
Gender and positional biases in LLM-based hiring decisions: evidence from comparative CV/résumé evaluations
- Published
- Accepted
- Received
- Academic Editor
- Ankit Vishnoi
- Subject Areas
- Human-Computer Interaction, Artificial Intelligence, Data Mining and Machine Learning, Natural Language and Speech, Social Computing
- Keywords
- LLMs, CV screening, AI bias, Algorithmic bias, Fairness
- Copyright
- © 2026 Rozado
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Gender and positional biases in LLM-based hiring decisions: evidence from comparative CV/résumé evaluations. PeerJ Computer Science 12:e3628 https://doi.org/10.7717/peerj-cs.3628
Abstract
This study examines the choices made by Large Language Models (LLMs) when selecting professional candidates for a job based on their résumés or curricula vitae (CVs). In an experiment involving 22 leading LLMs, each model was systematically given a job description along with a pair of profession-matched CVs—one bearing a male first name, the other a female first name—and asked to select the more suitable candidate for the job. Each CV pair was presented twice, with names swapped to ensure that any observed preferences in candidate selection stemmed from gendered names cues. Despite equalized professional qualifications between genders, all LLMs consistently favored female-named candidates across 70 different professions. Adding an explicit gender field (male/female) to the CVs further increased the preference for female applicants. When gendered names were replaced with gender-neutral identifiers (i.e., Candidate A/B), several models displayed a slight preference for selecting “Candidate A”. Counterbalancing gender assignment between these gender-neutral identifiers resulted in gender parity in candidate selection. When asked to rate CVs in isolation rather than compare pairs, LLMs assigned slightly higher average scores to female CVs overall, but the effect size was negligible. Including preferred pronouns (he/him or she/her) next to a candidate’s name slightly increased the odds of the candidate being selected. Finally, most models exhibited a substantial positional bias to select the candidate listed first in the prompt. These findings underscore the need for caution when deploying LLMs in high-stakes autonomous decision-making contexts and raise doubts about whether LLMs consistently apply principled reasoning.
Introduction
Previous studies have explored whether human evaluators exhibit gender or ethnic biases in hiring by submitting résumés/curricula vitae (CVs) to real job postings or mock selection panels, systematically varying the gender or ethnicity signaled by applicants (Quillian et al., 2017; Birkelund et al., 2022; Park & Oh, 2025; Lippens, Vermeiren & Baert, 2023). Using controlled résumés/CVs experiments enables researchers to isolate the effects of demographic characteristics on hiring or preselection decisions.
Building on the controlled résumé/CV experimental design, the present analysis evaluates whether Large Language Models (LLMs) exhibit algorithmic gender bias (Corbett-Davies et al., 2017; Rozado, 2020; Caliskan, Bryson & Narayanan, 2017) when tasked with selecting the most qualified candidate for a given job description. Each evaluation involves a pair of CVs—one from a male candidate and one from a female candidate—with systematic gender swapping across every CV pair. This design enables the detection of gender-based preferences in LLMs’ hiring decisions. Beyond the core experimental setup, this study employs further conditions to assess the sensitivity of LLM behavior to additional gender cues. These include adding an explicit gender field (“male” or “female”) to each CV, appending gender-congruent pronouns (he/him or she/her) to candidate names, and substituting gendered names with neutral identifiers (“Candidate A” and “Candidate B”). By manipulating the degree and form of gender signaling, the analysis examines whether LLMs’ preferences are influenced by contextual gender cues or lack thereof. Additionally, the investigation considers whether the position of candidates within the model context window (i.e., first or second) affects the selections made by LLMs as there is a growing body of literature indicating that order effects in an LLM prompt have an impact on LLM responses (Puutio & Lin, 2025; Yin, Vardi & Choudhary, 2025).
The analysis is particularly timely, as LLMs are increasingly being adopted in job selection processes (CiiVSOFT, 2025; Shellshear, 2024; Zoolatech, 2025; Vagale et al., 2024). Understanding whether and how these models introduce or perpetuate demographic biases is crucial for evaluating their fitness for deployment in contexts where fairness, accountability, and transparency are paramount. By systematically mapping LLM choices in the context of candidate selections, this pilot study aims at contributing to broader conversations about algorithmic governance and the ethical use of artificial intelligence (AI) in decision-making.
Prior work
Equal treatment of genders in hiring processes ensures that organizations tap into the full spectrum of available talent; it also strengthens organizational compliance with legal standards and contributes to a fairer society where opportunities are based on skills and merit rather than demographic characteristics such as gender. Given the increasing role of LLMs in automating processes, previous studies have investigated gender bias in LLMs.
Earlier explorations of LLMs in professional assessment tasks demonstrated their emerging capabilities and limitations. For example, prior work measured intersectional biases within ChatGPT and LLaMA and identified distinct biases toward various demographic identities, such as both models consistently suggesting low-paying jobs for Mexican workers or preferring to recommend secretarial roles to women (Salinas et al., 2023).
Subsequent research has further examined the risks of bias when LLMs are used in employment-related settings. Lippens (2024) audited ChatGPT’s ratings of CVs and revealed ethnic discrimination as more pronounced than gender discrimination and mainly occurring in jobs with favourable labour conditions or requiring greater language proficiency. In contrast, gender bias emerged in gender-atypical roles (Lippens, 2024).
Other authors evaluated Massive Text Embedding (MTE) models instead of LLMs and found MTEs to favor White-associated names and disadvantage Black males. The work also reported an impact of document length as well as the corpus frequency of names in the selection of résumés (Wilson & Gender, 2025).
Finally, other work has reported additional limitations beyond gender or ethnic bias in LLMs job applicant screening such as structural ordering bias, where ChatGPT favored the first résumé it processed, effectively disadvantaging candidates presented later in the sequence (Puutio & Lin, 2025).
Together, these studies highlight the risks of applying LLMs to CV screening and hiring evaluations: while LLMs are capable of generating syntactically coherent assessments, such models can also introduce biases in recruitment processes. The aforementioned body of work establishes a critical foundation for examining fairness, robustness, and the practical utility of LLMs in employment decision-making.
Many existing studies on the use of LLMs for professional evaluations however do not employ the methodology proposed in this work: presenting a pair of CVs to an LLM at the same time and requiring it to choose which candidate is more qualified for a given job description. Thus, this approach fills a methodological gap in the existing literature.
The reasoning behind the method proposed in this work is that when an LLM evaluates CVs individually (i.e., in isolation from other CVs), potential biases may remain hidden. In contrast, when the LLM is required to compare two CVs side by side and decide which candidate is the better fit for a specific role, such biases are more likely to surface.
Materials and Methods
Portions of this text were previously published as part of a preprint version of the manuscript (Rozado, 2025).
Generating synthetic CVs/résumés
The terms CV and résumé are used slightly differently across countries. In the United States and Canada, a résumé typically refers to a concise, tailored summary of a candidate’s professional background, generally limited to one or two pages. A CV (curriculum vitae), by contrast, is a more comprehensive document, often used in academic, medical, or research contexts. However, in countries such as the United Kingdom, Ireland, Australia or New Zealand, CV is the standard term used in place of résumé. In these regions, the term résumé is either rarely used or treated synonymously with CV, though CV is far more prevalent. In other countries, such as India both résumé and CV can be used, but with some nuanced preferences depending on context, but most people use the terms interchangeably, and most recruiters understand both.
To ensure this study’s findings are not constrained to specific national-context language quirks, several different prompts were created to elicit CVs/résumés tailored to 70 target professions. Prompt variation mitigates spurious effects from individual prompts and avoids prompt-specific biases (Park et al., 2024).
The prompts used asked Large Language Models (LLMs) to generate either a CV, a résumé, or a CV/résumé. Manual inspection of outputs confirmed that the generated documents adhered to professional standards appropriate for job application contexts. For the purposes of this study, the terms CV and résumé are used interchangeably, with CV preferred for consistency.
