
Bridging code and timely feedback: integrating generative AI into a programming platform
- Published
- Accepted
- Received
- Academic Editor
- Paulo Jorge Coelho
- Subject Areas
- Artificial Intelligence, Computer Education, Data Mining and Machine Learning, Emerging Technologies, Programming Languages
- Keywords
- Automatic feedback, GPT4o-mini, Generative AI, LLMs, Judge0, Coding skills assessment
- Copyright
- © 2025 Martínez-Araneda et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Bridging code and timely feedback: integrating generative AI into a programming platform. PeerJ Computer Science 11:e3070 https://doi.org/10.7717/peerj-cs.3070
Abstract
Purpose
This article examines how generative artificial intelligence (GenAI) can improve students’ programming skills through timely feedback. Specifically, it evaluates the effectiveness of feedback provided through two custom-developed applications: (1) A chatbot-like virtual assistant powered by the GPT-4o-mini model designed to assist students interactively; (2) A programming platform that combines GenAI-generated feedback and a virtual judge for source code evaluation. The study explores whether these tools contribute to improving students’ programming performance.
Method
The proposed method consists of the following tasks: (1) Development of two functional prototypes powered by GPT-4o-mini, the first of them a conversational chatbot with access to a specific programming knowledge base, and the second an innovative development that integrates in a single platform a GenAI and an open-source virtual judge for the joint generation of an automated assessment and timely feedback of the source code. (2) Designing and executing the experiment to evaluate whether providing feedback to students in a beginner programming course using GEN’s AI-based tools improved the passing rate in an assessment. To achieve this, a quasi-experimental study was conducted in which students engaged in context-enriched problem-solving. Two-course sections served as experimental groups, receiving feedback from the AI tools. At the same time, the other two groups served as controls. (3) Measuring students’ performance in problem-solving and collecting student perceptions on usability for the chatbot and the competitive programming platform.
Results and Conclusions
Students who received feedback generated by GenAI did not show improvement in their performance, although they perceived it as useful. Conversational (tutorB@t) and non-conversational platform (tutorBot+) versions are available at https://cdn.botpress.cloud/webchat/v3.2/shareable.html?configUrl=https://files.bpcontent.cloud/2025/01/20/23/20250120232250-Q9SCHBOO.json and https://supc.ucsc.cl:23380/, respectively, under an AGPL 1.0 license. From the processing and analysis, a good perception of the usability of both tools was obtained (70.6% and 65.2%, respectively), which is reinforced by the 81% and 79% of students who stated that they would use them again. Although the usefulness and perception of the tools are considered positive, there is insufficient evidence to definitively evaluate the effect of GenAI-generated feedback on students’ passing rates in an assessment.
Introduction
According to Hattie & Timperley (2007), feedback refers to the information provided to students about their performance to enhance learning and academic outcomes. It can come from various sources, such as teachers, peers, study materials, or even us, and can be corrective, formative, clarifying, or motivating. A systematic review conducted by Haughney, Wakeman & Hart (2020) about the potential of feedback in higher education found common elements that include widely accepted quality standards, such as that feedback should be positive, specific, timely, and encourage active participation of students, as well as less known characteristics that emerge the impact of peer feedback, the use of novel tools. The study by Yang & Carless (2013) shows the feedback triangle where three dimensions are mentioned: the cognitive, related to the content of the feedback; the socio-affective, focused on interpersonal interaction and the emotional aspects of the delivery of feedback; and the structural, related to the organization and framework within which the feedback is provided. The literature analysis also reveals an increase in studies focused on students’ perceptions of feedback. Qualitative research by Quezada & Salinas (2021) shows the difference between the effort that a teacher makes when giving feedback and the appreciation of his students, who in many cases associate it with a negative and demotivating task when their expectation was rather detailed feedback, delving into strengths and weaknesses where aspects such as motivation, emotionality and autonomy of the student are considered. Feedback is considered adequate when a comment helps improve the task and is delivered immediately and positively. The lack of time for the teacher and the massiveness of his courses often prevent him from giving this type of feedback, and even less so, from knowing the actual effect on learning. The contributions of AI to education are undeniable; the history since the first intelligent tutorials emerged, defined as “software systems that use artificial intelligence (AI) techniques to represent knowledge and interact with students to teach them” (VanLehn, 1988) proposed in the 80s and constituting the first approximations to what is known today as a chatbot for education defined as “intelligent agents capable of interacting with a user-student to answer a series of questions and give the appropriate response” (Clarizia et al., 2018).
This article assesses whether using a generative artificial intelligence (GenAI) to provide feedback to programming students improves their performance. The rest of the article is structured as follows: “Introduction” includes an Introduction, followed by “Literature Review”, which discusses the background and work related to automatic feedback, AI in learning strategies, positive feedback and its effects, and a literature review on the use of GenAI for feedback in computer science. “Materials and Methods” describes the work methodology. “Applications Development” includes the developing process in its non-conversational and conversational versions. “Design and Experimentation” presents the results of applying the instruments. “Results and Discussion” discusses the main results obtained. Finally, “Conclusions” describes the conclusions of the work, its limitations, and future work.
Framework
In undergraduate courses in the computer science area, both scientific and technological, one of the specific skills in the graduate profiles is problem-solving. This type of problem places students in a realistic scenario where they are at the center of the problem and are asked to make certain decisions. Their situation cannot be solved simply by applying formulas to find a single and exact answer to a previously structured problem; they must begin by understanding and structuring the problem, which can be real or a didactic simulation (Bangs, 2007; Cárdenas-Hernández & Rodríguez-Araque, 2020). At Universidad Católica de la Santísima Concepción (UCSC) Computer Science courses employ strategies such as analysis, design, programming, and testing (ADPT), which combines problem-based learning with a sequential software development model (Martínez & Muñoz, 2014). Students must analyze a problem by identifying inputs, processes, outputs, and restrictions. Then, they must design an algorithmic solution using semi-structured representations (such as pseudocode, flowcharts, or Nassi-Schneidermann diagrams), build it in a programming language, and execute the test cases (see Fig. 1).
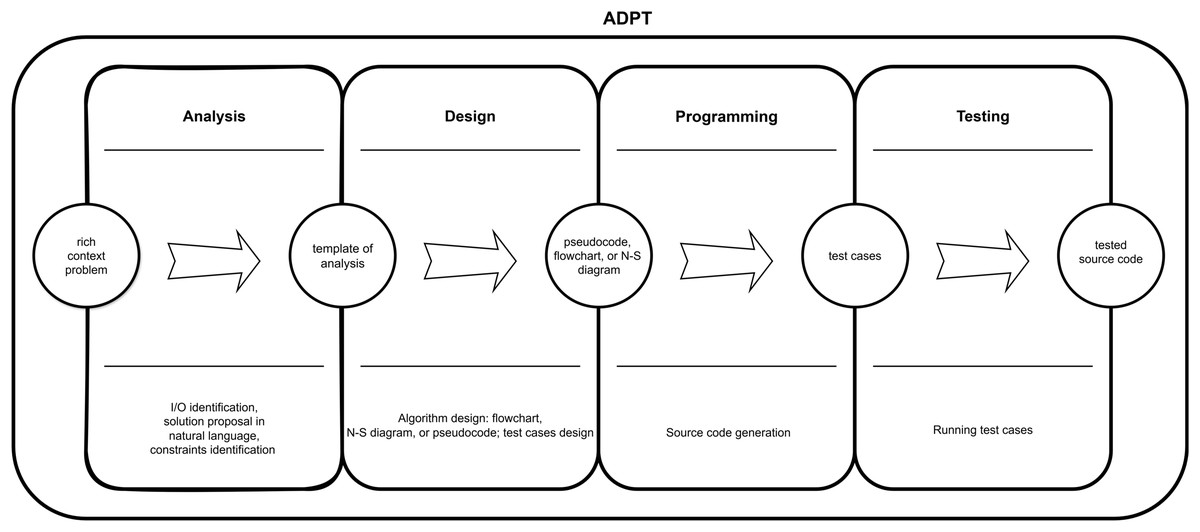
Figure 1: ADPT strategy (Martínez & Muñoz, 2014).
{kind=link}
Problem-solving skills are developed in several courses of the computer science curriculum, particularly in those of the programming line, which include initial programming courses under the structured approach, algorithms and data structures, initial course of artificial intelligence, object-oriented programming, database workshop, as well as specialization courses such as competitive programming and metaheuristic algorithms, inspired by nature, among others. At our university, programming subjects typically have a failure rate of around 50%, so finding ways to improve student performance and motivation by proposing novel strategies is necessary. A preliminary proof of concept enabled us to assess the capabilities of large language models (LLMs), particularly GPT models, in the context of university teaching and learning. In particular, given an adequately specified input or prompt, they can not only add context to a basic programming problem but also provide complete feedback in natural language about the errors identified and a proposal for how to improve the source code created by the student as a solution to the problem, a substantial advantage over the feedback provided by the compiler or interpreter of the programming language used.
