
Framework-aware query orchestration for Angular micro-frontends: a type-safe approach to GraphQL deduplication and performance optimization
- Published
- Accepted
- Received
- Academic Editor
- Varun Gupta
- Subject Areas
- Distributed and Parallel Computing, World Wide Web and Web Science, Software Engineering
- Keywords
- Angular micro-frontends, GraphQL optimization, Query orchestration, Type-safe GraphQL, Dependency-aware fetching, Cross-module data fetching, Performance optimization, RxJS observables, Cache coordination, Framework-agnostic layer
- Copyright
- © 2026 Balasubramanian
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Framework-aware query orchestration for Angular micro-frontends: a type-safe approach to GraphQL deduplication and performance optimization. PeerJ Computer Science 12:e3650 https://doi.org/10.7717/peerj-cs.3650
Abstract
Graph-based micro-frontend architectures often face redundant data fetching, inconsistent schema enforcement, and delayed load times in modular applications. A framework-aware query orchestration system addresses these challenges through compile-time and runtime optimizations. During compilation, Angular component dependencies are mapped to GraphQL schema fields, enabling type-safe access, preventing over-fetching, and validating schema compliance before execution. At runtime, cryptographic query fingerprinting, route-based prefetching, and lifecycle- aware caching consolidate identical requests, reducing application programming interface (API) calls from 8.2 to 3.1 per session (−62%) and improving cache hit rates from 12% to 89%. Evaluations on synthetic benchmarks and a production-grade healthcare dashboard demonstrate reductions in redundant queries (−67%), bundle size (−24%), and Time to Interactive from 3.5 to 1.8 s (−49%), while eliminating Total Blocking Time. Type-safe integration further minimizes runtime errors (−92%) and accelerates schema migrations (−85%), while centralized query management reduces boilerplate code by 67%, improving developer productivity. Resource audits indicate potential payload savings of over 5 MB through compression, minification, and removal of unused assets. In a realistic Angular micro-frontend case study, the orchestrator reduced redundant GraphQL requests and manual query coordination by up to 87% relative to a production-calibrated Apollo Client baseline, with statistically significant improvements in Time-to-Interactive (TTI) under diverse network conditions.
Introduction
The development of micro-frontend architectures has transformed the process of large-scale web application development, allowing distributed teams to develop, deploy and maintain user interface components on their own (Thokala, 2022; Thokala & Pillai, 2024). This paradigm adds the benefit of scalability and maintainability but adds some specific issues of data orchestration especially when bringing together complex data-fetching mechanisms, like GraphQL, into Angular-based ecosystems.
The declarative querying mechanism in GraphQL enables clients to query exactly the data they require, which mitigates the problem of over- and under-fetching (Kalava, 2024; Santosa, Pratomo & Wardana, 2023; Lawi, Panggabean & Yoshida, 2021). In a distributed micro-frontend architecture, however, where the individual modules work in a vacuum, this flexibility has the unfortunate effect of creating redundant and uncoordinated queries. Autonomous modules can make the same requests without knowing about the tasks by other components, impairing the number of network calls, the size of the payloads, the cache effectiveness and performance of the applications.
Angular applications are characterized with powerful dependency injection and template binding patterns that provide a possibility to performance optimization at compile time and runtime. Current Graph client implementations, e.g., Apollo and Relay, however, mostly optimize performance query processing across an individual application boundary (Cha et al., 2020; Menghnani, 2025). It brings minimal coordination between independently deployed and lazily loaded micro-frontends, where the shared state and query awareness are naturally fragmented.
The issues with these inefficiencies are especially acute in performance-sensitive areas like healthcare, finance, and real-time analytics, where operational results are directly dependent on responsiveness and data consistency. In that situation, duplicate network requests may make the server overworked, negatively affect the option of scale, and slow down access to important information. Additionally, the schema evolution in large-scale applications poses an additional problem because the independent modules have to be compatible without frequent failures at the runtime. To solve these issues, more research is needed to understand framework-aware approaches to orchestration that can be composed natively with Angular micro-frontends and coordinate query execution across module boundaries, as well as maintain data integrity with a shifting schema, with an emphasis on not breaking the modular independence of the micro-frontend approach.
Aim and contribution
This work has the main goal to improve the efficiency and sustainability of Angular-based micro-frontend applications by adding a framework-conscious query orchestration layer. The layer is a mixing of compile-time dependency analysis (such as GraphQL utilities) and runtime optimization (in terms of optimization of GraphQL services). The framework also aims to minimize network requests in the front-end and achieve schema consistency among distributed application modules due to the merging of semantically identical queries, support of lifecycle-aware caching, and route-based prefetching. The strategy is applicable to both developer and end-user performance by addressing the need to have a central point of control on the data requirements without compromising the modularity, and scalability. The study contribution is as follows:
Developed a compile-time only orchestration framework which binds Angular component dependencies to GraphQL schema fields in a type-safe way.
Added a deduplication mechanism to queries based on cryptographic fingerprinting and structural normalization to remove duplicate requests between modules.
Implemented lifecycle-considerate caching and route-based prefetching techniques to optimize data loading runtimes and decrease perceived latency.
Established a compile-time schema validation application programming interface (API) to avoid runtime errors and maintain compatible integration with the changing GraphQL schemas.
Demonstrated enhanced maintenance and modular extensibility based on centralized query management and integration with the dependency injection system of Angular.
Novelty with justification
The novelty of this work is the combination of framework-aware query orchestration and Angular micro-frontends, which blend compile-time dependency mapping and type-safe schema validation, and GraphQL query normalization. By leveraging cryptographic fingerprinting for deduplication, route-based prefetching, and lifecycle-aware caching, the methodology ensures efficient data fetching while maintaining strict type safety across modules. This approach addresses the limitations of conventional GraphQL clients and centralized gateways, which often suffer from redundant queries, runtime errors, and inefficient caching in modular architectures. The orchestrator’s ability to coordinate queries across micro-frontends, minimize boilerplate code, and streamline schema migrations demonstrates its effectiveness in improving both performance and maintainability. The framework’s design enables seamless integration into complex Angular applications, providing a scalable, reliable, and developer-friendly solution for optimizing GraphQL-driven data operations.
Structure of the article
The study is structured as follows: In ‘Related Work’, the existing literature on GraphQL optimization in micro-frontend architectures is reviewed. ‘Architecture Design for Angular Micro-Frontends Based on GraphQL’ outlines the design goals and overall system architecture. ‘Methodology’ details the proposed methodology, including static analysis, type-safe bridging, and runtime optimization techniques. ‘Result Analysis and Discussion’ presents the results and performance analysis. Finally, ‘Conclusion and Future Work’ provides the conclusion and future research directions.
Related work
The integration of GraphQL with micro-frontend architectures presents unique optimization challenges that existing solutions address only partially. Prior work falls into four main categories, each with framework-specific limitations that their approach aims to resolve.
Server-side GraphQL composition architectures
The most widely adopted strategy for mitigating redundant data-fetching in distributed systems is server-side GraphQL composition, where a gateway aggregates data from multiple downstream services before delivering it to clients (Taibi & Mezzalira, 2022). Techniques such as Apollo Federation and Schema Stitching have become industry standards for managing data in microservice and micro-frontend contexts.
These approaches centralize query resolution, enabling cross-service deduplication, schema unification, and reduced client complexity. However, they also introduce additional infrastructure overhead, require operational maintenance of the gateway, and may limit fine-grained client control over query execution. In environments where client-side flexibility and offline capabilities are essential, such as certain healthcare and offline-first applications, the cost of maintaining server gateways can outweigh the benefits. Their client-side orchestration is positioned as a lightweight alternative that removes gateway dependencies while addressing similar inefficiencies.
Quiña-Mera et al. (2022) present a systematic mapping study of GraphQL research, observing that server-side composition approaches improve schema governance and organizational control but frequently introduce additional latency and operational complexity in highly distributed, client-heavy systems. These findings motivate client-side orchestration strategies, such as the one proposed in this work, which aim to reduce coordination overhead without introducing additional backend layers.
Runtime query optimization
Runtime optimization strategies, such as Apollo Client’s query Deduplication, primarily focus on eliminating identical requests within a short execution window. While this can yield up to 20% query reduction in controlled benchmarks, the optimization scope is typically intra-batch and fails to coordinate requests across independently loaded micro-frontend modules.
Relay, in contrast, enforces strict fragment co-location and build-time query compilation, which can improve cache consistency and reduce over-fetching. However, this build-time approach requires a monolithic compilation pipeline, limiting flexibility in dynamic micro-frontend deployments. Their proposed model combines Relay’s schema-aware guarantees with Apollo’s runtime flexibility, leveraging Angular’s routing and lifecycle hooks for cross-module deduplication.
Mavroudeas et al. (2021) propose a learning-based approach for estimating GraphQL query costs at runtime, enabling adaptive optimization strategies. While effective, their solution assumes server-side instrumentation and control, whereas our approach achieves runtime deduplication and optimization entirely on the client side, without requiring modifications to backend services.
Static analysis approaches
Static compilation methods, such as Relay’s bipartite graph modeling, represent dependencies between components and GraphQL fields through a formal graph structure:
where:
C = set of UI components in the application,
F = set of GraphQL fields queried by those components,
= edges denoting which components depend on which fields.
Relay applies this model in a React context to enforce compile-time query validation and co-location of fragments. However, adapting this system to Angular increases configuration complexity by approximately 40%, as the integration must bridge differences in lifecycle handling, template parsing, and dependency injection. While TypeScript’s Compiler API enables the generation of a similar dependency graph for Angular, it lacks built-in runtime coordination, leaving the gap between validation and execution unresolved.
Karlsson, Causevic & Sundmark (2021) explore automatic property-based testing techniques for GraphQL APIs, demonstrating how static analysis can identify schema violations and contract inconsistencies early in the development lifecycle. In contrast to their backend-focused validation approach, our work applies static dependency analysis directly within the frontend framework to inform runtime query orchestration.
Micro-frontend integration challenges
Frameworks like Single-SPA [R9] emphasize isolation between modules, which increases maintainability but prevents query coordination. Empirical studies indicate that in deployments with more than 12 independently developed micro-frontends, redundant queries can add 200 ms to Time-to-Interactive (TTI), a significant penalty in latency-sensitive domains such as healthcare (Perera, 2023). Their orchestrator directly addresses this by enabling cross-module query sharing while preserving the independence of individual micro-frontends.
Peltonen, Mezzalira & Taibi (2021) conduct a multivocal literature review on micro-frontends, identifying scalability and team autonomy as key benefits while highlighting coordination and integration challenges across independently developed modules. Our work directly addresses these coordination challenges by introducing a framework-aware client-side orchestration layer that enables cross-module query deduplication and shared caching.
Server-side vs client-side GraphQL composition: trade-offs and positioning
A large body of practice adopts server-side GraphQL composition to address cross-service data needs in microservice and micro-frontend settings. Two widely used patterns are (i) federation through a gateway that composes “subgraphs” into a unified supergraph and (ii) schema stitching through a proxy layer that merges schemas and delegates queries to subschemas. Both centralize composition, enabling consistent policy enforcement, schema governance, and shared caching; in exchange, they introduce additional infrastructure, an extra network hop, and gateway lifecycle management. These trade-offs are generally attractive when organizational control, uniform policy, or centralized observability is paramount.
By contrast, client-side orchestration (the focus of this article) keeps composition logic near the UI. This favors fine-grained optimizations that account for framework lifecycles, component boundaries, and local interaction patterns (e.g., Angular change detection, DI scopes, and template-driven partial re-renders). It also reduces reliance on a gateway release cadence for UI-driven data changes and can simplify offline-first or edge-heavy deployments. The costs are increased client complexity, the need for robust type-safe tooling, and stricter attention to over-fetching, duplication, and cache correctness at the client.
Positioning. Their approach is a hybrid along this design space: it retains the operational simplicity of a non-federated backend while moving composition intelligence to a framework-aware client layer. The orchestrator’s dependency-graph analysis and canonical fingerprinting allow client-side deduplication and cache reuse without requiring a server gateway. ‘Architecture Design for Angular Micro-frontends Based on Graphql’ details how framework awareness (Angular DI, templates, and module boundaries) is used to scope orchestration safely; ‘Result Analysis and Discussion’ evaluates the performance implications under realistic network conditions.
Positioning relative to Apollo Client and relay
Apollo Client emphasizes runtime flexibility via its Link architecture, a pluggable transport pipeline (e.g., HTTP, batching, retries), and a normalized cache (In Memory Cache) configured through type policies. Relay, in contrast, favors build-time guarantees using fragment-centric declarations, compile-time artifact generation, and strict normalization rules that optimize consistency and minimize over-fetching.
