
An empirical comparison of ensemble and deep learning models for multi-level Arabic fake news detection using the JoNewsFake dataset
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Data Mining and Machine Learning, Natural Language and Speech, Neural Networks
- Keywords
- Arabic fake news detection, Multi-level and multi-label classification, JoNewsFake dataset, Transformer model, Deep learning, Ensemble learning, AraBERT embeddings, Arabic NLP
- Copyright
- © 2026 Alkudah et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. An empirical comparison of ensemble and deep learning models for multi-level Arabic fake news detection using the JoNewsFake dataset. PeerJ Computer Science 12:e3510 https://doi.org/10.7717/peerj-cs.3510
Abstract
We present a comparative study of ensemble and deep learning architectures for multi-label, multi-level Arabic fake news detection on the JoNewsFake dataset, a dataset of 50,000 Facebook posts from 12 verified Jordanian news agencies annotated with 22 main categories, ~75 subcategories, and Fake/Real labels. The models include Random Forest, Extra Trees, LightGBM, Convolutional Neural Network (CNN) + Bi-LSTM, CNN + Bi-GRU, and a Transformer encoder. All systems use a hybrid representation that concatenates AraBERT semantic embeddings, POS-based syntactic features, and emotion indicators (894 dimensions). Extra Trees yields the strongest overall performance with a Macro F1-score of ≈0.95 (Main), ≈0.98 (Sub), and ≈0.95 (Fake/Real), while the Transformer achieves a Subcategory Macro F1-score of ≈0.93, suggesting that self-attention offers benefits for fine-grained label spaces. We provide a clear account of data collection, filtering, annotation, and evaluation to support reproducibility. The findings show that carefully engineered features paired with efficient ensembles remain highly competitive for Arabic news, whereas Transformer encoders excel when hierarchical granularity increases. This work offers a rigorous, data-driven baseline for Arabic fake news detection across multiple classification levels and can guide future extensions (e.g., cross-dialect coverage and cross-platform validation).
Introduction
Many people get their news from social media platforms because of their ease of access and instant updates. A lot of people in the Arab world use social media, for example, as their primary source of news instead of newspapers and television. Facebook and Twitter are among the most important sources of instant news in Jordan, especially during political and regional events. According to Thaher et al. (2021) and Al-Jalabneh & Safori (2022), social media is better at spreading breaking news than traditional media. But not all of the information that circulates is reliable. People often intentionally alter information because of economic, political, or societal reasons. This makes content that is not completely true or is entirely fraudulent (Al-Taie, 2025).
This unclear conformity between the true and the false has resulted in a lot of fake news on digital platforms. This has caused problems like people not knowing the truth and instability in society. Rumors, hoaxes, satirical pieces, misleading headlines, and political stories are just a few examples of the many types of information that are part of the larger category of fake news (Rahmanian, 2023). Researchers have found that fake news spreads faster than true news (Bsoul, Qusef & Abu-Soud, 2022), which has motivated a wave of research into developing automated systems to detect its dissemination (Al-Jalabneh & Safori, 2022). As an example, Google introduced the initiative of Google News as a part of the bigger endeavor to curb the spread of misinformation and assist the users in making the distinction between fake and real information.
It is known that the problem of fake news detection is highly limited to the changing nature of false information and the necessity of strong linguistic knowledge (Alkhair et al., 2019). The model used to detect fake news is usually aimed at assigning news articles or posts as fake or real, usually by using previous examples of both categories. This classification problem can be binary or discussed as a multi-class or multi-label situation that is more complicated (Khalil, Jarrah & Aldwairi, 2024). Since 2017, researchers have developed various benchmark datasets such as SANAD, ArSarcasm, ARACOVID19-MFH, MAWQIF, AraNews, AFND, JoNewsFake, FA-KES, and RTAnews fake news datasets to improve model training and evaluation (Salem et al., 2019; Al-Salemia et al., 2019; Ameur & Aliane, 2021; Alturayeif, Luqman & Ahme, 2022; Khalil et al., 2022; Wotaifi & Dhannoon, 2023).
Although most of the literature reviewed is based on English-language datasets and classification models, the problem of Arabic fake news detection is under-researched (Alturayeif, Luqman & Ahme, 2022; Al-Taie, 2025). Models dealing with Arabic multi-label and multi-level classification, which is a necessary step to demonstrate how news is actually structured in the real world, are not available (Almuzaini & Azmia, 2022). The linguistic challenges associated with Arabic, such as morphological complexity, diglossia, and dialectal variation, further complicate the detection process and underscore the need for more tailored modeling approaches (Al-Yahya et al., 2021).
While Arabic fake news detection has attracted increasing attention, most existing studies focus on binary classification tasks and do not address the hierarchical nature of real-world news. Moreover, few works conduct a comprehensive, unified comparison between ensemble machine learning models and deep learning approaches, including transformer-based models, under a multi-label, multi-level setup. In addition, there is a lack of studies that fine-tune transformer-based models like AraBERT specifically for Arabic fake news detection, or that integrate semantic, syntactic (POS), and emotional signals into a hybrid representation. This study fills these gaps by evaluating a diverse set of models on a real-world dataset (JoNewsFake), introducing a fine-tuned AraBERT model, and incorporating rich linguistic features for enhanced classification performance across multi-label, multi-level classification.
There are a number of Arabic fake news corpora such as AFND (Khalil et al., 2022), ArCOV-19 (Haouari et al., 2020), FA-KES (Salem et al., 2019), and RTAnews (Al-Salemia et al., 2019), which provide valuable starting points but remain limited in scope. Most are binary or single-level, lack hierarchical topic labeling, and often mix user-generated and unverified content. Furthermore, few benchmarks are both ensemble and deep architectures under a unified feature space. These constraints leave a gap for a high-quality, hierarchically labeled Arabic dataset reflecting authentic news agency communication.
JoNewsFake addresses this gap by offering 50,000 manually annotated posts from 12 verified Jordanian news agencies, covering 22 main categories, ~75 subcategories, and a Fake/Real dimension. Beyond the dataset contribution, this work introduces a hybrid feature representation (AraBERT embeddings + POS tags + emotion signals; 894 dimensions) and conducts the first unified benchmarking of ensemble and deep models across all three classification levels. Table 1 summarizes the main differences between JoNewsFake and existing Arabic fake news resources.
| Dataset | Type | Size | Label(s) | Source | Hierarchical/Multi-label | Verified news sources |
|---|---|---|---|---|---|---|
| AFND | News articles/organizations | ≈606k | Credible, Non-credible, Undecided | 134 Arabic news websites and portals | (binary) | ✓ |
| FA-KES | News articles | ≈800 | Fake, Real | Various online sources | (binary) | ✗ |
| RTAnews | News articles | ≈23k | 40 topics (categorical) | Russia Today Arabic portal | Partial (Top-level only) | ✗ |
| ArCOV-19 | Tweets | ≈3 million | Accurate, Inaccurate | Twitter API + GetOldTweets3 library | (binary) | ✗ |
| COVID fake news | Social media posts | ≈10k | Fake, Real | Facebook/Instagram | (binary) | ✗ |
| AraNews | News articles from 15 countries | ≈16k | Politics, Economy, Culture, Sports etc. | Online news sites | (binary) | ✗ |
| JoNewsFake (this work) | Facebook posts from verified news agencies (Jordan) | 50k posts | 22 Main categories, ~75 Subcategories, Fake/Real | 12 verified Jordanian news agencies | ✓ (multi-level + multi-label) | ✓ |
This study’s main contributions are as follows:
We compare several ensemble classifiers (Random Forest, Extra Trees, LightGBM) and deep learning models (CNN + Bi-LSTM, CNN + Bi-GRU, fine-tuned CNN variants, Transformer-based models).
We employ a hybrid Tuned-AraBERT feature representation combining semantic embeddings from AraBERT with syntactic (POS tags) and emotional indicators.
We evaluate performance across multi-label, multi-level classification tasks: binary fake/real classification, main-category classification, and subcategory classification.
We analyze model strengths, limitations, and the role of linguistic features in Arabic fake news classification.
This is how this article has been organized: ‘Related Work’ provides an overview of related work in Arabic fake news detection and multi-level multi label text classification. ‘Research Objective’ outlines the research objectives. ‘Background’ explains the machine learning and deep learning models used, along with the experimental setup and evaluation metrics. Then ‘Dataset’ describes the JoNewsFake dataset, including data collection, filtering, and pre-processing steps followed by experimental setup and evaluation matrices in ‘Evaluation’. ‘Methodology’ detailed methodology with data precreation and feature extraction to the preprocessing phase. ‘Experimental Outcome’ presents and analyzes the experimental results and detailed discussion and limitans. Finally, ‘Conclusion and Future Work’ concludes the article and suggests potential directions for future research.
Related work
Since the use of social media has remained a dominant force in disseminating news, detecting fake news has become a highly important NLP problem. Initial research was focused mainly on fake news as a binary classification problem and addressed by common ML algorithms like SVM, RF, and NB (Khalil et al., 2022). The development of deep learning led to the usage of such models as CNN, LSTM, and Bi-LSTM to identify contextual and sequential regularities (Salem et al., 2019).
But in the real world, the news tends to have several themes that overlap and this makes researchers change their perspective towards a multi-label, multi-level classification strategy. They are strategies that give more than one name (e.g., politics, local, economy) and work on the hierarchical level (e.g., main category, subcategory, veracity). To illustrate this, Sorour & Abdelkader (2022) have offered a hybrid CNN-LSTM network to classify fake news in multiple classes. Liu et al. (2022) proposed a recommendation-based architecture that incorporates deep features in hierarchical decision making. Most of the studies on the fake news detection problem in the Arabic context continue to treat it as a binary classification problem and negates its hierarchical and multi-dimensional nature (Hadeel, Mohamed & Orasan, 2020; Khalil, Jarrah & Aldwairi, 2024). A limited number of recent works have identified this limitation. As an example, Almuzaini & Azmia (2022) addressed the necessity of hierarchical models that would be related to the morphological intricacy of Arabic. Alturayeif, Luqman & Ahme (2022) have tried to classify the stance on multi-level but did not entirely enforce the fake news detection in this stratum.
Although the topic of Arabic fake news detection has been actively discussed in recent times, the majority of the existing studies are based on the binary or single-level classification paradigm. Alruily (2021) and (Aljedani, Alotaibi & Taileb, 2020) both posited the lack of robust, multi-label, hierarchical categorization models of Arabic text and in particular, with the real-world streams of news. The multi-label, multi-level classification in Arabic is still under-represented in few datasets, thus, it is hard to train and test models. It is important to note here that the need arises to create such a resource as JoNewsFake that will fill in this gap of crucial need. In terms of datasets, only a limited number of Arabic corpora offer partial support for multi-label, multi-level annotation. The AFND dataset (Khalil et al., 2022) provides fake/real labels but is limited to flat classification. FA-KES (Salem et al., 2019) includes topic-level labels such as politics and religion, while RTAnews (Al-Salemia et al., 2019) offers multi-topic news articles tagged with several content categories. But none of these datasets were designed to work with hierarchical or multi-level categorization frameworks. They don’t provide a clear list of main categories and subcategories; thus, they cannot be utilized directly to train models for multi-level, multi-label fake news detection without substantial modification. This gap significantly limits the development and benchmarking of advanced models in this domain.
Research on multi-label, multi-level English-language classification has explored a broader range of problem-transformation methods, including Label Powerset (LP) and Classifier Chains (CC), as well as ensemble- and deep-learning-based models. Basic techniques of converting the multi-label problems to multi-binary or multi-class problems using such a classifier as k-NN, Naive Bayes, and SMO were described by researchers such as Tarekegn, Ullah & Cheikh (2024) and Yildirim, Bakhshi & Can (2024). In other studies, such as Maxwell et al. (2017) and Qandos et al. (2024), medical or product-review datasets were utilized to evaluate the LSTM and deep neural networks. Such research demonstrate that the multi-label method can be used in various areas. Along with that, Kaur, Kumar & Kumaraguru (2020) proposed the mixture of multiple English datasets (including Reuters and Kaggle) to train multi-level voting classifiers to detect fake news and demonstrated good performance in the accuracy and training efficiency.
Thus, although some attempts are beginning, Arabic fake news detection still does not have powerful models and resources of multi-label, multi-level classification, which is the focus of this study. The proposed study is the pioneer to provide a multi-label, multi-level Arabic fake news classifier using JoNewsFake, which is augmented with syntactic and emotional features, making it possible to experiment and evaluate the model on deeper levels within the under-researched subject matter.
