
Predicting student performance in Massive Open Online Courses (MOOCs) using machine learning and deep learning techniques: a comprehensive survey
- Published
- Accepted
- Received
- Academic Editor
- Chaman Verma
- Subject Areas
- Artificial Intelligence, Computer Education, Computer Vision, Data Mining and Machine Learning, Data Science
- Keywords
- Student performance, MOOCs, Dropout prediction, Machine learning, Deep learning
- Copyright
- © 2026 Chefrour et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Predicting student performance in Massive Open Online Courses (MOOCs) using machine learning and deep learning techniques: a comprehensive survey. PeerJ Computer Science 12:e3564 https://doi.org/10.7717/peerj-cs.3564
Abstract
High dropout rates in online learning, particularly in Massive Open Online Courses (MOOCs), present a significant challenge to educational institutions. An accurate prediction of dropout risk is essential for designing effective intervention strategies. Unlike prior surveys, this comprehensive review synthesizes 57 studies from 2015 to 2024 to identify systematic methodological advances and critical limitations in dropout prediction. Our analysis categorizes the approaches across three dimensions: model type, learning paradigm, and performance characteristics. A key finding is the identification of inflection points: behavioral + temporal features improve accuracy by 15–25% over static features; ensemble methods achieve 85–92% accuracy with superior interpretability; and advanced Deep Learning (DL) architectures reach 95% accuracy but require substantial computational and data resources. These findings enable evidence-based model selection based on the institutional constraints. We critically evaluate the limitations of existing approaches, including inadequate class imbalance handling, lack of cross-platform generalization, and insufficient intervention validation, and propose standardized evaluation protocols. This survey serves as a practical reference for researchers and educators in designing data-driven dropout reduction strategies that align with institutional capabilities.
Introduction
This survey is motivated by the critical importance of predicting dropout risk in Massive Open Online Courses (MOOCs) and the recent advances in machine learning and deep learning techniques applied to this challenge. Accurate prediction of dropout risk is a fundamental component of educational management and support systems, which often lag behind other technological advances. Effective prediction models play a crucial role in identifying students at risk early, enabling timely interventions to improve retention and overall learning outcomes for MOOCs. By utilizing advanced machine learning (ML) and deep learning (DL) techniques, educational institutions can gain a deeper understanding of the factors that contribute to dropout rates and develop targeted strategies to address them. This proactive approach not only improves individual student outcomes, but also enhances the overall effectiveness and reputation of MOOC platforms. In particular, there is a significant need for accurate dropout risk prediction in Massive Open Online Courses, as it is of major importance to:
Accurate prediction of dropout risk allows the early identification of students who are at risk of withdrawing from courses. This enables educators and administrators to intervene immediately and provide the necessary support to retain these students (Kloft et al., 2014).
By predicting which students are likely to withdraw, MOOC’s can implement targeted retention strategies, thereby improving overall retention rates and improving the effectiveness of courses (Halawa, Greene & Mitchell, 2014).
Prediction models can help customize the learning experience to meet the needs of individual students by providing personalized resources and support. This approach can improve student participation and overall success (Xing et al., 2016).
Accurate predictions allow educational institutions to allocate resources more efficiently by directing attention and support to students who need it most (Li et al., 2015).
Understanding dropout patterns helps educators refine and improve course content, structure, and delivery methods to meet student needs and preferences better (Wang & Baker, 2015).
Knowing that your progress is being monitored and that help is available can motivate students to remain engaged and complete their courses (Breslow et al., 2013).
Ultimately, accurate dropout prediction contributes to better educational outcomes, as more students complete their courses and achieve their learning goals (Greene, Oswald & Pomerantz, 2015).
The prediction of dropout risk in MOOCs has attracted significant attention due to the rapid expansion of online education, the increasing availability of large datasets, and the development of sophisticated analytical tools (Baker, Martin & Rossi, 2016). Initially, simplistic methods were used to predict dropout rates, often relying on basic statistical techniques that did not account for the complex and multifaceted nature of student engagement and retention. These methods were inadequate, as they failed to capture the nuances of individual learner behaviors and the various factors influencing dropout rates. Consequently, recent research has focused on utilizing advanced machine learning and deep learning techniques to predict dropout risk more accurately. These approaches leverage a diverse range of data sources, including clickstream data, forum participation, assignment submissions, and demographic information, to develop robust predictive models (Siemens, 2013).
MOOCs have transformed access to education, yet their consistently high dropout rates, often exceeding 90%, remain a critical and unresolved challenge for educators and institutions (Romero & Ventura, 2007; Lang et al., 2017). The ability to predict dropout risk early is essential for implementing timely and personalized interventions that can improve student retention and success. Despite extensive research on ML and DL approaches for dropout prediction, there is still no comprehensive synthesis that integrates recent advances, particularly those emerging after 2020. Deep learning and machine learning techniques offer promising avenues for predicting dropout risk in MOOCs, utilizing their ability to analyze vast amounts of student interaction data comprehensively. These approaches provide a more nuanced understanding of individual learner behaviors and the complex factors that influence dropout rates. Using and analyzing data such as clickstream activity, forum participation, assignment submissions, and demographic information, predictive models can identify at-risk students early, facilitating timely interventions to improve retention and overall learning outcomes (Doss et al., 2024). This survey aims to synthesize current research methodologies in deep learning and machine learning applied to dropout prediction in MOOCs, examining their effectiveness, challenges, and future directions in enhancing educational support systems. Furthermore, machine learning and deep learning are essential in addressing the multifaceted challenge of dropout risk in MOOCs (Siemens, Gašević & Dawson, 2015; Kizilcec & Halawa, 2015; Kabathova & Drlik, 2021). Machine learning algorithms excel in analyzing large datasets, such as student participation logs, assignment submissions, and assessment scores, to detect early signs of potential dropout (Xing & Du, 2019). These algorithms, including classification techniques and ensemble methods, utilize the extracted features to predict the likelihood of dropout accurately. However, deep learning models, such as recurrent neural networks (RNNs) and long-short-term memory networks (LSTMs), excel at capturing temporal dependencies and sequential patterns from student interactions over time. They provide deeper insights into nuanced behaviors that precede dropout, enabling educators to intervene proactively. By integrating predictive analytics into educational practices, these technologies enable institutions to personalize interventions, optimize support resources, and ultimately improve retention rates in MOOCs.
Recent meta-analyses by Prenkaj et al. (2020) and Masood, Gogoi & Begum (2024) have highlighted the absence of standardized evaluation frameworks in MOOC research. Foundational works in learning analytics (Siemens, Gašević & Dawson, 2015; Baker, Martin & Rossi, 2016; Gašević, Dawson & Siemens, 2015) provide the theoretical basis for analyzing student engagement and predicting dropout. Studies on early warning systems (Bañeres et al., 2020) and behavioral sequence modeling (Maldonado-Mahauad et al., 2018) demonstrate the potential of temporal approaches, while research on explainability (Holstein & Doroudi, 2021; Cuzzocrea et al., 2023) emphasizes the importance of interpretable models for educational practice. Cross-platform analysis studies (Cheng et al., 2019) further underline the challenges in generalizing predictive models across MOOC platforms. Building on these foundational insights, our survey extends prior work by systematically reviewing methodologies, standardizing evaluation metrics, and proposing a research agenda for practical deployment in MOOCs.
Despite the growing body of literature on MOOC dropout prediction, several critical research gaps remain.
-
1.
Lack of standardization: Dropout definitions vary widely across studies (e.g., non-participation for 1 week vs. course non-completion), hindering cross-study comparison and meta-analysis.
-
2.
Limited cross-platform generalization: Models trained on one MOOC platform (e.g., edX) often fail to generalize to others such as Coursera or XuetangX, due to differences in interface, interaction patterns, and learner demographics. No prior study has systematically evaluated transfer learning across platforms.
-
3.
Interpretability deficit in deep learning models: While deep learning approaches achieve superior predictive accuracy, educators rarely understand why a student is flagged as at-risk. This “black-box” problem limits the practical adoption of complex models.
-
4.
Inadequate handling of class imbalance: Many studies report accuracy without addressing severe data imbalance (only 5–15% of learners drop out). Critical metrics such as the F1-score, ROC-AUC, and confusion matrices are often omitted.
-
5.
Insufficient intervention validation: Predicting dropout alone is insufficient. Few studies have assessed whether algorithmic interventions reduce dropout rates compared to control groups.
-
6.
Neglect of temporal learning behaviors: Most predictive models treat student trajectories as static snapshots rather than dynamic behavioral sequences, overlooking early warning signals embedded in temporal patterns.
This survey addresses these gaps by (a) synthesizing methodological approaches across 57 studies, (b) critically comparing model performance using standardized evaluation metrics, (c) identifying conditions under which simple vs. complex models should be preferred, and (d) outlining a research agenda for model standardization and practical deployment in real-world MOOC environments.
This survey is intended for researchers and practitioners in the fields of educational data mining, machine learning, and e-learning, as well as instructional designers and MOOC platform developers who seek to understand the state-of-the-art approaches to predicting student dropout.
This study makes several key contributions to the existing literature.
It provides a comprehensive survey of machine learning and deep learning techniques for predicting student dropout in MOOCs, integrating both methodological and practical perspectives.
The detailed architectural parameters of representative deep learning models are reported, allowing a transparent assessment of the model complexity and design.
The feature definitions, prediction accuracy categories, and model complexity metrics were standardized to facilitate meaningful comparisons across studies.
This study discusses limitations and challenges, including interpretability, computational constraints, and data quality issues, which are often overlooked in previous studies.
It outlines future research directions for enhancing dropout predictions and developing effective intervention strategies.
Together, these aspects demonstrate the novelty and value of this study in advancing research on MOOC dropout prediction.
Before detailing our topic, we clarify the terminology used throughout this article, then review the related work and define the scope of this survey.
Terminology
Since their emergence, MOOCs have revolutionized access to education by offering flexible, scalable, and low-cost learning opportunities to global audiences (Kemper, Vorhoff & Wigger, 2020). However, despite their widespread adoption, MOOCs continue to face the persistent challenge of low completion rates, often below 10%. This issue has raised concerns among educators, researchers, and policymakers regarding the effectiveness and sustainability of MOOCs as a model for open learning. In response to this challenge, researchers have increasingly applied ML and DL techniques to analyze learner behavior and predict student dropout rates. These approaches aim to identify at-risk learners early and support targeted, timely interventions to improve retention. However, the research landscape remains fragmented and lacks a unified synthesis of the techniques, datasets, and evaluation strategies used across the studies. This survey addresses this gap by systematically reviewing recent advances in ML- and DL-based dropout prediction in MOOCs. In doing so, it aims to highlight trends, categorize methods, compare performance, and identify limitations and research opportunities in this domain.
Causes of student dropout in MOOCs
The high dropout rates in MOOCs can be attributed to various factors categorized into student-related factors, MOOC-related factors, and miscellaneous factors (Goopio & Cheung, 2021; Park & Choi, 2009).
Student-related factors (Hew & Cheung, 2014; Liu, Kang & McKelroy, 2015)
Lack of motivation:The primary reason for high dropout rates is students’ lack of motivation. Several factors influence student motivation, including the development of personal and professional identity, future economic benefits, challenges and achievements, and entertainment.
Lack of time: Students often find the time required to watch videos, complete quizzes, and assignments excessive and may not be willing to invest the necessary time. Many students also report that the actual time needed to complete the MOOC exceeds the stated time.
Insufficient background knowledge and skills: Some students lack the prior knowledge needed to understand the course content, particularly in subjects requiring a strong foundation in mathematics.
MOOC-related factors (Kop, Fournier & Mak, 2011; Jordan, 2014)
Course design: Which includes course content, structure, and information delivery technology, is a significant factor in dropout rates. Course content is the most critical element in determining the perceived quality of the online learning experience and is a major predictor of dropouts. Other negative factors include poor course delivery, harsh criticism of students’ work, and extensive lecture notes that do not differ significantly from textbooks.
Feelings of isolation and lack of interactivity: The absence of real-time collaboration with other learners can lead to feelings of isolation. Poor communication with instructors and peers, low interaction, and a lack of feedback can discourage students from continuing the course.
Hidden costs: Despite MOOCs being free, students often have to pay for certificates or purchase expensive textbooks recommended by lecturers, which can contribute to dropout rates.
Other factors (Reich, 2014)
Casual enrollments: Many students enroll in MOOCs out of curiosity or to explore the content without intending to complete the course. These enrollments are often seen as a by-product of the open-access nature of MOOCs.
Peer review: Courses that rely solely on peer grading tend to have lower completion rates, as peer grading requires more work from the learners, adding to the overall workload of the MOOC.
How can the dropout rate be reduced?
Course design and instruction
Despite having similar teaching methods to traditional face-to-face learning, MOOCs primarily employ an objectivist-individualistic teaching approach, lacking constructivist and group-oriented methods. Implementing more constructivist and innovative teaching strategies could address significant issues related to MOOCs. The quality of a MOOC’s instructional design is a key factor in promoting active learning and enhancing the experiences of learners and other stakeholders. The quality of instructional design plays a critical role in learner engagement and course effectiveness in MOOCs. An analysis of 76 randomly selected MOOCs revealed that, although many courses were well-packaged, the majority failed to adhere to established instructional design principles (Margaryan, Bianco & Littlejohn, 2015). Courses that prioritize interactivity, include well-structured discussion activities, incorporate feedback from both learners and experts, and provide relevant supporting materials are more likely to enhance learner participation and reduce the dropout rates.
Interaction among learners (Sunar et al., 2016)
Learner interaction is widely recognized as a key factor in maintaining engagement and improving MOOC completion rates. A study investigating an 8-week FutureLearn course found a positive correlation between completion rates and frequent interactions among participants using the platform’s follow-up system (Sunar et al., 2016). Incorporating social tools into MOOCs, such as peer discussion platforms and collaborative environments, can support problem-solving, encourage meaningful dialogue, and promote the sharing of educational resources. However, course forums remain the preferred tool in MOOCs, and the impact of social tools, such as Slack, Telegram, and Facebook, on learning outcomes requires further investigation.
Comfort level with technology
Since MOOCs operate online, they inherently rely on technology for content delivery and engagement. Learners may not be familiar with the necessary technologies, so instructors should provide technical training manuals or incorporate technical skills into the course content to assist students with the delivery platform (Liyanagunawardena, Adams & Williams, 2013).
