
Security and privacy for Binance-based integrated blockchain for blood supply chain management systems
- Published
- Accepted
- Received
- Academic Editor
- Syed Hassan Shah
- Subject Areas
- Cryptography, Data Mining and Machine Learning, Security and Privacy, Cryptocurrency, Blockchain
- Keywords
- Binance, Blood supply chain, AdaBoost, Hardhat, Smart contract, BscScan
- Copyright
- © 2025 Ch et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Security and privacy for Binance-based integrated blockchain for blood supply chain management systems. PeerJ Computer Science 11:e3123 https://doi.org/10.7717/peerj-cs.3123
Abstract
The world faces a severe blood shortage, with a gap of 1.95 million units, highlighting the need for efficient blood allocation and management systems. Traditional cloud and blockchain approaches have been explored for blood bank management but faced implementation challenges. This study proposes designing and developing a decentralized Binance blockchain-based application framework to ensure transparency and security. It uses the AdaBoost algorithm to predict the availability of the nearest blood bank and blood donor. Supply chain management provides transparency without the intervention of third parties thereby preventing blood crimes. Metamask is incorporated for crypto transactions in the Binance Smart Chain test network (BSC). BSC stands out for its low transaction fees and high scalability, enabling swift transaction processing at a fraction of the cost compared to Ethereum. The smart contracts are deployed using hardhat configuration enabling BscScan as an Application Programming Interface (API) gateway to record transactions within the decentralized application (dApp). The proposed system achieved an accuracy of 99.5%, demonstrating the robustness of the AdaBoost model in predicting blood availability. The integration of blockchain technology ensures transparency, immutability, and secure traceability of blood transactions across the network.
Introduction
Blood is one of the main fluids in the human body. It helps to support the organs with the necessary and useful things needed for survival. As the demand for blood is exceeding all the medical requirements, the governments educate their citizens about blood donation by organizing awareness programs. The number of donors in the years 2018–2019 was estimated to be 136,908 donors, contributing to a total of 216,639 donations (Mandal et al., 2023; Hawashin et al., 2021). In general, every 56 days, mostly healthy individuals give blood donations. The World Health Organization estimates that the annual amount of blood donations collected is 112.5 million units, which is approximately 50 million liters, per year (Kim, Kim & Kim, 2020). However, the lack of blood donors has increased with the emergence of new diseases. The requirement to enable reliable and efficient blood donation management has been raised. Blood management for patients is a huge and complex task (Musamih et al., 2021). The current system of blood management contains various restrictions and gaps that limit the supply chain to perform efficiently. Hannon (Kumar et al., 2024) reported that the blood component wastage rates usually run from 1% to 5% and that the amount of disposal is not shared or visible to clarify the reason behind it. Therefore, any development or improvement in this regard is an important consideration in providing efficient health care globally.
Maintaining secure communications for sensitive healthcare information is paramount for both patients and providers. However, the widespread adoption of cloud-based solutions introduces significant concerns regarding data security, especially with the inclusion of third-party services (Nazir et al., 2023). Fundamental to managing data security is the Confidentiality, Integrity, and Availability (CIA) triad, which emphasizes confidentiality, integrity, and availability. Blockchain technology offers a promising solution to enhance the performance, management, and security of information systems, primarily due to its inherent non-repudiation feature (Ekanayake & Halgamuge, 2021). The Binance Smart Chain (BSC) has emerged as an ideal candidate for managing blood resources, thanks to its compatibility with the Ethereum Virtual Machine (EVM) and optimized transaction performance (Gia et al., 2023).
AdaBoost is vital in optimizing the prediction of available blood units concerning geographical location and blood type. AdaBoost combines many “weak classifiers” to get one strong predictive model. Similarly, calculations of geodesic distance are necessary to find nearby blood banks relative to the location of a user (Ramakrishna et al., 2023). These calculations show, among other things, the shortest distance between two points on the Earth’s surface, enabling the accurate filtering of blood banks within a specified radius from the user.
Motivation
India needs 15 million units of blood annually but has a shortage of about 4 million. It is also estimated that in this country, about 12,000 people die daily because quality blood is not available. This is the side of the coin, while on the other, it is indicated that India wastes approximately 6.5 lakh units of blood and blood components every year, just due to poor storage facilities. According to the World Health Organization (WHO), 54% of the countries have poor blood bank management systems (Vo et al., 2023).
Research contributions
Our main contributions can be summarized as follows:
To analyse and identify the nearest blood banks and donors concerning the user.
To collect and analyse the National AIDS Control Organization (NACO) standards required for a blood donor and design test data.
To implement the AdaBoost algorithm for efficiently predicting the nearest blood bank and blood donor availability.
To design and develop an integrated framework with a decentralized Binance blockchain in blood supply chain management (SCM).
To test security algorithms to investigate the efficiency of blockchain in SCM and appropriate traceability of the blood bank supply chain.
Route map of the paper
The article is structured as follows: section ‘Related Work’ of the article explains the methodologies used in the existing studies followed by gap analysis. Section ‘Methodology’ contains the proposed methodology of the system and section ‘Results and Discussions’ justifies the results and discussions. Section ‘Security Analysis’ contains the security analysis followed by section ‘Performance Analysis’ which analyses the performance of the system. Finally, section ‘Conclusion and Future Work’ gives insights into the conclusion and future work of the system.
Related work
Hawashin et al. (2022) proposes a blockchain-based system for the management of the blood donation supply chain, ensuring transparency, security, and auditability. It uses a private Ethereum blockchain integrated with InterPlanetary File System (IPFS), used for storing large data files. It employs smart contracts for the core functionalities and dApp at the frontend interface, while software devices can be hooked with the former through Application Programming Interfaces (APIs). It is one of the permissioned Ethereum blockchain-based solutions providing all privacy and authorization controls. It has not been tested or deployed on the real network, it lacks analysis on performance and scalability, and very limited security analysis and details on what roles exist and the sort of access controls that would be required.
Fiore et al. (2023) proposes the current state of blockchain utilization in healthcare supply chains, pointing out that private/consortium blockchains have largely been implemented due to control, confidentiality, lower energy use, and cost benefits; Ethereum is a widely implemented platform; smart contracting is to support automation; and main blockchain principles regarding accountability, security, transparency, confidentiality, and reliability are covered. These proposed solutions are still not technologically mature and require many studies on scalability and real-world applications. Only one real-world application shows the potential of blockchain to reduce costs and enhance efficiency.
Imamoglu, Topcu & Aydin (2023) proposed an intense analysis of 265 articles in the Web of Science database, making use of bibliometric and network analyses to dissect the literature on the blood supply chain. Data visualization and statistical analysis tools help provide insights into deeper research trends and gaps within the blood supply chain research. The methodology used includes a mixed review methodology, which integrates technology-driven approaches toward providing a comprehensive understanding of the literature on the blood supply chain, the identification of gaps within the research, and the future directions. The limitations of this study are that it is dependent on English-language publications, hence potentially excluding relevant research from linguistic diversity.
Roozkhosh, Pooya & Agarwal (2023) aimed at supply chain resilience improvement by predicting the blockchain acceptance rate in blood donation and supply chains. Herein, it makes a case for the hybrid combination of Hyperledger Fabric and Caliper with system dynamics in simulating the long-term behavior of blockchain acceptance rate (BAR) and machine learning techniques like Multilayer Perceptron (MLP) and Support Vector Regression (SVR) for its prediction. Ensuring that the issues of implementation challenges and data privacy and security, scalability, and performance limitations have been fully addressed, the study concludes by asserting that resilient supply chains are significantly influenced by inflationary control, R&D, exchange rates, and political risks, thereby underlining the need for effective analysis in these respects and eliciting proper policy making.
Emmanuel et al. (2023) proposed the use of machine learning in drug supply management chains in the case of outbreaks of infectious diseases, with a view of predictive parameters for spread of diseases like COVID-19, influenza, dengue, malaria, and Ebola. Some shared methods applied are neural networks, Bayesian networks, and reinforcement learning. Predictive parameters include demographic data, environmental factors, mobility data, and social media data; among them, demographic data is most used. The study would really increase the need for more efficacious research into the topic, especially in developing countries. It does not mention any blockchain technology or application, but only a systematic literature review on machine learning in drug supply chain management.
Le et al. (2022) propose BloodChain, a blockchain-based system using Hyperledger Fabric to manage blood information and improve the blood supply chain. It provides detailed information about blood consumption and its disposal to recipients. The implementation performance will be benchmarked through the transaction-per-second (TPS) metric by means of Hyperledger Caliper. BloodChain deploys a permissioned blockchain with an inbuilt governance model that assures trust among defined participants, doing away with the requirement of expensive mining. This might include governance and participant policy management, data privacy and security, and scalability and performance challenges, as indirectly reflected in latency results.
Trong et al. (2022) proposed a blockchain-based system for the management of the supply chain of blood using Hyperledger Fabric. The system provides a blockchain architecture for decentralized data storage, smart contracts for data control, and proof-of-concept implementation with evaluations that prove its benefits and feasibility. The current implementation, however, only covers a subset of processes, lacking an authorization mechanism across stakeholders. It potentially brings out the use of Hyper-ledge Fabric in enhancing transparency, security, and data integrity of the blood supply chain management but needs further work in bringing it fully to end-to-end.
Ben Elmir, Hemmak & Senouci (2023) aimed at proposing a smart platform for the enhancement of the blood supply chain. This will be achieved through the development of an information system that spans from the receipt of blood donation to the utilization stage. The model enhances coordination via a centralized database. The paper proposes the reduction in uncertainty related to blood demand through machine learning and time series forecasting models such as Autoregressive Moving Average (ARMA) and Autoregressive Integrated Moving Average (ARIMA). It also develops a blood donor classifier using artificial neural networks (ANN), Logistic Regression, Support Vector Machine (SVM), Decision Trees, K-Nearest Neighbors (KNN), and Naive Bayes. Limitations of the work include that there is a need for clear-cut statistical procedures considering resiliency and effectiveness, simplicity of the solution, and specialist expertise in some techniques.
Khalid et al. (2023) proposed blockchain-based decentralized storage systems, their benefits, solutions of challenges, and deployment strategies. It gives an analysis of applications such as Sia, Filecoin, and Storj against cloud storage, discussing various advantages and disadvantages. Security issues are addressed in the survey, some solutions are shown, and future research is suggested. However, it does not provide an in-depth analysis on the implementation challenges, detailed performance comparison, scalability issues, cost-effectiveness, and truly regulatory and legal implications. In a nutshell, the limitations include not discussing the regulatory and legal implications of using blockchain for decentralized data storage, which can turn out to be a big hindrance to its wide adoption.
Abdullah et al. (2022) proposed a decentralized blood donation system on the Ethereum blockchain to attain transparency, traceability, and safety in blood transfusion procedures. On this platform, peer-to-peer interactions can be facilitated because of token incentives to the donors through smart contracts. Since there are no hierarchical procedures, the turnaround time is reduced with full traceability through the blockchain. Along with that, some benefits include transparency and traceability of blood donations. The scalability challenges and the need for a wide adoption of the system among stakeholders might not permit the implementation of such a system’s traceability.
Research gap
Existing studies exhibit significant limitations, including challenges in real-world deployment, the absence of machine learning integration for accurate blood availability prediction, minimal adoption of public blockchains such as BSC, and a lack of robust access control mechanisms to ensure secure data handling and system integrity (Table 1) gives a gist of existing studies.
