
The effect of the dispersal kernel on isolation-by-distance in a continuous population
- Published
- Accepted
- Received
- Academic Editor
- Jeffrey Ross-Ibarra
- Subject Areas
- Computational Biology, Evolutionary Studies, Genetics, Mathematical Biology
- Keywords
- Identity-by-descent, Neighborhood size, Kinship coefficients, Triangular distribution, Simulation, Individual based, Fine scale, Correlograms
- Copyright
- © 2016 Furstenau and Cartwright
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ) and either DOI or URL of the article must be cited.
- Cite this article
- 2016. The effect of the dispersal kernel on isolation-by-distance in a continuous population. PeerJ 4:e1848 https://doi.org/10.7717/peerj.1848
Abstract
Under models of isolation-by-distance, population structure is determined by the probability of identity-by-descent between pairs of genes according to the geographic distance between them. Well established analytical results indicate that the relationship between geographical and genetic distance depends mostly on the neighborhood size of the population which represents a standardized measure of gene flow. To test this prediction, we model local dispersal of haploid individuals on a two-dimensional landscape using seven dispersal kernels: Rayleigh, exponential, half-normal, triangular, gamma, Lomax and Pareto. When neighborhood size is held constant, the distributions produce similar patterns of isolation-by-distance, confirming predictions. Considering this, we propose that the triangular distribution is the appropriate null distribution for isolation-by-distance studies. Under the triangular distribution, dispersal is uniform over the neighborhood area which suggests that the common description of neighborhood size as a measure of an effective, local panmictic population is valid for popular families of dispersal distributions. We further show how to draw random variables from the triangular distribution efficiently and argue that it should be utilized in other studies in which computational efficiency is important.
Introduction
For many populations, individuals do not exist in discrete patches or demes; instead they are spread across a continuous landscape. Although there are no barriers separating individuals, dispersal distances are often limited, and individuals that are near one another in space will be more similar genetically than individuals further apart. This phenomenon is known as isolation-by-distance and introduces a spatial component that should be considered when studying population genetic processes (Jongejans, Skarpaas & Shea, 2008). Unfortunately, incorporating multiple dimensions of space at fine scales into analytical models is often analytically intractable (Epperson et al., 2010). Therefore, many researchers have turned to spatially-explicit, individual-based computer simulations which offer a more flexible way to incorporate spatial complexity into biological models (e.g., Barton et al., 2013; Cartwright, 2009; Epperson, 2003; Novembre & Stephens, 2008; Rousset, 2004; Slatkin, 1993).
A dispersal kernel describes the distribution of Euclidean distances between birth site and reproduction site. Ideally, when modeling dispersal, the dispersal distribution would be selected based on how well it fits the dispersal kernel estimated from natural populations. Classically, dispersal has been modeled as a diffusion process with Gaussian displacement; however, the observed dispersal kernels in many species tend to be more leptokurtic with a higher probability of short and long distance dispersal (Bateman, 1950). In plants, the shape of the dispersal kernel near the origin depends on the mechanism of dispersal; for example, there may be a high peak near the origin for gravity or animal dispersal whereas there may be a minimum near the origin for wind dispersal (Barluenga et al., 2011; Clark et al., 2005).
The shape of the dispersal kernel impacts many population processes including the rate of population expansion (Clark, Lewis & Horvath, 2001; Kot, Lewis & Van den Driessche, 1996), responses to environmental changes (Nathan et al., 2011), local adaptation (Berdahl et al., 2015), speciation (Hoelzer et al., 2008), and the spatial distribution of genetic diversity (Bialozyt, Ziegenhagen & Petit, 2006; Ibrahim, Nichols & Hewitt, 1996). Fat-tailed dispersal kernels, with a higher probability of long-distance dispersal, are a good fit to many empirical data sets (Bullock & Clarke, 2000; Clark et al., 2005; Gonzàlez-Martìnez et al., 2006; Martìnez & Gonzàlez-Taboada, 2009; Klein et al., 2006). Many studies have shown that population models behave differently when fat-tailed dispersal distributions are used instead of Gaussian dispersal. Kot, Lewis & Van den Driessche (1996) demonstrated that population spread is sensitive to the shape of the dispersal kernel and models using a normal distribution underestimated the rate of invasion compared to fat-tailed distributions. Nathan et al. (2011) found that long distance dispersal plays a large role during range shifts of wind-dispersed trees in response to projected climate changes. Houtan et al. (2007) showed that heavy tailed dispersal kernels were a better fit for dispersal of Amazonian birds but the shape of the dispersal kernel can change in response to forest fragmentation.
While the shape of the dispersal kernel impacts many population processes at different scales, it remains unclear how it effects patterns of isolation-by-distance within a continuous population. It has been argued that the number of long-distance dispersal events will not have a noticeable effect because new long-distance alleles are more likely to be lost due to drift than become established at the new location (Epperson, 2007; Ibrahim, Nichols & Hewitt, 1996). On the other hand, the shape of the dispersal kernel near the origin may have a significant impact on the overall rate of migration. In plants, this could result in a higher probability of self-fertilization and/or a reduction in the number of successful offspring when there is density dependent regulation (Barluenga et al., 2011; Howe, Schupp & Westley, 1985; Moyle, 2006).
Isolation-by-distance theory predicts that the probability of identity-by-descent between two neutral genes will decrease as the geographic distance between them increases and this pattern can help quantify spatial genetic structure. The analytical model developed by Malécot (1969) depends on the effective population density, the mutation rate, the spatial dimensions of the population, and the dispersal distribution. Much of the isolation-by-distance work has focused on the lattice model which forces a constant population density (Malécot, 1969; Maruyama, 1970; Sawyer, 1977) but these results hold when considering continuously distributed populations with spatial clustering (Barton et al., 2013). In two dimensions, the relationship between the probability of identity-by-descent and the log of distance is linear over a certain range of distances and the relationship is proportional to 1∕(Deσ2) where De is the effective population density and 2σ2 is the mean squared distance of dispersal (i.e., non-central second moment of Euclidean distance; Barton et al., 2013; Malécot, 1969; Rousset, 1997; Rousset, 2004; Wright, 1946). Over this range, the slope of the probability of identity-by-descent function is independent of most aspects of the dispersal distribution except for 2σ2; however, when the distance between individuals falls below the range, the shape of the dispersal distribution becomes important (Rousset, 1997). This suggests that as long as 2σ2 stays constant, any dispersal distribution will produce similar patterns of isolation-by-distance. However, Rousset argues that the magnitude of genetic differentiation will always depend on the shape of the distribution (Rousset, 1997; Rousset, 2008).
Despite the increase in the use of spatially explicit simulations in studies of spatial genetic structure, it remains unclear whether the shape of the dispersal kernel should be considered. There has not been a clear comparison of how the shape of different dispersal kernels affect observable patterns of isolation-by-distance in these simulations. Here we attempt to offer such a comparison using a spatially-explicit, individual-based model to simulate local dispersal in a continuous population to determine if patterns of isolation-by-distance vary based on the shape of several different dispersal distributions: Rayleigh, half-normal, exponential, triangular, gamma, Lomax, and Pareto. Each dispersal distribution has a different shape, but they can be parameterized such that their non-central second moment is 2σ2. If the simulations reveal a similar pattern of isolation-by-distance across all dispersal distributions, we can conclude that, for a wide range of dispersal distributions, 2σ2 is the main determining factor of how genetic similarity declines with increasing distance in a continuous population. Consequently, when designing isolation-by-distance simulations, researchers may choose a dispersal distribution based on computational needs instead of biological fit.
