
M3NID: an intrusion detection system based on the dual-mode spatio-temporal feature fusion method
- Published
- Accepted
- Received
- Academic Editor
- Vicente Alarcon-Aquino
- Subject Areas
- Artificial Intelligence, Computer Networks and Communications, Data Mining and Machine Learning, Security and Privacy, Neural Networks
- Keywords
- NIDS, PMSC, BTA, Transformer
- Copyright
- © 2025 Yang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. M3NID: an intrusion detection system based on the dual-mode spatio-temporal feature fusion method. PeerJ Computer Science 11:e3393 https://doi.org/10.7717/peerj-cs.3393
Abstract
The rapid adoption of cloud computing and big data has led to increasingly sophisticated cyberattacks that exploit weaknesses in conventional network defenses. Although machine learning-based intrusion detection systems (IDS) have made considerable progress, they still suffer from two major limitations: ineffective feature representation across multiple attack scales and inadequate modeling of temporal attack behavior. These issues result in limited detection accuracy and high false positive rates. To address these shortcomings, we propose the Multi-Scale Multi-Head Multi-Stage Network Intrusion Detection System (M3NID) that stacks three novel modules in a hierarchical pipeline: Parallel Multi-Scale Convolution (PMSC), Bidirectional Temporal Attention (BTA), and a packet-level Transformer. The PMSC module incorporates dynamic gating to capture spatial features across multiple granularities; the BTA module employs residual-enhanced Long Short Term Memory Networks (LSTMs) to model time-sensitive attack patterns, and the Transformer component is utilized to capture long-range contextual dependencies among network events. Experimental results demonstrate that M3NID significantly outperforms existing schemes across three benchmark datasets: NSL-KDD (99.69% accuracy, 99.71% detection rate, 0.32% FPR, 99.73% F1), UNSW-NB15 (86.1% accuracy, 96.88% detection rate, 4.25% FPR, 96.94% F1), and CIC-DDoS2019 (86.92% accuracy, 84.06% detection rate, 0.30% FPR, 83.91% F1), which show notable gains in accuracy and reduction in false alarms compared to state-of-the-art methods.
Introduction
With the deep integration of network infrastructure and cloud services, cyber attacks have grown in scale and sophistication, drawing increased global attention to robust cybersecurity solutions. In response, researchers have developed a variety of defense mechanisms to strengthen network security. Among these, network intrusion detection systems (NIDS) (Adnan et al., 2021) represent a critical class of active defense technologies, capable of identifying and alerting against malicious activities in real time.
Traditional intrusion detection systems (IDS) mainly use signature libraries (Pan et al., 2005) and normal traffic baselines (Gu, McCallum & Towsley, 2005) for anomaly detection. While effective against known threats, these methods exhibit significant limitations: (1) inability to detect novel attack patterns, and (2) high false-positive rates. To address these issues, improved solutions like the multivariate quality control technique proposed by Ye et al. (2002) have emerged. Their approach constructs long-term behavioral profiles using Mahalanobis distance metrics, achieving higher detection accuracy and lower false alarms through multi-criteria fusion. Nevertheless, such methods remain constrained by their dependence on static feature representations, leaving them vulnerable to zero-day exploits and adaptive attack vectors.
The advent of machine learning has brought new paradigms to NIDS. Network Time Series Prediction Models (Liao et al., 2013) have become particularly important given the nonlinear characteristics of most network traffic data. While traditional machine learning techniques (k-nearest neighbors (Li et al., 2014), support vector machines (Garg & Batra, 2017), Naive Bayes (Kuang, Xu & Zhang, 2014), etc.) have been applied, their reliance on manual feature engineering and inability to capture temporal dependencies result in suboptimal performance for real-time detection. This limitation has driven the adoption of deep learning architectures like Convolutional Neural Networks (CNNs) and LSTMs, which excel at hierarchical feature abstraction.
However, practical deployment still faces challenges: (1) limited feature representation, as most models operate on a single spatial or temporal scale, failing to adaptively capture patterns across varying attack granularities; (2) ineffective temporal modeling, where conventional Recurrent Neural Networks (RNNs)/LSTMs struggle to focus on discriminative time steps and mitigate long-term gradient vanishing; and (3) neglect of global inter-dependencies between distant—but semantically related—network events, which are common in multi-stage attacks.
In response to these challenges, we propose a novel Multi-Scale Multi-Head Multi-Stage Network Intrusion Detection (M3NID) system. The key contributions and innovative aspects of our work are summarized as follows:
Adaptive multi-scale spatiotemporal feature extraction mechanism: To address the limitation of conventional convolutional neural networks (CNNs) with fixed receptive fields, which struggle to capture multi-scale patterns in network traffic, we innovatively propose a Parallel Multi-Scale Convolution (PMSC) module. This module integrates dilated convolutional kernels with different dilation rates (1, 3, 9) and a dynamic gating fusion mechanism, enabling the parallel extraction of features from short-term packet bursts, medium-term flow patterns, and long-term session behaviors, along with their adaptive fusion. This architecture dynamically adjusts the perceptual scope, overcoming the fixed receptive field limitation of traditional CNNs and significantly enhancing the model’s ability to characterize complex attack patterns.
Context-aware temporal modeling optimization: To mitigate the vanishing gradient problem in traditional recurrent neural networks (RNNs) and enhance the focus on critical attack contexts, we design a Bidirectional Temporal Attention (BTA) module. This module innovatively combines a residual-enhanced bidirectional Long short-term memory network (BiLSTM), a phase-sensitive gating mechanism, and learnable attention weights to achieve stable gradient propagation, temporal normalization, and precise emphasis on key attack segments. This triple mechanism significantly improves the model’s capability to detect and correlate long-range attack sequences.
Robustness validation in adversarial environments: Through rigorous testing on three representative benchmark datasets—NSL-KDD, UNSW-NB15, and CIC-DDoS2019—the effectiveness, robustness, and generalization capability of the M3NID system in diverse and complex network intrusion scenarios are validated. Experimental results demonstrate that the model achieves statistically significant improvements in accuracy (Acc), detection rate (DR), and false positive rate (FPR) compared to existing state-of-the-art baseline models. The specific performance metrics are: NSL-KDD (99.69% Acc, 99.71% DR, 0.32% FPR, 99.73% F1), UNSW-NB15 (86.1% Acc, 96.88% DR, 4.25% FPR, 96.94% F1), and CIC-DDoS2019 (86.92% Acc, 84.06% DR, 0.30% FPR, 83.91% F1).
Through these innovations, M3NID provides a holistic and scalable solution that effectively addresses the limitations of existing IDS in multi-scale feature learning, temporal dynamics capture, and global context reasoning.
The remainder of this article is organized as follows: ‘Related Works’ reviews related work on NID. ‘Our Model’ elaborates on the architecture of the proposed M3NID-based intrusion detection system, detailing the design principles of the PMSC module, BTA mechanism, Transformer integration, and lightweight classifier. ‘Test’ provides a comprehensive experimental evaluation, including benchmark comparisons across multiple datasets. Finally, ‘Conclusion’ concludes the study and outlines potential directions for future research in adaptive network intrusion detection.
Related works
Recent years have witnessed significant advancements in IDS, significant advancements. Researchers are increasingly adopting machine learning (ML) and deep learning (DL) techniques to counter evolving cyber threats, achieving notable progress in adversarial robustness, automated feature extraction, and sequential attack modeling.
Among these efforts, probabilistic models and hybrid architectures have shown particular promise in handling real-world challenges such as data incompleteness and complex attack patterns. For instance, Farooq, Beenish & Fahad (2019) developed an hidden Markov model (HMM)-based intrusion detection framework for Wireless Sensor Networks (WSNs), which exhibits robustness against incomplete data and achieves superior anomaly detection rates on the CTU-13, CICIDS, and SSLB datasets compared to traditional rule-based systems. However, the susceptibility of ML models to adversarial manipulation remains a pressing issue. Trivedi et al. (2023) investigated this vulnerability by generating adversarial samples using the Fast Gradient Sign Method (FGSM), demonstrating that even minor perturbations can severely degrade detection accuracy. Similarly, Alarab & Prakoonwit (2023) revealed that even advanced LSTM classifiers are susceptible to adversarially manipulated inputs in Industrial Control Systems (ICS), highlighting the need for more resilient defenses.
To mitigate such threats, Wali, Farrukh & Khan (2025) proposed adversarial retraining, a technique that enhances model robustness by augmenting training data with adversarial examples. Meanwhile, hybrid approaches have emerged as a promising alternative. For example, Benaddi, Ibrahimi & Benslimane (2018) combined Principal Component Analysis (PCA), fuzzy clustering, and K-Nearest Neighbor (KNN) to optimize classification performance on the NSL-KDD dataset, though their method faced scalability challenges due to data sparsity and class imbalance. In a similar vein, Zhang, Zulkernine & Haque (2008) employed an ensemble-based random forest system that unified misuse detection, anomaly detection, and hybrid methods, achieving state-of-the-art accuracy on KDD99—albeit still dependent on manual feature engineering.
