
Comparative evaluation of machine learning models for museum exhibit recognition from video-derived datasets
- Published
- Accepted
- Received
- Academic Editor
- Siddhartha Bhattacharyya
- Subject Areas
- Artificial Intelligence, Computer Vision, Data Mining and Machine Learning, Neural Networks
- Keywords
- Machine learning, Museum exhibit recognition, Video-derived datasets, Object detection, Cultural heritage, Real-time recognition, Augmented reality (AR)
- Copyright
- © 2025 Ipalakova et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Comparative evaluation of machine learning models for museum exhibit recognition from video-derived datasets. PeerJ Computer Science 11:e3207 https://doi.org/10.7717/peerj-cs.3207
Abstract
This study evaluates the performance of multiple deep learning models for automatic recognition of museum artifacts using image frames extracted from real-world video footage. A comparative analysis is conducted across eight state-of-the-art architectures—MobileNetV3, ResNetV2, EfficientNetV2, You Only Look Once v8 (YOLOv8), Visual Geometry Group 16 (VGG16), ConvNeXtTiny, SwinV2-Base, and Dual Attention Vision Transformer (DaViT)—on a custom dataset collected in an actual museum environment. The dataset comprises labeled video frames categorized by artifact type and is used to train and test models for both classification and object detection tasks. Results indicate that YOLOv8, MobileNetV3, and DaViT achieve superior performance for real-time mobile and augmented reality (AR) applications, while ResNetV2 and SwinV2-Base provide high classification accuracy suitable for archival and cataloging systems. This work offers practical guidance on dataset design, model choice, and deployment strategies for artificial intelligence (AI)-powered cultural heritage technologies.
Introduction
The increasing application of artificial intelligence in cultural heritage has significantly transformed how museums recognize and present exhibits. Machine learning-based object recognition systems provide promising solutions for real-time identification in digital museums, promoting more interactive and engaging visitor experiences (Kiourexidou & Stamou, 2025; Meyer et al., 2024). Unlike traditional static and labor-intensive approaches, modern computer vision techniques—especially those leveraging deep learning—enable dynamic, scalable, and precise artifact recognition. However, despite advancements in convolutional neural networks (CNNs) and single-stage detectors, comparative studies evaluating various architectures under realistic museum conditions, such as inconsistent lighting, object occlusion, and varying perspectives, remain limited (Khan et al., 2022; Patil, Sharma & Jain, 2024). Therefore, selecting appropriate architectures is critical for developing successful museum applications, given the continuous evolution of deep learning models across diverse fields such as healthcare, security, and education.
Integrating machine learning (ML) technologies into museum exhibitions represents a significant step toward the digital transformation of cultural heritage, offering multiple opportunities ranging from enhancing artifact classification accuracy to delivering personalized visitor interactions. Luo & Li (2024) illustrate the development of an intelligent real-time exhibit recognition system based on deep learning, significantly improving visitor engagement. Further, hybrid approaches, as highlighted by Bobasheva, Gandon & Precioso (2022), demonstrate that combining symbolic artificial intelligence (AI) with ML substantially enhances cultural metadata quality, enabling more precise navigation through museum collections.
The effectiveness of ML models in museum contexts heavily depends on the quality and diversity of training data, particularly for visual recognition tasks. Data augmentation techniques have thus become essential for expanding datasets and improving model generalizability. Specifically, simulating variations in images captured by smartphones—such as adjustments in color profiles, sharpness, noise, dynamic range, and lens distortion—helps overcome the limitations associated with uniform data sources. Lee (2025) emphasizes structured data preparation and dataset diversity as critical components for successful ML implementation in cultural heritage. Wang & Zhao (2023) also confirm that improved data quality directly impacts museum collection management and exhibition optimization.
The broader potential of intelligent museum systems extends to spatial exhibition design, visitor behavior analysis, and ethical considerations related to inclusive representation (Cai, Zhang & Pan, 2023; Tang et al., 2024; Acosta et al., 2021; Walsh et al., 2021; Huang & Liem, 2022). Li (2024) outlines opportunities and challenges in implementing AI in museum development, highlighting the need for adaptive and high-performing models to enhance visitor experiences. Similarly, Bazarbekov et al. (2024) emphasize the successful application of AI-powered image analysis across medical and industrial domains, underscoring the importance of adaptive visual modeling. Rahim et al. (2025) further demonstrate the effectiveness of pretrained convolutional networks, reinforcing the value of robust datasets and augmentation strategies in successful ML applications.
These advances in deep learning are already evident across various domains, including medicine, cybersecurity, and autonomous systems. For example, the modified U-Net architecture (D-UNet), combining 2D and 3D features, significantly improved segmentation accuracy for stroke lesions and retinal blood vessels by leveraging dimension fusion and deformable convolutions (Zhou et al., 2021; Jin et al., 2019). Dense-UNet, another variation, effectively segmented cellular images under noisy conditions by enhancing information flow through dense connections, mitigating gradient issues (Cai et al., 2020). Such innovations highlight the extensive potential of deep learning architectures to transform museum exhibit recognition and interaction profoundly.
In cybersecurity, the X-NET architecture, grounded in explainable AI, achieved high accuracy in detecting network threats and offered interpretable results, although it can be computationally demanding (Patel et al., 2024; Li et al., 2024). X-NET’s adaptations have also successfully segmented video scenes with dynamic backgrounds (Zhang et al., 2019). CNN-based methods, like U-Net, similarly demonstrated effectiveness in seismic data reconstruction from sparse samples (Huang & Nowack, 2020).
Other deep-learning architectures such as SegNet, PSPNet, and V-Net showed effectiveness across various applications, including road infrastructure segmentation, medical diagnostics, and remote sensing. SegNet efficiently segmented road scenes and skin lesions but exhibited limitations in resolution and accuracy compared to specialized models (Shabalina et al., 2021; Sokolov, 2024; Zaitseva & Kazankov, 2021). PSPNet leveraged pyramid spatial pooling to capture contextual information but was computationally intensive, limiting real-time use (Gorbachev et al., 2020; Taran et al., 2018; Yuan, Wang & Xu, 2022). V-Net excelled in volumetric medical imaging and road network extraction, proving its effectiveness in complex 3D environments (Milletarì, Navab & Ahmadi, 2016; Abdollahi, Pradhan & Alamri, 2020; Kato & Hotta, 2020).
The DeepLab v3+ model, tested on TS1 (Plant Village) and TS2 (real vineyard) datasets, demonstrated improved mean intersection over union (mIOU), recall, and F1-score metrics for grapevine black rot spot segmentation, providing an effective method for assessing disease severity and potentially applicable to other plant diseases (Yuan et al., 2022).
Additional methods, such as meta pseudo labels and NoisyNN architectures, advanced the performance of deep-learning models by improving training efficiency and robustness to noise (Pham et al., 2021; Go & Moon, 2024; Gesmundo & Dean, 2022; Gesmundo, 2022; Gao et al., 2024; Foret et al., 2020; Papers with Code, 2025; Yu et al., 2023; Liu et al., 2023). Such innovations indicate significant potential for museum-related recognition tasks, yet practical challenges persist, including domain adaptation, limited data, and real-time performance constraints (Zhang, Tas & Koniusz, 2018; Koniusz et al., 2018; Ypsilantis et al., 2021; Perera et al., 2020; Pasqualino et al., 2020; Wang & Li, 2022).
