
Collaborative distributed prediction model based on decentralized federated learning for efficient energy resources utilization
- Published
- Accepted
- Received
- Academic Editor
- Nicole Nogoy
- Subject Areas
- Artificial Intelligence, Data Mining and Machine Learning, Distributed and Parallel Computing, Neural Networks, Internet of Things
- Keywords
- Energy resources, Distributed intelligence, Deep learning, Federated learning
- Copyright
- © 2025 Ahmed et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Collaborative distributed prediction model based on decentralized federated learning for efficient energy resources utilization. PeerJ Computer Science 12:e3449 https://doi.org/10.7717/peerj-cs.3449
Abstract
Forecasting domestic energy needs is crucial to ensure a reliable and affordable energy supply, which is vital for maintaining economic stability and promoting growth. It also aids in planning and managing resources efficiently, reducing the risk of energy shortages and price volatility. The traditional literature presents numerous deep learning-inspired energy forecasting frameworks. However, this field may still be limited by various issues, as most frameworks focus solely on predicting short-term or long-term energy consumption. The research studies that have attempted to predict both long-term and short-term energy simultaneously may have failed to achieve optimal results concurrently, in terms of both high accuracy and low error. This research work presents a novel hybrid framework that combines long short-term memory (LSTM), convolutional neural network (CNN), and bi-directional long short-term memory (Bi-LSTM) in a distributed federated learning setup. This framework constitutes a simple yet effective predictive model designed to simultaneously forecast both immediate (short-term) and sustained (long-term) energy consumption. It harnesses the capability of CNN for local and spatial feature extraction. Subsequently, LSTM and Bi-LSTM are utilized for capturing current, past, and future contexts. The proposed model achieved an mean absolute percentage error (MAPE) score of 1.39. It achieves high accuracies in the simultaneous prediction of short and long-term energy, outperforming similar techniques in the literature for hourly, daily, weekly, and monthly energy consumption, with minimal computational costs.
Introduction
Energy consumption prediction using deep learning models involves developing advanced models to predict energy consumption accurately (Hassan et al., 2016). Energy is essential for the cost-effective development and growth of a country, and it is considered a key factor in determining a country’s level of production and financial growth. Accurate energy consumption is crucial for utility companies in managing resources and balancing supply and demand to ensure services are provided with reliability (Hassan et al., 2016). It is also vital, as both overestimation and underestimation of energy needs can severely influence industry and economic growth. This, in turn, underscores the importance of accurate energy predictions for effective domestic energy and supply chain management. Therefore, accurately predicting energy consumption is crucial for improving efficient energy management and planning systems. Recent literature highlights the significance of energy consumption prediction in the context of resource scarcity, increasing emissions, and the need for sustainable energy management (Ahmed et al., 2025). Deep learning methods are particularly powerful in improving the accuracy and robustness of these prediction models. There is a need for collaborative innovation in adaptive methodologies to enhance prediction accuracy (Jaramillo, Pavón & Jaramillo, 2024).
Deep learning models use historical data and predictive features to achieve more accurate predictions as compared to other traditional methods (Shapi, Ramli & Awalin, 2021). In the field of literature, researchers are developing deep learning models to predict energy consumption with greater efficiency and accuracy. The Random Forest (RF) model has been previously used for energy consumption prediction tasks. However, it struggles to capture sequential dependencies over time (Pham et al., 2020). Another hybrid model, recurrent neural network (RNN), integrates with long short-term memory (LSTM), which is a powerful model but fails to capture the spatial patterns and local features effectively. LSTM with an attention mechanism is also used for energy consumption prediction tasks, where this model faces the challenge of capturing very long-term dependencies. Convolutional neural network (CNN) is also used for energy consumption prediction, which is primarily designed for local feature extraction and faces the challenge of capturing temporal dependencies in time series data effectively (Kim & Cho, 2019). LSTM is hierarchically designed for handling long-term dependencies, but it struggles to extract spatial features effectively. LSTM also struggles to handle noisy data. Bi-LSTM did not effectively capture relationships among several variables in multivariate time series data (Le et al., 2019).
The LSTM comprises an RNN and is often employed for modeling the temporal or sequential features of input data. Traditional RNNs suffer from a vanishing gradient problem when training sequential data, an issue that the LSTM model addresses. The bidirectional long short-term memory (Bi-LSTM) model is a unique RNN version that combines two long short-term memory layers. These layers incorporate information in both forward and backward directions, effectively updating hidden states in two-way directions. The Bi-LSTM model is an extension of the LSTM (Le et al., 2019). This model has the capability of keeping past and future information. The amount of information that the network may access increases significantly. But the solo Bi-LSTM technique is vulnerable to overfitting when a small dataset is used (Le et al., 2019). Hence, the network can understand the context more effectively compared to the traditional model. CNN can extract features from the energy consumption data (Kim & Cho, 2019). CNN is essential to reduce noise and correlation among multivariate variables. CNNs are most suitable for time series analysis and feature extraction across multiple variables to minimize the data spectrum (Kim & Cho, 2019).
Study contributions
This study proposes a novel hybrid deep learning model that leverages the strengths of CNNs, LSTM, and Bi-LSTM models to simultaneously predict both short-term and long-term energy expenditure with low computational complexity.
The proposed novel and straightforward deep learning model demonstrates impressive results and significantly outperforms other models in terms of mean absolute error (MAE), root mean square error (RMSE), mean absolute percentage error (MAPE), and mean squared error (MSE). This state-of-the-art performance underscores the robustness and accuracy of our proposed model.
Research hypothesis
RQ1: Can the proposed hybrid CNN–LSTM–Bi-LSTM model in the DFL setup effectively predict short-term and long-term household energy consumption compared to existing models?
RQ2: What advantages does the combination of CNN (for feature extraction), LSTM (for sequential learning), and Bi-LSTM (for bidirectional temporal dependencies) provide in improving forecasting performance?
RQ3: Can a single hybrid model efficiently handle both short-term (minutes to hours) and long-term (days to weeks) energy consumption forecasting without sacrificing accuracy?
RQ4: How robust is the hybrid model against noisy or missing energy consumption data, and does it maintain stable performance across different time granularities (minute, hourly, daily, weekly)?
The remaining article is organized as follows: ‘Related Works’ presents related work on energy expenditure prediction. ‘Materials and Methods’ presents the material and methods, while ‘Results and Discussions’ provides details of the dataset used in this research. ‘Conclusions’ presents the research methodology. ‘Average comparison analysis’ presents the results of the applied models. ‘Discussion’ summarizing the study’s contribution.
Related works
Several techniques related to energy consumption prediction have been studied in the literature. The review of the literature is divided into three sections based on the time interval of its predictions: short-term energy consumption predictions, long-term energy consumption predictions, and short-term and long-term energy consumption prediction techniques.
Short-term energy consumption prediction
Somu, Gauthama Raman & Ramamritham (2020) developed the ISOCA-LSTM model, which focuses on behavior and occupancy sensor data for predicting household energy consumption. In this study, the influence of characteristics on the energy consumption value is not examined, and the author did not compare the results with traditional models. Only one accuracy measure is used. Jallal et al. (2020) forecast domestic energy consumption using a neuro-fuzzy inference system-based algorithm, which still lacks sufficient effort to predict energy consumption with high performance. The model calculates a 7.04% MAPE after implementation on a small dataset and still requires investigation with larger datasets. A hybrid approach named EEMDRF, which integrates random forest with empirical mode decomposition (EEMD), is proposed in Bouktif et al. (2020) for predicting daily energy usage. While the EEMDRF model demonstrates strong performance in short-term energy consumption forecasting, its effectiveness diminishes for long-term prediction scenarios.
Zhong et al. (2019) proposed a new vector field-based regression method. The results demonstrate good precision, robustness, and generality in estimating energy consumption. Limitations of the research include that while the vector field-based regression model is used for the intelligent grid system, energy use must be predicted promptly. Effective scheduling, strategic management, and energy conservation can significantly improve the outcomes of this study. Forecasting short-term electrical energy usage offers several advantages, including optimizing resource utilization, reducing emissions, and minimizing overall costs (Divina et al., 2018). Due to these benefits, Divina et al. (2018) present an assembly learning-based strategy. The system yields a lower error compared to recent state-of-the-art approaches used on a similar dataset. This study lacks an analysis of long-term energy consumption forecasting.
Long-term energy consumption prediction
Ullah, Ahmad & Kim (2018) present a method based on the hidden Markov (HMM) approach for energy consumption prediction using residential data gathered from four multi-floor buildings located in South Korea. The performance of the HMM model was evaluated against SVM, ANN, and CART models. Findings show that HMM achieved a 2.96% higher performance compared to the other approaches. In a separate study, Pan & Zhang (2020) proposed a predictive model based on CatBoost to effectively handle heterogeneous data obtained from a large residential facility. The model categorized forecasted energy usage as either regular or irregular, achieving an outlier detection accuracy of 99.32%, which aids in early hazard detection and the formulation of strategies to enhance energy efficiency. Liao et al. (2021) present the PSVM-PMLPMLR model to predict building energy consumption. The PSVM-PMLPMLR model achieves the best results as compared to SVM, MLP, and MLR. The work can be extended to other industrial electrolysis using a transfer learning approach.
Li et al. (2017) analyzed the performance of four artificial intelligence-based algorithms using an energy consumption dataset. The proposed model achieves the best results as compared to BPNN, SVR, and ANFIS. This study lacks accuracy measures. Kaytez (2020) proposed a hybrid approach that integrates a least squares support vector machine with an autoregressive integrated moving average model. The results indicate that this study generates more realistic and reliable predictions. The system is more complex due to its division into subparts. Pallonetto et al. (2019) developed a model based on simulation and used it to assess the effectiveness of demand response approaches by analyzing multiple instances of electrical consumption. The model is beneficial for very short-term load prediction.
Both short-term and long-term energy consumption prediction
Advanced deep learning models and algorithms can be utilized to fine-tune hyperparameters, thereby enhancing the performance of the proposed model. Load forecasting for the smart grid is a crucial element in meeting energy demands (Johannesen, Kolhe & Goodwin, 2019). The experiments do not report standard accuracy metrics, such as RMSE, MSE, and MAE. In their work, Kim & Cho (2019) proposed a hybrid approach combining CNN and LSTM models. The CNN component is employed to extract intricate features from multivariate inputs, while the LSTM component captures the non-linear temporal dependencies in the time series data. This CNN-LSTM framework demonstrates enhanced performance over recent methods in energy consumption forecasting, yielding a lower RMSE.
A new RF-based approach is developed by Pham et al. (2020) for short-term energy consumption prediction. The RF-based model’s experimental results indicate that it has better prediction accuracy in the forecast. The seasonality of data is not considered in predictions. Le et al. (2019) develop a framework, Electric Energy Consumption Prediction (EECP)-CBL, for predicting electrical energy consumption by integrating Bi-LSTM and CNN. The EECP-CBL framework outperforms other traditional approaches. The performance of the EECP-CBL model was evaluated and compared with other methods, including linear regression, LSTM, LSTM-CNN, and the original EECP-CBL model. To enhance the effectiveness of EECP-CBL, further improvements can be achieved through techniques such as evolutionary algorithms and optimized versions of the EECP-CBL model.
Research gaps
Prior works relying on LSTM, Bi-LSTM, or CNN and ANN architectures have shown promise in short-term load forecasting but often struggle with long-term dependencies or local fluctuations. These models lack robustness when applied across multiple temporal granularities, which our hybrid model directly addresses.
Materials and Methods
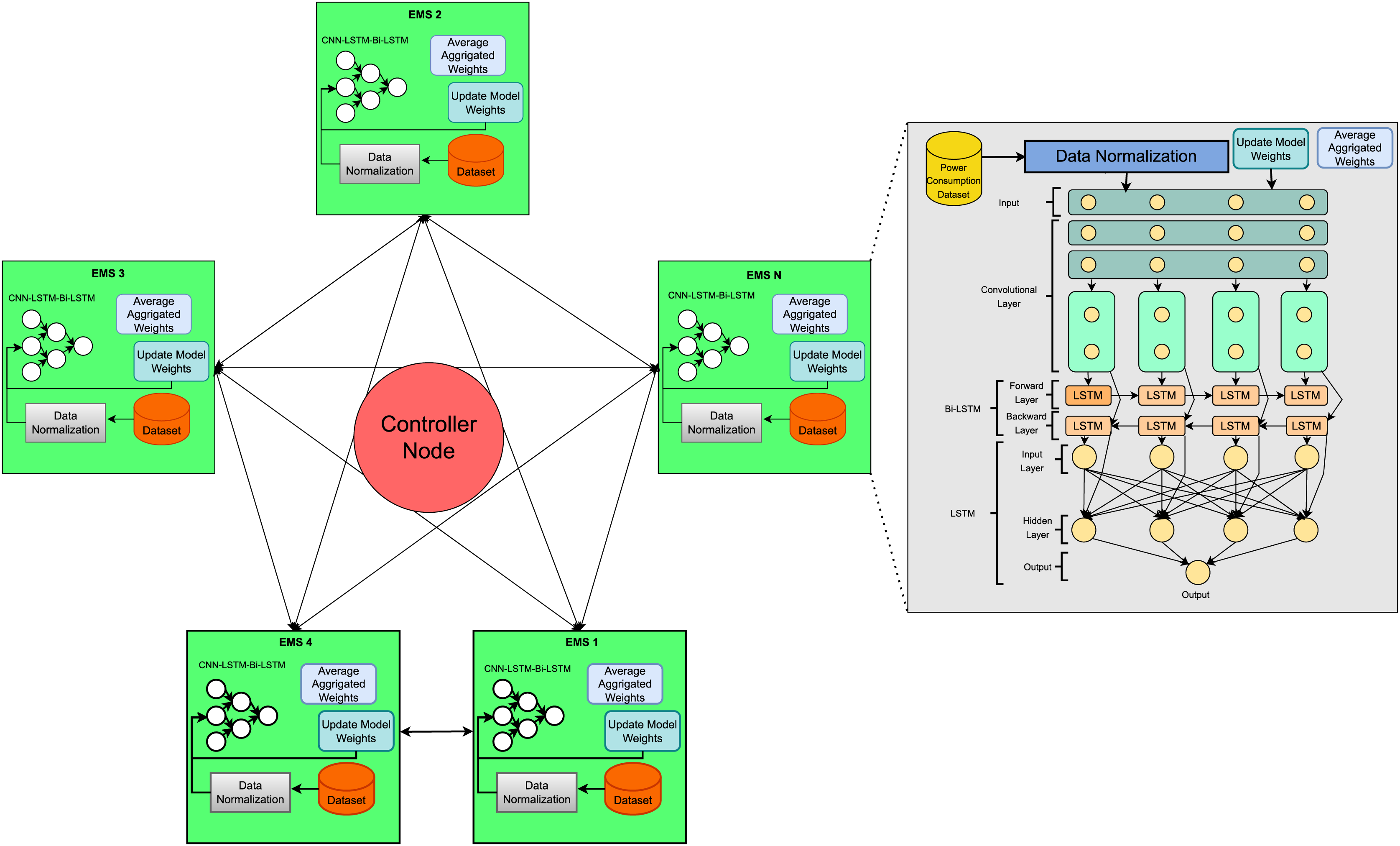
The proposed methodology steps are illustrated in Fig. 1. Every Distributed Edge Machine Learning System (DEMS) node sends its local weights to other DEMS nodes. Federated averaging weights receive weights from other DEMS nodes and perform federated averaging. To ensure model integrity, hash storage is utilized, enabling the model to store aggregated weights using a blockchain. The controller Node plays a vital role in managing and coordinating the training process with several DEMS nodes. Every DEMS Node trains its local LSTM model with its dataset and shares the updated model weights with other DEMS nodes via the controller node. The controller node is also responsible for synchronizing the training process, confirming that all DEMS nodes have completed their local training before proceeding. The controller node also checks performance, measuring evaluation metrics such as loss, accuracy, and model convergence to assess the training progress. Overall, the controller node is mandatory in the Distributed Federated Learning(DFL) approach for efficient, scalable, and privacy-preserving federated learning, ensuring that DFL operates smoothly and reliably.
