
Blockchain-based image copyright registration method supporting multi-dimensional data query
- Published
- Accepted
- Received
- Academic Editor
- Anwitaman Datta
- Subject Areas
- Computer Architecture, Databases, Digital Libraries, Security and Privacy, Blockchain
- Keywords
- Blockchain, Image copyright, Copyright confirmation, Copyright registration, Multidimensional data query
- Copyright
- © 2025 Chen et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Blockchain-based image copyright registration method supporting multi-dimensional data query. PeerJ Computer Science 11:e3284 https://doi.org/10.7717/peerj-cs.3284
Abstract
Blockchain technology for image copyright registration eliminates the dependence on third-party institutions, making it a current research hotspot. However, existing methods suffer from a critical bottleneck: the lack of an efficient on-chain mechanism for originality detection, as they rely on inefficient, single-mode queries. This article proposes the multi-dimensional query (MDQ) scheme, a blockchain-based image copyright registration framework designed to solve this challenge. The core of our scheme is a novel block storage structure, the Merkle-KD (MKD) tree, which synergistically combines the verifiability of Merkle trees with the efficiency of KD-trees. This structure enables fast, multi-dimensional similarity searches directly on the blockchain, allowing for robust originality checks to be performed prior to registration. At the same time, user identity is embedded within the copyright data to enable user-specific information queries. The effectiveness of our scheme is validated through simulation experiments, which demonstrate that our proposed method significantly improves the efficiency of image copyright registration and expands the on-chain copyright query modes.
Introduction
With the rapid development of the mobile Internet, digital images have become one of the important media of information dissemination. With the popularization of various intelligent terminals and the development of image processing technology, people can copy and modify images without reducing the quality of the images, which increases the likelihood of infringement during information dissemination (Samuelson, 2023). Protecting digital images, which have a high rate of copyright infringement, from a technical standpoint has become an urgent problem to be solved.
In recent years, digital watermarking (Rahaman et al., 2023), cryptography, image content retrieval (Öztürk, Çelik & Çukur, 2023), big data, and other technologies have been applied to the field of copyright protection, which have promoted the improvement of the image copyright protection system to a certain extent. Digital watermarking technology can be used to authenticate the copyright of image works and protect the integrity of the content. Cryptography is mostly used in image verification (Anand & Singh, 2021), privacy protection (Wang & Liu, 2022; Zhang & Li, 2022), and other aspects of the image copyright protection. For image infringement detection (Pandey et al., 2022), image content retrieval and big data technology can play an important role. However, the adoption of these technologies cannot completely eliminate the dependence on a centralized copyright authority. The arbitration of trusted agencies is still needed in the image copyright protection process, so security and efficiency cannot be fully guaranteed.
Blockchain is a distributed ledger that integrates key technologies such as distributed storage, point-to-point transmission, consensus mechanisms, cryptographic algorithms, and smart contracts (Nakamoto, 2008). Its unique characteristics of decentralization and tamper-resistance provide new ideas for copyright protection. Researchers use blockchain to replace the traditional third-party central agency. In the event of a copyright dispute, the tamper-proof and traceable nature of the blockchain ensures the authenticity and provenance of copyright data.
However, blockchain-based approaches to image copyright registration also face some challenges. For example, most existing methods store copyright information or copyright certificates on the blockchain. With the continuous growth of data, the storage burden of the blockchain is increasing, and many studies have adopted the method of collaborative storage to solve the problem (Heo et al., 2024; Sun et al., 2021). In this method, nodes only store a part of the data locally, and when they need to query the data, they can request the blockchain for an on-chain query.
Furthermore, some collaborative storage blockchain models for copyright registration permit images to be registered without a valid originality test, thereby failing to prevent infringement at the source. Therefore, there are also some studies that use the method of storing regular hash values (Dorgham, Aburass & Issa, 2024) on the chain, which has a particularly precise and strict definition of uniqueness. However, the user is usually concerned with the content of the image, rather than the specific details, making it unsuitable for the copyright registration of an image. From the perspective of originality detection queries, in blockchain copyright registration methods that store image fingerprints and other information on the chain, the existing blockchain query mode is singular and inefficient, which affects the efficiency of copyright registration (Zhang et al., 2023). The limitations of single-dimensional queries become apparent in practical copyright infringement scenarios. For instance, a simple perceptual hash can be defeated by more sophisticated modifications, such as cropping a key element from a copyrighted photograph and incorporating it into a new composite artwork. A single global hash would fail to detect this form of plagiarism. The value of a copyright database extends beyond infringement detection to content discovery and management. A truly functional system should allow users to perform attribute-based searches, such as “find all registered photographs taken in Paris (location feature) that have a predominantly blue color palette (color feature).” Single-dimensional query methods are incapable of supporting such complex, multi-attribute searches. Therefore, a multi-dimensional query capability is not merely an enhancement but a fundamental requirement for a robust and practical image copyright protection system.
Despite the promise of blockchain technology, implementing an efficient and scalable on-chain system for copyright protection remains a significant challenge. A review of the field’s state-of-the-art research reveals several major developmental thrusts: some works focus on enhancing the security and fairness of the copyright transaction process using advanced cryptography; others concentrate on ensuring the data integrity of the original work through techniques like zero-watermarking; and a third group aims to build end-to-end comprehensive management systems with custom consensus protocols.
However, beneath these diverse explorations, a common and critical bottleneck has emerged: the efficiency of the on-chain originality search at scale. To verify a work’s originality before registration, a system must compare the new work’s features against all existing works in the database. Current advanced solutions, when performing this crucial step, either are not designed to address content-based similarity search at all, or they universally rely on a linear scan of all stored fingerprints. As the number of registered works grows, this exhaustive search method inevitably leads to a dramatic increase in query time, becoming the primary obstacle to building a practical, large-scale copyright blockchain. This article, therefore, focuses on addressing this specific scalability bottleneck by introducing a novel on-chain data structure for efficient originality detection.
(1) To address the inefficient on-chain originality detection, this article proposes a blockchain-based image copyright registration method, called the multi-dimensional query (MDQ) scheme. The main contributions of this work are as follows:
(2) We propose a novel block storage structure, the Merkle-KD (MKD) tree, specifically designed to overcome the trade-off between verifiability and query efficiency on the blockchain. It synergistically combines the hierarchical verification capabilities of the Merkle tree with the spatial indexing efficiency of the KD tree.
(3) Based on this structure, we design a complete copyright registration workflow that supports efficient, multi-dimensional similarity searches directly on-chain. This enables flexible and accurate originality detection before registration, a key feature for preventing infringement at the source.
Related work
Traditional image copyright registration
Traditional research on image copyright registration covers methods based on cryptography, digital watermarking, image content retrieval, and artificial intelligence technology (Chalom, Asa & Biton, 2013). Methods based on cryptography mainly establish copyright by protecting the secure distribution of image content, such as copyright protection schemes based on proxy re-encryption (PRE), public key infrastructure (PKI) (Akram & Anaissi, 2024), identity encryption (Deng et al., 2020), attribute encryption (Walid, Joshi & Choi, 2024). However, once the content is decrypted, the image becomes ordinary content, devoid of copyright information, and this kind of method cannot track its subsequent reproduction or dissemination. Copyright registration methods based on digital watermarking technology can be used to protect the author identity, control the integrity of data, and verify the source of data, including robust watermarking (Hemdan, 2021) and fragile watermarking. The former is often used for image copyright authentication, while the latter is used to protect the integrity of the content.
The methods based on image content retrieval and big data technology are mostly used to monitor and analyze suspected infringing content, which is conducive to infringement warnings and rights protection. Among them, image content retrieval includes unencrypted image retrieval and encrypted image retrieval. Traditional methods cannot prevent infringement at the source of copyright registration and instead rely on the arbitration of a third party authority.
Copyright registration based on blockchain
The integration of blockchain into copyright protection has evolved significantly. Early approaches focused on storing cryptographic hashes (e.g., SHA256) on-chain to ensure data immutability, as seen in the work of Jing, Liu & Sugumaran (2021) on code copyright. However, this method is unsuitable for images, where perceptual similarity is key, as any minor modification results in a completely different hash.
This limitation led to a crucial evolution: the adoption of perceptual hashes and local features to capture visual similarity. For instance, Mehta et al. (2019) utilized perceptual hashing for originality detection, but their approach did not store the resulting fingerprints on the blockchain, thus sacrificing the benefits of decentralized traceability. Addressing this, works by Agyekum et al. (2019) and Shi et al. (2020) integrated perceptual hashing and local features (like Scale-Invariant Feature Transform (SIFT)) with blockchain storage. While these systems represented an important step towards content-based verification, their on-chain query mechanisms remained rudimentary, often relying on inefficient, single-mode searches. This early focus on feature-based similarity highlighted a foundational challenge that would be addressed by subsequent, more specialized research: how to efficiently query multi-dimensional data on-chain.
As the field has matured, recent state-of-the-art research has diverged into several distinct research thrusts.
1. On-chain indexing
Some research explored building on-chain indexes to improve query efficiency. For instance, the hybrid index by Zheng et al. (2020) and the Adaptive Balanced Merkle (ABM) scheme (based on SE-chain) by Jia et al. (2021) and utilize tree-based structures to accelerate the retrieval of one-dimensional data. These works are significant as benchmarks for on-chain indexing. However, their fundamental limitation is that the index structure is designed for single-dimensional data and is unsuitable for the multi-dimensional similarity search required for image content analysis, where its performance degrades significantly.
2. Transactional security and fair trading
A significant research thrust aims to secure the copyright transfer and trading process against malicious activities. A prime example is the “Proactive Defense” scheme by Chen et al. (2023), which uses advanced cryptographic tools like double-authentication-preventing (DAP) signatures to prevent the fraudulent double-selling of a copyright before a transaction is finalized. Similarly, Yu et al. (2023) proposed a fair image trading scheme that uses searchable symmetric encryption and smart contracts to ensure fairness and privacy during the transaction process. While these works provide robust security for the transaction phase, their query mechanisms are designed to trace the history of a specific, exact copyright hash or to facilitate private retrieval between specific users. This highlights that even the most secure transaction frameworks still fundamentally rely on an efficient underlying mechanism to first determine a work’s originality, a problem they do not solve.
3. Data integrity and lifecycle management
Another direction concentrates on ensuring the integrity of the original media and managing its entire lifecycle. The work by Wang et al. (2022) combines a zero-watermarking algorithm with blockchain and InterPlanetary File System (IPFS), allowing copyright information to be associated with an image without modifying the image data itself. The framework by Liu et al. (2021) utilizes Hyperledger Fabric and smart contracts to manage the full life cycle of digital rights, including registration, transfer, and query. While these schemes provide robust frameworks for verification and management, their query mechanisms are based on specific identifiers (like a copyright number or user ID) or exact hash values. They are designed for one-to-one verification of known items, indicating that robust lifecycle management requires an efficient, one-to-many originality search as a foundational component, which remains an unaddressed challenge in these approaches.
