
Hybrid 3D modelling framework for indoor navigation using federated learning and Internet of Things-enabled edge devices
- Published
- Accepted
- Received
- Academic Editor
- Ankit Vishnoi
- Subject Areas
- Artificial Intelligence, Autonomous Systems, Internet of Things
- Keywords
- Federated learning, Machine learning, Edge computing, Three-dimension model, Indoor positioning
- Copyright
- © 2026 Tyagi et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Hybrid 3D modelling framework for indoor navigation using federated learning and Internet of Things-enabled edge devices. PeerJ Computer Science 12:e3503 https://doi.org/10.7717/peerj-cs.3503
Abstract
Background
There has been a recent trend towards using three-dimensional (3D) models to enhance spatial awareness and maximize resource utilization in complex environments. 3D building model can be used in various applications, such as real-time guidance and tracking the positions of individuals in multi storied buildings. Cities are now being modeled and studied in three dimensions as an improved method of urban planning.
Method
This study proposes an advanced indoor navigation framework that combines 3D modelling, federated learning (FL), and Internet of Things (IoT) integration to deliver reliable floor-level localization and real-time guidance. In Phase 1, highly accurate 3D models were created using Quantum Geographic Information System (QGIS) software and validated against Light Detection and Ranging (LiDAR) sensor measurements, achieving an error percentage of approximately 0.99%. In Phase 2, a federated learning approach using a hierarchical recurrent neural network (H-RNN) was developed to improve indoor positioning accuracy based on the 3D model data. In Phase 3, a dedicated navigation application was integrated with IoT devices strategically placed throughout multi-story buildings to enable real-time routing.
Results
The error percentage was very low (approximately 0.99%), demonstrating excellent agreement between the LiDAR and QGIS models. An RNN method using FL was implemented in the second part of the project to enhance the location accuracy of the system using a three-dimensional model. During Phase 3, a navigation application was integrated into IoT devices placed at strategic places within the building. This work is novel in its integration of accurate 3D modelling, federated learning, and IoT-based routing in a single system that achieves over 99% positioning accuracy and 98.7% routing accuracy across multi-story buildings. Current indoor navigation systems lack scalability, privacy preservation, and adaptability across complex multi-story buildings. This study proposes a novel three-phase approach integrating 3D modelling in QGIS, federated learning-based positioning, and IoT-enabled routing.
Introduction
The use of 3D models makes urban modeling simpler and more accessible in three dimensions. Simple two-dimensional visualizations cannot capture the detailed representations of cities that can be created using a three-dimensional model (Singh et al., 2021). It is possible to define a three-dimensional replica of a real building, and it can be utilized to gain a better understanding of the building. Digital twining, augmented reality, and virtual reality are examples of contemporary technologies to promulgate 3D visualization (Rohil & Ashok, 2022). Building Information Models, often known as BIMs, serve as a data source that supports three-dimensional models. Three-dimensional modelling allows for a wide range of simulation applications like lane guidance, routing, placement, and localization (Teo & Cho, 2016; Kumar et al., 2021; Shahrubudin, Lee & Ramlan, 2019). The majority of geographic information system (GIS) software is capable of carrying out theme queries, geographical data mining, analysis, and simulation, offering enormous benefits for a wide range of applications (Guleria, Atham & Kumar, 2021).
Recent advances in Building Information Modelling (BIM) and GIS have enabled the creation of detailed, navigable 3D indoor maps, while Light Detection and Ranging (LiDAR) and virtual reality (VR) technologies further enhance spatial capture and immersive visualization (Wang, Wong & Cheng, 2025). BIM is a promising technology for digital transformation in construction (Li, Han & Gao, 2024). LiDAR and VR further enhance these models through spatial capture and visualization, which are key to accurate indoor mapping. LiDAR is used for creating 3D point-cloud data of environments by measuring distances with laser light (Chen et al., 2024). VR offers experiential learning in zero-risk environments, integrating with BIM to enhance user-focused spatial assessments during initial design phases (Li et al., 2025; Shirinyan & Petrova-Antonova, 2022).
There has been a notable rise in academic research aimed at enhancing indoor navigation, security, and tailored services. This results from progress in wireless communication technologies. The Received Signal Strength Indicator (RSSI) is an essential metric utilized in wireless communication systems to quantify the strength of radio frequency (RF) transmissions between devices. The integration of RSSI and sophisticated machine learning methodologies, especially in federated learning, could accurately ascertain a user’s indoor location (Nessa et al., 2020). The machine learning methods employed in indoor localization utilize RSSI data to determine the spatial coordinates of a user within an indoor environment (Shahbazian et al., 2023). Furthermore, to preserve anonymity, advanced machine learning technology can be utilized in the background (Chhabra, Singh & Khullar, 2023; Alsamhi et al., 2023). Precise indoor navigation systems are increasingly essential in complex facilities such as hospitals, airports, shopping malls, and large office complexes. In hospitals, accurate navigation reduces patient stress and improves response times in emergencies. However, existing solutions often face limitations related to privacy, scalability across multi-story layouts, and adaptability to diverse building types. Addressing these challenges provides direct societal and industrial value, enabling smarter, more inclusive, and efficient indoor environments (Abdelalim, O’Brien & Shi, 2017; Li et al., 2019). Nonetheless, these investigations exhibit constraints regarding the scalability of their frameworks in extensive or intricate multi-floor edifices, adaptability to varied interior designs, and the incorporation of real-time user data (Li et al., 2019; Zhan et al., 2022). Conventional fingerprinting methods inadequately represent spatial interactions among floors and buildings, hence diminishing the accuracy potential. Only model updates are transmitted to a remote server (Li et al., 2019; Abd, Hameed & Nsaif, 2020). In contrast to the aforementioned work, our suggested method presents an innovative approach to indoor navigation that thoroughly addresses these challenges (Abdelalim, O’Brien & Shi, 2017). The integration of federated learning, machine learning, data mining, and the Internet of Things seeks to enable a transformational shift towards the development of intelligent and ecologically sustainable systems. The real-time adaptation to fluctuating indoor conditions, such as crowded environments or ongoing maintenance, coupled with precise accuracy, signifies a significant progression in indoor navigation, as illustrated in Fig. 1.
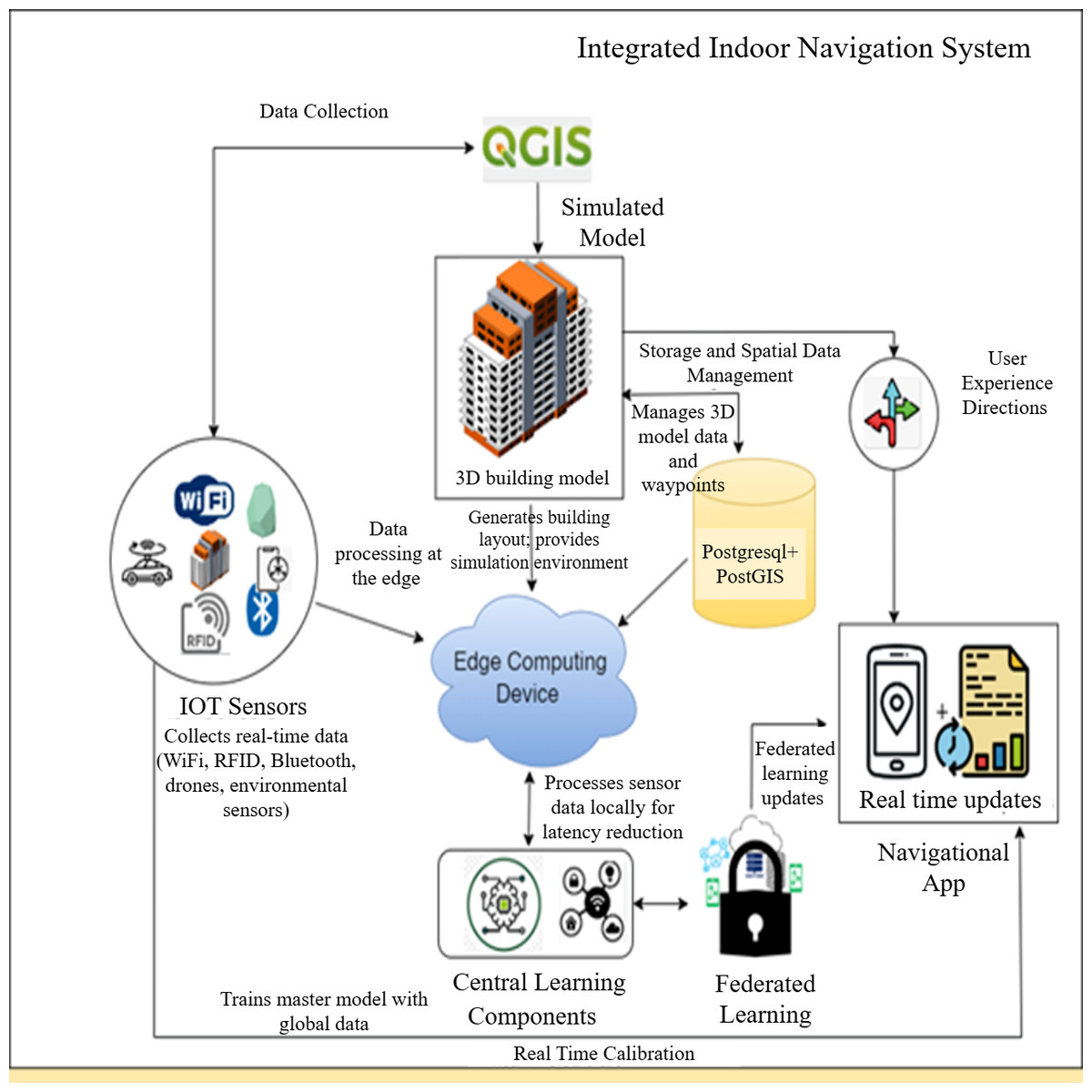
Figure 1: Integrating federated learning, edge computing, and IoT devices to create indoor navigation systems.
