
Attribute-based people search: open attribute recognition for person re-identification in surveillance and security
- Published
- Accepted
- Received
- Academic Editor
- Shibiao Wan
- Subject Areas
- Artificial Intelligence, Computer Vision, Data Mining and Machine Learning, Neural Networks
- Keywords
- Person re-identification, Open attribute recognition, Natural language processing, Computer vision, Neural networks
- Copyright
- © 2025 Alayary et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Attribute-based people search: open attribute recognition for person re-identification in surveillance and security. PeerJ Computer Science 11:e3217 https://doi.org/10.7717/peerj-cs.3217
Abstract
The extraction and use of textual descriptions to identify and retrieve individuals in a given video footage is known as person attribute recognition for person re-identification (ReID). This approach bridges the gap between natural language processing (NLP) and computer vision, expanding the research field with diverse applications, including surveillance, security, and autonomous driving technologies. Current person re-identification (ReID) systems often rely on an image as input, which limits their usefulness in cases where only a textual description is available, such as in law enforcement investigations or searches for missing persons. As a result, effective retrieval is obstructed when visual data is scarce or unavailable. Moreover, current text-based ReID methods, which depend on full sentences to find the target person, can be computationally expensive, especially when handling long surveillance videos. Attribute-based ReID offers a faster alternative; however, its dependence on a fixed set of predefined attributes restricts the system’s ability to handle variations found in real-world descriptions, thus reducing robustness. This work addresses these limitations by proposing a novel framework that uses open attributes in person re-identification and mitigates the image dependency of traditional methods. Crucially, our work’s novelty lies in introducing a unique text-to-text similarity approach for person re-identification, operating entirely within a semantic textual open attribute space. This framework consists of three main modules. A natural language processing (NLP) module is implemented to process the input textual query from the user and extract the keywords that describe the target person. A person detection module localizes individuals within the video frames, generating the search gallery. A person open attribute recognition (POAR) module is used to generate open attributes from each given gallery image, compare the text query attributes with the gallery image attributes using cosine similarity, and retrieve the best-ranked image for the user. Experiments demonstrate the effectiveness of our proposed framework, achieving a rank-1 accuracy of 84.8% in identifying and retrieving individuals from video data. These results outperform state-of-the-art methods, thus validating the potential of the approach in real-world applications. For training and evaluation, we employed the PA-100k dataset, accessible at https://www.kaggle.com/datasets/yuulind/pa-100k.
Introduction
Our digital age is characterized by an abundance of readily accessible data. This is due to widespread technology and the deployment of surveillance cameras everywhere. However, this abundance introduces challenges in data analysis and interpretation (Selvan et al., 2025; Cao et al., 2025). One such challenge is the task of identifying individuals within surveillance footage that often produce low-quality images (Ye et al., 2021; Yadav & Vishwakarma, 2024; Saad et al., 2024; Lavi et al., 2020; Islam et al., 2024). The ability to identify and locate individuals based on descriptions alone has become an important tool in surveillance and for law enforcement (He et al., 2025). People search systems are designed to retrieve individuals based on specific attributes and thus help in finding missing persons, tracking suspects, and ensuring safety in crowded areas (Chaudhari et al., 2023; Li et al., 2024a, 2024b; Shao, Si & Yang, 2025). Textual descriptions from witnesses (such as clothing, physical characteristics, and behavior) are frequently crucial in real-world situations, such as the Boston Marathon bombing investigation, to identify particular individuals, especially when visual evidence is limited or of poor quality (Landman et al., 2015).
Current person search algorithms focus on image-based inputs and majorly neglect the added value of textual descriptions. This gap is significant, as text-based descriptions, while valuable, are inherently ambiguous and incomplete (Zhang et al., 2025; Aggarwal, Radhakrishnan & Chakraborty, 2020; Farooq et al., 2020). Statements can often vary in detail, accuracy, and consistency due to differences in observer perception and memory. Therefore, the importance of text-based person search, shown in Fig. 1, is monumental, as they integrate both modalities to increase the effectiveness of the person search (Chaudhari et al., 2023; Li et al., 2024b; Zhang et al., 2023; Wu et al., 2023a). Person search transforms video footage from a passive recording system to meaningful insights. Useful information can be detected and used accordingly by locating a specific person in a large set of images or videos. For instance, it can enhance security as an investigative tool to identify those trying to gain unauthorized access or assist in finding missing people based on descriptions (Wang et al., 2022b; Zheng et al., 2024a). Physical characteristics, behavioral patterns, and historical data can be collected from each detected individual to enhance understanding (Wu et al., 2024c; Jha et al., 2025). Additionally, tracking the behavior of individuals can improve the retail experience or allow immediate intervention in case of emergencies or suspicious activity (Jha et al., 2023; Wang et al., 2022a). Person search can be useful in various fields, such as healthcare, education, finance, and security (Zhai et al., 2022; Wang et al., 2022b; Zheng et al., 2024a; Wu et al., 2023a).

Figure 1: Illustration of the text-based person search problem in surveillance systems.
A user provides a text query, which the system processes to search a gallery of images containing people of interest and outputs the best match.{kind=link}
Person search queries are categorized as image-based search (Ye et al., 2021; Yadav & Vishwakarma, 2024; Saad et al., 2024), attribute-based search (Ahmed & Oyshee, 2025; Zhang et al., 2023; Zhao et al., 2022; Qu et al., 2023), and text-based search (Wang, Yang & Cao, 2024; Li et al., 2024b; Lv, Sun & Nian, 2024; Chaudhari et al., 2023; Hu et al., 2025) based on the modality of the query. Although there is a vast quantity of video data, identifying a person of interest in this amount of data can prove to be challenging if there are insufficient reference images of the target or if small details change in their appearance, such as changing their clothes or hair. Textual descriptions of a pedestrian’s appearance are more accessible and handle the lack of image or video references for the target person (Liu et al., 2019; Zha et al., 2020). Natural language descriptions are easier to obtain and offer greater flexibility than visuals. However, feature granularity is a key component in the modality gap between images and text (Shao et al., 2022; Jing et al., 2020; Wang et al., 2021). Generally, the textual feature describes coarse qualities, whereas the visual feature offers fine-grained information. As a result, different images can be described using the same words. This makes it challenging to extract consistent visual and textual representations from both raw images and their textual descriptions, especially when they belong to the same category but have subtle differences (Shao, Si & Yang, 2025). Another aspect is learning discriminative visual representation with challenges such as background clutter, occlusion, and variations in illumination (Wu et al., 2024c; Subramanian & Namboodiri, 2023; Jing et al., 2020; Yang et al., 2023a; Zha et al., 2020).
The format of the textual input is also important in the model structure. Full semantic sentences provide rich context and are natural for users to use. However, they require high processing power and complexity and are prone to ambiguity from the user, thus losing precision in performing the person search task (Chaudhari et al., 2023; Zhai et al., 2022). On the other hand, using attributes as the textual input introduces faster inference and consistency in person search, yet becomes limited in providing details outside of the predefined attributes and user input is rigid (Zhou et al., 2025; Wang et al., 2022a; Zhao et al., 2022; Qu et al., 2023). To mitigate sentences and attributes’ limitations, our pipeline merges both advantages by utilizing open attributes in textual description input, which is represented in Fig. 2. Open attributes are flexible yet structured, providing an ease in processing. The detailed but customized queries mean that the model can dynamically introduce and recognize new features to aid in the person search process (Zhang et al., 2023).

Figure 2: Visualization of open attributes as the fusion of the text sentences and attributes approaches to textual input.
{kind=link}
Open attribute recognition identifies various attributes of people in images or videos, such as gender, age, clothing, hair color, accessories and carrying objects (Zhang et al., 2023). This enables the detection and classification of a wide range of attributes unlike traditional methods that rely on predefined categories (Ma et al., 2023; Saranrittichai et al., 2022; Wu et al., 2024a). This is especially needed when faced with diverse and unexpected variations in appearance and helps search algorithms to narrow down the pool of potential matches, even with ambiguous textual descriptions or low-resolution images. Other approaches (Wang et al., 2022a; Liu et al., 2017; Galiyawala, Raval & Patel, 2024; Wu et al., 2025) rely on pre-defined attribute recognition models that lack adaptability to novel or unseen descriptions which limits their robustness in real-world settings. Open attribute-based systems promise greater inclusivity by accommodating cases where traditional identification methods are either unavailable or ethically challenging by allowing the identification of individuals based on descriptive attributes (Zhang et al., 2023; Zara, Rota & Ricci, 2025).
This research addresses these gaps by proposing a novel approach to person search, utilizing open attribute recognition to expand the limitations of person re-identification by considering any descriptive attributes that are attainable from the data. Moreover, it aims to demonstrate the feasibility and efficiency of integrating open attributes into large-scale surveillance systems by addressing both practical challenges and ethical considerations. This article lays the foundation for a paradigm shift, highlighting the significant societal benefits and advancements possible with an open-attribute-based approach to people search.
Current people search systems primarily rely on visual identifiers, which limits the applicability in real-world scenarios when facial features are obscured, images are low resolution, or the required biometric data is unavailable. While attribute-based search methods exist, they are constrained by closed-set recognition as the system can only identify predefined attributes. This limitation makes them ineffective for real-world applications that require adaptability to ambiguous descriptions, such as “a tall person in a red jacket carrying a bag”. The research gap lies in the absence of systems capable of handling open attribute recognition where descriptions are not constrained to a predefined set. This enables the system to perform robust, flexible, and accurate people searches. Our contribution addresses this gap by introducing a novel framework that integrates open attribute recognition into people search. This enables diverse, text-based queries and effectively retrieves individuals in challenging and complex environments. This approach builds on the idea of inclusion and real-world usability.
The contributions of this study are as follows:
-
Design and implement an NLP module to process text-based queries and extract key attributes describing the person of interest.
-
Develop a person detection system to identify and isolate individuals in complex surveillance environments.
-
Develop an open attribute generation model to recognize and classify descriptive attributes of individuals’ images (e.g., clothing, height, gender) without being limited to predefined attribute sets.
-
Extract relevant visual attributes from detected individuals and align them with the text-based query for accurate person identification.
-
Create a ranking system to measure the similarity between extracted attributes and the text query to ensure individuals are chosen based on how closely they match the description.
-
Combine the models to develop an end-to-end system to retrieve the individual matching the query in real-world applications.
This article is organized as follows: The first section, ‘Introduction’, is an introduction, highlighting the motivation and contributions of the study. ‘Related Work’ details the related work of this research, with an overview of key concepts, followed by a detailed literature review covering text-based person re-identification, person attribute recognition, and open attribute recognition. ‘Methodology’ outlines the methodology. ‘Results’ presents the results, describing experimental settings and evaluating end-to-end system performance compared to the state of the art. Finally, ‘Conclusion and Future Work’ concludes the article and suggests directions for future research.
Related work
Text-based person re-identification
Although using images for person ReID is effective for certain surveillance and security applications, it is not always practical in real-world scenarios. For instance, when an initial image of the target person is not easily available, relying only on image-based ReID is insufficient. This frequently occurs due to problems including low image quality, subject occlusion, or limitations in surveillance systems (Yadav & Vishwakarma, 2024). On the other hand, text-based ReID provides a useful alternative by utilizing natural language descriptions provided by witnesses or extracted from case files (Li et al., 2024a; Yang & Zhang, 2024). This approach proves particularly useful in cases involving missing persons or criminal investigations, where verbal descriptions might be the only available lead (Huang, Qi & Chen, 2024; Wu et al., 2023a).
