
Adaptations of data mining methodologies: a systematic literature review
- Published
- Accepted
- Received
- Academic Editor
- Sebastian Ventura
- Subject Areas
- Data Mining and Machine Learning, Data Science
- Keywords
- Data mining, CRISP-DM, Literature review, Data mining methodology
- Copyright
- © 2020 Plotnikova et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2020. Adaptations of data mining methodologies: a systematic literature review. PeerJ Computer Science 6:e267 https://doi.org/10.7717/peerj-cs.267
Abstract
The use of end-to-end data mining methodologies such as CRISP-DM, KDD process, and SEMMA has grown substantially over the past decade. However, little is known as to how these methodologies are used in practice. In particular, the question of whether data mining methodologies are used ‘as-is’ or adapted for specific purposes, has not been thoroughly investigated. This article addresses this gap via a systematic literature review focused on the context in which data mining methodologies are used and the adaptations they undergo. The literature review covers 207 peer-reviewed and ‘grey’ publications. We find that data mining methodologies are primarily applied ‘as-is’. At the same time, we also identify various adaptations of data mining methodologies and we note that their number is growing rapidly. The dominant adaptations pattern is related to methodology adjustments at a granular level (modifications) followed by extensions of existing methodologies with additional elements. Further, we identify two recurrent purposes for adaptation: (1) adaptations to handle Big Data technologies, tools and environments (technological adaptations); and (2) adaptations for context-awareness and for integrating data mining solutions into business processes and IT systems (organizational adaptations). The study suggests that standard data mining methodologies do not pay sufficient attention to deployment issues, which play a prominent role when turning data mining models into software products that are integrated into the IT architectures and business processes of organizations. We conclude that refinements of existing methodologies aimed at combining data, technological, and organizational aspects, could help to mitigate these gaps.
Introduction
The availability of Big Data has stimulated widespread adoption of data mining and data analytics in research and in business settings (Columbus, 2017). Over the years, a certain number of data mining methodologies have been proposed, and these are being used extensively in practice and in research. However, little is known about what and how data mining methodologies are applied, and it has not been neither widely researched nor discussed. Further, there is no consolidated view on what constitutes quality of methodological process in data mining and data analytics, how data mining and data analytics are applied/used in organization settings context, and how application practices relate to each other. That motivates the need for comprehensive survey in the field.
There have been surveys or quasi-surveys and summaries conducted in related fields. Notably, there have been two systematic systematic literature reviews; Systematic Literature Review, hereinafter, SLR is the most suitable and widely used research method for identifying, evaluating and interpreting research of particular research question, topic or phenomenon (Kitchenham, Budgen & Brereton, 2015). These reviews concerned Big Data Analytics, but not general purpose data mining methodologies. Adrian et al. (2004) executed SLR with respect to implementation of Big Data Analytics (BDA), specifically, capability components necessary for BDA value discovery and realization. The authors identified BDA implementation studies, determined their main focus areas, and discussed in detail BDA applications and capability components. Saltz & Shamshurin (2016) have published SLR paper on Big Data Team Process Methodologies. Authors have identified lack of standard in regards to how Big Data projects are executed, highlighted growing research in this area and potential benefits of such process standard. Additionally, authors synthesized and produced list of 33 most important success factors for executing Big Data activities. Finally, there are studies that surveyed data mining techniques and applications across domains, yet, they focus on data mining process artifacts and outcomes (Madni, Anwar & Shah, 2017; Liao, Chu & Hsiao, 2012), but not on end-to-end process methodology.
There have been number of surveys conducted in domain-specific settings such as hospitality, accounting, education, manufacturing, and banking fields. Mariani et al. (2018) focused on Business Intelligence (BI) and Big Data SLR in the hospitality and tourism environment context. Amani & Fadlalla (2017) explored application of data mining methods in accounting while Romero & Ventura (2013) investigated educational data mining. Similarly, Hassani, Huang & Silva (2018) addressed data mining application case studies in banking and explored them by three dimensions—topics, applied techniques and software. All studies were performed by the means of systematic literature reviews. Lastly, Bi & Cochran (2014) have undertaken standard literature review of Big Data Analytics and its applications in manufacturing.
Apart from domain-specific studies, there have been very few general purpose surveys with comprehensive overview of existing data mining methodologies, classifying and contextualizing them. Valuable synthesis was presented by Kurgan & Musilek (2006) as comparative study of the state-of-the art of data mining methodologies. The study was not SLR, and focused on comprehensive comparison of phases, processes, activities of data mining methodologies; application aspect was summarized briefly as application statistics by industries and citations. Three more comparative, non-SLR studies were undertaken by Marban, Mariscal & Segovia (2009), Mariscal, Marbán & Fernández (2010), and the most recent and closest one by Martnez-Plumed et al. (2017). They followed the same pattern with systematization of existing data mining frameworks based on comparative analysis. There, the purpose and context of consolidation was even more practical—to support derivation and proposal of the new artifact, that is, novel data mining methodology. The majority of the given general type surveys in the field are more than a decade old, and have natural limitations due to being: (1) non-SLR studies, and (2) so far restricted to comparing methodologies in terms of phases, activities, and other elements.
The key common characteristic behind all the given studies is that data mining methodologies are treated as normative and standardized (‘one-size-fits-all’) processes. A complementary perspective, not considered in the above studies, is that data mining methodologies are not normative standardized processes, but instead, they are frameworks that need to be specialized to different industry domains, organizational contexts, and business objectives. In the last few years, a number of extensions and adaptations of data mining methodologies have emerged, which suggest that existing methodologies are not sufficient to cover the needs of all application domains. In particular, extensions of data mining methodologies have been proposed in the medical domain (Niaksu, 2015), educational domain (Tavares, Vieira & Pedro, 2017), the industrial engineering domain (Huber et al., 2019; Solarte, 2002), and software engineering (Marbán et al., 2007, 2009). However, little attention has been given to studying how data mining methodologies are applied and used in industry settings, so far only non-scientific practitioners’ surveys provide such evidence.
Given this research gap, the central objective of this article is to investigate how data mining methodologies are applied by researchers and practitioners, both in their generic (standardized) form and in specialized settings. This is achieved by investigating if data mining methodologies are applied ‘as-is’ or adapted, and for what purposes such adaptations are implemented.
Guided by Systematic Literature Review method, initially we identified a corpus of primary studies covering both peer-reviewed and ‘grey’ literature from 1997 to 2018. An analysis of these studies led us to a taxonomy of uses of data mining methodologies, focusing on the distinction between ‘as is’ usage versus various types of methodology adaptations. By analyzing different types of methodology adaptations, this article identifies potential gaps in standard data mining methodologies both at the technological and at the organizational levels.
The rest of the article is organized as follows. The Background section provides an overview of key concepts of data mining and associated methodologies. Next, Research Design describes the research methodology. The Findings and Discussion section presents the study results and their associated interpretation. Finally, threats to validity are addressed in Threats to Validity while the Conclusion summarizes the findings and outlines directions for future work.
Background
The section introduces main data mining concepts, provides overview of existing data mining methodologies, and their evolution.
Data mining is defined as a set of rules, processes, algorithms that are designed to generate actionable insights, extract patterns, and identify relationships from large datasets (Morabito, 2016). Data mining incorporates automated data extraction, processing, and modeling by means of a range of methods and techniques. In contrast, data analytics refers to techniques used to analyze and acquire intelligence from data (including ‘big data’) (Gandomi & Haider, 2015) and is positioned as a broader field, encompassing a wider spectrum of methods that includes both statistical and data mining (Chen, Chiang & Storey, 2012). A number of algorithms has been developed in statistics, machine learning, and artificial intelligence domains to support and enable data mining. While statistical approaches precedes them, they inherently come with limitations, the most known being rigid data distribution conditions. Machine learning techniques gained popularity as they impose less restrictions while deriving understandable patterns from data (Bose & Mahapatra, 2001).
Data mining projects commonly follow a structured process or methodology as exemplified by Mariscal, Marbán & Fernández (2010), Marban, Mariscal & Segovia (2009). A data mining methodology specifies tasks, inputs, outputs, and provides guidelines and instructions on how the tasks are to be executed (Mariscal, Marbán & Fernández, 2010). Thus, data mining methodology provides a set of guidelines for executing a set of tasks to achieve the objectives of a data mining project (Mariscal, Marbán & Fernández, 2010).
The foundations of structured data mining methodologies were first proposed by Fayyad, Piatetsky-Shapiro & Smyth (1996a, 1996b, 1996c), and were initially related to Knowledge Discovery in Databases (KDD). KDD presents a conceptual process model of computational theories and tools that support information extraction (knowledge) with data (Fayyad, Piatetsky-Shapiro & Smyth, 1996a). In KDD, the overall approach to knowledge discovery includes data mining as a specific step. As such, KDD, with its nine main steps (exhibited in Fig. 1), has the advantage of considering data storage and access, algorithm scaling, interpretation and visualization of results, and human computer interaction (Fayyad, Piatetsky-Shapiro & Smyth, 1996a, 1996c). Introduction of KDD also formalized clearer distinction between data mining and data analytics, as for example formulated in Tsai et al. (2015): “…by the data analytics, we mean the whole KDD process, while by the data analysis, we mean the part of data analytics that is aimed at finding the hidden information in the data, such as data mining”.
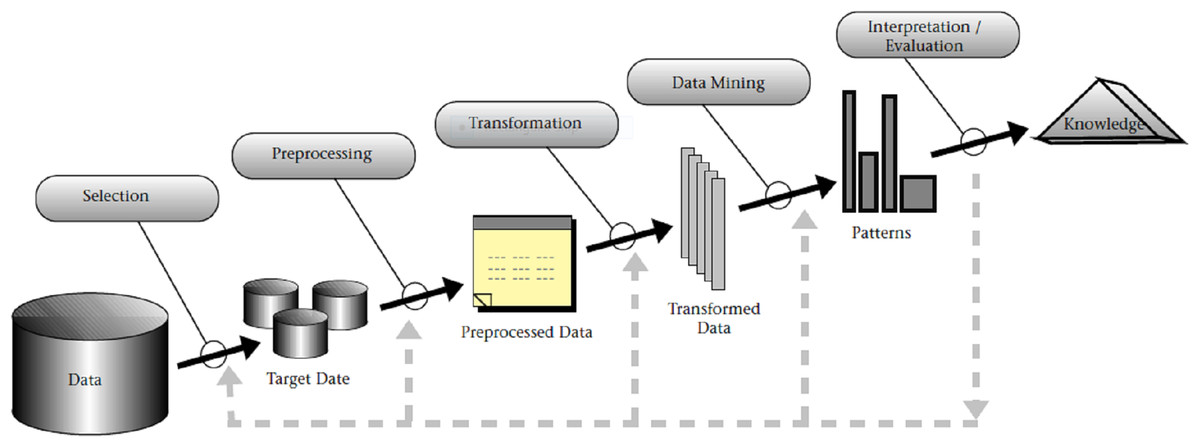
Figure 1: An overview of the steps composing the KDD process, as presented in Fayyad, Piatetsky-Shapiro & Smyth (1996a, 1996c).
{kind=link}
The main steps of KDD are as follows:
Step 1: Learning application domain: In the first step, it is needed to develop an understanding of the application domain and relevant prior knowledge followed by identifying the goal of the KDD process from the customer’s viewpoint.
Step 2: Dataset creation: Second step involves selecting a dataset, focusing on a subset of variables or data samples on which discovery is to be performed.
Step 3: Data cleaning and processing: In the third step, basic operations to remove noise or outliers are performed. Collection of necessary information to model or account for noise, deciding on strategies for handling missing data fields, and accounting for data types, schema, and mapping of missing and unknown values are also considered.
Step 4: Data reduction and projection: Here, the work of finding useful features to represent the data, depending on the goal of the task, application of transformation methods to find optimal features set for the data is conducted.
Step 5: Choosing the function of data mining: In the fifth step, the target outcome (e.g., summarization, classification, regression, clustering) are defined.
Step 6: Choosing data mining algorithm: Sixth step concerns selecting method(s) to search for patterns in the data, deciding which models and parameters are appropriate and matching a particular data mining method with the overall criteria of the KDD process.
Step 7: Data mining: In the seventh step, the work of mining the data that is, searching for patterns of interest in a particular representational form or a set of such representations: classification rules or trees, regression, clustering is conducted.
Step 8: Interpretation: In this step, the redundant and irrelevant patterns are filtered out, relevant patterns are interpreted and visualized in such way as to make the result understandable to the users.
Step 9: Using discovered knowledge: In the last step, the results are incorporated with the performance system, documented and reported to stakeholders, and used as basis for decisions.
The KDD process became dominant in industrial and academic domains (Kurgan & Musilek, 2006; Marban, Mariscal & Segovia, 2009). Also, as timeline-based evolution of data mining methodologies and process models shows (Fig. 2 below), the original KDD data mining model served as basis for other methodologies and process models, which addressed various gaps and deficiencies of original KDD process. These approaches extended the initial KDD framework, yet, extension degree has varied ranging from process restructuring to complete change in focus. For example, Brachman & Anand (1996) and further Gertosio & Dussauchoy (2004) (in a form of case study) introduced practical adjustments to the process based on iterative nature of process as well as interactivity. The complete KDD process in their view was enhanced with supplementary tasks and the focus was changed to user’s point of view (human-centered approach), highlighting decisions that need to be made by the user in the course of data mining process. In contrast, Cabena et al. (1997) proposed different number of steps emphasizing and detailing data processing and discovery tasks. Similarly, in a series of works Anand & Büchner (1998), Anand et al. (1998), Buchner et al. (1999) presented additional data mining process steps by concentrating on adaptation of data mining process to practical settings. They focused on cross-sales (entire life-cycles of online customer), with further incorporation of internet data discovery process (web-based mining). Further, Two Crows data mining process model is consultancy originated framework that has defined the steps differently, but is still close to original KDD. Finally, SEMMA (Sample, Explore, Modify, Model and Assess) based on KDD, was developed by SAS institute in 2005 (SAS Institute Inc., 2017). It is defined as a logical organization of the functional toolset of SAS Enterprise Miner for carrying out the core tasks of data mining. Compared to KDD, this is vendor-specific process model which limits its application in different environments. Also, it skips two steps of original KDD process (‘Learning Application Domain’ and ‘Using of Discovered Knowledge’) which are regarded as essential for success of data mining project (Mariscal, Marbán & Fernández, 2010). In terms of adoption, new KDD-based proposals received limited attention across academia and industry (Kurgan & Musilek, 2006; Marban, Mariscal & Segovia, 2009). Subsequently, most of these methodologies converged into the CRISP-DM methodology.
