
Bi-objective trail-planning for a robot team orienteering in a hazardous environment
- Published
- Accepted
- Received
- Academic Editor
- Bilal Alatas
- Subject Areas
- Adaptive and Self-Organizing Systems, Agents and Multi-Agent Systems, Algorithms and Analysis of Algorithms, Autonomous Systems, Robotics
- Keywords
- Robot teams, Robot path-planning, Team orienteering in hazardous environments, Ant colony optimization
- Copyright
- © 2025 Simon et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Bi-objective trail-planning for a robot team orienteering in a hazardous environment. PeerJ Computer Science 11:e3376 https://doi.org/10.7717/peerj-cs.3376
Abstract
Consider a team of mobile (aerial, ground, or aquatic) robots for orienteering in a hazardous environment. Modeling the environment as a directed graph, each arc is labeled with a probability that a robot will survive upon traversing it, and each node is labeled with the reward given to the robot team if visited by a robot. The arc-traversal hazards could emanate from e.g., rough terrain or seas, strong winds, radiation, or adversaries capable of attacking or capturing robots. Each reward represents the utility gained by the team when a robot e.g., delivers a good, takes an image or measurement, or actuates some process to/of/at a node. We want to obtain the Pareto-optimal set of robot-team trail plans on this graph that maximize two (conflicting) team objectives: the expected (1) team reward and (2) number of robots that survive the mission. This way, a human decision-maker can inspect the reward-survival tradeoffs along the Pareto-front, then make an informed selection of a Pareto-optimal robot-team trail plan that balances, according to his or her values, reward and robot survival. To search for the Pareto-optimal set of robot-team trail plans, we implement bi-objective ant colony optimization, guided by both pheromone and problem-specific heuristics. We solve and analyze three problem instances: a synthetic one on a two-community graph; an information-gathering mission in an art museum; and an item-tagging and -verification mission at an abandoned nuclear power plant. We find that ant colony optimization outperforms or performs indistinguishably from a simulated annealing baseline. Ablating the pheromone trails or heuristics reveals that both are important for guiding artificial ants towards Pareto-optimal robot-team trail plans. By inspecting a sample of Pareto-optimal robot-team trail plans along the Pareto-front, we find robots take the safest trails to visit the nodes assigned to them and visit higher-reward nodes earlier in their trail; multiple robots may plan to redundantly visit the same subgraphs to make the team reward robust to robot failures; and rewards from visiting nodes must be balanced against robot survival.
Introduction
Applications of a team of mobile robots
Mobile (aerial (Leutenegger et al., 2016), ground (Chung & Iagnemma, 2016), or aquatic (Choi & Yuh, 2016)) robots equipped with sensors, actuators, and/or cargo have applications in agriculture (Santos et al., 2020; Bawden et al., 2017; McAllister et al., 2018), commerce (Wurman, D’Andrea & Mountz, 2008), the delivery of goods (Coelho, Cordeau & Laporte, 2014), search-and-rescue (Queralta et al., 2020; Rouček et al., 2020), CBRN (chemical, biological, radiological, or nuclear) hazard mapping and localization (Murphy et al., 2012; Hutchinson et al., 2019), environmental monitoring (Dunbabin & Marques, 2012; Hernandez Bennetts et al., 2012; Yuan et al., 2020; Apprill et al., 2023), inspection of infrastructure (Lattanzi & Miller, 2017), process monitoring in industrial chemical plants (Soldan et al., 2014; Francis et al., 2022), forest fire monitoring and fighting (Merino et al., 2012), wildlife conservation (Kamminga et al., 2018), patrolling (Basilico, 2022), target tracking (Robin & Lacroix, 2016; Hausman et al., 2016), and military surveillance and reconnaissance.
Algorithms for both low-level, tactical planning and high-level, strategic planning of the paths/routes of mobile robots in (static or dynamic; known or uncertain) environments (LaValle, 2006; Liu et al., 2023; Ugwoke, Nnanna & Abdullahi, 2025; Siegwart, Nourbakhsh & Scaramuzza, 2011; Patil, Van Den Berg & Alterovitz, 2012; Van Den Berg, Patil & Alterovitz, 2016) are vital for autonomy and pivotal for efficiency, safety, and good performance on the objectives.
The classic, low-level path-planning problem for a robot (LaValle, 2006; Agrawal, Singh & Kumar, 2022) involves finding the least-cost (e.g., shortest), collision-free path from a starting location to a destination in a static, known environment containing obstacles. By discretizing the environment with a cell decomposition method (Latombe, 2012), we can model the environment as a graph, where nodes represent locations and edges represent traversable connections between locations. Then, a variety of graph search (e.g., Dijkstra’s algorithm; Candra, Budiman & Hartanto, 2020), random sampling (e.g., rapidly exploring random trees; LaValle, 1998), heuristic (e.g., A-star; Candra, Budiman & Hartanto, 2020), meta-heuristic (e.g., ant colony optimization; Brand et al., 2010), and reinforcement learning (Singh, Ren & Lin, 2023) algorithms can be adopted for finding a low-cost, collision-free path in this graph. The selection of a path-planning algorithm involves tradeoffs in solution quality, computational cost, memory usage, parallelizability, and scalability (Ugwoke, Nnanna & Abdullahi, 2025). In multi-robot path-planning (Wagner & Choset, 2011), each robot has unique start and end locations; robot-robot collisions must be avoided as well as robot-obstacle collisions; and the configuration space is much larger. In multi-objective robot path-planning (Tarbouriech & Suleiman, 2020; Jiménez-Domínguez et al., 2024; Ntakolia & Lyridis, 2022; Dao, Pan & Pan, 2016; Thammachantuek & Ketcham, 2022), a tradeoff between the length of the path and e.g., the energy expenditure of the robot to take the path (encouraging smoothness) must be met.
For many applications, we wish for a team of multiple mobile robots to coordinate their routes in an environment to cooperatively achieve a shared, high-level objective (Parker, 1995; Parker, 2007). Compared to a single robot, a coordinating robot team can increase spatial coverage, enhance performance on the objective, achieve the objective more quickly, and make achievement of the objective robust to the failure of some robots (Schranz et al., 2020; Brambilla et al., 2013). Multi-robot, coordinative route-planning involves high-level, strategic decision-making; fine-grained details like obstacle avoidance and the exact paths in Euclidean space are delegated to lower-level decision-making systems. Typically, such a multi-robot, coordinative routing problem is framed as a combinatorial optimization problem.
A prominent example of multi-robot, coordinative route-planning is the team orienteering (Golden, Levy & Vohra, 1987) problem (TOP) (Chao, Golden & Wasil, 1996b; Gunawan, Lau & Vansteenwegen, 2016; Vansteenwegen, Souffriau & Van Oudheusden, 2011). In the TOP, a team of robots are mobile in an environment modeled as a graph, and each node gives a reward to the team if visited by a robot. The TOP is to plan the routes of the robots, from a source to destination node, to gather the most rewards as a team under a travel budget for each robot. Loosely, the TOP problem combines aspects of the classic knapsack problem (selecting the nodes from which to collect rewards, under the travel budget) and the traveling salesman problem (finding the shortest path that visits these nodes) (Vansteenwegen, Souffriau & Van Oudheusden, 2011). The TOP can be formulated as an integer program. Approaches to obtain a solution to the TOP include exact (e.g., a branch-and-price scheme; Boussier, Feillet & Gendreau, 2007), heuristic (Chao, Golden & Wasil, 1996b), and meta-heuristic (e.g., ant colony optimization (Ke, Archetti & Feng, 2008)) algorithms (Vansteenwegen, Souffriau & Van Oudheusden, 2011). Again, algorithm selection involves tradeoffs in solution quality and computational efficiency.
Teams of mobile robots orienteering in hazardous environments
In some applications, robots move in a hazardous environment (Trevelyan, Hamel & Kang, 2016) and incur spatially-inhomogeneous risks of failure, destruction, disablement, and/or capture. These uncertain hazards could originate from dangerous terrain, rough seas, strong winds, extreme temperatures, radiation, corrosive chemicals, or mines—or, an adversary with the capability to attack and destroy, disable, or capture robots (Agmon, 2017).
Robots traversing a hazardous environment should plan and coordinate their routes in consideration of risks of failure. First, each robot should take the safest route to visit its destination(s). Second, the robots should collaborate when planning their routes to make achievement of the team objective resilient to robot failures (Zhou & Tokekar, 2021). A resilient team of robots (Prorok et al., 2021) (i) anticipates failures and makes risk-aware route plans that endow the team with robustness—the ability to withstand failures with minimal concession of the objective—e.g., by redundantly assigning multiple robots to a task requiring only one robot, and/or (ii) adapts their route plans during the mission in response to realized robot failures to recoup the otherwise anticipated loss in the objective. Third, the route plans must balance the rewards gained from visiting different locations against the risks incurred by the robots to reach those locations. Notably, classical robot path-planning algorithms have been extended to handle environments containing uncertain hazards by minimizing two conflicting objectives: the length of the path and the robot’s exposure to hazards (radiation, landmines, etc.) along the path (Zhang et al., 2023; Zhang, Gong & Zhang, 2013; Cui et al., 2023).
A few route-planning problems for robots orienteering in hazardous environments, abstracted as graphs, have been framed and solved (Zhou & Tokekar, 2021). In the Team Surviving Orienteers problem (TSOP) (Jorgensen et al., 2018, 2017; Jorgensen & Pavone, 2024), each node of the graph offers a reward to the team when visited by a robot, and a robot incurs some probability of destruction with each edge-traversal. The objective in the TSOP is to plan the paths of the robots, from a source to destination node, to maximize the expected team reward. As constraints, each robot must survive the mission with a probability above a tolerable threshold. In the offline TSOP, the paths of the robots are set at the beginning of the mission, then followed without adaptation; in the online setting, the paths are updated during the mission in response to realized robot failures. Relatedly, the Foraging Route with the Maximum Expected Utility problem (Di et al., 2022) is to plan the foraging route of a robot collecting rewards in a hazardous environment, but the rewards are lost if the robot is destroyed before returning to the source node to deposit the goods it collected. In the Robust Multiple-path Orienteering Problem (RMOP) (Shi, Zhou & Tokekar, 2023), similarly, each node gives a reward to the team only if a robot visits it and survives the mission to deposit the reward. The paths of the K robots, subject to travel budgets, are planned to maximize the team reward under the worst-case attacks of of the robots by an adversary. The offline version of the RMOP constitutes a two-stage, sequential game with perfect information: (1) the robot team chooses a set of paths then (2) the adversary, knowing these paths, chooses the subset of robots to attack and destroy. The optimal path plans for the robots must trade (i) redundancy in the nodes visited, to give robustness against attacks, and (ii) coverage of many nodes, to collect many rewards. In the hazardous orienteering problem (HOP) (Santini & Archetti, 2023; Montemanni & Smith, 2025), robots incur a risk of destruction while carrying valuable parcels picked up at some nodes, and the reward is received iff the robot returns safely to the depot node. Notably, Sherali et al. (1997) was perhaps the first to model stochastic hazards encountered by a robot taking a path on a graph. Other work involving robots traversing hazardous environments includes maximizing coverage of an area containing threats to robots (Korngut & Agmon, 2023; Yehoshua, Agmon & Kaminka, 2016), handling adversarial attacks on the sensors of the robots (Liu et al., 2021; Zhou et al., 2022; Mayya et al., 2022; Zhou et al., 2018), gathering information in an environment with unknown hazards (Schwager et al., 2017), finding the optimal formation for a robot team (Shapira & Agmon, 2015), and multi-robot patrolling under adversarial attacks (Huang et al., 2019). Though not a robot routing problem, the time-bomb knapsack problem (Monaci, Pike-Burke & Santini, 2022) is relevant to robots carrying hazardous cargo or cargo that invites attacks: maximize the expected profit of items placed in a knapsack under a capacity when each item has a probability of exploding and causing the profit to be lost.
