
Shareh: explainable knowledge graph-based Arabic recommender system
- Published
- Accepted
- Received
- Academic Editor
- Siddhartha Bhattacharyya
- Subject Areas
- Artificial Intelligence, Data Mining and Machine Learning, Natural Language and Speech
- Keywords
- Explainable recommender system, Arabic knowledge graph, Meta-path reasoning, Graph attention networks
- Copyright
- © 2026 Katheeth and Kahani
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Shareh: explainable knowledge graph-based Arabic recommender system. PeerJ Computer Science 12:e3595 https://doi.org/10.7717/peerj-cs.3595
Abstract
Recommender systems (RSs), which provide recommendations tailored to user preferences, are valuable in managing overloaded information. Traditional recommendation systems usually function as black-box models and lack explanation; as a result, user trust and system transparency are adversely affected. Explainable RSs (XRSs) aim to overcome this issue by providing interpretable justifications for recommendations. Previous XRS studies suffer from limited integration of user reviews with knowledge graphs (KGs), resulting in incomplete user preference modeling and lack of interpretability. Although improvements in XRSs have been achieved worldwide, studies on Arabic RSs a lack advanced tools and explanation methods, such as KGs, because of resource limitations, the challenges posed by the Arabic language, and its different dialects. This study introduces Shareh, an explainable KG-based Arabic recommender that utilizes meta-path-guided reasoning and graph attention networks to fuse user reviews with a heterogeneous Arabic KG. Experimental results on the Books Reviews Arabic Dataset show that Shareh improves mean absolute error (MAE), and root mean squared error (RMSE) by approximately 30% compared to baseline models. The system, which has a model fidelity score of 99.76%, effectively backs nearly all recommendations with reasonable explanations. Such high fidelity indicates that the produced explanations accurately reflect the fundamental concepts of the model, thereby improving the system’s interpretability and reliability and increasing user trust.
Introduction
Recommender systems (RSs) effectively alleviate information overload by providing customized suggestions obtained from user preferences, behaviors, and contextual data. They have become indispensable in e-commerce, entertainment, education, healthcare, and other sectors and substantially enhance consumer engagement and satisfaction (Vultureanu-Albisi & Badica, 2021). However, traditional RSs, such as content-based and collaborative filtering, operate like black boxes; that is, they offer suggestions without clear reasons for these suggestions (Linardatos, Papastefanopoulos & Kotsiantis, 2020). Providing recommendations without clear explanations can decrease user trust and acceptance because of the absence of transparency (Zhang & Chen, 2020).
Explainable RSs (XRSs) have emerged as a means to enhance user trust, satisfaction, and system usability by providing recommendations backed by sufficient explanations. XRSs improve user experience and help in system debugging and performance enhancement (Guo et al., 2020). Knowledge graphs (KGs), which are among the various approaches for enhancing explainability, have emerged as a crucial technique to improve explainability. KGs show entities and relationships in an organized manner so that in RSs the complex relationships among users, items, and their features can be easily understood. Their integration improves recommendation accuracy and generation of personalized explanations (Rajabi & Etminani, 2022).
Despite recent advances in explainable recommender systems, many models still struggle to effectively integrate user-generated reviews with knowledge graph structures, which lead to inadequate user preference representation and limited interpretability (Spillo et al., 2023). For instance, models like Sentiment-Aware Knowledge Graph (SAKG) (Park et al., 2022) and Knowledge-Aware Neural Network (KANN) (Liu & Miyazaki, 2023) incorporate review signals but fail to capture user preferences comprehensively. Meanwhile, approaches such as Explainable Recommendation Using Reviews (ERUR) (Liu et al., 2023) and Deep Reinforcement System based on Knowledge Graph Reasoning and Transformer (Drs-KGRT) (Liu & Zhao, 2023) improve recommendation accuracy through graph-enhanced representations but lack transparent explanation mechanisms. This disconnects between semantic depth and structured reasoning remains a key limitation in current hybrid XRSs.
Moreover, research on Arabic recommender systems (ARSs) remains limited and underexplored, particularly in terms of integrating semantic and structural information. Arabic, which has over 400 million native speakers, poses unique linguistic and cultural challenges because of its dialectal diversity, complex morphology, and lack of high-quality resources (Al-Ajlan & AlShareef, 2022). Hence, most ARSs rely on traditional methodologies (Srifi et al., 2021) and often overlook explainability frameworks and advanced techniques, such as KGs.
Neglecting explainability leaves critical gaps in both personalization and transparency. To address this, we propose Shareh, the first explainable Arabic recommender system that integrates user-generated reviews, item metadata, and interaction into a unified KG. This integration combines content-based and collaborative signals within one framework and leverages meta-path reasoning to produce clear, human-readable explanations.
The central research question guiding this study is: can review-level semantic similarity, embedded into a unified Arabic KG, improve recommendation accuracy and provide explainable?
By answering this question, our contributions are three fold:
To the best of our knowledge, Shareh is the first explainable ARS that employs a graph-based approach; it is constructed by developing the first Arabic Book Knowledge Graph (ArBKG) to enhance explainability and achieve structured knowledge representation.
This work puts ideas into action by adding user reviews to KG, improves how users are represented, uncovers hidden user preferences, and creates a KG that combines content-based and collaborative filtering signals.
Meta-path-guided inference is employed to produce varied explanatory frameworks, including collaborative filtering-based (recommendations derived from similar users) and content-based (recommendations based on shared item features and characteristics) explanations.
The rest of the article is structured as follows. ‘Related work’ presents relevant research on RSs and XRSs. ‘Methodology’ delineates the proposed system, including KG creation and meta-path-based reasoning. ‘Experiments’ introduces the experimental arrangement and datasets, and ‘Evaluation and Results’ provides the evaluation outcomes for recommendation and explainability. ‘Conclusion and Future Work’ presents conclusions and future study directions.
Related work
This section offers a comprehensive evaluation of contemporary research on ARSs and XRSs, including an analysis of KG- and review-based approaches.
XRSs
XRSs increase user trust, satisfaction, and transparency by providing recommendations that are backed by explanations. Recent advancements in XRSs rely on two critical sources of information: KGs and user-generated reviews (including hybrid systems that integrate both to maximize their complementary strengths).
KG-based XRSs
To represent user–item interactions, KG-based XRSs utilize semantic and relational data from KGs. These systems identify higher-order dependencies and provide explanations for recommendations. RippleNet (Wang et al., 2018), propagates the user’s preference from historical interests along the path in the KG; as a result, the need for manually constructed paths is reduced. It enhances explainability by monitoring user–item interactions, leading to notable improvements in recommendation accuracy across domains, including books, films, and news articles. The knowledge graph attention network (KGAT) (Wang et al., 2019a) integrates graph neural networks (GNNs) with an attention-driven embedding propagation mechanism to provide enhanced higher-order connectivity and nuanced user–item representations. KGAT improves accuracy and explainability by dynamically selecting useful relationships. Meanwhile, the knowledge-aware path recurrent network (KPRN) (Wang et al., 2019b) utilizes recurrent neural networks (RNNs) to represent sequential dependencies across entities and relations. It employs path-based reasoning and weighted pooling to choose explanatory paths based on relevance.