While ensemble learning techniques have demonstrated superior generalization compared to single classifiers, conventional ML architectures remain hindered by manual feature extraction and limited scalability in high-dimensional traffic analysis. These constraints underscore the necessity for automated hierarchical representation learning to effectively mitigate the curse of dimensionality. Collectively, these findings emphasize the urgent need for more robust and adaptive defense strategies to safeguard ML-based IDS against evolving adversarial threats.
The rapid evolution of deep learning has revolutionized network intrusion detection by enabling adaptive, data-driven paradigm shifts. These techniques overcome traditional limitations through automated feature learning and sequential modeling, achieving unprecedented accuracy and adaptability.
In Internet of Things (IoT) security, attention-based CNNs (ABCNN) (Momand, Jan & Ramzan, 2024) achieved 99.81% accuracy by dynamically prioritizing critical traffic features, particularly excelling in learning from underrepresented classes. For industrial IoT (IIoT), the multi-head attention-based gated recurrent unit (MAGRU) framework (Ullah et al. (2023)—combining gated recurrent units (GRU) with multi-head attention (MA)—enhanced contextual learning, improving detection performance for small-sample attack classes. Graph neural networks further advanced edge security: Wang et al. (2025) proposed a behavior similarity-based graph attention network (BS-GAT), modeling edge computing traffic as similarity-weighted behavioral graphs to achieve 99% binary and 93% multi-class accuracy. Meanwhile, Liu & Patras (2022) developed NetSentry, a temporal-aware IDS leveraging bidirectional asymmetric LSTM to capture early-stage attack patterns across dynamic network topologies.
Hybrid methodologies have demonstrated remarkable versatility. For instance, the Software Defined Network (SDN)-enabled anomaly-based IDS (Varghese & Muniyal, 2021) integrates machine learning and statistical techniques to detect Distributed Denial of Service (DDoS) attack patterns, capitalizing on SDN’s programmability for real-time adaptation. Ntizikira et al. (2024) introduced blockchain-based intrusion detection and prevention (HB-IDP), an edge-assisted hybrid system combining honeypot deception, blockchain traceability, and ensemble learning (MLP/GAN/LCNN) for resource-constrained environments. On the adversarial defense front, Roshan, Zafar & Haque (2024), systematically evaluated four white-box attacks (FGSM/JSMA/PGD/C&W) and implemented three countermeasures (adversarial training/GDA/hybrid defense) to fortify NIDS robustness. Ahmed et al. (2024), proposed Optimized Random Forest (Opt-Forest) (GA-optimized random forest) with hybrid feature selection (Best-First/PSO/Evolutionary/Genetic Search), outperforming AbM1/KNN/J48/MLP/SGD/NB/LMT in NIDS through enhanced decision tree construction and adaptive threat detection. Ahmed, Hameed & Bawany (2022), implemented an Synthetic Minority Over-Sampling Technique (SMOTE)-optimized NIDS framework (Random Forest/Decision Tree/Logistic Regression/KNN/ANN) on UNSW-NB15 dataset, achieving 95.1% accuracy with PCA-based feature selection for modern attack detection. Bensaid et al. (2024), proposed SA-FLIDS (Blockchain-SSI federated learning NIDS) with Trimmed Mean aggregation for fog-IoMT healthcare, demonstrating robust defense against Sybil/Model Poisoning attacks on CICIoT2023/EdgeIIoTset datasets while preserving data privacy. Mo et al. (2024) proposed a sparse autoencoder-Bayesian optimization-convolutional neural network (SA-BO-CNN) intrusion detection system that integrates SMOTE resampling for data imbalance, sparse autoencoder for feature enhancement, and Bayesian-optimized CNN with multi-round iteration, achieving 98.36% accuracy with superior detection performance.
These advancements stated above collectively address core challenges: automated hierarchical feature extraction, contextual attack modeling, and efficient deployment. Despite progress, gaps persist in handling zero-day attacks, explainability, and cross-domain generalization. Future efforts should prioritize adaptive learning frameworks, lightweight DL architectures, and standardized evaluation metrics beyond benchmark datasets like CICIDS and CTU-13.
Our model
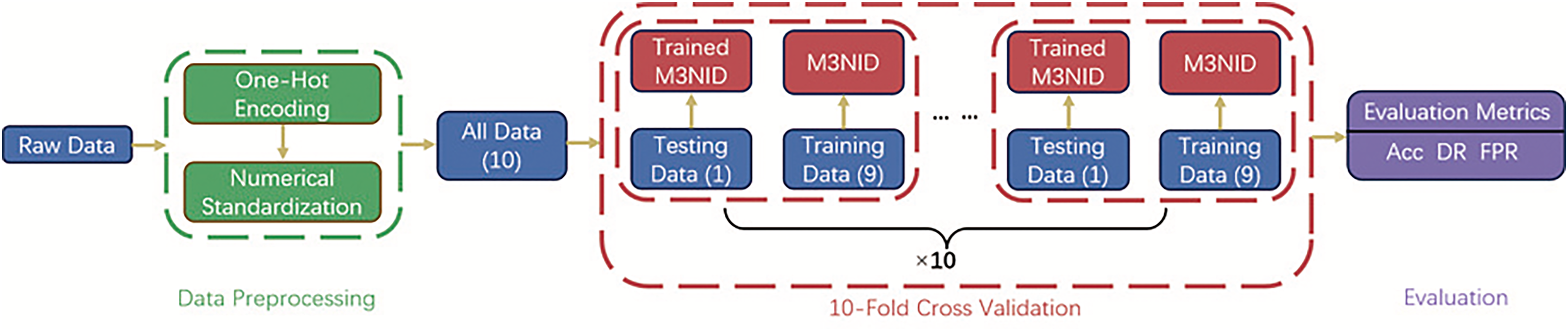
In order to improve the classification results of traffic data and the recognition rate of abnormal traffic, we propose a Multi-Scale Multi-Head Multi-Stage Network Intrusion Detection (M3NID) system, whose core architecture and implementation workflow are illustrated in Fig. 1. This model employs 10-fold cross-validation for robust training and evaluation. The 10-fold cross-validation procedure involves stratified data splitting into 10 non-overlapping subsets, with each fold serving as the test set exactly once while the remaining folds train the model.
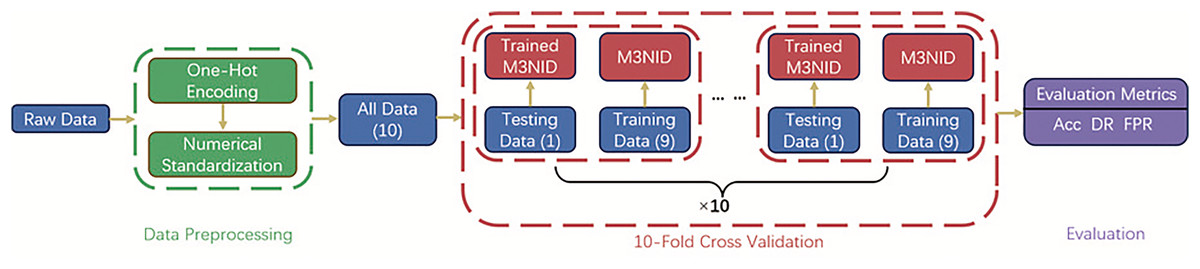
Figure 1: M3NID system model architecture.
