
RARE: right algorithm for the right errand; a multi-model machine learning-based approach for tourism routes and spots recommendation
- Published
- Accepted
- Received
- Academic Editor
- Bilal Alatas
- Subject Areas
- Adaptive and Self-Organizing Systems, Agents and Multi-Agent Systems, Algorithms and Analysis of Algorithms, Autonomous Systems, Spatial and Geographic Information Systems
- Keywords
- Travel routes, Tourism recommendation, Machine learning, Multi-model tourism system
- Copyright
- © 2025 Luo
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. RARE: right algorithm for the right errand; a multi-model machine learning-based approach for tourism routes and spots recommendation. PeerJ Computer Science 11:e2791 https://doi.org/10.7717/peerj-cs.2791
Abstract
With the globalization of the economy, tourism has emerged as a significant sector of entertainment and economic growth. Optimizing tourist attractions and routes has become crucial in modern travel planning, driven by the increasing demand for personalized recommendations. However, traditional static route-based algorithms struggle to adapt to the rapid expansion of the tourism industry, necessitating the development of dynamic, machine-learning-driven solutions. This study introduces a novel tourism recommendation system integrating multiple machine learning algorithms to provide personalized tourist spot and route recommendations. The proposed approach models the tourist map as a 2D grid of interconnected nodes, allowing for dynamic and adaptive recommendations. The framework employs long short-term memory (LSTM) for spot relevance prediction, support vector machine (SVM) for spot name classification, and depth first search (DFS) for optimal route generation. A k-means clustering approach is also utilized to designate a cluster leader (CL) responsible for managing node information within a specific zone. By inputting a simple textual query, tourists receive optimized travel routes tailored to their preferences, incorporating relevant attractions. The model is implemented in a Python-based environment and evaluated using an augmented Travel Recommendation dataset from Kaggle. Experimental results demonstrate the model’s effectiveness in enhancing tourism planning and user experience, showcasing its potential for advancing intelligent tourism solutions.
Introduction
Tourism is not a mere hobby; it is a form of entertainment that enhances the quality of people’s lives (Lyu & Han, 2022). Tourists prefer to visit scenic and historical spots for serenity, solace, non-formal education, revolutionary feelings and adventurous experiences. Whether it is honeymoon tours, island tours, or red tourism, people prefer to enjoy their leisure fully, full of natural calmness and free from worldly worries. However, to endure a calm and congenial trip, route selection based on personal priorities is of utmost importance (Flisberg et al., 2012). Traditionally, tourists relied on guidebooks, magazines, and static websites for travel recommendations. These methods lag far behind in addressing personalized priorities and dynamic demands of modern-day tourism. In the current day and age, machine learning (ML) technology may be used to revolutionize tourism, mainly to select optimal travel routes.
With the advent of internet technology, easy availability of information has become the norm of the day. This unprecedented advancement has made a remarkable surge in the tourism industry. The progress in tourism is further fueled by the emerging AI methods, which make tourism-related data ubiquitous and ensure personalized route planning (García-Madurga & Grilló-Méndez, 2023). Consequently, nowadays, tourists are privileged with many options in terms of route selection, availability of facilities and other prudent options. However, besides various challenges, man’s search for an effortless model to exploit personal preference, budgetary consideration, and time constraints has yet to be fulfilled (García-Madurga & Grilló-Méndez, 2023).
Building on the success of machine learning (ML) in education, healthcare, and sports, advanced AI models can revolutionize the tourism industry by providing personalized travel recommendations. This research extends the role of AI in tourism by integrating long short-term memory (LSTM), support vector machine (SVM), and k-means clustering to generate travel routes based on tourists’ preferences for attractions. The tourist map is modeled as a 2D grid of interconnected nodes, utilizing mental map (MM) and distance vector (DV) structures of Dijkstra’s presentation. Since the dataset lacks distance information, additional distance and direction columns are incorporated before training. Dijkstra’s algorithm is employed to calculate distances between nodes. A k-means clustering approach selects a cluster leader (CL) responsible for managing attraction data within a given zone, with CLs dynamically sharing updates.
At the CL level, an LSTM network is trained on dominant attraction data, while an SVM classifier predicts spot names from spot features. Given a simple spot attraction query, LSTM generates attraction-related sequences, which are then processed by SVM to predict the optimal target spot name. The depth first search (DFS) algorithm then traces possible routes from the source to the target destination.
The model is implemented in Python using an augmented Travel Recommend Kaggle’s dataset from Kaggle and evaluated on 52 randomly selected tourism queries, achieving a promising accuracy of 86%. These results validate the effectiveness and applicability of the proposed approach in enhancing personalized travel planning. The schematic representation of the RARE method is shown in Fig. 1.
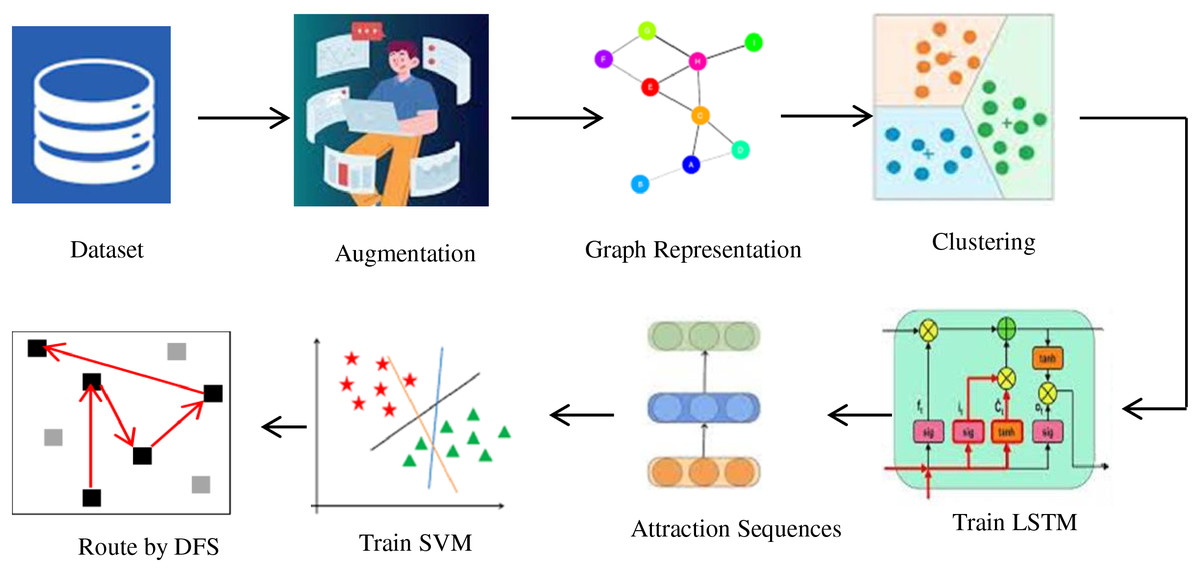
Figure 1: Schematics of the RARE method.
{kind=link}
Rest of the article is structured into five sections. A literature review is covered in ‘Literature Review’. ‘Methodology’ is about the detailed methodology, whereas implementation details are presented in ‘Implementation Details’. Experimentation and evaluation are reported in ‘Experimentation and Result Analysis’. The last section, the ‘Conclusion’, concludes the article with future research directions.
Literature review
With the easy availability of transportation facilities, tourism has grown to the level of a beneficial industry. The industry plays a significant role in the economic growth of the offering country (Malik & Kim, 2019). The effortless accessibility of tourist attraction information and luxuries enhances tourism (Basiri et al., 2018). The location attainment technologies and social and cellular networks have contributed to the uplifting of the tourism industry (Zhu et al., 2019; Cao et al., 2021). However, as mentioned in Basiri et al. (2018), challenges in tourism are yet to be resolved. The key challenges include how to tour, what to tour, and where to tour, specifically whence the destination is unfamiliar (Du et al., 2019). The prominent issue amthemu’. A number of research works have been proposed to cater to ‘how to tou’. Besides the traditional approaches, data mining techniques have been utilized to help tourists ‘how to tou’ (Yuan et al., 2016).
Due to individual differences, tourists’ preferences for various tourist attractions are different (Bao et al., 2015; Hang et al., 2018). Keeping in view the tourist preference, route recommendations can be categorized into destination recommendations and route recommendations. Where the former focuses on a single attraction satisfying the tourists’ interest, the latter is about suggesting multiple routes that suit a tourist’s interest. In either case, suggesting suitable routes for multiple attractions is challenging (Pu, Chen & Hu, 2012). Most of the conventional path-planning recommendation approaches are based on the shortest path (Pu, Chen & Hu, 2012). A number of methods have been suggested in this scenario, including the A* approaches (Singh et al., 2018; Song, Liu & Bucknall, 2019), particle swarm optimization (PSO) (Pongchairerks & Kachitvichyanukul, 2016), and Genetic Algorithm (GA) (Ghosn, Drouby & Harmanani, 2016), ACO algorithm (Mirjalili, Dong & Lewis, 2020), simulated annealing (SA) (Demiral & Işik, 2020), and graph-based algorithm (Skinderowicz, 2022). The vehicle routing planning problem (Bell & McMullen, 2004) and traveling salesman problems (Zou, Yang & Zhao, 2024) are also pertinent to mention in this regard.