| Author(s) | Blockchain | Coin | Scope | AIML | ACL | Application |
|---|---|---|---|---|---|---|
| Hawashin et al. (2022) | Private | ETH | Supply chain | No | No | Blood |
| Fiore et al. (2023) | Consortium | ETH | Supply chain | No | No | Healthcare |
| Imamoglu, Topcu & Aydin (2023) | Public | ETH | Supply chain | No | No | Blood |
| Roozkhosh, Pooya & Agarwal (2023) | Private | ETH | Supply chain | Yes | No | Blood |
| Emmanuel et al. (2023) | Public | ETH | Supply chain | Yes | No | Drugs |
| Le et al. (2022) | Private | ETH | Supply chain | No | No | Blood |
| Trong et al. (2022) | Private | ETH | Supply chain | No | No | Blood |
| Ben Elmir, Hemmak & Senouci (2023) | Private | ETH | Supply chain | Yes | No | Blood |
| Khalid et al. (2023) | Local | ETH | Stand alone | No | No | Networks |
| Abdullah et al. (2022) | Private | ETH | Supply chain | No | No | Blood |
| Proposed | Public | BNB | Supply chain | Yes | Yes | Blood |
Methodology
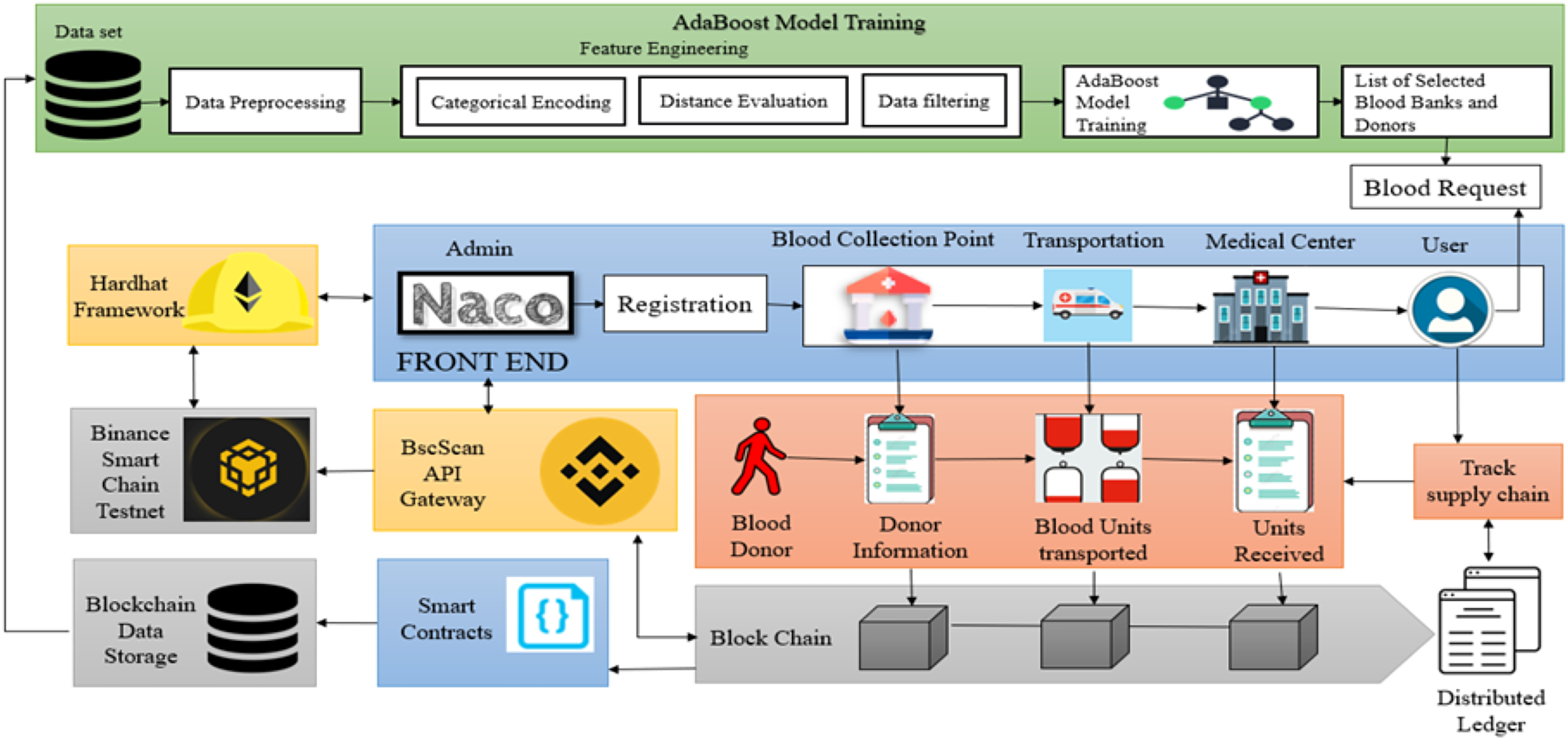
The proposed system architecture for the blood supply chain management system (B-SCM) is depicted in Fig. 1. B-SCM comprises different entities that include Admin i.e., National AIDS Control Organization (NACO), Collection Point (CP), Medical Centre (MC), Transporter (TS), and Donor (DR). The system contains four phases—Registration phase, Login and authentication phase, Logistics Management, and User request (Eghtesadifard & Jozan, 2022). The model runs on a system equipped with an 11th Generation Intel CoreTM i7-11390H processor, 16 GB RAM, a 64-bit Windows 10 operating system, and a 1 TB hard drive. The AdaBoost model was implemented using Python 3.9 with the scikit-learn library.
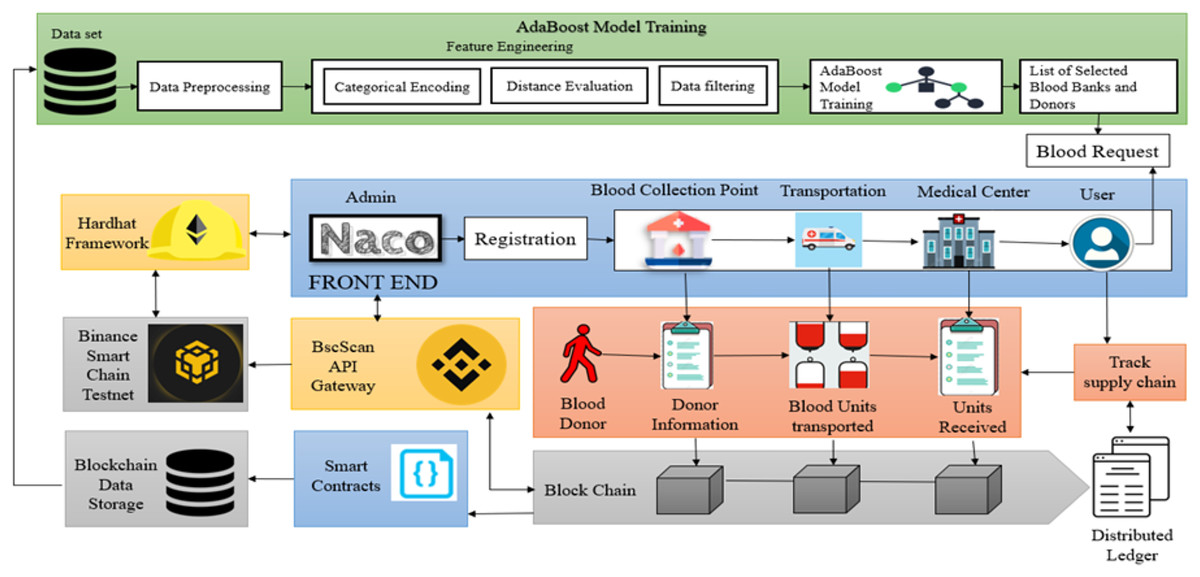
Figure 1: Proposed methodology for blockchain-based B-SCM (Bing, 2025d; Blockchains, 2025; Bing, 2025a; AltcoinsBox, 2025; Bing, 2025b; Google, 2025j; Flaticon, 2025; Google, 2025l, 2025i, 2025n, 2025b, 2025c, 2025f, 2025m, 2025e; Bing, 2025c).
{kind=link}
{kind=link}
{kind=link}
Registration phase
Entity registration phase
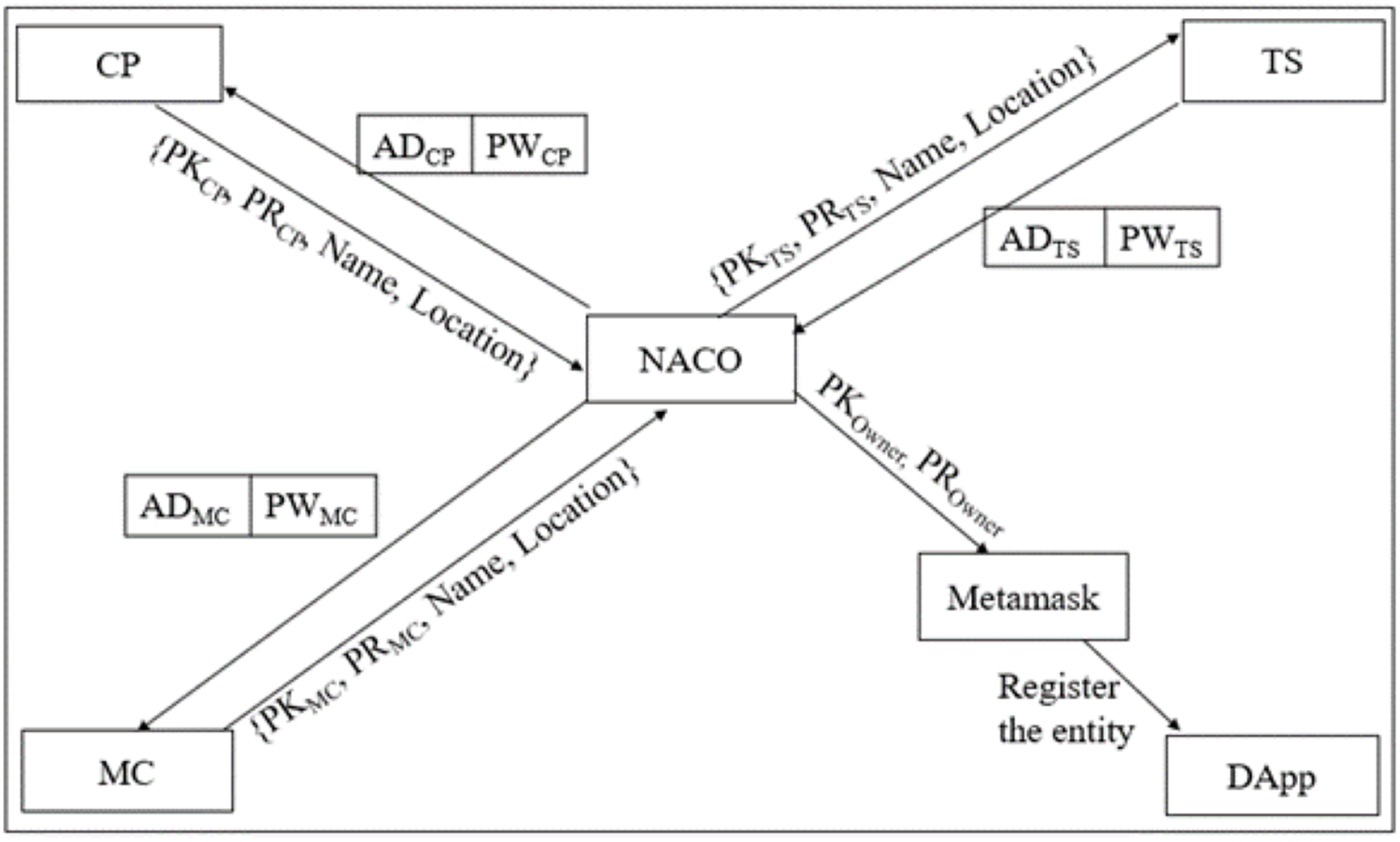
Figure 2 depicts the entity Registration phase which explains the process of each entity registration. B-SCM has three entities as in Eq. (1) that are solely registered by the central authority NACO. Each entity has a wallet address that is technically analogous to the public key of the entity symbolically as represented in Eqs. (2) and (3).
(1)
(2)
(3)
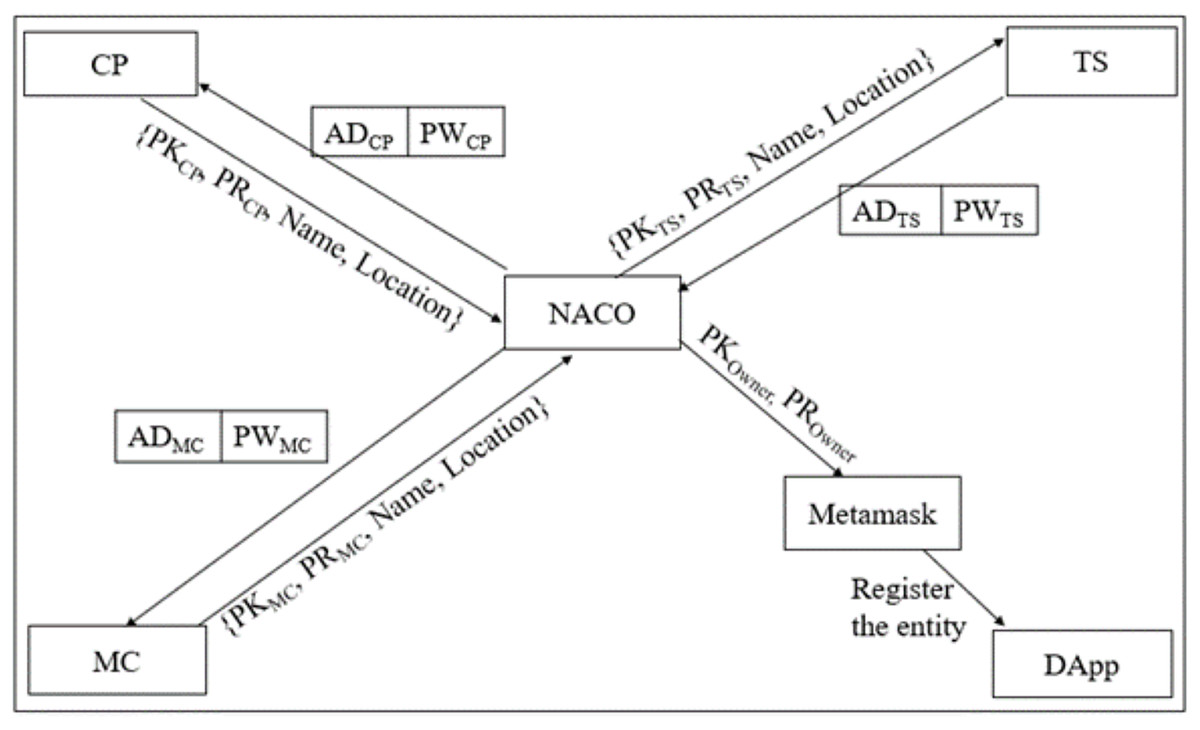
Figure 2: Entity registration phase of B-SCM.
{kind=link}
Step 1: NACO ; NACO ; NACO can access the dApp using . Once NACO registers into B-SCM, it is liable for registering in B-SCM with .
Step 2:
registers into the system with , Name, and Location. NACO validates the entity by considering the standards of the entity: (available (AV), accessible (AC), affordable (AF), safe (SF), and of standard quality (SQ)), i.e., should possess the standards of NACO, and then it is considered to be valid as in Eq. (4).
(4)
Step 3: MM ;
The Metamask connected to will be initiated, and the transaction of registering will be enforced.
Step 4: If is valid, the transaction will proceed further by processing to MM and subsequently adding into B-SCM. Otherwise, the access of is denied, as illustrated in Eqs. (5), (6), (7).
