
Addressing human speech characteristics in single-channel speaker extraction networks
- Published
- Accepted
- Received
- Academic Editor
- Xiangjie Kong
- Subject Areas
- Algorithms and Analysis of Algorithms, Data Mining and Machine Learning, Multimedia, Natural Language and Speech, Neural Networks
- Keywords
- Time domain, Speaker extraction, Single channel, Deep learning
- Copyright
- © 2025 Ye et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Addressing human speech characteristics in single-channel speaker extraction networks. PeerJ Computer Science 11:e3326 https://doi.org/10.7717/peerj-cs.3326
Abstract
The objective of single-channel speaker extraction is to isolate the clean speech of a target speaker from a mixture of multiple speakers’ utterances. Conventionally, an auxiliary reference network is utilized to extract the speaker’s voiceprint features from the speech signal, which are then fed as input cues to the primary speech extraction network, thereby enhancing the extraction robustness. Nevertheless, existing studies have largely overlooked the sequential characteristics of speech signals, leading to a mismatch between the receptive field of the model and the inherent signal features. Moreover, prevalent speaker extraction architectures fail to account for the spectral distribution properties of speaker speech. To address these limitations, this study presents an extended version of our previous work (DOI 10.36227/techrxiv.23849361.2), which proposes an innovative approach by extending the Convolutional Neural Network Next (ConvNeXt) model, originally designed for image processing, into the Time-Domain ConvNeXt model (TD-ConvNeXt). The TD-ConvNeXt model is integrated with Temporal Convolutional Networks (TCN) blocks to construct the core architecture of the speech extraction network. Additionally, the ConvNeXt model is adapted into a novel Spk block for the auxiliary network, which effectively learns the identity-related features from the reference speech and represents them as embedding vectors. This methodology enables high-fidelity extraction of the target speaker’s speech while maintaining excellent speech quality. The extraction network and the auxiliary reference network are jointly optimized via multi-task learning. Extensive experimental evaluations demonstrate that the proposed model substantially outperforms state-of-the-art methods in single-channel target speech extraction. Across various signal-to-noise ratios (SNRs), the proposed model achieves superior performance in terms of Scale-Invariant Signal-to-Distortion Ratio (SI-SDR), Perceptual Evaluation of Speech Quality (PESQ), and Short-Time Objective Intelligibility (STOI). Specifically, at an SNR of 5 dB, the proposed model attains SI-SDR, PESQ, and STOI scores of 14.83, 3.03, and 0.934, respectively.
Introduction
Speaker speech extraction is a special case of speech separation that aims to extract the speech signal of a target individual from mixed speech signals of multiple people, commonly referred to as the cocktail party problem (Chen et al., 2017). In recent years, deep learning-based methods have made significant progress in both speech quality and extraction speed. These methods can mine deep features from large amounts of data, possess strong nonlinear modeling capabilities, and improve the generalization performance of the network in speech extraction, achieving stronger adaptability and noise resistance (Saijo et al., 2024; Zmolikova et al., 2023; Wang et al., 2023; Tzinis et al., 2022; Karamatli & Kirbiz, 2022; Wang et al., 2022; Chen et al., 2020; Manamperi et al., 2022). However, current work is based on the assumption that mixed speech signals are mutually independent, which is not always valid in practical scenarios. The sounds of speakers commonly affect each other, causing their speech to no longer be independent and affecting the performance of speech extraction algorithms.
To address the low robustness of single-channel target speech extraction, many researchers have made significant progress using various deep learning techniques. Ju et al. (2023) slash computation via subband processing. Xu et al. (2019) balance speech quality and speaker fidelity with a new loss. Luo & Mesgarani (2019) propose an end-to-end fully convolutional time-domain speech separation network. The VoiceFilter series (Wang et al., 2018, 2020; Rikhye et al., 2021) pioneer speaker-conditioned masking, later optimized for on-device streaming. Delcroix et al. (2020) inject embeddings into time-domain networks, while Spex/SpEx+ (Xu et al., 2020; Ge et al., 2020) solve phase issues via multi-scale convolution and complex masking. Ge et al. (2021) integrate utterance and frame-level references using a multi-stage framework. Zmolikova et al. (2017) propose the speakerbeam model, which uses the speaker’s voiceprint information as a reference for the extraction network to focus on a single speaker’s speech. Subsequent research work mostly refers to similar structures, especially the convolutional neural network next (ConvNeXt) model’s application in speech processing (Liu et al., 2022), which demonstrate high accuracy, good scalability, and effectiveness in speech separation and extraction. However, current studies have paid little attention to the time-series characteristics of speech signals, resulting in a mismatch between the receiving field and the signal characteristics. In addition, the commonly used speaker extraction model does not consider the spectral distribution characteristics of the speaker’s speech. To address these shortcomings, we propose an improved TD-ConvNeXt structure that can process time-series speech data in the case of large receptive fields, which can match the features of the speech signal with strong front-to-back correlation in speech signals and, estimate the mask of target speech. In addition, we believe that the entire network needs TD-ConvNeXt structure to focus longer speech context contacts and temporal convolutional networks (TCN) structure to obtain more complete speech features. In the backbone network of speech extraction (speech extractor), we combine both structures to achieve better results (TCN and TD-ConvNeXt combination) and experimentally verify this hypothesis. In order to overcome the shortcomings of equal weight distribution between the channels of the reference speech, combined with the convolutional neural network and the channel attention module, we convert the ConvNeXt structure into the Spk structure, and add squeeze-and-excitation (SE) blocks to form a new Spk block. The block learns the speaker identity information features from the reference speech as embedding vectors to stimulate the main extraction network, which can strengthen the weight of channels that are beneficial for speaker identification, improving the accuracy of speech extraction while avoiding the phase estimation problem associated with learning and estimating time-frequency maps. To verify the effectiveness of our proposed system, we used SpEx+ (Ge et al., 2020) as a reference model, set up different extraction networks, and determined the optimal extraction network model structure parameters as well as the parameters of the auxiliary network. We also discussed the settings of different window encoder sizes. Finally, we compared our proposed model with SpEx+ (Ge et al., 2020), sDPCCN (Han et al., 2022) and other the state of the art models and verified that our model outperforms existing models in Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) (Roux et al., 2019), Perceptual Evaluation of Speech Quality (PESQ) (Rix et al., 2001), and Short-Time Objective Intelligibility (STOI) (Taal et al., 2011) indicators under different signal-to-noise ratios. Portions of this text were previously published as part of a preprint (Yuan, 2023). The main contributions of this article are:
-
1.
We extend the ConvNeXt block model in image processing to TD-ConvNeXt block suitable for processing temporal information in time-series data and combine it with TCN block to form the main body of our speech extraction network.
-
2.
We design a new Spk block that learns speaker identity information features from reference speech as embedding vectors to stimulate the main extraction network.
-
3.
We conduct extensive experiments to find the optimal structure parameters and network structure of the best extraction network and compare our proposed model with existing advanced speech extraction algorithms, verifying its effectiveness in improving single-channel target speech extraction performance.
This article is organized as follows. In ‘The Improvement of Speech Extraction Scheme’, we motivate and design the proposed architecture. In ‘Experiment Methology’, we report the experiments. In ‘Results’, We have conducted numerous experiments to validate the effectiveness of the new model. ‘Related Work’ discusses the related works. And ‘Conclusions’ concludes the study.
The improvement of speech extraction scheme
Selective auditory attention, an essential cognitive function of humans, empowers individuals to concentrate on pertinent auditory stimuli while effectively discarding irrelevant distractions (Mesgarani & Chang, 2012). This function encompasses the accurate manipulation of sound data, its organization into harmonious auditory sequences, and the isolation of target sounds by subduing competing auditory signals (Hill & Miller, 2010). Unlike a static and unidirectional information extraction approach, selective auditory attention is malleably influenced by diverse factors, including bottom-up sensory inputs and top-down task-specific goals (Kaya & Elhilali, 2017). Intriguingly, in complex environments, humans are capable of constantly learning to regulate and choose their auditory attention in real-time.
This research aims to enhance the precision of target speech extraction. In our previous work, while we laid the foundation for leveraging deep learning in auditory attention modeling, limitations in extraction accuracy persisted. Consequently, the core objective of this updated study is to more effectively utilize the learning capacity and nonlinear modeling capabilities of deep learning models to mimic human selective auditory attention, thereby achieving more accurate selective target speech extraction.
The speech extraction problem
We formally describe the speech extraction problem as follows. Let the speech signal of the target speaker be denoted as . The mixed speech can then be represented as follows:
(1) Here, , and denote the speech signal of the target speaker and the interference sources, respectively, refers to the time frame, and is the number of interference sources. The objective of speech extraction is to extract from .
