
Controllable Chinese landscape art creation using adversarially regularized autoencoder
- Published
- Accepted
- Received
- Academic Editor
- Trang Do
- Subject Areas
- Artificial Intelligence, Computer Vision, Data Mining and Machine Learning, Data Science, Neural Networks
- Keywords
- Chinese landscape painting, Digital art preservation, Artificial intelligence, Deep learning, Generative adversarial networks
- Copyright
- © 2026 Liu et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits using, remixing, and building upon the work non-commercially, as long as it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Controllable Chinese landscape art creation using adversarially regularized autoencoder. PeerJ Computer Science 12:e3457 https://doi.org/10.7717/peerj-cs.3457
Abstract
Chinese landscape painting represents a rich artistic tradition that spans over a millennium, reflecting the complex interplay of philosophy, nature, and cultural expression distinctive to China. However, as fewer contemporary artists master these traditional techniques, there is growing concern about preserving and transmitting this cultural knowledge to future generations. Recent advancements in artificial intelligence present new opportunities for addressing this challenge through the preservation and creative evolution of this art form. In this article, we propose a deep learning framework for generating Chinese landscape artworks, leveraging a curated image-text dataset of high-quality traditional works. Our architecture is designed to combine the advantages of both generative adversarial networks and variational autoencoders, achieving improved stylistic control and visual fidelity. We introduce a guided image generation approach that enables fine-grained manipulation of composition and style through embedding blending mechanisms. Experimental evaluations show that our model outperforms state-of-the-art baselines including StyleGAN2, SAPGAN, and CycleGAN, achieving superior Fréchet Inception Distance (FID) scores. The proposed approach not only demonstrates technical advances in generative modeling but also opens new avenues for digital preservation, aesthetic education, and contemporary reinterpretation of Chinese landscape art.
Introduction
History, philosophy, and modern challenges
Chinese landscape painting represents a profound and multifaceted tradition within Chinese visual arts. Its origins trace back to the Tang Dynasty (618–907 AD), with early pioneers such as Wang Wei who helped establish the foundation of ink and wash techniques. By the Song Dynasty (960–1279 AD), these approaches had matured into celebrated masterpieces that vividly portrayed the grandeur of mountains, rivers, flora, and seasonal changes. This developmental journey reflects the deep philosophical and aesthetic values of Chinese culture, emphasizing harmony between humanity and nature as well as the contemplative spirit embedded in the artistic process (Wang, 2022). This “shan shui” aesthetic, which translates to “mountain-water”, embodies the belief that nature and humanity are interconnected, and it encourages viewers to cultivate a sense of inner peace and connection with the natural world (Suk-mun Law, 2011). During the late Qing Dynasty, landscape art in China gradually absorbed Western artistic influences, particularly as watercolor techniques entered elite circles in the 18th century. Global trade exchanges through major ports like Guangzhou facilitated this cultural diffusion, enabling a stylistic synthesis that broadened the expressive range of Chinese landscape painting (Wen & White, 2020).
The value of Chinese landscape painting lies not only in its visual beauty but also in its ability to express philosophical concepts and evoke emotional resonance. These works transcend literal representation, serving as vehicles for the artist’s spiritual contemplation and cultural worldview (Chen, 2023). The art form draws upon foundational elements of Confucianism, Taoism, and Buddhism, emphasizing balance, natural order, and spiritual resonance. Each brushstroke is regarded as a manifestation of interconnectedness within creation (Bao et al., 2016).
Traditional materials such as xuan article (rice article), silk, and mineral pigments provide the distinctive textures and tonal depth that define landscape works, while techniques like layered washes and controlled ink diffusion contribute to their timeless expressiveness (Huang, Ito & Nakano, 2022). However, in the modern era, the preservation and revitalization of Chinese landscape painting face significant challenges due to globalization and the decline of traditional practices, which have been exacerbated by the pressures of modernization (Wang, 2025). Digital technologies such as high-resolution imaging, virtual reality, and generative design play an increasingly important role in conserving fragile works and making them accessible to broader audiences (Gao, 2023; Tang & Wang, 2024). Moreover, the blending of digital innovation with classical techniques fosters creative experimentation while ensuring the continuity of this cultural heritage (Tian & Tirakoat, 2024).
Age of digital Chinese landscape painting
In recent years, the advent of artificial intelligence (AI), particularly deep learning (DL) technologies, has sparked new possibilities for the digital creation and analysis of visual art. Deep learning models, with their powerful capabilities in pattern recognition and image synthesis, have revolutionized mainstream fields such as natural language processing, object detection, and medical imaging, and are making significant advances within computational art (Cheng, Wang & Wang, 2024). By automating and augmenting artistic processes, these models have begun to bridge the gap between traditional artistic skills and modern computational intelligence.
Despite the flourishing development of digital art and widespread adoption of neural style transfer in Western contexts, the adaptation of Chinese landscape painting to the digital domain remains challenging and underexplored. The distinctive characteristics of Chinese landscape painting present significant hurdles for conventional algorithmic approaches (He, 2025). Maintaining the spirit and artistic conception of traditional works during digital synthesis demands a nuanced understanding of both visual structure and cultural meaning, a requirement that standard deep learning techniques may struggle to fulfill without careful adaptation.
Research efforts have begun to address these challenges by leveraging specialized techniques such as convolutional neural networks (CNNs), generative adversarial networks (GANs), and custom style transfer methods adapted to traditional Chinese aesthetics (Lin et al., 2018). Advanced approaches including unpaired image-to-image translation techniques like CycleGAN and domain-adaptive data augmentation have enhanced the effectiveness of automated synthesis within the Chinese artistic context (Tang, 2022). These models aim to transform sketches or photographs into Chinese landscape paintings while capturing intricate visual characteristics and cultural nuances.
