
Deep feature fusion for melanoma detection using ResNet-VGG networks with attention mechanism
- Published
- Accepted
- Received
- Academic Editor
- José Manuel Galán
- Subject Areas
- Adaptive and Self-Organizing Systems, Algorithms and Analysis of Algorithms, Artificial Intelligence, Data Mining and Machine Learning, Neural Networks
- Keywords
- Melanoma detection, Skin lesion classification, Deep learning, Channel attention, Spatial attention
- Copyright
- © 2025 Naeem et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Deep feature fusion for melanoma detection using ResNet-VGG networks with attention mechanism. PeerJ Computer Science 11:e3248 https://doi.org/10.7717/peerj-cs.3248
Abstract
Skin cancer, especially melanoma, the most severe type, has increased in recent decades. Identifying skin carcinoma infection is important to improve treatment outcomes and patient survival. However, accurate identification of skin lesions remains problematic due to the large variability and heterogeneity of the source material, especially lesion characteristics, even though significant progress has been made in computer vision. To overcome these challenges, this study proposes the channel and spatial attention-based hybrid model (CA-SLNet), which combines the architectures of residual network-50 (ResNet50) and visual geometry group-16 (VGG-16) with updated attention mechanisms. It applies channel attention to enhance the important feature maps and spatial attention to illuminate the important area in the feature. CA-SLNet was evaluated on three dermatological benchmark datasets, ISIC-2016, ISIC-2017, and Ph2. The proposed model achieved an accuracy of 98.59%, 96.80%, and 99.50% for the ISIC-2016, ISIC-2017, and Ph2 datasets and high area under the curve (AUC) values. The proposed model is compared with state-of-the-art methods and emphasizes the robustness and precision of the model in differentiating between benign and malignant lesions. Although slightly more false negatives were observed in the ISIC-2017 dataset, the model’s overall performance proves its suitability for clinical application. CA-SLNet provides a reliable solution for early and accurate melanoma detection by effectively integrating complementary features and minimizing noise and redundancy.
Introduction
Melanoma, the most malignant skin cancer, is a global health challenge due to its rapid progression, high metastatic potential and high mortality rate. The human skin is the human body’s largest organ (Iravanimanesh et al., 2021; Wang et al., 2025). It is responsible for more than 75% of annual skin cancer-related deaths, underscoring the need for early detection and intervention (Hosny & Kassem, 2022). While early-stage melanoma is highly treatable through surgical removal, late-stage cases often metastasize, resulting in poor survival rates and increased healthcare costs (Cassidy et al., 2022; Jojoa Acosta et al., 2021). Dermoscopy, a non-invasive imaging technique, has become indispensable for skin cancer diagnosis as it provides high-resolution images that improve the detection of malignant tumors (Sufia, Hossain & Hossain, 2025). However, manual dermoscopic analysis remains labor-intensive, subjective and dependent on the dermatologist’s expertise, leading to variability in results and highlighting the need for scalable, automated diagnostic systems (Brinker et al., 2019; Li & Shen, 2018). Identifying skin cancer is particularly difficult due to the visual and size-related similarities between malignant lesions and benign moles. Tumours that resemble non-progressive moles are classified as ‘benign’, while those that show uncontrolled growth and a disfigured appearance are considered malignant, as shown in Fig. 1.
Figure 1: Few samples from ISIC-2016, ISIC-2017 and Ph2 datasets.
{kind=link}
Artificial intelligence (AI) and deep learning have transformed medical imaging, providing reliable, reproducible and highly accurate diagnostic tools (Wu et al., 2025; Zhao et al., 2025). Convolutional neural networks (CNNs) have automatically classified and segmented lesions (Song et al., 2024), achieving dermatologist-level performance with datasets such as the ISIC archive and Ph2 (Adegun & Viriri, 2019; Sahoo, Dash & Mohapatra, 2024). However, other challenges exist, such as the low contrast between melanomas and healthy skin, visual similarities between malignant and benign lesions and artifacts such as hairs, blisters and shadows in dermoscopic images. Distortions in the data set, such as unbalanced classes and duplicate images, further distort training and hinder generalizability (Mabrouk et al., 2022). These limitations emphasize the need for innovative solutions for melanoma detection. Conventional CNN models often struggle to accurately delineate the dataset and deal with bias, resulting in fuzzy segmentation of lesions and overfitting. While CNNs are effective in hierarchical feature extraction, they often lose spatial integrity, compromising segmentation results and clinical applicability (Tang et al., 2025; Al-Selwi et al., 2025).
This study examines recent AI-driven advances in skin cancer detection, focusing on CNNs, ensemble deep learning and transfer learning approaches. It identifies key challenges, including dataset diversity, overfitting and computational cost and proposes a novel hybrid deep learning model. The proposed model combines residual network-50 (ResNet50) and visual geometry group-16 (VGG-16) architectures with advanced attention mechanisms, channel attention and spatial attention to improve feature extraction and prioritize critical melanoma features. This approach aims to improve diagnostic accuracy and segmentation precision in dermoscopic images by refining the focus and attenuating irrelevant artifacts.
This study presents an innovative hybrid deep-learning system for melanoma detection. The main contributions of this study are as follows:
-
(i)
A hybrid model combining ResNet50 and VGG16 utilizes complementary features to improve the discrimination between benign and malignant lesions.
-
(ii)
The channel and spatial attention modules are integrated to prioritize features and focus on diagnostically significant regions.
-
(iii)
Random erasing, color jittering and affine transformations address class imbalances and strengthen training data.
-
(iv)
Performance is optimized by unfreezing select pre-trained layers to ensure efficient and accurate melanoma detection.
This work addresses the increasing need for reliable, scalable and clinically effective methods for early melanoma detection. The proposed model improves accuracy and generalizability by incorporating attention mechanisms and advanced data processing strategies, ultimately optimizing diagnostic workflows.
The remaining sections are organized as follows: ‘Related Work’ discusses related studies; ‘Materials and Methods’ describes the materials and methods; ‘Experiments Results’ explains the experimental results; ‘Discussion’ provides a discussion; and ‘Conclusion and Future Work’ concludes with findings and future directions.
Related work
The field of automated melanoma detection has evolved rapidly thanks to the transformative impact of deep learning on medical image analysis. Convolutional neural networks (CNNs) are fundamental as they extract complex hierarchical and discriminative features, outperforming traditional machine learning methods based on hand-crafted features (Khouloud et al., 2022; Shaik et al., 2025). The U-Net, a widely used architecture in biomedical segmentation, is particularly effective due to its encoder-decoder structure that captures local and global features (Ronneberger, Fischer & Brox, 2015; Gutman et al., 2016). However, standard U-Net models often cannot preserve spatial details, resulting in fuzzy lesion boundaries and lower segmentation accuracy (Kaneria & Jotwani, 2024).
To overcome these limitations, researchers have improved CNN architectures with multiscale feature extraction, residual connections and attention mechanisms to increase segmentation accuracy and generalizability (Su et al., 2024; Liu et al., 2024). Ensemble learning methods, such as those of Codella et al. (2018) combine CNNs with traditional techniques to achieve better performance in lesion segmentation and classification. Similarly, encoder-decoder architectures with skip connections improve spatial continuity and segmentation results for datasets such as ISIC (El-Khatib, Popescu & Ichim, 2020).
Despite the progress, biases in publicly available datasets such as ISIC and Ph2, including duplicate images, unbalanced classes and inconsistent annotations, remain a major challenge. These biases distort training and evaluation, inflating performance metrics and limiting generalizability (Akram et al., 2024; Nazari & Garcia, 2025). Robust data curation and augmentation strategies are crucial to solving these problems. Skin cancer, especially melanoma, is a significant health threat worldwide. Early detection is crucial for effective treatment, but diagnostic challenges include visual similarities between benign and malignant lesions, low contrast and complex features (Khan et al., 2020). Although melanoma accounts for only a small percentage of skin cancer cases, it is responsible for the majority of skin cancer-related deaths worldwide (Montaha et al., 2022).
Recent studies have shown significant advances in the automatic classification and segmentation of lesions using deep learning and computer-aided diagnosis (CAD) systems. Frameworks such as DermoExpert, which integrates segmentation, augmentation and transfer learning, have improved the classification accuracy on datasets such as ISIC-2016 and ISIC-2018 (Hasan et al., 2022). Other models, such as BF2SkNet, use deep feature fusion and fuzzy entropy optimization and provide competitive results for different datasets (Ajmal et al., 2023). MobileNet-V2, which incorporates attention mechanisms and multiscale feature extraction, is an example of lightweight models that achieve excellent accuracy (Nirupama, 2024).
Hybrid models that combine CNN frameworks with advanced preprocessing and feature extraction have come to the fore. Attention mechanisms, such as channel and spatial attention, improve segmentation accuracy by prioritizing diagnostically significant regions and minimizing the impact of irrelevant artifacts. Advanced data augmentation techniques, such as random deletion, color jittering and affine transformations, increase the robustness of the model by increasing the diversity of data sets and mitigating overfitting. AI-based diagnostic tools now achieve dermatologist-level accuracy. For example, faster region-based convolutional neural networks (R-CNN) achieved 91.5% accuracy in classifying clinical images, outperforming dermatologists on certain metrics (Jinnai et al., 2020). Ensemble approaches, such as the integration of Mask R-CNN and DeeplabV3+ by Goyal et al. (2019) achieved a high sensitivity of 89.93% and a specificity of 97.94% on ISIC-2017. Hybrid frameworks using optimization techniques such as the artificial bee colony algorithm have also shown impressive performance, achieving an F1-score of 93.12% (Farea et al., 2024). Transfer learning approaches that utilize pre-trained models such as VGG16, VGG19 and AlexNet are also effective, especially with limited datasets (Nakai, Chen & Han, 2022). Fine-tuned VGG-based models have achieved up to 98.18% accuracy in melanoma classification (Faghihi, Fathollahi & Rajabi, 2024). However, challenges such as dataset diversity and overfitting remain, necessitating robust preprocessing, augmentation and ensemble techniques.
This study proposes a hybrid model that integrates ResNet50 and VGG16 and effectively combines complementary features to account for lesion variability. The system improves segmentation and classification accuracy by incorporating channel and spatial awareness mechanisms and compensating for dataset biases through robust data augmentation. These innovations represent a significant advance in automated melanoma detection and pave the way for scalable, clinically reliable diagnostic tools.
Materials and Methods
Pre-trained CNN models
CNNs are deep feed-forward architectures known for their remarkable performance in feature extraction and classification tasks (Saleem et al., 2024). Their architecture integrates convolutional, pooling and fully connected layers, enabling efficient hierarchical feature extraction. In this study, two pre-trained models, ResNet50 and VGG16, are used for feature extraction, selected for their robust architectures and proven accuracy in large datasets such as ImageNet.
ResNet50
ResNet50 is a residual network comprising 50 layers. Its architecture allows bypass connections from certain layers to other layers, so that certain layers can be skipped to solve the vanishing gradient problem and save computation time (Ramanagiri, Mukunthan & Balamurugan, 2024). The image features previously extracted from the dataset ImageNet were trained with a pre-trained model. As input image size, the ResNet50 uses 224 224 3 with kernels of 3 3 and 7 7, respectively. We fine-tuned the final layers to fit our particular dataset, so the model contains these pre-trained features from the earlier layers.
VGG16
A deep CNN architecture of VGG16 consists of 16 layers (Faghihi, Fathollahi & Rajabi, 2024; Meitantya et al., 2024). The architecture consists of a uniform block of convolutional layers with small receptive fields (3 3) and a stride value of 1. As a result, high accuracy can be maintained with efficient feature extraction. By pre-training VGG16 on ImageNet, similar to ResNet 50, a strong baseline is achieved. Uniform (3 3) kernel sizes; input image size is (224 224 3). We fine-tuned the final layers to optimize the model for the task.
Proposed framework
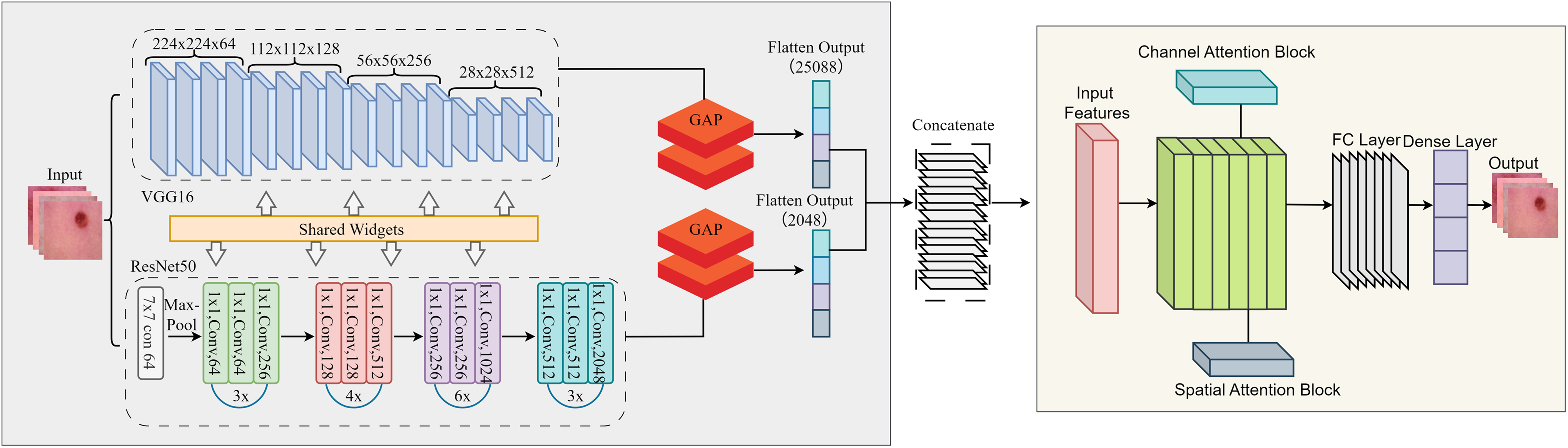
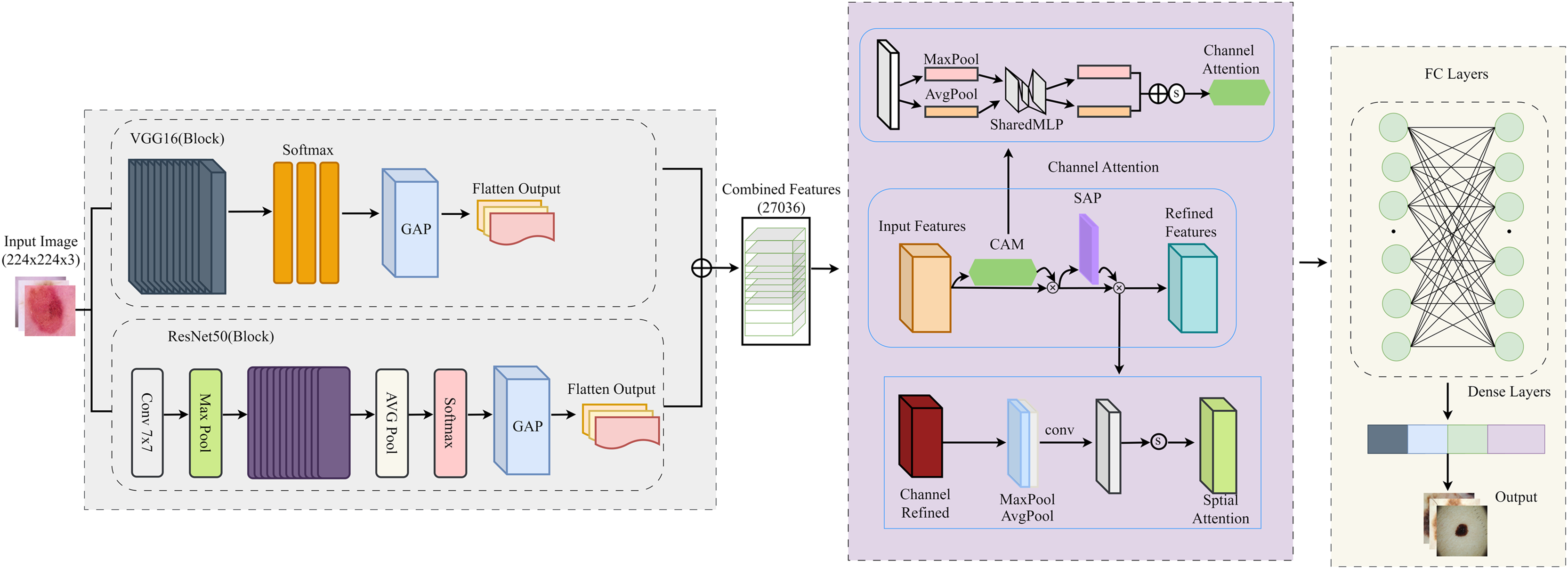
This study uses a unified framework with feature extraction, attention mechanism and classification. By combining pre-trained models with innovative attention modules, the proposed framework solves the main challenges in binary classification tasks: the lack of distinguishable features and redundant data. Deep features were extracted using two pre-trained models, ResNet50 and VGG16, which use different architectural paradigms to capture different feature representations of the input images. A feature fusion approach was used to reduce the redundant and meaningless component that results from the fusion of features in multiple models. It is simply a way to combine the strengths of ResNet50 and VGG16 while preserving the important features. To focus the model on critical data, we added attention mechanisms to refine the fused features. The workflow of the proposed model is shown in Fig. 2.