Research objective
Fake news has spread rapidly as people depend more on social media as their main source of news, especially in Arabic digital media. A lot of early work has focused on binary fake news detection, but this approach doesn’t work well because real-world news is generally about more than one issue and is organized into hierarchical categories. In addition, traditional methods like blacklisting sources or relying solely on human verification don’t work well, especially when trustworthy sources sometimes spread false information. Because Arabic is linguistically rich and has highly complicated grammar, we need a more advanced and context-aware way to detect it. Therefore, this research aims to develop a multi-label, multi-level Arabic fake news detection model capable of classifying news articles not only by veracity (fake/real), but also by main and subcategories (e.g., politics → local). The study leverages ML and DL models to learn semantic, syntactic, and emotional patterns that distinguish fake from real news. This work also introduces a novel Arabic dataset specifically designed to support hierarchical classification, addressing an important gap in current fake news detection resources.
Background
This section introduces a concise overview of the ML and DL models employed in this study for multi-label, multi-level Arabic fake news classification across tasks.
Random forest (RF)
Random Forest is an ensemble learning model that is extensively utilized and creates a large amount of decision trees during training and combines the results to create strong predictions. To produce a bag of trees, each tree is now trained on a random sub-sample of the training data (bootstrap aggregating), and random sub-samples of features are chosen at each split of the tree to add even more sources of variance reduction and eliminate overfitting. This group method increases accuracy of classification as well as generalization of the model particularly with noisy or complex data (Al-Ahmad et al., 2021; Imani, Beikmohammadi & Arabnia, 2025).
The effectiveness of Rand Forest in text classification including fake news detection has been affirmed by several research studies. Alazab et al. (2022) noted, for example, its appropriateness in dealing with structured and unstructured data of moderate imbalance with classes. On the same note, Fouad, Sabbeh & Medhat (2022) have shown that it can be used to generate stable predictions with reasonable computational efficiency on natural language processing tasks. In this study, the RF classifier was implemented using the optimized hyperparameters, such as n_estimators, max depth as well as min samples split, to accommodate the nature of the Arabic fake news data. Each of the three levels of classification was used with the hybrid feature representation on this model, i.e., main category, subcategory, and fake/real. Although it was getting reasonable accuracy and was a good baseline, its ability to handle dependencies in the context was lacking in comparison to deep learning-based models. The Random Forest classifier of the present study is shown in Fig. 1.
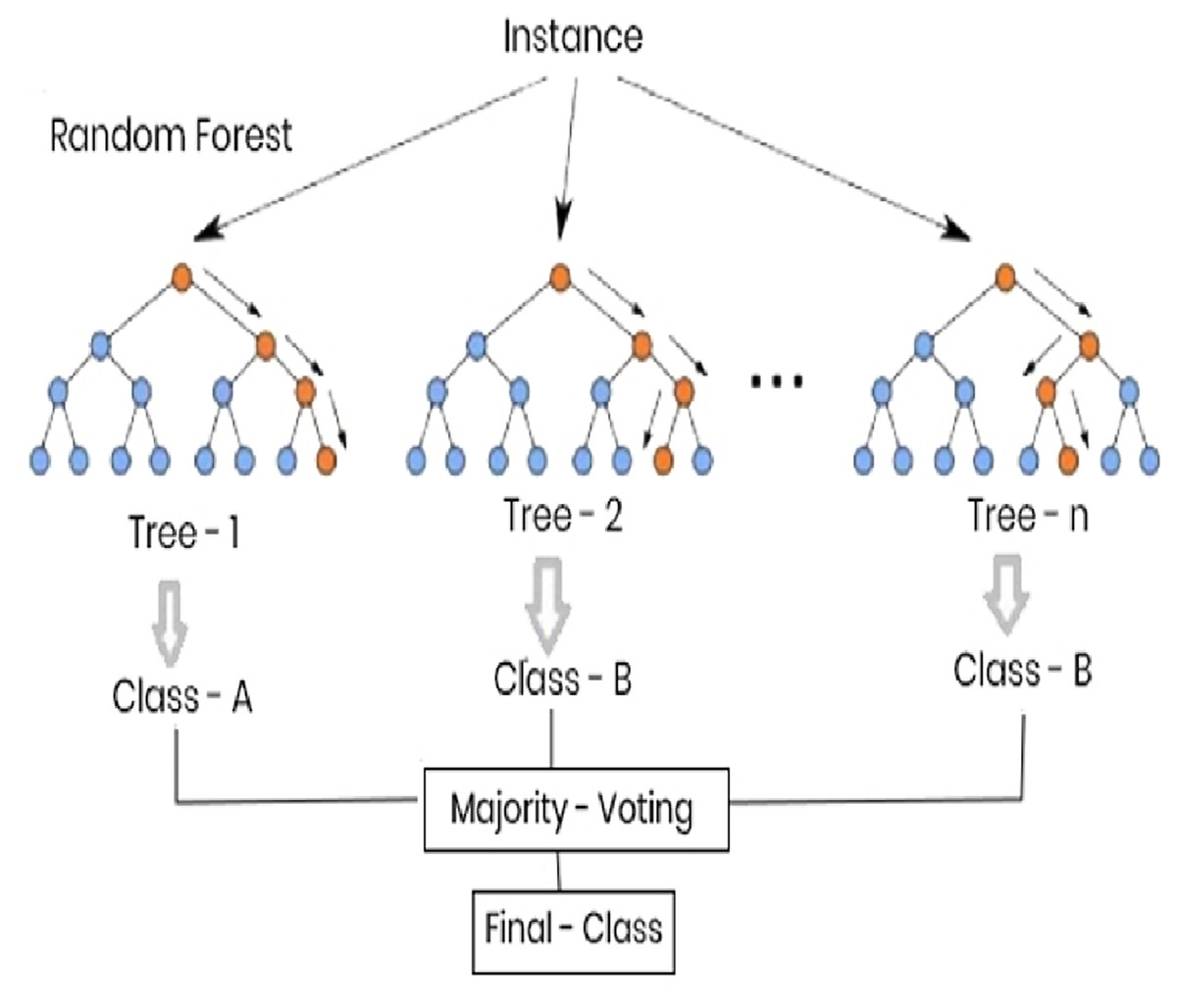
Figure 1: Random forest structure.
{kind=link}
Extra trees classifier (ETC)
Extra Trees Classifier refers to ensemble learning which builds a large number of decision trees to increase prediction accuracy as well as minimise variance. Extra Trees also introduces additional randomness; the randomly selected split points are values among possible feature values. This approach is not identical to Random Forest which makes use of the information gain or Gini index to find the best split. It also trains every tree on the whole dataset and not on bootstrapped samples, which accelerate the training process and enhance generalization (Patil, 2022; Imran et al., 2024). Extra Trees can be used especially on high-dimensional data, where there can be irrelevant or noisy features. It is strong because it can de-correlate the trees to avoid overfitting. Like other ensemble techniques, the results of all trees in the ensemble are combined to obtain the results.
The recent research has confirmed the usefulness of the Extra Trees model in detecting fake news. The classification accuracy of 94.5 was reported by Patil (2022) hence showing that it can be trusted. On the same note, Extra Trees performed better than various models since (Fauzan, Putri & Laura, 2024) attained 0.96 accuracy with the combination of TF-IDF and BoW features, PCA and Chi-square selection. These findings affirm that this model has a high predictive capability in conjunction with good feature engineering. In this study, max_depth = 30, max_features = sqrt, and extra trees model were trained on 100 estimators. It was utilized in the three classification tasks including main category, subcategory and fake/real utilizing hybrid textual features which incorporated AraBERT embeddings, part-of-speech (POS) tags, and emotional indicators. The model was always high in accuracy, especially in the subcategory classification and was considered to be a steady guideline in the comparison of conventional ensemble procedures and deep learning ones. Figure 2 shows the algorithm of the Extra Trees classifier and its structure used in this study.
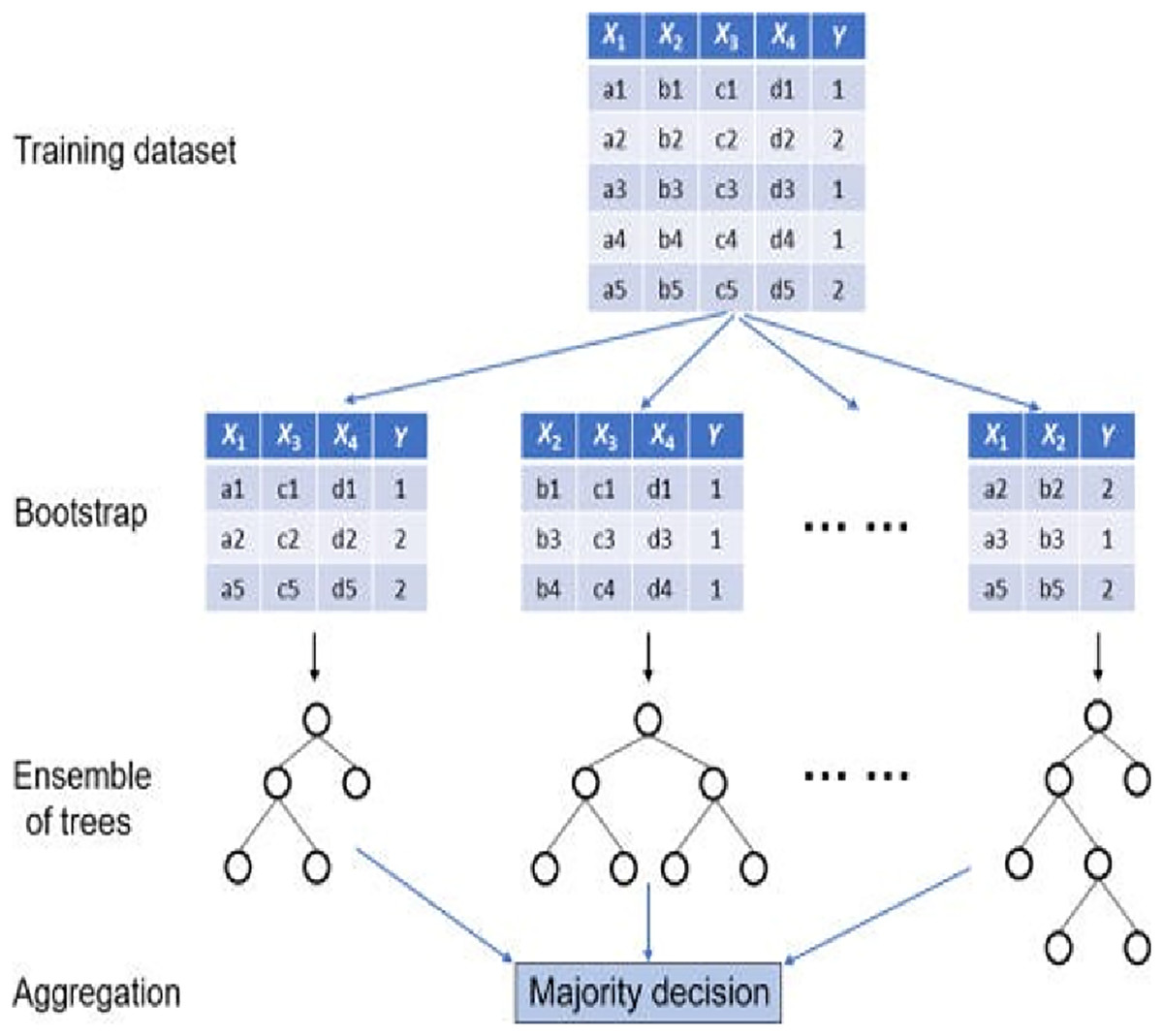
Figure 2: Extra trees classifier.
{kind=link}
LightGBM (LGBM)
LightGBM (Light Gradient Boosting Machine) is a Microsoft-developed gradient boosting framework that was designed to optimize in terms of efficiency and speed and was built to scale. It uses histogram-based decision splitting, as well as tree growth, leaf-wise, and thus more quickly converges and has higher accuracy than the traditional level-wise boosting methods. LightGBM can also be trained in parallel and with memory-efficient operations, which makes it especially effective when working with big high-dimensional data (Belinda et al., 2024). LightGBM has demonstrated good results in text classification and fake news detection in recent research. As an illustration, Dhiman et al. (2024) suggested a hybrid model that used LightGBM and BERT to identify fake news, which demonstrated the state-of-the-art results on various datasets. Equally, its ability to compete in multi-class and multilingual NLP tasks was noted by Pillai (2024) and Barua, Rahman & Joy (2025).
