
Topic-aware transformer with hierarchical prompting learning for multi-label image classification
- Published
- Accepted
- Received
- Academic Editor
- Siddhartha Bhattacharyya
- Subject Areas
- Artificial Intelligence, Computer Vision, Data Mining and Machine Learning
- Keywords
- Multi-label learning, Topic model, Vision transformer, Deep learning, Hierarchical prompt, Auxiliary learning
- Copyright
- © 2026 Wang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Topic-aware transformer with hierarchical prompting learning for multi-label image classification. PeerJ Computer Science 12:e3552 https://doi.org/10.7717/peerj-cs.3552
Abstract
While existing multi-label classification methods primarily focus on capturing label co-occurrence patterns, they often fail to explore the global contextual information and the semantic hierarchy inherent in multi-label datasets, especially in large-scale label spaces, leading to suboptimal feature extraction. To address this limitation, a novel Topic-Aware Transformer with Hierarchical Prompting Learning (TATHPL) is proposed, which is capable of hierarchically integrating latent topic information to improve the performance of multi-label image classification tasks. Specifically, we leverage prompt learning and introduce multiple prompt tokens to learn topic relationships among label combinations. These prompts are hierarchically inserted into specific transformer blocks, where the self-attention mechanism facilitates their influence on subsequent feature extraction. Compared to previous methods, our approach requires only a minimal increase in parameters on top of a standard Vision Transformer while maintaining high effectiveness. Our proposed TATHPL demonstrates state-of-the-art performance on three benchmark datasets. Specifically, it achieves an mean average precision (mAP) score of 81.9% and 67.0% on Microsoft Common Objects in Context (MS-COCO) dataset and NUS-WIDE, and an overall F1-measure (OF1) of 69.7% on Corel5k, outperforming the best baseline methods by 1.3%, 0.7%, and 22.7%, respectively. The results demonstrate that our method significantly outperforms the baseline models, highlighting its potential for improving multi-label classification tasks. The code is available at https://github.com/JiangPengWang-c/TATHPL.
Introduction
Multi-label image classification aims to assign multiple labels to a single image based on the presence of objects, scenes, or concepts. Compared to single-label classification, which assumes each image is associated with a single category, multi-label classification more accurately reflects the complexity of real-world images, where multiple objects and semantic elements frequently co-occur. As a result, multi-label image classification has broader applications in fields such as medical image diagnosis (Zhang et al., 2023) and scene understanding (Shao et al., 2015).
One of the key challenges in multi-label classification is how to effectively discover the correlation among the labels. Implicit methods commonly employ sequential models or graph models to capture label dependencies (Wang et al., 2016; Chen et al., 2019c). However, these methods typically rely on predefined label orders or static graph structures, which significantly limits their generalization capability. In recent years, transformer-based approaches have demonstrated strong capabilities in modeling complex label interactions through attention mechanisms (Liu et al., 2021; Ridnik et al., 2021; Lanchantin et al., 2020). Despite their advantages, these methods still predominantly focus on pairwise label correlations. However, in real-world scenarios, label combinations often exhibit certain semantic coherence, where a group of co-occurring labels jointly implies a latent topic (e.g., “beach”, “umbrella” and “surfboard” forming a “vacation” topic). Existing approaches typically overlook this contextualized semantic structure embedded in label combinations, referred to in this work as topic information. While ML-GCN (Chen et al., 2019c) models label correlations via Graph Convolutional Networks (GCNs) and CDAM (Chen et al., 2019b) fuses spatial-semantic contexts, neither captures latent topics in label combinations. This limits their ability to filter irrelevant labels. These methods do not consider the hierarchical semantic structure inherently present in the label space. In contrast, explicit methods model label correlations by constructing a label co-occurrence matrix at various levels (e.g., dataset-level (Chen et al., 2019a), scene-level (Zhu et al., 2023), or instance-level (Ye et al., 2020)) through statistically estimating the frequency of label pairs. While simple and intuitive, such approaches either introduce coarse-grained and potentially noisy label correlation, which may lead to spurious or incorrect label interactions, or fail to learn an accurate label co-occurrence matrix that is specific to individual instances or scenes, thereby providing limited guidance for effective label-correlation modeling.
To address these limitations, we propose a novel model based on Vision Transformer (ViT) (Dosovitskiy et al., 2020) that enhances multi-label classification by hierarchically incorporating topic information at multiple granularities. The core insight of our approach lies in the observation that there are intrinsic associations among the label combinations in multi-label classification datasets, often sharing a latent topic. For instance, when labels such as “soccer”, “goalkeeper” and “audience” co-occur in an image, the image is likely to be associated with the sports topic. Consequently, labels that do not align with this topic, such as “ocean”, “beach” and “palm tree” are less likely to appear in the label set. The effectiveness of our method can be interpreted through the global-priority mechanism proposed in Granular Ball Computing theory (Xia, Wang & Gao, 2023), which suggests that humans tend to prioritize coarse-grained information when perceiving and interpreting data such as images. In our framework, the topic information extracted from label co-occurrence serves as a coarse-grained semantic abstraction of the image. By injecting such topic-level cues into the Transformer encoder, we align the model’s processing flow with this cognitive principle, thereby enhancing the performance and robustness of multi-label classification. Furthermore, we note that the topic relationships among the label combinations exhibit a hierarchical structure. For example, when the number of topics is restricted to two, images are coarsely categorized into warm-toned or cool-toned topics. As the number of topics increases, the topic information of the images becomes more refined, with images being delineated into more specific topics such as sports or animals. Inspired by this, we aim to uncover the sample-level topic information at multiple granularities and sequentially guide the model to focus on image regions that conform to the injected topic information through a hierarchical incorporation of topic prompts, progressing from coarse to fine granularity. This strategy enables the model to first capture general semantic context and then gradually refine its attention to more task-relevant image regions. We achieve the injection of topic information through prompt learning, which introduces only a minimal set of parameters to learn topic information and guide the image feature extraction process.