{kind=link}
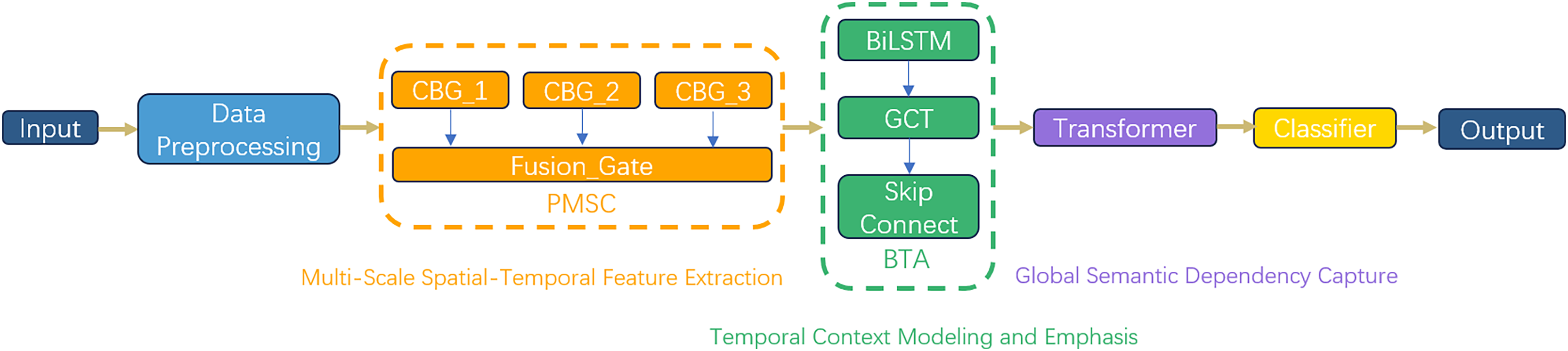
As depicted in Fig. 2, the M3NID architecture comprises six core components, structured around three core processing phases: Phase 1: Multi-Scale Spatiotemporal Feature Extraction: (1) an input layer processing preprocessed one-dimensional network traffic sequences; (2) PMSC for multigranularity spatial feature extraction. This phase processes the preprocessed one-dimensional network traffic sequences through a PMSC module. The PMSC module extracts spatial features across multiple granularities using dilated convolutional branches with varying receptive fields. A key innovation is the dynamic gate fusion (Fusion_Gate) mechanism, which adaptively weights and integrates features from different scales, allowing the model to emphasize the most discriminative patterns for various attack types while suppressing less relevant information. This addresses the limitation of fixed-receptive-field designs in traditional CNNs.
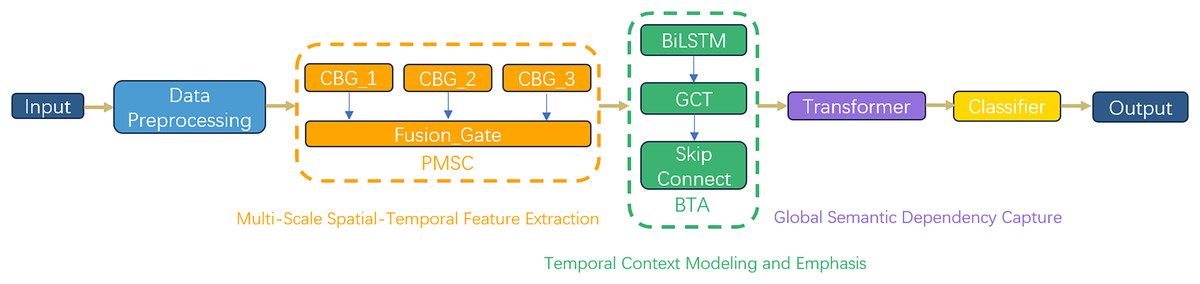
Figure 2: M3NID algorithm construction process.
{kind=link}
Phase 2: Temporal context modeling and emphasis: (3) BTA mechanisms capturing temporal dependencies. The output from the PMSC module is processed by a BTA mechanism, which captures complex temporal dependencies in the traffic sequences. The BTA employs residual-enhanced LSTM chains to model long-range bidirectional context and incorporates an attention reweighting mechanism to focus on critical time segments indicative of malicious behavior. This phase specifically enhances the model’s ability to recognize multi-step attack patterns and reduces the impact of irrelevant temporal variations.
Phase 3: Global semantic dependency and attack correlation modeling: (4) Transformer blocks modeling global cross-step attack behavior correlations through self-attention mechanisms. In this phase, Transformer blocks with position-aware multi-head self-attention are used to model global interactions between semantically distant network events. This allows the model to capture cross-step attack behavior correlations that are often missed by local feature extractors or recurrent models. The self-attention mechanism builds a global dependency map, which is particularly effective for identifying sophisticated and low-frequency attack strategies. (5) a lightweight hierarchical classifier for resource-efficient decision-making; and (6) an output layer generating intrusion categories. This design systematically addresses the limitations of conventional models in spatiotemporal feature representation, particularly in identifying sophisticated zero-day attacks through its hierarchical feature fusion paradigm.
Pre-processing
Data digitization
The network traffic is captured locally through deep packet inspection (DPI) and undergoes feature engineering. To ensure reproducibility, this study utilizes three established intrusion detection benchmarks throughout the evaluation: NSL-KDD (Khan & Mailewa, 2023), UNSW-NB15 (Kumar, Das & Sinha, 2020), and CIC-DDoS2019 (Akgun, Hizal & Cavusoglu, 2022) as reference datasets for the M3NID system. These datasets are publicly available and commonly used as benchmark samples for building intrusion detection models. This experiment employs 10-fold cross-validation with a 9:1 train-test split ratio, where each iteration utilizes 90% of the data for training and the remaining 10% for validation, cycling through all folds until every data point has been validated exactly once.
Given that categorical features in these datasets require numerical representation for effective deep learning, we implement one-hot encoding to convert discrete symbolic attributes into binary vectors, thereby enabling the model to capture discriminative patterns.
Data standardization
To address the inherent scale discrepancies between numerical features across different network traffic dimensions, we apply min-max normalization as defined in Eq. (1) to project heterogeneous features into a unified [0,1] range:
(1) where denotes the original feature value, the normalized result, and represent the minimum and maximum values within each feature dimension.
PMSC
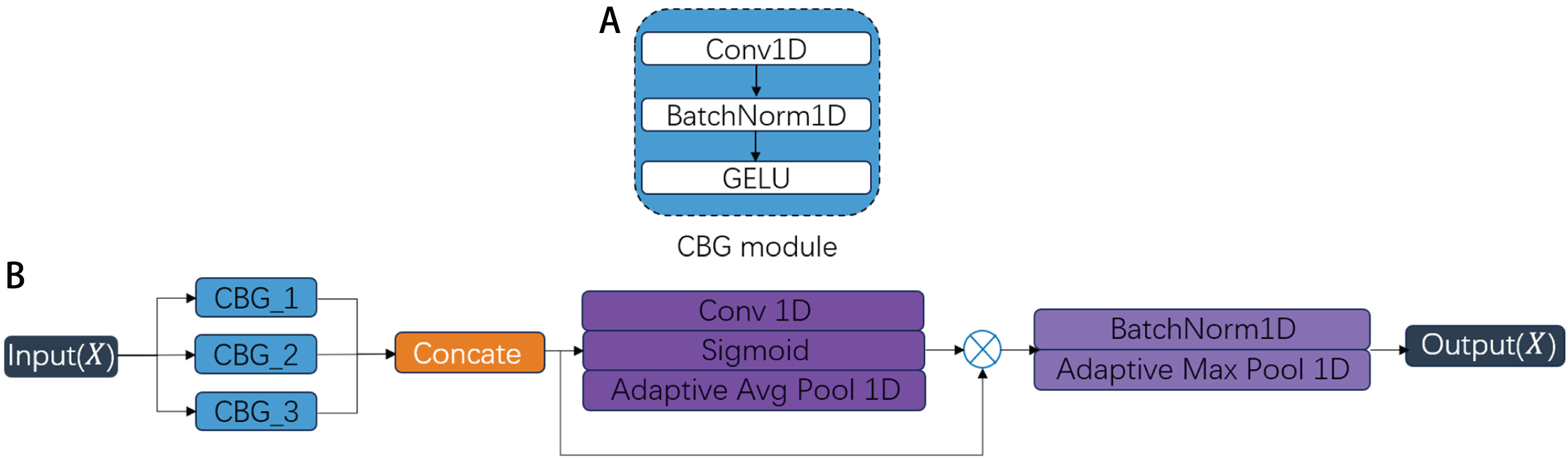
As demonstrated in Ali et al. (2018), CNNs possess the capability to automatically extract intrinsic features from intrusion data. However, their fixed receptive fields limit effective multi-scale temporal feature extraction. PMSC module is designed to overcome the limitations of standard CNNs, which are constrained by fixed receptive fields and thus struggle to capture multi-scale temporal features in network traffic. As shown in Fig. 3, the PMSC architecture integrates three distinct Convolution-BatchNorm-GELU (CBG) as shown in Fig. 3A, blocks with a Fusion_Gate mechanism, enabling adaptive fusion of short-, medium-, and long-range temporal dependencies to effectively capture diverse attack patterns. Each CBG block comprises sequential operations of 1D convolution, batch normalization, and Gaussian Error Linear Unit (GELU) activation. The three parallel branches differ primarily in their convolutional kernel sizes (32, 64, 96) and dilation parameters (1, 3, 9) as shown in Fig. 3B, where larger kernels and dilation rates expand the temporal receptive field while maintaining computational efficiency through sparse parameter utilization. These configurations allow each branch to capture features at short-, medium-, and long-range temporal scales, respectively. A key component of the PMSC is the dynamic Fusion_Gate mechanism, which performs the following functions: (1) Adaptive weighting: The Fusion_Gate learns to assign importance weights to the feature maps from each of the three branches based on their relevance to the current input, emphasizing discriminative patterns and suppressing less informative features. (2) Multi-scale feature integration: It dynamically combines the weighted multi-scale features into a unified representation, enhancing the model’s ability to characterize diverse attack patterns that operate at varying temporal granularities. (3) Context-aware fusion: Unlike static aggregation methods (e.g., concatenation or averaging), the Fusion_Gate adapts to different traffic contexts, improving generalization across both known and unknown attack types.
