
Influence of tweets and diversification on serendipitous research paper recommender systems
- Published
- Accepted
- Received
- Academic Editor
- Nick Higham
- Subject Areas
- Data Mining and Machine Learning, Digital Libraries
- Keywords
- Recommender system, Experimental study, User study, Scholarly articles, Serendipity, Digital library
- Copyright
- © 2020 Nishioka et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2020. Influence of tweets and diversification on serendipitous research paper recommender systems. PeerJ Computer Science 6:e273 https://doi.org/10.7717/peerj-cs.273
Abstract
In recent years, a large body of literature has accumulated around the topic of research paper recommender systems. However, since most studies have focused on the variable of accuracy, they have overlooked the serendipity of recommendations, which is an important determinant of user satisfaction. Serendipity is concerned with the relevance and unexpectedness of recommendations, and so serendipitous items are considered those which positively surprise users. The purpose of this article was to examine two key research questions: firstly, whether a user’s Tweets can assist in generating more serendipitous recommendations; and secondly, whether the diversification of a list of recommended items further improves serendipity. To investigate these issues, an online experiment was conducted in the domain of computer science with 22 subjects. As an evaluation metric, we use the serendipity score (SRDP), in which the unexpectedness of recommendations is inferred by using a primitive recommendation strategy. The results indicate that a user’s Tweets do not improve serendipity, but they can reflect recent research interests and are typically heterogeneous. Contrastingly, diversification was found to lead to a greater number of serendipitous research paper recommendations.
Introduction
To help researchers overcome the problem of information overload, various studies have developed recommender systems (Beel et al., 2016; Bai et al., 2019). Recommendations are generated based on considerations such as a user’s own papers (Sugiyama & Kan, 2010; Kaya, 2018) or the papers a user has accessed or liked in the past (Nascimento et al., 2011; Achakulvisut et al., 2016). Most previous studies have focused only on improving the accuracy of recommendations, one example of which is normalised discounted cumulative gain (nDCG). However, several studies on recommender systems conducted in other domains (e.g. movies) have drawn attention to the fact that there are important aspects other than accuracy (McNee, Riedl & Konstan, 2006; Herlocker et al., 2004; Kotkov, Wang & Veijalainen, 2016; Kotkov, Veijalainen & Wang, 2018). One of these aspects is serendipity, which is concerned with the unexpectedness of recommendations and the degree to which recommendations positively surprise users (Ge, Delgado-Battenfeld & Jannach, 2010). A survey by Uchiyama et al. (2011) revealed that researchers think that it is important for them to be recommended serendipitous research papers.
In this article, we study a research paper recommender system focusing on serendipity. Sugiyama & Kan (2015) investigated serendipitous research paper recommendations, focusing on the influence of dissimilar users and the co-author network on recommendation performance. In contrast, this study investigates the following research questions:
(RQ1) Do a user’s Tweets generate serendipitous recommendations?
(RQ2) Is it possible to improve a recommendation list’s serendipity through diversification?
We run an online experiment to facilitate an empirical investigation of these two research questions using three factors. For RQ1, we employ the factor User Profile Source, where we compare the two sources of user profiles: firstly, a user’s own papers; and secondly, a user’s Tweets. The user’s own papers are a feature of existing recommender systems, as evidenced by the work conducted by Sugiyama & Kan (2015) and Google Scholar (https://scholar.google.co.jp/). In this study, we assume that the user’s Tweets produce recommendations that cannot be generated based on papers, since researchers Tweet about recent developments and interests that are yet not reflected in their papers (e.g. what they found interesting at a conference or in their social network) (Letierce et al., 2010). In addition, they are likely to have used their Twitter accounts to express private interests. We conjecture that taking private interests into consideration delivers serendipitous recommendations, since the recommender system will then suggest research papers that include both professional interests and private interests, and which are thus likely to be serendipitous. We also observed that recommendations based on a user’s Tweets received a precision of 60%, which is fairly high in the domain of economics (Nishioka & Scherp, 2016).
Furthermore, we analyse the factor Text Mining Method, which applies different methods of candidate items (i.e. research papers) for computing profiles, as well as user profiles comprising different content (i.e. Tweets or previous papers).
As text mining methods, we compare TF-IDF (Salton & Buckley, 1988) with two of its recent extensions, namely CF-IDF (Goossen et al., 2011) and HCF-IDF (Nishioka, Große-Bölting & Scherp, 2015). Both have been associated with high levels of performance in recommendation tasks (Goossen et al., 2011; Nishioka, Große-Bölting & Scherp, 2015). We introduce this factor because text mining methods can have a substantial influence on generating recommendations. For RQ2, we introduce the factor Ranking Method, where we compare two ranking methods: firstly, classical cosine similarity; and secondly, the established diversification algorithm IA-Select (Agrawal et al., 2009). Cosine similarity has been widely used in recommender systems (Lops, De Gemmis & Semeraro, 2011), while IA-Select ranks candidate items with the objective of diversifying recommendations in a list. Since it broadens the coverage of topics in a list, we assume that IA-Select delivers more serendipitous recommendations compared to cosine similarity.
