
Temporal-spatial skeleton modeling for real-time human dance behavior recognition using evolutionary algorithms
- Published
- Accepted
- Received
- Academic Editor
- Muhammad Asif
- Subject Areas
- Computational Biology, Algorithms and Analysis of Algorithms, Artificial Intelligence, Computer Education, Data Science
- Keywords
- Artificial neural networks, Data science, Evolutionary algorithm, Skeletal articulation points, Behaviour detection, Feature extraction
- Copyright
- © 2025 Liu and Fan
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Temporal-spatial skeleton modeling for real-time human dance behavior recognition using evolutionary algorithms. PeerJ Computer Science 11:e3359 https://doi.org/10.7717/peerj-cs.3359
Abstract
In the context of online dance instruction, accurately recognizing and assessing students’ movements in real time remains a key challenge due to occlusions, low-resolution input, and inconsistent lighting. To address these limitations, this study proposes a real-time human behavior detection framework that integrates evolutionary algorithms with a skeleton-based deep learning model. The system captures continuous video streams via a Camera Serial Interface (CSI) camera module, extracts skeletal joint coordinates, and models movement through a set of hybrid temporal and spatial features—including torso angle, joint positions, and limb velocity. These features are fused into a frame-level expansion vector, which is subsequently fed into a behavior classifier built on a long short-term memory (LSTM) network. The evolutionary algorithm optimizes the feature representation and classification structure to enhance generalization and avoid local optima. Experimental evaluation on the UTKinect dataset demonstrates that the proposed method achieves an average recognition accuracy of 95.47%, outperforming traditional RGB-and depth-based baselines. Furthermore, the system demonstrates real-time performance with a recognition latency below 0.6 s and frame processing time under 0.08 s. The results validate the effectiveness of multi-feature fusion and evolutionary enhancement in dynamic action scenarios. This framework offers a reliable tool for performance evaluation in online dance instruction and can be extended to domains such as rehabilitation, virtual fitness, and intelligent surveillance.
Introduction
Computer vision applications have become increasingly diverse. Behaviour detection has emerged as a research hotspot in computer science, with significant potential for application in intelligent monitoring and human-computer interaction. At present, behaviour detection technology is primarily employed for monitoring and issuing alarms regarding potential danger and for detecting the behaviour of individuals in outdoor public spaces. This technology can also safely monitor older people and children in indoor settings. However, existing behaviour detection technologies frequently rely on infrared sensors to sense the location of the human body in space, coupled with information concerning the location of objects in the scene, to determine the current behaviour of the human body and any changes therein. While this approach can provide a rough determination of the type of movement in which the human body is engaged, the limitations inherent in the sensor’s working principles prevent the accurate detection of detailed body movements.
With the advent of mobile and wearable devices, Human Action Recognition (HAR) has become one of this field’s most desirable research areas (Li et al., 2021). The primary objective of HAR is to classify human actions and obtain behavioural information, which finds broad application in remote video surveillance, life assistance, and remote surgery or medical treatment. Nonetheless, current HAR research has thus far focused on developing relevant action category databases and conducting action recognition and classification based on RGB video data. However, in dance instruction classrooms, student movements are often subject to frequent occlusions, and formation changes are common. Under such circumstances, the camera responsible for capturing human movement data may encounter obstructions from the background environment or external objects. Consequently, to mitigate this interference, researchers are compelled to initially segment the human body from the intricate background space or preprocess the image when executing action recognition based on RGB video. Although RGB video data enables human-computer interaction from both single-view and multi-view angles, single-view RGB video falls short in effectively dealing with human body occlusion.
In recent years, both machine learning and deep learning have undergone significant advancements, with the application of convolutional neural networks (CNNs) reaching maturity. The theoretical basis of this deep learning model provides an innovative solution for the representation of action features. Moreover, the fusion of evolutionary algorithms with deep learning offers a way to overcome the problem of local optima and also improves the computational efficiency of the algorithm. In the case of action detection in online dance classes, the objective is to predict multiple continuous actions contained within the video, which can be achieved by frame-level action classification. Subsequently, a sliding window-based approach can fine-tune the predicted frame-level expansion class probabilities and obtain the desired output.
Using image processing and recognition classification techniques, the human action recognition based on frame-level skeleton expansion class features first extracts the joint point locations of the human body in the video before extracting action features from the temporal skeleton information to complete human action recognition. This method provides a new approach to analyzing the behaviour of college students in online dance classes. Especially for the online teaching scene of the current education reform, movement recognition can well identify whether the current class students’ movements meet the standards and meet the requirements of the subject. Occlusion handling holds particularly significant importance in object detection. On one hand, occlusion can alter the appearance features of objects and result in the loss of critical information, leading to missed detections and false positives by algorithms, thereby reducing detection accuracy and undermining correct scene understanding. For instance, in autonomous driving scenarios, failure to detect occluded pedestrians poses substantial safety hazards. On the other hand, given the complexity and variability of real-world scenes, occlusion is inevitable, and algorithms lacking robust occlusion handling capabilities struggle to operate stably, demonstrating poor robustness. Moreover, effective occlusion processing enables algorithms to learn object features under various occlusion conditions, enhancing generalization ability and expanding application scope. However, current existing methods still exhibit deficiencies in addressing complex occlusion scenarios, such as limited processing capacity and suboptimal real-time performance. To this end, we detected human behaviors in the video through the behavior detector in the main control module, extracted temporal skeleton information, and established joint behavior models by using the joint space movement Angle and limb association difference of human skeleton. After feature fusion, behavioral features were extracted by using the short and long time memory network, and real-time behavior detectors were trained.
Related works
Action recognition under the deep video
Depth cameras have garnered significant interest from the academic community due to their affordability and operational simplicity. Notably, human action recognition predicated on depth video surpasses recognition based on RGB video. Researchers have conducted extensive investigations into human action recognition using depth video and have presented several innovative contributions toward feature extraction from depth action. These include proposals such as spatiotemporal interest points (Ma & Gan, 2020), joint trajectory maps (JTM) (Wang et al., 2018), 3D point clouds (Han et al., 2017), and skeletal joints. In Peng et al. (2014), text-intensive trajectories through stacked two Fisher vector encoding layers were encoded to improve the detection accuracy of behavioural patterns using aggregated nightly video feature descriptions based on the original work study.
