial interpolation technique that combines a regression of the dependent variable and auxiliary variables (such as terrain parameters, remote sensing imagery and thematic maps) with kriging of the regression residuals (Odeh, McBratney & Chittleborough, 1995; Hengl, Heuvelink & Stein, 2004). We applied RK to interpolate the spatial distribution of SOC and STN following these five steps: (1) determining the SOC and STN prediction model using multiple linear regressions (MLR); (2) calculating the SOC and STN prediction model residuals at each calibration location; (3) modeling the covariance structure of the SOC and STN residuals using a variogram GS+ 7.0 statistical software (Gamma Design Software, Plainwell, MI) was used to implement this process; (4) spatially interpolating the SOC and STN residuals through the parameters of the variogram model; and (5) adding the SOC and STN prediction model surface to the interpolated residuals surface to get the final predicted map.
Boosted regression trees
Boosted regression trees model is a machine learning algorithm based on classification and regression trees, which was proposed by Friedman, Hastie & Tibshirani (2000). The BRT model is similar to other boosting models improving model performance by training multiple models and combining them for prediction. It consists of two algorithms: regression trees and gradient boosting. In the model, gradient lifting algorithm is used to linearly combine multiple regression trees of weak regression to form an efficient and a strong regression model (e.g., Wang et al., 2016; Yang et al., 2016a; Yang et al., 2016b). The implementation of BRT model requires users to define four parameters: learning rate (LR), tree complexity (TC), bag fraction (BF) and tree number (NT). LR represents the contribution of each tree in the model to the final fitting model (Yang et al., 2016a; Yang et al., 2016b). TC is a direct predictor of tree depth and maximum interaction level (Yang et al., 2015a; Yang et al., 2016b). BF represents the scale of data used in each model (Wang et al., 2018a; Wang et al., 2018b). NT is determined by LR and TC. In order to obtain the best prediction performance of BRT model, different parameter combinations LR (0.0025, 0.025, 0.25, 0.50), TC (3, 6, 9), BF (0.20, 0.35, 0.50, 0.65), NT (600, 800, 1000, 1200) were tested by 10-fold cross-validation. Finally, LR, TC, BF and NT values that achieved the minimum prediction error through 10-fold cross-validation were set to 0.0025, 6, 0.65, and 800, respectively, for SOC prediction, and 0.025, 6, 0.65 and 1000, respectively, for STN prediction.
Model validation
In each landscape, 30% sampling points (38 observations in total) were randomly selected to test the prediction performance of the ISA, GWR, RK, and BRT methods. Three commonly-used indices including mean absolute prediction error (MAE), root mean square error (RMSE), coefficient of determination (R2) , and maximum relative difference (RD) (Eqs. (9) to (11)) were used to compare the model. All indices were calculated in the R version 3.2.2 (R Development Core Team, 2013):
(9) (10) (11) (12) where ai, bi, , and are the observed values, predicted values, and mean values of soil property at site i, and n is the number of the sampling point.
Results
Exploratory Data Analysis
Exploratory analysis of measured SOC and STN contents and values of environmental variables at sampling locations are summarized in Table 1. Average SOC and STN in the topsoil were (±3.78), and 0.85 (±0.23) g kg−1, respectively. The skewness and kurtosis coefficients were 1.07 and 0.06 for SOC and 0.81 and -0.31 for STN, respectively, indicating that the measured SOC and STN approximately followed a normal distribution. In addition, both distribution passed Kolmogorov–Smirnov (K-S) test (ρ = 0.11 and 0.09), respectively, suggesting that SOC and STN data did not need to be transformed for subsequent analysis and modeling.
SOC and STN were positively correlated with NDVI, MAP, elevation, and slope gradient but negatively correlated with MAT and TWI (Fig. 4). We observed multicollinearity among environmental variables and believed that predicting SOC and STN with these variables using traditional statistical methods such as simple multiple regression equations would be unreliable (McBratney, Santos & Minasny, 2003; Yang et al., 2016a; Yang et al., 2016b) and using ISA model could effectively overcome this problem. In the process of GWR modeling, we eliminated the slope gradient variable as it was highly correlated with MAT and elevation, to avoid the problem of multicollinearity, and used the remaining five variables for spatial prediction.