As shown in Fig. 1, our model comprises two main steps: firstly, we perform clustering on the label combinations of each training sample to extract sample-specific topic information, and secondly, we employ prompt learning to incorporate this topic information into intermediate layers, referred to as prompt blocks, thereby enhancing the overall performance of the model. We evaluate our model on several well-known benchmarks, including MS-COCO, NUS-WIDE and Corel5k, achieving new state-of-the-art results.
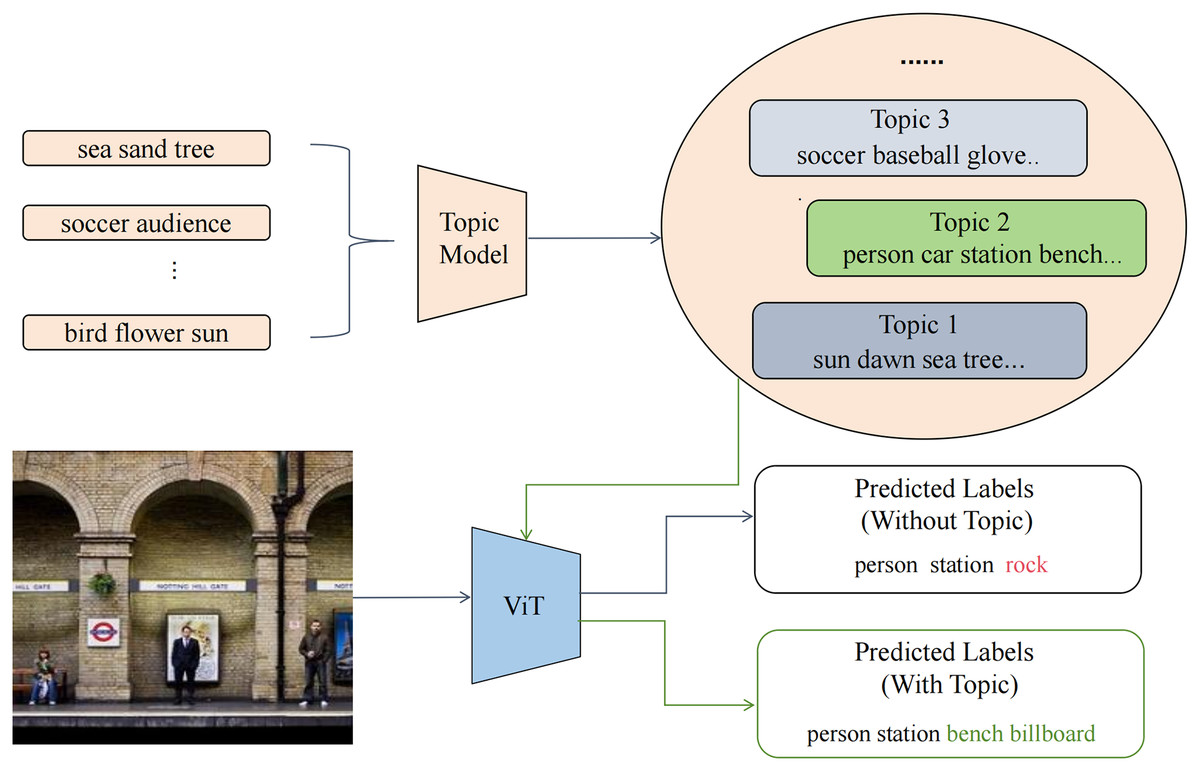
Figure 1: Overview of the proposed TATHPL framework.
We first construct a document by aggregating all label combinations from the training set and apply a topic model to exploit the underlying semantic information. The extracted topic information is then injected into the intermediate stage of the ViT, guiding the model to focus on image regions that are semantically aligned with the discovered topics. This enhances the model’s ability to make more accurate label predictions. As illustrated in the figure, the sample image is more semantically aligned with Topic 2. By incorporating this topic information, TATHPL successfully suppresses the irrelevant label “rock” and additionally predicts two highly relevant labels, “bench” and “billboard.”{kind=link}
The remainder of this article is organized as follows. ‘Related Works’ reviews related works on multi-label classification and prompt learning, providing the background and motivation for our proposed method. Materials and Methods section details our proposed methodology, including the topic information extraction and hierarchical prompt injection framework. ‘Computing Infrastructure’ describes the computing infrastructure used in our experiments, including details about the hardware setup and the associated computational cost. Experiments section presents extensive experimental results, including performance comparisons on benchmark datasets and ablation studies showing the improvements over the baseline model and validating each component. Then, ‘Conclusion’ concludes the article and discusses potential future directions. Finally, Appendix section provides implementation details and formulas for evaluation metrics.
Our contributions are as follows:
We employ a topic model to extract the underlying dependencies among various label combinations, referred to as topic information, thereby facilitating a deeper understanding of the semantic structures within multi-label datasets.
We propose a novel end-to-end framework for multi-label classification, which employs a prompt learning strategy to hierarchically inject topic information at multiple granular levels. This approach progressively directs the model to attend to topic-relevant image regions, enhancing performance while requiring only a minimal increase in parameters.
