
Advancing named data networking: a comprehensive survey on naming and packet lookup mechanisms
- Published
- Accepted
- Received
- Academic Editor
- Markus Endler
- Subject Areas
- Computer Networks and Communications, Mobile and Ubiquitous Computing
- Keywords
- Internet, NDN, Packet, Interest, Data
- Copyright
- © 2026 Asif et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Advancing named data networking: a comprehensive survey on naming and packet lookup mechanisms. PeerJ Computer Science 12:e3551 https://doi.org/10.7717/peerj-cs.3551
Abstract
Named Data Networking (NDN) has emerged as a promising content-centric paradigm for the future Internet, transitioning from host-based to data-centric communication. This survey presents a comprehensive review of state-of-the-art naming and packet lookup mechanisms in NDN, addressing critical challenges including scalability, memory efficiency, lookup latency, table update complexity, and deployment feasibility. To the best of our knowledge, this is the first survey to jointly examine both naming and packet lookup mechanisms within a unified taxonomy, providing comparative insights across diverse domains, including wired and wireless NDN environments. We classify naming schemes into hierarchical, flat, attribute based, and hybrid approaches, and evaluate packet lookup schemes in the Content Store (CS), Pending Interest Table (PIT), and Forwarding Information Base (FIB) data structures. Here, we defines packet lookup in a specific context, referring exclusively to the name-based search conducted on the CS, PIT, and FIB, as compared to the wider packet processing flow. This survey highlights domain-specific design trade-offs, architectural directions, and the implications of emerging technologies. Finally, we identify open research challenges and propose future directions that involve dynamic naming, distributed PIT designs, integration with emerging technologies, and standardization, aiming to advance the efficiency and adaptability of NDN in real-world scenarios.
Introduction
Named Data Networking (NDN) is a revolutionary communication paradigm that retrieves content based on names instead of Internet Protocol (IP) addresses. This approach is designed to enhance the efficiency and reliability of data delivery by shifting focus from the location of the content to its identity. NDN, a prominent architecture within the broader ICN framework, promises transformative advancements in wired and wireless networks. Based on the traditional Transmission Control Protocol/Internet Protocol (TCP/IP) model, current Internet architectures face challenges such as dynamic topology changes, mobility, connectivity issues, and centralized communication dependencies. NDN addresses these limitations by introducing a decentralized, content-centric model (Team, 2019).
In NDN, the network retrieves and forwards content using unique names, replacing the reliance on IP addresses (Zhang et al., 2014). Unlike the stateless nature of TCP/IP networks, NDN operates as a stateful architecture, incorporating in-network caching, which reduces latency and bandwidth consumption. The core distinction between NDN and TCP/IP networks lies in how they handle forwarding. NDN bases forwarding decisions on content names rather than addresses. Two types of packets underpin NDN operations: Interest packets and Data packets. Consumers request content by issuing Interest packets, which are forwarded along the network until a matching Data packet is returned (Yuan, Song & Crowley, 2012). This mechanism inherently supports efficient data delivery, mobility, and caching, making NDN an attractive solution for modern networking needs.
The hourglass architecture of NDN preserves key design principles from the original Internet architecture, as shown in Fig. 1. NDN routers consist of three primary components: (1) Content Store (CS) for caching data to fulfill future requests, (2) Pending Interest Table (PIT) to track Interest packets awaiting corresponding Data packets, and (3) Forwarding Information Base(FIB) for routing Interest packets based on the longest prefix matching (LPM) (Saxena et al., 2016b). Despite these advancements, NDN introduces new challenges due to its use of variable-length, hierarchical content names. These names demand significant memory and processing resources for storage, lookup, and updates (Jacobson et al., 2009). Name lookup operations in NDN rely on an exact matching technique for CS and PIT and LPM for FIB, which is computationally more intensive than traditional IP-based mechanisms (Dai et al., 2012). Efficient name lookup and scalable table management remain key challenges in NDN forwarding. The scalability of tables in NDN routers is crucial, particularly as the content and network size continue to expand. Addressing these challenges requires advanced naming mechanisms, optimized URL formats, and fast, hierarchical-based lookup strategies. These efforts aim to balance memory consumption, processing time, and update efficiency, ensuring the feasibility of NDN in large-scale deployments. Table 1 shows some of important abbreviations used in this article.
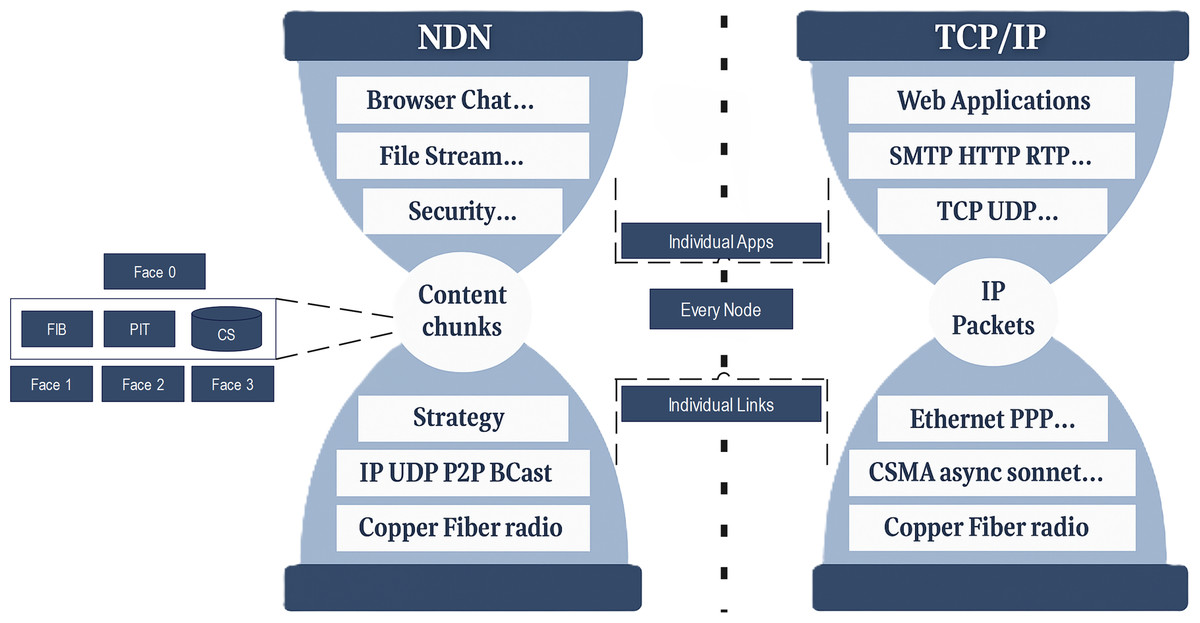
Figure 1: A comparison of the NDN hourglass architecture (left) and TCP/IP hourglass architecture (right).
{kind=link}
| Abbreviation | Definition |
|---|---|
| NDN | Named Data Networking |
| ICN | Information-Centric Networking |
| CT | Compact Trie |
| PIT | Pending Interest Table |
| PNL | Parallel Name Lookup |
| NPT | Name Prefix Trie |
| ENPT | Encoding Name Prefix Trie |
| GPU | Graphics Processing Unit |
| ATA | Aligned Transition Array |
| BF | Bloom Filter |
| DFA | Deterministic Finite Automata |
| NRT | Name Radix Trie |
| UBF | Unified Bloom Filter |
| DHT | D-left Hash Table |
| CCN | Content-Centric Networking |
| LPM | Longest Prefix Matching |
| CS | Content Store |
| FIB | Forwarding Information Base |
| MLPS | Million Lookup Per Second |
| NCE | Name Component Encoding |
| PTH | Perfect Hash Table |
| STA | State Transition Array |
| HT | Hash Table |
| NCT | Name Component Trie |
| CRT | Cyclic Redundancy Checksum |
| DiPT | Distributed PIT |
| LHT | Linear Chaining Hash Table |
| NPHT | Name Prefix Hash Table |
Motivations and contributions
Despite a growing body of research on NDN, existing surveys often treat naming and lookup separately, with limited emphasis on their interdependence and domain-specific implementation challenges. Moreover, there is a lack of comparative evaluation across wired and wireless environments where naming impacts lookup complexity, latency, and resource allocation. This survey is motivated by the need to consolidate diverse strands of work into a unified framework that guides future research, system design, and real-world adoption. It is intended for network researchers, protocol designers, and practitioners seeking to understand how naming strategies influence lookup performance and vice versa. The key contributions of this article include the following:
This is the first work that jointly explores both naming and packet lookup (specifically referring to mean name-based lookup on CS/PIT/FIB) mechanisms in NDN, presenting a layered taxonomy of approaches and examining their performance in both wired and wireless environments.
We systematically identify and analyze key technical challenges, including scalability, memory limitations, lookup latency, update overhead, and deployment constraints across different network environments.
This article evaluates hierarchical, flat, attribute-based, and hybrid naming approaches, and assesses their suitability for various NDN use cases.
The article analyses FIB-based, PIT-based, and entire router-wide packet lookup approaches across wired and wireless networks, identifying critical performance bottlenecks, including scalability, memory overhead, and update efficiency.
This article highlights open issues in NDN, including scalability for unbounded name lengths, table design optimizations, and memory-efficient caching strategies.
The remainder of this article is organized as follows: ‘Background’ reviews the NDN architecture and fundamental packet processing logic. ‘Survey Methodology’ presents the research methodology by defining three research questions. ‘Related Work’ discusses the related work in the NDN. ‘NDN Naming Schemes’ addresses RQ1 by analyzing naming schemes, including hierarchical, flat, attribute-based, and hybrid formats. ‘Packet Lookup Schemes’ addresses RQ2 by evaluating packet lookup mechanisms (FIB, PIT, CS) and their performance in different deployment contexts. ‘Key Research Challenges and Future Directions’ addresses RQ3 by identifying key challenges and future directions. ‘Conclusion’ concludes the article.
Background
NDN is a well-known and prominent architecture of the ICN concept. Multiple architectures have been represented under ICN, for example, the Network of Information (NetInf) (Team, 2012), publish-subscribe Internet technology (PURSUIT), and the Data-oriented Network architecture (DONA), among others. A similar key concept is employed in almost all architectures, referred to as a constructed transmission layer in place of TCP/IP addresses (Ahlgren et al., 2012). It gives the content an excellent citizen instead of a data location. Thus, it is entirely independent of network location, and content names are utilized for the data access at the network layer. Content-centric networking (CCN) architecture was developed before NDN, as part of a project at the Palo Alto Research Centre. The architecture of CCN is expanded to NDN, and the procedures for transferring Interests and data to retrieve data items are comprehended. In CCN, when the request information is received at the router, it first examines the CS. On the other hand, NDN primarily examines the PIT to find the matched item and then examines the CS for content retrieval. It is clear from the literature that CS is far greater than PIT, so to reduce the delay, it initially examines the PIT.
NDN packet type
In NDN, content retrieval is based on the recipient (Amadeo et al., 2014; Naseer et al., 2024). Packets of two categories participate in the transmission process: Data and Interest packets. Interest and Data packet layouts are shown in Fig. 2. In both packets, the content name is inserted as a string. In the Interest packet, the requested name is inserted on the customer side and is directed towards the next hop. The routers use exact naming to distribute packets to the network in the direction of the provider. Upon receiving the Interest packet at the producer node, it verifies the requested information and generates a corresponding Data packet containing the requested content and the producer’s signature.
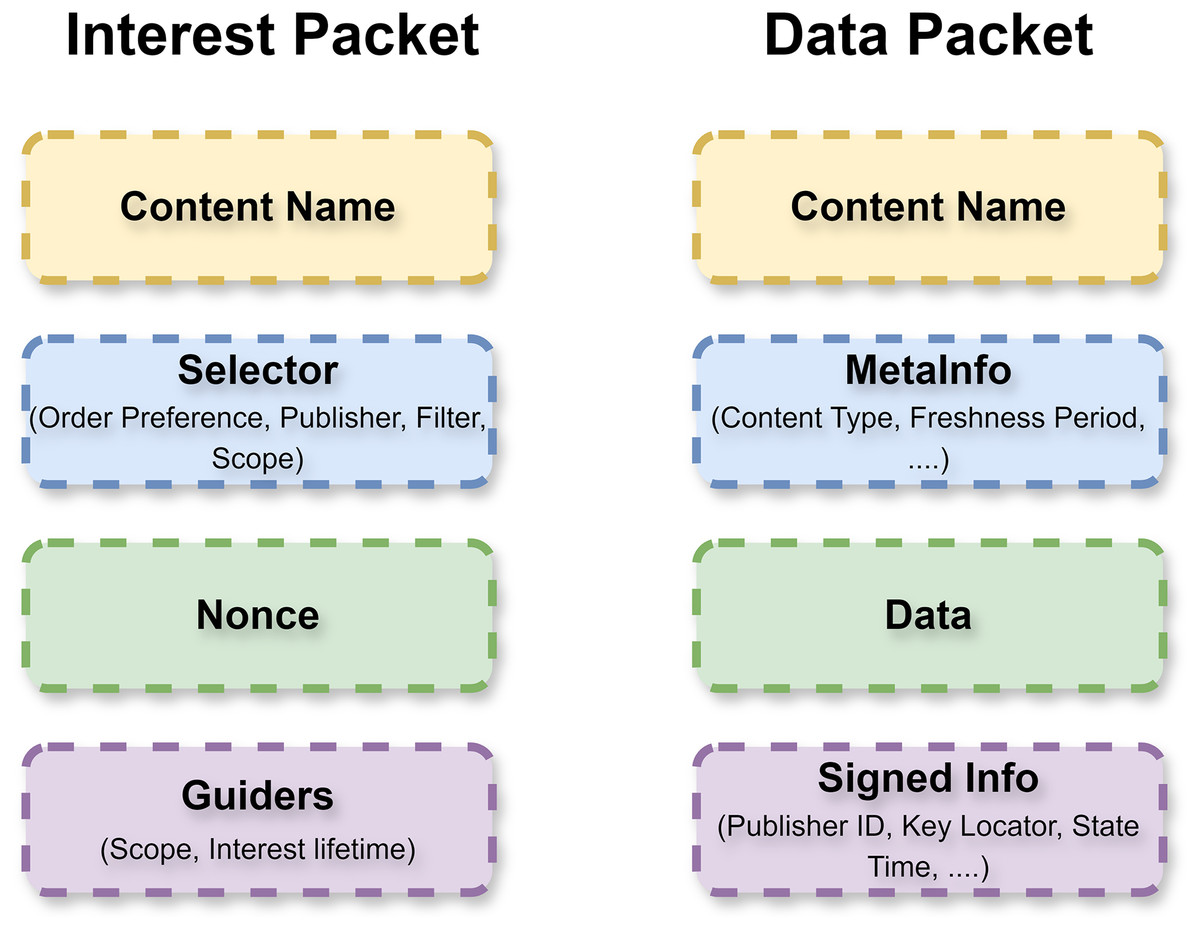
Figure 2: Interest and data packets formats.
{kind=link}
NDN data structures
In NDN, three data structures are also mentioned on each node and details of each data structure is given below.
FIB: It transmits the requested content name packet to the next router in the upstream direction using the LPM. It contains the information about the interfaces of the Interest packet. The provider that includes the requested data-name prefixes and subsequent interfaces is maintained in FIB (Saxena & Raychoudhury, 2016b).
PIT: It stores the requested information packet until its lifetime has expired or is satisfied. In this table, each entry contains the name of the Interest packet, a set of arriving interfaces that display the preceding hop, and outgoing interfaces that display the subsequent hop chosen by the Interest packet of the specific name. Exact matching technique is employed to search for entries and forward numerous Interest packets to the next hop. Whenever the requested information has multiple demands, it simply transmits the first packet, although the remaining Interests are delayed and waiting for the subsequent request (Li et al., 2014a).
-
CS: It is used for in-network caching of data content. The primary purpose of the CS is to conserve bandwidth, reduce distribution latency, and minimize retrieval time. A temporary cache memory stores Data packets since multiple users request the same data. For example, various users may listen to the same audio. PIT also uses an exact matching technique to search entries in the cache memory. Figure 3 shows the NDN router containing all three data structures.
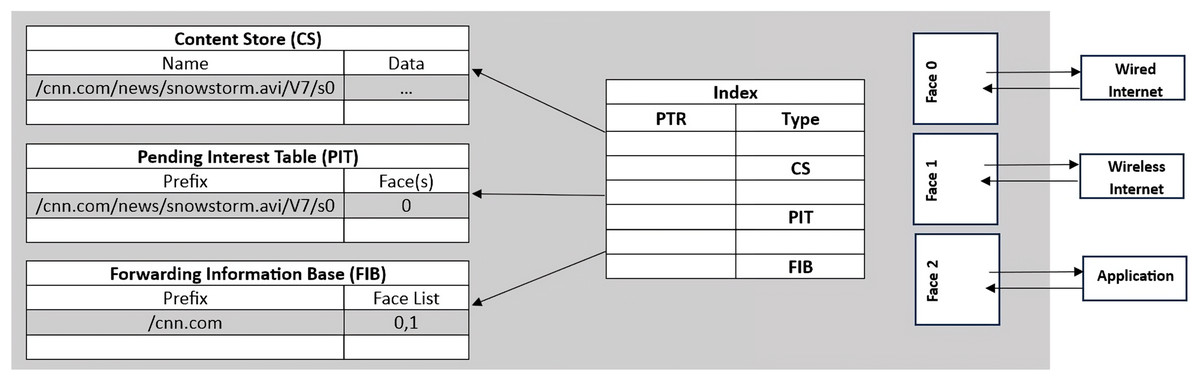
Figure 3: NDN router and its components.
{kind=link}
NDN packet working flow
Whenever the content request is received at the NDN node, the following processes are executed as shown in Fig. 4.
-
1.
First, the CS is checked or discovered if the requested data is cached by this time. It found the exact name, if accessible afterwards. The requested content is directed toward the path that the requested information follows.
-
2.
If the requested data is not present in the CS, it examines the PIT to determine the request for the required information. If an entry for that requested information is already present, it is combined with the directory of arriving interfaces in PIT.
-
3.
Whenever there is no request, it inserts the corresponding request in the table for the packet of type Interest. It examines the FIB constructed based on the LPM to determine the subsequent router for transmitting the requested information to that router (Yu & Pao, 2016).
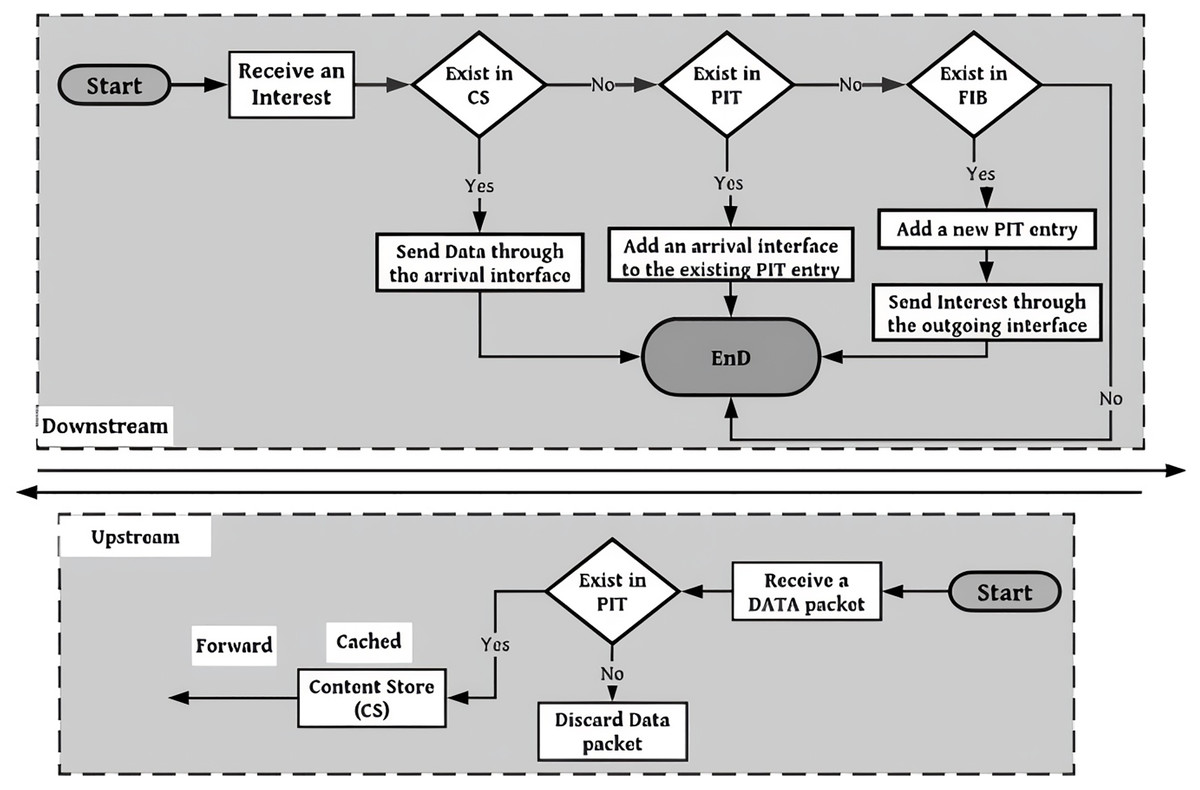
Figure 4: Forwarding process at NDN router.
{kind=link}
Packet processing in an NDN forwarder includes the parsing of Interest/Data, verification of signatures or freshness, management of nonce and hop-limit, and the resulting forwarding or caching decisions. In this survey, packet lookup refers primarily to the name-based searching within the router’s data structures (FIB, PIT, CS), including longest-prefix matches, exact/prefix queries, and associated data-structure operations. The overall operational processes are described for clarity but are not examined. Therefore, our taxonomy, metrics, and analyses focus on name-based lookups and associated implementations (e.g., Tries, Hashing, Bloom Filters, and Hybrid), which primarily impact lookup latency and memory trade-offs in reality.
Survey methodology
This survey uses a structured methodology to analyse naming and packet lookup mechanisms in NDN systems comprehensively. Based on the findings, we formulated the subsequent research questions (RQs):
RQ1: How do naming schemes (hierarchical, flat, hybrid, and attribute-based) perform in wired and wireless NDN environments? What are their comparative strengths, limitations, and design implications in terms of scalability, aggregation, readability, and routing efficiency across different deployment domains?
RQ2: How do name-based packet lookup schemes in FIB, PIT, and CS perform across different NDN domains, and what are the trade-offs in latency, memory, and hardware efficiency?
RQ3: What are the open challenges and future opportunities for integrating scalable, secure, and context-aware naming and lookup mechanisms in real-world NDN deployments?
Database and journal search
We conducted a structured survey across various academic databases, including IEEE Xplore, SpringerLink, ScienceDirect, and Google Scholar, to ensure a thorough and impartial review of the literature. These databases serve to collect an extensive range of journal articles and conference articles. This includes specialized journals within the domains of engineering and computer science.
Keywords and search criteria
A preliminary search was conducted to categorize the various domains within the IoT and their intersections with NDN. This initial phase enabled the identification of significant thematic clusters related to naming mechanisms, packet lookup strategies, and network architecture paradigms in both wired and wireless contexts. A depth-oriented search was conducted within each identified domain to examine current solutions and methodologies. Targeted research issues were formulated to guide the review, leading to the development of composite search strings designed to retrieve precise and relevant publications. The search strings included a comprehensive array of keywords and phrases such as “Named Data Networking”, “NDN naming mechanisms”, “PIT and FIB in NDN”, “Packet Lookup in NDN”, “Emerging Technologies”, “Big Data”, “Naming in NDN”, “Wired NDN” and “Wireless NDN”. We strategically employed Boolean operators to refine and optimize search results (e.g., “NDN AND ‘Emerging technologies”’, “NDN OR ‘Content-Centric Networking’”, “Naming Approaches AND ‘Packet lookup”’).
Inclusion and exclusion criteria
We incorporated both peer-reviewed scholarly articles and selected grey literature sources to guarantee a thorough and impartial review. Grey literature, including technical reports, government publications, and white articles, was utilized to document emerging innovations, standardization efforts, and regulatory developments that may not yet be represented in academic databases. The articles were selected based on their technical depth, relevance to NDN naming and lookup mechanisms, and clarity of methodological approaches. Publications that contradicted previous efforts without making a substantial addition, lacked methodological clarity, or did not fit the parameters of our survey were not included.