Along with the three factors User Profile Source, Text Mining Method, and Ranking Method, we conduct an online experiment in which 22 subjects receive research paper recommendations in the field of computer science. As an evaluation metric, we use the serendipity score (SRDP), which takes unexpectedness and usefulness of recommendations into account. It considers a recommendation as unexpected, if it is not recommended by a primitive recommendation strategy (i.e. baseline). The results reveal that a user’s Tweets do not improve the serendipity of recommender systems. On the other hand, we confirm that the diversification of a recommendation list by IA-Select delivers more serendipitous recommendations to users.
The remainder of the paper is organised as follows: firstly, we describe related studies; in turn, we describe the recommender system and the experimental factors and evaluation setup; and finally, before concluding the article, we report on and discuss the experimental results.
Experimental Factors
In this article, we build a content-based recommender system along with the three factors User Profile Source, Text Mining Method, and Ranking Method. It works as follows:
Candidate items of the recommender system (i.e. research papers) are processed by one of the text mining methods, and paper profiles are generated. A candidate item and a set of candidate items are referred as d and D, respectively. d’s paper profile Pd is represented by a set of features F and their weights. Depending on text mining methods, a feature f is either a textual term or a concept. Formally, paper profiles are described as: Pd = {(f, w(f, d)) | ∀ f ∈ F }. The weighting function w returns a weight of a feature f for data source Iu. This weight identifies the importance of the feature f for the user u.
A user profile is generated based on the user profile source (i.e. Tweets or own papers) using the same text mining method, which is applied to generate paper profiles. Iu is a set of data items i of a user u. In this article, Iu is either a set of a user’s Tweets or a set of a user’s own papers. u’s user profile Pu is represented in a way that it is comparable to Pu as: Pu = {(f, w(f, Iu)) | ∀ f ∈ F }.
One of the ranking methods determines the order of recommended papers.
The experimental design is illustrated in Table 1, where each cell is a possible design choice in each factor.
| Factor | Possible design choices | ||
|---|---|---|---|
| User profile source | Own papers | ||
| Text mining method | TF-IDF | CF-IDF | HCF-IDF |
| Ranking method | Cosine similarity | IA-select |
In this section, we first provide a detailed account of the factor User Profile Source. In turn, we show three of the different text mining methods that were applied in the experiment. Finally, we note the details of the factor Ranking Method, which examines whether diversification improves the serendipity of recommendations.
User profile source
In this factor, we compare the following two data sources that are used to build a user profile.
Research papers: The research papers written by a user are used as a baseline. This approach is motivated by previous studies that have investigated research paper recommender systems, including Sugiyama & Kan (2010) and Google Scholar.
Twitter: In contrast to the user’s papers, we assume that using Tweets leads to more serendipitous recommendations. It is common practice among researchers to Tweet about their professional interests (Letierce et al., 2010). Therefore, Tweets can be used to build a user profile in the context of a research paper recommender system. We hypothesise that a user’s Tweets improve the serendipitous nature of recommendations because researchers are likely to Tweet about recent interests and information (e.g. from social networks) that are not yet reflected in their papers.
Text mining method
For each of the two data sources (i.e. the user’s own papers or their Tweets) and the candidate items, we apply a text mining method using one of three text mining methods. Specifically, we compare three methods, namely TF-IDF (Salton & Buckley, 1988), CF-IDF (Goossen et al., 2011), and HCF-IDF (Nishioka, Große-Bölting & Scherp, 2015), to build paper profiles and a user profile. This factor was introduced because the effectiveness of each text mining method is informed by the type of content that will be analysed (e.g. Tweets or research papers). For each method, a weighting function w is defined. This weighting function assigns a specific weight to each feature f, which is a term in TF-IDF and a semantic concept in CF-IDF and HCF-IDF.
TF-IDF: Since TF-IDF is frequently used in recommender systems as a baseline (Goossen et al., 2011), we also use it in this study. Terms are lemmatised and stop words are removed (http://www.nltk.org/book/ch02.html). In addition, terms with fewer than three characters are filtered out due to ambiguity. After pre-processing texts, TF-IDF is computed as: (1) tf returns the frequency of a term w in a text t. A text t is either a user profile source Iu or candidate item d. The term frequency acts under the assumption that more frequent terms are more important (Salton & Buckley, 1988). The second term of the equation presents the inverse document frequency, which measures the relative importance of a term w in a corpus D (i.e. a set of candidate items).
-
CF-IDF: Concept frequency inverse document frequency (CF-IDF) (Goossen et al., 2011) is an extension of TF-IDF, which replaces terms with semantic concepts from a knowledge base. The use of a knowledge base decreases noise in profiles (Abel, Herder & Krause, 2011; Middleton, Shadbolt & De Roure, 2004). In addition, since a knowledge base can store multiple labels for a concept, the method directly supports synonyms. For example, the concept “recommender systems” of the ACM Computing Classification Systems (ACM CCS) has multiple labels, including “recommendation systems”, “recommendation engine”, and “recommendation platforms”.