(5)
(6)
(7)
Donor registration phase
CP registers DR in B-SCM, validating the DR as depicted in Fig. 3 and adhering to the regulatory standards of NACO (Rekha & Siddappa, 2023) as follows:
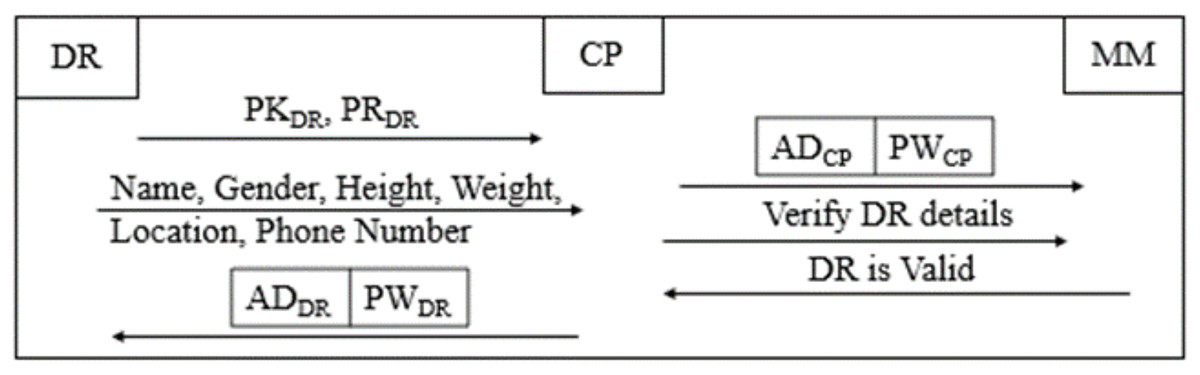
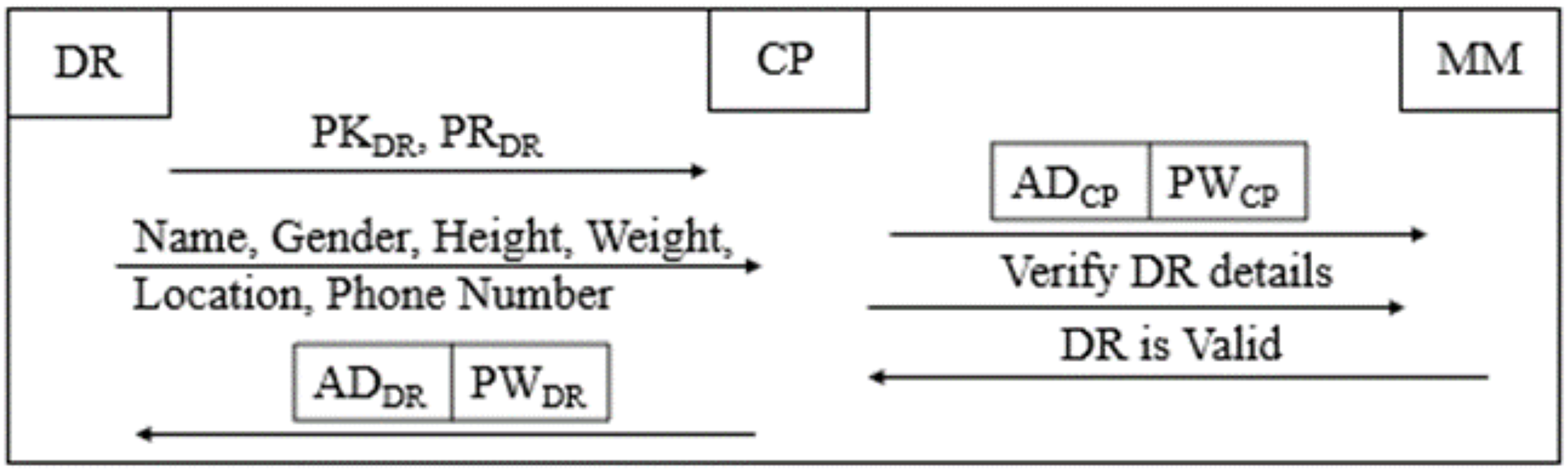
Figure 3: Donor registration phase of B-SCM.
{kind=link}
Step 1: CP DR;
DR ; CP collects the details of DR, which include name, age, gender, weight, height, location, and phone number.
(8)
Step 2: After verifying whether the respective DR is eligible, as illustrated in Eq. (8), for donating blood by the details collected in Step 1, is shared with CP and registered on B-SCM.
Step 3: DR B-SCM: DR can access B-SCM with and then confirm their details. This ensures two-step authentication of DR details to ensure safe and secure blood maintenance (Ghadge et al., 2022).
Login and authentication phase
Each entity upon registration goes through the login and authentication phase as shown in Fig. 4 by following the steps below:
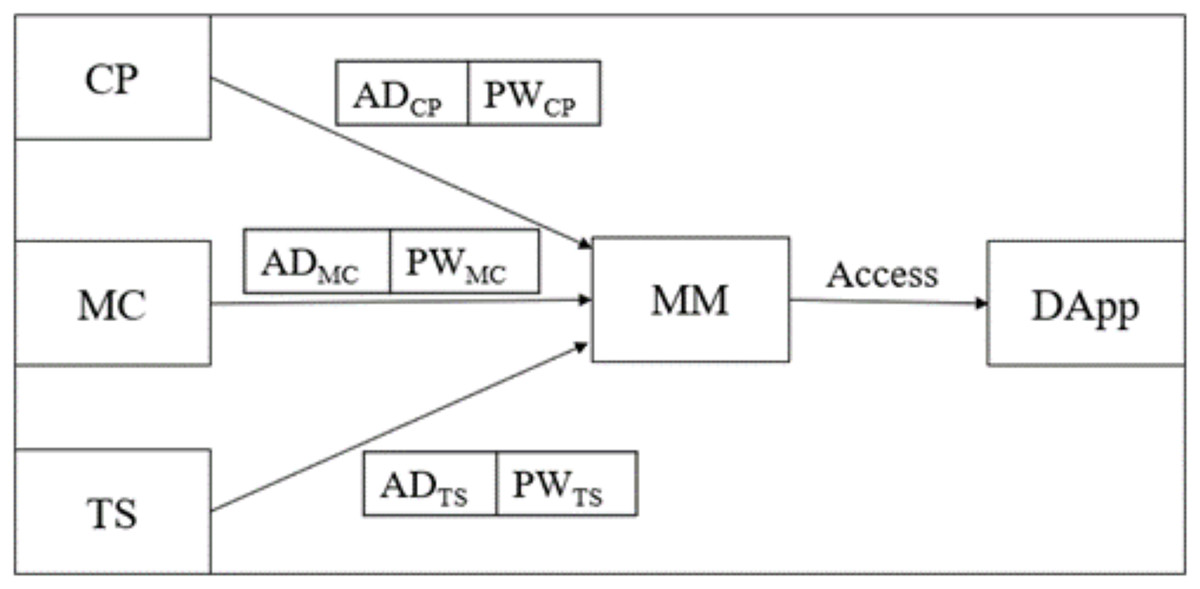
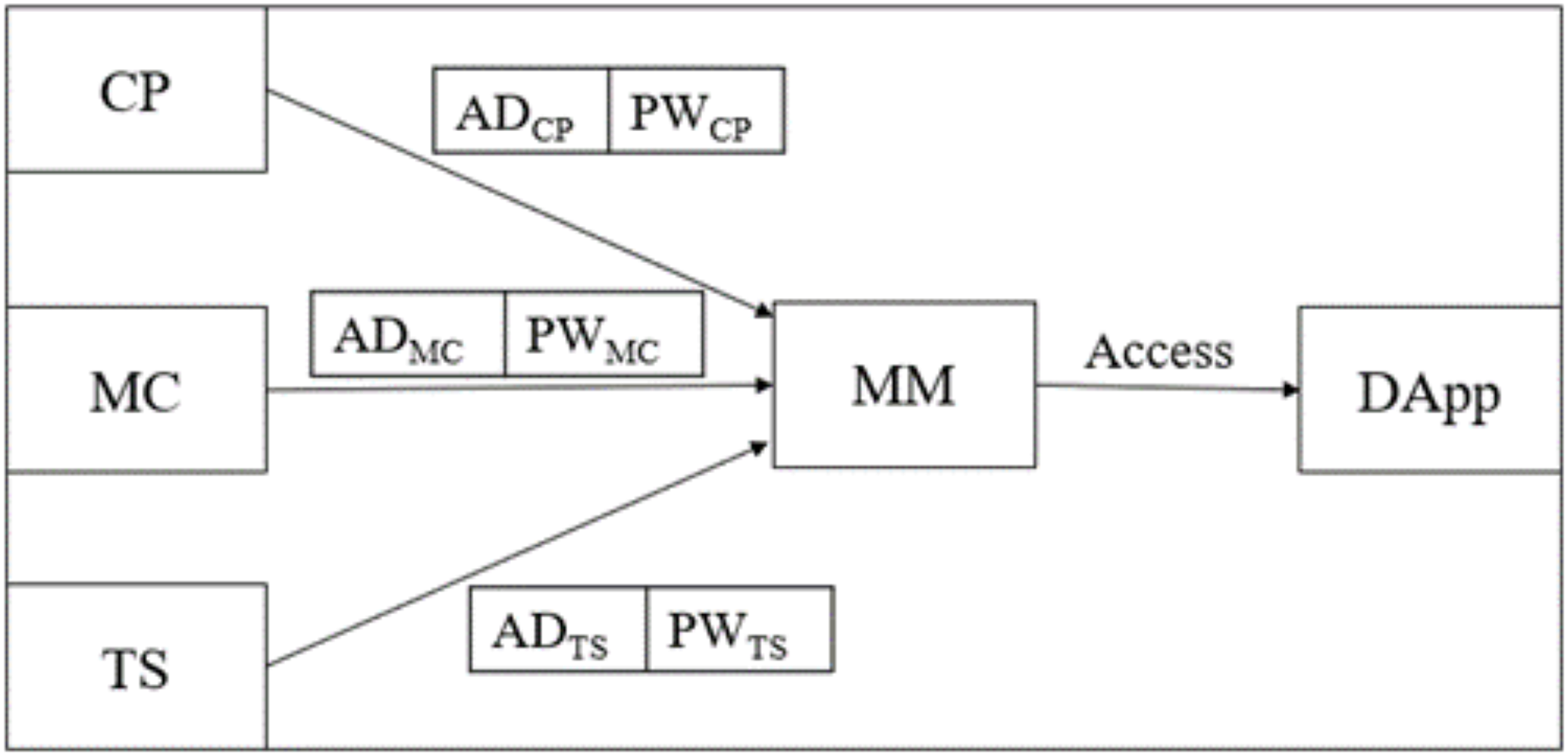
Figure 4: Login and authentication phase of B-SCM.
{kind=link}
Step 1: ; enters to log into B-SCM. It enables Metamask (MM) and performs a three-step mutual authentication. This includes verifying the existence of the address of in MM and cross-checking the authenticity of .
Step 2: ; each has its functions to perform in dApp. CP has that are verified by MM for mutual authentication.
Step 3: ; CP can receive blood from donors and supply it to MC as requested, whereas MC has that are verified by MM for mutual authentication.
Step 4: ; TS supplies the blood from CP to MC, whereas TS has that are verified by MM for mutual authentication.