In this research, LightGBM was employed to classify Arabic news articles across three tasks: Main Category, Subcategory, and Fake/Real. The model was trained with an 894-dimensional feature representation that included semantic, syntactic, and affective aspects. We set LightGBM up with n_estimators = 100, max_depth = 10, and learning rate = 0.1. It showed particularly high accuracy in Subcategory classification, thanks to its fast-training speed and generalization capacity across fine-grained labels. However, its binary classification performance (Fake/Real) showed slight sensitivity to class imbalance. Figure 3 illustrates the workflow of LightGBM training in this study, highlighting its role in Arabic news classification across multiple levels.
Figure 3: The optimal parameters of the LightGBM model.
{kind=link}
CNN + Bi-LSTM
The CNN + Bi-LSTM hybrid model is a deep learning architecture that uses both CNN and Bi-LSTM networks to get the best of both of them. CNN layers are good at identifying local features like n-grams and word collocations. Bi-LSTM layers also find long-range relationships by looking at sequences in both directions. This kind of combination enhances both local and global feature learning, which is essential for understanding Arabic text. There have been a number of studies that show this hybrid design works well for classifying Arabic text (Jain, Gopalani & Meena, 2025). For example, Fouad, Sabbeh & Medhat (2022) reported that combining CNN and Bi-LSTM achieved superior accuracy in Arabic fake news detection by taking advantage of both local and contextual representations. Similarly, Khalil, Jarrah & Aldwairi (2024) employed a CNN + Bi-LSTM + Attention model for detecting fake content in Arabic news articles and achieved substantial improvements in Macro F1-score compared to standalone models. Additionally, in this research, the hybrid architecture was further enhanced by integrating an attention mechanism, which lets the model pay attention to the individual elements of the input that are most important. The full model was trained on a unified 894-dimensional input vector that includes semantic, syntactic, and emotional features. It outputs three classification labels: main category, subcategory, and fake/real. This architecture has been widely adopted in Arabic NLP tasks due to its high performance in multi-label classification problems. CNN, Bi-LSTM, and Attention all work together to make predictions more accurate and easier to understand. Figure 4 shows how the CNN + Bi-LSTM + Attention model employed in this study is set up, with an emphasis on how the input characteristics lead to the multi-task outputs.
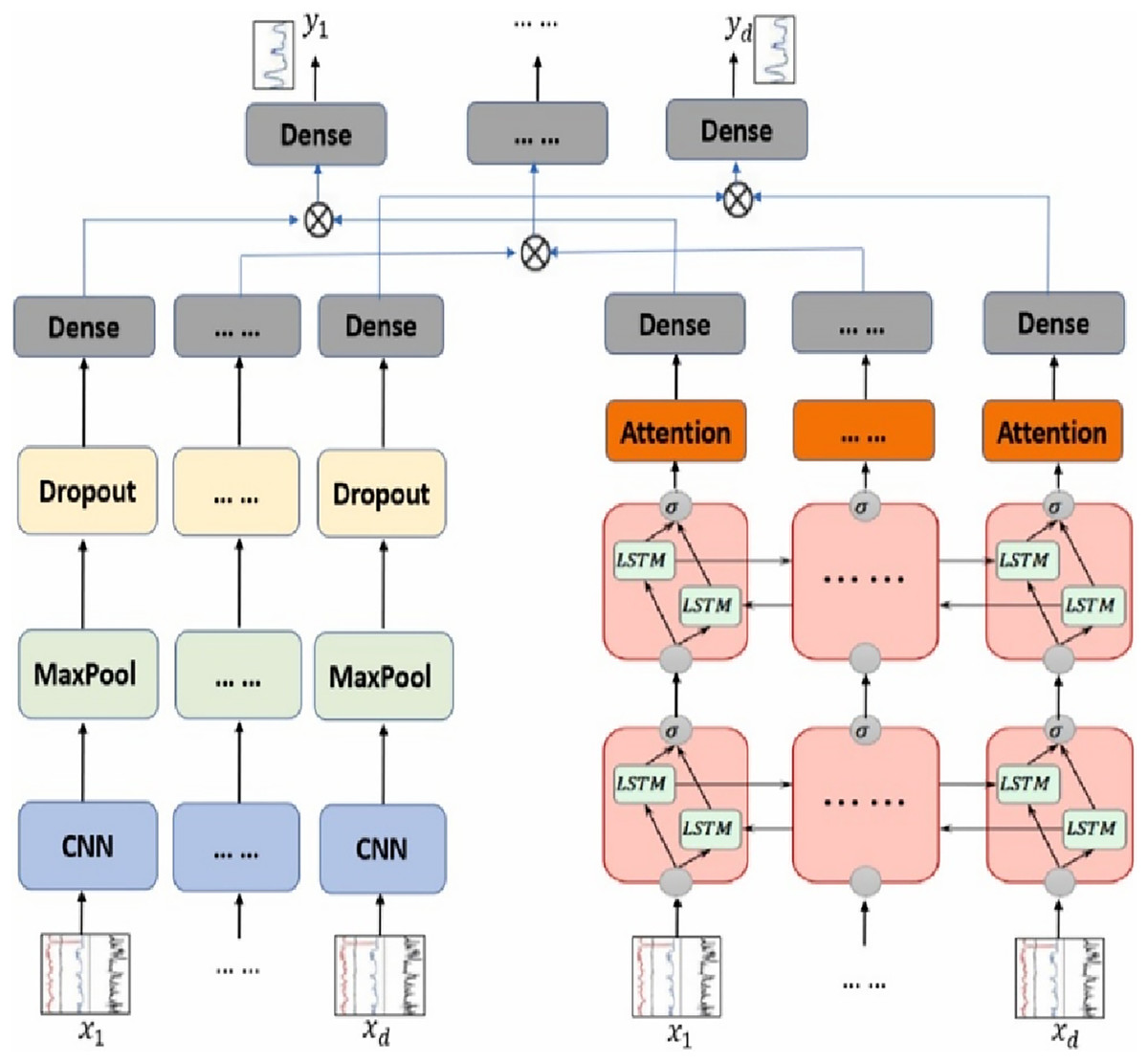
Figure 4: Bi-LSTM + CNN (A Hybrid model).
{kind=link}
CNN + Bi-GRU
The CNN + Bi-GRU hybrid model integrates CNN with Bi-GRU, augmented by an attention mechanism. This architecture uses CNN’s capacity to identify local n-gram features and stylistic patterns and Bi-GRU’s ability to capture contextual dependencies in forward and backward directions. This provides a more complete representation of Arabic text sequences. Several prior studies have highlighted the effectiveness of this hybrid structure (Aljohani, 2024). For instance, Wotaifi & Dhannoon (2023) showed that combining CNN and Bi-GRU significantly improved performance on Arabic sentiment and fake news detection tasks. Sorour & Abdelkader (2022) also demonstrated that attention-enhanced Bi-GRU models outperformed traditional GRUs, particularly when classifying complex and morphologically rich Arabic text.
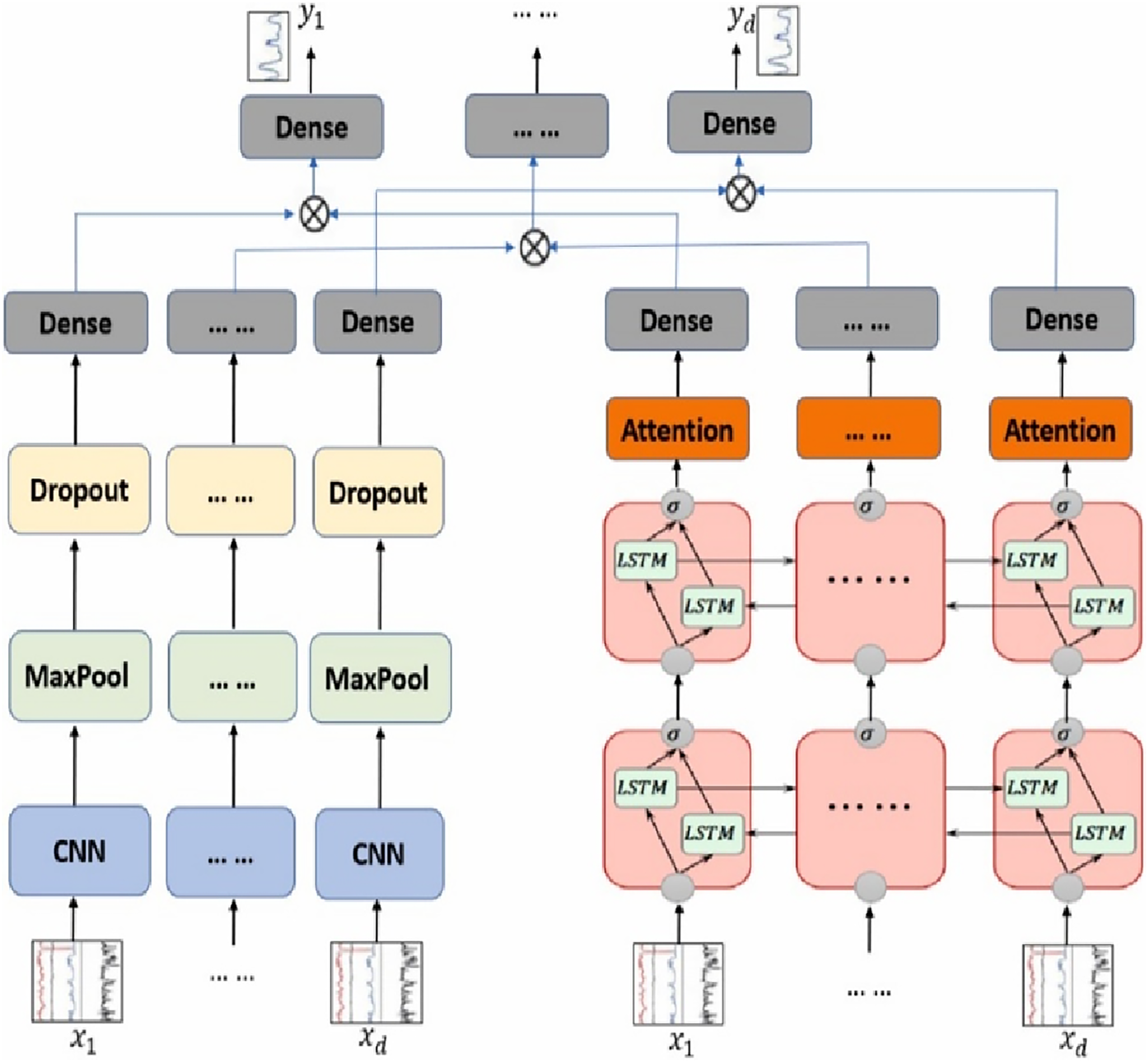
This model was trained in this study on a unified 894-dimensional feature vector composed of semantic (AraBERT), syntactic (POS tags), and emotional features. The attention layer dynamically weighed the relevance of individual tokens, which improved both prediction accuracy and model interpretability. To address the problem of unbalanced categories, the model was enhanced using standard callbacks (EarlyStopping, ReduceLROnPlateau, ModelCheckpoint) and class weights. Figure 5 illustrates the CNN + Bi-GRU + Attention model employed in this research, showcasing the data flow from the multi-dimensional input to the multi-task output layers (main category, subcategory, and fake/real classification).