Several person ReID and retrieval techniques handling text and images have been developed and are categorized depending on their methods for handling cross-modal data. Different methodologies in cross-modal and multi-modal ReID offer unique advantages and limitations, influencing their suitability for various scenarios, and their features are represented in Table 1. Some methods concentrate on global feature alignment, in which models are trained to embed text and image data into a shared space and calculate similarities using these global representations (Zhai et al., 2022; Zheng et al., 2024a; Zhao et al., 2024; Hu et al., 2025). For instance, early methods implement visual geometry group (VGG) and long short-term memory (LSTM) networks, while more recent methods employ ResNet and bidirectional encoder representations from transformers (BERT) backbones (Huang, Qi & Chen, 2024). Other methods incorporate attention mechanisms in their methodology to improve feature alignment (Lv, Sun & Nian, 2024; Wang et al., 2022b; Zhai et al., 2022). Local feature alignment, which aims to match specific parts of an image with corresponding phrases or words in the text, is examined by other techniques. These methods often use part-level or fine-grained features to achieve more refined alignments, occasionally incorporating body-part relationships. However, more computational power is needed to implement local matching (Wu et al., 2024c; Qin et al., 2024; Zhai et al., 2022). Some methods approach the modality gap between images and text by extracting modality-shared features and reducing inter-modal differences (Shao et al., 2024; Huang, Qi & Chen, 2024; Wu et al., 2023a, 2023b; Wang et al., 2022b). More recent approaches utilize the rich alignment knowledge of vision-language pre-training models such as CLIP for both local and global alignments (Li, Sun & Li, 2023; Cao et al., 2024). Finally, some methods address the challenge of noisy correspondence in image-text pairs by specifically modeling the uncertainty in visual and textual data using Gaussian distributions and multi-granularity uncertainty estimates (Qin et al., 2024; Zhao et al., 2024). These methodologies are often complementary rather than mutually exclusive and can be combined to provide a more comprehensive understanding of the cross-modal data, such as merging global and local feature alignment techniques (Wang et al., 2022b).
| Methodology | Cross-modal Interaction | Noise Robustness | Occlusion Handling | Uncertainty Modeling | Large language Models | Multi-modal Fusion | Accuracy (Rank-1) | Dataset used |
|---|---|---|---|---|---|---|---|---|
| IEE (Wang et al., 2022b) | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | 83.93% | Market-1501 (Masson et al., 2021) |
| DFM (Zhai et al., 2022) | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | 80% | TriReID (Zhai et al., 2022) |
| MUM (Zhao et al., 2024) | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | 74.25% | CUHK-PEDES (Zhang et al., 2021b) |
| CPCL (Zheng et al., 2024b) | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | 70.03% | CUHK-PEDES (Zhang et al., 2021b) |
| RDE (Qin et al., 2024) | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | 71.33% | CUHK-PEDES (Zhang et al., 2021b) |
| MDDC (Shao et al., 2024) | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | 84.02% | RegDB (Li et al., 2020) |
| MGCC (Wu et al., 2024c) | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | 62.75% | CUHK-PEDES (Zhang et al., 2021b) |
| MCL (Wu et al., 2023a) | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | 61.21% | CUHK-PEDES (Zhang et al., 2021b) |
| MLLM (Yang & Zhang, 2024) | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | 76.7% | MSMT17 (Wei et al., 2018) |
Person attribute recognition
Within the rapidly evolving fields of computer vision and machine learning, person attribute recognition (PAR) strives to identify specific semantic characteristics of individuals from visual data, such as images or video frames (Wang et al., 2022a). These characteristics, including gender, age, style of clothing, accessories, and even behavioral characteristics, provide useful contextual information for real-world applications such as autonomous systems, human-computer interaction, and security monitoring. Recent developments in deep learning, convolutional neural networks (CNNs) and attention mechanisms have significantly improved the accuracy and robustness of PAR systems (Liu et al., 2017; Bui et al., 2024; Wang et al., 2024b).
Different aspects of attribute modeling that are emphasized by PAR techniques can be categorized into several main approaches. Attribute localization is performed using part-based models that divide the human body into parts or attention-based mechanisms that focus on informative regions using multi-scale or channel-aware attention (Wang et al., 2022a; Weng et al., 2023). An attribute localization module may be employed to enhance attribute-related features (Li et al., 2022). Local part-based models extract the fine-grained details that global image-based models struggle to capture at the expense of increased complexity. Attention-based procedures balance accuracy and efficiency by dynamically focusing on informative regions in the image (Liu et al., 2017; Bui et al., 2024; Wang et al., 2024b). Attribute correlations between attributes or contextual correlations between different image regions can be investigated through relation-aware models that apply graph convolutional networks or relation mining, occasionally combined with an attribute correlation module (Zhao et al., 2022; Zuo et al., 2024; Yu et al., 2024; Wu et al., 2024b; Weng et al., 2023). Some approaches represent attributes as semantic properties and use attribute prompts or textual descriptions (Bui et al., 2024; Yang et al., 2023b; Wang et al., 2024b). Additional methods include attribute-aware style adaptation for semantic consistency, grouped knowledge distillation to minimize the disparity between visual and text embeddings, and adaptive feature scale selection to select relevant feature maps (Qu et al., 2023; Shen et al., 2024; Li et al., 2024b; Zhang et al., 2023). Transformer-based models, often combined with CNNs, are used to capture long-range dependencies and model global context (Zhang et al., 2023; Wang et al., 2024b; Bui et al., 2024; Bui, Le & Ngo, 2024; Cormier et al., 2024; Weng et al., 2023). Multi-scale feature aggregation and knowledge distillation can be used to further improve the model’s robustness (Zhang et al., 2023; Bui et al., 2024; Yu et al., 2024; Wu et al., 2024b). To address the challenge of data imbalance, some methods introduce novel loss functions or weighting strategies (Zhang et al., 2023; Bui et al., 2024; Wang et al., 2024b; Yu et al., 2024; Wu et al., 2024b). Multi-modal fusion techniques can be implemented to integrate visual and textual data and improve person retrieval (Wang et al., 2024b; Cormier et al., 2024; Galiyawala, Raval & Patel, 2024).
The reviewed methods offer diverse approaches to PAR and attribute-based person retrieval tasks, each excelling in different scenarios, and the methods used in each article are highlighted in Table 2. Person open attribute recognition (POAR) (Zhang et al., 2023), with its Transformer-based Embedding + Attribute Search (TEMS) approach, leverages general knowledge distillation (GKD) to enhance cross-dataset transferability, achieving higher Recall@1 in PETA-to-PA100K and PETA-to-RAPv1 setups. However, it underperforms in reverse dataset transitions. UFineBench (Zuo et al., 2024) introduces a novel ultra-fine-grained dataset (UFine6926) and the mSD metric, excelling in textual descriptiveness but lacking robust numerical performance comparisons with other methods. Cross-Transformers with Pre-trained Language model is All you need for Person Attribute Recognition and Retrieval (CLEAR) (Bui et al., 2024) enhances embedding vector separation through hybrid attribute representations, outperforming other models in retrieval accuracy on Market-1501 and PA100K. In contrast, Label2Label (Li et al., 2022) sets a benchmark in mA, accuracy, and F1-score for PA100K, utilizing a language modeling framework. For text-image retrieval, Multi-Attribute and Language Search (MALS) (Yang et al., 2023b) stands out, offering significant Recall@1 improvements using the Attribute Prompt Learning and Text Matching (APTM) framework and large-scale image-text pairs. Video-based person attribute recognition (PAR) benefits from VTFPAR++ (Wang et al., 2024b), which uses spatiotemporal tuning for superior accuracy and F1-scores on Matching Attribute-aware Representations for Text-based Sequential Recommendation (MARS)-Attribute and DukeMTMC-VID-Attribute. Meanwhile, methods like Exploring Attribute Localization and Correlation (EALC) (Weng et al., 2023) and Knowledge Distillation Pedestrian Attribute Recognition (KD-PAR) (Wu et al., 2024b) focus on attention mechanisms and knowledge distillation, respectively, achieving competitive accuracy and F1-scores with lightweight designs. For datasets emphasizing pose discrimination, HydraPlus-Net (HP-Net) (Liu et al., 2017) offers state-of-the-art top-1 accuracy through multi-scale key-point learning. In cross-modal attribute relationships, Multi-Correlation Graph Convolutional Network (MCGCN) (Yang et al., 2023a) uses graph convolutional networks for high recall but lacks dominance in mA on PA100K. Finally, the UPAR-Challenge 2024 baseline (Cormier et al., 2024) highlights the need for improved harmonic mean metrics in benchmark challenges. Overall, the method selection depends on task requirements: CLEAR for retrieval accuracy, MALS for cross-modal granularity, and VTFPAR++ for spatiotemporal analysis, while Label2Label dominates attribute prediction tasks.
| Methodology | Attention mechanism | Multi-task learning | Knowledge distillation | Data augmentation | Fine-grained | Transformer | Language modeling |
|---|---|---|---|---|---|---|---|
| POAR (Zhang et al., 2023) | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| UFineBench (Zuo et al., 2024) | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ |
| CLEAR (Bui et al., 2024) | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Label2label (Li et al., 2022) | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ |
| MALS (Yang et al., 2023b) | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| VTFPAR++ (Wang et al., 2024b) | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| DRN (Bekele & Lawson, 2019) | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| HP-Net (Liu et al., 2017) | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| UPAR (Cormier et al., 2024) | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| KD-PAR (Wu et al., 2024b) | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
Open attribute recognition
Despite significant advancements in person search, the exploration of open attribute recognition, where attributes are not predefined, remains a largely under-explored field. One article that pioneered in the field is POAR, a novel approach introduced by Zhang et al. (2023) that uses image-text search to predict pedestrian attributes beyond predefined classes. POAR employs a Transformer-based encoder with a masking strategy to focus on attributes of specific pedestrian parts and encode them into visual embeddings. A many-to-many contrastive loss with masked tokens is applied to handle multiple attributes. The effectiveness of this method as a baseline for POAR is demonstrated through evaluations on three PAR datasets in an open-attribute setting.
The methodologies presented for open attribute recognition vary significantly depending on the task, but some common themes and contrasts emerge. For object retrieval, the MS-UGCML method’s unsupervised, collaborative metric learning approach (Tang et al., 2024) offers a more flexible alternative to methods that rely on labeled data. However, its dependence on feature embedding dimensionality might limit its performance. Attribute extraction benefits from OpenTag’s active learning and attention mechanisms (Zheng et al., 2018), which are better for handling complex, real-world product descriptions than older, hand-engineered feature methods. Similarly, SOAE’s multi-component approach combining Semi-Open Attribute Extraction (SOAE) and Ontology-based Attribute Extraction (OBAE) is effective for extracting a wide range of attribute information (Zhang et al., 2021a). While open-set recognition methods often incorporate semantic information to identify the unknown, approaches like Dynamic Attribute-guided Few-shot Open-set Network (DAFON) offer potential advantages. DAFON, for instance, utilizes attribute-guided feature alignment, which may make it more robust and interpretable than traditional methods, particularly when facing scarce data and unknown distributions in medical imaging (Luo et al., 2024). However, the reliance on attribute information is also a limitation when it is not available. For zero-shot learning (Long, Liu & Shao, 2017), the semantic-to-visual embedding approach is a departure from visual-to-semantic embeddings and is more suitable when the focus is on generating visual representations based on semantic descriptions. This is particularly useful in fine-grained settings, where visual differences are subtle. When analyzing the VQA models, Tri-VQA’s triangular reasoning is better than joint embedding methods for medical VQA due to the explicit reasoning process, improving the answer’s reliability (Fan et al., 2024). Finally, the survey on open vocabulary learning (Wu et al., 2024a) shows that knowledge distillation techniques are beneficial, but their ability is tied to the teacher model’s capabilities. The multi-attribute open-set recognition method explored here uses a simple extension of single-task open-set recognition (Saranrittichai et al., 2022) with multiple prediction heads for each attribute. This is the least sophisticated method for open-set recognition with multiple attributes, especially compared to methods such as DAFON.