{kind=link}
The devised methodology is evaluated on the specific use case. Despite its need for manual digitization, the approach provides a viable option for LiDAR indoor mapping. The data is structured within a database, and most 3D modelling operations are executed procedurally via computer-generated architectural guidelines (Tekavec & Lisec, 2020). Consequently, information of a 3D model can be updated without reiterating all the stages. Structured data is a crucial resource for numerous applications, such as indoor navigation. This information is generally retained in a database. Integrating procedural 3D modelling with principles of computer-generated architecture enhances the adaptability and efficiency of updating information or improving 3D models, hence obviating the necessity to repeat the entire process. The salient features of the proposed work are as follows:
-
To acquire Ground Control Points (GCP) using LiDAR technology and to develop a database to ensure very accurate collection and storage of two-dimensional data in three-dimensional indoor space.
-
To minimize the percentage inaccuracy between the visualized model and the real GCP while accessing the geo map and the visualized map.
-
To deploy federated learning and machine learning to determine the location of a user within a building using an RSSI signal with high accuracy.
The document will be organized in the following manner: ‘Related Studies’ will examine prior research on the topic. ‘Methodology’ will delineate the methodology employed to construct a three-dimensional model and apply FL and ML techniques for the development of a floor detection and routing information system. ‘Results’ will give the investigation results and a thorough analysis of the acquired data. Ultimately, ‘Discussion and Future Work’ will encapsulate the findings and offer insightful perspectives for further study.
Related Studies
This section explores the integration of advanced technologies in 3D modelling, FL, edge computing, and routing in an indoor environment. These tools are used to model and optimize the energy performance of buildings (Jamali et al., 2017). The integration of 3D BIM with energy simulation was presented; this makes it easier for designers and engineers to visualize and analyze buildings in terms of energy performance in an effective and efficient manner (Wei & Akinci, 2019). A few researchers demonstrated the potential benefits of using BIM for building simulation, including increased accuracy in modelling and analysis, better communication and collaboration, and better optimization of building performance (Laksono, Aditya & Riyadi, 2019). Research is also being carried out to demonstrate the ability of GIS to improve the accuracy and efficiency of building simulations, especially if integrated with BIM, in a way that can enable sustainable construction, urban planning, and operation (Biljecki, Ledoux & Stoter, 2017; Xu, Mumford & Zou, 2021).
Advanced devices like LiDAR and cameras, as well as matching and feature point identification, are required for visual-based indoor localization. It might be affected by environmental factors and require significant computational resources. Moreover, it does not have semantic understanding, which is crucial for 3D modelling (Mendez et al., 2022). Several papers discussed the usability of QGIS in creating 3D models of outdoor space for multiple purposes. One method for creating a 3D model using QGIS and OpenStreetMap data was presented, while other approaches use CityEngine software to create outdoor 3D models. Yet, the volunteer data is not fully reliable (Farahsari et al., 2022). It also combines deep learning for self-map maintenance and utlizes a grid-based algorithm for pathfinding. The Indoor Positioning System has also widely adopted edge computing to attain low latency, improved reliability, lower bandwidth, and real-time processing ability. Edge caching, edge training, edge inference, and edge offloading are the four significant levels of edge intelligence, which are aimed at improving the velocity, value, and privacy of data processing at proximity to sources using AI-driven systems (Sattarian et al., 2021). The growth of IoT devices fastens the requirement for machine learning, specifically deep learning. Edge intelligence or Edge AI presents the fundamental concepts such as cloud, edge, and fog computing, as well as contemporary methodologies and application scenarios at the intersection of edge computing and artificial intelligence. It discusses novel approaches to deploying deep learning models at the network edge and evaluates their performance in terms of model accuracy, latency, and energy consumption (Etiabi, Njima & Amhoud, 2023). One approach was proposed for preserving the privacy of Indoor Positioning using Federated Learning in a Mobile Edge Computing environment. A real-time system using deep neural networks to enhance robustness and accuracy in dynamic environments, while other works have combined autoencoders with convolutional neural network (CNN) for improved feature extraction and unified floor and location estimation was proposed (Nabati & Ghorashi, 2023). Hybrid Convolutional Neural Network–Long Short-Term Memory (CNN-LSTM) models have also been introduced to leverage both spatial and temporal features in Wi-Fi and BLE fingerprint data, achieving superior accuracy and stability (Yoon et al., 2024). Federated learning (FL) is being explored for indoor localization to address privacy concerns associated with traditional centralized data collection methods (Jan, Njima & Zhang, 2024). One survey broadly examines FL design and functional models, emphasizing aggregation and knowledge transfer within distributed local data frameworks (Ayeelyan et al., 2024). Another survey focuses on fairness and privacy preservation in FL, relevant given the sensitive nature of location data (Rafi et al., 2024).
Prior approaches often trade accuracy for scalability or privacy. Traditional centralized models achieve ∼2 m error but lack privacy safeguards and are hard to scale across floors. Deep learning fingerprinting methods reduce error to ∼1–1.5 m but require extensive centralized training data. Federated learning approaches improve privacy by exchanging only model weights, with errors of ∼0.5 m. Our system advances this by integrating precise 3D modelling, FL with H-RNN, and Internet of Things (IoT)-based routing to achieve 0.22–0.36 m root mean square error (RMSE) while preserving privacy and supporting multi-story navigation. The paper proposes a research method to reduce data leakage risk using differential privacy and an algorithm that could achieve the best convergence speed, time efficiency in localization, and precision. Indoor navigation requires machine learning, data mining, and the Internet of Things. Such positioning systems as Wi-Fi and ZigBee report the exact position of a person or mobile robot indoors with high resolution. Machine learning algorithms like KNN, SVM, and neural networks predict positions in real time based on data from positioning systems.
Methodology
The study encompasses three interrelated phases. Each phase is meticulously crafted to enhance the development of an accurate and reliable three-dimensional indoor navigation system. The main goal of Phase 1 is to produce precise and comprehensive three-dimensional models of the indoor environment. The process entails utilizing QGIS software to accurately depict the structure, including architectural features, interior configurations, and other pertinent characteristics vital for enhancing indoor navigation. The 3D model has been meticulously crafted to depict the building’s architectural composition precisely. Subsequently, the model’s correctness is assessed by conventional procedures, wherein it is juxtaposed with established protocols to validate its precision. Phase 2 involves the design and implementation of the positioning system with federated learning and machine learning methods. FL can be used in pinpointing the spatial coordinates of individuals in the building. It can provide highly accurate spatial coordinates, especially in 3D indoor locations. The machine learning model is trained using this study with the use of a distributed architecture. This could significantly enhance the accuracy of a person’s spatial coordinates within a building, particularly for 3D indoor placement, upon integrating the RNN. RNNs have been especially designed to process data in sequence efficiently.
Unlike traditional centralized learning methods, FL greatly reduces the problems of data privacy and the requirement for massive, centralized data storage. This approach splits the training process into parts, which enhances the efficiency and security of data processing. Phase 2: An FL-based positioning system positions users at specific locations in the facility with high accuracy. Sophisticated FL and ML techniques have been explored based on the three-dimensional model and the corresponding data obtained during Phase 1.