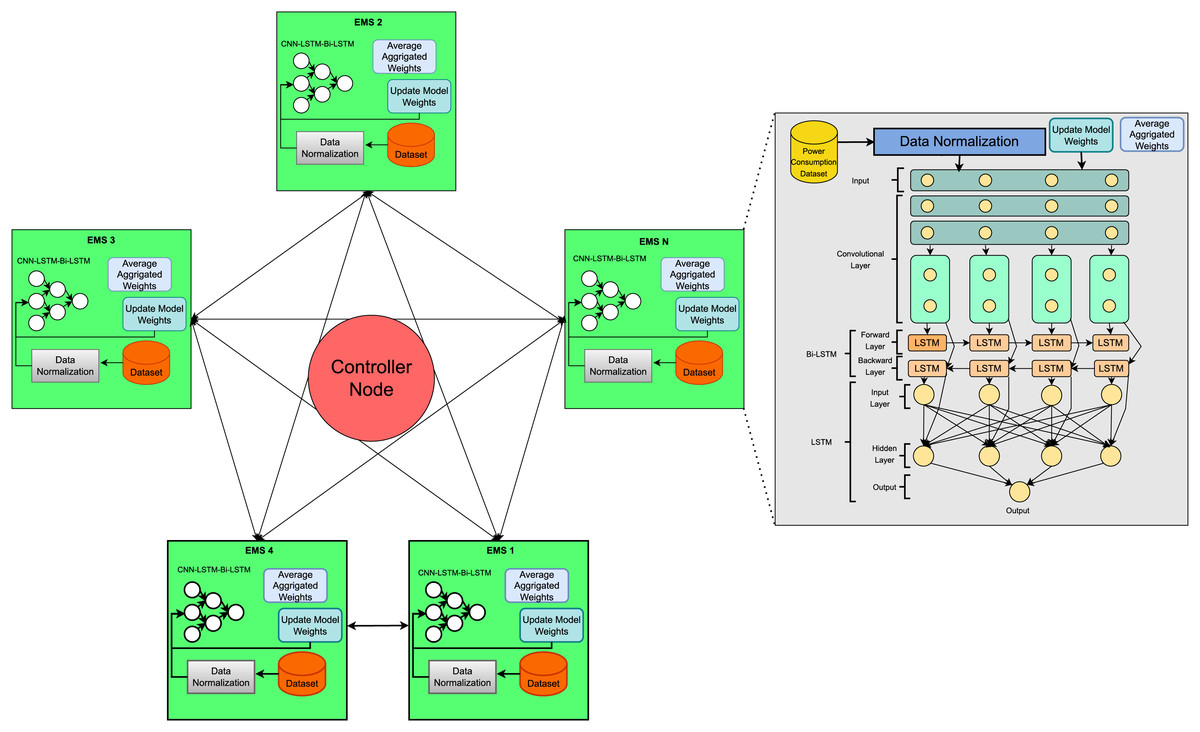
Figure 1: Proposed distributed energy resources prediction model based on decentralized federated learning.
{kind=link}
FL configuration: We partitioned the dataset at four edge nodes and executed the federated learning algorithm through five global communication rounds. Each node locally trained a CNN–LSTM–BiLSTM model, for a total of 100 epochs (batch size = 32). After every round, the weights were sent back to the central server, and the central server used an inverse MSE approach for performance-weighted aggregation to create a global model. The global weights were recorded on a blockchain to enhance the security and traceability of training history, providing immutable documentation.
Our deployment incorporates the secure aggregation process, which guarantees that no single node’s contribution can be singled out during the global update. For future research, differential privacy methods can be incorporated further to enhance resistance to gradient inversion or inference attacks.
Ethical implications
This study does not involve personal data or any procedures requiring ethical approval. Therefore, ethical approval is not necessary for this research.
Dataset collection
This study utilises the benchmark Individual Household Electric Power Consumption (IHEPC) dataset (Hebrail & Berard, 2006) to evaluate the reliability of the proposed novel approach, which employs a federated learning technique. Experiments using IHEPC datasets provide us with greater confidence in obtaining more accurate insights into the results. The IHEPC dataset has been widely adopted in recent research to assess the performance of various models for forecasting energy consumption.
Data preprocessing
One of the most essential preprocessing methods employed in this research is dataset normalization, specifically min-max scaling. This technique is used to scale the features of the dataset. By using this scaling strategy, all features were given a comparable scale, preventing any one feature from disproportionately influencing the learning process. Normalization is a fundamental component of experiments, enabling the creation of fair and precise predictions. Additionally, another approach, known as the “moving average value,” is used to fill in the null and missing values with average values.
Feature engineering
In addition to the original nine attributes of the IHEPC dataset, we added five temporal features (day of the month, month, year, hour, and minute), which were extracted from the Date and Time columns. The intention for these features was to account for patterns of energy demand that included diurnal and seasonal variation. During real-time implementation, all smart meters or other IoT devices should revert to timestamp parsing when transferring information to be used in this manner.
Selection method: novel hybrid CNN-LSTM-Bi-LSTM
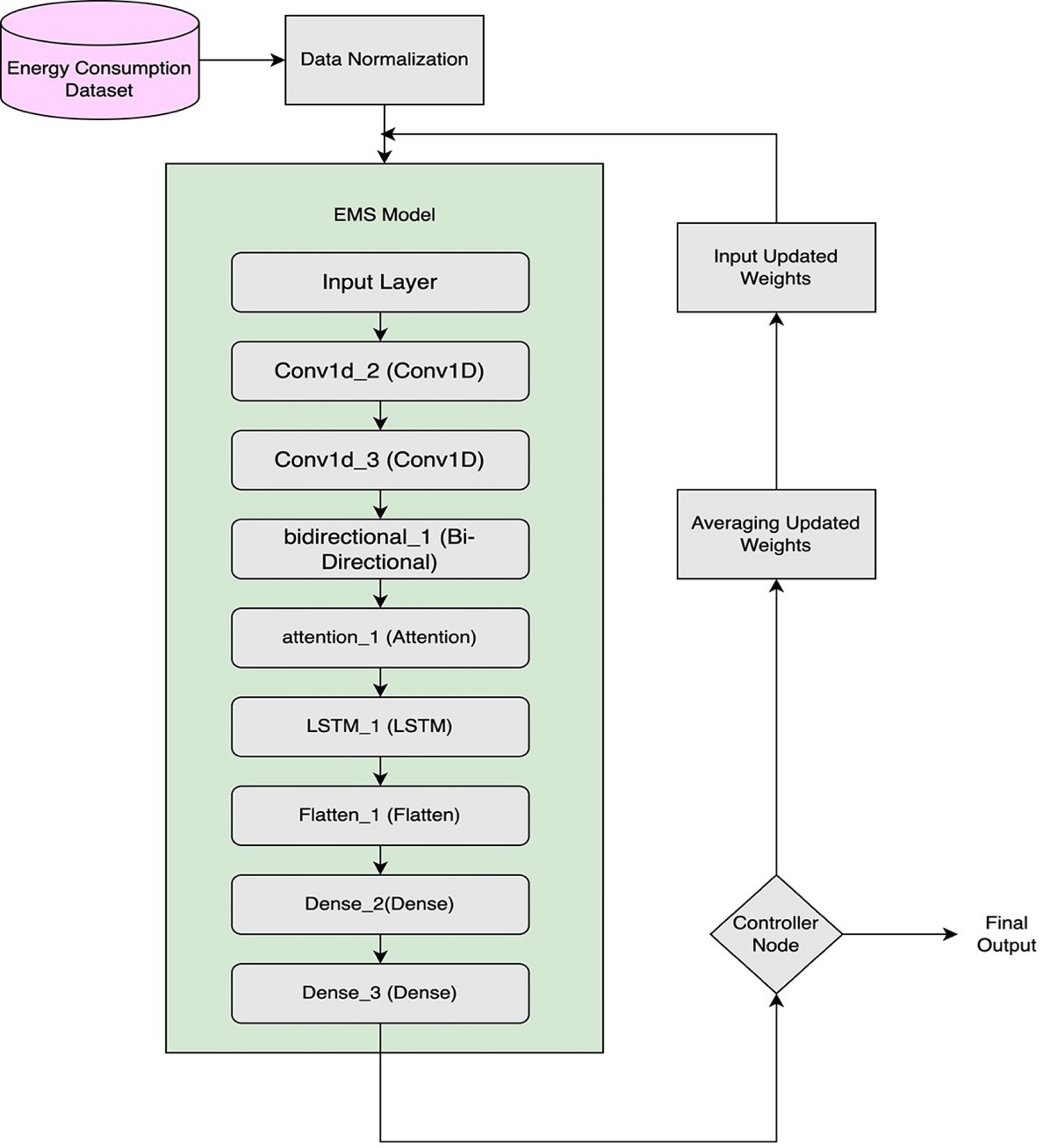
The CNN, LSTM, and Bi-LSTM models are successfully integrated into the proposed architecture using distributed federated learning (DFL). Each of these layers is crucial for enhancing the precision and accuracy of energy consumption prediction. This unique combination of components enables this architecture to conduct in-depth data analysis while leveraging the distinct characteristics of each element, as illustrated in Fig. 2.
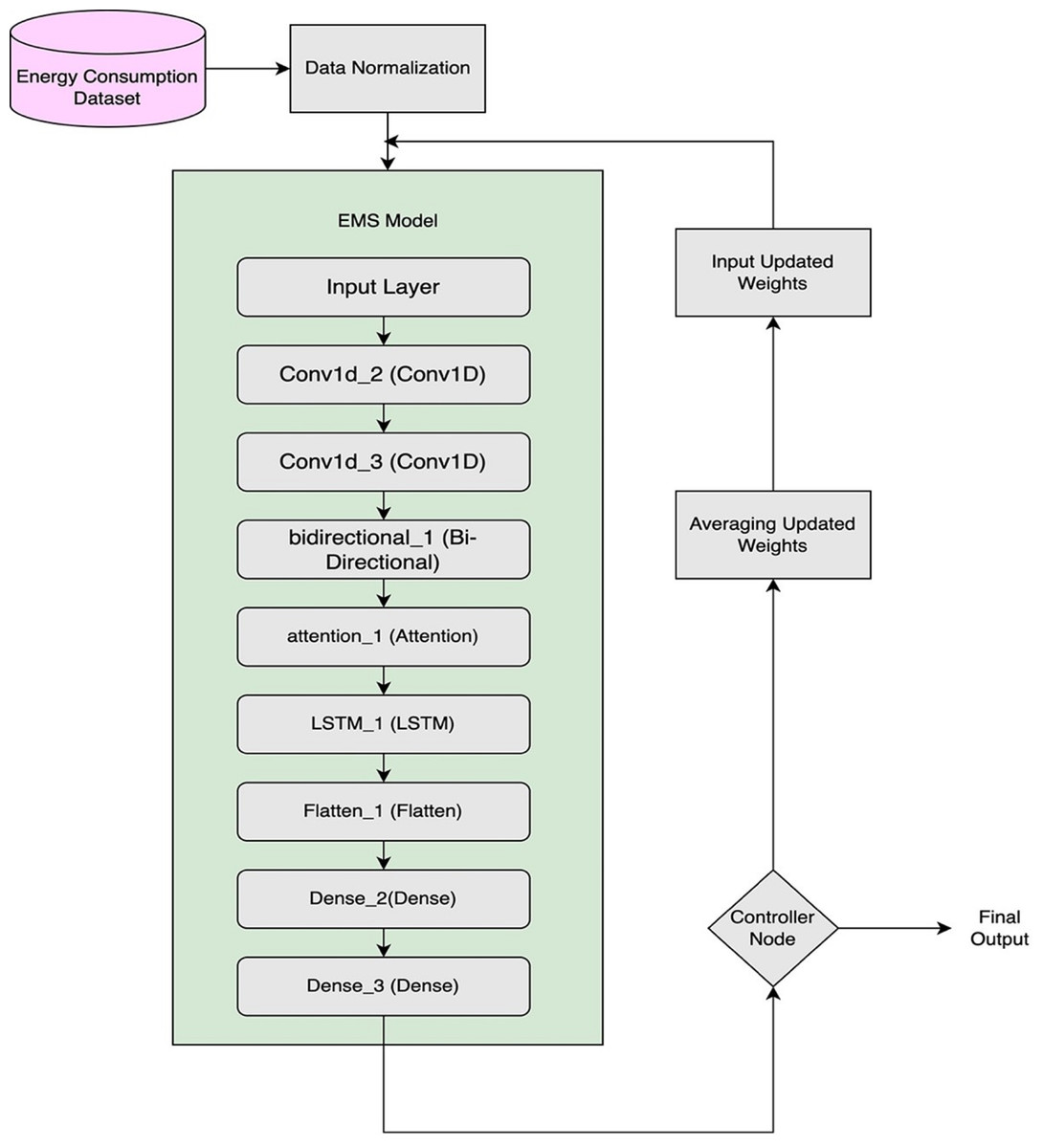
Figure 2: Internal architecture of DEMS node model.