To enhance diversity in LLMs’ generated outputs, seven distinct prompts were used to prime LLMs to generate CVs. These prompts are included in the Supplemental Material and in electronic form (https://doi.org/10.5281/zenodo.17173798). An illustrative prompt template is provided next: “Your task is to create a CV/resume for the following profession: {profession}. The CV/resume should contain synthetic, yet realistic, information regarding qualifications, experience, job performance, achievements, etc. However, do not include any names, telephone numbers, addresses, emails, or any other personal information. The CV/resume should be between 300 and 800 words long and be written in a professional tone. Do not add any additional comments in your output other than the CV/resume itself. Do not use template fillers or placeholders like ‘Lorem Ipsum’ or ‘Your Name’, [Company Name], [Location], [Month, Year], etc. Use realistic information like company names, cities and states but do not include any personal names or gender cues in the CV. Make sure the CV is coherent and well-structured”.
A set of frontier LLMs was used to generate 10 profession-specific CVs/résumés for each of 70 common occupations. Instead of using the 22 LLMs analyzed in the study, a reduced subset of LLMs was used to maximize CV content quality by pruning out the smaller models in the set such as mistral-7B-Instruct-v0.3 or gemma-2-9b-it. The set of LLMs used to generate the 700 CVs was: gpt-4o, grok-3-beta, DeepSeek-V3, gpt-4o-mini, Meta-Llama-3.1-405B-Instruct-Turbo, o1-mini, gemini-1.5-flash, gemini-2.0-flash, gemini-1.5-pro, o3-mini, DeepSeek-R1, claude-3-5-sonnet-20241022, and claude-3-5-haiku-20241022.
To promote variability, a random temperature between 0 and 1 (uniformly sampled) was applied during CV generation, except for models without configurable temperature parameters (e.g., o1-mini, o3-mini).
The full list of the 70 occupations analyzed is displayed in the Results section. The 70 occupations were compiled by first requesting ChatGPT to generate a list of 100 popular professions. After manually reviewing the list and removing redundant entries, the final set of 70 distinct occupations was derived. All 700 synthetic CVs are available as Supplemental Material.
Generating synthetic job descriptions
The same set of frontier LLMs used to generate CVs was used to generate 10 representative job descriptions for each one of the 70 professions analyzed. These job descriptions incorporate the typical requirements around experience, technical skills, soft skills, and any unique qualifications or achievements found in real-world job descriptions and distilled in jobs listings.
To maximize diversity in generated outputs, five different prompt templates were used to prime the LLMs to generate job descriptions. These prompts are provided as Supplemental Material. An illustrative prompt template used to generate a job description is provided next: “Your task is to create a detailed job description for the profession: {profession}. The description should be well-structured, realistic yet fictional, and include key responsibilities, expected qualifications, and required experience. However, do not include any personal information such as telephone numbers, addresses, or emails. The job description should be between 300 and 800 words, written in a professional tone, and free of placeholders like “Lorem Ipsum” or “[Company Name].” Ensure that all details are natural, coherent, and original. The output should consist solely of the job description, without any introductory or concluding remarks”.
To maximize output diversity, for each job description generation, a random temperature between 0 and 1 drawn from a uniform distribution was used (note that some of the reasoning models do not accept this parameter, as explained above). The 700 synthetic job descriptions generated are provided as Supplemental Material.
Experiment 1-LLMs candidate selection on male and female CV pairs with gender swaps
The 22 LLMs analyzed were each asked to select the most suitable candidate for the 700 job descriptions given a sample of two profession-matched CVs for each job description. The CVs were prepended with a name field header containing either a randomly chosen male or a female first name and a random last name. To test for gender bias, the model’s context window was reset before re-prompting it with the same CV pair but with the gendered-names swapped between CVs. This process allows assessment of whether models demonstrate consistent or biased decision-making based solely on gender.
A set of 110 male names, 110 female names and 110 last names were created by prompting ChatGPT to generate lists of popular male/female/last names. These lists were used in the random generation of candidate names assigned to each CV and are provided as Supplemental Material. Out of the 220 male and female names used in the experiments, only a very small percentage can be considered unisex or ambiguous. Namely, Jordan, Cameron, Alexis, Taylor and Ashley.
For each CV pair selection task, a random temperature drawn from a uniform distribution between 0 and 1 was chosen. The same temperature was used for both gender orders in each CV pair selection. This temperature parameter does not apply to some of the reasoning models (i.e., o1-mini, o3-mini) as explained above, where a fixed temperature is used by the OpenAI API. For consistency across experimental output files, the random temperature value in output files is still present for the reasoning models that do not accept this parameter, although for this reduced set of models, the parameter had no functional effect.
Models long-form responses elaborating which candidate was most qualified for the job description given their CVs qualifications were parsed with gpt-4o-mini to extract the specific name of the candidate chosen as most qualified.
Although 30,800 models’ decisions (22 models × 70 professions × 10 different job descriptions per profession × 2 presentations per CV pair for gendered name assignments reversal) were expected, there were around 0.4% invalid model responses which left 30,690 model decisions to use in the subsequent analysis. Examples of invalid responses include: a model refusing to choose a candidate as more qualified or a model selecting a name that does not exactly match any of the two candidates in the prompt.
For an analysis of the correlation between LLM choices and the female share of occupations, data from the U.S. Bureau of Labor Statistics was used as the main source with a few other sources, listed in the Supplemental Material, also consulted for missing entries (Bureau of Labor Statistics, 2024). When an exact match between the occupational labels used in this work and those in the main source was not available, a reasonable approximation when possible was employed as a proxy (e.g., software engineer → software developer).
Experiment 2-LLMs candidate selection on male and female CV pairs with an additional explicit gender field in CVs
To investigate whether an additional gender cue in CVs impacts the odds of a candidate being selected, experiment 1 was replicated while injecting an additional gender field to each CV that explicitly states whether the candidate is male or female (i.e., Gender: Male or Gender: Female) in addition to the gendered first name. Although it is not customary in many countries to include a gender field in a CV or résumé, there are some countries where it is customary to do so—such as China, Japan, South Korea, several Middle Eastern countries, and in some traditional CV formats in India or Germany. This experiment allows testing whether the inclusion of additional gender cues has an influence on LLMs candidate selection. The explicit gender field can also help the model to disambiguate the gender of candidates with a first name that can be used by both males and females (i.e., Jordan).
Methodologically, the remainder of the experiment was the same as in Experiment 1.
Experiment 3-LLMs candidate selection on CV pairs with gendered names masked by gender-neutral labels “Candidate A” and “Candidate B”
To mask candidates’ gender in each CV pair comparison from Experiment 1, applicant names were replaced with gender-neutral identifiers: “Candidate A” for male candidates and “Candidate B” for female candidates. The LLMs evaluation was then repeated. As in Experiment 1, each CV pair was presented twice with the candidates’ positions swapped, thereby controlling for order effects.
Experiment 4-LLMs candidate selection on CV pairs with gendered names masked by gender-neutral labels “Candidate A” and “Candidate B” and counterbalancing gender assignment to labels in order to control for LLM’s preferences for a given gender-neutral label
To defuse any influence of the labels “Candidate A” and “Candidate B” on candidate selection, experiment 1 was replicated with alternating assignment of gender to the gender-neutral labels “Candidate A” and “Candidate B” in order to neutralize the impact of the labels in LLMs’ selections.
Experiment 5-Evaluating CVs in isolation
To assess LLMs evaluation of CVs presented in isolation (that is, outside of a scenario where the LLMs are choosing between a pair of CVs), LLMs were asked to assess the professional qualifications in a single CV by assigning a numerical score from 1 to 10 for all the male and female CVs used in Experiment 1.
Experiment 6-Adding preferred pronouns as a suffix to candidate names
To test the impact of adding preferred pronouns as a suffix to candidate names, an experiment was conducted using pairs of CVs randomly assigned male and female first names. Each pair was presented to the LLM twice, alternating which candidate had pronouns appended to their name—he/him for male-named candidates and she/her for female-named candidates. Each LLM under study was then tasked with choosing the more qualified candidate for all the job descriptions.