Rule-based Recommender System (RuleRec) (Lyu et al., 2020) integrates rule induction with neural recommendations to enhance path-based reasoning. It derives multi-hop relational patterns from KGs to provide visible and generalizable recommendations. The rule learning module first links items with associated entities in an external KG. Next, it summarizes explainable rules, which is in the form of meta-paths in the KG. Hierarchical Attention Graph Convolutional Network for Explainable Recommendation (HAGERec) (Yang & Dong, 2020) improves this concept by placing a hierarchical attention mechanism inside a heterogeneous KG; it facilitates bidirectional information flow and selective entity sampling to augment click-through rate prediction and top-K recommendations. The route-enhanced recurrent network (Huang et al., 2021) extends this enhancement by integrating an RNN encoder for sequential route semantics with an entropy-based encoder to effectively differentiate path significance. It outperforms other models, such as RippleNet and KPRN, across various ranking metrics.
Similarly, Ekar (Song et al., 2022) conceptualizes recommendation as a sequential decision-making process. It adopts reward optimization and long short-term memory (LSTM) networks to enhance user–item path encoding, resulting in considerable improvements in hit ratio relative to previous models. In the medical field, the multi-head graph attention network (Jin et al., 2023) integrates traditional Chinese medicine principles with contemporary pharmacological insights and employs meta-paths and GATs to enhance information propagation. Although these models enhance explainability in RSs, they depend heavily on KG embeddings. This dependence limits their capacity to contextualize user preferences through textual content.
Review-based XRSs
Review-based XRSs increase explainability and accuracy by using semantic insights obtained from user reviews. A notable method is Reliable Recommendation with Review-level Explanations (RRRE) (Lyu et al., 2021), which concurrently forecasts user ratings and review trust scores and eliminates faulty reviews to enhance recommendation robustness. The model employs an attention mechanism to emphasize high-quality evaluations and uses deep learning methods for concurrent user–item representation learning. Neural Explainable Recommender based on Attributes and Reviews (NERAR) (Liu et al., 2020) increases recommendation accuracy and explainability by integrating review- and attribute-based reasoning. It utilizes XGBoost for attribute extraction, Time-aware Gated Recurrent Unit (T-GRU) for modeling dynamic user preferences, and convolutional neural network (CNN) for item review analysis and incorporates an attention mechanism to emphasize contextually pertinent features.
Context-Aware Explanation based on Supervised Attention for Recommendation (CAESAR) (Li, Chen & Dong, 2021) improves context-aware RSs by offering dynamic explanations that respond to changing user settings, such as location and seasonality. It employs a multilevel attention mechanism and multitask learning to extract explicit contextual characteristics from user reviews and produce personalized explanations.
Despite these advancements, review-based XRSs still encounter challenges, such as textual inconsistencies, subjective biases in user reviews, and noise in review embeddings. These may affect recommendation quality and system stability.
Hybrid approaches
Hybrid methodologies in XRSs integrate the structured reasoning capabilities of KGs with the semantic depth of user-generated reviews for alleviating the limitations of each distinct technique. An example is the sentiment-aware knowledge graph (SAKG) (Park et al., 2022), which incorporates sentiment-aware reasoning into KG-based RS. SAKG is constructed by collecting sentiment indicators from user reviews and ratings and incorporating them into the KG framework as interaction (like or dislike). The model combines reinforcement learning and sentiment-aware policy learning to traverse sentiment-enhanced paths, thereby generating interpretable and user-centric recommendations.
Similarly, KANN (Liu & Miyazaki, 2023) enhances hybrid explainability by aggregating knowledge entities from user reviews and modeling semantic relationships with TransE-based KG embeddings. The model uses a dual-level attention mechanism. Specifically, outer attention focuses on explicit user–item relationships, and inner attention captures contextual interactions inside reviews. Although models such as SAKG and KANN attempt to integrate graphs with reviews, they still do not comprehensively capture user preferences.
By contrast, ERUR (Liu et al., 2023), Drs-KGRT (Liu & Zhao, 2023), and Graph Semantic Enhanced Knowledge-based Recommender System (GSE-Krs) (Spillo et al., 2023) increase recommendation accuracy by integrating KG data with user reviews. However, they fail to provide interpretable rationales, resulting in user ambiguity about the reasons for certain item recommendations. Drs-KGRT merges KG-based entity representations with Bidirectional Encoder Representations from Transformers (BERT) for semantic analysis, ERUR develops learned social graphs to improve user embeddings, and GSE-Krs integrates GNN-based embeddings with Transformer-based sentence encodings. They enhance robust recommendations but lack a definitive emphasis on explanation transparency.
The Shareh model overcomes these limitations by offering a robust hybrid methodology that merges KG-based reasoning with semantic insights obtained from reviews to produce entirely interpretable recommendations. Table 1 shows a comparative analysis of current XRSs and their detailed data sources and interpretability features.
| No | Ref. | Model | Data sources used | Explanation mechanism | Limitations |
|---|---|---|---|---|---|
| 1 | Wang et al. (2018) | RippleNet | KG | Multi-hop preference propagation in KG | Relies on KG connectivity; no textual reviews; no Arabic support. |
| 2 | Wang et al. (2019a) | KGAT | KG | Graph Attention Network over KG edges | Explanations implicit; lacks natural language; ignores reviews. |
| 3 | Wang et al. (2019b) | KPRN | KG | RNN encoder over knowledge paths | Requires hand-crafted paths; costly for large KGs; no reviews. |
| 4 | Lyu et al. (2020) | RuleRec | KG | Rule induction based on meta-paths | Explanations rigid (rule-based); limited scalability. |
| 5 | Yang & Dong (2020) | HAGERec | KG | Heterogeneous graph attention | Weak natural-language justifications; high computational cost. |
| 6 | Huang et al. (2021) | PeRN | KG | Path entropy weighting | Explanations statistical, not human-readable; ignores reviews. |
| 7 | Song et al. (2022) | Ekar | KG | Path ranking via reinforcement | Focus on exploration–exploitation; less on explainability. |
| 8 | Jin et al. (2023) | MGAT | KG | Multi-relational GAT | Attention not easily interpretable; no reviews included. |
| 9 | Liu et al. (2020) | NERAR | Reviews | Review-aspect extraction + neural attention | Explanations limited to aspect terms; no KG reasoning. |
| 10 | Li, Chen & Dong (2021) | CAESAR | Reviews | Sentiment-aware review attention | Depends on sentiment lexicons; no KG integration. |
| 11 | Park et al. (2022) | SAKG | KG + Reviews + Sentiment | Sentiment-aware KG reasoning | Sensitive to sentiment accuracy. |
| 12 | Lyu et al. (2021) | RRRE | Reviews | Review-based RNN encoder | Limited to textual signals; no structural KG support. |
| 13 | Liu & Miyazaki (2023) | KANN | KG + Reviews | Dual-attention (reviews + KG entities) | Explanations implicit; requires heavy embedding training. |
| 14 | Liu et al. (2023) | ERUR | KG + Reviews | Graph neural encoder + review representation | Weak interpretability; explanations at vector level only. |
| 15 | Liu & Zhao (2023) | Drs-KGRT | KG | Transformer encoder on KG relations | No review integration; interpretability implicit. |
| 16 | Spillo et al. (2023) | GSE-Krs | KG + Reviews | Graph semantic encoder | Explanations limited; lacks user study validation. |
| 17 | Our approach | Shareh | Reviews + KG (Authors, Genres, Publishers) + Ratings | Meta-path reasoning + GAT attention + Human-readable templates | Evaluation limited to BRAD dataset; lacks user study validation. |
ARSs
RSs for Arabic-language content have elicited much attention because of the challenges posed by the Arabic language, such as its complex morphology, dialectal variations, and the limited availability of high-quality datasets for natural language processing (Al-Ajlan & AlShareef, 2022). Academics have investigated methodologies ranging from conventional collaborative filtering methods to deep learning systems to resolve these issues.