Our contribution
Herein, our contribution is: (1) framing and intuiting a bi-objective variant of the offline TSOP (Jorgensen et al., 2018, 2017; Jorgensen & Pavone, 2024), the bi-objective team orienteering in hazardous environments (BOTOHE) problem, then (2) specifying, implementing, and benchmarking a bi-objective ant colony optimization algorithm (Iredi, Merkle & Middendorf, 2001), guided by BOTOHE-specific heuristics, to search for the Pareto-optimal set of robot-team trail plans, then (3) solving and analyzing BOTOHE problem instances on synthetic and real-world graphs for insights.
In the BOTOHE problem, a team of robots are mobile in a hazardous environment, modeled as a directed graph where each arc presents a known probability of destruction to a robot that traverses it. Each node of the graph gives a reward to the team if visited by a robot. The robots begin at a source node. The BOTOHE problem is to plan the closed trails of the robots to maximize two team-level objectives: the expected (1) rewards accumulated by the team and (2) number of robots that survive the mission. See Fig. 1A (We focus on the offline setting, corresponding with a lack of communication with/between robots after the mission executes).
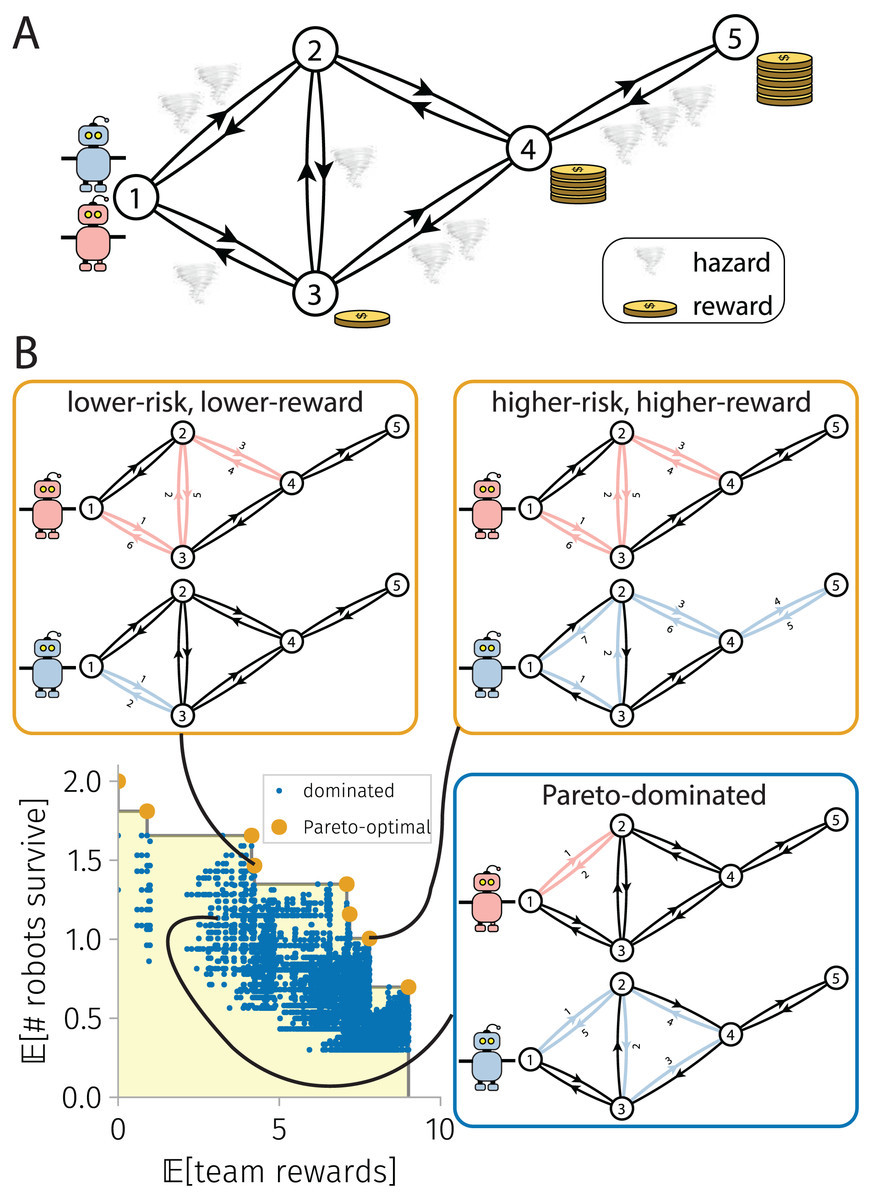
Figure 1: The bi-objective team orienteering in hazardous environments (BOTOHE) problem.
(A) A team of robots are mobile on a directed graph whose nodes offer a reward to the team if visited by a robot and arcs present a probability of destruction to robots that traverse them (tornado: 1/10 probability of destruction). The task is to plan the trails of the robots to maximize the expected reward collected and the expected number of robots that survive. (B) Pareto-optimal and -dominated robot-team trail plans scattered in objective space, with two Pareto-optimal plans and one Pareto-dominated plan shown.{kind=link}
Three interesting features of the BOTOHE are: (1) for the survival objective, robots (a) risk-aversely avoid visiting dangerous subgraphs despite rewards offered by nodes therein and (b) take the safest closed trails to visit the nodes assigned to them; (2) for the reward objective, the robots (a) daringly visit dangerous subgraphs to attempt collection of the rewards offered by nodes therein, (b) visit the lower-risk and higher-reward subgraphs earlier in their trails, and (c) build node-visit redundancy into their trail plans (i.e., multiple robots plan to visit the same node despite zero marginal reward for a second, third, and so-on visit) to make the team-reward robust to the loss of robots during the mission; and (3) comparing (1a) and (2a), the two objectives are inherently conflicting, as the robots must risk their survival while taking their trails to visit nodes and collect rewards.
To handle the conflict between the reward and survival objectives in the BOTOHE, we search for the Pareto-optimal set (Pardalos, Žilinskas & Žilinskas, 2017; Branke et al., 2008) of robot-team trail plans. By definition, a Pareto-optimal robot-team trail plan cannot be altered to give a higher expected reward without lowering the expected number of robots that survive—and vice versa. The Pareto front is the set of expected (rewards, survivals) objective vectors corresponding with the Pareto-optimal set of robot-team trail plans. Figure 1B illustrates. As opposed to aggregating the two objectives into a single, scalar objective, a Pareto front (i) reveals the tradeoffs between expected rewards and robot survivals and (ii) allows us to delay placement of quantitative preferences on each of the two objectives. Later, a human decision-maker presented with the Pareto-front can examine the tradeoffs then make an informed selection of a Pareto-optimal robot-team trail plan that suites their preferences/values at the moment. E.g., for a team of aerial robots on a covert information-gathering mission in an adversarial environment, a human must choose how to balance (a) the utility gained from obtaining images of the locations of interest with (b) the possible loss of (expensive) robots due to attacks.
To search for the Pareto-optimal set of robot-team trail plans in the BOTOHE, we specify, implement, and benchmark a bi-objective ant colony optimization (ACO) algorithm (Iredi, Merkle & Middendorf, 2001), guided by heuristics. We adopt the ACO meta-heuristic (Dorigo, Birattari & Stutzle, 2006; Bonabeau, Dorigo & Theraulaz, 1999; Blum, 2005) for the BOTOHE for several reasons. Generally, ACO, a swarm intelligence method, excels at searching for (near-)optimal trails on graphs. In ACO, a simulated colony of decentralized ants constructs trails stochastically and iteratively while (1) collectively learning from feedback (i.e., computed objective values associated with trails they construct) by laying pheromone on their constructed trails in proportion to their quality (i.e., objective value) and (2) during trail construction, balancing (a) exploitation of the colony’s memory of good trails via biasing towards taking arcs with high pheromone and (b) exploration of new trails via stochasticity and pheromone evaporation. (As the search proceeds, the colony gradually switches from exploration to exploitation.) Advantageously, ACO allows us to incorporate TOHE-specific heuristics to bias ants’ trail construction in the beginning of the search and accelerate convergence. ACO handles our bi-objective problem by (1) assigning ants to specialize to different regions of the Pareto front and (2) maintaining two species of pheromone—one for each objective—on the arcs (Iredi, Merkle & Middendorf, 2001). Finally, ACO is computationally efficient (compared to integer program solvers (Pascariu et al., 2021)), straightforward to implement, embarrassingly parallelizable (allocate one ant per thread), and likely extendable to efficiently handle dynamic or online BOTOHE problem variants via exploiting the knowledge stored in the pheromone trail for a warm start to the modified problem (Montemanni et al., 2005; Angus & Hendtlass, 2005; Leguizamón & Alba, 2013; Mavrovouniotis et al., 2020).
For illustration, we solve and analyze a series of three BOTOHE problem instances: (1) a synthetic, two-community graph with random node-rewards and arc-survival-probabilities; (2) an information-gathering mission in the San Diego art museum; and (3) a mission to tag or verify items in the (unfinished) Satsop Nuclear Power Plant used for the Defense Advanced Research Projects Agency (DARPA) Subterranean Robotics Challenge (Ackerman, 2022; Orekhov & Chung, 2022). For each problem, we visualize and discuss (A) the problem setup (graph; rewards, survival probabilities, robot team start); (B) the search progress of ACO in terms of the area under the Pareto-front of robot-team trail plans as a function of iterations; (C) the Pareto-front at the end of an ACO run along with a sample of three Pareto-optimal robot-team trail plans; and (D) the pheromone trails at the end of an ACO run. Further, we quantify the contribution of (a) the greedy heuristics and (b) the pheromone to the search efficiency of ACO through two ablation studies. Diminished search efficiency upon ablation revealed that both the heuristics and pheromone are important for guiding ants towards Pareto-optimal robot-team trail plans. We also benchmark bi-objective ACO against (a) random search and (b) bi-objective simulated annealing. We find that ACO consistently outperforms—or, at worst, performs indistinguishably from—the competitive baseline of simulated annealing.
The bi-objective team orienteering in hazardous environments (BOTOHE) problem
Problem setup
Here, we frame the Bi-Objective robot-Team Orienteering in Hazardous Environments (BOTOHE) problem.
A homogenous team of K robots are mobile in an environment modeled as a directed graph . Each node represents a location in the environment (e.g., a room in a building). Each arc , an ordered pair of distinct nodes, represents a one-way, direct spatial connection (e.g., a door- or hall-way) to travel from node to node . Mobility of the robots implies they may walk on the graph G, i.e., sequentially hop from a node to another node via traversing arc . All K robots begin at a base node . We assume G is strongly connected so that each node is reachable.
Owing to unpredictable and/or uncertain hazards in the environment, a robot incurs a probability of destruction of when, beginning at node , it attempts to traverse arc to visit node . Each outcome (survival or destruction) is an independent event. The arc survival probability map is known, static over the course of the mission, and not necessarily symmetric (owing to e.g., (directional) air/water currents or sunlight or an adversary with limited attack range nearer one node than another).
