
Improvement strategies for heuristic algorithms based on machine learning and information concepts: a review of the seahorse optimization algorithm
- Published
- Accepted
- Received
- Academic Editor
- Bilal Alatas
- Subject Areas
- Algorithms and Analysis of Algorithms, Data Mining and Machine Learning, Optimization Theory and Computation
- Keywords
- Entropy crossover strategy, Metaheuristic algorithm, Seahorse optimization, Swarm intelligence, Logistic-KNN inertia weights, Statistic, Machine learning
- Copyright
- © 2025 Zheng
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Improvement strategies for heuristic algorithms based on machine learning and information concepts: a review of the seahorse optimization algorithm. PeerJ Computer Science 11:e2805 https://doi.org/10.7717/peerj-cs.2805
Abstract
To overcome the mechanical limitations of traditional inertia weight optimization methods, this study draws inspiration from machine learning models and proposes an inertia weight optimization strategy based on the K-nearest neighbors (KNN) principle with dynamic adjustment properties. Unlike conventional approaches that determine inertia weight solely based on the number of iterations, the proposed strategy allows inertia weight to more accurately reflect the relative distance between individuals and the target value. Consequently, it transforms the discrete “iteration-weight” mapping ( ) into a continuous “distance-weight” mapping ( ), thereby enhancing the adaptability and optimization capability of the algorithm. Furthermore, inspired by the entropy weight method, this study introduces an entropy-based weight allocation mechanism in the crossover and mutation process to improve the efficiency of high-quality information inheritance. To validate its effectiveness, the proposed strategy is incorporated into the Seahorse Optimization Algorithm (SHO) and systematically evaluated using 31 benchmark functions from CEC2005 and CEC2021 test suites. Experimental results demonstrate that the improved SHO algorithm, integrating the logistic-KNN inertia weight optimization strategy and the entropy-based crossover-mutation mechanism, exhibits significant advantages in terms of convergence speed, solution accuracy, and algorithm stability. To further investigate the performance of the proposed improvements, this study conducts ablation experiments to analyze each modification separately. The results confirm that each individual strategy significantly enhances the overall performance of the SHO algorithm.
Introduction
Non-convex function optimization presents a complex challenge due to the presence of numerous local optima, often resulting in convergence to suboptimal solutions rather than the global optimum. These optimization problems are of critical importance across various fields. In data mining, for instance, model training fundamentally involves minimizing a complex, non-convex loss function (So et al., 2020). In financial engineering, non-convex optimization plays a role in portfolio optimization and option pricing (Lou, 2023). Similarly, in industrial design, the optimization of components or product designs is often formulated as a non-convex optimization problem (Yu et al., 2025). Additionally, non-convex optimization is used in signal processing to enhance the performance of image processing and communication systems (Vlaski & Sayed, 2021).
To address these challenges, numerous heuristic algorithms have been proposed in recent years. Inspired by natural phenomena and biological behaviors, these algorithms aim to solve complex optimization problems and have shown significant performance in large-scale searches and complex structural optimization. Heuristic algorithms can generally be categorized into four types: swarm intelligence-based algorithms, evolutionary algorithms, physics-inspired algorithms, and human behavior-based algorithms. Representative algorithms within each category are listed in Table 1. These methods have achieved remarkable success across various domains as powerful tools for non-convex optimization. However, issues such as susceptibility to local optima, slow convergence speed, lack of population diversity, and premature convergence remain prevalent.
| Classification | Algorithm name | Inspired by |
|---|---|---|
| Swarm intelligence-based | PSO (Kennedy & Eberhart, 1995) | Flocking behavior of birds and fish |
| ACO (Dorigo, Birattari & Stutzle, 2006) | Ants’ pheromone-based path optimization | |
| ABC (Okwu & Tartibu, 2021) | Bees’ foraging strategy | |
| GWO (Mirjalili, Mirjalili & Lewis, 2014) | Wolves’ cooperative hunting | |
| DMOA (Agushaka, Ezugwu & Abualigah, 2022) | Collective hunting in dwarf mongooses | |
| AO (Abualigah et al., 2021b) | Eagles’ hunting and vision | |
| SHO (Zhao et al., 2023) | Seahorses’ adaptive habitat behavior | |
| Evolutionary algorithms | GA (Holland, 2012) | Natural selection and evolution |
| DE (Storn & Price, 1997) | Differential mutation for diversity | |
| Physics-inspired | SA (Rutenbar, 1989) | Simulated annealing process |
| GSA (Kalivas, 1992) | Gravitational interactions | |
| Human and mathematics-based | TS (Khalid et al., 2024) | Tabu list from human memory |
| AOA (Abualigah et al., 2021a) | Arithmetic operations in optimization |
To address these limitations, various improvement strategies have been proposed by researchers. For example, the concept of inertia weight has been widely adopted in particle swarm optimization (PSO) to regulate particle velocity updates within the search space. Gu et al. (2022) introduced the inverted S-shaped inertia weight (ASCSO-S) algorithm, which utilizes an S-shaped function to adaptively adjust the inertia weight across different stages of the algorithm. Specifically, the S-shaped inertia weight starts with a relatively high value during the initial iterations and gradually decreases as the iterations progress, enabling the algorithm to dynamically adjust its “exploration speed” throughout the optimization process. Compared to linearly decreasing inertia weight, the non-linear decrement characteristic of the S-shaped weight allows for flexible adjustment of the decrement rate based on different optimization scenarios, thereby enhancing the algorithm’s generalization capability. Furthermore, in the hybrid particle swarm optimization based on intuitionistic fuzzy entropy (IFEHPSO) algorithm, Wang et al. (2021) utilized the concept of intuitionistic fuzzy entropy from fuzzy mathematics to introduce adaptive perturbations into the inertia weight. This approach departs from the conventional “function-based” weight framework and focuses on the aggregation degree of the population. By using intuitionistic fuzzy entropy to measure population aggregation (with lower aggregation leading to higher entropy and higher aggregation resulting in lower entropy), this method aligns with the PSO algorithm’s iterative dynamics, where exploration is more intense in the early stages and diminishes over time. As a result, intuitionistic fuzzy entropy allows for more intelligent, real-time adjustments of the inertia weight during iterations, further enhancing the algorithm’s performance in solving complex optimization problems.
In addition, improving initialization strategies to enhance population diversity has been proven to be a crucial research focus in optimization algorithms. In the Cauchy Gray Wolf Optimizer (CGWO) algorithm, Li & Sun (2023) proposed an initialization strategy based on the Cauchy distribution, while the authors of the Tent-enhanced Aquila Optimizer (TEAO) introduced an initialization strategy based on the Tent map (Fu et al., 2024). By refining the initialization phase, these methods ensure a more random distribution of the population, providing broader global information coverage during the early stages of the algorithm and strengthening its global search capability.
At the same time, update strategies for the exploration phase have also been extensively studied. For instance, Hu et al. (2022b) incorporated fast-moving and crisscross mechanisms into the enhanced sine cosine algorithm (QCSCA) algorithm, significantly improving its performance during the exploration phase and enhancing its precision in global searches. Additionally, Hu et al. (2022a) integrated multiple optimization algorithms within the improved golden eagle optimizer (IGEO) framework, leveraging the strengths of various strategies to achieve a better balance between exploration accuracy and convergence speed, thereby further improving the overall performance.
These improvement strategies have significantly enhanced the algorithm and provided new insights into the innovation of metaheuristic algorithms. In particular, they offer valuable perspectives on how to effectively adjust individual search strategies and optimize the update of inertia weights, which serve as the motivation for further research in this article.
In swarm intelligence optimization algorithms, the degree of population aggregation directly affects the search efficiency. When the distance between individuals is too small, it may lead to premature convergence, restricting the search space and affecting global optimization capability. On the other hand, if individuals are too widely dispersed, search efficiency may decrease, and computation time may increase. Therefore, properly controlling the aggregation of the population is crucial to improving algorithm performance. Similarly, the K-nearest neighbor (KNN) algorithm is closely related to the distance between individuals. KNN is a non-parametric classification method that determines the nearest neighbors of a target data point by calculating the distances between the target and the sample data, and then classifies the target based on the category labels of its neighbors. Moreover, the inference process of KNN relies entirely on sample data, effectively reflecting the local distribution characteristics of the data.
Similarly, logistic regression, as a classic S-shaped curve function, has a simple structure that is easy to interpret, and similar ideas can be applied in the optimization process. In logistic regression, introducing the concept of S-shaped inertia weights can enhance the optimization process. Inertia weights adaptively adjust the update step size during the algorithm’s iterations, balancing the exploration of global optima and the exploitation of local optima, thus further improving the algorithm’s search performance.
At the same time, the principle of information entropy provides another potential optimization approach. Information entropy is often used to quantify the informational disparity between indicators and determine their weights accordingly. The core idea is that a lower entropy value means the indicator contains more significant information, exhibits greater variability, and has a more substantial impact on the comprehensive evaluation, thus deserving a higher weight. Conversely, a higher entropy value indicates the indicator provides less information and should be assigned a lower weight. This method, similar to the update of inertia weights, can further optimize the weight allocation process, thereby enhancing the algorithm’s exploration and search efficiency.
In recent years, many researchers have combined machine learning with intelligent optimization algorithms. For example, Ran et al. (2024) integrated genetic algorithms (GA), Ant Colony Optimization (ACO), and K-means clustering to enhance performance; Long et al. (2025) employed ACO to optimize reinforcement learning models, providing a novel approach for solving QCSP problems; Hemdan et al. (2025) combined GA with ensemble learning, offering new insights for real-time fault detection.
However, most existing studies focus primarily on leveraging meta-heuristic algorithms to improve the performance of machine learning models, whereas the application of machine learning concepts to enhance meta-heuristic algorithms has received relatively less attention. To address this research gap, this study proposes two novel strategies inspired by the KNN algorithm, logistic regression, and the entropy-weighting method from information concept to enhance the performance of swarm intelligence algorithms. These strategies include a logistic-KNN-based inertia weight mechanism and an entropy-weighted crossover mutation strategy, designed to tackle common challenges in meta-heuristic algorithms such as susceptibility to local optima, insufficient convergence speed, reduced population diversity, and premature convergence.
To validate the effectiveness of the proposed strategies, they were applied to the Seahorse Optimization Algorithm (SHO) and evaluated comprehensively using the IEEE benchmark test functions. The experimental results demonstrate that the proposed strategies significantly enhance the optimization capabilities of SHO, confirming their potential and effectiveness in improving swarm intelligence algorithms.
This research aims to provide new insights into addressing common issues in swarm intelligence optimization, ultimately contributing to the development of efficient optimization methods.
Introduction to the seahorse optimization algorithm
The Seahorse Optimization Algorithm (SHO) simulates the behavior of seahorses in nature, including movement, predation, and reproduction, to balance between global exploration and local exploitation in optimization tasks. The following sections provide a detailed description of the mathematical models and parameters associated with each behavior.
Initialization strategy
In SHO, each seahorse represents a candidate solution in the search space. The population matrix, denoted as , is initialized as follows in Eq. (1):
(1) where represents the dimension of the search space, and denotes the population size.
Each individual seahorse is initialized within the boundary range [LB, UB] as shown in Eq. (2):
(2) where is a random number in the range , and and are the lower and upper bounds for the -th variable, respectively.
The individual with the smallest fitness value in the initial population is selected as the elite individual , as shown in Eq. (3):
(3) where denotes the objective function of the optimization problem.
Movement behavior
SHO employs two movement patterns to balance exploration and exploitation: spiral motion and Brownian motion.
Spiral motion (local exploitation)
When a seahorse is influenced by ocean eddies, it moves along a spiral path toward the elite individual , as defined in Eq. (4):
(4) where ‘t’ represents the current iteration count of the algorithm, and , , and are given by Eq. (5):
(5)
The parameter is defined in Eq. (6):
(6) where , , and is a random value in the range .
The Lévy flight step size is computed as in Eq. (7):
(7) where , and and are random numbers in . The parameter is defined as in Eq. (8):
(8)
In this study, is set to 1.5.
Brownian motion (global exploration)
If the seahorse moves in response to ocean waves, it follows a Brownian path as defined in Eq. (9):
(9) where , and is a step-size coefficient following a standard normal distribution, as given by Eq. (10):
(10)
Predation behavior
The predation behavior simulates a 90% probability of successful predation.
Predation success (90% probability)
When predation is successful, the seahorse moves closer to the elite individual, as shown in Eq. (11):
(11)
Predation failure (10% Probability)
If predation fails, the seahorse explores a larger space as defined in Eq. (12):
(12)
The parameter gradually decreases with iterations, calculated by Eq. (13):
(13) where T is the maximum number of iterations.
Reproduction behavior
In SHO, reproduction generates new individuals that inherit traits from parent individuals to enhance population diversity.
Individual grouping
The population is sorted by fitness, with the top half as fathers and the bottom half as mothers, as shown in Eqs. (14), (15):
(14)
(15) where represents all individuals sorted in ascending order by fitness.
Offspring generation
Each pair of parents produces a new individual as shown in Eq. (16):
(16) where is a random number in the range , and and are randomly selected father and mother individuals, respectively.
Related work
Inspiration
The logistic function, as a classical nonlinear model, is well-known in statistics and machine learning for its smooth S-shaped curve. Inspired by the characteristics of the Logistic function, the design of inertia weight in swarm intelligence algorithms can leverage its nonlinear mapping properties to achieve adaptive weight adjustment by balancing the exploration and exploitation behaviors of individuals.
The KNN algorithm is widely used in machine learning for classification and regression tasks. Its core concept involves calculating the distance between a target point and training data points to identify the nearest neighbors, and then predicting the target point’s attributes based on those neighbors’ characteristics. Drawing inspiration from this idea, the distance measurement mechanism of KNN can be introduced into swarm intelligence algorithms to strengthen the correlation between individuals and the global optimum.