Thus, deep neural network architectures are actively used today for the recognition of museum objects. However, challenges related to adaptation to real-world conditions, limited training data, and the need for real-time performance remain relevant. The research presented in this study complements existing approaches by offering a comparative evaluation of eight models—MobileNetV3, ResNetV2, EfficientNetV2, You Only Look Once v8 (YOLOv8), Visual Geometry Group 16 (VGG16), ConvNeXt-Tiny, SwinV2-Base, and DaViT—on video data collected in a museum setting, with a focus on their use in developing mobile AR applications. These architectures were selected based on their image classification and detection capabilities, computational efficiency, and potential for integration into various digital museum systems. MobileNetV3 was chosen for its compactness and speed, ResNetV2 for its deep architecture and high accuracy, EfficientNetV2 for its balance between computational load and accuracy, YOLOv8 for its fast and precise object detection, and VGG16 as a well-established solution with strong generalization capabilities. ConvNeXt-Tiny, a modern architecture that integrates CNN and transformer principles, was also evaluated, along with SwinV2-Base—a powerful visual transformer model known for its high accuracy and robustness, and DaViT, a hybrid model that effectively combines the strengths of convolutional and transformer-based approaches for classifying museum exhibits. By systematically comparing eight neural network architectures on a custom video-derived dataset, this study not only fills a methodological gap in the literature but also provides practical recommendations for deploying AI in real-world museum settings.
Materials and Methods
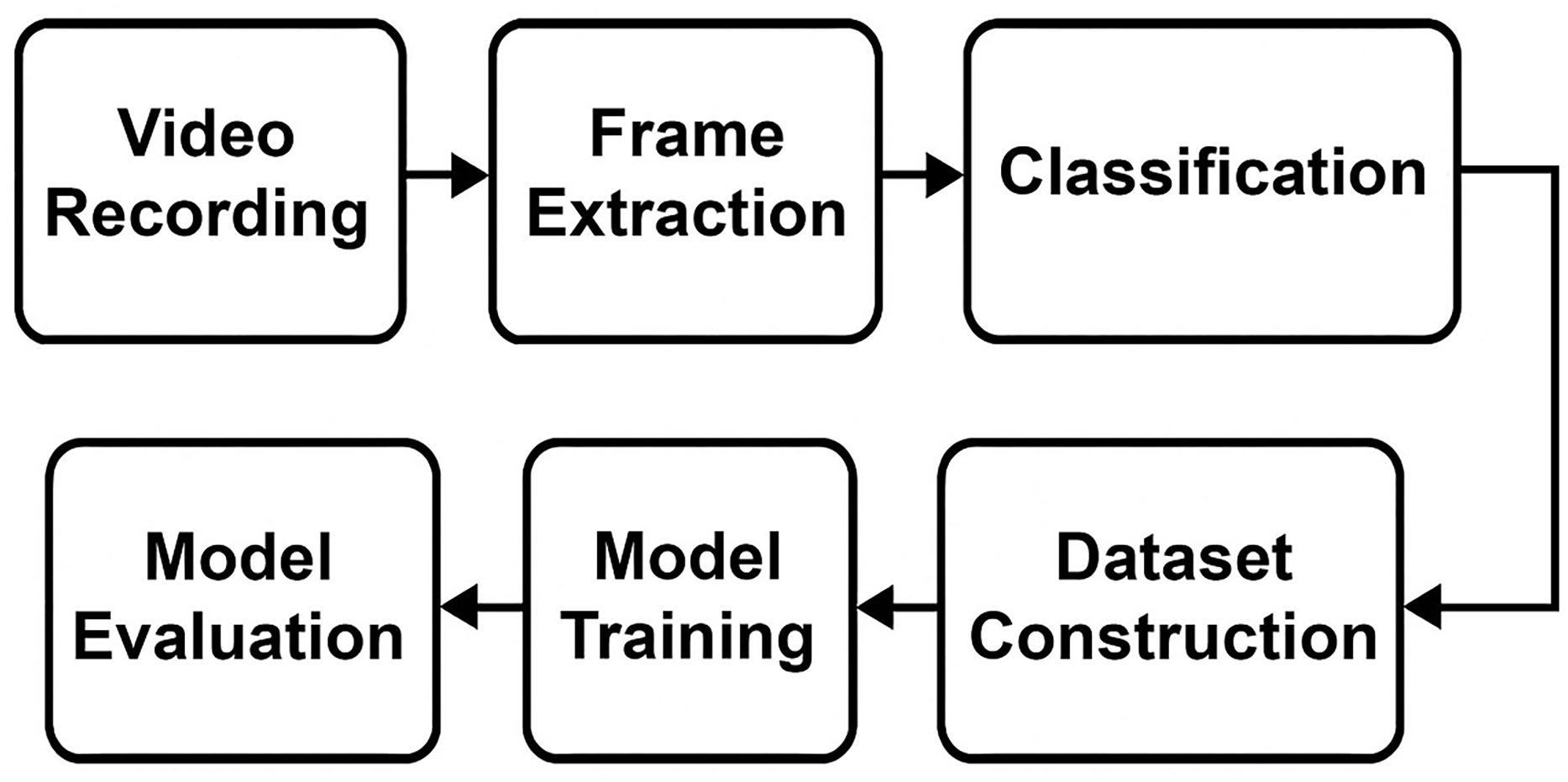
To prepare the dataset used in this research, a comprehensive methodology involving multiple sequential stages was employed. As illustrated in Fig. 1, the primary steps included: video recording in a museum environment, frame extraction from collected videos, manual classification and labeling, and the subsequent dataset construction and expansion to ensure robust model training and evaluation. Each of these stages is described in detail in the following subsections.
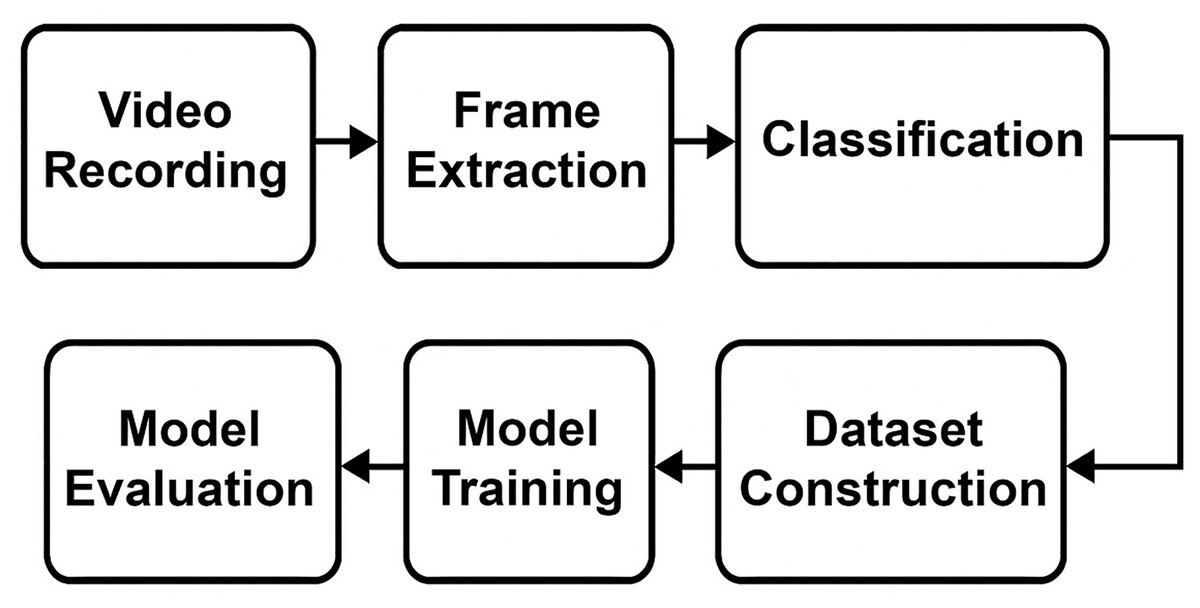
Figure 1: The visual depiction of the methodology.
