
Detection of false data injection in point-of-sale systems during credit card transactions using tuned deep learning models and oversampling techniques
- Published
- Accepted
- Received
- Academic Editor
- Paulo Jorge Coelho
- Subject Areas
- Computer Networks and Communications, Data Mining and Machine Learning, Emerging Technologies, Real-Time and Embedded Systems, Security and Privacy
- Keywords
- Credit card, False data injection, Machine learning, Optimized algorithm, Tuned model, Point of sale, Attack detection, Attack prevention, Bayesian optimization, Hardware attack
- Copyright
- © 2025 Jhansi Ida and Balasubadra
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Detection of false data injection in point-of-sale systems during credit card transactions using tuned deep learning models and oversampling techniques. PeerJ Computer Science 11:e3279 https://doi.org/10.7717/peerj-cs.3279
Abstract
Background
False data injection attack (FDIA) occurs during credit card transactions at point-of-sale systems (POS). FDI increases in POS due to free WIFI access at sales counters. FDIA occurs through novel hardware attacks such as side channel, readout-bypass, and control flow attacks. The false data injection in POS leads to a data breach and financial loss to the customer and the seller/credit card owner.
Method
To solve the above problem, we have developed architecture-tuned deep learning models such as random search (RS), artificial neural network (ANN), Bayesian optimized (BO), convolutional neural network (CNN), long short term memory (LSTM), Hyperband (HB), Autoencoder (AE). Moreover, tuned architecture model access is increased through oversampling methods such as random oversampling (ROS), synthetic minority oversampling (SMOTE), adaptive synthetic sampling (ADASYN), synthetic minority oversampling for nominal and continuous features (SMOTENC), and Borderline SMOTE (BL-SMOTE). BO-CNNLSTM model with SMOTE detects FDIA attack quickly and correctly to reduce overfitting of data through optimizing the number of hidden units of the LSTM model.
Results
Hence, the proposed BO-CNNLSTM model achieves an accuracy of about 98%, a precision of about 94%, a recall of about 96%, and an F1-score of about 96%.
Introduction
Recently, credit card fraud increases due to the growth in digital transaction and free WIFI access at various sales counters such as malls, theatre, and hospital. Credit card fraud leads to financial losses for seller and credit card owner. The different types of credit card fraud are card-not-present (CNP) fraud, credit card application fraud (CCAF), account takeover, credit card skimming, and lost or stolen cards. In CNP fraud, scammers steal cardholder’s personal information and used for purchase. CNP fraud prevention is difficult because there is no physical card-based transaction during purchasing. CCAF fraud is undetected until the person checks his credit report because scammers use stolen credit card holders’ personal information such as name, address, birthday, and social security numbers for applying the credit cards. CCAF damages to the cardholder’s credit score. Account takeover fraud is defined as scammers directly contacts the credit card companies and changes the cardholder’s passwords and PIN numbers. Scammers handle the account until the cardholder logs for next to purchase. In credit card skimming, skimmers attach a magnetic strip to the back of the credit card and steals the credit card information. The skimmers sell the credit card information to other scammers. Lost or stolen credit card fraud is using the stolen/lost credit card.
Credit card attacks refer to unauthorized access or fraudulently using credit card information. Credit card attacks are carding, phishing, data breaches, carding bots, card testing, and bin attack. In carding (Peretti, 2008) refers to the usage of stolen credit card information for unauthorized access or purchase. Phishing attackers sends a fake message to the cardholder and gets credit card numbers and passwords. Phishing attack (Parvesh et al., 2023) is prevented through 2-step verification when the credit card number is entered for online transaction. Credit card data breach occurs due to access of card by an unauthorized person. The data are name, address, card number, expiration date, and CVV number (Agarwal & Usha, 2023). The credit card data breach is avoided through secure and frequent update of password, two-step authentication, automatic reissuing the credit card, when the card meets a lower social cost (Graves, Acquisti & Christin, 2018), and freezing the credit card due to unauthorized transactions. Carding bots are automated programs or scripts, which test bulk credit card numbers on e-commerce sites and identifies the valid credit card number and used for unauthorized purchases without manual verification (Alarfaj et al., 2022). A bank identification number (BIN) attack is an act of guessing the combination of credit card number, card verification value, and expiry date using brute force computing. Brute force computing will directly target the bank identification number.
Credit card server attack is the unauthorized access to the servers, systems, or networks, while processing or storing credit card information. There are some common types of credit card server attacks such as SQL injection attacks, distributed denial of service attacks (DDoS), man in the middle (MiTM) attacks, data interception, brute force attacks, server exploits, remote code execution, malware and rootkits, and insider threats. An SQL injection attack allows an attacker for interaction with the database, steals or deletes the information (Crespo-Martínez et al., 2023). In DDoS attack, overload the network or server with traffic and interrupt the payment processing on the server (Hasan et al., 2023). The MiTM attack attacker interrupts the communication between the client and server, accesses the credit card details during the transaction. A data interception attack indicates unauthorized access to the credit card details. There are three different methods of data interception such as direct observation, interception of data transmission, and mechanical interception. Server exploit server software programs misconfigure the unauthorized credit card data stored. An attacker executes malware code, such as keyloggers or rootkits, and provides backdoor access to attackers.
FDI is called as data tampering attack. An attacker injects false data into the system or database. FDI occurs in point-of-sale terminals, payment gateways, and databases. Attacks change the amount of the transaction and payment method, and redirect funds to their accounts. During an online transaction, the attackers interfere with the confirmation page or email receipt and redirect the payment to their account. Attackers may cause a denial of service by injecting false data into the system, which leads to financial losses. False data is injected into account balances. This attack leads to credit and permits unapproved transactions. Attackers inject false data into chargebacks, which leads to financial losses for card holders and creates problems for card holders.
People have lost billions of dollars because of fraudulent transactions. People purchase things through online, they pay their bills through online. and conduct their banking transactions online as well. Increase in online business leads to an increase in online fraud. Online rule-based systems are used for detection of online fraud. The systems detect fraud through handcrafted rules by human specialists. The rule-based system detects static, fraudulent behavior in people. However, Amazon Web Services offers an online fraud detection system via Amazon Sage Maker. Amazon Sage Maker effectively creates a dynamic, self-improving, and maintainable fraud detection system. To detect anomalies, Amazon Sage Maker employs an unsupervised Random Cut Forest (RCF) unsupervised learning algorithm. To make predictions, the model employs the XG Boost model. The RCF model gives a low score to normal transactions and a high score to fraudulent transactions. To address highly unbalanced data, a Sage maker Boost model is used, which access synthetic minority oversampling. Amazon Sage maker needs data scientist to train the model to detect fraud.
Online retailers such as Amazon use different type of techniques for credit card fraud detection. Credit card attack prevention methods are secure websites, multi-factor authentication (MFA), account monitoring, address verification, payment verification, machine learning algorithms, location tracking, seller verification, two-step verification, and phishing awareness. Amazon has secure socket layer, which ensure secure data transmission. Amazon provides a one-time passcode, password for account protection and monitors unusual user account behaviour. Amazon provides billing address verification and payment verification to credit card holders through transferring of small amount. Amazon detects fraudulent transactions and tracks their location in unfamiliar areas using a predefined machine learning algorithm. Amazon verifies transactions from third-party sellers. Amazon provides phishing awareness to customers to identify fraudulent emails or websites.
