
Utilizing the YOLOv8 model for accurate hand recognition with complex background
- Published
- Accepted
- Received
- Academic Editor
- Martina Iammarino
- Subject Areas
- Artificial Intelligence, Computer Vision, Data Mining and Machine Learning, Optimization Theory and Computation, Neural Networks
- Keywords
- Deep learning, Machine learning, Hand detection, YOLOv8, Convolutional neural network, Object detection, Hand gesture recognition
- Copyright
- © 2025 Kristianto et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Utilizing the YOLOv8 model for accurate hand recognition with complex background. PeerJ Computer Science 11:e3244 https://doi.org/10.7717/peerj-cs.3244
Abstract
Background
The recognition of human hands is essential in the pre-processing stage of several computer vision tasks, as they are actively involved in these actions. This task encompasses hand posture estimation, hand gesture recognition, human activity analysis, and related activities. The human hand shows a wide range of motion and experiences many morphological changes. The presence of numerous individuals in a limited area complicates the precise identification of distinct hand movements, while some hands display a wide variety of motion capabilities. This research’s motivation is to open up new opportunities to solve the problems above.
Methods
This article provides a concise analysis of convolutional neural network (CNN)-based object detection algorithms, notably emphasizing the YOLOv8n and YOLOv8s models trained for 50 and 100 epochs. This research examines various object detection algorithms, including ones specifically utilized for hand identification. Furthermore, our proposed method is trained and evaluated on the Oxford Hand Dataset and EgoHand Dataset using the YOLOv8 framework. Performance measures are employed to assess and quantify critical data, including the number of Giga Floating-Point Operations Per Second (GFLOPS), the mean average precision (mAP), and the detection duration.
Results
The results of our experiments show that utilizing YOLOv8n with a training period of 100 epochs produces a more reliable conclusion than other previously published methods. In the training phase, the model exhibited a mean Average Precision (mAP) of 86.7% for the Oxford Hand Dataset and 98.9% for the EgoHand Dataset. Moreover, YOLOv8n with 100 epochs surpasses the maximum average score (mAP) relative to prior research for both datasets.
Introduction
The use of one’s hands in everyday life is important for a variety of reasons, including communication with other people and engagement with one’s surroundings. To accurately discern hand gestures and other human activities, it is imperative to diligently check the precise positioning and motion of an individual’s hands while they are being recorded in writing (Xu et al., 2020). The ability to accurately identify and discern hands depicted in images and videos holds significant potential for enhancing various visual processing tasks, including but not limited to the comprehension of gestures and scenes (Gopikha & Balamurugan, 2023). The presence of numerous hand variations depicted in images poses a challenge in identifying hands within uncontrolled scenarios (Narasimhaswamy et al., 2019). The hand can adopt various orientations, shapes, and sizes. The presence of occlusion and motion blur accentuates the distinct visual characteristics shown by hand (Dewi & Juli Christanto, 2022). Several applications of computer vision, particularly human-computer interaction, face considerable difficulties while using in cluttered surroundings (Rapp, Curti & Boldi, 2021; Ashiquzzaman et al., 2020), sign language recognition (Shin et al., 2021), and hand action analysis (Knights et al., 2021).
Noteworthy progress has been achieved in the field of hand position estimation and gesture detection in constrained environments in recent years, leading to a notable level of development and refinement. Hand-related applications in un-constrained environments are expected to be a significant trend soon. In the given conditions, the recognition of hands in an uncontrolled setting presents a significant obstacle in the field of hand-related work. Implementing a high-precision hand recognition method is of utmost importance for applications focused on hand-related tasks and functions inside surroundings with restricted limitations. Nevertheless, the use of deep learning techniques for gesture identification may result in a significant reduction in recognition accuracy when confronted with intricate background interferences, such as variations in skin tones included within the gesture image. This is because complex background interferences might make it difficult to distinguish between different people’s gestures. The complexity of the hand detection job is strongly correlated with the wide array of hand appearances, which include changes in hand morphology, skin pigmentation, orientation, size, and partial obstruction, among several other attributes. This can pose a significant challenge to the execution of the task (Guan et al., 2021). To improve results on the hand identification task, we can use the common information supplied in the training signal for the hand appearance reconstruction task as an inductive bias (Alam, Islam & Rahman, 2022). The “hand appearance reconstruction task” involves training a model to recreate the visual characteristics of a hand, such as its shape, texture, and color, from input data. This process requires the model to learn detailed representations of hand features, which can be beneficial for tasks like hand identification.
The YOLO model is named after the maxim “You Only Look Once,” referring to the fact that it can complete object recognition tasks with just one forward pass of the neural network rather than requiring multiple passes. YOLOv8 is not merely a more efficient iteration of its forerunner. It is the most up-to-date state-of-the-art model in the YOLO family and includes several architectural upgrades, such as a new backbone network, loss function, anchor-free detecting head, etc. (Dillon et al., 2023). YOLOv8’s latest version has the same architecture as its predecessors 6, but it introduces numerous improvements compared to the earlier versions of YOLO. These improvements include a new neural network architecture that utilizes both Feature Pyramid Network (FPN) and Path Aggregation Network (PAN), as well as a new labeling tool that simplifies the annotation process. Additionally, this latest version has the same architecture as its predecessors 6. This labeling tool has several helpful features, such as labeling shortcuts, auto labeling, and customized hotkeys (Lou et al., 2023). Because these features work together, it is now much simpler to annotate photos to train the model. For the FPN to function, the spatial resolution of the input image is gradually lowered while the number of feature channels is progressively raised. This leads to the production of feature maps that can find things on a variety of scales and resolutions because of the process. On the other hand, the PAN design uses skip connections to aggregate features from multiple tiers of the network. The network will be able to better collect features at many scales and resolutions if this is done, which is essential for reliably detecting objects of varying sizes and forms (Ultralytics, 2022; Rossoshansky, 2023).
Research gap and work intention
Hand gesture identification in intricate backgrounds poses considerable difficulties due to elements such as fluctuating illumination conditions, obstructions, and background disarray. For example, it’s difficult to identify object with very bright background or with chaotic background that has similar cross section of colors. Although prior research has used diverse deep learning models for hand gesture detection, numerous algorithms show deficiencies in effectively finding motions inside intricate contexts. Furthermore, there is a dearth of research concentrating on the use of YOLOv8 models specifically designed for hand motion identification in intricate backgrounds. To address this gap, we explore the application of YOLOv8 models, specifically YOLOv8n and YOLOv8s, for hand gesture recognition tasks. By training these models on comprehensive datasets and evaluating their performance, we aim to enhance the accuracy and reliability of hand gesture recognition systems in complex backgrounds.
The following is the most important contribution that can be made from conducting this research: (1) this research contains a synopsis of the YOLOv8 family of object identification algorithms, which includes YOLOv8n and YOLOv8s with 50, 100, and epochs, as well as a brief discussion of each of these variants. (2) Many different types of object detectors are employed in this study. Metrics of performance keep a close eye on essential pieces of information, such as the average mean accuracy (mAP), the intersection over union (IoU), and the number of Giga Floating-Point Operations Per Second (GFLOPS). (3) Our proposed technique is trained and tested on the Oxford Hand Dataset and EgoHand Dataset using the YOLOv8 framework.
The outline of the article is as follows. ‘Related Works’ presents a comprehensive overview of the existing research articles in the field, along with a detailed explanation of the method employed in this study. The results of the experiments are presented in ‘Methodology’. The findings are discussed in ‘Experiments and Results’, while ‘Discussion’ provides an outline of the conclusions drawn from the study and suggests potential avenues for future research.
Related works
Convolutional neural network (CNN) used for hand recognitions
Convulational neural networks (CNNs) have proved extraordinary performance in image identification tasks due to their capacity to automatically learn and extract relevant features from images. This ability has enabled CNNs to achieve this level of success. After trying out several assorted color spaces, Girondel, Bonnaud & Caplier (2006) found that the Cb and Cr channels in the YCbCr color space were particularly effective for the skin recognition job. The Gaussian mixture model was proposed by Sigal, Sclaroff & Athitsos (2004), and it performed exceptionally well under a wide variety of illumination conditions. Because precise hand detection is necessary for a wide variety of applications, Mittal, Zisserman & Torr (2011) developed a method that makes use of several movable parts.
Hand detection is a computer vision technique that involves showing and finding human hands in images or videos. It has various applications across different domains. Some of the popular hand detection applications include (1) The detection of hands plays a pivotal role in the realm of gesture recognition, as it helps the identification and interpretation of hand gestures. These gestures, in turn, have the potential to exert control over various devices, facilitate interaction with user interfaces, and even help the translation of sign language (Adhikari et al., 2023). (2) Human-computer interaction (HCI): hand detection can enhance natural user interfaces by allowing users to interact with computers, smartphones, or other devices through hand movements and gestures (De Souza Vieira, Ribeiro Filho & De Salles Soares Neto, 2021). (3) Augmented reality (AR): in AR applications, hand detection enables users to interact with virtual objects or manipulate the virtual environment using their hands (Marrahi Gomez & Belda-Medina, 2023). (4) Virtual reality (VR): like AR, hand detection is used in VR to create a more immersive experience, allowing users to interact with the virtual world using their hands (Tran et al., 2023). (5) Sign language translation: hand detection combined with natural language processing can be used to interpret sign language and translate it into spoken or written language (Farooq, Mohd Rahim & Abid, 2023). (6) Gaming: hand detection is used in motion-controlled games, where users can control the game characters or perform in-game actions using hand gestures (Meriläinen, 2023). (7) Biometrics: hand detection can be used as a biometric authentication method, identifying individuals based on the unique characteristics of their hands (Azhar et al., 2023). (8) Robotics: in robotics, hand detection helps robots understand and respond to human gestures, allowing for more intuitive human-robot interactions. (8) Health and rehabilitation: hand detection can be used in healthcare settings for monitoring and analyzing hand movements in patients during rehabilitation exercises or evaluating conditions related to hand dexterity (Mengash et al., 2023).