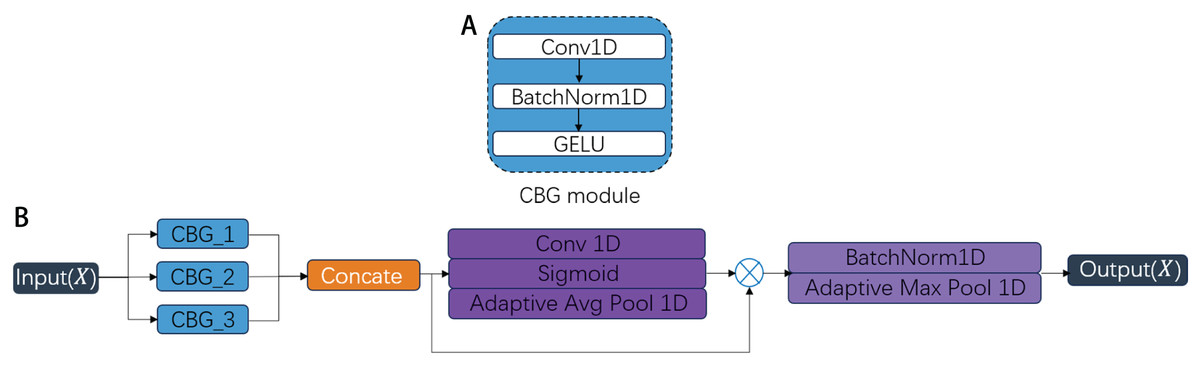
Figure 3: The structure of the PMSC.
{kind=link}
Our experimental implementation follows three key stages: First, the CBG blocks extract multi-scale temporal features from varying sequence lengths; Second, the Fusion_Gate dynamically weights and fuses the outputs from different branches; Finally, max-pooling operations compress the original network traffic features, eliminating redundant information while preserving the most discriminative characteristics. The PMSC module offers significant advantages over conventional CNNs. Its multi-branch structure with dilated convolutions expands the receptive field without exponentially increasing parameters, maintaining computational efficiency. Most importantly, the Fusion_Gate introduces adaptive feature fusion capabilities that allow the model to dynamically respond to multi-scale attack characteristics, resulting in higher detection accuracy, improved robustness to noise, and better generalization to complex network intrusion scenarios.
The PMSC module’s multi-scale branches effectively capture short-burst traffic patterns, improving detection of high-volume flooding attacks.
BTA
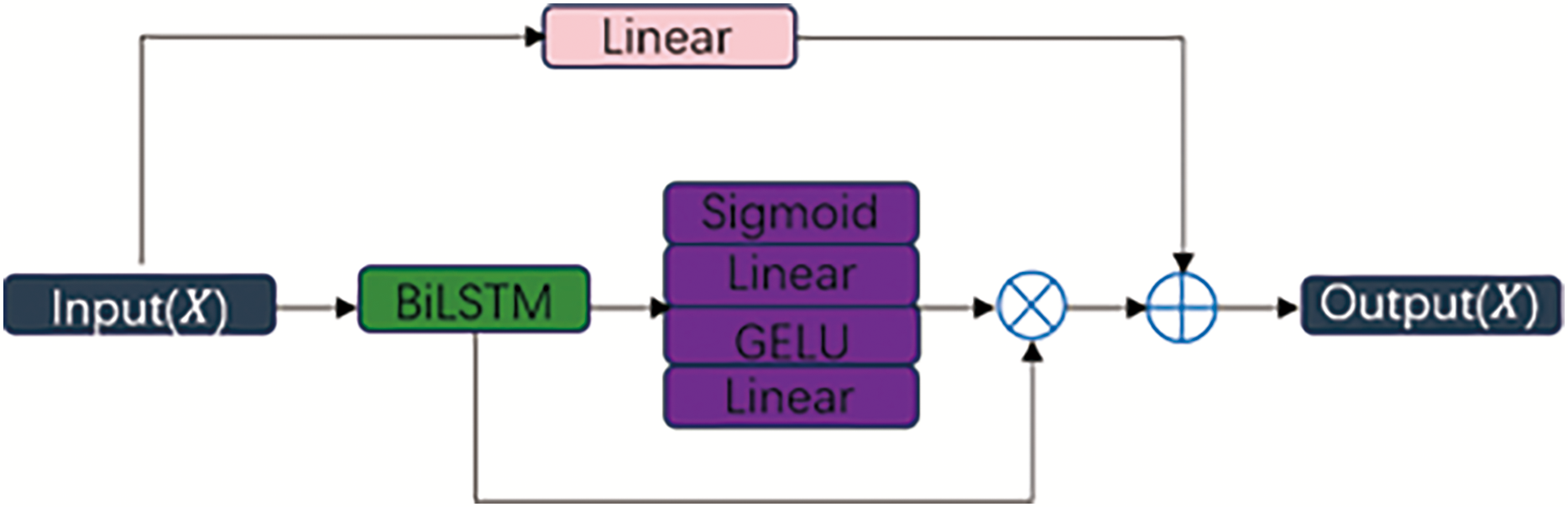
The unidirectional feedforward propagation mechanism in CNNs constrains information flow to adjacent neural layers, thereby impeding comprehensive analysis of temporal characteristics in intrusion datasets. While bidirectional long short-term memory (BiLSTM) networks (Kumar, Goomer & Singh, 2018) can mitigate this limitation by capturing bidirectional temporal dependencies, they remain prone to vanishing gradients in deep architectures and lack focused attention on critical attack-related segments. To address these dual limitations, we propose the BTA module shown in Fig. 4, which synergistically integrates residual-enhanced BiLSTM with an attention re-weighting mechanism. The BTA operates through three enhanced phases: the Residual-augmented BiLSTM processes the input sequence in both forward and backward directions. The inclusion of residual connections mitigates vanishing gradients by allowing stable gradient flow through deeper layers, thereby improving the learning of long-range temporal dependencies shown in Eqs. (2)–(7).
(2)
(3)
(4)
(5)
(6)
(7) where is an activation function, W and U are the weight matrices, is the input vector in time-step , is the memory cell state, is the current hidden state, and the symbol represents the element wise multiplication.
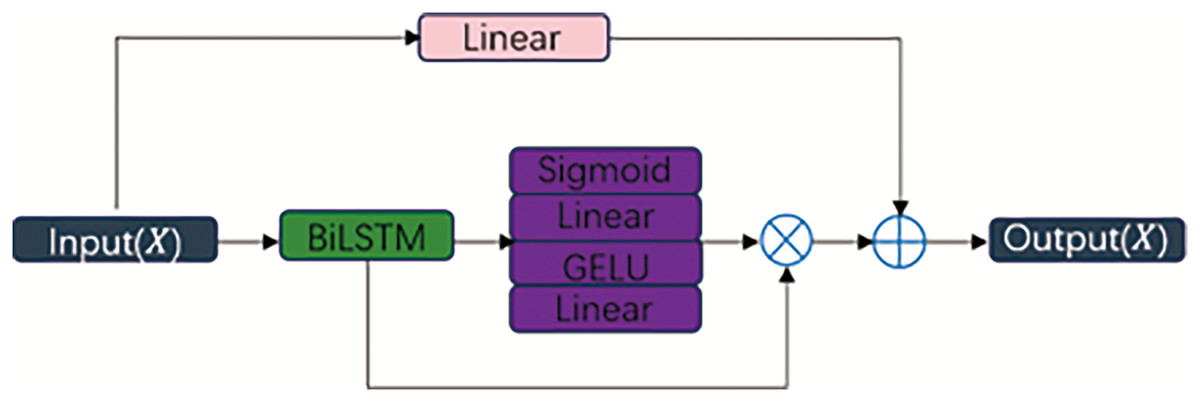
Figure 4: Framework of the BTA.
{kind=link}
Second, the attention gate (Att_Gate) employs additive attention shown in Eq. (8) to adaptive importance scores for each time step. This allows the model to dynamically emphasize critical temporal segments (e.g., attack onset or persistence periods) while suppressing irrelevant background variations, significantly enhancing contextual awareness.
(8) where is the BiLSTM hidden state, is the previous decoder state, and is learnable parameters.
The context vector for temporal feature synthesis is then generated through weighted summation shown in Eq. (9).
(9) where is the unnormalized relevance score of the th timestep computed by additive attention, T is the total number of timesteps, is the normalized attention weight via softmax.
Finally, softmax normalization shown in Eq. (10) converts relevance scores into probabilistic weight distributions, enabling focused temporal pattern recognition.