The credit card is used in different methods such as card chip insertion, tap to pay, card swipe, and manual entry. During the transaction, the cardholder details are verified through application identifiers (AID), the cardholder verification method (CVM). The card details are encrypted and sent through the payment gateway to route them to the appropriate payment processor. The payment processor checks the initial six or eight digits of the card or account range to decide the services such as the transaction details. The processor, along with the payment switch, is responsible for determining the card network, routing the transaction, and sending the right message format. Fraudulent transactions are detected through the payment gateways such as PayPal, Amazon Payment, and Google Pay. However, payment gateways provide limited fraud detection techniques which are vulnerable to attack. Normally, Attacks happen in any card reader machine (i.e.,) point-of-sale system (POS), when longer time required for processing the transaction through the payment gateway.
The client swipes the card through the POS system. The POS system is linked to Wi-Fi network. The payment gateway gathers and transmits transaction information to the merchant’s bank’s computer control system. Through credit card interchange (CCI), the bank processor forwards the verification process, such as processing, clearing, and settlement. The CCI sends the information to the credit card provider’s computer control system. Based on the available funds on the credit card, the card provider accepts or rejects the transaction and sends the transaction details back to the CCI. The CCI sends the information back to the merchant computer control system. The merchant computer control system sends transaction information to the payment gateway. The payment gateway sends transaction information to the client via the POS system. CCI transfers the required funds via merchant bank account. As a result, Fig. 1 shows the overall processing of a credit card transaction. The different hardware attacks on the microcontroller of the POS system are side channel attack (SCA), read-out protection bypass attack (RB), and control flow manipulation (CFM) attacks lead to false data injection. To avoid these problems, attacks detected earlier through deep learning and machine learning techniques. Early detection attacks need to be detected and prevents attacks in POS. The POS is vulnerable to attack due to free WIFI access to the customers in the sales counters. Attack uses the free WIFI access to steal the information during credit card transactions.
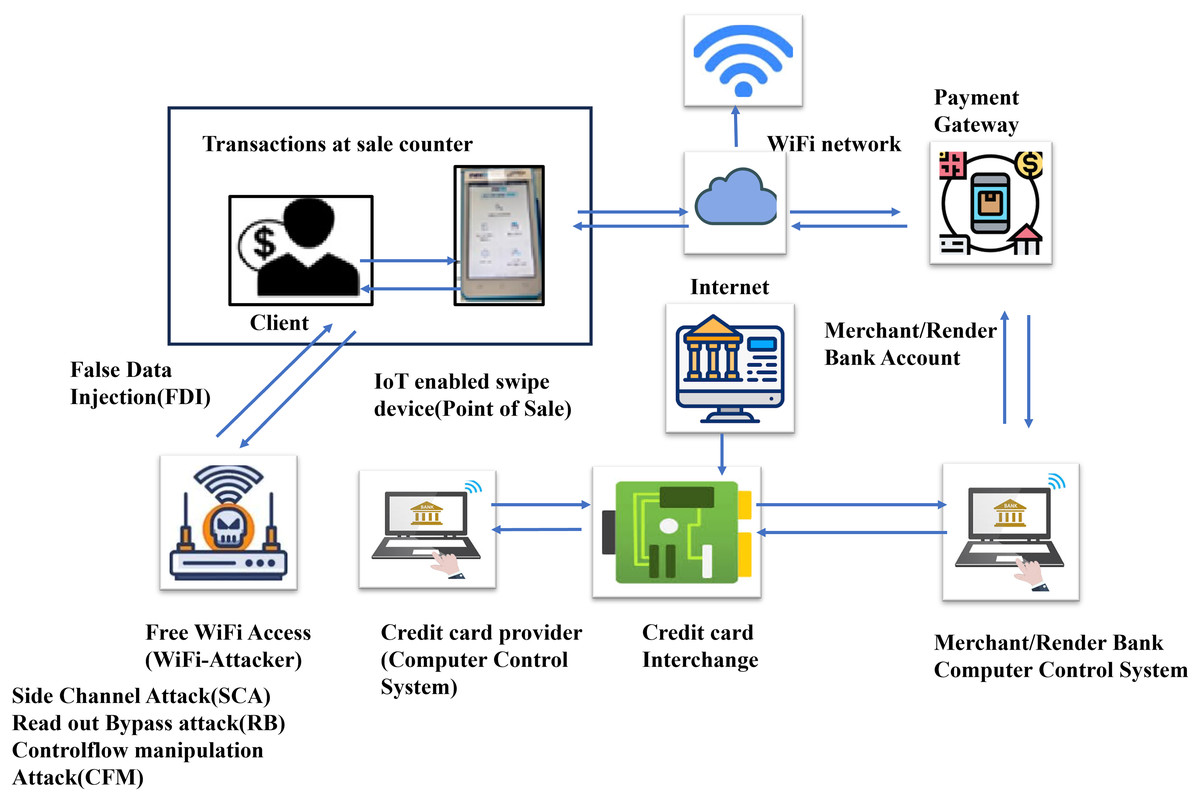
Figure 1: Credit card processing and WIFI attack.
{kind=link}
Attack scenario in POS system during credit card transaction
To validate the robustness and security of detecting FDI attacks in POS systems, scenario testing was performed by altering Control Flow Manipulation Side Channel Attack and changes in RAM.
Control flow manipulation attack
The attacker injects malicious code, such as unauthorized scripts, into the POS application software through the cloud interface or insecure update mechanisms. This malicious code allows unauthorized access to sensitive information, such as payment credentials and user details. The scenario highlights the necessity for secure application update channels, input validation, and software integrity verification to mitigate control flow manipulation attacks.
Side channel attack
An EMI probe was used to capture electromagnetic signals during transaction processing. These signals were analyzed and converted into binary sequences. The Luhn algorithm was then applied to reconstruct valid credit card numbers. The unshielded POS hardware produce information leakage through side-channel emissions. This SCA attack gives the importance of electromagnetic shielding and physical layer defenses in POS hardware design.
Readout bypass attack
In this scenario, attackers attempt to retrieve unencrypted credit card data by bypassing normal readout protections. A magnetic stripe reader was used to acquire Track 1 and Track 2 data from swiped cards. RAM scraping techniques were applied to extract in-memory transaction data during real-time operations. Consequently, the absence of runtime encryption or data tokenization allows sensitive information to be extracted through memory dumps. This scenario validates the need for implementing runtime encryption, secure memory management, and tokenization to protect volatile transaction data.