By integrating the logistic function with the KNN method, an intelligent and adaptive inertia weight adjustment mechanism can be developed. This mechanism allows the dynamic adjustment of weights to more accurately reflect the distance between individuals and the global optimum, as well as the overall distribution characteristics of the population. Specifically, the KNN method serves as a distance-based quantitative tool to evaluate the relative relationship between individuals and their neighborhood or the global optimum. Meanwhile, the nonlinear mapping properties of the logistic function enable smooth and flexible adjustments of inertia weights based on the degree of aggregation within the population, thereby optimizing the weight adjustment process.
This approach allows the inertia weight to intelligently adapt to the dynamic changes during algorithm iterations, enabling real-time adjustments to balance exploration and exploitation effectively. The proposed strategy demonstrates significant advantages in enhancing the performance of swarm intelligence algorithms, particularly in accelerating convergence and improving global optimization capabilities. Moreover, it reduces the risk of the algorithm becoming trapped in local optima, further improving the robustness and efficiency of global search processes.
Furthermore, it can be envisioned that individuals within the population carry optimization information (such as lower or higher fitness values). Based on this information, the fitness level of the region where an individual is located can be roughly estimated. In traditional entropy weighting methods, “entropy” serves as an indicator of information richness, measuring the amount of information contained in the data. Therefore, in this study, the fitness value of each individual is treated as the “entropy” it contains, which is then used to guide individuals toward regions with superior information, thereby further enhancing the optimization process.
Logistic-KNN inertia weight
In swarm intelligence algorithms, the strategy of inertia weight plays a crucial role in algorithm performance. Typically, an ideal inertia weight should satisfy the following properties:
Decreasing trend: The inertia weight should gradually decrease with the increase of iterations, ensuring that the search strategy shifts from global to local convergence.
Large initial value: A larger initial weight is favorable in the early stages of the algorithm, enhancing the population’s ability for global exploration and promoting diversity.
Small final value: A smaller weight toward the end of iterations supports a more detailed local search.
An appropriate inertia weight strategy can effectively guide the population to balance exploration and exploitation in the solution space, thereby enhancing the algorithm’s ability to navigate global and local search areas. However, traditional linearly decreasing inertia weights are overly rigid, potentially leading to insufficient flexibility in guiding strategies or premature convergence in complex optimization tasks. Consequently, researchers have proposed nonlinear inertia weight strategies, with the logistic function-based nonlinear weight being among the most widely applied. In such functions, the weight decreases gradually in the early stage, allows adjustable convergence in the mid-stage, and stabilizes in the later stages. Due to its favorable mathematical properties, this approach has gained broad acceptance.
However, such inertia weight strategies are designed based on the entire population, and thus lack precision in adjusting for individual differences. Consequently, traditional weight strategies fail to provide adaptive guidance for certain outlier individuals within the population. To address this issue, this study proposes a learning strategy inspired by the KNN algorithm, termed the distance-based learning strategy (KNN-Weight), integrating it into the nonlinear inertia weight design. This approach enables adaptive inertia guidance for each individual. The specific model is as follows:
In the proposed algorithm, the inertia weight is dynamically adjusted based on distance, while leveraging the nonlinear characteristics of the Logistic function to enhance adaptive control for individuals. The mathematical model for inertia weight is shown in Eq. (17):
(17) where and are two hyperparameters used to adjust the weight magnitude, respectively; is a parameter that controls the rate of change in inertia weight, and represents the distance between individual and the global best solution at iteration . The formula for has three calculation methods,as shown in Eq. (18):
(18) where denotes the position of individual at iteration , represents the inverse of the covariance matrix of the current iteration individual’s fitness value, which measures the correlation and variance between the individual’s dimensions (Euclidean distance is used by default), and denotes the position of the global best solution at iteration . The mean distance of the population is defined as shown in Eq. (19):
(19)
By applying this inertia weight strategy to each individual, the algorithm can adjust different search strategies based on the population’s dispersion. When , the inertia weight is larger, allowing individuals to perform broader exploration. Conversely, when , a smaller inertia weight encourages more detailed local search. The logistic function’s favorable nonlinear properties allow the weight to smoothly control the rate of descent, providing adaptive flexibility. Increasing the parameter enhances the inertia weight of individuals distant from the global best solution, further optimizing the algorithm’s convergence behavior and global exploration capabilities. To more intuitively illustrate the variation pattern of inertia weights, this study has generated function plots of inertia weights under different values of , as shown in Fig. 1. Additionally, the complete process of the logistic-KNN inertia weight strategy is depicted in Fig. 2.
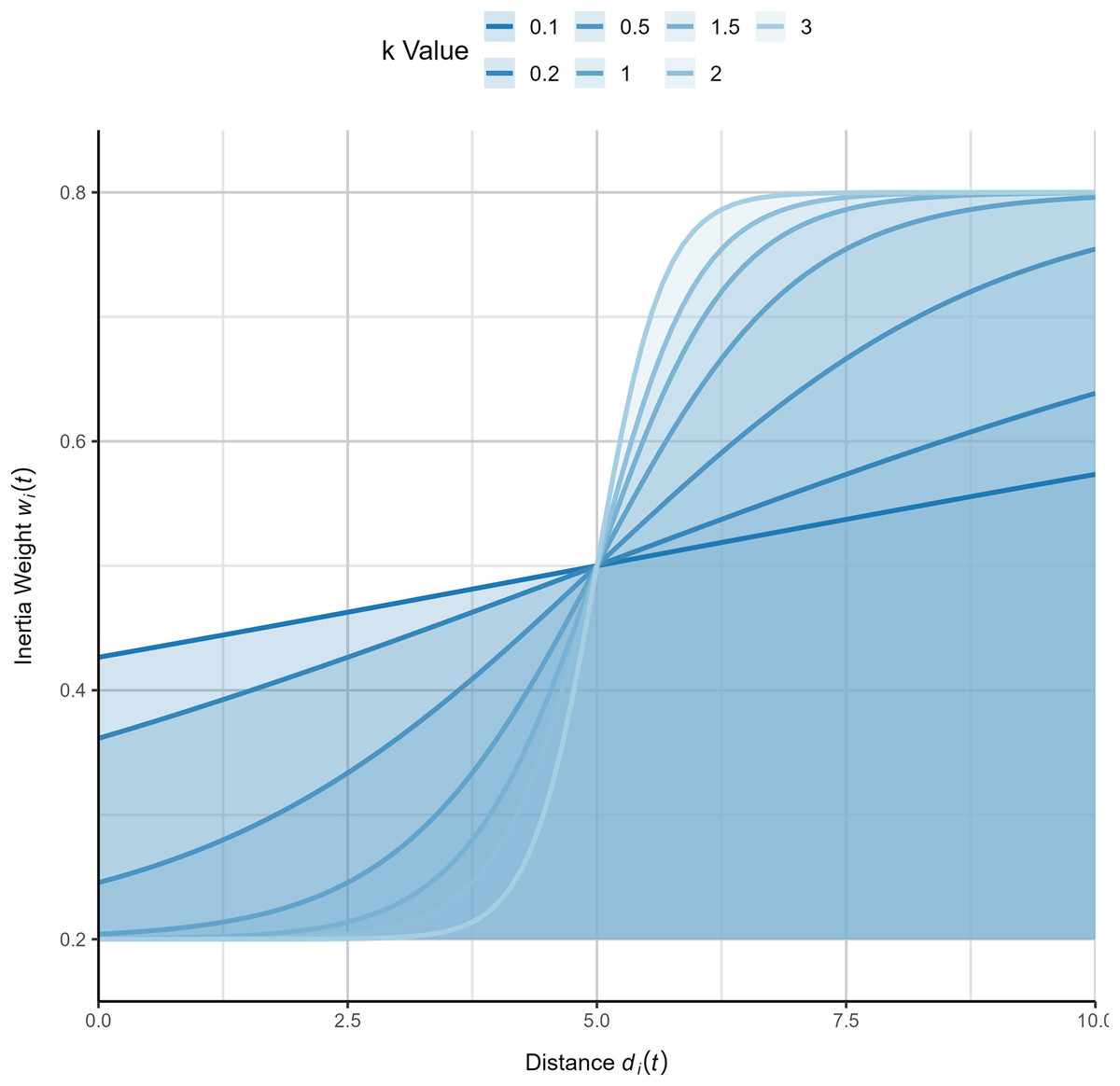
Figure 1: Diagram of logistic-KNN-Inertia weight (x-axis represents , y-axis represents the corresponding value).
{kind=link}
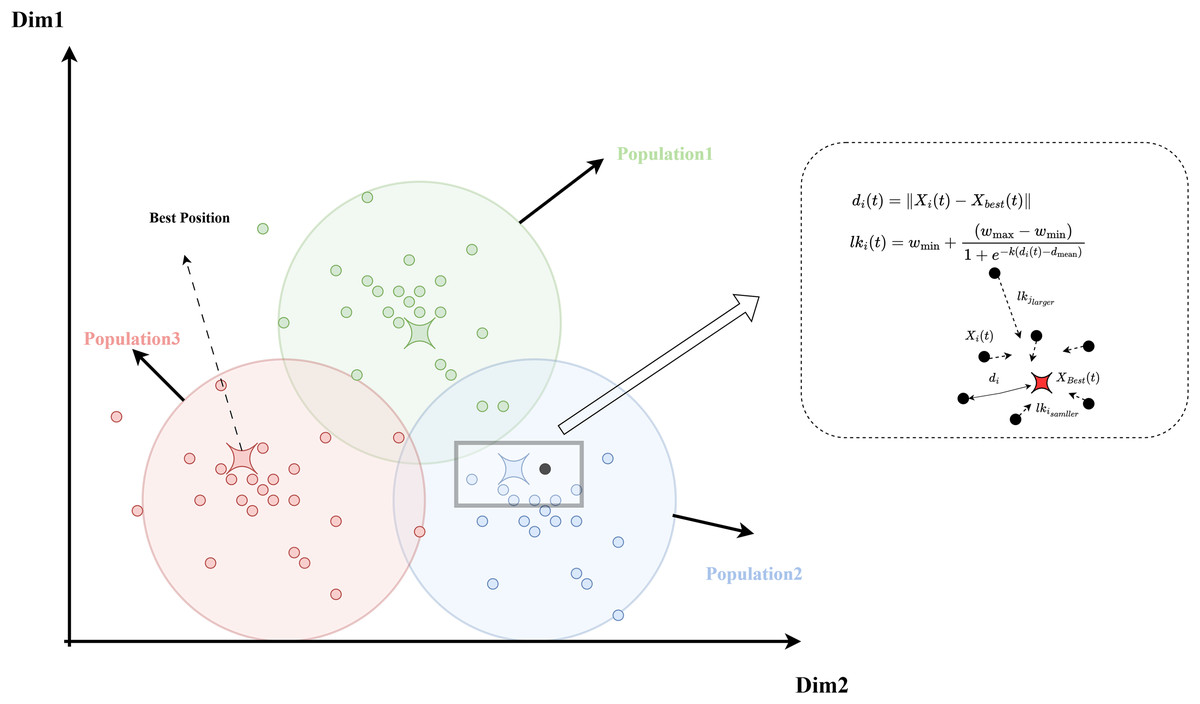
Figure 2: Diagram of the logistic-KNN-inertia weight strategy model.
{kind=link}
Entropy crossover strategy
In group intelligence algorithms, the ‘Uniform Crossover Mutation’ strategy was first introduced in genetic algorithms (GAs). This strategy is described by a mathematical optimization model that captures the recombination and random mutation of individuals to generate a new generation. The classic mathematical model is shown in Eqs. (20), (21):
(20)
(21) where, is a randomly generated weighting factor within the interval [0, 1] or ome random numbers between [0, 1] (e.g., standard normal distribution), and P and C represent the positional information of the parent and offspring, respectively. However, this random weighting factor fails to effectively capture critical information from both the father and mother, which limits the ability of new solutions to inherit superior traits from the parent generation. To address the limitations of random weighting in representing information, this study proposes an entropy-weighted crossover mutation strategy. By introducing the entropy-weighting method to determine the random parameter, the proposed strategy better incorporates the genetic information of the previous generation, thereby enhancing the algorithm’s performance in global optimization.
1. Extraction of parental fitness values
First, the population is sorted by fitness, with the top half designated as fathers and the bottom half as mothers. The fitness values are represented as shown in Eqs. (22), (23):
(22)
(23) where and represent the sets of fitness values for fathers and mothers, respectively.
2. Normalization of fitness values
The fitness values of both fathers and mothers are normalized to facilitate subsequent weight calculations. The normalization formula is shown in Eqs. (24), (25):
(24)
(25) where is a small constant to prevent division by zero.
3. Calculation of parental weights
After normalization, the fitness values are used to measure the extent to which an individual contains ‘better’ information. Individuals with smaller fitness values carry more valuable information and, from an information-theoretic perspective, have higher entropy. Conversely, individuals with larger fitness values are considered to contain less valuable information, resulting in lower entropy. The specific calculation is as shown in Eq. (26):
(26)
4. Normalization of weights
Finally, the weights of fathers and mothers are normalized so that their sum equals 1, as shown in Eqs. (27), (28):
(27)
(28)
After normalization, the sum of the weights for fathers and mothers should equal to 1 as Eq. (29):
(29)
Through this fitness-weighted combination approach, individuals with higher fitness contribute more to the genes of the offspring, enhancing the balance between global exploration and local exploitation in the algorithm. This improved crossover and mutation strategy can more effectively guide the algorithm toward the global optimum, ensuring effective transmission of fitness information while retaining randomness.
Entropy-distance-SHO
To evaluate the effectiveness of our improved strategies, this study applies these two enhancements to the SHO algorithm. The improved algorithm is named Entropy-Distance-SHO. The strategy improved through Logistic-KNN-Weight is shown in Eq. (30):
(30)
The crossover mutation strategy modified by the entropy-weighting method is shown in Eq. (31):
(31) where represents the information weight from the father, and represents the information weight from the mother. The principle of this strategy is intuitively demonstrated in Fig. 3. The pseudocode of the algorithm is shown in Algorithm 1.