Follow-up analysis of order effects
A follow-up analysis of the results from Experiment 1 examined how frequently the first-listed candidate in the prompt (used to prompt the LLM to select the more suitable candidate from a pair of CVs) was chosen over the second-listed candidate.
Prompts design
To ensure that the experimental results were not influenced by specific prompt formulations, I created multiple prompts for CV generation, job description creation, and candidate selection. The process began with a seed prompt drafted by the author, which was then used to instruct ChatGPT to generate additional similar prompts by rewording the original seed prompt. These variations rephrased the original instructions while preserving their intended meaning.
All prompt templates used to create synthetic CVs, job descriptions, and the instructions guiding the LLM to select the most suitable candidate for a given job description are provided in the Supplemental Material.
Results
Using 13 frontier LLMs, 10 synthetic résumés/CVs were generated for each of 70 distinct professions, representing a broad range of skill sets. In addition, 10 profession-specific job descriptions were created per profession to introduce variability and reduce the likelihood that results were driven by a narrow set of inputs. All candidate selection tasks were carried out with the LLMs operating under a reset context window, that is, the context state was cleared between LLM requests to prevent information carryover between models’ decisions.
Experiment 1
In the initial experiment, each LLM was tasked with selecting the more qualified candidate for each job description, given a randomly sampled pair of profession-matched CVs—one including a full name featuring a male first name, and the other a full name featuring a female first name. To control for potential candidate order and CV content based confounds, each CV pair was presented twice, with gendered name assignments to CVs reversed in the second presentation.
This procedure yielded a total of 30,800 models’ requests (22 models × 70 professions × 10 different job descriptions per profession × two presentations per CV pair with gendered name assignments reversed between presentations), with only 0.4% invalid model responses excluded from the analysis. The overall results revealed a consistent pattern (see Fig. 1): female candidates were selected in 56.9% of cases, compared to 43.1% for male candidates (two-proportion z-test = 33.99, p = 3.60 10−253). The observed effect size was small to medium (Cohen’s h = 0.28; odds = 1.32, 95% CI [1.29–1.35]). Two proportion z-tests conducted separately for each model, with a False Discovery Rate (FDR) correction for multiple comparisons using the Benjamini-Hochberg procedure, showed that LLMs’ preference for selecting female CVs was statistically significant (p < 0.05) across all models tested.
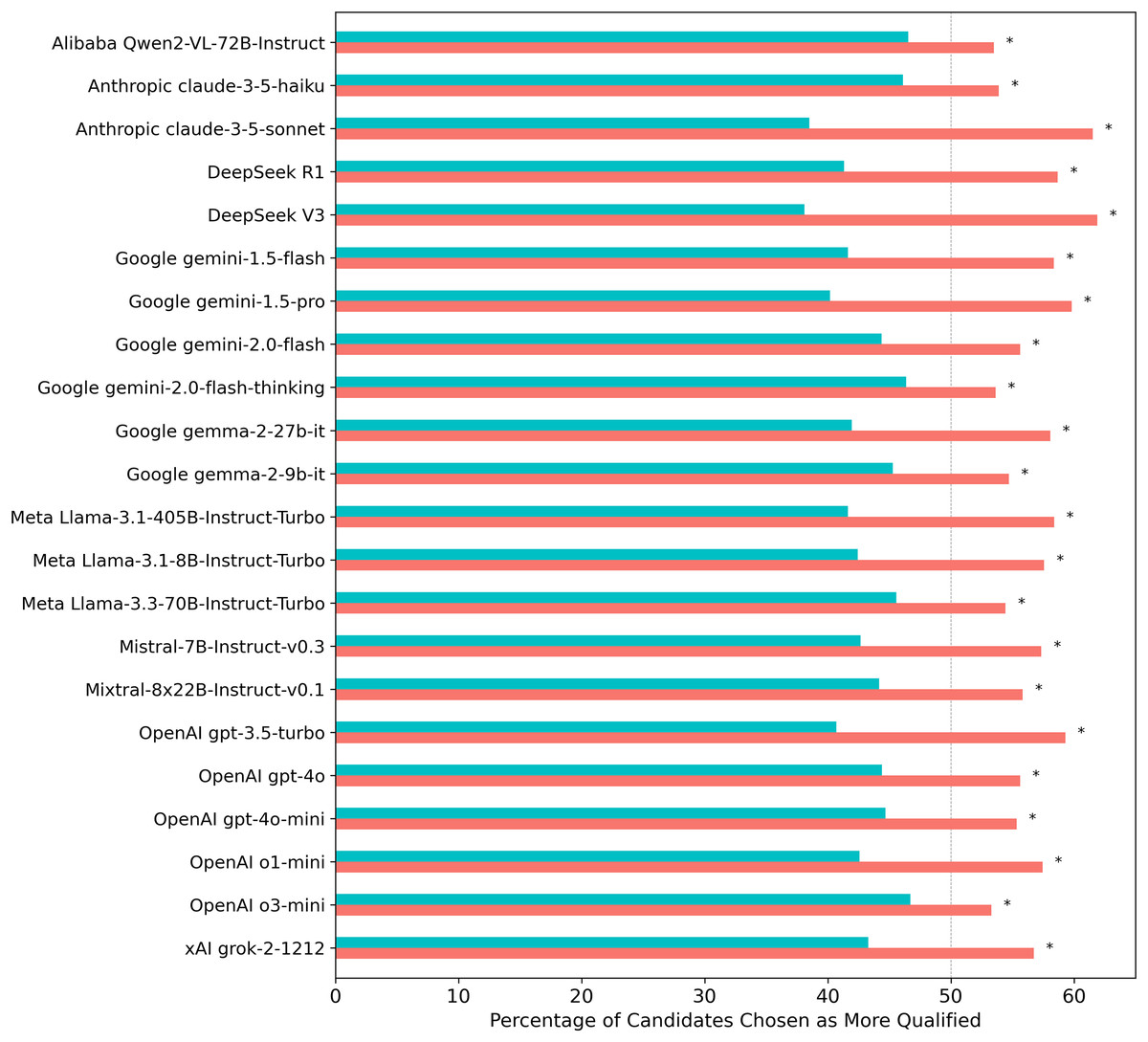
Figure 1: Percentage of times each LLM selected a female vs. a male candidate when evaluating gender-swapped CV pairs across 70 professions.