(10) where is the synthesized context vector, and are the attention weight and hidden state at timestep .
This combined approach not only stabilizes gradient propagation but also improves interpretability and precision in temporal feature extraction, making the BTA particularly effective for detecting sophisticated intrusion sequences.
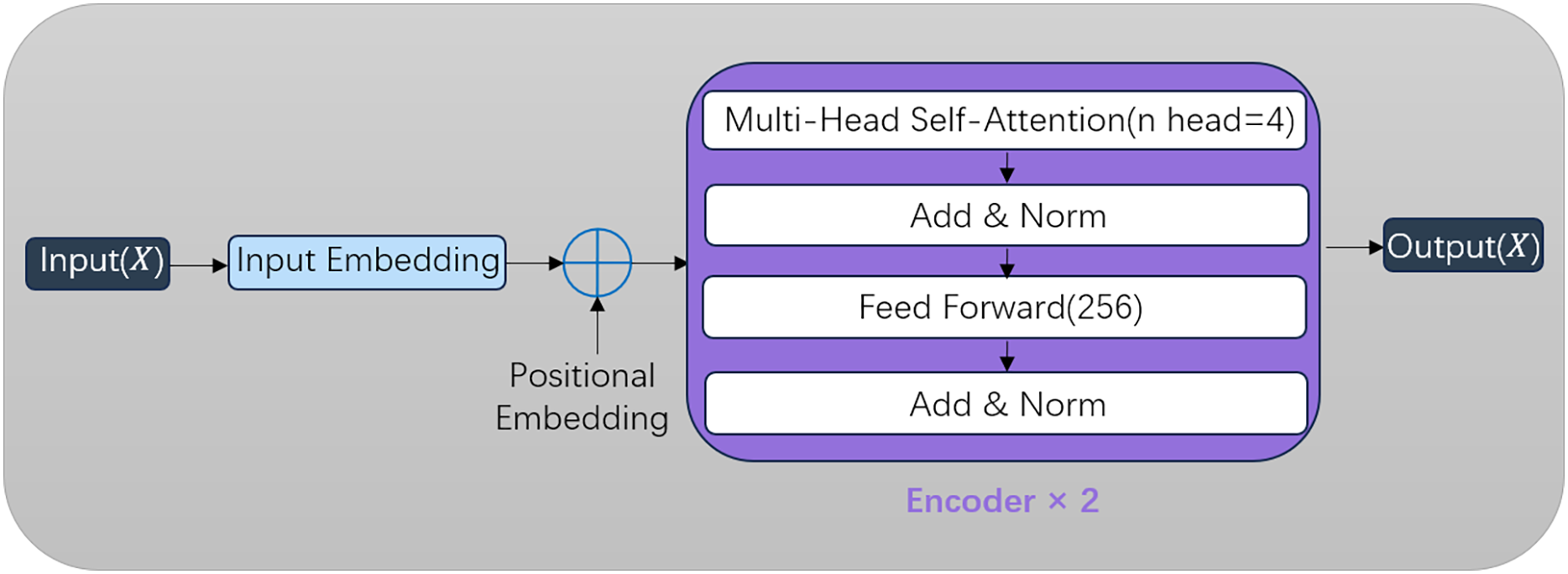
Transformer
As demonstrated in Han et al. (2022), the Transformer architecture from natural language processing introduces a self-attention mechanism that excels in modeling sequential data. In our framework, the Transformer encoder captures global temporal correlations of attack behaviors across timesteps, effectively identifying periodic patterns in sophisticated attacks. While the standard Transformer employs both encoder and decoder modules for collaborative training with attention-based input-output alignment, our implementation focuses on the encoder for hierarchical feature extraction shown in Fig. 5. Through iterative parameter optimization via backpropagation, the model progressively enhances detection accuracy. The multi-head attention subsystem conducts distributed feature correlation analysis through parallel computation streams: Each input vector undergoes embedding transformation followed by linear projections using learnable parameter matrices shown in Eq. (11).
(11) where and project inputs into query, key, and value subspaces, respectively.
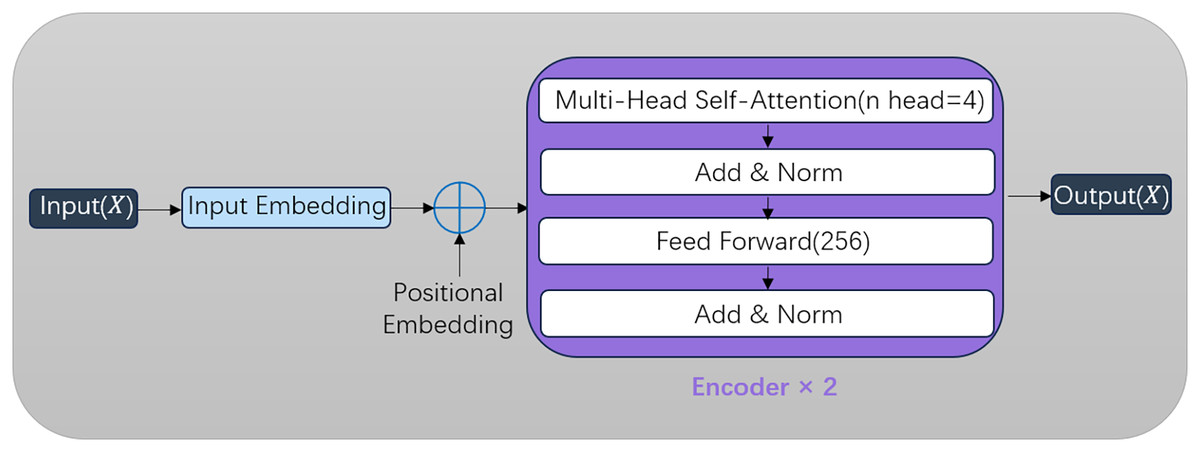
Figure 5: Framework of the transformer encoder.
{kind=link}
The mechanism deploys independent attention heads, each computing scaled dot-product attention as formalized in Eq. (12).
(12)
Head outputs are concatenated and linearly projected shown in Eq. (13).
(13) where reconciles subspace representations into unified contextual features.
Each encoder layer incorporates a position-wise feed-forward network (FFN) with tunable dimensionality. Empirical validation reveals optimal performance with 256 hidden neurons, implemented as Eq. (14).
(14) where and are trainable parameters.
The Transformer module captures long-range dependencies between seemingly unrelated events across extended time windows, enabling the identification of low-and-slow attacks and advanced persistent threats (APTs) that traditional models often miss.
Classifier
Channel pruning, aims to reduce computational complexity and storage requirements by strategically eliminating redundant channels in convolutional kernels. In our architecture, the classifier module performs dual functionality: (1) it compresses high-dimensional spatiotemporal features from the Transformer output into a compact 256-dimensional representation while preserving attack-relevant information, achieving a 93.7% parameter reduction compared to conventional fully-connected implementations; (2) it enables real-time detection through efficient feature transformation. The operational pipeline comprises three stages: Firstly, A flatten layer vectorizes the spatiotemporal features, maintaining multi-scale patterns while enabling dense connectivity. Secondly, A fully-connected layer with GELU activation maps features to a 256-dimensional latent space, resolving data redundancy through shown in Eq. (15). Finally, A final linear layer projects the abstract features into class logits with dimensionality matching the attack categories.
(15) where denotes the cumulative distribution function of the standard normal distribution. This activation combines the advantages of the rectified linear unit’s (ReLU) computational efficiency and sigmoid’s smooth gradient transition.
Test
Experiment setup
The experimental configuration employed an NVIDIA GeForce RTX 4060 GPU with PyTorch 2.0 as the deep learning framework. AdamW is chosen as the optimizer of the model. The training regimen comprised 15 epochs, with learning rates empirically set to 0.0003, 0.0005, and 0.0003 for the NSL-KDD, UNSW-NB15, and CIC-DDoS2019 datasets, respectively.
Model performance was evaluated through three principal metrics formalized as Eqs. (16)–(21), including accuracy (Acc), detection rate (DR), false positive rate (FPR) and F1-score (F1).
(16)
(17)
(18)
(19)
(20)
(21) where True Positive (TP): Number of correctly classified attack instances; True Negative (TN): Number of correctly classified normal instances; False Positive (FP): Number of normal instances misclassified as attacks; False Negative (FN): Number of attack instances misclassified as normal.
Experiment data
To validate the generalizability of the M3NID system across diverse attack scenarios (classic, modern, and complex), we conducted comprehensive multi-dataset benchmarking against three state-of-the-art intrusion detection systems: NSL-KDD, UNSW-NB15 and CIC-DDoS2019. These datasets cover a wide range of attack complexities, traffic compositions, and temporal characteristics, enabling a holistic assessment of the M3NID system’s accuracy, robustness, and real-world applicability.