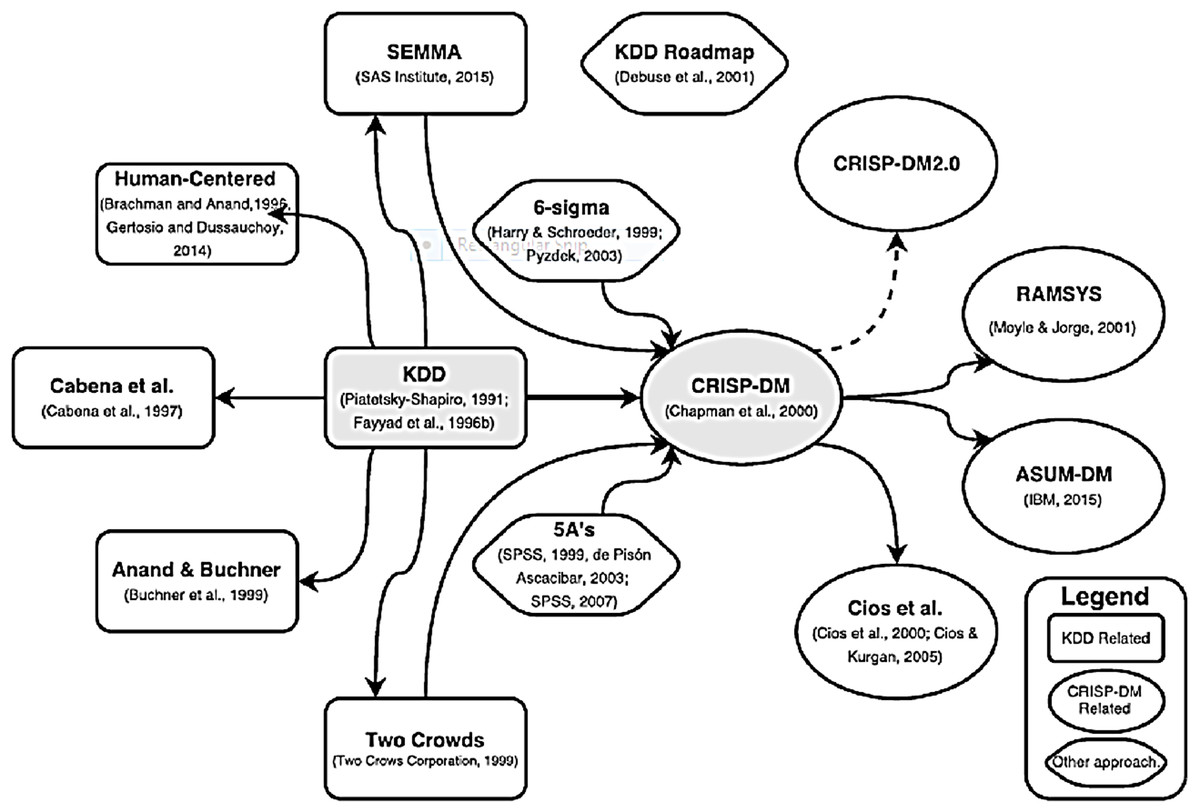
Figure 2: Evolution of data mining process and methodologies, as presented in Martnez-Plumed et al. (2017).
{kind=link}
Additionally, there have only been two non-KDD based approaches proposed alongside extensions to KDD. The first one is 5A’s approach presented by De Pisón Ascacbar (2003) and used by SPSS vendor. The key contribution of this approach has been related to adding ‘Automate’ step while disadvantage was associated with omitting ‘Data Understanding’ step. The second approach was 6-Sigma which is industry originated method to improve quality and customer’s satisfaction (Pyzdek & Keller, 2003). It has been successfully applied to data mining projects in conjunction with DMAIC performance improvement model (Define, Measure, Analyze, Improve, Control).
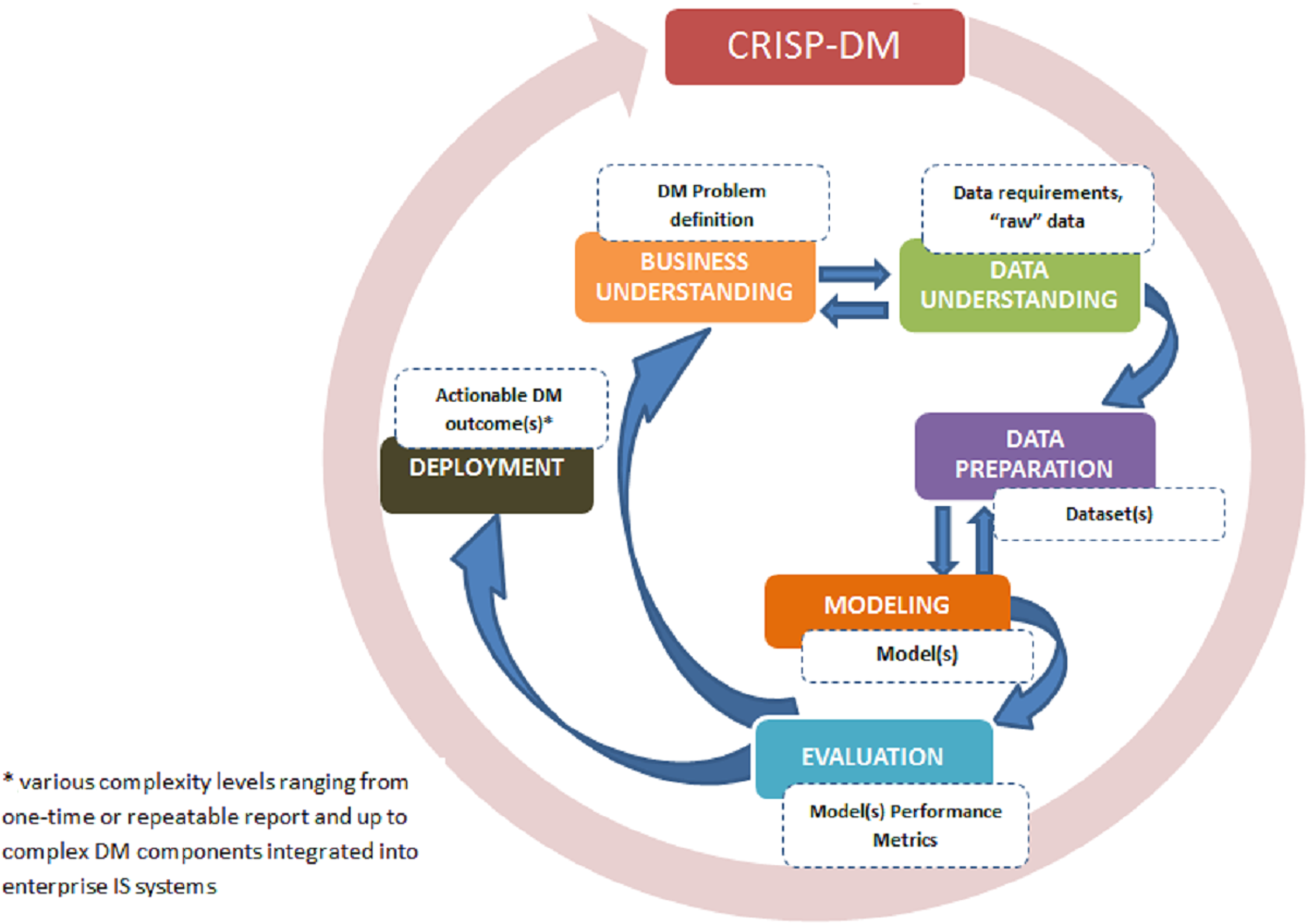
In 2000, as response to common issues and needs (Marban, Mariscal & Segovia, 2009), an industry-driven methodology called Cross-Industry Standard Process for Data Mining (CRISP-DM) was introduced as an alternative to KDD. It also consolidated original KDD model and its various extensions. While CRISP-DM builds upon KDD, it consists of six phases that are executed in iterations (Marban, Mariscal & Segovia, 2009). The iterative executions of CRISP-DM stand as the most distinguishing feature compared to initial KDD that assumes a sequential execution of its steps. CRISP-DM, much like KDD, aims at providing practitioners with guidelines to perform data mining on large datasets. However,CRISP-DM with its six main steps with a total of 24 tasks and outputs, is more refined as compared to KDD. The main steps of CRIPS-DM, as depicted in Fig. 3 below are as follows:
Phase 1: Business understanding: The focus of the first step is to gain an understanding of the project objectives and requirements from a business perspective followed by converting these into data mining problem definitions. Presentation of a preliminary plan to achieve the objectives are also included in this first step.
Phase 2: Data understanding: This step begins with an initial data collection and proceeds with activities in order to get familiar with the data, identify data quality issues, discover first insights into the data, and potentially detect and form hypotheses.
-
Phase 3: Data preparation: The third step covers activities required to construct the final dataset from the initial raw data. Data preparation tasks are performed repeatedly.
Phase 4: Modeling phase: In this step, various modeling techniques are selected and applied followed by calibrating their parameters. Typically, several techniques are used for the same data mining problem.
Phase 5: Evaluation of the model(s): The fifth step begins with the quality perspective and then, before proceeding to final model deployment, ascertains that the model(s) achieves the business objectives. At the end of this phase, a decision should be reached on how to use data mining results.
Phase 6: Deployment phase: In the final step, the models are deployed to enable end-customers to use the data as basis for decisions, or support in the business process. Even if the purpose of the model is to increase knowledge of the data, the knowledge gained will need to be organized, presented, distributed in a way that the end-user can use it. Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process.
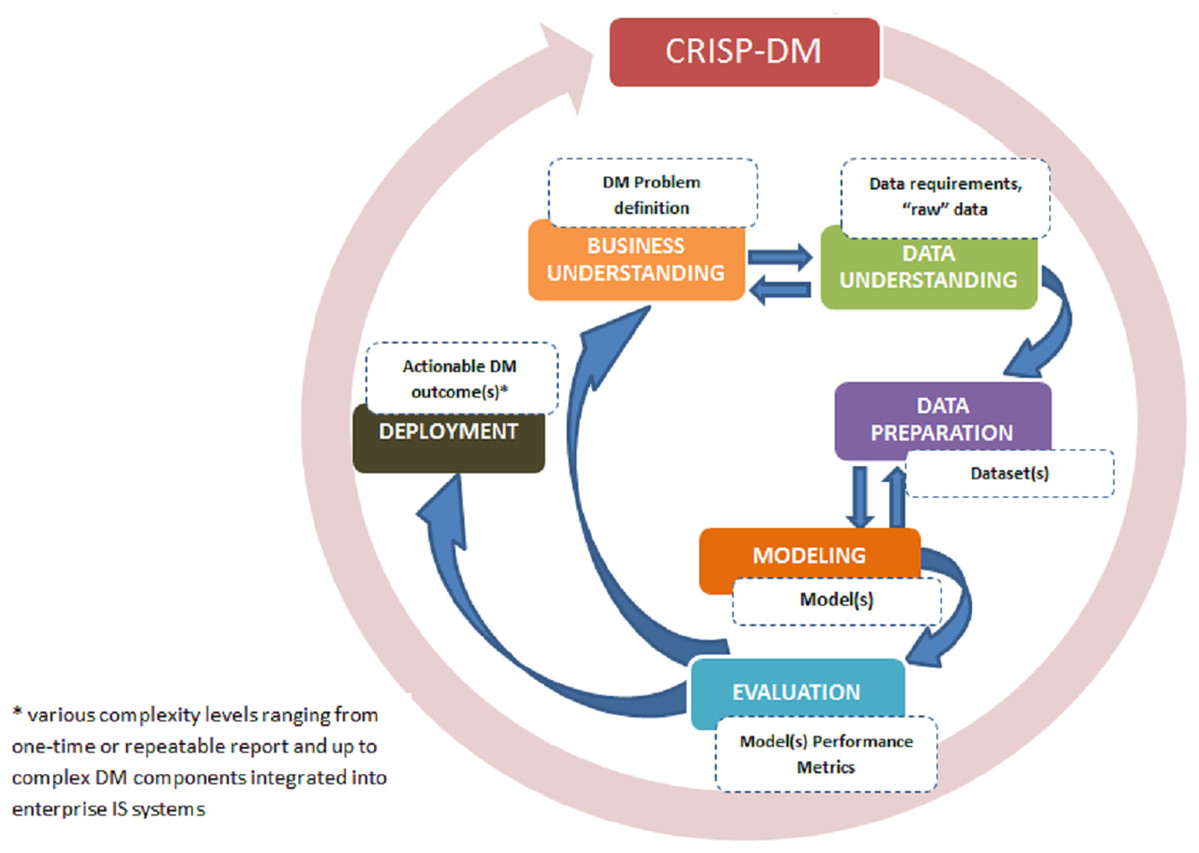
Figure 3: CRISP-DM phases and key outputs (adapted from Chapman et al. (2000)).
{kind=link}
The development of CRISP-DM was led by industry consortium. It is designed to be domain-agnostic (Mariscal, Marbán & Fernández, 2010) and as such, is now widely used by industry and research communities (Marban, Mariscal & Segovia, 2009). These distinctive characteristics have made CRISP-DM to be considered as ‘de-facto’ standard of data mining methodology and as a reference framework to which other methodologies are benchmarked (Mariscal, Marbán & Fernández, 2010).
Similarly to KDD, a number of refinements and extensions of the CRISP-DM methodology have been proposed with the two main directions—extensions of the process model itself and adaptations, merger with the process models and methodologies in other domains. Extensions direction of process models could be exemplified by Cios & Kurgan (2005) who have proposed integrated Data Mining & Knowledge Discovery (DMKD) process model. It contains several explicit feedback mechanisms, modification of the last step to incorporate discovered knowledge and insights application as well as relies on technologies for results deployment. In the same vein, Moyle & Jorge (2001), Blockeel & Moyle (2002) proposed Rapid Collaborative Data Mining System (RAMSYS) framework—this is both data mining methodology and system for remote collaborative data mining projects. The RAMSYS attempted to achieve the combination of a problem solving methodology, knowledge sharing, and ease of communication. It intended to allow the collaborative work of remotely placed data miners in a disciplined manner as regards information flow while allowing the free flow of ideas for problem solving (Moyle & Jorge, 2001). CRISP-DM modifications and integrations with other specific domains were proposed in Industrial Engineering (Data Mining for Industrial Engineering by Solarte (2002)), and Software Engineering by Marbán et al. (2007, 2009). Both approaches enhanced CRISP-DM and contributed with additional phases, activities and tasks typical for engineering processes, addressing on-going support (Solarte, 2002), as well as project management, organizational and quality assurance tasks (Marbán et al., 2009).
Finally, limited number of attempts to create independent or semi-dependent data mining frameworks was undertaken after CRISP-DM creation. These efforts were driven by industry players and comprised KDD Roadmap by Debuse et al. (2001) for proprietary predictive toolkit (Lanner Group), and recent effort by IBM with Analytics Solutions Unified Method for Data Mining (ASUM-DM) in 2015 (IBM Corporation, 2016: https://developer.ibm.com/technologies/artificial-intelligence/articles/architectural-thinking-in-the-wild-west-of-data-science/). Both frameworks contributed with additional tasks, for example, resourcing in KDD Roadmap, or hybrid approach assumed in ASUM, for example, combination of agile and traditional implementation principles.