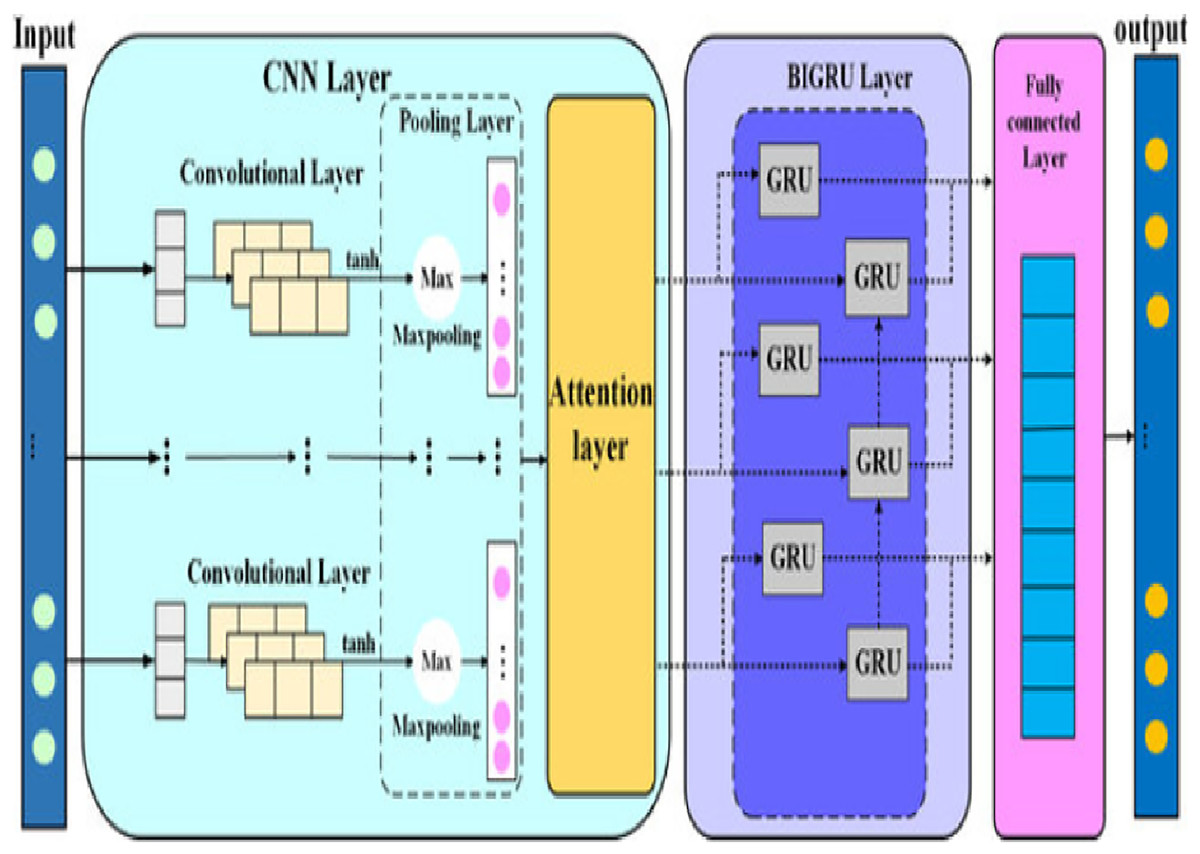
Figure 5: Bi-GRU + CNN (A Hybrid model).
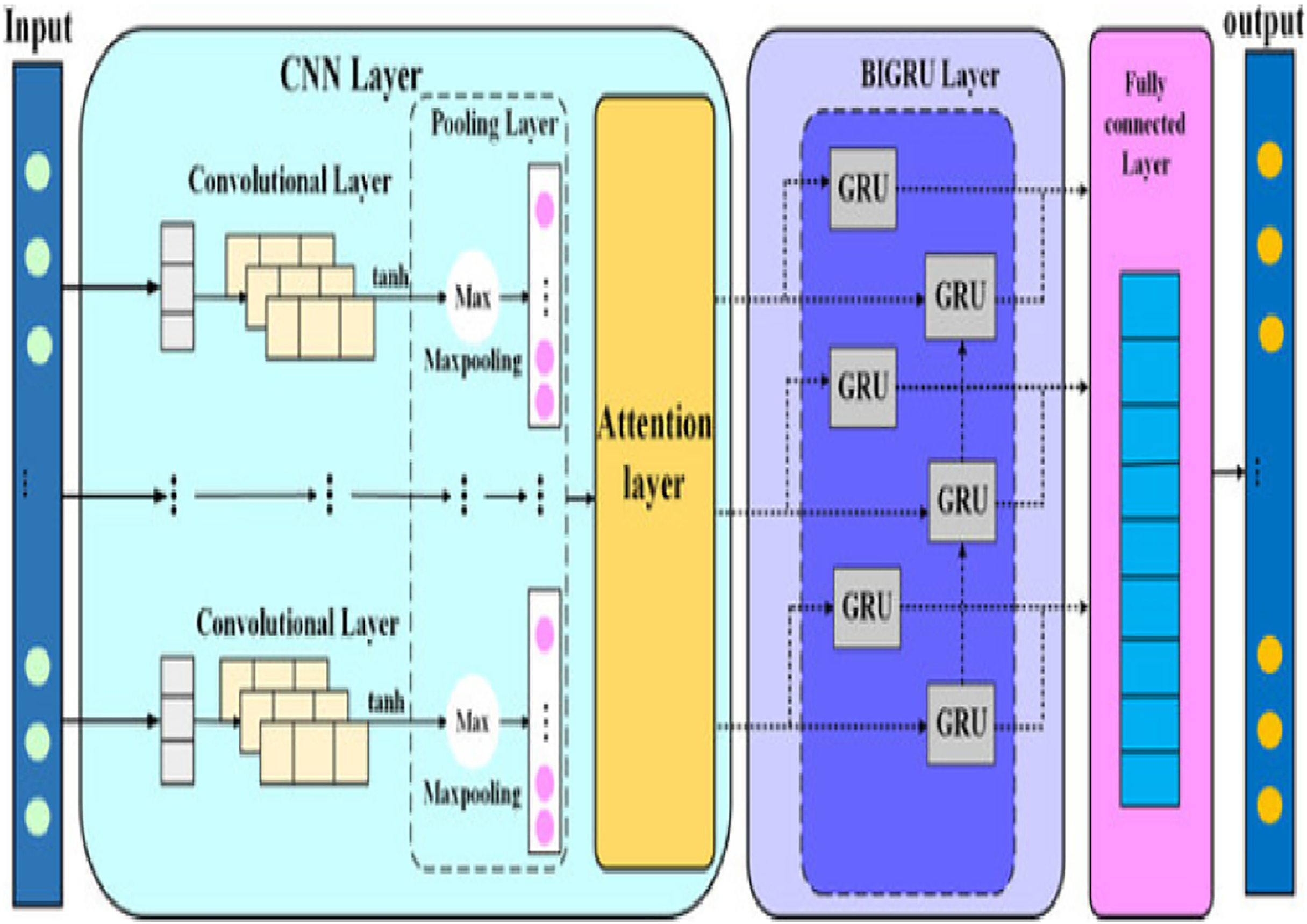{kind=link}
Fine-tuning CNN + Bi-LSTM
To enhance the working of the CNN + Bi-LSTM model in all three tasks of the classification (main category, subcategory, and fake/real), fine-tuning was utilized as an important optimization stage. In the first stage, the model has been trained on frozen base layers. This enabled the dense layers to learn without instability that would have occurred during simultaneous updating of all weights. Once the first convergence was achieved, the entire model was unfrozen, and it was again trained at a significantly lower learning rate to enhance overall generalization.
The Adam optimizer, with a learning rate of 0.00005, and the sparse categorical cross-entropy loss function, which is suitable when dealing with integer-encoded multi-class targets, were used in the fine-tuning process. The model was trained on a batch size of 64, and 15 epochs were used. Multiple adaptive callbacks were incorporated to guarantee the training of the model and avoid overfitting. The best-performing model in terms of validation accuracy was stored using the ModelCheckpoint callback, and ReduceLROnPlateau was used to automatically reduce the learning rate when the validation performance was not improving anymore. Furthermore, the training history was tracked with CSVLogger, which could then be used to resume training in case of session interruption, which is a sensible need when training on platforms such as Google Colab.
In this strategy each of the versions of the model corresponding to the main category, subcategory, and fake/real classification was fine-tuned separately. Fine-tuning made a strong impact on the Macro F1-score and recall measurements, particularly in classes that had low representation, which showed an overfitting or weak generalization effect. The final CNN + Bi-LSTM model is shown in Fig. 6 following fine-tuning. The model takes an 894-dimensional input (size of AraBERT embeddings + POS + emotion features) and transforms it into a reshaped form before undergoing convolutional and recurrent layers. The attention mechanism allows the model to target the informative and significant tokens and generate multi-output predictions through the three tasks of classification.
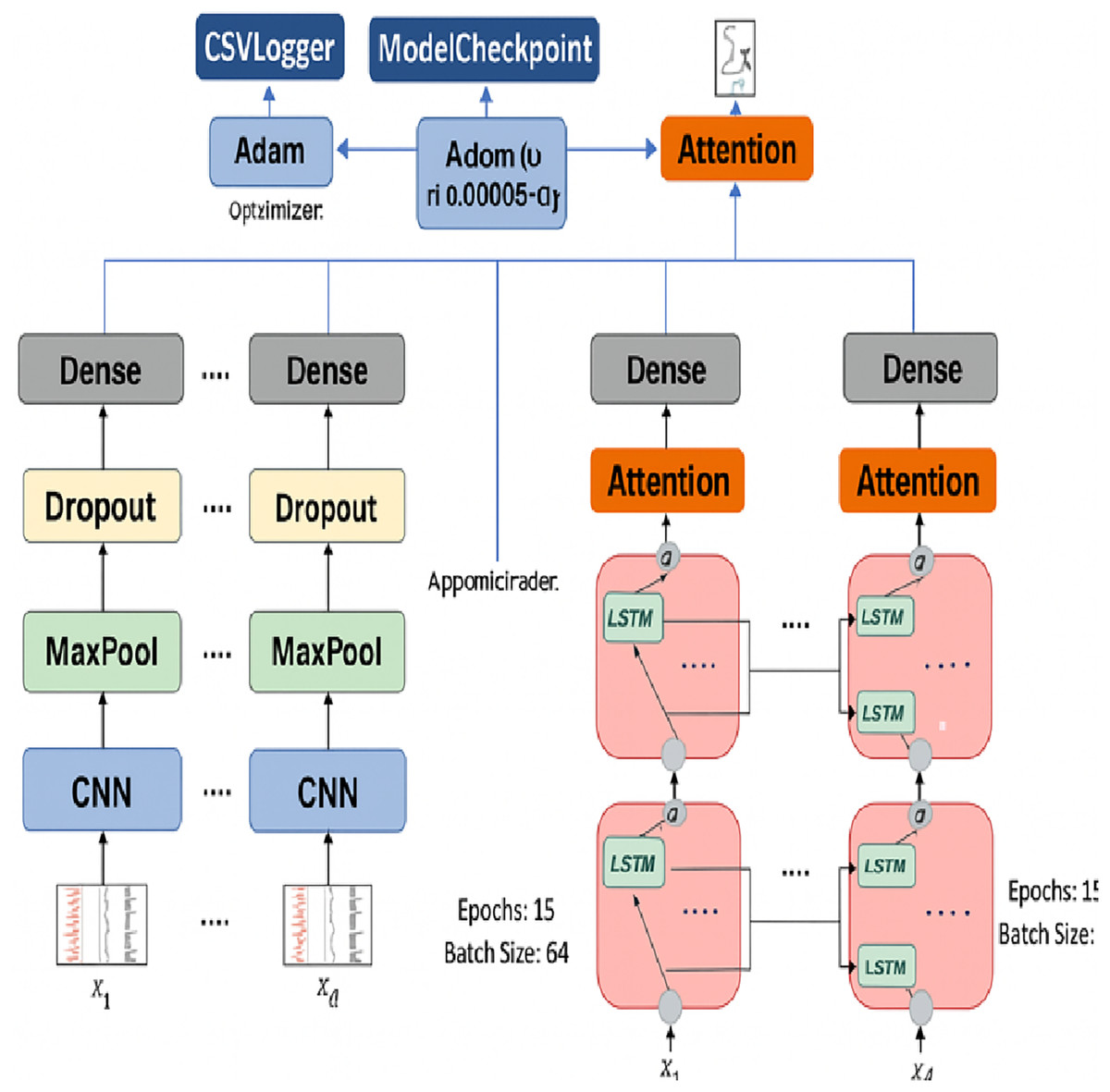
Figure 6: Fine-tuning CNN + Bi-LSTM architecture.