Recommendation systems based on user textual data have been suggested to facilitate tourists (Du et al., 2019). Similarly, the system of Zhang et al. (2012) works on travel notes to help tourists, whereas that of Chen et al. (2025) uses tourist records. The research work of Ye et al. (2011) is about improving classification preference by using textual and geographical information. The information cumulative approach of Qiao et al. (2024a) extracts data from tourism-related blogs to easily identify attraction of interest. The work of Yuan et al. (2016) utilizes the big data mining approach to trace the most popular spot in a region. The Photo2Trip method proposed in Lu et al. (2010) exploits photos that are geotagged adequately for recommending travel routes. The pattern-ware system of Wei, Peng & Lee (2013) searches out the top K paths to scenic spots and recommends the optimal one. The framework of Hu et al. (2015) recommends urban attractions using the DBSCAN clustering algorithm. The K+V-DBSCAN algorithm in Pla-Sacristán et al. (2019) is suggested to accurately identify a particular zone’s most significant tourist attractions. The context-aware system of Majid et al. (2013) exploits geotagged graphical data to recommend places based on the interest of tourists. Similarly, the point-of-interest-based system of Zuo et al. (2024) utilizes sentimental attributes for attraction recommendation. Tourists prefer to use personalized recommendation systems (Santos et al., 2019). Therefore, collaborative techniques have also been utilized for effective attraction recommendations (Bin et al., 2019). Such systems give tourists various friendly options to improve recommendations (Park, Park & Hu, 2021). A fuzzy ontology method is proposed in Abbasi-Moud et al. (2022). The method analyzes the tourists’ reviews for future consideration. The model of Hong & Jung (2021) analyzed the reviews and rated significant attractions. The stability and performance of the model are assessed correctly as well. The ant colony optimization (ACO) method of Sun et al. (2022) recommends optimal routes by using travel pattern sequences.
Since the last decade, the techniques of machine learning (ML) are been widely utilized in the realm of tourism. For systematic analysis of tourism data, the support vector regression (SVR) model is used in Yang & Ren (2024). Similarly, the models based on multilayer perceptron (MLP) are used in Batista e Silva et al. (2018), Li & Law (2020) for analysis and minimizing the occurrences of errors in tourism-related information. The cutting-edge neural network (NN) was successfully implemented by Zhang & Tang (2022) to predict travel routes. The convolutional neural networks (CNN) based approach of Logesh et al. (2020) recommends attractions after analyzing the sentiment of the tourists. The model needs the necessary dataset to enhance the effectiveness of the recommendation system. Cheng (2021) proposed a commendable travel route commendation system using the distance matching technique (Raees & Ullah, 2019). The system considers preference or the user interests to suggest an appropriate destination. The hierarchical multi-clue fusion (HMCF) based system of Yang et al. (2018) exploits user-generated content (UGC) for precise prediction. The model improves the accuracy rate in tourism and enhances travel route recommendations. Similarly, a collaborative mining and filtering process (CMFP) based method is proposed in Nan & Wang (2022) to reduce the mining cost in travel recommendations. The Bidirectional Encoder Representations from the Transformers (BERT) model of Wen, Liang & Zhu (2023) are based on sentiment analysis, whereas the LSTM networks (Law et al., 2019) make use of time series forecasting in tourism. The model effectively traces long-term dependencies for demand forecasting in the tourism domain. Though most of the recommendation systems in the literature focused on route recommendation, there is a pressing need for an effective tourism spot recommendation system based on user’s interest, hence this research.
Methodology
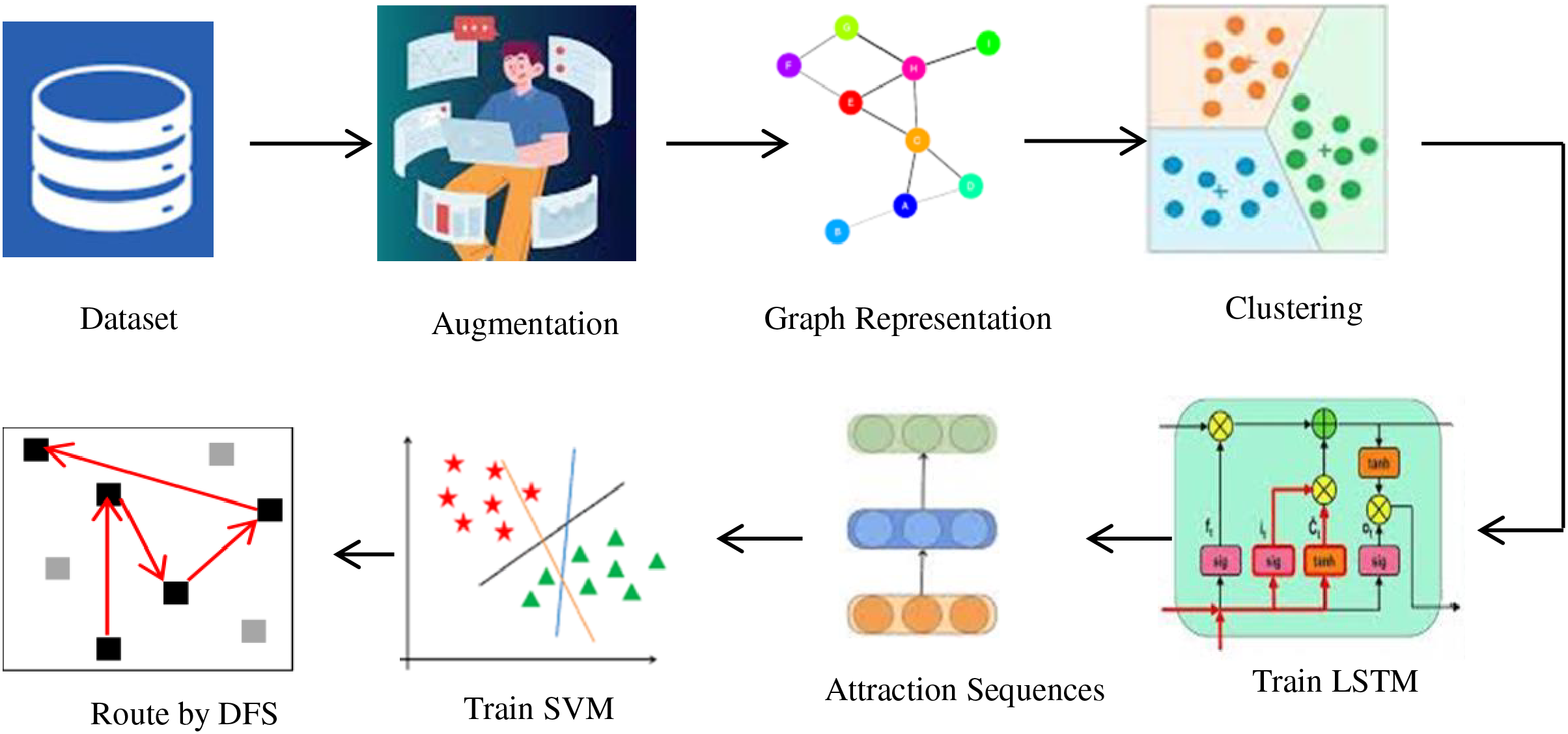
To assure tourists’ satisfaction, the proposed method recommends tourist spots and routes based on a single-token textual input. The method intends to enhance the tourism experience by presenting an optimized route map based on personal preference. The technique utilizes machine learning classifiers to perform each subsequent process effectually. The system’s algorithm is shown in Fig. 2, whereas details about each process are presented in the following sub-section.

Figure 2: The rare algorithm.
{kind=link}
Preceded by graph representation, a CL is selected while nodes in the region share their information with the CL. The CL keeps a record in a CSV file, which contains each attraction’s information. for of a particular node with spot name SNj; . At the CL level, LSTM is trained by the resources/facilities available in the region. Spot name is predicted by feeding the generated word-level sequences of LSTM to the trained SVM. The benefit of using LSTM at CL is that it provides information on related attractions at the nearest tourist spots. Suppose a tourist searches for a facility , the LSTM will provide a list of facilities; . The set of attractions or facilities is then forwarded to SVM to predict the spot name for onward operation.