The weighting function w for CF-IDF is defined as: (2) cf returns the frequency of a semantic concept a in a text t. The second term presents the IDF, which measures the relative importance of a semantic concept a in a corpus D.
HCF-IDF: Finally, we apply hierarchical concept frequency inverse document frequency (HCF-IDF) (Nishioka, Große-Bölting & Scherp, 2015), which is an extension of CF-IDF. HCF-IDF applies a propagation function (Kapanipathi et al., 2014) over a hierarchical structure of a knowledge base to assign a weight to concepts at higher levels. In this way, it identifies concepts that are not mentioned in a text but which are highly relevant. HCF-IDF calculates the weight of a semantic concept a in a text t as follows: (3) BL(a, t) is the BellLog propagation function (Kapanipathi et al., 2014), which is defined as: (4) where cf(a, t) is a frequency of a concept a in a text t, and . The propagation function underlies the assumption that, in human memory, information is represented through associations or semantic networks (Collins & Loftus, 1975). The function h(a) returns the level, where a concept a is located in the knowledge base. Additionally, nodes provides the number of concepts at a given level in a knowledge base, and pc(a) returns all parent concepts of a concept a. In this study, we employ HCF-IDF since it has been shown to work effectively for short pieces of text, including Tweets (Nishioka & Scherp, 2016), in the domain of economics.
Ranking method
Finally, we rank all the candidate items to determine which items should be recommended to a user. In this factor, we compare two ranking methods: cosine similarity and diversification with IA-Select (Agrawal et al., 2009).
Cosine similarity: As a baseline, we employ a cosine similarity, which has been widely used in content-based recommender systems. The top-k items with largest cosine similarities are recommended.
-
IA-Select: Following this, we employ IA-Select (Agrawal et al., 2009) to deliver serendipitous recommendations. IA-Select was originally introduced for information retrieval, but it is also used in recommender systems to improve serendipity (Vargas, Castells & Vallet, 2012). This use case stems from the algorithm’s ability to diversify recommendations in a list, which relies on the avoidance of recommending similar items (e.g. research papers) together. The basic idea of IA-Select is that, for those features of a user profile that have been covered by papers already selected for recommendation, the weights are lowered in an iterative manner. At the outset, the algorithm computes cosine similarities between a user and each candidate item. In turn, IA-Select adds the item with the largest cosine similarity to the recommendation list. After selecting the item, IA-Select decreases the weights of features covered by the selected item in the user profile. These steps are repeated until k recommendations are determined.
For example, recommendations for the user profile Pu = ((f1, 0.1), (f2, 0.9)) will contain mostly those documents that include feature f2. However, with IA-Select, the f2 score is decremented iteratively in the event that documents contain the f2 feature. Thus, the probability increases that documents covering the f1 feature are included in the list of recommended items.
Overall, the three factors with the design choices described above result in 2 × 3 × 2 = 12 available strategies. The evaluation procedure used to compare the strategies is provided below.
Evaluation
To address the two research questions with the three experimental factors described in the previous section, we conduct an online experiment with 22 subjects. The experiment is based in the field of computer science, in which an open access culture to research papers exists, and Twitter is chosen as the focal point because it is an established means by which researchers disseminate their works. The experimental design adopted in this study is consistent with previous studies (Nishioka & Scherp, 2016; Chen et al., 2010).
In this section, the experimental design is described, after which an account of the utilised datasets (i.e. a corpus of research papers and a knowledge graph of text mining methods) is given. Following this, descriptive statistics are presented for the research subjects, and finally, the serendipity score is stated. The purpose of the serendipity score is to evaluate the degree to which each recommender strategy is effective in generating serendipitous recommendations.
Procedure
We implemented a web application that enabled the subjects (n = 22) to evaluate the 12 recommendation strategies described above. First, subjects started on the welcome page, which asked for their consent to collect their data. Thereafter, the subjects were asked to input their Twitter handle and their name, as recorded in DBLP Persons (https://dblp.uni-trier.de/pers/). Based on the user’s name, we retrieved a list of their research papers and obtained the content of the papers by mapping them to the ACM-Citation-Network V8 dataset (see below). The top 5 recommendations were computed for each strategy, as shown in Fig. 1. Thus, each subject evaluated 5 × 12 = 60 items as “interesting” or “not interesting” based on the perceived relevance to their research interests.