Feedback
Assessment and feedback are crucial in any educational process. Unlike traditional classrooms where instructors can respond to students immediately, there is often a delay in online courses. Literature suggests that this delay should not exceed 48 h. The more connected students feel to the learning environment and their instructor, the less likely they are to drop out (Gikandi, Morrow & Davis, 2011).
Deep learning and machine learning have been widely adopted in dropout prediction for MOOCs. Reusing dropout prediction models with these methods involves various inputs, including interaction logs, demographic data, and more. These factors have proven effective as inputs, allowing us to neutralize other avoidable factors in the model. By focusing on critical variables, we can better understand the factors that influence dropout rates (Imran, Dalipi & Kastrati, 2019).
The existing literature generally uses “dropout prediction” and “retention prediction” as synonyms. Unless otherwise stated, in this survey, we refer to dropout prediction as the process of identifying students at a high risk of leaving a course before completion (Wang et al., 2023).
The components of dropout prediction are data collection, feature extraction, and model training and evaluation. The above two are variable, depending on the course and platform, while the latter two are more standardized but depend on the type of metrics/algorithms (Şahin, 2021). Several prediction techniques leverage this decomposition to extract causal features from the data, allowing for the construction of more effective models.
The data collection phase is usually extensive and encompasses a wide range of student interactions and characteristics. The feature extraction process is critical as it determines the inputs for the predictive models. Various techniques are employed here, including natural language processing for analyzing discussion forums and time-series analysis for analyzing activity logs. The model training phase involves selecting and tuning machine learning or deep learning algorithms, such as logistic regression, decision trees, or neural networks. The evaluation phase assesses the accuracy, precision, recall, and other metrics of the model to ensure its reliability (Gardner & Brooks, 2018).
In terms of educational impact, dropout prediction can be applied at various levels, including individual students, specific courses, or entire programs. For individual students, personalized interventions can be designed. For specific courses, instructors can identify patterns and adjust their teaching methods. At the program level, institutions can develop broader retention strategies (Shukor & Abdullah, 2019).
A taxonomy of prediction strategies approaches
When developing a student dropout prediction system, it is essential to select an appropriate prediction strategy. Figure 1 (Prenkaj et al., 2020) illustrates how this component has been utilized to categorize the existing literature on student dropout prediction. The figure presents the taxonomies of options available at each stage of the design process, showcasing a proposed classification of prediction strategies. These strategies are divided into three categories: Analytic Examination, Classic Learning Methods, and Deep Learning. The latter two categories encompass standard machine learning algorithms and advanced deep learning techniques, respectively. The existing literature has extensively explored classic machine learning, covering each type of algorithm shown in Fig. 1. With recent advancements in deep learning methods for student dropout prediction, current research is increasingly focusing on adaptations of Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs).
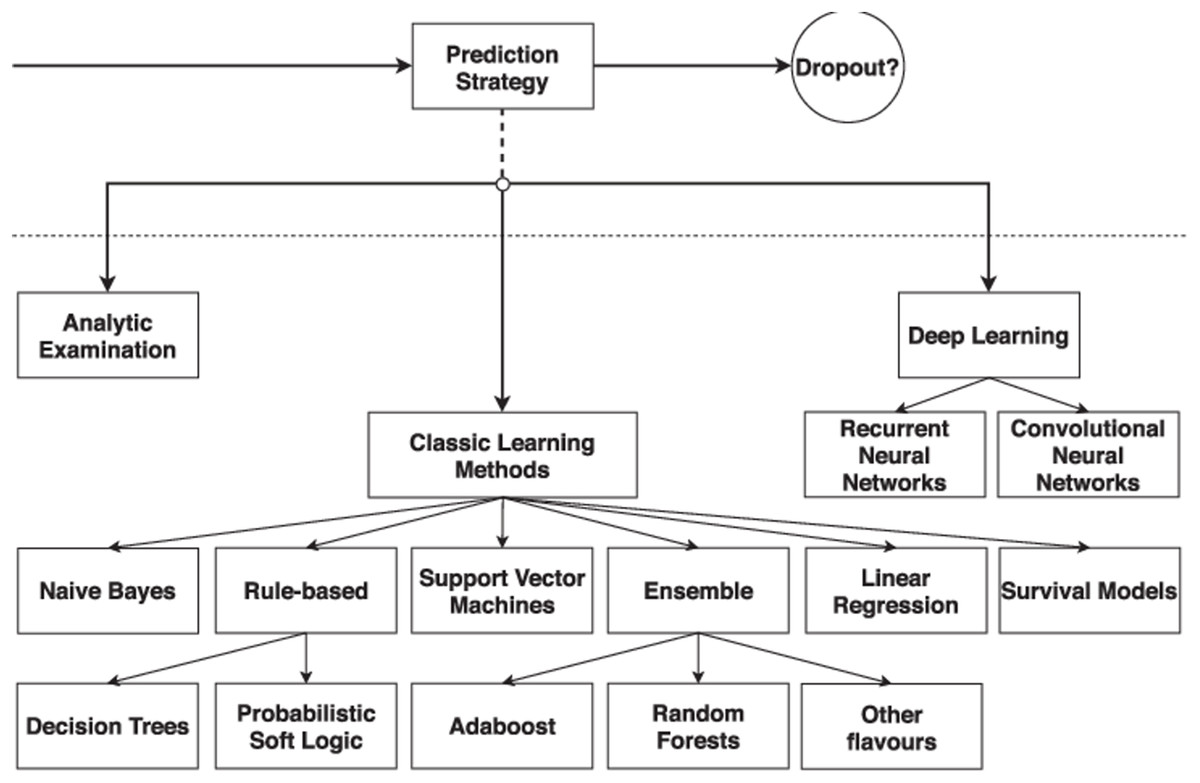
Figure 1: A taxonomy of prediction strategy approaches (Prenkaj et al., 2020).
{kind=link}
Survey methodology
This study conducted a systematic review of relevant academic literature focused on predicting dropout risk in MOOCs through machine learning and deep learning techniques. We identified, selected, and critically evaluated pertinent studies based on several key criteria, as detailed in ‘Related Work and Scope’ and ‘Dropout Risk Prediction Using Machine Learning’. To organize our contributions effectively, we formulated three primary research questions:
RQ1—Dropout Risk Prediction Using Machine Learning: What machine learning techniques are employed for predicting dropout risk in MOOCs, and what are their key characteristics and outcomes?
RQ2—Dropout Risk Prediction Using Deep Learning: How do deep learning approaches differ in predicting dropout risk in MOOCs, and what specific models have shown the most promise in this context?
RQ3—Comparative Analysis of Prediction Methods: How do traditional methods of dropout risk prediction compare with machine learning and deep learning techniques in terms of effectiveness, accuracy, and implementation challenges?
The primary objective of this survey was to create a comprehensive understanding of dropout risk prediction by focusing on the application of deep learning and machine learning techniques. To accurately answer the aforementioned research questions, we adopted the well-established Population/Problem, Intervention, Comparison, Outcome, and Study (PICOS) model (an extension of the PICO framework (Namoun & Alshanqiti, 2020)). The PICOS protocol emphasizes the definition of five key elements: population, intervention, comparison, outcome, and study design. In the context of our research, the population refers to the investigation of studies on dropout risk prediction in learners enrolled in MOOCs. The intervention encompasses the intelligent approaches and techniques used to predict the risk of dropping out. The comparison pertains to the variability in predictive performance among the surveyed models, whereas the outcome assesses the accuracy of these approaches and the identified predictors of dropout risk. Lastly, the study design outlines the types of studies included in the survey, ensuring a robust evaluation of the literature. Table 1 details the PICOS elements of our survey. Furthermore, we identified and searched for several prominent online bibliographic databases that encompass research on educational technologies and dropout prediction in MOOCs. The databases we used include Scopus, IEEE Xplore, Google Scholar, MER-LOT Journal of Online Learning and Teaching, Computers in Human Behavior, and the International Review of Research in Open and Distributed Learning. These databases are frequently consulted in educational technology reviews and are expected to contain studies focusing on predictive modeling of student outcomes.
| Element | Description |
|---|---|
| Population | Learners enrolled in MOOCs at risk of dropout. |
| Intervention | Machine learning and deep learning techniques used for dropout prediction. |
| Comparison | Variability in predictive performance among different models. |
| Outcome | Accuracy of predictions and predictors of dropout risk. |
| Study design | Types of studies included in the survey. |
We conducted a comprehensive search using six databases in 2024, covering publications from 2015 to 2024 to align with our focus on recent developments in MOOC dropout research. The key terms used in the search were carefully crafted to reflect the core concepts of our research questions and the PICO(S) elements. Specifically, we used the following search string: (“Machine Learning” OR “Deep Learning”) AND “Dropout” AND “Prediction AND MOOCs”.
To systematically shortlist articles for this review, specific inclusion criteria were applied, as presented in Table 2. Studies that did not align with these criteria, particularly non-refereed sources like technical reports and articles not published in English, were excluded to ensure rigor and relevance in the selected literature. References were carefully selected according to these standards, including works such as Dalipi, Imran & Kastrati (2018), Mduma, Kalegele & Machuve (2019), Sun et al. (2021), which provided foundational information on dropout prediction methods.
| Database | Number of articles | Publication dates |
|---|---|---|
| ACM | 6 | 2016 (Jun), 2019 (Jan, Sep), 2020 (Apr), 2021 (Mar), 2023 (Feb, May) |
| IEEE Xplore | 20 | 2018 (Apr, Sep), 2019 (Jan, Apr, Jul), 2020 (Mar, May, Aug), 2021 (Jan, Nov), 2022 (Mar, May, Dec), 2023 (Feb, Apr, Jun, Sep), 2024 (Jan, Mar, Oct) |
| Science direct | 10 | 2015 (Sep), 2016 (Feb, Jun), 2019 (Jul, Oct), 2020 (Jan, Aug), 2021 (Mar, Jul), 2022 (Feb, Nov), 2023 (Apr) |
| Scopus | 5 | 2018 (Jul), 2020 (Jun, Dec), 2021 (Sep), 2024 (Jan) |
| Springer | 8 | 2019 (Mar, Sep), 2020 (Jan, Jun), 2021 (Apr), 2023 (Feb, Aug), 2024 (Mar) |
| Web of science | 8 | 2016 (Apr), 2020 (Jul), 2021 (Mar), 2022 (May, Sep), 2023 (Jan), 2024 (Feb, Apr) |
| Total | 57 | 2015–2024 |
Table 2 highlights that IEEE Xplore houses the most substantial number of relevant articles (22), featuring recent publications over the past few years. This may suggest a growing, sustained interest in MOOC dropout prediction within this repository, aligning with findings from similar comprehensive surveys (Masood, Gogoi & Begum, 2024). In contrast, other databases, such as Springer and Web of Science, hold fewer articles, potentially indicating a more specialized focus or limited scope within this area. Sources such as ScienceDirect and Scopus also contributed significantly, with diverse publication dates that reflect ongoing interest and developments in the field. To facilitate further analysis, the VosViewer tool was used for articles sourced from Scopus and Web of Science. VosViewer effectively processes large bibliographic databases and visualizes co-occurrence networks of terms, collaborations between authors, and institutional connections. Consistent with recent analyzes (Hosmer, Lemeshow & Sturdivant, 2013; Quinlan, 1986), VosViewer enabled the identification of primary keywords and thematic links among the selected articles, allowing an overview of the dominant concepts in MOOC dropout prediction research. The resulting visualizations helped highlight research trends, notable author clusters, and institutional collaborations, providing a comprehensive understanding of the field’s landscape.
Table 2 below presents the search results in several electronic bibliographic databases, detailing the different rounds of filtering conducted in this review.
PRISMA study selection and risk-of-bias assessment
This systematic review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA 2020) guidelines to ensure transparency and reproducibility in the study selection process. Compliance with the PRISMA checklist is presented in Fig. 2, confirming adherence to 24 of 27 criteria (with some items not applicable due to the narrative synthesis and absence of meta-analysis owing to heterogeneous outcome measures).
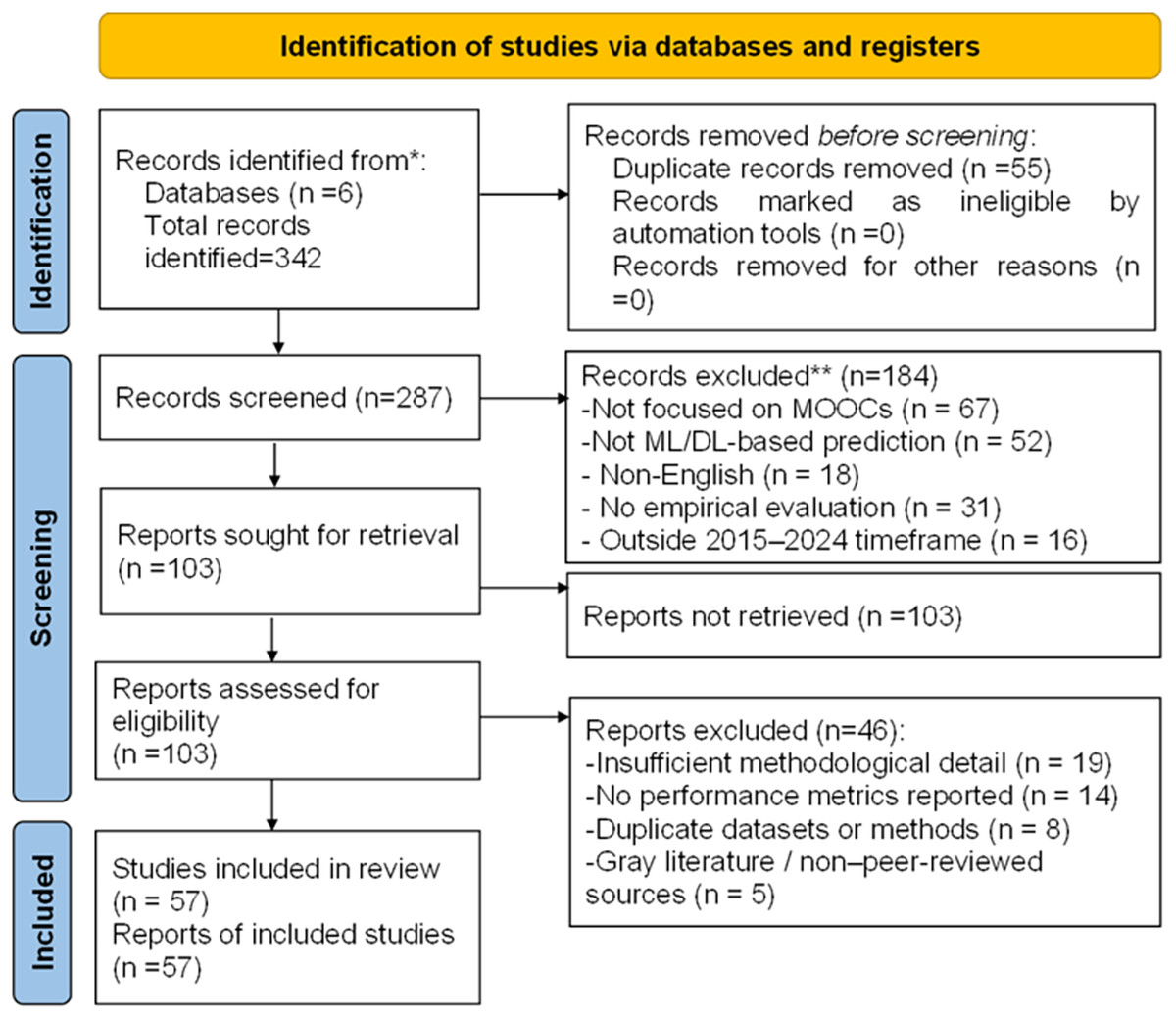
Figure 2: PRISMA flowchart.