Research gap
The vulnerabilities in POS devices are design flaws, inadequate security measures, and the inherent characteristics of embedded systems. Key vulnerabilities need to be addressed are the lack of robust security measures (Noora & Vinila Jinny, 2023), out-of-band signal injection attacks (Giechaskiel & Rasmussen, 2019), debugging and fuzzing gaps (Eisele et al., 2022), hardware imperfections, and insufficient update mechanisms (Visinescu, 2021). Among the above, major problem in POS system is the insufficient update mechanisms. POS devices lack in proper mechanisms for firmware updates, leaving them vulnerable to known exploits. The attacks exploit vulnerabilities in the conversion process of physical signals to analog properties, which cannot be authenticated. Such attacks can manipulate sensor measurements and leads to significant security risks. The literature on these types of attacks is still developing, indicating a need for further understand their implications and defences. Moreover, the dataset of POS has limited number of fields and entries which lead to the unbalanced data. The unbalanced data leads to inaccurate prediction of attacks.
Contributions
POS Device attack detection during transaction of credit card using WiFi Network.
-
(1)
To detect FDI in POS through attacks such as, (i) side channel attacks (ii) readout by pass attacks (iii) control flow manipulation attack. Synthetic data set is created which contains POS based data such as running time, number of memories accessed, packets transmitted, and voltage glitching.
-
(2)
To balance the unbalanced data, the following algorithms are processed such as (i) random oversampling (ROS), (ii) synthetic minority oversampling (SMOTE) (iii) adaptive synthetic sampling (ADASYN) (iv) synthetic minority oversampling for nominal and continuous features (SMOTENC) (v) Borderline SMOTE, which improve the detection accuracy of attacks.
-
(3)
To detect false data injection in POS through proposed fine-tuned deep learning architectures such as (i) random search artificial neural network (RS-ANN), (ii) Bayesian optimized-convolutional neural network long short-term memory (BO-CNNLSTM), (iii) hyperband-autoencoder (HB-AE).
To evaluate the performance of the proposed method using metrics such as robustness to perturbations (RTP), impact on system accuracy (ISA), mean time to detect (MTD), false data injection detection rate (FDIDR), false alarm rate (FAR), precision, recall, F1-score, and accuracy.
The article is structured as follows: The literature review is discussed in Literature Survey section. The suggested methodology was explained in Materials and Method section. The results and discussions are presented in the Results section. The conculsions are presented in the Conclusion section.
Literature survey
POS attacks are classified into three types such as keyloggers, memory dumpers, and network sniffers. Retail transactions are performed through POS systems. Attacker steals personal information from electronic payment cards, such as debit and credit cards during transaction through POS. False data injection are defined as injecting false data into the system leads to financial loss and physical infrastructure damage. FDI in POS machine is performed through hardware attack i.e., microcontroller during transaction time. FDI is performed through side channel attacks where private keys from the POS physical are stolen and false data injected into the POS machine. Readout bypass protection attack bypasses read out protection mechanism in POS machine and inject false data into the machine. Control flow manipulation attack manipulates control flow in POS, runs arbitrary code and inject false data.
Table 1 depicts the various types of attacks and their detection techniques in various hardware systems such as microcontrollers and smart grid systems using machine learning and deep learning models.
| Reference | Attack type | Methodology | Pros | Cons | Remarks |
|---|---|---|---|---|---|
| Li & Ou (2023) | Side channel attack | Deep learning | Detects circuit changes | Overfitting | Cannot prevent false data injection (FDI) |
| Ni et al. (2023) | Side channel attack | CNN | Real-time detection | Low sensitivity | Useful in real-time scenarios |
| Le et al. (2021) | Electromagnetic-side channel attack | CNN + Random forest | Hardware specificity | Sensitive to noise and variability | Electromagnetic noise impacts accuracy |
| Kwon, Hong & Kim (2022) | Side channel attack | Timon deep learning model | High speed | High true negatives may miss positives | Efficient but potentially unbalanced |
| Hu, Wang & Wang (2022) | Trace multiple leakage points | Multi-input deep learning | Improved accuracy | Noise presence acknowledged | Robust in noisy environments |
| Huang, Li & Ding (2022) | False data injection | Finite-time fuzzy observer | Rapid detection in finite time | Cannot detect FDI via side channels | Based on Takagi-Sugeno fuzzy model |
| Acharya et al. (2022) | False data injection | Defense in charging stations | Enhances security | Limited domain | Designed for EV charging systems |