Related work
This section presents a comparative review of existing surveys and research articles related to NDN naming and lookup mechanisms. We analyze the scope, contributions, and limitations of prior work to contextualize the novelty of our survey. The research (Nurhayati et al., 2022) presents a thorough survey of naming approaches within NDN, focusing on the performance impacts on data retrieval systems. This analysis categorizes naming approaches into three categories: flat, hierarchical, and hybrid, to examine how they affect lookup speed, memory usage, and scalability. The research investigates project developments involving entropy-based approaches, name component encoding protocols, and intelligent name lookup optimization techniques. NDN router scalability and rapid name lookup implementations present challenges that highlight the necessity for future research into efficient naming schemes for content retrieval. The article (Majed, Wang & Yi, 2019) examines NDN name lookup bottlenecks at the data structure level to analyze the available solutions among trees, hash tables, and Bloom filters. This research investigates the scalability of name retrieval systems in terms of their memory usage and computational efficiency, while addressing issues related to dynamic name lengths and the frequency of lookup operations. A comparative review of lookup solutions has revealed the direction analytics should pursue to enhance performance while reducing resource utilization and system delays. The article also establishes how forthcoming solutions can scale up lookup capabilities more effectively than before. While Majed, Wang & Yi (2019) offers a strong technical analysis of classical lookup techniques in static environments, our work expands the scope by integrating naming scheme evolution and an extended taxonomy of packet lookup approaches. We acknowledge that semantic-based and ML-driven lookup techniques are not explored in our current research and may offer valuable extensions for future survey efforts. In Li et al. (2019), the authors analyses NDN packet forwarding requirements while examining how the CS collaborates with the PIT and FIB. The authors review options for forwarding techniques alongside efficiency gains, memory requirements, and computational complexity analysis. The article demonstrates why future data structures must strike a balance between lookup speed and memory performance, while enabling adaptive forwarding solutions for large-scale deployments. In Li et al. (2022), the authors present Pyramid-NN as a neural network solution to enhance the speed of NDN name searching. According to the authors, traditional indexing methods suffer from increasing lookup delays and excessive memory usage due to changing distribution patterns of names over time. Their machine-learning model reduces memory usage while maintaining excellent lookup precision. New research indicates that their learning-based FIB implementation significantly boosts network performance and scalability, making it a strong candidate for future NDN systems deployment. In Mastorakis et al. (2018), fuzzy Interest forwarding is examined as an algorithm that supports approximate name-match operations in NDN networks. A conventional forwarding system relies solely on precise name comparisons, yet these conditions do not necessarily apply to dynamic systems. The proposed fuzzy forwarding mechanism employs semantic similarity techniques to improve data retrieval success rates, particularly in heterogeneous and ad-hoc network environments. Simulation results indicate that this method enhances content discovery efficiency and reduces Interest drop rates while delivering improved network response times. Authors in Gunti & Rojas-Cessa (2023) presents BalanceDN as a proposed distributed load-balancing scheme that addresses the congestion and inefficient content retrieval challenges in NDN networks. A distributed resolver-based approach inspired by DNS serves as the backbone of this method to enhance name resolution performance. Results from the ndnSIM simulator confirm that BalanceDN reduces traffic congestion through timely content detection and decreased demand for blind Interest exchange transmissions. The integration of NDN and CCN is explored within the IoT system (Aboodi, Wan & Sodhy, 2019). Name-based routing, in-network caching, and scalable naming schemes, as outlined in NDN standards, outperform traditional IP-based designs. The research addresses various implementation hurdles related to energy efficiency constraints, mobility, and security requirements, laying the core foundation for developing strategies for NDN-based IoT deployment. This study is crucial for analyzing how principles of Internet content networking align with IoT implementations. A novel vehicular named data networking (V-NDN) routing method is presented that selects optimal paths through fuzzy logic implementation (Kaushik, Bali & Srivastava, 2023). The V-NDN method invokes dynamic evaluations of forwarding nodes using fuzzy parameters, which minimize data delivery delays. Experimental results demonstrate that V-NDN achieves a higher popularity of Interest connections with fewer Data packets through networks, thereby enhancing operational effectiveness in mobile environments. A systematic review (Karim et al., 2022) of NDN routing approaches identifies three distinct methodologies: link-state, distance-vector, and software-defined networking (SDN)-based techniques. This research analyses routing strategies to determine their scalability capacity, efficiency, and adaptability while pinpointing constraints related to routing overhead and scalability requirements. The authors propose future research priorities for designing adaptive and context-aware routing frameworks to meet the growing demands of data-intensive applications. In Yassine, Najib & Abdellah (2024b), the authors appraises NDN routing protocols based on their scalability capabilities and ability to manage overhead while meeting efficiency standards. The analysis examines the differences between decentralized and centralized control routing approaches, evaluating how each design operates across wired and wireless communication networks. Effective routing mechanisms must scale while ensuring security to address the increasing complexity of modern networks. The research identifies three primary limitations concerning the dynamic adaptability of routing protocols, energy efficiency considerations, and software-defined network implementations of NDN functionalities. In Paul & Selvan (2021), the authors conduct a qualitative survey of naming formats and cache-placement strategies in NDN, providing relevant statistics on hit ratios; however, they do not address the scalability of lookup tables or the integration of queries in naming. In Alhawas & Belghith (2024), Ansari, Rehman & Arsalan (2023), the authors analyze software-defined named data networking (SD-NDN), which integrates SDN with NDN to enhance network scalability, efficiency, and performance. The research demonstrates that SD-NDN improves forwarding quality through better routing protocols and caching mechanisms. However, it confronts challenges regarding controller compliance when merging SDN elements with NDN components. Several SD-NDN models are evaluated for their capabilities in content performance retrieval, user mobility functionality, and cache organization enhancements. The article identifies future investigation topics focusing on the growth capacity of controllers, integration strategies, and superior management inefficiencies. This review advocates for adaptive routing and AI-driven optimizations to enhance the possibilities of SD-NDN implementation. In Zhang et al. (2023), the authors propose a hybrid search approach that integrates Bloom filters with tree structures to enhance content lookup efficiency in NDN environments. This approach effectively minimizes search overhead while ensuring high data retrieval accuracy, especially in extensive IoT deployments. The integration of Bloom filters with tree-indexed paths facilitates the rapid exclusion of invalid content names and effectively reduces the search space. In Yassine, Najib & Abdellah (2024a), the authors present a systematic survey of how SDN paradigms can improve routing efficiency in NDN. The review classifies SDN-enabled protocols according to their architectural layers and emphasizes their adaptability to changing network conditions. The authors highlight the importance of programmable control planes for improved forwarding state management, dynamic topology adjustment, and name-based traffic engineering, establishing a basis for future integration of NDN and SDN technologies. Authors examine the categorization of hierarchical naming strategies specifically designed for IoT contexts. This study introduces a taxonomy of naming models categorized by structure, readability, and interoperability. This also underscores challenges, including naming collisions, security vulnerabilities in prefix-based resolution, and inconsistencies in naming induced by mobility. Their insights connect naming conventions with practical constraints in IoT. In Lian et al. (2022), the authors introduces a notable improvement in name resolution within ICN, particularly designed for dynamic environments. The authors identify two limitations of current Bloom filter–based routing overlays: (1) inadequate management of content mobility and deletion, and (2) elevated false-positive rates that lead to superfluous network traffic. The proposed framework incorporates a Simplified Adaptive Cuckoo Filter (SACF) within a hierarchical routing overlay that dynamically directs Interest packets to the closest content replica. SACF, in contrast to Bloom filters, facilitates deletion, thereby effectively managing dynamic or removed content. Furthermore, it exhibits a lower rate of false positives, which minimizes misdirected traffic. To reduce false positives, an error-correction feedback mechanism is implemented, ensuring synchronization of cuckoo filter states among nodes. Simulation results demonstrate that the proposed scheme reduces false-positive-induced overhead by approximately 50% in comparison to conventional Bloom filter-based systems. Moreover, their architecture effectively handles content location dynamics, facilitating efficient and latency-aware name routing. This study enhances existing ICN initiatives by illustrating that the integration of Cuckoo filters with hierarchical routing and feedback loops significantly improves scalability, correctness, and adaptability. This is particularly pertinent for content mobility and system maintenance, thereby rendering it highly applicable to forthcoming NDN implementations that require dynamic name resolution and path-aware forwarding. In Kim & Ko (2025), the authors introduce a novel distance-encoded Bloom filter designed to enhance FIB name lookup efficiency in NDN routers by incorporating shortest (sd) and longest (ld) descendant distances directly into the Bloom filter framework. Their approach differs from traditional Bloom-filter-aided binary search, which often requires multiple on-chip and expensive off-chip memory accesses. Instead, it utilizes encoded distances to promptly narrow the search range for the longest matching prefix, thereby minimizing both Bloom filter and hash-table lookups. By retaining only actual prefix nodes in the hash table and determining if a queried node is a prefix (sd = 0), the method eliminates redundant off-chip queries. Their experiments, involving large-scale URL-derived FIBs (2.9 million prefixes, expanded to 5.2 million nodes) with 10 million lookup queries, indicate a reduction of up to 44% in Bloom filter accesses, lower false-positive rates, and a significant decrease in hash table lookup failures compared to previous schemes. This design facilitates more efficient and memory-conscious name lookup, which is particularly important for high-speed or resource-constrained NDN routers, thereby representing a significant improvement in forwarding-plane performance. In Shah et al. (2022), the authors present a systematic review of hierarchical naming strategies in NDN, with a focus on their application in IoT environments. The authors classify hierarchical naming schemes according to their structural patterns, naming components, and relevance in resource-constrained environments. The article highlights the advantages of hierarchical naming in facilitating name aggregation, scalability, and semantic clarity, which are particularly advantageous in IoT environments where topology-aware and domain-based structuring is essential. The article identifies security vulnerabilities in hierarchical naming, including prefix hijacking and naming-based DoS attacks, and discusses potential countermeasures. This study enhances the comprehension of structural trade-offs in NDN naming. It highlights critical avenues for secure name design in IoT-focused NDN systems, thereby augmenting our examination of naming strategies in wireless and mobile NDN contexts. In Ma, You & Deng (2024), the authors introduce DINNRS, a distributed in-network name resolution system intended to facilitate flat-naming architectures within content-centric networks. Conventional IP-based systems depend on hierarchical and location-specific identifiers, which are insufficient for modern networking paradigms that prioritize content retrieval based on names instead of locations. DINNRS mitigates this limitation by integrating name resolution capabilities within the network, distributing the resolution functionality across multiple nodes instead of depending on a centralized infrastructure. This in-network design enables routers to dynamically convert flat names into routable identifiers, thereby improving the system’s scalability and responsiveness. The authors implement and evaluate DINNRS via simulation, demonstrating its capacity to reduce name resolution latency and minimize overhead in comparison to traditional centralized methods. The system facilitates dynamic updates to name mappings and demonstrates resilience to node failures. DINNRS signifies progress in enabling efficient and scalable communication within networks founded on content-centric and flat-naming principles, especially in contexts where decentralization and adaptability are essential. In Arsalan et al. (2023), the authors introduce an accumulative interest-based content-store architecture called Efficient Data Retrieval and Forwarding (E-DRAFT), which is specifically tailored for NDN-enabled WMSNs. This scheme seeks to improve efficiency at both the node and network levels while minimizing packet flooding. The ndnSIM simulator was employed to implement E-DRAFT, demonstrating superior performance relative to existing methods through content storage and retrieval management, optimization of processing overhead, and reduction of redundant transmissions in multimedia-rich sensor environments. In Ni & Lim (2015), the authors present the creation and implementation of a functional NDN testbed intended for interoperability with the global NDN infrastructure. The NDN paradigm improves data retrieval by utilizing intermediate cache nodes, leading to enhanced efficiency and resilience. This article outlines the creation of a domestic Named Data Networking (NDN) testbed in Korea, describing its physical and software architecture, which includes eleven nodes designed for climate modeling data applications. This comprises routers, consumers, and a producer node interconnected through high-speed links. The authors executed important elements of NDN, including the NDN Forwarding Daemon (NFD), the ndn-cxx library, and the Name-based Link State Routing (NLSR) protocol. The configuration process is clarified, emphasizing hierarchical key signing for secure integration with the global NDN network, where Router 3 was incorporated into an extensive testbed across multiple countries.
NDN mechanisms
NDN naming schemes
This section addresses RQ1: How do naming schemes (hierarchical, flat, hybrid, and attribute-based) perform in wired and wireless NDN environments? What are their comparative strengths, limitations, and design implications in terms of scalability, aggregation, readability, and routing efficiency across different deployment domains?
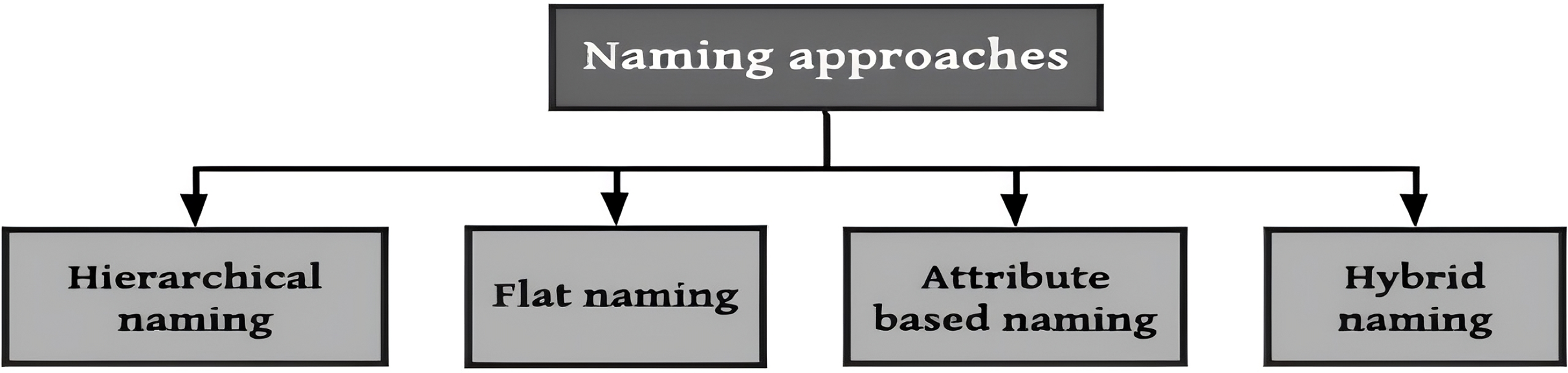
NDN packets are recognized through a globally unique and hierarchical name. Packet names are dependent on system applications and obscure to the network (Dai et al., 2015). System applications can execute a naming scheme constructed according to their constraints and are self-determining within the network. Names in NDN are hierarchies, which consist of chunks disconnected via dots (‘.’) and slashes (‘/’). The structure of hierarchies enables the requested name to be integrated and optimistically influence the scalability and rapidity of the lookup function in the nodes of NDN. An instance of an NDN name includes five parts, /cnn.com/news/snowstrom.avi/V7/s0, where cnn.com/news is the name of the domain and snowstorm.avi/V7/s0 is the content’s name directory path. The classification scheme for naming approaches is shown in Fig. 5.
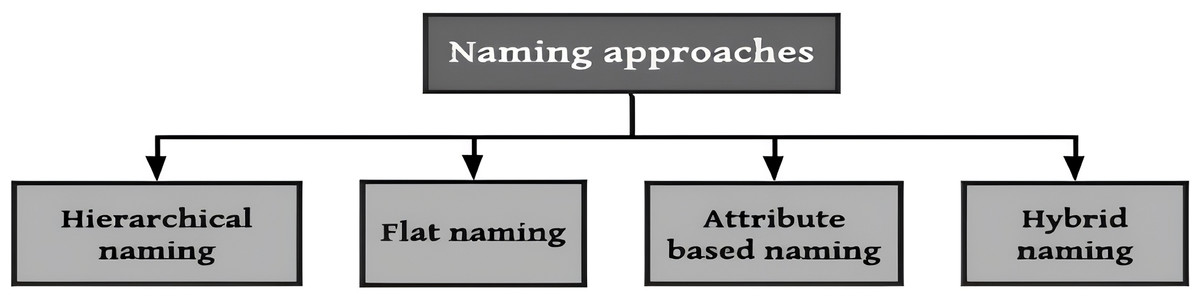
Figure 5: Classification of NDN naming approaches.
{kind=link}
To provide critical information, we divide naming and packet lookup strategies into wired and wireless domains. These two categories differ significantly in terms of performance requirements, architectural stability, and resource constraints. Wired NDN benefits from stable infrastructure and higher processing capacity, while wireless environments demand lightweight and mobility-resilient designs. This separation allows us to analyze domain-specific approaches more effectively.
Naming approaches in wired NDN environments
This section begins by discussing naming schemes deployed in wired NDN environments. These mechanisms are foundational to name resolution and forwarding behavior in fixed infrastructure networks, where factors like scalability, memory usage, and hierarchical aggregation are central concerns.
-
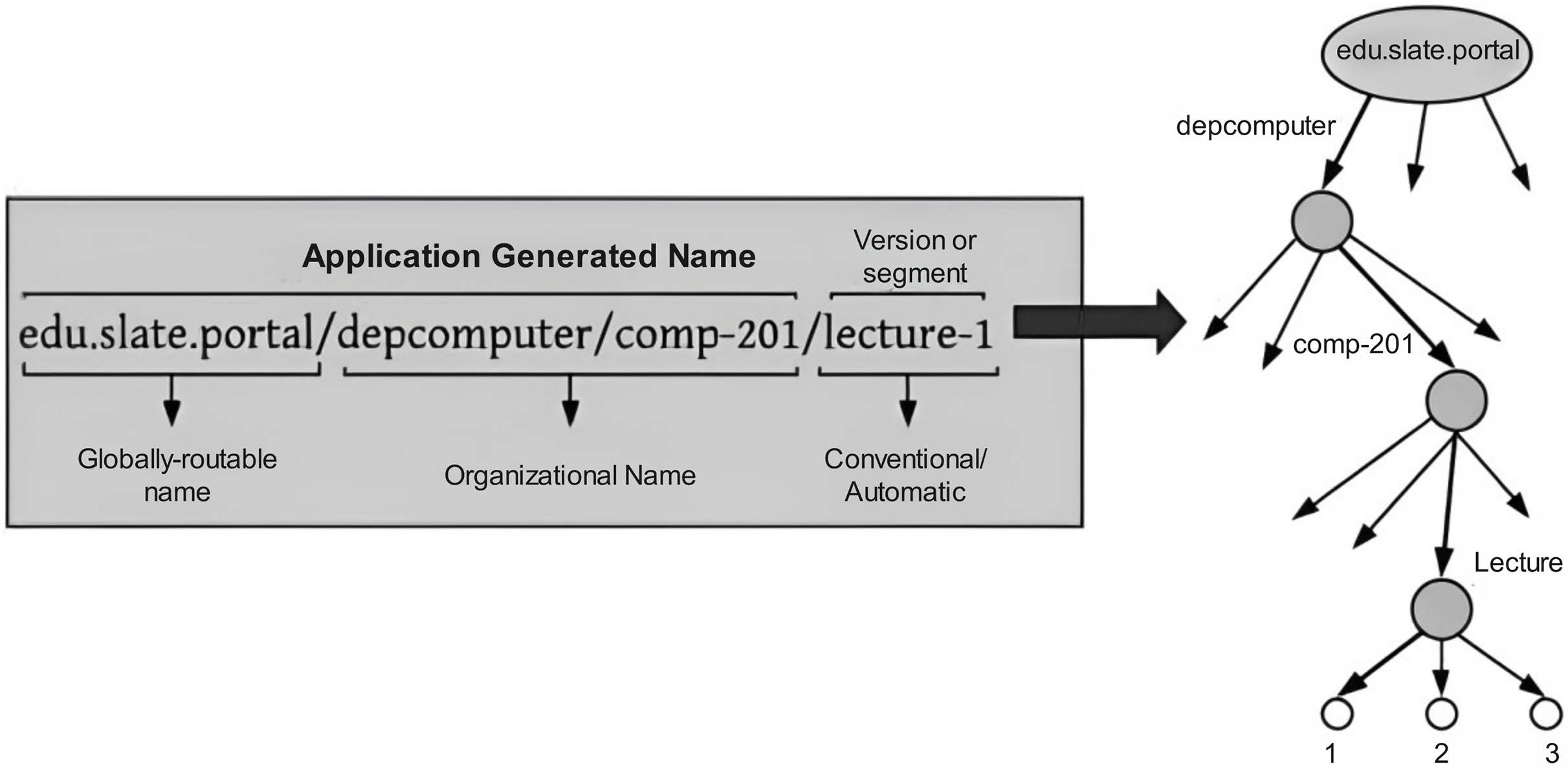
Hierarchical naming approaches: Hierarchical names are human-readable and give the benefits of aggregation by reducing the table sizes of NDN routers. CCN and NDN approach work on hierarchical naming. The structure of hierarchies is obeyed as the name of the requested content is specified via the URLs on the web documents. Hierarchical names also provide good semantics; for example, a customer can demand the initial content packet of the last kind by stating /filename/maxver/minseg, where maxver and minseg are pointers to the router indicating how to forward the packet. It consists of a sequence of flexible-length name components delimited by (‘.’) or (‘/’), where every single component signifies the features of the content (Quan et al., 2016). In a customer/provider system, users can also specify the granularity of the technique or method by using hierarchical names. Figure 6 represents a requested content name utilized by the Institute of Education and its structure of hierarchies (Bouk, Ahmed & Kim, 2014). For example, an undergraduate student needs to get material on computer networks from the computer science department of Fast University. Therefore, an application can generate an Interest packet comprised of subsequent keywords, such as “/edu/slate/portal/depcomputer/comp-201/lecture-1.”
Flat and self-certifying naming approaches: Flat naming methods are used by NetInf and DONA in the structural design of ICN. The flat name of content is typically generated by getting the hash value of the content itself or its attribute. These names can be human-readable or not, and have fixed or variable length. It isn’t easy to aggregate flat names as IP addresses. The lookup of flat names is more efficient than hierarchical naming. A simple hash table or Bloom filter can determine the next hop for a content request. Flat names are simple and easy to process in a router because they require fewer computing resources and less cache space (Hong, Chun & Jung, 2015). While flat names are structurally non-hierarchical and often fixed-length, self-certifying names focus on embedding cryptographic information to verify the data source. Though they may co-exist (e.g., hash-based flat names), they are conceptually distinct.
Attribute-based naming approaches: This technique extracts the content’s attributes (location, date, time, video duration, etc.). The global individuality of content is not confirmed in attribute-based naming, as multiple replies quickly contradict a particular query. Furthermore, it provides searching using well-known and simple keywords for the content. It is accessible through the use of ontologies to achieve content in a specified environment. It gives better privacy, easy namespace management, and reduces the computational cost of accessibility. Attributes are saved using keywords or a hash to provide additional security. Furthermore, it is difficult to fetch names with attribute-based naming (Li et al., 2018).
Hybrid naming approaches: Hybrid naming methods combine any two or three naming schemes. The intention of merging the above-defined methods is to consume their finest features. The advantages of these naming methods are multifaceted, including enhanced scalability, improved compatibility, better security, and simplified name management (Quan et al., 2016; Bouk, Ahmed & Kim, 2014).
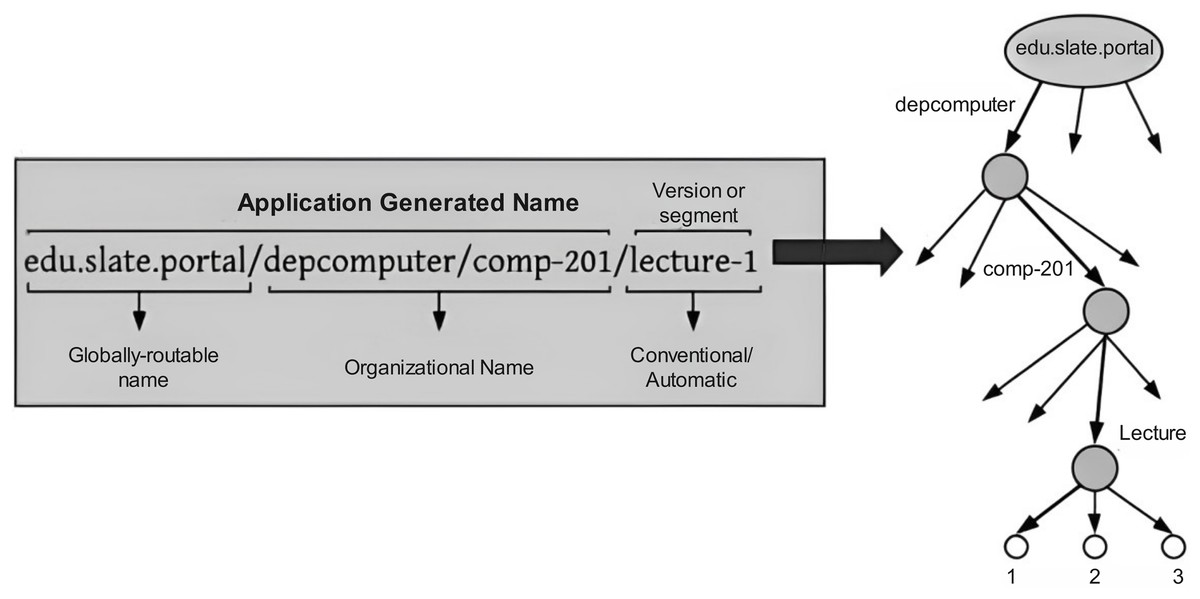
Figure 6: Human readable content name and its hierarchical representation.