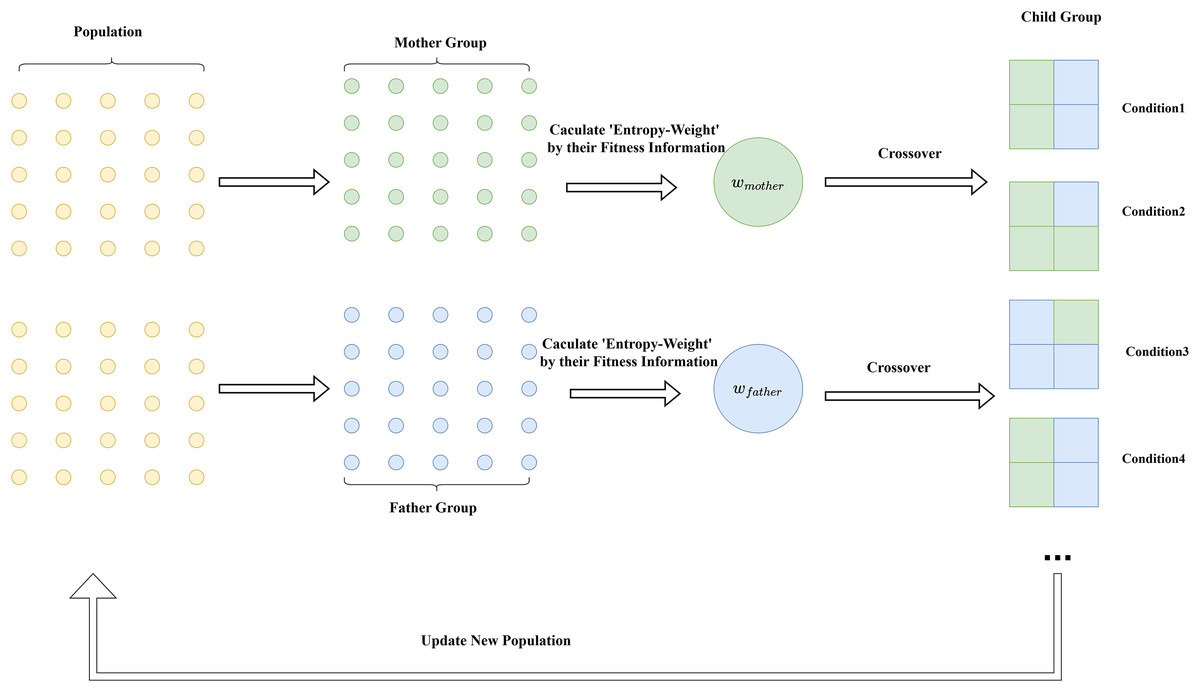
Figure 3: Diagram of the entropy weight cross-mutation strategy.
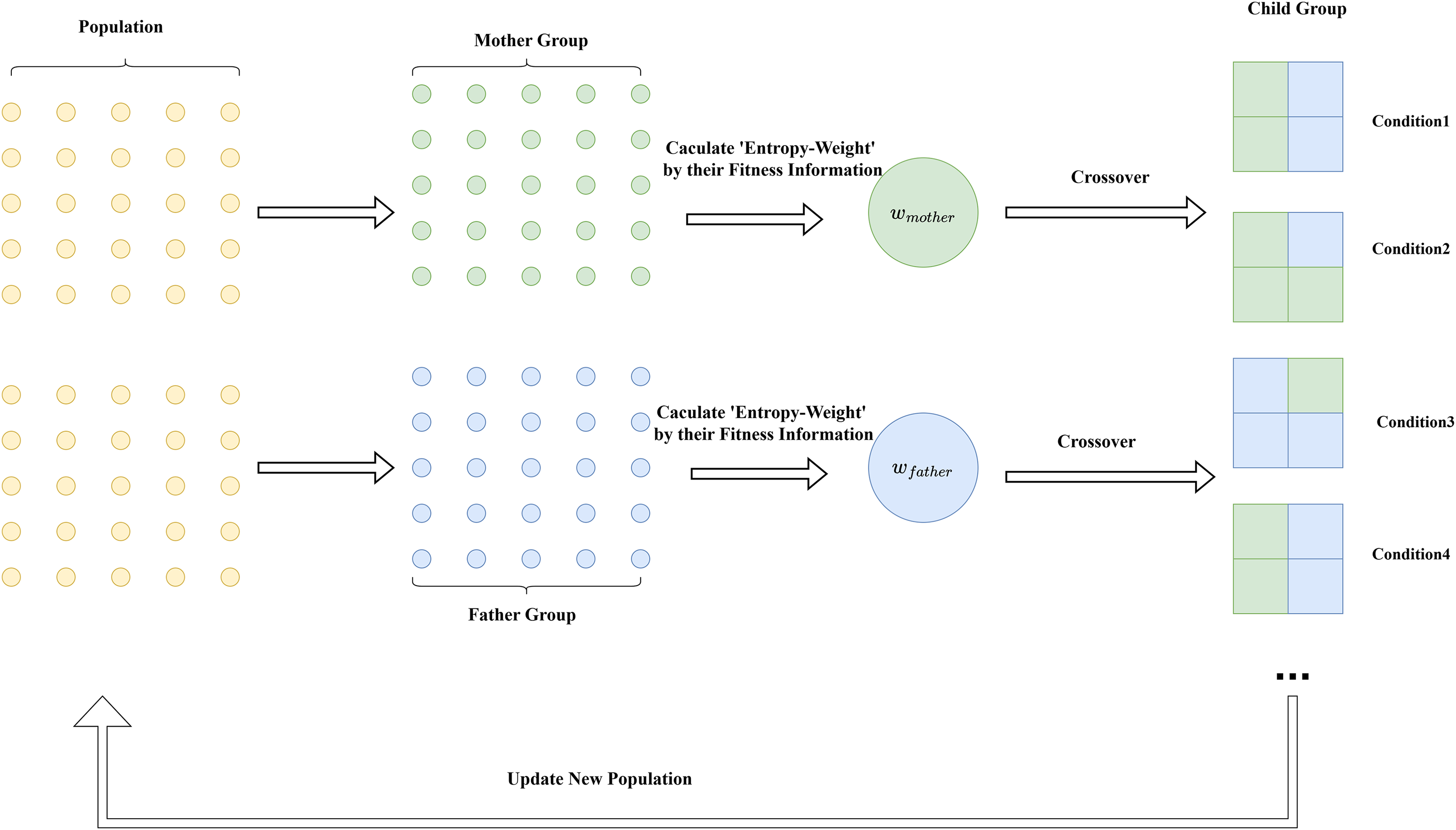{kind=link}
| 1: Initialize population X |
| 2: Configure the EDSHO parameters ( , , etc.) |
| 3: Calculate the fitness value of each individual |
| 4: Determine the best individual |
| 5: while do |
| 6: if then |
| 7: Update positions of the sea horses using Eq. (30) |
| 8: else |
| 9: Update positions of the population using Eq. (9) |
| 10: end if |
| 11: Update positions of the sea horses using Eqs. (11), (12) |
| 12: Handle variables out of bounds |
| 13: Calculate the fitness value of each individual |
| 14: Select mothers and fathers using Eqs. (22), (23): |
| 15: Breed offspring using Eq. (31) |
| 16: Handle variables out of bounds |
| 17: Calculate the fitness value of offspring |
| 18: Select the next iteration population from the offspring and parents ranked top in fitness values |
| 19: Update the best individual position |
| 20: |
| 21: end while |
Time complexity analysis
The time complexity of the algorithm is primarily determined by initialization, fitness evaluation, and the main loop, which includes inertia weight updates, predation behavior, reproduction, and fitness sorting. In each iteration, the complexity of inertia weight updates and predation behavior is , while reproduction and fitness sorting have complexities of and , respectively. Therefore, the time complexity for a single iteration can be expressed as . Taking into account the maximum number of iterations , the overall time complexity of the algorithm is . When the problem dimension is large, the impact of becomes negligible compared to , making the time complexity predominantly governed by . However, the time complexity of the improved algorithm has not increased, demonstrating the superiority of the proposed improvement strategies.
Experiment
Experiment overview
This study verifies the effectiveness of the proposed Entropy-Distance Seahorse Optimization (EDSHO) algorithm through three experimental groups:
-
1.
Qualitative Analysis of the Algorithm
-
2.
Benchmark Testing
-
3.
Statistical Analysis
-
4.
Ablation Experiment
The study uses 31 benchmark functions from the CEC2005 and CEC2021 suite to evaluate the EDSHO algorithm’s performance. These well-known optimization problems are widely used in various real-world applications, and the structure of these functions is detailed in Table 2. To ensure fairness, all algorithms are configured with a population size of 100 and 1,000 iterations. All experiments are conducted on the MATLAB 2024a platform, using a PC with an AMD Ryzen 7 6800H processor with Radeon Graphics, clocked at 3.20 GHz.
| Test function | Dim | Range | |
|---|---|---|---|
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | −12,569.5 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 30 | 0 | ||
| 2 | 1 | ||
| 4 | −10.1532 | ||
| 2 | 0.398 | ||
| 2 | 3 | ||
| 4 | −3.86 | ||
| = Shifted and Rotated Bent Cigar Function (CEC 2017[4] F1) | 20 | 100 | |
| = Shifted and Rotated Schwefel’s Function (CEC 2014[3] F11) | 20 | 1,100 | |
| = Shifted and Rotated Lunacek bi-Rastrigin Function (CEC 2017[4] F7) | 20 | 700 | |
| = Expanded Rosenbrock’s plus Griewangk’s Function (CEC 2017[4]) | 20 | 1,900 | |
| = Hybrid Function 1 (N = 3) (CEC 2014[3] F17) | 20 | 1,700 | |
| = Hybrid Function 2 (N = 4) (CEC 2017[4] F16) | 20 | 1,600 | |
| = Hybrid Function 3 (N = 5) (CEC 2014[3] F21) | 20 | 2,100 | |
| Composition Function 1 (N = 3) (CEC 2017[4] F22) | 20 | 2,200 | |
| = Composition Function 3 (N = 5) (CEC 2017[4] F25) | 20 | 2,500 | |
| 4 | −3.32 | ||
| 4 | −10 | ||
| 4 | −10 | ||
| 4 | −10 |
Qualitative analysis
This study performs a detailed analysis of the EDSHO algorithm on high-dimensional unimodal, multimodal, and fixed-dimensional multimodal functions. The population size is set to 30, and the number of iterations is 300, with 30 independent runs on each test function. The results are shown in Figs. 4–6, with the analysis including the following aspects:
-
1.
Function space search: The first column presents the distribution of the algorithm’s search in the function space.
-
2.
Search history: The second column shows the search trajectory on the first and second dimensions, illustrating the population distribution within the search space. It is observed that on unimodal functions, the algorithm’s distribution is more concentrated, with more consistent optimal values found. In contrast, in high-dimensional function spaces, the search distribution is more scattered, and the optimal values found are similarly dispersed.
-
3.
Mean fitness values: The third column displays the curve of the population’s mean fitness values. It is evident that the algorithm converges quickly after only a few iterations, reflecting its rapid convergence speed.
-
4.
Optimal individual search trajectory: The fourth column records the search trajectory of the optimal individual on the first dimension. On unimodal functions, the curve shows larger oscillations in the initial stages and stabilizes in the later stages. For multimodal functions, there are also significant fluctuations initially, followed by small, persistent fluctuations.
-
5.
Convergence curve: The fifth column is the convergence curve of the algorithm, clearly showing that the algorithm has high convergence speed and strong exploration capabilities.
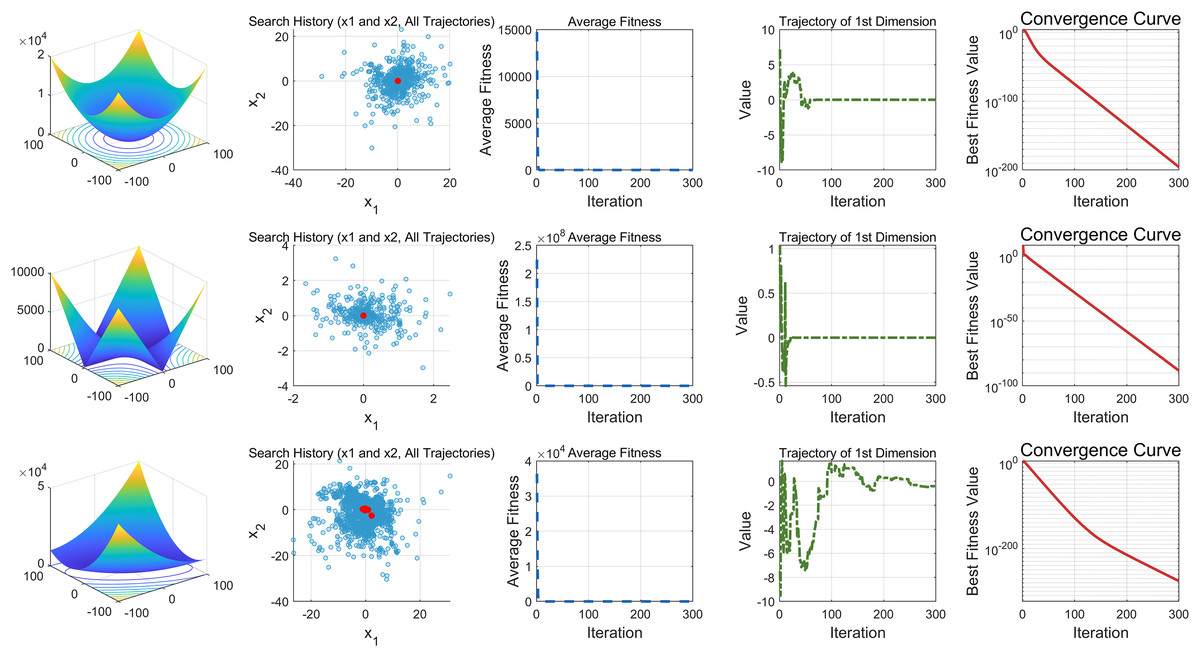
Figure 4: High dimension unimodal functions.
