
CE-Prompt: enhance prompt expression stability by multiple understanding
- Published
- Accepted
- Received
- Academic Editor
- Bilal Alatas
- Subject Areas
- Artificial Intelligence, Natural Language and Speech, Text Mining, Sentiment Analysis
- Keywords
- Composite-Embedding, Generative pretrained models, Prompt-Tuning, Parameter Efficient Fine-Tuning
- Copyright
- © 2025 Yang et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. CE-Prompt: enhance prompt expression stability by multiple understanding. PeerJ Computer Science 11:e3231 https://doi.org/10.7717/peerj-cs.3231
Abstract
In this article, we propose CE-Prompt, an enhanced version of Prompt-Tuning designed to address issues such as the instability of random initialization and inefficiencies caused by long text in pre-trained large language models (LLMs). Inspired by the multi-head attention mechanism, CE-Prompt introduces the concept of composite embedding, which utilizes multiple randomly initialized embedding layers to generate more expressive prompt representations. To effectively integrate the information expressed by these composite embeddings, an additive fusion approach is employed, allowing each prompt vector to capture task-specific information more comprehensively, thereby improving the model’s task adaptability and inference efficiency. Experimental results show that CE-Prompt outperforms traditional Prompt-Tuning methods, with average improvements of 0.82% in Bilingual Evaluation Understudy (BLEU)-4 and 0.65% in ROUGE-L. Additionally, time complexity analysis indicates that CE-Prompt significantly reduces computational costs during inference. Compared to other methods, it achieves higher efficiency with the same training parameter budget, providing a more efficient solution for practical deployment.
Introduction
With the increasing use of pre-trained large language models (LLMs) (Alberts et al., 2023) in natural language processing (NLP), a variety of approaches have been proposed to fine-tune these models for specific tasks. Among the prominent techniques for parameter-efficient fine-tuning (PEFT) (Mangrulkar et al., 2022) are Adapter-Tuning, Low Rank Adaptation (LoRA), and Prefix-Tuning. The specific schematic diagram refers to Fig. 1.
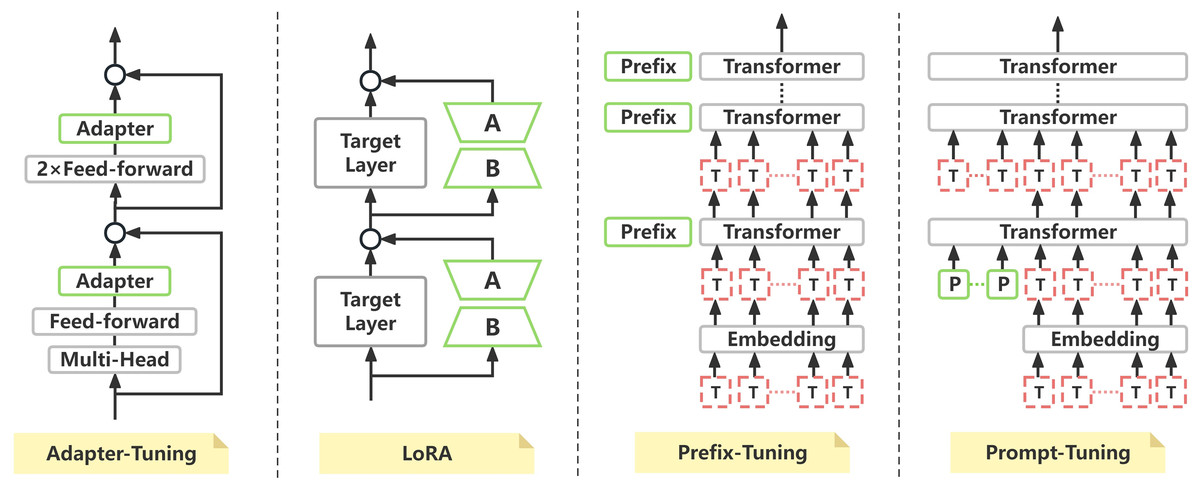
Figure 1: Structural flow diagram of different efficient parameter fine-tuning methods.
{kind=link}
Adapter-Tuning (Houlsby et al., 2019) introduces adapter modules (the green part) between each Transformer layer. These adapter modules typically include additional feed-forward layers and multi-head attention mechanisms. In Fig. 1, the “Adapter” modules are inserted between the core structure of the original model. By fine-tuning these additional adapter layers, the model can capture task-specific features without needing to modify all parameters of the original model. This makes adapter layers a parameter-efficient fine-tuning method.
LoRA (Hu et al., 2021), on the other hand, injected low-rank matrices (A and B) into the weight matrices of the target layers for fine-tuning. The core idea of LoRA is to reduce the number of trainable parameters during the training process, thus improving computational efficiency. In Fig. 1, the green “A” and “B” represent the low-rank matrices introduced by LoRA. The weight matrices of the target layer (“Target Layer”) are updated using these low-rank matrices, significantly reducing computational and storage demands.
Prefix-Tuning (Li & Liang, 2021) improves task-specific performance by introducing learnable prefix vectors (the green “Prefix” modules) at the input stage of the model. In Fig. 1, a set of new prefix vectors is added before each Transformer layer. These prefix vectors help the model better understand and process task-related information. As the prefixes propagate through the layers, the model can efficiently fine-tune for the task without adjusting the entire set of model parameters.
Despite the successes of these PEFT approaches, Prompt-Tuning (Lester, Al-Rfou & Constant, 2021) (soft prompt) uses fixed-length trainable prompt vectors (“P”) to improve the task-specific performance of the model. In Fig. 1, “P” represents these adjustable prompt vectors, which are inserted before the input to each Transformer layer. This ensures the model adjusts its generative process based on the prompt vectors, enabling efficient computation and focusing on task-specific features. There are two primary methods for initialization: random initialization and the use of task-relevant text. While task-relevant text initialization has been shown to improve performance, it often leads to excessively long prompts that can increase inference time and hinder the model’s ability to efficiently extract critical information.
While Prompt-Tuning has been successful, it still faces challenges in optimizing long prompts and balancing inference efficiency. The standard implementation of Prompt-Tuning involves determining the length L of the prompt, initializing embeddings for the L tokens, and freezing the pre-trained model while training only the embedding layer. Although the method performs well across multiple tasks, their effectiveness under limited prompt-token budgets remains inadequate. Enhancing prompt tuning to achieve comparable performance with shorter prompts is essential for improving model efficiency.
In light of these challenges, this article introduces CE-Prompt, an enhanced version of Prompt-Tuning. CE-Prompt uses a Multi-Embedding approach to improve the performance of LLMs, particularly in small-task scenarios within specific domains. Unlike traditional Prompt-Tuning, CE-Prompt initializes multiple embedding layers, transforming the L tokens into more expressive vectors, thereby enhancing the model’s performance. By employing a random initialization strategy, CE-Prompt achieves more stable results, especially in small-task scenarios, improving both inference stability and model performance.
Experimental results show that CE-Prompt outperforms traditional approaches in various NLP tasks, with its greatest advantages observed in domain-specific small-task scenarios. This article provides a detailed exploration of CE-Prompt’s design, implementation, and experimental results, offering new insights and directions for future research in Prompt-Tuning.