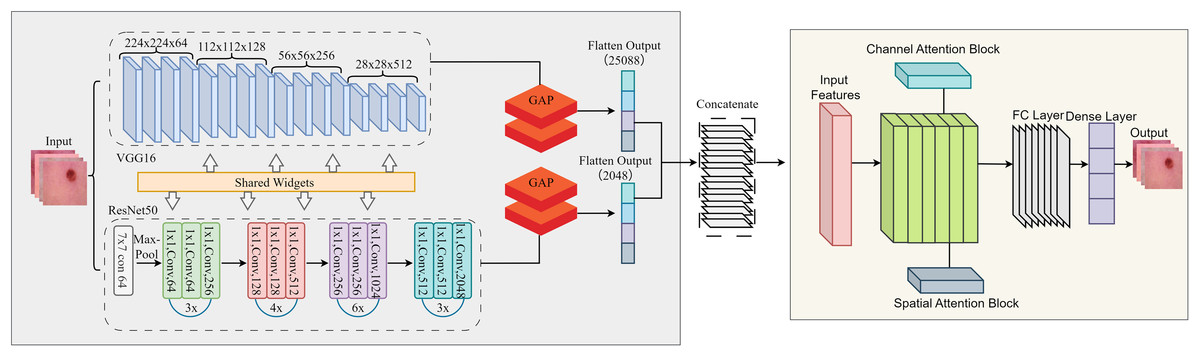
Figure 2: Detailed flow of proposed skin lesion classification framework.
{kind=link}
After the feature maps are independently extracted from ResNet50 and VGG16, they are flattened and concatenated into a single feature vector that retains both global and local representations. This fused feature is then successively refined with the channel and spatial attention modules. The channel attention module focuses on which features are important by adaptively reweighting the channels based on the global average and maximum pooled descriptors and boosting critical texture and lesion-specific filters while suppressing irrelevant ones. Next, the spatial attention module determines “where” to focus by analysing the mean and maximum projections of the feature maps along the channel axis, helping the model to highlight lesion-relevant spatial regions. These refined features are then passed to the final fully linked layers for binary classification. This integration allows CA-SLNet to utilise complementary feature hierarchies from both backbones while dynamically refining attention to discriminative content, improving sensitivity to subtle lesion patterns in different inputs.
Feature fusion strategy
The feature fusion strategy combines the feature maps extracted by ResNet50 and VGG16 by flattening their outputs into 1D vectors. These vectors are then concatenated along the channel dimension to form a unified feature vector that includes global and local image details. The channel and spatial attention modules are applied sequentially to enhance the fused features. Channel-based attention highlights significant channels, while spatial attention highlights prominent spatial regions in the combined feature map. This ensures a rich, focused feature representation for subsequent processing.
To validate the discriminative power of the fused feature embeddings, we performed a t-SNE visualization of the high-dimensional feature space generated by the proposed model. Figure 3, the feature embeddings form different clusters corresponding to the Ph2, ISIC-2016 and ISIC-2017 datasets. The clear separation between these clusters demonstrates the model’s ability to create compact and distinguishable feature representations, thus improving classification performance.
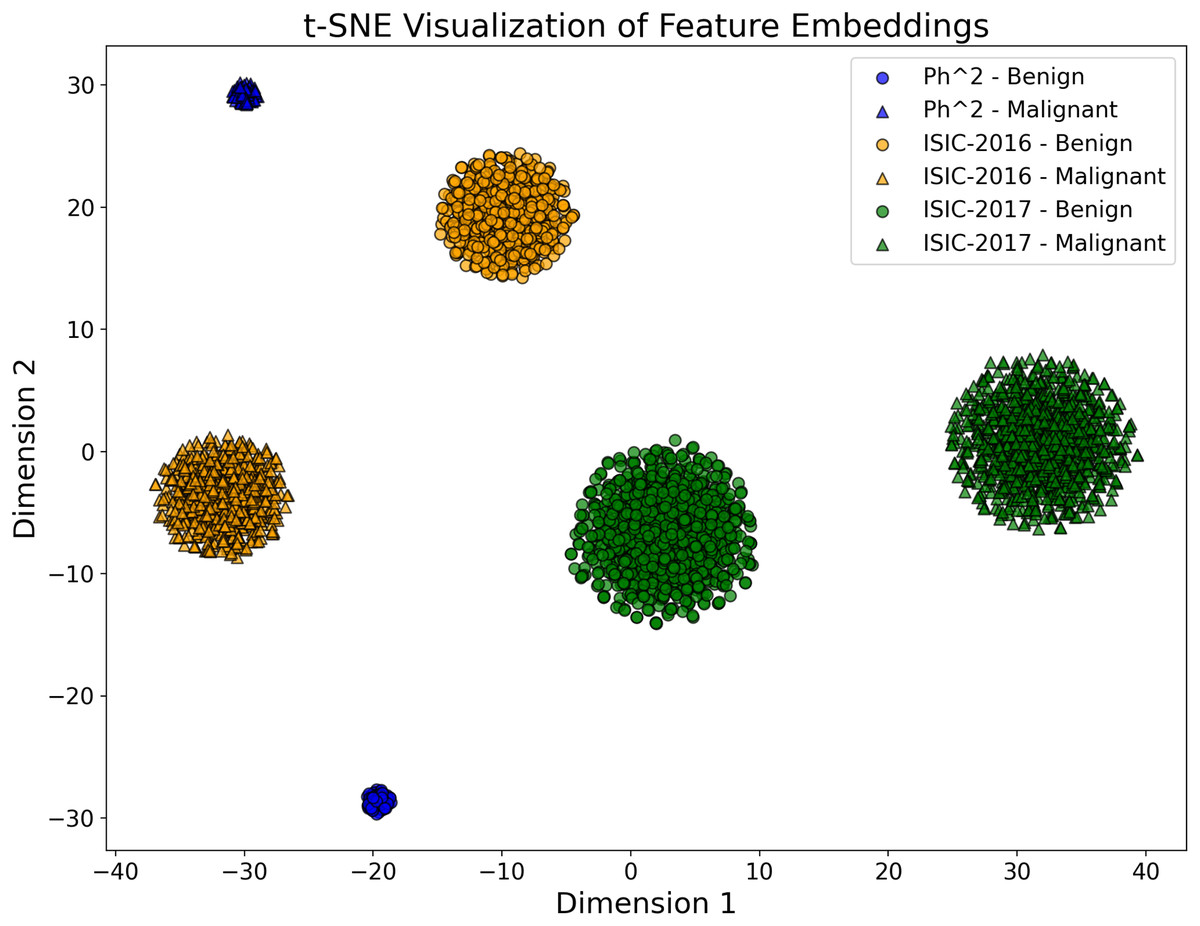
Figure 3: The t-SNE plot visualizes the 2D projection of the feature embeddings of the proposed CA-SLNet model for the Ph2, ISIC-2016 and ISIC-2017 datasets.
The different dataset clusters emphasize the model’s ability to extract discriminative features, while the clear separation of benign and malignant classes demonstrates its effectiveness in classification. The compact Ph2 cluster reflects homogeneity, while the broader ISIC-2016 and ISIC-2017 clusters capture greater variability.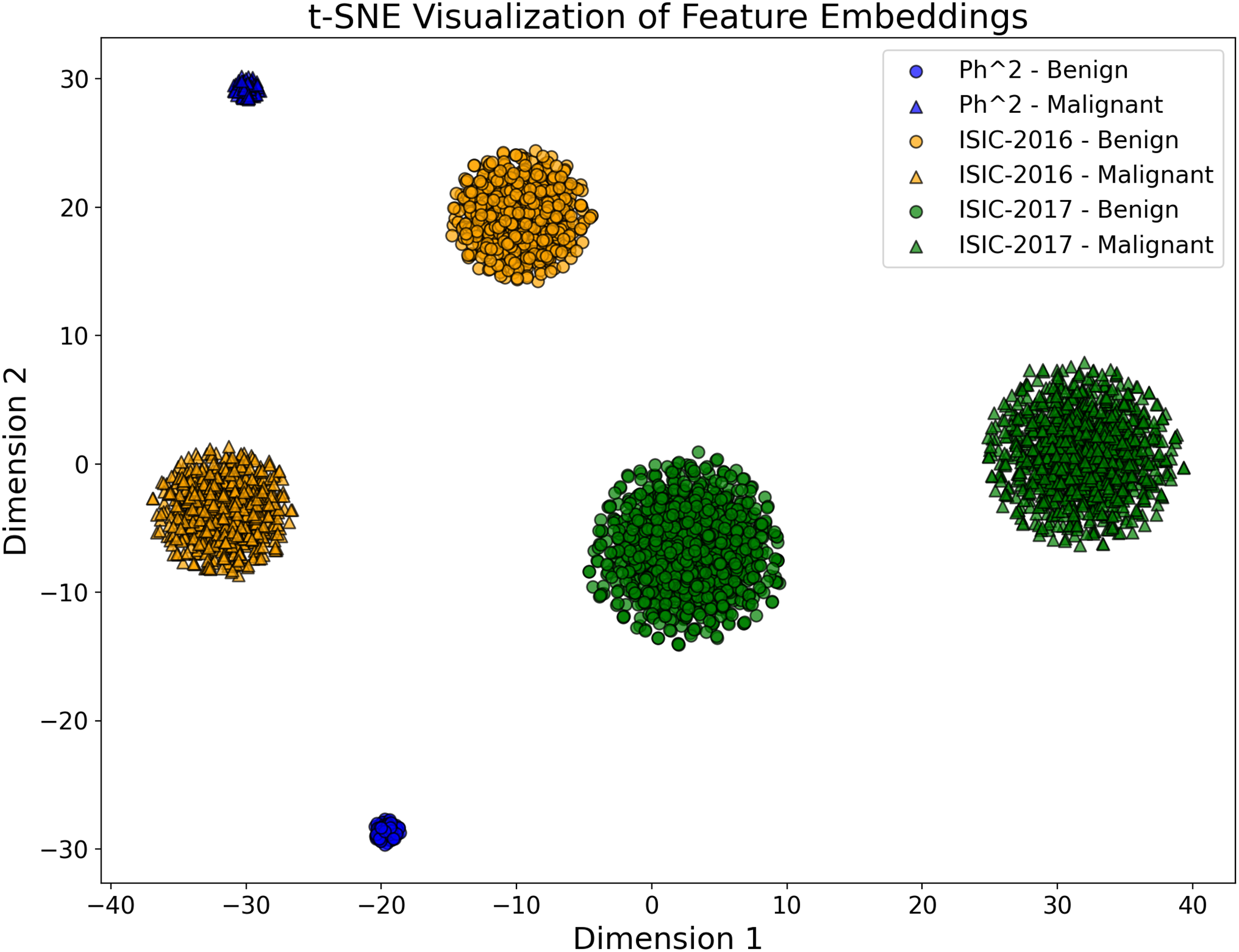{kind=link}
Channel attention module
The channel attention module uses adaptive average pooling and adaptive max pooling to compress the spatial dimensions of the input feature map into channel-wise descriptors, effectively summarizing each channel’s global and local importance. These pooled features are passed through a common two-layer, fully connected network with a bottleneck structure (channel reduction followed by expansion). The outputs of the Average and Max Pooling branches are then combined by element-wise addition. A sigmoid activation function generates channel-wise attention weights to re-weight the input feature map and highlight the most relevant channels for the classification task.
Spatial attention module
The spatial attention module improves the spatial relevance of features by learning the importance of different regions in the feature map so that the network can localize and highlight key areas of the image. The refined features are then passed through fully concatenated layers with dropout to avoid overfitting and classified with a sigmoid activation function. Regularization and learning rate scheduling techniques were used to reduce overfitting and optimize performance. A low learning rate combined with a stepwise learning rate scheduler provides fine-tuning of the pre-trained weights for the particular dataset while preserving the learned representations.