{kind=link}
Video recording
This stage involved recording video footage in the museum using a smartphone camera. The recordings were made with iPhone 12 Pro and Samsung S22 Plus smartphones in .mov format, at Full HD resolution and 60 frames per second. As the authors collaborate with the A. Kasteyev State Museum of Arts in Almaty, the exhibits from this museum were used for the study.
The filming was conducted under natural conditions, without special preparation, simulating the behavior of regular museum visitors. Approximately 80 video clips were collected during this process, which were later categorized and used for analysis.
All collected video materials were categorized into the following categories:
-
•
Sculpture—12 objects, including:
-
○
“Candlestick. Camel” (N. I. Pavlenko, 1970)
-
○
“Decorative Sculpture. Ram” (N. I. Pavlenko, 1971)
-
○
“Sculptural Composition. Caravan” (Yu. G. Popov, V. G. Popov, 1983)
-
○
“Vase” (20th century, unknown author)
-
○
“Kimono” (R. F. Kozhakhmetov, 2012)
-
○
“Petroglyphs” (G. Z. Dosmagambetova, 1998)
-
○
“Cry” (B. Abishev, 1991)
-
○
“Four-Part Composition. Fragment” (R. Akhmetov, 1980)
-
○
“Portrait of Olzhas Suleimenov” (T. Dosmagambetov, 1977)
-
○
“Saule” (A. Yesenbayev, 1990)
-
○
“Three Swords” (A. Zhumabay, 2006)
-
○
“Family” (Kazaryan)
-
-
•
Tapestry—six objects, including:
-
○
“Syrmak—Felt Floor Carpet” (unknown author)
-
○
“Legend of the Mountains and Steppes” (K. T. Tynybekov, 1979)
-
○
“Wall Panel. Jailau” (B. E. Zaurbekova)
-
○
“Tree of Life” (R. E. Bazarbayeva, 2016)
-
○
“Galaxy” (S. S. Bapanova, 2016)
-
○
“Tükki Kilem—Pile Carpe”t (unknown author, Southern Kazakhstan)
-
-
•
Painting—18 objects, including:
-
○
“Herd in the Jailau” (A. Kasteyev, 1947)
-
○
“Blooming Apple Trees” (A. Kasteyev, 1958)
-
○
“Portrait of Kenesary” (A. Kasteyev)
-
○
“Portrait of Folk Akyn Zhambyl” (A. Kasteyev, 1937)
-
○
“Collective Farm Celebration” (A. Kasteyev)
-
○
“Turksib” (A. Kasteyev, 1969)
-
○
“Portrait of Ch. Valikhanov” (A. Kasteyev, 1951)
-
○
“Collective Farm Dairy Farm” (A. Kasteyev, 1936)
-
○
“Haymaking” (A. Kasteyev, 1934)
-
○
“Lake Issyk” (A. Kasteyev, 1953)
-
○
“Portrait of Amangeldy Imanov” (A. Kasteyev, 1950)
-
○
“On the High-Mountain Skating Rink” (A. Kasteyev)
-
○
“Milking Mares” (A. Kasteyev, 1936)
-
○
“Kapchagay Hydroelectric Station” (A. Kasteyev, 1972)
-
○
“Happiness” (S. Aitbayev, 1966)
-
○
“Sounds of the Kobyz” (K. Yesirkeyev, 1973)
-
○
“Earth and Time. Kazakhstan. Triptych. Harvest Time” (K. V. Mullashev, 1978)
-
○
“Milking the Red She-Camel” (A. Sydykhanov, 1986–1987)
-
-
•
Decorative and Applied Arts—nine objects, including:
-
○
“Decorative Vase. Gemstone” (V. V. Tarasova, 1967)
-
○
“Saukele” (unknown author, 19th century)
-
○
“Torsyk—Leather Vessel for Kumis” (G. K. Zhuvaniyazova, 20th century)
-
○
“Kübi—Churn for Kumis” (K. Malaev, 1982)
-
○
“Zhaglan and Kebeje” (unknown author)
-
○
“Dombry” (unknown author)
-
○
“Er—Men’s Saddle” (unknown author)
-
○
“Women’s Saddle” (unknown author)
-
○
“Vase from the “Patches” Series” (R. F. Kozhakhmetov, 2006)
-
-
•
Mixed Media—one object, including:
-
○
“Kobyz” (unknown author, 21st century)
-
-
•
Jewelry Art—two objects:
-
○
Jewelry showcase
-
○
Jewelry items (exhibition display)
-
Filming was conducted in public areas of the museum without recording any personal data of visitors, ensuring complete anonymity and compliance with privacy regulations. All supplementary information about the exhibits (including descriptions, author attribution, and creation dates) was officially provided by the A. Kasteyev State Museum of Arts solely for the purpose of this research project and is not publicly available.
The use of this data is strictly limited to the scope of the research project and is carried out with the museum’s permission. Currently, the dataset is closed. Its publication in open-access repositories (such as Zenodo or Kaggle) is only possible upon formal agreement with the museum and in full compliance with copyright regulations and data distribution requirements.
Frame extraction
Video recordings were captured using smartphone cameras at 60 frames per second. From these recordings, 2–3 distinct frames per second were extracted. This frequency was chosen to ensure sufficient variation between frames in terms of object pose, lighting, and angle, thereby enriching the training data with diverse visual samples.
Classification
Each extracted frame was manually reviewed and assigned to a specific exhibit class based on the depicted artifact. The labeling was performed with the help of metadata and descriptions provided by the museum.
Dataset construction
Initially, a dataset of approximately 60 labeled images per class was created. However, this limited sample size led to insufficient recognition performance (~30% accuracy during in-museum testing). To address this, the dataset was augmented by repeating the same video processing methodology, resulting in an average of 120 images per class. This enhancement allowed the models to generalize better and significantly improved recognition accuracy (up to 96%).
These preprocessing steps ensured the dataset captured the variability of real-world museum conditions (e.g., different lighting, partial occlusion), laying a solid foundation for robust model training and evaluation. The overall training and evaluation procedure is outlined in pseudocode (Algorithm 1, File S2), presenting the step-by-step workflow of the proposed approach.
As part of the study, eight deep learning models were tested: YOLOv8, MobileNetV3, ResNetV2, EfficientNetV2, VGG16, ConvNeXt-Tiny, SwinV2-Base, DaViT (Redmon et al., 2016; Howard et al., 2017; He et al., 2015; Tan & Le, 2019; Simonyan & Zisserman, 2014; Liu et al., 2022, 2021; Ding et al., 2022). The selection of models was based on their effectiveness in image classification and detection tasks, as well as their computational efficiency.
YOLOv8—a modern single-stage object detection model that delivers high accuracy and speed, making it well-suited for real-time processing applications.
MobileNetV3—a compact and energy-efficient architecture optimized for mobile and embedded devices, offering high accuracy with minimal resource consumption.