Related work
Generative pre-trained models
Generative pre-trained (GPT) models (Radford et al., 2018) are pre-trained on large-scale datasets to learn language patterns and semantic relationships (Ouyang et al., 2022), enabling them to handle complex linguistic structures. Fine-tuning adapts these models to specific tasks, preserving their general language capabilities while optimizing performance on downstream applications.
The development of GPT builds on earlier advancements like Embeddings from Language Models (ELMo) (Ilić et al., 2018), which addressed polysemy by dynamically modeling word meanings in context. However, ELMo’s reliance on recurrent neural networks (RNNs) (Zaremba, Sutskever & Vinyals, 2014) limited its scalability due to sequential computation. The introduction of the attention mechanism revolutionized NLP by enabling parallel processing, leading to the GPT model. GPT leverages the Transformer’s Masked Self-Attention (Li & Liang, 2021) and adopts an auto-regressive approach, where each token prediction depends on previously generated tokens, enhancing both efficiency and language understanding.
Recent advancements have produced powerful auto-regressive models like Large Language Model Meta AI (LLaMA) (Touvron et al., 2023), GPT-3 (Brown et al., 2020), T5 (Raffel et al., 2020), General Language Model (GLM) (Du et al., 2021), and Qwen (Bai et al., 2023). These models excel in tasks such as text generation, summarization, translation, and question answering (McCann et al., 2018), thanks to their extensive pre-training and scalable architectures. Notably, GPT-3 introduced few-shot and zero-shot learning capabilities, reducing the need for task-specific fine-tuning. Additionally, models like T5 unified diverse NLP tasks into a text-to-text framework, further simplifying their application.
The success of these models stems from their ability to leverage massive datasets, advanced architectures, and computational resources. However, challenges remain, such as high computational costs and the need for more efficient training methods, which are active areas of research.
Prompt-Engineer
In the evolution of prompt engineering (Sahoo et al., 2024), researchers initially proposed Zero-shot Prompting and Few-shot Prompting to address new tasks without extensive training, enabling inference with minimal or no examples. However, as tasks grew more complex, models still struggled with logical reasoning and multi-step thinking. This led to the development of Chain-of-Thought (CoT) (Wei et al., 2022), followed by extensions like Automatic Chain-of-Thought (Auto-CoT) (Zhang et al., 2022) and Self-Consistency to improve reasoning accuracy. Further innovations, such as Logical CoT (LogiCoT) (Liu et al., 2023), Chain-of-Symbol (CoS) (Hu et al., 2023), Tree-of-Thoughts (ToT) (Yao et al., 2024), Graph-of-Thought (GoT) (Besta et al., 2024), Thread of Thought (ThoT) (Zhou et al., 2023), and Chain of Table Prompting, provided structured solutions for complex logical tasks.
To reduce hallucinations, researchers integrated external retrieval and verification into methods like Retrieval-Augmented Generation (RAG) (Zhao et al., 2024), ReAct (Yao et al., 2022), Chain-of-Verification (CoVe) (Dhuliawala et al., 2023), Chain-of-Note (CoN) (Yu et al., 2023), and Chain-of-Knowledge (CoK) (Li et al., 2023), leveraging external knowledge or self-verification to minimize errors. For user-model interaction, Active-Prompt allows dynamic guidance, while Automatic Prompt Engineer (APE) automates prompt construction, reducing manual effort.
In knowledge-driven reasoning, Automatic Reasoning and Tool-use (ART) (Paranjape et al., 2023) and Contrastic Chain-of-Thought (CCoT) (Chen et al., 2022) enhance reasoning by integrating knowledge bases or toolchains. Efforts to improve textual consistency and readability ensure logical coherence, while Emotion Prompting incorporates emotional cues for better user interaction.
For code generation, techniques like Scratchpad Prompting, Program of Thoughts (PoT) (Wang et al., 2018), Structured Chain-of-Thought (SCoT) (Li et al., 2025), and Chain-of-Code (CoC) (Li et al., 2023) embed programming logic, expanding models’ applicability in software development. Research on optimization by prompting improves inference efficiency, while Rephrase and Respond (RaR) (Deng et al., 2023) and Take a Step Back Prompting enable iterative self-correction, fostering higher levels of intelligence and self-reflection.
Parameter-efficient fine-tuning
In the fine-tuning process of large-scale pre-trained models, efficiently adapting to downstream tasks has become a critical issue. To address the computational overhead and storage costs, a variety of Parameter-Efficient Fine-Tuning methods have been proposed in recent years. These methods aim to reduce the number of parameters that need to be adjusted while maintaining the model’s task adaptation capabilities.
One strategy for efficient fine-tuning is modifying the model structure. For instance, Adapter-Tuning inserts adapter layers between the Transformer blocks, enabling task-specific adaptations without altering the original model parameters. This approach offers a high level of parameter efficiency. Another common method involves fine-tuning only a subset of the model’s parameters. LoRA achieves this by injecting low-rank matrices, reducing the number of parameters that need to be updated. This technique leverages matrix factorization to efficiently update the model, thereby reducing computational costs. Additionally, methods like Prefix-Tuning and Prompt-Tuning adapt the model by adding task-specific virtual tokens or soft prompt embeddings to the input. These approaches update only the prefix of the input, without altering the internal parameters of the model, thus providing a lightweight adaptation mechanism.
Building upon these foundational methods, several extensions have been proposed, such as DoRA (Liu et al., 2024), Multitask Prompt-Tuning (Wang et al., 2023), and P-Tuning v2 (Liu et al., 2021). While these methods have shown certain advantages in specific scenarios, they also come with limitations, such as strong dependency on specific tasks or unstable performance when handling long-range dependencies.
Overall, the research on PEFT continues to evolve, with new methods offering diverse options for efficient fine-tuning of large-scale pre-trained models. The central challenge remains how to reduce the number of parameters adjusted while improving the model’s performance.
Method
Prompt engineering (Sahoo et al., 2024) traditionally relies on manually designed hard prompts to guide a model’s task understanding and output generation. However, hard prompt methods are limited by scalability and the need for domain expertise. To overcome these issues, Prompt-Tuning (soft prompt) replaces manually crafted prompts with learnable vector representations, referred to as “learnable prefixes” or “soft prompts”. These prompts are concatenated with the input sequence and fed into the pre-trained model, which is typically frozen during fine-tuning. This approach offers parameter efficiency, as only the prompt vectors are updated, while the rest of the model parameters remain fixed, allowing for faster and more flexible adaptation to different tasks. In Fig. 2, the input sequence is combined with a prompt embedding, and the resulting input is passed through a multi-layer decoder. Each layer includes multi-head self-attention, layer normalization, and a feed-forward network. The model then generates the next word, with only the prompt embeddings being fine-tuned.