Furthermore, Núñez et al. (2018) employed a neural network in conjunction with a long short-term memory (LSTM) network to discern three-dimensional hand motions by using the temporal characteristics of a skeletal structure (Xia & Xu, 2022). The computer vision field has seen a discernible surge in the level of attention dedicated to CNN-based detection algorithms as a subject of research. The situation in question can be attributed to the capacity of networked systems to acquire more profound and advanced features. The application of CNNs enables proficient resolution of the challenges associated with multi-scale and diverse rotations, as previously mentioned.
Current scholarly investigations have prioritized three primary domains to enhance the efficacy of object-detecting systems. The principles can also be applied to the task of hand detection using CNN-based methods (Dai, Fan & Dewi, 2023). In this section, we shall explain the three main directions. The primary and essential stage in this method involves altering the fundamental architecture of these networks. The second principal aim is to improve the data’s potential through the augmentation of training data quality and diversity. The statement pertains to the determination of the second principal direction (Dewi et al., 2021). The opportunity for further study is clear in the use of proxy tasks to enhance object detection representations, particularly in reasoning and other top-down processes (Dewi et al., 2022). Our efforts are mostly focused on this third primary direction. We are now able to incorporate data that is readily accessible across the world into our detection system because of advances in hand appearance reconstruction (Chen et al., 2020; Dewi et al., 2023).
Methodology
YOLOv8 architecture
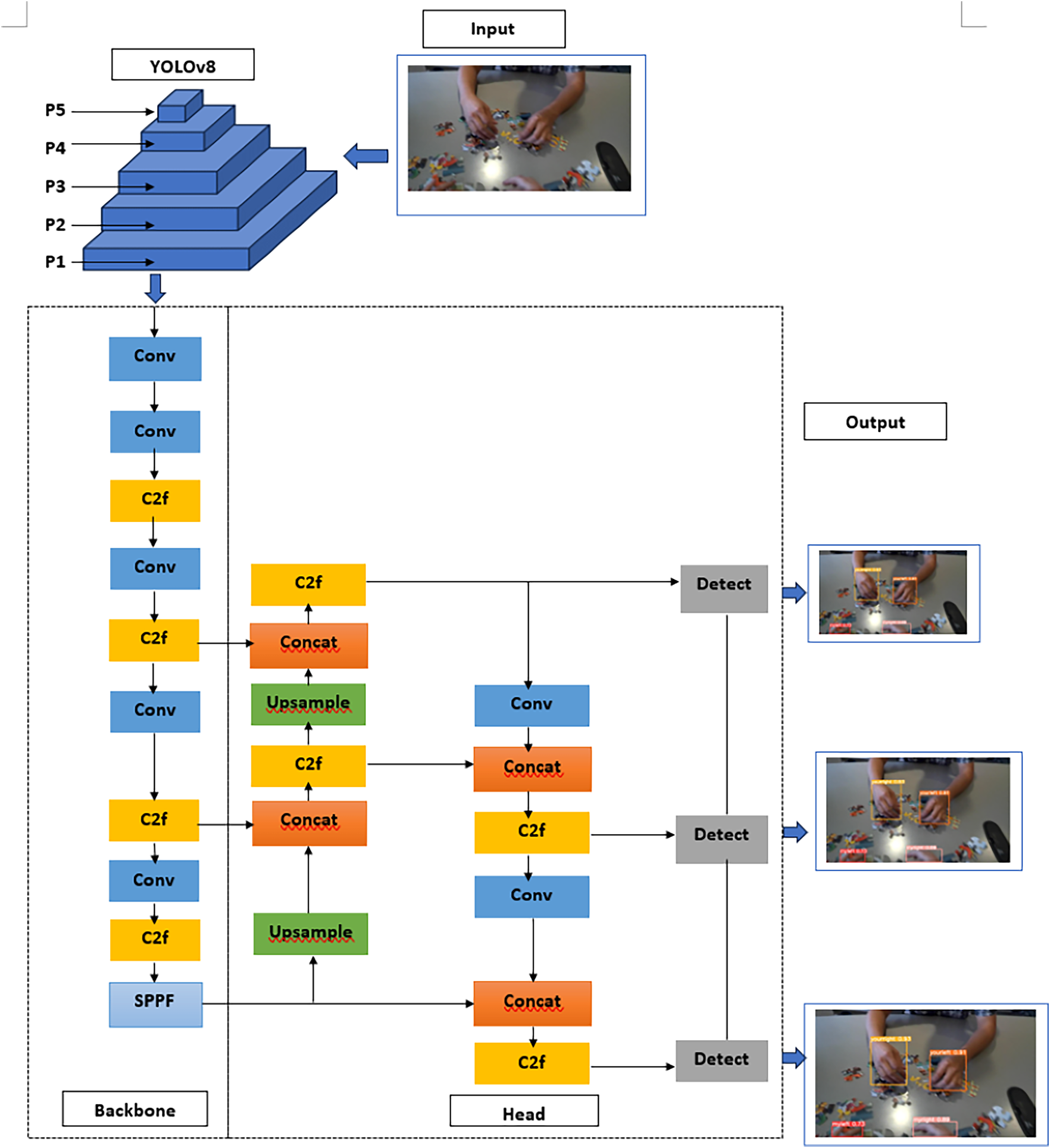
The fundamental structure of YOLOv8 is like that of YOLOv5, with the C3 module being substituted by the C2f module, which is derived from the Cross-Stage Partial Network (CSP) concept. The C2f module in YOLOv8 was developed by incorporating the Efficient Layer Aggregation Network (ELAN) concept from YOLOv7 and combining it with C3. This integration aimed to enhance the gradient flow information in YOLOv8 without compromising its lightweight design. In the final stage of the backbone architecture, the prevailing Spatial Pyramid Pooling-Fast (SPPF) module continued to be employed. This was followed by a sequential application of three Waxpools, each with a size of 5 × 5. Subsequently, the output of each layer was concatenated to ensure accurate detection of objects at different scales, while maintaining a lightweight design.
Within the cervical region, YOLOv8 utilizes the Path Aggregation Network-Feature Pyramid Network (PAN-FPN) feature fusion methodology to augment the amalgamation and use of feature layer information across different scales. The neck module in YOLOv8 was constructed by the researchers through the use of two up-sampling approaches, several C2f modules, and the final decoupled head structure. The technique of detaching the head in YOLO was previously used by YOLOv8 in the latter portion of the neck. Through the integration of confidence and regression boxes, a heightened level of accuracy was achieved. The YOLOv8 model shows the ability to support several iterations of YOLO and shows the adaptability to smoothly switch between different versions as needed. Moreover, the program has a remarkable level of adaptability as it has the ability to operate on various hardware architectures, encompassing both central processing units (CPUs) and graphics processing units (GPUs). The convolutional neural network (CNN) illustrated in Fig. 1 comprises three primary elements, including convolution, batch normalization, and Sigmoid Linear Unit (SiLU) activation functions.