{kind=link}
Naming approaches in wireless NDN environments
Naming in wireless NDN environments must accommodate mobility, intermittent connectivity, and energy-constrained devices. This section presents naming models customized to these environments, analyzing adaptations of hierarchical, flat, and hybrid approaches under wireless-specific constraints.
-
Hierarchical naming approaches: NDN enables services to be assigned in a flexible and distributed manner, particularly in heterogeneous WSNs. Additionally, the challenge of creating a hierarchical structure for the requested content name remains unresolved. For example, there is no arrangement of services in WSN. While TCP/IP networks support IPv6 auto-configuration and DHCP, no corresponding technique is available for CCN. Wang et al. (2012a) presented and established a solution to the naming problem for wireless topologies. The naming scheme or solution distributes the names of services into multiple fragments allocated at different stages of the deployment cycle. Naming services operating at the gateway among the wireless topologies display the configuration scheme for service names throughout the runtime. A service alias naming scheme is also proposed to map long names to short names requested in WSN, thereby displaying the benefits and flexibility of the method. Due to the massive growth in data content and devices in smart cities or IoT, the suggested NDN representation causes problems due to security, mobility, network management, and scalability. Several solutions have been proposed to address the limitations of IoT due to TCP/IP. With these methods, NDN is a highly suitable candidate for IoT networks. NDN maintains pull-based traffic, where content is backed simply by customers’ demands. Through specific use cases in IoT, push-based traffic is required whenever providers broadcast data based on the state or condition, without any explicit requests from the customer. A name-based broadcast manipulation method is proposed in Ullah, Rehman & Kim (2019) for IoT systems, particularly in vehicular and innovative building applications. For requested content, it features a robust design intended for devices, minor adjustments to the content, and an unwanted content strategy to optimize the working flow of the packet. Data packets are controlled in a specific area where they are designed, as opposed to broadcasting the packet to all nodes in the network. It’s not just about saving resources, although profound or essential content may be directed to a particular customer at a suitable time. The suggested scheme organizes the amount of pointless requested content in the system using this robust technique. Results show that the proposed scheme performs better in terms of the number of Data packets and the average speeds of vehicular vehicles. Hierarchies and a self-certifying, constructed naming approach through a practical organization approach are proposed in Bouk, Ahmed & Kim (2015) for vehicular systems, known as the CT. It enables the most effective utilization of characteristics suggested by the hierarchies and self-certifying approaches. Hierarchies involve information about their types, attributes, subtypes, and content providers that provide shared content among different vehicles. For the unique detection of content, the hash value is utilized in vehicular applications. It fulfills two main objectives: initially, it reduces the size of the node table by compressing the content names and eliminating duplicate entries. Secondly, it involves temporal and spatial information and their varieties to discover and solve the content. This consists of managing prefixes in the FIB and PIT tables. It is comparatively simple, faster, and space-efficient, and has improved execution compared to existing naming solutions. Results demonstrate that the suggested scheme achieves faster prefix search and delete procedures than simple Trie and Bloom filter-based approaches. The arrival of IoT presents a massive opportunity for the rapid growth of novel applications and services that link the simulated world to the physical world. Due to the rapid development and diversity of related data, it’s challenging for customers to access services that can be integrated. A practical content discovery approach for naming characteristics that produce high-level abstraction entrance to IoT devices is proposed in Labbi & Benabdellah (2019). It provides location distinctiveness, allowing for precise and rapid retrieval of content. Naming characteristics can provide proper services and data to the right users and authenticate users. The initial step is to launch a group to develop information on the network’s demands. Appropriate service selection is taken out based on content naming. The last is to deliver the services as explained to the authenticated user. Figure 7 shows the combined effect of hybrid composition and Trie-based aggregation, while simpler pure-hierarchical or flat schemes are omitted for simplicity. It is designed for NDN-IoT, providing a variable, costly, and secure approach that facilitates data retrieval and configuration instructions across multiple connections in an IoT system. This article (Rehman, Ullah & Kim, 2019) suggests a diverse range of use cases based on the performance of the proposed structure in various instances. The grouping of data and instruction conversation considerably enhances the fulfillment rate of both Interest and Command packets. Results demonstrate that the suggested structure will reduce the system’s communication. LAT is used to transform lengthy content names into concise, localized names to facilitate clear communication. However, maintaining the scalability property is beneficial for global usage, resulting in a 30% decrease in bandwidth and 40% storage savings. Its effectiveness is proven by model evaluation analysis. The sink node is considered a translator node that operates on the lengthy data prefixes and the shortcode prefixes (Yang & Song, 2018). Instead of losing granularity, it simply calculates the hash and f-prefix issued by a sensor. An approach is proposed in Hermans, Ngai & Gunningberg (2011), in which indirect points nearby map all requests for persistent data names to demand providential location names. That exposes the current network’s dedicated points. The scheme does not need assistance for intermediate nodes or routers and maintains multi-hop, soft handovers, and networks of mobile sources. The essential route section problem is alleviated by assisting cached data from the indirection points. Initial results demonstrate that it reduces recovery time and load on source nodes in the case of multiple requests compared to a scheme that uses an allocated naming database to locate mobile sources.
In Rehman et al. (2021), the authors present a unique naming methodology crucial in cluster-based WSNs. The naming scheme hierarchically divides node roles, assigning distinct statuses to the resource-full cluster heads and resource-starving child nodes. The elements that make up names include node IDs, physical location, data type, and timestamp, allowing for quick data dissemination and retrieval. The presented architecture enables node movement, cluster synchronization, and resource utilization. These results demonstrate the effectiveness of simulations, where energy savings range from 71% to 90% and data access time varies from 74% to 96% better than the current actual life implementation of the NDN framework.
-
Hybrid naming approaches: A sophisticated NDN-constructed naming scheme for IoT smart cities is proposed in Arshad et al. (2017). Furthermore, they classified IoT applications. It functions in three critical steps to allocate a name to all contents. As an initial step, it controls values about the campus content creators and the content itself. In another step, it denotes attributes of content, its popularity, freshness, and the type of tasks. The third module enhances the authentication and integrity of the content. The suggested algorithm is evaluated, resulting in an improved request satisfaction rate for the smart city. Furthermore, the goal is to give a simple and easy scheme for smaller content. A multi-component, multi-layer algorithm for the hierarchical characteristics constructed approach for wireless nodes is proposed in Nour et al. (2017) and is shown in Fig. 8. The flat naming approach is integrated to accomplish a consistent method that is accessible, routable, efficient, and protected throughout the design. A flexible interval encoding method and prefix classification signify the ordered location. It is customized and costly due to tree representation, where every level shows semantic functionality. The results demonstrate that it is inherently superior to numerous network architectures and can reduce memory and time requirements for routing and lookup purposes. LNS to change names among particular long-length names and representative short names for the support of an equally usable lightweight global and local transmission (Raza et al., 2024) are shown in Fig. 9. It identifies the possibility of name translation while maintaining data authentication in NDN packets. Figure 9 shows the LNS indirection workflow. This sole surveyed scheme transforms long global names into short local aliases without the need for additional signaling, thus serving as the representative example of compression. In Yang & Song (2017), the authors introduce a new concept of a combined naming system tailored to IoT scenarios, utilizing hierarchical naming with added semantic labels. The scheme incorporates NLP methods, including normalization, stemming, and stop-word elimination in content names, to achieve an optimal name length. Semantic tags are created based on the context of name meanings, enabling quick, semantic-tag-aware forwarding and retrieval. The study also clearly shows that having semantic awareness in a design working in conjunction with a hierarchy provides solutions to issues such as name length, memory consumption, and expensive lookup time. Performance analysis indicates that the proposed approach helps reduce the overall content update time, energy cost, and number of detected data in wired NDN networks. Therefore, this work highlights how NDN-based IoT systems can benefit from using a hybrid naming scheme that combines an efficient hierarchical approach with context awareness.
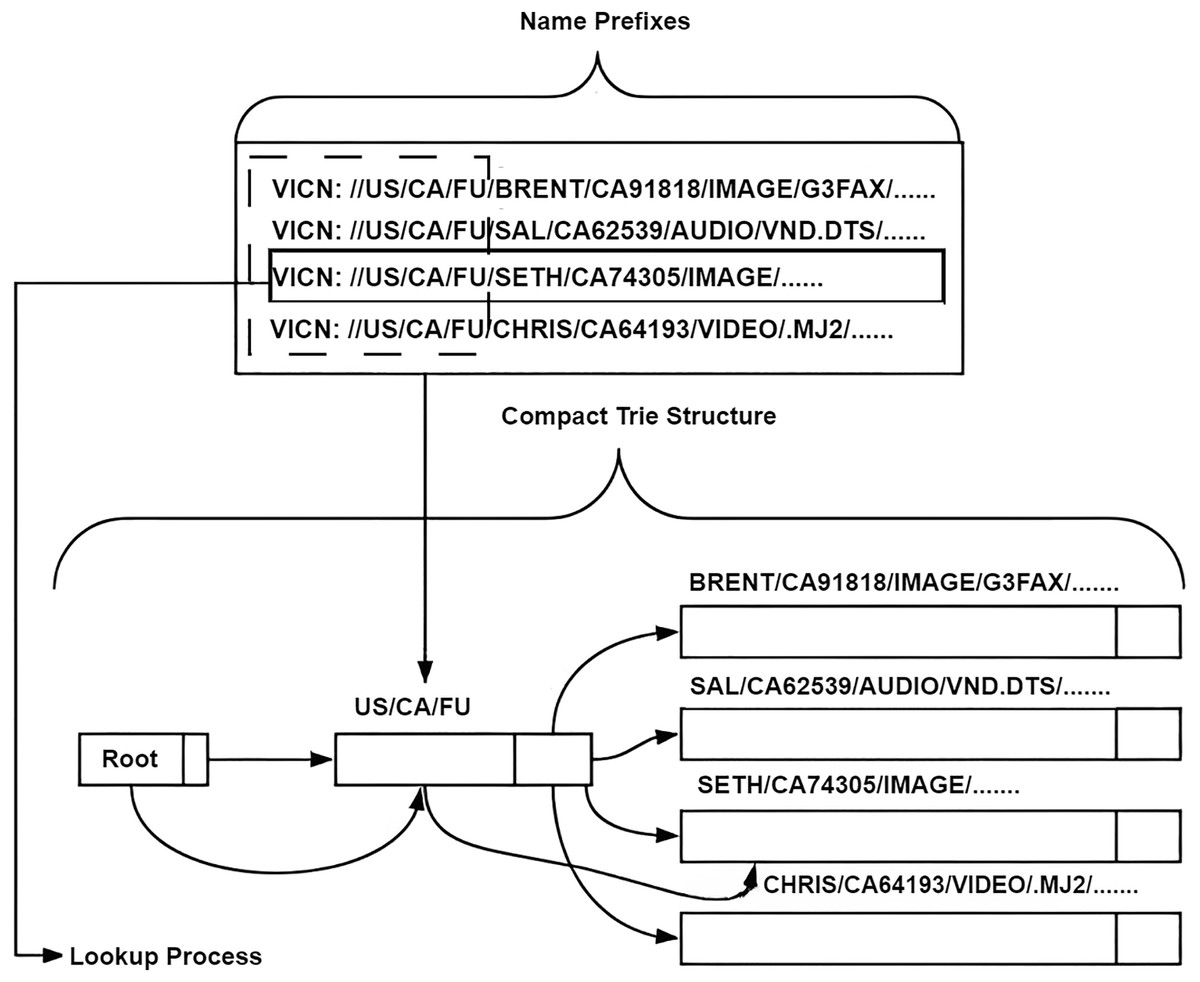
Figure 7: Compact-Trie representation of a hybrid hierarchical-hash naming scheme (Bouk, Ahmed & Kim, 2015), demonstrating attribute insertion, hash suffix, and prefix compaction.
{kind=link}
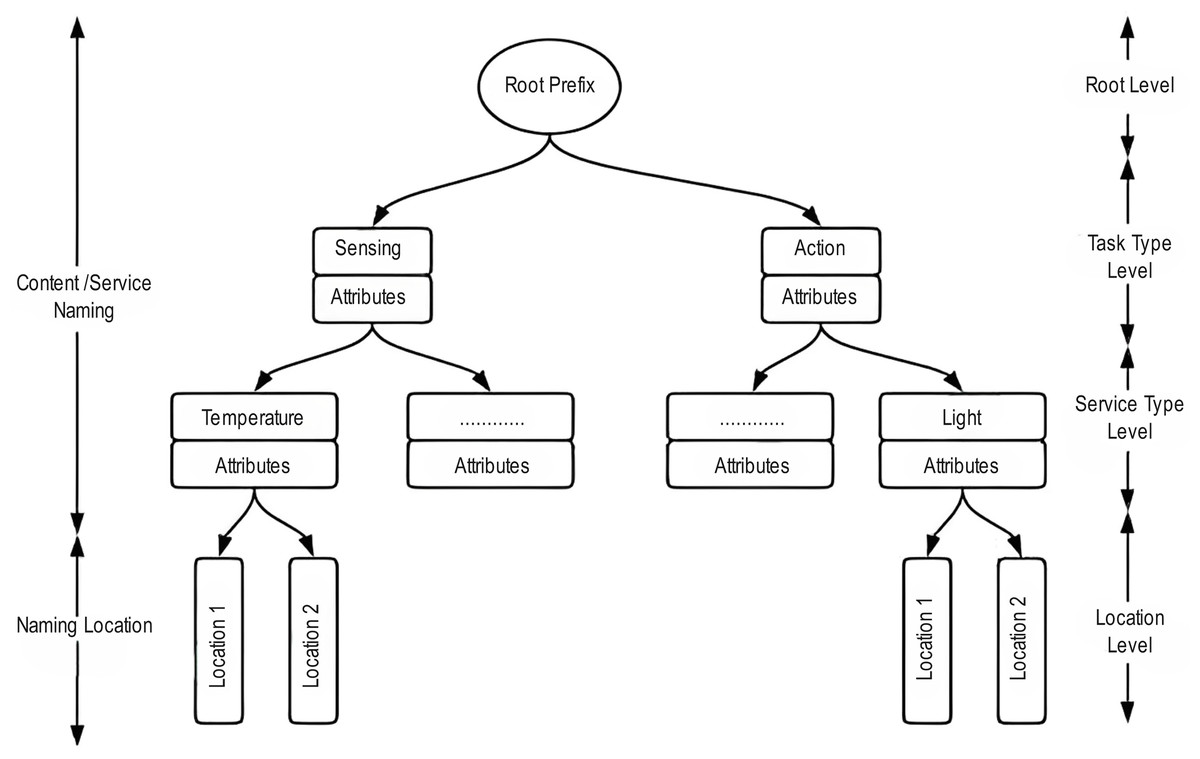
Figure 8: Multi-layer naming design.
{kind=link}
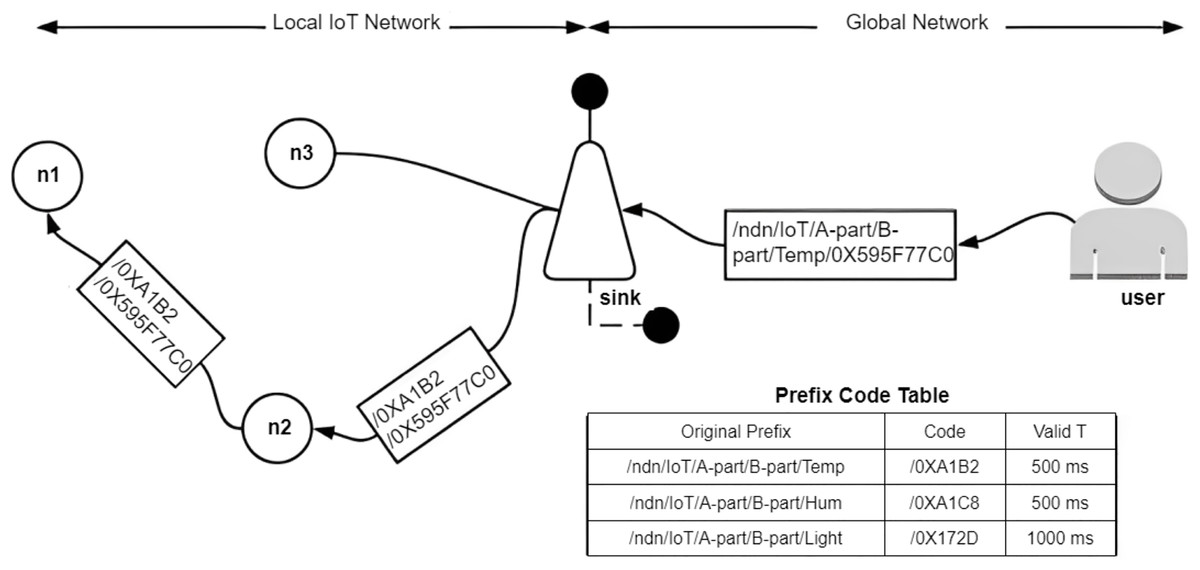
Figure 9: LNS for IoT sensors (Raza et al., 2024).
This is a name-to-alias translation that maintains data authentication while reducing FIB entries, serving as the standard example of the “Scalability” attribute in Table 3.{kind=link}
Naming approaches in wireless NDN are comprehensively elaborated in Table 2. Table 3 summarizes that all ten articles maintain a hierarchical prefix, while only three provide an explicit hybrid composition that integrates hierarchical and self-certifying elements. The initial three columns of Table 3 represent the fundamental connection of each scheme, whereas the final three emphasize the functional capabilities that directly come from those structures. The query field shows the potential of expressive hierarchies to eliminate the need for distinct application-layer protocols. Mobility-friendly indirection demonstrates the function of persistent hierarchical supports, or hash handles, in preventing re-registration when producers change their connection points. In conclusion, prefix-aggregation and various scalability mechanisms demonstrate how Trie compaction, local aliasing, and Bloom filters mitigate the FIB/PIT explosion that typically arises with IoT-scale namespaces. These attributes collectively evaluate whether a proposal simply changes the nomenclature or also provides new operational advantages for wireless NDN deployments.
| Category | Ref | Naming approach | Year | Contribution | Parameters | Limitations |
|---|---|---|---|---|---|---|
| IoT | Bouk, Ahmed & Kim (2015) | Compact Trie-based hashing naming Scheme | 2015 | It best uses characteristics of the hierarchical and hash function offers. | N/A | It does not implement forwarding strategies and delays in VCCN applications. |
| Labbi & Benabdellah (2019) | Context-aware service discovery | 2019 | It delivers a location-based binding wherever content can be retrieved precisely and accurately. | N/A | It does not consider real use cases, such as vehicular and smart cities, to evaluate the performance of service discovery. | |
| Rehman, Ullah & Kim (2019) | NINQ | 2019 | It delivers an expensive, flexible, and secure method that supports content retrieval, control, and command transfer within nodes in smart cities. | Interest Satisfaction rate, Command satisfaction rate | Effective caching are not considered in the suggested scheme. | |
| Yang & Song (2018) | Local name translation (LAT) | 2018 | It translates long-length names into short names while keeping the benefits of scalable naming in global utilisation. | Bandwidth reduction and storage saving | N/A | |
| Arshad et al. (2017) | NDN-based Hybrid Naming Scheme | 2017 | It functions in three important steps to allocate a name to any content. The proposal is to provide a simple and easy mechanism for smaller content. | N/A | N/A | |
| Li et al. (2014c) | Hybrid Naming Scheme | 2023 | Proposes a hierarchical naming approach enhanced with semantic tags for intelligent forwarding and data retrieval. Uses Natural Language Processing (NLP) techniques to optimize name length and retrieval precision. | Interest satisfaction rate, energy consumption, and retrieval time | Focuses on IoT use cases but does not explicitly address mobility or dynamic reconfiguration scenarios. | |
| Yang & Song (2017) | Local Naming Service (LNS) | 2017 | To support global and lightweight communication, it transforms particular long names into short names. | Data Authentication and Security | It does not handle mobility. | |
| Wireless sensor networks | Ullah, Rehman & Kim (2019) | Hierarchical name-based push-data broadcast | 2019 | It considers two scenarios: smart buildings and vehicular networks. Regarding the total number of packets, it outperforms other algorithms. | Vehicle speed, Average delay, Total energy consumption, Number of Data packets, | It does not consider applying the approach in vehicular network-enabled edge cloud computing. |
| Rehman et al. (2021) | Hierarchical Naming Approach | 2020 | Introduces a hierarchical naming approach for cluster-based Wireless Sensor Networks (WSNs). Supports node mobility, synchronization, and resource optimization. Reduces energy consumption and retrieval delays compared to existing NDN frameworks. | Interest satisfaction rate, energy consumption, and data retrieval delay | Primarily focuses on cluster-based networks and may not generalize well to other WSN architectures. | |
| Nour et al. (2017) | Multi-Layer multi-component Hierarchical attribute value | 2017 | It uses a variable-length encoded mechanism to display hierarchical location names with prefix classification. | Time and memory | N/A |
| Ref | Core structural flags | Other attributes | ||||
|---|---|---|---|---|---|---|
| Hier. | Flat/SC | Hybrid | Query | Mobility | Scalability | |
| Ullah, Rehman & Kim (2019) | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Bouk, Ahmed & Kim (2015) | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| Labbi & Benabdellah (2019) | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ |
| Rehman, Ullah & Kim (2019) | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ |
| Yang & Song (2018) | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Rehman et al. (2021) | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Arshad et al. (2017) | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| Nour et al. (2017) | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| Raza et al. (2024) | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Yang & Song (2017) | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ |
Naming challenges
The naming model of NDN is conceptually sound; however, practical implementations face several unresolved challenges. These challenges are given below.
Scalability: An essential factor is the scalability of names. The growing expressiveness and contextual depth of content naming, especially in IoT and multimedia streaming, may result in considerable expansion in the length and complexity of hierarchical names. This phenomenon may result in memory overflow and inefficient table lookups in the FIB and PIT. Addressing growth while maintaining performance continues to be a significant challenge.
Name ambiguity: In contrast to traditional networks, NDN does not have universal naming conventions, resulting in potential semantic overlap or redundancy (e.g., /weather/today and /today/weather may refer to the same data). This leads to inefficient cache utilization, lookup errors, and routing loops. Ensuring name clarification in decentralized and dynamic environments presents significant challenges.
Security: Malicious nodes may utilize naming flexibility to execute prefix hijacking, cache pollution, or name flooding attacks. Furthermore, the verification of authenticity and ownership of names, while avoiding significant cryptographic overhead, remains an unresolved challenge.
Routing-table update: This challenge occurs in highly dynamic networks, including mobile IoT and vehicular systems, where name-to-route bindings require frequent refreshing. Efficient name aggregation, dynamic prefix advertisement, and proactive cache updates are essential yet remain insufficiently investigated.
Comparative evaluation of naming schemes
To provide a consolidated view of the relative strengths and limitations of different naming schemes, Table 4 presents a qualitative comparison across four key metrics: scalability, aggregation support, readability, and routing efficiency. These metrics were selected based on their relevance to both wired and wireless NDN deployment contexts as discussed in previous subsections.
| Naming scheme | Scalability | Aggregation | Readability | Routing efficiency |
|---|---|---|---|---|
| Hierarchical | High | High | High | Medium |
| Flat | Medium | Low | Low | High |
| Hybrid | High | Medium | Medium | High |
| Attribute-Based | Low | Low | High | Low |
Packet lookup schemes
This section addresses RQ2: How do name-based packet lookup schemes in FIB, PIT, and CS perform across different NDN domains, and what are the trade-offs in latency, memory, and hardware efficiency?