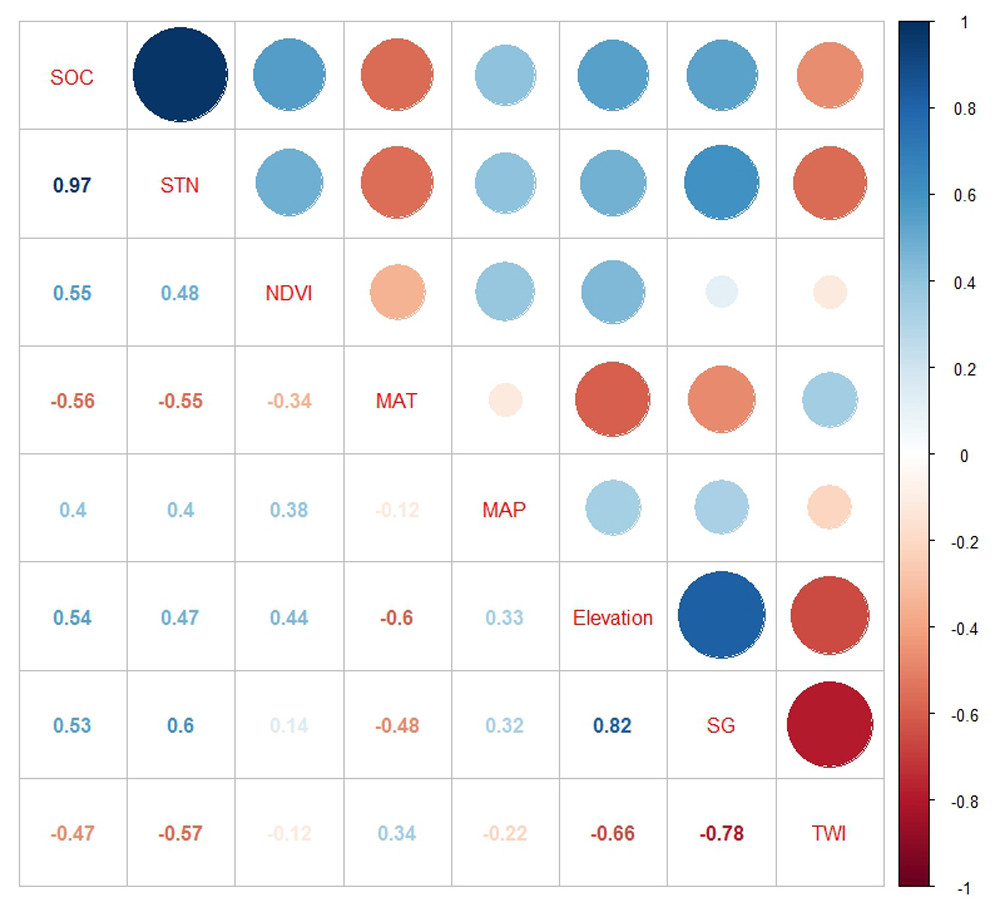
Figure 4: Pearson correlation coefficients of SOC and STN with environmental variables: SOC, soil organic carbon; STN, soil total nitrogen; TWI, topographic wetness index; SG, slope gradient; MAP, mean annual precipitation; MAT, mean annual temperature; and NDVI: Normalized Difference Vegetation Index.
{kind=link}
Climate-vegetation landscape
SOC and STN usually vary in the long term and are influenced by various environmental factors (i.e., rainfall, temperature, and vegetation). As a typical coastal ecosystem in Northeast China, Lushun has both continental and marine climate characteristics with an absence of cold winter and hot summer. Therefore, we selected the elevation, MAT, MAP, and NDVI to divide the region into the climate-vegetation landscape units. The results showed that the study area can be divided into six climate-vegetation landscapes (BIC, -678247.3) (Fig. 2). Landscapes 1, 2 are mainly distributed in the northern and western region of the study area; Landscapes 3 and 4 are mainly for the central region; and Landscapes 5, 6 are mainly distributed in the northeastern and southern regions. In terms of the area distribution area of landscapes, landscape 5 accounting for 25% of the total area of the study area, followed by landscape 3 (21%), landscape 2 (18%), landscape 4 (18%), landscape 1 (12%), and landscape 6 (6%) (Fig. 2).
The distribution of climate-vegetation landscapes and soil observations by elevation, MAP, MAT, and NDVI is shown in Fig. 5. The statistical characteristics of the four environmental variables at sampling points were similar to those in the landscapes, indicating that the sampling points could efficiently describe the characteristics of the major environmental factors in the study area. However, some differences in the main environmental variables of each landscape were observed. The Landscape 1 showed the lowest average elevation, a low MAP (608 mm), and the highest MAT (10.6 °C), and the average NDVI value approached 0.4. Therefore, the landscape type was coastal plain. Compared with landscape 1, landscape 2 was distributed at a relatively low elevation but presented a better vegetation cover; therefore, the landscape type was named interior plain. Landscape 6 showed the highest elevation (210 m), lowest MAT (10.0 °C), and lowest value of NDVI; thus, the landscape type was low-mountain shrub. Landscapes 3, 4, and 5 were mainly distributed in the middle elevation, but their MAT and NDVI values were different. Landscapes 3 and 4 showed higher precipitation rates; however, given the limitation of temperature, low vegetation cover was observed, thus landscapes 3 and 4 were classified as medium-coverage grasslands and high-coverage grasslands. Landscape 5 presented a better vegetation cover, and was classified as low-elevation forest.

Figure 5: Boxplots of main environmental features related (elevation (A), mean annual precipitation (MAP) (B), mean annual temperature (MAT) (C), and normalized difference vegetation index (NDVI)) to climate-vegetation landscapes including CP: coastal plain; IP: interior plain; MCG: medium-coverage grasslands; HCG: high-coverage grasslands; LEF: low-elevation forest; and LMS: low-mountain shrub.