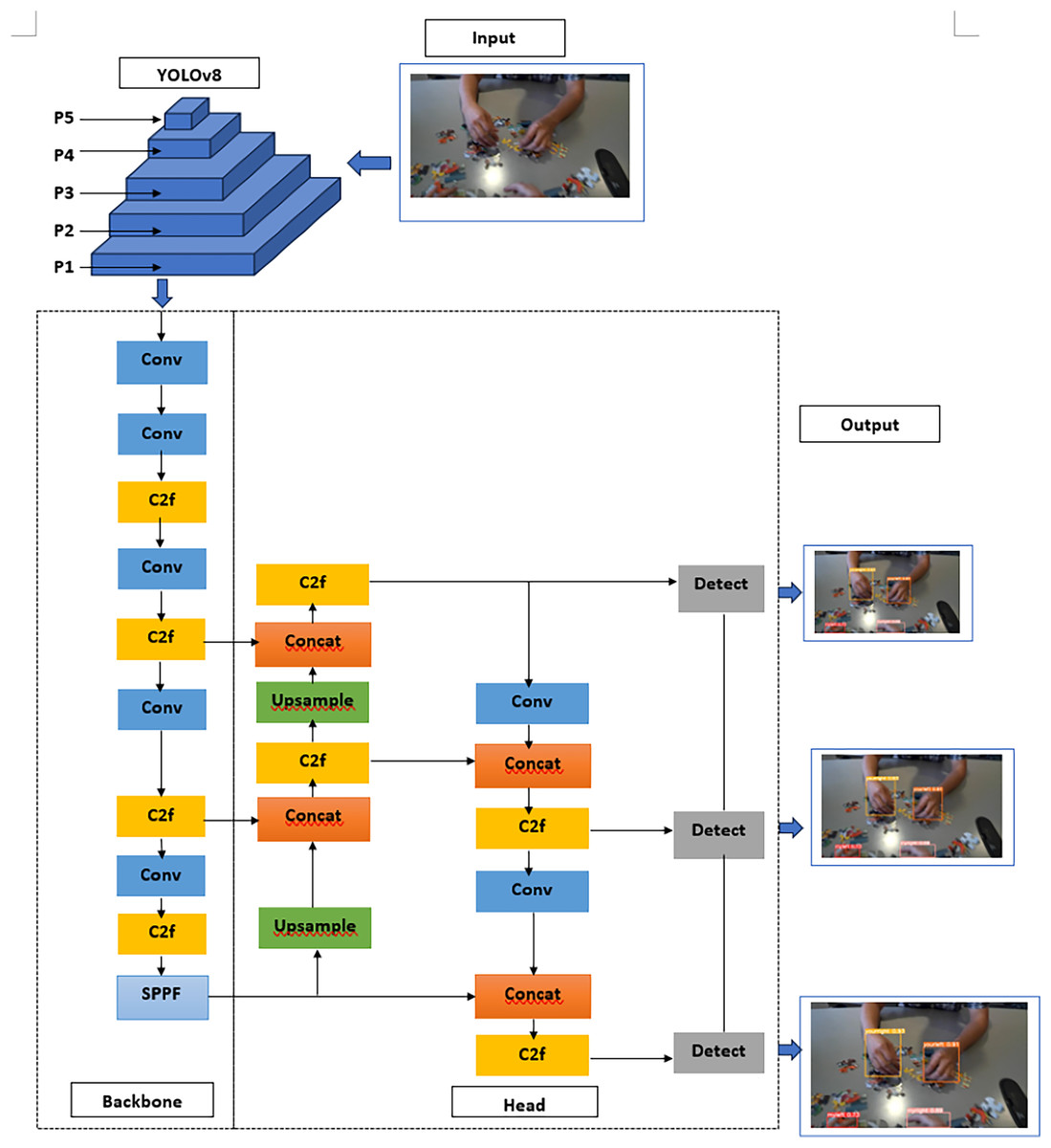
Figure 1: The architecture of YOLOv8.
{kind=link}
The YOLOv8 network can be divided into the input network, the backbone network, and the head network, as shown in the structural diagram (Dong et al., 2022). SiLU was employed as the activation function in YOLOv8, just like it was in YOLOv7 and YOLOv5, respectively. There was a recommendation made that we make use of the ELAN module. The cardinality of the network was augmented, randomized, and merged to consistently enhance its learning capabilities while preserving the original gradient trajectory. This was achieved without altering the channel count in our feature map ensembles from their original design. The preservation of the same channel count eased the accomplishment of this goal. Ultimately, the quantity of channels seen on the output of the ELAN module is twice as many as the number of channels seen on the input. The max-pooling operation that was conducted by the top branch of the MaxPooling (MP) module resulted in a reduction of fifty percent in both the dimensions of the feature map and the number of channels. Following the completion of the primary convolution, the lower branch decreased the length and width of the feature map by a factor of fifty each, while simultaneously increasing the kernel size and stride by a factor of one and two, respectively. Both tree tiers have been combined into one. After all that effort, we were finally able to produce a feature map that had input and output channels of equal size (Ultralytics, 2022). Hence, the present research initially employed a 1 × 1 convolution to reduce dimensionality, followed by a 3 × 3 convolution for down sampling. This approach effectively minimizes computational load. In this procedure, the Maxpool layer and depth-wise separable convolution were combined. This approach has the potential to effectively compensate for the loss of information that occurs during the down-sampling process of each item.
The research workflow is depicted in Fig. 2. In this study, the hand detection procedure was employed, using photos sourced from the Oxford hand dataset (Mittal, Zisserman & Torr, 2011) as the input data. Subsequently, we are engaging in training our dataset using the advanced YOLOv8n and YOLOv8s architectures, employing 50 and 100 epochs for each respective model. Subsequently, we shall engage in a comprehensive examination and discourse about the outcomes derived from the training and testing stages of YOLOv8. This intricate process encompasses the meticulous computation of the bounding box through the use of Non-Maximum Suppression (NMS). We do not implement data processing other than that provided by the basic YOLOv8 model.
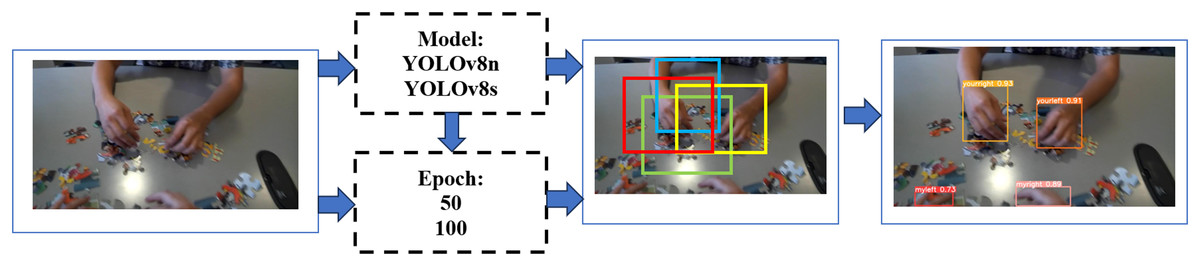
Figure 2: Research procedures.
The images of people’s faces were obtained from a publicly available database (the Oxford Hand Dataset).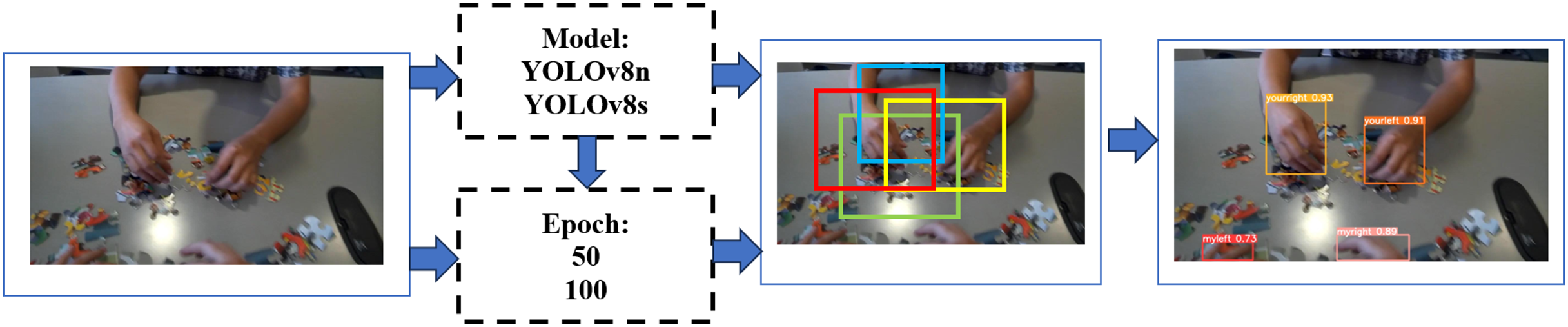{kind=link}
The Yolo labeling format is commonly used by annotation programs to generate output. This format organizes annotations for each image into a single text file. The annotation for each graphical element in an image is represented by a bounding box, also referred to as a “BBox” abbreviation, in the corresponding text file. The scale of the annotations has been changed to maintain proportionality with the image. The values of the annotations range from 0 to 1 (Long et al., 2021). In the computation that will be done using the YOLO format, Eqs. (1) through (6) will serve as the basis for the adjustment technique.
(1)
(2)
(3)
(4)
(5)
(6)
The variable H is employed to stand for the height of the image, while dh is utilized to signal the absolute height of the image. Similarly, the variable W is employed to signify the width of the image, while dw is used to stand for the absolute width of the picture.
Experiments and results
Computing infrastructure
We employed a Windows 11 Enterprise system that was equipped with an Intel(R) Core(TM) i9-12900H CPU 2.50GHz, 32 GB of RAM, and an NVIDIA RTX 3060 GPU to conduct this investigation. Additionally, we implemented simulations with Google Colab pro+.
Model evaluation
Ultralytics has employed the Binary Cross-Entropy with Logits Loss function, provided by PyTorch, to quantify the extent of loss experienced concerning both the class probability and the object score. This has been done to calculate the amount of loss that has occurred (Zhao & Zhang, 2021). A true positive (TP) refers to the count of instances where the model evaluation and the actual situation both indicate a positive outcome. On the other hand, a true negative (TN) denotes the count of instances where the model evaluation and the actual situation both indicate a negative outcome. The terms “TP” and “TN” are commonly abbreviated to denote true positive and true negative, respectively. In the context of statistical modeling, a false positive (FP) refers to a situation where the observed data does not align with the predicted value derived from the model. Conversely, a false negative (FN) arises when the observed data does not align with the predicted value derived from the model (Dewi & Chen, 2022).
(7)
(8)
(9)
The metrics encompassed in this analysis include Precision, Recall, and Accuracy. Within the set of metrics, Precision and Recall are formally defined in Eqs. (7) and (8), respectively. Subsequently, Accuracy is precisely delineated in Eq. (9), correspondingly (Han & Zeng, 2022; Jiang et al., 2022).
The integration across the precision function p(o) yields the arithmetic mean of the average precision (mAP) and the intersection over union (IoU) as depicted in Eqs. (10) and (11) correspondingly.
