
Multinational sign language recognition framework for inclusive multimedia communication
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Computer Vision, Natural Language and Speech, Neural Networks
- Keywords
- Deep learning, Convolutional recurrent neural network, Human-computer interaction, Multilingual training, Sign language recognition, CRNN
- Copyright
- © 2026 Yüksel and Rada
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Multinational sign language recognition framework for inclusive multimedia communication. PeerJ Computer Science 12:e3634 https://doi.org/10.7717/peerj-cs.3634
Abstract
Recent advancements in multimedia technology have revolutionized digital device interactions, with sign language recognition emerging as a crucial tool for improving accessibility. This article introduces an innovative approach to integrating language-based sign language recognition into multimedia applications, enabling automatic recognition of gestures across various nationalities in dynamic sign language environments (video). Our research explores the potential of this technology to enhance accessibility and usability, particularly for individuals with hearing impairments, by facilitating intuitive and real-time control over video conferencing applications. We identify existing challenges in multimedia applications and propose a novel framework incorporating sign language recognition algorithms. Our approach involves developing a prototype multimedia application designed for fast communication in crowded environments and backgrounds. Feature extraction is performed using the Mediapipe Holistic framework, which captures hand-shoulder distances, finger angles, and finger usage. Gesture classification is achieved using the K-Nearest Neighbors (KNN) algorithm, effectively recognizing international sign language gestures. Additionally, for language and word prediction, we employ Convolutional Recurrent Neural Networks (CRNNs) enhanced by Long Short-Term Memory (LSTM) to process diverse linguistic contexts. Experimental results confirm the robustness of our approach, achieving 89% accuracy in multiclass gesture classification and exceeding 93% accuracy in word prediction across a large, diverse dataset collected from multiple sources and languages. To enhance practical applicability, we integrated our techniques into a custom video conferencing application built with Django. This application seamlessly incorporates our feature extraction and prediction models, offering an innovative, two-way communication platform with improved accessibility features.
Introduction
Gesture and sign language recognition technologies play a pivotal role in enhancing communication, particularly for individuals with hearing impairments. These technologies enable effective interaction with peers and the broader community, fostering inclusivity and accessibility (Rodríguez-Correa et al., 2023). However, children with hearing impairments often face significant challenges in their daily lives, including difficulties in understanding verbal instructions, feelings of isolation in social settings, and barriers to accessing traditional educational resources (Hall, Hall & Caselli, 2019; Jones, Brown & Taylor, 2019).
Recent advancements in deep learning, particularly in computer vision, pattern recognition, and machine learning, have revolutionized gesture and sign language recognition systems (Zhang & Jiang, 2024). These systems can be broadly categorized into two approaches: sensor-based methods, which rely on wearable devices or hardware, and vision-based methods, which utilize image and video processing techniques (Aksoy, Salman & Ekrem, 2021; Dang et al., 2020). While sensor-based methods have shown promise, they often require specialized equipment, which can be cumbersome and impractical for everyday use. In contrast, vision-based methods offer a non-intrusive and scalable alternative, making them more suitable for real-world applications.
Static sign language consists of signs that remain in a fixed position without movement, such as fingerspelling letters or certain nouns. In contrast, dynamic sign language involves movement, including directional gestures, repetition, and speed variations, often used for verbs and complex expressions. Both types are essential to sign-language recognition, and their combination enables fluent communication.
In the literature, there are real-time systems that recognize both static and dynamic sign-language gestures using deep learning. Most of the systems employ 2D Convolutional Neural Networks (CNNs) for static image recognition and 3D CNNs for dynamic video recognition.
This study focuses on the application of vision-based gesture recognition in real-life scenarios, such as student meetings, conferences, and video calls, where individuals from diverse linguistic and cultural backgrounds interact. These systems, as discussed in the following section, are particularly beneficial for individuals with speech impairments, as they provide an intuitive and real-time means of communication. However, recognizing sign language in complex, crowded environments remains a significant challenge, requiring both precision and speed to ensure effective communication.
To address these challenges, we propose a novel framework that leverages the Mediapipe Holistic library (Lugaresi et al., 2019), a powerful tool developed by Google, for extracting features across multiple sign languages, including German, English, Indian, Greek, Arabic, and Turkish. Our framework analyzes essential features such as hand and shoulder positioning, facial expressions, and the spatial relationships between hands and shoulders. By capturing fine-grained details like finger movements, joint angles, and motion patterns, we aim to enhance the accuracy and reliability of sign language recognition systems (Chen, Wang & Liu, 2021).
The proposed framework comprises two primary components:
A K-Nearest Neighbor (KNN) algorithm for identifying the nationality associated with each gesture, incorporating additional features such as finger count, inter-finger angles, and hand-to-shoulder distances.
A CRNN enhanced by Long Short-Term Memory (LSTM) (Hochreiter & Schmidhuber, 1997) for sequential data processing and image feature extraction, enabling robust handling of temporal and spatial data taking advantages of using a combination of supervised learning and sequence-to-sequence learning paradigms.
A key contribution of our work is its multilingual sign language recognition capability. By combining a KNN-based language identification mechanism with a CRNN model for contextual interpretation, our approach transcends linguistic boundaries and enhances the model’s generalizability. Furthermore, inspired by Cha et al. (2021), we implement background subtraction techniques to isolate gestures against a black background, thereby improving visibility and recognition accuracy. This pre-processing step is particularly effective in reducing noise and enhancing the model’s focus on relevant gesture features (Piccardi, 2004).
The proposed framework offers several key innovations over existing approaches:
Multilingual Sign Language Recognition: Supports gestures across six languages (English, German, Turkish, Indian, Arabic, and Greek) for broader real-world applicability.
Hybrid KNN-CRNN Model: Integrates KNN for language identification with CRNN-LSTM for contextual interpretation, ensuring robust handling of both temporal and spatial data.
Background Subtraction: Enhances gesture visibility and recognition accuracy by isolating gestures against a black background.
Real-Time Application: Integrated into a Django-based video conferencing platform (Django Software Foundation, 2005), promoting two-way communication and practical usability.
In the following sections, we discuss our methodology for dataset collection across various sign languages, provide a detailed explanation of our model architecture and training process, and conduct a comprehensive evaluation of performance metrics. Through this study, we aim to demonstrate the efficacy of CRNNs in gesture recognition, highlight the significance of background optimization for accurate recognition, and underscore the advantages of multilingual training in advancing artificial intelligence (AI)-driven multimedia applications.
Literature review
Existing literature reveals a limited number of studies focused on sign language recognition in video contexts. Most of the studies are related to static sign language recognition. Moreover, to the best of the authors’ knowledge, most existing studies rely exclusively on a single dataset, typically representing the sign language of a specific country or community. Although videos are essentially time sequences of images, data collection for sign language recognition in video formats remains limited.
To ensure a comprehensive review, the authors considered both image-based and video-based data, avoiding a narrow focus. This study examines video datasets for Indian, Greek, American (English), Chinese, Arabic, and Turkish Sign Language, all sourced from open-access resources. The authors also aimed to expand the range of languages included; however, despite reaching out to various researchers and searching for open datasets in other languages, these efforts were unsuccessful due to the lack of available data.
In this section, we review the most recent and significant works on static sign language recognition, as well as video datasets for sign language recognition available as open-source resources for these languages. In the appendix of this article readers can find a comprehensive summary of the reviewed studies on various sign languages in Table 1, with detailed explanations provided in each of the following subsections.
| Study | Methodology and dataset | Accuracy (%) |
|---|---|---|
| Arabic sign language | ||
| Halawani (2008) | Sign language recognition for mobile applications | Not specified |
| Maraqa & Abu-Zaiter (2008) | FFNN and RNN for 28 Arabic alphabet gestures | 95% |
| Hayani et al. (2019) | CNN for 28 Arabic letters and digits (0–10), 7,869 images | 90.02% |
| Ali (2011) | HMMs for Real Arabic Sign Language videos | 82.22% |
| Podder et al. (2023) | CNN-LSTM-SelfMLP for Recorded RGB videos | 87.69% |
| ElBadawy et al. (2017) | 3D CNN for 25 gestures from depth maps | 98% (observed), 85% (new data) |
| German sign language | ||
| Hanke & Storz (2011) | DGS corpus and Dicta-Sign corpus | 71.2% |
| Camgoz et al. (2018) | CNN with attention-based encoder-decoder (PHOENIX14T dataset) | 74.3% (val), 73.4% (test) |
| Indian sign language | ||
| Mittal et al. (2019) | NN for 942 sentences (35 sign words) | 72.3% (sentences), 89.5% (words) |
| Kothadiya et al. (2023) | CRNN, LSTM, CNN for Indian dataset | 97% |
| Chinese sign language | ||
| Liao et al. (2019) | BLSTM-3DRN (DEVISIGN D and SLR datasets, 500 words) | 89.8% (DEVISIGN D), 86.9% (SLR) |
| Greek sign language | ||
| Adaloglou et al. (2022) | ResNet + B-LSTM for video data | 93.37% (val), 93.90% (test) |
| Papastratis, Dimitropoulos & Daras (2021) | GAN with contextual info for Greek SL dataset | 76.6% |
| Italian sign language | ||
| Pigou et al. (2015) | CNN for 20 gestures by 27 users in varied environments | 91.7% (cross-validation) |
| American sign language | ||
| Hu et al. (2018) | RNN + CNN for NYU dataset | Not specified |
| Hu et al. (2019) | 3D Separable CNN for dynamic gestures | 82.22% recognition rate |
| Tarrés et al. (2023) | Transformer (I3D video features) for How2Sign dataset | 8.03 on the BLEU score |
| Turkish sign language | ||
| Özdemir et al. (2020) | 3D ResNets model for isolated Turkish signs (BosphorusSign22k dataset) | 94.76% |
| Sincan & Keleş (2020) | CNN-LSTM for continuous signing sequences (AUTSL dataset) | 95.95% |
Arabic sign language research available datasets and studies
Halawani (2008) introduced the first sign language recognition system applied in a multimedia context, specifically for Arabic Sign Language on mobile platforms. Their approach involved the conversion of Arabic Sign Language signs into textual output. This approach enables the use of sign language recognition for mobile applications. The proposed work focuses on developing a prototype multimedia application that incorporates advanced sign language recognition techniques. The initial idea for interacting with deaf individuals was promising, and with a simple software design, performance was not the main focus compared to accuracy and the variety of signs included.
Maraqa & Abu-Zaiter (2008) work focus on the capability of Neural Networks (NNs) in Arabic Sign Language recognition. The aim of the study is to demonstrate the use of various types of NNs, for hand sign language recognition. Firstly, they demonstrated the application of Feed Forward Neural Network (FFNN) and Recurrent Neural Network (RNN) with different topologies, complete and moderately recurrent systems. The evaluation results showed that the proposed structure has 95% accuracy for stationary motion recognition, though the dataset is limited on sign language recognition for 28 distinct gestures, each representing a letter of the Arabic alphabet and it has not yet been tested on videos or real-world.