{kind=link}
A novel hybrid model combining CNN, LSTM, and Bi-LSTM architectures has been designed within a federated learning framework to forecast energy consumption over both short and long time horizons. Distributed Energy Management System (DEMS) nodes take a normalized dataset as input and run the proposed hybrid CNN-LSTM-Bi-LSTM model locally, sharing the updated model weights with other DEMS nodes for updating the global weights. Every node receives updated weights from different nodes and performs the aggregation of these weights. These weights are stored in hash storage to ensure integrity and transparency.
Hybridization of CNN, LSTM, and Bi-LSTM layers best addresses several aspects of input data while efficiently leveraging each characteristic. The proposed hybrid novel framework produces precise and trustworthy energy consumption prediction. Furthermore, this novel proposed framework captures the complicated relationship within the energy consumption input data. These enhancements in the prediction mechanism provide an opportunity for effective resource management, reduce cost, and encourage sustainable energy consumption in domestic areas.
Model layers architecture
The architecture is designed to handle sequential data by integrating Conv1D, MaxPooling1D, Dropout, Bi-LSTM, LSTM, and Dense layers, resulting in 397,063 trainable parameters. Training is conducted using an appropriate loss function and optimization strategy to effectively reduce prediction errors and enhance the model’s performance on time-series tasks. A detailed breakdown of the model’s configuration is presented in Table 1.
| Model layers | Unit | Activation | Output shape | Trainable parameters |
|---|---|---|---|---|
| Conv1D | 32 | RELU | (None, 58, 32) | 1,408 |
| Dropout | 0.2 | – | (None, 58, 32) | 0 |
| LSTM | 64 | – | (None, 58, 64) | 197,632 |
| Bi-LSTM | 32 | – | (None, 58, 64) | 197,120 |
| Flatten | – | – | (None, 3,712) | 903 |
| Dense | 7 | Softmax | (None, 7) | 397,063 |
The Conv1D layer is used to capture local temporal dependencies and reduce noise. The LSTM layer then processes the output data of the Conv1D layer to model sequential temporal dependencies. The Bi-LSTM layer captures the bidirectional dependencies to improve the robustness of long-term dependencies. Finally, the output is passed through a fully connected dense layer with linear activation to generate the final prediction.
Input shape: , where after feature engineering.
CNN layer: 1D Convolution (filters = 64, kernel size = 3, activation = ReLU) with MaxPooling-1D (pool size = 2), and Dropout (rate = 0.2 for regularization) (Raza et al., 2024b).
LSTM block: LSTM layer (units = 64, activation = tanh, recurrent_activation = sigmoid), Dropout (rate = 0.2) (Raza et al., 2024a).
Bi-LSTM block: Bidirectional LSTM (units = 64, same activation functions), Dropout (rate = 0.2).
Dense output layer: Fully connected Dense (units = 1, activation = linear for regression).
Hyperparameters settings
Hyperparameters are optimized in two stages: first, with a coarse manual search based on other energy forecasting studies, and then with either a random or grid search within candidate ranges. The final model utilized 32 CNN filters (kernel size = 3, ReLU), an LSTM layer with 64 units, a Bi-LSTM layer with 32 units, a dropout rate of 0.2, and a final dense layer with linear activation. The final network was trained using the Adam optimizer (learning rate = 0.001) and Huber loss, for 100 epochs (batch size = 32) with early stopping. The configuration identified was overall the best trade-off in terms of accuracy (minimum RMSE value) and cost of savings computational resources.
Evaluation method
To ensure the generalizability of our model, we employed a robust evaluation strategy that included a dedicated validation split. Initially, the dataset is divided into training and testing sets to facilitate the model’s learning. During the training phase, a portion of the data is reserved for validation, allowing us to fine-tune the model and prevent overfitting. A separate, unseen portion of the dataset is held out to validate the model’s effectiveness independently.
Assessment metrics
In this research, four widely recognized performance metrics are utilized to assess time series forecasting models: RMSE, MAE, MSE, and MAPE. These metrics are employed to evaluate and compare the outcomes across various experimental approaches.
Computing infrastructure
Experiments are done using 70% of the data for training and 30% for testing of IHEPC (70121218, 2025). This study is conducted using Google Colab, an open platform accessible to all researchers. Google Colab offers free access to GPU/TPU systems, enabling fast and reliable experimentation.
Results and discussions
Results with minute energy data
Results indicate that the proposed model achieves significantly improved performance for short-term energy consumption prediction, as evidenced by lower RMSE, MSE, MAE, and MAPE values compared to other state-of-the-art models. Table 2 presents the comparative analysis of minute-level energy consumption prediction. Results demonstrate that the proposed model achieves superior accuracy with minimal error rates. Figure 3 illustrates the MAPE results comparisons of minute data.
| #No | Method | MSE | RMSE | MAE | MAPE |
|---|---|---|---|---|---|
| 1 | Linear regression (Le et al., 2019) | 0.405 | 0.636 | 0.418 | 74.52 |
| 2 | LSTM (Le et al., 2019) | 0.748 | 0.865 | 0.628 | 51.45 |
| 3 | CNN-LSTM (Kim & Cho, 2019) | 0.374 | 0.611 | 0.349 | 34.84 |
| 4 | EECP-CBL (Le et al., 2019) | 0.051 | 0.225 | 0.098 | 11.66 |
| 5 | Decision tree (Sajjad et al., 2020) | 0.59 | 0.77 | 0.54 | – |
| 6 | SVR (Sajjad et al., 2020) | 0.59 | 0.77 | 0.47 | – |
| 7 | CNN (Sajjad et al., 2020) | 0.37 | 0.67 | 0.47 | – |
| 8 | CNN-GRU (Sajjad et al., 2020) | 0.22 | 0.47 | 0.33 | – |
| 9 | RCC-LSTM (Chen et al., 2020) | 0.94 | 0.587 | – | |
| 10 | CNN-LSTM-Bi-LSTM (Khan et al., 2020) | 0.0001 | 0.011 | 0.002 | 11.39 |
| 11 | Proposed model (DFL-Hybrid) | 0.0025 | 0.050 | 0.001 | 1.63 |
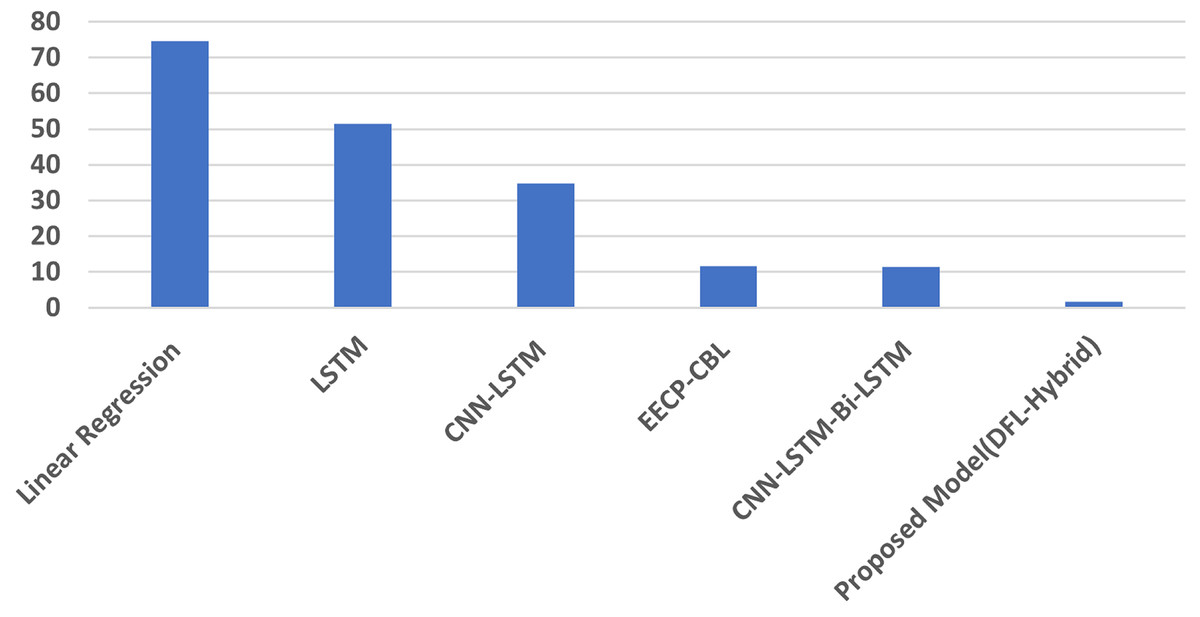
Figure 3: The minutely MAPE result analysis.
{kind=link}
Results with hour energy data
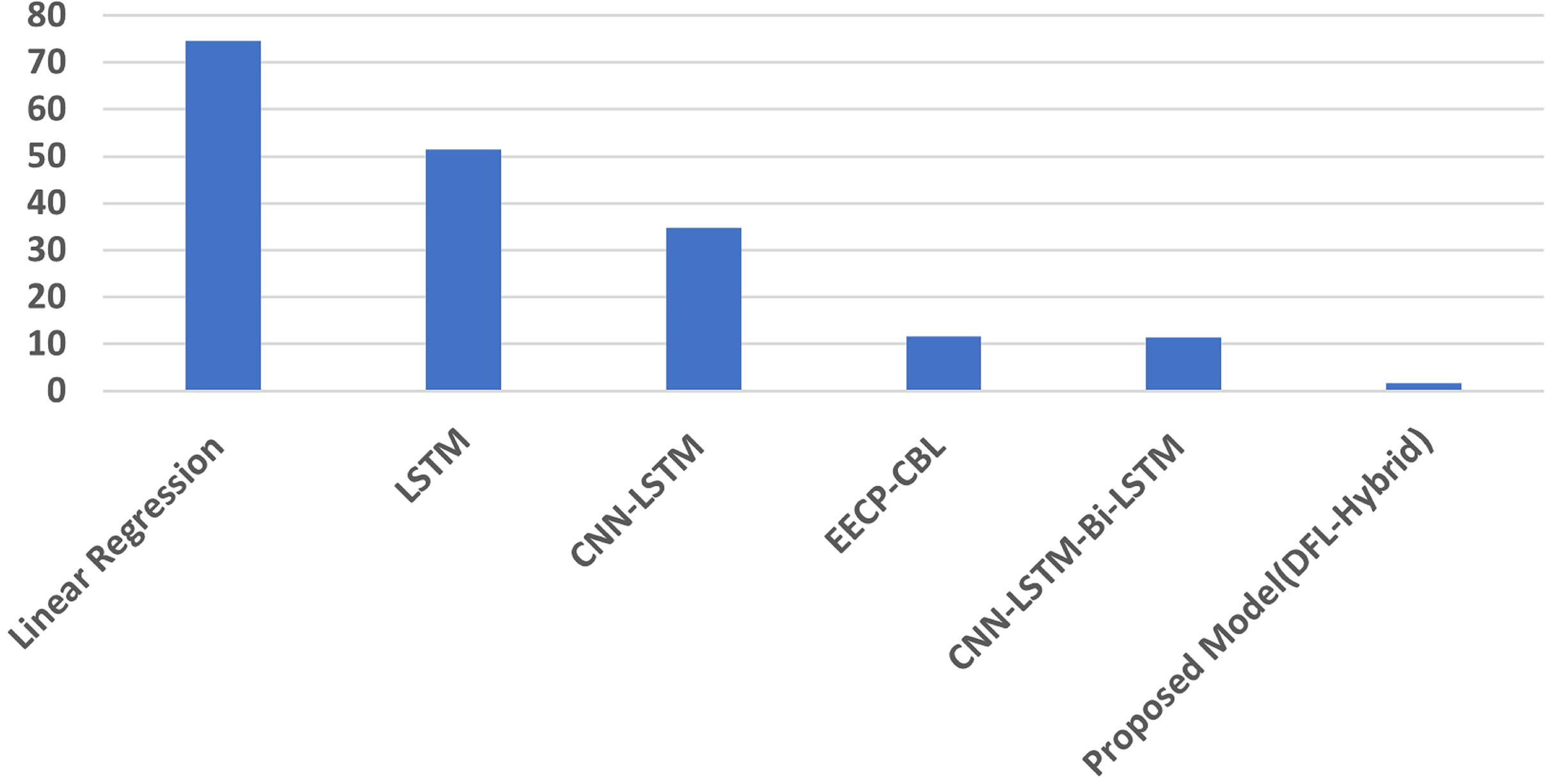
The experimental analysis for hourly energy consumption prediction is presented in Table 3. Hourly analysis results indicated the superior performance of our proposed model compared to MAE, RMSE, and MAPE, where the proposed model achieves an MAE of 0.0019, an RMSE of 0.008, and a MAPE value of 3.98, which is significantly lower than those of other state-of-the-art proposed models. Figure 4 illustrates the MAPE results comparisons of the hour data.
