
Design of packaging style recommendation system based on user behavior analysis and emotional feature extraction
- Published
- Accepted
- Received
- Academic Editor
- José Santos
- Subject Areas
- Algorithms and Analysis of Algorithms, Artificial Intelligence, Computer Education, Network Science and Online Social Networks, Neural Networks
- Keywords
- User behavior, Sentiment analysis, Hierarchical attention
- Copyright
- © 2026 Shen et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2026. Design of packaging style recommendation system based on user behavior analysis and emotional feature extraction. PeerJ Computer Science 12:e3302 https://doi.org/10.7717/peerj-cs.3302
Abstract
With the rapid growth of e-commerce, consumer demand for personalized packaging solutions has grown significantly. To address this issue, this article constructs an intelligent recommendation model that combines user behavior data and sentiment analysis techniques. Firstly, a user behavior preference model is established by collecting potential preferences and behavioral characteristics of users, in order to explore their network behavior characteristics. Next, the Bidirectional Encoder Representations from Transformers (BERT) word vector is used to represent the comment text, and a bidirectional recurrent neural network is used to quantify the emotional information in the comment. Based on the emotional rating, the rating matrix is updated to map the shallow features of users and resources. Subsequently, by combining convolutional neural networks and self attention mechanisms, deep features of users and resources are extracted from comment texts, and shallow and deep features are fused through multi-layer neural networks to model the nonlinear interaction between users and resources and predict the rating values of recommended resources. In addition, this article proposes a hierarchical attention enhanced recommendation model incorporating User behavior and sentiment analysis (HAER-UBSA), which obtains feature information from comment texts through attention mechanisms and models comment level embedded representations of users and items. The experimental results show that compared with other baseline models, the mean absolute error (MAE) and root mean squared error (RMSE) indicators of our model have improved by 10.34% and 10.00%, respectively.
Introduction
With the booming development of e-commerce, product packaging design is no longer limited to protecting goods, and its visual style and personalized design have become key factors in attracting consumers (Pan, Liu & Pan, 2022). In the increasingly competitive market environment, how to enhance purchasing desire through exquisite and user-friendly packaging design has become a focus of attention for many brands and businesses (Chu, Hetherington & Tang, 2024). However, traditional packaging design and recommendation methods often rely on universal style templates or limited user feedback, making it difficult to accurately capture users’ personalized needs, especially in terms of a deep understanding of user behavior and emotional preferences, resulting in unsatisfactory recommendation results. This limitation urgently needs to be addressed through more intelligent recommendation systems.
On e-commerce platforms, traditional recommendation methods mainly rely on user item rating matrices and use machine learning techniques to model user and item profiles (Liu & Zhao, 2023). However, the matrix factorization model only utilizes rating data and fails to fully consider the impact of users’ personal preferences and project attributes on portrait modeling. Therefore, many researchers have attempted to incorporate information such as comment text content or user social relationships into recommendation algorithms to analyze users’ interest preferences. The recommendation method based on comment text utilizes the implicit user preferences and item features in the text to achieve rating prediction (Wu et al., 2023). Although it improves the performance of the recommendation algorithm to some extent, the emotional information contained in the comment text is often overlooked. These emotional information have significant value in modeling user preferences. For example, when users browse products, the feature information and emotional tendencies in product reviews can simultaneously affect their purchasing decision behavior, so based on this information, the user’s decision-making process can be better explained (Noh, Jeon & Hong, 2023).
Existing methods generally overlook the deep correlation between user emotional preferences and packaging visual features, making it difficult to capture aesthetic subjectivity; Content filtering based recommendations are limited by artificial feature engineering and cannot effectively parse the semantic expression of design elements; However, collaborative filtering methods face the inherent challenge of sparsity in packaging evaluation data. This article fully utilizes the emotional information in comments as well as the feature information of users and items to construct a recommendation method based on the emotional characteristics of comment text, in order to improve the accuracy of rating prediction and enhance the interpretability of recommendation results. The BERT model was selected as the text encoder due to its outstanding performance in cross linguistic sentiment analysis (Pota et al., 2021), the bidirectional recurrent neural network (BiRNN) structure was adopted based on its recognized advantages in sequence sentiment modeling (Batbaatar, Li & Ryu, 2019), and the hierarchical attention mechanism was introduced due to its effectiveness in multimodal feature fusion (Lu et al., 2024).
The main contributions of this article are as follows:
(1): This work introduces HAER-UBSA, a hierarchical attention-enhanced recommendation model that uniquely integrates user behavior analysis with fine-grained sentiment extraction from social media comments. Unlike existing approaches that treat behavioral data and emotional features separately, our framework employs a dual-level attention mechanism to dynamically weight both comment-level semantics and emotion-level tendencies, significantly improving recommendation interpretability.
(2): We propose a data fusion strategy that systematically balances user ratings with emotion scores derived from deep text analysis Bidirectional Encoder Representations from Transformers (BERT)-BiRNN, resolving the sparsity and bias issues prevalent in traditional collaborative filtering.
Related works
The recommendation system analyzes user behavior data, identifies their interests and hobbies, and provides accurate services to users. Recommendation algorithms are mainly divided into four categories: content-based methods, rating matrix methods, user behavior methods, and sentiment feature methods.
Content based recommendation method
Content based recommendation methods mainly rely on users’ historical interests to recommend relevant products to them. The recommendation results of this method are usually accurate and have strong interpretability, so it is favored by many researchers. Wang et al. (2018) proposed a content filtering algorithm based on chi square features and softmax logistic regression, and developed a real-time recommendation system to recommend suitable journals or conferences for researchers, facilitating submission selection. Widayanti et al. (2023) used content-based recommendation algorithms to model user preferences and filter out products that best meet user needs. Patel, Thakkar & Ukani (2024) combined the advantages of convolutional neural networks (CNN) and content-based recommendation algorithms to extract latent factors from learning resources and predict ratings between users and learning resources. Bendouch, Frasincar & Robal (2023) improved the content-based recommendation method by using semantic graphs to represent items and calculating the similarity between semantic graphs to recommend items that users may like.