In 2019, Hayani et al. (2019) proposed a novel model for Arabic Sign Language Recognition using CNN to recognise 28 Arabic letters and digits ranging from 0 to 10. The seven-layer framework was trained on 7,869 images under multiple train–test splits, achieving a maximum accuracy of 90.02% with 80% of the images used for training.
Ali (2011) research framework on sign language identification has focused on hidden Markov models (HMMs), capable of identifying Arabic Sign Language up to 82.22%. A large sample set is used to recognize words in standard Arabic Sign Language. Experiments are carried out using real Arabic Sign Language videos for deaf people wearing different clothes and having different skin colours. Their system achieved an overall recognition rate of up to 82.22%.
Podder et al. (2023) presents Arabic Sign Language recognition system that can recognise from recorded RGB videos. Furthermore, in this study, a CNN-LSTM-SelfMLP architecture consisting of six different models for Arabic Sign Language recognition is constructed using MobilNetV2 and ResNet18 based CNN backbones and three SelfMLPs for performance comparison of CNN-LSTM-SelfMLP models. In this work, marker-independent mode is investigated to cope with real-time application conditions. As a result, on the segmented dataset, MobileNetV2-LSTM-SelfMLP achieved the best accuracy with 87.69% accuracy, 88.57% precision, 87.69% recall, 87.72% F1-score.
ElBadawy et al. (2017) proposed a 3D CNN used to recognise 25 gestures from the Arabic Sign Language. The model uses two 3D-Conv/Max Pool layers and one softmax layer. The recognition system was fed with data obtained from depth maps. The system achieved 98% accuracy for observed data and 85% average accuracy for new data, but as for the other up mentioned works is not applied on real videos where the complexity is higher.
German sign language research available datasets and studies
The data German Sign Language collection of both the DGS Corpus project and the DGS part of the Dicta-Sign corpus was first published by Hanke & Storz (2011). Following the release of the dataset, numerous research studies focused on advancing the automation of sign language recognition. The dataset was further enlarged into the PHOENIX14T dataset (Koller, Forster & Ney, 2015), that included real-life videos signing recorded on public TV broadcast manually labelled by native speakers. In 2018, Camgoz et al. (2018) employed a vision method mirroring tokenization and embedding in NN machine translation to analyze German Sign Language, achieving 74.3%/73.4% accuracy on the validation/test sets.
The accuracy achieved, while not particularly high, should be viewed as a meaningful first step toward building a larger and more comprehensive dataset. This initial effort lays the groundwork for future improvements and highlights the potential for more advanced developments in this area.
Indian sign language research available datasets and studies
Mittal et al. (2019) following the work of Camgoz et al. (2018) applied a similar idea for Indian Sign Language utilizing a neural network model that splits continuous signs into sub-units for training was proposed. This approach eliminates the need for considering different combinations of sub-units during training. Testing the system on 942 Indian Sign Language signed sentences, consisting of 35 different sign words, yielded an average accuracy of 72.3% for signed sentences and 89.5% for isolated sign words.
Kothadiya et al. (2022) conducted a comprehensive review of the existing literature and separately highlighted the widespread use of CRNNs, LSTMs, and CNNs as the primary approaches in research on video gesture and sign language recognition, especially in the context of Indian Sign Language. Although one study reports 97% accuracy, its applicability is limited to the Indian dataset.
Research available flemish sign language
De Coster, Van Herreweghe & Dambre (2020) introduced an OpenPose for human keypoint estimation and CNN for end-to-end feature learning in sign reconition of Flemish Sign Language. The study was further enhanced in Shterionov et al. (2024). Leveraging a multi-head attention mechanism from transformers, the proposed method excels in recognizing isolated signs within the Flemish Sign Language corpus, achieving a remarkable 74.7% accuracy for a vocabulary of 100 classes. His work was conducted as part of a Horizon 2020 project. While the main idea has been publicly shared, the dataset is not available. For this reason, we were unable to consider this data set in our study.
Chinese sign language research available datasets and studies
Liao et al. (2019) introduced dynamic sign language recognition method based on a deep Bi-directional Long Short-Term Memory on 3-dimensional Residual ConvNet (BLSTM-3DRN) for dynamic Chinese Sign Language recognition. Using a serialized bi-directional LSTM model, their system combined hand localization, spatiotemporal feature extraction, and gesture identification, specifically applied to DEVISIGN_D video dataset. The results demonstrate that their method achieves an accuracy of 89.8% on the DEVISIGN_D dataset and 86.9% on the SLR_Dataset. This approach effectively recognizes complex hand gestures from extended video sequences within a vocabulary of 500 words in Chinese Sign Language. We acknowledge that the researchers of this study made several attempts to contact the Chinese Sign Language team to incorporate their insights; however, due to the lack of response, we were unable to include this language in our article.
This work was further improved by the research of Visual Information Processing and Learning (VIPL) group (Min et al., 2021), led by Mr. Yuecong Min, of Institute of Computing Technology, Chinese Academy, where Visual Alignment Constraint (VAC) to enhance the feature extractor with alignment supervision was introduced. This work provided a good performance and proposed two metrics to reflect overfitting by measuring the prediction inconsistency between the feature extractor and the alignment module.
Greek sign language research available datasets and studies
Adaloglou et al. (2022) presented I3D, a Residual Network (ResNet) with Bidirectional Long Short-Term Memory Network (B-LSTM), for continuous Greek Sign Language recognition, focusing on syntax formation. The research introduces two new sequence training criteria from speech and scene text recognition domains and discusses various pre-training schemes. With the proposed models, results are similar 93.37% on the validation set and 93.90% on the test set.
Papastratis, Dimitropoulos & Daras (2021) present a method for video (continuous) sign language recognition that uses a Generative Adversarial Network architecture. This system improves sign language recognition accuracy by incorporating text or contextual information, which is a departure from previous approaches that only use spatiotemporal features from video sequences. Specifically, the system identifies sign language glosses by extracting features and evaluates prediction quality by modeling text information at the sentence and gloss levels. Their work demonstrates on three separate datasets which are Greek Sign Language, German Sign Language (named RWTH-Phoenix-Weather-2014), and Chinese Sign Language. Based on their experimental results the proposed methods has an accuracy 97.9%, 97.74%, and 76.6%, for German Sign Language, Chinese Sign Language and Greek Sign Language, respectively.
American and English sign language research available datasets and studies
Hu et al. (2019) work leverages the similarity between adjacent frames by using consecutive frames as input, rather than a single universally adopted frame for hand sign language recognition. They use New York University dataset as American Sign Language. They propose two methods in this article that combine RNN for sequential data and CNN for images. The first method involves adding an RNN module before the output layer of the basic CNN, with the RNN taking the one-dimensional vector as input. Because the dataset is not publicly available, we could not include it in our study.
In another article, the same authors (Hu et al., 2018) introduce a method for dynamic sign-language recognition based on a 3D separable CNN. The aim is to build a compact model with minimal computational complexity. To achieve this, he standard 3D convolution is factorized into depthwise and pointwise components to reduce the number of network parameters. However, this decomposition deepens the network, making training harder due to gradient-propagation issues.
Tarrés et al. (2023) improve transformer-based methods for sign-language recognition by presenting the first baseline results on the How2Sign dataset as American Sign Language, which is large and diverse. This dataset is available for research purposes. They utilize a Transformer model trained on I3D video features. Despite showing promising results, there is still room for improvement. While their approach relies solely on I3D features, we additionally incorporate pose landmarks. They observed that the decoder was disregarding the input from the encoder and operating solely as a language model.
Turkish sign language research available datasets and studies
The Spreadthesign project is an international initiative that offers a comprehensive online dictionary encompassing multiple sign languages, including Turkish Sign Language (Lydell, 2025). In the context of Turkish Sign Language, researchers have utilized this resource to analyze the unique grammatical structures of Turkish Sign Language, contributing to a deeper understanding of its typological aspects, Özdemir et al. (2020). Additionally, the dataset has facilitated the training of deep learning models with a 3D ResNets aimed at recognizing isolated Turkish signs, leveraging its extensive video collection to extract spatial and temporal features effectively. The accuracy achieved in their study is 94.76%.
While the Spreadthesign dataset excels in providing isolated signs, it lacks continuous sign sequences necessary for recognizing full sentences or conversations. To address this limitation, other datasets have been developed. For instance, the AUTSL dataset offers a large-scale, multi-modal collection of Turkish Sign Language videos, including continuous signing sequences, thereby complementing the resources available through Spreadthesign, Sincan & Keleş (2020). The authors apply CNNs to extract features, and unidirectional and bidirectional LSTM models to characterize temporal information archiving an accuracy of 95.95%.
More device-based sign language recognition studies and research gaps leading to our new framework
All of the above methods are vision-based sign-language recognition approaches that do not require auxiliary devices such as gloves. Below, we briefly summarize recent device-based sign-language recognition studies. Tubaiz, Shanableh & Assaleh (2015) propose a glove-based approach for Arabic Sign Language recognition, employing a modified KNN classifier with statistical feature extraction; the system leverages feature-vector context to improve classification accuracy. This consistent identification system utilizes the context of feature vectors to achieve accurate classification. Another similar work was introduced by Jo & Oh (2020) aiming to achieve sign language recognition by using a CRNN with pre-processing and an overlapping window approach. The CRNN combines LSTM for time-series information classification and CNN for feature extraction. They used a Myo-armband sensor to detect six hand gestures, including grips, hand signs, and rest. Pre-processing involved using existing methods like STFT and CWT, as well as a new method called SAWT, which showed high accuracy in stationary tests. The CRNN with overlapping window improved real-time prediction accuracy, especially in handling inconsistent start times and hand motion speeds. In stationary tests, the CRNN model with SAWT and overlapping window achieved the highest accuracy of 92.5%. However, these techniques require users to wear instrumented gloves to capture gesture details, which can be uncomfortable; therefore, our research focuses on improving video-based sign-language recognition.
Proposed model and required inputs
Our proposed work is particularly designed for crowded environments, in a dynamic communication, where the ability to facilitate swift and effective communication within the audience is crucial. The work consists of two parts, the first part utilizing the numpy feature files saved earlier in a KNN algorithm to ascertain the nationality associated with each gesture. Unlike the device-based method proposed by Tubaiz, Shanableh & Assaleh (2015), our approach enhances KNN with additional extracted features—such as finger count, finger angles, and the distance between the hand and shoulder—without relying on any external device. Additionally, we leveraged the weight files generated during the training of the CRNN model to align the detected language from the KNN with the appropriate linguistic match, capable of interpreting the language content of a given video.