The architecture of the scheme
Drawing inspiration from the design principles of speech extraction network frameworks proposed in previous research (Luo & Mesgarani, 2019), we have devised a novel deep learning-based speech extraction network, as vividly illustrated in Fig. 1. In this figure, Fig. 1A offers a comprehensive block diagram depicting the general process of speaker extraction, while Fig. 1B presents a detailed system flowchart of the proposed network architecture. The proposed network model is composed of five key components: the Mixture Encoder, Reference Speech Encoder, Speech Extractor, Speaker Encoder, and Speech Decoder. The Mixture Encoder and Reference Speech Encoder undertake the crucial task of transforming the time-domain waveform signals of mixed speech and reference speech, respectively, into high-dimensional time-domain feature representations. These representations capture the essential characteristics of the input speech data.
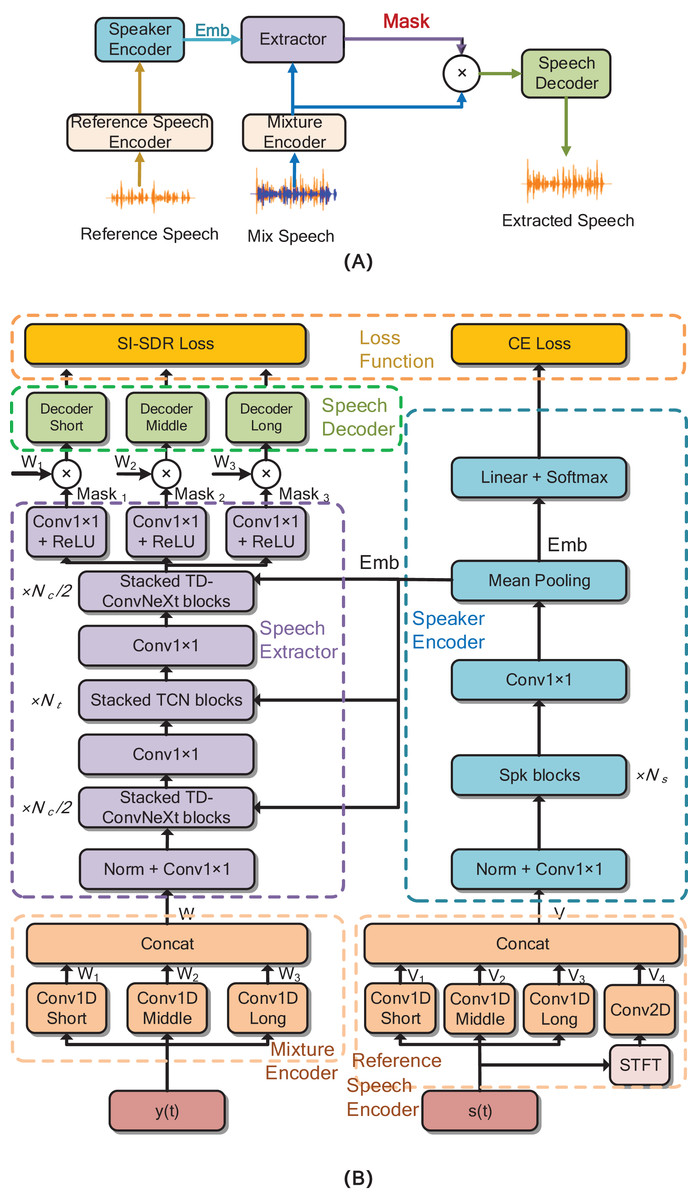
Figure 1: (A) The block diagram of the speaker extraction network. (B) The proposed TD-ConvNext network model, the blocks in modules with the same function share the same color.
is the mixed speech, is the reference speech. ‘Emb’ is the identifiable embedding vector of target speech. The Conv1 is convolutional operation, “Norm” is layer normalization, the detail of Spk block is shown in Fig. 3.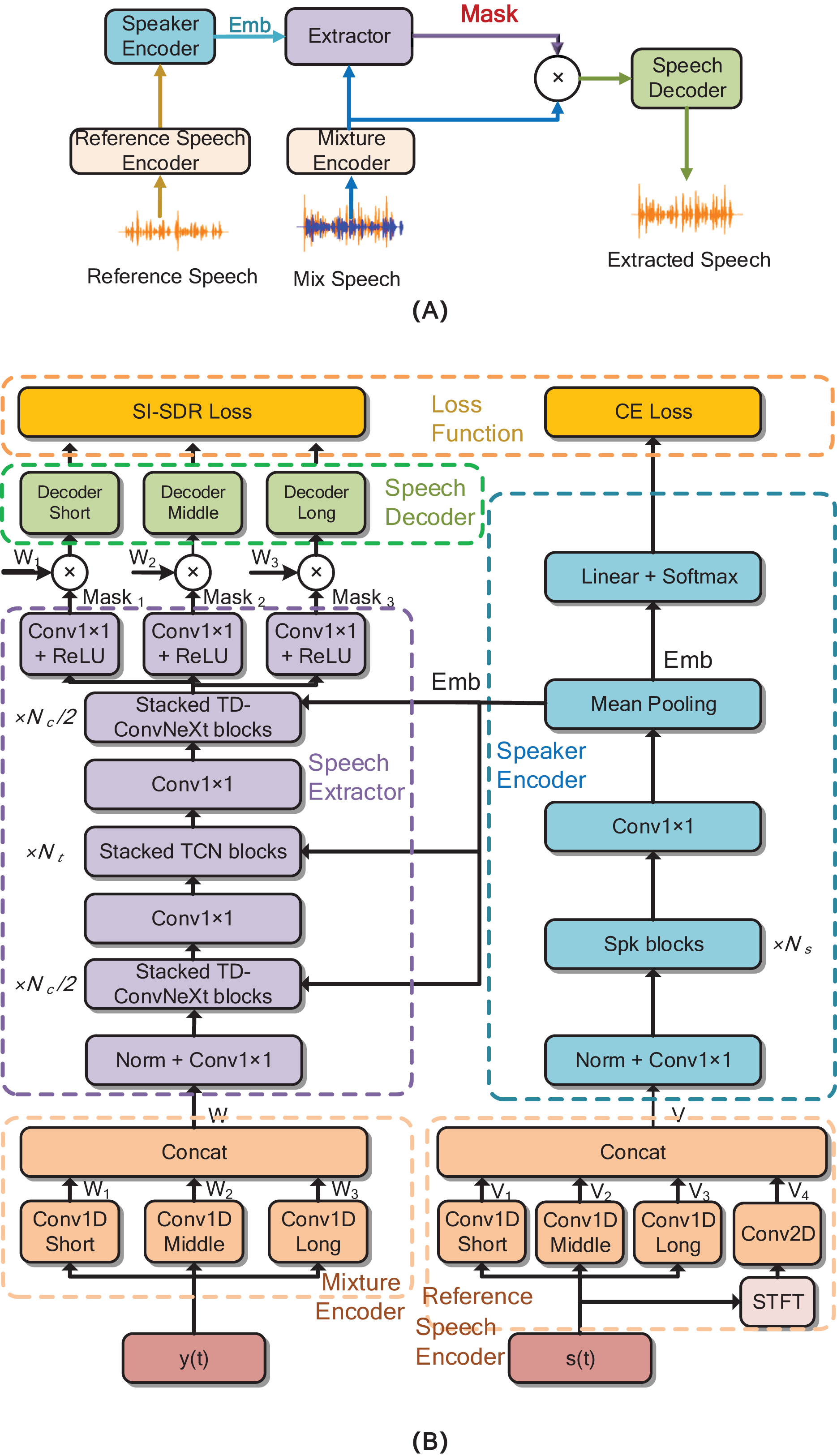{kind=link}
The Speaker Encoder, by contrast, represents an evolved design from our earlier previous work, engineered to more effectively differentiate the unique acoustic attributes of the target speaker from those of other speakers. Whereas the previous work exhibited limitations in capturing fine-grained acoustic variations, this updated encoder generates robust identity embedding information through enhanced discriminative learning. This information serves as a distinctive identifier for the target speaker within the network and is disseminated throughout the model, providing a solid foundation for subsequent processing steps. The integration of identity embedding information into the network architecture builds directly on our previous framework, addressing its prior constraint of suboptimal embedding utilization. Its primary role is to endow the model with the ability to selectively extract target speech from complex mixtures, a capability that was partially realized in the previous work but now refined through optimized information propagation. By leveraging this embedded identity information—now more deeply integrated across model layers—the model achieves higher precision in identifying and isolating the target voice, marking a significant advancement in speech extraction performance.
The Speaker Encoder, by contrast, is engineered to differentiate the unique acoustic attributes of the target speaker from those of other speakers. Through this discrimination process, it generates robust identity embedding information, which serves as a distinctive identifier for the target speaker within the network. This identity embedding information is then disseminated throughout the model, providing a solid foundation for subsequent processing steps. The integration of identity embedding information into the network architecture is of paramount importance. Its primary role is to endow the model with the ability to selectively extract the speech of the target speaker from complex auditory mixtures. By leveraging this embedded identity information, the model can more accurately identify and isolate the target speaker’s voice, thereby enhancing the overall performance of the speech extraction process.