(10) where p(o) denotes the level of accuracy achieved by object detection. IoU determines the percentage of overlap between the bounding box of the prediction (pred) and the ground-truth value (gt) (Arcos-García, Álvarez-García & Soria-Morillo, 2018).
(11)
Moreover, it is worth noting that FLOPS, which stands for Floating Point Operations Per Second, can be quantified and expressed in various degrees of precision. In our experimental setup, we have successfully incorporated the Gigaflops (Giga Floating Point Operations Per Second) metric, which denotes a computational speed of 109 FLOPS (Floating Point Operations Per Second). This achievement is evident in the equations referenced as Eq. (12) within our study.
(12)
Moreover, Eq. (13) (Redmon et al., 2016) shows the calculation of the YOLO loss functions.
(13)
Assume that S is the image’s total number of grid cells. The predicted class between each grid cell is denoted by c, and the number of bounding boxes that are expected to exist within each grid cell is denoted by B. Additionally, the sign denotes the confidence probability score. Within the framework of cell i, the variables and correspond to the coordinates of the anchor box’s center. The variable hij represents the height of the box, while indicates its width. Additionally, denotes the confidence score associated with the box. The relative relevance of localization in the context of the job at hand is determined by using the weights λcoord and λnoobj.
The YOLOv8 model employs the anchor-free approach as opposed to the Anchor-Based method, and it uses a dynamic TaskAlignedAssigner for its matching strategy. The alignment degree of the anchor level for each instance is computed by employing Eq. (14), where s stands for the classification score, u denotes the IOU value, and α and β are the weight hyperparameters. The algorithm strategically finds a set of m anchors, specifically those with the highest value (t), as positive samples within each instance. Conversely, it designates the remaining anchors as negative samples. Subsequently, the model undergoes training by optimizing the loss function.
(14)
Following the enhancements, YOLOv8 has showed a marginal yet noteworthy 1% increase in accuracy compared to its predecessor, YOLOv5. Consequently, it has appeared as the most precise detector hitherto developed. One salient attribute of YOLOv8 exists in its intrinsic capacity for extensibility. The YOLOv8 framework has been meticulously designed to ensure compatibility across all iterations of YOLO. This remarkable feature allows researchers involved in YOLO projects to effortlessly assess and compare the performance of their respective models, thereby enhancing the convenience and efficiency of their work. This feature presents noteworthy benefits to the scholarly community. Consequently, the YOLOv8 iteration was selected as the benchmark model.
Oxford hand dataset
The Oxford hand dataset (Mittal, Zisserman & Torr, 2011) is a compendious and openly accessible collection of images depicting hands, which has been meticulously curated from a diverse array of publicly accessible image datasets.
The provided image holds annotations that highlight various instances of hands, which are readily discernible to human observers. Throughout the entirety of the dataset, a cumulative count of 13,050 instances of hands is seen. The training set assigns 11,019 data points to each hand instance, while the testing set only assigns 2,031 data points to each hand instance. During the whole process of data collection, there were no limitations put on the subjects’ immediate environmental context, nor were there any restrictions placed on the subjects’ attitudes or visibility. In addition, there were no restrictions placed on the at-attitudes or visibility of the subjects. The photos are accompanied by captions that name all the hands that are visible to the naked eye within the photographs. Human observers can distinguish between these hands. The annotations should be properly positioned around the wrist, while the bounding rectangles are not required to be aligned along any specific axis. The annotations in the ‘annotations’ folder are stored in the standard MATLAB “.mat” format, specifically being the coordinates for the four corners of the hand-bounding box.
The building is in the shape of a series of boxes, with indices represented by hand boxes. We execute the necessary data preparation on this dataset before exporting it in YOLO format. Annotations must be converted to the YOLOv8 format, which involves creating text files for each image with lines indicating object class and bounding box coordinates. The format is: <class_id> <x_center> <y_center> <width> <height>, with all values normalized between 0 and 1 relative to the image dimensions.
The training dataset comprises 70% of the total data, whilst the testing dataset constitutes the remaining 30%. Both sections contain depictions of diverse hand-held objects. Figure 3 depicts an illustrative instance of a picture derived from the Oxford hand dataset.

Figure 3: Oxford hand dataset illustrations.
The human features depicted in the figures are derived from publicly available datasets (Oxford Hand Dataset).{kind=link}
EgoHand dataset
The EgoHand dataset (Bambach et al., 2015) consists of 48 Google Glass videos of complex and first-person interactions, such as card games, chess, puzzles, and Jenga, between two individuals in various locations. There are a total of 130,000 video frames, of which 4,800 have been labeled and 15,053 instances of hands have been annotated. The EgoHand dataset includes a total of 48 videos saved in the MP4 (h264) format. Each video is a minute and a half long and has a resolution of 720 × 1,280 pixels at 30 frames per second. The labeled folder contains all the frames with their respective labels saved as 720 × 1,280 px JPEG files. The ground-truth labels are provided as MATLAB files and offer a straightforward application programming interface for them. These masks are pixel-level and correspond to each hand type. We employ EgoHand Dataset to evaluate our proposed method YOLOv8 which consists of four classes (myleft, myright, yourleft, yourright). This dataset consists of complex backgrounds including : (1) dark background and incomplete gesture, (2) Skin-like background and incomplete gesture, (3) motion blur, and (4) extremely small gesture. Figure 4 shows an example of EgoHand Dataset. When dealing with a data set that consists of complex backgrounds for hand gesture recognition, it’s important to preprocess the data effectively to improve model performance.

Figure 4: Example of EgoHand dataset.
{kind=link}
Training result
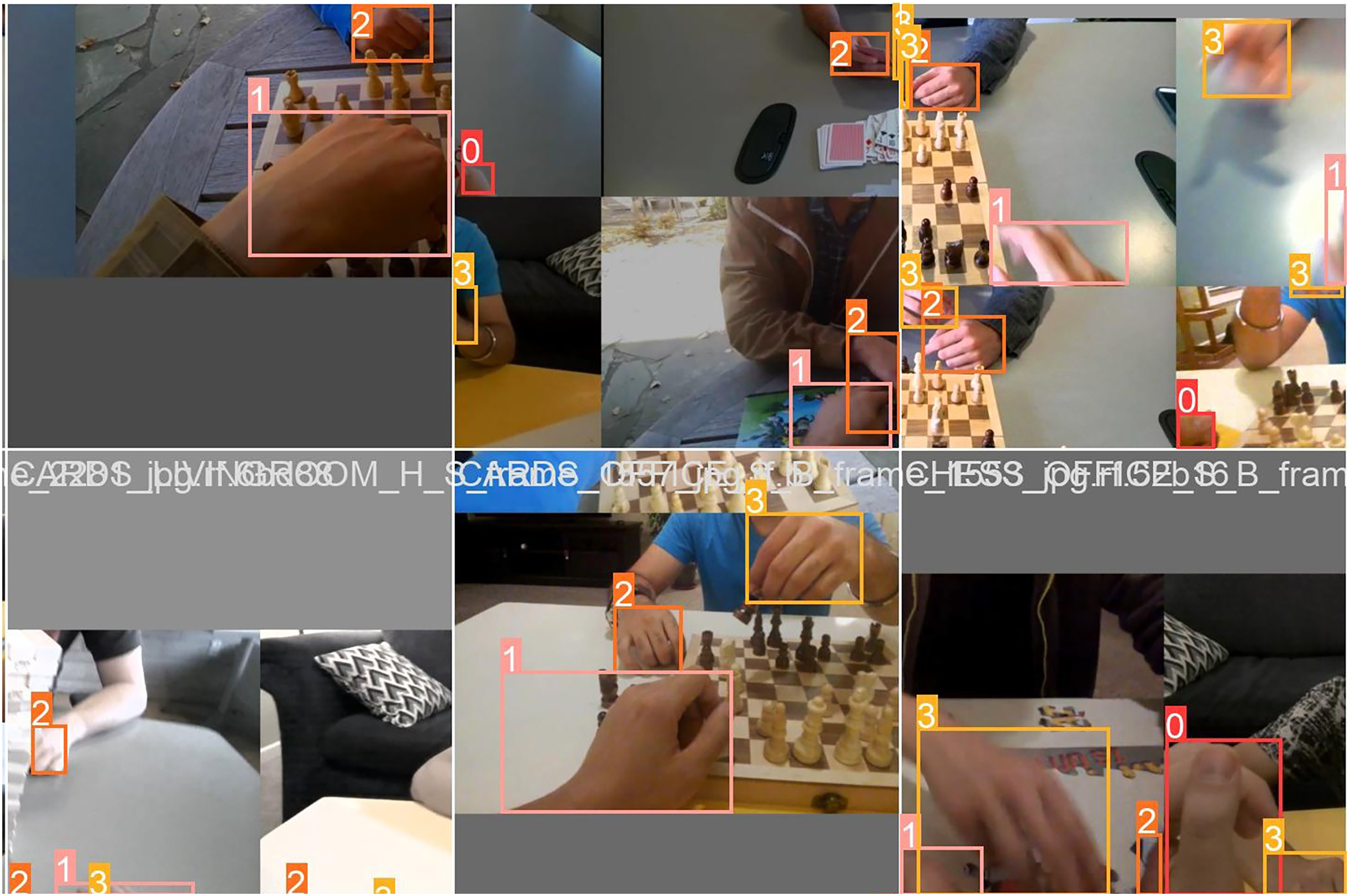
Within this segment, we shall try to furnish an all-encompassing elucidation of the training method and its corresponding outcomes. The elucidation of the training procedure for test batch 0 labels and test batch 0 predictions is depicted in Figs. 5 and 6.
