
Hierarchically enhanced feature fusion and loss prevention for prostate segmentation on micro-ultrasound images
- Published
- Accepted
- Received
- Academic Editor
- Consolato Sergi
- Subject Areas
- Radiology and Medical Imaging, Computational Science, Data Mining and Machine Learning, Data Science
- Keywords
- Medical image segmentation, Feature exploration, Feature aggregation, Deep learning, Micro-ultrasound
- Copyright
- © 2025 Huang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Hierarchically enhanced feature fusion and loss prevention for prostate segmentation on micro-ultrasound images. PeerJ Computer Science 11:e3346 https://doi.org/10.7717/peerj-cs.3346
Abstract
Micro-ultrasound (micro-US) provides superior resolution compared to conventional ultrasound, enabling improved visualization of anatomical structures and supporting more accurate prostate cancer detection. However, prostate segmentation in micro-US remains challenging due to imaging artifacts and indistinct tissue boundaries. While recent Transformer-based UNet models have achieved promising results, they still suffer from inefficient multi-scale feature fusion, limited contextual modeling, and inadequate integration of local and global information. To address these issues, we propose HEFFLPNet, a Transformer-based UNet architecture that introduces hierarchically enhanced feature fusion and loss prevention mechanisms. HEFFLPNet integrates three novel modules: the Tri-Cross Attention with Feature Enhancement (TriCAFE) module for strengthening semantic consistency across skip connections, the Multi-Scale Prediction Map Attention (MSPMA) module for scale-specific feature refinement, and the Upsample Fusion Attention (UpFA) module for attention-guided fusion of spatial details. The model adopts annotation-guided binary cross entropy (AG-BCE) loss and deep supervision across multiple scales, building on the MicroSegNet framework. We evaluate HEFFLPNet on two datasets: the micro-US dataset (55 training and 20 testing cases) and the CCH-TRUSPS dataset. Our model achieves a Dice coefficient of 0.938 and a Hausdorff distance of 2.12 mm on the micro-US dataset, and 0.914 Dice and 3.63 mm HD95 on CCH-TRUSPS, outperforming existing state-of-the-art methods. These results demonstrate the effectiveness and generalization ability of HEFFLPNet in segmenting prostate structures under challenging ultrasound conditions.
Introduction
Prostate cancer is one of the most common cancers that occurs in men. In its early stages, the disease typically presents without noticeable symptoms, often leading to delayed diagnosis. The risk of prostate cancer increases with age, posing a significant threat to men’s health (Rozet et al., 2005). Early detection plays a critical role in improving survival rates (Miller et al., 2022). Transrectal ultrasound (TRUS) is commonly used to guide prostate biopsies for diagnosis (Carter, 2013). However, TRUS has limitations in accuracy, with low contrast between tumors and surrounding tissues, making it difficult for clinicians to distinguish cancerous areas effectively. Moreover, TRUS does not provide full coverage of the prostate, which can result in missed diagnoses (Loeb et al., 2013), and in a recent study (Brisbane et al., 2022), only 3,552 of 30,191 biopsy cores can detect clinically significant cancers. Patients will experience psychological and physical pain during the biopsy process, which may include difficulty urinating, bleeding, and wound infection.
Recent studies (Eure et al., 2019; Lughezzani et al., 2019; Klotz et al., 2021) have shown that micro-US has the potential to be as accurate as MRI at a lower cost. The high-frequency (29 MHz) transducer of micro-ultrasound (micro-US) brings significant advantages in resolution compared with traditional TRUS (6–10 MHz), making it well-suited for visualization of fine anatomical structures and pathology changes. Its real-time imaging capability eliminates the need for image fusion, which can reduce the risk of misdiagnosis during biopsies. However, prostate disease may bring artifacts to micro-ultrasound images, with blurred boundaries between organs and tissues, and micro-US examinations are performed on an oblique plane, which is inconsistent with doctors’ usual habit of examining magnetic resonance imaging (MRI) and computed tomography (CT) on the axial plane (Jiang et al., 2024). The manual segmentation process of the prostate gland with large volumes is time-consuming and impractical. Therefore, automated and accurate prostate capsule segmentation is crucial for accurate localization and biopsy of lesions.
The first deep learning-based micro-ultrasound image prostate segmentation method, MicroSegNet (Jiang et al., 2024), integrates multi-scale deep supervision (Xie & Tu, 2015) into TransUNet (Chen et al., 2021a) to capture both local details and broader contextual relationships across different scales. However, before the segmentation head outputs, MicroSegNet does not process these highly differentiated features at different scales well. Insufficient fusion between features may lead to insufficient capture of key features such as shape and boundaries, and important local details are obscured by coarser global features, and the dependencies between the interrelated features extracted from different scales are not fully considered, resulting in insufficient expression of complex structures. In addition, while the TransUNet architecture uses a simplified jump connection scheme, this design poses challenges for global multi-scale context modeling. The varying receptive field sizes between deep and shallow features create a mismatch that cannot be effectively resolved by basic operations like addition or concatenation. This limited handling of multi-scale features in jump connections may lead to information loss and disrupt the balance between capturing local details and global contextual information. Consequently, this imbalance can result in missing critical local or structural details at broader scales, potentially reducing segmentation accuracy.
To address these challenges, we propose HEFFLPNet, a Transformer-based UNet architecture featuring hierarchically enhanced feature fusion and loss prevention mechanisms. Building upon MicroSegNet, our model adopts the annotation-guided binary cross entropy (AG-BCE) loss and incorporates multi-scale deep supervision. Key innovations include the tri-cross attention with feature enhancement (TriCAFE) module, which replaces standard skip connections to enhance encoder–decoder interactions, and the multi-scale prediction map attention (MSPMA) module for aggregating multi-level features. Within MSPMA, the upsample fusion attention (UpFA) module plays a critical role by upsampling and adaptively fusing low- and mid-level features to strengthen spatial detail and semantic richness. Together, these modules enable HEFFLPNet to achieve precise, robust segmentation while preserving fine-grained anatomical information. Our primary contributions are as follows:
We propose the HEFFFPNet for prostate segmentation on micro-ultrasound images with great generalization ability on other ultrasound datasets, which improves segmentation accuracy by layer-wise enhanced feature fusion and loss prevention.
We propose three novel modules:
-
-
TriCAFE: Replaces the simple concatenation operation in TransUNet skip connections to enhances skip connections, preserve original information, minimize information loss, and reduce the semantic gap between encoder and decoder.
-
-
MSPMA: Processes multi-scale features before the multi-scale deep supervision segmentation head, which enables specific and sufficient modeling of features at each scale, and effectively integrates multi-scale features through UpFA, hierarchically enhanced feature fusion.
-
-
UpFA within MSPMA, fuses three multi-level feature representations to capture high-level semantics and spatial details, as well as more critical detail information, which can effectively enhance the segmentation performance of the model, and its output aligns with the dimension of the lowest-level input feature.
-
Experimental results show that the HEFFFPNet exhibits outstanding learning and generalization capabilities on the micro-US dataset and TRUS dataset, respectively, outperforming state-of-the-art (SOTA) methods.
Related work
In recent years, prostate segmentation has seen significant advancements driven by the rapid development of deep learning and Transformer-based architectures. This section provides an overview of representative studies covering two key directions: (1) deep learning methods that enhance feature representation, boundary refinement, and real-time processing in prostate segmentation, especially under the challenging conditions of micro-ultrasound imaging; and (2) the integration of Transformer models and hybrid CNN-Transformer frameworks that improve multi-scale feature fusion and global context modelling in medical image segmentation tasks. By summarizing these approaches, we aim to highlight their contributions, limitations, and the motivations behind our proposed method.
Deep learning methods for prostate segmentation
In recent years, deep learning technology (Long, Shelhamer & Darrell, 2015; Ronneberger, Fischer & Brox, 2015; Chen et al., 2022; Lei et al., 2019; Zhu, Du & Yan, 2019; Wang et al., 2019) has achieved great success in various computer vision-related tasks such as object detection, image classification, semantic segmentation, and instance segmentation. Traditional methods usually rely on manually designed features (Jiang et al., 2023), while convolutional neural networks (CNNs) have the ability to automatically learn features without manual design. Many deep learning-based prostate segmentation methods for various imaging modalities have been proposed and have shown impressive performance, including TRUS (Lei et al., 2019; Wang et al., 2019; Yang et al., 2017; Ghavami et al., 2018; Orlando et al., 2020; Pellicer-Valero et al., 2021; Peng et al., 2022, 2023) and MRI (Chen et al., 2021b; Tian et al., 2018; Li et al., 2023). Yang et al. (2017) used a recurrent neural network (RNN) to learn the shape prior information of the prostate and implanted its core into a multi-scale automatic context scheme to achieve a gradual refinement of the prediction map details. Wang et al. (2019) used an attention mechanism to select multi-layer features integrated from different layers for utilization, and the prostate details were enhanced by suppressing non-prostate noise. Ghavami et al. (2018) replaced the convolutional layers in U-Net with residual network units to enhance the feature representation ability and optimize the prostate segmentation performance. Karimi et al. (2019) used the difference between models trained on simple and complex ultrasound scans to improve segmentation. Lei et al. (2019) combined the 3D supervision mechanism with the backbone network V-Net, and implemented the deep supervision mechanism by combining the binary cross entropy (BCE) and Dice loss functions in the training stage. Pellicer-Valero et al. (2021) combined checkpoint integration, deep supervision and neural resolution enhancement with the convolutional neural network (CNN) based on DenseNet-ResNet, and achieved excellent performance in prostate segmentation in multiple imaging modes. Peng et al. (2022) combined the improved principal curve method with the evolutionary neural network, and used redefined closed K-segment principal curve (RCKPC) and the modified cuckoo search and differential evolution algorithm (MCSDE) techniques at different stages to optimize the segmentation performance.
Previous prostate segmentation methods for 3D ultrasound images have addressed several challenges, including significant intensity variations, blurred prostate boundaries caused by speckle noise, low contrast between the prostate and surrounding tissues due to a low signal-to-noise ratio, and shadow artifacts. Micro-ultrasound imaging also faces difficulties with boundary clarity. Traditional approaches often lack real-time processing capability, as they typically operate on 3D volumes after the probe sweep. While micro-ultrasound offers much higher resolution and better image contrast than conventional ultrasound, it is particularly susceptible to artifacts from prostate calcifications, which complicate segmentation. Jiang et al. (2024) introduced MicroSegNet, the first deep learning-based method for prostate segmentation in micro-ultrasound images. It enables real-time processing of pseudo-sagittal views. However, MicroSegNet struggles to effectively capture and fuse highly differentiated features at multiple scales, primarily due to limited feature integration and inadequate modelling of dependencies among multi-scale features.