| Model (Hourly) | MSE | RMSE | MAE | MAPE |
|---|---|---|---|---|
| Linear regression (Le et al., 2019) | 0.425 | 0.652 | 0.502 | 83.74 |
| LSTM (Le et al., 2019) | 0.515 | 0.717 | 0.526 | 44.37 |
| CNN-LSTM (Kim & Cho, 2019) | 0.355 | 0.596 | 0.332 | 32.83 |
| EECP-CBL (Le et al., 2019) | 0.298 | 0.546 | 0.392 | 50.09 |
| ANN (Mubarak et al., 2024) | 0.0008 | 0.0288 | 0.021 | 17.531 |
| CNN (Mubarak et al., 2024) | 0.0007 | 0.0267 | 0.0129 | 16.551 |
| LSTM (Mubarak et al., 2024) | 0.0007 | 0.0264 | 0.0192 | 15.901 |
| CNN-attention (Mubarak et al., 2024) | 0.0006 | 0.0264 | 0.0198 | 15.954 |
| LSTM-attention (Mubarak et al., 2024) | 0.0005 | 0.0226 | 0.0181 | 14.865 |
| Proposed model (DFL-Hybrid) | 0.0007 | 0.026 | 0.001 | 0.90 |
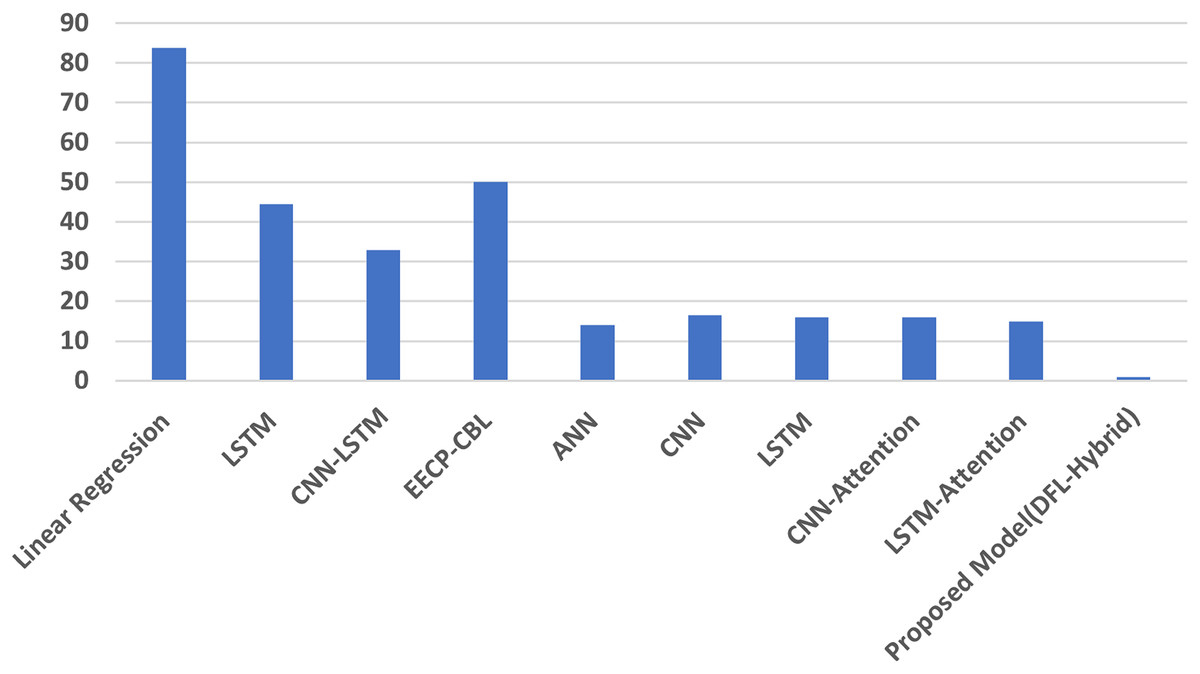
Figure 4: The hourly MAPE result analysis.
{kind=link}
Results with daily energy data
Table 4 displays the comparative results of daily performance between the proposed model and several state-of-the-art approaches using the IHEPC dataset. The evaluation metrics MAE, RMSE, and MAPE indicate that the proposed model outperforms the others, achieving the lowest values across all three measures. Specifically, it achieves an MAE of 0.0008, an RMSE of 0.003, and an MAPE of 1.380, making it the most accurate among the evaluated models. These findings confirm the effectiveness and robustness of the proposed approach. The comparative MAPE outcomes for daily data are visualized in Fig. 5.
| Model (Daily) | MSE | RMSE | MAE | MAPE |
|---|---|---|---|---|
| ANN (Mubarak et al., 2024) | 0.0012 | 0.03529 | 0.028 | 17.531 |
| CNN (Mubarak et al., 2024) | 0.0073 | 0.0627 | 0.027 | 26.901 |
| LSTM (Mubarak et al., 2024) | 0.0077 | 0.0824 | 0.0211 | 16.551 |
| CNN-attention (Mubarak et al., 2024) | 0.0006 | 0.0236 | 0.0193 | 8.6407 |
| LSTM-attention (Mubarak et al., 2024) | 0.0006 | 0.0244 | 0.0195 | 8.3807 |
| CNN-LSTM (Khan et al., 2020) | 0.47 | 0.33 | – | |
| Linear regression (Le et al., 2019) | 0.253 | 0.503 | 0.392 | 52.69 |
| LSTM (Le et al., 2019) | 0.241 | 0.491 | 0.413 | 38.72 |
| CNN-LSTM (Kim & Cho, 2019) | 0.104 | 0.322 | 0.257 | 31.83 |
| EECP-CBL (Le et al., 2019) | 0.065 | 0.255 | 0.191 | 19.15 |
| Proposed model (DFL-Hybrid) | 0.0002 | 0.014 | 0.001 | 0.81 |
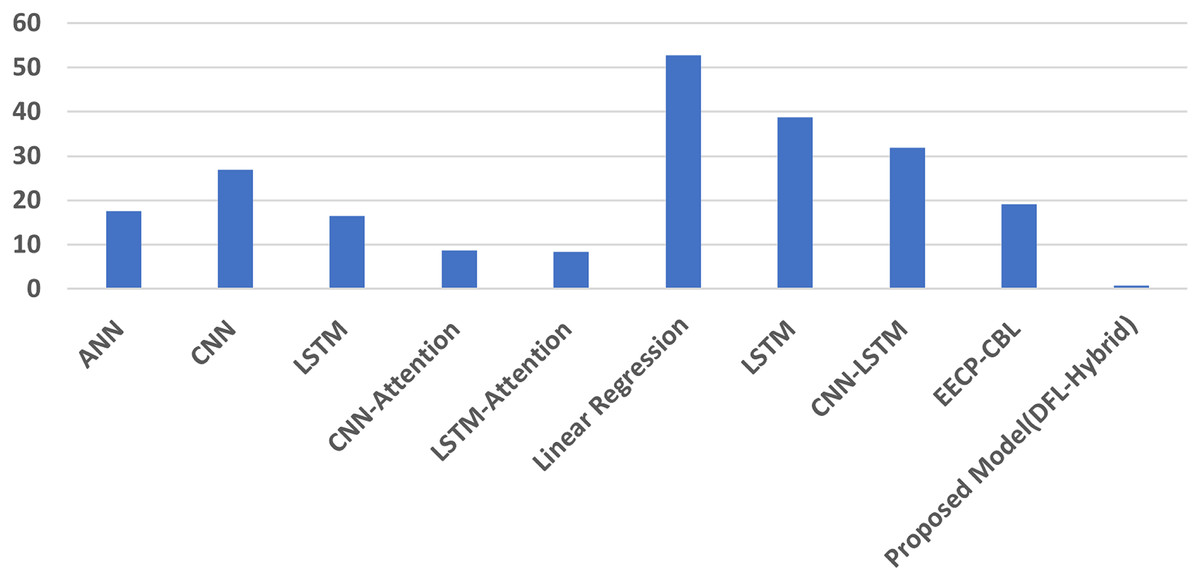
Figure 5: The daily MAPE result analysis.
{kind=link}
Results with weekly energy data
The long-term (sustained) energy consumption prediction analysis results, concerning RMSE, MAE, and MAPE, indicate the superior performance of the proposed novel hybrid model. Results of the proposed hybrid model in Table 5 are significantly improved compared to other state-of-the-art energy prediction models. The proposed model achieves an RMSE of 0.005, an MAE of 0.001, and an MAPE of 2.72, which represents a significant improvement compared to other models. Figure 6 illustrates the MAPE results comparisons of the weekly data.
| #No | Model | MSE | RMSE | MAE | MAPE |
|---|---|---|---|---|---|
| 1 | Linear regression (Le et al., 2019) | 0.148 | 0.385 | 0.320 | 41.33 |
| 2 | LSTM (Le et al., 2019) | 0.105 | 0.324 | 0.244 | 35.78 |
| 3 | CNN-LSTM (Kim & Cho, 2019) | 0.095 | 0.309 | 0.238 | 31.84 |
| 4 | EECP-CBL (Le et al., 2019) | 0.049 | 0.220 | 0.177 | 21.28 |
| 5 | Proposed model (DFL-Hybrid) | 0.0002 | 0.015 | 0.002 | 2.22 |
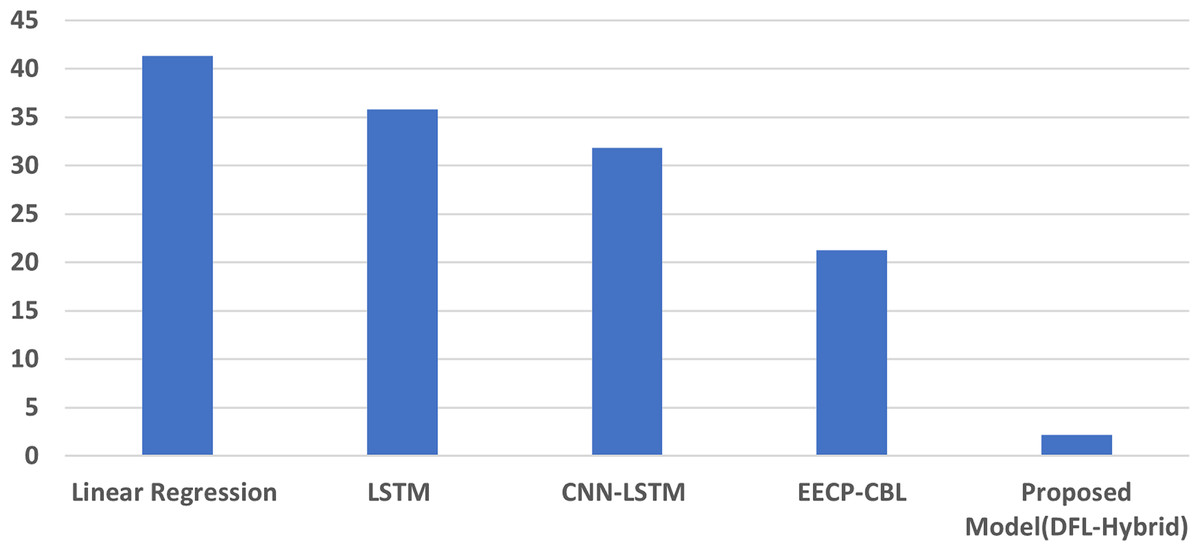
Figure 6: The weekly MAPE result analysis.
{kind=link}
Average comparison analysis
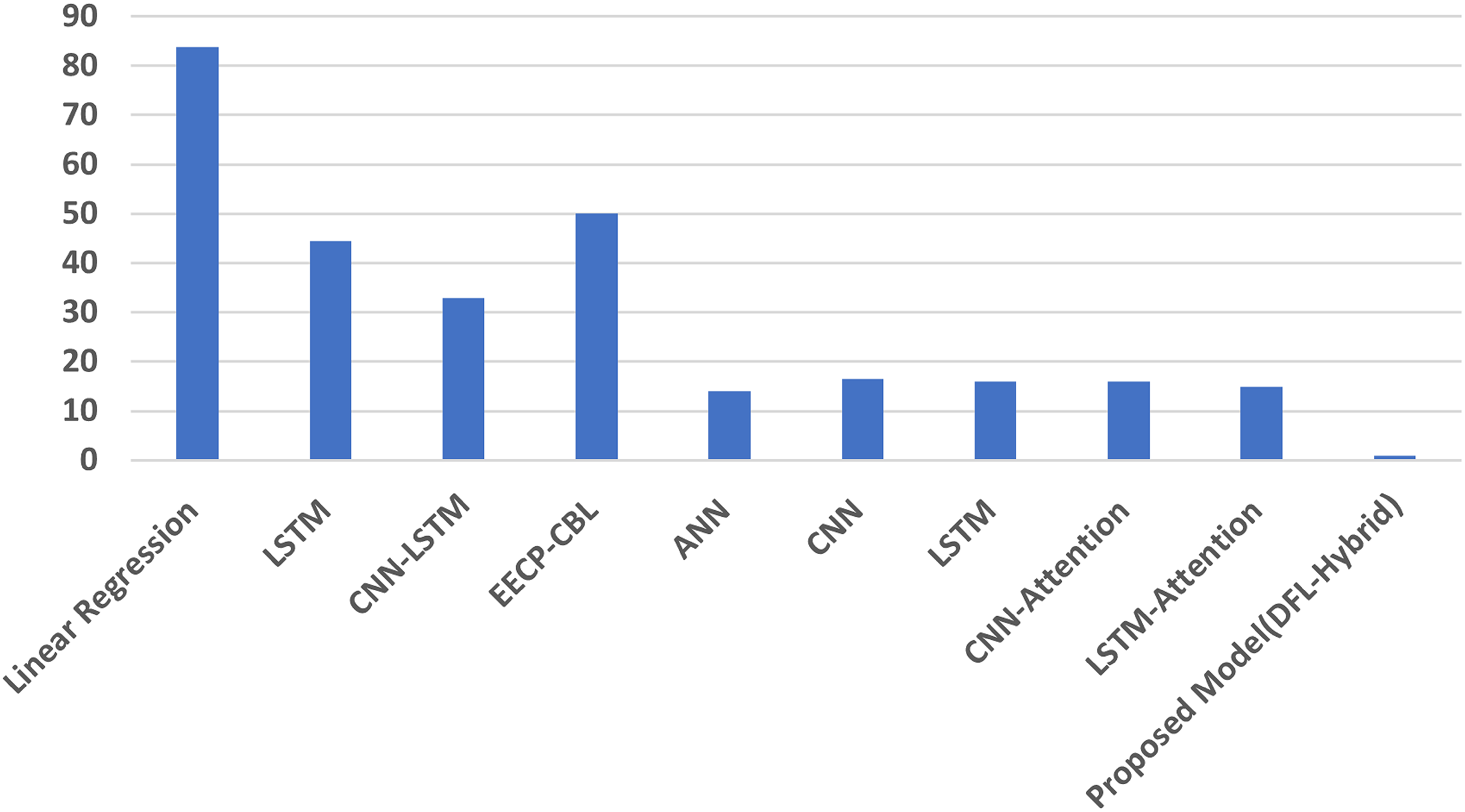
Overall, the proposed model’s results, on average, are analysed and compared with those of other state-of-the-art models for short-term and long-term energy consumption prediction. Table 6 contains the average results. The lowest MAE, RMSE, and MAPE values of the proposed model indicate its superior performance in predicting energy consumption across a range of periods, from short-term to long-term. Figure 7 illustrates the MAPE average results comparisons.