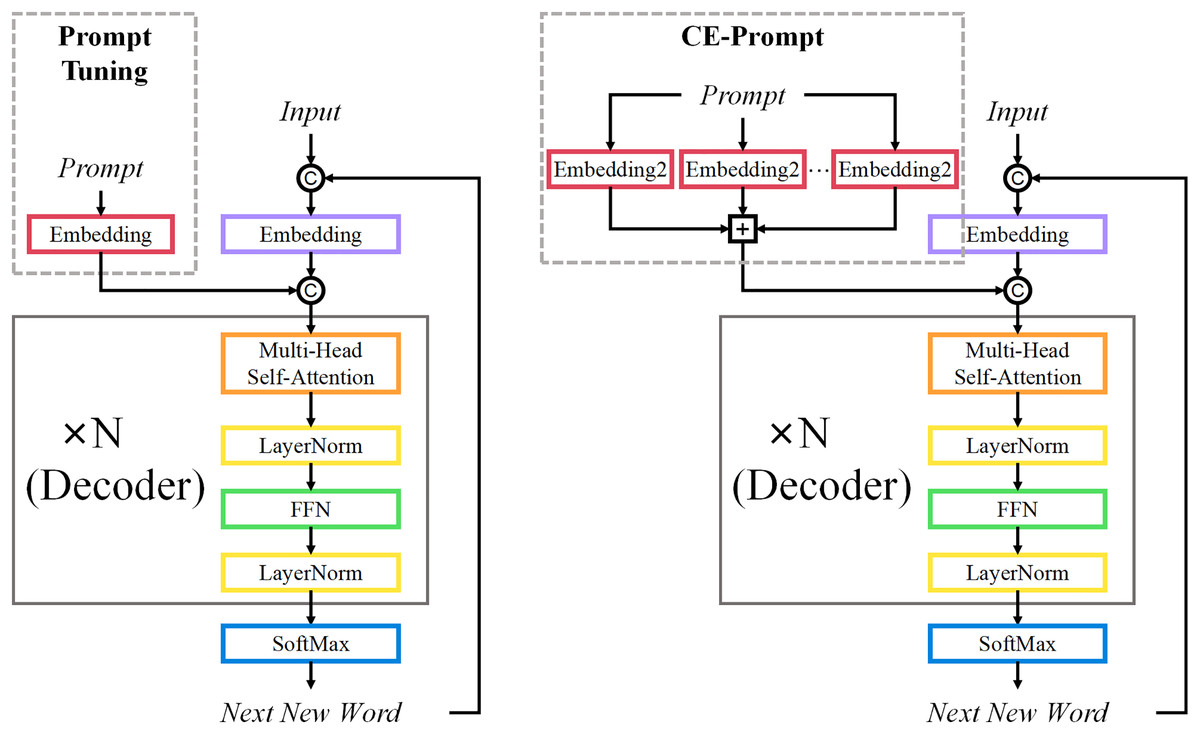
Figure 2: Structure diagram of GPT Model Fine-tuning with Prompt-Tuning and CE-Prompt.
{kind=link}
In this work, we build upon this idea with CE-Prompt, which expands the flexibility of standard Prompt-Tuning by incorporating multiple embedding layers. While traditional Prompt-Tuning uses a single embedding vector to represent task-specific information, CE-Prompt introduces multiple randomly initialized embedding vectors, each capturing different aspects of the input. This approach improves the model’s ability to generalize across various tasks, enhancing both task adaptability and performance.
Let denote the pre-trained language model with frozen parameters . In the Prompt-Tuning setup, we introduce a set of trainable prompt vectors , where L represents the length of the prompt and is the dimension of the embedding space. For a given input sequence , we first map it to the embedding space through the model’s embedding layer, yielding the sequence . We then concatenate the learned prompt vector with the input embeddings, resulting in the concatenated input representation:
(1) The concatenated input is passed through the frozen pre-trained model , generating the output:
(2)
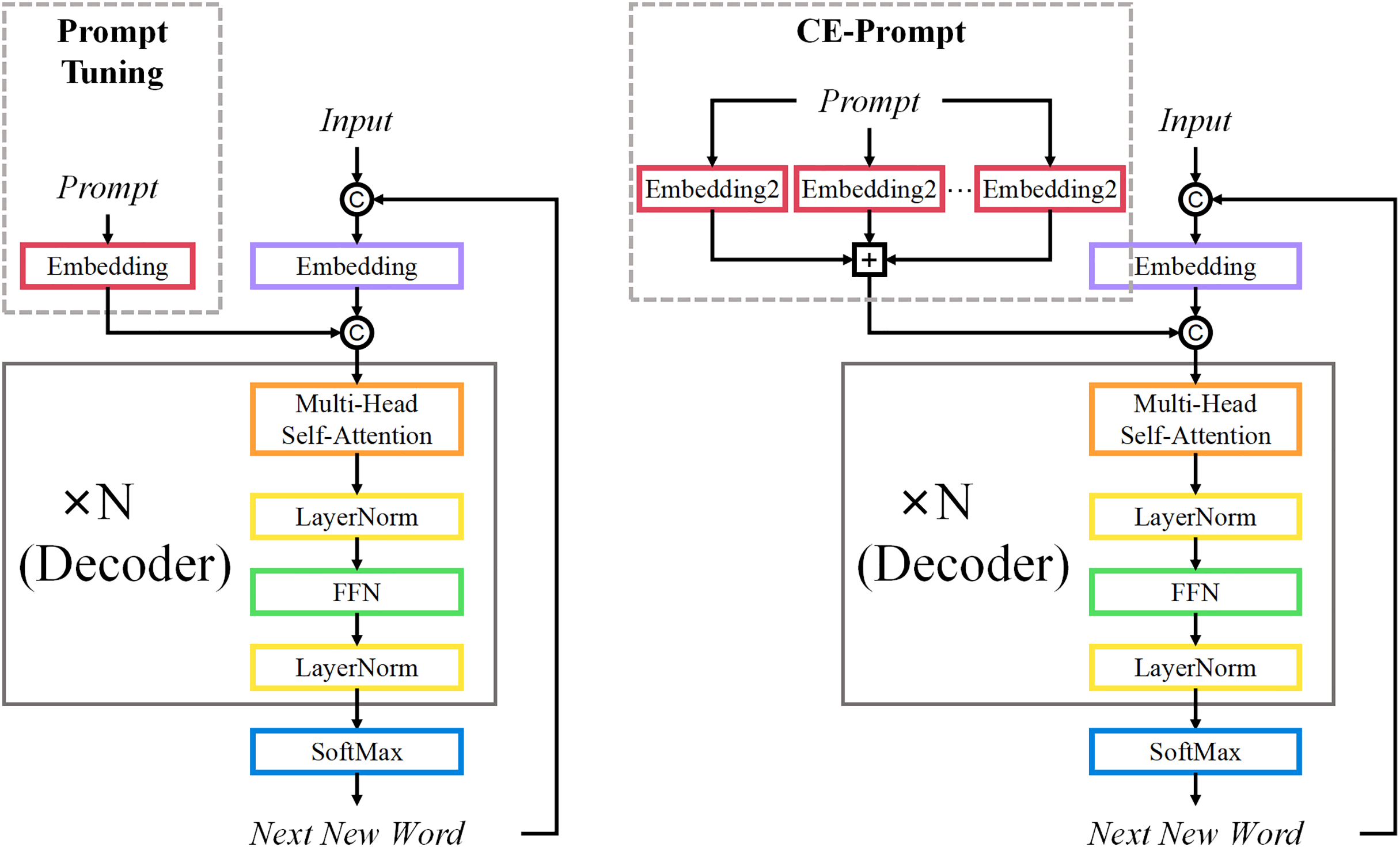
In contrast to the single soft prompt used in traditional Prompt-Tuning, CE-Prompt introduces multiple embedding layers to enrich the input representation. For each layer , we learn a separate embedding vector , which is randomly initialized to promote diversity across the layers. The composite input representation for each layer is formed by concatenating the corresponding embedding vector with the original input embeddings:
(3) Each composite embedding is then passed through the frozen pre-trained model to obtain the output representation:
(4) The outputs from all M composite embeddings are combined to enhance task-specific performance or generation capabilities. For more details, refer to Fig. 3, which illustrates the differences in the process of obtaining embedding vectors between Prompt-Tuning and CE-Prompt.