Grid representation of tourist spots
A tourism map is treated as a graph G, where where the nodes V represents the visiting spots, E the edges and W is the weights (distance in Km). A path represents the possible permutation between the nodes and . By utilizing the Dijkstra’s Algorithm, the distance between node , and is calculated as,
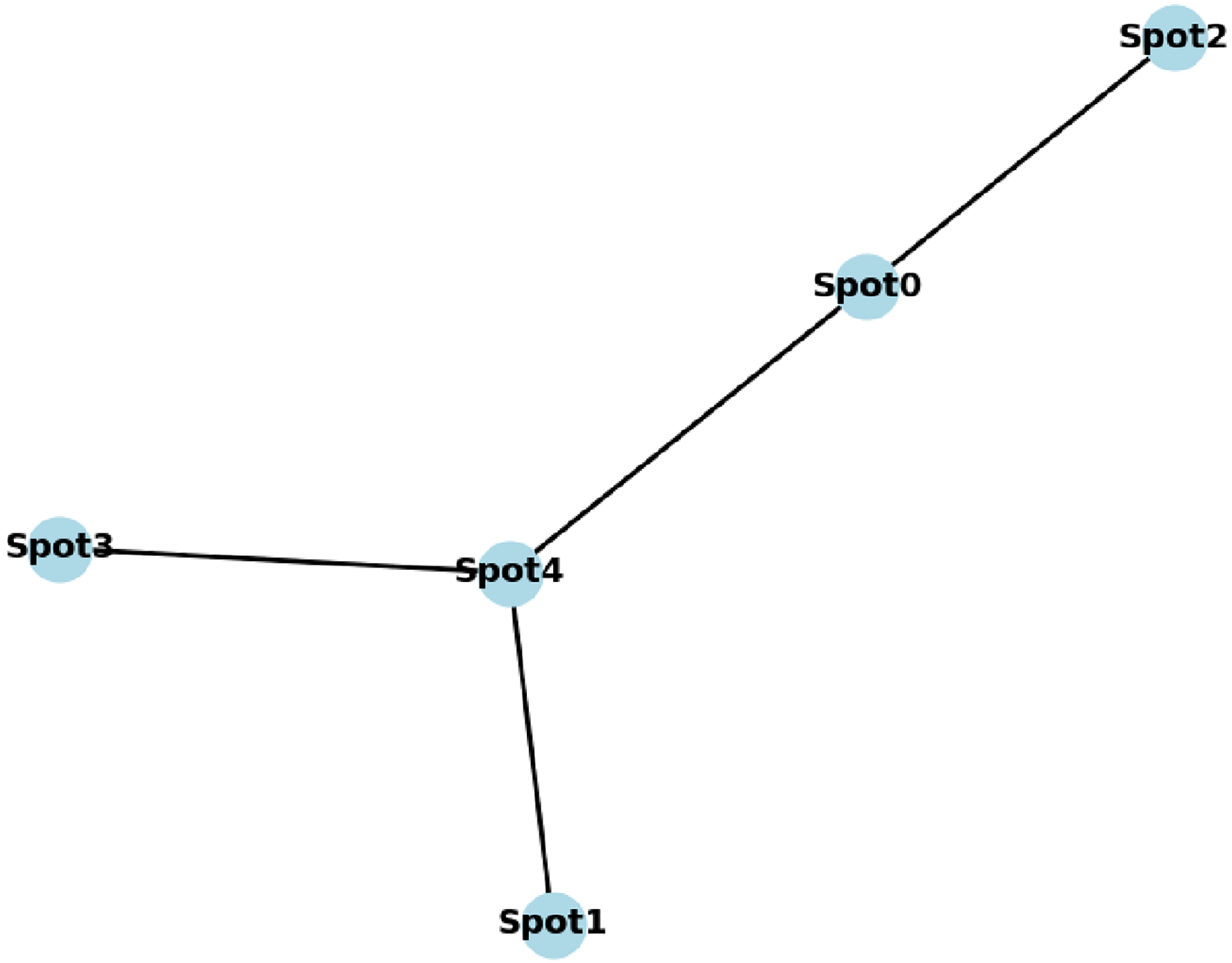
(1) where is the weight between the edge and . A simple graph illustration of the following list of connected tourism spots is presented in Fig. 3.
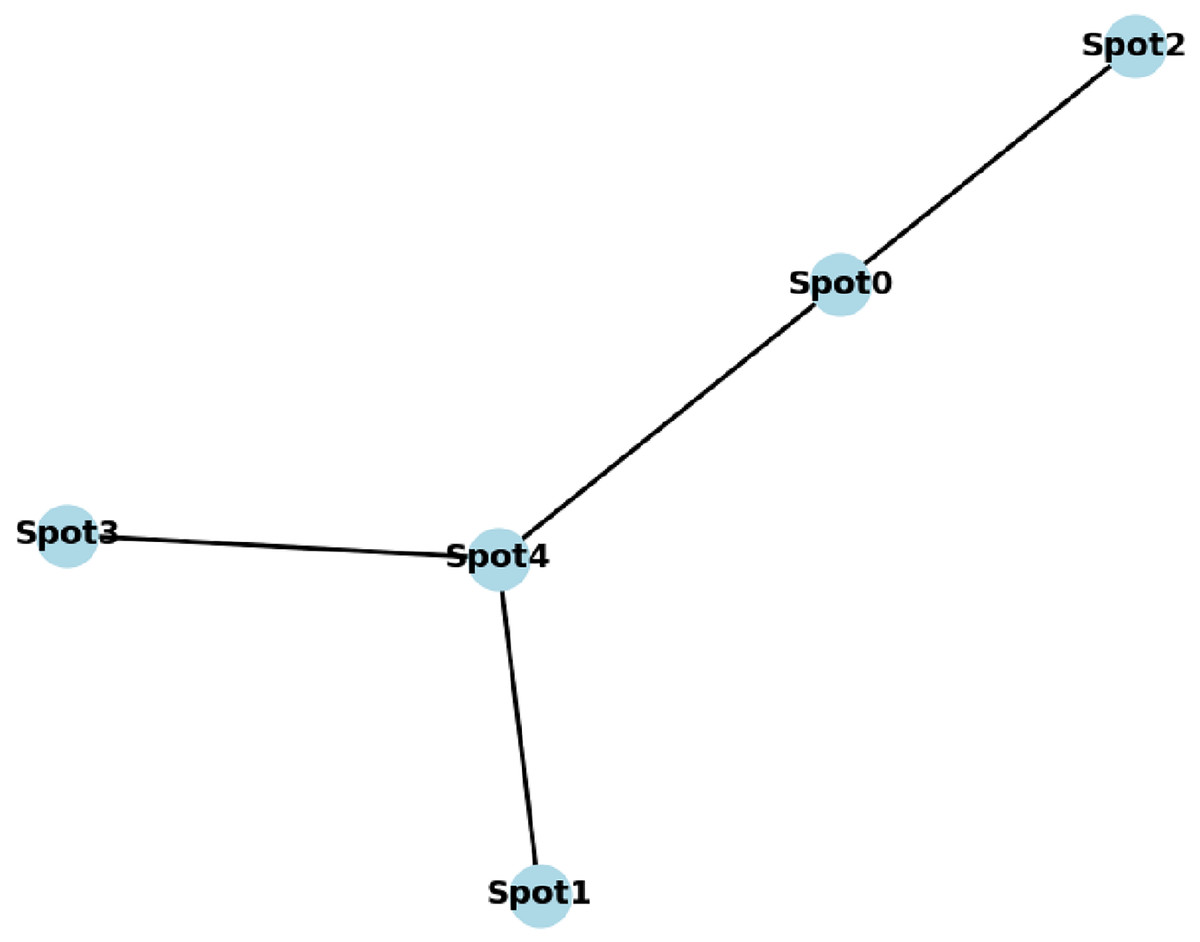
Figure 3: A generated graph of five connected nodes.
{kind=link}
[(‘Spot1’, ‘Spot4’), (‘Spot0’, ‘Spot4’), (‘Spot0’, ‘Spot2’), (‘Spot4’, ‘Spot3’)]
Determining node-to-node weights depends on examining a basic 3 × 3 tourist spot grid represented by nodes. The calculated weights for nodes represent edge connections between nodes in the graph. Thus, node v1 at (0,0) maintains a weight value of five units when connected to node v2 at (0,1), as well as a link weight of three units between node v2 and node v3 at (1,1). We begin the algorithm at node v1 while setting its distance to 0, then compute the minimum routes to neighboring nodes by changing their distance values according to weight information. The system uses Dijkstra’s algorithm to discover the most direct path between v1 (0,0) and v9 (2,2) by evaluating several nodes and choosing the shortest connection. This algorithm’s shortest distance tracking capability determines an optimal v1-to-v9 path through successive step progression.
Cluster leader selection
Detection of clustering patterns using k-means proves effective because it efficiently manages substantial dynamic datasets like those found in tourism data. Unsupervised learning algorithm k-means partitions data into separate clusters based on data similarity distributions. This method’s simplicity and computational power suit applications that need rapid and efficient clustering solutions while processing datasets with frequently changing features, like tourist preferences and regional features. Despite the dynamic characteristics of tourism data, k-means analyzes the data consistently into distinct clusters, which help identify key interests, making this method a strong selection for our system. With the k-means clustering approach, a CL node is selected for a region containing k tourist spots. In the process of finding CL, initially k centroids- are set to a visiting spot which in turn is assigned to the nearest cluster centroid ( ) using the given criteria,
(2) where represents Euclidean distance (Li et al., 2023). Next, the mean of the centroid is updated to accommodate the newly added spot information,
(3) where represents the number of nodes in the cluster. The convergence is checked to ensure that the centroid has no change or is negligible. For this purpose, convergence is achieved as,
(4)
In the given equation, is the number of iterations and being the threshold value. Our approach used empirical cross-validation testing on the tourism dataset to select the threshold value ( ) for the k-means clustering algorithm. Our study performed cluster analysis under various settings while measuring cluster outcomes to confirm their agreement and suitability for tourist preferences. The tested threshold , 0.5, served as the optimal value, generating clusters with high accuracy and efficient computation demands.