The Table 1 above summarizes reviewed data mining process models and methodologies by their origin, basis and key concepts.
| Name | Origin | Basis | Key concept | Year |
|---|---|---|---|---|
| Human-Centered | Academy | KDD | Iterative process and interactivity (user’s point of view and needed decisions) | 1996, 2004 |
| Cabena et al. | Academy | KDD | Focus on data processing and discovery tasks | 1997 |
| Anand and Buchner | Academy | KDD | Supplementary steps and integration of web-mining | 1998, 1999 |
| Two Crows | Industry | KDD | Modified definitions of steps | 1998 |
| SEMMA | Industry | KDD | Tool-specific (SAS Institute), elimination of some steps | 2005 |
| 5 A’s | Industry | Independent | Supplementary steps | 2003 |
| 6 Sigmas | Industry | Independent | Six Sigma quality improvement paradigm in conjunction with DMAIC performance improvement model | 2003 |
| CRISP-DM | Joint industry and academy | KDD | Iterative execution of steps, significant refinements to tasks and outputs | 2000 |
| Cios et al. | Academy | Crisp-DM | Integration of data mining and knowledge discovery, feedback mechanisms, usage of received insights supported by technologies | 2005 |
| RAMSYS | Academy | Crisp-DM | Integration of collaborative work aspects | 2001–2002 |
| DMIE | Academy | Crisp-DM | Integration and adaptation to Industrial Engineering domain | 2001 |
| Marban | Academy | Crisp-DM | Integration and adaptation to Software Engineering domain | 2007 |
| KDD roadmap | Joint industry and academy | Independent | Tool-specific, resourcing task | 2001 |
| ASUM | Industry | Crisp-DM | Tool-specific, combination of traditional Crisp-DM and agile implementation approach | 2015 |
Research Design
The main research objective of this article is to study how data mining methodologies are applied by researchers and practitioners. To this end, we use systematic literature review (SLR) as scientific method for two reasons. Firstly, systematic review is based on trustworthy, rigorous, and auditable methodology. Secondly, SLR supports structured synthesis of existing evidence, identification of research gaps, and provides framework to position new research activities (Kitchenham, Budgen & Brereton, 2015). For our SLR, we followed the guidelines proposed by Kitchenham, Budgen & Brereton (2015). All SLR details have been documented in the separate, peer-reviewed SLR protocol (available at https://figshare.com/articles/Systematic-Literature-Review-Protocol/10315961).
Research questions
As suggested by Kitchenham, Budgen & Brereton (2015), we have formulated research questions and motivate them as follows. In the preliminary phase of research we have discovered very limited number of studies investigating data mining methodologies application practices as such. Further, we have discovered number of surveys conducted in domain-specific settings, and very few general purpose surveys, but none of them considered application practices either. As contrasting trend, recent emergence of limited number of adaptation studies have clearly pinpointed the research gap existing in the area of application practices. Given this research gap, in-depth investigation of this phenomenon led us to ask: “How data mining methodologies are applied (‘as-is’ vs adapted) (RQ1)?” Further, as we intended to investigate in depth universe of adaptations scenarios, this naturally led us to RQ2: “How have existing data mining methodologies been adapted?” Finally, if adaptions are made, we wish to explore what the associated reasons and purposes are, which in turn led us to RQ3: “For what purposes are data mining methodologies adapted?”
Thus, for this review, there are three research questions defined:
Research Question 1: How data mining methodologies are applied (‘as-is’ versus adapted)? This question aims to identify data mining methodologies application and usage patterns and trends.
Research Question 2: How have existing data mining methodologies been adapted? This questions aims to identify and classify data mining methodologies adaptation patterns and scenarios.
Research Question 3: For what purposes have existing data mining methodologies been adapted? This question aims to identify, explain, classify and produce insights on what are the reasons and what benefits are achieved by adaptations of existing data mining methodologies. Specifically, what gaps do these adaptations seek to fill and what have been the benefits of these adaptations. Such systematic evidence and insights will be valuable input to potentially new, refined data mining methodology. Insights will be of interest to practitioners and researchers.
Data collection strategy
Our data collection and search strategy followed the guidelines proposed by Kitchenham, Budgen & Brereton (2015). It defined the scope of the search, selection of literature and electronic databases, search terms and strings as well as screening procedures.
Primary search
The primary search aimed to identify an initial set of papers. To this end, the search strings were derived from the research objective and research questions. The term ‘data mining’ was the key term, but we also included ‘data analytics’ to be consistent with observed research practices. The terms ‘methodology’ and ‘framework’ were also included. Thus, the following search strings were developed and validated in accordance with the guidelines suggested by Kitchenham, Budgen & Brereton (2015):
(‘data mining methodology’) OR (‘data mining framework’) OR (‘data analytics methodology’) OR (‘data analytics framework’)
The search strings were applied to the indexed scientific databases Scopus, Web of Science (for ‘peer-reviewed’, academic literature) and to the non-indexed Google Scholar (for non-peer-reviewed, so-called ‘grey’ literature). The decision to cover ‘grey’ literature in this research was motivated as follows. As proposed in number of information systems and software engineering domain publications (Garousi, Felderer & Mäntylä, 2019; Neto et al., 2019), SLR as stand-alone method may not provide sufficient insight into ‘state of practice’. It was also identified (Garousi, Felderer & Mäntylä, 2016) that ‘grey’ literature can give substantial benefits in certain areas of software engineering, in particular, when the topic of research is related to industrial and practical settings. Taking into consideration the research objectives, which is investigating data mining methodologies application practices, we have opted for inclusion of elements of Multivocal Literature Review (MLR)1 in our study. Also, Kitchenham, Budgen & Brereton (2015) recommends including ‘grey’ literature to minimize publication bias as positive results and research outcomes are more likely to be published than negative ones. Following MLR practices, we also designed inclusion criteria for types of ‘grey’ literature reported below.
The selection of databases is motivated as follows. In case of peer-reviewed literature sources we concentrated to avoid potential omission bias. The latter is discussed in IS research (Levy & Ellis, 2006) in case research is concentrated in limited disciplinary data sources. Thus, broad selection of data sources including multidisciplinary-oriented (Scopus, Web of Science, Wiley Online Library) and domain-oriented (ACM Digital Library, IEEE Xplorer Digital Library) scientific electronic databases was evaluated. Multidisciplinary databases have been selected due to wider domain coverage and it was validated and confirmed that they do include publications originating from domain-oriented databases, such as ACM and IEEE. From multi-disciplinary databases as such, Scopus was selected due to widest possible coverage (it is worlds largest database, covering app. 80% of all international peer-reviewed journals) while Web of Science was selected due to its longer temporal range. Thus, both databases complement each other. The selected non-indexed database source for ‘grey’ literature is Google Scholar, as it is comprehensive source of both academic and ‘grey’ literature publications and referred as such extensively (Garousi, Felderer & Mäntylä, 2019; Neto et al., 2019).
Further, Garousi, Felderer & Mäntylä (2019) presented three-tier categorization framework for types of ‘grey literature’. In our study we restricted ourselves to the 1st tier ‘grey’ literature publications of the limited number of ‘grey’ literature producers. In particular, from the list of producers (Neto et al., 2019) we have adopted and focused on government departments and agencies, non-profit economic, trade organizations (‘think-tanks’) and professional associations, academic and research institutions, businesses and corporations (consultancy companies and established private companies). The 1st tier ‘grey’ literature selected items include: (1) government, academic, and private sector consultancy reports2 , (2) theses (not lower than Master level) and PhD Dissertations, (3) research reports, (4) working papers, (5) conference proceedings, preprints. With inclusion of the 1st tier ‘grey’ literature criteria we mitigate quality assessment challenge especially relevant and reported for it (Garousi, Felderer & Mäntylä, 2019; Neto et al., 2019).
Scope and domains inclusion
As recommended by Kitchenham, Budgen & Brereton (2015) it is necessary to initially define research scope. To clarify the scope, we defined what is not included and is out of scope of this research. The following aspects are not included in the scope of our study:
Context of technology and infrastructure for data mining/data analytics tasks and projects.
Granular methods application in data mining process itself or their application for data mining tasks, for example, constructing business queries or applying regression or neural networks modeling techniques to solve classification problems. Studies with granular methods are included in primary texts corpus as long as method application is part of overall methodological approach.
Technological aspects in data mining for example, data engineering, dataflows and workflows.
Traditional statistical methods not associated with data mining directly including statistical control methods.
Similarly to Budgen et al. (2006) and Levy & Ellis (2006), initial piloting revealed that search engines retrieved literature available for all major scientific domains including ones outside authors’ area of expertise (e.g., medicine). Even though such studies could be retrieved, it would be impossible for us to analyze and correctly interpret literature published outside the possessed area of expertise. The adjustments toward search strategy were undertaken by retaining domains closely associated with Information Systems, Software Engineering research. Thus, for Scopus database the final set of inclusive domains was limited to nine and included Computer Science, Engineering, Mathematics, Business, Management and Accounting, Decision Science, Economics, Econometrics and Finance, and Multidisciplinary as well as Undefined studies. Excluded domains covered 11.5% or 106 out of 925 publications; it was confirmed in validation process that they primarily focused on specific case studies in fundamental sciences and medicine3 . The included domains from Scopus database were mapped to Web of Science to ensure consistent approach across databases and the correctness of mapping was validated.
Screening criteria and procedures
Based on the SLR practices (as in Kitchenham, Budgen & Brereton (2015), Brereton et al. (2007)) and defined SLR scope, we designed multi-step screening procedures (quality and relevancy) with associated set of Screening Criteria and Scoring System. The purpose of relevancy screening is to find relevant primary studies in an unbiased way (Vanwersch et al., 2011). Quality screening, on the other hand, aims to assess primary relevant studies in terms of quality in unbiased way.
Screening Criteria consisted of two subsets—Exclusion Criteria applied for initial filtering and Relevance Criteria, also known as Inclusion Criteria.
Exclusion Criteria were initial threshold quality controls aiming at eliminating studies with limited or no scientific contribution. The exclusion criteria also address issues of understandability, accessability and availability. The Exclusion Criteria were as follows:
Quality 1: The publication item is not in English (understandability).
Quality 2: Publication item duplicates which can occur when:
either the same document retrieved from two or all three databases.
or different versions of the same publication are retrieved (i.e., the same study published in different sources)—based on best practices, decision rule is that the most recent paper is retained as well as the one with the highest score (Kofod-Petersen, 2014).
if a publication is published both as conference proceeding and as journal article with the same name and same authors or as an extended version of conference paper, the latter is selected.
Quality 3: Length of the publication is less than 6 pages—short papers do not have the space to expand and discuss presented ideas in sufficient depth to examine for us.
Quality 4: The paper is not accessible in full length online through the university subscription of databases and via Google Scholar—not full availability prevents us from assessing and analyzing the text.
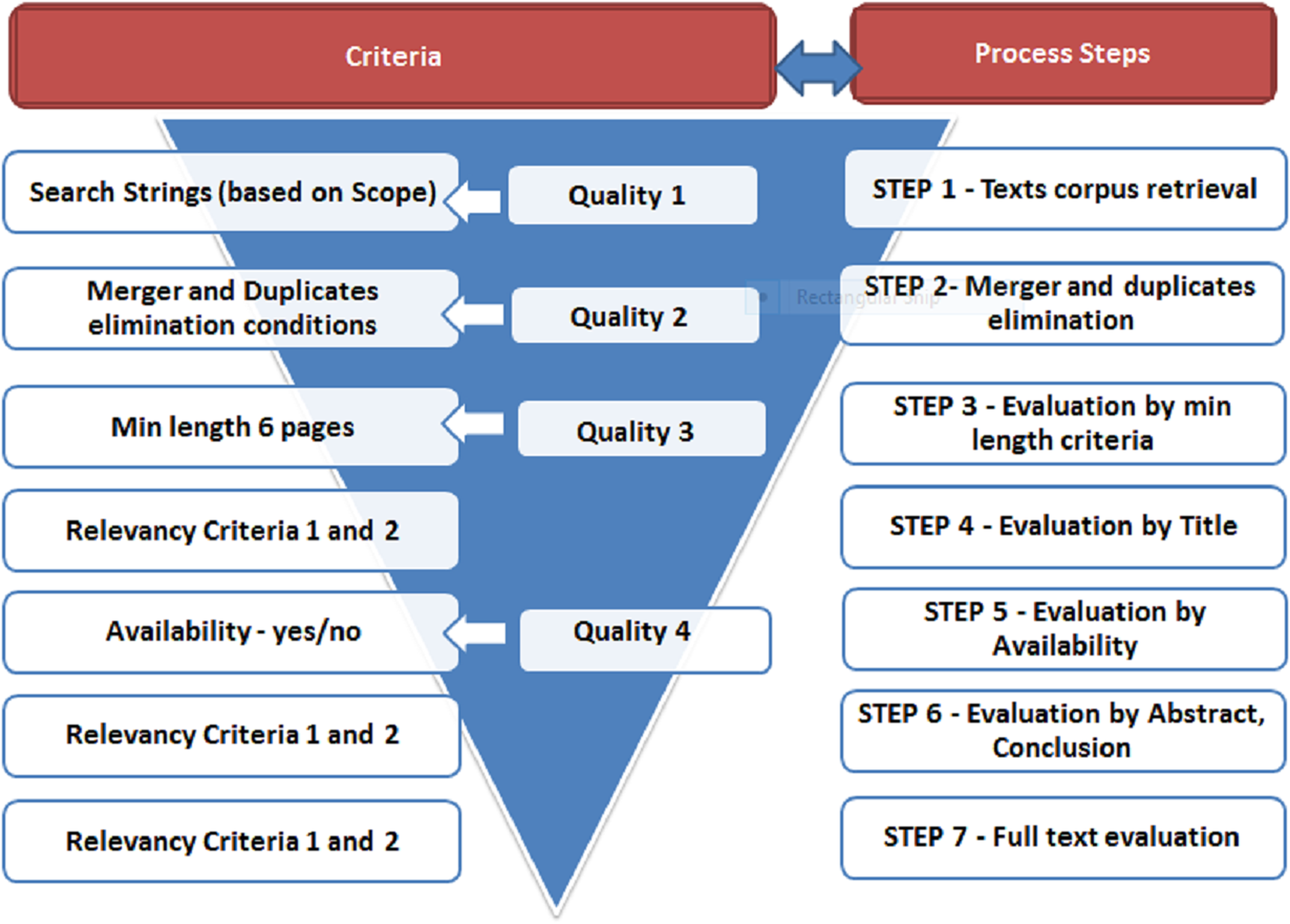
The initially retrieved list of papers was filtered based on Exclusion Criteria. Only papers that passed all criteria were retained in the final studies corpus. Mapping of criteria towards screening steps is exhibited in Fig. 4.