Each node of the graph G offers a reward to the robot team if visited by one or more robots over the course of the mission. The reward quantifies the utility gained by the team when a robot e.g., delivers a resource to node , takes an image of node and transmits it back to the command center, or actuates some process (e.g., turns a valve) at node . The total reward collected by the team is additive among nodes of the graph. Note, (1) even if a robot is destroyed after leaving a node, the harvested reward from that node is still accumulated by the team; and (2) multiple visits to a node by the same or distinct robot(s) do not give marginal reward over a single visit.
To collect rewards in this hazardous environment, the team of robots must plan a set1 of closed, directed trails on the graph G to follow. A directed trail (Clark & Holton, 1991; Yadav, 2023) is an ordered list of nodes where (i) is the th node in the trail, (ii) for each node in the trail except the last, an arc joints it to the subsequent node, i.e., for , (iii) is the number of arcs traversed in the trail, and (iv) the arcs traversed in the trail are unique, i.e., each arc in the multiset has a multiplicity of one. Note, unlike a path, the nodes in a trail are not necessarily distinct (Wilson, 1979). A closed trail begins and ends at the same node, i.e., , which, here, . Each trail belonging to the robot-team trail plan constitutes a plan because robot may be destroyed in the process of following and thus not actually visit all nodes in . A robot survives the mission if it visits all nodes in its planned trail and returns to the base node. I.e., robot survives the mission if and only if it survived each edge traversal in its trail plan .
We wish to design the robot-team trail plan to maximize two objectives: (1) the expected team reward, , and (2) the expected number of robots that survive the mission, . Both R and S (i) are random variables owing to the stochasticity of robot survival while trail-following and (ii) depend on the robot-team trail plan owing to different rewards among nodes and different dangers among arcs. That is, the BOTOHE problem is:
(1) when given the directed graph G as a spatial abstraction of the environment, the homogenous team of K mobile robots starting at the base node , the node reward map , and the arc survival probability map .
Because the bi-objective optimization problem in Eq. (1) presents a conflict between designing the robot-team trail plan to maximize the expected reward and the expected number of surviving robots, we seek the Pareto-optimal set (Pardalos, Žilinskas & Žilinskas, 2017; Branke et al., 2008) of team-robot trail plans. The conflict is: (1) to maximize survival, a risk-averse robot team would not visit a dangerous region even if large rewards were contained therein, sacrificing reward for survival; (2) to maximize reward, a daring robot team would visit a dangerous region even if only small rewards were contained therein, sacrificing survival for reward. Hence, a utopian robot-team trail plan that simultaneously maximizes both reward and survival objectives is unlikely to exist; the ultimate team trail plan selected for the mission must strike some tradeoff between reward and survival. By definition, a Pareto-optimal (Pardalos, Žilinskas & Žilinskas, 2017; Branke et al., 2008) robot-team trail plan cannot be altered to increase the survival objective without compromising (decreasing) the reward objective —and vice versa. See Fig. 1B and the formal definition below. The Pareto-optimal set of team trail plans is valuable for presenting a portfolio of team trail plans to a human decision-maker, who then (a) examines the possible tradeoffs then (b) ultimately, invokes their values on team-reward vs. robot-survival by selecting a reasonable robot-team trail plan from the Pareto set to execute.
Formal definition of Pareto-optimality and Pareto-front. Plan belongs to the Pareto-optimal set of plans if and only if no other plan Pareto-dominates it. By definition, a plan Pareto-dominates plan if and only if both:
(2)
(3) So, a Pareto-dominating plan is not worse than a Pareto-dominated plan for reward nor for survivability and is better for one or both of them. If a plan were to Pareto-dominate another plan , one would objectively never choose plan over plan , regardless of the values they place on the two objectives. The Pareto front is the set of objective vectors associated with the Pareto-optimal set of team trail plans .
Comparison with TSOP. The BOTOHE problem formulation follows the offline TSOP (Jorgensen et al., 2018) with three modifications: we (i) omit the constraints that each robot survives above a threshold probability (e.g., we accept if one (un-crewed) robot bears much more risk of destruction than another during the mission), (ii) allow robots to follow trails instead of restricting to paths, as paths prevent robots from visiting a given node more than once and thus from e.g., harvesting reward from a leaf node having one in-degree and one out-degree involving the same node, and (iii) specify two objectives instead of one and seek the Pareto-optimal set of team trail plans to examine trade-offs between reward and survival before selecting a team trail plan.
Probability distributions and expectations of and
We now write formulas for the two objectives—the expectations of the team reward and of number of robots that survive the mission —as a function of the robot-team trail plan . These formulas follow from the directed graph G, arc survival probability map , and node reward map . Figure 2 illustrates our notation.
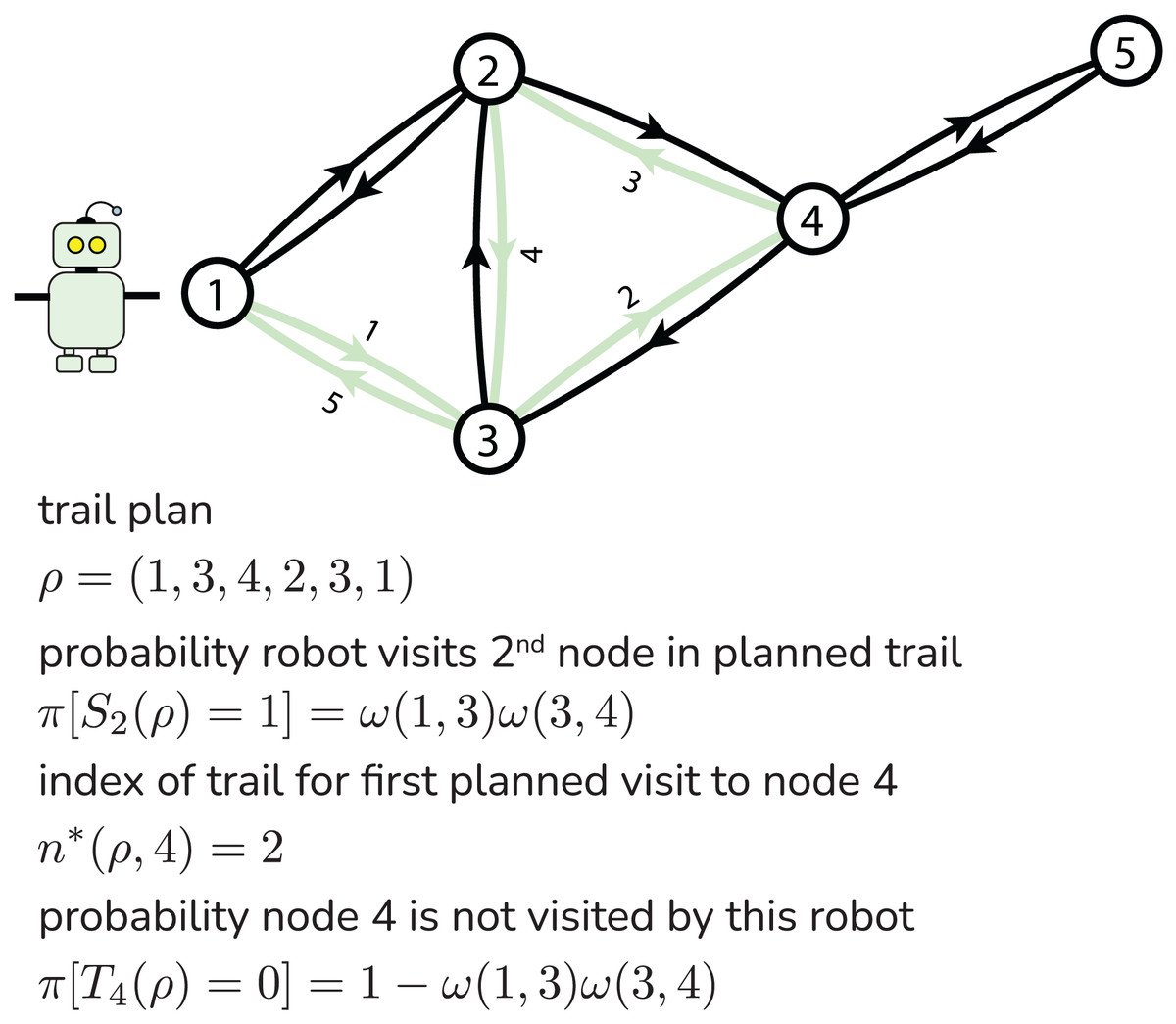
Figure 2: Illustrating notation for a particular robot’s trail plan.
{kind=link}
The survival of a single robot along its followed trail
Central to computing both and is the probability that a robot survives to reach a given node in its planned trail. Let for be the Bernoulli random variable that is one if a robot following trail survives to visit the th node in the trail and zero otherwise. For the event of survival, the robot must survive traversal of all of the first arcs in its trail to visit node . More, the survival of a robot over each arc traversal attempt is an independent event. Therefore, the probability that a robot following trail successfully visits node is the product of the survival probabilities of the first arc-hops in the trail:
(4) The second equality follows because the complement of the event of survival is destruction.
Expected number of robots that survive
Now, we write a formula for the expected number of robots that survive the mission, . The event of survival of each robot is independent of the other robots. Consequently, the number of robots that survive the mission, S, is the sum of the Bernoulli random variables indicating the survival of each robot over its entire planned trail:
(5) Thus, S follows the Poisson-Binomial distribution (Tang & Tang, 2023). Seen from Eq. (5) and the linearity of the expectation operator, the expected number of robots that survive the mission is:
(6) with given in Eq. (4).
Expected team reward
Now, we write a formula for the expected team reward, .
First, we calculate the probability that a robot following a given trail does not visit a given node . Let the Bernoulli random variable be one if a robot following trail visits node and zero if it does not. If node is not in the planned trail , with certainty. Now, suppose node is in the planned trail . Let be the index in the trail where the robot plans its first visit to node :
(7) Then, because the robot visits node if and only if it survives its first arc-hops to first land on node in the trail. So, the probability node is not visited by a robot following trail is:
(8) with calculated using Eq. (4).
Second, we calculate the probability that a given node is visited by one or more robots on a team following trail plans . Only in this event is the reward offered by that node, , accumulated by the team. Let be the Bernoulli random variable that is one if one or more robots on the team with trail plans visit node and zero otherwise (i.e., if and only if zero of the robots visit ). The complement of the event is that all K robots do not visit node (independent events), so:
(9) with in Eq. (8).
Finally, the total team reward collected by the robot-team following trail plan is the sum of the rewards given to the team by each node:
(10) where the reward from node , , is accumulated if and only if node is visited by one or more robots (i.e., iff ). So, the expected reward accumulated over the mission by a robot-team following trail plans is:
(11) with given in Eq. (9).
Summary: computing the objective values associated with a robot-team trail plan
Given a robot-team trail plan , we can compute the expected team reward, , via Eq. (11) and the expected number of robots that survive the mission, , via Eq. (6).
Bi-objective ant colony optimization to search for the pareto-optimal robot-team trail plans
To efficiently search for the Pareto-optimal set of robot-team trail plans defined by Eq. (1), we employ bi-objective (BO) ant colony optimization (ACO) (Iredi, Merkle & Middendorf, 2001). ACO (Dorigo, Birattari & Stutzle, 2006; Bonabeau, Dorigo & Theraulaz, 1999; Blum, 2005; Simon, 2013) is a meta-heuristic for combinatorial optimization problems that can be framed as a search for optimal paths or trails on a graph. As a swarm intelligence method (Bonabeau, Dorigo & Theraulaz, 1999), ACO is inspired by the behavior of ants efficiently foraging for food via laying and following pheromone trails (Bonabeau, Dorigo & Theraulaz, 2000). See Box 1. Variants of the single-robot- and team-orienteering problem have been efficiently and effectively solved by ACO (Ke, Archetti & Feng, 2008; Chen, Sun & Chiang, 2015; Verbeeck, Vansteenwegen & Aghezzaf, 2017; Sohrabi, Ziarati & Keshtkaran, 2021; Chen, Zeng & Xu, 2022; Montemanni, Weyland & Gambardella, 2011) (as well as by other (meta-) heuristics (Gavalas et al., 2014; Dang, Guibadj & Moukrim, 2013; Chao, Golden & Wasil, 1996a; Butt & Cavalier, 1994)), but not the TSOP.