Experimental results suggest that these models can achieve impressive technical fidelity and aesthetic quality, although challenges remain concerning interpretability and preservation of cultural subtleties (He, 2025). The integration of deep learning into Chinese landscape painting offers promising applications across multiple domains: supporting artistic creation through new digital workflows, enhancing education and preservation via teaching tools and archival systems, and facilitating cultural analysis by quantifying stylistic elements across large artwork datasets (Zhang, Duan & Gu, 2021; Chen, 2022).
Deep learning in Chinese landscape painting
The application of DL to Chinese landscape painting has increasingly attracted attention, driven by the desire to digitally preserve, replicate, and extend this culturally significant art form. This traditional art, characterized by ink diffusion, expressive brushwork, and masterful use of negative space, poses distinctive challenges for computational modeling due to its aesthetic subtlety and philosophical depth (Cohen-Duwek & Spitzer, 2019). Early approaches stemmed from breakthroughs in neural style transfer, where CNNs were utilized to blend content and style from different images. While effective in capturing general visual aesthetics, these methods fell short in preserving the intricate brush dynamics and tonal gradation that define traditional works (Wang & Alamusi, 2022). These techniques often treated style as superficial texture, neglecting the procedural and symbolic aspects critical to Chinese art (Desikan, Shimao & Miton, 2022). Contemporary research has illustrated significant advancements through specialized generative architectures. Models based on CycleGAN and DCGAN have been adapted to translate photographs or sketches into Chinese painting styles, emphasizing structural coherence and stylistic authenticity (Howard, 2022). Key improvements include multi-scale self-attention mechanisms that capture global layout alongside fine-grained ink textures, and bespoke loss functions emphasizing brushstroke fidelity and compositional balance (Wu, 2023). Human evaluation studies suggest that generated artworks are often perceived as visually plausible and culturally resonant (Zhang, Duan & Gu, 2021). A particularly promising application is sketch-to-painting conversion, where conditional GANs transform line drawings into landscape outputs. These models enable user interactivity, with expert assessments reporting high aesthetic quality and alignment with traditional visual norms (Gerardin et al., 2018; Hale & Brown, 2021). Advanced studies are incorporating algorithms that model pigment diffusion, color transparency, and stroke variation, with innovations in color-matching networks and adaptive feature extraction significantly improving landscape representation (Jia, 2024; Tian & Tirakoat, 2024). Complementary developments include large-scale dataset curation, artistic process modeling, and educational applications. Some models simulate step-by-step painting processes, providing benefits for art education and analysis (Yang & Min, 2022). However, important challenges persist: modeling the fluid dynamics of landscape techniques, maintaining stylistic diversity, and capturing the emotional and philosophical essence inherent in this art form. Addressing these challenges continues to motivate innovation at the intersection of AI and traditional aesthetics.
Motivation and key contributions
Despite recent advances in applying DL to style transfer and digital art generation, most progress has focused on Western art forms or general visual domains. In contrast, Chinese landscape painting creation remains significantly underexplored, with existing methods often encountering limitations such as style dilution, inadequate simulation of brushstroke textures, and loss of semantic or cultural depth when applied to this highly nuanced art form (Tang, 2022). The significance of Chinese landscape painting lies not just in its aesthetic appeal, but also in its deep philosophical roots and cultural heritage, which emphasize harmony between humans and nature. This makes it a vital area of focus, not only for artistic expression but also for its role in preserving cultural identity in a rapidly globalizing world. Understanding and innovating within this traditional art form can help bridge the gap between contemporary digital methods and age-old artistic philosophies. These challenges highlight the need for dedicated approaches that can faithfully capture both the technical and philosophical intricacies of this traditional art (Cheng, Wang & Wang, 2024). To address these limitations, we propose a novel DL model specifically designed for controllable Chinese landscape generation. Our approach integrates customized neural architectures with domain-aware training strategies, effectively connecting artistic authenticity and computational performance.
A key component of our model is the use of an adversarially regularized autoencoder (ARAE) architecture for several compelling reasons. First, the ARAE combines autoencoding with adversarial training, promoting realistic and coherent image generation that is crucial for capturing the intricate details of Chinese landscape painting. Additionally, this architecture allows for fine-tuning of styles and features, accommodating the diverse artistic expressions found within Chinese landscapes. It also effectively retains both the visual fidelity and the cultural essence of original artworks, ensuring sensitive digital representations. Finally, by reducing the risk of mode collapse, the ARAE guarantees varied and rich outputs that reflect the complexity of this art form, making it a superior choice over simpler generative models.
The key contributions of this work include:
Designing a model that is capable of capturing the hallmark features of Chinese landscape painting, such as expressive brushwork, ink wash diffusion, and deliberate spatial composition, with visual fidelity and stylistic coherence.
Preserving both the semantic content and the expressive “spirit” of original artworks, ensuring cultural sensitivity in digital renderings.
Validating the model through comprehensive experiments, including both qualitative visual assessments and quantitative performance metrics.
By advancing DL methods specifically for Chinese landscape painting, this work not only contributes technically to the field of AI-generated art but also supports the preservation, reinterpretation, and revitalization of Chinese cultural heritage in the digital age.