For the second stage, we employ CRNN + LSTM model that combined a CNN model strengthened by LSTM. In contrast to Kothadiya et al. (2022), we use background subtraction to obtain a black background. The resulting frames with a black background were then used to train a CRNN capable of handling sequential data and extracting image features effectively. The rationale behind black background choice is based on the principle of increasing gesture visibility inspired by the Cha et al. (2021). The stark contrast between the gestures and the black background serves to emphasize hand movements, thereby facilitating more accurate recognition. This approach is anticipated to elevate gesture saliency and, subsequently, recognition accuracy.
The novelty of our work lies in combining the distinction of multilingual sign language using a KNN approach with interpretation of the linguistic context. This is ensured by the applicability of the trained CRNN model, strengthened by LSTM, across different linguistic contexts. Incorporating different languages not only increased the diversity of the data set, but also improved the model’s ability to generalize gesture patterns beyond language boundaries.
In the following of this section, we detail the methodology employed in our study for dataset collection across various sign language, explain the details of how the model is built and structured, important aspects involved in the process, provide more details about training and test process, and conduct a comprehensive evaluation of performance metrics. We detail the developed multi-layer CRNN model with specific configurations to handle the complexities of sign language, including convolutional layers for feature extraction and recurrent layers for temporal sequence modeling.
Data collection and preparation
To validate our findings, we trained with a comprehensive dataset consisting of videos each in English, German, Indian, Greek, Arabic, and Turkish. Turkish and Indian videos were obtained in the range of 2 to 4 s, while German, English and Arab videos were obtained in the range of 1 to 2 s, given in the following web paths:
Hanke & Storz (2011): https://www.sign-lang.uni-hamburg.de/korpusdict/overview/index-dgs.html Youtube/@MarcoEfimov
• Turkish sign language (TİD) dataset: Colected by the European Sign Language Centre (Lydell, 2025): Youtube/@isaretdiliegitim4080
• Arabic dataset: Zayed (2023) https://menasy.com/, https://www.youtube.com/@eslzayed6970
• Greek dataset: Kouris, Giannakopoulos & Petridis (2019) https://vcl.iti.gr/dataset/gsl/
• American How2Sign dataset: Duarte et al. (2021) https://how2sign.github.io/
• English dataset: bib33 dataset (Learn How to Sign, 2025) and ASL LOVE Youtub chanel (Handspeak, 2025): https://www.handspeak.com/word/
Youtube/@bib33, Youtube/@ASLLOVE
For the purpose of our study we had to get an approximately balanced dataset, though we faced difficulties on searching different sources of getting the dataset. The German Sign Language is an extensive collection of sign language videos with annotations, showcasing various signs and their usage in context. Users can search for signs based on categories, hand shapes, or meanings, facilitating both learning and research. Regarding Turkish, Indian, and Arabic Sign Language datasets, we acknowledge that they consist of instructional videos on Turkish Sign Language, covering various topics and signs. It is a practical resource for learners seeking visual demonstrations. The online dictionary offers a vast collection of signs classified by themes such as colors, emotions, and numbers. Each entry includes a video demonstration. However, the American Sign Language used in this study is the How2Sign dataset and consists of annotations collected using training videos from videos and speech transcription. The dataset is publicly available large-scale dataset covering a variety of topics with word-level time alignments to basic real English transcription of 80 h with a visual full-body sign-language consisting of seven signers. The sign language videos included a total of 10 subjects, seven of whom were professional American Sign Language interpreters (two of whom were hard of hearing) and three of whom were deaf. Furthermore, a large-scale public dataset has been created for Greek Sign Language (GSL) recognition to support scientific research in the deep learning era. This dataset involves seven native Greek Sign Language signers interacting with various community services. Each signer performed five predefined dialogues in Greek Sign Language five times, resulting in 10,295 sentence instances and 40,785 gloss instances. The dataset also includes 310 unique glosses and 331 unique sentences. The videos are recorded in both RGB and depth streams at a resolution of 848 480 pixels, with recordings captured at 30 FPS. Additionally, the dataset includes temporal gloss annotations, sentence annotations, and translations to Modern Greek.
Proposed architecture and inputs
The proposed architecture for sign language recognition includes a RESTful web video conferencing application built with the Python Django framework and an integrated deep learning model. As a first step the frame taken from the video coming from the web application are transmitted to the neural network as a request. Our framework comprises two primary components: (1) a KNN algorithm for language identification (see ‘Key Concepts and Algorithms’ for details), and (2) CRNN for sequential data processing (see ‘Key Concepts and Algorithms’ for details). The image data from the request is then decoded and used for KNN classification and the correct weight files are selected for the language of the country. After that CNNs are used to extract spatial features taken from input images from the front camera of the device from the application with the request, and with RNNs, we process temporal information by taking the sequences of feature vectors extracted from CNNs. As a result, we display a prediction for the gesture made on the front end side of the application for other words application screen.
Network part of application
As a first step we combine Django Software Foundation (Django Software Foundation, 2005) and PyQt (Limited, 1998) frameworks for GUI and Video Conferencing applications to create a user interface for our video conferencing application. Django handles the backend logic, while PyQt provides the graphical user interface components. With the AgoraRTC integration (Agora Inc., 2014), we enable WebRTC support, allowing real-time video and audio communication in our application to be converted into sequence of frames. This allows us to visualise and test the functionality of our application in a real-life scenario. In the following more details are provided related to the steps taken for the web application. Firstly the lobby(request) and room(request) functions are responsible for rendering the Django templates “lobby.html” and “room.html”, respectively. These templates define the layout and appearance of the lobby and room views in our application. The functions return an HTTP response that displays the corresponding template. Lobby view is where we create user (if not exist) and room is where we display user in our application. The getMember(request) function is responsible for retrieving a RoomMember model object from the database based on the provided UID and room name in a GET request(HTTP GET/lobby). It utilizes the RoomMember.objects.get method to fetch the member object with the specified conditions. The name of the retrieved member object is obtained as a JSON format. With the generated response of lobby part of our application we create room request for entering room for using application and render lobby again for easily usage. The getToken(request) function plays a crucial role in our video conferencing application. It generates a session ‘token’ required service. The token is created using the buildTokenWithUid method from the RtcTokenBuilder class provided by AgoraIO (2024). The function takes parameters such as the channel name, a randomly generated user ID (UID), and a timestamp. The Token, which provides access to the Agora.io multimedia service, is returned as a JSON response. The token establishes connection with the app for real-time communication with audio and video. Agora.io’s documentation provides detailed information about the specific algorithm and encryption methods used for Token generation (AgoraIO, 2024). For a clear understanding of how the software works, the reader can refer to Figs. 1 and 2, while the pipeline of the proposed method for the training and testing phase can be found in Fig. 3.
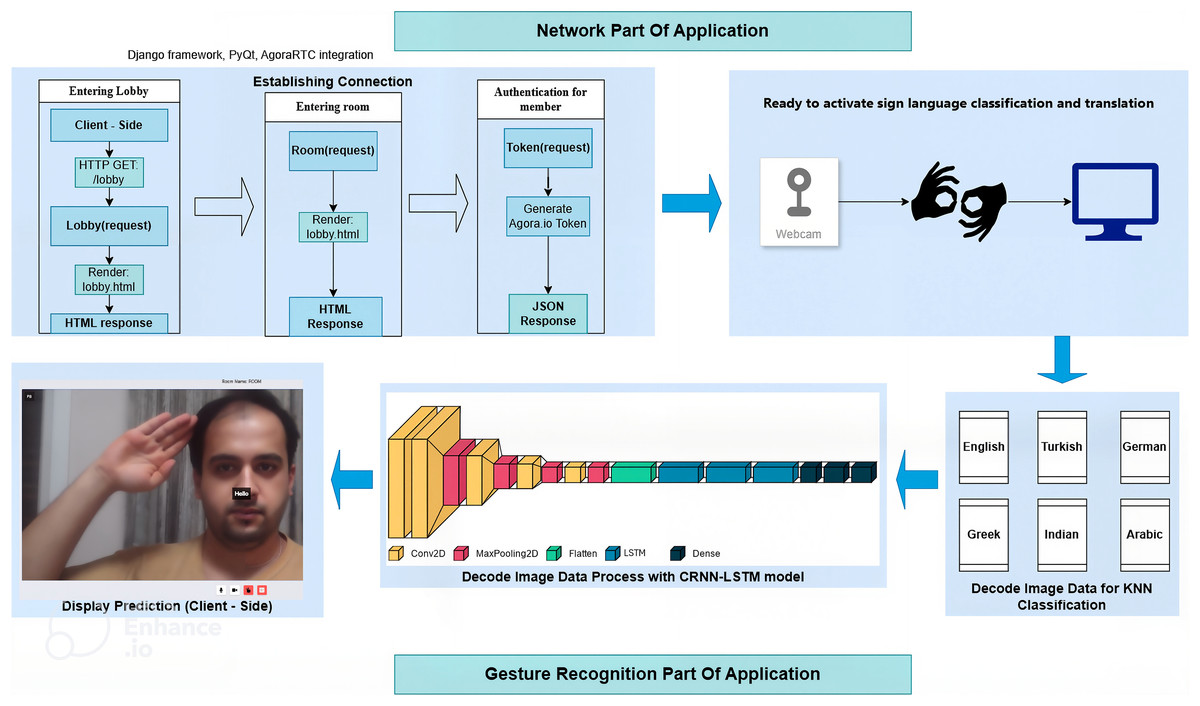
Figure 1: Network diagram of video conferencing application ahowing the integration of video processing components with the Django Framework, PyQt Interface, and AngoraRTC.