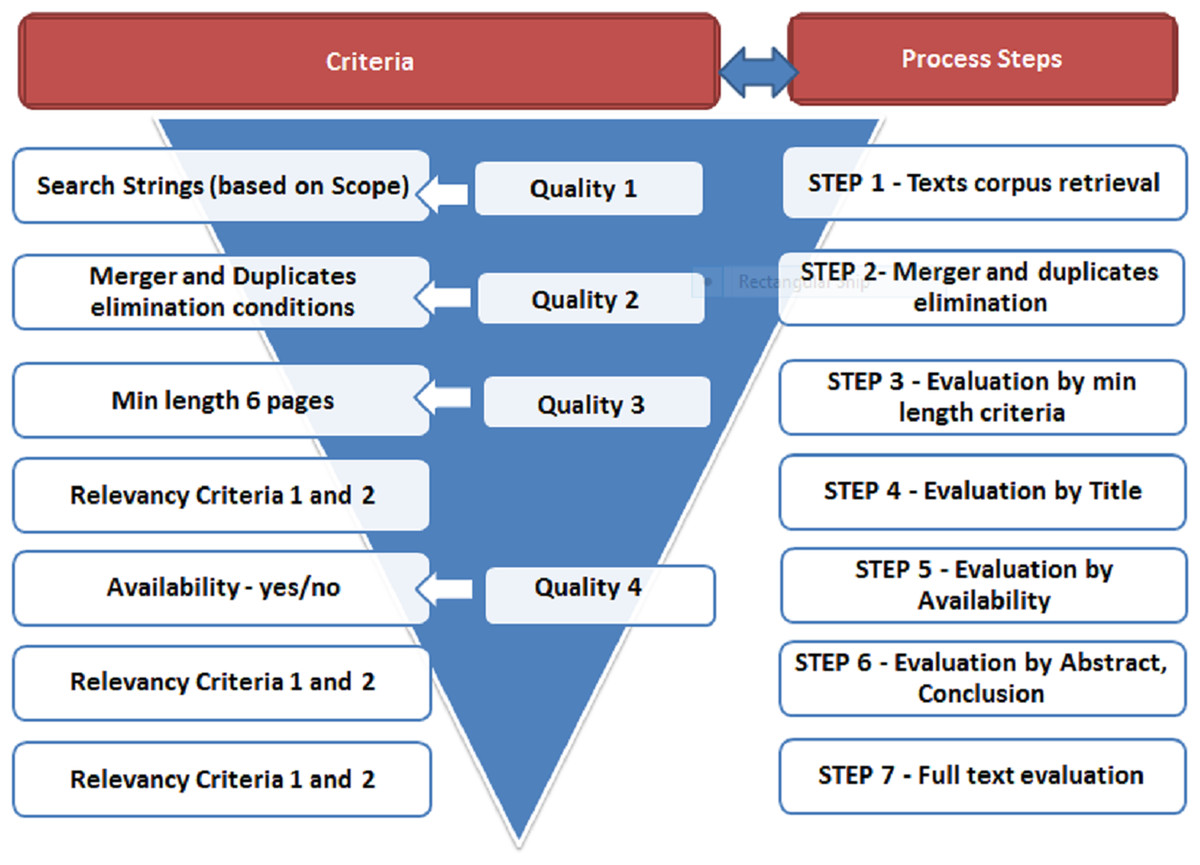
Figure 4: Relevance and quality screening steps with criteria.
{kind=link}
Relevance Criteria were designed to identify relevant publications and are presented in Table 2 below while mapping to respective process steps is presented in Fig. 4. These criteria were applied iteratively.
| Relevance criteria | Criteria definition | Criteria justification |
|---|---|---|
| Relevance 1 | Is the study about data mining or data analytics approach and is within designated list of domains? | Exclude studies conducted outside the designated domain list. Exclude studies not directly describing and/or discussing data mining and data analytics |
| Relevance 2 | Is the study introducing/describing data mining or data analytics methodology/framework or modifying existing approaches? | Exclude texts considering only specific, granular data mining and data analytics techniques, methods or traditional statistical methods. Exclude publications focusing on specific, granular data mining and data analytics process/sub-process aspects. Exclude texts where description and discussion of data mining methodologies or frameworks is manifestly missing |
As a final SLR step, the full texts quality assessment was performed with constructed Scoring Metrics (in line with Kitchenham & Charters (2007)). It is presented in the Table 3 below.
| Score | Criteria definition |
|---|---|
| 3 | Data mining methodology or framework is presented in full. All steps described and explained, tests performed, results compared and evaluated. There is clear proposal on usage, application, deployment of solution in organization’s business process(es) and IT/IS system, and/or prototype or full solution implementation is discussed. Success factors described and presented |
| 2 | Data mining methodology or framework is presented, some process steps are missing, but they do not impact the holistic view and understanding of the performed work. Data mining process is clearly presented and described, tests performed, results compared and evaluated. There is proposal on usage, application, deployment of solution in organization’s business process(es) and IT/IS system(s) |
| 1 | Data mining methodology or framework is not presented in full, some key phases and process steps are missing. Publication focuses on one or some aspects (e.g., method, technique) |
| 0 | Data mining methodology or framework not presented as holistic approach, but on fragmented basis, study limited to some aspects (e.g., method or technique discussion, etc.) |
Data extraction and screening process
The conducted data extraction and screening process is presented in Fig. 4. In Step 1 initial publications list were retrieved from pre-defined databases—Scopus, Web of Science, Google Scholar. The lists were merged and duplicates eliminated in Step 2. Afterwards, texts being less than 6 pages were excluded (Step 3). Steps 1–3 were guided by Exclusion Criteria. In the next stage (Step 4), publications were screened by Title based on pre-defined Relevance Criteria. The ones which passed were evaluated by their availability (Step 5). As long as study was available, it was evaluated again by the same pre-defined Relevance Criteria applied to Abstract, Conclusion and if necessary Introduction (Step 6). The ones which passed this threshold formed primary publications corpus extracted from databases in full. These primary texts were evaluated again based on full text (Step 7) applying Relevance Criteria first and then Scoring Metrics.
Results and quantitative analysis
In Step 1, 1,715 publications were extracted from relevant databases with the following composition—Scopus (819), Web of Science (489), Google Scholar (407). In terms of scientific publication domains, Computer Science (42.4%), Engineering (20.6%), Mathematics (11.1%) accounted for app. 74% of Scopus originated texts. The same applies to Web of Science harvest. Exclusion Criteria application produced the following results. In Step 2, after eliminating duplicates, 1,186 texts were passed for minimum length evaluation, and 767 reached assessment by Relevancy Criteria.
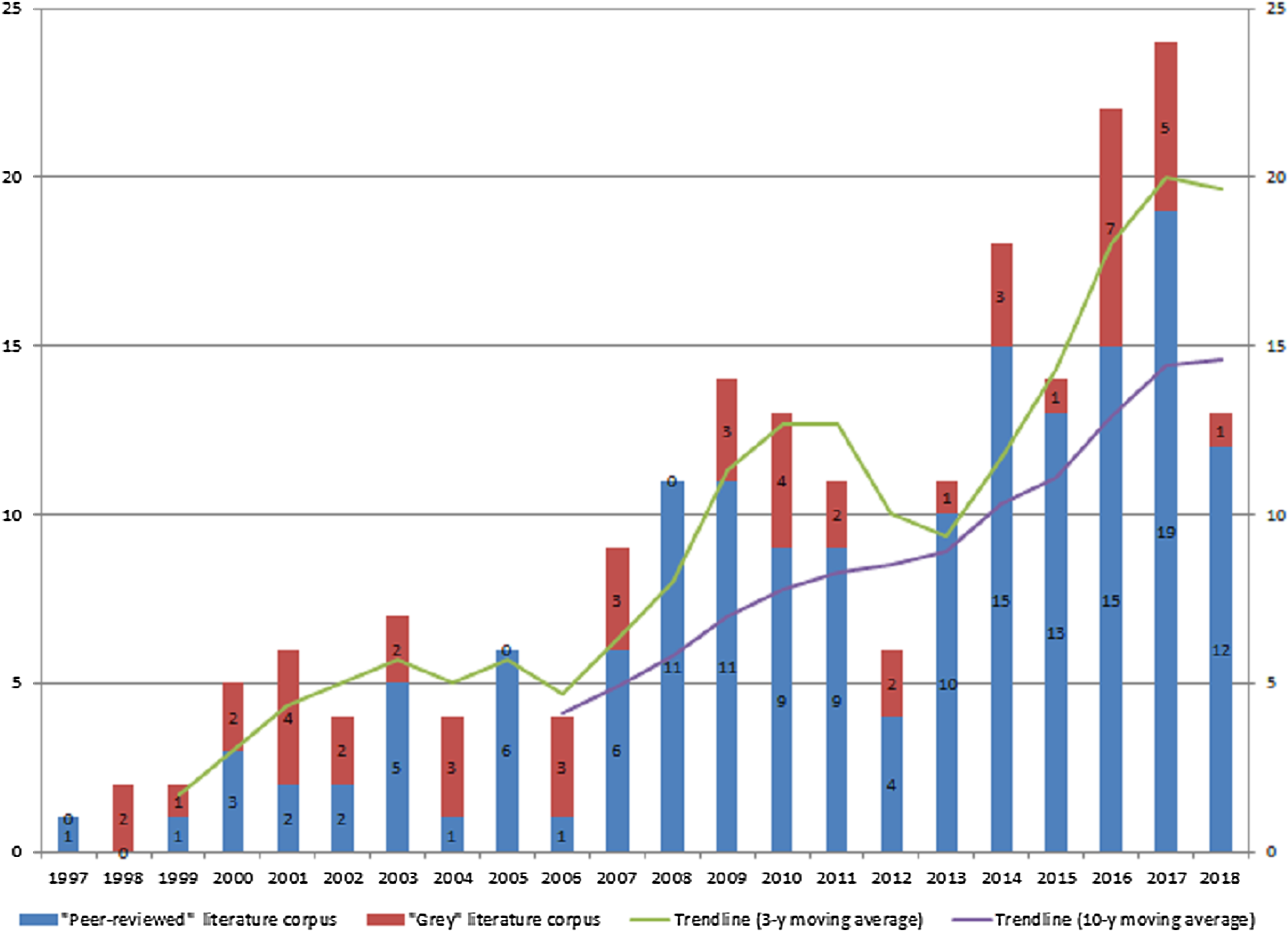
As mentioned Relevance Criteria were applied iteratively (Step 4–6) and in conjunction with availability assessment. As a result, only 298 texts were retained for full evaluation with 241 originating from scientific databases while 57 were ‘grey’. These studies formed primary texts corpus which was extracted, read in full and evaluated by Relevance Criteria combined with Scoring Metrics. The decision rule was set as follows. Studies that scored “1” or “0” were rejected, while texts with “3” and “2” evaluation were admitted as final primary studies corpus. To this end, as an outcome of SLR-based, broad, cross-domain publications collection and screening we identified 207 relevant publications from peer-reviewed (156 texts) and ‘grey’ literature (51 texts). Figure 5 below exhibits yearly published research numbers with the breakdown by ‘peer-reviewed’ and ‘grey’ literature starting from 1997.
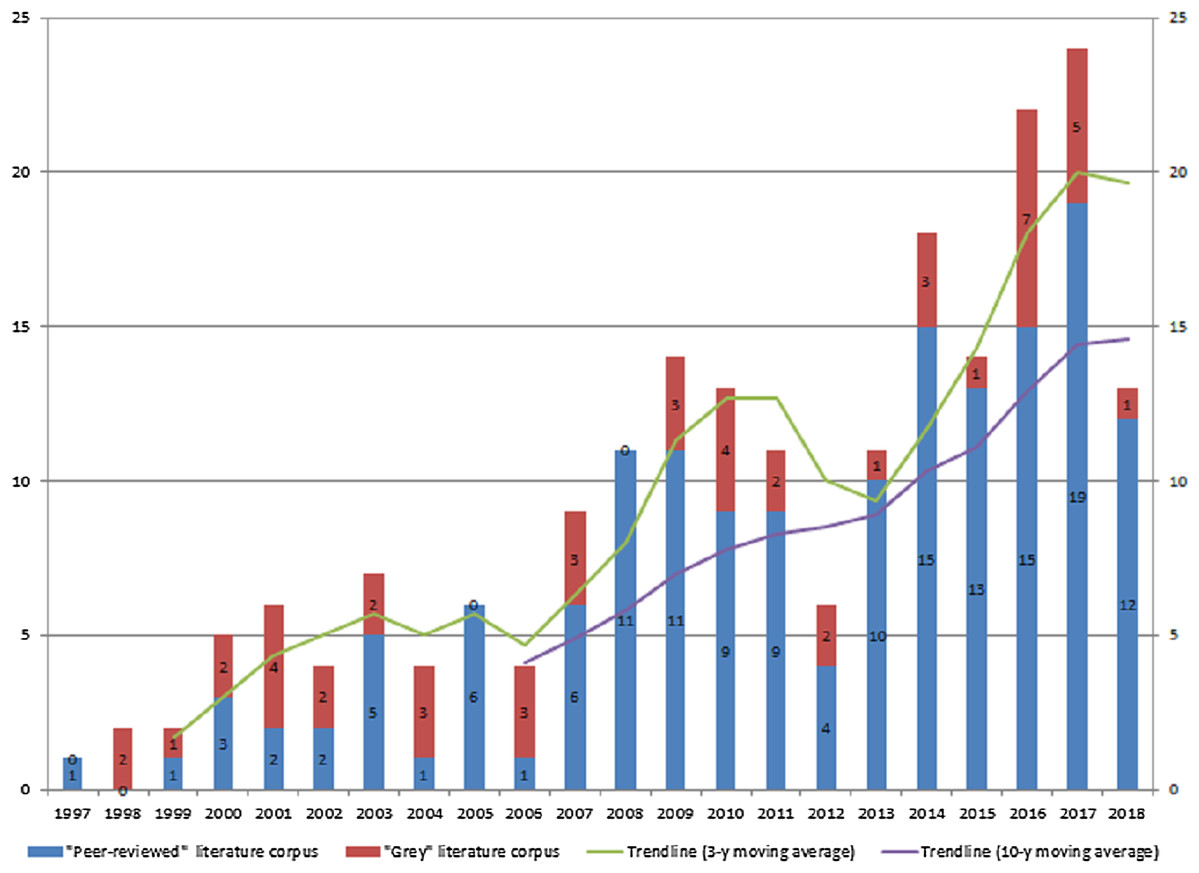
Figure 5: SLR derived relevant texts corpus—data mining methodologies peer-reviewed research and ‘grey’ for period 1997–2018 (no. of publications).
