
Efficient skyline query processing with user-specified conditional preference
- Published
- Accepted
- Received
- Academic Editor
- Catherine Higham
- Subject Areas
- Data Mining and Machine Learning, Data Science, Databases, Digital Libraries, Software Engineering
- Keywords
- Recommendation system, User preference, Data query, Data mining, Optimization, Skyline query, Personalized skyline, Conditional preference, CP-Skyline, CP-Nets
- Copyright
- © 2025 Ke et al.
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2025. Efficient skyline query processing with user-specified conditional preference. PeerJ Computer Science 11:e2659 https://doi.org/10.7717/peerj-cs.2659
Abstract
In the realm of multi-attribute decision-making, the utilization of skyline queries has gained increasing popularity for assisting users in identifying objects with optimal attribute combinations. With the growing demand for personalization, integrating user’s preferences into skyline queries has emerged as an intriguing and promising research direction. However, the diverse expressions of preferences pose challenges to existing personalized skyline queries. Current methods assume that user preferences are too simplistic and do not represent the interdependencies between attributes. This poses a challenge to the existing skyline methods in effectively managing complex user preferences and dependencies. In this article, we propose an innovative and efficient method for skyline query processing, leveraging conditional preference networks (CP-Nets) to integrate specific user’s conditional preferences into the query process, termed as CP-Skyline. Firstly, we introduce a user-defined conditional preference model based on CP-Nets. By integrating user’s conditional preference information, we prune the candidate dataset, effectively compressing the query space. Secondly, we define a new dominance relation for CP-Skyline computation. Finally, extensive experiments were conducted on both synthetic and real-world datasets to assess the performance and effectiveness of the proposed methods. The experimental results unequivocally demonstrate a significant enhancement in skyline quality, and it presents a practical and potent solution for personalized decision support.
Introduction
Skyline queries have gained significant attention in database management systems due to their ability to identify optimal solutions for multi-criteria decision-making problems. These queries return a set of non-dominated points, called the skyline, that represents the best trade-offs among multiple attributes (Borzsony, Kossmann & Stocker, 2001; Han, Jianzhong Li & Wang, 2013). In optimization problems with multiple conflicting objectives, finding the skyline solutions provides a set of trade-offs solutions that are not dominated by any other feasible solutions. This approach facilitates decision-making in identifying optimal solutions. Traditionally, skyline query is non-personalized, which does not consider the user’s preferences and only looks for all non-dominated points, so its results are more objective and comprehensive. However, the conventional skyline query method typically overlooks user-specific preferences, and the user’s expected results may vary according to individual needs and expectations.
Consider a scenario where the user seeks the optimal hotel in Table 1 without taking into account the hotel’s location. The user’s preference for selecting hotels is in the price range between 70 and 120, and the score range is between 5 and 10. Using a skyline query with no preference we need to find non-dominated points in all hotels, the result , because they do not dominate each other, that is, they are not weaker than each other in both dimensions of price and score. The user identifies the most preferred hotel in . If we add user’s preference into the skyline query, it is necessary to find only the non-dominated points within the specified preference range (i.e., ) given by the user, and the final query result .
| Hotels | Price | Score | District |
|---|---|---|---|
| 76 | 2 | Dongcheng | |
| 89 | 7 | Haidian | |
| 92 | 5 | Chaoyang | |
| 99 | 8 | Chaoyang | |
| 102 | 6 | Chaoyang | |
| 112 | 3 | Dongcheng | |
| 115 | 5 | Dongcheng | |
| 127 | 2 | Haidian | |
| 136 | 5 | Haidian | |
| 157 | 9 | Dongcheng |
It is evident that if a user’s preferences are not considered when generating skyline results, it may include points that are irrelevant or suboptimal to user’s needs. In such instances, the system is compelled to search for skyline points within a larger candidate set, requiring users to exert additional effort to filter out uninteresting points from the results. Moreover, as the dataset size increases, the resources required also significantly escalate.
To address this issue, personalized skyline queries have been introduced to filter out irrelevant points for users by integrating their preferences into skyline queries. However, the diverse ways to express user’s preferences pose a challenge for preference-based skyline queries. Current personalized skyline query methods often assume linearity and monotonicity in user’s preferences (Ding et al., 2018). In practice, user preferences may exhibit inter-dependencies between parameters (Wang et al., 2012). For example, when choosing a hotel, a user might express preferences such as, “I am looking for a hotel priced below 150. If the price is below 100, a score above 5 is acceptable. However, if the price exceeds 100 but remains under 150, the score should be above 8.” This preference style is classified as conditional, where the user’s preference for each attribute is contingent. The preference for the price below 150 is prioritized, and the score preference is influenced by the price. Consequently, existing skyline methods might encounter challenges in effectively managing user’s intricate preferences and dependencies.
The purpose of this article is to provide a personalized conditional preference skyline calculation scheme, using conditional preference networks (CP-Nets) (Boutilier et al., 2004) to handle user preferences and calculate skyline on this basis. CP-Net, as a preference-based conditional probability network, stand out in portraying intricate preference relationships across multiple attributes, including dependencies. Wang et al. (2015, 2012, 2008) propose usage condition preferences in the field of personalized service selection, and WCP-nets was proposed for representing and reasoning about conditional preferences in service composition, enhancing the expressive power of user preference. The significant advantage of integrating CP-Nets into skyline queries lies in their ability to manage complex preference relationships, effectively serving as a constrained skyline. We introduce an innovative skyline query methodology based on conditional preferences, integrating user-specific conditional preferences to enhance efficiency and accuracy. By adapting to the dependencies in user preferences for tuple’s attributes, the proposed approach ensures a more effective and user-centric decision-making process, ultimately elevating the overall user’s experience, which can be applied to service selection (Wang et al., 2015) or recommendations such as Netflix and Amazon (Bartolini, Zhang & Papadias, 2011). By pruning tuples that do not meet user preferences, this approach effectively minimizes computational time and enhances overall processing efficiency, allowing users to quickly find the best options that suit their needs. Moreover, the implementation code is publicly available on GitHub (https://github.com/aSmalltooth/CP-Skyline-Computation/).
The structure of this article is systematically outlined as follows: “Related Work” provides a review of related work on skyline queries and conditional preferences. “Problem Description” presents the formalization of the problem and the definition of CP-Skyline. “CP-Skyline Computation” describes the proposed algorithm for processing skyline queries with conditional preferences and its complexity analysis. “Experimental Evaluation” discusses the experimental evaluation of our approach. Finally, “Conclusion” concludes the article and suggests future research directions.
Related work
In this section, we review the mainstream skyline algorithms, especially the personalized skyline algorithms, and discuss the application of skyline technology in some new scenarios.
Skyline queries
Skyline queries have been extensively researched within the database community as an effective technique for multi-criteria decision-making. The concept of skyline queries was first introduced by Borzsony, Kossmann & Stocker (2001). The basic idea is to find the skyline, which consists of those tuples that are not dominated by any other tuple on all attributes, in the multi-attribute data space. They also proposed the Block nested Loop (BNL) algorithm for efficient skyline computation. Since then, various algorithms have been proposed to improve the efficiency of skyline query processing, such as the Sort-Filter-Skyline (SFS) algorithm (Han, Jianzhong Li & Wang, 2013), the Divide and Conquer (DC) algorithm (Kossmann, Ramsak & Rost, 2002), and the Branch and Bound Skyline (BBS) algorithm (Papadias et al., 2005).
Over the years, the research on skyline queries includes single skyline query processing algorithms, which assume no user preferences. Borzsony, Kossmann & Stocker (2001), Papadias et al. (2005), and multiple skyline query processing algorithms, which cater to diverse user preferences (Yuan et al., 2013). Additionally, skyline query processing has been explored in various application environments such as network information systems, P2P networks (Stefanini, Palo & Berger, 2024; Wang et al., 2007), and mobile road networks (Li et al., 2021; Cai et al., 2021). Recent advancements include distributed skyline query processing for big data (Kuo et al., 2022; Bai et al., 2022), dynamic skyline query processing for changing data (Zhang et al., 2022; Wang et al., 2023), probabilistic skyline query processing for uncertain data (Lai et al., 2020; Kuo et al., 2022), and personalized skyline query processing considering user preferences (Benouaret et al., 2021; Bartolini, Zhang & Papadias, 2011).
Personalized skyline queries
Due to the fact that traditional skyline query methods do not sufficiently take into account user’s personalized preferences, this may result in too many query results failing to meet user’s needs. One effective strategy involves minimizing the volume of query results through imerging the user’s preferences.
Therefore, many work have made great efforts in the research of skyline queries incorporating user-defined preferences. Liu et al. (2018), Yuan et al. (2013) have defined a new type of skyline operation, user-centric skyline computation, which allows users to select skyline points from a dataset based on their preferences for each dimension. Zhang et al. (2023) have proposed a user-defined skyline query, which adds a personalized definition of the user’s requirements for attribute values to the method and adding user-defined constraints to the subspace skyline query. Benouaret et al. (2021) requires users to propose the specific range of data to be searched to represent their preferences, using the value of user’s preference/relevant services (matching degree) to represent the degree to which an attribute meets a user’s preferences, and then using this matching degree to replace the specific attribute in the skyline calculation. Therefore, incorporating user-defined preferences into skyline queries is an interesting research hotspot that has attracted the attention of many people.
In recent years, the exploration of personalized skyline queries has seen expansion to encompass emerging challenges like uncertainty and incomplete environments. In a centralized computing environment, the definition of uncertain dimensions based on user preferences was introduced by Saad et al. (2021), who employed the skyline query on uncertain dimensions (SkyQUD) algorithm. This algorithm was utilized for partitioning data based on the characteristics of each dataset and conducting skyline probability dominance tests, while the handling of large-scale skyline queries was facilitated through the application of thresholds. In parallel computing environments, the skyline preference query (SPQ) algorithm for incomplete dataset preference skyline queries was introduced by Wang et al. (2017). Their innovative strategy involved the segregation and classification of massive incomplete datasets based on the importance of dimensions, resulting in a significant enhancement of the efficiency of skyline queries performed on such datasets. Considering user’s preferences, data objects were partitioned into different grids using Voronoi diagrams by Tai, Wang & Chen (2021). They conducted parallel computations on object combinations to acquire dynamic skyline results. Meanwhile, Top-k skyline preference queries under MapReduce were proposed by Zheng et al. (2021). Datasets were segmented into regions based on user-preferred dimensions, local skyline sets were computed in parallel, and relaxed dominance comparisons between regions were used to derive the global skyline set.
