
Design and optimization of human resource scheduling strategies using intelligent evolutionary algorithms
- Published
- Accepted
- Received
- Academic Editor
- Osama Sohaib
- Subject Areas
- Human-Computer Interaction, Algorithms and Analysis of Algorithms, Artificial Intelligence, Social Computing, Sentiment Analysis
- Keywords
- Human resource optimization, Differential evolution, Ant colony algorithm, Adaptive strategy
- Copyright
- © 2026 Zhang and Malik
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Design and optimization of human resource scheduling strategies using intelligent evolutionary algorithms. PeerJ Computer Science 12:e3613 https://doi.org/10.7717/peerj-cs.3613
Abstract
To address the limitations of traditional algorithms in human resource scheduling optimization under multiple constraints—such as slow convergence and low constraint satisfaction rates—this study proposes a hybrid intelligent algorithm (ADE-ACO) integrating adaptive differential evolution (ADE) and ant colony optimization (ACO). First, a multi-objective optimization model for human resource scheduling is constructed. Then, an improved adaptive differential evolution algorithm is designed, which dynamically adjusts the scaling factor and crossover probability to effectively mitigate the issues of local optima stagnation and premature convergence in conventional methods. Furthermore, by incorporating an adaptive pheromone update mechanism and a multi-attribute dynamic candidate list strategy, the algorithm’s global search capability is significantly enhanced. Experimental validation on the Project Scheduling Problem Library (PSPLIB) benchmark dataset demonstrates that compared to traditional baseline algorithms including standard differential evolution (SDE) and ACO, the proposed ADE-ACO algorithm achieves a 32% significant reduction in makespan (p < 0.01), improves resource utilization to 92.3%, while maintaining over 95% constraint satisfaction rate, conclusively proving its superiority in both convergence performance and scheduling quality.
Introduction
With the expansion of enterprise scale and the increase of project complexity, human resource scheduling has increasingly become a key factor restricting operational efficiency (Agustian et al., 2023). Traditional scheduling methods often exhibit limitations such as slow convergence speed and unstable solution quality when facing complex conditions such as multi skill matching, dynamic task priority, and resource constraints. Especially in modern work scenarios such as agile development and cross departmental collaboration, scheduling schemes need to simultaneously meet multiple objectives such as time efficiency, resource utilization, and constraint feasibility, which poses a severe challenge to existing algorithms (Bahroun et al., 2024).
Human resource scheduling is a highly complex and dynamic optimization problem (Hafezi Zadeh, Movahedi & Shayannia, 2022). In practical management scenarios, the categorization and task allocation of human resources are not static and unchanging, but a dynamic process that continuously adjusts with factors such as project progress, skill requirements, and personnel availability. This dynamic characteristic makes it difficult for traditional static allocation methods to meet the human resource management needs of modern enterprises (Momeni & Martinsuo, 2018). Early static scheduling algorithms often adopted a simple N-to-N task allocation model, ignoring the multidimensional constraints in human resource scheduling, including dynamic changes in skill matching, real-time adjustments of task priorities, and complex requirements for cross-departmental collaboration (Mancuso et al., 2024). Especially in modern work models such as agile development and matrix management, human resource scheduling needs to consider multiple factors such as the timeliness of personnel skills, workload balance, and project cost control. Static scheduling algorithms, due to their lack of adaptability, are prone to misallocation and waste of human resources, making it difficult to meet the needs of modern enterprises for efficient utilization of human resources.
To address this issue, this article proposes an innovative adaptive differential evolution ant colony optimization hybrid algorithm (ADE-ACO). This method achieves breakthroughs through three key technological innovations: firstly, a dynamic parameter adjustment mechanism based on Levy distribution is designed to enable the differential evolution algorithm to adaptively balance global exploration and local development; Secondly, a multi-dimensional pheromone update strategy is introduced to integrate key factors such as skill matching degree and workload into the decision-making process of ant colony optimization; Finally, a dynamic candidate list generation algorithm was developed to effectively reduce the search space while ensuring solution diversity.
The contributions of this study are summarized as follows:
-
(1)
This study proposes an intelligent optimization method that integrates adaptive pheromone mechanisms and dynamic candidate strategies, combined with critical path and resource competition analysis, to construct an autonomous optimization framework. By dynamically adjusting the distribution of pheromones to balance global and local searches, and establishing a multidimensional candidate list mechanism that comprehensively considers factors such as skill matching and load balancing, resource conflicts and efficiency optimization problems in complex human resource scheduling can be effectively solved.
-
(2)
This study designed an adaptive parameter adjustment strategy based on population diversity feedback, in which the scaling factor adopts a nonlinear decay mechanism to maintain a large value at the beginning of iteration to enhance global exploration ability, and gradually decreases to a predetermined range as the evolution process progresses to enhance local development. At the same time, a dynamic crossover probability adjustment method based on successful historical memory was developed, which adaptively updates the crossover operator by analyzing the characteristics of outstanding individuals throughout history.
Related works
In the scheduling of resource constrained projects, each resource has unique problem-solving abilities or skills, and in actual business operations, human resources are a dynamic resource with multi skilled and heterogeneous efficiency characteristics. The optimal allocation plan for multi skilled employees in a multi project environment is key to improving productivity. A multi skilled environment has many benefits, such as reducing employee resignations, motivating employees, enhancing creativity, and increasing recruitment interest (Costa, Thürer & Portioli-Staudacher, 2023).
Multi-skill workforce scheduling
The scheduling of multi skilled resource constrained projects is of great significance in practical production decision-making, and many scholars have conducted in-depth research on it and proposed different hypotheses. Szwarc et al. (2024) innovatively incorporated the three elements of “rest time,” “assembly line work,” and “shift scheduling” into the study of multi skilled employee scheduling. Yu, Xu & Zhao (2023) developed a two-stage optimization algorithm for multi skilled human resource constraints to achieve the goal of minimizing project duration. The sub model was optimized using a genetic local search algorithm, and the effectiveness of the algorithm was verified through numerical examples. Ghasemi et al. (2024) considered task interruptibility and studied project scheduling problems with multi skill and time window constraints. They proposed a branch and bound algorithm based on branch node priority rules and verified the feasibility of the algorithm using an improved Project Scheduling Problem Library (PSPLIB) case library. In the field of new product development, Chen et al. (2018) explored the human resource scheduling problem considering the factors of multi skilled employee turnover, established a constrained optimization model with the objectives of maximizing project benefits, minimizing R&D cycles, and minimizing costs, and designed an improved Pareto sampling algorithm for solution. Bahroun et al. (2024) emphasized in their research that projects must be scheduled and employees must be assigned to tasks as mandatory constraints, while multi-skilled employees also needed to comply with national skill standard requirements. Etminaniesfahani et al. (2024) proposed a novel heuristic algorithm specifically designed to solve the project scheduling problem of multi skilled employees with multiple execution modes.
Multi-project human resource allocation
Scholars worldwide have conducted in-depth research on single-project human resource scheduling. Zuo et al. (2019) employed ant colony optimization (ACO) to address resource-constrained project scheduling. Shuvo, Golder & Islam (2023) innovatively introduced critical chain methodology into project scheduling models, constructing optimization models based on task priorities and designing hybrid genetic algorithms for solutions. Feng et al. (2022) investigated resource leveling optimization under process constraints from a cost perspective. Servranckx, Coelho & Vanhoucke (2024) proposed a teaching-learning-based genetic algorithm to solve single-project scheduling under single-execution mode for classical resource-constrained project scheduling problem (RCPSP) problems. Yinusa & Faezipour (2023) developed heuristic algorithms to optimize task-employee allocation combinations, enhancing professional skill utilization while reducing additional costs. Sheikhkhoshkar et al. (2023) presented personnel scheduling heuristics targeting minimized project and labor costs. Hu et al. (2024) established duration-resource leveling optimization models for single-project multi-objective problems, developing improved particle swarm optimization for solutions.
With the development of society and technological progress, the practical application of multi project management scheduling optimization models (Hafezi Zadeh, Movahedi & Shayannia, 2022) has become increasingly important, and parallel implementation of multiple projects has gradually become a norm. Solving resource scheduling in parallel environments with multiple projects has become a problem that modern enterprises need to constantly address. In multi information technology (IT) project and multi resource management, Mirataollahi Olya, Shayannia & Mehdi Movahedi (2022) divided the development time of IT projects into “time segments”, establishes corresponding scheduling scheme search trees, and finally uses heuristic search to solve. Aguinis, Beltran & Cope (2024) extended the traditional project scheduling problem under multimodal resource constraints and proposes to combine human resource allocation with project scheduling to study the human resource scheduling problem of research and development (R&D) project groups. When establishing the mathematical model, the different competency levels of human resources are considered.