{kind=link}
In terms of composition, ‘peer-reviewed’ studies corpus is well-balanced with 72 journal articles and 82 conference papers while book chapters account for 4 instances only. In contrast, in ‘grey’ literature subset, articles in moderated and non-peer reviewed journals are dominant (n = 34) compared to overall number of conference papers (n = 13), followed by small number of technical reports and pre-prints (n = 4).
Temporal analysis of texts corpus (as per Fig. 5 below) resulted in two observations. Firstly, we note that stable and significant research interest (in terms of numbers) on data mining methodologies application has started around a decade ago—in 2007. Research efforts made prior to 2007 were relatively limited with number of publications below 10. Secondly, we note that research on data mining methodologies has grown substantially since 2007, an observation supported by the 3-year and 10-year constructed mean trendlines. In particular, the number of publications have roughly tripled over past decade hitting all time high with 24 texts released in 2017.
Further, there are also two distinct spike sub-periods in the years 2007–2009 and 2014–2017 followed by stable pattern with overall higher number of released publications on annual basis. This observation is in line with the trend of increased penetration of methodologies, tools, cross-industry applications and academic research of data mining.
Findings and Discussion
In this section, we address the research questions of the paper. Initially, as part of RQ1, we present overview of data mining methodologies ‘as-is’ and adaptation trends. In addressing RQ2, we further classify the adaptations identified. Then, as part of RQ3 subsection, each category identified under RQ2 is analyzed with particular focus on the goals of adaptations.
RQ1: How data mining methodologies are applied (‘as-is’ vs. adapted)?
The first research question examines the extent to which data mining methodologies are used ‘as-is’ versus adapted. Our review based on 207 publications identified two distinct paradigms on how data mining methodologies are applied. The first is ‘as-is’ where the data mining methodologies are applied as stipulated. The second is with ‘adaptations’; that is, methodologies are modified by introducing various changes to the standard process model when applied.
We have aggregated research by decades to differentiate application pattern between two time periods 1997–2007 with limited vs 2008–2018 with more intensive data mining application. The given cut has not only been guided by extracted publications corpus but also by earlier surveys. In particular, during the pre-2007 research, there where ten new methodologies proposed, but since then, only two new methodologies have been proposed. Thus, there is a distinct trend observed over the last decade of large number of extensions and adaptations proposed vs entirely new methodologies.
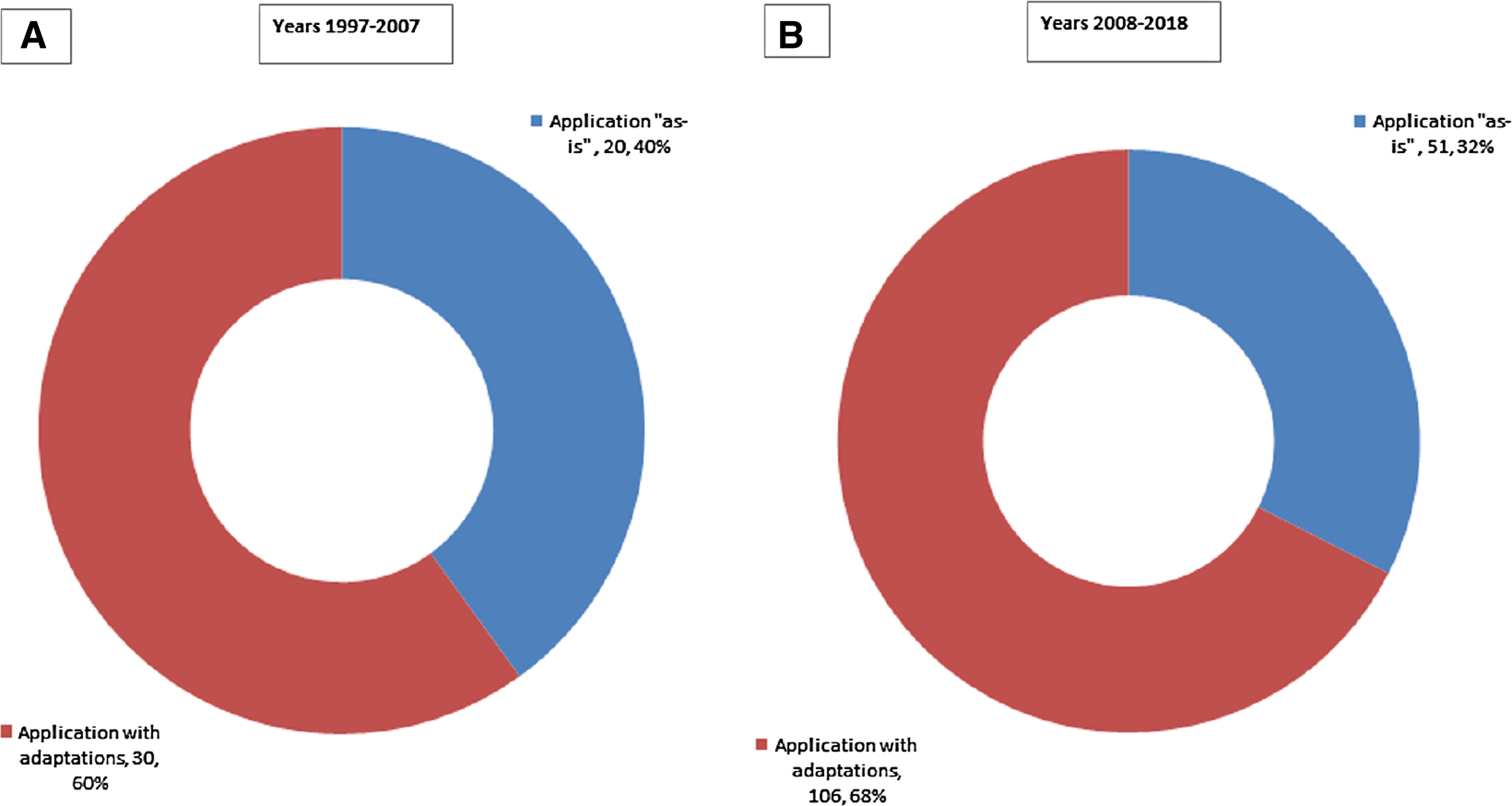
We note that during the first decade of our time scope (1997–2007), the ratio of data mining methodologies applied ‘as-is’ was 40% (as presented in Fig. 6A). However, the same ratio for the following decade is 32% (Fig. 6B). Thus, in terms of relative shares we note a clear decrease in using data mining methodologies ‘as-is’ in favor of adapting them to cater to specific needs.The trend is even more pronounced when comparing numbers—adaptations more than tripled (from 30 to 106) while ‘as-is’ scenario has increased modestly (from 20 to 51). Given this finding, we continue with analyzing how data mining methodologies have been adapted under RQ2.
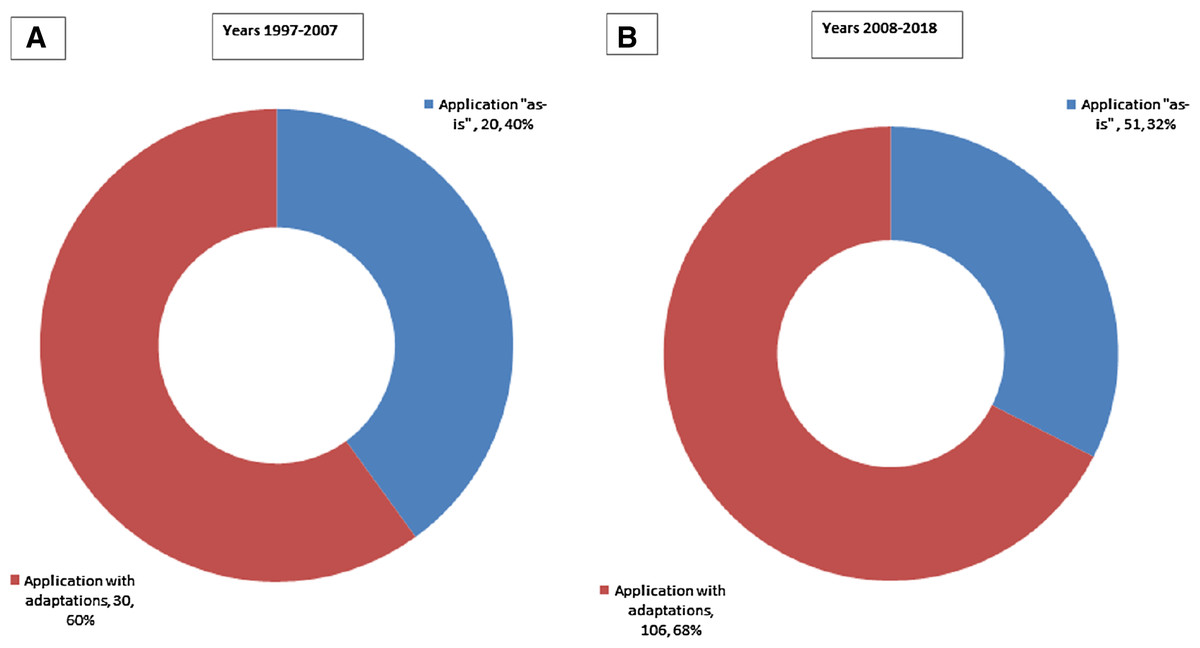
Figure 6: Applications of data mining methodologies: (A) breakdown by ‘as-is’ vs. adaptions for 1997–2007 period; (B) breakdown by ‘as-is’ vs. adaptions for 2008–2018 period.
{kind=link}
RQ2: How have existing data mining methodologies been adapted?
We identified that data mining methodologies have been adapted to cater to specific needs. In order to categorize adaptations scenarios, we applied a two-level dichotomy, specifically, by applying the following decision tree:
Level 1 Decision: Has the methodology been combined with another methodology? If yes, the resulting methodology was classified in the ‘integration’ category. Otherwise, we posed the next question.
Level 2 Decision: Are any new elements (phases, tasks, deliverables) added to the methodology? If yes, we designate the resulting methodology as an ‘extension’ of the original one. Otherwise, we classify the resulting methodology as a modification of the original one.
Thus, when adapted three distinct types of adaptation scenarios can be distinguished:
Scenario ‘Modification’: introduces specialized sub-tasks and deliverables in order to address specific use cases or business problems. Modifications typically concentrate on granular adjustments to the methodology at the level of sub-phases, tasks or deliverables within the existing reference frameworks (e.g., CRISP-DM or KDD) stages. For example, Chernov et al. (2014), in the study of mobile network domain, proposed automated decision-making enhancement in the deployment phase. In addition, the evaluation phase was modified by using both conventional and own-developed performance metrics. Further, in a study performed within the financial services domain, Yang et al. (2016) presents feature transformation and feature selection as sub-phases, thereby enhancing the data mining modeling stage.
Scenario ‘Extension’: primarily proposes significant extensions to reference data mining methodologies. Such extensions result in either integrated data mining solutions, data mining frameworks serving as a component or tool for automated IS systems, or their transformations to fit specialized environments. The main purposes of extensions are to integrate fully-scaled data mining solutions into IS/IT systems and business processes and provide broader context with useful architectures, algorithms, etc. Adaptations, where extensions have been made, elicit and explicitly present various artifacts in the form of system and model architectures, process views, workflows, and implementation aspects. A number of soft goals are also achieved, providing holistic perspective on data mining process, and contextualizing with organizational needs. Also, there are extensions in this scenario where data mining process methodologies are substantially changed and extended in all key phases to enable execution of data mining life-cycle with the new (Big) Data technologies, tools and in new prototyping and deployment environments (e.g., Hadoop platforms or real-time customer interfaces). For example, Kisilevich, Keim & Rokach (2013) presented extensions to traditional CRISP-DM data mining outcomes with fully fledged Decision Support System (DSS) for hotel brokerage business. Authors (Kisilevich, Keim & Rokach, 2013) have introduced spatial/non-spatial data management (extending data preparation), analytical and spatial modeling capabilities (extending modeling phase), provided spatial display and reporting capabilities (enhancing deployment phase). In the same work domain knowledge was introduced in all phases of data mining process, and usability and ease of use were also addressed.
Scenario ‘Integration’: combines reference methodology, for example, CRISP-DM with: (1) data mining methodologies originated from other domains (e.g., Software engineering development methodologies), (2) organizational frameworks (Balanced Scorecard, Analytics Canvass, etc.), or (3) adjustments to accommodate Big Data technologies and tools. Also, adaptations in the form of ‘Integration’ typically introduce various types of ontologies and ontology-based tools, domain knowledge, software engineering, and BI-driven framework elements. Fundamental data mining process adjustments to new types of data, IS architectures (e.g., real time data, multi-layer IS) are also presented. Key gaps addressed with such adjustments are prescriptive nature and low degree of formalization in CRISP-DM, obsolete nature of CRISP-DM with respect to tools, and lack of CRISP-DM integration with other organizational frameworks. For example, Brisson & Collard (2008) developed KEOPS data mining methodology (CRIPS-DM based) centered on domain knowledge integration. Ontology-driven information system has been proposed with integration and enhancements to all steps of data mining process. Further, an integrated expert knowledge used in all data mining phases was proved to produce value in data mining process.
To examine how the application scenario of each data mining methodology usage has developed over time, we mapped peer-reviewed texts and ‘grey’ literature to respective adaptation scenarios, aggregated by decades (as presented in the Fig. 7 for peer-reviewed and Fig. 8 for ‘grey’).
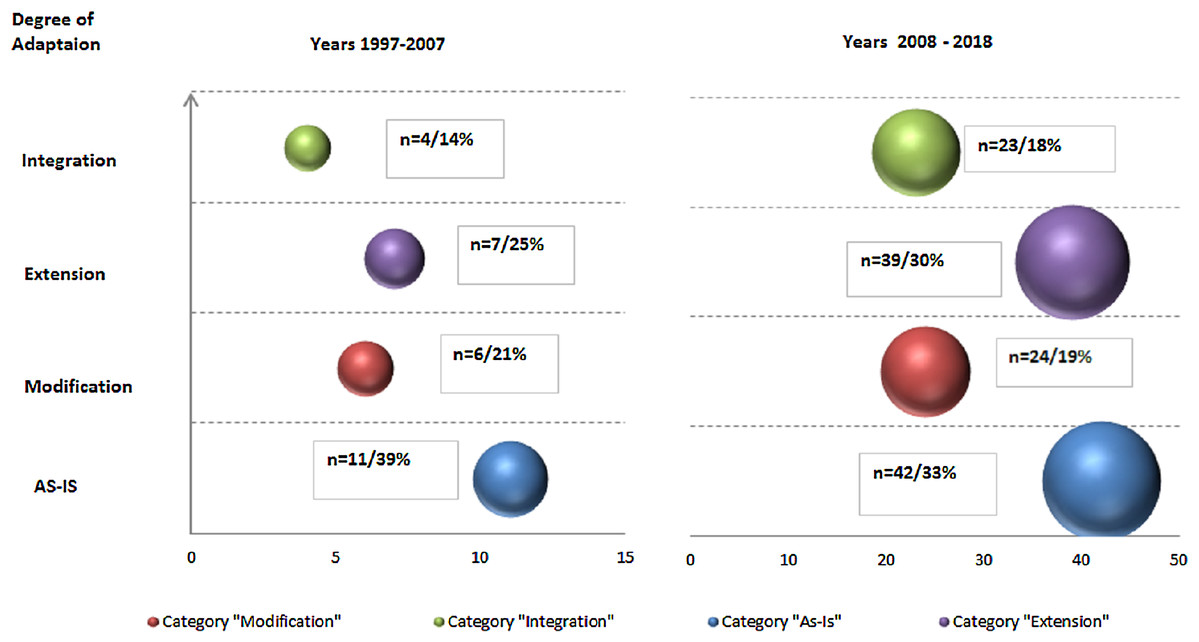
Figure 7: Data Mining methodologies application research—primary ‘peer-reviewed’ texts classification by types of scenarios aggregated by decades (with numbers and relative proportions).