4. Comprehensive systems with similarity search
A third approach involves building complete, end-to-end Digital Rights Management (DRM) systems that incorporate similarity-based originality checks. The DRPChain proposed by Yun et al. (2024) exemplifies this. They developed a robust anti-cropping perceptual hash for similarity detection and designed a novel consensus algorithm, K-Raft, tailored for copyright management. A similar approach is taken by Zhou et al. (2024), who use the SIFT algorithm for feature extraction and similarity computation within a Hyperledger Fabric framework. Both systems address originality by comparing a new image’s features against existing records. However, their search mechanism relies on a linear scan of all stored fingerprints. As the number of registered images grows, this exhaustive search will inevitably become a significant performance bottleneck, hindering the system’s scalability.
As illustrated in Table 1, state-of-the-art research addresses different but important facets of the copyright protection problem. Schemes that focus on transactional security, such as those by Chen et al. (2023) and Yu et al. (2023), excel at preventing fraudulent transfers but are not designed for content-based originality checks. Approaches centered on data integrity and lifecycle management, like those of Wang et al. (2022) and Liu et al. (2021), are effective for verifying specific images but lack a large-scale search capability. Comprehensive systems that do incorporate similarity checks, represented by Yun et al. (2024) and Zhou et al. (2024), often rely on a linear scan, making their efficiency a significant concern for large-scale applications. Similarly, early on-chain indexing efforts, such as those by Jia et al. (2021) and Zheng et al. (2020), provide efficient one-dimensional indexes but are not applicable to the multi-dimensional search required for image content. Our scheme addresses this specific scalability bottleneck by providing an indexed search mechanism (the MKD-Tree), which is designed for efficient, multi-dimensional similarity queries directly on-chain.
| Scheme | Primary goal | Supports similarity-based originality check | On-chain originality search mechanism | Search efficiency for originality check |
|---|---|---|---|---|
| Our scheme | Efficient originality query | Yes | Indexed search (MKD-Tree) | High (Logarithmic) |
| Jia et al. (2021) | Efficient 1D data retrieval | No | 1D index search (B+-Tree) | N/A |
| Chen et al. (2023) | Transactional security | No | Transaction history tracing | N/A |
| Yu et al. (2023) | Fair & private image trading | No | Secure retrieval (Amplifying Locality-Sensitive Hashing (ALSH)+Searchable Symmetric Encryption (SSE)) | N/A |
| Wang et al. (2022) | Data integrity | No | N/A | N/A |
| Liu et al. (2021) | Copyright lifecycle management | No | ID/Exact hash match | N/A |
| Yun et al. (2024) | Full DRM system & custom consensus | Yes | Linear scan | Low (Linear) |
| Zhou et al. (2024) | Visual art protection & penalty mechanism | Yes | Linear scan | Low (Linear) |
Methodology
Blockchain image copyright registration model
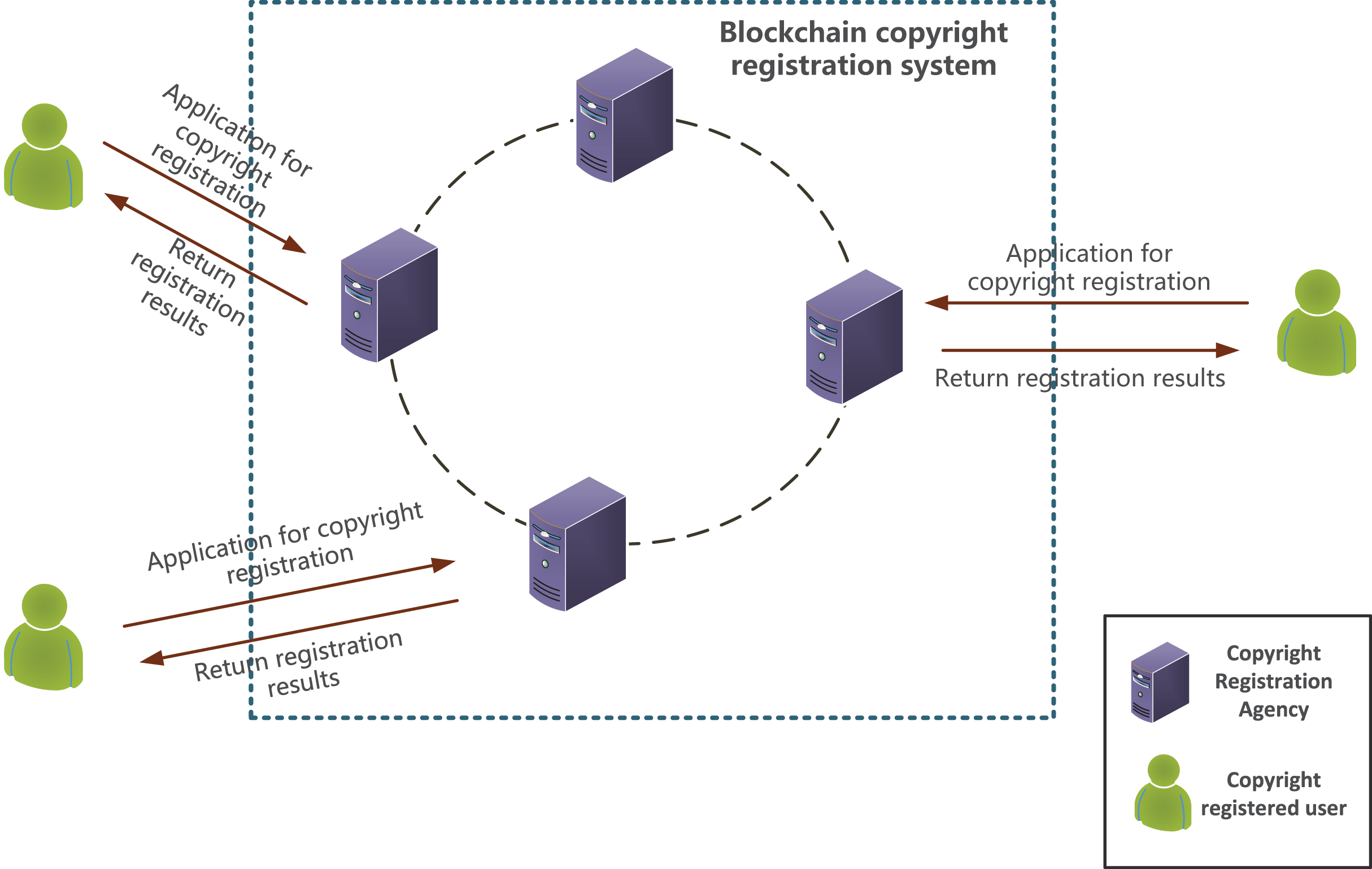
The proposed blockchain-based image copyright registration model involves three main participants: copyright registration authorities, copyright registration users and blockchain registration system. Since each node does not store complete block data, the model relies on on-chain queries to complete image copyright registration. Before copyright confirmation, originality detection based on multi-dimensional data queries must be completed.
(1) Registered copyright users
The copyright registration user is the applicant for image copyright. The user first applies to the copyright registration agency and then submits the user’s basic information and the image to be registered. The image query summary generated through image originality detection is stored on the blockchain and in the copyright database to complete the image copyright confirmation. Users who have completed the copyright registration can query the confirmed image copyright information based on their user ID.
(2) Copyright registration agency
After registration, the copyright agency can join the blockchain network and accept the applications from copyright registration users. It interacts with copyright registration users, assists users in completing the originality detection, queries, records copyright information on the chain to confirm the right, maintains their own off-chain image copyright database, and stores the image query information off-chain.
(3) Blockchain registration system
Multiple copyright registration agencies joined the blockchain network, overcoming the issue of image copyright information silos. The blockchain registration system interacts with the agencies, uses the image multi-dimensional feature data for originality detection and querying, and completes the copyright data confirmation work.
The blockchain-based image copyright registration model is shown in Fig. 1. All copyright registration agencies join the blockchain copyright registration system and store copyright data in a collaborative manner. Copyright registration users obtain copyright by applying to copyright registration agencies. After the copyright registration agency carries out the originality detection and query, the image copyright information is stored on the chain for copyright confirmation.
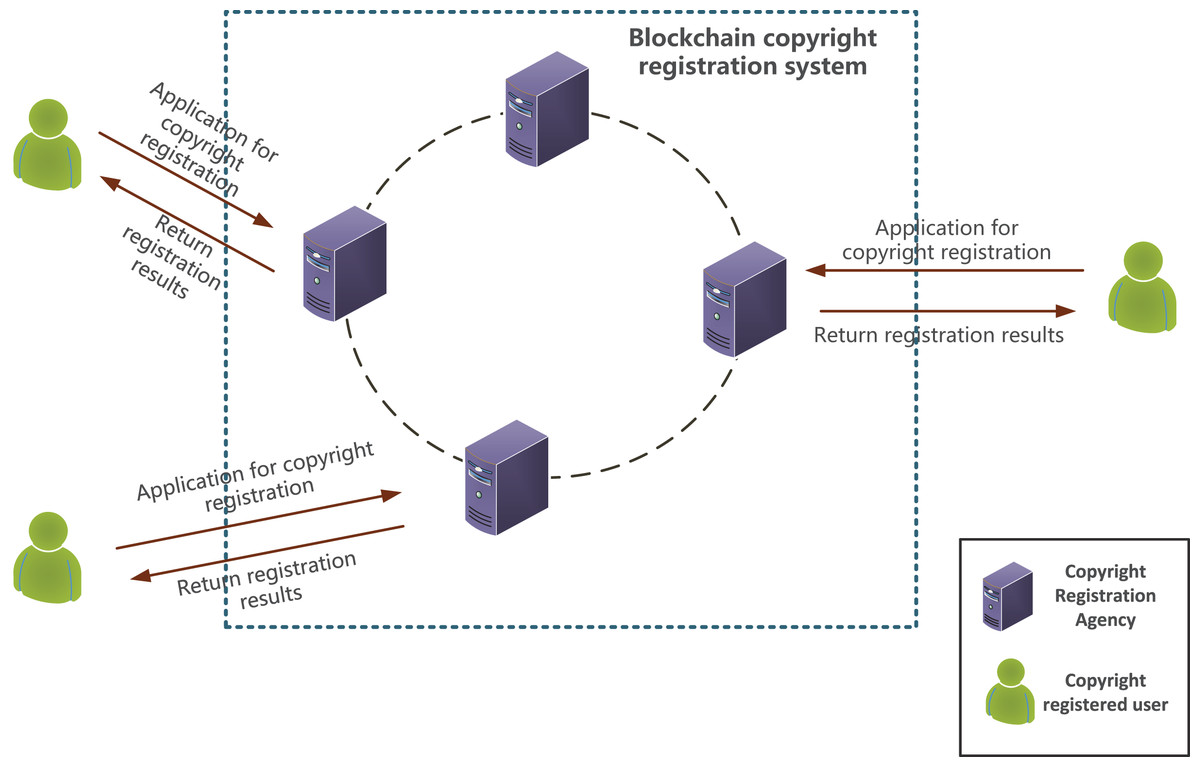
Figure 1: Image copyright registration model based on blockchain.
{kind=link}
Blockchain image copyright registration method
This section proposes a blockchain image copyright registration method that supports multi-dimensional data queries, named the MDQ scheme, which includes block storage structure construction based on MKD trees, image originality detection and querying, and user copyright information querying. Finally, a detailed copyright registration process for blockchain images supporting multi-dimensional data queries is designed. In the process of image copyright registration, the image fingerprint is stored on the chain to support the approximate querying of multi-dimensional data. At the same time, users can query copyright information by unique identifier. The blockchain image copyright registration method we designed can choose the image fingerprint generation method as needed. This section takes image content feature data as an example.