ResNetV2—a deep neural network featuring residual connections and pre-activation, enabling stable training and high classification performance, particularly for complex objects.
EfficientNetV2—a well-balanced model focused on training speed and accuracy, suitable for cloud-based solutions and augmented reality applications.
VGG16—a classic convolutional network known for its high accuracy but characterized by a large number of parameters and high resource consumption.
ConvNeXt—Tiny—a modern architecture that combines convolutional network principles with Vision Transformer techniques, delivering strong recognition performance with moderate computational complexity.
SwinV2-Base—an advanced transformer-based architecture with a hierarchical structure and window-based attention mechanism, offering high accuracy and stability when processing high-resolution images. This makes it particularly valuable for tasks requiring contextual understanding and detailed analysis.
DaViT—a hybrid architecture combining convolutional and transformer blocks with both vertical and horizontal attention mechanisms. It provides an effective balance between accuracy and computational efficiency, making it suitable for server-side applications and, potentially, edge deployments.
Each model was evaluated for its applicability in museum settings, including mobile applications, cloud services, and real-time systems. A comparative analysis of the models is presented in Table 1.
| Model | Architecture | Advantages | Limitations | Suggested application |
|---|---|---|---|---|
| YOLOv8 | Single-stage object detector | Very high speed, real-time detection | Possible reduction in localization accuracy | Mobile and AR applications, and automatic navigation systems |
| VGG16 | Classic convolutional CNN | High accuracy, easy to interpret | Large model size, high resource consumption | Cataloging and offline analytics |
| ResNetV2 | Deep network with residual connections | Stable training, high accuracy, suitable for complex objects | Requires significant computational resources | Archival systems and complex classification tasks |
| MobileNetV3 | Lightweight CNN for mobile devices | Compact and efficient, high accuracy with low resource consumption | Challenging to configure and interpret (AutoML-generated) | Mobile applications and resource-constrained devices |
| EfficientNetV2 | Balanced accuracy and speed (NAS-based) | Fast training, good accuracy, parameter efficiency | Challenging to reproduce, resource-intensive in larger versions | Cloud systems and AR/VR applications |
| ConvNeXt-Tiny | Modern CNN with Vision Transformer elements | High accuracy, competitive with ViT, upgraded architecture | Accuracy fluctuations during early training stages, requires fine-tuning | Challenging conditions and multimodal systems |
| SwinV2-Base | Hierarchical Vision Transformer | High accuracy, scalability, robust to resolution changes | Higher computational load, complex configuration | Medical imaging and satellite analysis |
| DaViT | Hybrid CNN+Transformer with directional attention (ViT+CNN) | Balanced accuracy and efficiency, versatility, stable generalization | Novel architecture, limited framework support | Video surveillance, autopilot systems, and cross-domain classifiers |
Experimental setup
This chapter provides a detailed overview of the experimental configuration used for training and evaluating various deep neural network architectures in the tasks of classification and detection of museum exhibits. Table 2 describes the key hyperparameters, data preprocessing procedures, regularization methods, as well as the software and hardware environments employed. To ensure a fair comparison, all models were trained on a uniformly prepared dataset using consistent augmentation techniques, validation strategies, and early stopping mechanisms. Additionally, this chapter outlines the metrics used for the quantitative evaluation of model performance, including accuracy, precision, recall, F1-score, and mean average precision (mAP).
| Hyperparameter | Value |
|---|---|
| Batch size | 8 (SwinV2-Base, DaViT) 16 (MobileNetV3, ResNetV2, EfficientNetV2, ConvNeXt-Tiny, YOLOv8) 32 (VGG16) |
| Image size | 224 × 224 pixels |
| Number of epochs | Up to 300 (with early stopping applied) |
| Optimizer | Adam |
| Initial learning rate | 0.0002 (2e−4) |
| Regularization | dropout (0.8) + L2-regularization (0.01) |
Data augmentation techniques included rotations, horizontal and vertical shifts, scaling (zooming), horizontal mirroring, and brightness adjustment—all applied randomly within a range of up to 20%.
Model training was conducted using both cloud-based and local computational resources, as detailed in Table 3. Specifically, VGG16 and ConvNeXt-Tiny were trained in Google Colab using NVIDIA Tesla T4 GPUs with 16 GB of RAM. For more demanding models such as ResNetV2, EfficientNetV2, and MobileNetV3, training was performed in Google Colab Pro+ with access to enhanced Tesla T4 or A100 GPUs. Meanwhile, YOLOv8 was trained on a local server equipped with a GeForce RTX 2080 Super, and SwinV2-Base and DaViT models were trained using a GeForce RTX 3070. The use of high-performance GPUs significantly accelerated training due to the parallel processing capabilities of the CUDA architecture.
| Model architectures | Hardware and software |
|---|---|
| VGG16, ConvNeXt-Tiny | Google Colab, GPU: NVIDIA Tesla T4, RAM: 16 ГБ |
| ResNetV2, EfficientNetV2, MobileNetV3 | Google Colab Pro+, GPU: enhanced versions of Tesla T4/А100 |
| YOLOv8 | Local server, GPU: GeForce RTX 2080 Super |
| SwinV2-Base, DaViT | Local server, GPU: GeForce RTX 3070 |
For the MobileNetV3, ResNetV2, and EfficientNetV2 models, more powerful GPU accelerators were used, which enabled faster training and improved performance due to larger batch sizes and higher processing speeds.
The following training characteristics were also applied:
Dataset split: 80% for training, 20% for validation (using ImageDataGenerator);
Cross-validation: built-in validation with validation_split was used;
Callbacks: saving the best weights based on the validation loss metric;
Early stopping: prevention of overfitting in the absence of improvement.
Table 4 provides an overview of the evaluation metrics used in the study. The confusion matrix is presented as a heatmap, offering a clear visualization of classification errors across different classes. The F1-confidence curve was utilized to determine the optimal confidence threshold for classification. In addition, comparative charts were generated to assess model performance based on accuracy and inference time, supporting a comprehensive evaluation of each architecture.
| Metric | Description |
|---|---|
| Accuracy | Proportion of correct predictions |
| Precision, Recall, F1-score | Calculated separately for each class |
| Mean average precision (mAP) | mAP0.5 and mAP0.5: 0.95 |
| Confusion matrix | Heatmap for analyzing classification errors |
| F1-confidence curve | Curve showing the relationship between F1-score and model confidence |
Based on the testing results:
MobileNetV3 and EfficientNetV2 demonstrated the best balance between speed and quality;
VGG16 provided high accuracy but required more resources;
ConvNeXt-Tiny showed excellent performance without significantly increasing computational load;
YOLOv8 delivered the best overall results;
SwinV2-Base exhibited outstanding accuracy and strong robustness, confirming its status as a powerful ViT architecture for recognition tasks;
DaViT combined transformer and convolutional approaches, providing stable results with acceptable training time and high versatility.
Training on powerful GPUs (A100/V100) significantly improved the performance of MobileNetV3, ResNetV2, and EfficientNetV2, nearly doubling the training speed compared to the T4. All models, regardless of their architecture, were trained under controlled conditions with enhanced augmentations and consistent regularization procedures. The use of accelerated hardware, particularly the GeForce RTX 2080 Super for YOLOv8, ensured efficient reduction of training time while maintaining high model accuracy. The SwinV2-Base and DaViT models were trained on the GeForce RTX 3070 GPU, where they demonstrated stable performance with high accuracy and moderate training times. Thus, the choice of the optimal model depends on the specific task, inference speed requirements, available computational resources, and the need for model adaptation to specific operating conditions.