{kind=link}
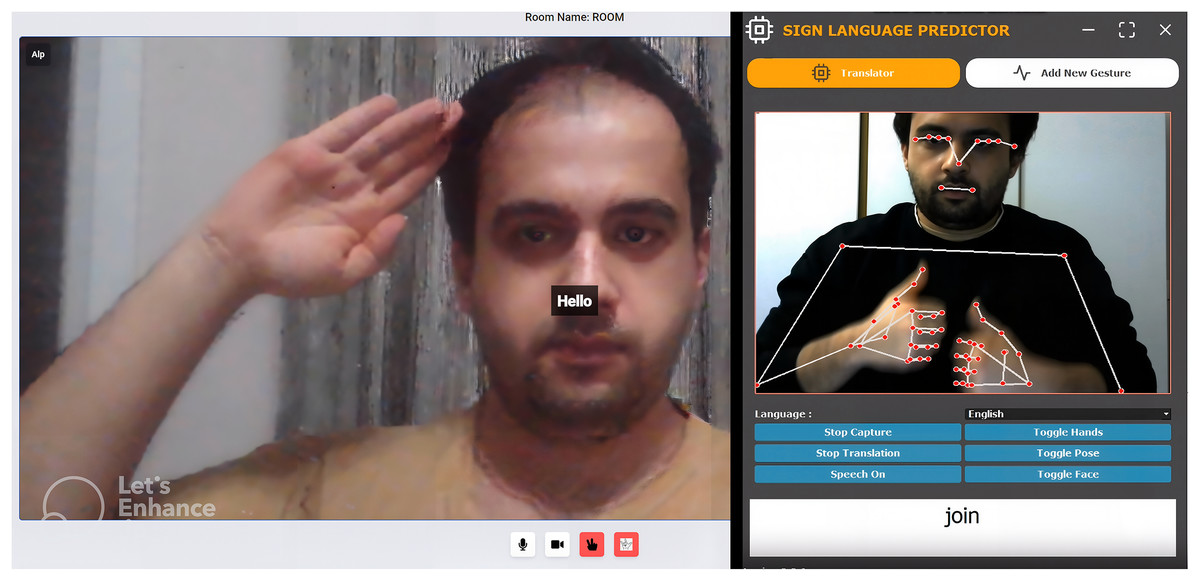
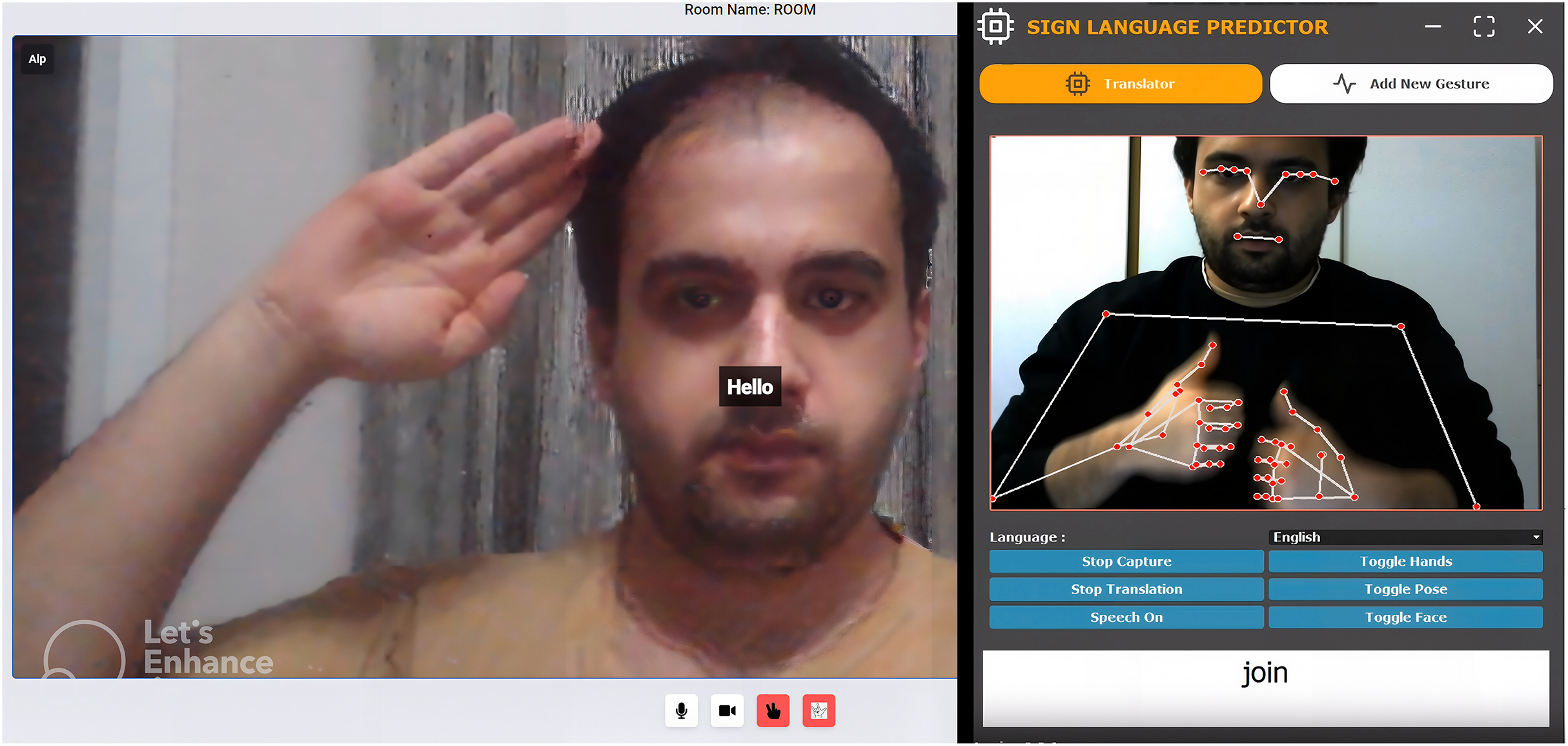
Figure 2: From left to right: video conference app and graphical user interface.
{kind=link}
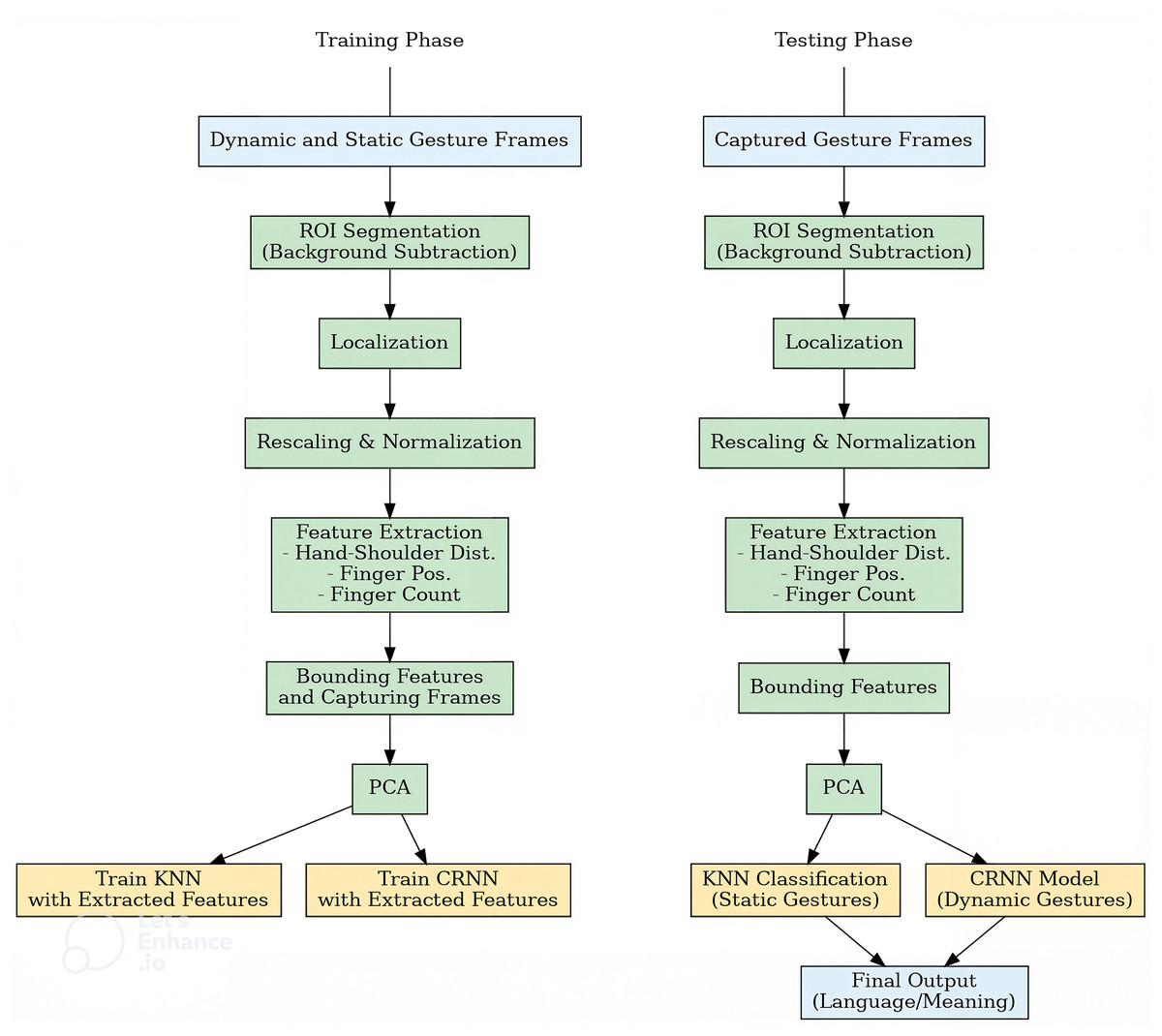
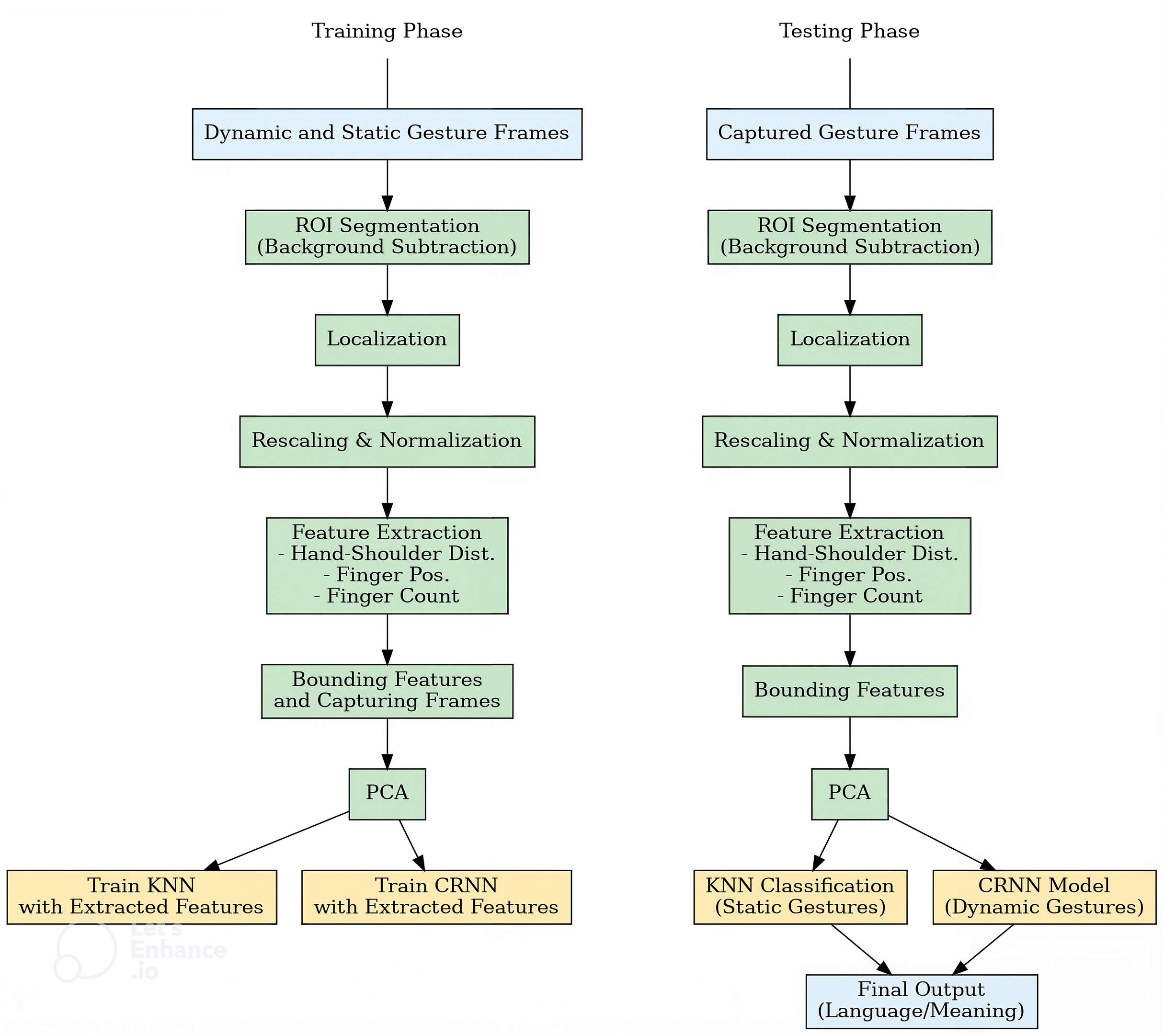
Figure 3: Left: training phase of dynamic and static gesture frames; Right: testing phase for new dynamic gesture recognition and final output of interpreting a video.