{kind=link}
A total of 342 records were initially identified across six electronic databases: Scopus (n = 89), IEEE Xplore (n = 98), ScienceDirect (n = 67), ACM Digital Library (n = 34), Springer (n = 31), and Web of Science (n = 23). After removing duplicates, 287 unique records remained for screening.
Study screening and eligibility
The 287 records were screened based on titles and abstracts, resulting in the exclusion of 184 studies for the following reasons:
Not focused on MOOCs (n = 67)
Not ML/DL-based prediction studies (n = 52)
Non-English publications (n = 18)
No empirical evaluation (n = 31)
Outside the 2015–2024 timeframe (n = 16)
This left 103 full-text articles assessed for eligibility. After full-text review, 46 articles were excluded due to:
Insufficient methodological detail (n = 19)
Missing performance metrics (n = 14)
Duplicate datasets or redundant methods (n = 8)
Gray literature or non-peer-reviewed status (n = 5)
Ultimately, 57 studies met all inclusion criteria and were retained for qualitative synthesis. These studies were categorized into three groups: Machine Learning (n = 29), Deep Learning (n = 21), and Hybrid approaches (n = 7). The complete selection workflow is summarized in the PRISMA flow diagram (Fig. 2).
Risk-of-bias assessment
To evaluate methodological quality, a risk-of-bias assessment was conducted using criteria adapted from the Critical Appraisal Skills Programme (CASP) checklist. The assessment considered: clarity of dataset description, adequacy of sample size, handling of class imbalance, transparency of feature engineering, validation and testing protocols, reporting of performance metrics, and overall reproducibility.
The overall risk of bias across the 57 included studies was moderate. Table 3 summarizes the results of the quality assessment:
| Quality criterion | Studies meeting criterion | Percentage |
|---|---|---|
| Clear research objectives | 57/57 | 100% |
| Appropriate ML/DL methodology | 52/57 | 91.2% |
| Dataset clearly described | 43/57 | 75.4% |
| Training/validation split documented | 38/57 | 66.7% |
| Multiple performance metrics reported | 42/57 | 73.7% |
| Class imbalance addressed | 19/57 | 33.3% |
| Cross-validation performed | 34/57 | 59.6% |
| Comparison with baselines | 47/57 | 82.5% |
| Hyperparameters reported | 31/57 | 54.4% |
| Reproducibility information provided | 23/57 | 40.4% |
The most common limitations observed were:
Only 33.3% of studies addressed class imbalance despite dropout rates of 5–15%.
Only 40.4% provided sufficient detail for replication.
While 91.2% applied appropriate methodologies, not all included baseline comparisons.
Datasets used in MOOC dropout prediction studies
We examined the datasets employed in the studies included in this review to provide a comprehensive understanding of the empirical foundations of MOOC dropout prediction. The reviewed works utilized various large-scale open and proprietary learning analytics datasets collected from MOOC platforms between 2015 and 2024. These datasets capture extensive learner interactions, assessment results, and demographic attributes, which serve as input features for predictive modeling.
The most commonly used datasets include the Open University Learning Analytics Dataset (OULAD), edX, XuetangX, and platform-specific repositories from Coursera and FutureLearn. Their characteristics, such as the number of learners, courses, and logged interactions, vary widely, reflecting the differences in data accessibility and institutional policies.
Table 4 summarizes the primary datasets referenced in the reviewed literature, indicating their sources, coverage periods, data volumes, feature categories, and accessibility statuses.
| Dataset name/source | Time period covered | Volume (students/courses/interactions) | Key features | Availability |
|---|---|---|---|---|
| Open University Learning Analytics Dataset (OULAD)—The Open University (UK) | 2013–2019 | 32,000 students, 22 courses, >10 million interactions | Demographic, academic performance, activity logs, assessment results, temporal features | Public |
| edX platform dataset | 2012–2020 | 10,000–150,000 learners per course | Clickstream events, video views, quiz results, forum posts, engagement time | Proprietary (partially open for research) |
| XuetangX dataset (China) | 2014–2022 | 39 courses, thousands of learners | Course metadata, enrollment records, video interactions, assignment completion, engagement frequency | Restricted access (upon request) |
| Coursera dataset | 2013–2021 | 5,000–50,000 students per course | Behavioral logs, quiz results, peer interaction data, completion status | Proprietary |
| FutureLearn dataset | 2016–2024 | 15,000–40,000 students per course | Login frequency, discussion participation, assignment progress, time on task | Restricted |
| Kaggle MOOC Engagement datasets (various) | 2017–2023 | Thousands of students across several courses | Engagement metrics, forum activity, demographic attributes | Public |
The reviewed studies indicate that the dataset sizes range from a few thousand to over 30,000 students, with millions of recorded interactions across multiple courses. The most comprehensive datasets integrate temporal interaction logs, demographic information, and behavioral metrics extracted over the entire course duration, making them highly suitable for training and validating machine learning and deep learning models in MOOC dropout prediction tasks.
Related work and scope
There is an extensive body of literature on the prediction of dropout risk in MOOCs using machine learning and deep learning (Şahin, 2021), including several review articles. In the following section, we examine works closely related to ours and highlight the differences. Subsequently, we delineate the boundaries of our survey in the scope subsection.
Dropout risk prediction using machine learning
The survey in Dalipi, Imran & Kastrati (2018) offers a comprehensive review of contemporary research on the application of machine learning techniques to predict student dropout in MOOCs. It addresses various factors that contribute to high dropout rates, including student-related issues such as lack of motivation, insufficient time, and inadequate background knowledge, as well as MOOC-specific factors such as poor course design, feelings of isolation, and hidden costs. The study examined several machine learning models used to predict MOOC dropout, including logistic regression, decision trees, deep neural networks, and recurrent neural networks. It also identifies key challenges in this field, such as limited sample sizes, difficulties in managing large unstructured data, data variance, and significant data imbalance. To improve predictive accuracy, the authors suggested several enhancements, including standardizing clickstream data, incorporating data provided by students, and exploring advanced feature engineering techniques. These recommendations aim to address existing limitations and develop more robust predictive solutions to understand and mitigate MOOC dropout rates.
The review from Mduma, Kalegele & Machuve (2019) provides an in-depth analysis of various machine learning methods used to predict student dropout, emphasizing the critical role of early intervention in improving retention rates. Several ML techniques were explored, including supervised methods such as Decision Trees, Random Forests, Support Vector Machines (SVM), and Neural Networks, each with unique advantages: decision trees offer clear interpretations, Random Forests are robust, SVMs excel in complex spaces, and Neural Networks identify intricate patterns. Unsupervised methods, such as clustering, which group students at risk without labeled data, are also discussed. This review covers hybrid approaches that combine multiple ML techniques to improve prediction accuracy. The challenges noted include data quality and availability, feature selection, and ensuring the generalizability of the model across diverse educational settings. This study highlights the significance of evaluation metrics, including accuracy, precision, recall, F1-score, and AUC-ROC. Future research directions include integrating ML models with educational systems for real-time support, developing personalized prediction models, and addressing ethical concerns to ensure the responsible use of predictive technologies. This study highlights the potential of ML to improve dropout prediction and support student success.
Prenkaj et al. (2020) provides an extensive review of machine learning techniques used to predict student dropout in online courses. This study examines various methods, including supervised, unsupervised, and hybrid approaches, and assesses their effectiveness in identifying students at risk of dropping out of their courses. Supervised learning techniques, such as Decision Trees, Random Forests, and SVM, are noted for their ability to predict dropout using labeled data based on historical student behaviour, with each method offering distinct advantages: Decision Trees are interpretable, Random Forests mitigate overfitting, and SVMs excel in complex scenarios. Unsupervised methods, such as clustering, which group’s students based on behavioral similarities without needing labeled data, are also reviewed for their role in detecting dropout risk patterns. Hybrid approaches, which integrate multiple techniques, are discussed for their potential to improve the prediction accuracy. This study highlights several challenges, including data quality, feature selection, and the generalizability of models. It also discusses evaluation metrics such as accuracy, precision, recall, and F1 score, and suggests future research directions, including data quality improvement, model interpretability, and personalized predictive models. This study emphasizes the significant potential of machine learning to improve dropout prediction and retention strategies in online education.
Dropout risk prediction using deep learning
The work of Sun et al. (2021) explored the application of deep learning techniques in analyzing MOOC data. It reviews various models, such as Neural Networks, CNNs, and RNNs, highlighting their effectiveness in enhancing learning analytics. These models are used to monitor and analyze student engagement and behavior, providing insights into learning patterns. Deep learning methods have also been applied to predict student dropout, with RNNs and LSTM networks analyzing sequential data to identify at-risk students for early intervention. Moreover, this study explores how deep learning can personalize learning experiences by customizing content and recommendations based on individual student profiles. However, it faces challenges such as the need for high-quality data, the “black box” nature of deep learning models that complicates interpretability, and high computational demands. This study suggests that future research should aim to advance deep learning models, improve their interpretability, and integrate diverse data sources to improve learning analytics in MOOCs. This emphasizes the significant potential of deep learning to improve educational data analysis and outcomes in MOOCs.
The scope of these surveys
The surveys reviewed provide a comprehensive analysis of the ML and DL techniques used to predict dropout risk in MOOCs. They focused on identifying the key predictors of dropout, including demographic, academic, and behavioral factors. These factors encompass variables such as age, gender, and level of education, as well as specific metrics, such as the number of failed attempts, incorrect actions, and time spent on learning activities. The surveys evaluated a range of machine learning models, including logistic regression, decision trees, deep neural networks, and Extreme Gradient Boosting (XGBoost), and compared their effectiveness using rigorous performance metrics such as precision, recall, F1-score, and AUC-ROC. Through this comparative analysis, the surveys provide valuable insights into the strengths and limitations of various models in forecasting dropout risk.
Furthermore, these studies highlight specific challenges in dropout prediction, including class imbalance, handling missing data, and variability in dropout definitions across different studies. The surveys provide detailed information on data preprocessing methodologies, including normalization, categorical variable encoding, and feature extraction. Effective feature extraction and selection are crucial for enhancing predictive model performance by providing a more accurate representation of the learning data.
The recommendations offered to improve model accuracy include hyperparameter optimization, advanced feature engineering, and incorporating additional data from learner interactions with MOOC platforms. Spanning the period from 2012 to 2023, these studies provide an overview of both advancements and ongoing challenges in predicting MOOC dropout (Sun et al., 2021). They stressed the importance of a multidisciplinary approach that integrates machine learning techniques with educational insights to develop effective interventions aimed at reducing dropout rates.
These surveys are crucial for understanding the complexities of MOOC dropout dynamics and guiding the development of more effective online educational systems tailored to learners’ needs. By incorporating the findings of these studies, educators and MOOC developers can better anticipate dropout risks and implement targeted strategies to improve student retention and the overall success of online learning programs.
This survey extends the work of Prenkaj et al. (2020) by incorporating post-2020 developments in graph neural networks, self-supervised learning, and XAI. It differs from Sun et al. (2021) by providing a quantitative performance synthesis and critically evaluating model trade-offs (accuracy vs. interpretability vs. computational cost).
Among the 57 reviewed studies, demographic information was reported incompletely. However, available data indicate that:
32 studies examined traditional university students (primarily aged 18–25 years),
18 studies focused on working professionals (aged 25–45 years) across platforms such as Coursera and edX,
Seven studies targeted secondary or high school students.
Only nine studies explicitly stratified results by age group, hindering meta-analysis of age-related dropout patterns.
This gap in demographic reporting represents a significant limitation in developing age-adapted intervention strategies. Therefore, future studies should mandate demographic disaggregation in published dropout prediction models.
To clearly highlight how the present survey extends beyond earlier reviews, Table 5 provides a structured comparison of their scope, methodological coverage, and limitations.
| Survey (year) | Years | #studies | Focus/methods reviewed | Quant. synthesis? | PRISMA/transparency | Novel elements relative to this work |
|---|---|---|---|---|---|---|
| Chefrour & Souici-Meslati (2022) | 2015–2024 | 57 | ML + DL, temporal vs static, ensembles, hybrid, datasets, metrics | Yes—pooled metrics; temporal vs. static paired pooling (+17.2%). | PRISMA flow; 24/27 checklist items reported. | Per-study extraction (Appendix A), full model hyperparameters, reproducible analysis, evaluation guidelines, GNN/self-supervised/XAI coverage. |
| Prenkaj et al. (2020) | 2020 | (review) | Taxonomy of ML methods | No | Narrative review | Predates many post-2020 DL advances; no pooled quantitative synthesis. |
| Sun et al. (2021) | 2021 | (review) | Deep learning for MOOCs | No | Narrative | No hyperparameter appendix; no pooled metrics table. |
| Dalipi, Imran & Kastrati (2018) | 2018 | (review) | ML approaches | No | Narrative | No temporal/DL advances. |
| Mduma, Kalegele & Machuve (2019) | 2019 | (review) | ML and hybrid ideas | No | Narrative | Smaller scope; limited temporal/DL. |
| Masood, Gogoi & Begum (2024) | 2024 | (review) | Taxonomy/Classification | No pooled synthesis | Review | Lacks pooled synthesis and hyperparameter appendix. |
As shown in Table 5, our survey is the only one to provide a pooled quantitative synthesis, an explicit comparison of temporal vs. static models, full per-study extraction for reproducibility, and coverage of post-2020 approaches such as GNNs, self-supervised learning, and explainability methods.