Logistics management
The blood inventory management ranges from the NACO to the user (Kumaran & Mohan, 2023), and all these logistics can be implemented by the entities in B-SCM as depicted in Fig. 5. The following steps outline the process:
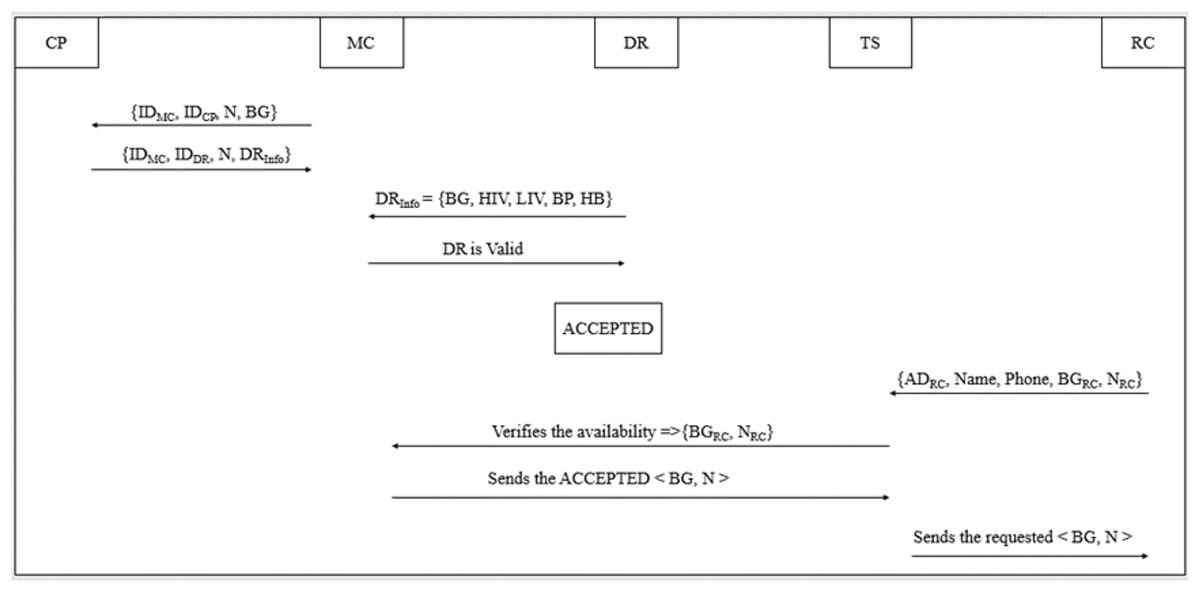
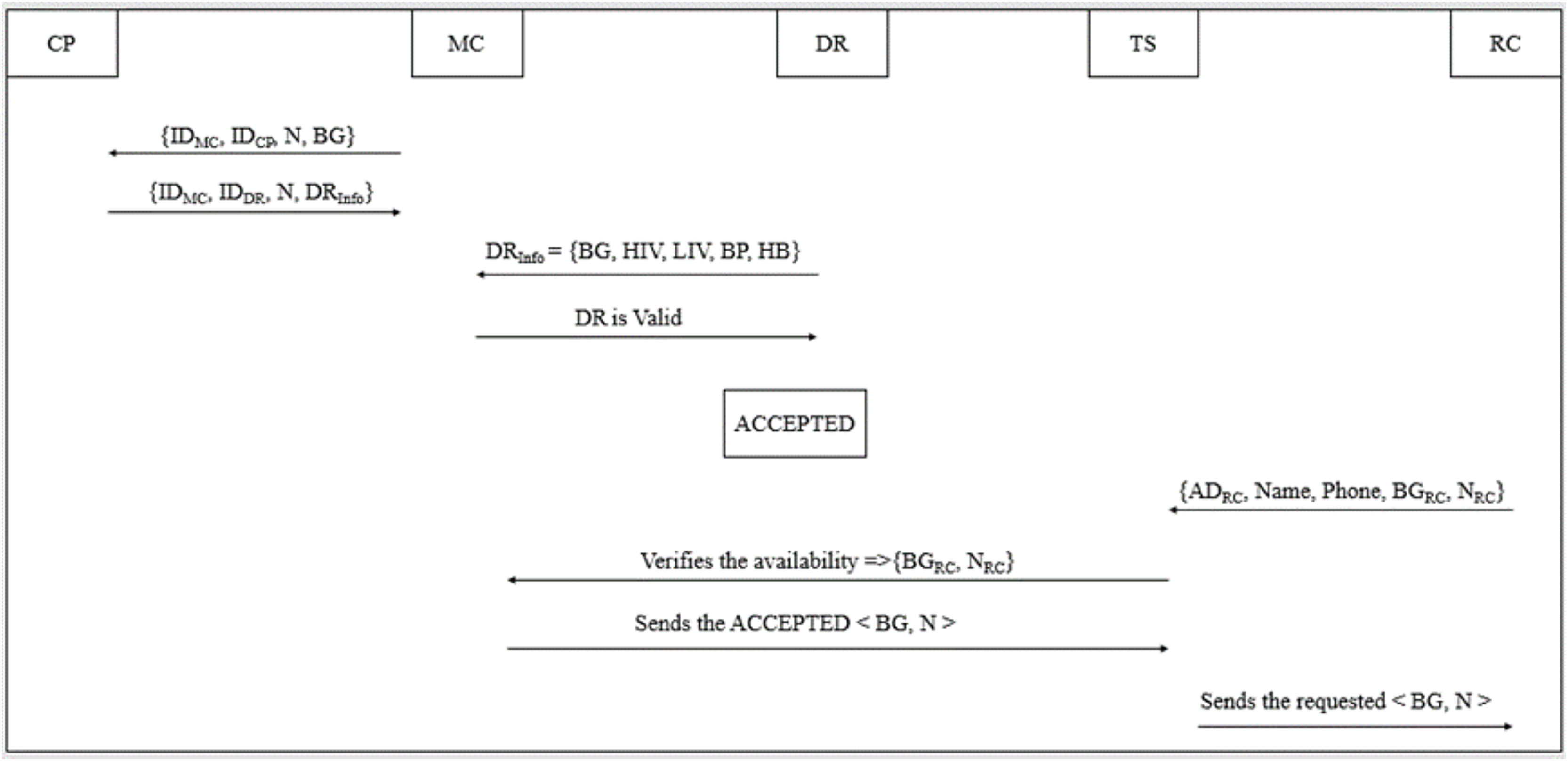
Figure 5: Logistics management phase of B-SCM.
{kind=link}
Step 1: ; the supply chain process begins when a patient requires blood at a MC. The MC contacts the CP with the CP’s identification number, the MC’s own identification number for verification purposes, the number of blood units needed, and the required blood group (Subramanian, 2024).
Step 2: ; CP evidences the MC and checks for availability of the intended blood group (BG) and required number of blood units as shown in Eq. (9).
(9)
Step 3: ; ; later, CP sends to MC, which ensures the safety, security, and quality of blood inventory management.
Step 4: ; ; with the , MC confirms the blood quality as illustrated in Eqs. (10) and (11) by verifying the that comprises information about health standards according to NACO.
(10)
(11)
Step 5: On confirming the blood quality, MC assigns an ACCEPTED/REJECTED tag to the blood unit (BU) received as illustrated in Eq. (12).
(12)
Step 6: ; ; TS will send the ACCEPTED blood units to the end user. TS collects recipient information for safe and secure logistics management.
User request
The blood bank dataset utilized for this study was sourced from the central government’s official website, eRaktKosh (Ministry of Health and Family Welfare, Government of India, 2016). The data was systematically organized into a structured format of rows and columns, enabling efficient preprocessing and model training. Specifically, the dataset comprises 106 entries across eight distinct attributes, providing a robust foundation for analysis and model development (Ministry of Health and Family Welfare, Government of India, 2025). This study employed a purposive sample of 106 participants, chosen for accessible direct engagement with the hospital system under evaluation. While the sample may seem limited, it aligns with similar exploratory research in health informatics. Future work will expand this to multiple institutions across different regions to improve generalizability. The user can request the intended BG and search for the nearest blood banks (BB) as follows:
Step 1: ; ; the user enables location services by logging into the dApp, which retrieves the user’s latitude and longitude.
Step 2: ; the user enters the required blood group and the number of necessary blood units into B-SCM. The of the blood banks are fetched, and the geodesic distance is calculated as shown in the following equations:
(13)
(14)
(15)
(16)
(17)
Step 3: The AdaBoost model identifies the nearest blood banks to the user based on and filters the blood banks by checking blood availability .
Step 4: The model filters blood banks based on the BG availability that matches with the user request along with the location that is nearest to the user’s location.
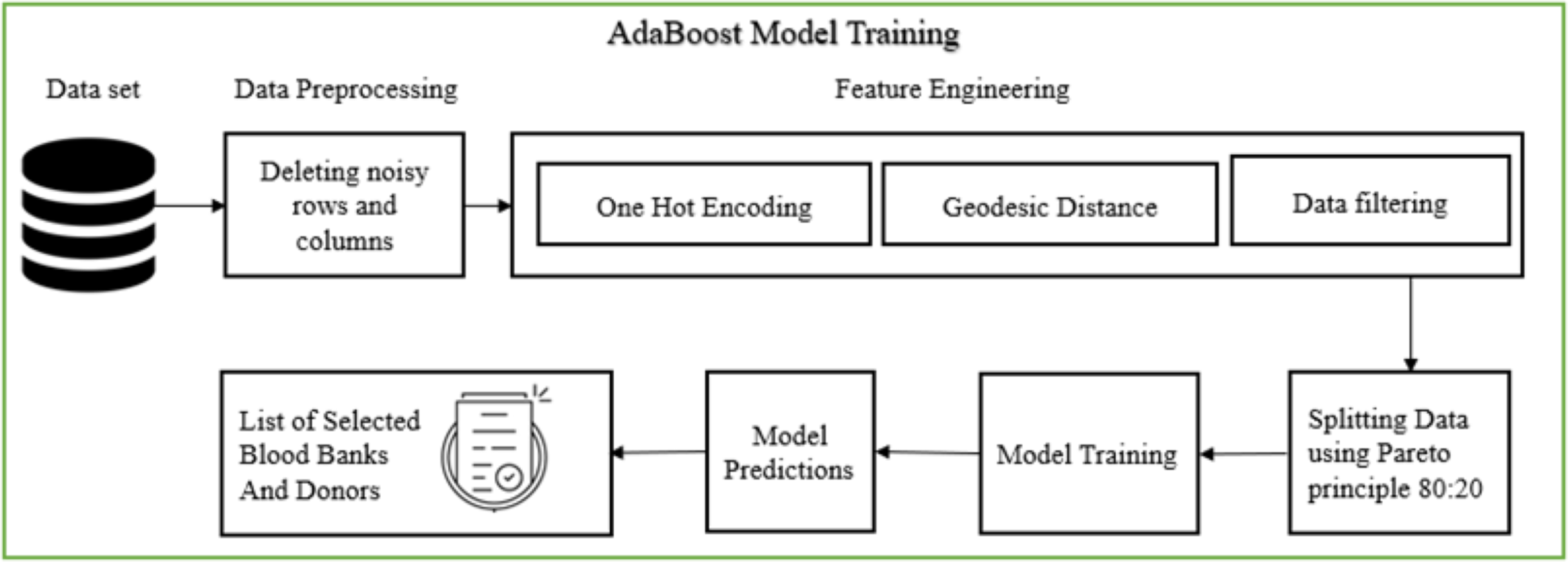
Figure 6 illustrates the AdaBoost model training pipeline, which comprises several stages: data pre-processing, feature engineering, data splitting, model training, and displaying the final list of selected blood banks and donors. During data pre-processing, the dataset was first screened for missing values, duplicates, and outliers. Missing values in critical fields (e.g., blood group, geographic coordinates, or availability status) were either imputed using domain-informed defaults or removed if imputation risked introducing bias. Duplicate entries were eliminated using record linkage based on blood bank names and GPS coordinates. Outliers in numerical attributes (e.g., extreme or incorrect latitude/longitude values) were detected using interquartile range (IQR) and Mahalanobis distance methods. Furthermore, categorical attributes were standardized to maintain consistency in labels (e.g., “B+” and “B Positive” unified).
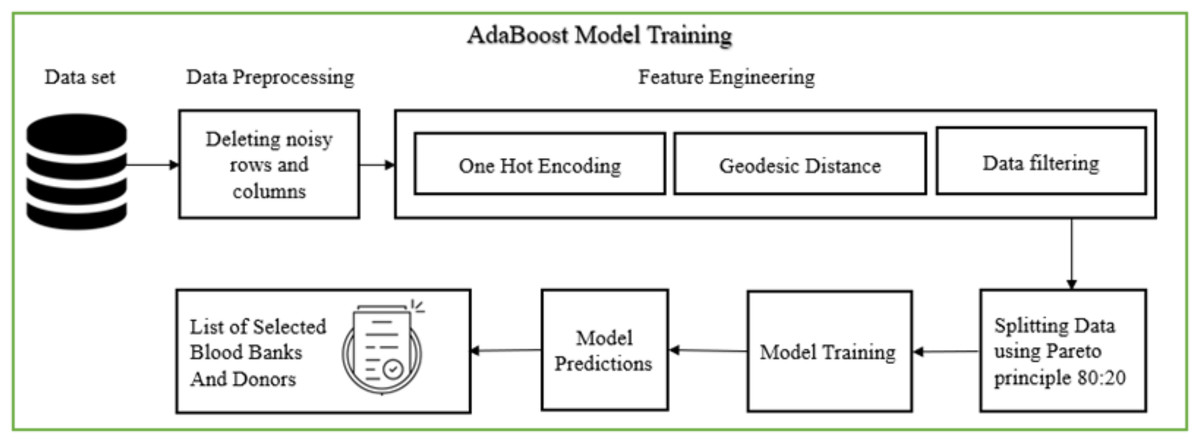
Figure 6: AdaBoost model training (Bing, 2025d).
{kind=link}
The cleaned dataset ensured higher model reliability and minimized noise during training. Feature engineering followed, involving one-hot encoding for blood groups and normalization of geospatial coordinates. Independent variables included user-provided latitude and longitude, the requested blood group (BG), and required units (N), while dependent variables were blood availability and system-generated selection of suitable blood banks. The model applied the Haversine formula for precise geodesic distance calculations, enabling spatial filtering of blood banks. The curated dataset was then partitioned into training and validation sets, and used to train the AdaBoost classifier—selected for its high accuracy in imbalanced datasets. The final output lists eligible blood banks based on both proximity and stock availability.
The AdaBoost algorithm was selected for its high classification accuracy and ability to handle imbalanced datasets, which are common in donor availability and blood stock prediction scenarios. Its ensemble learning approach, combining weak learners to form a strong predictor, makes it well-suited for our use case involving multiple features such as donor location, blood group, availability history, and urgency level. The AdaBoost model is implemented off-chain within the decision-support layer of the system. Performing such computations on-chain is not feasible due to gas cost constraints and the computational limitations of blockchain environments.