The method mainly includes three parts: image copyright registration application and right confirmation, image originality detection and querying, and user copyright information querying. The copyright registry stores the image copyright information it accepts on the chain and synchronizes the data according to its own storage capacity. Therefore, before copyright registration, originality detection querying is divided into on-chain querying and local querying. At the same time, the MKD tree structure improves the query efficiency within each block and supports the querying of user copyright information.
For ease of exposition, the abbreviations in our method are defined in Table 2.
| Abbreviations | Meaning |
|---|---|
| Image copyright registration users, there is a need to register copyright | |
| Image copyright registration agency refers to the agency that assists users in completing the examination of image originality and registration through blockchain | |
| The blockchain-based image copyright registration system, which contains copyright registration agency nodes; it can confirm the copyright on the chain and query the copyright information of users | |
| An image uploaded by the user who wishes to confirm the copyright | |
| An image whose copyright has been confirmed and whose copyright information is stored in the copyright database | |
| The fingerprint of the image that has completed the copyright confirmation | |
| Fingerprint of the image to be registered |
Implementing an efficient multi-dimensional query system on a blockchain presents a significant technical challenge centered on the inherent trade-off between query efficiency and the blockchain’s fundamental requirement for data verifiability.
Traditional databases utilize dynamic index structures like R-trees, which are optimized for fast spatial queries but are mutable and not natively verifiable in a decentralized context. Conversely, blockchains guarantee data integrity through immutable, hash-linked structures like Merkle trees. While excellent for verification, Merkle trees are extremely inefficient for search operations, as they offer no indexing capability and typically require a full scan of the data.
Therefore, designing a practical solution requires a novel hybrid data structure that can synergistically combine the search capabilities of a spatial index with the verifiable integrity of a Merkle-based structure, all while remaining lightweight enough to be viable on-chain. Our proposed MKD-tree is specifically engineered to address these challenges.
Block storage structure based on MKD tree
The traditional hash fingerprint method has strict requirements on the uniqueness of the image. In fact, images need to be represented in terms of content (such as global or local features), and for some photographs, positional features can also be used. In order to achieve approximate queries, images need to be represented by features that can represent the similarity of images rather than the traditional hashing method. Therefore, the image fingerprint used in this article has the characteristics of representing similarity. The originality on-chain query of this method is to retrieve approximate images through multi-dimensional data. In the original Merkle tree storage mode of the blockchain, originality detection queries need to traverse the data of each block for similarity judgment, which is inefficient and does not support multi-dimensional data queries.
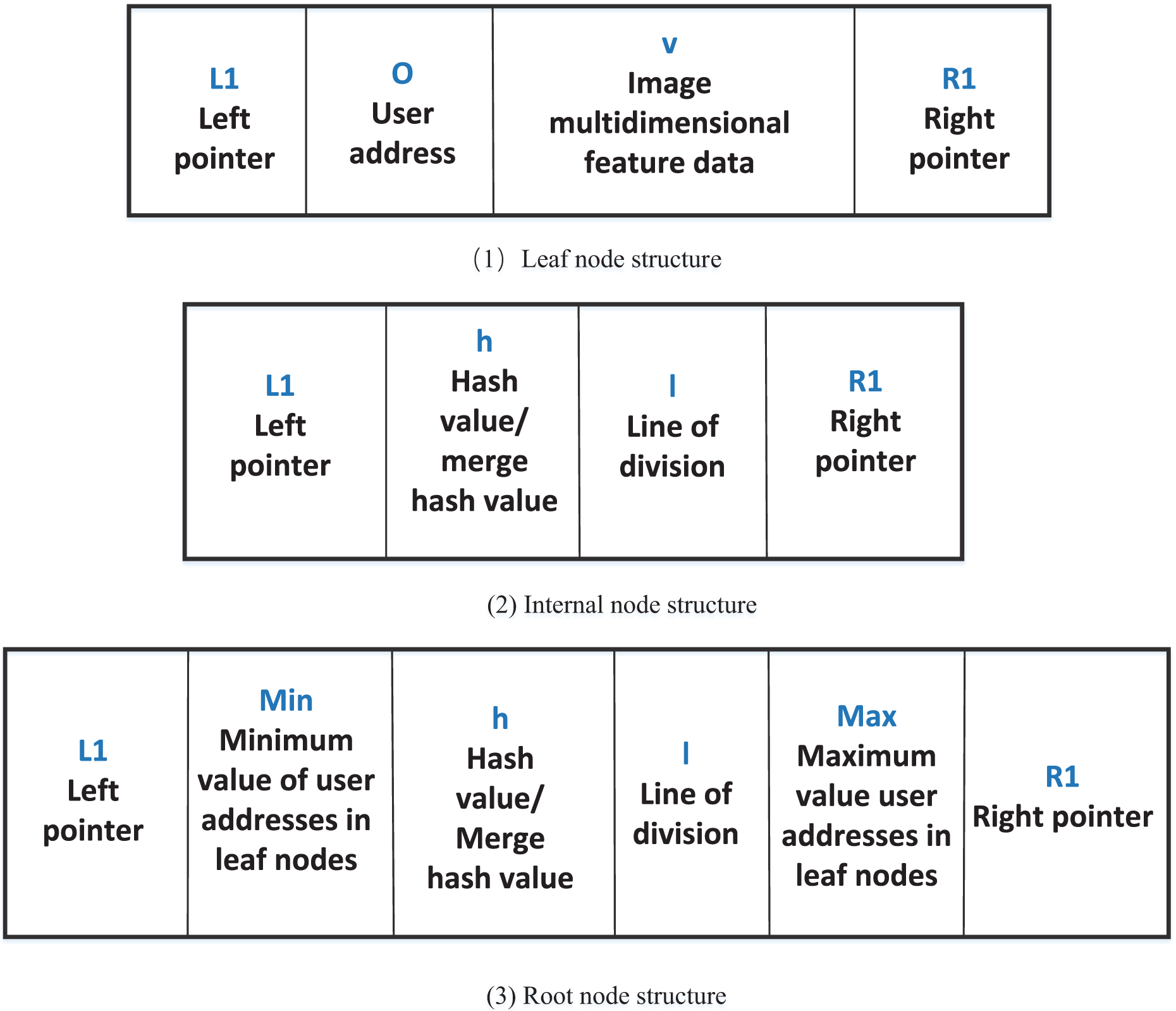
To support the originality detection function of our method, this article designs a block storage structure based on the Merkle-KD tree (MKD Tree). The MKD tree is a binary tree structure that integrates a Merkle tree with a KD tree. The Merkle structure ensures data integrity and tamper-resistance, while the KD tree enables efficient indexing and retrieval in multi-dimensional feature space (Zheng et al., 2022).
Specifically, this structure is designed to support multi-dimensional data queries (MDQ), where each image is represented as a multi-dimensional feature vector (e.g., color histograms, textures, spatial information). These feature vectors are organized using the KD tree structure to allow for range-based or nearest-neighbor queries. The Merkle tree component provides verifiability of the retrieved results, ensuring that the query process is auditable and secure.
In our MDQ scheme, given a query image, its feature vector is extracted and used to traverse the MKD tree to find similar images. This integration of KD-based indexing and Merkle-based verification enables the system to perform fast, accurate, and secure similarity queries required for blockchain-based copyright registration. Taking the image content feature data as an example to describe the image, suppose that the selected image multi-dimensional feature data is , then an image can be expressed as , which is the image fingerprint used in image originality detection. For example, can represent content-based features, while can represent positional features. Then, the MKD tree is constructed by using the multi-dimensional feature data of the image. Assume that each block contains multi-dimensional features of image data set , where the multi-dimensional feature data of the -th image . Firstly, the KD-tree index is constructed according to the set . In order to make it preserve the verifiable query feature of the blockchain, the MKD-tree root is generated by merging the Merkle hash values of the nodes. Taking the user address as the unique user identification, we define the node data structure of the MKD tree, including leaf nodes, internal nodes, and root nodes, as shown in Fig. 2.
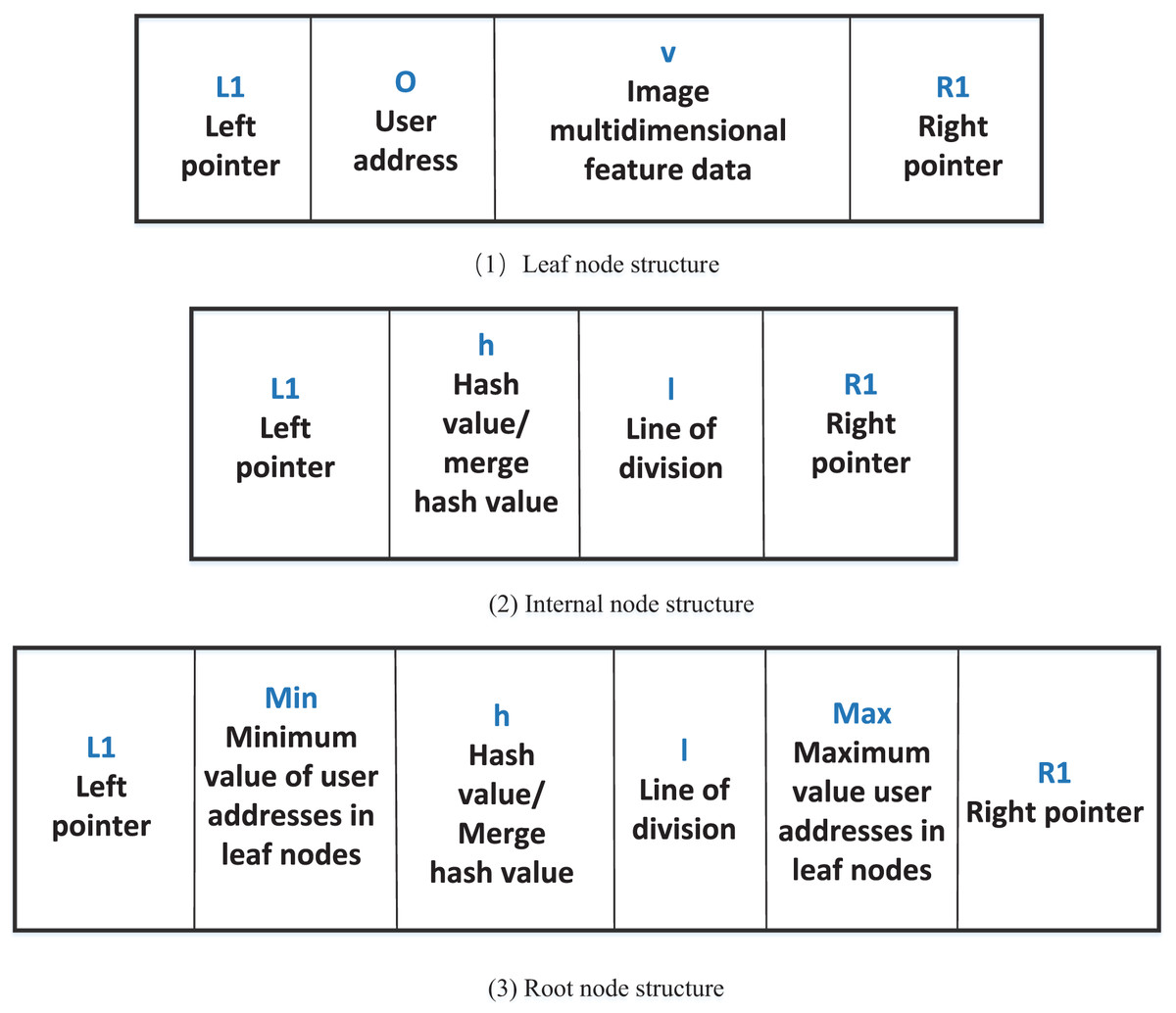
Figure 2: MKD tree node data structure.