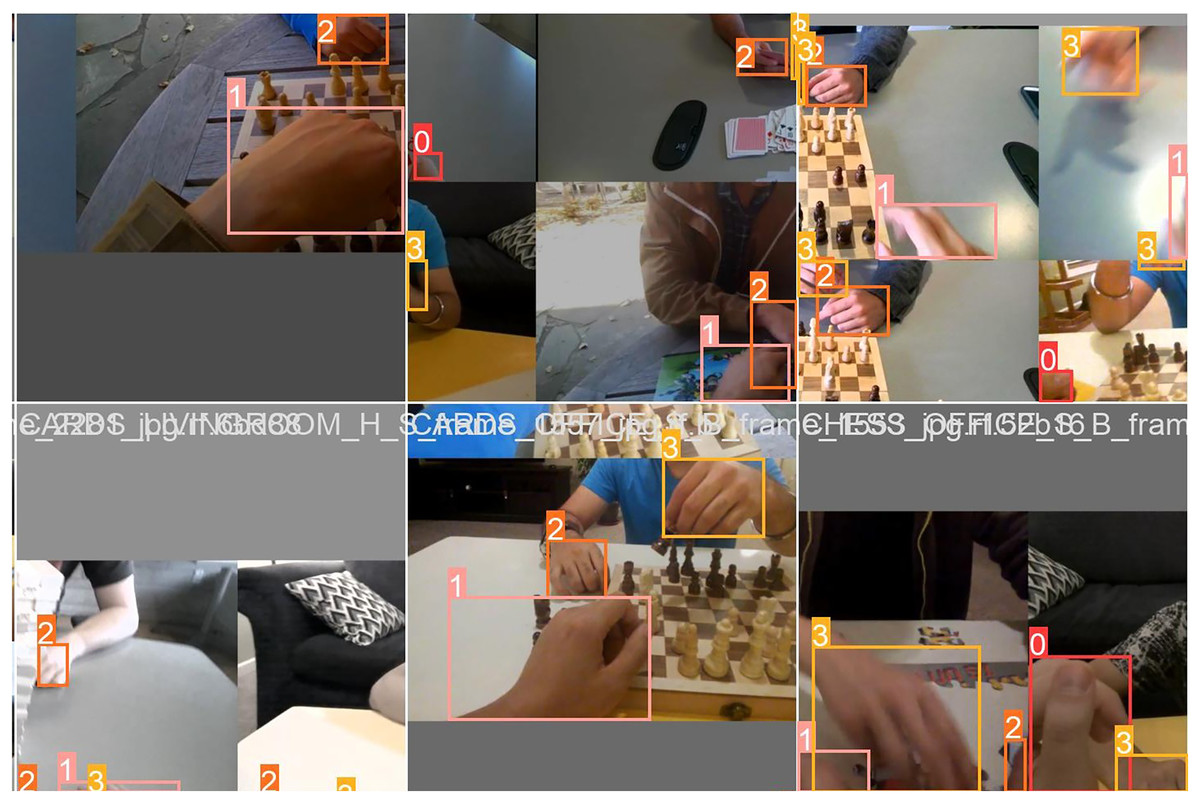
Figure 5: Batch 0 labels and batch 0 prediction for testing with Oxford Hand Dataset.
{kind=link}
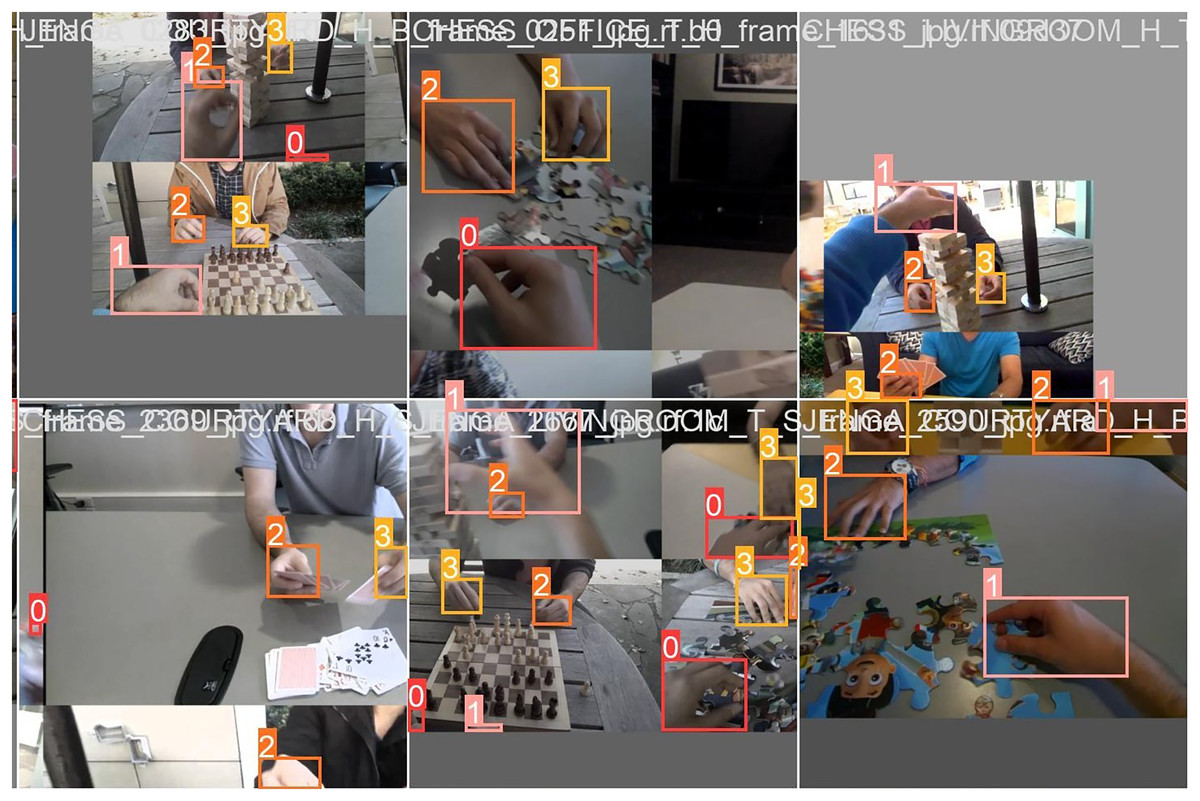
Figure 6: Batch 0 labels and batch 0 prediction for testing with EgoHand Dataset.
{kind=link}
The YOLOv8 model uses a genetic algorithm to autonomously generate the anchor boxes, thereby enhancing its ability for independent decision-making and adaptive optimization. The procedure is commonly denoted as “auto anchor” due to its inherent capability to autonomously recalibrate the anchor boxes, thereby enhancing their suitability for the given data, especially in cases where the default anchor boxes are deemed inadequate. The information provided is after incorporated into the k-means algorithm to generate k-means evolved anchor boxes. To imbue a network with profound supervision, one may opt to strategically introduce an auxiliary head within the intermediate layers at any given position. The auxiliary head can be effectively steered by using the shallow network weights and incorporating the assistance loss. In circumstances wherein the model weights would conventionally converge, this approach can still prove helpful for effectuating modifications to the model. Within the architectural framework of YOLOv8, the training head is denoted as an auxiliary head, while the primary head assumes the responsibility of overseeing the production of the final output. The utilization of lead head prediction within the YOLOv8 model serves to offer guidance in generating hierarchical labels that progress from a general to a more specific level. The labels are subsequently utilized for auxiliary head acquisition and primary head acquisition, correspondingly.
Furthermore, the training process of YOLOv8 involves the merging of four separate images through concatenation. In addition, YOLOv8’s training phase involves the combination of four distinct images. Following a random processing step during the splicing phase, each of the four distinct images has different dimensions and configurations than the others. The validation script will be employed to analyze our model. The ‘task’ setting enables users to personalize the evaluation of their model’s performance, choosing between the whole training set, the validated test set, or the test set exclusively. The default location for storing results is the “runs/train” directory. In subsequent training sessions, a new directory called “experiment” is created within the “runs/train” directory. Each new directory is assigned a unique name, such as “exp1”, “exp2”, and so on. Please refer to the train and val.jpg files to observe the mosaics, labels, forecasts, and augmentation effects. It is noteworthy to mention that the training process necessitates the utilization of an Ultralytics Mosaic Data loader, which is a device designed to amalgamate four distinct photos into a unified mosaic. Upon completing 50 and 100 epochs of training, we proceeded to save the weight obtained from the model.
The discretionary nature of fine-tuning makes it the concluding stage of training. During this phase, the whole model that was previously constructed will be unfrozen and subjected to retraining using a significantly reduced learning rate, using our dataset. Significant improvements may be achievable by iteratively changing the pre-existing trained features to adapt to the new data. A hyperparameters configuration file is a file that stores various settings and values for the hyperparameters of a machine learning model or algorithm. Hyperparameters are parameters that are set before the learning process begins and affect the behavior and performance of the model during training. When the learning rate is significantly decreased compared to conventional settings in a machine learning model, it can have several implications on the model’s training process and overall performance. The weights will be initialized with the most recently saved values from the preceding stage. Following the established convention in PyTorch, the trained model has been saved using the .pt file extension.