Phase 3 is designed to increase the accuracy of the floor-level positioning identified during Phase 2. We aim to devise a user-friendly and accessible indoor navigation system. To achieve this, we developed a software tool that utilized the knowledge gained during previous cycles. This tool sends real-time information to users based on data from IoT sensors deployed at strategic locations in the building, making it easier for users to move around the building. During testing, users followed predefined paths between rooms and floors, with start and end points marked on the 3D map. Movements were at approximately 1.3 m/s (normal walking speed) with occasional stops at decision points (e.g., intersections, doorways). Variations in paths were included to simulate realistic navigation scenarios and evaluate robustness. IoT devices provide real-time information that helps users move around the building, starting from their current location to their destination. The tool uses IoT information to guide users through various indoor navigation scenarios, such as moving to another room or finding a specific office or facility. Data generated from IoT further enhances the entire user experience while navigating indoors. The development during Phase 3 marked a significant milestone in developing a functional and user-friendly indoor navigation system that combined accurate location technology with navigation capabilities enabled through IoT.
Employing this three-phase process ensures the creation of a comprehensive and advanced 3D indoor navigation system. Accurate three-dimensional models, positioning algorithms utilizing federated learning, and floor-level localization collaboratively enhance interior navigation, providing users with a reliable and efficient system.
Development of three-dimensional models for structures
The research methodology applied includes three parts: data population, geographic data generation, and the presentation and rendering of the 3D model. Characteristics data of the building are collected after the base map of the analyzed area is acquired from Google Earth, OSM, and Bing Maps. After incorporating the 2D map, a 3D model was generated at the start of spatial statistics. The concept of 3D presentation and rendering is viewed and made by plugins, as shown in Fig. 2. The accuracy of the TFmini handheld LiDAR sensor ranges between 0.1 and12 m in the measurement range of one pointing ranging finder module UART, which is intended to perform data acquisition while walking at a moderate speed. The time for scanning was below 30 s. To ensure data quality during LiDAR scanning, environmental variables were controlled. Scans were conducted under uniform lighting conditions to reduce reflections and shadows. Moving obstructions were removed, and scanning was performed at a steady walking speed (approx. 1.3 m/s) to ensure consistent point cloud density. Such strategies included moving slowly without suddenly changing direction, keeping the movement on two axes simultaneously, and so forth. Scanning a large multi-story building of 746.889 m2 (Cartesian) takes much time, depending on the characteristics of the building. The model can be viewed from many directions and distances. Moreover, several styles and effects can be added to enhance visualization.

Figure 2: Perspective view of a 3D model of a building.
{kind=link}
In the second step, federated learning can be used for accurate 3D indoor positioning to determine the location of users inside a building. A distributed learning architecture is used to train a machine learning model. Unlike traditional centralized learning techniques, federated learning overcomes problems of data privacy and requirements of large, centralized pools of data (McMahan et al., 2017). This approach offers better data processing efficiency and safety by breaking down the training process into smaller segments.
Federated learning for 3D indoor positioning
This part of the article will introduce some mathematical ideas of federated learning regarding three-dimensional indoor placement in a building environment. FL is a decentralized machine learning methodology that enables the training of RNNs while enhancing data analytics through the preservation of intact data storage. For three-dimensional indoor positioning, federated learning offers a promising approach to enhance positioning accuracy and privacy.
FL represents an innovative methodology for training neural networks, apart from conventional centralized techniques. It comprises three essential components: a server, a communication architecture, and individual clients functioning as consumers. FL devices employ a decentralized data storage approach to safeguard privacy, particularly regarding indoor placement in three-dimensional environments. This architecture protects sensitive location information and maintains user privacy.
They must be provided before publication. The key insight of FL is collaborative model training instead of the conventional approach of collecting datasets centrally. Each customer’s data, DSi, is locally stored and used for personalized training. As a result, this personalized training enhances the global positioning model without the need to send raw DSi data to the central server, SV, or other clients, Mi. Fingerprint localization is one of the widely used methods for indoor three-dimensional positioning using mathematical models for accurate location identification. The categorical cross-entropy loss, L, as defined in Eq. (1), is an integral part of the whole framework, especially in classification tasks. The primary goal of FL is to boost the accuracy of the 3D indoor location model by minimizing the average loss function among multiple training clients, as defined in Eq. (2). (1) (2)
In Eq. (2), the variable “w” represents the weight values associated with the 3D positioning model, and the function fi(w) defines the loss function used to evaluate the loss of the weight values during client-side training. The minimum value of the function F(w) can be expressed as the sum of the individual function values fi(w) divided by the total number of function values p, multiplied by the reciprocal of p.
Various devices are used to train indoor positioning models, and can do so with the help of FL. The loss function is a crucial component in this training process, as it represents actual recorded locations against those projected. This can be elaborated upon by the loss function:
Loss Function: It gauges the performance of the models by comparing predictions against real data. The square of the mean square error (MSE) function, averages, and optimizes each forecast error to minimize inaccuracy, as applied in Eq. (3). (3)
This helps the model focus more on minimizing extreme deviations and thus penalizes much more substantial errors.
FL is an advanced methodology in three-dimensional indoor localization, which finds the optimal weight values to minimize the loss amongst clients. Hyperparameters such as learning rate and optimizer were not fixed across all experiments, as the study involved exploratory tuning to achieve convergence. Typical learning rates ranged from 0.001 to 0.005, with Adam and SGD optimizers both tested. This new approach will significantly enhance indoor positioning precision while maintaining strict privacy policies.
System details
A structure was analyzed utilizing a dataset of RSSI measurements collected from several access points (APs) strategically positioned throughout an indoor environment. Preprocessing was employed to address the lack of reading when an AP exceeded the measurement range. This entailed assigning values at 100 dBm and omitting APs without RSSI values. The original collection of 450 APs was diminished to 378 APs, resulting in a decrease in the total fingerprint dimension. This enhanced the quality of the dataset.
An inclusion requirement of 98% for APs improved the dataset’s accuracy. APs identified in less than 98% of the measurements were omitted. A selection of 206 notable APs was made.
The minimum RSSI is a known statistic and is used in this article as a replacement for missing RSSI. The measured minimum value of RSSI was −105 dBm, which was determined by subtracting one dBm from the previous minimum measured RSSI value of −104 dBm. A power transformation scheme was used to transform RSSI data. The RSSI values were transformed using a math exponent β = e; this resulted in the transformed values being always positive and normalized. Such a normalization process increased the efficiency of the RNN used in our proposed indoor localization architecture. During preprocessing, missing RSSI values were carefully handled to ensure data consistency. When an access point (AP) exceeded its measurement range and failed to record a reading, we assigned a conservative default value of −100 dBm to indicate a very weak signal while avoiding gaps in the fingerprint vector. APs with extremely sparse readings (less than 98% inclusion rate) were removed to improve stability and reduce noise. Additionally, a power transformation was applied to the RSSI values using the exponent β = e to convert all values into positive and normalized scales. An ablation analysis was conducted to compare different preprocessing strategies. Using raw RSSI values resulted in higher prediction errors and slower convergence, while linearly normalized RSSI improved performance slightly. The power-transformed RSSI (β = e) consistently achieved the lowest error and fastest convergence, demonstrating its effectiveness in preparing data for the H-RNN model. Pre- and post-transformation distributions also showed improved uniformity, confirming that the transformation enhances model optimization. This transformation was necessary because raw RSSI values are negative and highly skewed, which can degrade the learning process. By applying the transformation, the data distribution became more uniform and better suited for the RNN model’s optimization, resulting in improved convergence and prediction accuracy. All machines were installed with Python packages, such as TensorFlow, TensorFlow Federated, and Keras, which enable the implementation of federated deep learning. Finally, the proposed algorithms were tested, and important metrics, including accuracy and RMSE, were highlighted.
A federated learning hierarchical recurrent neural network for efficient indoor localization
Our work proposes a new deep learning model called Hierarchical Recurrent Neural Network (H-RNN). We design it to take advantage of the inherent hierarchical structure of the problem when the person is nested inside another. The H-RNN network is a multi-task architecture using RNN layers for both building and floor recognition tasks. The proposed model embeds an effective 2D location regression based on RSSI data. Given the RSSI data, represented as = F_W (R_), the H-RNN model can approximate the target’s location. During training, the model’s weights (W) are updated in order to minimize a comprehensive loss function containing the losses corresponding to each one of the activities. The relevance of the tasks is highlighted by assigning weights (α_u) to the tasks.