Turquoise/salmon bars indicate the proportion of male/female candidates selected. The gray dashed line indicates the expected selection rate under gender-neutral decision-making, given that CV content was equalized across gender. Asterisks (*) indicate statistically significant results (p < 0.05) from two-proportion z-tests conducted on each individual model, with significance levels adjusted for multiple comparisons using the Benjamini-Hochberg False Discovery Rate correction.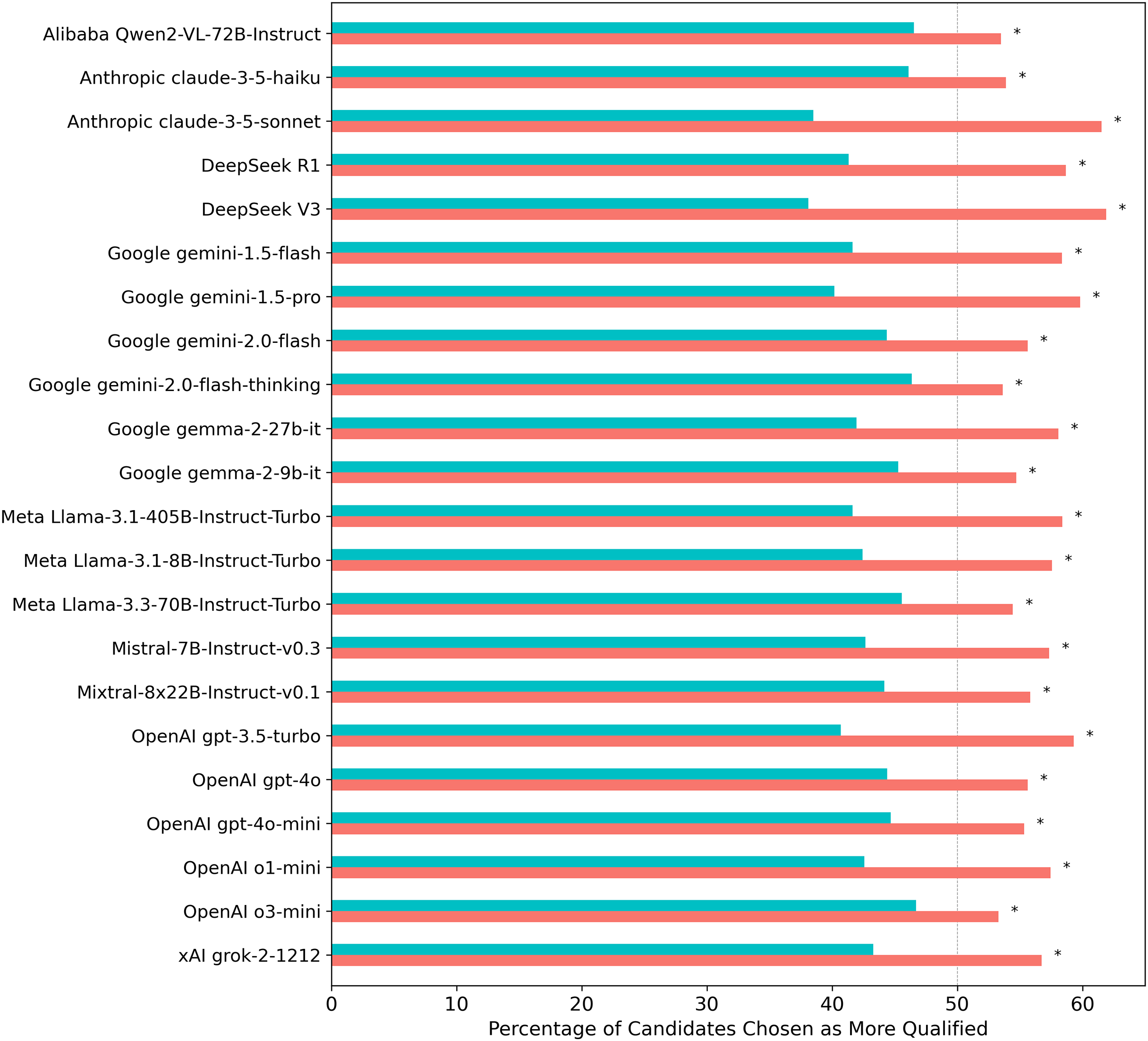{kind=link}
Given that the CV pairs were perfectly balanced by gender by presenting them twice with reversed gendered names, an unbiased model would be expected to select male and female candidates at equal rates. The consistent deviation from this expectation across all models tested indicates a bias in favor of female candidates.
A Pearson correlation test between model temperature and the proportion of female candidate selections (r = −0.37) did not reach statistical significance.
Larger models do not appear to be inherently less biased in this task than smaller ones. Reasoning models—such as o1-mini, o3-mini, gemini-2.0-flash-thinking, and DeepSeek-R1—which allocate more compute during inference, also show no measurable association with gender bias in this task. That is, increasing inference time compute to decide which candidate is more qualified for a given job doesn’t seem to have a consistent directional impact on the gender skew described above.
When aggregating results by profession, female candidates were preferred over male candidates across all occupations tested, although for one profession (carpenter), the two-proportion z-test did not reach statistical significance after FDR correction (see Fig. 2).
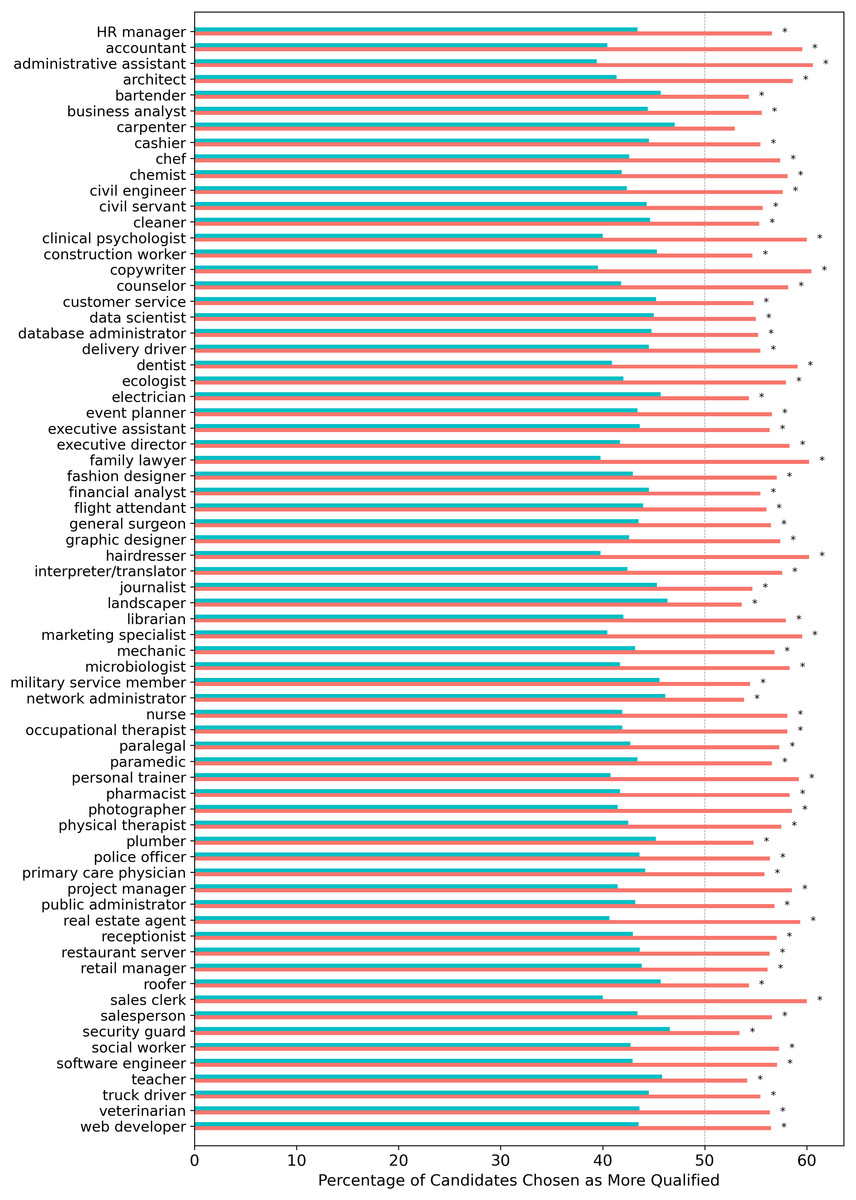
Figure 2: Percentage of times for each profession that 22 LLMs selected a female vs. a male candidate when evaluating gender-swapped CV pairs.