Dataset
The ISIC-2016 dataset is an important resource in dermatology and computer vision. It is often used to further develop and evaluate machine learning algorithms for skin cancer detection based on dermoscopic images. It consists of dermoscopic images categorized as melanoma and benign cases. In addition, based on the ISIC archive, which contains images with different resolutions, a diverse set of skin lesion images was used for the study. The ISIC-2016 dataset contains a total of 1,279 images. The ISIC-2017 dataset includes 2,000 images of skin lesion cases. This dataset serves as an important benchmark for the development and validation of machine-learning models for skin cancer diagnosis. Due to the high prevalence of keratoses, the images are often divided into two main categories: benign and malignant. The Ph2 dataset was also included in this study (Benyahia, Meftah & Lézoray, 2022). It contains 200 dermoscopic RGB images. This dataset, curated at the Hospital Pedro Hispano in Matosinhos, contains both dermatoscopic images and clinical assessments by dermatologists indicating whether an image represents a normal case, a melanoma, or an atypical nevus. The ISIC-2016, 2017 and Ph2 datasets evaluate melanoma detection as they offer a large variety and with good annotations. Dermatologists have manually annotated all images in these datasets with precise basic annotations. To assess class balance, we analysed the distribution of benign and malignant cases in all datasets. The ISIC-2016 dataset consists of 900 benign and 379 malignant samples, while ISIC-2017 contains 1,400 benign and 600 malignant cases. The Ph2 dataset contains 160 benign and 40 malignant images. These ratios reflect inherent class imbalances, especially in ISIC-2016 and Ph2, which may bias model learning towards the majority class. Therefore, we implemented customised augmentation and attention mechanisms to improve sensitivity and reduce misclassification, especially false negatives in minority classes.
Design and optimization of CA-SLNet for skin lesion classification
In this section, we develop and optimize the proposed CA-SLNet for skin lesion classification. To improve the generalization, data augmentation techniques such as rotation, flipping and color jittering were applied to the data. The ResNet50 and VGG16 models are combined with attention modules for refined feature extraction. Binary cross-entropy loss, an Adam optimizer and a StepLR scheduler for learning rate decay were used in training. They quickly improve the model’s ability to be classified and to classify. The detailed flowchart in Fig. 4 shows the stages of the proposed framework, from image acquisition to the final classification process.
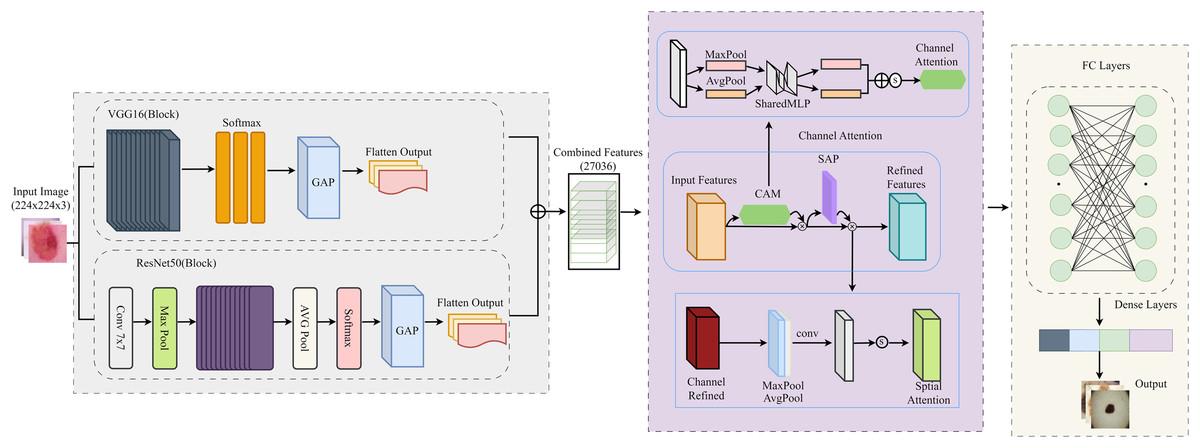
Figure 4: Detailed flow of the proposed architecture for the classification of skin lesions.
{kind=link}
Data augmentation
To improve the model’s generalization, data augmentation techniques were used for both data sets. Random rotation, flipping, affine transformation and possibly partial color jittering were used. Random deletions were introduced to simulate further occlusions. These transformations not only increased the training set, but also helped to reduce the imbalance of the classes by artificially increasing the variability of the (malignant) samples of the minority class. For example, random deletion simulates occlusions that are common in dermoscopic images, while color jittering enhances robustness to lighting variation. These enhancements were increasingly applied to the underrepresented malignant class to promote balanced feature learning. This strategy helped to reduce the number of false negatives. ImageNet means and standard deviations were used for normalization.
(1) where mean = [0.485, 0.456, 0.406], = [0.229, 0.224, 0.225] are normalize inputs.
Model architecture
The CA-SLNet model integrates ResNet50 and VGG16 architectures with channel and spatial attention mechanisms to optimize feature extraction. The feature maps generated by the ResNet50 and VGG16 backbones are concatenated as follows:
(2) where and and denotes concatenation.
To emphasize critical features, the channel attention module computes channel-wise weights:
(3) where is the sigmoid activation function and are learnable weights of the attention layer.
The spatial attention module enhances spatial focus:
(4) where and are the mean and max pooled features and [;] denotes concatenation.
The refined features are passed through fully connected layers for classification:
(5) where is the attended feature map.
Training protocol
The binary cross-entropy (BCE) loss function was used to optimize the model:
(6) where M is the batch size, is the ground truth label and is the predicted probability.
Optimization was performed using the Adam optimizer with the update rule:
(7) where is the gradient, is the second moment estimate and is a small constant for numerical stability.
A StepLR scheduler was employed to decay the learning rate after every seven epochs:
(8) where is the decay factor.
Training environment
All training and evaluation experiments were performed on a dedicated local workstation equipped with an NVIDIA RTX 4070 GPU, an Intel Core i9 processor and 32 GB RAM running Windows 11. The model was implemented with Python 3.10 and PyTorch 2.1.0. Image preprocessing and augmentation were performed with Torchvision 0.16.0, while performance metrics and analysis were performed with scikit-learn 1.3.0 and Matplotlib 3.7.2. GPU acceleration was managed with CUDA 11.8. This environment ensured consistent model training, uniform evaluation and reproducibility of results.
Training hyperparameters
The CA-SLNet model was trained using the Adam optimiser with a learning rate of 0.001, a batch size of 32 and a maximum of 100 epochs. All input images were resized to 224 224 3. A dropout layer with a rate of 0.5 was applied before the last fully concatenated layers to prevent overfitting. Weight initialization was used when initialising the weights and early stopping was applied with a patience of 10 epochs based on validation loss to prevent overtraining. No planner was used for the learning rate. These hyperparameters were kept consistent across all data sets to ensure a fair and reproducible evaluation, as shown in Table 1.
| Hyperparameter | Value |
|---|---|
| Device | CUDA |
| Batch size | 32 |
| Input image size | 224 224 pixels |
| Normalization | Mean = [0.485, 0.456, 0.406], Standard Deviation = [0.229, 0.224, 0.225] |
| Data augmentation | Random Resized Crop, Horizontal Flip, Random Rotation (30∘), Color Jitter, Random Erasing |
| Learning rate | 1e-5 |
| Optimizer | Adam |
| Loss function | Binary Cross-Entropy with Logits Loss |
| Scheduler | StepLR (Step size = 7 epochs, Decay = 0.1) |
| Dropout rate | 0.5 |
| Epochs | 100 |
| Pretrained models | ResNet50, VGG16 |
| Fine-tuned layers | Last 10 layers |
| Attention mechanisms | Channel attention, Spatial attention |
A five-fold cross-validation was performed for each experiment to ensure the robustness of the results and to avoid bias in the assessment. Each data set was randomly divided into five equal folds, with four folds used for training and validation 80% and one fold retained for testing 20%. An internal split of 80:20 was made within the training area to form the training and validation sets. The splitting process was stratified by class to maintain the original distribution of benign and malignant samples across all folds. The performance metrics were averaged across all five folds to obtain stable and generalised results.
Proposed model algorithm
The proposed algorithm CA-SLNet (channel attention for skin lesion network) describes a systematic approach to melanoma detection that utilises attention mechanisms for robust feature extraction and classification Algorithm 1. By incorporating preprocessing, feature fusion and feature refinement into the attention method, the algorithm provides high accuracy, strong capabilities and feature generalisation in melanoma classification. The operation of CA-SLNet consists of several important steps: First, the data is pre-processed by normalising the input images to ImageNet mean and standard deviations. Data augmentation techniques such as random flipping, rotation and affine transformations are applied to the data to artificially augment and improve the generalisation of the model.
| Require: Dataset , batch size M, learning rate α, epochs T, decay factor γ, folds |
| Ensure: Best model , average validation accuracy |
| 1: Initialize , |
| 2: for to K do |
| 3: Split , from |
| 4: Initialize model parameters |
| 5: Preprocess : Resize, normalize and apply data augmentation |
| 6: Extract features using ResNet50 and VGG16 |
| 7: Compute channel attention and spatial attention |
| 8: for to T do |
| 9: Train model: |
| 10: Apply dropout to prevent overfitting |
| 11: Compute binary cross-entropy loss |
| 12: Update model parameters using gradient descent |
| 13: Adjust learning rate α using decay factor γ |
| 14: end for |
| 15: Evaluate model on validation set |
| 16: Compute validation accuracy Ak |
| 17: Store Ak and |
| 18: end for |
| 19: Compute average validation accuracy |
| 20: Select best model |
| 21: return , |
In the following phase, feature extraction is performed using two deep learning architectures, ResNet50 and VGG16. The feature maps generated by these backbones are linked to form a comprehensive feature representation. After feature extraction, attention mechanisms are used to refine the concatenated features. Attention to the channels is calculated by combining the global average pooling and global max pooling operations, followed by fully concatenated layers to assign weights to the important channels. At the same time, spatial attention is computed by applying a convolution operation to the combined average and max feature maps to highlight critical spatial regions for melanoma detection. These attention mechanisms work in tandem to produce a refined feature representation.
In the classification phase, the features are flattened and fed into a fully concatenated layer with a sigmoid activation function that generates the final prediction probabilities. Training is performed by iteratively optimizing the model parameters according to the BCE loss objective function. Second, efficient convergence of the weights is achieved by using the first and second-order moments of the gradient updates provided by the Adam optimizer. A learning rate scheduler (StepLR) keeps the learning rate stable and optimal throughout the training. The algorithm systematically employs feature fusion, attention mechanisms and robust optimization to ensure that the final model has accurate classification and discrimination capability. CA-SLNet integrates spatial and channel attention and effectively highlights critical lesion regions to improve its robustness in different datasets and clinical scenarios.
Evaluation metrics
The evaluation metrics used were accuracy, precision, recall, F1-score and the area under the receiver operating characteristic (ROC) curve. The metrics for precision and recall are defined as follows:
(9) where TP, FP and FN are the number of true-positive, false-positive and false-negative results.
The F1-score, a harmonic mean of precision and recall, is computed as:
(10)
The area under the curve-receiver operation characteristic (AUC-ROC) curve measures the discriminatory ability of the model:
(11)
The true-positive rate depends on the false-positive rate , which is noted as . This model guarantees its performance and reliability in detecting melanoma. It has been tested with the ISIC 2016, 2017 and Ph2 datasets.
To assess the performance of the model, we used different evaluation metrics, such as confusion matrices, to assess accuracy along with the receiver operating characteristic (AUC). The model used cross-validation to obtain a reliable and generalized assessment of performance. The efficiency of the model was improved by carefully selecting several hyperparameters, in particular, the batch size, the loss function, the learning rate, the target size and the optimization function.
Ablation study
The ablation study evaluates how the different parts and parameters of the CA-SLNet architecture change the model’s capacity. The primary focus of this analysis is to identify the essential operations in the design of signal processing, such as attention mechanisms, feature fusion and hyperparameters, to achieve optimal performance. In this way, attention mechanisms have increased the importance of focusing on appropriate components to conceal interference upstream. By turning off the channel attention (CA) module, the performance degradation in ISIC-2016, ISIC-2017 and Ph2 was 3.25%, 2.98% and 3.85%, respectively. Switching off the spatial attention (SA) module led to a reduction of up to 4.2%. These results show that attention mechanisms are crucial for improving feature representation and increasing discriminative capacity. Therefore, using ResNet50 and VGG16 features was very important for both overall and local features. The average accuracy of ResNet50 and VGG16 is 5.6% and 6.4%, respectively, showing that feature fusion is crucial for proper visualization.
Hyperparameter tuning was crucial for optimal performance. A learning rate of achieved the best balance between stability and convergence, as higher rates ( ) led to instability and lower rates ( ) slowed down training. A batch size of 32 balanced computational efficiency and accuracy, while a dropout rate of 0.5 effectively curbed overfitting. As shown in Table 2, these configurations were experimentally validated as the most effective for training CA-SLNet. Using pre-trained ResNet50 and VGG16 models was critical for achieving high performance. Replacing the pre-trained weights with random initialization decreased accuracy by more than 10% for all datasets, with corresponding reductions in AUC values. This underlines the importance of transfer learning for improving generalization and accelerating convergence. These results confirm the robustness and optimality of the CA-SLNet architecture for automatic melanoma detection.