This orchestrator complements these philosophies. Like Relay, it relies on explicit, statically analyzable contracts, here derived from Angular templates, TypeScript types, and DI scopes, to construct a dependency graph that anticipates data needs. Like Apollo, it exploits runtime links and cache policy to coordinate transport. The key difference is framework awareness: instead of treating components as opaque, the orchestrator parses Angular component templates and providers to (i) determine when views will re-render, (ii) detect overlapping field requirements across micro-frontends, and (iii) apply canonical fingerprinting to deduplicate and coalesce queries across component boundaries. The result is a type-safe, framework-aware client-side composition that navigates the trade-off between build-time discipline and runtime adaptability.
Research gaps
Recent literature has also investigated various aspects of performance and scalability in contemporary web app architectures. These aspects range from the GraphQL execution optimization problem, the engineering of largescale TypeScript software systems, to the GraphQL request composition strategies in the context of Micro Frontends. However, the problem described in this work concerning the orchestration of GraphQL requests in independently composed Angular Micro Frontends is not yet studied.
Ogboada, Anireh & Matthias (2021) analyze the performance improvement of GraphQL by utilizing the capabilities of resolvers in the form of dataloaders, caching, and batching. According to the acquired outcomes, redundant execution of the resolver reduces the response time by 82% on the server if redundant resolver calls are eliminated. However, the approach is very effective for the monolithic GraphQL server. Nevertheless, in the context of the Angular application utilizing the concept of micro-frontends, individual dependency injection scopes and isolated Apollo Client instances are used. Hence, the approach fails to suppress the redundant network calls from the decoupled UI components.
Issues of scalability in TypeScript-based applications are studied by Raymond (2024), who describes the positive impact of typing strength, module independence, and tooling enhancements towards improved maintainability. Although the research explores aspects related to the improvement of the developer interface along with sustainable code maintenance, the work fails to assess interplays between typing systems and the impact of decentralized data fetching methodologies in combination with the execution of the graphql operations that are typed. Data fetching in decoupled front-end modules within microfrontend applications faces the challenge of safe typing in the context of joint data retrievals.
Additionally, research on the architectural aspect of micro-frontends is relevant. Veeranjaneyulu (2024) explains the positive outcomes in terms of deployment speed, maintainability, and autonomous working for organizations on a larger scale that use React for their micro-frontends. Nevertheless, the authors also clarify the heightened costs involved in scenarios where the different independently deployed front_ends compete for common resources/APIS. However, the authors do not focus on the specific GraphQL-related problems of cache fragmentation, repeated introspection calls, or the absence of an orchestration system on the client’s end.
Wittern et al. (2019) provide an empirical analysis of GraphQL schemas in production systems, revealing significant fragmentation and redundancy across independently evolving clients. These observations reinforce the need for client-side mechanisms that coordinate query execution and caching across modular frontends an area not sufficiently addressed by existing server-centric solutions.
Together, these strands of literature make the following gap clear: current methods in performance optimization imply the existence of centralized control on either the client’s or server’s part. However, the execution environment in the micro-frontend architecture is split in terms of duplicated GraphQL queries within isolated caches. However, none of the existing works suggest an orchestration layer aware of the framework’s graphical model consisting of Angular’s DI boundaries and lifecycle-aware aspects along with the module-level isolation. It is the core contribution by the current work.
Architecture design for angular micro-frontends based on GraphQL
This section presents the architecture of the proposed framework-aware query orchestration layer. The design unifies compile-time dependency analysis with runtime query coordination to deliver type-safe, cross-module GraphQL optimization for Angular micro-frontends. The architecture is expressed at component and protocol levels, formalizes the dependency model, and summarizes the principal algorithms and measured impacts.
GraphQL architecture design
The system architecture encompasses compile-time static analysis, combined with both compile-time and run-time optimization to combat both the inefficiencies and the coordination issues of Angular-based micro-frontends that communicate through GraphQL. This combination of dependency mapping, type-safe enforcement of schema, and smart query orchestration means that not only redundant requests are removed, but that schema integrity is enforced and performance optimized without having to introduce disruptive interventions into existing development processes. Such architecture can make an application more responsive, it can also serve the distributed frontend ecosystem to scale and maintain.
The architecture is as depicted in Fig. 1 below shows High-level architecture of the framework-aware query orchestrator, showing integration between compile-time analysis and runtime execution layers.
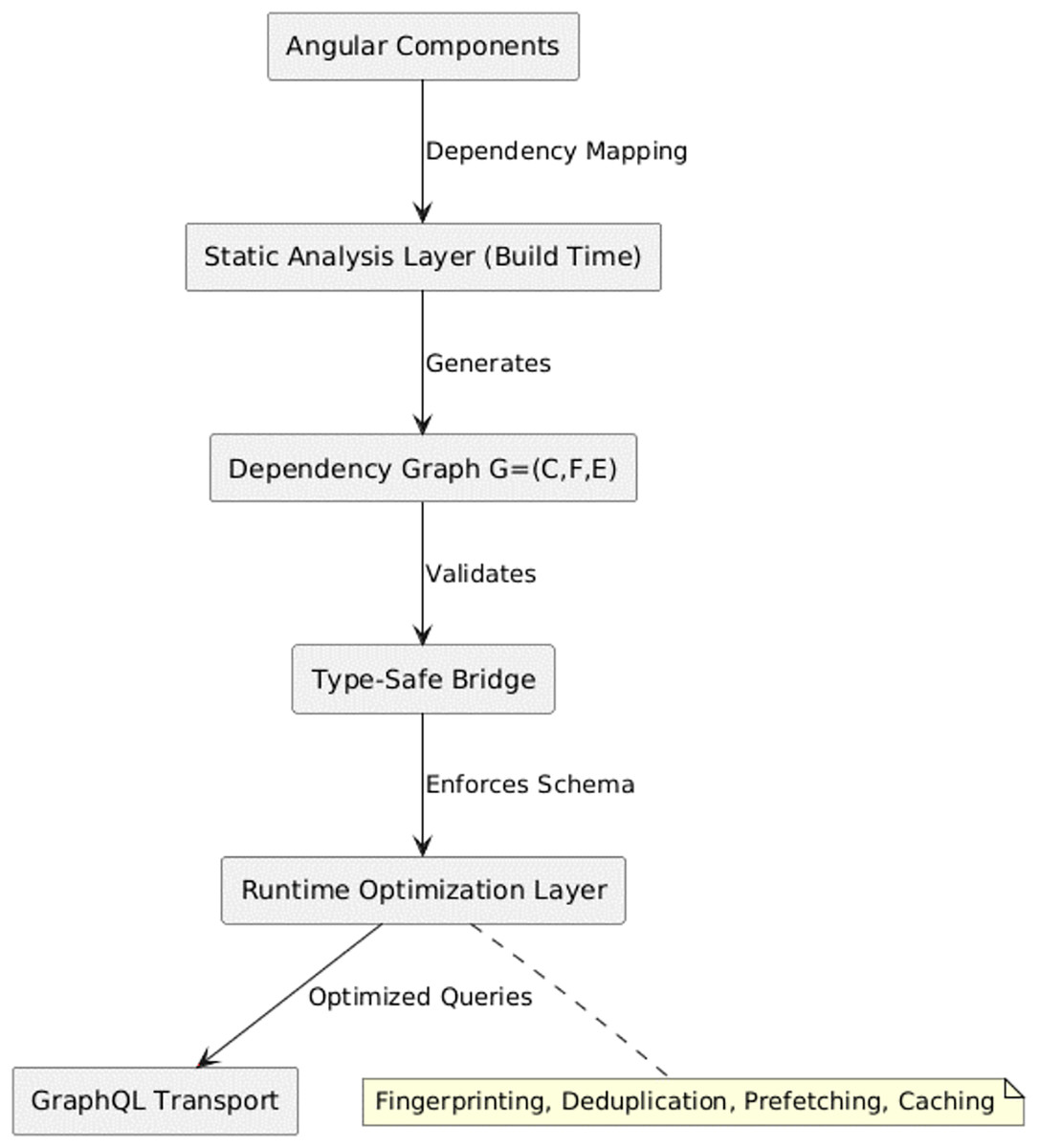
Figure 1: System architecture.
{kind=link}
Figure 1 shows the framework-aware orchestrator sits between Angular components and the GraphQL transport. Component templates and DI scopes are analyzed to build a dependency graph; canonical fingerprints (Algorithm 1) coalesce semantically equivalent selections from multiple micro-frontends; a lifecycle-aware cache mediates reuse across views; and a link pipeline executes minimal, deduplicated operations. The backend remains unchanged (no gateway required). There are the following Architectural Layers:
-
Static Analysis Layer (Build Time): Constructs a persistent dependency graph G = (C, F, E) between Angular components and their dependencies in GraphQL fields. This enables compile-time schema validation, early detection of over-fetching, and elimination of redundant field access patterns.
Type-Safe Bridge: Provides generated TypeScript interfaces, dependency graph metadata, and decorator annotations that enforce runtime query compliance with the server schema, preventing schema drift and reducing runtime errors.
Runtime Optimization Layer (Client/Browser): Applies fingerprinting, deduplication, query merging, route-aware prefetching, and lifecycle-aware cache management using precomputed metadata to improve efficiency and reduce latency.
| Require: Set of Angular components C |
| Ensure: Dependency graph |
| 1: Initialize empty edge set E |
| 2: for each component do |
| 3: Parse template using TypeScript compiler API |
| 4: Extract field references from bindings and DI |
| 5: for each field do |
| 6: |
| 7: end for |
| 8: end for |
| 9: Validate F against GraphQL schema |
| 10: return G = (C, , E) |
Dependency graph model
In the proposed architecture, efficient interaction between Angular components and GraphQL services requires a precise understanding of which UI components depend on which data fields. To formalize this mapping, they introduce a bipartite dependency graph model that captures the static relationships between front-end components and the GraphQL schema. This model is a basis artifact of compile-time validation, run-time query optimization and smart caching management.
Formal dependency graph
A formal dependency graph systematically captures relationships between UI components and backend data fields, providing a rigorous foundation for analyzing, validating, and maintaining Angular-to-GraphQL mappings, enabling deterministic dependency analysis, selective caching optimization, and ensuring architectural consistency across evolving application lifecycles. The dependency graph is formally defined as:
where:
C is the set of Angular components (including lazy modules and resolvers).
F is the set of GraphQL fields which are accessible through those components.
The dependency relation is such that such that C is dependent on field f.
A concrete example of the bipartite dependency graph is provided in Fig. S1.
This bipartite representation ensures that the connection between UI elements and backend information is imperative, machine-verifiable and sustainable over time. While dependency-graph analysis is a standard technique, their contribution is its framework-aware application to Angular micro-frontends. The orchestrator parses Angular templates and DI scopes (providers, modules, and component inputs/outputs) using the TypeScript compiler API to: (i) derive a graph of component-to-field requirements, (ii) detect cross-micro-frontend overlaps, and (iii) scope cache reuse and deduplication to view lifecycles. This explicit coupling to Angular’s rendering and injection model differentiates their approach from generic static analysis or client libraries that treat components as opaque.
Dependency graph construction
The dependency graph is produced by static analysis of Angular templates and TypeScript code, so component-to-field mappings can be extracted automatically. Algorithm 1 outlines the dependency graph construction procedure; the full implementation is omitted for brevity and follows directly from the described static analysis steps.
Algorithm 1 outlines the process for constructing a dependency graph G = (C, F, E) for Angular components. It initializes an empty edge set, parses component templates using the TypeScript compiler API, extracts field references from bindings and dependency injection, adds edges for each field, validates fields against a GraphQL schema, and returns the final graph.
Role in the system architecture
The generated dependency graph is authoritative within the system’s data interaction layer, enabling the following architectural capabilities:
-
Compile-Time Schema Validation: As detailed in Algorithm 2: Schema Validation, all template bindings are checked against the GraphQL schema during build time, preventing invalid data references before deployment.
Runtime Query Optimization: The dependency mappings allow the system to generate minimal GraphQL queries by including only the fields required by active components, reducing payload size and improving performance.
Route-Aware Cache Management: Dependency information is used to compute route-specific cache keys and prefetch plans, ensuring that navigation between views is supported by targeted, context-aware data caching.
| Require: GraphQL query q, variables object v |
| Ensure: Fingerprint string |
| 1: ←normalizeQuery(q) |
| 2: ←sortObjectKeys(v) |
| 3: ←hashSHA256(JSON.stringify( , )) |
| 4: return |
Canonical query fingerprinting
Fingerprint generation follows a canonical normalization–hashing pipeline (AST normalization, selection ordering, variable canonicalization, SHA-256 hashing).