Additionally, Wang et al. (2018) proposed a method for encoding skeletal joint trajectories, representing 3D skeleton sequence data obtained from a depth camera as three 2D images and converting the dynamic information to JTM. A CNN was utilized to learn and identify distinguishing human action features. Furthermore, Xu et al. (2021) uses RGBD sensors as input sensors and computes a set of features based on human pose and motion, image, and point cloud information. Their algorithm employs a hierarchical maximum entropy Markov model, which views human activity as consisting of a set of self-activities. It utilizes a dynamic programming approach to infer a two-layer graphical structure, experimentally demonstrated with impressive results. All the above methods require external wearable sensors to detect video behaviors. However, for difficult movements in online dance classes, wearable devices will affect the teaching effect.
Lv, Nevatia & Lee (2005) presents a technique to extract regional objects by converting videos into frame images and combining the colour and motion information. Wei, Zhang & Chai (2012) proposes a precise 3D skeleton joint position estimation approach by constructing a local pop frame of skeletal node data features, thereby identifying human actions in a depth image sequence. Birk et al. (1979) applies background deduction methods to extract foreground objects, extract histogram-directed fading features (Girsang, 2021), and employ multi-class support vector machines as classifiers for classification, improving accuracy.
Deep learning-based behaviour detection
Deep learning-based approaches are more adept at detecting human actions in video imagery than conventional methods. The Yao & Zhu (2020) combines the Gaussian Mixed Model (GMM) with the K-Means clustering algorithm to classify target objects’ behaviour. In contrast, the Lu et al. (2019) models the target and extracts geometric features of the human body to detect abnormal behaviour in real-time. In recent years, CNN has shown remarkable advantages in image processing and target detection. The Dhillon & Verma (2020) proposed a human action recognition algorithm based on a learning space pyramid representation. This method uses the cosine measure and cross-view quadratic discriminant analysis to calculate the similarity between different behaviour categories, achieving 92.2% accuracy on the Hollywood2 dataset. In the Yang & Tian (2016), a dual-stream CNN tackles behavior detection. First, it extracts spatial appearance features from a single RGB image to create a spatial stream, capturing static visual info of human behavior. Second, it feeds the continuous optical flow map with behavior motion into a deep CNN to extract temporal trajectory features, forming a temporal stream. Finally, the temporal and spatial features are fused to complete the behaviour detection. This feature combination mode of spatial and temporal flows achieves better recognition accuracy. However, the direct convolutional extraction of spatial features may include redundant information, such as the background. Optical flow features are sensitive to light changes, possibly leading to complex backgrounds’ instability.
Convolutional 3D (C3D), a three-dimensional convolutional network, was used by numerous researchers (Hao et al., 2021; Cao, Ren & Sun, 2022) to execute convolutional operations on consecutive video frames in both the temporal and spatial dimensions to more effectively use the temporal information in films. This allowed for capturing human motion information in the video stream and learning behavioural features. Liu & Zhang (2022) and Hu et al. (2021) respectively extracted the apparent features and motion features of each candidate region through dual-channel CNN network, and then calculated the action scores of the candidate regions. Finally, the candidate regions were connected by the optimization algorithm in the time dimension to form action pipelines, and the behavior recognition effect was good. In Choy, Gwak & Savarese (2019), researchers observed the intuitive behavioural expression of bones and joints during human movement and the robustness to external factors such as background and light. They built a platform with behavioural picture acquisition and category detection and extracted behavioural features using Long Short-Term Memory (LSTM) networks to achieve behavioural detection. Convolutional neural networks were combined with the capabilities of LSTM for time series processing to build a behaviour detection approach with spatiotemporal feature fusion (Chen et al., 2019; Gavahi, Abbaszadeh & Moradkhani, 2021), which led to superior results.
Evolutionary deep learning-based action recognition
Action recognition principle and framework
The action recognition detection system comprises three principal modules: the image acquisition module, the master control module, and the display module. Figure 1 illustrates the framework flow. The image acquisition module captures the current behavioural screen and transmits it to the master control module, which extracts the human joints and detects the behaviour depicted on the screen. The master control module mainly obtains the video data transmitted by the image acquisition module. It executes the human behaviour detector to extract joint information and identify the behaviour categories in the received images. The Jetson Nano artificial intelligence computing device was used in this study because the master control module, which is the crucial component of the entire system, needs strong data processing capabilities when running the human behaviour detector to extract joint information and identify the behaviour categories in the received images (Zhuang et al., 2020; Li et al., 2019). The detection results are relayed to the display module through the serial port, which superimposes the human skeleton posture and detection outcomes on the original screen, enabling real-time display.
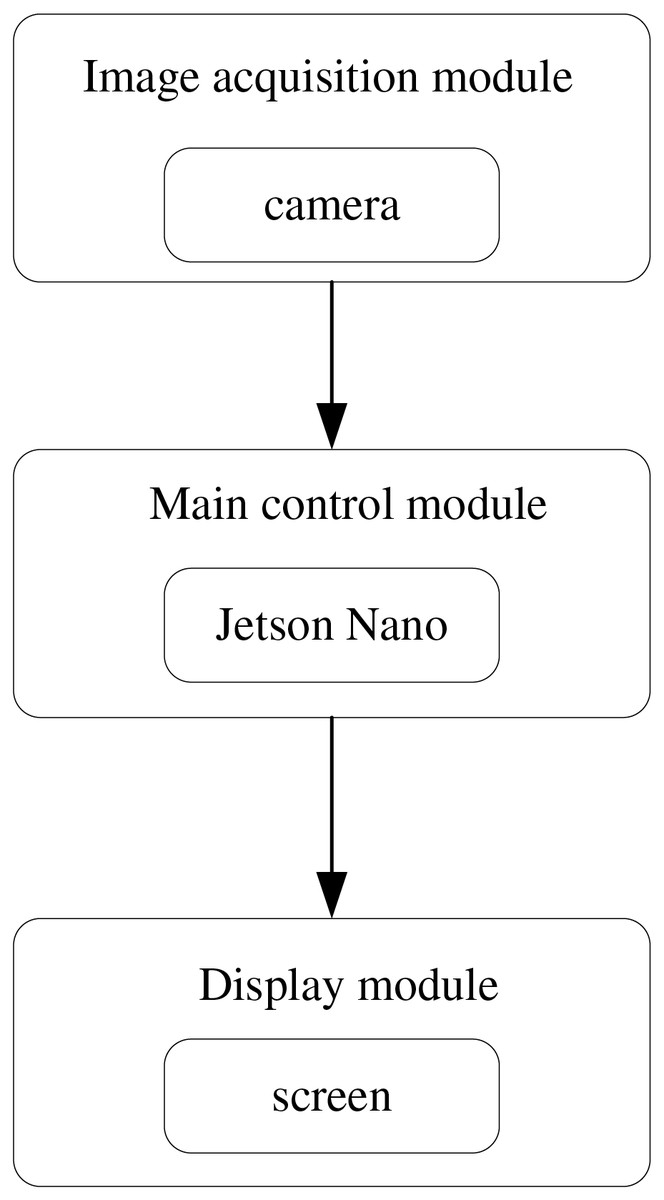
Figure 1: Behaviour detection structure flowchart.