It is assumed that all the nodes of a cluster, Have their own attraction and facilities information except the distance measured from the rest of the nodes. Though the user may feed explicit distance information, Dijkstra’s algorithm may be utilized to find out the distance measures, whereas all the nodes Shared their information with the CL. The dataset with rows and columns at the is updated with the new feature and is inserted at the second last column; . For this purpose, is split into sub-matrices with columns and with columns as;
(5) (6)
To get the resultant dataset , , the new column and are concatenated as;
(7)
Tracing relevant facilities by LSTM
In the proposed method, the deep learning-based approach is followed to recommend attraction-related information in the textual entry of a tourist. The method predicts travel preferences after analyzing the input query by utilizing the sequence modeling and attention mechanisms. LSTM is particularly exploited to suggest optimized tourist attraction facilities based on fashion preferences. At the CL level, LSTM is trained based on the attraction information offered by region nodes. Taking the input token from the tourist, LSTM presents related attraction information of the tourist spots, as shown in Fig. 4. The output of LSTM is further fed to SVM to name the appropriate tourist spot.
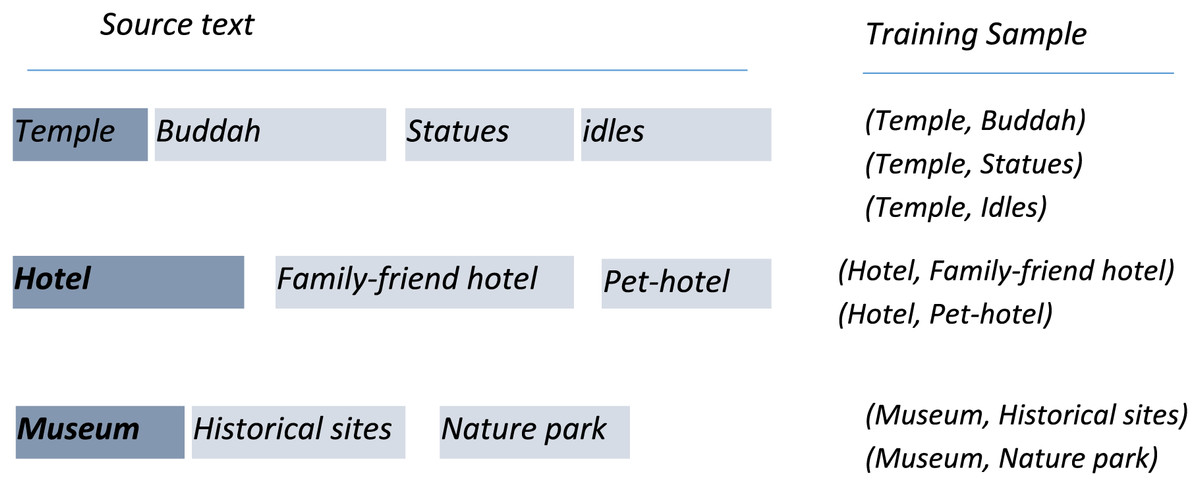
Figure 4: Attraction sequence prediction by LSTM.
{kind=link}
LSTM is the enhanced recurrent neural network (RNN) deep learning model where the vanishing gradient issue is overcome by backpropagation (Karmiani et al., 2019), where RNN is an artificial neural network (ANN). In RNN, the nodes are connected to form a temporal sequence directed graph. At each stage, the output of RNN is to coincide to generate new output. However, the network suffers from the issue of preserving the extensive past information (Supakar, Satvaya & Chakrabarti, 2022). LSTM is the modified and advanced form of RNN (Supakar, Satvaya & Chakrabarti, 2022) with the ability to back-propagate to retain a large number of related information If” is the hidden node at a particular time instance t, its output Oh t is given as
(8) where, is the activation function at node h and is the bias value at a particular node’’. and represent the total number of inputs and the number of nodes in a layer, respectively. is the ith input occurring at node at time , connection weight between input ‘i’ and node ‘h’. Similarly, is the connection weight between the nodes h and m, which belong to the same layer, whereas is the output of at m node in time t − 1.
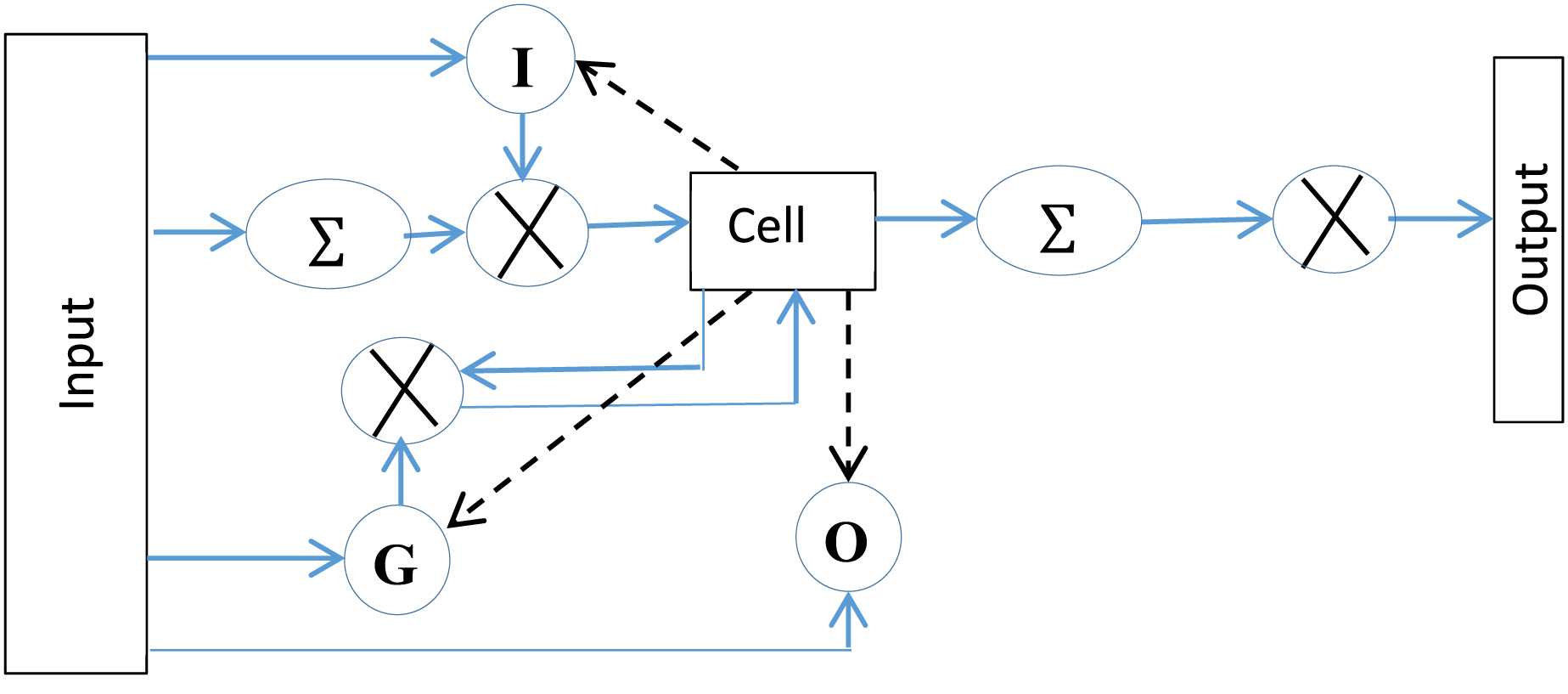
A simple architecture of LSTM is represented by three gates with a memory cell. The gates control information to and from the cell. The input gate manages the input of the flow of information into the memory. The forget gate controls how long information be retained in the cell, whereas the output gate is responsible for generating the output of the LSTM. The working of LSTM, as depicted in Fig. 5 is represented mathematically as follows,
(9) (10) (11) (12)
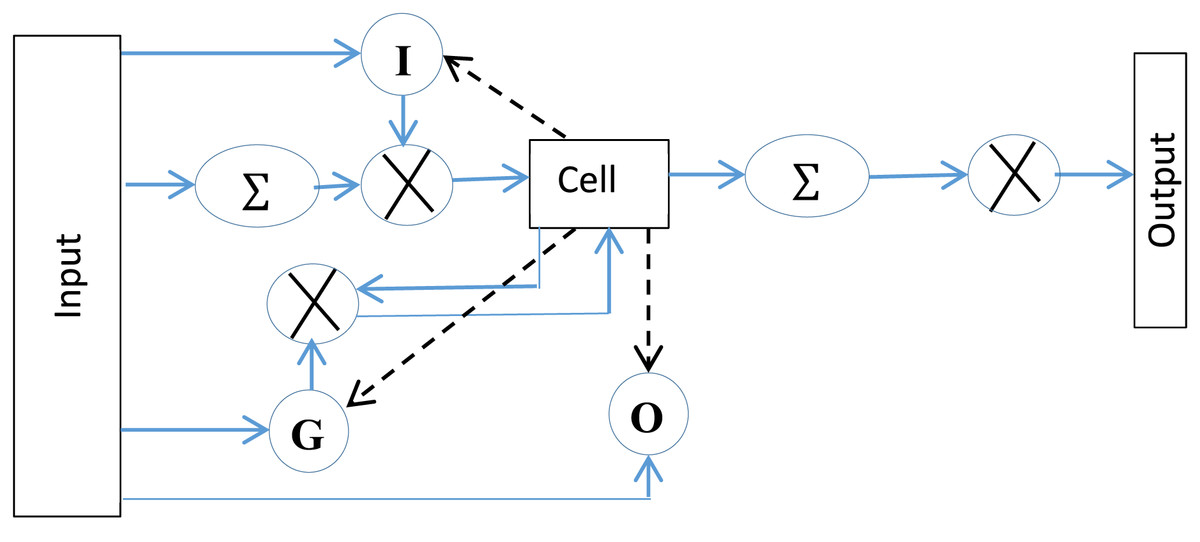
Figure 5: The standard LSTM structure, represents activation function.