Wright (1946) uses the term “neighborhood” to describe a local population from which parents are randomly drawn. He measures the magnitude of the effective size of the neighborhood, Nb, as the inverse of the probability that two gametes at the same location came from the same parent. Assuming dispersal is normally distributed along each axis, he calculated that Nb = 4πσ2De, where De is the effective density of individuals, and 2σ2 is the mean squared distance of dispersal. In his model this captures 86.5% of parents of central individuals. Although Wright assumed Gaussian dispersal, his formula can be used to calculate Nb for many different dispersal models at equilibrium due to the central-limit theorem. Nb is important because it helps define the rate of decay of genetic similarity over spatial distance, i.e., the amount of isolation-by-distance in a population (Barton et al., 2013; Rousset, 1997; Rousset, 2000).
If a neighborhood is supposed to represent a local panmictic unit, then in the ideal model parents should be chosen uniformly from within a circle of radius 2σ centered on an offspring, and the Euclidean distance between parents and offspring should follow a triangular distribution: f(r; σ) = r∕(2σ2), where 2σ2 is again the non-central second moment. This type of neighborhood is similar to the neighborhood defined in the spatially continuous Λ-Fleming-Voit disc model in which a number of parents, v, are chosen uniformly at random from a disc with radius r to replace a fraction u of the population (Barton et al., 2013). In this model, neighborhood size is defined by the ratio v∕u and the individuals occupying the disc constitute a panmictic population. If 100% of the population is replaced (u = 1), the definition of neighborhood size reduces to the number of individuals competing for the central location.
Below, we demonstrate that patterns of isolation-by-distance are equivalent for different dispersal kernels with the same second moment, and discuss the use of the triangular distribution to model dispersal in a continuous population.
Methods
Simulation
In our individual-based simulation, a population exists on a 100 × 100 rectangular lattice (cf. Epperson, 1995; Epperson & Li, 1997; Epperson, 2007; Hardy & Vekemans, 1999). Individuals are uniformly spaced with a single individual per cell. Each individual contains one haploid locus. The initial population of 10,000 individuals each carry a unique allele. Generations are discrete, and individuals reproduce by generating 15 clonal offspring that experience mutations according to the infinite alleles model at rate μ. All starting and mutant alleles are selectively neutral.
The offspring disperse from the parent cell following a given dispersal distribution. The landscape boundaries are absorbing, and when offspring disperse off of the lattice they are lost. Offspring that land in the same cell will compete to become a parent in the next generation. Because all alleles are selectively neutral, a single successful offspring is uniformly selected for each cell. To avoid storing all the offspring in memory until dispersal is completed, we use a reservoir sampling method to immediately accept or reject offspring when they land on a cell (Vitter, 1985). This method allows us to keep track of two randomly chosen offspring per cell. The first offspring becomes a parent in the next generation and the second individual is recorded to measure the probability of identity-by-descent for offspring competing for the same cell. While it is possible for a cell to remain empty after dispersal, we determined that when each parent generates 15 offspring the number of empty cells per generation is negligible so we assume a constant homogeneous population density.
Modeling Dispersal
The simulation is spatially-explicit with space represented on a rectangular lattice. Due to the discrete nature of the lattice, the dispersal kernels will be discretized approximations of continuous distributions (Chesson & Lee, 2005; Chipperfield et al., 2011). The dispersal kernel function, f(r, θ; σ), takes a parameter σ and returns continuous polar coordinates. The σ parameter is the square root of one-half the second moment of dispersal distance. The polar coordinates include the angle, θ ∈ [0, 2π], which is uniformly distributed to ensure isotropic dispersal and distance, r > 0, which is drawn from a continuous distribution.
Once the angle and distance are drawn, the final position is determined by converting the polar coordinates into rectangular coordinates and adding them to the parent’s position. The new coordinates are then rounded to determine the integer coordinates of the destination cell. This dispersal scheme is similar to the centroid-to-area approximation of continuous dispersal kernels described by Chipperfield et al. (2011), which showed minimal deviation from expectations especially when cell length is less than the expected distance.
We looked at seven different dispersal distance kernels (Fig. S1): Rayleigh, exponential, half-normal, triangular, gamma, Pareto, and Lomax. We chose these distributions because they provide a range of shapes for short, intermediate, and long distance dispersal.
The Rayleigh is a distribution of Euclidean distances that result from bivariate normal displacement along the x and y axis. The Rayleigh distribution follows the assumptions of Wright (1946)’s two-dimensional isolation-by-distance model.
The exponential distribution is more leptokurtic with higher probability of dispersal at short and long distances and less at intermediate distances. The exponential tail is the boundary that separates truly heavy-tailed distributions with potentially infinite higher moments from distributions with all moments finite. The distinction is important because leptokurtic, heavy-tailed dispersal kernels are typically a better fit to observed dispersal in nature (Clark, 1998).
The half-normal distribution is equivalent to a normal distribution that has been folded over the y-axis. In this case, Euclidean distance is simply the absolute value of normally distributed random variables. The half-normal is a monotonically decreasing distribution with a convex shoulder near zero. This distribution has a higher probability of dispersal at intermediate distances compared to the exponential.
The triangular distribution is typically defined using three points: a lower limit, a, an upper limit, b, and a mode, c. Here we use a special case of the triangular distribution where a = 0 and b = c = 2σ. We chose this special case of the triangular distribution because in our dispersal function it will return polar coordinates that are uniformly sampled from within a circle with area 4πσ2 which is the same as the neighborhood area (see proof in Appendix A). The triangular distribution is also the only one of our distributions that has a finite range, r ∈ [0, 2σ].
Unlike the previous single parameter distributions, the final three distributions have an additional α shape parameter. The gamma distribution is equivalent to the exponential distribution when α = 1, and as α increases the distribution becomes more symmetrical with a higher probability for intermediate distances and a lower probability for short distances.
The Lomax and Pareto distributions are both heavy-tailed power-law distributions. The n-th moments are finite only when α > n. The support for the Pareto distribution, r ∈ [xmin, + ∞), begins at a parameter xmin > 0. The Lomax distribution is a Pareto distribution that has been shifted so that the support begins at zero. We chose values of α between 2 and 3 so that the second moment of the distribution would be finite but higher moments are infinite.
The dispersal function is executed over 100-billion times per simulation, and thus it is important to make the implementation as efficient as possible. With this aim, we used an xorshift algorithm for uniform pseudo-random number generation and the ziggurat rejection sampling algorithm when applicable (Marsaglia & Tsang, 2000b; Marsaglia, 2003). We used two different versions of the ziggurat algorithm to draw distances from the exponential and half-normal distribution. For the gamma distribution we used a rejection sampling method that uses the ziggurat algorithm to draw normal variates (Marsaglia & Tsang, 2000a). Random variables from the Pareto distribution are generated by xmineX∕a where X is an exponentially distributed random variable that we draw using the ziggurat algorithm. The Lomax distribution is sampled similarly: xmineX∕a − xmin.
In addition to generating random distances, the dispersal function requires costly conversions from polar to Cartesian coordinates. We were able to avoid this conversion for the Rayleigh and triangular distributions. We simulated the Rayleigh distribution by drawing vertical and horizontal offsets from independent normal distributions using the ziggurat algorithm. For the triangular distribution, we developed a discrete sampling algorithm using the alias method that allows us to draw the vertical and horizontal offsets simultaneously in constant time (Vose, 1991). See Appendix D for a description of the algorithm, and Appendix E for an analysis of its superior efficiency compared to the other distributions we used.