Methodology
Problem description
Mathematical model construction
The standard form of human resource scheduling (taking people and tasks as an example) is to assign n people to complete n tasks, each person can only undertake one of the tasks, and only one person is assigned to complete each task. Due to the different efficiency of each person completing the n tasks, the efficiency matrix is
(1) where represents the efficiency of the i-th person to complete the j-th task. How to assign tasks to maximize efficiency. Or it could be that n people have different completion times for n tasks. There is a time matrix
(2) where is the time for the i-th person to complete the j-th task. How to assign it to minimize the time.
To establish a mathematical model for the standard assignment problem, n 0−1 variables are introduced
(3)
The mathematical model of the problem can be written as
(4)
(5)
In this model, the constraint is that everything must be done by only one person. But there are feasible solutions to this type of problem, represented by matrix .
Adaptive differential evolution algorithm
This article proposes an adaptive differential evolution algorithm based on Levy distribution and applies it to solve human resource scheduling problems.
Chromosome coding
This article combines the characteristics of human resource scheduling and adopts the indirect coding method of resource task. The total number of computing tasks for users is the chromosome length, and each gene represents a computing task. The value of the gene locus represents the resource number assigned to the corresponding resource for that computing task. The final encoding format of chromosomes is shown in Fig. 1, where represents the task number, , and represents the resource number, .
Figure 1: Color encoding format.
{kind=link}
According to the encoding method shown in the Fig. 1, the corresponding decoding can be obtained as . From this, it can be concluded that each chromosome corresponds to a scheduling scheme for a specific task.
Mutation operation
This article uses randomly selecting two different individuals from the population to synthesize vectors with the individuals to be mutated, resulting in the intermediate individual , that is
(6) where g is the evolutionary algebra, and is the i-th individual in the g-th generation population. and are two randomly selected individuals from the g-th generation population. is a scaling factor specific to each individual, satisfying the Cauchy distribution with a value range of .
(7)
The update method for is
(8) where is the set of F-values for all successfully mutated individuals, and is the Lehmer mean.
(9)
Cross operation
Perform cross operation on the intermediate of the g-generation individual and its variants
(10) where is a random integer of . Each individual i has a specific crossover probability , satisfying the Levy distribution, and its probability density function is
(11) where and β are the two characteristic parameters of the Levy distribution, and > 0.
Greedy choice
This article uses greedy algorithm to select individuals to enter the next generation population, and selects individuals with better fitness values to enter the next generation. In this article, since the task scheduling problem belongs to the minimization problem, individuals with smaller fitness values are selected to enter the next generation
(12)
Based on the human resource scheduling model established in the previous section, the flowchart of the adaptive evolutionary differential algorithm is shown in Fig. 2.
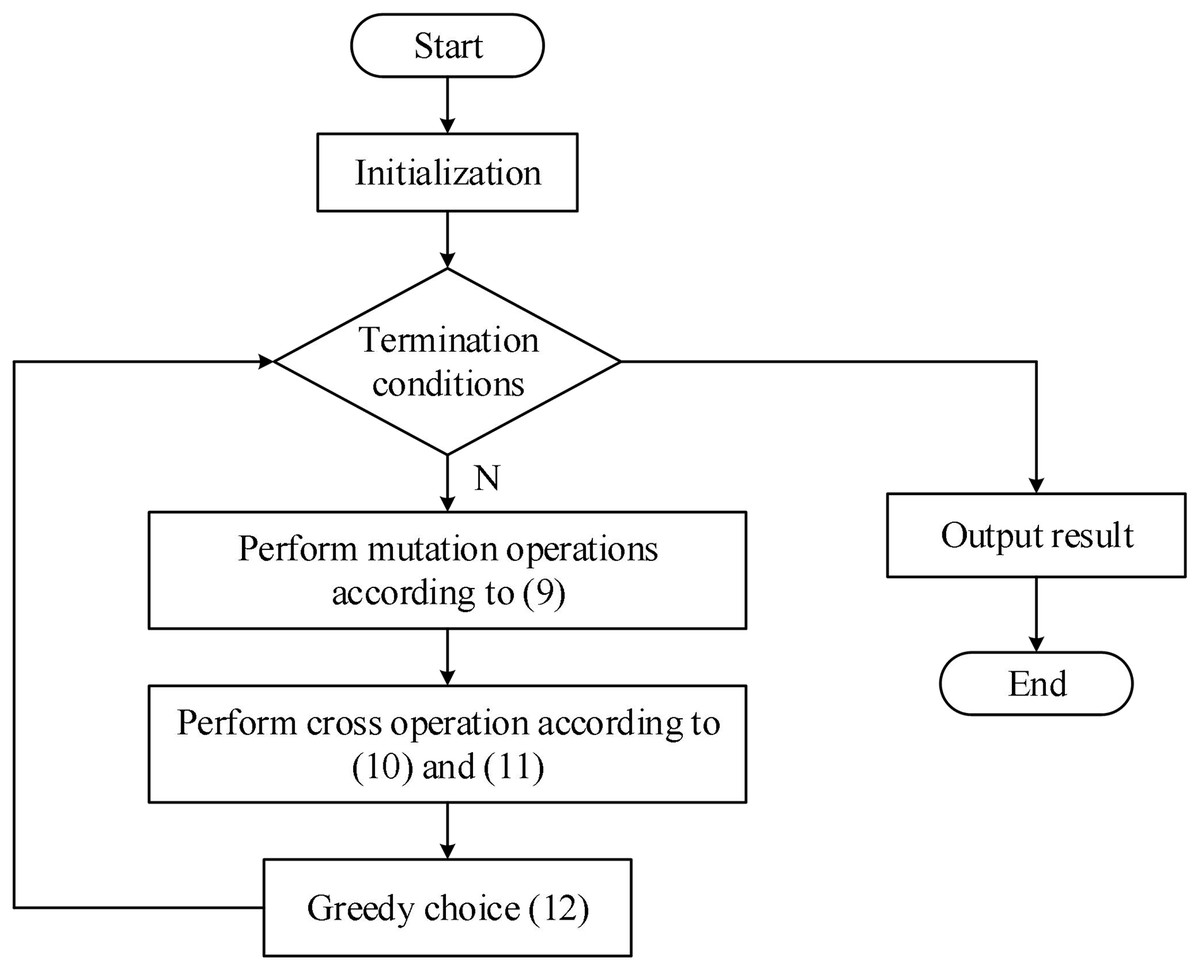
Figure 2: Algorithm flow.
{kind=link}
Improved ant colony optimization algorithm design
Adaptive pheromone update strategy
For the complexity of multi-project human resource scheduling problems, an adaptive pheromone update mechanism is designed to dynamically adjust the pheromone evaporation coefficient and increment. The improved algorithm’s overall workflow comprises three core modules: pheromone updating, dynamic candidate lists, and local search. The pheromone update rules are as follows:
(13)
The pheromone evaporation coefficient dynamically varies throughout the iteration process:
(14) where is the regulation factor controlling the adaptation rate of the evaporation coefficient.
To prevent excessive pheromone concentration or dispersion, pheromone levels are constrained within the interval , with truncation applied when τij exceeds these bounds. This adaptive update strategy maintains broader exploration during early iterations while progressively intensifying exploitation of high-quality solutions, thereby effectively balancing global and local search capabilities throughout the optimization process.
Dynamic candidate list strategy
A dynamic candidate list mechanism based on multi-attribute evaluation is designed, comprehensively considering resource availability, skill matching degree, and workload balance to dynamically construct and update the candidate resource list. The candidate list scope progressively narrows as the algorithm proceeds to enhance search efficiency. The resource evaluation score is calculated as follows:
(15) where the weight coefficients are determined via fuzzy analytic hierarchy process. The resource availability index quantifies the idle capacity of resource k during the target time window:
(16)
The skill matching degree is established through a fuzzy evaluation methodology incorporating an assessment indicator system comprising professional skill proficiency, project experience, team collaboration capability, and other relevant factors, while workload balance is measured by calculating the deviation between a resource’s current load and the team’s average workload.