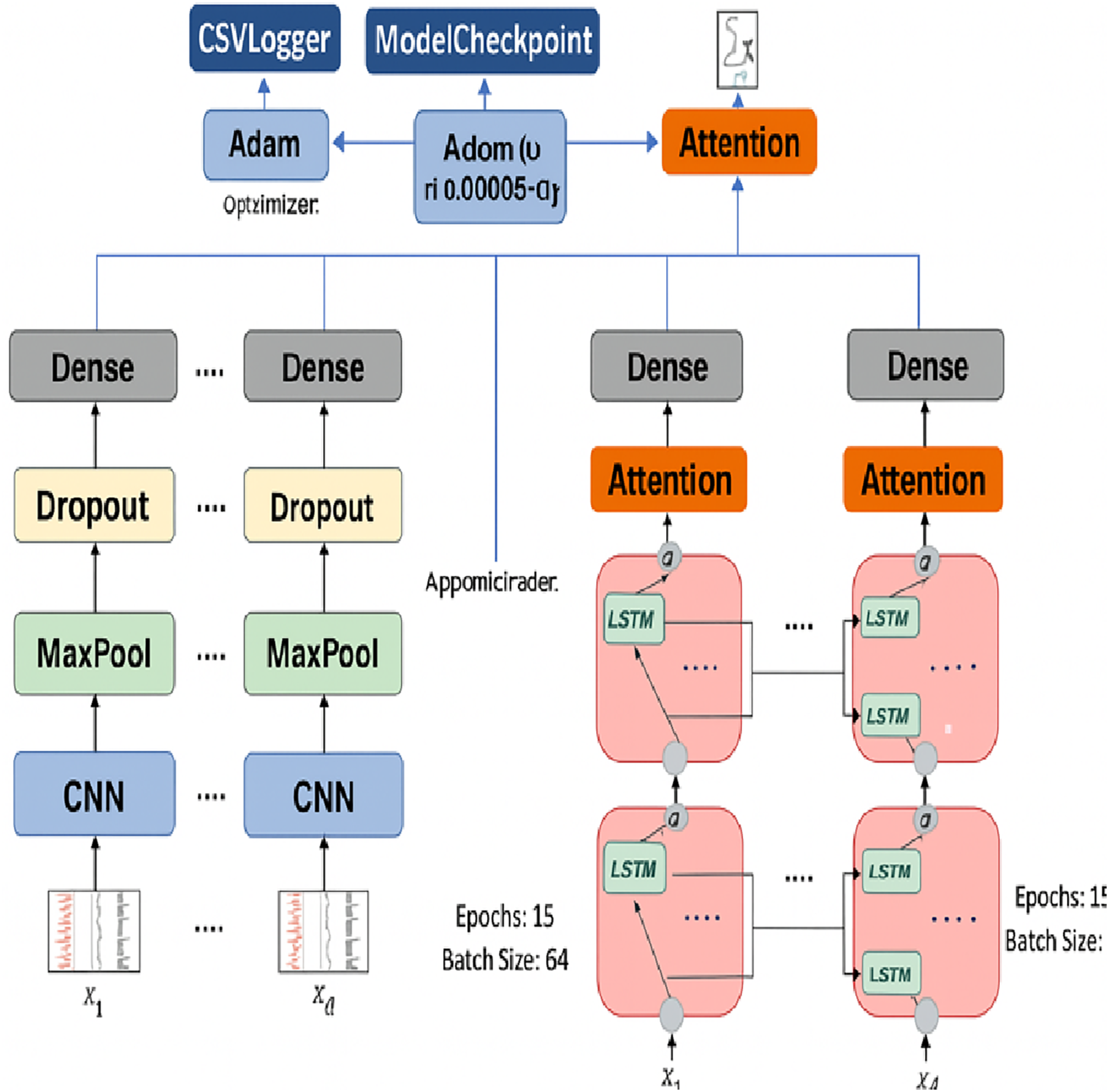{kind=link}
Fine-tuning CNN + Bi-GRU
The CNN + Bi-GRU hybrid model was fine-tuned on each of the three tasks of the output, which are the main category, the subcategory, and the fake/real. This was further done to enhance the performance in classification. The fine-tuning process commenced with a restart of the training on the weight saved. All the base layers were not frozen, and the learning rate was reduced very slowly to stabilize the gradient updates. This experiment had a slightly adjusted version of the callbacks to the fine-tuning strategy adopted compared to the Bi-LSTM-based fine-tuning strategy to optimize the stability of training and minimize the chances of overfitting.
The Adam optimizer with a learning rate of 0.00005 was used to train the model. The size of the batch was kept constant at 64. The maximum number of epochs could be 15, but Early Stopping used the patience value of 2. This implied that the model would cease training once the validation loss had ceased to decrease, hence preventing unnecessary calculus and minimizing the chances of overfitting. Another tool we used was the ReduceLROnPlateau callback, which helps to reduce the learning rate at the point of the performance plateau, and we used ModelCheckpoint to save the weights of the best model according to the validation accuracy. This configuration did not have a CSVLogger, as was the case with CNN + Bi-LSTM. Rather, typical assessment measures and visualization of training curves were used to monitor the training process.
The CNN + Bi-GRU model was also more stable in terms of training behavior and converged quicker than the Bi-LSTM architecture. It had shown good generalization on all classification tasks as well as in subcategory classification, where it was especially efficient in learning, which is useful in the Bi-GRU since its gating mechanism is simplified, and it is sensitive to context. The detailed CNN + Bi-GRU architecture that will be used in this study is shown in Fig. 7. The model takes the 894-dimensional input vector and then derives local and contextual features using convolutional and bidirectional GRU layers, which are followed by an attention mechanism. Then it generates multi-output predictions of the main category, subcategory, and fake/real tasks. This design is effective in balancing training efficiency and high classification performance among all the outputs.
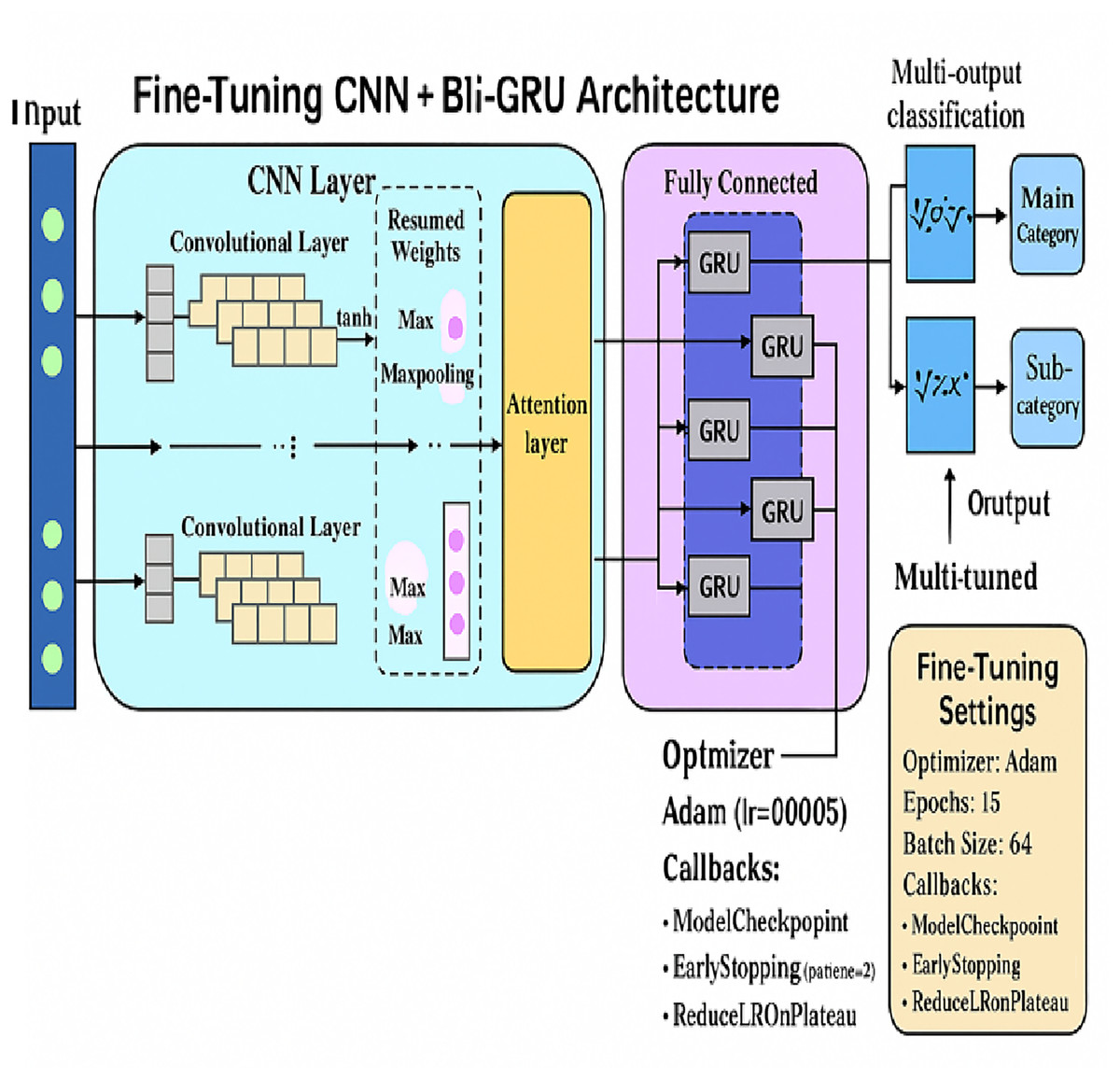
Figure 7: Fine-tuning CNN + Bi-GRU architecture.
{kind=link}
Transformer encoder block
This research created a Transformer Encoder-based architecture to help with the problems of multi-level multi-label classification in Arabic fake news detection. The self-attention used by the transformer encoder captures global dependencies over the whole sequence at once, unlike recurrent models like Bi-LSTM and Bi-GRU, which process tokens one at a time. This parallel attention technique is very helpful for Arabic literature since its syntax is complicated, its morphology is rich, and its meaning changes depending on the situation. The model begins by projecting the 894-dimensional input comprising semantic, syntactic, and emotional features into a 128-dimensional space using a dense layer with ReLU activation (Almarashy, Feizi-Derakhshi & Salehpour, 2023; Alzahrani & Al-yahya, 2024). The resulting vector is reshaped to conform to the expected Transformer input format. At the foundation of the model is a transformer encoder block that includes multi-head self-attention (with two attention heads), a position-wise feedforward layer, residual connections, and both layer normalization and batch normalization to promote training stability and convergence.
After encoding, a GlobalAveragePooling1D layer turns the contextualized sequence representation into a vector of a certain size. Then, there was a fully linked dense layer with 64 units and ReLU activation, as well as a dropout layer (rate = 0.3) to stop overfitting. The architecture concludes with softmax-activated output layers that provide classification results for each task. Training was conducted using the RMSprop optimizer with a learning rate of 0.0005, and sparse categorical cross-entropy was adopted as the loss function. The training process included several callbacks, such as ModelCheckpoint to store the best model, ReduceLROnPlateau to adjust learning rates when validation performance plateaued, and CSVLogger to record training metrics for potential resumption. Class weights were also applied to mitigate the effects of label imbalance, particularly in subcategory classification. The model was trained for up to 15 epochs with a batch size of 256. This Transformer-based design offers a context-aware and scalable way to do multi-task classification, as shown in Fig. 8. The model can pick up minor textual signals and tell the difference between complex categories due to the combination of multi-head attention and feedback on sublayers. This makes it especially good at finding fake news in Arabic, which is a language with a lot of structure and variation.