{kind=link}
Let the MKD-tree have a total of 10 leaf nodes, which are denoted by , and . Let be the internal node of the MKD tree, and contains . Let the left child node of be , the right child node be , and be the split line, then . represents the root node of the MKD tree, contains . The leaf nodes contain the maximum value and the minimum value of the user addresses. The MKD tree structure is shown in Fig. 3.
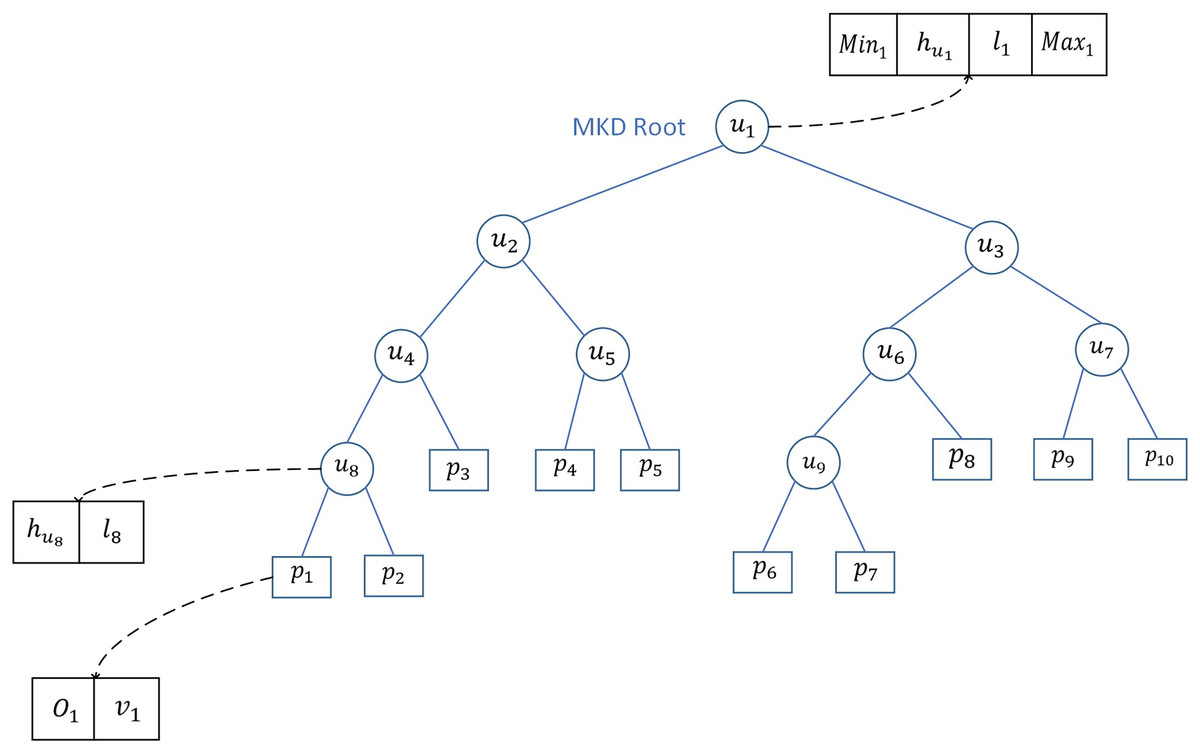
Figure 3: MKD tree structure.
{kind=link}
The efficiency of the registration process is enhanced by our block storage structure, which utilizes the MKD tree. This architecture serves as the foundation for performing both image originality detection and user copyright information queries. A diagram of this on-chain storage structure is provided in Fig. 4.
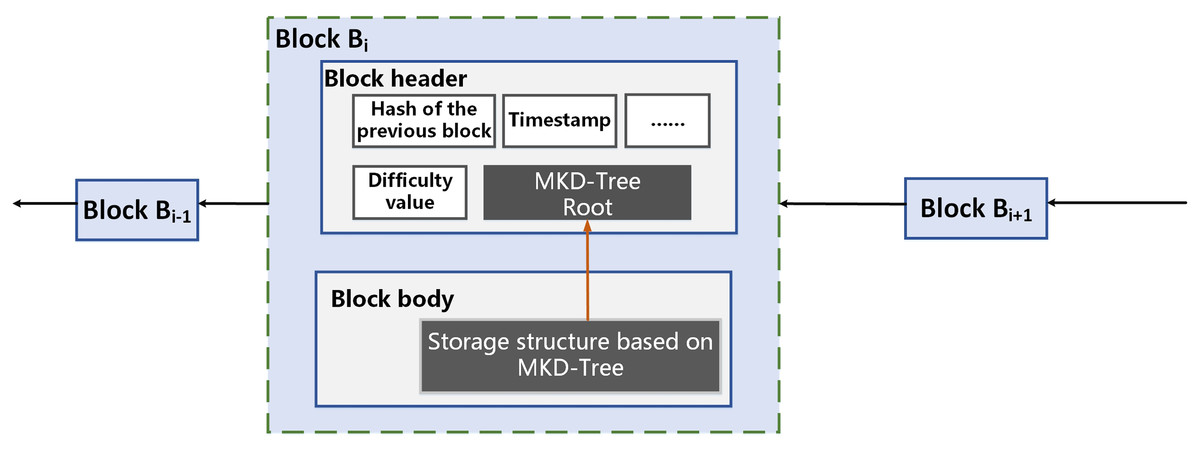
Figure 4: On-chain off-chain storage structure.
{kind=link}
Blockchain copyright registration based on MKD tree
The blockchain-based image copyright registration algorithm first accepts the user’s registration application through the copyright registration authority. After verifying the identity of the user, the copyright registration authority makes an originality query of the registered image. When the image passes the originality detection, the copyright agency stores the image’s on-chain query summary and the user identity information (such as user address) in the blockchain as copyright data in the structure of the MKD tree, ensuring the immutability of the on-chain query summary and improving the efficiency of on-chain queries. At the same time, it supports users who have registered copyrights to query based on identity.
This section first introduces the summary of on-chain queries, then designs a blockchain-based image copyright registration process, and explains the originality query process and user copyright information query process in detail.
On-chain query summary
The MKD tree-based block storage architecture supports two types of on-chain queries, including the user copyright information query and the originality detection query. The user copyright information query can use the user identity (such as the user address) as the on-chain query summary. Originality detection query is based on the multi-dimensional feature data of the image, and the image fingerprint is the query summary on the chain. By searching and querying the authenticated image feature data on the blockchain, the approximate query is used to determine the results of the originality audit. When the of an image uploaded by a user is similar to the corresponding on-chain query summary, the image is considered to be similar.
Image copyright registration process
-
(1)
Before submitting a copyright registration application, the image uploader must first encrypt the image to be registered and submit it to the blockchain together with relevant metadata. Subsequently, the submits a registration application to the nearest in its area, which includes the identity information and the image to be registered .
-
(2)
After receiving the copyright registration application, verifies the identity of , obtains the image to be registered, and carries out the originality detection based on on-chain query summary. If a registration is rejected due to image duplication, may choose to disclose the confidential image content to prove its ownership of the image and challenge the rejection.
-
(3)
performs on-chain data query, starting from the MKD tree root of the current block, until the corresponding leaf node is found, and that are similar to are found;
-
(4)
Determine whether the images represented by and meet the approximation under a certain threshold. If so, returns a notification that the originality test has not passed and the registration has failed, and the query ends; if not, query the next block;
-
(5)
If all blocks are queried and there is no similar on-chain query summary, the result of originality detection passing is returned
-
(6)
uploads the user identifier of the copyright registration (such as user address) and the image on-chain query summary to the blockchain and stores them in the MKD tree structure to complete the ownership confirmation.
Originality detection query
This section introduces the query process of image originality detection. First, after submitting an image for registration, the user sends the copyright image to be registered to the copyright registration agency, which verifies the user’s identity and runs the originality detection and query algorithm. uses the query summary to query in the local block and will refuse to register if similar results are returned. Otherwise, other nodes are requested to query the on-chain query summary of the image copyright registry blockchain using to retrieve approximate data. If similar results are returned, the result of denied registration is still returned. When similar images are not queried, the copyright registration blockchain system confirms the copyright of the user’s image, stores the image copyright data in the blockchain, and completes the registration. Taking the number of approximate items as 1 as an example, the query process of originality detection on the blockchain is shown in Algorithm 1.
| Input: Image to be registered |
| Output: Originality detection query results |
| 1: |
| 2: |
| 3: .Empty |
| 4. Current |
| 5: While Current Do |
| 6: |
| 7: |
| 8: If And Then |
| 9: Return ( , “OnChain”) |
| 10: End If |
| 11: |
| 12: |
| 13: End While |
| 14: Return |
The core of the process is an efficient nearest neighbor search performed within each block. For each block, the system takes the query image’s fingerprint, , and uses the block’s MKD-tree to find the single most similar fingerprint, , that has been previously registered. This search operation is highly optimized by the MKD-tree’s structure, which avoids an inefficient linear scan of all data within the block. The search algorithm operates as follows:
(1) The search starts at the root of the MKD-tree and traverses down to a leaf node. This path is determined by comparing the query fingerprint against the splitting criteria at each internal node, leading to an initial candidate for the nearest neighbor.
(2) The algorithm then backtracks up the tree from the leaf. During this process, it continuously updates the “current best” nearest neighbor if a closer one is found. Crucially, it prunes entire branches of the tree that cannot possibly contain a fingerprint closer than the one already identified, which is the source of the KD-tree’s efficiency.
After the search within a block is complete, the algorithm proceeds to the decision step. As shown in Algorithm 1, the distance between the query fingerprint and the found nearest neighbor is calculated. If this distance is less than or equal to a predefined similarity threshold , the image is deemed non-original, and the registration process is immediately rejected. If the entire blockchain is traversed without finding such a match, the image is confirmed as original and can be registered.
User copyright information query
Copyright registration users often want to query the on-chain information of their completed copyright registration through their identity identifier (such as user address ), which usually exists in multiple blocks. With the continuous growth of copyright registration blockchain data, the method of traversing and querying all the data in each block is inefficient.
Our proposed block storage structure based on the MKD tree is specifically designed to optimize this type of query. As described previously, the root node of each block’s MKD-tree stores the minimum (Min) and maximum (Max) user addresses among all copyright data contained within that block. This architectural feature enables a highly efficient pruning mechanism during the search process.