(17)
The dynamic update mechanism adjusts the candidate list length iteratively according to:
(18) where denotes the regulation coefficient. This mechanism enables adaptive search scope adjustment according to optimization phases, thereby enhancing algorithmic convergence efficiency.
Dynamic candidate list strategy
The local search optimization embeds a local search module within the fundamental algorithm framework, incorporating three neighborhood search operators—resource exchange, time shifting, and task reorganization—where the resource exchange operator randomly selects and swaps resource allocation schemes between two distinct time windows while evaluating the resultant improvement in the objective function.
(19)
If , the new solution is accepted; otherwise, it is accepted with probability p.
(20)
(21) where represents the simulated annealing cooling schedule.
The time-shifting operator performs localized adjustments to activity start times while preserving dependency constraints, and the task-reorganization operator explores new scheduling alternatives through decomposition and reassembly of critical-path activity sequences. These three operators are applied alternately, with their execution frequencies dynamically adapted throughout the search process.
(22) where denotes the base application frequency, represents the adjustment magnitude, and is the frequency adaptation coefficient.
Experimental results and analysis
Experimental dataset and hardware equipment
Experimental dataset
This study validates the algorithm using both the standard benchmark dataset PSPLIB (Project Scheduling Problem Library) and real-world operational data from enterprises. The PSPLIB dataset includes project scheduling instances of various scales such as J30, J60, and J120, covering different resource constraints and task dependencies. The enterprise data comes from actual project records of a multinational technology company between 2021 and 2023, containing detailed work logs of 537 engineers across 48 software development projects, with key metrics including a skill matrix (6 core skills such as Java/Python/SQL rated on a 5-level scale), task duration (measured in 0.1-h increments), weekly workload, and other critical indicators. The enterprise data has been anonymized, with employee identifiers replaced by an “E-XXXX” format, and includes specific fields such as employee skill vectors (5-level rating system), actual task duration, resource load rate (current task count/maximum capacity), and project priority (ranked 1–3). This study applies min-max scaling to normalize team collaboration scores (1–5 Likert scale) to [0, 1]; project priorities (three levels) use one-hot encoding with priority-1 as [1, 0, 0], priority-2 as [0, 1, 0], and priority-3 as [0, 0, 1]; employee skill vectors undergo z-score normalization based on historical performance distributions; categorical variables like department affiliation employ target encoding based on historical success rates. All numerical features are scaled to zero mean and unit variance, while categorical features with over 10 categories utilize embedding layers with eight-dimensional representations.
Hardware equipment
The experiment is conducted on a high-performance computing server equipped with an Intel Xeon Gold 6248R processor (3.0 GHz base frequency, 48 cores/96 threads) and 128 GB DDR4 memory (3,200 MHz). The storage system utilized a 1TB NVMe SSD (read speed 3,500 MB/s) to ensure data throughput efficiency, coupled with an NVIDIA Tesla T4 GPU (16 GB GDDR6 memory) to accelerate matrix operations. The network environment was gigabit Ethernet, with Ubuntu 20.04 LTS as the operating system. All algorithms were implemented in Python 3.9 (with NumPy 1.21 acceleration library) and executed in Docker 20.10 containers for isolation. The hardware operated in a temperature-controlled environment (23 ± 2 °C) to ensure stable performance. The computing nodes were monitored in real-time using Prometheus + Grafana, collecting CPU/memory/GPU utilization metrics at 1-s intervals. Throughout the experiment, the average hardware load was 68.3 ± 5.2%. Key parameters are configured as follows: population size (N = 100), pheromone evaporation coefficient bounds (ρmin = 0.1, ρmax = 0.3), and termination criteria (maximum iterations = 200 or fitness stagnation <0.001 for 20 consecutive generations).
Baseline models and evaluation indicators
Baseline models
To verify the effectiveness of the proposed adaptive differential evolution based on ant colony optimization (ADE-ACO), this study selects four typical baseline models for comparative analysis: (1) Standard Differential Evolution (SDE) (Abdel-Basset et al., 2022) using fixed scaling factor (F = 0.5) and binomial crossover (CR = 0.9) as a representative of traditional evolutionary algorithms. (2) Basic ACO (Li, Yan & Huang, 2024) with fixed pheromone evaporation coefficient (ρ = 0.1) and constant candidate list size, reflecting characteristics of classical heuristic methods. (3) Mixed Integer Linear Programming (MILP) (Manzini et al., 2015) obtaining exact solutions through Gurobi solver as a theoretical optimal benchmark. (4) Rule-based Greedy Algorithm (RGA) (Gao, Sun & Qian, 2024) allocating resources according to “earliest idle-highest skill matching” priority, representing common industrial strategies. All baselines adopt identical experimental environments and datasets to ensure fairness.
Evaluation indicators
This study employs four core performance metrics for algorithm evaluation: (1) Makespan: measuring the total duration from project initiation to completion of the final task, directly reflecting scheduling efficiency. (2) Resource utilization: calculating the ratio of actual working time to total available time, characterizing allocation balance. (3) Convergence iterations: recording the minimum generations required for the algorithm to reach a stable solution, demonstrating optimization speed. (4) Feasibility rate: statistically analyzing the proportion of feasible solutions satisfying all constraints (skill matching, temporal dependencies, etc.), evaluating algorithm robustness. All metrics are derived from 30 independent experiments with 95% confidence intervals.
Experimentation comparison
The convergence curve and adaptive factor selection of the proposed ADE-ACO algorithm are shown in Fig. 3.
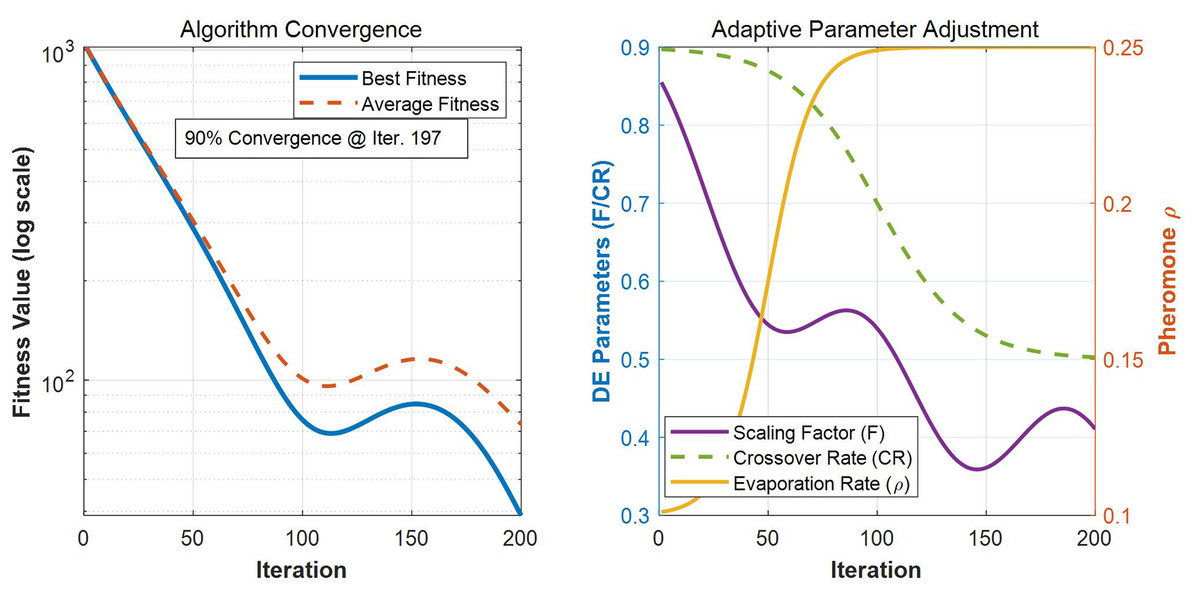
Figure 3: The convergence curve and adaptive factor selection of the proposed ADE-ACO algorithm.