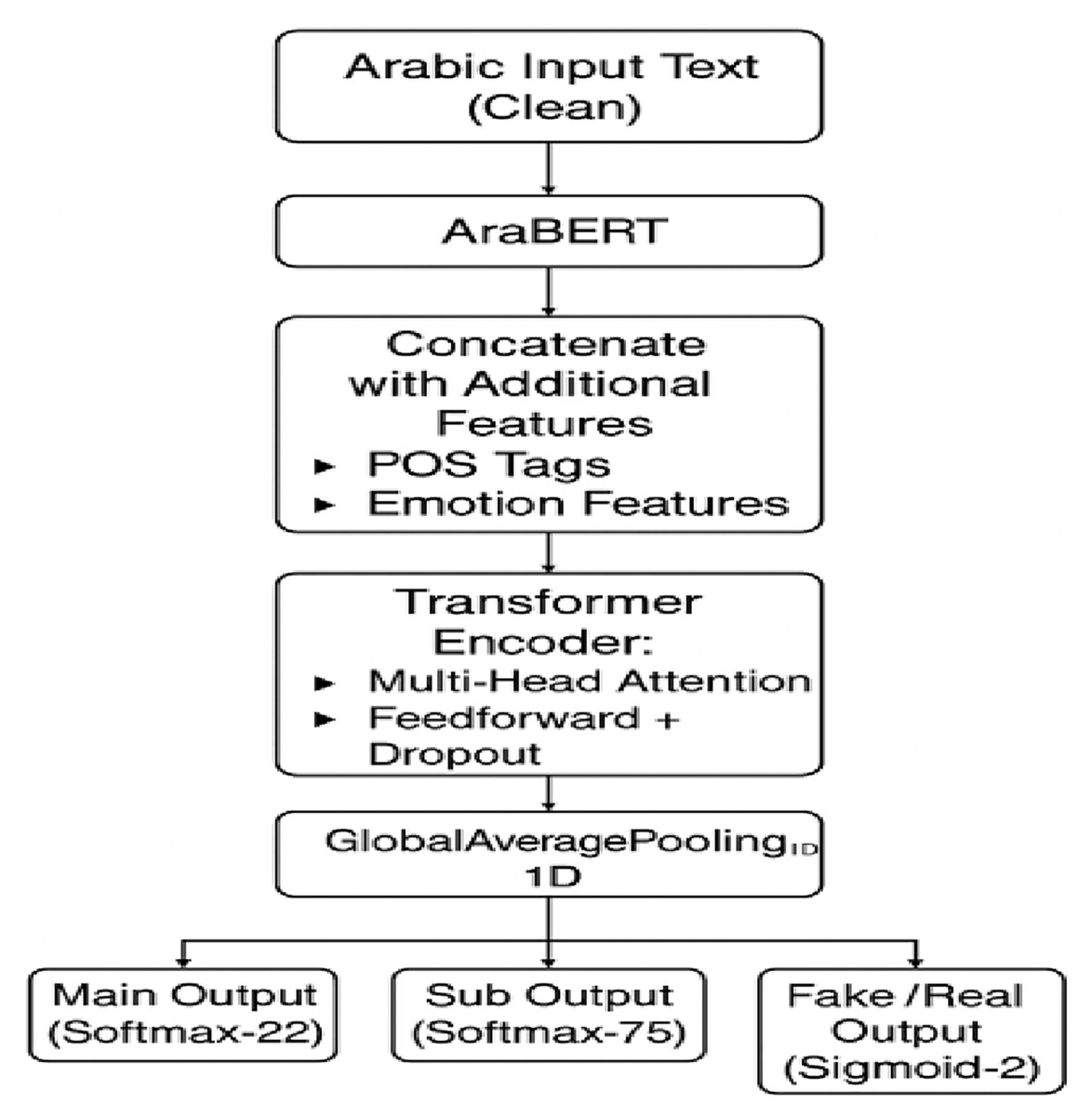
Figure 8: Transformer-based architecture.
{kind=link}
Dataset
To corroborate the multi-level, multi-label of Arabic fake and real news, this article employed a dataset called JoNewsFake, which was gathered by their own researchers. To counter the lack of large-scale, annotated Arabic corpora to detect fake news, the dataset in question has been carefully selected to include those that have a multi-level, multi-label classification structure. JoNewsFake consists of 50,000 Arabic news items obtained on the official Facebook pages of 12 legitimized Jordanian news agencies. This information is rich in the variety of topics, sources, and publication contexts, and it can be attributed to the linguistic and thematic diversity of Arabic digital media.
Initially, the process of data collection retrieved over 134,000 posts that were publicly available. These were then sorted on the basis of language, length, and relevancy. In order to be able to guarantee quality and consistency of the dataset, we filtered the posts to include only those that had at least four unique Arabic words and were related to reporting the news. A clean set of 50,000 entries was obtained after this filtering, and each entry corresponded to a unique news post in Modern Standard Arabic or a dialect spoken in Jordan.
The sample is restricted to Facebook accounts of confirmed Jordanian news sources. The reason why this was done was to maintain linguistic consistency, encourage the use of formal Arabic, and also to ensure that the content was validated by journalists. Such emphasis reduces the level of dialectal noise and misinformation characteristic of user-generated data. Nonetheless, it also restricts the external validity of the dataset to bigger Arabic-speaking settings. This structure will be expanded to cover cross-country and cross-platform sources in the future to determine the strength and flexibility of the model in the various Arabic dialects and media contexts.
The posts of JoNewsFake are labeled with three different labels, namely:
A Main Category (22 classes), which includes politics, economy, education, or health.
A subcategory label (75 classes), providing more specific categorizing of each major category (e.g., education school).
Fake/Real label (binary), which is a measure of the factuality of the news post according to an expert rating and cross-validation by official sources.
To improve model learning and the richness of the features, every instance has:
A Clean Text column (following the advanced Arabic preprocessing).
Part-of-speech (POS) tag sequence used to aid in syntactic analysis.
An emotional indicator vector, which measures emotion and feeling cues in the post.
JoNewsFake offers a valid basis in the assessment of supervised models in multi-task environments. Its architecture not only allows binary and multi-class classification but also allows multi-label, multi-level classification research, a structure not common in current Arabic databases. Table 2 presents two representative sample data of the dataset.
| Text | Post | Emotin | Main | Sub | R/F |
|---|---|---|---|---|---|
| مع المقاطعة ربنا ما بينساهم ورزقهم على الله هاد اقل شي ممكن الواحد يقدمه |
/DTNN’), المقاطعة/NN’), (“, ‘مع[(“, ’ /WP’), (“, ما/VBD’), (“, ‘ربنا(“, ’ /NNP’), ورزقهم/VBD’), (“, ‘بينساهم’ /NNP’), (“, الله/IN’), (“, ‘على(“, ’ /JJR’), (“, ‘اقل/NNP’), (“, ‘هاد’ /JJ’), (“, ممكن/NNP’), (“, ‘شي’ /VBP’)]يقدمه/DTNN’), (“, ‘الواحد‘ | [‘حزن’] | Economy | Boycott | Real |
| هناك نعم حماد ابو للخضار تصدير لاسرائيل والفواكه تجار ويوجد معروفين |
/NNP’), (“, ‘حماد/NNP’), (“, ‘ابو[(“, ’ /RB’), (“, ‘هناك/UH’), (“, ‘نعم’ /NN’), (“, ‘للخضار/NN’), (“, ‘تصدير’ /NNP’), لاسرائيل/NNP’), (“, ‘والفواكه’ /NN’), (“تجار/NNP’), (“, ‘ويوجد(“, ’ /JJ’)]معروفين’ | [‘اشمئزاز’] | Economy | Local | Real |
| شهداء عدد ارتفاع الإسرائيلي القصف سيارة استهدف الذي جنوبي رفح في مدنية إلى غزة قطاع التلفزيون الأردن الأردني |
/NN’), (“, عدد/NN’), (“, ‘ارتفاع[(“, ’ /DTNN’), (“, القصف/NN’), (“, ‘شهداء’ /WP’), (“, الذي/DTJJ’), (“, ‘الإسرائيلي’ /NN’), (“, سيارة/VBD’), (“, ‘استهدف’ /IN’), (“, في/JJ’), (“, ‘مدنية’ /NN’), (“, جنوبي/NNP’), (“, ‘رفح’ /NNP’), (“, غزة/NN’), (“, ‘قطاع’ /DTNN’), (“, الأردن/VBD’), (“, ‘إلى’ /DTJJ’)]الأردني/DTNN’), (“, ‘التلفزيون’ | [‘حزن’] | Politics | Israeli-Palestinian Conflict | Real |
Evaluation
Experimental setup
We did all of the trials on Google Colab Pro, which gave us access to GPU acceleration and more memory. The models were implemented using Keras with TensorFlow backend, and training was performed on Arabic text inputs represented by 894-dimensional feature vectors. Standard training strategies and callbacks were used to optimize model performance across all classification tasks.
Evaluation metrics
We use important metrics like average accuracy, precision, average recall, and the Macro F1-score to judge how each classifier works. These are based on Eqs. (1)–(4).
(1)
(2)
(3)
(4)
Methodology
The study uses a multi-stage methodology to detect fake news in Arabic, with an emphasis on a multi-label, multi-level classification approach that is unique to the JoNewsFake dataset. The proposed method has four main steps: data preparation, feature extraction, labeling, and modeling. It is designed to address both the linguistic challenges of Arabic and the difficulties of hierarchical classification.
Note: Portions of this text were previously published as part of a preprint (https://www.researchsquare.com/article/rs-7424709/v1) and as part of the first author’s PhD thesis at Universiti Malaya.
Data preparation
The dataset of JoNewsFake used by the authors of this article was gathered by researchers through 12 verified Facebook pages of Jordanian news agencies within 3 months (December 2023 to February 2024). The original dataset obtained about 134,000 Arabic news posts. They were then filtered according to post length, language verification and metadata availability. This left a clean list of 50,000 unique posts. The process of filtering sent the irrelevant and duplicate or non-Arabic content to trash and ensured that the dataset remained linguistically sound and semantically rich to proceed with the task of classification. The posts were classified according to the three axes, which included main category, subcategory and fake/real. The last JoNewsFake data set will have 50,000 Facebook posts categorized into 22 broad categories and to the order of 75 subcategories. The data are comparatively even at all three levels of classifications. The real/fake groups consist of 52 percent of actual posts and 48 percent of fake posts. Under the broad categories, more than 3,000 publications will be in highly represented areas, including politics, economics, health, and education, whereas less frequent ones, such as environment, culture, and tourism, will have between 300 and 500 publications. The number of subcategories is distributed as such with about 12 subcategories of over 1,000 publications, and 10 of the rare subcategories with less than 300 samples. This equal representation trimmed down the artificial resampling techniques like SMOTE and provided an equal evaluation at different classification levels.
There were four trained annotators who were to carry out the annotation process, and whom had experienced the analysis of Arabic texts before. They attended a formal training session, before taking part in the large-scale classification process, which was founded on the set annotation rules outlining all 22 major categories, 75 subcategories and the real/fake dichotomy. Annotating 500 publications was a pilot phase and the difference that arose was collectively discussed to further refine category definition and build up a common understanding. The guidelines were reviewed by two academic professionals of the Arabic linguistics field and randomly verified 10 percent of the given data. The measures of concordance were quite high with the κ value of Fleis of 0.98 and Cohen of 0.96 which implied that there was almost near-perfect consistency in all annotation levels.
Textual feature extraction
To enhance the performance of the model and facilitate contextual knowledge on the Arabic language, we got three varieties of features:
-
ArBERT Implications: The code [CLS] was used to produce semantic implications, which produce 768-dimensional contextual vectors (Antoun, Baly & Hajj, 2020).
-
Speech point Labeling Properties: A speech point label was given to each word with the Phrasal Tools (Al-Twairesh et al., 2016) and then coded into a 100-dimensional representation by either single-heat or frequency coding.
-
Emotional responses: In line with Nahar et al. (2020), the emotional indicators (joy, anger, sadness) were identified based on an Arabic lexicon of emotions and were coded in a 26-dimensional binary array.
The article introduces a new hybrid representation of features, which is a combination of semantic, grammatical, and emotional data, into a single 894-dimensional (768 + 100 + 26) vector. Such a way contributes to the realization of minor differences in Arabic scripts that can be used to fill the gap between innuendo contextual meaning and direct linguistic indicators. This hybridization is independent of the model and can be applied to either ensemble learning or deep learning models, and it is the first framework-independent systematic attempt to combine these three categories of features in detecting fake news in Arabic.
Preprocessing phase
To guarantee the quality and consistency of the Arabic text prior to feature extraction a detailed preprocessing procedure was adopted:
Deletion of non-Arabic characters.
The diacritics were removed in order to minimize spelling differences.
Cutting of punctuations, special characters and URLs.
Stop words removed.
Social media traces and ticks (user) eliminated.
Duplicates, blank, or unclassified posts were deleted.
Roots identified and normalized to minimize morphological variance.
Prefixes and suffixes were eliminated in a bid to minimize redundancy.
The text was cleaned followed by coding with the AarBERT encoder to make sure it is compatible with further embedding steps. Such a preprocessing pipeline minimized noise, regularised pattern of language and boosted the quality of contextual representation.
Handling class imbalance
Preliminary data analysis showed that there were imbalances in classifications, in terms of subcategories and dummy/real categories. SMOTE was also an option but it was not chosen because it could not be applied to high-dimensional contextual implications. Rather, category weighting was used in training the model to deal with this imbalance, without introducing the artificial noise.
Overfitting and cross-verification
When working with deep learning techniques, dimensionalities, and unbalanced classes, overfitting is an important issue to be considered. In order to prevent overfitting, a number of measures were undertaken:
-
-
Projection Layers
-
-
Early Stop
-
-
ReduceLROnPlateau
-
-
ModelCheckpoint (to save the best model in terms of accuracy of verification)
-
-
csvlogger (to monitor training dynamics)
All of the models were tested on a fixed 80/20 split between training and testing, as opposed to k-fold cross-validation. This option lowered the computational expenses which is particularly notable with the deep learning environments that are resource-intensive. Although cross-validation based on k-fold is normally more sound, fixed partitioning was considered appropriate to conduct a fair comparison of all the models and classification tasks.