{kind=link}
In the given equations, input, forget, and output gates are represented by I, F and O, respectively. Weight matrices are represented by W (e.g., , , are weight matrices for input, forget and output neuron, respectively). The previous state of LSTM, at timestamp , is represented by whereas the bias value for a gate is represented by . The network’s output activation functions (softmax) is represented by . Similarly, is the cell’s hyperbolic tangent activation function. and is the matrix weights of the connections and recurrent connections respectively to the memory cell of LSTM. Af, Ai and Ct are the activation functions of the memory cell’s forget gate, input gate and state vector. b represents bias it may be bi, bf, bo, or bc which shows bias at input, forget, output gate, or at the memory cell, respectively. The operation (°) represents the Hadamard product.
Tracing of tourist Spot by SVM
The SVM classifier is one of the effective supervised ML models used for regression and classification. In its simple form (binary classification), the model intends to find a hyperplane between two classes with class labels for the given training dataset where the feature vector. The hyperplane is given as,
where is the weight and the bias.
For an unknown input point , the decision function f( ) is given as,
(13)
In case of high dimensional data, the decision function be as,
(14) where is the Lagrange multiplier.
In the proposed method, the SVM is trained by features strongly correlated with the spot name. The attraction facilities of tourist spots- are taken as features, whereas the names of spots as labels; . The features, as found out by LSTM, are fed to the SVM to prompt the most appropriate tourist spot name, . Multiple elements determine the LSTM algorithm’s decreasing accuracy during extended sequence length prediction. The algorithm’s nature makes it difficult to process elaborate sequences because the vanishing gradient problem affects it even with its built-in long-range dependency capabilities. Longer sequences cause the model to lose its ability to capture important sequence data from previous parts, making predictions less precise. The escalating number of sequence configurations leads to improved model overfitting, which degrades the model’s ability to adapt to new data.
Routes recommendation by DFS
The effective DFS is exploited for route recommendation (Hagerup, 2020; Gers & Schmidhuber, 2001; Gedela & Karthikeyan, 2022; Ni et al., 2021; Li et al., 2021; Qiao et al., 2024b; Zeng et al., 2015; Paulson & Tzanavari, 2003; Abadi et al., 2016; Rafay, Suleman & Alim, 2020). The algorithm offers a comprehensive exploration of all possible routes based on the priorities and constraints of a user. Once a spot name is suggested, routes from the predicted spot to the rest of the spots in a are searched out by DFS.
The algorithm is designed to explore all possible paths recursively till the end of the destination node. Let G = {V,E} represents the tourist spots in a with nodes and edges . Any edge is a pair (v1, v2), where . The steps of the algorithm are presented in Fig. 6. Suppose a cluster Has five such nodes (A, B, C, D, E) containing the required or matching tourism facilities; as predicted by the LSTM, the possible routes, as recommended by DFS, are shown in Fig. 7.

Figure 6: The routes finding DFS algorithm.
{kind=link}
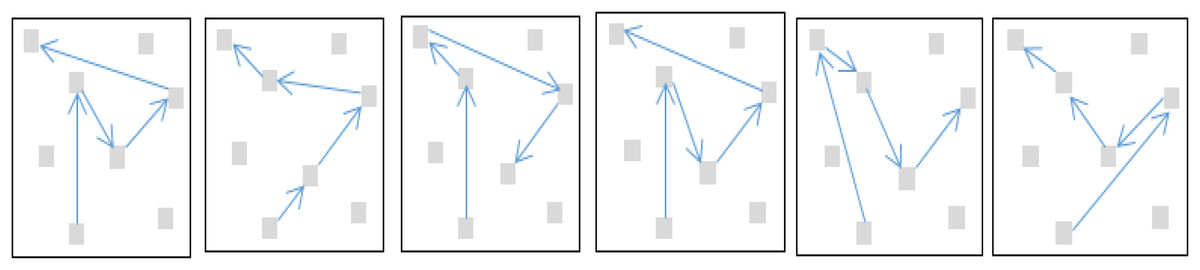
Figure 7: The recommended routes as generated by the DFS algorithm.
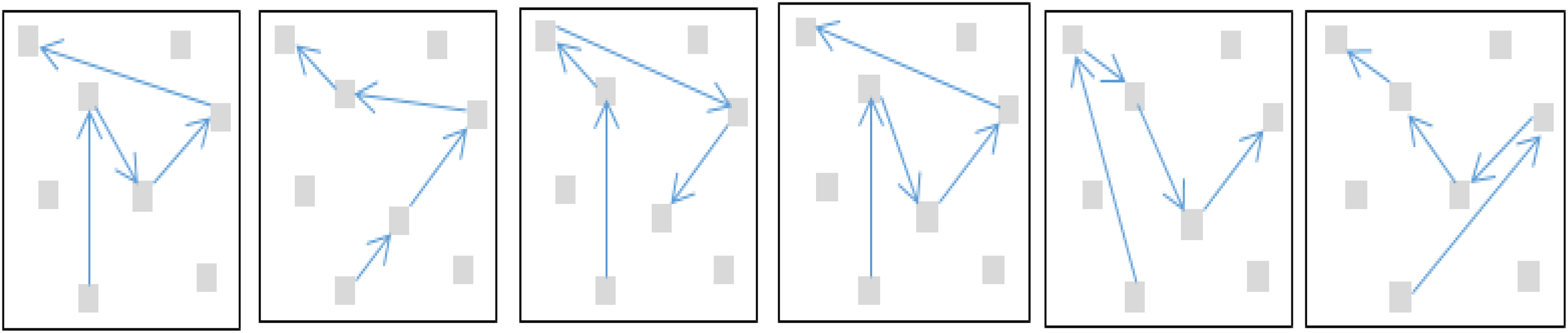{kind=link}
In a nutshell, key contributions of this research work include: (1) a machine learning framework is proposed to provide tourist spots with travel routes based on the requirements or priorities of the tourists. (2) The method is implemented in a case-study project by using a real-world dataset and augmented with the required attributes. (3) The results obtained are analyzed, and they show promising improvements in contemporary systems.
Implementation details
The proposed method is implemented in VSCode using various advanced machine learning libraries, including TensorFlow, Keras, and Python networks. The system contains four modules: representation, selection, information tracing and spot-name tracing. In the representation module, data is taken from the dataset and is represented in 2D graph form using Dijikstra’s algorithm from the Networkx library (Chollet, 2015; Jabbar, Abass & Hasan, 2023). In the said module, the spot names and their distances are taken as inputs. A simple demonstration of the module is shown in Fig. 8. The computational complexity of the algorithms varies. LSTM has higher complexity due to its recurrent nature, while SVM can be slow with large datasets. DFS is efficient for small datasets but could be optimized for larger ones.