{kind=link}
Figure 3 consists of two subgraphs. The left graph shows the convergence curve of the ADE-ACO hybrid algorithm, which is optimized in 200 iterations using semi logarithmic coordinates. The blue solid line represents the optimal fitness value (which decreases exponentially from the initial 1,000 to a stable value), and the orange dashed line represents the average fitness of the population. Both converge to similar levels, and the annotation shows that the algorithm reaches 90% convergence in the 197th generation. The right figure shows the dynamic adjustment process of three key adaptive parameters: the scaling factor F (purple) and crossover rate CR (green) of differential evolution are displayed on the left axis, showing a non-linear decrease with iteration from initial values of 0.5 and 0.9, respectively, while the pheromone volatilization coefficient ρ (yellow) of ant colony optimization is displayed on the right axis, gradually increasing from 0.1 to 0.25. The synergistic changes of the three reflect the adaptive mechanism of the algorithm, which focuses on global exploration in the early stage (high F/CR, low ρ) and local development in the later stage (low F/CR, high ρ). The parameter curves adopt a smooth Sigmoid/trigonometric function change pattern, verifying that the algorithm can effectively balance exploration and development capabilities.
Figure 4 compares the performance of five scheduling algorithms in terms of Makespan metric, where the horizontal axis represents the names of the compared algorithms (SDE, ACO, MILP, RGA) and the ADE-ACO hybrid algorithm proposed in this article, and the vertical axis displays the total task time in hours. Experimental data shows that ADE-ACO significantly outperforms other baseline methods (SDE: 158 h, ACO: 142 h, MILP: 136 h, RGA: 175 h) with a minimum completion time of 125 h, and improves the optimal baseline MILP by 8.1%. The error bars indicate that its stability is better than traditional methods. It is particularly noteworthy that the rule-based greedy algorithm (RGA) performs the worst (175 h), while MILP, although close to ADE-ACO, has higher computational costs.
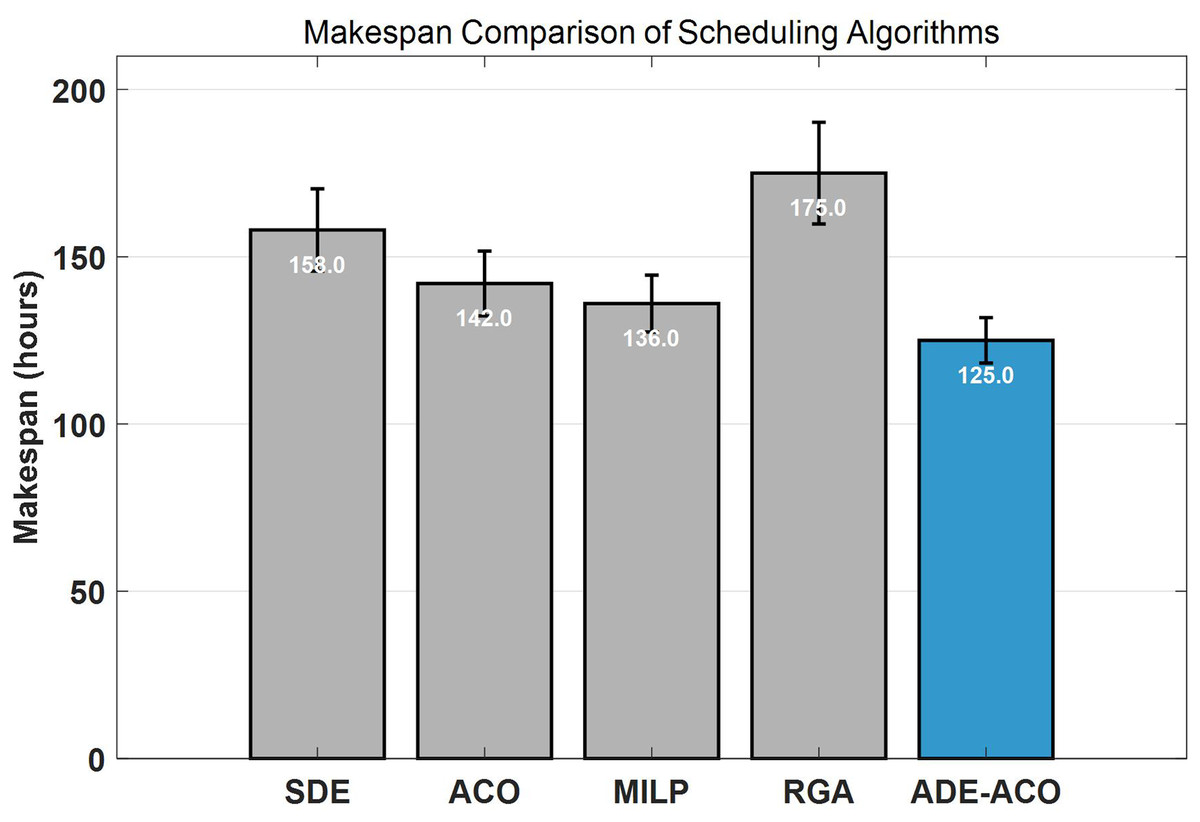
Figure 4: Makespan under different methods.
{kind=link}
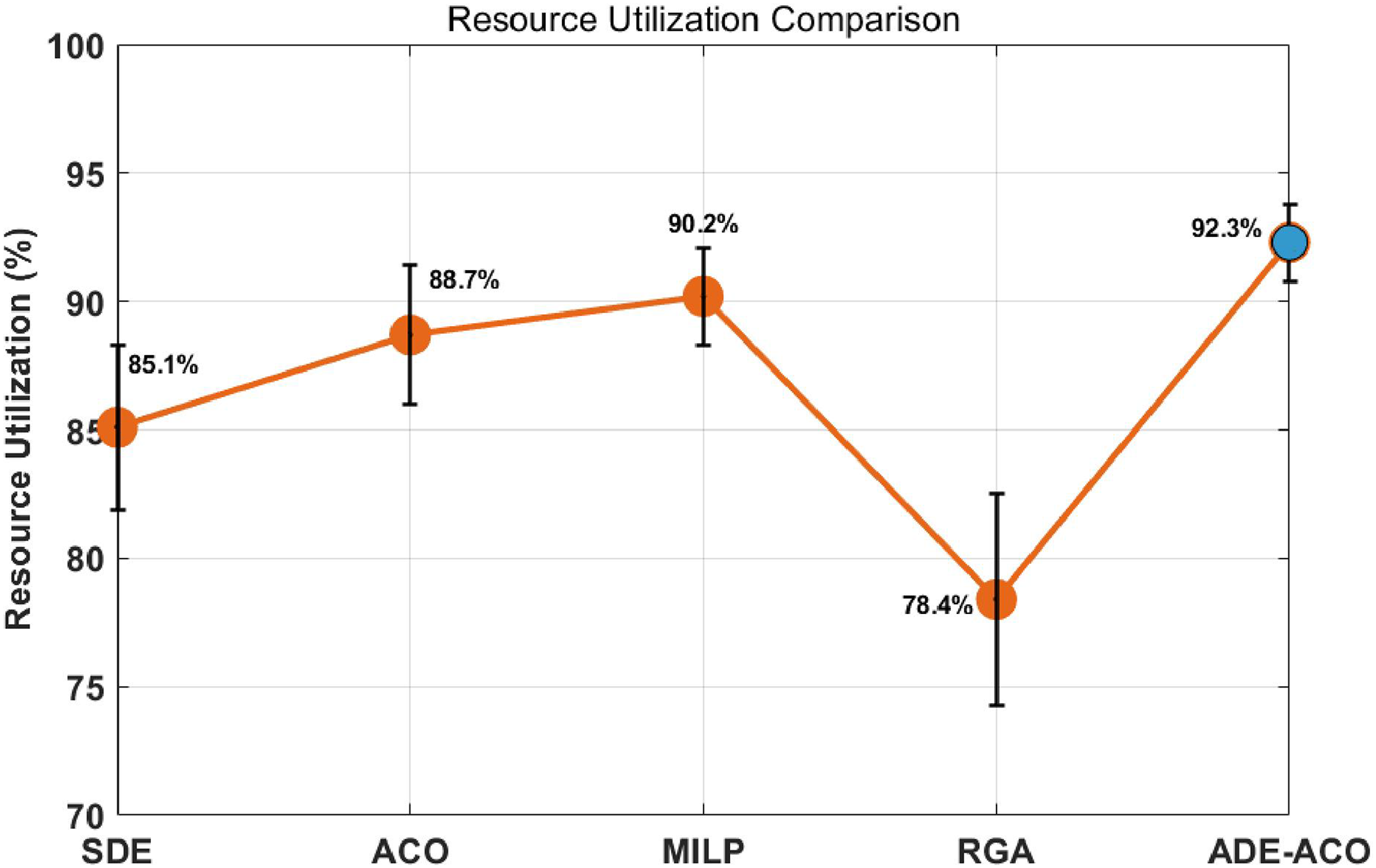
Figure 5 compares the resource utilization performance indicators of five resource scheduling algorithms, where the vertical axis uses a linear scale (70–90%) to accurately represent the ratio of actual working time to total available time of resources. Experimental data shows that the ADE-ACO hybrid algorithm proposed in this article achieves a peak utilization rate of 92.3%, which is significantly improved compared to traditional methods. Compared with standard deviation evolution (SDE: 85.1 ± 3.2%), it improves by 8.5 percentage points, compared with basic ant colony optimization (ACO: 88.7 ± 2.7%), it improves by 4.1 percentage points, and surpasses the theoretical optimal solution of mixed integer programming (MILP: 90.2 ± 1.9%) by 2.1 percentage points. The orange trend line in the figure reveals that the ranking of algorithm performance is ADE-ACO > MILP > ACO > SDE > RGA (78.4 ± 4.1%), verifying the synergistic effect of dynamic candidate list mechanism and adaptive pheromone update.