Analysis
A simulation was run for each of the seven types of dispersal distributions under 4 levels of dispersal (σ = 1, 1.5, 2 and 4) with a mutation rate of μ = 10−4. Each simulation was run for a burn-in period of 10,000 generations to allow the population to reach a mutation-drift equilibrium. After the burn-in, data was collected from populations that were 1,000 generations apart to decrease the correlation between them for a total of 2,000 replicate populations per simulation. In each population, a straight transect of 50 individuals was sampled from the center of the landscape to avoid measuring edge effects.
From the transect, all possible pairs of individuals were placed into distance classes based on the geographical distance between the pair. The number of pairs that shared an identical allele was determined and recorded as a proportion of the total number of pairs in the distance class. The probabilities for each distance class were then averaged over all sampled populations. Under this sampling scheme, the number of pairs per distance class decreases as distance increases so in distance class 50 there is only one pair sampled per population.
The parameters for each dispersal distribution were calculated so that E[X2] = 2σ2; the calculations are reflected in the probability distribution functions in Fig. S1. Due to the discrete nature of the lattice, some parameters values were adjusted slightly until the simulations produced an average, observed, squared distance between parent and offspring, s2, that was within 5% of the expected value, σ2. Three of the distributions require a second α parameter. For the gamma distribution we used α = 1, 2, 4, 8. For the Lomax and Pareto distributions we used α = 2.4, 2.6, 2.8, 3.0 all of which are infinite in the 3rd and higher moments.
Under isolation-by-distance, individuals geographically near one another will tend to be genetically similar, and this similarity will decrease as the distance between pairs of individuals increases. Therefore, isolation-by-distance is described by constructing correlograms of genetic similarity between individuals versus the distance between them. Genetic similarity can be measured using identity-by-descent, identity-by-state, relatedness, conditional kinship, or F-coefficients and can be based on coalescent times, an ancestral population, or the current population (Hardy & Vekemans, 1999; Hardy, 2003; Malécot, 1969; Rousset, 1997; Rousset, 2002; Wang, 2014). For two-dimensional populations, genetic similarity is often plotted against the log-distance separating pairs because theory predicts that this relationship is approximately linear (Barton et al., 2013; Hardy & Vekemans, 1999; Rousset, 2000).
We recorded the probability of identity-by-descent for pairs of individuals in each distance class. Under the infinite alleles model, pairs of individuals were considered identical-by-descent if they shared the same allele. The probability of identity-by-descent in each distance class depends on the mutation rate; the probability will be greater when there are fewer alleles. For more consistent results that are nearly independent of mutation rate, the probability of identity is often calculated as a ratio that measures genetic similarity (or differentiation) relative to a particular reference group. We calculated the kinship coefficient which measures the correlation of genetic similarity between pairs of individuals a certain distance apart relative to the genetic similarity in the whole sample. (1)
Here pij is the probability of identity-by-descent between haploid individuals i and j at distance r and is the probability of identity-by-descent between random haploid individuals in the current sample (Hardy & Vekemans, 1999). The kinship coefficient is related to differences in the expected coalescent times, T, between a specific pair of individuals and a random pair in the population (Barton et al., 2013). Kinship coefficients were calculated for each transect and then averaged across transects for each distance class. Since this statistic is highly dependent on the sampling scheme, we sampled the same transect in all simulations.
We also calculated the ar parameter of Rousset (2000): (2) which measures genetic differentiation over distance relative to the probability of identity-by-descent within a location. The ar parameter is independent of sampling scheme, but it does depend on the level of local identity-by-descent, p0, in the population such that ar approaches infinity as p0 approaches one (Vekemans & Hardy, 2004). Typically, p0 is estimated from the amount of autozygosity in the population; however, we estimated p0 as the probability that an individual shared an allele with one of the offspring that it competed with for the cell, which is suitable for haploid organisms and better fits its definition (Vekemans & Hardy, 2004).
For each simulation, we calculated the average number of unique alleles in a 50-individual transect () and the average squared distance between parents and offspring (2s2). Using , we estimated the population-level diversity, (Ewens, 2004 eq. 9.32) and estimated effective haploid population size as and effective density as , where A = 10, 000.
Finally, we estimated neighborhood size using two different methods. First we used our estimated demographic parameters to calculate neighborhood size as the product . We calculated an estimate from samples from each population and calculated an average over all populations. We then estimated neighborhood size using the regressions of both Fr and ar on the log of distance. The slope of the ar regression is an estimate of 1∕2πσ2De and the slope of Fr regression is an estimate of −(1 − F0)∕2πσ2De (Barton et al., 2013; Hardy & Vekemans, 1999; Rousset, 2000). We performed the regression for distance classes between 5 and 35. We estimated the slope from each population sample then pooled the data from all the samples to get a combined slope estimate.
Results
Behavior of dispersal distributions
The more leptokurtic distributions (exponential, gamma-1 and Lomax) with a high probability peak near zero have a much higher probability of not dispersing from the original cell, especially when σ is low. The Pareto distribution, which has a fat tail but has been shifted so it does not have a peak at zero, has a very low probability of not dispersing. Under the gamma distribution as the α parameter increases, the probability of remaining at the origin decreases; when α = 8 the probability is nearly zero for all values of σ. Figure S2 shows the empirical cumulative distributions generated from 10,000 simulated dispersal events from each distribution. The probability of not dispersing from the original cell is indicated by the height of the left-most horizontal line for each distribution.
The average squared parent–offspring dispersal distance, s2, observed for each distribution was very similar with a relative error of less than 5% from the expected σ2 value (Table 1); however, the distribution of these values over sampled generations varied (Fig. S3A). Expectedly, the thin tailed or no-tail (triangular) dispersal distributions have the smallest variance because their properties are easier to represent with a small number of samples. The Lomax distribution has the highest variance with the median falling slightly below the expected value.