Related works
Multi-label classification
Multi-label classification (MLC) tasks have long been an important focus in the field of computer vision, given their significant implications for enabling computers to comprehend the real world. Early methods typically transformed MLC into multiple binary classification tasks or employed convolutional neural networks (CNNs) to extract image features, subsequently applying a sigmoid function to execute multi-label classification. However, these approaches often neglected to explore label dependencies. In recent years, several studies have investigated the interrelationships among labels. Wang et al. (2016) proposed a Convolutional Neural Network-Recurrent Neural Network (CNN-RNN) architecture to model label dependencies and compute label probabilities in a predefined order. Chen et al. (2017a) introduced an automatic method for learning label order without predefined sequences using a CNN-RNN network. However, these RNN-based methods are constrained by the enforced label order, which limits their ability to fully exploit the dependencies among all label pairs. To address this issue, some studies have utilized graph neural networks and label co-occurrence matrices for multi-label classification tasks. Chen et al. (2019a) leveraged the semantic features of categories to guide the learning of image features related to these categories and used a statistical label co-occurrence map to establish relationships among these features. Additionally, Chen et al. (2019c) applied a GCN to map label representations into a set of interdependent classifiers, utilizing image features produced by the visual network for multi-label classification. Zhu et al. (2023) proposed a method where training images are first categorized by scene, and corresponding label co-occurrence matrices are maintained within the same scene to prevent erroneous label relationships. Ma, Xu & Rong (2024) introduces adaptive graph diffusion to preserve higher-order structural information between instances. Wang et al. (2024) proposes a robust coarse and fine-grained Noise Multi-graph Multi-label method, which effectively classifies targets using a bag-of-graphs representation. These methods rely on predefined graph structures that focus on pairwise label relationships, which limits their ability to capture higher-dimensional label correlations. To address this issue, many approaches have adopted hypergraphs to model higher-dimensional label correlations. Wu et al. (2020) explore the high-order semantic interactions by constructing an adaptive hypergraph with label embeddings. Gu et al. (2024) propose a hypergraph transformer layer that uses an attention mechanism to propagate relationships between label features within the hypergraph. While these methods have achieved some success, these methods still rely on predefined hypergraph structures, making it difficult to scale or extend them effectively. Additionally, they fail to fully explore the dependencies between labels and neglect to fully explore the semantic relationships among label combinations—specifically, the sample-level topic information.
Prompt
Prompt was originally applied in natural language processing tasks, where it constrains the overall model by incorporating prompt instructions into the model’s input, enabling pre-trained large language models to adapt more effectively to downstream tasks. Initially, Generative Pre-trained Transformer-3 (GPT-3) (Brown et al., 2020) was adapted to various downstream tasks by manually designing prompt instructions. However, it faced limitations related to token length, as well as the quality and cost of manual prompts. Prefix-tuning (Li & Liang, 2021) and prompt tuning (Lester, Al-Rfou & Constant, 2021), which prepend a series of task-specific, learnable parameters to the model’s input, effectively address these challenges. In recent years, prompt engineering has been increasingly applied in the domain of computer vision. Wang et al. (2021) introduced prompts in the context of continual learning to retain acquired knowledge and mitigate catastrophic forgetting. Visual Prompt Tuning (VPT) (Jia et al., 2022) was the first to incorporate prompts into visual encoders, introducing a small number of learnable parameters into the input space of the ViT while keeping the backbone network parameters frozen, achieving performance comparable to or exceeding that of full fine-tuning. Transhp (Wang et al., 2023), on the other hand, utilized the hierarchical nature of datasets, designing multiple prompts to learn the ancestor class information of images, guiding the model to focus on the subtle distinctions among descendant classes. The success of these methods led us to realize that using prompt learning to capture topic information and influence the multi-label classification process within ViT presents a viable approach.
Table 1 provides a concise summary of related works, highlighting their core ideas as well as the key limitations that motivate our work.
| Category | Key idea | Limitations |
|---|---|---|
| RNN-based methods | Model label dependencies sequentially using RNNs; learn label order automatically | Constrained by label order; cannot fully capture all label-pair dependencies |
| Graph-based methods | Model label correlations using graph structures; treat both patches and labels as graph nodes; build label correlation matrices from statistical co-occurrence | Rely on predefined graph structures; limited generalization capability; Introducing coarse-grained correlations may contain noisy or incorrect label relationships |
| Hypergraph-based methods | Model complex, higher-dimensional label correlations beyond pairwise interactions | Still often relies on pre-defined hypergraph structures, posing challenges for scalability and flexibility |
| Prompt learning in NLP | Use prompt instructions to adapt LLMs; employ learnable prompt parameters | Manual prompts are costly; limited by token length constraints |
| Prompt learning in vision | Incorporate prompts in continual learning; add learnable parameters to ViT input; use hierarchical information within the dataset | Most focus on single-label tasks; fail to autonomously discover hierarchical data |
| Our work | Hierarchical topic prompts for multi-label classification; sample-level topic information extraction | Sensitive to topic distribution accuracy (see Conclusion section) |
Materials and Methods
In this section, we introduce our approach, which leverages a topic model for clustering label combinations and a ViT for image recognition. We begin with the necessary definitions and notations, followed by a detailed description of our multi-label classification framework. This includes the hierarchical injection of topic information and a brief introduction to the overall model’s loss function. Finally, we discuss the selection of key hyperparameters relevant to our framework. Notably, our method does not apply any data preprocessing operations.
Preliminaries
Topic model
Topic models are a class of probabilistic models designed to uncover latent semantic structures within a collection of documents by representing each document as a mixture of hidden topics. In our work, a topic model is employed to capture the latent structure within the label combinations associated with each image. By utilizing a probabilistic topic modeling approach with a predefined number of topics L, we derive a matrix that represents the probability distribution of documents over the identified topics.
Vision transformer
For a standard ViT model, the input image is initially divided into N patches . Here, H and W are the height and width of the input images, C is the number of channels, and P denotes the patch size. Each patch is flattened into a 1D vector and passed through a trainable linear projection layer, mapping it into a latent space of dimension , with position encodings added. This process is represented as . A learnable class token is then prepended to the patch embeddings as input to the transformer blocks. The -th transformer block can be formulated as:
(1)
Here , represent the class token and patch embeddings as the outputs of the -th transformer block. Finally, the final block’s class token is used to predict the probability of each label appearing in the image. The class token is passed into the classification head and activated by the sigmoid function, represented by the formula:
(2) where represents predicted probabilities for N categories. denotes the classification head parameters.
Framework
As shown in Fig. 2, our TATHPL framework comprises two distinct stages. In the first stage, we employ a topic model to perform clustering on the label combinations associated with each training sample to extract latent topic information. In the second stage, we introduce a topic-aware prompt pool to store topic information at multiple levels of granularity. To effectively leverage this information, we propose a hierarchical prompt strategy in which prompt tokens corresponding to different topic granularities are injected into selected transformer blocks. These tokens progressively infuse the model with topic-specific semantics, ranging from coarse to fine-grained levels, enabling the encoder to focus on image regions that are more aligned with the topics. This guided semantic enhancement ultimately contributes to improved performance in the downstream multi-label classification task. Finally, we formulate the multi-label classification task as a series of independent binary classification problems, training one classifier for each label.