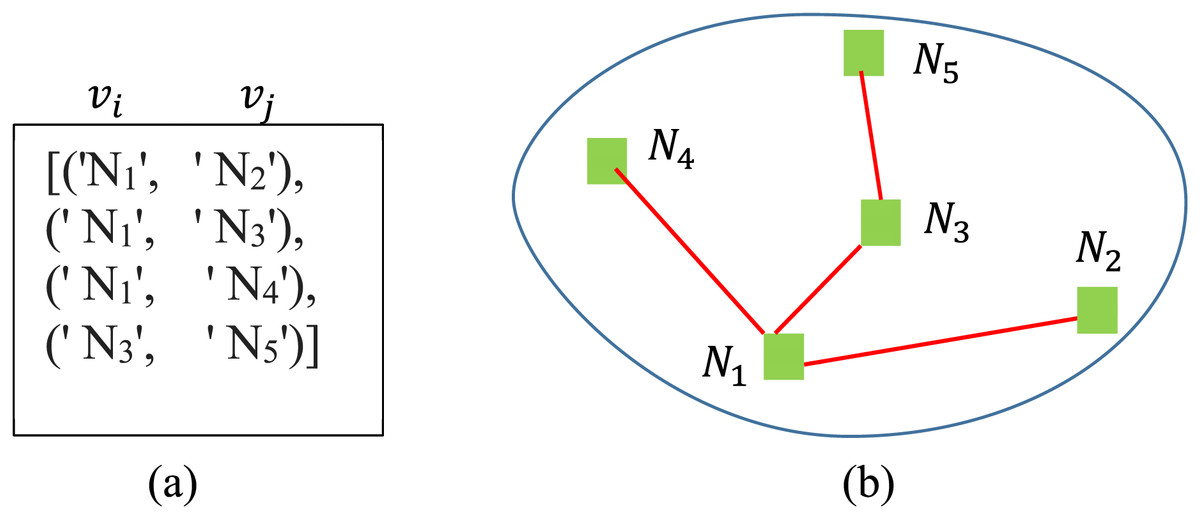
Figure 8: (A) List of the connected nodes and (B) graph representation of the algorithm.
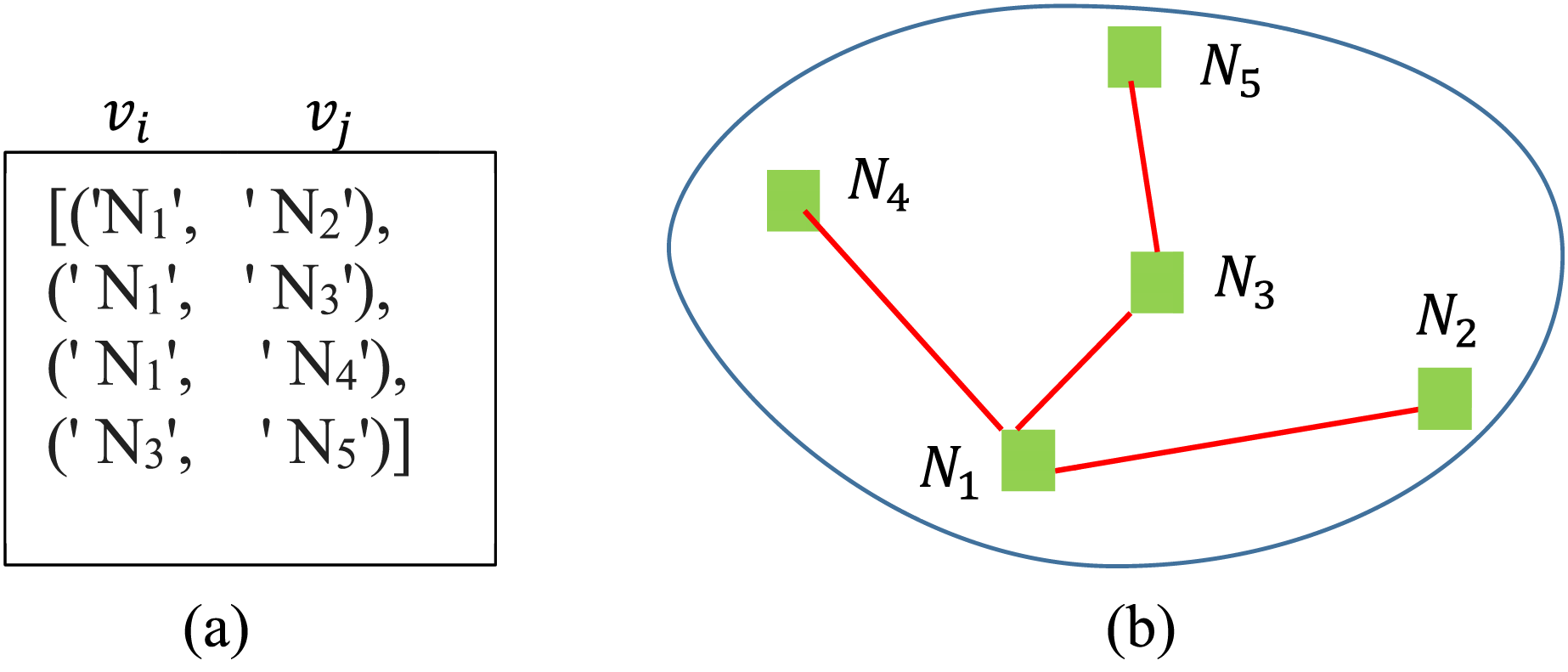{kind=link}
In the selection module, the CL is selected out of ‘n’ nodes in the cluster using the centroid-based approach. Each node ‘n’ shares its available attraction information with the CL, which is appended to the dataset and is stored in a CSV file. Some of the tourism information of a CL in tabular form is presented in Table 1.
| Name | State | Type | Popularity | Best time to visit | Currency | Culture | Distance (Km) |
|---|---|---|---|---|---|---|---|
| Taj Mahal | Uttar Pradesh | Historical | 8.6919062031 | Nov–Feb | Indian (Rs) | Indian | 123 |
In the information-tracing module, LSTM is trained by the available information of the node where . LSTM is an effective model for learning context-free and context sensitive languages (Gers & Schmidhuber, 2001). LSTM retains previously learned knowledge through a memory cell at the hidden layer. In the proposed system, LSTM is used to map input sequence to output sequence . By applying unit activation iteratively, where and represent tourist information by which it is trained. A predicted sequence is concatenated to the formerly predicted sequence to generate the next sequence . This sequence prediction process is repeated till the last token term; as shown in the following equations for the predicted sequence.
(15)
An illustration of generated is shown in Fig. 9 by entering Restaurant as an input to the LSTM.

Figure 9: Input sequence and predated sequence by LSTM.
{kind=link}
The spot-name tracing module deals with the tracing of spot names based on the generated of LSTM. To predict the optimal Spot-Name, the features train SN, SVM , being the training dataset and as class label where .
Experimentation and result analysis
Unlike other deep learning methods where a classifier is trained, validated and tested by different dataset splits, the proposed system is trained by all tuples of the dataset that lies at a CL. The entire dataset was used solely to ensure the most optimal results. A data augmentation approach was implemented to boost model robustness and enhance generalization because we added artificial dataset elements to the input data. Our approach expanded rows through multiple data transformation tools, including random dimensional changes, scaling operations and flipping mechanics on tourist location records. We developed synthetic features (columns) from historical travel data to analyze potential tourist behavior characteristics, including seasonality choices and travel window behaviors. Observational tests verified the usefulness of the enlarged dataset, which resulted in a 15% increase in model accuracy, thus validating the performance-enhancing effects of these data improvements. The original Kaggle dataset was augmented heuristically by 83 rows and 12 columns. The system was evaluated 52 times by entering textual tourism query— of variant dimensions; . A was obtained by feeding a random attraction term to the information tracing module. Though each of the evaluation iterations assessed the entire system, from sequence-related tourism information to possible routes, the results of each section were analyzed individually. The 52 queries used for evaluation were carefully selected to cover a broad spectrum of tourism scenarios, ensuring that they reflect diverse tourist preferences and behaviors. These queries were designed to represent various trip types, including cultural, historical, and recreational tourism, and they included different levels of complexity, such as simple requests for specific attractions or more detailed queries involving routes between multiple spots. The selection process aimed to ensure the model was tested under conditions that closely mirror real-world tourism planning, capturing the full range of user preferences and geographic contexts.
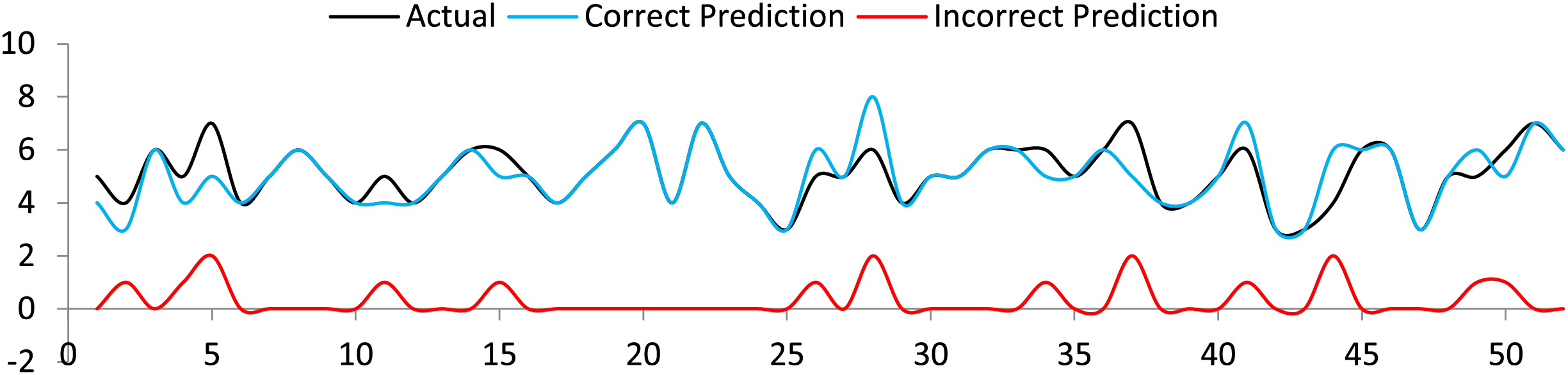
LSTM was assessed to generate the available tourist attraction information in 1 and 7 sequences. A user only needs to input a textual term and the number of sequences to be generated. The accuracy of LSTM was up to the mark for a lesser number of sequences. However, irrelevant terms were predicted in case of a greater number of sequences. This is clear from the correct and irrelevant sequence prediction graph shown in Fig. 10. As a whole, reasonable accuracy, precision, and F1 score were obtained, as shown in Table 2. The formulas for precision, sensitivity, specificity and F1 score (Gedela & Karthikeyan, 2022) are follows.