Transformers for medical image segmentation
Vaswani (2017) proposed the Transformer architecture for natural language processing tasks. Its self-attention mechanism allows capturing long-range dependencies and global context information, making it a remarkable success in text classification, machine translation, and language modeling, with subsequent extensions to medical image processing tasks. Parmar et al. (2018) made some modifications to the application of self-attention. The self-attention mechanism is not applied globally, but applied to the local neighborhoods of each query pixel. Wang et al. (2022) used the Transformer to optimize the UNet model, replacing the original skip connection with a connection consisting of Channel Cross fusion with Transformer (CCT) for multi-scale channel cross fusion and Channel-wise Cross-Attention (CCA) for guided fusion. Chen et al. (2021a) proposed TransUNet, which strong global context and models long-range dependencies by treating image features as sequences, while low-level CNN features can be well utilized through UNet. Zhang, Liu & Hu (2021) proposed Transfuse, which operates in parallel, combining the strengths of CNNs and Transformers. Cao et al. (2022) proposed Swin-UNet, which replaced the convolution operation in the U-Net encoder with a hierarchical Swin Transformer with shifted windows, aimed at enhancing global semantic information interaction. Valanarasu & Patel (2022) proposed UNext for medical image segmentation, which reduced the number of convolutional blocks in the shallow encoder and decoder, and the traditional UNet bottleneck layer was also replaced by tokenized MLP blocks to achieve a more lightweight structure. Ding et al. (2023) embedded multi-scale channel self-attention (CSA) in the skip connection of UNet. Jiang et al. (2024) combined multi-scale deep supervision in the TransUNet architecture (Chen et al., 2021a) to overcome the challenges of imaging artifacts caused by prostate calcification in micro-ultrasound images and unclear prostate boundaries. They also proposed an AG-BCE loss function, which assigned different weights to the prediction errors of identifying hard areas and easy areas, and more weights were assigned to the prediction errors of identifying more challenging areas. Our study leverages MicroSegNet, aiming two better handle the multi-scale features captured by its multi-scale deep supervision, optimize feature fusion, consider the dependencies between interrelated features extracted from different scales, and better handle multi-scale features in skip connections to reduce information loss and the imbalance between local details and global contextual information.
Method
Overall structure
Figure 1 illustrates the proposed HEFFLPNet, which is based on the MicroSegNet model. MicroSegNet is based on the TransUNet architecture, a Transformer-based UNet model for medical image segmentation. MicroSegNet integrates a multi-scale deep supervision module with TransUNet, helping the model retain local information while capturing global contextual dependencies. It also introduces an AG-BCE loss function, which is incorporated across all intermediate layers and the final output layer to emphasize accurate segmentation of challenging regions during training.
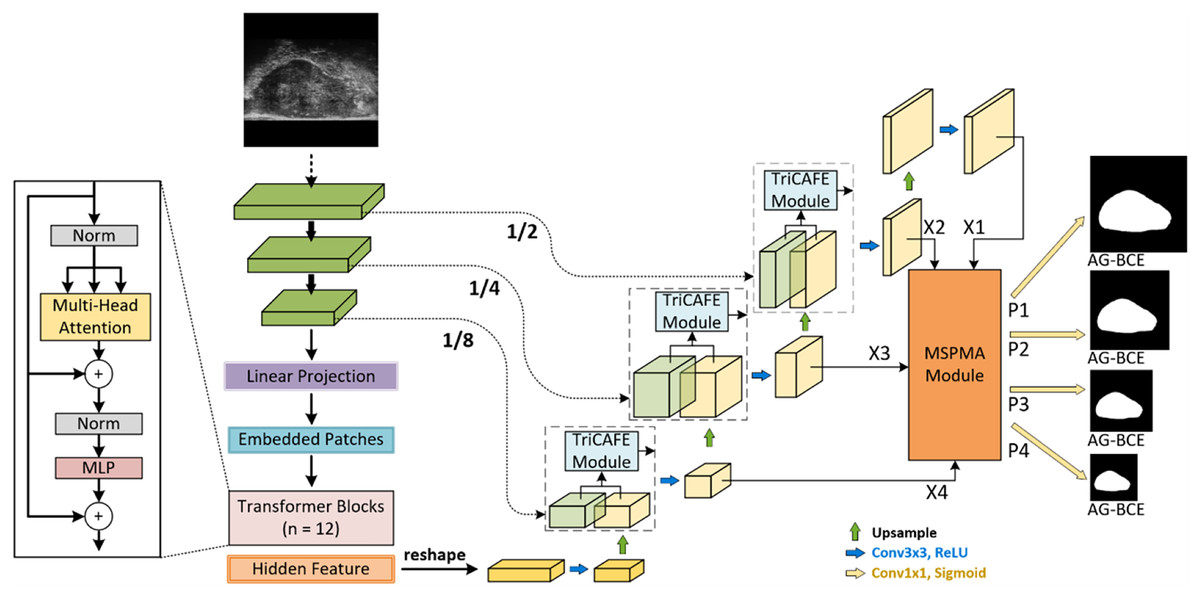
Figure 1: Architecture of HEFFLPNet network.
Architecture of the proposed HEFFLPNet network. HEFFLPNet builds upon the TransUNet framework with multi-scale deep supervision and introduces two key modules: TriCAFE and MSPMA. The input micro-ultrasound image is first processed by a convolutional stem and Transformer encoder composed of 12 Transformer blocks with multi-head self-attention and feed-forward MLP layers. Features are extracted at multiple scales (1/2, 1/4, 1/8 of the input resolution) and are forwarded through skip connections enhanced by TriCAFE modules. Each TriCAFE module fuses encoder and decoder features using multi-branch attention (channel and spatial) and feature enhancement. The resulting features are progressively upsampled and integrated. The final four decoder features {X1, X2, X3, X4} are input into the MSPMA module, which performs attention-guided multi-scale prediction and fusion. It outputs four prediction maps {P1, P2, P3, P4}, each supervised by the AG-BCE loss, ensuring both spatial detail retention and semantic consistency across scales.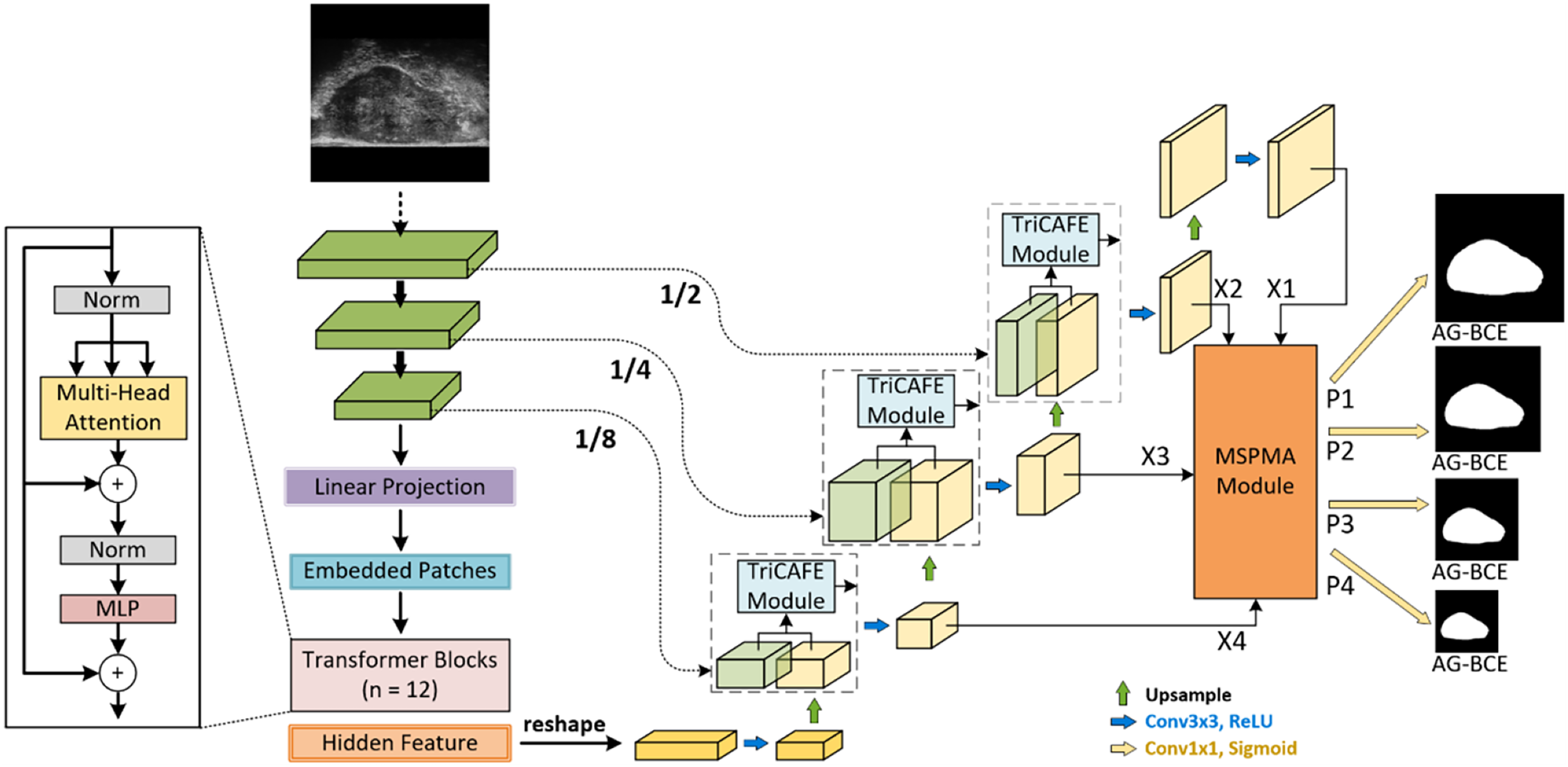{kind=link}
Our proposed method is based on MicroSegNet, combining TransUNet with a multi-scale deep supervision module and AG-BCE loss. We propose two innovative modules: the TriCAFE module, which replaces the original skip connection, and the MSPMA module, positioned before the segmentation head of the final prediction output to process multi-scale features.
The TriCAFE Module enhances the function of skip connections, preserving essential features from earlier layers while enabling the network to adjust these features through learned weight. It mainly consists of three channels. The features of each channel are initially created through operations such as addition and concatenation, and then pass through channel attention (Woo et al., 2018) (CA) and spatial attention (Hu, Shen & Sun, 2018) (SA). The learned spatial weights modulate the features across the three channels, enabling adaptive feature fusion. We also designed a feature enhancement ratio (FER) mechanism to amplify the fused features to increase the weight of strong features in subsequent outputs, and finally concatenated with the decoder features to be fused to maximize the retention of original information, prevent information loss, and narrow the semantic gap between the encoder and decoder.
The MSPMA module allows the network to combine features across multiple scales effectively, thereby achieving multi-scale prediction that captures both high-level semantics and low-level spatial details. This module primarily consists of the PKI module (Cai et al., 2024), UpFA module, and Channel Aggregation (CA) block (Li et al., 2022). The PKI module captures multi-scale texture features and enhances high-level semantic features. The UpFA module upsamples and fuses low- and mid-level features through the attention mechanism, producing a final fused feature that matches the dimensionality of the lowest-level input feature. By extracting more representative information from multi-scale features, the UpFA module ensures that the network can capture high-level semantic information while selectively emphasizing to maintain low-level spatial details through the attention mechanism, ultimately improving the overall expressiveness of the model. The CA block aggregates channel information from low-level, spatially detailed features, adaptively forcing the network to encode expressive interactions that might otherwise be overlooked (Li et al., 2022). The feature enhancement ratio (FER) mechanism is also used here to achieve feature enhancement. Together, these mechanisms ensure that the network can produce accurate and well-calibrated predictions at multiple scales while leveraging semantic richness and spatial details. Overall, the MSPMA module processes and fuses features at each scale in a manner that maximally preserves and utilizes critical information, supporting robust and precise predictions across different scales.
MicroSegNet architecture
MicroSegNet (Jiang et al., 2024) is the first deep learning-based prostate segmentation method for micro-ultrasound images. It leverages the TransUNet architecture (Chen et al., 2021a) and integrates multi-scale deep supervision (Xie & Tu, 2015) to capture local details and broader contextual relationships at different scales.