| σ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| s2 | s2 | |||||||||
| 1 | 1.5 | |||||||||
| Ray | 1.82 | 0.91 | 0.99 | 11.31 | 13.07 | 1.83 | 0.91 | 2.33 | 26.79 | 31.16 |
| Exp | 2.09 | 1.04 | 1.04 | 13.70 | 14.32 | 2.04 | 1.02 | 2.26 | 29.04 | 29.00 |
| Nor | 1.94 | 0.97 | 0.98 | 11.94 | 13.49 | 1.91 | 0.95 | 2.31 | 27.69 | 30.61 |
| Tri | 1.82 | 0.91 | 1.00 | 11.37 | 13.58 | 1.83 | 0.92 | 2.36 | 27.18 | 31.02 |
| Gam 1 | 2.07 | 1.04 | 1.05 | 13.63 | 14.41 | 2.01 | 1.00 | 2.32 | 29.22 | 30.07 |
| Gam 2 | 1.89 | 0.94 | 0.98 | 11.62 | 12.80 | 1.85 | 0.92 | 2.32 | 26.98 | 30.13 |
| Gam 4 | 1.83 | 0.92 | 1.00 | 11.49 | 12.88 | 1.87 | 0.94 | 2.32 | 27.31 | 28.27 |
| Gam 8 | 1.80 | 0.90 | 1.01 | 11.45 | 13.31 | 1.79 | 0.90 | 2.32 | 26.16 | 29.91 |
| Lom 2.4 | 2.97 | 1.49 | 1.06 | 19.70 | 13.41 | 2.62 | 1.31 | 2.16 | 35.53 | 26.65 |
| Lom 2.6 | 2.88 | 1.44 | 0.97 | 17.61 | 13.23 | 2.47 | 1.24 | 2.34 | 36.25 | 26.11 |
| Lom 2.8 | 2.73 | 1.36 | 1.04 | 17.78 | 12.82 | 2.41 | 1.21 | 2.22 | 33.66 | 25.30 |
| Lom 3 | 2.72 | 1.36 | 1.00 | 17.07 | 14.28 | 2.36 | 1.18 | 2.34 | 34.71 | 28.50 |
| Par 2.4 | 1.98 | 0.99 | 0.98 | 12.18 | 11.71 | 1.93 | 0.97 | 2.19 | 26.56 | 27.12 |
| Par 2.6 | 1.95 | 0.98 | 1.04 | 12.74 | 13.82 | 1.81 | 0.91 | 2.28 | 25.98 | 27.95 |
| Par 2.8 | 1.90 | 0.95 | 0.97 | 11.57 | 12.25 | 1.85 | 0.93 | 2.25 | 26.16 | 30.85 |
| Par 3 | 1.89 | 0.95 | 0.99 | 11.80 | 13.56 | 1.89 | 0.94 | 2.24 | 26.54 | 29.79 |
| 2 | 4 | |||||||||
| Ray | 1.97 | 0.99 | 4.07 | 50.39 | 58.81 | 2.02 | 1.01 | 16.11 | 204.93 | 236.23 |
| Exp | 2.02 | 1.01 | 4.08 | 51.88 | 49.60 | 2.09 | 1.05 | 16.16 | 212.48 | 154.94 |
| Nor | 1.95 | 0.97 | 4.08 | 49.87 | 55.00 | 2.04 | 1.02 | 16.04 | 205.76 | 189.69 |
| Tri | 1.94 | 0.97 | 4.11 | 50.13 | 54.57 | 2.09 | 1.04 | 16.09 | 210.87 | 245.02 |
| Gam 1 | 2.03 | 1.01 | 4.06 | 51.74 | 52.25 | 2.16 | 1.08 | 16.15 | 218.67 | 257.28 |
| Gam 2 | 1.89 | 0.95 | 4.12 | 48.88 | 54.39 | 2.02 | 1.01 | 16.08 | 204.41 | 214.04 |
| Gam 4 | 1.94 | 0.97 | 4.08 | 49.80 | 55.60 | 1.98 | 0.99 | 15.94 | 197.97 | 191.02 |
| Gam 8 | 1.89 | 0.94 | 4.06 | 48.21 | 52.47 | 2.02 | 1.01 | 16.11 | 203.96 | 231.04 |
| Lom 2.4 | 2.48 | 1.24 | 3.98 | 62.01 | 47.94 | 2.19 | 1.09 | 16.06 | 220.82 | 180.03 |
| Lom 2.6 | 2.36 | 1.18 | 3.94 | 58.49 | 48.10 | 2.15 | 1.07 | 15.45 | 208.62 | 219.14 |
| Lom 2.8 | 2.27 | 1.13 | 4.16 | 59.23 | 51.08 | 2.14 | 1.07 | 15.81 | 212.44 | 241.05 |
| Lom 3 | 2.24 | 1.12 | 3.97 | 56.05 | 47.23 | 2.07 | 1.04 | 16.55 | 215.21 | 211.19 |
| Par 2.4 | 1.93 | 0.97 | 4.13 | 50.12 | 48.20 | 2.03 | 1.02 | 16.04 | 204.74 | 192.65 |
| Par 2.6 | 1.95 | 0.97 | 4.11 | 50.29 | 51.74 | 2.03 | 1.02 | 15.91 | 203.23 | 189.19 |
| Par 2.8 | 1.98 | 0.99 | 4.02 | 49.95 | 47.73 | 1.95 | 0.97 | 15.53 | 189.90 | 219.90 |
| Par 3 | 1.98 | 0.99 | 4.10 | 50.92 | 49.58 | 2.01 | 1.00 | 16.30 | 205.48 | 169.53 |
Figure S3B shows the distribution of the average cubed parent–offspring dispersal distances, s3, for each transect. The theoretical third moment of the Lomax and Pareto distributions is infinite, while it is not possible to simulate this on a finite landscape, we do observe values of s3 that are several orders of magnitude larger than distributions with finite third moments. The distribution of s2 and s3 for the Lomax and Pareto distributions both have a large positive skew.
Allelic diversity
The distribution of the number of unique alleles is similar for most of the dispersal kernels with the median falling near the expected value under the infinite alleles model (Fig. S4). The expected number of alleles under the infinite alleles model is equal to where n = 50 is the number of individuals in the sampled transect. The Lomax distributions have a higher median number of alleles at lower values of σ but this gets closer to the expected value when σ > 2. The average diversity is also slightly elevated for the exponential and gamma-1 simulations.
Differences in effective population size between simulations can be measured by comparing the number of unique alleles observed in the transects. Different dispersal kernels produce similar levels of diversity, except for the Lomax distributions which have a higher θk and consequently a larger effective population size (Table 1).
Spatial autocorrelation and isolation-by-distance
To describe the patterns of isolation-by-distance, we first measured the average probability of identity-by-descent for each sampled population as a function of distance. All dispersal kernels produced very similar patterns of isolation-by-distance especially for larger distance classes (Fig. 1). The probability of identity-by-descent is higher at small distance when σ is small but the relationship flattens out when σ = 4. Differences between the different dispersal distributions become apparent when the distance between individuals is small. The more leptokurtic dispersal distributions have a steeper incline as distance decreases and they have a higher probability of autozygosity at distance class zero. The plots for the triangular distribution nearly perfectly overlap the plots for the Rayleigh distribution in all cases.

Figure 1: Identity-by-descent is similar between different dispersal models.