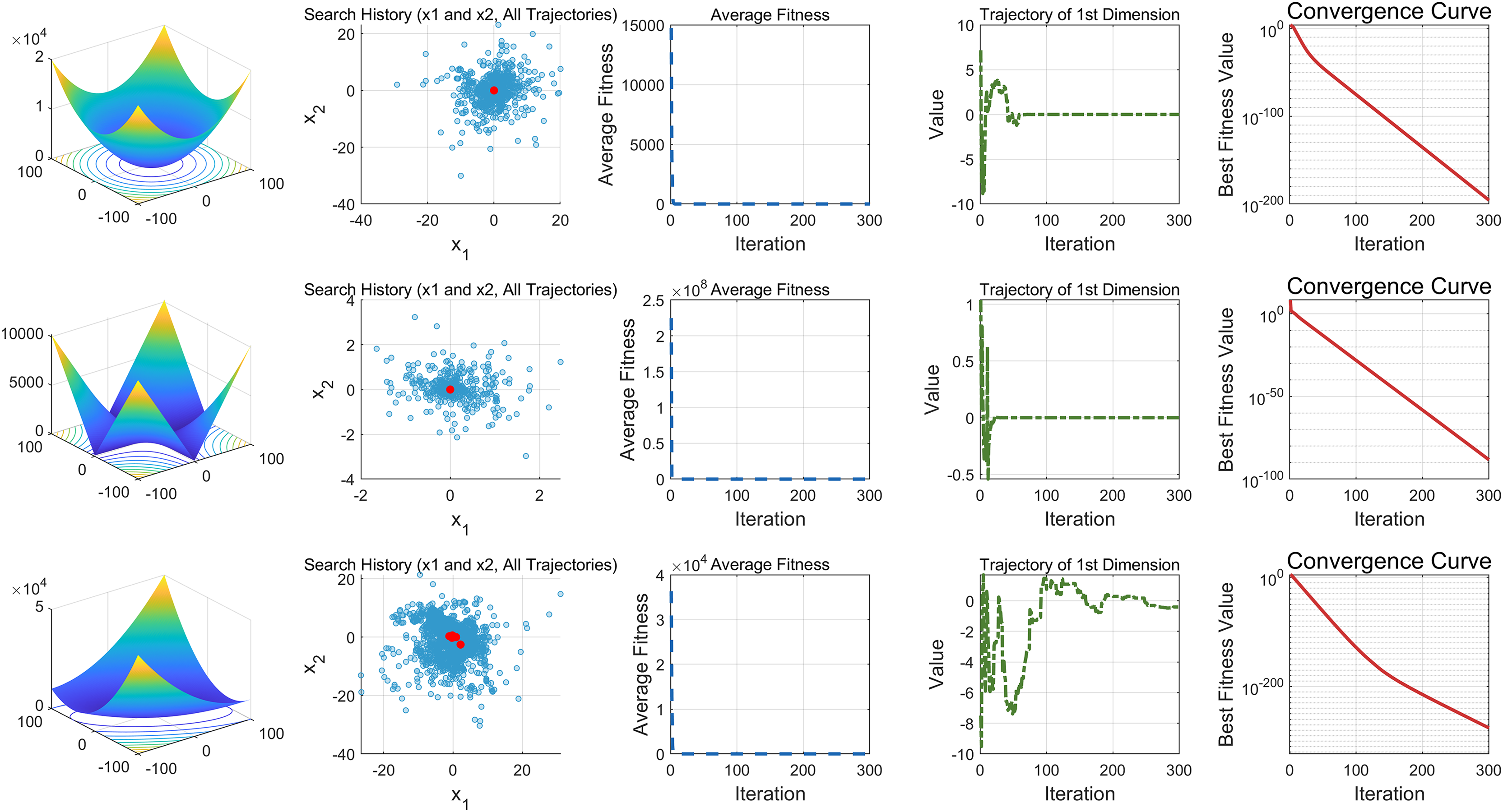{kind=link}
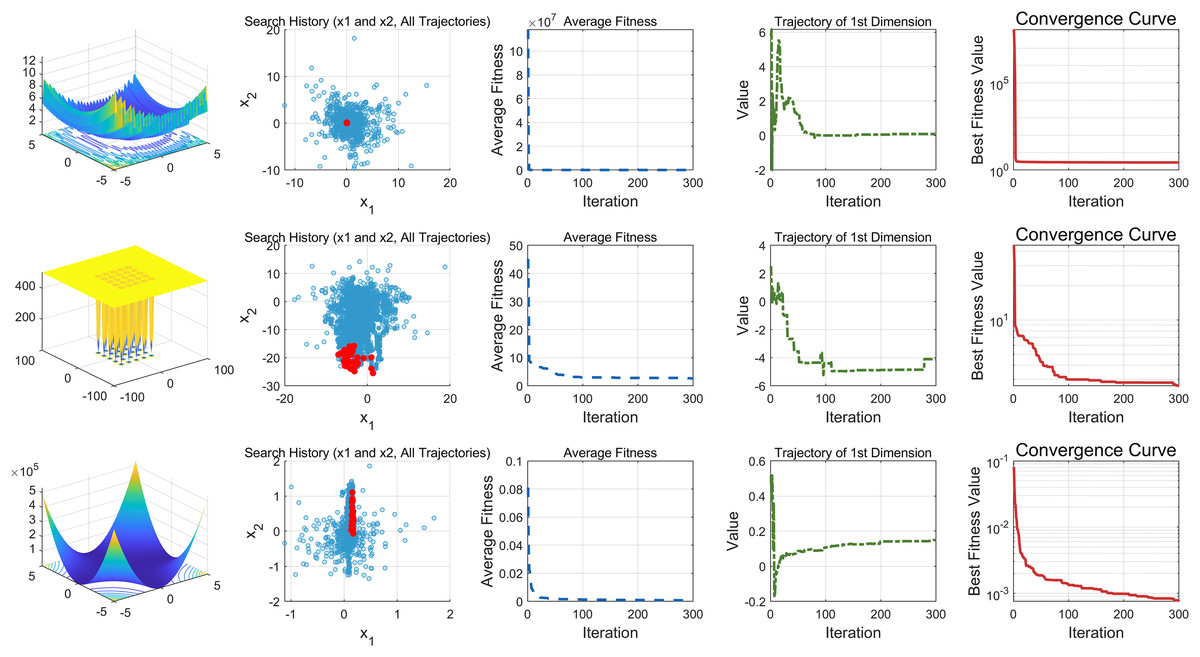
Figure 5: High dimension multimodal functions.
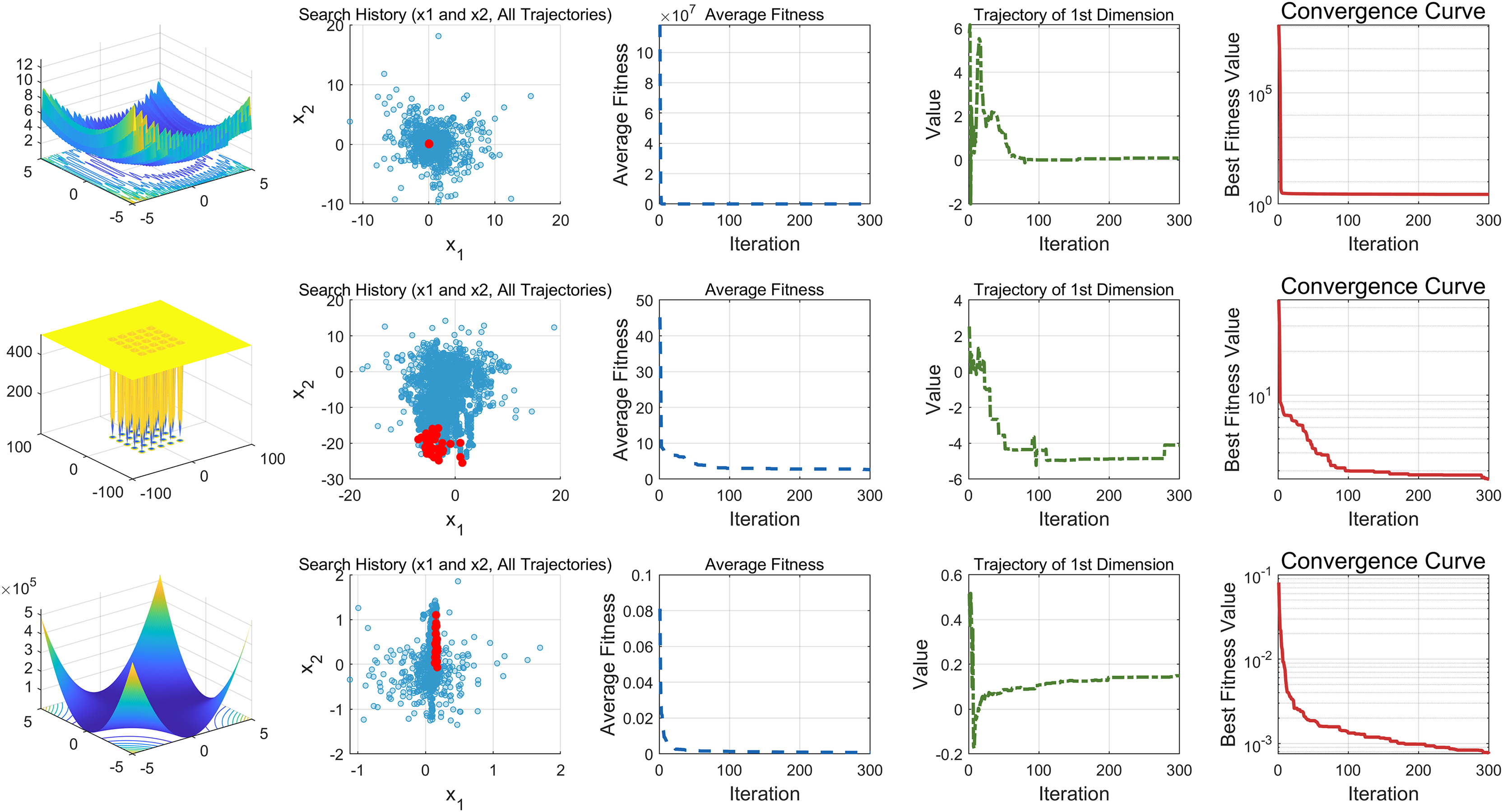{kind=link}
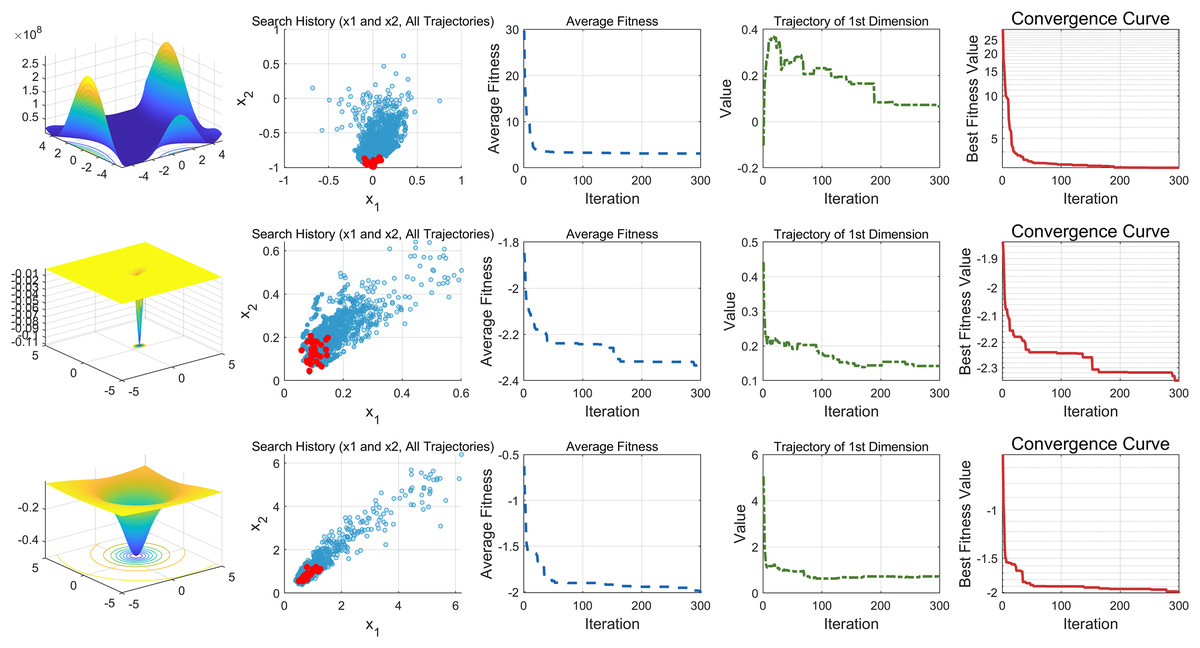
Figure 6: Fixed-dimension multimodal functions.