It is necessary to consider that delivering feedback in the classroom is an iterative process, which requires customization, as the generated code, being a personal creation, differs between students. If an optimistic estimate is considered, each feedback could take on average 2 to 3 min in a 2-module laboratory session with 30 students, where at least a couple of problems are solved and considering that each student could require at least five feedbacks for each problem solved, it would be necessary to have a teacher or assistant would be needed for each student during the construction phase alone, this means that it greatly exceeds those values. According to Pardo et al. (2017), teachers face significant pressure because as they increase the size of the sections, they reduce the time dedicated to each student, which impacts the delivery of adequate and timely feedback.
A. The importance of feedback
Feedback is a critical component in the teaching-learning process and is particularly important in computer science college education. Feedback refers to the information provided to students about their performance to enhance learning and academic outcomes (Hattie & Timperley, 2007). It also helps students identify errors and areas for improvement, deepening their understanding of the material and improving their ability to apply it in future contexts (Schraw & Dennison, 1994). Feedback can be provided by a teacher, classmates, or through technology, and can be formal or informal, depending on the context in which it is provided. Effective feedback combines at least two key qualities: personalization and immediacy. A study by Shute et al. (2016) indicates that students perceive late feedback as ineffective. Furthermore, Rubio-Manzano et al. (2020) emphasises that feedback must be frequent and detailed to support effective learning. Among the aspects that feedback encourages, the following can be described.
1) Self-regulation
Feedback can also foster self-regulation of learning in students. According to Bailey & Garner (2010), self-regulation of learning refers to students’ ability to plan, monitor, and evaluate their learning. Through self-regulation of learning, students can identify areas in which they need to improve and specifically focus on them. Feedback can also enhance student effectiveness by allowing students to understand their progress and giving them a sense of control over their learning.
2) Student engagement and motivation
Feedback can promote student engagement and motivation by providing a sense of progress and success in learning. Students who receive positive feedback, i.e., feedback emphasizing the positive aspects of their code, may feel motivated and engaged in the learning process, which can improve their performance and enhance their ability to apply what they have learned to future situations. Feedback plays a crucial role in the teaching-learning process, as it enables students to recognize their strengths and weaknesses and provides actionable guidance to enhance learning and academic outcomes (Hattie & Timperley, 2007). Additionally, feedback can foster dialogue and reflection between teachers and students, thereby strengthening their relationship and enhancing student motivation and engagement in learning (Schraw & Dennison, 1994).
3) Development of metacognitive skills
Feedback can also foster the development of metacognitive skills in students. According to Schraw & Dennison (1994), metacognitive skills refer to students’ ability to think critically about their learning process. Feedback provides students with information about their performance, allowing them to reflect on their learning process. Students can develop metacognitive skills through reflection and critical thinking to gain a deeper understanding of their learning process (Raju et al., 2022).
B. AI and its presence and impact on teaching-learning processes
Artificial intelligence (AI) is a scientific discipline concerned with creating systems that can perform tasks requiring human intelligence, such as learning, decision-making, and problem-solving. AI has had a significant impact on various fields, including education. AI has been utilized in various ways in teaching and learning processes. One approach is adaptive learning, which utilizes AI algorithms to personalize learning based on a student’s needs and abilities (Zawacki-Richter et al., 2019). This allows students to learn at their own pace and receive immediate feedback on their performance. Another application of AI in education is intelligent tutoring, which uses AI systems to provide students with real-time personalized feedback and guidance. These systems can analyze student data to identify patterns and provide specific recommendations to improve their learning (VanLehn, 1988). Additionally, AI has been utilized in student assessment, particularly in evaluating complex skills such as writing and problem-solving. AI systems can analyze students’ natural language and reasoning skills to determine their understanding and ability to apply knowledge in practical situations (Shute et al., 2016). In Rubio-Manzano et al.’s (2020) study, automatic feedback based on linguistic data description was explored to support the assessment task during a pandemic.
AI has had a significant impact on teaching and learning processes. It has enhanced the effectiveness and efficiency of education, enabling students to learn more personally and independently. AI has also improved the quality of feedback and assessment, allowing students to receive immediate and accurate feedback on their performance (Koedinger et al., 2015). However, AI has also raised concerns about the privacy and security of student data, as well as the responsibility of AI systems in making important educational decisions (Luckin et al., 2016). Educators must understand the potential of generative AI, its limitations, and work to ensure that it is used ethically and responsibly in education.
C. LLMs and coding skills
LLMs are deep neural network models that can effectively process and analyze complex linguistic structures (Billis et al., 2023). LLMs are making important contributions to natural language processing (NLP) due to their ability to generate human-like text.
A study by Chen et al. (2021) highlighted the capabilities in debugging and identifying errors in code, specifically for transformer-based models, surpassing students’ performance in the code debugging task by 12%. Zhong, Wang & Shang (2024) published a significant advance in the debugging of programs generated by LLMs, leveraging real-time execution information to enhance the accuracy and effectiveness of debugging. A third study reported experimental results showing that self-planned code generation achieves a relative improvement of up to 25.4% in the correctness measure of the first solution generated by the model (Pass1) compared to direct code generation, while also improving other code quality attributes, such as readability. Since advanced models like GPT-4o-mini tend to do more self-planning on complex problems, while simpler models like GPT-3.5 can do more straightforward coding, it should be understood that using our tutorBot+ platform supports feedback and debugging tasks from beginner programming courses (Programming Lab 1) to advanced courses (Algorithms Inspired by Nature) where, in general, one works with context-rich problems.
GPT-4o-mini excels in mathematical reasoning and coding tasks, outperforming previous small models on the market. On the Mathematics Generalized Structural Model (MGSM), which measures mathematical reasoning, GPT-4o-mini scored 87.0%, compared to 75.5% for Gemini Flash and 71.7% for Claude Haiku. GPT-4o-mini scored 87.2% on HumanEval, which measures encoding performance, compared to 71.5% for Gemini Flash and 75.9% for Claude Haiku (OpenAI, 2024).
Other sources supporting numerous benchmark platforms place the OpenAI models (GPT-4o and GPT-4o-mini) in a competitive position (Xu et al., 2022; Zhuo et al., 2024), however, critical views on the capabilities of the GPT models appear in Chen et al. (2021) who show GPT3 and GPT-J in disadvantaged positions with the first-time correctness metric @p1 of 0% and 11% respectively. Other platforms with similar orientations, such as chatbotArena (Chiang, Lin & Chen, 2024), rank GPT-4o first and GPT-4o-mini 13th in the coding task among 70 models. In contrast, BigCodeBench (Zhuo et al., 2024) ranks the GPT4o-mini model in fifth position among 60 models. On the other hand, Livebench (White et al., 2024) ranks GPT-4o and GPT-4o-mini in 12th and 29th positions, respectively, among 62 models, with 51.44% and 43.15% of test cases solved correctly, respectively.
Another factor in choosing the LLMs was their cost. The pricing structure of the API is USD 5 per million for input tokens and USD 15 per million for output tokens for the GPT-4o version, compared to USD 0.60 per million for input tokens and USD 0.15 per million for output tokens for the GPT-4o-mini version. GPT-4o-mini is manageable for a university operating with a limited budget, making it a balanced choice in terms of functionality, hardware requirements, and costs.