Each plot shows the average probability of identity-by-descent for pairs of individuals in each distance class. Each panel represents simulations run with different σ parameters (gray box) for different groups of dispersal distributions.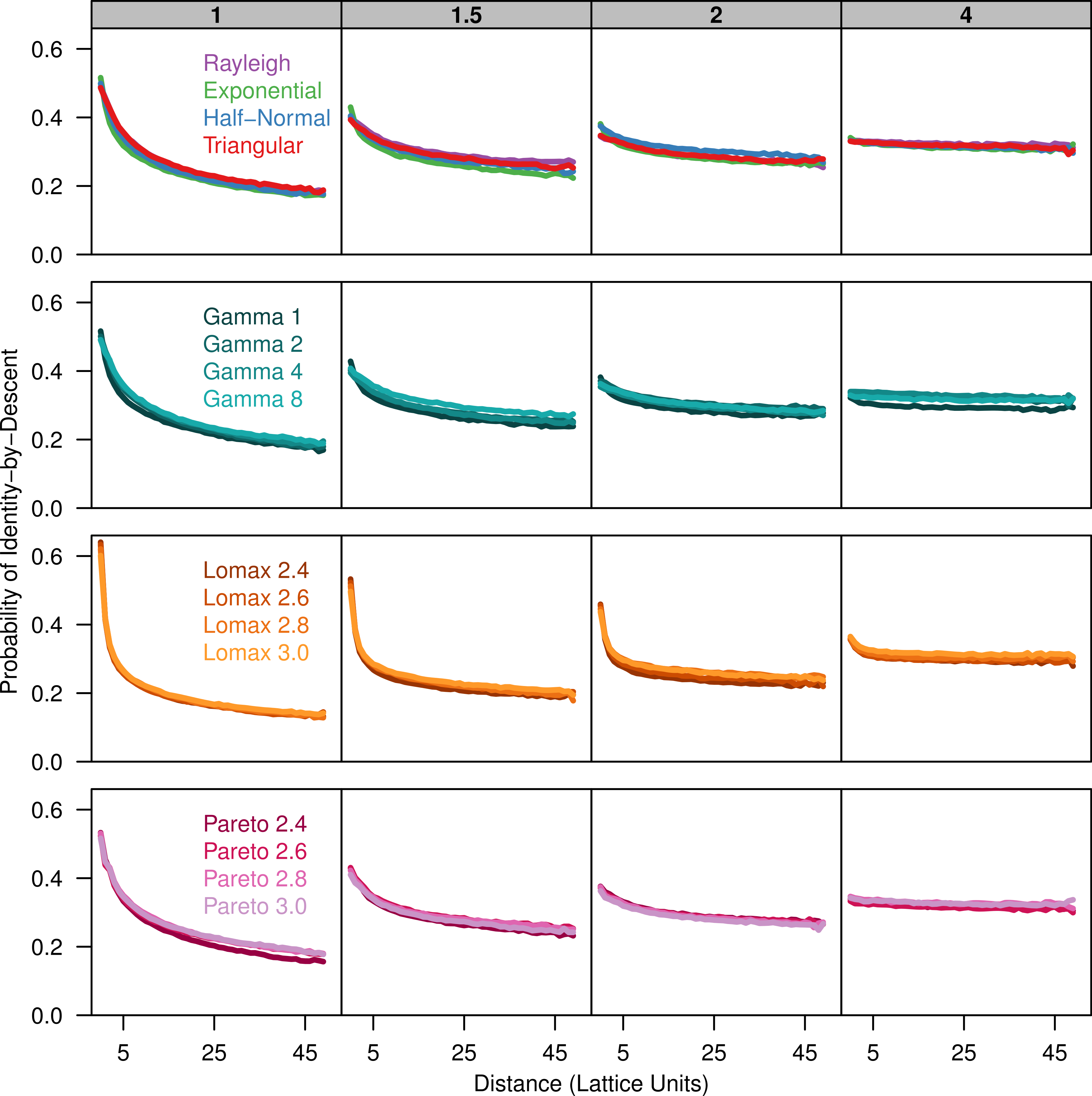{kind=link}
Because the probability of identity-by-descent is sensitive to differences in the number of alleles present in the sample, we also calculated the pairwise-kinship coefficient over the log of distance (Fig. 2). The kinship coefficient shows how much more or less similar pairs of individuals in a given distance class are compared to the sample as a whole. The kinship coefficient is nearly independent of differences in allele number and there is much better overlap of the plots for the different dispersal distributions. When the kinship coefficient is plotted against the log of distance there is a negative linear relationship over a certain range of distances (Hardy & Vekemans, 1999). The slope of this linear range is also similar across distributions for each value of σ.
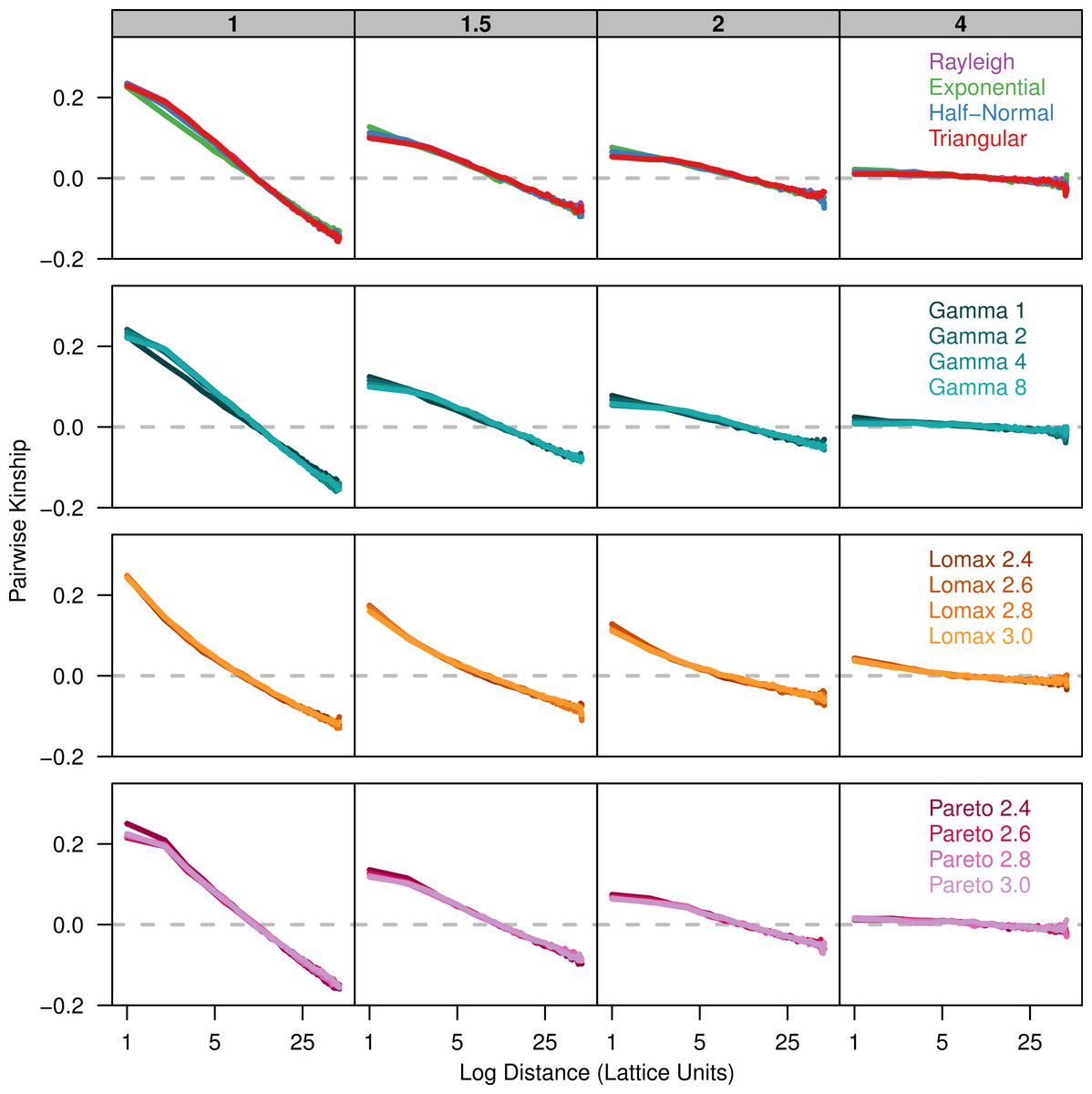
Figure 2: Kinship coefficients are similar between different dispersal models.