MobileNetV3 training results
MobileNetV3 demonstrated high classification accuracy (99.93%) already by the 99th epoch. During training, accuracy increased from 86.63% in the first epoch to nearly perfect accuracy, while the loss value decreased from 3.2130 to 0.7425. This model is especially effective for mobile and web applications due to its minimal computational resource requirements. However, MobileNetV3 may struggle with recognizing fine details of exhibits and under varying lighting conditions.
ResNetV2 training results
ResNetV2 showed steady accuracy improvement, starting at 98.90% in the first epoch and reaching 99.78% by the 80th epoch. The use of pre-trained ImageNet weights accelerated the model’s convergence. ResNetV2 performs particularly well in classifying complex museum objects such as textiles, ceramics, and relief items, but it requires substantial computational power, making it less suitable for mobile solutions.
EfficientNetV2 training results
Starting with a low accuracy of 28.73%, EfficientNetV2 reached 87.8% by the 75th epoch. This is attributed to its optimized architecture, which enables high accuracy with a relatively small number of parameters. However, the model exhibited fluctuations in accuracy at different stages of training, indicating the need for more precise hyperparameter tuning. EfficientNetV2 can be effectively utilized in cloud computing environments and augmented reality (AR)/virtual reality (VR) applications.
YOLOv8 training results
The YOLOv8 model was trained for museum exhibit detection and achieved a mean average precision ([email protected]) of 99.5%. The confusion matrix revealed that the model made virtually no errors, except when dealing with objects similar in shape and texture. The precision-recall (PR) curve confirmed high accuracy even under varying parameters. The F1-confidence curve determined an optimal confidence threshold of 0.691, at which the best balance between precision and recall was achieved. YOLOv8 is particularly effective for real-time applications, such as in automated museum navigation systems.
Training results of VGG16
VGG16 initially showed low accuracy (5.18%) in the first epoch; however, by the 20th epoch, accuracy reached 99.47%. The model demonstrated a steady improvement in metrics and exhibited high validation accuracy. The use of pre-trained weights accelerated the training process, and final results indicated that VGG16 performs well in classification tasks but lags behind modern architectures in terms of performance. It is more resource-intensive, making it a suboptimal choice for mobile applications, but suitable for cataloging museum data.
Training results of ConvNeXtTiny
ConvNeXtTiny achieved high accuracy (97%) at the final training stage, though significant fluctuations were observed in the early epochs. Unlike other models, ConvNeXtTiny combines the strengths of CNNs and transformers, making it promising for complex computer vision tasks. However, it proved less accurate than ResNetV2 and VGG16, indicating the need for further architectural refinement.
Training results of SwinV2-Base
The SwinV2-Base model showed consistently high performance, achieving 97.72% accuracy in the final training epoch. By combining the benefits of convolutional networks and transformer architecture with a hierarchical structure, it effectively handles detailed images of exhibits. Thanks to architectural enhancements, including shifted window attention, the model exhibits excellent generalization ability and performs particularly well on images where both local and global contexts are important. However, compared to lighter models, it requires significant computational resources, limiting its use on low-end hardware.
Training results of DaViT
The Dual Attention Vision Transformer (DaViT) model achieved 99.71% classification accuracy, demonstrating high stability and fast convergence throughout the epochs. Its hybrid architecture integrates axial and spatial attention, allowing more accurate recognition of complex elements in museum exhibits. DaViT showed excellent adaptability to class diversity and object variability. It occupies a middle ground between lightweight and heavy architectures in terms of computational load, making it suitable for desktop and server solutions in museum information systems.
Results
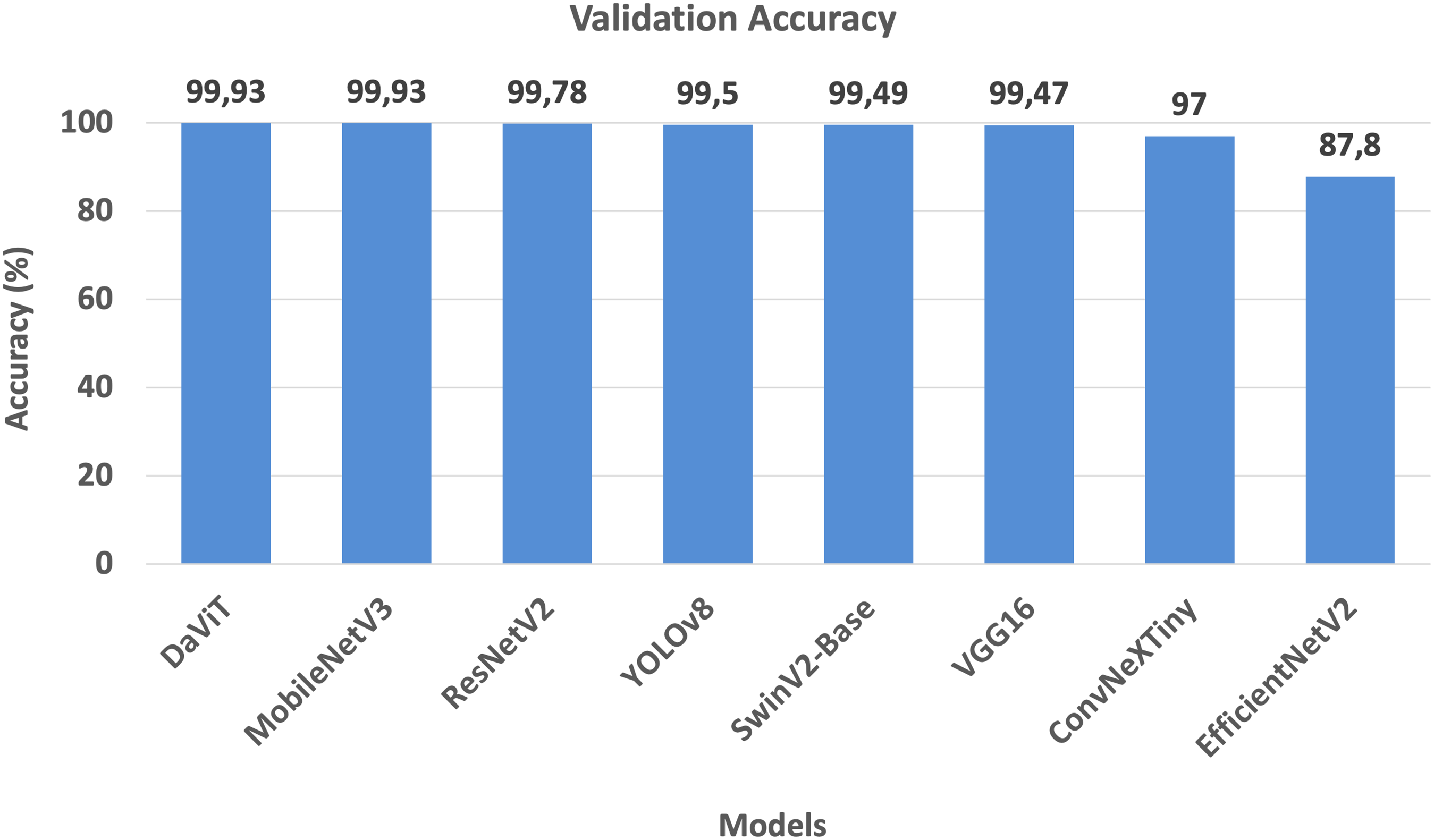
To evaluate the effectiveness of various neural network architectures in the task of classifying museum exhibits, a comparative analysis of eight popular models was conducted. The study considered three key indicators: prediction accuracy, computational complexity, and training time. The results are visualized in the form of graphs (Figs. 2–4), which clearly illustrate the strengths and weaknesses of each architecture.