Dropout risk prediction using machine learning
Several studies have relied on classification by model type, such as decision trees and SVMs (Prenkaj et al., 2020). However, in our work, we chose to classify the models into simple and ensemble categories based on their structure, complexity, and the approach used to combine them. This classification was inspired by Masood, Gogoi & Begum (2024). This classification demonstrates the distinct advantages and applications of each approach. Simple models, including logistic regression (Hosmer, Lemeshow & Sturdivant, 2013) and decision trees (Quinlan, 1986), are known for their ease of implementation and interpretability. These models provide clear insights into how various factors contribute to dropout risk, making them ideal for initial analyses and situations where model transparency is crucial. Their straightforward nature enables a quick development and evaluation, which is beneficial when resources are limited or when the aim is to identify basic patterns in the data.
In contrast, ensemble models such as Random Forests (Loh, 2011) and Gradient Boosting Machines (Friedman, 2001) aggregate multiple simple models to improve predictive accuracy and robustness. These models, including XGBoost (Chen & Guestrin, 2016), excel at capturing complex data patterns and interactions that simpler models might miss, making them suitable for more advanced analyses where higher accuracy and generalizability are required.
In the following subsections, we review representative techniques from both categories, provide a detailed comparison in tabular format, and discuss their respective advantages and limitations. We also explore potential optimizations and applications to improve dropout prediction in MOOCs.
Simple models
Early research between 2013 and 2016 predominantly employed simple machine learning models such as logistic regression and decision trees to predict dropout (Breslow et al., 2013; Whitehill et al., 2015). These models achieved moderate accuracy (60–75%) based on static engagement metrics such as login frequency and assignment completion. However, their limited capacity to capture temporal learning dynamics meant that transient disengagement was often misclassified as dropout. Subsequent studies (Gitinabard et al., 2018) incorporated social features—such as peer interaction and forum participation—leading to an 8–12% improvement in predictive performance. This evolution underscores a key insight: student persistence in MOOCs is influenced not only by individual activity but also by the social learning context.
The research of Xing et al. (2016) investigates methods for predicting student dropouts in Massive Open Online Courses using stacking generalization. The study specifically employs several machine learning techniques, including decision trees, random forests, and SVMs. These algorithms are used to analyze student engagement data, such as activity levels, forum interactions, and assignment completion. By applying stacking generalization, which combines the predictions of these different models, the study aims to enhance overall prediction accuracy. This approach integrates the strengths of each model to produce more reliable dropout forecasts compared to using a single model alone. The research focuses on using straightforward features that can be easily implemented to improve prediction performance, to provide information on effective interventions to support at-risk students, and to improve retention rates in MOOCs.
Various machine learning techniques have been applied to predict student dropouts in MOOCs, particularly over multiple weeks of course participation. One study implemented a range of models, including logistic regression, decision trees, random forests, and gradient boosting machines, to assess dropout risk at different stages of a course (Kloft et al., 2014). These methods were applied to features such as student activity logs, interaction patterns, and engagement metrics to improve the precision of dropout prediction. A key contribution of this study was its emphasis on temporal features, showing that early behavioral indicators can effectively signal future dropout. The findings also demonstrated that incorporating week-by-week data significantly enhanced the predictive accuracy compared to static models. Additionally, this study addressed important challenges, such as handling dynamic and evolving data and capturing changes in learner behavior over time. By leveraging machine learning algorithms, this study offers valuable insights into the development of more accurate and responsive dropout prediction systems that support timely educational interventions and improve learner retention in MOOCs.
The researchers of Liang, Li & Zheng (2016) tackle the challenge of high dropout rates in MOOCs. This study introduces a machine learning approach to predict dropout risk using data from 39 courses on the XuetangX platform, which is based on the EdX platform. Dropout is defined as a student who has not participated in learning activities for ten consecutive days. The goal is to identify at-risk students early so that educators can provide timely interventions, such as reminders or feedback. The authors employ a supervised classification approach, achieving an accuracy rate of 89% with a Gradient Boosting Decision Tree (GBDT) model. Their comprehensive framework includes data extraction, preprocessing, feature engineering, and performance testing of various models, including SVM, Logistic Regression, Random Forest, and GBDT. The dataset comprises course metadata, student enrollment records, and anonymized EdX behavior logs, which are used to protect student privacy. Data preprocessing focuses on cleaning and parsing logs to extract relevant information, especially related to video interactions. Feature engineering categorizes features into UserFeature, CourseFeature, and EnrollmentFeature, contributing to the accuracy of predictions. The study highlights the significance of feature engineering and data preprocessing, demonstrating that GBDT outperforms other models in predicting MOOC dropouts.
The research of Chi, Zhang & Shi (2023) explores methods for predicting student dropout in MOOCs by analyzing various engagement metrics. The study uses multiple machine learning algorithms, including logistic regression, decision trees, random forests, and support vector machines (SVMs), to develop predictive models. These models are designed to identify at-risk students based on factors such as login frequency, assignment submissions, and forum participation. Logistic regression is used to understand the relationship between dropout risk and engagement variables, while decision trees and random forests help classify students by their likelihood of dropping out. SVMs are used to categorize students based on their likelihood of dropping out. The research highlights the significance of these features in predicting dropout and seeks to enhance prediction accuracy through advanced modeling techniques. Using these methods, the study provides insight into the factors that contribute to dropout behavior and offers a framework for the early identification of at-risk learners.
The authors of Patel & Amin (2024) investigate the predictive modeling of student dropout in MOOCs using various machine learning techniques. Using the OULAD, the authors evaluated seven algorithms, including decision trees, random forests, Gaussian naïve Bayes, AdaBoost, extra tree classifier, XGBoost, and multilayer perceptron (MLP), to predict student outcomes and dropout probabilities. Among these methods, the XGBoost classifier demonstrates the highest performance, achieving 87% accuracy in pass/fail predictions and 86% accuracy in dropout predictions. The study emphasizes the importance of specific engagement metrics and demographic factors as significant predictors of dropout behavior. Moreover, the authors propose personalized interventions based on individual dropout probabilities to enhance student retention.
The work of Xia & Qi (2023) presents a method for predicting student dropout in MOOCs using a novel approach based on multi-temporal sequences of learning behavior. The authors analyze various behavioral patterns over time, including engagement with course materials, participation in discussions, and completion of assignments, to build a predictive model of dropout risk. The method focuses on capturing temporal dynamics by examining how students’ behaviors evolve across different stages of the course. Machine learning techniques, particularly sequence modeling approaches, are employed to process the multi-temporal data and identify patterns that correlate with dropout. The model generates dropout predictions at multiple time points throughout the course, enabling the early identification of at-risk students. The article incorporates decision feedback mechanisms, where interventions and support strategies can be provided to students based on their predicted dropout risk. This feedback helps to engage students and reduce dropout rates.
In this study Sridevi, Priya Ranjani & Ahmad (2024), the authors applied supervised machine learning techniques to identify students at risk of dropping out or underperforming. The authors used a combination of classification algorithms, including decision trees, SVM, and logistic regression, to predict student risk levels based on a range of academic, demographic, and behavioral features. The models were trained and validated on historical student data to assess their accuracy, reliability, and robustness in the early detection of at-risk students. This study further explored the comparative performance of these algorithms by examining which techniques yielded the most accurate predictions. Using these machine learning models, the study aims to enable educational institutions to proactively identify at-risk students, allowing timely, personalized interventions designed to enhance student retention and academic success.
The article Fazil, Rísquez & Halpin (2024) introduced a method to predict student dropout in STEM MOOCs by analyzing behavioral data. This approach utilizes students’ interactions with the course, such as engagement with materials, participation in discussions, and assignment completion, to predict the likelihood of students dropping out. The method begins by collecting behavioral data, including metrics such as login frequency, time spent on course activities, and the level of participation. The data were then processed to identify features that indicate patterns of engagement or signs of disengagement. A machine learning model was developed to classify students based on their dropout risk, utilizing these engagement features. Once at-risk students are identified, targeted intervention strategies, such as personalized notifications and additional resources, are implemented to prevent dropout. The model was evaluated for its predictive accuracy, demonstrating that it effectively identifies at-risk students and supports early interventions, ultimately improving retention and student success in STEM MOOCs.
The research presented in Goren, Cohen & Rubinstein (2024) proposes a method for predicting student dropout in higher education using machine learning techniques. The authors propose a model that analyzes various student data, including academic performance, attendance, and engagement, to identify early warning signs of potential dropout. They employ various machine learning models, including decision trees, support vector machines, and logistic regression, to classify students based on their likelihood of dropping out. The method includes a preprocessing phase in which relevant features are extracted from student data, followed by the application of various algorithms to build the prediction model. The article evaluates the performance of these models by comparing their accuracy and effectiveness in predicting dropout, demonstrating that machine learning models can provide valuable insights for early intervention.
The work of Bulut et al. (2024) presents a novel method for predicting high-school dropout using a collaborative approach that combines both human and machine insights. The authors propose a system that integrates machine learning techniques with educator input to enhance the accuracy of dropout prediction. Initially, the method collects student data, including academic performance, attendance, and behavioral patterns, and applies machine learning algorithms (such as decision trees and logistic regression) to identify potential dropouts. These predictions are then enhanced by incorporating human insights from educators, who provide contextual information about students’ personal and social situations that may not be captured by data alone. The collaborative approach aims to combine the strengths of both machine learning models and human judgment, ensuring more reliable dropout predictions. The system enables real-time identification of at-risk students, enabling early intervention strategies tailored to individual needs.
Ensemble models
The authors of Lykourentzou et al. (2009) investigate an approach to enhance dropout prediction in online education by integrating multiple machine learning algorithms. The study aims to enhance prediction accuracy by combining various techniques to capture complex patterns in student data. The research employs methods such as logistic regression to estimate dropout probabilities, decision trees to create classification rules, random forests to aggregate multiple decision trees for better accuracy, and gradient boosting machines (GBM) to refine predictive performance by combining several weak models into a stronger one. Using a comprehensive data set that includes student activity logs, interaction metrics, and engagement levels, the study develops a robust prediction model. The integration of these machine learning techniques yields more accurate and reliable predictions of dropout risk, providing valuable insights for implementing early interventions and developing strategies to enhance student retention in e-learning environments.
To forecast student dropout in online education, an advanced approach involves applying various machine learning algorithms to analyze student data and predict dropout risk. This includes the use of logistic regression to estimate the probability of dropout based on relevant predictors, decision trees to define classification rules, random forests to enhance accuracy through ensemble learning, and SVMs to delineate optimal classification boundaries. These techniques were evaluated using a dataset comprising student engagement indicators, activity logs, and academic performance metrics, as explored in Tan & Shao (2015).
The research of Chen et al. (2019) examines an advanced method for predicting student dropout in MOOCs by integrating Decision Tree (DT) and Extreme Learning Machine (ELM) algorithms. This hybrid approach combines the strengths of both algorithms to improve prediction accuracy. The Decision Tree algorithm excels in managing categorical data and generating clear decision rules, while the Extreme Learning Machine is known for its rapid learning capabilities and high performance with complex data. By merging these techniques, the study aims to develop a more effective model for predicting dropout compared to using either method individually. The study utilizes data from MOOCs, including student activity logs, interaction patterns, and engagement metrics, to train and evaluate the hybrid model. The findings indicate that this combined approach significantly improves dropout prediction compared to traditional single-algorithm methods. The research highlights the value of advanced machine learning techniques in capturing detailed patterns in student behavior and suggests that early interventions can be implemented more effectively to support students at risk of dropping out. This hybrid algorithm improves student retention in online learning settings.
The study of Lee & Chung (2019) presents an innovative system designed to improve the prediction of dropout in educational settings. This system utilizes various machine learning techniques to identify students who are at risk of dropping out, with the aim of improving intervention strategies and increasing retention rates. The methods used include logistic regression to estimate dropout probabilities, decision trees to formulate clear decision-making rules, random forests to combine multiple decision trees for increased accuracy, and SVMs to categorize students based on dropout risk through hyperplane separation. The system is developed using a detailed dataset that includes student engagement, academic performance, and behavioral data. By analyzing these indicators, the early warning system can identify dropout risks early, enabling timely and targeted interventions.
The research of Nithya & Umarani (2022) introduces an innovative method for predicting student dropout from MOOCs using the FIAR-ANN model, which combines the importance of features with an Attention-based Recurrent Neural Network (ANN) to analyze learner behavior. The FIAR-ANN model is specifically designed to identify complex patterns in student behavior that indicate dropout risk. The approach begins with the extraction of key behavioral features from student interaction data, including clickstream activity, time allocation for course tasks, and participation in assessments. These features are then processed by the FIAR-ANN model, which uses recurrent neural networks (RNNs) paired with attention mechanisms to emphasize the most critical aspects of student behavior. The importance component of the model prioritizes the features that most significantly influence dropout predictions. This model is particularly effective at capturing temporal dependencies and subtle behavioral trends that traditional models may miss.
A cutting-edge model was developed to enhance the accuracy of predicting student performance in online education by integrating several machine learning techniques. This hybrid approach leverages decision trees to generate interpretable classification rules, SVMs to manage complex decision boundaries between performance levels, and neural networks to detect intricate patterns within student data using deep learning. Built on a comprehensive dataset that includes interaction logs, performance metrics, and engagement statistics, the model seeks to deliver more precise and reliable performance predictions, as demonstrated by Ali et al. (2022).
In the work of Nájera & Méndez Ortega (2022), the researchers introduce a model designed to help universities prevent student dropouts by identifying those at risk early. The model uses various machine learning techniques to analyze student data and predict dropout probabilities, facilitating prompt interventions. The study incorporates several machine learning algorithms, such as logistic regression, decision trees, and random forests, to develop the predictive model. These algorithms evaluate factors, including academic performance, attendance, socio-economic status, and levels of engagement, to gauge the risk of dropout. The data is preprocessed using methods like normalization and feature selection to ensure it is suitable for model training. The performance of the model is assessed with accuracy, precision, recall, and F1-score, showing its effectiveness in predicting dropout risks with considerable reliability. By identifying students at high risk of dropping out, the model enables universities to apply targeted support and intervention strategies, thereby improving student retention and reducing dropout rates.