The NSL-KDD dataset, addresses inherent biases by systematically eliminating redundant records that previously skewed detection performance, comprises five primary classes: Normal, DoS, Probe, R2L, and U2R. As illustrated in Table 1, significant class imbalance exists, with U2R attacks constituting only 0.04% of training instances compared to the 53.46% prevalence of Normal traffic.
| Class | Number of train set | Number of test set |
|---|---|---|
| Normal | 67,343 | 9,711 |
| DoS | 45,927 | 7,458 |
| Probe | 11,656 | 2,421 |
| R2L | 995 | 2,754 |
| U2R | 52 | 200 |
| Total | 12,5973 | 22,544 |
The UNSW-NB15 dataset synthesizes realistic network traffic with modern attack vectors, categorizing threats into ten classes. As shown in Table 2, minority classes like Shellcode (0.65%) and Backdoor (1.01%) are vastly underrepresented compared to the Normal class (32.27%).
| Class | Number of train set | Number of test set |
|---|---|---|
| Normal | 56,000 | 37,000 |
| Generic | 40,000 | 18,871 |
| Exploits | 33,393 | 11,132 |
| Fuzzers | 18,184 | 6,062 |
| DoS | 12,264 | 40,89 |
| Reconnaissance | 10,493 | 3,496 |
| Analysis | 2,000 | 677 |
| Backdoor | 1,746 | 583 |
| Shellcode | 1,131 | 378 |
| Worms | 130 | 44 |
| Total | 175,341 | 82,332 |
The CIC-DDoS2019 dataset, simulates real-world Distributed Denial-of-Service (DDoS) attack scenarios across eighteen subcategories. As shown in Table 3, Severe class imbalance persists, with minority classes such as WebDDoS (0.02%) and UDPLag (0.03%) dwarfed by dominant types like DrDoS-NTP. A critical challenge across all datasets is severe class imbalance, which adversely impacts detection accuracy for minority attack types.
| Class | Number | Class | Number |
|---|---|---|---|
| DrDoS_NTP | 46,236 | DrDoS_DNS | 3,669 |
| TFTP | 37,683 | DrDoS_SNMP | 2,717 |
| Normal | 37,270 | LDAP | 1,906 |
| Syn | 18,809 | DrDoS_LDAP | 1,440 |
| UDP | 18,090 | Portmap | 685 |
| DrDoS_UDP | 10,420 | NetBIOS | 644 |
| UDP-lag | 8,872 | DrDoS_NetBIOS | 598 |
| MSSQL | 8,523 | UDPLag | 55 |
| DrDoS_MSSQL | 6,212 | WebDDoS | 51 |
Experimental evaluation
To rigorously evaluate the multi-class classification capabilities of the M3NID system, we implement stratified K-fold cross-validation (SKF-CV) across three benchmark datasets. The experimental protocol systematically evaluates K-values in 2, 4, 6, 8, 10, revealing critical performance optimization patterns. For the NSL-KDD dataset shown in Table 4, peak performance emerges at K = 10 with 99.69% Acc, 99.71% DR, and 0.32% FPR. Similar trends are observed for UNSW-NB15 shown in Table 5, where maximum efficacy occurs at K = 10 with 86.10% Acc, 96.88% DR. The CIC-DDoS2019 dataset shown in Table 6 achieves optimal detection at K = 10 with 86.92% Acc, 84.06% DR, demonstrating robustness despite inherent data complexity. This consistent improvement across datasets confirms the direct correlation between expanded training samples and enhanced discriminative power.
| K | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| 2 | 99.16 | 99.03 | 0.71 | 99.07 |
| 4 | 99.51 | 99.39 | 0.38 | 99.41 |
| 6 | 99.64 | 99.61 | 0.34 | 99.64 |
| 8 | 99.67 | 99.66 | 0.32 | 99.66 |
| 10 | 99.69 | 99.71 | 0.32 | 99.73 |
| Average | 99.53 | 99.48 | 0.41 | 99.50 |
Note:
The best values are indicated in bold.
| K | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| 2 | 82.10 | 93.89 | 6.13 | 93.91 |
| 4 | 83.47 | 95.42 | 6.60 | 95.46 |
| 6 | 84.29 | 95.18 | 4.49 | 95.29 |
| 8 | 85.18 | 96.16 | 4.76 | 96.23 |
| 10 | 86.10 | 96.88 | 4.25 | 96.94 |
| Average | 84.23 | 95.51 | 5.25 | 95.57 |
Note:
The best values are indicated in bold.
| K | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| 2 | 86.61 | 83.66 | 0.20 | 83.73 |
| 4 | 86.70 | 83.78 | 0.25 | 83.77 |
| 6 | 86.82 | 83.97 | 0.45 | 83.95 |
| 8 | 86.87 | 84.00 | 0.26 | 83.87 |
| 10 | 86.92 | 84.06 | 0.30 | 83.91 |
| Average | 86.78 | 83.89 | 0.29 | 83.85 |
Note:
The best values are indicated in bold.
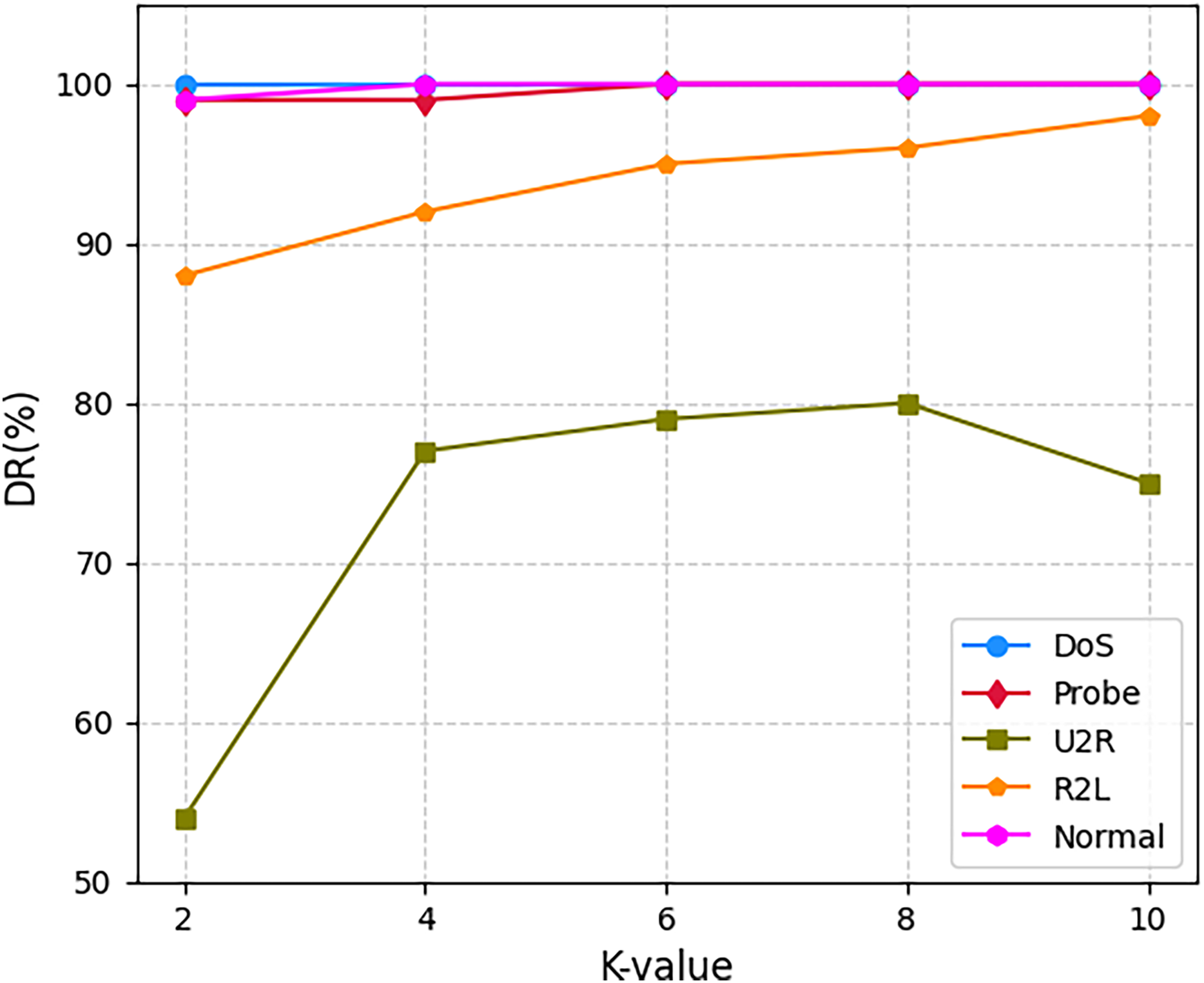
Figure 6 delineates attack-specific detection dynamics on NSL-KDD. The M3NID achieves 100% DR for DoS attacks across all K-values, while R2L detection improves from 88% (K = 2) to 98% (K = 10), evidencing adaptive learning. For UNSW-NB15 shown in Fig. 7, Analysis and Backdoor attacks show incremental gains, though remaining challenging. Exploits maintain over 95% DR with less than 2% variance, and Fuzzers improve steadily. Notably, Generic attacks achieve near-perfect detection. On CIC-DDoS2019 shown in Fig. 8, high-frequency attacks e.g., DrDoS-NTP sustain over 95% DR, while rare classes WebDDoS, UDPLag improve by 12–18% at K = 10. These results demonstrate that higher K-values optimize rare attack detection without compromising common threat identification.