Table 1 presents a set of LLMs, including their sizes, creators, architectures, context windows, average costs, latencies, performances, and computing requirements.
| LLMs and size1 | Owner | Open source | Architecture | Context window (k) | Average cost2 | Latency (ms) | GPU | RAM (GB) | CPU (cores) | Storage (GB) |
|---|---|---|---|---|---|---|---|---|---|---|
| Gemma 2 (9B) | Si | Encoder-Decoder | 8 | 0.2 | 0.29 | NVIDIA A100 | 64 | 8–16 | 200 | |
| Mistral 8x22B (176B) | Mistral AI | Si | Decoder-Only | 65 | 1.2 | 0.29 | NVIDIA A100 | 128 | 32 | 500 |
| Llama 3 (8B) | Meta AI | Si | Decoder-Only | 8 | 0.17 | 0.31 | NVIDIA V100 | 16–32 | 8 | 100 |
| Gemma (7B) | Si | Decoder-Only | 8 | 0.15 | 0.31 | NVIDIA A100 | 32 | 8 | 100 | |
| GPT-3.5 Turbo (~175B) | OpenAI | No | Decoder-Only | 16 | 0.75 | 0.36 | NVIDIA V100 | 16–32 | 8 | 100 |
| Command R (~52B) | Cohere | Si | – | 128 | 0.75 | 0.41 | NVIDIA A100 | 32 | 8 | 100 |
| Llama 3 (70B) | Meta AI | Si | Decoder-Only | 8 | 0.9 | 0.43 | NVIDIA Tesla V100/A100 | 128–256 | 32 | 500 |
| Command-R+ (~90B) | Cohere | Si | – | 128 | 6 | 0.44 | NVIDIA A100 | 32 | 8 | 100 |
| Mistral Large (~22B) | Mistral AI | No | Decoder-Only | 33 | 6 | 0.50 | NVIDIA A100/V100 | 64 | 16 | 200 |
| Code Llama (7B, 13B, 34B according to the version) | Meta AI | Si | Decoder-Only | 16 | 0.9 | 0.50 | NVIDIA A100/V100 | 32–64 | 8 | 100 |
| GPT-4o mini (~13B) | OpenAI | Si | Decoder-Only | 4 | 0.85 | 0.51 | NVIDIA Tesla V100/A100 | 16–32 | 8 | 100 |
| Llama 2 chat (70B) | Meta AI | Si | Decoder-Only | 4 | 1 | 0.51 | NVIDIA A100 | 128–256 | 32 | 500 |
| Claude 3 Haiku (~52B) | Anthropic | No | – | 200 | 0.5 | 0.52 | NVIDIA A100 | 32 | 8–16 | 100 |
| GPT-4o (~220B) | OpenAI | No | Decoder-Only | 128 | 7.5 | 0.53 | NVIDIA A100/V100 | 64–128 | 16 | 200 |
| GPT-4 Turbo (~175B) | OpenAI | No | Decoder-Only | 128 | 15 | 0.59 | NVIDIA A100 | 32–64 | 8–16 | 100 |
| Mistral Medium (~13B) | Mistral AI | No | Decoder-Only | 33 | 4.05 | 0.61 | NVIDIA A100 | 64 | 16 | 200 |
| GPT-4 (~220B) | OpenAI | No | Decoder-Only | 8 | 37.5 | 0.68 | NVIDIA A100/V100 | 64–128 | 16 | 300 |
| Claude 3.5 Sonnet (~75B) | Anthropic | No | – | 200 | 6 | 0.88 | NVIDIA A100 | 32–64 | 8–16 | 100 |
| Claude 3 Sonnet (~52B) | Anthropic | No | – | 200 | 6 | 0.93 | NVIDIA A100/V100 | 32–64 | 8–16 | 100 |
| Mistral Small (~7B) | Mistral AI | No | Decoder-Only | 33 | 1.5 | 0.95 | NVIDIA A100 | 32 | 8–16 | 100 |
| Gemini 1.5 Pro (~175B) | No | Encoder-Decoder | 1,000 | 5.25 | 1.01 | NVIDIA A100 | 64 | 16 | 200 | |
| Gemini 1.5 Flash (~175B) | No | Encoder-Decoder | 1,000 | 0.53 | 1.06 | NVIDIA A100/V100 | 64 | 16 | 200 | |
| Claude 3.5 Sonnet Opus (~75B) | Anthropic | No | – | 200 | 30 | 1.91 | NVIDIA A100/V100 | 32 | 8–16 | 100 |
Based on all the antecedents, we decided to use the GPT-4o-mini model in both cases due to its balance between cost, capabilities, performance, and hardware requirements. With a low cost per million tokens, an open license, low latency, and very accessible hardware requirements, it provides an efficient solution for applications that demand performance and resource optimization.
Literature review
The reviewed studies highlight a wide range of objectives related to automatic feedback. Some correspond to developments of intelligent tutors for web platforms or integrations of chatbots in existing platforms, which facilitate interaction, enhance accessibility to educational resources, and improve the collaborative learning experience (Sharma & Harkishan, 2022; Zamfirescu-Pereira et al., 2023; Chiang, Lin & Chen, 2024).
Other studies focus on evaluating the effectiveness of generative AI models in providing personalized feedback on programming tasks, such as error correction and code completion, on improving student learning (Smolansky et al., 2023; Rubio-Manzano et al., 2023; Bull & Kharrufa, 2024; Mahon, Mac Namee & Becker, 2024; Phung et al., 2024; Azaiz, Kiesler & Strickroth, 2024). Among the results obtained by Azaiz, Kiesler & Strickroth (2024), it was found that 60% of the feedback generated by GPT-4 contained correct corrections, while 40% presented partially correct corrections, indicating improvements over previous versions. On the other hand, Phung et al. (2024) highlighted that the feedback provided by the GPT-3.5 and GPT-4 models significantly improves students’ understanding and resolution of programming bugs by providing high-quality clues and explanations that simulate interaction with a human tutor. Regarding the performance of the models, it was found that GPT-4 (66.0%) outperformed ChatGPT (based on GPT-3.5) (18.0%) in the general metric. However, it still fell short of the human tutor’s performance (92.0%). Rubio-Manzano et al. (2023) explored the use of GitHub Copilot to automatically generate programs and evaluate the generated code according to quality criteria.
The studies conducted by Smolansky et al. (2023) and Bull & Kharrufa (2024) were focused on analyzing the perception of students and educators on the impact of generative AI on feedback and learning, as well as on aspects of academic integrity (Lindsay et al., 2024; Mahon, Mac Namee & Becker, 2024). Bull & Kharrufa (2024) argue that there is a positive perception towards the use of these tools. However, there is also concern about the dependency they can generate and the risk of being unable to distinguish between correct and incorrect answers. On the other hand, Mahon, Mac Namee & Becker (2024) highlight findings indicating that educators favour assessments designed with the assumption of AI integration and a focus on fostering critical thinking. However, students’ responses to such assessments vary, partly due to concerns about potential loss of creativity.
Pedagogical concerns are also raised within the research regarding whether it is possible to improve the teaching-learning process in terms of interaction and engagement, accessibility, or student performance (Yilmaz & Yilmaz, 2023; Bassner, Frankford & Krusche, 2024; Stamper, Xiao & Hou, 2024). Among the results obtained, it is noted that generative AI can significantly enhance the quality and quantity of feedback provided to students, thereby improving their learning levels. However, challenges related to biases in AI models and the need for more personalized support for specific students were also identified. Additionally, the importance of establishing ethical frameworks to ensure the responsible and equitable use of these technologies in education was emphasized (Lindsay et al., 2024). Table 2 presents the studies, including the publishing year, objectives, results, and main difficulties encountered.
| Year | Study | Purpose | Results | Difficulties |
|---|---|---|---|---|
| 2024 | Feedback-Generation for Programming Exercises With GPT-4 (Azaiz, Kiesler & Strickroth, 2024) | Evaluate the effectiveness of GPT-4 for programming feedback. | Personalized feedback and performance improvement | Generic responses in some cases. |
| 2024 | Iris: An AI-Driven Virtual Tutor Bassner, Frankford & Krusche (2024) | Provide contextualized feedback. Use GPT-3.5-Turbo | Increase in programming skills and positive perception | Limitations in complex tasks |
| 2024 | Enhancing LLM-Based Feedback (Stamper, Xiao & Hou, 2024) | Integrate LLMs with intelligent systems for feedback. | Greater accuracy and relevance in feedback. | Difficulties in unforeseen cases. |
| 2024 | Developing a Course-Specific Chatbot (Chiang, Lin & Chen, 2024) | Create a chatbot for specific programming courses. | Improved interaction and accessibility to educational resources. | Limited integration with existing platforms. |
| 2024 | Generative AI for Programming Education (Phung et al., 2024) | Validate the quality of automatically generated feedback, using GPT-4 for cues, GPT-3.5 for validation | Generation of useful and adapted clues. | Occasionally inaccurate feedback. |
| 2024 | The Responsible Development of Automated Feedback (Lindsay et al., 2024) | Propose ethical guidelines for AI feedback. | Identification of best practices. | Complexity in implementing universal ethical guidelines. |
| 2024 | Generative AI Assistants in Software Development Education (Bull & Kharrufa, 2024) | Exploring the role of generative AI in teaching software development | Increased motivation and self-efficacy in students. | Risk of over-reliance on tools. |
| 2023 | Large Language Models for Automating Feedback (Pankiewicz & Baker, 2023) | Evaluate the impact of GPT-3.5 on programming task feedback. | Reduction in review time. Identification of common errors. | Limitations in the complexity of advanced tasks. |
| 2023 | Conversational Programming with LLM Support (Zamfirescu-Pereira et al., 2023) | Evaluate the use of interactive chatbots in introductory programming courses. | Improved collaborative learning experience. | Limited adaptation to different contexts. |
| 2023 | Exploring Copilot Github (Rubio-Manzano et al., 2023) | Explore the use of Copilot to automate the resolution of programming problems. | Efficient automation in problem-solving. | Dependency on the quality of the code provided. |
| 2023 | The effect of generative artificial intelligence (AI)-based tool use on students’ computational thinking skills, programming self-efficacy, and motivation (Yilmaz & Yilmaz, 2023) | Investigate the effect of ChatGPT on students’ computational thinking skills, programming self-efficacy, and motivation, hypothesizing that its use would improve these aspects. | Students in the experimental group showed significant improvements in computational thinking skills, self-efficacy, and motivation compared to the control group. | The implementation period (5 weeks) and a small sample size (45 students) suggest the need for longitudinal studies. |
Materials and Methods
After a preliminary study reviewed several topics of interest, an adequate theoretical framework could be established (GenAI, LLMs, automatic feedback, and related works). The following steps are shown in Fig. 2.