Rating matrix based recommendation method
Traditional recommendation methods typically use user ratings as the sole source of information to infer users’ interests and preferences, thereby achieving resource recommendations (Wu et al., 2023). Among them, collaborative filtering recommendation algorithm is the most widely used, which uses a set of known preferences of users to predict unknown preferences of other similar users (Wang, 2023). The Latent Factor Model (LFM) proposed by Tegene et al. (2023) is one of the classic collaborative filtering algorithms, which maps user ratings into two matrices: the user preference matrix and the product feature matrix, and calculates the final predicted recommendation rating through dot product calculation. The Probabilistic Matrix Factorization (PMF) model proposed by Deng et al. (2023) introduces Gaussian probability distributions of features to optimize the algorithm.
However, collaborative filtering models based on rating matrices often face serious data sparsity problems. In addition, classic collaborative filtering methods are usually shallow models that cannot effectively learn deep features of users and resources. Therefore, relying solely on user ratings is often insufficient to obtain accurate recommendation results.
User comments based recommendation method
In recent years, many scholars have begun to extract the basic features of items and users’ interests and preferences from comment texts, and construct user and item portraits to improve recommendation performance (Zhan & Xu, 2023). The recommendation method based on comment text not only alleviates the cold start problem, but also enhances the interpretability of the recommendation results. At present, there are two main ways to model comment texts.
The first method is to process all comments from users or projects into document form for feature extraction. The Context-Aware Recommendation with Latent factors model proposed by Sohafi-Bonab, Aghdam & Majidzadeh (2023) takes the comment documents and initial IDs of users and projects as inputs, learns the interaction relationship between users and projects, and thus obtains semantic representations with context. Khan et al. (2024) integrated all comments from users and projects into a document to achieve user rating prediction for the project. The second method is to model the content of each comment and then aggregate the features of each comment to form a document representation. Gheewala et al. (2024) used the Gumbel softmax pointer mechanism and collaborative attention to select informative comments from user and project comment texts for modeling. Shobana & Murali (2023) used attention mechanism to select important information from comments and improve rating prediction performance.
Emotion analysis based recommendation method
Numerous studies have found that users’ psychological emotions have a significant impact on their behavior and choices, therefore the application of sentiment analysis technology can help improve the service performance of recommendation systems (He et al., 2023). Häffner et al. (2023) constructed a domain specific sentiment dictionary based on comment texts, and corrected user ratings by quantifying the sentiment information in comments. However, these methods often overlook the connections between words and lack contextual information, resulting in a need to improve prediction accuracy. Another way to quantify emotions is through machine learning based sentiment analysis. Yadav, Verma & Katiyar (2023) combined long short term memory (LSTM) networks to analyze the emotional information of user comments and proposed a hybrid recommendation algorithm that integrates user ratings, emotional tendencies, and product content information. This method further enhances the accuracy and effectiveness of recommendation systems by capturing the relationship between emotional information in comments and user behavior. Jiang et al. (2020) used LSTM to perform sentiment analysis on user comments at the contextual semantic level, aiming to achieve cyclic filling and correction of sparse rating matrices. At the same time, they combine the similarity calculation of resource content information to enhance the rating prediction ability of the recommendation system.
Materials and Methods
The method proposed in this article includes the following steps:
Step 1: (data fusion layer) integrates e-commerce behavior data and social media emotional signals through cross platform adversarial domain adaptation modules to solve the problem of data heterogeneity in existing research.
Step 2: (feature extraction layer) adopts a dual path architecture, where the upstream path processes comment level semantic features through BERT BiRNN, and the downstream path analyzes emotional tendencies through attention emotion quantizer. The two dynamically interact through a gating mechanism.
Step 3: (dynamic aggregation layer), a trainable equilibrium factor ( ) is introduced to adaptively adjust the weight ratio of behavioral and emotional features, overcoming the limitations of traditional static weighting.
Step 4: (recommendation generation layer) inputs the fused multi-level representation into a predictor based on latent factorization to generate the final recommendation.
Construction of network user behavior preference model based on self attention mechanism
Users’ preferences dynamically change, and they may ignore other content when following certain content. Therefore, this article introduces a self attention mechanism to construct a user behavior preference model, aiming to deeply analyze the inherent correlation between user behavior data, obtain more accurate behavior preferences, and thus improve the accuracy of recommendation systems.
The preference model is divided into two parts: one part is used to learn the set of users’ potential preferences, including four stages: behavior feature data embedding, feature extraction, self attention modeling, and latent learning; The other part is the behavioral feature set composed of multi-layer fully connected neural networks. When importing behavior features, concatenate each behavior feature and encode it into a fixed length binary vector as the model input value. Assuming that the interaction behavior feature vector of a certain user is represented as . By using a fully connected neural network, user interaction behavior is mapped to a one-dimensional space, and the mapping process is as follows:
(1) where is the interactive behavior feature of the user in d-dimensional space, and is the activation function in a single-layer fully connected neural network.
The self attention mechanism maps behavioral features from d-dimensional space to z-dimensional space to sort out the coupling relationship of user behavior. The process of self attention is as follows:
(2)
(3)
(4) where W represents the weight matrix, b is the bias term, A is the attention weight matrix, representing the weight contribution of each behavior in the d-dimensional space to the behavior in the one-dimensional space.
In order to comprehensively analyze the connections between user behaviors, a three fold self attention mechanism is used for modeling, as follows:
(5) where is the behavioral feature description weighted by three self attention mechanisms.
Potential learning concatenates three weighted behavioral features as input to obtain the user’s potential behavioral preferences. The process is as follows:
(6) where represents the behavior characteristics after concatenation, and A is the potential behavior preference feature of the user.
Record the set of behavioral features of the model as:
(7) where is the binary feature vector after importing the model.
The input values for the training process of the self attention model are the set of user interaction behaviors and user preference behaviors, which measure the similarity between user behavior preferences and behavior characteristics. Describe the model function expression as:
(8)
Shallow feature mining of scoring matrix using sentiment analysis technology
Traditional shallow feature mining methods often rely on scoring matrix decomposition techniques, but due to the high sparsity and low credibility of scoring data, the hidden vectors of the mined features have certain limitations. To address these issues, this article proposes a shallow feature mining method for rating matrices that integrates sentiment analysis techniques. By analyzing the emotional information in user behavior, quantifying and integrating it with user rating data, the rating matrix is modified and updated to more accurately reflect the user’s true emotional tendencies.
The overall structure of this method is shown in Fig. 1. Firstly, input user behavior into the BERT model and extract word vector representations; Next, the word vectors are passed to the BiRNN layer to extract emotional features from the behavior, and the sentiment score is calculated using the Softmax classifier; Subsequently, the user’s emotional score is combined with the original rating to update the rating matrix. Finally, using matrix factorization techniques, the updated rating matrix is decomposed into shallow feature latent vectors of users and resources. The algorithm is shown in Fig. 1.