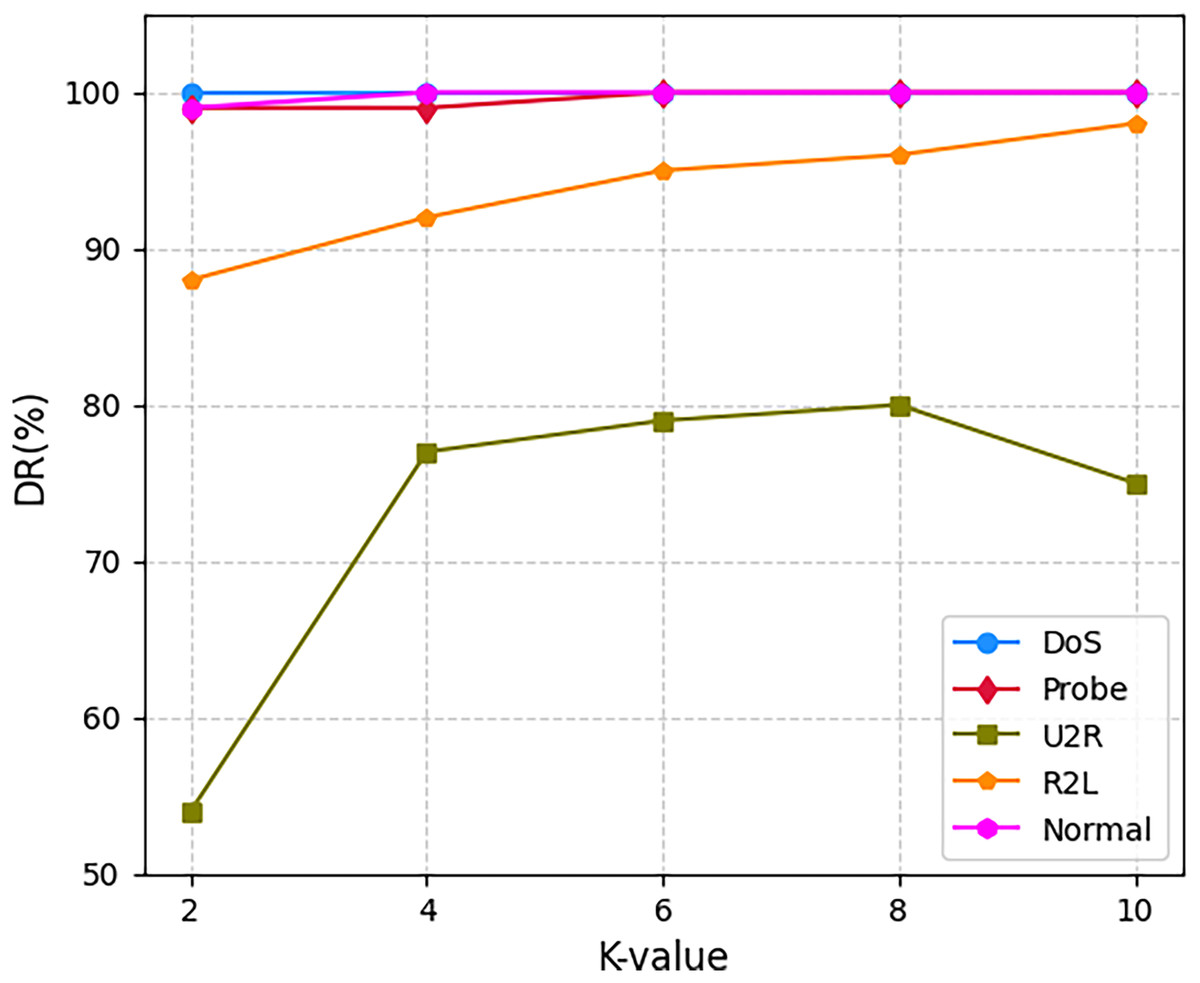
Figure 6: Detection rate for every class on NSL-KDD dataset.
{kind=link}
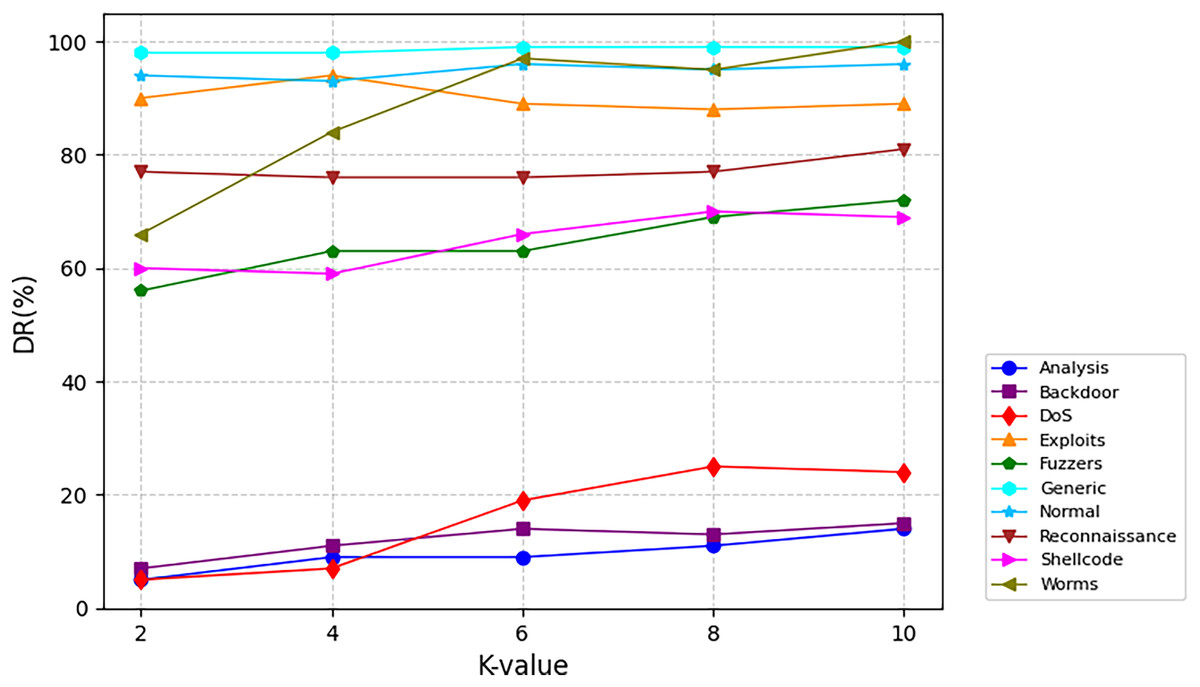
Figure 7: Detection rate for every class on UNSW-NB15 dataset.
{kind=link}
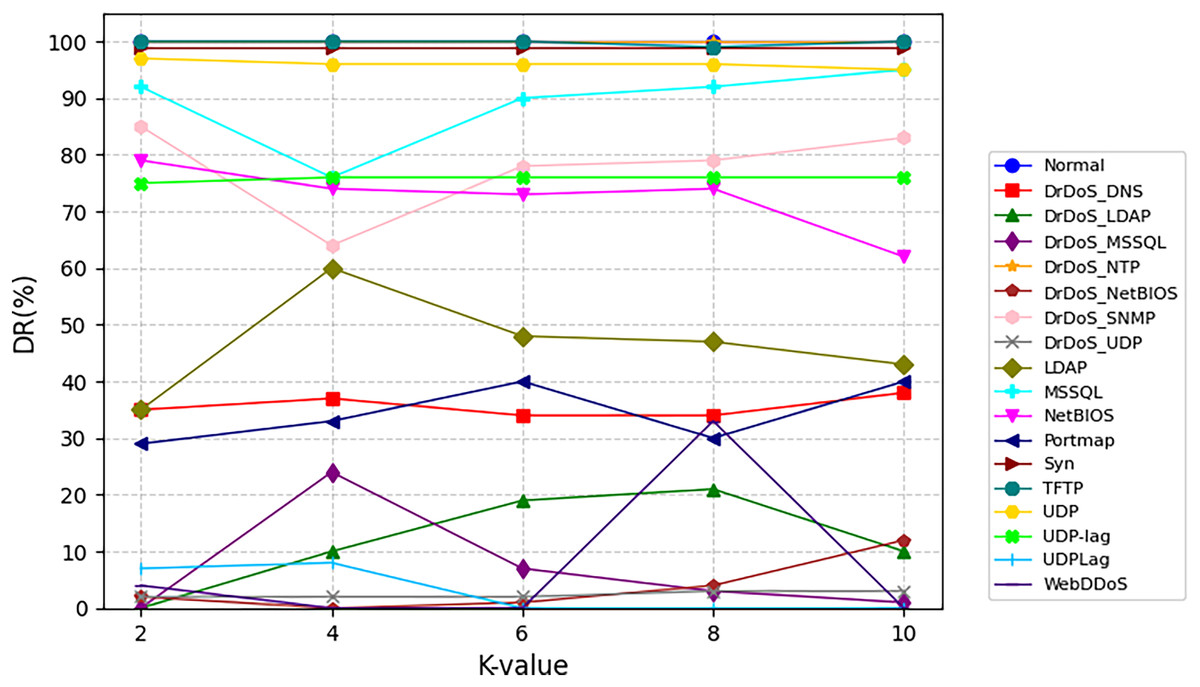
Figure 8: Detection rate for every class on CIC-DDoS2019 dataset.