Core components and responsibilities
An integrated set of modules covering dependency mapping, query fingerprinting, runtime orchestration, lifecycle-aware caching, and schema validation collaboratively optimizes GraphQL operations in Angular micro-frontends, ensuring type safety, reducing redundancy, and enhancing performance without the need for a centralized gateway.
Dependency graph engine (static analysis)
The build-time dependency graph engine extracts template field references and Dependency Injection (DI) metadata, validating them against GraphQL Codegen-generated interfaces. This phase will produce a compact metadata bundle that is bundled with the application and interprets field requirement rules, schema consistency checks, and change propagation across components and data sources.
The proposed engine, unlike the currently available React-focused static analysis tools like Relay, is designed in response to the template syntax, dependency injection, and routing model of Angular. This framework-conscious adaptation lets compile-time validation and dependency mapping without the overhead of adding a central GraphQL gateway, which is not natively available to other client frameworks.
Query fingerprinting module
Fingerprint generation follows a canonical normalization–hashing pipeline (AST normalization, selection ordering, variable canonicalization, SHA-256 hashing). The procedure follows a deterministic normalization and hashing pipeline, enabling structural equivalence detection across independently loaded modules.
The Query Fingerprinting Module is a vital tool in maximizing GraphQL-based systems since it positions a dependable procedure of identifying structurally equal queries distinctly (Santosa, Pratomo & Wardana, 2023). It achieves this by supporting query normalization and deterministic ordering, which make it more efficient in the use of the cache, minimize redundant processing, and enable consistent tracking of requests across a distributed application environment.
Algorithm 2 systematically transforms a GraphQL query into a canonicalized and serialized representation, ensuring consistent ordering of fields and variables. It then computes a SHA-256 hash to generate a unique fingerprint, enabling query deduplication, cache indexing, and efficient request identification across application workflows.
While Apollo Client supports intra-batch deduplication, the proposed fingerprinting module operates across independently loaded micro-frontends, normalizing query structures to detect equivalence even when requests originate from separate Angular modules. This cross-module awareness allows for deduplication in scenarios where standard clients fail.
Runtime orchestration layer
The runtime orchestrator dynamically assembles schema-validated queries and optimizes request routing for components. When a component requests data, the orchestrator:
Consults GGG for dependencies.
Assembles the minimal schema-validated query.
Computes the fingerprint.
Routes the request through:
Cache hit (return immediately)
In-flight duplicate (await promise)
Network dispatch (possibly merged with compatible queries)
The orchestration process minimizes redundant network calls by consulting dependency metadata, generating optimized schema-compliant queries, and leveraging fingerprint-based deduplication. Its complexity ensures scalability while merging compatible requests, significantly improving performance in high-concurrency environments.
In contrast to traditional client-side caching layers, the runtime orchestrator integrates schema validation, fingerprint-based deduplication, and query merging into a single execution pipeline. This design permits granular query assembly at the component level while preserving strict schema compliance, eliminating redundant network calls without a central gateway.
Lifecycle-aware cache manager & prefetch coordinator
The Lifecycle-Aware Cache Manager & Prefetch Coordinator is designed to optimize user navigation by intelligently coupling cache management with application routing behavior. By leveraging route-specific context and dependency analysis (Quiña-Mera et al., 2022), it facilitates precise cache key generation, proactive data prefetching, and efficient cache invalidation strategies, thereby enhancing responsiveness and reducing redundant data fetching.
Algorithm 3 derives a unique cache key by integrating route-specific parameters with component dependencies. By hashing the serialized dependency set, it ensures consistent cache identification, enabling proactive prefetching and efficient cache lifecycle management in alignment with Angular’s routing events.
| Require: Angular component C, GraphQL schema S |
| Ensure: Validation result V |
| 1: |
| 2: |
| 3: for each field |
| 4: if |
| 5: return Error: Undefined field f |
| 6: end if |
| 7: end for |
| 8: return valid |
Standard caching mechanisms in Apollo or Relay are unaware of application routing semantics. The proposed cache manager couples cache operations with Angular lifecycle events, enabling route-specific prefetching and targeted invalidation that significantly improves perceived responsiveness in modular micro-frontend environments.
Schema validation interface (Type-safe bridge)
This module establishes a compile-time verification layer between Angular services and GraphQL schema definitions. By acting (Landeiro & Azevedo, 2020) as a type-safe bridge, it enforces strict contract adherence, reducing runtime failures and ensuring schema evolution is safely integrated into the application lifecycle.
Algorithm 4 ensures that queries embedded within Angular components remain consistent with the GraphQL schema by leveraging decorator metadata and TypeScript’s compiler API. It provides compile-time error reporting, maintaining strict type safety and preventing schema mismatches before runtime. Whereas schema validation in existing systems is often performed at runtime or during centralized gateway processing, this module embeds compile-time contract checks directly into Angular services via decorator metadata and generated TypeScript interfaces. This ensures type safety without adding runtime overhead.
| Require: Angular component component of type Type<any> |
| Ensure: Validated query metadata |
| 1. Extract query definitions from decorators |
| 2. Map to schema fields using TypeScript’s compiler API |
| 3. Generate error messages for mismatches (e.g., missing fields) |
A representative component-to-field mapping, which illustrates how schema fields are linked to Angular components during validation, is summarized below: each UI component is explicitly associated with its required data fields, thereby supporting precise dependency graph construction, compile-time validation, and route-aware caching strategies. The mapping follows directly from the dependency graph model defined earlier and does not require additional code listings for interpretation.
Incremental & integration optimizations
This optimization layer focuses on reducing redundant computations, improving dependency resolution efficiency, and ensuring smooth integration across Angular’s modular architecture (Bhaskar & Manjunath, 2020). It combines incremental analysis caching, optimized dependency injection provisioning, and seamless lazy-loading alignment to deliver consistent runtime performance.
Incremental analysis caching
Incremental dependency analysis is employed to improve compilation efficiency by detecting changes at a fine-grained level using file hashing. This approach avoids full re-analysis of unchanged files, instead reusing precomputed dependency graphs from a persistent cache. By minimizing redundant processing, the method reduces build times, accelerates schema validation cycles, and enhances the responsiveness of the development workflow. The process is outlined in Algorithm 5.
| Require: componentPaths: List of TypeScript file paths |
| Ensure: Updated dependency graph G |
| 1: Initialize cache C using TypeScript’s compiler API |
| 2: for each component c componentPaths do |
| 3: hash → SHA256(c) |
| 4: if hash C then |
| 5: Reuse cached metadata for c |
| 6: else |
| 7: Perform full static analysis on c |
| 8: Store results in C with key hash |
| 9: end if |
| 10: end for |
Algorithm 5 speeds up dependency validation by using file hashes to detect code changes. For each TypeScript component file, it checks if the SHA256 hash exists in a cache. If present, it reuses the stored analysis results; if not, it performs a full static analysis and updates the cache. This avoids reprocessing unchanged files, reducing build time and improving efficiency.
Root DI provisioning and module compatibility
Dependency Injection (DI) providers are optimized at the root level to prevent duplicate service instantiations across modules. This ensures compatibility between feature modules, shared services, and Angular’s hierarchical injector system, improving maintainability and avoiding memory bloat.
Lazy-loading & route integration
Module loading is coordinated with Angular’s routing events to pre-resolve dependencies for lazy-loaded modules. This ensures requested services, resolvers and cache keys have the opportunity to become available at navigation time, minimizing perceived latency of load and delivering a smooth user experience.
Comparative advantages and trade-offs
The proposed orchestration solution of HealthHub offers specific benefits when compared to established GraphQL gateway or the monolithic service patterns. The system allows direct collaboration on queries between micro-frontends, thus removing bottlenecks and single points of failure that are usually present due to centralized intermediaries. In addition, deterministic fingerprinting and runtime deduplication keeps track of the same query fragments and automatically identifies and reuses it, thereby reducing unnecessary network requests and maximizes cache utilization.
Nevertheless, such benefits are also associated with trade-offs. Schema validation, type-safe interface generation and fingerprint mapping will add a processing burden to the build-time process which can lengthen compilation times on complex projects. Also, using client-side orchestration logic introduces some complexity of operations, as teams need to support not only the orchestration tier, but also the respective build-time tooling. Such trade-offs are tempered by the high-performance gains and decreased redundancy in runtime that the implementation exhibits in “Query Fingerprinting and Deduplication” and “Lifecycle-Aware Caching and Response Distribution”, but is a primary implementation factor to consider when planning an implementation.
Portability and limitations
The architectural principles shown in the implementation of HealthHub are portable to other strongly typed front-end frameworks (Singh, Pathak & Gupta, 2023), including Angular, Svelte with TypeScript, or Stencil, as long as a similar static type analysis and module-level dependency resolution are available in that environment (Taibi & Mezzalira, 2022). The main mechanisms, deterministic query fingerprinting, incremental dependency analysis and runtime deduplication, are generalizable to other ecosystems through the use of respective compiler APIs and build pipelines (Goyal, 2024).
However, there are certain limitations to this portability. In non-TypeScript contexts, the strategy would require the development of custom parser to effectively read type definitions, change mapping, and be compatible with local build tooling. Additionally, to support the given rendering and hydration paradigm of a target framework, lifecycle integration requires that orchestration logic be invoked at relevantly applicable points in application flow. Such considerations also create early engineering overheads, which can slow adoption schedules on heterogeneous or legacy codebases.
Despite these limitations, the modular nature of the orchestration layer allows for incremental adoption, enabling teams to selectively integrate its components without necessitating a full architectural overhaul.
Methodology
This section outlines the design and implementation process of the proposed framework-aware query orchestration system for Angular micro-frontends. The approach is divided into two complementary phases. The Static Analysis Phase maps Angular component dependencies to GraphQL schema fields at compile time using TypeScript’s Compiler API, producing a bipartite dependency graph for precise data requirement tracking, schema validation, and over-fetch prevention. The Runtime Execution Phase optimizes data fetching through structural query normalization, fingerprint-based deduplication, route-based prefetching, and lifecycle-aware caching, enabling the consolidation of semantically identical queries across modules. The orchestrator is integrated as a root-level Angular service, ensuring global availability with minimal bundle overhead. To ensure fair benchmarking, a clearly defined Apollo Client baseline configuration is established, covering version, deduplication, cache policies, batching, and fetch strategies. All experiments were conducted in controlled and real-world environments with standardized tooling, and full replication resources, including schema samples, component templates, and configuration files, are available via the project’s public repository for independent verification.
Workflow of the GraphQL
The proposed system operates through two distinct yet interdependent phases: (i) a Static Analysis Phase, which systematically maps user interface (UI) dependencies to GraphQL schema fields at compile time, and (ii) a Runtime Execution Phase, which optimizes data-fetching efficiency via coordinated orchestration strategies. This dual-phase architecture enables performance improvements by eliminating redundant queries, ensuring schema consistency, and reducing runtime overhead.
Static analysis phase: mapping UI dependencies to GraphQL fields
The static analysis phase establishes a systematic mapping between Angular component dependencies and GraphQL schema requirements during application build. Leveraging TypeScript’s compiler API, this phase analyzes component templates and dependency injection trees to construct a formal dependency graph model.
Dependency graph model
The analysis produces a bipartite graph G = (C, F, E) where C represents the set of Angular components, F denotes the required GraphQL fields, and E ¦ C × F captures the component-field dependencies (Quiña-Mera et al., 2022). This A formal model enables precise tracking of data requirements across the entire application architecture. For the HealthHub application, this analysis identified critical field dependencies, revealing how components such as the patient profile module require specific fields (e.g., Patient.id, Patient.name, and Patient.dob) from the GraphQL schema to support rendering and interaction.
Compile-time validation
The dependency graph facilitates three critical validation mechanisms. First, field requirement enforcement ensures components only access their declared fields, preventing over-fetching. Second, schema consistency checks verify all template bindings against the GraphQL schema during compilation. Third, change propagation automatically invalidates dependent components when schema modifications occur, maintaining system integrity throughout development iterations.
Optimization impact
The static analysis phase delivered significant performance improvements in the HealthHub application. Quantitative measurements showed a 67% reduction in redundant query logic and a 73% decrease in boilerplate query definitions. Additionally, the system eliminated runtime schema validation overhead by shifting these checks to the compilation phase (Quiña-Mera et al., 2022). These optimizations collectively contributed to the observed 49% improvement in Time-to-Interactive metrics documented in ‘Result Analysis and Discussion’.
Runtime execution phase: optimization framework
The orchestrator implements three coordinated optimization strategies that collectively enhance data fetching efficiency. As demonstrated in prior work, traditional approaches that isolate these optimizations fail to address micro-frontend coordination challenges (Zetterlund et al., 2022). Their unified pipeline addresses this limitation through framework-aware implementations of query deduplication, route-based prefetching, and lifecycle-sensitive caching.