| Method | MSE | RMSE | MAE | MAPE |
|---|---|---|---|---|
| Linear regression (Le et al., 2019) | 0.30775 | 0.544 | 0.408 | 63.07 |
| LSTM (Le et al., 2019) | 0.40225 | 0.59925 | 0.45275 | 42.58 |
| CNN-LSTM (Kim & Cho, 2019) | 0.232 | 0.4595 | 0.294 | 32.835 |
| EECP-CBL (Le et al., 2019) | 0.11575 | 0.3115 | 0.2145 | 25.545 |
| Proposed model (DFL-Hybrid) | 0.0009 | 0.02625 | 0.00125 | 1.39 |
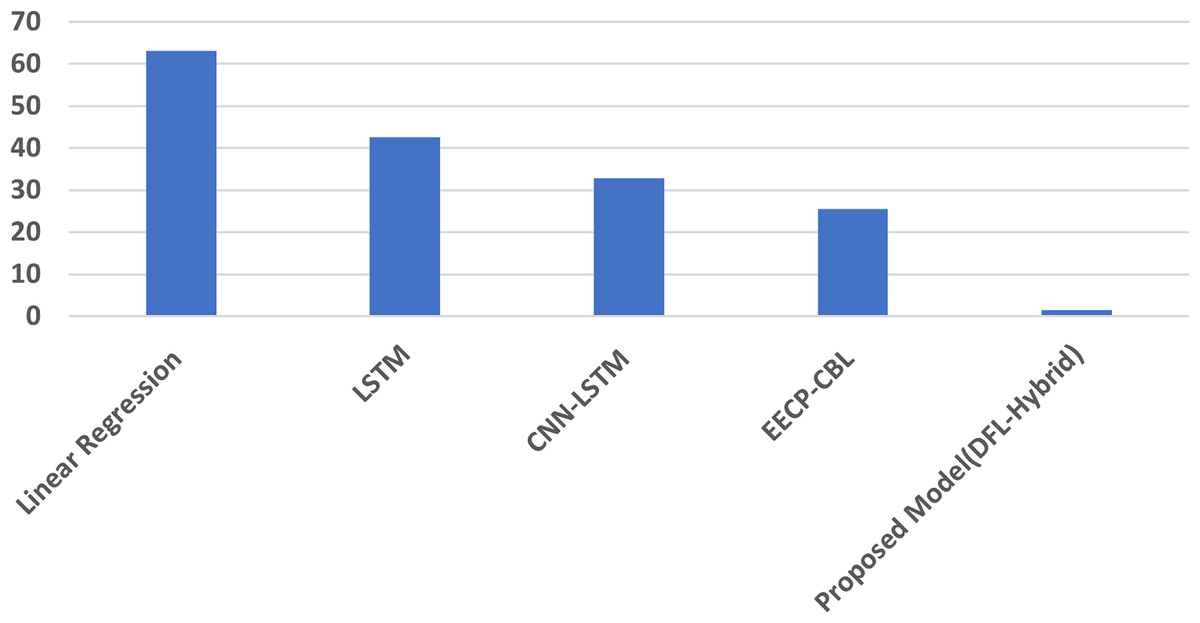
Figure 7: The average MAPE result analysis.
{kind=link}
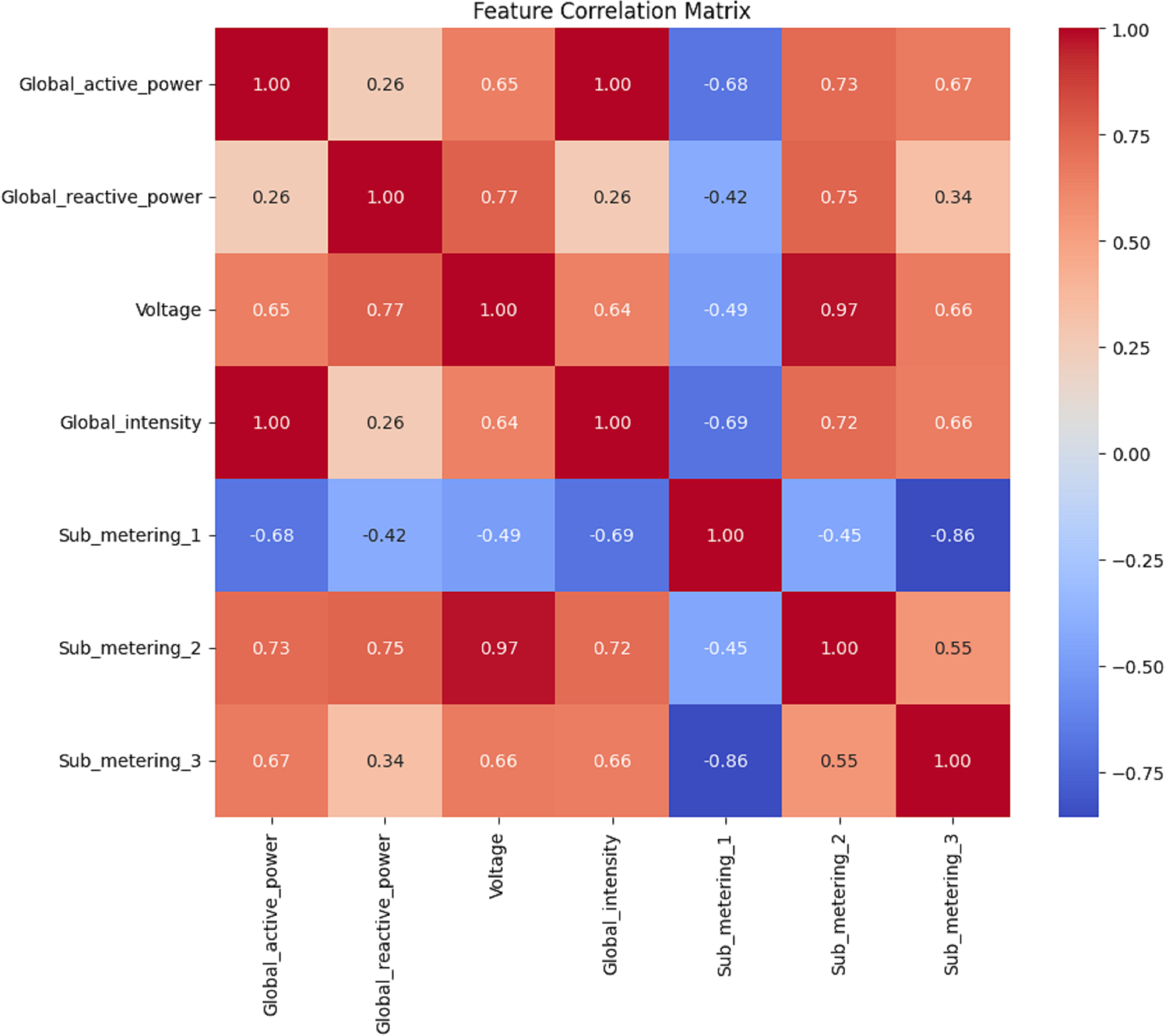
Features correlation analysis
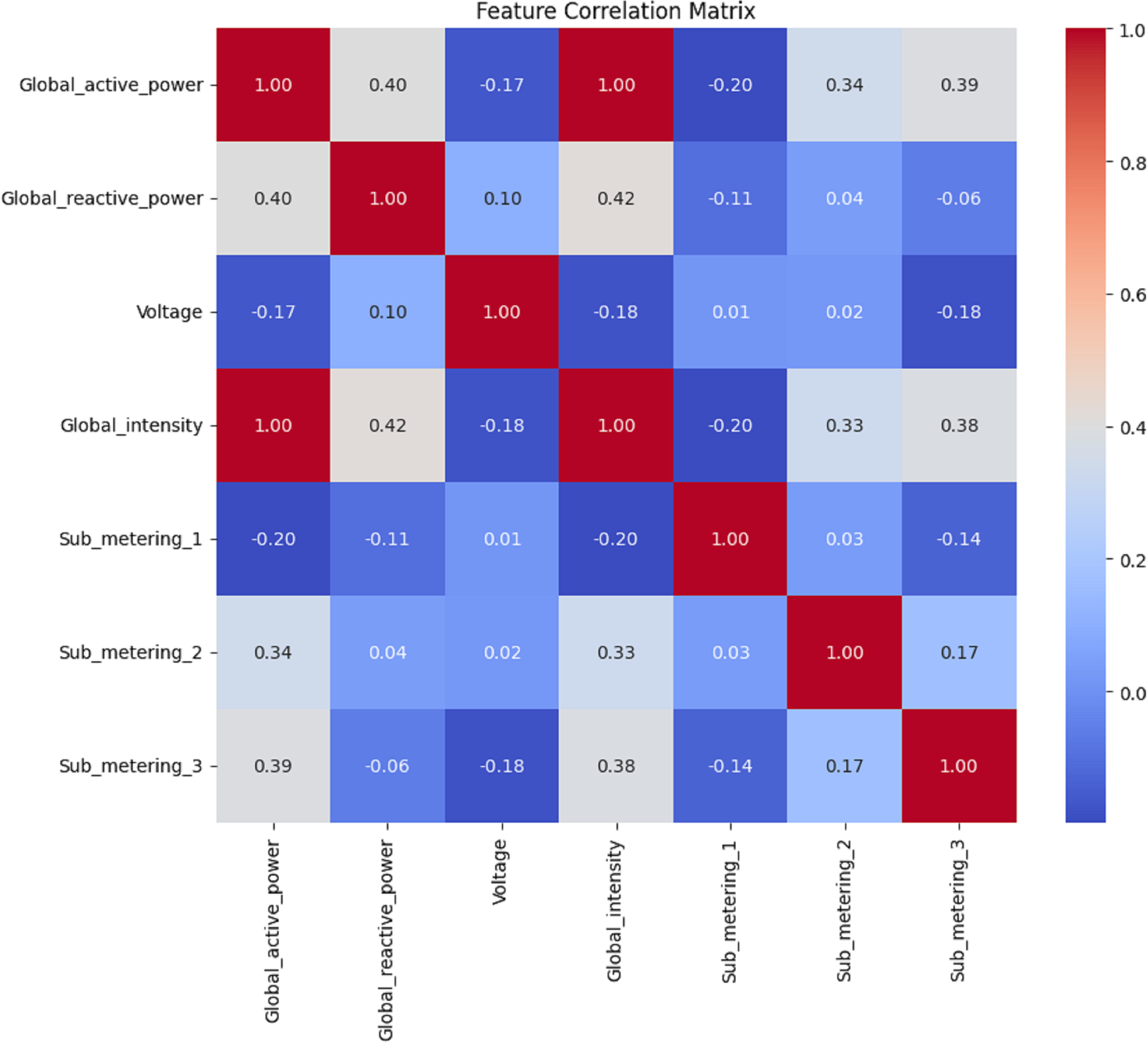
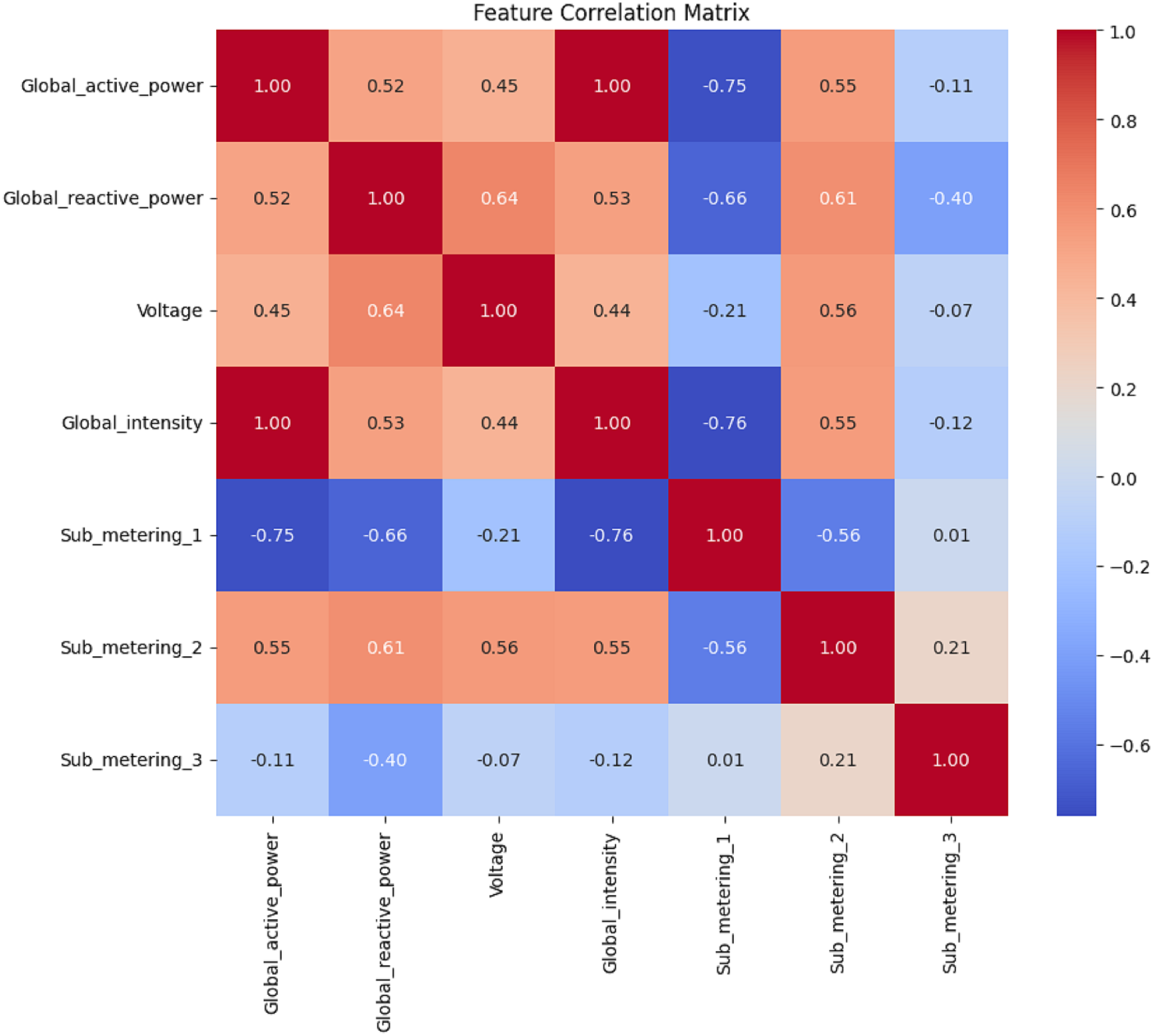
Figures 8, 9, 10 and 11 shows the feature selection and model development. A correlation matrix of minute, hour, day, and week energy consumption datasets reveals strong dependencies between specific variables. Global Active Power exhibited a very high positive correlation with Global Intensity (0.79), indicating a close association between the two and a likely impact on energy consumption forecasting models. Additionally, a moderate relationship of 0.24 can be established between Global Active Power and Global Reactive Power, indicating that these two variables tend to influence the system’s energy dynamics. Such insights would also lead to having some of these influential features in the predictive models, while giving less priority to weakly correlated features such as Voltage and Sub_metering_1, capable of making the models more complex. The heatmap representation enhances interpretability, offering a clear view of strong, moderate, and weak correlations. This can be utilized to design optimized hybrid models that focus on the most important features, enhancing both accuracy and computational efficiency in forecasting applications by effectively leveraging correlations.
