
Efficient Parkinson’s disease classification from speech with filter-based feature selection and Genetic Algorithm–Bayesian Optimization ensemble integration
- Published
- Accepted
- Received
- Academic Editor
- Nicole Nogoy
- Subject Areas
- Artificial Intelligence, Computer Education, Data Mining and Machine Learning, Neural Networks
- Keywords
- Hybrid filter-based selection, Iterative majority voting ensemble, GA–BO ensemble voting, Parkinson’s disease classification
- Copyright
- © 2025 Gunduz
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Efficient Parkinson’s disease classification from speech with filter-based feature selection and Genetic Algorithm–Bayesian Optimization ensemble integration. PeerJ Computer Science 11:e3430 https://doi.org/10.7717/peerj-cs.3430
Abstract
Parkinson’s disease (PD) is a progressive neurodegenerative disorder of the central nervous system that significantly impairs quality of life. Early and accurate diagnosis is essential to improve treatment outcomes and slow disease progression. In this study, we propose a computationally efficient and clinically feasible framework for PD classification based solely on vocal biomarkers. Our method leverages selective feature optimization and lightweight ensemble learning, avoiding reliance on deep or computationally intensive architectures. Three ensemble strategies are evaluated: (i) iterative majority voting, (ii) Genetic Algorithm (GA)-based classifier selection, and (iii) Bayesian Optimization (BO)-based probabilistic weighting. Building on these, we introduce a hybrid GA–BO ensemble method that combines GA-driven model selection with BO-guided weighting to optimize diagnostic performance. Experimental results demonstrate that the hybrid ensemble achieves state-of-the-art metrics, including 96.4% accuracy, 97.6% F1-score, and a Matthews Correlation Coefficient (MCC) of 0.906. The proposed system is adaptable across diverse feature sets and suitable for integration into mobile or edge-computing platforms. Overall, the framework offers a non-invasive, scalable, and cost-effective decision support tool for early-stage PD diagnosis.
Introduction
Parkinson’s disease (PD) is a progressive neurodegenerative disease that affects the central nervous system. The primary feature of PD is the reduction of dopamine levels in the substantia nigra, a part of the brain critical for movement coordination (Massano & Bhatia, 2012). Dopamine is essential to ensure smooth and precise motor movements; therefore, its insufficiency results in motor problems, including tremors (Tysnes & Storstein, 2017), muscle stiffness (Raiano et al., 2020), reduced movement ability (Jankovic, 2008), and walking difficulties (Palakurthi & Burugupally, 2019). Additional symptoms can include fatigue, disturbances in sleep, cognitive challenges, and depression (Goldman et al., 2018). Importantly, speech impairments often serve as early indicators of PD (Goberman, Blomgren & Metzger, 2010; Tolosa et al., 2021).
The exact cause of PD is not fully understood, as it is believed to arise from a combination of genetic and environmental factors. Although there is currently no cure, treatments that involve medication, surgery, and physical therapy can help manage symptoms. The condition is generally more common in those over 60 years of age and marginally more widespread in men, but younger adults can also be affected (Stoker & Barker, 2020).
Alterations in speech, such as diminished vocal clarity, monotonic intonation, and hoarseness, frequently occur before motor symptoms, rendering speech-based diagnostics a promising path (Gunduz, 2019; Karaman et al., 2021; Quan et al., 2022). Despite this, diagnosing early on poses difficulties due to the requirement for clinical expertise, which may be scarce in low-resource regions. This has motivated the development of computer-aided diagnosis (CAD) systems to aid clinicians, reduce diagnostic errors, and enhance scalability.
Earlier studies have investigated various modalities for PD diagnosis, including electroencephalogram (EEG) (Li et al., 2024), magnetic resonance imaging (MRI) (Rana et al., 2017), Gamma scans (Tassew, Xuan & Chai, 2023), handwriting analysis (Diaz et al., 2019; Islam et al., 2024), and gait freezing patterns (El Maachi, Bilodeau & Bouachir, 2020). Among these, speech-based detection has emerged as particularly effective due to its non-invasive and cost-efficient nature (Moro-Velazquez et al., 2021; Jeancolas et al., 2021). Accordingly, a wide range of machine learning (ML) and deep learning (DL) methods have been proposed. Classical ML approaches, including support vector machines (SVMs) (Gunduz, 2019, 2021), boosting algorithms (Lamba, Gulati & Jain, 2022), and meta-heuristics such as Minimum Redundancy Maximum Relevance (mRMR), Genetic Algorithms (GA), and particle swarm optimization (PSO) (Lamba, Gulati & Jain, 2022; Ouhmida et al., 2024; Elkharadly et al., 2025), have shown considerable promise. Meanwhile, DL architectures—such as convolutional neural networks (CNNs) (Gunduz, 2019), CNN–long-short term memory (LSTM) hybrids (Pal, Pandey & Pal, 2024), and LSTM–Gated Recurrent Unit (GRU) models (Rehman et al., 2023)—have demonstrated strong capabilities in modeling nonlinear temporal dependencies in vocal signals.
Despite these advances, several critical challenges persist. High-dimensional voice-based feature sets can lead to redundancy and overfitting. Monolithic classifier approaches often lack generalization across datasets. Furthermore, the computational cost of many DL-based models limits their feasibility for real-time or embedded systems. These limitations motivate the development of classification systems that are both efficient and robust.
To address these limitations, this study introduces a lightweight and computationally efficient hybrid ensemble classification framework. Our approach leverages GA for dynamic base model selection and Bayesian Optimization (BO) for probabilistic weighting of individual learners. This strategy facilitates the construction of adaptive ensembles tailored to dataset structure, feature dimensionality, and clinical constraints. The proposed framework is explicitly designed to be deployable in real-world clinical and edge-computing scenarios, where computational resources and latency are critical factors.
In the following sections, we first elaborate on the underlying motivations of the study, followed by a summary of its specific contributions.
Motivation
Current state-of-the-art PD classification models frequently trade off between accuracy and computational cost. Deep models, while highly performant, are often unsuitable for real-time or low-resource settings. Conversely, lightweight models struggle with generalization, particularly when faced with diverse or redundant feature spaces. Moreover, ensemble learning strategies—while potentially powerful—are often underutilized or statically defined, ignoring opportunities for adaptive optimization.
This study addresses these challenges by introducing a hybrid ensemble classification framework that delivers high diagnostic accuracy while avoiding the computational overhead typical of deep neural networks. The proposed method combines GA for subset selection and BO for adaptive model weighting. It integrates three complementary feature sets—baseline acoustic parameters (e.g., jitter, shimmer, harmonic-to-noise ratio), Mel-Frequency Cepstral Coefficients (MFCCs), and Tunable Q-Factor Wavelet Transform (TQWT) features—into a unified processing pipeline. By coupling statistical filtering with evolutionary optimization, the framework dynamically tailors both feature subsets and classifier weights on a per-fold basis. This design enables scalable, data-driven ensemble construction suitable for deployment in clinical and edge-computing environments.
Contributions
The key contributions of this study are summarized below:
We introduce a flexible and extensible filter-based feature selection framework that integrates conventional statistical filters—Mutual Information (MI), F-score, and Chi-square—with ensemble-driven strategies including score fusion, voting-based hybridization, and classwise filtering. These techniques are systematically applied across three distinct feature domains: baseline acoustic features, MFCCs, and TQWT features.
A comprehensive multi-domain evaluation is conducted using SVM and -Nearest Neighbors (kNN) classifiers under stratified 10-fold cross-validation. The analysis encompasses various feature retention ratios as well as fixed-length feature configurations, enabling a robust assessment of model performance across different dimensionality settings.
We propose a two-stage hybrid ensemble integration strategy—GA–BO Ensemble—which initially selects an optimal subset of base classifiers via GA, followed by the application of BO to assign probabilistic weights for soft-voting. This hybrid mechanism enhances both classification robustness and interpretability by systematically leveraging the strengths of diverse learners.
The proposed framework is benchmarked against both classical and DL-based baselines using a real-world pathological speech dataset. Despite its computational efficiency, the framework achieves competitive accuracy and generalization. Its validity is further supported by statistical significance testing (e.g., Wilcoxon signed-rank test), ablation studies, and hyperparameter sensitivity analyses, demonstrating its potential for practical clinical deployment.
Related work on PD classification
Numerous studies have investigated feature selection and classification methods to improve the accuracy of Parkinson’s disease (PD) detection. In early efforts, Sakar & Kursun (2010) employed mutual information (MI) for feature selection combined with SVM classification, achieving an accuracy of 92.75%. Similarly, Ozcift & Gulten (2011) utilized correlation-based feature selection (CFS) in conjunction with Random Forest (RF), reporting an accuracy of 87.13%. Chen et al. (2013) adopted principal component analysis (PCA) to reduce redundant features and used fuzzy KNN (FKNN) for classification, yielding 96.07% accuracy. Zuo et al. (2013) further enhanced FKNN performance by tuning its hyperparameters via PSO, achieving a mean accuracy of 97.47%.
Several studies have blended sophisticated feature selection strategies with enhanced classifiers. Chen et al. (2016) assessed a variety of filter techniques, including information gain (IG), Relief and mRMR, alongside extreme learning machines (ELM) and kernel-based ELM (KELM). They achieved their highest accuracy of 95.97% using mRMR combined with KELM. In another study, Cai, Gu & Chen (2017) employed Relief with bacterial foraging optimization (BFO) for optimizing SVM hyperparameters, reporting an accuracy of 97.42%. A subsequent study (Cai et al., 2018) furthered this work by implementing chaotic BFO (CBFO) to boost FKNN performance, obtaining 97.89% accuracy.