| Configuration | ISIC-2016 (%) | ISIC-2017 (%) | Ph2 (%) |
|---|---|---|---|
| Proposed model (CA-SLNet) | 98.59 | 96.80 | 99.50 |
| Without CA | 95.34 | 93.82 | 95.65 |
| Without SA | 94.39 | 92.76 | 95.30 |
| Only ResNet50 | 92.85 | 91.63 | 93.72 |
| VGG16 only | 92.19 | 91.02 | 93.11 |
| Random weights | 88.27 | 85.67 | 89.34 |
| Learning rate ( ) | 94.52 | 92.75 | 94.31 |
| Learning rate ( ) | 95.11 | 93.20 | 95.10 |
| Dropout rate (0.3) | 95.21 | 93.68 | 95.90 |
| Dropout rate (0.7) | 94.58 | 92.89 | 94.78 |
| Batch Size (16) | 94.92 | 93.45 | 95.13 |
| Batch Size (64) | 93.87 | 92.01 | 94.15 |
Feature localization and explainability in CA-SLNet
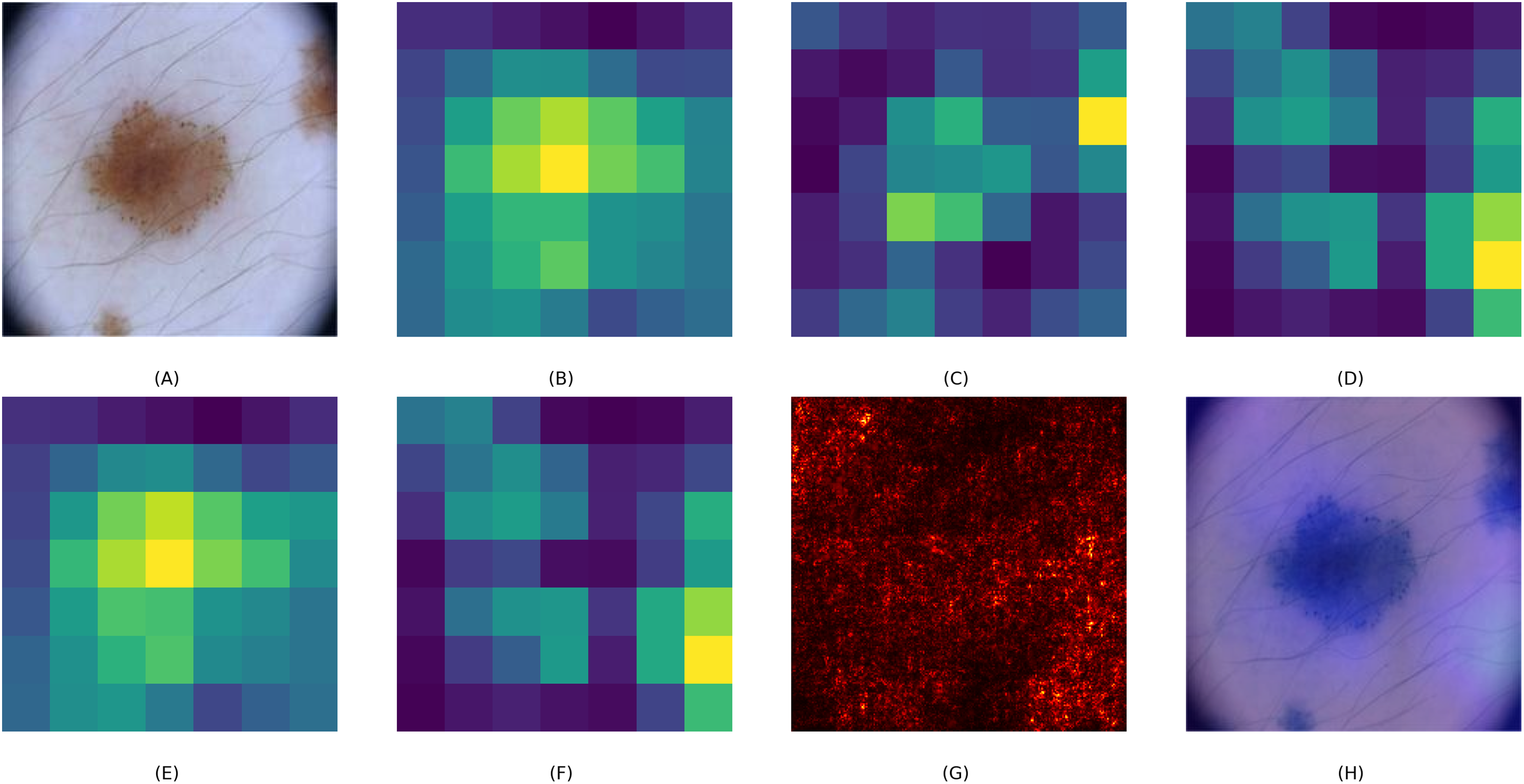
To assess the interpretability of the CA-SLNet model, we created visual explanations using Grad-CAM overlays, saliency maps and attention heat maps. These visualisations help to understand how the model prioritises different image regions when making classification decisions. Figure 5 illustrates this process using a skin lesion as an example. The base feature maps of ResNet50 and VGG16, Figs. 5B and 5C, show a general feature extraction, while the fused CA-SLNet feature map, Fig. 5D, localises the lesion-critical regions more precisely. The channel attention map, Fig. 5E, highlights the feature dimensions that have the greatest influence on classification, while the spatial attention map, Fig. 5F, identifies the lesion-relevant regions in the spatial domain. The saliency map Fig. 5G illustrates pixel-level influence and the Grad-CAM overlay Fig. 5H provides an intuitive heatmap that confirms the model’s focus on lesion boundaries and morphological features. These interpretation tools increase the transparency of CA-SLNet and show that its predictions are based on medically meaningful image regions, which is crucial for clinical validation.
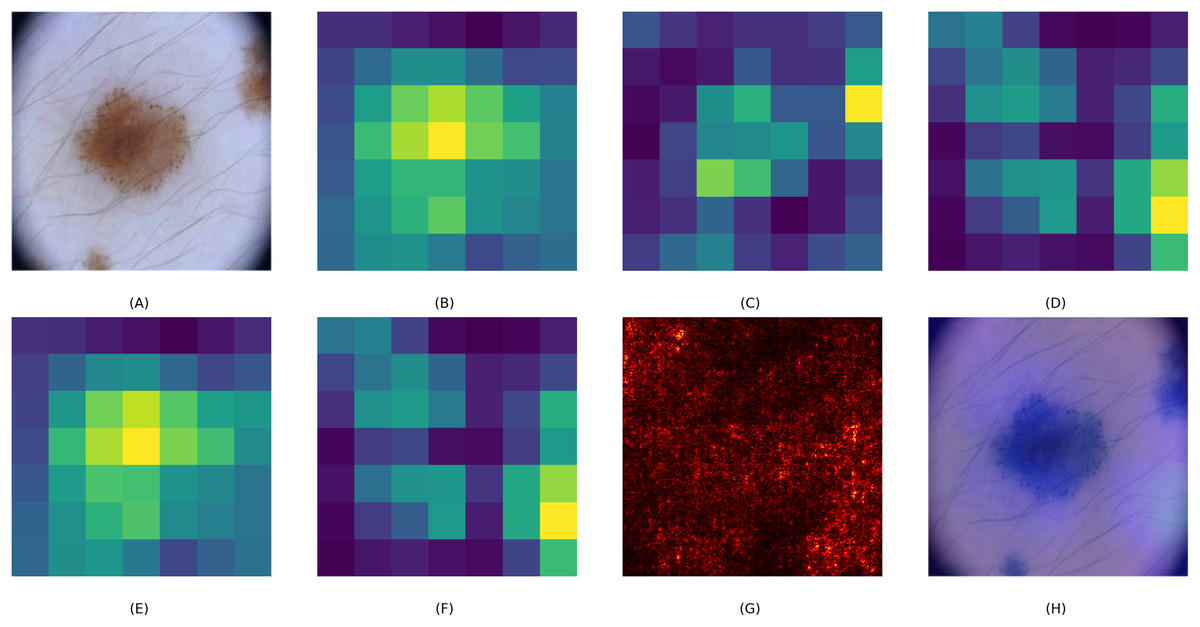
Figure 5: Visual explanation of CA-SLNet: (A) original lesion image, (B, C) ResNet and VGG base feature maps, (D) CA-SLNet feature map highlighting lesion critical regions, (E, F) channel and spatial attention heat maps highlighting diagnostic areas, (G) saliency map showing influential pixels and (H) Grad-CAM overlay for interpretability.
{kind=link}
Comparison with state-of-the-art methods
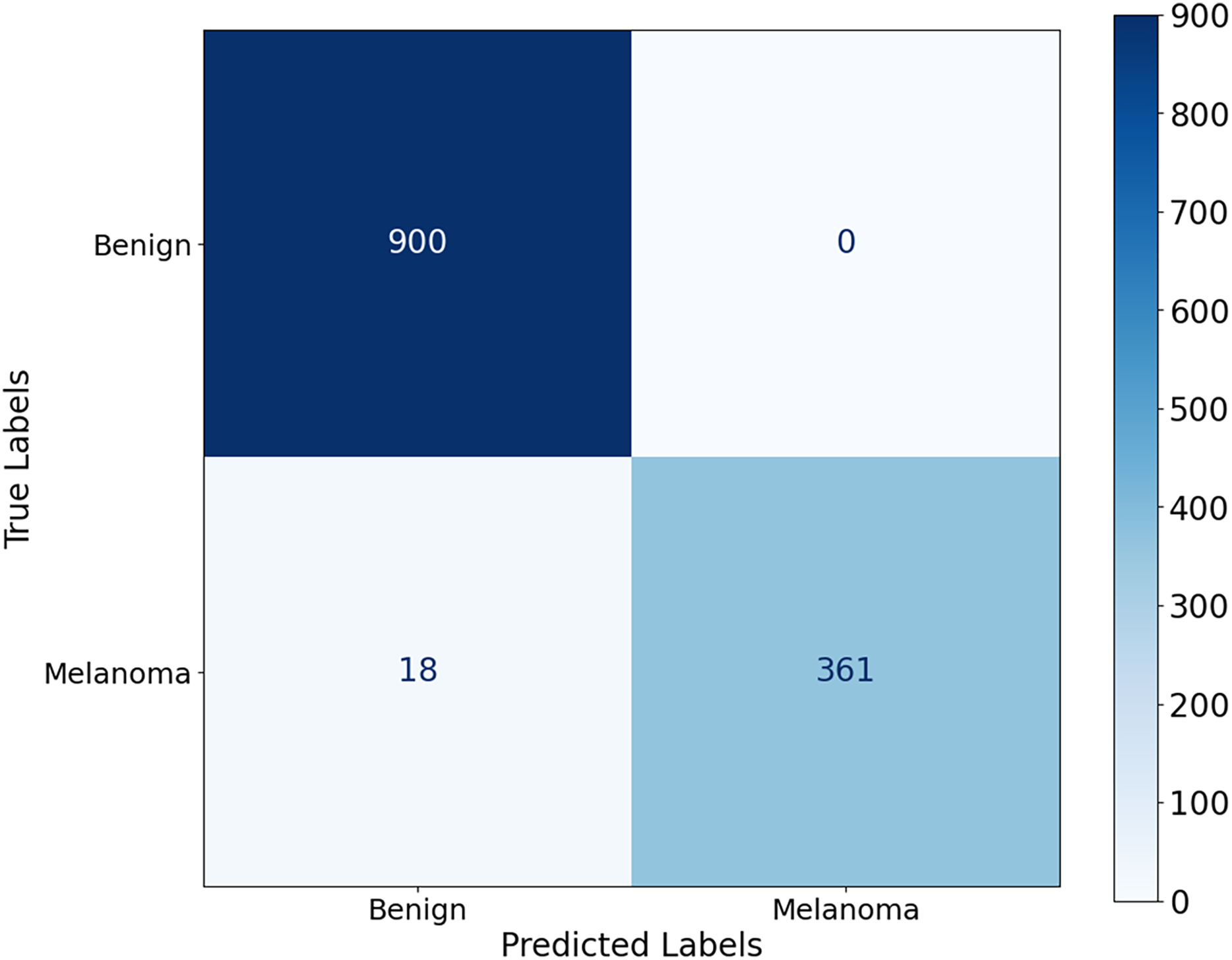
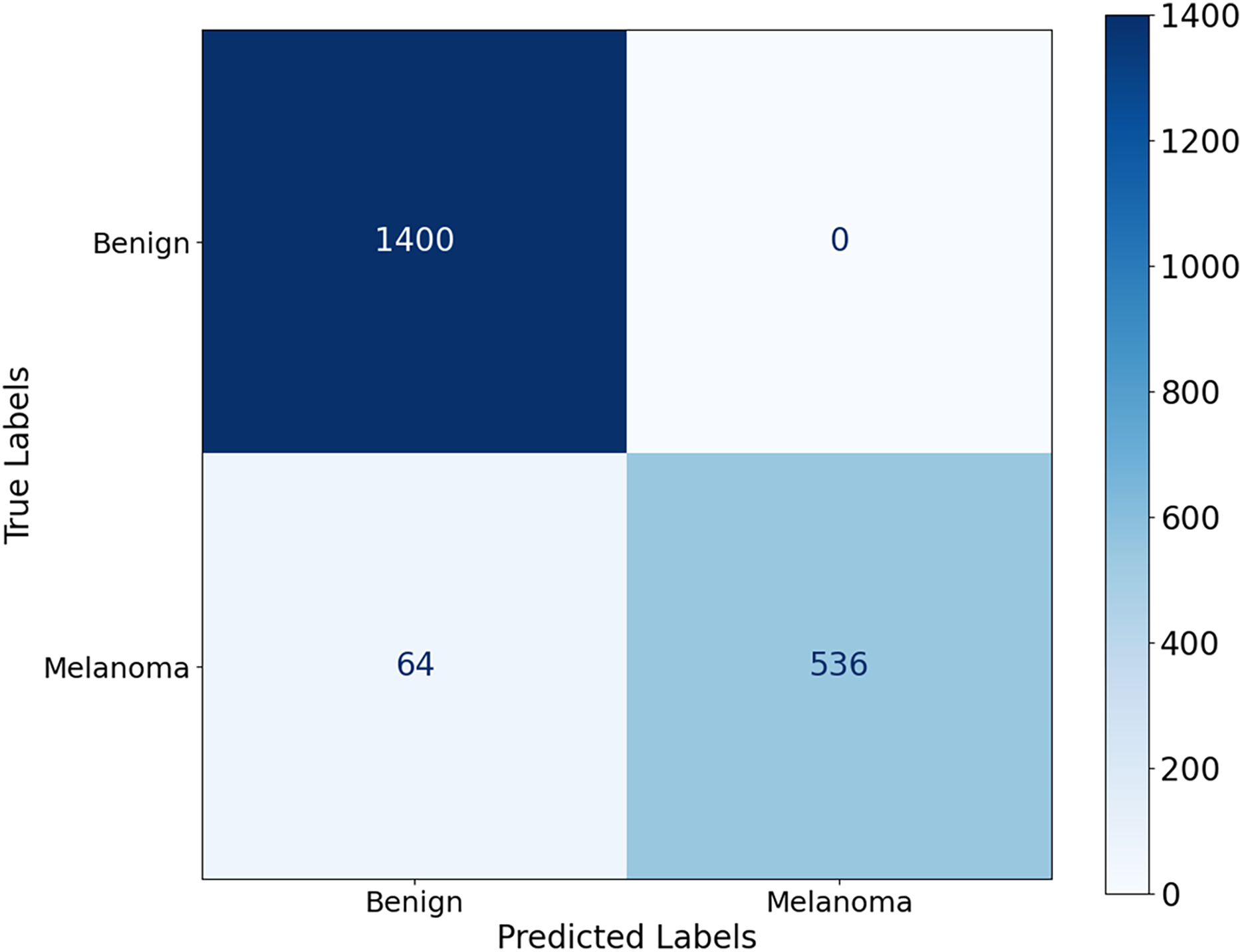
The proposed CA-SLNet performs better than existing state-of-the-art (SOTA) models across multiple dermatological benchmark datasets, including ISIC-2016, ISIC-2017 and Ph2. For the classification, the results of the ISIC-2016 dataset showed the robust performance of the model. Figure 6 shows a high accuracy and correct classification of 900 benign and 361 malignant samples, with no false positives and only 18 false negatives. The minimal misclassification confirms that the model will reliably identify melanomas in clinical applications. The effectiveness of the model is shown in Fig. 7. The model showed excellent performance in classifying cancerous lesions with an average AUC value of 0.9814 0.0121. The individual AUC values obtained in the five cross-validation folds ranged from 0.9643 to 0.9968, demonstrating the reliable and consistent performance of the model. These results suggest that the model could be a robust model for dermatologists to aid clinical diagnosis. Table 3 compares the classification accuracy of CA-SLNet with previous work on the ISIC-2016 dataset. The table summarizes the performance of the models developed in recent years and their respective accuracy levels.