Materials and Methods
Dataset
In this study, we utilized the CCLAP dataset (Wang et al., 2023), a curated collection of 3,560 image-text pairs comprising traditional Chinese landscape paintings alongside detailed textual descriptions. This dataset captures a wide variety of brush techniques, compositional styles, and thematic elements typical of classical Chinese art. Representative samples from the dataset are illustrated in Fig. 1, showcasing the diversity and artistic richness of the included works. The original artwork samples were aggregated from publicly accessible sources, including online museums and search engine results. A rigorous manual screening process was conducted to retain only authentic Chinese landscape artworks. Samples that were poorly digitized, blurred, or non-representative of the landscape genre were eliminated. This curation process was conducted to ensure both the visual fidelity and thematic consistency required for training robust generative models. The dataset was randomly split into training and validation sets at a 9:1 ratio, yielding 3,204 samples for training and 356 samples for validation.

Figure 1: Representative examples from the CCLAP dataset.
{kind=link}
Data pre-processing
To create a uniform input standard, all paintings were subjected to a multi-stage preprocessing pipeline:
Image processing: The shorter dimension of each image was resized to 512 pixels while preserving the original aspect ratio. If the resulting image had an aspect ratio smaller than 1.5, it was center-cropped to a fixed size of 512 512 pixels. For wider paintings, a sliding window mechanism with 256-pixel steps was applied to extract multiple overlapping patches, each of size 512 512.
Textual content removal: Many traditional paintings include poetic calligraphy that can interfere with visual learning objectives. To address this, an automated cleaning process was employed. A pre-trained scene text detector was adapted to identify regions containing text, and these regions were subsequently filled using an inpainting method based on fast marching algorithms. This ensures that the resulting training data focuses purely on pictorial elements.
The CCLAP dataset, with its combination of artistic diversity, high resolution, and semantically aligned text-image pairs, provides a valuable foundation for developing and evaluating generative models in the context of Chinese landscape painting.
Methodology
Generative adversarial network
Generative adversarial networks (GANs) (Goodfellow et al., 2014) are effective in modeling complex data distributions through adversarial training between two networks: a generator and a discriminator (critic). Given a noise variable , the generator aims to produce images resembling real landscape paintings. To minimize the divergence between the generated distribution and the real data distribution , GANs utilize the Wasserstein GAN objective:
(1) where is a 1-Lipschitz continuous function. Training converges when , allowing the generator to produce convincing landscape images. Despite this, GANs often struggle with discrete or highly structured outputs, making them less suitable for diverse styles found in traditional paintings.
Variational autoencoder
Variational autoencoders (VAEs) (Kingma & Welling, 2019) learn latent variable models by approximating the posterior distribution and reconstructing the input through a decoder . The loss function includes a reconstruction loss and a Kullback-Leibler divergence term:
(2) where is the prior distribution (typically Gaussian), and . Although VAEs can model latent spaces efficiently, they often suffer from “holes” in latent space, resulting in implausible outputs, especially problematic for multimodal data such as various painting styles.
Proposed model
Our proposed model is inspired by the study of Hong et al. (2019). As shown in Fig. 2, it mitigates the drawbacks of both GANs and VAEs by incorporating adversarial training within an autoencoder framework. The encoder maps input to a latent variable , while the decoder reconstructs from . Simultaneously, a generator learns to produce latent vectors from random noise , and adversarial training aligns the two distributions:
(3) where the Wasserstein distance is:
(4)
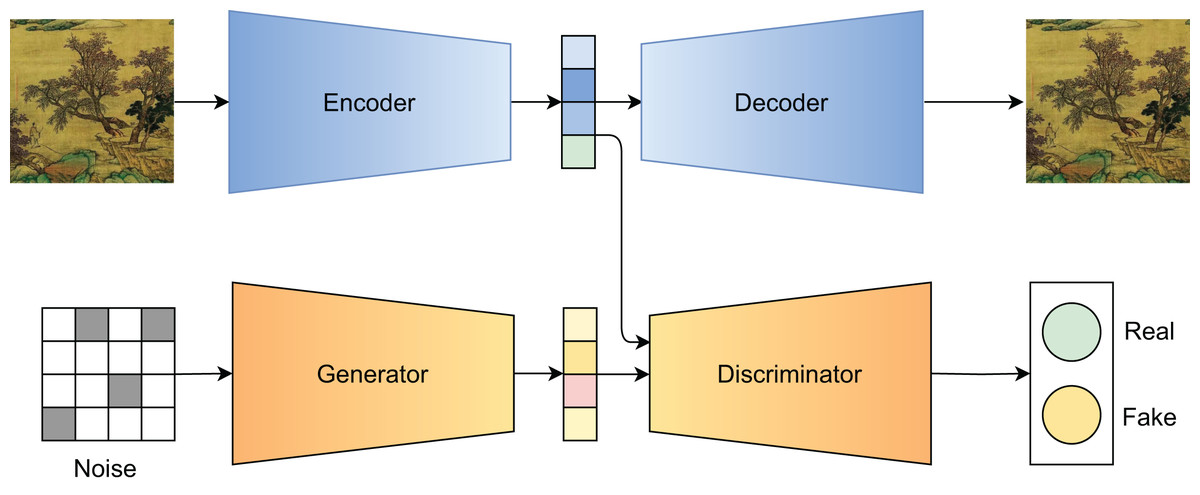
Figure 2: Adversarially regularized autoencoder architecture.
{kind=link}
This approach enables smooth interpolation and better control over stylistic representations.
In the decoding phase, a latent vector is sampled and combined with the desired condition to generate new paintings:
(5)
This enables us to generate Chinese landscape artworks with explicit control over style while maintaining structure integrity.