{kind=link}
KNN multi class classification
Properly defining the sign language the person uses in an environment where there is no such acknowledgment is the hardest task to be considered and as for the author’s knowledge, this is the first research on this topic. To differentiate between different sign languages, the authors found the KNN model introduced by Cover & Hart (1967) easy and with a fast performance. A short description of KNN clasification model is given in ‘Key Concepts and Algorithms’.
In our study, the T training data points consists of tuple points, with a feature vector (in this case, a vector of pixel intensities) and is the corresponding class label (in this case, English, German, Indian, Arabic, Greek, or Turkish). Alternatively, the test data points denoted as S, consist of data points is a feature vector form . Prediction of the class label for each test data point is aimed. For our classification task involving sign languages, we experimented with different values of and found that strikes a balance. This value provides a good compromise between robustness to noise and sensitivity to subtle differences, resulting in an accuracy of 0.892 for the classification of each of the six languages considered in this study.
The KNN algorithm detects the language and calls the weight file for the language generated during the training of the CRNN model. Subsequently, the model is loaded, and the prediction result is obtained. The resulting prediction is returned in JSON format as the response. Finally, the client-side or video conferencing application displays the prediction on the screen until the sign prediction button is disabled. If disabled, it means the translation stops for the current stream, respectively. During the test phase, the model is adapted to process random videos in various languages, predict the language, and then perform translation, as detailed below.
Sign language recognition and translation
The SignLangRecTrans(request) function is designed to handle a post request containing image data. It decodes the image data from base64. Base64 is a binary-to-text encoding scheme that is commonly used to represent binary data, such as images or video frames, in a text format. In a live video conferencing application, capturing the live video feed means continuously processing video frames and converting them into a format suitable for representation as text. This is typically achieved using Base64 encoding, which transforms each frame into an image array for efficient transmission or storage. In the process_video(image_base64) function, the base64 code is decoded to convert it into an image array. This image array is then processed using a embedded CRNN model for sign language recognition and translation.
The proposed architecture was trained and evaluated using separate datasets, with distinct validation sets for English, Turkish, Indian, Arabic, Greek, and German Sign Languages.
Details on sign language recognition approach
For the gesture recognition, our algorithm takes as input a sequence of sign language images and outputs the corresponding sign language phrase or sentence from request. Three deep learning models—CNN, LSTM, and CRNN—were utilized for this task. The CNN model incorporates convolutional and pooling layers followed by fully connected layers, while the LSTM model consists of multiple layers of LSTM cells. In contrast, the CRNN model integrates convolutional and recurrent layers to capture both spatial and temporal features simultaneously. Training was conducted using the Adam optimizer with a learning rate of , while categorical cross-entropy served as the loss function. The CRNN model can be mathematically formulated as follows:
(1) where X represents the input tensor. Initially, a 2D convolutional layer is applied, followed by a GRU layer and a dropout layer. Finally, the output is obtained through a fully connected layer with softmax activation. The categorical cross-entropy loss function is defined as:
(2) where L denotes the loss, is the true label of the input, and represents the predicted probability for each class.
In the classification phase, the Rectified Linear Unit (ReLU) and Softmax activation functions were utilized. The Softmax function, commonly used in multi-class classification problems, is defined as:
(3) where is the output of the final layer and K denotes the number of classes. This function converts the model’s raw outputs into a probability distribution over the classes, similar to the work of Mehdi & Khan (2002).
The CRNN architecture consists of convolutional layers for feature extraction, followed by recurrent layers for sequence modeling. The convolutional layers apply filters to the input images gathered from videos, extracting relevant features such as edges, corners, and shapes, which also aid in the calculation of hand and body features. The recurrent layers, typically implemented as LSTM units, process the output of the convolutional layers over time, capturing the temporal dynamics of sign language gestures.
Furthermore, our CRNN model is trained using a combination of supervised learning and sequence-to-sequence learning paradigms. Supervised learning is employed to train the convolutional layers to extract meaningful spatial features, while sequence-to-sequence learning is utilized to train the recurrent layers to predict the sequence of sign language gestures. The CNN part includes multiple Conv2D layers with increasing filters (32, 64, 128, 256, 512), kernel size of (3, 3), and stride of (2, 2) for downsampling. The use of stride 2 reduces the spatial dimensions of the feature maps by a factor of 2, which helps in reducing the computational load and extracting higher-level features. MaxPooling2D layers with pool size (2, 2) follow each Conv2D layer. The LSTM layers, configured to return sequences, have 64, 128, and 64 units, respectively, and use the ReLU activation function. Dense layers with 64 and 32 units, respectively, and softmax activation are used for classification. The model is compiled with the Adam optimizer (lr=0.001) and categorical crossentropy loss, trained for 200 epochs, and a batch size of 32. The CRNN combines CNN’s feature extraction with LSTM’s sequence modeling, suitable for tasks requiring spatial and temporal information integration. For a better understanding the readers can refer to Fig. 4.
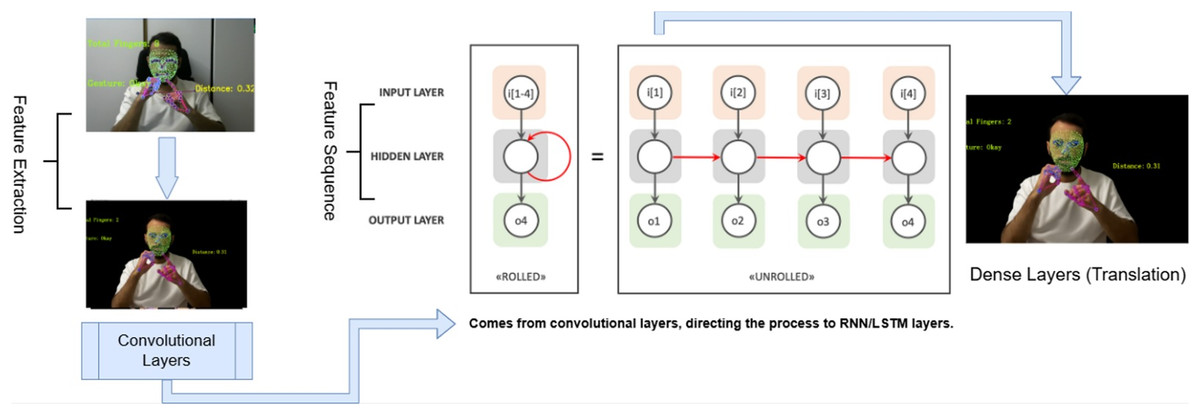
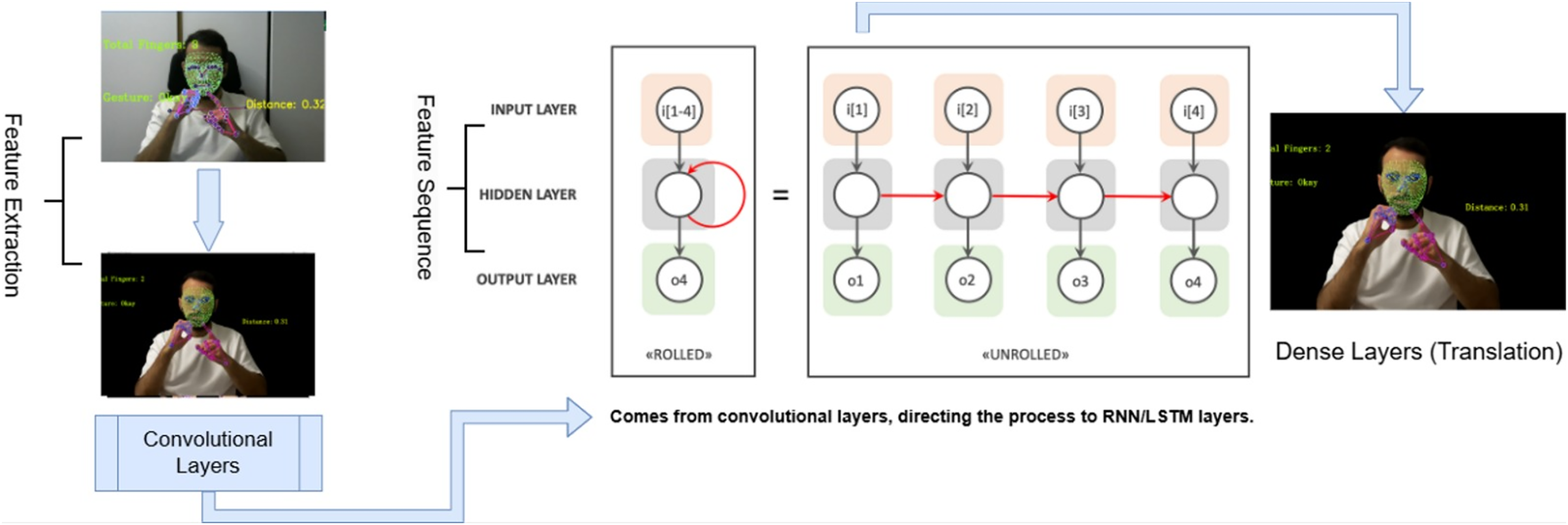
Figure 4: End-to-end sign language translation using CNN and LSTM-based deep learning pipeline.