{kind=link}
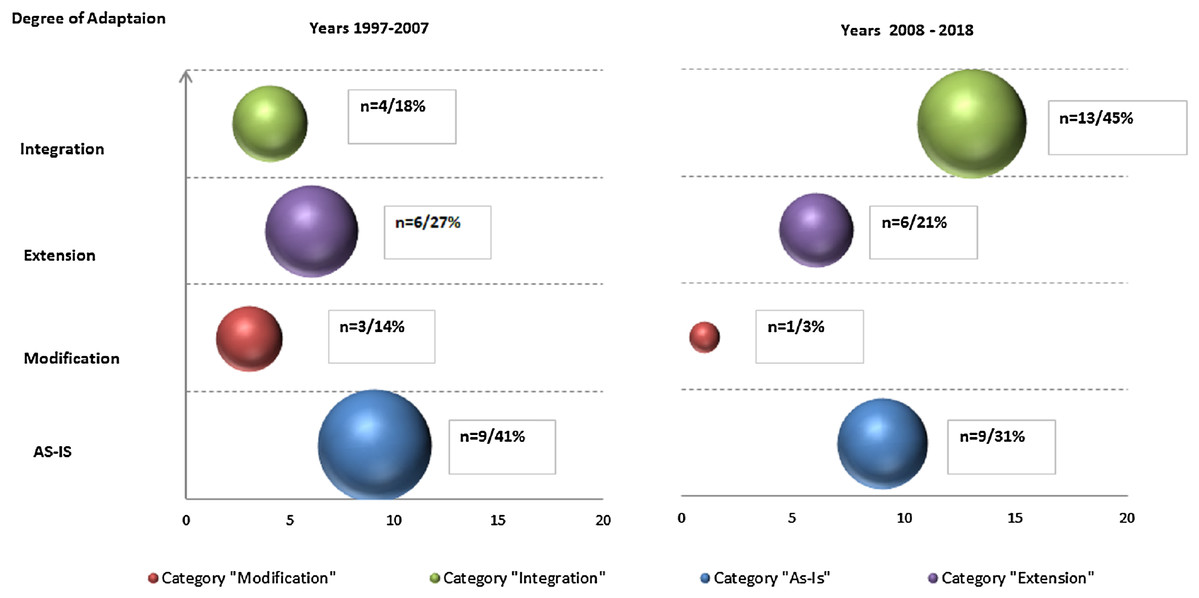
Figure 8: Data Mining methodologies application research—primary ‘grey’ texts classification by types of scenarios aggregated by decades (with numbers and relative proportions).
{kind=link}
For peer-reviewed research, such temporal analysis resulted in three observations. Firstly, research efforts in each adaptation scenario has been growing and number of publication more than quadrupled (128 vs. 28). Secondly, as noted above relative proportion of ‘as-is’ studies is diluted (from 39% to 33%) and primarily replaced with ‘Extension’ paradigm (from 25% to 30%). In contrast, in relative terms ‘Modification’ and ‘Integration’ paradigms gains are modest. Further, this finding is reinforced with other observation—most notable gaps in terms of modest number of publications remain in ‘Integration’ category where excluding 2008–2009 spike, research efforts are limited and number of texts is just 13. This is in stark contrast with prolific research in ‘Extension category’ though concentrated in the recent years. We can hypothesize that existing reference methodologies do not accommodate and support increasing complexity of data mining projects and IS/IT infrastructure, as well as certain domains specifics and as such need to be adapted.
In ‘grey’ literature, in contrast to peer-reviewed research, growth in number of publications is less profound—29 vs. 22 publications or 32% comparing across two decade (as per Fig. 8). The growth is solely driven by ‘Integration’ scenarios application (13 vs. 4 publications) while both ‘as-is’ and other adaptations scenarios are stagnating or in decline.
RQ3: For what purposes have existing data mining methodologies been adapted?
We address the third research question by analyzing what gaps the data mining methodology adaptations seek to fill and the benefits of such adaptations. We identified three adaptation scenarios, namely ‘Modification’, ‘Extension’, and ‘Integration’. Here, we analyze each of them.
Modification
Modifications of data mining methodologies are present in 30 peer-reviewed and 4 ‘grey’ literature studies. The analysis shows that modifications overwhelmingly consist of specific case studies. However, the major differentiating point compared to ‘as-is’ case studies is clear presence of specific adjustments towards standard data mining process methodologies. Yet, the proposed modifications and their purposes do not go beyond traditional data mining methodologies phases. They are granular, specialized and executed on tasks, sub-tasks, and at deliverables level. With modifications, authors describe potential business applications and deployment scenarios at a conceptual level, but typically do not report or present real implementations in the IS/IT systems and business processes.
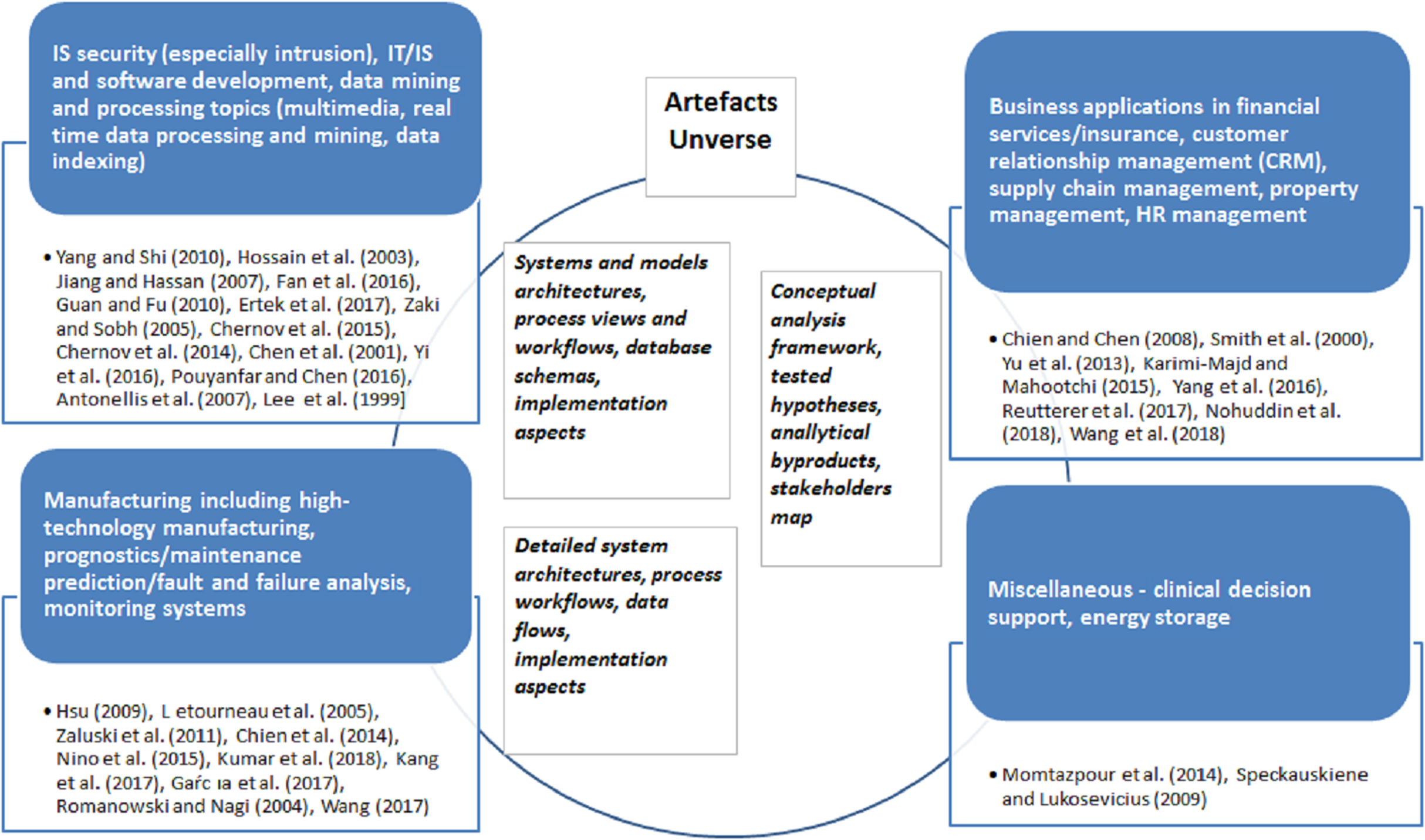
Further, this research subcategory can be best classified based on domains where case studies were performed and data mining methodologies modification scenarios executed. We have identified four distinct domain-driven applications presented in the Fig. 9.
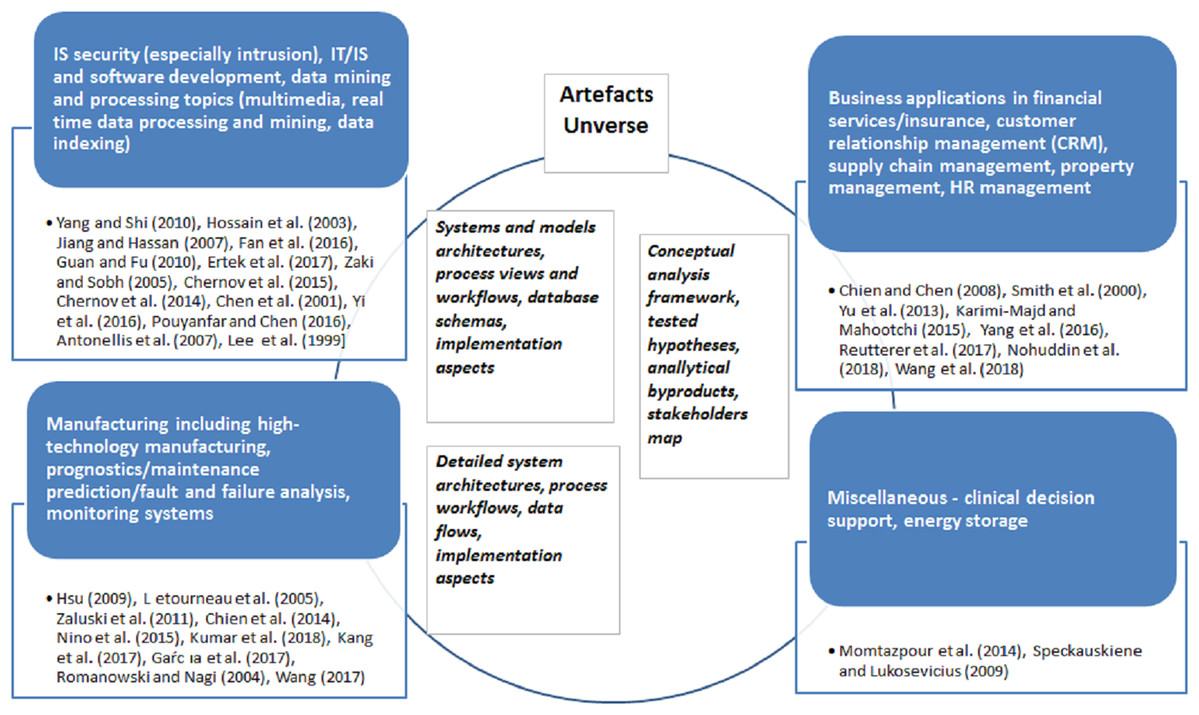
Figure 9: ‘Modification’ paradigm application studies for period 1997–2018—mapping to domains.
{kind=link}
IT, IS domain
The largest number of publications (14 or app. 40%), was performed on IT, IS security, software development, specific data mining and processing topics. Authors address intrusion detection problem in Hossain, Bridges & Vaughn (2003), Fan, Ye & Chen (2016), Lee, Stolfo & Mok (1999), specialized algorithms for variety of data types processing in Yang & Shi (2010), Chen et al. (2001), Yi, Teng & Xu (2016), Pouyanfar & Chen (2016), effective and efficient computer and mobile networks management in Guan & Fu (2010), Ertek, Chi & Zhang (2017), Zaki & Sobh (2005), Chernov, Petrov & Ristaniemi (2015), Chernov et al. (2014).
Manufacturing and engineering
The next most popular research area is manufacturing/engineering with 10 case studies. The central topic here is high-technology manufacturing, for example, semi-conductors associated—study of Chien, Diaz & Lan (2014), and various complex prognostics case studies in rail, aerospace domains (Létourneau et al., 2005; Zaluski et al., 2011) concentrated on failure predictions. These are complemented by studies on equipment fault and failure predictions and maintenance (Kumar, Shankar & Thakur, 2018; Kang et al., 2017; Wang, 2017) as well as monitoring system (García et al., 2017).
Sales and services, incl. financial industry
The third category is presented by seven business application papers concerning customer service, targeting and advertising (Karimi-Majd & Mahootchi, 2015; Reutterer et al., 2017; Wang, 2017), financial services credit risk assessments (Smith, Willis & Brooks, 2000), supply chain management (Nohuddin et al., 2018), and property management (Yu, Fung & Haghighat, 2013), and similar.
As a consequence of specialization, these studies concentrate on developing ‘state-of-the art’ solution to the respective domain-specific problem.
Extension
‘Extension’ scenario was identified in 46 peer-reviewed and 12 ‘grey’ publications. We noted that ‘Extension’ to existing data mining methodologies were executed with four major purposes:
Purpose 1: To implement fully scaled, integrated data mining solution and regular, repeatable knowledge discovery process—address model, algorithm deployment, implementation design (including architecture, workflows and corresponding IS integration). Also, complementary goal is to tackle changes to business process to incorporate data mining into organization activities.
Purpose 2: To implement complex, specifically designed systems and integrated business applications with data mining model/solution as component or tool. Typically, this adaptation is also oriented towards Big Data specifics, and is complemented by proposed artifacts such as Big Data architectures, system models, workflows, and data flows.
Purpose 3: To implement data mining as part of integrated/combined specialized infrastructure, data environments and types (e.g., IoT, cloud, mobile networks).