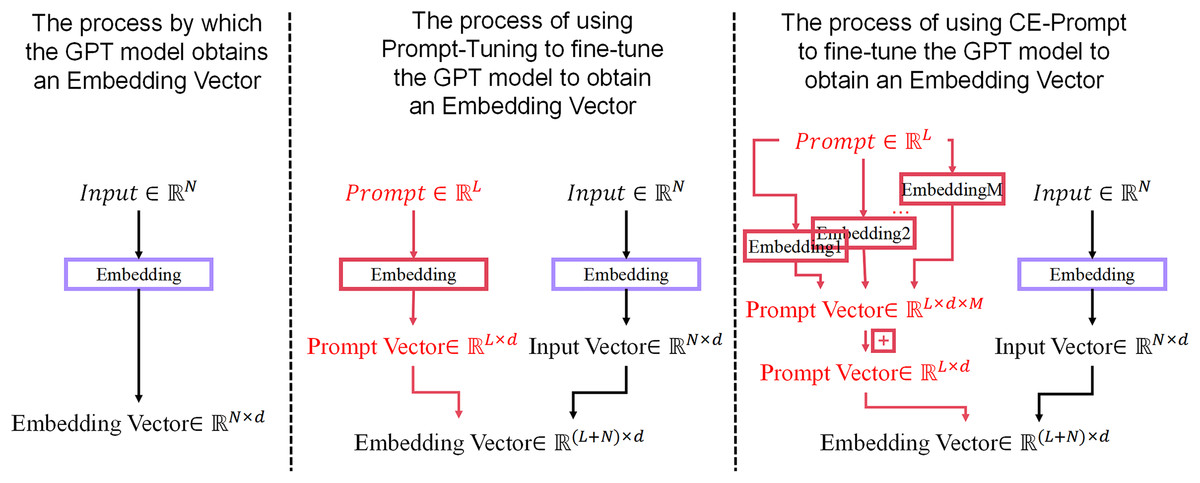
Figure 3: The process of obtaining embedding vectors in normal GPT, Prompt-Tuning fine-tuned GPT, and CE-Prompt fine-tuned GPT.
{kind=link}
During training, we optimize the embedding vectors using a task-specific loss function, typically cross-entropy loss (De Boer et al., 2005), for each layer . The expression for the loss function is given by the following formula:
(5) where represents the model’s predicted probability for label based on the composite embedding . The optimization process updates each embedding layer’s vector via gradient descent (Kingma & Ba, 2014):
(6) where is the learning rate. After training, the learned soft prompts for each embedding layer are concatenated with new input sequences and passed through the pre-trained model to obtain the final output.
| 1: Input: Pre-trained Language Model LLM, input sequence , Prompt length L, number of composite embeddings M. |
| 2: Output: Optimized parameters of composite Prompt embeddings. |
| 3: Initialize M embedding layers. |
| 4: Freeze parameters of the language model LLM. |
| 5: for each training iteration do |
| 6: Generate from L-length Prompt using M embedding layers. |
| 7: Perform additive fusion of M vectors. |
| 8: Construct extended input sequences. |
| 9: Perform forward pass and compute loss. |
| 10: Backpropagate to update embedding parameters. |
| 11: end for |
By introducing CE-Prompt, we effectively leverage the concept of the multi-head attention mechanism, integrating multiple differently initialized embedding layers into a single task model. This approach not only preserves the general capabilities learned by pre-trained models but also enhances the model’s flexibility and adaptability through composite embedding. CE-Prompt provides a novel and effective method for customizing models across a wide range of natural language processing tasks, enabling more diverse and robust task-specific performance.
Once training is complete, we save a fixed number of token embedding vectors, which are then used during inference. Instead of recomputing these embeddings from scratch, we precompute and store the optimized prompt vectors for each layer. During inference, these token embeddings are directly loaded and indexed, significantly reducing computational overhead.
Given a new input sequence , we retrieve the corresponding learned token embeddings and concatenate them with the input embeddings , forming the final input representation:
(7)
These precomputed embeddings eliminate the need for additional forward passes through the embedding layers, enabling more efficient real-time inference.
Finally, the processed input is passed through the frozen pre-trained model , generating the final output:
(8)
Since only the indexed prompt vectors are used, inference becomes computationally lightweight and efficient, making CE-Prompt well-suited for applications requiring rapid adaptation across different tasks.
Experiments setup
Datasets and tasks
In this study, we categorize the datasets into two types according to their experimental purposes: the primary dataset, which is used for model comparison, sensitivity analysis, and clustering visualization; and the auxiliary datasets, which are used to analyze the training dynamics under different prompt initialization strategies.
Text2Cypher (Ozsoy et al., 2024) dataset
We construct the Text2Cypher task based on a Chinese Medical Dialogue Data (Chinese-medical-dialogue-data, 2019). This dataset spans six major medical domains and includes structured question-answer pairs with four key fields: department, title, question, and answer, ensuring strong domain relevance and semantic diversity.
A total of 60,000 question-answer pairs were randomly sampled (10,000 from each department). We then employ the LLaMA3-70B model, guided by carefully designed prompts that describe the structure and semantics of entities and relations, to generate corresponding Cypher query statements. Each QA pair is transformed into a Cypher-based QA instance.
To ensure data quality, the generated Cypher statements are validated against a pre-constructed Chinese medical knowledge graph (CmKG). A query is considered valid if it successfully retrieves at least one node or edge from the CmKG. Ultimately, 20,000 valid Cypher QA pairs were retained 18,000 for training and validation, and 2,000 for testing. This dataset provides a solid foundation for evaluating the effectiveness of the proposed CE-Prompt method in domain-specific reasoning tasks. The final training and testing datasets used in the article can be accessed via the link provided in the Data Availability Statement.
Standard NLP dataset
To investigate the effect of different prompt initialization methods—specifically random initialization vs text-based initialization—we utilize several standard NLP benchmarks to analyze training loss trends. These include:
Corpus of Linguistic Acceptability (CoLA) and Recognizing Textual Entailment (RTE), both from the General Language Understanding Evaluation (GLUE) (Wang et al., 2018) benchmark suite, which test syntactic acceptability and logical inference capabilities, respectively;
Massive Multitask Language Understanding (MMLU), a comprehensive benchmark covering a wide range of academic and professional domains;
Internet Movie Database (IMDB), a sentiment analysis dataset used to evaluate subjective emotion classification.