As shown in Table 2, blood should only be collected by a licensed blood bank, considering certain factors. Blood should be drawn from the donor by a qualified physician or under their supervision by trained assistants. The blood is then stored over a blockchain using the proposed distributed application (dApp).
| Factors | Characteristics | Scoring mechanisms |
|---|---|---|
| Donor recruitment | Voluntary | |
| Non-remunerated, Low risk, Safe and healthy donors | ||
| Name & Address | Govt. authorized Documents | |
| Donor selection | Age | 18 and 65 years |
| Hemoglobin or packed Cell Volume (Hematocrit) | Hemoglobin more than 12.0 gm/dl or Hematocrit less than 36% | |
| Weight | 45–55 Kg–350 ml collection | |
| 55 Kg–450 ml collection | ||
| Blood pressure | Systolic blood pressure: 100 and 160 mm | |
| Diastolic pressure: 60–90 mm | ||
| Temperature | 37.5 C/99.5 F | |
| Pulse | 60 to 100 beats per minute | |
| Blood group | Temp & Expiry date | Use before 12 weeks |
| Medical history | Not suffering from any serious illness | Ex: malignant disease, epilepsy, bronchial asthma, diabetes, excessive menstrual bleeding, cardio-vascular conditions, renal disease, allergic diseases, abnormal bleeding tendency. |
| Deferred permanently | ||
| HIV, HBsAg/HCV | Deferred permanently | |
| Swollen glands, Persistent cough, | ||
| Unexplained weight loss, | ||
| Night sweats/fever, Skin rashes and skin infections, diarrhea | ||
| Alcohol, Any drug abuse | Not accepted if not providing reliable answers to the standard questionnaire |
The implemented system incorporates predefined rules within Access Control Lists (ACLs), outlined in Table 3, to safeguard the security and privacy of sensitive user, donor, and blood bank information. These rules ensure that digitalization processes are securely managed under authorized control, thereby protecting highly confidential details throughout the system. This comprehensive approach to access control ensures that only authorized entities can interact with specific functionalities, maintaining data integrity and regulatory compliance in the B-SCM system.
| Rule | Entity | Access control | Justification |
|---|---|---|---|
| R1 | NACO | Register entities | NACO is authorized to register the central entities (CP, MC, TS) into B-SCM. This ensures that only authorized entities, validated by NACO, are included in the system, maintaining data integrity and regulatory compliance. |
| R2 | CP | Register donors | CP can register donors into B-SCM after collecting and validating donor information. This rule ensures that only validated donors meeting regulatory standards can participate in the blood supply chain. |
| R3 | E (CP, MC, TS) | Access B-SCM | Entities (CP, MC, TS) can access their respective operations within B-SCM using their public-private key pairs. This rule implements mutual authentication to ensure secure access and operation within the dApp. |
| R4 | CP | Manage logistics | CP manages logistics such as blood inventory from collection points to medical centers. This rule allows CP to maintain efficient supply chain operations, verifying blood availability and quality before distribution. |
| R5 | MC | Receive blood units | MC receives blood units from CP after verification of donor and blood quality. This rule ensures that only blood meeting specified health standards and donor eligibility criteria is accepted by MC. |
| R6 | User | Request blood units | Users can request blood units based on blood group and location. This rule facilitates user access to critical blood supply information, ensuring efficient matching with available donors and blood banks. |
Results and discussions
The Home page of blood block supply chain management system (BB-SCM) shown in Fig. 7 depicts the entities involved in BB-SCM where each entity has been provided with Login and Register options. The smart contracts written ensure that only the owner i.e., NACO can register all the entities. Figure 8 depicts all entities registered in BB-SCM by the Admin which details the public address, name, and contact number of each entity E. An entity is registered as a transaction initiated by the Admin that ensures authorization. As soon as the contract has been confirmed in Metamask, the dApp pops up a message showing the registration has been completed. CP can register donors since blood is collected by CP which can be seen in Fig. 9 As per NACO standards, the details to be collected from the donor by CP are name, age, weight, gender, and mobile number. The public wallet address is collected in addition, to ensure donor authorization. Figure 10 depicts the process of distributing blood from the CP to the MC as requested by the MC to the CP. For initiating the transportation, CP requires the name of the intended MC, public address for authenticity, and volumes of blood required.
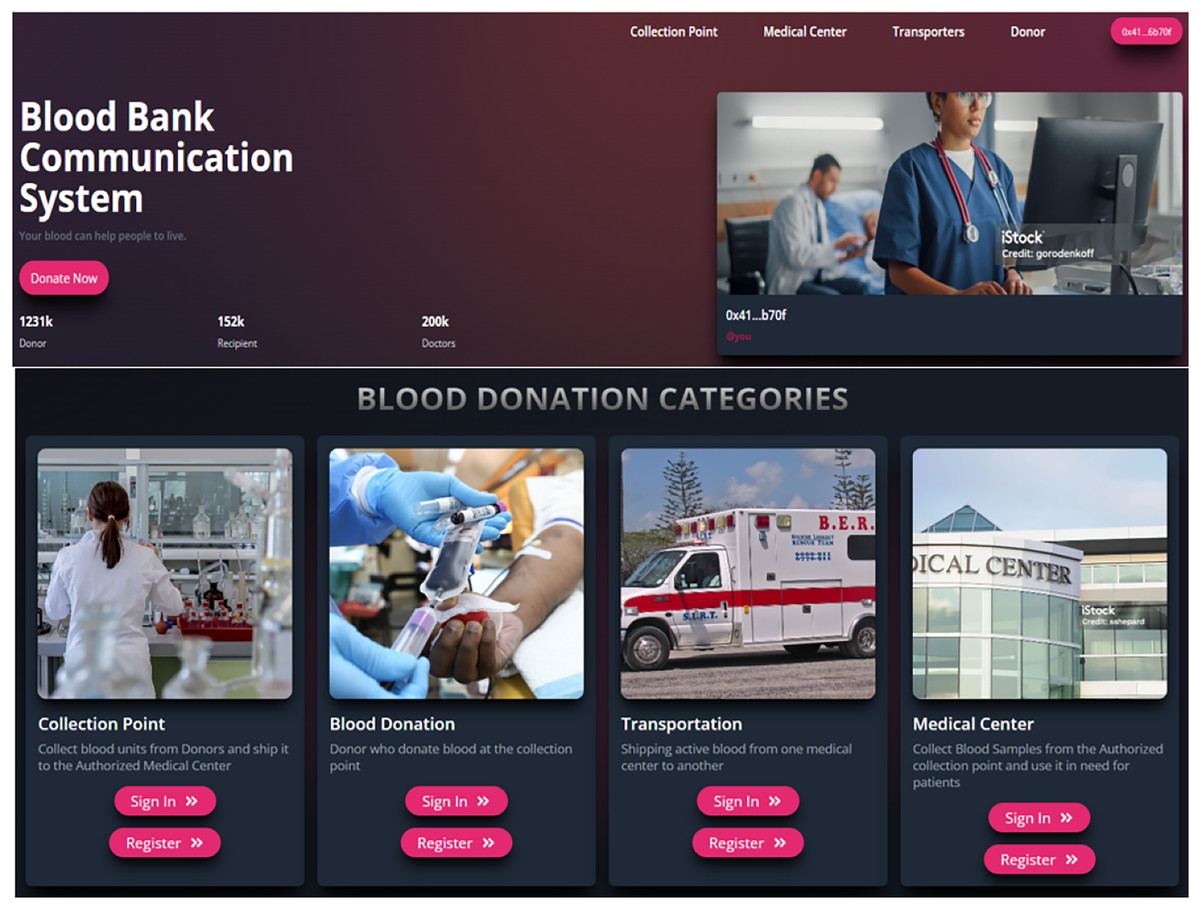
Figure 7: Home page of blood bank dApp (Google, 2025d, 2025a, 2025k, 2025h, 2025g).
{kind=link}
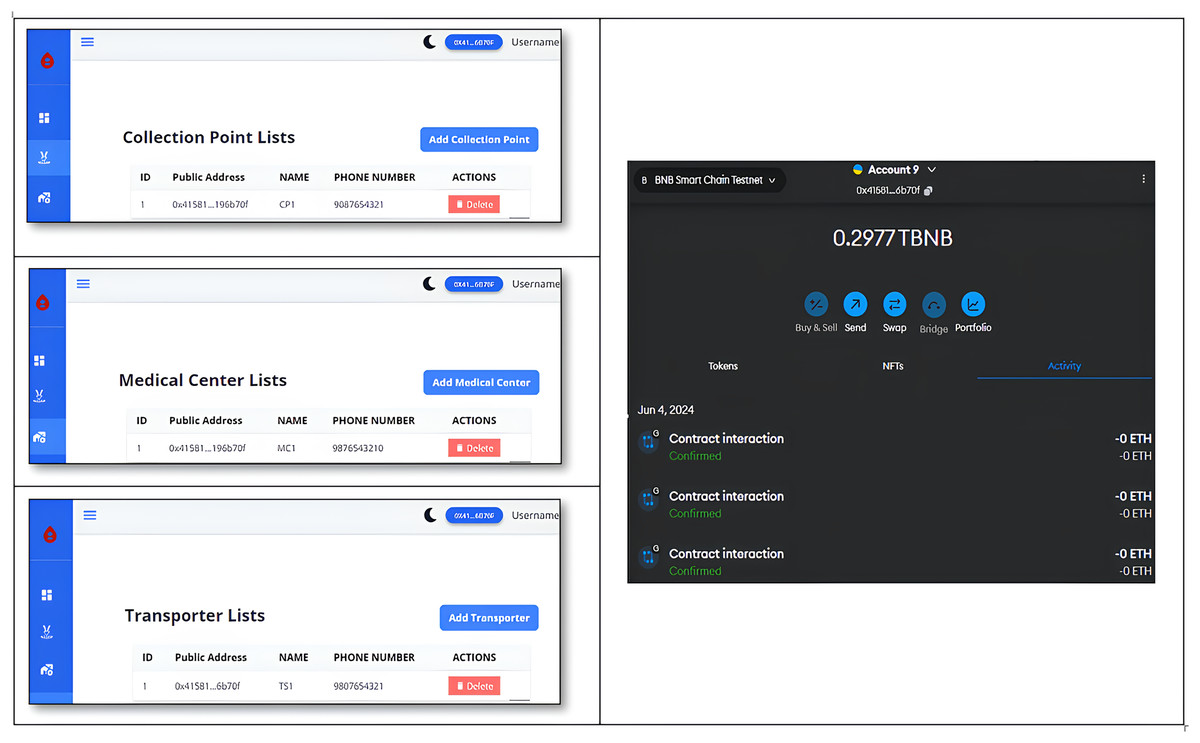
Figure 8: Registered entities in B-SCM.
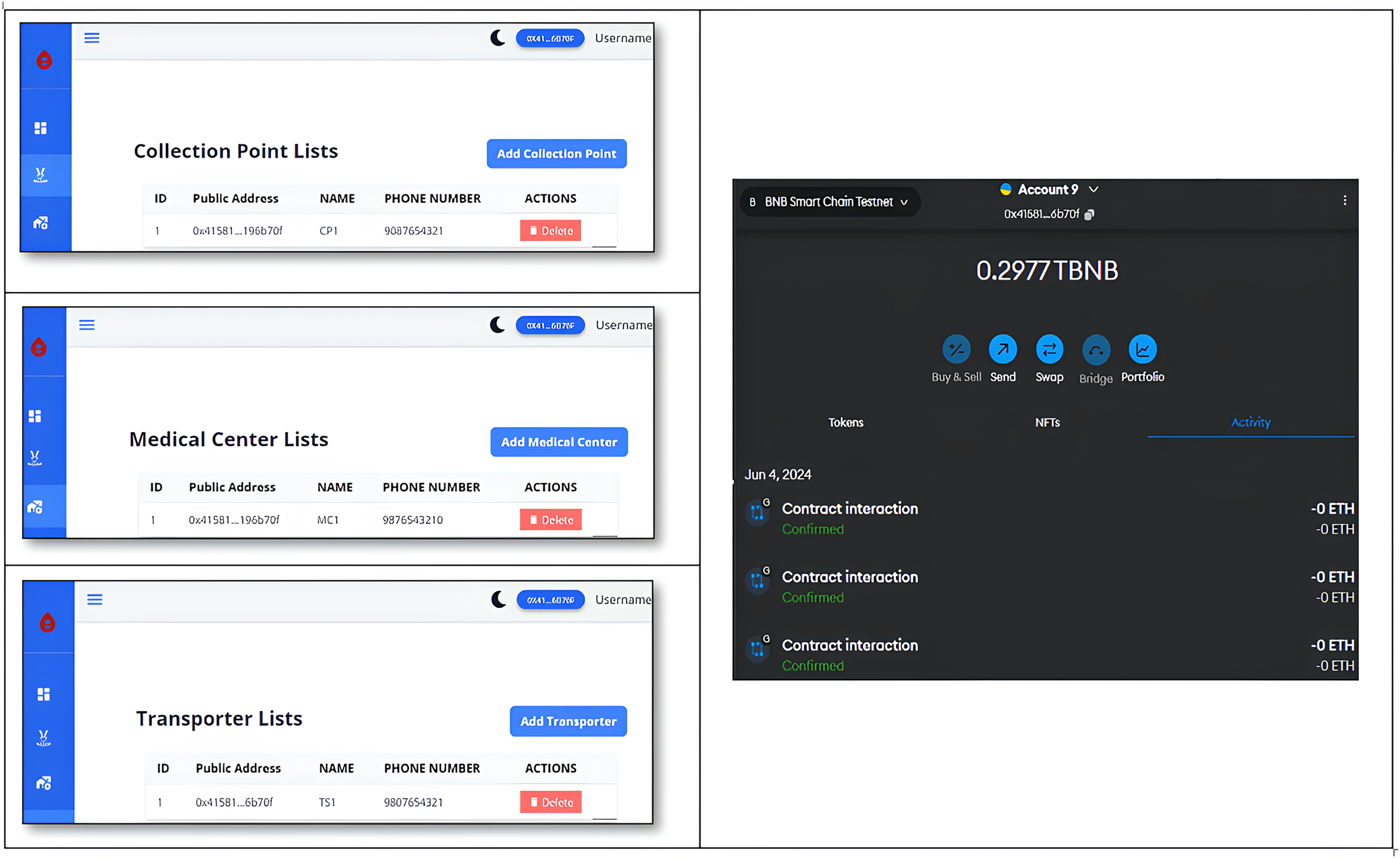{kind=link}
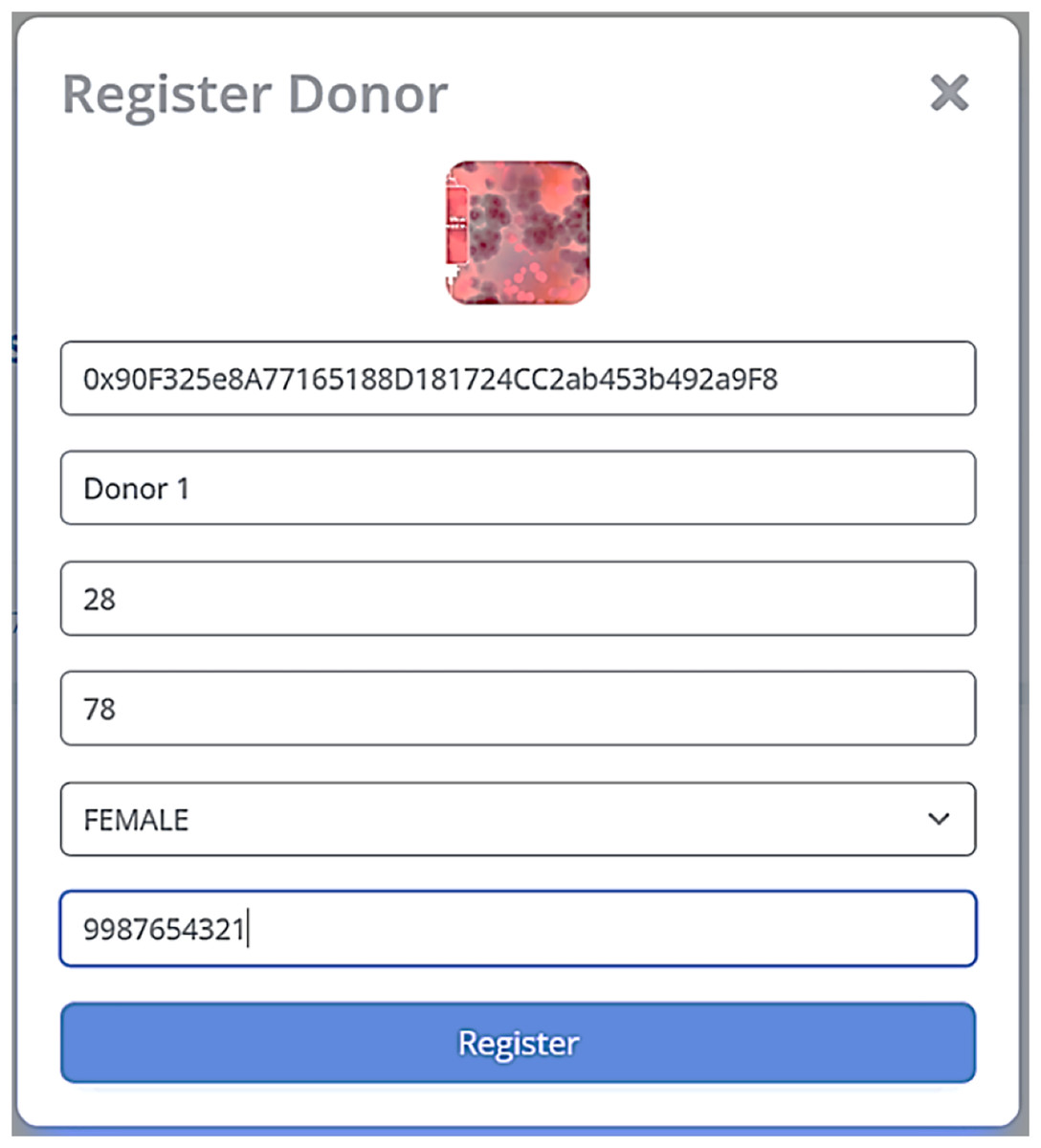
Figure 9: Donor registration at CP in B-SCM.