Each plot shows the average kinship coefficient for pairs of individuals over the log of the distance between them. Each panel represents simulations run with different σ parameters (gray box) for different groups of dispersal distributions. The gray dashed line is at zero so values above the line are more similar than the sample as a whole while values below the line are less similar than the population as a whole.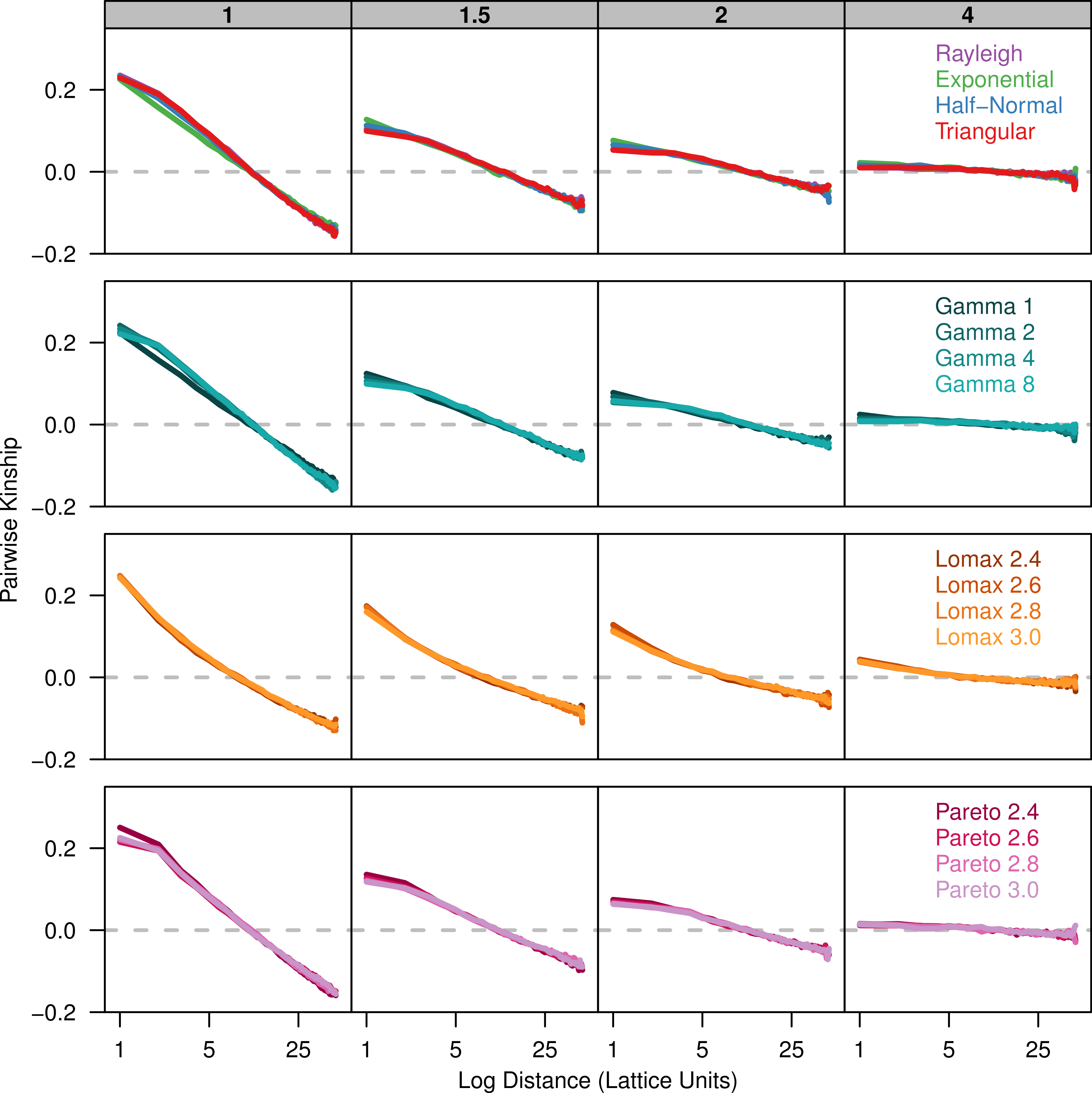{kind=link}
Finally, we plot Rousset (2000)’s ar parameter against the log of distance. There is a positive linear relationship between ar and the log of distance (Fig. 3). The slope of ar is fairly similar among the dispersal distributions for a given value of σ. However, there is less overlap in the plots for the different dispersal distributions because the overall amount of differentiation varies.
Figure 3: Slopes of genetic differentiation are similar between different dispersal models.
Each plot shows the average differentiation, ar, for pairs of individuals over the log of the distance between them. Each panel represents simulations run with different σ parameters (gray box) for different groups of dispersal distributions.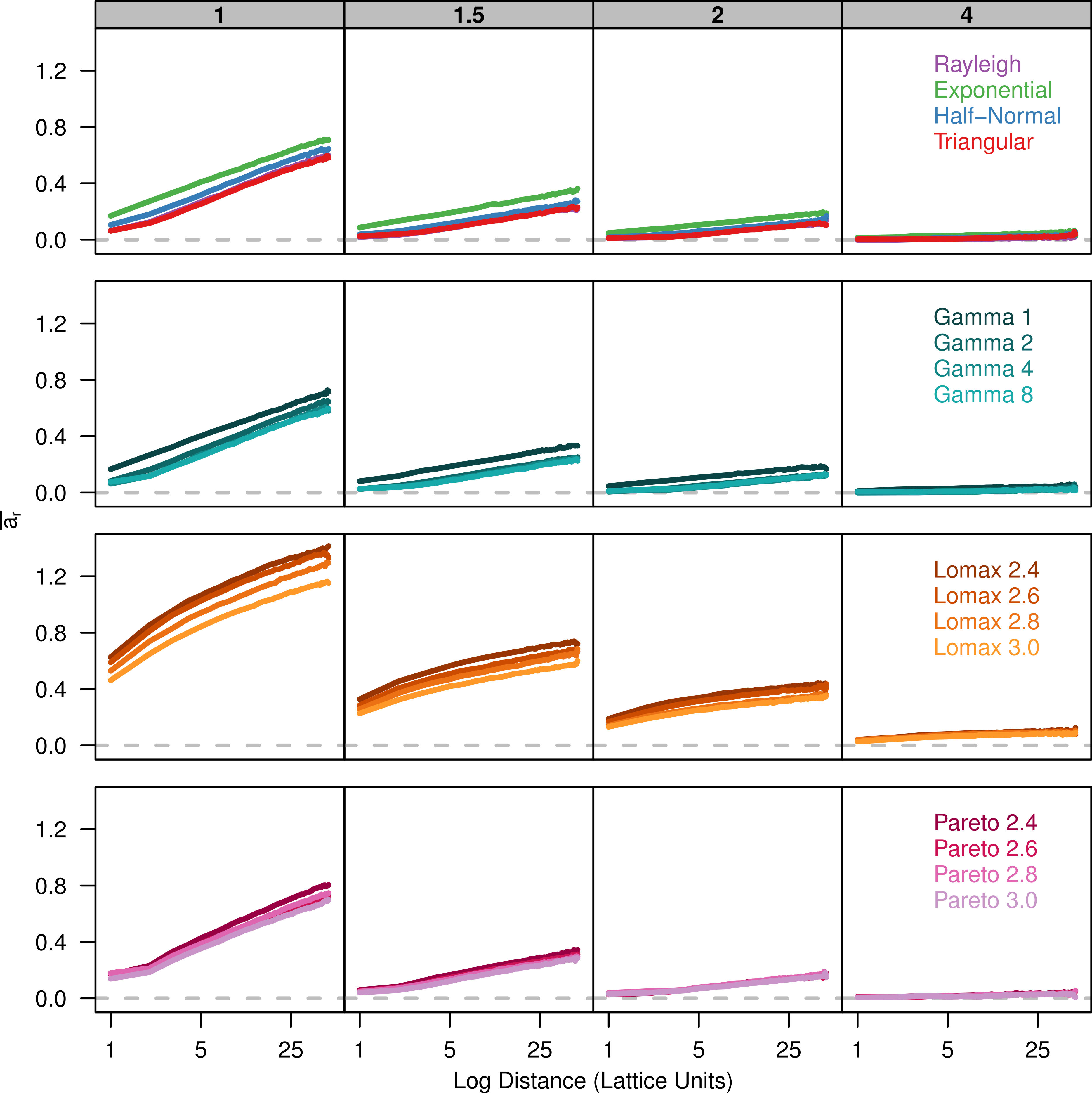{kind=link}
Estimated neighborhood size
The estimates are shown in Table 1 and Fig. 4A. Table 1 shows the average estimate over all population samples. The colored dots in Fig. 4A show this same average relative to the expected values and the bars represent the middle 50% of the individual sample estimates. As mentioned previously, the populations with Lomax dispersal tend to have a greater number of unique alleles and this translates to higher , higher effective population size, and ultimately higher effective density. The estimates for s2 were highly variable but skewed towards lower values. As a result, the estimates of for the Lomax distribution appear to be higher on average but the estimates are skewed. Otherwise, the estimates for the other dispersal distributions are similar and close to the expected values.