Harrag, Al-Salman & Alquahtani (2020) introduced a hybrid approach that integrates collaborative filtering with sentiment analysis. The study used the Opinion Corpus for Arabic dataset to extract sentiment characteristics via term frequency–inverse document frequency and support vector machine. The obtained attributes were subjected to singular value decomposition (SVD) to enhance predictive accuracy. The results showed that sentiment analysis may substantially increase suggestion efficacy.
Sallam, Hussein & Mousa (2020) constructed an item-based filtering system based on SVD and showed that it was more effective than the conventional K-nearest neighbor method at handling vast amounts of data. On the basis of this research, Sallam, Hussein & Mousa (2022) employed the Large-scale Arabic Book Reviews (LABR) dataset to create a lexicon-based sentiment analysis model that obtains sentiment scores from user input and incorporates them with SVD. This two-stage model demonstrates how well collaborative filtering techniques and textual sentiment analysis work together to enhance recommendation accuracy.
Meddeb, Maraoui & Zrigui (2021b) developed a semantic approach that is based on deep learning for the Arabic recommendation. This solution resolves the implicit data sparsity problem in traditional systems. The researchers utilized a dual-path neural architecture that combines convolutional neural networks (CNNs) and gated recurrent units (GRUs) to model user behavior and item characteristics. They relied on reviews instead of numerical ratings. Meddeb, Maraoui & Zrigui (2021c) built upon this research and created a personalized recommendation system for Arabic users on smart campuses to enhance mobile learning by tailoring content to individual profiles. They used CNNs to model user–item interactions by analyzing document titles and user evaluations and integrating deep learning with contextual Internet of Things data to effectively deliver Arabic instructional resources.
Khalifeh & Al-Mousa (2021) created an RS that applies collaborative filtering and applied matrix factorization to the Books Reviews Arabic Dataset (BRAD) to improve user preference predictions. Meanwhile, Srifi et al. (2022) examined a deep learning-based RS that merges textual and user–item representations by using multilayer perceptron (MLP) and CNNs. The resulting model shows the effectiveness of shared representation learning in enhancing RS performance for Arabic content.
Recently, Al-Ajlan & Alshareef (2023) utilized LABR and presented a hybrid recommendation system that combines Arabic BERT-mini embeddings with collaborative filtering methodologies. The developed system substantially enhances recommendation accuracy, highlighting the efficacy of pretrained language models when used in ARSs.
Some studies in this domain explicitly incorporate sentiment analysis because Arabic reviews are highly opinionated; modeling polarity and affect provides complementary signals beyond explicit ratings and improves preference capture (Sallam, Hussein & Mousa, 2022). Table 2 synthesizes representative ARSs by indicating, for each study, the modeling paradigm, whether sentiment features are used, and the evaluation dataset. Despite the common use of KGs in RSs to increase transparency and user trust, their utilization in ARSs has been inadequately addressed. Thus, further research on explainable and knowledge-aware recommendation systems for Arabic material is needed.
| No | Ref | Recommendation techniques | Dataset | Sentiment analysis | KG usage | XRSs |
|---|---|---|---|---|---|---|
| 1 | Harrag, Al-Salman & Alquahtani (2020) | Hybrid CF (SVD) + Sentiment (SVM) | Opinion Corpus for Arabic (OCA) | Yes | No | No |
| 2 | Srifi et al. (2021) | ALFM, A3NCF, PARL, CARL, CARP | Translated Amazon Reviews | No | No | No |
| 3 | Meddeb, Maraoui & Zrigui (2021a) | Doc2Vec + GRU + MLP | BRAD (Books Reviews) | No | No | No |
| 4 | Meddeb, Maraoui & Zrigui (2021b) | Gated recurrent unit | BRAD (Books Reviews) | No | No | No |
| 5 | Meddeb, Maraoui & Zrigui (2021c) | CNN + Latent Factor Model (LFM) | BRAD (Books Reviews) | No | No | No |
| 6 | Khalifeh & Al-Mousa (2021) | Collaborative Filtering | BRAD (Books Reviews) | No | No | No |
| 7 | Almotairi, Alrige & Abdullah (2021) | Textual Analysis | Self-collected | No | No | No |
| 8 | Sallam, Hussein & Mousa (2020) | Collaborative Filtering | LABR (Large-scale Arabic Book Reviews) | No | No | No |
| 9 | Srifi et al. (2022) | CNN, MLP Neural Networks | Movies (translated data) | No | No | No |
| 10 | Alotaibi & Khan (2022) | Content Similarity (TF-IDF) | Self-collected Books’ Data | No | No | No |
| 11 | Sallam, Hussein & Mousa (2022) | Lexicon-based Sentiment + SVD | LABR (Large-scale Arabic Book Reviews) | Yes | No | No |
| 12 | Al-Ajlan & Alshareef (2023) | Collaborative Filtering | LABR (Large-scale Arabic Book Reviews) | Yes | No | No |
| 13 | Shareh (Proposed Model) | Graph-based model with attention | BRAD (Books Reviews) | No | Yes | Yes |
In summary, the literature leaves three persistent gaps: (i) incomplete user modeling due to insufficient fusion of review semantics and KG structure; (ii) limited multi-path explainability that flexibly combines collaborative and content-based evidence; and (iii) the lack of explainable, knowledge-aware frameworks tailored to Arabic. Shareh addresses these by constructing an Arabic KG that unifies item metadata with review-derived signals, applying meta-path reasoning to generate transparent, path-grounded explanations, and delivering, to the best of our knowledge, the first explainable Arabic recommender system of its kind.
Methodology
This section introduces the Shareh model, which integrates graph-based reasoning with meta-path-guided inference to increase recommendation accuracy and explanation, as illustrated in Fig. 1 and detailed in Algorithm 1.