Sakar et al. (2019) utilized mRMR as a feature selection method and assessed numerous classifiers such as naive Bayes (NB), logistic regression (LR), KNN and SVM with a radial basis function (RBF) kernel, achieving the highest performance with mRMR and SVM-RBF at 86%. In Gunduz (2019), two deep learning frameworks were proposed to detect PD based on speech. The initial model, a 9-layer CNN with combined features, reached an accuracy of 84.5%; the latter model, a parallel 10-layer CNN, attained 86.8%. In Nissar et al. (2019), a combination of mRMR and recursive feature elimination (RFE) was employed for feature selection using various classifiers (KNN, LR, multi layer perceptron (MLP), RF, XGBoost, and SVM), with XGBoost delivering an accuracy of 95.39%. According to Senturk (2020), feature importance (FI) and RFE were used for feature reduction, leveraging SVM, artificial neural network (ANN), and CART for classification; the RFE-SVM approach achieved an accuracy of 92.84%. Solana-Lavalle, Galán-Hernández & Rosas-Romero (2020) applied forward and backward stepwise selection (FSS/BSS) in conjunction with different classifiers (SVM, MLP, RF, KNN), with the highest accuracy of 94.7% achieved using SVM-RBF.
Recent studies have explored meta-heuristic optimization for both feature selection and model enhancement. Xiong & Lu (2020) proposed an adaptive grey wolf optimization (AGWO) algorithm for feature selection and a sparse autoencoder for deep representation, achieving accuracy rate of 95%. Lamba et al. (2022) applied MI, GA, and extra tree classifier for feature selection, with GA-RF achieving 95.85% accuracy. Dao et al. (2022) used grey wolf optimization (GWO) for feature selection and tested multiple classifiers, reporting Light Gradient Boosting Machine (LGBM) with the highest accuracy (89.4%), followed by KNN (87.8%), SVM (86.6%), and decision tree (DT) (79.5%).
Hybrid methods have also gained traction. Lamba, Gulati & Jain (2022) employed MI and RFE, with XGBoost and RF achieving 93.88% and 92.72% accuracy, respectively. Rana et al. (2022) explored a comprehensive pipeline involving univariate methods (e.g., IG), multivariate reduction (e.g., PCA), and wrapper-based evaluation with classifiers including SVM, NB, KNN, and ANN. Among these, ANN achieved the highest accuracy of 96.7%. Abdel-fattah, Eid & Yakoub (2023) integrated correlation-based feature selection with emperor penguin colony (EPC) optimization, utilizing DT, KNN, NB, SVM, and RF, with the ensemble model yielding 89.4% accuracy.
Bdaqli et al. (2024) proposed a novel 1D CNN-LSTM architecture for feature extraction, achieving 99.51% accuracy. Rehman et al. (2023) developed a hybrid LSTM–GRU framework and reported 98% accuracy in PD classification. Akila & Nayahi (2024) introduced a multi-agent salp swarm (MASS) optimization for feature selection and pulse-coupled neural network (PCNN) for classification, reaching 96.77% accuracy.
Additional studies have focused on ensemble techniques and transfer learning to enhance generalization. In Mohapatra, Swain & Mishra (2025), CatBoost was combined with Grid Search Optimization and SMOTE to address class imbalance, and RReliefF was employed for feature selection. This model achieved 92.61% accuracy and 0.9549 AUC. Another advanced framework (Pal, Pandey & Pal, 2024) proposed Transfer Learning combined with LSTM (TL-LSTM), utilizing the Hybrid Firefly Butterfly Optimization Algorithm (HFBOA) for feature selection. This model achieved 98.90% accuracy using only 10 features selected via HFBOA. Finally, Ouhmida et al. (2024) introduced a hybrid ensemble feature selection (HEFS) framework integrated with multiple-layer dimensionality reduction (MLDR) and a deep neural network (DNN). It achieved 97.08% accuracy and 0.98 AUC, outperforming CNN, bidirectional long short-term memory (Bi-LSTM), and Multi-Kernel SVM models in comparative evaluation.
Building upon these advancements, our study addresses key limitations in existing research—such as limited generalizability across feature groups, insufficient exploration of hybrid ensemble techniques, and inconsistent evaluation under uniform feature budgets. We propose a comprehensive framework that incorporates multiple filter-based and meta-heuristic selection methods, evaluates their effectiveness at varying feature retention levels, and integrates a novel ensemble strategy combining iterative majority voting, GA, and BO. By systematically unifying these strategies, our framework aims to deliver robust, interpretable, and scalable PD classification performance across diverse feature sets and classifiers.
Methods
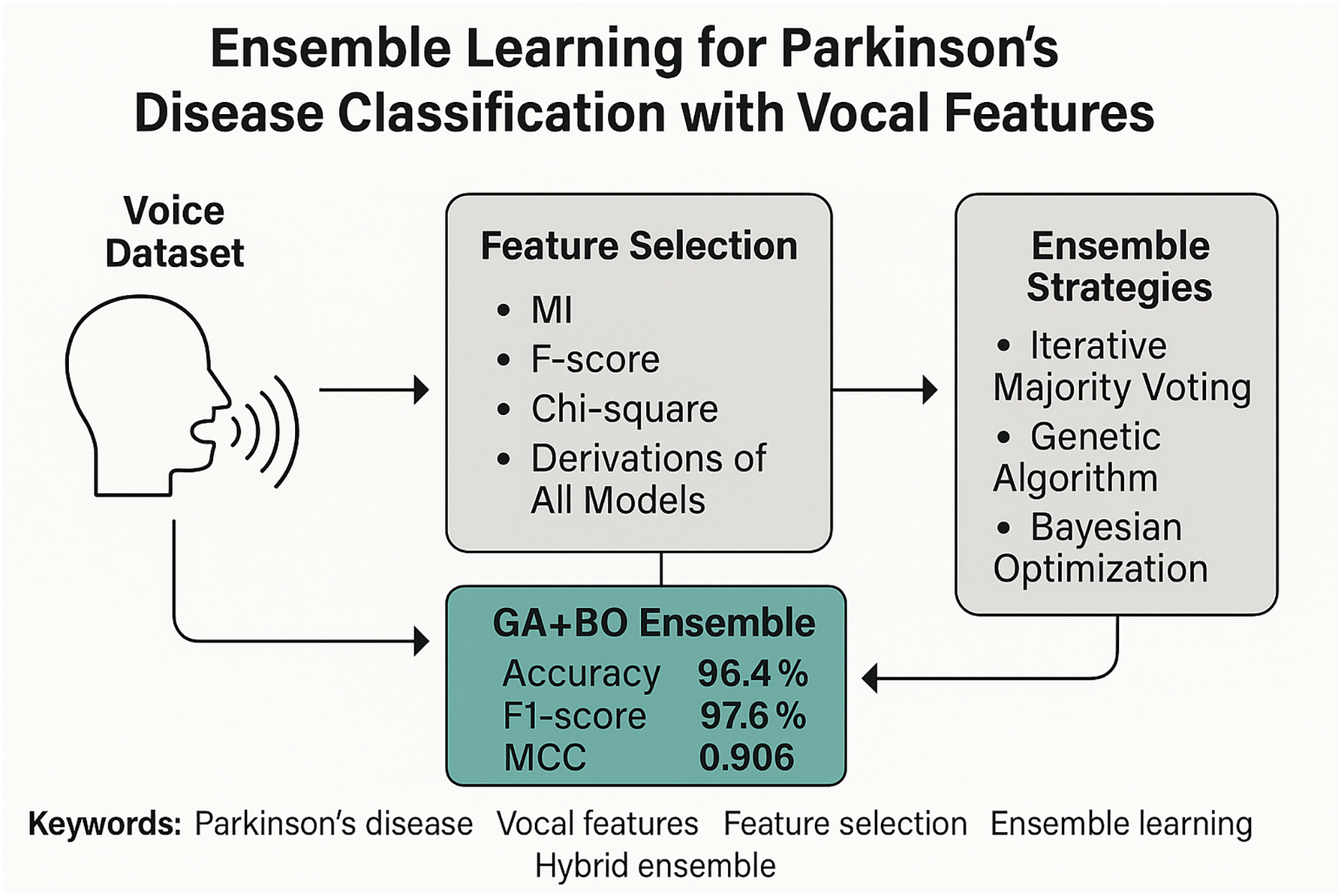
Figure 1 illustrates the overall architecture of the proposed framework through a graphical abstract. This high-level overview encapsulates the core stages of our methodology, beginning with raw vocal feature extraction and proceeding through multi-stage feature selection, classifier training, and ensemble integration. The pipeline highlights the use of three classical filter-based selection methods—Mutual Information (MI), F-score, and Chi-square—along with their composite derivations such as hybrid voting and score fusion. These selection techniques generate compact and informative feature subsets, which are then processed by multiple base classifiers. Finally, a hybrid ensemble strategy that combines GA for classifier selection and BO for adaptive weighting is employed to achieve robust PD classification. In the following subsections, we provide a detailed description of the dataset, feature sets, selection strategies, classifiers, and evaluation metrics that constitute this framework.