Experimental outcome
Training and testing
A constant 80/20 training-test split methodology has been used in this research to test the performance of the proposed models. Each model was then fitted using the training set and the test set was then used to assess performance on untried data. This was done to achieve a trade-off between computational efficiency and evaluation reliability, particularly, deep learning models are expensive to train.
We were using Python (3.8 and higher) along with the Keras/TensorFlow framework of deep learning. Each shuffle was done with the same seed so that the data would be randomly mixed and then partitioned to give fair and reproducible comparisons. All of the models were trained on their best hyperparameters and organization policies. The last analysis involved accuracy, fine-tuning, recall and macro F1-score. The dataset was stratified into 80 training and 20 testing by keeping the ratios of classes at the three levels of labeling constant. Even though the k-fold cross-validation offers estimates of the variance, it was not implemented to prevent the high computational cost as the large volume of data (50,000 publications) and its structure as a multi-output. The fixed-segmentation method allowed the evaluation of all the models of crowdlearning and deep learning to be made in the same partitions.
Synthetic Minority Oversampling (SMOTE) was the first algorithm which was tested to correct the imbalance between classes but it was eventually abandoned. Since the feature space is full of thick contextual inclusions of AraBERT, SMOTE produced semantically inconsistent synthetic samples, which leads to low performance. Class weighting was instead used to deal with small labeling imbalances without changing the inclusion space. These organised choices, and such organizational tricks as dropout, early stop, and learning rate scheduling, served to avoid overfitting and to make comparisons of models fair and computationally efficient.
Experimental results
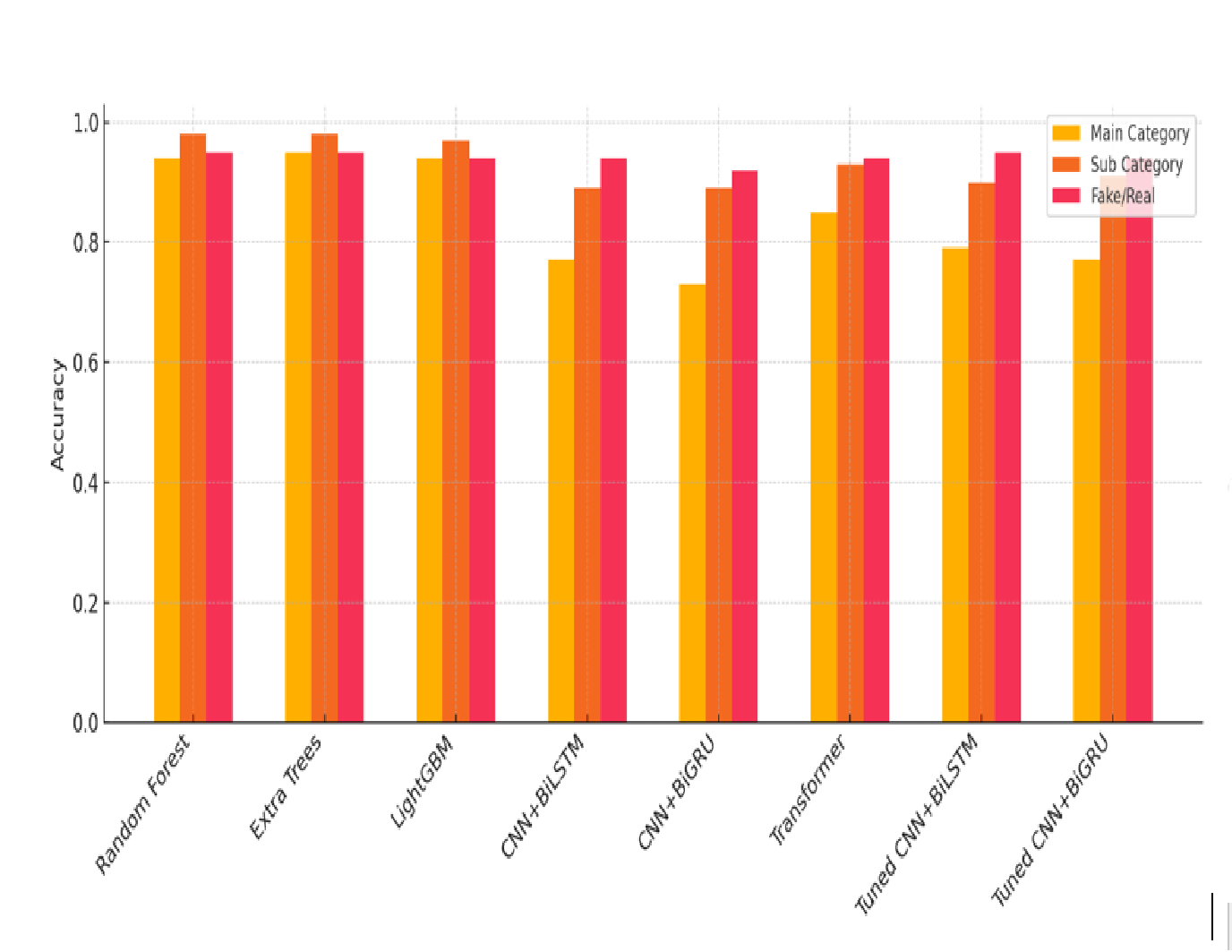
We also applied a collection of the traditional evaluation measures, such as accuracy, precision, recall, and Macro F1-score, to estimate the success of each classifier in identifying fake news in the Arabic language. These measures have been calculated in three classification tasks, including Main Category (22 classes), Subcategory (75 classes), and Fake/Real (binary). All the models were evaluated by a fixed train-test split (80/20). In Table 3, the comparison of the overall results is shown.
| Model | Main category | Sub category | Fake/Real | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | precision | Recall | F1 | Accuracy | precision | Recall | F1 | Accuracy | Precision | Recall | F1 | |
| RF | 0.94 | 0.94 | 0.94 | 0.94 | 0.98 | 0.97 | 0.98 | 0.97 | 0.95 | 0.96 | 0.94 | 0.95 |
| Extra Trees | 0.95 | 0.95 | 0.95 | 0.95 | 0.98 | 0.97 | 0.98 | 0.98 | 0.95 | 0.96 | 0.94 | 0.95 |
| Light GBM | 0.94 | 0.94 | 0.93 | 0.94 | 0.97 | 0.97 | 0.97 | 0.97 | 0.94 | 0.94 | 0.94 | 0.94 |
| CNN + Bi-LSTM | 0.77 | 0.76 | 0.77 | 0.76 | 0.89 | 0.88 | 0.89 | 0.88 | 0.94 | 0.94 | 0.94 | 0.94 |
| CNN + Bi-GRU | 0.73 | 0.73 | 0.72 | 0.73 | 0.89 | 0.87 | 0.89 | 0.88 | 0.92 | 0.93 | 0.92 | 0.91 |
| Transformer | 0.85 | 0.86 | 0.85 | 0.85 | 0.93 | 0.93 | 0.93 | 0.93 | 0.94 | 0.93 | 0.94 | 0.92 |
| Tuned CNN + Bi-LSTM | 0.79 | 0.76 | 0.77 | 0.79 | 0.90 | 0.89 | 0.88 | 0.90 | 0.95 | 0.94 | 0.94 | 0.93 |
| Tuned CNN + Bi-GRU | 0.77 | 0.73 | 0.73 | 0.76 | 0.91 | 0.90 | 0.89 | 0.90 | 0.94 | 0.94 | 0.93 | 0.94 |
Generally, the classical machine learning models, including the Random Forest and the Extra Trees, have worked well, particularly on the Fake/Real task, which Macro F1-scores were higher than 0.94. Extra Trees model recorded the most stable findings in all the three levels of classifications. Other models that have demonstrated good performance on the social media tasks including MARBERT and QARiB, although Arabic based, were omitted due to methodological consistency. Both models are trained on Twitter and user-generated content mostly, JoNewsFake is composed of formal news articles by verified Jordanian agencies. This instance of domain mismatch might have an undesirable impact on linguistic coherence in the application to Modern Standard Arabic (MSA).
Rather, AraBERT was chosen to be the semantic base of all models since it is well-versed in MSA, and it is possible to use it in news and credibility-related activity. This provided a consistent semantic depiction between the ensemble and deep learning models, and enabled observed performance variation to be due to model design and not variation in pre-training corpora.
One of the deep learning structures was the CNN + Bi-LSTM model, which first offered a good baseline, especially in the domain of Main Category classification. Afterward, more improvements were made through Bi-GRU and fine-tuned CNN layers which yielded better performance. Transformer Encoder model performed better than other models in the Subcategory classification with a Macro F1-score of around 88.2. The mechanism of its self-attention is effective to catch long-range dependencies which is the key benefit of Arabic since the morpheme can be varied significantly.
Overall, CNN + Bi-GRU was the most successful model with a high accuracy of over 0.93, by classifying Fake and Real. In Subcategory classification, the Transformer Encoder was the most successful, whereas Extra Trees did not lose in Main Category predictions. These results indicate that despite the fact that the traditional models continue to be effective in terms of simpler tasks, deep learning and transformer-based architecture will be more effective in terms of hierarchical and multi-label classification in Arabic.
The results of all the models in the three tasks are shown in Fig. 3. Extra Trees has the best accuracy in general and uniform performance in all measures. Random Forest and LightGBM were also the traditional ensemble techniques that retained high and consistent performance. Intial results of deep learning models such as CNN + Bi-LSTM and CNN + Bi-GRU were not very high, but when fine-tuning was performed, the results were significantly higher- especially in Fake/Real classification. Model based on transformers were superior because they could highlight relationships between context in the sequences.
This comparison shows that ensemble methods have a high level of generalization and transformer-based architecture has a strong level of contextual modeling capability particularly with structured Arabic news data with hierarchical and multi-label classification problems.
To further analyze model performance at the subcategory level, a confusion matrix was created to illustrate the distribution of prediction errors across the 75 subcategories. This matrix shows the thematic areas most frequently misclassified and how often the model conflates with semantically related categories. Figure 9 shows that most misclassification errors occur across closely related subcategories, including Politics ↔ Local News, Economics ↔ Business, and Education ↔ Training. These conflations reflect the linguistic and thematic similarities commonly observed in Arabic media coverage, where news content may convey multiple domain signals simultaneously. Thus, the confusion matrix provides valuable insight into how hierarchical and semantically overlapping structures within Arabic news affect model performance.
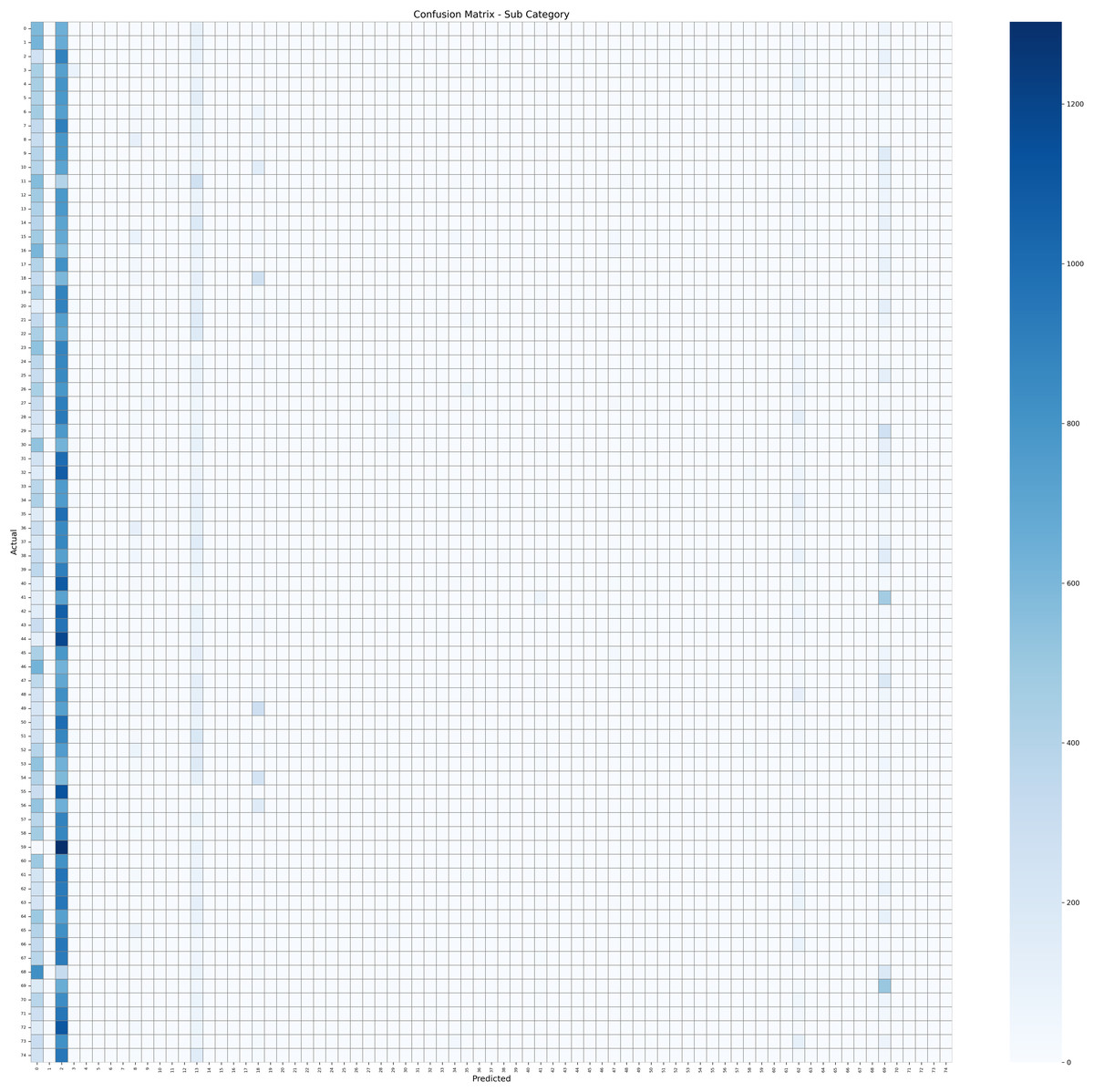
Figure 9: Confusion matrix for subcategory classification using the transformer model.