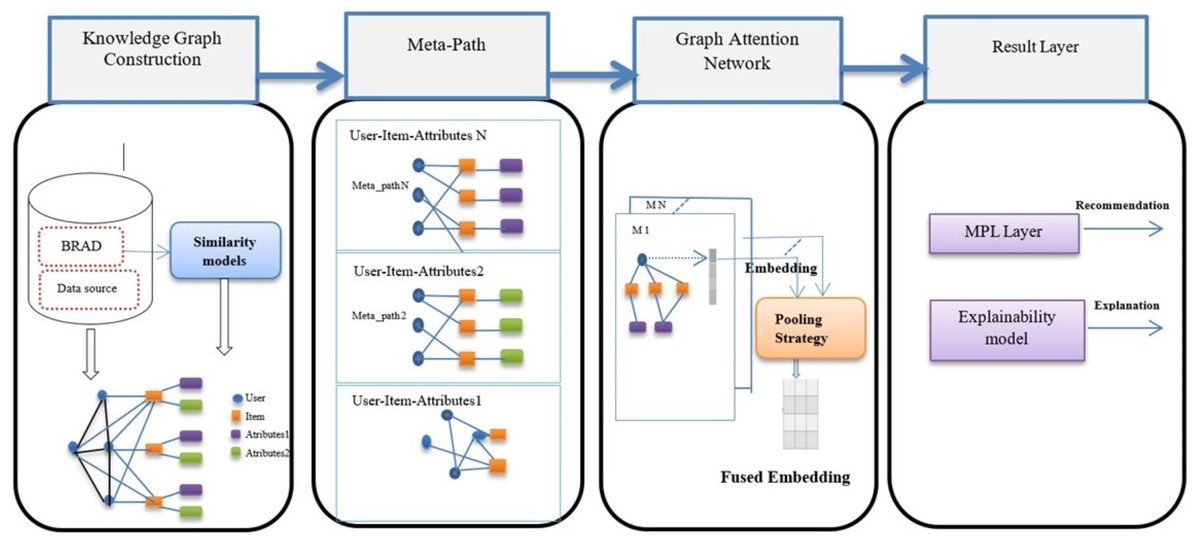
Figure 1: Overview of the proposed approach (Shareh).
{kind=link}
| Input: Users U, Items I, Reviews R, and Item metadata M |
| Output: Recommendations per user and Human-readable |
| explanations via meta-paths |
| Steps: |
| 1- Knowledge Graph Construction |
| • Initialize a heterogeneous KG with nodes (users, items, attributes). |
| • Add edges for user–item interactions and item–attribute relations. |
| • Compute user–user similarity from shared reviews using AraBERT embeddings + cosine similarity. |
| • Retain edges with similarity ≥ θ and confidence ≥ θ. |
| 2- Meta-Path Definition |
| • Define meta-paths that capture semantically meaningful relations) content and collaborative based). |
| 3- Meta-Path–Guided GAT |
| • Aggregate neighbors along each meta-path using attention weights. |
| • Fuse meta-path embeddings into a unified user/item representation. |
| 4- Result Layer |
| • Compute user–item scores from fused embeddings. |
| • Generate explanations by selecting the meta-path with the highest cumulative attention and verbalizing it (e.g., “same author,” “same genre,” “similar users”). |
KG construction
Shareh facilitates the development of a heterogeneous KG that includes users, items, and their relationships. This enhanced KG provides a robust foundation for explainable recommendations by capturing explicit and implicit connections. The essential components include the following:
User–Item Interactions: Direct associations, such as user-rated items, derived from explicit inputs (e.g., ratings and reviews) are shown.
Item Attributes: Encoding metadata enhances item representations by including attributes, such as genres, authors, and categories related to books.
User Similarity Relations: Previous studies (Liu et al., 2023; Spillo et al., 2023), utilized a review encoder module to generate low-dimensional latent representations from user reviews and user similarity relations. By contrast, Shareh develops linguistic similarity models on the basis of shared reviews from persons who have engaged with the same items.
The integration of these factors allows the model to discern higher-order semantic relationships (indirect connections) and first-order correlations (direct interactions), hence guaranteeing the generation of personalized and comprehensible recommendations.
In Shareh, explicit connections represent direct relations observed in the data, such as user–item interactions and item entity links. Implicit connections are inferred through semantic similarity between users’ reviews on the same items, computed using Arabic Bidirectional Encoder Representations from Transformers (AraBERT). Only pairs exceeding a similarity threshold are linked. In some cases, explicit interactions may also imply hidden semantic patterns; such dual-nature relations are treated as explicit edges, while their implicit aspects are captured through attention weighting in the GAT layers.
Meta-path-guided information propagation
Meta-paths are used inside the expanded KG by examining higher-order connections between users and items to enhance Shareh’s reasoning capabilities. Meta-paths are defined sequences of entities and relationships that represent crucial interactions within KG and facilitate information dissemination and reasoning throughout the graph (Jin et al., 2023).
As summarized in Table 3, we adopt three meta-paths that capture the most salient user–item relations in the Arabic book domain: M1 models user preferences with respect to authors (content-based), M2 captures tendencies toward genres (content-based), and M3 exploits user–user similarity to support collaborative reasoning (collaborative). This set was derived through a domain-informed, empirically screened procedure: candidate paths were first enumerated based on domain knowledge (author, genre, and publisher) and then evaluated in preliminary experiments. Publisher-based paths were ultimately excluded because they introduced noise and offered limited explanatory value compared with the more discriminative author- and genre-oriented alternatives.
| Meta-path | Meaning of meta-path | Type filter |
|---|---|---|
| M1: (‘user’, ‘rated’, ‘book’) → (‘book’, ‘written_by’, ‘author’) → (‘author’, ‘wrote’, ‘book’) | Focuses on user preferences tied to authors, facilitating recommendations of books by the same author. | Content filter |
| M2: (‘user’, ‘rated‘, ‘book’) → (‘book’, ‘categorized_as’, ‘genre’) → (‘genre’, ‘categorized_in’, ‘book’) | Captures the user‘s inclination towards specific genres, helping recommend similar books. | Content filter |
| M3: (‘user’, ‘similar_to’, ‘user’) → (‘user’, ‘rated’, ‘book’) | Leverages user-user similarities to propagate preferences and improve recommendation accuracy. | Collaborative filter |
The relative contribution of each meta-path is not static but is dynamically determined during training. Using the attention mechanism of the GAT, each edge along a path receives an attention coefficient (α), reflecting its semantic relevance in the recommendation process. The overall importance score of a meta-path is then computed as the cumulative product of attention weights across its hops. This dynamic weighting ensures that paths most aligned with user preferences (M1 for strong author affinities) naturally emerge with higher importance scores, thereby improving both recommendation accuracy and explanation clarity.
By prioritizing semantically rich and discriminative paths (authors, genres, user similarities), Shareh ensures that recommendations are not only accurate but also supported by human-readable justifications, such as “recommended because you liked books by the same author” or “other users with similar tastes enjoyed this title.” This integration of meta-path reasoning and attention-based scoring significantly enhances both transparency and user trust.
GAT for representation learning
The proposed model adopts GAT (Veličković et al., 2018) to describe node embeddings on the basis of the semantic importance of neighboring nodes and their relationships. The main steps include the following:
Neighbor selection: The neighbors of a node are selected in terms of meta-paths in a manner where only meaningful relations contribute to its embedding.
Attention mechanism: The importance of each neighbor is calculated through the Eq. (1).
(1) where eq and et refer to representations of nodes q and t, respectively, and WM is meta-path M’s specific weight matrix.
Feature aggregation: The embedding for node q under meta-path M is calculated as defined in Eq. (2).