Discussion
Cross-modal and multimodal ReID aims to bridge the gap between different modalities, such as images, text, and sketches, to improve person re-identification. Cross-modal interaction modules (Wang et al., 2022b) are effective for integrating information from different modalities while preserving unique features; however, they may not address issues like background clutter or occlusions. For handling multi-modal data, multi-modal margin loss can be beneficial for learning modality-specific representations. Methods like descriptive fusion models (Zhai et al., 2022), which combine text and sketches, excel in scenarios where detailed descriptive information is available, but are complex and computationally intensive. Multi-modal uncertainty modeling (Zhao et al., 2024) is advantageous when dealing with inherent data uncertainty, offering a probabilistic approach, but may add complexity to the model. Approaches using prototypical contrastive learning (Zheng et al., 2024b) are useful for weakly supervised settings, leveraging prototypes to overcome intra-modal variations and cross-modal gaps, but their performance is closely tied to the quality of the generated prototypes. Methods like robust dual embedding (RDE) (Qin et al., 2024) are specifically designed for noisy environments, making them suitable when data is not perfectly aligned. Mask-guided dynamic dual-task collaborative learning (Shao et al., 2024) is beneficial for handling background clutter by using masks but may require precise mask generation. Multi-granularity contrastive consistency models (MGCC) (Wu et al., 2024c) are suited for handling occlusions by using token selection mechanisms. Multi-level cross-modality learning (Wu et al., 2023a) is valuable for extracting and aligning both global and local features and is suitable when both are critical for performance. Finally, multimodal large language models (Yang & Zhang, 2024) are powerful for leveraging the capabilities of LLMs in ReID, especially with their instruction-following capabilities, but they are computationally intensive and may not be suitable for edge devices. Choosing a method depends on the specific needs of the task, such as available data, presence of noise or occlusion, and computational resources.
Methodology
This section details the approach and techniques used to develop the text-based person search end-to-end system based on open attribute recognition. This system, shown in Fig. 3, combines natural language processing and computer vision techniques to identify and retrieve individuals from surveillance videos based on natural language descriptions given by the user. The section explains each component of the system, starting with the NLP module for attribute extraction and the person detection module for localizing individuals in video frames. The outputs of both modules are then inserted into the POAR model for extracting attributes from detected people and matching them to the text attributes. The image with the best match is then retrieved for the user.
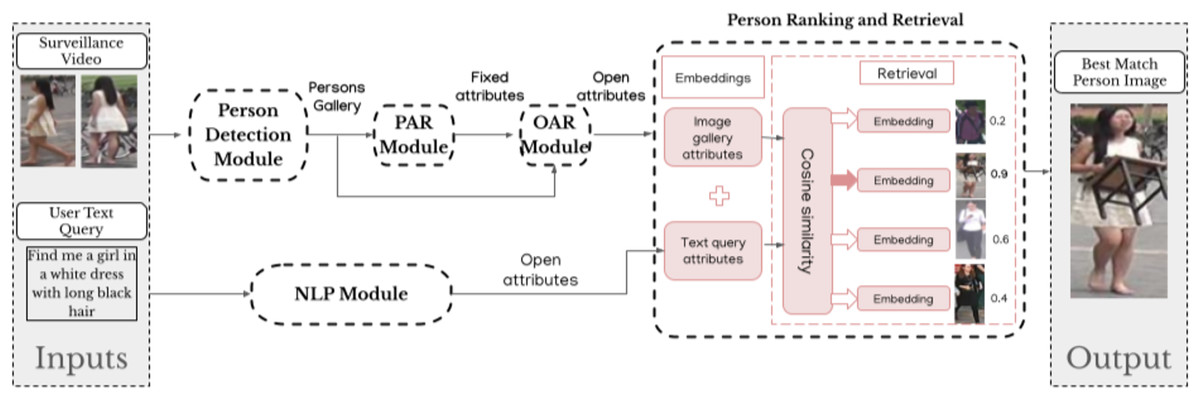
Figure 3: Detailed illustration of the methodology workflow.
NLP extracts attributes from text queries to create the open text query attributes. Person detection identifies individuals in video frames and creates the persons gallery. The images are then passed through PAR to get fixed attributes, which are then passed to OAR to generate open image gallery attributes for each image in the gallery. Person ranking and retrieval module matches the attributes and retrieves the best-matching individual.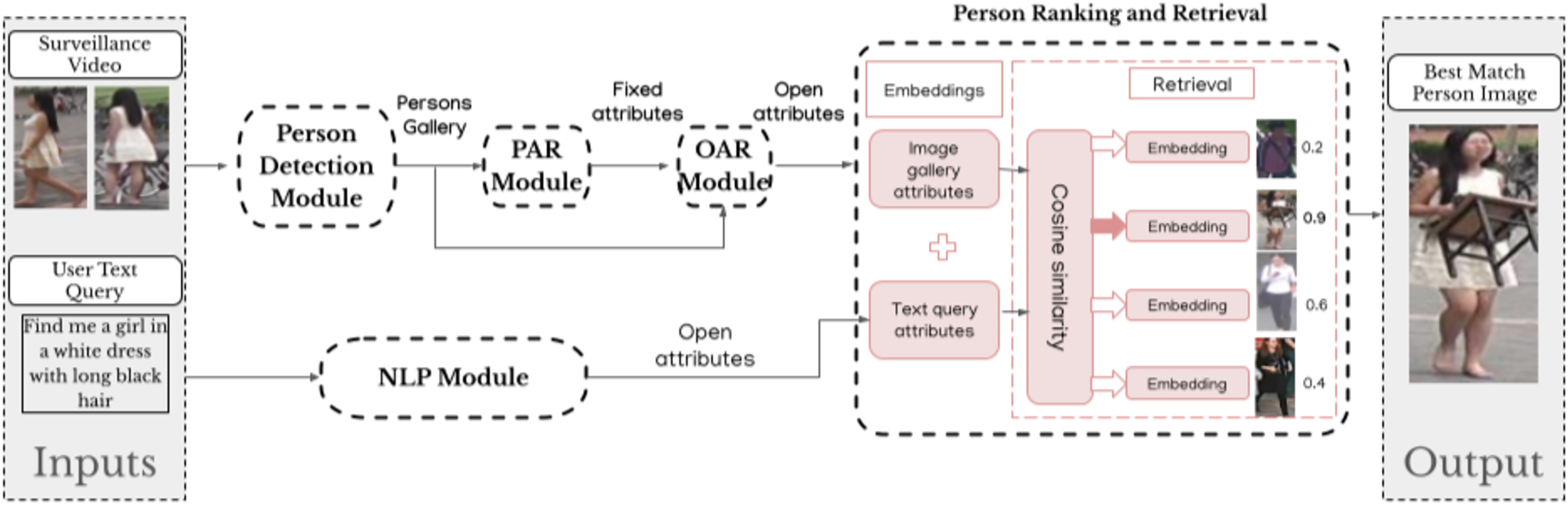{kind=link}
NLP module
The natural language processing (NLP) module, shown in Fig. 4, transforms user-provided text queries into a structured format suitable for attribute-based people search. The module consists of three main steps: keyword extraction, attribute verification, and synonym generation. This is done to ensure that textual descriptions are correctly mapped to relevant visual features for integration with the system’s subsequent components.

Figure 4: Workflow of the NLP module.
The NLP module’s three-step process converts text queries into structured attributes: keyword extraction (identifying descriptive terms via a BERT-based approach), attribute verification (mapping keywords to predefined PA100k attributes), and synonym generation (using a T5 model to create variations). This module outputs open text query attributes for subsequent person ranking and retrieval.{kind=link}
The process begins with keyword extraction, which employs a deep learning approach based on bidirectional encoder representations from transformers (BERT) to identify descriptive terms from the input sentence. BERT’s bidirectional transformer architecture allows it to process the input sequence concurrently from both left to right and right to left, thereby capturing the contextual relationships of words within the entire sentence. For instance, in a query like “Find a tall man wearing a red jacket,” keywords such as “tall,” “man,” and “red jacket” are isolated. Tokenization, part-of-speech tagging, and named entity recognition (NER) are used in this step. The extracted keywords are then inserted into the attribute verification stage, where the keywords are mapped to a predefined set of 26 attributes derived from the PA100k dataset, including categories such as clothing color, gender, and carrying objects.
The module then incorporates a synonym generation mechanism. Synonyms for recognized attributes are generated using a T5 (Text-to-Text Transfer Transformer) model. This allows the system to handle different linguistic variations in user queries using T5’s robust capabilities in text generation and transformation. For instance, synonyms like “blonde” for “fair-haired” or “coat” for “jacket” are aligned with the predefined attributes. This module produces a structured output that includes a list of verified attributes and their synonyms, which are used for the subsequent tasks of image attribute extraction, ranking, and retrieval.
Person detection module
The Person Detection module, shown in Fig. 5, is responsible for accurately identifying and localizing individuals within an image or video frame. This module uses a YOLOv9 model augmented with RetinaFace model, which is a state-of-the-art deep learning framework for person detection that offers high accuracy and speed. The model has a single-stage detection architecture. The feature extractor used has a ResNet backbone to extract hierarchical features from input images. Additionally, a Deformable Convolutional Networks (DCNs) is incorporated to enhance contextual understanding by adaptively adjusting the receptive fields to focus on areas with high relevance, such as regions that are likely to contain faces or body parts. For the detection, a cascade regression strategy is used to enhance the bounding box predictions iteratively for better accuracy and more precise bounding boxes that encapsulate the detected individuals. This approach ensures that the bounding boxes closely align with the detected individuals, minimizing false positives and missed detections. A multi-task loss function is used to simultaneously minimize errors in bounding box regression and landmark localization. Finally, the feature pyramid network in RetinaFace enables multi-scale detection, ensuring that both small and large individuals within the same frame are accurately localized. The bounding box predictions are processed in real time which makes RetinaFace an ideal choice for video surveillance systems that require high-throughput processing.
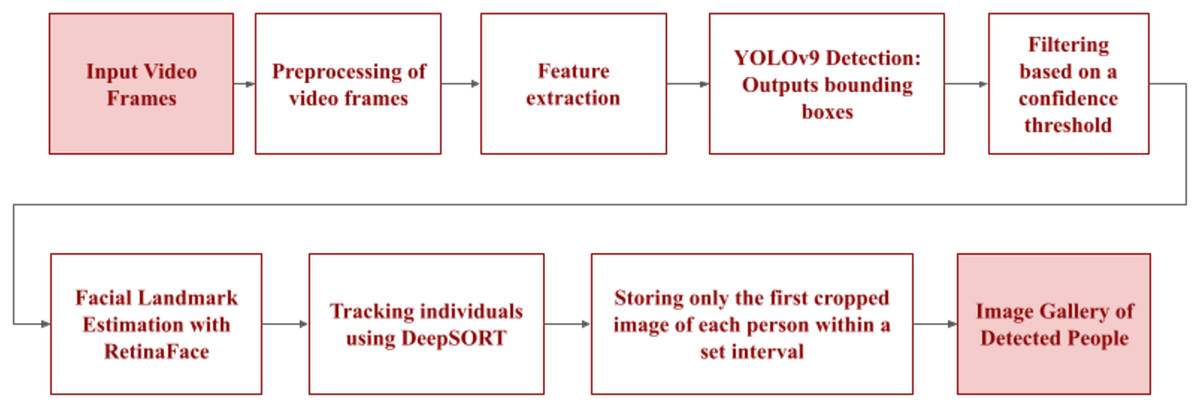
Figure 5: Workflow of the person detection module.