In essence, existing skyline query research mainly focuses on processing techniques and applications. Preference-driven skyline queries have gained widespread attention for their potential in reducing costs and improving user’s experiences. However, current methods often oversimplify user’s preferences, neglecting intricacies like dependencies between attributes. This article addresses these issues using CP-Nets, enhancing both query efficiency and result quality. This method supports reasoning based on local preferences and can effectively handle the problem of query time increasing with increasing dimensions.
Problem description
In this section, we present the fundamental concepts utilized in this article and provide a formal definition of CP-Skyline. Furthermore, we illustrate an example of employing CP-Nets to model user’s preferences. The calculation process of finding CP-Skyline tuples will be subsequently elaborated upon based on this example. Additionally, a comprehensive summary of the frequently used symbols and their corresponding descriptions is presented in Table 2.
| Symbol | Description |
|---|---|
| Set of tuples, a specific tuple | |
| Set of attributes, a specific attribute | |
| Set of hierarchies, a specific hierarchy | |
| The outcome space, a specific outcome | |
| The number of attributes | |
| The number of user’s specified attributes | |
| Conditional preference table of | |
| Preference order of | |
| The value of on attribute | |
| Tuple strictly dominates tuple | |
| Tuple hierarchy dominates tuple | |
| Tuple CP-dominates tuple | |
| CS | Candidate set |
| CPS | CP-Skyline points |
Representing user’s preference with CP-Nets
To incorporate user conditional preferences into skyline queries, several fundamental issues need addressing: representing user preferences, the methods or tools used to model these preferences, and reasoning about preference statements (Mouhoub & Ahmed, 2018). CP-Nets offer a natural and clear way to represent conditional preferences. Structurally, CP-Nets form a directed graph where vertices represent tuple attributes and directed edges indicate dependencies between attributes. Each vertex’s conditional preference table shows user preferences for different attribute values. CP-Nets also express dominance relationships between outcomes through sparse attribute dependencies (e.g., a less than 150 with a greater than 7 is preferred over a of 100 with a greater than 5).
In CP-Skyline query process, we allow users to provide preferences that are more detailed than the constrained subspace (Dellis et al., 2006), i.e., incorporating dependency relationships across different dimensions. CP-net is used to represent the user’s conditional preference, and the user’s preference for data is derived from the semantics and properties of CP-net. Therefore, we start by introducing some notions from decision theory and the CP-nets formalism for preference representation. In addition, CP-Nets can be learned from the preference database, which is not involved in this article (Alanazi, Mouhoub & Zilles, 2020). So, we start by introducing some notions from decision theory and the CP-nets formalism for preference representation.
Definition 1 (CP-Net; Boutilier et al., 2004). A CP-Net over attributes is a directed graph G over in which each node is annotated with conditional preference tables . Each conditional preference table associates a preference order with each instantiation of ’s parents . The conditional preference rule (CPR) on variable is an expression: , where is the assignment of U, , is the assignment of the attribute . Such a rule means “assuming holds, all other variables being equal, is better than ”. The conditional preference table CPT( ) on attribute is the set of CPRs on .
Given a simple example, the preference for hotel selection, to illustrate how to use CP-Nets to represent the user’s conditional preferences:
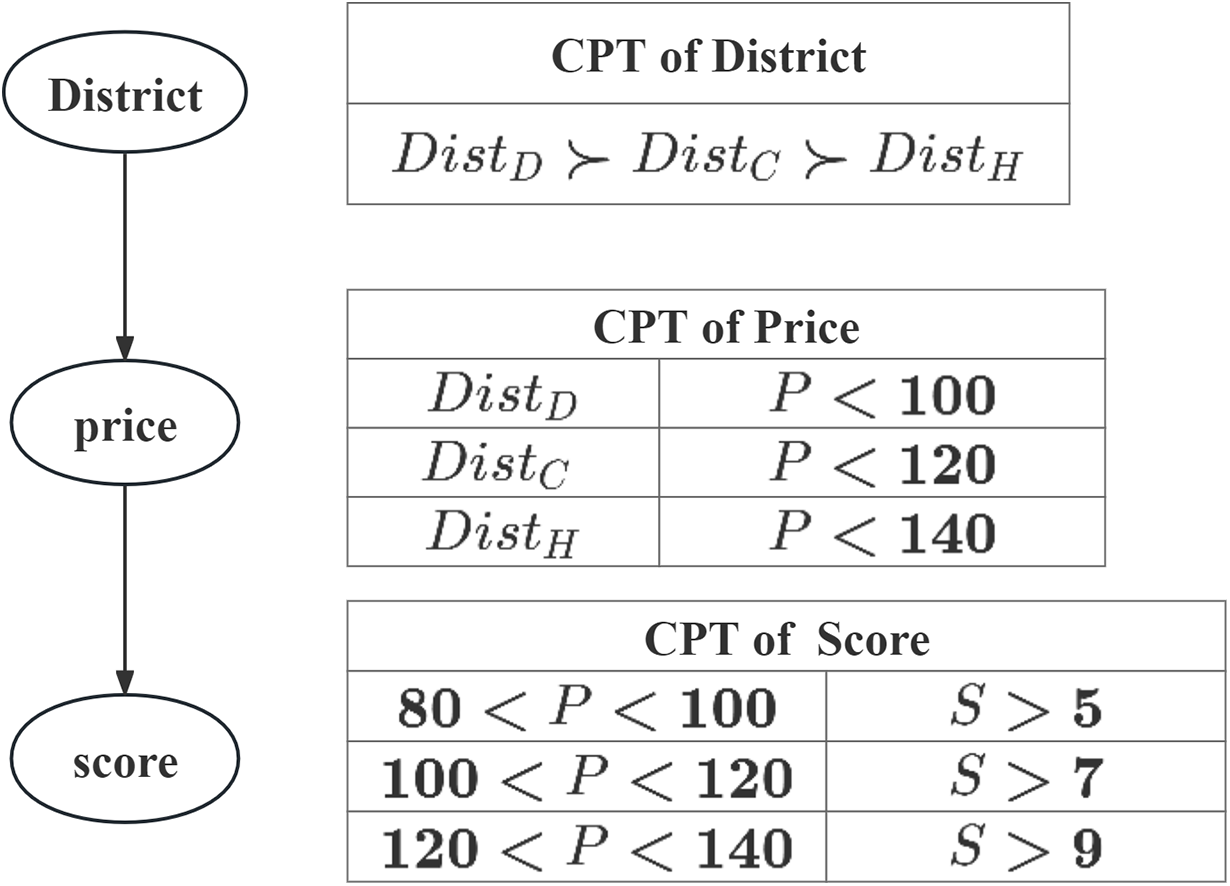
Example 1 (CP-Net). Consider a traveler want to find hotel, his complete preference for the trip is provided shows as Fig. 1, and the details of his preferences are summarized as follows:
(1) Assume that there are three options for where the hotels located: it can be located in Dongcheng District, Chaoyang District or Haiding District. The user’s preference over the options is unconditional: Dongcheng District Chaoyang District Haiding District, where “ ” denotes one is more preferred than the other.
(2) Assume the user’s preference over the is conditional: Dongcheng District: ; Chaoyang District: ; Haiding District: . And the lower the , the better.
(3) Assume the user’s preference over the is conditional: ; ; . And the higher the , the better.
Now we apply the above notions and definitions to create a CP-Net for representing user preferences in our Travel example, and the CP-Nets and CPT shown in Fig. 1 according to the user’s preferences. The arrows in Fig. 1 mean the relations among the attributes. For example, depends on the values of , depends on the values of .
Next, we formally define CP-Skyline and the dominance relations involved in the calculation process.
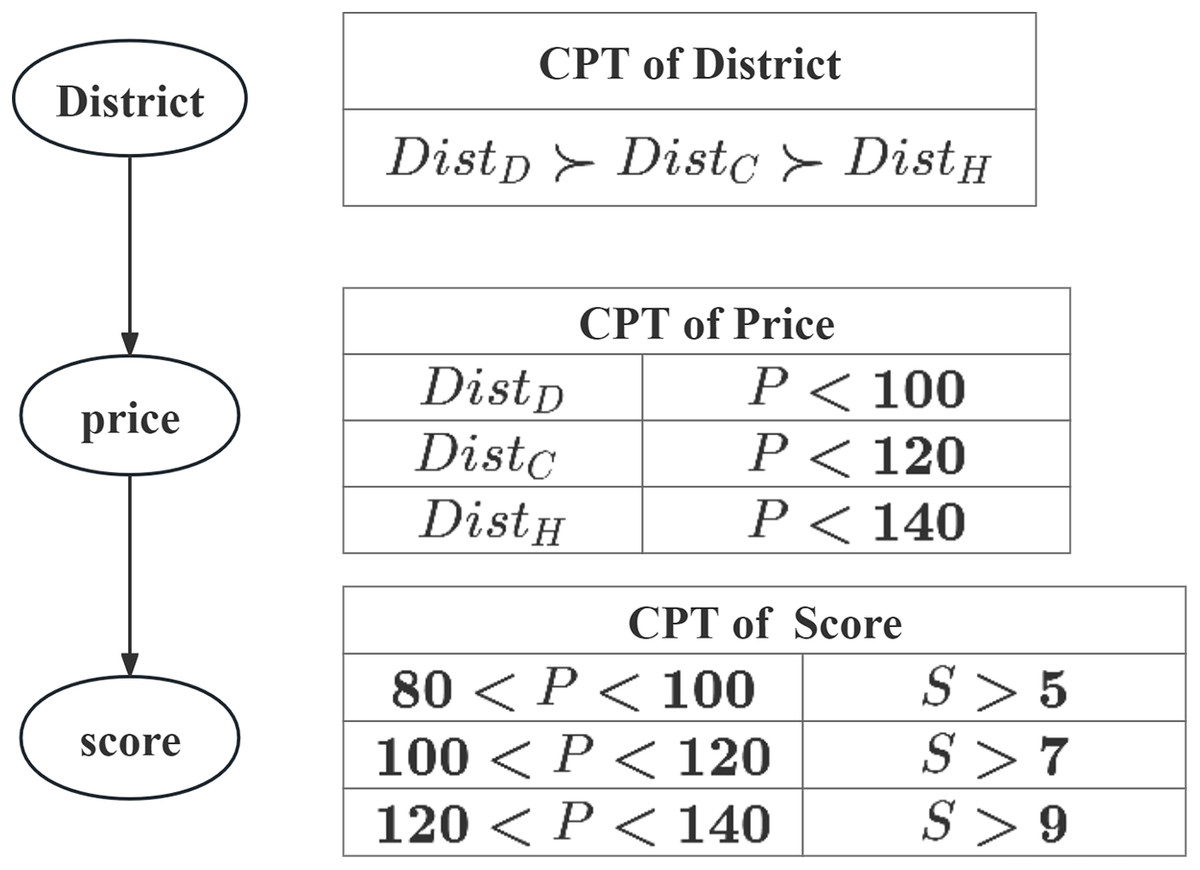
Figure 1: CP-Net for Example 1.