(2)
Multi-hop information propagation: To capture higher-order relationships, GAT spreads information over several hops. The representation of node q at layer l is recursively updated as described in Eq. (3)
(3)
During training, the GAT mechanism adaptively learns the relative importance of both explicit and implicit connections through its attention weights, allowing the model to balance direct behavioral relations with inferred semantic ones. The model collects context-rich information from distant neighbors through this propagation, thereby enriching the nodes’ semantic representations.
Result layer
The final node embeddings generated by GAT are employed to calculate recommendation scores. For user u and item i, the predicted interaction score is calculated as as shown in Eq. (4)
(4) where σ is the sigmoid function and and are the embeddings for the user and item, respectively.
For enhanced explainability, the system adopts the most important meta-path to explain recommendations by connecting user preferences with item properties or the preferences of similar users. The cumulative importance score is calculated as described in Eq. (5)
(5) where αh refers to the attention weight for each hop in the path.
In rare cases where two meta-paths have equal importance, the model resolves the tie deterministically by prioritizing content-based paths, as they provide clearer and more interpretable explanations for users. Such cases are uncommon because the attention mechanism in the GAT assigns distinct importance weights to each meta-path based on contextual semantic signals, making exact equality between paths statistically rare.
Evaluation metrics
The performance of the recommendation system was evaluated using key metrics commonly adopted in rating prediction tasks, mean absolute error (MAE) and root mean squared error (RMSE) (Sallam, Hussein & Mousa, 2022). These metrics quantify the discrepancy between the predicted ratings and the actual user ratings.
MAE: Measures the average absolute difference between predicted and actual values, providing a straightforward interpretation of the average error magnitude.
RMSE: Represents the square root of MSE, which is in the same units as the original ratings and is sensitive to large errors.
Experiments
Dataset description
In this study, we used the BRAD dataset (Elnagar & Einea, 2016) to train and evaluate the Shareh model. The dataset includes user–book interactions with explicit numerical ratings and user-generated reviews written in Arabic. The reviews were used to extract semantic features and to infer user-to-user similarity based on shared opinions. This supported the construction of a graph that combines book metadata with user interaction data. The dataset is suitable for assessing models that integrate both structured and unstructured information. Table 4 outlines its key properties.
| Attribute | BRAD statistics |
|---|---|
| Number of reviews | 156,500 |
| Number of books | 4,957 |
| Number of users | 44,490 |
| Rating scale | 0 to 4 |
KG construction
User similarity relations
In Shareh, user similarity was computed based on the semantic similarity of their shared book reviews. Cosine similarity was applied to sentence embeddings generated by AraBERT, which encodes reviews into dense vector representations. This method captures nuanced semantic relationships and topical alignment, connecting users who discuss similar themes or contexts, irrespective of lexical overlap. Before the similarity scores were computed, the review dataset underwent preprocessing operations to reduce noise as follow:
Removal of non-Arabic words—eliminating foreign terms and symbols.
Filtering hashtags and hyperlinks—removing social media artifacts.
Normalization—standardizing Arabic orthography (e.g., converting “أ“, “إ“, ”آ” to “ا“).
Diacritics and elongation removal—stripping unnecessary vocalization.
Punctuation and special character removal—excluding symbols, such as ?, (), !, @, #, and $.
Summarization of long reviews—for reviews that exceed 250 tokens, the MT5 model was applied to generate concise summaries while preserving key semantic information.
We employed two sentence similarity approaches to compute user similarity:
Fine-tuned AraBERT: In this approach, AraBERT was fine-tuned on the Mawdoo3 dataset (11,997 samples) to learn contextual similarity patterns and then evaluated on the MSRvid dataset (1,010 samples) to measure sentence similarity performance. This enabled the model to capture deep semantic relationships between reviews.
AraBERT with Cosine Similarity: This approach uses AraBERT to build sentence embeddings, which are then compared using cosine similarity to measure similarity between sentences.
This dual evaluation facilitates a comprehensive assessment of sentence similarity and supports the selection of the most suitable model for constructing user–user relations within the knowledge graph. The comparison focused on F1-score, scalability, and computational efficiency to determine which approach provides the most accurate and reliable estimation of semantic similarity between users based on their review content. Table 5 summarizes the performance of both models by comparing their F1-scores and computation times. Although fine-tuned AraBERT exhibited enhanced accuracy, it incurred high computing expenses, making it impractical for extensive applications. Given the extensive dataset (156,500 evaluations from 4,957 books), AraBERT and cosine similarity were selected for Shareh because they considerably reduced the processing time while maintaining a commendable F1-score (0.92).
| Model | Dataset | F1-score | Processing time |
|---|---|---|---|
| Fine-tuned AraBERT | MSRvid | 0.96 | 1 h 49 m 42 s (453 reviews for four book) |
| AraBERT and cosine similarity | MSRvid | 0.92 | 1 h 6 m 15 s (156,500 reviews for 4,957 books) |
User similarity scores above 0.8 were retained to ensure robust and reliable connections. This threshold was selected based on preliminary experiments, which demonstrated that a value of 0.8 effectively balanced coverage and noise reduction, producing connections that were both meaningful and stable. The confidence score further refines user–user relationships by differentiating between levels of interaction activity. Users with high interaction activity (many shared reviews) tend to establish strong similarity links with other highly active users, as the abundance of evidence supports a high level of confidence in their shared preferences. Similarly, users with limited interactions can still form similarity relations among themselves. By contrast, links between highly active and sparsely active users naturally yield the weakest confidence scores. This stratification ensures that similarity connections in the graph are not only semantically meaningful but also aligned with the degree of user engagement, thereby improving the reliability of the constructed knowledge graph. Formally, the confidence score between two users’ u1 and u2 is defined as shown in Eq. (6):
(6)
Based on preliminary experiments and multiple validation runs, a confidence threshold of ≥ 0.4 was adopted, as it provided the best balance between retaining sufficient coverage of user–user relations and minimizing noisy or unreliable connections. Lower thresholds introduced excessive noise by connecting weakly related users, whereas higher thresholds significantly reduced graph connectivity and coverage.
Explainable Arabic knowledge graph for shareh
ArBKG is a heterogeneous KG designed to capture relationships among books, authors, genres, publishers, and other book data derived from platforms, such as Arabic Goodreads (https://www.kaggle.com/datasets/z3rocool/arabic-goodreads-reviews) and Abjjad (https://www.abjjad.com/).
A sample of the constructed ArBKG is provided in Appendix A, The construction of a comprehensive KG for the Shareh model requires the integration of ArBKG with user relationship results obtained from the similarity model. Table 6 shows a comprehensive overview of the resultant explainable Arabic knowledge graph (XArKG), including its architecture and the incorporation of several relationship elements.
| Node type | Count | Edge types | Count |
|---|---|---|---|
| Users | 44,490 | “rated” | 156,500 |
| Books | 4,957 | “written_by,” | 4,945 |
| Authors | 2,021 | “similar_to” | 742,039 |
| Genres | 165 | “categorized_as,” | 12,717 |
| Publishers | 222 | Publication_by | 4,916 |
| Total | 51,855 | Total | 1,100,195 |
This framework guarantees multifaceted reasoning by integrating content-driven and collaborative filtering indicators. To capture higher-order relationships, XArKG uses meta-paths. These paths guide information propagation and reasoning, allowing the system to explain recommendations.