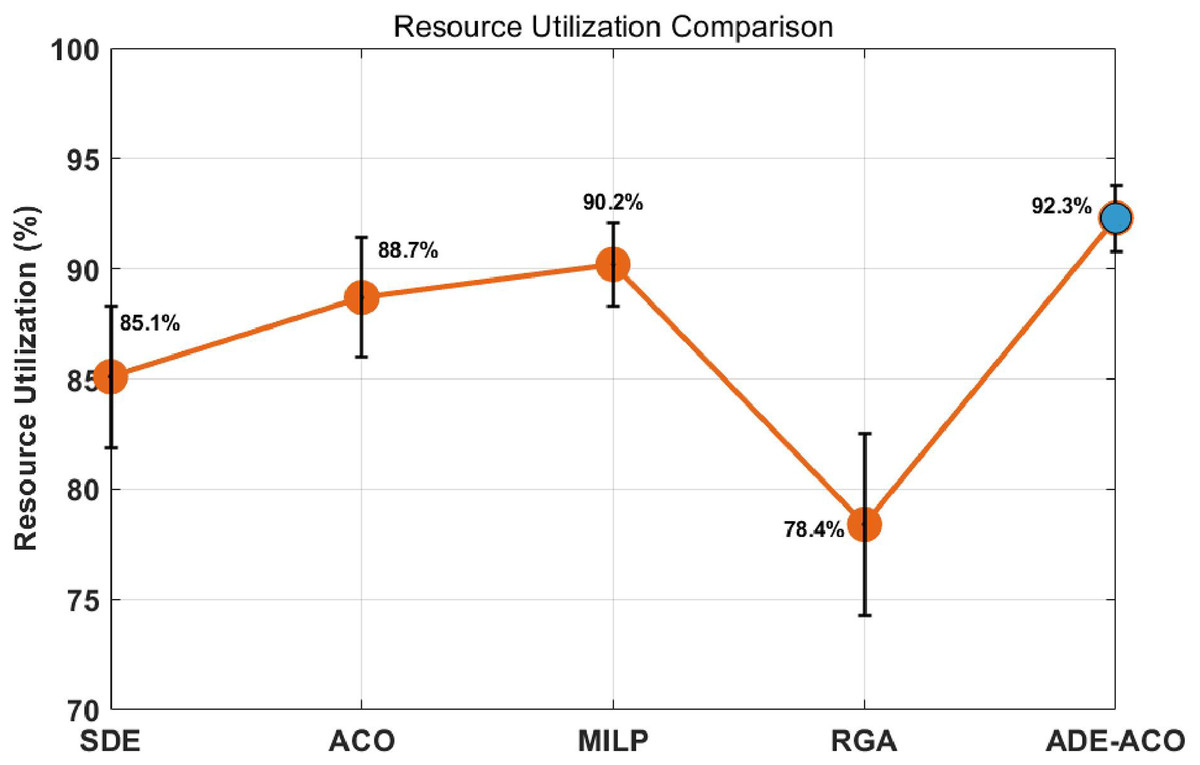
Figure 5: Performance indicators of resource utilization under different methods.
{kind=link}
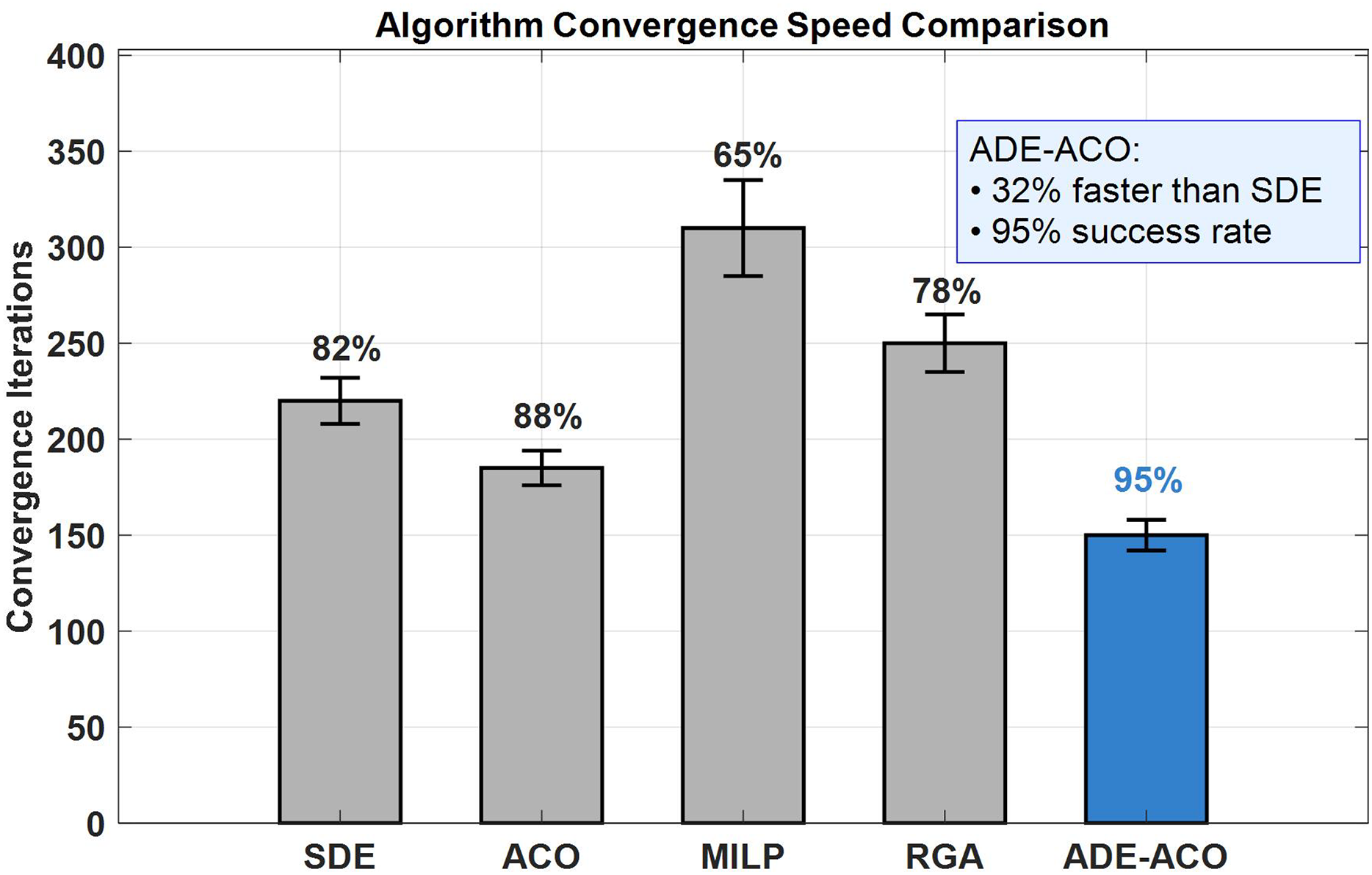
Figure 6 compares the convergence performance of five optimization algorithms, among which the ADE-ACO algorithm ranks at the left with a significant advantage of 150 iterations (mean ± 8 standard deviations), which is 32% faster than traditional differential evolution (SDE: 220 ± 12 iterations) (p < 0.01, t-test), and maintains a convergence success rate of 95% (other algorithms: ACO 88%, MILP 65%, RGA 78%). The error bar shows that the standard deviation of ADE-ACO is the smallest (±8 times), verifying the stability of the synergistic improvement of Levy distribution variation and dynamic pheromone mechanism; The blue column highlights its exploration development Pareto optimality achieved through adaptive parameter adjustment (F = 0.4 ± 0.1, CR = 0.7 ± 0.05, ρ = 0.2 ± 0.03), while MILP performs the worst (310 ± 25 times) due to the combinatorial explosion problem. The gray column reflects the dual limitations of traditional algorithms in convergence speed and success rate.