Input video frames undergo preprocessing of video frames and feature extraction. YOLOv9 detection then identifies people, outputting bounding boxes that are filtered based on a confidence threshold. Facial landmark estimation with RetinaFace is performed. DeepSORT continuously tracks individuals to store only the first cropped image of each person within a set interval, building the image gallery of detected people.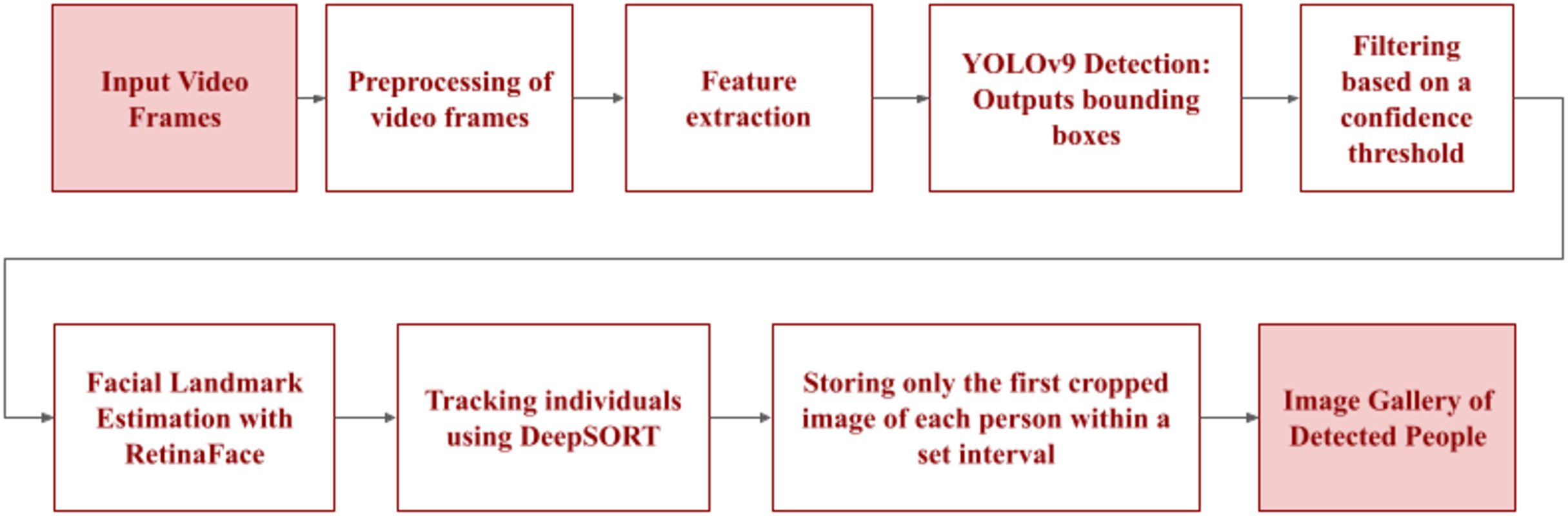{kind=link}
Person open attribute recognition module
The POAR model is divided into two stages: the traditional PAR model and the open attribute recognition model. The PAR model, shown in Fig. 6, is designed to extract and identify various attributes of individuals in surveillance video. The model is trained to recognize a wide range of open-set attributes, meaning it can identify attributes that are not limited to a predefined set. This offers flexibility in recognizing diverse and dynamic features. Once the open attributes are obtained from the people detected in video frames, the attributes are compared to the attributes extracted from the NLP query to find and retrieve the best-matching individual image.
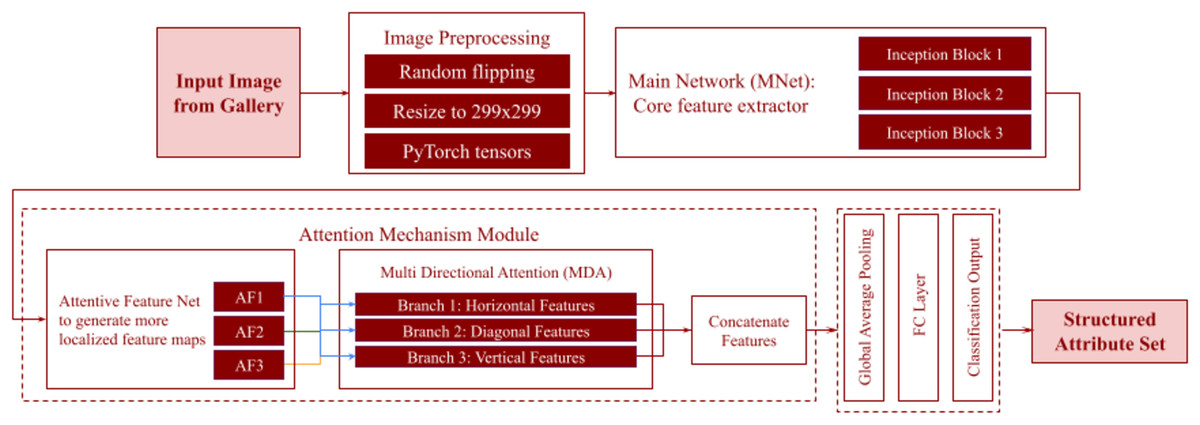
Figure 6: Workflow of the Person Attribute Recognition (PAR) module.
This module extracts structured attributes from an input image from gallery. Each image undergoes image preprocessing before passing into the main network (MNet), which acts as the core feature extractor (inception blocks). An attention mechanism module then refines these features, comprising an attentive feature net to generate localized feature maps (AF1, AF2, AF3) and multi-directional attention (MDA) with its horizontal, diagonal, and vertical branches for fine-grained detail. The refined features are then concatenated and passed through global average pooling and an FC layer, producing a classification output that forms the structured attribute set.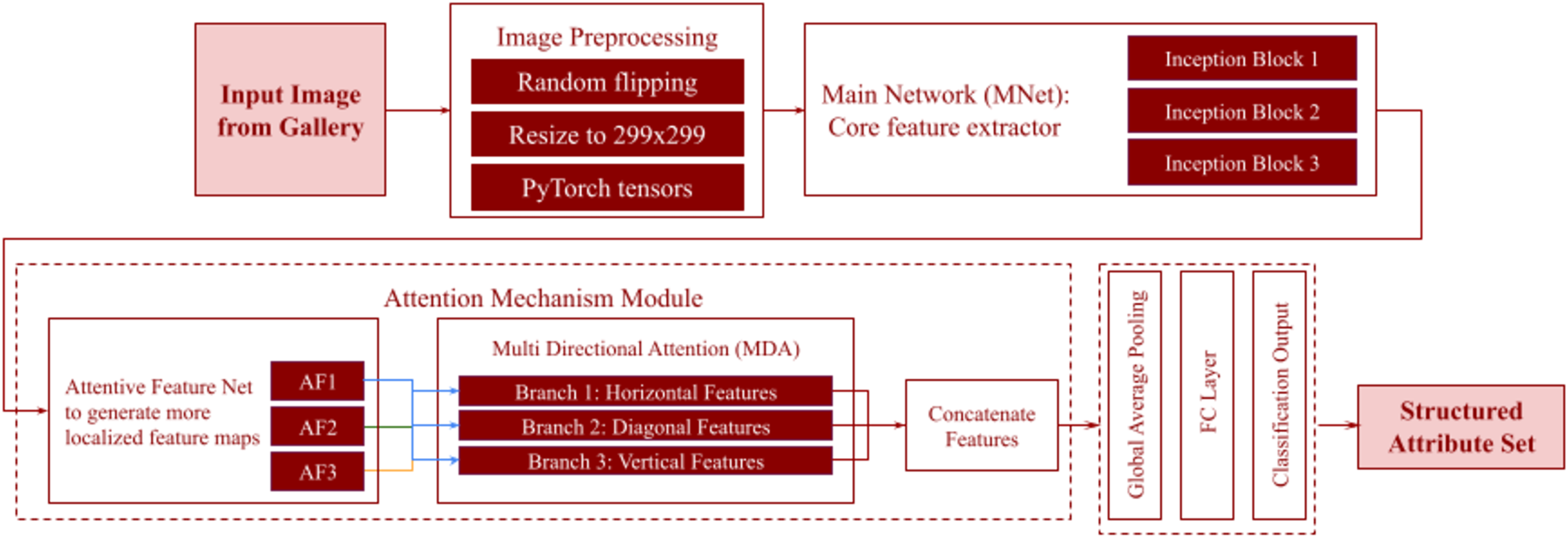{kind=link}
Image attribute extraction
The model’s primary functions are identifying and extracting relevant visual attributes from pedestrian images and associating these attributes with the descriptive features specified in the query. The first stage is preprocessing the input images. Images are resized to a fixed resolution to ensure compatibility with the input size of the network. Random horizontal flipping and normalization are applied for better diversity of the training data and to improve model generalization. The feature extraction process uses a convolutional neural network (CNN) backbone, namely ResNet to capture hierarchical and discriminative features. The input image is passed through convolutional layers starting with basic operations such as convolution and max-pooling, and then more complex residual connections. These layers extract multi-scale features, capturing fine-grained details such as clothing patterns and broader contextual information like pose and orientation. To focus on the most relevant regions of the image, the features are passed to multi-directional attention (MDA) mechanism. This uses horizontal, vertical, and diagonal attention branches that prioritize specific spatial regions of the image. For example, the horizontal branch might focus on torso-level features, while the vertical branch emphasizes full-body traits. Each branch uses a 1 × 1 convolutional layer to compute attention weights to suppress irrelevant noise and emphasize important regions. The next step is attribute classification, where we predict the presence or absence of predefined attributes, such as clothing color (e.g., “red,” “blue”), gender (e.g., “male,” “female”), or accessories (e.g., “hat,” “backpack”). A binary cross-entropy loss function is used during training to calculate the difference between predicted logits and ground-truth labels. The final feature map is passed through a global average pooling layer and a fully connected layer, which outputs the logits for each attribute.
Attention Mechanisms in the PAR Module
The module uses a MDA mechanism that has three distinct branches (horizontal, vertical, and diagonal) that specialize in analyzing specific spatial orientations. Each branch captures unique patterns that may correspond to attributes like torso-level clothing, accessories on the head or shoulders, or posture-related cues. The implementation starts with a feature map , where C is the number of channels, and H and W are the height and width of the feature map extracted by the backbone network. For each attention branch, the first step is to compute attention weights. A using a lightweight convolution operation, shown in Eq. (1), where and are the learnable weights and biases for the attention computation, * denotes convolution, and is the sigmoid activation function. These weights represent the spatial importance of each feature in the input map. The attention weights are then applied to the original feature map through element-wise multiplication as shown in Eq. (2), where represents the Hadamard (element-wise) product (Million, 2007). The resulting attention-modulated feature map emphasizes regions that are most relevant to the recognition task while suppressing irrelevant areas such as background noise.
(1)
(2)
Each branch in the MDA mechanism focuses on a specific spatial orientation by processing through a series of convolutional layers and pooling operations tailored to the branch’s directional focus. The horizontal branch aggregates features along rows to prioritize attributes distributed across the width of the image. The vertical branch aggregates features along columns to capture vertically aligned attributes like full-body clothing. The diagonal branch combines horizontal and vertical features to detect attributes in slanted or tilted orientations. The outputs from these branches, , are combined through concatenation or weighted summation shown in Eq. (3), where are learnable parameters that determine the contribution of each branch. The aggregated feature map is then passed to the classification layer for attribute prediction.
(3)
Open attribute recognition
This methodology improves the detection of comprehensive person attributes by introducing a two-stage attribute recognition process. The predefined attributes from the previous module are extracted and structured as key-value pairs, representing attribute types and their corresponding values. The system then employs an open attribute recognition stage, shown in Fig. 7, where both the structured attributes and visual data are input into a multimodal model. This model utilizes the BLIP-2 architecture and a 6.7 billion parameter OPT backbone to expand attribute detection beyond the initial set effectively.