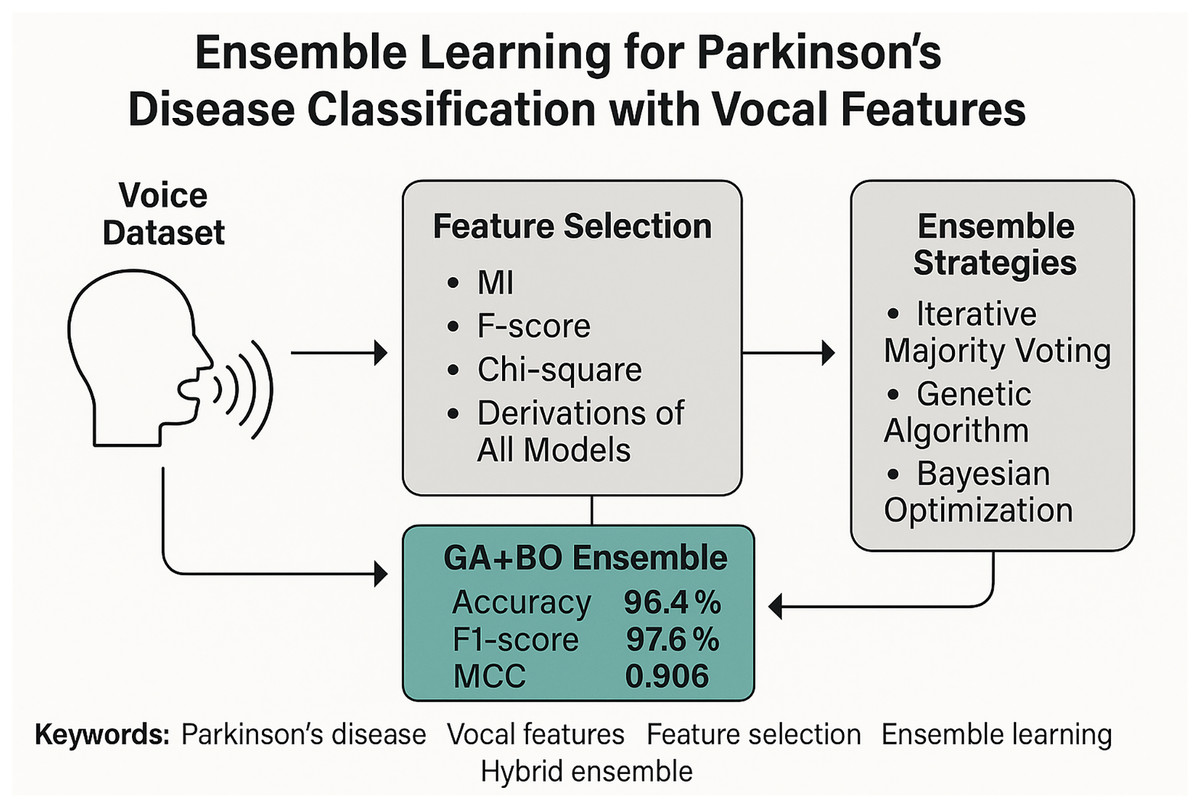
Figure 1: Graphical diagram of the proposed study.
{kind=link}
Dataset
The dataset used in this study originates from the UCI Machine Learning Repository and was collected at the Department of Neurology, Cerrahpasa Faculty of Medicine, Istanbul University (Sakar et al., 2019). It comprises sustained phonation recordings of the vowel /a/ from 252 participants: 188 patients diagnosed with Parkinson’s disease (107 males, 81 females) and 64 healthy controls (23 males, 41 females). Subjects with PD ranged in age from 33 to 87 years, while healthy individuals were between 41 and 82 years. Each subject was asked to vocalize the sustained vowel three times, and recordings were captured at a sampling rate of 44.1 kHz.
The dataset includes a diverse array of vocal features extracted from time, frequency, and time-frequency domains. A total of 754 features were obtained and grouped into six primary categories, as summarized in Table 1.
| Feature set | Measure | # Features |
|---|---|---|
| Baseline features | Jitter variants | 5 |
| Shimmer variants | 6 | |
| Fundamental frequency parameters | 5 | |
| Harmonicity parameters | 5 | |
| Recurrence Period Density Entropy (RPDE) | 1 | |
| Detrended Fluctuation Analysis (DFA) | 1 | |
| Pitch Period Entropy (PPE) | 1 | |
| Time frequency features | Intensity parameters | 3 |
| Formant frequencies | 4 | |
| Bandwidth | 4 | |
| MFCCs | Mel frequency cepstral coefficients | 84 |
| Wavelet-based features | Wavelet transform features related with | 182 |
| Vocal fold features | Glottis Quotient (GQ) | 3 |
| Glottal to Noise Excitation (GNE) | 6 | |
| Vocal Fold Excitation Ratio (VFER) | 7 | |
| Empirical Mode Decomposition (EMD) | 6 | |
| TQWT features | Tunable Q-factor Wavelet Transform features related with | 432 |
The key feature categories are described below:
Baseline features: This group includes traditional voice quality measures such as jitter, shimmer, harmonicity, and fundamental frequency statistics, along with nonlinear dynamic features (recurrence period density entropy (RPDE), detrended fluctuation analysis (DFA), pitch period entropy (PPE)) known to reflect neuromotor impairments in speech production.
MFCCs: A set of 84 Mel-Frequency Cepstral Coefficients—including log-energy, delta, and delta-delta coefficients—was extracted to capture articulatory behavior. MFCCs are particularly effective for modeling tongue and lip movements, which are often affected in PD.
Wavelet-based features (WT): A total of 182 features were derived from Discrete Wavelet Transform (DWT) applied to the F0 contour. These include signal energy, Shannon and log-energy entropies, and Teager–Kaiser energy extracted from both approximation and detail coefficients.
TQWT features: The Tunable Q-Factor Wavelet Transform (TQWT) was employed to model oscillatory impairments in voice by capturing fine-grained periodic disturbances in vocal fold vibrations. The dataset used in this study is publicly available and pre-processed, which facilitates consistent and reproducible feature extraction. Following prior evidence supporting the effectiveness of TQWT in biomedical vocal signal decomposition (Sakar et al., 2019), we adopted fixed parameter values of Q = 2, r = 4, and J = 35, resulting in the extraction of 432 features per instance.
Vocal fold and glottal features: This set includes GQ, GNE, VFER, and EMD-based measures, aiming to quantify glottal closure patterns, airflow turbulence, and phonatory noise—all of which are useful indicators of vocal fold dysfunction in PD.
To ensure a fair comparative analysis and mitigate potential bias arising from differences in feature set dimensionality, the experimental design was structured around three distinct groups of features:
-
Baseline + MFCC features: Combining classical acoustic markers and articulatory features for comprehensive phonation modeling.
-
Wavelet-based features (WT): Capturing multi-resolution frequency domain characteristics of the F0 signal.
-
TQWT features: Focused on detecting oscillatory degradation in voice with high frequency selectivity.
These subsets were evaluated separately to identify the most discriminative feature representations and to explore how different domains (time, frequency, and time frequency) contribute to the classification of PD. Prior to classification and feature selection, all features were normalized using min-max scaling to ensure consistent value ranges and eliminate potential scale-induced bias.
Feature selection methods
Feature selection is a critical preprocessing step in high-dimensional classification tasks, particularly for biomedical applications such as Parkinson’s disease diagnosis. In this study, we employ both traditional filter-based methods and several devised variants to reduce dimensionality, remove irrelevant features, and enhance classification performance.
Filter-based methods: Filter-based methods are computationally efficient and independent of any specific classifier. These methods evaluate each feature based on statistical criteria with respect to the target label, offering a scalable solution for large datasets (Theng & Bhoyar, 2024).
F-score: F-score evaluates the discriminative power of a feature by comparing inter-class and intra-class variances. For a feature , the F-score is defined as:
(1) where and are the means of the feature for the positive and negative classes, is the overall mean, and , are the variances within each class. A higher F-score indicates greater class separability (Yan et al., 2025).
Chi-square ( ) Test: The test assesses the dependency between features and class labels. For a feature and class , it is computed as:
(2) where N is the total number of samples, and denotes the probabilities of feature-class co-occurrence and marginals (Abdo, Mostafa & Abdel-Hamid, 2024).
Mutual information (MI): Mutual information quantifies the amount of shared information between a feature and the class label C. It is defined as:
(3) This measure captures both linear and non-linear statistical dependencies, thereby offering robustness across heterogeneous and non-Gaussian data distributions (Gong et al., 2024). It is particularly well-suited for high-dimensional feature spaces where traditional correlation-based metrics may fail to identify informative patterns.
Devised feature selection variants: To further enhance the discriminative power of the selected features, we propose several hybrid and composite filter-based strategies that combine classical statistical metrics in systematically defined ways. These variants aim to exploit complementary strengths of , MI, and F-score:
Hybrid voting: A majority-voting scheme is employed across the ranked lists of the three classical filters. Features appearing in the top- positions in at least two of the three rankings are retained. This method emphasizes consensus while tolerating mild divergence across ranking criteria.
Score fusion: Raw scores from , MI, and F-score are min-max normalized to the range to ensure comparability. The normalized scores are then aggregated via an unweighted arithmetic mean to compute a unified relevance score for each feature. Top- features with the highest composite scores are selected. This approach balances feature importance across heterogeneous criteria while preserving interpretability.
Intersect: Only features that concurrently appear in the top- lists of all three filter methods are selected. This conservative strategy emphasizes agreement and robustness, potentially favoring features with consistently high relevance across all criteria.
Union: All features that appear in at least one top- list are included. This inclusive approach maximizes feature diversity, potentially capturing complementary information, albeit at the cost of larger feature sets.
Classwise filtering: Each feature is evaluated separately for each class label (e.g., using class-conditional distributions in MI or F-score). The class-specific scores are then averaged to compute a balanced relevance score, mitigating class dominance and enhancing sensitivity to minority classes.
Each of these devised selection strategies is applied independently to Baseline + MFCC, Wavelet-based, and TQWT features thereby generating multiple reduced-dimensional representations for downstream ensemble learning and comparison.
Classifiers
Support vector machines
Support Vector Machines (SVM) are a commonly recognized supervised learning technique employed for both classification and regression problems. In the context of binary classification, SVM aims to pinpoint the best separating hyperplane by maximizing the distance, or margin, between data points of differing classes. In scenarios where the data cannot be linearly separated in the initial feature space, SVM leverages kernel functions to map the data into a higher-dimensional space, enabling linear separation. This mapping is accomplished using kernel methods like polynomial, radial basis function (RBF), or sigmoid kernels. The decision boundary is influenced by support vectors, which are the data points situated nearest to the separating hyperplane. A critical parameter in SVM models is the regularization constant C, which modulates the balance between maximizing the margin and reducing classification errors. A smaller C implies a broader margin with the possibility of misclassifying samples (underfitting), whereas a larger C aims to correctly classify every training instance, potentially causing overfitting (Rojas-Domínguez et al., 2017).