The Speech Decoder is architected to reconstruct the time-domain waveform signals at varying resolutions. Its operational mechanism involves leveraging the time-domain masking information generated by the core Speech Extractor component, enabling the recognition and subsequent reconstruction of the target speech waveform. This process is crucial for restoring the original speech signal quality after the extraction process. Ensuring the fidelity of the extracted speech necessitates that the Speech Extractor is equipped with the capacity to analyze the intricate speech features and their inherent interdependencies, while simultaneously adapting to the dynamic and complex acoustic environments. To address these requirements, we employ a non-causal convolutional model with adjustable dilation rates to build a long-sequence processing architecture. This design allows the model to effectively capture the long-range contextual information within speech signals, thereby facilitating a more comprehensive and nuanced analysis of the speech content. The detailed design and implementation of the Speech Extractor are further elaborated in ‘Speech Extractor’.
Mixture encoder
The speech encoder utilizes one-dimensional convolution to perform multi-scale encoding (with convolution kernels of varying lengths) to juice the time domain features of human speech. This operation bypasses the challenge of phase estimation in short-time Fourier transforms, ultimately improving the performance of speech extraction.
The length of the convolution kernel is determined as , and respectively, the step size is set to . The output obtained through the speech encoder is a N-dimensions vector with length K:
(2) where , and K can be calculated by . ReLU is the activation function, is the one-dimensional convolution layer, and is the original mixed speech. The complete output obtained by multi-scale encoder is a concatenation of the three vectors and .
Similaly, in the proposed network model, we share the same convolutional layer and weights of mixed speech coding with the reference speech coding, the adoption of the twin operation can effectively improves the performance of speech separation that was validated in the SpEx+ model (Ge et al., 2020). The output of the reference speech coding can be obtained as .
Reference speech encoder
The reference speech encoder design is depicted in Fig. 2. The reference speech signal is first passed through one-dimensional convolutional encoders (Conv1Ds) to obtain time domain features. Simultaneously, the reference speech signal undergoes short time Fourier transform (STFT) operation to obtain a two-dimensional time-frequency map. The time-frequency map is then convolved using a 2-D convolution (Conv2D) to obtain two-dimensional time-frequency features. The time domain features obtained by Conv1Ds are concatenated along the channel, while the time-frequency domain features from the Conv2D are concatenated along the frequency direction. These features are then combined to create new features.
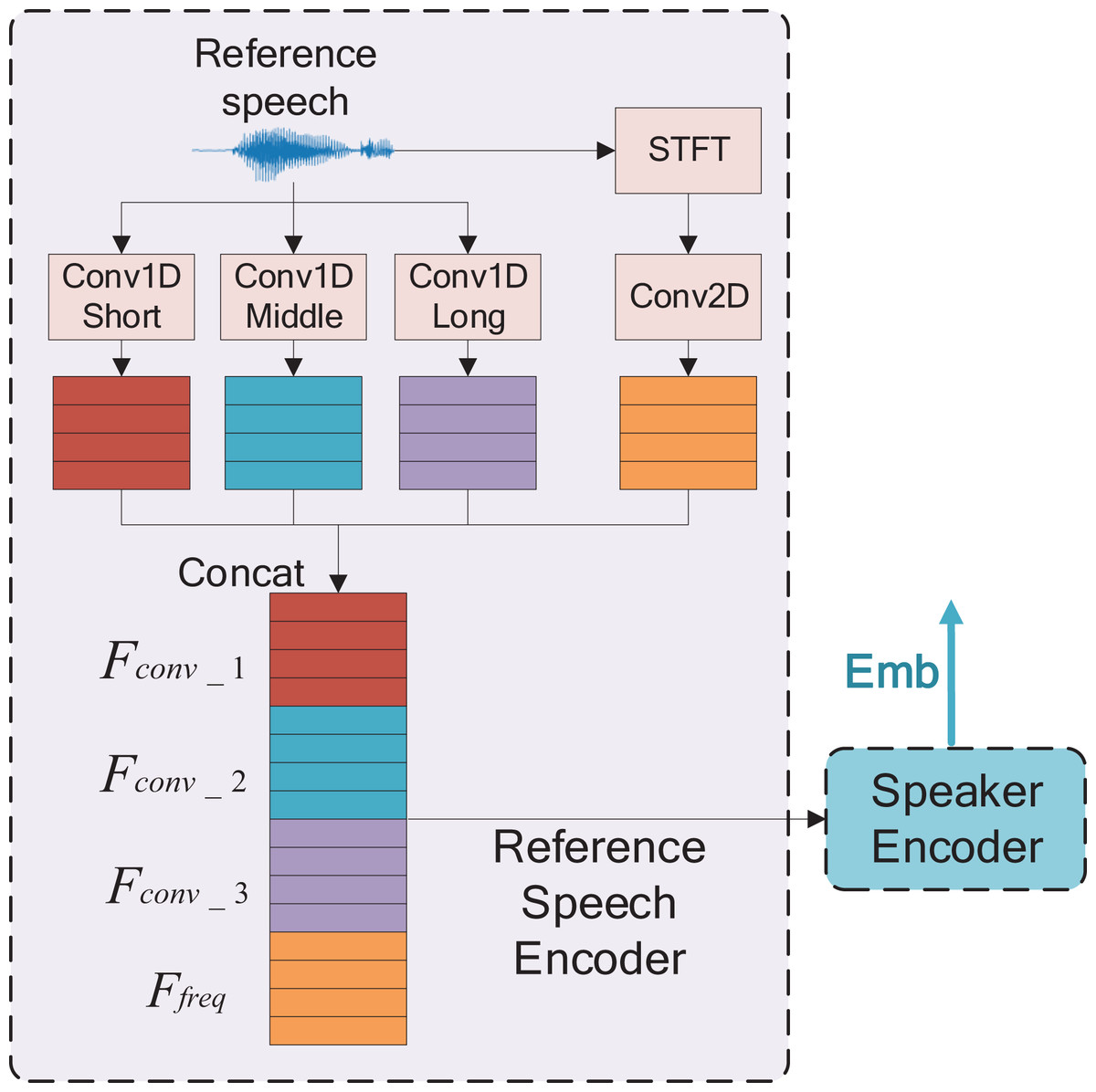
Figure 2: The reference speech encoder with a mixture of time and time-frequency domains, , and are the convolution operations, whose convolution kernels are from short to long, respectively.
, and are the time domain features of the output of the above convolution, respectively, STFT is short-time Fourier transform, is the spectral feature after convolution, concat is concatenation.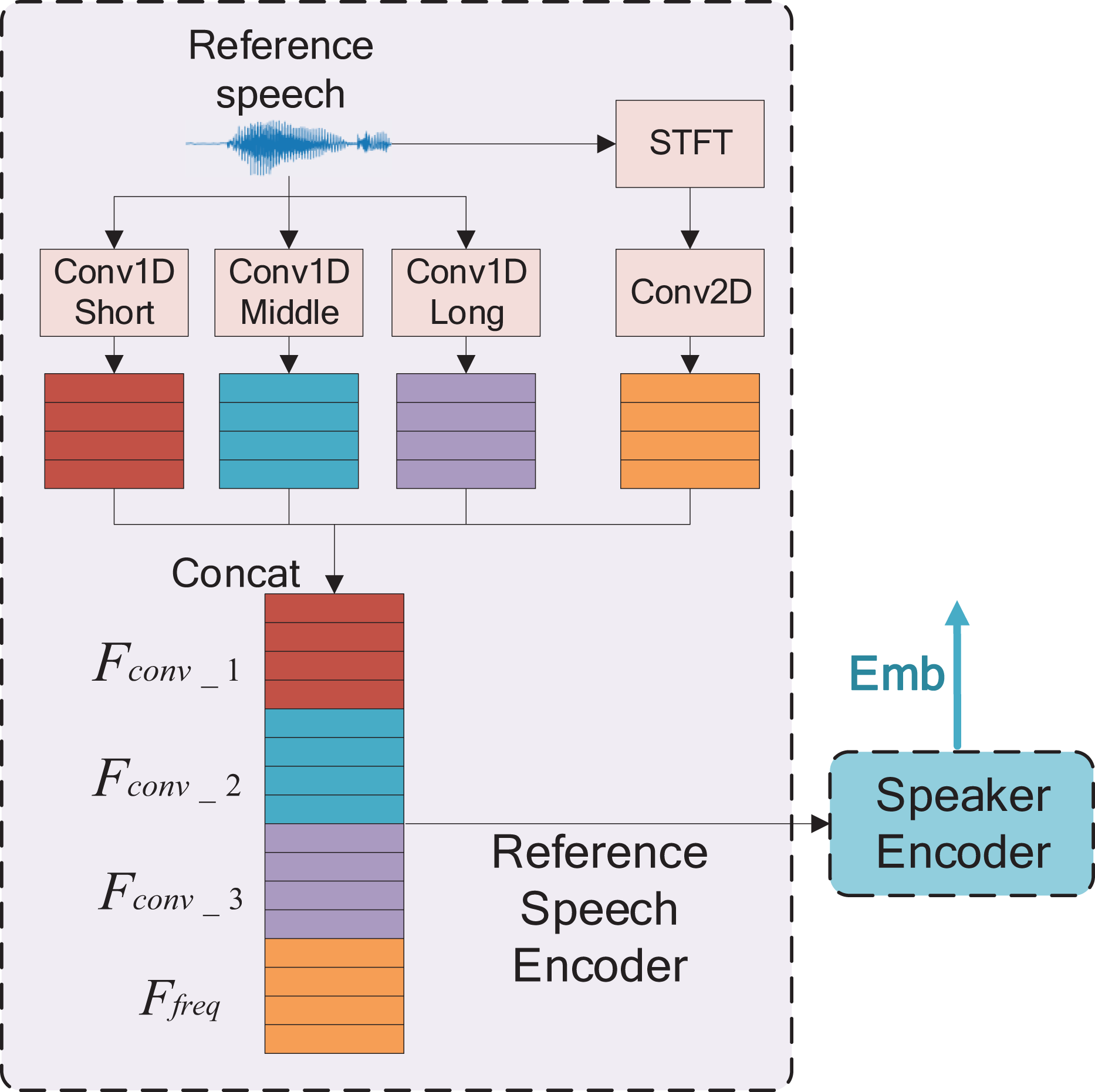{kind=link}
However, the one-dimensional convolution has three types of convolutional kernel lengths (20, 80, and 160) with a step size of 10. These kernel lengths correspond to time window lengths of 2.5, 10, and 20 ms respectively when the sampling rate is 8,000.