(16) (17) (18) (19)
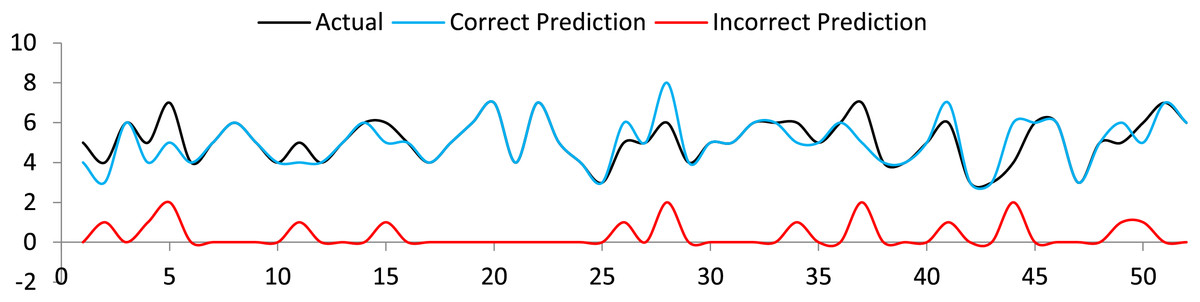
Figure 10: Actual sequence, correct and incorrect sequence prediction by LSTM.
{kind=link}
| Accuracy (%) | Precision | F1 score | Specificity | Sensitivity |
|---|---|---|---|---|
| 82 | 0.9 | 0.89 | 0.5 | 0.88 |
The generated sequences are forwarded to SVM to predict the appropriate spot names. Most of the spot name classes were accurately predicted. In the odd cases where the predicted sequences are fewer than the training sequences, incorrect class names were expected, see Fig. 11. Analysis of the results obtained for the SVM is presented in Table 3.
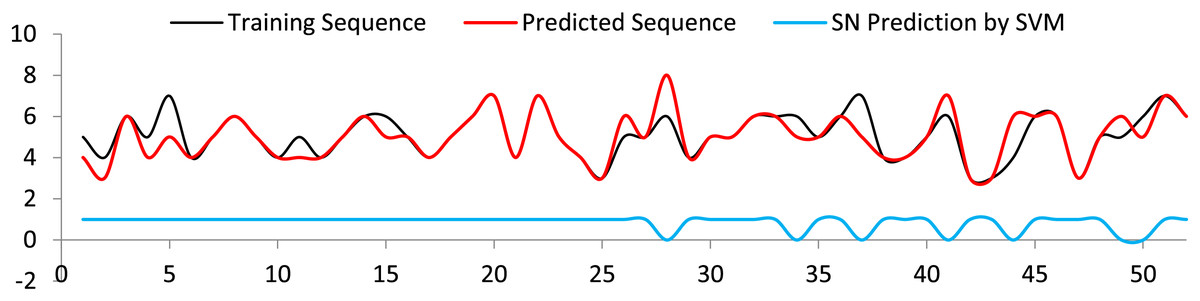
Figure 11: Spot name prediction with respect to training sequence, and predicted sequence.
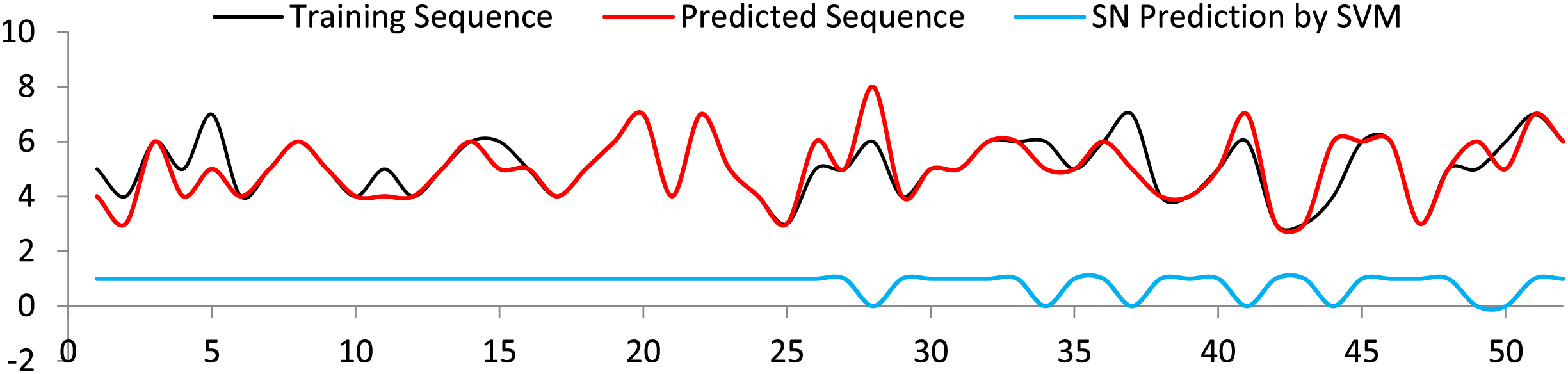{kind=link}
| Accuracy (%) | Precision | F1 score | Specificity | Sensitivity |
|---|---|---|---|---|
| 90 | 0.93 | 0.94 | 0.4 | 0.95 |
The DFS algorithm precisely depicts all the routes between a current node, nc and the predicted destination route np. Hence, the accuracy of the algorithm was simply 100%. Our augmentation technique that builds synthetic features using historical information has the potential to strengthen existing patterns within the original dataset. Specific tourist demographic biases often become more pronounced when we use historical data to determine popular destinations. Instrumented modifications to original data through special transformations such as scaling and random rotations might not adequately interpret natural modifications in tourism behavior patterns. The model’s generalization capability faces challenges when using the data for areas lacking adequate representation within the initial dataset. Real-world data performance assessments led to continual updates of the augmentation system that reduced the effect of biases discovered in the process.