We used a polynomial kernel-based SVM classifier with degree set to three. Hyperparameters including C are tuned via a stratified 10-fold cross-validation scheme, ensuring robustness and generalizability of the trained models across all folds. This setup enables the classifier to effectively handle nonlinear patterns in vocal signal features associated with Parkinson’s disease.
k-nearest neighbors (KNN)
The -Nearest Neighbors algorithm is a widely adopted non-parametric classification method, particularly suitable for biomedical signal analysis, including voice-based PD (Nissar et al., 2019). The fundamental principle of KNN is to assign a class label to a test instance based on the majority class among its nearest neighbors in the feature space, where proximity is typically determined using the Euclidean distance metric.
Unlike parametric classifiers, -NN does not assume any prior distribution over the input data. Instead, it leverages the local geometry of the data manifold, making it well-suited for capturing intricate class boundaries when used in conjunction with appropriate feature representations and distance metrics.
In this study, we employ the -NN variant, wherein classification is determined solely by the single closest training instance. The selection of is empirically motivated by preliminary stratified cross-validation experiments, which demonstrated that this configuration yields heightened sensitivity to subtle acoustic variations in the high-dimensional vocal features characteristic of Parkinsonian speech. Although computationally simple, -NN serves as a robust baseline within our ensemble learning framework, particularly when coupled with optimized feature subsets derived from the proposed selection methods.
All -NN models are evaluated using stratified 10-fold cross-validation to ensure statistical robustness and fair comparison across feature domains and classifiers (Zhang et al., 2017).
Majority voting-based ensemble methods
Given the diversity of features extracted from vocal signals, ensemble learning offers a promising strategy to consolidate the predictive power of individual models. Rather than relying on a single classifier trained on a specific feature subset, ensemble approaches aggregate outputs from multiple base learners, each trained on different representations. This not only enhances classification robustness but also mitigates model bias and variance. In this study, we propose and evaluate three distinct majority voting-based ensemble strategies tailored to exploit the complementary strengths of classifiers: Iterative Majority Voting (IMV), Genetic Algorithm-Based Voting (GA–Voting), and Bayesian Optimization-Based Voting (BO–Voting).
Iterative majority voting (IMV)
IMV begins with the best-performing individual classifier and incrementally adds classifiers from the pool . At each step, the ensemble prediction is computed using majority voting over selected classifiers :
(4)
If the accuracy improves after adding , then . This process continues until no further accuracy gain is observed (Tasci et al., 2024).
Genetic algorithm-based voting (GA–Voting)
GA–Voting frames the ensemble selection as a binary optimization problem. Each individual (chromosome) in the population is a binary vector indicating the inclusion of classifiers. The ensemble prediction is:
(5)
The fitness function is defined as the validation accuracy of the ensemble formed by the selected classifiers:
(6) where is the indicator function. Genetic operations such as crossover and mutation evolve the population toward higher fitness (Dhar, 2021).
Bayesian optimization-based voting (BO–Voting)
In BO–Voting, classifier outputs are weighted through soft voting. Each classifier is assigned a weight , forming a continuous weight vector under the constraint . The aggregated score for class is:
(7) The predicted class is then:
(8) BO is used to find the optimal that maximizes the ensemble accuracy:
(9)
This formulation enables adaptive weighting of classifiers, allowing stronger models to contribute more while suppressing weaker ones (Tasci, Uluturk & Ugur, 2021).
Together, these ensemble strategies allow a comparative investigation into how classifier selection (IMV, GA–Voting) and weighting (BO–Voting) impact diagnostic accuracy in PD classification. By integrating ensemble learning with diverse filter-based feature selection techniques, the proposed methods form a comprehensive framework for robust biomedical decision-making.
Evaluation method and metrics
To validate the effectiveness and generalizability of the proposed classifiers and ensemble strategies in distinguishing between PD patients and healthy controls, we adopt a stratified 10-fold cross-validation protocol as the primary evaluation method. In this approach, the dataset is divided into 10 mutually exclusive folds while preserving class distributions, and each fold is used once as a test set while the remaining nine folds are used for training. This process ensures robustness, reduces variance in performance estimation, and mitigates the risk of overfitting.
Following this procedure, we compute several standard performance metrics on each fold, including Accuracy, Precision, Recall, F-Measure, and the Matthews Correlation Coefficient (MCC). While accuracy is the most commonly reported indicator, it can be misleading under class imbalance. Therefore, we include additional metrics that provide a more balanced view of classifier performance.
Let the confusion matrix for binary classification be defined as:
True Positives (TP): correctly predicted PD cases,
False Positives (FP): healthy individuals misclassified as PD,
False Negatives (FN): PD patients misclassified as healthy,
True Negatives (TN): correctly predicted healthy individuals.
Based on these values, the evaluation metrics are calculated as follows:
(10)
(11)
(12)
(13)
Matthews Correlation Coefficient (MCC) is a robust metric that considers all four components of the confusion matrix. It yields a value between and , where indicates perfect classification, represents no better than random guessing, and indicates total disagreement:
(14)
These evaluation metrics, when computed over the repeated folds of the cross-validation procedure, provide a statistically reliable and comprehensive assessment of model performance. This ensures the proposed ensemble framework’s robustness and real-world applicability, even in the presence of imbalanced class distributions (Gunduz, 2021).
Experimental results
This section presents the experimental evaluation of the proposed PD classification framework using multiple vocal feature sets. Building upon the methods described in Methods Section, our approach integrates both filter-based feature selection techniques and hybrid ensemble strategies to improve classification performance.
As mentioned earlier, the dataset comprises three distinct groups of voice-based features derived from pathological speech recordings: (i) Wavelet Transform (WT) features ( ), capturing localized frequency components from raw pitch contours; (ii) Baseline + MFCC features ( ), which combine statistical acoustic descriptors with Mel-Frequency Cepstral Coefficients to model articulatory behavior; and (iii) Tunable Q-Factor Wavelet Transform (TQWT) features ( ), designed to capture high-resolution oscillatory signal properties using tunable decomposition parameters. To identify the most informative and discriminative features from each group, we applied a total of eight feature selection strategies, comprising three traditional filter-based techniques—Chi-square, Mutual Information and F-score—as well as five ensemble-based selectors: hybrid, score fusion, union, intersect, and class-wise filtering. These methods were applied independently to each of the three feature groups, resulting in a total of 24 unique feature subsets (8 selectors 3 feature groups).
Each selected feature subset was subsequently evaluated using two classifiers: KNN and SVM, both trained under a stratified 10-fold cross-validation protocol. This yielded a total of 48 distinct model configurations (24 feature subsets 2 classifiers), whose outputs were recorded for further ensemble-based integration and comparative analysis. All experiments were conducted in the Google Colab environment, ensuring reproducibility and leveraging cloud-based computational resources for efficient execution.
To assess and highlight the most effective configurations, the performance of all individual models was ranked based on classification accuracy. The top 10 performing models were identified and listed in the results section, offering insights into the combinations of feature types, selection strategies, and classifiers that yielded the highest predictive accuracy for classification.
Baseline results without feature selection
To establish a performance baseline for our subsequent feature selection and ensemble learning strategies, we first evaluated the classification accuracy, F1-score, MCC, and average training time per fold using the entire set of features from each feature group—without applying any feature selection. These initial experiments were conducted using a 10-fold stratified cross-validation approach to ensure a balanced distribution of class labels across folds and to provide more reliable variance estimates.
We employed two classifiers: SVM using a polynomial kernel of degree 3, and KNN with , across three primary feature groups. The results, reported as means and standard deviations across folds, are presented in Table 2, which includes the average running time per fold in seconds to reflect computational efficiency alongside predictive performance.
| Model | Accuracy | F1-score | MCC | Time (s) |
|---|---|---|---|---|
| Wavelet + KNN | ||||
| Wavelet + SVM | ||||
| TQWT + KNN | ||||
| TQWT + SVM | ||||
| Baseline_MFCC + KNN | ||||
| Baseline_MFCC + SVM |
These results indicate that, even without dimensionality reduction, both the Baseline_MFCC and TQWT feature sets achieved notably higher classification performance compared to the wavelet-based features. The KNN classifier consistently outperformed SVM in terms of accuracy, F1-score, and MCC across the two stronger feature sets. Additionally, KNN showed significantly lower average running time, reinforcing its suitability for real-time or resource-constrained settings.
These findings establish a strong reference point for evaluating the effectiveness and efficiency of the proposed feature selection and hybrid ensemble learning strategies presented in subsequent sections.
Performance with feature selection (Top 10 models)
To evaluate the impact of feature selection on classification performance, we applied multiple filter-based and hybrid methods using feature retention ratios of 20%, 40%, and 60%. The primary objective was to reduce the dimensionality of the original feature sets while preserving the most informative attributes. All models were trained using KNN and SVM classifiers across three major feature groups—TQWT, Baseline + MFCC, and Wavelet—using the selected subsets. As in the baseline evaluation, a 10-fold stratified cross-validation procedure was employed to ensure balanced representation of class labels in each fold and to obtain reliable variance estimates.