Take user address as an example, the block storage structure based on the MKD tree saves the maximum and minimum value of user addresses in the root node, which can support range query and improve the efficiency of user copyright information query. The user copyright information query process is shown in Algorithm 2. Its working principle is as follows:
(1) When searching for a user’s data, the system iterates through the blockchain from the first block. For each block, it does not immediately traverse the internal data. Instead, it first inspects the Min and Max address values stored in the MKD-tree root in the block header.
(2) It performs a simple range check: if the target user’s address does not fall within the [Min, Max] range of the current block (i.e., < Min or > Max), it implies that this user’s data cannot possibly exist in this block.
(3) If the check fails, the system skips this entire block and moves to the next one, avoiding any costly internal traversal. If the check passes (Min ≤ ≤ Max), it indicates that the user’s data might be in this block, and only then does the algorithm proceed to search within that block’s MKD-tree.
| Input: Copyright registration user address |
| Output: Copyright information query results |
| 1: |
| 2: .Empty |
| 3: While Do |
| 4: |
| 5: If And Then |
| 6: |
| 7: If Then |
| 8: |
| 9: End If |
| 10: End If |
| 11: |
| 12: End While |
| 13: Return |
| 14: |
| 15: Function |
| 16: If Then |
| 17: Return .Empty |
| 18: End If |
| 19: |
| 20: If And Then |
| 21: |
| 22: End If |
| 23: |
| 24: |
| 25: |
| 26: |
| 27: Return |
| 26: End Function |
This block-level pruning strategy dramatically reduces the search space, especially on a long blockchain where a user’s transactions may only be present in a small fraction of the blocks. It transforms the problem from a full-chain traversal to a much faster, targeted search.
As shown in Algorithm 2, our scheme iterates through each block of the blockchain. For each block, it does not immediately traverse the internal data. Instead, it first inspects the and address values stored in the MKD-tree’s root node within the block header. It performs a simple range check: if the target user’s address does not fall within the range of the current block, it implies that this user’s data cannot possibly exist in this block.
In such cases, the method skips this entire block and moves to the next one, avoiding any costly internal tree traversal. Only if the check passes does the algorithm proceed to call the helper function to perform a recursive search within that specific block’s MKD-tree to locate all matching records. This block-level pruning strategy dramatically reduces the search space, especially on a long blockchain where a user’s transactions may only be present in a small fraction of the blocks, transforming the problem from a full-chain traversal to a much faster, targeted search. The function itself then performs a complete search within the given tree to find all records associated with the user address.
Results
Experimental setup
This section elaborates on the experimental environment established to validate our proposed scheme. We utilized the SimBlock blockchain simulation platform for our experiments. SimBlock is an open-source, Java-based simulation tool capable of effectively modeling node behaviors, block propagation, transaction processing, and consensus mechanisms within a blockchain network. This allows for the performance evaluation various protocols and optimization schemes in a highly controllable environment.
Our experimental environment was set up on a server equipped with an Intel(R) Core(TM) i5-12600KF CPU and 32.00 GB of RAM, running CentOS 7.8 as the operating system. This setup provides sufficient computational resources to support simulations involving a large number of nodes and transactions. SimBlock itself is developed in Java. To run and modify the SimBlock source code, we installed Java Development Kit (JDK) 11 and Gradle 6.9 for project management and building. Furthermore, Git was used for version control and source code management. Within the SimBlock simulation platform, we made necessary modifications and extensions to its core modules to accommodate our scheme.
Efficiency analysis
Baseline comparison and causal link analysis
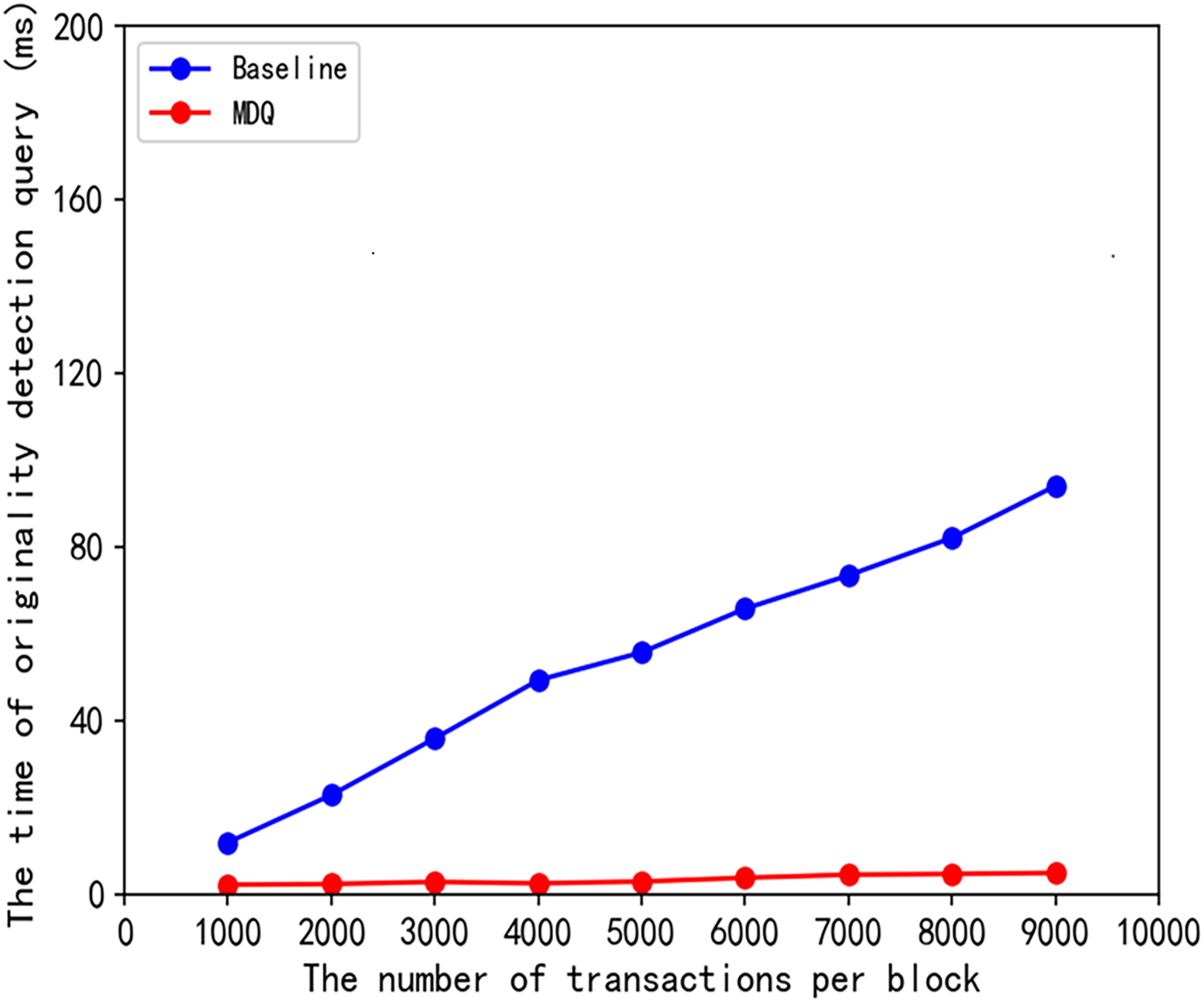
To establish the causal relationship between the theoretical innovation and the observed efficiency improvement and to illustrate the effectiveness of our scheme, we conducted a baseline comparison experiment. In this experiment, we compared the MDQ scheme with a linear scan method (labeled as “baseline”). The baseline scheme performs originality detection by exhaustively comparing the query fingerprint with all fingerprints in the block without utilizing any index structure.
The results are presented in Fig. 5. As shown, the query time of the baseline scheme grows linearly with the number of transactions per block (denoted as ), which is consistent with its theoretical time complexity. In stark contrast, the query time for our MDQ scheme remains consistently low and exhibits almost flat, sub-linear growth across the same range of data volumes.
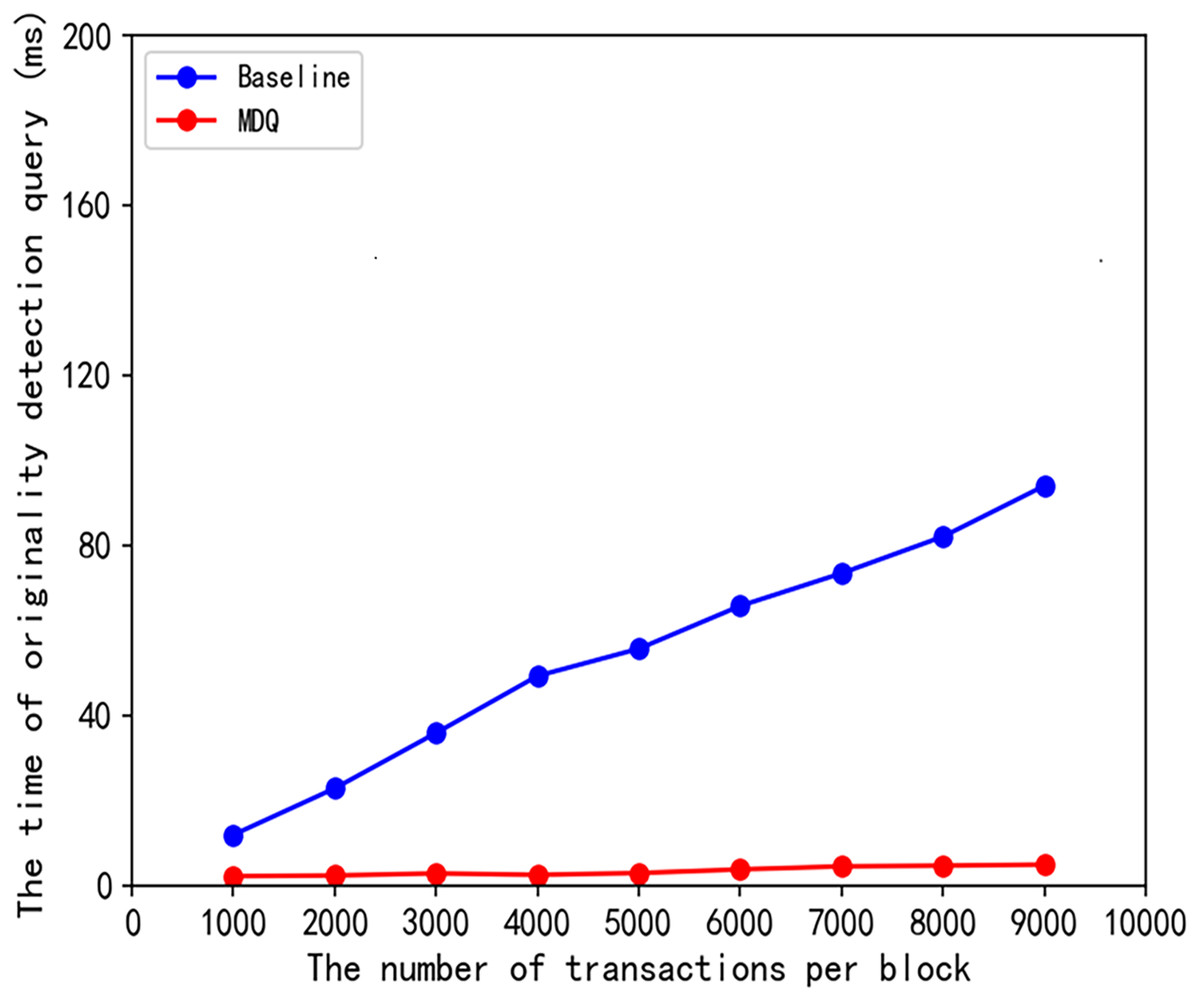
Figure 5: Query time scalability with increasing transactions per block.