Turquoise/salmon bars indicate the proportion of male/female candidates selected. Asterisks (*) indicate statistically significant results (p < 0.05) from two-proportion z-tests conducted on each profession, with significance levels adjusted for multiple comparisons using the Benjamini-Hochberg False Discovery Rate correction.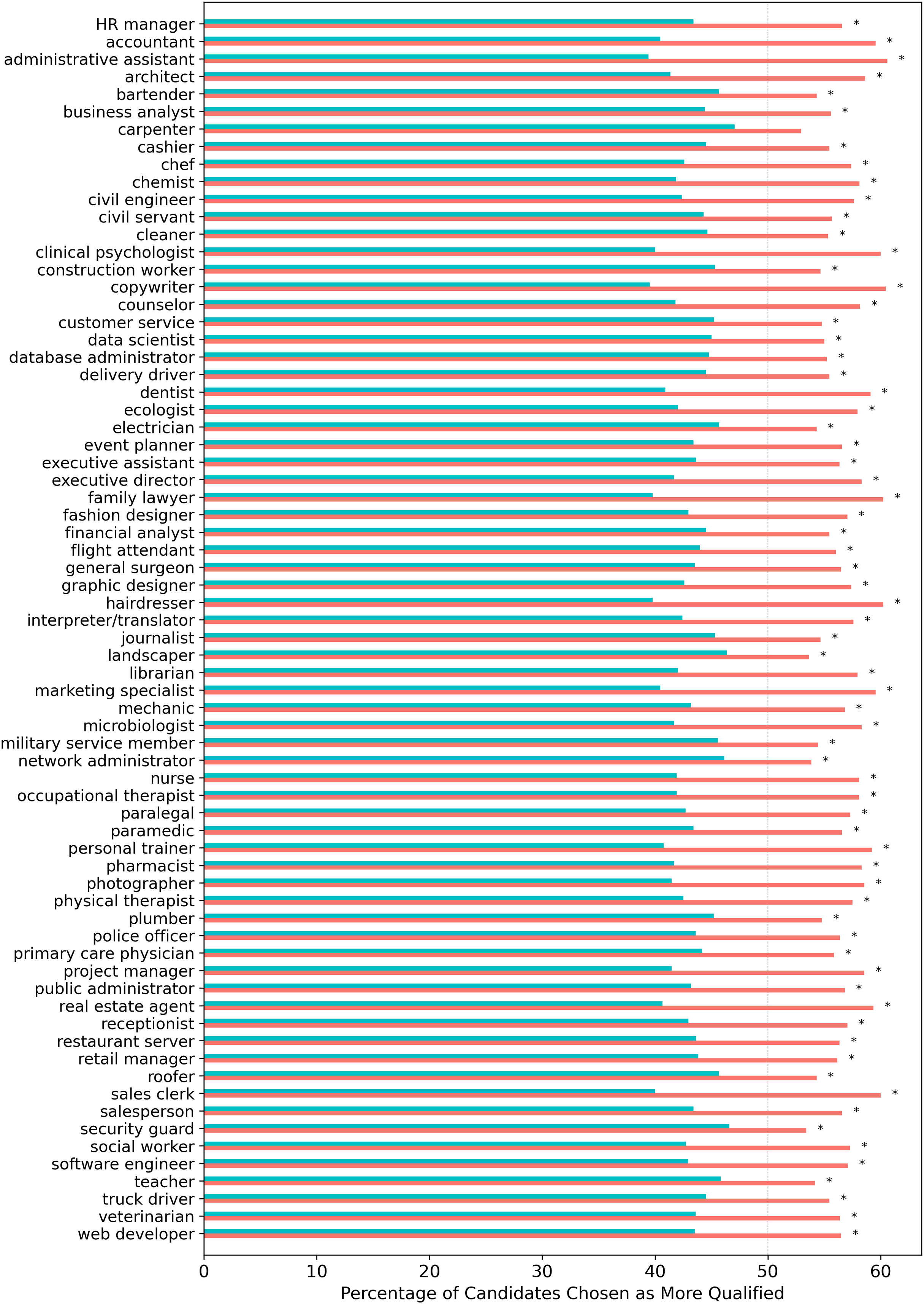{kind=link}
There was a statistically significant moderate positive correlation (r = 0.48, p < 0.001) between the proportion of females selected by LLMs for each profession and the female share of the profession in the U.S. That is, the larger the proportion of females in a profession, the more likely LLMs were to choose females as the most qualified candidate for the profession. This is somewhat consistent with previous works that noted the presence of gender and ethnic stereotypes in word embeddings about professions (Garg et al., 2018).
Experiment 2
Experiment 1 was replicated with the addition of an explicit gender field to each CV (i.e., Gender: Male or Gender: Female), alongside gendered names. This modification amplified LLMs’ preference for female candidates further (58.9% female selections vs. 41.1% male selections; two-proportion z-test = 43.95, p ≈ 0; Cohen’s h = 0.36; odds = 1.43, 95% CI [1.40–1.46]).
Experiment 3
In a follow-up experiment, candidate genders were masked by replacing gendered names with generic labels (“Candidate A” for males and “Candidate B” for females). Overall, there was a slight preference for selecting “Candidate A” (52.3% Candidate A selections vs. 47.7% Candidate B, two-proportion z-test = 11.61, p = 3.70 10−31; Cohen’s h = 0.09; odds = 1.10, 95% CI [1.07–1.12]). Individually, 12 out of 22 LLMs showed a statistically significant preference for selecting “Candidate A,” while two models significantly preferred “Candidate B” (FDR-corrected).
Experiment 4
As a sanity check, when the gender assignment to CVs from Experiment 1 was counterbalanced across the generic identifiers “Candidate A” and “Candidate B” (i.e., alternating hidden male and female assignments to each label), candidate selections reached gender parity across all models (see Fig. 3).
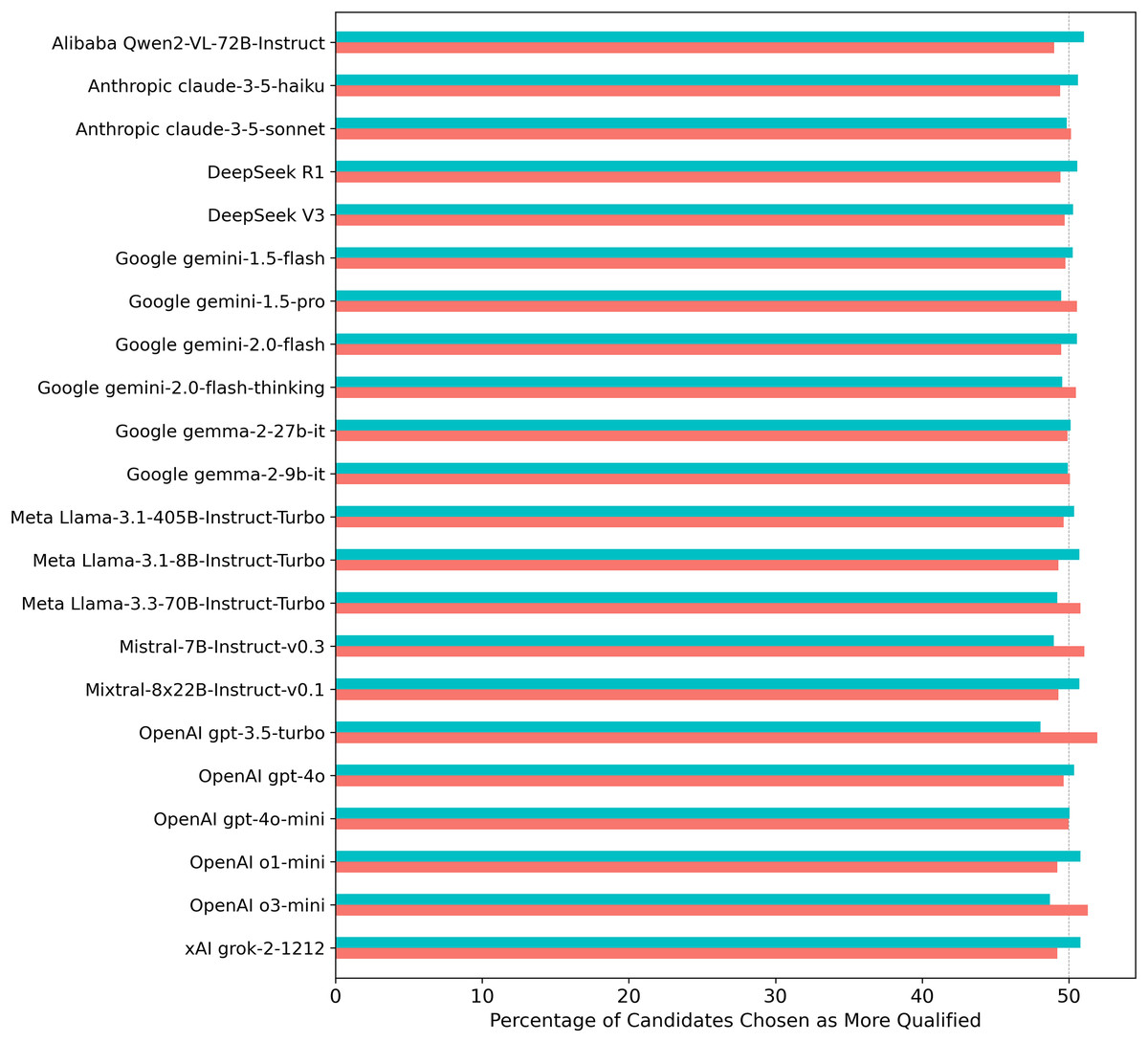
Figure 3: Percentage of times each LLM selected a female vs. a male candidate from Experiment 1 when evaluating gender-masked CV pairs across 70 professions with counterbalancing of gender assignment to Candidate A/B labels.