Table 3 presents the top 10 models at the 20% retention level, sorted by classification accuracy. Even with a reduced feature set, the TQWT-based models combined with KNN classifiers consistently achieved the highest performance. The best-performing model at this stage was TQWT + Hybrid + KNN, reaching an accuracy of , F1-score of , and MCC of with an average running time of 0.0023 s per fold. These results indicate that even when only 20% of the original features are retained, the classification performance remains competitive and, in many cases, surpasses the baseline models that utilize the complete feature sets.
| Model | Accuracy | F1-score | MCC | Time (s) |
|---|---|---|---|---|
| TQWT + Hybrid + KNN | 0.0023 | |||
| TQWT + F-score + KNN | 0.0024 | |||
| TQWT + Chi2 + KNN | 0.0024 | |||
| TQWT + Score fusion + KNN | 0.0024 | |||
| TQWT + MI + KNN | 0.0024 | |||
| TQWT + Intersect + KNN | 0.0020 | |||
| TQWT + Score fusion + SVM | 0.0177 | |||
| TQWT + Hybrid + SVM | 0.0179 | |||
| TQWT + Union + SVM | 0.0172 | |||
| TQWT + Chi2 + SVM | 0.0183 |
Table 4 shows the results for a 40% feature retention ratio. TQWT-based models continued to dominate, particularly when paired with KNN classifiers. Baseline + MFCC features combined with class-wise F-score or Chi-square selection also emerged as top performers, reflecting the benefits of class-dependent feature relevance scoring. The highest performance at this level was achieved by TQWT + Hybrid + KNN with an accuracy of , F1-score of , and MCC of .
| Model | Accuracy | F1-score | MCC | Time (s) |
|---|---|---|---|---|
| TQWT + Hybrid + KNN | 0.0044 | |||
| TQWT + Intersect + KNN | 0.0028 | |||
| TQWT + F-score + KNN | 0.0048 | |||
| TQWT + MI + KNN | 0.0049 | |||
| Baseline_MFCC + F-score (Class-wise) + KNN | 0.0021 | |||
| Baseline_MFCC + Chi-square (Class-wise) + KNN | 0.0020 | |||
| TQWT + Union + KNN | 0.0031 | |||
| TQWT + Score fusion + KNN | 0.0049 | |||
| TQWT + Chi2 + KNN | 0.0047 | |||
| TQWT + F-score (Class-wise) + KNN | 0.0048 |
Finally, Table 5 reports results for a 60% feature retention ratio. TQWT-based models remained dominant, and class-specific feature selection methods further improved discriminative capacity. Notably, TQWT + F-score (Class-wise) + KNN and TQWT + Chi-square (Class-wise) + KNN both achieved the top performance with an accuracy of , F1-score of , and MCC of .
| Model | Accuracy | F1-score | MCC | Time (s) |
|---|---|---|---|---|
| TQWT + F-score (Class-wise) + KNN | 0.0036 | |||
| TQWT + Chi-square (Class-wise) + KNN | 0.0041 | |||
| TQWT + Chi2 + KNN | 0.0036 | |||
| TQWT + Hybrid + KNN | 0.0036 | |||
| Baseline_MFCC + F-score (Class-wise) + KNN | 0.0037 | |||
| Baseline_MFCC + Chi-square (Class-wise) + KNN | 0.0036 | |||
| TQWT + Union + KNN | 0.0037 | |||
| TQWT + F-score + KNN | 0.0038 | |||
| TQWT + Intersect + KNN | 0.0030 | |||
| Baseline_MFCC + MI + KNN | 0.0035 |
These findings confirm that even under reduced or fixed feature budgets, TQWT-based features combined with KNN classifiers consistently achieve superior performance. Class-dependent feature selection methods further enhance discriminative capacity, especially at larger feature retention ratios, while maintaining low average running times per fold.
To ensure a fair and controlled comparison among the three feature groups—TQWT, Baseline + MFCC, and Wavelet—we fixed the number of selected features to 100 per group. This constraint allows observed performance differences to be attributed solely to the discriminative capacity of each feature type, eliminating the potential confounding effect of varying feature dimensionality. Using the same set of filter-based selection methods, both KNN and SVM classifiers were evaluated on each feature group. The results are summarized in Table 6. Among all evaluated models, the best performance was achieved by the configuration using Baseline + MFCC features with Score Fusion and KNN classifier, yielding an accuracy of , F1-score of , and MCC of . Overall, MFCC-based KNN models consistently outperformed their TQWT and Wavelet counterparts when constrained to a uniform feature count. Moreover, KNN demonstrated superior performance compared to SVM across all feature sets, highlighting its robustness in low-dimensional settings.
| Model | Accuracy | F1-score | MCC | Time (s) |
|---|---|---|---|---|
| Baseline MFCC + Score fusion + KNN | 0.0025 | |||
| Baseline_MFCC + MI + KNN | 0.0025 | |||
| Baseline_MFCC + F-score (Class-wise) + KNN | 0.0025 | |||
| Baseline_MFCC + Chi-square (Class-wise) + KNN | 0.0026 | |||
| Baseline_MFCC + Hybrid + KNN | 0.0024 | |||
| Baseline_MFCC + Chi2 + KNN | 0.0024 | |||
| Baseline_MFCC + MI (Class-wise) + KNN | 0.0024 | |||
| Baseline_MFCC + F-score + KNN | 0.0025 | |||
| Baseline_MFCC + Union + KNN | 0.0033 | |||
| Baseline_MFCC + Intersect + KNN | 0.0024 |
These results confirm that, even under a uniform feature selection budget, Baseline + MFCC features combined with ensemble-based selection strategies such as Score Fusion and class-wise statistical filters offer the highest discriminative capacity for PD classification.
To assess the impact of different feature retention levels on classification performance, we conducted an evaluation using 20%, 40%, 60% of the ranked features as well as a fixed selection of the top 100 features. The box plot in Fig. 2 visualizes the accuracy distribution across multiple runs.

Figure 2: Box plot comparison of classification accuracies at different feature retention levels (20%, 40%, 60%, and 100 features).
The 60% retention consistently yielded better median accuracy and lower variance, motivating its selection for ensemble modeling.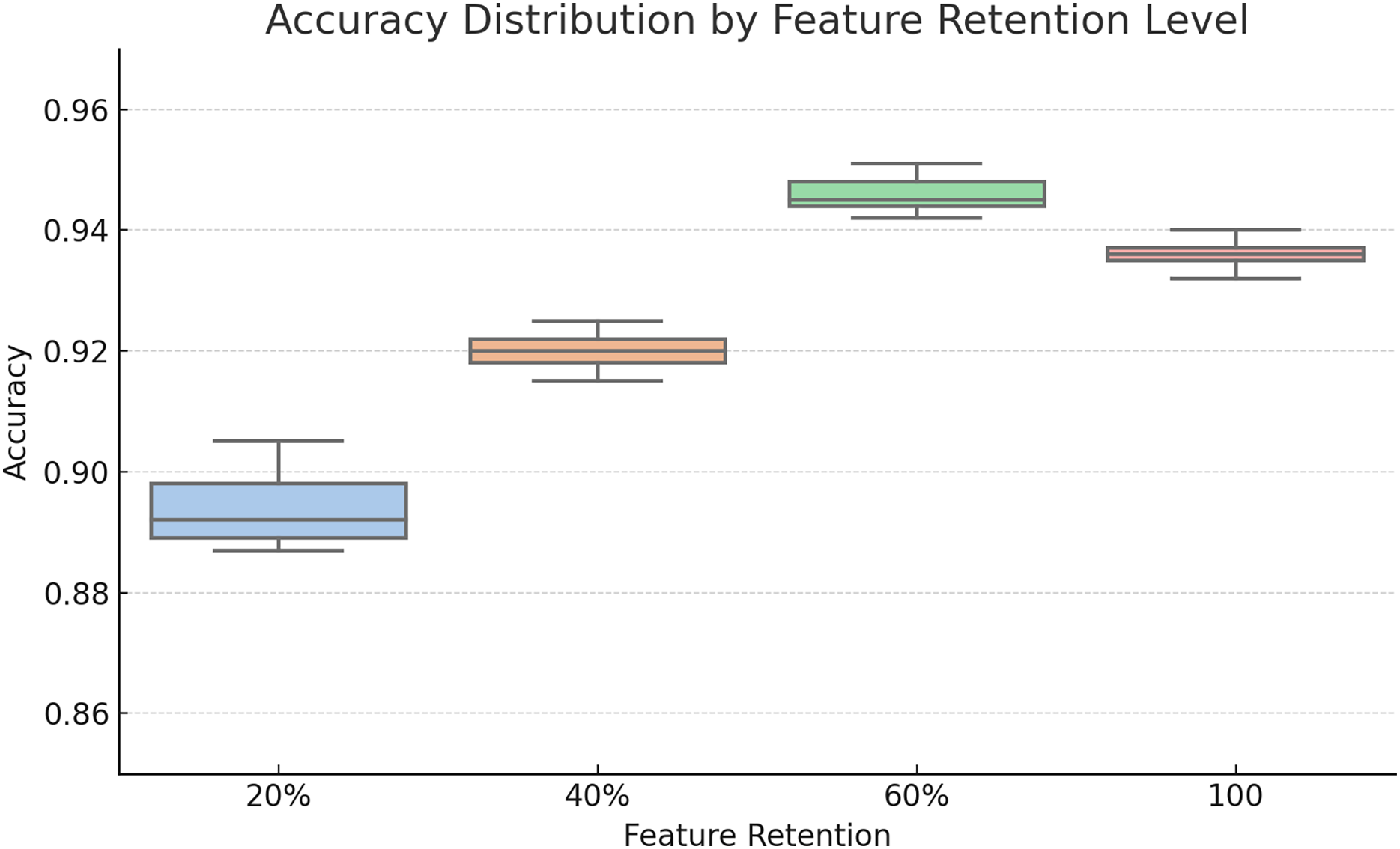{kind=link}
As seen in the plot, 60% feature retention yielded the highest median accuracy and a tighter interquartile range, suggesting improved generalizability. These findings guided our decision to use the 60% threshold for subsequent ensemble construction.
Ensemble learning strategies and hybrid integration
To further enhance classification performance while maintaining fairness across feature groups, we explored a set of ensemble learning strategies applied to models trained with the top-performing 60% feature retention from each group. These strategies aim to leverage the complementary strengths of individual classifiers through systematic combination and optimization.
Three principal ensemble methods were investigated:
Iterative Majority Voting (IMV): A sequential ensemble construction approach that incrementally adds high-performing base models. At each step, the ensemble output is determined via majority voting, and the configuration yielding the highest classification accuracy is retained.