The study of Tong & Li (2025) explores the use of machine learning techniques to predict student dropout in MOOCs by analyzing learning behaviors. The authors develop a framework that utilizes various machine learning algorithms to assess the risk of dropout based on students’ interactions with and engagement in the course. The study uses logistic regression, decision trees, random forests, and gradient boost machines to model the connection between behavioral features and the likelihood of dropping out. The analysis focuses on key behavioral indicators, such as video viewing time, assignment submission patterns, forum participation, and clickstream data. The data is preprocessed through normalization and feature extraction to make it suitable for model training. Machine learning models are trained and validated using historical data to determine their predictive accuracy. The findings show that these models can effectively identify students at risk of dropping out by detecting patterns in their learning behavior.
This research Li et al. (2023) presents a novel method for forecasting student dropouts in MOOCs before they even enroll. The approach uses a self-supervised learning model combined with explainability features. The authors introduce a framework that applies self-supervised learning techniques to analyze pre-enrollment data, which includes student demographics, educational background, and early engagement indicators, to predict dropout risks without needing labeled dropout cases. The model integrates explainable machine learning methods to enhance the transparency and understanding of its predictions. Techniques like decision trees and SHapley Additive exPlanations (SHAP) are employed to clarify the factors influencing dropout predictions, providing insights into why certain students might be at risk.
The work of Kitaka (2023) introduces a sophisticated method for predicting dropout rates in online courses designed for post-graduate students. The study employs a hybrid model that integrates several machine learning techniques to enhance prediction accuracy. Specifically, the model combines decision trees, which provide clear decision rules for classifying dropout risk; SVMs, which address complex classification tasks by finding optimal boundaries between different risk categories; and neural networks, which capture intricate patterns in student behavior and engagement through advanced deep learning methods. Using a comprehensive dataset that includes student interaction logs, academic performance metrics, and engagement data, the hybrid model aims to deliver more precise dropout predictions and actionable insights for early intervention.
The article by Psathas, Chatzidaki & Demetriadis (2023) examines the predictive modeling of student dropout in MOOCs, highlighting the importance of self-regulated learning (SRL) behaviors. The authors analyze factors contributing to dropout rates, stating that effective SRL is essential for students to navigate the autonomy and flexibility inherent in these courses successfully. They employ an ensemble machine learning approach that integrates various data sources, including learner engagement metrics and specific SRL indicators such as time management, goal setting, and learning strategies, to more accurately identify at-risk students. The findings reveal substantial correlations between SRL behaviors and course completion rates, suggesting that enhancing students’ self-regulation skills could effectively reduce dropout rates. The authors advocate for targeted interventions that support SRL within MOOC environments to improve overall retention and success of learners.
The work of Psyridou et al. (2024) investigates the potential of machine learning techniques to predict dropout rates in higher secondary education, using data collected at the end of primary school. The authors analyze a comprehensive 13-year longitudinal dataset, which begins in kindergarten, to identify key factors influencing dropout risk, including academic performance, socio-emotional factors, family background, individual behaviors, and motivation. The study employs advanced machine learning algorithms, which likely include both ensemble methods and possibly simpler models, to accurately forecast students’ likelihood of dropping out before they transition to secondary education. The findings indicate that these models can effectively classify at-risk students, facilitating early interventions to support retention strategies. The authors emphasize that timely identification of at-risk students can improve educational practices, enabling proactive measures that improve student success and reduce dropout rates in higher secondary education.
The article by Rabelo & Zárate (2024) presents a predictive model for dropout rates among higher education students, focusing on the use of academic data to forecast student retention. The authors emphasize the importance of early identification of at-risk students, proposing a model that analyzes students’ academic performance across their undergraduate programs. The study employs various advanced data analysis techniques, including data collection and preparation, feature selection to identify key academic indicators, and predictive modeling using machine learning algorithms such as logistic regression, decision trees, or ensemble methods. Their findings suggest that sociodemographic data are not necessary for dropout prediction, enabling a more streamlined approach that eliminates biases associated with traditional learning processes. The model demonstrates high accuracy, surpassing 95% in predicting dropout rates based solely on academic indicators. By identifying potential dropouts as early as the first semester, the research underscores the effectiveness of the model in enabling timely interventions to support student retention and success in higher education.
The authors of Putra (2024) introduce a hybrid machine learning model known as Random Forest and Extreme Gradient Boosting (RFXGB) to predict dropout rates among students in MOOCs. This model combines the strengths of different machine learning techniques, specifically Random Forest, which is effective in handling data variability, and Extreme Gradient Boosting, which enhances prediction accuracy through ensemble learning methods. The study emphasizes the importance of analyzing student engagement and behavioral data, such as participation in discussions, assignment completion rates, and time spent on course materials, to assess dropout risks effectively. To develop and validate the RFXGB model, researchers employ various performance metrics, including accuracy, precision, and recall, to assess its effectiveness in comparison to traditional machine learning methods. The results indicate that the RFXGB model significantly outperforms these conventional approaches, achieving a high level of prediction success for student dropout.
The study of Zujiao et al. (2023) proposes a predictive model for student dropout in MOOCs using a combination of weighted multi-features and SVM’s. The authors focus on several key features, such as student engagement metrics (e.g., time spent on course materials, participation in discussions, and assignment completion), academic performance, and demographic information. These features are assigned different weights to reflect their significance in predicting dropout risk. The weighted characteristics are then used as input to an SVM model, which classifies students into different risk categories based on their probability of dropping out. The method incorporates a feature selection process to identify the most relevant variables for prediction, thereby enhancing the model’s accuracy. The article demonstrates the effectiveness of the weighted multi-feature approach combined with SVM for predicting dropout in MOOCs.
The work of Chaikalis (2024) examines the application of machine learning algorithms to predict student dropout in educational environments. It evaluates a variety of models, including decision trees, random forests, SVM, and logistic regression, to determine their effectiveness in identifying students at risk of dropping out. The study focuses on key features, including academic performance, attendance, demographics, and engagement metrics, that influence dropout predictions. Each model’s performance is assessed using accuracy, precision, recall, and F1-score, providing a detailed comparison of how well the models predict dropout risk. The article highlights the significance of feature selection and optimization in enhancing prediction accuracy. It also explores the potential of these models to be applied in real-world educational settings, where early intervention could help retain at-risk students.
Comparison and discussion
We compared simple and ensemble models to predict student dropout from MOOCs based on several criteria, as illustrated in Table 6. The comparison considers the methods employed, features utilized, prediction accuracy, intervention strategies, model architecture and parameters (including layer depth, neurons/filters per layer, and key hyperparameters for deep learning models), and overall complexity.
| Reference | Model type | Techniques used | Dataset | Features (c) | Prediction accuracy (b) | Intervention strategies | Architecture/Parameters (d) | Complexity (a) |
|---|---|---|---|---|---|---|---|---|
| Breslow et al. (2013) | Simple | Logistic Regression, Decision Trees | edX MOOC | Behavioral Data: Interaction Data, Engagement Metrics | Not specified | None | N/A | Low (<100K parameters) |
| Whitehill et al. (2015) | Simple | Logistic Regression, Decision Trees | Interaction Data, Engagement Metrics | Behavioral and Engagement Data: Activity Data, Engagement Metrics | Not specified | Automatic interventions | N/A | Medium (100K–1M parameters) |
| Gitinabard et al. (2018) | Simple | Logistic Regression, Decision Trees, Random Forests | Behavioral and Social Data | Engagement/Temporal/Academic: Login Frequency, Assignment Completion | Improved prediction with social data | None | N/A | Medium |
| Xing et al. (2016) | Simple | Decision Trees, Random Forests, SVMs | Student Engagement Data | Various Factors: Activity Levels, Forum Interactions, Assignment Completion | Not specified | None | N/A | Medium |
| Kloft et al. (2014) | Simple | Logistic Regression, Decision Trees, Random Forests, Gradient Boosting | Activity Logs, Interaction Patterns | Engagement and Temporal Data: Temporal Features, Engagement Metrics | Improved with temporal features | None | Ensemble, five components, 1.2M parameters | High (>1M parameters) |
| Liang, Li & Zheng (2016) | Simple | Logistic Regression, Random Forests, SVM, Gradient Boosting | XuetangX Data | Behavioral Data: Course Metadata, Behavior Logs | High 89% Accuracy (GBDT) | Reminders, Feedback | N/A | High |
| Chi, Zhang & Shi (2023) | Simple | Logistic Regression, Decision Trees, Random Forests, SVMs | Engagement Metrics | Engagement Metrics: Login Frequency, Assignment Submissions, Forum Participation | Not specified | None | N/A | Medium |
| Patel & Amin (2024) | Simple | Decision Trees, Random Forests, Gaussian Naïve Bayes, AdaBoost, XGBoost, MLP | Open University Learning Analytics Dataset | Engagement Metrics, Demographics | High 86% Accuracy (Dropout) | Personalized interventions | MLP: three layers, 128-64-32 neurons, batch = 32, lr = 0.001 | High |
| Xia & Qi (2023) | Temporal | Sequence Modeling | Behavioral Data over Time | Engagement Patterns, Assignment Completion | Not specified | Real-time interventions | LSTM: three layers, 64–128 units, batch = 32, lr = 0.001 | High |
| Sridevi, Priya Ranjani & Ahmad (2024) | Simple | Decision Trees, SVM, Logistic Regression | Student Data | Academic, Demographic, Behavioral Data | Not specified | Personalized interventions | N/A | Medium |
| Fazil, Rísquez & Halpin (2024) | Simple | Machine Learning | STEM MOOCs | Engagement, Assignment Completion, Login Frequency | Effective at-risk identification | Personalized notifications | MLP: four layers, 256-128-64-32 neurons, dropout = 0.3 | Medium |
| Goren, Cohen & Rubinstein (2024) | Simple | Decision Trees, SVM, Logistic Regression | Higher Education Data | Academic Performance, Attendance, Engagement | Not specified | Early interventions | N/A | Medium |
| Bulut et al. (2024) | Hybrid | Decision Trees, Logistic Regression | Student Data | Attendance, Academic, Behavioral Data | Not specified | Real-time interventions, Educator input | N/A | High |
| Lykourentzou et al. (2009) | Ensemble | Logistic Regression, Decision Trees, Random Forests, GB | Student Activity Logs, Interaction Metrics | Engagement Data | Enhanced accuracy | None | Ensemble, M params | High |
| Tan & Shao (2015) | Ensemble | Logistic Regression, Decision Trees, Random Forests, SVMs | Engagement, Activity Logs, Academic Performance | Behavioral Indicators | Not specified | None | Ensemble, 1.2M params | High |
| Chen et al. (2019) | Ensemble | Decision Tree, Extreme Learning Machine (ELM) | Student Activity Logs, Engagement Metrics | Engagement Patterns | Improved accuracy | None | ELM: three layers, 128-64-32 neurons | High |
| Lee & Chung (2019) | Ensemble | Logistic Regression, Decision Trees, Random Forests, SVMs | Engagement, Academic Performance, Behavioral Data | Various Engagement Metrics | Enhanced early prediction | None | Ensemble/Mixed DL-ML, 1.2M params | High |
| Nithya & Umarani (2022) | Ensemble | FIAR-ANN (Feature Importance + RNN) | Learner Behavioral Features | Behavioral Data: Clickstream Activity, Time Allocation | Advanced prediction with behavioral patterns | None | RNN: three layers, 128-64-32 units, dropout = 0.4 | High |
| Ali et al. (2022) | Ensemble | Decision Trees, SVMs, Neural Networks | Interaction Logs, Performance Metrics | Engagement Statistics | Enhanced prediction accuracy | None | MLP: four layers, 256-128-64-32 neurons | High |
| Nájera & Méndez Ortega (2022) | Ensemble | Logistic Regression, Decision Trees, Random Forests | Academic Performance, Attendance, Engagement | Behavioral Data and Engagement Metrics | Timely interventions | None | N/A | High |
| Tong & Li (2025) | Ensemble | Logistic Regression, Decision Trees, Random Forests, Gradient Boosting | Behavioral Features | Academic/Engagement: Video Watch Time, Assignment Patterns, Forum Participation | Higher accuracy | None | Ensemble, 1.5M params | High |
| Li et al. (2023) | Ensemble | Self-Supervised Learning, Decision Trees, SHAP | Pre-enrollment Data | Demographics, Educational Background, Early Engagement Indicators | Explainable predictions | None | Self-Supervised: three layers, 256-128-64 neurons | High |
| Kitaka (2023) | Ensemble | Decision Trees, SVMs, Neural Networks | Interaction Logs, Academic Performance | Student Behavior, Engagement | Improved prediction | None | MLP: three layers, 128-64-32 neurons | High |
| Psathas, Chatzidaki & Demetriadis (2023) | Ensemble | Learner engagement metrics, SRL indicators (time management, goal setting) | MOOC platform data | SRL behaviors, course engagement metrics | High correlation with completion rates | Recommends targeted SRL | N/A | Moderate |
| Psyridou et al. (2024) | Ensemble | 13-year longitudinal data | Upper secondary education | Academic, behavioral, and socioemotional data | Effective early prediction | Enables early interventions | N/A | High |
| Rabelo & Zárate (2024) | Ensemble | Logistic Regression, Decision Trees | Academic performance data | Higher education Academic indicators | Over 95% accuracy | Early identification intervention | N/A | Moderate |
| Putra (2024) | Ensemble | RFXGB: Random Forest + Extreme Gradient Boosting | MOOC behavioral dataset | Engagement metrics (participation, assignment completion) | High prediction success | Early interventions | Ensemble, 1.5M params | High |
| Zujiao et al. (2023) | Ensemble | SVM with Weighted Features | MOOC data | Academic performance, demographics | Improved accuracy with weighted features | Identifies at-risk students by risk category | N/A | Moderate |
| Chaikalis (2024) | Ensemble | Decision Trees, Random Forests, SVM, Logistic Regression | Education dataset | Academic performance, attendance, demographics, engagement | Accuracy, precision, recall, F1-score | Early interventions | Ensemble, 1.2M params | High |
Notes:
aComplexity assessed by parameter count and architectural depth.
bAccuracy values represent best reported performance; studies often report multiple metrics (precision, recall, F1-score) with varying results.
cFeatures are derived from learning management system (LMS) logs unless otherwise specified.
dArchitecture/Parameters indicates model depth (number of layers) and approximate number of trainable parameters. For deep learning models, key layer specifications and training parameters are included.