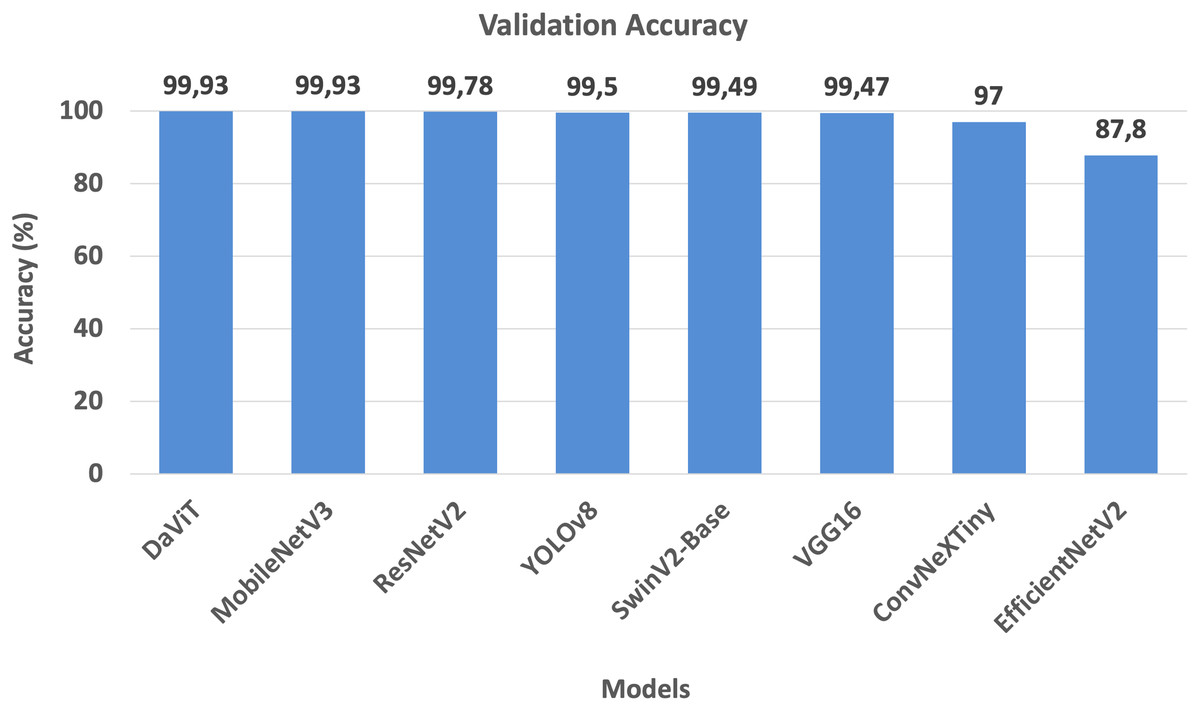
Figure 2: Training accuracy of the models.
{kind=link}
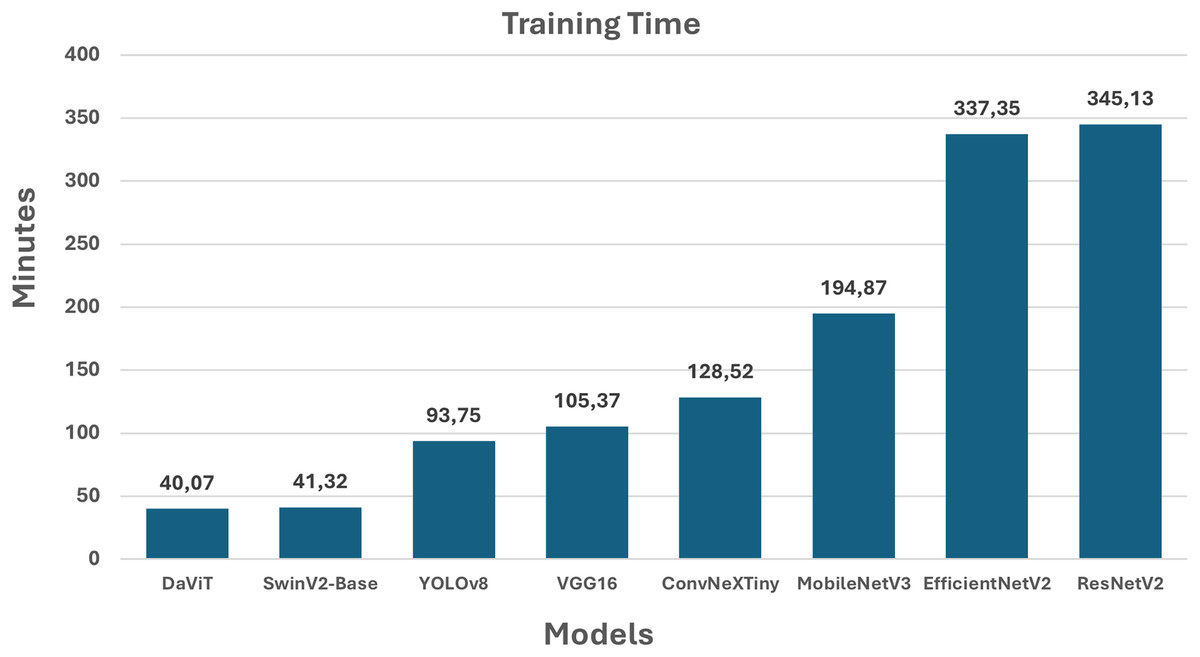
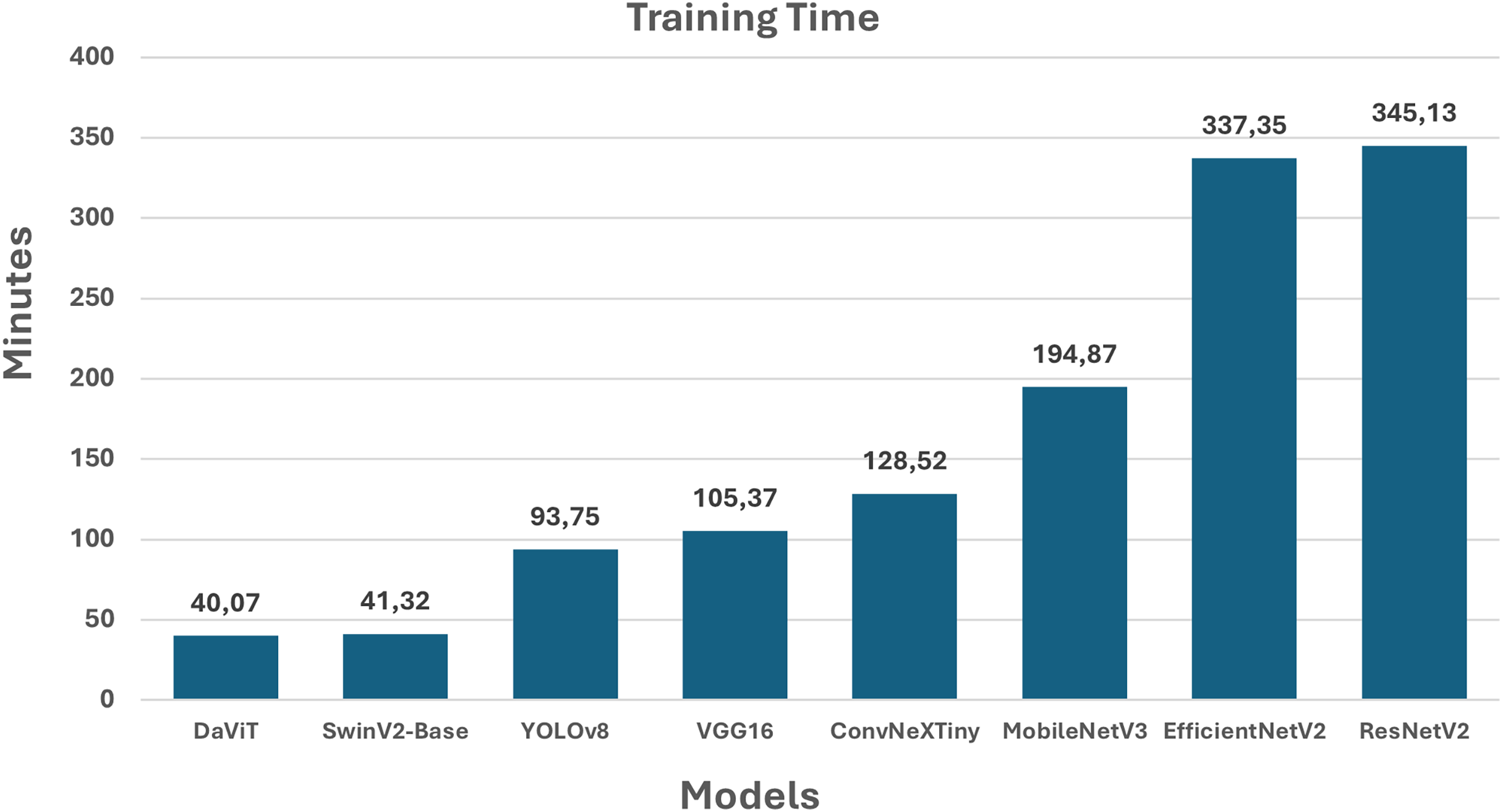