TransUNet architecture
The Vision Transformer (ViT) proposed by Dosovitskiy (2020) is a Transformer-based architecture originally designed for image classification tasks. It exploits the self-attention mechanism (Vaswani et al., 2017) to capture global context. Our proposed method builds on MicroSegNet by leveraging the TransUNet architecture. TransUNet leverages the self-attention mechanism and a hybrid CNN-Transformer to effectively capture and combine local details and global context information, combining the advantages of the Transformer’s global context modelling ability with the UNet architecture’s accurate segmentation ability. Specifically, It starts with a convolutional stem that extracts low-level features and reduces spatial resolution. These features are then tokenized by dividing them into sequential patches, which are flattened and projected into a high-dimensional space. The Transformer encoder, composed of multi-head self-attention (MHSA) layers and feed-forward networks (FFN) with residual connections, processes these patch embeddings iteratively to capture global context. The UNet decoder then uses up-sampling blocks, convolutional layers, and skip connections to fuse the high-resolution spatial information from the convolutional layers with the global features from the Transformer, producing a pixel-wise segmentation map. This combination of self-attention for global understanding and CNN-based UNet for precise localization results in superior segmentation performance compared to traditional CNN models.
Multi-scale deep supervision
Our work follows MicroSegNet and employs multi-scale deep supervision within the TransUNet architecture, allowing the model to integrate information across multiple scales during segmentation (Xie & Tu, 2015), which enhances robustness when input images vary in shape, size, or appearance. Features at different scales are captured and analyzed by different paths in the network to consider both local and global information in the network. Intermediate image features at three different scales (12, 14, and 18) are processed by 1 × 1 convolutional layers with sigmoid activation functions to produce prostate segmentation images at different resolutions (see Fig. 1). The difference between each prediction and the downsampled ground truth segmentation image is incorporated into the loss function to ensure the accuracy of predictions at different scales. By seamlessly integrating different feature sets, both global information contained in lower-scale outputs and local contextual information emphasized by higher-scale outputs can be captured.
Tri-cross attention with feature enhancement (TriCAFE) module
Skip connections enable the direct transfer of low-level features to high-level layers, thereby enhancing information flow, preserving features, and preventing gradient vanishing. However, the simple skip connection scheme in the TransUNet architecture, as applied in MicroSegNet, faces the challenge of modeling global multi-scale contexts. In this scheme, skip connections pass low-level detail features in the encoder layer with a smaller receptive field directly to the decoder, while the deeper layers in the encoder extract features with a larger receptive field, leading to a mismatch when directly fused with shallow features via simple skip connections, which brings about the problem of receptive field mismatch, and simple operations like addition, concatenation, or hybrid operations fail to reconcile this discrepancy. In addition, inadequate fusion processing of these two features may lead to information loss and an imbalance between local details and global contextual information, potentially diminishing segmentation accuracy by omitting crucial local or structural details at broader levels.
To address these challenges, we propose the TriCAFE module as a replacement for the simple concatenation operation in the original skip connections. The structure of the TriCAFE module is shown in Fig. 2, which visualizes the internal flow and interactions among components.
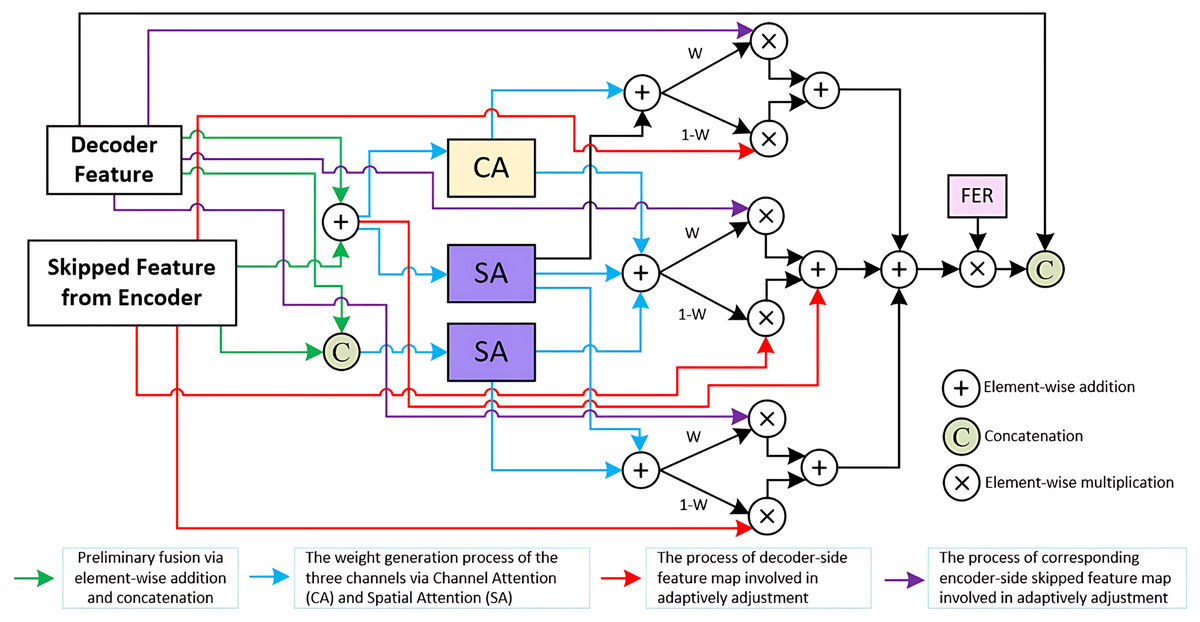
Figure 2: Details of TriCAFE module.
Architecture of the proposed TriCAFE module. The input consists of the decoder feature (Xd) and the corresponding encoder skip feature (Xe). The two features are fused in three parallel channels through addition and concatenation, followed by channel attention (CA) and spatial attention (SA) mechanisms. The spatially weighted features are then adaptively fused using learnable weights (W and 1-W). Each fusion path contributes to the final output, which is further enhanced via a feature enhancement rate (FER) mechanism to amplify strong responses. The final enhanced feature is concatenated with the original decoder feature for skip connection.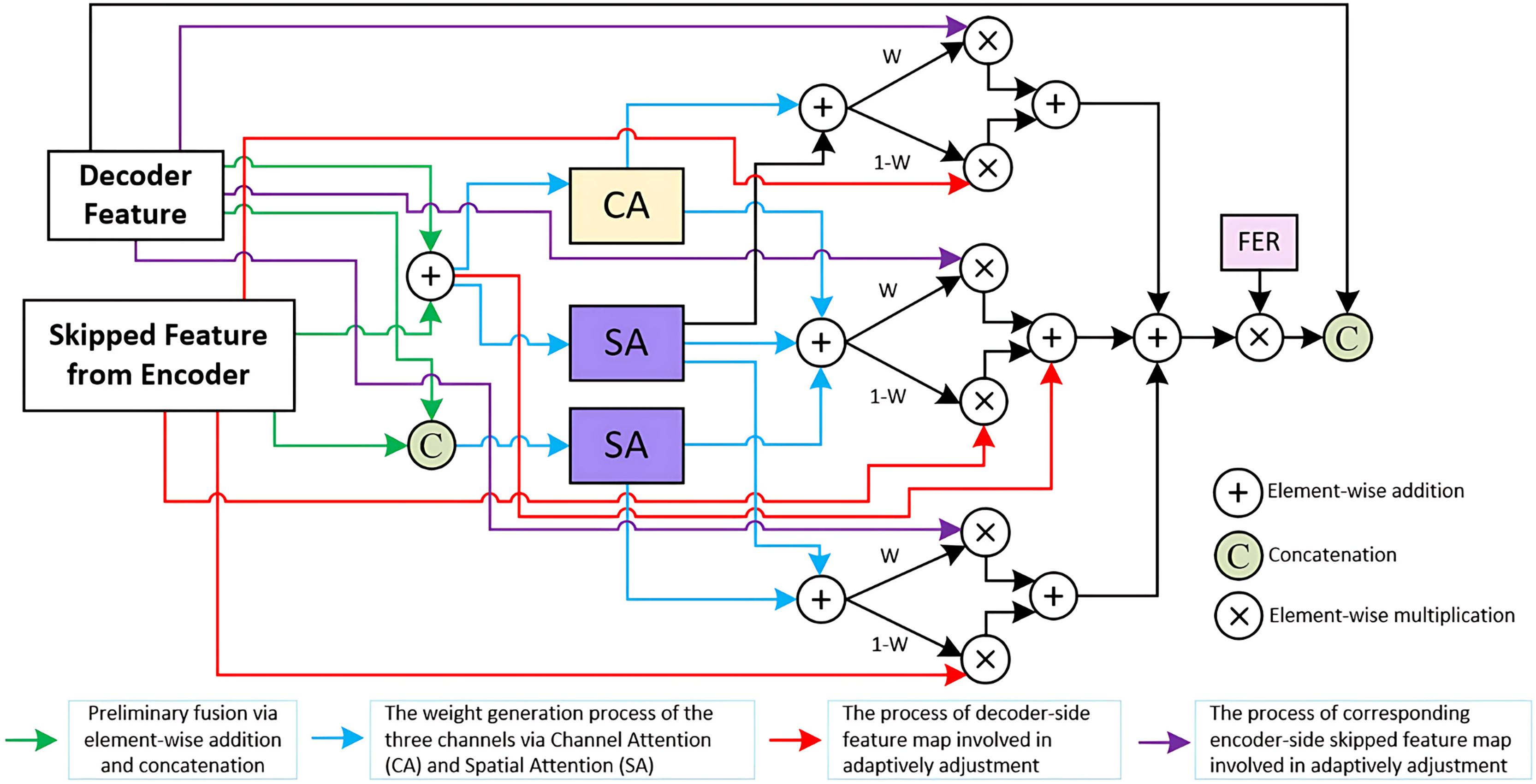{kind=link}
The input to the TriCAFE module consists of two features: the decoder-side feature map (denoted as ) and the corresponding encoder-side skip feature ( ). These two inputs are simultaneously processed through three parallel attention branches. In each branch, the inputs are combined via both element-wise addition and channel-wise concatenation, producing two intermediate representations and , where “ ” denotes element-wise addition, and represents concatenation along the channel dimension. This dual representation captures both aligned spatial structure and enhanced feature diversity.
In the first branch, attention weights are generated by applying channel attention (CA) and spatial attention (SA) to , forming . The second and third branches generate and . These attention maps dynamically guide the fusion of encoder and decoder features, enabling adaptive weighting of each source through learned masks.
Each branch constructs a channel-level fusion output by blending the decoder and encoder features using the learned attention weights, which can be formally written as Eq. (1):
(1) where “ ” denotes element-wise multiplication, and acts as the complementary gate to balance decoder and encoder feature contributions.
These three fusion results are then aggregated through element-wise addition and scaled by a FER (set to 1.5), which increases the discriminative power of the fused features. The enhanced result is then concatenated with the original decoder feature . This process can be expressed as Eq. (2):
(2)
Channel attention (CA): Channel attention weights the features of each channel to highlight useful channel features and suppress redundant channels. The channel attention is given in Eq. (3):
(3) where denotes the Sigmoid activation, is a convolutional layer with a kernel size of 1 to reduce the channel dimension 16 times, is another convolutional layer to recover the original channel dimension, denotes the adaptive maximum pooling, denotes the adaptive average pooling, and refers to the Hadamard product.
Spatial attention (SA): Spatial attention generates an attention map based on the spatial dimension to enhance the features of key spatial positions in the image. The spatial attention is given in Eq. (4):
(4) where refers to a convolutional layer with a kernel size of 7 and padding set to 3, and denote the maximum and average values obtained along the channel dimension.