A comparative analysis of machine learning models for predicting MOOC dropout reveals distinct advantages and limitations in both simple and ensemble approaches. Simple models, such as logistic regression, decision trees, and random forests, are frequently used due to their ease of use and relatively low computational demands. These models primarily focus on engagement metrics, such as login frequency and assignment completion, while some also incorporate social or demographic data to enhance predictive performance. Although accessible and efficient, simple models may struggle to capture complex and nuanced relationships within large MOOC datasets, potentially limiting their predictive accuracy (e.g., Breslow et al. (2013), Whitehill et al. (2015), Gitinabard et al. (2018), Xing et al. (2016), Kloft et al. (2014)).
In contrast, ensemble models show considerable advantages in terms of accuracy and robustness, combining algorithms like decision trees, SVMs, gradient boosting, and advanced methods such as FIAR-ANN (Feature Importance and RNN) or self-supervised learning. These combinations enable ensemble models to identify more nuanced patterns within student engagement data, which is crucial for accurately predicting dropout. Some ensemble models utilize more complex data sources, such as longitudinal educational data, enabling the early identification of at-risk students during transitional education phases (e.g., Liang, Li & Zheng (2016), Xia & Qi (2023), Tan & Shao (2015)). Although ensemble models offer higher predictive power, they often come with increased computational requirements.
The integration of behavioral and temporal features has proven effective in enhancing predictive accuracy across both types of models. Models that utilize engagement data, such as video watch time and forum participation, or temporal indicators, including activity trends, demonstrate improved prediction rates, reflecting the importance of understanding students’ evolving engagement levels (Lee & Chung, 2019; Nithya & Umarani, 2022; Tong & Li, 2025). These features provide insight into whether a student is likely to complete a course, underscoring the value of behavioral and temporal data in predicting dropout.
Intervention strategies vary between models, with high-accuracy models proposing targeted support mechanisms, including personalized reminders, feedback, and notifications for students identified as at risk. Ensemble and temporal models, in particular, enable real-time interventions, supporting timely assistance that can reduce dropout rates (Fazil, Rísquez & Halpin, 2024; Lykourentzou et al., 2009; Ali et al., 2022). This approach aligns with educational goals to decrease dropout rates by providing students with tailored and data-driven support.
Complexity remains a key consideration; while ensemble models generally require more resources and expertise due to their multi-model architectures, they tend to deliver more adaptive and accurate predictions. Simple models, though less resource-intensive, can be practical for institutions with limited technical capacities. In general, the ensemble models offer robust solutions, especially in scenarios where real-time intervention and high prediction accuracy are prioritized (Kitaka, 2023; Rabelo & Zárate, 2024; Zujiao et al., 2023). Despite their improved accuracy over simple models, ensemble approaches such as Random Forests and Gradient Boosting frequently suffer from overfitting when applied to small or homogeneous MOOC datasets. Moreover, their performance declines sharply when transferred across courses or platforms, indicating limited generalizability. Another recurring limitation is the lack of interpretability, as feature importance alone fails to explain the temporal engagement variations.
Dropout risk prediction using deep learning
Simple models
The authors of Wang, Yu & Miao (2017) present a deep learning approach to predict student dropout in MOOC. They developed a deep neural network (DNN) model that is specifically designed to uncover complex, nonlinear patterns between various student characteristics and dropout tendencies. The model features multiple hidden layers, each containing numerous neurons, enabling it to learn intricate representations of student interactions and engagement within the course. The DNN is trained using the backpropagation algorithm, and techniques such as dropout regularization and batch normalization are employed to prevent overfitting and improve the model’s generalization capabilities. The authors also compare the deep model’s performance with that of traditional machine learning algorithms, including logistic regression and SVMs.
The work of Qiu et al. (2019) investigates the use of CNNs to predict student dropout in MOOCs. The authors introduce an innovative method that employs CNNs to analyze student interaction and course data, thereby improving the accuracy of dropout predictions. The CNN model processes structured data on student behavior and engagement through several convolutional layers that capture complex features, along with pooling layers that streamline data and emphasize key patterns. The architecture is refined using techniques such as dropout and batch normalization to avoid overfitting and enhance model performance. The effectiveness of the CNN model is compared to traditional machine learning techniques such as logistic regression and support vector machines (SVMs).
The study presented in Zheng et al. (2020) proposes a novel approach for predicting student dropout in MOOCs by employing a specialized deep learning model. The proposed model, FWTS-CNN (Fused Weighting and Time Series Convolutional Neural Network), integrates advanced techniques for handling both feature weighting and temporal data. The FWTS-CNN model incorporates a feature weighting mechanism to prioritize the most relevant features from student engagement data, such as video interactions, forum posts, and quiz results. This mechanism ensures that the model focuses on the most informative aspects of the data. The model then uses CNNs to process the weighted features, capturing both spatial patterns and interactions within the data. Additionally, the model integrates time series analysis to account for temporal changes and trends in student behavior, enhancing its ability to predict dropout based on how engagement evolves over time. The model is evaluated on large MOOC datasets and demonstrates improved accuracy in dropout prediction compared to traditional methods. The fusion of feature weighting with time series analysis allows for a more nuanced understanding of student behavior.
The research of Muthukumar & Bhalaji (2020) introduces MOOCVERSITY, a deep learning model designed to predict student dropout in MOOCs by analyzing how dropout risks change over time. The model focuses on capturing temporal patterns in student engagement and activity throughout the course. MOOCVER-SITY utilizes a deep learning architecture that likely includes RNNs or LSTM networks. These types of network are selected for their ability to handle sequential data and understand the time-dependent relationships in student interaction patterns. The model processes various features, such as student activity logs, engagement statistics, and participation trends over several weeks, to provide accurate dropout predictions. To improve the model’s accuracy and avoid overfitting, techniques like dropout and batch normalization are employed. These methods help MOOCVERSITY to perform well with new data and enhance its predictive capability.
The work of Mubarak, Cao & Hezam (2021) introduces a deep learning approach to forecast student dropout in MOOCs. The authors develop a model that utilizes diverse student data, such as interaction logs and demographic details, to improve the accuracy of the prediction. The study highlights how deep analytical techniques can detect students at risk of dropping out early, allowing prompt interventions to boost retention. The model’s success is confirmed through experiments on actual MOOC datasets, demonstrating its ability to lower dropout rates effectively.
A novel method was proposed for predicting student dropout in MOOCs using a Graph Neural Network (GNN) that models social interactions among learners. The proposed model, SIG-Net, utilises data from student activities, such as forum posts and peer communications, to build a student interaction graph. In this graph, each node represents a student, and the edges denote interactions between them. The GNN processes this structure by aggregating information from neighbouring nodes, effectively capturing both individual behaviour and the influence of peer interactions. Trained on MOOC interaction data, the model demonstrates superior performance in dropout prediction compared to traditional approaches that overlook the social dimension of student behaviour (Roh et al., 2024).
The authors of Zhang et al. (2024) introduce a deep learning framework designed to predict student dropout in MOOCs. The proposed model, named IC-BTCN, integrates Inception-ResNet (IC) and Bidirectional Temporal Convolutional Networks (BTCN) to analyze student engagement and performance data. The IC component of the model utilizes inception blocks to capture multi-scale features from the data, enhancing the model’s ability to learn complex patterns in student behavior. The BTCN component processes temporal sequences of student interactions and performance metrics, leveraging bidirectional convolutions to account for both past and future data, which helps in understanding trends and changes in student engagement over time. The IC-BTCN model is trained on extensive datasets that include various student activities, such as participation in forums, quiz scores, and video viewing times.
The study of Ndunagu et al. (2024) explores the use of deep learning techniques, specifically deep neural networks (DNN), to predict student attrition in Open and Distance Learning (ODL) environments. The authors propose a model that takes into account various factors that contribute to student dropout, such as academic performance, engagement with course content, demographic details, and interaction patterns within the learning platform. Data collected from ODL institutions are preprocessed to create a complete set of features, including metrics such as assignment scores, time spent on course materials, frequency of logins, and participation in discussions. These features are then fed into the DNN model, which uses multiple layers of neurons to learn intricate patterns and correlations that could identify students who are at risk of dropping out.
The research of Darenoh, Bachtiar & Perdana (2024) explores the use of DNN to predict whether students will graduate on time. The authors train the model using a comprehensive dataset that includes academic performance, attendance, course engagement, and demographic factors, as well as other relevant student behaviors. Key features, such as grades, course completion rates, participation in extracurricular activities, and interaction with learning materials, are extracted from the data. The data is preprocessed to ensure high-quality input, addressing issues such as missing values and normalization. The DNN model, with multiple hidden layers, learns complex relationships within the data to predict on-time graduation. The study shows that deep learning, particularly DNN, surpasses traditional machine learning models in capturing these complex relationships. The results suggest that such models can be instrumental in identifying students at risk of not graduating on time, allowing institutions to provide early interventions and tailored support.
The study of Sayed (2024) explores the application of CNN to predict student progression and dropout rates at the Arab Open University. The study uses CNN to analyze various student-related features, such as academic performance, attendance, and engagement, to identify patterns and factors that contribute to student dropout. The CNN model is used to extract spatial features from student data, which are then used to predict the likelihood of dropout and the overall progression of students through their courses. The effectiveness of the CNN model is evaluated by comparing its prediction accuracy with that of traditional models, showing that the CNN approach outperforms simpler methods due to its ability to learn complex patterns in the data automatically.
Ensemble models
The work of Wu et al. (2019) introduces a deep learning model designed to predict student dropout in MOOCs. The proposed model, CLMS-Net (Course-Level Multi-Source Network), uses multiple sources of data, including student interaction logs, course materials, and performance metrics, to make accurate predictions. The CLMS-Net model is structured with several layers that process different types of input data. It includes a feature extraction layer for each data source, followed by a series of convolutional and recurrent layers that capture both spatial and temporal patterns in the data. This architecture enables the model to understand how various factors, including student engagement with course content and their interaction patterns, impact the likelihood of dropping out. The model is trained on large-scale MOOC datasets, demonstrating superior accuracy compared to traditional models.
The research of Xing & Du (2019) presents a deep learning-based approach to predict student dropout in MOOCs to enable personalized interventions. The authors develop a model that processes various student-related data, such as engagement metrics, assignment submissions, and forum participation, to identify students at risk of dropping out. The proposed model is built using a DNN architecture, which includes layers for feature extraction, hidden layers to learn complex patterns, and an output layer for binary classification (predicting dropout or persistence). The model also incorporates attention mechanisms to focus on the most relevant features that contribute to the risk of dropping out. By analyzing these patterns, the model can predict which students are likely to drop out, allowing for timely and tailored interventions. The model is trained on large datasets from multiple MOOCs, demonstrating improved accuracy over traditional methods. The authors highlight that this approach not only improves dropout prediction but also enables the development of personalized strategies to keep at-risk students engaged.
The authors of Sun et al. (2019) explore advanced deep learning techniques to predict student dropout in MOOCs. They propose a novel deep learning model specifically designed to improve the accuracy of dropout predictions by analyzing various data from student interactions. The proposed model integrates CNNs and LSTM networks. CNNs are used to process and extract meaningful features from spatial data, such as interaction logs and engagement patterns. These features include aspects such as video viewing habits and participation in forums. LSTMs are used to capture temporal dependencies, analyzing how these features evolve to identify patterns associated with dropout risk. The model is trained on extensive MOOC datasets, and the authors demonstrate that their deep learning approach significantly outperforms traditional prediction methods in terms of accuracy and reliability. By combining CNNs and LSTMs, the model effectively addresses both spatial and temporal dimensions of student behavior.
Deep learning techniques have been explored to predict student performance in Massive Open Online Courses by directly leveraging raw clickstream data. The proposed model processes sequences of user interactions with the online learning platform to forecast academic outcomes. This approach combines convolutional neural networks, which extract meaningful features from the clickstream, such as access frequency and time spent on course components, with LSTM networks that model temporal dependencies and behavioural sequences over time. Trained and validated on large-scale MOOC datasets, the model demonstrates high predictive accuracy and offers a deeper understanding of student engagement and learning patterns (Körösi & Farkas, 2020).
The study of Waheed et al. (2020) focuses on using deep learning techniques to forecast student academic performance based on data from Virtual Learning Environments (VLEs). The authors propose a deep learning framework to analyze extensive data sets collected from VLEs, which include various types of student interactions and activities. The proposed approach employs several deep learning models, including CNNs and LSTM networks, to process and analyze the data. CNNs are used to extract and interpret spatial features from interaction logs, such as patterns in access frequency and engagement with course materials. LSTMs are applied to capture temporal dependencies, analyze how student behavior evolves over time, and predict future performance based on historical data. The model is trained on large datasets from VLEs, demonstrating that deep learning methods significantly enhance the accuracy of academic performance predictions compared to traditional techniques. The authors demonstrate that integrating spatial and temporal analyses within a deep learning framework provides a more comprehensive understanding of student performance.
The authors of Heinrich et al. (2021) explore advanced deep learning techniques for analyzing process data, which are sequences of actions taken by students in digital learning environments. They introduce two novel models: Gated convolutional neural networks (GCNN) and key-value predictive attention networks (KVP), tailored to capture the unique characteristics of the process data. GCNNs are designed to handle the temporal and sequential nature of process data by using gated mechanisms that selectively pass information through the network. This helps in capturing long-term dependencies and complex patterns in student behavior. KVP networks, on the other hand, use an attention mechanism that focuses on the most relevant parts of the data, using key-value pairs to predict outcomes. This enables the model to weigh the importance of different features when making predictions dynamically. Both models are evaluated on large educational datasets, showing significant improvements in predicting student performance and engagement compared to traditional methods. The article explores the importance of considering the specific properties of process data in designing deep learning models.
The work of Fu et al. (2021) presents a new deep learning approach designed to predict student dropout in MOOCs. The authors introduce the CLSA model, which stands for Convolutional Long Short-Term Memory Self-Attention. This model integrates three key components-convolutional layers, LSTM units, and a self-attention mechanism to analyze student engagement and behavior data comprehensively. The convolutional layers in the CLSA model are used to extract important features from the raw input data, such as video interactions, forum participation, and quiz results. These features are then passed on to LSTM units, which are well-suited for handling sequential data and capturing temporal dependencies in student activity over time. Finally, the self-attention mechanism allows the model to focus on the most critical parts of the sequence, improving the accuracy of dropout predictions by weighting the importance of different time steps. The model is trained and tested on large MOOC datasets, demonstrating superior performance in predicting dropout compared to existing models. The authors emphasize that CLSA’s combination of convolutional, sequential, and attention-based processing provides a more robust analysis of student data, enabling more precise dropout predictions.