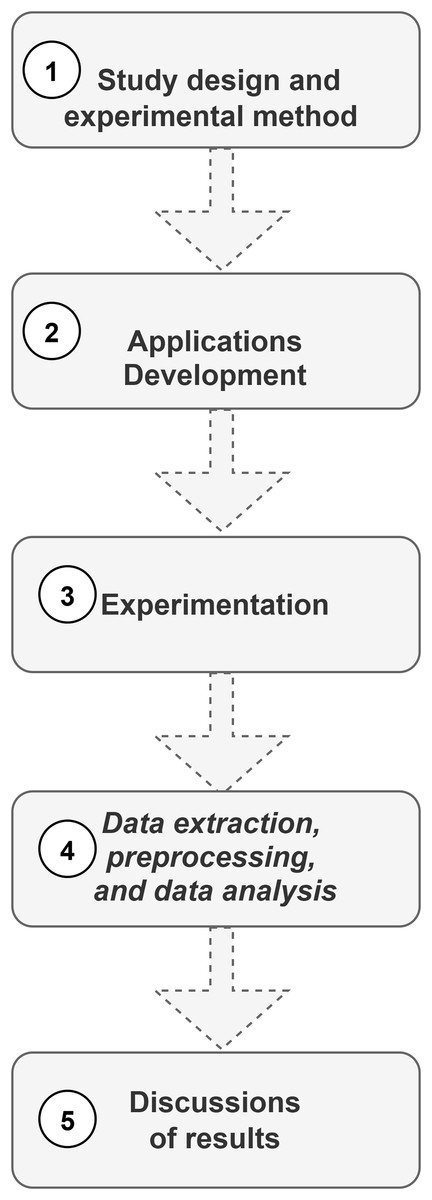
Figure 2: Method of work.
{kind=link}
The following describes the method phases, including the authorization of the study by the ethics committee, study design and experimentation, application development, data extraction, preparation, and analysis, as well as the computational infrastructure used.
A. Authorizations
The Academic Ethics Office of UCSC granted authorization No. 44 to conduct the study (included in Supplemental Files), as it involved working with students and using their uploaded responses on the platform, as well as the usability measurements of the developed applications.
B. Study design and experimental method
After a preliminary study that reviewed several topics of interest, an adequate theoretical framework was built about LLMs, automatic feedback, and related works. This framework guided both the development of applications and the definition of the experimental design.
A quasi-experimental design was employed due to the non-random nature of the courses’ compositions, which depend on factors beyond our control, such as the availability of rooms or students’ scheduling preferences. In both cases, a dossier containing a couple of context-rich problems was prepared, ensuring that the complexities for the groups were equivalent, taking into account the peer review. Test data sets were also prepared to evaluate the code, both manually for the case without an assistant and automatically for the group that used the programming assistant. Additionally, a well-known system usability scale (SUS) (Brooke, 1986) was conducted to measure student perceptions.
C. Applications development
In both cases, an incremental method of software development was employed, progressing through four distinct phases.
-
(1)
tutorB@t (conversational version): It involves defining the bot’s personality, establishing knowledge bases, prompting for task execution, and shaping the bot’s behavior through the design of a workflow using the Botpress platform, which offers the possibility of building AI agents powered by the latest LLMs.
-
(2)
tutorBot+ (non-conversational version): Requirements were established in collaboration with programming teachers, and a modular architecture was developed based on these. A virtual judge (Judge0) and GPT-4o mini were integrated to evaluate the source code and generate feedback from students, respectively. Finally, a user interface was programmed. Judge0 was used because it offers better documentation, robust community support, and a wide range of programming languages covered; in the case of GPT-4o mini, its problem-solving and coding skills, computing requirements, and low cost. Both choices were made based on benchmarks described in the previous sections (LLMs and coding skills).
D. Experimentation
First, each student signed an informed consent form that explained the purpose of the study, the activities to be conducted, and how their data would be protected. In addition, each teacher explained the dynamics of the activity, how to use the platform (for the experimental group), and the problems to be developed.
E. Data extraction, preprocessing, and data analysis
Data collection was conducted using the problem-solving outcomes described above and by applying SUS proposed by Brooke (1986), which was implemented in Google Forms.
The source codes of the control group were evaluated using a manual rubric based on test cases, unlike those of the experimental group, whose source codes were automatically assessed by the virtual judge based on the test cases (included in the Supplemental Documentation).
Then, the students’ records were anonymized, removing personal identifiers, and descriptive statistics were applied, including measures of central tendency, distribution, and dispersion. T-tests for equal and unequal variances, including the Two-sample t-test and Welch’s t-test, were then performed to assess group homogeneity. Particular care is taken to present the results in an aggregate format to maintain anonymity.
The following specifications characterize the computing infrastructure utilized in this study.
Applications development
Both development processes were conducted using the incremental method. In this approach, the platform was built gradually through four successive increments. Each increment added functionality until the application was complete.
A. The conversational version (tutorB@t)
The development begins with the design of the workflow for the conversational version implemented in Botpress, a chatbot development platform available at https://botpress.com/ that allows integration with other applications such as the web, WhatsApp, Telegram, Discord, among others, after the basic configuration of the bot, which begins with the identification and establishment of the application domain, the user, their age range, and language, followed by the design of the interaction flow between the student and the bot.
The knowledge bases were configured through their specific URLs and utilized AI tasks, which involved accessing a GenAI for specific tasks. The GPT 3.5 turbo was originally used as an engine, which migrated to ChatGPT-4o-mini when its use was released. After the above, an attempt was made to assign a positive and relaxed personality through the following instruction: “You are a cheerful programming assistant. Use emojis at the end of your messages to reinforce moods.”
On the other hand, the engineering prompt was used and set as follows: “You are a programming assistant. First, identify the syntax errors in the code {{workflow.code}} in the programming language {{workflow.language}} by providing comments for each line of code using bullets. Then, indicate general strengths and weaknesses of the code.” To deliver feedback, analyze the problem as follows: “Summarize the problem {{workflow.theproblem}} considering only the essential data to be able to solve it computationally, then identify the inputs to the problem, the outputs, the algorithm in natural language to solve it step by step, a step in each line process and the constraints to the input. Additionally, use representative emojis for each idea. The output must be in markdown format.”
The conversational version begins when the student types “hello”, “hi”, “hola”, or “/”. The information is presented in text and audio formats, as shown in the left section of Fig. 3A. Next, the student chooses whether they need assistance analyzing the problem in context according to the ADPT strategy (Martínez & Muñoz, 2014) or if they require feedback on the source code. The options for source code feedback include C, SQL, and Python, although this can be expanded to other programming languages as well. This selection is integrated into the model, prompting the bot to request the appropriate input based on the student’s choice. The outcome is feedback that includes an analysis of the problem (Fig. 3B), which consists of a summarized version of the problem and its analysis, including inputs, outputs, mental process, and restrictions or line-by-line feedback of code, ending with the identification of strengths and weaknesses of the source code. In the case of the source code, a second iteration was considered if the student had not received adequate feedback to solve the problem and was referred to resources available on the web or the support of a human assistant.