| Nawaz et al. (2021) | False data injection | Linear regression | Topology-independent | Not suitable for PoS attacks | Attacks are network topology-based |
| Dehghani et al. (2021) | False data injection | Wavelet singular entropy (WSE) | Fast and accurate detection | Limited to AC systems | Effective in alternating current applications |
| Yu, Bu & Hou (2022) | DA and FDIA | Model-free adaptive controller (MFAC) | Secure in nonlinear systems | Doesn’t support linear systems | Designed for nonlinear control systems |
| Ünal et al. (2021) | FDI in smart grids | Big Data + ML/DL | Supports non-technical losses | High computational demand | Applicable to smart grid distribution level |
| Dong, Gupta & Chopra (2020) | FDI in BTOSs | Physics-based detection with encoding-decoding | Detects destabilizing attacks | Domain-specific | For bilateral teleoperation systems |
| Mohammadi et al. (2022) | FDI in P2P energy trading | Instance-based ML classifier | Transparent decisions | Model complexity | Tailored for energy trading platforms |
| Guibene et al. (2024) | FDI in industrial CPS | Anomaly detection + sequential pattern mining | Efficient detection | Requires pattern history | Supports cyber-physical system security |
| Takiddin et al. (2023) | FDI in smart grids | GNN + Convolutional recurrent graph autoencoder | Captures spatiotemporal correlations | Complex training | Detects in large smart grid infrastructures |
| Ruan et al. (2023a) | FDI in smart grids | Spatiotemporal graph deep learning (STGDL) | Captures spatiotemporal features | Training and data dependency | Enhances spatial-temporal detection capabilities |
| Ruan et al. (2024) | Adversarial learning attack | Deep learning with gradient descent | Selects optimal features | Susceptible to adversarial examples | Targeted at renewable energy forecasting |
| Ruan et al. (2023b) | False data injection | Deep learning | Captures spatial features | Generalization risk | Designed for smart grid data anomalies |
| Naderi & Asrari (2023) | False data injection | Deep learning | Economic gains for retailers | Limited scalability | Applied to wind turbines, smart homes, etc. |
| Naderi, Aydeger & Asrari (2022) | False data injection | MLP with Levenberg-Marquardt optimization | Optimized feature capture | Requires tuning | Useful in distributed networks |
Materials and Methods
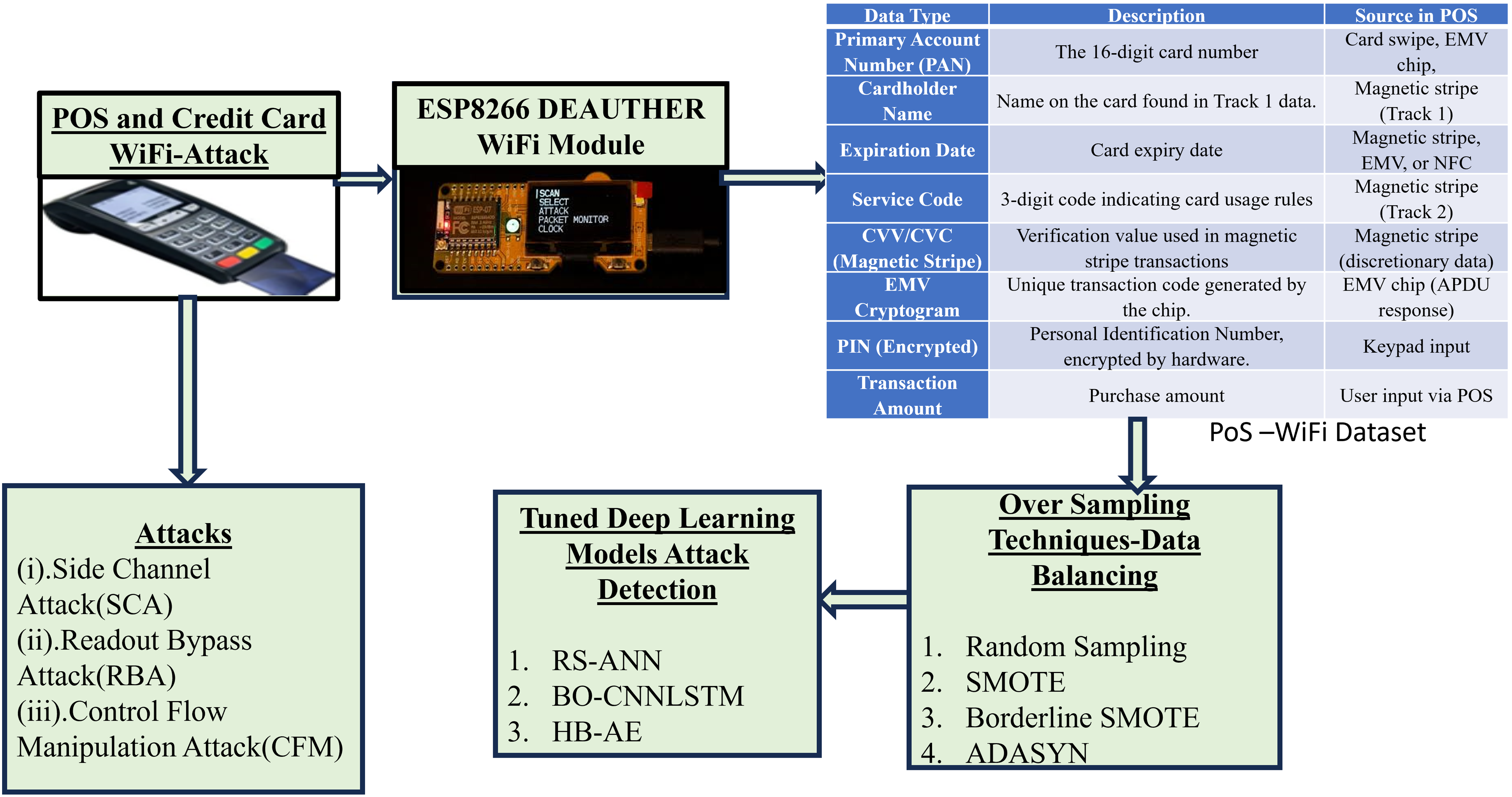
Hardware attack in PoS system is shown in Fig. 2 and proposed detection methods to detect the FDI attack are shown in the Fig. 2. Wi-Fi attacker injects false data into the microcontroller of swiping machine through free WIFI access. WIFI attacker alters the voltage, and power consumption in microcontroller of PoS through SC, RB and CFM. During false data injection, time delay occurs in payment gateway of PoS. Moreover, the time delay occurs at merchant bank/computer control system. An attacker uses time delay to steal the information from computer control system. The transaction log stores all transaction details. Hence, we proposed tuned deep learning-based model to analyse the transaction log details. To avoid unbalanced data oversampling techniques are combined with tuned deep learning models to detect FDI.
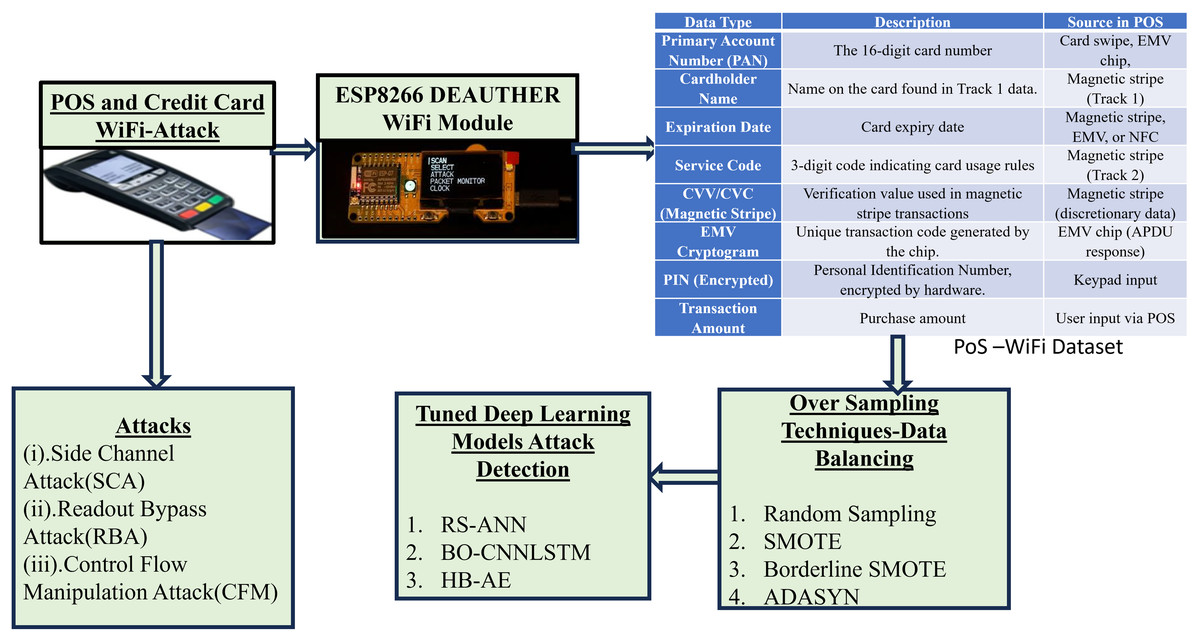
Figure 2: Hardware attack in POS and proposed detection methods.
{kind=link}
POS-Wi-Fi dataset for hardware attack detection
The dataset (Kaggle, 2013) is collected form the POS, after hardware attack is performed through ESP8266 DEAUTHER WIFI MODULE. The collected dataset is termed as POS-Wifi dataset. The dataset contains various fields such as distance from home, distance from last transaction, ratio to media buy price, repeat retailer, used chip, used pin number, online order, and fraud. The dataset includes behavioural transaction analysis along with hardware statistics such as voltage changes, running duration, power consumption, number of packets delivered, and memory accesses. The dataset contains 10 lakh entries and 70% dataset are used for training and 30% of dataset is used for testing. The datatype and field descriptions are described in Table 2.
| Fields | Description | Datatype |
|---|---|---|
| Distance from home | Location of transaction | Numeric |
| Distance from last transaction | Location of last transaction | Numeric |
| Ratio to median purchase price | Ratio of purchased price to median price | Numeric |
| Repeat retailer | Transaction performed from same retailer | Binary |
| Used chip | Card present/not present | Binary |
| Used pin number | Pin number in card usage | Binary |
| Online order | Online purchase | Binary |
| Running time | Time taken to run software program | Numeric |
Balanced to unbalanced data—oversampling technique
Oversampling techniques are applied to balance the imbalanced data through augment number of instances in the minority classes. The difference in class distribution leads to less prediction accuracy for minority classes. To improve the detection accuracy in FDI minority classes are balanced through oversampling techniques such as (i) ROS (ii) SMOTE (iii) ADASYN (iv) SMOTENC and (v) Borderline SMOTE.