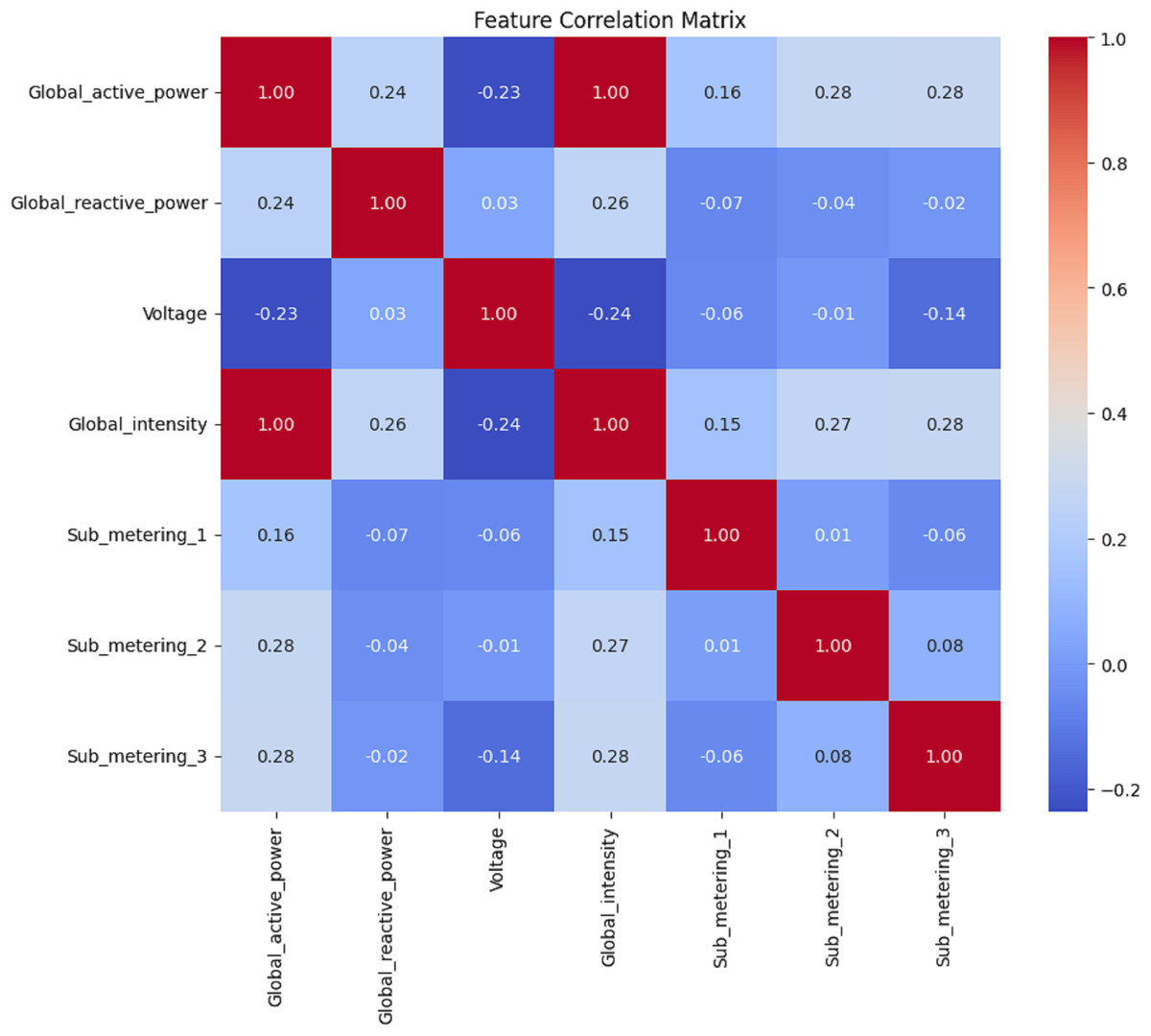
Figure 8: Minute data: the correlation matrix analysis.
{kind=link}
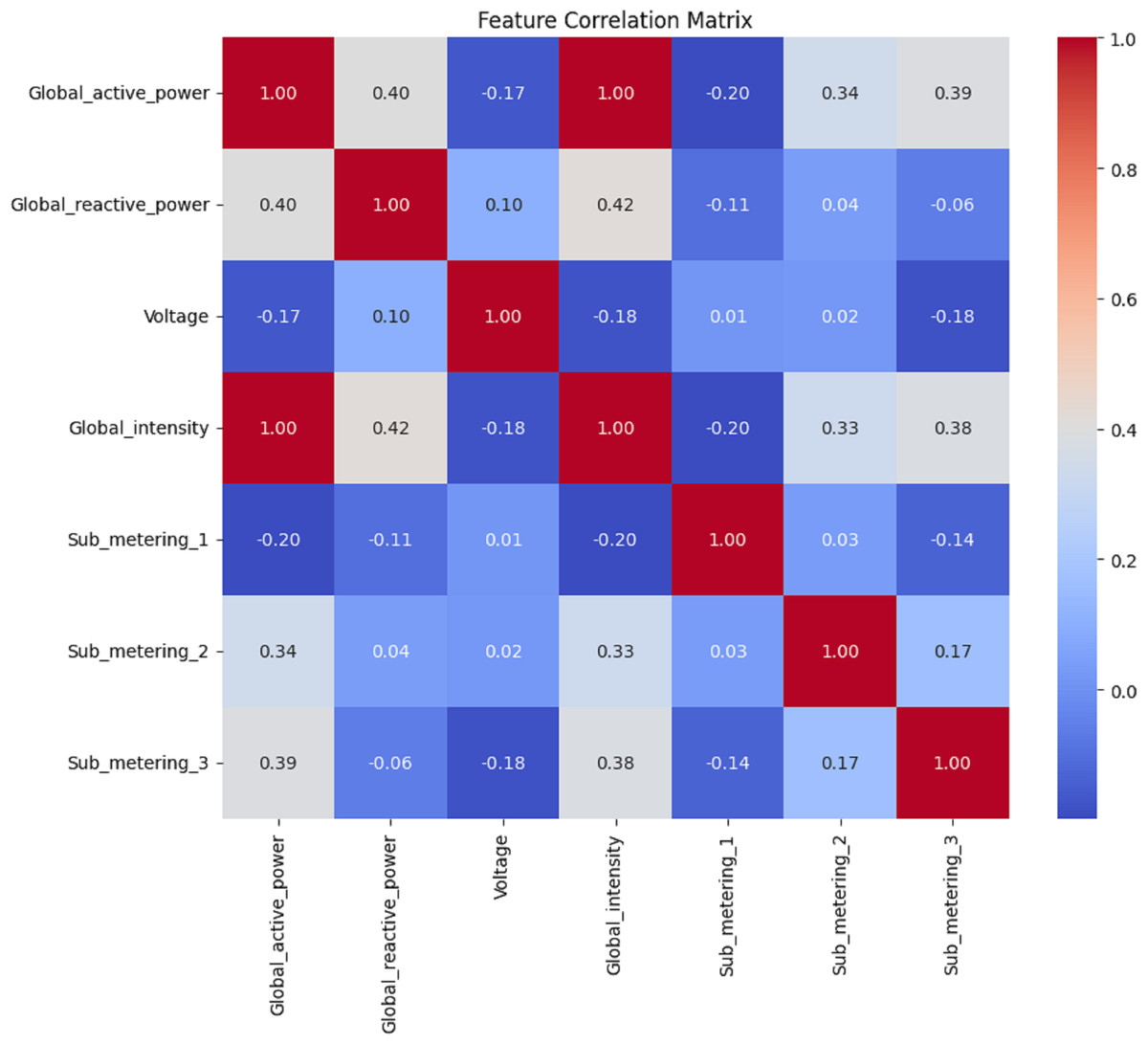
Figure 9: Hour data: the correlation matrix analysis.
{kind=link}
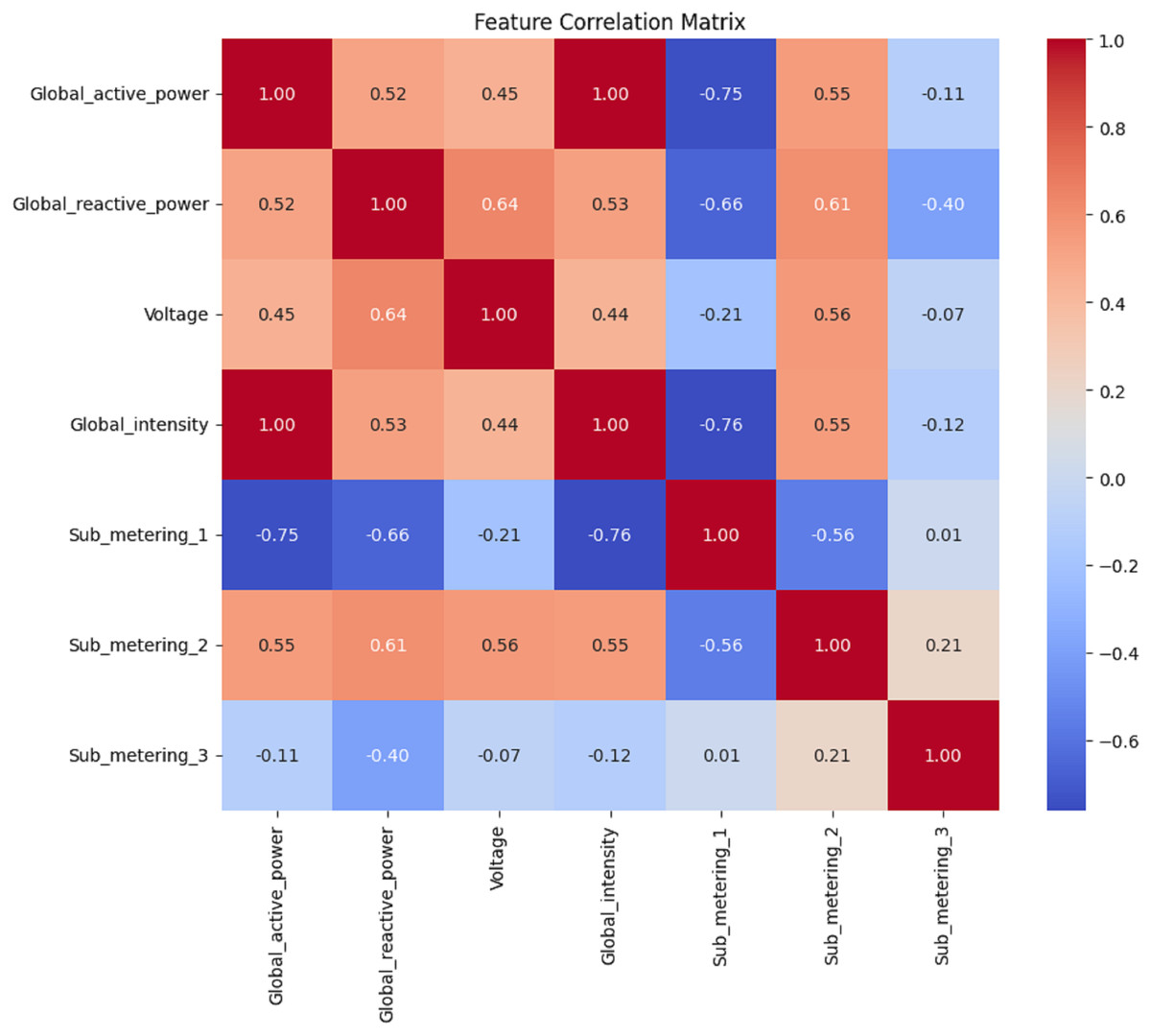
Figure 10: Daily data: the correlation matrix analysis.
{kind=link}
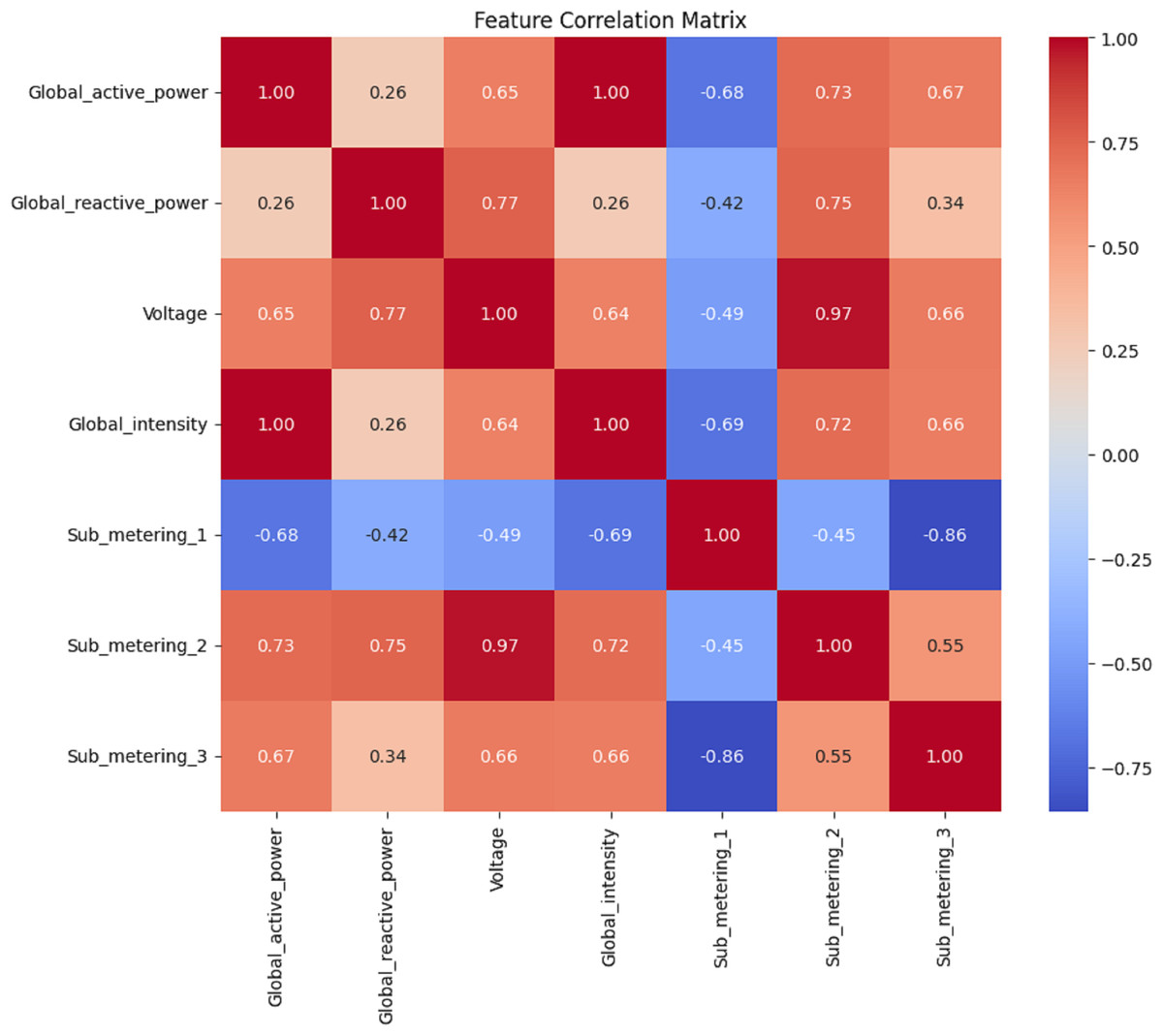
Figure 11: Week data: the correlation matrix analysis.