{kind=link}
This result provides direct evidence that the dramatic efficiency gain is causally linked to the spatial pruning capability of the MKD-tree. By avoiding a full scan of the data, the MKD-tree’s underlying average query complexity is empirically validated. This comparison confirms that the MKD-tree’s ability to perform multi-dimensional spatial pruning is the primary driver of the significant efficiency improvement observed in the MDQ scheme. The experiment thus empirically validates the causal link between our proposed data structure and its high query efficiency.
Performance comparison with ABM scheme
To evaluate the performance of our MDQ scheme against a relevant state-of-the-art method, we selected the ABM scheme (Jia et al., 2021) as the primary baseline for this comparison. Unlike systems that focus primarily on off-chain storage or simple duplication checks (e.g., Agyekum et al., 2019), the ABM scheme represents an advanced, on-chain indexing structure designed for efficient data retrieval, making it a suitable and challenging benchmark. It integrates the fast search capability of a balanced binary tree with the verification efficiency of a Merkle tree and dynamically adjusts its structure based on query demand.
Our simulation experiments were designed to compare the two schemes across two key metrics: (1) block storage structure construction time and (2) originality detection query time. These metrics were evaluated under various conditions, including different numbers of approximate items ( ) and transactions per block ( ). The specific experimental parameters are detailed in Table 3.
| Parameter | Number | Parameter | Number |
|---|---|---|---|
| 10 | 128 | ||
| 20 | 256 | ||
| 30 | 512 | ||
| 40 | 1,024 | ||
| 50 | 2,048 | ||
| 60 | 4,096 | ||
| 70 | 8,192 |
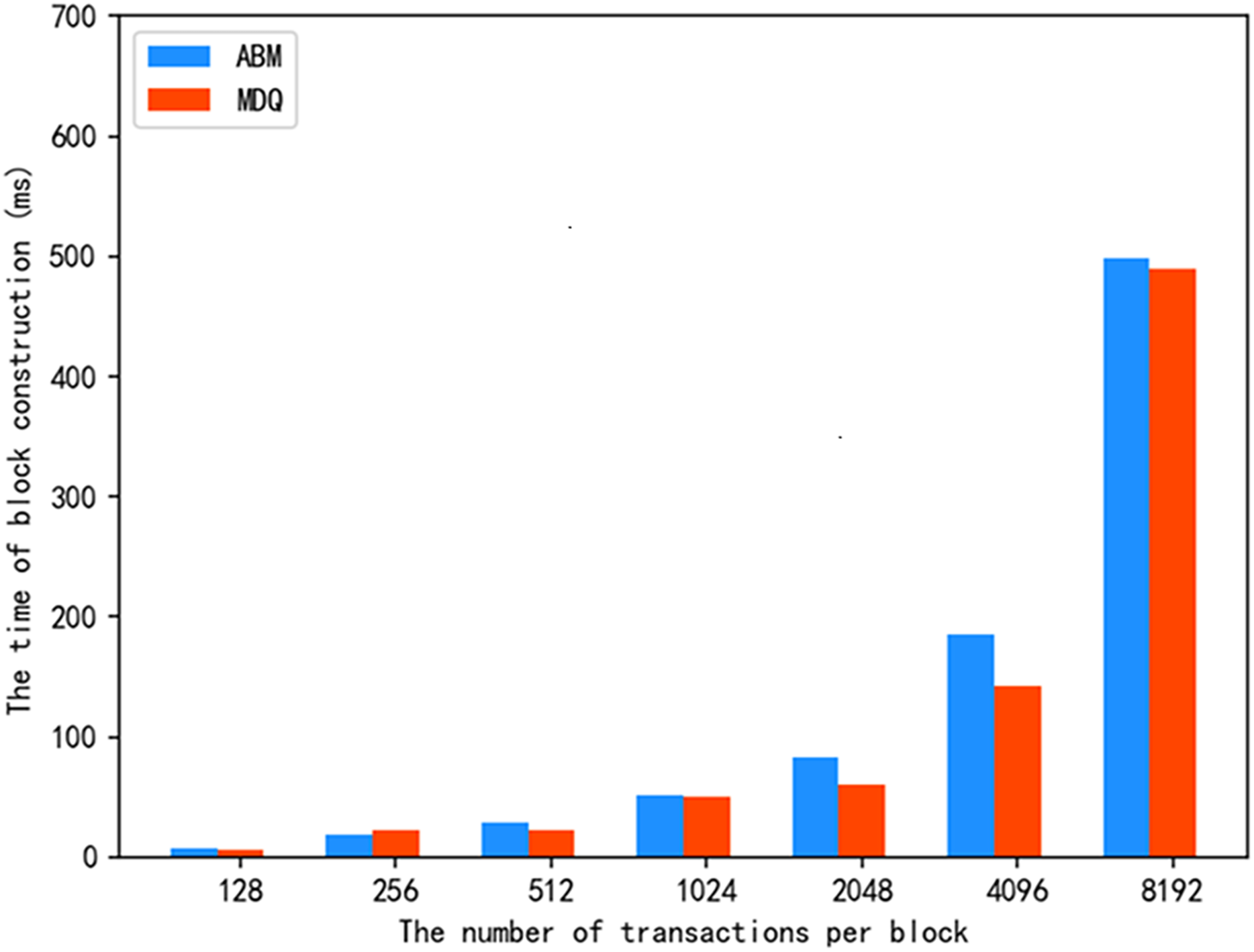
For the query of the ABM scheme and MDQ query of the proposed scheme, the construction time of the block storage structure is shown in Fig. 6 under different numbers of transactions per block. It can be seen from the experimental results that when the number of transactions in a single block is 128, 256, or 512, the construction time of the storage structure of our scheme is similar to that of the ABM scheme, both of which are in the millisecond range. As the number of transactions increases, the construction time of the block storage structure of the MDQ scheme is lower than that of the ABM scheme. The results in Fig. 6 show that the construction time of the block storage structure of the MDQ scheme is similar to other schemes when the number of transactions per block is small, and the time consumption is lower when the number of transactions per block increases to a large value, which demonstrates certain advantages. This efficiency stems from the average-case complexity of building the KD-tree structure, which scales effectively with a large number of transactions ( ). The MDQ scheme’s ability to support multi-dimensional data storage with low construction time gives it a distinct advantage over the ABM scheme.
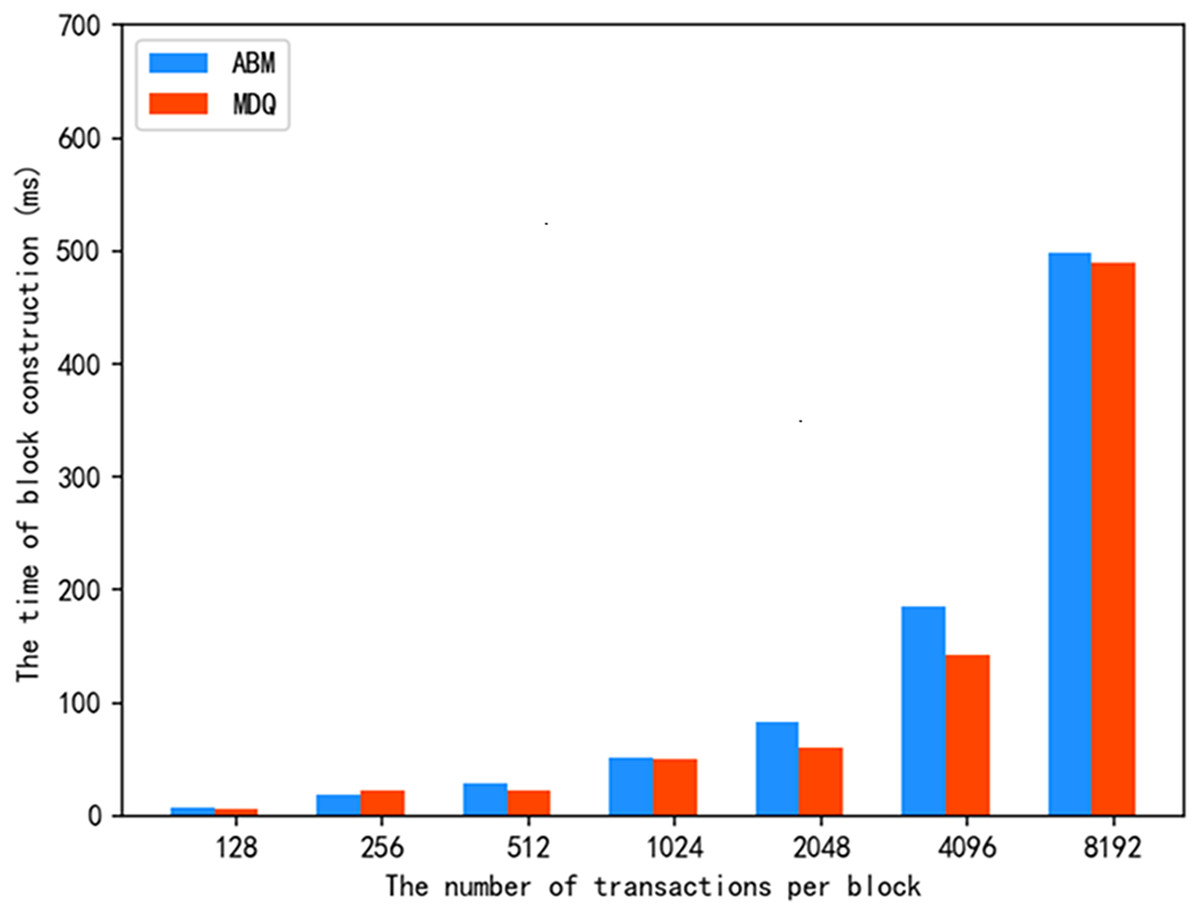
Figure 6: Construction time of block storage structure.