Model architecture
To better illustrate the architectural components of our adversarially regularized autoencoder, we provide the detailed network configuration in Table 1. This architecture corresponds directly to the model described in Fig. 2. The encoder processes high-resolution input paintings through a series of convolutional layers with increasing channel depth and progressive spatial downsampling. Each convolutional block includes batch normalization and rectified linear unit (ReLU) activation to stabilize training and enhance non-linearity. The final representation is obtained via global average pooling, producing a compact latent vector . The decoder reconstructs images from latent embeddings , which may either come from the encoder or be generated by the generator . It begins with a fully connected layer to reshape the latent vector into a low-resolution feature map, followed by a series of transposed convolutions (Deconv2D) to progressively upscale to the original image resolution. The output layer uses a Tanh activation function to normalize pixel values to the range . The generator, responsible for sampling from the prior , mirrors the decoder in structure but starts from a noise vector . It utilizes slightly larger convolutional kernels (5 5) in the deconvolution layers to encourage smoother interpolation and generation diversity. Its output is intended to approximate the latent distribution learned by the encoder. The discriminator operates in the latent space, distinguishing between encoder-generated latent vectors and those synthesized by the generator. It comprises three fully connected layers with progressively decreasing dimensionality, concluding with a sigmoid output to produce the adversarial signal used in the Wasserstein loss function.
| Component | Input | Output | Layers |
|---|---|---|---|
| Encoder | Conv2D(64, 3 3, stride = 2) + ReLU | ||
| Conv2D(128, 3 3, stride = 2) + BN + ReLU | |||
| Conv2D(256, 3 3, stride = 2) + BN + ReLU | |||
| Conv2D(512, 3 3, stride = 2) + BN + ReLU | |||
| GlobalAvgPool2D | |||
| Decoder | FC 512 4 4 reshape | ||
| Deconv2D(256, 3 3, stride = 2) + BN + ReLU | |||
| Deconv2D(128, 3 3, stride = 2) + BN + ReLU | |||
| Deconv2D(64, 3 3, stride = 2) + BN + ReLU | |||
| Deconv2D(3, 3 3, stride = 2) + Tanh | |||
| Generator | FC 512 4 4 reshape | ||
| Deconv2D(256, 5 5, stride = 2) + BN + ReLU | |||
| Deconv2D(128, 5 5, stride = 2) + BN + ReLU | |||
| Deconv2D(64, 5 5, stride = 2) + BN + ReLU | |||
| Deconv2D(3, 5 5, stride = 2) + Tanh | |||
| Discriminator | FC(d, 256) + ReLU | ||
| FC(256, 128) + ReLU | |||
| FC(128, 1) + Sigmoid |
Metric for assessment
We employ the Fréchet inception distance (FID) as the primary metric to evaluate the quality of generated images. FID measures the distance between feature distributions of generated images and real reference images, extracted from the final pooling layer of the Inception-V3 network. The formula is as follows:
(6) where and denote the mean vectors and covariance matrices of the features from generated and real images, respectively. Lower FID values indicate closer resemblance to real samples in terms of visual fidelity and style consistency.
Implementation details
To enhance the performance and robustness of the proposed model, systematic hyperparameter tuning was conducted. The tuning process involved exploring a range of values for critical parameters as detailed in Table 2. This table outlines the possible values for each parameter, along with the final selected values based on the validation results. Parameters such as learning rate, optimizer type, batch size, number of epochs, weight decay, latent dimension, activation function, kernel size, and normalization techniques were meticulously evaluated to identify the optimal configuration. Following this tuning process, the model was trained with the selected hyperparameters, leading to improved model efficacy. Our model requires approximately 385 seconds of training time per epoch.
| Parameter | Value for tuning | Tuned value |
|---|---|---|
| Learning rate | ||
| Optimizer | {Adam, RMSProp, SGD} | Adam ( , ) |
| Batch size | {16, 32, 64} | 16 |
| Epochs | {50, 80, 100, 150} | 100 |
| Weight decay | {0, , , } | |
| Latent dimension ( ) | {128, 256, 512} | 512 |
| Activation function | {ReLU, LeakyReLU, GELU} | ReLU |
| Kernel size (Conv/Deconv) | {3 3, 5 5, 7 7} | 3 3/5 5 |
| Normalization | {None, BatchNorm, LayerNorm} | BatchNorm |
Following this hyperparameter optimization, the model was trained on a curated Chinese landscape painting dataset for 100 epochs using the Adam optimizer with parameters , , a learning rate of , and a weight decay of . All experiments were carried out on an NVIDIA RTX 3090 GPU with 24 GB of VRAM, using a batch size of 16. Input images were resized or center-cropped to a fixed resolution of pixels to ensure consistency. A learning rate scheduler was employed to reduce the learning rate by half if the validation FID score did not improve for 20 consecutive epochs. Additionally, gradient clipping with a maximum norm of 1.0 was applied to maintain training stability.
Evaluation method
We evaluate the proposed framework with two complementary experiments.
Experiment 1: Comparisons with state-of-the-art models. We conduct a head-to-head comparison against representative baselines for Chinese-style or landscape painting generation: GAN (Goodfellow et al., 2014), StyleGAN2 (Karras et al., 2019), SAPGAN (Xue, 2020), and CycleGAN (Zhu et al., 2017). Each baseline is evaluated under our data preprocessing pipeline, and performance is summarized by FID against a reference set of real landscape paintings. This experiment is designed to test both overall visual realism and domain fidelity of the synthesized landscapes. The choice of baselines reflects widely used families of generative models (adversarial, style-controllable, and unpaired translation).