Figure 4: Estimated neighborhood sizes are similar across all dispersal distributions.
Neighborhood size is estimated two different ways. (A) Nb(θk) is where is estimated from . The dot is the average from all populations samples and the bars represent the middle 50% of estimates from individual samples. (B) The slope estimates, , of ar and the log of distance. The dots represent the slope estimate from the combined data from all samples and the bars represent the middle 50% of slopes from individual samples.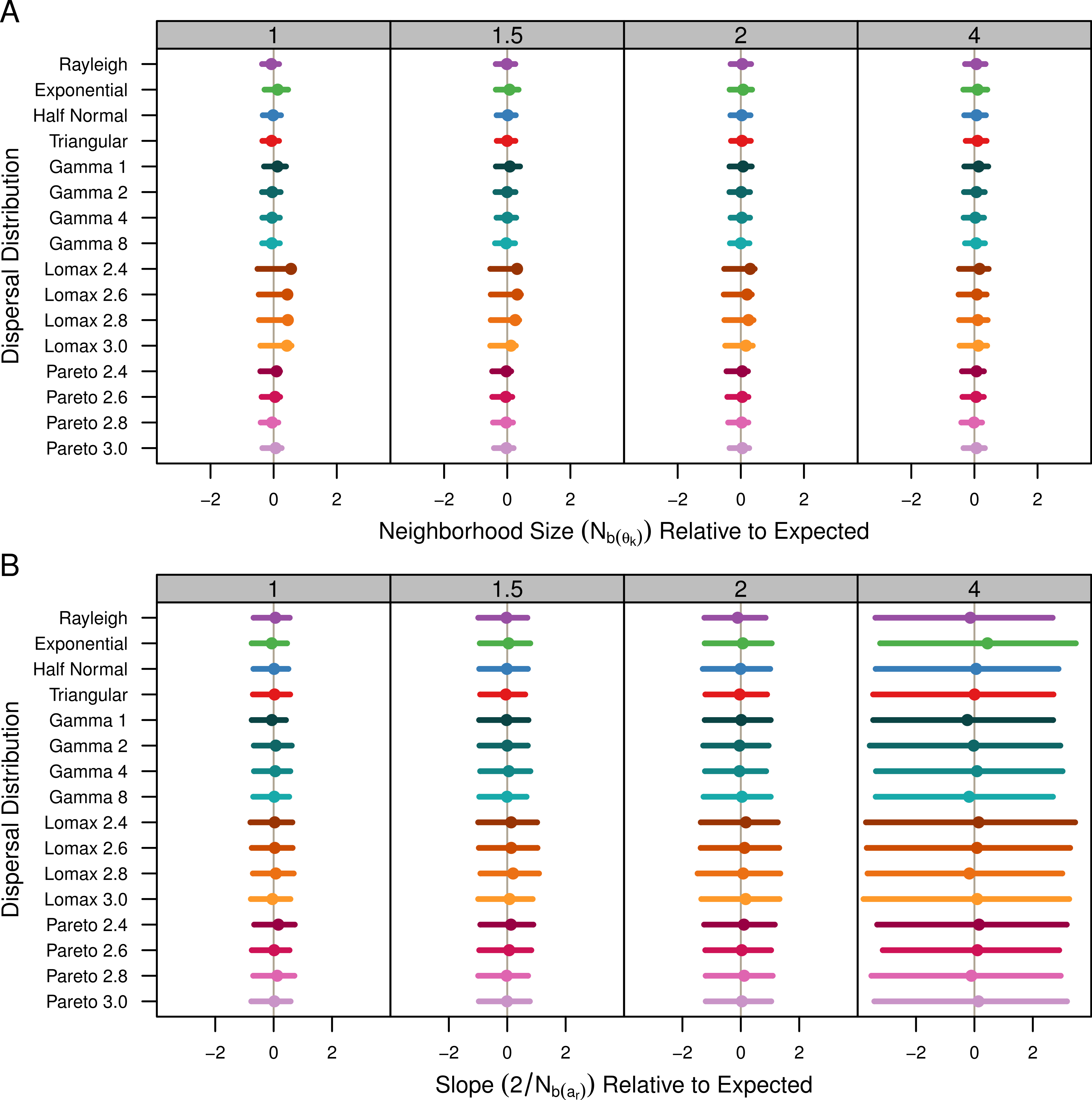{kind=link}
Table 1 shows the estimates calculated as the twice the inverse of the regression of ar and the log of distance for the pooled sample data. Estimates using the slope of the Fr statistics were identical so they are not shown. The colored dots in Fig. 4B show the slope estimate of the combined data relative to the expected slope and the bars represent the middle 50% of the slopes from individual populations. All of the dispersal distributions have similar slopes. When σ = 4, the actual spread of the slope values is smaller than the the spread of the slopes for the other values of σ (not shown), but in Fig. 4 the values are relative so the middle 50% is wider.
Discussion
Approximating continuous dispersal on a discrete lattice will introduce obvious biases when the dispersal distance is small compared to the scale of the lattice nodes (Chipperfield et al., 2011). This bias can be seen in Fig. S2 by the jagged nature of the empirical cumulative distribution (ECDF) (especially when σ is small) compared to the CDF of the continuous distribution. In the simulation, the distance between nodes is one lattice unit so dispersal has to exceed at least a distance of 0.5 lattice units to leave the original cell. For Lomax simulations with small σ, the high probability density near zero falls rapidly before a distance of 0.5 lattice units has been reached. This means that the majority of dispersal events do not leave the parent cell. The Pareto and Lomax distributions share a similar shape and a wide tail, but unlike the Lomax distribution, the mode of the Pareto is greater than zero and almost all dispersal events leave the original cell. We refer back to the differences between the Lomax and the Pareto when we discuss whether we can differentiate results that are specific to dispersal with a high peak at zero or are more general to wide-tailed dispersal.