Random oversampling (ROS) balances the imbalance class through replicating data from the minority class. ROS improves the performance of machine learning models through increasing the number of samples in the minority class in the dataset. Moreover, ROS causes overfitting in the data and adds noise into the dataset. The procedure is repeated indefinitely, until distribution of the majority and minority classes are balanced. ROS selects instances from the minority class and adds to the imbalance dataset. ROS is as in Eq. (1).
(1)
In unbalanced datasets, SMOTE is used to balance the distribution of classes. Synthetic instances from the minority classes are produced through SMOTE. The feature vectors of nearby instances are interpolated and constructs the artificial examples. By providing more representative training data for the minority class, SMOTE helps machine learning algorithms to perform better on imbalanced datasets. To generate artificial examples in the feature space, the algorithm selects random sets from the minority class and determines the nearest neighbour value. Equation (2) represents the mathematical formula for the SMOTE distance used for creation of samples between the k nearest neighbours and the total number of observations.
(2)
ADASYN creates minority data samples in an adaptive manner according to the degree of learning required. ADASYN calculates the density of minority classes through learning their lower density. Hence, ADASYN generates more synthetic samples through low-density minority classes and reduces the bias through balance the classes. Equation (3) computes the density of the minority class.
(3)
The ratio of minority samples is computed within the ‘k’ nearest neighbour range. Equation (4) calculates the degree of difficulty associated with learning from each feature vector for the minority class.
(4)
Equation (5) is used to generate number of samples in minority classes.
(5)
In Eq. (5), difference = number of majority samples – number of minority samples.
Nominal and continuous data are balanced through SMOTENC. SMOTENC is used for encoding categorical variables. SMOTENC generates categorical samples through one-hot encoder. SMOTENC creates minority classes through preserving the relationship between categorical and numerical features.
Borderline SMOTE is used to generate samples, which is close to the decision boundary. The closest neighbour belongs to the minority class and the borderline instance within the minority class are interpolated for creation of the sample data to balance. Borderline SMOTE attempts to improve the decision boundary and raise minority sample classification accuracy based on borderline cases. Equation (6) generate the data to balance the dataset.
(6)
Further, the unbalanced data is converted to balanced data and fed to the tuned layers.
Tuned architecture for credit card fraud detection
Tuned architecture for credit card fraud detection are (i) RS-ANN (ii) BO-CNNLSTM (iii) HB-AE. Figure 3 shows the tuned deep learning architecture for credit card fraud detection. The fine-tuning models save time and resources, lower data requirements, handle data scarcity, provide superior performance, and provide access to unavailable domains. Figure 3 shows the layer tuned architecture for credit card fraud detection.
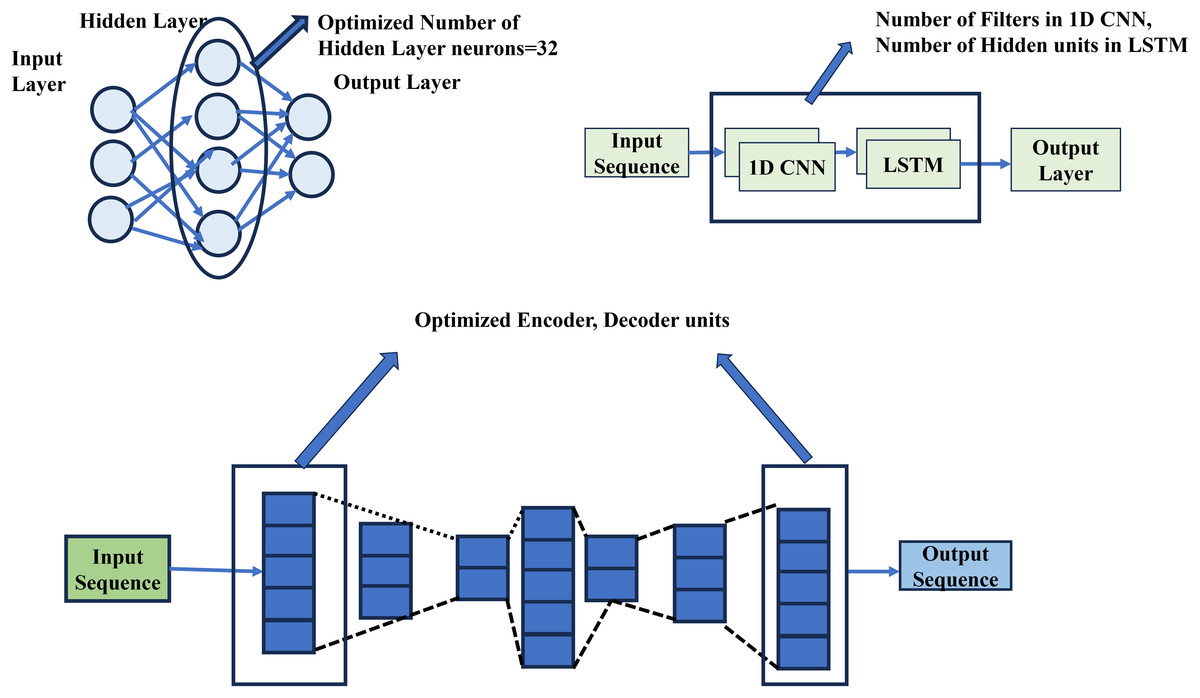
Figure 3: Layer tuned architecture.
{kind=link}
The credit card dataset is imbalanced, with only 0.2% of transactions being fraudulent. This imbalance leads to reduced accuracy and increases the risk of overfitting. To address this issue, oversampling techniques are applied to balance the dataset. Attackers frequently change their tactics for credit card fraud, making real-time detection challenging. Therefore, optimized deep learning models, such as RS-ANN, BO-CNN, LSTM, and HB-AE, are used for credit card fraud detection. Table 3 presents the tuned parameters of the optimized deep learning model and their impact on false data injection through PoS hardware.
| RS-ANN | BO-CNNLSTM | HB-AE |
|---|---|---|
|
|
|
|
|
|
|
|
|
Results
The dataset variables such as running duration, power consumption, memory access, voltage glitching, kind of fraud, distance from home, distance from the last transaction, ratio of the median purchase retailer, repeat retailer, used chip, used pin number, and online order.