Experiment 2: Guided painting generation. To evaluate controllability, we test a guided generation protocol that blends a reference image embedding with a noise-driven latent using a mixing coefficient . Specifically, the encoder extracts an embedding from the reference painting; this embedding is linearly fused with features produced from a noise vector by the generator, and the decoder synthesizes the final image. Varying allows us to move from purely stochastic output ( ) to faithful, structure-preserving reconstructions of the reference ( ), thereby revealing how well the model balances content preservation and creative variation. Qualitative results across multiple values are used to assess the smoothness and usefulness of this control.
Results and discussion
Comparisons with state-of-the-arts
Figure 3 illustrates the FID and IS scores, providing a comprehensive comparison between our model and the selected baselines. Our model achieves a low FID score of approximately 24.13, indicating superior performance in replicating fine-grained brushwork, ink diffusion, and the distinctive stylistic essence of traditional Chinese landscape painting. Additionally, it records a high IS score of approximately 4.82, further emphasizing its ability to generate diverse and meaningful compositions. In contrast, SAPGAN shows moderate results with an FID score of about 30.15 and an IS score of 3.67, indicating limited style diversity and brush fidelity. StyleGAN2, while achieving an FID score of approximately 28.42, also manages a respectable IS score of 4.04; however, it demonstrates limitations in adapting to domain-specific characteristics. These findings suggest that our method effectively bridges the gap between technical fidelity and artistic authenticity in the context of Chinese landscape generation.
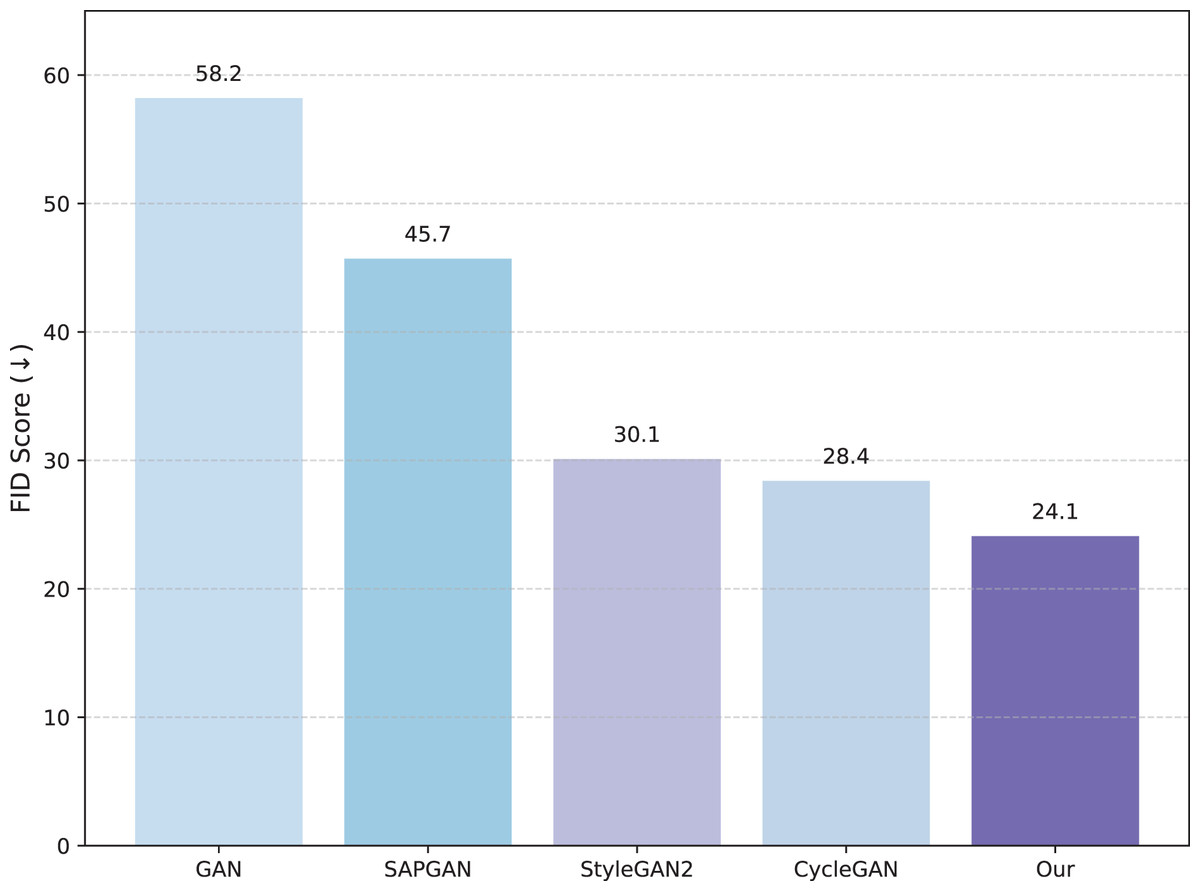
Figure 3: FID scores comparing our model with state-of-the-art models.