{kind=link}
Formal definition of CP-skyline
Definition 2 (Strictly Dominance). Given a dataset T, we say that a tuple dominates another tuple , denoted as if and only if has better performance than on all specified preference attributes, and strictly better performance on at least one attributes. i.e.,
For example, hotels in Table 1 meet if and only if is superior to in at least one attribute.
Definition 3 (Hierarchy Dominance). Given the user’s preference and divides it into different preference levels (e.g., the most interested, and second interested, etc.), which termed as the hierarchy. Given a dataset T, we say that a tuple hierarchy dominates another tuple , denoted as , if and only if is in hierarchy , is in another hierarchy , and have a higher preference level than for user. i.e., .
For example, hotels in Table 1 meet if and only if the preference level of is higher than the preference level of . Because is better than in both price and score, if is better than : for the user, the preference level of is higher than , for example, the user’s preference is better than other prices.
Definition 4 (CP-Dominance). Given a -dimensional dataset T and a user’s CP-Net, we say a tuple CP-Dominance another tuple , denoted as , if and only if has better performance than on all specified preference attributes, and strictly better performance on at least one attributes, at the same time, ’s preference level is not lower than ’s preference level , and the tuples with high preference level unconditionally dominate the tuples with low preference level, i.e., .
For example, hotels in Table 1 meet if and only if and are in the same preference level, at this time, for and , users have no obvious preference, so they only need to judge based on attribute values ( ). And if and only if the preference level of is higher than the preference level of , at this time, for and , the importance of user preference is greater than the quality of attribute values, so with a high preference level is better than . ( ).
In other words, CP-Dominance satisfies both Strictly Dominance and Hierarchy Dominance.
Definition 5 (CP-Skyline). Given a dataset T and a user’s CP-Net, the CP-Skyline comprises the set of tuples are not CP-Dominated by other tuples. i.e., .
We now provide the formal definition of the problem of using CP-Nets to represent user’s conditional preferences.
Definition 6 (Problem Statement). Given user’s personalized Conditional Preference (expressed as CP-Nets) and a dataset T on a set of attributes A defined by a set of attributes , a tuple object is represented as an -dimensional tuple where is the value on attribute . Based on this information, we calculate the CP-Skyline set (CPS) based on user’s conditional preference, that is, the set of tuples that are not CP-Dominaned by other tuples.
Cp-skyline computation
Our algorithm unfolds in two distinct stages: the initial phase, denoted as the Pruning stage, aims to refine the candidate set based on CP-Nets semantics, thereby identifying tuples that align with user’s preferences. The subsequent stage, computes the CP-Skyline from the pruned tuples, ultimately yielding the final skyline set.
Firstly, in the stage 1, the candidate set is pruned based on the semantics of CP-Nets to derive a set of tuples that satisfies all user’s preferences. The preference induced graph (Li, Vo & Kowalczyk, 2011) from the user’s CP-Nets enables us to ascertain the relative importance of various outcomes to the user. Subsequently, a traversal of all tuples is conducted for classification. At this stage, each tuple within the candidate set is allocated to a specific category. These categories are then sorted according to the induced graph derived from the user-provided CP-Nets, referred to as a hierarchy, representing the user’s preference levels for different outcomes. In the stage 2, the CP-Skyline is computed based on the definition of CP-dominance.
Pruning strategy
The pruning strategy in stage 1 involves two processes. Firstly, it prunes the candidate set using CP-Nets semantics, filtering out tuples that do not meet preferences and assigning satisfying tuples to different preference levels via a classification tree. Secondly, it uses the induced graph from CP-Nets to determine the significance of each hierarchy to the user, allowing us to sort the hierarchies and select tuples only from the most satisfactory level as the candidate set, thus achieving pruning effects.
Construction of classification tree
A classification tree segmentally categorizes tuples based on a sequence of conditional checks. Its fundamental concept involves partitioning the feature space into rectangles. Starting from the root node, the tuple is progressively separated through a series of decisions. When the division is complete, and the tuple cannot be further separated, it forms a leaf node.
Definition 7 (Classification tree). Given a CP-Net G over , a classification tree structured by G. Among C, the node set V contains all the attribute nodes corresponding to the tuple attributes. Each attribute node represents a specific attributes of the tuple. The edge set describes the causal relationship and conditional dependence between the various attributes. For each attribute node, the set of its parent nodes is denoted by , and for all possible parent node value combinations . Related to it is a conditional preference table , the table specifies that when the parent node value of the attribute is , the user pairs the attribute represents preference ordering of attributes possible values.
Constructed upon this foundation, the classification tree exhibits the following characteristics:
Root node. The root node, is chosen due to its independence from other attributes, eliminating the need for a CPT.
Internal nodes. Each root node value corresponds to an internal node within a sub-tree, representing geographical branches. For attributes like and , internal nodes are determined by the associated CPT, reflecting user preferences under specific conditions.
Leaf nodes. Leaf nodes represent unique attribute configurations and detailed conditional preferences, indicating that a candidate tuple aligns with the user’s overall preference profile.
Edges. Each directed edge from node to node , denoted as , shows that the optimal choice for the next related attribute can be inferred from the CPT of node . These edges demonstrate the dependency structure in the decision process.
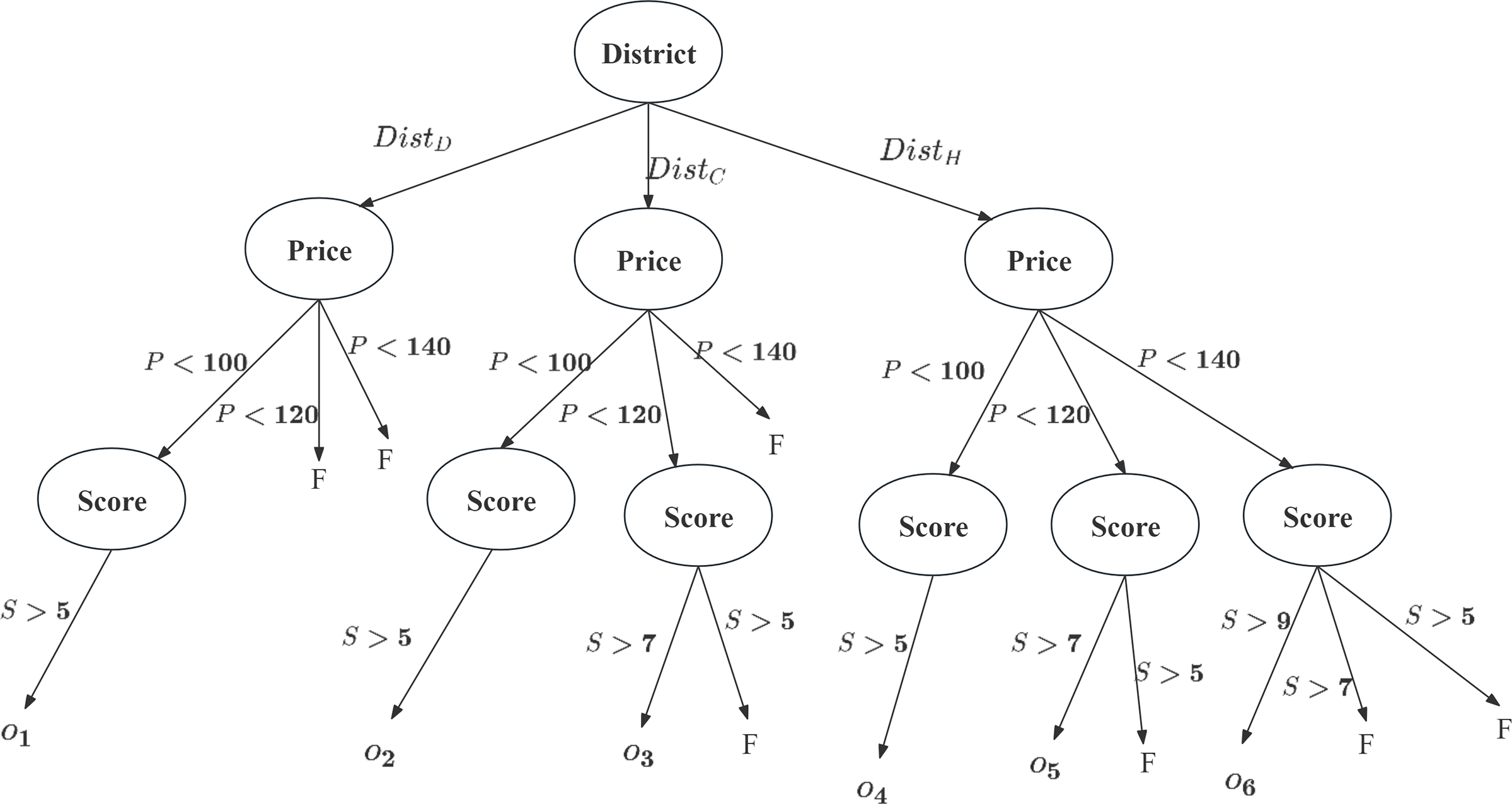
Upon constructing the classification tree, each is traversed starting from the root node. At each internal node, the attribute value of tuple is checked against the current criterion. If it meets the condition, traversal continues along the relevant branch; otherwise, “No Valid Category” is returned (represented by F in classification tree), or the process halts. Tuples that satisfy the user’s conditional preferences are classified ( ), while those failing the CP-Nets criteria are pruned. This completes the first pruning step, resulting in .
Using the CP-Net from Example 1 and tuples from Table 1, a classification tree is constructed as shown in Fig. 2. Tuples are excluded due to their being outside , and are excluded because their Scores are not greater than 5. Consequently, each tuple is assigned to a classification that meets the user’s conditional preferences.