Multi-scale prediction map attention (MSPMA) module
Following MicroSegNet, we employ multi-scale deep supervision (Xie & Tu, 2015) to integrate information across multiple scales during segmentation, enhancing robustness against variations in the shape, size, and appearance of input images. However, MicroSegNet certain limitations in handling highly differentiated features at different scales. Its inadequate modeling of interrelationships during feature fusion before the segmentation head output may lead to decreased performance, especially in capturing critical features such as shapes and boundaries. For instance, when small, intricate local features are combined with coarse global ones, important details are often masked or overlooked, which ultimately affects model accuracy. Moreover, MicroSegNet lacks in-depth modelling of multi-scale features, failing to fully utilize these features to represent complex structures accurately. This limitation can result in suboptimal performance when handling objects with complex geometric structures or edges, thereby reducing segmentation accuracy.
To address these challenges, we propose the MSPMA module, which enables specific and sufficient modeling of features at each scale, allowing the network to effectively integrate multi-scale features for predictions that capture both high-level semantics and fine-grained spatial details. As illustrated in Fig. 3, the MSPMA module mainly consists of four components: PKI block, UpFA, CA block, and the FER mechanism. The PKI block is applied to the shallowest feature map , where it extracts global semantic cues and injects position-aware knowledge to enhance low-level representations. The output is further refined via a residual connection to preserve fine texture details, forming prediction map . The UpFA module is responsible for fusing the mid- and low-level features , , and , where and is passed through a 1 × 1 convolution and then combined with the upsampled by UpFA module. This fusion undergoes attention-guided refinement, allowing the model to adaptively focus on semantically meaningful regions while retaining spatial precision. To further enhance the fused features, we employ the FER mechanism, which introduces channel-wise modulation through element-wise multiplication to produce the output . The is directly passed to generate . Meanwhile, the deepest encoder feature is fed into the CA block, where global channel dependencies are modeled to recalibrate channel responses. This helps the network emphasize discriminative feature channels and suppress irrelevant ones. A residual connection is then applied to obtain the final output . By designing parallel attention-enhanced paths for multi-scale prediction, the MSPMA module effectively bridges the semantic gap across features at different depths.
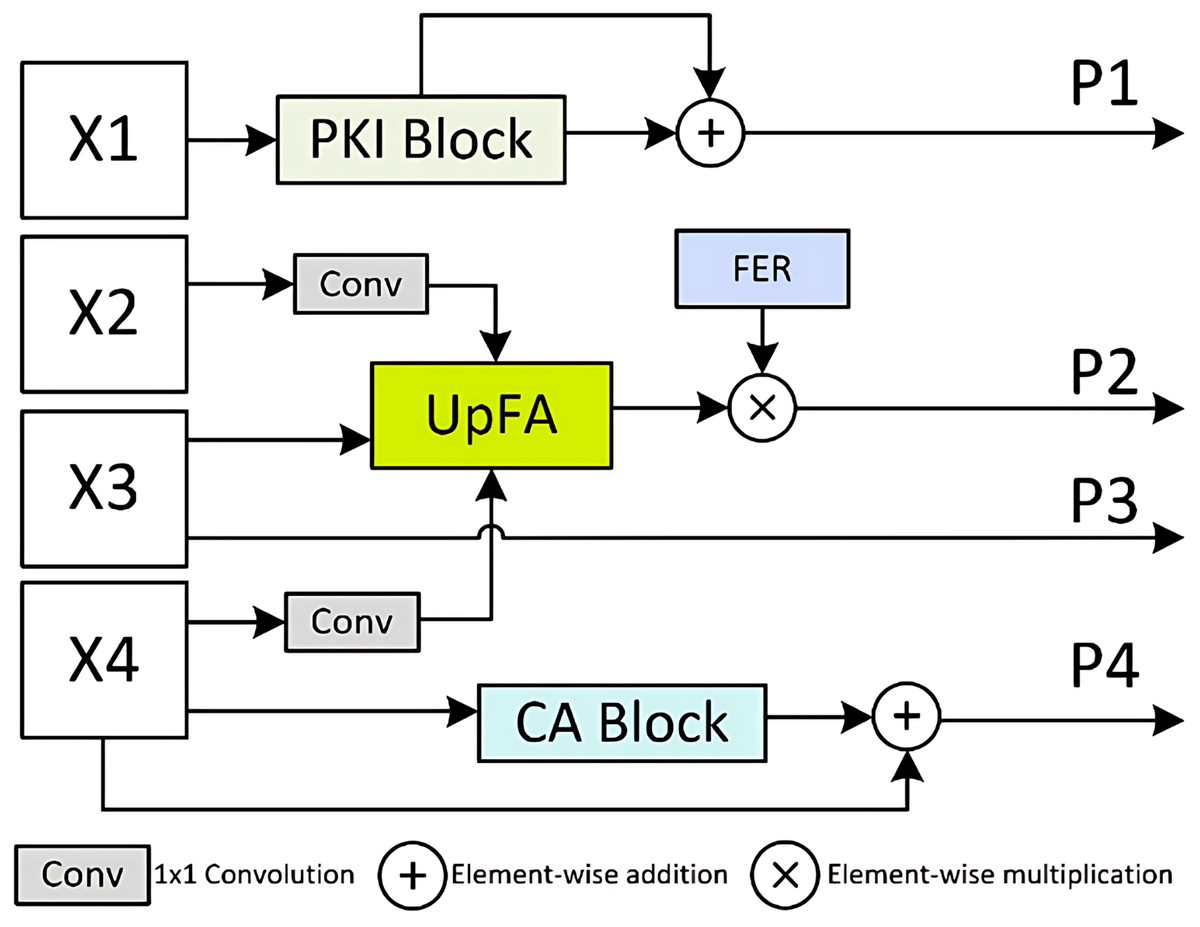
Figure 3: Details of Multi-Scale Prediction Map Attention (MSPMA) module.
Architecture of the MSPMA module. It processes multi-scale encoder features from X_1 to X_4 through different sub-modules: PKI block for enhancing low-level semantic features, UpFA for fusing and refining mid-level features, and CA block for channel-wise attention on deep features. FER module provides additional feature enhancement to guide attention during fusion. Element-wise addition and multiplication are used for residual enhancement and attention-based modulation.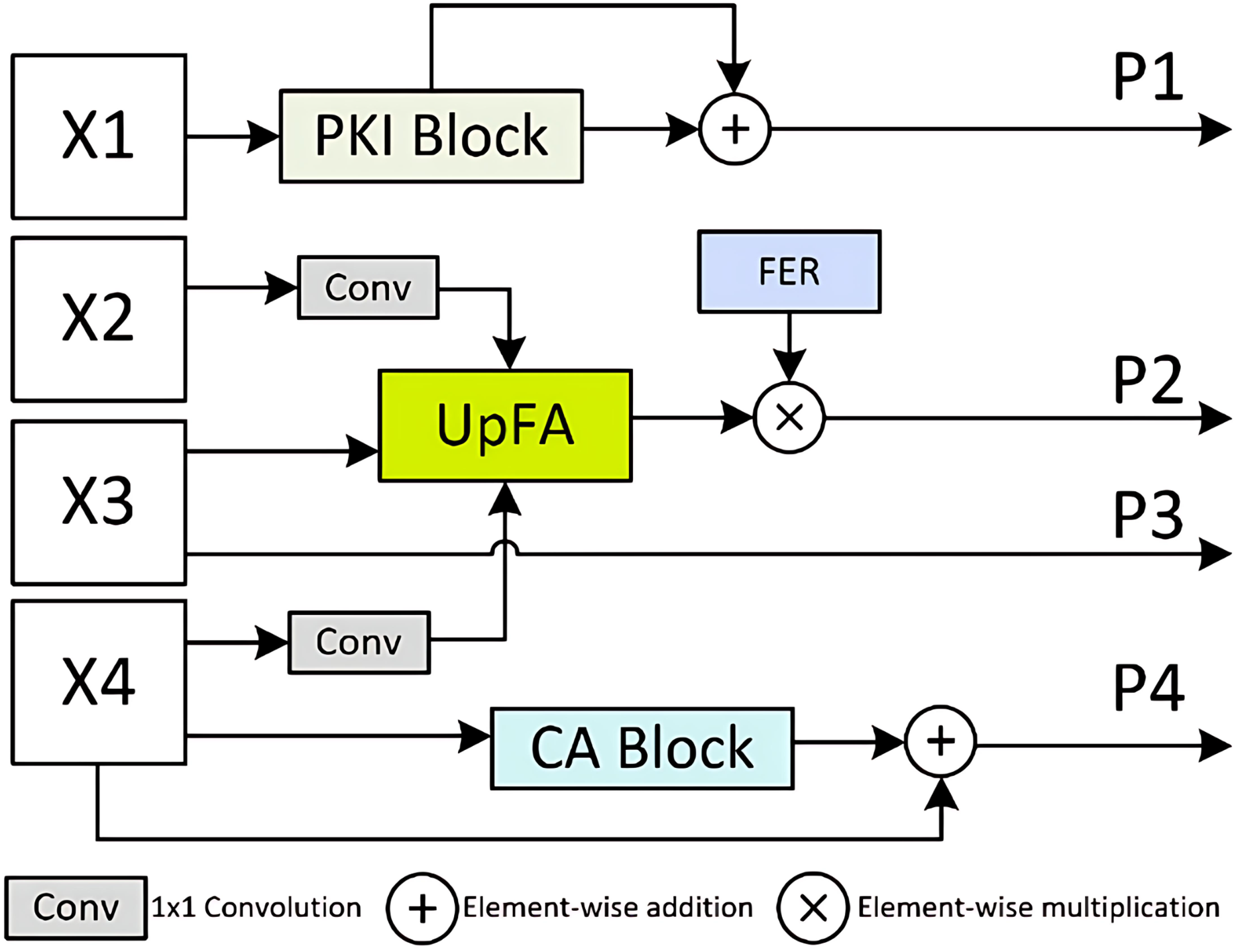{kind=link}
These mechanisms collectively ensure that the network can produce accurate and well-calibrated predictions at multiple scales while exploiting semantic richness and spatial details. The MSPMA module ensures that features at each scale are processed and fused in a way that maximizes the retention and exploitation of important information, thereby ensuring robust and accurate predictions across scales. Four prediction outputs
, can be formally written as Eq. (5):
(5) where refers to PKI module, refers to UpFA Module, refers to CA Module, is a convolutional layer with a kernel size of 1, and denotes the feature enhancement ratio, which is set to 2 here.
Upsample fusion attention (UpFA) module
The UpFA module in MSPMA is designed to fuse mid-level and low-level semantic prediction maps in multi-scale deep supervision. As illustrated in Fig. 4, the high-level features are fused with the mid-level features by addition after upsampling, and are fused with the low-level features by addition after upsampling through the PreActBottleneck block. The low-level features are output by addition after passing through the channel attention (CA) and the spatial attention (SA) respectively, and concatenated with the fused high-level and mid-level features, and finally fused with the high-level features after passing through the PreActBottleneck block by addition after convolution. The feature dimension of the final output aligns with the dimension of the lowest-level features in the input. This fusion strategy integrates multi-level feature representations, making the UpFA module particularly effective in enhancing the model’s segmentation performance, preserving detail, and strengthening global features. As a result, this module is highly suitable for multi-scale information processing in complex image segmentation tasks. The process can be formally represented by Eq. (6):
(6) where refers to the PreActBottleneck block that keeps the number of intermediate channels the same, and then doubles the number of output channels, refers to the PreActBottleneck block that halves the number of intermediate channels and keeps the number of output channels the same.