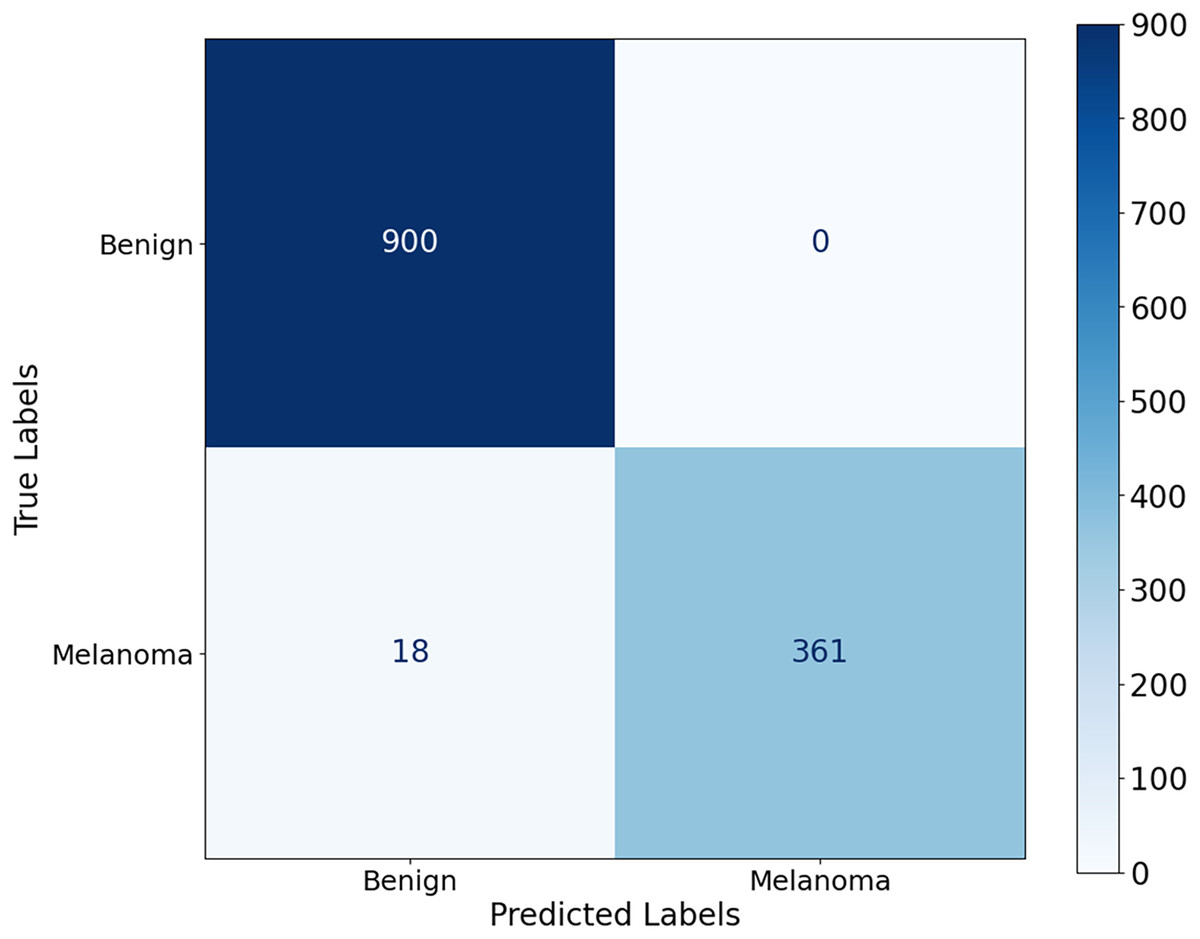
Figure 6: Confusion matrix for the ISIC 2016 dataset.
{kind=link}
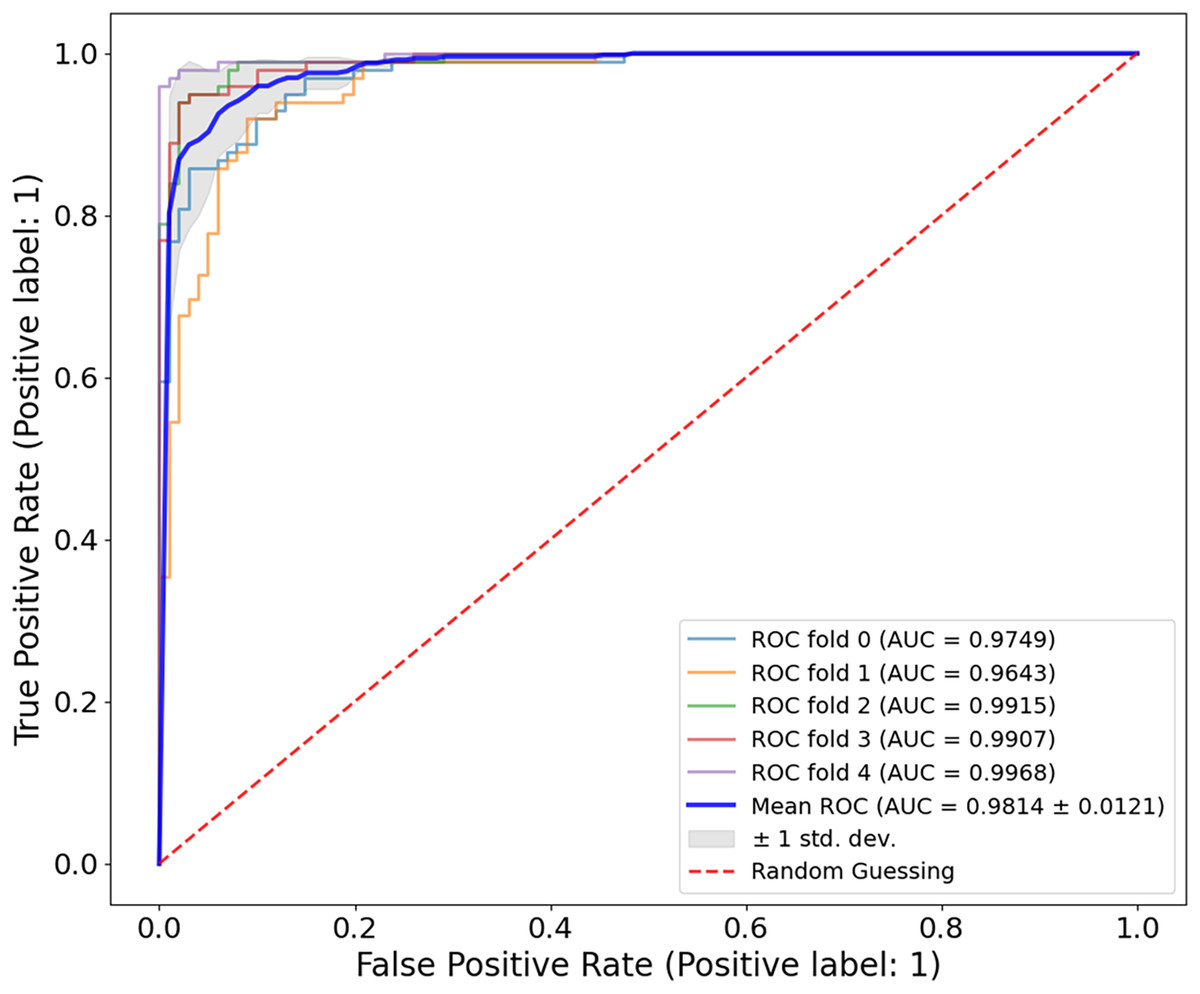
Figure 7: ROC curve for the ISIC-2016 dataset.
The model achieved a mean AUC of 0.9814 0.0121, demonstrating strong discriminatory power between benign and malignant lesions.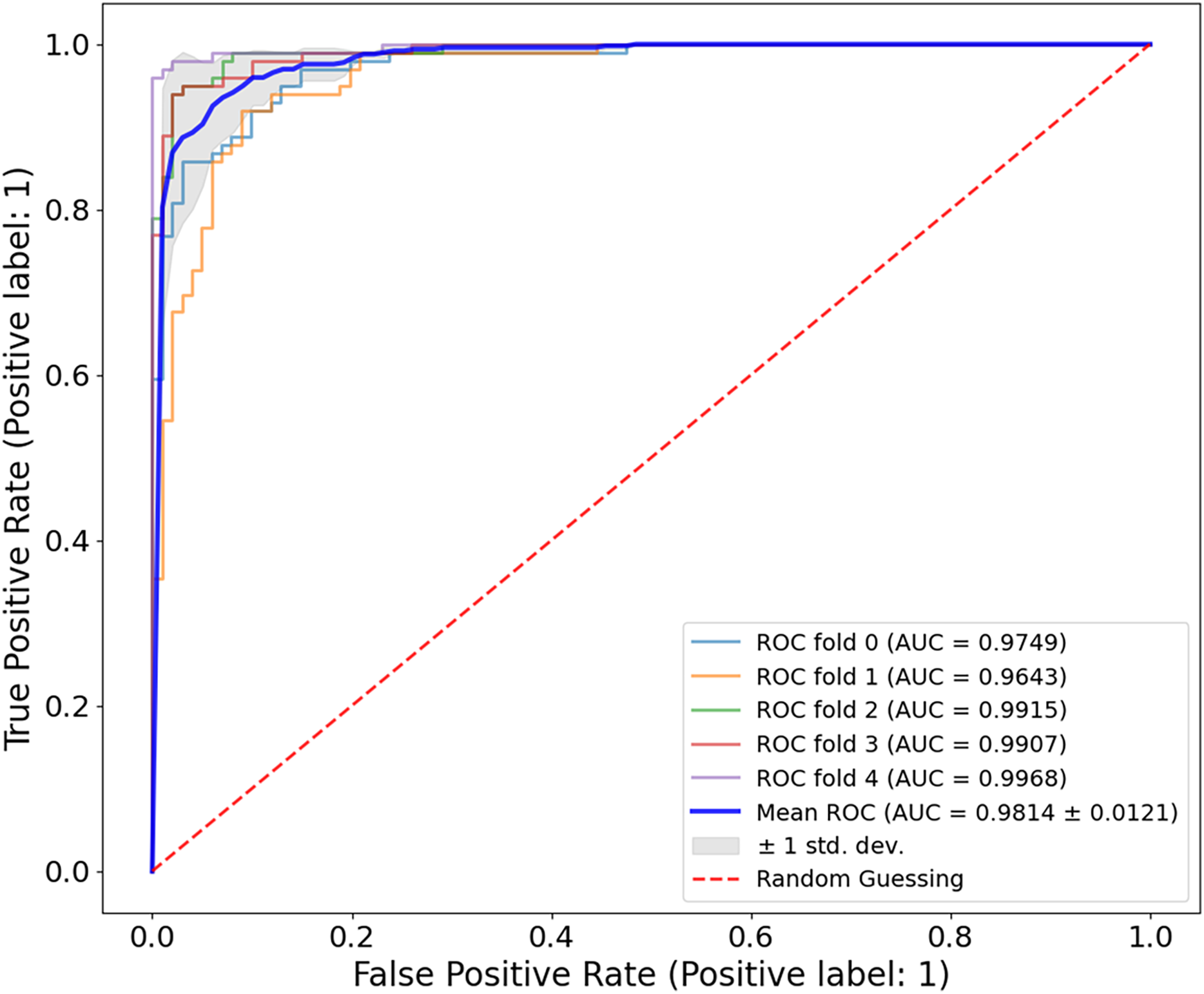{kind=link}
| Authors | Year | Problem type | Accuracy (%) | Recall (%) | Precision (%) | F1-score (%) |
|---|---|---|---|---|---|---|
| Sahoo, Dash & Mohapatra (2024) | 2024 | Classification | 80.61 | – | – | – |
| Mabrouk et al. (2022) | 2022 | – | 88.39 | 88.39 | 87.81 | 87.51 |
| Hosny & Kassem (2022) | 2022 | – | 92.57 | – | – | – |
| Akram et al. (2024) | 2024 | – | 96.26 | 96.00 | 96.40 | 96.20 |
| Khouloud et al. (2022) | 2022 | – | 97.49 | – | – | – |
| Amin et al. (2020) | 2020 | – | 98.39 | – | – | – |
| Proposed model | 2024 | Classification | 98.59 | 95.25 | 99.00 | 97.57 |
Experiments results
The evaluation of the proposed CA-SLNet experiments were performed using three publicly available datasets Ph2 (Hosny & Kassem, 2022), ISIC-2017 (Hasan et al., 2022) and ISIC-2016 (Gutman et al., 2016). The selected benchmarking datasets were chosen because they contain different skin lesion examples in Ph2, ISIC-2017 and ISIC-2016.
Misclassification analysis
To analyse the model errors, we examined the confusion matrices for each dataset. In ISIC-2016, the model misclassified only 18 malignant cases as benign, with zero false positives. In ISIC-2017, 64 malignant cases were classified as benign, reflecting the visual complexity of the dataset and the overlap of lesions. In contrast, the model in the Ph2 dataset achieved near-perfect classification, with only one benign image incorrectly categorised as malignant. These results indicate that false-negative images were the main cause of misclassification, particularly in ISIC-2017. Our augmentation strategy and attention-based fusion mitigated the imbalance between classes and improved overall recall, but further improvements may be needed to reduce critical misclassifications.
Model inference time and hardware efficiency
To assess the clinical suitability of CA-SLNet, we measured the inference time and hardware efficiency with an NVIDIA RTX 4070 GPU and an Intel Core i9 processor. The model processes a dermatoscopic image in 42 ms, enabling near real-time support. Despite its dual backbone design (ResNet50 and VGG16), efficiency is maintained through selective layer tuning. CA-SLNet has a model size of 97 MB, 29.6 million parameters and uses 1.8 GB of GPU memory during inference, confirming its suitability for use in clinical environments with moderate hardware.
The proposed model was developed to accurately discriminate between melanoma and non-melanoma skin lesions.
Table 3 shows that CA-SLNet achieves an accuracy of 98.59% and outperforms most other models, including the original work in Amin et al. (2020) with 98.39%. CA-SLNet exhibits high accuracy and provides several additional advantages by incorporating the ResNet50 backbone and the VGG16 backbone and attention mechanisms in feature extraction. In particular, it is generalized through an advanced data augmentation technique. These features make the classification robust and adaptable to different datasets, making this tool an actionable tool for melanoma classification. The CA-SLNet achieves the highest possible accuracy in discriminating melanoma and its accuracy is commercially attractive and state-of-the-art.