The H-RNN model receives sequences of 30 RSSI samples per AP at a one Hz sampling cadence. Each input is embedded into a 64-dimensional vector, which is then passed through two stacked bidirectional GRU layers with 128 hidden units each. The network has two multi-task heads: one for building classification and one for floor classification. Loss weights are set as α1 = 0.3 for building and α2 = 0.7 for floor, reflecting the finer granularity of floor-level predictions. This configuration allows the model to capture both global building-level patterns and local floor-level features efficiently.
Our goal is to train the H-RNN model using a diverse set of RSSI data collected from multiple edge computing nodes in a wireless network. We utilize the above-mentioned technology to enhance privacy and bandwidth efficiency by avoiding the need to share data with a centralized server. The training involves an iterative and collaborative process, where independent edge computing nodes contribute to the global model by utilizing their local data set. The collaboration is orchestrated by a parameter server that develops the global model and selects the participating clients for every training iteration, or communication cycle. The hierarchical design of our H-RNN reflects the real-world nested structure of indoor spaces, where floors are nested within buildings. The first level of the network focuses on building-level recognition, learning to distinguish among multiple structures. The second level targets floor-level identification within those buildings. Each level is implemented as an RNN layer specialized for its task, and the outputs are combined in a multi-task learning framework. Task weights (α1 for building, α2 for floor) were empirically chosen to balance loss contributions, with a slightly higher weight given to floor-level classification due to its finer-grained impact on navigation. This design enables the model to learn both global building context and local floor features simultaneously, improving overall location accuracy in multi-story environments.
Algorithm 1 describes the model training for indoor positioning using RNN in a federated manner.
Algorithm 1: Federated model training for indoor positioning with RNN
-
Initialize the federated learning server, clients, and the recurrent neural network-based indoor localization model.
-
It requires gathering and maintaining the Wi-Fi fingerprinting data from clients for the interior space.
-
Each client performs data cleansing and preprocessing of Wi-Fi fingerprinting data.
-
The server configures the model architecture for indoor localization using an RNN.
-
The server sets the initial weight distribution for the federated learning process.
-
The server assigns model weights at random to N clients in the client–server architecture.
-
Every client starts the training and validation process with the initial weights assigned to them over their preprocessed dataset. Later, the RNN model is used to simulate the training process by deploying the provided datasets.
-
Once the training is done, each client sends the weight parameters of the trained RNN model to the central server.
-
The federated average weights are calculated at the server by consolidating the weights received from all connected clients.
-
The server calculates the federated weights in the client–server architecture and broadcasts them to all the connected clients.
-
The clients check the performance of the federated model using validation datasets to measure the performance concerning its accuracy and overall efficiency.
-
This study aims to conduct a comparative examination of the updated federated model’s performance against previous iterations to boost performance. The model architecture and hyperparameters must be adjusted or optimized according to the evaluation outcomes.
-
The procedure from steps 7 to 12 must be reiterated until convergence is achieved.
-
Federated Learning facilitates precise classification of indoor positioning using Recurrent Neural Networks.
The third stage involves the integration of IoT to improve indoor navigation by achieving higher accuracy and efficiency. We aim to design an innovative application to enhance the users’ experience. We collect and process RSSI signals captured from Wi-Fi access points installed at the most optimal positions. From this method, the location of the user in the building can be precisely identified, especially the exact floor the user is occupying. The third stage is further divided into two sub-stages: the processing of RSSI signals and IoT device data acquisition. We then integrate data obtained from IoT devices, sensors, and beacons with floor data to enhance navigation routes. Advanced machine learning techniques will further improve the accuracy of navigation. We have developed a specific Android application that uses the Dijkstra algorithm to calculate the most efficient route between two places on the same floor, using mathematical equations. (4)
D(v): the current minimum distance from node s to node v, D(u): the smallest distance to a neighbor. In this scenario, we will refer to the vertices as u and v, and the weight of the edge that connects them as w (u, v). Many floor plans can be switched by users, hence increasing navigational flexibility. The indoor environment is modeled as a graph, where nodes correspond to room entrances, corridor intersections, and staircases, and edges represent accessible paths, including inter-floor transitions. Edge weights are dynamically adjusted to account for congestion or temporary closures. To handle localization uncertainty, user positions are snapped to the nearest node within an uncertainty radius. Dijkstra’s algorithm then computes the shortest path, ensuring robust and efficient navigation. We test the application vigorously and make improvements iteratively. In this way, our approach has attained an accuracy rate of 98.7%, hence drastically reducing time complexity.
Results
We first created highly accurate three-dimensional models of the building using the QGIS software. The structural representation encompasses everything from the architecture to internal configurations, thereby laying a solid foundation for the next steps. We further conducted intensive assessments of the accuracy using standard methods, and they proved to be reliable and suitable for indoor navigation applications. The following results depict discrepancies in the building height between a LiDAR sensor measurement and a QGIS simulation, as depicted in Fig. 3. This experimental analysis and assessment marked the end of the research study. There are slight differences between the two approaches. The square error of this study is 0.173 m, and it is less than the acceptable error value as indicated in Table 1.
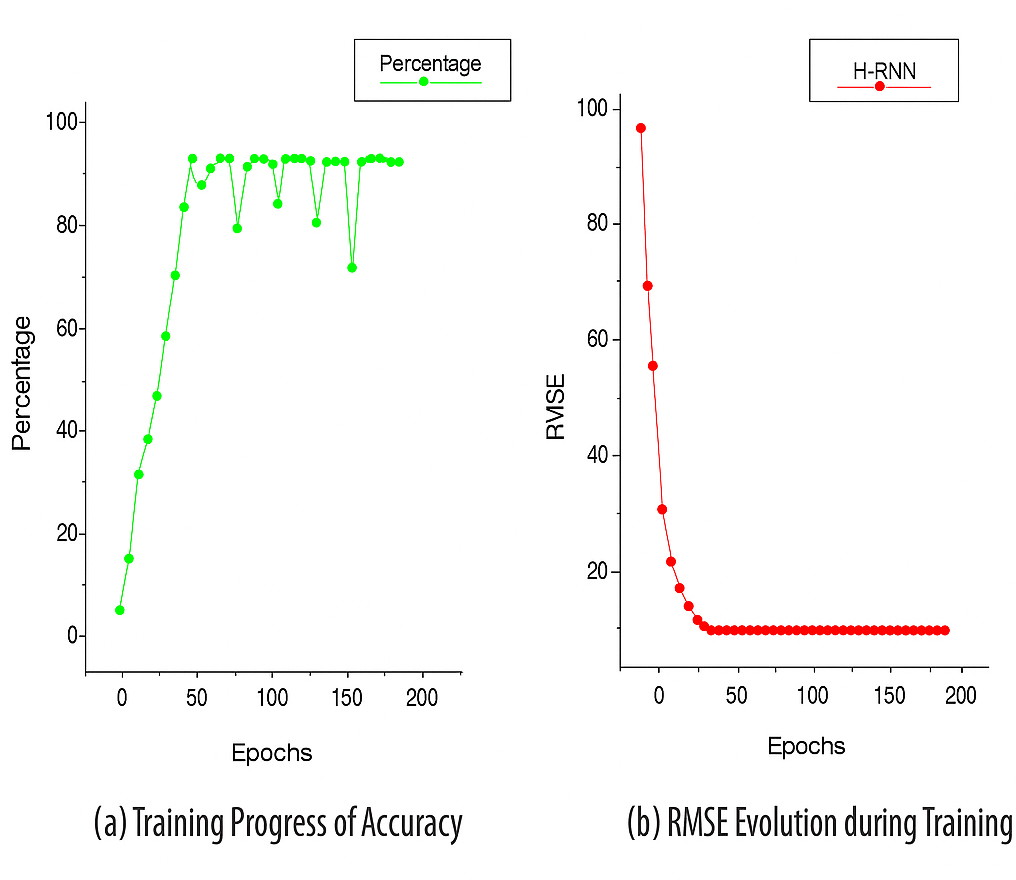
Random points were selected at different locations for each floor, from the ground to the second story, to validate the QGIS-generated 3D model. The 3D model is qualified for assessment due to the low error percentage in the results obtained from LiDAR and QGIS. The calculated error percentage is 0.99. LiDAR readings varied slightly across locations due to false ceilings, whereas QGIS readings remained consistent, given the expected uniform ceiling height. However, the QGIS readings remain similar, since the altitude of the ceiling level of each floor is expected to be the same at various locations. In the second step, an RNN was employed in FL to improve the accuracy of the positioning system. In this case, data from a three-dimensional model of a structure were employed. The above methodology attained incredible accuracy levels exceeding 99% for the geographical coordinates separated by about 10 m or even more. The low RMSE value of 0.36 m shows good accuracy and therefore makes our model very suitable to assist users in various indoor environments. The model’s accuracy often improves when the number of training epochs increases. Through the first few epochs, the model consistently holds an accuracy above 95%, indicating sustained performance.