The mean average precision at a threshold of 0.5 ([email protected]) will be assessed during the training process to evaluate the proficiency of our detector in showing objects in the validation dataset. A higher value of [email protected] signifies enhanced performance. The dataset written in YAML Ain’t Markup Language is a vital component in the training process of YOLOv8. This file contains a list of class names and the corresponding data locations used for training and validation. To ensure proper determination of the positions of the images, labels, and classes in the training script, it is essential to include the file path as an argument. The dataset is already populated with the necessary data.
Table 1 presents a comprehensive overview of the training procedure for YOLOv8n and YOLOv8s, encompassing 50 and 100 epochs, respectively. The YOLOv8n model, trained in over 100 epochs, exhibits notable performance metrics. It achieves a precision of 88.3%, a recall of 78.4%, and a mean average precision (mAP) of 86.7%. The training process requires approximately 8.616 hours, and the resulting model size is 142.1 MB. Moreover, when YOLOv8s is trained for 100 epochs, it demonstrates a precision value of 76.8%, a recall value of 69.5%, and a mean average precision (mAP) of 74.9%.
| Epoch | Model | Images | Class | Labels | P | R | [email protected] |
|---|---|---|---|---|---|---|---|
| 50 | Yolov8n | 1,223 | All | 2,898 | 0.776 | 0.687 | 0.758 |
| 100 | Yolov8n | 1,223 | All | 2,898 | 0.883 | 0.784 | 0.867 |
| 50 | Yolov8s | 1,223 | All | 2,898 | 0.762 | 0.706 | 0.749 |
| 100 | Yolov8s | 1,223 | All | 2,898 | 0.768 | 0.695 | 0.749 |
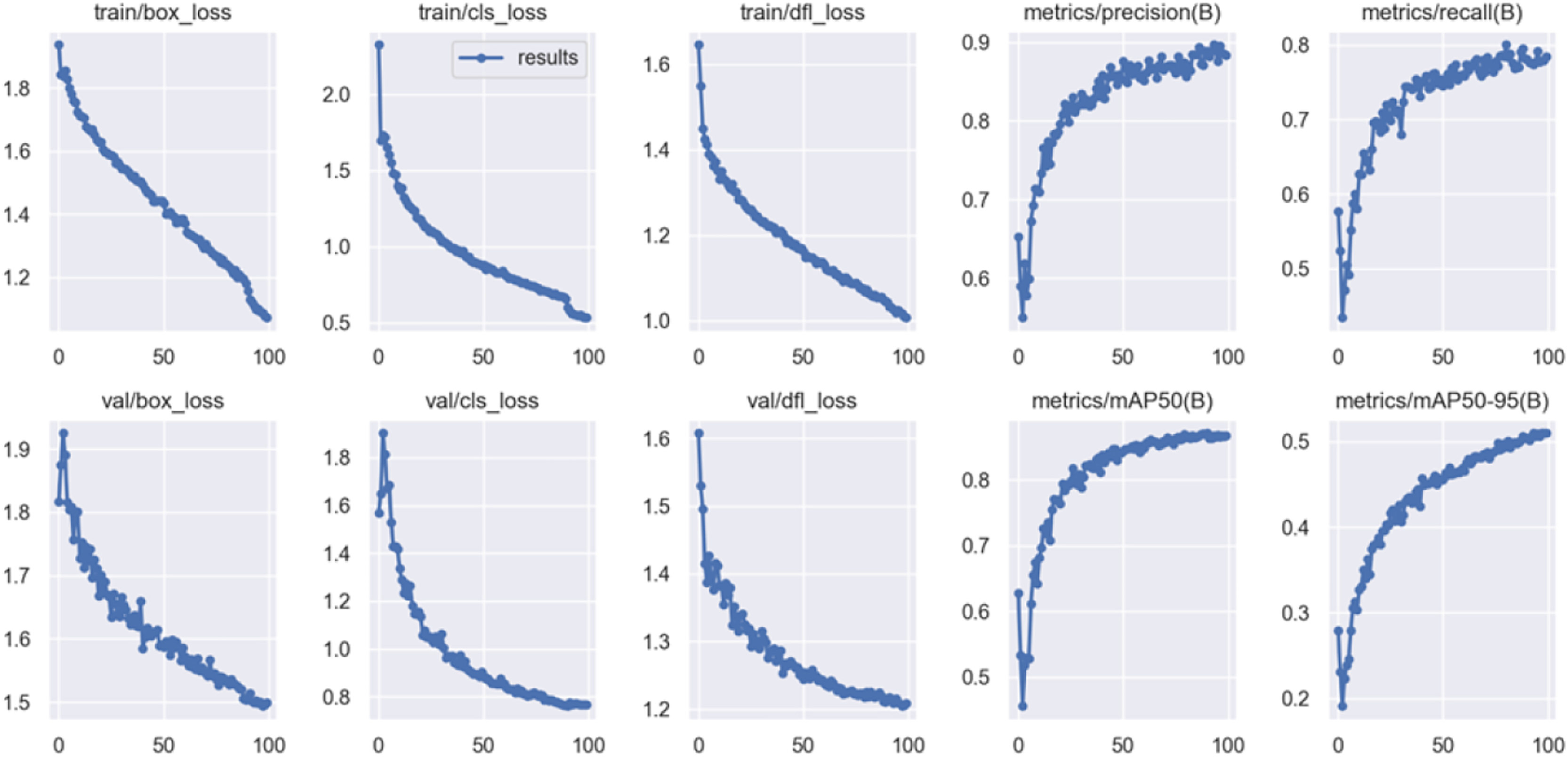
The training approach for YOLOv8n with 100 epochs is laid out in detail in Table 2, which also provides an overview of the process. The mAP for all classes is 98.9%, ‘myleft’ achieves 98.5%, ‘myright’ 99.3%, ‘yourleft’ 98.8%, and ‘yourright’ 99%. Based on the empirical evidence obtained from the two datasets, it was found that the performance of the model reached its maximum level after 100 epochs. This observation suggests that the number of epochs has a substantial impact on the outcome of the training process. As the duration of the period increases, there is a corresponding increase in performance level; however, this improvement comes at the cost of longer processing time. The training graph of YOLOv8 for 100 epochs is depicted in Fig. 7.
| Epoch | Model | Images | Class | Labels | P | R | [email protected] |
|---|---|---|---|---|---|---|---|
| 100 | Yolov8n | 480 | All | 1,515 | 0.975 | 0.968 | 0.989 |
| 100 | Yolov8n | 480 | myleft | 262 | 0.949 | 0.962 | 0.985 |
| 100 | Yolov8n | 480 | myright | 384 | 0.984 | 0.971 | 0.993 |
| 100 | Yolov8n | 480 | yourleft | 455 | 0.983 | 0.971 | 0.988 |
| 100 | Yolov8n | 480 | yourright | 450 | 0.984 | 0.967 | 0.99 |
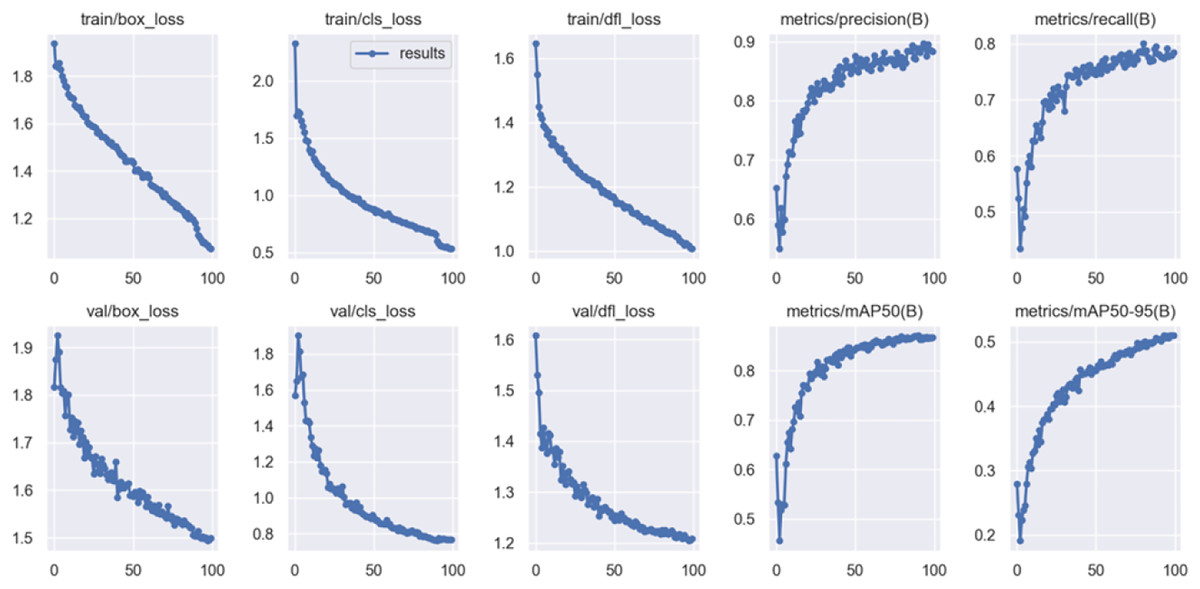
Figure 7: YOLOv8n training graph with 100 epochs.