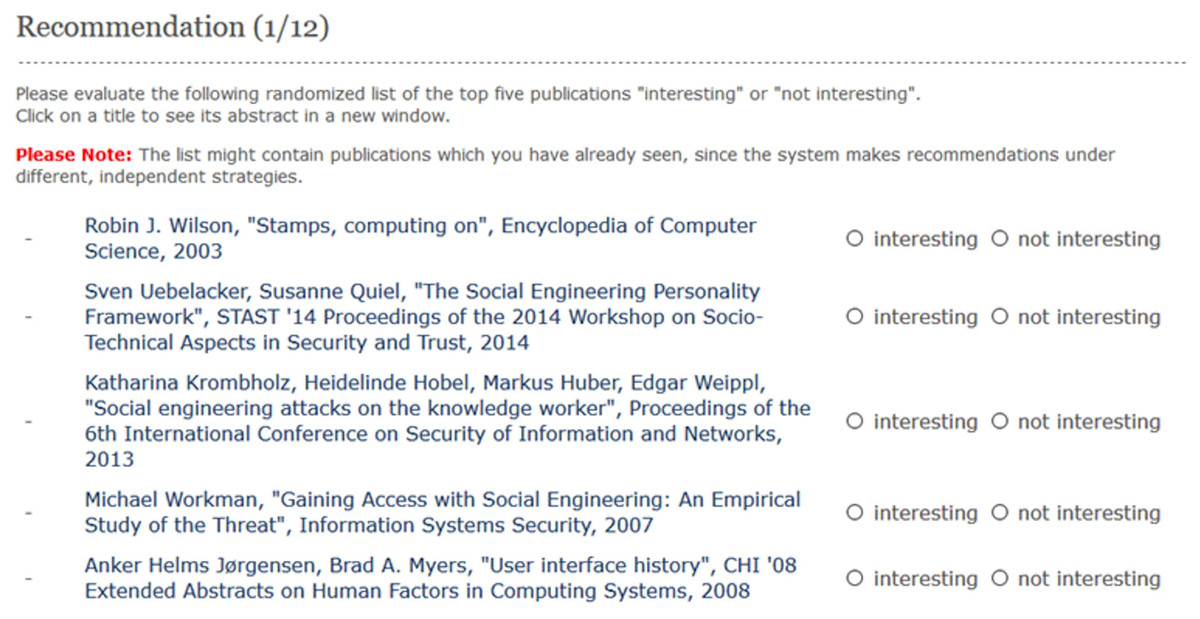
Figure 1: Screenshot of the evaluation page.
Each subject rated an item as either “interesting” or “not interesting” based on their research interests.{kind=link}
A binary evaluation was chosen to minimise the effort of the rating process, consistent with several previous studies (Nishioka & Scherp, 2016; Chen et al., 2010). As shown in Fig. 1, the recommended items were displayed with bibliographic information such as the authors, title, year, and venue. Finally, the subjects were provided with the opportunity to access and read the research paper directly by clicking on a link. In order to avoid bias, the sequence in which the 12 strategies appeared was randomised for each subject. This corresponds to earlier experimental setups such as a research paper recommender system in the domain of economics (Nishioka & Scherp, 2016) and other studies (Chen et al., 2010). At the same time, the list of the top 5 items for each strategy was also randomised to avoid the well-documented phenomenon of ranking bias (Bostandjiev, O’Donovan & Höllerer, 2012; Chen et al., 2010). The subjects were informed about the randomised order of the strategies and items on the evaluation page.
The actual ranks of the recommended items, as well as their position on the evaluation page, were stored in a database for later analyses. After evaluating all strategies, the subjects were asked to complete a questionnaire focusing on demographic information (e.g. age, profession, highest academic degree, and current employment status). Finally, an opportunity was provided for the subjects to provide qualitative feedback.
Datasets
The candidate items for the experiment were computer science articles drawn from a large dataset of research papers. To analyse and extract semantic concepts from the research papers and Tweets, an external computer science knowledge base was used. This section describes the research papers and knowledge graphs used for the experiment.
Research papers
Since the experiment recommended research papers from the field of computer science, a corpus of research papers and a knowledge base from the same field were used. The ACM citation network V8 dataset (https://lfs.aminer.org/lab-datasets/citation/citation-acm-v8.txt.tgz), provided by ArnetMiner (Tang et al., 2008), was used as the corpus of research papers. From the dataset, 1,669,237 of the available 2,381,688 research papers were included that had a title, author, year of publication, venue, and abstract. Titles and abstracts were used to generate paper profiles.
Knowledge graph
The ACM Computing Classification System (CCS) was used as the knowledge graph for CF-IDF and HCF-IDF (https://www.acm.org/publications/class-2012). The knowledge graph, which is freely available, is characterised by its focus on computer science, as well as its hierarchical structure. It consists of 2,299 concepts and 9,054 labels, which are organised on six levels. On average, a concept is represented by 3.94 labels (SD: 3.49).
For the text mining methods (i.e. CF-IDF and HCF-IDF), we extracted concepts from each user’s Tweets and research papers by matching the text with the labels of the concepts in the knowledge graph. As such, we applied what is known in the literature as the gazetteer-based approach. Before processing, we lemmatised both the Tweets and research papers using Stanford Core NLP (https://stanfordnlp.github.io/CoreNLP/), and stop words were removed. Regarding Tweets, which often contain hashtags to indicate topics and user mentions, only the # and @ symbols were removed from the Tweets. This decision stemmed from an observation made by Feng & Wang (2014), namely that the combination of Tweets’ texts with hashtags and user mentions results in the optimal recommendation performance.