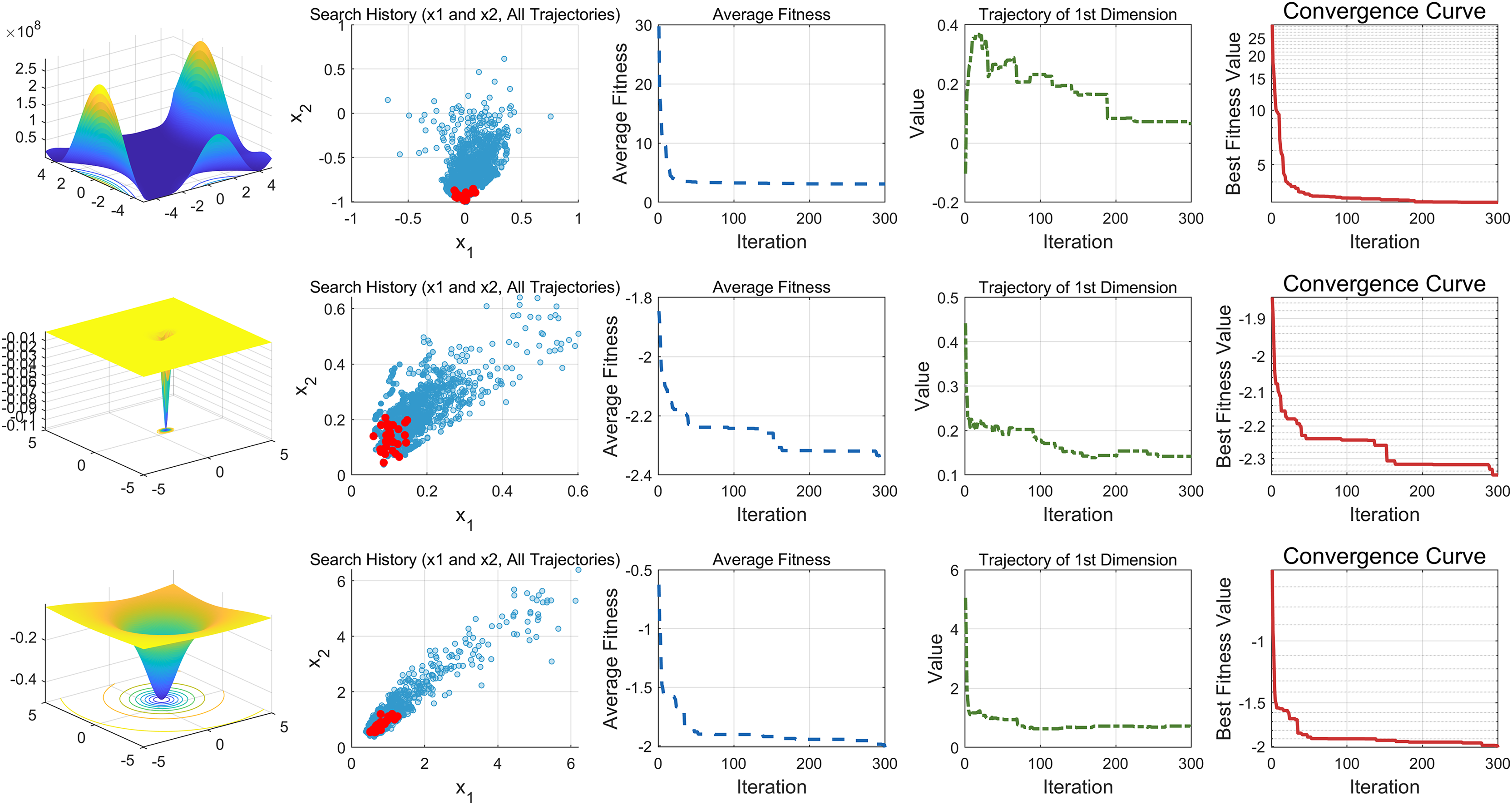{kind=link}
Benchmark testing
This study compares the EDSHO algorithm against eight well-known algorithms recently proposed in the literature on the CEC2005 benchmark functions, including: SHO, GWO, nutcracker optimization algorithm (NOA) (Abdel-Basset et al., 2023), dung beetle optimizer (DBO) (Xue & Shen, 2023), snake optimizer (SO) (Hashim & Hussien, 2022), pigeon-inspired optimization (PIO) (Duan & Qiao, 2014), whale optimization algorithm (WOA) (Mirjalili & Lewis, 2016), and the seagule optimization algorithm (SOA) (Dhiman & Kumar, 2019). During testing, each algorithm is run 30 times independently on each test function, and the reported metrics include mean fitness value, standard deviation, best value, and worst value. Detailed results are shown in Tables 3–5, and Figs. 7–10 provides an intuitive visualization of algorithms performance.
| Function | Metric | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EDSHO | SHO | SOA | WOA | PIO | SO | DBO | NOA | GWO | ||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Function | Metric | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EDSHO | SHO | SOA | WOA | PIO | SO | DBO | NOA | GWO | ||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F19 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F20 | Mean | 5,753.8 | ||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F21 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F22 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Function | Metric | Algorithm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EDSHO | SHO | SOA | WOA | PIO | SO | DBO | NOA | GWO | ||
| F23 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F24 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F25 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F26 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| F27 | Mean | |||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
| Mean | ||||||||||
| Std | ||||||||||
| Best | ||||||||||
| Worst | ||||||||||
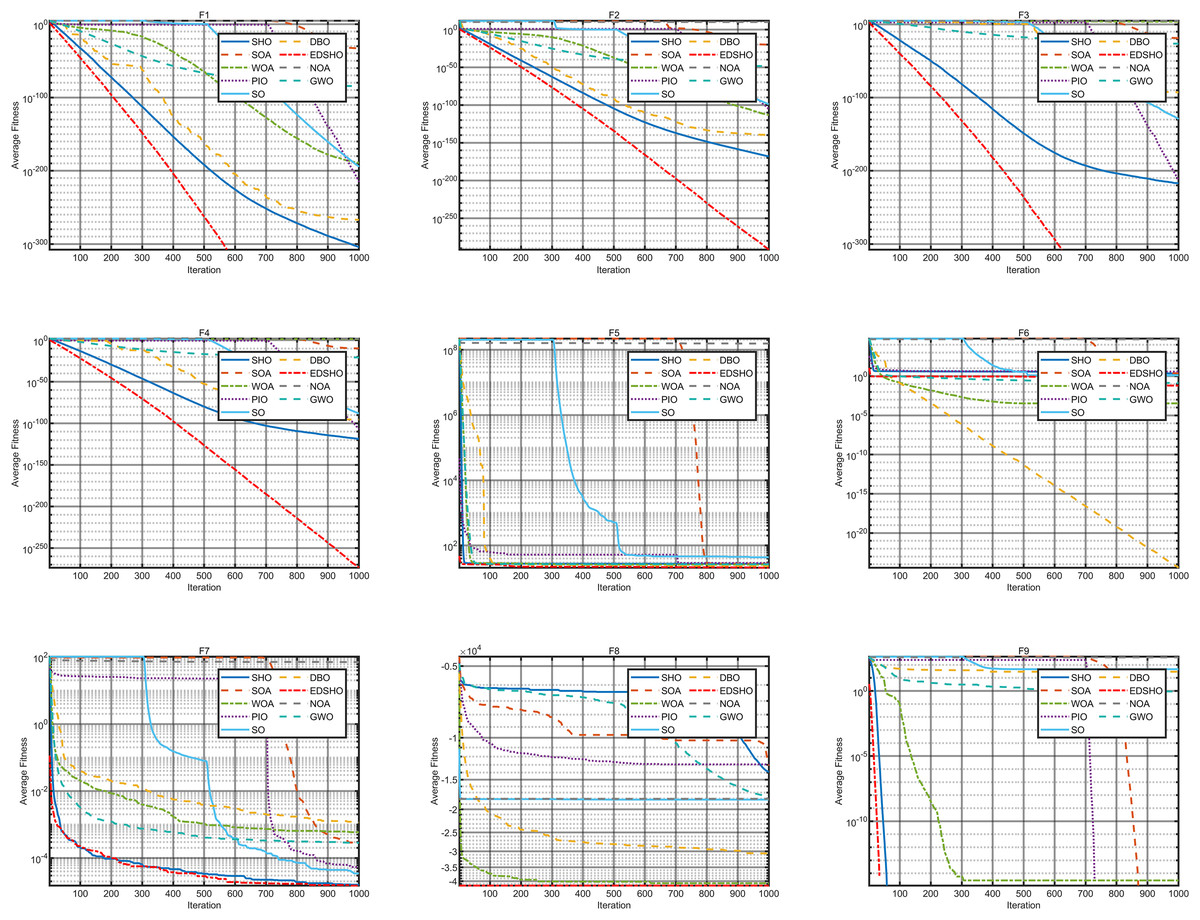
Figure 7: Convergence curves of F1–F9.
{kind=link}
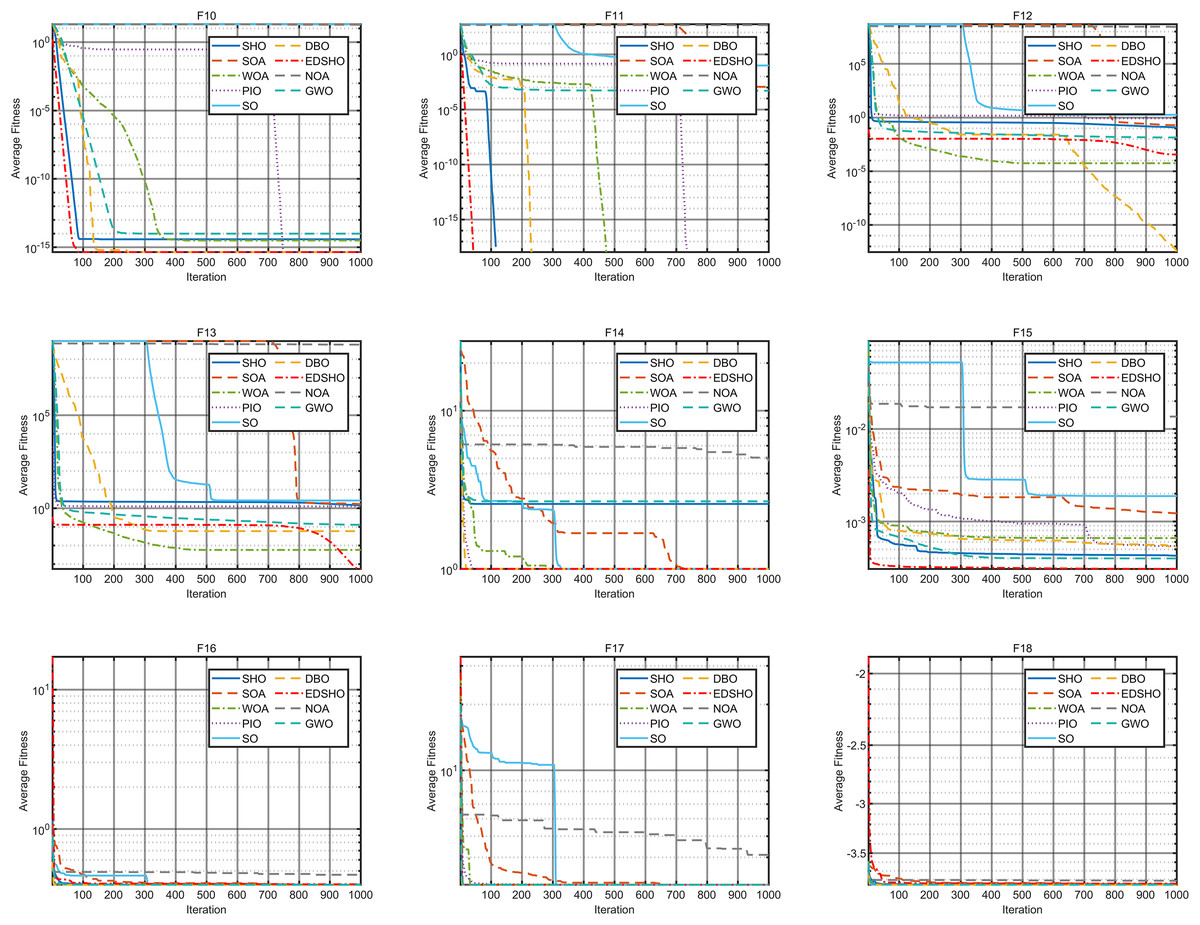
Figure 8: Convergence curves of F10–F18.
{kind=link}
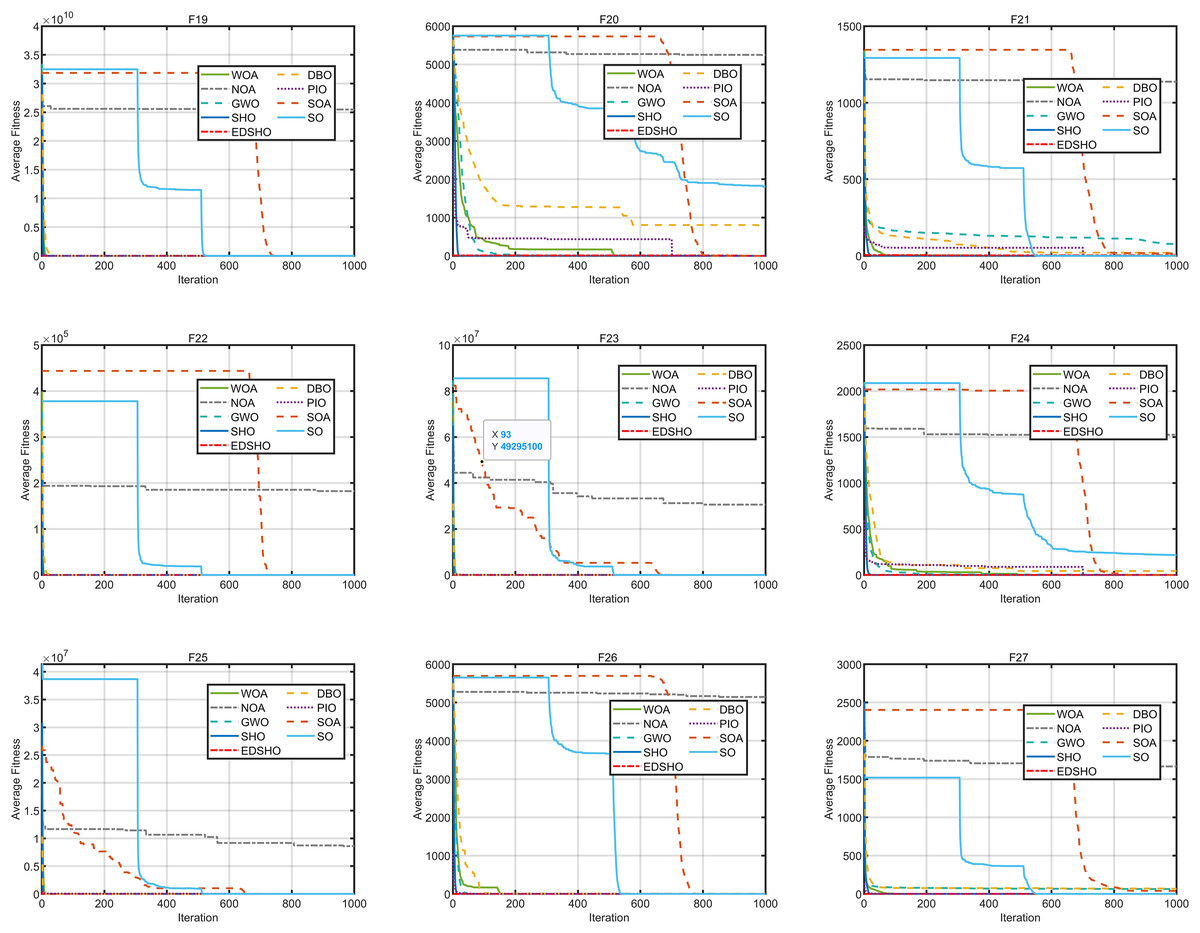
Figure 9: Convergence curves of F19–F27.