{kind=link}
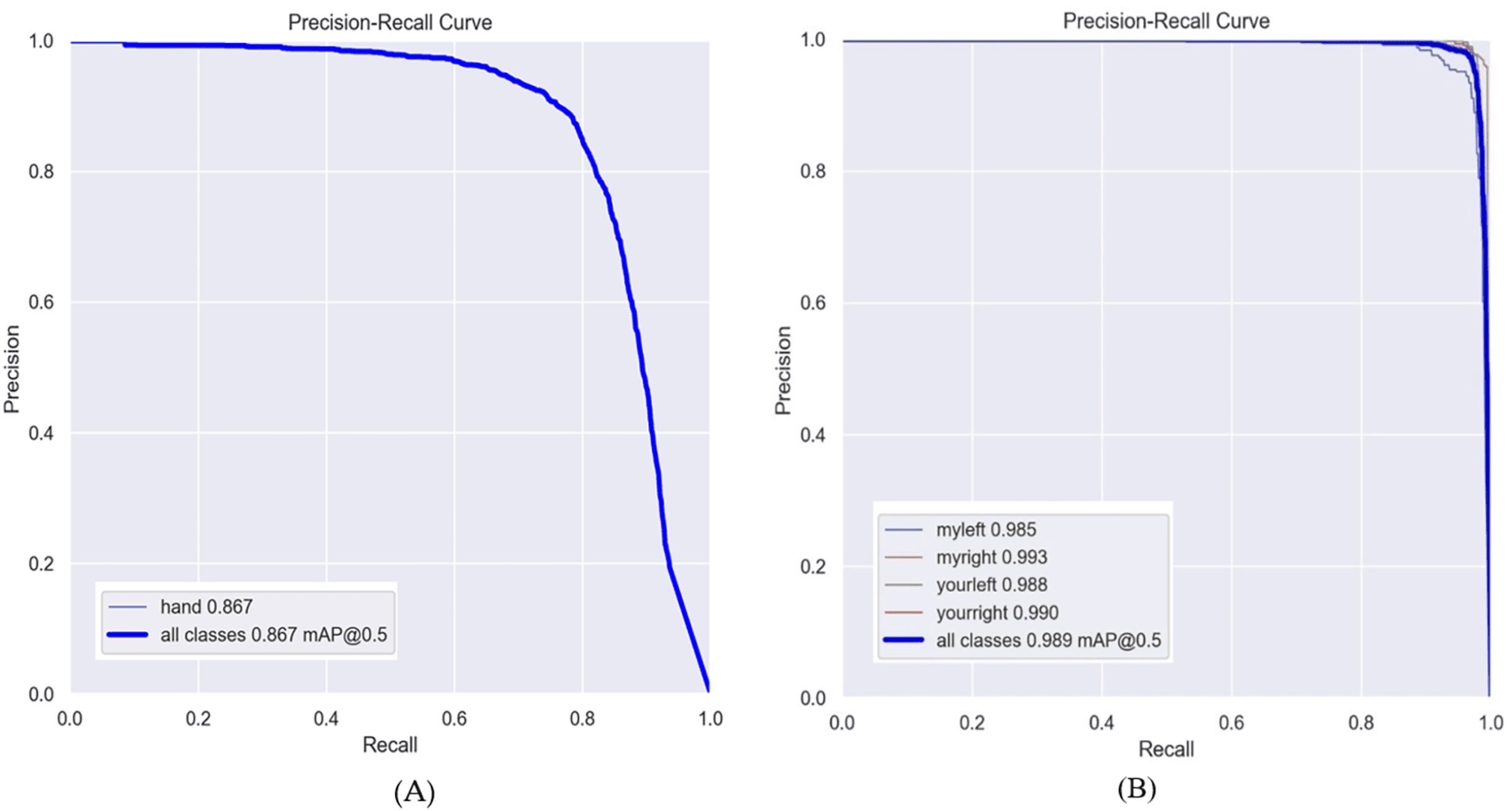
Furthermore, there exists the possibility of obtaining the precision-recall curve, which is retained persistently after each validation process. Figure 8 illustrates the accuracy and recall metrics of YOLOv8n throughout 100 epochs. In this study, we evaluate the efficacy of the Oxford Hand Dataset and EgoHand Dataset through simulations employing the YOLOv8n and YOLOv8s models. We employ specific metrics to quantify the performance of the dataset in these simulations.
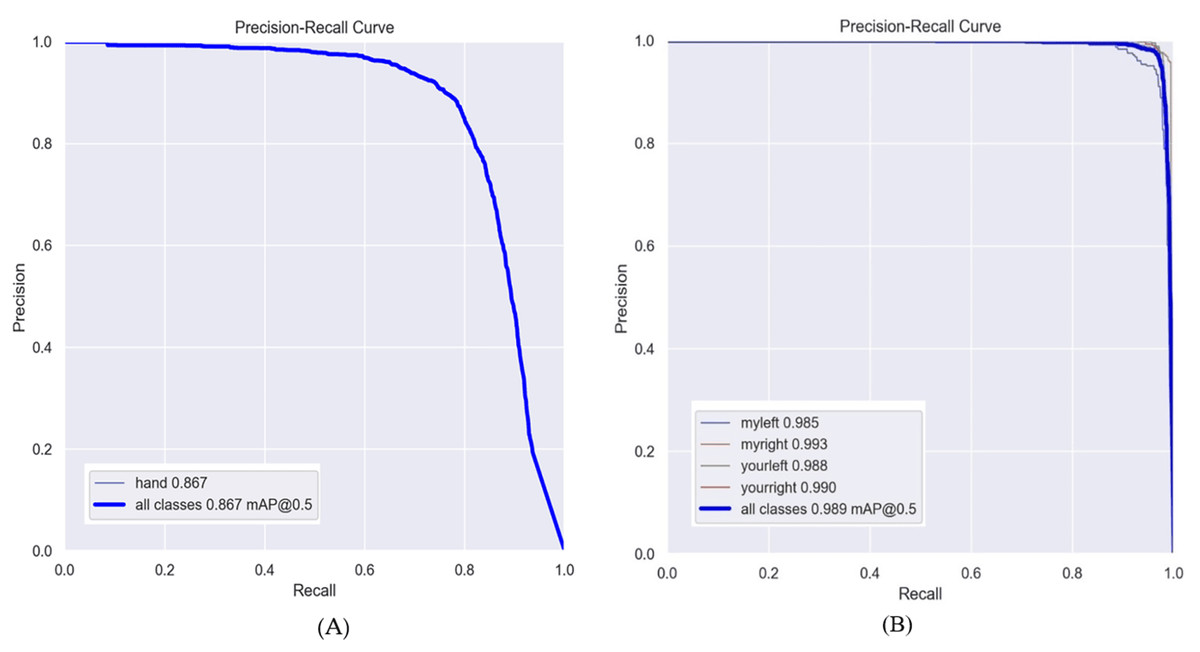
Figure 8: Precision and Recall curve (A) Oxford Hand Dataset and (B) EgoHand Dataset used YOLOv8n with 100 epochs.
{kind=link}
Discussion
According to the findings presented in Table 3, an evaluation was conducted on YOLOv8n and YOLOv8s models using 50 and 100 epochs. The results indicate that both models showed comparable performance. The ultimate prediction is a collective representation comprising all the enhanced iterations of the photos. Test-time augmentations, also known as Test-Time Augmentation (TTA), can be used to enhance the accuracy of predictions by applying them after the inference process.
| Epoch | Model | Images | Class | Labels | P | R | [email protected] |
|---|---|---|---|---|---|---|---|
| 50 | Yolov8n | 1,223 | All | 2,898 | 0.776 | 0.687 | 0.758 |
| 100 | Yolov8n | 1,223 | All | 2,898 | 0.882 | 0.784 | 0.867 |
| 50 | Yolov8s | 1,223 | All | 2,898 | 0.762 | 0.706 | 0.747 |
| 100 | Yolov8s | 1,223 | All | 2,898 | 0.768 | 0.696 | 0.75 |
The performance evaluation of YOLOv8 models involved the use of sample sets of images from each category. Based on the results obtained from our experimental study, it can be concluded that YOLOv8n and YOLOv8s exhibit superior performance when subjected to a training regimen consisting of a cumulative 100 epochs. The YOLOv8n model proves a precision of 88.2%, a recall of 78.4%, and a mean average precision (mAP) of 86.7%. Subsequently, YOLOv8s exhibited a precision of 76.8%, a recall of 69.6%, and a mean average precision (mAP) of 75%. In the field of deep learning, a set of parameters known as hyperparameters is established before the commencement of formal training. This stays true, even in situations when the rise in model complexity is accompanied by a proportionate growth in validation loss. Even though the model’s ability to detect outliers showed only a moderate improvement. Two indices of model complexity are the substantial size of its weight and the abundance of its parameters. The indices show an upward trend in tandem with the increase in model complexity. Consequently, the GPU needs a greater amount of memory (RAM) to accommodate the model during the training process.
The recognition result of the Oxford Hand Dataset with YOLOv8n after 100 epochs is depicted in Fig. 9. The YOLOv8n model successfully detects all hands in Fig. 9, achieving accuracy ranging from 40% to 80%. Table 4 shows the testing YOLOv8 performance with the EgoHand Dataset. During the testing stage, YOLOv8n with 100 epochs achieves the average mAP of 98.9% for all classes.