{kind=link}
The initial phase of the behaviour detection system entails the image acquisition module capturing and collecting the human motion picture. Conventional cameras typically involve data, clocks, and synchronization signal lines, necessitating more data lines for the interface. The internal logic structure is also more intricate. The horizontal and vertical synchronization signals and clock signals must be highly synchronized to guarantee that the camera data output and screen signal receiving end has an excellent performance to satisfy the signal transmission requirements. Additionally, during the continuous transmission of the picture, the transmitted signal is susceptible to external disturbances, posing difficulties in maintaining picture quality and transmission rate. By contrast, the CSI camera employs differential data signals during the pixel information transmission to ensure better stability. A single set of data signal lines and differential clock lines suffice for data transmission, reducing the number of interface lines used.
Human action recognition process
When constructing the object detection model, we first employ a series of convolutional and pooling layers to extract image features. Specifically, three convolutional layers are utilized, with kernel sizes of 3 × 3, 3 × 3, and 5 × 5 respectively, all featuring a stride of 1 and a “same” padding scheme to preserve the size of the feature maps. Each convolutional layer is followed by a max-pooling layer with a kernel size of 2 × 2 and a stride of 2. After these convolutional and pooling operations, feature maps rich in semantic information are obtained.
To handle the temporal features of targets when they are occluded across consecutive frames, we introduce LSTM layers after the feature extraction section. The model incorporates a two-layer LSTM architecture, a design that ensures a certain model depth while avoiding gradient vanishing or explosion issues caused by excessive layer numbers. The first LSTM layer consists of 128 neurons and serves to perform preliminary temporal modeling on the features extracted by the convolutional layers, capturing the basic changing trends of target features along the temporal dimension. This layer adopts the tanh activation function, which maps input values to the range between −1 and 1, facilitating better gradient information handling and accelerating model convergence. Meanwhile, to prevent overfitting, a dropout rate of 0.3 is set, meaning that 30% of the neuron connections are randomly discarded during the training process.
The second LSTM layer contains 64 neurons and further refines the temporal features based on the first LSTM layer, enabling more detailed modeling of the target occlusion patterns. This layer also employs the tanh activation function and sets a dropout rate of 0.2, ensuring the model’s generalization ability while minimizing the impact on model performance due to excessive neuron discarding. After processing through these two LSTM layers, the model can effectively capture the dynamic features of targets when they are occluded across consecutive frames, providing strong support for subsequent more accurate detection in combination with random forest.
The workflow of human action recognition is depicted in Fig. 2. The first step is extracting human skeleton joints from video frames with the skeleton extraction module. In practical applications, small-sized skeletons and those lacking the main torso, such as the thighs and head, are considered noise and hence discarded. The action feature capture module performs temporal normalization of the extracted skeleton information to make it scale-independent and angle-independent. Subsequently, the skeleton is fed into the feature extractor to extract torso angle features, skeletal joint point location features, and joint motion velocity features, fused into the frame-level skeleton expansion class total features. The motion discrimination module takes the extracted hybrid features and feeds them into the random forest classifier and then compares multiple motion confidence levels using the discrimination model. Finally, it outputs the predicted motion labels.
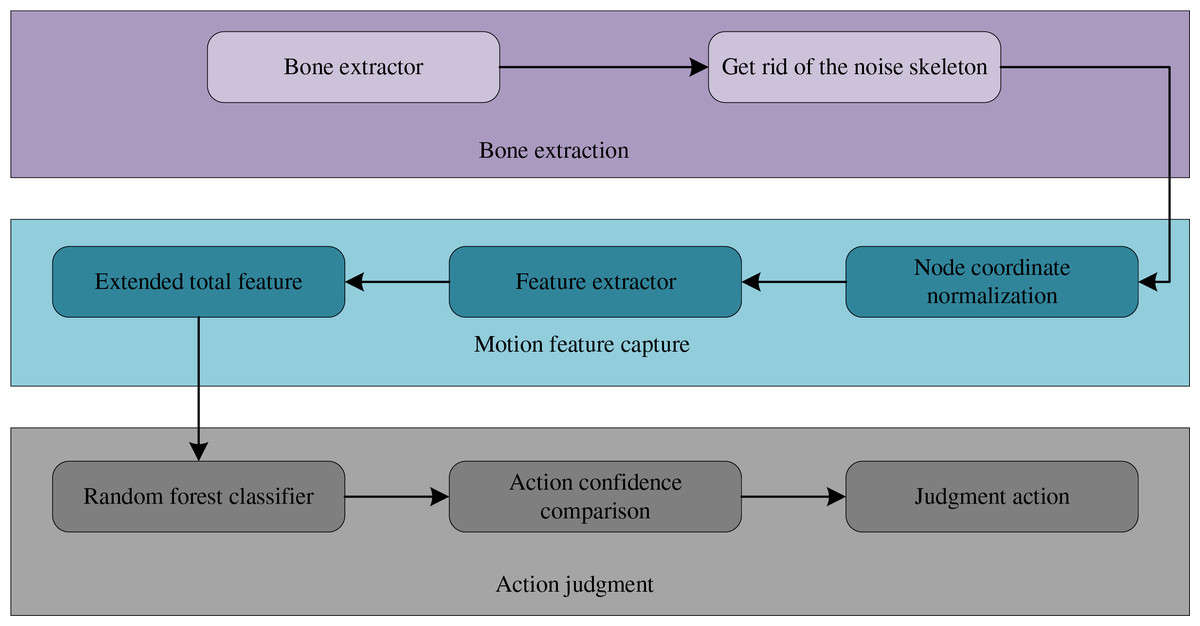
Figure 2: Human motion recognition process.
{kind=link}
LSTM excels at processing sequential data, enabling it to capture the temporal feature changes of targets when they are occluded across consecutive frames, uncover the dynamic patterns of occlusion, and accurately predict the information of the occluded parts. However, LSTM has certain limitations in handling complex nonlinear relationships. In contrast, Random Forest demonstrates robust nonlinear modeling capabilities, allowing it to further analyze and integrate the features output by LSTM. Through ensemble learning involving multiple decision trees, Random Forest effectively reduces the risk of overfitting and enhances the model’s generalization ability across diverse occlusion scenarios. The combination of these two methods leverages their respective strengths, offering a novel approach to addressing occlusion challenges in object detection.