In bi-objective ACO (Iredi, Merkle & Middendorf, 2001), we simulate a heterogenous colony of artificial ants walking on the graph G and, by loose analogy, foraging for food over many iterations. At each iteration, each worker ant stochastically constructs a robot-team trail plan robot-by-robot, arc-by-arc, biased by (i) the amounts of two species of pheromone on the arcs that encode the colony’s memory of trails that gave high reward and high survival and (ii) two heuristics that score the greedy, a priori appeal of each arc for constructing trails that give high reward and high survival. As a division of labor, each worker ant specializes by searching for team trail plans belonging to a different region of the Pareto-front. At the end of each iteration, ants that found Pareto-optimal team trail plans over that iteration deposit reward and survival pheromone on the arcs involved, in proportion to the expected reward and survival, respectively, achieved by the plan. An elitist ant (Dorigo, Maniezzo & Colorni, 1996) maintains a set of global (i.e., over all iterations) Pareto-optimal team trail plans and also deposits pheromone on arcs. Finally, to prevent stagnation and promote continual exploration, a fraction of the pheromone evaporates each iteration. After many iterations, the ACO algorithm returns the (approximate2 ) Pareto-optimal set of robot-team trail plans maintained by the elitist ant.
The heterogenous artificial colony of ants, the pheromone, and the heuristics
Our heterogenous artificial ant colony consists of (i) worker ants and (ii) an elitist ant. Worker ant in the colony is assigned a parameter dictating its balance of the two objectives when searching for Pareto-optimal team trail plans. A closer to zero (one) implies the ant prioritizes maximizing the expected reward (robot survivals ). So, different ants seek team trail plans belonging to different regions of the Pareto front. The elitist ant maintains the global-Pareto-optimal set of team trail plans.
Each arc of the graph is associated with (i) amounts of two distinct species of pheromone, reward pheromone and survival pheromone , and (ii) two heuristic scores and . Both and score the promise of arc for belonging to Pareto-optimal team trail plans that maximize and guide worker ants’ construction of robot-team trail plans. The pheromone is (1) learned, reflecting the past collective experience/memory of the ant colony, and (2) dynamic over iterations, due to deposition by the ants and evaporation. By contrast, the heuristic is static and scores the a priori, greedy/myopic appeal of each arc. We incorporate the heuristics into ACO to accelerate its convergence.
Constructing robot-team trail plans
Each iteration, every worker ant stochastically constructs a team trail plan by sequentially allocating trails to the robots while (conceptually) following the closed trail the ant designs for each robot. Computing the objectives achieved under each plan made by each ant, via Eqs. (6) and (11), gives the colony data . This data is used by the worker ants to deposit pheromone on the arcs and by the elitist ant to update the global Pareto-optimal set.
A worker ant constructs a robot trail by iteratively applying a stochastic, partial-trail extension rule until the closed trail is complete. Suppose an ant with objective-balancing parameter is constructing the closed trail for robot , , and currently resides at node . Namely, the ant has selected (i) the trails for the previous robots, , and (ii) an incomplete/partial trail for robot , , giving its first arc-hops. The ant extends the partial trail for robot by choosing the next node via a roulette-wheel selection of outgoing arcs of not yet traversed in . Specifically, the probability of next hopping to node across arc not yet traversed in the partial trail is:
(12) The partial trail is more likely to be extended with if arc has more pheromone and/or greedy heuristic appeal —with more or less emphasis on the reward or survivability pheromone/heuristic depending on the ant’s . Note, the probability of transitioning to a node is zero if or if arc was already traversed in the partial trail . Iteratively extending the partial trail using Eq. (12), the ant completes the trail for robot after it traverses the self-loop of the base node, , signifying an end. Then, the ant begins trail construction for robot if or completes its team trail plan if .
Heuristics. For the survivability objective, we score the desirability of arc with the probability of the robot surviving traversal of that arc, . This survival heuristic is myopic because it does not consider survivability of arcs later in the trail. For the reward objective, we greedily score the desirability of arc with the expected marginal reward the team receives by robot visiting node next, which is if (i) none of the previous robots visit node , (ii) node is not planned to be visited earlier in the trail of robot , and (iii) robot survives its hop to node and zero otherwise:
(13) with the indicator function. This reward heuristic is myopic because it does not account for rewards robot could collect further along the trail nor the trails of the remaining robots on the team. Note, to prevent either heuristic from being exactly zero (resulting in never selecting that arc), we add a small number to each heuristic.
Pheromone update
At the end of each iteration, we update the pheromone maps and to capture the experience of the ants in finding Pareto-optimal robot-team trail plans, better-guide the ants’ trail-building in the next iteration, and prevent stagnation (premature convergence).
The pheromone update rule is:
(14) with the evaporation rate (a hyperparameter) and the amount of new pheromone deposited on arc by the ants.
Evaporation, accomplished by the first term in Eq. (14), removes a fraction of the pheromone on every arc. This negative feedback mechanism prevents premature convergence to suboptimal trails and encourages continual exploration.
Deposition, accomplished by the second term in Eq. (14), constitutes indirect communication to ants in future iterations about which arcs tend to belong to Pareto-optimal team trail plans and the value of the expected reward and robot survivals achieved under those plans. First, the ants collaborate by (i) among the worker ants, comparing the solutions constructed this iteration to obtain the iteration-Pareto-optimal set of plans and (ii) worker ants sharing the solutions constructed this iteration with the elitist ant, who then updates the global-Pareto-optimal set. Second, the worker ants with an iteration-Pareto-optimal team trail plan execute their constructed plan while depositing pheromone on the arcs. Third, the elitist ant executes all global-Pareto-optimal team trail plans while depositing pheromone on the arcs. Each ant deposits both reward and survival pheromone in proportion to the reward and survival objectives, respectively, achieved under the plan they are following. (The value of the objective is analogous with food quality). Specifically, amalgamating the iteration- and global-Pareto-optimal team trail plans into a multiset , arc receives pheromone:
(15) where counts the number of times arc appears in team trail plan . By construction, arcs that receive the most reward (survival) pheromone frequently belong to trails in the Pareto-optimal team trail plans with high reward (survival).
We initialize the pheromone maps as uniform: for each arc , and . First, compared to the amount of pheromone that could accumulate over iterations, this small quantity allows the heuristic to dominantly bias the beginning of the search. Second, this initialization accommodates different numbers of robots and ranges of rewards for different problems.
Shared vs. per-robot pheromone maps
The reward and survival pheromone maps are shared by the ant colony as a form of collective memory of arcs that led to Pareto-optimal trails with high expected reward and survival. Through sharing the two pheromone maps, the ants in the colony, despite focusing on different regions of the Pareto-front, collaborate in finding Pareto-optimal robot-team trail plans. More, seen in the trail-construction rule in Eq. (12) and the pheromone-laying rule in Eq. (14), each ant uses the same pair of pheromone trails to construct the trail plan for all of the robots. (Still, through the heuristic in Eq. (13), when an ant is sequentially allocating trails to the robots, it is aware of the trail plans for the previously-planned robots when constructing the trail plan for robot .) A contrasting approach is to maintain a distinct, independent pair of pheromone maps for each robot on the team (Bell & McMullen, 2004). This would allow pheromone to explicitly promote sending the first robot to one region of the graph, the second robot to a different region, and so on. However, allocating a pair of pheromone trails to each robot would require more memory and seems to conflict with the inherent permutation-invariance in the homogenous team of robots. Though, order could be imposed onto the robots after their trails are assigned, based on features of their trails.
Area indicator for pareto-set quality
From iteration-to-iteration, we measure the quality of the global (approximate) set of Pareto-optimal robot-team trail plans, tracked by the elitist ant, using the area in objective space enclosed between the origin and the (approximated) Pareto-front (Cao, Smucker & Robinson, 2015; Guerreiro, Fonseca & Paquete, 2020). Formally, the quality of a Pareto set is the area of the union of rectangles in 2D objective space:
(16) illustrated with the shaded yellow area in Fig. 1B. To disallow one objective to dominate the area indicator, we report the normalized area indicator by first normalizing the expected (i) survival by the number of robots and (ii) reward by the sum of rewards over nodes.
Baseline search method: simulated annealing
As a competitive baseline against which to benchmark ACO, we also implemented a bi-objective simulated annealing (SA) algorithm (Kirkpatrick, Gelatt & Vecchi, 1983; Simon, 2013; Zomaya & Kazman, 2010) to search for the Pareto-optimal set of robot-team trail plans.
Inspiration for and idea behind simulated annealing
In metallurgy and materials science, annealing is the process of heating a crystalline material to a high temperature, then cooling it slowly to improve its crystallinity (i.e., reduce defects) and, thereby, enhance some property (e.g., ductility) (Callister & Rethwisch, 2020).
From a statistical mechanics (Chandler, 1987) perspective, a material is an atomistic system characterized by an energy landscape that assigns a potential energy to each configuration of the atoms. For realistic atomistic systems, the energy landscape is high-dimensional and multi-modal. At high temperatures, an atomistic system fluctuates wildly and broadly explores its energy landscape. The system can climb energy barriers and, consequently, visit different basins hosting various local minima. On the other hand, at lower temperatures, energy fluctuations reduce, and the system becomes trapped in a specific basin corresponding with some local minimum.
In the process of annealing a material, the high temperature in the beginning allows the atomistic system to escape a meta-stable basin hosting a local minimum corresponding with many defects. Then, as the system is cooled, it settles into some basin of the energy landscape hosting a lower-energy local minimum corresponding with a more crystalline (i.e., fewer defects) material.
Inspired by this, simulated annealing (SA) (Kirkpatrick, Gelatt & Vecchi, 1983; Simon, 2013; Zomaya & Kazman, 2010) is a method to search for a global-optimal solution to a multi-modal optimization problem via iteratively and stochastically evolving a solution. SA draws an analogy between the objective function of the optimization problem and the energy landscape of an atomistic system. Particularly, SA borrows the Metropolis Markov chain Monte Carlo simulation of an atomistic system under the canonical statistical mechanical ensemble (Frenkel & Smit, 2023), but it decreases the temperature as the search proceeds to mimic cooling. At the beginning of the search, when the temperature is high, SA is highly exploratory by often moving to a worse solution than the current one. Thereby, SA can escape local minima and broadly search the solution space. As the temperature decreases, SA becomes more exploitative by focusing on improving the current solution and settling into exploration of a specific basin of the objective function—hopefully, one that contains a good extremum.
To apply an SA algorithm for a given optimization problem, we must devise (Simon, 2013): (1) a method to randomly perturb the current solution to obtain a neighboring solution as a proposed move; and (2) the cooling schedule by which the temperature decreases over iterations to control exploration transitioning to exploitation.
Bi-objective SA of the TOHE problem
To apply SA to our bi-objective TOHE problem, we run single-objective SA to minimize a sequence of scalarized objective functions of the robot-team trail plan :
(17) with the weight on the reward objective that we adjust to scan the Pareto-front. The notation emphasizes the analogy of the scalar objective function with the energy of an atomistic system; the robot-team trail plan is analogous to the configuration of an atomistic system.