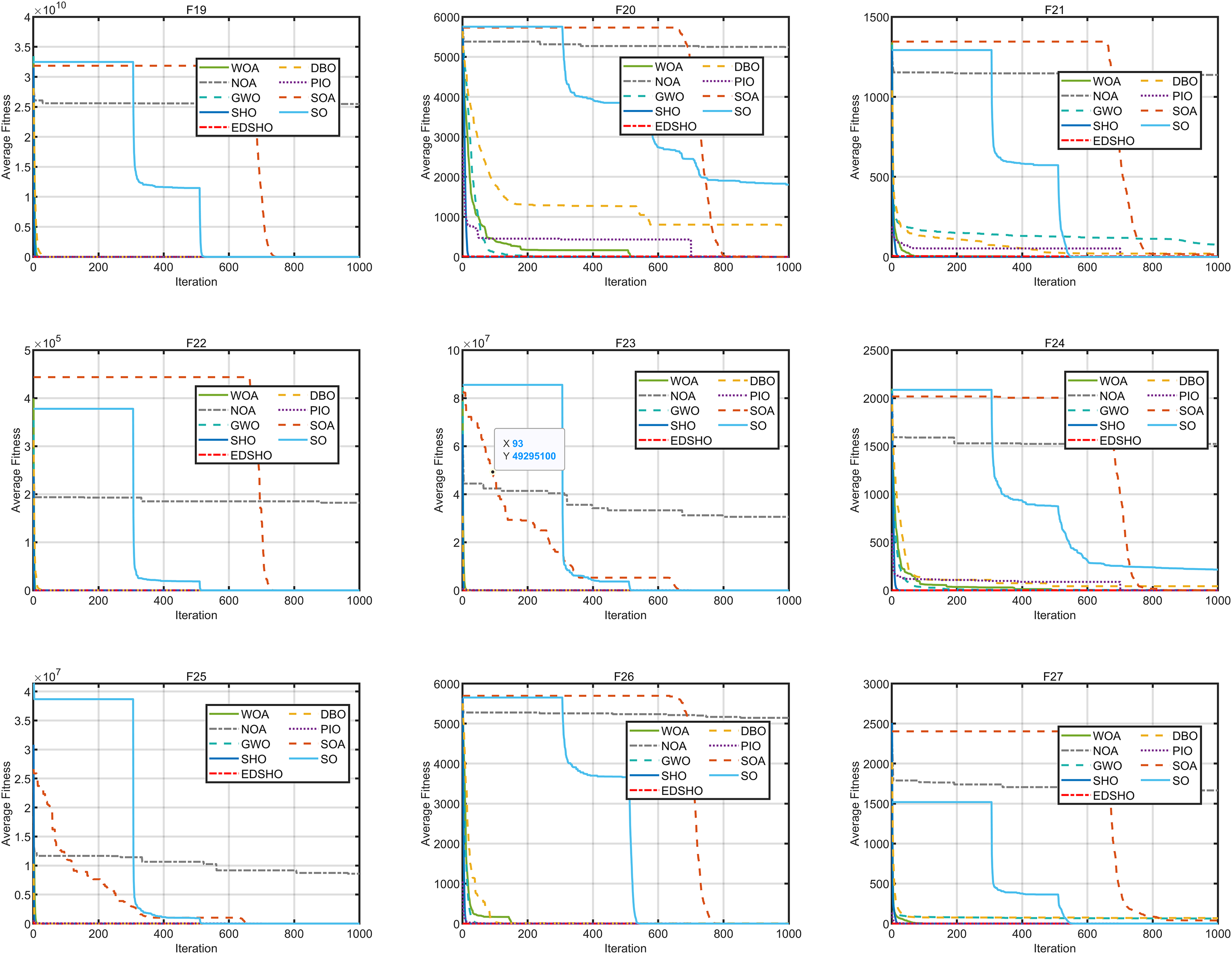{kind=link}
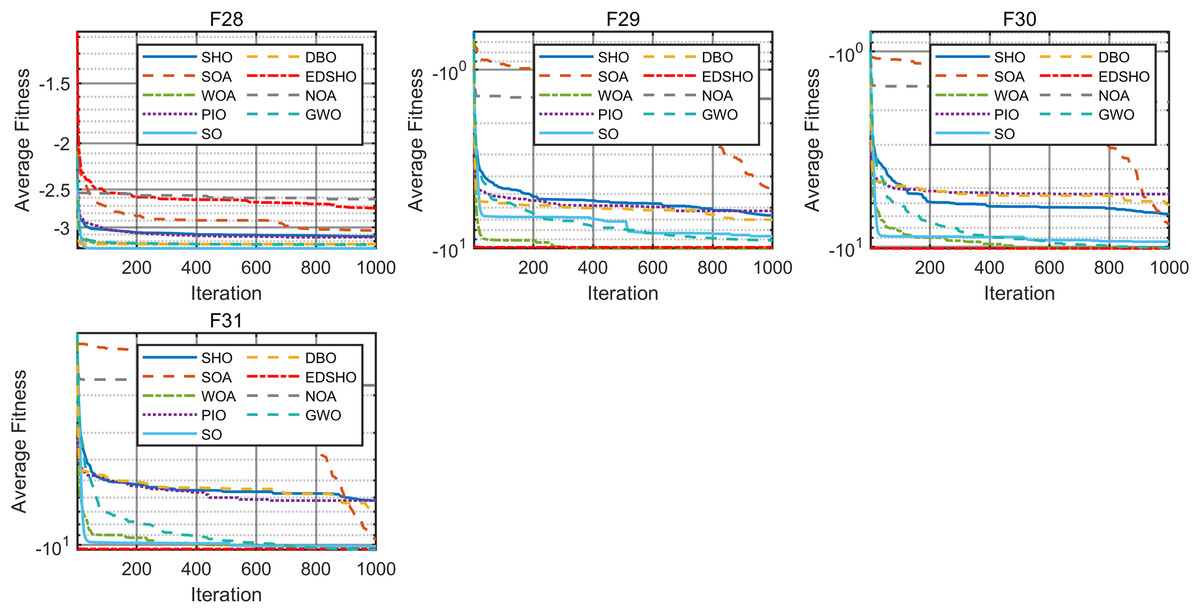
Figure 10: Convergence curves of F28–F31.
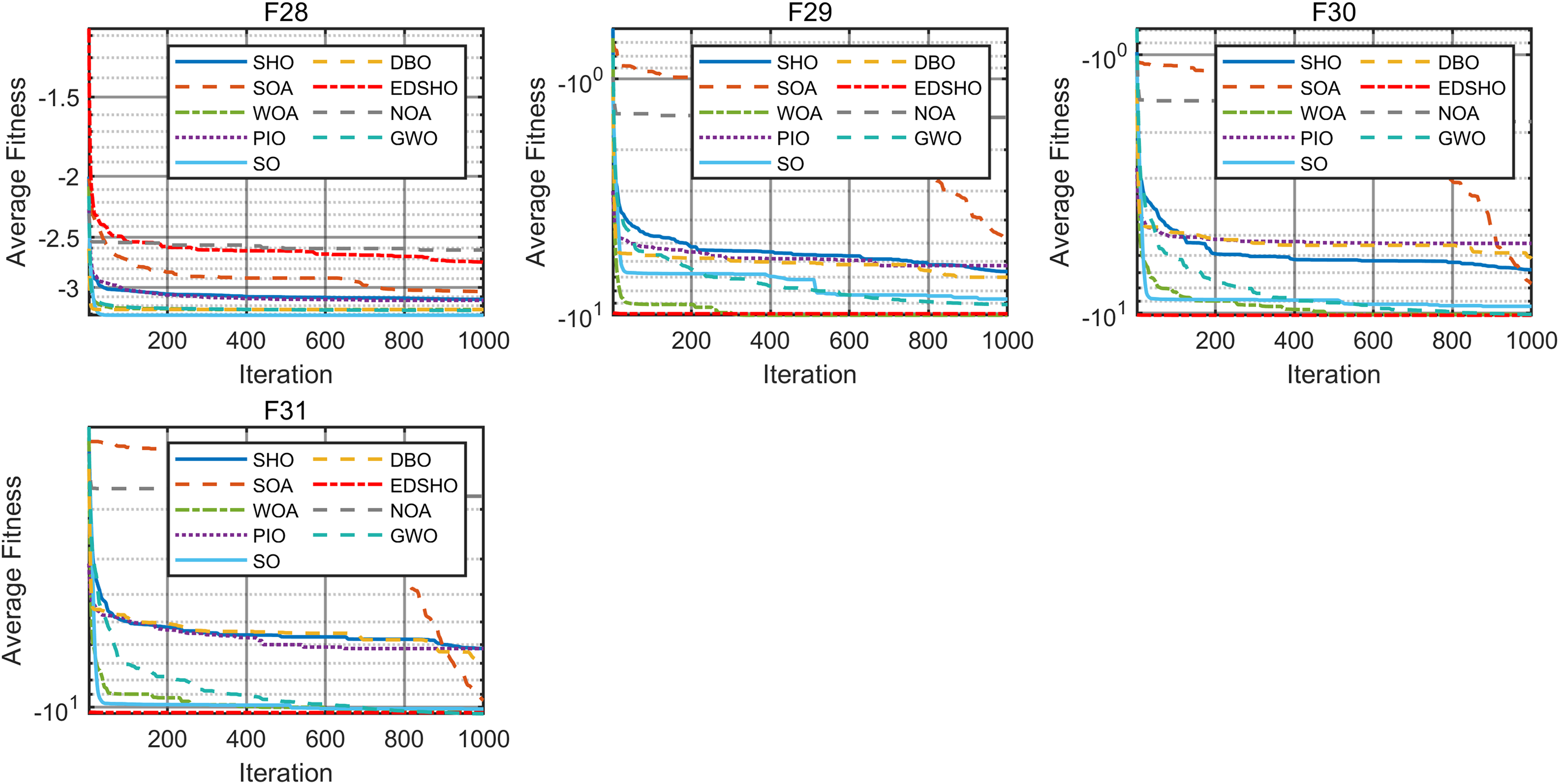{kind=link}
The results indicate that EDSHO outperforms most other algorithms in terms of convergence speed and exploration capability on unimodal functions, with all metrics showing optimal values. On multimodal functions, EDSHO maintains stable performance across different types of optimization problems. For fixed-dimensional multimodal function optimization, EDSHO, WOA, and SO algorithms perform well; although EDSHO may slightly underperform in certain metrics, the differences remain minimal.
To further evaluate the performance of EDSHO, this study conducts the following statistical analyses.
Statistical analysis
This study conducted the Wilcoxon rank-Sum test on the results of each algorithm run independently. The results indicate that, on most test functions, the performance of each algorithm is significantly different from the others, with only a few cases showing no significant difference. In cases where the optimization results of two algorithms are identical, “N/A” is recorded. Detailed results are shown in Table 6.
| Function | SHO | SOA | WOA | PIO | SO | DBO | NOA | GWO |
|---|---|---|---|---|---|---|---|---|
| N/A | N/A | N/A | ||||||
| N/A | N/A | |||||||
| N/A | N/A | N/A | N/A | |||||
| F19 | N/A | 0.75632 | ||||||
| F20 | ||||||||
| F21 | 1 | |||||||
| F22 | N/A | N/A | ||||||
| F23 | N/A | |||||||
| F24 | ||||||||
| F25 | ||||||||
| F26 | N/A | N/A | N/A | N/A | ||||
| F27 | ||||||||
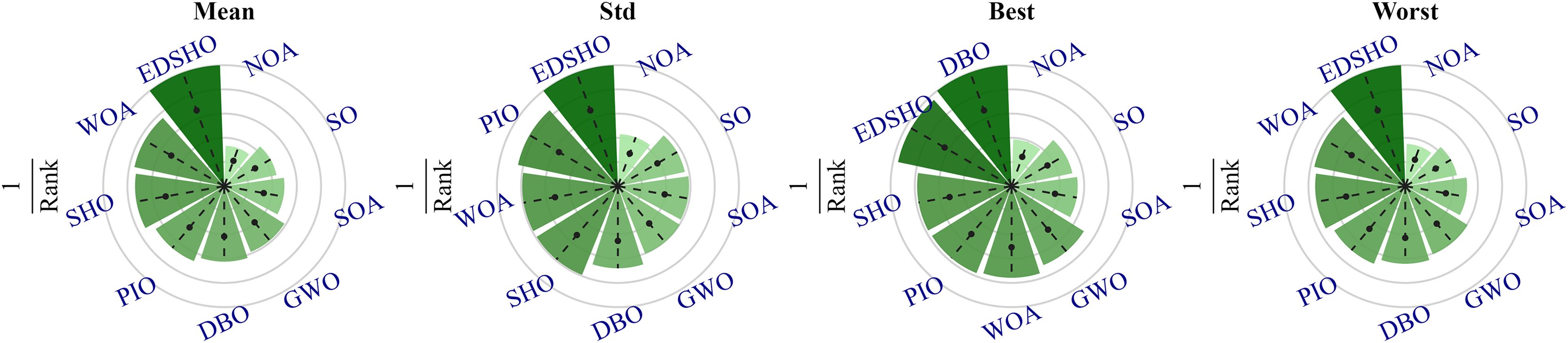
To further investigate the differences among the algorithms, a Friedman sum rank test was performed to rank their performance, as shown in Table 7, while Fig. 11 illustrates the relative performance levels of the algorithms. It is evident that EDSHO achieved excellent rankings in terms of average fitness, best fitness, and worst fitness values among all algorithms. Across all performance metrics, EDSHO consistently outperformed SHO, demonstrating the effectiveness of the improvements (significance level: ).