These auxiliary datasets are used specifically to examine how different prompt initialization strategies affect the training behavior of Prompt-Tuning, by comparing loss curves across tasks and highlighting differences in convergence speed and training stability.
Model
We select LlaMA3-8B-Instruct and Qwen2.5-7B-Instruct as the base models.
LlaMA3-8B-Instruct: LlaMA3-8B-Instruct is a third-generation LlaMA model with around 8 billion parameters. By using a more diverse pre-training dataset and instruction tuning, it improves instruction following, contextual reasoning, and handling of complex queries. It also enhances long-text comprehension and reduces contradictory outputs.
Qwen2.5-7B-Instruct: Qwen2.5-7B-Instruct is a multilingual language model with around 7 billion parameters. It focuses on Chinese, English, and other multilingual tasks, leveraging broader domain data and diverse training approaches. Optimized for cross-lingual tasks, it provides accurate, context-consistent outputs and offers faster inference and lower deployment costs.
Baseline
In this study, we established a baseline by performing Prompt-Tuning on two advanced pre-trained language models, LlaMA3-8B-Instruct and Qwen2.5-7B-Instruct. These models, known for their outstanding language generation capabilities and task adaptability, provided a reliable foundation for comparison with our proposed methods.
For the baseline evaluation on medical domain data, we utilized BLEU-4 (Papineni et al., 2002) and ROUGE-L (Lin, 2004) as the evaluation metrics.
BLEU-4 is a widely used metric for evaluating machine-generated text by comparing it with human-written reference texts. It calculates the precision of n-grams (Majumder, Mitra & Chaudhuri, 2002) while incorporating a brevity penalty (BP) to prevent bias toward shorter sentences. The BLEU score is computed using the following formula:
(9) where represents the precision of n-grams, is the weight assigned to each n-gram (typically, equal weights for to ), the BLEU score is expressed by the formula:
(10) where is the length of the generated text, and is the length of the reference text. A higher BLEU-4 score indicates better alignment with the reference text in terms of fluency and accuracy.
ROUGE-L measures the similarity between generated text and reference text based on the Longest Common Subsequence (LCS). Unlike BLEU, which is precision-based, ROUGE-L emphasizes recall, capturing the overall sentence structure similarity. The formula for ROUGE-L is given by:
(11) where is the longest common subsequence between the generated text X and the reference text Y, |X| and |Y | denote the lengths of the generated and reference texts, respectively.
ROUGE-L provides insights into the coherence and relevance of generated text, particularly useful for evaluating dialogue systems and summarization tasks. A higher ROUGE-L score indicates that the generated text better preserves the structure and meaning of the reference response.
These evaluation metrics help assess the fluency, coherence, and relevance of generated medical dialogues, ensuring an objective comparison with reference responses.
Implementation details
To comprehensively evaluate the proposed CE-Prompt method, we design three core experiments focusing on overall performance, parameter sensitivity, and representation ability.
Comparative experiments
We conduct systematic comparisons between CE-Prompt and several mainstream parameter-efficient fine-tuning methods, including P-Tuning, Prefix-Tuning, Prompt-Tuning, and LoRA. All experiments are implemented on two widely used LLMs, LLaMA and Qwen. Performance is evaluated using BLEU-4 and ROUGE-L metrics to measure generation accuracy and semantic coverage.
Sensitivity analysis
The sensitivity experiments are designed to investigate how model performance varies under different prompt configurations. We performed experiments by varying both the number of composite embeddings (M) and the prompt length (L), comparing the performance of CE-Prompt with standard Prompt-Tuning. All configurations were evaluated on both LLaMA and Qwen backbones using BLEU-4 to examine the robustness and scalability of CE-Prompt across different settings.
Clustering analysis
To further analyze the differences in how CE-Prompt and Prompt-Tuning learn prompt representations during training, we conduct clustering analysis. By visualizing the distribution of learned prompt embeddings, we explore the structural distinctions in representation space, providing additional insights into the effectiveness of CE-Prompt.
Result and analysis
Figure 4 illustrates the loss trends during Prompt-Tuning training on four NLP datasets (CoLA, RTE, MMLU, and IMDB) using two different initialization strategies: text initialization (Text Init) and random initialization (Random Init). Overall, text initialization (refer to Appendix C) demonstrates faster convergence and lower loss values across most tasks. In particular, on CoLA and RTE, the loss curves decrease more smoothly and exhibit less fluctuation, indicating that the model can more quickly capture effective task-specific features. In contrast, random initialization generally leads to slower convergence with greater instability, especially in early training stages, where the model struggles to approach an optimal solution. While the final loss values on MMLU and IMDB are relatively close under both strategies, text initialization still shows a more stable downward trend. These observations suggest that Prompt-Tuning is sensitive to initialization methods, and a well-chosen strategy can enhance both convergence efficiency and training stability.
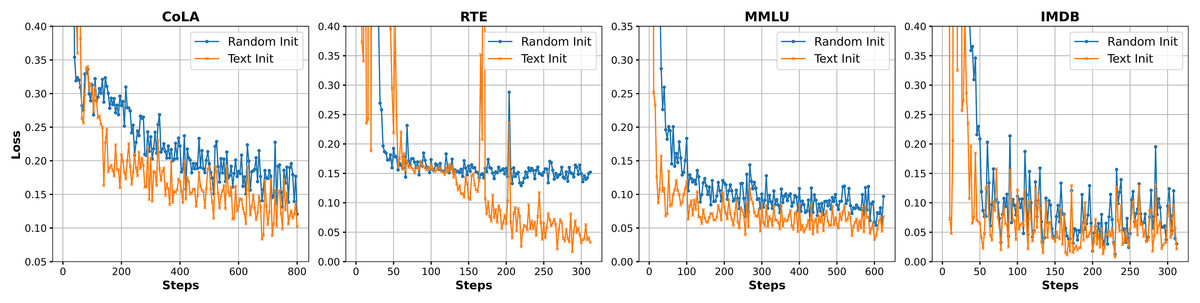
Figure 4: Loss trend chart of different initialization methods on different datasets.