Figure 3 shows the mark of the human skeleton. In college students’ dance classes, it is mainly the eyes and ears of the face that have slight changes. Therefore, the eyes and ears of the face are mainly marked, while the nose and mouth are ignored, in addition to the human neck, shoulder, left arm, wrist, waist, thigh and leg bending marks.
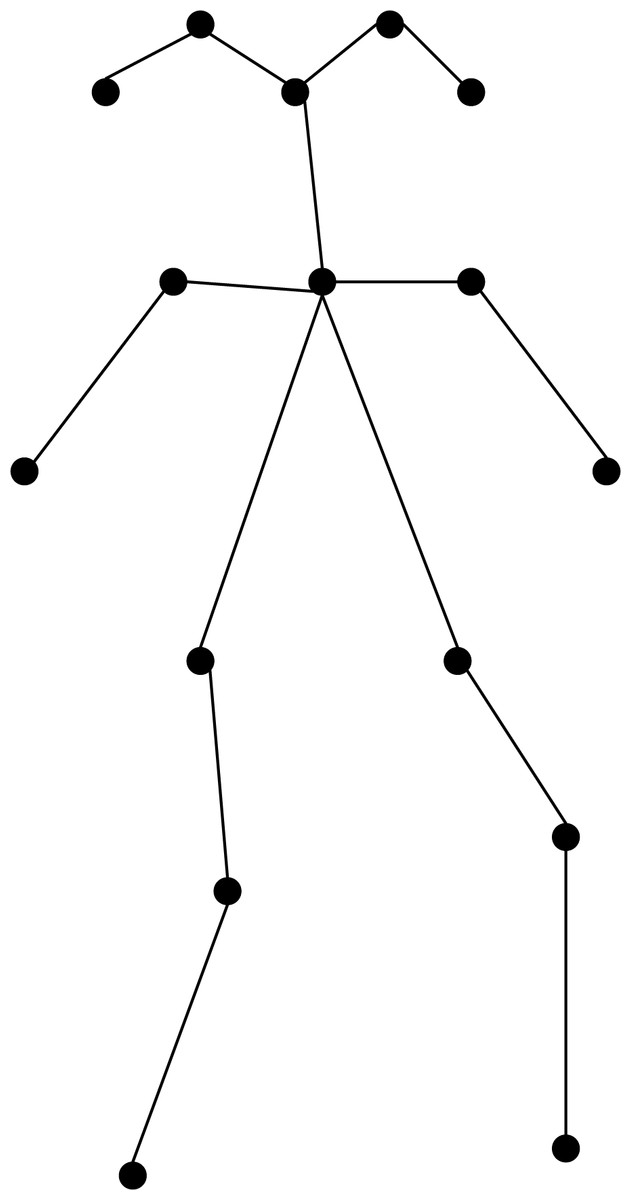
Figure 3: Bone junction marker.
{kind=link}
Algorithm-specific implementation
First of all, for the video captured by the camera for processing, the video in this article is set to 640 * 480 size, where the skeletal joint point coordinates are .
Where , corresponds to the size of the upper video with the number of markers of the human skeletal joints.
If a node is in the extractor extraction stage and is not successfully identified, then it is necessary to force the node coordinates to be set to . In order to maintain a fixed-size feature vector in the next feature classification process, the solution in this article is to automatically fill the eye coordinates based on the previous frame. Let the coordinates of the nose in the previous frame be , and the coordinates of the missing skeletal joint point in this frame in the previous frame is , then the coordinates of the missing skeletal joint point will be populated as:
(1)
The coordinates of the neck joint point are then set as the origin, and the skeletal joint point position is normalized with respect to the image size to eliminate the effect of perspective and scale. Then the coordinates of the normalized joint point are:
(2) where is the width of the skeletal frame, h is the height of the skeletal frame, and . is the coordinate of the skeletal joint point before normalization.
Following the coordinate processing, the skeleton expansion class undergoes feature extraction based on each video frame. Human movements can be interpreted as an articulated system comprising line segments that connect the joints. Consequently, human movements may be considered a continuous evolution of the spatial structure of these line segments. In action, as the torso moves, each skeletal joint point moves in a different degree and direction. To prevent the overfitting phenomenon in action classification due to single features, this study extracts torso angle features, skeletal joint point position features, and joint point timing features over consecutive frames of length S for classification, as illustrated in Fig. 4.

Figure 4: Different features over consecutive frames of length S.
{kind=link}
For a series of action skeletons, there are time-series variations, so the skeleton nodes within the frame can be connected point-to-point, at which point the action skeleton at frame n can be represented as follows.
(3)
is the average height of the skeleton in the frame , which can be calculated from the height of the highest point of the skeleton and the height of the lowest point of the skeleton .
(4)
The normalized skeletal articulation point position at frame is represented as:
(5)
To accurately recognize human actions, it is essential to model skeletal features effectively through an algorithm. Therefore, this article proposes a method for fusing frame-level skeleton expansion class features. Following the above-mentioned method, we combine the temporal sequences to extract three structured frame-level skeleton expansion class features from the unstructured skeleton sequence containing S-frame images. These include torso angle features, skeletal joint point position features, and joint point timing features. We then obtain the total frame-level expansion class features F by fusing the three features.
(6) where is the flexion angle of each joint of the trunk, is the position characteristics of the skeletal joint points, and is the velocity characteristics of the joint movements.
In terms of feature representation, the evolutionary algorithm takes the initial feature set as the starting point of the population and generates new feature subsets through selection, crossover, and mutation operations. The selection operation retains more discriminative features and eliminates redundant or irrelevant ones based on their importance for the classification task, thereby improving feature quality. The crossover operation combines excellent segments from different feature subsets to create new feature combinations, exploring potentially useful feature patterns. The mutation operation introduces random perturbations to the features, enhancing feature diversity and preventing the algorithm from getting stuck in local optima.
Regarding the classification architecture, the evolutionary algorithm optimizes the structural parameters of the LSTM network. It uses different numbers of network layers and neurons as genetic encodings and searches for the optimal network structure combination through evolutionary iterations. This optimization approach can adaptively adjust the complexity of the classification architecture, enabling the model to maintain high classification accuracy while avoiding overfitting. As a result, it enhances the model’s generalization ability, allowing it to more effectively accomplish the task of dance class movement detection.
Analysis of experimental results
After completing the system design, the behaviour detection network must first undergo training on a computer to attain the desired detection effectiveness. Subsequently, the trained behaviour detector is deployed to the main control module to verify the detection effect of the system.