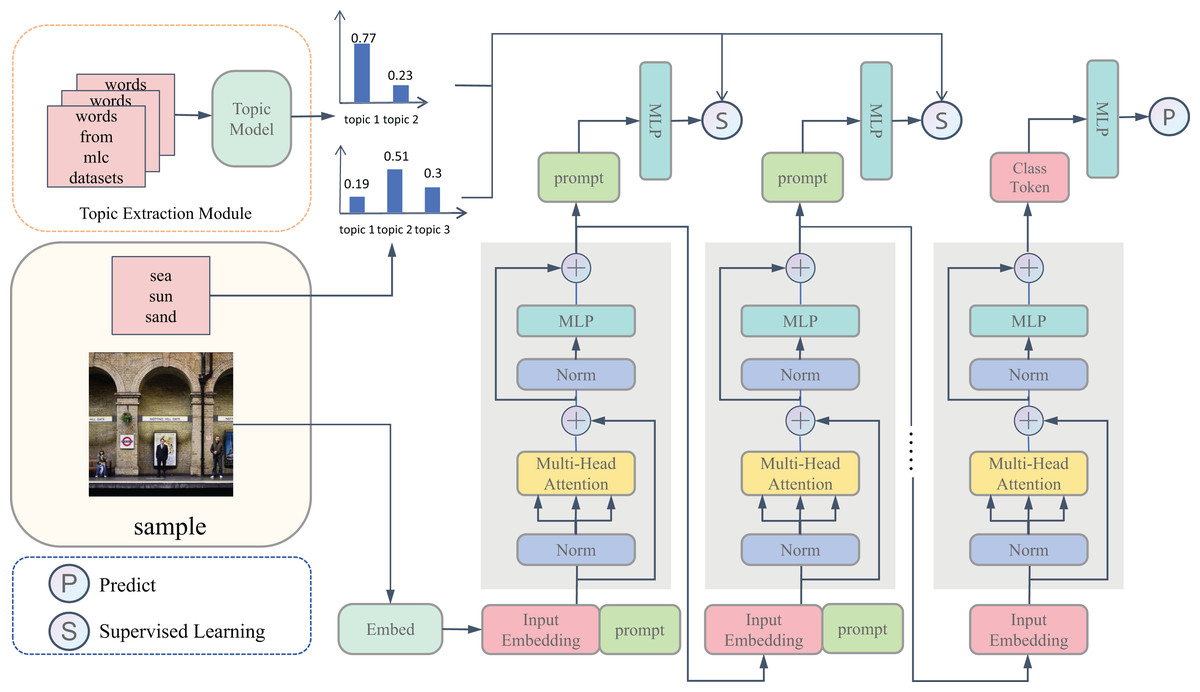
Figure 2: Here is the framework of the proposed TATHPL.
Initially, we conduct clustering on the label combinations associated with all training samples to derive the topic information for each individual sample. While training, we concatenate a prompt token to the input of each prompt block to capture the topic information and optimize it based on the derived topic information. The objective is to utilize the attention mechanism to instruct the image feature extraction process, thereby enhancing the model’s predictive capabilities.{kind=link}
Multi-granularity topic information extraction
Multi-label datasets encapsulate not only profound visual content but also intricate semantic structures. Effectively extracting and leveraging these semantic relationships can enhance the model’s capacity to accurately perform multi-label classification. Topic models are particularly well-suited for this purpose, as they can uncover latent co-occurrence patterns and provide semantic representations from discrete label data. To this end, we employ a topic model to identify sample-level topic information, which serves as auxiliary signals to augment the transformer, thereby improving its classification performance.
Given a multi-label dataset consisting of M samples, we represent the combination of labels associated with each sample as a document . The collection of all such documents from the training set forms a corpus , which serves as the input to the topic model. By specifying the number of topics as L, the topic model learns a latent semantic structure and outputs a document-topic distribution matrix of size M L. In this matrix, the -th row represents the probability distribution of the document across the L topics. Since each document corresponds to a unique image sample, we interpret this distribution as the probability of the -th image sample being associated with each of the L topics, thereby providing an enriched semantic representation for subsequent classification tasks. Furthermore, we assign each image to the topic with the highest probability. To further refine this representation, we extract topic distributions at multiple granularities by varying the number of topics L. Coarse-grained topic distributions (with smaller L) capture broader semantic structures, while fine-grained distributions (with larger L) provide more detailed label dependencies.
Topic-aware prompt pool
Topic models are capable of extracting latent semantic structures from multi-label datasets, offering valuable guidance for multi-label classification tasks. However, directly aligning these semantic topic representations with visual features remains a nontrivial challenge. To bridge this gap, we introduce an auxiliary task that incorporates a learnable prompt token into the transformer architecture. The prompt token is designed to capture topic-level semantics and facilitates the integration of external semantic knowledge into the model’s internal representation space. While the naive way of learning a single shared prompt for multi-granularity topic structures is parameter efficient and promotes the learning of global semantic representation, it still suffers from severe supervision entanglement and insufficient capacity to capture the semantic distinctions across different levels of granularity. Therefore, we adopt a prompt pool to store topic information, where each prompt is responsible for modeling topic information at a specific level of granularity. The prompt pool is denoted as , where , represents the embedding size and K is the number of prompt tokens as well as the number of prompt blocks. Correspondingly, for each prompt token , we define a learnable linear projection layer serving as a classification head mapping the learned prompt token to one of the topic categories associated with the image. The collection of these classifiers is denoted as .