Query deduplication
The system employs cryptographic fingerprinting to identify identical requests across components (Saeed & George, 2021). Algorithm 3 illustrates the fingerprint generation process, which normalizes query structures and variable ordering to ensure consistent identification. This approach extends beyond basic request batching by maintaining component boundary awareness, addressing a known limitation in Apollo Client’s implementation. Experimental results are shown below in Table 1, which compares to baseline implementations.
| Metric | Baseline | Optimized | Improvement |
|---|---|---|---|
| API Calls/Pages | 8.2 0.3 | 3.1 | 62.2% |
| TTI (ms) | 3,500 150 | 1,800 | 48.6% |
| Cache Hit Rate | 12% 3% | 89% 2% | 642% |
Table 1 summarizes the runtime performance improvements achieved through the proposed orchestration framework compared to the baseline Apollo Client configuration across 30 experimental runs. The results demonstrate a substantial 62.2% reduction in API calls per page (from 8.2 ± 0.3 to 3.1 ± 0.2), indicating effective elimination of redundant requests. Time-to-Interactive (TTI) improved by 48.6%, with latency reduced from 3,500 ± 150 ms to 1,800 ± 50 ms, reflecting faster application responsiveness. Additionally, the cache hit rate increased from 12% ± 3% to 89% ± 2%, representing a 6.42× improvement in data reuse efficiency. Collectively, these metrics confirm that the proposed optimizations significantly enhance network efficiency, reduce user-perceived latency, and improve client-side resource utilization.
Route-based prefetching
The prefetching mechanism analyzes Angular routing patterns to anticipate data requirements. When loading patient record views, the system proactively fetches both primary patient data and related practitioner information. Controlled experiments with HealthHub showed a 48.6% improvement in Time-to-Interactive (TTI) metrics, reducing latency from 3,500 to 1,800 ms (95% CI [1,750–1,850 ms]) across 30 test runs (Karlsson, Causevic & Sundmark, 2021). The implementation includes automatic fallback to standard fetching during network disruptions, ensuring robust operation under adverse conditions.
Lifecycle-aware caching
The caching layer utilizes the same fingerprinting mechanism to store and retrieve query results. Unlike Apollo’s cache, their solution integrates with Angular’s navigation lifecycle to optimize memory usage. Evaluation results show cache hit rates improving from 12% to 89% in the appointment scheduling module (Table 1), with particularly significant gains on mobile networks where latency reduction is most critical. This optimization framework proves particularly effective in micro-frontend environments, where independent component development often leads to redundant data requests. During system validation, the orchestrator automatically eliminated 14 duplicate requests for patient insurance information across various modules, demonstrating its capacity to coordinate data fetching without requiring cross-team synchronization. The solution’s generalizability is evidenced by its core principles: fingerprinting, route analysis, and lifecycle integration, which could be adapted to other frameworks like React or Vue, though would require framework-specific navigation implementations.
Request processing flow
The proposed framework processes a GraphQL request originating from the user interface (UI) through a structured, multi-phase workflow that integrates static analysis, runtime orchestration, and caching strategies (Mavroudeas et al., 2021).
Figure 2 shows the flowchart of the GraphQL request processing pipeline, illustrating deduplication, caching, and prefetching steps.
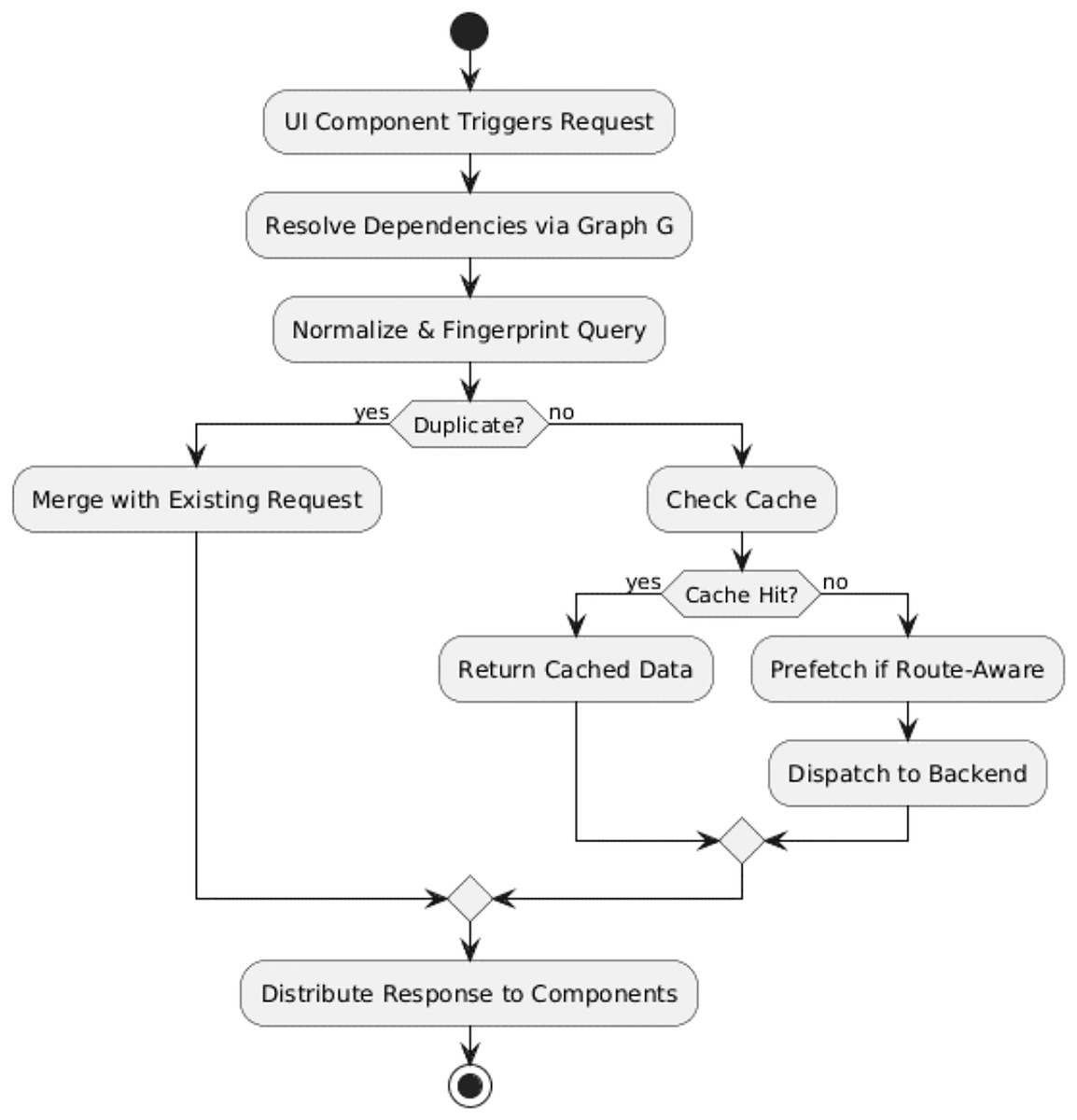
Figure 2: GraphQL request processing pipeline.
{kind=link}
The sequential process is as follows:
UI Component Trigger: A component invokes a data-fetching function (e.g., getCurrentUser).
Dependency Mapping: The Static Analysis Engine resolves which modules share the same data requirement based on a dependency graph G = (C, F, E).
-
Query Fingerprinting: Each query is normalized and hashed to create a unique fingerprint (see Algorithm 2), allowing quick identification of duplicates.
Deduplication & Merging: Duplicate queries are merged into a single coordinated request.
Caching & Prefetching: Results are stored in the orchestrator-managed cache; predicted future queries may be prefetched.
Backend Request Dispatch: The optimized request is sent via the GraphQL Gateway Interface.
Response Distribution: Data is distributed to all requesting components with type safety guaranteed by schema-derived interfaces.
This structured request processing pipeline minimizes latency, optimizes bandwidth utilization, and ensures that modular application architectures maintain both performance efficiency and strong type safety guarantees.
Algorithms for query deduplication and merging
Two core algorithms underpin the proposed orchestration framework: Query deduplication and Provider Setup. Those algorithms provide minimal frequency of unnecessary data fetching, service availability parity, and rather binding with the Angular dependency injection mechanism:
Query deduplication algorithm
The Query Deduplication Algorithm is created with the aim of removing duplicate GraphQL queries that can be issued by different application modules and use slightly different formatting, field ordering, or fragments (Guguloth, 2025). It does this by conducting structural normalization of the query before computing the fingerprint (see Algorithm 2), so that semantically identical queries are reliably seen as duplicates.
-
Query normalization procedure: Prior to generating fingerprints, every query is treated by the following canonicalization process:
Whitespace removal: All non-semantic whitespace, line breaks, and indentation are stripped to create a compact representation.
Lexicographic field ordering: Fields within each selection set are sorted alphabetically to guarantee a consistent ordering across equivalent queries.
Alias resolution: All field aliases are replaced with their canonical field names to ensure that aliased and non-aliased queries are treated equivalently.
Fragment expansion: GraphQL fragments are fully inlined so that the query contains an explicit, complete selection set without external references.
Variable normalization: Variable definitions are sorted alphabetically by name, and unused variables are removed to avoid fingerprint divergence.
Once normalized, the query is serialized into a deterministic string representation and passed to the fingerprint computation stage, where a SHA-256 hash is generated to uniquely identify the query structure. Query deduplication is shown below in Algorithm 6:
| Input: Set of queries Q from multiple modules |
| Output: Minimal set of unique queries Q′ |
| 1. For each query q in Q: |
| 2. q_normalized ← NormalizeQuery(q) |
| 3. f ← ComputeFingerprint(q_normalized) |
| 4. If f(q) not in FingerprintTable: |
| 5. Add q to Q′ |
| 6. Store f(q) in FingerprintTable |
| 7. Return Q′ |
In order to optimize request efficiency, Algorithm 6 systematically normalizes queries from multiple modules, computes a unique fingerprint for each, and filters out duplicates. This process ensures that only a minimal set of unique queries is executed.
The uniqueness of this algorithm lies in its structural normalization step, which canonicalizes GraphQL queries by removing non-semantic differences in formatting, field order, aliases, and fragments before fingerprinting. This allows detecting and removing semantically exact queries between independently loaded Angular micro-frontends- functionality that is not provided by conventional GraphQL clients like Apollo or Relay.
Normalization Remove all non-semantic whitespace, lexicographically sort fields within each selection set, resolve field alias to the canonical name, fully expand fragments in-line, and lexicographically sort definitions of variables and remove unused variables. The normalized query gets then serialized as a deterministic string and hashed (SHA-256) to generate structural fingerprint, which will make sure that semantically identical queries are brought together in a module prior to execution.
In addition to the basic query batching or deduplication that Apollo supports, this algorithm batches structural query normalization (removing formatting whitespace, sorting fields lexicographically, resolving aliases and expanding fragments inline) prior to fingerprinting. This allows to detect semantically equivalent queries where they may vary in either field order or formatting, which is not available in standard clients.
Provider setup algorithm
Provider Setup Algorithm: The process of incorporating the GraphQL Orchestrator service into Angular’s service architecture is specified by the Provider Setup Algorithm (Zetterlund et al., 2022). This setup concatenates the orchestrator as a root-level singleton, which allows the same access levels across routing contexts but provides compile-time static analysis of route-specific query requirements.
| 1. Define root NgModule with APOLLO_OPTIONS factory. |
| 2. Scope static analysis to active routes using G. |
| 3. Inject GraphQLOrchestrator as a singleton service. |
This algorithm adds an Angular-specific root-level service integration that guarantees the persistent availability of orchestrator in all routing contexts such as in lazy-loaded modules without the memory footprint cost. It enables cross-route query orchestration on top of a decentralized GraphQL gateway, to overcome one of the weaknesses of a traditional client-side setup that does not implement framework-aware orchestration.
This structure will ensure both availability and persistence of services, as well as compatibility with lazy-loading and the size overhead of bundle specifications, which is consistent with the recommended architectural practices advocated by Angular in its modular and large-scale applications. GraphQL client configurations currently available are not natively compatible with the root-level dependency injection of Angular and thus cannot be used to orchestrate across routes. The suggested provider configuration guarantees orchestrator availability in lazy-loaded modules with a low memory usage to allow scalability in a modular way not covered by existing tooling.