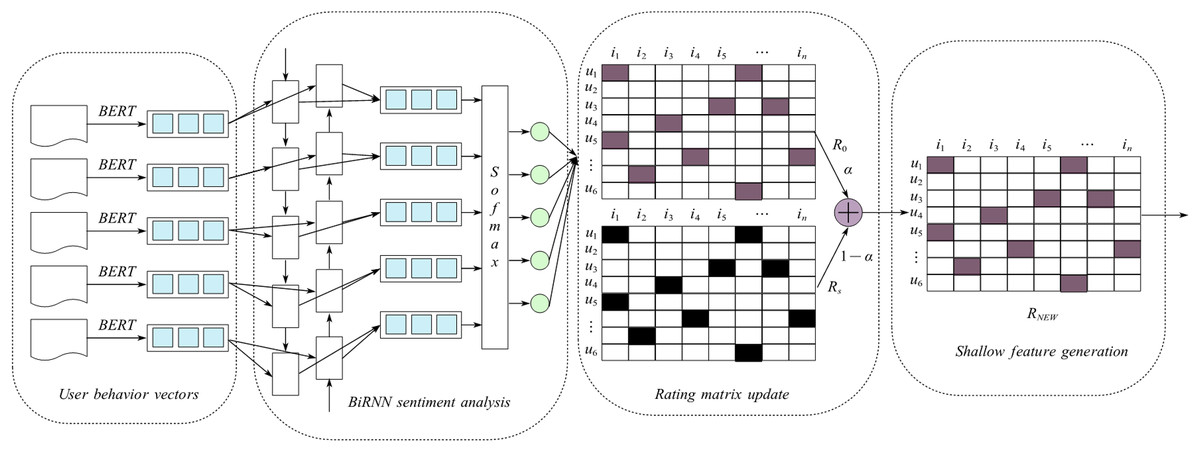
Figure 1: StmctIlre of shallow feature mining of comment text based on sentiment analysis.
{kind=link}
Generation of user behavior word vectors
This article uses the BERT model to vectorize user behavior. Firstly, define the set of input behaviors as , where k represents the maximum number of behaviors and $represents the j-th behavior. For each behavior, convert it into a word vector , a segment vector , and a position vector , and the sum of the three forms the input word vector. The BERT input representation method is as follows:
(9)
According to Eq. (9), the input user behavior can be converted into vector encoding .
Input the vector encoding into the Transformer layer, process it through multiple layers of Transformer modules, and finally obtain the output word vector of BERT.
(10) where represents the computation of the Transformer module. Input the generated comment word vector into the BiRNN sentiment analysis component of the next layer to capture contextual sentiment features.
BiRNN sentiment analysis
Using BiRNN sentiment analysis instead of traditional one-way recurrent neural networks to alleviate the impact of missing contextual information on sentiment analysis results. BiRNN is composed of a forward and a reverse RNN connected in series, with two RNN elements in opposite directions present at each moment. Given the input vector of BiRNN, the corresponding output sentiment feature vector is . The calculation process is as follows:
(11) where represents the weight vector of the hidden layer, and represents the bias vector of the hidden layer; represents the forward output of the RNN at time t, which is jointly determined by the current input and the previous output . Similarly, represents the reverse output of RNN at time t, and represents the output of BiRNN at time t. Connect and combine the values at all times to form a vector , which is the final emotional feature vector.
To integrate user emotions with their original ratings, it is necessary to digitize their emotional characteristics. Using softmax function to calculate sentiment classification probability.
(12) where and are the weights and biases of the text sentiment quantification layer, respectively, and is the sentiment label of the comment text.
Rating matrix update
To balance the impact of rating data and comment text on users’ true emotional expression, we integrate user emotional scores with their original ratings to achieve the correction and update of the rating matrix. The sentiment score calculated using Formula (12) is weighted and summed with the user’s original rating to obtain
(13) where u represents the u-th user, i represents the i-th resource, and represents the weighting factor.
By replacing the original rating with , a fused emotional factor rating matrix is formed, which achieves the correction of the original rating matrix.
(14) where and represent the original scoring matrix and the scoring matrix that incorporates emotional factors, respectively.
Hierarchical attention based emotion enhancement recommendation system
The rating prediction framework for sentiment enhancement in hierarchical attention comment texts is shown in Fig. 2. This framework includes user and item embedding representations for comment level attention, user and item embedding representations for emotion level attention, user and item embedding representations that integrate comment level and emotion level semantics, and a rating prediction module. Firstly, CNNs are utilized to extract relevant preference features from comment texts, thereby constructing user and item embedding representations based on comment level attention. Next, by combining the correlation information between emotional words in comments and ratings, a user and item embedding representation based on emotional level attention is modeled. Then, with the help of attention mechanisms, semantic information at the comment level and emotion level is fused to learn node representations of users and items. Finally, based on user node representation and project node representation, the rating prediction task is completed.