{kind=link}
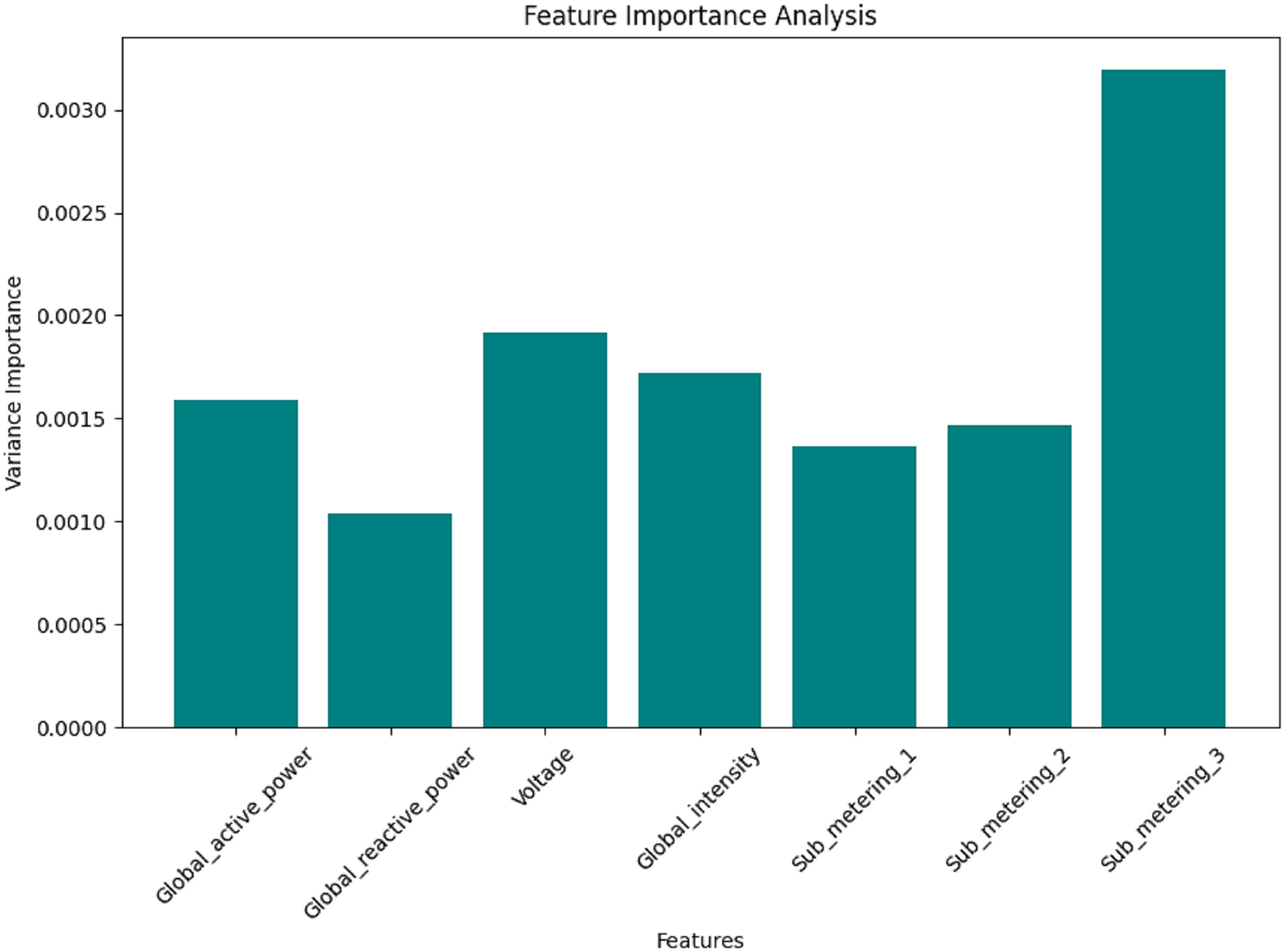
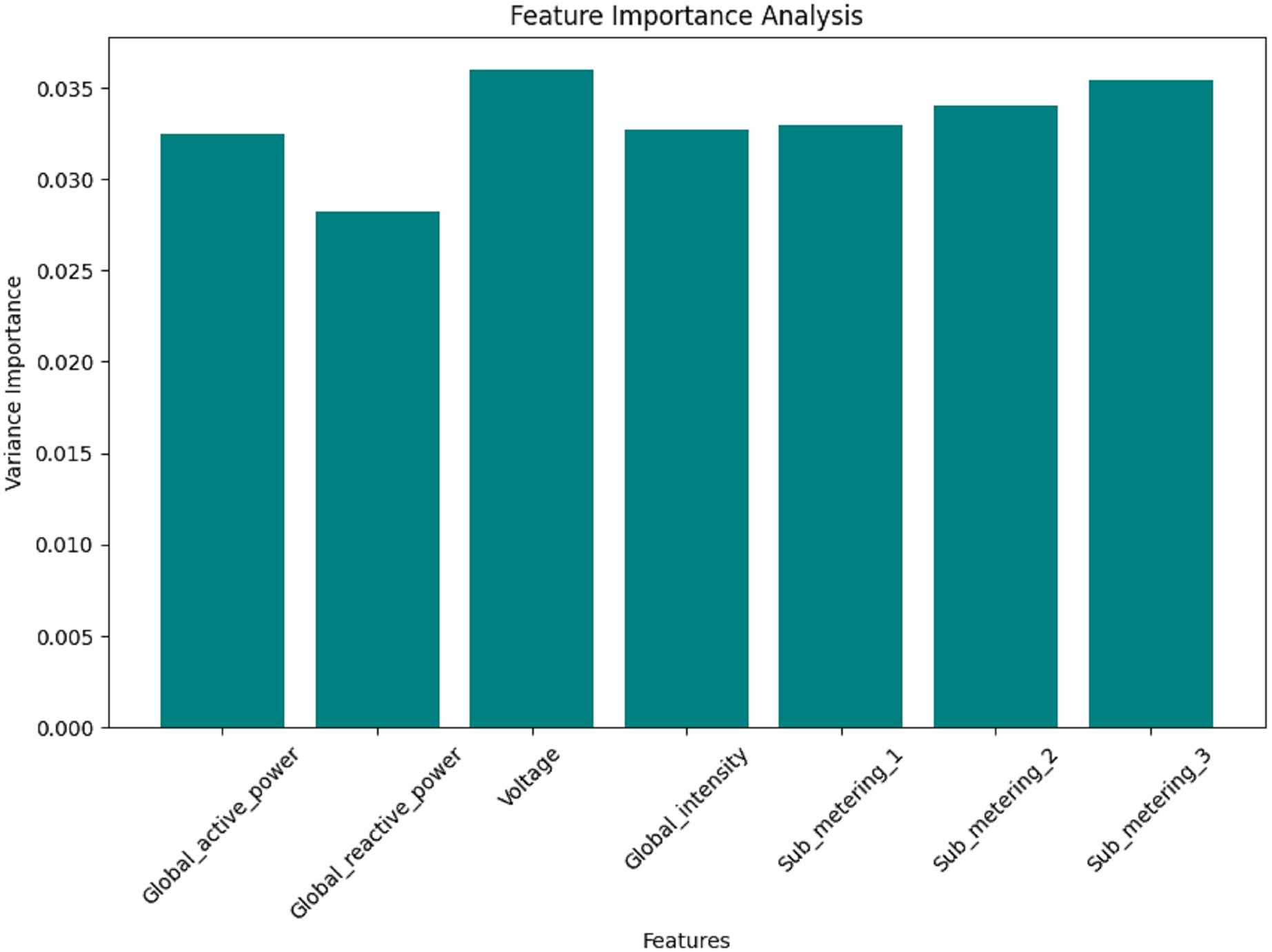
Figures 12, 13, 14, and 15 are bar plots that demonstrate the feature importance ranking for a prototype model of minutely, hourly, daily, and weekly energy consumption forecasting using Federated Learning. This assesses the contribution of each feature to the model’s predictive ability. The feature importance value indicates that the most significant feature is Sub_metering_2, which has an importance value, thus assuming a dominant role in its prediction. Global Active Power and Sub_metering_3 are also considerably important. However, Global Intensity and Sub_metering_1 record moderate scores compared to Voltage, making them the least important features.
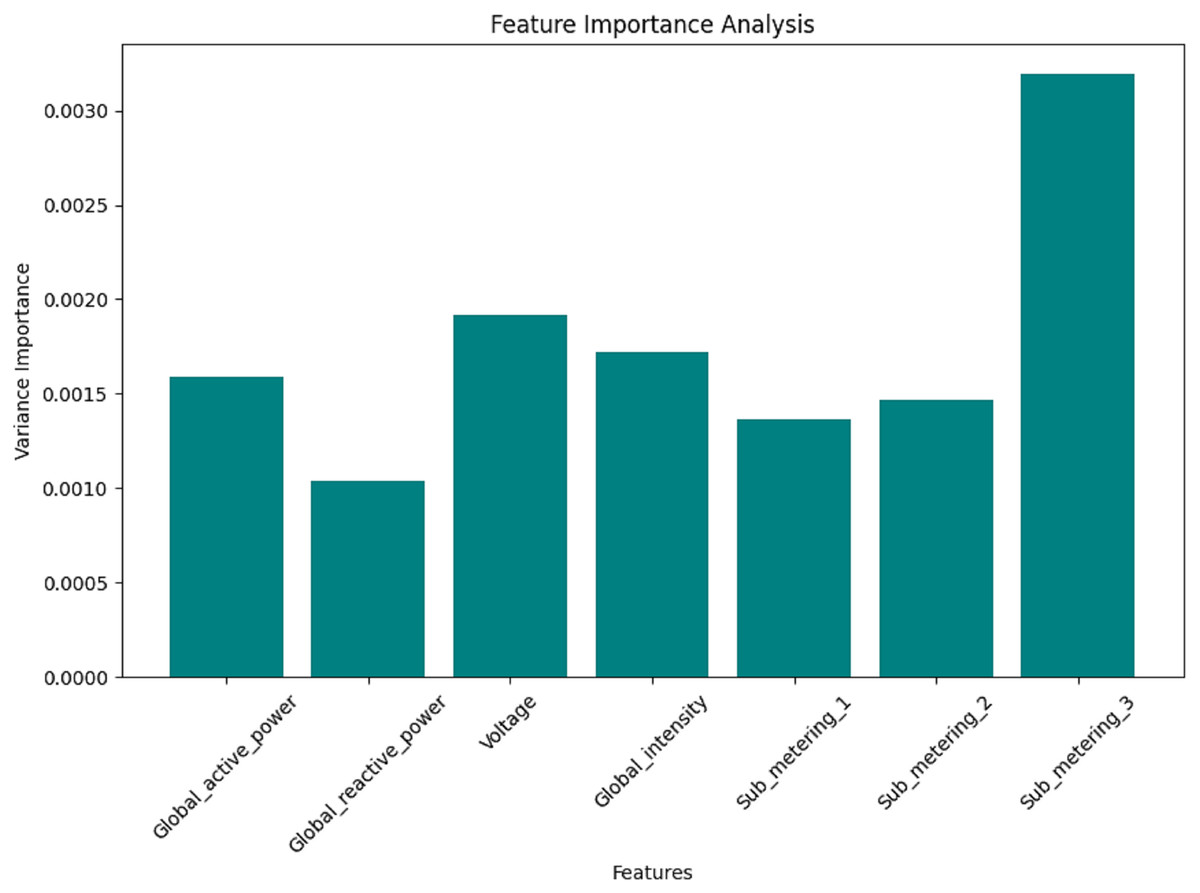
Figure 12: Minute data: the feature importance analysis.