Figure 8, the model shows a high classification accuracy for the ISIC-2017 dataset with correct identification of 1,400 benign and 536 malignant samples. The model also achieved 0 false positives and 64 false negatives, which is important as it shows the robust predictive ability. This reflects that the model avoided overdiagnosis, which is crucial for avoiding unnecessary treatment. While the slightly increased rate of false-negative results provides an improvement to minimize the number of missed melanoma cases, this is important in clinical applications. The mean AUC value from Fig. 9 is 0.9626 0.0215. The AUC value demonstrates that CA-SLNet shows strong performance in discriminating benign from malignant skin lesions, reinforcing its position as a reliable model for skin cancer diagnosis. The individual AUC metrics of five cross-validation splits ranged from 0.9317 to 0.9873, indicating a stable and reliable performance of the model. The model classifies the images with high accuracy and an evident capacity to distinguish between skin diseases and other conditions. This underlines the great potential of the model to help dermatologists in clinical practice. Table 4 shows the performance of the latter studies as well as their gradual advancement in melanoma classification sensitivity.
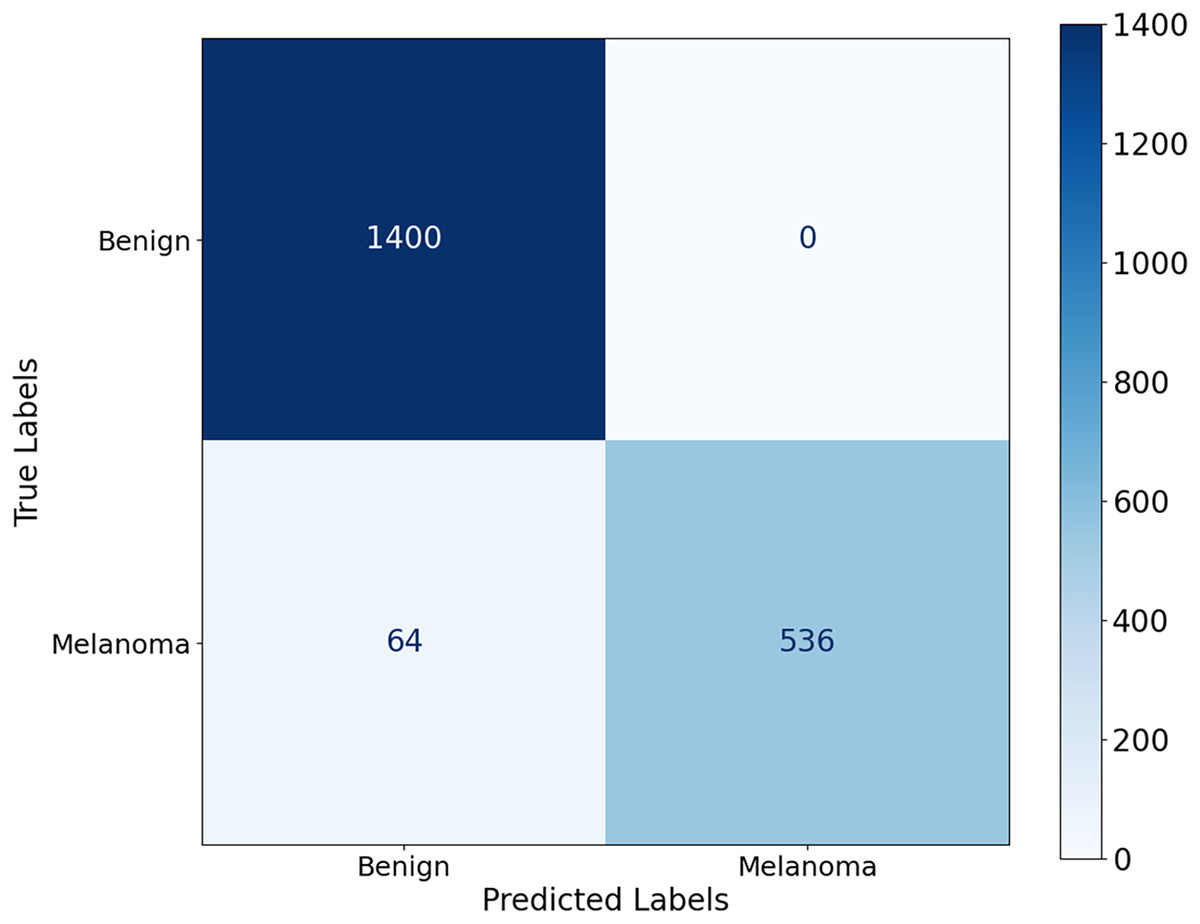
Figure 8: Confusion matrix for the ISIC 2017 dataset.
{kind=link}
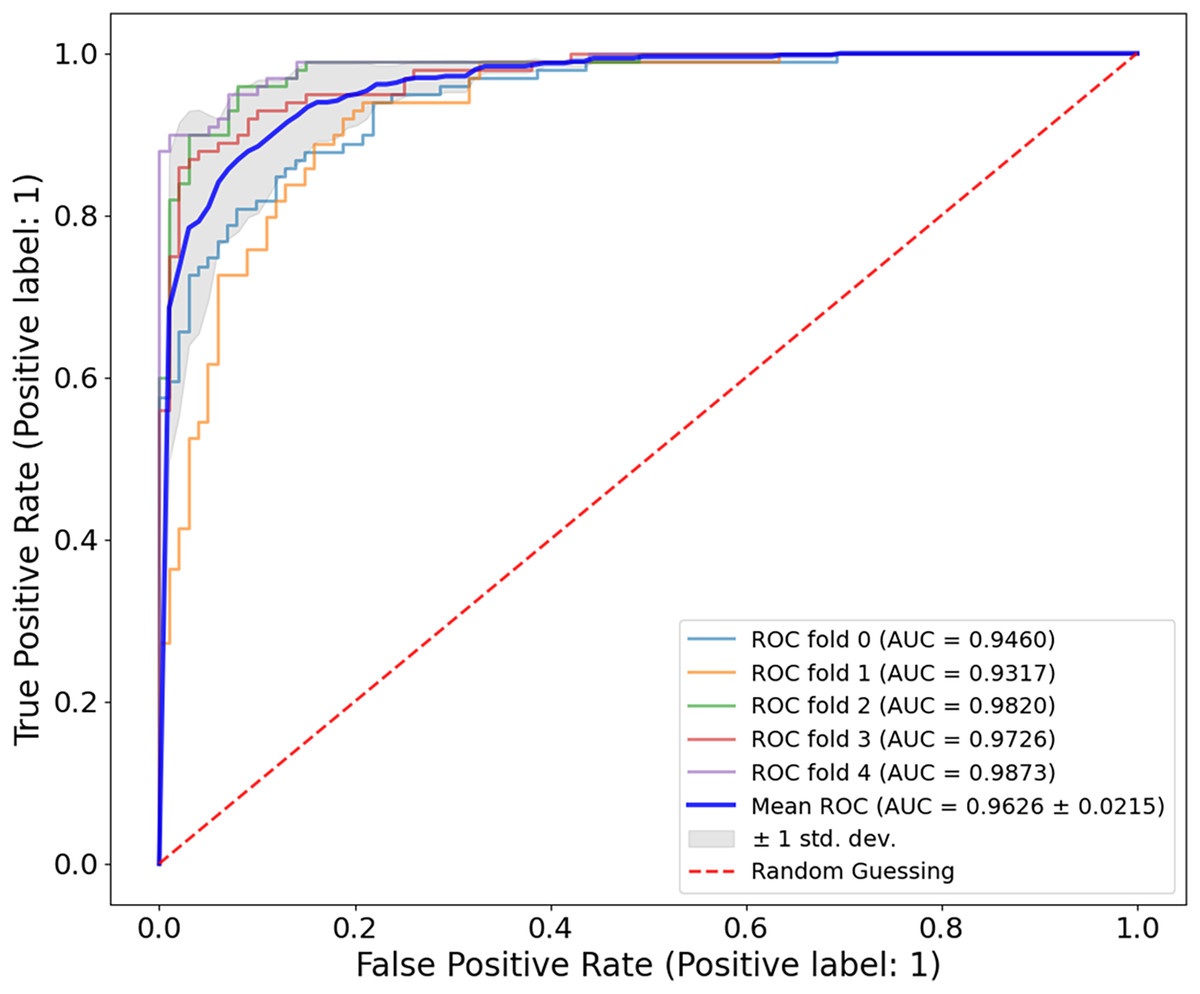
Figure 9: ROC curve for the ISIC-2017 dataset.
The CA-SLNet model achieved an average AUC of 0.9626 0.0215 with five-fold cross-validation, with individual AUC values ranging from 0.9317 to 0.9873. This demonstrates the strong and stable ability of the model to discriminate between benign and malignant lesions in different clinical presentations.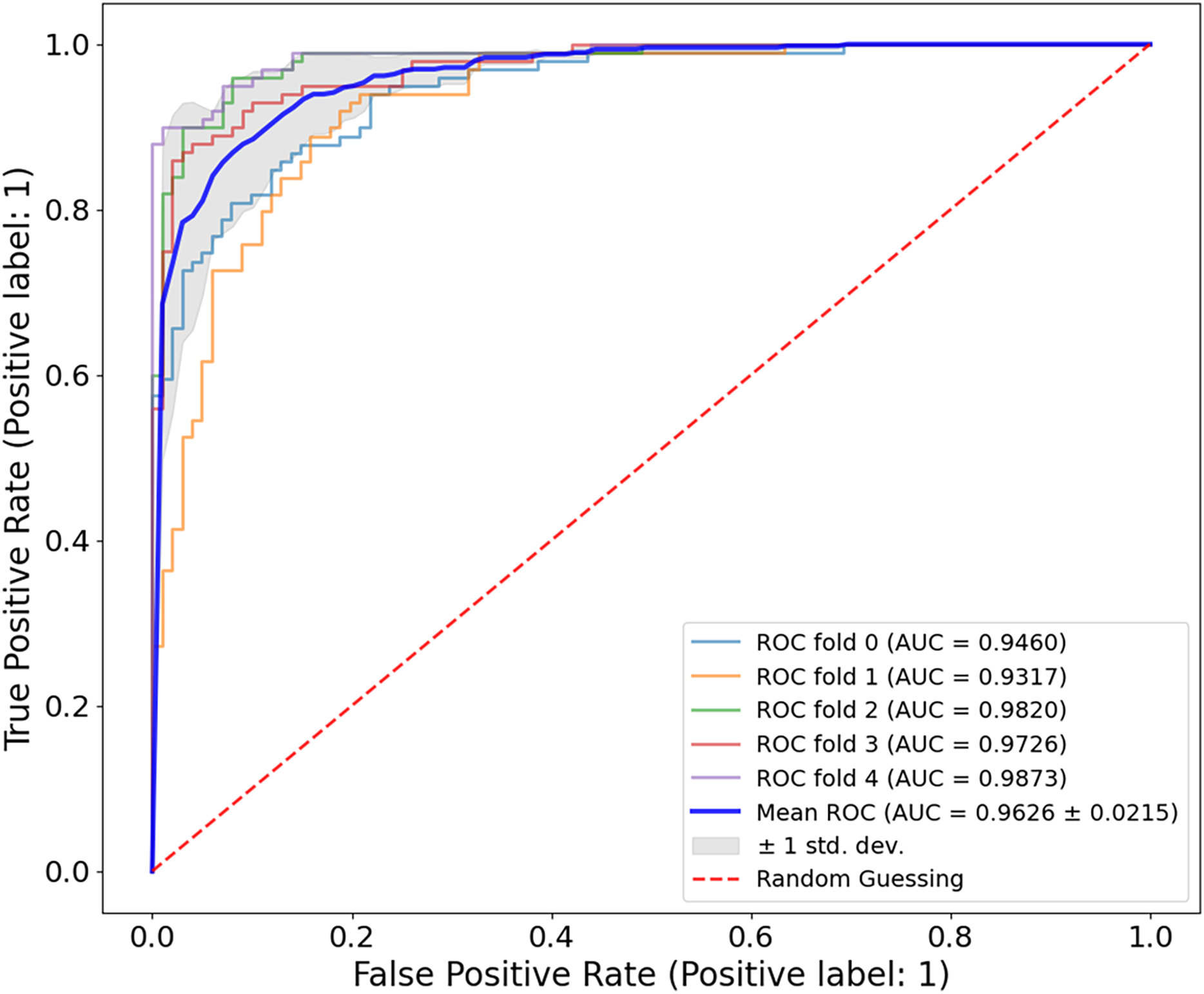{kind=link}
| Authors | Year | Problem type | Accuracy (%) | Recall (%) | Precision (%) | F1-score (%) |
|---|---|---|---|---|---|---|
| Nakai, Chen & Han (2022) | 2022 | Classification | 92.10 | 84.31 | 72.00 | 87.41 |
| Hasan et al. (2022) | 2022 | – | 93.10 | 92.80 | 92.00 | 91.80 |
| Khan et al. (2020) | 2020 | – | 93.40 | – | 94.40 | 94.29 |
| Song, Wang & Wang (2023) | 2023 | – | 95.60 | – | – | – |
| Akram et al. (2024) | 2024 | – | 95.71 | 95.90 | 95.70 | 95.70 |
| Proposed model | 2024 | Classification | 96.80 | 89.33 | 95.70 | 94.37 |
In addition, the results shown in Figs. 8 and 9 demonstrate the perfect predictive power of the model with a high AUC and minimal false positives. The CA used for dermoscopy performed better than others because its attention planes extracted more features. However, they only focus on important parts of the dermoscopic images. In addition, the model created in this work is more general due to the application of new methods for data augmentation, e.g., random deletion and color shifting. This is reflected in the consistently high performance of CA-SLNet over a given dataset, which in turn emphasizes the robustness of the network for use in clinical practice.
Figure 10 shows that the model correctly identified 40 malignant cases and correctly classified 159 benign lesions, with only one misdiagnosis of benign as malignant and no misdiagnosed malignant cases. The model achieves its results through significant accuracy with almost no errors in classification. The model achieves exceptional performance by completely suppressing misdiagnosis of melanoma, as the elimination of false negatives contributes significantly to early detection of melanoma and improved patient outcomes.