As shown in Fig. 2, denotes the encoder with a kernel length of 20, while the other two encoders have kernel sizes of 80 and 160. The process for obtaining temporal features is calculated as follows:
(3) where , and are convolution operations with kernels of varying lengths.
To obtain time-frequency features using STFT, we set the window length to 20 and the frame shift to 10 to match the kernel length. We apply STFT to the input speech signal , and the calculation process is as follows:
(4)
We separate the real and imaginary parts of it to obtain:
(5)
Then, we obtain the magnitude spectrum as:
(6)
We input into a two-dimensional convolution layer to obtain time-frequency features:
(7)
After completing these steps, we obtain both temporal and spectral features, concatenate them, and input them into the speaker encoder to learn the embedded vector.
Speaker encoder
After encoding the reference speech with time domain features, it must meet with further training by the network to obtain a vector that can be used for extracting. The speaker encoder, as depicted in blue in Fig. 1B, aims to produce an identifiable embedding vector for the speech extraction network. Unlike traditional voiceprint extraction networks that use i-vector (Dehak et al., 2010) and x-vector (Snyder et al., 2016) to classify speakers, our speaker encoder concentrates on discovering similar embedding vectors in the time domain system to provide references for speech extraction networks.
The speech encoder encodes the reference speech and generates a high-dimensional identity feature vector V. To further enhance the features obtained by different scale encoders, layer normalization (LN) and a convolution are enforced. The resulting high-dimensional features are then subject to channel integration and cross-channel fusion, ultimately resulting in a dimension change from to .
In order to obtain a desirable embedding vector, we have developed the Spk block, which is illustrated in Fig. 3A, we explain the structure of it as follows.
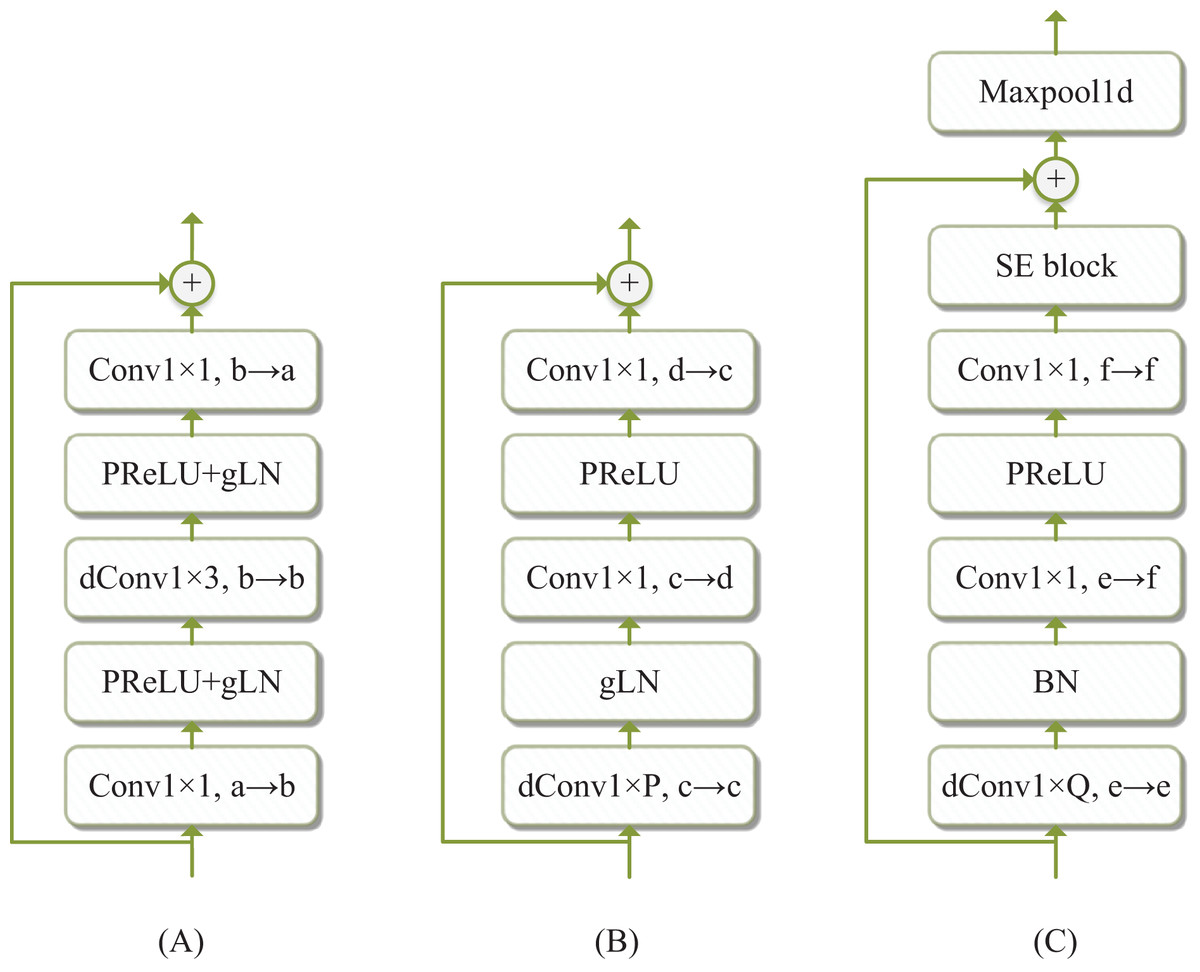
Figure 3: The details of three blocks, (A) Spk block, (B) TCN block, (C) TD-ConvNeXt block.
‘ ’ is the residual connection, ‘Conv’ and ‘dConv’ are convolution and depth-wise separable convolution, ‘gLN’ is global layer normalization (gLN) (Luo & Mesgarani, 2019), ‘PReLU’ is the parametric linear unit, ‘BN’ is the batch normalization, ‘SE’ is the channel attention module, ‘Maxpool 1d’ is the maximum pooling layer (Hu, Shen & Sun, 2018).{kind=link}
The Spk block: The Spk block utilizes a depth-wise separable convolution (dConv) to separate the signal into channels, followed by s batch normalization (BN). Subsequently, a convolution layer is applied to transform the channel number from to , with a PReLU non-linear layer, then another convolution layer is adopted, the number of channels still maintained as . Next, the channel attention module SE block (Hu, Shen & Sun, 2018) was utilized to employ the attention mechanism to each channel, thereby increasing the weight of channels that have positive effects. To prevent the loss of shallow features and the vanishing gradient problem in the training process, the input and output of the SE block were added by skip-connection in the figure. Subsequently, a threshing operation was performed by the maximum pooling layer, which boosted the generalization performance of the trained embedding vector and reduced its length.
In the Speaker encoder, Spk block has been repeatly utilized times. Then a convolutional layer was employed to set the output dimension to N′, and the global average layer was exploited to obtain the identity embedding vector with length 1 and dimension N′.