| Algorithm | Mean rank | Rank | Std rank | Rank | Best rank | Rank | Worst rank | Rank |
|---|---|---|---|---|---|---|---|---|
| EDSHO | 2.86 | 1 | 3.30 | 1 | 3.42 | 2 | 2.92 | 1 |
| WOA | 3.77 | 2 | 4.17 | 3 | 4.33 | 5 | 3.80 | 2 |
| SHO | 3.88 | 3 | 4.17 | 3 | 4.20 | 3 | 3.92 | 3 |
| PIO | 4.28 | 4 | 3.91 | 2 | 4.23 | 4 | 4.22 | 4 |
| DBO | 4.58 | 5 | 4.86 | 7 | 3.28 | 1 | 4.55 | 5 |
| GWO | 4.88 | 6 | 5.47 | 8 | 4.66 | 6 | 4.81 | 6 |
| SOA | 5.75 | 7 | 5.61 | 9 | 6.00 | 8 | 5.72 | 7 |
| SO | 6.47 | 8 | 5.84 | 6 | 6.39 | 9 | 6.70 | 8 |
| NOA | 8.55 | 9 | 7.67 | 10 | 8.48 | 10 | 8.36 | 9 |
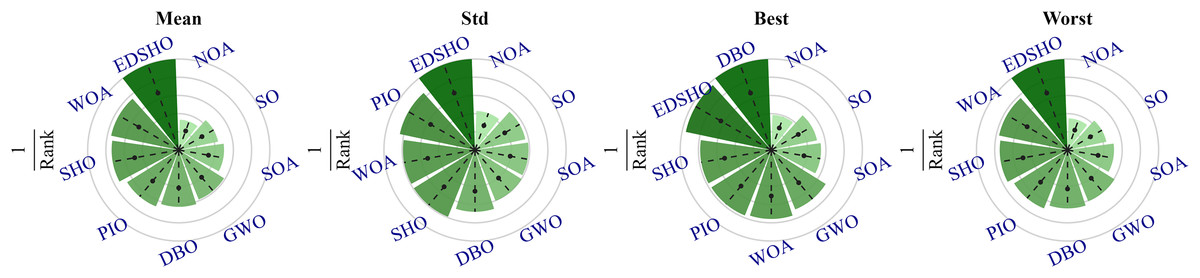
Figure 11: Algorithm ranking results.
{kind=link}
Ablation experiment
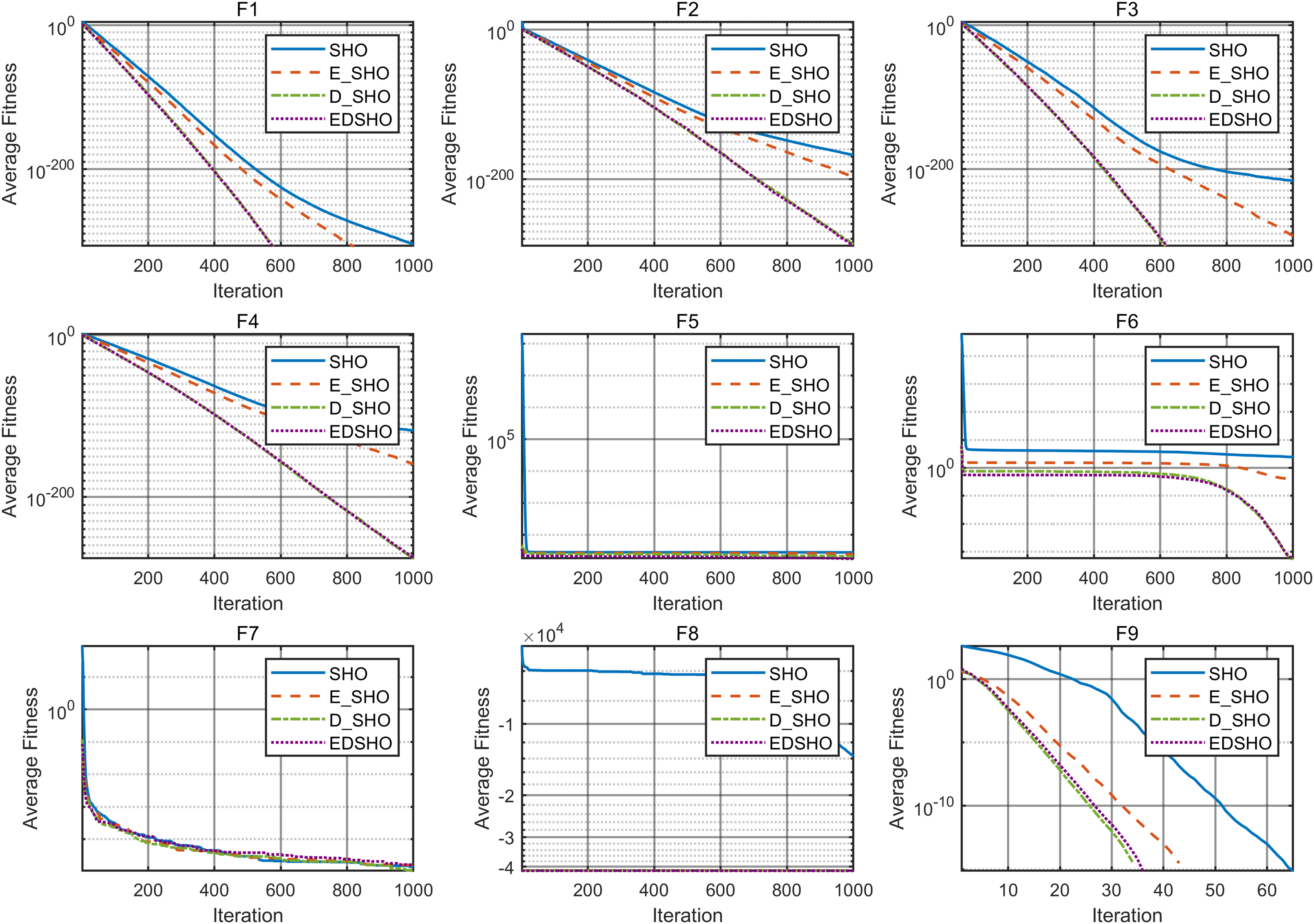
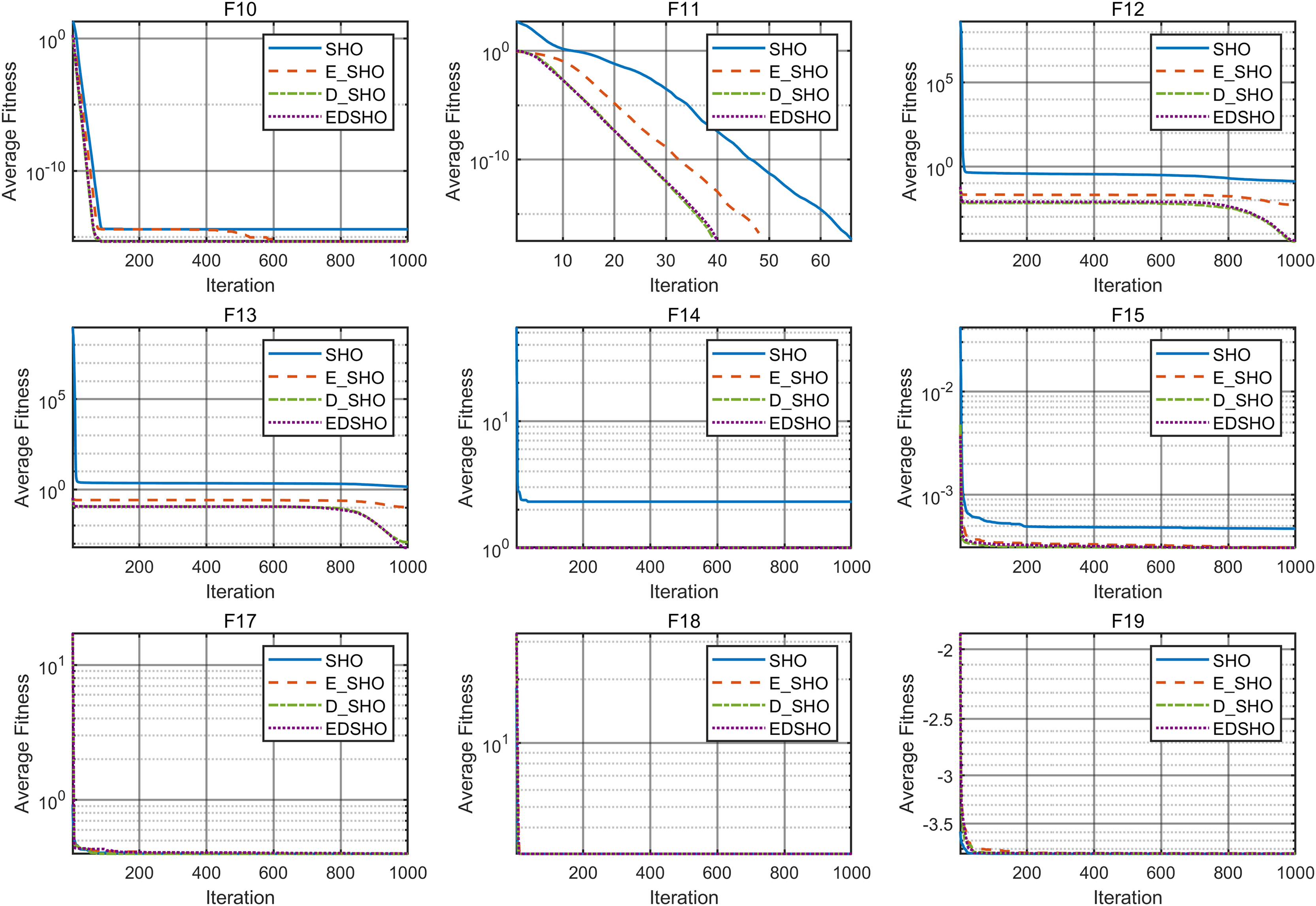
To further evaluate the contribution of each component, this article adopts ablation experiments to investigate the specific impact of each component on the SHO algorithm. E_SHO represents the SHO algorithm with the entropy-based crossover mutation strategy, while D_SHO represents the SHO algorithm with the Logistic-KNN Inertia Weight strategy. The experiments were conducted on 18 CEC2005 benchmark test functions, and the reported evaluation metrics include mean, best, worst, and standard deviation (std). The results are presented in Tables 8, 9, while the convergence curves are shown in Figs. 12, 13.