Figure 2 illustrates the structure of the resulting XArKG, explicitly depicting the relationships between users, items, authors, and genres. The graph integrates both content-based (genre, author) and collaborative (similarity, rating) relations, thereby supporting multifaceted reasoning and enhancing the explainability.
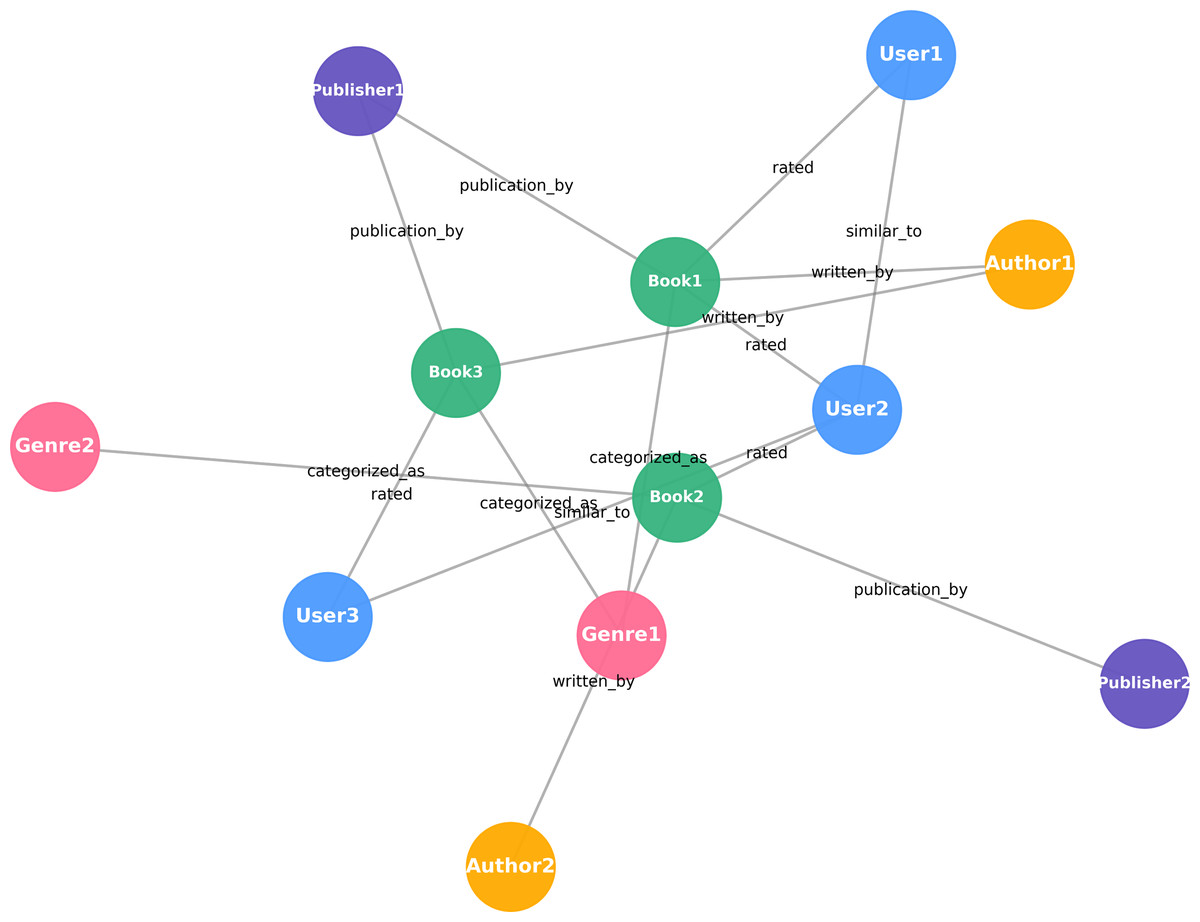
Figure 2: XArKG illustrating users, items, and key relationships.
{kind=link}
Experimental setup
The experimental setup was implemented using a combination of environments: a local laptop, the Ferdowsi Cloud computing platform, and Google Colaboratory, which provided access to GPU resources for handling computationally demanding tasks. The model was developed using PyTorch as the core deep learning framework, Transformers for processing textual input from user reviews, and Deep Graph Library (DGL) for constructing and managing graph-based structures. The finalized hyperparameter settings used in the best-performing configuration are detailed in Table 7. For dataset splitting, all user–book interactions were partitioned into training, validation, and test sets using an 80/10/10 ratio. The split was performed at the user level to avoid information leakage, and overlap checks confirmed zero shared edges across partitions, ensuring a fair evaluation protocol. Model selection relies exclusively on the validation set, and the test set is evaluated once at the end.
| Hyperparameter | Value | Description |
|---|---|---|
| Hidden dimension | 64 | Size of node embeddings in GAT. |
| Attention heads | 16 | Number of attention heads in each GAT layer. |
| Layer structure | [[64, 32, 16], [64, 32, 16], [64], [64]] | GAT architecture per edge type. |
| Dropout rate | 0.2 | Reduces overfitting by randomly dropping connections. |
| Batch size | 2048 | Number of samples per training batch. |
| Epochs | 10 | Maximum number of training iterations. |
| Learning Rate (LR) | 0.001 | Step size for weight updates using Adam optimizer. |
| Weight initialization | Xavier uniform | Ensures balanced weight distribution at initialization. |
| Prediction model | MLP (512, 256, 128) | Final-layer MLP for interaction prediction. |
| Loss function | BCE With LogitsLoss | Ensures stable computation for binary predictions. |
| Optimizer | Adam | Adaptive gradient-based optimizer. |
| LR scheduler | Cosine Annealing LR (Tmax = 50) | Gradually reduces learning rate during training. |
Hyperparameters were tuned via a structured manual search over learning rate ([1e−4, 1e−3, 1e−2]), dropout rate ([0.1, 0.2, 0.3]), number of attention heads ([8, 16]), and hidden dimensions ([64, 128]), selecting the configuration that minimized validation loss. To mitigate overfitting, we employed dropout and early stopping with a patience of 3 epochs; training typically converged by epoch 4 when no further improvement in validation loss was observed.
We treat evaluation as a rating-prediction task and therefore report MSE, RMSE, and MAE on the held-out test set. We retrained the entire pipeline three times from scratch with different random initializations and report mean ± std; the standard deviation (std) across runs for MSE, RMSE, and MAE was negligible (e.g., <0.001), confirming the stability of our results.
Evaluation and results
This section assesses the accuracy and explainability of the Shareh model via a comprehensive analysis.
Analysis of recommendation performance
Performance metrics
We assessed performance using the metrics defined in section ‘Evaluation Metrics’ (MSE, RMSE, and MAE). Three experiments are being conducted to evaluate the influence of different information propagation strategies.
Content-based graph modeling (using only item attributes).
Collaborative-based modeling (leveraging user–user similarities).