In NDN, the forwarding of Interest and Data packets relies heavily on efficient packet lookup operations across three primary data structures: the CS, PIT, and FIB. Specifically, CS and PIT rely on an exact matching technique, while FIB uses LPM. This combination introduces a lookup chain that can affect processing latency, memory usage, and forwarding speed. When an Interest packet arrives at a router, the lookup process begins with the CS. If no match is found, the PIT is consulted. If the PIT also lacks a matching entry, a FIB lookup is performed using LPM to determine the next-hop router. Conversely, when a Data packet returns, the router performs a PIT lookup to find the corresponding Interest, then stores the content in the CS using exact matching. This process yields a layered lookup dependency that must be efficiently managed to ensure real-time performance.
To structure our analysis, we categorize packet lookup schemes both in the wired and wireless domains based on the router components, which contain the following approaches.
FIB-based Approaches: Techniques optimized for prefix-based Interest forwarding using Trie, hash, or Bloom filter structures.
PIT-based Approaches: Mechanisms designed to improve Interest aggregation, state tracking, and memory efficiency.
Full Router Approaches: Unified strategies that holistically enhance lookup across CS, PIT, and FIB together.
Figure 10 shows the taxonomy of the surveyed packet lookup approaches. Additionally, we include CCN-based studies, as NDN evolved from CCN and shares its core forwarding principles. While prior studies often treat CS and PIT separately, our survey acknowledges their architectural and functional overlaps, particularly regarding exact matching-based lookup behavior. The reviewed literature spans the period from 2010 to 2019 and encompasses both classical and emerging approaches, with a particular focus on structural design, lookup latency, update cost, and hardware feasibility.
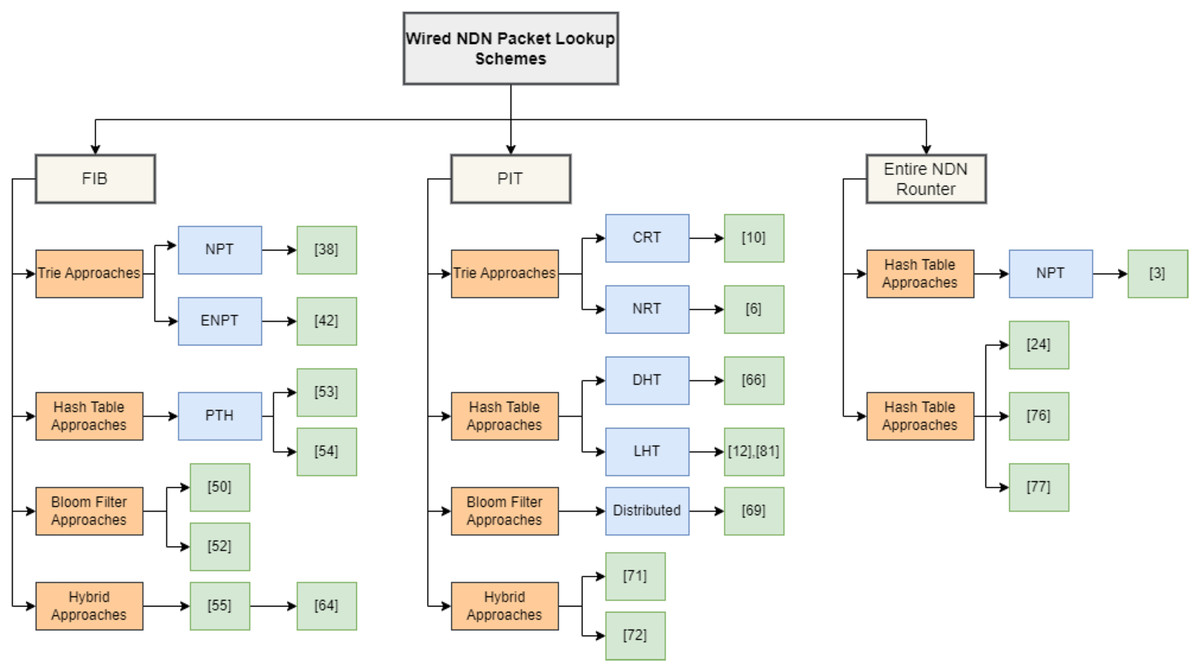
Figure 10: Classification of packet lookup schemes in wired NDN.
{kind=link}
Packet lookup in wired NDN environments
This section classifies wired NDN packet lookup approaches according to structural design. We categorize lookup techniques based on their architectural foundation and practical deployment relevance.
FIB-based approaches
The FIB data structure contains content names and their associated port numbers. In NDN, FIB lookup is performed using Longest Prefix Matching (LPM). For example, if a packet with the content name /cnn.com/news/snowstorm.avi/v7/s0 matches the second or third entry in the FIB, the content is forwarded through the corresponding interfaces. The comparative analysis of FIB-based packet lookup approaches in wired NDN is shown in Table 5 and in Table 6. This section discusses the various approaches used for content lookup within the FIB.
-
Trie-Based Approaches: Parallel name lookup (PNL) is a FIB-based first name lookup approach proposed to handle forwarding in NDN (Wang et al., 2011). PNL names can be represented by the name prefix tier (NPT) or by the module granularity, rather than the bit granularity. It’s an allocation algorithm that assigns logically tree-based names to physical components with measured and less storage redundancy. As the update occurs more frequently, the approach is planned to be executed with low complexity. Whenever FIB collects data elements, it examines whether the first element corresponds to the root edge. If so, the transfer condition becomes true and is transmitted from the root to the node at the pointed level. This process is repeated iteratively. It stops when the transfer condition is false and the state reaches its leaf node. Then, the process terminates, returning the last port. In specific memories, the name of the content is matched when multiple inputs arrive concurrently. They store all memories and work simultaneously to achieve high-speed lookup. Although various nodes may be replicated during the allocation phase, this results in a burst of memory usage, which is directly proportional to the number of nodes. Name component encoding, using 32-bit to encode the names of components, is proposed in Wang et al. (2012b). It reduces the number of component codes and the length of the component code without compromising accuracy. It separates the encoding process from the LPM, making it possible to use parallel processing techniques to speed up name lookup. To execute this technique, two approaches are proposed: a code assignment approach to reduce the memory size for name components and to speed up the LPM, and an enhanced state transition array (STA). Once the name is encoded, the code is allocated to matching edges in the NPT, which yields a new Trie named the encoded name prefix Trie (ENPT), as shown in Fig. 11. Experimental results show a 30% increase in memory and achieve 1.3 million lookups per second. The first wire-speed mechanism based upon a hardware accelerator is proposed in Wang et al. (2013c) that utilized the vast dealing ability of the GPU. The multi-stream mechanism of the GPU-based structure is used to mitigate the lookup latency resulting from the GPU’s massive computational power. GPU-based schema operates as follows: Initially, the table of contents names are organized in a tree of characters. Furthermore, the tier of characters is reformed into multi-aligned transition arrays (MATA) that unite the finer of the two worlds. Then, it is further transformed into a GPU-based name lookup approach. It receives the data requested name as input and implements the name lookup operation using MATA. Whenever the operation of lookup is considered, the outcome is conveyed from the GPU to the CPU to obtain the evidence of the subsequent hop boundary. Results demonstrate that it controls the 63.53 MLPS and attains greater than 30 K plus 600 K for each instant deletion and insertion. In the NDN, the field-programmable gate array (FPGA) method for content lookup is proposed (Li et al., 2014b). However, handling name lookups using an FPGA is a challenging task. A possible collision could occur between transitions of a single tree level. To distribute through the names of the class, the authors proposed an algorithm that was implemented using hierarchical aligned transition arrays (HATA). The modifications are kept in aligned transition arrays, while there is only one possible transition through employing numerous candidates and corresponding verification techniques. The verification phase is handled similarly, as the transition array is stored in diverse memory, allowing for additional plotting. The consequences indicate that the suggested approach utilizes approximately 95% of the GPU storage. Furthermore, it reduces latency to 3%, and its lookup performance is 2.4 times. HATA attains 125 MLPS on average. Figure 12 shows the generic Trie based implementation of FIB. The tokenized Patricia-constructed content lookup approach is suggested in Song et al. (2015) as an effective data structure for storing billions of names, as shown in Fig. 13. This approach combines routers containing only one node with their parents to decrease cost and memory burden. Consider an appropriate approach to support subsequent purposes. Initially, it employs a dual approach, utilizing NameTrie to compress the distributed portion into names. Second, any naming system handles the names as a bit string. Third, direct names are stored and used for lookup, eliminating the need for parsing. To improve the lookup, a speculative technique is also presented that transmits the packets using leaf prefix count (LPC) instead of LPM. If a match exists, LPC behaves similarly to LPM and sends the Data packet to the next router. If no correspondence exists, forward the packet to the next router rather than releasing it. To support forwarding, they employed a dual Patricia with LPC. Instead of storing the whole name of packets, it simply stores the dissimilarity between the components. Hence, the memory overhead is visibly reduced. Results are evaluated using an SRAM-based scheme that achieves 142 MLPS with an estimated 16M names; DRAM is more suitable for extensive content and achieves 20 MLPS. Content lookup rapidity is increased by decreasing the number of contrasts with the assistance of the port number in the node Trie. This concept presents the P-Trie approach in Dagang, Junmao & Zheng (2016). In this approach, nodes are categorized into three types: Accepted (which retains the final character of the names), Evolved (where every prefix has the same outgoing port, while no parent has dissimilar information), and Midway (which retains the previous packets). Whenever a packet arrives through any evolved packet, the node sends it instantly. On the other hand, if a mismatch occurs at some node, the packets are resumed due to the port information. It is executed in MATA to enhance memory efficiency. Results show that it is quicker than ATA and MATA and a ternary search by 15 times, respectively. A name-based forwarding approach called N-FIB is suggested in Saxena & Raychoudhury (2016a) and constructed upon Patricia Trie. It consists of two stages: FIB lookup and aggregation. The previous component gathers various entries into a single entry. Moreover, it provides the deletion and insertion procedure for NDN forwarding. The final component searches for LPM in an aggregated component or aggregated FIB. The difficulty of the FIB combination is O(N/K), where K means the depth of the Trie and N means the number of names. It is evaluated against the Bloom filter to show the memory and time efficiency budget. It reduces router computation and memory overhead, ensuring the correctness of forwarding. In Saxena et al. (2016a), a scalable and practical memory-based Radix Trie Component Encoding Approach (RaCE) is proposed. RadixTrie decreases memory overhead and provides reliability for the NDN router. First, the received component name and name prefix are divided into components. Afterward, unique tokens are created for every single component, where the same components share the same encoding. Results show that it consumes less memory than the original NCE for 29 million datasets. Name Trie-based data structures are proposed in Ghasemi et al. (2018) to index and keep forwarding table records. Nodes are kept compact, enhancing the packet speedup and cache efficiency for processing. Edges are executed using a hash table, enabling fast name updates and lookups. Within Nametrie, a new approach controls information without consuming extra memory for Trie granularity. Extensive experimental results demonstrate that it achieves fast updates while consuming a small portion of memory, resulting in 35% less memory usage and faster performance in name lookup and updates. This (Ghasemi et al., 2019) is the first article to address the influence of granularity and establishes a comprehensive association between the third Trie-constructed content lookup structure and updates (at the character, bit, and component levels). A new tool named NameGen generates a collection of large datasets with diverse characteristics of names. It’s essential to examine name structure from three different perspectives. Initially, it allows end-users to modify the characteristics of the name, which plays a crucial role in performance. Secondly, it eliminates the need to trust a small dataset. Lastly, it delivers the uniformity of the dataset for upcoming research. Results explicitly highlight the limitations and strengths of every single Trie-constructed approach and describe a supposition upon the selection of granularity.
-
Bloom-Filter Based Approaches: A Bloom filter remains a rapid and memory-efficient structure that indicates whether an element is present in a set. Using a bloom filter for FIB name lookup can help speed up the name lookup process. Inappropriately, it cannot be used directly. A name filter based on a two-stage bloom filter mechanism is proposed in Wang et al. (2013b). In the first phase, prefixes are mapped to a single memory control, and the interval between the names is verified. In the binary phase, content lookup is performed within a simple group of combined Bloom filters that are applied at the initial stage. The consequences demonstrate that it achieves a high throughput of 37 MLPS with a low storage cost, which is directly equivalent to 12 times faster than the character tier speed, and are illustrated in Fig. 14. A two-stage Bloom filter structure, executing the Level-Priority Trie (LPT), is proposed in Byun & Lim (2019). It consists of two operational Bloom filters, one for returning an identical or similar level and the other for returning an output face. The number of components encoded in the bloom filter is minimized by using an LPT. Hence, it is sufficiently small to be kept in on-chip memory. Its performance is significantly enhanced by only querying the bloom filter, without retrieving the off-chip hash table. The off-chip hash table is only retrieved for this case whenever indeterminable results are obtained at the second stage. Simulation results display that 99% of the input is obtained only by searching the on-chip bloom filter. An efficient technique that merges routing connectivity with a bloom filter is proposed in Mun & Lim (2019) to reduce memory and traffic requirements for creating FIB tables. The routing connectivity information is shared as a summary bloom filter (S-BF). Nodes gather the summary and create a forwarding bloom filter (F-BF). Interest packets are distributed by searching the F-BFs. An auxiliary FIB table is also proposed to mitigate the extra traffic generated by false positives. Simulation results show that it can attain optimal performance compared to link-state algorithms and substantially reduce the memory needed. It does not require any prior information about the system’s topology and operates entirely distributively. FIB-based approaches for wired NDN, such as Trie and Bloom filter-based approaches, are extensively elaborated in Table 7.
-
Hash Table Based Approaches: In FIB, LPM restricts the name lookup to a Hash table. To overcome these limitations, a greedy name lookup approach known as Hungry-SPHT remains, which is combined using a sequence of hash tables. The hungry approach enhances the tracking of content names in router tables. Moreover, a drawback of hash tables is that they are often implemented using string-oriented perfect hash tables (PHT) to speed up name lookup and reduce memory overhead. It retains only the value of the content name in the catalogue, rather than the content name itself. Motivated through the provision of name modules, the author enhances the lookup implementation by reordering the examination sequence of name prefixes constructed by allocating their components. It is compared with CCN-PHT and simple greedy-PHT to assess its performance. Experiments with 3-M or 10-M table entries illustrate that it achieves high-speed lookup as compared to others while occupying less memory as well (Wang et al., 2014). Longest name prefix matching (LNPM) (Yuan & Crowley, 2015) that unites a hash table with the dual examination of one billion entries. Encrypted tables are constructed for the prefixes of names using K components, corresponding to the number of components in the name. A binary search is performed for every node in the hash table of K components. If a prefix match is an exit, it transmits to the right subtree to check whether or not the other names are appropriate. If no match exists after that, it transmits to the leftward subtree for a lookup of whether a prefix exists or not. It ends when it reaches the leaf node or the bottom of the binary search tree. To reduce the number of memory accesses, the fingerprint-based hash table is used wherever the fingerprint is the hash value of keys in the name prefix table. Results show that 6MLPS can be achieved with one billion entries in a seven-component name table. Hash-based and hybrid methods are elaborated in Table 8 in terms of their approach, naming scheme, contributions, and limitations.
-
Hybrid Approaches: Multiple techniques are considered for executing FIB, which may involve merging more than one structure and employing other approaches, such as using a GPU. A packet corresponding to the name is sent at a similar interval to the subsequent router that runs towards the delay in DRAM storage. Influenced by this performance, a new scheme based on a non-aggregatable name prefix for FIB is suggested in Fukushima, Tagami & Hasegawa (2013). The prefix length is added to the packet forwarded to the next router to prevent the same prefix length from being looked for again. When an Interest packet reaches FIB, it is handled in the following phases: the leaf prefix count table (LPCT) filters prefixes based on their length and number. If no prefix exists, the Bloom filter prevents redundant probing that would occur with hash tables. A hash table is employed through one access to DRAM memory to search for prefix entries. If the match prefix entry is found and contains no child, then it is LPM. On the other hand, if the name is taken instead of prefixes and the LPM is looked up, then the next router and length of the name are returned. It is executed on both hardware and software-based FIBs. The hardware-based approach achieves 66 MLPS with under 50 million names, whereas the throughput of software-based approaches is high. The NCE approach is employed by utilizing the massive parallel computing power of GPUs (Wang et al., 2013a). Using code allocation and evolution selection, NCE consumes only a particular entrance memory among the transitions occurring among the NDN routers. Pipeline and multi-stream CUDA techniques are implemented in the GPU to improve name lookup performance and reduce delay. The FIB content index is organized using a module Trie and is encrypted into integers to arrange the module’s encryption. Afterward, it is remodeled using a single array dimension, for which the change among the nodes is accumulated through a particular memory access. A distinct code assignment technique exists to decrease the storage burden of ENCT. It reduces memory overhead and speeds up name lookup compared to NCE for a dataset of over 10 million. The adaptive content name constructed lookup filter is introduced in Quan et al. (2014). In this approach, every content name is categorized into B-prefix and T-suffixes. B-content refers to the Bloom filter and is restricted in the distance handled by counting the Bloom filter (CBF). B-prefix is utilized with a hash table to validate the location of resultant T-suffices. T-suffice length is smaller than its full name and is executed using the tree structure. Using the Trie, a similar procedure continues till the corresponding LPM is found. The lengths of both B-prefixes and T-suffixes can be organized through recognition to accelerate the lookup. For T-suffices, a similar procedure runs for multiple repeated storage accesses. Therefore, the size of the B prefix can be adjusted to conform to the acceptance of the prefix. It is directly proportional to length. If their exit is strongly popular, then the length would be higher, and so on. Compared to other approaches, it achieves a higher speed of lookup while, in terms of memory cost, it shows an average usage of resources. The content router-based name lookup approach, Caesar, is proposed in Perino et al. (2014). A unique prefix bloom filter (PBF) is merged to achieve optimistic wired speed with a hash table, which utilizes a GPU for the provision. Later, it employs the hash table lookup to retrieve information about the next hope and eliminate false positives. Experimental outcomes demonstrate that Caesar supports a line card of 95 MLPS, utilizing a packet size and index size of 10 million. In Tan & Zhu (2015), authors utilize the MATA data structure, which was introduced in Wang et al. (2013c). Initially, an encrypted operation is employed to signify the content of NDN using an integer string. Secondly, the split name character exploits this integer as a state transition array to construct a character Trie. Lastly, the character Trie employs a novel structure known as MATA-CH, which differs from the MATA in two ways: it’s more variable, as it’s neither extended nor restricted through progress. The amount of state decreases as each module is updated through single changes. Motivated by the divided model lookup, SNT is employed to improve the number of name lookups. The names are distributed to the slightly sub-levels. As other content names are reached, they are divided into dual segments to execute independent lookups. It reduces the memory cost by employing component hash and splitting them into Tries, which are shown in Fig. 15. A fast LPM framework using a hybrid Trie and hash array structure is proposed in Saxena et al. (2016a). It consists of two lookup strategies: a quick and a slow path. Previously, when the packet reaches the NDN router, a size decrease of the content name scheme is requested to change the content name to a human-comprehensible name. Afterward, the converted name is added and isolated as of FIB using a double-encrypted operation. Whenever the packet arrives at the router node, the same size reduction name scheme is not employed. In its place, a key production scheme is used through the content name to construct the group of formless solutions. Outcomes show that it can achieve high throughput on both CPU and GPU platforms. The hybrid construction of Patricia Trie and the hash table is proposed in Yuan, Crowley & Song (2017) to improve the name lookup speed using fingerprint-based methods. Based on hypothetical forwarding string matching, different issues are planned. There is no consistent name prefix exit in the router table. By reducing the Trie size, the Patricia Trie minimizes the delay for lookups by utilizing the Patricia Trie method. Considering the memory overhead issue, the fingerprint-based hash table only keeps fingerprint names. The proposed algorithm implementation demonstrates that the Patricia Trie-based approach reduces lookup latency while consuming only 3.2 GB of memory to store the names of 1 billion, as shown in Fig. 15. Content- and shape-based frameworks with static random access memory and ternary addressable memories are proposed in Huang & Wang (2018) to achieve low memory costs and high-speed lookups. Shrink the minor load scheme to group many name prefixes of shapes in a small content memory. The form of the content name is an arrangement of its constituent letters. To enhance the performance of content search, a two-model-based fingerprint scheme with a hash table is used in static RAM. Experiment results illustrate that it outperforms in attaining high throughput and low memory cost. To provision LPM in hash tables, random search is used to enhance lookup speed by updating the FIB and optimizing the search path. A composite structure for random search is proposed in Hu & Li (2019) by integrating the Trie and the encrypted table. It is presented to preserve the association between content names by avoiding backtracking and discarding memory, thus improving lookup efficiency. Results indicate that introducing a Trie structure restricts the influence of examining speed and memory utilization. The implementation of examinations is facilitated through the use of longer names in the packet and smaller terms in the FIB table. An effective name splitting mechanism named as split name into the basis and suffixes (SNBF) (Wu et al., 2019). In this approach, we decompose B-suffices into multiple components. Every component is kept in a counting bloom filter (CBF). The correlation verification method is also proposed to confirm the inherent relation of the components of all bases. On the other hand, suffixes are handled by Tree bitmaps. Simulation results demonstrate that it enhances the lookup rate and reduces the probability of false-positive results.