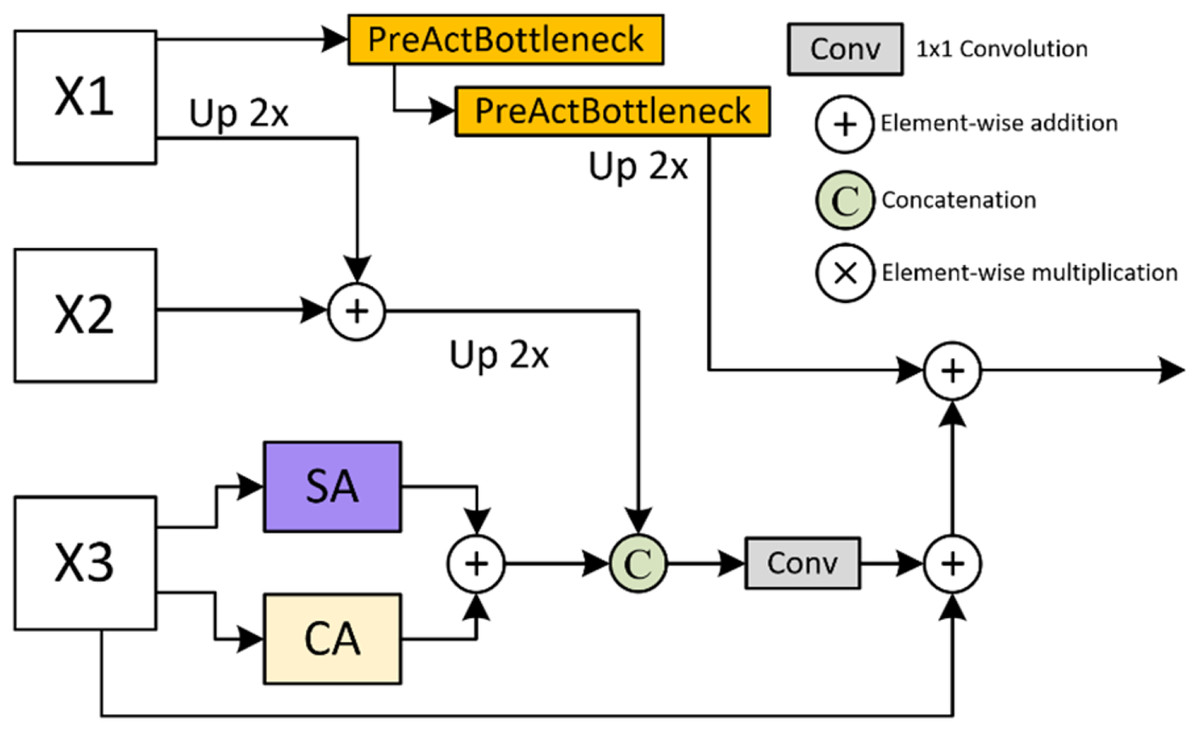
Figure 4: Details of Upsample Fusion Attention (UpFA) module.
Details of the UpFA module. This module fuses multi-scale features from various encoding stages using a combination of upsampling, PreActBottleneck refinement, and spatial/channel attention. The integration process preserves spatial details while enhancing semantic coherence across scales.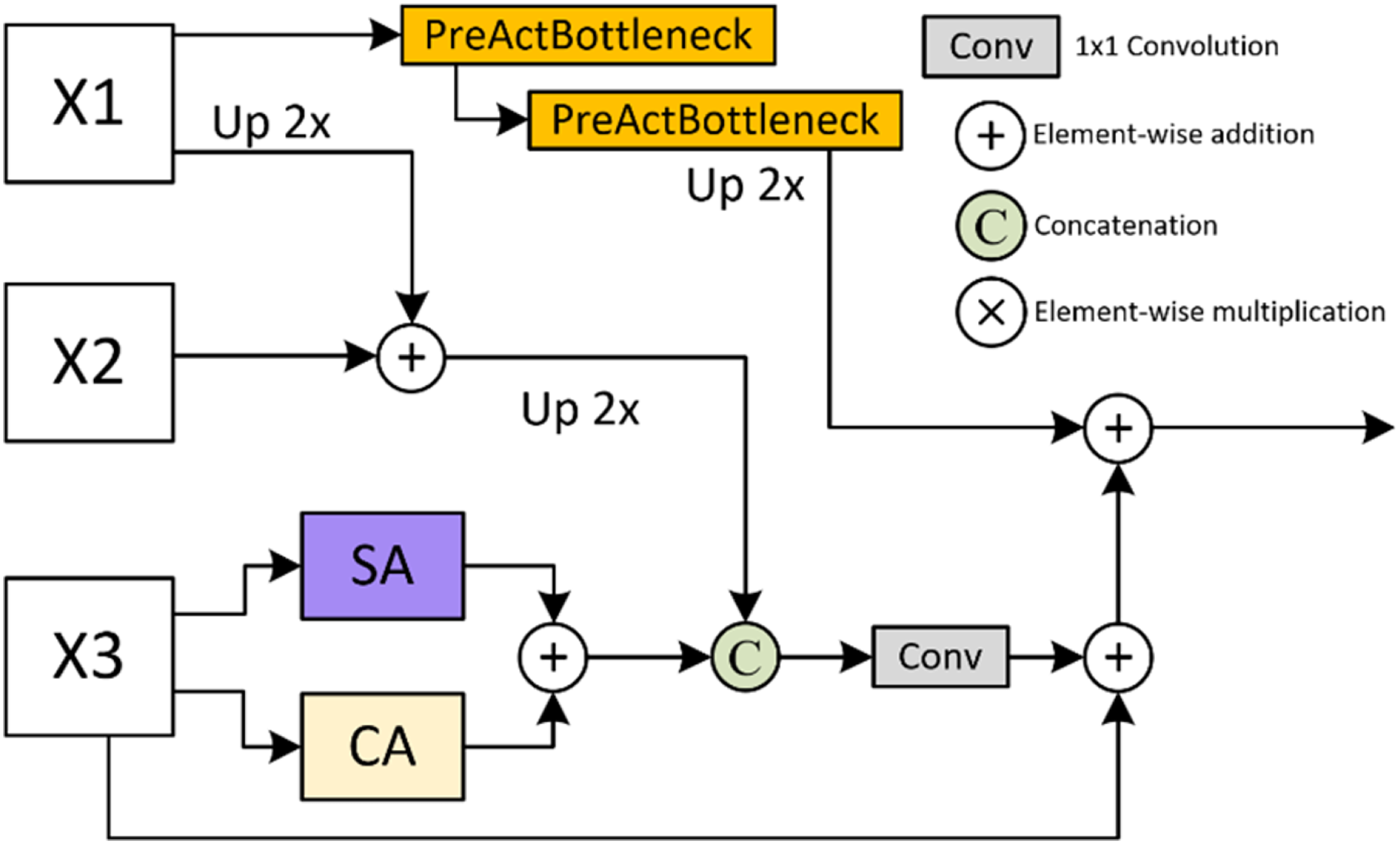{kind=link}
PreActBottleneck: The PreActBottleneck (He et al., 2016a) block is an improved form of the bottleneck structure based on ResNet (He et al., 2016b), aimed at optimizing information flow in deep networks, thereby improving model performance without additional computational cost. This structure enhances gradient flow and feature representation. Its design is particularly well-suited for networks with multiple stacked layers, making it ideal for processing features rich in semantic information from high-level networks. The pre-activation structure minimizes information loss between layers, enabling deeper stacking to capture complex features efficiently.
Training loss
BCE loss is widely used as a loss function in binary image segmentation tasks. It quantifies the discrepancy between the predicted probability map and the ground truth segmentation . The BCE loss is defined as shown in Eq. (7):
(7) where refers to the number of pixels in the image, denotes the ground truth label for pixel , and denotes the predicted probability for pixel .
BCE loss assigns equal weights to all pixels in the image. However, this approach does not account for the increased difficulty of classifying pixels in areas affected by artifacts in micro-ultrasound images. This limitation makes BCE loss less suitable for prostate segmentation in these images. To address this, Jiang et al. (2024) introduced the AG-BCE function, which places greater emphasis on penalizing prediction errors in challenging areas. In our proposed HEFFLPNet, we followed MicroSegNet, adopted the AG-BCE function, combined it with multi-scale deep supervision, and applied the AG-BCE loss to the segmentation predictions generated by all layers. The AG-BCE loss is defined in Eq. (8):
(8) where refers to the weight assigned to the pixel . Consistent with the original definition in MicroSegNet (Jiang et al., 2024), we set for pixels in easy regions, and for pixels in hard regions, which has been empirically validated to enhance segmentation in challenging areas.
We apply the AG-BCE loss to segmentation predictions generated by all layers. The loss function for training HEFFLP can be written as Eq. (9):
(9) where prefers to the predicted segmentation at layer , and prefers to the ground truth segmentation at layer , .
To provide a clear overview of the proposed architecture and its forward pass, we summarize the key steps of HEFFLPNet in Algorithm 1. This representation illustrates how the Transformer encoder, TriCAFE modules, and MSPMA module work together to produce multi-scale prostate segmentation predictions.
| Input: Micro-ultrasound image I |
| Output: Prostate segmentation mask |
| 1. // Step 1: Transformer Encoder |
| 2. |
| 3. |
| 4. // Step 2: Reshape and Generate Multi-Scale Features |
| 5. |
| 6. |
| 7. resolution |
| 8. |
| 9. // Step 3: Decoder with TriCAFE |
| 10. for each skip connection do |
| 11. Compute dual features: |
| 12. |
| 13. Compute attention weights: |
| 14. |
| 15. |
| 16. Channel-level fusion: |
| 17. |
| 18. Aggregation with FER (Eq. (2)): |
| 19. |
| 20. end for |
| 21. |
| 22. // Step 4: MSPMA Module for Multi-Scale Feature Fusion |
| 23. |
| 24. |
| 25. |
| 26. |
| 27. |
| 28. // Step 5: Apply Deep Supervision with AG-BCE Loss |
| 29. for i = 1 to 4 do |
| 30. |
| 31. |
| 32. where AG-BCE: |
| 33. |
| 34. end for |
| 35. |
| 36. // Step 6: Final Output |
| 37. |
| 38. |
Dataset
In this study, we utilized the micro-US dataset published by Jiang et al. (2024) to evaluate the learning ability of HEFFLP, as well as the CCH-TRUSPS dataset (Feng et al., 2023) to assess the model’s generalization ability. The micro-US dataset comprises micro-ultrasound scans with human-prostate annotations from 75 patients who underwent micro-ultrasound-guided prostate biopsies at the University of Florida. The training set consists of 2,060 images from 55 patients, while the test set includes 768 images from 20 patients. Additionally, the CCH-TRUSPS dataset provides 1,820 2D ultrasound images of prostate cancer, collected from 364 male patients aged 40 to 90 at Chongqing University Cancer Hospital. For each patient, five representative images were taken from the apex, body, and base of the prostate. The preprocessing steps for the micro-US dataset, including downsampling images for efficiency, converts them to NumPy arrays, normalizes pixel intensities to 0–255, extracts 2D slices from 3D medical scans, resizes them to 224 × 224, and binarizes segmentation masks before saving them as PNG images. The DOI/URL of Micro-US dataset is provided by Jiang et al. (2024) at: https://zenodo.org/records/10475293, and the CCH-TRUSPS (Feng et al., 2023) dataset is introduced by Feng et al. (2023) together with their Multi-Stage FCN method in: https://doi.org/10.1016/j.bbe.2023.08.002.