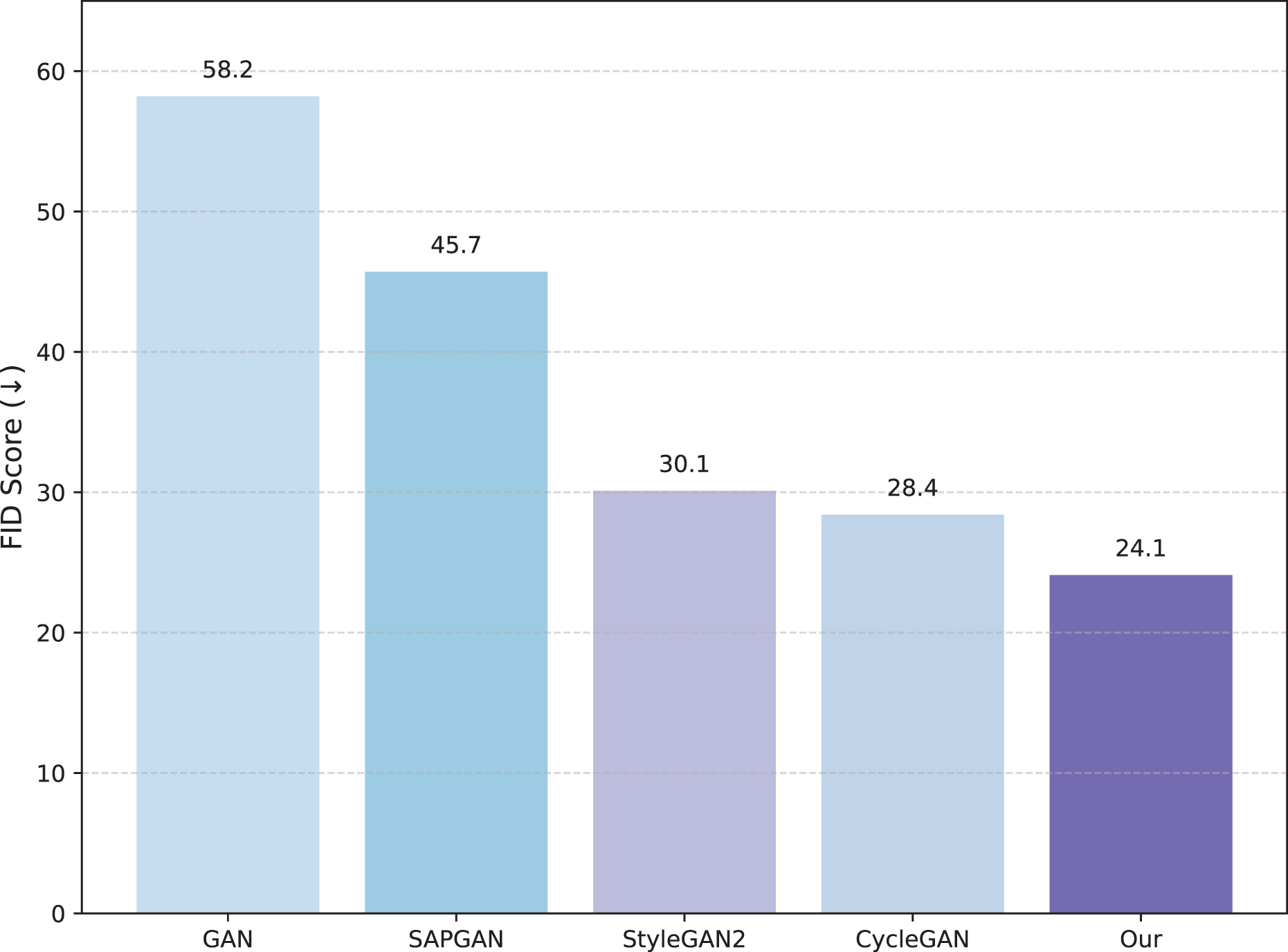{kind=link}
Guided painting generation
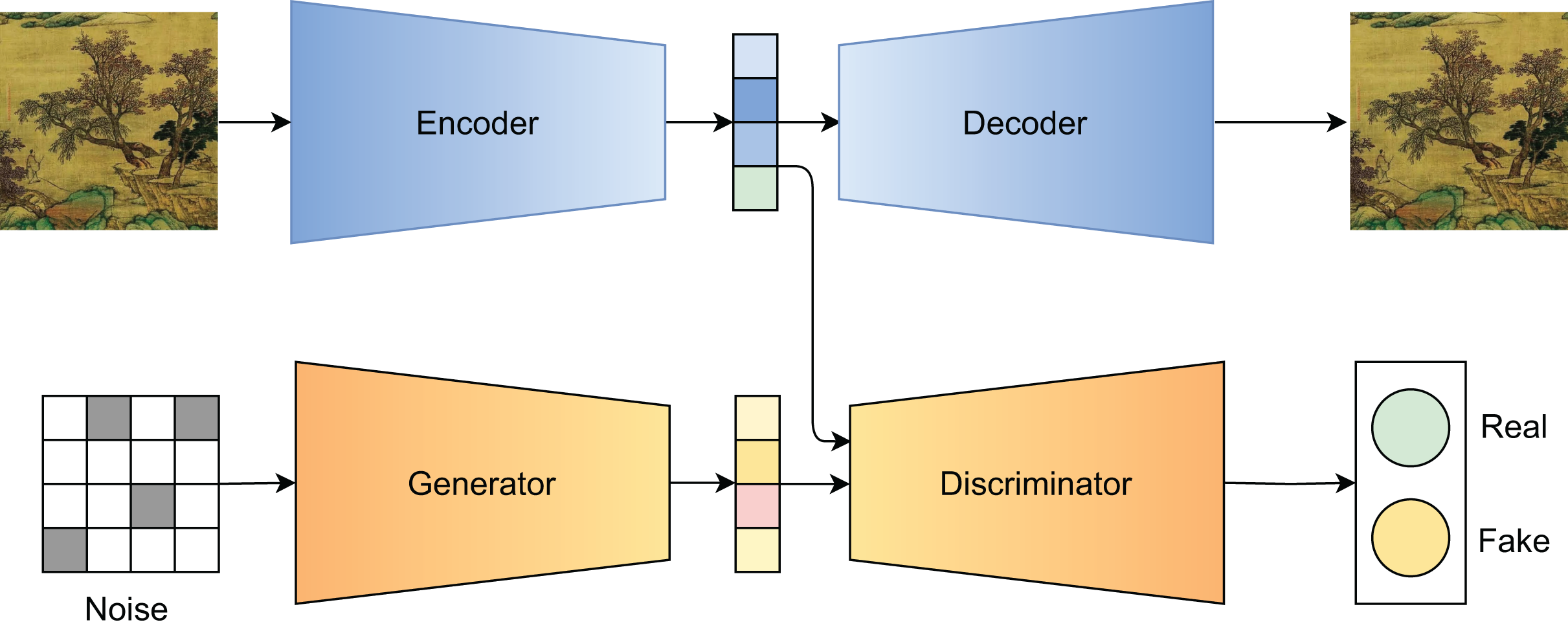
Figure 4 illustrates the guided generation pipeline. In Fig. 5, we visualize the generated results under varying levels of , demonstrating the controllability of our method.