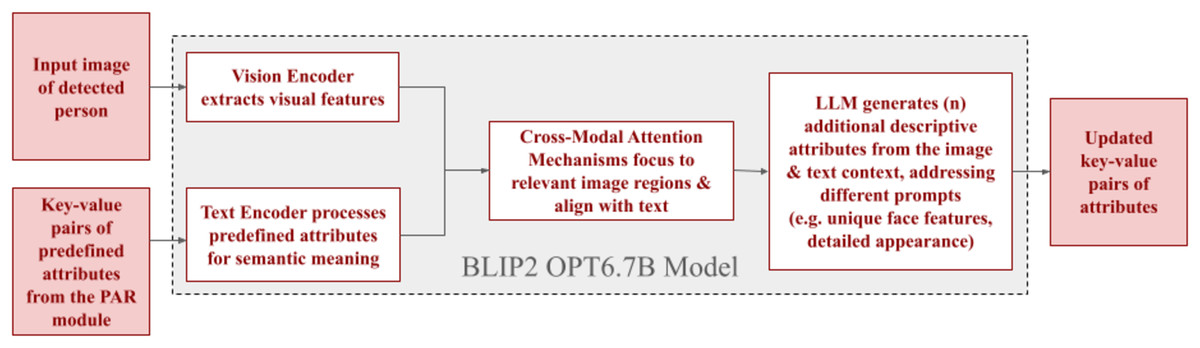
Figure 7: Workflow of the open attribute recognition (OAR) module.
A vision encoder extracts visual features from an input image of the detected person. Concurrently, a text encoder processes key-value pairs of predefined attributes from the PAR module for semantic meaning. Cross-modal attention mechanisms then align these, enabling a large language model (LLM) to generate additional descriptive attributes from the combined context. The output consists of updated key-value pairs of attributes.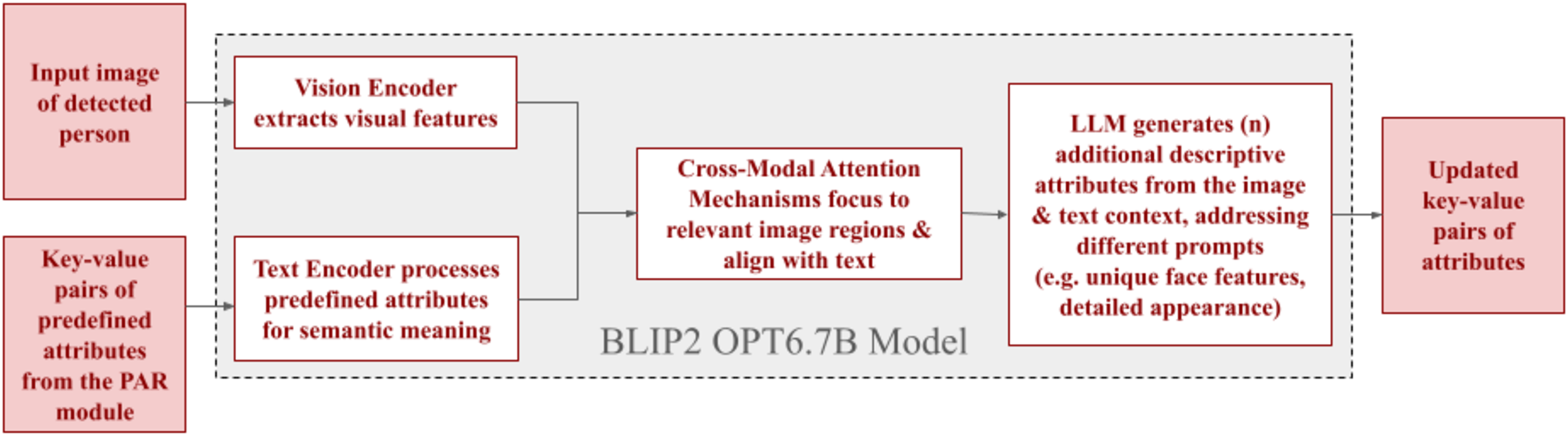{kind=link}
To start, the image is analyzed using a fixed visual processor, similar to Vision Transformers (ViT), to convert it into a set of precise, numerical representations of its different sections. A key improvement is the introduction of a Q-former as a refining mechanism by using adjustable ‘prompt’ indicators to interact with the encoded image data. The Q-Former within BLIP-2 functions as an information bottleneck and condenses the visual information from the person’s image using cross-attention mechanisms. This efficient compression enables the large language model to focus its attention on the most relevant visual aspects alongside the input attribute pairs. This targeted attention facilitates the recognition and extraction of unseen attributes, surpassing the limitations of conventional systems restricted to predefined attribute lists.
The condensed visual data is then fed into OPT, a pre-trained language model. The language model uses attention mechanisms to reference previously generated words and refined visual information to generate detailed and unseen attributes. The identified novel attributes are organized into key-value pairs and grouped under the ’additional attributes’ key to maintain data consistency and integrate seamlessly into the person ranking module. Furthermore, the corresponding person image is linked to the attribute key-value pairs, enabling robust multimodal reasoning.
Person ranking and retrieval
The purpose of the person ranking and retrieval system is to semantically align the open textual attributes extracted from the images of the gallery outputted from the POAR module and the textual attributes extracted from the input text query outputted from the natural language processing (NLP) module. This methodology outlines a process for retrieving images based on extracted attribute sets, operating entirely within a textual attribute space. Initially, attribute sets are used to generate text embeddings. Every individual attribute-value pair from the image gallery attribute sets and the input query’s attribute set is converted into a dense vector representation. This transformation is achieved using a pre-trained contextual text embedding model, which maps discrete textual attributes into a continuous, high-dimensional semantic space. In this space, attributes with similar meanings are positioned in closer proximity, thereby allowing for semantic understanding beyond exact word matches.
Query-gallery attribute matching then proceeds through the calculation of cosine similarity. To ascertain the degree of correspondence between a text query and an image gallery entry, the embeddings of their respective attributes are compared. Specifically, each attribute in the text query is compared against its corresponding attribute within each image gallery entry’s attribute set, where present. The attribute set keys are structured in alignment with PA100k attribute groups, and an “other attributes” key is included to accommodate open-ended descriptions. Cosine similarity, which quantifies the cosine of the angle between two non-zero vectors in a high-dimensional space, serves as the primary metric. A cosine similarity value approaching 1 signifies strong semantic congruence, while values closer to 0 or −1 indicate dissimilarity.
-
•
A and B are the vectors representing the text queries.
-
•
: The dot product of the vectors.
-
•
and : The Euclidean norms (magnitudes) of the vectors.
-
•
The cosine similarity value ranges between −1 and 1, where:
-
–
1: Perfectly similar (vectors point in the same direction).
-
–
0: No similarity (vectors are orthogonal).
-
–
−1: Perfectly dissimilar (vectors point in opposite directions).
-
The overall similarity score for an image gallery entry in relation to the text query is derived by combining the cosine similarities of their matched attribute pairs. This aggregation is accomplished by averaging the individual similarity scores. This aggregated score reflects the semantic alignment between an image’s complete attribute profile and the user’s query. Finally, image retrieval is performed by ranking the image gallery entries in descending order based on these aggregated similarity scores. The image associated with the highest-scoring attribute set is then retrieved and presented as the best match to the user-inputted text query, utilizing rank-1 accuracy in the ranking process. This ranking system ensures that the person most closely matching the input description is retrieved first. This attribute comparison method, rooted entirely in text, facilitates adaptable and robust matching, even when exact keyword matches are absent, by relying on the semantic comprehension capabilities of the system.
Results
This section depicts an extensive evaluation of the proposed person open attribute recognition system. First, the experimental settings and dataset details are introduced to provide a comprehensive representation of the study. Then, the results of each module are discussed and compared with state-of-the-art approaches to highlight their performance.
Experimental settings
The framework was developed using Python and PyTorch. All experiments were conducted on Google Colab with a Tesla V100 GPU with 32 GB of VRAM and an Intel Xeon Gold 6130 CPU with 4 vCPUs and 25 GB of RAM. The PAR module training initially used a batch size of 16, a learning rate of 0.01, and the stochastic gradient descent (SGD) optimizer. However, overfitting was observed and adjustments were made to the training parameters. The optimized training setup included an increased batch size of 125, a reduced learning rate of 0.001, and a switch to the Adam optimizer. The performance of the models was evaluated using accuracy for overall prediction correctness, mean accuracy for the average accuracy across all attributes, precision for the accuracy of positive predictions, recall for the model’s ability to identify all relevant instances, F1-score for balancing precision and recall, and Rank-1 accuracy to evaluate if the top predicted result matches the ground truth of the retrieved person.
Data description
The PA-100k dataset (Jin et al., 2024), shown in Fig. 8, is considered the largest available for pedestrian attribute recognition and is used for both training and evaluation. It contains 100,000 images captured from outdoor surveillance cameras, with 26 binary attributes (yes/no) labeled for each image. The dataset is split into 80,000 images for training, 10,000 for validation, and 10,000 for testing. The images were collected from 598 outdoor surveillance cameras which gives a rich and diverse set of real-world scenarios. Due to the diverse quality and resolution of the images, some are blurry, which makes precise attribute recognition more difficult. Additionally, several binary attributes are infrequent in the dataset, which may introduce class imbalance and affect model training performance. The images vary in resolution, ranging from 50 × 100 pixels to 758 × 454 pixels. The dataset attributes can be categorized as follows:
Gender: “Female” (yes/no).
Age Groups: “AgeOver60”, “Age18-60”, “AgeLess18”.
Viewpoint: “Front”, “Side”, “Back”.
Accessories: “Hat”, “Glasses”, “HandBag”, “ShoulderBag”, “Backpack”, “HoldObjectsInFront”.
Clothing Style: “ShortSleeve”, “LongSleeve”, “LongCoat”, “Trousers”, “Shorts”, “Skirt&Dress”, “Boots”.
Clothing Patterns and Details: “UpperStride”, “UpperLogo”, “UpperPlaid”, “UpperSplice”, “LowerStripe”, “LowerPattern”.

Figure 8: Snapshots of the PA100k dataset.
{kind=link}
NLP module results
The NLP module’s performance in processing input textual queries for person re-identification is detailed in this subsection, focusing on key performance metrics across keyword extraction, attribute verification, and synonym generation.