Turquoise/salmon bars indicate the proportion of male/female candidates selected. Asterisks (*) would indicate statistically significant results (p < 0.05) from two-proportion z-tests conducted on each individual model, with significance levels adjusted for multiple comparisons using the Benjamini-Hochberg False Discovery Rate correction.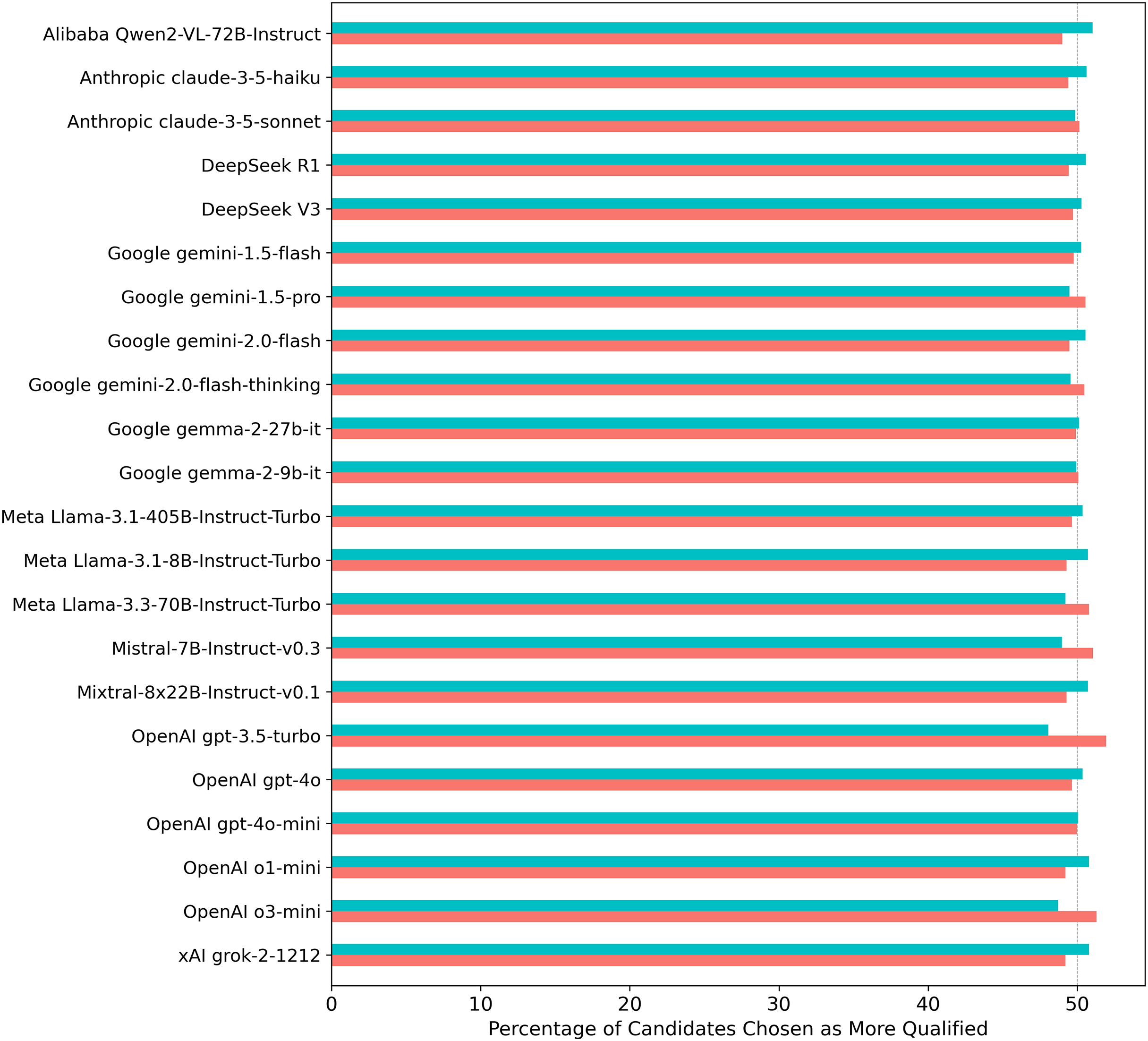{kind=link}
Experiment 5
To also investigate whether LLMs exhibit gender bias when evaluating CVs in isolation—absent direct comparisons between CV pairs—another experiment asked models to assign numerical merit ratings (on a scale from 1 to 10) to each individual CV used in Experiment 1. Overall, LLMs assigned female candidates marginally higher average ratings than male candidates ( , ), a difference that was statistically significant (paired t-test = 16.14, p = 2.26 10−58), but the effect size was negligible (Cohen’s d = 0.09). Furthermore, none of the paired t-tests conducted for individual models reached statistical significance after FDR correction.
Experiment 6
In a further experiment, each pair of CVs included one candidate with preferred pronouns appended to their name and one without. Pronoun assignments were systematically swapped between the two CVs across trials. The results showed that including gender-congruent preferred pronouns (i.e., he/him, she/her) alongside a candidate’s name increased the likelihood of that candidate being selected by the LLMs both for male and female applicants with still an overall preference for selecting female candidates. Overall, candidates with listed pronouns were chosen 53.0% of the time, compared to 47.0% for those without (two-proportion z-test = 14.75, p < 3.07 −49; Cohen’s h = 0.12; odds = 1.13, 95% CI [1.10–1.15]). Out of 22 LLMs, 17 reached individually statistically significant preferences (FDR corrected) for more often selecting the candidates with preferred pronouns appended to their names.
Follow-up analysis on the effects of candidate order in prompts
A follow-up analysis of Experiment 1 results revealed a strong positional bias in candidate selection, independent of gender (see Fig. 4). When asked to choose the more qualified candidate, LLMs consistently favored the individual listed first in the prompt, selecting the first candidate in 63.5% of cases compared to 36.5% for the second (two-proportion z-test = 67.01, p ≈ 0; Cohen’s h = 0.55; odds = 1.74, 95% CI [1.70–1.78]). Out of 22 LLMs, 21 exhibited individually statistically significant preferences (FDR corrected) for selecting the first candidate in the prompt. The reasoning model gemini-2.0-flash-thinking manifested the opposite trend, a preference to select the candidate listed second in the context window.