Red is the training dataset (n = 88) and green is the independent verification dataset (n = 38).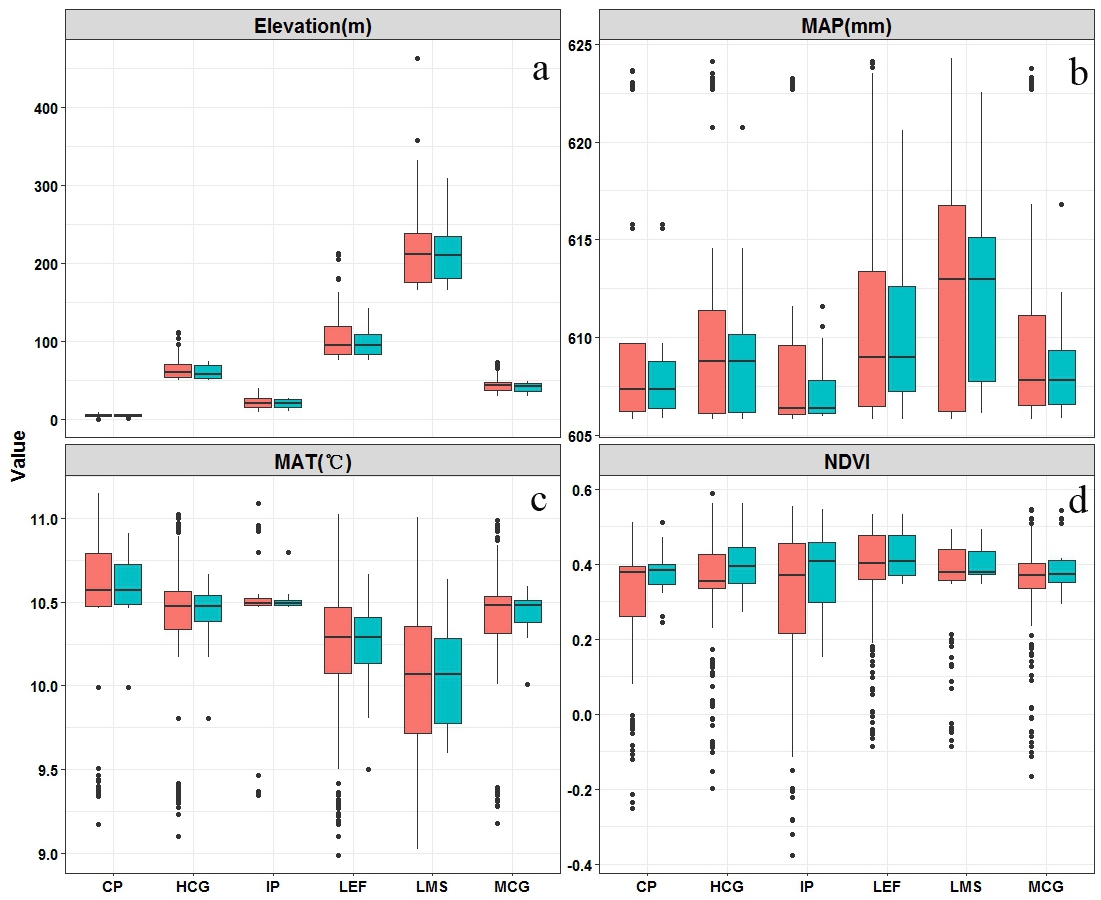{kind=link}
Model performance
In order to determine whether the study area should be divided into unique landscape units, and then use the best prediction model to predict the spatial distribution of SOC and STN in each landscape, the MAE, RMSE, and R2 were compared between the observed and predicted values (Table 2). The results showed that the model was significantly improved by dividing the study area into climate-vegetation landscapes (Table 2).
| Property | Category | Item | MAE | RMSE | R2 |
|---|---|---|---|---|---|
| SOC (g kg −1) | Classified | ISA | 0.74 | 1.01 | 0.76 |
| GWR | 0.96 | 2.35 | 0.57 | ||
| RK | 1.12 | 2.87 | 0.48 | ||
| BRT | 0.87 | 1.68 | 0.64 | ||
| Unclassified | ISA | 0.98 | 1.34 | 0.54 | |
| GWR | 1.17 | 2.67 | 0.46 | ||
| RK | 1.27 | 2.97 | 0.41 | ||
| BRT | 1.05 | 2.13 | 0.51 | ||
| STN (g kg −1) | Classified | ISA | 0.03 | 0.04 | 0.83 |
| GWR | 0.08 | 0.09 | 0.54 | ||
| RK | 0.11 | 0.15 | 0.43 | ||
| BRT | 0.06 | 0.07 | 0.67 | ||
| Unclassified | ISA | 0.12 | 0.09 | 0.57 | |
| GWR | 0.13 | 0.16 | 0.41 | ||
| RK | 0.15 | 0.19 | 0.38 | ||
| BRT | 0.11 | 0.13 | 0.51 |
Notes:
- SOC
-
soil organic carbon
- STN
-
soil total nitrogen
- MAE
-
mean absolute prediction error
- RMSE
-
root mean square error
- R2
-
coefficient of determination
- GWR
-
geographically weighted regression
- RK
-
regression kriging (RK)
- BRT
-
boosted regression trees
To obtain the best prediction model, four models (ISA, GWR, RK, and BRT) were compared using 38 independent validation points. Results showed that the ISA model outperformed GWR, RK, and BRT models with a lower MAE and RMSE, and a higher R2 values. We also found that the performance of BRT was better than the GWR and RK models. ISA model was efficient and powerful in spatial prediction of SOC, and STN among six climatic vegetation landscape units based on the accuracy verification. The prediction accuracy of ISA model in each landscape is listed in Table 3. The mean predicted values of SOC and STN in the topsoil were comparable to the mean observed values of the sampling points (Table 3). RD was obtained in the interior plain (RD about 7.1% and 4.2%), followed by the coastal plain (RD about 3.4% and 3.3%) and low-mountain shrub (RD about −4.2% and −4.1%), and the RD values of the other landscapes were smaller (Table 3). The predicted R2 ranged from 0.37 (Low-mountain shrub) to 0.77 (Interior plain) for SOC and 0.39 (Low-mountain shrub) to 0.89 (Median-coverage grassland) for STN, respectively. The lowest RMSE (0.13 g kg−1) in SOC prediction was reported for Medium-coverage grassland and the highest (2.53 g kg−1) for Low-elevation forest. For the STN, RMSE ranged from 0.01 to 0.06 depending on the landscape types. Overall, the lower MAE and RMSE, and higher R2 value for ISA model compared to the rest of the models indicated that the ISA model could better predict SOC and STN distribution.