Figure 3: Training time of the models.
{kind=link}
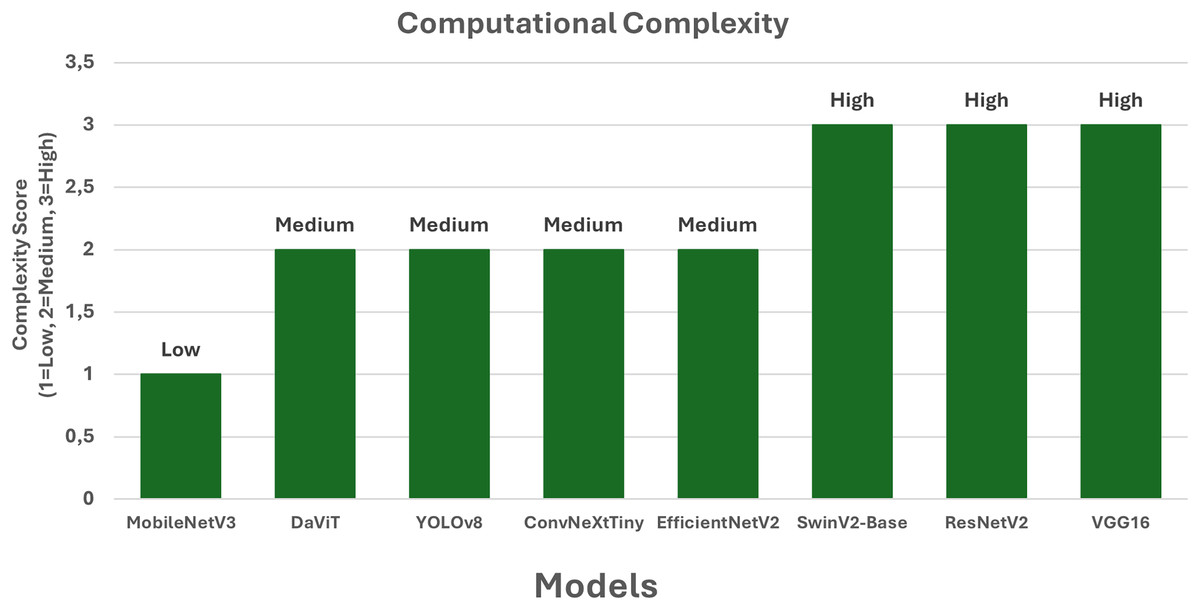
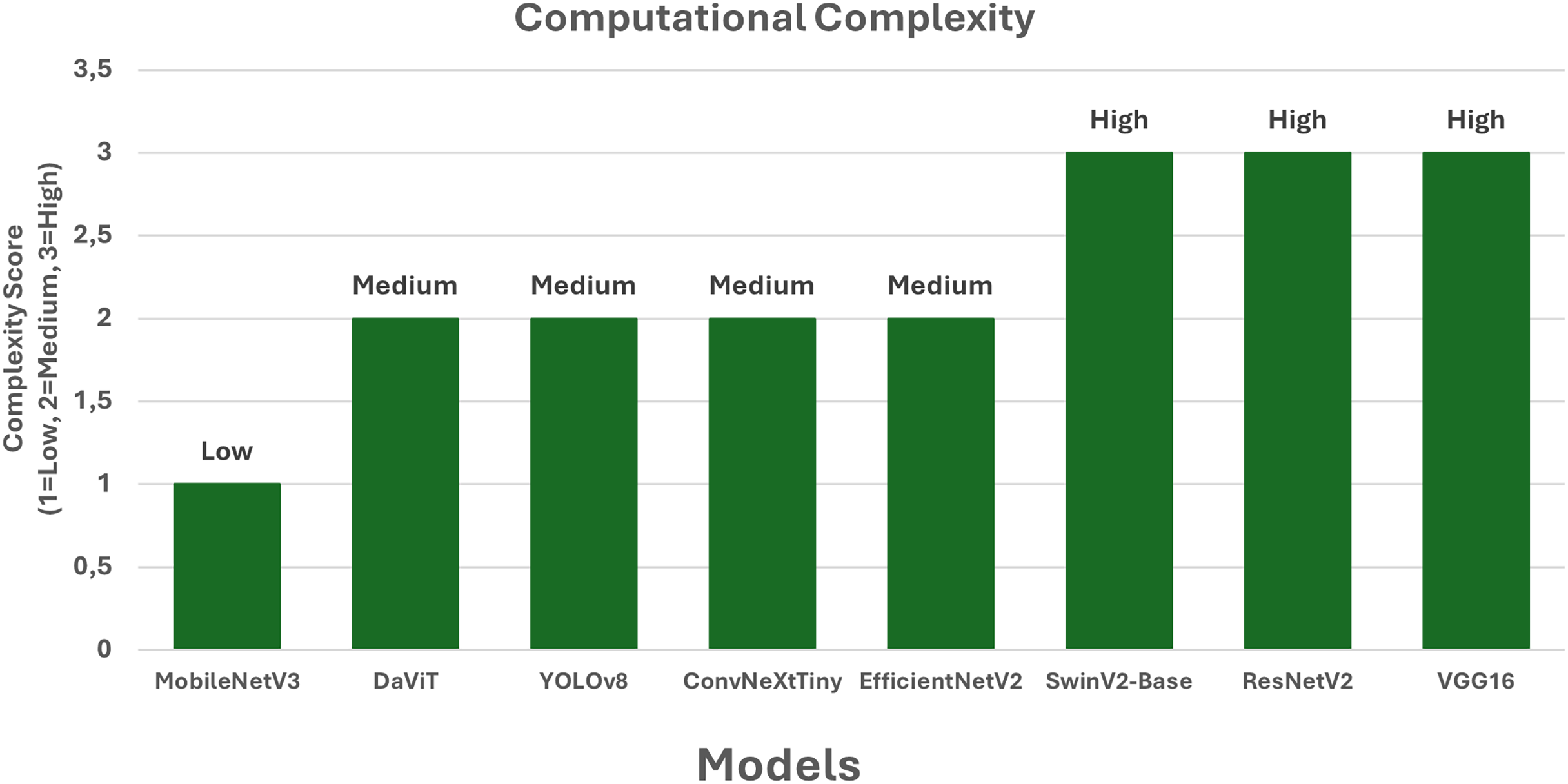
Figure 4: Computational complexity of the models.