{kind=link}
In the following section readers can find more details on extensive hyperparameter tuning, adjusting parameters such as batch size, and the number of epochs, which resulted in a significant reduction in validation error.
Experimental design and experimental results
We begin this section by highlighting that, rather than explicitly distinguishing between static and dynamic gestures in our research, we treated them as temporal sequences. Instead of using statical frames, we applied feature extraction to the video data before feeding it into the model. This approach allowed us to extract meaningful features beneficial to both integrated components of our study: language classification using KNN and the effective learning of temporal patterns for sign recognition with CRNN.
To facilitate training, we saved the extracted features as NumPy files, which were used for both KNN and CRNN models. Initially, we trained the KNN model for gesture classification in each language and later evaluated it using newly added YouTube videos for each language.
The dataset, collected from different links and YouTube videos, was split into training, validation, and test sets in an 80:10:10 ratio. The videos cover comprehensive framework for 3D motion capture, where we extracted 3D landmarks from facial, hand, and body keypoints to represent gestures accurately. To enhance model performance, we implemented feature weighting, assigning different weights to features based on their significance in predicting sign language gestures. This approach allowed the model to prioritize more relevant features during classification, improving overall accuracy.
For the test phase, which assigns and determines the correct sign language in a randomly chosen video, we utilized a sequence length of up to 90 frames (first 90 frames) out of all the frames given in the video to allows the KNN model to classify the language, after which the model proceeds with the video translation. This range was chosen because certain gestures in the training set required a longer duration to be accurately captured and classified. The decision to limit the number of frames was motivated by the need to facilitate fast and efficient real-time translation, especially in scenarios such as conferences where participants may come from diverse sign language backgrounds. This approach not only optimized performance within the constraints of our hardware but also maintained the system’s practicality in dynamic, real-world environments. Nevertheless, if the loss of a few initial words from each speaker’s dialogue is considered acceptable, increasing the number of frames could lead to further improvements in the accuracy of the language classification phase.
Landmarks obtained from facial, hand, and body key-points
Finger counting: To count the number of fingers raised in a hand, the concept of convex hull and defects was used. Convex hull is a technique to find the outermost points of a shape. Defects are the local maxima of the deviation between the convex hull and the actual shape. Furthermore the convex hull and defects were calculated using OpenCV library.
Let hull be the convex hull and defects be the defects calculated for a given hand. The number of fingers raised can be computed using the following formula:
Figure 5 shows one of such examples.

Figure 5: Image taken from a video recorded by our team mimicking signs from How2sign dataset.
On the right side we have the image without background substantiation and on the the left side we have a background substruction leading to better key-feature description of the gesture representing the sign Okay.{kind=link}
Finger position: To determine which finger is raised, we can calculate the angle between the defects for a given hand. Let denote the angle between the points , , and , where is the starting point of the finger, is the local maxima of the deviation, and is the ending point of the finger. We calculate the angle using the cosine rule as follows:
where , , and are the lengths of the sides of the triangle formed by , , and . The angle is then calculated using the inverse cosine function as follows:
The angles for each pair of defects were calculate and stored in a list angles. Let maxangle be the maximum angle in the list angles. The finger raised can be determined as follows:
(4) where , , , , and are the predefined thresholds for each finger.
Distance between the hand and the shoulder: To calculate the distance between the hand and the shoulder, we first determine the location of the shoulder using the OpenPose library. Let Hand be the location of the hand and Shoulder be the location of the shoulder. The Euclidean distance between the hand and the shoulder can be computed using the following formula:
where and are the coordinates of the hand and shoulder, respectively.
Mathematical integration of feature and their importance in predicting sign language gestures
The above mathematical equations determine the number of fingers raised, the finger position, and the distance between the hand and the shoulder. By using these calculations, we can accurately track the movement of the hand and fingers, which is essential for applications such as virtual reality, gaming, and sign language recognition, Saman & Stanciu (2019).
With the feature extraction of videos we saved them as a numpy files for training both KNN and CRNN model and during the test they serve as a firect imput for the algorithm.
Different weights were assigned to the features based on their relevance in predicting sign language gestures. This allowed the model to prioritize the most significant features, improving the accuracy of the prediction process.
Hand features (Fingers position, Finger counting): 0.3 weight
Hands landmarks: 0.3 weights
Shoulder-to-hand distance: 0.2 weight
Pose landmarks: 0.1 weight
Facial landmarks: 0.1 weight.
These weights indicate the relative importance of each feature in the sign language recognition task. During the CRNN model prediction, these features are used in the order specified above, and if the prediction is correct at any step, the remaining features are not used.
Experiment results performance valuation metrics
In the following, we summarize the performance of the proposed method based on accuracy, precision, recall, and F1-scores metrics as valuation criteria. Details on those metics are given ‘Key Concepts and Algorithms’ of this article.
Evaluation of the K-Nearest Neighbor Algorithm: Table 2 presents the evaluation results of the K-Nearest Neighbor algorithm for language classification for the test of video data in each language. Key metrics like accuracy, loss, precision, recall, and F1-score provide insights into KNN’s performance across languages. Accuracy shows overall correctness, while loss reflects model error. Precision measures correct positive predictions, and recall indicates how well true positives are identified. The F1-score balances precision and recall, crucial for imbalanced data. High accuracy suggests KNN distinguishes linguistic features well, while variations in precision and recall highlight challenges with specific language structures. Lower recall may indicate missed patterns, and low precision suggests frequent misclassification. These metrics help assess KNN’s suitability for multilingual tasks. The algorithm demonstrates strong performance, especially evident in the high accuracy scores for Turkish and Indian languages.
| Language | Accuracy (%) | Loss | Precision (%) | Recall (%) | F1-score |
|---|---|---|---|---|---|
| English | 0.81 | 0.45 | 0.73 | 0.74 | 0.71 |
| German | 0.86 | 0.0103 | 0.79 | 0.81 | 0.80 |
| Turkish | 0.93 | 0.2865 | 0.91 | 0.98 | 0.95 |
| Indian | 0.97 | 0.2103 | 0.94 | 0.97 | 0.97 |
| Greek | 0.89 | 0.135 | 0.85 | 0.87 | 0.86 |
| Arabic | 0.97 | 0.3278 | 0.93 | 0.96 | 0.96 |
Prediction Results for Each Gesture for Different Languages: Table 3 shows the prediction results for each gesture for different languages. This table showcases the results of the model predictions for each gesture in English, German, Turkish, Indian, Arabic and Greek languages. The evaluation metrics for the validation dataset include accuracy, loss, precision, recall, and, F1-score for each individual language. Moreover, we present a comprehensive comparison of state-of-the-art methodologies for sign language recognition in Table 4. This table evaluates a range of models, including CNN, LSTM, Transformer-based models, Graph Convolutional Networks (GCNs) (Kipf & Welling, 2017), CNN + Transformer, 3D CNNs (Ji et al., 2013), and CRNN, across different key metrics such as accuracy, loss, precision, recall, F1-score, and the number of training epochs in order compare with the proposed method. Table 4 provides insights into the blind testing results of different neural networks with our sign language mechanism evaluated on 1,200 images of sign gestures, 200 per each language to keep data balance.
| Language | Accuracy (%) | Loss | Precision (%) | Recall (%) | F1-score |
|---|---|---|---|---|---|
| English | 0.96085 | 0.0375 | 0.81 | 0.83 | 0.84 |
| German | 0.9347 | 0.0457 | 0.90 | 0.88 | 0.91 |
| Turkish | 1.0 | 3.2627e−07 | 0.93 | 0.96 | 0.95 |
| Indian | 1.0 | 2.46342e−08 | 0.97 | 0.99 | 0.98 |
| Greek | 0.982 | 0.0053 | 0.95 | 0.96 | 0.96 |
| Arabic | 0.9108 | 4.54631e−07 | 0.93 | 0.97 | 0.96 |
| Component | Accuracy (%) | Loss | Precision (%) | Recall (%) | F1-score (%) | No. of epochs |
|---|---|---|---|---|---|---|
| Transformer | 0.95 | 0.05 | 0.96 | 0.95 | 0.95 | 500 |
| 3D CNN | 0.92 | 0.08 | 0.93 | 0.92 | 0.92 | 400 |
| CNN + Transformer | 0.98 | 0.02 | 0.99 | 0.98 | 0.98 | 600 |
| GCN (Skeleton-based) | 0.88 | 0.12 | 0.89 | 0.88 | 0.88 | 300 |
| CNN | 0.77 | 0.1701 | 0.93 | 1.0 | 0.97 | 2,000 |
| LSTM | 0.20 | 1.2858 | 0.20 | 0.23 | 0.28 | 2,000 |
| CRNN-LSTM | 1.0 | 0.00123 | 1.0 | 1.0 | 1.0 | 350 |
Among the evaluated models, the LSTM exhibits the lowest performance, followed by a standard CNN. In contrast, the GCN approach, which leverages skeletal-based representations, achieves a competitive accuracy of 0.88. Transformer-based models (Vaswani et al., 2017) demonstrate strong performance with an accuracy of 0.95, while 3D CNNs achieve an accuracy of 0.92. The CNN + Transformer hybrid model outperforms these with an accuracy of 0.98, highlighting the effectiveness of combining convolutional operations with attention mechanisms. Notably, the CRNN model achieves a perfect accuracy of 1.0, underscoring its exceptional capability in sign language recognition tasks.
These results illustrate the diverse strengths of various deep learning architectures in addressing the challenges of sign language recognition. While CRNNs excel in overall accuracy, Transformer-based models and hybrid approaches demonstrate the advantages of incorporating attention mechanisms. On the other hand, GCNs, though slightly less accurate, provide unique insights into skeletal-based gesture modeling. Collectively, these findings offer valuable insights into the trade-offs and potential applications of different methodologies, paving the way for future advancements in the field. Under the limitation of the open source sign language data, we have constraints on expanding this experiment, but this is one of our future aim aiming a larger dataset collection, by incorporating a broader variety of samples obtained from both controlled laboratory settings and real-world environments. Furthermore, we aim to conduct further experiments to evaluate the performance of dynamic gesture analysis similar to Table 4.