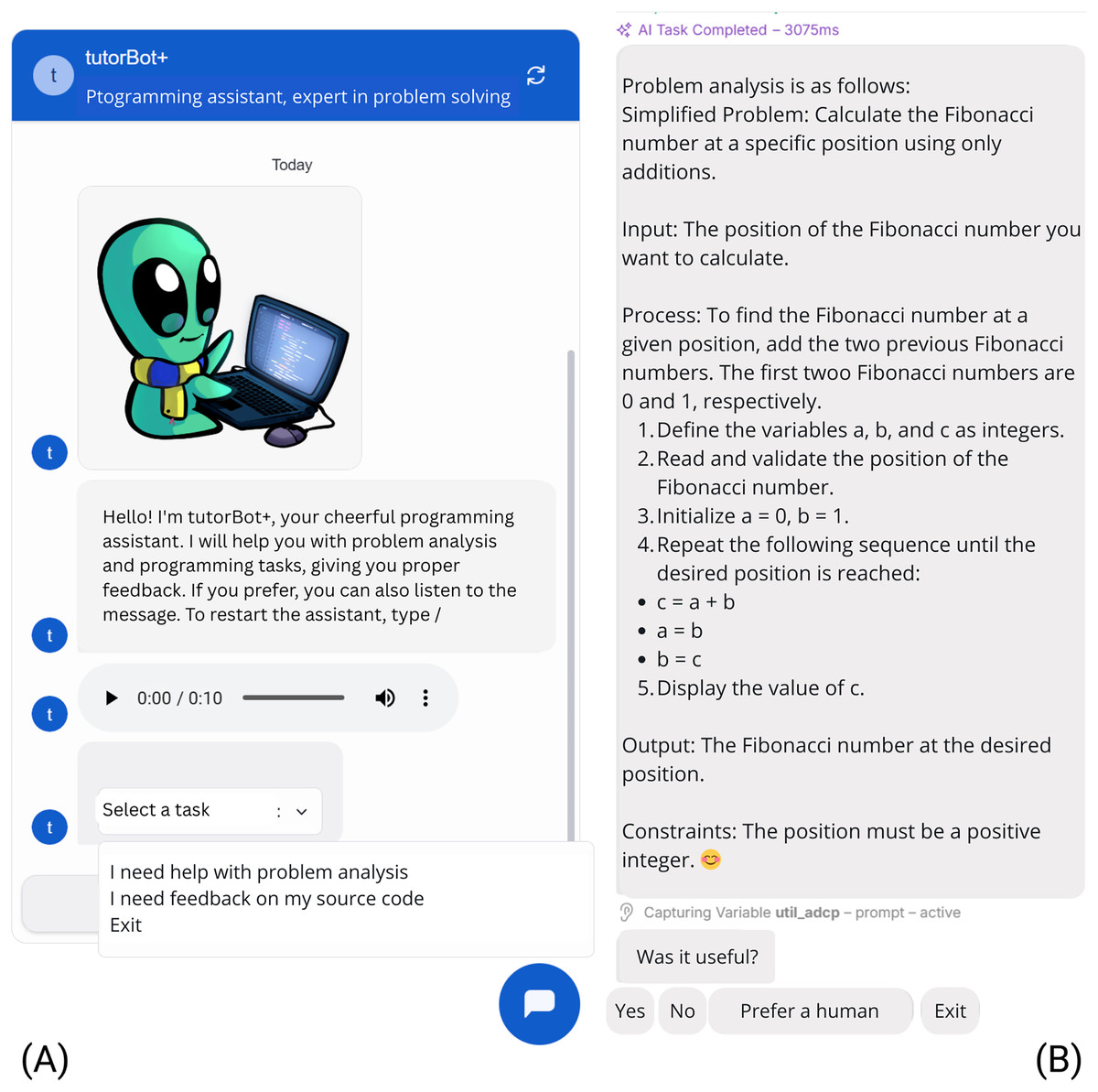
Figure 3: Problem analysis in conversational version: (A) Choosing the option of assistance and submitting the problem. (B) Receiving a detailed analysis of the problem.
{kind=link}
B. The non-conversational version (tutorBot+ platform)
The development of the competitive programming platform involved creating the front-end and integrating it with the virtual judge, Judge0, for evaluating solutions, as well as GPT4o-mini for generating feedback to students. Judge0 has an open-source license, allowing access to the source code and enabling the rebuilding of its back end. This process involved adding a GenAI module based on the GPT4o-mini API and implementing the front end according to the UCSC graphical standards. A similar platform, based on DMoj, was used for students from the competitive programming team who were interested in improving their problem-solving skills. This work evaluated whether to continue with the same platform. Due to the active support provided by the community, the availability of comprehensive API documentation, and its scalability, it was decided to switch to Judge0. It will be available not only to the competitive programming interest group, but also to students of related courses such as Programming Fundamentals, Programming Laboratory I and II, and Database Laboratory and Databases, among others, given that the virtual judge supports 60 languages, including C, C++, Python, C#, SQL, Java, among others. Figure 4 shows the tutorBot+ platform client-server architecture and the API access to the Judge0 and GPT-4o-mini services. Additionally, it illustrates the client-server interaction in a system’s architecture. It highlights the communication flow among user roles (students, programming teachers, and administrators) and the backend services.
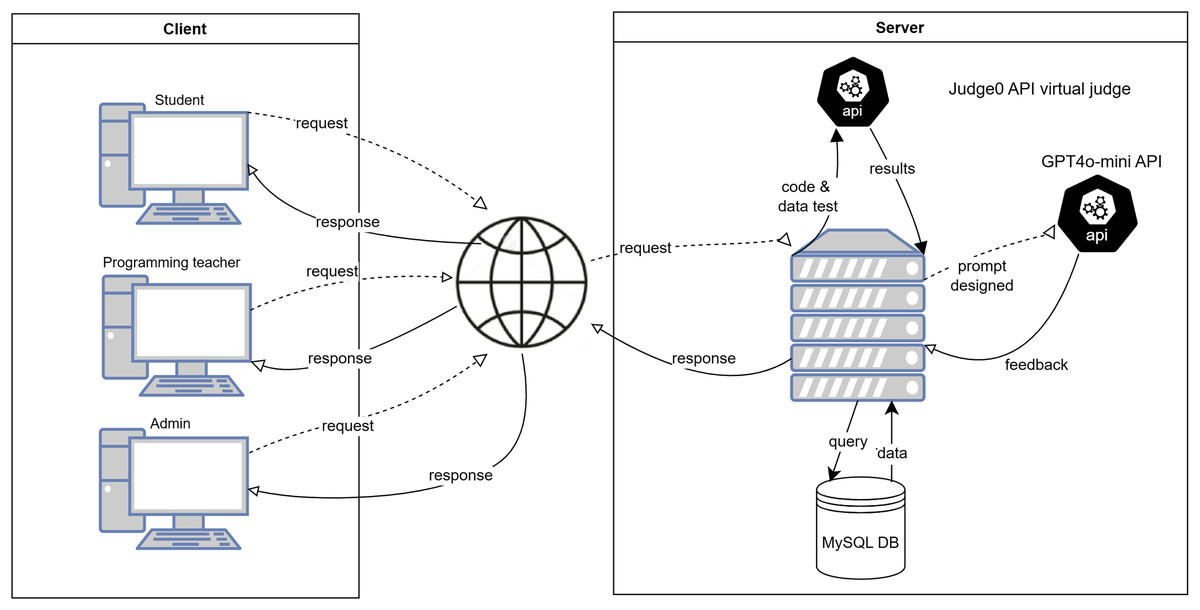
Figure 4: Client-server tutorBot+ platform’s architecture.
{kind=link}
The elements of the client-side, server-side, and the flow of interactions are described below, which can be observed.
-
1.
Client Side:
-
a.
Student: Sends requests (problem-solving attempts) and receives responses (feedback or results).
-
b.
Programming teacher: Sends similar requests (reviewing or assigning problems) and receives responses.
-
c.
Admin: Manages system configurations and data with requests and receives responses for administrative tasks.
-
-
2.
Server Side:
-
a.
Judge0 API Virtual Judge:
-
•
Processing code and data test submissions from the client.
-
•
Returning results to the server after evaluation.
-
-
b.
GPT4o-mini API
-
•
Designed for generating prompts and providing feedback.
-
•
Sending feedback to the client based on requests.
-
-
c.
MySQL Database (DB)
-
•
Storing and retrieving user information, problem details, and logs.
-
•
Managing queries initiated by the server.
-
-
-
3.
Interaction flow
-
a.
The client sends requests (submitting code or administrative actions) through the internet to the server.
-
b.
The server interacts with the Judge0 API Virtual Judge for code evaluation and the GPT4o-mini API for feedback generation.