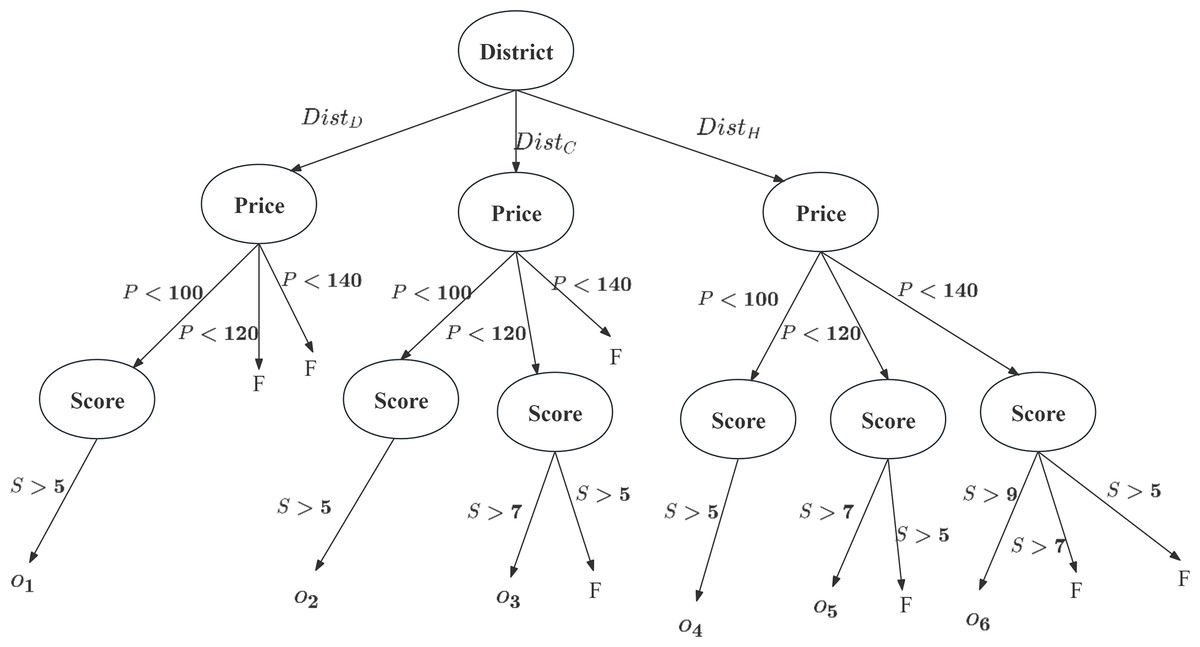
Figure 2: Classification tree for this case.
{kind=link}
According to the user’s CP-Nets, the most important attribute is the administrative , followed by , with being the least important. The classification tree removes tuples not meeting the preferences (e.g., does not satisfy: if , then ). Tuples satisfying the preferences are assigned to specific categories ( ), such as and . At this stage, non-compliant tuples are removed from the candidate set, resulting in .
Construction of induced graph
Presently, through the utilization of a classification tree, we can filtered out tuple that does not align with user’s preferences. Our current focus lies in sorting based on varying degrees of user’s satisfaction. As a precursor to pruning, we introduce the concept of the induced graph, outlining the procedure for attaining optimal results using CP-Nets.
Definition 8 (Induced graph Li, Vo & Kowalczyk, 2011). Given a acyclic CP-Net G, the Induced preference graph donated by , is defined by following edges between outcomes, where is the user’s preference for the two outcomes. For each attribute , that differ only on the value of , let there be a directed edge if a user prefer to ; there be a directed edge if a user prefer to . If and are incomparable, I does not contain any edge between and .
Based on the current preference-induced graph, we can rank the importance of different outcome to the user. Selecting the outcomes with the highest preference level as CS allows us to perform the second step of pruning.
According to Definition 7, the induced graph is constructed as shown in Fig. 3. The node set, , represents different outcomes. The edge set, derived from the user’s CP-Nets, includes directed edges , where and differ by only one attribute value. For example, the preference for over , indicated by the directed arc, reflects the semantics of .
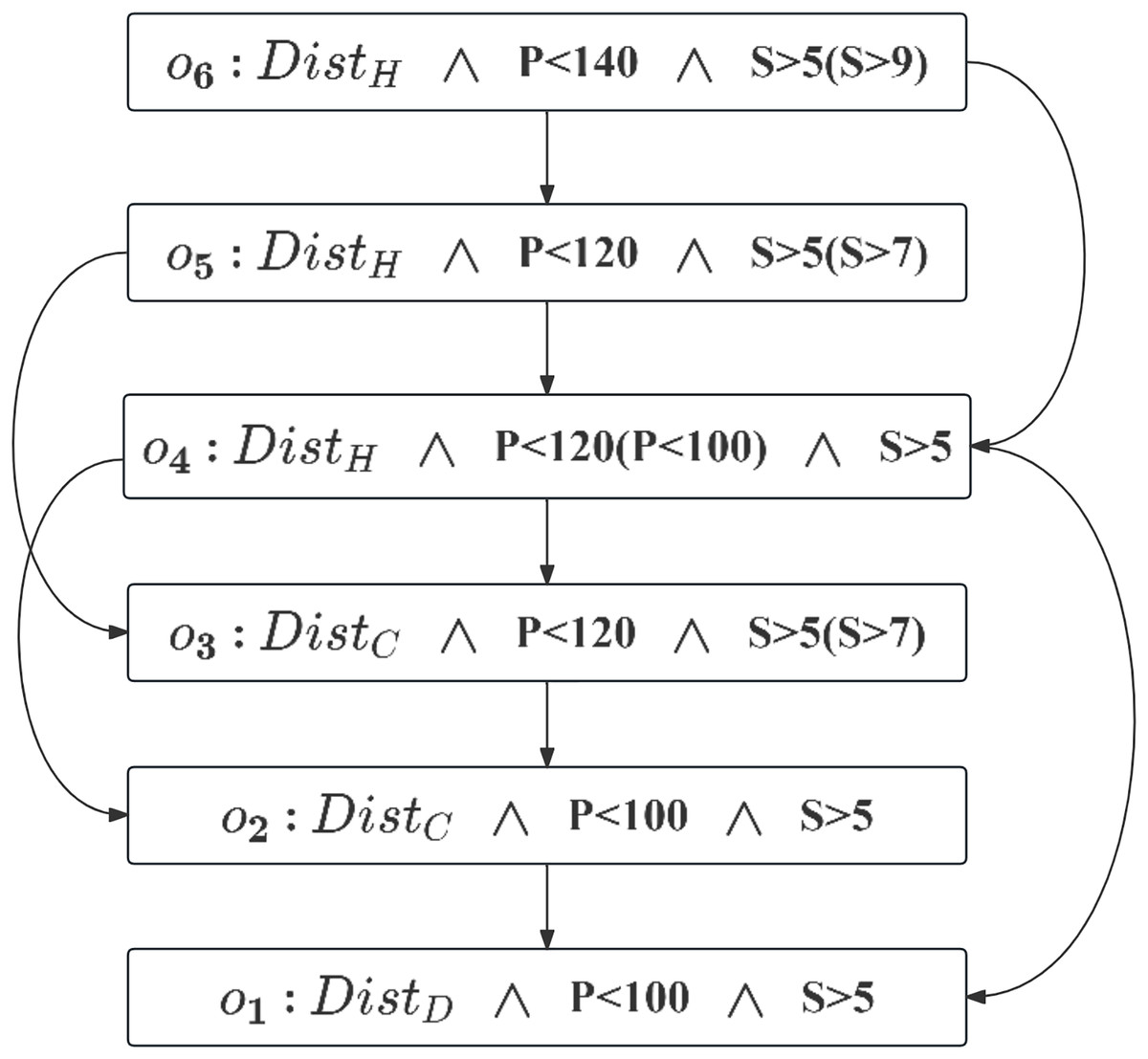
Figure 3: Induced preference graph.
{kind=link}
Conducting a topological sort on the preference-induced graph can determine the ranking of outcomes: . The top-level node ( ) represents the least preferred outcome, while the bottom-level node ( ) represents the most preferred. We select , the outcome to the user is most interested in, as CS. If is empty, the next best is chosen as CS. After determining CS, we proceed with the CP-Skyline calculation.
Pruning
Pruning based on the above two process are presented in Algorithm 1 (Line 4). The algorithm aims to systematically derive a candidate set (CS) from an acyclic CP-Net G and a set of tuples T. The algorithm commences by initializing CS and Hierarchies as empty sets. Subsequently, it constructs a classification tree C and a preference induced graph I based on the characteristics of the given acyclic CP-Net (line 5). The algorithm then enters a loop that iterates through tuples in T which align with the branches of the classification tree C. For each tuples, it categorizes it into various outcomes ( ). The identified that satisfy the user’s conditional preferences are subsequently appended to the Hierarchies set. The hierarchies are further sorted in accordance with a topological reverse sort of the preference-induced graph I, since the CP-Nets discussed are acyclic, their derivation is also acyclic and therefore does not form a cycle (Boutilier et al., 2004). For example, Fig. 3 shows the acyclic derived graph obtained through acyclic CP-Nets. The topological sorting result is , that is, the hierarchies set . According to definition 3, it can be seen that no cycle will be formed. Following this, the algorithm iterates through each hierarchy in , commencing with the highest hierarchy. If the hierarchy is not empty, it sets CS to the current hierarchy. Otherwise, it advances to the next hierarchy. Finally, the algorithm concludes by returning the resulting candidate set CS. This descriptive passage outlines the steps and purpose of the “Pruning” algorithm, emphasizing its operations on acyclic CP-Nets and tuples to generate a refined candidate set in accordance with user’s preferences.
| Input: Acyclic CP-Net G, dataset T |
| Output: set of CP-Skyline points (CPS) |
| 1: Initialize |
| 2: Initialize Candidate dataset (CS) |
| 3: Initialize CP-Skyline points (CPS) |
| 4: Stage 1 (Pruning): |
| 5: Generate Classification tree C and preference induced graph I by G |
| 6: while do |
| 7: Classify ti to different outcomes ( ) by C |
| 8: end while |
| 9: |
| 10: Sort Hierarchies by topological reverse sort of I |
| 11: for each (starting from the highest hierarchy) do |
| 12: if then |
| 13: CS = current hierarchy |
| 14: else |
| 15: CS = next hierarchy |
| 16: end if |
| 17: end for |
| 18: Stage 2 (Skyline computation): |
| 19: for each do |
| 20: |
| 21: for each do |
| 22: if cj dominates ci then |
| 23: |
| 24: break |
| 25: end if |
| 26: end for |
| 27: if not dominated then |
| 28: Remove all cj from CPS such that ci dominates cj |
| 29: Add ci to CPS |
| 30: end if |
| 31: end for |
| 32: return CPS |
Skyline computation stage
The stage 2 is employed for computing the CP-Skyline set (line 18), it takes CS from pruning stage as input and produces the set of CP-Skyline set denoted as CPS. The algorithm iterates through each candidate in CS. For each , it checks whether it is dominated by any existing tuple in CPS, the current CP-Skyline set. If is not dominated by any tuple in CPS, it removes all the tuples in CPS that are dominated by and adds to CPS.
The complete process is encompassed by Stage 1 and Stage 2, which collectively ensure the CP-Skyline computation algorithm. This process effectively prunes dominated tuples from the candidate set, ensuring that only non-dominated tuples are retained in the resulting CP-Skyline set.