To search for the robot-team trail plan that minimizes for a fixed , SA evolves a single robot-team trail plan over many iterations. We begin with an initial robot-team trail plan . Throughout the search, we archive any minimum-energy team trail plan (minimum over all plans evaluated over the search so far) to avoid losing it via an accepted but ultimately unhelpful perturbation. At each iteration, SA (1) with probability , replaces the current solution with , resembling elitism; (2) randomly perturbs the current robot-team trail plan to obtain a new, neighboring solution then (3) stochastically decides to accept or reject this perturbation based on the change in energy and the current temperature T then (4) reduces the temperature T to decrease exploration. After the iterations are exhausted, SA returns the lowest-energy team trail plan .
To search for the Pareto-optimal set of robot-team trail plans according to Eq. (1), we run a sequence of single-objective SA minimizations of the scalarized objective function in Eq. (17) with a successively increasing weight on the reward objective to scan the Pareto front. At the beginning of each SA episode, we (1) set the initial robot-team trail plan to be the lowest-energy (according to the previous ) plan observed during the recent SA episode for a warm start and (2) reset the temperature to the initial (high) temperature to increase exploration, now that the objectives are weighted differently. The approximate Pareto-optimal set obtained by our bi-objective SA approach is the Pareto-optimal subset of the optimal robot-team trail plans found from each SA minimization of a scalarized objective function.
Initialization. We begin bi-objective SA with wr = 0 and an initial trail plan where all robots stay at the base node for maximal survival.
Sampling a neighbor team-trail plan. We sample a robot-team trail plan that neighbors the current plan by randomly perturbing each robot’s trail plan , through random selection of: (i) insert a random new node into the trail, (ii) delete a random node in the trail, (iii) swap two random nodes in the trail, (iv) substitute a random node in the trail with another random node; (v) delete a random segment of the trail, or (vi) reverse the trail. Unlike a search space consisting of paths in a complete graph, significant coding effort was required to sample perturbations that maintain a feasible trail on the graph.
Acceptance rules. Given the proposed new state , we compute the difference in energy, , from the current state . If , where is lower in energy than , we replace the old trail plan with the new, better trail plan . If , where is higher in energy than , we replace the old trail plan with the new, worse trail plan with probability and reject it otherwise. The new, worse plan is unlikely to be accepted if (i) it is much higher in energy (i.e., is large) or if (ii) the temperature T is low. Hereby, the temperature controls exploration of the space of robot-team trail plans.
Cooling schedule. We adopt an exponential cooling schedule: for each iteration of SA, , where α is the cooling rate, with initial temperature . We can set the initial temperature as relatively low; thanks to our warm start on the robot-team trail plan from the previous SA minimization with only slightly less, less exploration should be needed compared to initiating with a random robot-team trail plan.
Partitioning the iterations to different regions of the Pareto front. Given a budget of total iterations for bi-objective SA, we run through a sequence of weights equally-spaced on to scan the Pareto-front. For each , we run a single-objective SA for iterations.
Standardization of the objectives. Different problems concern different numbers of robots and distributions of arc-survival probabilities and node-rewards. To (1) properly balance the two objectives in the scalarized objective function in Eqs. (17) and (2) make temperature values transferrable across problems, we standardize the expected rewards by the sum of rewards over all nodes and the expected survival by the number of robots when computing .
Comparing bi-objective ACO and SA. ACO maintains a population of robot-team trail plans over each iteration, while SA evolves just one. For SA, disadvantageously, one must set the number of iterations a priori; incrementally adding more iterations is not effective since we have already scanned the Pareto-front. By contrast, adding more iterations to ACO is quite natural. Consequently, when comparing ACO and SA in our benchmarks: (1) we divide the total number of SA iterations by to give each the same number of robot-team trail-plan evaluations for proper comparison and (2) for each budget of iterations, we run a distinct bi-objective SA from scratch and plot its performance as a point. Explaining (2), the progress of a longer SA run at iteration is distinct from a shorter SA run at iteration because of the different dynamics of the weight and temperature T.
Results
We now implement bi-objective ant colony optimization (ACO) to search for Pareto-optimal robot-team trail plans for three instances of the bi-objective team orienteering in a hazardous environment (BOTOHE) problem.
While the first example is a random, two-community graph, the second and third examples are based on real environments, namely an art museum and an abandoned nuclear power plant.
For each case study, we visualize the results in Figs. 3–5 containing:
-
(A)
the problem setup, i.e., the graph, node–to–reward map, arc–to–survival-probability map, and robot team at the start;
-
(B)
the search progress of bi-objective ACO—guided by both (i) static heuristics that greedily score the appeal of traversing a given arc and (ii) the dynamic pheromone maps that encapsulate the memory of the ant colony over previous iterations—in terms of the quality of the Pareto-front, measured by the area indicator, over iterations (average and standard deviation over four runs);
-
(C)
the final Pareto-front found by a run of ACO, along with a sample of three Pareto-optimal robot-team trail plans to intuit the reward-survival tradeoff; and
-
(D)
the learned reward and survival pheromone trails at the end of ACO.
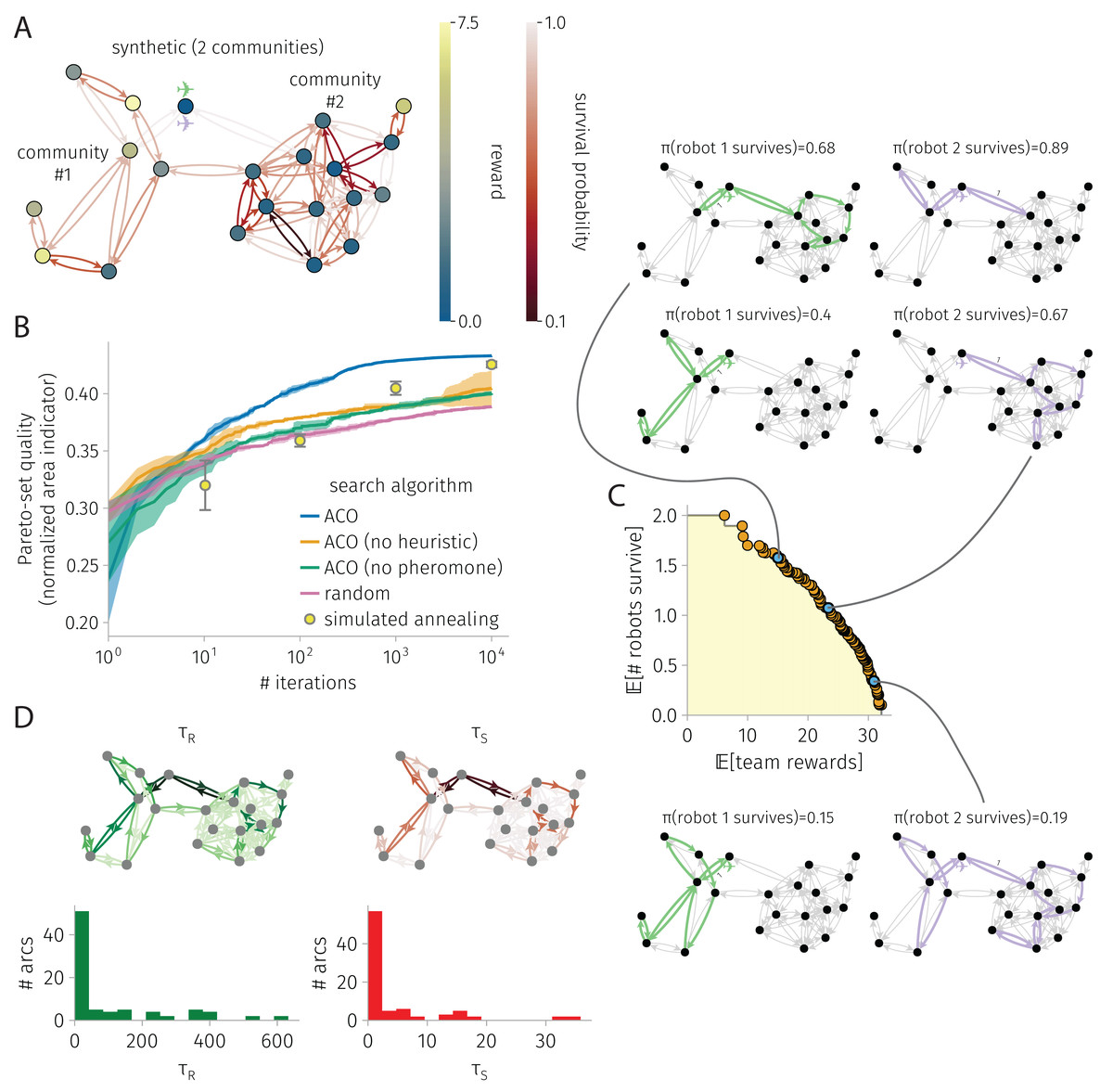
Figure 3: BOTOHE problem on a random, two-community graph.