{kind=link}
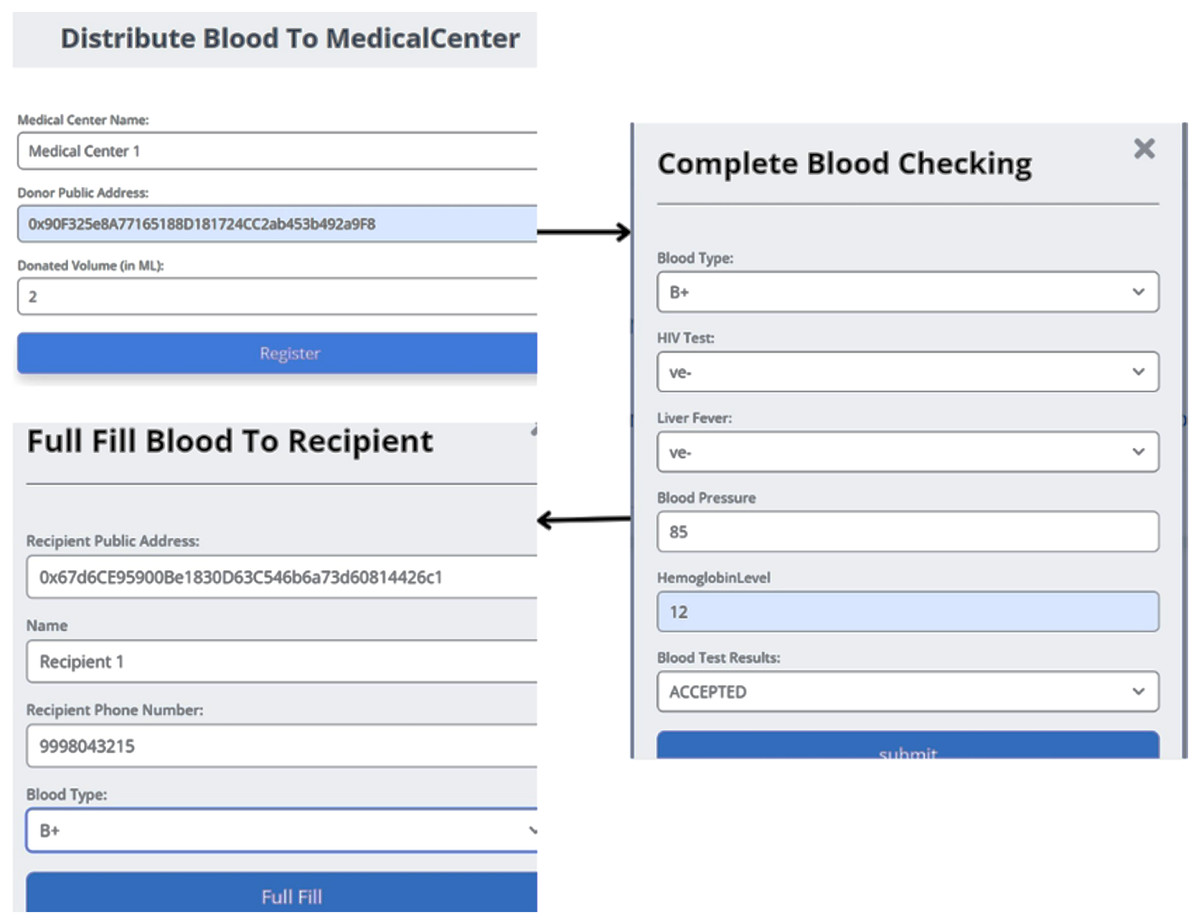
Figure 10: Distributing blood from the collection point to the medical center.
{kind=link}
After the blood is transported to the MC, the second step of verification is presided over blood units by the MC. According to NACO standards, the following parameters of the DR are substantiated: ; if the DR meets all requirements specified by NACO, the blood unit is accepted. When the end user is in need of blood, the TS will receive the details of the RC and supply the blood unit from NACO to the end user. Later, the details of the RC are to be collected at the time of blood transportation. The end user can track the status of intended blood units to be received by logging in with their respective wallet address, as shown in Fig. 11.

Figure 11: Tracking the stages of blood unit in supply chain management.
{kind=link}
Figure 12 describes a user interface where the user is prompted to enter their blood type and location by providing the latitude and longitude. When the user clicks the “Search Blood Banks” button, the system calculates the nearest blood banks using the geodesic distance method. Based on this data, it lists the blood banks closest to the user, ensuring that the user can quickly find available blood supplies.
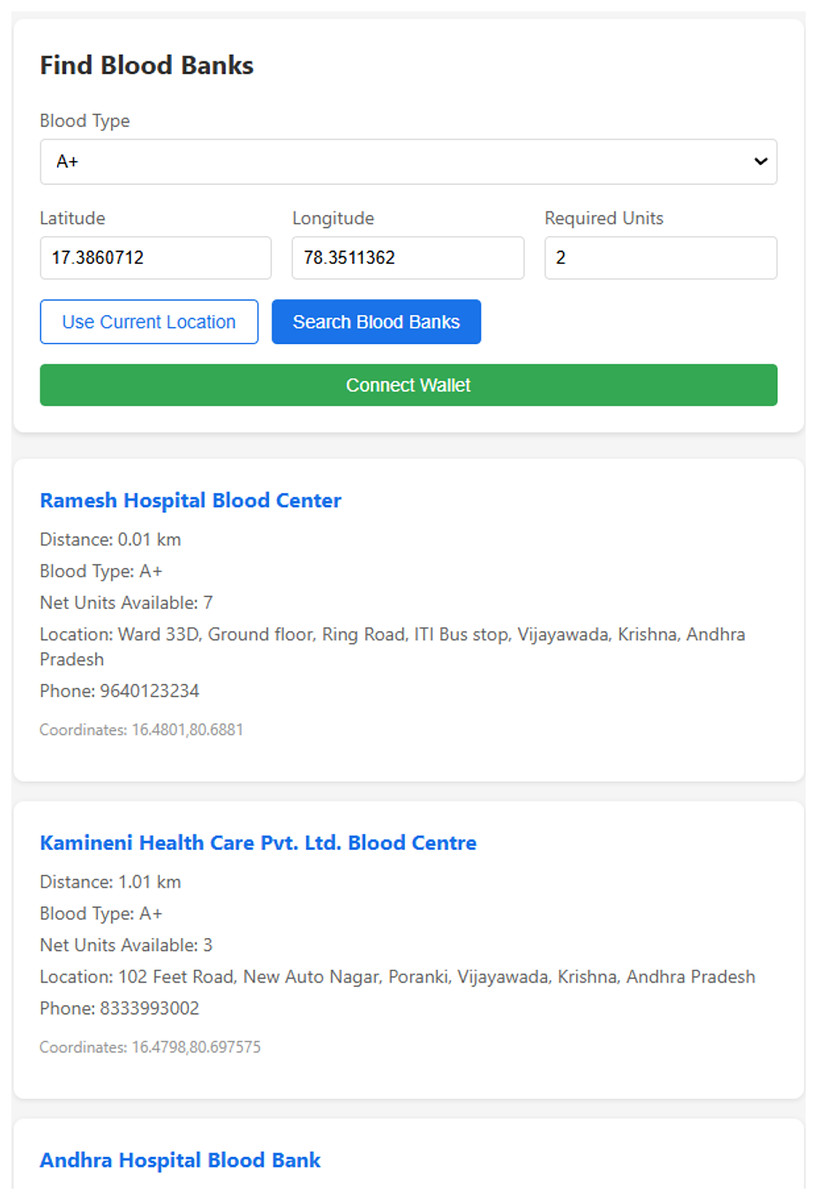
Figure 12: Prediction of the nearest blood banks.
{kind=link}
Security analysis
Formal analysis
Theorem: The security and privacy of the data are provided in the B-SCM by implementing a Byzantine Fault Tolerance (BFT) system for the nodes in the system (Al-Farsi, Rathore & Bakiras, 2021). The nodes in the system, namely NACO, DR, CP, TS, and MC, are interconnected in the network as shown in Fig. 13.
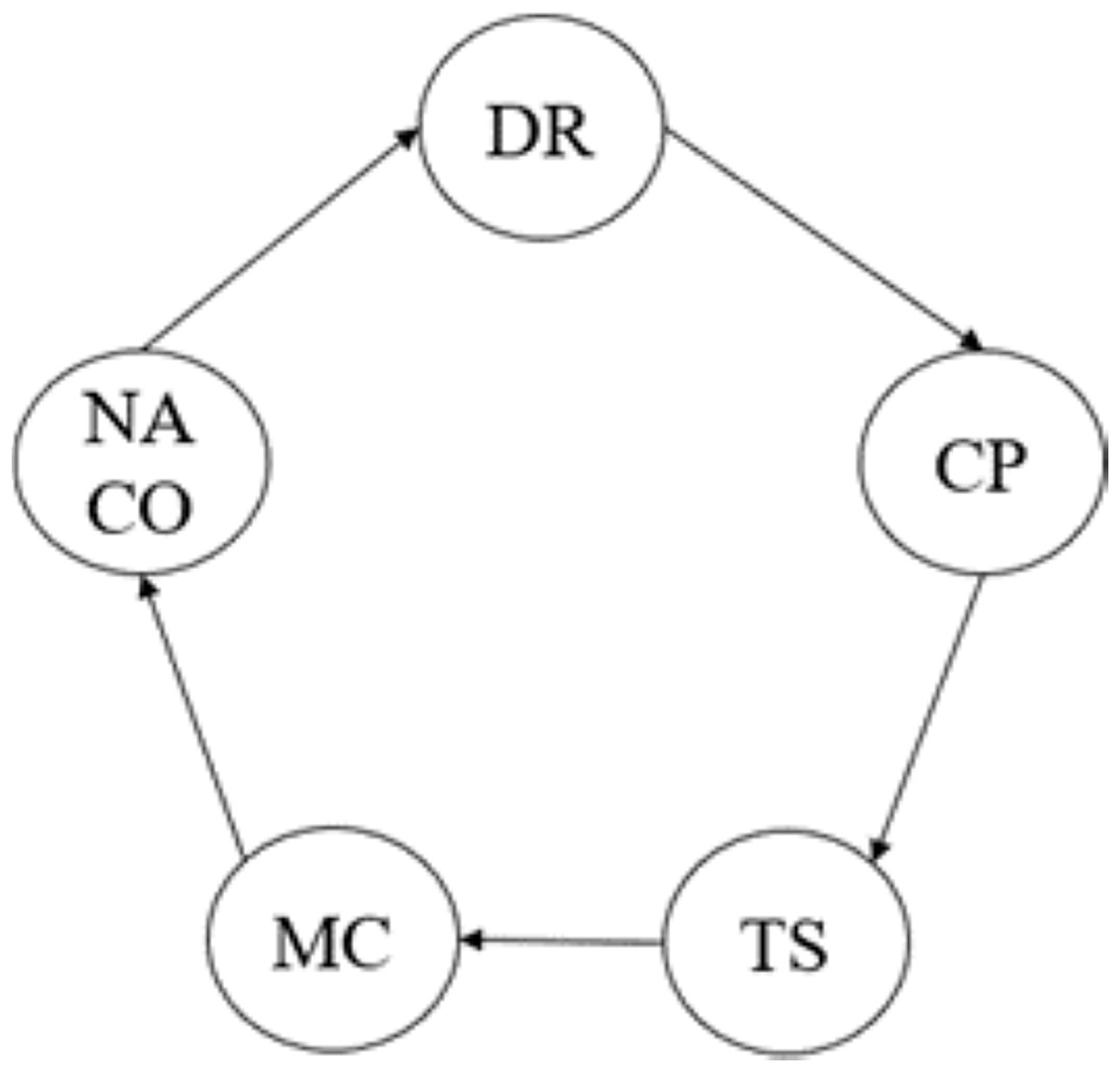
Figure 13: Nodes in B-SCM.