{kind=link}
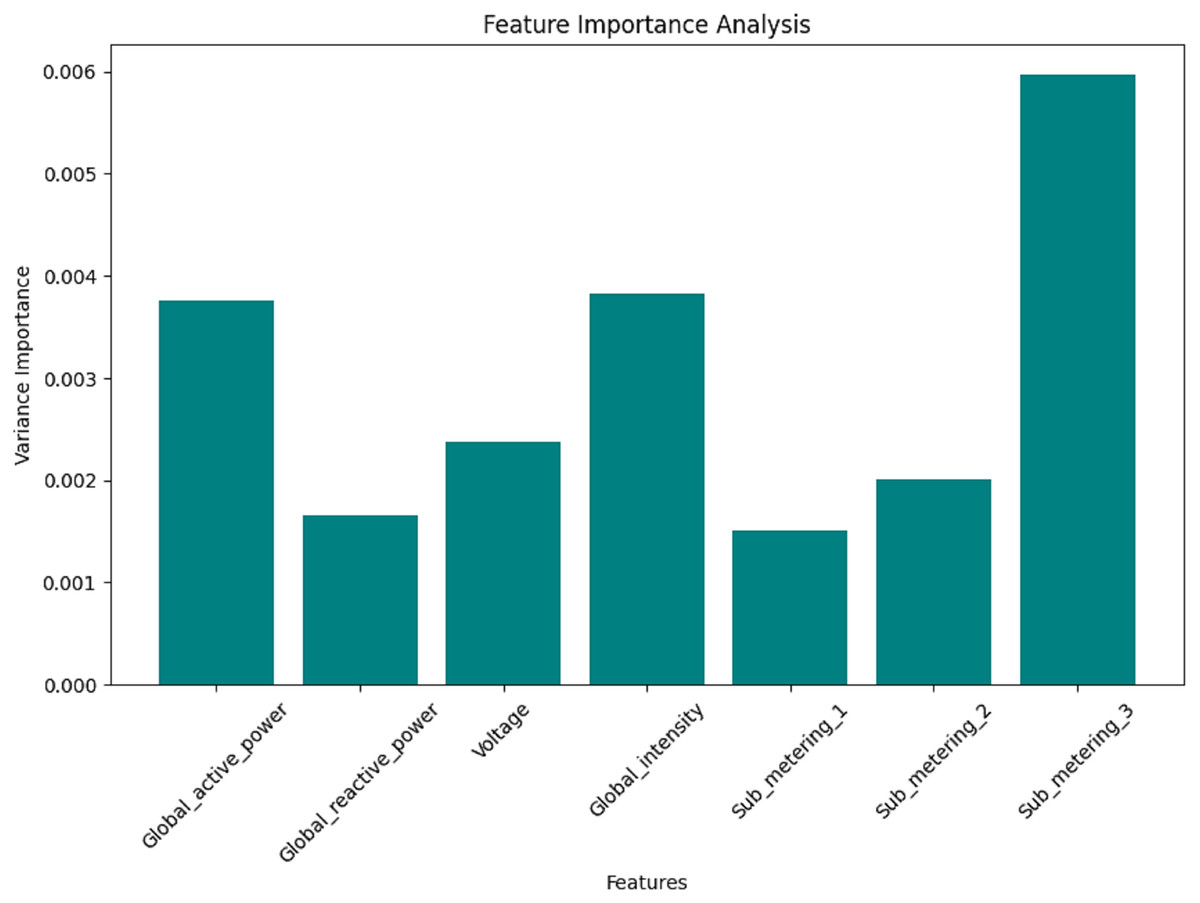
Figure 13: Hour data: the feature importance analysis.
{kind=link}
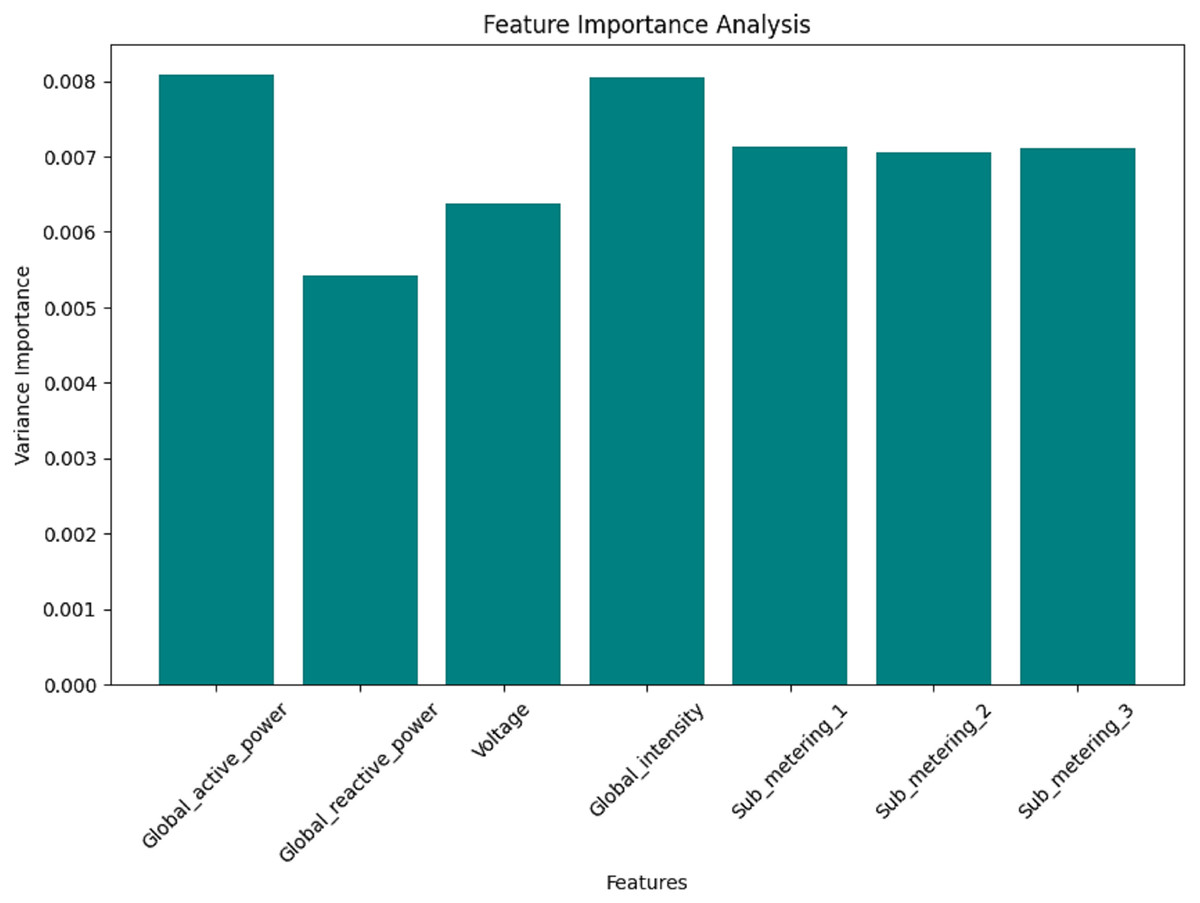
Figure 14: Daily data: the feature importance analysis.
{kind=link}
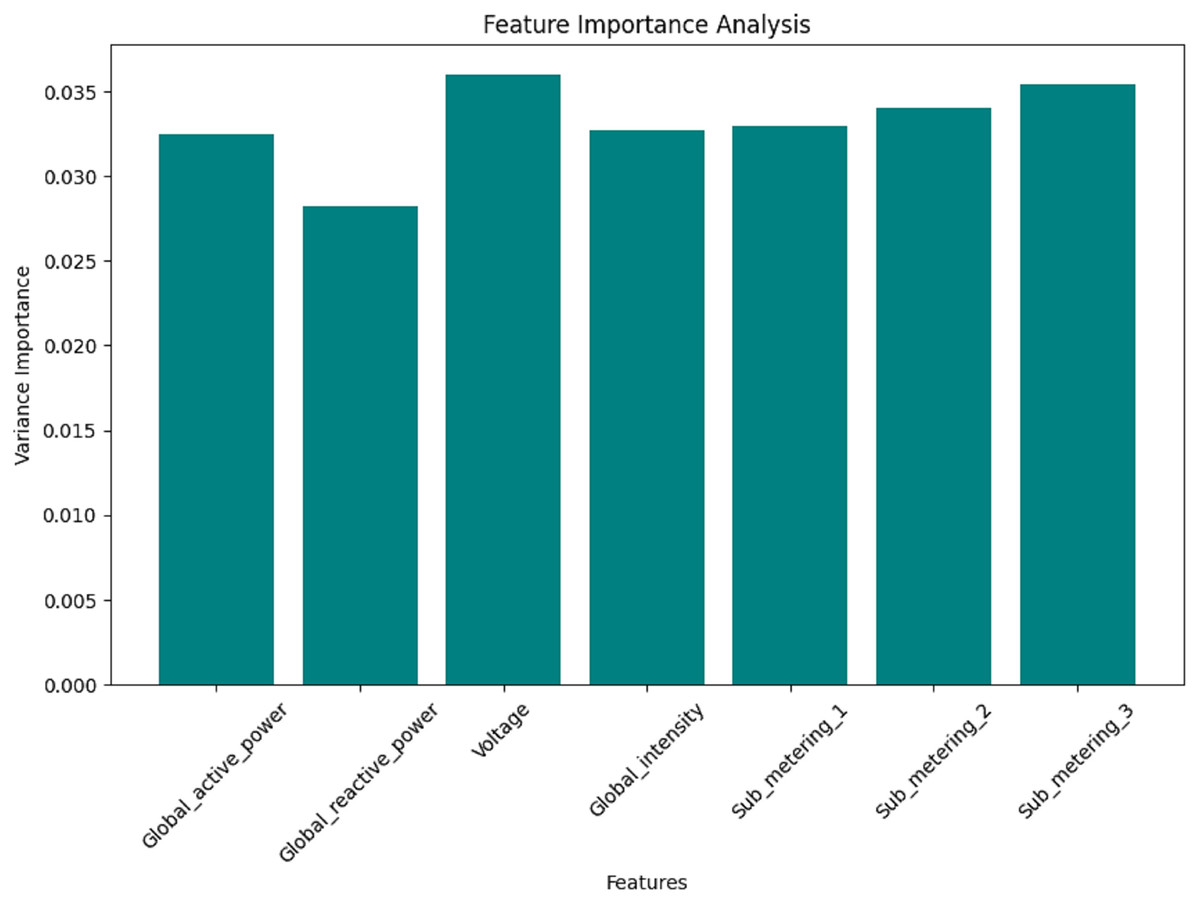
Figure 15: Week data: the feature importance analysis.
{kind=link}
These results align with the correlation analysis, where the most highly ranked features also exhibited strong relationships with the target variables. Therefore, this feature importance ranking validates the critical predictor selection and hints at the possibility of dimensionality reduction through feature elimination, such as voltage. This will enhance the model’s efficiency and accuracy by focusing solely on the most essential variables; therefore, this analysis is crucial for developing effective hybrid forecasting models.
On the contrary, the levels of importance for features such as Global Intensity and Sub_metering_1 are slightly moderate compared to the last-ranked feature of Voltage. The findings align with those of correlation analyses, which revealed strong relationships between the same features and the target variables, most highly ranked. This feature importance ranking helps not only to legitimize crucial predictor selection but also opens up potential dimensionality reduction by excluding insignificant features, such as Voltage. Concentrating on the most influential variables enables the model to achieve high efficiency and accuracy, making it a crucial step in establishing hybrid forecasting models.
These findings are supported by the correlation analyses, which displayed strong relationships between the same features and the target variables, with the most highly ranked features. The feature importance ranking is not only evidence for critical predictor selection but also an avenue through which potential dimensionality reduction can arise by eliminating weak and unimportant features, such as Voltage. Improved efficiency and accuracy of the model can be achieved by focusing on the most influential variables. This makes this analysis particularly significant in closing in on the establishment of hybrid forecasting models.
State of the art comparisons
Table 7 presents a comparative analysis of our proposed DFL-Hybrid model against state-of-the-art approaches. Traditional methods, such as linear regression and LSTM-based models, demonstrate limited accuracy due to their inability to fully capture nonlinear dependencies in consumption data. More advanced architectures, including CNN-LSTM and EECP-CBL, have improved performance by integrating temporal and spatial features. However, they still fall short in balancing prediction accuracy with robustness across diverse scenarios. In contrast, our proposed DFL-Hybrid approach achieves a remarkably low MAPE of 1.39 and a prediction accuracy of 98.61%, significantly outperforming existing methods.
| Ref. | Method type | MAPE score | Accuracy scoe |
|---|---|---|---|
| Le et al. (2019) | Linear regression | 63.07 | 36.93 |
| Le et al. (2019) | LSTM | 42.58 | 57.42 |
| Kim & Cho (2019) | CNN-LSTM Kim | 32.835 | 67.165 |
| Le et al. (2019) | EECP-CBL | 25.545 | 74.455 |
| Proposed | DFL-Hybrid | 1.39 | 98.61 |
Real world implications
Energy consumption and its accurate prediction are crucial for various sectors, including smart grid management, sustainable urban planning, and industrial optimization. Reliable forecasting enables policymakers and engineers to improve efficiency, reduce operational costs, and lower environmental impacts. Moreover, in the context of renewable energy integration, accurately predicting energy demand and consumption patterns helps balance supply with intermittent sources, thereby ensuring system reliability and sustainability.
Impact of the proposed work on research and academia
This work provides future directions on privacy-preserving deep learning in smart grids using blockchain-backed federated aggregation.
This study bridges the gap between theory and implementation, providing a reproducible pipeline in real-world applications. This pipeline can be applied to an academic curriculum.
This study will lead to other cross-domain applications in multiple areas, including demand-side management, renewable energy estimation, and anomaly detection in IoT-based energy systems.
Discussion
The replicability of the proposed model was ensured by providing a transparent description of the preprocessing data, including log transformation, resampling into multiple granularities, normalisation, model hyperparameters, and a federated learning setup, which included the number of nodes, aggregation strategy, and communication rounds. To further facilitate reproducibility, the implementation is based on widely available open-source libraries, including Keras, TensorFlow, and scikit-learn. With minor adjustments, the framework can be re-implemented on other publicly available energy datasets.
In terms of generalization, although the experiments were conducted using the IHEPC dataset, the proposed architecture is not limited to this dataset. The hybrid CNN–LSTM–Bi-LSTM model is designed to capture multi-scale temporal dependencies inherent in most energy consumption patterns. Future work will focus on validating the model using several datasets, such as PJM, EKPC, and ISO datasets, as well as in real-world application deployments to assess its generalisation capability further.
Conclusions
This study proposes a hybrid model, DFL, integrated with CNN, LSTM, and Bi-LSTM, for predicting energy consumption at multiple temporal resolutions: per minute, per hour, daily, and weekly. The model was tested using the IHEPC dataset, and the experiments demonstrated that this model has shown excellent predictions across all temporal levels. This hybrid architecture leverages the strengths of CNNs in feature extraction, combined with the ability of LSTM to learn sequential patterns and Bi-LSTM’s proficiency in identifying bidirectional dependencies within the data. This well-thought-out combination proved to be very effective in producing highly accurate predictions, as indicated by the performance metrics obtained. The model outperformed traditional models by a significant margin in improving accuracy and reducing error for each temporal resolution. This research examines the robustness and versatility of the proposed model, a DFL-based CNN-LSTM-Bi-LSTM hybrid model for predicting energy consumption. It offers insights into energy management and planning, and also establishes a benchmark for future studies aimed at enhancing prediction accuracy through a hybrid deep learning architecture. Results indicate that our proposed model outperforms all datasets for short-term and long-term predictions. The high accuracy of the proposed model’s results gives us confidence to explore its application in building control systems for improved energy consumption prediction.
Limitations
The complexity introduced by combining multiple deep architectures increases computational cost and training time, which may pose challenges for real-time or resource-constrained environments.
The federated learning framework leveraged weighted aggregation and blockchain logging, but other advanced privacy-preserving methods, such as differential privacy or secure multiparty computation, were not investigated.