| Ref | Environment | Dataset/Setup | Metrics | Summary of results |
|---|---|---|---|---|
| Mun & Lim (2019) | Software-based NDN router | Synthetic NDN names/FIB rules | Lookup time, FPR, memory usage | Uses Bloom filter table for fast lookup with low memory and near-zero false positives. |
| Wang et al. (2014) | FIB emulator | Prefix-aware dynamic entries | Latency, memory, update rate | access time with dynamic hashing; reduces memory. |
| Yuan & Crowley (2015) | Emulated DPDK ICN router | 100 K–10 M prefixes | Throughput, memory, scalability | Uses cuckoo hashing with 60 Mpps and 85% memory use. |
| Fukushima, Tagami & Hasegawa (2013) | Prototype CCN forwarder | DRAM with hop-based LPM | Prefix latency, memory traffic | Avoids redundant LPM, improves DRAM access. |
| Wang et al. (2013a) | FPGA (Xilinx) | 10 K–1 M hierarchical prefixes | Latency, throughput, BRAM use | Lookup <200 ns; 200 Mpps with pipelined trie. |
| Quan et al. (2014) | NDN simulator | Variable-length names | FPR, memory, delay | Uses Bloom+trie to reduce memory/FPR vs. others. |
| Perino et al. (2014) | Line-card router sim | 1B+ prefixes, 400 cards | Fwd rate, memory, scale | Caesar supports 100 Gbps; filters speed up FIB matching. |
| Tan & Zhu (2015) | Component-hashing sim | Decomposed names | Memory, LPM support | Uses split tries; improves memory by 23–49%. |
| Yuan, Crowley & Song (2017) | SW+distributed sim | 1B names, 1 comp each | Memory, lookup | Uses Patricia Trie + hashing: 0.29 s lookup, 3.2 GB/1B names. |
| Hu & Li (2019) | LPM testbed sim | Hierarchical synthetic names | Speed, memory, update rate | Uses hash+trie for 30–60% LPM gain; adapts well. |
| Wu et al. (2019) | PIT sim | Interest packet sizes, flows | PIT size, delay, collisions | Simple PIT suffers in bursts; adaptive helps. |
| Ghasemi et al. (2019) | NDN router+trace | CCNx multi-consumer traffic | PIT occupancy, lifetimes | PIT usage varies by RTT and timeouts, not cache. |
| Ref | Environment | Dataset/Setup | Metrics | Summary of results |
|---|---|---|---|---|
| Varvello, Perino & Linguaglossa (2013) | Intel IXP testbed | 1M PIT entries, 10 Gbps traffic | PIT latency, throughput | Supports wire-speed PIT using multistage lookup; feasible 10 Gbps hardware PIT. |
| Yuan & Crowley (2014) | PIT software prototype | 100 Gbps link capacity sim | Memory, delivery success | Uses fingerprints and relaxed aggregation; PIT size 37–245 MiB at 100 Gbps. |
| Li et al. (2014c) | MaPIT simulation | 2M entries, Bloom filters | On-chip memory, FPR | Mapping Bloom Filter PIT: 2.097 MB storage with <1% FPR; SRAM-compliant. |
| You et al. (2012) | Distributed PIT sim | Multi-interface, high volume | Memory, FPR, throughput | DiPIT with local+central filters; saves 63% memory; faster than hash table PIT. |
| Li et al. (2012) | PIT perf. simulation | High concurrency name traffic | PIT size, compression | Bloom summary compresses PIT; scalable but prone to false positives. |
| Tsilopoulos, Xylomenos & Thomas (2014) | ISP topology sim | Unicast/multicast over d-hop | State size, bandwidth | Semi-stateless PIT: 54–70% state reduction (unicast), 6–13% overhead (multicast). |
| Carofiglio et al. (2015) | Emulation + analysis | ISP-scale NDN + delay trace | PIT size, memory, accuracy | Analytical + emulated PIT dynamics; proves PIT size is small even without caching. |
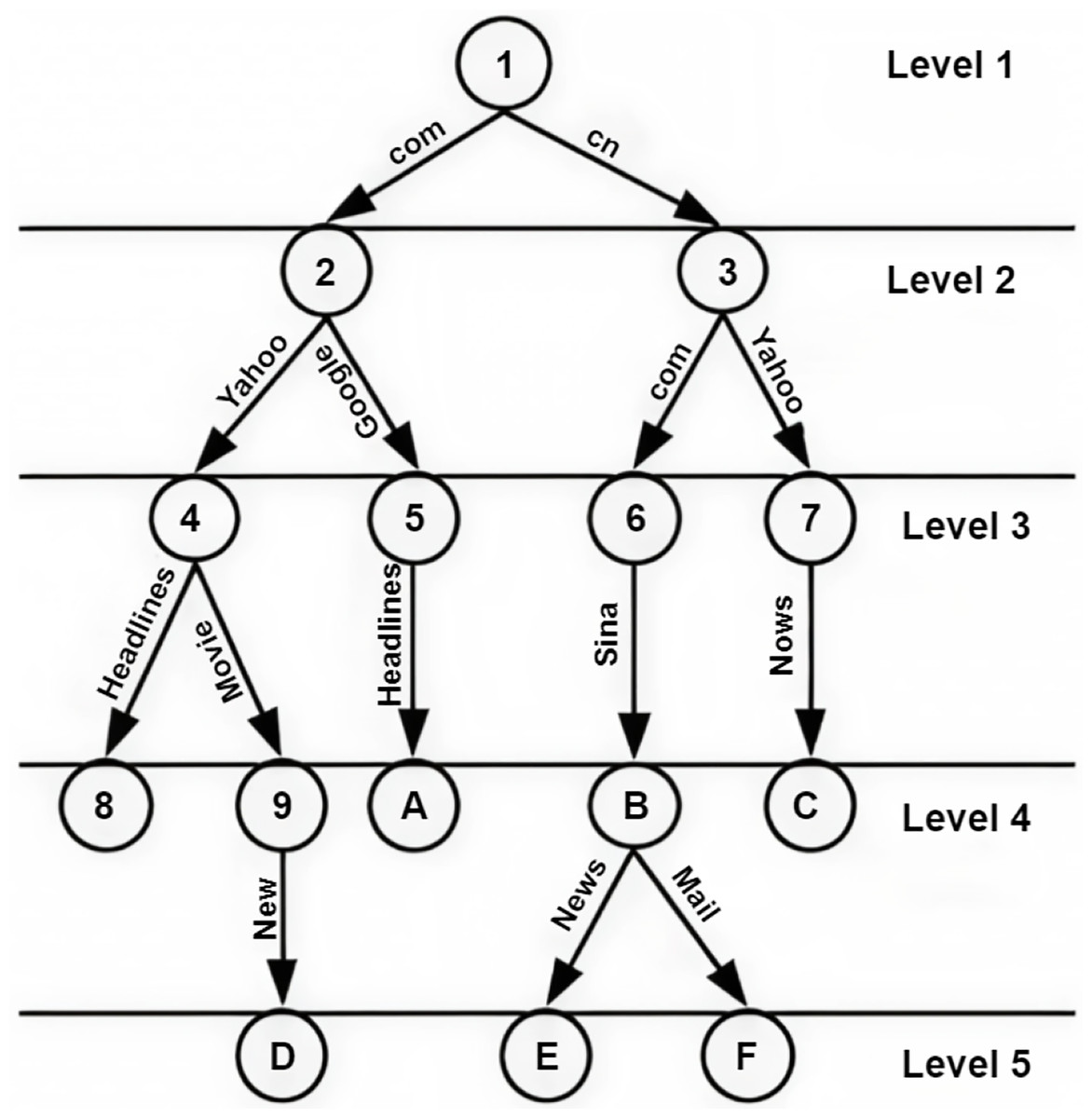
Figure 11: An example of name prefix trie (NPT).
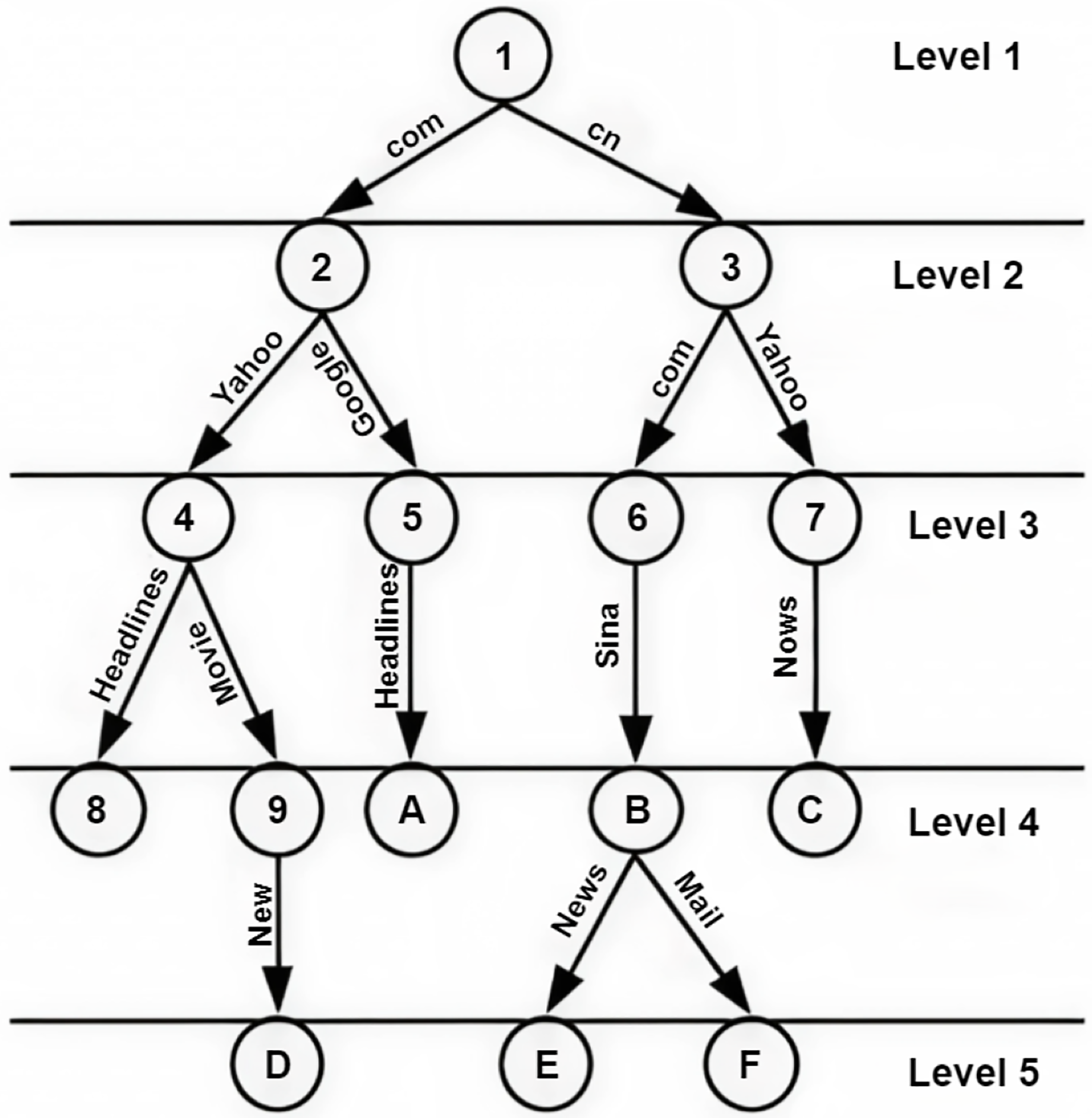{kind=link}
Figure 12: An example of trie implementation of FIB.
{kind=link}
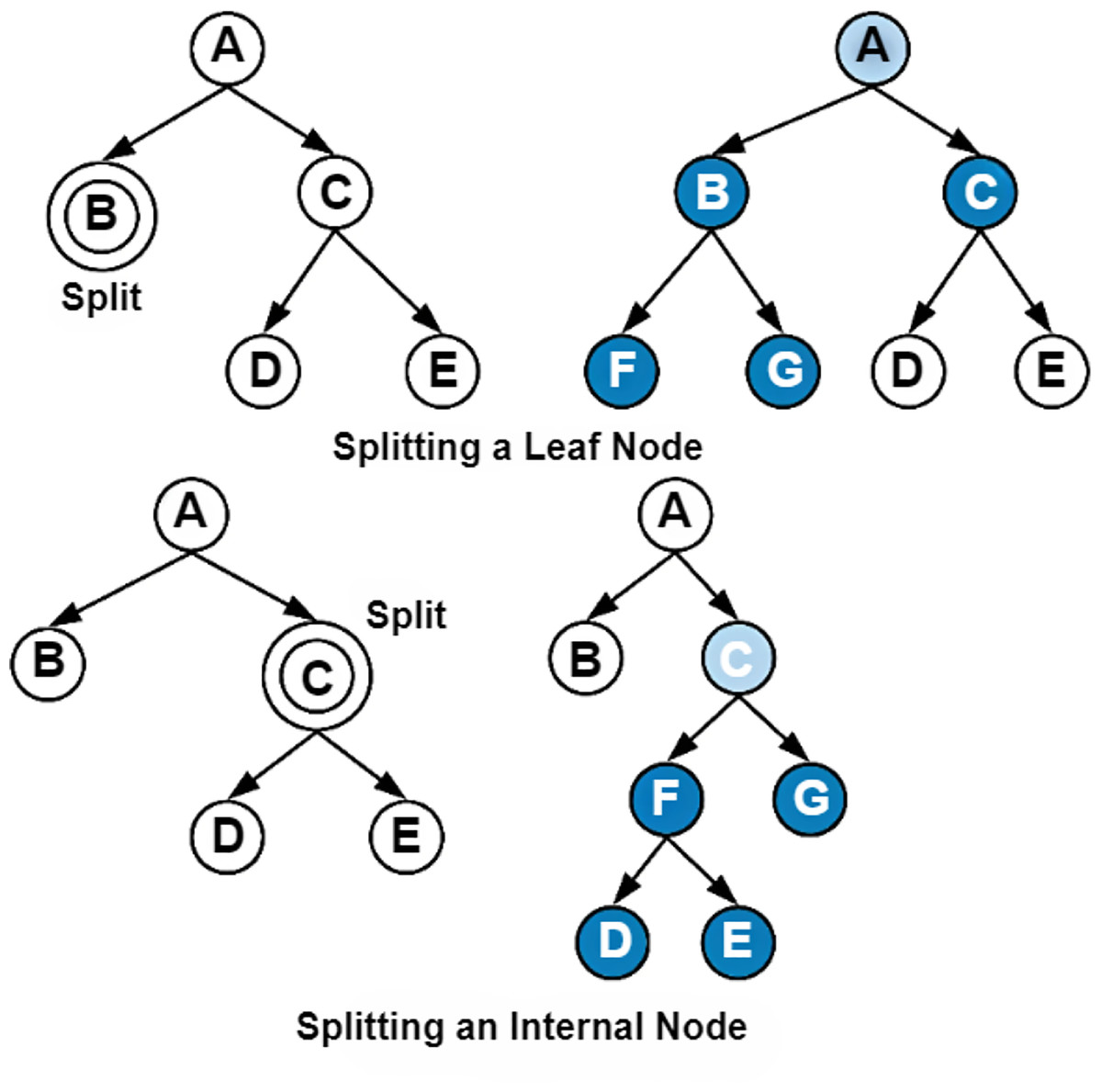
Figure 13: An example of Patricia-trie.
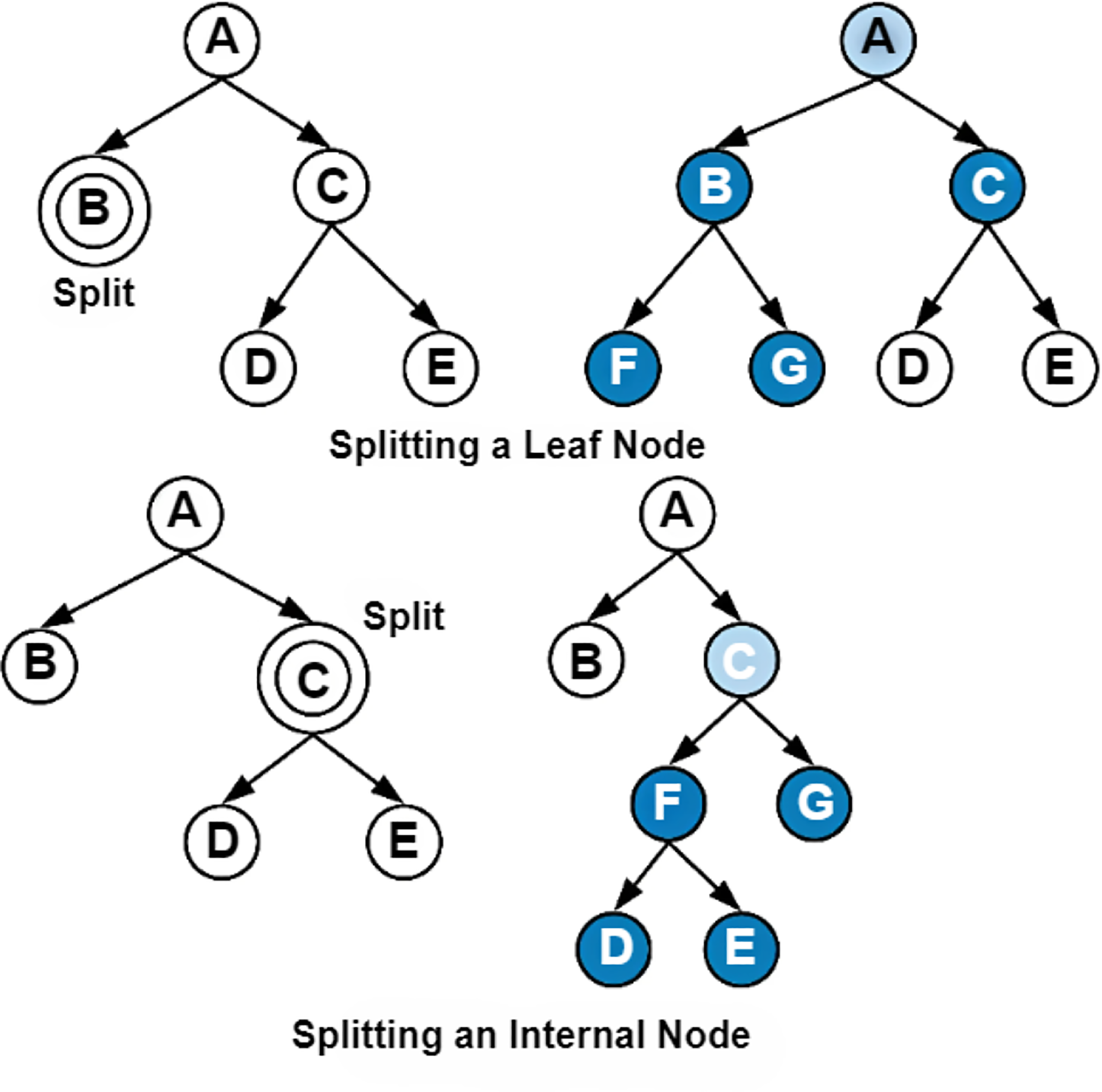{kind=link}
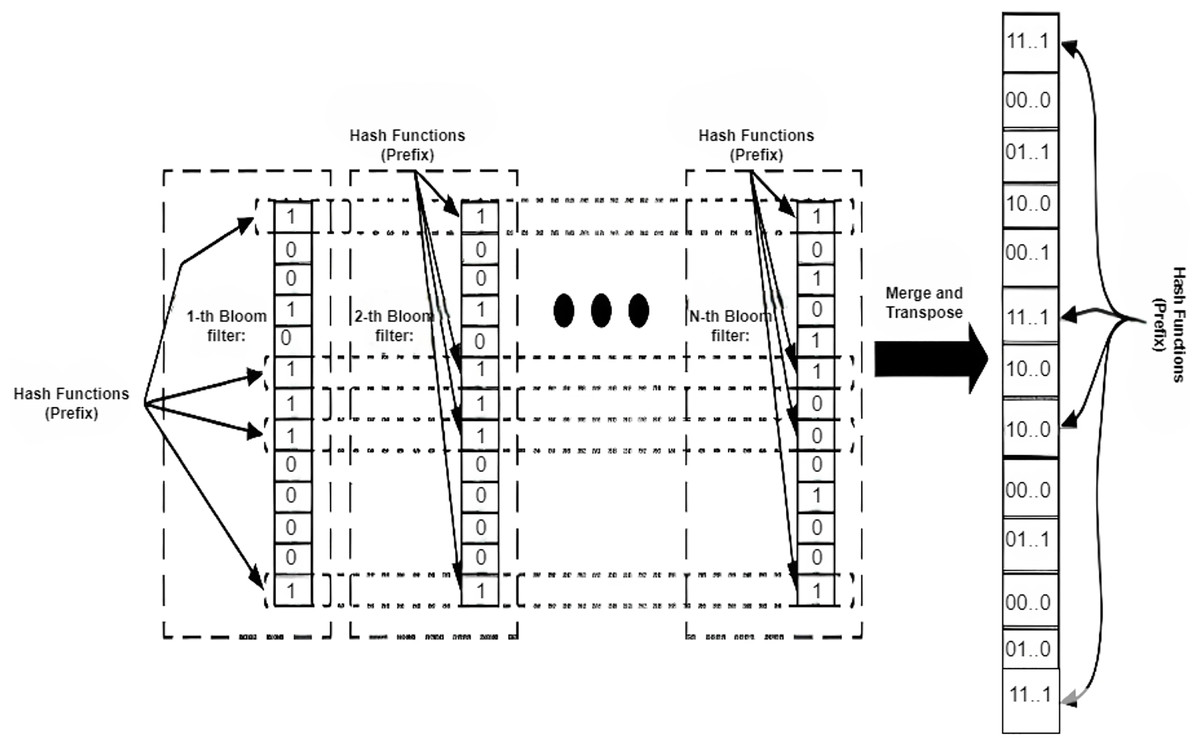
Figure 14: An example of a bloom filter with hash values.
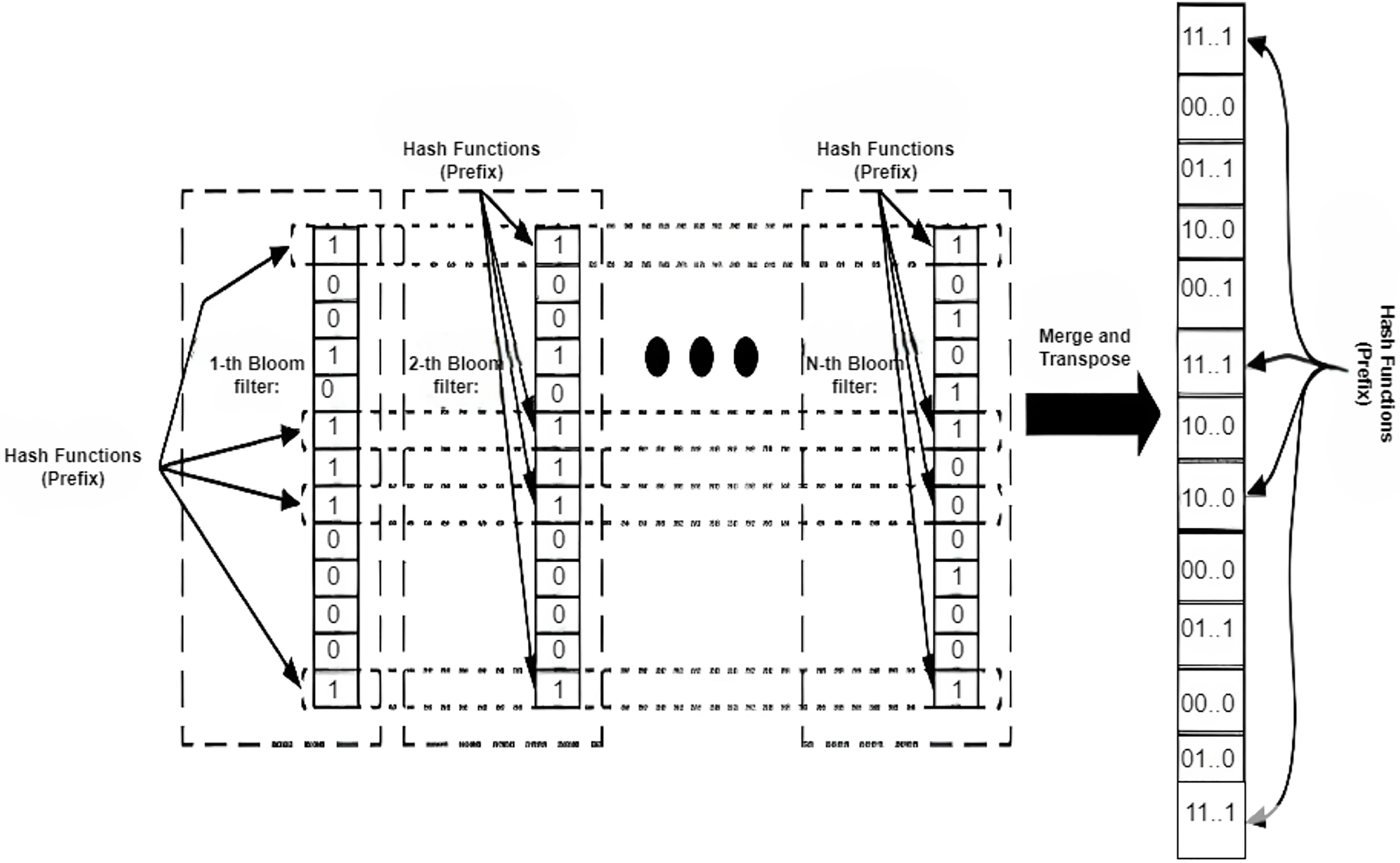{kind=link}
| Category | Reference | Name lookup approach | Year | Contribution |
|---|---|---|---|---|
| Tier | Wang et al. (2011) | Parallel Name Lookup (NPL) | 2011 | High-speed lookup with low redundancy. |
| Wang et al. (2012b) | Name Component Encoding (NCE) | 2012 | Enhances LPM performance in NDN routers. | |
| Wang et al. (2013c) | GPU-based name lookup | 2013 | Achieves 63.5 MSPS with lower delay. | |
| Li et al. (2014b) | HATA | 2014 | Compresses memory and supports parallel name verification. | |
| Song et al. (2015) | Binary Patricia Trie | 2015 | Size-optimized trie structure. | |
| Dagang, Junmao & Zheng (2016) | P-Trie | 2016 | Accelerates hierarchical name lookup. | |
| Saxena & Raychoudhury (2016a) | Scalable Patricia Trie | 2016 | Efficient updates for scalable name matching. | |
| Saxena et al. (2016a) | Radix-Trie Encoding (RaCE) | 2016 | Reduces memory footprint of trie traversal. | |
| Ghasemi et al. (2018) | NameTrie | 2018 | Optimizes lookup and update throughput. | |
| Ghasemi et al. (2019) | Markov-based NameGen | 2019 | Evaluates performance-granularity relation. | |
| Bloom filter | Wang et al. (2013b) | NameFilter (2-stage BF) | 2013 | Fast FIB lookup using staged Bloom filters. |
| Mun & Lim (2019) | 2-phase Bloom Filter | 2019 | Integrates priority trie to cut lookup components. |
| Category | Ref | Name lookup approach | Year | Contribution | Limitations | Naming scheme |
|---|---|---|---|---|---|---|
| Hash table | Wang et al. (2014) | Near Perfect Hash Table (PHT) | 2014 | Fast name lookup approach by restructuring FIB. | N/A | Flat naming |
| Yuan & Crowley (2015) | LNPM-based Binary Search of Hash Table | 2015 | Optimizes prefix pulling and binary search efficiency. | PIT and CS can be integrated into future work. | Hierarchical naming | |
| Hybrid | Fukushima, Tagami & Hasegawa (2013) | Non-Aggregatable Name Prefix Schema | 2013 | Reduces FIB lookup bottlenecks using non-aggregatable prefixes. | Further experiments needed. | Hierarchical naming |
| Wang et al. (2013a) | Encoding Name Component Trie (ENCT) | 2013 | Trie-based split model routing technique. | High cost of off-chip DRAM. | Flat naming | |
| Quan et al. (2014) | NLAPB (Adaptive Prefix Bloom Filter) | 2013 | Uses Bloom filter and Trie for suffix matching. | GPU acceleration needed. | Hierarchical naming | |
| Perino et al. (2014) | Caesar Content Router Lookup Schema | 2014 | High-speed lookup using Bloom filters. | Lacks scalability and speed. | Hierarchical naming | |
| Tan & Zhu (2015) | Split Name Character Trie (SNT) | 2015 | Enhances memory efficiency via decomposition. | N/A | Hierarchical naming | |
| Saxena et al. (2016a) | Fast LPM Framework | 2014 | CPU-GPU collaborative framework for fast lookup. | N/A | Hierarchical naming | |
| Yuan, Crowley & Song (2017) | Fingerprint-Based Patricia Trie | 2017 | Reduces leaf-node depth and latency. | N/A | Hierarchical naming | |
| Huang & Wang (2018) | Hybrid Scalable Name Prefix Matching | 2018 | Uses TCAM with fingerprint hash table. | N/A | Hierarchical naming | |
| Hu & Li (2019) | Composite Random Search Structure | 2019 | Combines hash and Trie for hybrid lookup. | Memory cost optimization needed. | Hierarchical naming | |
| Wu et al. (2019) | Split Name: Basis and Suffixes (SNBS) | 2019 | Reduces false positives and boosts lookup rate. | N/A | N/A |
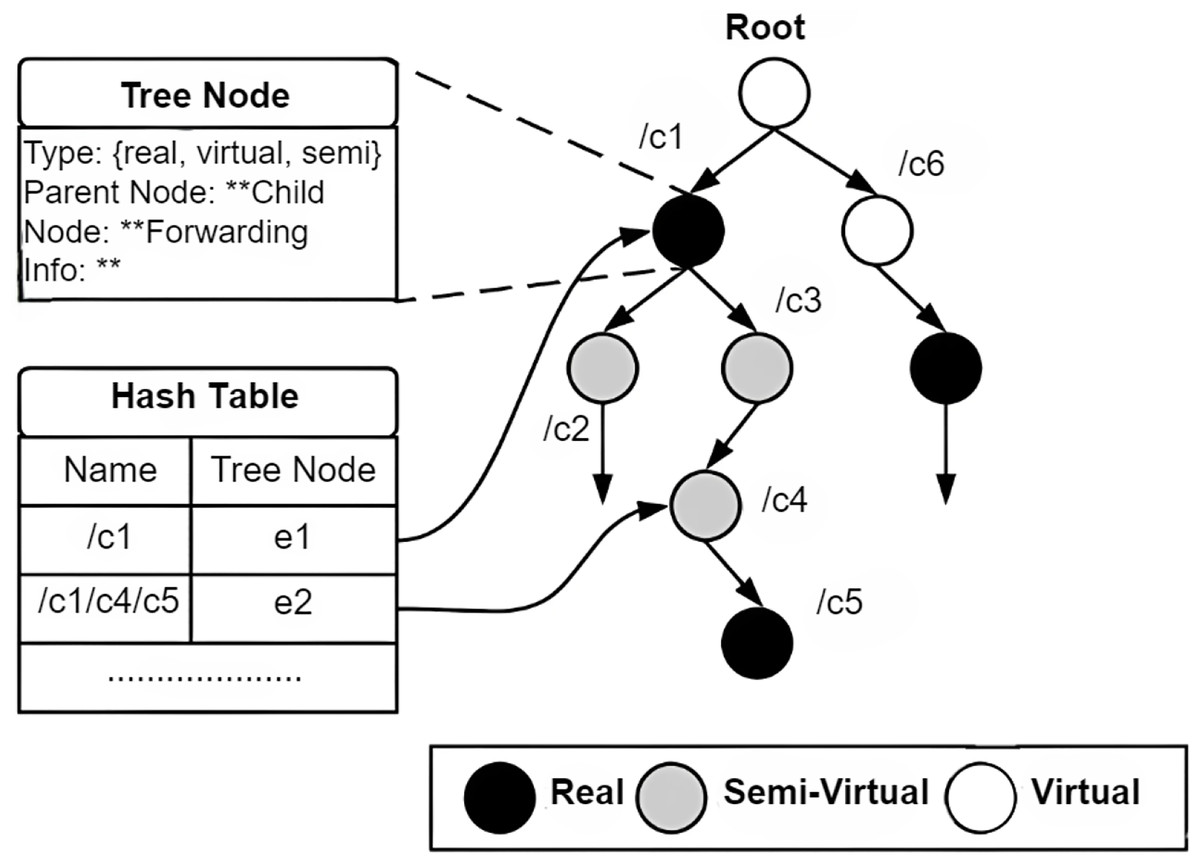
Figure 15: Hash table data structure based FIB combine with Trie.