Computational complexity
The computational cost of our method is the sum of two stages. In the pruning stage, the Classification tree is used to filter and divide the candidate data requires sorting all attributes and calculating each possible split point, which takes the time complexity of each split , in the worst case The depth of the classification tree is , so the total time complexity is ( is the number of tuples in T). The time taken to obtain the preference induced graph is . During topological sorting, each vertex is processed only once. Each edge is also processed only once, either to update the in-degree of the vertex or to perform a depth-first search (DFS). Therefore, the total time complexity of topological sorting is . The second stage is to perform CP-dominance calculation on the candidate data set, which requires domination calculation between pairs of data, and the time complexity is , which takes times ( ). The complexity of constructing the exported graph and topological sorting it is constant level, and the query dimension and the size of the candidate set data have the greatest impact on it, so the final time complexity is . However, in the worst case (e.g., data imbalance), the depth of classification tree may reach , so the worst case time complexity is . In practical applications, while the theoretical worst-case complexity is high, the actual runtime is often much lower. The pruning stage effectively removes tuples that do not meet user preferences early on, significantly reducing the candidate set size and overall computation time. This efficiency gain means the method performs well in most practical scenarios, despite the high worst-case complexity.
Experimental evaluation
In this section, we first describe the experiment setup and then we present and discuss the respective results. To verify the effectiveness and performance of the CP-Skyline query method, we design and implement relevant experiments and analyze the results. Prior to conducting the comparative experiments, it was imperative to ensure a consistent evaluation framework across all skyline methods. To achieve this, we employed a uniform approach by instructing each method to utilize a brute-force algorithm for computing result sets.
The experimental environment is Intel® Xeon® Gold 6330, 80G RAM, 64-bit Windows 11 professional operating system, PyCharm 2022 development environment, Python 3.8 development language.
Datasets
To evaluate the effectiveness of CP-Skyline queries on various datasets, experiments were conducted using both real and synthetic data, the proposed method was evaluated on dataset sizes ranging from 10 to 800 k.
The real datasets include:
QWS (https://qwsdata.github.io/): Measures the quality of 2,507 Web services, collected in 2008 using the Web Service Broker framework, with each entry containing nine QWS measurements. Each row in this dataset represents a web service and its corresponding nine QWS measurements (separated by commas). The first nine elements are QWS metrics that were measured using multiple Web service benchmark tools over a 6-day period. The QWS values represent averages of the measurements collected during that period.
NBA Players NBA Players (https://www.kaggle.com/datasets/justinas/nba-players-data/): Contains demographic and biographical details, as well as performance statistics for NBA players over 20 years, 12,843 entries in total. The data set contains over two decades of data on each player who has been part of an NBA teams’ roster. It captures demographic variables such as age, height, weight and place of birth, biographical details like the team played for, draft year and round. In addition, it has basic box score statistics such as games played, average number of points, rebounds, assists, etc.
Synthetic dataset: data was randomly generated within the range of the QWS parameters’ maximum and minimum values, with a total of 800,000 pieces of data.
Synthetic anti-correlated dataset: Synthetic anti-correlated dataset: data was randomly generated within the range of the QWS parameters’ maximum and minimum values, with a total of 800,000 pieces of data. This dataset is created by generating random values for each attribute (e.g., availability, throughput) and subtracting them from fixed values to ensure inverse correlation. The resulting dataset contains multiple anti-correlated attributes.