{kind=link}
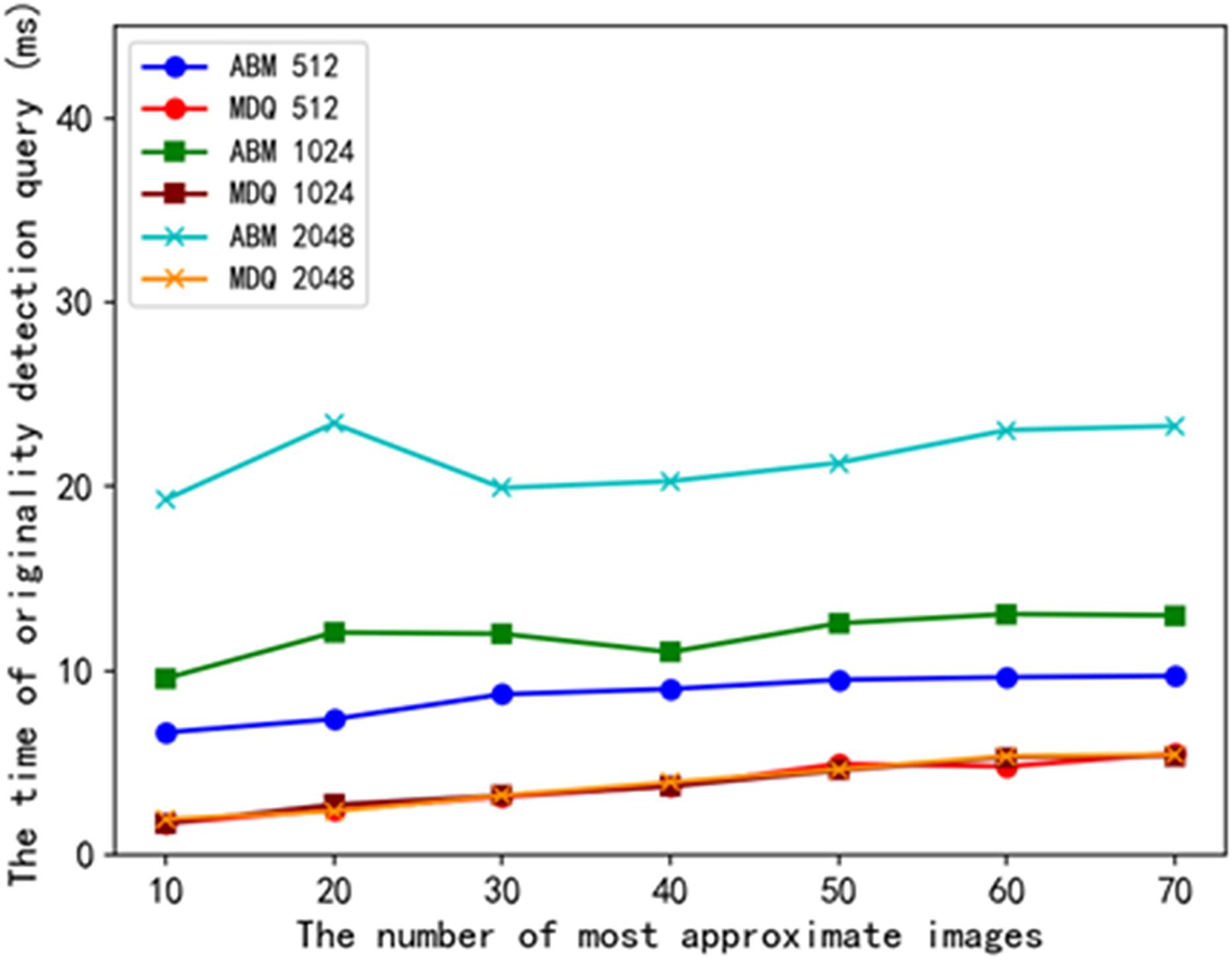
As shown in Fig. 7, we plot the relationship between the number of searches and the query time consumption of originality detection when the number of transactions per block is 512, 1,024, and 2,048, respectively. With the increase in the number of approximate items searched, the query time of the ABM scheme and the MDQ scheme increases. The experiments compare the query time of the schemes under three different numbers of transactions: 512, 1,024, and 2,048. The originality detection query time of the MDQ scheme is lower than that of the ABM scheme. The experimental results show that the MDQ scheme has higher query efficiency in originality detection queries compared to the ABM scheme.
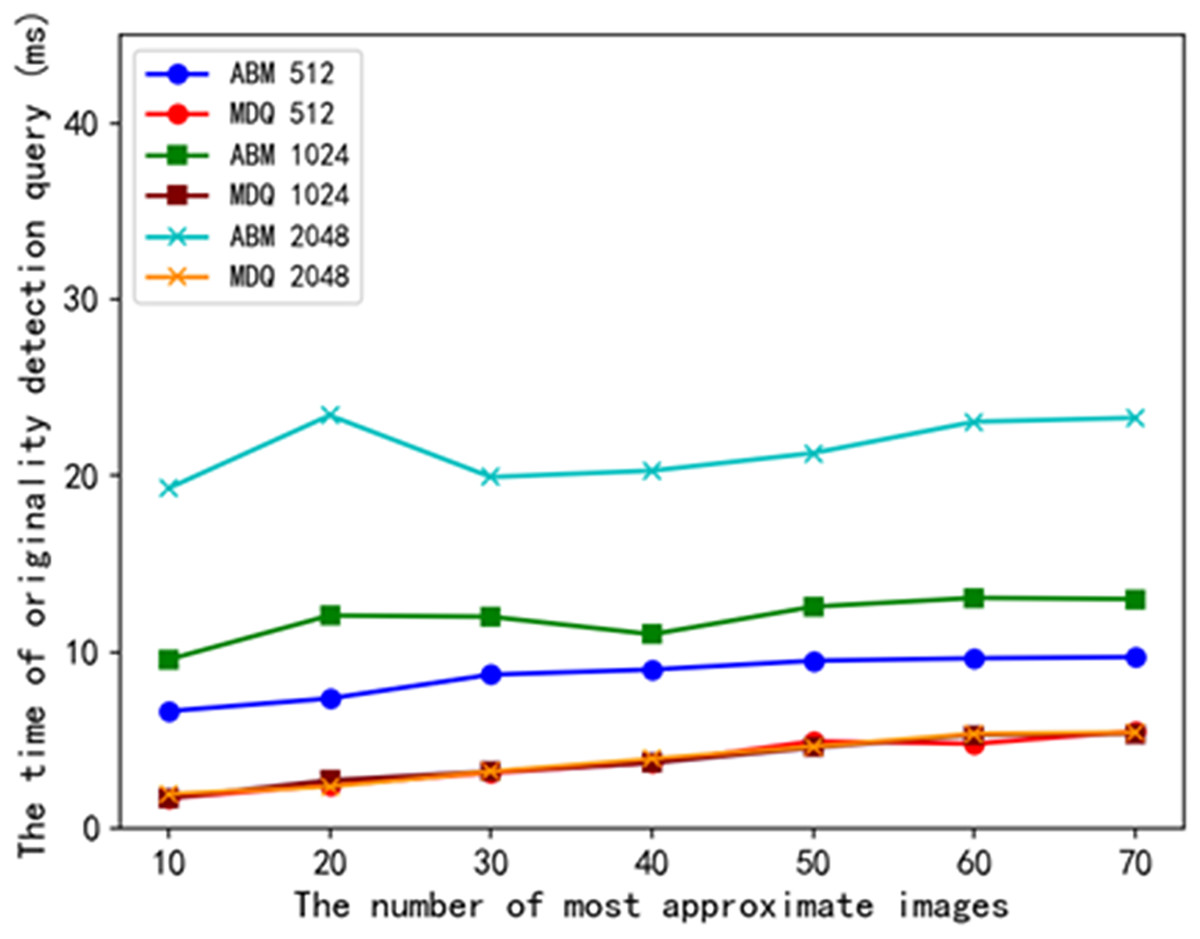
Figure 7: Comparison of time consumption for originality detection queries.
{kind=link}
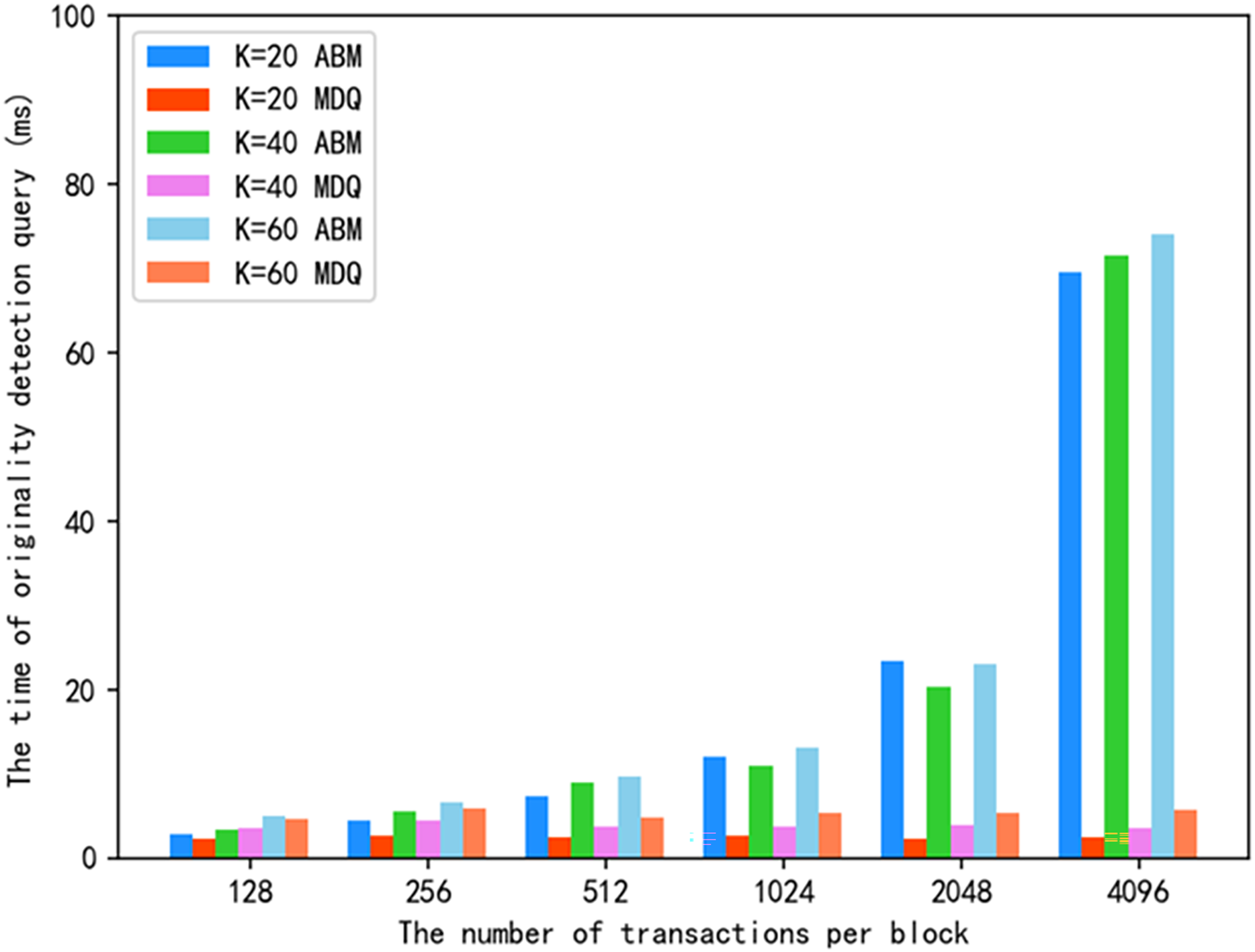
Figure 8 shows the originality detection query time of the proposed scheme and ABM scheme for the same value. The experimental results show that the number of searches is closely related to the originality detection query efficiency. Let the similarity threshold be and the similarity function be . We discuss this in two cases:
-
(1)
. In the originality detection, the search number is set to 1, that is, the image that is most similar to the image to be registered in each block is searched. Its on-chain query summary is , and the similarity . Since the current is the fingerprint data with the highest similarity to in this block, the similarity distance between and is the minimum value in this block. Therefore, the originality detection result of the current block is shown in Eq. (1): (1)
If , it means that the fingerprint most similar to the image fingerprint to be registered in this block satisfies the similarity threshold condition, so the originality detection query fails and the registration is rejected. If , it means that the similarity distance between the most similar image fingerprint in this block and the image fingerprint to be registered has exceeded the threshold, so there is no similar image in this block, and the next block is directly queried.