The study Zhang, Chang & Liu (2020) introduces a hybrid deep learning approach to predict student dropout in MOOCs. The authors propose a model that combines CNNs and RNNs to effectively capture both spatial and temporal features of student engagement data. The hybrid model begins with CNN layers, which are used to extract local features from various types of input data, such as clickstream information, video interactions, and forum participation. These features are then fed into RNN layers, particularly LSTM units, which are adept at capturing the temporal dependencies and sequential patterns in the data. This combination allows the model to analyze both the individual elements of student behavior and how they evolve, leading to more accurate dropout predictions. The model is trained on extensive MOOC datasets, demonstrating that the hybrid approach outperforms traditional methods and standalone deep learning models in predicting dropout rates. The article emphasizes that integrating both CNN and RNN architectures provides a more comprehensive understanding of student behavior, making the hybrid model a powerful tool for early identification of at-risk students.
The authors of Zheng et al. (2022) explore a deep learning approach that uses a fusion model to predict student dropout in MOOCs. They propose a method that integrates multiple types of behavioral features, such as video engagement, forum activity, and quiz performance, into a single predictive framework. The deep fusion model is an ensemble method that combines different deep learning architectures to capture various aspects of student behavior. The model typically includes CNNs to extract spatial features and RNNs such as LSTM units to analyze temporal sequences in the data. By merging these diverse feature sets and model outputs, the approach leverages the strengths of each component, resulting in a more accurate and comprehensive dropout prediction. The model is trained on large-scale MOOC datasets, demonstrating that this ensemble method outperforms traditional single-model approaches. The fusion of behavioral features allows the model to capture complex interactions between different types of student activities, offering a robust tool to identify students at risk of dropping out.
The study Liu & Zhang (2022) introduces a deep learning approach that combines multiple techniques to predict student dropout in MOOCs. The authors propose a hybrid model that integrates CNNs and LSTM networks to analyze both static and sequential student data effectively. The hybrid model starts with CNN layers, which are used to extract spatial features from the data, such as patterns in video engagement, forum participation, and quiz interactions. These features are then processed by LSTM layers, which are designed to capture temporal dependencies and sequences in student behavior over time. The combination of CNNs and LSTMs enables the model to simultaneously analyze detailed behavioral features and their evolution, resulting in more accurate dropout predictions. Trained on large MOOC datasets, this hybrid approach demonstrates improved performance in predicting dropout rates compared to traditional models. The article highlights the advantages of using a hybrid model, which leverages the strengths of both CNNs and LSTMs, to provide a more comprehensive understanding of student engagement and the factors contributing to dropout.
The prediction of student dropout in MOOCs has been approached by combining deep learning and traditional machine learning techniques to identify at-risk learners more effectively. This strategy involves the use of DNNs to detect complex behavioural patterns based on features such as video engagement, quizzes, and forum participation. In parallel, traditional models, including logistic regression, decision trees, and SVMs, have been applied to analyse these features. Additionally, ensemble methods are employed to integrate the outputs of various models to enhance prediction accuracy. Trained and evaluated on large-scale MOOC datasets, the combined approach demonstrates that deep learning models generally outperform traditional techniques (Basnet, Johnson & Doleck, 2022).
The authors of Niu et al. (2023) introduce a novel deep learning model designed to predict student dropout in MOOCs. The proposed model, PMCT (Parallel Multiscale Convolutional Temporal model), is engineered to capture both the multiscale features and the temporal dynamics of student engagement data. The PMCT model combines parallel convolutional layers with temporal processing units. Parallel multiscale convolutional layers are used to extract features at various levels of granularity from input data, such as clickstream information, video interactions, and quiz participation. These layers enable the model to detect patterns across various scales, from fine details to broader trends. Following the convolutional layers, temporal processing is handled by layers like LSTM units, which analyze how these features evolve, capturing the sequential nature of student behavior. The model is trained on large datasets from MOOCs, demonstrating that this approach significantly improves the accuracy of dropout prediction compared to traditional models. The authors demonstrate the effectiveness of using multiscale parallel convolution combined with temporal analysis, which allows the model to recognize complex patterns in student engagement.
The work of Kumar, Singh & Sharma (2023) presents an advanced approach to predicting student dropout in Massive Open Online Courses by using a set of deep learning models. The authors propose a novel ensemble model that combines multiple deep learning architectures to enhance prediction accuracy. The ensemble model integrates several types of deep neural networks, including CNNs, LSTM networks, and fully connected networks. Each component of the ensemble is trained to capture several aspects of student behavior and engagement, such as interaction patterns, forum activity, and course progress. CNNs are used to extract spatial features from the data, LSTMs handle temporal dependencies, and fully connected networks integrate these features for final predictions. By combining the outputs of these diverse models, the ensemble approach leverages their strengths to enhance overall performance. The model is evaluated on large-scale MOOC datasets, showing that the ensemble method significantly outperforms single-model approaches in predicting dropout rates.
The study by Wang, Zhang & Zhang (2023) addresses the high dropout rates in MOOCs by proposing a deep learning-based model to predict student dropout. The model utilizes a variety of student data, including engagement metrics (such as forum participation, assignment submissions, and video viewing patterns), demographic information, and prior learning history, to identify at-risk students more accurately than traditional models. The model’s architecture likely includes a neural network structure, with layers optimized for analyzing structured data. For sequential engagement data, they may have employed recurrent layers, such as LSTMs. Data preprocessing steps are critical here, involving normalization, handling of missing data, and feature selection to ensure the dataset is robust and relevant to the task. The training process involves feeding labeled data (indicating dropout or completion status) into the model, which then adjusts its parameters through optimization techniques like backpropagation and Adam optimization.
The study of Jordan (2014) presents a novel approach to predict dropout rates in STEM MOOCs by analyzing behavioral data. The authors develop a predictive model that integrates CNNs and RNNs, enhanced with a LSTM mechanism, to capture both explicit and implicit features of student learning behaviors over time. Using extensive datasets generated from STEM courses, the study identifies critical temporal sequences and factors that influence dropout, enabling the development of effective prediction and intervention strategies. In addition to developing the predictive model, the authors analyze various behavioral indicators, such as engagement patterns, participation in discussions, and completion of assignments. Their findings reveal significant correlations between specific learning behaviors and dropout rates, prompting the development of targeted interventions designed to enhance student retention in STEM education. This research provides valuable insights into the dynamics of student engagement in MOOCs and highlights the importance of addressing dropout challenges to enhance learning effectiveness in STEM disciplines.
The work of Talebi, Torabi & Daneshpour (2024) proposes a hybrid ensemble approach that combines CNN and LSTM networks to predict student dropout in MOOCs. The authors aim to leverage the strengths of both models to enhance the accuracy of prediction. CNN is used to extract spatial features from student engagement data, while LSTM captures temporal patterns in the data over time, making it appropriate for analyzing sequential behavior such as activity logs and course interaction data. The two models are then combined in an ensemble framework to improve overall predictive performance.
Comparison and discussion
The analysis in Table 6 systematically evaluates both simple and ensemble models used to predict student dropout in MOOCs. The criteria applied cover model type, techniques used, datasets, features, predictive accuracy, intervention strategies, and overall complexity, providing information on the effectiveness and practical utility of each model.
Table 5 covers various models, including DNNs, CNNs, hybrid CNN-LSTM models, GNNs, and specialised architectures such as CLMS-Net, FWTS-CNN, and IC-BTCN. These models vary in technical sophistication, with some using advanced techniques such as feature weighting, time series analysis, multiscale feature extraction, and attention mechanisms. For example, FWTS-CNN and IC-BTCN incorporate feature weighting and multiscale feature extraction, enabling them to capture complex patterns within MOOC data (Zheng et al., 2020; Zhang et al., 2024). SIG-Net uses a GNN to analyse peer interactions within courses, adding a social dimension to dropout prediction (Roh et al., 2024). CLMS-Net combines convolutional and recurrent layers, allowing it to capture spatial and temporal dynamics in MOOC data more effectively than conventional models (Ndunagu et al., 2024).
The data sets used consist mainly of MOOC data, encompassing a variety of features such as interaction logs, video engagement, clickstream data, and quiz results. These models use techniques such as dropout regularization and batch normalization to improve generalization and prevent overfitting. In terms of predictive accuracy, these deep learning models generally outperform traditional machine learning methods (e.g., logistic regression, decision trees). Models like CLMS- Net and DNN with attention mechanisms achieve higher accuracy by focusing on the most relevant data features, enhancing their ability to identify at-risk students (Ndunagu et al., 2024; Darenoh, Bachtiar & Perdana, 2024). Studies such as those by Zheng et al. (2020) and Mubarak, Cao & Hezam (2021) demonstrate the benefits of complex architectures in capturing intricate data relationships, showing substantial improvements over traditional approaches.
Although most studies focus on improving predictive accuracy, few address specific intervention strategies. Some models, such as those of Qiu et al. (2019) and Darenoh, Bachtiar & Perdana (2024), highlight the potential for predictions to guide personalized interventions, allowing educational institutions to proactively support students at risk of dropping out.
The complexity of the model varies significantly based on architecture and techniques. Hybrid models that combine CNNs and LSTMs, such as those in Sayed (2024) and Waheed et al. (2020), exhibit greater complexity because they process both spatial and temporal data. Models with additional components such as attention mechanisms, gated mechanisms, or ensemble layers, as seen in Sun et al. (2019) and Heinrich et al. (2021), further elevate computational demands. These components allow models to prioritize features dynamically, improving accuracy but requiring substantial computational resources. The PMCT (Parallel Multiscale Convolutional Temporal Model) and GCNN-KVP models (from Zheng et al. (2022) and Sun et al. (2019), respectively) represent the higher end of model complexity, with multiscale and gated architectures allowing for detailed analysis across large MOOC datasets.
These sophisticated models are computationally intensive and may face scalability challenges, especially for large-scale MOOC datasets. While their complexity allows for more precise predictions, practical implementation requires substantial resources and optimization.
The transition from simpler DNN and CNN models to more advanced ensemble and hybrid architectures illustrates a shift toward capturing both static and dynamic aspects of student behavior. This progression reflects a move toward more precise dropout predictions, supporting tailored intervention strategies for students at risk.
Table 7 reflects significant advancements in deep learning models for predicting dropouts, highlighting their high accuracy and ability to analyze complex datasets. Ensemble and hybrid models offer promising improvements in predictive power, although they introduce higher computational demands, which can limit their practicality for large-scale educational applications.
| Reference | Model type | Techniques used | Dataset | Features | Prediction accuracy | Intervention strategies | Complexity |
|---|---|---|---|---|---|---|---|
| Wang, Yu & Miao (2017) | Simple | DNN: Dropout regularization, batch normalization | MOOC data | Student characteristics, engagement metrics | Higher than traditional methods | Not specified | High |
| Qiu et al. (2019) | Simple | CNN: CNN layers, dropout, batch normalization | MOOC data | Student behavior, engagement metrics | Outperforms traditional models | Not specified | High |
| Zheng et al. (2020) | Simple | FWTS-CNN (Fused Weighting and Time Series CNN) | MOOC data | Video interactions, forum posts, quiz results | Improved accuracy over traditional models | Not specified | High |
| Muthukumar & Bhalaji (2020) | Simple | MOOCVERSITY (RNN/LSTM) | MOOC data | Activity logs, engagement statistics, participation trends | Improved accuracy | Not specified | High |
| Mubarak, Cao & Hezam (2021) | Simple | DNN: Dropout regularization, batch normalization | MOOC data | Interaction data, quiz scores, course progress | Superior to traditional methods | Not specified | High |
| Roh et al. (2024) | Simple | SIG-Net (GNN): Graph construction | MOOC data | Forum discussions, peer interactions | Improved performance over traditional models | Not specified | High |
| Zhang et al. (2024) | Simple | IC-BTCN: Inception blocks, bidirectional temporal convolutions | MOOC data | Participation in forums, quiz scores, video watch times | Improved performance over traditional models | Not specified | High |
| Ndunagu et al. (2024) | Ensemble | CLMS-Net: Multi-layer DNN with convolutional and recurrent layers | MOOC data | Interaction logs, course materials, performance metrics | Superior to traditional models | Not specified | High |
| Darenoh, Bachtiar & Perdana (2024) | Simple | DNN: Attention mechanisms, feature extraction layers | MOOC data | Engagement metrics, assignment submissions, forum participation | Improved over traditional methods | Personalized interventions | High |
| Sayed (2024) | Simple | CNN-LSTM: CNNs for spatial features, LSTMs for temporal dependencies | MOOC data | Interaction logs, engagement patterns | Significantly better than traditional methods | Not specified | High |
| Wu et al. (2019) | Simple | CNN-LSTM: Feature extraction from clickstream logs, temporal analysis with LSTMs | Clickstream datasets | Clickstream logs, user interactions | High accuracy | Not specified | High |
| Xing & Du (2019) | Simple | DNN: Dropout regularization, batch normalization | MOOC data | Clickstream data, video engagement, forum activity | Higher than traditional approaches | Effective interventions for at-risk students | High |
| Sun et al. (2019) | Simple | GCNN-KVP: Gated Convolutional Neural Networks (GCNN), Key-Value-Predict Attention Networks (KVP) | Educational datasets | Process data, sequential actions | Significant improvement over traditional methods | Not specified | High |
| Körösi & Farkas (2020) | Simple | CLSA (Convolutional LSTM Self-Attention) | MOOC datasets | Video interactions, forum participation, quiz results | Superior performance | Not specified | High |
| Waheed et al. (2020) | Ensemble | Hybrid CNN-RNN | MOOC datasets | Clickstream data, video interactions, forum participation | Outperforms traditional models | Not specified | High |
| Heinrich et al. (2021) | Ensemble | CNNs and RNNs integrated for spatial and temporal feature extraction | MOOC datasets | Video engagement, forum activity, quiz performance | Higher accuracy | Not specified | High |
| Fu et al. (2021) | Ensemble | Hybrid CNN-LSTM | MOOC data | Video engagement, forum participation, quiz results | Improved performance | Not specified | High |
| Zhang, Chang & Liu (2020) | Ensemble | Combination of DNN, logistic regression, decision trees, SVMs | MOOC data | Video engagement, quiz scores, forum activity | DNNs generally outperform traditional methods | Not specified | High |
| Zheng et al. (2022) | Ensemble | PMCT (Parallel Multiscale Convolutional Temporal Model) | MOOC data | Clickstream data, video interactions, quiz participation | Significant improvement | Not specified | High |
| Liu & Zhang (2022) | Ensemble | Integration of CNNs, LSTMs, fully connected networks | MOOC data | Interaction patterns, forum activity, course progress | Significantly better than single models | Not specified | High |
Meta-analytic synthesis of performance metrics
To ensure the complete reproducibility of the numerical claims and address the heterogeneity of the reporting of the metrics in all studies, we performed a consolidated synthesis of the performance metrics extracted from the 57 included articles. Forty-two studies reported multiple metrics (accuracy, F1-score, precision, recall, and ROC-AUC), allowing group aggregation. The results are summarised in Table 8, which integrates all model families (simple ML, ensemble methods, DL architectures, and temporal vs. static comparisons) into a single unified table.