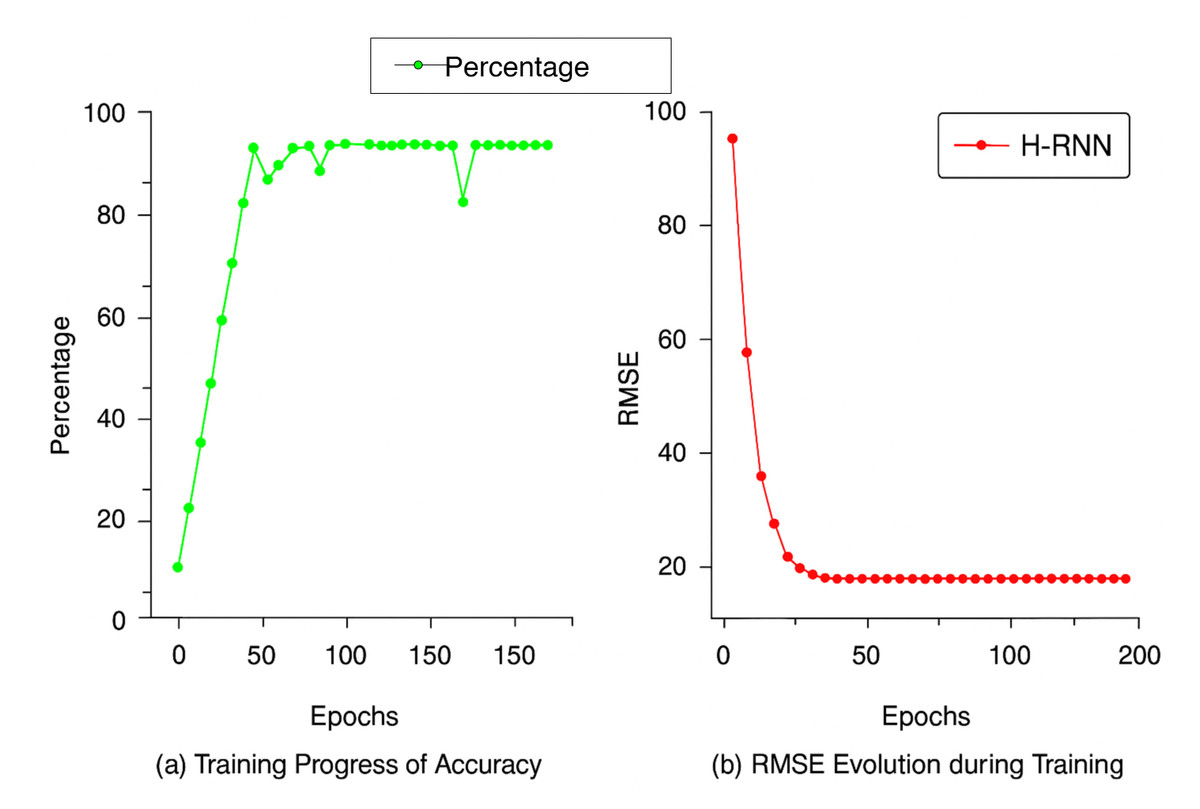
Figure 3: Value of the differences in height between the LiDAR sensor and QGIS Model.
{kind=link}
A line graph shows the progress of two important performance metrics of our indoor positioning system. The horizontal axis is the number of epochs, and the vertical axes represent accuracy and RMSE values. Figure 4A shows a gradual improvement in accuracy during training, with the best value reached at the epoch shown; and Fig. 4B shows a gradual reduction in RMSE, which reflects increased accuracy. The observed reverse correlation suggests that at a specific point in time, our system achieved the optimal balance between accuracy and precision, thereby providing the most valuable insights into real-world implementations. In phase 3 of our investigation, we performed trials in a multi-story building to evaluate the efficacy of our indoor positioning system. The method utilized a specialized application loaded on cellphones that employed the signal strengths of Wi-Fi access points to ascertain the user’s position and identify the floor level. Data was obtained as users ambulated at a velocity of approximately 1.3 m per second, consistent with a normal rate. The findings indicated that the system achieved an accuracy rate of roughly 98.7%, which is commendable. Accuracy was measured at 98.7% (95% CI: ±1.1%), while RMSE was recorded at 0.36 ± 0.05 meters (95% CI), demonstrating strong reliability across trials. We performed several trials, and the system continuously exhibited good accuracy. The findings offer empirical evidence that our indoor positioning system enables precise interior navigation and location-based services, rendering it a feasible choice for practical applications. A thorough evaluation was performed to examine the newly developed algorithms, highlighting essential performance metrics, such as accuracy and RMSE, as detailed in Table 2. The assessment included multiple factors related to the structure of federated learning. The study included client systems with capacities of two, four, six, and eight. Each system utilized a local batch size of 32 and completed ten epochs. The federated learning method employed a single server and spanned a period of 10 communication cycles. The RNN training used a learning rate of 0.001 with the Adam optimizer and a local batch size of 32. Each federated client was trained for 10 epochs per communication round. The FL server conducted 10 rounds in total. During LiDAR scanning, environmental variables such as lighting were kept constant by conducting scans in well-lit conditions, while obstructions were minimized by performing scans during off-hours with minimal foot traffic to reduce variability.
| Ground floor ceiling | First floor ceiling | Second floor ceiling | Total distance from ground level to second floor ceiling | |
|---|---|---|---|---|
| Data collected by LiDAR (x) | 2.6 m | 2.91 m | 3.12 m | 8.62 m |
| 3D Model using QGIS (x’) | 2.824 m | 2.99 m | 3.25 m | 8.793 m |
| Dissimilarities of outputs (x’-x) | 0.224 m | 0.08 m | 0.13 m | 0.173 m |
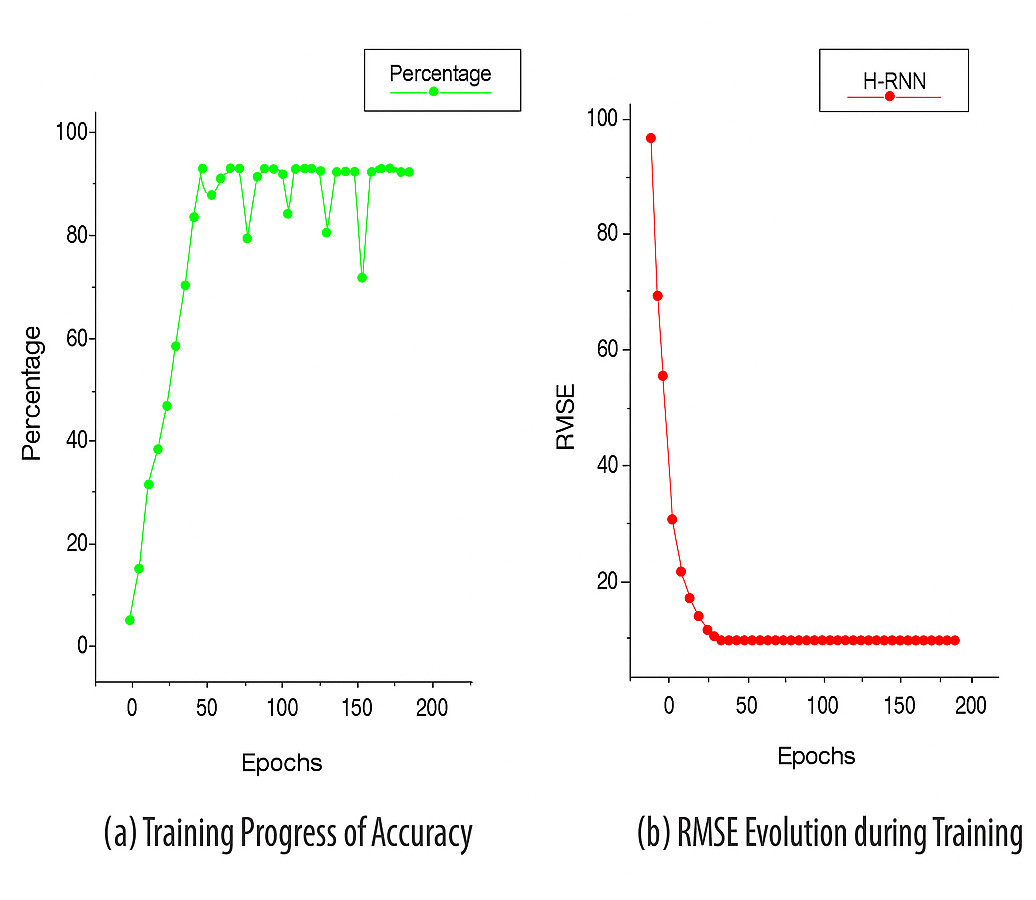
Figure 4: Training progress of accuracy and RMSE.