{kind=link}
Proof: Let be the total number of nodes in the network. For a Byzantine Fault Tolerance system to function correctly, it must tolerate up to faulty nodes where . The BFT consensus algorithm used is Practical Byzantine Fault Tolerance (PBFT), which ensures consensus if at least nodes agree on the validity of a transaction. Given , the maximum number of tolerated Byzantine nodes is , which satisfies (Eq. (18)). Therefore, we get the value as evaluated in Eq. (19):
(18)
(19)
To analyze the relationship between correct nodes and faulty nodes, consider the following inequality derived from Eq. (18):
(20)
Simplifying Eq. (20), we get:
(21)
Therefore, from Eqs. (19) and (21), we get:
(22)
To validate the number of correct nodes required for consensus, we calculate:
(23)
Hence, the system can tolerate up to 1 faulty node ( ). For a transaction T (e.g., blood donation, transport, or utilization) to be validated, each node (where ) independently validates T. The transaction T is considered valid if at least the number of nodes as computed in Eq. (23) vote in favor of it. This ensures that even if up to 1 node is malicious or faulty, the system remains secure. Therefore, from Eqs. (22) and (23), if four nodes agree, T is added to the blockchain. Additionally, in the case where TS submits conflicting transport data, the other nodes (NACO, DR, CP, and MC) identify the inconsistency and reject TS’s transaction. Continuous misbehavior by TS leads to its removal from the consensus process by a majority vote, ensuring system integrity.
Lemma 1: In a PBFT system, consensus is reached.
Proof: In a PBFT system, is the maximum number of faulty nodes the system can tolerate. Since , there are always at least correct nodes. The consensus requires votes, thereby from Eq. (22) ensuring that a majority of correct nodes can reach consensus even if up to nodes are faulty.
Lemma 2: The system ensures data integrity and privacy.
Proof: The data is stored and transmitted using blockchain technology, which leverages cryptographic techniques inherent in blockchain systems to ensure that data cannot be altered once it is committed to the ledger. Each transaction is digitally signed by the submitting node, and the integrity of the data is verified by all participating nodes. The immutable audit trail on the blockchain ensures that all transactions are verifiable and traceable, further ensuring data integrity and privacy. This system implements this framework by maintaining a ledger that records every crypto transaction.
Informal analysis
Proposition 1: The proposed B-SCM model can prevent a 51% attack.
Proof: A 51% attack in blockchain systems involves an adversary gaining majority control of the network’s hashing power, enabling them to manipulate transactions and undermine network integrity. The B-SCM system achieves consensus through a decentralized Proof of Authority (PoA) mechanism (Manolache, Manolache & Tapus, 2022). Validators, comprising entities , are selected based on their authority and reputation within the supply chain network. Let N denote the total number of validators, and denote the number of validators required to approve a transaction. By design, the B-SCM system ensures that is sufficiently large to prevent any single entity or coalition from controlling more than of the network’s validation power. Therefore, through the distributed authority and consensus mechanism, the B-SCM model ensures that the network remains secure and resilient against such attacks, preserving the integrity of blood supply chain transactions.
Proposition 2: The proposed blockchain model is resilient to Eclipse attacks.
Proof: An Eclipse attack aims to isolate a target node V in a blockchain network by surrounding it with malicious nodes controlled by an attacker (Jabbar et al., 2021). Let denote the blockchain network graph, where V represents nodes, , and E denotes edges representing communication links. Each node maintains connections with a set of neighboring nodes and updates this set periodically using decentralized protocols. To prevent Eclipse attacks, the B-SCM system employs a consensus mechanism enforced by smart contracts, ensuring that each transaction T initiated by nodes in V undergoes validation by a subset comprising multiple nodes. Formally, for any transaction T initiated by node , verifies T according to , ensuring , where is a consensus threshold. This decentralized validation approach, coupled with cryptographic signatures and secure communication protocols, ensures that the B-SCM system maintains network integrity, effectively resisting Eclipse attacks by preventing malicious nodes from controlling the information seen by targeted nodes and maintaining robustness in transaction verification across the decentralized network.
Proposition 3: The proposed model can prevent a Sybil attack.
Proof: A Sybil attack involves creating multiple fake identities to gain disproportionate influence in a network. The proposed B-SCM system uses identity certification to counter this attack. The Central Authority (NACO) registers all entities in the system, ensuring that each entity has a verified and unique identity. This prevents malicious actors from creating multiple fake identities to manipulate the system. NACO checks each entity’s credentials, such as private key of entity (PRE), wallet address of entity (ADE), and , to ensure their authenticity. This certification process effectively mitigates the risk of Sybil attacks by ensuring that only legitimate entities can participate in the network (Choudhury et al., 2021).
Proposition 4: The proposed model is resilient to man-in-the-middle attacks.
Proof: A man-in-the-middle (MITM) attack involves an attacker intercepting and possibly altering the communication between two parties. In the B-SCM system, communication between entities is secured using cryptographic techniques. Each transaction is hashed using a cryptographic hash function hash of entity (HE). The hash value is kept confidential and is not included in the application binary interface (ABI) file, preventing attackers from gaining access. For an attacker to successfully intercept the communication, they would need to provide valid credentials , public key of entity (PKE) matching the hashed values of the legitimate entities. Since these values are kept secret, an attacker can’t perform an MITM attack (Maroun, Daniel & Fynes, 2019).
Performance analysis
The model’s performance was assessed using a confusion matrix, as shown in Fig. 14. In Eqs. (24), (25), (26) and (27) blood availability (BA) is analogous to True Positives, indicating the number of correct predictions of blood supply availability when it was indeed available. Blood unavailability (BU) corresponds to True Negatives, representing correct predictions of unavailability when the blood supply was unavailable (Younis et al., 2021). False blood availability (FBA) represents False Positives, where the model incorrectly predicted availability when the blood supply was unavailable. Similarly, false blood unavailability (FBU) corresponds to False Negatives, indicating incorrect predictions of unavailability when the blood supply was available. This evaluation provides a comprehensive breakdown of the model’s accuracy in predicting blood supply availability within the given context (Rupa et al., 2025).
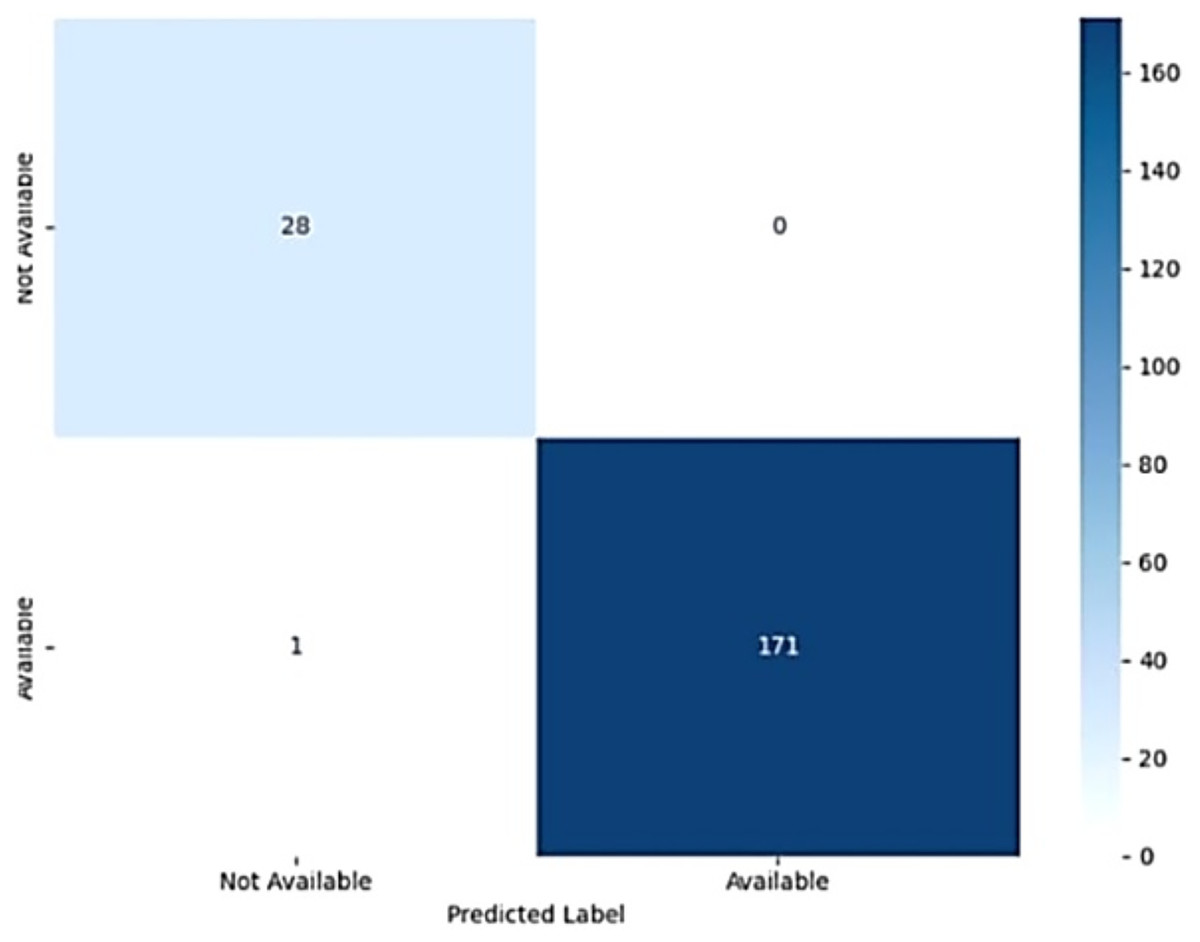
Figure 14: Confusion matrix of the AdaBoost model.
{kind=link}
The model achieved an accuracy of 96%, demonstrating its effectiveness in predicting the availability of blood from nearby blood banks and donors. The study possesses a precision of 97.95%, highlighting the model’s ability to accurately identify true positive blood availability predictions. The recall was also 97.95%, indicating the model’s effectiveness in detecting actual blood availability. Similarly, the F1-score was 97.95%, reflecting the balance between precision and recall and confirming the model’s overall high performance in predicting blood supply availability.
(24)
(25)
(26)
(27) where:
BA = True Positives (Blood Available)
BU = True Negatives (Blood Unavailable)
FBA = False Positives (False Blood Available)
FBU = False Negatives (False Blood Unavailable)
B-SCM includes entities such as NACO, CP, MC, TS, and DR, as shown in Fig. 15. These entities interact and access data according to specific rules defined by Access Control Lists (ACLs), as illustrated in Table 2. To represent and enforce these rules, we use two matrices: a Binary Connection Matrix A and a Weighted Connection Matrix W.
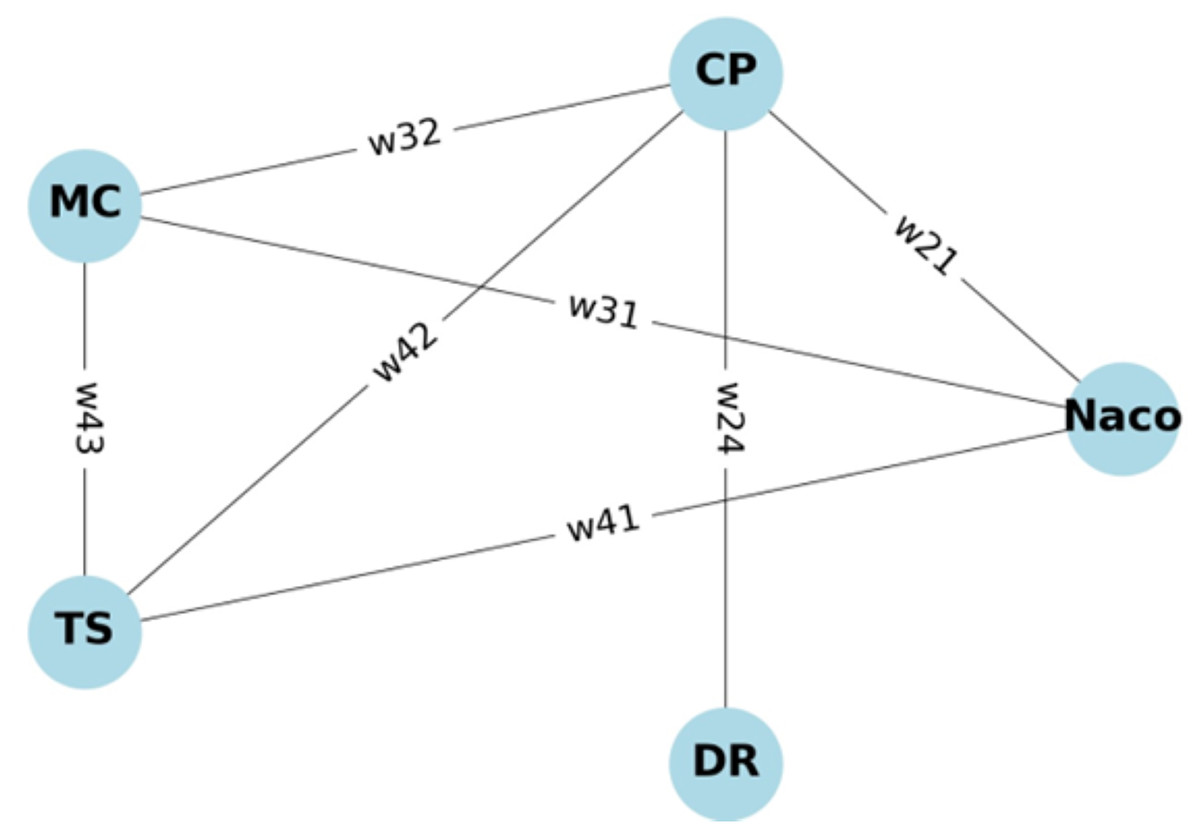
Figure 15: Graph representing entities in B-SCM.