Purpose 4: To incorporate context-awareness aspects.
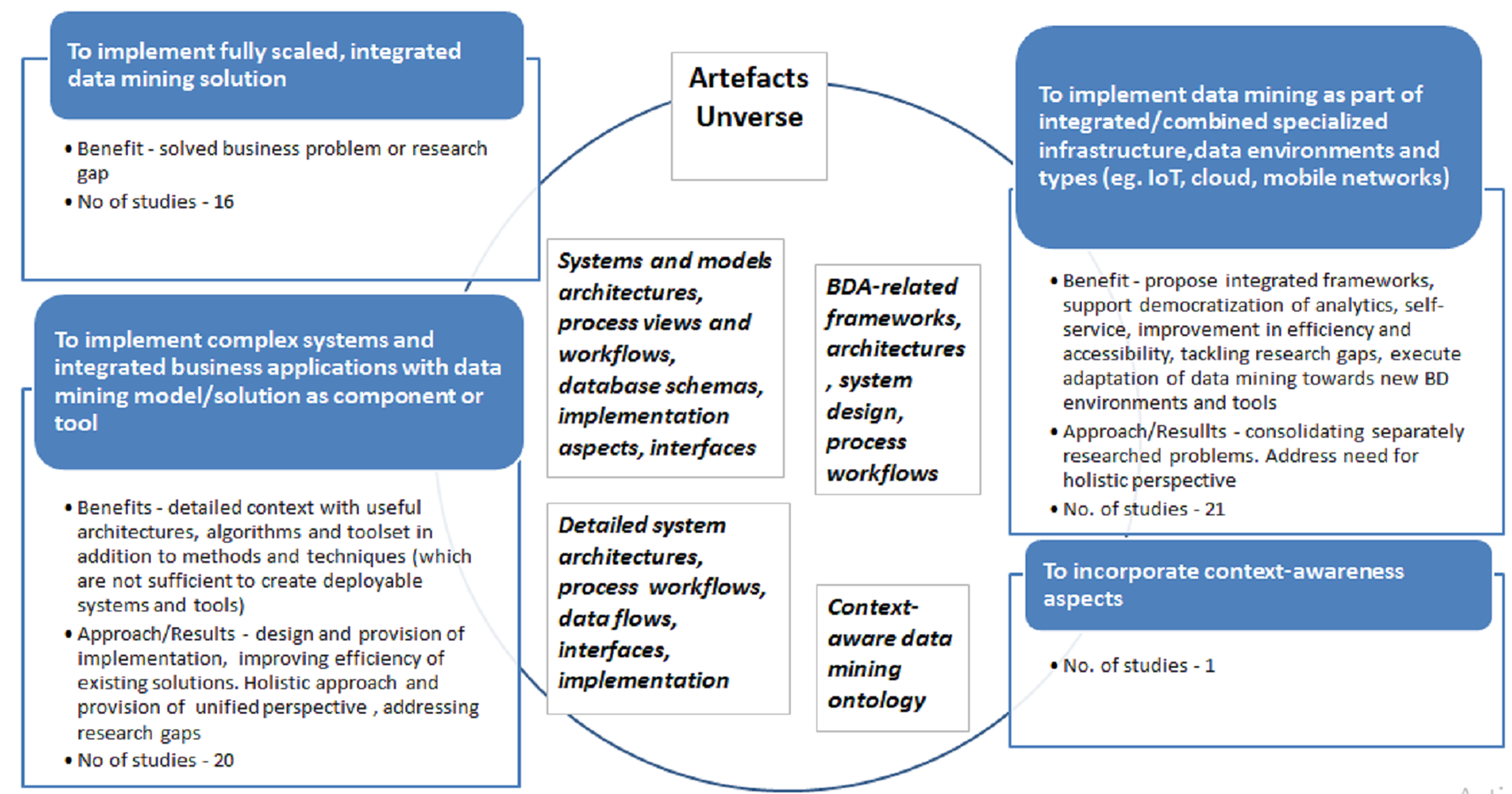
The specific list of studies mapped to each of the given purposes presented in the Appendix (Table A1). Main purposes of adaptations, associated gaps and/or benefits along with observations and artifacts are documented in the Fig. 10 below.
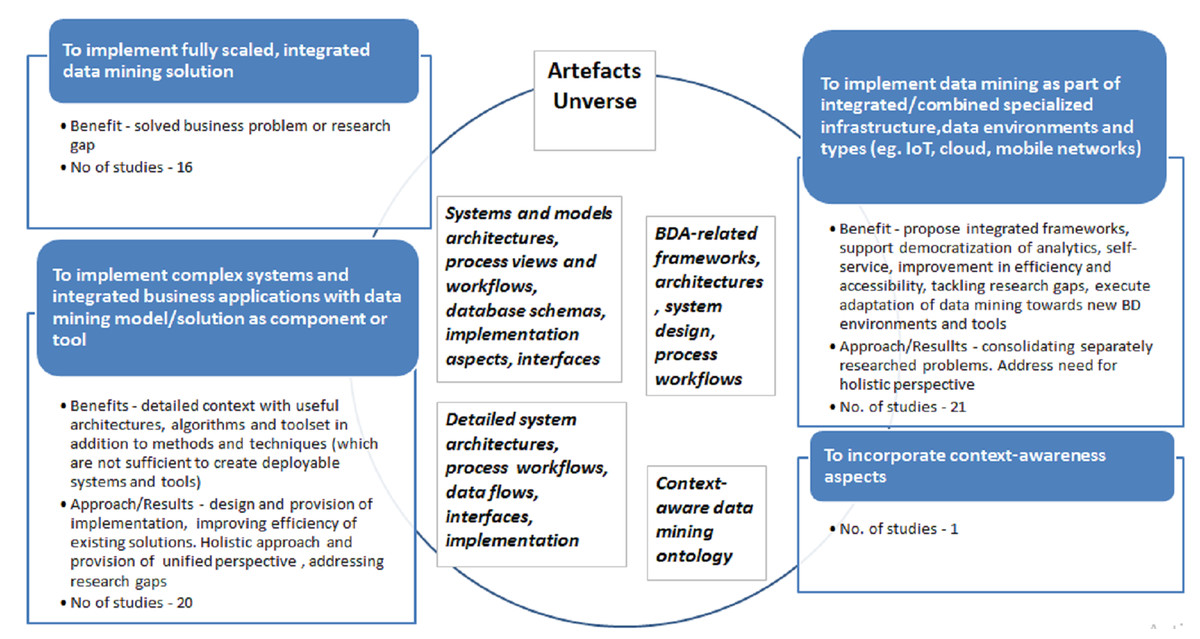
Figure 10: ‘Extension’ scenario adaptations goals, benefits, artifacts and number of publications for period 1997–2018.
{kind=link}
In ‘Extension’ category, studies executed with the Purpose 1 propose fully scaled, integrated data mining solutions of specific data mining models, associated frameworks and processes. The distinctive trait of this research subclass is that it ensures repeatability and reproducibility of delivered data mining solution in different organizational and industry settings. Both the results of data mining use case as well as deployment and integration into IS/IT systems and associated business process(es) are presented explicitly. Thus, ‘Extension’ subclass is geared towards specific solution design, tackling concrete business or industrial setting problem or addressing specific research gaps thus resembling comprehensive case study.
This direction can be well exemplified by expert finder system in research social network services proposed by Sun et al. (2015), data mining solution for functional test content optimization by Wang (2015) and time-series mining framework to conduct estimation of unobservable time-series by Hu et al. (2010). Similarly, Du et al. (2017) tackle online log anomalies detection, automated association rule mining is addressed by Çinicioğlu et al. (2011), software effort estimation by Deng, Purvis & Purvis (2011), network patterns visual discovery by Simoff & Galloway (2008). Number of studies address solutions in IS security (Shin & Jeong, 2005), manufacturing (Güder et al., 2014; Chee, Baharudin & Karkonasasi, 2016), materials engineering domains (Doreswamy, 2008), and business domains (Xu & Qiu, 2008; Ding & Daniel, 2007).
In contrast, ‘Extension’ studies executed for the Purpose 2 concentrate on design of complex, multi-component information systems and architectures. These are holistic, complex systems and integrated business applications with data mining framework serving as component or tool. Moreover, data mining methodology in these studies is extended with systems integration phases.
For example, Mobasher (2007) presents data mining application in Web personalization system and associated process; here, data mining cycle is extended in all phases with utmost goal of leveraging multiple data sources and using discovered models and corresponding algorithms in an automatic personalization system. Authors comprehensively address data processing, algorithm, design adjustments and respective integration into automated system. Similarly, Haruechaiyasak, Shyu & Chen (2004) tackle improvement of Webpage recommender system by presenting extended data mining methodology including design and implementation of data mining model. Holistic view on web-mining with support of all data sources, data warehousing and data mining techniques integration, as well as multiple problem-oriented analytical outcomes with rich business application scenarios (personalization, adaptation, profiling, and recommendations) in e-commerce domain was proposed and discussed by Büchner & Mulvenna (1998). Further, Singh et al. (2014) tackled scalable implementation of Network Threat Intrusion Detection System. In this study, data mining methodology and resulting model are extended, scaled and deployed as module of quasi-real-time system for capturing Peer-to-Peer Botnet attacks. Similar complex solution was presented in a series of publications by Lee et al. (2000, 2001) who designed real-time data mining-based Intrusion Detection System (IDS). These works are complemented by comprehensive study of Barbará et al. (2001) who constructed experimental testbed for intrusion detection with data mining methods. Detection model combining data fusion and mining and respective components for Botnets identification was developed by Kiayias et al. (2009) too. Similar approach is presented in Alazab et al. (2011) who proposed and implemented zero-day malware detection system with associated machine-learning based framework. Finally, Ahmed, Rafique & Abulaish (2011) presented multi-layer framework for fuzzy attack in 3G cellular IP networks.
A number of authors have considered data mining methodologies in the context of Decision Support Systems and other systems that generate information for decision-making, across a variety of domains. For example, Kisilevich, Keim & Rokach (2013) executed significant extension of data mining methodology by designing and presenting integrated Decision Support System (DSS) with six components acting as supporting tool for hotel brokerage business to increase deal profitability. Similar approach is undertaken by Capozzoli et al. (2017) focusing on improving energy management of properties by provision of occupancy pattern information and reconfiguration framework. Kabir (2016) presented data mining information service providing improved sales forecasting that supported solution of under/over-stocking problem while Lau, Zhang & Xu (2018) addressed sales forecasting with sentiment analysis on Big Data. Kamrani, Rong & Gonzalez (2001) proposed GA-based Intelligent Diagnosis system for fault diagnostics in manufacturing domain. The latter was tackled further in Shahbaz et al. (2010) with complex, integrated data mining system for diagnosing and solving manufacturing problems in real time.
Lenz, Wuest & Westkämper (2018) propose a framework for capturing data analytics objectives and creating holistic, cross-departmental data mining systems in the manufacturing domain. This work is representative of a cohort of studies that aim at extending data mining methodologies in order to support the design and implementation of enterprise-wide data mining systems. In this same research cohort, we classify Luna, Castro & Romero (2017), which presents a data mining toolset integrated into the Moodle learning management system, with the aim of supporting university-wide learning analytics.
One study addresses multi-agent based data mining concept. Khan, Mohamudally & Babajee (2013) have developed unified theoretical framework for data mining by formulating a unified data mining theory. The framework is tested by means of agent programing proposing integration into multi-agent system which is useful due to scalability, robustness and simplicity.
The subcategory of ‘Extension’ research executed with Purpose 3 is devoted to data mining methodologies and solutions in specialized IT/IS, data and process environments which emerged recently as consequence of Big Data associated technologies and tools development. Exemplary studies include IoT associated environment research, for example, Smart City application in IoT presented by Strohbach et al. (2015). In the same domain, Bashir & Gill (2016) addressed IoT-enabled smart buildings with the additional challenge of large amount of high-speed real time data and requirements of real-time analytics. Authors proposed integrated IoT Big Data Analytics framework. This research is complemented by interdisciplinary study of Zhong et al. (2017) where IoT and wireless technologies are used to create RFID-enabled environment producing analysis of KPIs to improve logistics.
Significant number of studies addresses various mobile environments sometimes complemented by cloud-based environments or cloud-based environments as stand-alone. Gomes, Phua & Krishnaswamy (2013) addressed mobile data mining with execution on mobile device itself; the framework proposes innovative approach addressing extensions of all aspects of data mining including contextual data, end-user privacy preservation, data management and scalability. Yuan, Herbert & Emamian (2014) and Yuan & Herbert (2014) introduced cloud-based mobile data analytics framework with application case study for smart home based monitoring system. Cuzzocrea, Psaila & Toccu (2016) have presented innovative FollowMe suite which implements data mining framework for mobile social media analytics with several tools with respective architecture and functionalities. An interesting paper was presented by Torres et al. (2017) who addressed data mining methodology and its implementation for congestion prediction in mobile LTE networks tackling also feedback reaction with network reconfigurations trigger.
Further, Biliri et al. (2014) presented cloud-based Future Internet Enabler—automated social data analytics solution which also addresses Social Network Interoperability aspect supporting enterprises to interconnect and utilize social networks for collaboration. Real-time social media streamed data and resulting data mining methodology and application was extensively discussed by Zhang, Lau & Li (2014). Authors proposed design of comprehensive ABIGDAD framework with seven main components implementing data mining based deceptive review identification. Interdisciplinary study tackling both these topics was developed by Puthal et al. (2016) who proposed integrated framework and architecture of disaster management system based on streamed data in cloud environment ensuring end-to-end security. Additionally, key extensions to data mining framework have been proposed merging variety of data sources and types, security verification and data flow access controls. Finally, cloud-based manufacturing was addressed in the context of fault diagnostics by Kumar et al. (2016).
Also, Mahmood et al. (2013) tackled Wireless Sensor Networks and associated data mining framework required extensions. Interesting work is executed by Nestorov & Jukic (2003) addressing rare topic of data mining solutions integration within traditional data warehouses and active mining of data repositories themselves.
Supported by new generation of visualization technologies (including Virtual Reality environments), Wijayasekara, Linda & Manic (2011) proposed and implemented CAVE-SOM (3D visual data mining framework) which offers interactive, immersive visual data mining with multiple visualization modes supported by plethora of methods. Earlier version of visual data mining framework was successfully developed and presented by Ganesh et al. (1996) as early as in 1996.
Large-scale social media data is successfully tackled by Lemieux (2016) with comprehensive framework accompanied by set of data mining tools and interface. Real time data analytics was addressed by Shrivastava & Pal (2017) in the domain of enterprise service ecosystem. Images data was addressed in Huang et al. (2002) by proposing multimedia data mining framework and its implementation with user relevance feedback integration and instance learning. Further, exploded data diversity and associated need to extend standard data mining is addressed by Singh et al. (2016) in the study devoted to object detection in video surveillance systems supporting real time video analysis.