The figure presents loss trends for different initialization methods across four datasets: CoLA, RTE, MMLU, and IMDB. The x-axis represents the number of training steps, and the y-axis shows the loss value. The blue line indicates Random Initialization, while the orange line represents Text Initialization. Each plot shows how the loss evolves over time for both initialization methods.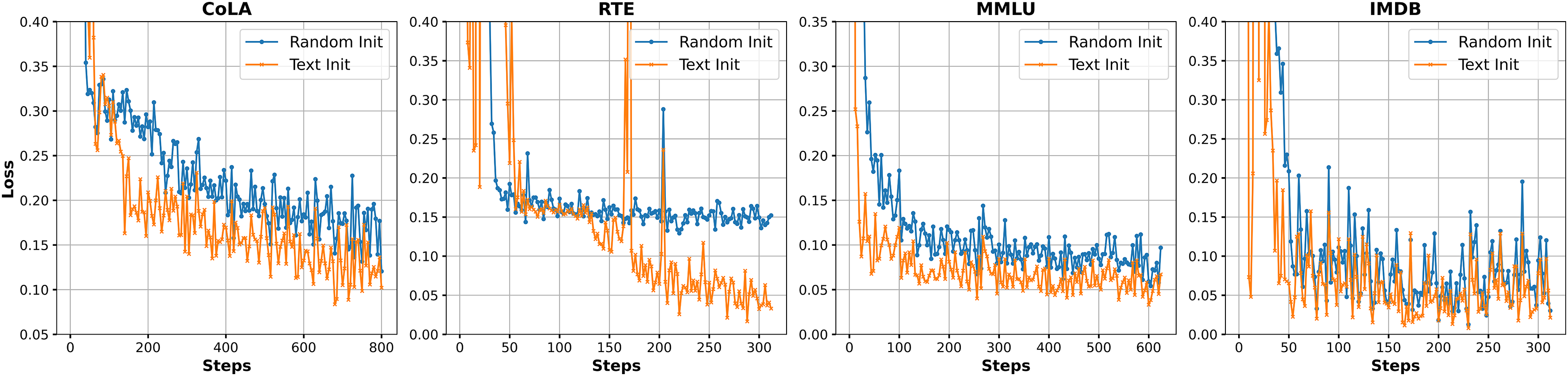{kind=link}
Comparative experiments
To comprehensively evaluate the performance of the proposed CE-Prompt method on generative tasks, we conduct systematic comparisons with several mainstream parameter-efficient fine-tuning approaches, including P-Tuning, Prefix-Tuning, Prompt-Tuning, and LoRA. All methods are implemented on two representative large language models, LLaMA and Qwen, and evaluated using BLEU-4 and ROUGE-L metrics to measure the accuracy and semantic coverage of generated outputs. The detailed results are shown in Table 1.
| METHOD | LLaMA | Qwen | ||||
|---|---|---|---|---|---|---|
| Para | BLEU | ROUGE | Para | BLEU | ROUGE | |
| P-Tuning | 0.087% | 89.51 | 92.37 | 0.081% | 88.01 | 92.37 |
| Prefix-Tuning | 0.843% | 90.64 | 93.35 | 0.196% | 88.73 | 92.86 |
| Prompt-Tuning | 0.002% | 90.33 | 93.12 | 0.002% | 88.35 | 92.70 |
| LoRA | 0.259% | 90.78 | 93.41 | 0.265% | 88.96 | 93.04 |
| CE-Prompt | 0.013% | 91.09 | 93.64 | 0.012% | 89.25 | 93.39 |
As shown in the figure, CE-Prompt achieves the best performance across both model backbones. On the LLaMA model, it reaches a BLEU-4 score of 91.09% and a ROUGE-L score of 93.64%, outperforming all baseline methods. Similarly, on the Qwen model, CE-Prompt yields a BLEU-4 score of 89.25% and a ROUGE-L score of 93.39%, again ranking highest among all approaches. These results suggest that the multi-embedding mechanism employed in CE-Prompt effectively enhances the model’s adaptability to task-specific features, leading to improvements in both generation quality and consistency.
It is worth noting that Prompt-Tuning requires fewer trainable parameters than LoRA and Prefix-Tuning. For instance, on the Qwen model, Prompt-Tuning achieves a BLEU-4 score of 88.35% and a ROUGE-L score of 92.70%, closely matching LoRA’s performance (88.96%/93.04%). A similar trend is observed on the LLaMA model. This indicates that for tasks like Text2Cypher, where the semantic structure is relatively well-defined and the domain boundaries are clear, Prompt-Tuning can sufficiently activate the language modeling capabilities already embedded within the pretrained model, achieving competitive results with minimal parameter updates.
Overall, while CE-Prompt demonstrates strong performance advantages due to its composite embedding strategy, these results also suggest that Prompt-Tuning remains a viable and efficient fine-tuning method in structured generation tasks, particularly when computational resources or parameter budgets are constrained.
Sensitivity analysis
To thoroughly evaluate the behavior of CE-Prompt under different configurations, we conducted extended sensitivity experiments focusing on two key factors: prompt length and the number of composite embeddings (M). Experiments were performed on both LLaMA and Qwen models across various configurations, and results were compared against standard Prompt-Tuning. The findings are summarized in Tables 2 and 3.
| Prompt length | Prompt-Tuning | CE-Prompt (M = 2) | CE-Prompt (M = 4) | CE-Prompt (M = 8) |
|---|---|---|---|---|
| Length = 16 | 89.16 | 90.61 | 90.67 | 91.04 |
| Length = 32 | 90.33 | 90.61 | 90.94 | 91.22 |
| Length = 64 | 90.48 | 91.11 | 91.19 | 91.28 |
| Length = 128 | 90.46 | 90.86 | – | – |
| Length = 256 | 90.76 | – | – | – |
| Prompt length | Prompt-Tuning | CE-Prompt (M = 2) | CE-Prompt (M = 4) | CE-Prompt (M = 8) |
|---|---|---|---|---|
| Length = 16 | 88.01 | 88.04 | 88.26 | 88.34 |
| Length = 32 | 88.35 | 88.59 | 88.91 | 89.25 |
| Length = 64 | 88.59 | 88.69 | 88.92 | 89.12 |
| Length = 128 | 88.86 | 89.11 | – | – |
| Length = 256 | 88.98 | – | – | – |
From the perspective of prompt length, both Prompt-Tuning and CE-Prompt show performance improvements as the length increases. However, the gains tend to diminish with longer prompts. For example, on LLaMA, the BLEU-4 score of Prompt-Tuning improves from 89.16% (Length = 16) to 90.48% (Length = 64), but further increases to Length = 256 only yield a minor improvement to 90.76%. A similar saturation trend is observed across CE-Prompt settings with different M values. These two phenomena can be seen more clearly in the line chart of Fig. 5. This indicates that while longer prompts can enhance expressiveness to some extent, the marginal benefit decreases beyond a certain length.
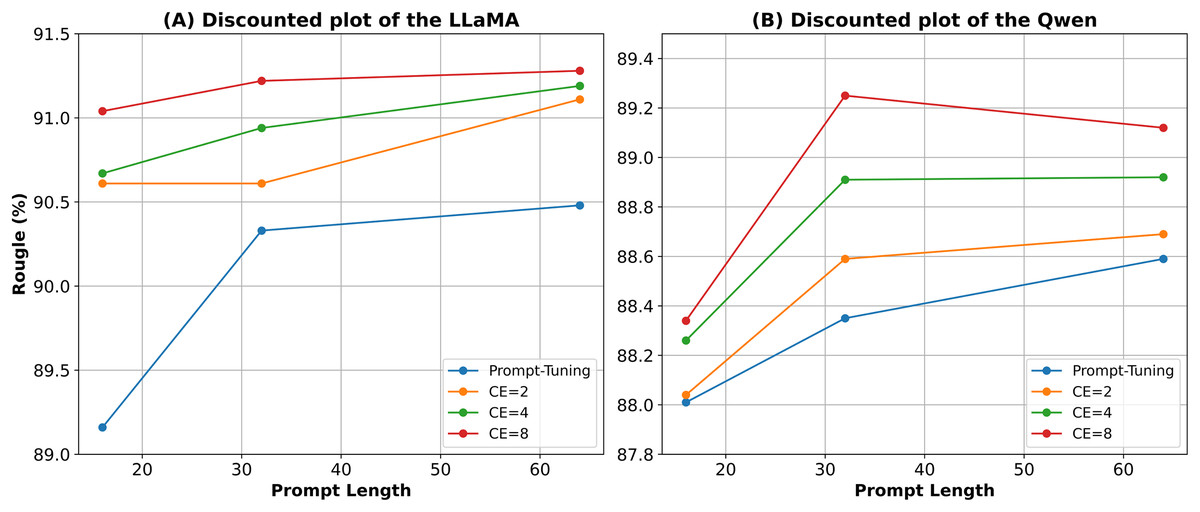
Figure 5: This line chart illustrates the performance of Prompt-Tuning and CE-Prompt methods on the LLaMA (A) and Qwen (B) models under different prompt lengths and CE counts.