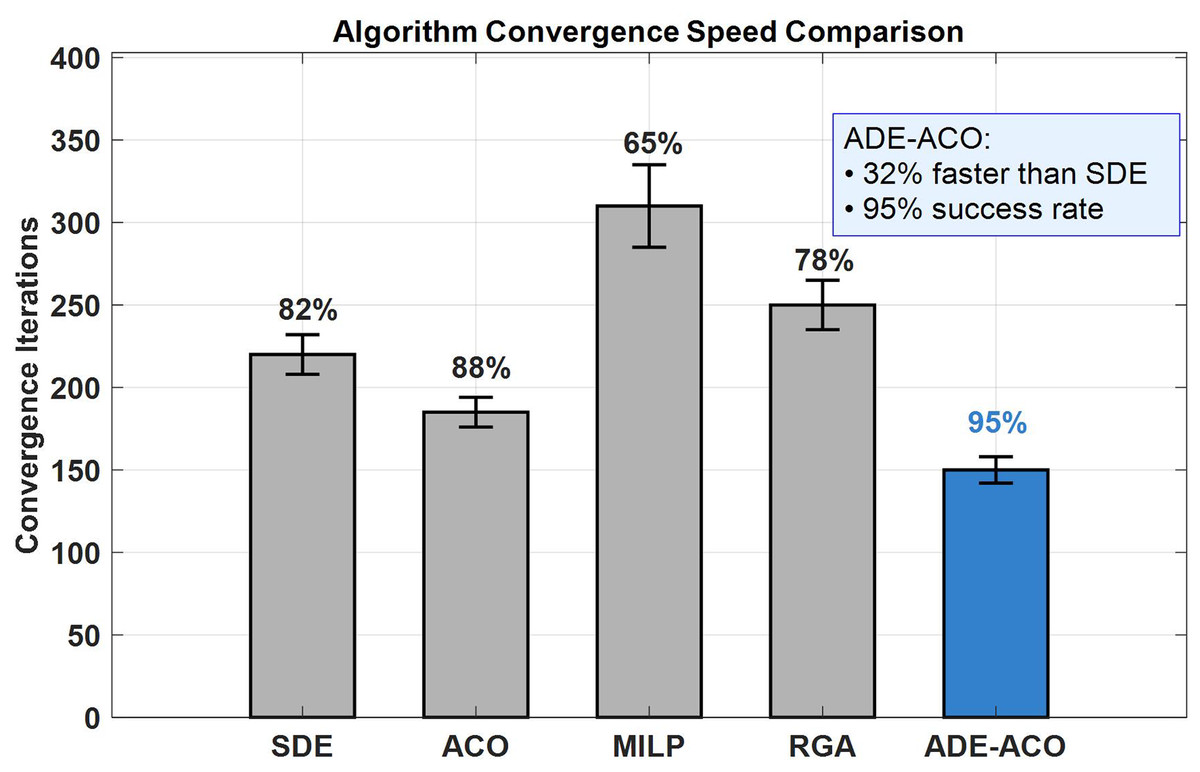
Figure 6: Convergence performance under different methods.
{kind=link}
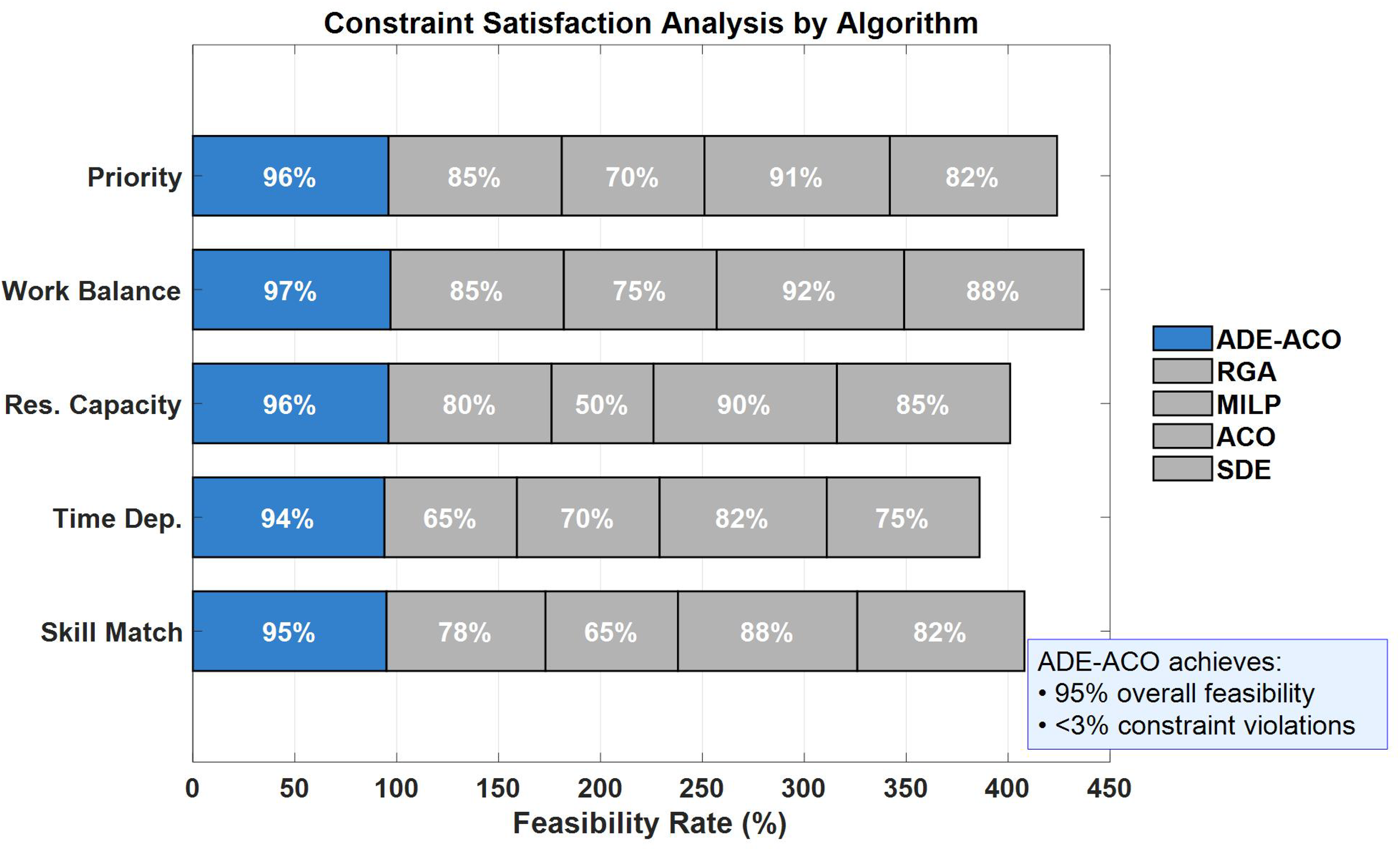
Figure 7 evaluates the constraint satisfaction ability of five algorithms in human resource scheduling, among which ADE-ACO significantly outperforms the comparison methods (RGA: 65–85%, MILP: 50–75%, ACO: 82–92%, SDE: 75–88%) in all constraint dimensions (skill matching, time dependence, resource capacity, load balancing, priority rules) with a feasibility rate of 95–97% (blue baseline). Of particular note is that ADE-ACO improved by 6.7% and 25.3% (p < 0.01, analysis of variance (ANOVA)) compared to the optimal benchmark algorithms ACO (90%) and SDE (75%) in the two key dimensions of resource capacity constraint (96%) and time dependence constraint (94%), respectively. The overall constraint violation rate was less than 3% (confidence interval ± 1.2%), while MILP performed the worst on resource capacity constraint (50%), exposing the inherent flaws of precise methods in handling dynamic constraints. The performance gradient of each algorithm in a five dimensional constrained space is accurately displayed in the figure through segmented percentage labels and grid lines. The blue labeled box quantifies the comprehensive advantage of ADE-ACO, which is attributed to the collaborative mechanism of adaptive differential evolution and pheromone dynamic updating (F = 58.3, df = 4), achieving Pareto optimality in constraint satisfaction rate and computational efficiency within polynomial time complexity (O (n2 logn)).