Allelic diversity is near the expected value predicted by the infinite alleles model for most distributions. The Lomax distributions tend to have a higher number of alleles up until σ = 4. This appears to be in agreement with Maruyama (1972) which showed that the effective population size is larger than the census size when σ < 1 which is the case in many of the Lomax simulations (Fig. S3). Because the median allele number for the Pareto simulations falls near the expected value, it seems likely that the higher allelic diversity in the Lomax simulations is due to the high probability of not dispersing. This is supported by the fact that the average diversity is slightly higher for the exponential and gamma-1 as well. When dispersal is unlikely to occur outside of the original cell, the number of migrants is low and the pool of offspring before competition will consist mostly of offspring from the same parent. It is unlikely that migrants will become established at their new location after competition and thus more alleles will be maintained.
Much of the theory of isolation-by-distance in continuous populations is based on infinite or periodic lattice models. Here we simulated dispersal in a continuous population occupying a finite lattice with absorbing boundaries to better understand the effect of the dispersal kernel on isolation-by-distance models on a more natural landscape. As expected under isolation-by-distance, the probability of identity-by-descent between neutral alleles in pairs of individuals decreases as the distance between them increases. When neighborhood size is small, the relationship is very pronounced with a high initial probability that quickly declines. As neighborhood size increases (σ = 4), this relationship nearly disappears. This is similar to two-dimensional stepping stone models that show strong differentiation between populations when Nm ≪ 1 and little differentiation when Nm > 4 (Kimura & Maruyama, 1971).
Simulations with our different dispersal kernels show a strikingly similar pattern of isolation-by-distance. However, theory predicts that when distance is small, deviation in the shape of the dispersal kernel relative to the Rayleigh distribution will become important (Rousset, 1997; Rousset, 2000). This is evident in our results when we compare the probabilities of identity-by-descent at small distances between the different dispersal kernels. When the dispersal kernel is leptokurtic, the probability is higher between individuals occupying the same location and it is slightly lower for short distances compared to the Rayleigh results. The pattern of identity-by-descent in other distributions, including the triangular are nearly identical to the Rayleigh. The situation is similar for the pairwise kinship except there is even greater similarity between the different dispersal kernels.
Rousset (2008) makes it clear that the increase of genetic differentiation with distance is robust to the shape of the dispersal kernel but the overall magnitude of differentiation will depend on the shape of the kernel. Looking at the relationship between ar and the log of distance for our simulations, we can see that the slope for each distribution is similar for larger distance values but the plots are shifted up or down depending on kurtosis. Compared to the other wide tailed distributions, the Pareto distribution is not shifted upward due to the lack of dispersal at the origin. The ar statistic is a ratio that compares the amount genetic differentiation between individuals at certain distance to the differentiation within a single individual. When the probability of identity-by-descent within an individual is high, the differentiation between neighbors will appear much higher due to a steep initial drop in identity. As a result, the ar statistic will be greater for leptokurtic distributions even if the actual probability of identity is similar to other distributions.
As expected, the neighborhood-size estimates are similar to the expected value for all simulations. Neighborhood size was slightly higher for the Lomax simulations when using allele diversity to estimate effective density. Otherwise, the slopes of the regression methods were similar and thus predicted similar neighborhood sizes. This reconfirms that neighborhood size is a robust descriptor of the decrease of genetic identity with distance. It also seems clear that fat-tailed dispersal kernels do not have much of an effect in isolated continuous populations.
The triangular distribution has not been considered a reasonable distribution to use for modeling biological dispersal. However, as discussed previously, it arises from the simple assumption that dispersal is locally panmictic, making it potentially useful. When we compared the triangular distribution against more popular dispersal models, there were no qualitative differences between the resulting patterns of isolation-by-distance.
The triangular dispersal model can serve as a null model for the probability that two lineages will meet and coalesce in a previous generation. Identity-by-descent may be defined as the total probability of coalescence between the current generation, t0, and a generation at some time t in the past (Rousset, 2002). When a population is not panmictic due to limited dispersal, the time to coalescence depends on the probability that the two lineages will move close enough together so that there is some probability that they shared a parent in the previous generation. When the dispersal kernel has an infinite tail, there is always some small probability that two individuals coalesce even if they are very far apart. Because the triangular distribution is finite with a maximum distance of 2σ, the probability that two individuals coalesce in the previous generation is 1∕(4πσ2D) if they are separated by a distance less than 2σ and zero otherwise.
| Dispersal function | CPU seconds | Relative time |
|---|---|---|
| Triangular | 21.853 | 1 |
| Rayleigh | 27.713 | 1.268 |
| Exponential | 106.434 | 4.870 |
| Half Normal | 106.771 | 4.886 |
| Gamma | 119.357 | 5.462 |
| Pareto | 127.218 | 5.822 |
| Lomax | 127.376 | 5.829 |
The triangular distribution allows us to simulate dispersal more efficiently than other dispersal kernels because it is uniform over a finite area. It allows us to easily pre-compute probabilities of dispersal to neighboring cells and use an efficient discrete sampling algorithm to sample dispersal positions. A similar approach is possible for other dispersal distributions. For distributions with infinite tails this would require defining a truncated distribution which captures the bulk of the dispersal probabilities. Then, for two dimensions, double integrals would need to be calculated to determine the probabilities of dispersal to locations on the lattice. These pre-computations are laborious because in addition to the double integrals, many cells will have non-zero probabilities. For the triangular distribution, only cells in a radius of 2σ will have non-zero probability and since the distribution is uniform, the probabilities are easy to calculate.
Our results suggest that the relationship between probability of identity-by-descent and distance is similar for a wide range of dispersal kernels in a continuous population, and both theoretical and computational concerns suggest that triangular distributions should be included in the molecular ecologist’s toolkit. However, these results should not be taken to mean that it is always safe to ignore the shape of the dispersal kernel. As we demonstrate here, the high number of extremely limited dispersal events under the Lomax distribution increases the probability of identity-by-descent within a cell. In a hermaphroditic plant this could translate into a higher rate of self-fertilization. The shape of the tail can impact the number of long distance dispersal events which may affect the rate of population expansion, colonization, responses to climate change, population fragmentation and the movement of genes between locally adapted populations. Each of these processes will be affected by the dispersal distribution chosen for the simulation. However, when simulating a population structured by isolation-by-distance, the shape of the dispersal kernel does not appear to have a strong effect in a finite, isolated population. Because speed is an important factor in deploying isolation-by-distance simulations in analytical contexts, e.g., approximate Bayesian computation, we recommend using the triangular distribution when long distance dispersal and other features of the dispersal kernel can safely be ignored.
Supplemental Information
Dispersal kernels
The dispersal function, range, and probability density function for σ = 1.
Discretization has a small effect on dispersal distributions
The empirical cumulative distribution function for each dispersal distribution on a discrete lattice compared to the CDF of its continuous counterpart (black line). The different plots in each panel represent simulations run using different σ parameters: 1, 1.5, 2, 4. An increase in the thickness of the line corresponds to increasing σ parameter.
Different dispersal kernels have equivalent second moments but different third moments
Each panel represents groups of simulations run with different σ parameters and contains box-whisker plots summarizing the distribution of the average (A) squared or (B) cubed parent-offspring distance of 2,000 sampled transects. The top and bottom of the boxes represent the 75% and 25% quartiles, while the central bar represents the median. The gray dots outside the whiskers represent outliers. The gray horizontal line in A represents the expected σ2 value. The observed values are shown on a log scale which is different in some panels.
The distribution of unique alleles is similar for most dispersal kernels
Each panel represents simulations run with a the σ parameter provided in the gray box. For each dispersal distribution, the box-whisker plot summarizes the number of unique alleles (k) found in 2,000 50-individual transects. The gray horizontal line represents the expectation under the infinite alleles model. The features of the box-whisker summary are the same as Fig. S3.