Analysis of computational efficiency
As shown in Table 1, although HEFFLPNet introduces additional architectural modules compared to MicroSegNet, the overall computational overhead remains modest. Specifically, HEFFLPNet contains 94.234 million parameters and 29.738 GFLOPs, representing only a slight increase from MicroSegNet’s 93.235 million parameters and 24.683 GFLOPs. This marginal rise in complexity enables the integration of multi-scale attention mechanisms and enhanced feature fusion strategies, which we demonstrate in the experiment section to be beneficial for segmentation performance and robustness.
| Method | FLOPs (G) | Param (M) |
|---|---|---|
| MicroSegNet | 24.683 | 93.235 |
| HEFFLPNet | 29.738 | 94.234 |
Experiment
Evaluation metrics
We use the Dice coefficient to measure the relative overlap between the predicted prostate segmentation (P) and the true prostate segmentation (G), as defined in Eq. (10):
(10) where denotes the number of positive pixels in the predicted segmentation images, denotes the number of positive pixels in the ground truth images, is true positive instances, is false positive instances, and is false negative instances. In addition to using the Dice coefficient, we also apply the Hausdorff distance to evaluate the maximum separation between the two prostate boundaries, and . To reduce the impact of minor outliers, we use the 95th percentile of boundary point distances (HD95) instead of the absolute maximum distance (HD). The definition is provided in Eq. (11):
(11) where refers to the distance between and , and refers to the distance between and .
Implementation details
During training, we retained the same hyperparameter settings as MicroSegNet to ensure a fair and consistent comparison under identical training conditions, using a patch size of 16, a batch size of 8, a learning rate of 0.01, a momentum of 0.9, a weight decay of , and a fixed random seed of 1,234 for all experiments. These hyperparameters were kept consistent for all models. We used the same dataset of 2,060 micro-ultrasound images from 55 patients as MicroSegNet for training, and the same 758 images from 20 patients as the test dataset to test the learning ability. All images were resized to 224 × 224 to match the standard input size of the Vision Transformer backbone. Intensity values were normalized to the [0, 1] range to stabilize training and maintain consistency with pre-trained encoder expectations and commonly adopted preprocessing pipelines. We further tested the generalization ability of the models on the CCH-TRUSPS dataset. To prevent overfitting, all models were trained for 30 epochs. The training and evaluation process was performed on an NVIDIA RTX 3070 laptop GPU with 8 GB of memory. We used Python 3.9.19 and PyTorch 2.3.0 in all experiments. In this article, we compare the proposed method with x state-of-the-art image segmentation models, including UNet (Ronneberger, Fischer & Brox, 2015), UNet++ (Zhou et al., 2018), TransUNet (Chen et al., 2021a), Swin-UNet (Cao et al., 2022), MicroSegNet (Jiang et al., 2024).
Quantitative analysis of learning ability
Table 2 presents the average Dice coefficient and Hausdorff distance for six segmentation models on 758 images of 20 test cases. Our HEFFLPNet outperforms the other five models in both metrics. By substituting the basic concatenation operation in the original skip connection with the TriCAFE module and incorporating an MSPMA module before the multi-scale deep supervised segmentation head for multi-scale feature processing, we enhance the Dice coefficient of MicroSegNet from 0.931 to 0.938 and reduce the Hausdorff distance from 2.17 to 2.12 mm. Compared with TransUNet, leveraged by MicroSegNet, our model improves the Dice coefficient by 0.015 and reduces the Hausdorff distance by 0.17 mm, demonstrating outstanding learning ability. Notably, the UNet model, which without Transformer integration, performs significantly worse, underscoring the advantage of Transformer-based architectures in capturing long-range dependencies essential for complex image segmentation tasks.
| Model | Micro-US | |
|---|---|---|
| mDic | HD95 | |
| UNet | 0.908 | 3.11 |
| UNet++ | 0.917 | 2.96 |
| TransUNet | 0.923 | 2.29 |
| Swin-UNet | 0.926 | 2.25 |
| MicroSegNet | 0.931 | 2.17 |
| HEFFLPNet (Ours) | 0.938 | 2.12 |
Note:
The best result is bolded.
To further validate the robustness of the improvements, we conducted statistical significance tests between HEFFLPNet and the baseline MicroSegNet. The Dice improvement of HEFFLPNet (0.938 vs. 0.931) was statistically significant (paired t-test, p = 0.018; Wilcoxon, p = 0.026), with a moderate effect size (Cohen’s d = 0.564). For HD95, although HEFFLPNet achieved a slightly lower error (2.12 vs. 2.17 mm), the difference relative to the baseline was not statistically significant (p > 0.05).
Quantitative analysis of generalization ability
Table 3 presents a performance comparison of our HEFFLPNet model with five other methods on the CCH-TRUSPS dataset, which was previously unseen. HEFFLPNet achieves a Dice coefficient increase from 0.903 to 0.914 over MicroSegNet, while reducing the Hausdorff distance from 4.22 to 3.63 mm. In comparison to the TransUNet model leveraged by MicroSegNet, our model improves the Dice coefficient by 0.011 and reduces the Hausdorff distance by 0.56 mm, demonstrating its superior generalization capability. Notably, the UNet model, which lacks Transformer integration, continues to exhibit weak generalization, underscoring the advantages of a Transformer-based architecture in capturing the long-distance dependencies essential for complex image segmentation tasks.
| Model | CCH-TRUSPS | |
|---|---|---|
| mDic | HD95 | |
| UNet | 0.877 | 4.54 |
| UNet++ | 0.865 | 4.86 |
| TransUNet | 0.891 | 4.19 |
| Swin-UNet | 0.886 | 4.43 |
| MicroSegNet | 0.903 | 4.22 |
| HEFFLPNet (Ours) | 0.914 | 3.63 |
Note:
The best result is bolded.
Based on this analysis, our HEFFLPNet model demonstrates exceptional learning and generalization performance in the challenging task of prostate segmentation on micro-ultrasound images, surpassing other SOTA methods.
Qualitative analysis
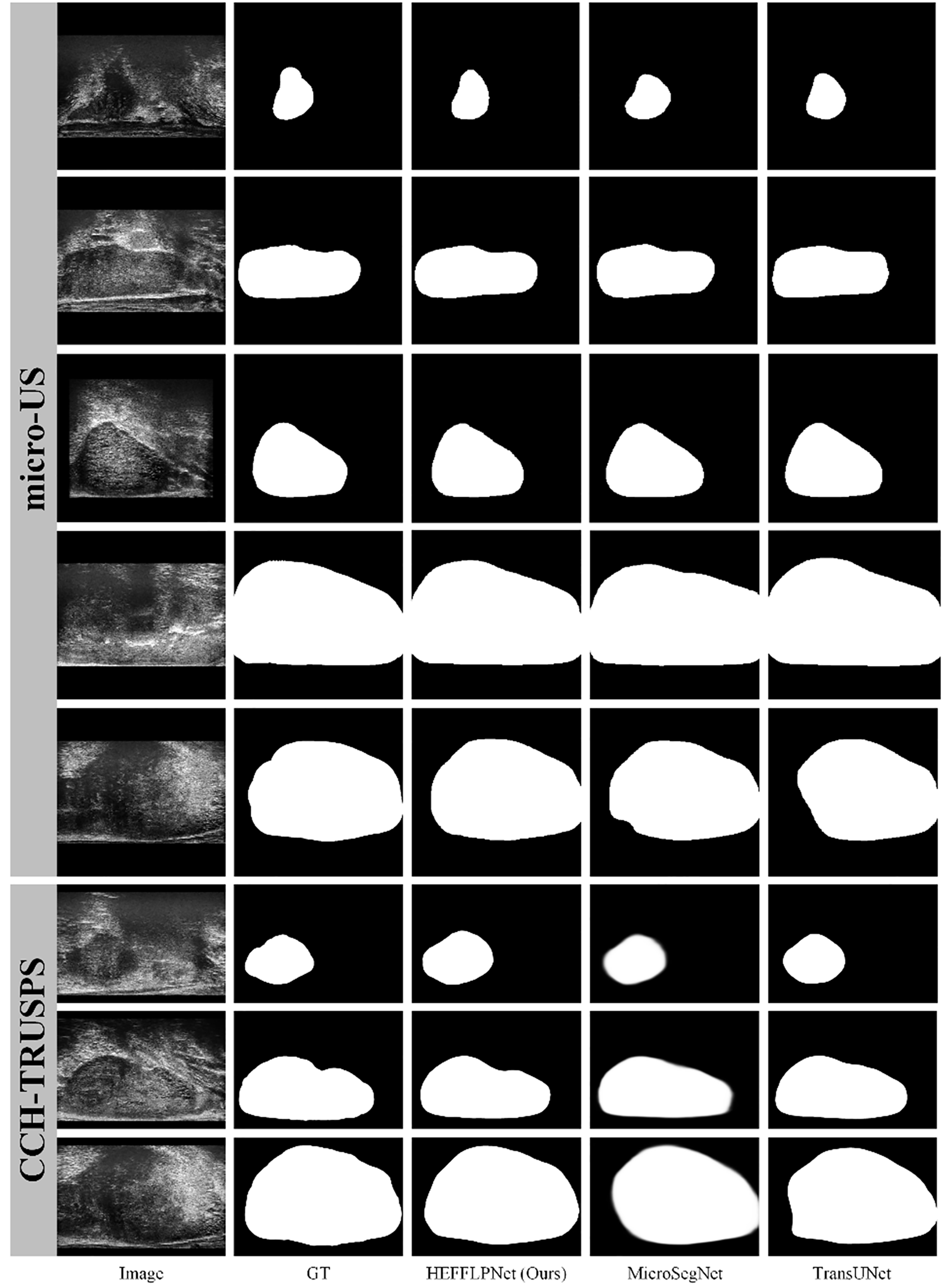
To comprehensively evaluate the effectiveness of our proposed method, we selected two high-performing representatives from five SOTA methods and compared them with our HEFFLPNet based on visual results. As illustrated in Fig. 5, micro-US ultrasound images demonstrate superior quality, fewer artifacts, and more defined prostate boundaries compared to traditional ultrasound images. Among the SOTA methods, our HEFFLPNet provides more accurate and smoother boundary segmentation for prostates of various sizes and shapes in both micro-US and traditional ultrasound images, underscoring the model’s accuracy and its robustness to artifacts. This improvement is largely due to our replacement of the original skip connection in TransUNet with an innovative TriCAFE module and the integration of an MSPMA module ahead of the multi-scale deep supervised segmentation head, enhancing multi-scale feature processing. By hierarchically reinforcing feature fusion and preventing loss, we preserve semantic richness and spatial detail across scales, which minimizes information loss and facilitates robust, precise predictions.