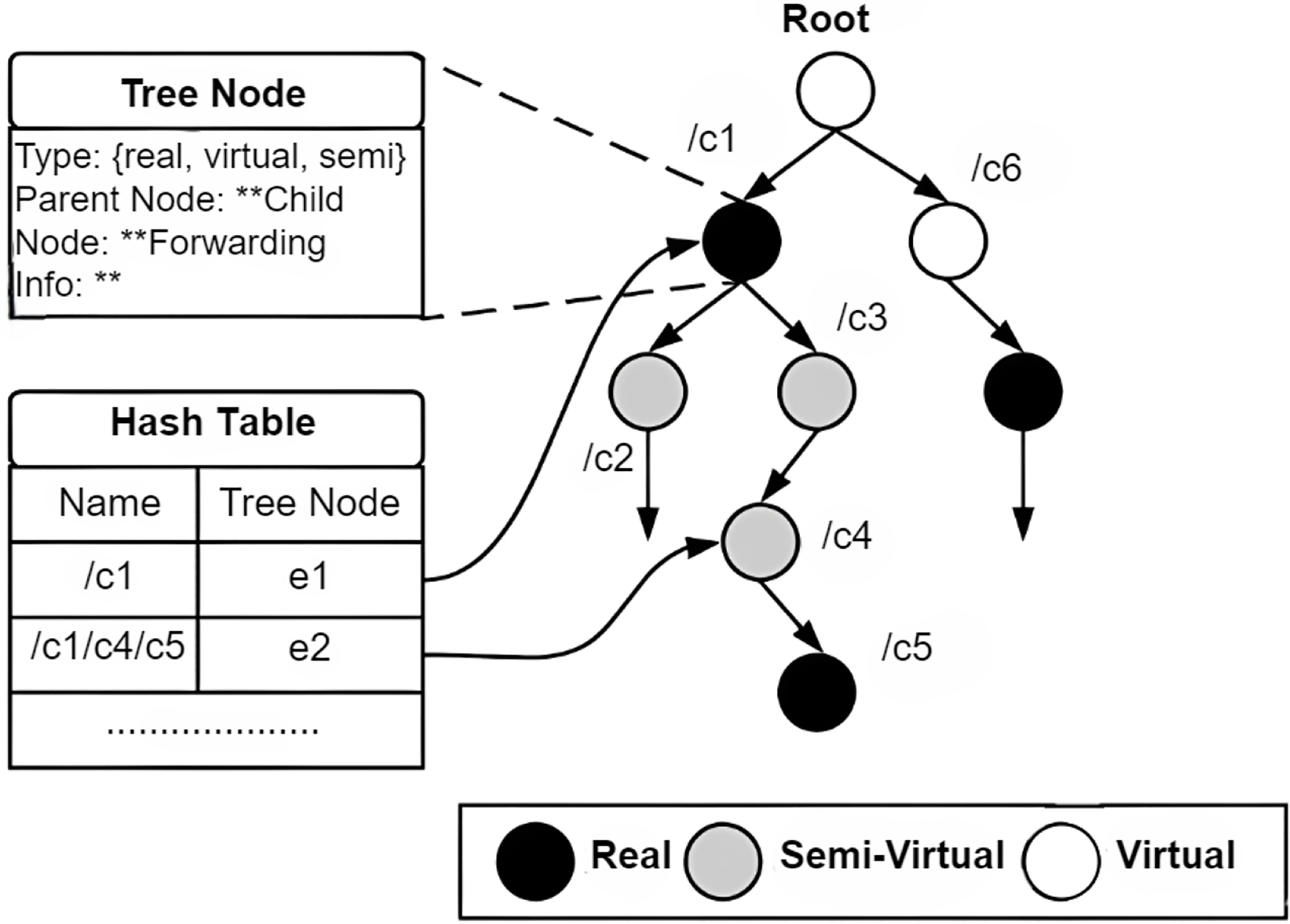{kind=link}
PIT-based approaches
PIT is equally significant in place of FIB and CS due to the regular modification of the operation. Every PIT entry comprises a nonce, content name, expiration time, and both incoming and outgoing interface addresses. Nonce and content names are used to identify packets and prevent the transmission of duplicate packets. Inward and outward interfaces signify the starting and ending nodes of the selected packet. The packet lifetime is linked to the packet’s entry whenever it transmits. If it does not return until the lifetime expires, the subsequent entry is deleted (Saxena & Raychoudhury, 2016b). Table 9 presents all PIT-based approaches in terms of their naming scheme, contributions, and limitations. The comparative analysis of PIT-based packet lookup approaches in wired NDN is shown in Table 10. Some operations are also implemented upon PIT, such as addition, deletion, and update. Whenever a new data request is received at the NDN router, it examines whether the request is already present in the router. If the data entry is not present, the corresponding entry is inserted by constructing a new one. The renew function is executed to avoid data replication if the packet is still alive. When the subsequent data arrives or expires, the delete operation is implemented. Such an operation consists of one lookup and deletion depending on the data structure (Dai et al., 2012).
-
Trie-Based Approaches: The first comprehensive article examining the size of PIT storage was presented in Dai et al. (2012). For the creation and building of tables in NDN, a further flexible and encrypted scheme is proposed in Wang et al. (2012b), which is employed to speed up the access operations and reduce the PIT size. Whenever the packet reaches the PIT, its content name component is determined, along with the allocation of a code production using NCE. After that, the data sequence is inserted into ENPT, which is then used to remove, update, and search for the content name in PIT. Using NCE, only the memory size of the PIT tables can be reduced, and the PIT shows good scalability. Regarding the retrieve function, the outcomes illustrate that the lookup functions for PIT deletion and insertion speed are 1.4 and 0.9, respectively.
An efficient name encoding technique known as radient is proposed in Ghasemi et al. (2019) and is demonstrated in Fig. 16, wherein a single named module is substituted through an exclusive program that is similar to modules that allocate matching programs. This method comprises a dual-module Trie, along with the encrypted content NameTrie. It includes the dual segment, plus the accessible symbol heap, which keeps a record of symbols that are recently inserted or removed, along with a recurrent symbol that keeps a record of each module inserted into the table entry. When the request for the latest packet is added to the table entry, the named module is divided into multiple segments, for which every search is examined in the CRT. Suppose the module is present within the CRT; after that, the assigned program is reverted. If no correspondence exists, the module is inserted into the heap, producing an original program. In advance, the occurrence of the inward packet is improved by utilizing a symbol occurrence chart. Next, the content name encoding is forwarded to the NRT for the PIT update. A lazy deletion method is adopted for deletion. The memory needed for the 29M dataset to execute the radient approach is 140.10 MB.
-
Hash Table Based Approaches: In Varvello, Perino & Linguaglossa (2013), the primary focus is on planning and executing a table to maintain the cable’s speed. The assignment of PIT and structure can affect the execution. LHT and d-left hash tables are presented in place of the structure using a lookup in the router tables. According to Dai et al. (2012), the position of PIT is limited to the output, input, and third-party methods. Outcomes demonstrate that the last method is highly effective, as it enables the examination of all table functions. This procedure takes the names of 10 Gbps and keeps the data of 1 million entries. In Yuan & Crowley (2014), a method is proposed for PIT among encrypted tables, based on the concepts of fundamental and boundary routers in TCP/IP network systems. This strategy aims to utilize a constant segment of the 16-bit fingerprint for fundamental routers. On the other hand, boundary routers typically use IP addresses instead of string names. However, collisions of fingerprints and the inability to differentiate such collisions arise from identical Interests. The problem of overlapping fingerprints is alleviated by reducing the Interest combination characteristics of fundamental routers. Packets are transmitted when they reach the router’s foundation. After the execution of fingerprint duplication, most Interest combinations occur at boundary nodes, and CS is employed to prevent duplicate request information. Simulation outcomes demonstrate that this approach reduces storage space for fundamental routers and can be utilized to support names at speeds of up to 100 GBPS. Platform execution through an improved open challenge hash table for the routers is proposed in Li et al. (2014c) and illustrated in Fig. 17. They delivered a model to implement maximum and average PIT sizes constantly. The results demonstrate which dimension size is less than the system settings, with no optimal bandwidth and caching. In Mahmoudi & Ahmadi (2022), the authors use Cuckoo filters to implement the PIT in NDN as a distributed data structure. To minimize the memory required and the time to accomplish PIT, look up the least proposed approach to divide the PIT into sub-tables, one for each router interface. A sub-table will eliminate redundancy from the global table to form part of the complete global table. As evidenced by the results, implementing these techniques yields an overall 36% increase in lookup time and consumes 68% less memory than a standard hash table lookup. To this end, this work establishes how distributed data structures can be used to enhance PIT design in wired NDN.
-
Bloom Filter Based Approaches: A distributed PIT-based data structure design is proposed in You et al. (2012) by employing a minimal amount of storage allocated to each boundary constructed on CBF. Router tables are distributed within associate tables known as PITi. It is implemented in a manner that, using the Bloom filter, keeps the tables within the related boundaries. It could not trust the naming approach, both flat and hierarchical. Evaluated using a hash table, it reduces memory usage and achieves a higher lookup data rate. United Bloom Filter (UBF) to compress the PIT efficiently is proposed in Li et al. (2012) and is shown in Fig. 18. Using the UBF prevents false negatives and counter leaks when counting the Bloom filter. UBF includes both current and non-current Bloom filters. The time for each PIT entry is split into periods. The Bloom filter non-current is set to a constant value at the start of every period. If the unknown content name is added to the table after that, this addition is constructed upon Bloom filters. On the other hand, the content lookup is executed simply on the present Bloom filter. At the end of each period, dual Bloom filters exchange their value. The Bloom filter displays the packets received in the current and previous periods. Afterward, all the names are inserted into the Bloom filter and disconnected from the last or the next period. Reduction in CBF occurs at the memory (10%) and error possibility (0.1). While UBF can reduce storage by 40%, the chance is decreased by nearly 0.027%. A mapping bloom filter-based design (MaPIT) is proposed in Li et al. (2014c), comprising a packet store and an index table. The index table shall consist of two structures of array bits: a usual Bloom filter and a 30-bit mapping array to map bits. A Bloom filter is used to check whether the entry exists in the MBF. The value of MA is utilized to approach the packet store. The initial state of the new incoming and its resultant bit in MA is assumed to be zero. Whenever the entries are added to MBF, a few bits are changed to 1s according to the subsequent hash value in the Bloom filter. The index table utilizes on-chip memory, while packet storage utilizes off-chip memory. In the MaPIT, the name of the content is encrypted using SHA1 or MD5. The performance of MaPIT is compared and evaluated with that of the hash table and NCE. It has a lower probability and memory consumption than a hash table and NCE. A half-stateless forwarding approach for the router tables is proposed in Tsilopoulos, Xylomenos & Thomas (2014). The request of Interest is discovered at a particular hop, in contrast to each hop. Afterwards, the demand is gathered in the opposite direction, and the information at intermediate nodes is used to deliver a response between the routers using the Bloom filter. During this scheme, the price of sending effectively decreased to 40%, and the distribution of unicast and multicast data decreased from 30% to 60%.
-
Hybrid Based Approaches: Linear-chained hash table and Bloom filter are proposed by co-designing software and hardware in Carofiglio et al. (2015). The operations of PIT are combined into a single demand. The packet’s name is divided into two segments: the data name and the segment number. Using the function, the flexible length requested data name is established utilizing a bit name. The Table ID is incorporated to maintain diverse IDs in the tables of the NDN router. If content previously exists in the table, the router explores the FIB to transmit packets of Interest. Limited on-chip block RAM is utilized for the lookup table, while the whole table is stored in SRAM. Using a hash function, a Key is mapped to the bucket. This approach was implemented on an FPGA, and its entire handling rate was equal to 60 MLPS. For PIT, a dimensional filter is adopted in Shubbar & Ahmadi (2019b) that outperforms other filters. It has improved performance in terms of low memory requirements, throughput, and false positives, making it very suitable for execution in PIT. It is based on a bit vector (quotient filter), which means that the bit vector has replaced the standard PIT. The number of the bit-vectors displays the number of faces in the corresponding NDN node, as shown in Fig. 19. Results show it fulfills the requirements for building an efficient PIB.
| Category | Ref | Name lookup approach | Year | Contribution | Limitations | Naming scheme |
|---|---|---|---|---|---|---|
| Tier | Dai et al. (2012) | Name Component Encoding (NCE) | 2012 | Reduces PIT size and access time while ensuring scalability. | N/A | Hierarchical naming |
| Saxena & Raychoudhury (2016b) | Radiant Scalable Memory-Efficient Approach | 2016 | Reduces storage required by PIT data structure. | Does not optimize PIT insertion, deletion, and update time. | Hierarchical naming | |
| Hash table | Varvello, Perino & Linguaglossa (2013) | d-left Hash Table (LHT) | 2013 | Combines Interest packets for multicast and symmetric routing. | Not implemented as a full prototype. | Hierarchical naming |
| Yuan & Crowley (2014) | Fast and Scalable PIT Design | 2014 | Ensures guaranteed packet delivery and compact storage. | N/A | N/A | |
| Mahmoudi & Ahmadi (2022) | Cuckoo Hash-Based PIT | 2022 | Uses Cuckoo filters to reduce memory by 68% and lookup time by 36%. | Optimized for static environments; may require additional mechanisms for dynamic routing. | Hierarchical naming | |
| Bloom filter | Li et al. (2014c) | Mapping Bloom Filter (MBF) | 2014 | Uses fast on-chip memory for PIT lookup. | Does not handle multiple parallel threads efficiently. | N/A |
| You et al. (2012) | Distributed Bloom Filter (DiPIT) | 2012 | Employs small, fast memory for efficient PIT table execution. | Designed for CCN, not the latest NDN. | Hierarchical naming | |
| Li et al. (2012) | Unified Bloom Filter (UBF) | 2012 | Eliminates need for deletion by preventing unnecessary anomalies. | N/A | N/A | |
| Hybrid | Yu & Pao (2016) | Linear Chain Hash Table and Bloom Filter | 2016 | Reduces I/O communication and processing time. | N/A | Hierarchical naming |
| Tsilopoulos, Xylomenos & Thomas (2014) | Semi-Stateless Forwarding Scheme | 2014 | Reduces forwarding states by reverse tracking paths. | Does not improve multicast scalability. | N/A | |
| Shubbar & Ahmadi (2019b) | FTDF-PIT | 2019 | Uses two-dimensional filter to reduce memory overhead and false positives. | N/A | Hierarchical naming |
| Ref | Environment | Dataset/Setup | Metrics evaluated | Summary of results |
|---|---|---|---|---|
| Dai et al. (2012) | Gateway-level trace-based PIT simulation | IP-to-NDN translated 20 Gbps traffic traces | PIT size, insert/delete frequency, memory, access latency | Proposes Name Component Encoding (NCE) for PIT compression; reduces PIT memory by 87.44%, achieves access rates of 0.9–1.4M ops/s; recommends egress channel PIT placement for parallel access and scalability |
| Saxena & Raychoudhury (2016b) | Gateway trace + software PIT prototype | 20 Gbps traffic with IP-to-NDN trace translation | PIT size, access frequency, memory reduction | Presents detailed PIT behavior under realistic traffic; PIT had 1.5M entries, with lookup/insert/delete rates of 1.4, 0.9, and 0.9 M/s respectively; introduces Name Component Encoding (NCE) which reduces PIT memory usage by up to 87.44% and accelerates access |
| Yu & Pao (2016) | Simulation-based CCIC-WSN evaluation | Clustered WSN with child/CH communication, mobility, and node registration | Energy consumption, data retrieval delay | Proposes CCIC-WSN framework for NDN-based WSNs with mobility and namespace discovery support; achieves 71–90% lower energy use and 74–96% lower data retrieval delay compared to prior ICN-WSN solutions across multiple test scenarios |
| Rehman et al. (2021) | Clustered WSN with NDN-based architecture | IoT simulation with mobile child nodes | Energy usage, data retrieval delay, CH association success | CCIC-WSN achieves 71–90% lower energy usage and 74–96% lower delay vs. recent NDN frameworks for WSNs; handles mobility and naming via namespace discovery and CH re-association |
| Raza et al. (2024) | ICN-based energy-aware caching in IoT WSNs | NS-2 simulations with clustered NDN routing | Cache hit ratio, energy usage, routing load | Proposes ICN-Cache scheme leveraging name popularity and hop-count; improves cache hit rate by 25%, reduces routing load and energy consumption by 15–27% vs. baseline LCE and ProbCache |
| Shubbar & Ahmadi (2019a) | NDN caching nodes with coordinated strategy | Uniform random traffic and distributed caches | Hit ratio, request satisfaction, redundancy | Caching with score-based priority coordination and replica suppression improves redundancy control and response ratio compared to LRU and MPC schemes |
| Li et al. (2017) | Simulated hybrid FIB-PIT in ICN routers | Packet-level simulator with name-based routing | PIT size, lookup time, state overhead | Integrates FIB-PIT into one structure using name-encoded radix Trie; reduces lookup latency and state storage by 20–35% compared to separated PIT/FIB tables |
| Lee & Lee (2016) | NDN router simulation with FIB bloom filters | Random name prefix dataset, CBF variations | FIB size, lookup latency, FPR | Introduces BF-FIB using Counting Bloom Filters for fast and compact forwarding table; achieves 33–50% memory reduction and maintains lookup latency under 3 s; FPR controlled with 2–3 hash functions |
| Khelifi et al. (2019) | Named Function Networking (NFN) prototype | NFN-enabled NDN nodes with caching | Execution latency, cache hit ratio, CPU overhead | Evaluates in-network computing via NFN; caching intermediate results improves latency up to 45% and reduces CPU load by avoiding recomputation; shows benefits of computation-aware caching |
| Mahmoudi & Ahmadi (2022) | NDN node simulation with PIT aggregation cache | Synthetic traffic with varied content popularity | PIT size, cache hits, access delay | Proposes PIT Aggregation Cache (PAC) to reduce PIT entries via caching pending Interests; achieves 30–55% PIT reduction and lowers access latency without impacting content retrieval success |
| Ma et al. (2024) | Hybrid NDN-SDN architecture with router-controller coordination | Simulated topology with congestion-triggered traffic | Throughput, RTT, duplicate Interest ratio | Proposes ndnSieve hybrid control scheme; SDN detects congestion and manages paths centrally; router performs shaping; improves RTT by 18%, throughput by 22%, reduces duplication vs. pure NDN methods |
Figure 16: Radient framework.
{kind=link}
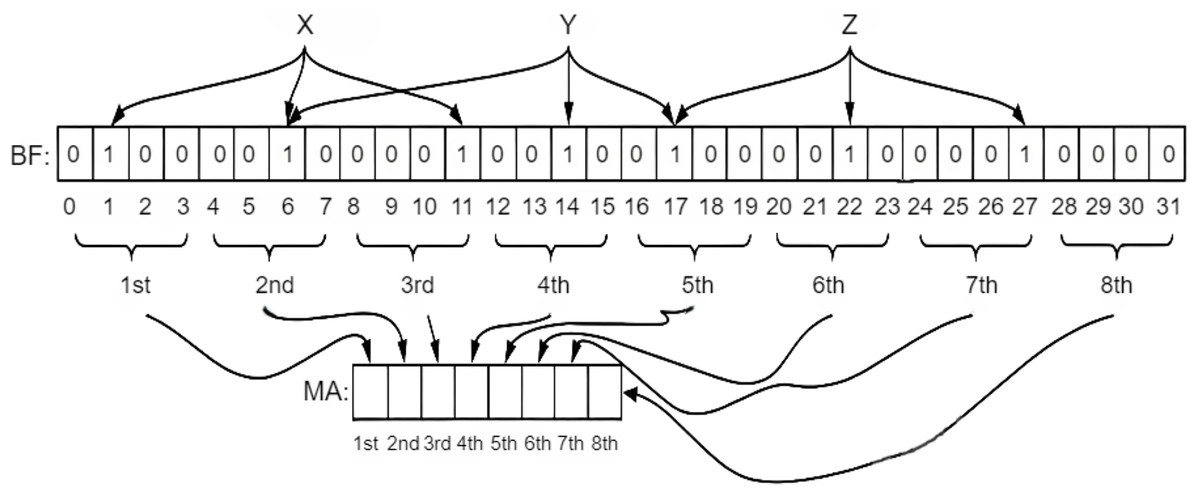
Figure 17: Index table of mapping bloom filter.