| Property | Index | Unit | Climate-vegetation landscapes | |||||
|---|---|---|---|---|---|---|---|---|
| Coastal plain | Interior plain | Medium-coverage grasslands | High-coverage grasslands | Low-elevation forest | Low-mountain shrub | |||
| SOC | Observed | (g kg−1) | 9.11 | 11.04 | 11.29 | 12.38 | 14.41 | 20.02 |
| Predicted | (g kg−1) | 8.80 | 10.26 | 11.06 | 12.19 | 14.78 | 20.86 | |
| RD | (%) | 3.40 | 7.07 | 2.04 | 1.53 | −2.57 | −4.20 | |
| MAE | (g kg−1) | 0.31 | 0.81 | 0.28 | 0.58 | 1.44 | 0.84 | |
| RMSE | (g kg-1) | 0.14 | 1.56 | 0.13 | 0.46 | 2.53 | 0.82 | |
| R2 | 0.64 | 0.77 | 0.6 | 0.55 | 0.49 | 0.37 | ||
| STN | Observed | (g kg−1) | 0.61 | 0.72 | 0.76 | 0.83 | 0.99 | 1.22 |
| Predicted | (g kg−1) | 0.59 | 0.69 | 0.76 | 0.81 | 1 | 1.27 | |
| RD | (%) | 3.28 | 4.17 | 0.00 | 2.41 | −1.01 | −4.10 | |
| MAE | (g kg−1) | 0.03 | 0.04 | 0.01 | 0.03 | 0.03 | 0.05 | |
| RMSE | (g kg−1) | 0.01 | 0.04 | 0.01 | 0.02 | 0.06 | 0.02 | |
| R2 | 0.76 | 0.82 | 0.89 | 0.5 | 0.89 | 0.39 | ||
Notes:
- SOC
-
soil organic carbon
- STN
-
soil total nitrogen
- RD
-
relative difference
- MAE
-
mean absolute prediction error
- RMSE
-
root mean square error
- R2
-
coefficient of determination
For SOC prediction using the ISA model, MAE, RMSE, and R2 values were 0.74, 1.01 g kg−1, and 0.76, respectively, and for STN, the values were 0.03, 0.04 g kg−1, and 0.83, respectively (Fig. 6). The ISA model overestimated the SOC and STN contents in the study area, but the overall accuracy was high. The model explained approximately 76% and 83% of the total SOC and STN variability in the study area, respectively. Predictive consistency maps of SOC and STN were obtained using Eq. (8). The higher the consistency value, the larger the difference between the predicted value and measured value. Mean prediction consistency values were 0.14 for SOC and 0.13 for STN, respectively (Figs. 7A, 7B), suggesting the ISA model had a reliable predictability.
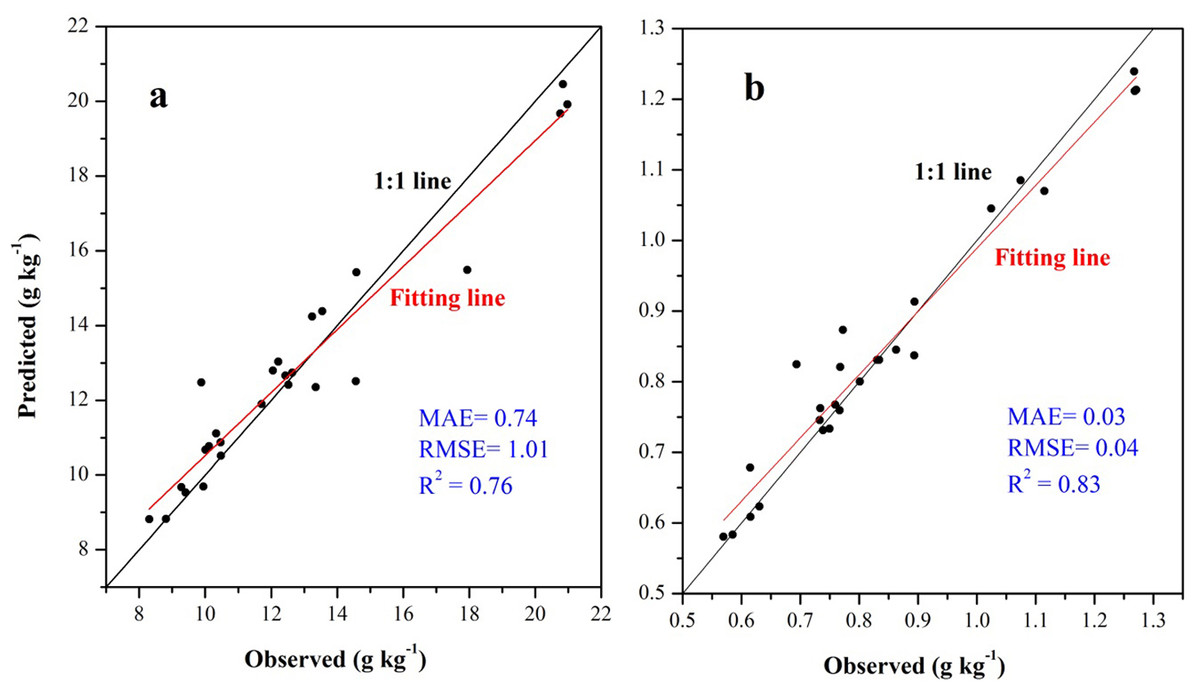
Figure 6: Scatter plot between the observed soil organic carbon (SOC) (A) and soil total nitrogen (STN) (B) content with its predicted values using the ISA model based on independent validation samples.