Regarding the keyword extraction stage, we investigated various models that employ different techniques. As Table 3 shows, DistilBERT, a BERT-based model, achieved superior keyword extraction performance, with an F1-score of 0.98, precision of 0.97, and recall of 0.99. This strong showing stems from its Transformer architecture and self-attention mechanism, which allow it to identify highly relevant and semantically meaningful keywords by analyzing complex word relationships rather than just frequency. Compared to traditional methods like TF-IDF and TextRank, DistilBERT demonstrated significantly better contextual understanding, accurately detecting keywords even in complex text. Attribute verification results were assessed against the PA-100K dataset, showing strong agreement between predicted and ground truth attributes. The model achieved high accuracy for various attributes, especially in well-represented categories like gender, accessory presence, and clothing color. The overall attribute verification accuracy reached 94.3%. This outcome highlights the model’s reliability in attribute recognition and its ability to generalize effectively to real-world situations.
| Model | Precision | Recall | F1-score |
|---|---|---|---|
| DistilBERT | 0.97 | 0.99 | 0.98 |
| SciBERT | 0.97 | 0.97 | 0.97 |
| FinBERT | 0.94 | 0.94 | 0.94 |
| KeyBERT | 0.28 | 0.22 | 0.25 |
| TF-IDF | 0.44 | 0.41 | 0.42 |
| TextRank | 0.43 | 0.33 | 0.38 |
For synonym generation, the T5 (Text-to-Text Transfer Transformer) model’s capabilities were assessed, focusing on its effectiveness in maintaining semantic accuracy while producing varied outputs. BERTScore and METEOR metrics were employed to evaluate T5’s performance against other language models, specifically ChatGPT API and GPT-3, in regard to paraphrased semantic text quality. As Table 4 details, T5 consistently outperformed both ChatGPT and GPT-3, achieving the highest BERTScore of 0.935 and a METEOR score of 0.7958. This indicates its superior ability to generate synonyms that closely preserve the original sentences’ semantic meaning. Furthermore, T5 models are generally known for their efficiency, often requiring fewer GFLOPs for inference compared to larger, more complex models like ChatGPT, making them more computationally efficient for real-world scenarios.
| Model | BERTScore | METEOR |
|---|---|---|
| ChatGPT | 0.9281 | 0.7397 |
| GPT-3 | 0.8788 | 0.5249 |
| T5 | 0.935 | 0.7958 |
Person detection module results
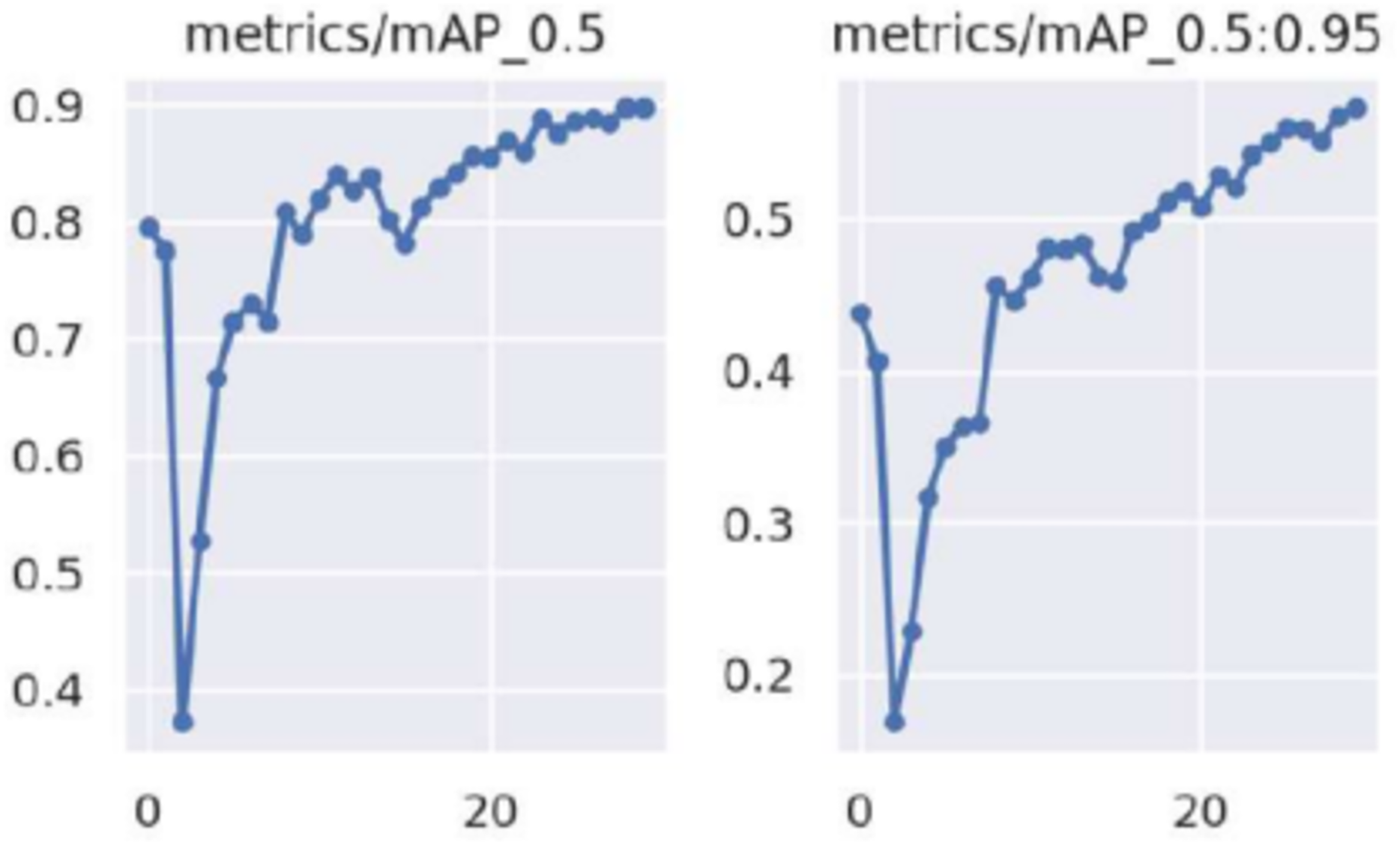
The person detection module, utilizing YOLOv9 and the RetinaFace model, demonstrated outstanding performance across test video surveillance footage under different conditions. The YOLOv9 model was evaluated on the WIDER FACE (Yang et al., 2016) benchmark dataset for person detection. Figure 9 shows the [email protected] and [email protected]:0.95 performance of YOLOv9 across various IoU thresholds, showcasing its robustness and precision in person detection across varying detection scales.
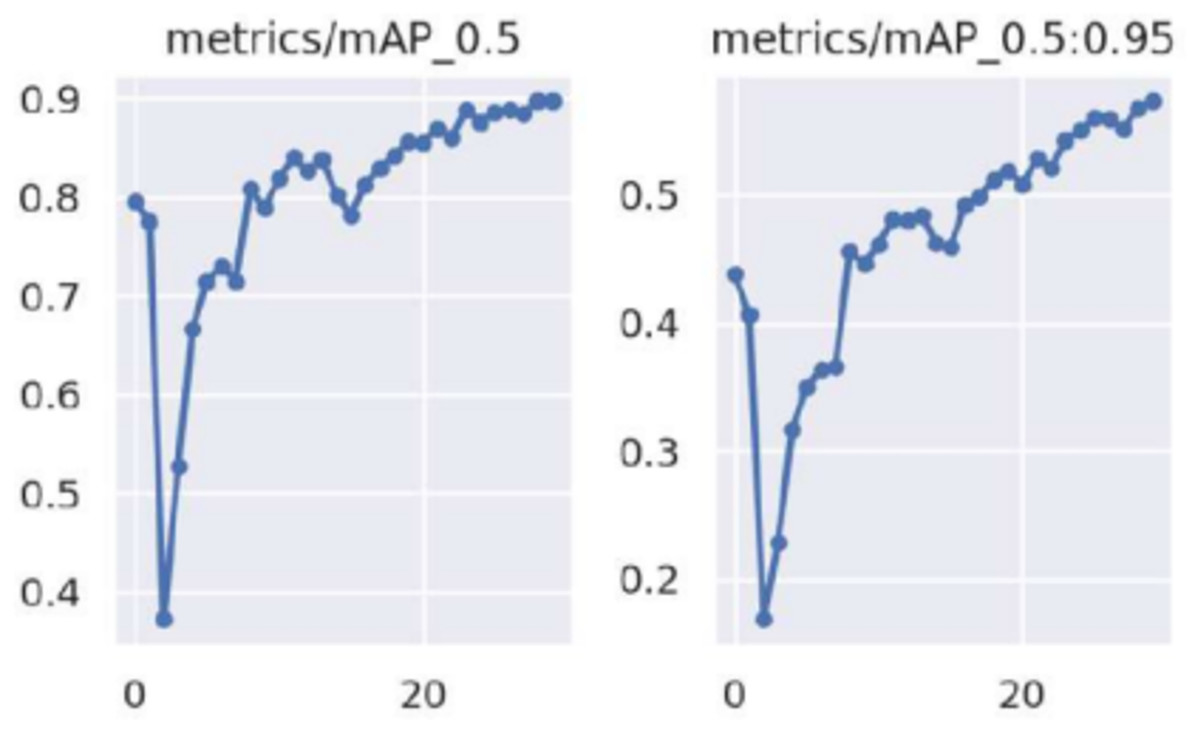
Figure 9: [email protected] and [email protected]:0.95 performance of YOLOv9 across different IoU thresholds, where the x-axis represents the different IoU thresholds and the y-axis represents the Mean Average Precision (mAP).
{kind=link}
Table 5 summarizes the quantitative performance metrics of YOLOv9 in comparison to state-of-the-art models, including YOLOv8, RetinaNet, and Faster R-CNN. YOLOv9 showed superior performance compared to YOLOv8 and other state-of-the-art models in both [email protected] and [email protected]:0.95, indicating its effectiveness in detecting individuals with high precision and recall. Specifically, YOLOv9 achieved a [email protected] of 89.7%, which is a 2.5% absolute improvement over YOLOv8. Despite the improved accuracy and speed, YOLOv9 maintains a tiny model size of 85 MB, comparable to YOLOv8 but significantly more compact than RetinaNet and Faster R-CNN. Therefore, YOLOv9 can be used for edge deployment in resource-constrained environments, including video surveillance, autonomous systems, and human-computer interaction.
| Model | [email protected] | [email protected]:0.95 | FPS | Model size (MB) |
|---|---|---|---|---|
| YOLOv9 (Ours) | 89.70% | 61.30% | 120 | 85 |
| YOLOv8 | 87.20% | 59.10% | 110 | 75 |
| RetinaNet | 84.60% | 56.40% | 35 | 145 |
| Faster R-CNN | 82.30% | 54.70% | 25 | 160 |
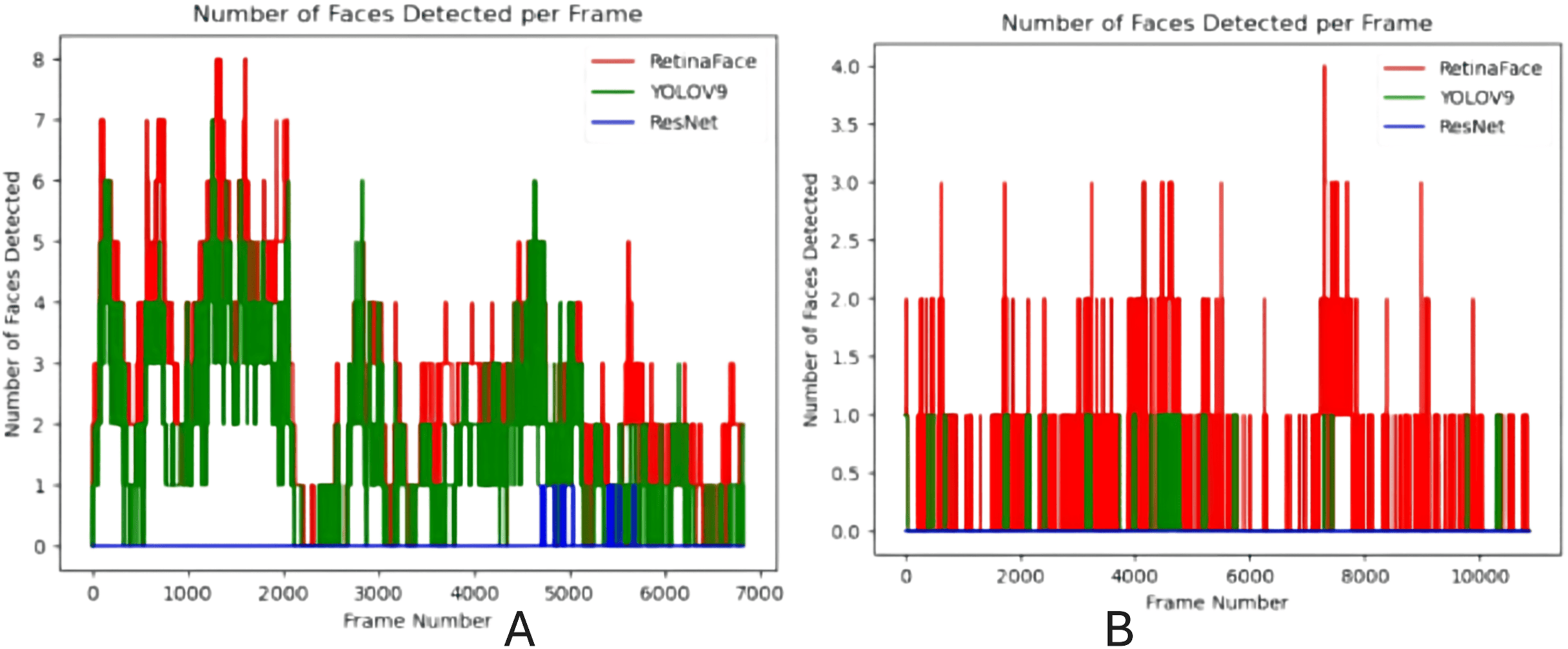
The YOLOv9 model augmented with the RetinaFace module was tested on bird’s eye view footage in both daylight and nighttime, and Fig. 10 demonstrate the results.