Finally, there is also limited number of studies which addresses context awareness (Purpose 4) and extends data mining methodology with context elements and adjustments. In comparison with ‘Integration’ category research, here, the studies are at lower abstraction level, capturing and presenting list of adjustments. Singh, Vajirkar & Lee (2003) generate taxonomy of context factors, develop extended data mining framework and propose deployment including detailed IS architecture. Context-awareness aspect is also addressed in the papers reviewed above, for example, Lenz, Wuest & Westkämper (2018), Kisilevich, Keim & Rokach (2013), Sun et al. (2015), and other studies.
Integration
‘Integration’ of data mining methodologies scenario was identified in 27 ‘peer-reviewed’ and 17 ‘grey’ studies. Our analysis revealed that this adaptation scenario at a higher abstraction level is typically executed with the five key purposes:
Purpose 1: to integrate/combine with various ontologies existing in organization.
Purpose 2: to introduce context-awareness and incorporate domain knowledge.
Purpose 3: to integrate/combine with other research or industry domains framework, process methodologies and concepts.
Purpose 4: to integrate/combine with other well-known organizational governance frameworks, process methodologies and concepts.
Purpose 5: to accommodate and/or leverage upon newly available Big Data technologies, tools and methods.
The specific list of studies mapped to each of the given purposes presented in Appendix (Table A2). Main purposes of adaptations, associated gaps and/or benefits along with observations and artifacts are documented in Fig. 11 below.
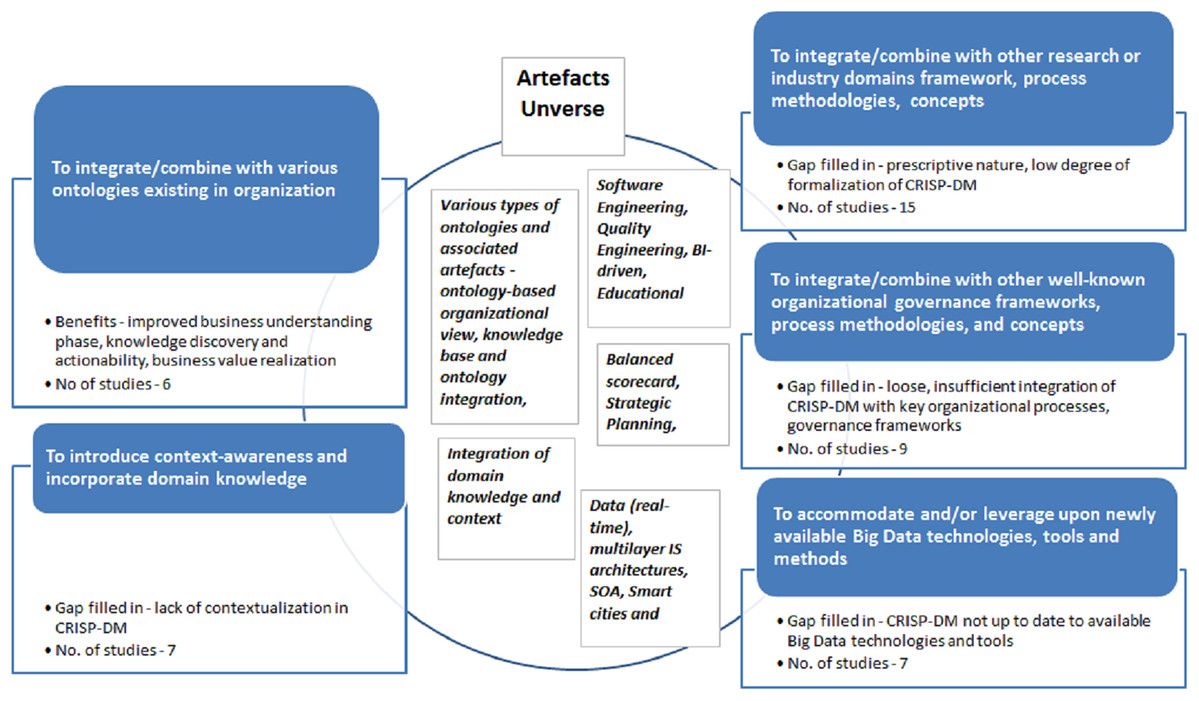
Figure 11: ‘Integration’ scenario adaptations goals, benefits, artifacts and number of publications for period 1997–2018.
{kind=link}
As mentioned, number of studies concentrates on proposing ontology-based Integrated data mining frameworks accompanies by various types of ontologies (Purpose 1). For example, Sharma & Osei-Bryson (2008) focus on ontology-based organizational view with Actors, Goals and Objectives which supports execution of Business Understanding Phase. Brisson & Collard (2008) propose KEOPS framework which is CRISP-DM compliant and integrates a knowledge base and ontology with the purpose to build ontology-driven information system (OIS) for business and data understanding phases while knowledge base is used for post-processing step of model interpretation. Park et al. (2017) propose and design comprehensive ontology-based data analytics tool IRIS with the purpose to align analytics and business. IRIS is based on concept to connect dots, analytics methods or transforming insights into business value, and supports standardized process for applying ontology to match business problems and solutions.
Further, Ying et al. (2014) propose domain-specific data mining framework oriented to business problem of customer demand discovery. They construct ontology for customer demand and customer demand discovery task which allows to execute structured knowledge extraction in the form of knowledge patterns and rules. Here, the purpose is to facilitate business value realization and support actionability of extracted knowledge via marketing strategies and tactics. In the same vein, Cannataro & Comito (2003) presented ontology for the Data Mining domain which main goal is to simplify the development of distributed knowledge discovery applications. Authors offered to a domain expert a reference model for different kind of data mining tasks, methodologies, and software capable to solve the given business problem and find the most appropriate solution.
Apart from ontologies, Sharma & Osei-Bryson (2009) in another study propose IS inspired, driven by Input-Output model data mining methodology which supports formal implementation of Business Understanding Phase. This research exemplifies studies executed with Purpose 2. The goal of the paper is to tackle prescriptive nature of CRISP-DM and address how the entire process can be implemented. Cao, Schurmann & Zhang (2005) study is also exemplary in terms of aggregating and introducing several fundamental concepts into traditional CRISP-DM data mining cycle—context awareness, in-depth pattern mining, human–machine cooperative knowledge discovery (in essence, following human-centricity paradigm in data mining), loop-closed iterative refinement process (similar to Agile-based methodologies in Software Development). There are also several concepts, like data, domain, interestingness, rules which are proposed to tackle number of fundamental constrains identified in CRISP-DM. They have been discussed and further extended by Cao & Zhang (2007, 2008), Cao (2010) into integrated domain driven data mining concept resulting in fully fledged D3M (domain-driven) data mining framework. Interestingly, the same concepts, but on individual basis are investigated and presented by other authors, for example, context-aware data mining methodology is tackled by Xiang (2009a, 2009b) in the context of financial sector. Pournaras et al. (2016) attempted very crucial privacy-preservation topic in the context of achieving effective data analytics methodology. Authors introduced metrics and self-regulatory (reconfigurable) information sharing mechanism providing customers with controls for information disclosure.
A number of studies have proposed CRISP-DM adjustments based on existing frameworks, process models or concepts originating in other domains (Purpose 3), for example, software engineering (Marbán et al., 2007, 2009; Marban, Mariscal & Segovia, 2009) and industrial engineering (Solarte, 2002; Zhao et al., 2005).
Meanwhile, Mariscal, Marbán & Fernández (2010) proposed a new refined data mining process based on a global comparative analysis of existing frameworks while Angelov (2014) outlined a data analytics framework based on statistical concepts. Following a similar approach, some researchers suggest explicit integration with other areas and organizational functions, for example, BI-driven Data Mining by Hang & Fong (2009). Similarly, Chen, Kazman & Haziyev (2016) developed an architecture-centric agile Big Data analytics methodology, and an architecture-centric agile analytics and DevOps model. Alternatively, several authors tackled data mining methodology adaptations in other domains, for example, educational data mining by Tavares, Vieira & Pedro (2017), decision support in learning management systems (Murnion & Helfert, 2011), and in accounting systems (Amani & Fadlalla, 2017).
Other studies are concerned with actionability of data mining and closer integration with business processes and organizational management frameworks (Purpose 4). In particular, there is a recurrent focus on embedding data mining solutions into knowledge-based decision making processes in organizations, and supporting fast and effective knowledge discovery (Bohanec, Robnik-Sikonja & Borstnar, 2017).
Examples of adaptations made for this purpose include: (1) integration of CRISP-DM with the Balanced Scorecard framework used for strategic performance management in organizations (Yun, Weihua & Yang, 2014); (2) integration with a strategic decision-making framework for revenue management Segarra et al. (2016); (3) integration with a strategic analytics methodology Van Rooyen & Simoff (2008), and (4) integration with a so-called ‘Analytics Canvas’ for management of portfolios of data analytics projects Kühn et al. (2018). Finally, Ahangama & Poo (2015) explored methodological attributes important for adoption of data mining methodology by novice users. This latter study uncovered factors that could support the reduction of resistance to the use of data mining methodologies. Conversely, Lawler & Joseph (2017) comprehensively evaluated factors that may increase the benefits of Big Data Analytics projects in an organization.
Lastly, a number of studies have proposed data mining frameworks (e.g., CRISP-DM) adaptations to cater for new technological architectures, new types of datasets and applications (Purpose 5). For example, Lu et al. (2017) proposed a data mining system based on a Service-Oriented Architecture (SOA), Zaghloul, Ali-Eldin & Salem (2013) developed a concept of self-service data analytics, Osman, Elragal & Bergvall-Kåreborn (2017) blended CRISP-DM into a Big Data Analytics framework for Smart Cities, and Niesen et al. (2016) proposed a data-driven risk management framework for Industry 4.0 applications.
Our analysis of RQ3, regarding the purposes of existing data mining methodologies adaptations, revealed the following key findings. Firstly, adaptations of type ‘Modification’ are predominantly targeted at addressing problems that are specific to a given case study. The majority of modifications were made within the domain of IS security, followed by case studies in the domains of manufacturing and financial services. This is in clear contrast with adaptations of type ‘Extension’, which are primarily aimed at customizing the methodology to take into account specialized development environments and deployment infrastructures, and to incorporate context-awareness aspects. Thirdly, a recurrent purpose of adaptations of type ‘Integration’ is to combine a data mining methodology with either existing ontologies in an organization or with other domain frameworks, methodologies, and concepts. ‘Integration’ is also used to instill context-awareness and domain knowledge into a data mining methodology, or to adapt it to specialized methods and tools, such as Big Data. The distinctive outcome and value (gaps filled in) of ‘Integrations’ stems from improved knowledge discovery, better actionability of results, improved combination with key organizational processes and domain-specific methodologies, and improved usage of Big Data technologies.
Summary
We discovered that the adaptations of existing data mining methodologies found in the literature can be classified into three categories: modification, extension, or integration.
We also noted that adaptations are executed either to address deficiencies and lack of important elements or aspects in the reference methodology (chiefly CRISP-DM). Furthermore, adaptations are also made to improve certain phases, deliverables or process outcomes.
In short, adaptations are made to:
improve key reference data mining methodologies phases—for example, in case of CRISP-DM these are primarily business understanding and deployment phases.
-
support knowledge discovery and actionability.
introduce context-awareness and higher degree of formalization.
integrate closer data mining solution with key organizational processes and frameworks.
significantly update CRISP-DM with respect to Big Data technologies, tools, environments and infrastructure.
incorporate broader, explicit context of architectures, algorithms and toolsets as integral deliverables or supporting tools to execute data mining process.
expand and accommodate broader unified perspective for incorporating and implementing data mining solutions in organization, IT infrastructure and business processes.
Threats to Validity
Systematic literature reviews have inherent limitations that must be acknowledged. These threats to validity include subjective bias (internal validity) and incompleteness of search results (external validity).
The internal validity threat stems from the subjective screening and rating of studies, particularly when assessing the studies with respect to relevance and quality criteria. We have mitigated these effects by documenting the survey protocol (SLR Protocol), strictly adhering to the inclusion criteria, and performing significant validation procedures, as documented in the Protocol.
The external validity threat relates to the extent to which the findings of the SLR reflect the actual state of the art in the field of data mining methodologies, given that the SLR only considers published studies that can be retrieved using specific search strings and databases. We have addressed this threat to validity by conducting trial searches to validate our search strings in terms of their ability to identify relevant papers that we knew about beforehand. Also, the fact that the searches led to 1,700 hits overall suggests that a significant portion of the relevant literature has been covered.
Conclusion
In this study, we have examined the use of data mining methodologies by means of a systematic literature review covering both peer-reviewed and ‘grey’ literature. We have found that the use of data mining methodologies, as reported in the literature, has grown substantially since 2007 (four-fold increase relative to the previous decade). Also, we have observed that data mining methodologies were predominantly applied ‘as-is’ from 1997 to 2007. This trend was reversed from 2008 onward, when the use of adapted data mining methodologies gradually started to replace ‘as-is’ usage.
The most frequent adaptations have been in the ‘Extension’ category. This category refers to adaptations that imply significant changes to key phases of the reference methodology (chiefly CRISP-DM). These adaptations particularly target the business understanding, deployment and implementation phases of CRISP-DM (or other methodologies). Moreover, we have found that the most frequent purposes of adaptions are: (1) adaptations to handle Big Data technologies, tools and environments (technological adaptations); and (2) adaptations for context-awareness and for integrating data mining solutions into business processes and IT systems (organizational adaptations). A key finding is that standard data mining methodologies do not pay sufficient attention to deployment aspects required to scale and transform data mining models into software products integrated into large IT/IS systems and business processes.
Apart from the adaptations in the ‘Extension’ category, we have also identified an increasing number of studies focusing on the ‘Integration’ of data mining methodologies with other domain-specific and organizational methodologies, frameworks, and concepts. These adaptions are aimed at embedding the data mining methodology into broader organizational aspects.
Overall, the findings of the study highlight the need to develop refinements of existing data mining methodologies that would allow them to seamlessly interact with IT development platforms and processes (technological adaptation) and with organizational management frameworks (organizational adaptation). In other words, there is a need to frame existing data mining methodologies as being part of a broader ecosystem of methodologies, as opposed to the traditional view where data mining methodologies are defined in isolation from broader IT systems engineering and organizational management methodologies.
Appendices
Supplemental Information
All publication graphs (11).
Unfortunately, we were not able to upload any graph (original png files). Based on Overleaf placed PeerJ template we constructed graphs files based on the template examples. Unfortunately, we were not able to understand why it did not fit, redoing to new formats will change all texts flow and generated pdf file. We submit graphs in archived file as part of supplementary material. We will do our best to redo the graphs further based on instructions from You.
SLR primary texts corpus in full.
File starts with Definitions page—it lists and explains all columns definitions as well as SLR scoring metrics. Second page contains"Peer reviewed" texts while next one "grey" literature corpus.