To analyze the sensitivity of the model we experimented over the proposed model under different light condition and noise and show the results in Tables 5 and 6. Table 5 presents the performance of the proposed model under different lighting conditions: low light (below 100 lux) and high light (above 500 lux). The results indicate that the lighting conditions affect the model’s accuracy, loss, and overall evaluation metrics. In low light environments, the contrast decreases, the shadows become more pronounced, and the camera compensates by increasing the ISO, which introduces noise. Consequently, the model’s accuracy is lower in low-light conditions across all languages. For example, English has an accuracy of 0.72 in low light but improves to 0.84 in high light. Similarly, the Turkish language shows an increase from 0.85 to 0.94 in accuracy. The loss values are notably higher in low-light conditions, indicating greater model uncertainty. For instance, in the German language, the loss drops from 0.052 to 0.007 under high light, highlighting the reduced error when the lighting is sufficient. Precision, recall, and F1-scores follow a similar trend, showing higher values in well-lit conditions. This suggests that high-light environments enhance the model’s ability to correctly classify and detect patterns with greater confidence. To address this limitation of the proposed algorithm, image processing techniques can be applied to adjust the intensity distribution to a more uniform one, enhancing performance in low-illumination videos. Another experiment conducted by the authors investigates the model’s performance on videos with distortion and clean noise. Table 6 presents the model’s performance under distortion and clean noise conditions across different languages. We evaluated distortion impact by introducing motion blur at different movement speeds. The results show that as motion blur increases, model accuracy declines. For instance, at lower motion speeds (e.g., 5 per second), accuracy remains relatively high, with Turkish and Indian languages achieving 83% and 87%, respectively. However, as speed increases to 25 per second, accuracy drops, with English and Greek showing the most significant declines. Across all languages, background noise reduction led to notable performance improvements. The accuracy gap between noisy and clean conditions ranges from 8% to 12%, with Indian and Arabic languages demonstrating the highest resilience to noise. Similarly, loss values significantly decrease under clean conditions, reinforcing the model’s improved stability when noise is mitigated. The overall findings highlight that while the model performs robustly across multiple languages, noise, especially motion blur, remains a critical factor in reducing classification accuracy and reliability. This behavior is to be expected for the same reason mentioned for the ilumination issue.
| Language | Accuracy (Low) | Accuracy (High) | Loss (Low) | Loss (High) | Precision (Low) | Precision (High) | Recall (Low) | Recall (High) | F1-score (Low) | F1-score (High) |
|---|---|---|---|---|---|---|---|---|---|---|
| English | 0.72 | 0.84 | 0.58 | 0.38 | 0.65 | 0.77 | 0.67 | 0.79 | 0.66 | 0.78 |
| German | 0.79 | 0.89 | 0.052 | 0.007 | 0.75 | 0.83 | 0.78 | 0.85 | 0.76 | 0.84 |
| Turkish | 0.85 | 0.94 | 0.30 | 0.20 | 0.84 | 0.91 | 0.89 | 0.98 | 0.86 | 0.94 |
| Indian | 0.91 | 0.97 | 0.27 | 0.15 | 0.89 | 0.95 | 0.93 | 0.97 | 0.91 | 0.96 |
| Greek | 0.82 | 0.89 | 0.18 | 0.12 | 0.78 | 0.86 | 0.80 | 0.88 | 0.79 | 0.87 |
| Arabic | 0.90 | 0.96 | 0.35 | 0.28 | 0.87 | 0.94 | 0.91 | 0.96 | 0.89 | 0.95 |
| Language | Speed (deg/sec) | Accuracy (Noisy) | Accuracy (Clean) | Loss (Noisy) | Loss (Clean) | Precision (Noisy) | Precision (Clean) | Recall (Noisy) | Recall (Clean) | F1-score (Noisy) | F1-score (Clean) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| English | 5 | 0.85 | 0.91 | 0.42 | 0.28 | 0.81 | 0.88 | 0.83 | 0.90 | 0.82 | 0.89 |
| 25 | 0.79 | 0.88 | 0.50 | 0.32 | 0.76 | 0.86 | 0.78 | 0.87 | 0.77 | 0.86 | |
| German | 5 | 0.86 | 0.92 | 0.38 | 0.24 | 0.83 | 0.89 | 0.85 | 0.91 | 0.84 | 0.90 |
| 25 | 0.80 | 0.90 | 0.45 | 0.28 | 0.78 | 0.88 | 0.80 | 0.89 | 0.79 | 0.88 | |
| Turkish | 5 | 0.83 | 0.93 | 0.35 | 0.22 | 0.80 | 0.91 | 0.85 | 0.98 | 0.82 | 0.95 |
| 25 | 0.76 | 0.89 | 0.42 | 0.26 | 0.74 | 0.87 | 0.79 | 0.91 | 0.76 | 0.89 | |
| Indian | 5 | 0.87 | 0.97 | 0.31 | 0.18 | 0.84 | 0.94 | 0.89 | 0.97 | 0.86 | 0.97 |
| 25 | 0.82 | 0.94 | 0.39 | 0.23 | 0.80 | 0.92 | 0.85 | 0.96 | 0.82 | 0.94 | |
| Greek | 5 | 0.78 | 0.89 | 0.29 | 0.17 | 0.74 | 0.85 | 0.76 | 0.87 | 0.75 | 0.86 |
| 25 | 0.71 | 0.86 | 0.37 | 0.22 | 0.69 | 0.84 | 0.74 | 0.86 | 0.71 | 0.85 | |
| Arabic | 5 | 0.88 | 0.97 | 0.30 | 0.19 | 0.84 | 0.93 | 0.89 | 0.96 | 0.86 | 0.96 |
| 25 | 0.81 | 0.95 | 0.37 | 0.21 | 0.79 | 0.92 | 0.84 | 0.95 | 0.81 | 0.94 |
Another aspect analyzed in our report relates to the performance of the model with and without background subtraction in different languages. Table 7 presents a comparative analysis of model performance with and without background subtraction across different languages. The results demonstrate that applying background subtraction consistently improves accuracy, precision, recall, and F1-score while reducing loss. The accuracy values indicate an average improvement of approximately 5–7% when background subtraction is applied. Similar, we notice the reduction in loss values implies that the model achieves more stable and reliable predictions with background subtraction. This suggests that removing background noise allows the model to focus more effectively on relevant features, leading to better classification results. The main reason of such improvement is that the videos used in this research are a mixture or green background and complex backgrounds introduce noise and ambiguity. As a result, precision and recall exhibit notable enhancements, which indicates that the model not only makes more correct predictions (higher precision) but also captures a larger proportion of relevant instances (higher recall). This is particularly evident in languages such as Turkish and Indian, where recall increased by approximately 5–7%. The overall F1-score improvements reflect a balanced gain in both precision and recall, further supporting the effectiveness of background subtraction.
| Language | Accuracy | Loss | Precision | Recall | F1-score | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| No subtraction | With subtraction | No subtraction | With subtraction | No subtraction | With subtraction | No subtraction | With subtraction | No subtraction | With subtraction | |
| English | 0.78 | 0.84 | 0.42 | 0.35 | 0.75 | 0.82 | 0.76 | 0.83 | 0.75 | 0.82 |
| German | 0.81 | 0.86 | 0.39 | 0.32 | 0.79 | 0.85 | 0.80 | 0.86 | 0.79 | 0.85 |
| Turkish | 0.84 | 0.89 | 0.35 | 0.28 | 0.83 | 0.88 | 0.85 | 0.90 | 0.84 | 0.89 |
| Indian | 0.88 | 0.92 | 0.31 | 0.26 | 0.86 | 0.91 | 0.89 | 0.93 | 0.87 | 0.92 |
| Greek | 0.79 | 0.85 | 0.41 | 0.34 | 0.76 | 0.82 | 0.78 | 0.84 | 0.77 | 0.83 |
| Arabic | 0.83 | 0.88 | 0.38 | 0.30 | 0.81 | 0.86 | 0.82 | 0.89 | 0.81 | 0.87 |
For the Table 8, we evaluate our methodology with the How2Sign dataset, using videos with 128 × 128 pixels and a sequence length of 90 × 5. We extend our sequence length to match the video length, which is equal to the sequence length, for this we extend our sequence length with respect to the Green Screen (frontal view) data inside the How2Sign dataset. Additionally, both the CRNN model for the GrSL dataset and the How2Sign dataset are trained for 400 epochs. The CRNN model combines CNN and LSTM layers, with the CNN part consisting of multiple Conv2D layers with increasing filters (32, 64, 128, 256, 512), a kernel size of (3, 3), and a stride of (2, 2) for downsampling. The LSTM layers are configured to return sequences, have 64, 128, and 64 units, respectively, and use the ReLU activation function. Dense layers with 64 and 32 units, respectively, and softmax activation are used for classification.
| Dataset | Training (%) | Validation (%) | Test (%) | No. of epochs |
|---|---|---|---|---|
| How2Sign | 96.33 | 76.12 | 61.92 | 400 |
| GSL | 89.24 | 69.57 | 59.53 | 400 |
Moreover in terms of Speed/Delay the average sign language recognition time was measured as 350 ms. This shows that our system can be used in real-time applications. The above results are obtained for a dataset contains on average 200 samples for each marker, with a variation diversity of backgrounds and varying lighting conditions. In total, with external How2Sign and GSL, datasets our dataset consists of almost 160,000 samples. This shows that our system performs well in a variety of environments.
Primary Limitations and Potential Biases of the Current Approach: The dataset, despite efforts to include participants from diverse age groups and cultural backgrounds, remains imbalanced, with a higher representation of adult samples compared to children and uneven distribution of gestures across languages, potentially skewing performance toward dominant demographics or gesture sets. Annotation bias may also be present, as gestures were labeled with the help of native speakers and sign language experts, yet cultural interpretations can vary, especially for gestures with overlapping semantics but different connotations across cultures, leading to possible inconsistencies. Although the model demonstrates good performance on the internal test set, its generalization to unseen gesture styles, varying lighting conditions, or different camera angles has not been fully explored, highlighting the need for further robustness testing under real-world noise and occlusion scenarios. Additionally, the current framework relies solely on visual (RGB) data; incorporating multimodal inputs such as depth sensors, skeletal data, or audio for co-speech gestures could enhance recognition but was not pursued in this study due to resource constraints.
The study focused on developing a robust and generalizable gesture recognition framework with multilingual and cross-cultural capabilities, where performance metrics like inference time, memory usage, and computational complexity were qualitatively considered. To ensure practical feasibility, the researchers selected a lightweight 3D CNN with attention mechanisms, optimized for a balance between accuracy and speed. On a mid-range GPU, the inference time per frame sequence averaged below 50 ms, suitable for near real-time applications. The architecture incorporated batch normalization and parameter sharing to reduce memory footprint, keeping peak GPU memory usage under 2 GB, making it deployable on edge devices or embedded systems with moderate resources. Additionally, the model avoided very deep networks in favor of shallower yet expressive backbones, significantly reducing FLOP count. Complexity was further managed through early fusion strategies and dimensionality reduction in attention blocks.