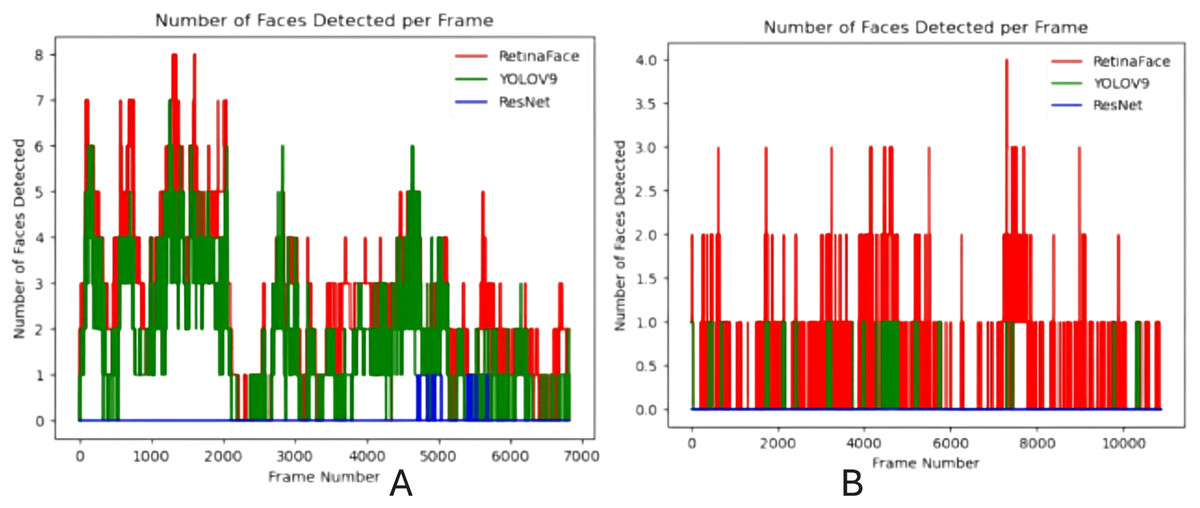
Figure 10: Comparison of the number of faces detected by person detection modules in bird’s-eye view surveillance video: (A) daytime and (B) nighttime.
{kind=link}
The integrated module achieved 98.1% average precision in daylight bird’s-eye view footage with 6,832 frames and 93% average precision in nighttime bird’s-eye view footage with 10,871 frames. The module has outperformed other person detection models, including ResNet and YOLOv9, across the test video footage, highlighting the robustness of RetinaFace in handling different environments and conditions such as low resolution, blurred images, and partial occlusions.
Person attribute recognition module results
The performance of the person attribute recognition module was evaluated by comparing the individual components (MNet, AF1, AF2, AF3) and the integrated whole model. The model was trained for 40 epochs using the fine-tuned weights of MNet, AF1, AF2, and AF3 modules. The initial training of MNet faced issues of overfitting due to a batch size of 16 and a learning rate of 0.01, with SGD as the optimizer. To resolve this, several optimizations were implemented to the module, including increasing the batch size to 128, reducing the learning rate to 0.001, and switching to the Adam optimizer. These changes yielded significant performance improvements. The use of Adam optimizer mitigated the overfitting issue and enhanced the MNET model’s convergence by adaptively adjusting the learning rate for each parameter and correcting gradient estimations, leading to improved learning efficiency and memory utilization. As shown in Table 6, the whole model consistently outperforms each individual component across all metrics, achieving an accuracy (Acc) of 83.7%, a mean accuracy (mAcc) of 83.3%, and an F1-score of 90.4%. MNet, which acts as the backbone of the module, achieved an accuracy of 82.4% and an F1-score of 89.7%. The attribute feature models AF1, AF2, and AF3 exhibited varying degrees of effectiveness, with AF3 achieving the highest performance among the individual components, with an accuracy of 82.8% and an F1-score of 89.8%. While each component contributes to the model’s overall performance, the integrated model demonstrated superior precision, recall, and recognition capabilities, highlighting the importance of combining these components for optimal person attribute recognition. The robustness of the model was further demonstrated by its stable performance across different data splits, emphasizing its capacity to generalize well to unseen data. The implementation of optimization techniques, particularly the Adam optimizer, played a critical role in these performance improvements, setting a strong foundation for future developments in pedestrian attribute recognition.
| Model | Acc | mAcc | Prec | Rec | F1 | Loss |
|---|---|---|---|---|---|---|
| MNet | 82.4% | 79.1% | 93.5% | 86.5% | 89.7% | 0.264 |
| AF1 | 79.1% | 77.6% | 91.4% | 83.9% | 87.5% | 0.311 |
| AF2 | 78.2% | 76.8% | 90.9% | 83.1% | 86.9% | 0.322 |
| AF3 | 82.8% | 80.5% | 92.6% | 87.1% | 89.8% | 0.265 |
| Whole model | 83.7% | 83.3% | 92.8% | 88.1% | 90.4% | 0.257 |
As shown in Table 7, the proposed model significantly outperforms Hydraplus-Net across all evaluation metrics. The proposed model achieves an accuracy (Acc) of 83.7%, which is 17.83% higher than the accuracy of Hydraplus-Net of 65.87%. It also surpasses Hydraplus-Net in mean accuracy (mAcc) by 16.26%, with the proposed model achieving 83.3% compared to 67.04% for Hydraplus-Net. The precision of the proposed model of 92.8% is 10.72% higher than that of Hydraplus-Net, which scored 82.08%. The proposed model outperforms Hydraplus-Net in recall by 13.66%, achieving 88.1% compared to 74.44%. Finally, the proposed model’s F1-score of 90.4% is 12.32% higher than the Hydraplus-Net F1-score of 78.08%. The results distinctly demonstrate significant improvements in the proposed model’s performance, indicating its higher performance in person attribute recognition tasks.
| Model | Acc | mAcc | Prec | Rec | F1 |
|---|---|---|---|---|---|
| Hydraplus-Net (Liu et al., 2017) | 65.87% | 67.04% | 82.08% | 74.44% | 78.08% |
| Proposed model | 83.7% | 83.3% | 92.8% | 88.1% | 90.4% |
Person open attribute recognition module results
Figure 11 provides a visual comparison of images before and after processing through the open attribute recognition (OAR) module and shows the capacity of the model to refine and improve attribute extraction. The module employs cross-attention mechanisms to identify and highlight key visual details, allowing it to infer attributes beyond those explicitly seen during training. The qualitative results confirm its effectiveness in generating detailed and contextually appropriate attribute descriptions and generalizing across various visual inputs.
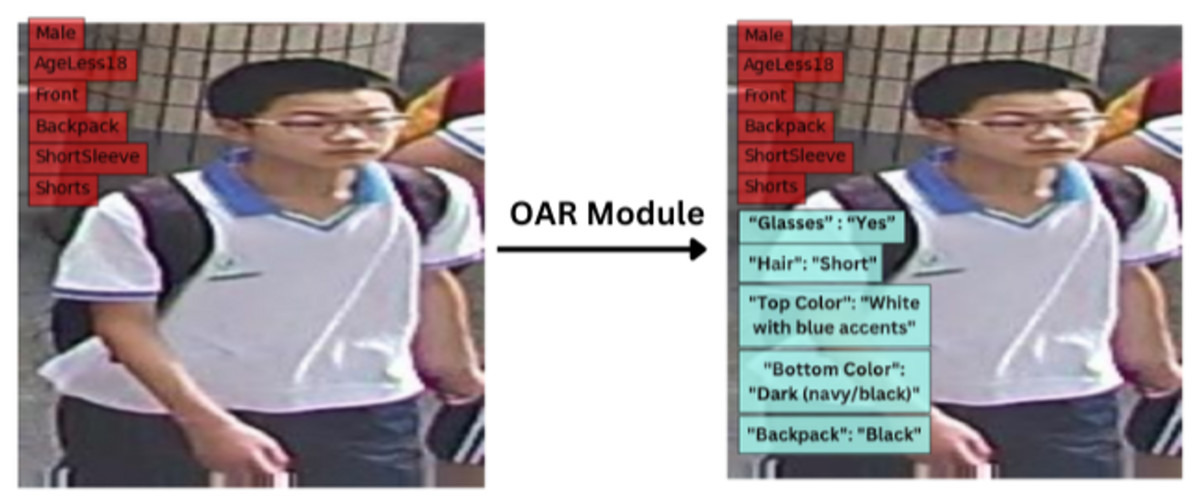
Figure 11: Comparison of images before and after processing through the open attribute recognition (OAR) module.
The red boxes represent the PAR output, and the blue boxes represent the OAR output.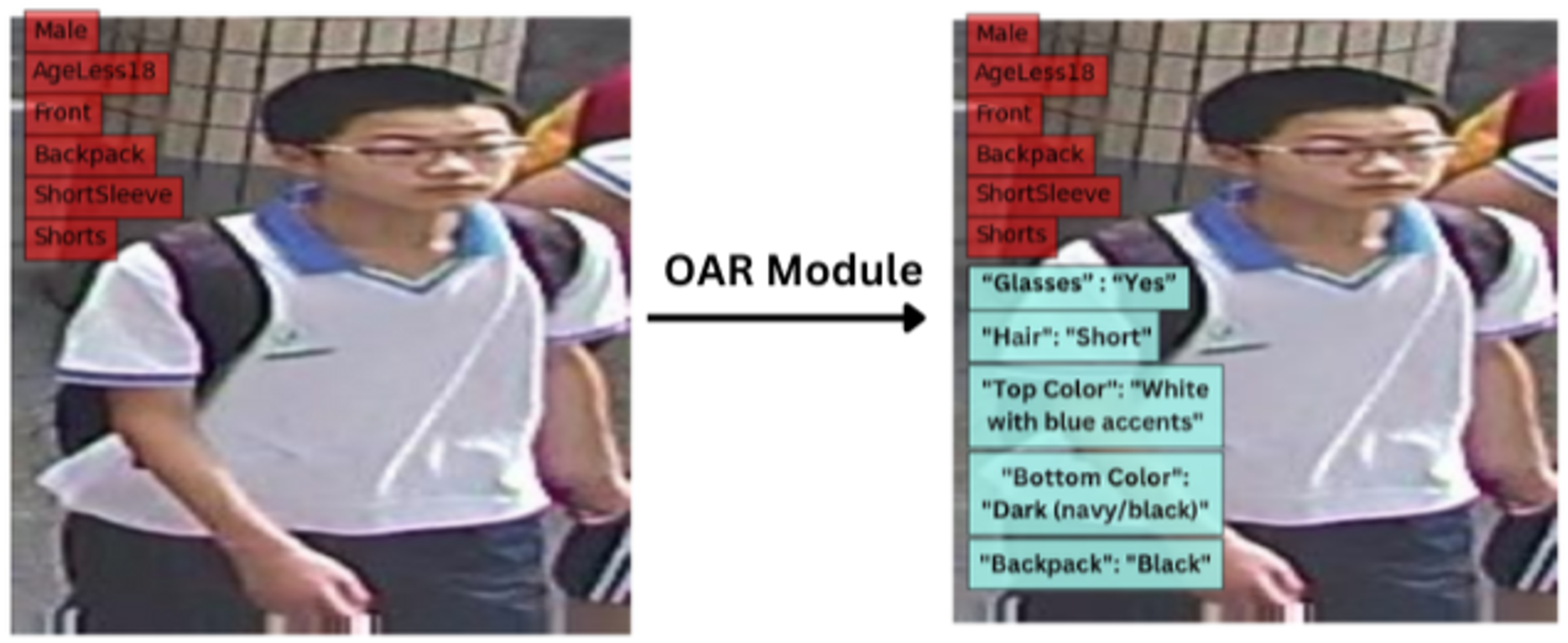{kind=link}
The images in Fig. 12 illustrate a selection of outputs after processing through the OAR module and demonstrate its ability to generate meaningful attribute descriptions in diverse scenarios. The results illustrate how the model adapts effectively to new visual inputs, recognizing attributes beyond predefined categories through its attention-based approach.