The target speaker identity embedding obtained from the aforementioned analysis serves two purposes. Firstly, it is used to guide the speech extraction network to estimate the correct target masking. Secondly, the identity is embedded through the linear layer and softmax for speaker label prediction. Manipulating co-training of SI-SDR loss and cross-entropy loss, can result in a better match between the identity embedding and the speaker identity, thereby enabling the model to more accurately name the target speaker’s voice and achieve preferable extraction performance.
Speech extractor
In this article, we propose a novel time-domain speech extraction network for obtaining the target speaker’s mask. Recently, the time-domain model based on TCN block (Bai, Kolter & Koltun, 2018) has achieved remarkable success in speech separation tasks. However, the hollow convolution’s receptive field is severely limited due to the convolution kernel size constraint. The ConvNeXt block model (Liu et al., 2022), which uses convolution kernels with larger adaptation, can theoretically achieve a larger receptive field. However, the original application scenarios of ConvNeXt is image processing, it still unable to meet the requirement for a large receptive field of temporal sequence data in speech signal processing. Therefore, we have elevated the ConvNeXt block model to TD-ConvNeXt model to improve its suitability for processing time series data.
The TD-ConvNeXt block: The ConvNeXt (Liu et al., 2022), which is derived from RseNet50 (He et al., 2016) and builds on the Swin Transformer (Liu et al., 2021), has demonstrated superior performance compared to Swin Transformer. To process one-dimensional time series data, we have revamped the ConvNeXt blocks, which is referred to as Time-Domain ConvNeXt block (TD-ConvNeXt block) and is illustrated in Fig. 3C. The original ConvNeXt nonlinear layer and the normalized layer are GELU and LN, respectively. We have modified them to PReLU and gLN.
Compared to the original ConvNext structure, we put the dConv convolution in the first layer, the TD-ConvNext structure has fewer nonlinear and normalized layers. The convolution kernel of dConv has a size of and an expansion factor, we put gLN and PReLU between the two convolutions. This approach reduces the number of parameters that need to be saved during training, making it easier to construct a deeper model. TD-ConvNeXt blocks are also a stacked structure in speech extractor, as depicted in Fig. 4B. They are stacked B times with the expansion factor of dConv gradually increasing from to to enhance the receptive field of modules.
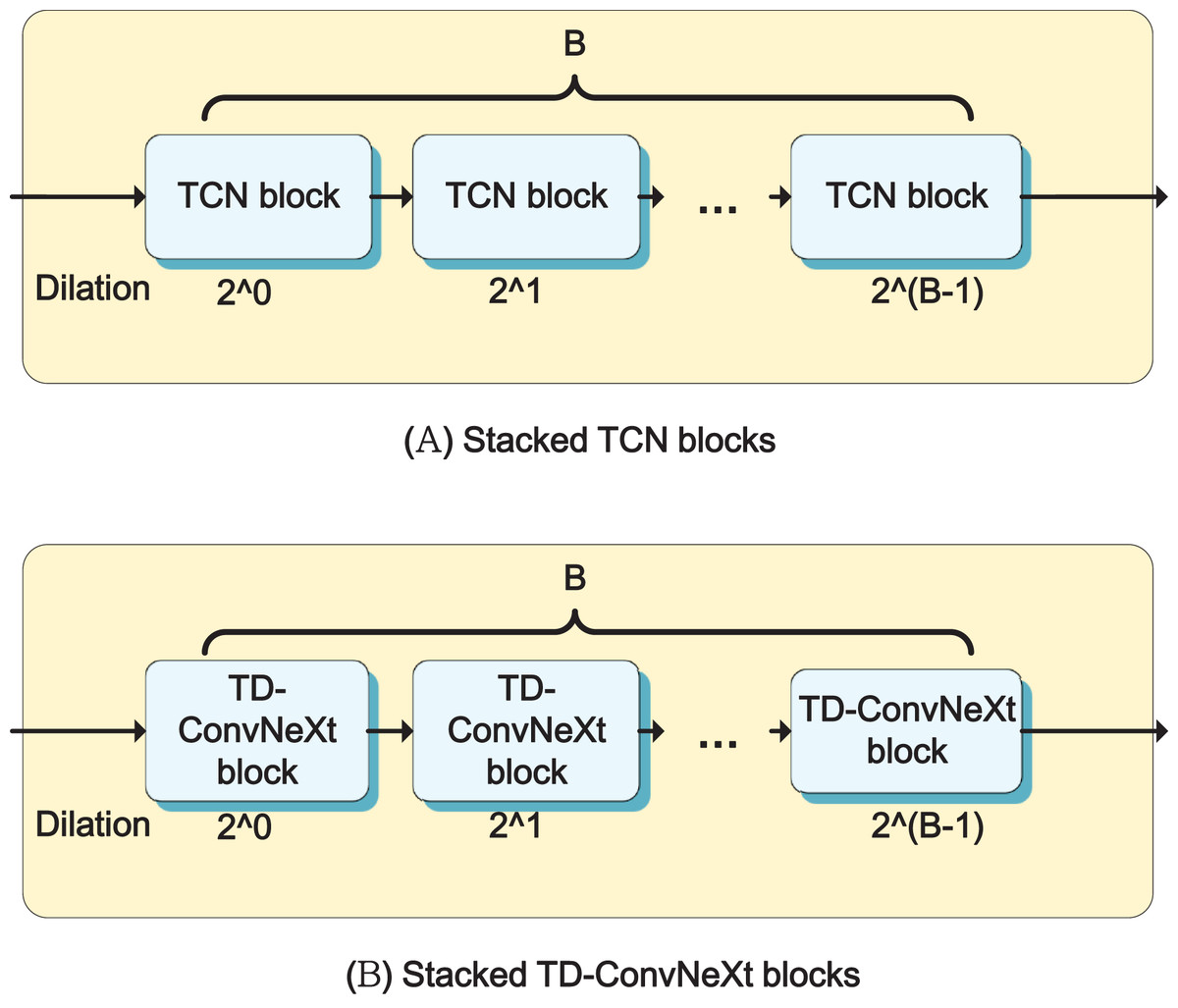
Figure 4: The internal structure of two modules, (A) the TCN blocks stack, (B) the TD-ConvNext blocks stack.
{kind=link}
Considering the excellent performance of TCN block in processing time series, we have incorporated it as one of the components in our proposed model. The block comprises two convolution layers and a dConv layer, as illustrated in Fig. 3B. The first layer is a convolutional layer, which changes the channel from to . Nonlinear layer PReLU and global layer normalization (gLN) (Luo & Mesgarani, 2019) are then added to accelerate network convergence. The middle convolution layer is a deeply separable convolution with a convolution kernel size of and an expansion factor. Since speech data is a long sequence of one-dimensional data, increasing the receptive field can ensure the integrity of the output speech to some extent. A PReLU+gLN layer is added to nonlinearize and normalize the intermediate output features. The last convolution layer communicates and fuses it across channels. To prevent the vanishing gradient issue during training, each module in the entire block is equipped with a skip-connection. As the TCN blocks are stacked B times, as shown in Fig. 4A, we refer to it as Stacked TCN blocks, where the expansion factor of each block increases from to .
Once the output vector W of the mixed speech encoder and the embedded vector of the speaker encoder are obtained, normalization is performed followed by dimension reduction using a convolution layer. This reduces the dimension of the feature vector from to . The feature vector includes both the target speaker and jammer, which necessitates integration of the speaker-encoded embedded vector to guide the subsequent speech extraction process. As shown in purple in Fig. 1B, the speech extractor comprises stacked TD-ConvNeXt blocks and stacked TCN blocks. The speaker feature embedding vector is fused with each large module to provide continuous stimulus to the speech extractor, thereby guiding the speech extraction process.
Furthermore, the size is , and it is copied to the same length as W′. Consequently, the fusion result size is , which is then input into each block. Between stacked TD-ConvNeXt blocks and stacked TCN blocks, convolution is used for dimension conversion. Therefore, the feature size of the first block of the stacked input TCN blocks in the model is . The time domain feature code obtained after connecting the two basic modules, is processed through a combination of convolution and ReLU to obtain a mask similar to IBM and IRM (Wang, Narayanan & Wang, 2014). Because we employ the multi-scale scheme, the mask can be denoted as , where after training. Consequently, the final speech encoded features can be expressed as follows.
(8) Here, represents the dot multiplication between the corresponding elements of the matrix, and denotes the estimated target speaker speech coding at a certain scale.
Speech decoder
The speech extraction network mixes the embedding vector of the auxiliary network with the time domain features of the mixed speech obtained by the encoder, followed with convolution operations to obtain the speech coding of the target speaker. Finally, the speech coding is reconstructed into a time series through the decoder, resulting in the reconstructed target speech data. This process can be expressed as:
(9) Here, represents the reconstructed target speaker speech, where denotes the estimation at different scales. refers to the deconvolution, which is the decoder with convolution kernels corresponding to the encoder with lengths , , and , respectively. The decoder generates estimated speech at multiple resolutions, with the estimated speech exhibiting the minimum discrimination rate serving as the output of the model.