Discussion, conclusion, and future work
Discussion
This study was based on the hypothesis that integrating sign language recognition algorithms into multimedia applications, using a vision-based approach (without the need for specialized wearable devices), can significantly improve accessibility for individuals with hearing impairments, enabling seamless communication across different sign languages. We further hypothesize that the inclusion of background subtraction techniques, as well as robust feature extraction (such as hand-to-shoulder distance, finger position, and counting), will enhance the model’s performance in dynamic, real-world environments, leading to improved recognition accuracy.
The hypothesis we propose is driven by the increasing demand for more accessible communication tools for individuals with hearing impairments. Traditional sensor-based systems, while promising, often require specialized devices that may not be suitable for everyday use. In contrast, vision-based recognition provides a non-intrusive, scalable approach that can be easily integrated into everyday environments such as video calls or virtual classrooms.
We have validated our hypothesis through experiments where we tested our framework on multiple datasets representing different sign languages (e.g., English, German, Turkish, Indian, Arabic, and Greek). The results of these tests indicate that combining the KNN algorithm for language classification with CRNN for gesture recognition, especially when enhanced with LSTM for handling sequential data, presents a viable solution for real-time multilingual sign language translation. Furthermore, our use of background subtraction significantly boosted the model’s ability to accurately recognize gestures, proving that this technique helps to isolate key features in complex, cluttered backgrounds, thus improving overall performance.
During our experiments we did observe some challenges and limitations during our experiments, which are important to highlight for a comprehensive understanding of the framework’s capabilities and its constraints. Specifically, we found that:
-
(1)
While our model performed well on the datasets from different languages, it encountered difficulties in recognizing certain gestures with high variability, such as rapid or complex hand movements. This was particularly evident in fast-paced gestures, where the model sometimes struggled with correctly classifying the sign language gesture in real-time.
-
(2)
The performance of the model gets impacted by varying lighting conditions and complex background noise. In low-light environments, the accuracy of gesture recognition decreased, and the model’s performance dropped in terms of precision and recall. This issue is common in computer vision tasks where image contrast is reduced, and it is an area that requires further improvement. Techniques such as dynamic contrast adjustment or the use of depth sensing could potentially mitigate these challenges.
We conducted an analysis of different components within our model to evaluate their individual contributions to the overall performance, as part of our ablation studies. Our findings are summarized as follows:
-
(1)
Impact of Feature Types: We experimented with different sets of features (e.g., finger counting, hand-shoulder distances, and facial landmarks) and found that some features had a more significant impact on model performance than others. Specifically, hand-related features (such as finger counting and hand position) proved to be more critical for gesture classification, while facial and shoulder features contributed less to the accuracy.
-
(2)
Background Subtraction: In our experiments, background subtraction significantly improved the performance of gesture recognition by isolating the relevant features from the background. We found that this technique resulted in a 5–7% improvement in accuracy across all languages tested.
-
(3)
KNN vs. CRNN Performance: We also compared the performance of the K-Nearest Neighbor (KNN) model alone with the combined CRNN-LSTM model. While the KNN model performed well for language classification, it was not as effective for recognizing dynamic gestures or handling temporal data. The CRNN-LSTM combination showed superior performance in terms of both gesture classification and language interpretation, underscoring the importance of integrating temporal sequence modeling.
Conclusion
In conclusion, our study focused on the development of a sign language recognition-based video conferencing application for individuals with hearing and speech impairments. We successfully employed background subtraction techniques, finger counting, finger position determination, and distance calculation algorithms to accurately track hand gestures and enhance the user experience. By utilizing deep learning models and the OpenCV and MediaPipe library, we achieved reliable finger counting and finger position, distance between hand and shoulder recognition results. The key recommendation proposed in this study involves the extraction of distinctive features from sign language, trained using the CRNN model. By employing precise algebraic calculations, these unique characteristics can be systematically processed, particularly under optimal background and lighting conditions. These distinct features can then be utilized by a classification algorithm like KNN (K-Nearest Neighbors) to determine the origin country of the sign language. This approach facilitates accurate real-time translation, ensuring that the translation is contextually appropriate and culturally sensitive.
Future work
Quantitative comparison with existing state-of-the-art multilingual gesture recognition systems (e.g., Chalearn LAP or RWTH-MULTI-SIGN) would significantly strengthen the claims in our work, however, direct benchmarking is constrained by dataset incompatibility and variations in annotation standards across these systems. The primary novelty of our framework lies not only in recognizing gestures across different languages but also in preserving the semantic equivalence of gestures across cultural boundaries, an aspect largely underexplored in existing benchmarks. Nonetheless, we recognize the importance of explicitly positioning our work against the state-of-the-art and plan to incorporate such comparative evaluations in our future work.
Building upon the success of our sign language recognition-based video conferencing application, several promising avenues for future research and development have emerged. One key enhancement involves the integration of advanced lip reading algorithms into our system. By leveraging computer vision and deep learning techniques tailored to analyze lip movements, we aim to improve the application’s capacity to interpret spoken language through visual cues, further bridging the communication gap for individuals with hearing impairments. To ensure broader accessibility, we also plan to share the system via Application Programming Interfaces (APIs), enabling easy integration into web and mobile applications. Additionally, we intend to explore multimodal fusion, combining data from hand gestures and lip movements to create a more nuanced and accurate understanding of user intent. This approach is expected to enhance overall recognition accuracy and reliability. Future iterations will also incorporate real-time feedback features, providing users with instant evaluations of the clarity and effectiveness of their gestures and lip movements. Interactive elements that respond dynamically to user actions will contribute to a more engaging and user-friendly experience, further enriching communication and accessibility within the platform.
Appendix 1: key concepts and algorithms
K-nearest neighbor algorithm
The K-Nearest Neighbor (KNN) algorithm is a non-parametric method used for classification and regression. Given a set of training data points , where represents feature vectors and represents class labels, the algorithm predicts the class of a test data point by identifying the nearest neighbors in the training set. The Euclidean distance metric is commonly used to measure the similarity between data points:
The predicted class for is determined by majority voting among the KNNs. Nearest neighbors: for all in . We assign the class label to be the class that occurs most frequently among the nearest neighbors of .
The value of the classes can be adjusted to improve the accuracy of the predictions. A larger value of , such as , makes the classifier more robust to noise and outliers, but it may cause it to overlook subtle differences between classes. On the other hand, a smaller value of , like , makes the classifier more sensitive to these differences, but it might be more affected by noise and outliers.
Convolutional recurrent neural network
A CRNN is a hybrid deep learning architecture that combines the strengths of CNNs and Recurrent Neural Networks (RNNs). CNN layers are used to automatically extract spatial features from input data, such as images or sequences of frames, while RNN layers, often using LSTM or Gated Recurrent Units (GRU), capture temporal dependencies and sequential patterns. This combination makes CRNNs particularly effective for tasks involving both spatial and temporal data, such as scene text recognition, speech recognition, gesture recognition, and sign language translation. The CNN component focuses on local feature extraction, while the RNN models the contextual relationships over time, resulting in a robust framework for sequence-based learning tasks.
Experiment results performance valuation metrics
Accuracy measures the overall correctness of a model by calculating the ratio of correctly predicted instances to the total number of instances:
where TP = True Positives, TN = True Negatives, FP = False Positives, and FN = False Negatives.
Precision evaluates the proportion of true positive predictions among all positive predictions, reflecting the model’s ability to avoid false positives:
Recall (or Sensitivity) measures the proportion of true positives identified out of all actual positive cases, indicating the model’s ability to capture relevant instances:
F1-score is the harmonic mean of Precision and Recall, providing a balance between the two, especially useful in cases of imbalanced datasets:
These metrics were chosen because they collectively address the key aspects of model performance, including overall correctness (accuracy), the ability to avoid false positives (precision), the ability to capture all relevant instances (recall), and a balanced measure of both precision and recall (F1-score). These metrics are widely used in sign language recognition research, as evidenced by related work such as Podder et al. (2023), ElBadawy et al. (2017), and Camgoz et al. (2018), ensuring that our evaluation aligns with standard practices in the field.
To enhance clarity and ensure that readers can easily reference the terms related to the proposed work, we include a detailed nomenclature Table 9.
| Symbol | Description | Relation to the proposed work |
|---|---|---|
| Abbreviations | ||
| KNN | K-Nearest Neighbor algorithm | Used to classify the active sign language (English, German, Turkish, Indian, Arabic, Greek) before translation. |
| CRNN | Convolutional Recurrent Neural Network | Main deep-learning architecture for joint spatial–temporal modeling of dynamic sign gestures. |
| LSTM | Long Short-Term Memory | Recurrent units in the CRNN for capturing long-range temporal dependencies in gesture sequences. |
| CNN | Convolutional Neural Network | Extracts spatial features from video frames and background-subtracted images. |
| RNN | Recurrent Neural Network | Generic term for temporal models; used conceptually and for comparison with CRNN/LSTM variants. |
| GRU | Gated Recurrent Unit | Alternative recurrent unit used in some CRNN formulations to model temporal dependencies. |
| FC | Fully Connected layer | Final dense layers that map extracted features to gesture, gloss, or word classes. |
| ReLU | Rectified Linear Unit | Non-linear activation function in convolutional and recurrent layers of the network. |
| PCA | Principal Component Analysis | Used to reduce dimensionality of extracted features before KNN classification when needed. |
| Variables and evaluation metrics | ||
| Accuracy | Ratio of correctly predicted instances to all instances | Global metric to evaluate overall performance of the KNN language classifier and CRNN gesture recognizer. |
| Precision | Proportion of true positives among predicted positives | Measures how many predicted gestures/languages are correct (low false-positive rate). |
| Recall | Proportion of true positives among all actual positives | Measures how many relevant gestures/languages are detected (low miss rate). |
| F1-score | Harmonic mean of Precision and Recall | Summarizes the trade-off between Precision and Recall for imbalanced gesture classes. |
| Loss | Training loss (categorical cross-entropy) | Optimization objective minimized during training of the CRNN-based recognition models. |
| Input tensor of video frames or feature sequences | Represents the spatio-temporal data (RGB or background-subtracted frames) given to the CRNN. | |
| Network output (softmax probability vector) | Provides class-wise probabilities over gestures or words for each input sequence. | |
| Euclidean distance between feature vectors and | Similarity measure used within the KNN algorithm for multilingual language classification. | |