-
c.
The MySQL Database supports the server by querying or storing necessary data.
-
d.
Responses (e.g., results, feedback) are returned to the respective clients, completing the interaction loop.
-
This setup demonstrates a modular architecture integrating automated code evaluation and AI-based feedback with data management, ensuring a seamless experience for students, teachers, and administrators.
Figure 5 shows the authentication and registration page of the tutorBot+ platform. The development tools used throughout the process were Laravel 10 as the PHP web application framework, MySQL as the Database System, Argon Dashboard Bootstrap 5 for the UI/UX development of the application dashboard, GPT-4o-mini through its API to receive feedback, and Judge0 API to evaluate the solutions submitted by the students.
Figure 5: tutorBot+ platform’s sign-in page.
{kind=link}
As shown in Fig. 6, the interaction between the student and the platform is sequential. After logging into the platform (see Fig. 5), the student starts by accessing the problem (Fig. 6A) and proceeds to solve it within the integrated code editor (Fig. 6B). After submitting his solution and receiving the results from Judge0 (Fig. 6C), he seeks the help of tutorBot+ to obtain detailed feedback (Fig. 6D).
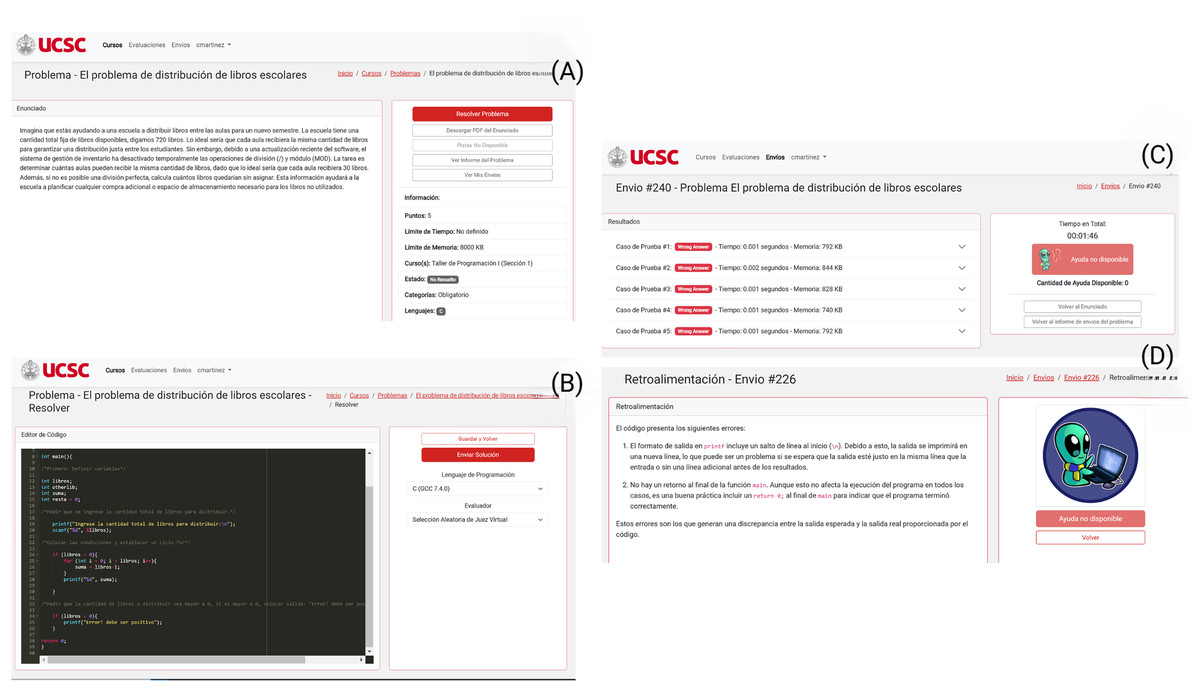
Figure 6: Problem-feedback sequence (A) Accessing the problem. (B) Solving the problem using the integrated code editor. (C) Submitting the solution to Judge0 and awaiting results. (D) Requesting assistance from tutorBot+ and receiving feedback.
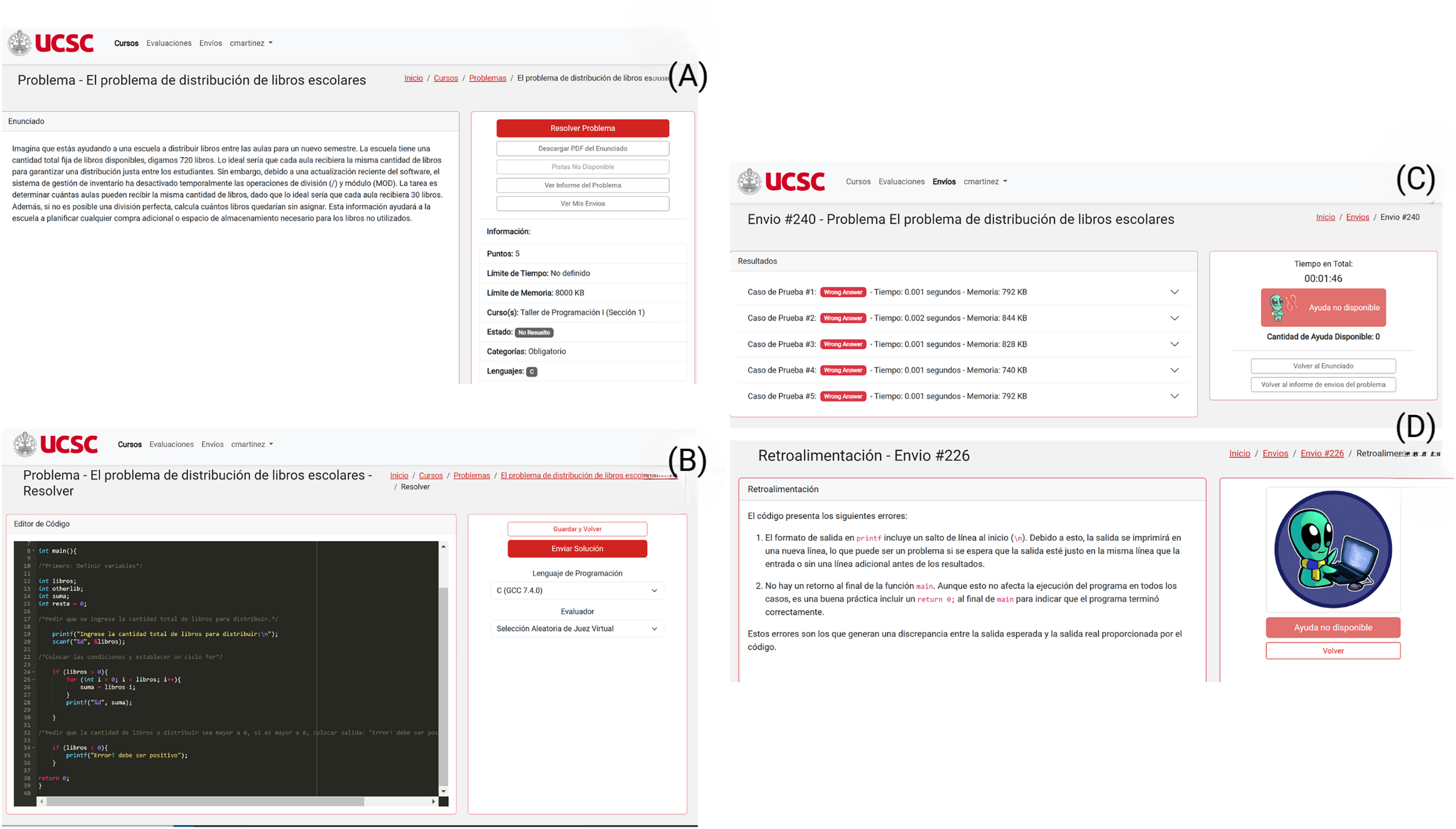{kind=link}
The tutorBot+ platform can be easily adapted to different programming levels and courses. Its flexible design allows instructors to use it with various languages and learning styles. This makes it easy to adjust for both beginners and advanced students, and to expand its use to more classes or institutions over time. Figure 7 displays the admin dashboard, which enables the management of users, courses, problems, and programming languages. Therefore, it is flexible enough to be adapted for use in another institution.