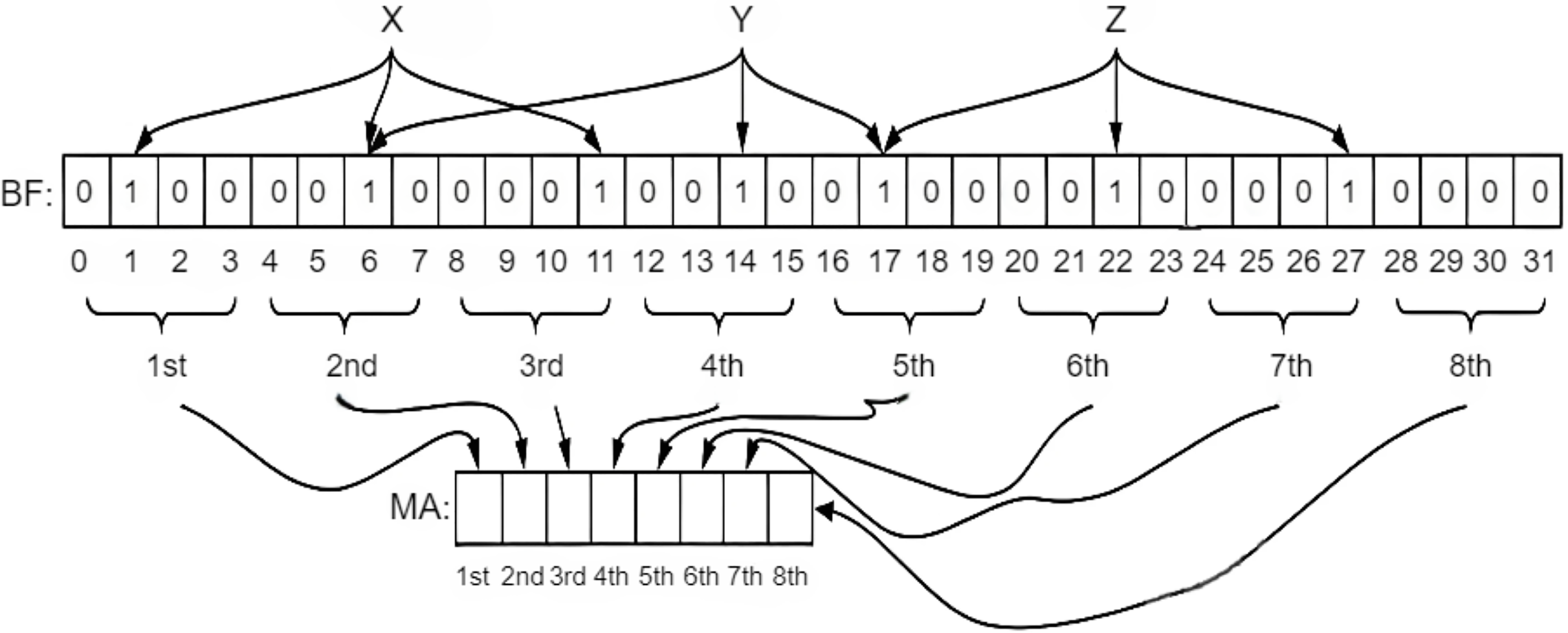{kind=link}
Figure 18: Unified bloom filter.
{kind=link}
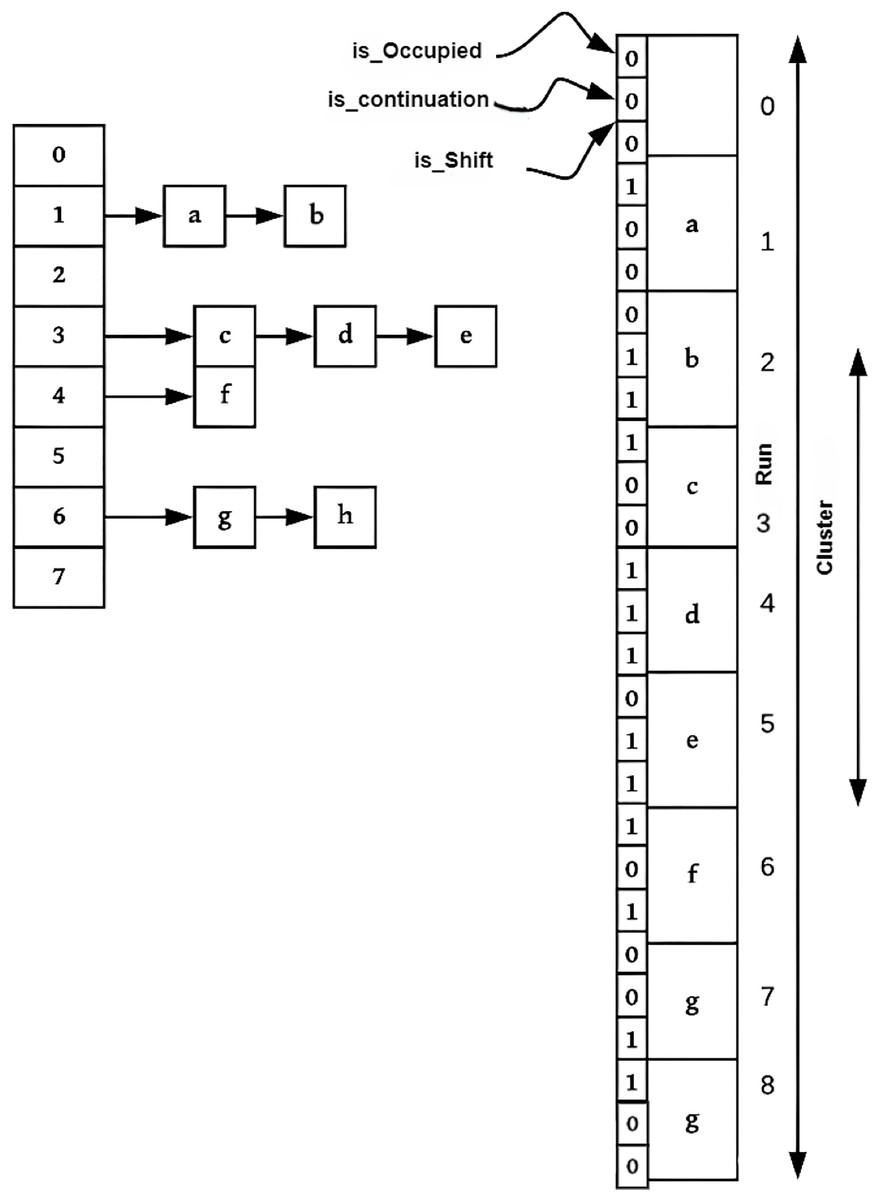
Figure 19: An example of quotient filter.
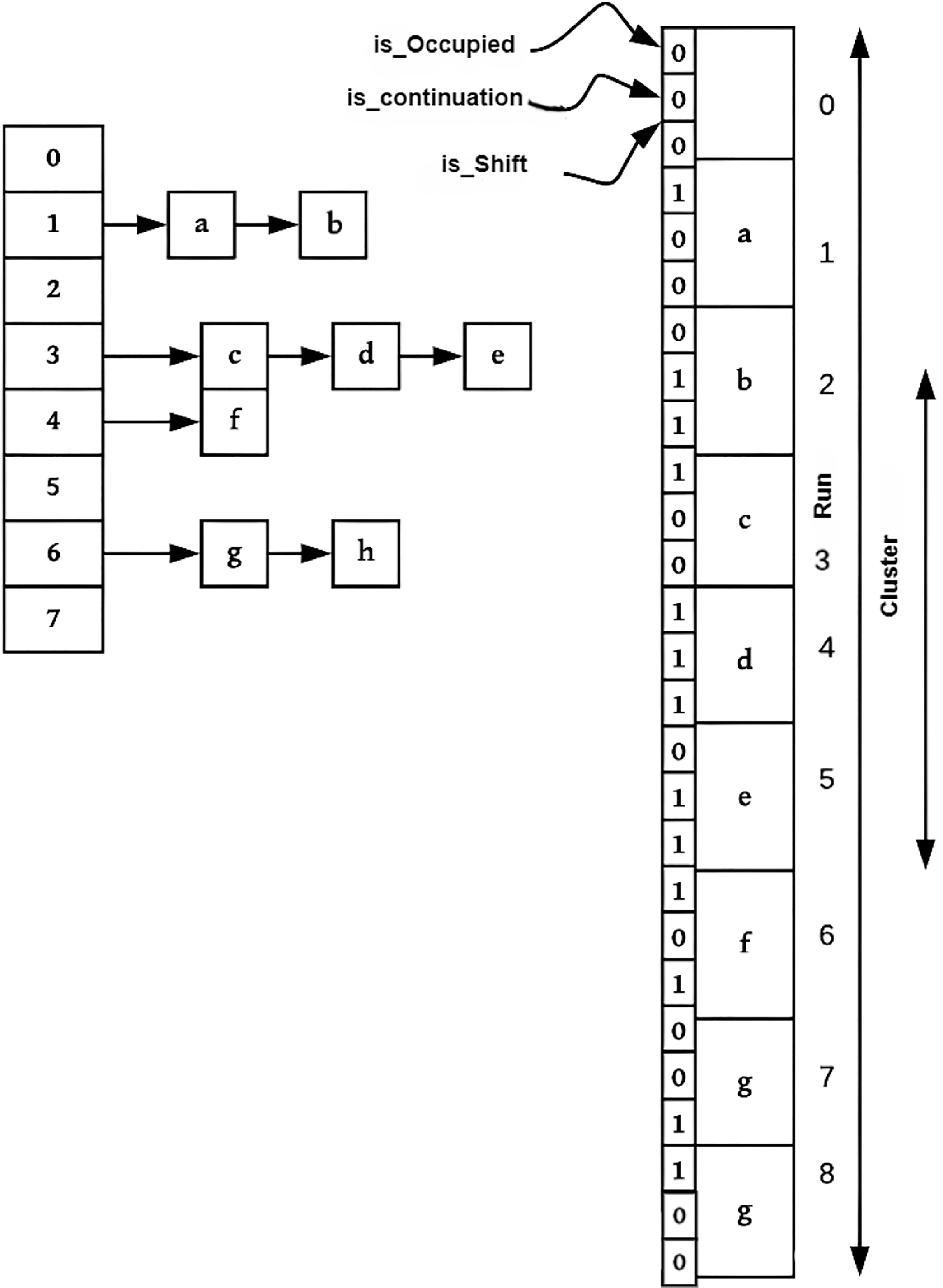{kind=link}
Entire router-based approaches
The original NDN proposal recommends leveraging the significant influence of TCAM to enhance the execution of name lookup for all NDN components. Notably, due to its limited memory, high power consumption, and high price, TCAM is unfeasible (Wang et al., 2013a). Some studies have proposed schemes to accelerate the lookup function within the router, without focusing on a particular component, by utilizing an encrypted table and Bloom filter approaches. Trie-based approaches are not functional due to their diverse class lookup functions in PIT or FIB. The Entire Router-based packet lookup approaches for wired NDN are shown in Table 11 and in Table 12. This section presents the works that comprise the overall scheme.
-
Hash Table Based Approaches: A detailed study of the current CCNx implementation is presented in Yuan, Song & Crowley (2012). They confirmed that achieving scalable performance requires considerable effort and provided an appropriate description of a key issue in NDN: scalability. The transmitting function in CCNx and NDN will be available for group learning. Name lookup identified three main issues: most extended prefix matching, exact matching technique, and flow maintainer on a large scale. CCNx combines the PIT and FIB in a single encrypted table, and every piece of content in the table has an indicator that specifies the FIB and PIT. Suppose the arriving Data packet corresponds to the preceding data with identical contents before the indicator provides content names, thereby decreasing the number of needed contrasts aimed at LPM. The characteristics they proposed are that the LPM and EPM must select the module name so that a unit of matching can be performed, instead of just considering the component’s name. An additional feature is the delivery of component names in the URL, which enables exceptional performance. After examining multiple design forwarding engines for NDN routers constructed on the chained hash table, as introduced in So et al. (2012). 64-bit siphash generates a value at each hash table entry to reduce string comparison. The dual-phase LPM approach is utilized for the lookup function. In the initial phase, it begins as the most employed module level signified by M. It attempts to transfer to the subsequent, minor content name until the correspondence of the prefix occurs. If the correspondence of the prefix does not survive after that, it does not correspond in the FIB. When a match is found, the next phase is started and displays a possible match at the highest depth of the prefix. The lookup begins, and the search continues until a match is found. In the case of PIT and CS, they employed a complete exact matching technique for name lookup and were integrated into a single hash table. It accomplishes the overall processing of up to 8.82 MLPS. It encrypts the variable-length prefix of 32-bit length by executing the cyclic redundancy checksum (CRC) function, thereby reducing the name lookup in NDN routers (Hsu & Chang, 2014). Altogether, the encrypted module eliminates the slash symbol and is connected to the name content of a 32-bit. If the nodes of NDN obtain a novel data element, the content name is encrypted, and the data information is gathered on the CS. Whenever a novel data element reaches the nodes of NDN through varying distances, its name is encrypted earlier and conveyed to the CS, PIT, and FIB. Through the utilization of the CRC bit encrypted approach, the memory space is reduced to 26.29, and the speed of lookup is increased by 21.63 using evaluation of the single NDN technique.
-
Hybrid Based Approaches: After discovering the deterministic finite-state automata (DFA) and hash table, it has been learned that the hash table is more efficient and effective than DFA due to the varying lengths of names in NDN (So et al., 2012). A linked list with a chained hash table is exploited to prevent additional comparisons and collisions. A hash table is also integrated with the Bloom filter to enhance the implementation of name lookup in PIT and CS. It accomplished 1.5 MLPS for the Interest and 2.14 for the Data packets. The United table is an encrypted table known as BFAST, consisting of NDN data structures (PIT, CS, and FIB) and a Bloom filter (Nurhayati et al., 2022). It is shown in Fig. 20. BFAST utilises the Bloom filter to assign the burden between the encrypted loads. To achieve a good execution of the look and to ensure functional control, a supplementary Bloom filter is employed, with the table for the minimum standby serving as the article renovation. Whenever this approach is used in PIT, CS, and FIB, the content name and its signature are computed through the encrypted function and stored in the table. The content is gathered in the area of the index entries, and the results demonstrate that it can acquire the lookup function and achieve a speed of 81.32 for the entire NDN structure. It performs much better than the NCE, CCNx, and Namefilter methods, but it consumes more memory than the others. The steerable name-lookup-based Bloom filter approach is presented in Huang et al. (2016) for NDN routers. The names in this approach are categorized according to the number of components and the name length to map them into a diverse Bloom filter. These mapped names are kept in the distinctive hash table. Every entry is assigned a specific memory size. Consequently, the memory access is reduced to one. Memory effective component steerable structure, known as the number of components, is constructed to optimize the number of components when executing matching. Results demonstrate that 2.5M names achieved improved lookup performance compared to BH and CCNx, but require more memory than the steerable lookup. A two-dimensional filter with a hash table is introduced in Shubbar & Ahmadi (2019a) to reduce memory overhead and accelerate lookup for FIB in NDN. The filter is used as a pre-searching process to decrease the redundant memory in the hash table. A hash table is built hierarchically to confirm the accuracy and speed of this approach. Moreover, the filter and hash table use the same value to reduce the hash calculation. Results show that it reduces the memory overhead and confirms the speed of lookup.
| Category | Ref | Name lookup approach | Year | Contribution | Limitations | Naming scheme |
|---|---|---|---|---|---|---|
| Hash table | Yuan, Song & Crowley (2012) | Forwarding plane | 2012 | Explains the forwarding plane and examines its operation in CCNx to accomplish scalable performance. | Does not emphasize a specified solution to the three main problems | Hierarchical naming |
| So et al. (2012) | Lookup Engine based on Hash table | 2012 | A lookup engine based on hash table and Bloom filter is presented for fast packet forwarding. | Does not handle multiple threads with real packet tracer. | Hierarchical naming | |
| Hsu & Chang (2014) | CRC-32 Hash Function | 2014 | Reduces the name length to enhance the efficiency of name lookup. | Does not deal with name collision. | Hierarchical naming | |
| Hybrid | Dai et al. (2015) | BFAST | 2015 | Employs a counting Bloom filter to balance the load between a hash table and make the number of prefixes close to 1. | N/A | Hierarchical naming |
| Huang et al. (2016) | Steerable Name Lookup (SNLBF) | 2016 | To achieve high scalability and lookup speed, it exhibits no steerable components. | Does not focus on memory consumption while maintaining high speed. | Hierarchical naming | |
| Shubbar & Ahmadi (2019a) | FTDF-HT | 2019 | To reduce memory overhead and speed up lookup, a filter is proposed to eliminate redundant memory access to the hash table. | N/A | Hierarchical naming |
| Ref | Evaluation environment | Metrics evaluated | Summary of results |
|---|---|---|---|
| Dai et al. (2015) | Synthetic NDN forwarding with CS, PIT, and FIB | Lookup rate, latency, memory usage | Proposes BFAST (Bloom Filter-Aided haSh Table) for unified table indexing; achieves 81.32 M/s lookup with 0.29 s latency; supports both EM and LPM with scalable memory footprint. |
| So et al. (2012) | Xeon CPU software forwarding engine | Packet throughput (MPPS) | Hash-based lookup engine reaches 1.5 MPPS with single thread; demonstrates performance gains via prefetching and table optimization. |
| Hsu & Chang (2014) | Smart building NDN testbed (NDNoT) | Energy efficiency, retrieval delay, PIT scalability | Context-aware aggregation and mobility handling reduce delay and energy use; optimizes PIT behavior for dynamic IoT deployments. |
| Huang et al. (2016) | Edge NDN with semantic caching | Cache hit ratio, delay, semantic relevance | Semantic-aware adaptive caching improves accuracy and response time vs. LRU and popularity-based caching schemes. |
| Shubbar & Ahmadi (2019a) | FTDF-HT with name hash and filtering | Lookup speed, scalability, memory usage | Two-dimensional filter minimizes memory and boosts speed; enables dynamic updates with low state overhead. |
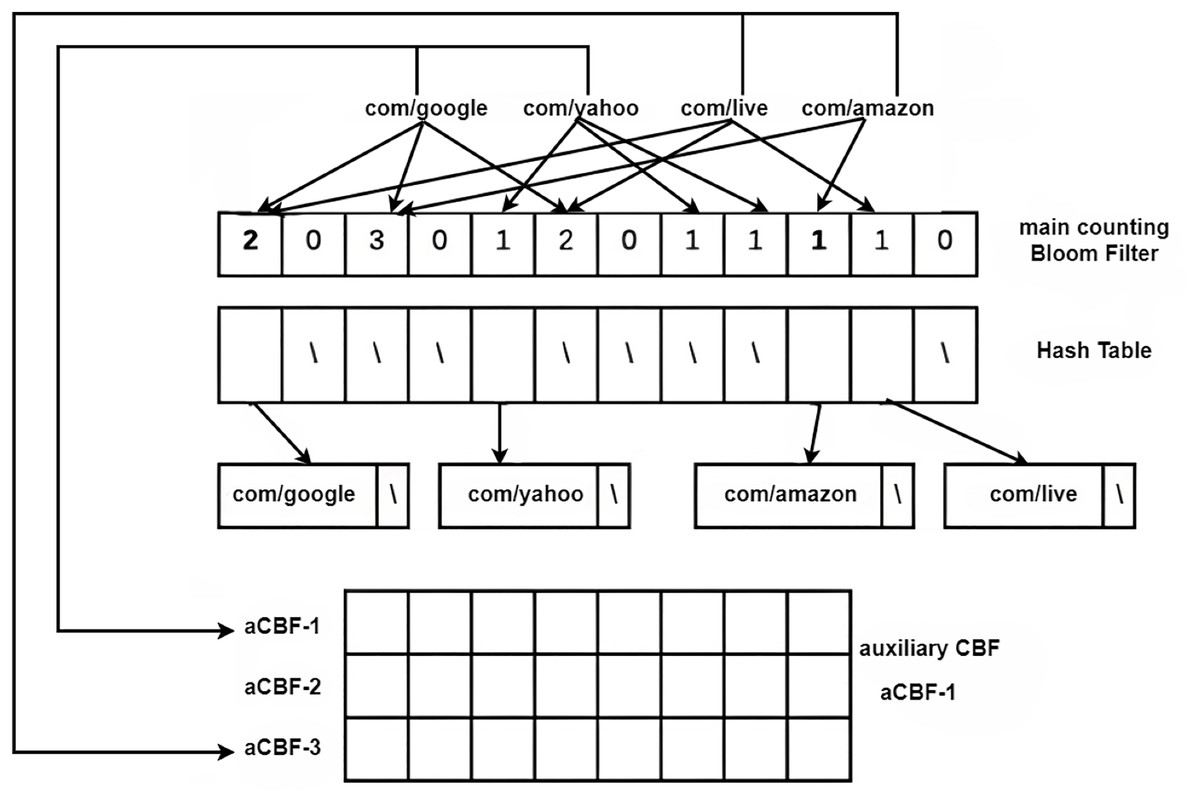
Figure 20: BFAST data structure, CBF auxiliary, and hash table.
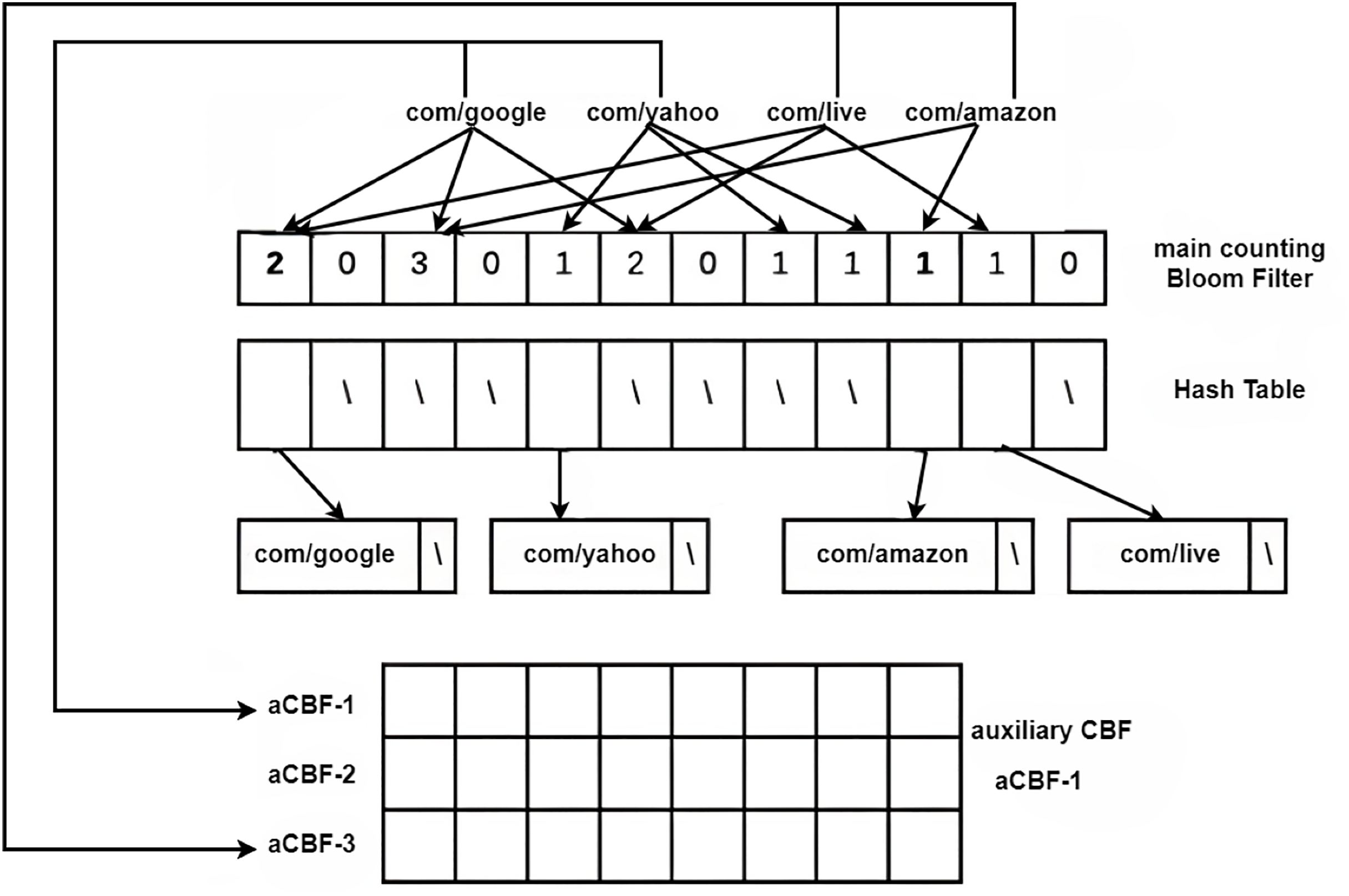{kind=link}
Packet lookup in wireless NDN environments
Wireless environments impose additional lookup challenges due to mobility, limited processing resources, and intermittent links. This section examines packet lookup strategies for wireless NDN, focusing on adaptive designs that strike a balance between responsiveness and overhead minimization.