-
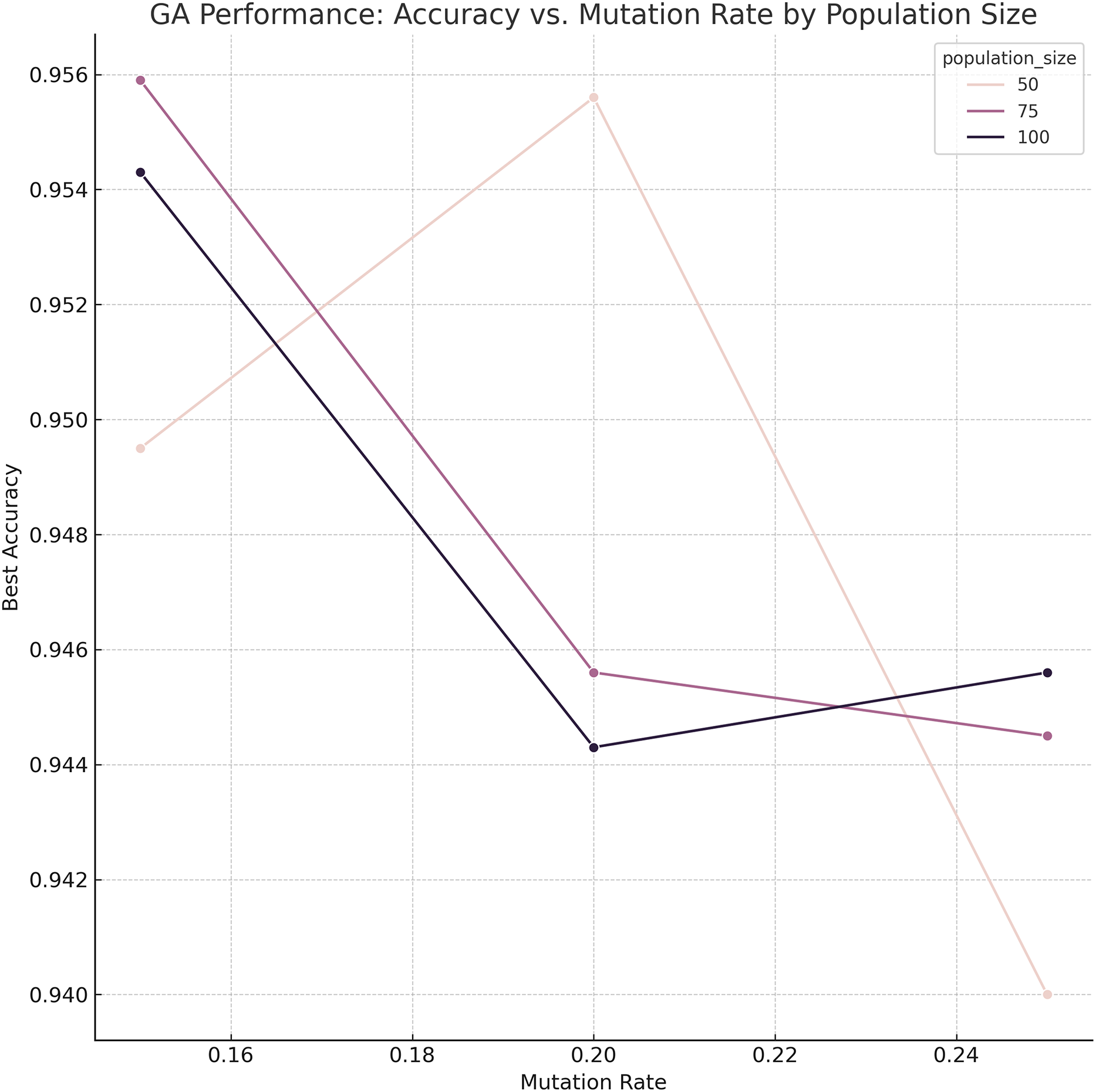
Genetic Algorithm-based Ensemble (GA–Ensemble): This method formulates model selection as an optimization problem and uses a genetic algorithm to identify the most effective subset of base classifiers. The GA was initially configured with a population size of 75, 150 generations, a mutation rate of 0.15, and tournament selection for parent selection. To ensure that these hyperparameters were not arbitrarily chosen, a grid search was conducted over multiple candidate configurations (population size, mutation rate, and number of generations). The results of this search and the sensitivity of GA to these parameters are visualized in Fig. 3. The figure reveals that higher population sizes and lower mutation rates tend to improve ensemble performance by enhancing exploration without sacrificing convergence stability.
-
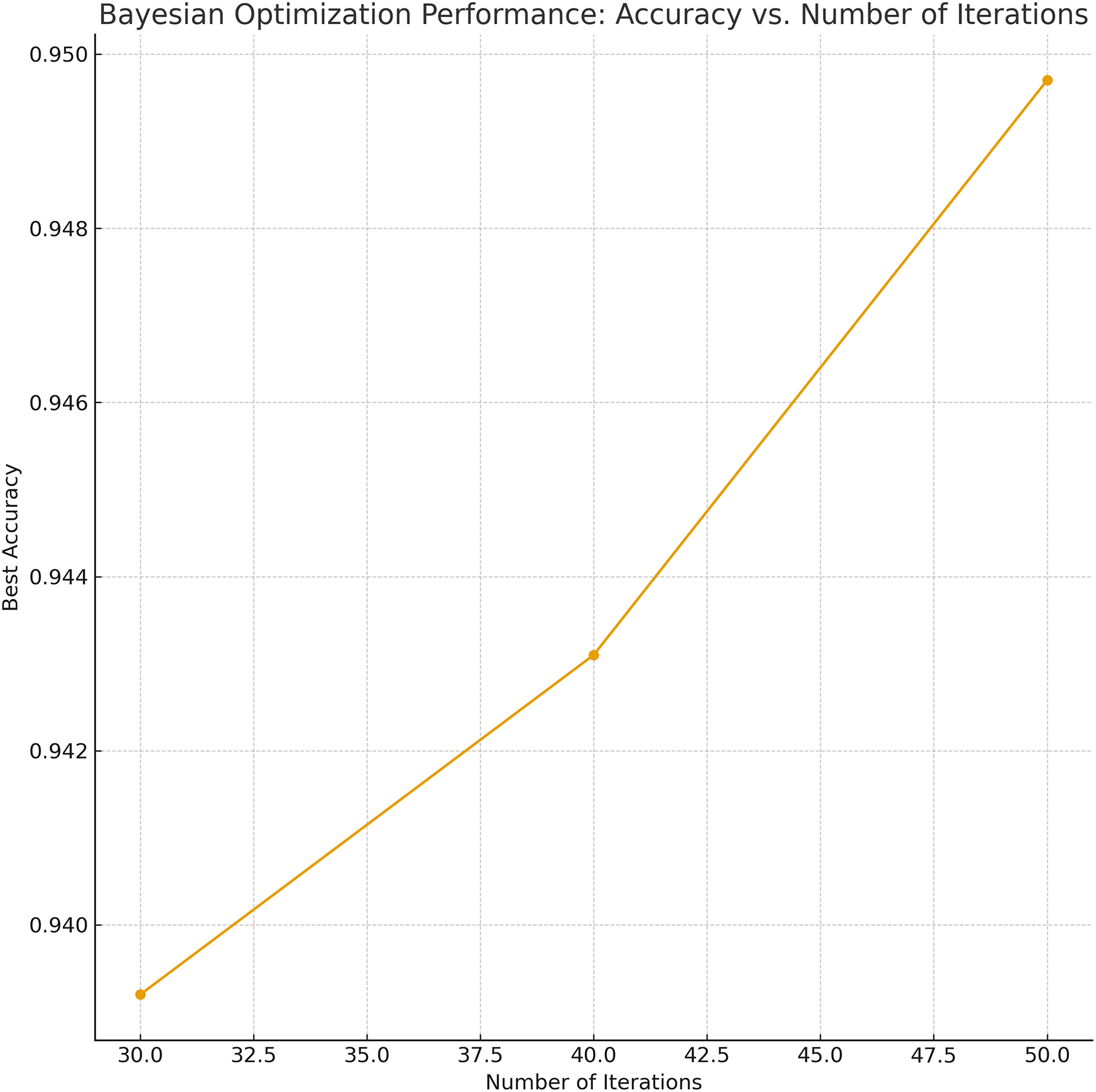
Bayesian Optimization-based Weighted Ensemble (BO–Ensemble): This strategy employs probabilistic modeling to assign dynamic weights to base models, enabling a soft-voting mechanism. The BO procedure began with 10 initial random samples and was iterated 50 times to find the optimal weight configuration. Similar to GA, the number of iterations and initial sample sizes for BO were also selected via grid search, and the parameter sensitivity is depicted in Fig. 4. The analysis indicates that 30–50 iterations strike a balance between performance gain and computational cost, stabilizing weight tuning across diverse base classifiers.