Hierarchical prompt of multi-granularity topic information
Recent advances have demonstrated the effectiveness of prompt-based tuning in adapting pre-trained Transformer models to downstream tasks. In this paradigm, a prompt token is prepended to the input sequence, enabling task-specific conditioning while keeping the backbone frozen. Accordingly, the computation of the transformer encoder turns into:
(3)
Motivated by this idea, we adopt ViT as the backbone model due to its self-attention mechanism, which not only enables the class token to absorb the semantic information injected by the prompt token, thereby enhancing the performance of the multi-label classification task, but also allows the prompt token to attend to visual features from the image, further optimizing the auxiliary task of topic classification. Moreover, we propose a hierarchical prompt strategy that integrates topic information at different levels of granularity into selected transformer blocks, thereby effectively incorporating the semantic structures captured by the topic model. According to the coarse-to-fine multi-level topic hierarchy, our proposed TATHPL first selects multiple transformer blocks and then reshapes them into prompt blocks. Specifically, for each prompt block, a corresponding prompt token that encodes topic information at a particular level of granularity is inserted into the input sequence of that layer, which can be expressed as
(4)
Here, represents the -th prompt, which indicates that the -th block is the -th selected prompt block. To clarify the hierarchical prompt injection mechanism, we provide an example based on the Corel5k dataset. In this setting, we insert prompts into the first and last blocks of the Transformer encoder, which consists of 12 blocks in total. The corresponding insertion operations at these two blocks are formulated as follows:
(5)
(6)
After the computation by the prompt block, the prompt is no longer passed to the subsequent block. Instead, it is used directly for the prediction of topic categories. To derive the similarity score, we project the prompt into a logit value through the linear projection layer followed by a softmax function. Finally, we compute the loss for the topic classification task generated by the -th prompt layer using the cross-entropy loss function as follows:
(7) where represents that the input image belongs to the -th topic. For simplicity, we omit the superscript . Correspondingly, the overall loss function of the topic classification task is formulated as follows:
(8) where is the balance parameter that controls the relative contribution of the -th prompt branch to the total loss. The balance parameters are introduced to facilitate stable learning across multiple levels of topic granularity, mitigating the risk of overemphasis on any individual prompt-level supervision during training.
Multi-label prediction
After the hierarchical integration of multi-granularity topic prompts into the transformer encoder, we obtain the final class token which encodes both enriched visual representations and external topic-aware semantics. Then we treat each label prediction as a binary classification task. Specifically, the final class token is projected into a logit using a linear projection layer, followed by a sigmoid activation to estimate the confidence score for the presence of this label:
(9) where , denotes the confidence score for the presence of each label, , represents the parameters of the linear projection layer.
Loss function
In our multi-label classification framework, we identify two key tasks. The primary task is the multi-label classification task, which serves as our main target task. In parallel with the multi-label task, we also perform an auxiliary task: the topic classification task. Accordingly, the loss function is divided into two parts: the loss for the multi-label classification task and the loss for the topic classification task.
First, we introduce the loss for the multi-label classification task. In our experiments, we employ the asymmetric loss (Baruch et al., 2020). Given the input image , we first predict its category probabilities , then we can calculate the loss as follows:
(10)
For simplicity, we omit the bias term.
The second part concerns the topic classification loss. We treat the topic classification task as a multi-class task and calculate the loss using the cross-entropy function. The total loss for the topic classification task is computed as the weighted sum of the losses from all prompt blocks:
(11) where is the balance parameter, represents the probability that the input image belongs to each topic. Finally, the total loss is defined as:
(12)
Hyper-parameter selection
Given the large variations across datasets, there is no well-established standard for selecting the number of topics or the placement of topic prompts. Typically as the number of topics decreases, the topic prompt should be inserted into shallower blocks (i.e., blocks closer to the input layer). In the experiments section, we present the insertion positions of topic prompts across different datasets, along with the corresponding number of topics and balance parameter values.
Computing infrastructure
We conducted the experiments using a PC equipped with an x64-based Windows 11 operating system, a Xeon Gold 6142 CPU, and a Tesla V100 16 GB GPU. On this hardware setup, training one epoch of our model on the MS-COCO dataset takes approximately 10 min, and testing the model on the entire test set takes around 6 min. Notably, these times are nearly identical to those of the ViT, indicating that the computational overhead introduced by our method is minimal.
Experiments
In this section, we evaluate the performance of the proposed TATHPL model on several datasets, comparing the results with several previous models to comprehensively demonstrate the effectiveness of our approach. Specifically, we first describe the datasets and evaluation metrics employed. Next, we outline the experimental setup, including the methods used for topic clustering in the first stage and the visual backbone network employed in the second stage. Then, we present the performance of our proposed model on the dataset and compare it with several state-of-the-art models. Finally, we compare the model with added topic prompts to the baseline model, demonstrating the effectiveness of our approach.
Datasets and metrice
We conducted experiments on three multi-label datasets to evaluate the performance of our model, including the MSCOCO (Lin et al., 2014), NUS-WIDE (Chua et al., 2009), and Corel5k datasets. Based on previous work, we use the mean average precision (mAP) across all categories as the primary performance evaluation metric. Additionally, we introduce the following metrics: per-category precision (CP), recall (CR), F1-measure (CF1), and average overall precision (OP), recall (OR), and F1-measure (OF1). Furthermore, we also incorporate hamming loss and one-error to provide a more comprehensive evaluation in the ablation study.
Experiments setup
Unless otherwise specified, our experiment will fully adhere to the setup described below. In the first stage, we apply the latent Dirichlet allocation (LDA) for topic clustering. The basic configuration of the LDA model requires adjusting two parameters: the number of topics and the maximum number of iterations. The maximum number of iterations is set to in all experiments. The number of topics varies depending on the dataset. We adopt ViT-B/16 pretrained on ImageNet (Deng et al., 2009) as the backbone network. Each prompt in the prompt pool, as well as its corresponding classification head, is initialized using a normal distribution with a standard deviation of . The parameters of all prompts are not shared. After initialization, we fine-tune the entire model on multi-label datasets. The input image resolution is resized to . Following previous multi-label frameworks, we use Adam (Kingma & Ba, 2014), asymmetric loss, and the one-circle learning rate scheduler. Further details on the implementation and training process can be found in Appendix.