{kind=link}
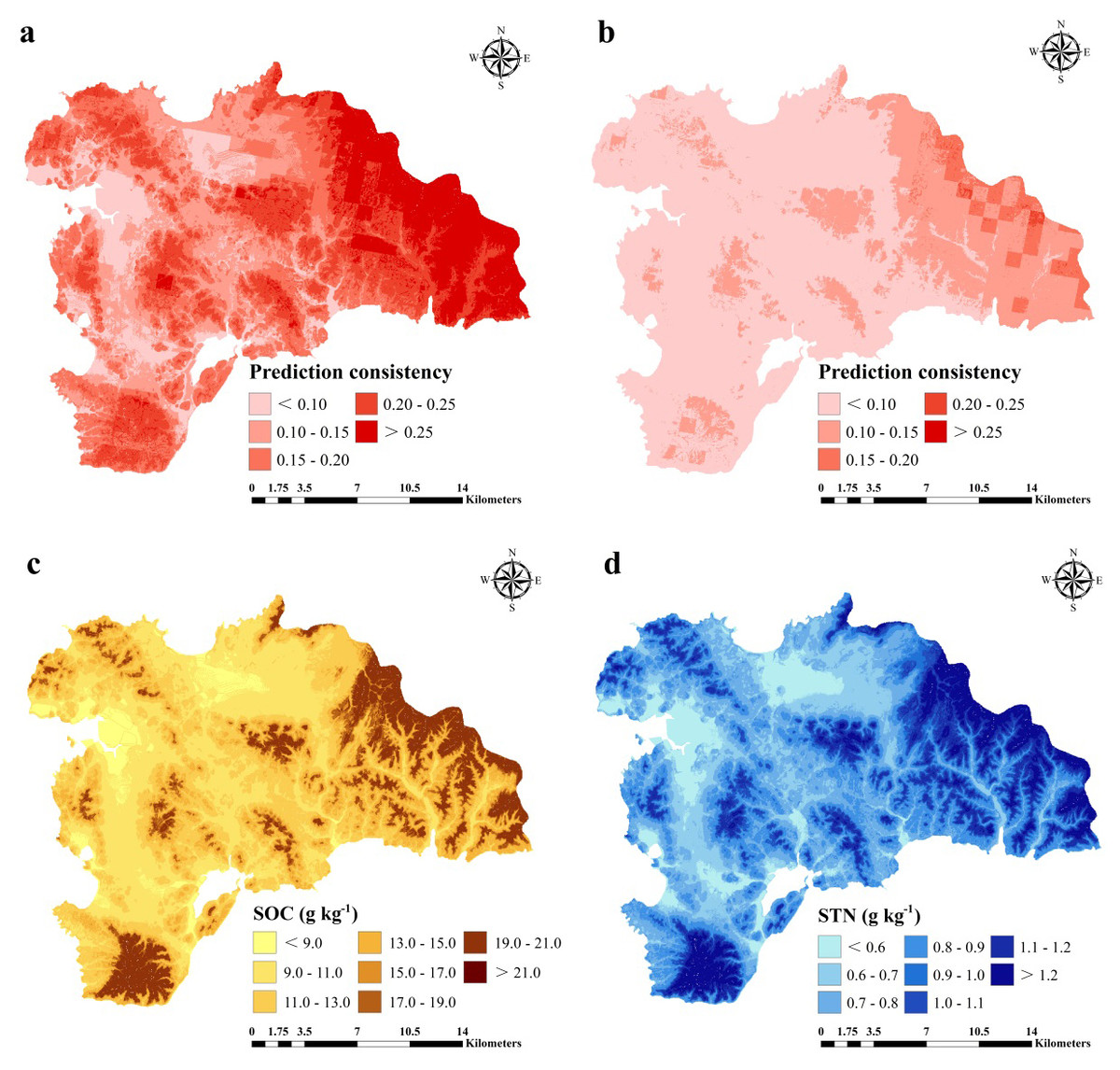
Figure 7: Prediction consistency map of SOC (A) and STN (B) and spatial distribution of SOC (g kg−1) (A) and STN (g kg−1) (B) predicted using an improved similarity-based approach (ISA).