Shareh (combining content-based and collaborative signals).
Such comparison allowed us to assess the individual and combined effects of content and collaborative filtering and obtain insights into the optimal recommendation strategy. The results are summarized in Table 8. Among the approaches, content-based filtering alone produced the highest RMSE (0.7047), indicating that relying solely on the item attributes limited the predictive power of the model. Collaborative filtering remarkably enhanced performance and reduced MSE from 0.4966 to 0.2501, revealing the importance of user–user relationships in improving accuracy. Shareh ensures balance between content-based and collaborative filtering techniques. These results highlight the need for integrating content and user interaction data to develop robust, comprehensible RSs.
| Strategy | MSE | RMSE | MAE |
|---|---|---|---|
| Shareh_Content-based | 0.4966 | 0.7047 | 0.4966 |
| Shareh_Collaborative-based | 0.2501 | 0.5001 | 0.4997 |
| Shareh (Unified Graph) | 0.2507 | 0.5007 | 0.5004 |
Comparison with related work
Table 9 presents a comparative evaluation of multiple Arabic recommender systems, all tested on the BRAD dataset, which is focused on book recommendations. Baseline values were taken directly from the original studies all of which used the same dataset. The results show that the Shareh model achieved the lowest RMSE (0.5001) and MAE (0.4998) among the compared methods. Previous models, including those developed by Meddeb, Maraoui & Zrigui (2021a) and Khalifeh & Al-Mousa (2021), reported RMSE values between 0.800 and 0.9928, with only one of them providing MAE results.
| Study | Key features | RMSE | MAE |
|---|---|---|---|
| Meddeb, Maraoui & Zrigui (2021b) | Semantic embedding with deep learning. | 0.975 | Not reported |
| Meddeb, Maraoui & Zrigui (2021c) | Smart learning recommender. | 0.815 | Not reported |
| Khalifeh & Al-Mousa (2021) | Collaborative filtering | 0.9928 | 0.7907 |
| Meddeb, Maraoui & Zrigui (2021a) | Deep learning with joint representation learning. | 0.800 | Not reported |
| Shareh model | Graph-based model with attention | 0.5001 | 0.4998 |
The improved performance of Shareh can be attributed to its unified integration of knowledge graph reasoning with semantic information extracted from user reviews. Unlike earlier approaches that treated reviews and structured data separately, Shareh constructs a combined graph that jointly represents books, user interactions, and user similarity relations. This design reduces sparsity and bias by leveraging both collaborative and content-based signals, while the meta-path-guided GAT enables the model to propagate information selectively, filtering noise and emphasizing semantically meaningful relations. These mechanisms collectively explain why Shareh achieves superior accuracy and interpretability.
Statistical analysis of pooling methods
We evaluated three pooling techniques, namely, mean pooling, sum pooling, and weighted sum pooling, to further refine the model’s aggregation strategy. One-way analysis of variance (ANOVA) was implemented to determine if the differences between the pooling methods were statistically significant (Park et al., 2023). The results, which are given in Table 10, reveal a statistically significant difference (p < 0.05) for MSE and RMSE, but not for MAE.
| Metric | F-statistic | p-value |
|---|---|---|
| MSE | 31.95 | 0.0095 |
| RMSE | 33.41 | 0.0089 |
| MAE | 0.198 | 0.8306 |
A post-hoc Tukey’s honestly significant difference (HSD) test was conducted to identify significant differences among the pooling methods. The results are shown in Table 11 and Fig. 3. The results showed that weighted sum pooling performed worse than mean pooling and sum pooling, with significantly higher MSE and RMSE (p-values < 0.05). The fact that the difference between mean pooling and sum pooling was not statistically significant (p-value = 0.0743) suggests that both methods performed similarly. Figure 3’s boxplots visually confirm that mean pooling consistently produces the lowest error values, proving its effectiveness in reducing prediction discrepancies.
| Group 1 | Group 2 | Mean difference | p-value | Significant (p < 0.05) |
|---|---|---|---|---|
| Mean pooling | Sum pooling | 0.0099 | 0.0743 | No |
| Mean pooling | Weighted sum | 0.0220 | 0.0084 | Yes |
| Sum pooling | Weighted sum | 0.0121 | 0.0435 | Yes |
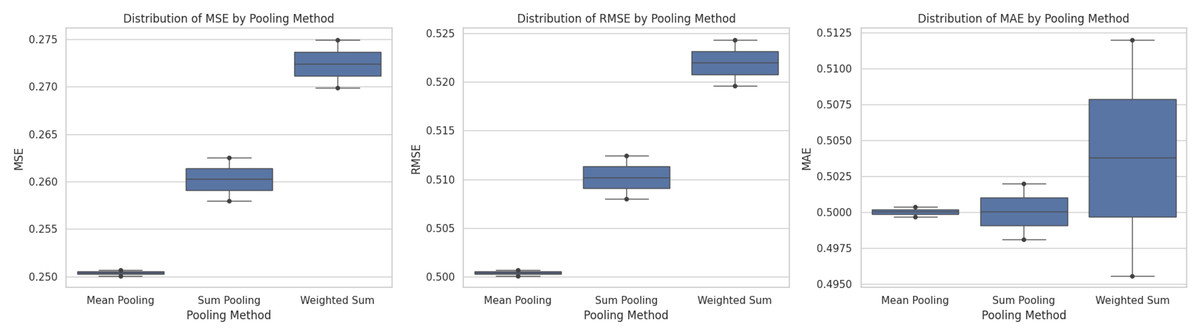
Figure 3: Distribution of MSE, RMSE, and MAE across different pooling methods.
{kind=link}
Analysis of explainability
The explainability of the Shareh model was examined using two fundamental elements, namely, cases of explainable recommendations and model fidelity. The system’s transparency and its ability to generate supported recommendations were validated.
Explainability recommendation cases
We assessed two recommendation instances from the system’s outcomes, as summarized in Table 12, to present the explainability features of the Shareh model. The examples demonstrated the system’s capability to offer varied, multifaceted justifications for recommendations by utilizing recognized meta-paths inside the explainable Arabic knowledge graph.
| Case | Meta-path | Value of important of meta-path | Type filter | Explanation by use temple |
|---|---|---|---|---|
| User: 17198221, Book: 16031620 | M1: (‘user’, ‘rated’, ‘book’) → (‘book’, ‘written_by’, ‘author’) → (‘author’, ‘wrote’, ‘book’) | 0.5874 | Content filter | “You’ve read and enjoyed books by Saud Alsanousi before, so you might like “The Bamboo Stalk” too.” “سبق لك قراءة كتب لـ سعود السنعوسي واستمتعت بها، لذا ربما يعجبك ”ساق البامبو“ أيضًا” |
| M2: (‘user’, ‘rated’, ‘book’) → (‘book’, ‘categorized_as’, ‘genre’) → (‘genre’, ‘categorized_in’, ‘book’) | 0.1856 | Content filter | ||
| M3: (‘user’, ‘similar_to’, ‘user’) → (‘user’, ‘rated’, ‘book’) | 0.2270 | Collaborative filter | ||
| User: 5843452, Book: 29381852 | M3: (‘user’, ‘similar_to’, ‘user’) → (‘user’, ‘rated’, ‘book’) | 1.0000 | Collaborative filter | “Similar users found ‘Lost’ a great book, so you might also like it.” “وجد مستخدمون مشابهون لك أن ’ذات فقد’ كتاب رائع، لذا قد يعجبك أيضًا” |
In Case 1 (Fig. 4), the system proposed a book (ID: 16031620) to a user (ID: 17198221) and recognized many meta-paths to substantiate the recommendation. The most significant contribution was from the M1 meta-path (importance: 0.5874), which reflected the user’s preference for particular authors. This importance score was dynamically computed through the GAT attention mechanism, where the cumulative product of attention weights along the path quantifies its overall contribution. The supplementary contributions comprised M2 (content-based, significance: 0.1856), which indicates genre inclinations, and M3 (collaborative, significance: 0.2270), which employs user–user relationships. The system prioritized the most significant meta-path when elucidating its advice to improve the clarity of its recommendations, thereby highlighting the content-based aspect of the filtering in this case.