Subjects
Overall, 22 subjects were recruited through Twitter and mailing lists. 20 were male and two were female, and the average age was 36.45 years old (SD: 5.55). Several of the subjects held master’s degrees (n = 2), while the others held a PhD (n = 13) or were lecturers or professors (n = 7). In terms of the subjects’ employment status, 19 were working in academia and three in industry. Table 2 shows countries where subjects work. On average, the subjects published 1,256.97 Tweets (SD: 1,155.8), with the minimum value being 26 and the maximum value being 3,158.
| Country | The number of subjects |
|---|---|
| Germany | 8 |
| US | 4 |
| China | 2 |
| UK | 2 |
| Austria | 1 |
| Brazil | 1 |
| France | 1 |
| Ireland | 1 |
| Norway | 1 |
| Sweden | 1 |
An average of 4,968.03 terms (SD: 4,641.76) was extracted from the Tweets, along with an average of 297.91 concepts (SD: 271.88). Thus, on average, 3.95 (SD: 0.54) terms and 0.24 concepts (SD: 0.10) were included per Tweet. We show a histogram regarding the number of terms in Tweets per subject in Fig. 2. We observe that subjects are divided into those with a small total number of terms in their Tweets and those with a large total number of terms in their Tweets. Regarding the use of research papers for user profiling, the subjects had published an average of 11.41 papers (SD: 13.53). On average, 687.68 terms (SD: 842,52) and 80.23 concepts (SD: 107.73) were identified in their research papers. This led to 60.27 terms (SD: 18.95) and 5.77 concepts (SD: 3.59) per paper. Figure 3 shows a histogram regarding the number of terms in research papers per subject. We see that there are a few subjects with a large total number of terms. Most subjects have a small total number of terms in their research papers because they published only a few research papers so far.

Figure 2: Distribution of subjects with regarding to the number of terms in their Tweets.
The x-axis shows the number of terms in their Tweets. The y-axis shows the number of subjects. For instance, there are five subjects whose total number of terms in Tweets is between 10,001 and 20,000.{kind=link}
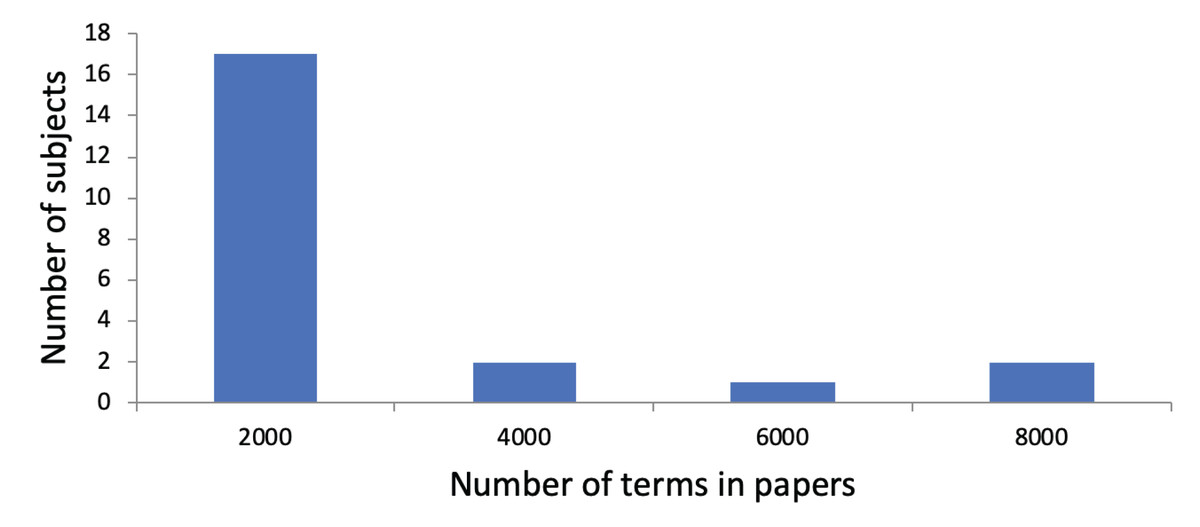
Figure 3: Distribution of subjects with regarding to the number of terms in their research papers.