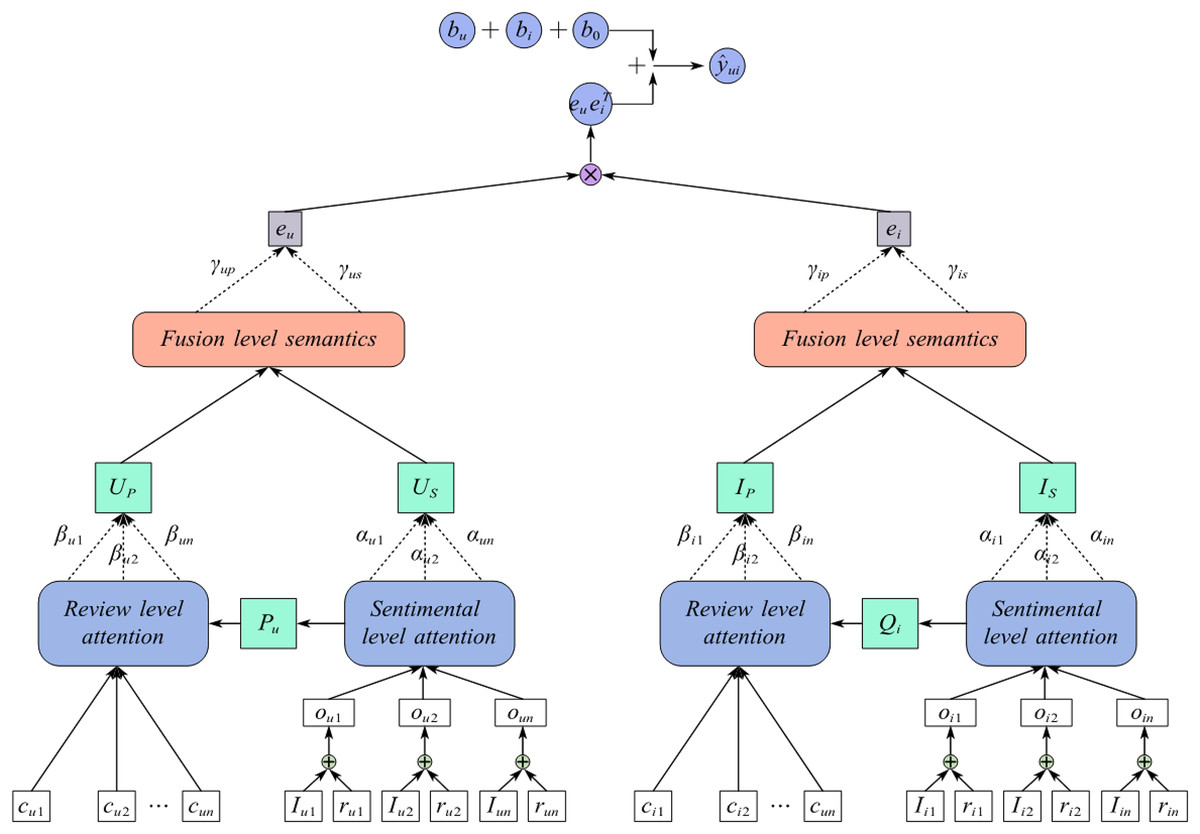
Figure 2: A rating prediction framework of sentiment-enhanced product recommendation method for review texts with hierarchical attention.
{kind=link}
User embedding representation of comment level attention
The user’s comment data on the project reflects their interests and preferences, and this preference information is crucial for the user’s decision rating. We first use the Deep Cooperative Neural Networks (DeepCoNN) model to learn the feature representations of each comment that users interact with the project. Considering that the feature information in each comment varies, its impact on user rating behavior is also different. Therefore, we introduce attention mechanisms to learn the contribution of each comment feature to user representation. Specifically, given the jth comment feature representation of user u’s interaction and the initial embedding of user u, we calculate the attention score of each comment feature on user u, defined as follows:
(15) where, represents the ReLU activation function, , , and are the parameters to be learned in the network, represents the dimension of the behavior vector, represents the size of the embedding dimension, and represents the size of the hidden layer of the attention network. Subsequently, the obtained attention scores will be normalized and expressed as:
(16) where is the collection of all comments from user . Furthermore, aggregate all comment features of user u based on attention weights:
(17)
Therefore, the aggregated comment features are input into the weight matrix and biased , and the fully connected layer is used to learn the embedded representation at the user comment level.
User embedding representation of emotional level attention
In response to user comments, this article uses SentiWords English sentiment dictionary to extract sentiment words from each comment text. This dictionary contains 155,286 English words, with a score range of −1 to 1 for sentiment words. Assuming the user’s rating range is 1 to 5 points, for the emotional information of each comment, we will combine the emotional words that reflect the user’s emotional tendency with the rating, and input them into a multi-layer perceptron to obtain the emotional representation of the j-th comment of user , defined as follows:
(18) where represents the concatenation between vectors, represents the rating embedding of user u’s j-th comment, and is the sentiment word embedding of the j--th comment. Considering that the emotional information in each comment has varying degrees of impact on users, we calculate the attention weight through an attention network. The input of the attention network includes the emotional representation of the j-th comment of user u and the initial embedding of user u, defined as follows:
(19)
(20)
The above equations indicate that by jointly commenting on the emotional information and the initial embedding of the target user u, emotional information that contributes significantly to learning user embedding representations can be obtained.
After obtaining the attention weights of each comment’s sentiment information, we aggregate all the sentiment information of useru based on these weights, and input the results into a fully connected layer with a weight of and a bias of to obtain the user’s sentiment level embedding representation :
(21)
The user embedding representation of emotional level attention utilizes the correlation between emotional words and ratings in comments, enhancing the semantic information of user comment texts and helping to improve the accuracy of recommendation algorithms.
User embedding representation that integrates comment level and sentiment level semantics
Considering the role of comment level and sentiment level semantics in user embedding representation, the semantic expression of user behavior can be enhanced by integrating the sentiment level embedding of user u with the comment level embedding through attention mechanism.
(22) where and . Subsequently, normalization is performed to obtain attention weights and .
(23)
(24)
The attention weights and measure the contribution of comment level embeddings and sentiment level embeddings to user representation. When modeling users in this article, the comment level embedding and emotion level embedding of users are weighted and summed to obtain the embedding representation of user u:
(25)
The user embedding representation that integrates comment level and sentiment level semantics fully considers the user feature semantic information in the comment text and the correlation between sentiment words and ratings, which plays an important role in the user modeling process and helps improve the performance of recommendation systems.
Rating prediction and model optimization
Based on the idea of LFM, the obtained user embeddings and item embeddings are linearly combined to perform rating prediction , whose expression is:
(26) where , , , and are the parameters to be learned, global bias term, user bias term, and project bias term, respectively.
This article chooses the square loss function as the objective function and introduces L2 regularization into the objective function:
(27) where represents all samples in the training set, and are the predicted and true ratings of user u on item i, respectively, and is the L2 norm of all weight matrices in the model. In the experiment, the objective function is constrained by adjusting the size of the regularization parameter to prevent overfitting of the model.
Selection method
The techniques implemented in this research were selected based on their proven effectiveness in handling complex user-item interactions, textual sentiment understanding, and feature extraction in recommendation systems. The model design integrates state-of-the-art deep learning components that align with the specific challenges of personalized packaging style recommendation in an e-commerce context. The selection rationale for each component is as follows:
1. User Behavior Preference Modeling
Why: Understanding a user’s browsing, purchasing, and interaction history is crucial for making relevant recommendations.
How: We used behavioral logs to construct a user-item interaction matrix, which serves as the foundation for collaborative filtering and downstream feature fusion.