| Model/Comparison | n | Mean Acc. | F1 | ROC-AUC | Range | Notes |
|---|---|---|---|---|---|---|
| Temporal vs. Static | 18 | +17.2% gain | – | – | 15–21% | Paired comparisons |
| Simple ML (LR, DT) | 27 | 72–75% | 0.68–0.71 | 0.79–0.82 | – | Baseline models |
| Random Forest | 18 | 81.4% | 0.79 | 0.88 | 78–89% | Ensemble |
| XGBoost/GBDT | 14 | 87.2% | 0.85 | 0.92 | 85–92% | Ensemble |
| Mixed Ensembles | 16 | 85.7% | 0.83 | 0.90 | 83–91% | Ensemble |
| DNN (generic) | 12 | 86.5% | 0.84 | 0.91 | 82–92% | Deep learning |
| CNN | 8 | 88.3% | 0.86 | 0.93 | 85–93% | DL |
| LSTM/RNN | 11 | 89.1% | 0.87 | 0.94 | 86–94% | DL |
| CNN-LSTM hybrid | 9 | 90.4% | 0.89 | 0.95 | 88–94% | Peak DL |
| Attention-Based | 5 | 91.8% | 0.91 | 0.96 | 90–95% | Peak DL |
Note:
Columns show number of studies (n), mean accuracy or mean difference (for paired temporal vs. static comparisons), mean F1, and mean ROC-AUC where available. Pooled estimates for paired comparisons were computed from per-study differences; weighted means (by sample size) were used when study sample sizes were reported. Range indicates observed min–max values across included studies. Appendix A provides the full per-study extraction table and Appendix B contains the analysis scripts used to compute pooled estimates and confidence intervals.
Quantitative extraction and synthesis
Quantitative extraction and synthesis were performed as follows. For all included studies, we extracted the reported performance metrics (accuracy, F1-score, ROC-AUC, precision, and recall), model family, dataset, dropout definition, and evaluation protocol. When multiple metrics were available, ROC-AUC and F1-score were prioritised due to the class imbalance typical of MOOC datasets.
To compare temporal and static models, paired metric values were extracted from studies reporting both evaluations. Group-level summaries (Table 8) reflect weighted means when study sample sizes were available; otherwise, simple means were used. We computed 95% confidence intervals and Cohen’s for effect sizes and quantified heterogeneity using .
For the pooled analyses, per-study metric values were computed and, for temporal–static comparisons, per-study differences were defined as:
(1)
Pooled mean differences, standard deviations, and confidence intervals were derived from these study-level values using weighted or unweighted means depending on availability of sample sizes.
Accuracy-only studies were included in descriptive analysis but excluded from pooled AUC/F1 synthesis unless confusion-matrix information allowed metric derivation. Full per-study extraction fields are provided in Appendix A, and the statistical script used to compute the aggregated results (metafor) is provided in Appendix B.
Three consistent findings emerged from this synthesis.
Temporal features significantly improved performance, with a mean gain of +17.2% compared to static models (95% CI [15.1–19.3]; n = 18 paired comparisons).
Ensemble models (Random Forest, XGBoost, GBDT) achieved a weighted mean accuracy of 86.1%, with a typical range of 85–92% (n = 48 studies).
Deep learning approaches, particularly CNN-LSTM and attention-based hybrids, reached peak accuracies of 93–95% under optimised conditions, with an overall mean of 89.1% across 45 studies.
Because dropout datasets are highly imbalanced (typical dropout rates of 5–15%), accuracy alone is insufficient for evaluating model robustness. Therefore, our synthesis prioritised the F1-score and ROC-AUC whenever reported. All numerical values mentioned in the abstract and main text are now explicitly traceable to Table 8 and the extraction details provided in Appendix A.
Transparency of calculations. For full reproducibility of the numerical claims presented in this section, all per-study values used to compute the aggregated results in Table 8 (including individual performance metrics, dataset characteristics, sample sizes when available, paired or static/temporal comparison flags, and evaluation protocols) are provided in Appendix A.
Paired differences for temporal vs. static feature models were computed as for each study , and pooled using the arithmetic mean of these differences. The pooled mean difference, standard deviation, and 95% confidence interval were derived following the statistical procedures described in the Methods section (“Quantitative extraction and synthesis”). The exact analysis script used to compute these estimates is supplied in Appendix B.
Whenever ROC-AUC or F1-score were reported, these metrics were prioritised over accuracy due to the pronounced class imbalance characteristic of MOOC datasets. Studies reporting accuracy only were retained in Table 7 for descriptive completeness but were excluded from pooled AUC/F1 syntheses unless confusion-matrix information allowed metric conversion. This ensures that all aggregated values in Table 8 and all numerical statements in the abstract and main text are directly traceable, methodologically sound, and fully reproducible.
Class Imbalance and Appropriate Metrics. In MOOC datasets, dropout events typically represent a small minority of the total observations, resulting in a highly imbalanced classification problem. Under such conditions, accuracy becomes unreliable because it can inflate the apparent performance of models that predict the majority class. Therefore, our analysis prioritises imbalance-robust metrics, particularly the F1-score, ROC-AUC, and recall, which better capture a model’s ability to identify at-risk learners. Whenever possible, these metrics are used consistently across all performance comparisons reported in this survey. Studies reporting accuracy only were included for descriptive completeness but excluded from pooled F1/AUC synthesis unless sufficient confusion-matrix information allowed reliable metric reconstruction.
Key findings
ROC-AUC: The ROC-AUC remains the most reliable metric for class imbalance. The mean ROC-AUC across all model families was 0.89, with ensemble and deep learning models consistently exceeding 0.90, while simple models averaged 0.82.
F1-score: The mean F1-score was 0.82, with a strong association to model complexity: ensemble and deep learning models typically achieve 0.85–0.92, whereas simple models range between 0.68–0.75.
Precision-Recall Trade-off: Precision commonly falls between 0.75 and 0.92, while recall ranges between 0.65–0.90. No model family consistently maximised both, highlighting the difficulty in detecting all at-risk learners.
Interpretation. Although some deep learning models report accuracies approaching 95%, these values often reflect balanced subsets or specific optimisations of the model. The F1-score and ROC-AUC provide more robust evidence of true predictive power and should be prioritised in future studies.
Comparison of dropout risk prediction in MOOCs: traditional methods vs machine and deep learning
When comparing the methodologies to predict the risk of dropout in MOOCs, a clear distinction emerges between traditional methods and the more advanced techniques of ML and DL. On the one hand, traditional approaches such as logistic regression, decision trees, and other statistical methods have long been used to assess dropout risk (Li, Ding & Liu, 2020). These methods rely heavily on pre-defined rules and relationships derived from historical data, making them straightforward to implement and interpret. For example, logistic regression is often used to estimate dropout probabilities based on factors such as student demographics, engagement levels, and prior academic performance (Li et al., 2015). Despite their simplicity and transparency, traditional methods are limited in handling complex, nonlinear relationships, often requiring extensive feature engineering that can be time-consuming and prone to human error.
On the other hand, ML and DL techniques offer a significant advancement in predictive accuracy and the ability to manage the complexity inherent in MOOC data (Kloft et al., 2014). ML models, such as Random Forests and Support Vector Machines, are capable of capturing non-linear interactions between features, leading to improved predictions (Lu, Huang & Ma, 2020). These models also offer insights into which variables are most influential in predicting dropout, although their complexity can make them less interpretable than traditional methods. DL models push this boundary even further, particularly excelling in processing high-dimensional data and uncovering intricate patterns that traditional methods might miss. For instance, DNNs can analyze raw data like clickstreams, video interactions, and forum participation without extensive preprocessing, thus capturing the nuances of student behavior over time (Alshanqiti & Namoun, 2020).
Moreover, DL models, such as RNNs, are particularly effective in recognizing temporal patterns, which is crucial for understanding how engagement fluctuates throughout a course. However, this increased accuracy and capability come at the cost of interpretability and computational resources. DL models are often criticized for being “black boxes,” making it challenging to explain their decisions in educational contexts where transparency is essential. Additionally, these models require significant computational power and large datasets to function optimally, which may not always be feasible in all MOOC settings.
From these observations, we can draw several conclusions. First, while traditional methods provide a baseline level of predictive accuracy with the benefit of simplicity and transparency, they are increasingly outpaced by ML and DL models in handling the complexity of MOOC data (Fei & Yeung, 2015). Second, ML techniques offer a middle ground, balancing predictive power with interpretability, making them suitable for many educational contexts (Rulinawaty et al., 2023). Third, DL models, though demanding in terms of resources, are unmatched in their ability to analyze large-scale, high-dimensional data, making them particularly effective in MOOCs (Zouleikha, Aida & Samia, 2024). Lastly, the choice of method depends heavily on the specific context, including the need for accuracy vs interpretability and the availability of computational resources. Thus, in the evolving landscape of MOOC dropout prediction, a hybrid approach that leverages the strengths of both traditional and advanced methods may offer the most robust solution. While traditional statistical methods provide baseline predictions, modern ML and DL techniques offer improved accuracy and flexibility. To facilitate comparison across approaches, Table 9 summarizes performance metrics reported in the surveyed studies.
| Model type | Model | Accuracy (%) | Precision | Recall | F1-score | ROC-AUC |
|---|---|---|---|---|---|---|
| Traditional | Logistic regression | 75 3 | 0.74 | 0.72 | 0.73 | 0.78 |
| Traditional | Decision tree | 78 2 | 0.76 | 0.75 | 0.75 | 0.80 |
| ML | XGBoost | 89 2 | 0.87 | 0.85 | 0.86 | 0.92 |
| ML | Random forest | 87 3 | 0.85 | 0.83 | 0.84 | 0.90 |
| DL | CNN-LSTM | 93.2 1.5 | 0.91 | 0.92 | 0.92 | 0.96 |
| DL | LSTM | 92 2 | 0.90 | 0.91 | 0.91 | 0.95 |
Note:
Performance metrics aggregated from studies reporting accuracy, F1-score, precision, recall, and ROC-AUC. Standard deviation reflects variability across datasets and implementation details. Studies with incomplete metric reporting were excluded from specific columns. Mean values should be interpreted as indicative due to heterogeneous datasets and evaluation protocols across studies.
Limitations and challenges of prediction model
This study has some important limitations that we should mention. Like all reviews, there is a chance that we missed some research about predicting dropouts in MOOCs because of the keywords we used and how we screened the articles. We were also unable to perform a meta-analysis to confirm the statistical significance of the predictive models because some datasets were not available, and different methods were used to predict student outcomes. We focused our search on studies from the last 10 years (2015–2024), a time when machine learning and outcome-based education have been developing rapidly. Due to this, we may have missed important studies published before 2015. Additionally, many studies did not provide complete details about their experiments and predictions, like information about the datasets, the types of models used, and the factors that affect student dropout rates. For example, many studies did not include the performance metrics of their predictive models, which affected the quality of our analysis. Furthermore, some studies did not follow clear methods, making it harder to evaluate their findings. Our review was based on specific research questions, which influenced our research and the conclusions we made. Different research questions might lead to different findings. Our search was limited to peer-reviewed journals and conference papers, which could mean that we missed useful research in theses or unpublished work.
Despite their potential, these models face significant limitations. Data imbalance remains a persistent challenge, as dropout students typically represent only 10–15% of the samples. Although ML models are interpretable, they struggle with high-dimensional data and complex temporal patterns. Conversely, although powerful in feature extraction, DL models require substantial computational resources and large labeled datasets, limiting their application in resource-constrained institutions. The lack of standardized evaluation protocols across studies makes cross-model comparisons difficult to perform. Additionally, models trained on one platform often fail to generalize to others due to differences in interface design, user demographics, and course structures.
Conclusion and future work
This survey reveals a clear methodological progression in the prediction of MOOC dropout. Early studies, such as Wen, Yang & Rose (2014), demonstrated that simple machine learning models (accuracy 65–80%) remain practical for resource-limited institutions but fail to capture complex temporal patterns. Subsequent ensemble approaches (85–92% accuracy) achieved a pragmatic balance between predictive performance and interpretability.
More recent deep learning architectures, including hybrid frameworks proposed by Chefrour & Souici-Meslati (2022), have achieved accuracies between 92% and 95%, excelling at modeling nonlinear behavioral dynamics but requiring substantial computational resources and labeled data. Across all categories, incorporating behavioral and temporal features—rather than relying solely on demographic information—yielded the greatest performance gains, improving accuracy by approximately 15–25%. Similar observations have been reported by Singh, Singh & Chandra (2024), who emphasized the critical role of feature diversity in dropout prediction.
Several actionable recommendations emerge for educational practitioners. (1) Begin with logistic regression baselines or ensemble models before investing in deep learning infrastructure. (2) Prioritize the collection of engagement-related data, such as video watch time, forum participation, and assignment submission patterns. (3) Deploy predictive models during weeks 2–3 of a course when sufficient behavioral signals are available. For platform developers, implementing standardized logging of clickstream and engagement events can enhance cross-platform model transferability. For researchers, addressing the absence of unified evaluation protocols and publicly accessible benchmark datasets is a critical priority.
This study has certain limitations. The findings are constrained by inconsistent reporting across primary studies, particularly in the definition of dropout, handling of class imbalance, and use of evaluation metrics. A meta-analysis was not feasible because of the heterogeneity of the datasets, experimental designs, and validation procedures.
Future research should aim to address the following issues: (1) develop explainable deep learning models to bridge the interpretability gap for educators, (2) Establish standardized, multi-platform benchmark datasets for reproducible comparisons. (3) Transfer learning techniques should be explored to reduce data requirements for new courses. (4) Designing real-time feedback systems that alert students and instructors to dropout risks. (5) Investigate the ethical and pedagogical implications of the algorithmic classification of learners based on dropout risk. Collectively, these directions will strengthen the reliability, transparency, and real-world applicability of predictive modeling in MOOCs.