The y-axis represents Rouge (%), and the x-axis represents prompt length.{kind=link}
Regarding the number of composite embeddings, we observe that increasing M generally leads to better performance under the same prompt length. For instance, under Length = 32 on LLaMA, BLEU-4 increases from 90.61% at to 90.94% at and reaches 91.22% at . However, this improvement also becomes less significant as M increases. These results suggest that although increasing M enhances representation capacity, the performance gain gradually stabilizes, and moderate values such as or offer a good balance between effectiveness and computational cost.
The two hyperparameters in the table determine the final number of trainable parameters for CE-Prompt. When Length * M is equal, the number of trainable parameters is the same, allowing us to make comparisons under these equal parameter settings. In this case, CE-Prompt consistently outperforms Prompt-Tuning, demonstrating that its performance advantage is not merely due to parameter scaling. Instead, the design of CE-Prompt—especially its composite embedding mechanism—plays a critical role in enhancing effectiveness. Moreover, while Prompt-Tuning relies on extending the prompt length to improve performance, this also increases the input sequence length, leading to higher computational and inference costs. In contrast, CE-Prompt achieves comparable or better performance under the same parameter budget using shorter prompt lengths, thereby reducing latency and improving efficiency.
Clustering analysis
To further understand the representational differences between CE-Prompt and traditional Prompt-Tuning, we conducted a clustering visualization experiment based on the learned prompt vectors. After training, we extracted the token-level prompt embeddings and applied principal component analysis (PCA) to reduce their dimensionality for visualization. The distributions of the token vectors under LLaMA and Qwen models are shown in Fig. 6.
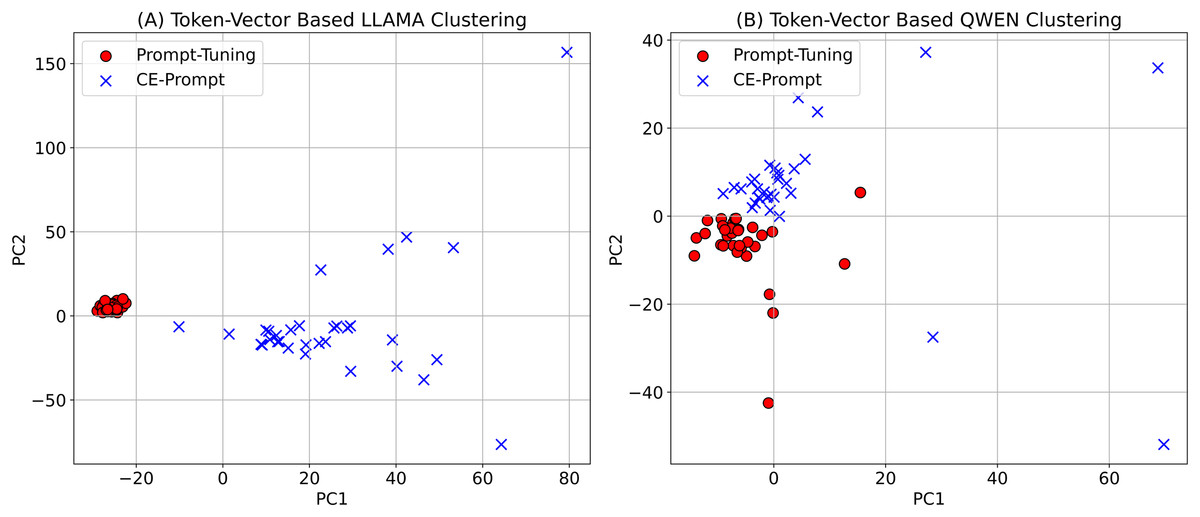
Figure 6: Token-Vector clustering results obtained by Prompt-Tuning and CE-Prompt.
The figure shows token-vector clustering results obtained using Prompt-Tuning and CE-Prompt methods for two models: (A) LLaMA and (B) Qwen. In both plots, the x-axis represents the first principal component (PC1), while the y-axis represents the second principal component (PC2). The red circles represent the clustering results for Prompt-Tuning, and the blue crosses represent the clustering results for CE-Prompt.{kind=link}
In Fig. 6A, the token vectors from CE-Prompt are more widely distributed across the feature space, indicating higher dispersion and semantic diversity. This suggests that CE-Prompt enables each token to learn more independent and distinct semantic representations, enriching the overall expressiveness of the prompt. In contrast, the token vectors from Prompt-Tuning are densely clustered in the lower-left region, implying that the learned embeddings are concentrated and semantically homogeneous. Such limited variation may restrict the model’s ability to encode nuanced task-specific features.
In Fig. 6B, a similar trend is observed. Although the separation in representation space is relatively less pronounced compared to LLaMA, CE-Prompt still yields a broader distribution of token vectors than Prompt-Tuning. This highlights the generalizability of CE-Prompt across different model architectures, as it consistently enhances embedding diversity.
Trainable parameter analysis
In terms of trainable parameter size, although CE-Prompt introduces more parameters than Prompt-Tuning, the overall proportion remains negligible relative to the base model size. As shown in Table 1, CE-Prompt accounts for only 0.013% and 0.012% of total parameters on LLaMA and Qwen, respectively—slightly higher than Prompt-Tuning (0.002%) but significantly lower than LoRA, which consumes 0.259% and 0.265% on the same models. Notably, despite using fewer parameters, CE-Prompt consistently outperforms LoRA in both BLEU-4 and ROUGE-L scores, achieving the best overall generation quality across both backbones. This indicates that CE-Prompt achieves a superior trade-off between parameter scale and performance. Its ability to deliver strong results with only a minimal number of updated parameters makes it particularly attractive for efficient and scalable deployment in practice.
Time complexity analysis
In terms of computational cost, the decoder stage of Transformer models is primarily dominated by multi-head self-attention, with an overall time complexity of , where is the sequence length and is the embedding dimension. Both Prompt-Tuning and CE-Prompt increase inference input length by prepending prompt embeddings, and thus their time complexity grows with , where L is the prompt length and N is the task input length. However, CE-Prompt is more efficient, as it achieves stronger performance with a shorter prompt.