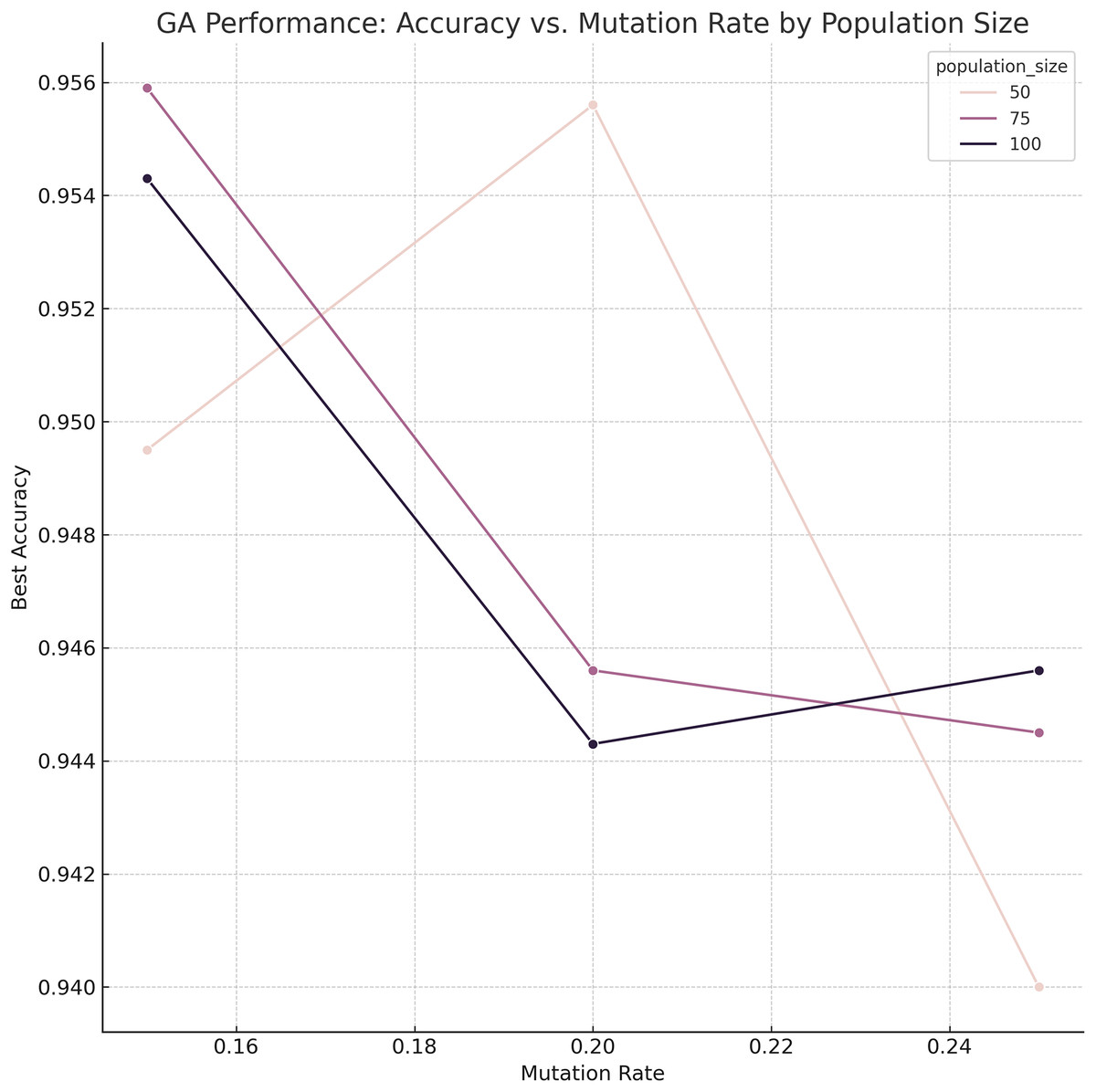
Figure 3: Sensitivity analysis and grid-search results for GA parameters (population size, mutation rate).
{kind=link}
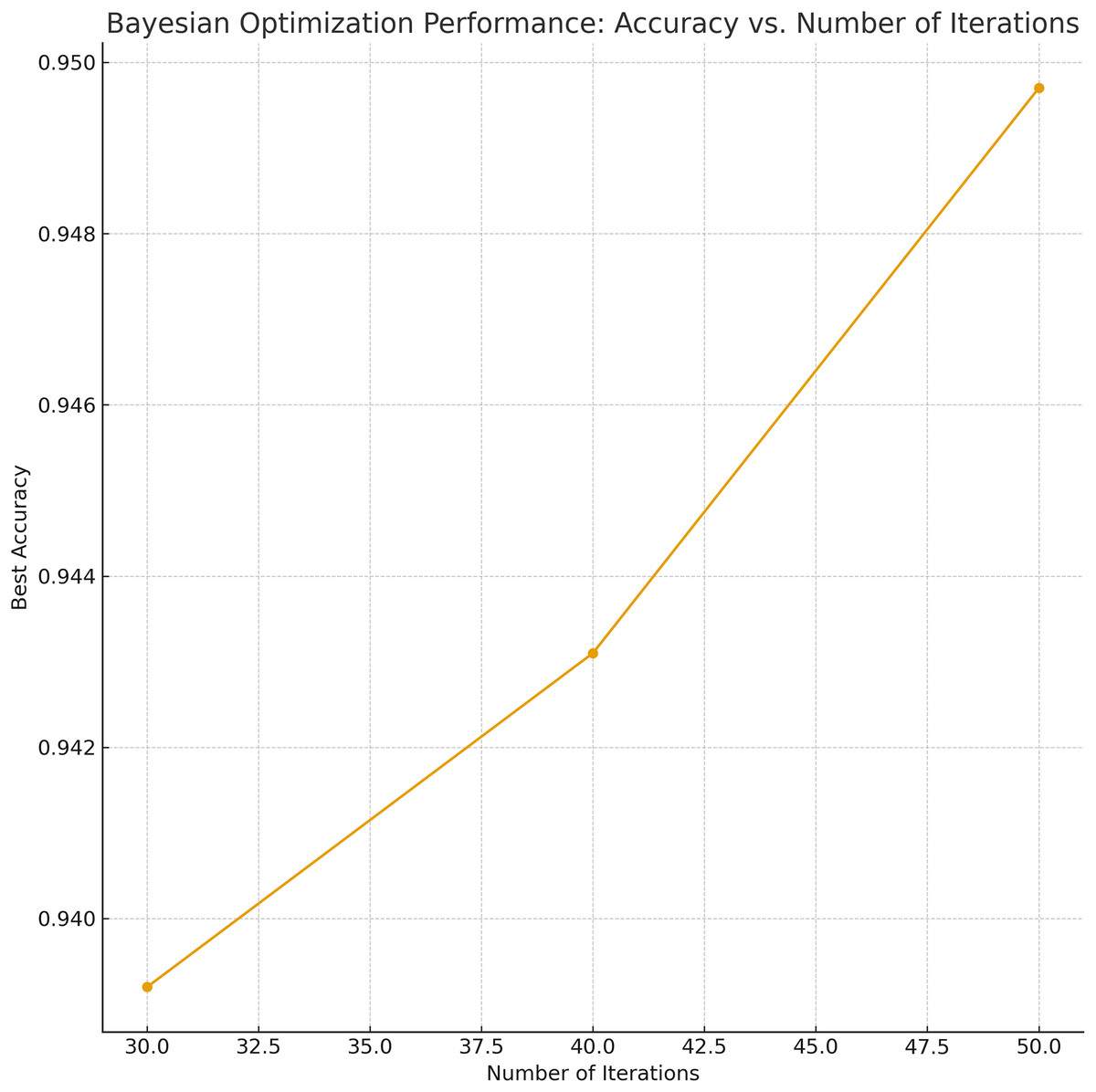
Figure 4: Sensitivity analysis and grid-search results for BO parameters (number of iterations).
{kind=link}
Building on these approaches, we propose a novel two-stage hybrid model, denoted as GA–BO–Ensemble, which first applies GA to determine a high-quality subset of base models and subsequently uses BO to fine-tune the fusion weights. This hybrid strategy combines the benefits of selective inclusion and adaptive weighting, offering improved robustness and predictive accuracy.
Algorithm 1 outlines the proposed GA–BO–Ensemble integration process, which proceeds in three systematic stages. In the first stage, a population of binary chromosomes is initialized, where each chromosome encodes a subset of base classifiers. The GA evolves this population over multiple generations using a fitness function based on majority voting accuracy. Through selection, crossover, and mutation operations, the algorithm converges on an optimal subset of models that exhibit high discriminative performance. In the second stage, BO is employed to determine the optimal soft-voting weights for the selected models. This is achieved by maximizing ensemble accuracy via adaptive tuning of real-valued weights under a unit-sum constraint. In the final stage, class predictions are generated by computing a weighted sum of the selected model outputs, and the label with the highest aggregated score is assigned. This two-tiered strategy ensures both selective inclusion of competent models and dynamic weighting based on individual reliability, yielding a robust and accurate ensemble framework.
| Input: |
| : Classifier predictions |
| Y: True class labels |
| G: Number of generations |
| M: Population size |
| r: Mutation rate |
| Output: |
| : Selected classifier subset |
| : Optimized weights |
| : Final predictions |
| Step 1: Genetic Algorithm for Subset Selection |
| Initialize a population where |
| for each generation to G do |
| Evaluate fitness of each zi as classification accuracy using majority voting over selected Pk |
| Select elite ze with highest fitness and add to next population |
| While new population do |
| Select two parents and perform one-point crossover |
| Apply bit-flip mutation to offspring with rate r |
| Add offspring to new population |
| Replace old population with new population |
| Select from best-performing chromosome |
| Step 2: Bayesian Optimization for Weight Learning |
| One-hot encode Y and prediction vectors in |
| Define soft voting function using weights |
| Use Bayesian Optimization to maximize voting accuracy over |
| Return optimal weights |
| Step 3: Final Ensemble Prediction |
| Compute weighted sum of predictions using |
| Assign class labels by argmax over weighted scores: |
| return , , |
To evaluate the effectiveness of the proposed GA–BO hybrid ensemble, we conducted an ablation study comparing its performance against three ensemble variants: GA-only, BO-only and IMV. The results are presented in Table 7.
| Ensemble strategy | Accuracy | F1-score | MCC | Wilcoxon -value | Time (s) |
|---|---|---|---|---|---|
| Iterative Majority Voting (IMV) | 0.9525 0.0236 | 0.9691 0.0149 | 0.8722 0.0659 | 0.2969 | 20.53 |
| Genetic Algorithm (GA) | 0.9444 0.0175 | 0.9639 0.0111 | 0.8507 0.0492 | 0.0039 | 34.21 |
| Bayesian Optimization (BO) | 0.9537 0.0179 | 0.9699 0.0113 | 0.8759 0.0506 | 0.0625 | 203.88 |
| GA–BO–Ensemble | 1.0000 | 103.12 |
The GA–BO hybrid ensemble achieved the best overall performance across all metrics, with an accuracy of 0.9643, F1-score of 0.9764, and MCC of 0.9047. Statistical analysis using the Wilcoxon signed-rank test confirmed the superiority of GA–BO over GA-only ( = 0.0039), with no significant difference observed when compared to BO-only or IMV ( ). In terms of execution time, GA–BO (103.12 s) balances between the fast but less adaptive GA (34.21 s) and the computationally expensive BO-only approach (203.88 s).