Data processing and parameter setting
In this study, we trained and evaluated a behaviour detection network model using the UTKinectDataset, constructed by the esteemed University of Texas at Austin. We selectively included eight distinct movement types, detailed in Table 1, commonly performed in dance classes. These include grand leaps, spins, synchronized clapping, swift side kicks, and fluid arm swings. Each participant performed each movement twice, and the images obtained comprised three channels, including RGB images, depth maps, and skeletal joint point locations. We partitioned the ultimate dataset into a training set and a test set in an 8:2 ratio and trained the behaviour detector iteratively using a gradient descent algorithm. The number of training iterations was set to 200, and the batch size was chosen as 32. This configuration strikes a good balance between memory usage and training efficiency. For the learning rate, we adopted a dynamic adjustment strategy. It was initially set to 0.001 and decayed to 0.8 times its previous value every 50 iterations, enabling the model to converge rapidly in the early stages of training and undergo fine adjustments in the later stages. The optimizer selected was Adam, which combines the advantages of momentum and adaptive learning rates, effectively accelerating model convergence and enhancing training performance.
| Serial number | Behavior | Serial number | Behavior |
|---|---|---|---|
| 1 | High swing arm | 5 | Side kick |
| 2 | Big jump | 6 | Front kick |
| 3 | Rotation | 7 | Split |
| 4 | Clap hands | 8 | Twist one’s waist |
In terms of the total number of frames, although each type of action has a relatively small number of repetitions, through continuous collection and segmentation of the movements, the actual total number of frames obtained has reached [X] frames. These frames encompass the postures and movement variations of different actions at various moments, providing a certain data foundation for model training and evaluation.
The computer is equipped with an Intel Core i9-13900K processor. Its powerful multi-core processing capability enables it to swiftly handle complex computational tasks. It is also outfitted with an NVIDIA GeForce RTX 4090 graphics card, which provides ample parallel computing resources for model training, thereby accelerating the training process. Meanwhile, a Kinect V2 sensor is employed to collect dance movement data. Thanks to its high-precision depth perception and skeletal tracking technologies, it can accurately capture movement details. The experimental environment is a quiet indoor space with stable lighting, which minimizes external interference and ensures high-quality data.
Comparison of different models
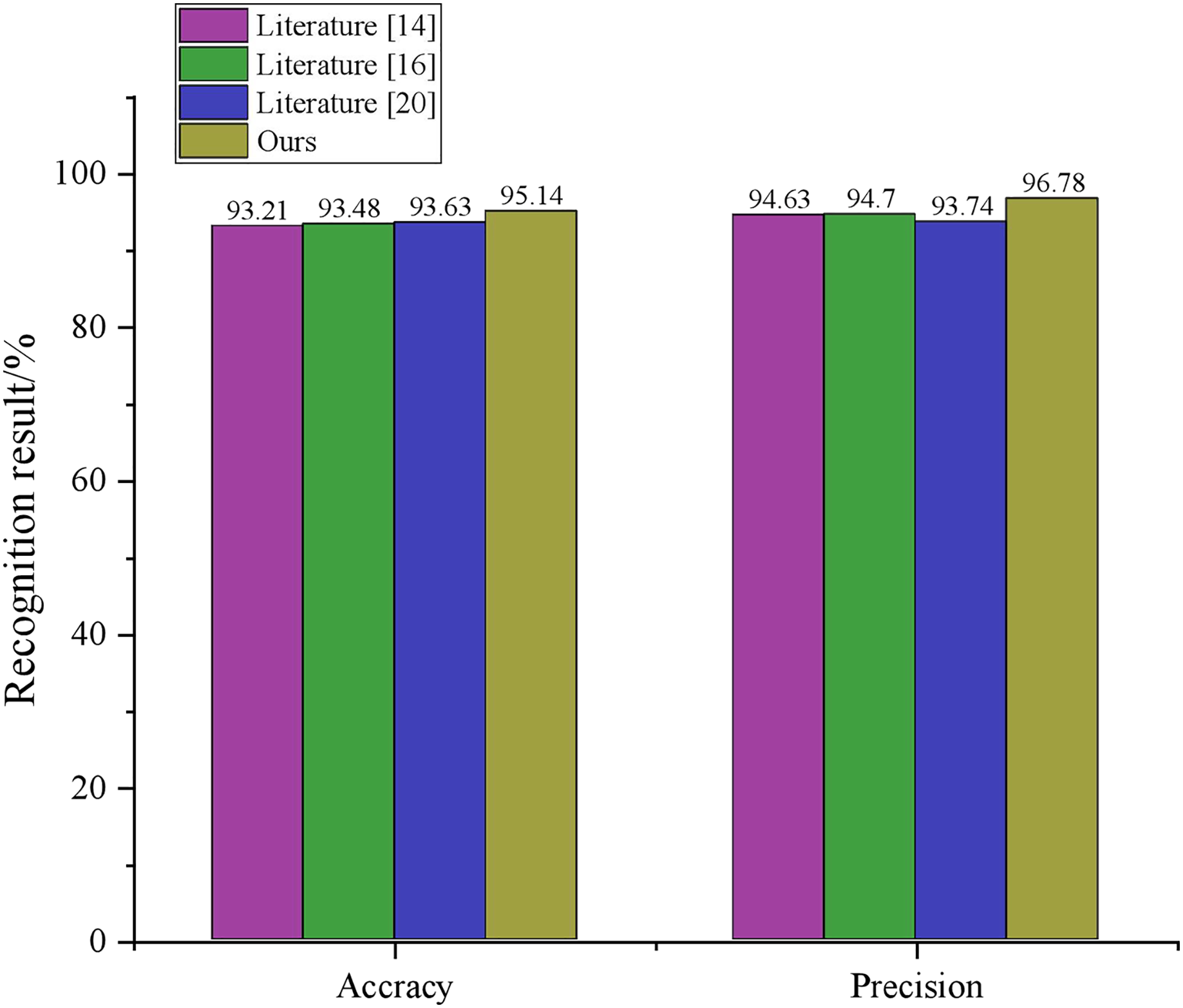
As the frame-level skeleton expansion class features inherently encompass skeleton timing features, an insufficient number of frame-level expansion classes can render the hybrid features deficient in valid skeleton information. Conversely, an excessive number of frame-level expansion classes may increase the number of parameters, resulting in redundant data and a decline in recognition accuracy. To establish the efficacy of the method proposed in this article, we conducted experiments on the dataset employing a random forest classifier. We juxtaposed the results with the efficiency and performance of extant behaviour detection algorithms Dhillon & Verma (2020), Yang & Tian (2016), Hao et al. (2021), and Choy, Gwak & Savarese (2019). Figure 5 portrays the accuracy vs precision of individual schemes. Dhillon & Verma (2020) nonlinearly projects the spatiotemporal representation of action sequences into an irreversible feature representation medium. It integrates sequences’ nonlinearity, sparsity, and spatial curvature properties into a single objective function to obtain a highly compact representation of discriminative attributes. Hao et al. (2021) utilizes a transfer square root velocity function to represent stream trajectories, which proves effective in action recognition, clustering, and multiple sequence sampling. The research (Choy, Gwak & Savarese, 2019) uses an approach akin to this article, utilizing depth sequences and corresponding skeletal joint information for deep learning-based action recognition, a multimodal feature fusion strategy based on LSTM cells, and combining learned features with an SVM classifier for action recognition. However, none of these schemes fuse multiple features and enhance them through evolutionary algorithms, resulting in lower accuracy and precision than the scheme presented in this article.