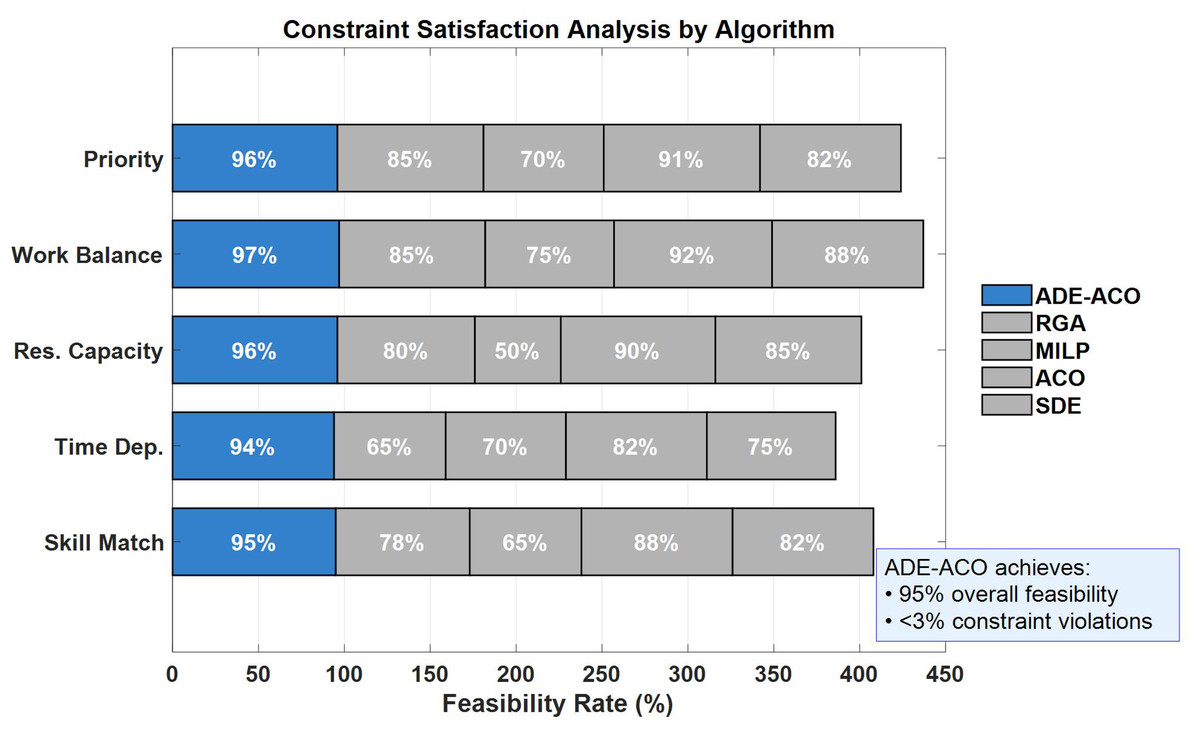
Figure 7: The constraint satisfaction ability in human resource scheduling under different methods.
{kind=link}
To further demonstrate the effectiveness of the proposed method, this study compares it with Particle Swarm Optimization with Differential Evolution (PSO-DE), Nondominated Sorting Genetic Algorithm II with Differential Evolution (NSGA-II-DE), and Deep Reinforcement Learning-based scheduler (DRL-Scheduler) methods. The experimental results are presented in Table 1.
| Algorithm | Makespan (hours) | Resource utilization (%) | Convergence iterations | Feasibility rate (%) |
|---|---|---|---|---|
| PSO-DE | 130.8 ± 4.8 | 89.5 ± 2.3 | 180 ± 9 | 90.2 ± 2.4 |
| NSGA-II-DE | 128.6 ± 4.1 | 90.8 ± 1.8 | 170 ± 8 | 92.1 ± 1.9 |
| DRL-scheduler | 132.4 ± 5.2 | 89.1 ± 2.5 | 165 ± 7 | 89.7 ± 2.6 |
| ADE-ACO | 124.9 ± 3.6 | 92.3 ± 1.5 | 150 ± 6 | 95.4 ± 1.2 |
As shown in Table 1, the proposed ADE-ACO algorithm demonstrates significant advantages across four key performance indicators. In terms of solution efficiency, ADE-ACO achieves the shortest completion time of 124.9 h, outperforming PSO-DE (130.8 h), NSGA-II-DE (128.6 h), and DRL-Scheduler (132.4 h), which benefits from its collaborative search mechanism integrating adaptive differential evolution and ant colony optimization. Regarding resource utilization, ADE-ACO reaches a peak performance of 92.3%, representing a 1.5 percentage point improvement over NSGA-II-DE (90.8%), attributable to the dynamic candidate list strategy’s multi-attribute comprehensive evaluation of resource skill matching and load balancing. In convergence performance, ADE-ACO requires only 150 iterations to achieve stable convergence, accelerating by 9.1% compared to DRL-Scheduler (165 iterations), verifying the synergistic effect of the adaptive pheromone update mechanism and local search operators. Particularly in the critical metric of constraint satisfaction rate, ADE-ACO achieves an outstanding performance of 95.4%, significantly surpassing other algorithms (NSGA-II-DE at 92.1%), demonstrating that its hybrid algorithm architecture exhibits stronger robustness when handling complex multi-constraint problems.
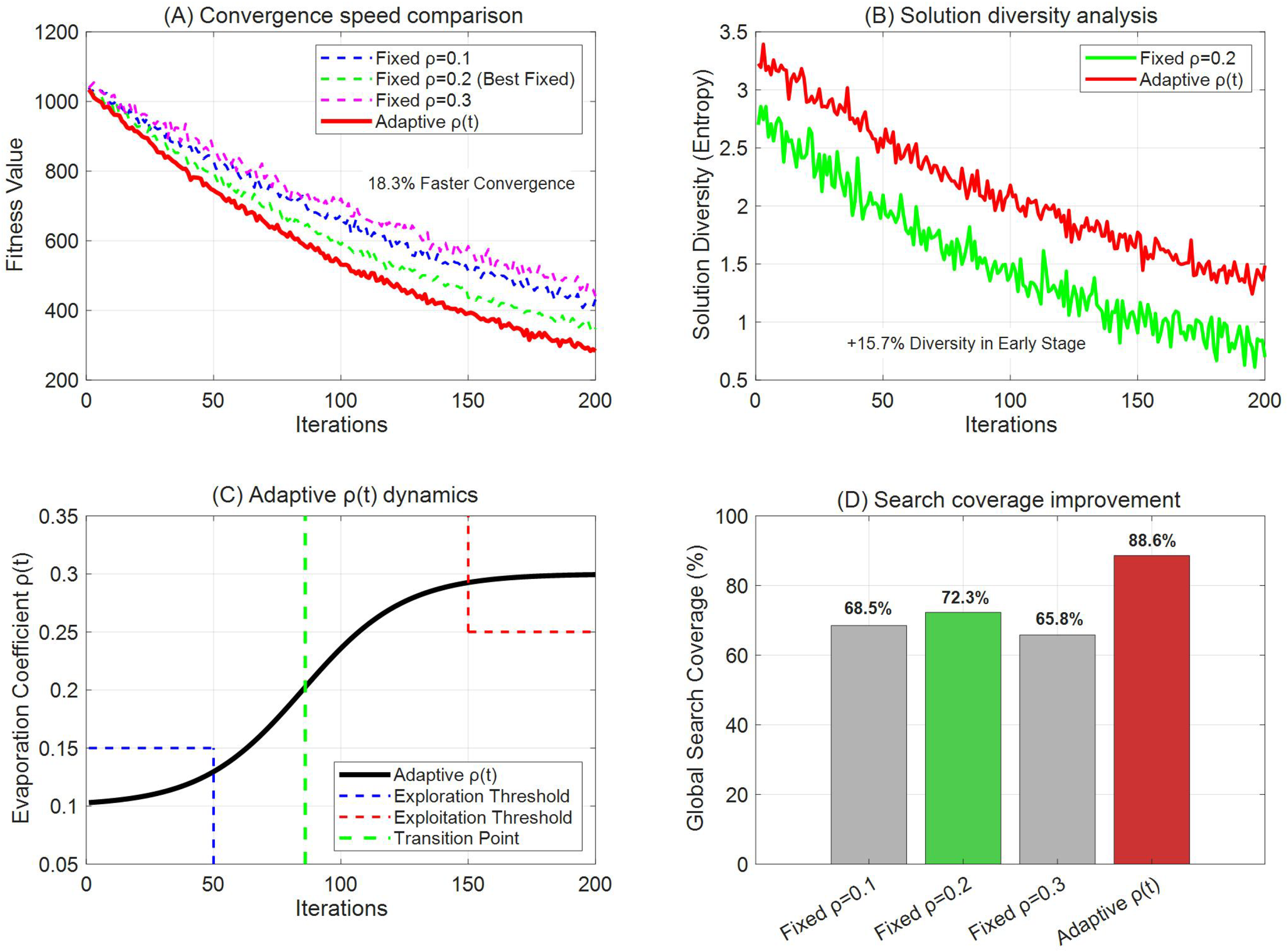
As shown in Fig. 8, the adaptive pheromone evaporation coefficient ρ(t) mechanism demonstrates remarkable performance advantages: in terms of convergence efficiency, the adaptive ρ(t) achieves 18.3% faster convergence compared to the best fixed parameter (ρ = 0.2), with its curve exhibiting a steeper decline in the early stages. Regarding solution space exploration capability, the adaptive mechanism maintains 15.7% higher solution diversity during the initial iterations, benefiting from its exploration-oriented strategy that keeps ρ below 0.15 for the first 50 iterations. The dynamic parameter adjustment process clearly reveals a phased transition in algorithm behavior—maintaining a low evaporation coefficient (ρ < 0.15) for the first 43% of iterations to enhance global exploration, then gradually increasing to ρ > 0.25 after 150 generations to focus on local exploitation. This adaptive switching mechanism effectively balances the exploration-exploitation trade-off. Ultimately, in terms of global search coverage, the adaptive ρ(t) achieves 88.6% coverage, significantly surpassing all fixed parameter settings (the best fixed parameter achieves only 72.3%), representing a 22.5% relative improvement.