{kind=link}
Estimates of SOC and STN
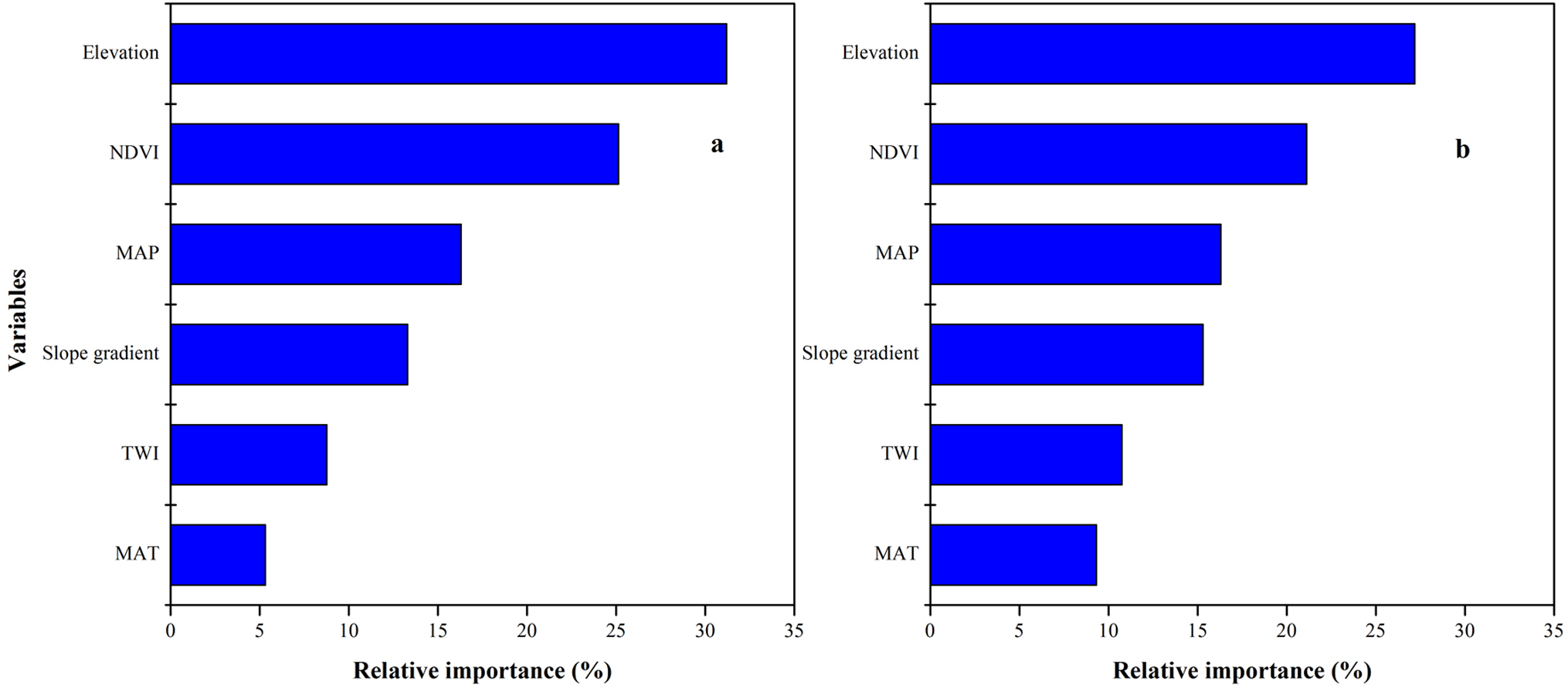
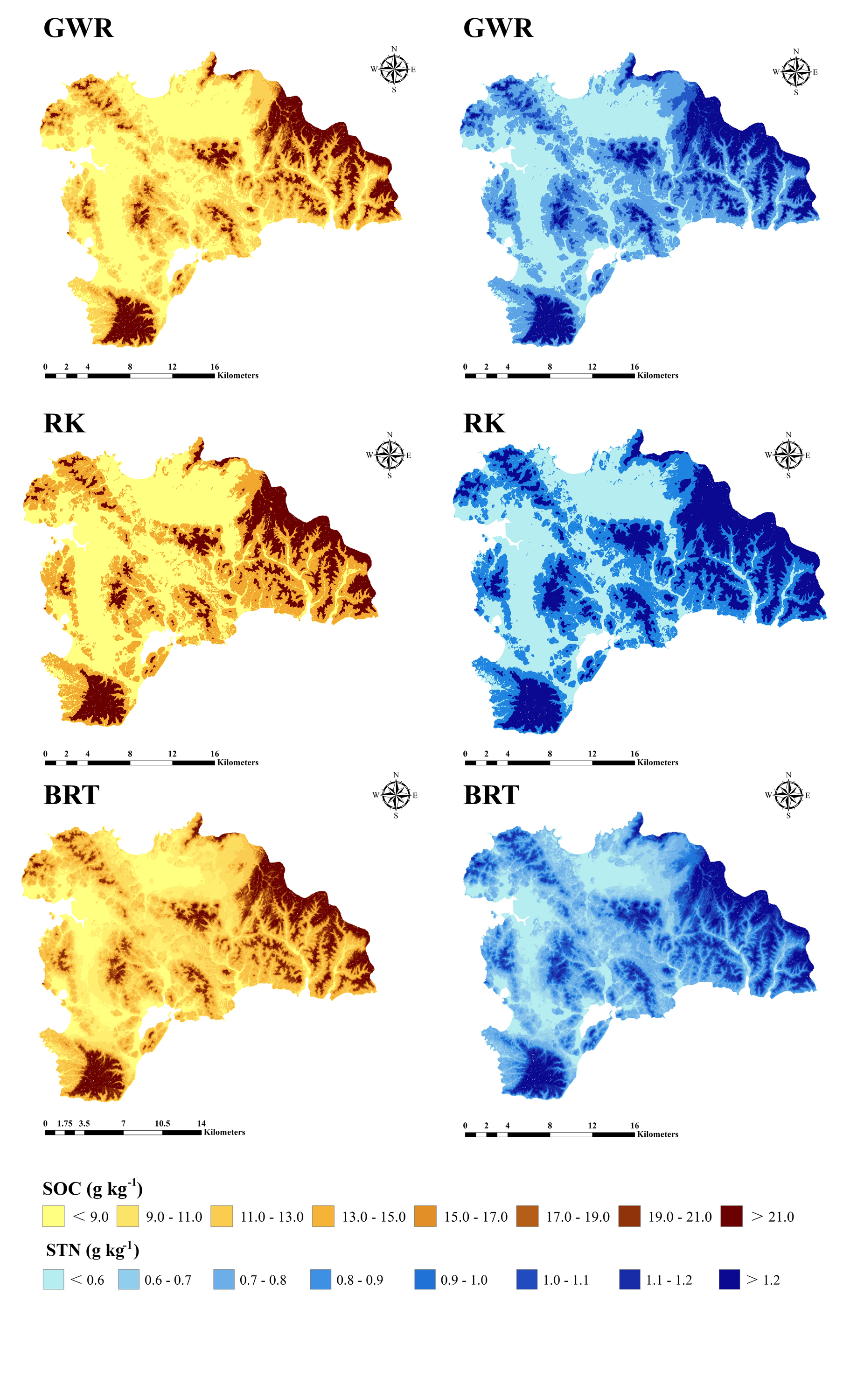
SOC and STN distribution was mapped using the ISA model where an average SOC and STN content in the study area was 11.37 (±3) and 0.89 (±0.2) g kg−1, respectively (Figs. 7C, 7D). In terms of spatial pattern, ISA model was more excellent than other models (Fig. S1). Among the climate-vegetation landscape units, soils under low-elevation forests contained more SOC and STN than the rest of the landscape units (Table 4). Of all predictors, elevation was the main predictor affecting the spatial distribution of SOC and STN in the study area (Fig. 8).