Based on the sensitivity experiments and assuming an average input length of 40 tokens, Prompt-Tuning typically requires a prompt length of 256 to achieve optimal performance, while CE-Prompt achieves comparable or better results with a prompt length of 32 and composite embeddings. The resulting total sequence lengths are:
Prompt-Tuning: , with complexity
CE-Prompt: , with complexity
This implies that CE-Prompt requires only about of the attention-related computation compared to Prompt-Tuning, demonstrating a significant advantage in inference efficiency.
Conclusions
This article proposes CE-Prompt, a compositional embedding-based prompt tuning method that enhances the structural expressiveness and semantic diversity of soft prompts by associating each token with multiple trainable embeddings, which are aggregated during forward computation. We evaluate CE-Prompt across multiple natural language generation tasks using two mainstream language models, LLaMA and Qwen, and conduct comprehensive comparisons against Prompt-Tuning, Prefix-Tuning, LoRA, and other representative fine-tuning methods. Supported by results from comparative experiments, sensitivity analysis, and clustering-based visualization, our findings consistently demonstrate that CE-Prompt outperforms existing methods in BLEU-4 and other generation metrics, particularly in low-resource, short-prompt, and mid-to-long text scenarios. Furthermore, CE-Prompt achieves better performance than Prompt-Tuning even under equal training parameter budgets, while maintaining shorter prompt lengths. This leads to reduced computational cost during training and inference, highlighting its efficiency, scalability, and deployment-friendliness.
Nevertheless, CE-Prompt remains fundamentally a form of soft prompt representation learning, and its effectiveness is inherently limited by the language modeling capacity of the underlying pretrained model. When the base model lacks knowledge in certain domains, languages, or task types, CE-Prompt cannot fully compensate for those deficiencies. In addition, the method is relatively sensitive to training data quality. Since the optimization of compositional embeddings relies heavily on consistent gradient signals, noisy, ambiguous, or weakly labeled samples may lead to unstable training dynamics and suboptimal results. Future work may consider improving the robustness of CE-Prompt in noisy environments, exploring its adaptability in low-resource and structurally underspecified tasks, and integrating it more tightly with the model’s internal representations to enhance generalization across a broader range of applications.
Appendix A
Appendix A.1 Llama3-70B system content illustration. (Since the dataset is in Chinese, it needs to be localized into Chinese according to the following template.)
You are an expert in knowledge graphs. There is an existing medical-related knowledge graph. The entities in the graph are defined as follows:
Entities
disease: Disease, storing basic information about various diseases.
department: Department, the medical department associated with a disease.
symptom: Symptoms of a disease.
check: Medical examinations related to a disease.
drug: Medications used for treating a disease.
producer: Drug product available for sale.
food: Food, including recommended and restricted food items.
Relationships Between Entities
Each relationship can be bidirectional, where represents an entity and represents a relationship:
Disease-Department Relationship:
Disease-Symptom Relationship:
Disease-Drug Relationship: ;
Disease-Check Relationship:
Producer-Drug Relationship:
Disease-Food Relationship: ; ;
Disease-Complication Relationship:
Main Attributes of Entities
disease: {name: disease name, desc: disease description, cause: causes of the disease, prevent: prevention measures, cure_lasttime: treatment duration, cure_way: treatment method, cured_prob: cure probability, easy_get: susceptible population}
department: {name: department name}
symptom: {name: symptom name}
check: {name: check item}
drug: {name: drug name}
producer: {name: drug name}
food: {name: food name}
Query Generation
Based on the above background and the user’s query, generate an OpenCypher query statement to accurately retrieve relevant knowledge from the graph.
Note:
Use only the provided entities, relationships, and attributes. Do not include any additional information.
Relationships between entities should strictly follow the provided relationships.
(Output only the OpenCypher query, without explanation.)
Appendix B
Appendix B.1 Knowledge graph entity-related categories. (Since the dataset is in Chinese, it needs to be localized into Chinese according to the following template.)
| Entity | Description | Attributes |
|---|---|---|
| Disease | Disease, storing basic information about various diseases | name: Disease name |
| desc: Disease description | ||
| prevent: Preventive measures | ||
| cause: Causes of the disease | ||
| cure_way: Treatment method | ||
| easy_get: Susceptible population | ||
| cure_lasttime: Treatment duration | ||
| cured_prob: Cure probability | ||
| Department | Department, the medical department corresponding to the disease | name: Department name |
| Symptom | Symptoms of the disease | name: Symptom name |
| Producer | Drug product in the market | name: Drug product name |
| Check | Medical examinations for the disease | name: Examination item |
| Drug | Medications for the disease | name: Drug name |
| Crowd | Population susceptible to the disease | name: Susceptible population |
| Food | Food, including recommended and restricted foods | name: Food |
Appendix B.2 Knowledge graph relationship-related categories. (Since the dataset is in Chinese, it needs to be localized into Chinese according to the following template.)
| Relationship category | Corresponding cypher query format |
|---|---|
| Disease-Department relationship | (v:disease)-[e:diseaseDepartmentRelation]->(v:department) |
| Disease-Symptom relationship | (v:disease)-[e:diseaseSymptomRelation]->(v:symptom) |
| Disease-Examination relationship | (v:disease)-[e:diseaseCheckRelation]->(v:check) |
| Disease-Medication relationship | (v:disease)-[e:diseaseDrugRelation]->(v:drug) |
| Disease-Recommended drug relationship | (v:disease)-[e:recommandDrugRelation]->(v:drug) |
| Producer-Drug relationship | (v:producer)-[e:drugsOfRelation]->(v:drug) |
| Disease-Suitable food relationship | (v:disease)-[e:diseaseSuitableFoodRelation]->(v:food) |
| Disease-Recommended food relationship | (v:disease)-[e:recommandEatRelation]->(v:food) |
| Disease-Restricted food relationship | (v:disease)-[e:noEatRelation]->(v:food) |
| Disease-Complication relationship | (v:disease)-[e:accompanyWithRelation]->(v:disease) |
Appendix C
Appendix C.1 The following are the prompt texts used for text initialization in the comparison of loss trends across four tasks:
-
CoLA (Corpus of Linguistic Acceptability):
Please judge the correctness or error of the sentence syntax according to the input sentence content output right or error.
-
RTE (Recognizing Textual Entailment):
Please output an entailment or not_entailment according to the contents of sentence1 and sentence2 determine whether the two sentences have an entailment relationship.
-
MMLU (Massive Multitask Language Understanding):
Please select the correct answer from the choices based on the content of the question.
-
IMDB (Movie Review Sentiment Analysis):
Please judge whether the sentence is positive or negative based on the content of the user review.
Supplemental Information
A representative sample from the main datasets used for training and validation.
Each data entry includes four fields: ’original_text’ is the input Chinese sentence; ’english_text’ refers to the English translation of the ’original_text’; ’cypher’ refers to the cypher statement corresponding to a Chinese sentenc; ’cypher_english’ refers to the English translation of ’cypher’ . The specific details of the data can be found in the dataset section of the paper.
The code implementation for the CE-Prompt structure.
The fields required to implement CE-Prompt, as well as the implementation of the forward function.