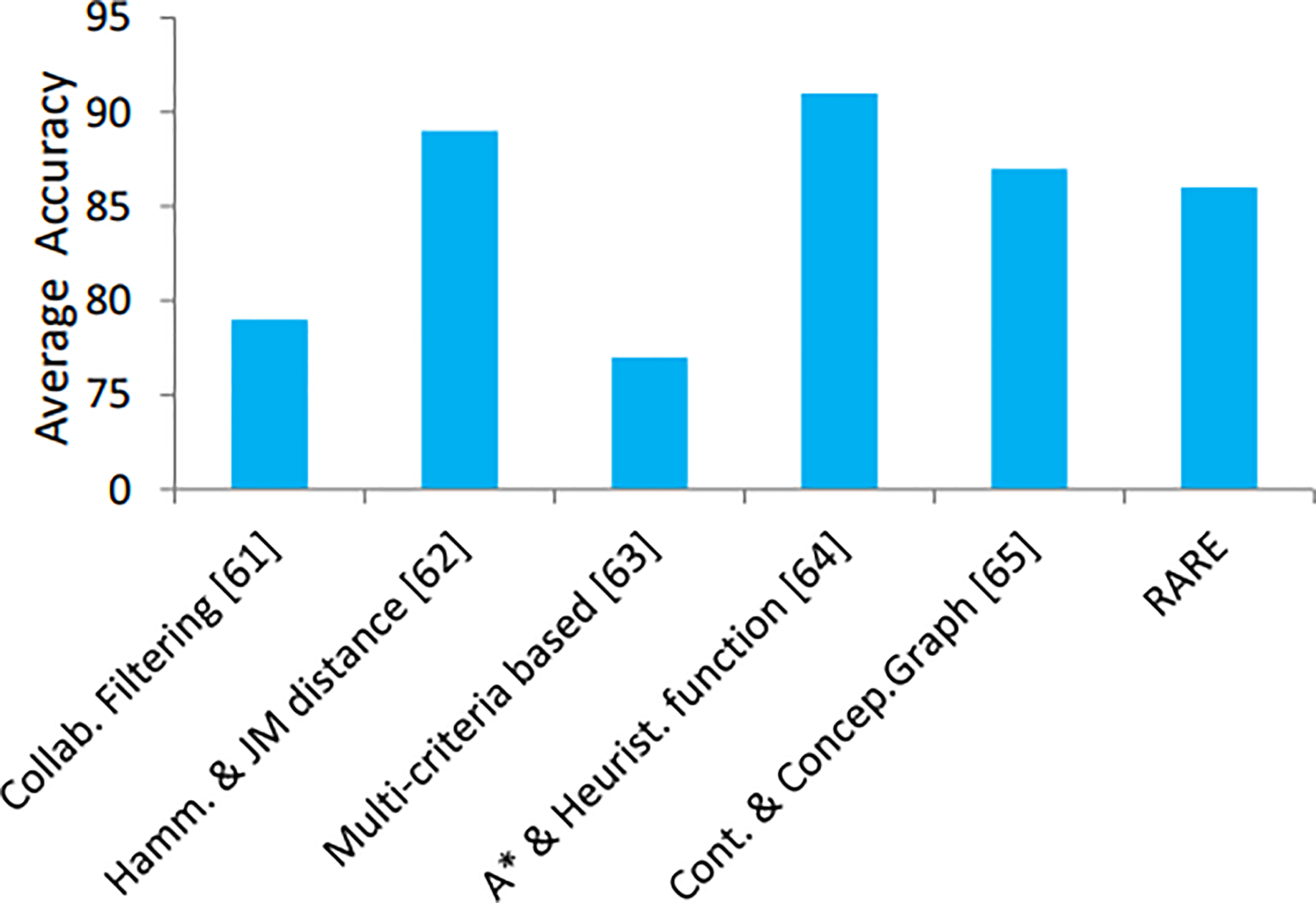
In addition, the proposed method is compared with some up-to-date, cutting-edge approaches, see Table 4. Comparison in terms of accuracy is shown in Fig. 12. The performance of RARE surpasses contemporary methods presented in Table 4 because it utilizes SVM and LSTM together with DFS in its architectural design. RARE defeats traditional techniques such as collaborative filtering and hybrid filtering by implementing LSTM to track unique visitor preferences. The DFS algorithm delivers efficient route optimization through tourist priority interests and geographic limitations, which other methods like A* do not handle properly. The unified framework of models enables RARE to generate travel guidance that surpasses the accuracy, adaptability, and tailored nature of standalone approaches.
| Author(s) | Title | Method used | Remarks |
|---|---|---|---|
| Ni et al. (2021) | “Collaborative Filtering Recommendation Algorithm Based on TF-IDF and User Characteristics” | Collaborative filtering based on (TF-IDF) and fuzzy membership | Needs to find similar users and resources |
| Li et al. (2021) | “Intelligent recommendation model of tourist places based on collaborative filtering and user preferences” | Hamming and Jeffries-Matusita distance approach | User preferences is supported and the issue of sparse data is addressed |
| Qiao et al. (2024a) | “Tourist Recommender System using Hybrid Filtering” | Multi-criteria based containing content, C-filtering, and Ontology | Predicts the ratings of demography and POIs to satisfy needs of users |
| Zeng et al. (2015) | “Optimal Route Search with the Coverage of Users’ Preferences” | Algorithm based on A* and heuristic function | The weighted user preference is considered in route researching, proposes convergence solution for optimal route. |
| Paulson & Tzanavari (2003) | “Combining Collaborative and Content-Based Filtering Using Conceptual Graphs” | Conceptual graphs and dataset contents for prediction and error reduction | Support only a limited fuzzy value fields and tourism attractions |
| RARE | The proposed system | Multi-model based method including SVM, LSTM and DFS | Tourist preference is supported to trace spot and routes. |
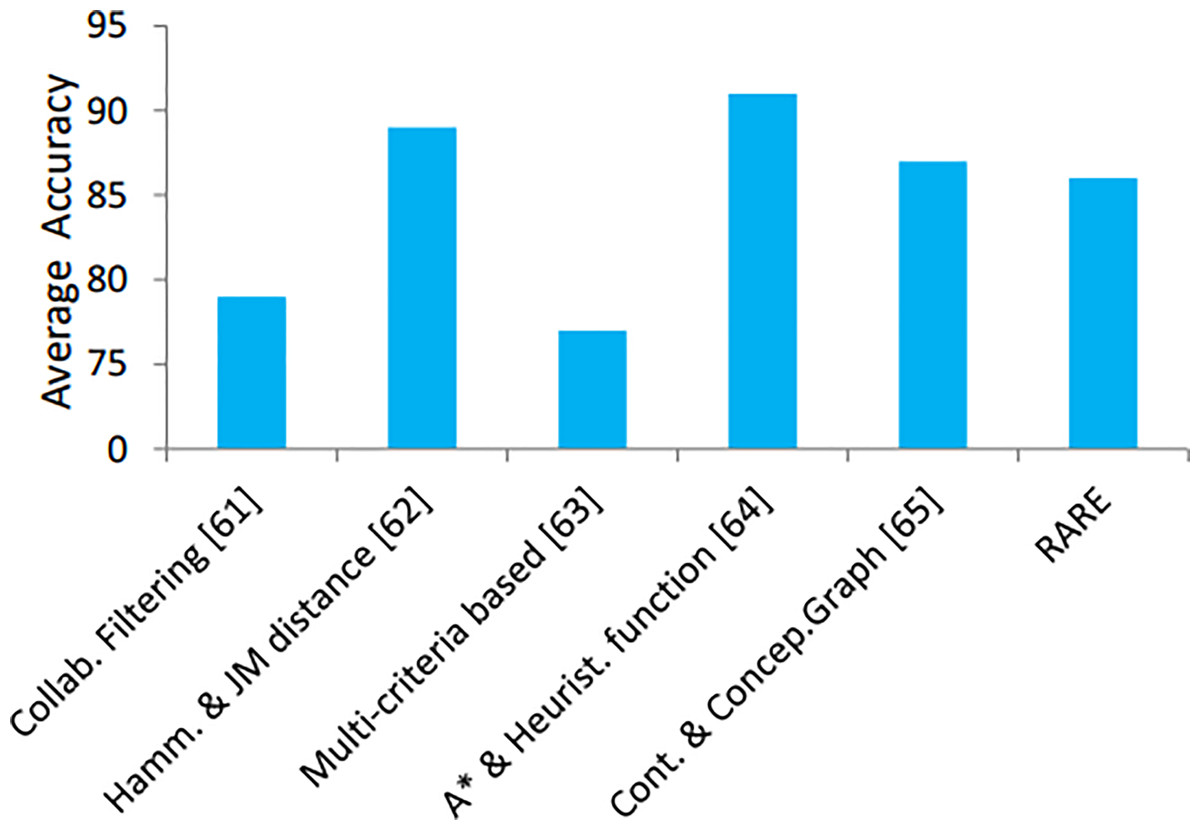
Figure 12: Accuracy comparison of the state-of-the-art recommendation methods.
{kind=link}
The model does not currently incorporate temporal data, such as opening and closing times, which could affect the accuracy of recommendations for time-sensitive travel plans. We plan to address this limitation in future work by integrating such data to improve the model’s relevance in dynamic tourism scenarios. Future work will also focus on integrating GIS data to enable the automatic detection and localization of tourist spots, reducing reliance on explicit user input and further improving the system’s usability.
Conclusion
Tourism is the modern-day valuable entertainment. Tourism adventure can be made more attractive if routes and spots are based on personal preference. This research proposes a multimodal approach for tourist routes and spot recommendations based on the personal priority of the visitor. The method exploits the approach of a right algorithm for the right task. To keep the attraction information of all the nodes, the k-mean clustering algorithm is used to select a cluster leader in a particular zone. The LSTM model is trained to generate relevant attraction information, whereas the SVM classifier is used to suggest the most optimal spot name based on the generated input sequences. By inputting a simple textual demand term, the matching and relevant spots are suggested, as well as presenting travel routes to the various tourist spots. The method is implemented in a Python based project and is evaluated by an augmented real-world dataset. The proposed method is systematically assessed and compared with the contemporary state-of-the-art recommendation systems. The satisfactory accuracy revealed that the process is applicable for enhancing tourism. The system has strong potential for real-world applications in large-scale tourism datasets, such as in smart tourism platforms. By leveraging its ability to process diverse tourist preferences and optimize routes, it can scale to accommodate millions of users. Future improvements, including better data integration and performance optimization, will enhance its scalability for large, dynamic datasets.
Though the research presents a novel approach for tracing tourist spot based on user’s preferences, the system fails to consider the opening and closing times, often critical for tourism planning. As our future strategy, we are scheming to enhance the model. Moreover, the GIS data will be incorporated into the dataset to automatically locate tourist spots without explicit inputting. As a whole, the research contributes to the realm of tourism and paves the way for future research.