{kind=link}
Discussion
The article has conducted a comparative analysis of different machine learning (ML) and deep learning (DL) models in three main tasks of classification: Main category, Subcategory, and Fake/Real detection. All models were trained on the same data splits, feature normalization and equal class representations to ensure the evaluation was fair and repeatable. The most successful model of the ML models was the Extra Trees classifier. It was always very precise and Macro F1-score in all tasks and in particular, in the Subcategory classification where there were 75 different classes. This model was a good baseline because it could cope with small classes imbalance without over-sampling, trained fast, and was able to generalize well. Random Forest and LightGBM results were also fairly consistent, however, not as good as Extra Trees, particularly with the finer subcategory assignment. Their ensemble-based forms allowed them to handle complex and high dimensional hybrid aspects.
Transformer received the highest ratings of Macro F1-score in both jobs, but it was more expensive to operate. The CNN + Bi-LSTM and CNN + Bi-GRU tuned hybrids performed better than their untuned counterparts especially in the fake and real classifications. Their convolutional filter and bidirectional recurrence unit use was successful to detect the short-range emotions and stylistic information which dominate fake content such as exaggeration, sensational tone, or subjective words. They also had the ability to store sequential dependencies. They did not outperform the Transformer but were decent compromise between accuracy and training speed. The success of Extra Trees to exploit the space of hybrid features explains why it is more successful in most levels of classification. In contrast to deep-based models that use a data-intensive backpropagation to learn representations, ensemble methods directly use pre-engineered linguistic features semantic (AraBERT embeddings), syntactic (PoS tags), and emotional (indicators) to learn nonlinear relationships without overfitting. Since the hybrid representation will already be using deep semantic knowledge provided by AraBERT, Extra Trees will serve as a feature-selection and hierarchical-decision control, thus improving interpretability and stability in the case of limited variation of data.
This design was also confirmed by a preliminary feature-ablation analysis. Elimination of PoS-based syntactic features induced an average decrease of the Macro F1-score by nearly 2.4 and the elimination of emotional indicators led to the decrease of about 2.1 in the Macro F1-score specifically in the Fake/Real classification. The semantic AraBERT embeddings continued to be the most prominent contributor, but the addition of syntactic and emotional features was evidently contributing to discriminative ability at all levels. The pattern of mistakes showed that most misclassifications have occurred within the subcategories that have semantic overlap, including Economy vs. Business and Health vs. Environment, highlighting the challenges posed by the similarity of hierarchical labels in the Arabic news. All these lessons point to the conclusion that whereas deep contextual networks like Transformers are also effective at sensitive semantic differentiation, hybrid CNNRNN models remain useful on sentiment- and discourse-driven detection problems, and feature-based ensemble performance is more robust and efficient.
In order to increase the validity of the given results, the experiments were repeated three times with the same data splits and random seed initiation. The performance parameters (accuracy, precision, recall, and Macro F1-score) were averaged across all the runs and standard deviation was calculated to determine the level of stability. All of the scores reported were in a small range of ±0.3, thus proving the consistency and reproducibility of behavior of the models. In addition, the paired t-test of the most successful ensemble and deep models (Extra Trees vs. Transformer) revealed that the results of the comparison were statistically significant (p < 0.05). These analyses alone justify the findings of this work since they demonstrate that they are robust, reliably applied, and statistically sound.
Execution and computational performance
In order to augment the accuracy-based assessment, both the runtime requirement and computational requirements of all the models were also analyzed. The ensemble classifiers, and especially the Extra Trees and LightGBM, showed to be highly efficient as they managed to fully train in 2–3 h using the Google Colab, Tesla T4, GPU setupOn the contrary, the deep learning models were much slower when it came to training large volumes of data. As an example, CNN + Bi-LSTM and CNN + Bi-GRU averagely required 75 h, and the Transformer encoder required over 50 h in that it had many parameters and sequential attention layers. These findings indicate that an evident trade off exists between cost and accuracy. Transformers (which are also known as deep architectures) are more representational and slightly more powerful in Macro F1-score on fine-grained classification. Nonetheless, it remains that ensemble methods are much more effective when it comes to large scale testing and real-time applications. This disparity demonstrates that ensemble learning can be quite useful when one does not have sufficient computing facilities or when the deployment process is time-intensive. Table 4 presents the implementation specifications of both ensemble and deep learning models to provide a further insight into the computational properties and efficiency of the reviewed models. The table indicates the size of the model, the mean time spent on training an epoch, the total time spent on training, the delay on inferences per post and the number of trainable parameters. These results were obtained with Google Colab Pro using a Tesla T4 graphics card (16 GB RAM) on the same experiment. It has been found that accuracy and cost are traded: ensemble models such as Extra Trees and LightGBM are lightweight, fast to train, and highly scalable, whereas Transformer-based architectures require much more computing power, but are better at semantics understanding and classification at fine-grained scales.
| Model | Trainable parameter | Total training time | Inference (ms/post) | Model size (MB) | Notes |
|---|---|---|---|---|---|
| Extra trees | ≈120 K | 2.5 h | 1.2 | 45 | Fastest; CPU-based; highly stable on large data |
| Random forest | ≈100 K | 3.1 h | 1.5 | 42 | Slightly slower due to bootstrapping |
| LightGBM | ≈80 K | 2.2 h | 1.1 | 40 | Leaf-wise growth; optimized memory usage |
| CNN + Bi-LSTM + Attention | ≈3.2 M | 75 h | 4.3 | 120 | Strong contextual learning; moderate training speed |
| CNN + Bi-GRU + Attention | ≈3.5 M | 70 h | 4.1 | 115 | Faster convergence; robust Fake/Real performance |
| Transformer encoder (AraBERT-based) | ≈110 M | 50+ h | 9.6 | 420 | Highest semantic accuracy; highest computational cost |
Limitations and threats to validity
Despite the positive outcomes of this research, it is necessary to note that there are some issues and threats to the validity of the research that need to be taken into consideration:
-
-
The data is taken exclusively on verifiable Jordanian news sources on Facebook. This will result in more accurate results, but may make them more inapplicable to other Arabic-speaking regions, to use on platforms such as Twitter, or less formal sources of material.
-
-
Additional Trees and Transformers This is typically an ensemble model, and a deep model that works well. They however overfit on more variable or noisy datasets. Transformers require much memory and training time which might not be feasible in real-time or resource limited conditions.
-
-
The classification assignments are hierarchically broken down into a number of degrees (say 75 subcategory), which increases the difficulty of learning. The misclassifications of some of the categories could have occurred due to the fact that similarity of the meaning of closely related categories is too close.
-
-
The data is predominantly of Modern Standard Arabic (MSA) in its application in formal journalism with only a little bit of dialectal Arabic. This language regularity renders the possibility of encountering casual, colloquial or mixed-code less probable in user generated content. The models must be more reliable across the various types of Arabic and can be accomplished by the inclusion of the data related to various dialects and various regions in future studies.
-
-
The other limitation is associated with the bias of the dataset. As all posts were gathered in legitimate and factual agencies, the corpus might not be inclusive of other opinions or stylistic variation of non-mainstream sources. Whereas this may guarantee the reliability of facts, it may incline models to formal reporting patterns. This bias can be addressed by including a greater number of broader data sources.
-
-
We simply tested the model’s using data of the same domain. In order to ensure that they can be applied in different scenarios, they need to experiment with their performance in future on external datasets or in a cross-lingual environment.
Fake news detection in Arabic ethical and legal considerations
It is difficult to locate fake news in Arabic media due to technological and language problems, but it also poses enormous ethical and legal problems. The legislation of false information is quite ambiguous in most Arab nations and in some cases, it is applied to suppress freedom of speech. In the case of political or religious content, automated detection mechanisms should be designed with caution to ensure that they do not take this type of excessive authority any more seriously. Furthermore, the guarding of user rights and aversion of probable misusing of detection technology needs entailing of data collection and model projections being confidential, honest, and transparent.
Conclusion and future work
In this article, a detailed analysis of the ML and DL models in the detection of fake news in Arabic was performed based on a multi-level multi-label classification strategy. JoNewsFake dataset Authoritative news was used to generate its own dataset named JoNewsFake that was used to train and evaluate various models depending on three tasks: Main Category, Subcategory, and Fake/Real. The experimental evidence showed that model performance is much affected by task complexity and richness of feature representation. The Extra Trees classifier was the most performing among the ensemble machine learning models in terms of Macro F1-score at 0.95 in the main category, 0.98 in the subcategory and 0.95 in the fake/real classification. Transformer-based model was the most effective on the deep learning side, as it offered a good balance of all tasks. It showed better contextual and hierarchical understanding whereby Macro F1-score of 88.2 in subcategory classification, about 0.85 in main category and 0.94 in fake/real classification is received. CNN + Bi-GRU model was the most accurate in fake/real classification (0.93) but not as good at the rest of the tasks as the Transformer. These findings demonstrate the capability of the Transformer models to comprehend the complex meaning and structure of Arabic news materials. It is the first research to make a comparison between the ensemble machine learning models, the Bi-RNN-based deep learning models, and the Transformer-based models applied to multi-level multi-label Arabic fake news detection by use of real news agency data. Overall, the findings indicate the significance of applying scalable and context-sensitive models to identify fake news in Arabic. Extra Trees and other models like it are good baselines, yet the designs having transformers are full of prospects to enhance multi-level Arabic NLP tasks. The results highlight the efficiency of ensemble ML models and transformer-based method to the processing of complex, imbalanced and hierarchical Arabic datasets. Semantics (AraBERT), syntactic (PoS), and emotional features integration also helped in improving performance, particularly when it comes to relatively difficult subcategory classifications. In general, the work is the first system benchmark that integrates ensemble, deep learning, and transformer-based architecture in the JoNewsFake dataset to become a strong basis of future studies of Arabic fake-news detectors.
To continue with research in the future we could expand this study on various directions. On the one hand, the inclusion of images, videos, and metadata into multimodal data may simplify the process of locating false information and do so more often than with social media. Second, training giant pre-trained Arabic transformer models (such as MARBERT and QARiB) with domain-specific data can perhaps enable them to generalise better and discern context better. Third, explainable AI (XAI) techniques would help to interpret the model predictions, which would make the systems more transparent and trusted. In another place, the cross-lingual transfer learning might also be considered, as fake news detection models in Arabic may utilize a vast number of resources that are not only in English but also in other languages. Finally, the real-world users would also be interested in testing these models in actual-time environments and how they can cope with the real-life situations.
Supplemental Information
The complete JoNewsFake dataset.
Arabic text, hierarchical labels (Main, Subcategory, Fake/Real), POS tags, emotional indicators, and preprocessing scripts
{kind=link}