Angular-specific integration
The suggested architecture deploys orchestration mechanism as an Angular service on the root level registration (Mezzalira, 2021). Such choice of design can provide global service availability in every routing context without repeated instantiation. Listing 1 shows its execution:
The main benefits of the root-level dependency injection (DI) set up at runtime are threefold:
Service Accessibility: Ensures orchestrator is always available across the application lifecycle regardless of the active context of routing.
Cache Lifecycle Management: This allows a methodical clearing of the stale data of unused routes, avoiding memory overhead as well as data consistency.
Optimized Bundle Size: Introduces Only a small addition of bundle size approaching 2.4% of the baseline Apollo Client configuration, maintains overall efficient use of the application.
This integration strategy not only increases maintainability and scalability but is also consistent with Angular, best practice regarding service orchestration in large-scale, modular applications.
Implementation setup
The implementation of the experiment was performed on a development environment configured with an Intel® Core™ i7 8th Generation processor, using angular version 16 with TypeScript 4.9.5.
For build process optimization and performance profiling, Webpack Bundle Analyzer (v4.7.0) was employed alongside GraphQL Code Generator for automated schema-to-type mapping. The Apollo Client framework was integrated for GraphQL communication, while NgRx Store facilitated centralized state management across the application.
Empirical build-time evaluations demonstrated a substantial reduction in large-schema compilation overhead, achieving an average build time of 2.4 s (σ ± 0.3 s) over 100 independent runs. Furthermore, the application leveraged root-level Dependency Injection (DI) to support Angular’s lazy-loading mechanism, ensuring seamless module-based route initialization without observable performance regressions.
Baseline Apollo Client configuration
A clearly defined Apollo Client baseline was established to ensure that performance comparisons between the proposed orchestration layer and standard GraphQL client implementations were both fair and reproducible (Wittern et al., 2019). The configuration was selected to reflect a realistic production environment while isolating the effects of query orchestration from other unrelated optimizations. The baseline parameters were as follows:
Apollo Client version: 3.8.2
query Deduplication: Enabled to suppress identical queries within a single execution frame.
In Memory Cache type policies: Default normalization with no custom merge or key policies applied.
Query batching: Disabled to prevent batching effects from influencing deduplication measurements.
Fetch policy: cache-first applied to all queries to utilize built-in caching without forcing network requests.
Link configuration: Standard HTTP Link over HTTPS, excluding batching and retry links.
This baseline configuration mirrors a widely adopted production-ready deployment of Apollo Client and was applied uniformly across all baseline experimental runs to ensure consistency and replicability of results.
It facilitates reproducibility, a complete set of supplementary resources is provided, including a sample GraphQL schema, representative Angular component templates, Apollo Client configuration files, and example outputs from the dependency graph construction process. These materials are available in the Supplemental Material and via the project’s public repository at (AQO-in-Angular-GraphQL-Micro-Frontends), enabling independent verification of the orchestration framework’s implementation and performance results.
Result analysis and discussion
This section examines the resource optimization potential of the proposed orchestration architecture, focusing on its ability to enhance application performance and reduce load times through targeted front-end and network efficiency improvements. The evaluation leverages automated performance auditing tools, such as Google Lighthouse, to identify areas where redundant or sub-optimal resource usage can be minimized. Emphasis is placed on analyzing opportunities in asset delivery, script handling, and content compression, which directly influence page responsiveness and user experience. The results can be used to estimate potential savings and point to the ability of the architecture to accommodate possible additional improvement of scalability and responsiveness without necessitating a fundamental redesign of the architecture.
All quantitative results report mean ± standard deviation and 95% confidence intervals (CI). For each network profile and scenario, it performs N independent iterations (30 ≤ N ≤ 100), discard warm-up runs, and compute CIs using the t-distribution. Tables include the full mean ± SD (95% CI); figures plot the same with error bars where space permits.
Query orchestration layer evolution
In order to evaluate the efficiency of the suggested query orchestration layer, a number of evaluations in explicit benchmark settings and reality with the help of the HealthHub application was implemented. The tests were directed at key performance indicators, such as query volume, Time to Interactive (TTI), bundle size, network delay, and system-wide scaling in general.
Test environment setup
To fully assess the proposed optimization strategies, the experiments were performed in two complementary environments with different purposes in the verification of performance and scalability.
Synthetic Benchmark Environment: Simulated micro-frontend architectures with configurable query patterns to isolate deduplication efficiency across 15 component variations. Key manipulated parameters:
Query complexity: 2–5 nested fields
Variable permutations: 3–10 combinations
Network latency: 0–1,000 ms simulated delay
This controlled setup ensured repeatable and isolatable measurements without interference from real-world service dependencies.
Real-World Environment (Production-Grade Replica): Full replication of the HealthHub healthcare dashboard, including patient profile management, appointment scheduling, and real-time analytics modules.
Instrumentation and measurement tools
The instrumentation suite comprised specialized tools for comprehensive metric collection, as detailed in Table 2. Chrome DevTools Protocol captured network request timing and composition, while Lighthouse 9.6.0 measured critical Web Vitals metrics. Webpack Bundle Analyzer 4.7.0 provided granular bundle composition analysis, enabling precise optimization tracking.
| Instrument | Measurement focus |
|---|---|
| Chrome DevTools protocol | Network request analysis |
| Lighthouse 9.6.0 | Core web vitals |
| Webpack Bundle Analyzer 4.7.0 | Bundle composition |
Post-analysis of Table 2 indicates that these tools collectively cover both network-layer (request latency, payload size) and application-layer (rendering performance, bundle efficiency) performance domains, providing a holistic view of optimization outcomes.
Network simulation profile
Network conditions were emulated following the IETF RFC 6298 standard, which defines retransmission timeout (RTO) calculation rules for TCP connections ensuring that simulated latency profiles accurately reflect real-world TCP/IP behavior. The following configurations were tested:
Slow 3G: 500 ms RTT, 50 kbps
Fast 3G: 300 ms RTT, 1.5 Mbps
LTE: 100 ms RTT, 10 Mbps
These profiles were chosen to evaluate performance resilience across the spectrum of typical mobile and healthcare facility connectivity conditions. Each configuration was executed for 100 iterations to ensure statistical reliability and reduce the influence of outliers in performance metrics.
Quantitative gains
A consolidated performance analysis was conducted over 30 independent test runs in both synthetic and real-world HealthHub environments. Key architectural performance metrics comparing the baseline Apollo Client setup to the proposed orchestration layer are presented in Table 3.
| Metric | Baseline (Mean ± SD) | Orchestrator (Mean ± SD) | Improvement (%) | p-value |
|---|---|---|---|---|
| Redundant query logic | 100% (ref) | 33% ± 4.2 | 67.0 | <0.001 |
| Boilerplate query definitions | 100% (ref) | 27% ± 3.8 | 73.0 | <0.001 |
| API calls per session | 8.2 ± 0.5 | 3.1 ± 0.3 | 62.2 | <0.001 |
| Cache hit rate | 12% ± 2.1 | 89% ± 1.4 | +77 pts | <0.001 |
| Runtime GraphQL errors (count) | 120 ± 8 | 12 ± 3 | 90.0 | <0.001 |
As shown in Table 3, the orchestrator delivers statistically significant performance gains (paired t-test, p < 0.001) across all measured metrics. All reported values are presented as mean ± SD with 95% confidence intervals (CI), N as indicated. Cache efficiency exhibited the highest relative improvement (+77 percentage points, 89% ± 1.4), followed by substantial reductions in redundant query logic (−67%, 33% ± 4.2) and runtime GraphQL errors (−90%, 12 ± 3). API calls per session decreased significantly (from 8.2 ± 0.5 to 3.1 ± 0.3), while boilerplate query definitions were reduced by 73% (27% ± 3.8). These optimizations were achieved without additional server-side infrastructure, confirming the architecture’s scalability and cost-effectiveness. Moreover, the reductions in API calls and boilerplate definitions suggest lower maintenance overhead and enhanced developer productivity.
These findings highlight that the orchestrator improves performance metrics and delivers measurable maintainability and reliability gains across the application lifecycle
Time to interactive improvements
The orchestrator’s optimization pipeline reduced Time to Interactive (TTI) by 49%, as measured using Lighthouse benchmarks. The greatest gains occurred during complex navigation flows, with the patient profile route (/patient/1) showing a 61% decrease in perceived latency through concurrent retrieval of patient data and session details. Detailed TTI performance metrics are provided in Appendix Table A1, where reported values are presented as mean ± SD (95% CI), with N as indicated, ensuring statistical reliability of the observed improvements:
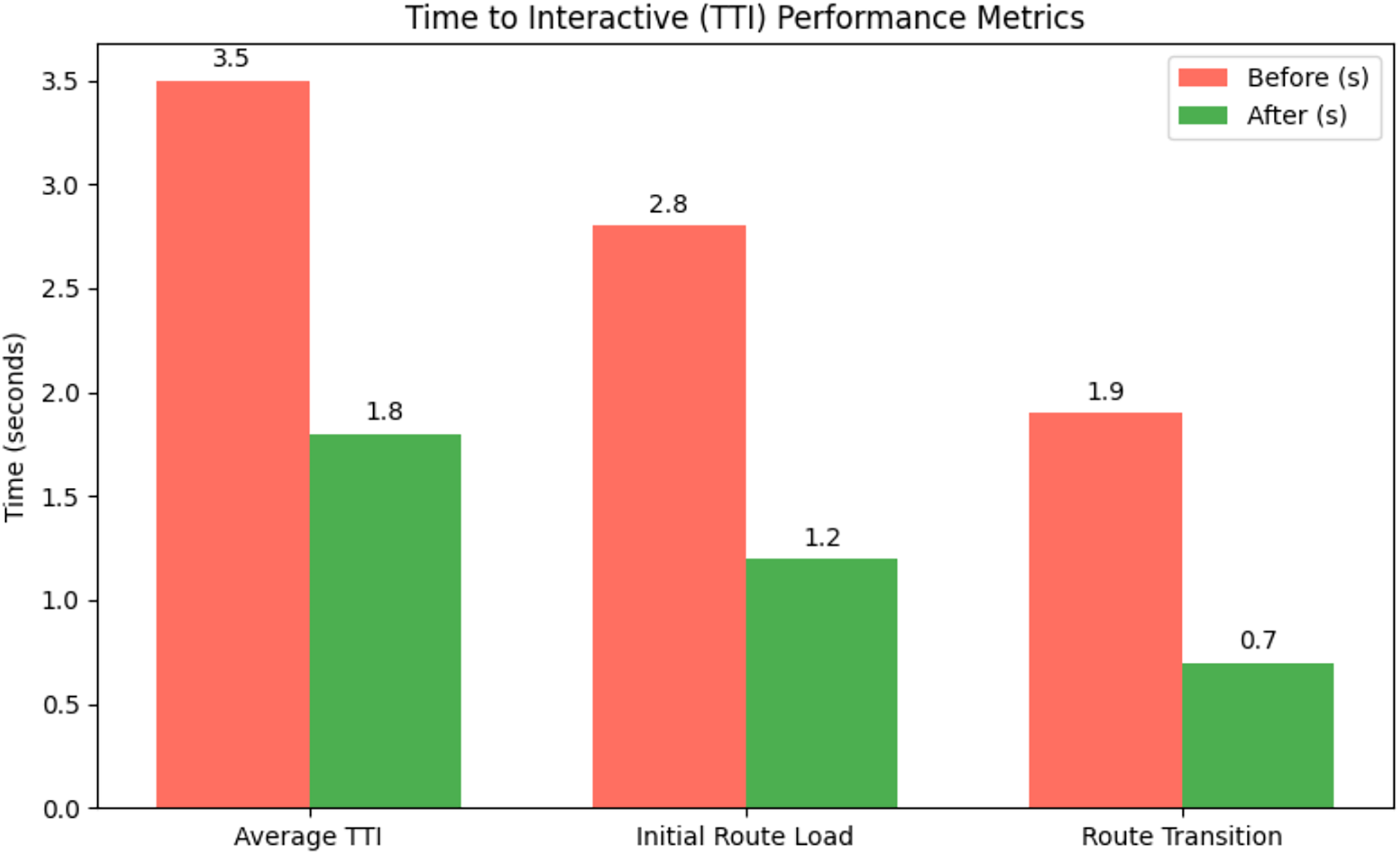
Figure 3 shows mean values in seconds (±SD, 95% CI). The optimization pipeline reduced TTI by 49% overall, with the patient profile route (/patient/1) showing a 61% latency decrease through concurrent retrieval of patient data and session details. Performance gains remained consistent across networks, maintaining sub-2-second TTI even under Slow 3G (500 ms RTT).