Performance metrics of FDI
The following metrics are used to analyse the performance of false data injection attacks such as true positive, false positive, true negative, false negative, precision, recall, F1-score, accuracy, robustness to perturbations (RTP), impact on system accuracy (ISA), mean time to detect (MTD), mean time to recover (MTR), and false data injection detection rate (FDIDR). The metrics are represented from Eqs. (7)–(16)
(7)
(8)
(9)
(10)
(11)
In Eqs. (7), (8), (9), (10) and (11), TP, TN, FP, FN is represented as follows
True Positive (TP) = Model correctly identifies the number of injected false data as false.
False Positive (FP) = Model incorrectly identifies the correct data as false data.
True Negative (TN) = Model correctly identifies the correct data as true.
False Negative (FN) = Model incorrectly identifies injected data as true.
False data injection detection rate (FDIDR) is used to identification of the injected false data correctly through proposed system. FDIDR is as in Eq. (12).
(12)
False alarm rate (FAR) measures the system and identification erroneous data inaccurately. A high false alarm rate suggests that the data are missing. FAR is computed with the use of Eq. (13).
(13)
Impact on system accuracy (ISA) is as in Eq. (14), which illustrates how accuracy is measured before and after an injection attack.
(14)
Mean time to detect (MTTD) is the average time to detection for an attack MTTD is as in Eq. (15).
(15)
Robustness to perturbations (RTP) calculates how variations in input parameters affect the system’s efficiency. The RTP is shown in Eq. (16).
(16)
Analysis of unbalanced data with and without tuned deep learning architecture
Performance analysis of unbalanced data without tuned layers of deep learning architectures such as ANN, CNN-LSTM and Auto encoder are shown in Fig. 4 which detects the false data injection in PoS during credit card transaction. Credit card fraud detection dataset is divided into 70% training and 30% testing set. The layers are not tuned in deep learning architecture such as ANN, CNN-LSTM and AE. Hence, the above existing models have overfit during the training data. Training data achieves high accuracy, precision, recall value compared to testing data. From Fig. 5, the proposed BO-CNN-LSTM achieves better accuracy, precision, recall value compared to existing models, which captures long term dependencies of data and captures spatial and temporal features. Figure 5 shows the confusion matrix of unbalanced dataset through tuned deep learning model.
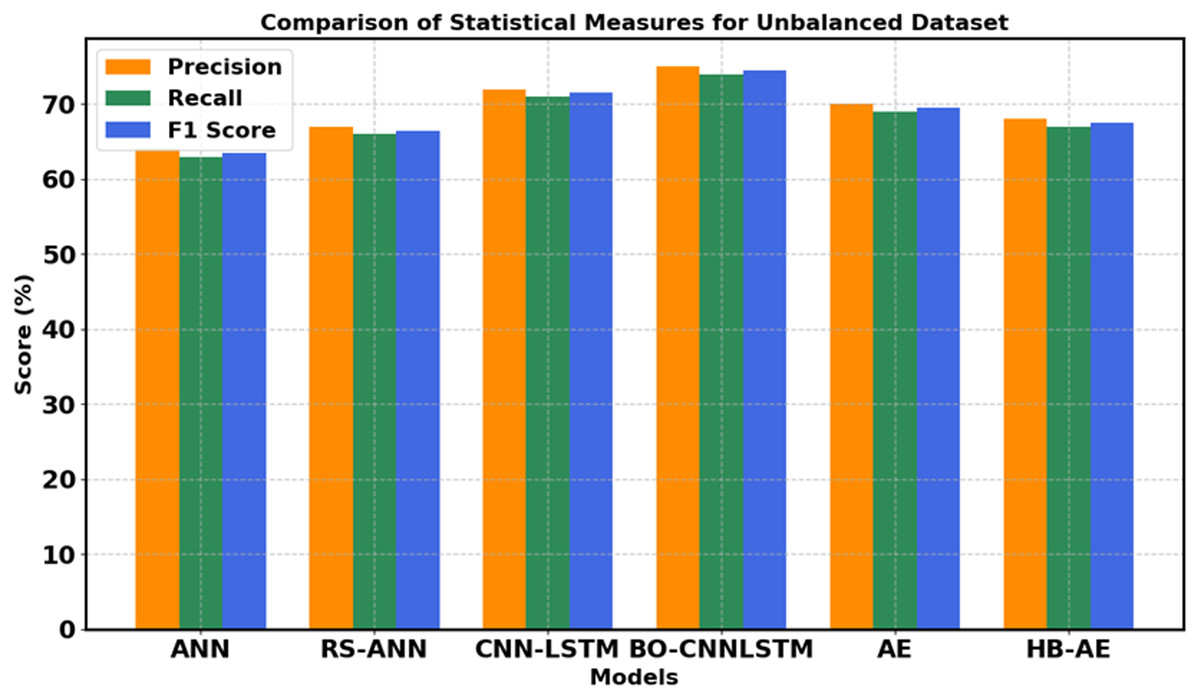
Figure 4: Performance analysis of unbalanced data with and without tuning layer of deep learning architectures.
{kind=link}
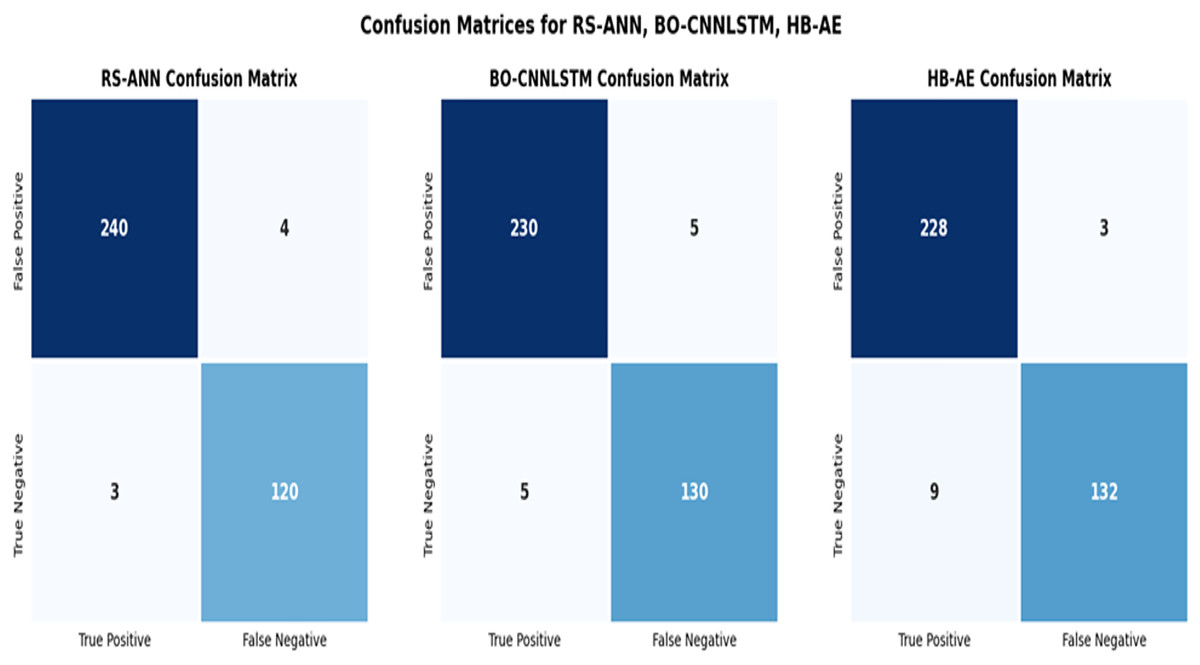
Figure 5: Confusion matrix for RS-ANN, BO-CNNLSTM and HB-AE.