These results highlight the synergistic advantages of the two-stage GA–BO integration. The GA module performs a structural selection by pruning suboptimal or redundant base classifiers, thereby enhancing ensemble diversity and reducing overfitting risk. The BO component subsequently assigns optimized probabilistic weights to the remaining classifiers, capturing fine-grained inter-model dependencies. In contrast, the GA-only method lacks the flexibility to tune the relative importance of selected models, while the BO-only approach may overfit due to assigning weights across a larger, unfiltered classifier pool. By combining structural pruning with adaptive weighting, the GA–BO hybrid strategy offers a principled and computationally balanced approach to ensemble construction. This yields improved robustness and discriminative capacity in classification.
Conclusion and discussion
This study presents a comprehensive and computationally efficient framework for PD classification using vocal features. Our results demonstrate that high classification accuracy can be achieved through selective feature optimization and lightweight ensemble learning strategies—without relying on deep or computationally intensive architectures.
A central contribution of this work is the systematic evaluation of three prominent feature groups—TQWT, Baseline + MFCC, and conventional Wavelet features—across eight feature selection techniques. Among these, the TQWT-based features consistently yielded superior performance, especially when combined with class-wise filter-based selectors and the KNN classifier. The best-performing filter-based configuration, which integrated TQWT features with class-wise F-score selection and KNN, achieved an accuracy of 93.3% and an F1-score of 95.5%, outperforming many existing approaches in the literature.
A notable observation is the shift in performance rankings between the percentage-based feature retention settings (Tables 3–5) and the fixed-size feature evaluation (Table 6). In the percentage-based evaluations, TQWT features consistently outperformed Baseline + MFCC and Wavelet features across most metrics. This suggests that the discriminative information in TQWT features is more diffusely distributed, requiring a larger proportion of features to retain class-separability. In contrast, the fixed-size (100-feature) analysis revealed that Baseline + MFCC features yielded the best performance, indicating that MFCC-based representations concentrate more relevant information in a smaller subset of dimensions. These findings highlight important implications for real-time systems: TQWT-based models benefit from higher feature budgets, while MFCCs are preferable for compact, low-latency models.
Another strength of the proposed framework is its ensemble-based feature selection strategy. Instead of relying on a single filter method, hybrid and consensus-based techniques, such as score fusion, union, and intersection, were employed to harness complementary strengths. This multi-strategy approach enhanced both the discriminative power and stability of selected features across validation folds, echoing recent findings in the literature that advocate multi-level dimensionality reduction pipelines. The integration of a two-stage ensemble strategy (GA–BO Ensemble) further enhanced performance. This hybrid ensemble method achieved the highest overall accuracy (96.43%), F1-score (97.64%), and MCC (0.9047) across all experiments, establishing it as the most robust and discriminative model in the study. Its success is attributed to the synergy between GA’s structural pruning and BO’s probabilistic weight tuning, effectively combining model diversity and optimal voting dynamics. Table 8 compares our approach with recent studies that employed acoustic features for PD detection.
| Author(s) | Methodology | Accuracy (%) |
|---|---|---|
| Gunduz (2019) | CNN (no FS) | 86.90 |
| Quan, Ren & Luo (2021) | Bi-LSTM (no FS) | 84.29 |
| Pramanik et al. (2021) | DF (no FS) | 94.12 |
| Gunduz (2021) | Multi-Kernel SVM + Relief + Fisher score (30 features) | 91.60 |
| Lamba, Gulati & Jain (2022) | MIRFE + XGBoost | 93.88 |
| Ouhmida et al. (2024) | DNN + HEFS-MLDR (ReliefF + mRMR + Chi2) | 97.08 |
| Our study | KNN + Filter selection + GA–BO–Ensemble (453 features) | 96.40 |
Compared to deep learning-based models such as CNNs (Gunduz, 2019) and DNNs (Ouhmida et al., 2024), our framework offers a superior balance between accuracy and computational cost. Deep models typically require extensive annotated datasets, high-performance GPUs, and long training times, which hinder deployment in low-resource or real-time clinical settings. In contrast, our hybrid ensemble approach achieves comparable accuracy without the heavy computational burden, making it suitable for edge devices and mobile health platforms.
Table 9 highlights the efficiency of the GA–BO–Ensemble model by comparing its cross-validation runtime with two deep learning baselines. The GA–BO model completed all folds in 103.12 s—significantly faster than the 771.21 s required by Gunduz (2019), despite the latter using GPU-based training. It also outperformed the HEFS-MLDR model by Ouhmida et al. (2024), which completed in 137.58 s.
| Model | Accuracy ( std) | F1-score ( std) | MCC ( std) | CV Time (s) |
|---|---|---|---|---|
| GA–BO–Ensemble (ours) | 0.9643 0.0196 | 0.9764 0.0128 | 0.9047 0.0539 | 103.12 |
| Ouhmida et al. (2024) | 0.9100 0.0347 | 0.9417 0.0221 | 0.7565 0.1009 | 137.58 |
| Gunduz (2019) | 0.8609 0.0566 | 0.9083 0.0339 | 0.6096 0.2296 | 771.21* |
Note:
Limitations
Despite the demonstrated effectiveness of the proposed GA–BO-based ensemble framework, several limitations warrant consideration.
First, the sequential nature of the GA followed by BO introduces potential biases related to the convergence path. Since GA serves as an initial heuristic search and BO subsequently refines the solution space, early suboptimal feature subsets identified by GA may constrain BO’s exploration capacity, potentially resulting in local optima. Future work could address this by integrating hybrid feedback mechanisms or employing multi-objective search strategies to improve convergence robustness.
Second, the reliance on the 1-NN classifier in several experiments, while interpretable and effective for clean datasets, presents challenges in noisy or high-dimensional feature spaces. Its sensitivity to local outliers and vulnerability to the curse of dimensionality could impair generalization performance on real-world, less curated clinical data. This motivates further benchmarking with more noise-robust classifiers (e.g., ensemble-based or probabilistic models) to strengthen performance under adverse conditions.
Third, although the proposed pipeline achieves competitive accuracy, its multi-stage design inherently increases training-time computational cost due to repeated evaluations across meta-heuristic iterations. This may limit scalability to larger datasets or real-time applications unless optimized further through parallelization or early stopping strategies.
Finally, a key limitation of this study lies in its evaluation on a single benchmark dataset. While the dataset is publicly available and widely used, the absence of cross-corpus validation restricts the assessment of the model’s robustness across different recording setups, accents, and demographics. Addressing this gap will be a key priority in future work through cross-dataset validation and adaptation studies.
Nevertheless, these limitations also underscore the need to examine the algorithmic complexity and scalability of the proposed framework—a pathway toward practical deployment and clinical integration, as elaborated in the following sections.
Algorithmic complexity
The proposed framework comprises three sequential computational stages during training—(i) filter-based feature selection, (ii) GA for ensemble subset selection, and (iii) BO for weight tuning. While these stages incur moderate training overhead, the inference pipeline remains lightweight and scalable, ensuring real-time applicability in clinical environments. Below, we summarize the theoretical time complexities of each component:
Filter-based feature selection: For samples and features, classical univariate filters (e.g., , F-score, Mutual Information) require operations, as each feature is evaluated independently. These methods are non-iterative and parallelizable.
GA-based ensemble subset selection: Let P be the population size, G the number of generations, and the cost of evaluating a single solution (e.g., via -fold cross-validation). The total complexity is , where . Given bounded P and G, the cost remains tractable.
BO-based weight optimization: For iterations in a C-dimensional continuous search space (where C is the number of classifiers), BO using Gaussian Process regression incurs complexity due to kernel matrix inversion. In our setting, both and C are small (e.g., , ), resulting in efficient convergence.
Inference phase: Given selected classifiers and features per instance, the prediction phase requires operations. This minimal cost supports deployment on edge devices and integration in time-sensitive clinical workflows.
Overall, the full training complexity is bounded by:
whereas inference remains constant-time with respect to data size. Since training is performed offline and each component is amenable to parallelization, the framework ensures a favorable trade-off between training efficiency and runtime deployment scalability.
Clinical translation and deployment
While the proposed GA–BO-powered framework demonstrates strong performance in experimental settings, transitioning this system into a clinically viable decision support tool necessitates several concrete steps. Given that the model relies solely on speech data, it presents a non-invasive, accessible, and low-cost modality for the early detection and monitoring of PD. This enables integration into diverse deployment environments, including smartphone-based mobile applications, telemedicine platforms, and outpatient clinic interfaces for routine screening. Such a system could assist neurologists in identifying at-risk individuals, particularly in underserved regions lacking access to movement disorder specialists, and could also serve as a supplementary tool for longitudinal disease tracking.
To facilitate clinical translation, future efforts will focus on:
testing the model on larger and more demographically diverse patient cohorts across multiple datasets to evaluate generalizability,
conducting prospective clinical studies in collaboration with neurology departments to validate real-world performance,
enhancing model transparency and interpretability through post hoc techniques such as SHAP or LIME, and
integrating the system into existing electronic health record (EHR) workflows to support seamless adoption by healthcare providers.
These steps will help transition the current research prototype into a robust, scalable, and clinically deployable decision support system for PD diagnosis and ongoing patient monitoring.
Future work
Beyond the clinical translation goals discussed in the previous subsection, several directions remain open for further research and methodological refinement. First, the current sequential design of the GA–BO ensemble introduces potential convergence bias, where suboptimal solutions from the GA may constrain the effectiveness of the subsequent Bayesian optimization phase. Future work will explore hybrid or co-evolutionary optimization strategies to mitigate such biases and improve global search capacity.
Second, while the 1-NN classifier was chosen for its interpretability, it may be susceptible to noise in more heterogeneous or high-dimensional clinical datasets. Subsequent studies will evaluate alternative classifiers, including ensemble-based and probabilistic models, for improved robustness.
Third, although the current framework achieves competitive performance, the training pipeline is computationally intensive due to meta-heuristic iterations. Future work will involve streamlining the training process through surrogate-assisted evaluation, parallelization, or adaptive resource allocation strategies to enable scalability for larger cohorts.
Finally, to assess generalizability, planned studies will extend the evaluation to additional benchmark datasets with diverse recording protocols and demographics. These investigations will also include transfer learning and domain adaptation methods to bridge dataset-specific variations and support broader clinical deployment.