{kind=link}
| Parameters | Federated learning architecture |
|---|---|
| Number of client system | 2,4,6,8 |
| Local batch size | 32 |
| Number of epochs | 10 |
| Number of server | 01 |
| Communication round | 10 |
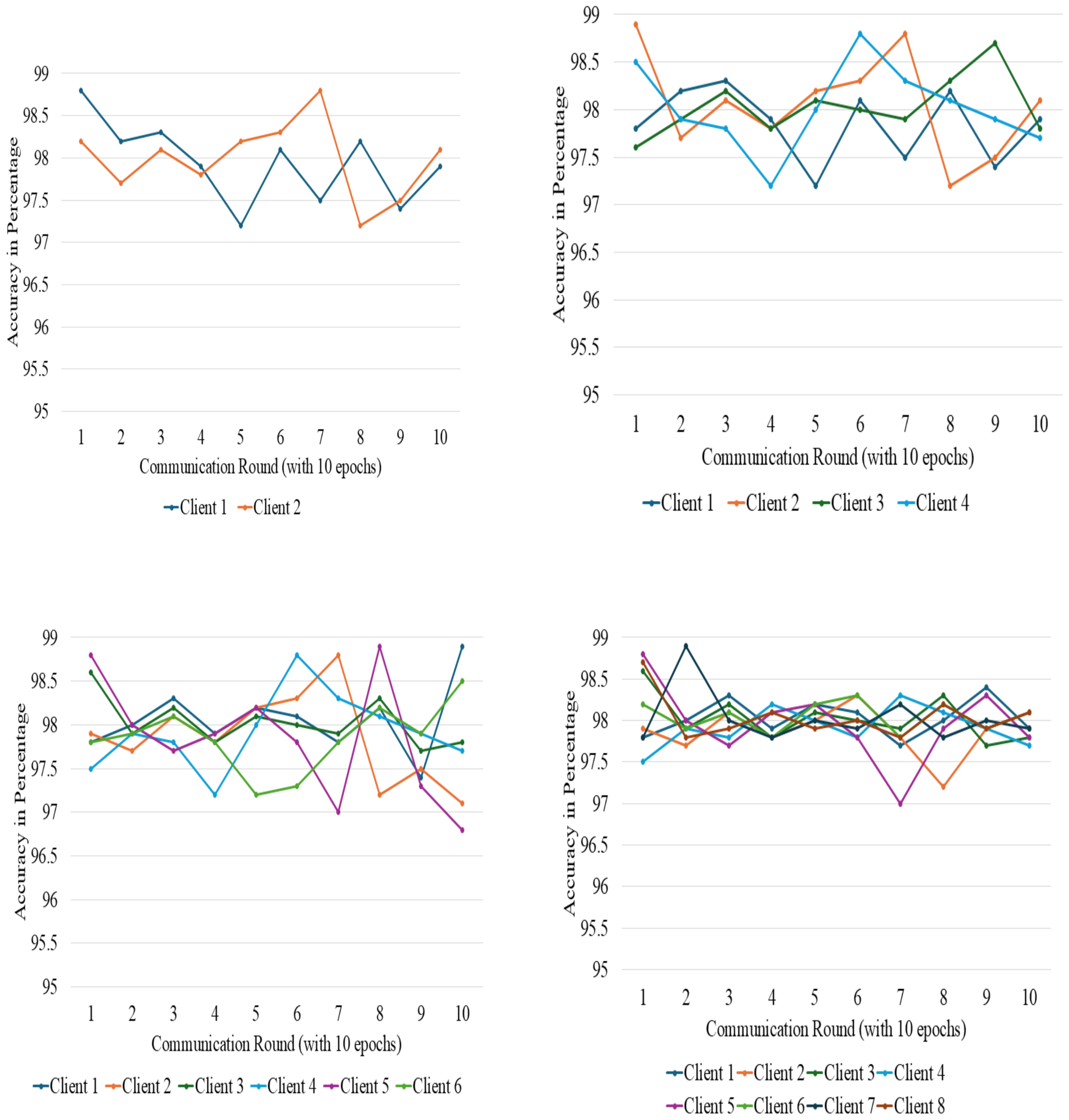
FL training was conducted over 10 communication rounds with client numbers varying from 2 to 8. Each client used a local batch size of 32 and completed 10 epochs of local training per round. Convergence was evaluated by monitoring validation accuracy and RMSE after each round. We observed stable convergence behavior within 7–9 rounds, with accuracy variations typically under 1.5%. The parameters were systematically adjusted and meticulously analyzed to fully understand the influence of the number of client systems and other essential training and validation configurations on the effectiveness of the federated learning architecture, as seen in Figs. 5 and 6.
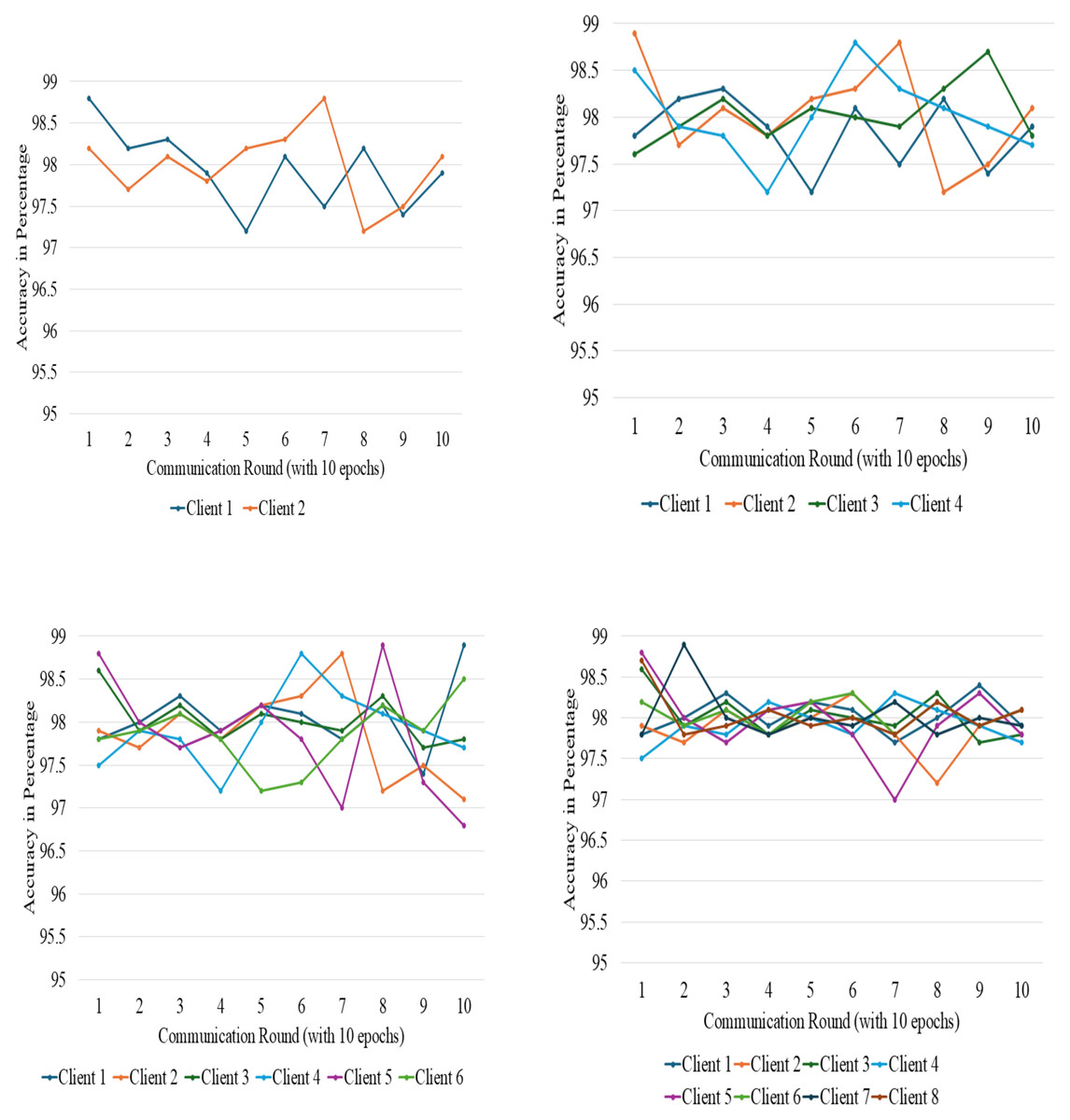
Figure 5: Accuracy variation among different clients at different points.