Experiments results
In the sets of experiments, a comparison was conducted between CP-Skyline and the traditional skyline alongside several personalized skyline queries across various aspects. Including the following methods: Subspace Skyline (2015) (Yuan et al., 2013), which allows users to provide attributes of interest and only perform queries in the subspace that the user is interested in, involves the simplest user preference. User-Defined Skyline (2023) incorporates personalized requirements for attributes values and User-Defined constraints (Zhang et al., 2023), and Decisive Skyline (2022) (Vlachou et al., 2022), which retrieves a set of points that balance all specified criteria, is a tuple that is better under all attributes in the skyline combination, also means a collection of high-quality skyline points. To highlight the query efficiency of CP-Skyline, we control for the same user preference attributes across several personalized skyline query methods, as the form of user preferences expressed by these methods varies.
When conducting comparative experiments, traditional skyline has no user preferences and is calculated in the entire space. Since several personalized skylines can handle different user preferences, we uniformly set user preferences to the most detailed conditional preference among several preferences.
Size of the skyline result sets
The size of the skyline result set is an important metric for evaluating query performance and efficiency according to the standards of scientific articles (Benouaret et al., 2021). A smaller result set typically indicates faster query processing, as the system returns only the most significant or valuable data set. By controlling the size of the skyline result set, it is possible to ensure that the returned result contains the most valuable and crucial information, thereby assisting users in making more accurate decisions and enhancing their overall experience.
We first compare the result sets of several skylines on the real data set QWS (Fig. 4A) and NBA players (Fig. 4B). Because the data set of the real data set is too small, we then analyze the changes of several skyline result sets with the size of the data set by synthesizing the data set (Fig. 5). Finally, we analyze the changes of various skyline result sets with the query attribute by changing the query attribute 2–5 on QWS (Fig. 6A) and NBA players (Fig. 6B).
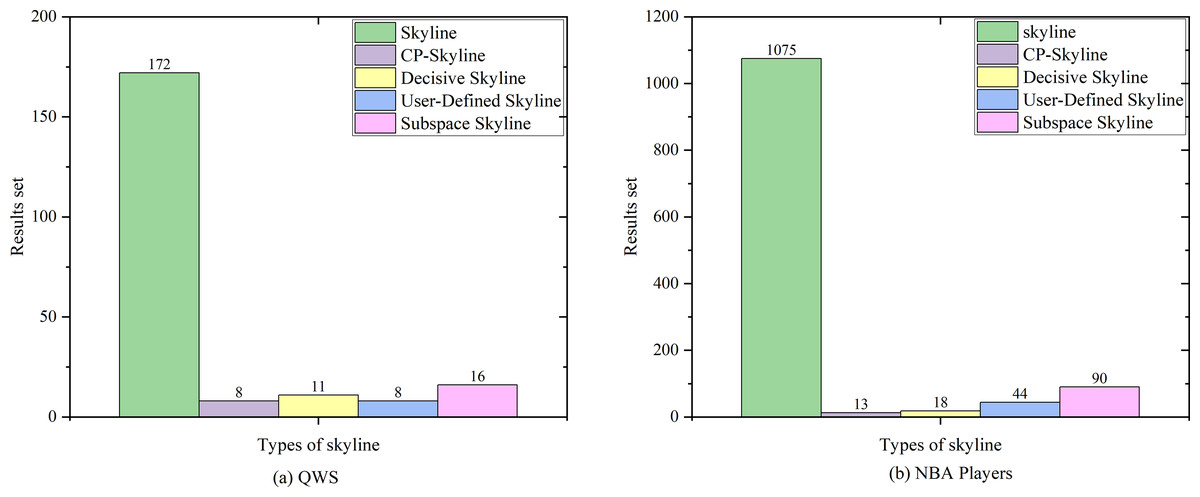
Figure 4: (A, B) Size of the result set vs. number of dimensions on different datasets.
{kind=link}
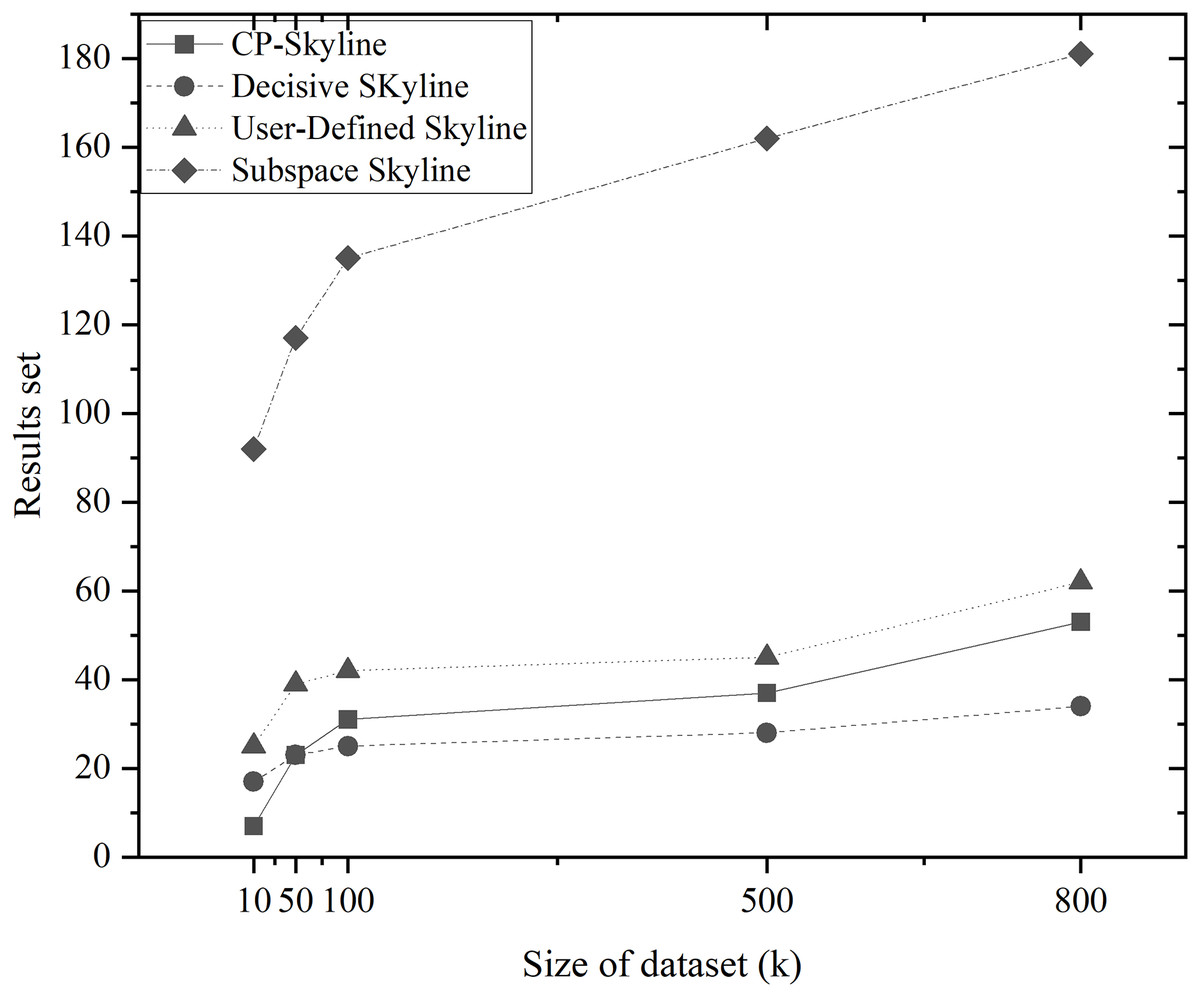
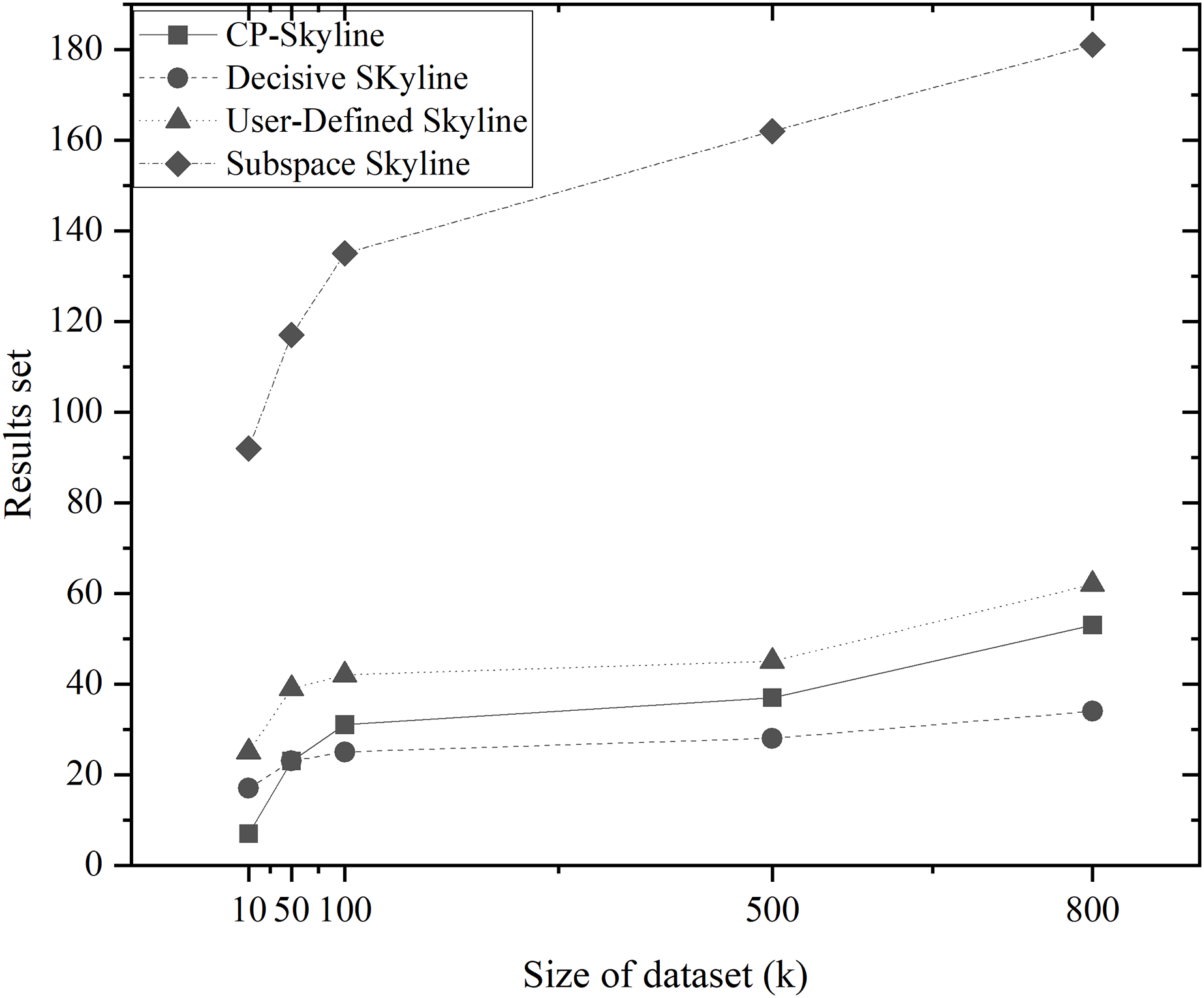
Figure 5: Size of the result set vs. size of dataset (k) on synth dataset.
{kind=link}
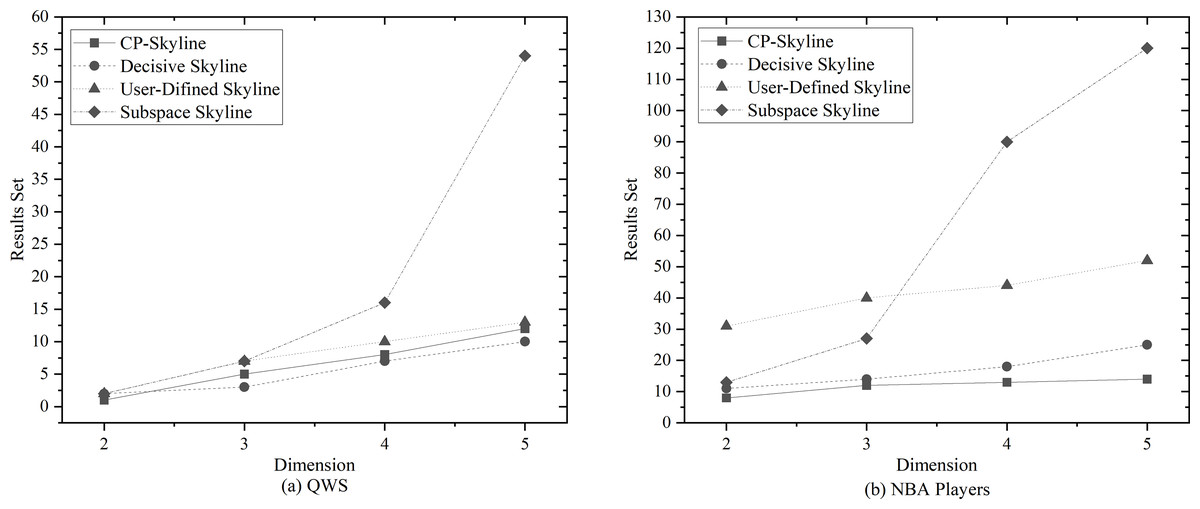
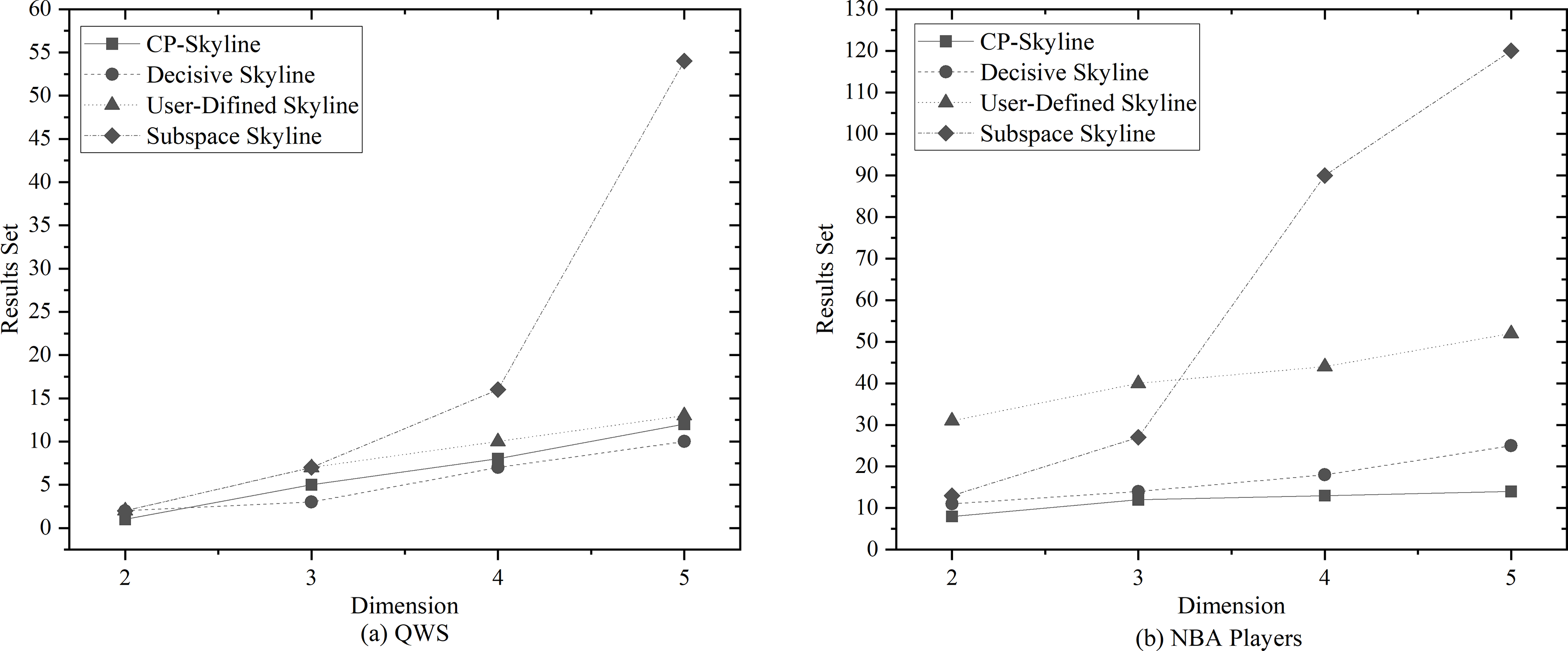
Figure 6: (A, B) Size of the result set vs. number of dimensions on different datasets.
{kind=link}
Figures 4A and 4B depicts the size of result set of different skyline query methods on QWS and NBA players, where in this case, the entire dataset was used as the candidate set. Traditional skyline queries were conducted with a full-dimensional query space, while personalized skyline queries were performed with a five-dimensional query space. Obviously, the result set obtained by the traditional skyline query method has the largest number, while the remaining personalized skyline algorithms have a smaller result set, because they exclude tuples that does not meet the personalized requirements. In Fig. 5, synthetic data was utilized to examine the effect of candidate set size on the result set size with a five-dimensional query space. In all cases, the size of the result set will increase with the size of the dataset. However, the size of the result set of the personalized skyline algorithm is smaller than the size of the result set obtained by the traditional skyline query. As illustrated in the figure, CP-Skyline eliminates a lot of tuples that does not meet the user’s personalized requirements compared to the traditional skyline query method. Compared with the user-defined skyline, it also has a certain improvement. As the the decisive skyline defined as the subset of skylines that balances all attributes, its size is smaller than CP-Skyline.