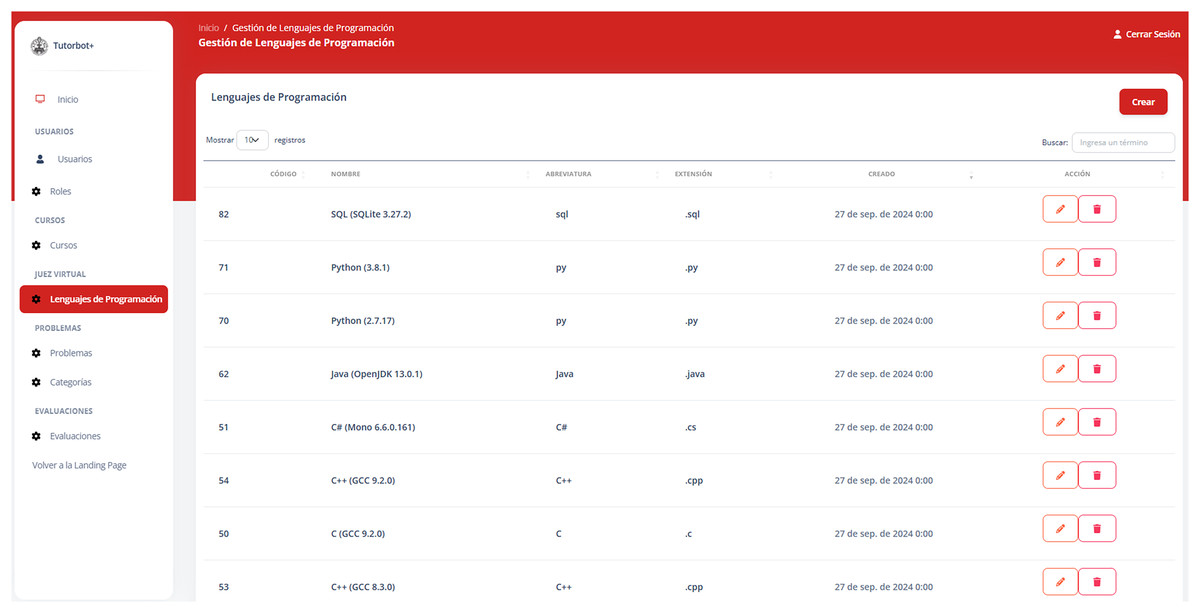
Figure 7: tutorBot+ platform admin’s dashboard.
{kind=link}
Design and experimentation
A quasi-experimental design was selected due to the non-random composition of course sections, which is influenced by factors beyond our control, such as classroom availability and students’ scheduling preferences. We established two control groups and two experimental groups.
Data collection took place in the second mid-semester of 2024, using equivalent instruments to collect data across the four sections of Programming Laboratory I, the first formal programming course of the Computer Science Program. At the beginning of the course, 96 students were enrolled; by mid-semester, enrollment had decreased to 91. At the time of application, 69 students were available, distributed between the control group (32) and the experimental group (37).
Two instructors participated in the preparation and administration of the assessments and surveys. The data collection instruments included two rich problem contexts inspired by competitive programming contests. Each problem included a title, a problem description, inputs, outputs, constraints, and a set of either four or five test cases.
These problems were administered in parallel: the control group completed them without the tutorBot+ platform, while the experimental group used the platform during the activity. Problem difficulty and instructor influence were controlled by assigning both teachers to sections from each condition.
As part of the experiment’s exclusion criteria, responses where the student did not use the GenAI-generated feedback were eliminated from the study. Students who, despite signing the consent form, do not submit any responses through the platform are also excluded.
For usability evaluation, we used the SUS (Brooke, 1986), a rubric based on test case results, as well as the virtual judge’s automatic scoring, which is also based on test case success.
Results and discussion
The analysis of the group’s performance in the pre-test, using Welch’s t-test, which accounts for different variances, revealed that the means of the two samples are significantly different, with a p-value of 0.019. This confirms the option of the quasi-experimental design.
On the day of work, the control group, composed of 32 students (15 from Section s1 and 17 from Section s3), was presented, to whom the instrument was applied, having 3 h to solve it. The human assistant and the students were instructed that they were allowed to make up to three queries about the problem statement or source code.
In the experimental group, according to protocol, 37 students signed the informed consent form, agreeing to participate in the study and authorizing the use of their data for its intended purposes. Of these, four did not respond, resulting in a total of 33 participants in the experimental group. Before starting, they were briefed on the study’s purpose and given an introduction on how to use the platform, and feedback was requested from the integrated virtual assistant. The students were instructed not to ask the human assistants questions about the problem, but only inquiries about using the platform or issues with internet access. Queries related to the source code could only be made to the virtual assistant, having three chances, as occurred in the control group. Similarly, the experiment lasted three chronological hours. It is worth highlighting that of those instances eliminated for not using feedback, 80% or more of the test cases were solved correctly.
Application of the exclusion criteria
The first exclusion occurred for four students who signed the consent form but did not submit any responses out of a total of 37 students.
As shown in Fig. 8, nine responses received were excluded: seven were from students who submitted only one response without using GenAI-generated feedback, and two were from students who submitted two responses, one with and one without GenAI-generated feedback. In this way, 34 responses, generated by 26 students, were ultimately considered. It is worth highlighting that of those instances eliminated for not using feedback, 80% or more of the test cases were solved correctly.

Figure 8: Decision tree from results.
{kind=link}
This fine analysis allowed us to filter the data and consider only those relevant to the study. Table 3 presents the average scores obtained by students (on a 1–7 scale) for the pre-test and post-tests, the sample variability (standard deviation), and the passing rates for both the experimental and control groups. Since it is impossible to ensure the homogeneity of the groups, comparisons can be made between the before and after for each one without comparing them.
| Experimental group (n = 26) | Control group (n = 32) | |||
|---|---|---|---|---|
| Assessment | Pre | Post | Pre | Post |
| subgroups | s2, s4 | s2, s4 | s1, s3 | s1, s3 |
| mean | 5, 71 | 2, 98 | 3, 08 | 3, 81 |
| std | 1, 85 | 1, 99 | 2, 07 | 2, 10 |
| passing rate | 77% | 41% | 59% | 56% |
Note:
std, standard deviation.
On the other hand, Fig. 9 shows the results of Brooks’ standardized usability scale (SUS). The chatbot version scored 70.6 points in perception (good), and the tutorBot+ platform scored 65.2 points (needs improvement), which is considered acceptable against the 68-point reference.
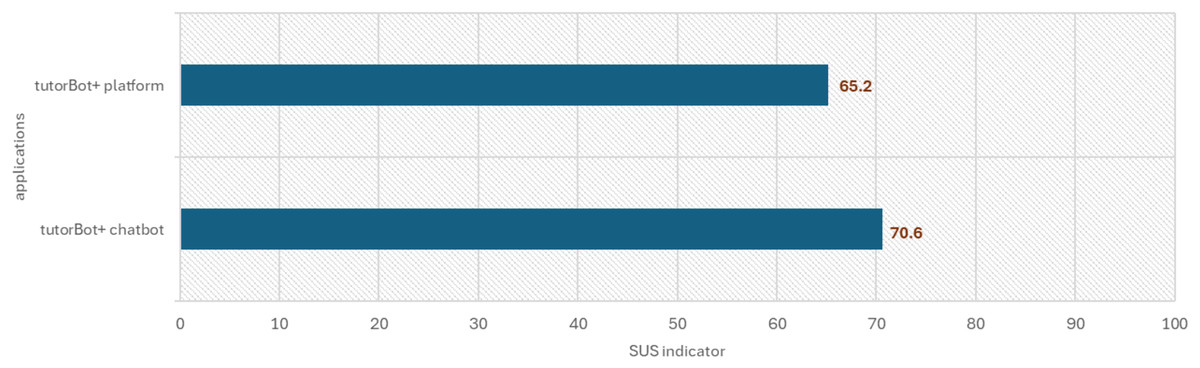
Figure 9: SUS indicator for conversational and non-conversational versions (0–100 range).
{kind=link}
Figures 10 and 11 provide an in-depth view of students’ perceptions of the conversational and non-conversational versions of each question.
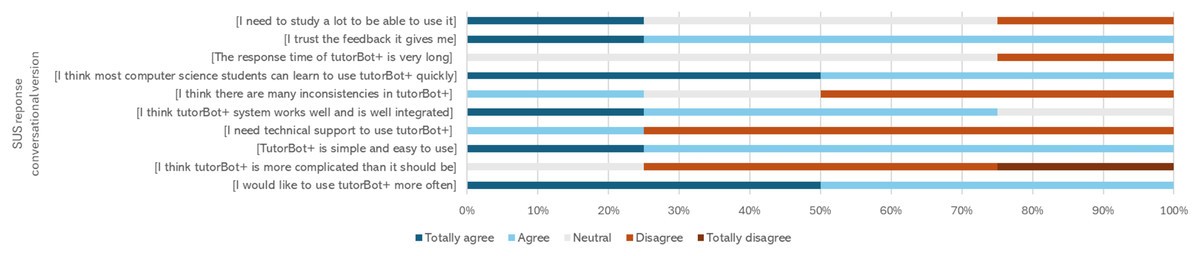
Figure 10: SUS scale perception (conversational version).