Discussion
Effects of ISA model on SOC and STN
The study area divided into unique landscape units, and then used the best prediction model to predict the spatial distribution of SOC and STN in each landscape. The results showed that the model was significantly improved by dividing the study area into climate-vegetation landscapes. This is consistent with previous studies using the same method. For instance, in Belgium, Lettens et al. (2004) divided the whole study area into 289 landscape units and predicted the SOC stocks for each landscape unit. They considered that SOC stocks were continuously influenced by a number of external factors, mainly land-use history and current land management and climate. The spatial distribution of SOC and STN varies closely with climate-vegetation-dominated landscapes. By dividing a large-scale complex landscape into small units, the SOC and STN could be better predicted. At the same time, compared to other SOC and STN prediction studies in the coastal area, the ISA model we constructed performed better. For example, in Santa Cruz Island, Galapagos, Rial et al. (2017) used terrain, climate and remote sensing variables combined with a GWR method to predict topsoil SOC stocks, and their model could explain 66% of SOC stocks variation in the region. In a separate study, Wang et al. (2018b) compared GWR and RK models to predict topsoil SOC in the Northeast coastal area of China and found GWR a better model that could explain 78% and 80% SOC variation during 1982 and 2012, respectively.
| Climate-vegetation landscapes | Number of independent validation points | SOC (g kg−1) | STN (g kg−1) | ||
|---|---|---|---|---|---|
| Range of change | Mean ± SD | Range of change | Mean ± SD | ||
| Coastal plain | 5 | 0.85–17.64 | 6.97 ± 5.47 | 0.34–1.13 | 0.63 ± 0.62 |
| Interior plain | 7 | 2.38–33.98 | 9.68 ± 6.69 | 0.43-1.32 | 0.8 ± 0.69 |
| Medium-coverage grasslands | 6 | 7.61–29.74 | 11.12 ± 6.32 | 0.74–2.07 | 0.88 ± 0.67 |
| High-coverage grasslands | 7 | 8.04–33.25 | 12.14 ± 6.91 | 0.77–2.28 | 0.94 ± 0.7 |
| Low-elevation forest | 8 | 10.24–33.8 | 16.84 ± 6.14 | 0.9–2.31 | 1.22 ± 0.66 |
| Low-mountain shrub | 5 | 7.32–26.33 | 11.49 ± 5.34 | 0.73–1.86 | 0.91 ± 0.61 |
Notes:
SD, Standard Deviation.
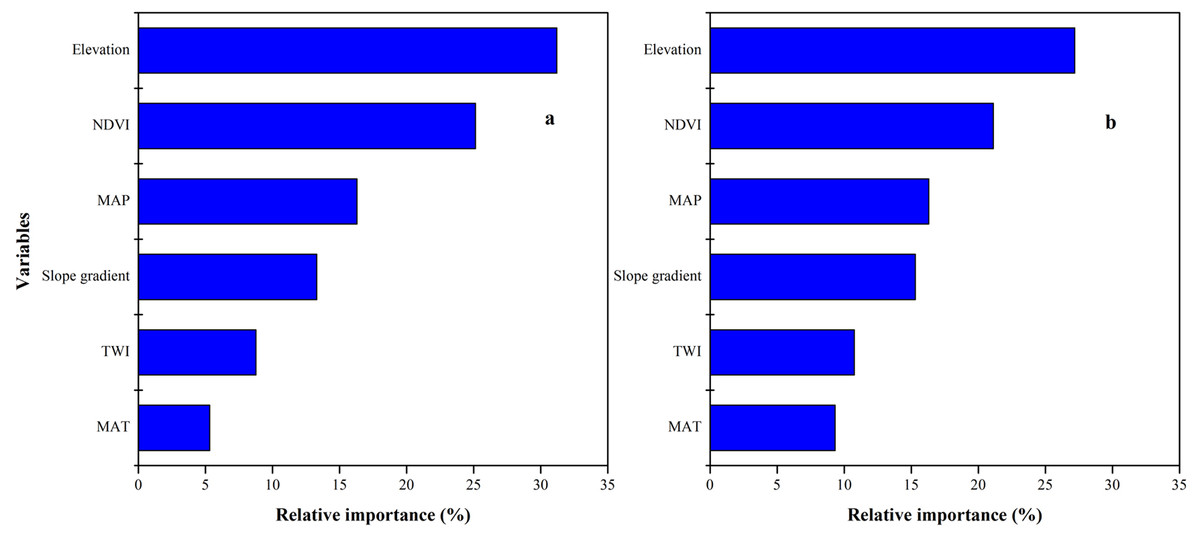
Figure 8: Relative importance of each variable as determined from the boosted regression trees (BRT) model in predicting soil organic carbon (SOC) (A) and soil total nitrogen (STN) (B).