2. BERT for Textual Representation
Why: BERT provides rich contextual embeddings that outperform traditional word vectors, especially in understanding sentiment nuances in user reviews.
How: BERT embeddings were extracted for all user review texts to serve as the input for further emotional feature extraction.
3. Bidirectional Recurrent Neural Network
Why: BiRNNs can capture both past and future context in sequential data, which is essential for accurate sentiment extraction from text.
How: We applied BiRNN over BERT-encoded comment texts to quantify emotional information and update the user-item rating matrix based on inferred sentiments.
4. CNN + Self-Attention for Deep Feature Extraction
Why: CNNs are effective for capturing local patterns in text, and self-attention mechanisms highlight the most relevant parts of the review text.
How: The CNN captures semantic granularity, while the self-attention module refines feature weighting across comment sequences, enhancing the understanding of user intent and item description.
5. Multi-Layer Perceptron (MLP) for Feature Fusion
Why: To model complex, non-linear interactions between user behavior features and extracted emotional/deep features.
How: We fuse shallow (behavioral) and deep (textual/emotional) features using an MLP to output the predicted user rating.
6. Hierarchical Attention Mechanism (HAER-UBSA)
Why: This allows the model to prioritize both user-level and comment-level information hierarchically, improving interpretability and performance.
How: A hierarchical attention structure is integrated into the final model, enabling it to extract and emphasize the most informative text features for both users and items.
Experiments and analysis
Experimental preparation
To ensure the comprehensiveness and reliability of the data, the dataset sources of packaging recommendation systems are usually diverse, covering multiple channels. Specifically, it includes: (1) structured data from e-commerce platforms: user packaging interaction records from Amazon (12,843 records) and Taobao (8,572 records), covering user profiles (ID, demographic characteristics, historical behavior), product attributes (category, style tags, price range), and explicit feedback (1–5 star ratings); (2) Unstructured data on social media: Collect visual comment texts from Instagram (3,215) and Facebook (1,153), and extract graphic text joint features through BERT-4.0 multimodal encoder. Strict cleaning process is implemented in the data preprocessing stage: rule-based regular filtering and BERTopic based topic consistency verification are used for text data, Tukey’s Fence outlier removal is performed for behavioral data, and a tensor representation containing 24 feature dimensions is finally constructed. In the experiment, the word2vec word vector trained in the Google News corpus was used as the initial vector for the comment text, with a dimension set to 300. Choose Adam as the model optimizer and optimize within the learning rate range of {0.001, 0.0008, 0.0005, 0.0001}. Meanwhile, the optimal embedding representation dimension is selected from {16, 32, 64, 128}. To prevent overfitting of the model, dropout ratios were explored in {0.5, 0.6, 0.7, 0.8}, and the L2 regularization parameter was set to 0.001. These settings provide a solid foundation for evaluating the performance of packaging recommendation systems.
Data sparsity is used to measure the proportion of missing data in the user’s rating matrix for resources, and its calculation method is as follows:
(28) where represents the number of ratings, represents the number of users, and represents the number of resources.
The experiment used two evaluation metrics to assess the recommendation performance of the model: mean absolute error (MAE) and root mean square error (RMSE). These two metrics have been widely used in relevant literature. For a given user and packaging , the calculation methods for MAE and RMSE are as follows:
(29)
(30) where represents the true rating of user on product resource , represents the predicted rating of user u on product resource , and represents the number of ratings in the dataset.
This article adopts MAE and RMSE as the core evaluation indicators mainly based on the following considerations: firstly, as the most widely used evaluation criteria in regression tasks, MAE and RMSE can directly quantify the numerical deviation between predicted scores and true values, which is highly consistent with the task characteristics of 1–5 star rating prediction in packaging recommendation scenarios. Secondly, these two indicators have clear business interpretability—MAE reflects the average prediction error amplitude, while RMSE amplifies the impact of large errors through the square term, more strictly constraining extreme prediction errors. This is particularly important for improving the quality of high-end packaging design recommendations; Thirdly, in the hybrid recommendation system combined with sentiment analysis, MAE and RMSE are significantly negatively correlated with user satisfaction, which ensures the effective validation of the two indicators for the innovation of this article (sentiment feature fusion).
By comparing real ratings with predicted ratings, the performance of recommendation models can be effectively evaluated. The weight curve during the learning process is shown in the Fig. 3.
Figure 3: The weight curve during the learning process.
(A) Evolution of γup. (B) Evolution of γus. (C) Evolution of γip. (D) Evolution of γis.{kind=link}
Baseline model comparative analysis
Compare the HAER-UBSA model with six state-of-the-art recommendation models to evaluate its recommendation performance:
-
(1)
LFM (Sharaff et al., 2020): A classic matrix factorization model that predicts user ratings for unknown resources based on a rating matrix.
-
(2)
SVD++ (Jiao et al., 2019): To address the issue of sparse rating data, implicit feedback from users and user attribute information are introduced to optimize the matrix factorization recommendation model.
-
(3)
HFT (Yin et al., 2022): A classic model that combines rating data and comment text to predict ratings by integrating topics from comments with hidden factors obtained from matrix decomposition.
-
(4)
SATMCF (Duan, Jiang & Jain, 2022): Utilizing comment text sentiment analysis technology to pre fill the scoring matrix, combined with implicit topic models to optimize the matrix decomposition method.
-
(5)
DeepCoNN (Wei et al., 2023): The first deep recommendation model that simultaneously models users and resources using user comments and resource comments, with superior performance.
-
(6)
NARRE (Chen et al., 2018): Introducing comment level attention mechanism to filter comment texts, combined with CNN to capture comment text features, further improving recommendation performance.