The x-axis shows the number of terms in their research papers. The y-axis shows the number of subjects. For instance, there are two subjects whose total number of terms in research papers is between 2,001 and 4,000.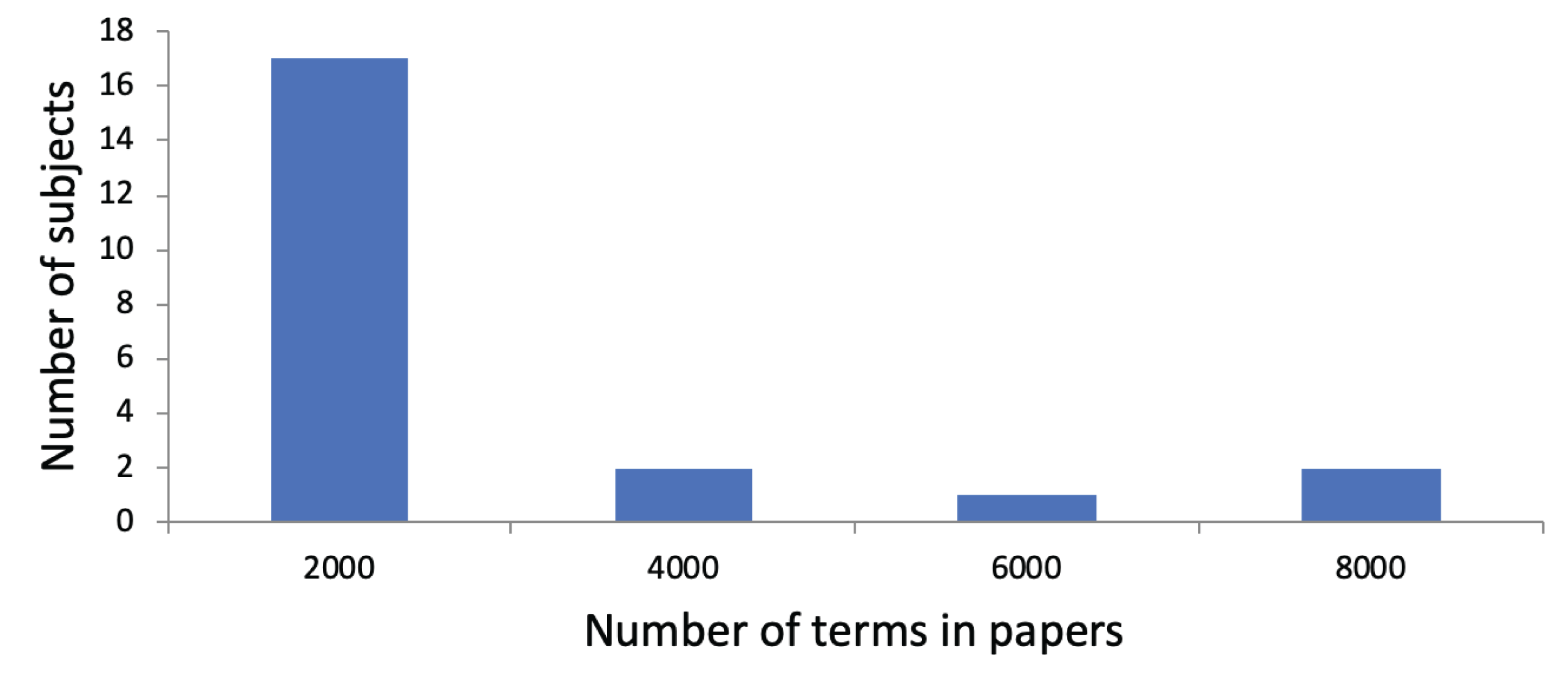{kind=link}
Subjects needed 39 s (SD: 43 s) on average to evaluate all five recommended items per strategy. Thus, the average length of time needed to complete the experiment was 468 s. It is worth noting that this time does not include reading the instructions on the welcome page, inputting the Twitter handle and DBLP record, and completing the questionnaire.
Evaluation metric
To evaluate the serendipity of recommendations, we used the serendipity score (SRDP) (Ge, Delgado-Battenfeld & Jannach, 2010). This evaluation metric takes into account both the unexpectedness and usefulness of recommended items, which is defined as: (5)
UE denotes a set of unexpected items that are recommended to a user. An item is regarded as unexpected if it is not included in a recommendation list computed by the primitive strategy. We used the strategy Own Papers × TF-IDF × Cosine Similarity as a primitive strategy since it is a combination of baselines. The function rate(d) returns an evaluation rate of an item d given by a subject. As such, if a subject evaluated an item as “interesting”, the function would return 1, otherwise 0.
We did not directly ask subjects to evaluate the unexpectedness of recommendations, because this is not the scenario in which the recommender system is used. Rather, we were aiming to detect indirectly from the subjects’ responses, if the serendipity feature had an influence on the dependent variables. Furthermore, we wanted to keep the online evaluation as simple as possible. Asking for “how surprising” a recommendation is, increases the complexity of the experiment. Subjects needed to know what a non-surprising recommendation is (in comparison). In addition, the cognitive efforts required to conduct a direct evaluation of unexpectedness is much higher and it is in general difficult for subjects to share the concept of the unexpectedness.
Results
The purpose of this section is to present the results of the experiment. At the outset, the quantitative analysis is examined, which shows the optimal strategy in terms of SRDP. In turn, the impact of each of the three experimental factors is analysed.