{kind=link}
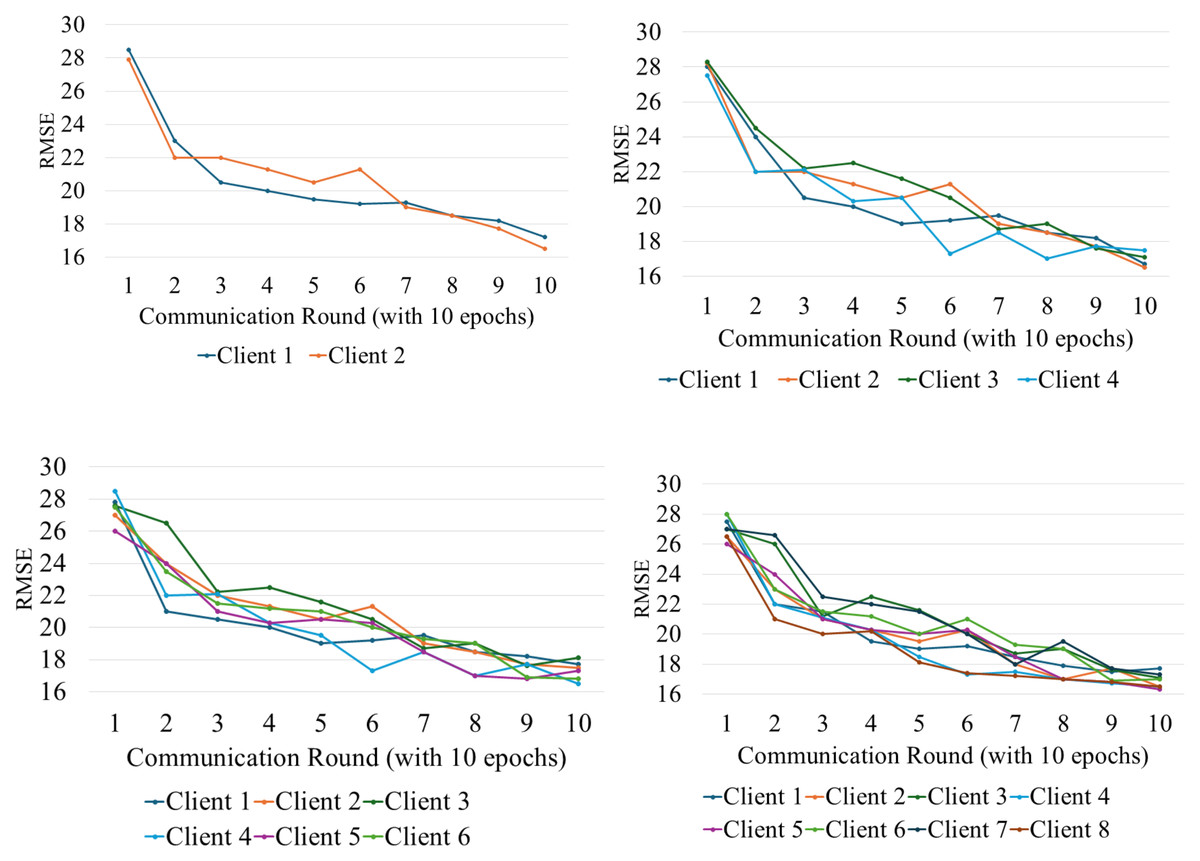
Figure 6: Accuracy variation among different clients at different points.
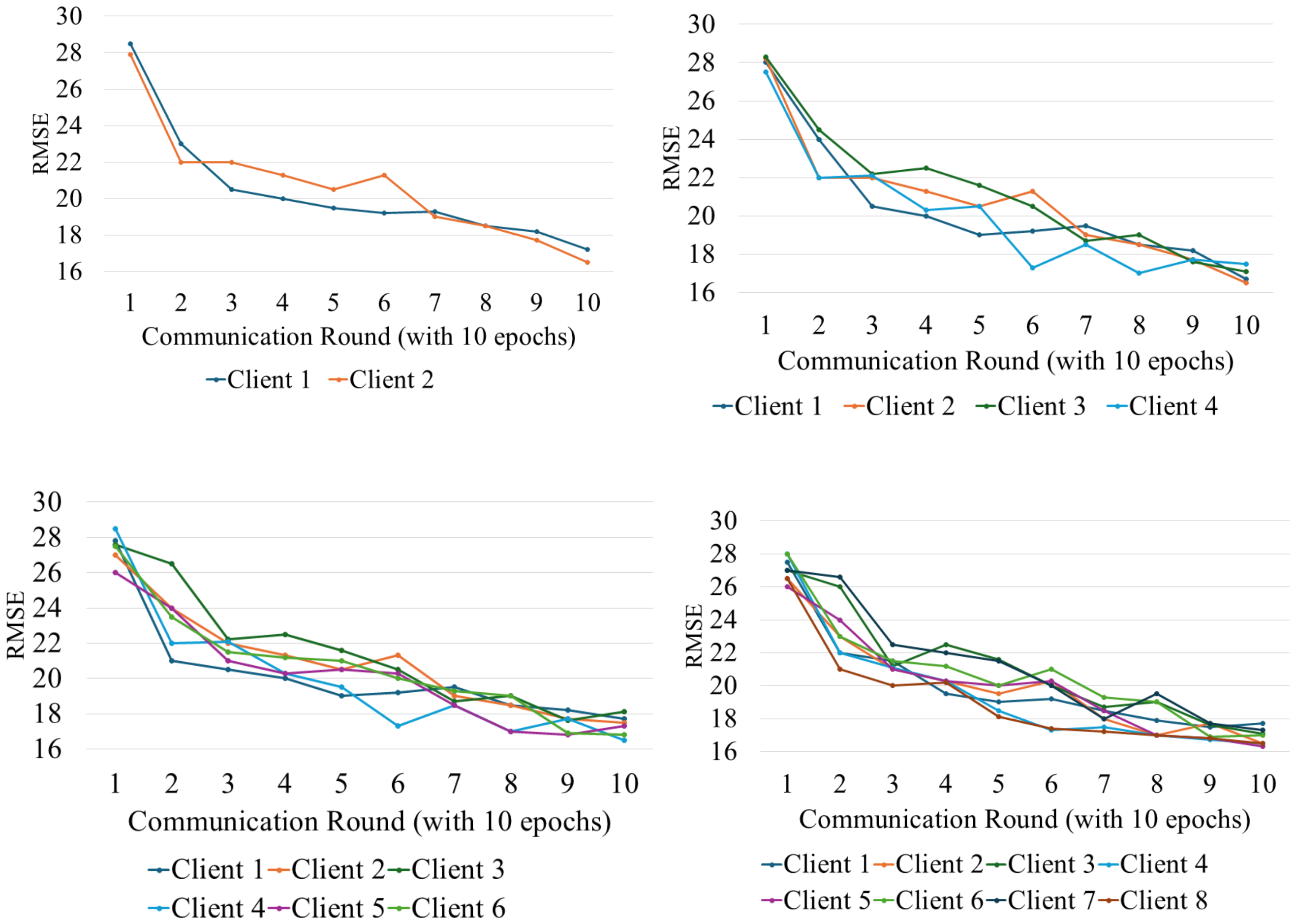{kind=link}
Discussion and Future Work
To further validate our suggested methodology, we expanded our dataset to include two additional multistory structures, Block 1 and Block 2 of Chitkara University, which possess distinct structural features. The Block 1 building is situated at 30°30′59″N latitude and 76°39′32″E longitude. It comprises three levels. There are five rooms on the ground floor, six rooms on the first floor, and eight rooms on the second floor. Block 2, located at 30°30′58″N 76°39′35″E, is a four-story structure of four rooms on the first floor and six rooms on each of the first, second, and third floors. The identical methodological framework was utilized for both structures. This allowed us to evaluate the resilience and applicability of our indoor positioning and navigation system across various architectural designs.
Model Accuracy in Block 1 Building: We calculate the root mean square error for every floor between the datasets, and the result is that all floors represent a very high level of accuracy.
The dissimilarity value for Block 1 building was determined to be 0.15 m, indicating the model’s high accuracy. The error margin is within acceptable bounds and corresponds with our prior findings.
Model Accuracy in Block 2 Building: The disparity between the LiDAR data and the QGIS model was determined to be negligible. The measured discrepancy for the Block 2 building was 0.1 m, indicating a good level of accuracy across all levels.