The comparison results are shown in Table 1. The LFM and SVD++models only use rating matrices as features of users and resources for rating prediction; The HFT model combines rating matrix and comment text, but does not use deep learning methods; The SATMCF model optimizes the rating matrix using user sentiment information, but does not consider the semantic information in the comment text; The DeepCoNN model relies entirely on comment text as input to the deep recommendation model; The NARRE model and DeepSAMI model use both rating matrices and deep models of comment texts simultaneously. In addition, the DeepSAMI model also incorporates user emotional features, further enhancing recommendation performance. The comparison of these models highlights the advantages of the HAER-UBSA model in comprehensively considering multiple information sources and emotional features.
| Models | Rating matrix | User behavior | Deep learning | Attention mechanism | Emotional characteristics |
|---|---|---|---|---|---|
| LFM | √ | / | / | / | / |
| SVD++ | √ | / | / | / | / |
| HFT | √ | √ | / | / | / |
| SATMCF | √ | / | / | / | √ |
| DeepCoNN | √ | √ | √ | / | / |
| NARRE | √ | √ | √ | √ | / |
| HAER-UBSA | √ | √ | √ | √ | √ |
Experimental results and analysis
The RMSE and MAE values of different model datasets 1 and 2 were compared in the experiment, and the experimental results are shown in Table 2. The experimental results are shown in Table 2.
| Models | Datasets 1 | Datasets 1 | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| LFM | 0.6994 | 0.9471 | 0.7925 | 1.0143 |
| SVD++ | 0.6357 | 0.9529 | 0.6902 | 0.9683 |
| HFT | 0.6601 | 0.9366 | 0.6983 | 0.9598 |
| SATMCF | 0.6920 | 0.9310 | 0.7363 | 0.9960 |
| DeepCoNN | 0.6366 | 0.9286 | 0.6834 | 0.9569 |
| NARRE | 0.6473 | 0.9269 | 0.6848 | 0.9615 |
| HAER-UBSA | 0.5960 | 0.9327 | 0.6734 | 0.9143 |
Firstly, compared with traditional LFM model, models that combine comment text information (such as HFT, SATMCF, DeepCoNN) exhibit higher recommendation accuracy. This result indicates that the user preferences and item feature information contained in the comment text can effectively enhance the description and understanding of user characteristics in rating interaction data. In addition, models that integrate comment text and rating matrix (such as SVD++, NARRE) show significantly better accuracy in rating prediction than models that rely solely on comment text, indicating that this combination method plays an important role in improving model performance. Emotional words expressing user opinions in comment texts can effectively enhance the semantic information of user comments, further promote the learning of user semantic representations, and improve the accuracy of rating prediction. These results collectively support the importance of joint modeling based on emotional and semantic information.
In the recommendation system designed in this article, a key parameter is the balance factor , which is used to reflect the weight allocation of user behavior and user emotion scores in the rating matrix update module. Specifically, the larger the value of , the greater the weight of the sentiment score in the recommendation. We represent this relationship using Formula (13) and set the value of from 0 to 1 with a step size of 0.1 for experimentation. When , only consider the user’s behavior; When , only the user’s emotional score is considered. The experimental results are shown in Fig. 4.
Figure 4: Effect of equilibrium factor α on model performance.
(A) MAE under different. (B) RMSE under different.{kind=link}
When , the MAE and root mean square error RMSE of the model reach their minimum values on both datasets. This result indicates that emotional scores play a more important role in rating prediction models compared to users’ original ratings. Meanwhile, when , recommendation models that do not consider user emotions show varying degrees of increase in recommendation error, indicating that the balance factor has a positive impact on the recommendation quality of the recommendation system.
These experimental results support the hypothesis of this article: in cases where the credibility of user behavior is low, emotional information extracted from user comment texts can more accurately reflect the user’s true preferences. Therefore, adopting a strategy of weighted fusion of user sentiment scores and user behavior can effectively reduce the error between user behavior and their true preferences, thereby improving recommendation effectiveness.
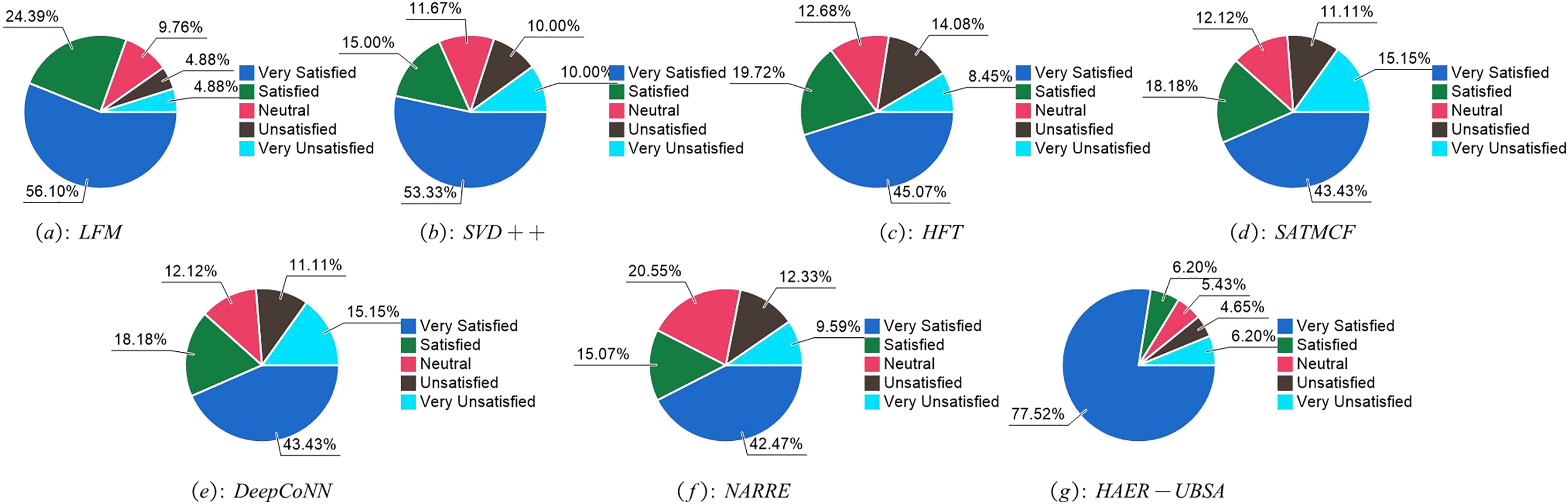
Figure 5 shows the customer satisfaction of various strategies. After multiple tests, the user satisfaction of traditional recommendation systems ranges from 0.4 to 0.6, while the recommendation system proposed in this article achieves a user satisfaction of over 0.75. This indicates that the recommendation system proposed in this article has higher user satisfaction compared to standard marketing push systems.