Results on benchmark and comparisons with state-of-the-arts
Performance on MS-COCO
MS-COCO is a large-scale image dataset designed for object detection, image segmentation, and multi-label classification. It contains 122,218 images, with 82,081 images in the training set and 40,137 images in the test set used for model evaluation. The dataset includes 80 object categories commonly found in scenes, with each image annotated with an average of 2.9 labels. This dataset datasets can be found at https://cocodataset.org. On the MSCOCO dataset, we select the first and second blocks as our prompt blocks and insert topic prompts containing 2 and 6 topics, respectively. The balance parameter is set to for all experiments.
As shown in Table 2, the results indicate that our model achieves an mAP score of at a resolution of , outperforming the sub-optimal model Spatial Regularization Network (SRN). Furthermore, it demonstrates improvements in other evaluation metrics, such as CF1 and OF1, indicating that our model not only improves overall classification accuracy but also balances precision and recall more effectively, demonstrating stronger robustness in multi-label classification. The key reason our model achieves these results lies in its ability to effectively capture the latent semantic structure of label combinations, referred to as “topic information.” By introducing hierarchical prompt learning, our ViT model learns label correlations at multiple granularities. In contrast, traditional methods often overlook this aspect. Specifically, our model guides attention to image regions aligned with topic information at different levels, from coarse-grained global semantics to fine-grained task-relevant areas, ensuring that the model effectively understands and distinguishes the latent relationships between labels at every level.
| Method | mAP | CF | CP | CR | OF | OP | OR |
|---|---|---|---|---|---|---|---|
| CNN-RNN (Wang et al., 2016) | 61.2 | 60.4 | 66.0 | 55.6 | 67.8 | 69.2 | 66.4 |
| RDAR (Chen et al., 2017b) | 73.4 | 67.4 | 79.1 | 58.7 | 72.0 | 84.0 | 63.0 |
| ResNet-101 (He et al., 2015) | 78.3 | 69.5 | 80.8 | 63.4 | 74.4 | 82.2 | 68.0 |
| ResNet-SRN-att (Zhu et al., 2017) | 76.1 | 70.0 | 81.2 | 63.3 | 75.0 | 84.1 | 67.7 |
| ResNet-SRN (Zhu et al., 2017) | 77.1 | 71.2 | 81.6 | 65.4 | 75.8 | 82.7 | 69.9 |
| IDA-Swins (Liu et al., 2023) | 80.6 | 71.8 | 64.5 | 81.1 | 73.8 | 65.8 | 65.8 |
| TATHPL | 81.9 | 77.1 | 83.0 | 71.8 | 79.1 | 83.5 | 75.3 |
Performance on NUS-WIDE
NUS-WIDE is a large-scale real-world web-based image dataset containing 269,648 images and 81 visual concepts. We trained our model on 161,789 images and evaluated it on 107,859 images. This dataset datasets can be found at https://www.kaggle.com/datasets/7cbbf047bc9c47b4f2c00e83531d3376ab8887bb0deed2ce2ee1596fe96aa94d?select=NUSWIDE. We insert a topic prompt containing 2 topics into the last block of the model and set the balance parameter to . The experimental results are shown in Table 3. We used three metrics—mAP, CF1, and OF1—to evaluate the performance of our model and compared it with five previously proposed state-of-the-art methods. In all experiments, the image resolution was . Our model outperforms other state-of-the-art and baseline models.
| Method | mAP | CF | OF |
|---|---|---|---|
| ResNet101 (He et al., 2015) | 59.8 | 55.7 | 72.5 |
| MS-CMA (You et al., 2019) | 61.4 | 60.5 | 73.8 |
| ResNet-SRN (Zhu et al., 2017) | 62.0 | 58.5 | 73.4 |
| ICME (Chen et al., 2019c) | 62.8 | 60.7 | 74.1 |
| TresNet (Ridnik et al., 2020) | 63.1 | 61.7 | 74.6 |
| CCD-R101 (Liu et al., 2022) | 64.2 | 61.8 | 74.6 |
| Q2L-R101 (Liu et al., 2021) | 65.0 | 63.1 | 75.0 |
| SADCL (Ma et al., 2023) | 65.9 | 63.0 | 75.0 |
| Q2L-TResL (Liu et al., 2021) | 66.3 | 64.0 | 75.0 |
| TATHPL | 67.0 | 64.8 | 75.3 |
Performance on Corel5k
Corel5k is a widely used multi-label dataset consisting of 4,999 images, with 4,500 images designated for the training set and 499 images for the validation set. The dataset is annotated with 260 categories. This dataset can be found at https://github.com/watersink/Corel5K. In this dataset, we select the first and last blocks as the prompt blocks and insert topic prompts with topic numbers of 2 and 3, respectively. And both of the balance parameters are set to be . As shown in Table 4, our method demonstrates superior performance compared to other state-of-the-art methods and the baseline, which exhibits strong transfer learning capabilities.
| Method | OR | OP | OF1 |
|---|---|---|---|
| FT DMN+SVM (Jiu & Sahbi, 2019) | 38.1 | 23.4 | 28.9 |
| CNN-RNN (Wang et al., 2016) | 41.3 | 32.0 | 36.0 |
| 3-layer DKN+SVM (Jiu & Sahbi, 2017) | 43.2 | 25.6 | 32.1 |
| LNR+2PKNN (Zhang, Hu & Hu, 2018) | 46.1 | 44.2 | 44.9 |
| DCKN (Jiu & Sahbi, 2019) | 44.1 | 33.4 | 38.1 |
| Q2L-TResL (Liu et al., 2021) | 48.1 | 43.5 | 45.7 |
| DMCKN-Cvt (Jiu, Zhu & Sahbi, 2024) | 49.1 | 45.2 | 47.0 |
| TATHPL | 74.4 | 65.5 | 69.7 |
Ablation study
Comparison with baseline methods
To prove the efficiency of the refinements put forward in our work, we compare the TATHPL with the baseline model ViT on MS-COCO. The results, presented in Table 5, show that our model consistently outperforms the baseline under various evaluation metrics. As expected, topic prompts facilitate a better understanding of label dependencies.