(A) Problem setup: the graph, node–to–reward map, arc–to–survival-probability map, and robot-team start. (B) Search progress of various algorithms (mean, standard deviation over four runs). (C) Pareto front of robot-team trail plans at the end of an ACO run and a sample of three plans. (D) Pheromone trails at the end of a run of ACO.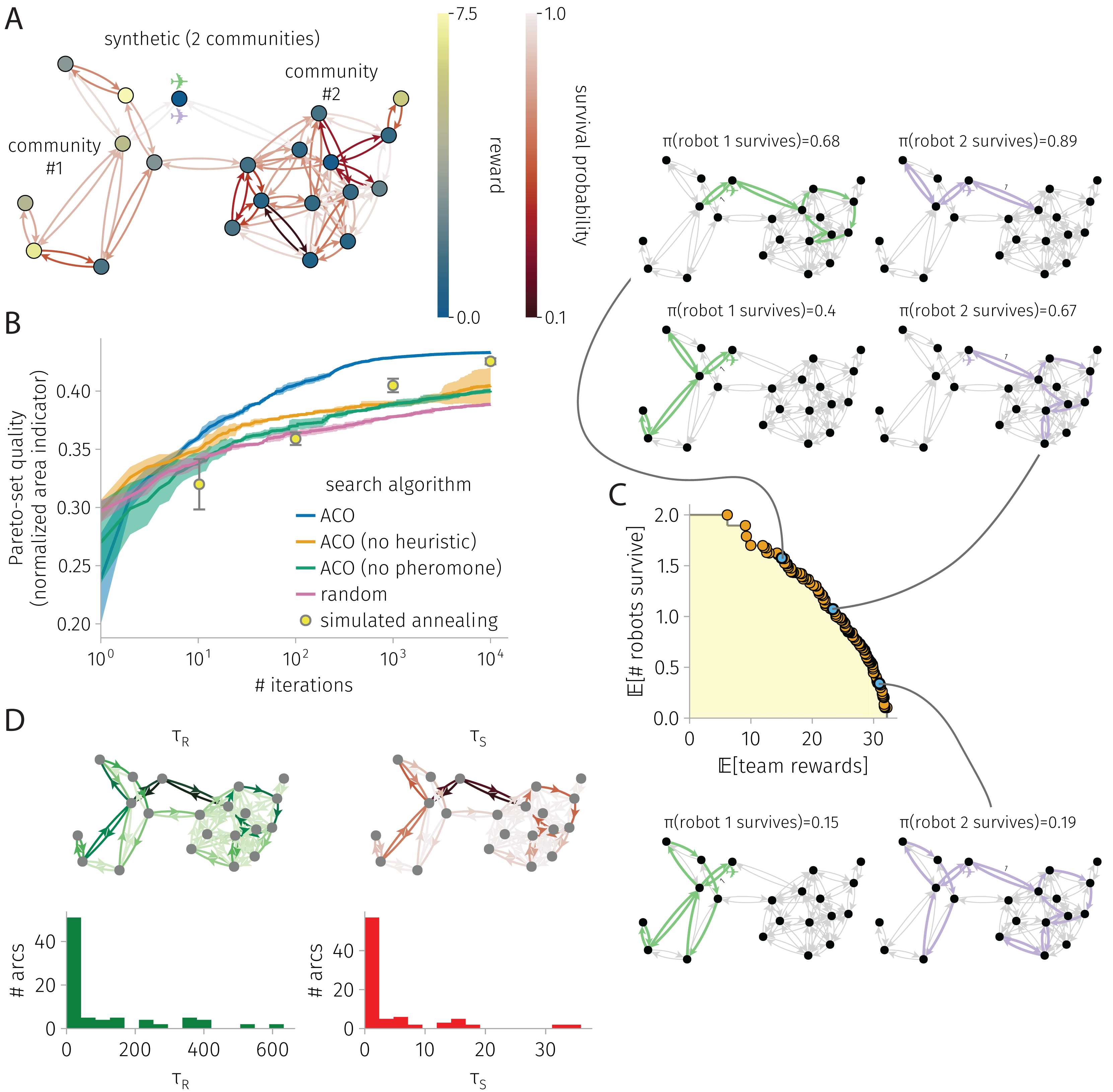{kind=link}
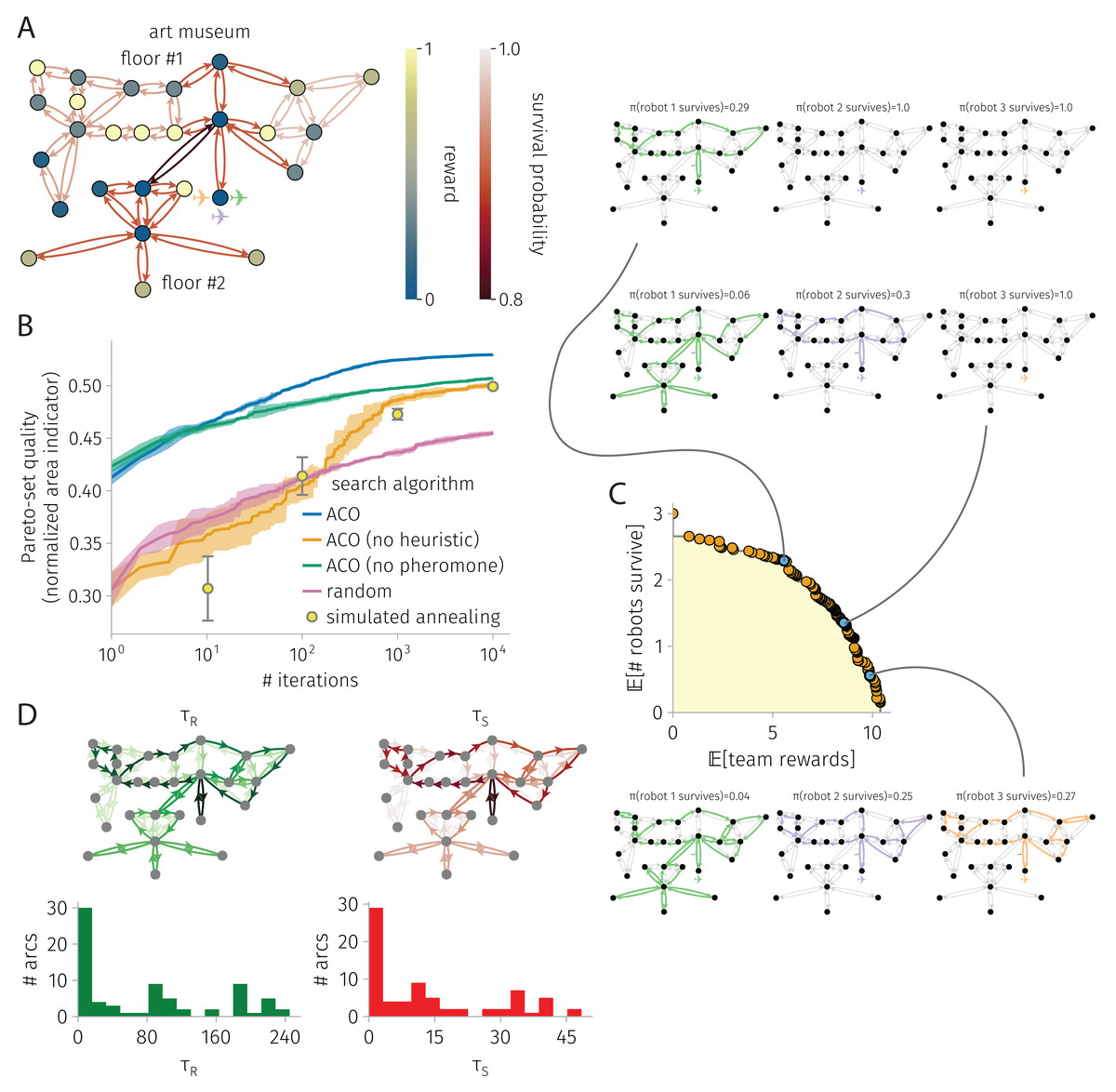
Figure 4: BOTOHE problem in the San Diego Art Museum.
(A) Problem setup: the graph, node–to–reward map, arc–to–survival-probability map, and robot-team start. (B) Search progress of various algorithms (mean, standard deviation over four runs). (C) Pareto front of robot-team trail plans at the end of a run of ACO and a sample of three plans. (D) Pheromone trails at the end of a run of ACO.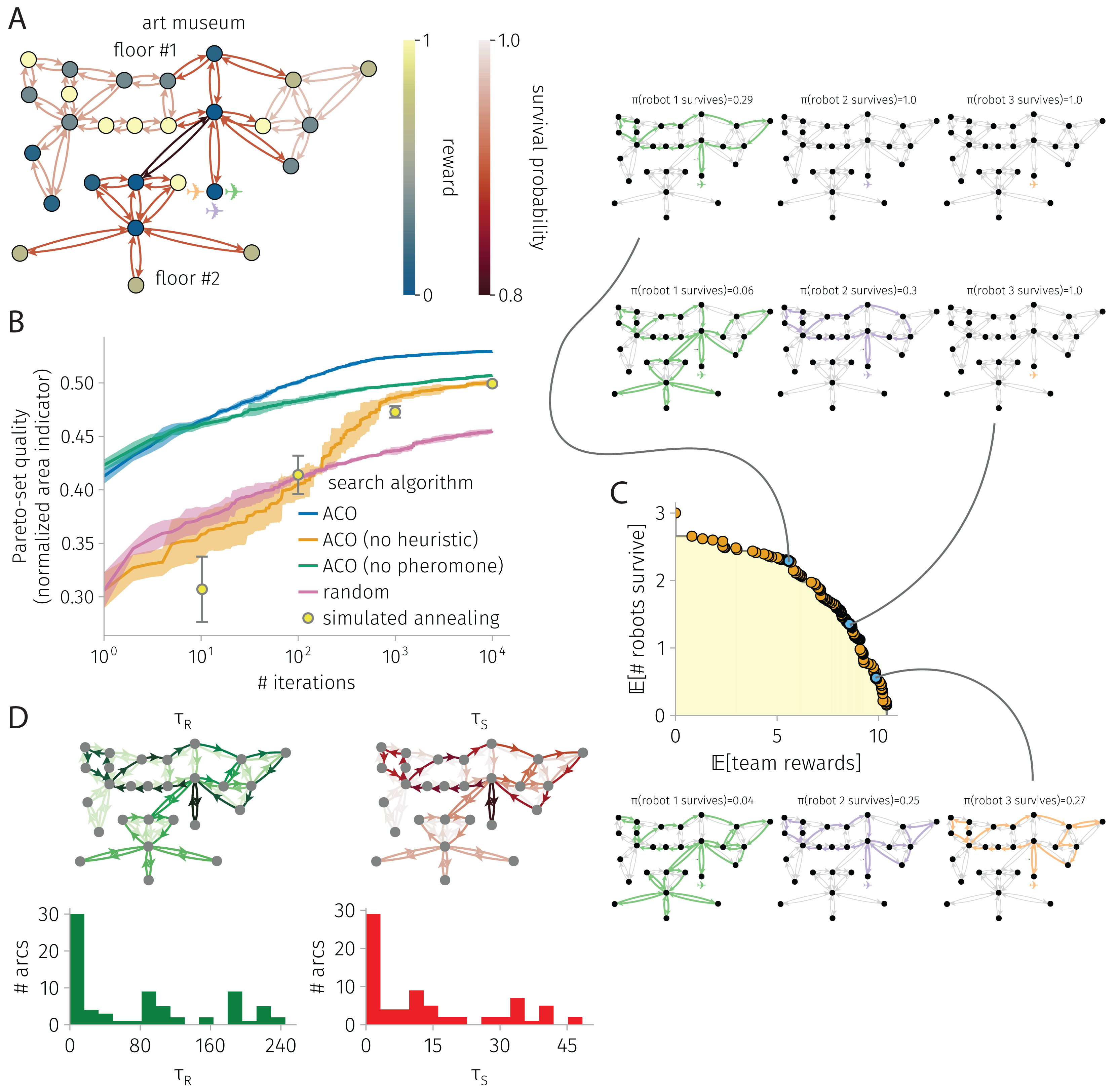{kind=link}
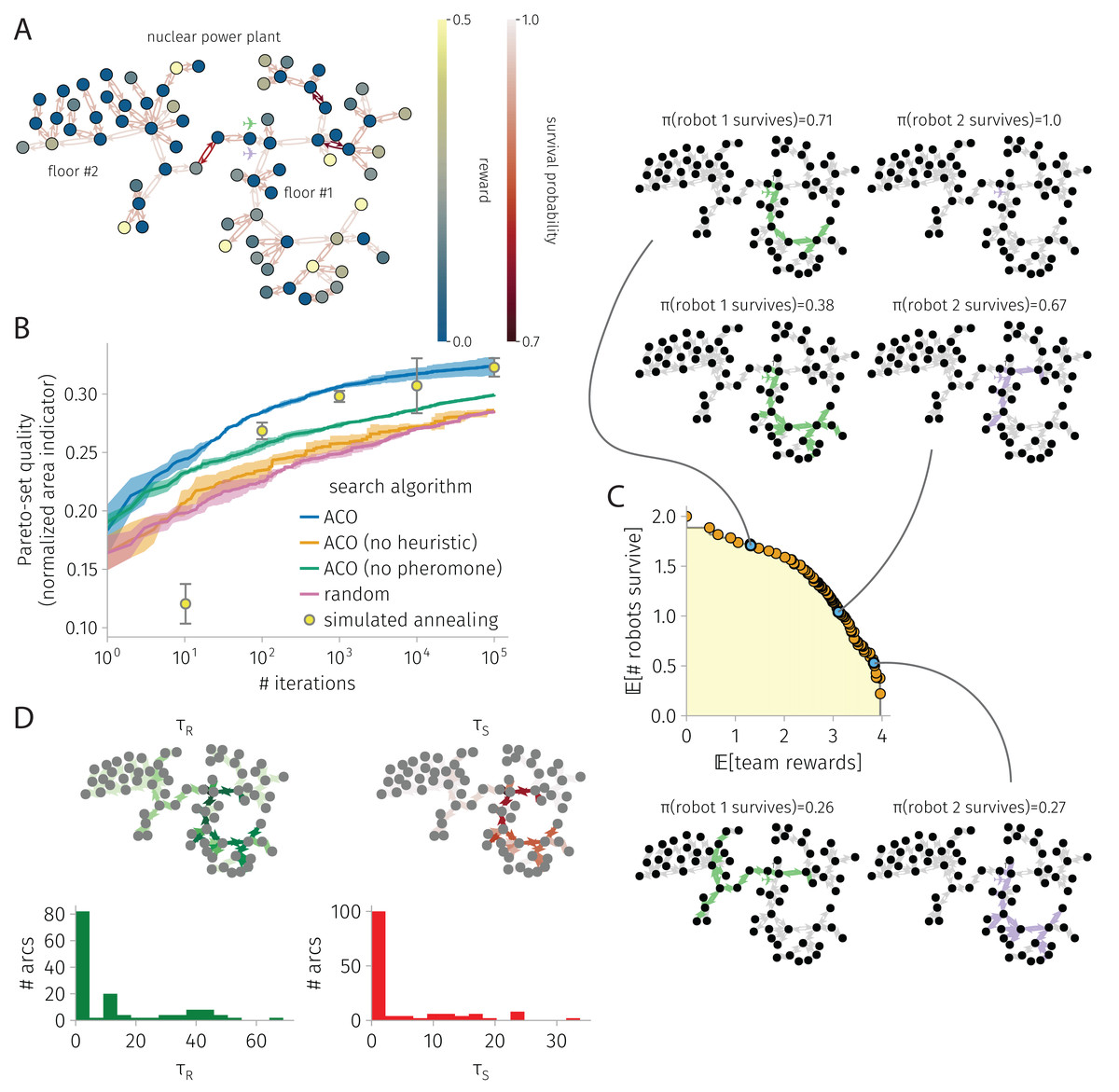
Figure 5: BOTOHE problem in the Satsop Nuclear Power Plant.