Multi-mission learning
Target speaker speech extraction can be viewed as a multi-task process. Firstly, the speech features of the target in the mixed speech are extracted and reconstructed into clean speech containing only the target speaker. Second, the reference speech is trained as the feature representation of the target speaker, which corresponds to the correct label classification, thereby providing a positive incentive for the speech extraction of the target speaker. Therefore, the overall target loss function can be divided into two parts. For the speech extraction of the target speaker, the scale invariant signal-to-noise ratio SI-SDR is used as the loss function, while the cross-entropy loss function is employed for the speaker label. The total loss function can be represented as follows:
(10) where denotes the weight factor occupied by the cross-entropy loss function. The loss functions for the two subtasks are presented separately below.
SI-SDR is a commonly used speech evaluation metric that has better robustness than SDR (Roux et al., 2019). To encode and decode operations in multi-scale scenarios, we use convolution kernels of different sizes. This enables the speech to have output in different resolution windows. Therefore, the entire SI-SDR loss during the training process can be expressed as follows:
(11)
In Eq. (11), represents the estimation of the mixed speech obtained under different resolution windows after extraction. denotes the SI-SDR loss.
The cross-entropy loss function (CE loss) is commonly employed for classification tasks, and can be represented as follows.
(12) where is the number of speakers, is the true vector of speaker labels, and is the estimated predicted probability.
Experiment methology
In this section, we conduct numerous experiments to validate the proposed scheme.
The data set
Our experimental dataset is the 100-h libriSpeech dataset (Panayotov et al., 2015), which comprises 251 speakers and approximately 28,000 clean sentences as the training and validation sets. The test set consists of 40 speakers and 2,620 clean sentences, with all original sentences sampled at a 16 k sampling rate. Each statement has a duration of approximately 10 s.
To simulate real-world environments, we used the WHAM! (Wichern et al., 2019) noisy dataset as ambient background noise. We randomly selected a clean sentence without background noise from two different speakers. We chose the first speaker as the target source and selected another sentence from the target speaker’s speech as the reference speech. The other speakers were regarded as the interference sources.
The mixed speech was generated using the direct stacking method. Firstly, environmental noise was mixed with the speech of another speaker. Then, the mixed speech was randomly combined with the speech of the target speaker at signal strengths of −5, 0, and 5db. A total of 20,000 statements were generated as the training set, with 5,000 selected for the validation set. In the test set, we used three signal-to-noise ratios (SNRs), and each test statement was a hybrid generation of LibriSpeech and WHAM! The reference sentence was randomly selected from all the speech of the target speaker, which was not repeated by the target speaker in the mixed speech.
Experiment environment
The hardware used for learning and training in this article was an NVIDIA Tesla V100 graphics card with 32G video memory. For the software environment, we used Pytorch version 1.10, CUDA version 10.2, and Python version 3.7.6. The main parameters used in model training are presented in Tables 1–3. The optimizer was Adam (Kingma & Ba, 2014), with an initial learning rate of and a batch size of 10. The initial was set to 20, representing a time window length of 2.5 ms, as the sampling rate of the initial speech in the dataset was 16 k, which was resampled to 8 k in the experiment. Similarly, the initial time window length of and were 10 and 20 ms, respectively. B represents the number of times small blocks are stacked into large blocks in the model. For instance, TCN block was stacked eight times into TCN blocks, and the expansion factor of dConv convolution kernel was increased from to . The number of Spk blocks was set to four, with a speech sample length of four seconds. and denote the weight of SI-SDR loss under medium window length and long window length in the loss function, which were pre-set to 0.1. represents the weight factor of the cross-entropy loss function, which was set to 10.
| Parameters | Value |
|---|---|
| Initial learning rate | |
| Epoch | 100 |
| Batch size | 10 |
| (short length) | 20 |
| (middle length) | 80 |
| (long length) | 160 |
| B (the number of blocks in stack) | 8 |
| (the number of Spk blocks) | 4 |
| Sampling rate | 8,000 Hz |
| Sampling length | 4 s |
| (the weight of middle length in loss) | 0.1 |
| (the weight of long length in loss) | 0.1 |
| (the weight factor of the cross-entropy loss) | 10 |
| Model configurations | Speech extractors | Number of parameters | SI-SDR (dB) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stacked TD-ConvNeXt | Stacked TCN | Values | Avg. | |||||||||
| c | d | P | a | b | −5 | 0 | 5 | |||||
| SpEx+ | – | – | – | – | 256 | 512 | 4 | 11.2M | 8.31 | 11.02 | 14.40 | 11.24 |
| 1 | 96 | 192 | 7 | 2 | 256 | 512 | 2 | 7.2M | 8.04 | 10.88 | 14.22 | 11.05 |
| 2 | 128 | 256 | 7 | 2 | 256 | 512 | 2 | 7.7M | 7.81 | 10.48 | 13.64 | 10.64 |
| 3 | 160 | 320 | 7 | 2 | 256 | 512 | 2 | 8.4M | 7.79 | 10.43 | 13.63 | 10.62 |
| 4 | 192 | 384 | 7 | 2 | 256 | 512 | 2 | 9.2M | 8.35 | 11.14 | 14.38 | 11.29 |
| 5 | 96 | 192 | 7 | 2 | 256 | 512 | 3 | 9.4M | 8.34 | 11.18 | 14.47 | 11.33 |
| 6 | 128 | 256 | 7 | 2 | 256 | 512 | 3 | 10M | 8.08 | 10.81 | 14.06 | 10.98 |
| 7 | 160 | 320 | 7 | 2 | 256 | 512 | 3 | 10.7M | 8.60 | 11.47 | 14.80 | 11.62 |
| 8 | 192 | 384 | 7 | 2 | 256 | 512 | 3 | 11.M | 8.54 | 11.29 | 14.48 | 11.44 |
| 9 | 96 | 192 | 7 | 4 | 256 | 512 | 3 | 10.1M | 8.29 | 11.04 | 14.30 | 11.21 |
| 10 | 128 | 256 | 7 | 4 | 256 | 512 | 3 | 11.2M | 8.35 | 11.16 | 14.45 | 11.32 |
| 11 | 160 | 320 | 7 | 4 | 256 | 512 | 3 | 12.5M | 8.24 | 11.14 | 14.61 | 11.33 |
| 12 | 192 | 384 | 7 | 4 | 256 | 512 | 3 | 14.1M | 8.20 | 11.13 | 14.50 | 11.28 |
| 13 | 160 | 320 | 3 | 2 | 256 | 512 | 3 | 10.7M | 8.31 | 11.08 | 14.32 | 11.24 |
| 14 | 160 | 320 | 11 | 2 | 256 | 512 | 3 | 10.7M | 8.58 | 11.38 | 14.63 | 11.53 |
| 15 | 160 | 320 | 7 | 2 | 256 | 256 | 3 | 7.3M | 7.54 | 10.37 | 13.82 | 10.58 |
| Model configurations | Speaker Encoders | Number of Parameters | SI-SDR (dB) | |||||
|---|---|---|---|---|---|---|---|---|
| Spk blocks | ||||||||
| Q | −5 | 0 | 5 | Avg. | ||||
| SpEx+ | – | – | – | 11.2M | 8.31 | 11.02 | 14.40 | 11.24 |
| 7 | – | – | – | 10.7M | 8.60 | 11.47 | 14.80 | 11.62 |
| 18 | 96 | 192 | 3 | 9.4M | 8.62 | 11.32 | 14.52 | 11.49 |
| 19 | 96 | 384 | 3 | 9.6M | 8.20 | 11.15 | 14.48 | 11.28 |
| 20 | 128 | 256 | 3 | 9.6M | 8.42 | 11.22 | 14.50 | 11.38 |
| 21 | 128 | 384 | 3 | 9.7M | 8.83 | 11.58 | 14.88 | 11.76 |
| 22 | 192 | 384 | 3 | 10.0M | 8.47 | 11.16 | 14.43 | 11.35 |
| 23 | 128 | 384 | 7 | 9.7M | 8.45 | 11.21 | 14.34 | 11.33 |
| 24 | 128 | 384 | 11 | 9.7M | 8.45 | 11.25 | 14.51 | 11.40 |
Results
This section aims to verify the effectiveness of the proposed model, starting from the benchmark model SpEx+ (Ge et al., 2020). The reference model uses stacked TCN blocks to process time-domain signals. However, in our experiments, we found that a combination of TCN block and TD-ConvNeXt block stacking can produce better results.