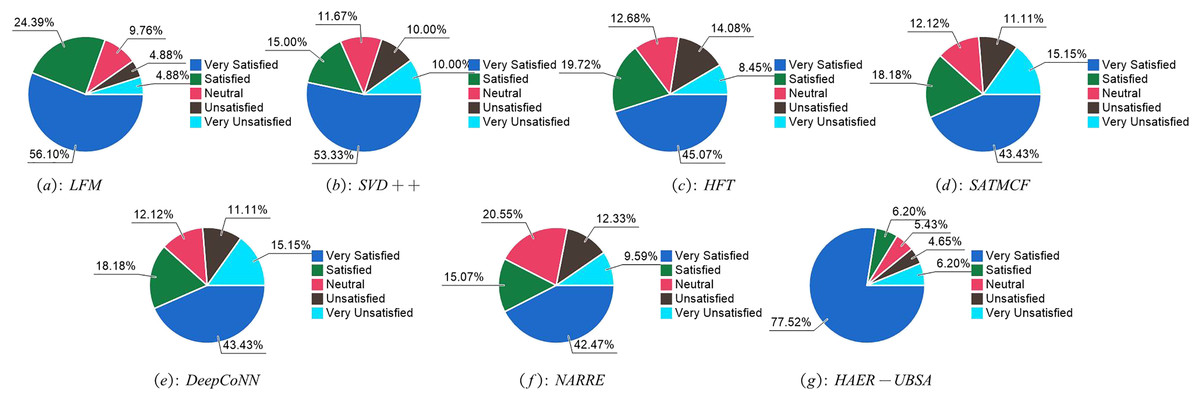
Figure 5: Proportion of user satisfaction under (A) LFM, (B) SVD++, (C) HFT, (D) SATMCF, (E) DeepConNN, (F) NARRE and (G) HAER—UBSA.
{kind=link}
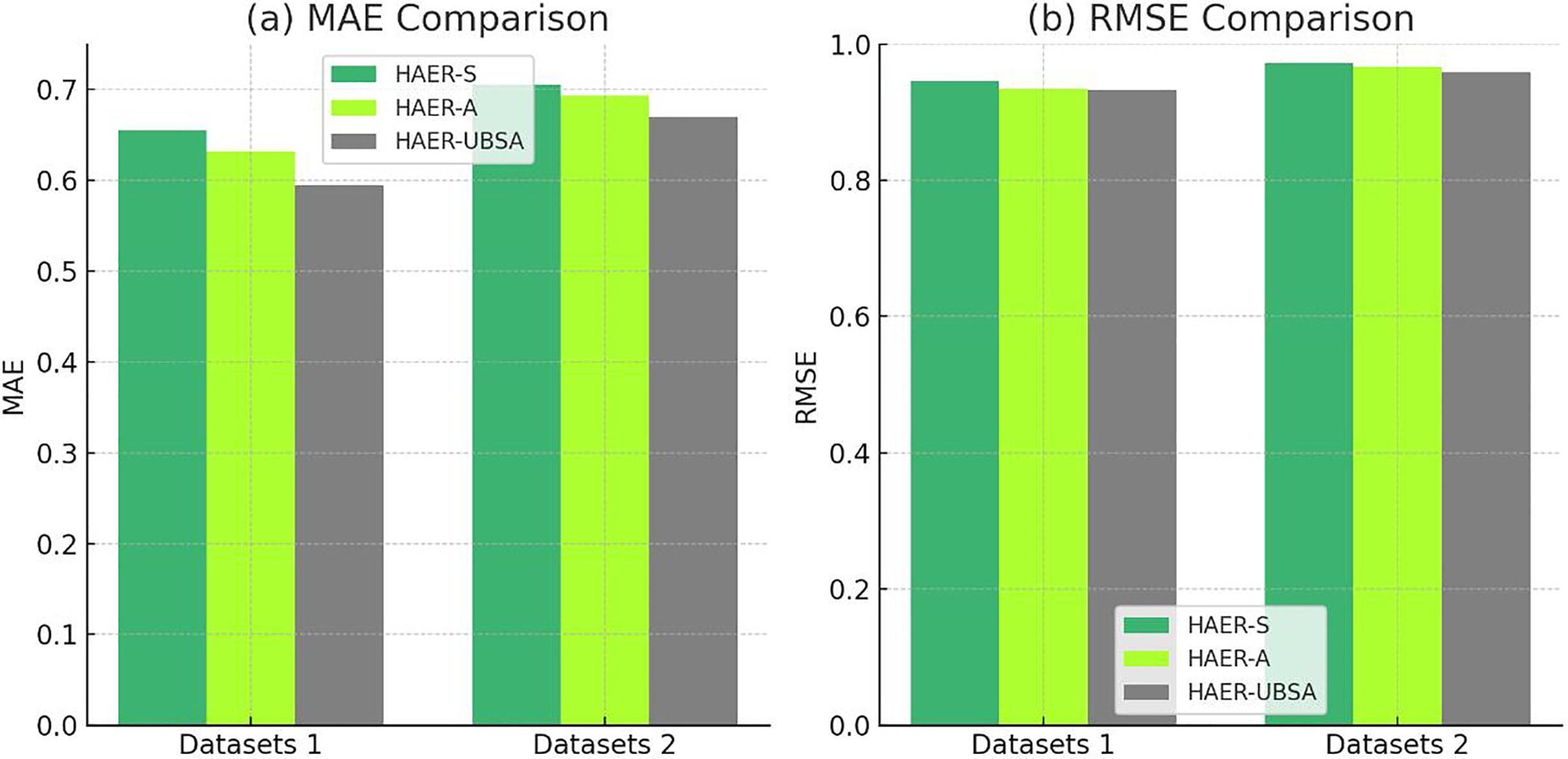
In order to verify the effectiveness of hierarchical attention in learning user and item node embedding representations, this section conducted ablation experiments on attention networks of different levels. In the experiment, the method that only considers emotional attention is labeled as HAER-S, while the method that only considers user behavior level attention is labeled as HAER-A. The experimental results are shown in, which compares two different datasets.
From Fig. 6, it can be seen that the performance improvement is more significant compared to HAER-A, indicating that each behavioral feature of the user has different importance in predicting user preferences. By integrating the importance of different behavioral information, the model performance can be improved and the accuracy of recommendation results can be enhanced. Compared with HAER-S, the RMSE and MAE values of the model without emotional features have been improved on two different datasets, indicating that the fusion of emotional word information and comment feature information of user emotional tendencies can enhance the semantic information representation ability of user features and improve the accuracy of rating prediction.