Next, in Figs. 6A and 6B, the impact of the query dimension (attribute) involved in the skyline on the size of the result set is examined on QWS and NBA players. In all cases, the size of the result set will increase as the number of tuple’s attribute increases. Since the skyline is a set that is not dominated by other tuples on at least one dimension, increasing the query dimension means that tuples are more difficult to be dominated. Due to the large volume and dense distribution of data in the NBAPlayers dataset, there may be multiple instances of the same data in low-dimensional cases. The user-defined skyline exclude those instances that can dominate these tuples, resulting in a higher number of undominated tuples, Which leads to the the situation in Fig. 6B. Overall, the personalized skyline query method has a smaller change in the result set. For users, when the query dimension increases, The user’s effort to locate the most preferred tuple intensifies, and the more specific the user’s preference is, the more tuples that do not meet user preferences are removed through pruning, the less likely these tuples are to become part of the Skyline. As a result, the smaller the result set is, and the less effort is spent.
Skyline query response time
In the skyline query algorithm, because it deals with large-scale multi-dimensional data sets, the running time of the algorithm will affect the efficiency of the entire query process. In practical applications, the shorter running time means that the algorithm can respond to user’s query requests faster and improve the responsiveness and user’s experience of the system. And the size of the data set may continue to expand, so the running time of the algorithm will be affected by the size of the data. If the running time of the algorithm increases significantly with the increase of data size, the scalability of the algorithm may be affected and cannot meet the needs of future data size growth.
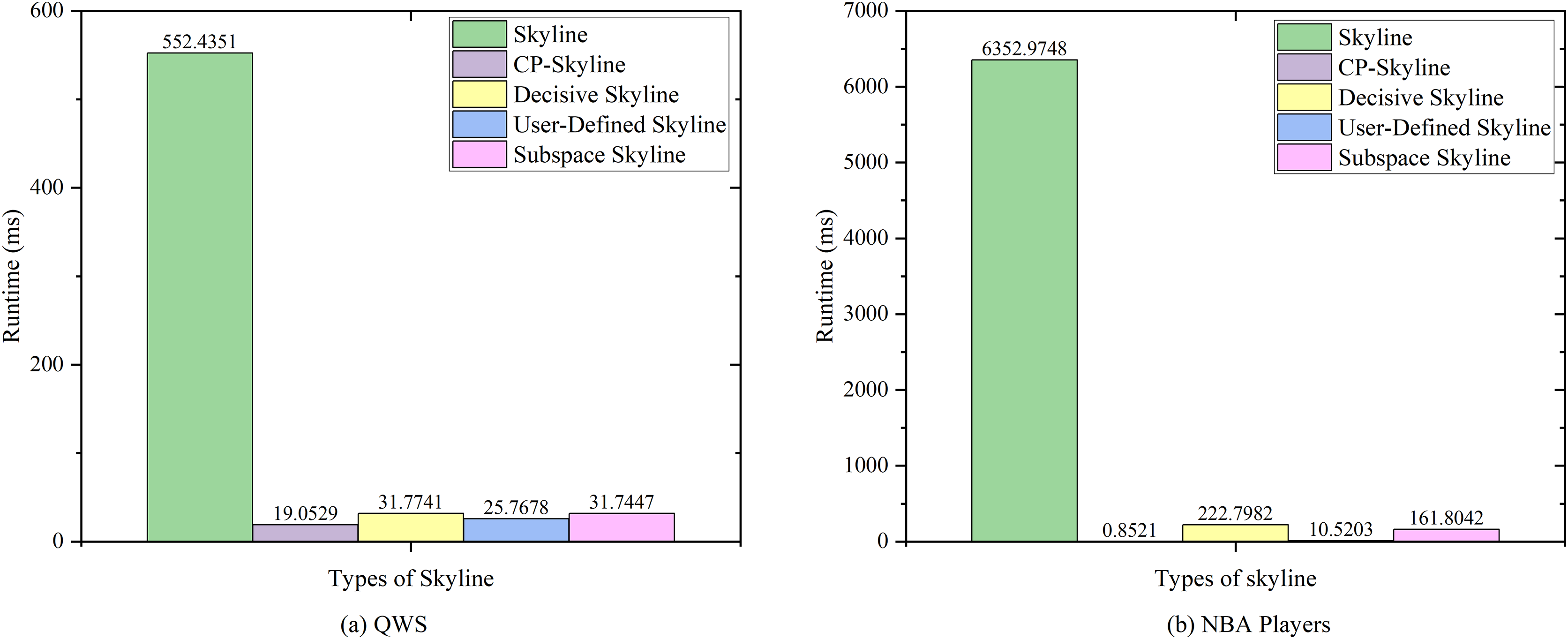
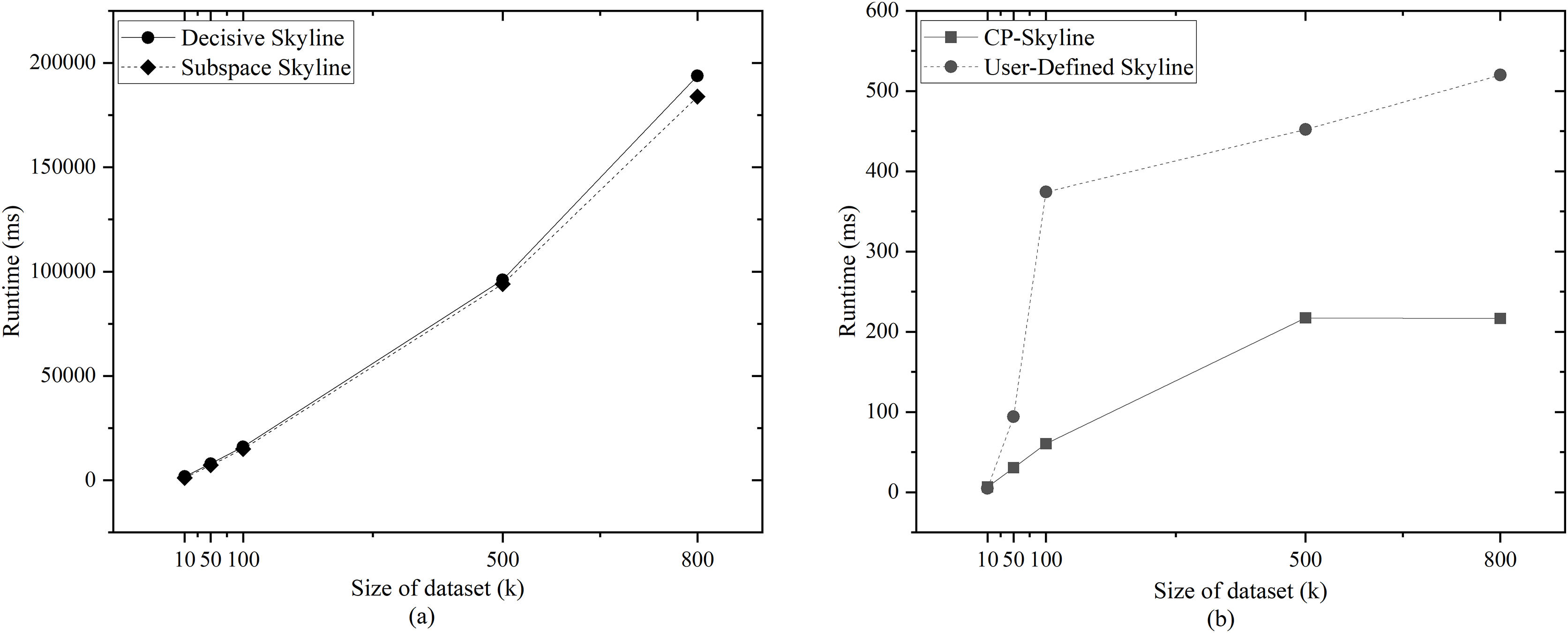
We first compare the query time of several skylines on the real data set QWS (Fig. 7A) and NBA players (Fig. 7B). Then we analyze the changes of query time of several with the size of the data set by synthesizing the data set (Fig. 8). We analyze the changes of query time of various skyline with the query dimension by changing the query dimension 2–5 on QWS (Fig. 9A) and NBA players (Fig. 9B). Finally, we analyze the changes of several query times with the size of the data set in the synthetic anti-correlation data set(Fig. 10).
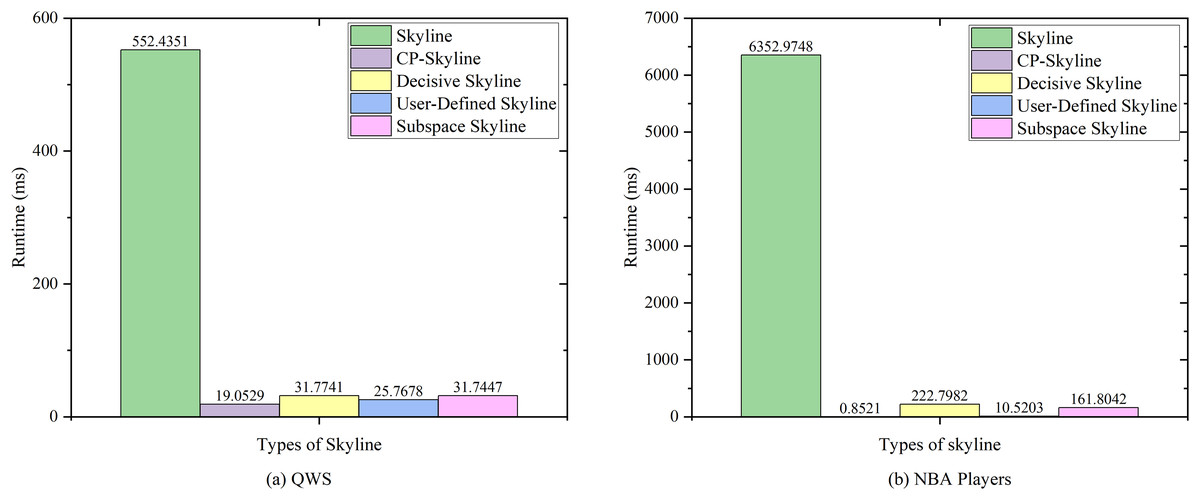
Figure 7: (A, B) Query times of various skyline on different datasets.