To evaluate the effectiveness of the proposed model, three speech quality evaluation metrics, namely SI-SDR (Roux et al., 2019), PESQ (Rix et al., 2001) and STOI (Taal et al., 2010), will be utilized. SI-SDR represents the waveform similarity between the reconstructed speech and the original speech, higher values indicating better restoration. PESQ is an objective evaluation index of speech, with values ranging from −0.5 to 4.5, higher values indicating better speech quality. STOI measures short-time speech intelligibility, with values ranging from 0 to 1, where higher values indicate better speech clarity.
The influence of different configuration of speech extractor on model performance
The speech extractors comprise different stacking patterns of TD-ConvNeXt blocks and TCN blocks, and the number of modules processed has a significant impact on speech extraction performance. This section mainly investigates the influence of different components of the speech extractor on the model’s performance through experiments, aiming to obtain the best configuration of the speech extractor.
Table 2 presents the SI-SDR results in the environment of two-person speech mixing and noise under different model structures and reference models. We created the speech extraction model using a stack of different combinations of TD-ConvNeXt blocks and TCN blocks, while keeping the speaker encoder section unchanged. It can be observed from Table 2 that configuration 7 has an average SI-SDR evaluation index that is 0.38 dB higher than that of the benchmark model. In model configurations 9–12, when the number of TD-ConvNeXt block stacks increased from 2 to 4, the system performance leveled off and slightly decreased compared to the 2-layer stacks. Therefore, the structure of the speech extractor is based on configuration 7, and the parameters c and d are set as 160 and 320, respectively, which correspond to the number of convolutional channels in Fig. 3B.
Based on the results presented in Table 2, it can be observed that the best performance is achieved when the size of the dConv convolution kernel is , larger convolution kernels slightly reduce the model’s performance. Compared to model 7, the SI-SDR index of Model 14 is approximately 0.1 dB lower, at the cost of greater computational complexity.
In addition, we made some changes to the configuration parameters and for TCN blocks. However, as seen in model structures 15–27 in the table, for the optimal model structure 7, the number of parameters is reduced, and the corresponding SI-SDR also decreases. Therefore, in this experiment, we keep and as the optimal configuration parameters.
The influence of different configurations of the speaker encoder
Previous works have mainly focused on the design of the speech extractor, while neglecting the role of the speaker encoder (embedding vector). In this section, based on the optimal speech extractor obtained in the previous experiment, we modify the structure of the speaker encoder to investigate the impact of different configurations on the overall model, aiming to obtain the configuration structure of the speaker encoder with the best performance.
Table 3 presents the results of our experiments. In Table 2, we selected the best speech extractor structure obtained in the previous section (Structure No. 7). The table shows that the models with Spk block outperform the benchmark model, SpEx+. Moreover, by fine-tuning parameters , and the size of the dConv convolution kernel in the Spk block, the average SI-SDR of model 21 is 0.14 dB higher than that of model 7, indicate that with the same conditions, the system can achieve better performance and better anti-interference, which means that the extracted speech is closer to the real speech.
Effect of encoder window length on model performance
Multi-scale encoders consist of multiple convolution kernel lengths. The encoded and decoded speech at different lengths contain information of different scales and resolutions, and the detailed features of speech at high resolution significantly impact the human auditory experience. Therefore, in addition to the SI-SDR evaluation indicator, we added PESQ (the speech perception evaluation) and STOI (the short-term intelligibility) to our evaluation metrics, we tested different combinations of window lengths to verify the model’s performance.
Table 4 presents the experimental results of different encoder window lengths. As shown in the table, compared to model 21, model 25 also uses a codec with a window length of 40. The SI-SDR slightly improved, the PESQ values are similar, and the STOI have significantly improved. Models 25–27 indicate that a higher STOI can be achieved with more short-window codecs.
| Model | SI-SDR (dB) | PESQ | STOI | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| – | −5 | 0 | 5 | −5 | 0 | 5 | −5 | 0 | 5 | |||
| 21 | 20 | 80 | 160 | 8.83 | 11.58 | 14.88 | 2.28 | 2.62 | 3.03 | 0.835 | 0.878 | 0.917 |
| 25 | 20 | 40 | 80 | 8.87 | 11.64 | 14.83 | 2.29 | 2.62 | 3.03 | 0.853 | 0.897 | 0.934 |
| 26 | 20 | 40 | 160 | 8.45 | 11.35 | 14.53 | 2.26 | 2.61 | 3.01 | 0.846 | 0.892 | 0.928 |
| 27 | 40 | 80 | 160 | 7.70 | 10.53 | 13.90 | 2.16 | 2.51 | 2.93 | 0.803 | 0.851 | 0.893 |
The impact of the weight setting of the loss function on the performance of the model
The multi-scale speech extraction model used in this article encounters a weight assignment problem during the loss calculation process. In the previous experiment, we pre-set and , resulting in a weight of 0.8 for the small scale with a window length of 20, and 0.1 for both the medium and long scales. In this section, we fine-tune the weights and of the loss function to investigate the impact of weight settings on the model’s performance.
Table 5 presents the experimental results after selecting the best performing model 25 from the previous section. Models 28 to 30 set different weights for Model 25. From the results, it can be observed that the SI-SDR and STOI of Model 25 are higher than those of Models 28 to 30. Therefore, we continue to keep and as 0.1 for the loss function weight setting.
| Model | SI-SDR (dB) | PESQ | STOI | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| – | −5 | 0 | 5 | −5 | 0 | 5 | −5 | 0 | 5 | ||
| 25 | 0.1 | 0.1 | 8.87 | 11.64 | 14.83 | 2.29 | 2.62 | 3.03 | 0.853 | 0.897 | 0.934 |
| 28 | 0.2 | 0.1 | 8.46 | 11.22 | 14.41 | 2.29 | 2.64 | 3.04 | 0.824 | 0.866 | 0.904 |
| 29 | 0.1 | 0.2 | 8.66 | 11.48 | 14.71 | 2.27 | 2.62 | 3.03 | 0.850 | 0.893 | 0.930 |
| 30 | 0.2 | 0.2 | 8.77 | 11.52 | 14.79 | 2.27 | 2.62 | 3.02 | 0.852 | 0.895 | 0.932 |
Comparison of the proposed network with the state of the art
Through the experiments described in the previous sections, we obtained the current best-performing network model 25, which we named TDNext. In this section, we reproduced five baseline models, SpEx+ (Ge et al., 2020), SpEx (Xu et al., 2020), TD-SpeakerBeam (Delcroix et al., 2020), SpeakerBeam (Delcroix et al., 2018) and sDPCCN (Han et al., 2022), and compared TDNext with these five baselines using the three evaluation indicators of SI-SDR, PESQ, and STOI to verify the effectiveness of our proposed algorithm.
From Table 6, it can be seen that TDNext outperforms all the baselines in SI-SER and STOI metrics at the same SNR levels. The above experimental results demonstrate the effectiveness of TDNext in the target speech extraction task.
| SNR | Models | Domain | SI-SDR (dB) | PESQ | STOI |
|---|---|---|---|---|---|
| −5 | sDPCCN (Han et al., 2022) | TFD | 6.36 | 1.89 | 0.778 |
| SpEx+ (Ge et al., 2020) | TD | 8.31 | 2.28 | 0.841 | |
| SpEx (Xu et al., 2020) | TD | 7.73 | 2.15 | 0.837 | |
| TD-SpeakerBeam (Delcroix et al., 2020) | TD | 7.34 | 2.08 | 0.831 | |
| SpeakerBeam (Delcroix et al., 2018) | FD | 6.02 | 1.86 | 0.768 | |
| TDNext (Our model) | TD | 8.87 | 2.29 | 0.853 | |
| 0 | sDPCCN (Han et al., 2022) | TFD | 9.68 | 2.20 | 0.854 |
| SpEx+ (Ge et al., 2020) | TD | 11.02 | 2.62 | 0.884 | |
| SpEx (Xu et al., 2020) | TD | 10.38 | 2.49 | 0.878 | |
| TD-SpeakerBeam (Delcroix et al., 2020) | TD | 9.87 | 2.4 | 0.865 | |
| SpeakerBeam (Delcroix et al., 2018) | FD | 9.25 | 2.18 | 0.843 | |
| TDNext (Our model) | TD | 11.64 | 2.62 | 0.897 | |
| 5 | sDPCCN (Han et al., 2022) | TFD | 13.56 | 2.60 | 0.909 |
| SpEx+ (Ge et al., 2020) | TD | 14.40 | 3.03 | 0.925 | |
| SpEx (Xu et al., 2020) | TD | 13.51 | 2.89 | 0.912 | |
| TD-SpeakerBeam (Delcroix et al., 2020) | TD | 12.86 | 2.77 | 0.903 | |
| SpeakerBeam (Delcroix et al., 2018) | FD | 13.02 | 2.54 | 0.897 | |
| TDNext (Our model) | TD | 14.83 | 3.03 | 0.934 |
Note:
TD/TFD/FD represents Time domain, Time Frequency domain, and Frequency domain respectively.