{kind=link}
Performance analysis of balanced data with different oversampling techniques
Table 4 presents the performance analysis of data balancing techniques that increase minority samples through oversampling techniques, under sampling techniques, contrast-sensitive learning, generative adversarial networks (GAN), variational autoencoders (VAE), and ensemble learning. Among these techniques, SMOTE achieves the highest accuracy by increasing minority samples in credit card fraud detection without data loss.
| Method | Precision | Recall | F1-score | Accuracy | AUC-ROC | Interpretation |
|---|---|---|---|---|---|---|
| SMOTE (Oversampling (Albattah & Khan, 2025) | 0.94 | 0.96 | 0.96 | 0.98 | 0.98 | Improves minority class in credit card fraud detection without data loss. |
| ADASYN (Oversampling) (Albattah & Khan, 2025) | 0.94 | 0.95 | 0.945 | 0.95 | 0.95 | Generates adaptive samples and improves generalization on difficult cases. |
| Random undersampling (Albattah & Khan, 2025) | 0.78 | 0.81 | 0.79 | 0.83 | 0.80 | Low performance on imbalanced high-variance datasets. |
| Tomek links (Business Analytics Review, 2025) | 0.81 | 0.83 | 0.82 | 0.84 | 0.82 | Reduces class overlap near decision boundary |
| Class weighting (Business Analytics Review, 2025) | 0.84 | 0.87 | 0.85 | 0.89 | 0.88 | Duplication of data is not possible and achieves good balance of precision and recall. |
| Cost-sensitive learning (Business Analytics Review, 2025) | 0.88 | 0.89 | 0.885 | 0.91 | 0.89 | suitable for privacy |
| GAN-based augmentation (Jiang et al., 2025) | 0.89 | 0.92 | 0.90 | 0.94 | 0.93 | High-quality sample generation |
| VAE-based augmentation (Jiang et al., 2025) | 0.88 | 0.91 | 0.89 | 0.93 | 0.92 | Easier to train than GAN on tabular data. |
| CTGAN (Advanced GAN) (Jiang et al., 2025) | 0.91 | 0.93 | 0.92 | 0.96 | 0.94 | Superior for generating structured tabular data |
| SMOTE + Ensemble (RF) (Jiang et al., 2025) | 0.90 | 0.93 | 0.91 | 0.94 | 0.95 | Boosts generalization and reduces overfitting; slower inference due to ensemble strategy. |
The performance analysis of graph convolutional network (GCN) model in false data injection attack is compared with proposed hyperparameters tuned deep learning model. BO-CNNLSTM achieves highest detection accuracy due to the extraction of long-range dependencies in spatial and temporal relationship among the features in the credit card fraud dataset as in Table 5. Table 6 provides the overall performance analysis of all hyperparameter tuned deep learning model with different oversampling techniques.
| Model | Precision | Recall | F1-score | Accuracy | AUC | Robustness after FDI | Best oversampling method |
|---|---|---|---|---|---|---|---|
| RS-ANN | 0.87 | 0.88 | 0.89 | 0.94 | 0.80 | Poor (ROC ≈ 0.5) | Borderline SMOTE, ADASYN |
| HB-AE | 0.92 | 0.92 | 0.93 | 0.96.2 | 0.84 | ROC drops to 0.5 | SMOTENC, Borderline SMOTE |
| BO-CNN-LSTM | 0.94 | 0.96 | 0.96 | 0.98 | 0.98 | Excellent | SMOTE, SMOTENC |
| GCN | 0.89 | 0.91 | 0.90 | 0.95 | 0.93 | Variable (graph-sensitive) | GCN-SMOTE, GraphSMOTE |
| Model | Oversampling method | Precision | Recall | F1-score | Accuracy | Optimizer | Tuned parameters | Remarks |
|---|---|---|---|---|---|---|---|---|
| RS-ANN | RS (without oversampling) | 0.76 | 0.78 | 0.80 | 0.82 | Random search | 64 neurons, Dropout rate: 0.02 | Sensitive to noise and decreases the performance |
| SMOTE | 0.82 | 0.84 | 0.83 | 0.84 | Better balance due to limited temporal learning | |||
| SMOTENC | 0.84 | 0.85 | 0.87 | 0.86 | Good generalization | |||
| Borderline SMOTE | 0.85 | 0.86 | 0.86 | 0.87 | Performs well with minimal class overlap | |||
| ADASYN | 0.87 | 0.88 | 0.89 | 0.92 | Improves model Sensitivity and harder to learn the minority samples | |||
| HB-AE | AE (without oversampling) | 0.82 | 0.84 | 0.83 | 0.84 | Hyperband | Encoder/Decoder: 128 units | Performs better on false data |
| SMOTE | 0.84 | 0.84 | 0.86 | 0.88 | Good reconstruction capability | |||
| SMOTENC | 0.92 | 0.92 | 0.93 | 0.94 | Best performer among HB-AE combinations | |||
| Borderline SMOTE | 0.85 | 0.87 | 0.88 | 0.86 | Stable performance because learning the credit card transaction pattern near the class boundary | |||
| ADASYN | 0.76 | 0.78 | 0.80 | 0.82 | Drop in performance because of high complexity occurs due to autoencoder configuration | |||
| BO-CNNLSTM | CNNLSTM(Without oversampling) | 0.85 | 0.86 | 0.86 | 0.87 | Bayesian optimization | 64 Filters, 128 LSTM units | Strong even with basic oversampling |
| SMOTE | 0.94 | 0.96 | 0.96 | 0.98 | Best overall performance | |||
| SMOTENC | 0.92 | 0.92 | 0.93 | 0.94 | Balanced across metrics | |||
| Borderline SMOTE | 0.87 | 0.88 | 0.89 | 0.92 | Differentiate among class overlap and injection | |||
| ADASYN | 0.94 | 0.95 | 0.945 | 0.95 | Suitable for minority sample pattern learning |
The performance analysis of control flow attack detection scenario, side channel attack detection and read out bypass attack scenario is shown in Tables 7, 8 and 9. From all the above tables BO-CNN-LSTM with SMOTE oversampling techniques achieves highest accuracy in all PoS hardware attack scenario because BO-CNN-LSTM captures the complex temporal attack patterns such as command injection sequences, malicious code injection between payment authentication and logging, power consumption over time and memory access patterns.