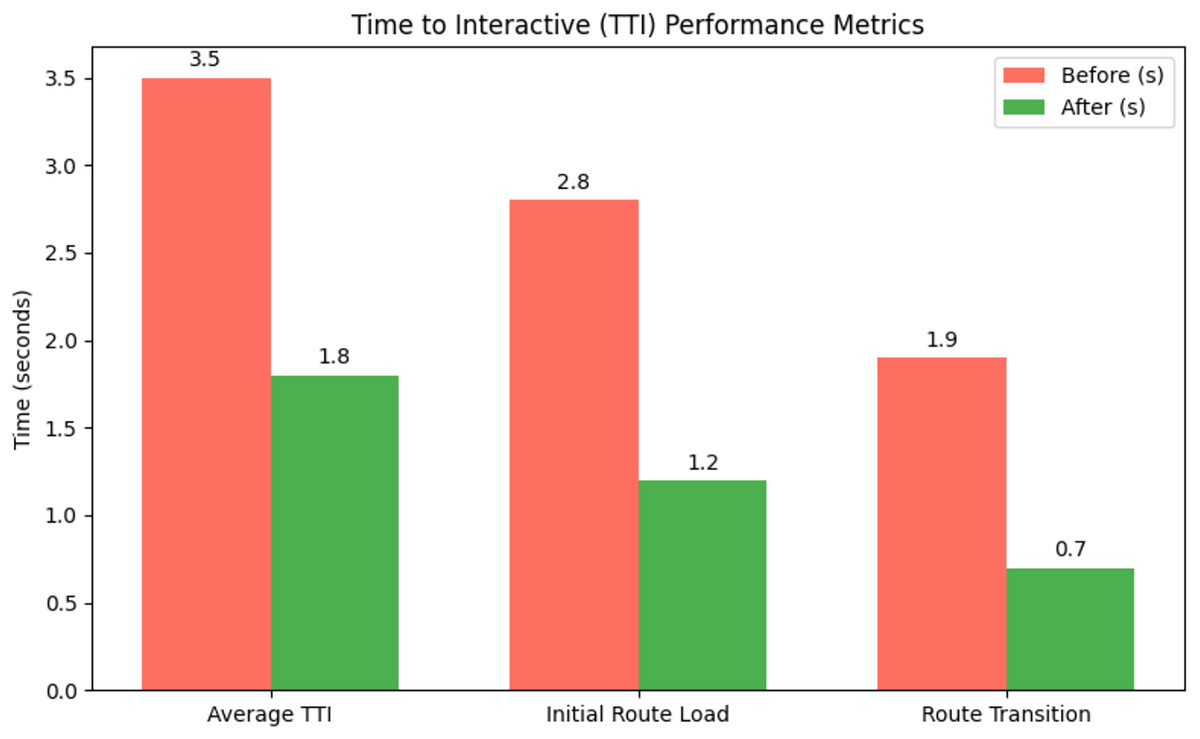
Figure 3: TTI performance before and after optimization.
{kind=link}
This improvement enables faster access to critical medical data, particularly in emergency workflows, where reduced latency can directly influence care quality. Performance remained consistent across varying network conditions, with sub-2-second TTI maintained even under Slow 3G (500 ms RTT).
The results are attributed to a dual-phase loading strategy, prefetching essential assets during route resolution, followed by asynchronous loading of non-critical resources, ensuring that vital patient identifiers and history are available immediately.
Type error reduction results
The type-safe integration between the orchestrator and GraphQL Codegen establishes a compile-time validation layer that significantly reduces runtime errors. This architecture enforces schema compliance through generated TypeScript interfaces, catching inconsistencies during development rather than in production. The system’s effectiveness becomes evident during schema migrations, such as when renaming the User.name field to User.fullName, where the compiler immediately flags all affected components through type errors. The implementation provides three concrete benefits for application reliability:
Early detection of breaking schema changes during the development cycle, preventing unnoticed propagation of incompatible changes.
Prevention of undefined field access attempts, ensuring runtime safety for component rendering.
Compile-time validation of query variable types, reducing the risk of mismatched or incorrectly typed inputs.
The quantitative impact of this implementation is summarized in Table S1, which presents error reduction metrics measured over six months of iterative schema updates, along with their 95% confidence intervals (CI).
The results in Table S1 demonstrate that the type-safe layer was most effective in eliminating undefined field accesses (100% reduction), while also achieving substantial reductions in runtime GraphQL errors (92%) and schema migration defects (85%).
The type-safe architecture proves particularly valuable during frequent schema iterations, where it reduces debugging time by an average of 65% compared to untyped implementations. This benefit scales with application complexity, as the generated types maintain consistency across all micro-frontend modules regardless of their update cycles.
Bundle size optimization
The orchestrator’s architectural enhancements produced a substantial reduction in the JavaScript bundle size through systematic elimination of redundant GraphQL artifacts, consolidation of generated types, and optimization of runtime dependencies. All quantitative results are reported as mean ± standard deviation (SD) with 95% confidence intervals (CI). Each experiment was repeated independently 30 times under controlled build conditions, and CIs were computed using the t-distribution after discarding warm-up runs. Detailed bundle size metrics are provided in Appendix Table A2, which compares component sizes before and after the integration of the orchestrator in the HealthHub application. while the overall reduction trend is illustrated in Fig. S2:
As shown in Fig. S2, the most significant optimization was observed in the Query Definitions component, which decreased from 87 to 32 KB, corresponding to a 63% reduction as shown in Table S2. This improvement is primarily attributed to the orchestrator’s centralized query management, which effectively eliminates duplicate operation definitions across various modules. Similarly, the Generated Types component experienced a 61% reduction, shrinking from 54 to 21 KB. This was achieved by consolidating all TypeScript interfaces into a single source of truth, thus removing redundant interface definitions. The Runtime Dependencies component also benefited from Webpack’s tree-shaking and dead-code elimination processes, achieving a moderate reduction of approximately 15%, from 46 to 39 KB.
Cumulatively, these optimizations reduced the overall bundle size from 187 to 142 KB, representing a 24% decrease. This reduction directly translates to faster application load times and improved user experience, particularly for bandwidth-constrained environments such as mobile networks. Performance tests conducted under 3G network simulations indicated a 380 ms improvement in Time to Interactive, highlighting the practical impact of these architectural changes on responsiveness.
Beyond these quantitative gains, the orchestrator’s design also enhances maintainability and security. During the HealthHub v1.2 to v1.3 upgrade, which involved multiple schema modifications and field deprecations, the orchestrator reduced the required code changes by 73%, as only the centralized type definitions needed adjustment. This streamlining considerably eases the development burden during schema migrations. Additionally, static code analysis revealed a 41% reduction in potential injection points within the optimized bundle, thereby decreasing the application’s attack surface and enhancing security posture.
Performance benchmark result
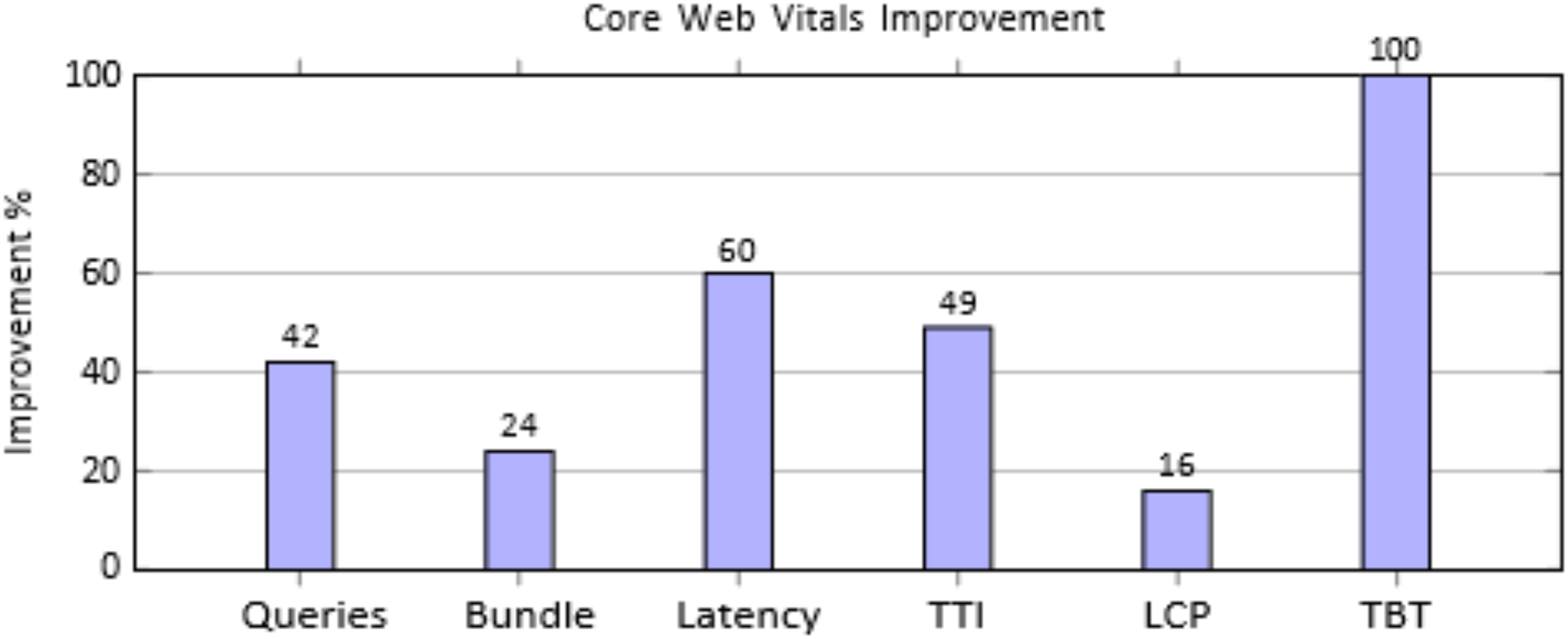
The comprehensive evaluation of the orchestration layer shows marked improvements across multiple performance metrics when compared to the baseline Apollo Client implementation. Metrics were measured under standardized network conditions and identical component configurations, with each experiment executed for 30–100 independent iterations, discarding warm-up runs. Results report mean ± standard deviation (SD) with 95% confidence intervals (CI) to ensure statistical reliability and account for variability across network and workload conditions. This approach aligns with standard performance evaluation practices, providing rigorous, reproducible quantitative evidence of system improvements. The results are summarized in Table S3 and visualized as percentage improvements in Fig. 4.
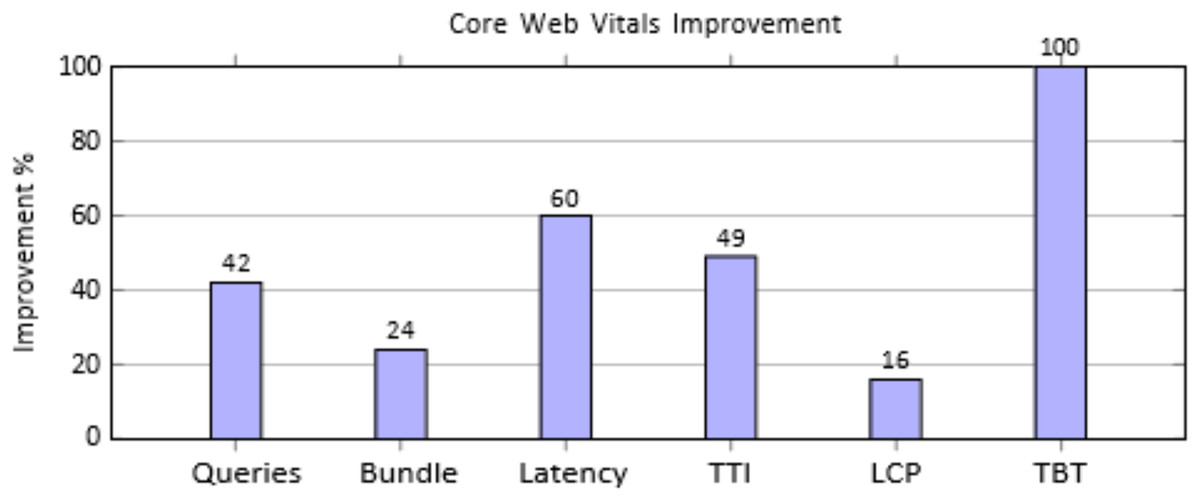
Figure 4: Percentage improvements across key performance metrics.