(A) Problem setup: the graph, node–to–reward map, arc–to–survival-probability map, and robot-team start. (B) Search progress of various algorithms (mean, standard deviation over four runs). (C) Pareto front of robot-team trail plans at the end of a run of ACO and a sample of three plans. (D) Pheromone trails at the end of a run of ACO.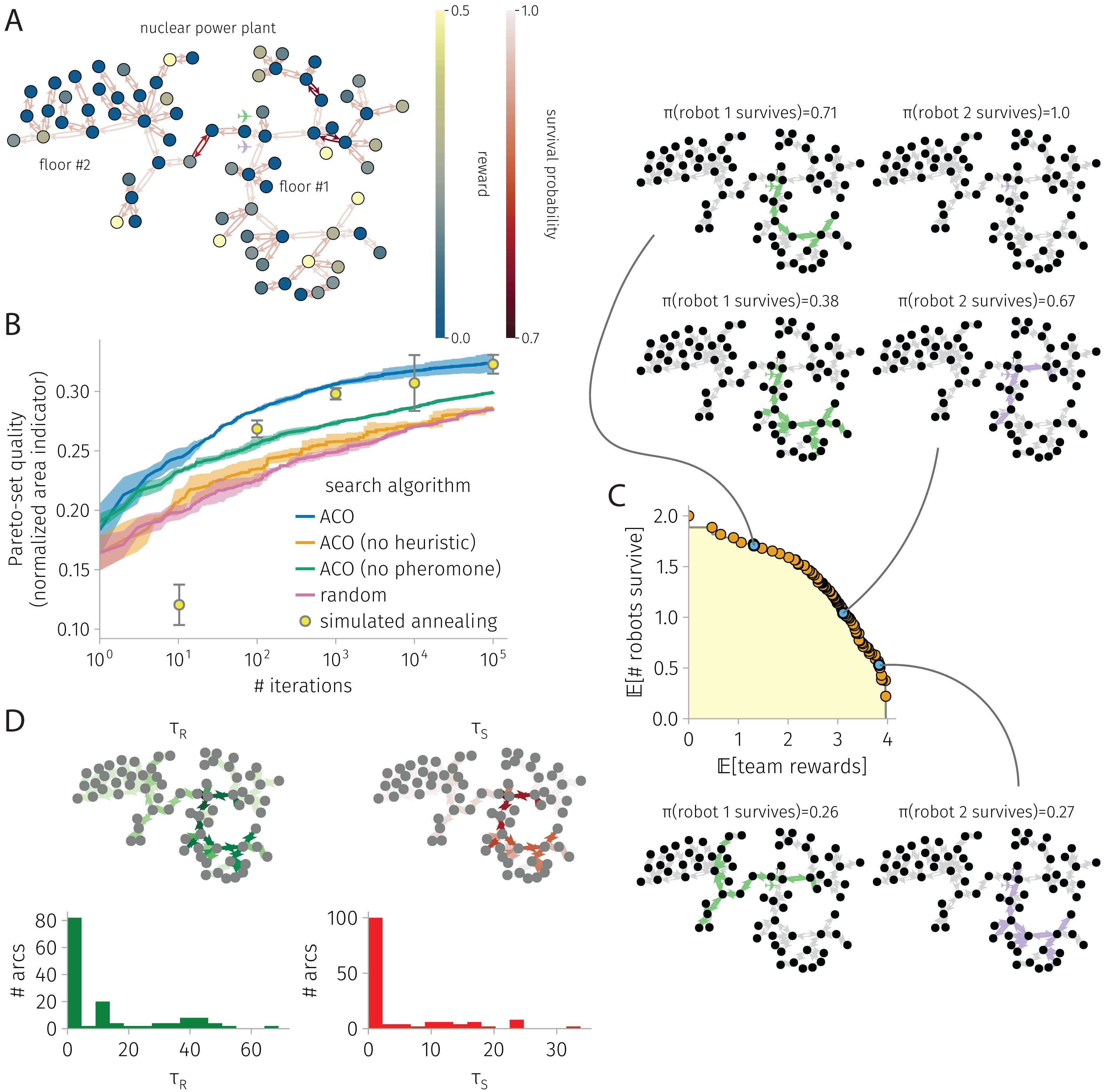{kind=link}
More, we compare the search progress of ACO with benchmarks in panel (B):
ACO with heuristics ablated, i.e., where for all arcs , to quantify the contribution of the heuristics for guiding the search;
ACO with pheromone ablated, i.e., where statically for all arcs, to quantify the contribution of the pheromone for guiding the search;
a (naive) random search where statically ;
a completely different and competitive search algorithm, bi-objective simulated annealing (SA).
Our Julia code to run ACO and SA reproduce our results in full is available at https://github.com/SimonEnsemble/BO_ACO_TOHE.
ACO settings. Our simulated ant colony comprises artificial ants. We conduct 10,000 to 100,000 iterations depending on the problem. We set the pheromone evaporation rate at .
SA settings. For the exponential cooling schedule, we experimentally found and to give good improvement in the solution in the latter-portion of the SA runs.
Synthetic graph with two communities
Figure 3 shows the results for a BOTOHE problem on a synthetic, random graph containing two communities.
Setup. Figure 3A shows the problem setup. We sampled the two-community graph from a stochastic block model. Community #1 was assigned eight nodes; community #2: 12 nodes. The probability of joining (both ways) a pair of nodes both in community #1 and both in community #2 was 0.3 and 0.4, respectively; and for two nodes in distinct communities, much lower: 0.025. We assigned a reward to each node by sampling from a distribution based on community membership (both Gaussian and truncated below zero; , ; , ). We sampled arc survival probabilities from a distribution regardless of community membership (Gaussian with , , truncated below zero and above one). At the base node, robots begin.
Search progress. Figure 3B shows the search progress of ACO in terms of the normalized area indicator of the Pareto-front of robot-team trail plans over iterations. After 10,000 iterations, the area indicator for ACO plateaus, suggesting convergence. By comparison, ACO without the heuristics and ACO without pheromone trails perform quite poorly, but better than random search. More, ACO outperforms the competitive SA baseline. Reflecting the competitiveness of SA, at 1,000 and 10,000 iterations, SA outperforms ACO without the heuristic and ACO without the pheromone. We conclude both the heuristic and pheromone are important in ACO for this problem.
Pareto-front and sample of Pareto-optimal robot-team trail plans. Figure 3C shows the Pareto-front at the end of an ACO run. The yellow highlighted region represents the (albeit, un-normalized) area indicator that scores the quality of the Pareto-front. Three Pareto-optimal robot-team trail plans are highlighted, running down the Pareto front: high expected survival with low expected reward; medium survival and reward; and high reward with low survival. In the high survival, low reward plan, the first robot explores one node of community #1 then takes a safe closed trail through community #2, while the other robot visits only three nodes by crossing safe arcs. In the medium survival and reward plan, we see more coverage and division of labor among the two robots. The first robot visits five nodes in community #1 while avoiding the most dangerous arc within it. Meanwhile, the second robot takes a safe closed trail to visit many nodes in community #2. Finally, in the high reward low survival plan, we see even more coverage, some division of labor, and also node-visit redundancy. The first robot visits all nodes in community #1 while avoiding the most dangerous arc. The second robot visits many nodes in community #2, then enters community #1 to reap the rewards therein in the case that the first robot fails. This node-visit redundancy in the team trail plan makes the team reward robust against the failure of one of the robots.
Pheromone trails. Finally, Fig. 3D shows the learned pheromone trails at the end of one of the ACO runs. First, the distribution of pheromone exhibits a positive skew; most arcs contain only a small amount of pheromone. Second, the reward and survival pheromone maps appear similar; the Pearson correlation coefficient between the reward and survival pheromone on an arc is 0.95. Third, comparing with the problem setup, the reward pheromone on an arc exhibits a small correlation (coefficient: 0.2) with the reward on its destination node, and the survival pheromone on an arc exhibits a small correlation (coefficient: 0.45) with the survival probability. The lack of a strong correlation further evidences that the pheromone contains information beyond the greedy heuristics that inspect these. Finally, the asymmetry, where sometimes arc has high pheromone but arc has low pheromone, allows promotion of the robot to take a counter-clockwise closed trail over a clock-wise one.
ACO runtime. On an Apple M1 iMac, an ACO run on this graph with 21 nodes and 84 arcs consisting of 10,000 iterations and routing two robots took 7 min.
Art museum
Figure 4 shows the results for a BOTOHE problem in the San Diego Art Museum.
Setup. Figure 4A shows the problem setup, where a team of mobile robots are assigned an information-gathering mission in the San Diego Museum of Art.
We spatially model the art museum as a directed graph . The set of 27 nodes represents the 23 art galleries/rooms, the outside entrance to the building (base node ), the main entrance rooms on the first and second floors, and the stairway. The set of arcs represents direct passages/doorways between the rooms or stairs.
Suppose, when a robot visits an art gallery in the museum, it images the art there and transmits this image back to the command center. The utility of each image to the command center is scored by the node reward map assigning rewards of (i) 2/3 for large galleries, (ii) 1/3 for medium-sized galleries, (iii) 1 for small galleries ([that, supposedly, contain the most valuable art], and (iv) 1/10 for the five galleries in corners of the museum or behind the stairway [that, supposedly, contain the least valuable art]).