-
(2)
. For originality detection, the number of searches , that is, the top image fingerprints in each block that are similar to the image fingerprint to be registered are queried. In this case, it is necessary to calculate the similarity distance between and one by one. If exists, the originality detection query fails and the registration is rejected. If there is no , then there is no approximate image in this block, and the query continues to the next block.
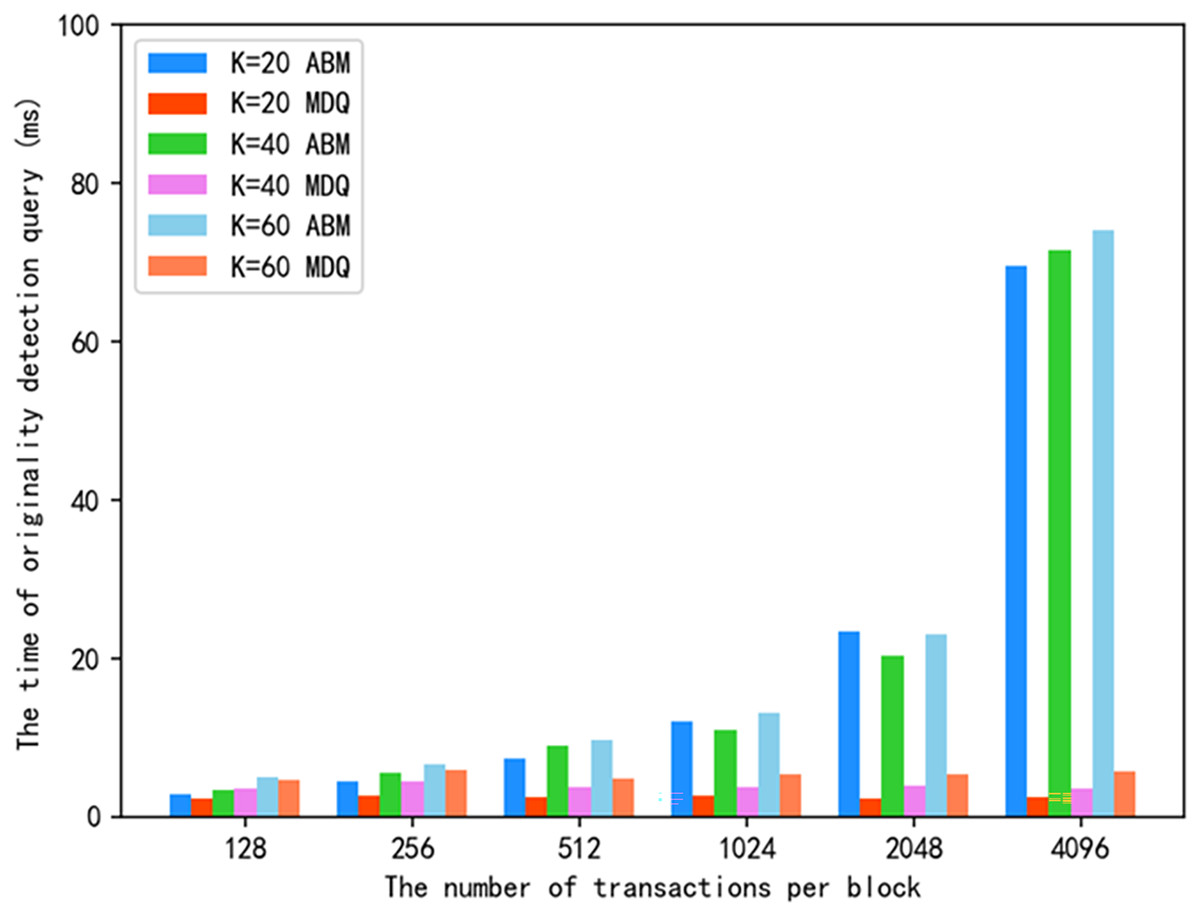
Figure 8: Originality detection query time under the same k value.
{kind=link}
When , it can query several approximate images, which is more accurate than . However, the method of range query on the MKD tree (that is, giving the similarity threshold and query target, retrieving the nodes that meet the threshold condition) needs to traverse all nodes, and the query efficiency is low. Considering several cases, is a compromise scheme, that takes into account both accuracy and query efficiency, and can be flexibly selected in specific applications.
The performance disparities observed between our MDQ scheme and the ABM scheme are not indicative of a flaw in the ABM approach, but rather highlight a fundamental mismatch between its design principles and the specific requirements of the originality detection task.
The ABM scheme is an efficient one-dimensional index, optimized for key-value retrieval. However, when tasked with a multi-dimensional similarity query, its underlying B+-Tree variant structure cannot leverage multiple feature dimensions to prune the search space. To satisfy such a query, the search process is compelled to traverse a substantial portion of its nodes to compute the multi-dimensional distance for each data point. This effectively neutralizes its indexing advantage for this specific task, causing its performance to scale in a manner that approaches the linear complexity of a full scan, which is consistent with the -like growth observed in our experiments.
In contrast, our MDQ scheme’s MKD-tree is a native multi-dimensional index. Its KD-tree foundation is specifically designed to partition the high-dimensional feature space. During a k-NN search, the algorithm can aggressively prune entire hyper-rectangles of the search space that are guaranteed not to contain any points closer than the current k-th nearest neighbor. This spatial pruning is the core mechanism that allows our scheme to maintain its theoretical average-case complexity. This deeper analysis underscores that for complex tasks like image copyright protection, a data structure that is natively aligned with the multi-dimensional nature of the data is paramount for achieving on-chain scalability.
Scheme comparison
Table 4 shows the comparative analysis between the proposed scheme and several other blockchain-based image copyright confirmation schemes. The schemes of Mehta et al. (2019) and Shi et al. (2020) adopted off-chain storage systems to save the image fingerprint and only stored the hash addresses of image files on the chain. Compared with the scheme in Agyekum et al. (2019) and our scheme in this article, this mode saves storage space on the chain, but it can only detect the originality of the copyright registration image through an exhaustive search, which has low query efficiency and cannot guarantee the tamper resistance of the image fingerprint. Both the scheme in Agyekum et al. (2019) and our scheme store image fingerprints on the chain and perform originality detection and query based on fingerprints, but the scheme in Agyekum et al. (2019) uses the block traversal method based on Merkle tree to search, and the query time is longer.
| Our scheme | Literature (Agyekum et al., 2019) | Literature (Mehta et al., 2019) | Literature (Shi et al., 2020) | |
|---|---|---|---|---|
| Fingerprint storage method | Transaction storage | Transaction storage | IPFS | IPFS |
| Originality query scope | On the chain | On the chain | Off the chain | Off the chain |
| Relying on specific fingerprints | No | Yes | Yes | Yes |
| Support multi-dimensional data query | Yes | No | No | Yes |
| Search pattern | MKD Tree search | Merkle Tree search | Exhaustive search | Exhaustive search |
| The criteria for originality | Similarity | Consistency | Similarity | Similarity |
Agyekum et al. (2019), Mehta et al. (2019), and Shi et al. (2020) all adopt specific image fingerprint generation methods (such as perceptual hashing, SIFT features, etc.), while our scheme does not rely on specific fingerprints. Different image fingerprints can be selected according to willingness or application requirements. Different from the determination of originality based on approximation, in Agyekum et al. (2019), to reduce the computational cost, the image fingerprint was determined to be non-original only when it was completely consistent, which reduced the accuracy of the determination of originality to some extent.
Discussion
This article proposes a novel and efficient scheme for blockchain-based image copyright registration, but there are still several promising research directions for the future. These directions aim to address issues such as the economics, accuracy, and privacy of the system.
(1) Economic cost and optimization analysis of on-chain operations
A significant avenue for future research is the quantitative analysis and optimization of the economic costs associated with on-chain operations. While this article focuses on temporal efficiency, the practical deployment of our system on public blockchains such as Ethereum necessitates a thorough investigation of the gas consumption for key operations, including MKD-tree construction, data insertion, and originality queries. We plan to conduct empirical analysis on a public testnet and explore optimization strategies, aiming to enhance the economic viability of the proposed framework.
(2) Integration of advanced AI fingerprinting for enhanced accuracy
To further enhance the accuracy and robustness of originality detection, we intend to investigate the integration of advanced, AI-driven fingerprinting techniques. The current framework is flexible, but perceptual hashes may be limited in detecting complex infringement scenarios like style transfer or semantic imitation. Future work will explore the use of feature vectors extracted from deep convolutional neural networks (DCNNs) as image fingerprints. Such deep embeddings are capable of capturing a higher level of semantic similarity, which would empower the system to identify a broader spectrum of copyright violations that go beyond mere visual resemblance.
(3) Privacy-preserving queries with zero-knowledge proofs
Another promising research direction lies in enhancing privacy through the integration of zero-knowledge proofs (ZKP). Although the blockchain ensures data integrity, the feature fingerprints stored in the public MKD-tree could potentially lead to information leakage, as a user might not want the features of their unreleased work to be publicly accessible. To address this, we will explore the application of ZKP technologies, such as zk-SNARKs, to enable privacy-preserving originality queries. In such a paradigm, a user could generate a cryptographic proof attesting that their new image’s fingerprint is not within a predefined distance of any existing fingerprint in the MKD-tree, without revealing the feature vector itself. This would solve the data privacy challenge in the registration process, representing a critical step towards a truly secure and trustless copyright protection system.
Conclusions
This article first analyzed the status quo of image copyright confirmation methods and the shortcomings of blockchain-based image copyright confirmation research, and designed a blockchain-based image copyright registration method that supports multi-dimensional data queries. The method uses the copyright registration blockchain to confirm the copyright of the data on the chain, reducing the cost of copyright confirmation, improving the efficiency of copyright registration, and ensuring the immutability of copyright data. It provides two copyright data query methods that can be used as needed. In addition, a block storage structure based on MKD tree is proposed, which supports multi-dimensional data retrieval and does not depend on specific image fingerprints. Based on this structure, an originality detection method is proposed, which improves the efficiency of copyright confirmation and guarantees the security of image fingerprints. Finally, an experimental analysis and scheme comparison of the originality detection query method were carried out, the effectiveness of the method was evaluated, and future research directions were discussed. Simulation results show that this method improves the query efficiency of originality detection in image copyright confirmation based on the blockchain.
Supplemental Information
The construction time of the block storage structure; The relationship between the number of searches and the query time consumption of originality detection when the number of transactions per block is 512, 1024, and 2048, respectively; The o.
The construction time of the block storage structure; The relationship between the number of searches and the query time consumption of originality detection when the number of transactions per block is 512, 1024, and 2048, respectively; The originality detection query time of the proposed scheme and ABM scheme for the same k value.