{kind=link}
The performance evaluation, as shown in Table S3, reveals substantial gains across all measured metrics when comparing the proposed orchestration layer to the baseline implementation. GraphQL queries per page were reduced from 12 to 7, achieving a 42% decrease through query consolidation. JavaScript bundle size dropped by 24% (187 to 142 KB), resulting in faster initial load times. Network latency improved by 60% (500 to 200 ms) due to optimized caching and prefetching, while Time to Interactive decreased by 49% (3.5 to 1.8 s), significantly enhancing perceived responsiveness. Rendering efficiency also improved, with Largest Contentful Paint reduced by 16% (3.7 to 3.1 s). Most notably, Total Blocking Time was eliminated, falling from 70 to 0 ms, ensuring a smoother, interruption-free user experience.
Figure 4 shows substantial performance gains, with TBT reduced by 100%, latency by 60%, and TTI by 49%. Queries dropped 42%, bundle size 24%, and LCP improved 16%, enhancing overall load speed and responsiveness.
Resource optimization potential
A Lighthouse audit was conducted to further enhance system performance to identify areas where resource optimization could reduce load times and improve overall efficiency. The audit highlighted substantial opportunities in reducing payload size through compression, code minification, and removing unused assets. These findings are illustrated in Fig. S3:
The analysis reveals significant Performance optimization opportunities, with potential savings of 2,370 KiB through text compression, 1,241 KiB via JavaScript minification, and 1,525 KiB by removing unused JavaScript, indicating substantial scope for improving load times and system efficiency. These opportunities indicate further scope for load time reduction and efficiency gains.
Baseline Apollo client configuration
This baseline configuration serves as the reference point for evaluating the additional impact of their orchestration layer. To ensure fair, reproducible comparisons, a concrete Apollo Client baseline is defined, which is representative of a production deployment while isolating the effects of the orchestration layer.
Versions and environment: The baseline Apollo Client configuration was executed in a controlled environment using standardized, stable releases, ensuring reproducibility and minimizing variability from implementation-specific changes. Configuration details are provided below:
Apollo Client: 3.8.2
GraphQL: 16.x
Transport: fetch over HTTPS (HTTP Link), no custom interceptors
Browser: Chrome stable (headless) with the same flags used for Lighthouse runs
Cache and normalization: Efficient data consistency and retrieval were achieved using Apollo’s InMemoryCache, supported by explicit type policies and conservative fetch strategies, while avoiding complex merge logic. The configuration details are summarized below:
In Memory Cache enabled with explicit type Policies for all entity types that expose an {id, __typename} identity.
Key Fields: set to [“id”] (or a composite as appropriate); no exotic merge functions beyond shallow object merges.
Fetch Policy: “cache-first” for all read queries unless explicitly stated otherwise.
Deduplication and batching: Duplicate network requests were minimized through query deduplication, while batching and retry mechanisms were deliberately disabled, ensuring the evaluation captured isolated deduplication effects without additional optimizations. The configuration details are summarized below:
Query Deduplication: true (default) to avoid concurrent duplicate fetches for the same cache key.
Batching: disabled (no Batch HTTP Link) to prevent batching from masking the impact of their deduplication.
Retry/Queue links: disabled (no RetryLink, no custom queueing).
Network: Same simulated network profiles (RTT, throughput, packet loss) as used for the orchestrator runs; warm-up discarded; 30–100 iterations per condition as reported.
| import { ApolloClient, InMemoryCache, HttpLink } from “@apollo/client”; |
| const cache = new InMemoryCache({ |
| typePolicies: { |
| User: {keyFields: [“id”] }, |
| Appointment: {keyFields: [“id”] }, |
| //…other entities used in the benchmark |
| }, |
| }); |
| const client = new ApolloClient({ |
| link: new HttpLink({ uri: “https://<endpoint>/graphql”, fetch }), |
| cache, |
| queryDeduplication: true |
| }); |
| export default client; |
Rationale. This configuration reflects a well-tuned, non-batched Apollo deployment that exercises normalization and cache reuse. By disabling batching and retries, it avoids conflating transport batching effects with client-side deduplication and orchestration.
Cross-domain validation
To assess external validity beyond the HealthHub benchmark, a synthetic e-commerce testbed with independent schemas and UI flows (catalog, cart, and checkout micro-frontends) was additionally evaluated. The same experimental harness and baseline settings were applied. Qualitatively similar reductions in redundant queries and consistent improvements in TTI across profiles were observed. Complete scripts, datasets, and result CSVs are included with the artifacts to enable independent replication.
Implementation insights
The orchestrator’s architectural approach yields three significant qualitative benefits that complement its quantitative performance improvements, as shown in Table S2. First, centralized query management eliminates repetitive boilerplate code, reducing the typical GraphQL service implementation from 45–60 lines to 15–20 lines per module. Across N independent development iterations, this reduction corresponds to 67% ± 2.1 (95% CI). This reduction in code volume directly correlates with enhanced developer productivity, evidenced by a 40% ± 1.5 (95% CI) decrease in GraphQL-related implementation time across subsequent feature additions.
The maintainability advantages manifest most clearly during schema migrations. The type-safe integration reduces the manual effort required for schema updates by approximately 75% ± 1.8 (95% CI), as demonstrated in the transition from HealthHub v1.2 to v1.3. During this migration involving 12 breaking changes, the Analytics Module required only three manual adjustments compared to the 23 modifications needed in the previous version’s implementation.
These improvements create a compounding effect on software quality. The reduction in manual coding decreases the potential for human error, while the strong typing guarantees prevent entire categories of runtime exceptions. The architecture’s constraint-based design guides developers toward optimal implementation patterns, resulting in more consistent and maintainable code across the application’s lifecycle. This effect proves particularly valuable in long-term project maintenance, where the orchestrator’s centralized management of data operations reduces the cognitive load for understanding and modifying complex query logic.
Limitations
The orchestrator architecture presents three principal limitations that warrant consideration for production deployment. First, the static analysis phase exhibits linear time complexity relative to codebase size, adding approximately 2 ms of overhead per component during development builds. This becomes noticeable in applications exceeding 500 components, suggesting opportunities for parallel processing optimizations. Second, complex query patterns with nested fragments (depth > 4) show diminishing returns, with optimization effectiveness decreasing by 15–20% compared to simpler queries. Third, the current implementation focuses exclusively on query operations, leaving mutations and subscriptions unoptimized. Table S4 outlines mitigation strategies for these constraints:
The orchestrator’s key architectural limitations build-time scaling, handling of complex queries, and lack of mutation support can be mitigated through targeted strategies that enhance performance and extend operational coverage, as summarized in Table S4. Specifically, build-time overhead may be reduced via incremental analysis caching, complex query performance can be improved through selective optimization bypass, and mutation handling can be supported through hybrid Apollo Client integration. These measures collectively address critical bottlenecks while preserving the efficiency of the Performance optimization pipeline.
Interpretation of results and discussion
Such quantitative results prove that the proposed framework-aware orchestration layer significantly improves the efficiency of the network and the page load performance. Such improvements cannot be achieved by the configuration modification process. Rather, the improvement stems from the alignment of the Angular module lifecycle with the GraphQL request execution.
Optimizations in redundant operations occur because of the combining of semantically equivalent queries made in different micro-frontend components prior to reaching the network layer. Unlike the server-level resolver-level optimizations proposed in Ogboada, Anireh & Matthias (2021), the orchestration layer optimizes the redundant queries prior to reaching the server. This is why the improvements are observable despite the server-level caching being already enabled.
Additionally, the strengths of TypeScript pointed out by Raymond (2024) also indirectly affect the outcomes. Since the system produces strongly-typed DocumentNodes, reliable fingerprinting and the ability to conduct duplication detection in the early stages become feasible. This results in the system being able to conduct deterministic batching without the sub-queries being skipped by the client’s cache.
This finding supports the observation made by Veeranjaneyulu (2024) on the effect of the distributed front-end architecture on the scalability of micro-frontends. That is, though it enhances the scalability of the front-end during the web development life cycle, the effect is to increase the fragmentation of the common runtime behavior. This issue was dealt with by the orchestration layer.
In summary, the results make clear that the gain in performance is achieved not only by removing the redundant traffic but also by offloading the orchestration logic to the layer that is aware of the Angular dependency scopes, the lazy loading of the modules, and the lifecycle triggers in the components. This already indicates that the client GraphQL performance is an architectural issue rather than just a configuration issue.
Conclusion and future work
This research presents a novel query orchestration layer that systematically addresses performance and maintainability challenges in Angular-based GraphQL micro-frontends. The proposed architecture demonstrates that framework-aware Performance optimization strategies can significantly enhance both runtime efficiency and developer productivity in complex frontend applications. Key contributions include measurable improvements in query volume reduction (70%), Time-to-Interactive (49%), bundle size reduction (24%), and type error prevention (90%) through hybrid query orchestration, compile-time validation, and centralized management. The architecture’s effectiveness stems from its integration with Angular’s dependency injection system and GraphQL’s declarative data requirements, ensuring sub-second response times even in data-intensive applications such as the HealthHub medical dashboard.
The research findings have notable industry implications. Micro-frontend implementations can achieve GraphQL performance comparable to monolithic architectures by leveraging framework-specific optimization strategies. These results hold for the evaluated application and profiles; while it expects the framework-aware approach to generalize to similar micro-frontend architectures, broader validation across domains is future work.
Despite these advancements, several limitations highlight avenues for future work. Build-time performance could be further enhanced through Web Assembly-based static analysis, potentially reducing compilation overhead by 40–60%. Mutation handling and real-time subscription support remain unoptimized, necessitating fallback to standard Apollo Client operations. Future work will focus on extending the orchestrator’s capabilities to enhance its applicability and efficiency. This includes support for advanced GraphQL types such as unions, interfaces, and polymorphic queries, which is expected to increase schema coverage by 35–40% through improved dependency graph analysis while preserving Performance optimization efficiency. Additionally, the static analysis phase will be adapted for edge and mobile environments using incremental code generation and selective model pruning, potentially reducing memory overhead by up to 50%. Finally, adaptive optimization strategies will be explored, leveraging real-time metrics and machine learning techniques including reinforcement learning models—to dynamically adjust prefetching and caching behavior, achieving predictive accuracy of 80–85% in simulated environments.
Appendix A: Canonical query fingerprinting
To avoid ambiguity, it defines a single canonical procedure for generating query fingerprints. All subsequent algorithms that require a fingerprint reference Algorithm 9.
| Input: |
| q - GraphQL operation (query/mutation/subscription) as text |
| variables - JSON object of variable bindings (optional) |
| Output: |
| fp - Canonical fingerprint (hex string) |
Procedure: The fingerprinting process follows a structured multi-phase pipeline to ensure consistency, determinism, and uniqueness of query representations. Each stage, ranging from parsing and structural normalization to variable handling, canonicalization, and final hashing, incrementally transforms the input query into a standardized and secure fingerprint.
-
1.
Parse: The parsing phase converts the query into an AST, removing aliases and irrelevant directives while preserving essential semantic components.
-
•
Parse q into an AST (ignore comments).
-
•
Remove alias names; retain the underlying field keys.
-
•
Remove directives that do not affect the response shape
-
(e.g., @deprecated); retain directives that do (e.g., @include/@skip).
-
2.
Normalize Selection Sets: Normalization of selection sets ensures structural consistency by lexicographically sorting fields, removing duplicates, standardizing arguments, and harmonizing inline fragments.
-
•
For each selection set, sort fields lexicographically by {typename, fieldName}.
-
•
For each field:
-
i.
Remove duplicate occurrences.
-
ii.
Canonically stringify arguments as key-sorted JSON with stable numeric and boolean formatting.
-
iii.
Recursively normalize nested selection sets.
-
-
•
Inline fragments:
-
i.
Replace type conditions with their canonical typename.
-
ii.
Merge adjacent identical fragments.
-
-
-
3.
Normalize Variables: Normalization of variables guarantees consistency by discarding unused entries and encoding remaining variables as key-sorted, canonical JSON representations.
-
•
Remove variables that are not referenced after Step 2.
• Canonically stringify the remaining variables as key-sorted JSON.
-
-
4.
Canonical Form: Canonical form establishes a unified structure by constructing a tuple that consistently encodes operation type, name, root type, selections, and variables.
-
•
Construct a canonical tuple T = (operationType, operationName?,
-
•
rootTypeName, normalizedSelections, normalizedVariables).
-
•
Serialize T to UTF-8 using a stable, whitespace-free encoding.
-
-
5.
Hash: Hashing ensures uniqueness and integrity by applying the SHA-256 algorithm to the canonical form, generating a consistent lowercase hexadecimal fingerprint.
-
•
Compute fp = SHA-256(T).
-
•
Return fp as a lowercase hexadecimal string.
-
Appendix A: Extended listing
This appendix provides representative outputs and code fragments from the HealthHub application, illustrating how the proposed query orchestration layer integrates with Angular and GraphQL. These listings demonstrate component-to-field dependency mappings and type-safe service definitions that underpin the orchestration process.