Comparison of the 12 strategies
The results of the 12 strategies in terms of their SRDP values are presented in Table 3. As previously noted, this study drew on Own Papers × TF-IDF × Cosine Similarity as a primitive strategy. Thus, for this particular strategy, the mean and standard deviation are 0.00.
| Strategy | SRDP | |UE| | |||
|---|---|---|---|---|---|
| Text mining method | Profiling source | Ranking method | M (SD) | M (SD) | |
| 1. | TF-IDF | Own papers | IA-Select | 0.45 (0.38) | 2.95 (1.05) |
| 2. | CF-IDF | CosSim | 0.39 (0.31) | 4.91 (0.29) | |
| 3. | TF-IDF | IA-Select | 0.36 (0.29) | 4.91 (0.43) | |
| 4. | CF-IDF | IA-Select | 0.31 (0.22) | 4.95 (0.21) | |
| 5. | CF-IDF | Own papers | CosSim | 0.26 (0.28) | 4.91 (0.29) |
| 6. | CF-IDF | Own papers | IA-Select | 0.25 (0.28) | 4.91 (0.29) |
| 7. | HCF-IDF | Own papers | IA-Select | 0.24 (0.22) | 4.95 (0.21) |
| 8. | HCF-IDF | CosSim | 0.22 (0.28) | 5.00 (0.00) | |
| 9. | TF-IDF | CosSim | 0.20 (0.24) | 4.95 (0.21) | |
| 10. | HCF-IDF | IA-Select | 0.18 (0.21) | 5.00 (0.00) | |
| 11. | HCF-IDF | Own papers | CosSim | 0.16 (0.18) | 5.00 (0.00) |
| 12. | TF-IDF | Own papers | CosSim | 0.00 (0.00) | 0.00 (0.00) |
The purpose of an analysis of variance (ANOVA) is to detect significant differences between variables. Therefore, in this study, ANOVA was used to identify whether any of the strategies were significantly different. The significance level was set to α = 0.05. Mauchly’s test revealed a violation of sphericity (χ2(54) = 80.912, p = 0.01), which could lead to positively biased F-statistics and, consequently, an increase in the risk of false positives. Therefore, a Greenhouse-Geisser correction with ε = 0.58 was applied.
The results of the ANOVA test revealed that significant differences existed between the strategies (F(5.85, 122.75) = 3.51, p = 0.00). Therefore, Shaffer’s modified sequentially rejective Bonferroni procedure was undertaken to compute the pairwise differences between the strategies (Shaffer, 1986). We observed significant differences between the primitive strategy and one of the other strategies.
Impact of experimental factors
In order to analyse the impact of each experimental factor, a three-way repeated measures ANOVA was conducted. The Mendoza test identified violations of sphericity for the following factors: firstly, User Profile Source × Text Mining Method × Ranking Method (χ2(65) = 101.83, p = 0.0039); and secondly, Text Mining Method × Ranking Method (χ2(2) = 12.01, p = 0.0025) (Mendoza, 1980). Thus, a three-way repeated measures ANOVA was applied with a Greenhouse-Geiser correction of ε = 0.54 for the factors User Profile Source × Text Mining Method × Ranking Method and ε = 0.69 for the factor Text Mining Method × Ranking Method. Table 4 shows the results with the F-Ratio, effect size η2, and p-value.
| Factor | F | η2 | p |
|---|---|---|---|
| User profile source | 2.21 | 0.11 | 0.15 |
| Text mining method | 3.02 | 0.14 | 0.06 |
| Ranking method | 14.06 | 0.67 | 0.00 |
| User profile source × Text mining method | 0.98 | 0.05 | 0.38 |
| User profile source × Ranking method | 18.20 | 0.87 | 0.00 |
| Text mining method × Ranking method | 17.80 | 0.85 | 0.00 |
| User profile source × Text mining M. × Ranking M. | 2.39 | 0.11 | 0.11 |
Regarding the single factors, Ranking Method had the largest impact on SRDP, as the effect size η2 indicates. For all the factors with significant differences, we applied a post-hoc analysis using Shaffer’s MSRB procedure. The results of the post-hoc analysis revealed that the strategies using IA-Select resulted in higher SRDP values when compared to those using cosine similarity. In addition, we observed a significant difference in the factors User Profile Source × Ranking Method and Text Mining Method × Ranking Method. For both factors, post-hoc analyses revealed significant differences when a baseline was used in either of the two factors. When a baseline was used in one factor, |UE| became small unless a method other than a baseline was used in the other factor.
Discussion
This section discusses the study’s results in relation to the two research questions. In turn, we review the results for the Text Mining Method factor, which was found to have the largest influence on recommendation performance among the three factors.
RQ1: Do a user’s Tweets generate serendipitous recommendations?