| mAP | CF1 | OF1 | Hamming loss | One-error | |
|---|---|---|---|---|---|
| Baseline | |||||
| Ours |
Effect of model components
Our proposed framework incorporates two essential components: topic extraction and the hierarchical prompt. In this subsection, we conduct an ablation study to evaluate the contribution of each module. The results are shown in Table 6. Compared with the baseline backbone network, introducing the Hierarchical Prompt alone yields a slight improvement in performance, increasing the mAP from to on the Corel5k dataset. When the Topic Extraction module is further incorporated, the performance is significantly enhanced, achieving an mAP of . While the Hierarchical Prompt alone contributes modest gains, the more substantial improvement observed with the addition of Topic Extraction indicates that the extracted topic information plays a valuable role in boosting multi-label classification performance.
| HP | TE | mAP |
|---|---|---|
| ✓ | ||
| ✓ | ✓ |
Statistical significance analysis
We conducted an ablation study and statistical significance analysis to compare the performance of our proposed model with the baseline model ViT on the Corel5k dataset. Specifically, for each test sample, we generated multi-label classification probability predictions from both models. We then compared the differences between the two models using the paired t-test and Wilcoxon Signed-Rank Test. The paired t-test yielded a p-value of 0.028, while the Wilcoxon Signed-Rank Test produced a p-value of 0.022. Both p-values are below the significance threshold of 0.05, indicating that the performance differences between the two models are statistically significant.
The results show that our model outperforms the baseline model, confirming the effectiveness and advantages of our approach.
Effect of the number of topics L
For the topic extraction module, the number of topics L is a critical hyperparameter. We investigate its impact by injecting topic information with varying values of L (ranging from 2 to 8) into both the first and the last encoder layers of a standard ViT-B/16 model. The results are illustrated in Fig. 3. As shown, when topics are injected into the first layer, the best performance is achieved with , while increasing L gradually leads to performance degradation. Based on this observation, we typically choose for shallow layers. In contrast, when topic information is injected into the final encoder layer, smaller values of L result in suboptimal performance. When , the performance improved to some extent. These results suggest that as the number of topics increases, the topic prompts should be injected into deeper layers of the transformer for optimal performance.
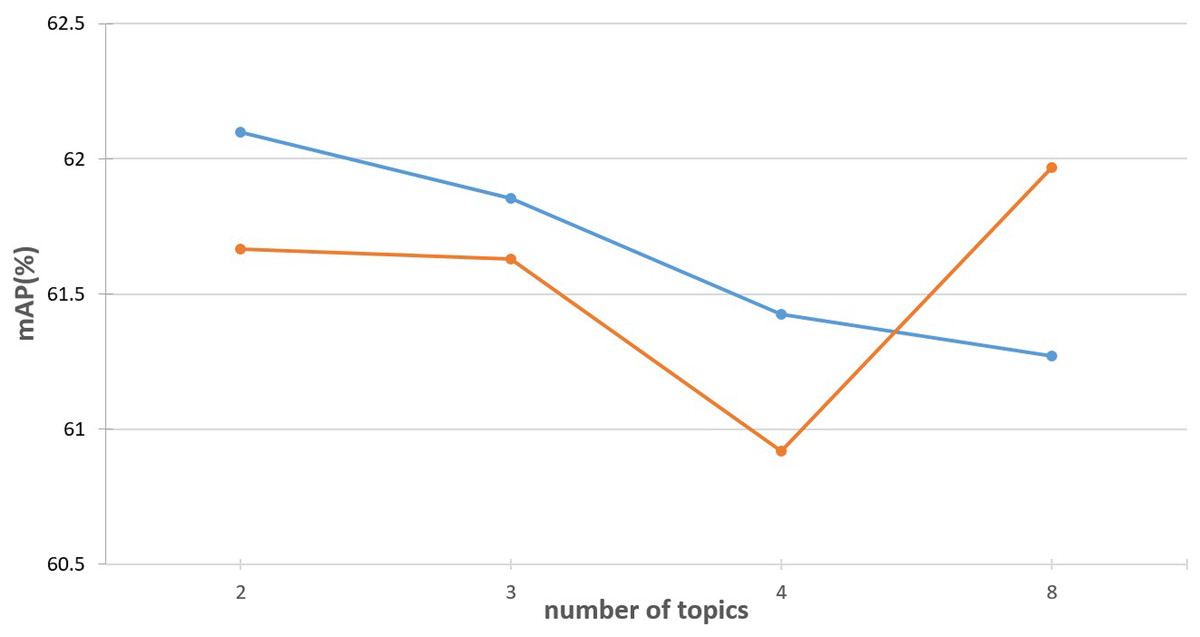
Figure 3: Effect of the number of topics L.