{kind=link}
The Binary Connection Matrix A in Eq. (28) indicates whether there is access (1) or no access (0) between entities. The rows and columns represent the entities, and each element shows if entity has access to the resources of entity .
(28) where in Eq. (28):
rows and columns represent the entities in the order: NACO, CP, MC, TS, DR.
Each element indicates whether entity has access to the resources of entity .
The Weighted Connection Matrix W assigns weights to the access permissions, representing the priority or level of access. These weights could be based on transactional data, security levels, and access frequency.
(29)
This study has successfully implemented Access Control Lists (ACLs) and priority scores were assigned for the entities for secure communication. The performance analysis of ACLs, priorities of entity operations, alongside the security and privacy requirements are clearly stated as follows:
(30)
(31)
To ensure ACLs are maintained, we sum the priority scores for all granted accesses as depicted in Eqs. (32) and (33). To illustrate the enforcement of ACLs, we use the priority scores of each entity along with the access level assigned to each entity.
For
(32)
For
(33)
To strengthen the rationale for selecting Binance Smart Chain (BSC) over other platforms such as Ethereum and Hyperledger Fabric, a quantitative comparison is presented in Table 4. The comparison evaluates core parameters including transaction fees, throughput, confirmation time, development complexity, and use case suitability. BSC offers significantly lower transaction costs (approximately $0.10) compared to Ethereum’s $5–$10 range, making it highly cost-effective for frequent interactions in decentralized applications. While Hyperledger Fabric provides higher throughput, it is a permissioned network, making it less suitable for publicly accessible systems like ours. Additionally, BSC achieves a good balance between scalability, development simplicity (due to EVM compatibility), and public accessibility. These factors make BSC a more practical and efficient choice for the implementation of a decentralized blood supply chain management system.
| Criteria | BSC | Ethereum (Mainnet) | Hyperledger fabric |
|---|---|---|---|
| Average transaction fee | $0.10 | $5–$10 | None (permissioned) |
| Transaction throughput (TPS) | 55–100 TPS | 15–30 TPS | 1,000+ TPS |
| Block confirmation time | 3 s | 13–15 s | 1 s |
| Public/Private | Public | Public | Permissioned |
| Development complexity | Low (EVM-compatible) | Medium | High |
| Use case suitability | Scalable public DApps | Public DApps with high trust | Enterprise-grade apps |
Table 5 describes the comparison between the proposed system with the existing studies. The proposed system, utilizing AdaBoost, demonstrates superior performance across all metrics, achieving an accuracy of 99.5%, which is the highest among the compared models. In terms of precision, recall, and F1-score, the proposed system consistently scores 0.99, 0.96, and 0.98, respectively, surpassing the performance of models like SVM, KNN, and MLP. These results indicate that the proposed AdaBoost system is not only more accurate but also more reliable in correctly identifying positive instances and capturing all relevant instances, making it the best-performing model in this comparison. This comprehensive improvement across all evaluation criteria underscores the robustness and effectiveness of our proposed approach. The superior performance of the proposed system can be demonstrated graphically in Fig. 16.
| Model | Accuracy | Precision | Recall | F1-score |
|---|---|---|---|---|
| MLP | 96.5 (%) | 0.82 | 0.63 | 0.71 |
| SVM | 96.5 (%) | 0.84 | 0.94 | 0.89 |
| KNN | 91.0 (%) | 0.89 | 0.91 | 0.91 |
| AdaBoost | 99.5 | 0.99 | 0.96 | 0.98 |
Note:
Since AdaBoost algorithm is used in the proposed methodology because of its highest performance, it is highlighted in bold. This is to mention that AdaBoost is utilized in the proposed work which stands as best fit model.
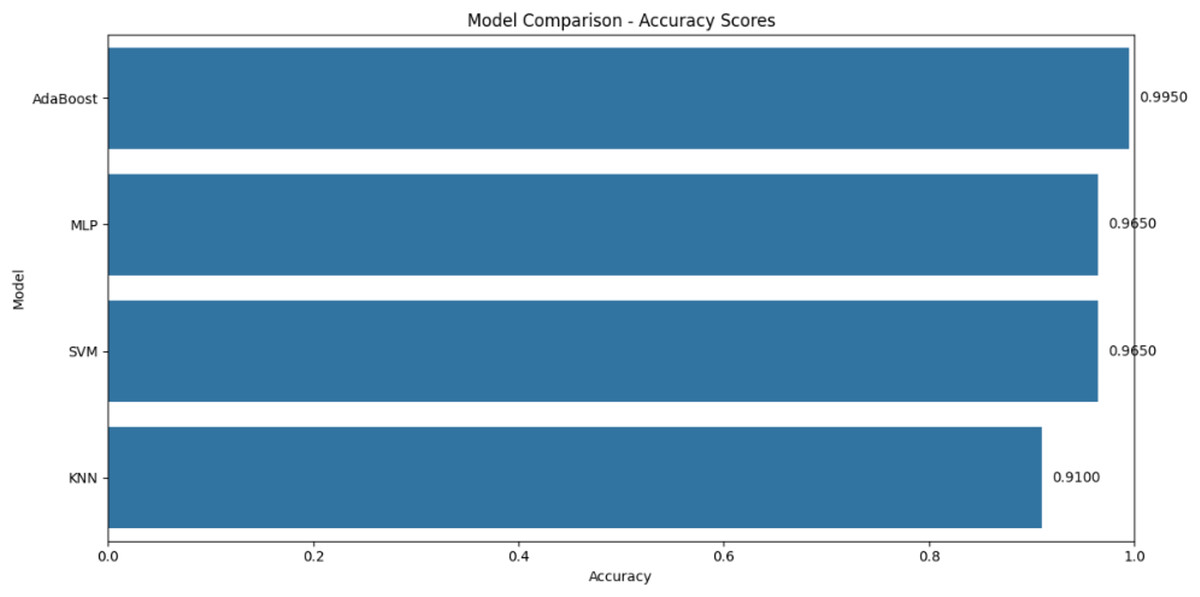
Figure 16: Comparative analysis with different models.
{kind=link}
The comparative analysis demonstrates the AdaBoost model’s superiority over alternative approaches, achieving 99.5% accuracy compared to 96.5% for SVM and MLP models. Beyond prediction performance, BSC provides distinct advantages over other blockchain platforms: its $0.10 average transaction cost is 50–100× lower than Ethereum’s $5–$10 range, while maintaining 3-s confirmation times vs Ethereum’s 13–15 s. Although Hyperledger Fabric offers higher throughput (1000+ TPS vs. BSC’s 100 TPS), its permissioned nature limits suitability for public health applications. This balance of low cost, developer-friendly EVM compatibility, and public accessibility makes BSC ideal for decentralized blood supply chains.
This study aimed to develop an intelligent and secure blood supply chain management system by integrating the AdaBoost machine learning algorithm with a blockchain-based infrastructure. The rationale behind this integration is to overcome key limitations of traditional systems, such as low accuracy in predicting donor and blood bank availability, and the absence of secure, transparent data handling. Existing centralized systems are often prone to data tampering and lack the intelligence needed for real-time decision-making. The proposed system addresses these gaps by using the AdaBoost algorithm off-chain to provide high-accuracy predictions for locating the nearest eligible donors and available blood banks, outperforming conventional models like SVM, KNN, and MLP in terms of both accuracy and speed. Simultaneously, the blockchain layer is deployed on the Binance Smart Chain, ensuring immutable and verifiable records of all supply chain events, from donor registration to blood unit tracking, using smart contracts. By combining predictive intelligence with decentralized trust, the proposed framework offers superior performance, enhanced transparency, and greater reliability compared to existing centralized or siloed approaches, thereby meeting the core research objectives effectively.
Conclusion and future work
The blockchain system configured for blood supply chain management integrates nodes with different levels of access, thereby enhancing authorization mechanisms and ensuring secure handling of sensitive information. By configuring the Binance Coin (BNB) gas price through the Hardhat environment, the system avoids high transaction costs, as demonstrated in the experiments. The integration of the AdaBoost algorithm achieves a 99.5% prediction accuracy, significantly enhancing user experience by efficiently identifying suitable donors and blood banks. The use of BscScan validates the reliability of public blockchain operations, while essential security features such as immutability via access control, confidentiality, integrity of records, and non-repudiation through distributed ledgers strengthen the trustworthiness of the system.
In contrast to traditional centralized systems that are often prone to data tampering, single-point failures, and limited transparency, our system offers decentralized trust, traceability, and predictive intelligence. The comparative analysis demonstrates significant advantages: AdaBoost outperforms alternative models (SVM, KNN, MLP) by 3–8.5% in accuracy, while Binance Smart Chain reduces transaction costs 50–100x compared to Ethereum. However, limitations including potential integration challenges with existing healthcare infrastructure (particularly regarding HL7/FHIR interoperability and HIPAA/GDPR compliance), dependency on public blockchain gas fees during network congestion, and limited deployment across diverse geographic regions need to be addressed in future iterations.
From a practical perspective, deploying such a system in real-world healthcare environments presents several benefits, including increased transparency, improved traceability, and faster, data-driven decisions. However, challenges may arise, such as integrating with legacy hospital systems, complying with healthcare data privacy regulations, managing blockchain scalability, and ensuring affordability of gas fees under high-volume transactions. Although the current system is built on a public blockchain, future adaptations may consider private or consortium blockchains for enhanced data safety and interoperability. Specific infrastructure compatibility solutions will include developing standardized API gateways and hybrid architectures that maintain backward compatibility with existing hospital systems.
In addition, scalability studies using more advanced machine learning models will be undertaken to optimize performance further. Future work will specifically address current limitations through: (1) multi-institutional trials across diverse healthcare ecosystems, (2) implementation of Layer-2 scaling solutions for gas optimization, (3) expansion of training datasets via partnerships with national blood networks, and (4) smart contract modularization for regulatory adaptation across jurisdictions. This work lays the foundation for a scalable, secure, and intelligent blood supply chain management system, with promising implications for broader healthcare applications, including secure e-blood donation platforms and digital payment integration.
Abbreviations
The following Table 6 lists the abbreviations used in this manuscript:
| Acronym | Description |
|---|---|
| CP | Collection point |
| MC | Medical centre |
| TS | Transporter |
| DR | Donor |
| RC | Recipient |
| E | Entities = {CP, MC, TS} |
| PKE | Public key of E |
| PRE | Private key of E |
| PKOwner, PROwner | Public key and Private key of NACO |
| PKDR, PRDR | Public key and Private key of Donor |
| MM | Metamask |
| ADE, PWE | Wallet address and Password of E |
| IDCP, IDMC, IDDR | Unique ID of CP, MC, and DR |
| N | Number of blood units |
| BG | Blood group |
| DRInfo | Personal information of DR |
| ADRC | Wallet address of recipient |
| BGRC | Blood group of recipient |
| HIV | HIV test |
| LIV | Liver fever test |
| BP | Blood pressure |
| HB | Hemoglobin |
| LATUser, LONUser | Latitude and longitude of the user |
| LATBB, LONBB | Latitude and longitude of the blood bank |
| Identical | |
| (Condition): x ? y | If condition is true then return x else y |
Data Source
The dataset was compiled using information sourced from the official e-RaktKosh platform of the Ministry of Health and FamilyWelfare, Government of India: https://eraktkosh.mohfw.gov.in/BLDAHIMS/bloodbank/transactions/bbpublicindex.html. The dataset has been curated and published with an assigned DOI via the Zenodo repository: https://doi.org/10.5281/zenodo.15667720.
Supplemental Information
The real-time transactional data extracted from the e-Raktkosh portal.
The dataset contains details of blood unit availability, donor information, blood bank details, transaction timestamps, and other operational data. No personal or confidential information is disclosed in this file.
The source code written in Solidity, originally created using the Remix IDE.
The code defines smart contract logic for tracking and managing blood supply chain operations. It outlines core functionalities like donor registration, blood unit tracking, and verification processes.
Script orchestrating the loading, prediction, and evaluation of different ML models (KNN, SVM, MLP, AdaBoost) trained on the bloodbank dataset.
Includes preprocessing steps, input/output handling, and final decision logic.
The serialized version of the trained K-Nearest Neighbors (KNN) model.
The model trained on the bloodbank dataset to classify demand/supply urgency and is used for making real-time predictions during testing.
The serialized Support Vector Machine (SVM) model trained on the bloodbank dataset.Primary.
The model supports decision-making in blood stock management based on transactional trends.
The trained Multi-layer Perceptron (MLP) model.
The model is designed to capture complex patterns in blood demand and availability data through a neural network architecture.
The trained AdaBoost ensemble learning model.
This was included in the study to compare the accuracy and performance of boosting techniques over traditional classifiers for the blood supply use case.