{kind=link}
Figure 2 shows that MobileNetV3 and DaViT achieve the highest accuracy—99.93%—which is impressive for both a lightweight and a hybrid architecture. ResNetV2, YOLOv8, VGG16, and SwinV2-Base also demonstrate high accuracy values, ranging from 99.47% to 99.78%, confirming their reliability in recognizing museum exhibits. EfficientNetV2 lags significantly behind at 87.80%, which may be due to suboptimal model tuning or specific characteristics of the dataset. ConvNeXtTiny achieved 97.00% accuracy, demonstrating a good compromise between performance and computational cost. Overall, the chart highlights that both compact and transformer-based architectures can reach near-perfect accuracy with proper customization.
The training time of the models (Fig. 3) exhibit significant differences that should be considered when selecting an architecture for practical applications. DaViT and SwinV2-Base demonstrate the shortest training time—approximately 40 min—making them particularly appealing for rapid deployment and frequent fine-tuning. YOLOv8, VGG16, and ConvNeXtTiny occupy intermediate positions, with training times ranging from 93 to 128 min, striking a balance between speed and accuracy, especially for computer vision and classification tasks. MobileNetV3 requires more time (194.87 min), despite being typically classified as a lightweight model. This may be due to specific training configurations, or the characteristics of the dataset used. The models that are the most resource-intensive in terms of training time are EfficientNetV2 (337.35 min) and ResNetV2 (345.13 min). While these models demonstrate high accuracy, their application in scenarios that necessitate rapid iteration may be constrained.
Consequently, the chart highlights the crucial importance of training time in applied tasks: when computational resources are scarce, priority should be given to models with shorter training times, even if it entails a compromise in accuracy.
According to the computational complexity chart (Fig. 4), MobileNetV3 remains the least resource-intensive model with a low level of complexity, making it ideal for mobile and embedded solutions. The most resource-demanding models are ResNetV2, VGG16, and SwinV2-Base—their architectural characteristics require significant computational power, which limits their use in systems with strict performance constraints. EfficientNetV2, YOLOv8, ConvNeXtTiny, and DaViT demonstrate a moderate level of complexity, offering a good balance between computational cost and accuracy. This makes them attractive for use in versatile museum systems where both classification quality and available resources must be taken into account. Thus, the chart highlights the importance of balancing accuracy and computational load when selecting an architecture.
The comparative analysis of eight deep learning models revealed that each has its own unique advantages and limitations that determine its applicability in museum digital systems.
Therefore, the choice of architecture should be guided by specific tasks: the need for real-time performance, resource availability, the characteristics of the museum environment, and the type of visual data. Combining models may further enhance recognition quality and system adaptability under real-world conditions.
Discussion
The training and testing results of eight machine learning models confirmed their high effectiveness in the task of automatic recognition of museum exhibits. However, each architecture demonstrated unique characteristics in terms of accuracy, training speed, and computational load.
MobileNetV3 remains the best choice for mobile applications due to its high accuracy and minimal computational cost. ResNetV2 delivers consistently high accuracy but requires significant resources, making it preferable for stationary archival solutions. EfficientNetV2 represents a compromise between accuracy and speed, proving especially effective in cloud and AR applications. YOLOv8 shows excellent performance in real-time tasks thanks to its high speed and detection accuracy. VGG16 still offers high accuracy, but due to its resource intensity, it falls behind more modern architectures and is better suited for offline cataloging tasks. ConvNeXtTiny is a balanced model that combines elements of CNNs and transformers but requires fine-tuning to achieve optimal performance. SwinV2-Base ranks among the top in terms of accuracy but demands substantial computational resources, which is justified in high-end systems. DaViT demonstrated outstanding accuracy with moderate complexity and training time, making it a versatile candidate for both cloud-based and local solutions.
Based on the obtained results, a mobile application utilizing augmented reality technology was developed for the A. Kasteyev State Museum of Arts (Almaty, Kazakhstan). The system enables real-time object recognition using YOLOv8 and provides users with interactive information about the exhibits, thereby enhancing digital engagement within the museum environment. The developed application is currently undergoing testing.
Future research may focus on developing hybrid solutions that combine YOLOv8 for fast and accurate object detection with high-precision classification architectures such as DaViT or SwinV2-Base. Using ConvNeXtTiny as an intermediate feature extractor could improve the model’s generalization capability. Another promising direction is the analysis of the effectiveness of various data augmentation strategies to improve model robustness under real-world conditions—including changing lighting, partial occlusion, and background variability.
Conclusion
Thus, the study demonstrated the high effectiveness of modern deep learning models for automatic recognition of museum exhibits in conditions close to real-world scenarios. Eight models were comparatively analyzed: MobileNetV3, ResNetV2, EfficientNetV2, YOLOv8, VGG16, ConvNeXtTiny, SwinV2-Base, and DaViT. Each architecture was evaluated based on accuracy, training time, and computational complexity, allowing for the identification of the most suitable use cases within digital museum systems.
The results showed that MobileNetV3, YOLOv8, and DaViT are optimal for mobile solutions and augmented reality systems due to their combination of high accuracy and performance. ResNetV2, VGG16, and SwinV2-Base deliver high classification quality, making them effective for tasks such as cataloging, archiving, and analytics. EfficientNetV2 and ConvNeXtTiny demonstrate strong potential for use in cloud-based platforms and adaptive systems, though they require careful tuning and parameter control.
Based on the selected models, a mobile application with augmented reality functionality was developed for the A. Kasteyev State Museum of Arts, confirming the practical relevance of the proposed solution and its potential for widespread implementation in the museum sector.
Therefore, the integration of computer vision and deep learning technologies into the cultural heritage domain opens new horizons for the digital transformation of museums, enhancing visitor engagement and enabling the development of intelligent navigation and educational systems. Promising directions for future research include improving model robustness to varying imaging conditions, developing hybrid architectures, and integrating multimodal data (images, text, audio) into a unified interactive platform.
Supplemental Information
Algorithm pseudocode.
The step-by-step workflow of the proposed approach.
Self-curated dataset.
The list of art pieces based on the data collected during the research.