FIB-based approaches
A unique execution of FIB, known as MaFIB, is proposed in Li et al. (2017) that facilitates flexible and ordered name lookup in content name searching. For now, the employment of plotting filters along with multi-hierarchical memory further enhances the rapidity of lookup. It decreases the frequency of retrieving memory and understanding the meaningful decrease in memory utilization. Evaluation results show that it can reduce on-chip memory and speed up the lookup procedure in the memory. For the time to begin, the possibility of a false positive is below 1 in 2 million names. It enables the enhanced FIB to utilize the memory of the onboard chip and fulfills the requirements for the present system. The practical name prefix approach for mobile IoT is proposed in Lee & Lee (2016) to decrease the delay desirable for the content name throughout the MCS delivery. The suggested scheme is based on the TBR and pDND methods. It uses pre-allocated name prefixes and a naming collection structure to deliver uniform MCS association in mobile NDN. They keep the resource utilization of nodes up-to-date by reducing the routing scope. Moreover, it can maintain suitable resource consumption due to the low overhead of Interest messages compared to the fDND method. This characteristic is significant in CCN, as multiple contents are inherently found due to dynamic topology changes and a limited number of route combinations. In Khelifi et al. (2019), they target the identification characteristics in vehicular data networks and suggest a name translation to the hash encryption method. The approach involves securing every component of the name content individually to a permanent interval, and after that, an algorithm for the lookup process is executed. The previous procedure improves the NDN by utilizing fewer comparisons than ordered names, and the final procedure gives a quick speed lookup. The proposed algorithm is evaluated in contrast to dissimilar connected solutions using real domain datasets. Theoretical and experimental analysis show that it is more effective in terms of memory utilization and complexity than in terms of lookup time. Hierarchies and self-certifying constructed naming approaches, through an effective organization approach, are proposed in Mahmoudi & Ahmadi (2022) for vehicular systems.
It enables the optimal utilization of characteristics suggested by the hierarchies and self-certifying approaches, as shown in Fig. 21. Hierarchies involve information about their types, attributes, and subtypes, as well as content providers that provide shared content among different vehicles. The hash value is used in vehicular applications to identify content uniquely. It fulfills two main objectives; initially, it reduces the size of the node table by shortening the content names and combining them. Secondly, it involves temporal and spatial information and their varieties to discover and solve the content. This consists of managing prefixes in the FIB and PIT tables. It is comparatively simple, faster, and space-efficient, and has improved execution compared to existing naming solutions. Results demonstrate that the suggested scheme achieves faster prefix search and delete procedures than simple Trie and Bloom filter-based approaches. In Ma et al. (2024), the authors introduce ndnSieve, a congestion control approach that combines SDN with NDN to control packets’ flows in wireless NDN. The scheme separates congestion control from routing to facilitate the intervention of the SDN controller. It incorporates a path replacement strategy and Interest rate adjustments that involve real-time network states. The results demonstrate that the proposed ndnSieve improves throughput by 33.55%, offers better latency, and fairly balances multipath wireless environments. This approach is designed to overcome fundamental issues in complex, limited wireless NDN environments. Packet lookup approaches for Wireless NDN are shown in Table 13 and in Table 14.
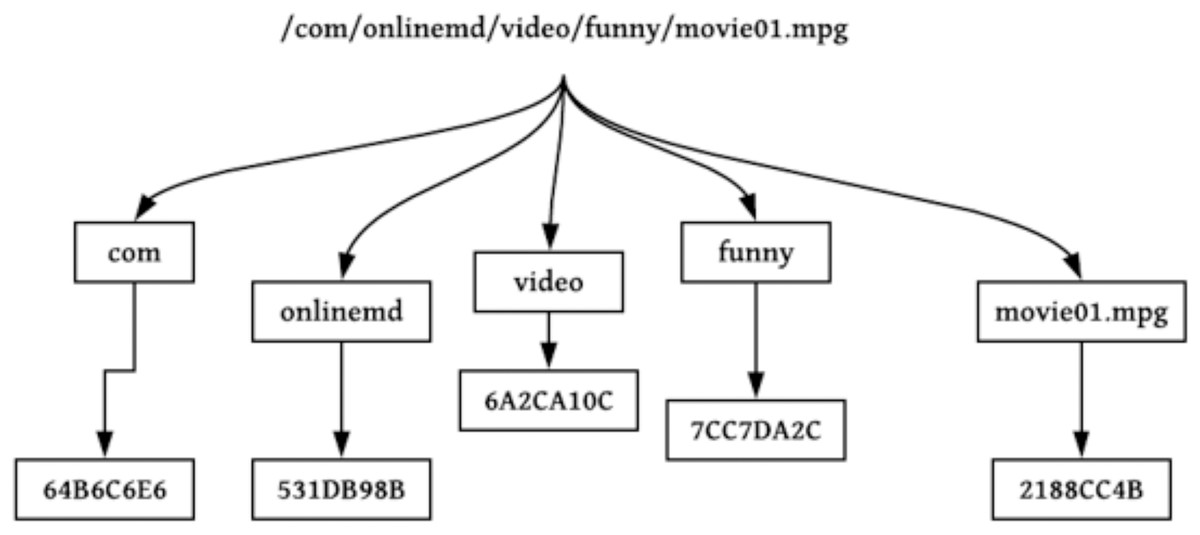
Figure 21: Tree structure for naming scheme.
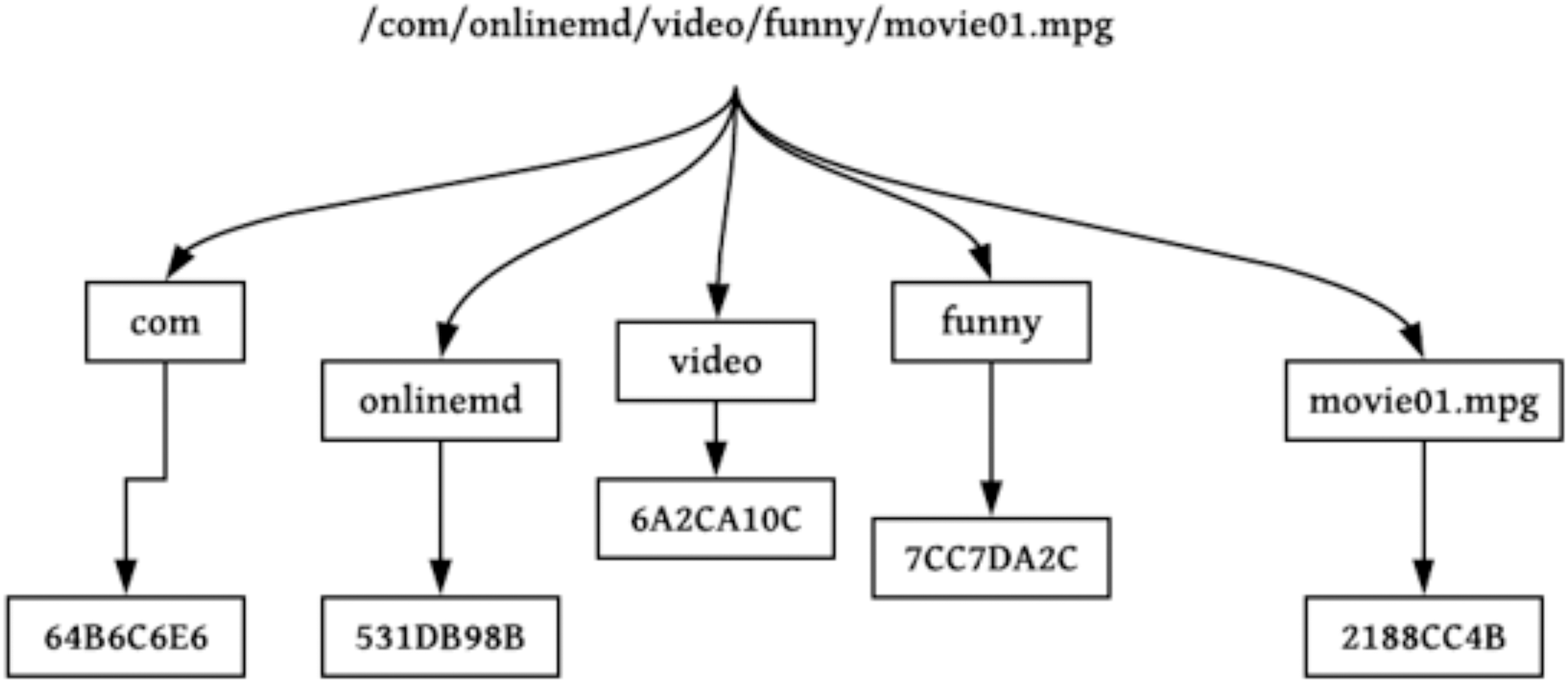{kind=link}
| Ref | Year | Naming approach | Contribution | Limitation | Naming scheme |
|---|---|---|---|---|---|
| Bouk, Ahmed & Kim (2015) | 2015 | CT-based hashing naming Scheme | Utilizes characteristics of both hierarchical and hash functions for optimized prefix processing. | Does not implement forwarding strategies and delays in VCCN applications. | Hybrid (Hierarchical + Flat) |
| Huang et al. (2016) | 2016 | Name prefix configuration scheme | Reduces latency during mobile handovers through adaptive name prefix adjustment. | Not specified. | Hierarchical naming |
| Li et al. (2017) | 2017 | FIB Implementation (MaFIB) | Proposes an efficient lookup algorithm that reduces memory cost and improves lookup speed with low false positives. | Lacks multithreaded engine integration with real packet traces. | Hierarchical naming |
| Khelifi et al. (2019) | 2019 | Name-to-Hash Encoding | Encodes each name component with fixed-length hashing and applies heuristic-based lookup. | Not specified. | Hierarchical naming |
| Ma et al. (2024) | 2024 | SDN-Integrated Hybrid Lookup Scheme | Implements hybrid congestion-aware path replacement and Interest rate control in SDN-NDN scenarios. | Focuses on congestion; lacks enhancements for high-speed wireless mobility. | Hierarchical naming |
| Ref | Evaluation setup | Metrics evaluated | Summary of results |
|---|---|---|---|
| Bouk, Ahmed & Kim (2015) | Custom VCCN simulation with synthetic name prefixes | Prefix search time, deletion latency, memory usage | Proposes a compact Trie-based hybrid naming scheme; achieves 45.5% faster prefix search and 55% faster delete latency vs. Simple Trie; memory usage reduced by 24 ; supports spatial-temporal name encoding. |
| Huang et al. (2016) | 3M-prefix dataset from DMOZ with synthetic components | Lookup speed, update rate, false positives | Introduces SNLBF (Steerable Name Lookup with One-Memory Bloom Filter); enhances lookup speed, reduces memory access; NCS structure minimizes redundant probing in large prefix spaces. |
| Ma et al. (2024) | SDN-based NDN testbed with real-world topology | Throughput, RTT, fairness | Implements hybrid congestion control (ndnSieve) with SDN-driven adaptive routing; improves throughput by 33.55% over PCON; ensures lowest RTT and fairness under network congestion. |
| Li et al. (2017) | Multi-million name simulation with SRAM profiling | Memory usage, false positive rate, lookup latency | Uses MaFIB with hierarchical Mapping Bloom Filter; reduces memory to 4.19MB for 2M names; maintains <1% FPR; suitable for high-speed SRAM-based NDN forwarding. |
| Wu et al. (2019) | Emulated dataset with variable-length name components | False positive rate, update complexity, lookup accuracy | Presents SNBS (Split Name into Basis and Suffix) using CBF and tree bitmap; reduces false positives through correlation verification; scalable insert/delete operations with consistent lookup. |
Packet lookup challenges
To utilise high-rated speed forwarding, packet lookup must take into account the following challenges:
Scalability: As time passes, the increasing amount of content leads to a proliferation of NDN routers’ table sizes, making scalability a significant issue.
High-speed Lookup: To execute forwarding in an extensive router, the name lookup must maintain a speed of 160 GB/s. On the other hand, the NDN router has to decrease the latency. So, sending packets with low delay while preserving the high-speed lookup is a challenging task (Hermans, Ngai & Gunningberg, 2011).
Memory Storage: Routers in NDN consist of thousands of names, as each name can contain hundreds or tens of characters, and the length of each name varies. So, nodes at the NDN might require gigabytes of memory to execute the lookup function on a huge-scale router.
Fast Update: The nodes in the NDN must handle at least one type of update as the requested content is inserted and removed from the NDN nodes. Entries of the name would be inserted and removed from the nodes, reducing the current operations updates. Update complexity becomes critical due to rapid prefix changes in the edge router. So, the updating operation in routers creates a fast update concern that is further serious to address and affects the overall performance.
Comparative evaluation of packet lookup schemes
To provide a consolidated view of the relative strengths and limitations of different packet lookup schemes, Table 15 presents a qualitative comparison across four key metrics: memory efficiency, lookup speed, packet update complexity, and scalability. These metrics were selected based on their relevance to both wired and wireless NDN deployment contexts as discussed in previous subsections.
| Lookup scheme | Memory efficiency | Lookup speed | Update complexity | Scalability |
|---|---|---|---|---|
| Trie-based | Medium | High | Medium | High |
| Bloom Filter | High | High | Low | Medium |
| Hash Table | Medium | High | Medium | Low |
| Ternary CAM | Low | Very High | High | Medium |
| Bitmap Indexing | High | Medium | Medium | Medium |
Key research challenges and future directions
This section addresses RQ3: What are the open challenges and future opportunities for integrating scalable, secure, and context-aware naming and lookup mechanisms in real-world NDN deployments?
Challenges in wired and wireless NDN environments
Despite notable advancements and testbed deployments in NDN, several design challenges remain active areas of research, particularly in the context of naming scalability, lookup latency, and real-time performance in dynamic environments. This section presents a comprehensive analysis of the key research challenges and open issues that need to be addressed for the widespread adoption of NDN. Table 16 shows the challenges in wired and wireless NDN.
| Challenge | Wired NDN | Wireless NDN |
|---|---|---|
| Scalability | Name explosion, FIB/PIT growth, lookup latency | Frequent topology changes, high lookup failures, mobility-induced overhead |
| Memory efficiency | Large routing tables, complex lookup mechanisms, | Constrained device memory, need for lightweight caching |
| Security | Interest Flooding, cache pollution, authentication overhead | Vulnerability to eavesdropping, resource-limited encryption |
| Mobility | Relatively stable routing, but lacks adaptive forwarding | High mobility, seamless handovers, predictive caching required |
| Deployment | Backward compatibility with IP, large-scale ISP challenges | Energy efficiency, SDN, and Edge Computing integration |
Scalability challenges in NDN naming and lookup
NDN introduces a content-centric paradigm, which inherently requires scalable naming and efficient lookup mechanisms. In wired networks, hierarchical naming structures can lead to a name explosion, increasing memory overhead and lookup time. The LPM in FIB and the exact matching technique in PIT create computational bottlenecks. Unlike DNS, NDN lacks a globally scalable, distributed name resolution mechanism for efficient content retrieval. In wireless environments, scalability issues are further exacerbated due to constrained resources and frequent topology changes. High mobility and intermittent connectivity increase lookup latency and name resolution failures. Additionally, wireless NDN must handle dynamic data caching to optimize bandwidth usage while maintaining content availability.
Memory efficiency and lookup optimization
Memory storage requirements in NDN routers pose a significant challenge in wired and wireless networks. FIB, PIT, and CS require extensive storage in wired networks, especially for large-scale deployments. Existing solutions, such as Trie-based, Bloom filter-based, and Hash table-based approaches, require further optimization to manage vast naming tables efficiently. In wireless scenarios, memory limitations are even more severe due to the constrained hardware capabilities of IoT and edge devices. The high cost of maintaining large PIT tables in mobile devices necessitates lightweight and distributed lookup mechanisms that reduce redundancy and improve cache utilisation. Additionally, adaptive caching strategies are required to minimise memory overhead while ensuring low retrieval latency.
Security and privacy issues in NDN
Due to its content-centric approach, NDN introduces new security challenges. Cache pollution attacks, Interest flooding attacks, broadcast storm attacks, timing attacks and data authentication issues impact performance and trustworthiness in wired as well as in wireless networks (Arsalan & Rehman, 2022). Attackers can inject invalid data into caches, disrupting efficient content delivery. Ensuring content integrity and authenticity without incurring excessive overhead remains a significant challenge. Enhancing NDN’s security framework by integrating cryptographic techniques and blockchain-based authentication can provide robust protection against emerging threats. In wireless networks, security concerns become increasingly critical due to heightened vulnerability to eavesdropping and tampering. Mobile and IoT devices face additional risks stemming from their open communication channels and limited processing power for cryptographic operations. Designing lightweight encryption and authentication schemes for wireless environments is essential to mitigate these challenges.
Mobility and routing in dynamic environments
As NDN is considered for IoT, vehicular networks, and mobile edge computing, mobility remains a significant challenge. In wired environments, routing strategies are relatively stable; however, the lack of adaptive forwarding techniques can affect dynamic traffic conditions. Seamless handovers between different NDN routers require optimized FIB management and caching policies. Wireless networks face intensifying challenges due to rapid topology changes and frequent disconnections. Efficient strategies are needed to handle seamless handovers while maintaining low latency. Name-based multicast strategies and AI-driven predictive mobility management solutions can significantly enhance content delivery efficiency in highly dynamic scenarios.
Deployment and real-world implementation challenges
While NDN has been widely studied, its real-world implementation faces practical challenges in both wired and wireless domains. In wired networks, transitioning from IP-based architectures to NDN requires hybrid mechanisms to ensure backward compatibility. Large-scale deployment in ISP networks remains a critical challenge, as ensuring QoS guarantees for end-users is essential. In wireless environments, real-world deployments must address challenges related to energy efficiency, intermittent connectivity, and scalability. Integrating NDN with SDN and Edge Computing can provide more flexibility in dynamically managing wireless resources. Future research should focus on developing energy-efficient routing and caching solutions to facilitate the widespread adoption of these technologies in mobile and IoT applications.
Future research directions
The evolving landscape of NDN presents numerous opportunities for innovation, particularly in designing scalable, secure, and context-aware naming and lookup mechanisms suited for real-world deployments. Building on the challenges discussed, this section outlines key future research directions aimed at advancing NDN across both wired and wireless environments.
Domain-specific naming innovations
Future research should explore hybrid naming frameworks that combine the structure of hierarchical names with the flexibility of flat or attribute-based schemes. For wired NDN, optimising naming hierarchies to minimise redundancy and improve prefix aggregation can reduce lookup latency. In contrast, wireless and IoT environments require context-aware, lightweight naming systems that can adapt to device heterogeneity, mobility, and intermittent connectivity. Research into semantic or ML-enhanced naming strategies could provide personalised and efficient content retrieval without incurring excessive memory or processing overhead.
Advanced lookup structures and caching models
Scalable lookup mechanisms must be designed to handle rapid content growth and diverse network scales. For wired settings, refinement of high-speed structures such as Trie variants, compressed Bloom filters, and hybrid Hash table models can improve FIB/PIT performance. Wireless networks demand decentralized, memory-efficient structures suitable for constrained devices. Cross-layer and cooperative caching models, especially those leveraging predictive analytics, should be explored to enhance cache hit rates and minimize redundant transmissions across dynamic wireless networks.
Security and privacy-aware protocol design
As NDN shifts toward mainstream adoption, developing integrated security solutions remains a top priority. Lightweight, distributed trust management schemes are needed to protect content authenticity and user privacy in both wired and wireless domains. Future work should investigate blockchain-assisted naming and lookup mechanisms, Interest signature schemes, and context-aware access control for content-centric data flows. For wireless NDN, research into energy-aware encryption protocols and tamper-resistant Interest validation strategies can enhance deployment in vulnerable environments, such as IoT and VANETs.
AI-driven forwarding and mobility management
The integration of AI into NDN forwarding decisions offers promising opportunities for improving adaptability and reducing latency. Reinforcement learning, federated learning, and mobility prediction techniques can be used to enhance routing performance under dynamic network conditions. In vehicular and mobile IoT scenarios, predictive FIB updates and AI-powered caching placement can ensure seamless handovers and high data availability. Wired NDN can also benefit from adaptive routing strategies to respond to traffic bursts and link failures in real-time.
Real-world testbeds and cross-domain integration
To validate theoretical models, there is a pressing need for large-scale NDN testbeds that include both fixed and mobile nodes. These testbeds should evaluate performance under realistic traffic loads, failures, and content distribution patterns. Furthermore, integrating NDN with complementary paradigms, such as SDN, Edge Computing, and Digital Twin technologies, can unlock new levels of network orchestration and simulation-driven optimization. Cross-domain use cases, including healthcare, smart agriculture, and industrial automation, can help establish NDN’s relevance in emerging sectors.
Standardization and interoperability
A future-ready NDN ecosystem will require a strong emphasis on interoperability across different naming and lookup protocols. Standardization of naming conventions, metadata encoding, and FIB/PIT management APIs will facilitate integration with legacy systems and enable cross-network collaboration. Collaboration with industry bodies and open-source consortia will be essential to push NDN from academic labs into production-grade deployments.
By pursuing these directions, the NDN research community can collectively address the gaps identified in this survey and move toward a robust, adaptable, and secure architecture capable of meeting the demands of next-generation networking.
Conclusion
NDN represents a notable progress in ICN, enabling a shift from host-centric to content-centric communication. This survey presents a detailed examination of the two fundamental components of NDN: naming systems and packet lookup schemes, which are vital for effective data retrieval, routing, and forwarding.
The core principles of NDN have been presented, including its communication model, the main packet types (Interest and Data), and essential components such as the FIB, PIT, and CS. Based on this structure, a comprehensive taxonomy of NDN naming schemes was developed, categorizing them into hierarchical, flat, hybrid, and attribute-based classifications. We compared these schemes across key dimensions, including scalability, aggregation, readability, and routing efficiency, and highlighted the naming challenges specific to context-awareness, name-length explosion, semantic resolution, and security.
The second primary focus was an exhaustive study of packet lookup approaches, covering both wired and wireless NDN domains. We conducted a systematic organization and analysis of FIB-based, PIT-based, and router-level approaches, including methods such as trie structures, bloom filters, hash tables, CAM-based hardware acceleration, and hybrid lookup frameworks. Detailed reviews were conducted on wireless-specific mechanisms that address resource-constrained environments, mobility, and adaptive caching. A comparative analysis table was proposed for packet lookup approaches, benchmarking them on criteria such as memory usage, lookup latency, update complexity, and scalability.
We performed a comprehensive review of advanced schemes and conducted a critical evaluation of research challenges and open issues by identifying limitations related to scalability, memory efficiency, mobility handling, security, and real-world deployment. The difference between wired and wireless NDN environments was highlighted, and domain-specific optimization strategies were recommended. Furthermore, we proposed a set of research directions, including integration with SDN and edge computing, use of AI-based routing, and development of energy-aware, lightweight lookup algorithms. Finally, we addressed three research questions (RQs) to guide the systematic exploration and evaluation of existing works, covering the evolution of naming approaches (RQ1), the classification and comparative analysis of packet lookup approaches (RQ2), and the unresolved challenges and future opportunities for real-world deployment (RQ3).
In summary, we present a comprehensive and structured analysis of naming and packet lookup in NDN, targeting beginners and researchers within the domain. This survey connects theoretical constructs with practical implementation insights, serving as a valuable reference for designing scalable, secure, and efficient NDN systems specific for next-generation Internet architectures.