Regarding RQ1, the results of the experiment indicate that a user’s Tweets do not improve the serendipity of recommendations. As shown in the rightmost column of Table 3, Tweets deliver unexpected recommendations to users, but only a small fraction of these are interesting to the users. This result is different from previous works. For instance, Chen et al. (2010) observed the precision of a webpage recommender system based on user’s Tweets was around 0.7. In addition, Lu, Lam & Zhang (2012) showed that a concept-based tweet recommender system based on user’s Tweets achieves a precision of 0.5. One way to account for this result is by drawing attention to the high probability that the users employed their Twitter accounts for purposes other than professional, research-related ones. In particular, the users are likely to have used their Twitter accounts to express private interests. We presume that taking private interests into consideration delivers serendipitous recommendations. This is because the recommender system will then suggest research papers that include both professional interests and private interests, and which are thus likely to be serendipitous. In the future, it may be helpful to introduce explanation interfaces for recommender systems (Herlocker, Konstan & Riedl, 2000; Tintarev & Masthoff, 2007). The purpose of these explanation interfaces is to show why a specific item is being recommended to users, thereby enabling users to find a connexion between a recommended paper and their interests.
RQ2: Is it possible to improve a recommendation list’s serendipity through diversification?
In terms of RQ2, the results indicate that the diversification of a recommendation list using the IA-Select algorithm delivers serendipitous recommendations. This confirms results published elsewhere in the literature, which have found that IA-Select improves serendipity (Vargas, Castells & Vallet, 2011; Vargas & Castells, 2011). For instance, in the domain of movies and music, Vargas & Castells (2011) employed IA-Select for recommender systems and confirmed that it provides unexpected recommendations. Additionally, the iterative decrease of covered interests was associated with greater variety in recommender systems for scientific publications. Furthermore, the experiment demonstrated that diversified recommendations are likely to be associated with greater utility for users.
Text mining methods
Among the three factors, the Text Mining Method factor was associated with the most substantial impact on recommender system performance. In contrast to observations made in previous literature (Goossen et al., 2011; Nishioka & Scherp, 2016), CF-IDF and HCF-IDF did not yield effective results. It is worth emphasising that this result could have been influenced by the quality of the knowledge graph used in this study (i.e. ACM CCS), particularly in view of the fact that the performance of many text mining methods is directly informed by the quality of the knowledge graph (Nishioka, Große-Bölting & Scherp, 2015).
Another way to account for the poor outcomes relates to the variable of the knowledge graphs’ age. In particular, ACM CCS has not been updated since 2012, despite the fact that computer science is a rapidly changing field of inquiry. Furthermore, relatively few concepts and labels were included in the knowledge base, which contrasts with the large number included in the knowledge graphs used in previous studies. For example, the STW Thesaurus for Economics used 6,335 concepts and 37,773 labels, respectively (Nishioka & Scherp, 2016). Hence, the number of concepts and labels could have influenced the quality of the knowledge graph and, in turn, the recommender system’s performance.
In addition, while a previous study that used HCF-IDF (Nishioka & Scherp, 2016) only drew on the titles of research papers, our study used both titles and abstracts to construct paper profiles and user profiles when a user’s own papers were selected as the user profile source. Furthermore, since our study used sufficient information when mining research papers, we did not observe any differences among TF-IDF, CF-IDF, and HCF-IDF, which can include related concepts. Finally, as with any empirical experiment, data triangulation is needed before generalising any of the conclusions drawn in this paper. Therefore, further studies of recommender systems in other domains and similar settings should be conducted.
In this article, we used only textual information in Tweets. We did not use contents from URLs mentioned in Tweets, images, and videos. We observed that Tweets by subjects contain on average 0.52 URLs (SD: 0.59). In the future, we would like to take these contents into account, as Abel et al. (2011) did.
Threats to validity
In this article, we only considered the domain of computer science. In other domains, the results and findings might be different. In the future, we would like to conduct studies in other domains such as biomedical science using MEDLINE and social science, economics. In addition, the results shown in this article may potentially be influenced by the number of subjects we recruited. Finding significances with few subjects is harder than with many subjects. However, we observed several significances and measured the effect sizes. We assume that adding more subjects would bring almost no additional insights.
As noted in the related work, this study evaluates serendipity of recommendations focusing on “unexpectedness to be found” and “unexpectedness to be recommended”. This is motivated by our library setting, where we assume researchers are working on research papers and like to receive recommendations for literature that they have not found yet (Vagliano et al., 2018). Referring to the other variations of serendipity as proposed by Kotkov et al. (2018), like “unexpectedness to be relevant” and “implicit unexpectedness”, we leave them for future studies.
Conclusion
The purpose of this study’s online experiment was to determine whether Tweets and the IA-Select algorithm have the capability to deliver serendipitous research paper recommendations. The results revealed that Tweets do not improve the serendipity of recommendations, but IA-Select does. We anticipate that this insight will contribute to the development of future recommender systems, principally because service providers and platform administrators can use the data presented here to make more informed design choices for the systems and services developed. The data from this experiment are publicly available for further study and reuse (https://doi.org/10.5281/zenodo.3367795).