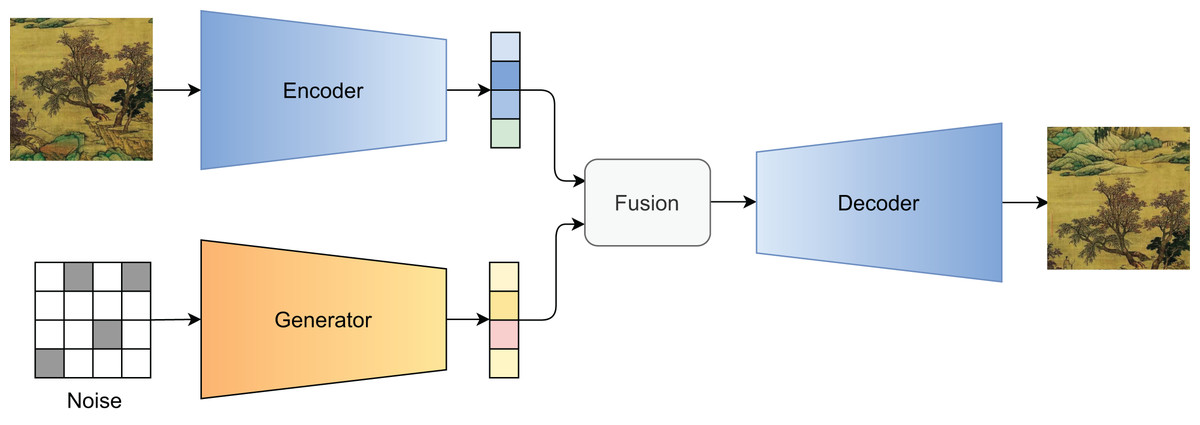
Figure 4: Illustration of the guided generation process.
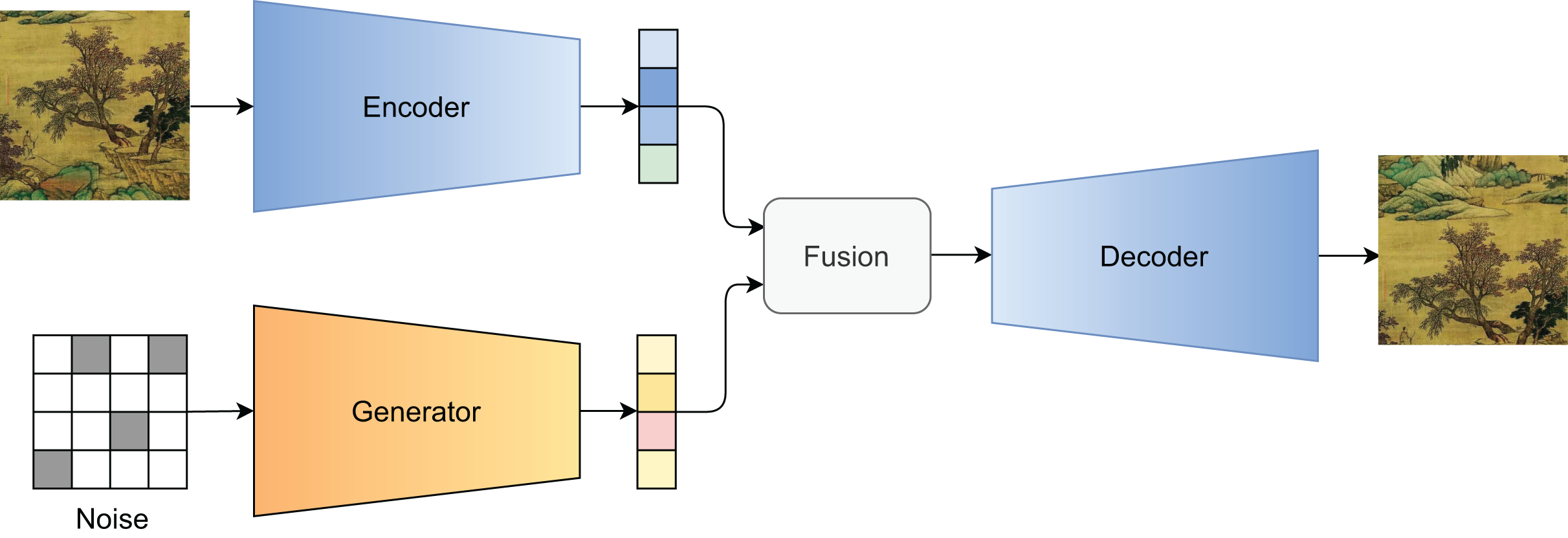{kind=link}

Figure 5: Generated samples under different values of .