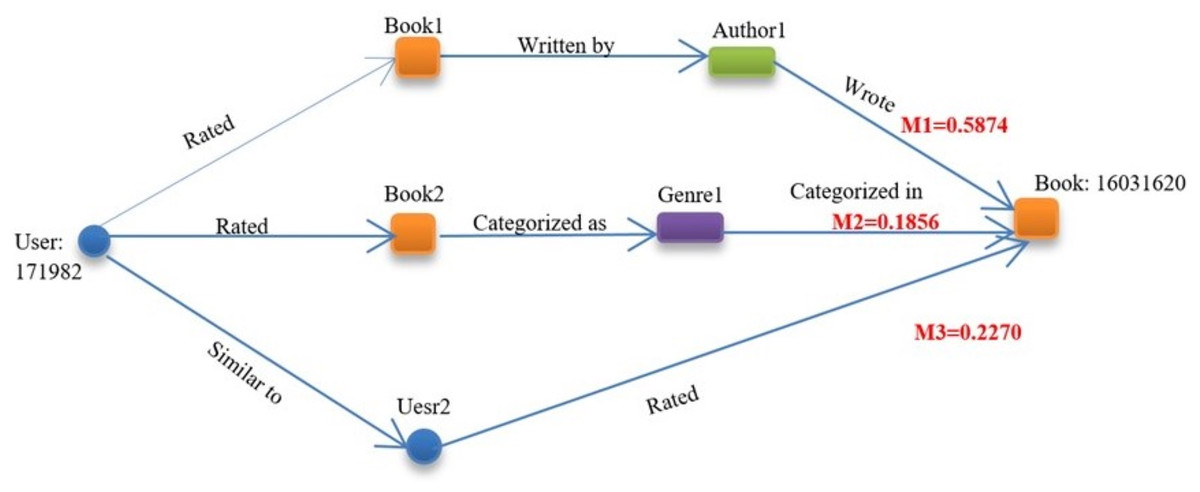
Figure 4: Visualization of three paths with prediction scores the prediction scores are normalized for illustration.
{kind=link}
Case 2 involved an alternative explanatory framework, where the system recommended a book (ID: 29381852) to a user (ID: 5843452) based exclusively on collaborative filtering indicators. A solitary meta-path (M3, significance: 1.0000) linked the user to the recommended book on the basis of only user–user similarities.
This differentiation between scenarios highlights the flexibility of the system in elucidating suggestions obtained from accessible user data. The system ensures that recommendations are accurate and comprehensible through content-based and collaborative filtering, and it customizes explanations for individual users in accordance with their interaction history and relevant contextual data.
Model fidelity
Model fidelity is important for assessing the explainability of recommendation systems because it quantifies the ratio of recommendations that are supported by explanations (Peake & Wang, 2018; Zhang & Chen, 2020). This study evaluated the reliability of the Shareh system to establish an interpretable rationale for its recommendations. Fidelity was defined as the proportion of recommendation cases that yielded a valid explanation and computed as described in Eq. (7):
(7)
Our assessment, which employed empirical data, showed that explanations were effectively produced for 15,014 out of 15,050 user–item recommendation combinations, resulting in a faithfulness score of 99.76%. The system effectively provided explanations for nearly all recommendations, confirming its reliability and interpretability.
Conclusion and future work
Shareh, the first explainable KG-based Arabic recommender system, was developed to address challenges of accuracy and transparency in Arabic recommender systems. By unifying user reviews, item metadata, and user–user similarities into a heterogeneous knowledge graph and leveraging graph attention networks with meta-path-guided reasoning, Shareh significantly outperformed existing baselines. It is important to emphasize that the reported performance improvements and conclusions are specifically demonstrated within the domain of Arabic book recommendations using the BRAD dataset; generalizability to other domains or languages requires further investigation. While Shareh’s architecture is designed to be general-purpose, its effectiveness in other Arabic domains such as e-commerce or e-learning depends on domain-specific adaptations, including the availability of structured knowledge, the quality of user-generated content, and cultural-linguistic nuances. Empirical validation across these domains remains a central objective of future research. Experimental results demonstrated that Shareh reduced RMSE and MAE by more than 30% while providing varied, interpretable rationales through human-readable meta-path explanations.
Importantly, Shareh mitigates the cold-start problem by leveraging the diversity of meta-paths within the unified KG. Users with limited interactions benefit from content-based paths (e.g., User–Item–Author, User–Item–Genre), while users with richer histories gain from collaborative paths (e.g., User–User–Item). This balanced integration ensures that even sparsely active users receive meaningful recommendations, thereby enhancing robustness and coverage across the dataset.
Despite these achievements, several challenges remain. The reliance on GATs and meta-path reasoning introduces computational overhead, and broader validation beyond the BRAD dataset is required to confirm generalizability. Accordingly, future research will focus on the following directions:
Performance Optimization: Apply dimensionality reduction and graph pruning to reduce computational complexity while preserving high-quality recommendations.
Cross-Domain and Multi-domain Expansion: Validate Shareh on additional Arabic datasets and extend it to other domains, such as e-commerce and e-learning, ensuring broader applicability, fairness, and privacy preservation.
Sentiment-Aware Similarity: Incorporate sentiment analysis into user similarity computations to capture review polarity, thereby refining similarity links and improving both accuracy and explanation quality.
Benchmarking Against Generic KG-Based Models: Compare Shareh with non-language-specific KG-based recommenders (e.g., KGAT) after adapting them to Arabic metadata, to further validate robustness.
User-Centered Evaluation: Conduct controlled user studies to directly assess the clarity, persuasiveness, and trustworthiness of explanations, complementing fidelity metrics with human-centered evaluation.
Appendix: sample from the arbkg
{
“id”: “16014434”,
“book_name”: “قواعد العشق الأربعون”,
“author_name”: “اليف شافاك”,
“genres”: [“الروايات“, ”الخيال التاريخي”],
“num_pages”: 511,
“publisher”: “دار الآداب”,
}
Supplemental Information
Knowledge graph dataset.
The dataset consists of a little bit more than 156K reviews in Arabic language. The reviews were collected from GoodReads.com website during June/July 2016.