Figure 9: Oxford hand dataset recognition result with YOLOv8n.
{kind=link}
| Epoch | Model | Images | Class | Labels | P | R | [email protected] |
|---|---|---|---|---|---|---|---|
| 100 | Yolov8n | 480 | All | 1,515 | 0.975 | 0.968 | 0.989 |
| 100 | Yolov8n | 480 | myleft | 262 | 0.949 | 0.962 | 0.986 |
| 100 | Yolov8n | 480 | myright | 384 | 0.984 | 0.972 | 0.994 |
| 100 | Yolov8n | 480 | yourleft | 455 | 0.984 | 0.971 | 0.989 |
| 100 | Yolov8n | 480 | yourright | 450 | 0.985 | 0.967 | 0.991 |
When examining Fig. 10A, it is seen that the backdrops exhibit a darker shade and there are instances of incomplete gestures. However, it is noteworthy that the YOLOv8n algorithms successfully found all gestures with an accurate rate of 91%. In Fig. 10B, where the pictures have skin-like backgrounds and incomplete gestures, the YOLOv8n model detects all classes correctly with an accuracy of 91%, 89%, 93%, and 87%. From looking at Fig. 10C, some movements are obscured by motion and our proposed model can detect them properly. Despite this, our proposed methods accurately recognized the blurred gesture, which had a slightly lower recognition accuracy for ‘myleft’ class only achieving 67%.

Figure 10: Recognition result of EgoHand Dataset with YOLOv8n in complex background.
{kind=link}
Table 5 presents an overview of YOLOv8 models using the Oxford Hand Dataset and EgoHand Dataset. The YOLOv8n model is included of 168 layers and has a total of 3,005,483 parameters. During training, it achieves a performance of 8.1 GFLOPS. The model is trained for 50 and 100 epochs. On the other hand, YOLOv8s is composed of 168 layers, has 11,125,971 parameters, a gradient of 0, and a computational power of 28.4 GFLOPS. The YOLOv8 model serves as the basis for efficient general GPU processing, prioritizing maximum efficiency.
| Epoch | Dataset | Model | Layers | Parameters | Gradient | GFLOPS |
|---|---|---|---|---|---|---|
| 50 | Oxford hand dataset | YOLOv8n | 168 | 3,005,843 | 0 | 8.1 |
| 100 | Oxford hand dataset | YOLOv8n | 168 | 3,005,843 | 0 | 8.1 |
| 50 | Oxford hand dataset | YOLOv8s | 168 | 11,125,971 | 0 | 28.4 |
| 100 | Oxford hand dataset | YOLOv8s | 168 | 11,125,971 | 0 | 28.4 |
| 100 | EgoHand dataset | YOLOv8n | 168 | 3,006,428 | 0 | 8.1 |
Hand recognition in real-world situations faces obstacles such as data transfer interruptions, lighting instability, noisy background, and various hand orientations. YOLOv8 provides real-time and high-precision object detection, which ideal for gesture-based recognition as well as in security, healthcare, robotics, and augmented/virtual reality applications. It allows us to take advantages such as (1) accommodates diverse hand positions and sizes, (2) functions effectively across different skin tones and cultural contexts, and (3) manages hand motion blur in real-time video streams. Furthermore, sign language recognition enhances multilingual accessibility.
The benefits of YOLOv8 are abundant, such like: (1) YOLOv8 demonstrates incredible speed, which is one of its main advantages compared to alternative deep learning architectures. According to Ultralytics, the YOLOv8 model shows significant improvements in the area of image segmentation, most notably an impressive throughput of 81 frames per second. This model shows superior performance compared to other models, such as Mask region-based convolutional neural network (R-CNN), which is limited to processing about 6 frames per second. Information processing speed is becoming a critical factor in real-time applications, including autonomous vehicle domains, surveillance systems, and video analytics (Iriani Sapitri et al., 2023). (2) Accuracy: YOLOv8 demonstrates excellent precision in object and segment identification within images while maintaining fast processing speed. The updated loss function and advanced model architecture improve accuracy by reducing false positive and false negative occurrences. (3) The cohesive architecture for model training offered by YOLOv8 allows the execution of multiple image segmentation tasks within a single model. The tasks encompass object detection, instance segmentation, and image classification. This adaptability is crucial for applications requiring the execution of several tasks, such as video surveillance and image retrieval systems. Additional instances encompass autonomous vehicles.
The procedure for integrating YOLOv8 hand recognition into practical systems is as follows: (1) Data Acquisition and Preprocessing: collect varied hand gesture datasets in real-world conditions. Implement data augmentation techniques, including alterations in lighting, simulation of occlusion, and application of motion blur. (2) Model Training and Optimization: refine YOLOv8 for domain-specific gestures in rehabilitation, gaming, and security. Employ quantization and pruning to enhance real-time performance on edge devices. (3) System Deployment and Empirical Testing: integrate the model with software application programming interfaces (API) (Python, TensorFlow, OpenCV).
The comparison to the preceding study is described in Table 6. Our proposed YOLOv8n method with 100 epochs outperforms prior models on the Oxford Hand datasets in terms of mAP, with an accuracy of 86.7%. Le et al. (2017) proposed the Multiple Scale Region-based Fully Convolutional Networks (MS RFCN) and showed only 75.1% mAP. Another researcher (Yang et al., 2019) implements CNN and MobileNet and achieves 83.2% mAP. Furthermore, Dewi, Chen & Christanto (2023), implement YOLOv7x and achieves 86.3% mAP. Moreover, with the EgoHand dataset, our proposed method achieves the highest performance, 98.9% compared to previous research results. Roy, Mohanty & Sahay (2017) with Faster R-CNN and skin only achieved 96%. We were able to boost the overall performance of a recent study on hand detections in research.
| Dataset | Author | Method | mAP (%) |
|---|---|---|---|
| Oxford hand dataset | Mittal, Zisserman & Torr (2011) | Classify framework and two-stage hypothesize |
48.2 |
| Oxford hand dataset | Roy, Mohanty & Sahay (2017) | R-CNN and skin | 49.1 |
| Oxford hand dataset | Deng et al. (2018) | Joint model | 58.10 |
| Oxford hand dataset | Le et al. (2017) | Multiple scale region-based fully convolutional networks (MS RFCN) |
75.1 |
| Oxford hand dataset | Yang et al. (2019) | Convolutional neural network (CNN) and MobileNet |
83.2 |
| Oxford hand dataset | Dewi, Chen & Christanto (2023) | YOLOv7x | 86.3 |
| Oxford hand dataset | Mohammed, Lv & Islam (2019) | Lightweight CNN hand gesture recognition |
72 |
| Oxford hand dataset | Our method | YOLOv8n with 100 epochs | 86.7 |
| EgoHand dataset | Chen & Tian (2023) | YOLOv5l + ELAN + CBAM | 75.6 |
| EgoHand dataset | Mohammed, Lv & Islam (2019) | Lightweight CNN based hand gesture recognition |
93 |
| EgoHand dataset | Deng et al. (2018) | Joint model | 77.10 |
| EgoHand dataset | Roy, Mohanty & Sahay (2017) | Faster R-CNN | 50 |
| EgoHand dataset | Roy, Mohanty & Sahay (2017) | R-CNN and skin | 92.96 |
| EgoHand dataset | Roy, Mohanty & Sahay (2017) | Faster R-CNN and skin | 96 |
| EgoHand dataset | Our method | YOLOv8n with 100 epochs | 98.9 |
Conclusions
This research contains a synopsis of the YOLOv8 family of object identification algorithms, which includes YOLOv8n and YOLOv8s with 50, 100, and epochs, as well as a brief discussion of each of these variants. Furthermore, the YOLOv8n and YOLOv8s algorithms, each with 50 and 100 epochs, will serve as the primary centers of examination for the duration of this study. During our exploratory research, we put a wide variety of today’s object detectors to the test and analyzed them. Detectors that are created specifically to recognize the Oxford Hand Dataset and EgoHand Dataset are only one example of the kind of detectors that we investigate. After compiling all the findings of our inquiry into a single body of data, the following is the overall conclusion that we have come to begin, the YOLOv8n model, when trained with 100 epochs, consists of 168 layers, and has a total of 3,005,483 parameters. Next, according to the results of the experiment, out of all the models that were evaluated, the one with 100 iterations had the best performance, and the number of iterations influenced the training result. The longer the period, the better the performance; however, the longer it takes to process, the longer the epoch needs to be.
In addition, the YOLOv8n technique that we have suggested with 100 epochs beats previous models that have been applied to the Oxford Hand datasets in terms of mAP, with an accuracy of 86.7% and with EgoHand Dataset with 98.9% mAP. In comparison to the existing approaches, our method demonstrated superior performance. Notwithstanding these gains, numerous limits persist. The experiment focuses solely on YOLOv8, employing two publicly accessible datasets: the Oxford Hand Dataset and the Ego Hand Dataset. The advancement of YOLO models is rapid, exemplified by YOLOv9, YOLOv10, and YOLOv11. In our upcoming research, we are going to investigate the possibility of combining hand detection with real-time video datasets and explainable artificial intelligence (XAI). Further, we plan to couple hand detection in a logic-based framework to make automatic inferences based on the detected scene (Calimeri et al., 2019).