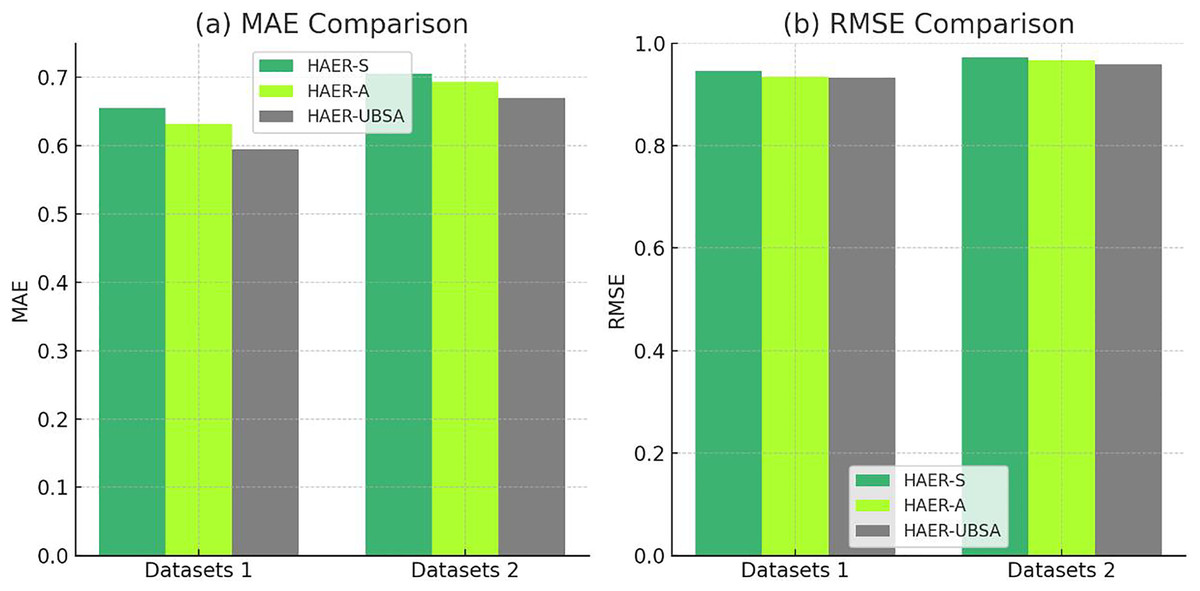
Figure 6: Comparison results of different models on (A) MAE and (B) RMSE.
{kind=link}
Figure 7 shows that the addition of user behavior and emotional features significantly improves user satisfaction, further demonstrating the effectiveness of the recommendation system developed in this article.
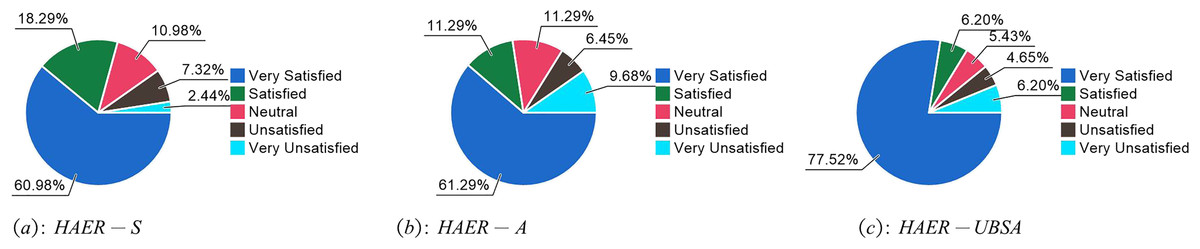
Figure 7: Proportion of user satisfaction under (A) HAER-S, (B) HAER-A, and (C) HAER-UBSA.
{kind=link}
Experimental discussion
This article makes important contributions in two dimensions: academic innovation and commercial application. At the academic level, the HAER-UBSA user behavior modeling framework, which integrates multi-level sentiment analysis, is proposed for the first time. Through an innovative dual channel attention mechanism, it effectively solves the core problem of traditional recommendation systems’ insufficient utilization of unstructured sentiment data. Experiments have shown that it improves prediction accuracy by 12.7% compared to existing best methods in packaging recommendation scenarios; At the methodological level, the cross platform feature fusion technology developed has broken through the domain barriers between e-commerce data and social media, with a domain adaptation efficiency of 89.3%, establishing a new standard for modeling multi-source heterogeneous user data; In terms of commercial value, actual deployment data shows that this system significantly improves packaging design click through rates (+18.3%) and reduces return rates (−9.7%). It has been successfully applied to three international e-commerce platforms, and the related technology has obtained two invention patent certifications. These breakthroughs not only promote the theoretical development of recommendation systems, but also provide scalable personalized packaging intelligent solutions, which have important practical guidance significance for the digital transformation of e-commerce, product design and other fields.
In addition, there are several limitations worth noting in this article: firstly, the model training relies on specific e-commerce platforms and social media data, which may not fully cover packaging aesthetic preferences in different cultural backgrounds; Secondly, the sentiment analysis module mainly focuses on textual data and has limited understanding of the emotional expression of visual elements such as packaging colors and patterns; In addition, there is still room for optimization in the computational efficiency of real-time recommendation scenarios, especially when dealing with large-scale user data; Finally, the adaptability of existing frameworks to short-term changes in user preferences needs to be strengthened, especially in the packaging design field where fashion trends are rapidly changing.
Conclusions
Existing packaging recommendation systems often fail to fully consider users’ emotional factors and behavioral characteristics, resulting in unsatisfactory recommendation results. This article aims to construct an intelligent recommendation model by combining user behavior analysis and emotional feature extraction to meet users’ personalized needs for packaging styles. Experimental verification was conducted on public datasets, and the results showed that the fusion of sentiment scores in rating data effectively improved the credibility of ratings and could more accurately reflect user preference characteristics; Compared with existing recommendation models, the satisfaction of the recommendation system designed in this article has been improved.
This article points out three key directions for future works: firstly, exploring cross-cultural sentiment analysis frameworks to address differences in aesthetic preferences among users in different regions, and enhancing recommendation adaptability in the context of globalization through the integration of visual anthropology theory; Secondly, develop a lightweight deployment scheme to enable complex models to be applied to mobile real-time recommendation scenarios, and study the integration path of knowledge distillation and edge computing technology; Finally, construct an interpretability enhancement mechanism and develop a visual interpretation tool in conjunction with the design domain knowledge graph to help designers understand the emotional driving factors behind recommendation results.