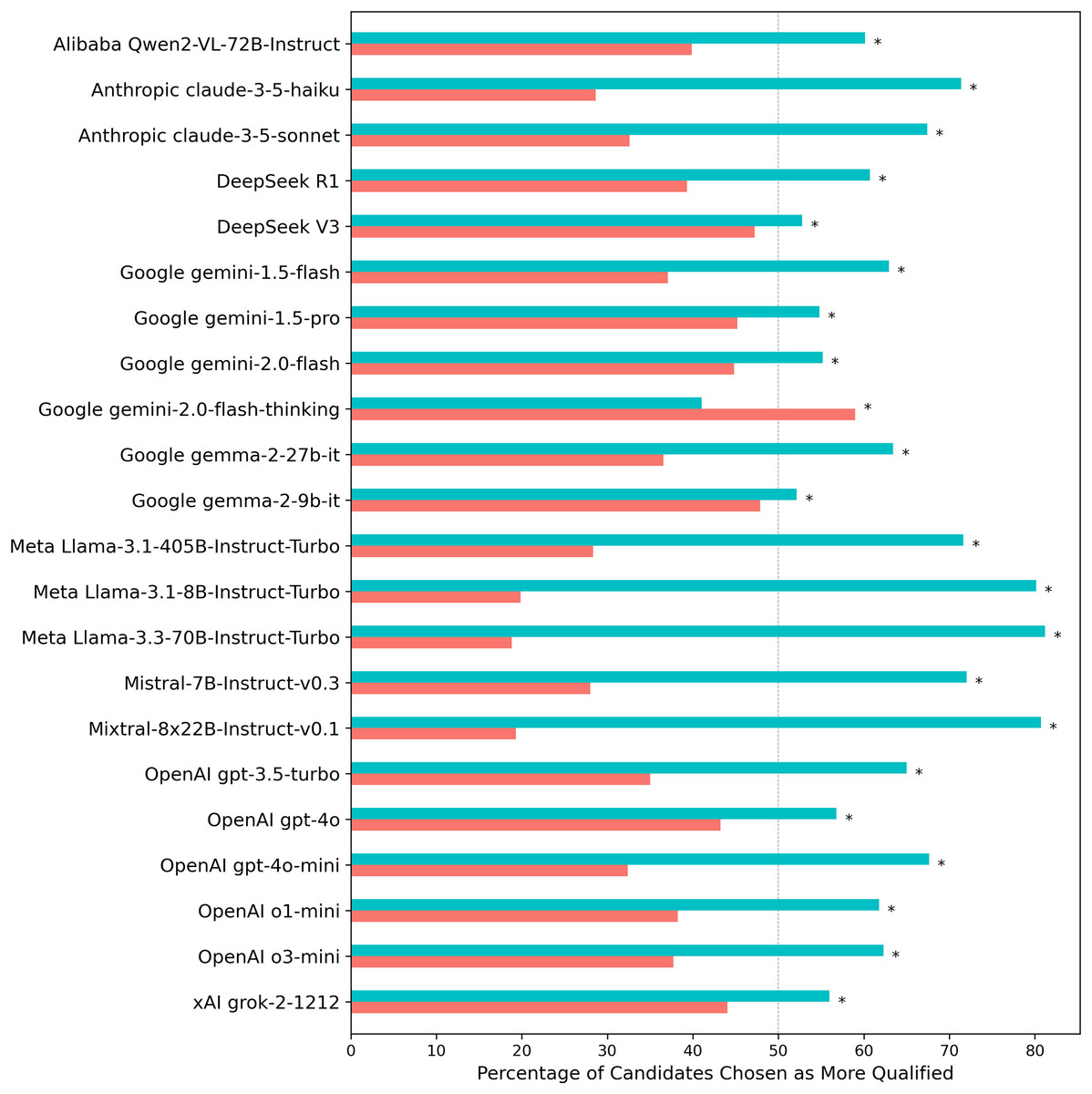
Figure 4: Percentage of selections by each LLM for the candidate appearing first vs. second in the prompt when evaluating CV pairs across 70 professions.
Turquoise/salmon bars indicate the proportion of first/second listed candidates selected. The gray dashed line represents the expected selection rate under positionally neutral decision-making, given that CV content was identically distributed across prompt positions. Asterisks (*) indicate statistically significant results (p < 0.05) from two-proportion z-tests conducted on each individual model, with significance levels adjusted for multiple comparisons using the Benjamini-Hochberg False Discovery Rate correction.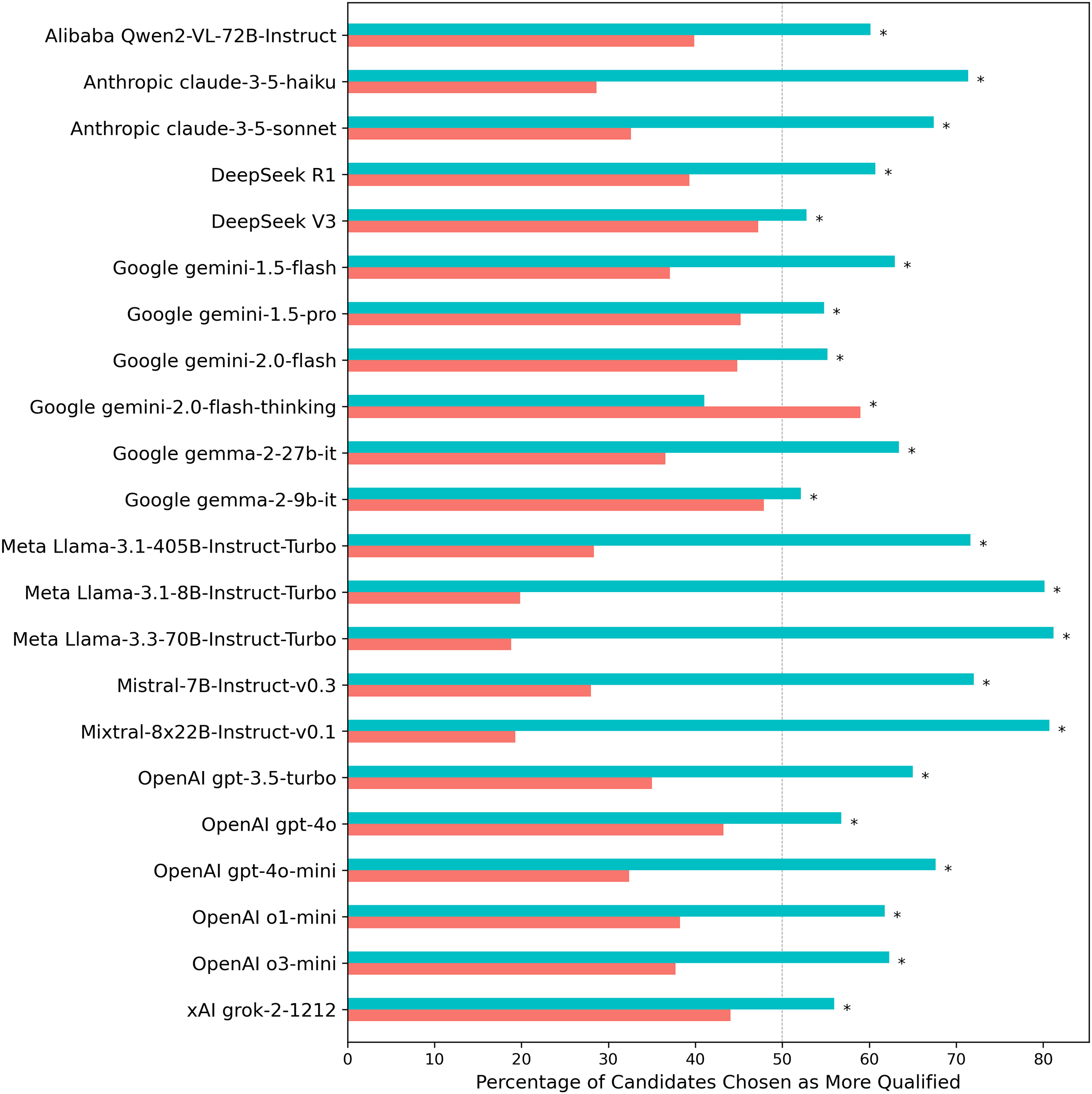{kind=link}
Discussion
Empirical context and alignment with prior findings
The results presented above illustrate that frontier LLMs, when tasked with selecting the most qualified candidate for a job based on a job description and a pair of profession-matched CVs (one from a male candidate and the other from a female candidate), exhibit behavior that departs from conventional expectations of fairness. The positional bias results also suggest that at least in this task, LLMs are not reasoning from first principles.