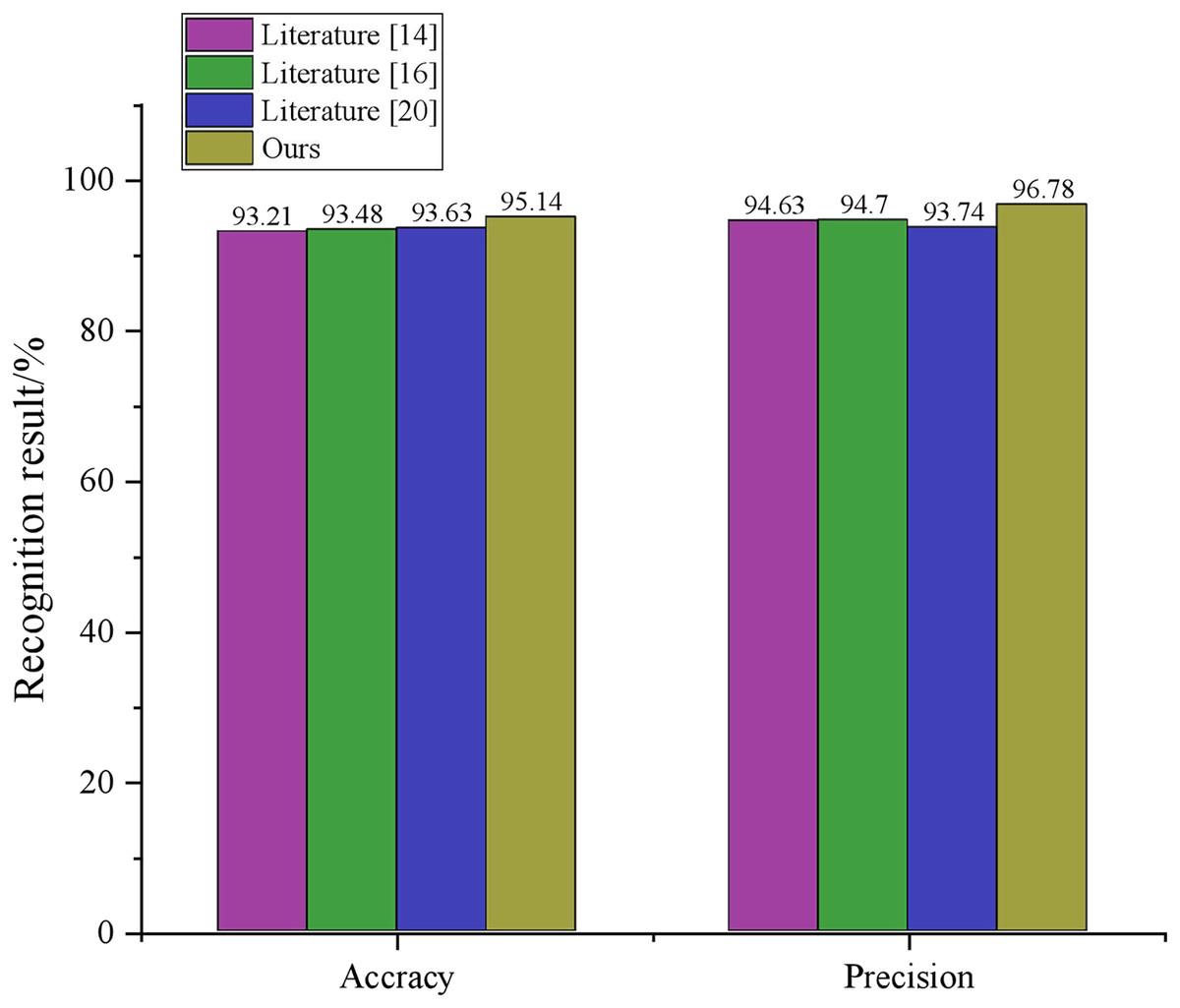
Figure 5: Comparison results.
{kind=link}
Figure 6 depicts the impact of the quantity of multi-group frame-level expansion classes on the recall and F1-score of the proposed scheme’s outcomes in this study. From the trend analysis, it is evident that both recall and F1-score exhibit a gradual increase as the number of expansion classes increases, with the algorithm attaining the maximum recall and F1-score on the test set when the expansion classes amount to 15. Moreover, when the number of expansion classes falls between 10 and 28, the algorithm’s recall and F1-score on the test set surpass 95%.