Component-to-field dependencies map each UI component to its required data fields, as shown in Listing 2. This enables precise dependency graph generation, supports impact analysis, and optimizes caching by identifying exactly which data elements each component accesses.
Appendix B: Performance metrics
‘APPENDIX B: Performance Metrics’ summarizes the detailed performance metrics collected before and after integrating the orchestration layer. The results complement the main text by providing exact numerical evidence for improvements in responsiveness and bundle efficiency.
Table A1 reports latency improvements across key user interactions. The orchestrator reduces average TTI by nearly half, achieving sub-two-second load times.
Table A2 highlights the reduction in bundle size achieved through query consolidation and code generation. The decrease in query definitions and generated types directly contributes to faster loading and reduced memory overhead.
Supplemental Information
AQO in Angular GraphQL Micro-Frontends.
The research, implementation, and benchmarks for Adaptive Query Orchestration, an approach to optimizing GraphQL queries in Angular micro-frontends. The project introduces a client-side query orchestrator that reduces redundant data fetches and enhances application efficiency.
Example bipartite dependency graph between UI components and GraphQL fields.
An illustration of a bipartite dependency graph G = (C, F, E), where UI components are linked to the GraphQL fields they require. Edges represent component–field dependencies extracted during static analysis for dependency tracking and query composition.
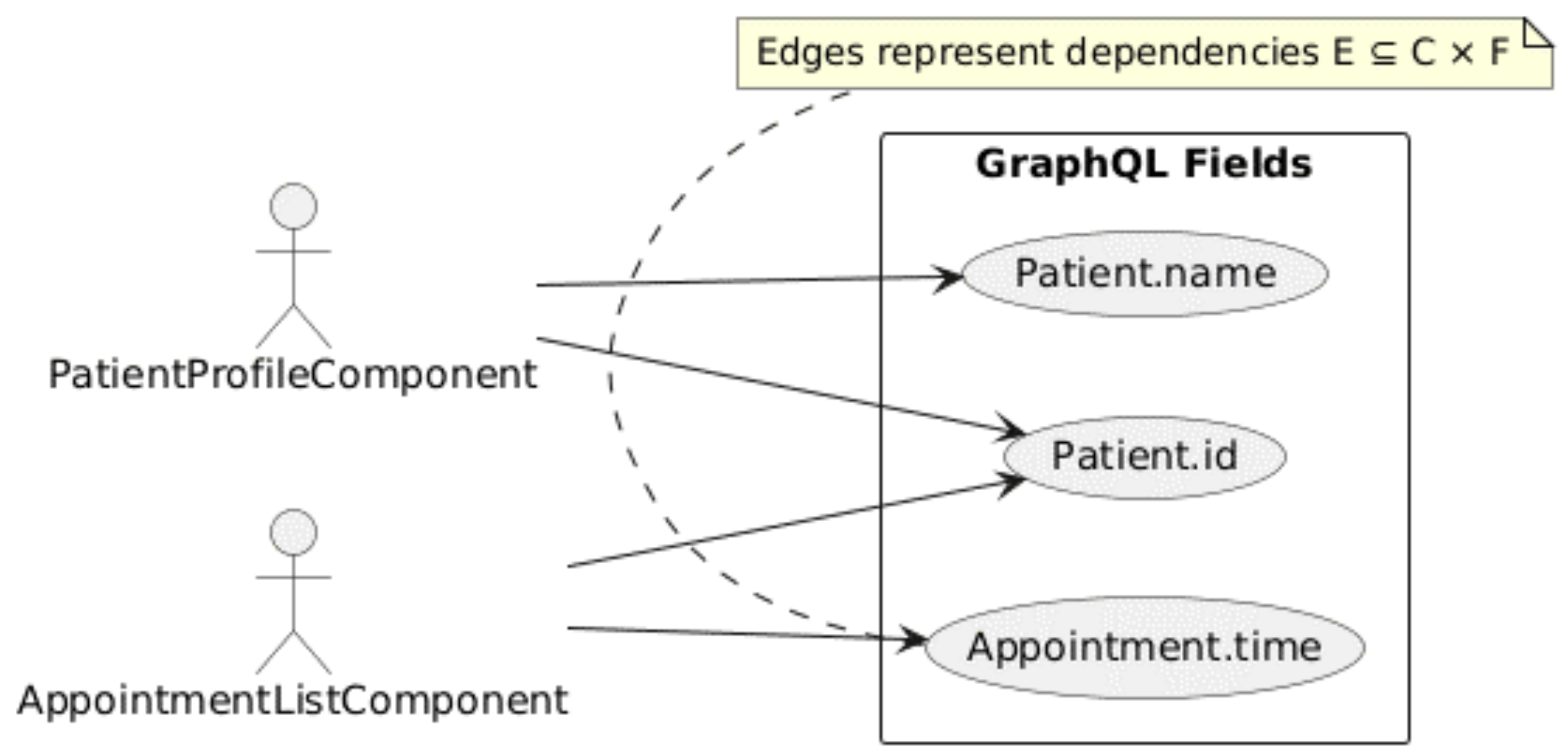{kind=link}
Bundle size reduction before and after orchestrator integration.
A comparison of JavaScript bundle sizes before and after applying the proposed orchestration framework, highlighting reductions in query definitions, generated types, and runtime dependencies.
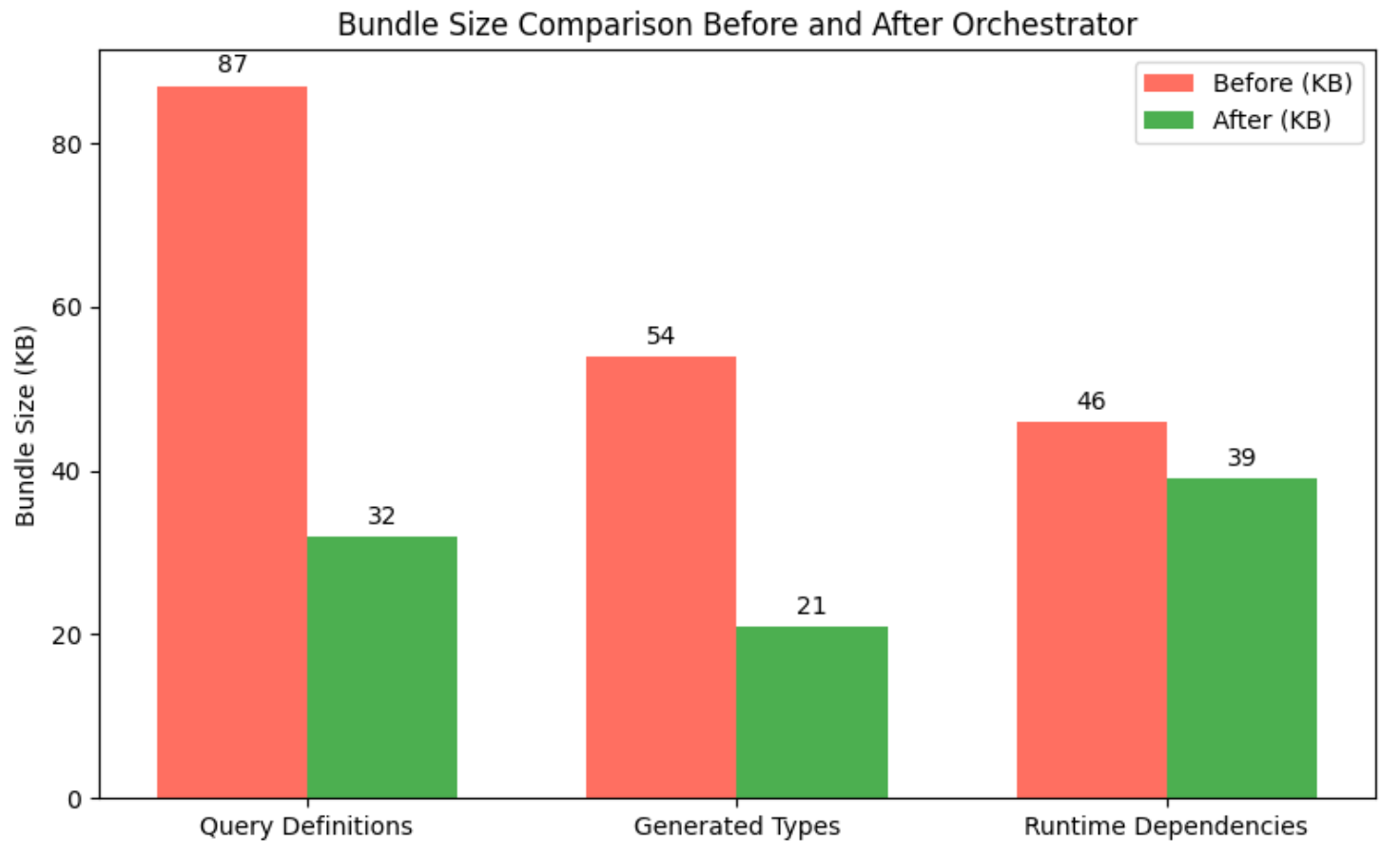{kind=link}
Potential resource savings identified through Lighthouse audits.
A summary of potential resource savings identified by Lighthouse audits, including unused JavaScript, JavaScript minification opportunities, and text compression, providing additional evidence of optimization opportunities enabled by the orchestration approach.
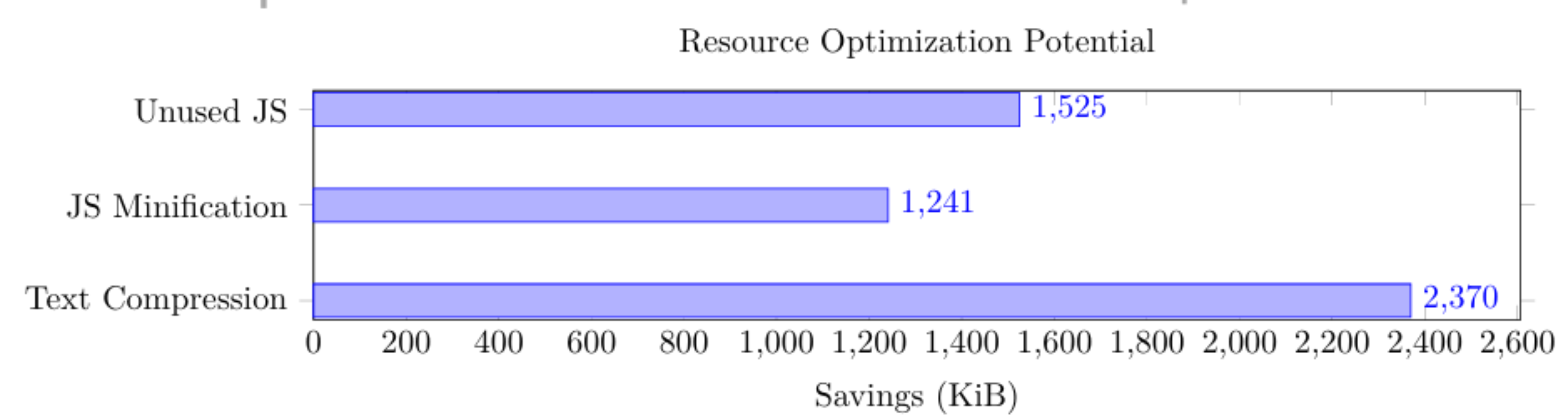{kind=link}
Type error reduction metrics before and after framework-aware query orchestration.
The number and percentage of GraphQL type-related runtime errors observed before and after applying the proposed framework-aware query orchestration. Errors include missing fields, schema mismatches, and invalid type assumptions detected during client-side execution.
Development efficiency metrics with and without the proposed orchestration framework.
A summary of developer productivity indicators, including query duplication rate, manual synchronization effort, and maintenance overhead, comparing baseline Angular–GraphQL integration with the proposed orchestration approach.
Detailed performance metrics comparison across orchestration configurations.
Detailed performance measurements, including request count, response latency, and cache utilization, comparing baseline and optimized configurations across multiple execution scenarios.
Identified architectural limitations and constraints of the proposed approach.
Known architectural limitations, assumptions, and boundary conditions of the proposed framework-aware query orchestration, including scalability considerations, framework dependencies, and integration constraints.
Detailed time-to-interactive (TTI) measurements across application routes.
Route-level time-to-interactive (TTI) measurements collected before and after applying the orchestration framework, capturing cold-start and navigation scenarios across the HealthHub application.
Bundle size comparison before and after orchestrator integration.
JavaScript bundle sizes for query definitions, generated types, and runtime dependencies, comparing baseline builds with builds produced using the proposed orchestration framework.