{kind=link}
The ISA model could explain approximately 76% and 83% of the total SOC and STN variability in the study area, respectively. In comparison with previous studies, we observed a better prediction performance of the ISA method. Yang et al. (2016a) and Yang et al. (2016b) developed a BRT model that explained 50 to 58% of the SOC variability in the Qinghai Tibet Plateau, China. Using a GWR approach, Wang, Zhang & Li (2013) captured approximately 57% of the STN variability in Fujian Province, China. In the Medinipur Block, Paschim Medinipur District and West Bengal in India, Bhunia, Shi & Pourghasemi (2019) used remote sensing techniques and multivariate regression model, which explained 71% of SOC variability. Xu et al. (2018) used six different remote sensing spectral indices of RK models to predict STN in two smallholder villages, Kothapally and Masuti in South India, which helps explain 59% of the STN variability in the region.
Overall, the ISA model prediction consistency was higher towards the eastern part of the study area compared to the rest area for both SOC and STN predictions. Although there were other sources of uncertainty and error in mapping SOC and STN, including sampling error, laboratory analysis errors, and low predictor precision (Wang et al., 2017; McBratney, Santos & Minasny, 2003; Yang et al., 2016a; Yang et al., 2016b; Grimm et al., 2008; Fuchset et al., 2009), quantification of these inevitable errors were not considered in this study.
Predicted distribution of SOC and STN content
In general, the spatial distribution pattern for SOC and STN was similar and varies with different climate-vegetation landscape units (Figs. 3, 5 and 7). Spatially, higher SOC and STN were in the northeastern and southern regions that were dominated by low-elevation forest and low-mountain shrub. Coastal plain has the lowest SOC and STN. Overall, the lowest SOC and STN contents were found in the northern and central regions with low MAT and vegetation coverage. These results are consistent with the findings of Jobbagy & Jackson (2000) and Ding et al. (2018) who reported for humid and rainy areas. Soil particles in high-elevation areas were easy to lose and thick soil layers were formed in low-elevation areas, which were conducive to the accumulation of SOC and STN. Of the six climate-vegetation landscape units, soil under coastal plain had the lowest SOC and STN as also reported in Causarano et al. (2008). The low SOC and STN in these landscape units might be caused by increased organic matter decomposition and erosion and tillage losses (Burke et al., 1989; Lettens et al., 2004; Adhikari & Hartemink, 2015).
We observed that with increasing elevation, this is true for forest pixels (Fig. 8). The effect of elevation on SOC and STN has been examined in a number of studies (e.g., Kieft et al., 1998; Kunkel et al., 2011; Minasny et al., 2013; Adhikari et al., 2013; Chen et al., 2015; Minasny et al., 2017; Liang et al., 2019). Wang et al. (2017) reported that SOC and STN significantly increased with elevation. Differences in elevation gradients may have affected the input and loss of soil carbon and nitrogen mainly through indirect factors along the gradient, such as precipitation and temperature (Minasny et al., 2013; Elbasiouny et al., 2014; Were et al., 2015; Adhikari & Hartemink, 2015).
The predicted distribution of SOC and STN showed a discontinuous pattern (Figs. 7C and 7D). We found that the abrupt change in SOC and STN contents were located at the junction of landscapes. Such a pattern was due to the method of landscape division leading to an abrupt change of different landscape boundaries (Jaeger, 2000; Peilin et al., 2010). The apparent partitioning between landscapes led to spatially discontinuous distribution of SOC and STN, resulting in may lead to certain unreasonable predictions (Rosenbloom et al., 2006). This pattern may be attributed to the evident transition between the two landscapes, but the transition zone was smaller than the pixel resolution (Belshe et al., 2012).
Limitation of the study
Although the ISA model constructed in this study had a good performance in predicting SOC and STN content, there were still some limitations. Firstly, we used a soil-landscape model to collect soil samples, which is idiosyncratically suitable for the ISA model. An independent probability sampling method would be required in our subsequent research. Secondly, this study area was divided into several typical climate-vegetation landscape units and then applied the model to simulate their SOC and STN. This treatment ignored the gradual transition between landscape units with respect to SOC and STN, which might have biased our regional prediction. In the future, the model should be revised to avoid this bias. Thirdly, because the study area was dominated by mountains, which were easily affected by the terrain and clouds, the high-altitude areas were prone to produce shadows in the process of image segmentation, resulting in large reflectivity errors of satellite image data. This might have also introduced prediction errors. Finally, this research was limited to topsoil (0–20 cm) SOC and STN content, which might have led to underestimating SOC and STN due to a large amount of SOC and STN typically stored in deeper soil layers in the region.
Conclusions
This study advanced an ISA model to predict the spatial distribution of SOC and STN in the Northeast coastal area of China. The ISA model incorporated a GMMC method to divide the study area into six climatic-vegetation landscapes first. The six landscapes were then modeled using a t theory of environmental similarity. Comparing the prediction of GWR, RK, and BRT models, we found that the ISA model was the most robust and effective method in mapping SOC and STN, which explained 78% and 83% of the spatial variation of SOC and STN in the study area, respectively. Of the six climate-vegetation landscape units, the soils under low-elevation forest had the highest level of SOC and STN content than soils under the rest of the landscape units including coastal plain, interior plain, medium-coverage grasslands, low-mountain shrub, and high-coverage grasslands. Topography is the main driving force of SOC and STN distribution in the Northeast coastal area. Therefore, we suggested that terrain variables should be included in future SOC and TN mapping studies, especially in coastal and hilly areas of China. Overall, the improved ISA method better predicted SOC and STN in the region. Our predicted SOC and STN distribution shall provide important information for soil and water conservation, ecological restoration, environmental management and agricultural production planning in the Northeast coastal agricultural region.
{kind=link}