{kind=link}
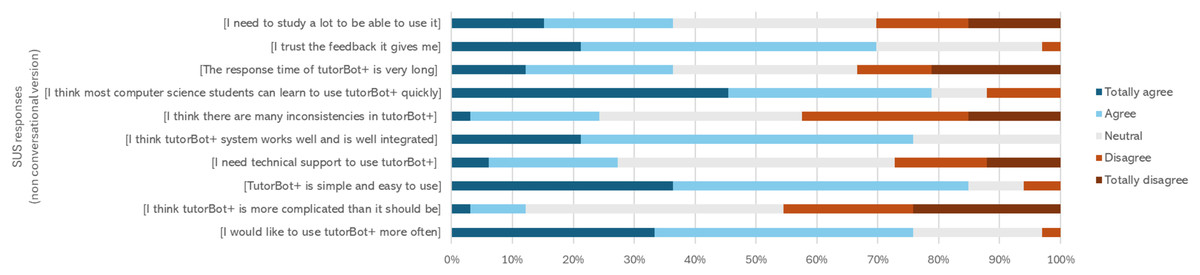
Figure 11: SUS scale perception (non-conversational version).
{kind=link}
Students evaluated several features of the application. Regarding the conversational version (tutorB@t chatbot), they make the following statements.
Students make the following statements about the non-conversational version (tutorBot+ platform).
Notably, 81% of students indicated they would use the tutorB@t chatbot again, while 79% expressed the same for the tutorBot+ platform.
The results allow us to comment on and analyze aspects of the student’s performance, perception of the tool’s usability, and the limitations presented.
A. About student performance
Table 3 does not show a positive effect of the intervention in the experimental group. From the perspective of a quasi-experimental design, where it is impossible to guarantee homogeneity between the groups at the beginning of the study, the results can be interpreted considering the differences between the initial and final states of each group. This includes the participants’ inherent characteristics and the conditions under which they were evaluated. A comparative analysis between the control and experimental groups is not possible.
-
1.
Initial differences between groups
-
(i)
Experimental group: Table 3 shows that the experimental group started with a higher mean (5.71) and a significantly higher pass rate (77%) than the control group, suggesting that the participants performed better before the intervention.
-
(ii)
Control group: This group started with a lower mean (3.08) and a lower pass rate (59%), indicating that it may have had a lower initial level.
-
These differences confirm the results of the homogeneity test obtained earlier.
-
2.
Effects of the intervention
-
(i)
Experimental group: There was a considerable decrease in the mean (5.71 to 2.98) and the pass rate (77% to 41%). This could be interpreted as an adverse effect of the intervention in sections s2 and s4. However, it could also be that these sections were more difficult after the intervention or that the students were more demanding in the new scheme, even though it was a permanent concern on the part of the research team to reduce the effect of external variables to avoid differences in the type of content evaluated, in the instruments used, in the impact of the teacher in each group. Despite the precautions taken, some of these factors could be confounding variables.
-
(ii)
Control group: Although the mean increased slightly (from 3.08 to 3.81), the pass rate decreased moderately (59% to 56%). This could indicate that sections s1 and s3 remained more stable in difficulty or were not significantly affected by the lack of intervention.
-
Despite attempts to eliminate external factors by standardizing the instruments and providing training in platform use, the teacher effect was minimized, as both teachers were part of both the control and experimental groups, considering that each group consisted of two course sections. Some external factors that may help explain this include the fact that students in the experimental group were less motivated, or, conversely, more pressured by the change in methodology, which negatively affected their performance. The external academic load of the week, with subjects in high demand during that period (exams, projects, etc.), could have affected their performance, unrelated to the intervention itself. Some students may have struggled to interpret or apply the GenAI-generated feedback effectively, particularly if it was dense or too generic. Some students may have placed less trust in GenAI-generated feedback compared to human feedback, leading to lower engagement or motivation to act on it.
B. Regarding the usability of the conversational tutorB@t and tutorBot+ platform
According to the results of applying the SUS scale of usability perception (Brooke, 1986), the tutorBot+ platform achieved an average score of 65.2, which is close to the standard (68), indicating that the system has acceptable usability, although there is room for improvement. A variability in the students’ experience was observed. Some perceived the system as highly usable (scores close to 85), while others had a less satisfactory experience (scores close to 45). The perception of the usability of the conversational version was 5.4 points higher than the non-conversational version, which could be explained since the chatbot version not only provides feedback to the source code but also supports the ADPT strategy by providing support for Problem Analysis, that is, identifying inputs, outputs, algorithms in natural language and restrictions, as well as giving a summarized version of the problem rich in context, which makes it easier for the student to understand it.
In addition to the above, impressions were collected from the assistants and students after the intervention, which can explain the specific results and are summarized as follows.
-
(1)
The comment “I need to study a lot to be able to use it”, can be explained by the need to know specific rules of competitive programming and understand that it is software (virtual judge) that reviews the solutions uploaded to the platform and compares the outputs of the test cases with the outputs that the code gives for the same inputs.
-
(2)
Three students connected from their personal computers indicated that the response time was excessive due to “WIFI fail” and not necessarily problems with the tutorBot+ platform.
-
(3)
By applying the premise of dividing and conquering, the students uploaded part of the solution to the platform, receiving the error report from the virtual judge given that, as the program is not complete, the test cases are not solved (related to the inexperience of the students), even when the code is on the right track.
Conclusions
This work aimed to investigate whether GenAI feedback influenced the performance of programming students. The experiment provided no evidence to confirm this, except for the students’ positive perception of the tools’ usefulness. The conversational (tutorB@t) and non-conversational (tutorBot+ platform) are available at https://cdn.botpress.cloud/webchat/v3.2/shareable.html?configUrl=https://files.bpcontent.cloud/2025/01/20/23/20250120232250-Q9SCHBOO.json and https://200.14.96.135:23380/, respectively, under an AGPL 1.0 license. The GPT-4o mini model was integrated in both cases due to its balance between cost, performance, and hardware requirements. With a low cost per million tokens, license of use, low latency, and accessible hardware requirements, it provides an efficient solution for applications that demand performance and resource optimization. From the perception point of view, students view the tool that serves as a virtual assistant in their programming courses positively; 79% of those who answered affirmatively are proof of this. Having a proven platform in a relevant environment (TRL6), customized and integrating both a virtual judge and a GenAI to support the delivery of feedback, satisfies us and puts us on the path to registering the tutorBot+ platform under an open-source license equivalent to the original Judge0.
The work regarding innovating, improving teaching practices, and measuring the effects entails challenges. It is necessary to view GenAI as an ally in developing various academic activities and demonstrate to students its potential, responsibility, and consideration of ethical aspects that its proper use requires. This means that if GenAI can perform many of the tasks that humans do, teachers should emphasize active learning activities in authentic contexts and multidisciplinary teams, skills that machines cannot yet replicate. This study demonstrates how the targeted use of generative artificial intelligence (GenAI) facilitates the development of autonomous work skills and offers ongoing student support.
Within the limitations of the study, the following sentences could be considered.
In a quasi-experimental design, it cannot be ensured that groups are homogeneous at the start of the study, which introduces potential bias in the results.
The personal characteristics of participants, which are not fully controlled, may influence the results, thereby limiting the generalizability of the findings.
Other external academic factors could have affected the intervention (load of the week, high demand during that period.
Futures improvements to the tutorBot+ platform are considered to ensure universal accessibility, incorporating the W3C ATAG guidelines (including alternative text, sufficient contrast, and ReadSpeaker, among others). The integration of a chatbot with WhatsApp is an idea we have, which would make tutorB@t more accessible.
The experiment is planned to be repeated during the second semester of 2025, with the participation of professors who did not participate in the formulation or implementation of the project, to obtain an external perspective and address the identified deficiencies. It is also intended to apply the motivation survey based on the ARCS model (Keller, 2010), called IMMS (Cardoso-Júnior & Faria, 2021), to incorporate the affective dimension of feedback and measure the motivation students can generate by having only one virtual assistant, a real one, or both.