The blue line illustrates the performance variation when injecting different numbers of topic prompts into the first layer of the ViT encoder. In contrast, the orange line shows the performance changes when the topic prompts are inserted into the final layer.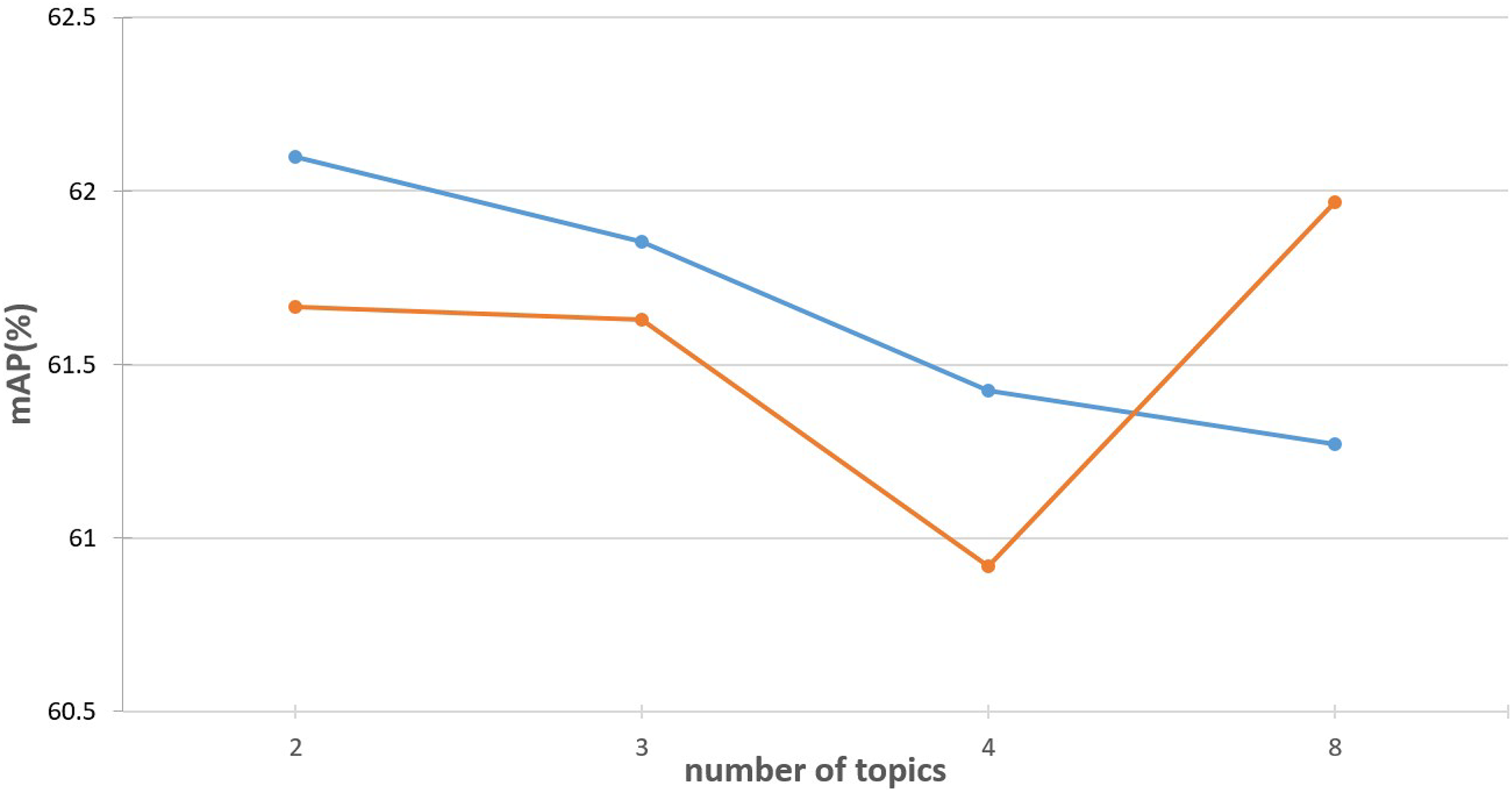{kind=link}
Conclusion
In this article, we propose a novel multi-label classification framework, utilizing a pre-trained Vision Transformer. By inserting topic prompt tokens containing image-related topic information into specific transformer blocks, our approach helps the model focus on objects that align more closely with the relevant topic features. Our experiments show that, with minimal additional parameters, our method outperforms prior approaches. We hope our work will inspire future research into how visual models can uncover and utilize latent semantic information in downstream tasks.
Limitation: Our approach exhibits sensitivity to the distribution of image topics. In particular, if the topic distribution estimated during the first stage is inaccurate, it may negatively impact the performance of subsequent multi-label classification tasks. This initial stage has not been thoroughly investigated and remains an open area for improvement. One promising direction is to introduce a dynamic topic adjustment mechanism, where the number of topics can be treated as a learnable parameter and optimized jointly during training, rather than being manually fixed in advance. Additionally, while we focus on multi-label tasks in this article, we have not yet explored other tasks that could potentially benefit from our method, such as object detection.
Appendix
More implementation details
In the first stage of the framework, we utilize the CountVectorizer model from the scikit-learn library to convert the document collection into a term frequency matrix. Next, we apply the LDA model from scikit-learn, using the term frequency matrix as input, and set the maximum number of iterations to , keeping all other parameters set to their defaults.
In the second stage, we use the ViT as the baseline model. Specifically, it consists of attention heads and transformer blocks, with an embedding size of . The topic prompt token, which we introduce, is a -dimensional vector. During training, we utilize the Adam optimizer along with the One-Cycle policy (Smith, 2018), running for epochs with a maximum learning rate of 1e−4. For regularization, we apply true-weight-decay (Loshchilov & Hutter, 2017) with a coefficient of , and for data augmentation, we use CutoutPIL (Devries & Taylor, 2017) with a cutout factor of , in addition to RandAugment (Cubuk et al., 2019). Moreover, we employ an exponential moving average (EMA) with a decay rate of .
Evaluation metrics
We employ mean average precision (mAP) as the primary metric, supplemented by the overall precision (OP), recall (OR), F1-measure (OF1) and per-category precision (CP), recall (CR), F1-measure (CF1). These metrics are computed as follows:
Given a dataset with N images and C classes, let denote the ground truth label and denote the predicted probability for image and class . The binary prediction is obtained by applying a specific threshold to .
Mean average precision (mAP)
For a single class, given N samples sorted by prediction scores in descending order, the average precision (AP) is defined as:
(13) where: is the total number of positive samples in the class and is the precision at the position of the -th positive sample in the ranked list AP measures the average precision at all positions where a positive sample is found, providing a single score that combines both ranking quality and classification accuracy. For predictions with C classes, the mean average precision is computed as:
Per-class metrics
For each class , the fundamental counts are defined as:
(14)
(15)
(16) where , , and represent the counts of true positives, false positives, and false negatives for class , respectively.
(17)
(18)
(19)
Overall metrics
(20)
(21)
(22)