Now, suppose traversing the art museum is hazardous for the robots, owing to (i) adversarial security guards that (a) seek to prevent the robots from imaging the art and (b) possess the ability attack and/or capture the robots; (ii) obstacles that the robots could (a) crash into or (b) become entangled in; (iii) difficult terrain (i.e., the stairs). To model risks of destruction or capture, we assign survival probabilities for the arc(s) (i) traversing the staircase of 0.8, (ii) inside and in/out of the main entrance room of 0.9, (iii) on the right side of the first floor of 0.97, (iv) on the left side of the first floor of 0.95, and (v) on the second floor of 0.9. So, the stairway is the most dangerous arc.
The two objectives of the command center are to plan the trails of the robots in the art museum to maximize the (1) expected reward, via robots visiting art galleries, imaging them, then transmitting the images back to the command center, and (2) expected number of robots that return from the mission.
Search progress. Figure 4B shows the search progress of ACO, in terms of the normalized area of the Pareto-front as a function of iterations, in comparison with baselines over 10,000 iterations. Again, ACO outperforms the competitive SA baseline. Both heuristic and pheromone are important contributors to the ACO search progress, as ablating each diminishes performance significantly. ACO, ACO without heuristics, ACO without pheromone, and SA all perform much better than random search.
Pareto-front and sample of Pareto-optimal robot-team trail plans. Figure 4C shows the Pareto-front at the end of an ACO run along with a sample of three Pareto-optimal robot-team trail plans with different reward-survival tradeoffs. In the high-survival, low-reward robot-team trail plan, only a single robot enters the museum to image galleries on the first floor—avoiding the dangerous staircase to the second floor. The other two robots safely stay behind. In the medium survival and reward plan, the first robot covers much of the first floor and daring traverses the dangerous stairway to visit the second floor to image the galleries there. The second robot covers much of the first floor. The third robot safely stays behind. The redundancy in first-floor coverage by the first two robots makes the team reward robots against the failure of the first (second) robot, as then the second (first) robot could still image most of the galleries on the first floor. Finally, in the high reward, low survival plan, all three robots enter the museum. The first robot covers most of the first and, daringly, the second floor. The second and third robots cover most of the first floor. Again, node-visit redundancy, via all three robots covering most of the first floor, makes the team reward robust to the failure of two of the robots on the team. Note, all three of the robots avoid taking the risk to enter the bottom left corner of the first floor, whose galleries offer only a small reward.
Pheromone trails. Figure 4D visualizes the pheromone maps at the end of an ACO run. Again, the pheromone is very unevenly distributed, with most arcs containing comparably very little pheromone. So, indeed the pheromone expresses a strong preference for which arcs to include in robot trails. Remarking on pheromone asymmetry, note the clock-wise vs. counter-close-wise preferences for some closed trails—to promote pursuit of high-reward nodes earlier in the trails to maximize expected reward. Interestingly, the reward and survival pheromone on an arc are very strongly correlated (coefficient: 0.99), but they are very weakly correlated with the reward on the destination node and arc survival probability, respectively (coefficients: 0.09 and −0.01).
ACO runtime. On an Apple M1 iMac, an ACO run on this graph with 27 nodes and 74 arcs consisting of 10,000 iterations and routing three robots took 4 min.
Nuclear power plant
Figure 5 shows the results for a BOTOHE problem in the Satsop Nuclear Power Plant.
Setup. Figure 5A shows the problem setup. The directed graph represents the unfinished Satsop Nuclear Power Plant in Elma, Washington that was used for the Defense Advanced Research Projects Agency (DARPA) robotics challenge held in 2021 (Ackerman, 2022; Orekhov & Chung, 2022) (the Subterranean Challenge Urban Circuit (systems_urban_ground_truth, 2022)). For the robotics challenge, items were placed at different locations—a (fake) survivor, cell phone, backpack, gas, or vent. Suppose the mission is for the robots to visit the nodes containing the items to mark, tag, or destroy the artifacts and confirm the presence or status of the survivors, despite the power plant containing obstacles and adversaries patrolling it. We assigned (1) rewards to each node based on the item present (survivor: 0.5; cell phone: 0.3; backpack: 0.2; gas: 0.15; vent: 0.12) and (2) arc survival probabilities based on the type of traversal or obstacles present (open-area traversal: 0.98; doorway traversal: 0.95; stairway traversal: 0.8; obstacle: 0.75). A team of robots begin at the entrance to the power plant on the first floor.
Search progress. Figure 5B shows the search progress of ACO—the normalized area under the Pareto-front of robot-team trail plans as a function of iterations—in comparison with baselines, over 100,000 iterations. ACO is the best-performing search algorithm over 10, 100, 1,000, and 10,000 iterations; but, at 100,000 iterations, the performance of SA and ACO are indistinguishable. Again, ablating the pheromone or the heuristic in ACO leads to significantly poorer performance; both the pheromone and heuristic are important for guiding ACO’s search. Interestingly, ACO without the heuristic is not much better than random search, suggesting synergy between the pheromone and heuristic.
Pareto-front and sample of Pareto-optimal robot-team trail plans. Figure 5C shows the Pareto-front and a sample of three Pareto-optimal robot-team trail plans at the end of an ACO run. In the low-reward, high-survival plan, the first robots visits the bottom portion of the first floor of the power plant containing the highest rewards while the second robot stays behind for safety. In the medium-reward and -survival plan, the two robots visit highly-overlapping portions of the first floor. In the high-reward and low-survival plan, the first robots daringly visits the second floor, taking the dangerous staircase, then also visits three nodes on the first floor before returning. The second robot visits most of the bottom portion of the first floor containing the highest rewards. Interestingly, the trail plans of the two robots contain little redundancy. And, none of the plans send the robots to the upper portion of the first floor where many nodes offer no rewards yet there are two very dangerous arcs.
Pheromone trails. Figure 5D shows the reward and survival pheromone trails at the end of an ACO run. The pheromone expresses strong preferences for the robot trails to be constructed with certain arcs, indicated by the highly skewed-right distributions. The reward and survival pheromone on an arc are quite correlated (coefficient: 0.97), with a good degree of correlation with the reward on the destination node and arc survival probability, respectively (coefficients: 0.3, 0.25).
ACO runtime. On an Apple M1 iMac, an ACO run on this graph with 73 nodes and 144 arcs consisting of 100,000 iterations and routing two robots took 30 min.
Conclusions and discussion
Teams of mobile robots—ground (wheeled (Chung & Iagnemma, 2016), legged (Wieber, Tedrake & Kuindersma, 2016), or snake-like (Walker, Choset & Chirikjian, 2016)), underwater (Choi & Yuh, 2016), or flying (Leutenegger et al., 2016) robots—have many applications: gathering information, delivering resources, locating and mapping CBRN hazards, fighting forest fires, tracking targets, patrolling for wildlife poachers, inspecting infrastructure, etc. In these applications, the environment may contain hazards or adversaries that can destroy, immobilize, or capture a robot or damage a robot’s sensors or actuators, compromising its functionality for the mission (Trevelyan, Hamel & Kang, 2016). Hazards could emanate from the presence of radiation or corrosive chemicals, extreme temperatures, smoke that obscures obstacles, rough terrain or seas, high winds, dust and debris, etc. For a robot team to perform well on a shared, high-level objective in a hazardous environment, the robots must coordinate their trails while considering the risks of failure, balancing the rewards from visiting locations against the risks to reach them, and including redundancy to make achievement of the objective robust to robot failures.
Heavily inspired by the Team Surviving Orienteers Problem (Jorgensen et al., 2018; Jorgensen et al., 2017; Jorgensen & Pavone, 2024), we framed the bi-objective team orienteering in a hazardous environment (BOTOHE) problem. A team of robots are mobile on a directed graph whose nodes offer rewards when visited by a robot and arcs are dangerous to traverse. We sought the Pareto-optimal set of robot-team trail plans that trade maximizing the expected team reward with maximizing the expected number of robots that survive. With this approach, a human decision-maker can inspect the Pareto-front to see reasonable choices of reward-survival tradeoffs. Then, this decision-maker can make an informed selection of a Pareto-optimal robot-team trail plan for the mission, invoking their values placed on reward vs. robot-survival.
We employed bi-objective ant colony optimization to search for the Pareto-optimal team trail plans, guided by both (i) pheromone trails serving as a collective memory about which arcs led to Pareto-optimal robot team trail plans and (ii) TOHE problem-specific heuristics. We deployed ACO on three BOTOHE problem instances: (1) a synthetic mission on a random two-community graph; (2) an information-gathering mission in an art museum; and (3) an artifact-marking and status-checking mission in a nuclear power plant involved in a DARPA robotics challenge. Despite lacking theoretical guarantees to find the Pareto-optimal set, ACO was effective, easy to implement, and can be readily adapted to handle extensions to the TOHE problem. We found ACO to consistently outperform or, at worst, perform indistinguishably from, bi-objective simulated annealing. Ablating the heuristics or pheromone in ACO both significantly degraded the quality of the Pareto-set of robot-team trail plans. This underscores the importance of pheromone and the heuristics for guiding the simulated ants in ACO to search for Pareto-optimal robot-team trail plans. Finally, inspecting high-survival & low-reward, medium reward & survival, and high-reward & low-survival Pareto-optimal robot-team trail plans for each case study provided intuition about the BOTOHE problem specification and demonstrated the practical utility of our work for planning the trails of a team of robots mobile in a hazardous environment.
Future work
For the BOTOHE, we wish to devise and benchmark ACO variants that: (i) handle the online setting, where the robots adapt their planned trails during the mission, in response to observed failures of robots; (ii) handle the dynamic setting, where, over time, arcs may become more or less dangerous to traverse and nodes may increase or decrease the reward they offer; (iii) run a local search algorithm to improve the robot trails the ants found after each iteration and thereby accelerate convergence (Dorigo, Birattari & Stutzle, 2006), (iv) concurrently extend the planned trails of the robots instead of sequentially allocating their planned trails robot-by-robot (Ke, Archetti & Feng, 2008), and (v) employ multiple ant colonies (Iredi, Merkle & Middendorf, 2001).
Interesting and practical extensions of robot-team orienteering in adversarial/hazardous environments abstracted a graphs include treating (some of these ideas from Ref. Jorgensen et al. (2018)): (i) a heterogenous team of robots with different (a) capabilities to harvest rewards from nodes and (b) survival probabilities for each arc traversal owing to e.g., stealth; (ii) more complicated reward structures, e.g., time-dependent, stochastic, non-additive (correlated (Yu, Schwager & Rus (2014)), multi-category, or multi-visit rewards; (iii) fuel/battery constraints of the robots via nodes representing refueling, recharging, or battery-switching stations (Asghar et al., 2023; Khuller, Malekian & Mestre, 2011; Liao, Lu & Shen, 2016; Yu, O’Kane & Tokekar, 2019); (iv) constraints on the rewards a robot can harvest e.g., for resource delivery applications where each robot holds limited cargo capacity (Coelho, Cordeau & Laporte, 2014); (v) non-binary surviving states of the robots due to various levels of damage; (vi) non-independent events of robots surviving arc-traversals; (vii) risk metrics different from the expected value (Majumdar & Pavone, 2020).
Another interesting direction is to update uncertain survival probabilities associated with the edges of the graph from data over repeated missions (an inverse problem (Burton & Toint, 1992)) under a Bayesian framework. Specifically, suppose we are uncertain about the survival probability of each arc . We have a prior distribution on each . Then, when a robot survives or gets destroyed while following a planned trail during a mission, we update this prior distribution with this data. The trail-planning of the robots over sequential missions may then balance (a) exploitation to harvest the most reward and take what appear to be, under uncertainty, the safest trails and (b) exploration to find even safer trails.