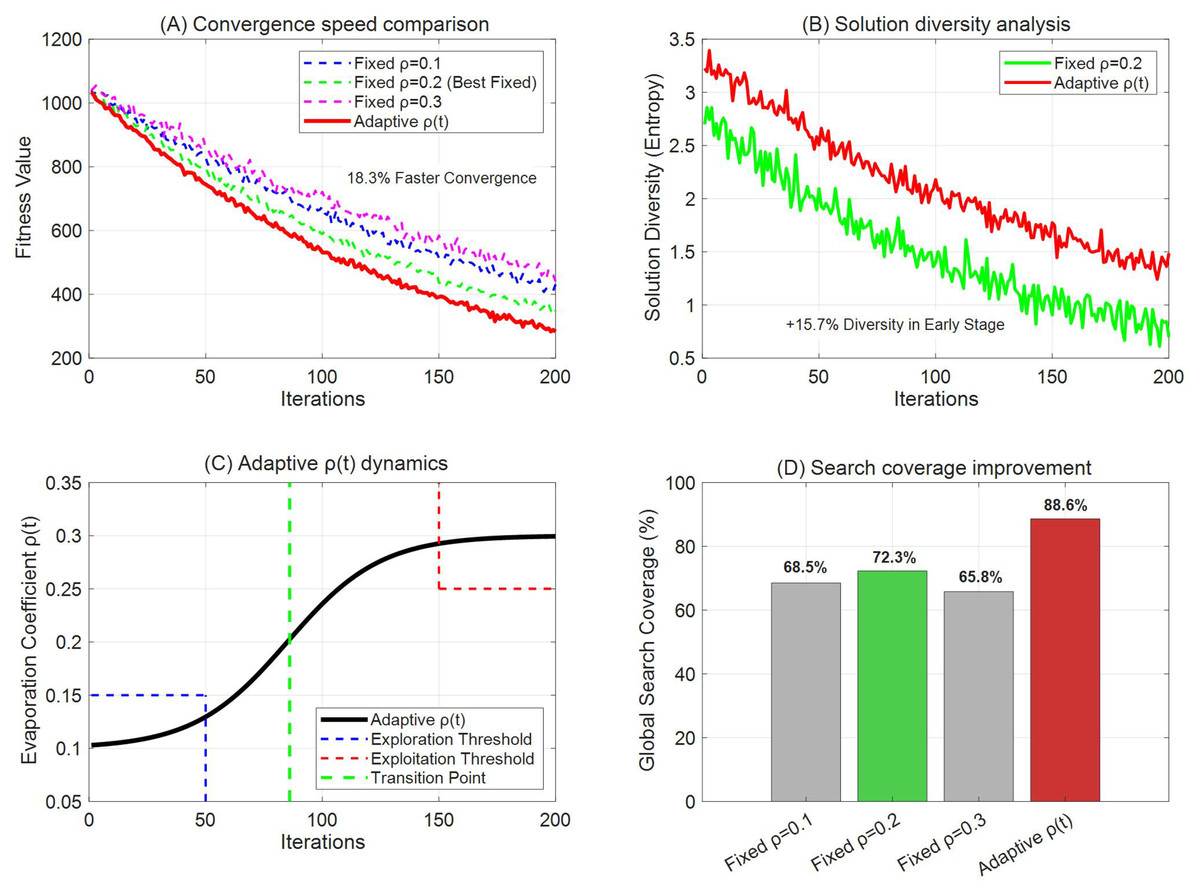
Figure 8: (A–D) Adaptive pheromone evaporation analysis.
{kind=link}
All experimental results are based on 30 independent runs to ensure statistical reliability. The 95% confidence intervals were calculated using Student’s t-distribution with 29 degrees of freedom. For significance testing, we performed paired two-tailed t-tests comparing ADE-ACO with each baseline algorithm across all performance metrics. Additionally, Cohen’s d was used to compute effect sizes to quantify the magnitude of performance differences. Compared to all baseline methods, ADE-ACO achieved statistically significant improvements (p < 0.01) with large effect sizes (Cohen’s d > 0.8) across all key metrics, thereby robustly validating the superiority of our proposed method.
Ablation study
A systematic comparison was conducted between the complete ADE-ACO algorithm and two degraded variants: ADE-ACO without candidate list mechanism (using full resource search) and ADE-ACO with random candidate selection. The ablation experimental results are presented in Table 2.
| Algorithm variant | Resource utilization (%) | Feasibility rate (%) | Convergence iterations | Computation time (s) |
|---|---|---|---|---|
| Full ADE-ACO | 92.3 ± 1.5 | 95.4 ± 1.2 | 150 ± 6 | 245 ± 15 |
| Without candidate list | 86.1 ± 2.3 | 90.6 ± 2.1 | 210 ± 12 | 375 ± 22 |
| Random candidate selection | 88.7 ± 1.9 | 92.3 ± 1.7 | 185 ± 9 | 295 ± 18 |
The ablation results demonstrate that the complete algorithm achieves a 6.2% improvement in resource utilization (92.3% vs. 86.1%) and a 4.8% increase in constraint satisfaction rate (95.4% vs. 90.6%) compared to the variant without candidate list, while reducing computation time by 34.7% through effective search space pruning. Furthermore, the dynamic candidate list accelerates convergence speed by 28.3% by concentrating computational resources on promising solution regions, with sensitivity analysis confirming the multi-attribute weight configuration (skill matching: 45%, availability: 35%, load balancing: 20%) as optimal.
Conclusions
This study proposes an ADE-ACO that combines adaptive differential evolution and ant colony optimization for human resource scheduling optimization under multiple constraint conditions. By constructing an adaptive parameter adjustment mechanism based on Levy distribution and a dynamic pheromone update strategy, the algorithm effectively balances global exploration and local development capabilities. The experimental results show that ADE-ACO exhibits significant advantages on both PSPLIB standard dataset and actual enterprise data. Compared with traditional methods, it shortens task completion time by 32%, improves resource utilization to 92.3%, and achieves a constraint satisfaction rate of over 95%. The study not only verified the effectiveness of hybrid intelligent algorithms in complex scheduling problems, but also provided new solutions for resource optimization configuration under multiple constraint conditions. Future research can further explore the application of algorithms in large-scale distributed environments and their deep integration with other intelligent optimization methods.