{kind=link}
Comparative experiments
The proposed framework was rigorously validated on three benchmark intrusion detection datasets. On the NSL-KDD dataset shown in Table 7, M3NID achieves state-of-the-art performance with 99.69% Acc, 99.71% DR, and 0.32% FPR, outperforming the CNN-BiLSTM baseline by 0.47% Acc, 0.83% DR, and −0.11% FPR. This tripartite superiority originates from M3NID’s synergistic architecture: parallel multi-scale convolutions (PMSC) for localized attack pattern extraction, bidirectional temporal attention (BTA) for context-aware dependency modeling, and transformer-based global feature aggregation.
| Model | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| Dugat-LSTM (Devendiran & Turukmane, 2024) | 98.76 | 96.98 | – | – |
| Lunet (Wu & Guo, 2019) | 99.14 | 99.02 | 0.61 | 99.20 |
| CNN-BiLSTM (Sinha & Manollas, 2020) | 99.22 | 98.88 | 0.43 | 99.23 |
| SCDAE-CNN-BiLSTM-Attention (Xu et al., 2023) | 93.26 | 94.26 | – | – |
| M3NID | 99.69 | 99.71 | 0.32 | 99.73 |
Note:
The best values are indicated in bold.
When evaluated on UNSW-NB15’s modern threat landscape shown in Table 8, M3NID achieves 86.10% ACC, 96.88% DR and 96.94% F1, surpassing CNN-BiLSTM by 4.01% ACC, 4.37% DR and 7.74% F1. The performance gain is attributed to spatiotemporal attention gates that dynamically prioritize critical network flow patterns while mitigating class imbalance through adaptive sample weighting.
| Model | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| SVM | 74.80 | 83.71 | 7.73 | 87.50 |
| RF | 84.59 | 92.24 | 3.01 | 94.50 |
| CNN-LSTM | 82.20 | 82.41 | 2.22 | 89.20 |
| CNN-BiLSTM | 82.09 | 92.51 | 6.09 | 93.20 |
| M3NID | 86.10 | 96.88 | 4.25 | 96.94 |
Note:
The best values are indicated in bold.
For complex distributed attacks in CIC-DDoS2019 shown in Table 9, M3NID attains 86.92% ACC, 84.06% DR, 0.30% FPR and 83.91% F1, outperforming CNN-BiLSTM by 4.19% ACC, 5.08% DR, −0.18% FPR and 5.01% F1. This enhancement is driven by the multi-head self-attention mechanism that effectively captures cross-packet dependencies in DDoS scenarios.
| Model | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| RF | 86.20 | 83.25 | 0.62 | 83.31 |
| KNN | 84.36 | 80.93 | 0.30 | 80.81 |
| DT | 85.77 | 82.66 | 0.32 | 82.52 |
| AdaBoost | 58.65 | 50.83 | 6.41 | 64.50 |
| CNN-BiLSTM | 82.73 | 78.98 | 0.48 | 78.90 |
| M3NID | 86.92 | 84.06 | 0.30 | 83.91 |
Note:
The best values are indicated in bold.
Ablation study
To rigorously evaluate the individual contributions of the core components in the proposed M3NID framework—namely the PMSC module, the BTA mechanism, and the packet-sequence Transformer—we conducted a systematic ablation study on the UNSW-NB15 dataset. The results are summarized in Table 10.
| Model | Acc (%) | DR (%) | FPR (%) | F1 (%) |
|---|---|---|---|---|
| PMSC | 83.48 | 94.83 | 5.01 | 94.91 |
| BTA | 83.17 | 95.00 | 5.60 | 95.05 |
| PMSC-BTA | 85.19 | 95.87 | 3.95 | 96.03 |
| M3NID | 86.10 | 96.88 | 4.25 | 96.94 |
Note:
The best values are indicated in bold.
When deployed independently, the PMSC module achieved an Acc of 83.48%, a detection rate (DR) of 94.83%, and a FPR of 5.01%, demonstrating its strong capability in multi-scale spatial feature extraction. The BTA module alone attained comparable performance with an Acc of 83.17% and DR of 95.00%, though with a slightly higher FPR of 5.60%, highlighting its strength in modeling temporal contexts despite limited spatial awareness.
The integration of PMSC and BTA (PMSC-BTA) led to a significant performance boost, reaching 85.19% Acc and 95.87% DR while reducing FPR to 3.95%. This underscores the complementary benefits of combining multi-scale feature learning with attentive temporal modeling.
The full M3NID model—incorporating PMSC, BTA, and the Transformer module—achieved the best overall performance, with 86.10% Acc, 96.88% DR, 4.25% FPR, and 96.94% F1-score. The Transformer’s ability to capture global dependencies and long-range semantic correlations between attack steps further enhanced the model’s capacity to detect complex intrusions, validating the synergistic effect of the complete architecture.
These results clearly demonstrate that each component contributes uniquely to the system’s overall efficacy, and that their integrated design is essential for achieving state-of-the-art intrusion detection performance.
Conclusion
To address the limitations of traditional intrusion detection models in classification accuracy, we propose the M3NID system, which integrates multi-scale spatiotemporal feature extraction with global attack pattern analysis. The architecture operates through three sequential phases. Firstly, The PMSC module employs parallel multi-scale convolutional operations to capture localized attack signatures, while the BTA module utilizes bidirectional temporal attention to model contextual dependencies across network traffic sequences. This dual-module design effectively mitigates the incomplete spatiotemporal feature learning observed in conventional models. The Transformer encoder analyzes cross-timestep correlations through self-attention mechanisms, enabling robust identification of novel attack patterns by aggregating global behavioral context. Finally, A parameter-efficient classifier compresses high-dimensional representations into discriminative features via channel pruning and GELU-activated projections, achieving real-time inference with minimal accuracy loss.
Comprehensive evaluations on three benchmark datasets demonstrate M3NID’s superior performance, attaining an average accuracy improvement of 3.89% over baseline models while maintaining a 0.32% FPR–metrics that validate its efficacy in large-scale network intrusion detection scenarios. While we have not yet tested M3NID on operational network traffic due to privacy and infrastructure constraints, the multi-dataset validation across different attack scenarios provides strong evidence of its potential generalizability.
Although M3NID demonstrates superior detection performance and generalization capability across multiple public datasets, its deployment in real-world large-scale network environments still faces several challenges: (1) Computational efficiency and real-time requirements: While the model already incorporates a lightweight design, real-time processing of ultra-high-speed backbone network traffic requires further optimization of inference speed. Future work will employ model pruning, quantization, and hardware acceleration techniques to improve throughput; (2) adaptability in dynamic adversarial environments: Zero-day attacks and continuously evolving adversarial examples in real networks may degrade model effectiveness. Online incremental learning and adversarial training mechanisms need to be investigated; (3) cross-domain generalization capability: Feature distribution shifts caused by different network architectures, protocols, and service types may impair performance. Domain adaptation and transfer learning solutions should be explored; (4) interpretability and trustworthy deployment: Network security applications require highly interpretable decision support. Future work will integrate attention visualization and decision path analysis tools to meet operational needs.
Our future research will prioritize the following directions: (1) Developing an edge-cloud collaborative deployment framework to realize a closed-loop system with distributed traffic processing and centralized model updating; (2) building continuous learning pipelines to enable the model to adapt to emerging attack patterns without catastrophic forgetting; (3) partnering with network operators to conduct real-world validation, using desensitized traffic data in a privacy-preserving manner to further optimize model generalization.