To visually observe the effectiveness of different models in extracting speech, we present typical spectrograms of the original mixed speech, clean speech, and the speech extracted by our proposed model and the comparative models in Fig. 5. From the figures, it can be seen that there is a high-frequency blank area without speech energy distribution in the beginning area of clean speech. In contrast, the interference speech energy distribution can be observed in this area in the spectrogram of the mixed speech. The performance of SpEx+ model and our proposed model is better, with clear blank areas in the silent region, achieving a good noise reduction effect. Correspondingly, there is a clear boundary between sentences in the blank area in the middle of clean speech, only our model shows a clear separation with a distinct boundary between each sentence, which may result in clearer auditory perception and better speech understanding, as demonstrated in the spectrogram.

Figure 5: Model extraction speech time-frequency diagram, (A) mixed voice, (B) clean voice, (C) speech time-frequency diagram extracted by sDPCCN (Han et al., 2022), (D) speech time-frequency diagram extracted by SpEx+ (Ge et al., 2020), (E) speech time-frequency diagram extracted by TDNext.
{kind=link}
Ablation experiment
To further verify the effectiveness of the TD-ConvNeXt block proposed in this article, an ablation experiment was conducted in this section with and without removing the TD-ConvNeXt block and its expansion factor. The results are presented in Table 7.
| Models | SI-SDR (dB) | PESQ | STOI | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 5 | 0 | 5 | −5 | 0 | 5 | −5 | 0 | 5 | |
| TDNext | 8.87 | 11.64 | 14.83 | 2.29 | 2.62 | 3.03 | 0.853 | 0.897 | 0.934 |
| W/O D.Conv. | 8.37 | 11.07 | 14.23 | 2.23 | 2.57 | 3.01 | 0.848 | 0.887 | 0.932 |
| W/O TD. | 8.03 | 10.62 | 13.66 | 2.18 | 2.54 | 2.97 | 0.838 | 0.879 | 0.915 |
In Table 7, it can be observed that after removing the expansion factor from the TD-ConvNeXt block of the whole network and returning to an ordinary convolutional neural network (W/O D.Conv), all three indicators decreased. Moreover, after removing the TD-ConvNeXt block (W/O TD) from the whole network, the three indicators decreased further. The increased decline rate confirms the performance improvement effect of the TD-ConvNeXt block proposed in this article for the whole network.
Related work
In recent years, deep learning has demonstrated enormous potential in speech extraction, leading to the adoption of deep learning techniques in almost all speech extraction methods. Therefore, this article will only focus on summarizing the deep learning-based methods that have been developed in recent years for speech extraction.
Unlike speech seperation, for speech extraction tasks, it is not necessary to determine the number of speakers. The output content is a single source signal (Choi et al., 2005). In 2017, Zmolikova et al. (2017) proposed the SpeakerBeam model, which uses the speaker’s voiceprint information as the embedding of the extraction network to focus only on a single speaker. This is also the first deep learning model that uses embedding vectors to guide the model to extract the target speech, and subsequent work mostly refers to similar ideas. Based on the SpeakerBeam model, Xu et al. (2019) propose an optimized reconstruction spectrum loss function, introducing dynamic information error and considering multiple changes in time and amplitude. In literature (Wang et al., 2018) proposed the VoiceFilter model, which also splices the speaker’s voiceprint information and mixed speech into the separation network to improve the performance of the speech recognition system. Then, by improving long short-term memory (LSTM) to speed up training speed and reduce computation costs, VoiceFilter-lite is proposed (Wang et al., 2020), making it possible to run on mobile devices and greatly reducing computational complexity. Following this, in 2021, this team proposed a speaker embedding technology based on attention mechanism (Rikhye et al., 2021), which can extract speech from multiple speakers at the same time.
For speech encoding, there is also a direct use of convolutional encoding operations to skip the STFT transformation, avoiding the problem of estimating phase. Literature (Delcroix et al., 2020) proposes the Time-Domain SpeakerBeam (TD-SpeakerBeam), replacing the STFT operation with a learnable encoder. Compared with previous work, the quality of the extracted target speech has been significantly improved. SpEx (Xu et al., 2020) proposes an end-to-end time-domain speech extraction network based on Conv-TasNet, using a multi-scale encoder to obtain features of different scales. Based on this work, the original author proposed the SpEx+ (Ge et al., 2020) model, which believes that the speaker encoding method used by SpEx and the mixed speech encoding method are different, which will lead to performance degradation. Therefore, a shared weight encoder is used to map reference speech and mixed speech to a similar space and prove the effectiveness through experiments. In addition, this team proposed SpEx++ (Ge et al., 2021) soon, which believes that using pre-registered speech as reference speech in actual environments is unreasonable. Table 8 shows the comparison of speech extraction methods based on deep learning.
| Models | Architecture | Supervision method | Speaker embedding | Domain focus |
|---|---|---|---|---|
| SpeakerBeam (Zmolikova et al., 2017) | Extraction network with speaker voiceprint as embedding | Magnitude spectrum reconstruction loss | Direct voiceprint embedding | General extraction |
| SBF-MTSAL (Xu et al., 2019) | Optimized network with dynamic time-amplitude error loss | Temporal Spectrum Approximation (TSA) loss | Voiceprint embedding with dynamic error term | Loss optimization |
| VoiceFilter (Wang et al., 2018) | Separation network with voiceprint-mixed speech concatenation | Speaker-conditioned spectrogram masking | Voiceprint concatenated with mixed speech | ASR integration |
| VoiceFilter-lite (Wang et al., 2020) | LSTM-optimized model for real-time inference | Spectrogram masking with reduced computation | Voiceprint integration for streaming | Mobile/on-device |
| Multi-user VoiceFilter-Lite (Rikhye et al., 2021) | Attention-based speaker embedding for multi-speaker extraction | Multi-speaker attentive masking | Attentive embedding for simultaneous extraction | Multi-speaker extraction |
| TD-SpeakerBeam (Delcroix et al., 2020) | Time-domain model with learnable encoder replacing STFT | Time-domain reconstruction loss | Speaker-aware embedding in raw audio domain | Time-domain processing |
| SpEx (Xu et al., 2020) | Conv-TasNet-based multi-scale time-domain encoder | End-to-end time-domain reconstruction loss | Reference speech encoding for speaker cues | Multi-scale features |
| SpEx+ (Ge et al., 2020) | Shared weight encoder for reference and mixed speech | Time-domain loss with feature space alignment | Shared encoder for consistent embedding | Embedding alignment |
| SpEx++ (Ge et al., 2021) | Multi-stage extraction with utterance and frame-level reference signals | Enhanced supervision for real-world scenarios | Utterance/frame-level references | Real-world flexibility |
Additionally, there are works that use speaker image information as embedding vectors to extract speech. Pan, Ge & Li (2022) advocates using auxiliary information such as speaker lip movement images as a reference for the speaker. Sato et al. (2021) simultaneously uses speaker image information and speech information as reference information, avoiding the situation where speaker images are occluded in practical applications and achieving more robust results.
In recent years, speech-aware objective functions like PESQNet (Xu, Strake & Fingscheidt, 2022) and MOSNet (Lo et al., 2019) have emerged in the field of speech processing. PESQNet is an end-to-end deep neural network that estimates PESQ scores of enhanced speech signals, allowing reference-free loss for real data. It can be trained in a weakly supervised manner, combining with denoising and dereverberation loss terms. MOSNet is a speech quality evaluation model based on a deep neural network. It takes speech signals as input and outputs a mean opinion score (MOS) reflecting human perception of speech quality. It can evaluate speech quality under various conditions and has been widely applied in speech enhancement and recognition. These speech-aware objective functions optimize speech enhancement models and other systems based on human auditory perception, improving speech quality and intelligibility. Compared to traditional loss functions, they better reflect human speech perception. In the future, speech-aware objective functions are expected to become more sophisticated and accurate, providing stronger support for speech processing technologies.
Compared with traditional methods of speech extraction systems, deep learning systems can achieve higher accuracy in extraction. As the demand for speech extraction technology continues to increase, single-channel speech extraction systems face new challenges. For example, how to improve the real-time and stability of the model, how to selectively extract multiple people’s speech signals at the same time, how to accurately extract in reverberant and low signal-to-noise ratio environments, etc., require further research and exploration.
Conclusions
In this article, we address the issue of the traditional ConvNeXt model’s inability to adapt to the time-series characteristics of speech signals in single-channel target speech extraction. We extend the ConvNeXt structure to TD-ConvNeXt, and mix TCN and TD-ConvNeXt structures to estimate the mask of the target speech. In the auxiliary network, we design a new Spk block model as embedding vectors to stimulate the main extraction network. We utilize STFT in the reference speech encoder to enhance the robustness of the model. Extensive experiments are conducted to verify the significant single-channel target speech extraction performance improvements of our proposed model.