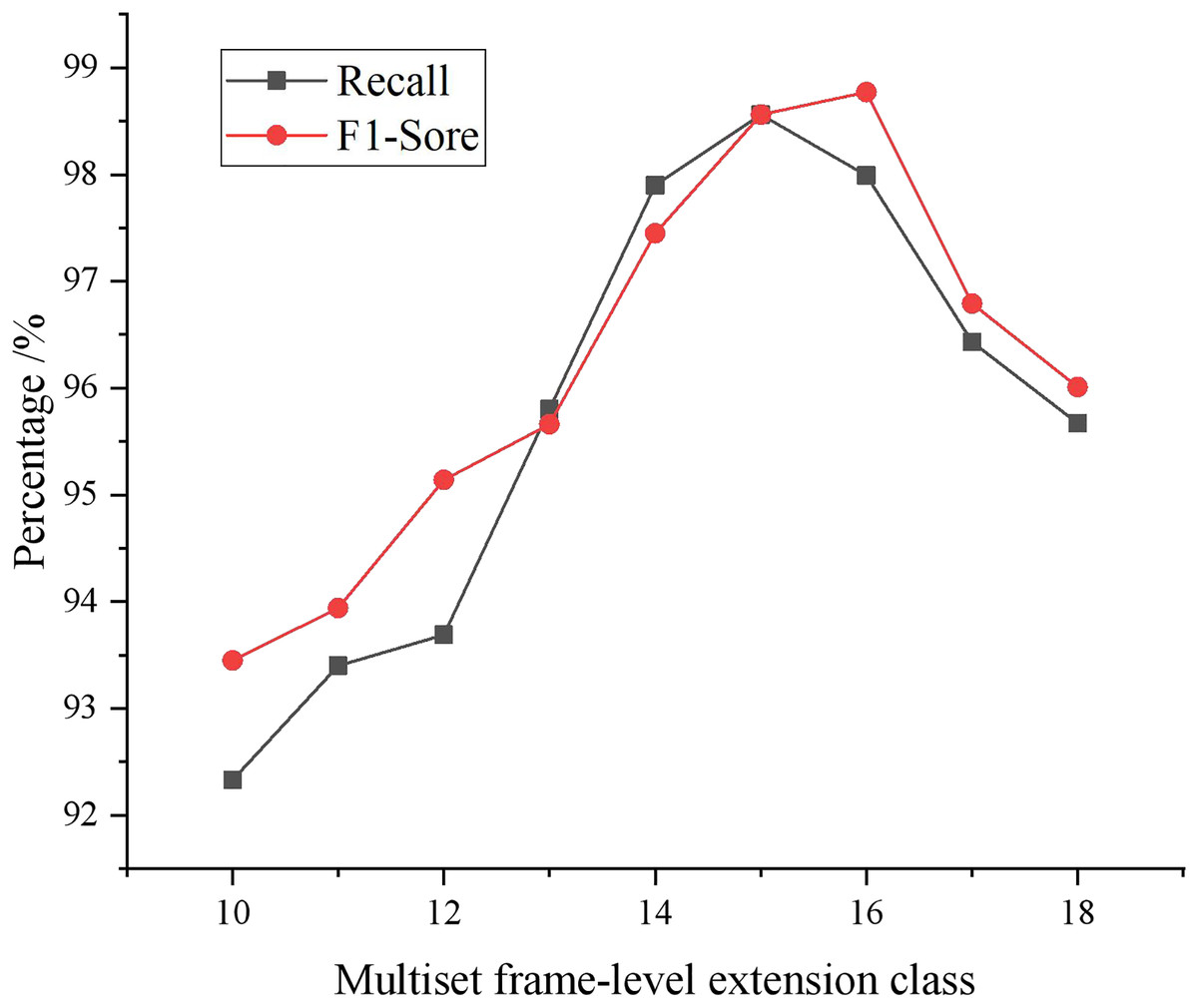
Figure 6: The effect of the number of multiple frame-level extension classes on the recall rate and F1-score.
{kind=link}
Analysis of dance movement state recognition
Within collegiate dance courses, students frequently engage in fluid movements that necessitate real-time behavioral detection to monitor their progress. As a result, conducting simulation experiments on the dance movements of college students becomes imperative. Prior to commencing the experiment, each constituent of the system undergoes functionality checks to ensure seamless operation, including the camera’s ability to capture images without any disruptions. Subsequently, real-time action detection ensues.
During the experiment, the target detector identifies continuous actions, such as waving, clapping, or rotating, prompting the display module to intercept frames capturing these ongoing actions. The detection results for each frame pertaining to distinct behaviors prove to be precise, consistently appearing on the screen. Notably, the screen exclusively exhibits the current behavioral category, as depicted in Fig. 7. The system achieves real-time detection, as evidenced by the minimal time delay of a mere 0.6 s for each recognition detection. From the perspective of time proportion, the joint detection stage accounts for 23% of the total runtime. This stage is primarily responsible for locating and initially identifying areas where actions might occur within the raw data, and its time consumption is related to data complexity and the efficiency of the detection algorithm. The feature extraction stage accounts for 37%. In this stage, discriminative features need to be extracted from the detected areas, and the complexity of the feature extraction algorithm directly affects its time consumption. The classification stage accounts for 40%. It classifies actions based on the extracted features, and the complexity of the classification model and the dimensionality of the input features are the key factors influencing the time taken in this stage.
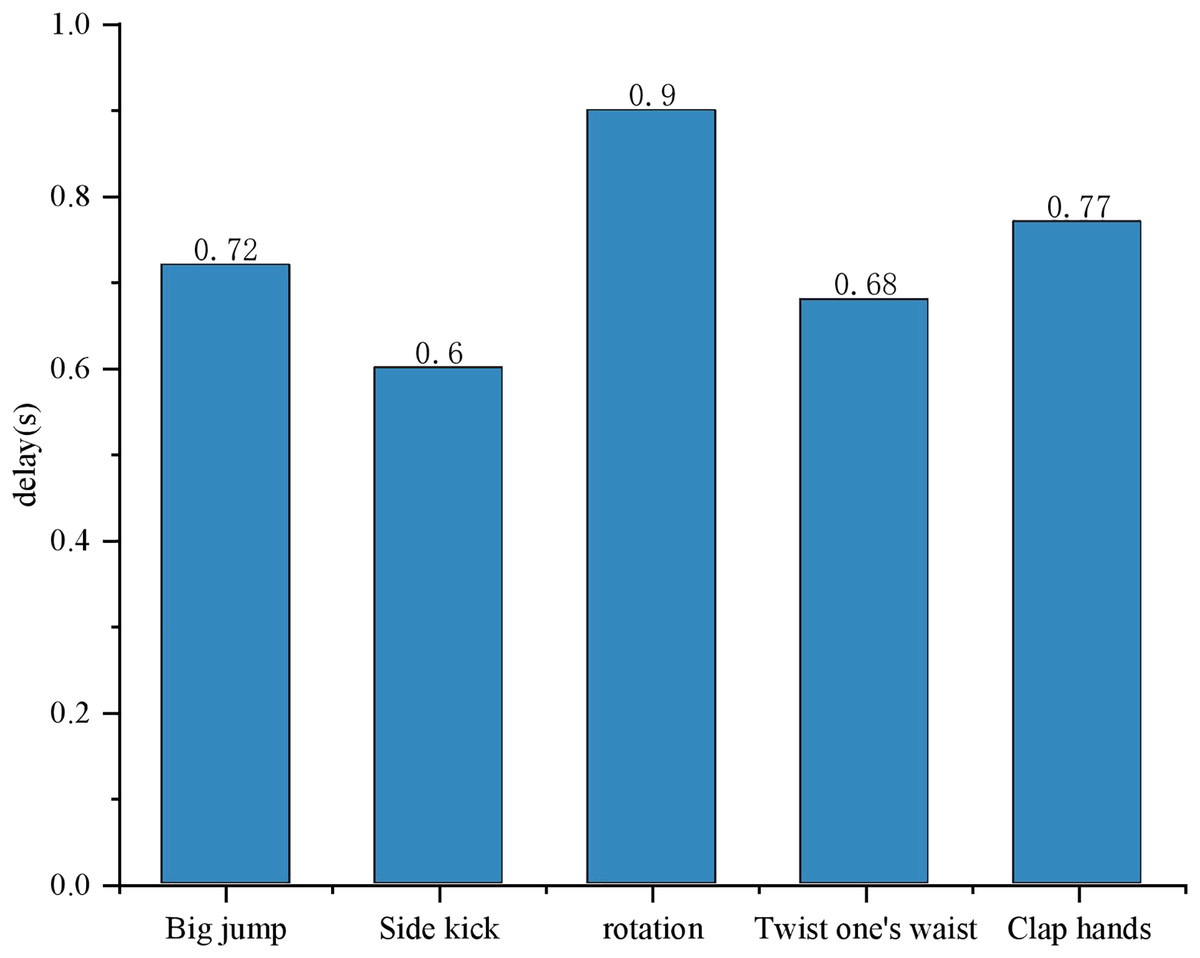
Figure 7: Delay in real-time monitoring of action status.