| Model | Oversampling method | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) |
|---|---|---|---|---|---|
| RS-ANN | SMOTE | 89.4 | 85.7 | 86.9 | 86.3 |
| RS-ANN | BL-SMOTE | 90.1 | 86.3 | 87.8 | 87.0 |
| BO-CNNLSTM | SMOTE | 95.2 | 91.0 | 93.4 | 93.1 |
| BO-CNNLSTM | BL-SMOTE | 94.1 | 90.2 | 92.1 | 91.1 |
| HB-AE | SMOTE | 87.2 | 83.5 | 85.1 | 84.3 |
| HB-AE | BL-SMOTE | 88.4 | 84.6 | 86.0 | 85.3 |
| Model | Oversampling method | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) |
|---|---|---|---|---|---|
| RS-ANN | SMOTE | 87.5 | 84.0 | 85.6 | 84.8 |
| RS-ANN | BL-SMOTE | 88.3 | 84.6 | 86.1 | 85.3 |
| BO-CNNLSTM | SMOTE | 93.7 | 89.1 | 91.5 | 90.3 |
| BO-CNNLSTM | BL-SMOTE | 92.8 | 88.4 | 90.1 | 89.2 |
| HB-AE | SMOTE | 85.1 | 81.2 | 83.0 | 82.1 |
| HB-AE | BL-SMOTE | 86.4 | 82.3 | 83.9 | 83.1 |
| Model | Oversampling method | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) |
|---|---|---|---|---|---|
| RS-ANN | SMOTE | 88.1 | 84.3 | 85.9 | 85.1 |
| RS-ANN | BL-SMOTE | 89.0 | 85.1 | 86.5 | 85.8 |
| BO-CNNLSTM | SMOTE | 94.5 | 90.5 | 92.6 | 91.5 |
| BO-CNNLSTM | BL-SMOTE | 93.6 | 89.7 | 91.1 | 90.4 |
| HB-AE | SMOTE | 86.3 | 82.5 | 84.4 | 83.4 |
| HB-AE | BL-SMOTE | 87.4 | 83.6 | 85.1 | 84.3 |
Comparison of state-of-the-art methods
Table 10 shows the comparison of state-of-the-art techniques and their performance metrics. Table 10 provides the discussion about the detection of false data injection with the state-of the-art methods and proposed techniques.
| Methods | Statistical measure | Discussions |
|---|---|---|
| Generative adversarial network (Feng et al., 2024) | Precision-0.68 | Generator is unable to generate important part of data. GAN increases the training time |
| Recall-0.72 | ||
| F1-score-0.7 | ||
| Accuracy-0.7 | ||
| Spatial temporal transformer (Li, Hu & Lu, 2024) | Precision-0.75 | Needs high quality data to perform well. |
| Recall-0.68 | ||
| F1-score-0.71 | ||
| Accuracy-0.76 | ||
| Multigraph convolutional neural network (Han et al., 2023) | Precision-0.8 | Large number of graphs needs more computational resources. Computational cost is high. |
| Recall-0.78 | ||
| F1-score-0.78 | ||
| Accuracy-0.8 | ||
| LSTM autoencoder (Yang, Zhai & Li, 2021) | Precision-0.82 | LSTM autoencoders struggle to reconstruct the input data due to complex pattern. |
| Recall-0.76 | ||
| F1-score-0.79 | ||
| Accuracy-0.82 | ||
| RS-ANN (Proposed) | Precision-0.87 | RS-ANN is less adaptable, because does not learn the performance of previous model configuration. RS-ANN considers each hyperparameter is independent. |
| Recall-0.88 | ||
| F1-score-0.89 | ||
| Accuracy-0.92 | ||
| HB-AE (Proposed) | Precision-0.92 | HB-AE supports initial weight assignment. Hence, the initialization leads to poor performance in FDI detection due to convergence of local minima. |
| Recall-0.92 | ||
| F1-score-0.93 | ||
| Accuracy-0.94 | ||
| BO-CNNLSTM (Proposed) | Precision-0.94 | BO-CNNLSTM converges optimal solution at fast rate. Hence, proposed BO-CNNLSTM model performs well. |
| Recall-0.96 | ||
| F1-score-0.96 | ||
| Accuracy-0.98 |
Discussion
The performance metrics for BO-CNN LSTM, RS-ANN, and HB-AE models under false data injection attacks are shown in Table 11. In comparison to the other models, BO- CNN LSTM shows slightly greater robustness to perturbations in both the original and false injected data. When compared to the other models, the BO-CNN LSTM shows the highest FDIDR (perfect detection rate) and lower FAR, which indicates the superior detection performance. BO-CNN LSTM model reduces 0.2% detection accuracy after injecting false data into the PoS machine. BO-CNNLSM requires 15 min to detect the false data injection attack.
| Method | Fault data injection parameters | Values |
|---|---|---|
| RS-ANN | RTP original | 0.885 |
| RTP modified | 0.56 | |
| FDIDR | 0.7 | |
| FAR | 45.57 | |
| ISA | 0.8 | |
| MTD | 30 min | |
| BO-CNN LSTM | RTP original | 0.9 |
| RTP modified | 0.57 | |
| FDIDR | 1.0 | |
| FAR | 4.06 | |
| ISA | 0.2 | |
| MTD | 15 min | |
| HB-AE | RTP original | 0.905 |
| RTP modified | 0.56 | |
| FDIDR | 0.6 | |
| FAR | 10.5 | |
| ISA | 0.4 | |
| MTD | 25 min |
Conclusions
POS hardware attack increases of false data injection attacks (FDIA) in credit card transactions. A rise in data breach vulnerabilities leads to financial losses, business interruptions, and reputational damage to companies. These attacks manipulate transaction data through taking advantage of hardware defects such as side-channel, readout bypass, and control flow weaknesses to change transaction amounts or steal personal data. To detect the attack, we propose hybrid artificial intelligence techniques such as machine learning and deep learning models into the POS machine dataset analysis. The innovative proposed models are BO-CNN-LSTM RS-ANN and HB-AE, which detects FDI in POS machine during transaction. The proposed models perform better than traditional models. BO-CNN-LSTM model performs well when combined with SMOTE, quickly and precisely identify fraudulent transactions and FID. However, the proposed tuned deep learning models with oversampling techniques achieved high accuracy of about 98%, precision of about 94%, recall of about 96%, and F1-score of about 96%. In the future, we will extend our model to detect FDI attacks in POS systems. We will utilize characteristics inspired by the Stuxnet worm, a modular malware that targeted industrial control systems. Stuxnet employed zero-day exploits and altered system behavior without detection. Therefore, we have developed a method to detect hidden and complex FDI threats similar to those used by Stuxnet in side channels and RAM memory.
Supplemental Information
Program file.
Script for loading, preprocessing, and oversampling credit card fraud data using BorderlineSMOTE.
Program File.
Python code defining and tuning an ANN model with Hyperband, optimizing units and dropout for fraud classification.
Program File.
Program for training tuned ANN models, computing performance metrics (accuracy, AUC, PR-AUC), and exporting evaluation results to Excel.
Program File.
Script for training the best-performing ANN model and generating performance visualizations including accuracy/loss curves and confusion matrices.
Program File.
Workflow comparing oversampling methods (SMOTE, ADASYN, Random Oversampling, BorderlineSMOTE, SMOTENC) on original and false-data-injected datasets, with visualization of accuracy, PR-AUC, and ROC curves.
Dataset for Credit Card Transaction.
Records of transactions made at physical or online retail locations. It includes features like transaction amount, merchant details, cardholder information (masked for privacy), payment method (chip, swipe, or online), and fraud indicators.