{kind=link}
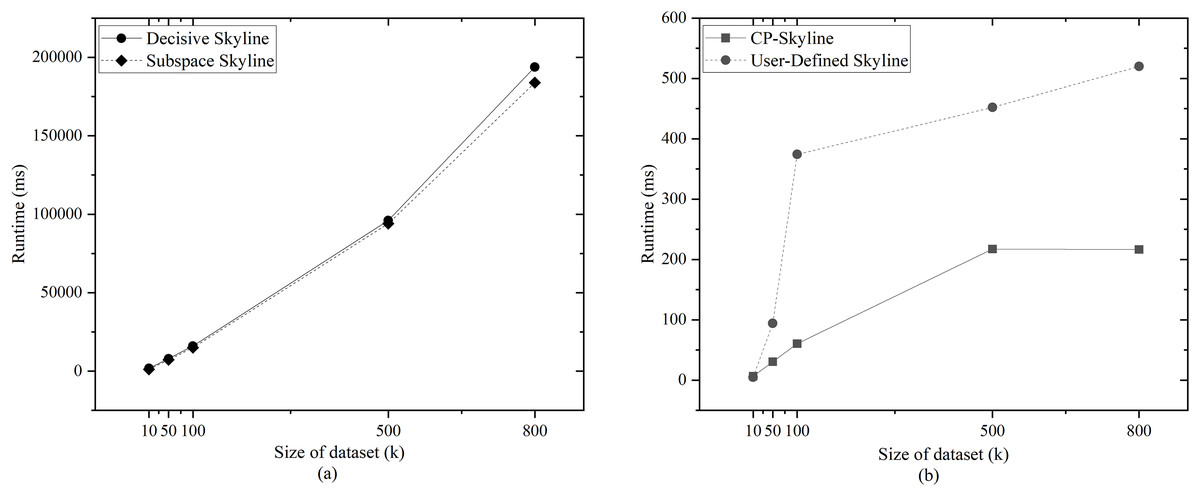
Figure 8: (A, B) Query time vs. size of dataset (k) on synth dataset.
{kind=link}
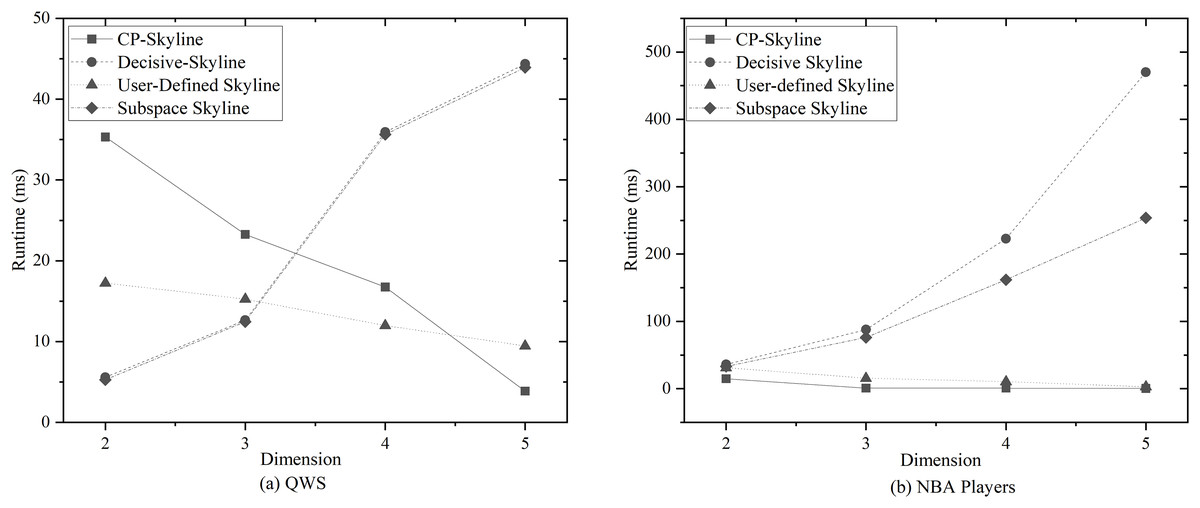
Figure 9: (A, B) Query time vs. number of dimensions on different datasets.
{kind=link}
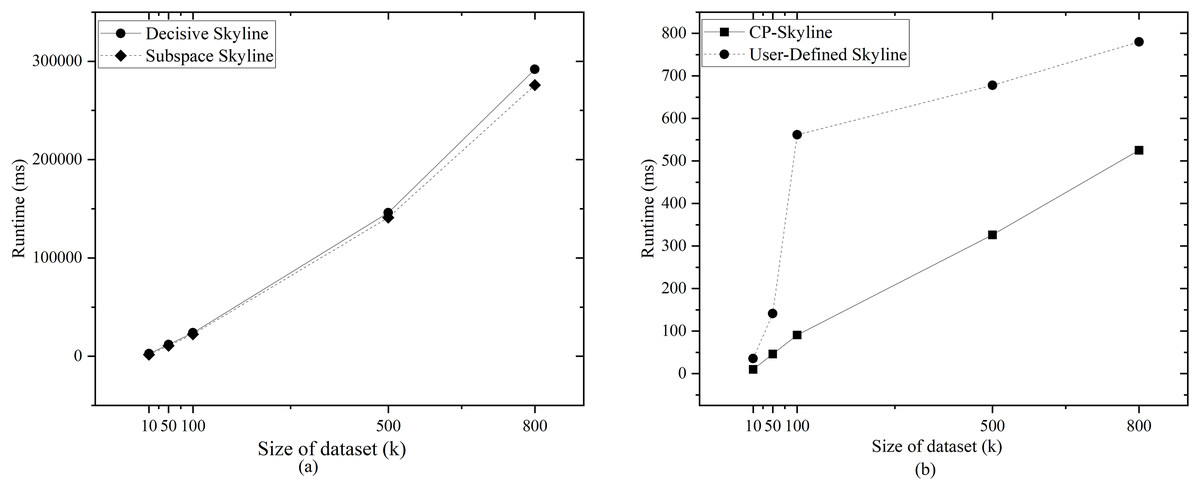
Figure 10: (A, B) Query time vs. size of dataset (k) on Synthetic anti-correlated dataset.
{kind=link}
Figures 7A and 7B shows the query time of different types of skyline query methods on QWS and NBA players, where in this case, the entire dataset was used as the candidate set. Traditional skyline queries were conducted with a full-dimensional query space, while personalized skyline queries were performed with a five-dimensional query space. The traditional skyline query does not have any preference, so it needs to calculate the dominance relationship of all candidate data, so the query time is much higher than other personalized skyline query methods. Next, since the query time of subspace skyline and decisive skyline is much longer than that of CP-Skyline and user-defined skyline, Fig. 8A only describes the query time of decisive skyline and subspace skyline with a five-dimensional query space, Fig. 8B describes the query time of CP-Skyline and user-defined skyline with a five-dimensional query space. As the dataset size changes, we can see that CP-Skyline not only provides more detailed user’s preferences than user-defined, but also spends less query time.
Figures 9A and 9B show the impact of the query dimension (attribute) involved in the skyline on the query time is examined on QWS and NBA players; it can be found that the query time of subspace skyline and decisive skyline is not much different, and the query time increases with the increase of query dimension. The reason is that the decisive skyline is based on the result of subspace skyline. The user-defined skyline and CP-Skyline reduce the query time with the increase of the dimension. The reason for this result is that with the increase of the query dimension, when the candidate data is pruned by the user’s preference, a large number of data that the user is not interested in can be eliminated, which reduces the time spent on the skyline calculation, because the time complexity of the pruning is , and the time complexity of the skyline query is . Due to the small amount of QWS data, less time is spent in the Skyline calculation phase at low latitudes, while the user-defined skyline and CP-Skyline require additional processing of user preferences, and then pruning candidate data based on user preferences. Pruning takes a relatively large proportion of time, and as the dimension increases, the time spent on pruning gradually decreases, and the advantages of using preference for pruning are gradually revealed, so there is a situation as shown in Fig. 9A.
Finally, we compared the query times of several methods as the data increases on the synthetic anti-correlated data set. Given that the query times for subspace skyline and decisive skyline are significantly longer than those for CP-Skyline and user-defined skyline, Fig. 10A focuses on the query times for decisive skyline and subspace skyline within a 5-dimensional query space. Meanwhile, Fig. 10B illustrates the query times for CP-Skyline and user-defined skyline within the same 5-dimensional query space. Similarly, because the advantage of CP-Skyline lies in its excellent pruning ability, CP-Skyline still has better performance. In general, a substantial portion of the computational time in skyline queries is allocated to the dominance calculation of the skyline. In personalized skyline queries, after incorporating user preferences, we can prune many tuples that do not meet the user’s preferences. These tuples do not need to be included in the dominance calculation, thus reducing query time. Therefore, the more specific the user’s preferences, the more tuples are removed during the pruning stage, and the less time it takes to obtain the Skyline set.
Precision
Precision refers to the proportion of the number of documents that match the required information to the total number of documents retrieved. The precision indicates how many data points in the skyline results returned by the query do meet the query conditions. High precision means that the returned results are credible and can be safely used for decision-making and analysis. High precision query results help users make more accurate decisions. Especially in important decision-making scenarios, achieving high precision in personalized skyline queries is critical for providing tailored and effective solutions. Since the all personalized skyline meets the user’s preferences, the precision of the personalized skyline is 1. The difference is that CP-Skyline provides more refined preferences.
Conclusion
Traditional personalized skyline query methods exhibit constraints in handling user’s dependency preferences. Our work proposes the utilization of CP-Nets to address user’s conditional preferences in the personalized skyline query process and define CP-Skyline. The CP-Skyline approach effectively incorporates user-defined conditional preference models, thereby narrowing down the query space during query processing. By establishing new dominance relationships for CP-Skyline computation, we can more accurately identify optimal solutions. Extensive experiments conducted on synthetic and real datasets distinctly confirm the significant advantages of the CP-Skyline method in enhancing skyline quality.
This research contributes a pragmatic and robust solution to the complexity of user’s preferences in personalized decision support. However, ensuring feasibility and efficiency in practical applications remains a critical area for continued investigation. Additionally, The effectiveness of this method is contingent upon accurately defined preference information as specified by users, if the user’s preferences are unclear or change frequently, it may affect the efficiency and accuracy of the algorithm. Further research should rigorously investigate methods for accurately deriving conditional user preferences from data and focus on protecting user’s preference privacy in skyline queries.
Supplemental Information
Experimental code.
We have developed a new personalized Skyline algorithm called CP-Skyline, based on CP-Nets, which describes the Skyline service query in scenarios where users have conditional preferences. This method effectively prunes the search space and reduces computational costs by leveraging the semantics and reasoning capabilities of CP-Nets. The algorithm is designed to adapt well to various service distributions, as well as the number of parameters and preferences. The synthetic database is generated in “Synthetic Generation”. We have given the code for screening candidate data and building a classification tree based on CP-net:filter data and Construction of Classification tree. NBAtest contains calculations of skyline under the NBA dataset.