This work is not the first to describe favorable treatment of females by LLMs in various contexts. For example, previous work found that LLMs award higher assessment scores to female candidates while controlling for work experience, education, and skills (An et al., 2025). Other work reported that when generating personas for occupational roles across fields like healthcare, engineering, and professional services, some LLMs consistently over-assign female identities, showing a pro-female skew in gender distributions compared to a uniform baseline (Mirza et al., 2025). In decision-making scenarios involving relationship conflicts, LLMs have also been described as favoring individuals with female or gender-neutral names over males (Levy et al., 2024).
This work is also not the first documenting prompt structure impact in LLM outputs. Other authors have previously describe the influence of prompt order effects in LLM responses (Yin, Vardi & Choudhary, 2025; Liu et al., 2023).
Whether the gender and position biases described in this work stems from LLMs’ pretraining data, post-training or other unknown factors remains an open question that warrants further investigation. But regardless of source, the presence of such consistent biases across all LLMs tested also raises broader concerns. In the race to develop ever-more capable artificial intelligence (AI) systems, subtle yet consequential and systemic misalignments may go unnoticed pre and post model release.
Limitations and generalizability considerations
A limitation of this work is the synthetic nature of the CVs and job descriptions templates used in the analysis and which were generated by LLMs rather than sourced from real-world data. Although these synthetic materials were designed to be realistic and profession-specific, it is conceivable that they do not fully capture the complexity, variability, or nuance present in authentic job applications and job advertisements. Real-world résumés may include more diverse formatting styles, informal cues, or implicit signals that LLMs might interpret differently when evaluating them. For instance, real CVs might contain subtle differences in how male and female candidates describe previous work experience or educational background.
Thus, the generalizability of the findings to actual hiring contexts may be constrained, and future work could consider validating the biases reported here using real CVs drawn from publicly available datasets or anonymized application corpora with controlled gender cues. Nevertheless, given that LLMs are trained on vast amounts of internet text, it is likely that the synthetic CVs and job descriptions generated in this study resemble real-world documents to a meaningful degree.
Another limitation of this work is that the CVs presented to the LLMs were closely matched in terms of qualifications and overall competitiveness. This is due to the usage of a similar set of prompts to induce LLMs to generate synthetic CVs. This approach was necessary to isolate gender effects and minimize confounds related to professional merit. However, in doing so, the study examined LLM behavior under conditions of similar CV qualifications, which may not reflect the broader range of applicant qualifications typically observed in real-world hiring scenarios.
The fact that male- and female-named CVs received nearly identical scores when evaluated in isolation and the fact that the background distribution of CVs is equalized between the genders by the gender-swapping technique suggests that the models are not making judgments based on clear skill differences but rather reacting to explicit identity cues such as gendered names or gender fields. While this design reveals implicit model biases, it does not capture how these systems might behave when confronted with a wider spectrum of candidate quality, nor does it explore whether such biases diminish or amplify when qualifications are more discrepant. Nonetheless, it is worth noting that in actual hiring contexts, particularly in the final stages of selection, employers typically narrow the candidate pool to a few finalists whose qualifications fall within a relatively tight range. Thus, while this study’s design may not reflect the full breadth of applicant variability, it does approximate the high candidate similarity conditions under which final hiring decisions are often made.
A further limitation is that this study operationalized gender in binary terms (male vs. female). While this enabled controlled comparisons, it does not capture the broader spectrum of self-reported gender identities. Future work could examine how LLMs respond under alternative frameworks.
It is also important to note that this study employed automated annotations—using an LLM (gpt-4o-mini)—to infer which candidate was selected as most qualified in each model response. While a small proportion of these annotations may contain errors due to contextual ambiguity in model selections, models refusing to clearly choose a candidate as more qualified or occasional model annotation errors, such limitations are not unique to automated methods and similar issues would also affect human annotators. Given the scale of the analysis (over 100,000 model decisions), manual annotation was not feasible. However, based on manual checks of a subset of the experimentally generated annotations, the author is confident that the vast majority are accurate.
One additional consideration is that most of the effect sizes reported in the results section fall within the very small to moderate range. While statistically significant, effect sizes at the lower end of this spectrum typically indicate subtle differences in model behavior. As such, their real-world impact is likely to be limited on a case-by-case basis. Nonetheless, even small biases can accumulate over time or across large applicant pools, highlighting the importance of scrutinizing such effects carefully.
Broader implications and future research directions
Future work could examine how demographic cues (such as gender or ethnicity), their correlated proxies (such as place of residence, educational background or income), and positional bias within the model’s context window interact with one another. The experimental results showing that some models displayed a slightly higher likelihood of choosing a candidate referred to as “Candidate A” over “Candidate B”, could be due to the fact that such labels may imply an order due to the sequential nature of A and B. Future work could explore using alternative identifiers that do not suggest any inherent order to determine the extent to which certain labels increase the likelihood of a candidate being selected.
Another noteworthy aspect of the findings is the correlation between LLMs’ gender bias and the gender distribution within a profession. The higher likelihood of LLMs selecting female candidates as more qualified in professions with a higher representation of females suggests that models may be incorporating stereotypical priors about gendered occupational distributions into their decision-making. This echoes earlier work on gendered associations in word embeddings and raises important questions about how LLMs balance statistical regularities in training data with fairness-oriented reasoning. On the one hand, this behavior could be interpreted as the models internalizing real-world labor market demographics; on the other, it demonstrates a failure to treat applicants on the basis of merit when qualifications are held constant. The broader implication is that LLMs may not simply note statistical regularities in their training data but project them into evaluative tasks with potential downstream consequences in applied domains such as hiring, admissions, or resource allocation.
Another layer of complexity revealed in the experiments concerns the positional effects. The strong bias toward selecting the first candidate in a prompt by most models illustrates that LLM responses are shaped not only by semantic content but also by structural features of prompts. These findings highlight a vulnerability in current LLM architectures: the models appear highly sensitive to surface-level prompt structure effects that bear no intrinsic relationship to candidate merit. While such effects may appear trivial in isolation, in real-world applications where prompt structures vary across evaluators, they could systematically distort outcomes. This underscores the importance of prompt design in applied AI systems and suggests that fairness interventions cannot be limited to training data alone but must also account for interface and deployment conditions. Future work could thus explore mitigation strategies that reduce sensitivity to positional artifacts.
Finally, I note that while this study builds on a growing body of empirical work examining demographic and positional biases in LLMs, the broader theoretical foundations underlying such behaviors remain comparatively underdeveloped. Much of the existing literature—including the work cited here—primarily reports empirical audit findings rather than offering formal theoretical models explaining why or how these biases emerge. As a result, the present study is likewise grounded mainly in empirical observations rather than in an established theoretical framework. A fuller theoretical account of the mechanisms driving gendered or positional preferences in LLMs is an important direction for future research.
Conclusion
This work has documented gender and positional biases in LLMs tasked with making selections about which candidate from a pair is more qualified for a given job description. The results of this work are markedly relevant as several companies are already leveraging LLMs to analyze CVs in hiring processes (CiiVSOFT, 2025; Shellshear, 2024; Zoolatech, 2025; Vagale et al., 2024), sometimes even promoting their systems as offering “bias-free evaluations” (CiiVSOFT, 2025). In light of the present findings, such claims appear questionable. The results presented here also raise doubts about whether current AI technology is mature enough to be suitable for job selection or other high stakes automated decision-making tasks.
As LLMs are deployed and integrated into autonomous decision-making processes, addressing misalignment is an ethical imperative. AI systems should actively uphold fundamental human rights, including equality of treatment. Yet comprehensive model scrutiny prior to model release and resisting premature organizational adoption remain challenging, given the strong economic incentives driving the field.