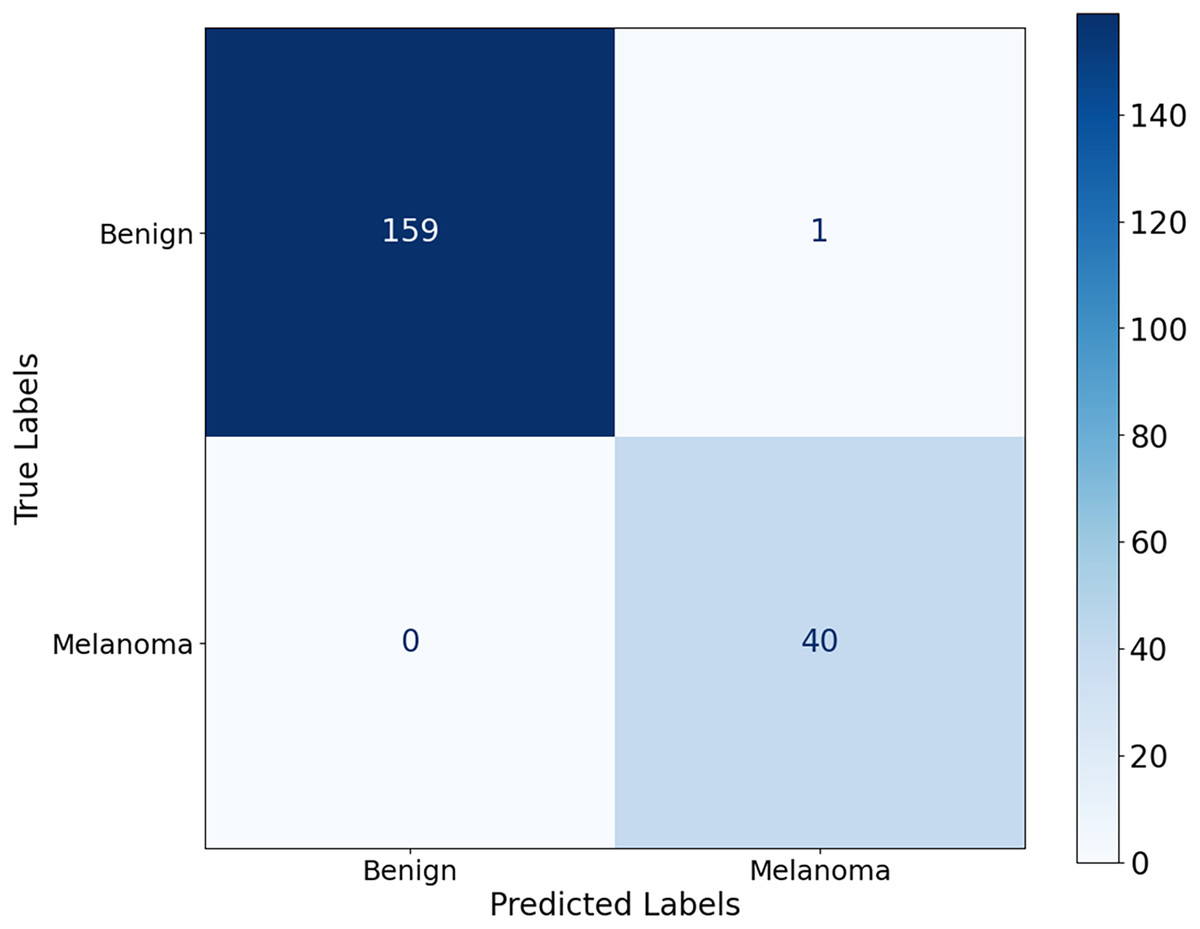
Figure 10: Confusion matrix for the Ph2 dataset.
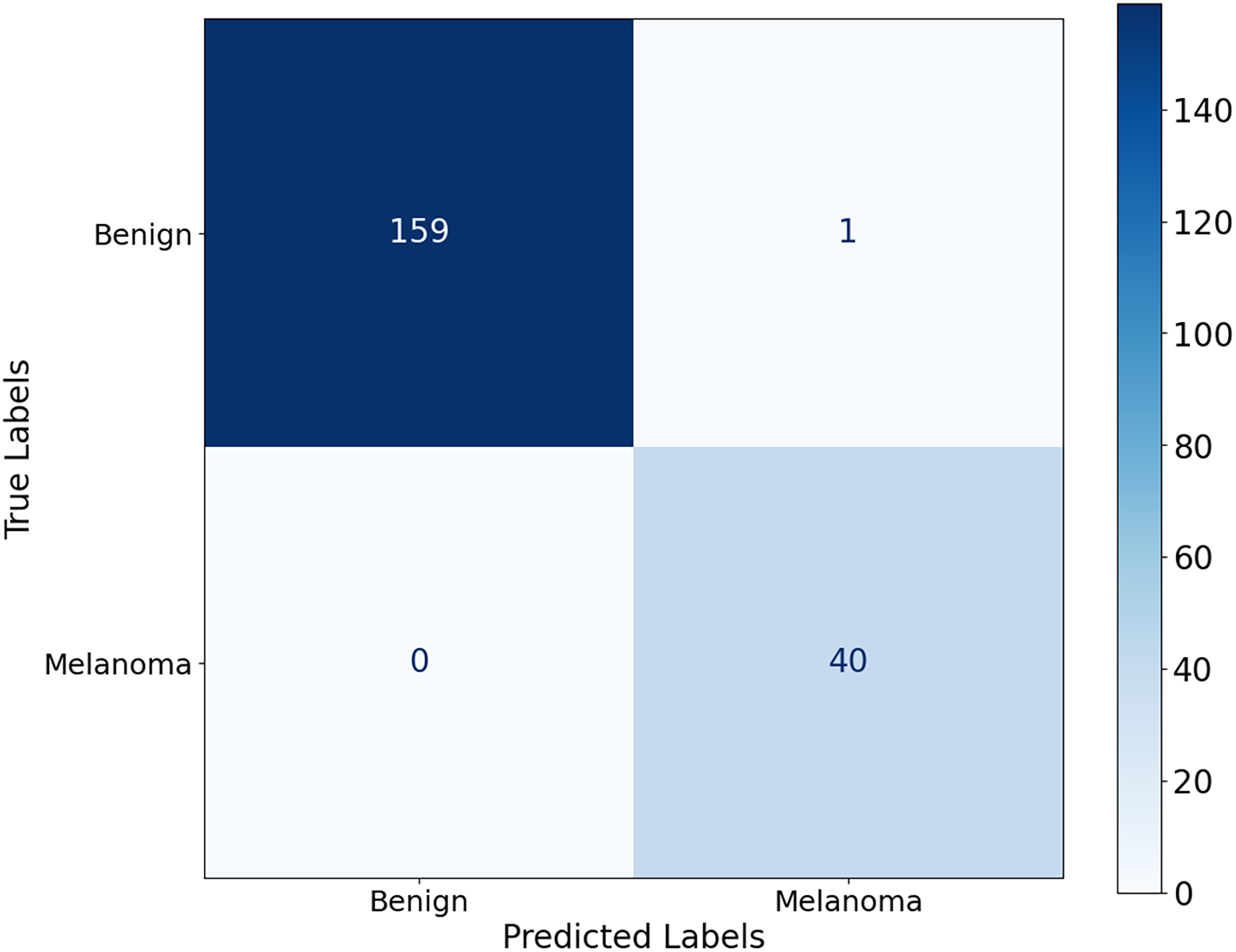{kind=link}
The evaluation of the Ph2 dataset of the proposed model shows both reliable and valid results. The model showed an average AUC value of 0.9814 0.0121 in Fig. 11, indicating its significant ability to discriminate between benign and malignant lesions. The AUC values measured in five-fold cross-validation ranged from 0.9644 to 0.9969, confirming the reliability of the model.
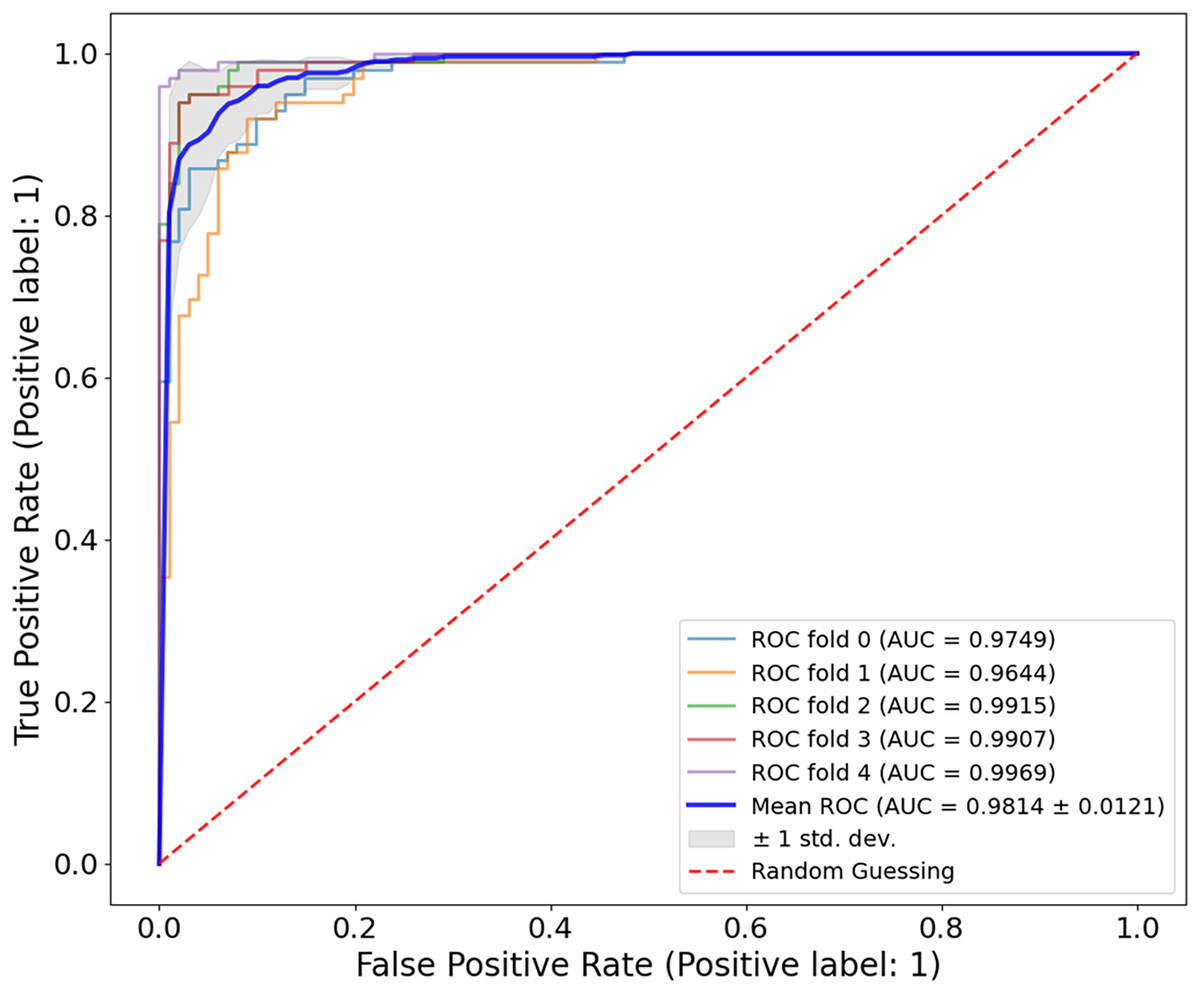
Figure 11: ROC curve for the Ph2 dataset.
The model showed exceptional classification ability with an average AUC of 0.9814 0.0121, with five-fold AUC values ranging from 0.9644 to 0.9969. The consistently high AUC underlines the generalisability and accuracy of the model, even with smaller, high-quality clinical datasets.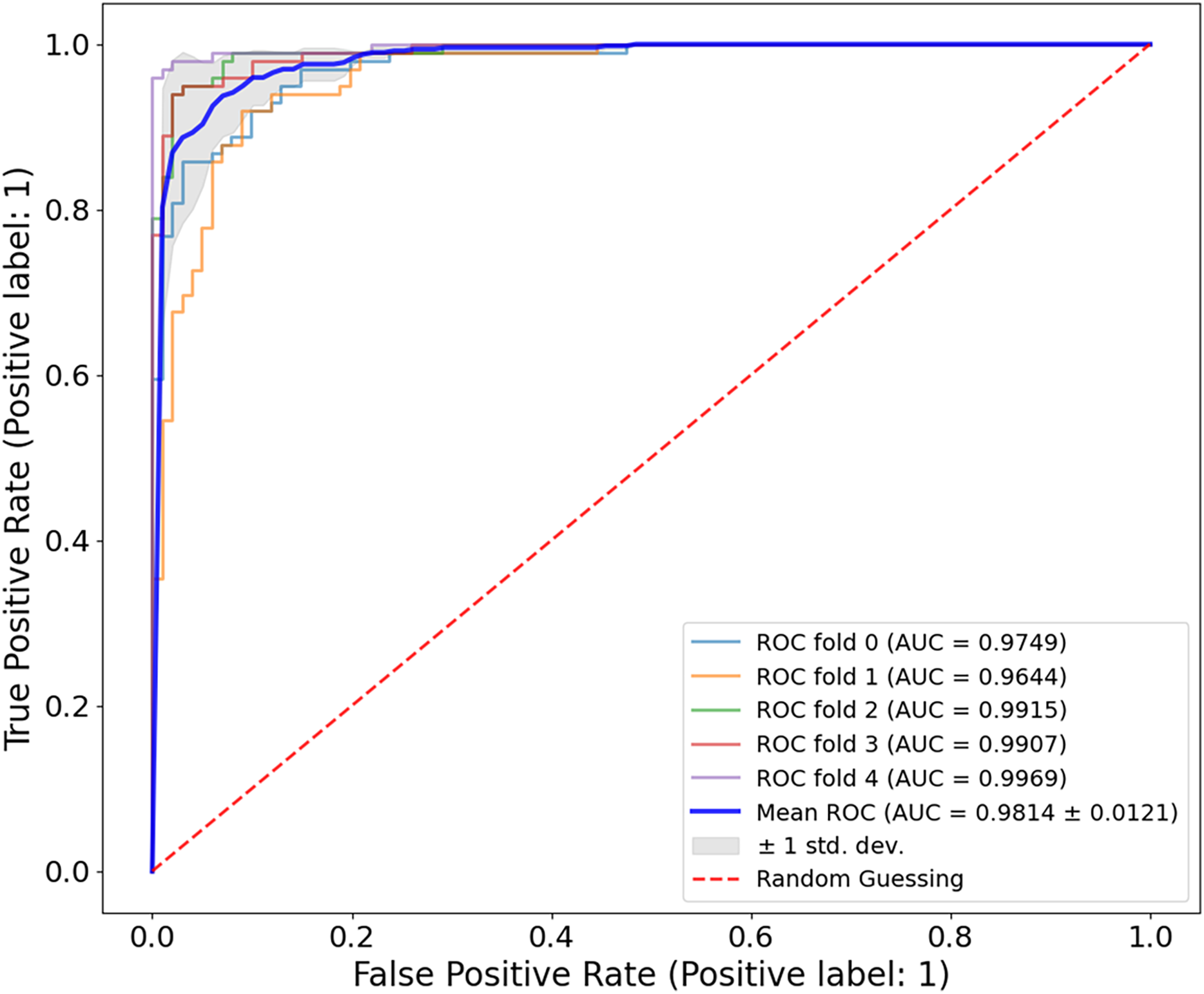{kind=link}
For all three datasets examined, ISIC-2016, ISIC-2017 and Ph2, the model achieved a very similar AUC, which could be due to specific characteristics of the concrete datasets, including the degree of disparity between classes and the range of lesions, as well as the overall resolution of the images. The results of these datasets showed that the proposed model is fully generalizable and has a high classification accuracy and a nearly flawless AUC metric, which is excellent for clinical use. Several challenges were encountered when working with the different datasets. The model can provide accurate and reproducible results when overcoming these challenges. It supports the accuracy of using a dermatoscopy in different clinical cases related to melanoma. Table 5 shows the classification accuracy of CA-SLNet compared to other models for the Ph2 dataset. Current models for melanoma classification have shown promising results, as seen in the table and the CA-SLNet proposed in this work has the highest accuracy among the models.