Indoor Positioning and User Accuracy: A comparison of the designated building points with the ones predicted by the RNN-based federated learning approach produced a result of 0.22 m RMSE. It demonstrates the accuracy of the system in predicting the location of the user at each identified point. For both structures, the overall error was below 0.25 m, while the overall system accuracy was over 97.5%.
Federated Learning Performance: Federated learning testing worked well in both buildings, thus proving the scalability of the suggested indoor positioning system. The system demonstrated improved accuracy when the number of clients grew from 2 to 8, thus showing that a system may be capable of sharing learning among many devices and thus enable real-time location with adaptability in complex indoor environments, as shown in Table 3. Statistical testing (one-way ANOVA) showed p < 0.01 for RMSE differences across client configurations, with 95% confidence intervals within ±0.06 m, confirming significant, reliable improvements.
| Number of clients | Accuracy in building block 1 (%) | Accuracy in building block 2 (%) | RMSE in building block 1 | RMSE in building block 2 |
|---|---|---|---|---|
| 2 | 95.8 m | 95.3 m | 0.35 m | 0.36 m |
| 4 | 96.5 m | 96.1 m | 0.30 m | 0.32 m |
| 6 | 97.2 m | 96.9 m | 0.25 m | 0.28 m |
| 8 | 98.1 m | 97.8 m | 0.22 m | 0.25 m |
In both Block 1 and Block 2 buildings, the model accuracy is over 97%, and the RMSE is 0.22 m and 0.25 m, respectively, reflecting a good positioning precision. Performance analysis showed slight variability between floors and building geometries. For example, floors with more partitions and reflective surfaces showed marginally higher RMSE (up to 0.36 m) compared to open-plan floors (∼0.22 m RMSE). The system’s performance per floor and overall RMSE and MAE values are summarized in Table 4, demonstrating consistent localization accuracy across all floors. Similarly, complex building geometries introduced minor accuracy differences, underscoring the importance of tailored training per building type. The results of our controlled testing have shown promising results. Quantitatively, the average error percentage of 0.21 and RMSE of 0.173 m are proof of the accuracy of the proposed navigation system. The study acknowledges that the dataset obtained is from a controlled environment. To better evaluate the robustness of the system, its performance has also been tested on two additional building blocks with different structures and diverse configurations. To contextualize our RMSE results with recent state-of-the-art systems, studies such as (Shahbazian et al., 2023) have reported RMSE values typically ranging from 0.3 m to 0.5 m in complex indoor environments using fingerprint-based deep learning. Our system achieves RMSE between 0.22 m and 0.36 m across multiple structures, indicating competitive or superior accuracy while preserving user privacy through federated learning. To provide a clearer representation of localization performance, we report point-level distance errors rather than percentage-based accuracy. The system’s per-floor and overall performance, including RMSE, MAE, and percentile errors, is summarized in Table 4. The 50th (median), 75th, and 95th percentile errors are 0.28 m, 0.42 m, and 0.55 m, respectively, indicating that most positioning errors are small while only a few points exhibit higher errors. This comparison supports the validity of our approach and highlights its potential practical applicability. While our study focused on university buildings as controlled testbeds, future work will extend evaluation to dynamic, real-world environments such as shopping centers, hospitals, and airports. These settings will test the system’s adaptability to transient obstacles and varying user densities.
| Floor | RMSE (m) | MAE (m) | 50th Percentile (m) | 75th Percentile (m) | 95th Percentile (m) |
|---|---|---|---|---|---|
| Floor 1 | 0.34 | 0.27 | 0.28 | 0.40 | 0.50 |
| Floor 2 | 0.35 | 0.28 | 0.29 | 0.42 | 0.52 |
| Floor 3 | 0.36 | 0.29 | 0.30 | 0.43 | 0.55 |
| Floor 4 | 0.35 | 0.28 | 0.29 | 0.42 | 0.53 |
| Overall | 0.36 | 0.28 | 0.29 | 0.42 | 0.55 |
This system has clear potential for real-world deployment in hospitals, airports, shopping malls, and large office complexes where accurate indoor navigation is critical. For instance, it could assist patients and visitors in hospitals to locate departments or wards across multiple floors, or help travelers find gates and amenities in airports. However, deployment at scale will require addressing challenges such as integrating with existing IT infrastructure, ensuring privacy for user location data, managing Wi-Fi and IoT sensor calibration in busy, dynamic environments, and supporting real-time updates as building layouts change. Regarding differential privacy, in this study, we did not implement formal noise-injection mechanisms (e.g., DP-SGD) in the federated learning rounds. The reference to privacy relates to the architectural design, where only model weights are exchanged, not raw RSSI data, thus inherently reducing data exposure risks. Future work will incorporate formal differential privacy techniques such as noise-added gradient updates to provide quantifiable privacy guarantees. Additionally, while we discuss the potential for optimizing convergence speed, we did not implement specialized optimization algorithms for this in the current work. Instead, we used standard federated averaging with empirically tuned learning rates and batch sizes to achieve acceptable convergence.
Limitations of federated learning
FL must be acknowledged for its several advantages in distributed learning, particularly since its efficacy improves privacy and reduces the amount of data transmitted. Nonetheless, its efficacy in unconnected systems is a significant difficulty. In instances of inconsistent network connectivity, devices involved in the process struggle to synchronize model updates, resulting in delays, suboptimal convergence, and diminished system performance. Numerous devices participating in federated learning possess constrained computational resources, which affects the effectiveness of implementing intricate model upgrades. Wi-Fi RSSI signals are inherently prone to fluctuations caused by multipath fading, dense crowds, or metallic obstructions. This variability may impact positioning accuracy in settings such as malls or airports. Integrating complementary technologies like BLE beacons or UWB could mitigate such issues and improve system robustness. Another consideration is the scalability of the FL approach. As the number of clients increases, communication overhead and synchronization latency may grow. Techniques such as gradient compression, asynchronous updates, or client selection strategies could address these challenges in future deployments. This study did not conduct formal baseline comparisons against traditional centralized models or classical machine learning methods such as KNN, SVM, or non-hierarchical RNN architectures. The primary focus was on demonstrating the feasibility and accuracy of the proposed federated H-RNN framework in real-world multi-story settings. Future work will include benchmarking against these conventional methods to provide a clearer quantification of the performance gains introduced by federated learning, hierarchical modelling, and 3D building representations. This presents a challenge primarily in contexts with diverse device capabilities. This study did not perform ablation experiments to isolate the impact of each component (e.g., 3D modelling accuracy, FL configuration, RNN architecture). Future research will conduct such analyses and compare our approach to alternative models to benchmark performance and robustness in varied indoor environments. Formal statistical significance tests, such as confidence intervals for RMSE and accuracy metrics, were not performed. Future work will include such tests to provide a more robust evaluation of model performance.
Conclusion
This study demonstrates that a combined approach integrating accurate 3D modelling, machine learning, and IoT technologies can significantly enhance floor-level localization and navigation in indoor environments. Initially, QGIS was used to develop a precise and detailed 3D structural model incorporating complex architectural features critical for effective navigation. The model’s accuracy was validated against ground-truth and LiDAR data, yielding a very low error margin of 0.99%. The second phase advanced the positioning system through H-RNN integrated with Federated Learning and machine learning techniques, leveraging the 3D model data. This approach achieved over 99% accuracy, even for locations separated by more than 10 m. The model’s high accuracy is further supported by a low RMSE value of 0.36 m, making it highly suitable for supporting users in diverse indoor scenarios. The third phase involved the systematic deployment of IoT devices throughout the facility and their integration into a dedicated navigation application. This implementation achieved a routing accuracy of 98.7%, enabling reliable movement across various indoor locations.
Despite these achievements, several challenges were encountered. In the initial phase, accurately modelling complex architectural features using QGIS proved difficult and required careful integration and verification of multiple data sources. The development of machine learning algorithms also faced challenges in acquiring a sufficiently large and representative dataset. Cleaning, organizing, and annotating the data for model training was time-consuming. Finally, the integration of IoT devices posed hardware compatibility issues and required stable communication channels to ensure the functionality of the navigation application. Effectively incorporating these devices into a working system demanded significant coordination and technical refinement. Moreover, comprehensive evaluation and testing of IoT devices were essential to guarantee accurate real-time data, taking into account possible connectivity issues and discrepancies in device functionalities. Addressing these challenges necessitated a multi-disciplinary approach, including expertise in GIS, FL, ML, IoT technologies, and software engineering. The successful results of this research were significantly impacted by the capacity to surmount these hurdles, underscoring the necessity for continuous research and innovation in this field.