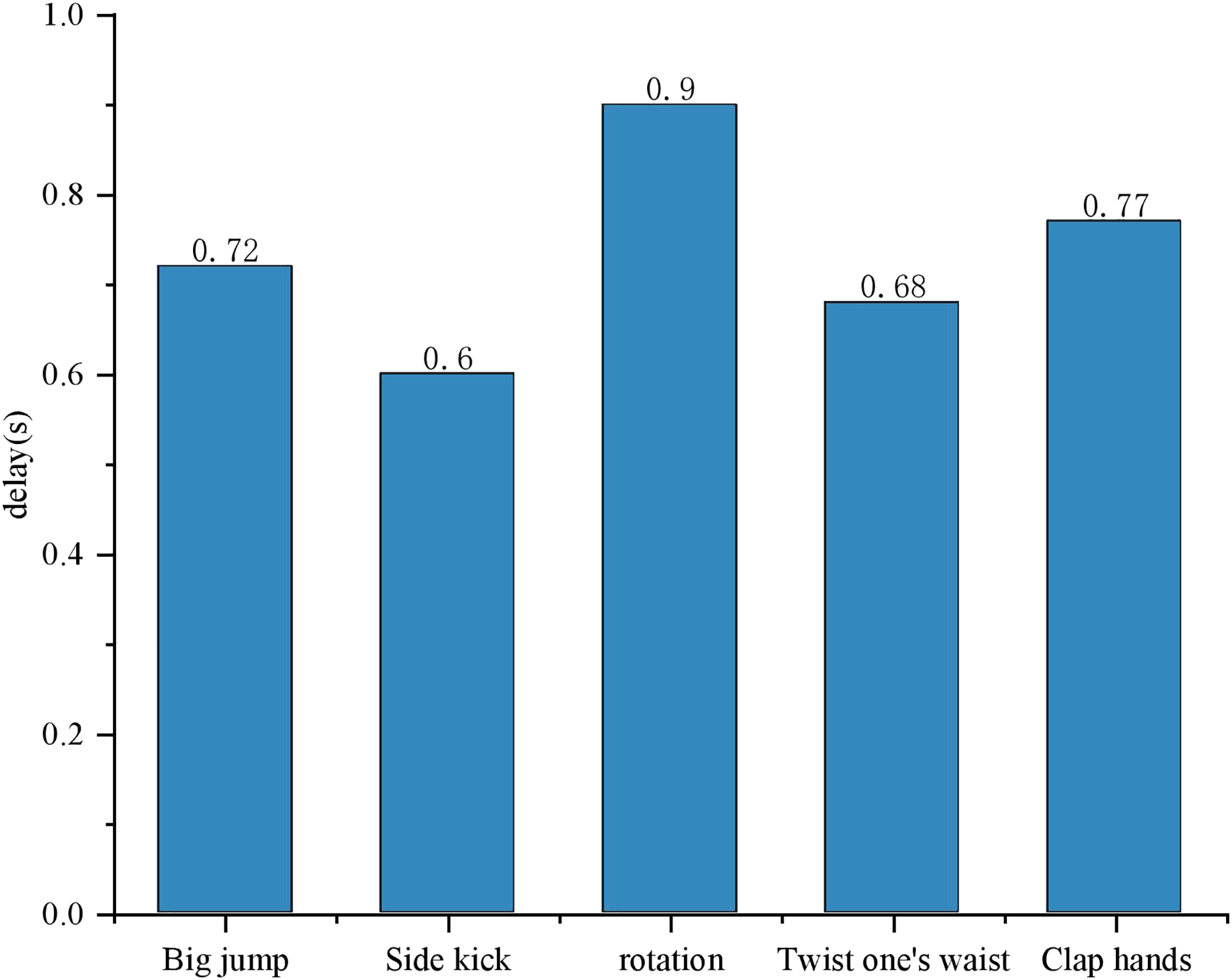{kind=link}
This expeditious response ensures that the current action promptly appears on the screen, meeting the requirements of real-time monitoring. The test results align with the anticipated outcome.
Conclusion
The article presents a behavioral detection framework employing human skeletal information to precisely analyze the movements of college students in online dance classes. The system utilizes the Jetson Nano artificial intelligence computing device and an image acquisition module to construct the platform, establishing a behavioral characterization model based on joint displacement vectors and changes in skeletal pinch angles. This model is derived from skeletal joint coordinates and incorporates variations in motion between limbs. Employing an evolutionary algorithm, the system extracts and classifies human behavioral features, combining three distinct features to enhance recognition accuracy. From the perspective of the accuracy metric, the model achieved a 92% accuracy rate on the test set. Taking grand jeté as an example, the test data included 200 grand jeté samples, and the model successfully detected 185 of them. The accurate detection stems from the model’s precise capture of features such as the change in body center of gravity during the take-off, the limb extension range during the aerial phase, and the landing posture. This is attributable to the rich and diverse grand jeté samples in the training data, which allowed the model to fully learn these key feature patterns. For pirouette movements, out of 150 test samples, 140 were correctly identified. Features such as the rotation speed and range of the body around the vertical axis during the pirouette, as well as the coordinated movements of the head and arms, were all adequately represented in the training data, enabling the model to accurately distinguish pirouette from other movements. Regarding side kicks, the model correctly detected 168 out of 180 test samples. Features such as the height and speed of the leg’s lateral extension during the side kick, as well as the maintenance of body balance, were effectively learned from the training data, allowing the model to accurately identify side kicks.