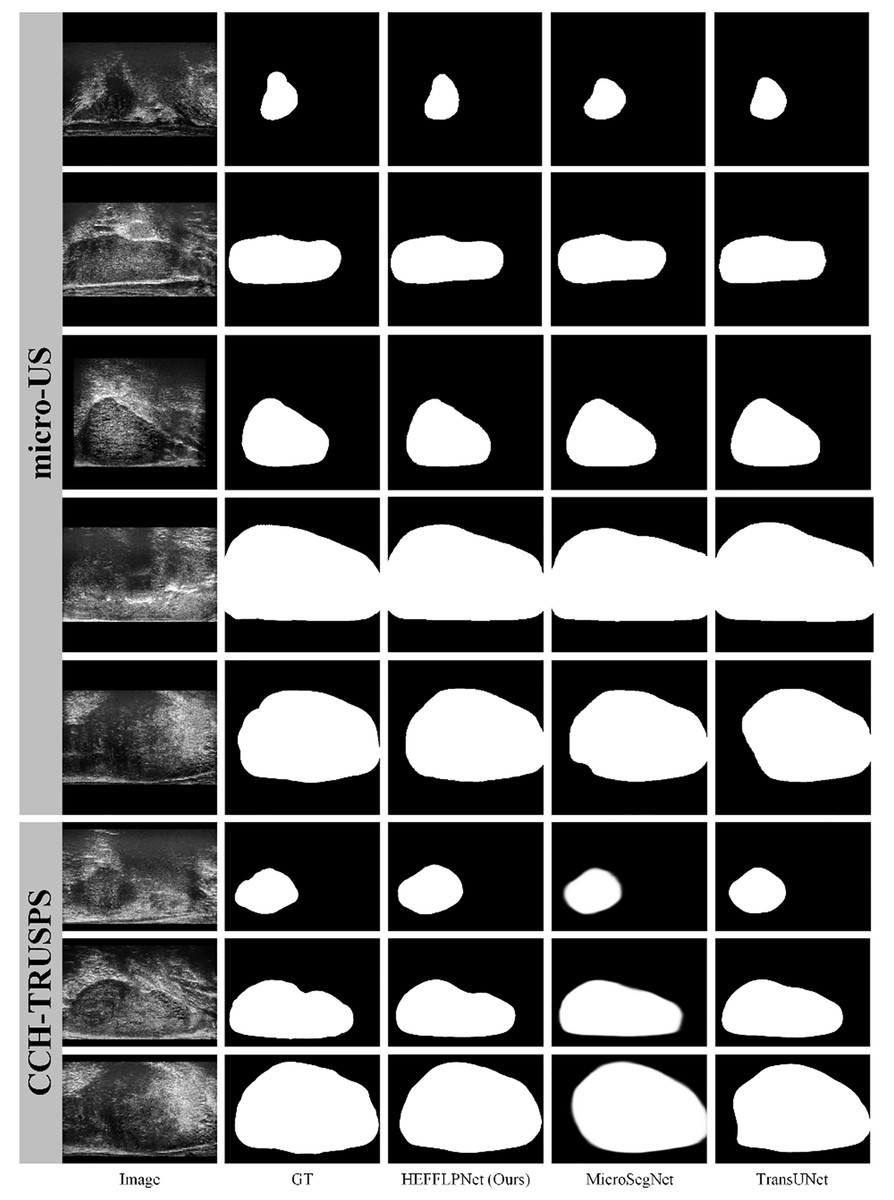
Figure 5: Visualization results of three methods: HEFFLPNet, MicroSegNet, and TransUNet on two datasets.
{kind=link}
Specifically, as shown in Fig. 5, in terms of boundary accuracy, HEFFLPNET demonstrates superior performance, particularly in the 6th and 8th rows (CCH-TRUSPS), where it closely adheres to the true anatomical boundaries with smooth and well-fitted contours. In contrast, MicroSegNet exhibits slight edge blurring in these rows, while TransUNet shows boundary over-expansion and reduced curvature conformity in the 8th row. For shape preservation, HEFFLPNET maintains high structural fidelity, as evidenced in the 1st and 5th rows (micro-US) and the 7th row (CCH-TRUSPS), producing segmentations that closely match the ground truth without noticeable geometric distortions. MicroSegNet and TransUNet, however, tend to over-segment or under-segment, especially around object boundaries, leading to shape inaccuracies. Overall, HEFFLPNET consistently produces results with higher conformity to the ground truth across both imaging modalities, indicating stronger generalization ability and robustness in multi-domain prostate segmentation tasks.
Ablation studies
We conducted ablation experiments to assess the impact of three core components in HEFFLPNet: the MSPMA module, the UpFA sub-module, and the TriCAFE module. Table 4 presents the results on both the micro-US and CCH-TRUSPS datasets using mDice and HD95 as evaluation metrics.
| micro-US | CCH-TRUSPS | |||
|---|---|---|---|---|
| mDic | HD95 | mDic | HD95 | |
| Baseline (MicroSegNet) | 0.931 | 2.17 | 0.903 | 4.22 |
| w/o UpFA | 0.934 | 2.19 | 0.914 | 3.67 |
| w/o MSPMA | 0.935 | 2.19 | 0.915 | 3.73 |
| w/o TriCAFE | 0.934 | 2.15 | 0.905 | 4.44 |
| HEFFLPNet | 0.938 | 2.12 | 0.914 | 3.63 |
When the TriCAFE module is removed, the model’s performance on CCH-TRUSPS declines notably: mDice drops from 0.914 to 0.905 and HD95 increases sharply from 3.63 to 4.44. This suggests that TriCAFE plays a critical role in improving segmentation quality in more complex scenarios, particularly those involving anatomical ambiguity and fine-grained boundaries. In contrast, on the micro-US dataset, the changes are more moderate (mDice from 0.938 to 0.934, HD95 from 2.12 to 2.15), indicating that TriCAFE’s benefits are especially pronounced in datasets with more challenging spatial structures. This aligns with our design goal for TriCAFE: to strengthen skip connections by reducing the semantic gap between encoder and decoder features and better preserving spatial consistency.
Similarly, the removal of the full MSPMA module or its internal UpFA component also leads to consistent degradation in performance, particularly in HD95, which reflects boundary precision. For instance, removing MSPMA increases HD95 to 2.19 on micro-US and to 3.73 on CCH-TRUSPS, indicating that the module plays a key role in fusing features across scales and preserving structural information throughout the network. MSPMA is designed to model multi-scale feature representations explicitly, ensuring that both fine-grained local textures and broader contextual cues are retained and utilized during decoding. This helps the model better delineate ambiguous or low-contrast regions.
The UpFA component within MSPMA is particularly important for effectively integrating mid-level and low-level features. Its removal results in a decrease in mDice on the micro-US dataset (from 0.938 to 0.932) and a slight degradation in HD95. This reflects UpFA’s role in selectively enhancing useful spatial details while avoiding the introduction of noise. Through attention-based fusion, UpFA ensures that important structural features from different encoder stages are emphasized appropriately, improving segmentation coherence and boundary localization.
These results validate the complementary contributions of each module. While TriCAFE enhances skip connection fidelity, MSPMA and its internal UpFA sub-module improve hierarchical feature integration and detail preservation. Together, these modules allow HEFFLPNet to produce more accurate and robust segmentation results, particularly in anatomically variable or noisy clinical scenarios.
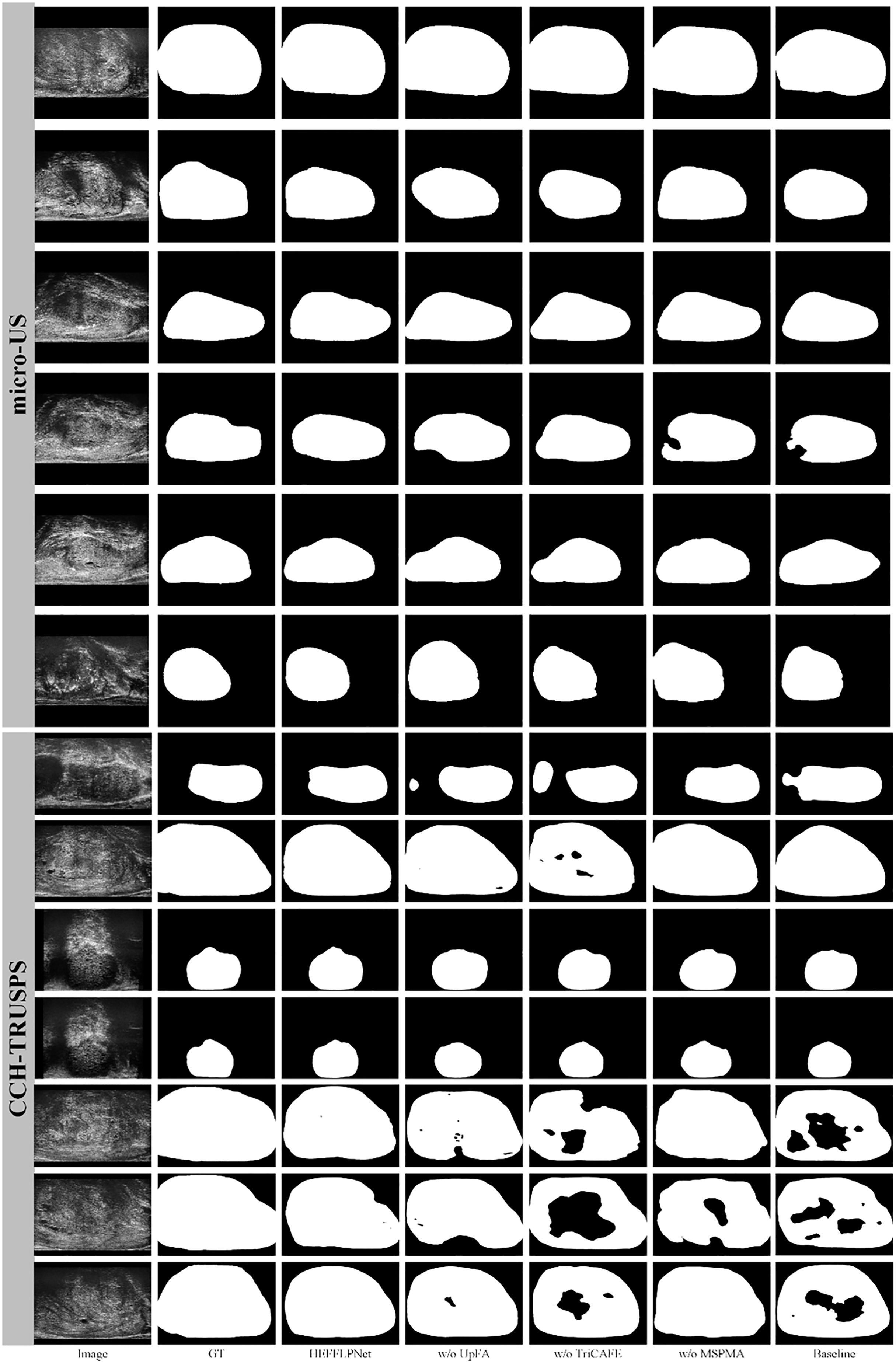
We present visualization results in Fig. 6 to further demonstrate the effectiveness of the proposed HEFFLPNet architecture and the impact of its core modules, including MSPMA, UpFA, and TriCAFE. As shown, the removal of any individual component leads to a noticeable decline in segmentation quality, particularly in boundary accuracy and structural completeness.
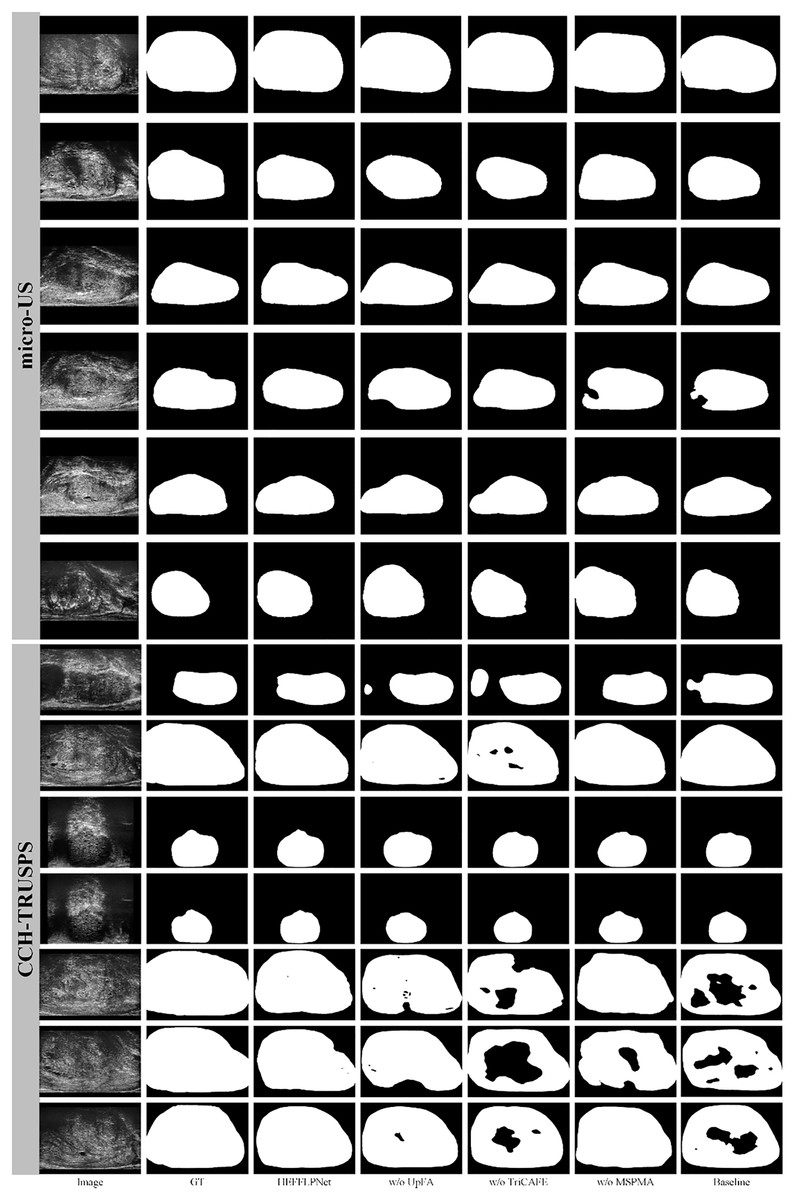
Figure 6: Segmentation results under different configurations of HEFFLPNet.