| Function | Metric | SHO | E_SHO | D_SHO | EDSHO |
|---|---|---|---|---|---|
| F1 | Mean | 9.31 10−306 | 0 | 0 | 0 |
| Std | 0 | 0 | 0 | 0 | |
| Best | 1.96 10−314 | 0 | 0 | 0 | |
| Worst | 1.02 10−304 | 0 | 0 | 0 | |
| F2 | Mean | 1.47 10−168 | 1.84 10−197 | 3.47 10−288 | 1.38 10−290 |
| Std | 0 | 0 | 0 | 0 | |
| Best | 6.19 10−172 | 5.27 10−204 | 3.33 10−295 | 6.88 10−306 | |
| Worst | 2.10 10−167 | 1.84 10−196 | 4.74 10−287 | 2.07 10−289 | |
| F3 | Mean | 4.49 10−217 | 7.69 10−294 | 0 | 0 |
| Std | 0 | 0 | 0 | 0 | |
| Best | 1.32 10−226 | 6.11 10−305 | 0 | 0 | |
| Worst | 6.26 10−216 | 1.01 10−292 | 0 | 0 | |
| F4 | Mean | 1.61 10−118 | 4.08 10−160 | 1.98 10−277 | 6.16 10−276 |
| Std | 5.77 10−118 | 1.18 10−159 | 0 | 0 | |
| Best | 8.69 10−122 | 6.65 10−166 | 1.30 10−284 | 7.93 10−287 | |
| Worst | 2.25 10−117 | 4.55 10−159 | 2.87 10−276 | 9.20 10−275 | |
| F5 | Mean | 2.77 101 | 2.44 101 | 2.06 101 | 1.31 101 |
| Std | 7.72 10−1 | 1.21 101 | 1.11 101 | 3.92 10−2 | |
| Best | 2.63 101 | 3.37 10−1 | 1.50 | 2.86 101 | |
| Worst | 2.88 101 | 5.35 101 | 2.80 101 | 1.75 101 | |
| F6 | Mean | 2.44 | 4.11 10−1 | 5.58 10−4 | 6.18 10−4 |
| Std | 5.46 10−1 | 3.57 10−1 | 2.21 10−4 | 3.42 10−4 | |
| Best | 1.26 | 6.59 10−2 | 2.53 10−4 | 2.10 10−4 | |
| Worst | 3.25 | 1.11 | 8.91 10−4 | 1.62 10−3 | |
| F7 | Mean | 1.42 10−5 | 1.62 10−5 | 1.07 10−5 | 1.66 10−5 |
| Std | 8.75 10−6 | 1.79 10−5 | 9.14 10−6 | 1.28 10−5 | |
| Best | 1.89 10−6 | 1.59 10−6 | 6.89 10−7 | 3.04 10−7 | |
| Worst | 2.79 10−5 | 7.28 10−5 | 3.40 10−5 | 4.22 10−5 | |
| F8 | Mean | −1.37 104 | −4.16 104 | −4.15 104 | −4.17 104 |
| Std | 8.82 102 | 4.06 102 | 3.21 102 | 2.98 102 | |
| Best | −1.48 104 | −4.19 104 | −4.19 104 | −4.19 104 | |
| Worst | −1.21 104 | −4.08 104 | −4.08 104 | −4.09 104 | |
| F9 | Mean | 0 | 0 | 0 | 0 |
| Std | 0 | 0 | 0 | 0 | |
| Best | 0 | 0 | 0 | 0 | |
| Worst | 0 | 0 | 0 | 0 |
| Function | Metric | SHO | E_SHO | D_SHO | EDSHO |
|---|---|---|---|---|---|
| F10 | Mean | 3.76 10−15 | 4.44 10−16 | 4.44 10−16 | 4.44 10−16 |
| Std | 9.17 10−16 | 0 | 0 | 0 | |
| Best | 4.44 10−16 | 4.44 10−16 | 4.44 10−16 | 4.44 10−16 | |
| Worst | 4.00 10−15 | 4.44 10−16 | 4.44 10−16 | 4.44 10−16 | |
| F11 | Mean | 0 | 0 | 0 | 0 |
| Std | 0 | 0 | 0 | 0 | |
| Best | 0 | 0 | 0 | 0 | |
| Worst | 0 | 0 | 0 | 0 | |
| F12 | Mean | 1.30 10−1 | 5.32 10−3 | 3.41 10−5 | 3.99 10−5 |
| Std | 6.29 10−2 | 6.40 10−3 | 2.23 10−5 | 1.99 10−5 | |
| Best | 4.98 10−2 | 1.01 10−4 | 4.69 10−6 | 1.38 10−5 | |
| Worst | 2.68 10−1 | 1.86 10−2 | 8.75 10−5 | 8.97 10−5 | |
| F13 | Mean | 1.42 | 1.07 10−1 | 1.22 10−3 | 5.85 10−4 |
| Std | 2.84 10−1 | 9.52 10−2 | 2.86 10−3 | 2.88 10−4 | |
| Best | 7.73 10−1 | 3.52 10−6 | 2.27 10−4 | 2.02 10−4 | |
| Worst | 1.94 | 3.55 10−1 | 1.16 10−2 | 1.32 10−3 | |
| F14 | Mean | 2.31 | 9.98 10−1 | 9.98 10−1 | 9.98 10−1 |
| Std | 2.52 | 7.96 10−16 | 3.80 10−16 | 2.78 10−16 | |
| Best | 9.98 10−1 | 9.98 10−1 | 9.98 10−1 | 9.98 10−1 | |
| Worst | 1.08 101 | 9.98 10−1 | 9.98 10−1 | 9.98 10−1 | |
| F15 | Mean | 4.72 10−4 | 3.11 10−4 | 3.08 10−4 | 3.08 10−4 |
| Std | 4.02 10−4 | 3.45 10−6 | 4.39 10−8 | 3.00 10−7 | |
| Best | 3.08 10−4 | 3.08 10−4 | 3.08 10−4 | 3.07 10−4 | |
| Worst | 1.49 10−3 | 3.17 10−4 | 3.08 10−4 | 3.09 10−4 | |
| F16 | Mean | 3.98 10−1 | 4.00 10−1 | 3.98 10−1 | 4.01 10−1 |
| Std | 2.94 10−5 | 2.98 10−3 | 5.74 10−4 | 5.38 10−3 | |
| Best | 3.98 10−1 | 3.98 10−1 | 3.98 10−1 | 3.98 10−1 | |
| Worst | 3.98 10−1 | 4.08 10−1 | 4.00 10−1 | 4.18 10−1 | |
| F17 | Mean | 3.00 | 3.00 | 3.00 | 3.00 |
| Std | 8.10 10−12 | 2.08 10−8 | 2.37 10−8 | 2.24 10−8 | |
| Best | 3.00 | 3.00 | 3.00 | 3.00 | |
| Worst | 3.00 | 3.00 | 3.00 | 3.00 | |
| F18 | Mean | −3.86 | −3.85 | −3.86 | −3.86 |
| Std | 4.08 10−3 | 2.05 10−3 | 2.93 10−3 | 3.63 −10−3 | |
| Best | −3.86 | −3.86 | −3.86 | −3.86 | |
| Worst | −3.85 | −3.85 | −3.85 | −3.85 |
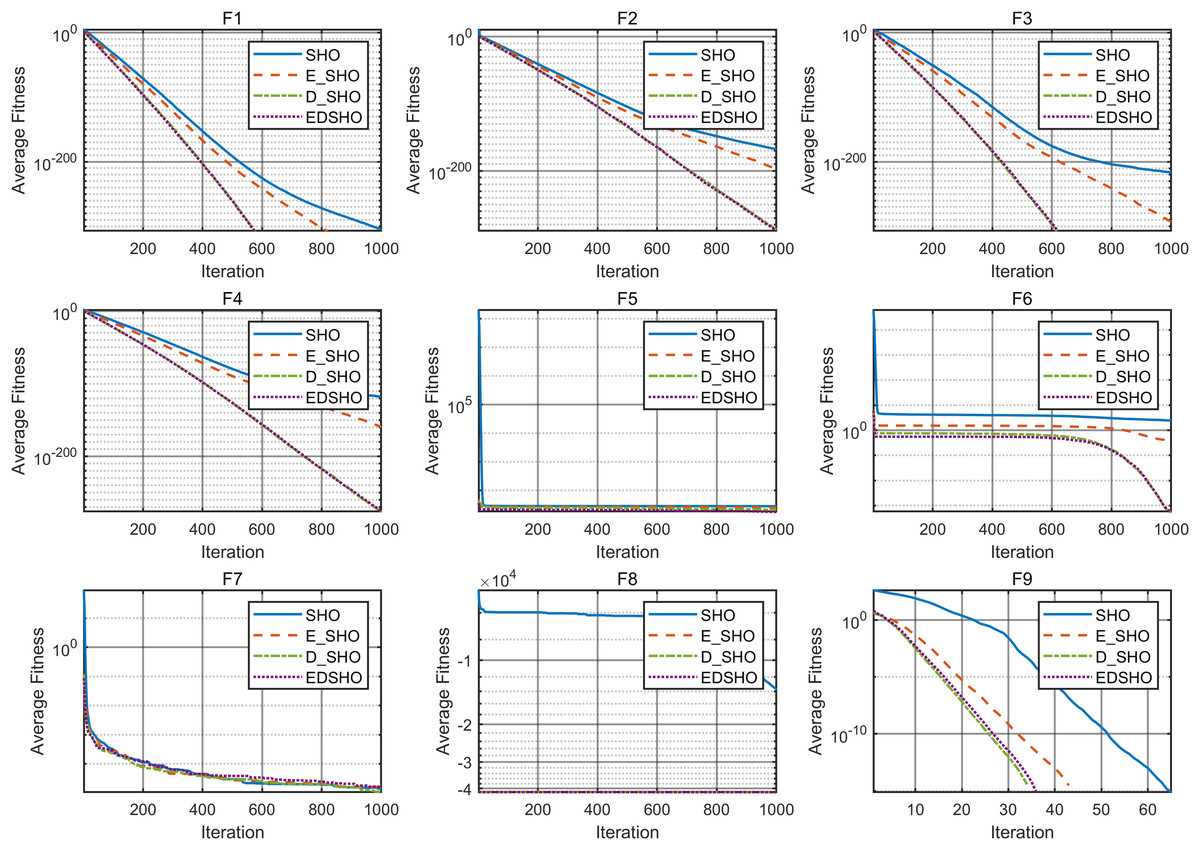
Figure 12: Ablation experiment convergence curve F1–F9.
{kind=link}
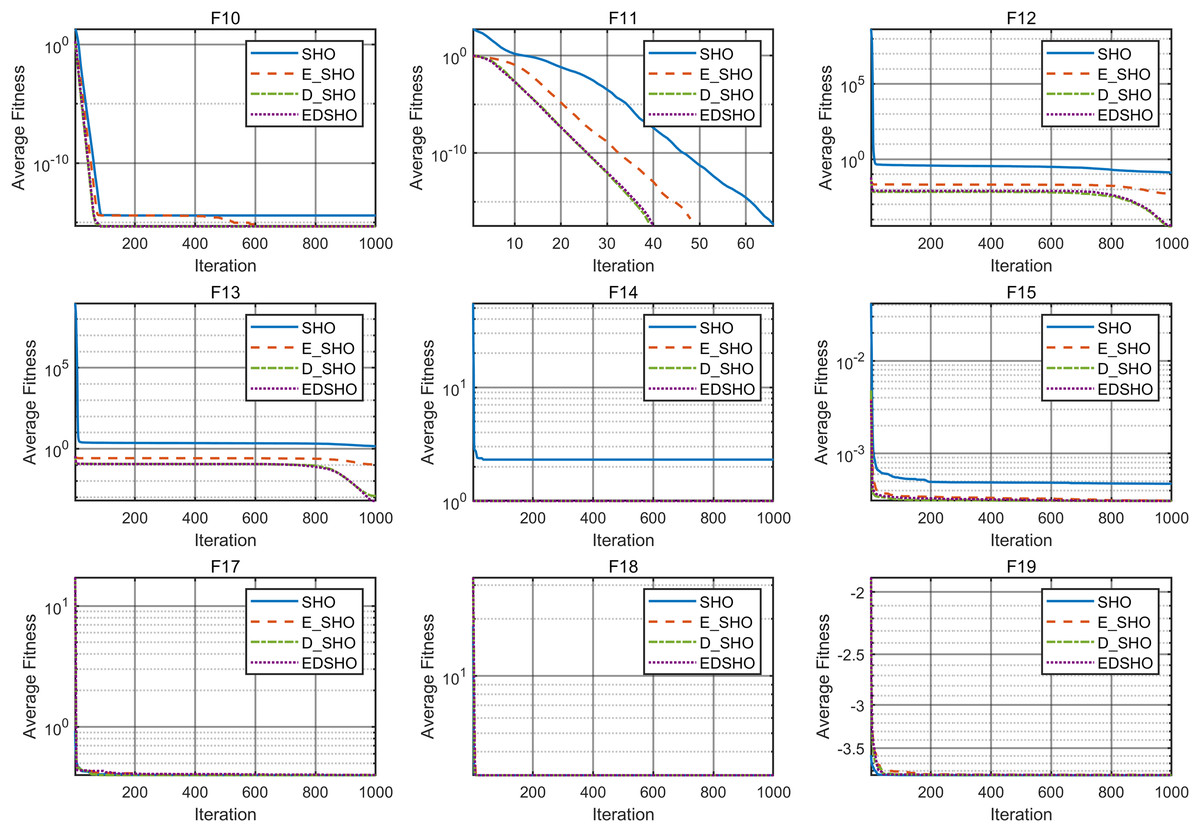
Figure 13: Ablation experiment convergence curve F10–F18.
{kind=link}
The results show that, for most test functions, each method significantly improves the original algorithm, leading to notable enhancements in both convergence speed and optimization accuracy. Furthermore, the combination of these two methods achieves higher efficiency and stronger stability during the optimization process. On the one hand, the improvement in efficiency is reflected in the algorithm’s ability to approach the global optimal solution more quickly, reducing redundant computations and resource consumption. On the other hand, the enhancement in stability ensures consistent and reliable results across multiple runs, even when dealing with complex multimodal problems, effectively avoiding local optima.
Conclusion and outlook
Conclusion
In this study, we propose two innovative optimization strategies: the Entropy Crossover Strategy and the logistic-KNN Inertia Weight. The logistic-KNN inertia weight addresses the limitations of traditional inertia weight frameworks by transitioning from an iteration-based weight assignment to a distance-based framework, where inertia weights are determined based on the distance between individuals and the optimal point. This approach transforms the mapping from “iteration-to-weight” ( ) to “distance-to-weight” ( ). Additionally, the study introduces “entropy” as an information measure to quantify the information content of parent individuals, refining the traditional random crossover mutation strategy. This enables offspring to inherit advantageous information from the previous generation while retaining a degree of randomness.
To validate the effectiveness of these strategies, they were applied to improve the SHO, resulting in EDSHO. Convergence analysis and benchmarking on 31 test functions selected from CEC2005 and CEC2021 demonstrate that EDSHO outperforms comparison algorithms in terms of convergence speed and solution accuracy, while also exhibiting significant robustness. Statistical analysis using the Wilcoxon rank sum test further confirms the statistical significance of these improvements, and the Friedman rank test quantifies EDSHO’s rankings, consistently placing it among the top-performing algorithms. Moreover, ablation experiments were conducted to assess the contributions of each strategy individually, and the results indicate that both strategies significantly enhance SHO’s performance, further substantiating the effectiveness of the proposed approaches.
Outlook
Given the powerful optimization capabilities of the proposed method, it can be applied not only to more single-objective metaheuristic models but also extended to multi-objective optimization models, with broad applications across various real-world domains. For instance, it can be integrated with deep learning models such as Informer or Transformer to optimize hyperparameters, thereby enhancing performance in time series forecasting, classification, and image recognition. In intelligent scheduling and route planning, this method can optimize logistics delivery routes and vehicle dispatch strategies. In industrial manufacturing, it can refine processing parameters to improve efficiency and reduce costs. In the healthcare field, it can be used for medical image processing and drug molecule optimization. Furthermore, it holds significant potential in energy management, financial model optimization, robotic control, and ecosystem management, offering effective solutions to complex problems and driving technological advancements.
In future research, applying this method to optimize more metaheuristic algorithms and addressing the following critical real-world challenges will be of great importance: (1) optimizing ISCSO engineering structural problems (Kazemzadeh Azad & Kazemzadeh Azad, 2023) to empirically assess the role of the proposed metaheuristic optimization algorithm in structural optimization; (2) optimizing the hyperparameters of neural networks, such as the number of hidden neurons and learning rate, to improve model performance; and (3) extending this method to multi-objective optimization algorithms to further enhance its practical value and application potential. These research directions will be pursued in future work, along with further in-depth discussions.