| Authors | Year | Problem type | Accuracy (%) | Recall (%) | Precision (%) | F1-score (%) |
|---|---|---|---|---|---|---|
| Ozkan & Koklu (2017) | 2017 | Classification | 92.50 | 90.86 | 92.38 | 90.45 |
| Xie et al. (2020) | 2020 | – | 94.20 | 94.00 | 95.00 | 94.60 |
| Hosny & Kassem (2022) | 2022 | – | 94.97 | 92.32 | 92.32 | 92.20 |
| Amin et al. (2020) | 2020 | – | 98.39 | – | – | – |
| Benyahia, Meftah & Lézoray (2022) | 2022 | – | 99.05 | – | – | – |
| Proposed model | 2024 | Classification | 99.50 | 99.40 | 98.80 | 99.77 |
The proposed CA-SLNet model shows exceptional performance and achieves 99.50% accuracy on the Ph2 dataset compared to SOTA, as shown in Table 6. This performance sets a new benchmark, exceeding the highest previously reported accuracy of 99.10% (Benyahia, Meftah & Lézoray, 2022). This significant improvement is due to CA-SLNet’s attention mechanisms, which increase focus on key lesion regions and a robust data augmentation strategy that improves generalisation. Figure 12 highlights the exceptional performance of the proposed model across multiple datasets. CA-SLNet consistently outperforms previous approaches, achieving near-perfect classification results in the Ph2 dataset and strong generalization in the ISIC 2016 and ISIC 2017 datasets. These results confirm the robustness and adaptability of the model and emphasize its potential for practical applications in clinical dermatology.
| Dataset | Accuracy (%) | Recall (%) | Precision (%) | F1-score (%) |
|---|---|---|---|---|
| Ph2 dataset | 99.50 | 99.40 | 98.80 | 99.77 |
| ISIC-2016 dataset | 98.59 | 95.25 | 99.00 | 97.57 |
| ISIC-2017 dataset | 96.80 | 89.33 | 95.70 | 94.37 |
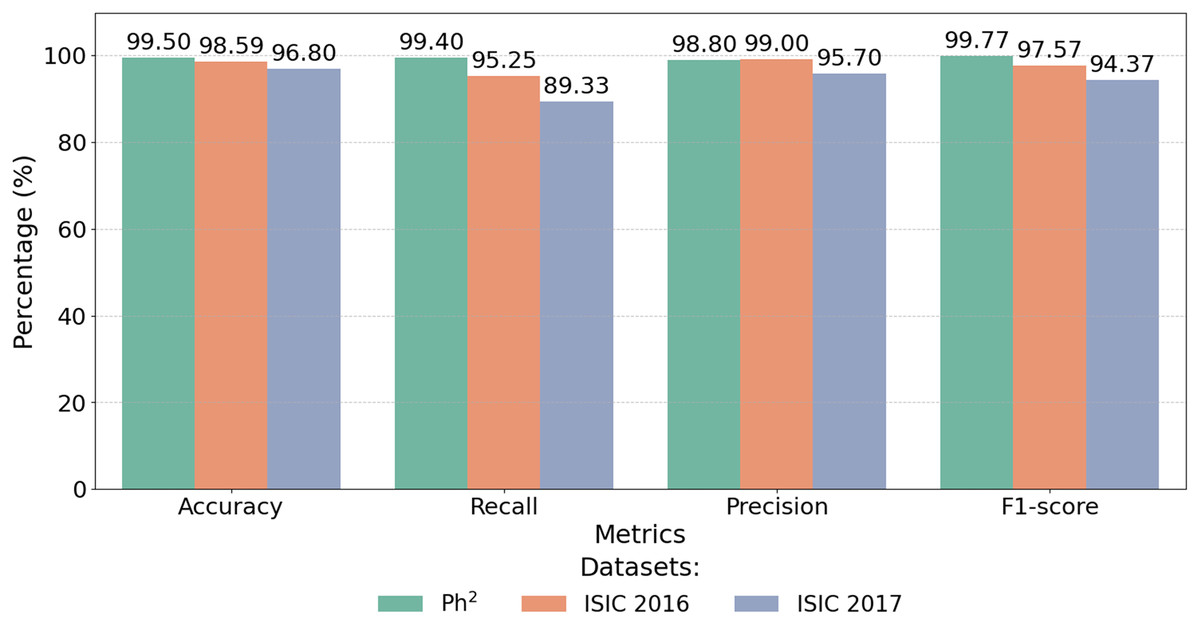
Figure 12: Performance metrics of CA-SLNet on Ph2, ISIC 2016 and ISIC 2017 datasets.
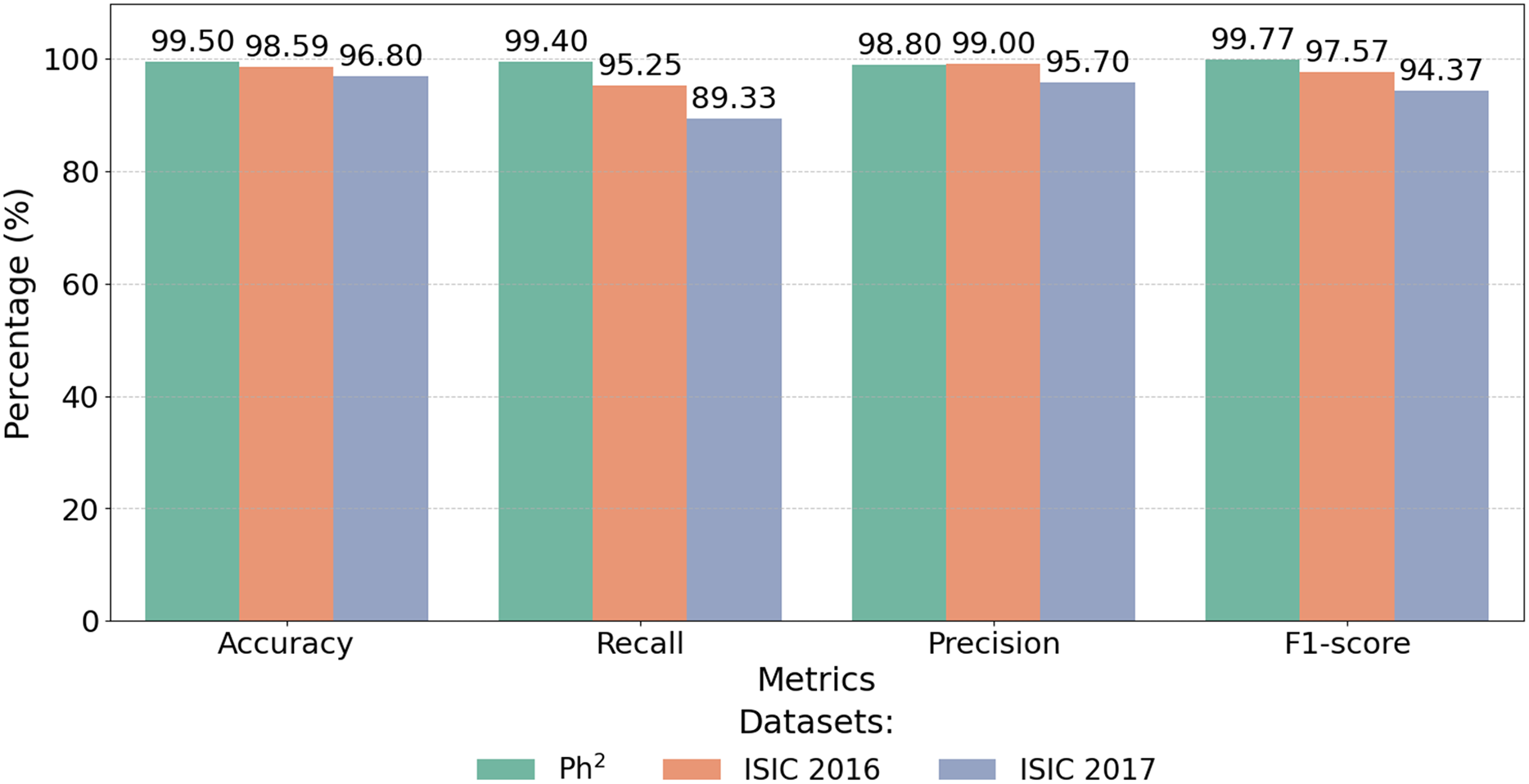{kind=link}
The integration of attentional mechanisms allows the model to extract more informative features from the lesion regions, ensuring higher precision, recall and F1-scores. Consequently, CA-SLNet proves to be a reliable solution for accurate and fast melanoma detection, which is promising for real-world applications.
Figure 12 illustrates the numerical results shown in Table 6 and shows that the model is able to achieve state-of-the-art results on different data sets. This makes CA-SLNet a scalable and suitable solution for real-world clinical applications where high precision and generalization are required.
Statistical reliability of results
To validate the robustness and reproducibility of the CA-SLNet model, we performed a five-fold cross-validation for each dataset. In all datasets, ISIC-2016, ISIC-2017 and Ph2, the model consistently provided high performance with low variance. The mean AUC values were reported along with their standard deviations in the respective ROC curve analyses: 0.9814 0.0121 for ISIC-2016, 0.9626 0.0215 for ISIC-2017 and 0.9814 0.0121 for Ph2. These small standard deviations reflect minimal variation in classification ability across different folds and demonstrate the statistical significance and reliability of the model’s predictions.
Discussion
The proposed CA-SLNet model has achieved significant results in classifying skin lesions in different datasets with channel-spatial attention implemented simultaneously with ResNet50 and VGG16 backbones. The proposed method achieved high accuracy, precision, recall and F1-scores due to global and local features. In the ISIC-2016 dataset, it achieved 98.59% accuracy, 95.25% recall, 99.00% precision and 97.57% F1-score on average. In the classification of the ISIC-2017 dataset, the model achieved an accuracy of 96.80%, a recall of 89.33%, a precision of 95.70% and an F1-score of 94.37%. The false negative rate is slightly higher due to the variety of lesions. When testing the Ph2 dataset, the model achieved near-perfect results with 99.50% accuracy, 99.40% recall rate, 98.80% precision and an F1-score of 99.77%. All of the above statistics demonstrate the excellent generality of the model, even with smaller datasets. Ablation studies confirmed the importance of each component. Disabling the CA module reduced accuracy by 3.25%, 2.98% and 3.85% for ISIC-2016, ISIC-2017 and Ph2, respectively, while removing the spatial attention (SA) module led to accuracy drops of up to 4.2%. Excluding ResNet50 or VGG16 resulted in average accuracy declines of 5.6% and 6.4%, respectively, emphasizing the complementary strengths of the dual-backbone architecture. These findings highlight the model’s ability to refine feature representation and suppress noise effectively. As shown in Table 6, CA-SLNet outperformed state-of-the-art models EfficientNet and Dermo-Optimizer. On the Ph2 dataset, CA-SLNet achieved 99.50% accuracy, surpassing EfficientNet 98.70% and Dermo-Optimizer 99.05%. Similarly, for the ISIC-2016 dataset, CA-SLNet’s 98.59% accuracy exceeded Deep CNN’s 96.3% and the Newton-Raphson framework’s 94.5%. For the ISIC-2017 dataset, which presents greater lesion variability, CA-SLNet maintained a competitive accuracy of 96.80%, outperforming most existing approaches. CA-SLNet’s high sensitivity, specificity and consistent performance across diverse lesion types establish it as a state-of-the-art automated skin lesion classification system. Its robustness and clinical relevance, particularly for early melanoma detection, indicate its potential to improve diagnostic accuracy and patient outcomes significantly. However, the model showed a comparatively higher false-negative rate in the ISIC-2017 dataset. This can be attributed to the greater lesion diversity of the dataset and complex visual overlap between benign and malignant cases, which can reduce the sensitivity of the classifier. Such cases underscore the importance of minimising false negatives in clinical diagnostics as they represent missed melanoma detections.
To evaluate the practicality of CA-SLNet, we compared its inference performance with baseline fusion strategies under the same hardware conditions. CNN models with a single backbone, such as ResNet50 and VGG16, showed the fastest inference times (28–30 ms per image). Concatenation-based fusion slightly increased this time (36 ms), while gated fusion caused more overhead (46 ms) due to the additional adaptive components. With the proposed adaptive softmax-weighted fusion strategy in CA-SLNet, a balanced inference time of about 42 ms per image was achieved, while maintaining high diagnostic accuracy at high computational performance. These results demonstrate that CA-SLNet is suitable for integration into clinical workflows that require real-time or near real-time inference, especially when deployed on a modern GPU infrastructure. In addition, the dual-backbone design combining ResNet50 and VGG16 significantly improves feature extraction and classification performance, but leads to higher computational complexity. This may limit the use of the model on edge devices or in resource-constrained clinical environments. Future work will reduce this overhead through architectural optimisation techniques such as model pruning, knowledge distillation, or replacing a backbone with a lightweight alternative such as MobileNet or EfficientNet.
Conclusion and future work
This study presented CA-SLNet, a hybrid model based on channel and spatial attention, developed for the classification of skin lesions. By integrating attention mechanisms into two backbone architectures, ResNet50 and VGG16, the model effectively captures both spatial and semantic features. The evaluation of three publicly available datasets, ISIC-2016, ISIC-2017 and PH2 showed the strong performance of the model, which achieved AUC values of 0.9814, 0.9626 and 0.9814 with corresponding classification accuracies of 98.59%, 96.80% and 99.50%, respectively. The integration of attention mechanisms with complementary features improved the model’s ability to discriminate between melanoma and non-melanoma lesions and also made it possible to identify critical spatial regions in dermoscopic images. However, the model has some limitations, including increased computational complexity due to the use of two backbones and a slightly increased false negative rate, especially for the ISIC-2017 dataset. These limitations indicate challenges for use in resource-constrained clinical settings and emphasize the need for improved sensitivity in datasets with high visual similarity between classes. Future work will focus on reducing the computational burden by optimising the model architecture, increasing the training diversity by generating synthetic data and improving the interpretability of predictions through explainable AI techniques. In addition, extending validation to larger and more diverse datasets such as ISIC-2018 and HAM10000 will be crucial to ensure better generalization and clinical applicability. Ensemble and calibration techniques can also be explored to further improve sensitivity and reduce false negatives.