Figure 12: Sample outputs from the open attribute recognition (OAR) module, highlighting its capacity to generate detailed and context-aware attribute descriptions.
The red boxes represent the PAR output, and the blue boxes represent the OAR output.{kind=link}
The evaluation of the proposed end-to-end retrieval system is conducted using Rank-1 Accuracy of the person retrieval as the primary metric, which is a standard measure in retrieval-based tasks that measures the proportion of test queries for which the system correctly identifies and retrieves the most relevant person as the top-ranked result. The evaluation was performed on the benchmark dataset PA100k annotated with detailed person attributes, ensuring a rigorous and standardized testing environment. By leveraging this metric, the results demonstrate the system’s retrieval accuracy and its practical usability in real-world applications.
Currently, only one study has explored POAR, which is the article by Zhang et al. (2023). However, it does not utilize an end-to-end framework. It also formulates attribute recognition as an image-text search problem and relies on similarity computations between visual and textual embeddings. On the other hand, our method integrates attribute extraction within a fully end-to-end framework. This eliminates the need for predefined attribute descriptions and manual text encoding, allowing our model to generalize more effectively to unseen attributes.
Table 8 provides a comparative analysis of rank-1 accuracy between the two approaches. As shown in Table 8, our proposed methodology achieves superior Rank-1 accuracy, which demonstrates the effectiveness of our end-to-end, attention-driven architecture in accurately recognizing both seen and unseen attributes.
| Method | Rank-1 accuracy |
|---|---|
| POAR (TEMS) (Zhang et al., 2023) | 83.3 |
| POAR (TEMS + GKD) (Zhang et al., 2023) | 81.3 |
| Proposed methodology | 84.8 |
With a Rank-1 accuracy of 84.8%, the proposed method outperformed POAR (TEMS) and POAR (TEMS + GKD) by 1.5% and 3.5%, respectively (Zhang et al., 2023). This indicates that the proposed method not only performs better than standard approaches but also demonstrates how well it handles open attribute recognition jobs and provides a more reliable solution in correctly identifying person attributes and retrieving the correct individual.
Table 9 presents a comparison of our proposed approach against various text-based and attribute-based person search methods on the PA100K dataset. Rank-1 accuracy is used as the evaluation metric, representing the proportion of correctly identified matches at the top rank. Traditional approaches such as 2WayNet and CMCE exhibit lower accuracy, while more recent techniques like ASMR and WSFG show improvements. Our method outperforms all existing models, achieving an impressive Rank-1 accuracy of 84.8% and proving its effectiveness in text-based person search.
| Method | Rank-1 accuracy |
|---|---|
| 2WayNet (Eisenschtat & Wolf, 2017) | 19.5 |
| CMCE (Li et al., 2017) | 25.8 |
| ASMR (Jeong, Park & Kwak, 2021) | 31.9 |
| WSFG (Peng et al., 2023) | 30.2 |
| AIMA (Wang et al., 2024a) | 42.5 |
| POAR (TEMS) (Zhang et al., 2023) | 83.3 |
| POAR (TEMS + GKD) (Zhang et al., 2023) | 81.3 |
| Proposed methodology | 84.8 |
End-to-end deployment
To validate the practical applicability of the proposed surveillance framework, an end-to-end deployment in a cloud environment that simulates real-world conditions was conducted. This comprehensive evaluation aimed to assess the system’s responsiveness and processing efficiency in retrieving the best-matching individual from a surveillance video based on a user-inputted textual query. The computational complexity of each module in the pipeline is shown in Table 10.
| Module | Average GFLOPs per instance |
|---|---|
| YOLOv9-Small | 26.4 GFLOPs |
| MNet + AFNet (PAR) | 20 GFLOPs |
| BLIP2-OPT-6.7B | 700–1,000 GFLOPs |
| DistilBERT-base | 1.5–3.0 GFLOPs |
| Attribute verification module | 0.1 GFLOPs |
| T5-base | 40–60 GFLOPs |
| Person ranking and retrieval | 0.1 GFLOPs |
The surveillance system is designed to operate in two distinct phases. The initial phase, where we create the image gallery’s attributes, is done offline since it’s computationally intensive. The second phase, however, handles making text query attributes from the user searches and then ranking and retrieving the person of interest by checking against the image gallery attributes. This part happens in real-time, so users can quickly type in a query and get results for a person from videos already processed by the system. This division makes the system efficient and scalable while still giving us rich details for describing and searching for people. For evaluation, the complete system was deployed on Google Colab Pro using an NVIDIA Tesla V100 GPU (16 GB). A 60-s surveillance video at 1,920 1,080 resolution and 12 frames per second (FPS) was used as the video input.
The image-based pipeline processes visual surveillance data offline to construct a structured attribute set for each image in the gallery. Due to the high computational cost of models such as BLIP2 and the large volume of image data within surveillance environments, this phase of processing is not executed in real-time. The process begins by extracting key frames at a rate of one per second from the video for the person detection module, which effectively manages workload while capturing all key actions. Powered by the V100 GPU, YOLOv9-Small quickly detects people, while DeepSORT tracking enables the system to store the first instance of each person in the gallery. Following this, the PAR module creates the closed-set attributes for each person in the image gallery. Finally, the OAR module uses BLIP2-OPT to generate the open attributes. The overall computational cost for the image-based pipeline is approximately 700–1,000 GFLOPs per person instance, which is mainly affected by the OAR module. However, performing this entire phase offline makes the system feasible for real-world use, allowing for the comprehensive and rich descriptions of surveillance footage without impacting the real-time operations of the person search.
On the other hand, the NLP module that processes the user text query to create the open text attributes is activated in real-time. This process begins with DistilBERT extracting keywords from your query, followed by the attribute verification step and a T5-base model to generate synonyms. The system then finds the best matching person of interest by performing person ranking and retrieval. The lightweight nature of these modules ensures minimal delay, with a computational complexity of 40-60 GLOPS per user query, making the retrieval system interactive and real-time, even under constrained computational environments.
We tested the end-to-end person re-identification system using three one-minute surveillance videos. On average, the system detected 20 people in these videos. The system processed the 20 detected people and compared their information to all 20 gallery attributes to retrieve the best-matching individual. We then calculated the GFLOPs needed by running the system on a Google Colab Pro V100 GPU. The real-time online text part was incredibly efficient, using only about 41.5 GFLOPs. In contrast, the offline image part is more computationally intensive and requires about 15,984 GFLOPs. Nevertheless, even with that higher demand, a powerful GPU can enable us to process small video segments in real-time with the offline system.
Conclusion and future work
In this research, we present a novel framework for text-based person retrieval in surveillance videos. This framework offers a robust and efficient approach to identifying individuals based on textual queries by integrating natural language processing and computer vision techniques. The person retrieval process begins with the extraction of discrete attributes from a natural language description. This transforms vague and ambiguous textual inputs into structured, actionable data. These discrete attributes, which represent key characteristics such as gender, clothing type, color, and accessories, are then matched against visual attributes detected in video frames. The vision subsystem uses YOLOv9 model for person detection to locate and extract human figures from the video. Once the individuals are detected, the Person Open Attribute Recognition model predicts their attributes, which are then fused with the textual discrete attributes through element-wise multiplication. This fusion allows the system to focus on the most likely candidates, minimizing the mismatch between the visual and textual data. Finally, the candidates are ranked based on their attribute similarity to the natural language description, providing an ordered list of potential matches. The system outputs the individual with the highest score as the best match. Through this approach, we have shown that person retrieval using text descriptions is both feasible and efficient, even in complex surveillance scenarios where ambiguity and variability are inherent.
The system showed promising results and has the potential to be a valuable tool in real-time surveillance applications by offering a new dimension to how individuals can be identified and tracked within dynamic environments. The proposed system demonstrated its effectiveness through the performance of its main modules. The NLP module achieved 95% accuracy in processing the input text query. The Person Detection module maintained a mean average precision (mAP) of 89.7%. Furthermore, the Person Open Attribute Recognition module achieved a rank-1 accuracy of 84.8%, which is comparable to state-of-the-art methods.
To the best of our knowledge, Zhang et al.’s (2023) POAR represents the only other existing work in person open attribute recognition and provides the key comparative baseline for our methodology. Their work focuses on a joint embedding space for images and textual attribute descriptions, trained with contrastive loss and knowledge distillation. Our pipeline adopts a more modular approach, first extracting predefined attributes and then using a powerful vision-language model, BLIP2, to generate additional open attributes, which are then used for matching against a textual query. This article argues that our methodology’s utilization of text-to-text similarity between the NLP query and the generated attributes leads to enhanced retrieval accuracy and the potential for more contextually rich attribute descriptions. The article also explicitly demonstrates superior performance on the PA-100K dataset compared to previous work. These results collectively validate the proposed methodology, highlighting its potential for real-world applications in surveillance and investigative scenarios where textual descriptions are the primary input for person re-identification.
While current models can process simple descriptions with reasonable accuracy, future advancements could include the ability to understand more detailed, ambiguous, and context-dependent inputs, and incorporate multi-modal data such as audio or environmental cues. Another avenue for future work involves improving the efficiency and scalability of the system to handle large-scale video datasets in real-time. This could be achieved through model optimization techniques, such as pruning, quantization, and hardware acceleration. Additionally, exploring the integration of multimodal approaches that combine person retrieval with other surveillance tasks, such as anomaly detection, behavior analysis, or event detection, could create a more comprehensive surveillance system. By advancing these areas, person retrieval systems can become more accurate.
Considering the growing use of surveillance tools, addressing the privacy issues of open attribute recognition in surveillance is a critical area for future investigation. As these systems become better at identifying complex human characteristics, the potential for revealing sensitive personal data significantly increases. This creates a need to develop and integrate robust privacy-enhancing technologies. For instance, differential privacy offers a measurable protection against the disclosure of personally identifiable information. By subtly introducing noise during model training or analysis, it becomes exceedingly difficult to reconstruct individual details from specific attribute data. Moreover, adopting decentralized learning paradigms like federated learning is vital. This approach allows models to be collaboratively trained across various surveillance devices without requiring the direct transmission of raw, sensitive video feeds, significantly reducing the risk of centralized large-scale data breaches and keeping information local. Furthermore, ensuring algorithmic fairness is crucial; dedicated research into bias mitigation techniques is essential to prevent attribute recognition models from producing unfair results for different groups of people. This helps maintain ethical standards and prevent unintended societal harm in surveillance applications.