From left to right: input image, results with , , , and .{kind=link}
The results demonstrate that our guided generation strategy effectively preserves the global structure and artistic intent of the reference image, while still enabling creative variations. Intermediate values of , such as 0.5 or 0.75, strike a desirable balance between stylistic transformation and content preservation, which is particularly valuable in the context of digital Chinese landscape painting creation.
Model reproducibility
Model reproducibility assessment was conducted to provide statistical evidence for the modeling experiments. The results summarize the performance of our model across five independent runs, highlighting its reproducibility and consistency in generating high-quality outputs (Table 3). The table shows the FID and Inception Score (IS) scores for evaluating the fidelity and diversity of generated images. Across the five runs, the FID scores range from 23.8 to 24.3, with a mean value of 24.08 and a standard deviation of 0.18, indicating stable performance with minimal variability. Similarly, the IS values vary slightly, from 3.83 to 3.90, yielding an average of 3.86 and a standard deviation of 0.03, which suggests that the model consistently produces diverse and meaningful images. The calculated 95% confidence intervals (CIs) further reinforce these findings, with FID values between [23.93–24.23] and IS values between [3.83–3.89], indicating that the model’s performance metrics are reliably reproducible. Overall, the relatively low standard deviations and narrow confidence intervals across multiple runs demonstrate the robustness of our model, suggesting its potential for reliable application in generating Chinese landscape paintings.
| Run | FID | IS |
|---|---|---|
| 1 | 24.1 | 3.85 |
| 2 | 23.8 | 3.88 |
| 3 | 24.3 | 3.83 |
| 4 | 24.0 | 3.90 |
| 5 | 24.2 | 3.84 |
| Mean | 24.08 | 3.86 |
| Std | 0.18 | 0.03 |
| 95% CI | [23.93–24.23] | [3.83–3.89] |
Limitations and future research
While our approach demonstrates promising results, we acknowledge several limitations. First, the CCLAP dataset, though carefully curated, contains only 3,560 samples and focuses exclusively on traditional landscape paintings, which may limit the model’s ability to generalize to broader Chinese art forms or contemporary styles. The fixed resolution of pixels restricts the level of fine detail that can be generated, potentially affecting the reproduction of intricate brushwork that is essential to traditional Chinese painting.
Our evaluation primarily relies on the FID metric, which, while quantitatively reliable, may not fully capture the cultural authenticity and artistic qualities that human experts or traditional artists would evaluate. Future work could integrate multi-perspective evaluation frameworks that consider both quantitative measures and human aesthetic judgments (Hussain et al., 2020; Zhang et al., 2025). The guided generation mechanism, though effective, uses a relatively simple linear blending approach that may not provide the sophisticated compositional controls desired by professional artists. Incorporating advanced controllable generation methods based on adversarial or transformer-enhanced autoencoding may enable richer stylistic manipulation (Wang & Nguyen, 2025a, 2025b).
Additionally, our training was limited to a single GPU setup, restricting batch sizes and model complexity compared to larger implementations. Future implementations could benefit from scalable adversarial frameworks capable of producing finer structural textures and material patterns (Chen et al., 2025). Furthermore, the lack of extensive human evaluation studies, particularly input from traditional Chinese painting experts or art historians, limits our understanding of the cultural appropriateness and aesthetic quality of the generated works. Finally, the model’s focus on replicating traditional styles may not address the evolving nature of contemporary Chinese landscape art or the integration of modern artistic elements. Future research should therefore explore adaptive models that merge traditional visual motifs with data-driven creative dynamics, promoting a deeper intersection of cultural preservation and computational innovation.
Conclusion
Our model captures the unique cultural and artistic features of Chinese landscape painting through several key mechanisms. Firstly, it employs the CCLAP dataset, which comprises authentic traditional artworks that reflect the rich themes and philosophies of this art form, such as the harmony between humans and nature. Secondly, the guided generation approach allows for fine-grained control over composition and style, preserving traditional artistic elements while facilitating creative expression. Additionally, the ARAE architecture is specifically designed to capture essential features like brushwork and ink diffusion, which maintain the aesthetic qualities of Chinese landscapes. We also integrate loss functions that prioritize stylistic fidelity, ensuring that the generated images reflect both the technical and emotional depth characteristic of traditional works.
This study presents a comprehensive framework that harnesses deep generative modeling to create Chinese landscape paintings, addressing both the technical challenges and the cultural significance of this art form. By introducing an adversarially regularized autoencoder and a guided blending strategy, our method bridges the gap between visual fidelity and stylistic authenticity, as validated by quantitative metrics. The results illustrate a significant advancement over conventional GAN- and VAE-based systems, successfully capturing the intricate brushwork, tonal transitions, and compositional harmony central to Chinese landscape aesthetics. Importantly, the model allows for controlled artistic exploration, supporting personalized and semantically meaningful generation. While this work marks an important step toward the digital preservation and creative expansion of traditional Chinese art, future research should explore broader datasets, incorporate multimodal user guidance, and examine the cultural impact of AI-assisted art creation. Ultimately, our findings contribute to the ongoing dialogue between tradition and technology, fostering a deeper appreciation of Chinese landscape painting in the digital era.