{kind=link}
Specifically, when the MSPMA module is omitted, the resulting masks exhibit incomplete contours and inaccurate boundaries, especially in cases with low contrast or blurred edges. This can be attributed to the loss of effective multi-scale feature modeling and fusion, which are crucial for precise delineation in complex anatomical regions.
Removing the UpFA module leads to under-segmentation in several cases, indicating a weakened ability to preserve and integrate fine spatial details from earlier encoder stages. Without UpFA, the network’s capacity to selectively highlight relevant spatial features is significantly reduced.
The absence of the TriCAFE module results in a decline in boundary accuracy and structural completeness. This suggests that TriCAFE plays an essential role in strengthening skip connections and bridging the semantic gap between encoder and decoder features, thereby maintaining spatial coherence.
These visual results align with our quantitative findings and confirm that each module in HEFFLPNet contributes complementarily to its overall segmentation robustness and precision across different datasets.
Limitations
Despite its strong segmentation performance, HEFFLPNet may have limitations. First, the model is trained on a relatively small and specific dataset, which may limit its generalizability to diverse imaging conditions and patient populations. While it demonstrates superior segmentation accuracy, its computational complexity is higher than that of traditional CNN-based approaches, potentially restricting real-time clinical applications. Additionally, the reliance on manually annotated data makes it susceptible to annotation variability, and its ability to handle extreme imaging artifacts remains an area for improvement, such as prostate calcifications or motion distortions.
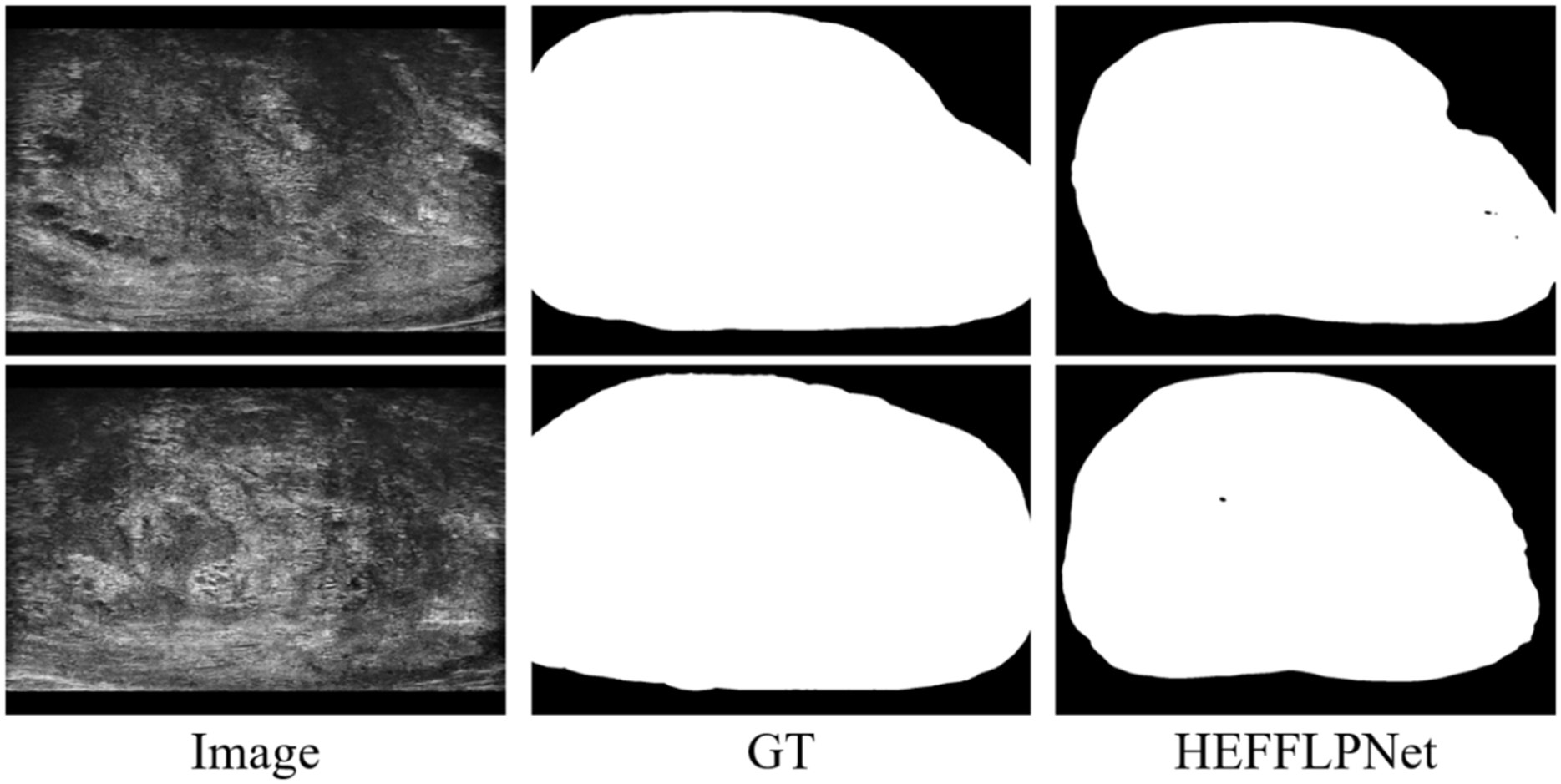
Another observed limitation is the model’s reduced ability to maintain internal consistency in the predicted masks. As shown in Fig. 7, small holes or disconnected regions occasionally appear within otherwise well-segmented prostate areas. These errors likely result from the model’s tendency to prioritize global shape accuracy over fine-grained structural uniformity. Future work should explore incorporating structure-aware or topology-preserving loss functions to explicitly penalize internal discontinuities and improve mask coherence. Moving forward, further research should focus on optimizing the model’s computational efficiency to better support real-time applications. It will also be valuable to expand the training dataset with more heterogeneous imaging cases and multi-center data to strengthen robustness across equipment and patient subgroups. In addition, exploring semi-supervised or self-supervised learning could help reduce the dependence on large amounts of manually labeled data, making the approach more scalable in practical settings.
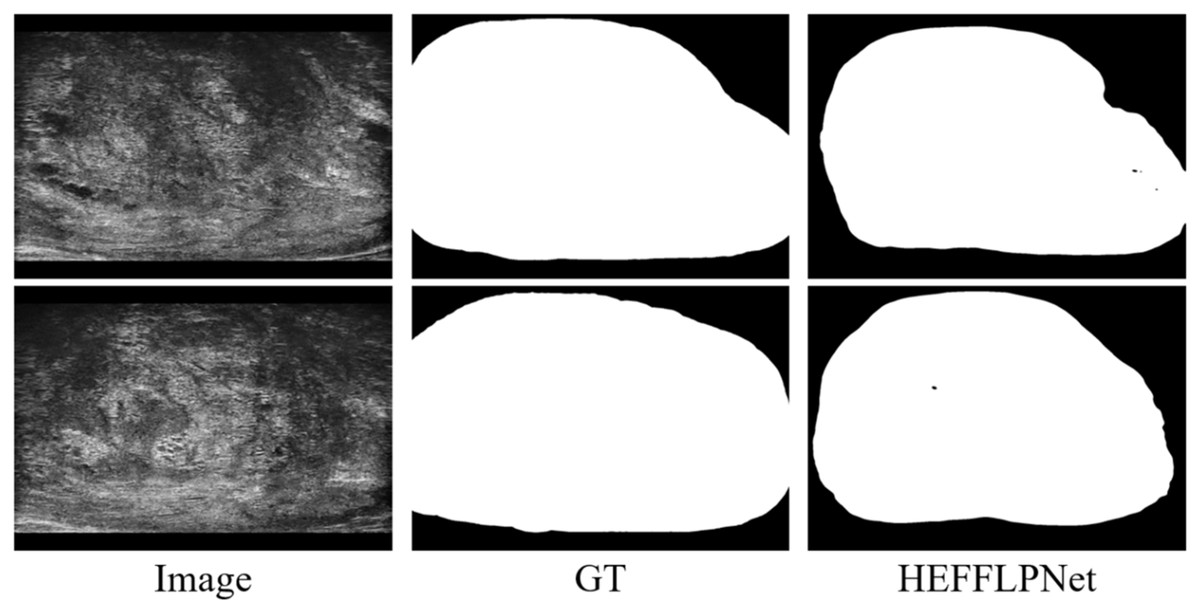
Figure 7: Example of internal segmentation inconsistency by HEFFLPNet.
{kind=link}
In addition, for clinical deployment, further validation on prospective, multi-center datasets is still required to ensure robustness across different scanners and patient populations. Moreover, although the computational overhead of HEFFLPNet is moderate, additional optimization may be needed to support real-time use in ultrasound-guided procedures.
Privacy and ethics
Both the micro-US and CCH-TRUSPS datasets used in this study are publicly available and were collected under appropriate ethical approvals. All patient data were fully anonymized, ensuring compliance with privacy protection standards and ethical guidelines.
Medical relevance
Accurate and efficient prostate segmentation has direct clinical implications for the early detection, diagnosis, and treatment planning of prostate cancer. By improving boundary delineation and robustness under challenging ultrasound conditions, our proposed HEFFLPNet may assist radiologists and urologists in guiding biopsies more precisely, minimizing sampling errors, and reducing unnecessary tissue removal. Additionally, the ability of HEFFLPNet to generalize well to different ultrasound modalities indicates its potential as a practical tool in diverse clinical scenarios.
Conclusions
This article introduces HEFFLPNet, a novel method for automatic segmentation of the prostate capsule in micro-US images, which also demonstrates strong generalization capabilities for prostate segmentation in conventional ultrasound images. Our primary contribution is the development of three innovative modules: the TriCAFE module, MSPMA module, and UpFA module, which collaboratively enhance hierarchical feature fusion and minimize information loss. Experimental results show that HEFFLPNet outperforms SOTA methods in prostate segmentation on both micro-ultrasound and conventional ultrasound images. These results underscore the effectiveness of the proposed modules in improving segmentation accuracy, robustness, and generalization. Additionally, our segmentation tool holds potential to assist urologists in early detection, prostate biopsy, cancer diagnosis, and treatment planning.